01 Redis 是如何执行的
命令执行流程
一条命令的执行过程有很多细节,但大体可分为:客户端先将用户输入的命令,转化为 Redis 相关的通讯协议,再用 socket 连接的方式将内容发送给服务器端,服务器端在接收到相关内容之后,先将内容转化为具体的执行命令,再判断用户授权信息和其他相关信息,当验证通过之后会执行最终命令,命令执行完之后,会进行相关的信息记录和数据统计,然后再把执行结果发送给客户端,这样一条命令的执行流程就结束了。如果是集群模式的话,主节点还会将命令同步至子节点,下面我们一起来看更加具体的执行流程。
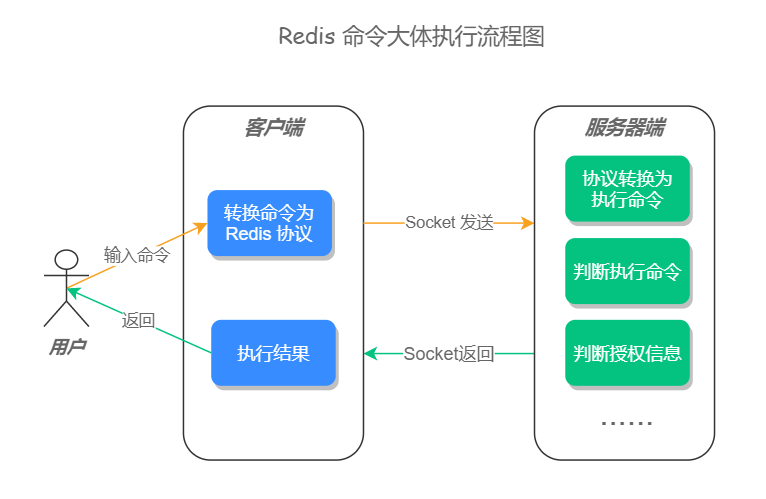
步骤一:用户输入一条命令
步骤二:客户端先将命令转换成 Redis 协议,然后再通过 socket 连接发送给服务器端
客户端和服务器端是基于 socket 通信的,服务器端在初始化时会创建了一个 socket 监听,用于监测链接客户端的 socket 链接,源码如下:
void initServer(void) {
//......
// 开启 Socket 事件监听
if (server.port != 0 &&
listenToPort(server.port,server.ipfd,&server.ipfd_count) == C_ERR)
exit(1);
//......
}socket 小知识:每个 socket 被创建后,会分配两个缓冲区,输入缓冲区和输出缓冲区。 写入函数并不会立即向网络中传输数据,而是先将数据写入缓冲区中,再由 TCP 协议将数据从缓冲区发送到目标机器。一旦将数据写入到缓冲区,函数就可以成功返回,不管它们有没有到达目标机器,也不管它们何时被发送到网络,这些都是 TCP 协议负责的事情。 注意:数据有可能刚被写入缓冲区就发送到网络,也可能在缓冲区中不断积压,多次写入的数据被一次性发送到网络,这取决于当时的网络情况、当前线程是否空闲等诸多因素,不由程序员控制。 读取函数也是如此,它也是从输入缓冲区中读取数据,而不是直接从网络中读取。
当 socket 成功连接之后,客户端会先把命令转换成 Redis 通讯协议(RESP 协议,REdis Serialization Protocol)发送给服务器端,这个通信协议是为了保障服务器能最快速的理解命令的含义而制定的,如果没有这个通讯协议,那么 Redis 服务器端要遍历所有的空格以确认此条命令的含义,这样会加大服务器的运算量,而直接发送通讯协议,相当于把服务器端的解析工作交给了每一个客户端,这样会很大程度的提高 Redis 的运行速度。例如,当我们输入 set key val 命令时,客户端会把这个命令转换为 *3\r\n$3\r\nSET\r\n$4\r\nKEY\r\n$4\r\nVAL\r\n 协议发送给服务器端。 更多通讯协议,可访问官方文档:https://redis.io/topics/protocol
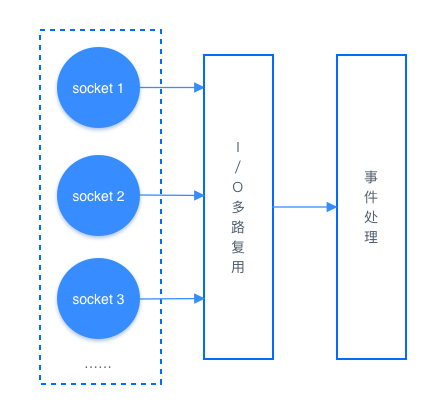
扩展知识:I/O 多路复用
Redis 使用的是 I/O 多路复用功能来监听多 socket 链接的,这样就可以使用一个线程链接来处理多个请求,减少线程切换带来的开销,同时也避免了 I/O 阻塞操作,从而大大提高了 Redis 的运行效率。
I/O 多路复用机制如下图所示:
综合来说,此步骤的执行流程如下:
- 与服务器端以 socket 和 I/O 多路复用的技术建立链接;
- 将命令转换为 Redis 通讯协议,再将这些协议发送至缓冲区。
步骤三:服务器端接收到命令
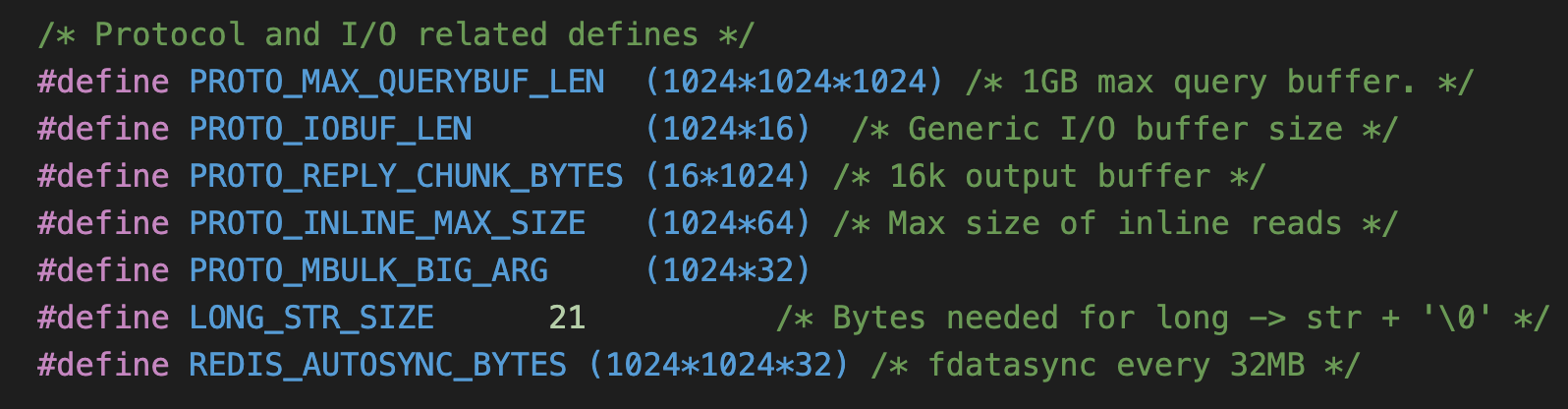
服务器会先去输入缓冲中读取数据,然后判断数据的大小是否超过了系统设置的值(默认是 1GB),如果大于此值就会返回错误信息,并关闭客户端连接。 默认大小如下图所示:
当数据大小验证通过之后,服务器端会对输入缓冲区中的请求命令进行分析,提取命令请求中包含的命令参数,存储在 client 对象(服务器端会为每个链接创建一个 Client 对象)的属性中。
步骤四:执行前准备
- 判断是否为退出命令,如果是则直接返回;
- 非 null 判断,检查 client 对象是否为 null,如果是返回错误信息;
- 获取执行命令,根据 client 对象存储的属性信息去 redisCommand 结构中查询执行命令;
- 用户权限效验,未通过身份验证的客户端只能执行 AUTH(授权) 命令,未通过身份验证的客户端执行了 AUTH 之外的命令则返回错误信息;
- 集群相关操作,如果是集群模式,把命令重定向到目标节点,如果是 master(主节点) 则不需要重定向;
- 检查服务器端最大内存限制,如果服务器端开启了最大内存限制,会先检查内存大小,如果内存超过了最大值会对内存进行回收操作;
- 持久化检测,检查服务器是否开启了持久化和持久化出错停止写入配置,如果开启了此配置并且有持久化失败的情况,禁止执行写命令;
- 集群模式最少从节点(slave)验证,如果是集群模式并且配置了
repl*min*slaves*to*write(最小从节点写入),当从节点的数量少于配置项时,禁止执行写命令; - 只读从节点验证,当此服务器为只读从节点时,只接受 master 的写命令;
- 客户端订阅判断,当客户端正在订阅频道时,只会执行部分命令(只会执行 SUBSCRIBE、PSUBSCRIBE、UNSUBSCRIBE、PUNSUBSCRIBE,其他命令都会被拒绝)。
- 从节点状态效验,当服务器为 slave 并且没有连接 master 时,只会执行状态查询相关的命令,如 info 等;
- 服务器初始化效验,当服务器正在启动时,只会执行 loading 标志的命令,其他的命令都会被拒绝;
- lua 脚本阻塞效验,当服务器因为执行 lua 脚本阻塞时,只会执行部分命令;
- 事务命令效验,如果执行的是事务命令,则开启事务把命令放入等待队列;
- 监视器 (monitor) 判断,如果服务器打开了监视器功能,那么服务器也会把执行命令和相关参数发送给监视器 (监视器是用于监控服务器运行状态的)。
当服务器经过以上操作之后,就可以执行真正的操作命令了。
步骤五:执行最终命令,调用 redisCommand 中的 proc 函数执行命令。
步骤六:执行完后相关记录和统计
- 检查慢查询是否开启,如果开启会记录慢查询日志;
- 检查统计信息是否开启,如果开启会记录一些统计信息,例如执行命令所耗费时长和计数器(calls)加1;
- 检查持久化功能是否开启,如果开启则会记录持久化信息;
- 如果有其它从服务器正在复制当前服务器,则会将刚刚执行的命令传播给其他从服务器。
步骤七:返回结果给客户端
命令执行完之后,服务器会通过 socket 的方式把执行结果发送给客户端,客户端再把结果展示给用户,至此一条命令的执行就结束了。
小结
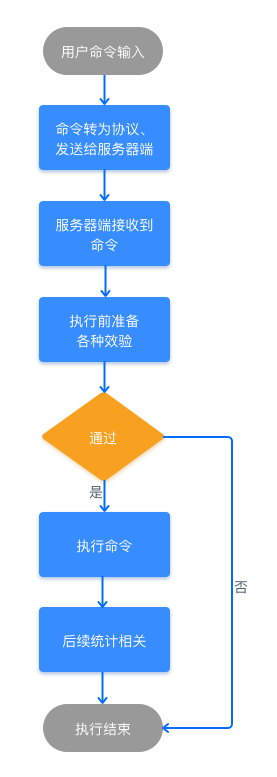
当用户输入一条命令之后,客户端会以 socket 的方式把数据转换成 Redis 协议,并发送至服务器端,服务器端在接受到数据之后,会先将协议转换为真正的执行命令,在经过各种验证以保证命令能够正确并安全的执行,但验证处理完之后,会调用具体的方法执行此条命令,执行完成之后会进行相关的统计和记录,然后再把执行结果返回给客户端,整个执行流程,如下图所示:
03 Redis 持久化——RDB
Redis 的读写都是在内存中,所以它的性能较高,但在内存中的数据会随着服务器的重启而丢失,为了保证数据不丢失,我们需要将内存中的数据存储到磁盘,以便 Redis 重启时能够从磁盘中恢复原有的数据,而整个过程就叫做 Redis 持久化。
Redis 持久化也是 Redis 和 Memcached 的主要区别之一,因为 Memcached 不具备持久化功能。
持久化的几种方式
Redis 持久化拥有以下三种方式:
- 快照方式(RDB, Redis DataBase)将某一个时刻的内存数据,以二进制的方式写入磁盘;
- 文件追加方式(AOF, Append Only File),记录所有的操作命令,并以文本的形式追加到文件中;
- 混合持久化方式,Redis 4.0 之后新增的方式,混合持久化是结合了 RDB 和 AOF 的优点,在写入的时候,先把当前的数据以 RDB 的形式写入文件的开头,再将后续的操作命令以 AOF 的格式存入文件,这样既能保证 Redis 重启时的速度,又能减低数据丢失的风险。
RDB简介
RDB(Redis DataBase)是将某一个时刻的内存快照(Snapshot),以二进制的方式写入磁盘的过程。
持久化触发
RDB 的持久化触发方式有两类:一类是手动触发,另一类是自动触发。
手动触发
手动触发持久化的操作有两个: save 和 bgsave ,它们主要区别体现在:是否阻塞 Redis 主线程的执行。
在客户端中执行 save 命令,就会触发 Redis 的持久化,但同时也是使 Redis 处于阻塞状态,直到 RDB 持久化完成,才会响应其他客户端发来的命令,所以在生产环境一定要慎用。
bgsave (background save)既后台保存的意思, 它和 save 命令最大的区别就是 bgsave 会 fork() 一个子进程来执行持久化,整个过程中只有在 fork() 子进程时有短暂的阻塞,当子进程被创建之后,Redis 的主进程就可以响应其他客户端的请求了,相对于整个流程都阻塞的 save 命令来说,显然 bgsave 命令更适合我们使用。
自动触发
说完了 RDB 的手动触发方式,下面来看如何自动触发 RDB 持久化? RDB 自动持久化主要来源于以下几种情况。
save m nsave m n是指在m秒内,如果有n个键发生改变,则自动触发持久化。 参数m和n可以在 Redis 的配置文件中找到,例如,save 60 1则表明在 60 秒内,至少有一个键发生改变,就会触发 RDB 持久化。 自动触发持久化,本质是 Redis 通过判断,如果满足设置的触发条件,自动执行一次bgsave命令。 注意:当设置多个save m n命令时,满足任意一个条件都会触发持久化。 例如,我们设置了以下两个save m n命令:save 60 10save 600 1当 60s 内如果有 10 次 Redis 键值发生改变,就会触发持久化;如果 60s 内 Redis 的键值改变次数少于 10 次,那么 Redis 就会判断 600s 内,Redis 的键值是否至少被修改了一次,如果满足则会触发持久化。
flushallflushall命令用于清空 Redis 数据库,在生产环境下一定慎用,当 Redis 执行了flushall命令之后,则会触发自动持久化,把 RDB 文件清空。主从同步触发
在 Redis 主从复制中,当从节点执行全量复制操作时,主节点会执行
bgsave命令,并将 RDB 文件发送给从节点,该过程会自动触发 Redis 持久化。
配置说明
RDB 配置参数可以在 Redis 的配置文件中找见,具体内容如下:
# RDB 保存的条件
save 900 1
save 300 10
save 60 10000
# bgsave 失败之后,是否停止持久化数据到磁盘,yes 表示停止持久化,no 表示忽略错误继续写文件。
stop-writes-on-bgsave-error yes
# RDB 文件压缩
rdbcompression yes
# 写入文件和读取文件时是否开启 RDB 文件检查,检查是否有无损坏,如果在启动是检查发现损坏,则停止启动。
rdbchecksum yes
# RDB 文件名
dbfilename dump.rdb
# RDB 文件目录
dir ./其中比较重要的参数如下列表:
save 参数
它是用来配置触发 RDB 持久化条件的参数,满足保存条件时将会把数据持久化到硬盘。 默认配置说明如下:
save 900 1:表示 900 秒内如果至少有 1 个 key 值变化,则把数据持久化到硬盘;save 300 10:表示 300 秒内如果至少有 10 个 key 值变化,则把数据持久化到硬盘;save 60 10000:表示 60 秒内如果至少有 10000 个 key 值变化,则把数据持久化到硬盘。
