https://github.com/kibaamor/geektime-mongodb-course
第一章:MongoDB再入门
03 | 认识文档数据库MongoDB
关于 MongoDB
| Q | A |
|---|---|
| 什么是 MongoDB | -个以JSON 为数据模型的文档数据库 |
| 为什么叫文档数据库? | 文档来自于”JSON Document”,并非我们一般理解的 PDF,WORD文档 |
| 谁开发 MongDB? | 上市公司 MongoDB Inc.,总部位于美国纽约。 |
| 主要用途 | 应用数据库,类似于 Oracle,MySOL海量数据处理,数据平台 |
| 主要特点 | 建模为可选、JSON 数据模型比较适合开发者、横向扩展可以支撑很大数据量和并发 |
| MongoDB 是免费的吗? | MongoDB 有两个发布版本:社区版和企业版。社区版是基于 SSPL,一种和 AGPL 基本类似的开源协议企业版是基于商业协议,需付费使用 |
MongoDB 版本变迁

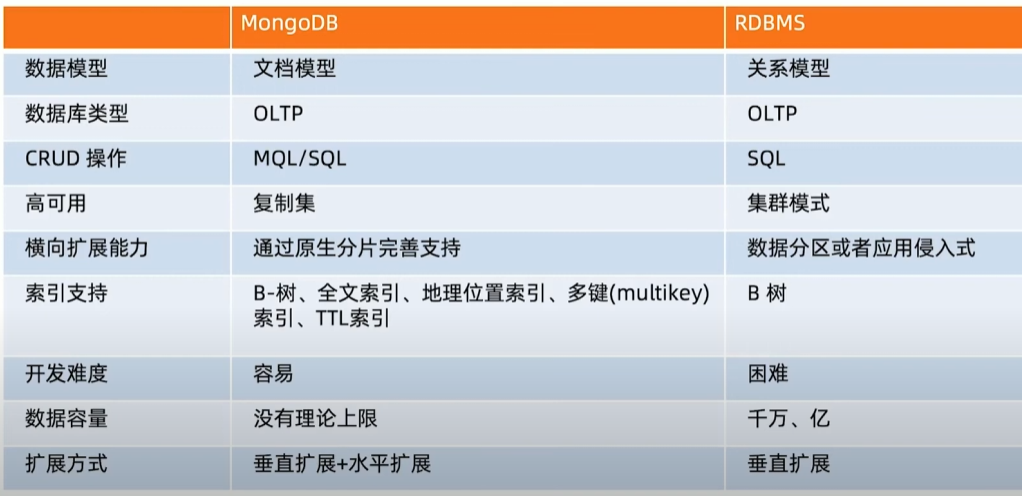
MongoDB和关系型数据库
MongoDB 使用
B+树 和 BSON(二进制 JSON) 组合来存储和管理数据。
04 | MongoDB特色及优势
MongoDB的优势
- 简单直观:以自然的方式来建模,以直观的方式来与数据库交互
- 结构灵活:弹性模式从容响应需求的频繁变化
- 快速开发:做更多的事,写更少的代码
灵活
- 多形性:同一个集合中可以包含不同字段(类型)的文档对象
- 动态性:线上修改数据模式,修改时应用与数据库均无须下线
- 数据治理:支持使用 JSON Schema 来规范数据模式。在保证模式 灵活动态的前提下,提供数据治理能力
快速
- 数据库引擎只需要在一个存储区读写
- 反范式、无关联的组织极大优化查询速度
- 程序API自然,开发快速
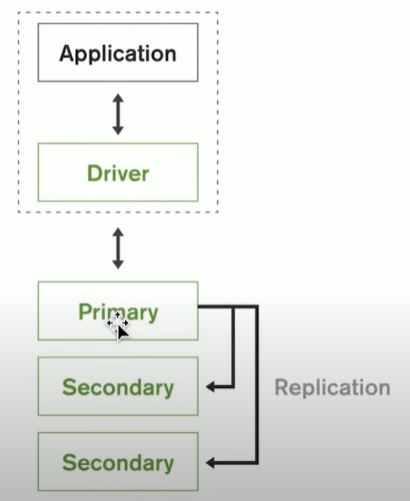
原生的高可用
- Replica Set-2 to 50 个成员
- 自恢复
- 多中心容灾能力
- 滚动服务-最小化服务终端
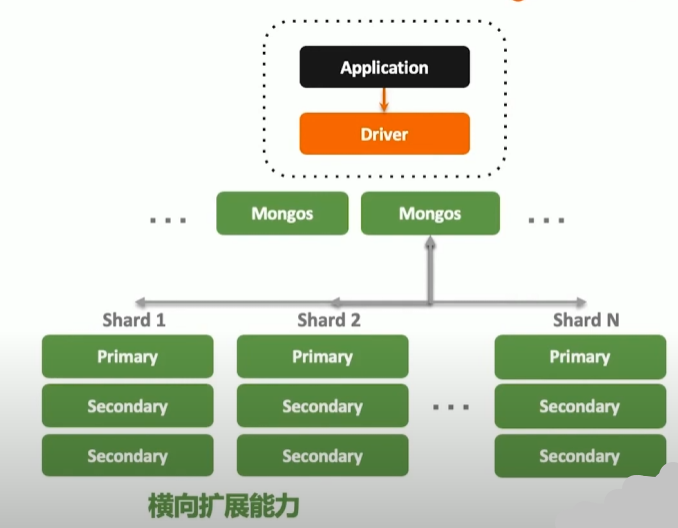
横向扩展能力
- 需要的时候无缝扩展
- 应用全透明
- 多种数据分布策略
- 轻松支持 TB-PB 数量级
MongoDB 技术优势总结
- JSON 结构和对象模型接近,开发代码量低
- JSON 的动态模型意味着更容易响应新的业务需求
- 复制集提供 99.999% 高可用
- 分片架构支持海量数据和无缝扩容
06 | MongoDB基本操作
插入
// 插入
db.fruit.insertOne({name: "apple"})
db.fruit.insertMany([
{name: "apple"},
{name: "pear"},
{name: "orange"}
])查询
- find 相当于SQL中的SELECT。
- find 返回的是游标
db.movies.find({"year": 1975}).pretty() //单条件查询
db.movies.find({"year": 1989,"title": "Batman"}) //多条件and查询
db.movies.find({$and: [ {"title": "Batman"}, {"category": "action"}]})//and的另一种形式
db.movies.find({$or: [{"year": 1989},{"title": "Batman"]})//多条件or查询
db.movies.find({"title": /^B/)//按正则表达式查找查询条件对照表
| SQL | MQL |
|---|---|
| a = 1 | {a: 1} |
| a <> 1 | {a: {$ne: 1}} |
| a > 1 | {a: {$gt: 1}} |
| a >= 1 | {a: {$gte: 1}} |
| a < 1 | {a: {$lt: 1}} |
| a <= 1 | {a: {$lte: 1}} |
| a = 1 AND b = 1 | {a: 1, b: 1}或{$and: [{a: 1}, {b: 1}]} |
| a = 1 OR b = 1 | {$or: [{a: 1}, {b: 1}]} |
| a IS NULL | {a: {$exists: false}} |
| a IN (1, 2, 3) | {a: {$in: [1, 2, 3]}}} |
查询逻辑运算符
$lt:存在并小于$lte:存在并小于等于$gt: 存在并大于$gte:存在并大于等于$ne:不存在或存在但不等于$in:存在并在指定数组中$nin:不存在或不在指定数组中$or: 匹配两个或多个条件中的一个$and:匹配全部条件
子文档查询
find 支持使用 “field.sub_field” 的形式查询子文档。
db.fruit.insertOne({
name: "apple"
from:{
country:"China"
province:"Guangdong"
}
})
// 考虑一下查询的意义
// 能查询到上面插入的文档
db.fruit.find({"from.country": "China"})
// 查询一个文档中有一个字段"from",其值为 `{country: "China"}` 的记录,查询不到上面插入的文档
db.fruit.find({"from": {country: "China"}})搜索数组
db.fruit.insert([
{"name": "Apple", color: ["red", "green"]},
{"name": "Mango", color: ["yellow", "green"]},
])
// 返回第一条数据
db.fruit.find({color: "red"})
// 返回两条数据
db.fruit.find({$or: [{color: "red"}, {color:"yellow"}]})另一个例子
db.movies.insertOne({
"title": "Raiders of the Lost Ark",
"filming_locations": [
{"city": "Los Angeles", "state": "CA", "country": "USA"},
{"city": "Rome", "state": "Lazio", "country": "Italy"},
{"city": "Florence", "state": "SC", "country": "USA"},
]
})
// 查找城市是 Rome 的记录
db.movies.find({"filming_locations.city": "Rome"})在数组中搜索子对象的多个字段时,如果使用 $elemMatch,它表示必须是同一个子对象满足多个条件。
// 查询满足 city 是 Rome 或者 country 是 USA 的文档
db.getCollection('movies').find({
"filming_locations.city":"Rome",
"filming_locations.country":"USA"
})
// 查询 满足 city 是 Rome 且 country 是 USA 的文档
db.getCollection('movies').find({
"filming_locations":{
$elemMatch:{"city":"Rome","country":"USA"}
}
})控制 find 返回的字段
- find 可以指定只返回指定的字段,
- id 字段必须明确指明不返回,否则默认返回;
- 在 MongoDB 中我们称这为投影(projection);
db.movies.find({"category": "action"},{"_id":0, title:1}):不返回_id,返回title。
使用 remove 删除文档
- remove 命令需要配合查询条件使用
- 匹配查询条件的的文档会被删除;
- 指定一个空文档条件会删除所有文档
db.testcol.remove({a: 1}) # 删除 a 等于1 的记录
db.testcol.remove({a: {$lt: 5}}) # 删除 a 小于5的记录
db.testcol.remove({}) # 删除所有记录
db.testcol.remove() # 报错使用 update 更新文档
db.fruit.insertMany([
{name: "apple"},
{name: "pear"},
{name: "orange"}
])
# 更新多条使用 updateMany,第一项为查询条件,第二项为更新内容,支持$set/$unset, $push/$pushAll/$pop, $pull/$pullAll, $addToSet
db.fruit.updateOne({name: "apple"}, {$set: {from: "China"}})- 使用 updateOne 表示无论条件匹配多少条记录,始终只更新第一条;
- 使用 updateMany 表示条件匹配多少条就更新多少条;
- updateOne/updateMany方法要求更新条件部分必须具有以下之一,否则将报错:
- $set/$unset
- $push/$pushAll/$pop
- $pull/$pulLAl
- $addToSet
意义
- $push: 增加一个对象到数组底部
- $pushAll: 增加多个对象到数组底部
- $pop: 从数组底部删除一个对象
- $pul: 如果匹配指定的值,从数组中删除相应的对象
- $pullAll: 如果匹配任意的值,从数据中删除相应的对象
- $addToSet: 如果不存在则增加一个值到数组
删除集合
- 使用
db.<集合>.drop()来删除一个集合 - 集合中的全部文档都会被删除
- 集合相关的索引也会被删除
db.colToBeDropped.drop()
删除数据库
- 使用
db.dropDatabase()来删除数据库 - 数据库相应文件也会被删除,磁盘空间将被释放
use tempDB
db.dropDatabase()
show collections //No collections
show dbs //The db is gone08 | 聚合查询
什么是 MongoDB 聚合框架
MongoDB聚合框架(Aggregation Framework)是一个计算框架,它可以:
- 作用在一个或几个集合上;
- 对集合中的数据进行的一系列运算;
- 将这些数据转化为期望的形式;
从效果而言,聚合框架相当于 SOL 查询中的:
- GROUP BY
- LEFT OUTER JOIN
- AS等
管道和步骤
整个聚合运算过程称为管道(Pipeline),它是由多个步骤(Stage)组成的每个管道:
- 接受一系列文档(原始数据)
- 每个步骤对这些文档进行一系列运算;
- 结果文档输出给下一个步骤;

聚合运算的基本格式
pipeline = [$stage1, $stage2, ... $stageN];
db.<COLLECTION>.aggregate(
pipeline,
{ options }
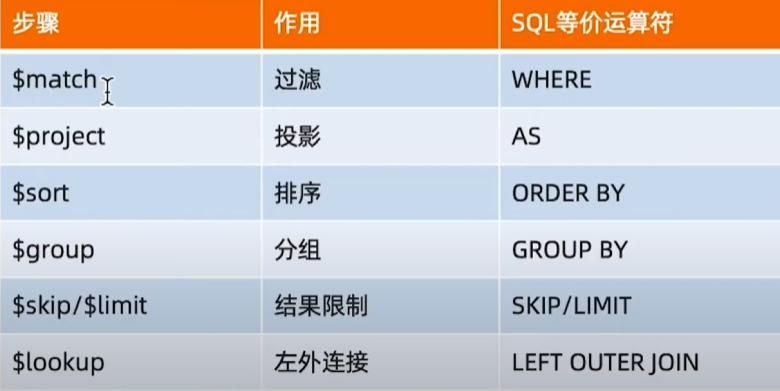
);常见步骤
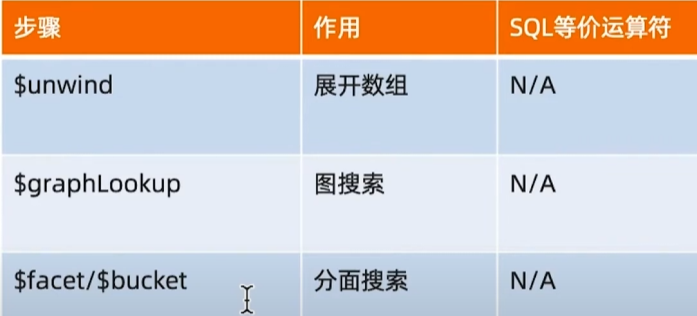

聚合运算的使用场景
聚合查询可以用于 OLAP 和 OLTP 场景。例如:
OLTP (Online Transaction Processing,联机事务处理),OLAP (Online Analytical Processing,联机分析处理)

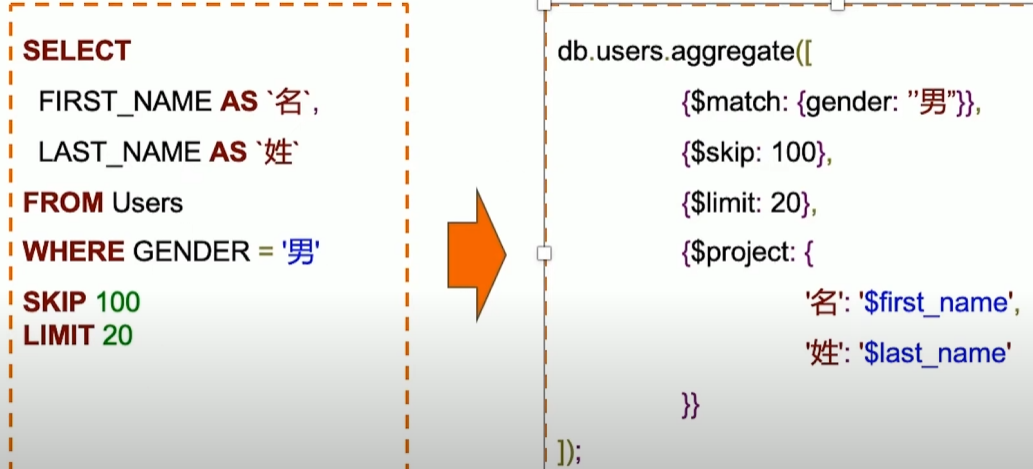
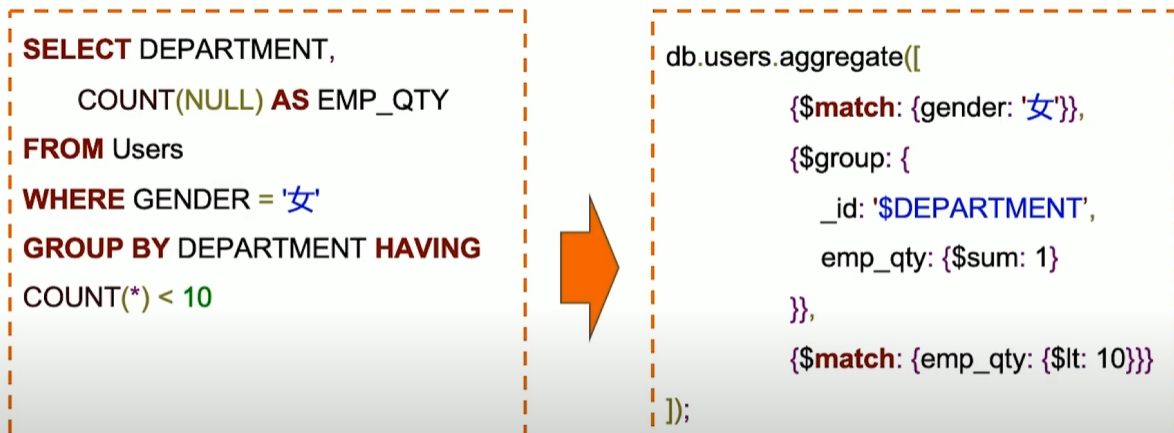
MQL常用步骤与SQL对比
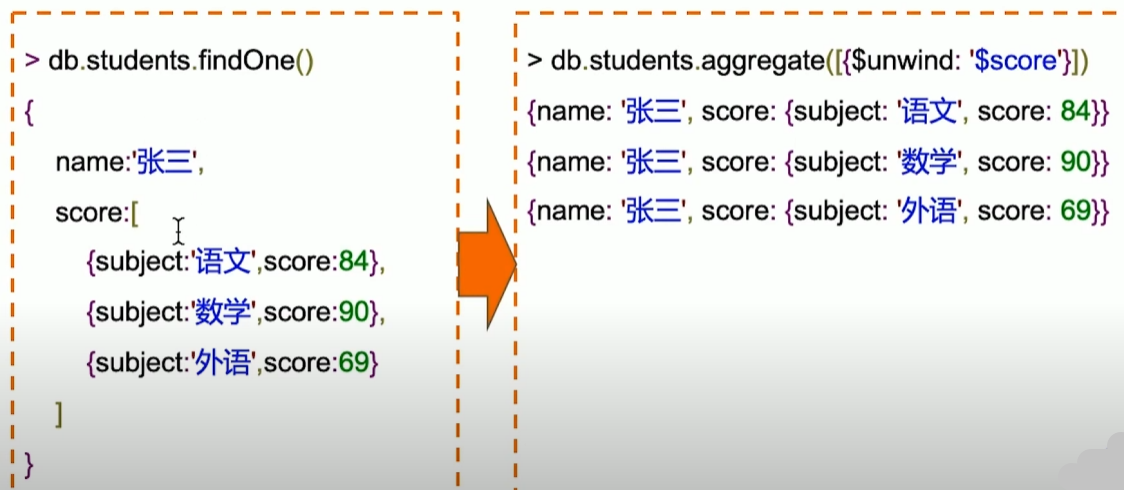
MQL特有步骤
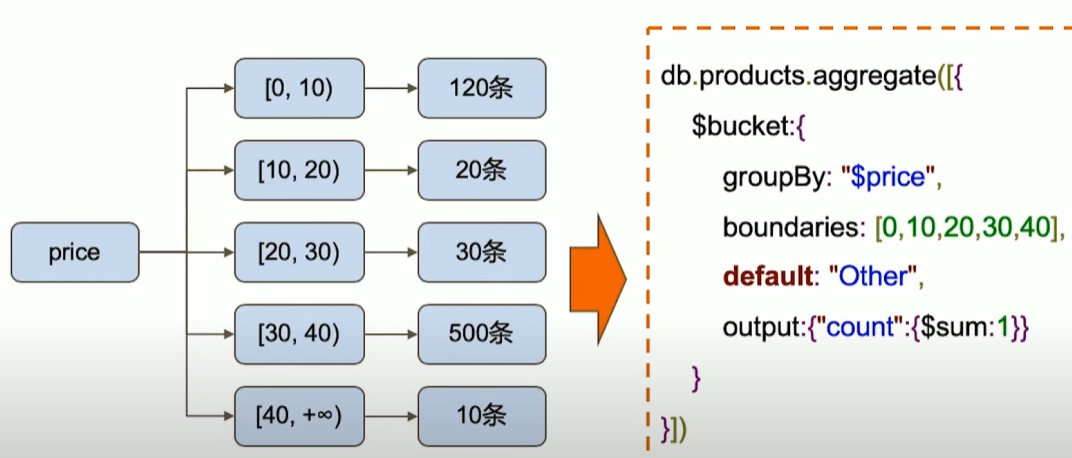
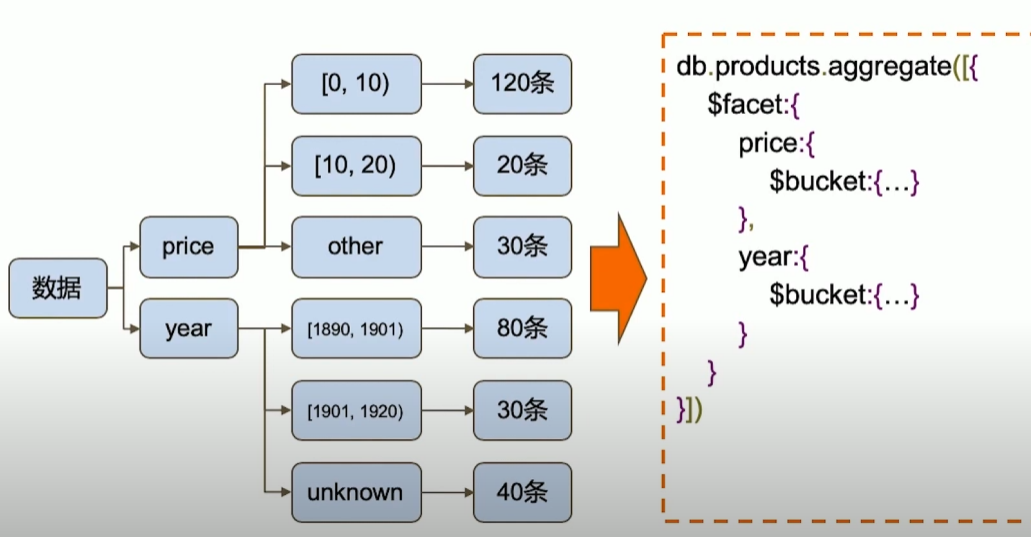
10 | 复制集机制及原理
复制集的作用
MongoDB 复制集的主要意义在于实现服务高可用。
它的现实依赖于两个方面的功能:
- 数据写入时将数据迅速复制到另一个独立节点上
- 在接受写入的节点发生故障时自动选举出一个新的替代节点
在实现高可用的同时,复制集实现了其他几个附加作用
- 数据分发:将数据从一个区域复制到另一个区域,减少另一个区域的读延迟
- 读写分离:不同类型的压力分别在不同的节点上执行
- 异地容灾:在数据中心故障时候快速切换到异地
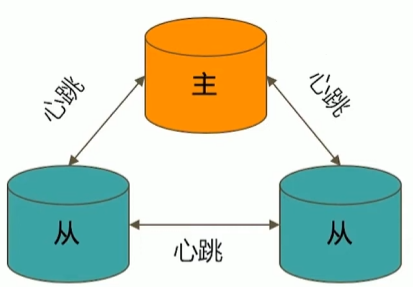
典型复制集结构
一个典型的复制集由3个以上具有投票权的节点组成,包括:
- 一个主节点(PRIMARY):接受写入操作和选举时投票
- 两个(或多个)从节点(SECONDARY):复制主节点上的新数据和选举时投票
- 不推荐使用Arbiter(投票节点)
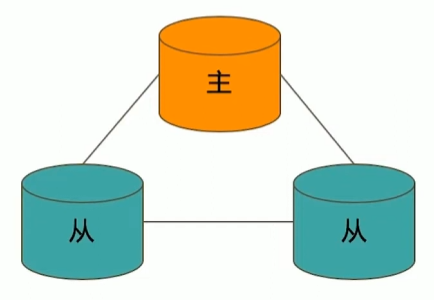
数据是如何复制的?
- 一个修改操作,当无论是插入、更新或删除,到达主节点时,它对数据的操作将被记录下来(经过一-些必要的转换),这些记录称为 oplog。
- 从节点通过在主节点上打开一个 tailable 游标不断获取新进入主节点的 oplog,并在自己的数据上回放,以此保持跟主节点的数据一致。
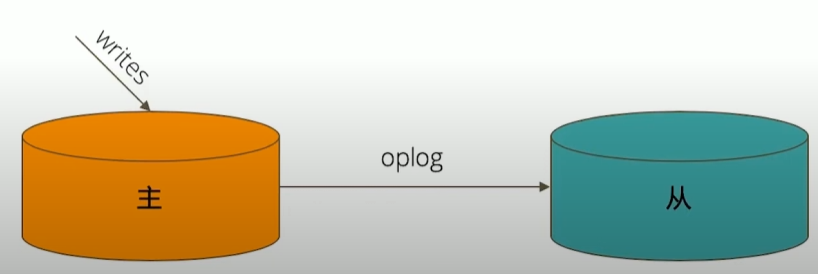
通过选举完成故障恢复
- 具有投票权的节点之间两两互相发送心跳,
- 当5次心跳未收到时判断为节点失联,
- 如果失联的是主节点,从节点会发起选举,选出新的主节点,
- 如果失联的是从节点则不会产生新的选举,
- 选举基于 RAFT一致性算法 实现,选举成功的必要条件是大多数投票节点存活;
- 复制集中最多可以有50个节点,但具有投票权的节点最多7个
影响选举的因素
- 整个集群必须有大多数节点存活;
- 被选举为主节点的节点必须:
- 能够与多数节点建立连接
- 具有较新的 oplog
- 具有较高的优先级(如果有配置)
常见选项
复制集节点有以下常见的选配项:
- 是否具有投票权(v 参数):有则参与投票;
- 优先级(priority 参数):优先级越高的节点越优先成为主节点。优先级为0的节点无法成为主节点;
- 隐藏(hidden 参数):复制数据,但对应用不可见。隐藏节点可以具有投票仅,但优先级必须为0;
- 延迟(slaveDelay 参数):复制n秒之前的数据,保持与主节点的时间差
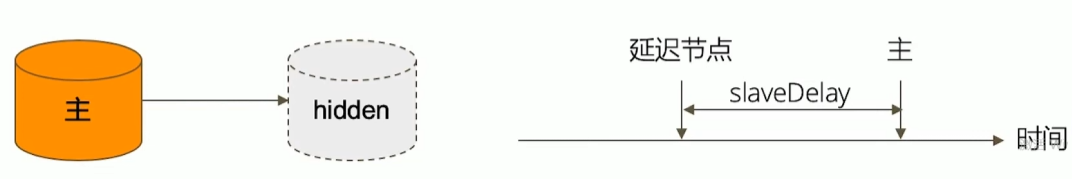
复制集注意事项
关于硬件:
- 因为正常的复制集节点都有可能成为主节点,它们的地位是一样的,因此硬件配置上必须一致;
- 为了保证节点不会同时宕机,各节点使用的硬件必须具有独立性。
关于软件:
- 复制集各节点软件版本必须一致,以避免出现不可预知的问题。
增加节点不会增加系统写性能!
11 | 实验:搭建MongoDB复制集
启动 3 个 MongoDB 实例
wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-ubuntu2404-8.0.11.tgz
tar xf mongodb-linux-x86_64-ubuntu2404-8.0.11.tgz
cd mongodb-linux-x86_64-ubuntu2404-8.0.11
mkdir -p db{1,2,3}
cat << EOF | tee ./db1/mongod.conf
systemLog:
destination: file
path: ./db1/mongod.log
logAppend: true
storage:
dbPath: ./db1
net:
bindIp: 0.0.0.0
port: 28017
replication:
replSetName: rs0
processManagement:
fork: true
EOF
cat << EOF | tee ./db2/mongod.conf
systemLog:
destination: file
path: ./db2/mongod.log
logAppend: true
storage:
dbPath: ./db2
net:
bindIp: 0.0.0.0
port: 28018
replication:
replSetName: rs0
processManagement:
fork: true
EOF
cat << EOF | tee ./db3/mongod.conf
systemLog:
destination: file
path: ./db3/mongod.log
logAppend: true
storage:
dbPath: ./db3
net:
bindIp: 0.0.0.0
port: 28019
replication:
replSetName: rs0
processManagement:
fork: true
EOF
./bin/mongod -f ./db1/mongod.conf
./bin/mongod -f ./db2/mongod.conf
./bin/mongod -f ./db3/mongod.conf配置复制集
安装mongosh
wget https://downloads.mongodb.com/compass/mongosh-2.5.5-linux-x64.tgz
tar xf mongosh-2.5.5-linux-x64.tgz
cd mongosh-2.5.5-linux-x64/bin方法一
注意:此方式 hostname 需要能被解析
./mongosh --port 28017
test> rs.initiate()
{
info2: 'no configuration specified. Using a default configuration for the set',
me: 'CTU-WKS-AB847:28017',
ok: 1,
'$clusterTime': {
clusterTime: Timestamp({ t: 1751878515, i: 1 }),
signature: {
hash: Binary.createFromBase64('AAAAAAAAAAAAAAAAAAAAAAAAAAA=', 0),
keyId: Long('0')
}
},
operationTime: Timestamp({ t: 1751878515, i: 1 })
}
rs0 [direct: secondary] test> rs.add("CTU-WKS-AB847:28018")
{
ok: 1,
'$clusterTime': {
clusterTime: Timestamp({ t: 1751878612, i: 1 }),
signature: {
hash: Binary.createFromBase64('AAAAAAAAAAAAAAAAAAAAAAAAAAA=', 0),
keyId: Long('0')
}
},
operationTime: Timestamp({ t: 1751878612, i: 1 })
}
rs0 [direct: primary] test> rs.add("CTU-WKS-AB847:28019")
{
ok: 1,
'$clusterTime': {
clusterTime: Timestamp({ t: 1751878630, i: 1 }),
signature: {
hash: Binary.createFromBase64('AAAAAAAAAAAAAAAAAAAAAAAAAAA=', 0),
keyId: Long('0')
}
},
operationTime: Timestamp({ t: 1751878630, i: 1 })
}
rs0 [direct: primary] test> rs.status()
{
set: 'rs0',
date: ISODate('2025-07-07T08:58:16.809Z'),
myState: 1,
term: Long('1'),
syncSourceHost: '',
syncSourceId: -1,
heartbeatIntervalMillis: Long('2000'),
majorityVoteCount: 2,
writeMajorityCount: 2,
votingMembersCount: 3,
writableVotingMembersCount: 3,
...
}方法二
./mongosh --port 28017
test> rs.initiate({
_id: "rs0",
members: [{
_id:0,
host: "localhost:28017"
},{
_id:1,
host: "localhost:28018"
},{
_id:2,
host: "localhost:28019"
}]
})
{
ok: 1,
'$clusterTime': {
clusterTime: Timestamp({ t: 1751879103, i: 1 }),
signature: {
hash: Binary.createFromBase64('AAAAAAAAAAAAAAAAAAAAAAAAAAA=', 0),
keyId: Long('0')
}
},
operationTime: Timestamp({ t: 1751879103, i: 1 })
}验证
在主节点上写
./mongosh --port 28017
rs0 [direct: primary] test> db.test.insertOne({a:1})
{
acknowledged: true,
insertedId: ObjectId('686b8e5e2e3134769f32a03d')
}在从节点上读
在 MongoDB 的 复制集环境中,默认情况下:
- 只允许从 Primary 节点读取数据
- 直接访问 Secondary 节点会被拒绝(抛出 not master 错误)
为了在 Secondary 节点上也允许读取,MongoDB 提供了 rs.slaveOk() 这个方法。
使用mongosh 连接从节点时不再需要手动运行
rs.secondaryOk()便可以直接读取数据。 Read Preference Behavior
./mongosh --port 28018
rs0 [direct: secondary] test> db.test.find()
[ { _id: ObjectId('686b8e5e2e3134769f32a03d'), a: 1 } ]12 | MongoDB全家桶
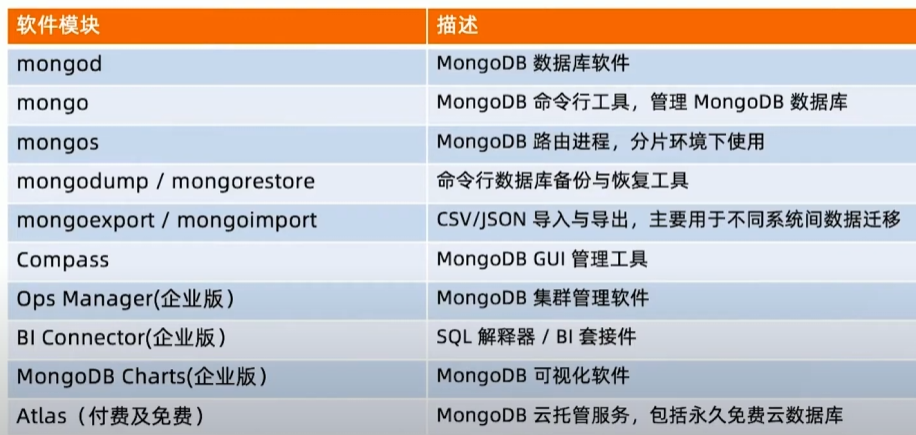
Mongodump/mongorestore
- 类似于 MySQL的 dump/restore 工具
- 可以完成全库 dump: 不加条件
- 也可以根据条件 dump 部分数据: -q 参数
- Dump 的同时跟踪数据就更:—oplog
- Restore 是反操作,把mongodump的输出导入到 mongodb
wget https://fastdl.mongodb.org/tools/db/mongodb-database-tools-ubuntu2404-x86_64-100.12.2.tgz
tar xf mongodb-database-tools-ubuntu2404-x86_64-100.12.2.tgz
cd mongodb-database-tools-ubuntu2404-x86_64-100.12.2/bin
./mongodump -h 127.0.0.1:28017 -d test -c test
./mongorestore -h 127.0.0.1:28017 -d test -c test xxx.bsonAtlas
MongoDB 公有云托管服务

