重点资料:
Practical Go: Real world advice for writing maintainable Go programs
第1课 微服务(微服务概览与治理)
1.1 微服务概览
1.1.1 单体架构
缺点:无法扩展,可靠性低。无法敏捷性开发和部署。
应对:化繁为简,分而治之。
1.1.2 微服务起源
SOA(Service-Oriented Architecture,面向服务的架构)和微服务的关系:微服务是 SOA 的一种实践。
You should instead think of Microservices as a specific approach for SOA in the same way that XP or Scrum are specific approaches for Agile software development.
微服务更细致的定义:
- 小即是美:小的服务代码少,bug 也少,易测试,易维护,也更容易不断迭代完善的精致进而美妙。
- 单一职责:一个服务也只需要做好一件事,专注才能做好。
- 尽可能早地创建原型:尽可能早的提供服务API,建立服务契约,达成服务间沟通的一致性约定,至于实现和完善可以慢慢再做。
- 可移植性比效率更重要:服务间的轻量级交互协议在效率和可移植性二者间,首要依然考虑兼容性和移植性。
1.1.3 微服务的定义
围绕业务功能构建的,服务关注单一业务,服务间采用轻量级的通信机制,可以全自动独立部署,可以使用不同的编程语言和数据存储技术。微服务架构通过业务拆分实现服务组件化,通过组件组合快速开发系统,业务单一的服务组件又可以独立部署
使得整个系统变得清晰灵活:
- 原子服务
- 独立进程
- 隔离部署
- 去中心化服务治理
缺点:
- 基础设施的建设、复杂度高
1.1.4 微服务的不足
- 微服务应用是分布式系统,由此会带来固有的复杂性。开发者不得不使用 RPC 或者消息传递,来实现进程间通信;此外,必须要写代码来处理消息传递中速度过慢或者服务不可用等局部失效问题。
- 分区的数据库架构,同时更新多个业务主体的事务很普遍。这种事务对于单体式应用来说很容易,因为只有一个数据库。在微服务架构应用中,需要更新不同服务所使用的不同的数据库,从而对开发者提出了更高的要求和挑战。
- 测试一个基于微服务架构的应用也是很复杂的任务。
- 服务模块间的依赖,应用的升级有可能会波及多个服务模块的修改。
- 对运维基础设施的挑战比较大。
1.1.5 组件服务化
传统实现组件的方式是通过库(library),库是和应用一起运行在进程中,库的局部变化意味着整个应用的重新部署。通过服务来实现组件,意味着将应用拆散为一系列的服务运行在不同的进程中,那么单一服务的局部变化只需重新部署对应的服务进程。我们用 Go 实施一个微服务:
- kit:一个微服务的基础库(框架)
- service:业务代码 + kit 依赖 + 第三方依赖组成的业务微服务
- rpc + message queue:轻量级通讯
本质上等同于,多个微服务组合(compose)完成了一个完整的用户场景(usecase)。
1.1.6 按业务组织服务
按业务能力组织服务的意思是服务提供的能力和业务功能对应,比如:订单服务和数据访问服务,前者反应了真实的订单相关业务,后者是一种技术抽象服务不反应真实的业务。所以按微服务架构理念来划分服务时,是不应该存在数据访问服务这样一个服务的。
事实上传统应用设计架构的分层结构正反映了不同角色的沟通结构。所以若要按微服务的方式来构建应用,也需要对应调整团队的组织架构。每个服务背后的小团队的组织是跨功能的,包含实现业务所需的全面的技能。
我们的模式:大前端(移动/Web) =》网关接入=》业务服务=》平台服务=》基础设施(PaaS/Saas)
开发团队对软件在生产环境的运行负全部责任!
You built it, you fix it.
1.1.7 去中心化
每个服务面临的业务场景不同,可以针对性的选择合适的技术解决方案。但也需要避免过度多样化,结合团队实际情况来选择取舍,要是每个服务都用不同的语言的技术栈来实现,想想维护成本真够高的。
- 数据去中心化
- 治理去中心化
- 技术去中心化
每个服务独享自身的数据存储设施(缓存,数据库等),不像传统应用共享一个缓存和数据库,这样有利于服务的独立性,隔离相关干扰。
1.1.8 基础设施自动化
无自动化不微服务,自动化包括测试和部署。单一进程的传统应用被拆分为一系列的多进程服务后,意味着开发、调试、测试、监控和部署的复杂度都会相应增大,必须要有合适的自动化基础设施来支持微服务架构模式,否则开发、运维成本将大大增加。
- CICD:Gitlab + Gitlab Hooks + k8s
- Testing:测试环境、单元测试、API自动化测试
- 在线运行时:k8s,以及一系列Prometheus、ELK、Control Panel
1.1.9 可用性 & 兼容性设计
著名的 Design For Failure 思想,微服务架构采用粗粒度的进程间通信,引入了额外的复杂性和需要处理的新问题,如网络延迟、消息格式、负载均衡和容错,忽略其中任何一点都属于对”分布式计算的误解”。
- 隔离
- 超时控制
- 负载保护
- 限流
- 降级
- 重试
- 负载均衡
一旦采用了微服务架构模式,那么在服务需要变更时我们要特别小心,服务提供者的变更可能引发服务消费者的兼容性破坏,时刻谨记保持服务契约(接口)的兼容性。
Be conservative in what you send, be liberal in what you accept.
发送时要保守,接收时要开放。按照伯斯塔尔法则的思想来设计和实现服务时,发送的数据要更保守,意味着最小化的传送必要的信息,接收时更开放意味着要最大限度的容忍冗余数据,保证兼容性。
1.2 微服务设计
1.2.1 API Gateway
第一版的设计
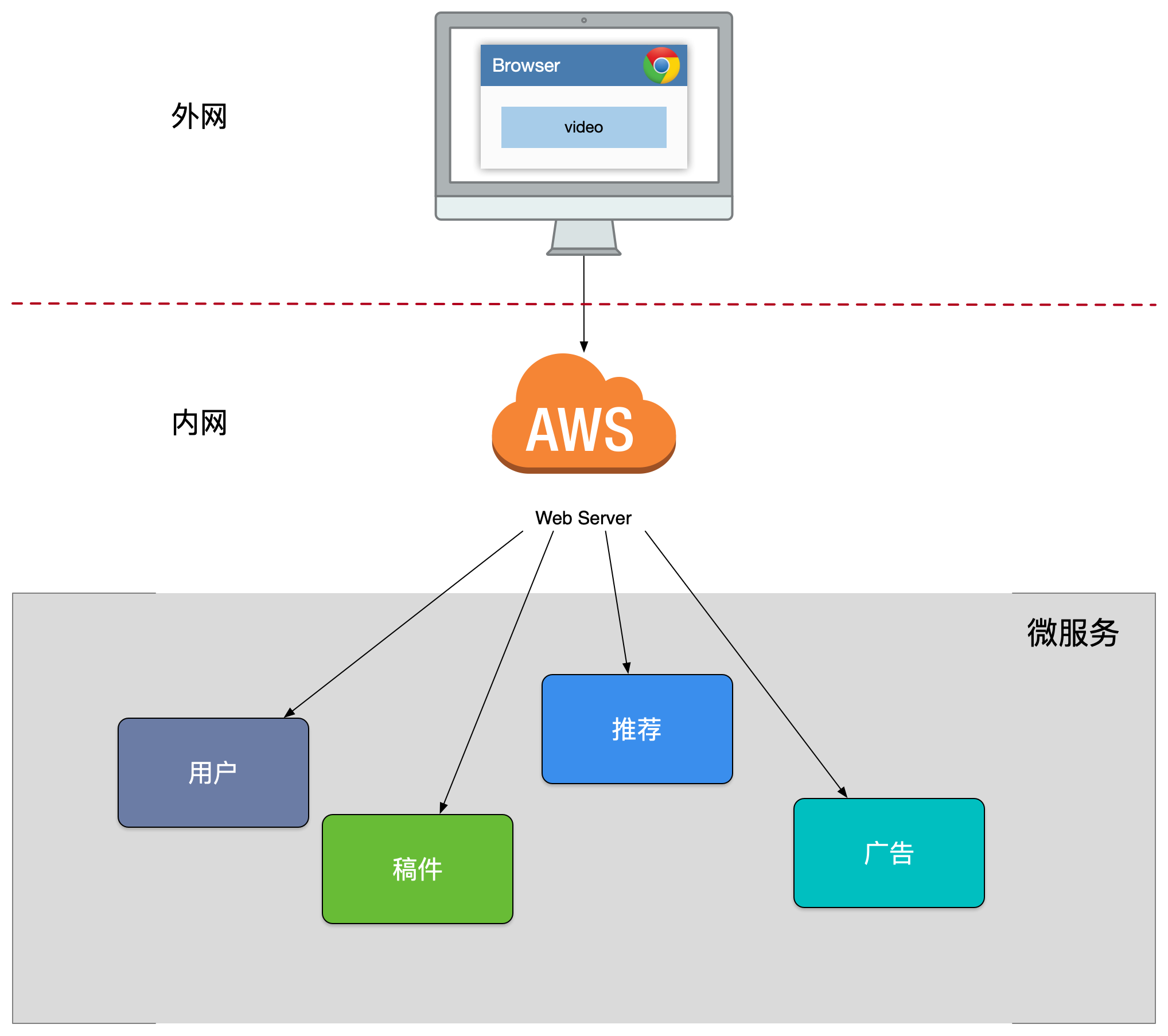
我们进行了 SOA 服务化的架构演进,按照垂直功能进行了拆分,对外暴露了一批微服务,但是因为缺乏统一的出口面临了不少困难:
- 客户端到微服务直接通信,强耦合(很老的客户端的可能一直存在)。
- 需要多次请求,客户端聚合数据,工作量巨大,延迟高(客户端工作量巨大)。
- 协议不利于统一,各个部门间有差异,需要端来兼容(各个部门的接口不统一)。
- 面向”端”的 API 适配,耦合到了内部服务(各个终端的适配代码复杂并耦合到服务内部)。
- 多终端兼容逻辑复杂,每个服务都需要处理。
统一逻辑无法收敛,比如安全认证、限流(每个服务都要做验证)。
我们之前提到了我们工作模型,要内聚模式配合。
第二版的设计
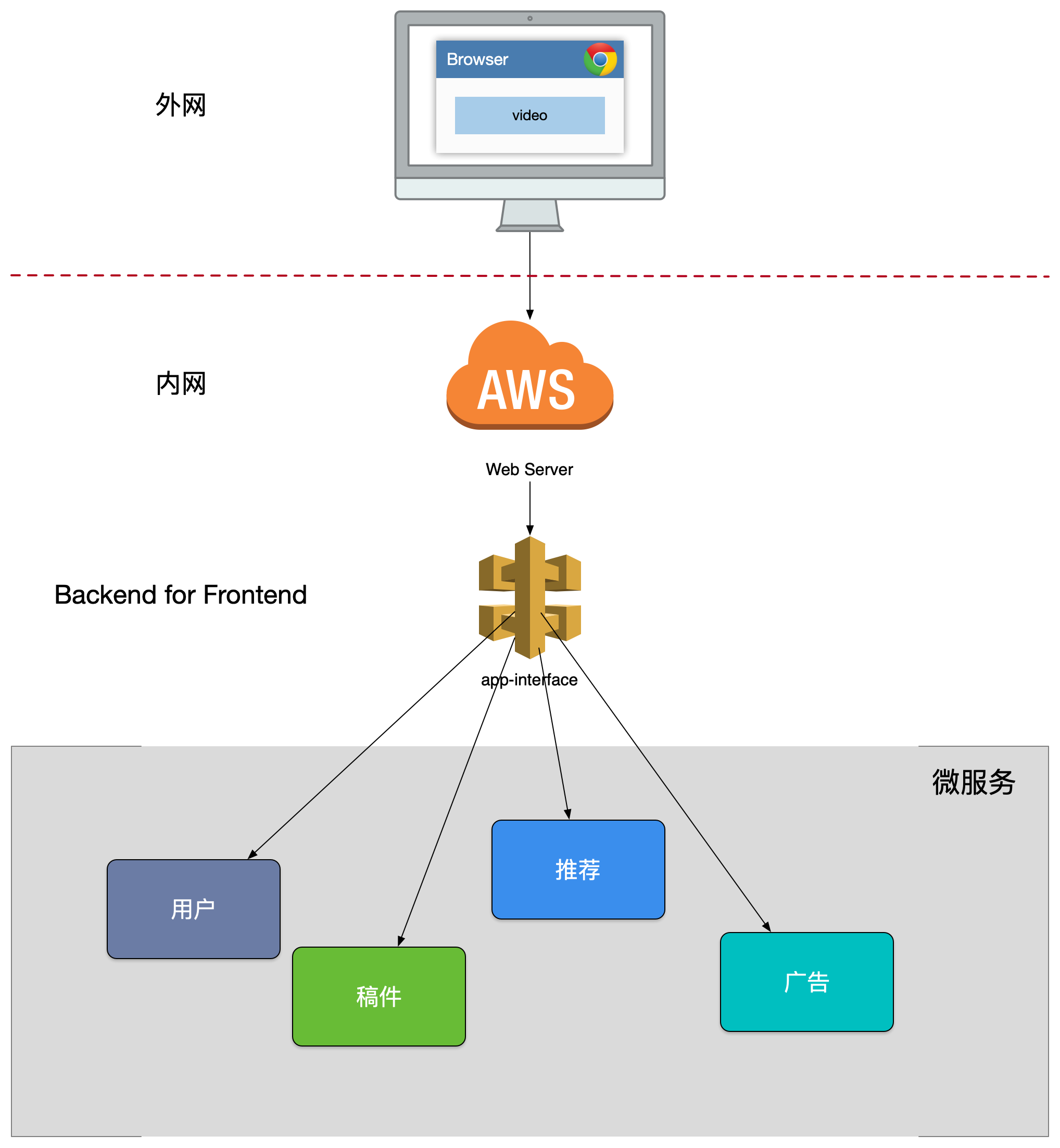
我们新增了一个 app-interface 用于统一的协议出口,在服务内进行大量的 dataset join,按照业务场景来设计粗粒度的 API,给后续服务的演进带来的很多优势:
- 轻量交互:协议精简、聚合。
- 差异服务:数据裁剪以及聚合、针对终端定制化 API。
- 动态升级:原有系统兼容升级,更新服务而非协议。
沟通效率提升,协作模式演进为移动业务+网关小组。
BFF 可以认为是一种适配服务,将后端的微服务进行适配(主要包括聚合裁剪和格式适配等逻辑),向无线端设备暴露友好和统一的API,方便无线设备接入访问后端服务。
第三版的设计
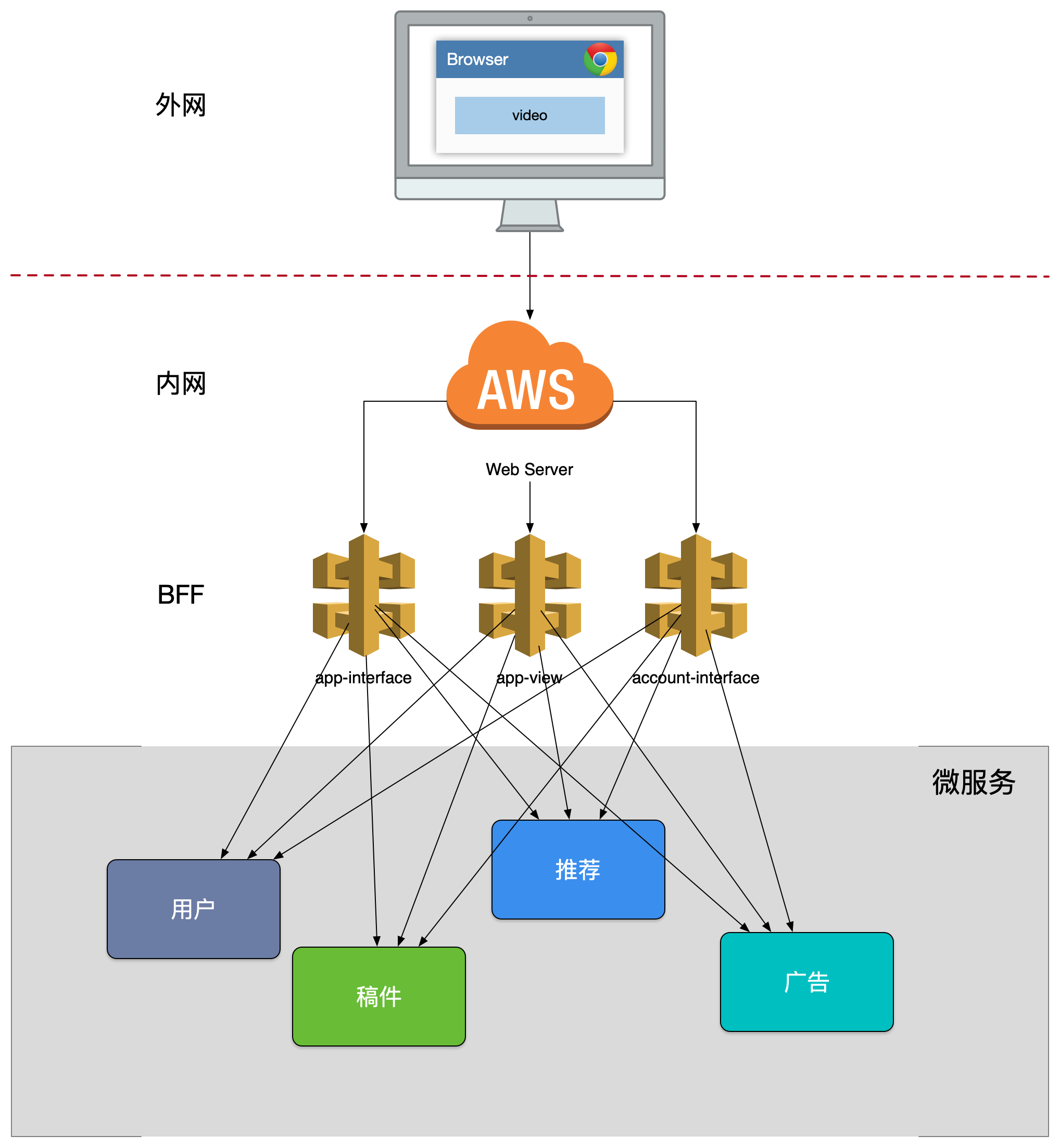
最致命的一个问题是整个 app-interface 属于 single point of failure,严重代码缺陷或者流量洪峰可能引发集群宕机。
单个模块也会导致后续业务集成复杂度高,根据康威法则,单块的无线BFF和多团队之间就出现不匹配问题,团队之间沟通协调成本高,交付效率低下。
解决方法是按照业务域和重要性拆分出了一些大的网关。这种模式在微服务设计模式中叫做 API Composition。
第四版的设计
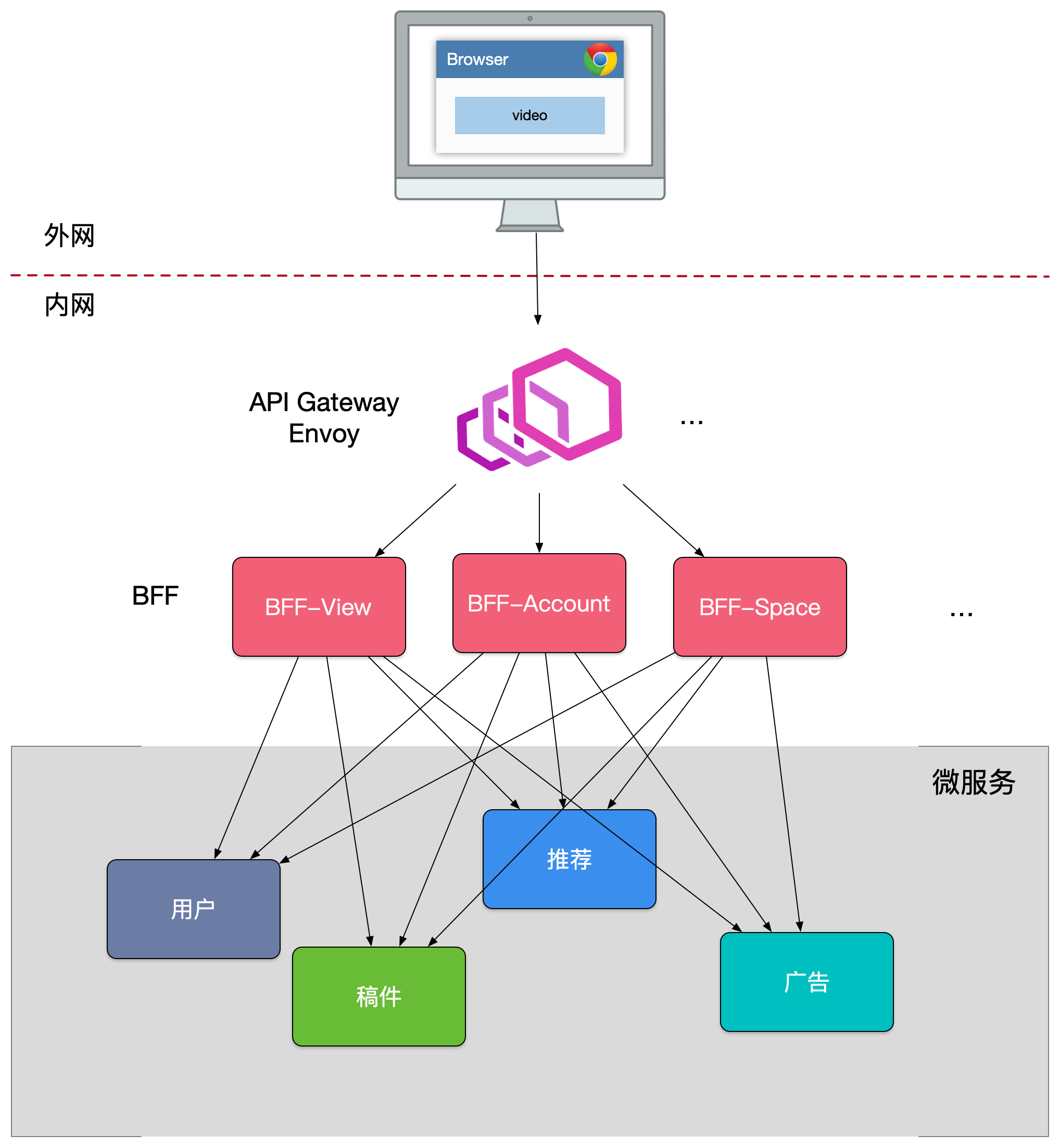
很多跨横切面逻辑,比如安全认证,日志监控,限流熔断等。随着时间的推移,代码变得越来越复杂,技术债越堆越多。
跨横切面(Cross-Cutting Concerns)的功能,需要协调更新框架升级发版(路由、认证、限流、安全),因此全部上沉,引入了API Gateway,把业务集成度高的BFF 层和通用功能服务层APIGateway 进行了分层处理。