rdbcompression 参数
它的默认值是 yes 表示开启 RDB 文件压缩,Redis 会采用 LZF 算法进行压缩。如果不想消耗 CPU 性能来进行文件压缩的话,可以设置为关闭此功能,这样的缺点是需要更多的磁盘空间来保存文件。
rdbchecksum 参数
它的默认值为 yes 表示写入文件和读取文件时是否开启 RDB 文件检查,检查是否有无损坏,如果在启动是检查发现损坏,则停止启动。
配置查询
Redis 中可以使用命令查询当前配置参数。查询命令的格式为:config get xxx ,例如,想要获取 RDB 文件的存储名称设置,可以使用 config get dbfilename。
查询 RDB 的文件目录,可使用命令 config get dir。
配置设置
设置 RDB 的配置,可以通过以下两种方式:
- 手动修改 Redis 配置文件;
- 使用命令行设置,例如,使用 config set dir “/usr/data” 就是用于修改 RDB 的存储目录。
注意:手动修改 Redis 配置文件的方式是全局生效的,即重启 Redis 服务器设置参数也不会丢失,而使用命令修改的方式,在 Redis 重启之后就会丢失。但手动修改 Redis 配置文件,想要立即生效需要重启 Redis 服务器,而命令的方式则不需要重启 Redis 服务器。
小贴士:Redis 的配置文件位于 Redis 安装目录的根路径下,默认名称为 redis.conf。
RDB 文件恢复
当 Redis 服务器启动时,如果 Redis 根目录存在 RDB 文件 dump.rdb,Redis 就会自动加载 RDB 文件恢复持久化数据。
如果根目录没有 dump.rdb 文件,请先将 dump.rdb 文件移动到 Redis 的根目录。
验证 RDB 文件是否被加载 Redis 在启动时有日志信息,会显示是否加载了 RDB 文件,我们执行 Redis 启动命令:src/redis-server redis.conf ,如下图所示:

从日志上可以看出, Redis 服务在启动时已经正常加载了 RDB 文件。
小贴士:Redis 服务器在载入 RDB 文件期间,会一直处于阻塞状态,直到载入工作完成为止。
RDB 优缺点
RDB 优点
- RDB 的内容为二进制的数据,占用内存更小,更紧凑,更适合做为备份文件;
- RDB 对灾难恢复非常有用,它是一个紧凑的文件,可以更快的传输到远程服务器进行 Redis 服务恢复;
- RDB 可以更大程度的提高 Redis 的运行速度,因为每次持久化时 Redis 主进程都会
fork()一个子进程,进行数据持久化到磁盘,Redis 主进程并不会执行磁盘 I/O 等操作; - 与 AOF 格式的文件相比,RDB 文件可以更快的重启。
RDB 缺点
- 因为 RDB 只能保存某个时间间隔的数据,如果中途 Redis 服务被意外终止了,则会丢失一段时间内的 Redis 数据;
- RDB 需要经常
fork()才能使用子进程将其持久化在磁盘上。如果数据集很大,fork()可能很耗时,并且如果数据集很大且 CPU 性能不佳,则可能导致 Redis 停止为客户端服务几毫秒甚至一秒钟。
禁用持久化
禁用持久化可以提高 Redis 的执行效率,如果对数据丢失不敏感的情况下,可以在连接客户端的情况下,执行 config set save "" 命令即可禁用 Redis 的持久化。
参考&鸣谢
- https://redis.io/topics/persistence
- https://blog.csdn.net/qq_36318234/article/details/79994133
- https://www.cnblogs.com/ysocean/p/9114268.html
- https://www.cnblogs.com/wdliu/p/9377278.html
04 Redis 持久化——AOF
使用 RDB 持久化有一个风险,它可能会造成最新数据丢失的风险。因为 RDB 的持久化有一定的时间间隔,在这个时间段内如果 Redis 服务意外终止的话,就会造成最新的数据全部丢失。
可能会操作 Redis 服务意外终止的条件:
- 安装 Redis 的机器停止运行,蓝屏或者系统崩溃;
- 安装 Redis 的机器出现电源故障,例如突然断电;
- 使用
kill -9 Redis_PID等。
那么如何解决以上的这些问题呢?Redis 为我们提供了另一种持久化的方案——AOF。
简介
AOF(Append Only File)中文是附加到文件,顾名思义 AOF 可以把 Redis 每个键值对操作都记录到文件(appendonly.aof)中。
持久化查询和设置
查询 AOF 启动状态
使用 config get appendonly 命令,如下图所示:

其中,第一行为 AOF 文件的名称,而最后一行表示 AOF 启动的状态,yes 表示已启动,no 表示未启动。
开启 AOF 持久化
命令行启动 AOF
命令行启动 AOF,使用 config set appendonly yes 命令。
命令行启动 AOF 的优缺点:命令行启动优点是无需重启 Redis 服务,缺点是如果 Redis 服务重启,则之前使用命令行设置的配置就会失效。
配置文件启动 AOF
Redis 的配置文件在它的根路径下的 redis.conf 文件中,获取 Redis 的根目录可以使用命令 config get dir 获取,如下图所示:

只需要在配置文件中设置 appendonly yes 即可,默认 appendonly no 表示关闭 AOF 持久化。
配置文件启动 AOF 的优缺点:修改配置文件的缺点是每次修改配置文件都要重启 Redis 服务才能生效,优点是无论重启多少次 Redis 服务,配置文件中设置的配置信息都不会失效。
触发持久化
AOF 持久化开启之后,只要满足一定条件,就会触发 AOF 持久化。AOF 的触发条件分为两种:自动触发和手动触发。
自动触发
有两种情况可以自动触发 AOF 持久化,分为是:
- 满足 AOF 设置的策略触发
- 满足 AOF 重写触发条件
其中,AOF 重写触发会在本文的后半部分详细介绍,这里重点来说 AOF 持久化策略都有哪些。 AOF 持久化策略,分为以下三种:
- always:每条 Redis 操作命令都会写入磁盘,最多丢失一条数据;
- everysec:每秒钟写入一次磁盘,最多丢失一秒的数据;
- no:不设置写入磁盘的规则,根据当前操作系统来决定何时写入磁盘,Linux 默认 30s 写入一次数据至磁盘。
这三种配置可以在 Redis 的配置文件(redis.conf)中设置,如下代码所示:
# 开启每秒写入一次的持久化策略
appendfsync everysec小贴士:因为每次写入磁盘都会对 Redis 的性能造成一定的影响,所以要根据用户的实际情况设置相应的策略,一般设置每秒写入一次磁盘的频率就可以满足大部分的使用场景了。
手动触发
在客户端执行 bgrewriteaof 命令就可以手动触发 AOF 持久化。
AOF 文件重写
AOF 是通过记录 Redis 的执行命令来持久化(保存)数据的,所以随着时间的流逝 AOF 文件会越来越多,这样不仅增加了服务器的存储压力,也会造成 Redis 重启速度变慢,为了解决这个问题 Redis 提供了 AOF 重写的功能。
什么是 AOF 重写?
AOF 重写指的是它会直接读取 Redis 服务器当前的状态,并压缩保存为 AOF 文件。例如,我们增加了一个计数器,并对它做了 99 次修改,如果不做 AOF 重写的话,那么持久化文件中就会有 100 条记录执行命令的信息,而 AOF 重写之后,之后记录一条此计数器最终的结果信息,这样就去除了所有的无效信息。
AOF 重写实现
触发 AOF 文件重写,要满足两个条件,这两个条件也是配置在 Redis 配置文件中的,它们分别:
auto-aof-rewrite-min-size:允许 AOF 重写的最小文件容量,默认是 64mb 。auto-aof-rewrite-percentage:AOF 文件重写的大小比例,默认值是 100,表示 100%,也就是只有当前 AOF 文件,比最后一次(上次)的 AOF 文件大一倍时,才会启动 AOF 文件重写。
小贴士:只有同时满足 auto-aof-rewrite-min-size 和 auto-aof-rewrite-percentage 设置的条件,才会触发 AOF 文件重写。
注意:使用 bgrewriteaof 命令,可以自动触发 AOF 文件重写。
AOF 重写流程
AOF 文件重写是生成一个全新的文件,并把当前数据的最少操作命令保存到新文件上,当把所有的数据都保存至新文件之后,Redis 会交换两个文件,并把最新的持久化操作命令追加到新文件上。
配置说明
AOF 的配置参数在 Redis 的配置文件中,也就是 Redis 根路径下的 redis.conf 文件中,配置参数和说明如下:
# 是否开启 AOF,yes 为开启,默认是关闭
appendonly no
# AOF 默认文件名
appendfilename "appendonly.aof"
# AOF 持久化策略配置
# appendfsync always
appendfsync everysec
# appendfsync no
# AOF 文件重写的大小比例,默认值是 100,表示 100%,也就是只有当前 AOF 文件,比最后一次的 AOF 文件大一倍时,才会启动 AOF 文件重写。
auto-aof-rewrite-percentage 100
# 允许 AOF 重写的最小文件容量
auto-aof-rewrite-min-size 64mb
# 是否开启启动时加载 AOF 文件效验,默认值是 yes,表示尽可能的加载 AOF 文件,忽略错误部分信息,并启动 Redis 服务。
# 如果值为 no,则表示,停止启动 Redis,用户必须手动修复 AOF 文件才能正常启动 Redis 服务。
aof-load-truncated yes其中比较重要的是 appendfsync 参数,用它来设置 AOF 的持久化策略,可以选择按时间间隔或者操作次数来存储 AOF 文件,这个参数的三个值在文章开头有说明,这里就不再复述了。
数据恢复
正常数据恢复
正常情况下,只要开启了 AOF 持久化,并且提供了正常的 appendonly.aof 文件,在 Redis 启动时就会自定加载 AOF 文件并启动,执行如下图所示:
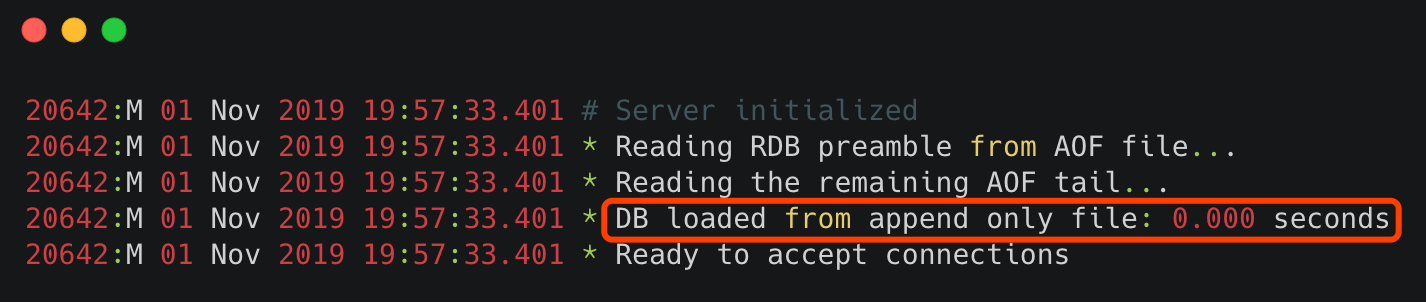
其中 DB loaded from append only file...... 表示 Redis 服务器在启动时,先去加载了 AOF 持久化文件。
小贴士:默认情况下 appendonly.aof 文件保存在 Redis 的根目录下。
持久化文件加载规则
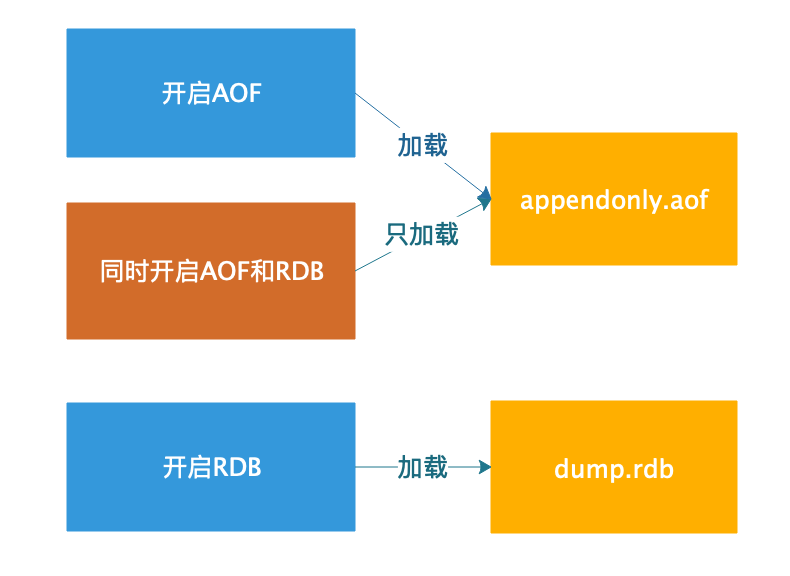
- 如果只开启了 AOF 持久化,Redis 启动时只会加载 AOF 文件(appendonly.aof),进行数据恢复;
- 如果只开启了 RDB 持久化,Redis 启动时只会加载 RDB 文件(dump.rdb),进行数据恢复;
- 如果同时开启了 RDB 和 AOF 持久化,Redis 启动时只会加载 AOF 文件(appendonly.aof),进行数据恢复。
在 AOF 开启的情况下,即使 AOF 文件不存在,只有 RDB 文件,也不会加载 RDB 文件。 AOF 和 RDB 的加载流程如下图所示:
简单异常数据恢复
在 AOF 写入文件时如果服务器崩溃,或者是 AOF 存储已满的情况下,AOF 的最后一条命令可能被截断,这就是异常的 AOF 文件。
在 AOF 文件异常的情况下,如果为修改 Redis 的配置文件,也就是使用 aof-load-truncated 等于 yes 的配置,Redis 在启动时会忽略最后一条命令,并顺利启动 Redis,执行结果如下:
* Reading RDB preamble from AOF file...