MongoDB BI Connector
企业版软件,提供MySQL语法兼容的SQL解释器,仅支持从MongoDB读数据。
MongoDB Ops Manager
MongoDB的集群管理平台
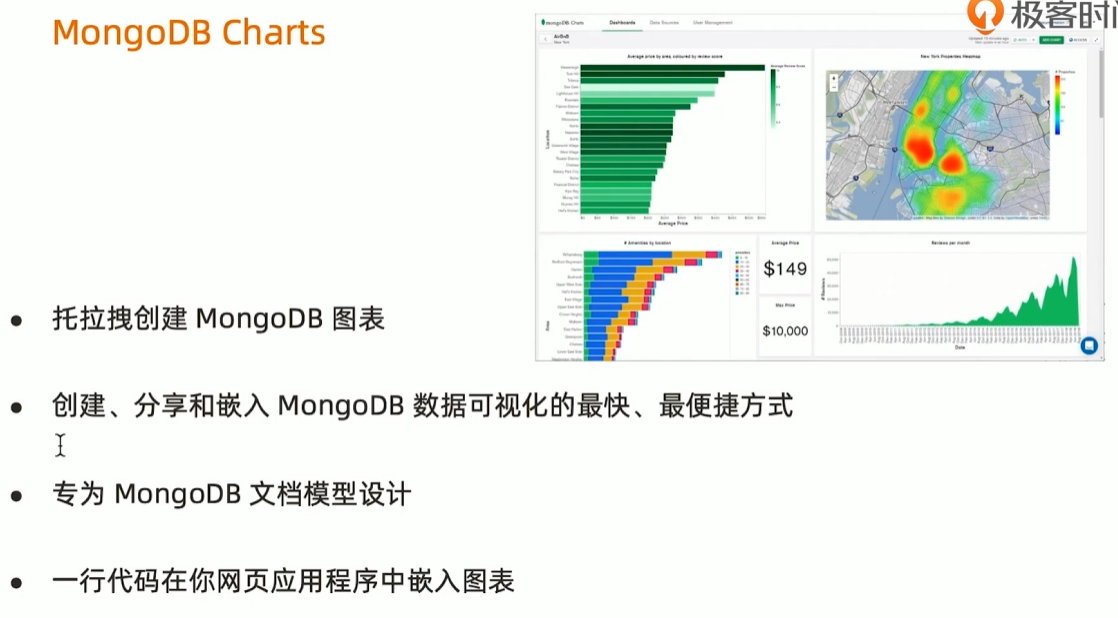
MongoDB Charts
第二章:从熟练到精通的开发之路
13 | 模型设计基础
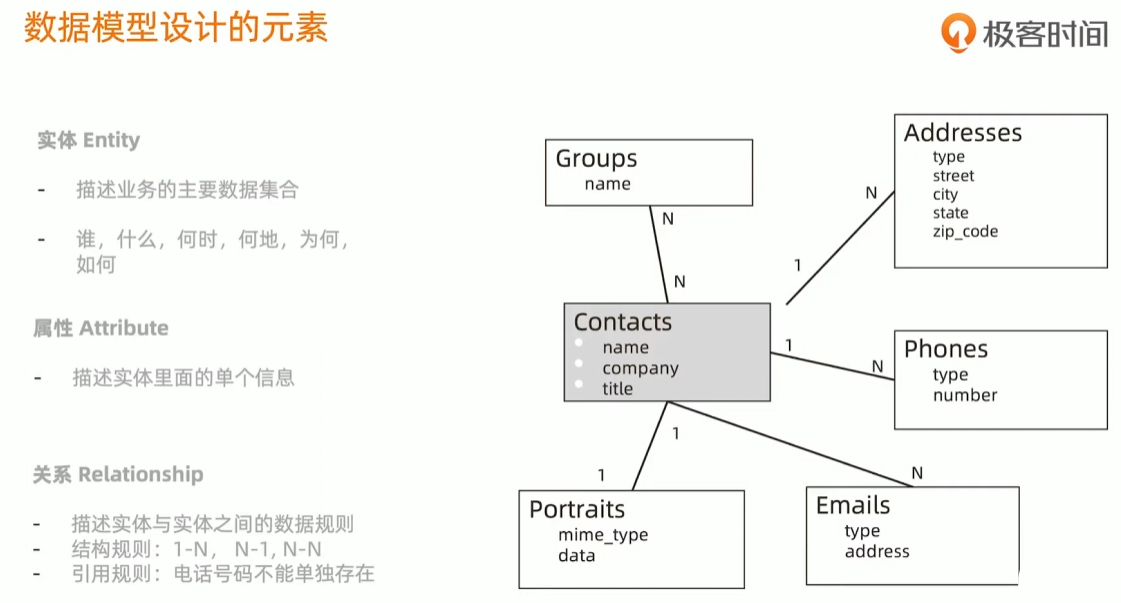
数据模型
什么是数据模型?
数据模型是一组由符号、文本组成的集合,用以准确表达信息,达到有效交流、沟通的目的。
Steve Hoberman 霍伯曼.数据建模经典教程
数据模型设计的元素
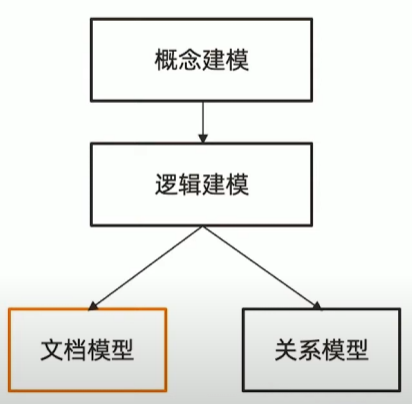
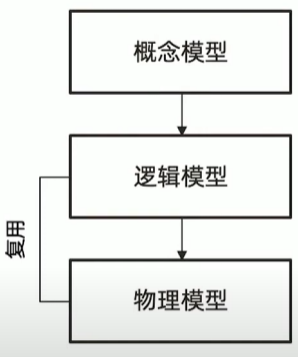
传统模型设计
从概念到逻辑到物理
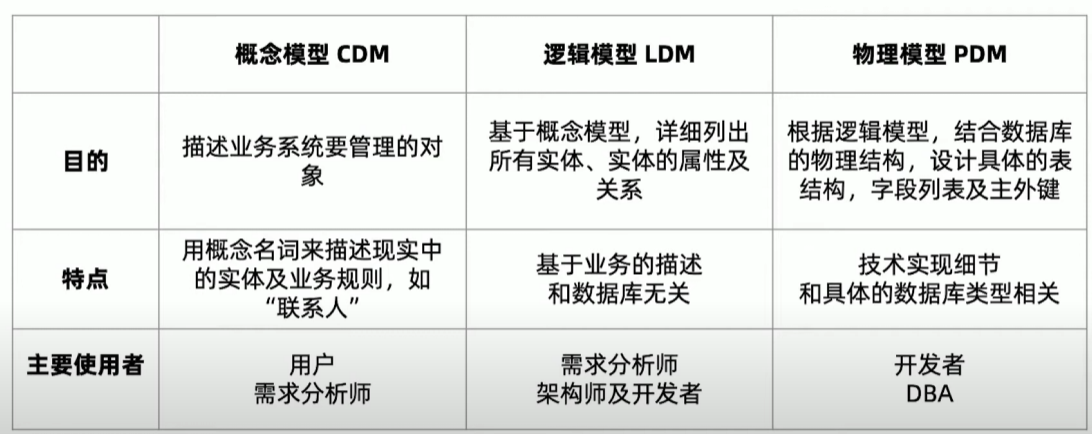
模型设计小结
数据模型的三要素:
- 实体
- 属性
- 关系
数据模型的三层深度 :
- 概念模型,逻辑模型,物理模型
- 一个模型逐步细化的过程
14 | JSON文档模型设计特点
MongoDB 文档模型设计的三个误区
下面的陈述均为错
- 不需要模型设计
- MongoDB 应该用一个超级大文档来组织所有数据
- MongoDB 不支持关联或者事务
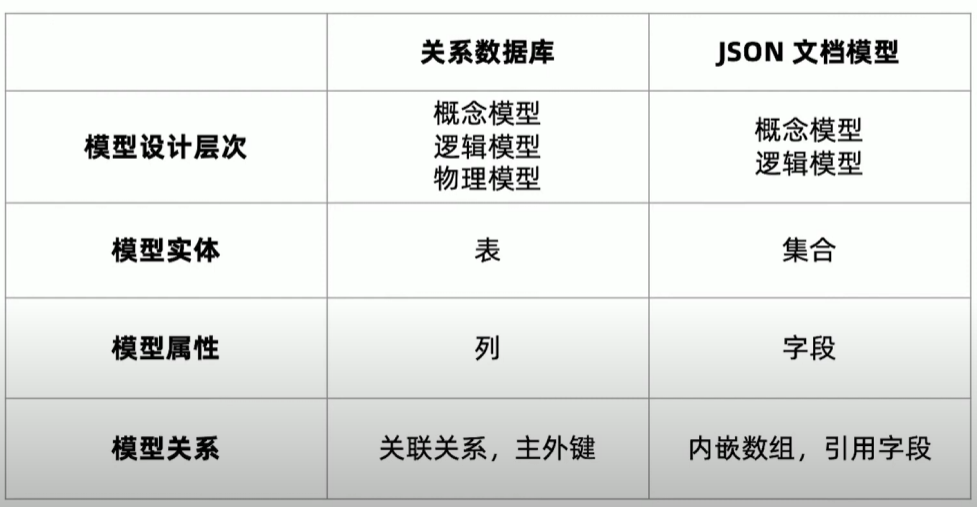
关于 JSON 文档模型设计
- 文档模型设计处于是物理模型设计阶段(PDM)
- JSON 文档模型通过内嵌数组或引用字段来表示关系
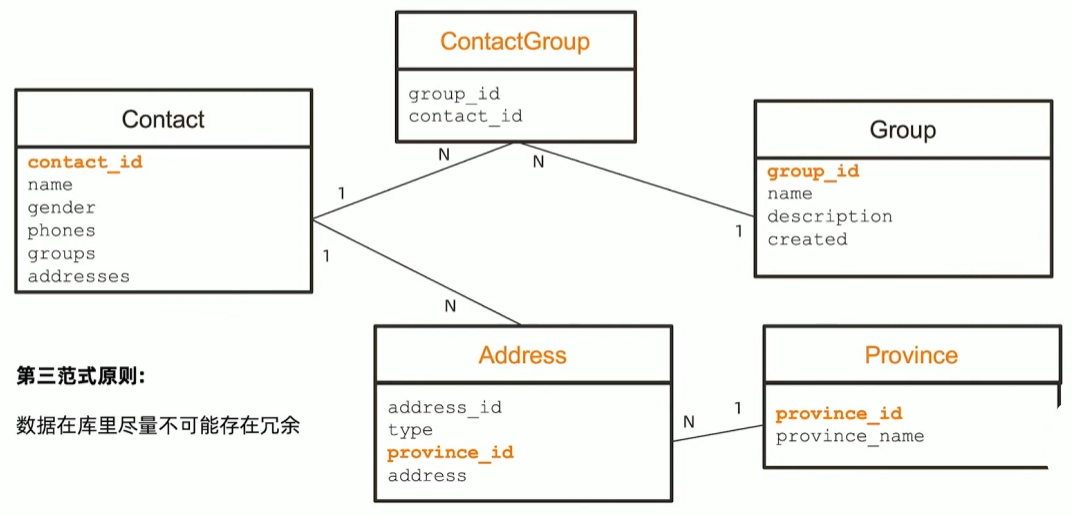
- 文档模型设计不遵从第三范式,允许冗余
为什么人们都说 MongoDB 是无模式?
严格来说,MongoDB同样需要概念/逻辑建模
文档模型设计的物理层结构可以和逻辑层类似
MongoDB 无模式由来:
- 可以省略物理建模的具体过程
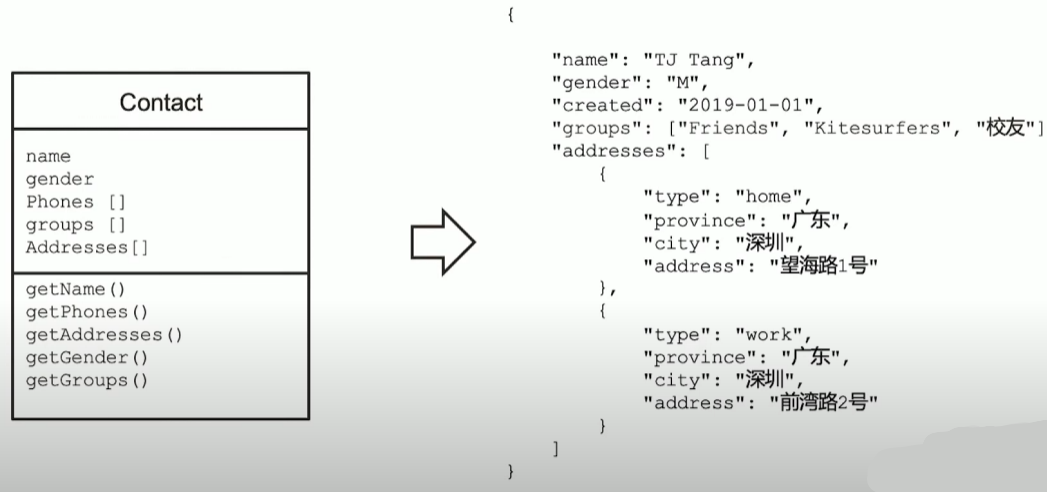
关系模型 vs 文档模型
15 | 文档模型设计之一:基础设计
MongoDB 文档模型设计三步曲
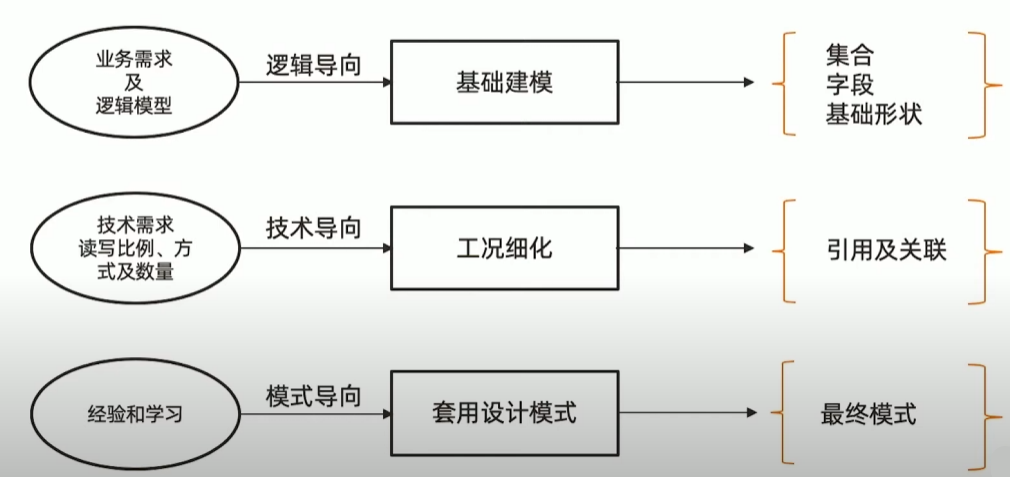
第一步:建立基础文档模型
- 根据概念模型或者业务需求推导出逻辑模型-找到对象
- 列出实体之间的关系(及基数)-明确关系
- 套用逻辑设计原则来决定内嵌方式-进行建
- 完成基础模型构建
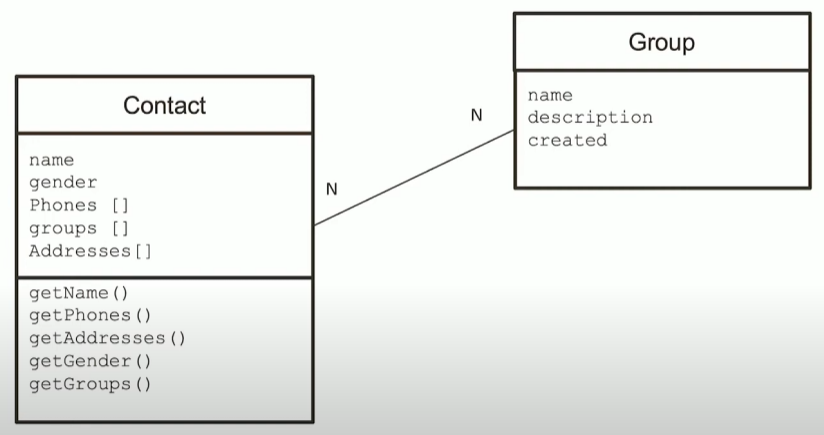
一个联系人管理应用的例子
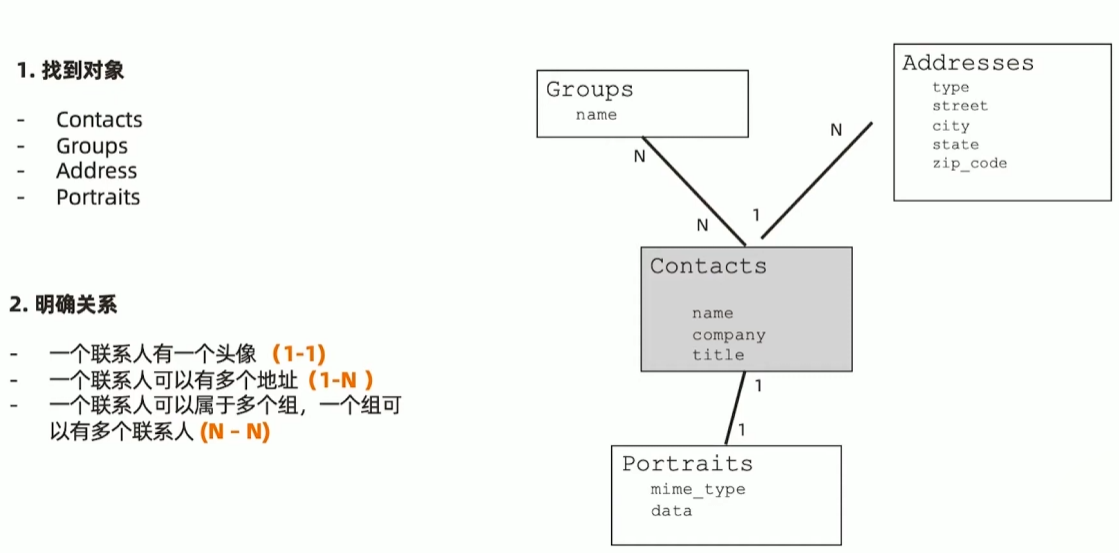
1-1 关系建模: portraits
- 基本原则
- 一对一关系以内嵌为主作为子文档形式 或者直接在顶级不涉及到数据冗余
例外情况
- 如果内嵌后导致文档大小超过16MB
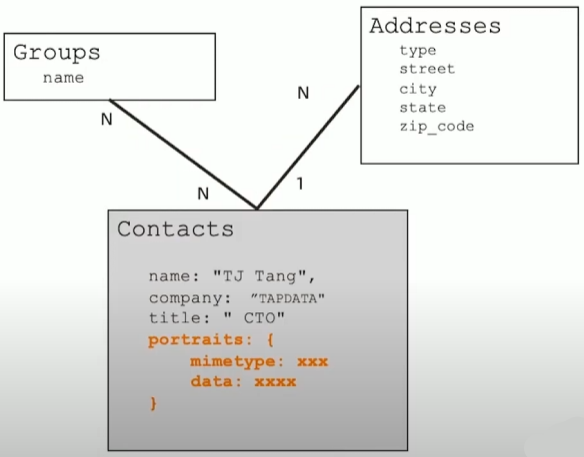
- 基本原则
1-N 关系建模: Addresses
- 基本原则
- 一对多关系同样以内嵌为主
- 用数组来表示一对多
- 不涉及到数据冗余
例外情况
- 内嵌后导致文档大小超过16MB
- 数组长度太大(数万或更多)
- 数组长度不确定
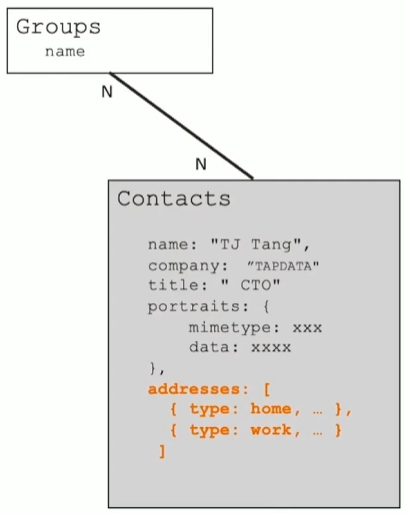
- 基本原则
N-N 关系建模:内嵌数组模式
- 基本原则
- 不需要映射表
- 一般用内嵌数组来表示一对多
- 通过冗余来实现N-N
例外情况
- 内嵌后导致文档大小超过16MB
- 数组长度太大(数万或更多)
- 数组长度不确定