在新的架构中,网关承担了重要的角色,它是解耦拆分和后续升级迁移的利器。在网关的配合下,单块BFF实现了解耦拆分,各业务线团队可以独立开发和交付各自的微服务,研发效率大大提升。另外,把跨横切面逻辑从BFF 剥离到网关上去以后,BFF 的开发人员可以更加专注业务逻辑交付,实现了架构上的关注分离(Separation of Concerns)。
我们业务流量实际为:
移动端-> API Gateway -> BFF -> Microservice,在Front-end Web业务中,BFF 可以是nodejs 来做服务端渲染(SSR,Server-Side Rendering),注意这里忽略了上游的CDN、4/7层负载均衡(ELB)。
1.2.2 Microservice 划分
微服务架构时遇到的第一个问题就是如何划分服务的边界。在实际项目中通常会采用两种不同的方式划分服务边界,即通过业务职能(BusinessCapability)或是DDD 的限界上下文(BoundedContext)。
在不熟悉业务领域时,可以用两种方式划分:
- Business Capability
按部门划分,由公司内部不同部门提供的职能。例如客户服务部门提供客户服务的职能,财务部门提供财务相关的职能。 - Bounded Context
限界上下文是 DDD 中用来划分不同业务边界的元素,这里业务边界的含义是”解决不同业务问题”的问题域和对应的解决方案域,为了解决某种类型的业务问题,贴近领域知识,也就是业务。
这本质上也促进了组织结构的演进:Service per team 。
建议:
- 尽量闭环的团队负责一个服务。
- 尽量在服务划分的很细,需要扇出的请求特别多时再和服务的整合。
1.2.3 Microservice 划分之 CQRS
CQRS,将应用程序分为两部分:命令端和查询端。命令端处理程序创建,更新和删除请求,并在数据更改时发出事件。查询端通过针对一个或多个物化视图执行查询来处理查询,这些物化视图通过订阅数据更改时发出的事件流而保持最新。
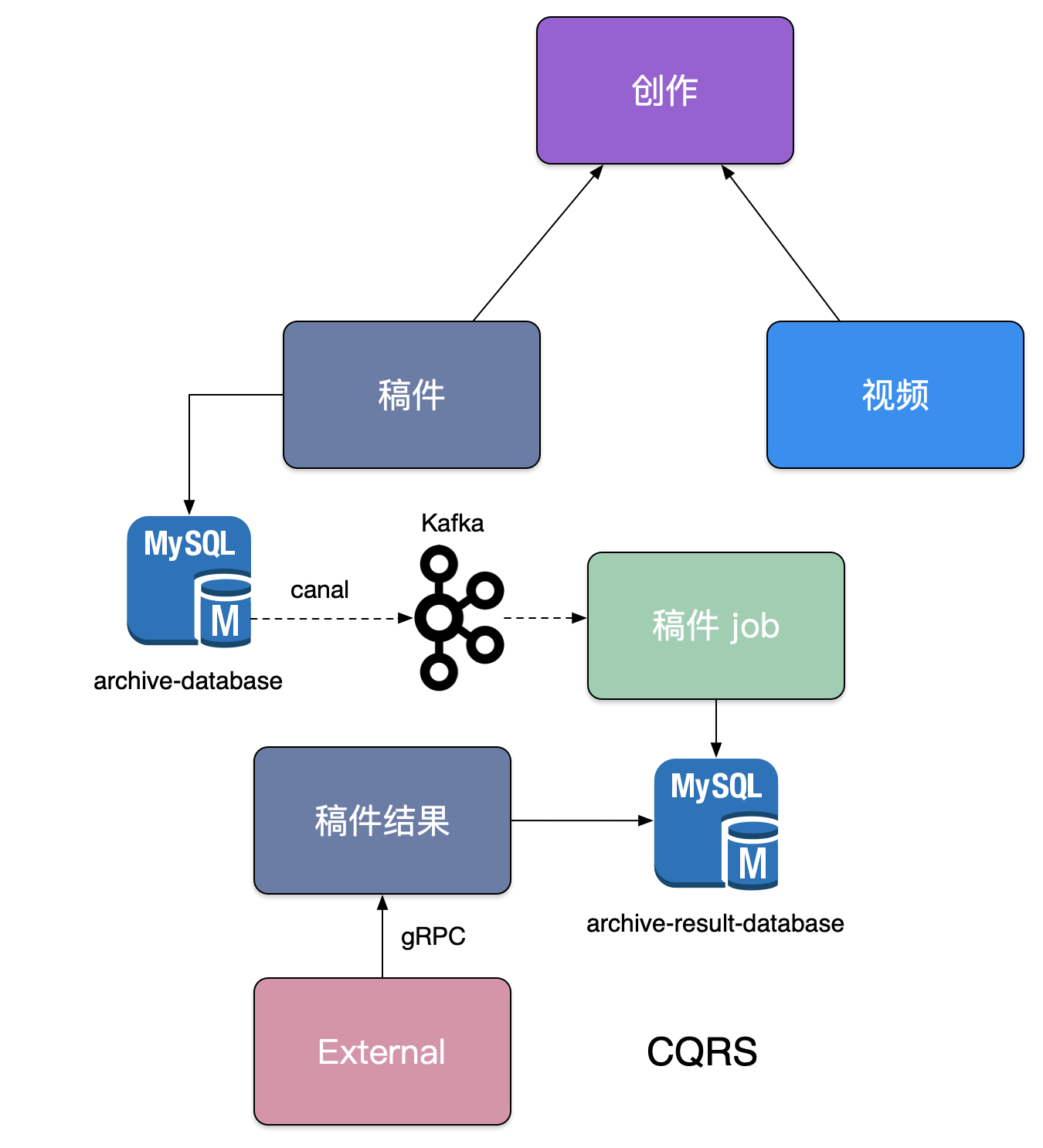
在稿件服务演进过程中,我们发现围绕着创作稿件、审核稿件、最终发布稿件有大量的逻辑揉在一块,其中稿件本身的状态也有非常多种,但是最终前台用户只关注稿件能否查看,我们依赖稿件数据库 binlog 以及订阅 binlog 的中间件 canal,将我们的稿件结果发布到消息队列 kafka 中,最终消费数据独立组建一个稿件查阅结果数据库,并对外提供一个独立查询服务,来拆分复杂架构和业务。
我们架构也从 Polling publisher -> Transaction log tailing 进行了演进(Pull vs Push)。
1.2.4 Microservice 安全
对于外网的请求来说,我们通常在 API Gateway 进行统一的认证拦截,一旦认证成功,我们会使
用 JWT 方式通过 RPC 元数据传递的方式带到 BFF 层,BFF 校验 Token 完整性后把身份信息注入到应用的Context 中,BFF 到其他下层的微服务,建议是直接在 RPC Request 中带入用户身份信息(UserID)请求服务。
- API Gateway -> BFF -> Service
- Biz Auth -> JWT -> Request Args
对于服务内部,一般要区分身份认证和授权(先做认证再做授权再通过RBAC控制)。
- Full Trust:认证且加密
- Half Trust:认证但不加密
- Zero Trust:不认证不加密
1.3 gRPC & 服务发现
1.3.1 gRPC
- 多语言:语言中立,支持多种语言。
- 轻量级、高性能:序列化支持PB(Protocol Buffer)和JSON,PB 是一种语言无关的高性能序列化框架。
- 可插拔
- IDL:基于文件定义服务,通过proto3 工具生成指定语言的数据结构、服务端接口以及客户端Stub。
- 设计理念
- 移动端:基于标准的HTTP2 设计,支持双向流、消息头压缩、单TCP 的多路复用、服务端推送等特性,这些特性使得gRPC 在移动端设备上更加省电和节省网络流量。
- 服务而非对象、消息而非引用:促进微服务的系统间粗粒度消息交互设计理念。
- 负载无关的:不同的服务需要使用不同的消息类型和编码,例如protocol buffers、JSON、XML 和Thrift。
- 流:Streaming API。
- 阻塞式和非阻塞式:支持异步和同步处理在客户端和服务端间交互的消息序列。
- 元数据交换:常见的横切关注点,如认证或跟踪,依赖数据交换。
- 标准化状态码:客户端通常以有限的方式响应API 调用返回的错误。
不要过早关注性能问题,先标准化。
1.3.2 gRPC - HealthCheck
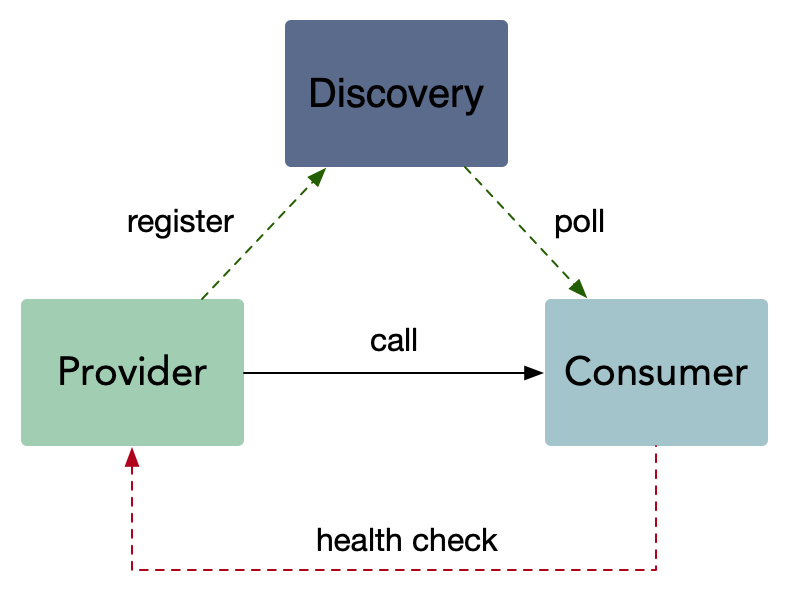
gRPC 有一个标准的健康检测协议,在 gRPC 的所有语言实现中基本都提供了生成代码和用于设置运行状态的功能。
主动健康检查 health check,可以在服务提供者服务不稳定时,被消费者所感知,临时从负载均衡中摘除,减少错误请求。当服务提供者重新稳定后,health check成功,重新加入到消费者的负载均衡,恢复请求。
health check,同样也被用于外挂方式的容器健康检测,或者流量检测(k8s liveness & readiness)。
1.3.3 服务发现
客户端发现模式
一个服务实例被启动时,它的网络地址会被写到注册表上;当服务实例终止时,再从注册表中删除;这个服务实例的注册表通过心跳机制动态刷新;客户端使用一个负载均衡算法,去选择一个可用的服务实例,来响应这个请求。
服务端发现模式
客户端通过负载均衡器向一个服务发送请求,这个负载均衡器会查询服务注册表,并将请求路由到可用的服务实例上。服务实例在服务注册表上被注册和注销(Consul Template+Nginx,kubernetes+etcd)。
对比
客户端发现: 直连,比服务端服务发现少一次网络跳转,Consumer 需要内置特定的服务发现客户端和发现逻辑。
服务端发现:Consumer 无需关注服务发现具体细节,只需知道服务的DNS 域名即可,支持异构语言开发,需要基础设施支撑,多了一次网络跳转,可能有性能损失。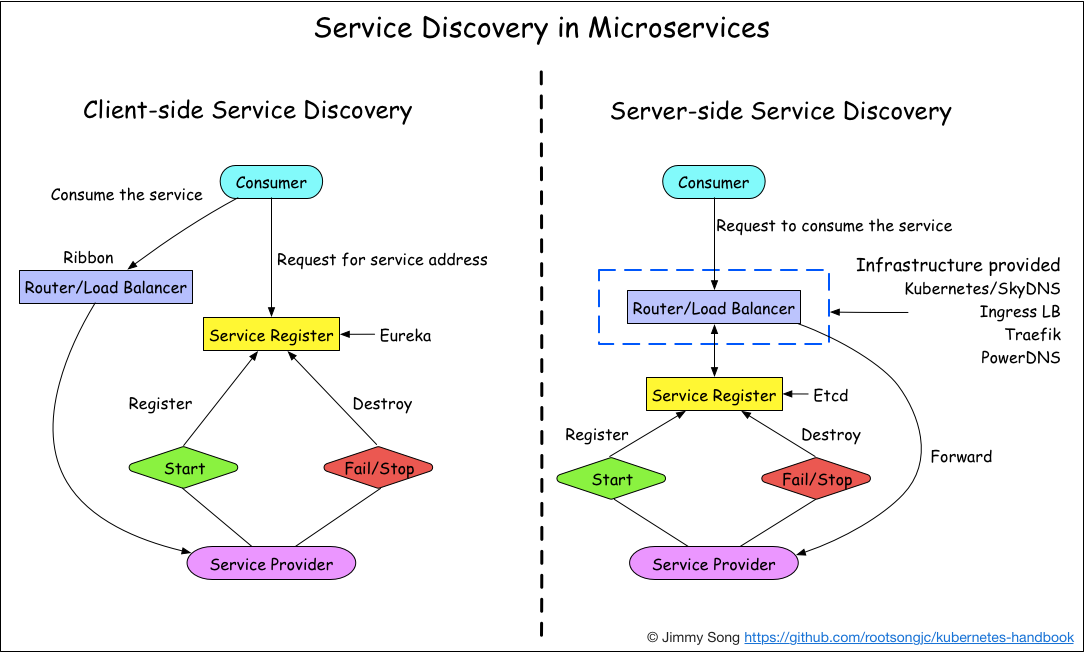
微服务的核心是去中心化,我们使用客户端发现模式。
1.3.4 服务发送的使用
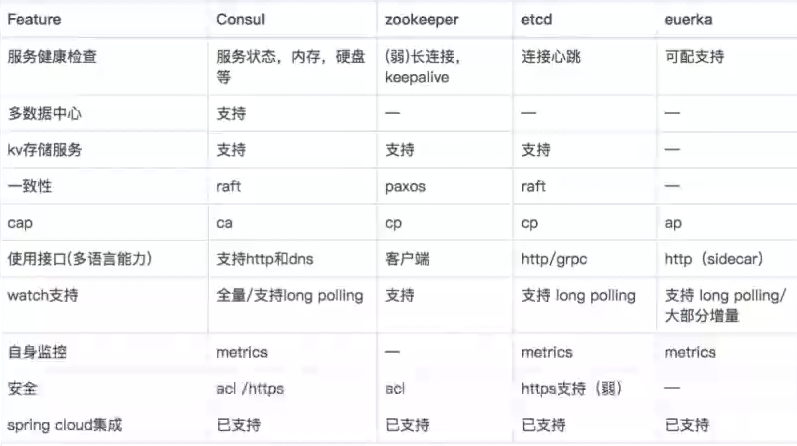
早期我们使用最熟悉的 Zookeeper 作为服务发现,但是实际场景是海量服务发现和注册,服务状态可以弱一致, 需要的是 AP 系统。
- 分布式协调服务(要求任何时刻对 ZooKeeper 的访问请求能得到一致的数据,从而牺牲可用性)。
- 网络抖动或网络分区会导致的 master 节点因为其他节点失去联系而重新选举或超过半数不可用导致服务注册发现瘫痪。
- 大量服务长连接导致性能瓶颈。
我们参考了 Eureka 实现了自己的 AP 发现服务。
现在推荐直接使用 nacos 。
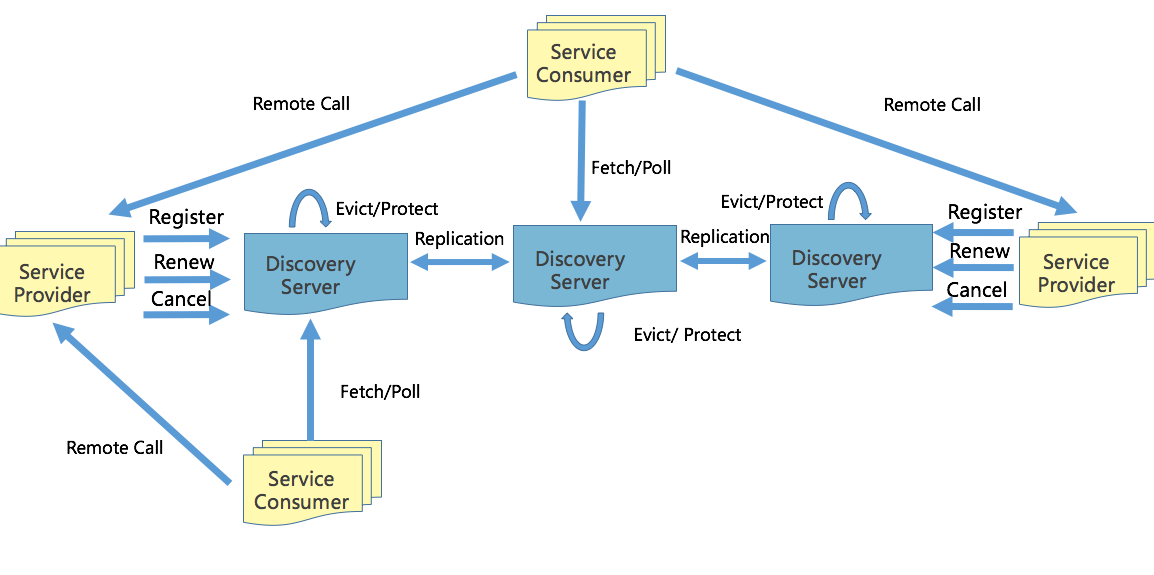
更多的细节:
- 通过Family(appid) 和Addr(IP:Port) 定位实例,除此之外还可以附加更多的元数据:权重、染色标签、集群等。
appid: 使用三段式命名,business.service.xxx
- Provider 注册后定期(30s)心跳一次,注册,心跳,下线都需要进行同步,注册和下线需要进行长轮询推送。
新启动节点,需要load cache,JVM 预热。
故障时,Provider 不建议重启和发布。
- Consumer 启动时拉取实例,发起30s长轮询。
故障时,需要client 侧cache 节点信息。
- Server 定期(60s) 检测失效(90s)的实例,失效则剔除。短时间里丢失了大量的心跳连接(15分钟内心跳低于期望值*85%),开启自我保护,保留过期服务不删除。
试想两个场景,牺牲一致性,最终一致性的情况:
- 注册的事件延迟
- 注销的事件延迟:有点到点 RPC 的 health check 能让节点及时的下线。
1.4 多集群 & 多租户
1.4.1 多集群
这里指定的是单个机房内的多集群。
Level 0(最重要的服务等级)服务,类似像我们账号,之前是一套大集群,一旦故障影响返回巨大,所以我们从几个角度考虑多集群的必要性:
- 从单一集群考虑,多个节点保证可用性,我们通常使用N+2 的方式来冗余节点。
- 从单一集群故障带来的影响面角度考虑冗余多套集群。
- 单个机房内的机房故障导致的问题。