* Reading the remaining AOF tail...
# !!! Warning: short read while loading the AOF file !!!
# !!! Truncating the AOF at offset 439 !!!
# AOF loaded anyway because aof-load-truncated is enabled复杂异常数据恢复
AOF 文件可能出现更糟糕的情况,当 AOF 文件不仅被截断,而且中间的命令也被破坏,这个时候再启动 Redis 会提示错误信息并中止运行,错误信息如下:
* Reading the remaining AOF tail...
# Bad file format reading the append only file: make a backup of your AOF file, then use ./redis-check-aof --fix <filename>出现此类问题的解决方案如下:
- 首先使用 AOF 修复工具,检测出现的问题,在命令行中输入 redis-check-aof 命令,它会跳转到出现问题的命令行,这个时候可以尝试手动修复此文件;
- 如果无法手动修复,我们可以使用 redis-check-aof —fix 自动修复 AOF 异常文件,不过执行此命令,可能会导致异常部分至文件末尾的数据全部被丢弃。
优缺点
AOF 优点
- AOF 持久化保存的数据更加完整,AOF 提供了三种保存策略:每次操作保存、每秒钟保存一次、跟随系统的持久化策略保存,其中每秒保存一次,从数据的安全性和性能两方面考虑是一个不错的选择,也是 AOF 默认的策略,即使发生了意外情况,最多只会丢失 1s 钟的数据;
- AOF 采用的是命令追加的写入方式,所以不会出现文件损坏的问题,即使由于某些意外原因,导致了最后操作的持久化数据写入了一半,也可以通过 redis-check-aof 工具轻松的修复;
- AOF 持久化文件,非常容易理解和解析,它是把所有 Redis 键值操作命令,以文件的方式存入了磁盘。即使不小心使用 flushall 命令删除了所有键值信息,只要使用 AOF 文件,删除最后的 flushall 命令,重启 Redis 即可恢复之前误删的数据。
AOF 缺点
- 对于相同的数据集来说,AOF 文件要大于 RDB 文件;
- 在 Redis 负载比较高的情况下,RDB 比 AOF 性能更好;
- RDB 使用快照的形式来持久化整个 Redis 数据,而 AOF 只是将每次执行的命令追加到 AOF 文件中,因此从理论上说,RDB 比 AOF 更健壮。
小结
AOF 保存数据更加完整,它可以记录每次 Redis 的键值变化,或者是选择每秒保存一次数据。AOF 的持久化文件更加易读,但相比与二进制的 RDB 来说,所占的存储空间也越大,为了解决这个问题,AOF 提供自动化重写机制,最大程度的减少了 AOF 占用空间大的问题。同时 AOF 也提供了很方便的异常文件恢复命令: redis-check-aof —fix ,为使用 AOF 提供了很好的保障。
参考&鸣谢
- https://redis.io/topics/persistence
- https://blog.csdn.net/qq_36318234/article/details/79994133
- https://www.cnblogs.com/wdliu/p/9377278.html
05 Redis 持久化——混合持久化
RDB 和 AOF 持久化各有利弊,RDB 可能会导致一定时间内的数据丢失,而 AOF 由于文件较大则会影响 Redis 的启动速度,为了能同时使用 RDB 和 AOF 各种的优点,Redis 4.0 之后新增了混合持久化的方式。
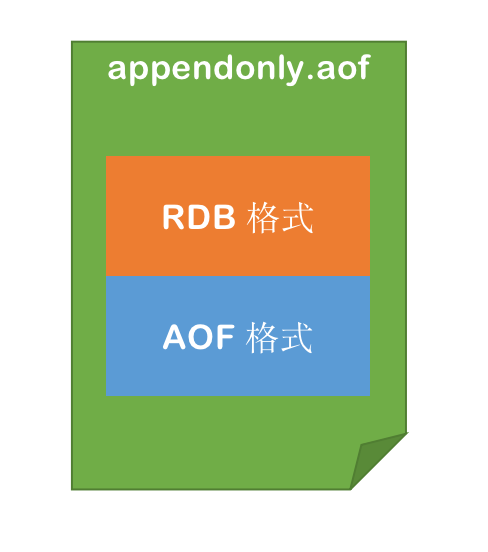
在开启混合持久化的情况下,AOF 重写时会把 Redis 的持久化数据,以 RDB 的格式写入到 AOF 文件的开头,之后的数据再以 AOF 的格式化追加的文件的末尾。
混合持久化的数据存储结构如下图所示:
开启混合持久化
查询是否开启混合持久化可以使用 config get aof-use-rdb-preamble 命令。
Redis 5.0 默认值为 yes。 如果是其他版本的 Redis 首先需要检查一下,是否已经开启了混合持久化,如果关闭的情况下,可以通过以下两种方式开启:
- 通过命令行开启
- 通过修改 Redis 配置文件开启
通过命令行开启
使用命令 config set aof-use-rdb-preamble yes。
小贴士:命令行设置配置的缺点是重启 Redis 服务之后,设置的配置就会失效。
通过修改 Redis 配置文件开启
在 Redis 的根路径下找到 redis.conf 文件,把配置文件中的 aof-use-rdb-preamble no 改为 aof-use-rdb-preamble yes。
实例运行
当在混合持久化关闭的情况下,使用 bgrewriteaof 触发 AOF 文件重写之后,查看 appendonly.aof 文件的持久化日志,如下图所示:
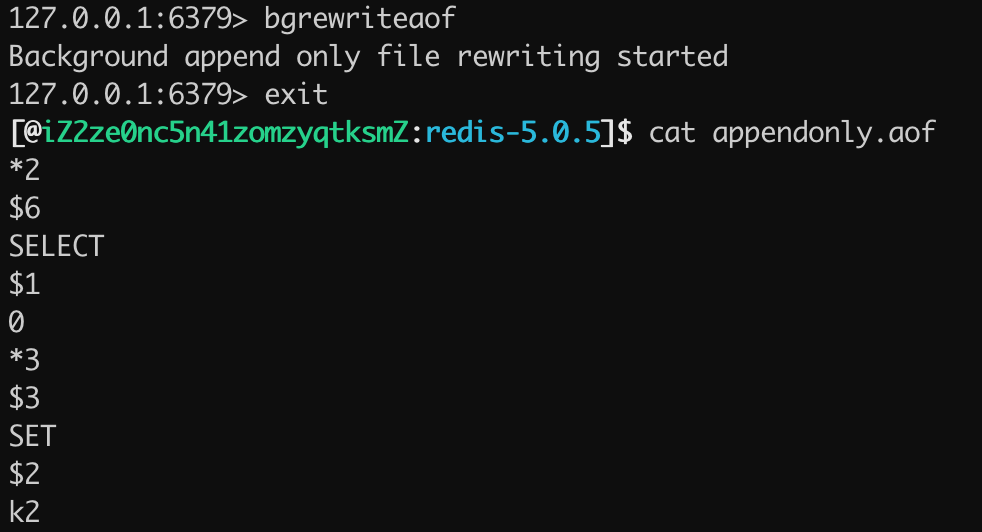
可以看出,当混合持久化关闭的情况下 AOF 持久化文件存储的为标准的 AOF 格式的文件。 当混合持久化开启的模式下,使用 bgrewriteaof 命令触发 AOF 文件重写,得到 appendonly.aof 的文件内容如下图所示:
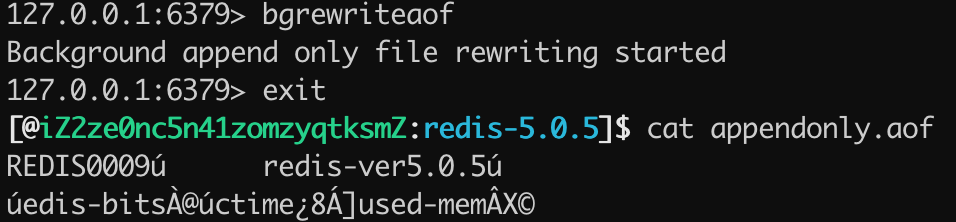
可以看出 appendonly.aof 文件存储的内容是 REDIS 开头的 RDB 格式的内容,并非为 AOF 格式的日志。
数据恢复和源码解析
混合持久化的数据恢复和 AOF 持久化过程是一样的,只需要把 appendonly.aof 放到 Redis 的根目录,在 Redis 启动时,只要开启了 AOF 持久化,Redis 就会自动加载并恢复数据。 Redis 启动信息如下图所示:

可以看出 Redis 在服务器初始化的时候加载了 AOF 文件的内容。
混合持久化的加载流程
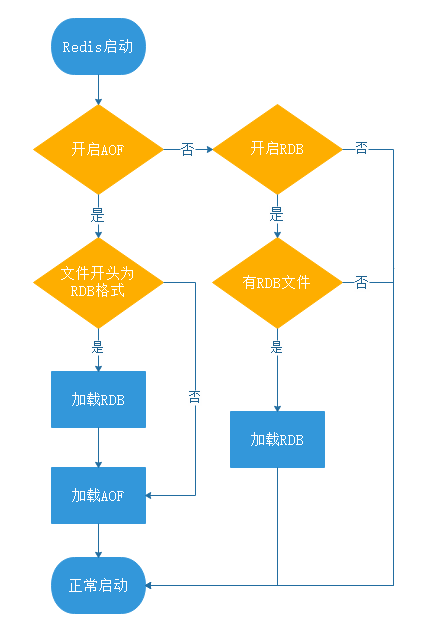
混合持久化的加载流程如下:
- 判断是否开启 AOF 持久化,开启继续执行后续流程,未开启执行加载 RDB 文件的流程;
- 判断 appendonly.aof 文件是否存在,文件存在则执行后续流程;
- 判断 AOF 文件开头是 RDB 的格式, 先加载 RDB 内容再加载剩余的 AOF 内容;
- 判断 AOF 文件开头不是 RDB 的格式,直接以 AOF 格式加载整个文件。
AOF 加载流程图如下图所示:
源码解析
Redis 判断 AOF 文件的开头是否是 RDB 格式的,是通过关键字 REDIS 判断的,RDB 文件的开头一定是 REDIS 关键字开头的,判断源码在 Redis 的 src/aof.c 中,核心代码如下所示:
char sig[5]; /* "REDIS" */
if (fread(sig,1,5,fp) != 5 || memcmp(sig,"REDIS",5) != 0) {
// AOF 文件开头非 RDB 格式,非混合持久化文件
if (fseek(fp,0,SEEK_SET) == -1) goto readerr;
} else {
/* RDB preamble. Pass loading the RDB functions. */
rio rdb;
serverLog(LL_NOTICE,"Reading RDB preamble from AOF file...");
if (fseek(fp,0,SEEK_SET) == -1) goto readerr;
rioInitWithFile(&rdb,fp);
// AOF 文件开头是 RDB 格式,先加载 RDB 再加载 AOF
if (rdbLoadRio(&rdb,NULL,1) != C_OK) {
serverLog(LL_WARNING,"Error reading the RDB preamble of the AOF file, AOF loading aborted");
goto readerr;
} else {
serverLog(LL_NOTICE,"Reading the remaining AOF tail...");
}
}
// 加载 AOF 格式的数据可以看出 Redis 是通过判断 AOF 文件的开头是否是 REDIS 关键字,来确定此文件是否为混合持久化文件的。
小贴士:AOF 格式的开头是
*,而 RDB 格式的开头是REDIS。
优缺点
混合持久化优点:
- 混合持久化结合了 RDB 和 AOF 持久化的优点,开头为 RDB 的格式,使得 Redis 可以更快的启动,同时结合 AOF 的优点,有减低了大量数据丢失的风险。
混合持久化缺点:
- AOF 文件中添加了 RDB 格式的内容,使得 AOF 文件的可读性变得很差;
- 兼容性差,如果开启混合持久化,那么此混合持久化 AOF 文件,就不能用在 Redis 4.0 之前版本了。
持久化最佳实践
持久化虽然保证了数据不丢失,但同时拖慢了 Redis 的运行速度,那怎么更合理的使用 Redis 的持久化功能呢? Redis 持久化的最佳实践可从以下几个方面考虑。
控制持久化开关
使用者可根据实际的业务情况考虑,如果对数据的丢失不敏感的情况下,可考虑关闭 Redis 的持久化,这样所以的键值操作都在内存中,就可以保证最高效率的运行 Redis 了。 持久化关闭操作:
- 关闭 RDB 持久化,使用命令:
config set save "" - 关闭 AOF 和 混合持久化,使用命令:
config set appendonly no
主从部署
使用主从部署,一台用于响应主业务,一台用于数据持久化,这样就可能让 Redis 更加高效的运行。
使用混合持久化
混合持久化结合了 RDB 和 AOF 的优点,Redis 5.0 默认是开启的。
使用配置更高的机器
Redis 对 CPU 的要求并不高,反而是对内存和磁盘的要求很高,因为 Redis 大部分时候都在做读写操作,使用更多的内存和更快的磁盘,对 Redis 性能的提高非常有帮助。
参考&鸣谢
- https://redis.io/topics/persistence
- https://blog.csdn.net/qq_36318234/article/details/79994133
- https://www.cnblogs.com/wdliu/p/9377278.html
06 字符串使用与内部实现原理
https://www.cnblogs.com/wan-ming-zhu/p/18078015
Redis 发展到现在已经有 9 种数据类型了,其中最基础、最常用的数据类型有 5 种,它们分别是:字符串类型、列表类型、哈希表类型、集合类型、有序集合类型,而在这 5 种数据类型中最常用的是字符串类型,所以本文我们先从字符串的使用开始说起。
字符串类型的全称是 Simple Dynamic Strings 简称 SDS,中文意思是:简单动态字符串。它是以键值对 key-value 的形式进行存储的,根据 key 来存储和获取 value 值,它的使用相对来说比较简单,但在实际项目中应用非常广泛。
1 字符串类型能做什么?