- 基本原则
16 | 文档模型设计之二:工况细化
第二步:根据读写工况细化
- 最频繁的数据查询模式
- 最常用的查询参数最频繁的数据写入模式
- 读写操作的比例
- 数据量的大小
基于内嵌的文档模型,根据业务需求,使用引用来避免性能瓶颈、使用冗余来优化访问性能。
联系人管理应用的分组需求
- 用于客户营销
- 有千万级联系人
- 需要频繁变动分组(group)的信息,如增加分组及修改名称及描述以及营销状态
- 一个分组可以有百万级联系人
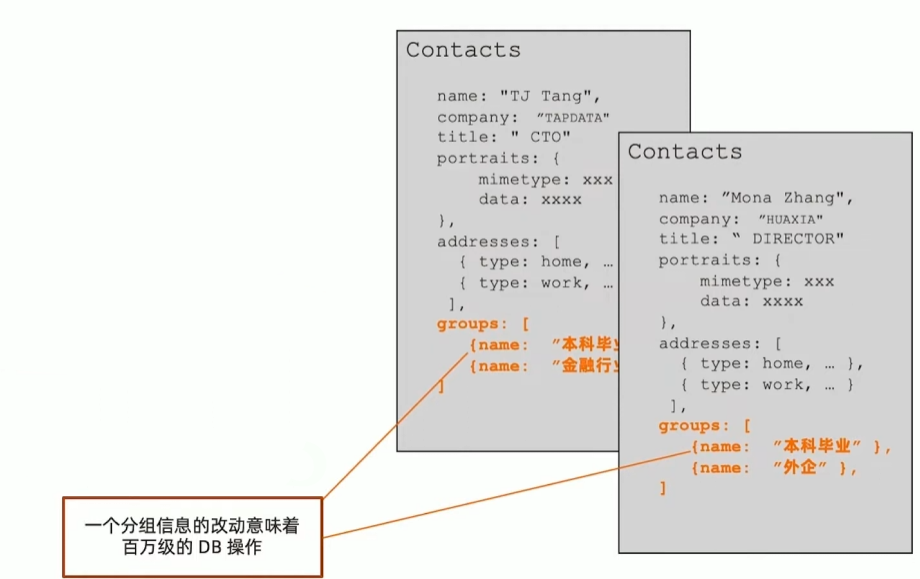
解决方案: Group 使用单独的集合
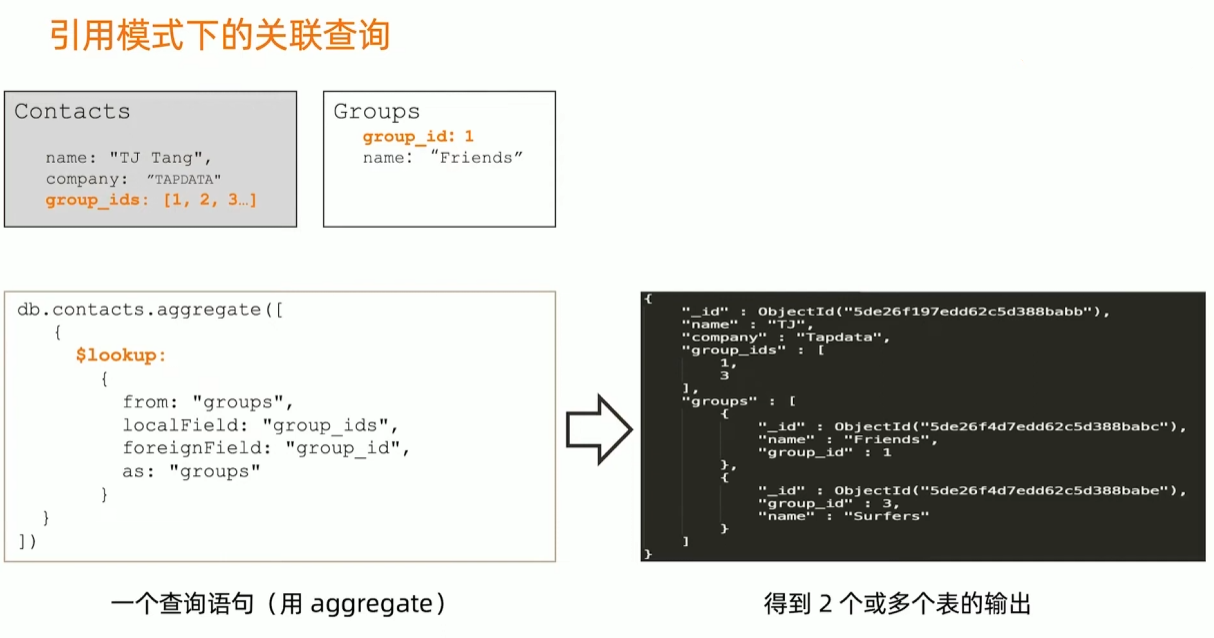
- 类似于关系型设计
- 用 id 或者唯一键关联
- 使用 $lookup 来提供一次查询多表的能力(类似关联)

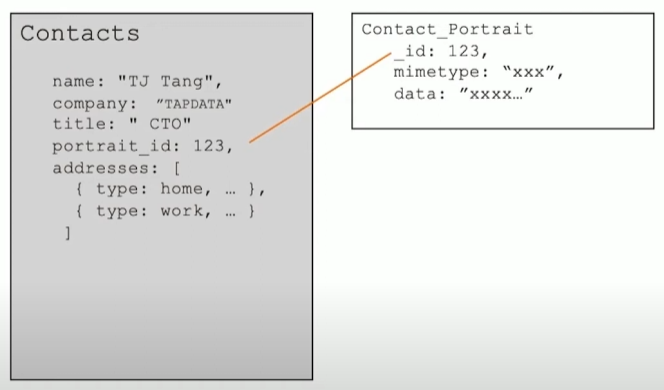
联系人的头像:引用模式
- 头像使用高保真,大小在5MB-10MB
- 头像一旦上传:一个月不可更换
- 基础信息查询(不含头像)和 头像查询的比例为9:1
- 建议: 使用引用方式,把头像数据放到另外一个集合,可以显著提升 90% 的查询效率
什么时候该使用引用方式?
- 内嵌文档太大,数 MB 或者超过16MB
- 内嵌文档或数组元素会频繁修改
- 内嵌数组元素会持续增长并且没有封顶
MongoDB引用设计的限制
- MongoDB 对使用引用的集合之间并无主外键检查
- MongoDB 使用聚合框架的 $lookup 来模仿关联查询
- $lookup 只支持 left outer join
- $lookup 的关联目标(from)不能是分片表

17 | 文档模型设计之三:模式套用
第三步:套用设计模式
文档模型:无范式,无思维定式,充分发挥想象力
设计模式:实战过屡试不爽的设计技巧,快速应用
举例:一个IOT场景的分桶设计模式,可以帮助把存储空间降低10倍并且查询效率提升数十倍.
问题:物联网场景下的海量数据处理-飞机监控数据
{
"_id":"20160101050000:CA2790",
"icao":"CA2790",
"callsign":"CA2790",
"ts":ISoDate("2016-01-01T05:00:00.000+0000"),
"events":{
"a":31418,
"b": : 173,
"p":[115,-134],
"s":91,
"v": 80
}
}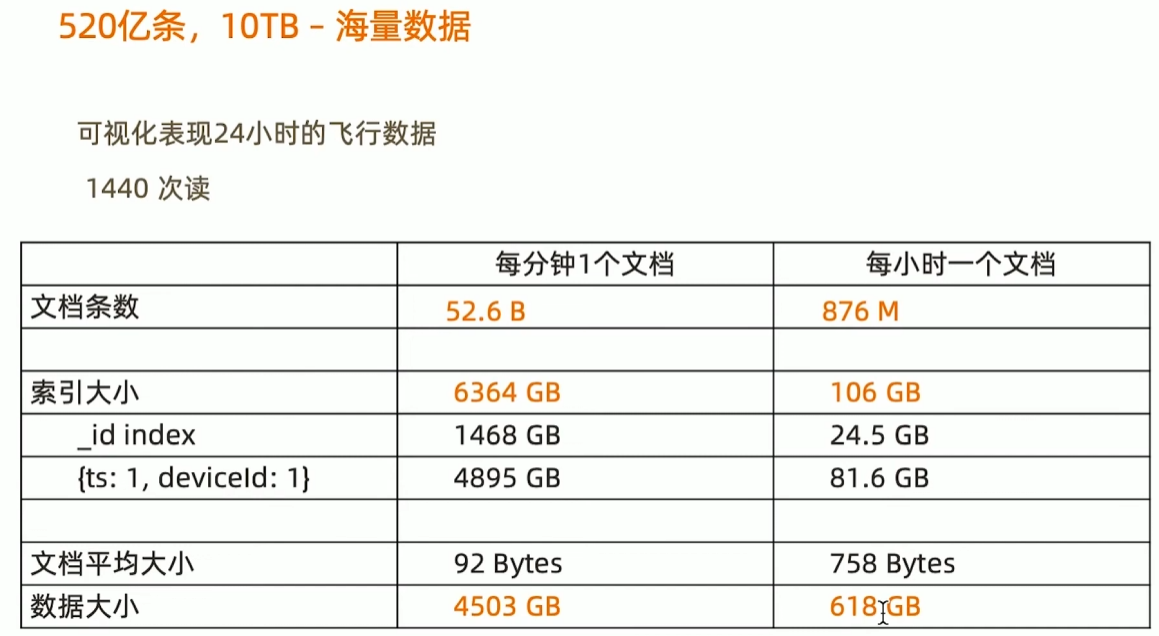
模式小结:分桶

本讲小结
一个好的设计模式可以显著地:
- 提升数据读写的效率
- 降低资源的需求
更多的MongoDB设计模式:

18 | 设计模式集锦
问题:大文档,很多字段,很多索引
{
title: "Dunkirk",
release_USA:"2017/07/23",
release_UK:"2017/08/01",
release_France:"2017/08/01",
release_Festival_San_Jose:"2017/07/22"
}需要很多索引
{
{release_UsA:1 }
{release_UK:1}
{release_France:1}
{release_Festival San Jose:1 }
}解决方案: 列转行

模式小结: 列转行

问题:模型灵活了,如何管理文档不同版本?

解决方案:增加一个版本字段

模式小结: 版本字段

问题:统计网页点击流量

解决方案:用近似计算
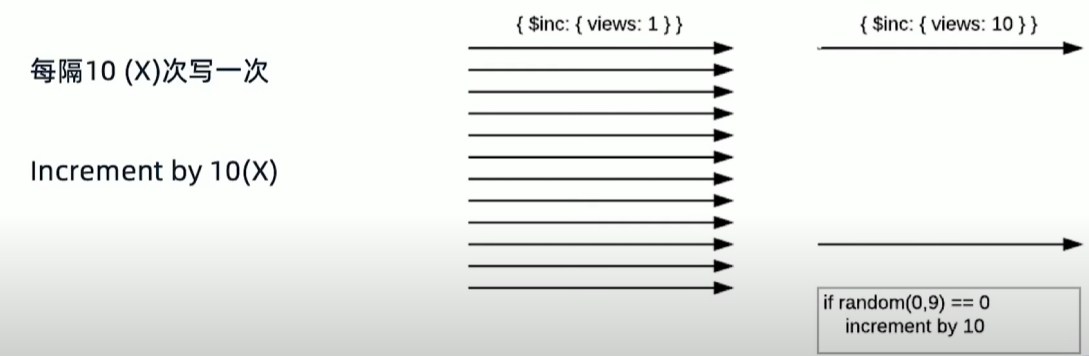
模式小结:近似计算

问题:业绩排名,游戏排名,商品统计等精确统计
- 热销榜:某个商品今天卖了多少,这个星期卖了多少,这个月卖了多少?
- 电影排行:观影者,场次统计
- 传统解决方案:通过聚合计算
痛点:消耗资源多,聚合计算时间长
解决方案:用预聚合字段

模式小结:预聚合

19 丨 事务开发:写操作事务
什么是 writeconcern?
writeConcern 决定一个写操作落到多少个节点上才算成功。writeConcern 的取值包括:
- 0: 发起写操作,不关心是否成功;
- 1~集群最大数据节点数: 写操作需要被复制到指定节点数才算成功;
- majority: 写操作需要被复制到大多数节点上才算成功,发起写操作的程序将阻塞到写操作到达指定的节点数为止
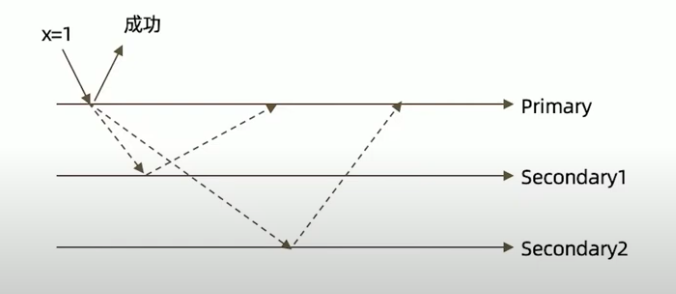
默认行为
主节点写到内存中后就返回成功。
以 3 节点复制集不作任何特别设定(默认值)为例。
w: “majority”
大多数节点确认模式
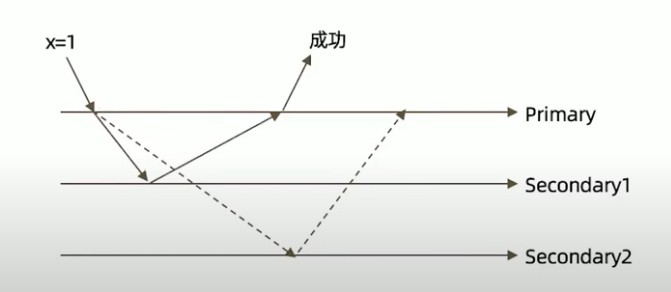
w: “all”
全部节点确认模式
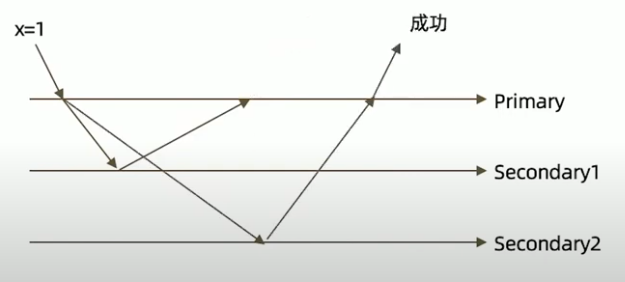
j: true
writeconcern 可以决定写操作到达多少个节点才算成功,journal 则定义如何才算成功。取值包括:
- true: 写操作落到journal文件中才算成功;
- false: 写操作到达内存即算作成功。
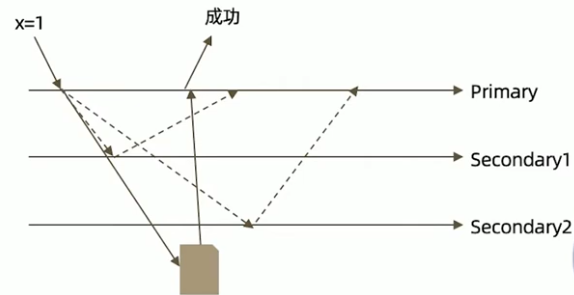
writeconcern 实验
在复制集测试writeConcern参数
db.test.insert( {count: 1},{writeconcern: {w: "majority"}})
db.test.insert( {count:1},{writeConcern: {w: 3 }})
db.test.insert( {count: 1},{writeConcern: {w: 4 }})配置延迟节点,模拟网络延迟(复制延迟)
conf=rs.conf()
conf.members[2].slaveDelay=5
conf.members[2].priority=0
rs.reconfig(conf)观察复制延迟下的写入,以及timeout参数
db.test.insert( {count:1},{writeConcern: {w: 3}})
db.test.insert( {count:1},{writeConcern: {w: 3, wtimeout:3000 }})注意事项
- 虽然多于半数的 writeConcern 都是安全的,但通常只会设置 majority,因为这是等待写入延迟时间最短的选择;
- 不要设置 writeconcern 等于总节点数,因为一旦有一个节点故障,所有写操作都将失败;
- writeConcern 虽然会增加写操作延迟时间,但并不会显著增加集群压力,因此无论是否等待,写操作最终都会复制到所有节点上。设置 writeconcern 只是让写操作等待复制后再返回而已;
- 应对重要数据应用
{w: "majority"},普通数据可以应用{w: 1}以确保最佳性能
20丨事务开发:读操作事务之一
综述
在读取数据的过程中我们需要关注以下两个问题:
- 从哪里读?关注数据节点 位置
- 什么样的数据可以读? 关注数据的隔离性
- 第一个问题是是由 readPreference 来解决
- 第二个问题则是由 readconcern 来解决
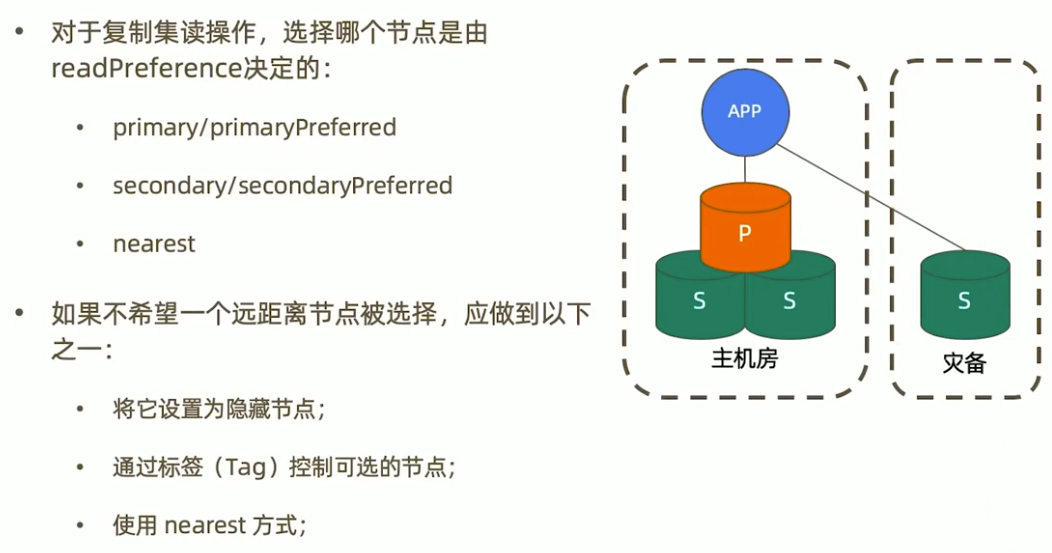
什么是 readPreference?
readPreference 决定使用哪一个节点来满足正在发起的读请求。可选值包括:
- primary: 只选择主节点;
- primaryPreferred:优先选择主节点,如果不可用则选择从节点;
- secondary:只选择从节点;
- secondaryPreferred:优先选择从节点如果从节点不可用则选择主节点;
- nearest:选择最近的节点;
readPreference 场景举例
- 用户下订单后马上将用户转到订单详情页—primary/primaryPreferred。因为此时从节点可能还没复制到新订单;
- 用户查询自己下过的订单—secondary/secondaryPreferred。查询历史订单对时效性通常没有太高要求;
- 生成报表—secondary。报表对时效性要求不高,但资源需求大,可以在从节点单独处理,避免对线上用户造成影响;
- 将用户上传的图片分发到全世界,让各地用户能够就近读取—nearest。每个地区的应用选择最近的节点读取数据。
readPreference 与Tag
readPreference 只能控制使用一类节点。Tag 则可以将节点选择控制到一个或几个节点。考虑以下场景:
一个5个节点的复制集;
- 3个节点硬件较好,专用于服务线上客户
- 2个节点硬件较差,专用于生成报表;
可以使用 Tag 来达到这样的控制目的:
- 为3个较好的节点打上{purpose:”online”};
- 为2个较差的节点打上{purpose:”analyse”};
在线应用读取时指定 online,报表读取时指定reporting。
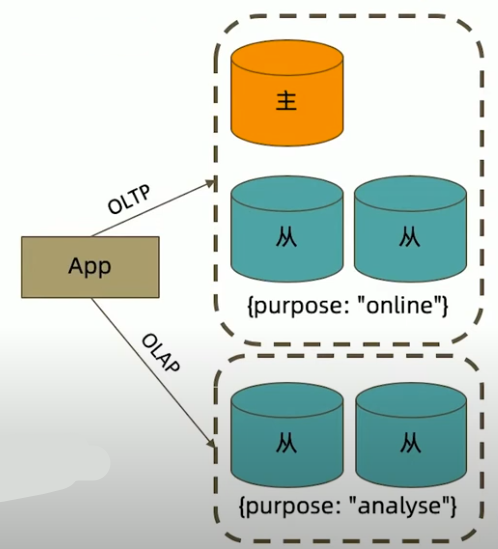
readPreference 配置
通过 MongoDB 的连接串参数:
mongodb://host1:27107,host2:27107,host3:27017/?replicaSet=rs&readPreference=secondary通过 MongoDB 驱动程序 API:
MongoCollection.withReadPreference(ReadPreference readPref)Mongo shell:
db.collection.find({}).readPref("secondary")readPreference 实验:从节点读
- 主节点写入
{x:1},观察该条数据在各个节点均可见 - 在两个从节点分别执行
db.fsyncLock()来锁定写入(同步) 主节点写入 {x:2}
db.test.find({a:123})db.test.find({a:123}).readPref( "secondary" )
解除从节点锁定
db.fsyncUnlock()db.test.find({a:123}).readPref( "secondary")
注意事项极客时间
- 指定 readPreference 时也应注意高可用问题。例如将 readPreference 指定 primary,则发生故障转移不存在 primary期间将没有节点可读。如果业务允许,则应选择 primaryPreferred;
- 使用 Tag 时也会遇到同样的问题,如果只有一个节点拥有一个特定 Tag,则在这个节点失效时将无节点可读。这在有时候是期望的结果,有时候不是。例如:
- 如果报表使用的节点失效,即使不生成报表,通常也不希望将报表负载转移到其他节点上,此时只有一个节点有报表 Tag 是合理的选择;
- 如果线上节点失效,通常希望有替代节点,所以应该保持多个节点有同样的Tag;
- Tag 有时需要与优先级、选举权综合考虑。例如做报表的节点通常不会希望它成为主节点,则优先级应为 0。
21丨事务开发:读操作事务之二
什么是 readconcern?
在 readPreference 选择了指定的节点后,readconcern 决定这个节点上的数据哪些是可读的,类似于关系数据库的隔离级别。可选值包括:
- available: 读取所有可用的数据:
- local: 读取所有可用且属于当前分片的数据;
- majority: 读取在大多数节点上提交完成的数据
- linearizable: 可线性化读取文档;
- snapshot: 读取最近快照中的数据;
readconcern: local 和 available
在复制集中 local和 available 是没有区别的。两者的区别主要体现在分片集上。
考虑以下场景:一个chunk x正在从shard1 向 shard2 迁移;
整个迁移过程中 chunk x中的部分数据会在 shard1和 shard2 中同时存在,但源分片 shard1 仍然是chunk x 的负责方:
- 所有对 chunk x 的读写操作仍然进入 shard1;
- config 中记录的信息 chunk x 仍然属于 shard1;
此时如果读 shard2,则会体现出 local 和 available 的区别。
- local: 只取应该由 shard2 负责的数据(不包括x);
- available: shard2 上有什么就读什么(包括x);
注意事项:
- 虽然看上去总是应该选择 local,但毕竟对结果集进行过滤会造成额外消耗。在一些无关紧要的场景(例如统计)下,也可以考虑 available;
- MongoDB <=3.6 不支持对从节点使用
{readconcern:"local"}; - 从主节点读取数据时默认 readconcern 是 local,从从节点读取数据时默认readconcern 是 available(向前兼容原因)。
readconcern: majority
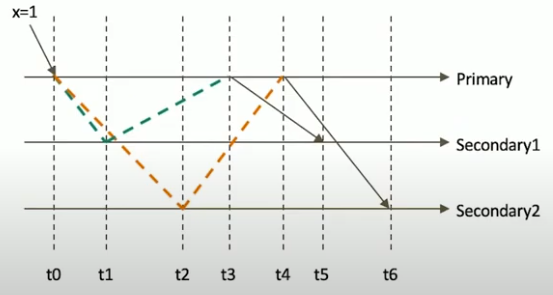
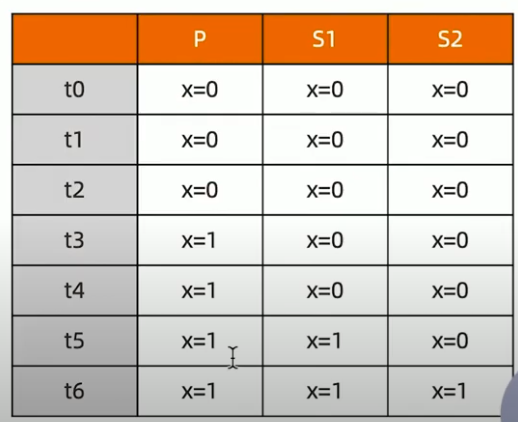
只读取大多数据节点上都提交了的数据。考虑如下场景: 集合中原有文档 {x: 0}; 将x值更新为1;
如果在各节点上应用 {readConcern:"majority"} 来读取数据
readconcern: majority 的实现方式
考虑 t3 时刻的 Secondary1,此时:
- 对于要求 majority 的读操作,它将返回 x=0;
- 对于不要求 majority 的读操作,它将返回 x=1;
如何实现?
节点上维护多个x版本,MVCC机制
MongoDB 通过维护多个快照来链接不同的版本:
- 每个被大多数节点确认过的版本都将是一个快照;
- 快照持续到没有人使用为止才被删除;
实验:readconcern: “majority” vs “local”
安装3节点复制集。
注意配置文件内 server 参数 enableMajorityReadConcern
replication: replSetName: rs0 enableMajorityReadconcern: true- 将复制集中的两个从节点使用 db.fsyncLock()锁住写入(模拟同步延迟)
readconcern 验证
db.test.save({"A":1})
db.test.find().readconcern( "local" )
db.test.find().readconcern( "majority" )在某一个从节点上执行 db.fsyncUnlock()
结论:
- 使用 local参数,则可以直接查询到写入数据
- 使用 majority,只能查询到已经被多数节点确认过的数据
- update与remove 与上同理。
readconcern: majority 与脏读
MongoDB 中的回滚:
- 写操作到达大多数节点之前都是不安全的,一旦主节点崩溃,而从节还没复制到该次操作,刚才的写操作就丢失了;
- 把一次写操作视为一个事务,从事务的角度,可以认为事务被回滚了。
所以从分布式系统的角度来看,事务的提交被提升到了分布式集群的多个节点级别的”提交”,而不再是单个节点上的”提交”在可能发生回滚的前提下考虑脏读问题:
- 如果在一次写操作到达大多数节点前读取了这个写操作,然后因为系统故障该操作回滚了,则发生了脏读问题;
使用 {readConcern:"majority"} 可以有效避免脏读
readconcern:如何实现安全的读写分离