我们利用 paas 平台,给某个 appid 服务建立多套集群(物理上相当于两套资源,逻辑上维护 cluster 的概念),对于不同集群服务启动后,从环境变量里可以获取当下服务的 cluster,在服务发现注册的时候,带入这些元信息。当然,不同集群可以隔离使用不同的缓存资源等。
实际使用时,是为不同的业务单独搭一套。比如:为直播的业务搭一套账号,为游戏的业务搭一套账号。
- 多套冗余的集群对应多套独占的缓存,带来更好的性能和冗余能力。
- 尽量避免业务隔离使用或者sharding 带来的 cache hit 影响(按照业务划分集群资源)。
业务隔离集群带来的问题是 cache hit ratio 下降,不同业务形态数据正交(会导致连其他业务对应的账号服务时有巨量的缓存穿透),我们退而求其次整个集群全部连接(让所有客户端连接所有(m x n)业务的账号服务,这样就能让所有账号服务对应的缓存热起来)。
1.4.2 多集群的高资源占用处理
让所有客户端都连接所有的账号服,导致即使空闲时,gRPC 因处理 HealthCheck 的 CPU 也高达 30% 。
下面的解决思路来自 Google SRE 。
统一为一套逻辑集群(物理上多套资源池),即 gRPC 客户端默认忽略服务发现中的 cluster 信息,按照全部节点,全部连接。能不能找到一种算法从全集群中选取一批节点(子集),利用划分子集限制连接池大小。
- 长连接导致的内存和CPU 开销,HealthCheck 可以高达30%。
- 短连接极大的资源成本和延迟。
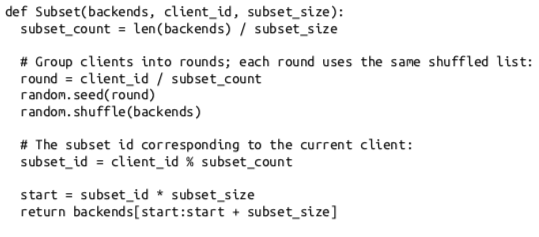
合适的子集大小和选择算法:
- 通常20-100个后端,部分场景需要大子集,比如大批量读写操作。
- 后端平均分给客户端。
- 客户端重启,保持重新均衡,同时对后端重启保持透明,同时连接的变动最小。
1.4.3 多租户
在一个微服务架构中允许多系统共存是利用微服务稳定性以及模块化最有效的方式之一,这种方式一般被称为多租户(multi-tenancy)。租户可以是测试,金丝雀发布,影子系统(shadow systems),甚至服务层或者产品线,使用租户能够保证代码的隔离性并且能够基于流量租户做路由决策。
对于传输中的数据(data-in-flight)(例如,消息队列中的请求或者消息)以及静态数据(data-at-rest)(例如,存储或者持久化缓存),租户都能够保证隔离性和公平性,以及基于租户的路由机会。
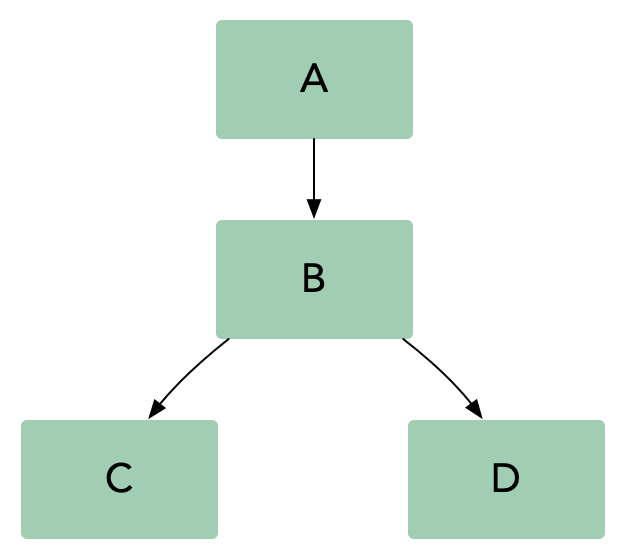
如果我们对服务 B 做出改变,我们需要确保它仍然能够和服务 A、C、D 正常交互。在微服务架构中,我们需要做这些集成测试场景,也就是测试和该系统中其他服务的交互。通常来说,微服务架构有两种基本的集成测试方式:并行测试和生产环境测试。
并行测试
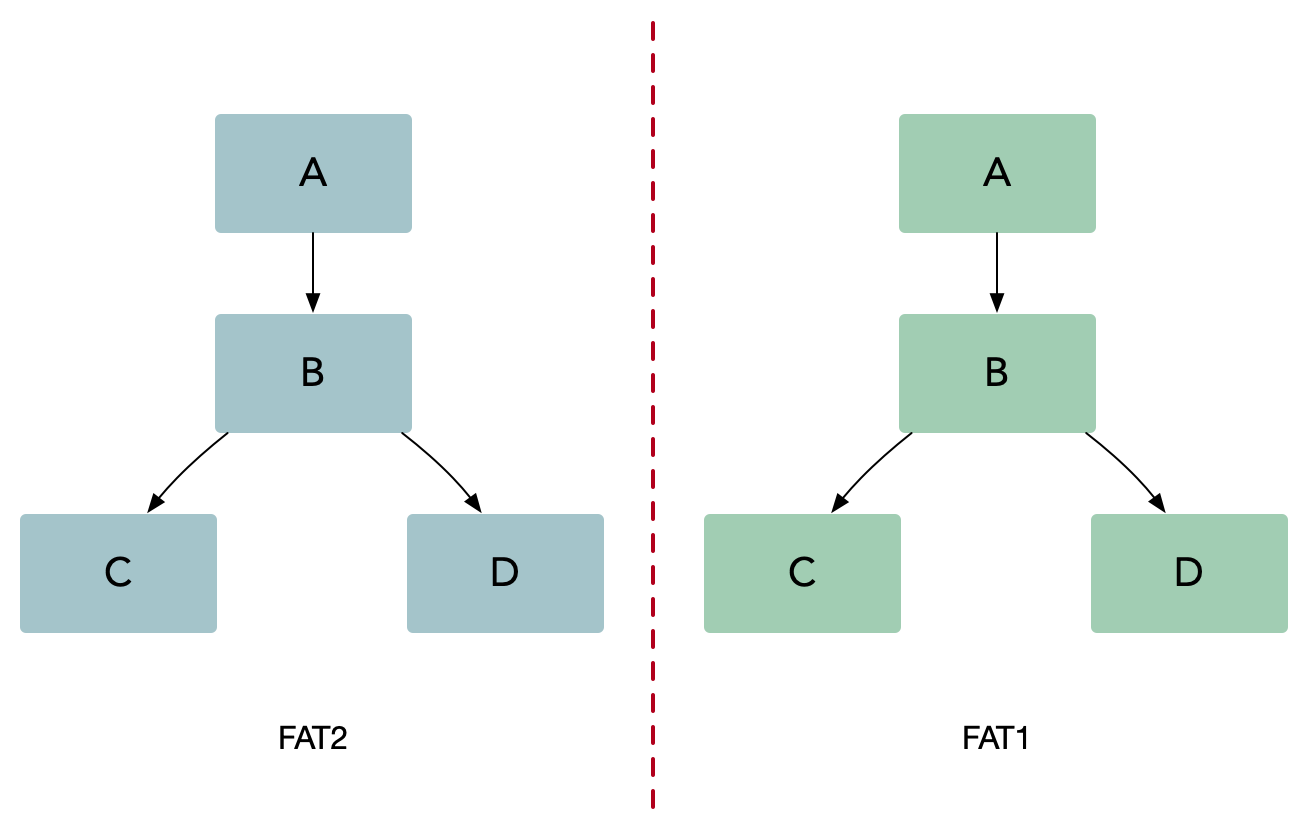
并行测试需要一个和生产环境一样的过渡(staging)环境,并且只是用来处理测试流量。在并行测试中,工程师团队首先完成生产服务的一次变动,然后将变动的代码部署到测试栈。这种方法可以在不影响生产环境的情况下让开发者稳定的测试服务,同时能够在发布前更容易的识别和控制bug。尽管并行测试是一种非常有效的集成测试方法,但是它也带来了一些可能影响微服务架构成功的挑战:
- 混用环境导致的不可靠测试。
- 多套环境带来的硬件成本。
- 难以做负载测试,仿真线上真实流量情况。
灰度测试
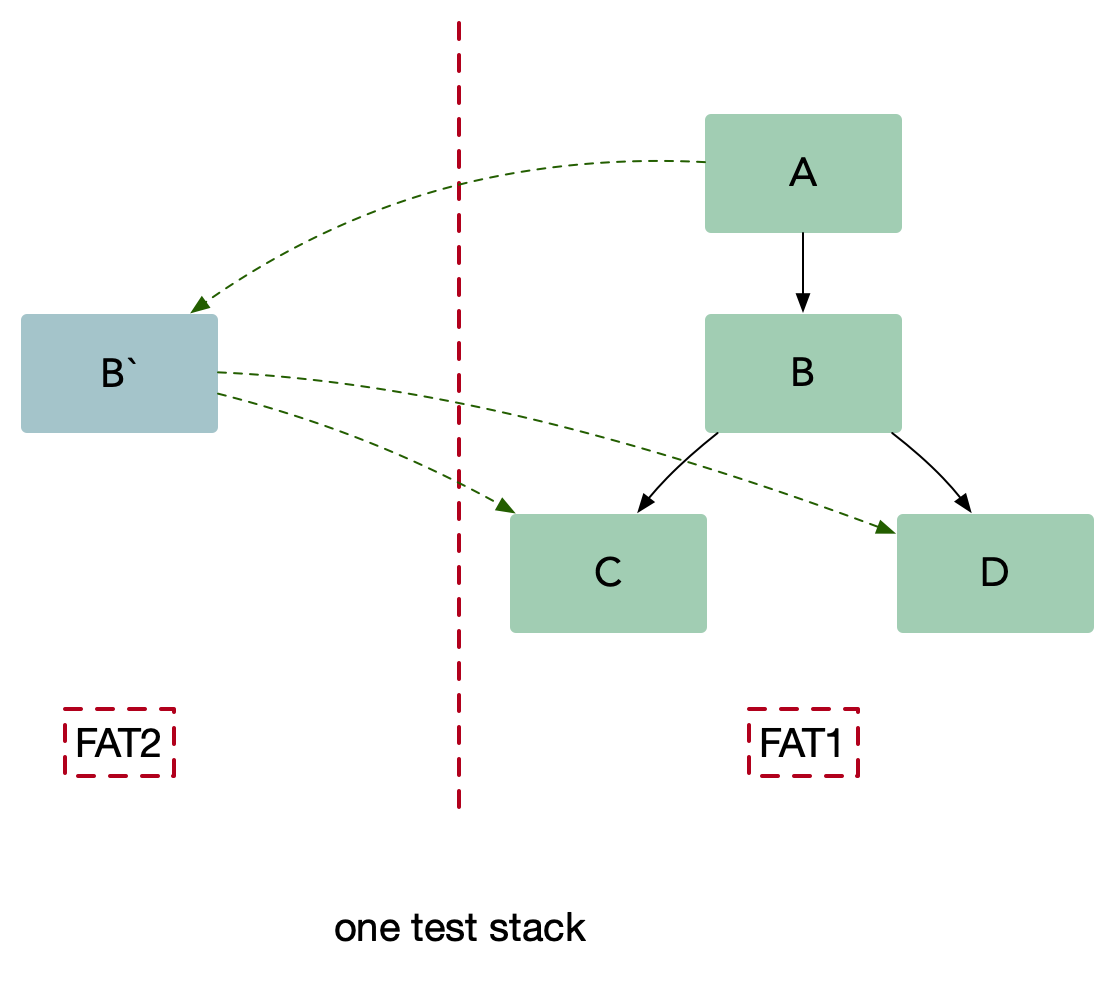
使用这种方法(内部叫染色发布),我们可以把待测试的服务 B 在一个隔离的沙盒环境中启动,并且在沙盒环境下可以访问集成环境(UAT) C 和 D。我们把测试流量路由到服务B,同时保持生产流量正常流入到集成服务。服务 B 仅仅处理测试流量而不处理生产流量。另外要确保集成流量不要被测试流量影响。生产中的测试提出了两个基本要求,它们也构成了多租户体系结构的基础:
- 流量路由:能够基于流入栈中的流量类型做路由。
隔离性:能够可靠的隔离测试和生产中的资源,这样可以保证对于关键业务微服务没有副作用。
灰度测试成本代价很大,影响 1/N 的用户。其中 N 为节点数量。
多租户
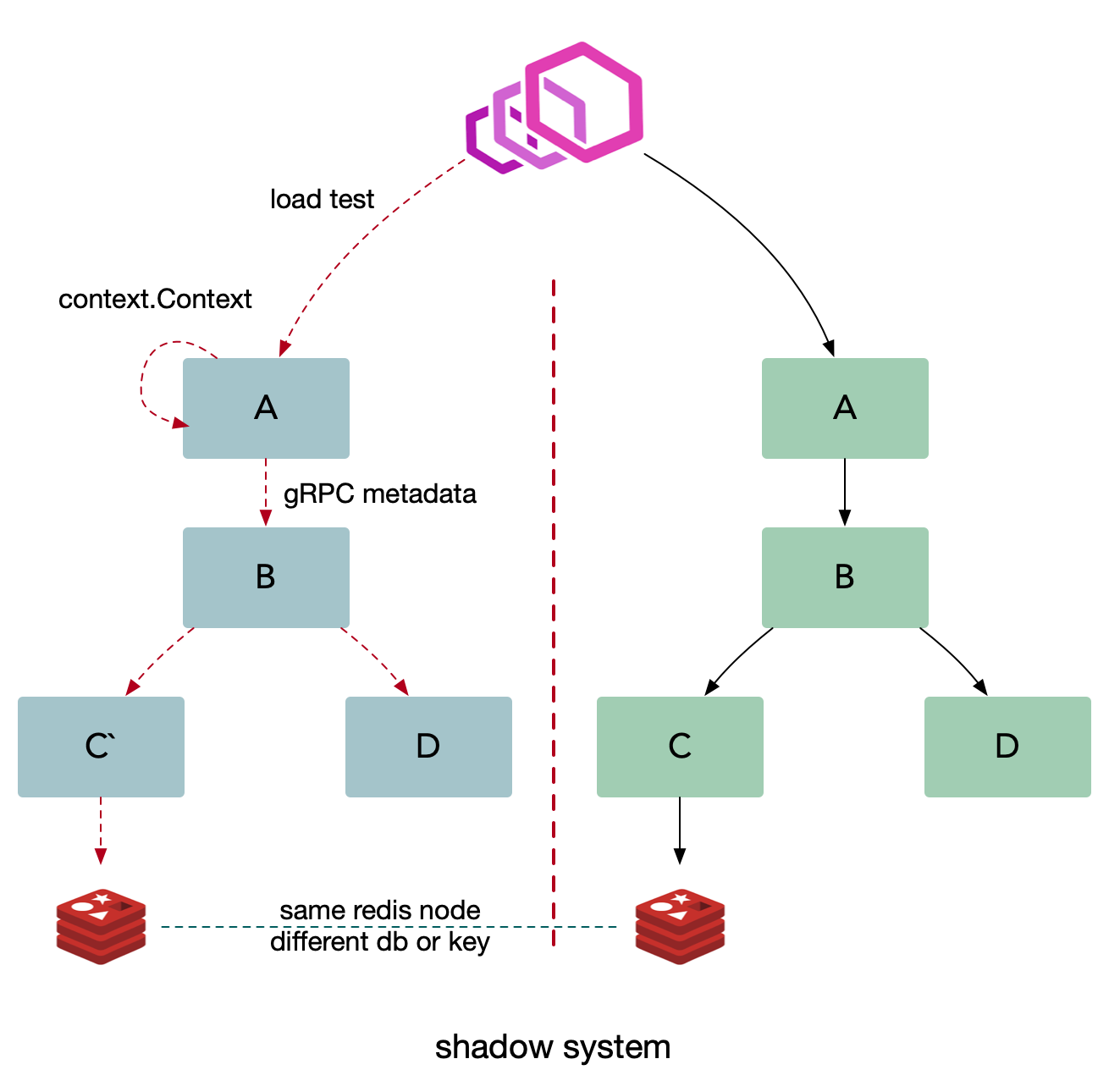
给入站请求绑定上下文(如: http header), in-process 使用 context 传递,跨服务使用metadata 传递(如: opentracing baggage item),在这个架构中每一个基础组件都能够理解租户信息,并且能够基于租户路由隔离流量,同时在我们的平台中允许对运行不同的微服务有更多的控制,比如指标和日志。在微服务架构中典型的基础组件是日志,指标,存储,消息队列,缓存以及配置。基于租户信息隔离数据需要分别处理基础组件。
多租户架构本质上描述为:跨服务传递请求携带上下文(context),数据隔离的流量路由方案。
利用服务发现注册租户信息,注册成特定的租户。
1.5 References
https://microservices.io/index.html
https://blog.csdn.net/mindfloating/article/details/51221780
https://www.cnblogs.com/dadadechengzi/p/9373069.html
https://www.cnblogs.com/viaiu/archive/2018/11/24/10011376.html
https://www.cnblogs.com/lfs2640666960/p/9543096.html
https://mp.weixin.qq.com/s/L6OKJK1ev1FyVDu03CQ0OA
https://www.bookstack.cn/read/API-design-guide/API-design-guide-02-面向资源的设计.md
https://www.programmableweb.com/news/how-to-design-great-apis-api-first-design-and-raml/how-to/2015/07/10
http://www.dockone.io/article/394
https://www.jianshu.com/p/3c7a0e81451a
https://www.jianshu.com/p/6e539caf662d
https://my.oschina.net/CraneHe/blog/703173
https://my.oschina.net/CraneHe/blog/703169
https://my.oschina.net/CraneHe/blog/703160
第2课 异常处理
2.1 Error vs Exception
2.1.1 Go 中的 error
Go error 就是普通的一个接口,普通的值。
// The error built-in interface type is the conventional interface for
// representing an error condition, with the nil value representing no error.
type error interface {
Error() string
}经常使用 errors.New() 来返回一个 error 对象。
errors.New() 返回的是内部 errorString 对象的指针。
返回指针是为了保证即使值相同的但是错误依然要不同(见代码中的注释)。
// New returns an error that formats as the given text.
// Each call to New returns a distinct error value even if the text is identical.
func New(text string) error {
return &errorString{text}
}2.1.2 其他语言中的错误处理
各个语言的演进历史:
C
单返回值,一般通过传递指针作为入参,返回值为 int 表示成功还是失败。
C++
引入了 exception,但是无法知道被调用方会抛出什么异常。
Java
引入了 checked exception,方法的所有者必须申明,调用者必须处理。在启动时抛出大量的异常是司空见惯的事情,并在它们的调用堆栈中尽职地记录下来。Java 异常不再是异常,而是变得司空见惯了。它们从良性到灾难性都有使用,异常的严重性由函数的调用者来区分。
Go
Go 的处理异常逻辑是不引入 exception,支持多参数返回,所以你很容易的在函数签名中带上实现了 error interface 的对象,交由调用者来判定。
如果一个函数返回了 value, error,你不能对这个 value 做任何假设,必须先判定 error。唯一可以忽略 error 的是,如果你连 value 也不关心。
Go 中有 panic 的机制,如果你认为和其他语言的 exception 一样,那你就错了。当我们抛出异常的时候,相当于你把 exception 扔给了调用者来处理。
比如,你在 C++ 中,把 string 转为 int,如果转换失败,会抛出异常。或者在 java 中转换 string 为 date 失败时,会抛出异常。
Go panic 意味着 fatal error(就是挂了)。不能假设调用者来解决 panic,意味着代码不能继续运行。
使用多个返回值和一个简单的约定,Go 解决了让程序员知道什么时候出了问题,并为真正的异常情况保留了 panic。
对于真正意外的情况,那些表示不可恢复的程序错误,例如索引越界、不可恢复的环境问题、栈溢出,我们才使用 panic。对于其他的错误情况,我们应该是期望使用 error 来进行判定。
you only need to check the error value if you care about the result. — Dave
This blog post from Microsoft’s engineering blog in 2005 still holds true today, namely:
My point isn’t that exceptions are bad. My point is that exceptions are too hard and I’m not smart enough to handle them.
Go 的错误设计:
- 简单。
- 考虑失败,而不是成功(Plan for failure, not success)。
- 没有隐藏的控制流。
- 完全交给你来控制 error。
- Error are values。
2.2 Error Type
2.2.1 Sentinel Error
预定义的特定错误,我们叫为 sentinel error,这个名字来源于计算机编程中使用一个特定值来表示不可能进行进一步处理的做法。所以对于 Go,我们使用特定的值来表示错误。
if err == ErrSomething { … }类似的 io.EOF,更底层的 syscall.ENOENT。
使用 sentinel 值是最不灵活的错误处理策略,因为调用方必须使用 == 将结果与预先声明的值进行比较。当您想要提供更多的上下文时,这就出现了一个问题,因为返回一个不同的错误将破坏相等性检查。
甚至是一些有意义的 fmt.Errorf 携带一些上下文,也会破坏调用者的 == ,调用者将被迫查看 error.Error() 方法的输出,以查看它是否与特定的字符串匹配。
不依赖检查 error.Error 的输出。
不应该依赖检测 error.Error 的输出,Error 方法存在于 error 接口主要用于方便程序员使用,但不是程序(编写测试可能会依赖这个返回)。这个输出的字符串用于记录日志、输出到 stdout 等。
Sentinel errors 成为你 API 公共部分。
如果您的公共函数或方法返回一个特定值的错误,那么该值必须是公共的,当然要有文档记录,这会增加 API 的表面积。
如果 API 定义了一个返回特定错误的 interface,则该接口的所有实现都将被限制为仅返回该错误,即使它们可以提供更具描述性的错误。
比如 io.Reader。像 io.Copy 这类函数需要 reader 的实现者比如返回 io.EOF 来告诉调用者没有更多数据了,但这又不是错误。
Sentinel errors 在两个包之间创建了依赖。
sentinel errors 最糟糕的问题是它们在两个包之间创建了源代码依赖关系。例如,检查错误是否等于 io.EOF,您的代码必须导入 io 包。这个特定的例子听起来并不那么糟糕,因为它非常常见,但是想象一下,当项目中的许多包导出错误值时,存在耦合,项目中的其他包必须导入这些错误值才能检查特定的错误条件(in the form of an import loop)。
结论: 尽可能避免 sentinel errors。
我的建议是避免在编写的代码中使用 sentinel errors。在标准库中有一些使用它们的情况,但这不是一个您应该模仿的模式。
2.2.2 Error types
Error type 是实现了 error 接口的自定义类型。例如 MyError 类型记录了文件和行号以展示发生了什么。因为 MyError 是一个 type,调用者可以使用断言转换成这个类型,来获取更多的上下文信息。
type MyError struct {
Msg string
File string
Line int
}
func (e *MyError) Error() string {
return fmt.Sprintf("%s:%d: %s", e.File, e.Line, e.Msg)
}
func test() error {
return &MyError{"kibazen.cn", "server.go", 42}
}
func main() {
err := test()
switch err := err.(type) {
case nil:
// call succeeded, nothing to do
case *MyError:
fmt.Println("error occurred on line: ", err.Line)
default:
// unknown error
}
}与错误值相比,错误类型的一大改进是它们能够包装底层错误以提供更多上下文。
一个不错的例子就是 os.PathError 他提供了底层执行了什么操作、那个路径出了什么问题。
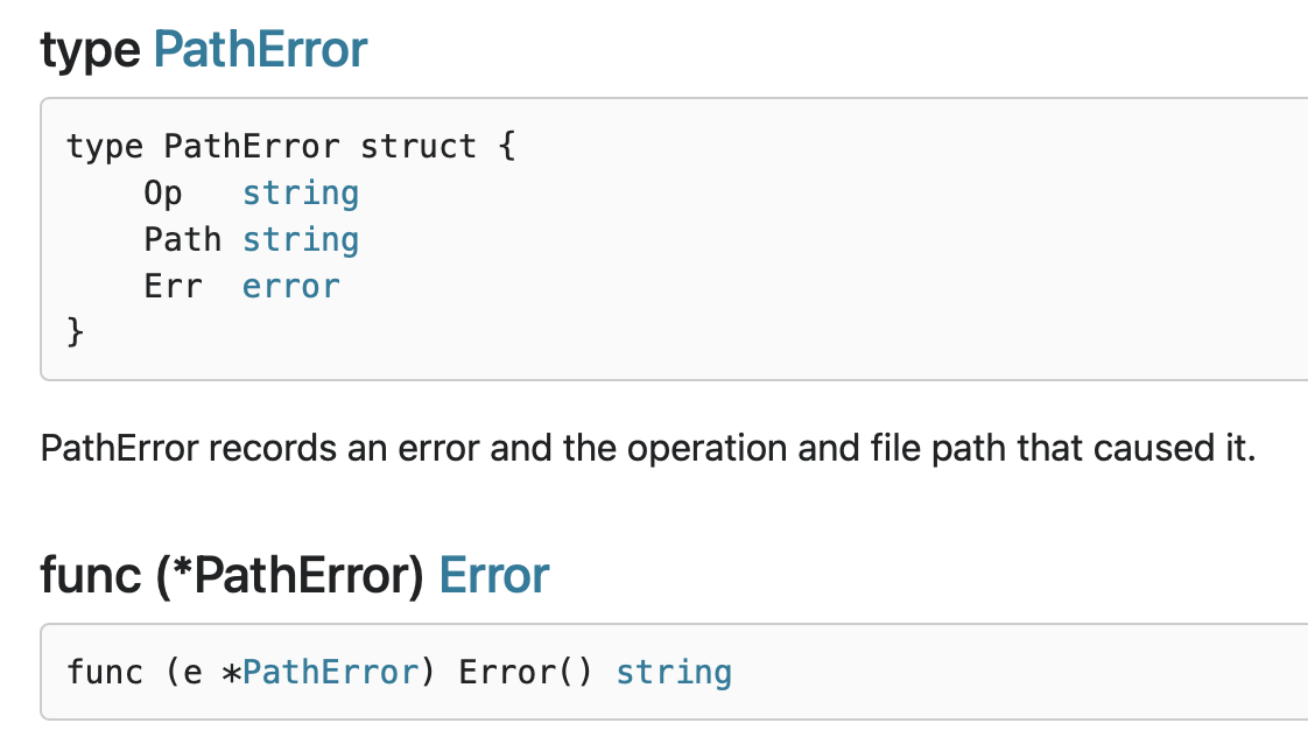
调用者要使用类型断言和类型 switch ,就要让自定义的 error 变为 public。这种模型会导致和调用者产生强耦合,从而导致 API 变得脆弱。
结论是尽量避免使用 error types,虽然错误类型比 sentinel errors 更好,因为它们可以捕获关于出错的更多上下文,但是 error types 共享 error values 许多相同的问题。
因此,我的建议是避免错误类型,或者至少避免将它们作为公共 API 的一部分。
2.2.3 Opaque errors
在我看来,这是最灵活的错误处理策略,因为它要求代码和调用者之间的耦合最少。
我将这种风格称为不透明错误处理,因为虽然您知道发生了错误,但您没有能力看到错误的内部。作为调用者,关于操作的结果,您所知道的就是它起作用了,或者没有起作用(成功还是失败)。
这就是不透明错误处理的全部功能–只需返回错误而不假设其内容。
func fn() error {
x, err := bar.Foo()
if err != nil {
return err
}
// use x
}Assert errors for behaviour, not type.
在少数情况下,这种二分错误处理方法是不够的。例如,与进程外的世界进行交互(如网络活动),需要调用方调查错误的性质,以确定重试该操作是否合理。在这种情况下,我们可以断言错误实现了特定的行为,而不是断言错误是特定的类型或值。考虑这个例子:
package net
// An Error represents a network error.
type Error interface {
error
Timeout() bool // Is the error a timeout?
Temporary() bool // Is the error temporary?
}type temporary interface {
Temporary() bool
}
// IsTemporary returns true if err is temporary.
func IsTemporary(err error) bool {
te, ok := errors.Cause(err).(temporary)
return ok && te.Temporary()
}这里的关键是,这个逻辑可以在不导入定义错误的包或者实际上不了解 err 的底层类型的情况下实现——我们只对它的行为感兴趣。
2.3 Handling Error
2.3.1 Indented flow is for errors
无错误的正常流程代码,将成为一条直线,而不是缩进的代码。
f, err := os.Open(path)
if err != nil {
// handle error
}
// do stuff2.3.2 Eliminate error handling by eliminating errors
Eliminate error handling by eliminating errors
2.3.3 Wrap error
Don’t just check errors, handle them gracefully
- 在你的应用代码中,使用 errors.New 或者 errros.Errorf 返回错误。
- 如果调用其他的函数,通常简单的直接返回。
- 如果和其他库进行协作,考虑使用 errors.Wrap 或者 errors.Wrapf 保存堆栈信息。同样适用于和标准库协作的时候。
- 直接返回错误,而不是每个错误产生的地方到处打日志。
- 在程序的顶部或者是工作的 goroutine 顶部(请求入口),使用 %+v 把堆栈详情记录。
- 使用 errors.Cause 获取 root error,再进行和 sentinel error 判定。
2.3.4 总结
Packages that are reusable across many projects only return root error values.
选择 wrap error 是只有 applications 可以选择应用的策略。具有最高可重用性的包只能返回根错误值。此机制与 Go 标准库中使用的相同(kit 库的 sql.ErrNoRows)。
If the error is not going to be handled, wrap and return up the call stack.
这是关于函数/方法调用返回的每个错误的基本问题。如果函数/方法不打算处理错误,那么用足够的上下文 wrap errors 并将其返回到调用堆栈中。例如,额外的上下文可以是使用的输入参数或失败的查询语句。确定您记录的上下文是足够多还是太多的一个好方法是检查日志并验证它们在开发期间是否为您工作。
Once an error is handled, it is not allowed to be passed up the call stack any longer.
一旦确定函数/方法将处理错误,错误就不再是错误。如果函数/方法仍然需要发出返回,则它不能返回错误值。它应该只返回零(比如降级处理中,你返回了降级数据,然后需要 return nil)。
2.4 Go 1.13 errors
Working with Errors in Go 1.13
2.4.1 Unwrap
go1.13为 errors 和 fmt 标准库包引入了新特性,以简化处理包含其他错误的错误。其中最重要的是: 包含另一个错误的 error 可以实现返回底层错误的 Unwrap 方法。如果 e1.Unwrap() 返回 e2,那么我们说 e1 包装 e2,您可以展开 e1 以获得 e2。
go1.13 errors 包包含两个用于检查错误的新函数:Is 和 As。
2.4.2 Wrapping errors with %w
使用 fmt.Errorf 向错误添加附加信息。
if err != nil {
return fmt.Errorf("decompress %v: %v", name, err)
}在 Go 1.13中 fmt.Errorf 支持新的 %w 谓词。
if err != nil {
// Return an error which unwraps to err.
return fmt.Errorf("decompress %v: %w", name, err)
}用 %w 包装错误可用于 errors.Is 以及 errors.As。
err := fmt.Errorf("access denied: %w", ErrPermission)
...
if errors.Is(err, ErrPermission) ...2.5 Go 2 Error Inspection
Proposal: Go 2 Error Inspection
Error Handling — Problem Overview
2.6 References
https://dave.cheney.net/2012/01/18/why-go-gets-exceptions-right
https://dave.cheney.net/2015/01/26/errors-and-exceptions-redux
https://dave.cheney.net/2014/11/04/error-handling-vs-exceptions-redux
https://rauljordan.com/2020/07/06/why-go-error-handling-is-awesome.html
https://morsmachine.dk/error-handling
https://blog.golang.org/error-handling-and-go
https://www.ardanlabs.com/blog/2014/10/error-handling-in-go-part-i.html
https://www.ardanlabs.com/blog/2014/11/error-handling-in-go-part-ii.html
https://dave.cheney.net/2016/04/27/dont-just-check-errors-handle-them-gracefully
https://commandcenter.blogspot.com/2017/12/error-handling-in-upspin.html
https://blog.golang.org/errors-are-values
https://dave.cheney.net/2016/06/12/stack-traces-and-the-errors-package
https://www.ardanlabs.com/blog/2017/05/design-philosophy-on-logging.html
https://crawshaw.io/blog/xerrors
https://blog.golang.org/go1.13-errors
https://medium.com/gett-engineering/error-handling-in-go-53b8a7112d04
https://medium.com/gett-engineering/error-handling-in-go-1-13-5ee6d1e0a55c
第3课 并行编程
3.1 Goroutine
3.1.1 Processes and Threads
操作系统会为该应用程序创建一个进程。作为一个应用程序,它像一个为所有资源而运行的容器。这些资源包括内存地址空间、文件句柄、设备和线程。
线程是操作系统调度的一种执行路径,用于在处理器执行我们在函数中编写的代码。一个进程从一个线程开始,即主线程,当该线程终止时,进程终止。这是因为主线程是应用程序的原点。然后,主线程可以依次启动更多的线程,而这些线程可以启动更多的线程。
无论线程属于哪个进程,操作系统都会安排线程在可用处理器上运行。每个操作系统都有自己的算法来做出这些决定。
3.1.2 Goroutines and Parallelism
Go 语言层面支持的 go 关键字,可以快速的让一个函数创建为 goroutine,我们可以认为 main 函数就是作为 goroutine 执行的。操作系统调度线程在可用处理器上运行,Go运行时调度 goroutines 在绑定到单个操作系统线程的逻辑处理器中运行(P)。即使使用这个单一的逻辑处理器和操作系统线程,也可以调度数十万 goroutine 以惊人的效率和性能并发运行。
Concurrency is not Parallelism.
并发不是并行。并行是指两个或多个线程同时在不同的处理器执行代码。如果将运行时配置为使用多个逻辑处理器,则调度程序将在这些逻辑处理器之间分配 goroutine,这将导致 goroutine 在不同的操作系统线程上运行。但是,要获得真正的并行性,您需要在具有多个物理处理器的计算机上运行程序。否则,goroutines 将针对单个物理处理器并发运行,即使 Go 运行时使用多个逻辑处理器。
3.1.3 Keep yourself busy or do the work yourself
Keep yourself busy or do the work yourself
空的 select 语句将永远阻塞。
如果你的 goroutine 在从另一个 goroutine 获得结果之前无法取得进展,那么通常情况下,你自己去做这项工作比委托它( go func() )更简单。
这通常消除了将结果从 goroutine 返回到其启动器所需的大量状态跟踪和 chan 操作。
3.1.4 Leave concurrency to the caller
Leave concurrency to the caller
这两个 API 有什么区别?
// ListDirectory returns the contents of dir.
func ListDirectory(dir string) ([]string, error)
// ListDirectory returns a channel over which
// directory entries will be published. When the list
// of entries is exhausted, the channel will be closed.
func ListDirectory(dir string) chan string- 将目录读取到一个 slice 中,然后返回整个切片,或者如果出现错误,则返回错误。这是同步调用的,ListDirectory 的调用方会阻塞,直到读取所有目录条目。根据目录的大小,这可能需要很长时间,并且可能会分配大量内存来构建目录条目名称的 slice。
- ListDirectory 返回一个 chan string,将通过该 chan 传递目录。当通道关闭时,这表示不再有目录。由于在 ListDirectory 返回后发生通道的填充,ListDirectory 可能内部启动 goroutine 来填充通道。
ListDirectory chan 版本还有两个问题:
- 通过使用一个关闭的通道作为不再需要处理的项目的信号,ListDirectory 无法告诉调用者通过通道返回的项目集不完整,因为中途遇到了错误。调用方无法区分空目录与完全从目录读取的错误之间的区别。这两种方法都会导致从 ListDirectory 返回的通道会立即关闭。
- 调用者必须继续从通道读取,直到它关闭,因为这是调用者知道开始填充通道的 goroutine 已经停止的唯一方法。这对 ListDirectory 的使用是一个严重的限制,调用者必须花时间从通道读取数据,即使它可能已经收到了它想要的答案。对于大中型目录,它可能在内存使用方面更为高校,但这种方法并不比原始的基于 slice 的方法快。
正确的方法是使用回调函数。
func ListDirectory(dir string, fn func(string))filepath.WalkDir 也是类似的模型,如果函数启动 goroutine,则必须向调用方提供显式停止该goroutine 的方法。通常,将异步执行函数的决定权交给该函数的调用方通常更容易。
3.1.5 Never start a goroutine without knowning when it will stop
Never start a goroutine without knowning when it will stop
Any time you start a Goroutine you must ask yourself:
- When will it terminate?
- What could prevent it from terminating?
Only use log.Fatal from main.main or init functions.
3.1.6 Incomplete Work
Concurrency Trap #2: Incomplete Work
使用 sync.WaitGroup 来追踪每一个创建的 goroutine。
将 wg.Wait() 操作托管到其他 goroutine,owner goroutine 使用 context 处理超时。
https://play.golang.org/p/p4gsDkpw1Gh
3.2 Memory model
3.2.1 Memory model
如何保证在一个 goroutine 中看到在另一个 goroutine 修改的变量的值,如果程序中修改数据时有其他 goroutine 同时读取,那么必须将读取串行化。为了串行化访问,请使用 channel 或其他同步原语,例如 sync 和 sync/atomic 来保护数据。
先行发生(happens before):如果事件 e1 发生在 e2 前,我们可以说 e2 发生在 e1 后。如果 e1不发生在 e2 前也不发生在 e2 后,我们就说 e1 和 e2 是并发的。
写入单个 machine word 将是原子的。
Reads and writes of values larger than a single machine word behave as multiple machine-word-sized operations in an unspecified order.
3.2.2 Memory Reordering
Memory Consistency Models: A Tutorial
3.3 Package sync
3.3.1 Share Memory By Communicating
传统的线程模型(通常在编写 Java、C++ 和Python 程序时使用)程序员在线程之间通信需要使用共享内存。通常,共享数据结构由锁保护,线程将争用这些锁来访问数据。在某些情况下,通过使用线程安全的数据结构(如Python的Queue),这会变得更容易。
Go 的并发原语 goroutines 和 channels 为构造并发软件提供了一种优雅而独特的方法。Go 没有显式地使用锁来协调对共享数据的访问,而是鼓励使用 chan 在 goroutine 之间传递对数据的引用。这种方法确保在给定的时间只有一个goroutine 可以访问数据。
Do not communicate by sharing memory; instead, share memory by communicating.
3.3.2 Detecting Race Conditions With Go
Detecting Race Conditions With Go
Introducing the Go Race Detector
data race 是两个或多个 goroutine 访问同一个资源(如变量或数据结构),并尝试对该资源进行读写而不考虑其他 goroutine。这种类型的代码可以创建您见过的最疯狂和最随机的 bug。通常需要大量的日志记录和运气才能找到这些类型的bug。
Ice cream makers and data races
interface 内部是是两个 machine word 的值。
Type 指向实现了接口的 struct,Data 指向了实际的值。Data 作为通过 interface 中任何方法调用的接收方传递。