字符串类型的使用场景有很多,但从功能的角度来区分,大致可分为以下两种:
- 字符串存储和操作;
- 整数类型和浮点类型的存储和计算。
字符串最常用的业务场景有以下几个。
1)页面数据缓存
我们知道,一个系统最宝贵的资源就是数据库资源,随着公司业务的发展壮大,数据库的存储量也会越来越大,并且要处理的请求也越来越多,当数据量和并发量到达一定级别之后,数据库就变成了拖慢系统运行的”罪魁祸首”,为了避免这种情况的发生,我们可以把查询结果放入缓存(Redis)中,让下次同样的查询直接去缓存系统取结果,而非查询数据库,这样既减少了数据库的压力,同时也提高了程序的运行速度。
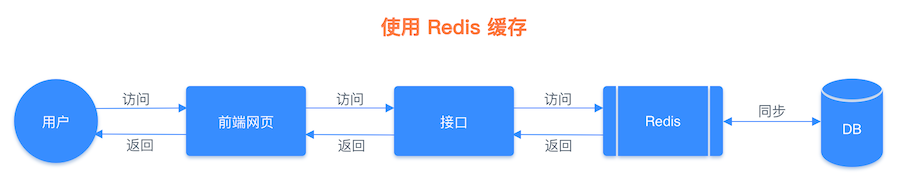
介于以上这个思路,我们可以把文章详情页的数据放入缓存系统。具体的做法是先将文章详情页序列化为字符串存入缓存,再从缓存中读取到字符串,反序列化成对象,然后再赋值到页面进行显示 (当然也可以用哈希类型进行存储,这会在下一篇文章中讲到),这样我们就实现了文章详情页的缓存功能,架构流程对比图如下所示。
原始系统运行流程图:
引入缓存系统后的流程图:
2)数字计算与统计
Redis 可以用来存储整数和浮点类型的数据,并且可以通过命令直接累加并存储整数信息,这样就省去了每次先要取数据、转换数据、拼加数据、再存入数据的麻烦,只需要使用一个命令就可以完成此流程,具体实现过程本文下半部分会讲。这样我们就可以使用此功能来实现访问量的统计,当有人访问时访问量 +1 就可以了。
3)共享 Session 信息
通常我们在开发后台管理系统时,会使用 Session 来保存用户的会话(登录)状态,这些 Session 信息会被保存在服务器端,但这只适用于单系统应用,如果是分布式系统此模式将不再适用。
例如用户一的 Session 信息被存储在服务器一,但第二次访问时用户一被分配到服务器二,这个时候服务器并没有用户一的 Session 信息,就会出现需要重复登录的问题。分布式系统每次会把请求随机分配到不同的服务器,因此我们需要借助缓存系统对这些 Session 信息进行统一的存储和管理,这样无论请求发送到那台服务器,服务器都会去统一的缓存系统获取相关的 Session 信息,这样就解决了分布式系统下 Session 存储的问题。
2 字符串如何使用?
通常我们会使用两种方式来操作 Redis:第一种是使用命令行来操作,例如 redis-cli;另一种是使用代码的方式来操作。
小贴士:mset 是一个原子性(atomic)操作,所有给定 key 都会在同一时间内被设置,不会出现某些 key 被更新,而另一些 key 没被更新的情况。
3 代码实战
4 字符串的内部实现
1)源码分析
Redis 3.2 之前 SDS 源码如下:
struct sds{
int len; // 已占用的字节数
int free; // 剩余可以字节数
char buf[]; // 存储字符串的数据空间
}可以看出 Redis 3.2 之前 SDS 内部是一个带有长度信息的字节数组,存储结构如下图所示:

为了更加有效的利用内存,Redis 3.2 优化了 SDS 的存储结构,源码如下:
typedef char *sds;
struct __attribute__ ((__packed__)) sdshdr5 { // 对应的字符串长度小于 1<<5
unsigned char flags;
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 { // 对应的字符串长度小于 1<<8
uint8_t len; /* 已使用长度,1 字节存储 */
uint8_t alloc; /* 总长度 */
unsigned char flags;
char buf[]; // 真正存储字符串的数据空间
};
struct __attribute__ ((__packed__)) sdshdr16 { // 对应的字符串长度小于 1<<16
uint16_t len; /* 已使用长度,2 字节存储 */
uint16_t alloc;
unsigned char flags;
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 { // 对应的字符串长度小于 1<<32
uint32_t len; /* 已使用长度,4 字节存储 */
uint32_t alloc;
unsigned char flags;
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 { // 对应的字符串长度小于 1<<64
uint64_t len; /* 已使用长度,8 字节存储 */
uint64_t alloc;
unsigned char flags;
char buf[];
};这样就可以针对不同长度的字符串申请相应的存储类型,从而有效的节约了内存使用。
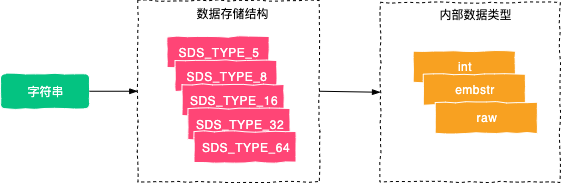
2)数据类型
我们可以使用 object encoding key 命令来查看对象(键值对)存储的数据类型,当我们使用此命令来查询 SDS 对象时,发现 SDS 对象竟然包含了三种不同的数据类型:int、embstr 和 raw。
int 类型
127.0.0.1:6379> set key 666
OK
127.0.0.1:6379> object encoding key
"int"embstr 类型
127.0.0.1:6379> set key abc
OK
127.0.0.1:6379> object encoding key
"embstr"raw 类型
127.0.0.1:6379> set key abcdefghigklmnopqrstyvwxyzabcdefghigklmnopqrs
OK
127.0.0.1:6379> object encoding key
"raw"int 类型很好理解,整数类型对应的就是 int 类型,而字符串则对应是 embstr 类型,当字符串长度大于 44 字节时,会变为 raw 类型存储。
3)为什么是 44 字节?
在 Redis 中,如果 SDS 的存储值大于 64 字节时,Redis 的内存分配器会认为此对象为大字符串,并使用 raw 类型来存储,当数据小于 64 字节时(字符串类型),会使用 embstr 类型存储。既然内存分配器的判断标准是 64 字节,那为什么 embstr 类型和 raw 类型的存储判断值是 44 字节?
这是因为 Redis 在存储对象时,会创建此对象的关联信息,redisObject 对象头和 SDS 自身属性信息,这些信息都会占用一定的存储空间,因此长度判断标准就从 64 字节变成了 44 字节。
在 Redis 中,所有的对象都会包含 redisObject 对象头。我们先来看 redisObject 对象的源码:
typedef struct redisObject {
unsigned type:4; // 4 bit
unsigned encoding:4; // 4 bit
unsigned lru:LRU_BITS; // 3 个字节
int refcount; // 4 个字节
void *ptr; // 8 个字节
} robj;它的参数说明如下:
type:对象的数据类型,例如:string、list、hash 等,占用 4 bits 也就是半个字符的大小;encoding:对象数据编码,占用 4 bits;lru:记录对象的 LRU(Least Recently Used 的缩写,即最近最少使用)信息,内存回收时会用到此属性,占用 24 bits(3 字节);refcount:引用计数器,占用 32 bits(4 字节);*ptr:对象指针用于指向具体的内容,占用 64 bits(8 字节)。
redisObject 总共占用 0.5 bytes + 0.5 bytes + 3 bytes + 4 bytes + 8 bytes = 16 bytes(字节)。
了解了 redisObject 之后,我们再来看 SDS 自身的数据结构,从 SDS 的源码可以看出,SDS 的存储类型一共有 5 种:SDS*TYPE*5、SDS*TYPE*8、SDS*TYPE*16、SDS*TYPE*32、SDS*TYPE*64,在这些类型中最小的存储类型为 SDS*TYPE*5,但 SDS*TYPE*5 类型会默认转成 SDS*TYPE*8,以下源码可以证明,如下图所示:
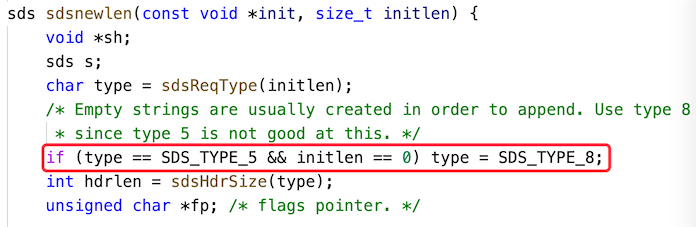
那我们直接来看 SDS*TYPE*8 的源码:
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; // 1 byte
uint8_t alloc; // 1 byte
unsigned char flags; // 1 byte
char buf[];
};可以看出除了内容数组(buf)之外,其他三个属性分别占用了 1 个字节,最终分隔字符等于 64 字节,减去 redisObject 的 16 个字节,再减去 SDS 自身的 3 个字节,再减去结束符 \0 结束符占用 1 个字节,最终的结果是 44 字节(64-16-3-1=44),内存占用如下图所示:

但 SDS 不需要用 \0 字符来标识字符串结尾,而是有个专门的 len 成员变量来记录长度,所以可存储包含 \0 的数据。但是 SDS 为了兼容部分 C 语言标准库的函数,还是会在结尾加上 \0 字符。注意:我们说 alloc 成员维护的是 buf[] 数组的长度,但是这个长度不包括结尾的 \0,比如 alloc 为 10,但 buf[] 的长度其实是 11。
5 小结
本文介绍了字符串的定义及其使用,它的使用主要分为:单键值对操作、多键值对操作、数字统计、键值对过期操作、字符串操作进阶等。同时也介绍了字符串使用的三个场景,字符串类型可用作为:页面数据缓存,可以缓存一些文章详情信息等;数字计算与统计,例如计算页面的访问次数;也可以用作 Session 共享,用来记录管理员的登录信息等。同时我们深入的介绍了字符串的五种数据存储结构,以及字符串的三种内部数据类型,如下图所示:
同时我们也知道了 embstr 类型向 raw 类型转化,是因为每个 Redis 对象都包含了一个 redisObject 对象头和 SDS 自身属性占用了一定的空间,最终导致数据类型的判断长度是 44 字节。
08 字典使用与内部实现原理
https://www.cnblogs.com/wan-ming-zhu/p/18079378
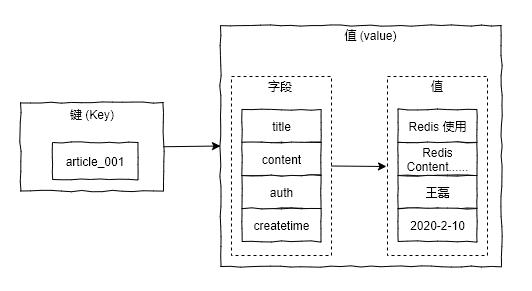
字典类型 (Hash) 又被成为散列类型或者是哈希表类型,它是将一个键值 (key) 和一个特殊的”哈希表”关联起来,这个”哈希表”表包含两列数据:字段和值。例如我们使用字典类型来存储一篇文章的详情信息,存储结构如下图所示:
同理我们也可以使用字典类型来存储用户信息,并且使用字典类型来存储此类信息,是不需要手动序列化和反序列化数据的,所以使用起来更加的方便和高效。
1.基础使用
2.代码实战
3.数据结构
字典类型本质上是由数组和链表结构组成的,来看字典类型的源码实现:
typedef struct dictEntry { // dict.h
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next; // 下一个 entry
} dictEntry;字典类型的数据结构,如下图所示:
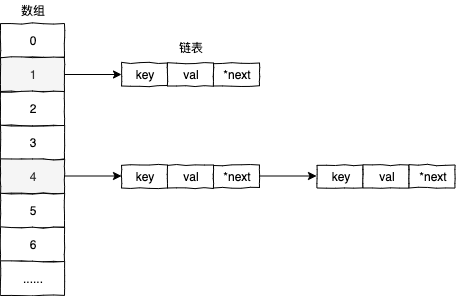
通常情况下字典类型会使用数组的方式来存储相关的数据,但发生哈希冲突时才会使用链表的结构来存储数据。
4.哈希冲突
字典类型的存储流程是先将键值进行 Hash 计算,得到存储键值对应的数组索引,再根据数组索引进行数据存储,但在小概率事件下可能会出完全不相同的键值进行 Hash 计算之后,得到相同的 Hash 值,这种情况我们称之为哈希冲突。
哈希冲突一般通过链表的形式解决,相同的哈希值会对应一个链表结构,每次有哈希冲突时,就把新的元素插入到链表的尾部,请参考上面数据结构的那张图。
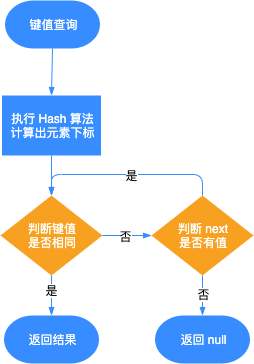
键值查询的流程如下:
- 通过算法 (Hash,计算和取余等) 操作获得数组的索引值,根据索引值找到对应的元素;
- 判断元素和查找的键值是否相等,相等则成功返回数据,否则需要查看 next 指针是否还有对应其他元素,如果没有,则返回 null,如果有的话,重复此步骤。
键值查询流程,如下图所示:
5.渐进式rehash
Redis 为了保证应用的高性能运行,提供了一个重要的机制——渐进式 rehash。 渐进式 rehash 是用来保证字典缩放效率的,也就是说在字典进行扩容或者缩容是会采取渐进式 rehash 的机制。
1)扩容
当元素数量等于数组长度时就会进行扩容操作,源码在 dict.c 文件中,核心代码如下:
int dictExpand(dict *d, unsigned long size)
{
/* 需要的容量小于当前容量,则不需要扩容 */
if (dictIsRehashing(d) || d->ht[0].used > size)
return DICT_ERR;
dictht n;
unsigned long realsize = _dictNextPower(size); // 重新计算扩容后的值
/* 计算新的扩容大小等于当前容量,不需要扩容 */
if (realsize == d->ht[0].size) return DICT_ERR;
/* 分配一个新的哈希表,并将所有指针初始化为NULL */
n.size = realsize;
n.sizemask = realsize-1;
n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = 0;
if (d->ht[0].table == NULL) {
// 第一次初始化
d->ht[0] = n;
return DICT_OK;
}
d->ht[1] = n; // 把增量输入放入新 ht[1] 中
d->rehashidx = 0; // 非默认值 -1,表示需要进行 rehash
return DICT_OK;
}从以上源码可以看出,如果需要扩容则会申请一个新的内存地址赋值给 ht[1],并把字典的 rehashindex 设置为 0,表示之后需要进行 rehash 操作。
2)缩容
当字典的使用容量不足总空间的 10% 时就会触发缩容,Redis 在进行缩容时也会把 rehashindex 设置为 0,表示之后需要进行 rehash 操作。
3)渐进式rehash流程
在进行渐进式 rehash 时,会同时保留两个 hash 结构,新键值对加入时会直接插入到新的 hash 结构中,并会把旧 hash 结构中的元素一点一点的移动到新的 hash 结构中,当移除完最后一个元素时,清空旧 hash 结构,主要的执行流程如下:
- 扩容或者缩容时把字典中的字段 rehashidx 标识为 0;
- 在执行定时任务或者执行客户端的 hset、hdel 等操作指令时,判断是否需要触发 rehash 操作(通过 rehashidx 标识判断),如果需要触发 rehash 操作,也就是调用 dictRehash 函数,dictRehash 函数会把 ht[0] 中的元素依次添加到新的 Hash 表 ht[1] 中;
- rehash 操作完成之后,清空 Hash 表 ht[0],然后对调 ht[1] 和 ht[0] 的值,把新的数据表 ht[1] 更改为 ht[0],然后把字典中的 rehashidx 标识为 -1,表示不需要执行 rehash 操作。
7.小结
本文我们学习了字典类型的操作命令和在代码中的使用,也明白了字典类型实际是由数组和链表组成的,当字典进行扩容或者缩容时会进行渐进式 rehash 操作,渐进式 rehash 是用来保证 Redis 运行效率的,它的执行流程是同时保留两个哈希表,把旧表中的元素一点一点的移动到新表中,查询的时候会先查询两个哈希表,当所有元素都移动到新的哈希表之后,就会删除旧的哈希表。
10 列表使用与内部实现原理
https://www.cnblogs.com/wan-ming-zhu/p/18078658
列表类型 (List) 是一个使用链表结构存储的有序结构,它的元素插入会按照先后顺序存储到链表结构中,因此它的元素操作 (插入\删除) 时间复杂度为 O(1),所以相对来说速度还是比较快的,但它的查询时间复杂度为 O(n),因此查询可能会比较慢。
1 基础使用
列表类型的使用相对来说比较简单,对它的操作就相当操作一个没有任何 key 值的 value 集合,如下图所示:

3 内部实现
我们先用 debug encoding key 来查看列表类型的内部存储类型,如下所示:
127.0.0.1:6379> object encoding list
"quicklist"从结果可以看出,列表类型的底层数据类型是 quicklist。
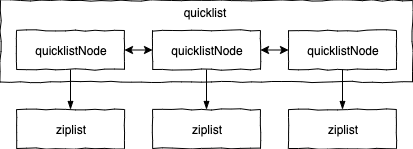
quicklist (快速列表) 是 Redis 3.2 引入的数据类型,早期的列表类型使用的是ziplist (压缩列表) 和双向链表组成的,Redis 3.2 改为用 quicklist 来存储列表元素。
我们来看下 quicklist 的实现源码:
typedef struct quicklist { // src/quicklist.h
quicklistNode *head;
quicklistNode *tail;
unsigned long count; /* ziplist 的个数 */
unsigned long len; /* quicklist 的节点数 */
unsigned int compress : 16; /* LZF 压缩算法深度 */
//...