小测试
readconcern 主要关注读的隔离性,ACID 中的 isolation,但是是分布式数据库里特有的概念
readconcern: majority 对应于事务中隔离级别中的 Read Committed。
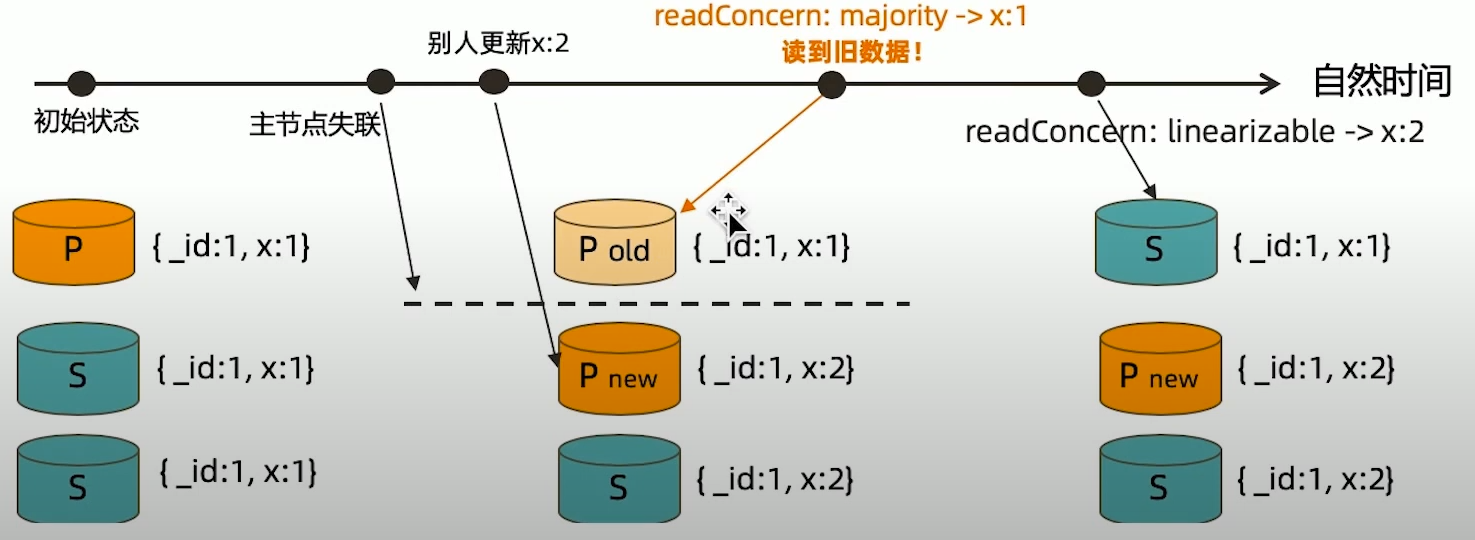
readconcern: linearizable
只读取大多数节点确认过的数据。和 majority 最大差别是保证绝对的操作线性顺序
- 在写操作自然时间后面的发生的读,一定可以读到之前的写
- 只对读取单个文档时有效;
- 可能导致非常慢的读,因此总是建议配合使用 maxTimeMS;
readconcern:snapshot
{readConcern:"snapshot"} 只在多文档事务中生效。将一个事务的readconcern设置为 snapshot,将保证在事务中的读:
- 不出现脏读;
- 不出现不可重复读;
- 不出现幻读。
因为所有的读都将使用同一个快照,直到事务提交为止该快照才被释放。
22丨事务开发:多文档事务
MongoDB 虽然已经在 4.2 开始全面支持了多文档事务,但并不代表大家应该毫无节制地使用它。相反,对事务的使用原则应该是:能不用尽量不用。
通过合理地设计文档模型,可以规避绝大部分使用事务的必要性
为什么?事务=锁,节点协调,额外开销,性能影响
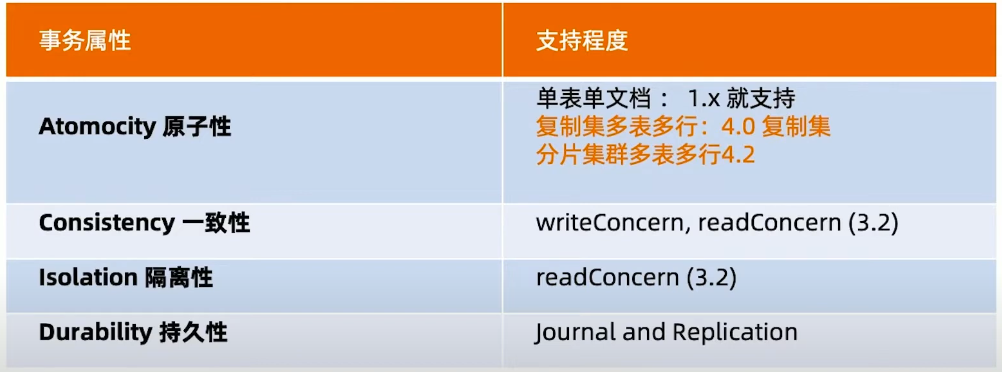
MongoDB ACID 多文档事务支持
使用方法
MongoDB 多文档事务的使用方式与关系数据库非常相似:

事务的隔离级别
事务完成前,事务外的操作 对该事务所做的修改不可访问
如果事务内使用{readconcern:"snapshot"},则可以达到可重复读 Repeatable Read


事务写机制
MongoDB 的事务错误处理机制不同于关系数据库:
- 当一个事务开始后,如果事务要修改的文档在事务外部被修改过,则事务修改这个文档时会触发 Abort 错误,因为此时的修改冲突了;
- 这种情况下,只需要简单地重做事务就可以了,
- 如果一个事务已经开始修改一个文档,在事务以外尝试修改同一个文档,则事务以外的修改会等待事务完成才能继续进行(write-wait.md实验)。


注意事项
- 可以实现和关系型数据库类似的事务场景
- 必须使用与 MongoDB 4.2 兼容的驱动;
- 事务默认必须在 60 秒(可调)内完成,否则将被取消
- 涉及事务的分片不能使用仲裁节点;
- 事务会影响 chunk 迁移效率。正在迁移的 chunk也可能造成事务提交失败(重试即可);
- 多文档事务中的读操作必须使用主节点读
- readConcern 只应该在事务级别设置,不能设置在每次读写操作上。
23丨Change Stream
什么是 Change Stream
Change Stream 是 MongoDB 用于实现变更追踪的解决方案,类似于关系数据库的触发器,但原理不完全相同:

Change stream 的实现原理
Change stream 是基于 oplog 实现的。它在 oplog 上开启一个 tailable cursor 来追踪所有复制集上的变更操作,最终调用应用中定义的回调函数。
- insert/update/delete: 插入、更新、删除;
- drop: 集合被删除;
- rename: 集合被重命名;
- 数据库被删除: dropDatabase;
- invalidate: drop/rename/dropDatabase 将导致invalidate 被触发并关闭 change stream;
Change stream 与可重复读
Change Stream 只推送已经在大多数节点上提交的变更操作。即”可重复读”的变更这个验证是通过 {readconcern:"majority"} 实现的。因此:
- 未开启 majority readconcern 的集群无法使用 Change Stream;
- 当集群无法满足
{w:"majority"}时,不会触发 Change Stream(例如 PSA 架构中的S因故障宕机)。
Change Stream 变更过滤
如果只对某些类型的变更事件感兴趣,可以使用使用聚合管道的过滤步骤过滤事件
例如:


配置中必须打开 enableMajorityReadConcern: true。
systemLog:
destination: file
path: ./db1/mongod.log
logAppend: true
storage:
dbPath: ./db1
net:
bindIp: 0.0.0.0
port: 28017
replication:
replSetName: rs0
enableMajorityReadConcern: true # <--------------------
processManagement:
fork: trueChange stream 故障恢复
假设在一系列写入操作的过程中,订阅 Change stream 的应用在接收到”写3”之后于 t0 时刻崩溃,重启后后续的变更怎么办?
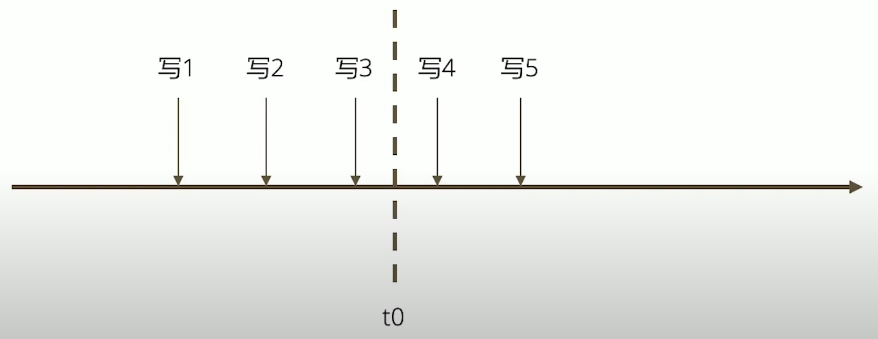

Change Stream 使用场景
- 跨集群的变更复制 —— 在源集群中订阅 Change Stream,一旦得到任何变更立即写入目标集群。
- 微服务联动 —— 当一个微服务变更数据库时,其他微服务得到通知并做出相应的变更。
- 其他任何需要系统联动的场景。
注意事项
- Change stream 依赖于 oplog,因此中断时间不可超过 oplog 回收的最大时间窗
- 在执行 update 操作时,如果只更新了部分数据,那么 Change Stream 通知的也是增量部分;
- 同理,删除数据时通知的仅是删除数据的 id。
24丨MongoDB开发最佳实践
连接到 MongoDB
- 关于驱动程序: 总是选择与所用之 MongoDB 相兼容的驱动程序。这可以很容易地从 驱动兼容对照表 中查到;
- 如果使用第三方框架(如 Spring Data),则还需要考虑框架版本与驱动的兼容性
- 关于连接对象 MongoClient: 使用 MongoClient 对象连接到 MongoDB 实例时总是应该保证它单例,并且在整个生命周期中都从它获取其他操作对象。
- 关于连接字符串: 连接字符串中可以配置大部分连接选项,建议总是在连接字符串中配置这些选项;
// 连接到复制集
mongodb://节点1,节点2,节点3.../database?[options]
//连接到分片集
mongodb://mongos1,mongos2,mongos3.../database?[options]常见连接字符串参数
- maxPoolSize 连接池大小
- Max Wait Time 建议设置,自动杀掉太慢的查询
- Write Concern 建议 majority 保证数据安全
- Read Concern 对于数据一致性要求高的场景适当使用
连接字符串节点和地址
- 无论对于复制集或分片集,连接字符串中都应尽可能多地提供节点地址,建议全部列出;
- 复制集利用这些地址可以更有效地发现集群成员;
- 分片集利用这些地址可以更有效地分散负载;
- 连接字符串中尽可能使用与复制集内部配置相同的域名或IP;
使用域名连接集群
在配置集群时使用域名可以为集群变更时提供一层额外的保护。例如需要将集群整体迁移到新网段,直接修改域名解析即可。
另外,MongoDB 提供的 mongodb+srv:// 协议可以提供额外一层的保护。该协议允许通过域名解析得到所有 mongos 或节点的地址,而不是写在连接字符串中。
mongodb+srv://server.example.com/
Record TTL Class Priority Weight Port Target
_mongodb._tcp.server.example.com.86400 IN SRV 0 5 27317 mongodb1.example.com.
_mongodb._tcp.server.example.com.86400 IN SRV 0 5 27017 mongodb2.example.com.不要在mongos前面使用负载均衡
基于前面提到的原因,驱动已经知晓在不同的 mongos 之间实现负载均衡,而复制集则需要根据节点的角色来选择发送请求的目标。如果在 mongos 或复制集上层部署负载均衡:
- 驱动会无法探测具体哪个节点存活,从而无法完成自动故障恢复
- 驱动会无法判断游标是在哪个节点创建的,从而遍历游标时出错
结论:不要在 mongos 或复制集上层放置负载均衡器,让驱动处理负载均衡和自动故障恢复。
游标使用
如果一个游标已经遍历完,则会自动关闭;如果没有遍历完,则需要手动调用 close() 方法,否则该游标将在服务器上存在 10 分钟(默认值)后超时释放,造成不必要的资源浪费。
但是,如果不能遍历完一个游标,通常意味着查询条件太宽泛,更应该考虑的问题是如何将条件收紧
关于查询及索引
- 每一个查询都必须要有对应的索引
- 尽量使用覆盖索引 Covered Indexes (可以避免读数据文件)
- 使用 projection 来减少返回到客户端的的文档的内容
关于写入
- 在update语句里只包括需要更新的字段
- 尽可能使用批量插入来提升写入性能
- 使用TTL自动过期日志类型的数据
关于文档结构
- 防止使用太长的字段名(浪费空间)
- 防止使用太深的数组嵌套(超过2层操作比较复杂)
- 不使用中文,标点符号等非拉丁字母作为字段名
处理分页问题-避免使用count
尽可能不要计算总页数,特别是数据量大和查询条件不能完整命中索引时。
考虑以下场景: 假设集合总共有 1000w 条数据,在没有索引的情况下考虑以下查询:
db.coll.find({x:100}).limit(50);
db.coll.count({x:100});- 前者只需要遍历前 n 条,直到找到 50 条队伍 x=100 的文档即可结束。
- 后者需要遍历完 1000w 条找到所有符合要求的文档才能得到结果
为了计算总页数而进行的 count() 往往是拖慢页面整体加载速度的原因
处理分页问题-巧分页
避免使用 skip/limit 形式的分页,特别是数据量大的时候;
替代方案: 使用查询条件+唯一排序条件;
例如:
- 第一页:
db.posts.find({}).sort({ id: 1}).limit(20); - 第二页:
db.posts.find({ id: {$gt:<第一页最后一个 id>}}).sort({ id: 1}).limit(20); - 第三页:
db.posts.find({ id: {$gt:<第二页最后一个 id>}}).sort({ id: 1}).limit(20);
…
关于事务
使用事务的原则:
- 无论何时,事务的使用总是能避免则避免;
- 模型设计先于事务,尽可能用模型设计规避事务
- 不要使用过大的事务(尽量控制在 1000个文档更新以内);
- 当必须使用事务时,尽可能让涉及事务的文档分布在同一个分片上,这将有效地提高效率;
第三章:分片集群与高级运维之道
25丨分片集群机制及原理
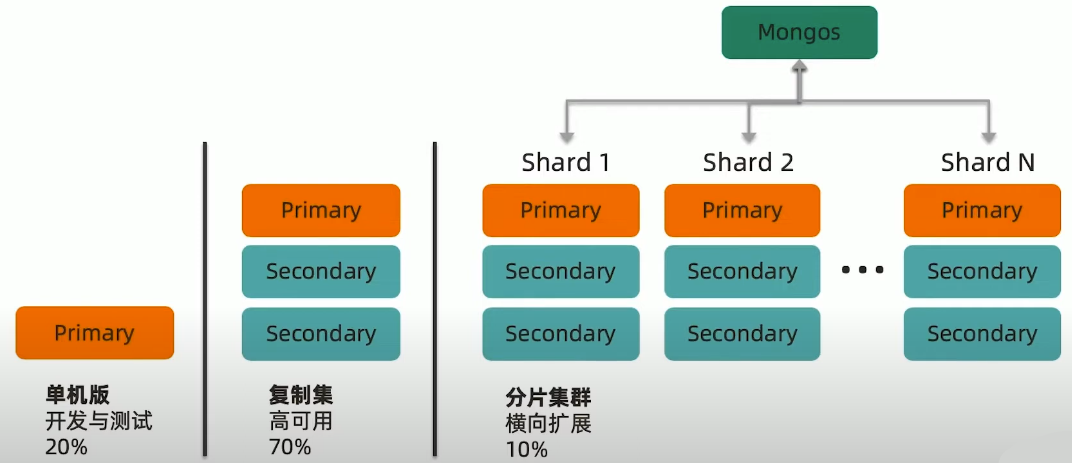
MongoDB 常见部署架构
为什么要使用分片集群?
- 数据容量日益增大,访问性能日渐降低,怎么破?
- 新品上线异常火爆,如何支撑更多的并发用户?
- 单库已有 10TB 数据,恢复需要1-2 天,如何加速?
- 地理分布数据
完整的分片集群
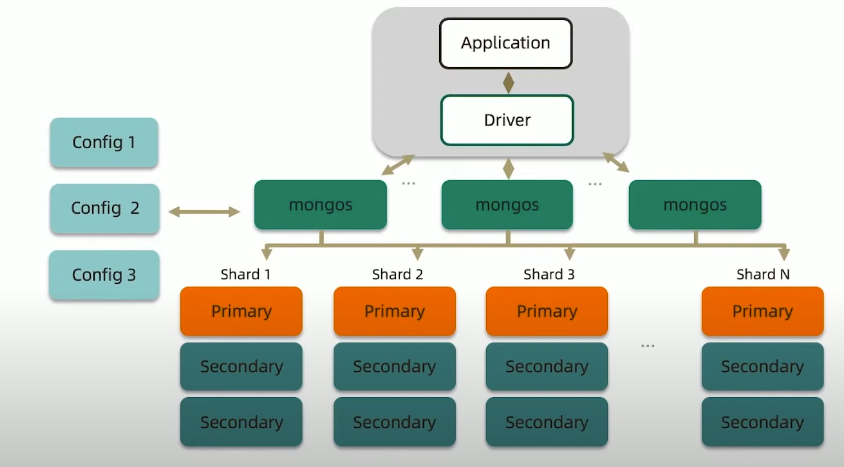
mongos
路由节点
提供集群单一入口转发应用端请求选择合适数据节点进行读写合并多个数据节点的返回
无状态
建议至少2个
config
配置(目录)节点
提供集群元数据存储分片数据分布的映射
普通复制集架构
primary/secondary
数据节点
以复制集为单位横向扩展
最大1024分片
分片之间数据不重复
所有分片在一起才可完整工作
MongoDB 分片集群特点
- 应用全透明,无特殊处理
- 数据自动均衡
- 动态扩容,无须下线
- 提供三种分片方式
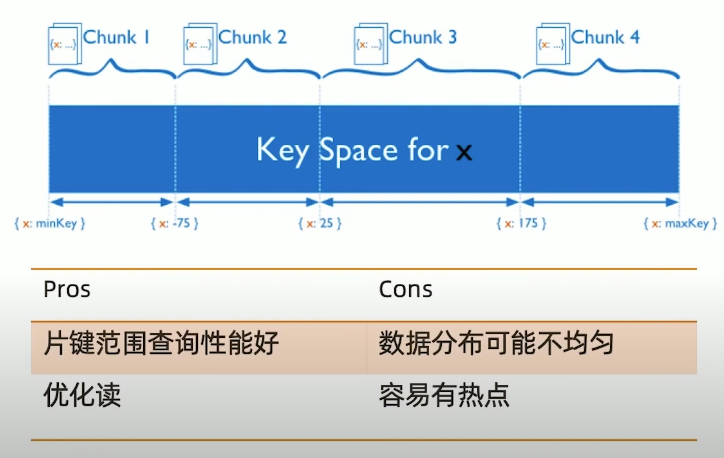
分片集群数据分布方式
基于范围
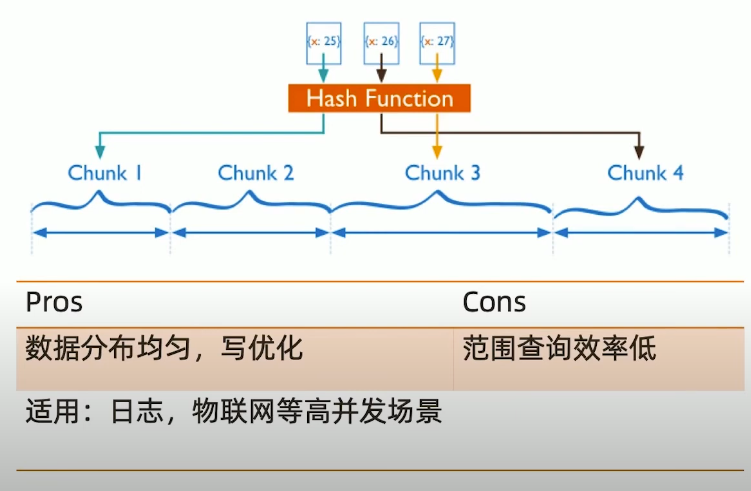
基于 Hash
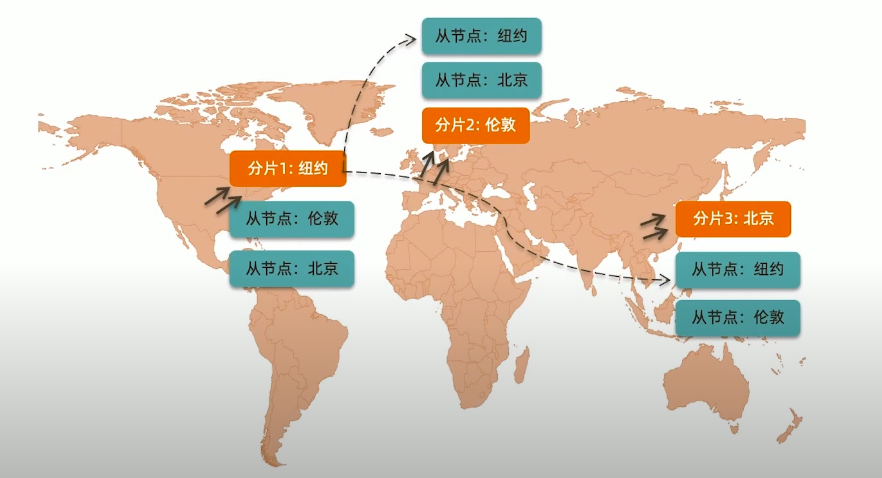
基于 zone/tag
小结
- 分片集群可以有效解决性能瓶颈及系统扩容问题
- 分片额外消耗较多,管理复杂,尽量不要分片
- 如果实在要用,请仔细学习下一讲
26丨分片集群设计
如何用好分片集群
合理的架构
- 是否需要分片?
- 需要多少分片?
- 数据的分布规则
正确的姿势
- 选择需要分片的表
- 选择正确的片键
- 使用合适的均衡策略
足够的资源
- CPU
- RAM
- 存储
合理的架构-分片大小
分片的基本标准
- 关于数据: 数据量不超过 3TB,尽可能保持在 2TB一个片;
- 关于索引: 常用索引必须容纳进内存;
按照以上标准初步确定分片后,还需要考虑业务压力,随着压力增大,CPU、RAM、磁盘中的任何一项出现瓶颈时,都可以通过添加更多分片来解决。
合理的架构-需要多少个分片