type interface struct {
Type uintptr // points to the type of the interface implementation
Data uintptr // holds the data for the interface's receiver
}3.3.3 sync.atomic
Copy-On-Write 思路在微服务降级或者 local cache 场景中经常使用。写时复制指的是,写操作时候复制全量老数据到一个新的对象中,携带上本次新写的数据,之后利用原子替换(atomic.Value),更新调用者的变量。来完成无锁访问共享数据。

3.3.4 Mutex
饥饿问题
func main() { done := make(chan bool, 1) var mu sync.Mutex // goroutine 1 go func() { for { select { case <-done: return default: mu.Lock() time.Sleep(100 * time.Microsecond) mu.Unlock() } } }() // goroutine 2 for i := 0; i < 10; i++ { time.Sleep(100 * time.Microsecond) mu.Lock() mu.Unlock() } done <- true }这个案例基于两个 goroutine:
- goroutine 1 持有锁很长时间
goroutine 2 每100ms 持有一次锁
都是100ms 的周期,但是由于 goroutine 1 不断的请求锁,可预期它会更频繁的持续到锁。我们基于 Go 1.8 循环了10次,下面是锁的请求占用分布:
Lock acquired per goroutine: g1: 7200216 g2: 10Mutex 被 g1 获取了700多万次,而 g2 只获取了10次。
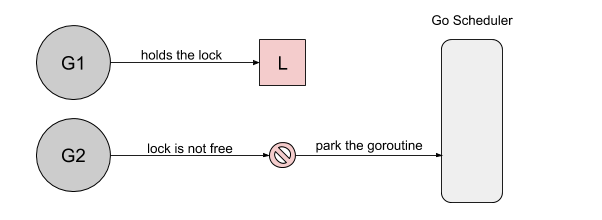
分析
首先,goroutine1 将获得锁并休眠100ms。当goroutine2 试图获取锁时,它将被添加到锁的队列中- FIFO 顺序,goroutine 将进入等待状态:
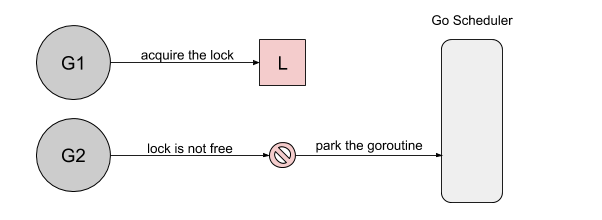
然后,当 goroutine1 完成它的工作时,它将释放锁。这次释放将通知队列唤醒 goroutine2。goroutine2 将被标记为可运行的,并且正在等待 Go 调度程序在线程上运行:
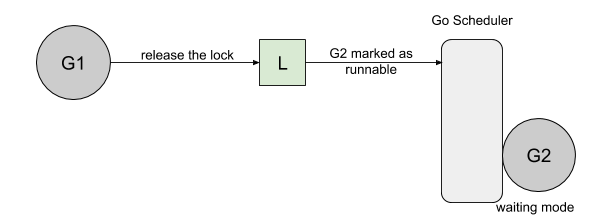
然而,当 goroutine2 等待运行时,goroutine1将再次请求锁:
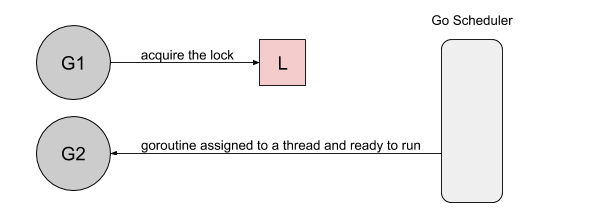
goroutine2 尝试去获取锁,结果悲剧的发现锁又被人持有了,它自己继续进入到等待模式:
goroutine 2对锁的获取将取决于它在线程上运行获取锁所需的时间。
The acquisition of the lock by goroutine 2 will depend on the time it takes for it to run on a thread.
解法方法
Barging
这种模式是为了提高吞吐量,当锁被释放时,它会唤醒第一个等待者,然后把锁给第一个等待者或者给第一个请求锁的人。
Handsoff
当锁释放时候,锁会一直持有直到第一个等待者准备好获取锁。它降低了吞吐量,因为锁被持有,即使另一个 goroutine 准备获取它。
一个互斥锁的 handsoff 会完美地平衡两个goroutine 之间的锁分配,但是会降低性能,因为它会迫使第一个 goroutine 等待锁。
Spinning
自旋在等待队列为空或者应用程序重度使用锁时效果不错。Parking 和 Unparking goroutines 有不低的性能成本开销,相比自旋来说要慢得多。
饥饿模式
Go 1.8 使用了 Barging 和 Spining 的结合实现。当试图获取已经被持有的锁时,如果本地队列为空并且 P 的数量大于1,goroutine 将自旋几次(用一个 P 旋转会阻塞程序)。自旋后,goroutine park。在程序高频使用锁的情况下,它充当了一个快速路径。
Go 1.9 通过添加一个新的饥饿模式来解决先前解释的问题,该模式将会在释放时候触发 handsoff。所有等待锁超过一毫秒的 goroutine(也称为有界等待)将被诊断为饥饿。当被标记为饥饿状态时,unlock 方法会 handsoff 把锁直接扔给第一个等待者。
在饥饿模式下,自旋也被停用,因为传入的goroutines 将没有机会获取为下一个等待者保留的锁。
使用 Go 1.9 运行上面的代码会得到一个更公平的结果:
Lock acquired per goroutine: g1: 57 g2: 10
3.3.5 errgroup
我们把一个复杂的任务,尤其是依赖多个微服务 rpc 需要聚合数据的任务,分解为依赖和并行,依赖的意思为: 需要上游 a 的数据才能访问下游 b 的数据进行组合。但是并行的意思为: 分解为多个小任务并行执行,最终等全部执行完毕。
https://pkg.go.dev/golang.org/x/sync/errgroup
核心原理: 利用 sync.Waitgroup 管理并行执行的 goroutine 。
- 并行工作流
- 错误处理 或者 优雅降级
- context 传播和取消
- 利用局部变量+闭包
3.3.6 sync.Pool
sync.Pool 的场景是用来保存和复用临时对象,以减少内存分配,降低 GC 压力(Request-Driven 特别合适)。
Get 返回 Pool 中的任意一个对象。如果 Pool 为空,则调用 New 返回一个新创建的对象。
放进 Pool 中的对象,会在说不准什么时候被回收掉。所以如果事先 Put 进去 100 个对象,下次 Get 的时候发现 Pool 是空也是有可能的。不过这个特性的一个好处就在于不用担心 Pool 会一直增长,因为 Go 已经帮你在 Pool 中做了回收机制。
这个清理过程是在每次垃圾回收之前做的。之前每次GC 时都会清空 pool,而在1.13版本中引入了 victim cache,会将 pool 内数据拷贝一份,避免 GC 将其清空,即使没有引用的内容也可以保留最多两轮 GC。
3.4 chan
3.4.1 Channels
channels 是一种类型安全的消息队列,充当两个 goroutine 之间的管道,将通过它同步的进行任意资源的交换。chan 控制 goroutines 交互的能力从而创建了 Go 同步机制。当创建的 chan 没有容量时,称为无缓冲通道。反过来,使用容量创建的 chan 称为缓冲通道。
3.4.2 Unbuffered Channels
ch := make(chan struct{})无缓冲 chan 没有容量,因此进行任何交换前需要两个 goroutine 同时准备好。当 goroutine 试图将一个资源发送到一个无缓冲的通道并且没有goroutine 等待接收该资源时,该通道将锁住发送 goroutine 并使其等待。当 goroutine 尝试从无缓冲通道接收,并且没有 goroutine 等待发送资源时,该通道将锁住接收 goroutine 并使其等待。
无缓冲信道的本质是保证同步。
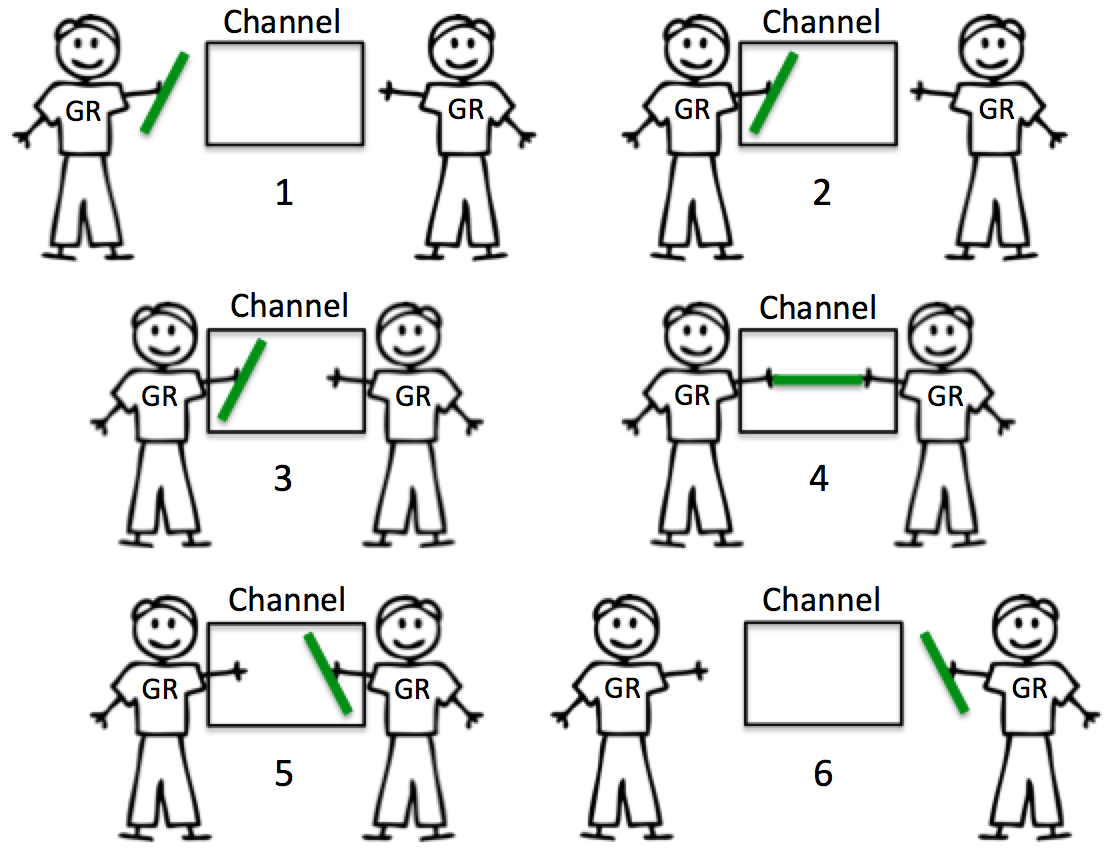
第一个 goroutine 在发送消息 foo 之后被阻塞,因为还没有接收者准备好。规范中对这种行为进行了很好的解释:
https://golang.org/ref/spec#Channel_types
“If the capacity is zero or absent, the channel is unbuffered and communication succeeds only when both a sender and receiver are ready.”
https://golang.org/doc/effective_go.html#channels
“If the channel is unbuffered, the sender blocks until the receiver has received the value”
- Receive 先于 Send 发生。
- 好处: 100% 保证能收到。
- 代价: 延迟时间未知。
3.4.3 Buffered Channels
buffered channel 具有容量,因此其行为可能有点不同。当 goroutine 试图将资源发送到缓冲通道,而该通道已满时,该通道将锁住 goroutine并使其等待缓冲区可用。如果通道中有空间,发送可以立即进行,goroutine 可以继续。当goroutine 试图从缓冲通道接收数据,而缓冲通道为空时,该通道将锁住 goroutine 并使其等待资源被发送。
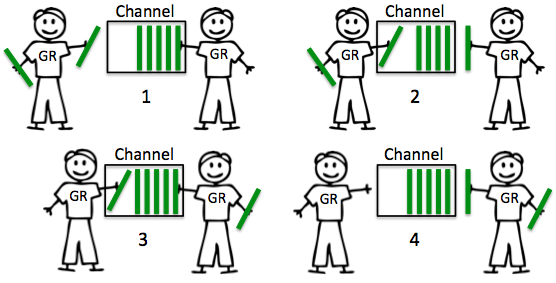
在 chan 创建过程中定义的缓冲区大小可能会极大地影响性能。
- Send 先于 Receive 发生。
- 好处: 延迟更小。
- 代价: 不保证数据到达,越大的 buffer,越小的保障到达。buffer = 1 时,给你延迟一个消息的保障。
3.4.4 Go Concurrency Patterns
- Timing out
- Moving on
- Pipeline
- Fan-out, Fan-in
- Cancellation
- Close 先于 Receive 发生(类似 Buffered)。
- 不需要传递数据,或者传递 nil。
- 非常适合去掉和超时控制。
- Contex
https://blog.golang.org/concurrency-timeouts
https://blog.golang.org/pipelines
https://talks.golang.org/2013/advconc.slide#1
https://github.com/go-kratos/kratos/tree/master/pkg/sync
3.4.5 Design Philosophy
If any given Send on a channel CAN cause the sending goroutine to block:
- Not allowed to use a Buffered channel larger than 1.
- Buffers larger than 1 must have reason/measurements.
- Must know what happens when the sending goroutine blocks.
- Not allowed to use a Buffered channel larger than 1.
If any given Send on a channel WON’T cause the sending goroutine to block:
- You have the exact number of buffers for each send.
- Fan Out pattern
- You have the buffer measured for max capacity.
- Drop pattern
- You have the exact number of buffers for each send.
Less is more with buffers.
- Don’t think about performance when thinking about buffers.
Buffers can help to reduce blocking latency between signaling.
- Reducing blocking latency towards zero does not necessarily - mean better throughput.
- If a buffer of one is giving you good enough throughput then - keep it.
- Question buffers that are larger than one and measure for size.
- Find the smallest buffer possible that provides good enough - throughput.
3.5 Package context
3.5.1 Request-scoped context
在 Go 服务中,每个传入的请求都在其自己的goroutine 中处理。请求处理程序通常启动额外的 goroutine 来访问其他后端,如数据库和 RPC服务。处理请求的 goroutine 通常需要访问特定于请求(request-specific context)的值,例如最终用户的身份、授权令牌和请求的截止日期(deadline)。当一个请求被取消或超时时,处理该请求的所有 goroutine 都应该快速退出(fail fast),这样系统就可以回收它们正在使用的任何资源。
Go 1.7 引入一个 context 包,它使得跨 API 边界的请求范围元数据、取消信号和截止日期很容易传递给处理请求所涉及的所有 goroutine(显示传递)。
在将 context 集成到 API 中时,要记住的最重要的一点是,它的作用域是请求级别的。例如,沿单个数据库查询存在是有意义的,但沿数据库对象存在则没有意义。
目前有两种方法可以将 context 对象集成到 API 中:
The first parameter of a function call
首参数传递 context 对象,比如,参考 net 包 Dialer.DialContext。此函数执行正常的 Dial 操作,但可以通过 context 对象取消函数调用。
func (d *Dialer) DialContext(ctx context.Context, network, address string) (Conn, error)Optional config on a request structure
在第一个 request 对象中携带一个可选的 context 对象。例如 net/http 库的 Request.WithContext,通过携带给定的 context 对象,返回一个新的 Request 对象。
func (r *Request) WithContext(ctx context.Context) *Request
3.5.2 Do not store Contexts inside a struct type
Do not store Contexts inside a struct type; instead, pass a Context explicitly to each function that needs it. The Context should be the first parameter, typically named ctx:
func DoSomething(ctx context.Context, arg Arg) error {
// ... use ctx ...
}Do not pass a nil Context, even if a function permits it. Pass context.TODO if you are unsure about which Context to use.
Understanding Go’s context package
Incoming requests to a server should create a Context, and outgoing calls to servers should accept a Context.
The chain of function calls between them must propagate the Context, optionally replacing it with a derived Context created using WithCancel, WithDeadline, WithTimeout, or WithValue.
When a Context is canceled, all Contexts derived from it are also canceled.
How to correctly use context.Context in Go 1.7
使用 context 的一个很好的心智模型是它应该在程序中流动,应该贯穿你的代码。这通常意味着您不希望将其存储在结构体之中。它从一个函数传递到另一个函数,并根据需要进行扩展。理想情况下,每个请求都会创建一个 context 对象,并在请求结束时过期。
不存储上下文的一个例外是,当您需要将它放入一个结构中时,该结构纯粹用作通过通道传递的消息。如下例所示:
// A message processes parameter and returns the result on responseChan.
// ctx is places in a struct, but this is ok to do.
type message struct {
responseChan chan<- int
parameter string
ctx context.Context
}3.5.3 context.WithValue
context.WithValue 内部基于 valueCtx 实现:
// A valueCtx carries a key-value pair. It implements Value for that key and
// delegates all other calls to the embedded Context.
type valueCtx struct {
Context
key, val interface{}
}为了实现不断的 WithValue,构建新的 context,内部在查找 key 时候,使用递归方式不断从当前,从父节点寻找匹配的 key,直到 root context(Background 和 TODO Value 函数会返回 nil)。
func (c *valueCtx) Value(key interface{}) interface{} {
if c.key == key {
return c.val
}
return c.Context.Value(key)
}context.WithValue 方法允许上下文携带请求范围的数据。这些数据必须是安全的,以便多个 goroutine 同时使用。这里的数据,更多是面向请求的元数据,不应该作为函数的可选参数来使用(比如 context 里面挂了一个sql.Tx 对象,传递到 Dao 层使用),因为元数据相对函数参数更加是隐含的,面向请求的。而参数是更加显示的。
同一个 context 对象可以传递给在不同 goroutine 中运行的函数;上下文对于多个 goroutine 同时使用是安全的。对于值类型最容易犯错的地方,在于 context value 应该是 immutable 的,每次重新赋值应该是新的 context,即:
context.WithValue(ctx, oldvalue)Context.Value should inform, not control.
It’s time to understand Golang Contexts.
Use context values only for request-scoped data that transits processes and APIs, not for passing optional parameters to functions.
比如 染色,API 重要性,Trace。
3.5.4 When a Context is canceled, all Contexts derived from it are also canceled
当一个 context 被取消时,从它派生的所有 context 也将被取消。WithCancel(ctx) 参数 ctx 认为是 parent ctx,在内部会进行一个传播关系链的关联。Done() 返回 一个 chan,当我们取消某个parent context, 实际上上会递归层层 cancel 掉自己的 child context 的 done chan 从而让整个调用链中所有监听 cancel 的 goroutine退出。
3.5.5 All blocking/long operations should be cancelable
如果要实现一个超时控制,通过上面的context 的parent/child 机制,其实我们只需要启动一个定时器,然后在超时的时候,直接将当前的 context 给 cancel 掉,就可以实现监听在当前和下层的额context.Done() 的 goroutine 的退出。
3.5.6 Final Notes
- Incoming requests to a server should create a Context.
- Outgoing calls to servers should accept a Context.
- Do not store Contexts inside a struct type; instead, pass a Context explicitly to each function that - needs it.
- The chain of function calls between them must propagate the Context.
- Replace a Context using WithCancel, WithDeadline, WithTimeout, or WithValue.
- When a Context is canceled, all Contexts derived from it are also canceled.
- The same Context may be passed to functions running in different goroutines; Contexts are safe for - simultaneous use by multiple goroutines.
- Do not pass a nil Context, even if a function permits it. Pass a TODO context if you are unsure about - which Context to use.
- Use context values only for request-scoped data that transits processes and APIs, not for passing - optional parameters to functions.
- All blocking/long operations should be cancelable.
- Context.Value obscures your program’s flow.
- Context.Value should inform, not control.
- Try not to use context.Value.
https://talks.golang.org/2014/gotham-context.slide#1
3.6 References
https://www.ardanlabs.com/blog/2018/11/goroutine-leaks-the-forgotten-sender.html
https://www.ardanlabs.com/blog/2019/04/concurrency-trap-2-incomplete-work.html
https://www.ardanlabs.com/blog/2014/01/concurrency-goroutines-and-gomaxprocs.html
https://dave.cheney.net/practical-go/presentations/qcon-china.html#_concurrency
https://golang.org/ref/mem
https://blog.csdn.net/caoshangpa/article/details/78853919
https://blog.csdn.net/qcrao/article/details/92759907
https://cch123.github.io/ooo/
https://blog.golang.org/codelab-share
https://dave.cheney.net/2018/01/06/if-aligned-memory-writes-are-atomic-why-do-we-need-the-sync-atomic-package
http://blog.golang.org/race-detector
https://dave.cheney.net/2014/06/27/ice-cream-makers-and-data-races
https://www.ardanlabs.com/blog/2014/06/ice-cream-makers-and-data-races-part-ii.html
https://medium.com/a-journey-with-go/go-how-to-reduce-lock-contention-with-the-atomic-package-ba3b2664b549
https://medium.com/a-journey-with-go/go-discovery-of-the-trace-package-e5a821743c3c
https://medium.com/a-journey-with-go/go-mutex-and-starvation-3f4f4e75ad50
https://www.ardanlabs.com/blog/2017/10/the-behavior-of-channels.html
https://medium.com/a-journey-with-go/go-buffered-and-unbuffered-channels-29a107c00268
https://medium.com/a-journey-with-go/go-ordering-in-select-statements-fd0ff80fd8d6
https://www.ardanlabs.com/blog/2017/10/the-behavior-of-channels.html
https://www.ardanlabs.com/blog/2014/02/the-nature-of-channels-in-go.html
https://www.ardanlabs.com/blog/2013/10/my-channel-select-bug.html
https://blog.golang.org/io2013-talk-concurrency
https://blog.golang.org/waza-talk
https://blog.golang.org/io2012-videos
https://blog.golang.org/concurrency-timeouts
https://blog.golang.org/pipelines
https://www.ardanlabs.com/blog/2014/02/running-queries-concurrently-against.html
https://blogtitle.github.io/go-advanced-concurrency-patterns-part-3-channels/
https://www.ardanlabs.com/blog/2013/05/thread-pooling-in-go-programming.html
https://www.ardanlabs.com/blog/2013/09/pool-go-routines-to-process-task.html
https://blogtitle.github.io/categories/concurrency/
https://medium.com/a-journey-with-go/go-context-and-cancellation-by-propagation-7a808bbc889c
https://blog.golang.org/context
https://www.ardanlabs.com/blog/2019/09/context-package-semantics-in-go.html
https://golang.org/ref/spec#Channel_types
https://drive.google.com/file/d/1nPdvhB0PutEJzdCq5ms6UI58dp50fcAN/view
https://medium.com/a-journey-with-go/go-context-and-cancellation-by-propagation-7a808bbc889c
https://blog.golang.org/context
https://www.ardanlabs.com/blog/2019/09/context-package-semantics-in-go.html
https://golang.org/doc/effective_go.html#concurrency
https://zhuanlan.zhihu.com/p/34417106?hmsr=toutiao.io
https://talks.golang.org/2014/gotham-context.slide#1
https://medium.com/@cep21/how-to-correctly-use-context-context-in-go-1-7-8f2c0fafdf39
第4课 Go 工程化实践
4.1 工程项目结构
4.1.1 Standard Go Project Layout
https://github.com/golang-standards/project-layout/blob/master/README_zh.md
如果你尝试学习 Go,或者你正在为自己建立一个 PoC 或一个玩具项目,这个项目布局是没啥必要的。从一些非常简单的事情开始(一个 main.go 文件绰绰有余)。当有更多的人参与这个项目时,你将需要更多的结构,包括需要一个 toolkit 来方便生成项目的模板,尽可能大家统一的工程目录布局。
/cmd
本项目的主干。
每个应用程序的目录名应该与你想要的可执行文件的名称相匹配(例如,/cmd/myapp)。
不要在这个目录中放置太多代码。如果你认为代码可以导入并在其他项目中使用,那么它应该位于 /pkg 目录中。如果代码不是可重用的,或者你不希望其他人重用它,请将该代码放到 /internal 目录中。
/internal
私有应用程序和库代码。这是你不希望其他人在其应用程序或库中导入代码。请注意,这个布局模式是由 Go 编译器本身执行的。有关更多细节,请参阅Go 1.4 release notes。注意,你并不局限于顶级 internal 目录。在项目树的任何级别上都可以有多个内部目录。
你可以选择向 internal 包中添加一些额外的结构,以分隔共享和非共享的内部代码。这不是必需的(特别是对于较小的项目),但是最好有有可视化的线索来显示预期的包的用途。你的实际应用程序代码可以放在 /internal/app 目录下(例如 /internal/app/myapp),这些应用程序共享的代码可以放在 /internal/pkg 目录下(例如 /internal/pkg/myprivlib)。
因为我们习惯把相关的服务,比如账号服务,内部有 rpc、job、admin 等,相关的服务整合一起后,需要区分 app。单一的服务,可以去掉 /internal/myapp。
/pkg
外部应用程序可以使用的库代码(例如 /pkg/mypubliclib)。其他项目会导入这些库,所以在这里放东西之前要三思:-)注意,internal 目录是确保私有包不可导入的更好方法,因为它是由 Go 强制执行的。/pkg 目录仍然是一种很好的方式,可以显式地表示该目录中的代码对于其他人来说是安全使用的好方法。
/pkg 目录内,可以参考 go 标准库的组织方式,按照功能分类。/internla/pkg 一般用于项目内的 跨多个应用的公共共享代码,但其作用域仅在单个项目工程内。
由 Travis Jeffery 撰写的 I’ll take pkg over internal 博客文章提供了 pkg 和 internal 目录的一个很好的概述,以及什么时候使用它们是有意义的。
当根目录包含大量非 Go 组件和目录时,这也是一种将 Go 代码分组到一个位置的方法,这使得运行各种 Go 工具变得更加容易组织。
4.1.2 Kit Project Layout
每个公司都应当为不同的微服务建立一个统一的 kit 工具包项目(基础库/框架) 和 app 项目。
基础库 kit 为独立项目,公司级建议只有一个,按照功能目录来拆分会带来不少的管理工作,因此建议合并整合。
“To this end, the Kit project is not allowed to have a vendor folder. If any of packages are dependent on 3rd party packages, they must always build against the latest version of those dependences.”
kit 项目必须具备的特点:
- 统一
- 标准库方式布局
- 高度抽象
- 支持插件
4.1.3 Service Application Project Layout
/api
API 协议定义目录,xxapi.proto protobuf 文件,以及生成的 go 文件。我们通常把 api 文档直接在 proto 文件中描述。
/configs
配置文件模板或默认配置。
/test
额外的外部测试应用程序和测试数据。你可以随时根据需求构造 /test 目录。对于较大的项目,有一个数据子目录是有意义的。例如,你可以使用 /test/data 或 /test/testdata (如果你需要忽略目录中的内容)。请注意,Go 还会忽略以”.”或”_”开头的目录或文件,因此在如何命名测试数据目录方面有更大的灵活性。
不应该包含:/src
有些 Go 项目确实有一个 src 文件夹,但这通常发生在开发人员有 Java 背景,在那里它是一种常见的模式。不要将项目级别 src 目录与 Go 用于其工作空间的 src 目录。
4.1.4 Service Application Project
一个 gitlab 的 project 里可以放置多个微服务的app(类似 monorepo)。也可以按照 gitlab 的 group 里建立多个 project,每个 project 对应一个 app。
- 多 app 的方式,app 目录内的每个微服务按照自己的全局唯一名称,比如 “account.service.vip” 来建立目录,如: account/vip/*。
- 和 app 平级的目录 pkg 存放业务有关的公共库(非基础框架库)。如果应用不希望导出这些目录,可以放置到 myapp/internal/pkg 中。
微服务中的 app 服务类型分为4类:interface、service、job、admin。
- interface: 对外的 BFF 服务,接受来自用户的请求,比如暴露了 HTTP/gRPC 接口。
- service: 对内的微服务,仅接受来自内部其他服务或者网关的请求,比如暴露了gRPC 接口只对内服务。
- admin:区别于 service,更多是面向运营测的服务,通常数据权限更高,隔离带来更好的代码级别安全。
- job: 流式任务处理的服务,上游一般依赖 message broker。
- task: 定时任务,类似 cronjob,部署到 task 托管平台中。
cmd 应用目录负责程序的: 启动、关闭、配置初始化等。
4.1.5 Service Application Project - v1
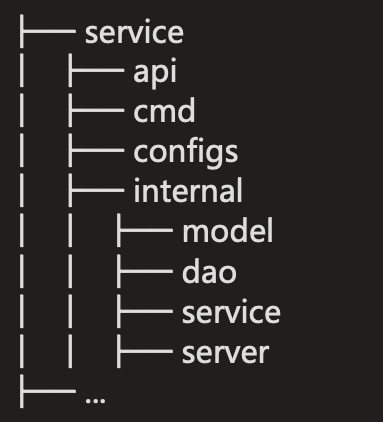
我们老的布局 ,app 目录下有 api、cmd、configs、internal 目录,目录里一般还会放置 README、CHANGELOG、OWNERS。
- api: 放置 API 定义(protobuf),以及对应的生成的 client 代码,基于 pb 生成的 swagger.json。
- configs: 放服务所需要的配置文件,比如database.yaml、redis.yaml、application.yaml。
- internal: 是为了避免有同业务下有人跨目录引用了内部的 model、dao 等内部 struct。
- server: 放置 HTTP/gRPC 的路由代码,以及 DTO 转换的代码。
DTO(Data Transfer Object):数据传输对象,这个概念来源于J2EE 的设计模式。但在这里,泛指用于展示层/API 层与服务层(业务逻辑层)之间的数据传输对象。
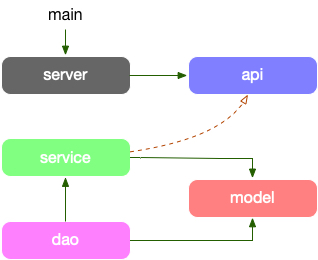
项目的依赖路径为: model -> dao -> service -> api,model struct 串联各个层,直到 api 需要做 DTO 对象转换。
- model: 放对应”存储层”的结构体,是对存储的一一隐射。
- dao: 数据读写层,数据库和缓存全部在这层统一处理,包括 cache miss 处理。
- service: 组合各种数据访问来构建业务逻辑。
- server: 依赖 proto 定义的服务作为入参,提供快捷的启动服务全局方法。
- api: 定义了 API proto 文件,和生成的 stub 代码,它生成的 interface,其实现者在 service 中。
service 的方法签名因为实现了 API 的 接口定义,DTO 直接在业务逻辑层直接使用了,更有 dao 直接使用,最简化代码。
DO(Domain Object): 领域对象,就是从现实世界中抽象出来的有形或无形的业务实体。缺乏 DTO -> DO 的对象转换。
4.1.6 Service Application Project - v2
app 目录下有 api、cmd、configs、internal 目录,目录里一般还会放置 README、CHANGELOG、OWNERS。
internal: 是为了避免有同业务下有人跨目录引用了内部的 biz、data、service 等内部 struct。
- biz: 业务逻辑的组装层,类似 DDD 的 domain 层,data 类似 DDD 的 repo,repo 接口在这里定义,使用依赖倒置的原则。
- data: 业务数据访问,包含 cache、db 等封装,实现了 biz 的 repo 接口。我们可能会把 data 与 dao 混淆在一起,data 偏重业务的含义,它所要做的是将领域对象重新拿出来,我们去掉了 DDD 的 infra层。
- service: 实现了 api 定义的服务层,类似 DDD 的 application 层,处理 DTO 到 biz 领域实体的转换(DTO -> DO),同时协同各类 biz 交互,但是不应处理复杂逻辑。
PO(Persistent Object): 持久化对象,它跟持久层(通常是关系型数据库)的数据结构形成一一对应的映射关系,如果持久层是关系型数据库,那么数据表中的每个字段(或若干个)就对应 PO 的一个(或若干个)属性。
https://github.com/facebook/ent
4.1.7 Lifecycle
Lifecycle 需要考虑服务应用的对象初始化以及生命周期的管理,所有 HTTP/gRPC 依赖的前置资源初始化,包括 data、biz、service,之后再启动监听服务。我们使用 https://github.com/google/wire ,来管理所有资源的依赖注入。为何需要依赖注入?