} quicklist;
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl; /* 对应的 ziplist */
unsigned int sz; /* ziplist 字节数 */
unsigned int count : 16; /* ziplist 个数 */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* 该节点先前是否被压缩 */
unsigned int attempted_compress : 1; /* 节点太小无法压缩 */
//...
} quicklistNode;
typedef struct quicklistLZF {
unsigned int sz;
char compressed[];
} quicklistLZF;从以上源码可以看出 quicklist 是一个双向链表,链表中的每个节点实际上是一个 ziplist,它们的结构如下图所示:
ziplist 作为 quicklist 的实际存储结构,它本质是一个字节数组,ziplist 数据结构如下图所示:

其中的字段含义如下:
- zlbytes:压缩列表字节长度,占 4 字节;
- zltail:压缩列表尾元素相对于起始元素地址的偏移量,占 4 字节;
- zllen:压缩列表的元素个数;
- entryX:压缩列表存储的所有元素,可以是字节数组或者是整数;
- zlend:压缩列表的结尾,占 1 字节,固定值 0xFF;
4 源码解析
1)添加功能源码分析
quicklist 添加操作对应函数是 quicklistPush,源码如下:
void quicklistPush(quicklist *quicklist, void *value, const size_t sz,
int where) {
if (where == QUICKLIST_HEAD) {
// 在列表头部添加元素
quicklistPushHead(quicklist, value, sz);
} else if (where == QUICKLIST_TAIL) {
// 在列表尾部添加元素
quicklistPushTail(quicklist, value, sz);
}
}以 quicklistPushHead 为例,源码如下:
int quicklistPushHead(quicklist *quicklist, void *value, size_t sz) {
quicklistNode *orig_head = quicklist->head;
if (likely(
_quicklistNodeAllowInsert(quicklist->head, quicklist->fill, sz))) {
// 在头部节点插入元素
quicklist->head->zl =
ziplistPush(quicklist->head->zl, value, sz, ZIPLIST_HEAD);
quicklistNodeUpdateSz(quicklist->head);
} else {
// 头部节点不能继续插入,需要新建 quicklistNode、ziplist 进行插入
quicklistNode *node = quicklistCreateNode();
node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_HEAD);
quicklistNodeUpdateSz(node);
// 将新建的 quicklistNode 插入到 quicklist 结构中
_quicklistInsertNodeBefore(quicklist, quicklist->head, node);
}
quicklist->count++;
quicklist->head->count++;
return (orig_head != quicklist->head);
}quicklistPushHead 函数的执行流程,先判断 quicklist 的 head 节点是否可以插入数据,如果可以插入则使用 ziplist 的接口进行插入,否则就新建 quicklistNode 节点进行插入。
函数的入参是待插入的 quicklist,还有需要插入的值 value 以及他的大小 sz。
函数的返回值为 int,0 表示没有新建 head,1 表示新建了 head。
2)删除功能源码分析
quicklist 元素删除分为两种情况:单一元素删除和区间元素删除,它们都位于 src/quicklist.c 文件中。
单一元素删除
单一元素的删除函数是 quicklistDelEntry,源码如下:
void quicklistDelEntry(quicklistIter *iter, quicklistEntry *entry) {
quicklistNode *prev = entry->node->prev;
quicklistNode *next = entry->node->next;
// 删除指定位置的元素
int deleted_node = quicklistDelIndex((quicklist *)entry->quicklist,
entry->node, &entry->zi);
//...
}可以看出 quicklistDelEntry 函数的底层,依赖 quicklistDelIndex 函数进行元素删除。
区间元素删除
区间元素删除的函数是 quicklistDelRange,源码如下:
// start 表示开始删除的下标,count 表示要删除的个数
int quicklistDelRange(quicklist *quicklist, const long start,
const long count) {
if (count <= 0)
return 0;
unsigned long extent = count;
if (start >= 0 && extent > (quicklist->count - start)) {
// 删除的元素个数大于已有元素
extent = quicklist->count - start;
} else if (start < 0 && extent > (unsigned long)(-start)) {
// 删除指定的元素个数
extent = -start; /* c.f. LREM -29 29; just delete until end. */
}
//...
// extent 为剩余需要删除的元素个数,
while (extent) {
// 保存下个 quicklistNode,因为本节点可能会被删除
quicklistNode *next = node->next;
unsigned long del;
int delete_entire_node = 0;
if (entry.offset == 0 && extent >= node->count) {
// 删除整个 quicklistNode
delete_entire_node = 1;
del = node->count;
} else if (entry.offset >= 0 && extent >= node->count) {
// 删除本节点的所有元素
del = node->count - entry.offset;
} else if (entry.offset < 0) {
// entry.offset<0 表示从后向前,相反则表示从前向后剩余的元素个数
del = -entry.offset;
if (del > extent)
del = extent;
} else {
// 删除本节点部分元素
del = extent;
}
D("[%ld]: asking to del: %ld because offset: %d; (ENTIRE NODE: %d), "
"node count: %u",
extent, del, entry.offset, delete_entire_node, node->count);
if (delete_entire_node) {
__quicklistDelNode(quicklist, node);
} else {
quicklistDecompressNodeForUse(node);
node->zl = ziplistDeleteRange(node->zl, entry.offset, del);
quicklistNodeUpdateSz(node);
node->count -= del;
quicklist->count -= del;
quicklistDeleteIfEmpty(quicklist, node);
if (node)
quicklistRecompressOnly(quicklist, node);
}
// 剩余待删除元素的个数
extent -= del;
// 下个 quicklistNode
node = next;
// 从下个 quicklistNode 起始位置开始删除
entry.offset = 0;
}
return 1;
}从上面代码可以看出,quicklist 在区间删除时,会先找到 start 所在的 quicklistNode,计算删除的元素是否小于要删除的 count,如果不满足删除的个数,则会移动至下一个 quicklistNode 继续删除,依次循环直到删除完成为止。
quicklistDelRange 函数的返回值为 int 类型,当返回 1 时表示成功的删除了指定区间的元素,返回 0 时表示没有删除任何元素。
3)更多源码
除了上面介绍的几个常用函数之外,还有一些更多的函数,例如:
- quicklistCreate:创建 quicklist;
- quicklistInsertAfter:在某个元素的后面添加数据;
- quicklistInsertBefore:在某个元素的前面添加数据;
- quicklistPop:取出并删除列表的第一个或最后一个元素;
- quicklistReplaceAtIndex:替换某个元素。
6 小结
通过本文我们可以知道列表类型并不是简单的双向链表,而是采用了 quicklist 的数据结构对数据进行存取,quicklist 是 Redis 3.2 新增的数据类型,它的底层采取的是压缩列表加双向链表的存储结构,quicklist 为了存储更多的数据,会对每个 quicklistNode 节点进行压缩,这样就可以有效的存储更多的消息队列或者文章的数据了。
12 集合使用与内部实现原理
https://www.cnblogs.com/wan-ming-zhu/p/18079410
集合类型 (Set) 是一个无序并唯一的键值集合。
之所以说集合类型是一个无序集合,是因为它的存储顺序不会按照插入的先后顺序进行存储,如下代码所示:
127.0.0.1:6379> sadd myset v2 v1 v3 #插入数据 v2、v1、v3
(integer) 3
127.0.0.1:6379> smembers myset #查询数据
1) "v1"
2) "v3"
3) "v2"从上面代码执行结果可以看出,myset 的存储顺序并不是以插入的先后顺序进行存储的。
集合类型和列表类型的区别如下:
- 列表可以存储重复元素,集合只能存储非重复元素;
- 列表是按照元素的先后顺序存储元素的,而集合则是无序方式存储元素的。
3 内部实现
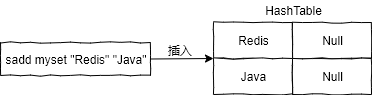
集合类型是由 intset (整数集合) 或 hashtable (普通哈希表) 组成的。当集合类型以 hashtable 存储时,哈希表的 key 为要插入的元素值,而哈希表的 value 则为 Null,如下图所示:
当集合中所有的值都为整数时,Redis 会使用 intset 结构来存储,如下代码所示:
127.0.0.1:6379> sadd myset 1 9 3 -2
(integer) 4
127.0.0.1:6379> object encoding myset
"intset"从上面代码可以看出,当所有元素都为整数时,集合会以 intset 结构进行(数据)存储。 当发生以下两种情况时,会导致集合类型使用 hashtable 而非 intset 存储:
- 当元素的个数超过一定数量时,默认是 512 个,该值可通过命令
set-max-intset-entries xxx来配置。 当元素为非整数时,集合将会使用 hashtable 来存储,如下代码所示:
127.0.0.1:6379> sadd myht "redis" "db" (integer) 2 127.0.0.1:6379> object encoding myht "hashtable"从上面代码可以看出,当元素为非整数时,集合会使用 hashtable 进行存储。
4 源码解析
集合源码在 t_set.c 文件中,核心源码如下:
/*
* 添加元素到集合
* 如果当前值已经存在,则返回 0 不作任何处理,否则就添加该元素,并返回 1。
*/
int setTypeAdd(robj *subject, sds value) {
long long llval;
if (subject->encoding == OBJ_ENCODING_HT) { // 字典类型
dict *ht = subject->ptr;
dictEntry *de = dictAddRaw(ht,value,NULL);
if (de) {
// 把 value 作为字典到 key,将 Null 作为字典到 value,将元素存入到字典
dictSetKey(ht,de,sdsdup(value));
dictSetVal(ht,de,NULL);
return 1;
}
} else if (subject->encoding == OBJ_ENCODING_INTSET) { // inset 数据类型
if (isSdsRepresentableAsLongLong(value,&llval) == C_OK) {
uint8_t success = 0;
subject->ptr = intsetAdd(subject->ptr,llval,&success);
if (success) {
// 超过 inset 的最大存储数量,则使用字典类型存储
if (intsetLen(subject->ptr) > server.set_max_intset_entries)
setTypeConvert(subject,OBJ_ENCODING_HT);
return 1;
}
} else {
// 转化为整数类型失败,使用字典类型存储
setTypeConvert(subject,OBJ_ENCODING_HT);
serverAssert(dictAdd(subject->ptr,sdsdup(value),NULL) == DICT_OK);
return 1;
}
} else {
// 未知编码(类型)
serverPanic("Unknown set encoding");
}
return 0;
}以上这些代码验证了,我们上面所说的内容,当元素都为整数并且元素的个数没有到达设置的最大值时,键值的存储使用的是 intset 的数据结构,反之到元素超过了一定的范围,又或者是存储的元素为非整数时,集合会选择使用 hashtable 的数据结构进行存储。
14 有序集合使用与内部实现原理
有序集合类型 (Sorted Set) 相比于集合类型多了一个排序属性 score(分值),对于有序集合 ZSet 来说,每个存储元素相当于有两个值组成的,一个是有序结合的元素值,一个是排序值。有序集合的存储元素值也是不能重复的,但分值是可以重复的。
3 内部实现
有序集合是由 ziplist (压缩列表) 或 skiplist (跳跃表) 组成的。
1)ziplist
当数据比较少时,有序集合使用的是 ziplist 存储的,如下代码所示:
127.0.0.1:6379> zadd myzset 1 db 2 redis 3 mysql
(integer) 3
127.0.0.1:6379> object encoding myzset
"ziplist"从结果可以看出,有序集合把 myset 键值对存储在 ziplist 结构中了。 有序集合使用 ziplist 格式存储必须满足以下两个条件:
- 有序集合保存的元素个数要小于 128 个;
- 有序集合保存的所有元素成员的长度都必须小于 64 字节。
如果不能满足以上两个条件中的任意一个,有序集合将会使用 skiplist 结构进行存储。 接下来我们来测试以下,当有序集合中某个元素长度大于 64 字节时会发生什么情况? 代码如下:
127.0.0.1:6379> zadd zmaxleng 1.0 redis
(integer) 1
127.0.0.1:6379> object encoding zmaxleng
"ziplist"
127.0.0.1:6379> zadd zmaxleng 2.0 aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
(integer) 1
127.0.0.1:6379> object encoding zmaxleng
"skiplist"通过以上代码可以看出,当有序集合保存的所有元素成员的长度大于 64 字节时,有序集合就会从 ziplist 转换成为 skiplist。
小贴士:可以通过配置文件中的
zset-max-ziplist-entries(默认 128)和zset-max-ziplist-value(默认 64)来设置有序集合使用 ziplist 存储的临界值。
2)skiplist
skiplist 数据编码底层是使用 zset 结构实现的,而 zset 结构中包含了一个字典和一个跳跃表,源码如下:
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;更多关于跳跃表的源码实现,会在后面的章节详细介绍。
注意:虽然查看结构时显示的是 skiplist,但它除了使用跳表之外,还使用了哈希表。所以有序集合比较特殊,它是唯一同时使用两种数据结构的类型。这样的好处是既能进行高效的范围查询,也能进行高效的单点查询。
跳跃表实现原理
跳跃表的结构如下图所示:
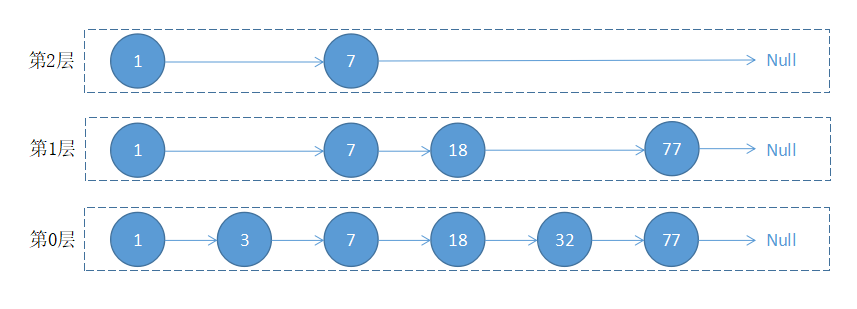
根据以上图片展示,当我们在跳跃表中查询值 32 时,执行流程如下:
- 从最上层开始找,1 比 32 小,在当前层移动到下一个节点进行比较;
- 7 比 32 小,当前层移动下一个节点比较,由于下一个节点指向 Null,所以以 7 为目标,移动到下一层继续向后比较;
- 18 小于 32,继续向后移动查找,对比 77 大于 32,以 18 为目标,移动到下一层继续向后比较;
- 对比 32 等于 32,值被顺利找到。
从上面的流程可以看出,跳跃表会想从最上层开始找起,依次向后查找,如果本层的节点大于要找的值,或者本层的节点为 Null 时,以上一个节点为目标,往下移一层继续向后查找并循环此流程,直到找到该节点并返回,如果对比到最后一个元素仍未找到,则返回 Null。
为什么是跳跃表?而非红黑树?