合理的架构-其他需求
考虑分片的分布:
- 是否需要跨机房分布分片?
- 是否需要容灾?
- 高可用的要求如何?
正确的姿势
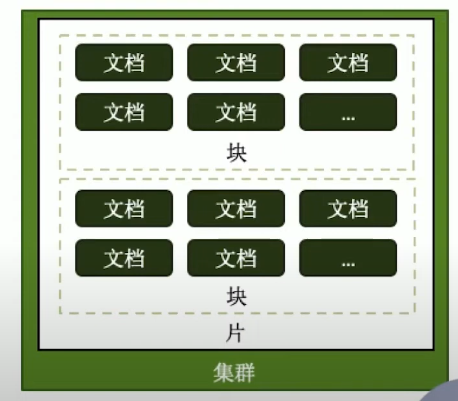
各种概念由小到大
- 片键 shard key:文档中的一个字段
- 文档 doc: 包含 shard key 的一行数据
- 块 Chunk: 包含n个文档
- 分片 Shard: 包含n个chunk
- 集群 Cluster: 包含n个分片
正确的姿势-选择合适片键
影响片键效率的主要因素
- 取值基数(Cardinality)
- 取值分布
- 分散写,集中读
- 被尽可能多的业务场景用到
- 避免单调递增或递减的片键
正确的姿势-选择基数大的片键
对于小基数的片键:
- 因为备选值有限,那么块的总数量就有限。
- 随着数据增多,块的大小会越来越大;
- 太大的块,会导致水平扩展时移动块会非常困难
例如:存储一个高中的师生数据,以年龄(假设年龄范围为15~65岁)作为片键,那么:
- 15<=年龄<=65,且只为整数
- 最多只会有 51个chunk
结论: 取值基数要大!
正确的姿势-选择分布均匀的片键
对于分布不均匀的片键:
- 造成某些块的数据量急剧增大
- 这些块压力随之增大
- 数据均衡以chunk为单位,所以系统无能为力
例如:存储一个学校的师生数据,以年龄(假设年龄范围为15~65岁)作为片键,那么:
- 15<=年龄<=65,且只为整数
- 大部分人的年龄范围为15~18岁(学生)
- 15、16、17、18四个chunk的数据量、访问压力远大于其他chunk
结论: 取值分布应尽可能均匀
正确的姿势-定向性好
考虑:
- 4个分片的集群,你希望读某条特定的数据
- 如果你用片键作为条件查询,mongos 可以直接定位到具体的分片
- 如果你不用片键,mongos需要把查询发到4个分片
- 等最后的一个分片响应,mongos才能响应应用端。
结论: 对主要查询要具有定向能力
一个mail 系统的片键例子
{
_id: ObjectId(),
user: 123,
time: Date(),
subject: "..."
recipients: [],
body: "...",
attachments:[]
}片建
{_id: 1}基数 good
写分布 bad
定向查询 bad
片建
{_id: "hashed"}基数 good
写分布 good
定向查询 bad
片建
{user_id: 1}基数 bad
写分布 good
定向查询 good
片建
{user_id: 1, time: 1}基数 good
写分布 good
定向查询 good
足够的资源
mongos与 config 通常消耗很少的资源,可以选择低规格虚拟机;
资源的重点在于 shard 服务器
- 需要足以容纳热数据索引的内存;
- 正确创建索引后 CPU 通常不会成为瓶颈,除非涉及非常多的计算;
- 磁盘尽量选用 SSD。
最后,实际测试是最好的检验,来看你的资源配置是否完备
即使项目初期已经具备了足够的资源,仍然需要考虑在合适的时候扩展。
建议监控各项资源使用情况,无论哪一项达到 60%以上,则开始考虑扩展,因为:
- 扩展需要新的资源,申请新资源需要时间;
- 扩展后数据需要均衡,均衡需要时间。应保证新数据入库速度慢于均衡速度
- 均衡需要资源,如果资源即将或已经耗尽,均衡也是会很低效的。
27丨实验:分片集群搭建及扩容
https://github.com/kibaamor/mongodb-docker-compose
28丨MongoDB监控最佳实践
- MongoDB Ops Manager
- Percona
- 通用监控平台
- 程序脚本
监控信息的来源
db.serverStatus()(主要)db.isMaster()(次要)mongostats命令行工具(只有部分信息)
注意:
db.serverStatus()包含的监控信息是从上次开机到现在为止的累计数据因此不能简单使用。
db.serverStatus()
- connections: 关于连接数的信息
- locks: 关于MongoDB使用的锁情况
- network: 网络使用情况统计
- opcounters: CRUD的执行次数统计
- repl: 复制集配置信息
wiredTiger:包含大量WiredTiger执行情况的信息
- block-manager: WT数据块的读写情况
- session: session使用数量
- concurrentTransactions: Ticket使用情况
mem: 内存使用情况
- metrics: 一系列性能指标统计信息
https://www.mongodb.com/docs/manual/reference/command/serverStatus/
监控报警的考量
- 具备一定的容错机制以减少误报的发生
- 总结应用各指标峰值
- 适时调整报警阈值
- 留出足够的处理时间
建议监控指标
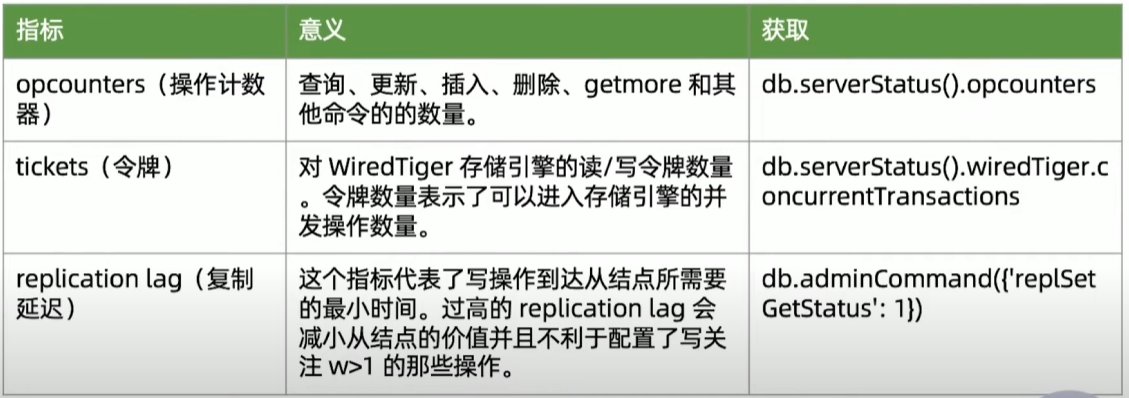
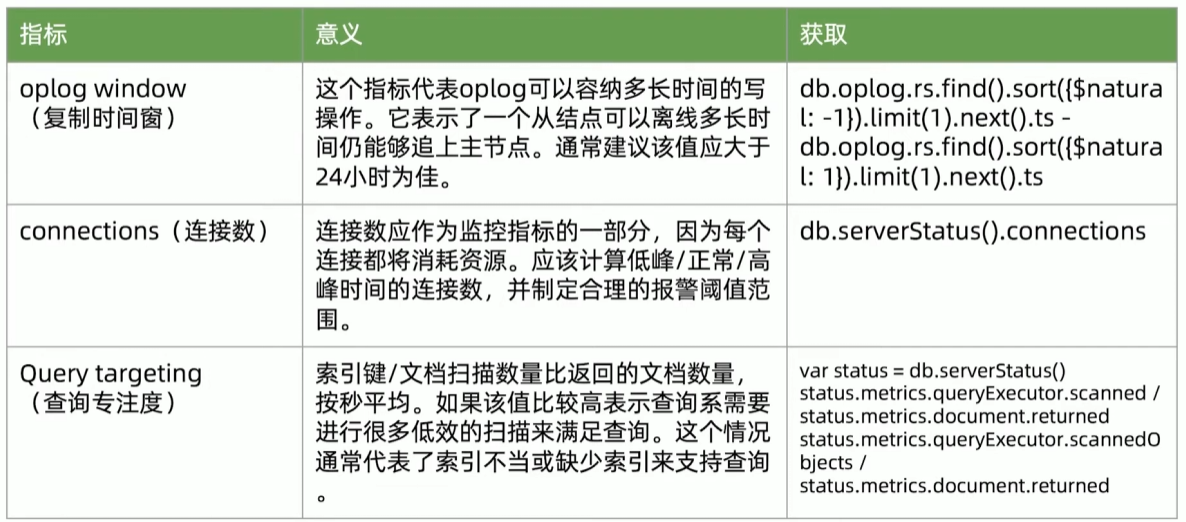
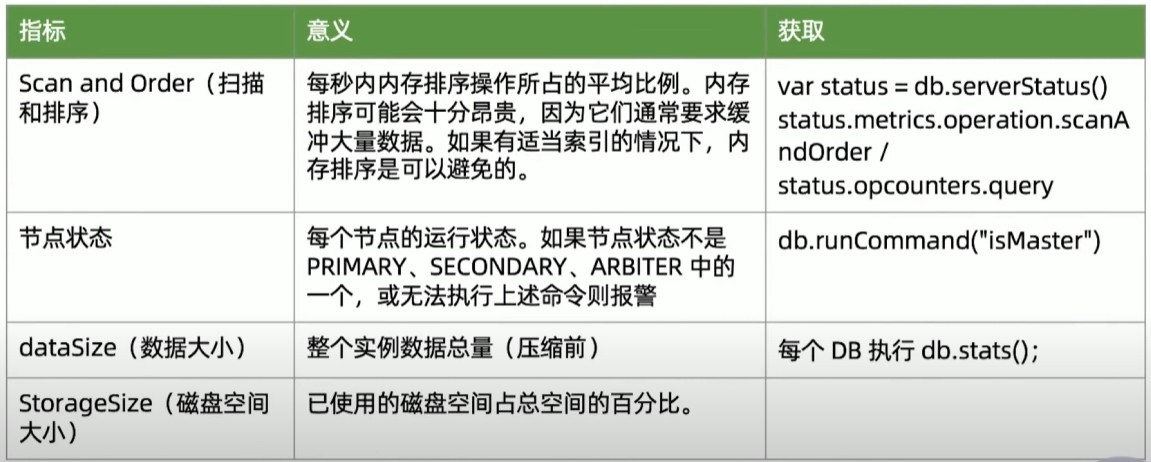
29丨MongoDB备份与恢复
为何备份
备份的目的:
- 防止硬件故障引起的数据丢失
- 防止人为错误误删数据
- 时间回溯
- 监管要求
第一点MongoDB生产集群已经通过复制集的多节点实现,本讲的备份主要是为其他几个目的。
MongoDB的备份
MongoDB的备份机制分为:
- 延迟节点备份
- 全量备份+Oplog 增量
最常见的全量备份方式包括
- mongodump;
- 复制数据文件;
- 文件系统快照;
方案一:延迟节点备份
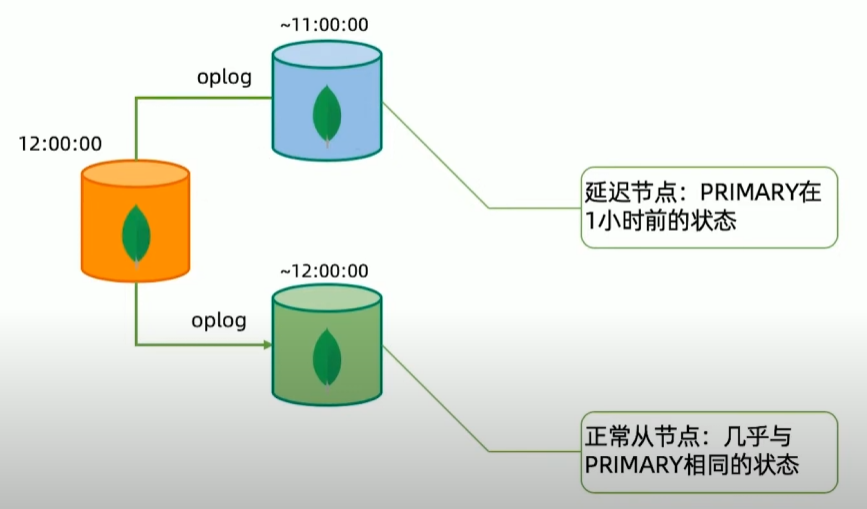
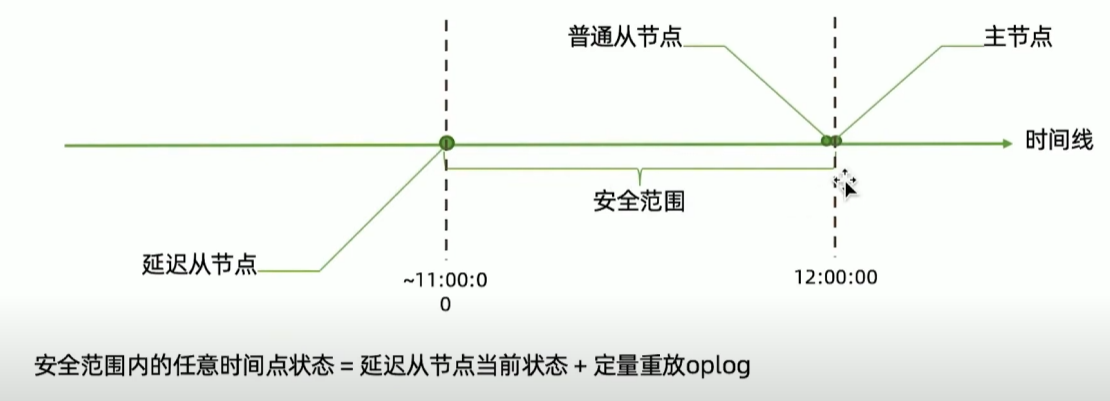
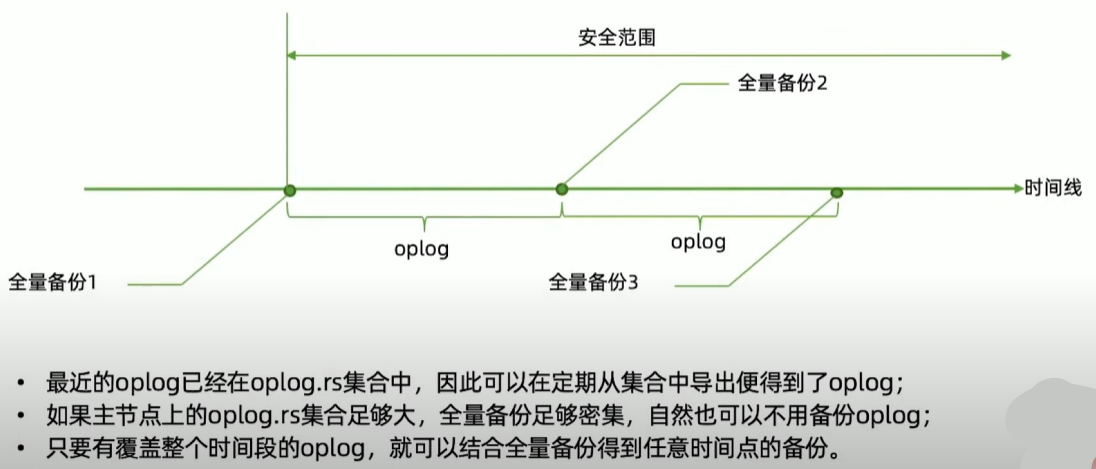
方案二:全量备份加oplog

复制文件全量备份注意事项
复制数据库文件:
- 必须先关闭节点才能复制,否则复制到的文件无效;
- 也可以选择
db.fsyncLock()锁定节点,但完成后不要忘记db.fsyncUnlock()解锁; - 可以且应该在从节点上完成;
- 该方法实际上会暂时宕机一个从节点,所以整个过程中应注意投票节点总数。
文件系统快照:
- MongoDB支持使用文件系统快照直接获取数据文件在某一时刻的镜像;
- 快照过程中可以不用停机;
- 数据文件和Journal必须在同一个卷上;
- 快照完成后请尽快复制文件并删除快照;
Mongodump全量备份注意事项
mongodump:
- 使用mongodump备份最灵活,但速度上也是最慢的;
- mongodump 出来的数据不能表示某个个时间点,只是某个时间段
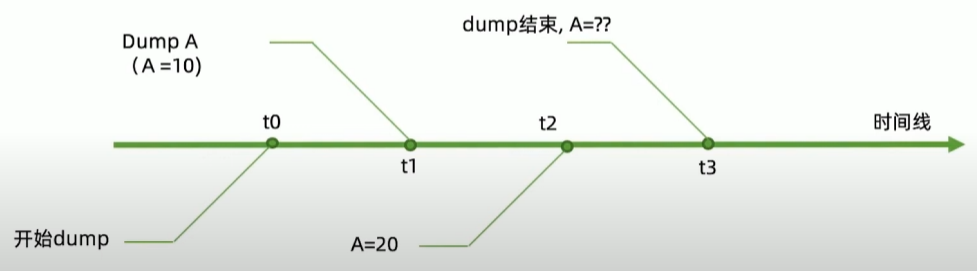
解决方案:幂等性
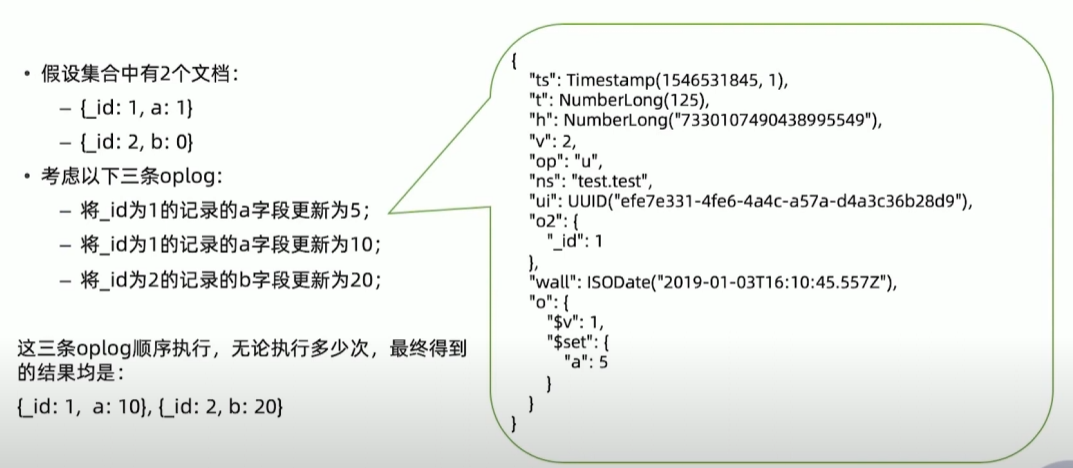
用幂等性解决一致性问题
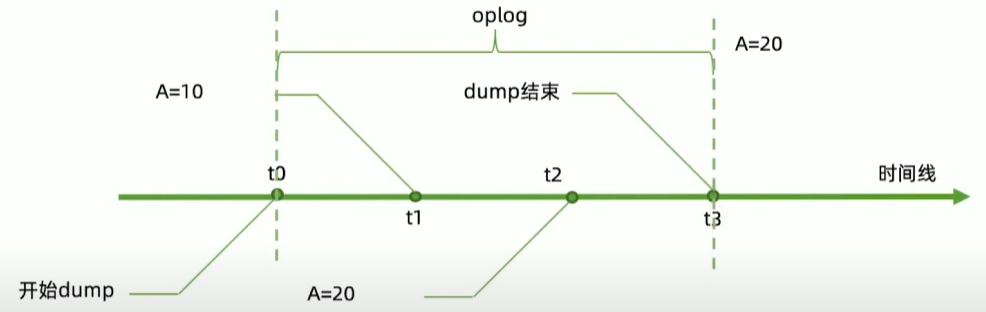
30丨备份与恢复操作
备份和恢复工具参数
几个重要参数:
mongodump
- —oplog:复制 mongodump 开始到结束过程中的所有 oplog 并输出到结果中。输出文件位于 dump/oplog.bson
mongorestore
- —oplogReplay: 恢复完数据文件后再重放 oplog。默认重放
dump/oplog.bson=><dump-directory>/local/oplog.rs.bson。如果 oplog 不在这,则可以: - —oplogFile:指定需要重放的 oplog 文件位置
- —oplogLimit: 重放 oplog 时截止到指定时间点
更多说明:
- https://www.mongodb.com/docs/database-tools/mongodump/
- https://www.mongodb.com/docs/database-tools/mongorestore/
实际操作:mongodump/mongorestore
为了模拟dump过程中的数据变化,我们开启一个循环插入数据的线程:
for(vari=0;i<100000; i++){db.random.insertOne({:Math.random()* 100000});在另一个窗口中我们对其进行mongodump:
mongodump -h 127.0.1:27017 --oplog使用mongorestore恢复到一个新集群:
mongorestore --host 127.0.0.1 --oplogReplay dump更复杂的重放oplog
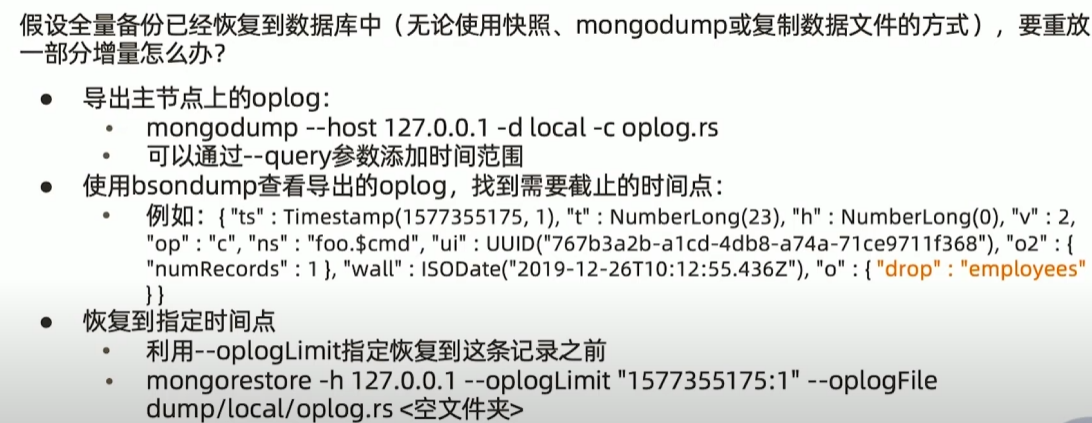
https://www.mongodb.com/docs/database-tools/bsondump/
分片集备份
分片集备份大致与复制集原理相同,不过存在以下差异:
- 应分别为每个片和config备份;
- 分片集备份不仅要考虑一个分片内的一致性问题,还要考虑分片间的一致性问题。因此每个片要能够恢复到同一个时间点;
尽管理论上我们可以使用与复制集同样的方式来为分片集完成增量备份,但实际上分片集的情况更加复杂。这种复杂性来自两个方面:
- 各个数据节点的时间不一致:每个数据节点很难完全恢复到一个真正的一致时间点上,通常只能做到大致一致,而这种大致一致通常足够好,除了以下情况;
- 分片间的数据迁移:当一部分数据从一个片迁移到另一个片时,最终数据到底在哪里取决于config中的元数据。如果元数据与数据节点之间的时间差异正好导致数据实际已经迁移到新分片上,而元数据仍然认为数据在旧分片上,就会导致数据丢失情况发生。虽然这种情况发生的概率很小,但仍有可能导致问题。
要避免上述问题的发生,只有定期停止均衡器;只有在均衡器停止期间,增量恢复才能保证正确,
31丨MongoDB安全架构
MongoDB 安全架构一览
- 认证
- 鉴权
- 审计
- 加密
MongoDB 用户认证方式

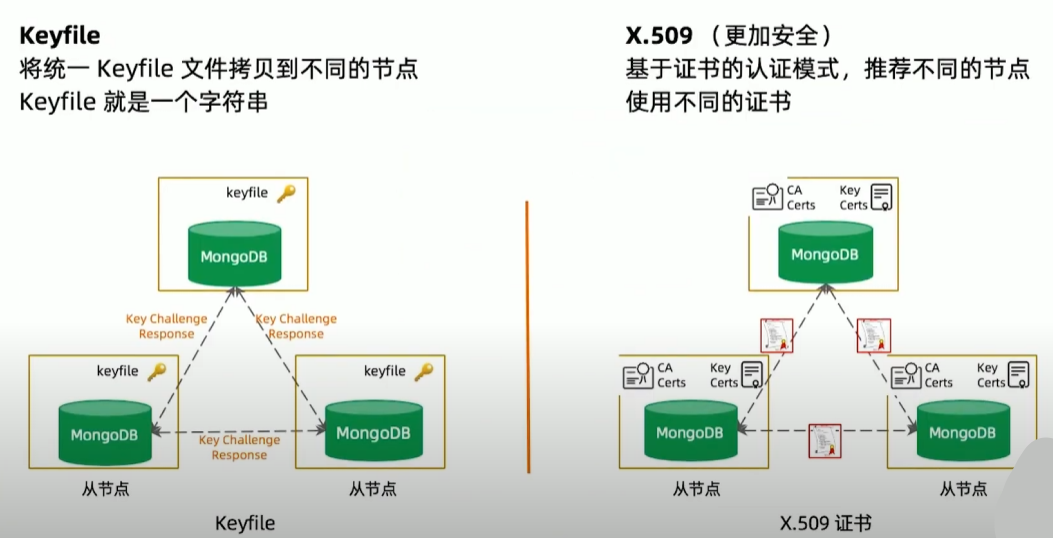
MongoDB 集群节点认证
MongoDB 鉴权-基于角色的权限机制
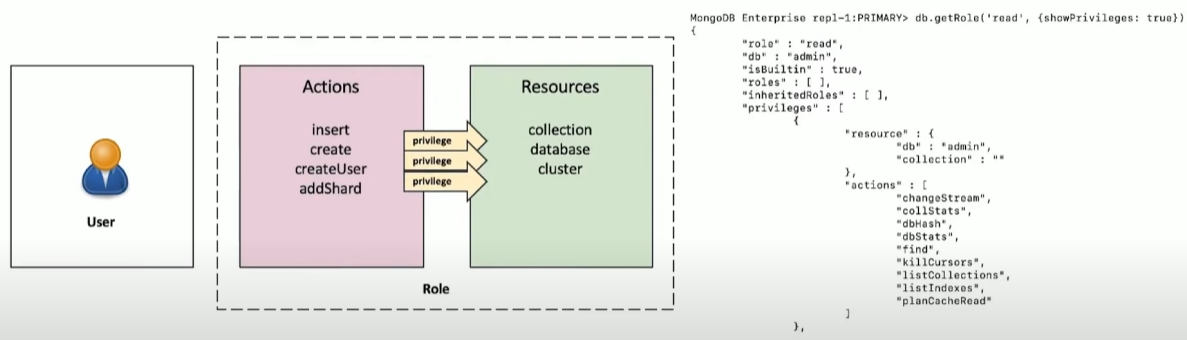
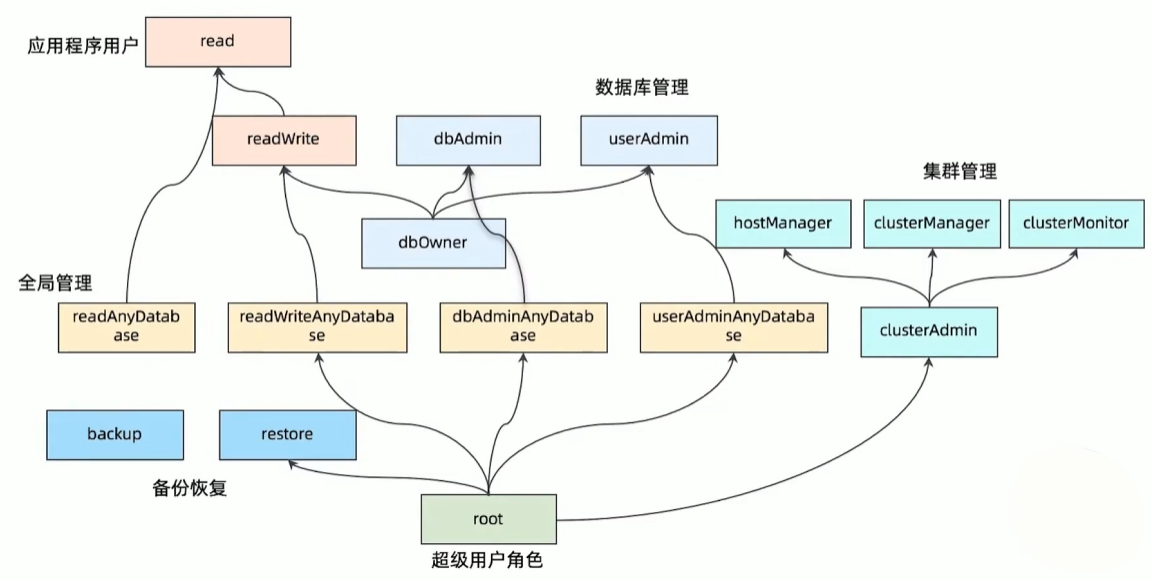
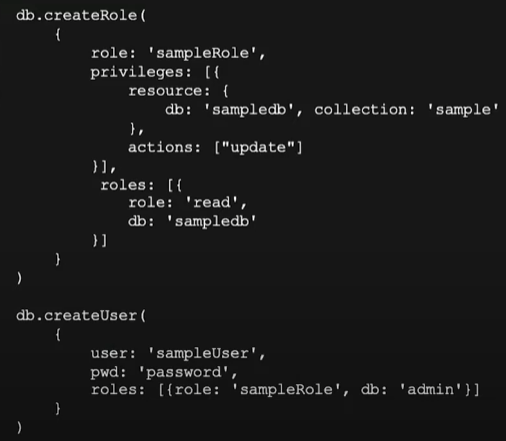
自定义角色
MongoDB 支持按需自定义角色,适合一些高安全要求的业务场景
传输加密
MongoDB支持TLS/SSL来加密 MongoDB 的所有网络传输(客户端应用和服务器端之间,内部复制集之间)
TLS/SSL确保 MongoDB 网络传输仅可由允许的客户端读取。
落盘加密
企业版功能
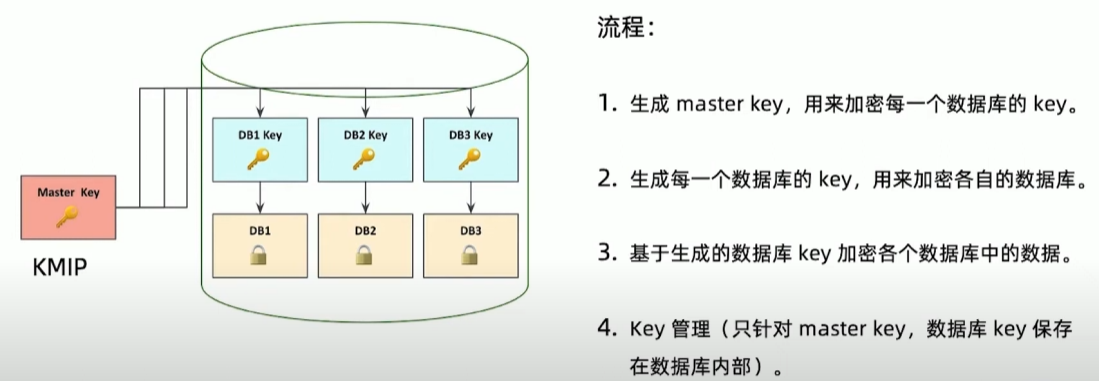
字段级加密
- 单独文档字段通过自身密钥加密
- 数据库只看见密文
- 优势
- 便捷:自动及透明
- 任务分开:(简化基于服务的系统步骤,因为没有服务工程师能够看到纯文本)
- 合规:监管”被遗忘权”
- 快速:最小性能代偿
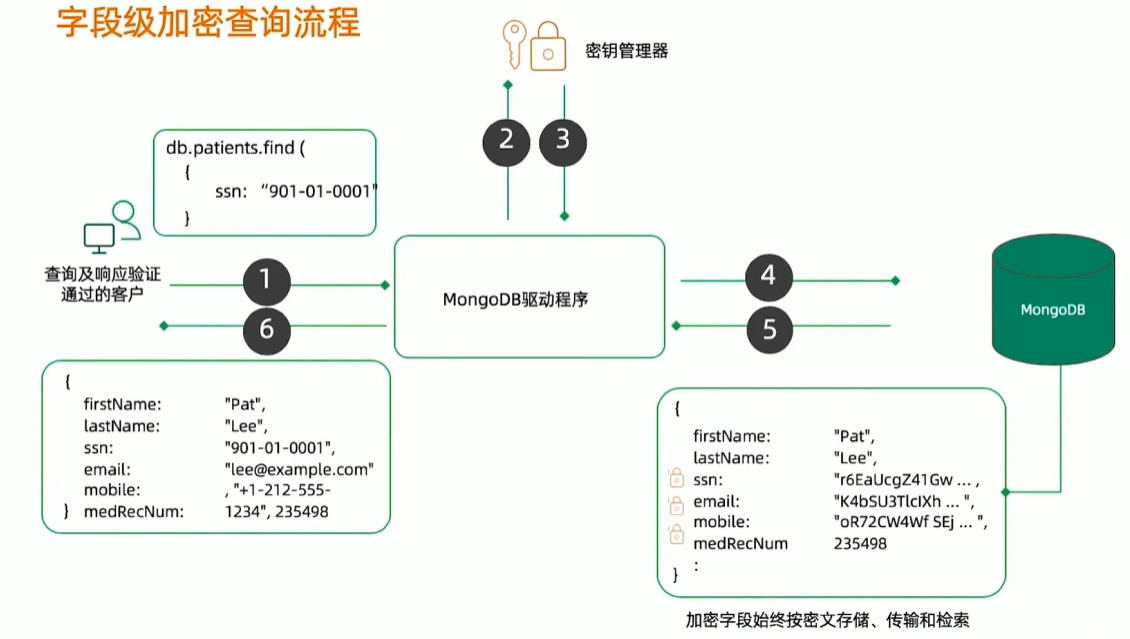
审计
- 数据库等记录型系统通常使用审计监控数据库相关的一些活动,以及对一些可疑的操作进行调查。
- 记录格式:JSON
- 记录方式:本地文件 或 syslog
- 记录内容:
- Schema change (DDL)
- CRUD 操作(DML)
- 用户认证
审计配置参数举例
审计日志记录到 syslog
--auditDestination syslog
审计日志记录写到指定文件
--auditDestination file --auditFormat jSON --auditPath /path/to/auditLog.json
对删表和创建表动作进行审计日志记录
--auditDestination file --auditFormatjSON --auditPath auditLog.json --auditFilter'{atype: {$in:["createCollection","dropCollection"]}}'
32丨MongoDB安全加固实践
MongoDB 安全最佳实践
启用身份认证
启用访问控制并强制执行身份认证
使用强密码
权限控制
基于 Deny All 原则
不多给多余权限
加密和审计
启用传输加密、数据保护和活动审计
网络加固
内网部署服务器
设置防火墙
操作系统设置
遵循安全准则
遵守不同行业或地区安全标准合规性要求
合理配置权限
- 创建管理员
- 使用复杂密码
- 不同用户不同账户
- 应用隔离
- 最小权限原则
启用加密
- 使用 TLS 作为传输协议
- 使用4.2版本的字段级加密对敏感字段加密
- 如有需要,使用企业版进行落盘加密
- 如有需要,使用企业版并启用审计日志
网络和操作系统加固
使用专用用户运行 MongoDB
- 不建议在操作系统层使用 root用户运行 MongoDB
限制网络开放度
- 通过防火墙,iptables 规则控制对 MongoDB 的访问
- 使用 VPN/VPCS 可以创建一个安全通道,MongoDB 服务不应该直接暴露在互联网上
- 使用白名单列表限制允许访问的网段
- 使用 bind ip 绑定一个具体地址
- 修改默认监听端口:27017
使用安全配置选项运行 MongoDB
- 如果不需要执行 JavaScript 脚本,使用
--noscripting禁止脚本执行 - 如果使用老版本MongoDB,关闭http接口:
net.http.enabled=False net.http.JSONPEnabled= False - 如果使用老版本 MongoDB,关闭 Rest API接囗:
net.http.RESTInterfaceEnabled= False
Demo:启用认证
- 方式一: 命令行方式通过”—auth”参数
- 方式二:配置文件方式在 security下添加
authorization:enabled
mongod --auth--port 27017--dbpath /data/db启用鉴权后,无密码可以登录,但是只能执行创建用户操作mongo
> use admin
> db.createUser({user: "superuser", pwd: "password", roles: [{role: "root", db: "admin"}]} )安全登录,执行如下命令查看认证机制
mongo -usuperuser -p password --authenticationDatabase admin
db.runCommand({getParameter:1,authenticationMechanisms:1})从数据库中查看用户
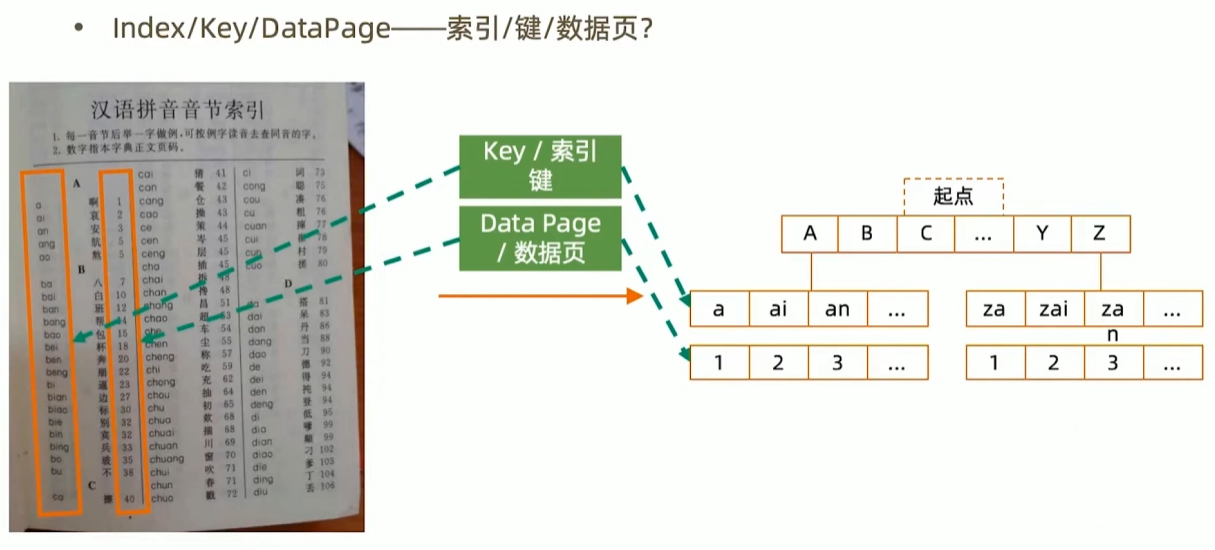
db.system.users.find()33丨MongoDB索引机制(一)
术语-Index/Key
术语-Covered Query