核心是为了:
- 方便测试;
- 单次初始化和复用;
4.1.8 Wire
手撸资源的初始化和关闭是非常繁琐,容易出错的。上面提到我们使用依赖注入的思路 DI,结合 google wire,静态的 go generate 生成静态的代码,可以在很方便诊断和查看,不是在运行时利用 reflection 实现。
4.2 API 设计
4.2.1 gRPC
4.2.2 API Project
https://github.com/googleapis/googleapis
https://github.com/envoyproxy/data-plane-api
https://github.com/istio/api
为了统一检索和规范 API,我们内部建立了一个统一的 bapis 仓库,整合所有对内对外 API。
- API 仓库,方便跨部门协作。
- 版本管理,基于 git 控制。
- 规范化检查,API lint。
- API design review,变更 diff。
- 权限管理,目录 OWNERS。
4.2.3 API Project Layout

项目中定义 proto,以 api 为包名根目录:

在统一仓库中管理 proto ,以仓库为包名根目录:

4.2.4 API Compatibility
向后兼容(非破坏性)的修改
- 给 API 服务定义添加 API 接口
从协议的角度来看,这始终是安全的。
- 给请求消息添加字段
只要客户端在新版和旧版中对该字段的处理不保持一致,添加请求字段就是兼容的。
- 给响应消息添加字段
在不改变其他响应字段的行为的前提下,非资源(例如,ListBooksResponse)的响应消息可以扩展而不必破坏客户端的兼容性。即使会引入冗余,先前在响应中填充的任何字段应继续使用相同的语义填充。
向后不兼容(破坏性)的修改
- 删除或重命名服务,字段,方法或枚举值
从根本上说,如果客户端代码可以引用某些东西,那么删除或重命名它都是不兼容的变化,这时必须修改major 版本号。
- 修改字段的类型
即使新类型是传输格式兼容的,这也可能会导致客户端库生成的代码发生变化,因此必须增加major版本号。 对于编译型静态语言来说,会容易引入编译错误。
- 修改现有请求的可见行为
客户端通常依赖于 API 行为和语义,即使这样的行为没有被明确支持或记录。 因此,在大多数情况下,修改 API 数据的行为或语义将被消费者视为是破坏性的。如果行为没有加密隐藏,您应该假设用户已经发现它,并将依赖于它。
- 给资源消息添加 读取/写入 字段
4.2.5 API Naming Conventions
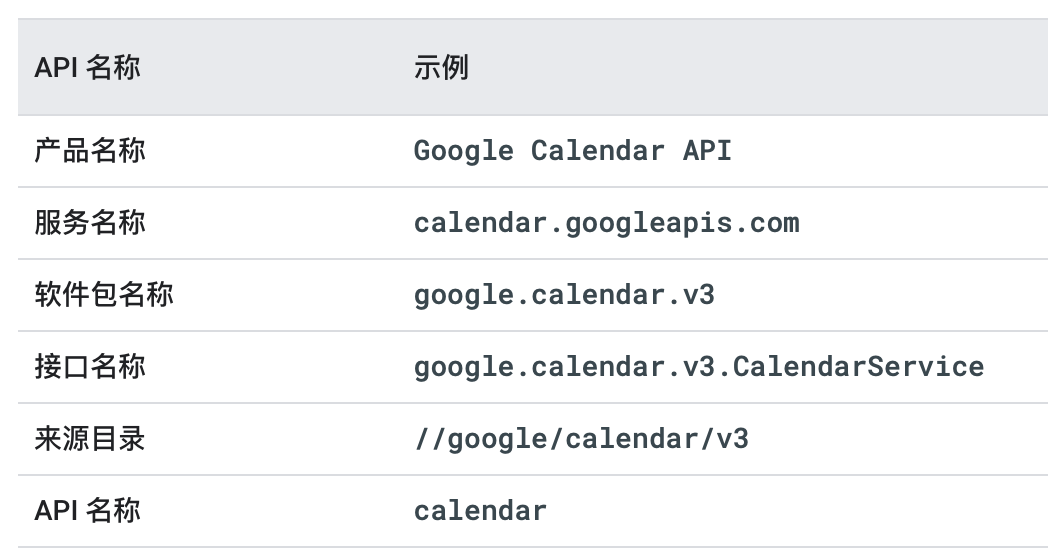
包名为应用的标识(APP_ID),用于生成 gRPC 请求路径,或者 proto 之间进行引用 Message。文件中声明的包名称应该与产品和服务名称保持一致。带有版本的 API 的软件包名称必须以此版本结尾。
my.package.v1,为 API 目录,定义service相关接口,用于提供业务使用。
// RequestURL: /<package_name>.<version>.<service_name>/{method}
package <package_name>.<version>;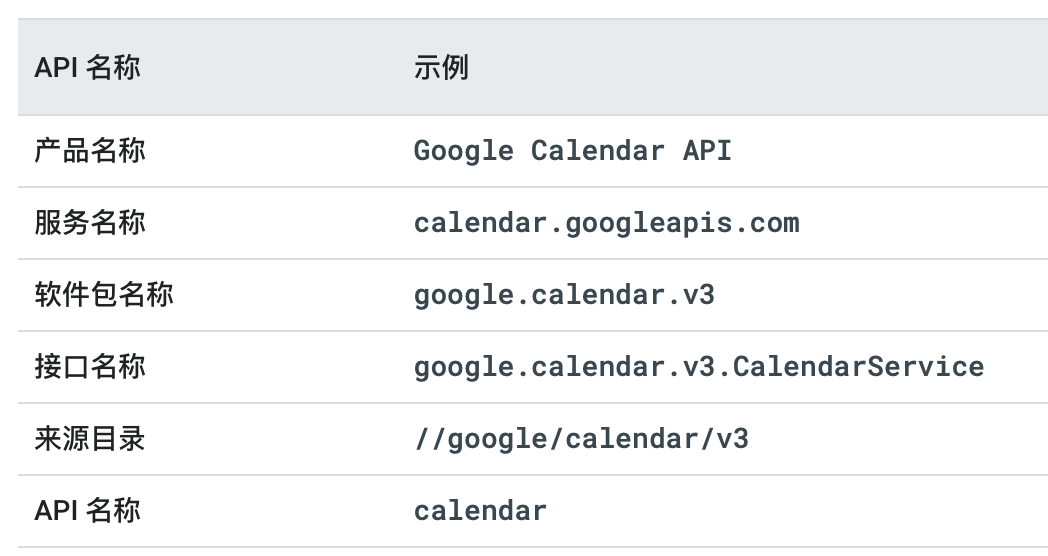
4.2.6 API Primitive Fields
gRPC 默认使用 Protobuf v3 格式,因为去除了 required 和 optional 关键字,默认全部都是 optional 字段。如果没有赋值的字段,默认会基础类型字段的默认值,比如 0 或者 “”。
Protobuf v3 中,建议使用:https://github.com/protocolbuffers/protobuf/blob/master/src/google/protobuf/wrappers.proto
Warpper 类型的字段,即包装一个 message,使用时变为指针。
Protobuf 作为强 schema 的描述文件,也可以方便扩展,是不是用于配置文件定义也可以?
4.2.7 API Errors
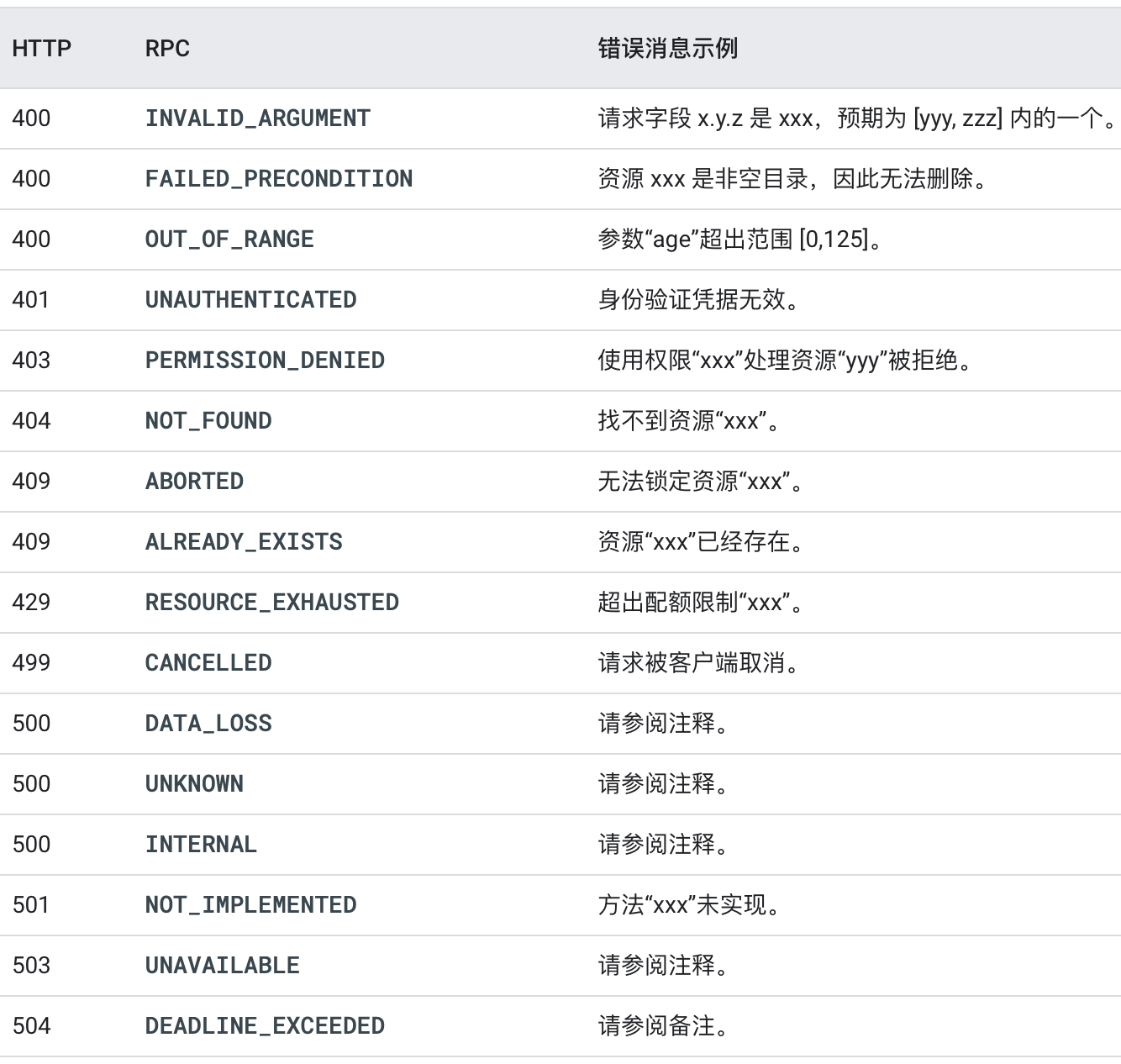
使用一小组标准错误配合大量资源
- 例如,服务器没有定义不同类型的”找不到”错误,而是使用一个标准 google.rpc.Code.NOT_FOUND 错误代码并告诉客户端找不到哪个特定资源。状态空间变小降低了文档的复杂性,在客户端库中提供了更好的惯用映射,并降低了客户端的逻辑复杂性,同时不限制是否包含可操作信息(/google/rpc/error_details)。
错误传播
如果您的 API 服务依赖于其他服务,则不应盲目地将这些服务的错误传播到您的客户端。在翻译错误时,我们建议执行以下操作:
- 隐藏实现详细信息和机密信息。
- 调整负责该错误的一方。例如,从另一个服务接收 INVALID_ARGUMENT 错误的服务器应该将 INTERNAL 传播给它自己的调用者。
全局错误码
- 全局错误码,是松散、易被破坏契约的,基于我们上述讨论的,在每个服务传播错误的时候,做一次翻译,这样保证每个服务 + 错误枚举,应该是唯一的,而且在 proto 定义中是可以写出来文档的。
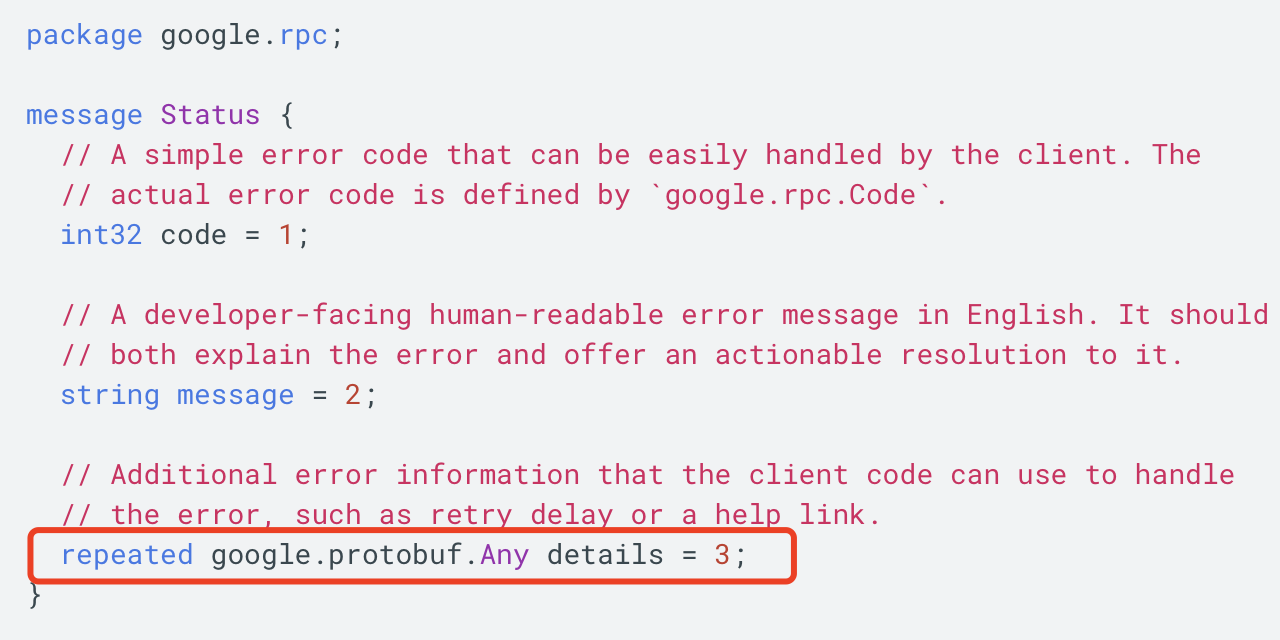