因为跳跃表的性能和红黑树基本相近,但却比红黑树更好实现,所有 Redis 的有序集合会选用跳跃表来实现存储。
16 Redis 事务深入解析
https://www.cnblogs.com/wan-ming-zhu/p/18079959
前言
事务指的是提供一种将多个命令打包,一次性按顺序地执行的机制,并且保证服务器只有在执行完事务中的所有命令后,才会继续处理此客户端的其他命令。
事务也是其他关系型数据库所必备的基础功能,以支付的场景为例,正常情况下只有正常消费完成之后,才会减去账户余额。但如果没有事务的保障,可能会发生消费失败了,但依旧会把账户的余额给扣减了,我想这种情况应该任何人都无法接受吧?所以事务是数据库中一项非常重要的基础功能。
事务基本使用
Redis 中的事务从开始到结束也是要经历三个阶段:
- 开启事务
- 命令入列
- 执行事务/放弃事务
其中,开启事务使用 multi 命令,事务执行使用 exec 命令,放弃事务使用 discard 命令。
开启事务
multi 命令用于开启事务,实现代码如下:
> multi
OKmulti 命令可以让客户端从非事务模式状态,变为事务模式状态,如下图所示:
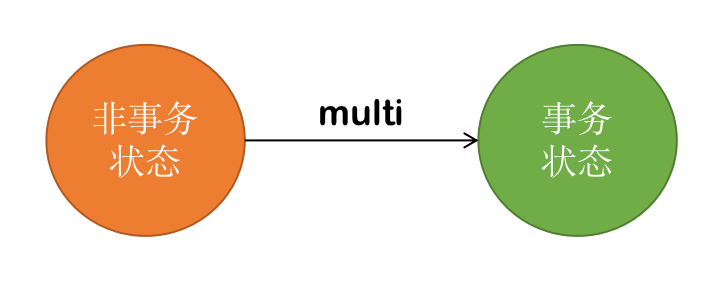
注意:multi 命令不能嵌套使用,如果已经开启了事务的情况下,再执行 multi 命令,会提示如下错误:
127.0.0.1:6379> multi
OK
127.0.0.1:6379> multi
(error) ERR MULTI calls can not be nested命令入列
客户端进入事务状态之后,执行的所有常规 Redis 操作命令(非触发事务执行或放弃和导致入列异常的命令)会依次入列,命令入列成功后会返回 QUEUED,如下代码所示:
> multi
OK
> set k v
QUEUED
> get k
QUEUED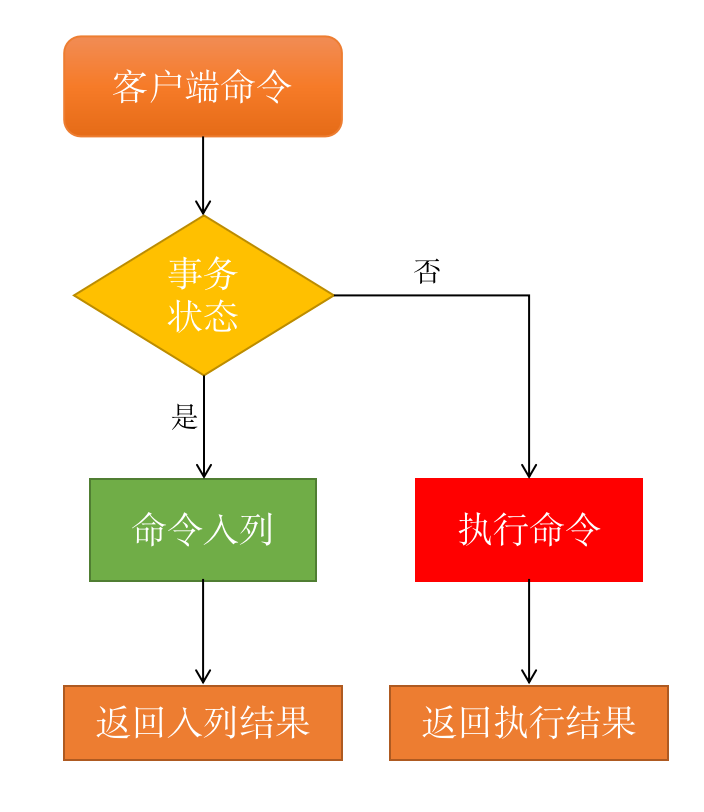
注意:命令会按照先进先出(FIFO)的顺序出入列,也就是说事务会按照命令的入列顺序,从前往后依次执行。
执行事务/放弃事务
执行事务的命令是 exec,放弃事务的命令是 discard。
执行事务示例代码如下:
> multi
OK
> set k v2
QUEUED
> exec
1) OK
> get k
"v2"放弃事务示例代码如下:
> multi
OK
> set k v3
QUEUED
> discard
OK
> get k
"v2"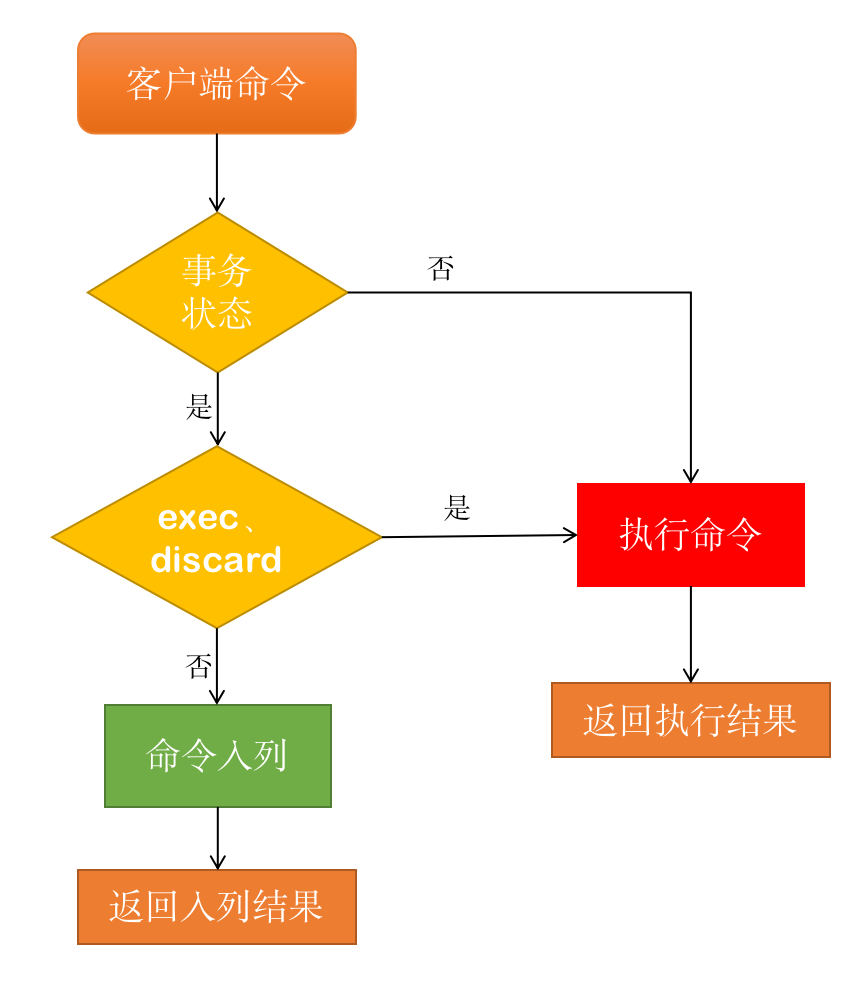
事务错误&回滚
事务执行中的错误分为以下三类:
- 执行时才会出现的错误(简称:执行时错误);
- 入列时错误,不会终止整个事务;
- 入列时错误,会终止整个事务。
执行时错误
示例代码如下:
> get k
"v"
> multi
OK
> set k v2
QUEUED
> expire k 10s
QUEUED
> exec
1) OK
2) (error) ERR value is not an integer or out of range
> get k
"v2"执行命令解释如下图所示:

从以上结果可以看出,即使事务队列中某个命令在执行期间发生了错误,事务也会继续执行,直到事务队列中所有命令执行完成。
入列错误不会导致事务结束
示例代码如下:
> get k
"v"
> multi
OK
> set k v2
QUEUED
> multi
(error) ERR MULTI calls can not be nested
> exec
1) OK
> get k
"v2"执行命令解释如下图所示:
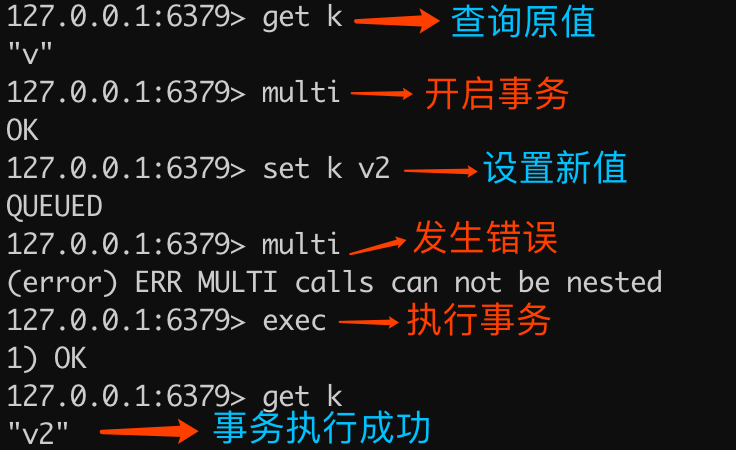
可以看出,重复执行 multi 会导致入列错误,但不会终止事务,最终查询的结果是事务执行成功了。除了重复执行 multi 命令,还有在事务状态下执行 watch 也是同样的效果,下文会详细讲解关于 watch 的内容。
入列错误导致事务结束
示例代码如下:
> get k
"v2"
> multi
OK
> set k v3
QUEUED
> set k
(error) ERR wrong number of arguments for 'set' command
> exec
(error) EXECABORT Transaction discarded because of previous errors.
> get k
"v2"执行命令解释如下图所示:

所以我们看到错误可以分为两种:一种是事务执行时才会发现的错误;另一种是在入队的时候就能发现的错误。
- 执行时出现的错误,不会影响事务队列中的其它命令;即使某条命令失败,其它命令依旧可以正常执行;
- 入队时发现的错误,如果是 multi、watch 这种错误也不会终止事务,只是不会让它入队;但如果是命令不符合 Redis 的规则,那么这种错误就类似于编程语言的语法错误,直接编译时就报错,没必要等到执行了。所以在 Redis 中的表现就是整个事务都废弃掉,里面的命令一条也不会执行;
为什么不支持事务回滚?
Redis 官方文档的解释如下:
If you have a relational databases background, the fact that Redis commands can fail during a transaction, but still Redis will execute the rest of the transaction instead of rolling back, may look odd to you.
However there are good opinions for this behavior:
- Redis commands can fail only if called with a wrong syntax (and the problem is not detectable during the command queueing), or against keys holding the wrong data type: this means that in practical terms a failing command is the result of a programming errors, and a kind of error that is very likely to be detected during development, and not in production.
- Redis is internally simplified and faster because it does not need the ability to roll back.
An argument against Redis point of view is that bugs happen, however it should be noted that in general the roll back does not save you from programming errors. For instance if a query increments a key by 2 instead of 1, or increments the wrong key, there is no way for a rollback mechanism to help. Given that no one can save the programmer from his or her errors, and that the kind of errors required for a Redis command to fail are unlikely to enter in production, we selected the simpler and faster approach of not supporting roll backs on errors.