术语-IXSCAN/COLLSCAN

术语-Query Shape
查询条件用到了哪些字段。

术语-Index Prefix

术语-Selectivity

B树结构
MongoDB使用 B+ 树
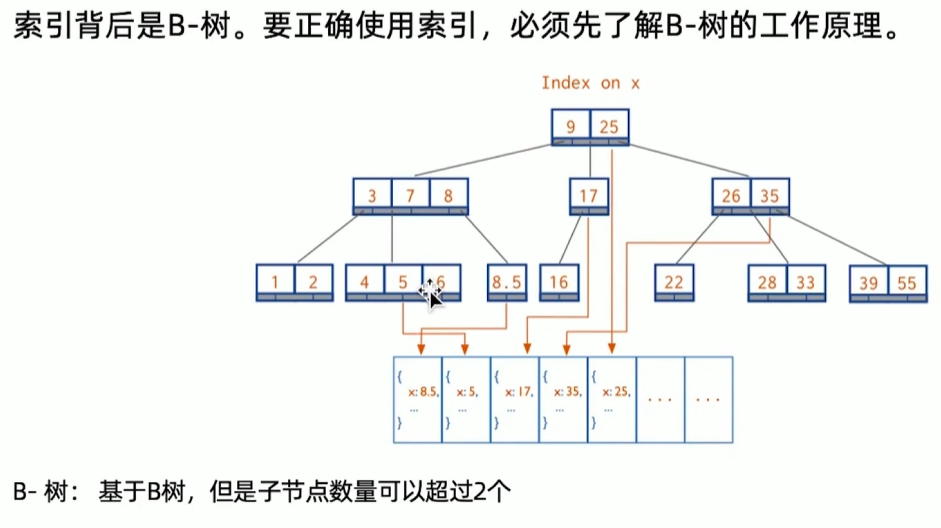
数据结构与算法复习
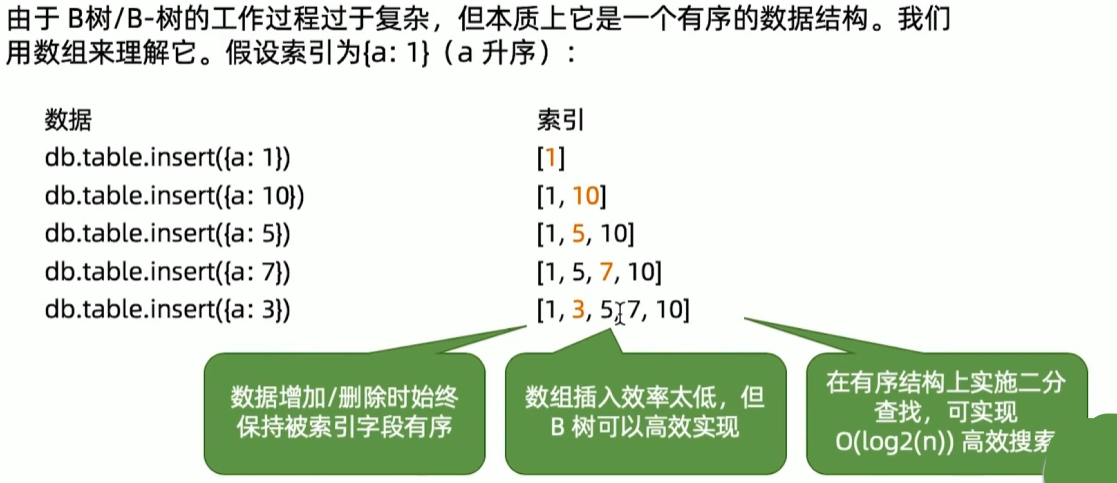
34丨MongoDB索引机制(二)
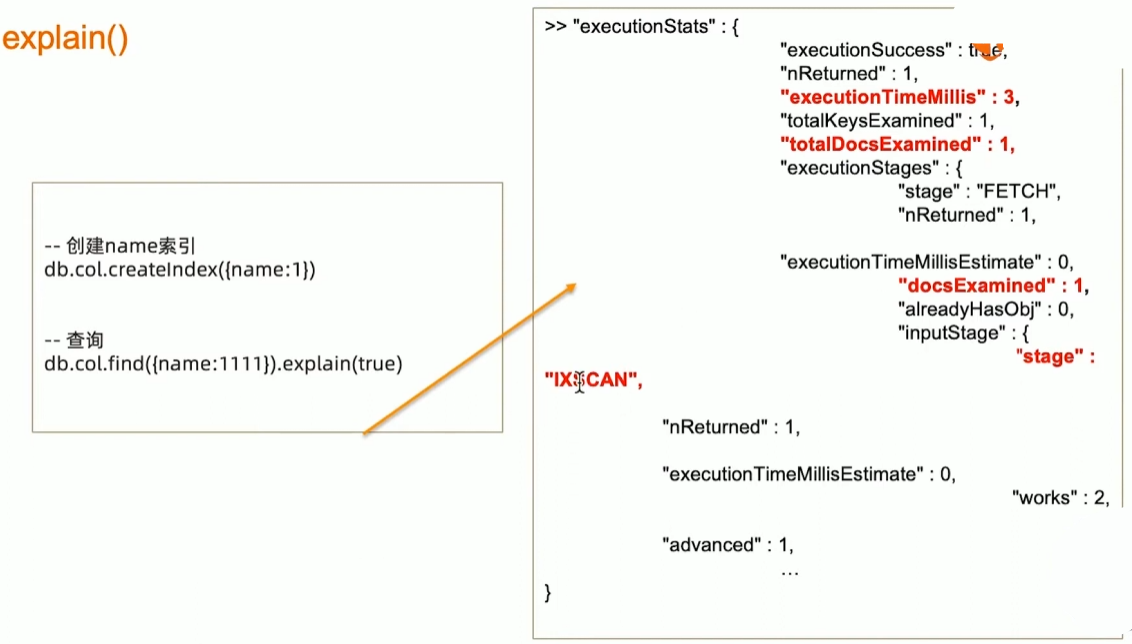
索引执行计划
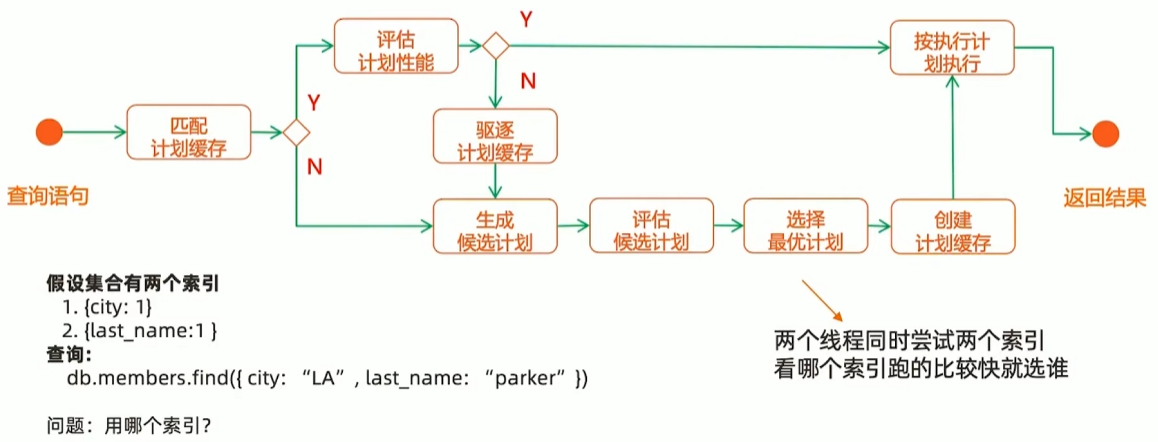
explain()

MongoDB 索引类型
- 单键索引
- 组合索引
- 多值索引
- 地理位置索引
- 全文索引
- TTL索引
- 部分索引
- 哈希索引
组合索引-Compound Index

组合索引工作模式
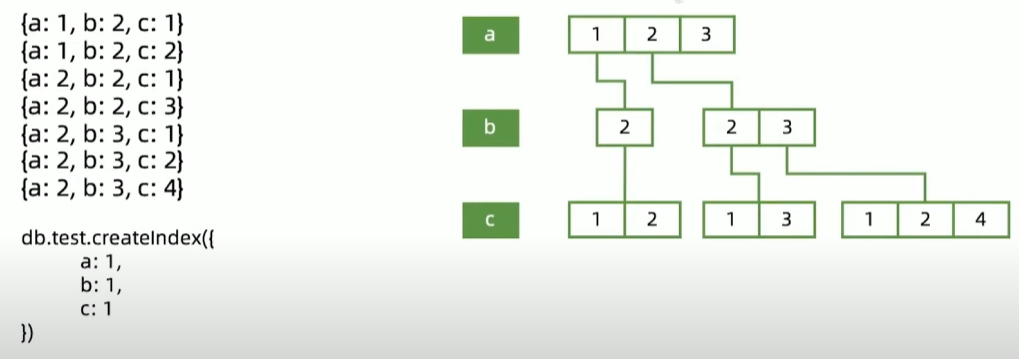
精确匹配
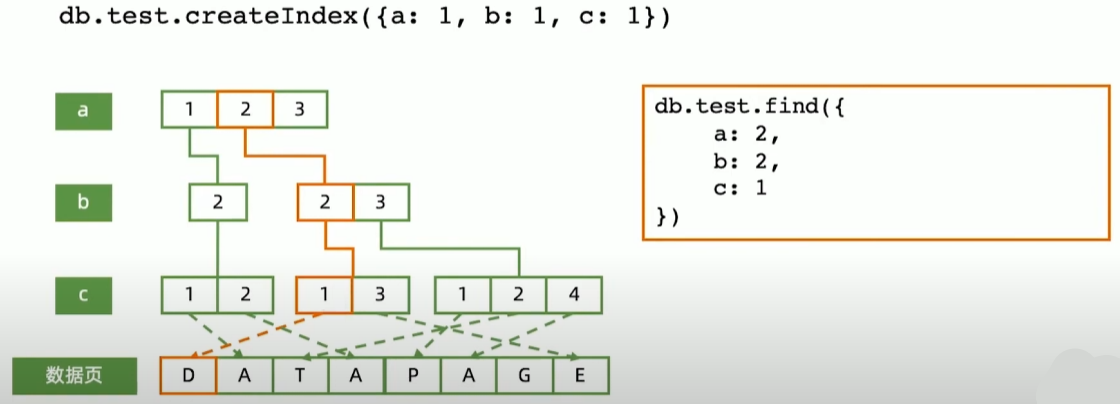
范围查询
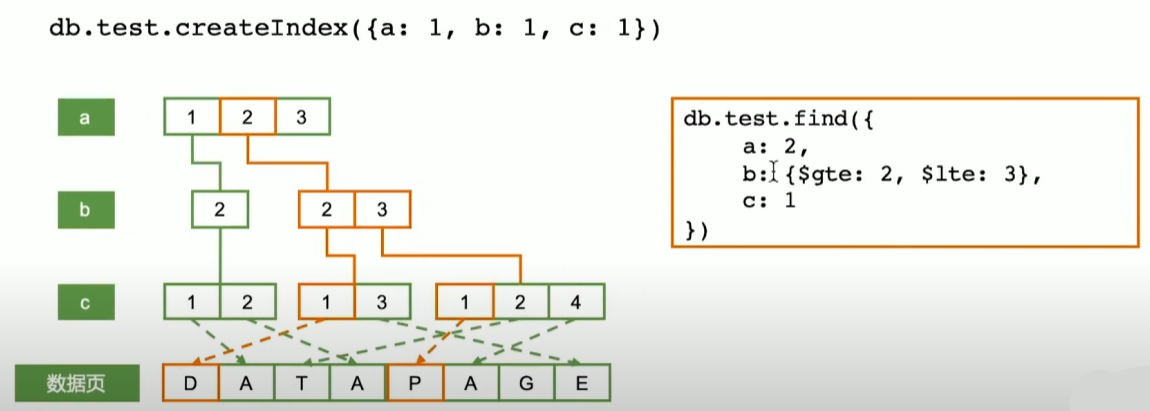
索引字段顺序的影响
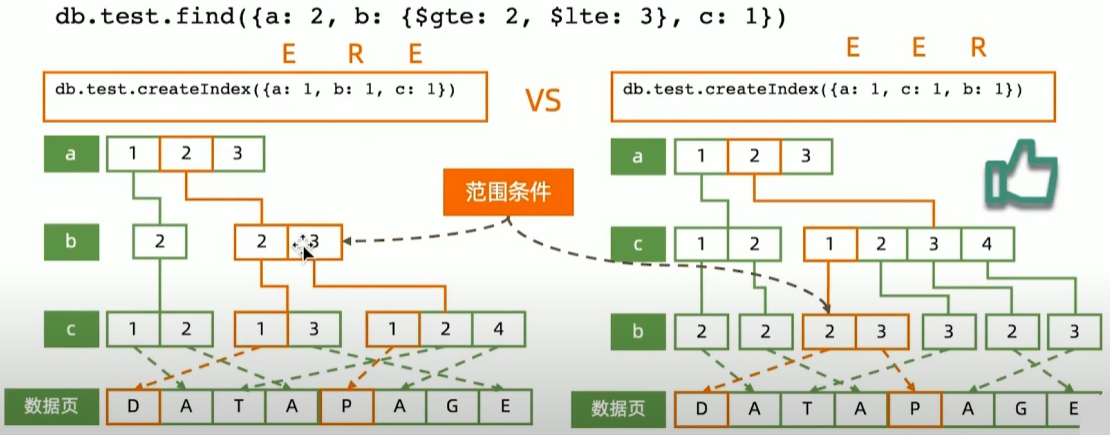
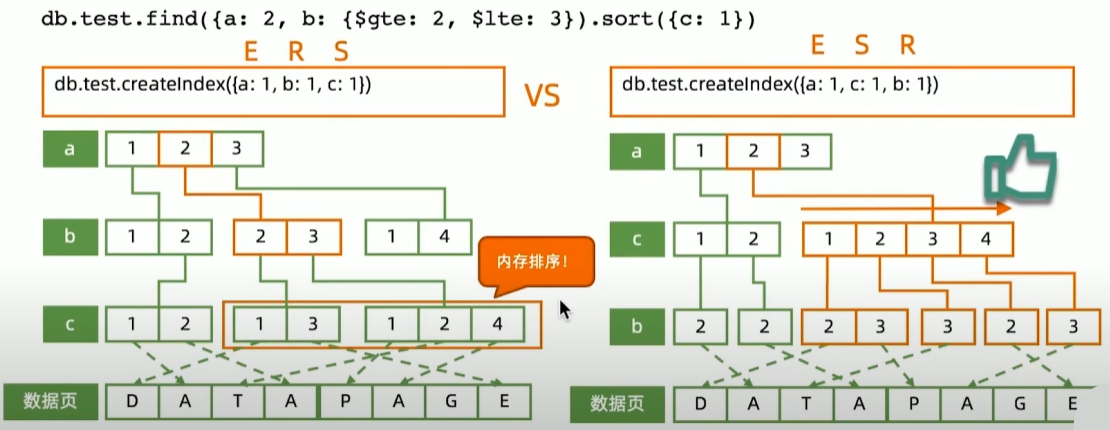
范围+排序组合查询: 索引字段顺序的影响
地理位置索引

全文索引

部分索引

其他索引技巧
后台创建索引
db.member.createindex( { city: 1}, {background: true} )对BI/报表专用节点单独创建索引
- 该从节点priority设为0
- 关闭该从节点,
- 以单机模式启动
- 添加索引(分析用)关闭该从节点,以副本集模式启动
35丨MongoDB读写性能机制
一次数据库请求过程中发生了什么