Status.details 中存放的就是 ErrorInfo 。
4.2.8 API Design
Practical API Design at Netflix, Part 1: Using Protobuf FieldMask
Practical API Design at Netflix, Part 2: Protobuf FieldMask for Mutation Operations
FieldMask 部分更新的方案:
- 客户端可以执行需要更新的字段信息。
- 空 FieldMask 默认应用到 “所有字段”。
4.3 配置管理
4.3.1 Configuration
- 环境变量(配置)
Region、Zone、Cluster、Environment、Color、Discovery、AppID、Host,等之类的环境信息,都是通过在线运行时平台打入到容器或者物理机,供 kit 库读取使用。 - 静态配置
资源需要初始化的配置信息,比如 http/gRPC server、redis、mysql 等,这类资源在线变更配置的风险非常大,我通常不鼓励 on-the-fly 变更,很可能会导致业务出现不可预期的事故,变更静态配置和发布 binary app 没有区别,应该走一次迭代发布的流程。 - 动态配置
应用程序可能需要一些在线的开关,来控制业务的一些简单策略,会频繁的调整和使用,我们把这类是基础类型(int, bool)等配置,用于可以动态变更业务流的收归一起,同时可以考虑结合类似 https://pkg.go.dev/expvar 来结合使用。 - 全局配置
通常,我们依赖的各类组件、中间件都有大量的默认配置或者指定配置,在各个项目里大量拷贝复制,容易出现意外,所以我们使用全局配置模板来定制化常用的组件,然后再特化的应用里进行局部替换。
4.3.2 Functional options
灵活的设置选项
Functional options for friendly APIs — Dave Cheney
// DialOption specifies an option for dialing a Redis server. type DialOption func(*dialOptions) // Dial connects to the Redis server at the given network and // address using the specified options. func Dial(network, address string, options ...DialOption) (Conn, error) { do := dialOptions{ dial: net.Dial, } for _, option := range options { option(&do) } // ... }临时改变配置的优雅做法
Self-referential functions and the design of options — Rob Pike
type option func(f *Foo) option // Verbosity sets Foo's verbosity level to v. func Verbosity(v int) option { return func(f *Foo) option { prev := f.verbosity f.verbosity = v return Verbosity(prev) } } func DoSomethingVerbosely(foo *Foo, verbosity int) { // Could combine the next two lines, // with some loss of readability. prev := foo.Option(pkg.Verbosity(verbosity)) defer foo.Option(prev) // ... do some stuff with foo under high verbosity. }支持使用者扩展选项
在 gRPC 中任何服务的实现都会接收一个
grpc.CallOption类型的参数:type GreeterClient interface { SayHello(ctx context.Context, in *HelloRequest, opts ...grpc.CallOption) (*HelloReply, error) }grpc.CallOption的实现如下:// CallOption configures a Call before it starts or extracts information from // a Call after it completes. type CallOption interface { // before is called before the call is sent to any server. If before // returns a non-nil error, the RPC fails with that error. before(*callInfo) error // after is called after the call has completed. after cannot return an // error, so any failures should be reported via output parameters. after(*callInfo, *csAttempt) }为了支持使用者扩展这个选项,gRPC 提供了一个
EmptyCallOption,它实现了CallOption接口的一个空实现。// EmptyCallOption does not alter the Call configuration. // It can be embedded in another structure to carry satellite data for use // by interceptors. type EmptyCallOption struct{} func (EmptyCallOption) before(*callInfo) error { return nil } func (EmptyCallOption) after(*callInfo, *csAttempt) {}任何想要扩展选项的客户端都可以自定义结构体并包含
EmptyCallOption来完成扩展:// TimeoutCallOption timeout option. type TimeoutCallOption struct { grpc.EmptyCallOption Timeout time.Duration }实际的完整的使用实例可以参考:https://github.com/grpc-ecosystem/go-grpc-middleware/blob/master/retry/examples_test.go
4.3.3 Hybrid APIs
使用了 Functional options 后:
- “JSON/YAML 配置怎么加载,无法映射 DialOption 啊!”
2。 “嗯,不依赖配置的走 options,配置加载走config”
一定需要维护两套 API 么?
// Dial connects to the Redis server at the given network and
// address using the specified options.
func Dial(network, address string, options ...DialOption) (Conn, error)
// NewConn new a redis conn.
func NewConn(c *Config) (cn Conn, err error)4.3.4 Configuration & APIs
“For example, both your infrastructure and interface might use plain JSON. However, avoid tight coupling between the data format you use as the interface and the data format you use internally. For example, you may use a data structure internally that contains the data structure consumed from configuration. The internal data structure might also contain completely implementation-specific data that never needs to be surfaced outside of the system.”
— the-site-reliability-workbook 2
正确做法:
仅保留 options API;
// Dial connects to the Redis server at the given network and // address using the specified options. func Dial(network, address string, options ...DialOption) (Conn, error)config file 和 options struct 解耦;
加载配置文件得到一个内存中的 Config 配置对象:
可以使用 protobuf 来定义和生成 Config 这个配置对象。
// instead use load yaml file. c := &Config{ Network: "tcp", Addr: "127.0.0.1:3389", Database: 1, Password: "Hello", ReadTimeout: 1 * time.Second, }提供配置转换为 Functional options 的方法:
// Options apply config to options. func (c *Config) Options() []redis.Options { return []redis.Options{ redis.DialDatabase(c.Database), redis.DialPassword(c.Password), redis.DialReadTimeout(c.ReadTimeout), } }最后使用转换后的 Functional options 来调用 options API:
r, err := redis.Dial(c.Network, c.Address, Options(c)...)配置工具的实践:
- 语义验证
- 高亮
- Lint
- 格式化
最后B站实际使用的是 YAML + Protobuf 这种方式。
4.3.5 Configuration Best Pratice
代码更改系统功能是一个冗长且复杂的过程,往往还涉及Review、测试等流程,但更改单个配置选项可能会对功能产生重大影响,通常配置还未经测试。配置的目标:
- 避免复杂
- 多样的配置
- 简单化努力
- 以基础设施 -> 面向用户进行转变
- 配置的必选项和可选项
- 配置的防御编程
- 权限和变更跟踪
- 配置的版本和应用对齐
- 安全的配置变更:逐步部署、回滚更改、自动回滚
4.4 包管理
https://github.com/gomods/athens
https://goproxy.cn
https://blog.golang.org/modules2019
https://blog.golang.org/using-go-modules
https://blog.golang.org/migrating-to-go-modules
https://blog.golang.org/module-mirror-launch
https://blog.golang.org/publishing-go-modules
https://blog.golang.org/v2-go-modules
https://blog.golang.org/module-compatibility
4.5 测试
4.5.1 Unittest
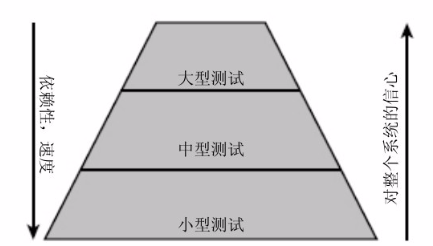
- 小型测试带来优秀的代码质量、良好的异常处理、优雅的错误报告;大中型测试会带来整体产品质量和数据验证。
单元测试。
- 不同类型的项目,对测试的需求不同,总体上有一个经验法则,即70/20/10原则:70%是小型测试,20%是中型测试,10%是大型测试。
集成测试。
- 如果一个项目是面向用户的,拥有较高的集成度,或者用户接口比较复杂,他们就应该有更多的中型和大型测试;如果是基础平台或者面向数据的项目,例如索引或网络爬虫,则最好有大量的小型测试,中型测试和大型测试的数量要求会少很多。
E2E,end-to-end 测试,端测试。
kit 库,基础库需要写的比较多的单元测试。
中间件要写单元测试和 chaos 测试。
大型测试直接测试接口。
“自动化实现的,用于验证一个单独函数或独立功能模块的代码是否按照预期工作,着重于典型功能性问题、数据损坏、错误条件和大小差一错误(译注:大小差一(off-by-one)错误是一类常见的程序设计错误)等方面的验证” - 《Google软件测试之道》
单元测试的基本要求:
- 快速
- 环境一致
- 任意顺序
- 并行
基于 docker-compose 实现跨平台跨语言环境的容器依赖管理方案,以解决运行 unittest 场景下的(mysql, redis, mc)容器依赖问题:
- 本地安装 Docker。
- 无侵入式的环境初始化。
- 快速重置环境。
- 随时随地运行(不依赖外部服务)。
- 语义式 API 声明资源。
- 真实外部依赖,而非 in-process 模拟。
细节:
- 正确的对容器内服务进行健康检测,避免 unittest 启动时候资源还未 ready。
- 应该交由 app 自己来初始化数据,比如 db 的scheme,初始的 sql 数据等,为了满足测试的一致性,在每次结束后,都会销毁容器。
- 在单元测试开始前,导入封装好的 testing 库,方便启动和销毁容器。
- 对于 service 的单元测试,使用 gomock 等库把 dao mock 掉,所以在设计包的时候,应该面向抽象编程。
- 在本地执行依赖 Docker,在 CI 环境里执行Unittest,需要考虑在物理机里的 Docker 网络,或者在 Docker 里再次启动一个 Docker。
利用 go 官方提供的: Subtests + Gomock 完成整个单元测试。
Using Subtests and Sub-benchmarks
/api
比较适合进行集成测试,直接测试 API,使用 API 测试框架(例如: yapi),维护大量业务测试 case。
/data
docker compose 把底层基础设施真实模拟,因此可以去掉 infra 的抽象层。
/biz
依赖 repo、rpc client,利用 gomock 模拟 interface 的实现,来进行业务单元测试。
/service
依赖 biz 的实现,构建 biz 的实现类传入,进行单元测试。
基于 git branch 进行 feature 开发,本地进行 unittest,之后提交 gitlab merge request 进行 CI 的单元测试,基于 feature branch 进行构建,完成功能测试,之后合并 master,进行集成测试,上线后进行回归测试。
Integration Testing in Go: Part I - Executing Tests with Docker
Integration Testing in Go: Part II - Set-up and Writing Tests
Without integration tests, it’s difficult to trust the end-to-end operation of a web service.
4.6 References
https://www.ardanlabs.com/blog/2017/02/package-oriented-design.html
https://www.ardanlabs.com/blog/2017/02/design-philosophy-on-packaging.html
https://github.com/golang-standards/project-layout
https://github.com/golang-standards/project-layout/blob/master/README_zh.md
https://www.cnblogs.com/zxf330301/p/6534643.html
https://blog.csdn.net/k6T9Q8XKs6iIkZPPIFq/article/details/109192475?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522160561008419724839224387%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=160561008419724839224387&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_v2~rank_v28-6-109192475.first_rank_ecpm_v3_pc_rank_v2&utm_term=阿里技术专家详解DDD系列&spm=1018.2118.3001.4449
https://blog.csdn.net/chikuai9995/article/details/100723540?biz_id=102&utm_term=阿里技术专家详解DDD系列&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-0-100723540&spm=1018.2118.3001.4449
https://blog.csdn.net/Taobaojishu/article/details/101444324?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522160561008419724838528569%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=160561008419724838528569&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_click~default-1-101444324.first_rank_ecpm_v3_pc_rank_v2&utm_term=阿里技术专家详解DDD系列&spm=1018.2118.3001.4449
https://blog.csdn.net/taobaojishu/article/details/106152641
https://cloud.google.com/apis/design/errors
https://kb.cnblogs.com/page/520743/
https://zhuanlan.zhihu.com/p/105466656
https://zhuanlan.zhihu.com/p/105648986
https://zhuanlan.zhihu.com/p/106634373
https://zhuanlan.zhihu.com/p/107347593
https://zhuanlan.zhihu.com/p/109048532
https://zhuanlan.zhihu.com/p/110252394
https://www.jianshu.com/p/dfa427762975
https://www.citerus.se/go-ddd/
https://www.citerus.se/part-2-domain-driven-design-in-go/
https://www.citerus.se/part-3-domain-driven-design-in-go/
https://www.jianshu.com/p/dfa427762975
https://www.jianshu.com/p/5732b69bd1a1
https://www.cnblogs.com/qixuejia/p/10789612.html
https://www.cnblogs.com/qixuejia/p/4390086.html
https://www.cnblogs.com/qixuejia/p/10789621.html
https://zhuanlan.zhihu.com/p/46603988
https://github.com/protocolbuffers/protobuf/blob/master/src/google/protobuf/wrappers.proto
https://dave.cheney.net/2014/10/17/functional-options-for-friendly-apis
https://commandcenter.blogspot.com/2014/01/self-referential-functions-and-design.html
https://blog.csdn.net/taobaojishu/article/details/106152641
https://apisyouwonthate.com/blog/creating-good-api-errors-in-rest-graphql-and-grpc
https://blog.cleancoder.com/uncle-bob/2012/08/13/the-clean-architecture.html
https://www.youtube.com/watch?v=oL6JBUk6tj0
https://github.com/zitryss/go-sample
https://github.com/danceyoung/paper-code/blob/master/package-oriented-design/packageorienteddesign.md
https://medium.com/@eminetto/clean-architecture-using-golang-b63587aa5e3f
https://hackernoon.com/golang-clean-archithecture-efd6d7c43047
https://medium.com/@benbjohnson/standard-package-layout-7cdbc8391fc1
https://medium.com/wtf-dial/wtf-dial-domain-model-9655cd523182
https://hackernoon.com/golang-clean-archithecture-efd6d7c43047
https://hackernoon.com/trying-clean-architecture-on-golang-2-44d615bf8fdf
https://manuel.kiessling.net/2012/09/28/applying-the-clean-architecture-to-go-applications/
https://github.com/katzien/go-structure-examples
https://www.youtube.com/watch?v=MzTcsI6tn-0
https://www.appsdeveloperblog.com/dto-to-entity-and-entity-to-dto-conversion/
https://travisjeffery.com/b/2019/11/i-ll-take-pkg-over-internal/
https://github.com/google/wire/blob/master/docs/best-practices.md
https://github.com/google/wire/blob/master/docs/guide.md
https://blog.golang.org/wire
https://github.com/google/wire
https://www.ardanlabs.com/blog/2019/03/integration-testing-in-go-executing-tests-with-docker.html
https://www.ardanlabs.com/blog/2019/10/integration-testing-in-go-set-up-and-writing-tests.html
https://blog.golang.org/examples
https://blog.golang.org/subtests
https://blog.golang.org/cover
https://blog.golang.org/module-compatibility
https://blog.golang.org/v2-go-modules
https://blog.golang.org/publishing-go-modules
https://blog.golang.org/module-mirror-launch
https://blog.golang.org/migrating-to-go-modules
https://blog.golang.org/using-go-modules
https://blog.golang.org/modules2019
https://blog.codecentric.de/en/2017/08/gomock-tutorial/
https://pkg.go.dev/github.com/golang/mock/gomock
https://medium.com/better-programming/a-gomock-quick-start-guide-71bee4b3a6f1
第5课 评论系统架构设计
5.1 功能模块
架构设计最重要的就是理解整个产品体系在系统中的定位。搞清楚系统背后的背景,才能做出最佳的设计和抽象。不要做需求的翻译机,先理解业务背后的本质,事情的初衷。
评论系统,我们往小里做就是视频评论系统,往大里做就是评论平台,可以接入各种业务形态。
发布评论: 支持回复楼层、楼中楼。
读取评论: 按照时间、热度排序。
删除评论: 用户删除、作者删除。
管理评论: 作者置顶、后台运营管理(搜索、删除、审核等)。
在动手设计前,反复思考,真正编码的时间只有5%。
5.2 架构设计
5.2.1 概览
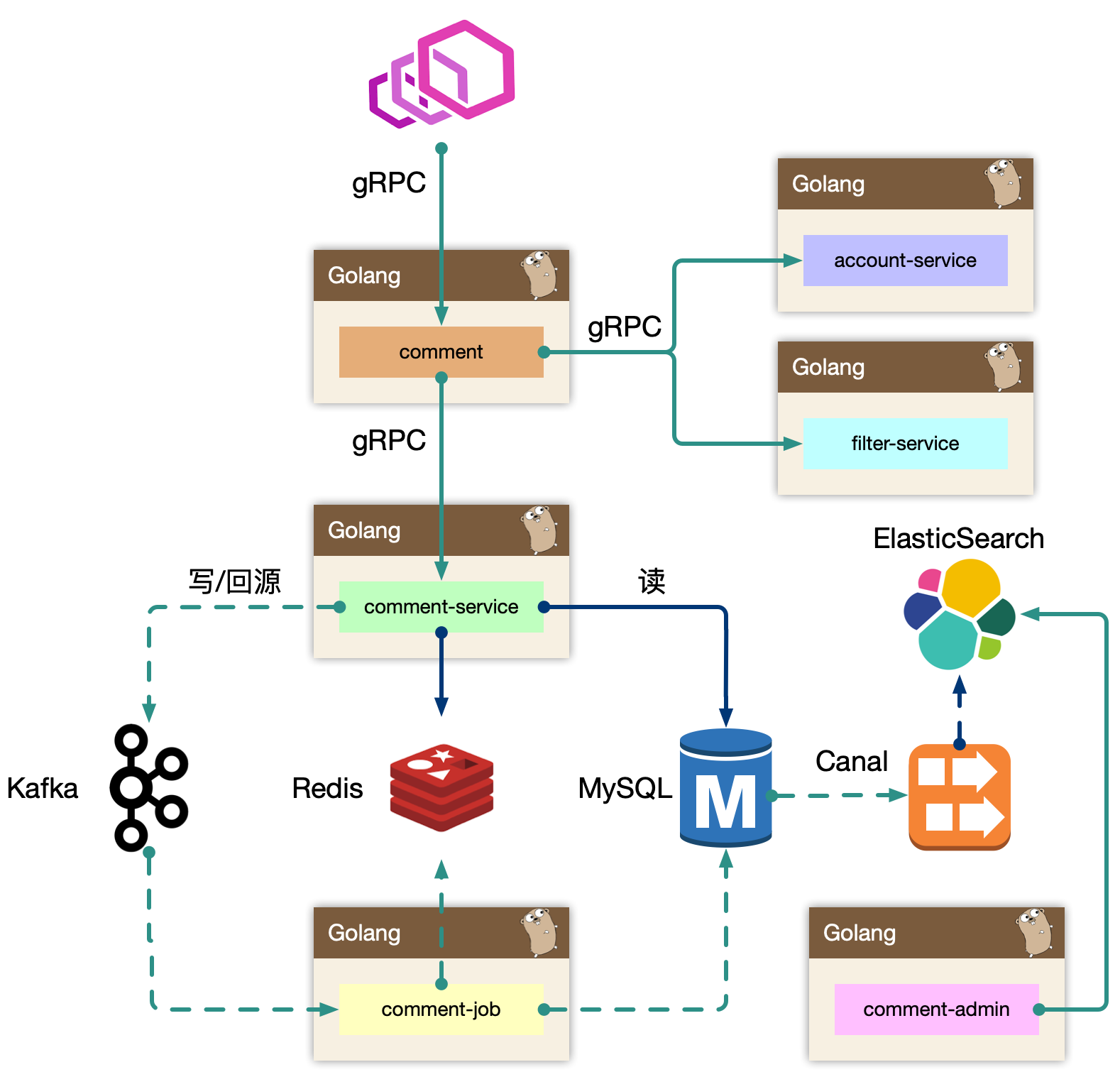
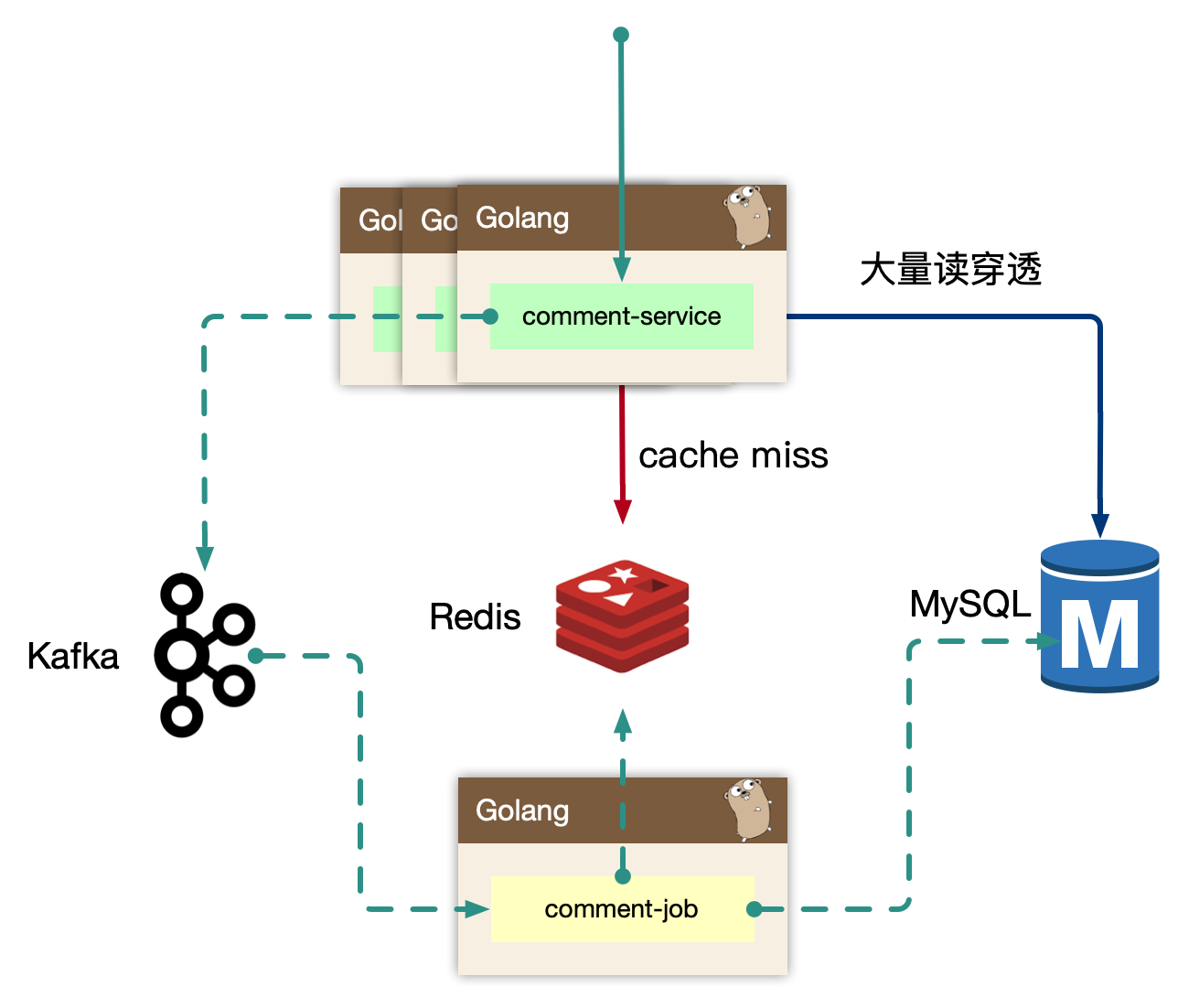
BFF: comment
复杂评论业务的服务编排,比如访问账号服务进行等级判定,同时需要在 BFF 面向移动端/WEB场景来设计 API,这一层抽象把评论的本身的内容列表处理(加载、分页、排序等)进行了隔离,关注在业务平台化逻辑上。
Service: comment-service
服务层,去平台业务的逻辑,专注在评论功能的 API 实现上,比如发布、读取、删除等,关注在稳定性、可用性上,这样让上游可以灵活组织逻辑把基础能力和业务能力剥离。
Job: comment-job
消息队列的最大用途是消峰处理。
Admin: comment-admin
管理平台,按照安全等级划分服务,尤其划分运营平台,他们会共享服务层的存储层(MySQL、Redis)。运营体系的数据大量都是检索,我们使用 canal 进行同步到 ES 中,整个数据的展示都是通过 ES,再通过业务主键更新业务数据层,这样运营端的查询压力就下方给了独立的 fulltext search 系统。
Dependency: account-service、filter-service
整个评论服务还会依赖一些外部 gRPC 服务,统一的平台业务逻辑在 comment BFF 层收敛,这里 account-service 主要是账号服务,filter-service 是敏感词过滤服务。
架构设计等同于数据设计,梳理清楚数据的走向和逻辑。尽量避免环形依赖、数据双向请求等。
5.2.2 comment-service
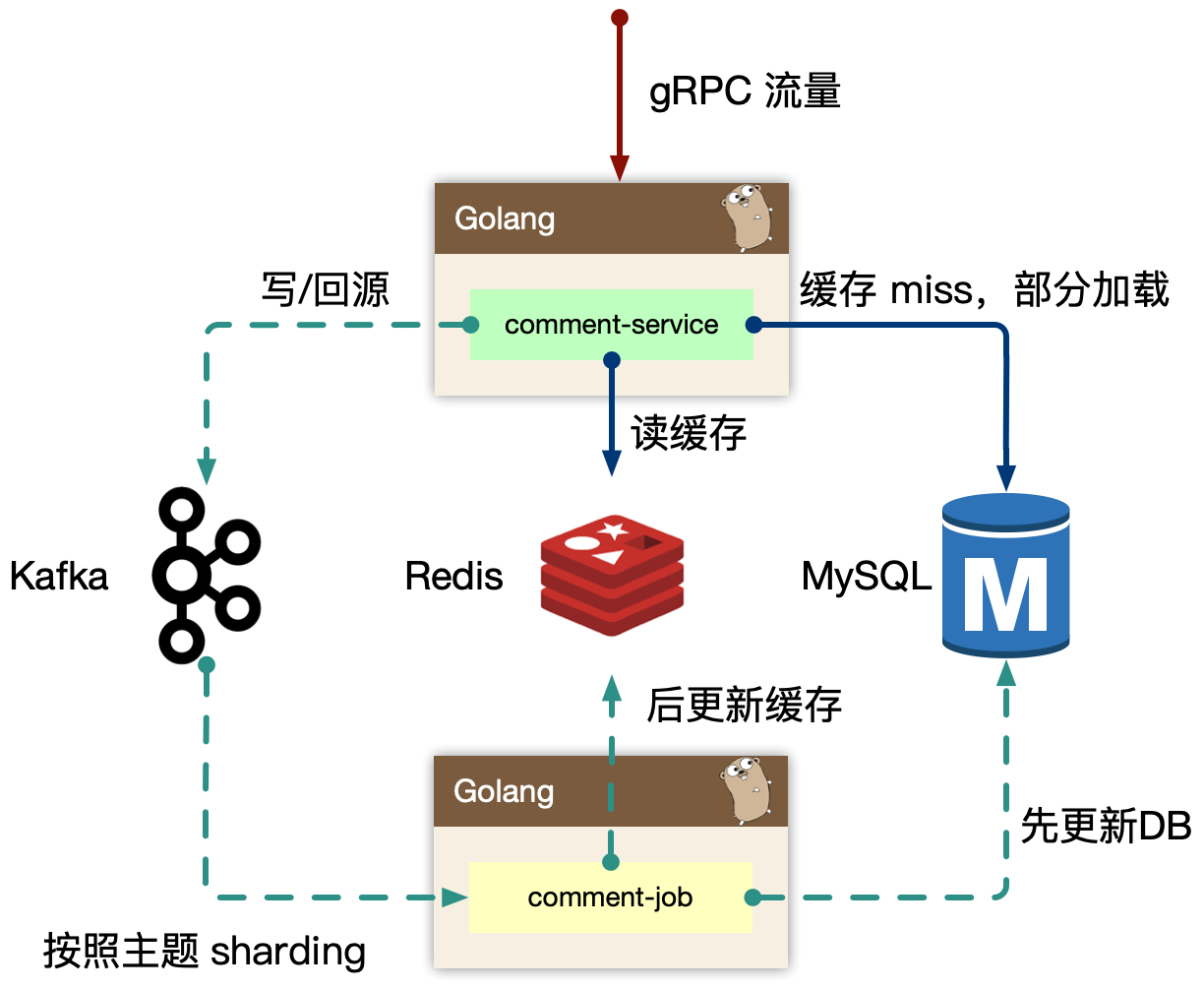
comment-service,专注在评论数据处理(认真想下 Separation of Concerns)。
我们一开始是 comment-service 和 comment 是一层,业务耦合和功能耦合在一起,非常不利于迭代,当然在设计层面可以考虑目录结构进行拆分,但是架构层次来说,迭代隔离也是好的。
读的核心逻辑:
Cache-Aside 模式,先读取缓存,再读取存储。早期 cache rebuild 是做到服务里的,对于重建逻辑,一般会使用 read ahead 的思路,即预读,用户访问了第一页,很有可能访问第二页,所以缓存会超前加载,避免频繁 cache miss。当缓存抖动是否,特别容易引起集群 hundering herd 现象,大量的请求会触发 cache rebuild,因为使用了预加载,容易导致服务 OOM。所以我们开到回源的逻辑里,我们使用了消息队列来进行逻辑异步化,对于当前请求只返回 mysql 中部分数据即止。
写的核心逻辑:
我们担心类似”明星出轨”等热点事件的发生,而且写和读相比较,写可以认为是透穿到存储层的,系统的瓶颈往往就来自于存储层,或者有状态层。对于写的设计上,我们认为刚发布的评论有极短的延迟(通常小于几 ms)对用户可见是可接受的,把对存储的直接冲击下放到消息队列,按照消息反压的思路,即如果存储 latency 升高,消费能力就下降,自然消息容易堆积,系统始终以最大化方式消费。
Kafka 是存在 partition 概念的,可以认为是物理上的一个小队列,一个 topic 是由一组 partition 组成的,所以 Kafka 的吞吐模型理解为: 全局并行,局部串行的生产消费方式。对于入队的消息,可以按照 hash(comment_subject) % N(partitions) 的方式进行分发。那么某个 partition 中的 评论主题的数据一定都在一起,这样方便我们串行消费。
同样的,我们处理回源消息也是类似的思路。
5.2.3 comment-admin
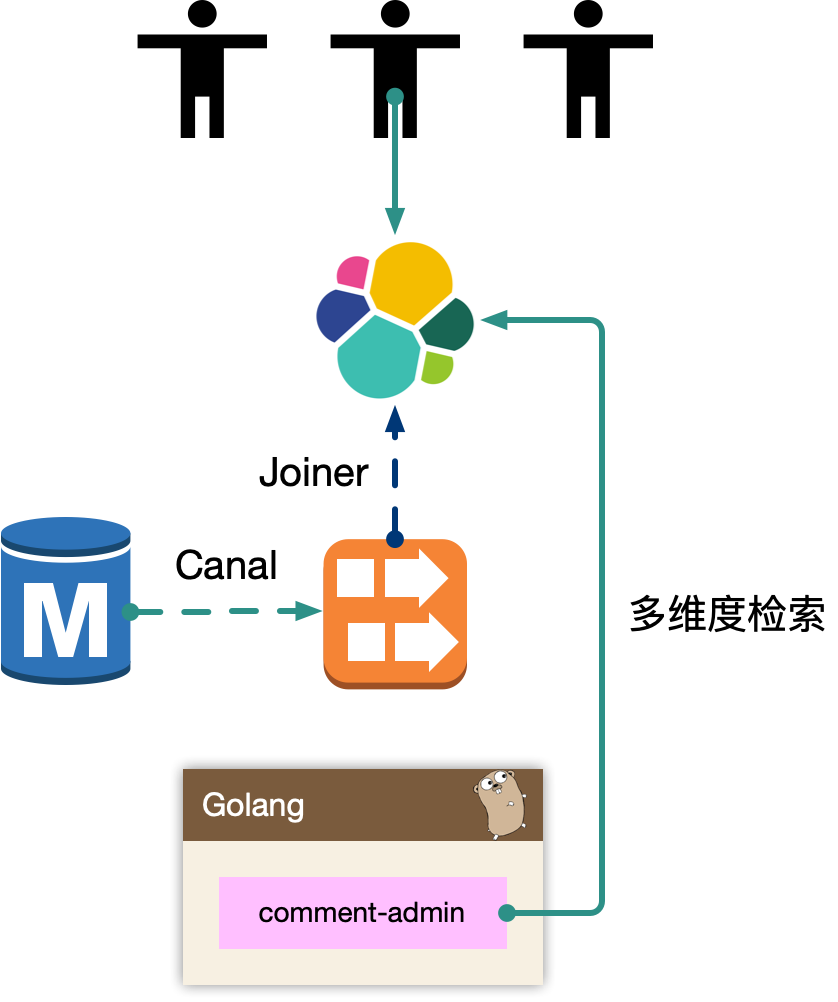
mysql binlog 中的数据被 canal 中间件流式消费,获取到业务的原始 CRUD 操作,需要回放录入到 es 中,但是 es 中的数据最终是面向运营体系提供服务能力,需要检索的数据维度比较多,在入 es 前需要做一个异构的 joiner,把单表变宽预处理好 join 逻辑,然后倒入到 es 中。
一般来说,运营后台的检索条件都是组合的,使用 es 的好处是避免依赖 mysql 来做多条件组合检索,同时 mysql 毕竟是 oltp 面向线上联机事务处理的。通过冗余数据的方式,使用其他引擎来实现。
es 一般会存储检索、展示、primary key 等数据,当我们操作编辑的时候,找到记录的 primary key,最后交由 comment-admin 进行运营测的 CRUD 操作。
我们内部运营体系基本都是基于 es 来完成的。
5.2.4 comment
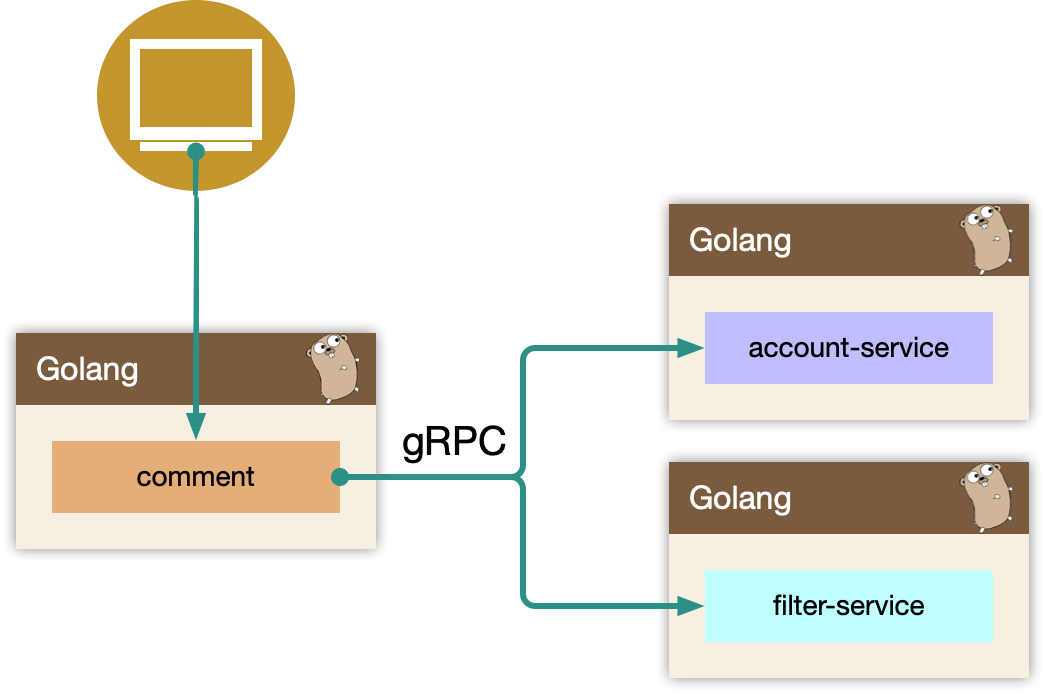
comment 作为 BFF,是面向端,面向平台,面向业务组合的服务。所以平台扩展的能力,我们都在 comment 服务来实现,方便统一和准入平台,以统一的接口形式提供平台化的能力。
- 依赖其他 gRPC 服务,整合统一平台测的逻辑(比如发布评论用户等级限定)。
- 直接向端上提供接口,提供数据的读写接口,甚至可以整合端上,提供统一的端上 SDK。
- 需要对非核心依赖的 gRPC 服务进行降级,当这些服务不稳定时。
5.3 存储设计
5.3.1 数据库设计