大概的意思是,作者不支持事务回滚的原因有以下两个:
- 他认为 Redis 事务的执行时,错误通常都是编程错误造成的,这种错误通常只会出现在开发环境中,而很少会在实际的生产环境中出现,所以他认为没有必要为 Redis 开发事务回滚功能;
- 不支持事务回滚是因为这种复杂的功能和 Redis 追求的简单高效的设计主旨不符合。
这里不支持事务回滚,指的是不支持运行时错误的事务回滚。
监控
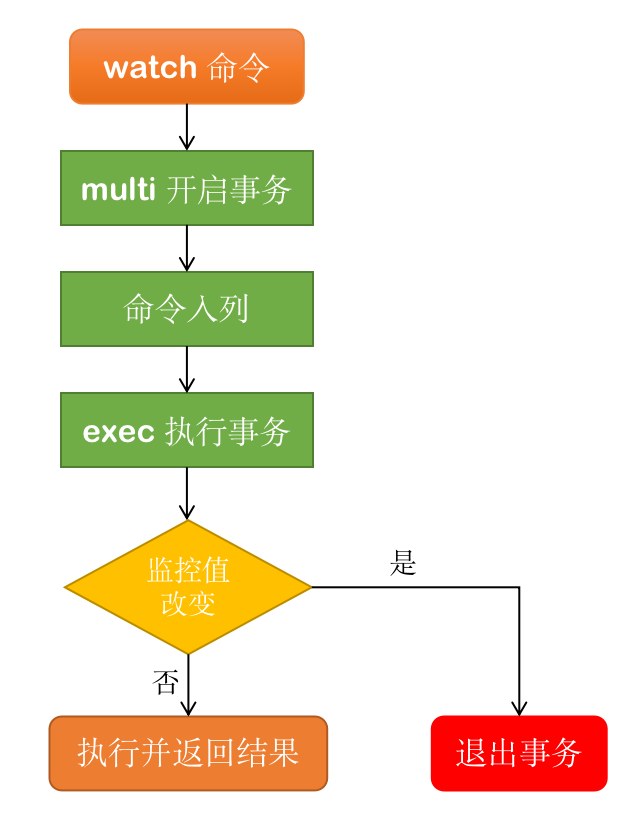
watch 命令用于客户端并发情况下,为事务提供一个乐观锁(CAS,Check And Set),也就是可以用 watch 命令来监控一个或多个变量,如果在事务的过程中,某个监控项被修改了,那么整个事务就会终止执行。
watch 基本语法如下:
watch key [key ...]watch 示例代码如下:
> watch k
OK
> multi
OK
> set k v2
QUEUED
> exec
(nil)
> get k
"v"注意:以上事务在执行期间,也就是开启事务(multi)之后,执行事务(exec)之前,模拟多客户端并发操作了变量 k 的值,这个时候再去执行事务,才会出现如上结果,exec 执行的结果为 nil。
可以看出,当执行 exec 返回的结果是 nil 时,表示 watch 监控的对象在事务执行的过程中被修改了。从 get k 的结果也可以印证,因为事务中设置的值 set k v2 并未正常执行。
执行流程如下图所示:
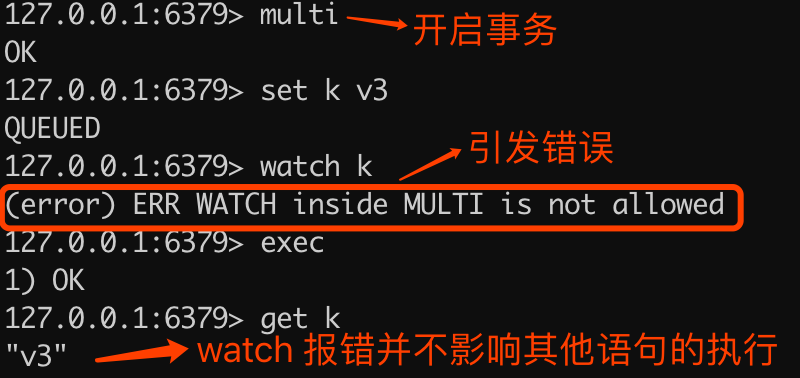
注意: watch 命令只能在客户端开启事务之前执行,在事务中执行 watch 命令会引发错误,但不会造成整个事务失败,如下代码所示:
> multi
OK
> set k v3
QUEUED
> watch k
(error) ERR WATCH inside MULTI is not allowed
> exec
1) OK
> get k
"v3"执行命令解释如下图所示:
一个 watch 对应一个事务,watch 之后只要执行了事务,不管里面的命令是成功还是失败,这个 watch 就算是结束了。再次开启事务,设置的 key 就是不被监视的 key 了。
unwatch 命令用于清除所有之前监控的所有对象(键值对)。
unwatch 示例如下所示:
> set k v
OK
> watch k
OK
> multi
OK
> unwatch
QUEUED
> set k v2
QUEUED
> exec
1) OK
2) OK
> get k
"v2"可以看出,即使在事务的执行过程中,k 值被修改了,因为调用了 unwatch 命令,整个事务依然会顺利执行。
知识点练习
以下两个客户端交替执行的结果是?
客户端一,执行如下命令:
> set k v
OK
> watch k
OK
> multi
OK
> set k v2
QUEUED客户端二,执行如下命令:
> set k v
OK客户端一,再执行如下命令:
> exec此时 k 的值为多少?
答: k 的值为 v,而非 v2。
题目解析:本题考查的是 watch 命令监控时,即使把原对象的值重新赋值给了原对象,这个时候 watch 命令也会认为监控对象还是被修改了。
小结
事务为多个命令提供一次性按顺序执行的机制,与 Redis 事务相关的命令有以下五个:
- multi:开启事务
- exec:执行事务
- discard:丢弃事务
- watch:为事务提供乐观锁实现
- unwatch:取消监控(取消事务中的乐观锁)
正常情况下 Redis 事务分为三个阶段:开启事务、命令入列、执行事务。Redis 事务并不支持运行时错误的事务回滚,但在某些入列错误,如 set key 或者是 watch 监控项被修改时,提供整个事务回滚的功能。
17 Redis 键值过期操作
过期设置
Redis 中设置过期时间主要通过以下四种方式:
expire key seconds:设置 key 在 n 秒后过期;pexpire key milliseconds:设置 key 在 n 毫秒后过期;expireat key timestamp:设置 key 在某个时间戳(精确到秒)之后过期;pexpireat key millisecondsTimestamp:设置 key 在某个时间戳(精确到毫秒)之后过期;
字符串中的过期操作
字符串中几个直接操作过期时间的方法,如下列表:
set key value ex seconds:设置键值对的同时指定过期时间(精确到秒);
-set key value px milliseconds:设置键值对的同时指定过期时间(精确到毫秒);setex key seconds valule:设置键值对的同时指定过期时间(精确到秒)。
移除过期时间
使用命令: persist key 可以移除键值的过期时间。
持久化中的过期键
Redis 持久化文件有两种格式:RDB(Redis Database)和 AOF(Append Only File),下面我们分别来看过期键在这两种格式中的呈现状态。
RDB 中的过期键
RDB 文件分为两个阶段,RDB 文件生成阶段和加载阶段。
1. RDB 文件生成
从内存状态持久化成 RDB(文件)的时候,会对 key 进行过期检查,过期的键不会被保存到新的 RDB 文件中,因此 Redis 中的过期键不会对生成新 RDB 文件产生任何影响。
2. RDB 文件加载
RDB 加载分为以下两种情况:
- 如果 Redis 是主服务器运行模式的话,在载入 RDB 文件时,程序会对文件中保存的键进行检查,过期键不会被载入到数据库中。所以过期键不会对载入 RDB 文件的主服务器造成影响;
- 如果 Redis 是从服务器运行模式的话,在载入 RDB 文件时,不论键是否过期都会被载入到数据库中。但由于主从服务器在进行数据同步时,从服务器的数据会被清空。所以一般来说,过期键对载入 RDB 文件的从服务器也不会造成影响。
RDB 文件加载的源码可以在 rdb.c 文件的 rdbLoad() 函数中找到,源码所示:
/* Check if the key already expired. This function is used when loading
* an RDB file from disk, either at startup, or when an RDB was
* received from the master. In the latter case, the master is
* responsible for key expiry. If we would expire keys here, the
* snapshot taken by the master may not be reflected on the slave.
*
* 如果服务器为主节点的话,
* 那么在键已经过期的时候,不再将它们关联到数据库中去
*/
if (server.masterhost == NULL && expiretime != -1 && expiretime < now) {
decrRefCount(key);
decrRefCount(val);
// 跳过
continue;
}AOF 中的过期键
1. AOF 文件写入
当 Redis 以 AOF 模式持久化时,如果数据库某个过期键还没被删除,那么 AOF 文件会保留此过期键,当此过期键被删除后,Redis 会向 AOF 文件追加一条 DEL 命令来显式地删除该键值。
2. AOF 重写
执行 AOF 重写时,会对 Redis 中的键值对进行检查已过期的键不会被保存到重写后的 AOF 文件中,因此不会对 AOF 重写造成任何影响。
主从库的过期键
当 Redis 运行在主从模式下时,从库不会进行过期扫描,从库对过期的处理是被动的。也就是即使从库中的 key 过期了,如果有客户端访问从库时,依然可以得到 key 对应的值,像未过期的键值对一样返回。
从库的过期键处理依靠主服务器控制,主库在 key 到期时,会在 AOF 文件里增加一条 del 指令,同步到所有的从库,从库通过执行这条 del 指令来删除过期的 key。
小结
18 Redis 过期策略与源码分析
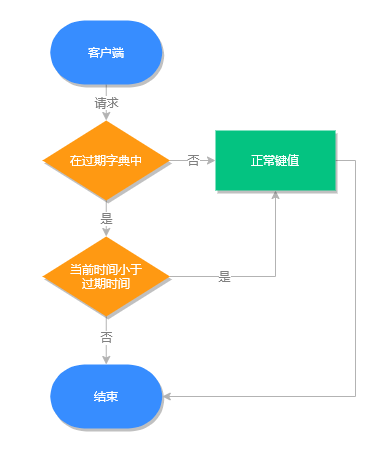
过期键执行流程
Redis 之所以能知道那些键值过期,是因为在 Redis 中维护了一个字典,存储了所有设置了过期时间的键值,我们称之为过期字典。
过期键判断流程如下图所示:
过期键源码分析
过期键存储在 redisDb 结构中,源代码在 src/server.h 文件中
/* Redis database representation. There are multiple databases identified
* by integers from 0 (the default database) up to the max configured
* database. The database number is the 'id' field in the structure. */
typedef struct redisDb {
dict *dict; /* 数据库键空间,存放着所有的键值对 */
dict *expires; /* 键的过期时间 */
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP)*/
dict *ready_keys; /* Blocked keys that received a PUSH */
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */
int id; /* Database ID */
long long avg_ttl; /* Average TTL, just for stats */
list *defrag_later; /* List of key names to attempt to defrag one by one, gradually. */
} redisDb;小贴士:本文的所有源码都是基于 Redis 5。
过期策略
Redis 会删除已过期的键值,以此来减少 Redis 的空间占用,但因为 Redis 本身是单线的,如果因为删除操作而影响主业务的执行就得不偿失了,为此 Redis 需要制定多个(过期)删除策略来保证糟糕的事情不会发生。
常见的过期策略有以下几种:
- 惰性删除
- 定期删除
下面分别来看每种策略有何不同。
惰性删除
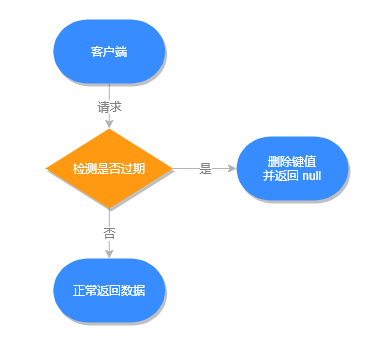
不主动删除过期键,每次从数据库获取键值时判断是否过期,如果过期则删除键值,并返回 null。
- 优点:因为每次访问时,才会判断过期键,所以此策略只会使用很少的系统资源。
- 缺点:系统占用空间删除不及时,导致空间利用率降低,造成了一定的空间浪费。
源码解析
惰性删除的源码位于 src/db.c 文件的 expireIfNeeded 方法中,源码如下:
int expireIfNeeded(redisDb *db, robj *key) {
// 判断键是否过期
if (!keyIsExpired(db,key)) return 0;
if (server.masterhost != NULL) return 1;
/* 删除过期键 */
// 增加过期键个数
server.stat_expiredkeys++;
// 传播键过期的消息
propagateExpire(db,key,server.lazyfree_lazy_expire);
notifyKeyspaceEvent(NOTIFY_EXPIRED,
"expired",key,db->id);
// server.lazyfree_lazy_expire 为 1 表示异步删除(懒空间释放),反之同步删除
return server.lazyfree_lazy_expire ? dbAsyncDelete(db,key) :
dbSyncDelete(db,key);
}
// 判断键是否过期
int keyIsExpired(redisDb *db, robj *key) {
mstime_t when = getExpire(db,key);
if (when < 0) return 0; /* No expire for this key */
/* Don't expire anything while loading. It will be done later. */
if (server.loading) return 0;
mstime_t now = server.lua_caller ? server.lua_time_start : mstime();
return now > when;
}
// 获取键的过期时间
long long getExpire(redisDb *db, robj *key) {
dictEntry *de;
/* No expire? return ASAP */
if (dictSize(db->expires) == 0 ||
(de = dictFind(db->expires,key->ptr)) == NULL) return -1;
/* The entry was found in the expire dict, this means it should also
* be present in the main dict (safety check). */
serverAssertWithInfo(NULL,key,dictFind(db->dict,key->ptr) != NULL);
return dictGetSignedIntegerVal(de);
}所有对数据库的读写命令在执行之前,都会调用 expireIfNeeded 方法判断键值是否过期,过期则会从数据库中删除,反之则不做任何处理。
惰性删除执行流程,如下图所示:
定期删除
每隔一段时间检查一次数据库,随机删除一些过期键。
Redis 默认每秒进行 10 次过期扫描,此配置可通过 Redis 的配置文件 redis.conf 进行配置,配置键为 hz 它的默认值是 hz 10。
需要注意的是:Redis 每次扫描并不是遍历过期字典中的所有键,而是采用随机抽取判断并删除过期键的形式执行的。
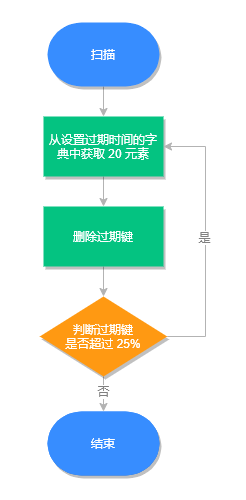
定期删除流程
- 从过期字典中随机取出 20 个键;
- 删除这 20 个键中过期的键;
- 如果过期 key 的比例超过 25%,重复步骤 1。
同时为了保证过期扫描不会出现循环过度,导致线程卡死现象,算法还增加了扫描时间的上限,默认不会超过 25ms。
定期删除执行流程,如下图所示:
- 优点:通过限制删除操作的时长和频率,来减少删除操作对 Redis 主业务的影响,同时也能删除一部分过期的数据减少了过期键对空间的无效占用。
- 缺点:内存清理方面没有定时删除效果好,同时没有惰性删除使用的系统资源少。
源码解析
定期删除的核心源码在 src/expire.c 文件下的 activeExpireCycle 方法中,源码如下:
void activeExpireCycle(int type) {
static unsigned int current_db = 0; /* 上次定期删除遍历到的数据库ID */
static int timelimit_exit = 0; /* Time limit hit in previous call? */
static long long last_fast_cycle = 0; /* 上一次执行快速定期删除的时间点 */
int j, iteration = 0;
int dbs_per_call = CRON_DBS_PER_CALL; // 每次定期删除,遍历的数据库的数量
long long start = ustime(), timelimit, elapsed;
if (clientsArePaused()) return;
if (type == ACTIVE_EXPIRE_CYCLE_FAST) {
if (!timelimit_exit) return;
// ACTIVE_EXPIRE_CYCLE_FAST_DURATION 是快速定期删除的执行时长
if (start < last_fast_cycle + ACTIVE_EXPIRE_CYCLE_FAST_DURATION*2) return;
last_fast_cycle = start;
}
if (dbs_per_call > server.dbnum || timelimit_exit)
dbs_per_call = server.dbnum;
// 慢速定期删除的执行时长
timelimit = 1000000*ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC/server.hz/100;
timelimit_exit = 0;
if (timelimit <= 0) timelimit = 1;
if (type == ACTIVE_EXPIRE_CYCLE_FAST)
timelimit = ACTIVE_EXPIRE_CYCLE_FAST_DURATION; /* 删除操作的执行时长 */
long total_sampled = 0;
long total_expired = 0;
for (j = 0; j < dbs_per_call && timelimit_exit == 0; j++) {
int expired;
redisDb *db = server.db+(current_db % server.dbnum);
current_db++;
do {
// .......