应用端
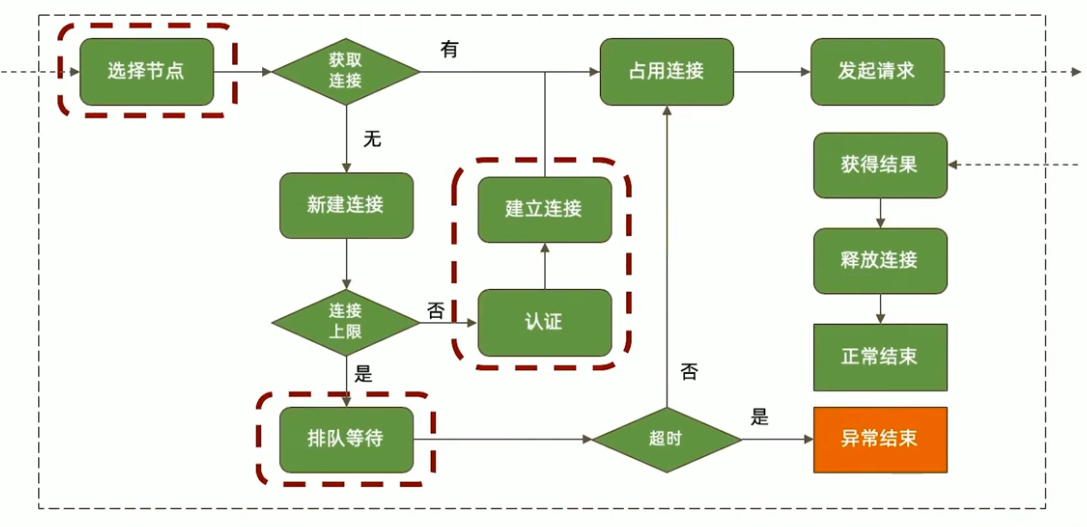
选择节点
排队等待
排队等待连接是如何发生的?
- 总连接数大于允许的最大连接数maxPoolSize;
如何解决这个问题?
- 加大最大连接数(不一定有用);
- 优化查询性能;
连接与认证
如果一个请求需要等待创建新连接和进行认证,相比直接从连接池获取连接,它将耗费更长时间。
可能解决方案:
- 设置 minPoolSize(最小连接数)一次性创建足够的连接;
- 避免突发的大量请求;
数据库端
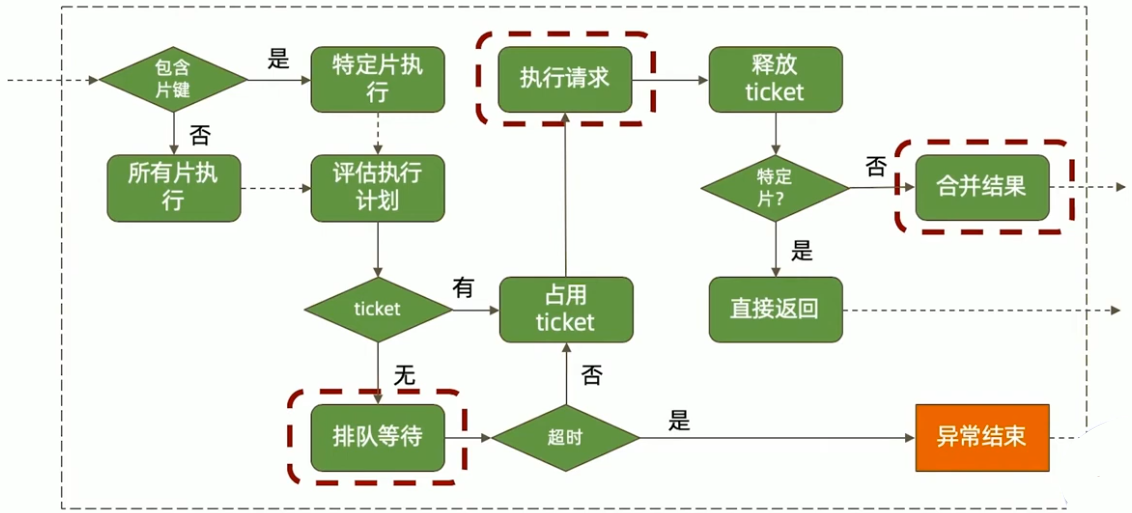
排队等待
由 ticket 不足引起的排队等待,问题往往不在 ticket本身,而在于为什么正在执行的操作会长时间占用 ticket。
可能解决方案:
- 优化 CRUD 性能可以减少 ticket 占用时间;
- zlib 压缩方式也可能引起 ticket 不足,因为 zlib 算法本身在进行压缩、解压时需要的时间比较长,从而造成长时间的 ticket 占用;
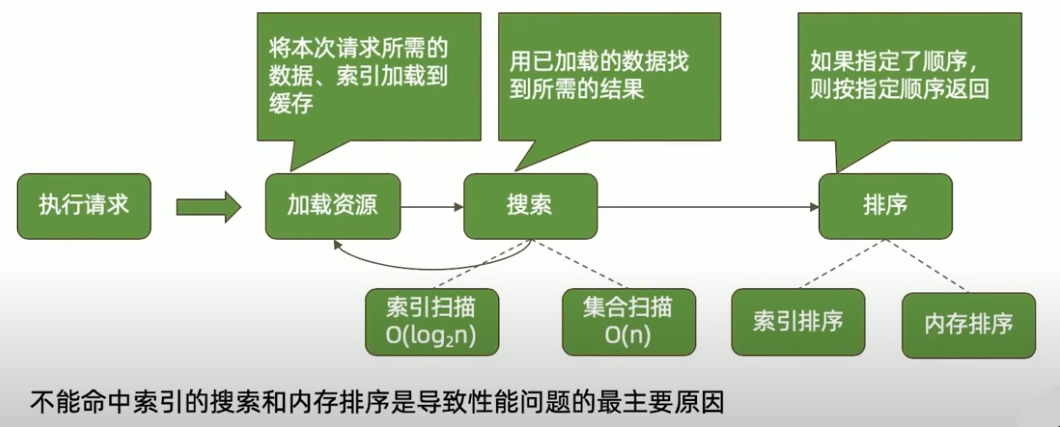
执行请求(读)
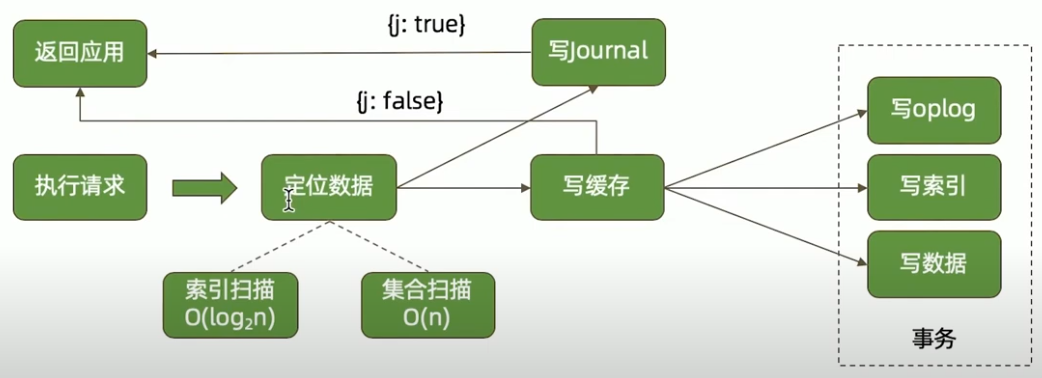
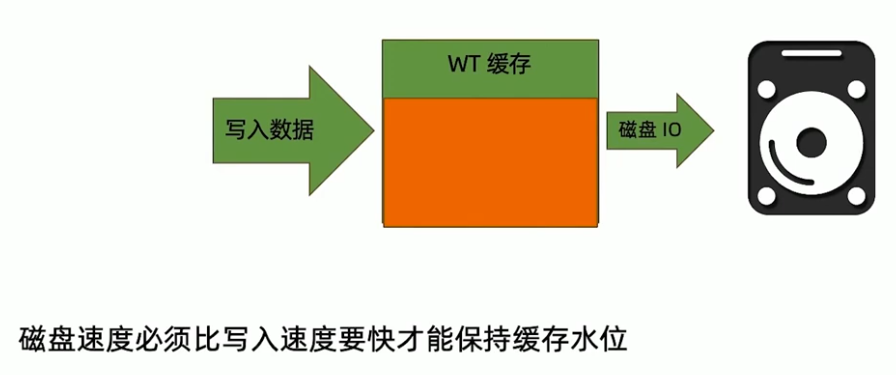
执行请求(写)
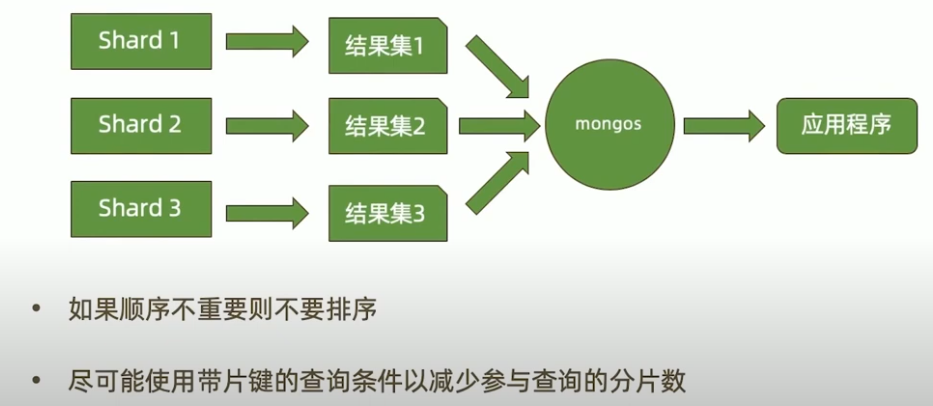
合并结果
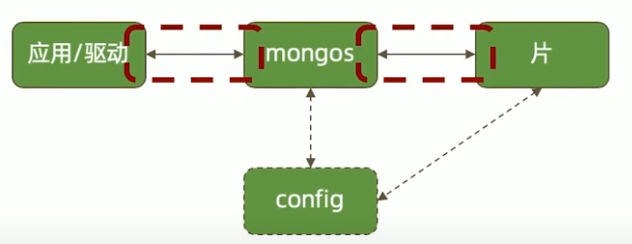
网络的考量
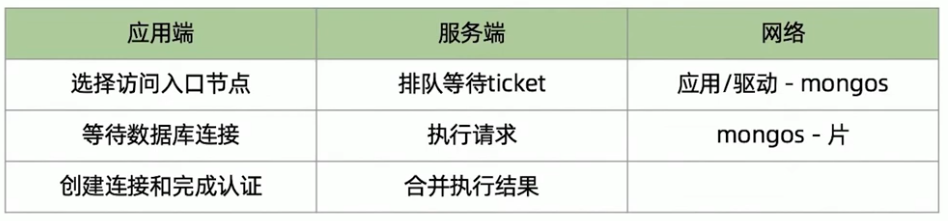
性能瓶颈总结
36丨性能诊断工具
mongostat
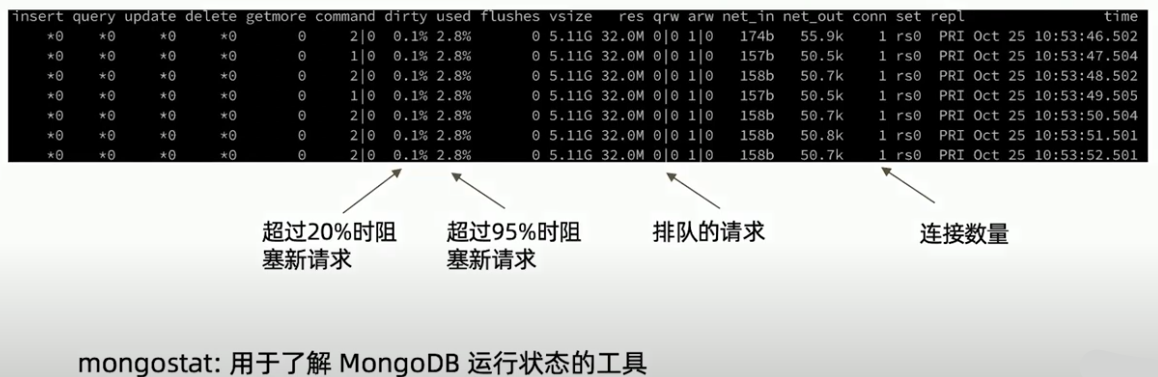
mongostat 是 MongoDB 自带的实时监控工具,用于展示实例的运行状态与性能指标。
它会每隔一段时间(默认 1 秒)采样一次,输出数据库的关键统计信息。
命令示例
$ mongostat --host localhost --port 27017
insert query update delete getmore command dirty used flushes vsize res qr|qw ar|aw net_in net_out conn
10 3 5 1 2 25|0 3.2% 76.8% 1 5.80G 3.20G 0|0 1|0 40kB 120kB 58各字段详细说明
| 字段 | 含义 | 示例值 | 说明 | ||
|---|---|---|---|---|---|
| insert | 每秒插入操作次数 | 10 | 每秒执行的 insert 操作数量(包括批量插入)。 |
||
| query | 每秒查询操作次数 | 3 | 每秒执行的 find 操作数量。 |
||
| update | 每秒更新操作次数 | 5 | 每秒执行的 update 操作数量。 |
||
| delete | 每秒删除操作次数 | 1 | 每秒执行的 remove 操作数量。 |
||
| getmore | 每秒从游标获取更多文档的次数 | 2 | 主要反映分页或游标查询的频率。 | ||
| command | 每秒执行的命令次数 | 25\ | 0 | 前者是普通命令(如 findAndModify、aggregate),后者是内部命令数。 | |
| flushes | WiredTiger checkpoint 次数 | 1 | 表示在采样间隔内,缓存同步到磁盘的次数(通常每分钟约 1 次)。 | ||
| dirty | 缓存中未落盘的脏页比例 | 3.2% | WiredTiger 缓存中已修改但未写入磁盘的页占比。 | ||
| used | 缓存使用率 | 76.8% | 表示 WiredTiger 缓存已使用的百分比。 | ||
| vsize | 虚拟内存占用 | 5.80G | MongoDB 进程使用的虚拟内存大小。 | ||
| res | 常驻内存(物理内存)占用 | 3.20G | MongoDB 实际驻留在物理内存中的大小。 | ||
| **qr\ | qw** | 等待队列中的读/写请求数 | 0\ | 0 | 当前阻塞等待的读写操作数量。 |
| **ar\ | aw** | 活跃的读/写请求数 | 1\ | 0 | 当前正在执行的读写操作数量。 |
| net_in | 网络输入流量 | 40kB | MongoDB 每秒接收的数据量。 | ||
| net_out | 网络输出流量 | 120kB | MongoDB 每秒发送的数据量。 | ||
| conn | 当前活动连接数 | 58 | 当前连接到 mongod 实例的客户端数量。 | ||
| time(部分版本) | 采样时间戳 | — | 显示统计采样的时间点。 |
WiredTiger 默认缓存大小为 max(0.5 * (RAM - 1 GB), 256 MB)。
注意:在某些情况下(例如在容器中运行时),数据库的内存限制可能低于系统总内存。此时,该内存限制(hostInfo.system.memLimitMB)而非系统总内存将被用作可用的最大RAM。
参考: https://www.mongodb.com/docs/manual/core/wiredtiger/#memory-use
辅助字段(在某些版本或参数下出现)
| 字段 | 含义 | 说明 |
|---|---|---|
| faults | 页面错误(Page Faults) | MongoDB 从磁盘加载数据到内存的次数,过高表示内存不足。 |
| repl | 副本集同步状态 | 对副本集节点显示同步操作的相关统计。 |
| opcounters | 操作计数 | 如果使用 --json 输出,可查看详细操作计数器。 |
| ttl_deletes / ttl_passes | TTL 索引相关 | TTL 索引触发的删除次数与扫描次数。 |
| scan_and_order | 排序扫描次数 | 查询中使用内存排序的次数。 |
| journaled / written | 日志写入量 | 写入 journal 和数据文件的字节数。 |
重点指标解释与诊断建议
| 指标 | 意义 | 异常表现 | 可能原因 | 建议 |
|---|---|---|---|---|
| dirty / used | 缓存健康度 | 长期偏高 | 写入压力大 / I/O 性能差 | 检查磁盘延迟,调整缓存大小 |
| qr / qw | 请求等待 | 持续非 0 | 锁竞争 / 慢查询 | 优化查询或增加资源 |
| ar / aw | 活跃操作 | 持续高 | 写入量大 | 分析操作类型与索引情况 |
| conn | 连接数 | 过高 | 应用连接池未复用 | 优化连接池配置 |
| net_in / net_out | 网络流量 | 异常激增 | 应用暴增或复制压力 | 检查客户端或复制链路 |
总结
mongostat 是监控 MongoDB 性能的首选命令之一,尤其适合快速判断:
- 数据库写入是否积压(dirty、used)
- 锁竞争情况(qr|qw)
- 网络及连接状态(net_in/out、conn)
- I/O 压力与内存健康状况(flushes、vsize、res)
配合 mongotop 与监控系统(如 Cloud Manager、Prometheus、Grafana)使用,可以获得更全面的性能视图。
mongotop
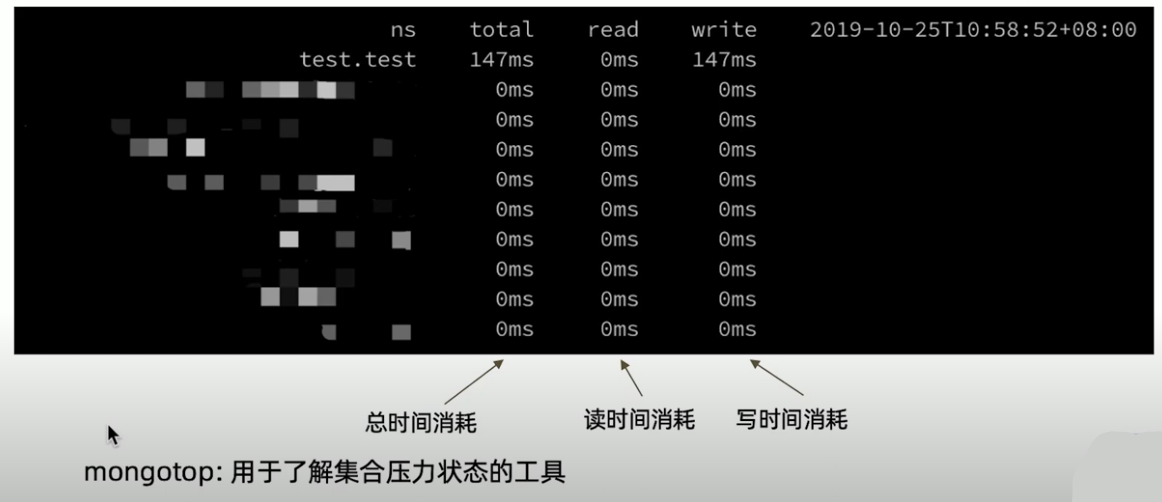
mongod日志
日志中会记录执行超过 100ms 的查询及其执行计划。

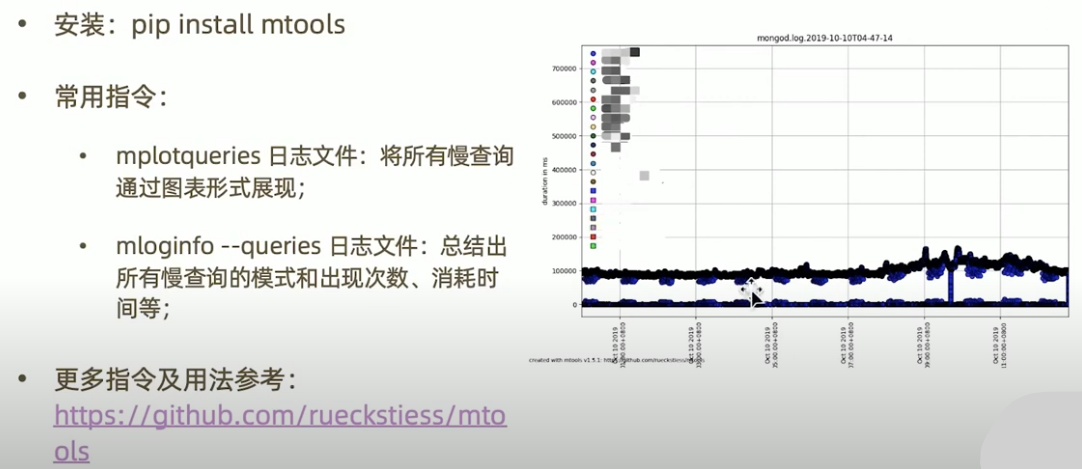
mtools
37丨高级集群设计:两地三中心
容灾级别

RPO — 数据丢失容忍度
Recovery Point Objective(恢复点目标)
- 含义:系统或数据在灾难发生时允许丢失的最大数据量或时间窗口。它衡量数据备份的频率和容忍的数据丢失程度。
- 核心意义:在灾难发生时,你能接受丢失多少数据?
- 举例:如果 RPO = 15 分钟,意味着系统发生故障后,你最多能容忍最近 15 分钟内的数据丢失。如果数据库每小时备份一次,RPO 可能就是 1 小时。
- 应用:决定数据备份频率(如增量备份、实时复制)。评估系统设计是否满足业务需求。
RTO — 系统恢复时限
Recovery Time Objective(恢复时间目标)
- 含义:系统或服务在发生故障后恢复到正常运行状态所允许的最长时间。它衡量业务可接受的中断时间长度。
- 核心意义:灾难发生后,你需要多快将系统恢复运行?
- 举例:如果 RTO = 2 小时,意味着系统宕机后必须在 2 小时内恢复业务。RTO 越短,通常意味着需要更多的高可用架构和资源投入。
- 应用:设计容灾架构(热备、冷备、异地灾备)。决定自动化恢复和故障转移方案。
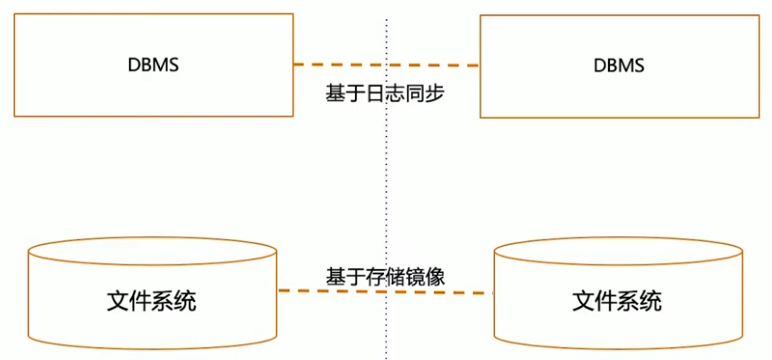
双活的技术组件
网络层解决方案
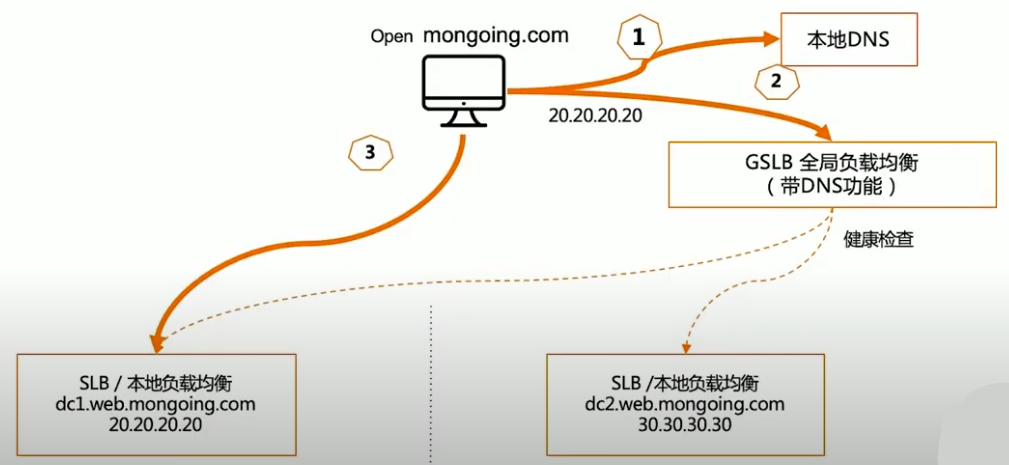
应用层解决方案
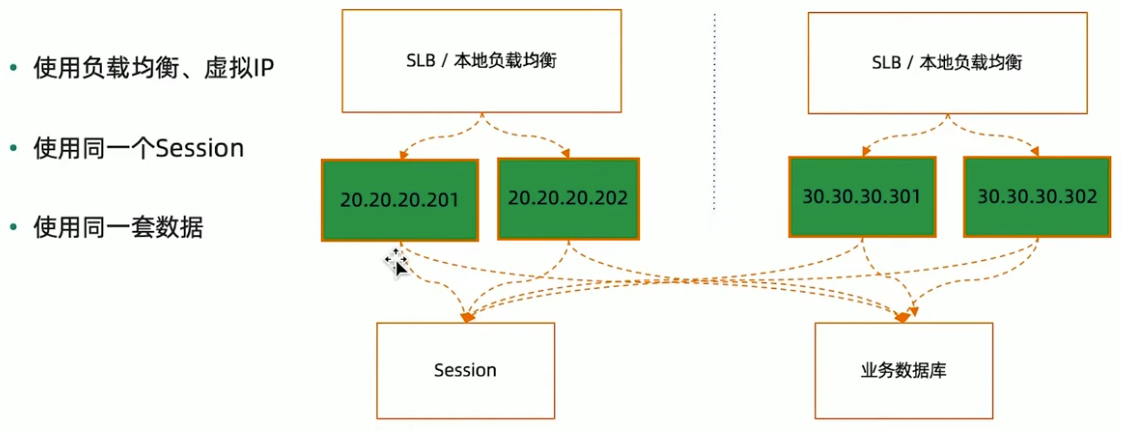
数据库解决方案
数据跨中心同步
MongoDB 三中心方案
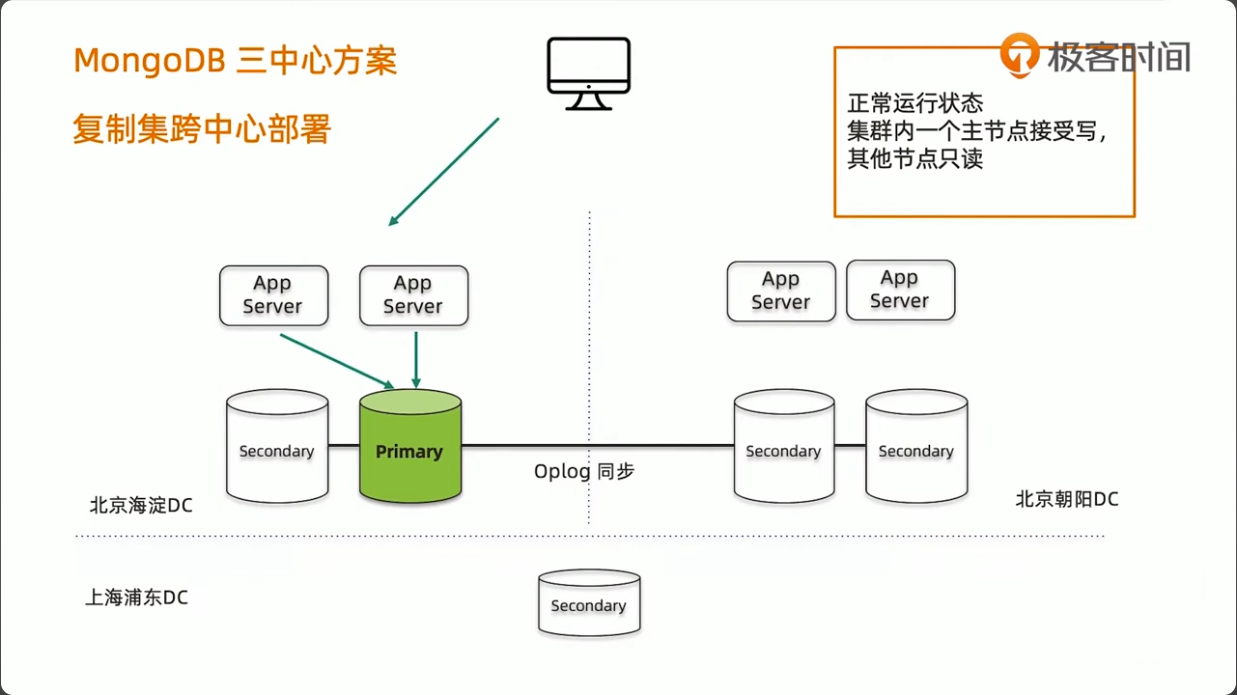
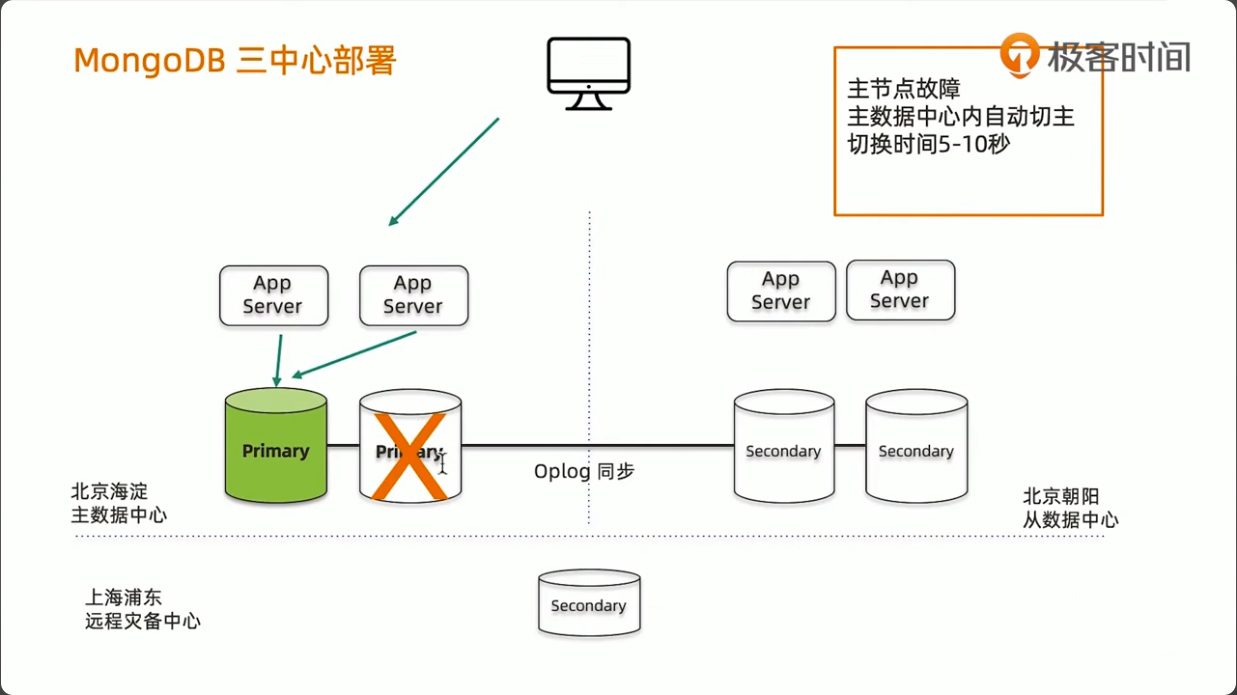
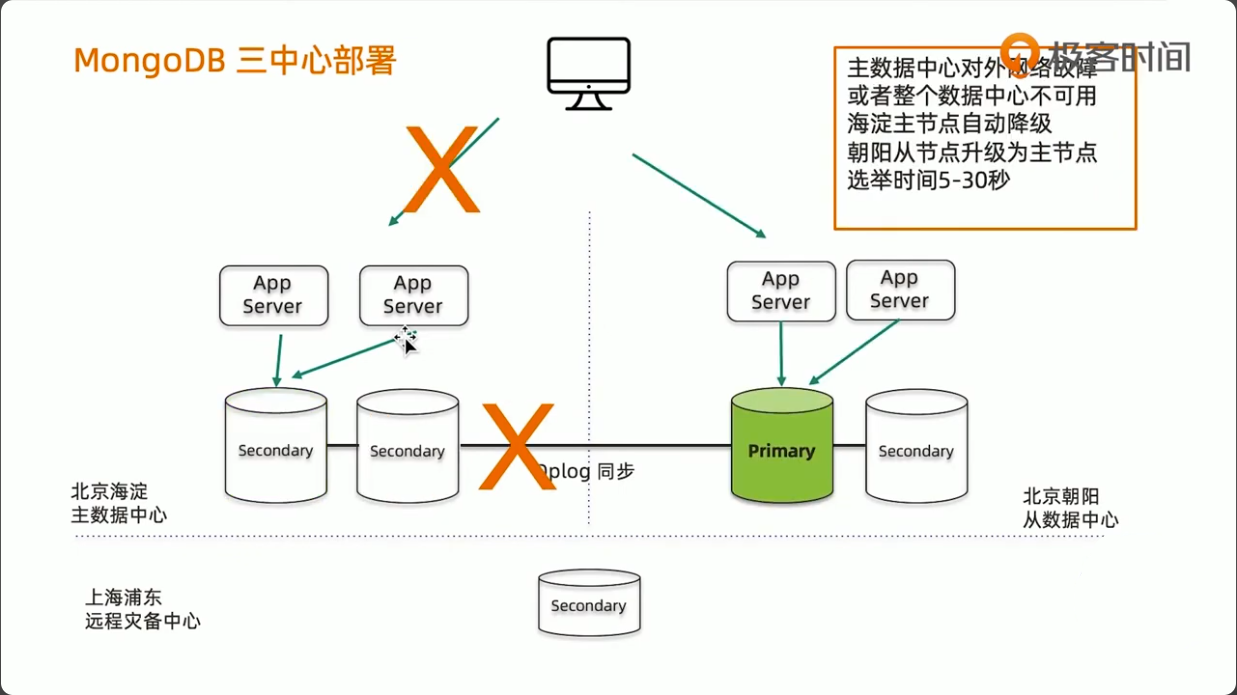
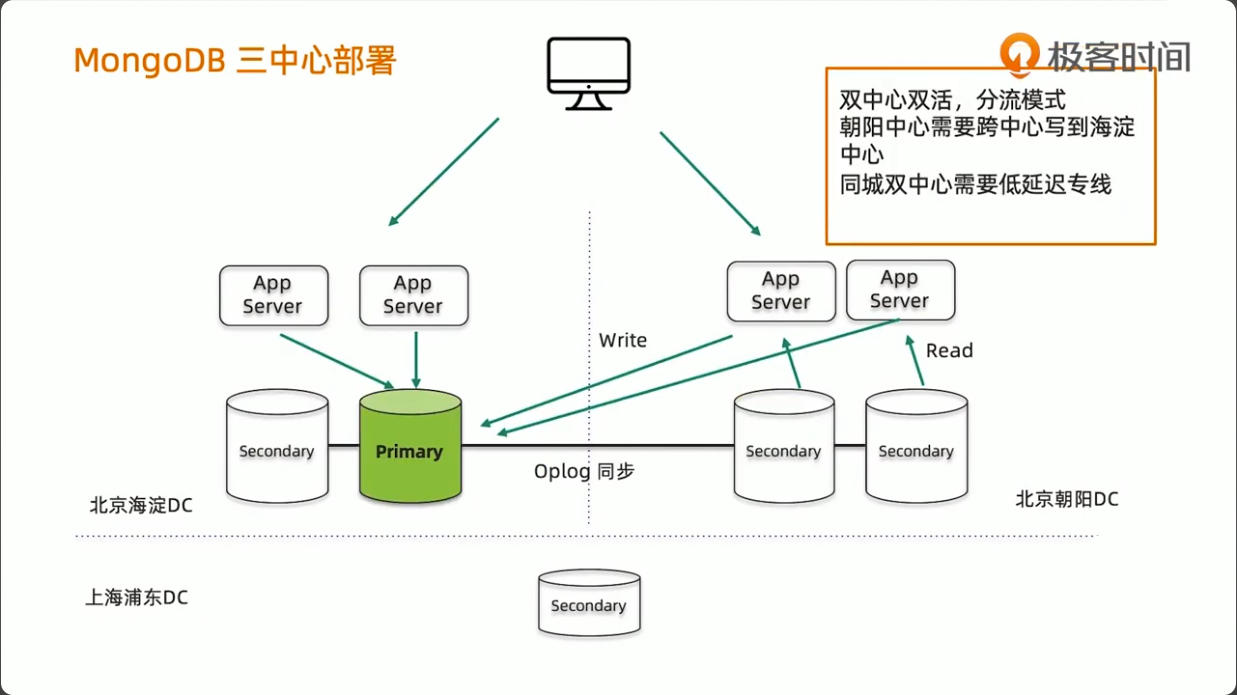
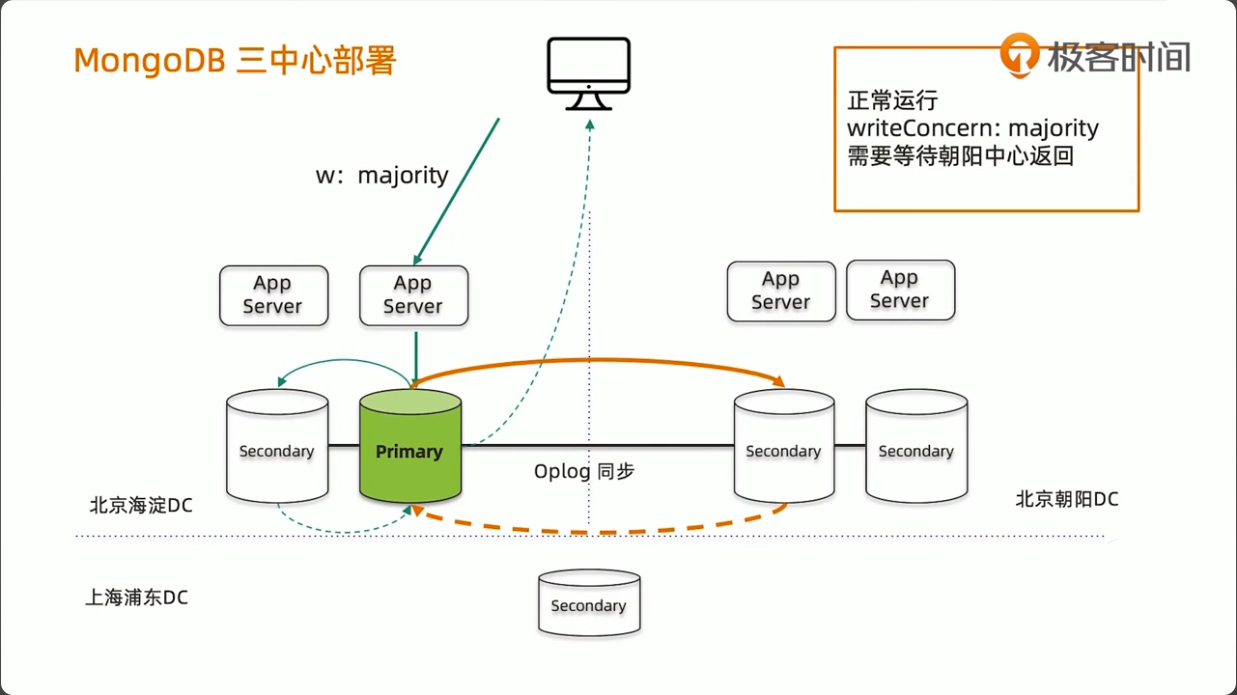
- 节点数量建议要5个,2+2+1模式
- 主数据中心的两个节点要设置高一点的优先级,减少跨中心换主节点
- 同城双中心之间的网络要保证低延迟和频宽,满足
writeConcern:Majority的双中心写需求 - 使用 Retryable Writes and Retryable Reads 来保证零下线时间
- 用户需要自行处理好业务层的双中心切换
38丨实验:搭建两地三中心集群
39丨高级集群设计:全球多写
MongoDB多中心部署的三种模式
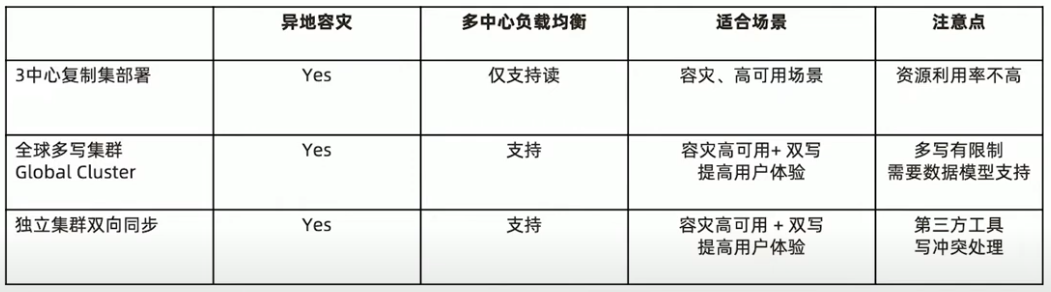
全球化业务需求
- 某奢侈品牌厂商业务集中在大中华地区
- 2020年的目标是要进入美国市场
- 他们的主要业务系统都集中在香港
- 如何设计我们的业务系统来保证海外用户的最佳体验?
远距离访问无法保证用户体验
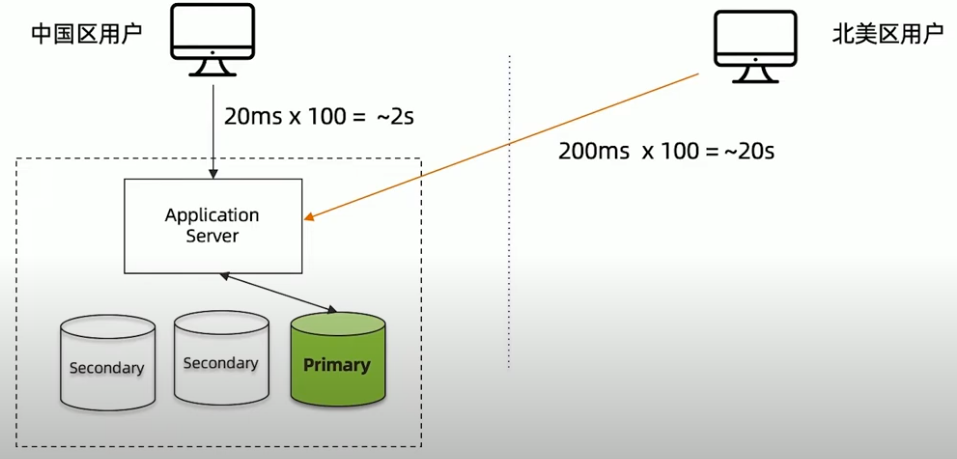
MongoDB复制集-只解决了读的问题
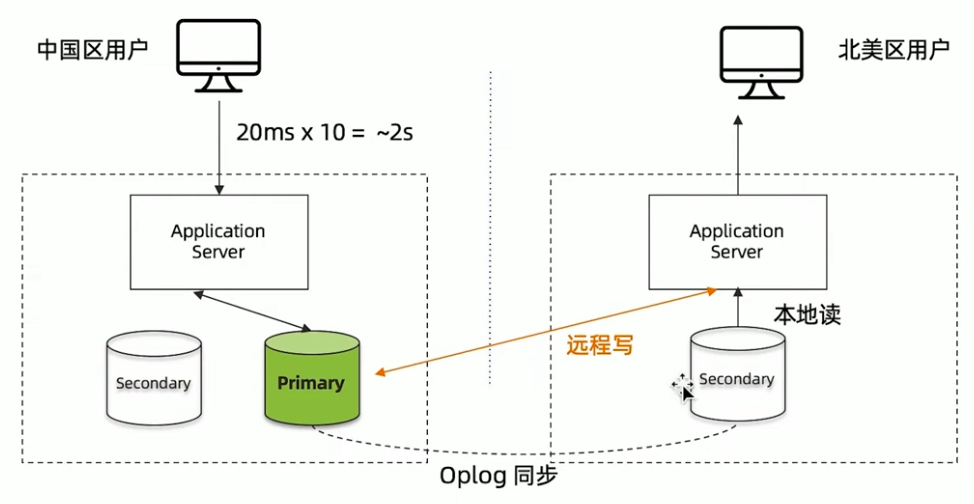
MongoDB Zone sharding-全球集群
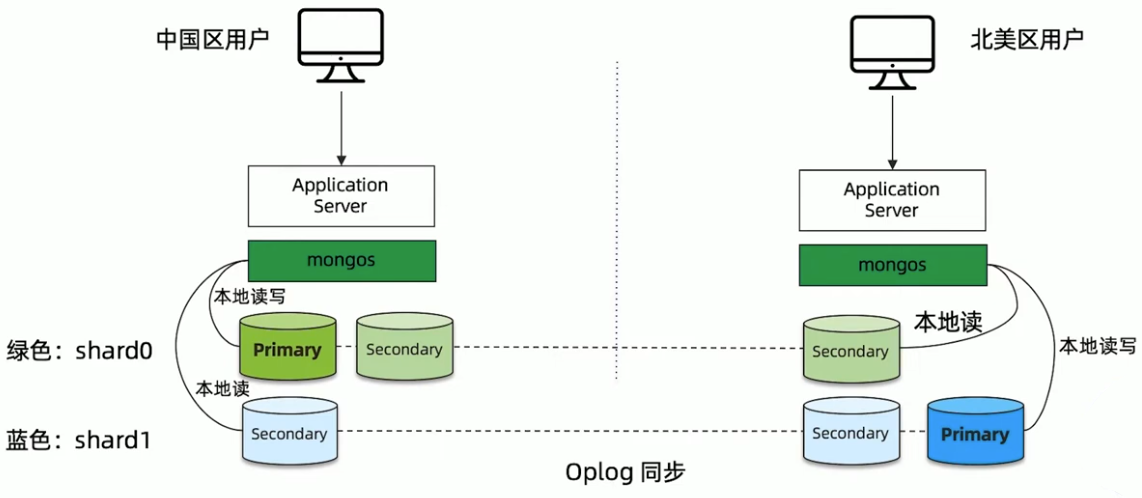
Zone sharding 设置步骤
- 针对每个要分片的数据集合,模型中增加一个区域字段
- 给集群的每个分片加区域标签
- 给每个区域指定属于这个区域的分片块范围(chunkrange)
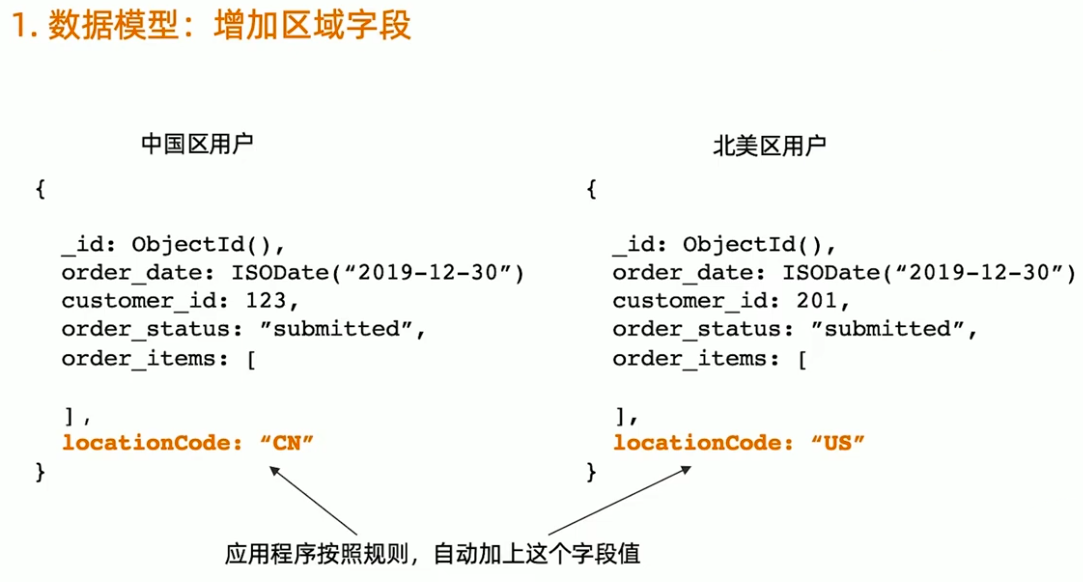
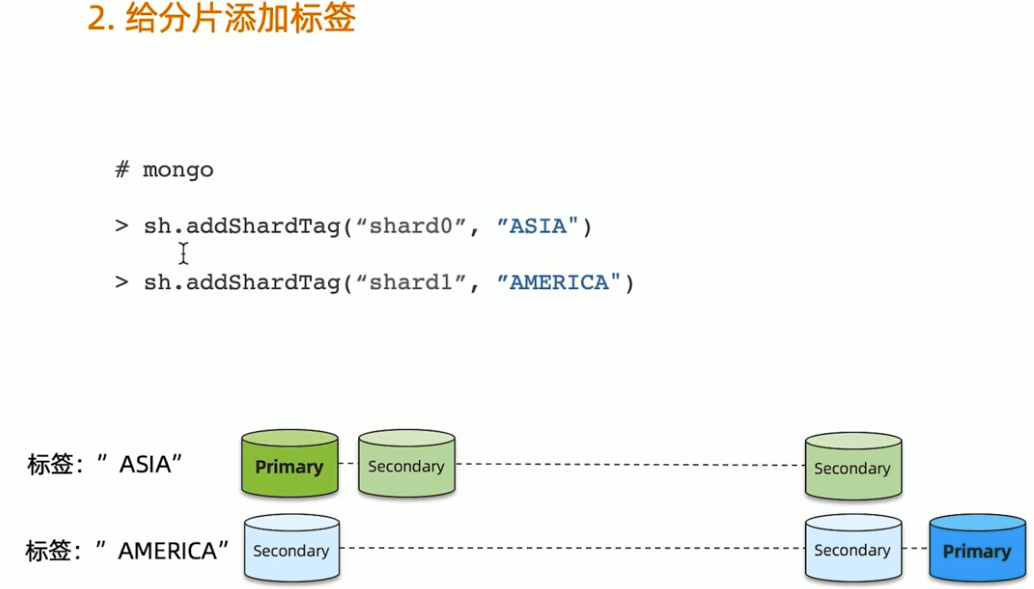