表说明:
comment_subject主题表- 为了方便接入各种系统加入了字段
obj_id和obj_type来表示不同的主题及子主题(比如:视频中用obj_id字段放视频 ID ,obj_type中的某个值表示视频)。 member_id作者 ID 。count是评论总数,也当作楼层使用(与表comment_index中的floor是相同的值)。root_count表示评论(不包含评论下的回复)总数。all_count表示评论以及评论下的回复的总数(避免在数据库中进行count (*)操作)。state评论状态。attrs评论属性。create_time和update_time表示创建时间和更新时间。每张 MySQL 表都会有这两个字段。id自增主键。因为 MySQL 写的核心优化一定要顺序写(随机写会导致 btree 不断的分裂,而导致大量的分页(mysql data page size is 16k))。如果一个张表没有主键, MySQL 会有一个隐藏的主键。[0-49] 用于 sharding 分片。因为担心数据量比较大,将
comment_subject拆分成了 50 张表。
- 为了方便接入各种系统加入了字段
comment_index索引表obj_id和obj_type与comment_subject主题表中的字段相同。- 用
root和parent来表示有层级的设计(这种方式很常见)。 id使用发号器生成的 ID 来保证全局唯一,方便后面存放到 kv 中。
comment_content内容表comment_id的值与comment_index中id的相同,且为主键,这是为了避免 MySQL 的二次索引查找。
为什么要分
comment_index索引表和comment_content内容表?因为 MySQL 的 IO 单位是 data page。如果每个 data page 中仅包含了几个评论,那么在读取一条视频的评论时将有大量的 IO。
数据操作:
数据写入:
事务更新 comment_subject,comment_index,comment_content 三张表,其中 content 属于非强制需要一致性考虑的。可以先写入 content (可以把内容放到 KV 数据库中),之后事务更新其他表。即便 content 先成功,后续失败仅仅存在一条 ghost 数据。
当有新评论时,用
SELECT FOR UPDATE从comment_subject表中读出count并加一,然后将得到的值作为comment_index中的floor写入comment_index中。数据读取
基于 obj_id + obj_type 在 comment_index 表找到评论列表,WHERE root = 0 ORDER BY floor。之后根据 comment_index 的 id 字段捞出 comment_content 的评论内容。对于二级的子楼层,WHERE parent/root IN (id…)。
注意每个表里面都有
create_time和update_time这两个字段。
因为产品形态上只存在二级列表,因此只需要迭代查询两次即可。对于嵌套层次多的,产品上,可以通过二次点击支持。
是不是可以 Graph 存储?DGraph、HugeGraph 类似的图存储思路。
5.3.2 索引内容分离

comment_index: 评论楼层的索引组织表,实际并不包含内容。
comment_content: 评论内容的表,包含评论的具体内容。其中 comment_index 的 id 字段和 comment_content 是1对1的关系,这里面包含几种设计思想。
- 表都有主键,即 cluster index,是物理组织形式存放的,comment_content 没有 id,是为了减少一次 二级索引查找,直接基于主键检索,同时 comment_id 在写入要尽可能的顺序自增。
- 索引、内容分离,方便 mysql datapage 缓存更多的 row,如果和 context 耦合,会导致更大的 IO。长远来看 content 信息可以直接使用 KV storage 存储。
动静分离,comment_content 的内容几乎不会变。把经常变的数据和不经常边的数据分开放。
5.3.3 缓存设计
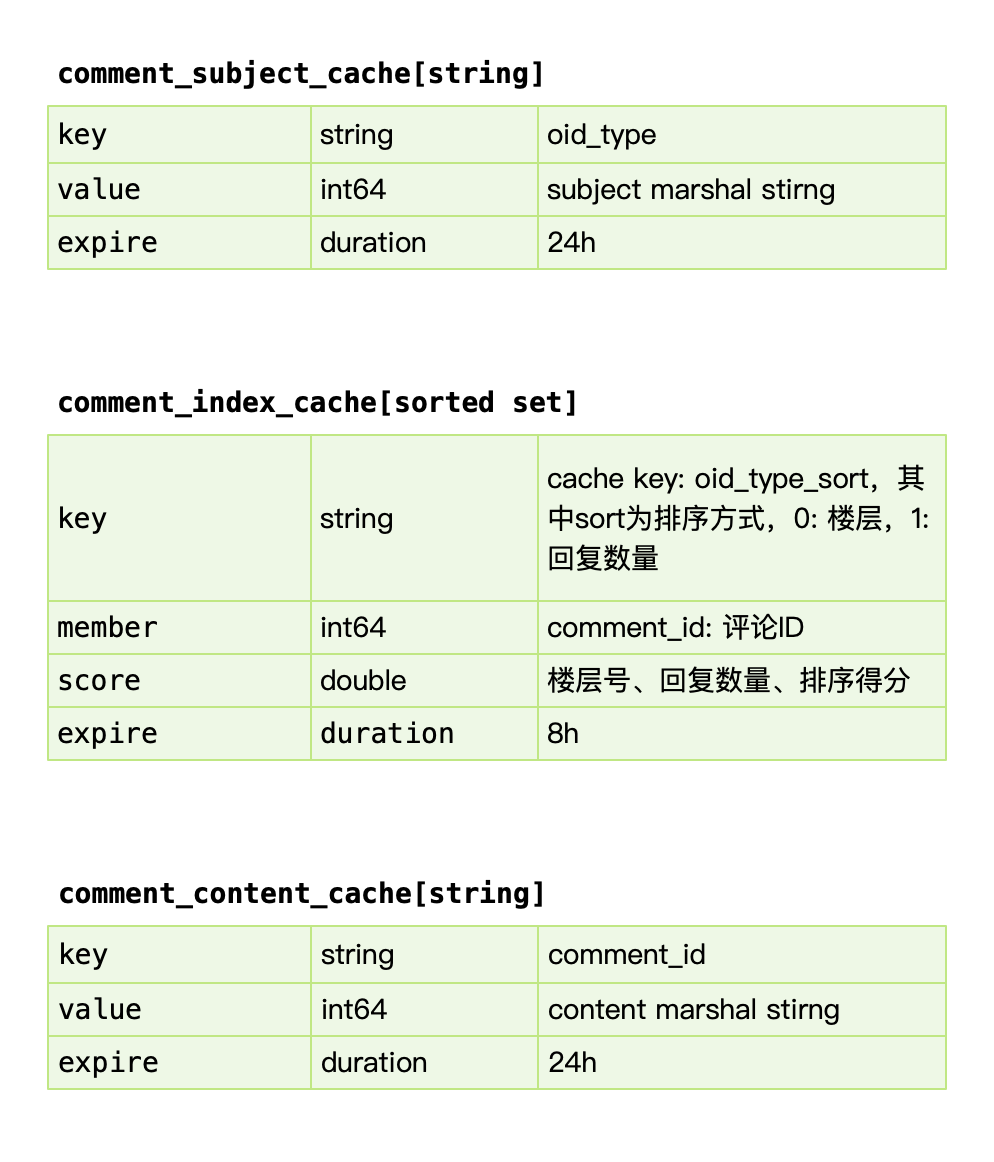
comment_subject_cache
对应主题的缓存,value 使用 protobuf 序列化的方式存入。我们早期使用 memcache 来进行缓存,因为 redis 早期单线程模型,吞吐能力不高。
comment_index_cache
使用 redis sortedset 进行索引的缓存,索引即数据的组织顺序,而非数据内容。参考过百度的贴吧,他们使用自己研发的拉链存储来组织索引,我认为 mysql 作为主力存储,利用 redis 来做加速完全足够,因为 cache miss 的构建,我们前面讲过使用 kafka 的消费者中处理,预加载少量数据,通过增量加载的方式逐渐预热填充缓存,而 redis sortedset skiplist 的实现,可以做到 O(logN) + O(M) 的时间复杂度,效率很高。
sorted set 是要增量追加的,因此必须判定 key 存在(用 expire 而不是用 exists),才能 zadd。
redis 中 sorted_set 的 score 是 double 类型,不能保存 int64 的值,会有溢出。
翻页功能可以用 zrang 做。
comment_content_cache
对应评论内容数据,使用 protobuf 序列化的方式存入。类似的我们早期使用 memcache 进行缓存。
增量加载 + lazy 加载
5.4 可用性设计
5.4.1 Singleflight
对于热门的主题,如果存在缓存穿透的情况,会导致大量的同进程、跨进程的数据回源到存储层,可能会引起存储过载的情况,如何只交给同进程内,一个人去做加载存储?
使用归并回源的思路: https://pkg.go.dev/golang.org/x/sync/singleflight
同进程只交给一个人去获取 mysql 数据,然后批量返回。同时这个 lease owner 投递一个 kafka 消息,做 index cache 的 recovery 操作。这样可以大大减少 mysql 的压力,以及大量透穿导致的密集写 kafka 的问题。
更进一步的,后续连续的请求,仍然可能会短时 cache miss,我们可以在进程内设置一个 short-lived flag,标记最近有一个人投递了 cache rebuild 的消息,直接 drop。
为什么我们不用分布式锁之类的思路?
太复杂,容易出问题,难调试。
5.4.2 热点
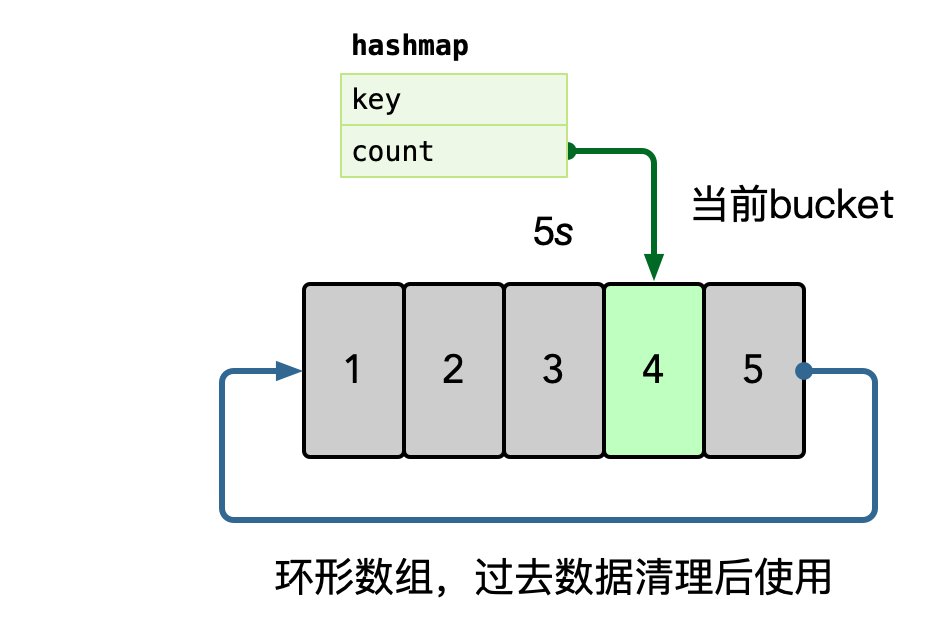
流量热点是因为突然热门的主题,被高频次的访问,因为底层的 cache 设计,一般是按照主题 key 进行一致性 hash 来进行分片,但是热点 key 一定命中某一个节点,这时候 remote cache 可能会变为瓶颈,因此做 cache 的升级 local cache 是有必要的,我们一般使用单进程自适应发现热点的思路,附加一个短时的 ttl local cache,可以在进程内吞掉大量的读请求。
在内存中使用 hashmap 统计每个 key 的访问频次,这里可以使用滑动窗口统计,即每个窗口中,维护一个 hashmap,之后统计所有未过期的 bucket,汇总所有 key 的数据。
之后使用小堆计算 TopK 的数据,自动进行热点识别。
5.5 References
第6课 微服务(微服务可用性设计)
6.1 隔离
隔离,本质上是对系统或资源进行分割,从而实现当系统发生故障时能限定传播范围和影响范围,即发生故障后只有出问题的服务不可用,保证其他服务仍然可用。
6.1.1 服务隔离
动静分离
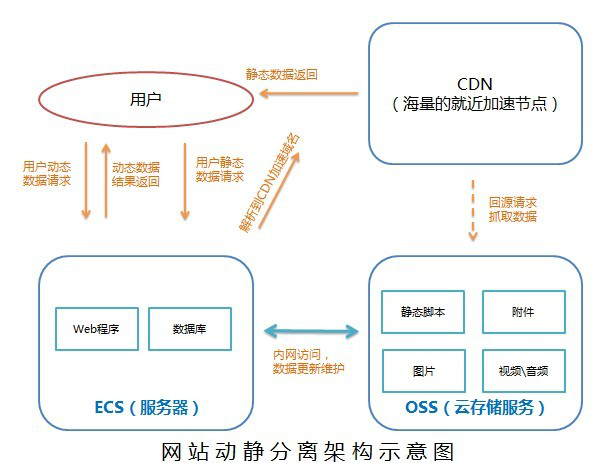
小到 CPU 的 cacheline false sharing、数据库 mysql 表设计中避免 bufferpool 频繁过期,隔离动静表,大到架构设计中的图片、静态资源等缓存加速。本质上都体现的一样的思路,即加速/缓存访问变换频次小的。比如 CDN 场景中,将静态资源和动态 API 分离,也是体现了隔离的思路:
- 降低应用服务器负载,静态文件访问负载全部通过CDN。
- 对象存储存储费用最低。
- 海量存储空间,无需考虑存储架构升级。
静态CDN带宽加速,延迟低。

archive: 稿件表,存储稿件的名称、作者、分类、tag、状态等信息,表示稿件的基本信息。
在一个投稿流程中,一旦稿件创建改动的频率比较低。
archive_stat: 稿件统计表,表示稿件的播放、点赞、收藏、投币数量,比较高频的更新。
随着稿件获取流量,稿件被用户所消费,各类计数信息更新比较频繁。
MySQL BufferPool 是用于缓存 DataPage 的,DataPage 可以理解为缓存了表的行,那么如果频繁更新 DataPage 不断会置换,会导致命中率下降的问题,所以我们在表设计中,仍然可以沿用类似的思路,其主表基本更新,在上游 Cache 未命中,透穿到 MySQL,仍然有 BufferPool 的缓存。
读写分离
主从、Replicaset、CQRS。
6.1.2 轻重隔离
核心隔离
业务按照 Level 进行资源池划分(L0/L1/L2)。
- 核心/非核心的故障域的差异隔离(机器资源、依赖资源)。
- 多集群,通过冗余资源来提升吞吐和容灾能力。
快慢隔离
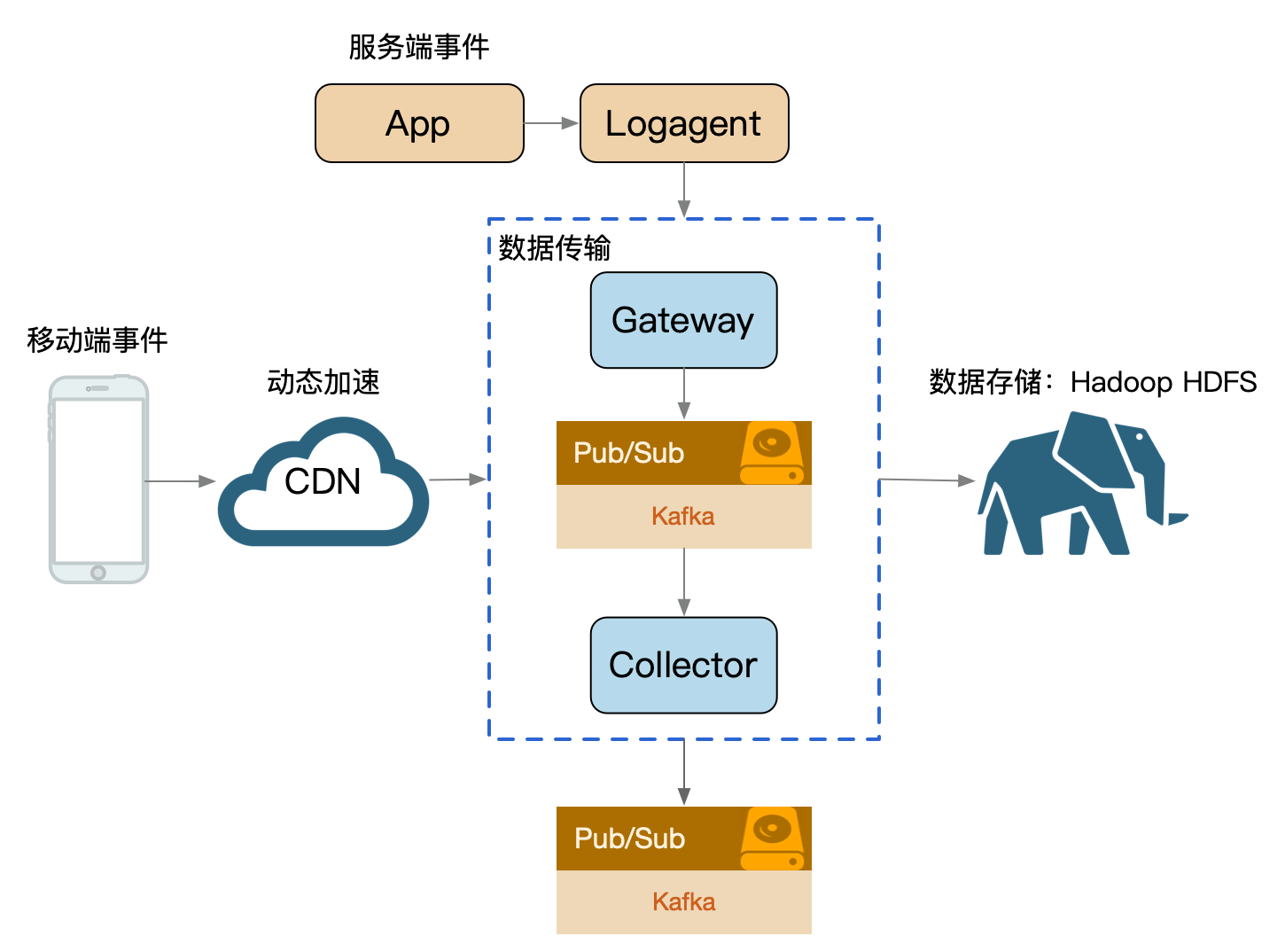
我们可以把服务的吞吐想象为一个池,当突然洪流进来时,池子需要一定时间才能排放完,这时候其他支流在池子里待的时间取决于前面的排放能力,耗时就会增高,对小请求产生影响。
日志传输体系的架构设计中,整个流都会投放到一个 kafka topic 中(早期设计目的: 更好的顺序IO),流内会区分不同的 logid,logid 会有不同的 sink 端,它们之前会出现差速,比如 HDFS 抖动吞吐下降,ES 正常水位,全局数据就会整体反压。
按照各种纬度隔离:sink、部门、业务、logid、重要性(S/A/B/C)。
业务日志也属于某个 logid,日志等级就可以作为隔离通道。
热点隔离

何为热点?热点即经常访问的数据。很多时候我们希望统计某个热点数据中访问频次最高的 Top K 数据,并对其访问进行缓存。比如:
- 小表广播: 从 remotecache 提升为 localcache,app 定时更新,甚至可以让运营平台支持广播刷新 localcache。atomic.Value
- 主动预热: 比如直播房间页高在线情况下bypass 监控主动防御。
6.1.3 物理隔离
线程隔离
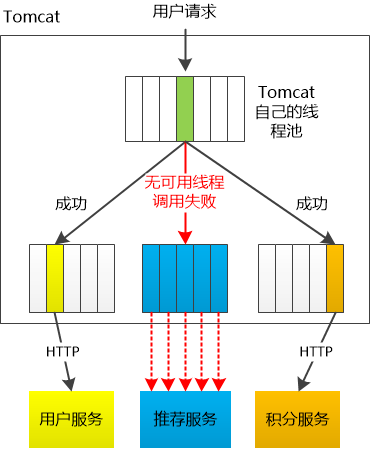
主要通过线程池进行隔离,也是实现服务隔离的基础。把业务进行分类并交给不同的线程池进行处理,当某个线程池处理一种业务请求发生问题时,不会讲故障扩散和影响到其他线程池,保证服务可用。
对于 Go 来说,所有 IO 都是 Nonblocking,且托管给了 Runtime,只会阻塞Goroutine,不阻塞 M,我们只需要考虑 Goroutine 总量的控制,不需要线程模型语言的线程隔离。
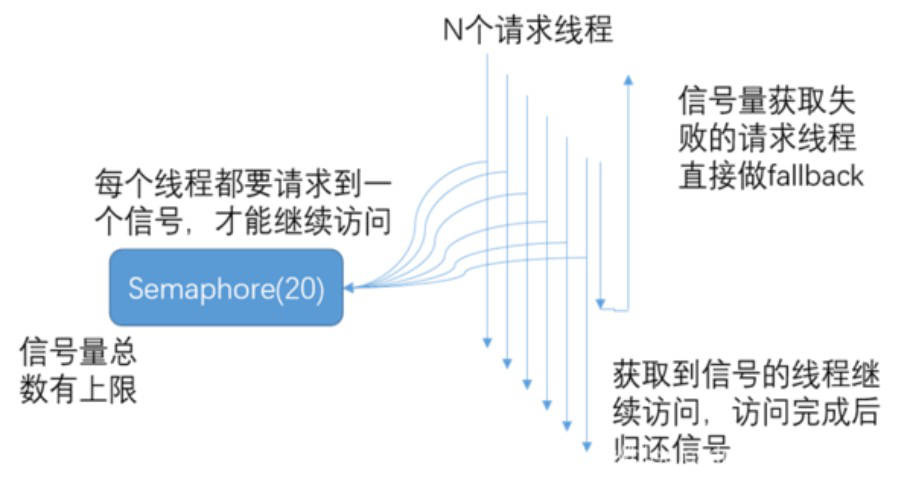
Java 除了线程池隔离,也有基于信号量的做法。
当信号量达到 maxConcurrentRequests 后,再请求会触发 fallback。
进程隔离
容器化(docker),容器编排引擎(k8s)。我们15年在 KVM 上部署服务;16年使用 Docker Swarm;17年迁移到 Kubernetes,到年底在线应用就全托管了,之后很快在线应用弹性公有云上线;20年离线 Yarn 和 在线 K8s 做了在离线混部(错峰使用),之后计划弹性公有云配合自建 IDC 做到离线的混合云架构。
集群隔离
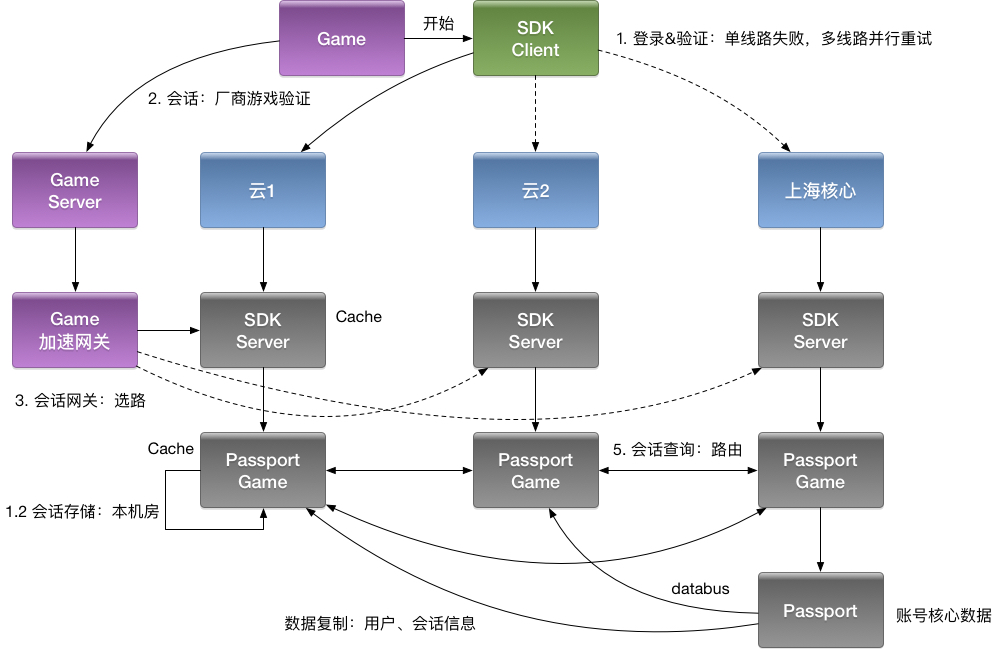
回顾 gRPC,我们介绍过多集群方案,即逻辑上是一个应用,物理上部署多套应用,通过 cluster 区分。
多活建设完毕后,我们应用可以划分为:region.zone.cluster.appid
机房隔离
6.1.4 Case Study
- 早期转码集群被超大视频攻击,导致转码大量延迟。
- 入口Nginx(SLB)故障,影响全机房流量入口故障。
- 缩略图服务,被大图实时缩略吃完所有 CPU,导致正常的小图缩略被丢弃,大量503。
- 数据库实例 cgroup 未隔离,导致大 SQL 引起的集体故障。
- INFO 日志量过大,导致异常 ERROR 日志采集延迟。
6.2 超时控制
超时控制,我们的组件能够快速失效(fail fast),因为我们不希望等到断开的实例直到超时。没有什么比挂起的请求和无响应的界面更令人失望。这不仅浪费资源,而且还会让用户体验变得更差。我们的服务是互相调用的,所以在这些延迟叠加前,应该特别注意防止那些超时的操作。
- 网路传递具有不确定性。
- 客户端和服务端不一致的超时策略导致资源浪费。
- “默认值”策略。
- 高延迟服务导致 client 浪费资源等待,使用超时传递: 进程间传递 + 跨进程传递。
超时控制是微服务可用性的第一道关,良好的超时策略,可以尽可能让服务不堆积请求,尽快清空高延迟的请求,释放 Goroutine。
实际业务开发中,我们依赖的微服务的超时策略并不清楚,或者随着业务迭代耗时超生了变化,意外的导致依赖者出现了超时。
- 服务提供者定义好 latency SLO(Service level objectives),更新到 gRPC Proto 定义中,服务后续迭代,都应保证 SLO。