expired = 0;
ttl_sum = 0;
ttl_samples = 0;
// 每个数据库中检查的键的数量
if (num > ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP)
num = ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP;
// 从数据库中随机选取 num 个键进行检查
while (num--) {
dictEntry *de;
long long ttl;
if ((de = dictGetRandomKey(db->expires)) == NULL) break;
ttl = dictGetSignedInteger
// 过期检查,并对过期键进行删除
if (activeExpireCycleTryExpire(db,de,now)) expired++;
if (ttl > 0) {
/* We want the average TTL of keys yet not expired. */
ttl_sum += ttl;
ttl_samples++;
}
total_sampled++;
}
total_expired += expired;
if (ttl_samples) {
long long avg_ttl = ttl_sum/ttl_samples;
if (db->avg_ttl == 0) db->avg_ttl = avg_ttl;
db->avg_ttl = (db->avg_ttl/50)*49 + (avg_ttl/50);
}
if ((iteration & 0xf) == 0) { /* check once every 16 iterations. */
elapsed = ustime()-start;
if (elapsed > timelimit) {
timelimit_exit = 1;
server.stat_expired_time_cap_reached_count++;
break;
}
}
/* 每次检查只删除 ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP/4 个过期键 */
} while (expired > ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP/4);
}
// .......
}activeExpireCycle 方法在规定的时间,分多次遍历各个数据库,从过期字典中随机检查一部分过期键的过期时间,删除其中的过期键。
这个函数有两种执行模式,一个是快速模式一个是慢速模式,体现是代码中的 timelimit 变量,这个变量是用来约束此函数的运行时间的。
快速模式下 timelimit 的值是固定的,等于预定义常量 ACTIVE_EXPIRE_CYCLE_FAST_DURATION,慢速模式下,这个变量的值是通过 1000000*ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC/server.hz/100 计算的。
Redis 使用的过期策略
Redis 使用的是惰性删除加定期删除的过期策略。
19 Redis 管道技术——Pipeline
https://www.cnblogs.com/wan-ming-zhu/p/18079991
管道技术(Pipeline)是客户端提供的一种批处理技术,用于一次处理多个 Redis 命令,从而提高整个交互的性能。
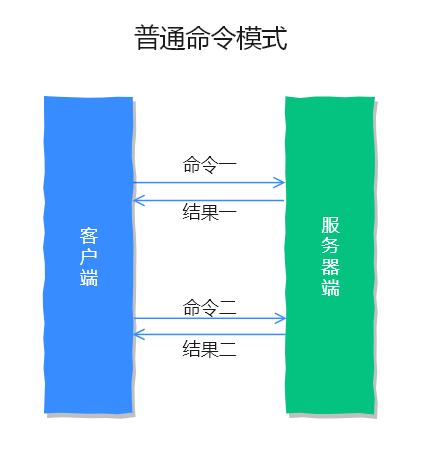
通常情况下 Redis 是单行执行的,客户端先向服务器发送请求,服务端接收并处理请求后再把结果返回给客户端,这种处理模式在非频繁请求时不会有任何问题。
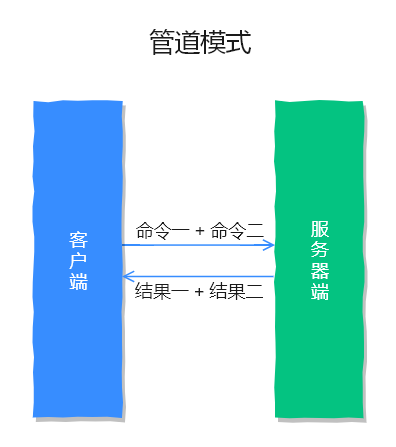
但如果出现集中大批量的请求时,因为每个请求都要经历先请求再响应的过程,这就会造成网络资源浪费,此时就需要管道技术来把所有的命令整合一次发给服务端,再一次响应给客户端,这样就能大大的提升了 Redis 的响应速度。
普通命令模式,如下图所示:
管道模式,如下图所示:
小贴士:管道中命令越多,管道技术的作用就更大,相比于普通模式来说执行效率就越高。
管道技术解决了什么问题?
管道技术解决了多个命令集中请求时造成网络资源浪费的问题,加快了 Redis 的响应速度,让 Redis 拥有更高的运行速度。但要注意的一点是,管道技术本质上是客户端提供的功能,而非 Redis 服务器端的功能。
管道技术需要注意的事项
管道技术虽然有它的优势,但在使用时还需注意以下几个细节:
- 发送的命令数量不会被限制,但输入缓存区也就是命令的最大存储体积为 1GB,当发送的命令超过此限制时,命令不会被执行,并且会被 Redis 服务器端断开此链接;
- 如果管道的数据过多可能会导致客户端的等待时间过长,导致网络阻塞;
- 部分客户端自己本身也有缓存区大小的设置,如果管道命令没有没执行或者是执行不完整,可以排查此情况或较少管道内的命令重新尝试执行。
20 查询附近的人——GEO
Redis 在 3.2 版本中增加了 GEO 类型用于存储和查询地理位置,关于 GEO 的命令不多,主要包含以下 6 个:
- geoadd:添加地理位置
- geopos:查询位置信息
- geodist:距离统计
- georadius:查询某位置内的其他成员信息
- geohash:查询位置的哈希值
- zrem:删除地理位置
小结
GEO 是 Redis 3.2 版本中新增的功能,只有升级到 3.2+ 才能使用,GEO 本质上是基于 ZSet 实现的,这点在 Redis 源码找到相关信息,我们可以 GEO 使用实现查找附近的人或者附近的地点,还可以用它来计算两个位置相隔的直线距离。
21 游标迭代器(过滤器)——Scan
https://www.cnblogs.com/wan-ming-zhu/p/18080118
Redis 2.8 时推出了 Scan。
官方文档地址:https://redis.io/commands/scan
翻译为中文的含义是:Scan 及它的相关命令可以保证以下查询规则。
- 它可以完整返回开始到结束检索集合中出现的所有元素,也就是在整个查询过程中如果这些元素没有被删除,且符合检索条件,则一定会被查询出来;
- 它可以保证不会查询出,在开始检索之前删除的那些元素。
然后,Scan 命令包含以下缺点:
- 一个元素可能被返回多次,需要客户端来实现去重;
- 在迭代过程中如果有元素被修改,那么修改的元素能不能被遍历到不确定。 (Elements that were not constantly present in the collection during a full iteration, may be returned or not: it is undefined.)
小结
通过本文我们可以知道 Scan 包含以下四个指令:
- Scan:用于检索当前数据库中所有数据;
- HScan:用于检索哈希类型的数据;
- SScan:用于检索集合类型中的数据;
- ZScan:由于检索有序集合中的数据。
Scan 具备以下几个特点:
- Scan 可以实现 keys 的匹配功能;
- Scan 是通过游标进行查询的不会导致 Redis 假死;
- Scan 提供了 count 参数,可以规定遍历的数量;
- Scan 会把游标返回给客户端,用户客户端继续遍历查询;
- Scan 返回的结果可能会有重复数据,需要客户端去重;
- 单次返回空值且游标不为 0,说明遍历还没结束;
- Scan 可以保证在开始检索之前,被删除的元素一定不会被查询出来;
- 在迭代过程中如果有元素被修改, Scan 不保证能查询出相关的元素。
22 优秀的基数统计算法——HyperLogLog
为什么要使用 HyperLogLog?
在我们实际开发的过程中,可能会遇到这样一个问题,当我们需要统计一个大型网站的独立访问次数时,该用什么的类型来统计?
如果我们使用 Redis 中的集合来统计,当它每天有数千万级别的访问时,将会是一个巨大的问题。因为这些访问量不能被清空,我们运营人员可能会随时查看这些信息,那么随着时间的推移,这些统计数据所占用的空间会越来越大,逐渐超出我们能承载最大空间。
例如,我们用 IP 来作为独立访问的判断依据,那么我们就要把每个独立 IP 进行存储,以 IP4 来计算,IP4 最多需要 15 个字节来存储信息,例如:110.110.110.110。当有一千万个独立 IP 时,所占用的空间就是 15 bit*10000000 约定于 143MB,但这只是一个页面的统计信息,假如我们有 1 万个这样的页面,那我们就需要 1T 以上的空间来存储这些数据,而且随着 IP6 的普及,这个存储数字会越来越大,那我们就不能用集合的方式来存储了,这个时候我们需要开发新的数据类型 HyperLogLog 来做这件事了。
HyperLogLog 介绍
HyperLogLog(下文简称为 HLL)是 Redis 2.8.9 版本添加的数据结构,它用于高性能的基数(去重)统计功能,它的缺点就是存在极低的误差率。
HLL 具有以下几个特点:
- 能够使用极少的内存来统计巨量的数据,它只需要 12K 空间就能统计 2^64 的数据;
- 统计存在一定的误差,误差率整体较低,标准误差为 0.81%;
- 误差可以被设置辅助计算因子进行降低。
基础使用
HLL 的命令只有 3 个,但都非常的实用,下面分别来看。
添加元素
127.0.0.1:6379> pfadd key "redis"
(integer) 1
127.0.0.1:6379> pfadd key "java" "sql"
(integer) 1相关语法:
pfadd key element [element ...]此命令支持添加一个或多个元素至 HLL 结构中。
统计不重复的元素
127.0.0.1:6379> pfadd key "redis"
(integer) 1
127.0.0.1:6379> pfadd key "sql"
(integer) 1
127.0.0.1:6379> pfadd key "redis"
(integer) 0
127.0.0.1:6379> pfcount key
(integer) 2从 pfcount 的结果可以看出,在 HLL 结构中键值为 key 的元素,有 2 个不重复的值:redis 和 sql,可以看出结果还是挺准的。
相关语法:
pfcount key [key ...]此命令支持统计一个或多个 HLL 结构。
合并一个或多个 HLL 至新结构
新增 k 和 k2 合并至新结构 k3 中,代码如下:
127.0.0.1:6379> pfadd k "java" "sql"
(integer) 1
127.0.0.1:6379> pfadd k2 "redis" "sql"
(integer) 1
127.0.0.1:6379> pfmerge k3 k k2
OK
127.0.0.1:6379> pfcount k3
(integer) 3相关语法:
pfmerge destkey sourcekey [sourcekey ...]pfmerge 使用场景
当我们需要合并两个或多个同类页面的访问数据时,我们可以使用 pfmerge 来操作。
HLL 算法原理
HyperLogLog 算法来源于论文 HyperLogLog the analysis of a near-optimal cardinality estimation algorithm,想要了解 HLL 的原理,先要从伯努利试验说起,伯努利实验说的是抛硬币的事。一次伯努利实验相当于抛硬币,不管抛多少次只要出现一个正面,就称为一次伯努利实验。
我们用 k 来表示每次抛硬币的次数,n 表示第几次抛的硬币,用 k_max 来表示抛硬币的最高次数,最终根据估算发现 n 和 k_max 存在的关系是 n=2^(k_max),但同时我们也发现了另一个问题当试验次数很小的时候,这种估算方法的误差会很大,例如我们进行以下 3 次实验:
- 第 1 次试验:抛 3 次出现正面,此时 k=3,n=1;
- 第 2 次试验:抛 2 次出现正面,此时 k=2,n=2;
- 第 3 次试验:抛 6 次出现正面,此时 k=6,n=3。
对于这三组实验来说,k_max=6,n=3,但放入估算公式明显 3≠2^6。为了解决这个问题 HLL 引入了分桶算法和调和平均数来使这个算法更接近真实情况。
分桶算法是指把原来的数据平均分为 m 份,在每段中求平均数在乘以 m,以此来消减因偶然性带来的误差,提高预估的准确性,简单来说就是把一份数据分为多份,把一轮计算,分为多轮计算。
而调和平均数指的是使用平均数的优化算法,而非直接使用平均数。
例如小明的月工资是 1000 元,而小王的月工资是 100000 元,如果直接取平均数,那小明的平均工资就变成了 (1000+100000)/2=50500 元,这显然是不准确的,而使用调和平均数算法计算的结果是 2/(1⁄1000+1⁄100000)≈1998 元,显然此算法更符合实际平均数。
所以综合以上情况,在 Redis 中使用 HLL 插入数据,相当于把存储的值经过 hash 之后,再将 hash 值转换为二进制,存入到不同的桶中,这样就可以用很小的空间存储很多的数据,统计时再去相应的位置进行对比很快就能得出结论,这就是 HLL 算法的基本原理,想要更深入的了解算法及其推理过程,可以看去原版的论文。