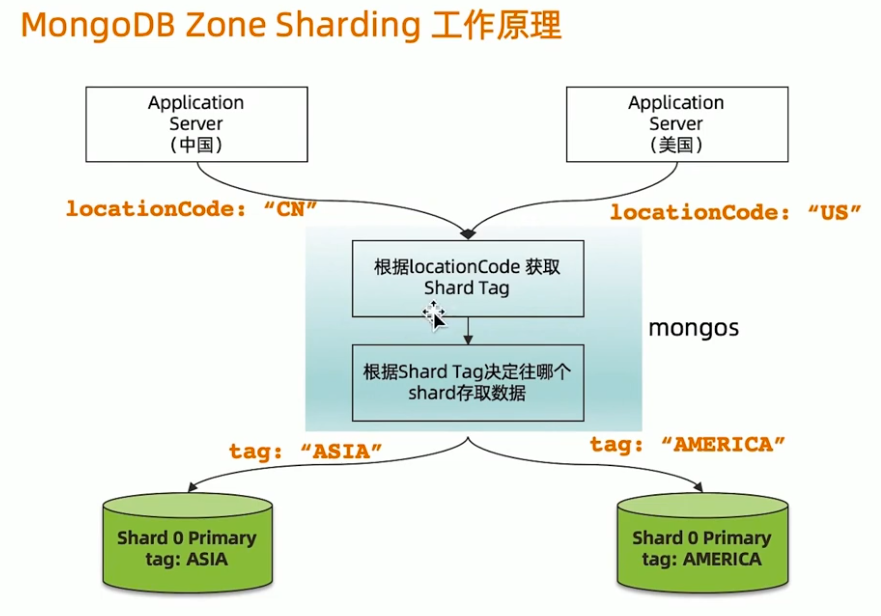
MongoDB Zone sharding 工作原理
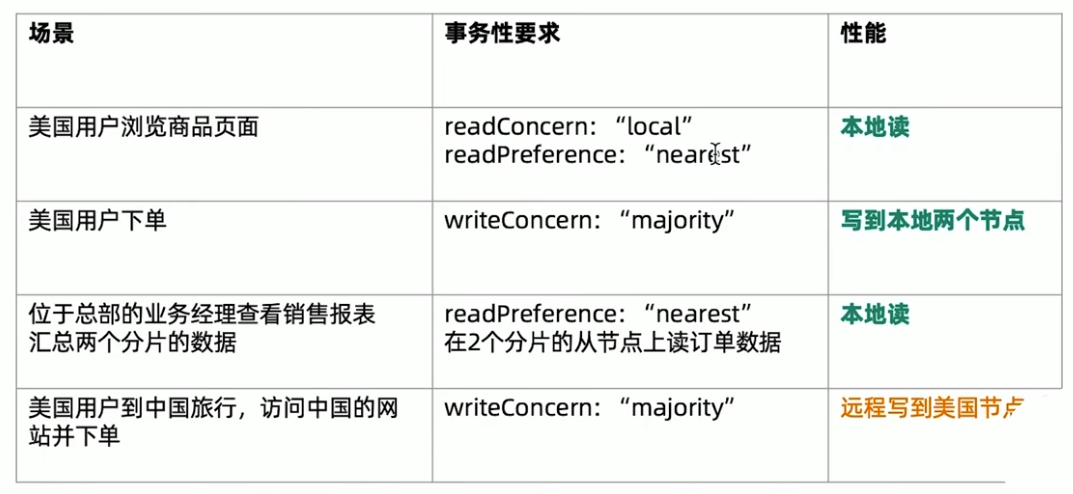
读写场景分析
独立集群模式-需要外部工具双向同步
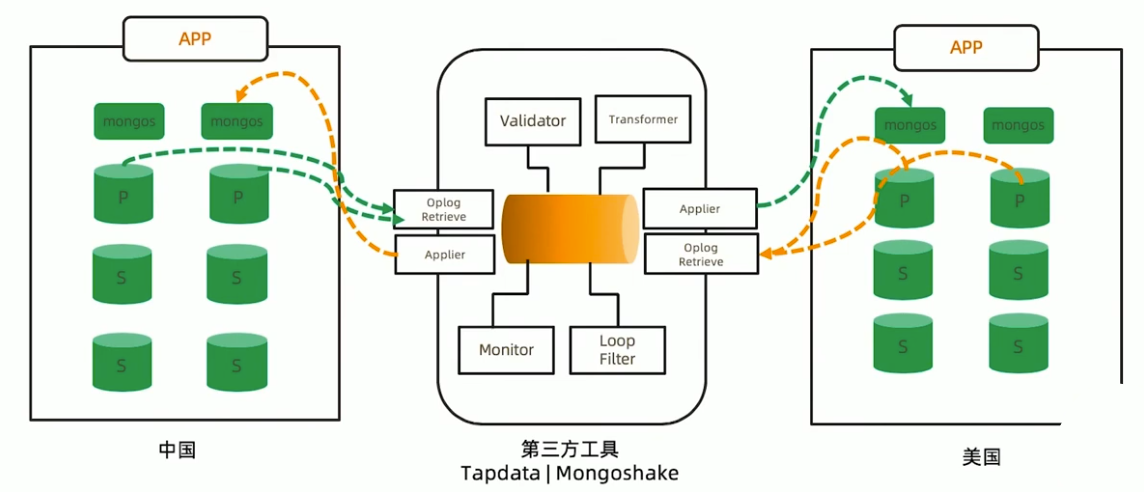
40丨MongoDB上线及升级
上线前:性能测试
模拟真实压力,对集群完成充分的性能测试,了解集群概况。
性能测试的输出:
- 压测过程中各项指标表现,例如CRUD达到多少,连接数达到多少等。
- 根据正常指标范围配置监控阈值;
- 根据压测结果按需调整硬件资源;
上线前:环境检查
按照最佳实践要求对生产环境所使用的操作系统进行检查和调整。最常见的需要调整的参数包括:
- 禁用NUMA,否则在某些情况下会引起突发大量swap交换
- 禁用Transparent Huge Page,否则会影响数据库效率;
- tcp keepalive time调整为120秒,避免一些网络问题;
- ulimit -n,避免打开文件句柄不足的情况;
- 关闭atime,提高数据文件访问效率;
更多检查项,请参考文档:Production Notes
上线后
性能监控
- 为防止突发状况,应对常见性能指标进行监控以及时发现问题。
- 性能监控请参考前述章节的内容
定期健康检查
- mongod日志;
- 环境设置是否有变动;
- MongoDB配置是否有变动
MongoDB 版本发布规律

主版本升级流程
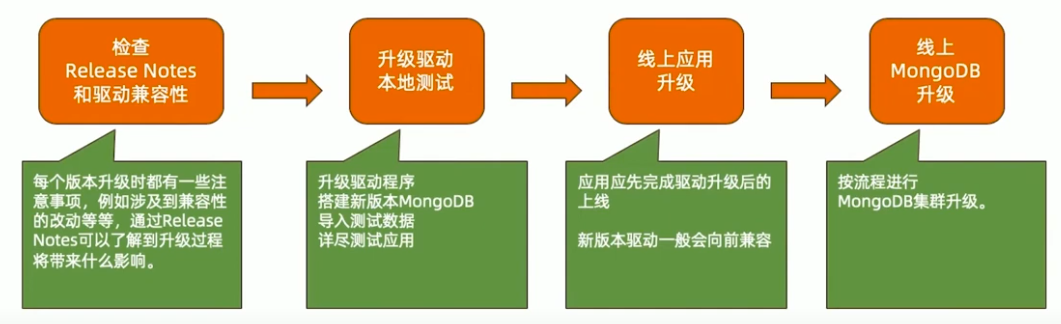
https://www.mongodb.com/docs/drivers/compatibility/
MongoDB单机升级流程

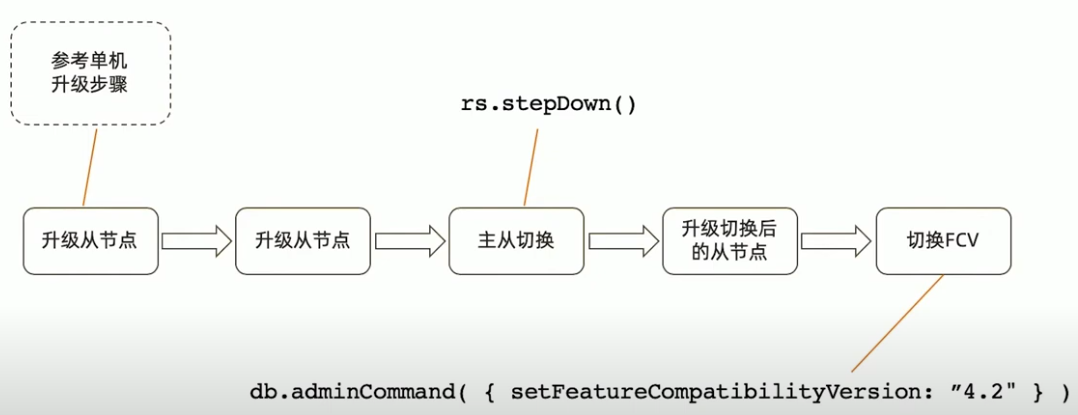
MongoDB复制集升级流程
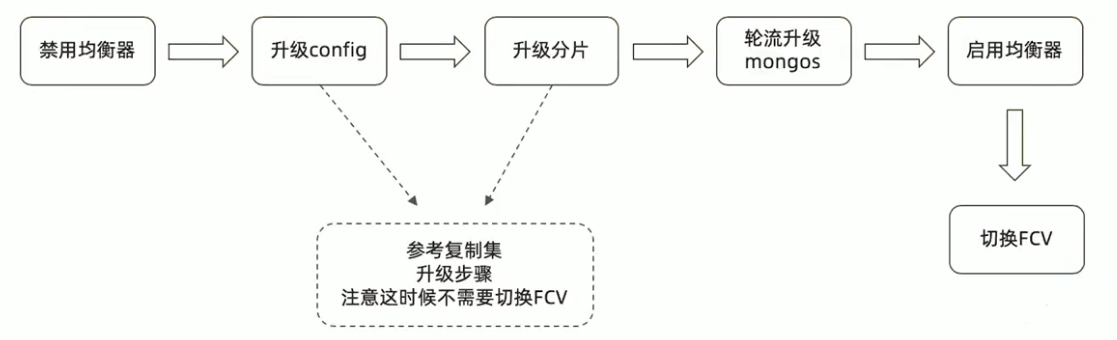
MongoDB分片集群升级流程
版本升级:在线升级
MongoDB支持在线升级,即升级过程中不需要间断服务;
升级过程中虽然会发生主从节点切换,存在短时间不可用,但是:
- 3.6版本开始支持自动写重试可以自动恢复主从切换引起的集群暂时不可写,
- 4.2开始支持的自动读重试则提供了包括主从切换在内的读问题的自动恢复;
升级需要逐版本完成,不可以跳版本:
- 正确:3.2->3.4->3.6->4.0->4.2
- 错误:3.2->4.2
- 原因:
- MongoDB复制集仅仅允许相邻版本共存
- 有一些升级内部数据格式如密码加密字段,需要在升级过程中由mongo进行转换
升级流程:降级
如果升级无论因何种原因失败,则需要降级到原有旧版本。在降级过程中:
- 滚动降级过程中集群可以保持在线,仅在切换节点时会产生一定的不可写时间;
- 降级前应先去除已经用到的新版本特性。例如用到了NumberDecimal则应把所有使用NumberDecimal的文档先去除该字段;
- 通过设置FCV(Feature compatibility Version)可以在功能上降到与旧版本兼容;
- FCV设置完成后再滚动替换为旧版本。
41丨MongoDB应用场景及选型
MongoDB 数据库定位
- OLTP 数据库
- 原则上 Oracle 和 MySQL能做的事情,MongoDB 都能做(包括 ACID 事务)
- 优点:横向扩展能力,数据量或并发量增加时候架构可以自动扩展
- 优点:灵活模型,适合迭代开发,数据模型多变场景
- 优点:JSON 数据结构,适合微服务/REST API
基于功能选择 MongoDB
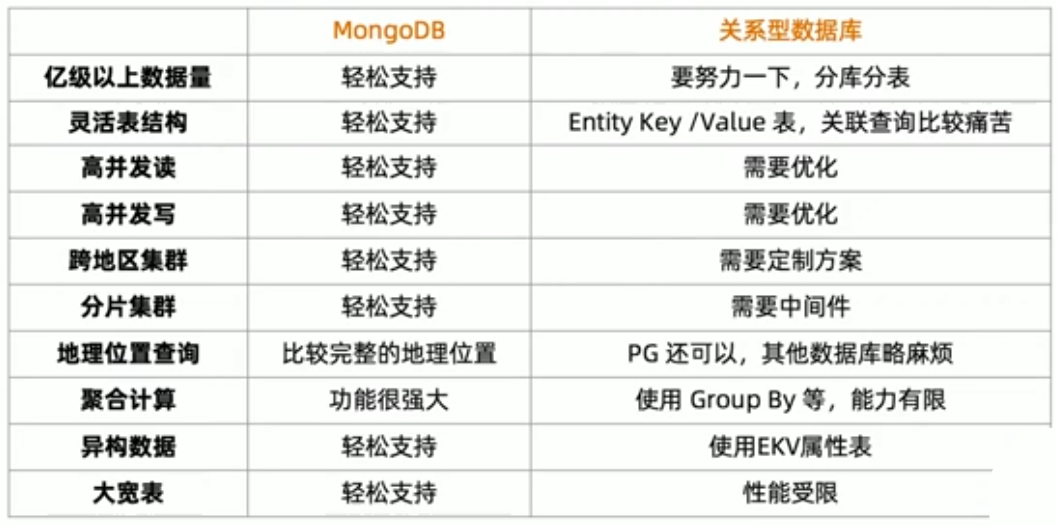
基于场景选择 MongoDB
- 移动/小程序App
- SaaS 应用
- 电商
- 主机分流
- 内容管理
- 实时分析
- 物联网
- 关系型迁移