package google.example.library.v1;
service LibraryService {
// Lagency SLO: 95th in 100ms, 99th in 150ms.
rpc CreateBook(CreateBookRequest) returns (Book);
rpc GetBook(GetBookRequest) returns Book);
rpc ListBooks(ListBooksRequest) returns (ListBooksResponse);
}避免出现意外的默认超时策略,或者意外的配置超时策略。
- kit 基础库兜底默认超时,比如 100ms,进行配置防御保护,避免出现类似 60s 之类的超大超时策略。
- 配置中心公共模版,对于未配置的服务使用公共配置。
6.2.1 超时传递
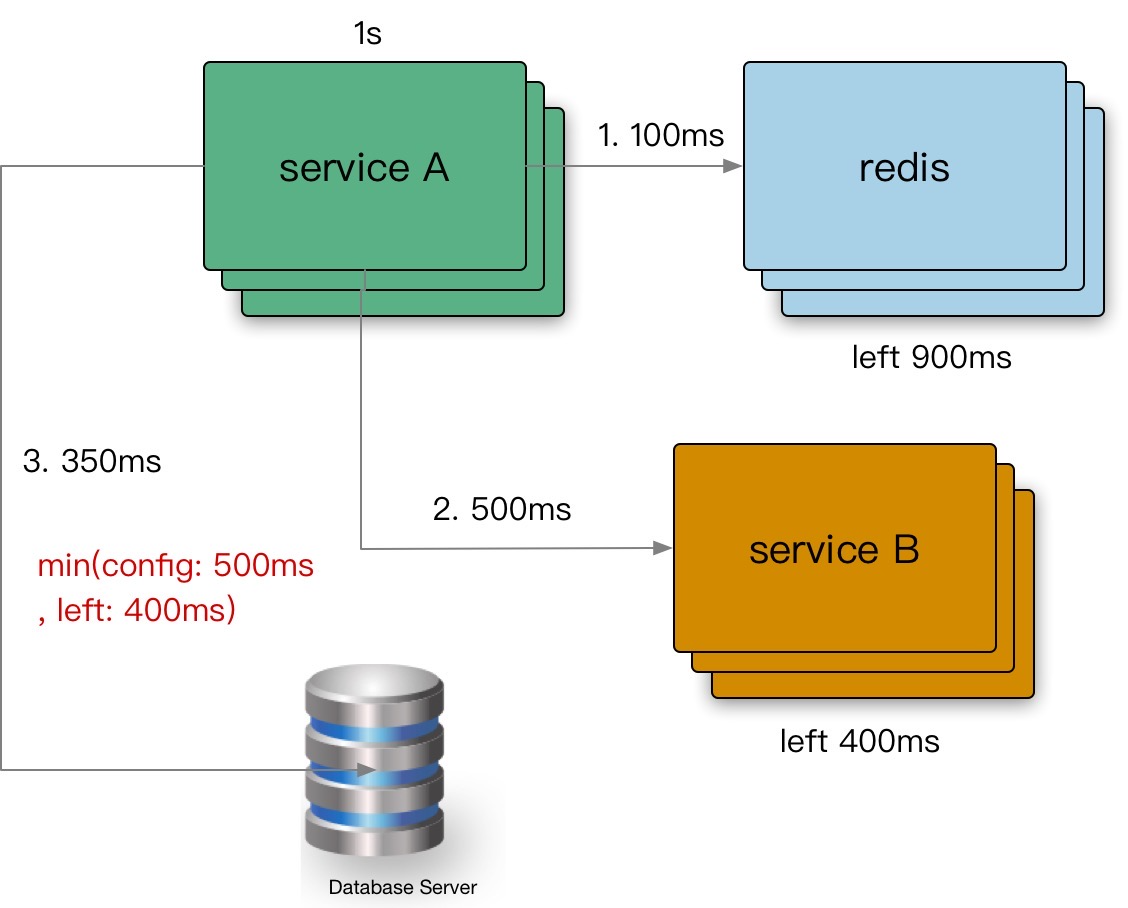
超时传递: 当上游服务已经超时返回 504,但下游服务仍然在执行,会导致浪费资源做无用功。超时传递指的是把当前服务的剩余 Quota 传递到下游服务中,继承超时策略,控制请求级别的全局超时控制。
进程内超时控制
- 一个请求在每个阶段(网络请求)开始前,就要检查是否还有足够的剩余来处理请求,以及继承他的超时策略,使用 Go 标准库的 context.WithTimeout。
func (c *asiiConn) Get(ctx context.Context, key string) (result *Item, err error) {
c.conn.SetWriteDeadline(shrinkDeadline(ctx, c.writeTimeout))
if _, err = fmt.Fprintf(c.rw, "gets %s\r\n", key); err != nil {
6.2.2 gRPC 的超时传递
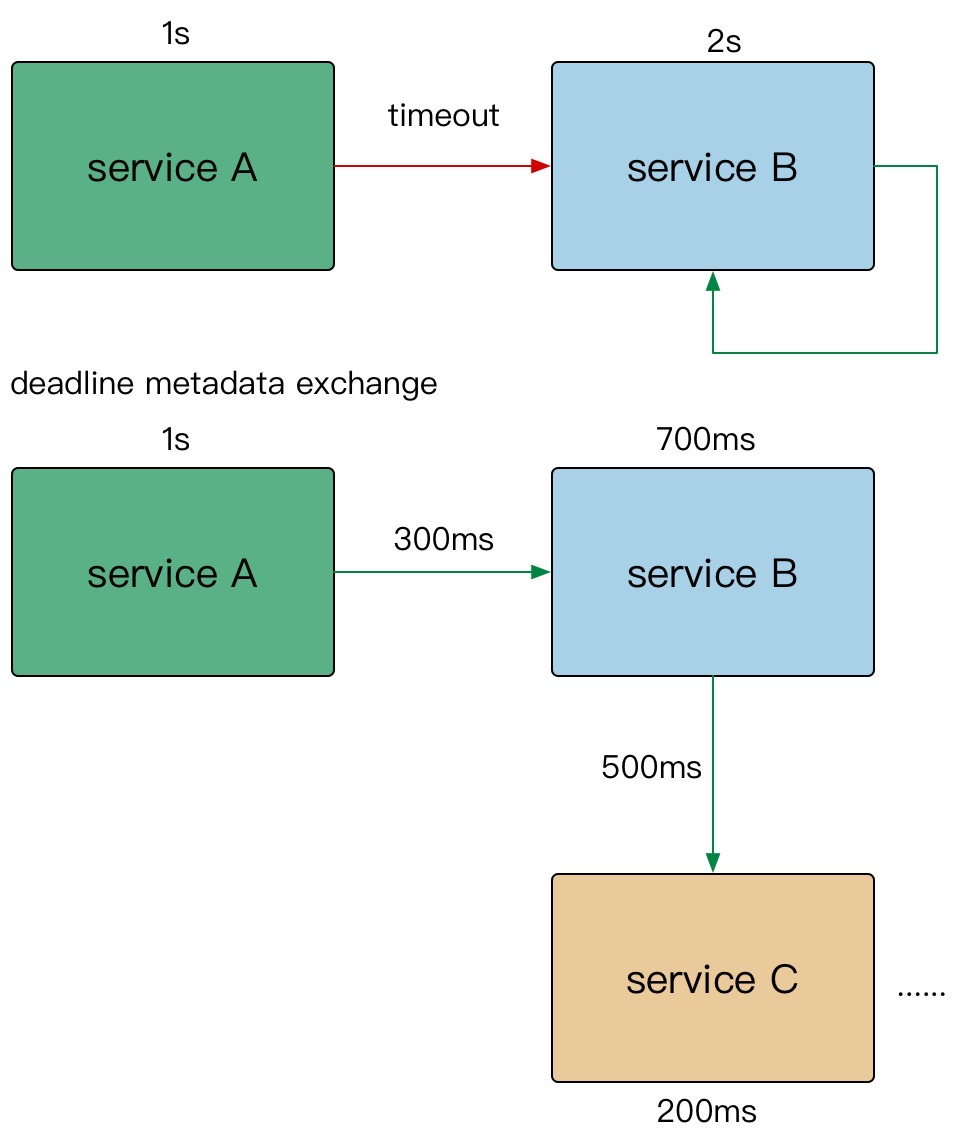
- A gRPC 请求 B,1s超时。
- B 使用了300ms 处理请求,再转发请求 C。
- C 配置了600ms 超时,但是实际只用了500ms。
- 到其他的下游,发现余量不足,取消传递。
在需要强制执行时,下游的服务可以覆盖上游的超时传递和配额。
在 gRPC 框架中,会依赖 gRPC Metadata Exchange,基于 HTTP2 的 Headers 传递 grpc-timeout 字段,自动传递到下游,构建带 timeout 的 context。
6.2.3 细节控制
- 双峰分布: 95%的请求耗时在100ms内,5%的请求可能永远不会完成(长超时)。
- 对于监控不要只看mean,可以看看耗时分布统计,比如 95th,99th。
- 设置合理的超时,拒绝超长请求,或者当Server 不可用要主动失败。
超时决定着服务线程耗尽。
6.2.4 Case Study
- SLB 入口 Nginx 没配置超时导致连锁故障。
- 服务依赖的 DB 连接池漏配超时,导致请求阻塞,最终服务集体 OOM。
- 下游服务发版耗时增加,而上游服务配置超时过短,导致上游请求失败。
6.3 过载保护
6.3.1 令牌桶算法
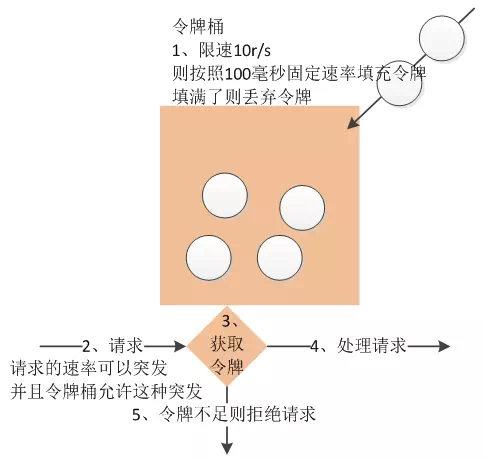
是一个存放固定容量令牌的桶,按照固定速率往桶里添加令牌。令牌桶算法的描述如下:
- 假设限制2r/s,则按照500毫秒的固定速率往桶中添加令牌。
- 桶中最多存放 b 个令牌,当桶满时,新添加的令牌被丢弃或拒绝。
- 当一个 n 个字节大小的数据包到达,将从桶中删除 n 个令牌,接着数据包被发送到网络上。
- 如果桶中的令牌不足 n 个,则不会删除令牌,且该数据包将被限流(要么丢弃,要么缓冲区等待)。
token-bucket rate limit algorithm: /x/time/rate
6.3.2 漏桶算法
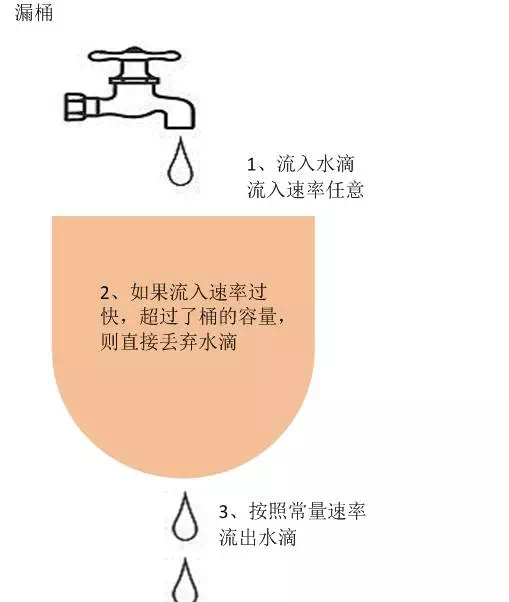
作为计量工具(The Leaky Bucket Algorithm as a Meter)时,可以用于流量整形(Traffic Shaping)和流量控制(TrafficPolicing),漏桶算法的描述如下:
- 一个固定容量的漏桶,按照常量固定速率流出水滴。
- 如果桶是空的,则不需流出水滴。
- 可以以任意速率流入水滴到漏桶。
- 如果流入水滴超出了桶的容量,则流入的水滴溢出了(被丢弃),而漏桶容量是不变的。
leaky-bucket rate limit algorithm: /go.uber.org/ratelimit
6.3.3 过载保护算法的缺陷
漏斗桶/令牌桶确实能够保护系统不被拖垮, 但不管漏斗桶还是令牌桶, 其防护思路都是设定一个指标, 当超过该指标后就阻止或减少流量的继续进入,当系统负载降低到某一水平后则恢复流量的进入。但其通常都是被动的,其实际效果取决于限流阈值设置是否合理,但往往设置合理不是一件容易的事情。
- 集群增加机器或者减少机器限流阈值是否要重新设置?
- 设置限流阈值的依据是什么?
- 人力运维成本是否过高?
- 当调用方反馈429时, 这个时候重新设置限流, 其实流量高峰已经过了重新评估限流是否有意义?
这些其实都是采用漏斗桶/令牌桶的缺点, 总体来说就是太被动, 不能快速适应流量变化。
因此我们需要一种自适应的限流算法,即: 过载保护,根据系统当前的负载自动丢弃流量。
6.3.5 过载保护
计算系统临近过载时的峰值吞吐作为限流的阈值来进行流量控制,达到系统保护。
- 服务器临近过载时,主动抛弃一定量的负载,目标是自保。
- 在系统稳定的前提下,保持系统的吞吐量。
在微服务中,流入速度是 QPS ,耗时就是 latency,整个系统的吞吐就是 QPS * latency 。
BBR 的思路就是交替探测出网络的 输入速度 和 延迟 。
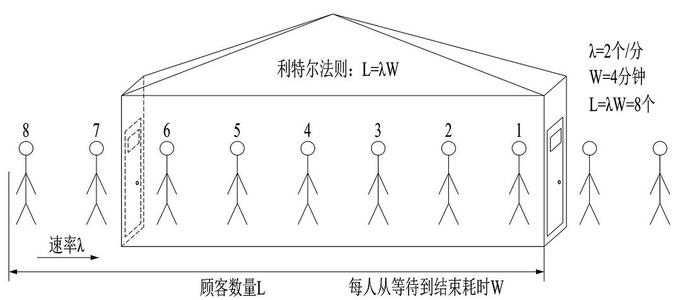
常见做法:利特尔法则
- CPU、内存作为信号量进行节流。
GO 一般仅用 CPU 就可以了。因为在 GO 中,如果内存涨的很快,要么就是每 2 分钟进行一次 GC,要么就是新申请的内存容量比之前的涨了多少倍,最终都会 GC 并反应在 CPU 上。
- 队列管理: 队列长度、LIFO。
- 可控延迟算法: CoDel
如何计算接近峰值时的系统吞吐?
CPU: 使用一个独立的线程采样,每隔 250ms 触发一次。在计算均值时,使用了简单滑动平均去除峰值的影响。
Inflight: 当前服务中正在进行的请求的数量。
atomic.int 来一个请求加一,处理完一个请求减一。用于计算QPS。
Pass&RT: 最近5s,pass 为每100ms采样窗口内成功请求的数量最大值,rt 为单个采样窗口中平均响应时间(与取最大 pass 值对应时间窗口)。
具体做法:
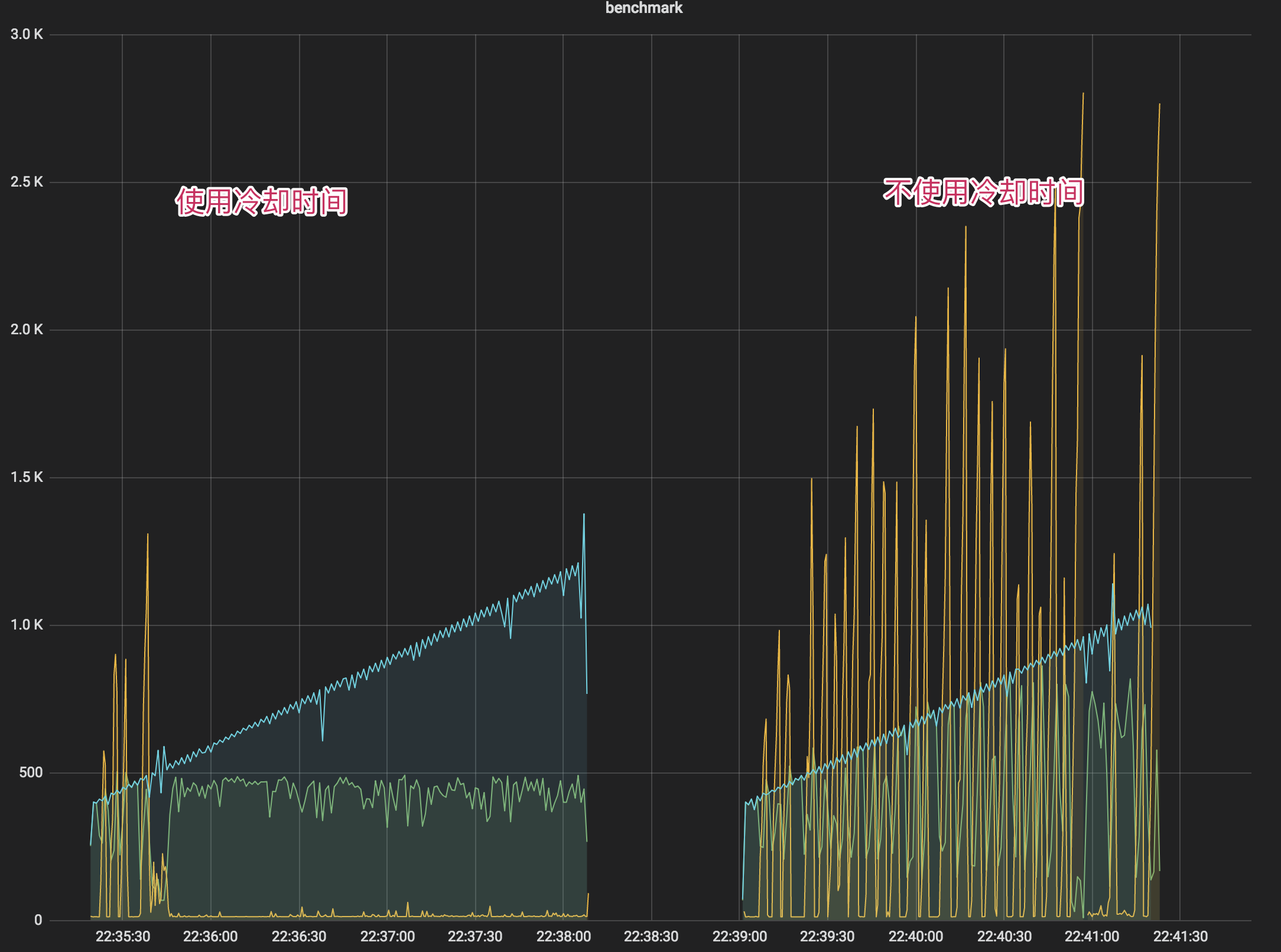
思路是:在服务器临近过载时(比如 CPU 80% 时),认为这个时候系统的吞吐就是系统的最大值。如果系统实际的吞吐比最大吞吐大,就丢掉部分 QPS ,如果系统实际吞吐比最大吞吐小,就放行更多的 QPS 进入系统。
- 我们使用 CPU 的滑动均值(CPU > 800)作为启发阈值,一旦触发进入到过载保护阶段,算法为:(pass * rt) < inflight
- 限流效果生效后,CPU 会在临界值(800)附近抖动,如果不使用冷却时间,那么一个短时间的 CPU 下降就可能导致大量请求被放行,严重时会打满 CPU。
- 在冷却时间(2s)后,重新判断阈值(CPU > 800 ),是否持续进入过载保护。
6.4 限流
6.4.1 介绍
限流是指在一段时间内,定义某个客户或应用可以接收或处理多少个请求的技术。例如,通过限流,你可以过滤掉产生流量峰值的客户和微服务,或者可以确保你的应用程序在自动扩展(Auto Scaling)失效前都不会出现过载的情况。
- 令牌桶、漏桶 针对单个节点,无法分布式限流。
- QPS 限流
- 不同的请求可能需要数量迥异的资源来处理。
- 某种静态 QPS 限流不是特别准。
- 给每个用户设置限制
- 全局过载发生时候,针对某些”异常”进行控制。
- 一定程度的”超卖”配额。
- 按照优先级丢弃。
- 拒绝请求也需要成本。
6.4.2 分布式限流
分布式限流,是为了控制某个应用全局的流量,而非真对单个节点纬度。
- 单个大流量的接口,使用 redis 容易产生热点。
- pre-request 模式(使用redis 的 incr 计数限流)对性能有一定影响,高频的网络往返。
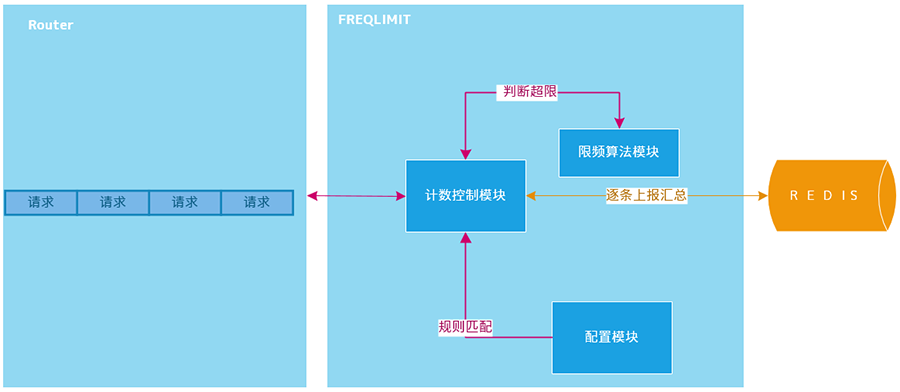
思考:
- 从获取单个 quota 升级成批量 quota(将incr换成incrby)。quota: 表示速率,获取后使用令牌桶算法来限制。
6.4.3 改进的分布式限流
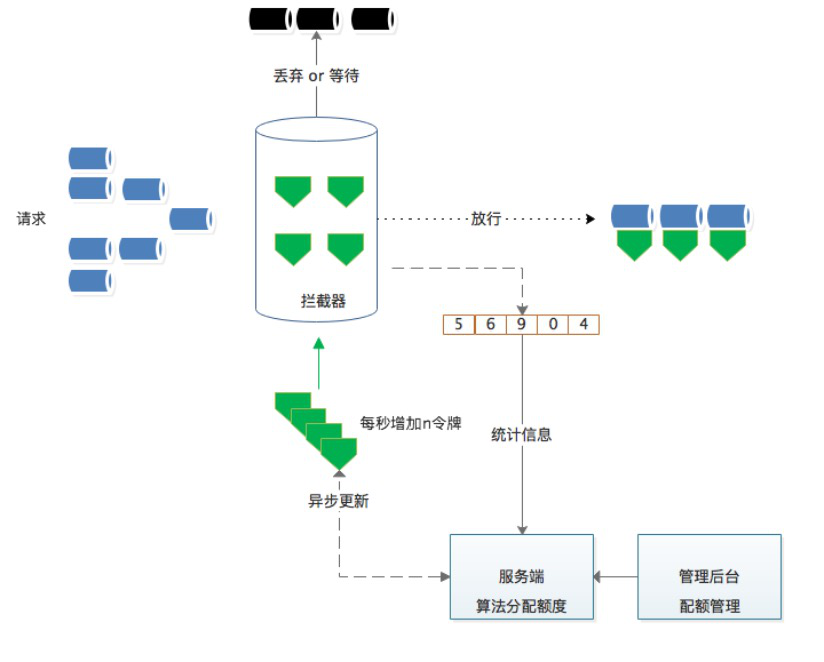
每次心跳后,异步批量获取 quota,可以大大减少请求 redis 的频次,获取完以后本地消费,基于令牌桶拦截。
每次申请的配额需要手动设定静态值略欠灵活,比如每次要20,还是50(限制的是QPS不是个数)。
如何基于单个节点按需申请,并且避免出现不公平的现象?
初次使用默认值,一旦有过去历史窗口的数据,可以基于历史窗口数据进行 quota 请求。
思考:
我们经常面临给一组用户划分稀有资源的问题,他们都享有等价的权利来获取资源,但是其中一些用户实际上只需要比其他用户少的资源。
那么我们如何来分配资源呢?一种在实际中广泛使用的分享技术称作”最大最小公平分享”(Max-Min Fairness)。
直观上,公平分享分配给每个用户想要的可以满足的最小需求,然后将没有使用的资源均匀的分配给需要’大资源’的用户。
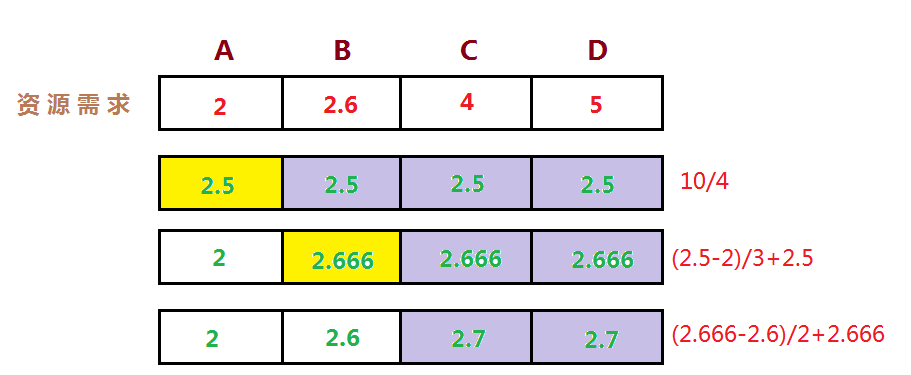
最大最小公平分配算法的形式化定义如下:
- 资源按照需求递增的顺序进行分配。
- 不存在用户得到的资源超过自己的需求。
- 未得到满足的用户等价的分享资源。
6.4.4 限流方式对比

6.4.5 重要性
每个接口配置阈值,运营工作繁重,最简单的我们配置服务级别 quota,更细粒度的,我们可以根据不同重要性设定 quota,我们引入了重要性(criticality):
- 最重要 CRITICAL_PLUS,为最终的要求预留的类型,拒绝这些请求会造成非常严重的用户可见的问题。
- 重要 CRITICAL,生产任务发出的默认请求类型。拒绝这些请求也会造成用户可见的问题。但是可能没那么严重。
- 可丢弃的 SHEDDABLE_PLUS 这些流量可以容忍某种程度的不可用性。这是批量任务发出的请求的默认值。这些请求通常可以过几分钟、几小时后重试。
- 可丢弃的 SHEDDABLE 这些流量可能会经常遇到部分不可用情况,偶尔会完全不可用。
gRPC 系统之间,需要自动传递重要性信息。如果后端接受到请求 A,在处理过程中发出了请求 B 和 C 给其他后端,请求 B 和 C 会使用与 A 相同的重要性属性。
- 全局配额不足时,优先拒绝低优先级的。
- 全局配额,可以按照重要性分别设置。
- 过载保护时,低优先级的请求先被拒绝。
6.4.6 熔断
断路器(Circuit Breakers): 为了限制操作的持续时间,我们可以使用超时,超时可以防止挂起操作并保证系统可以响应。因为我们处于高度动态的环境中,几乎不可能确定在每种情况下都能正常工作的准确的时间限制。断路器以现实世界的电子元件命名,因为它们的行为是都是相同的。断路器在分布式系统中非常有用,因为重复的故障可能会导致雪球效应,并使整个系统崩溃。
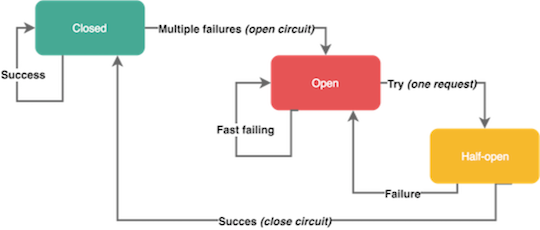
- 服务依赖的资源出现大量错误。
- 某个用户超过资源配额时,后端任务会快速拒绝请求,返回”配额不足”的错误,但是拒绝回复仍然会消耗一定资源。有可能后端忙着不停发送拒绝请求,导致过载。
原始的熔断器在熔断后的请求是一刀切(所有的请求都会失败),不够友好。
6.4.7 更友好的熔断恢复方式

Google SRE:max(0, (requests - K*accepts) / (requests + 1)) 得出的是一个丢弃的比率。
K 是常量,表示丢弃的激进性。一般用2。
6.4.8 Gutter
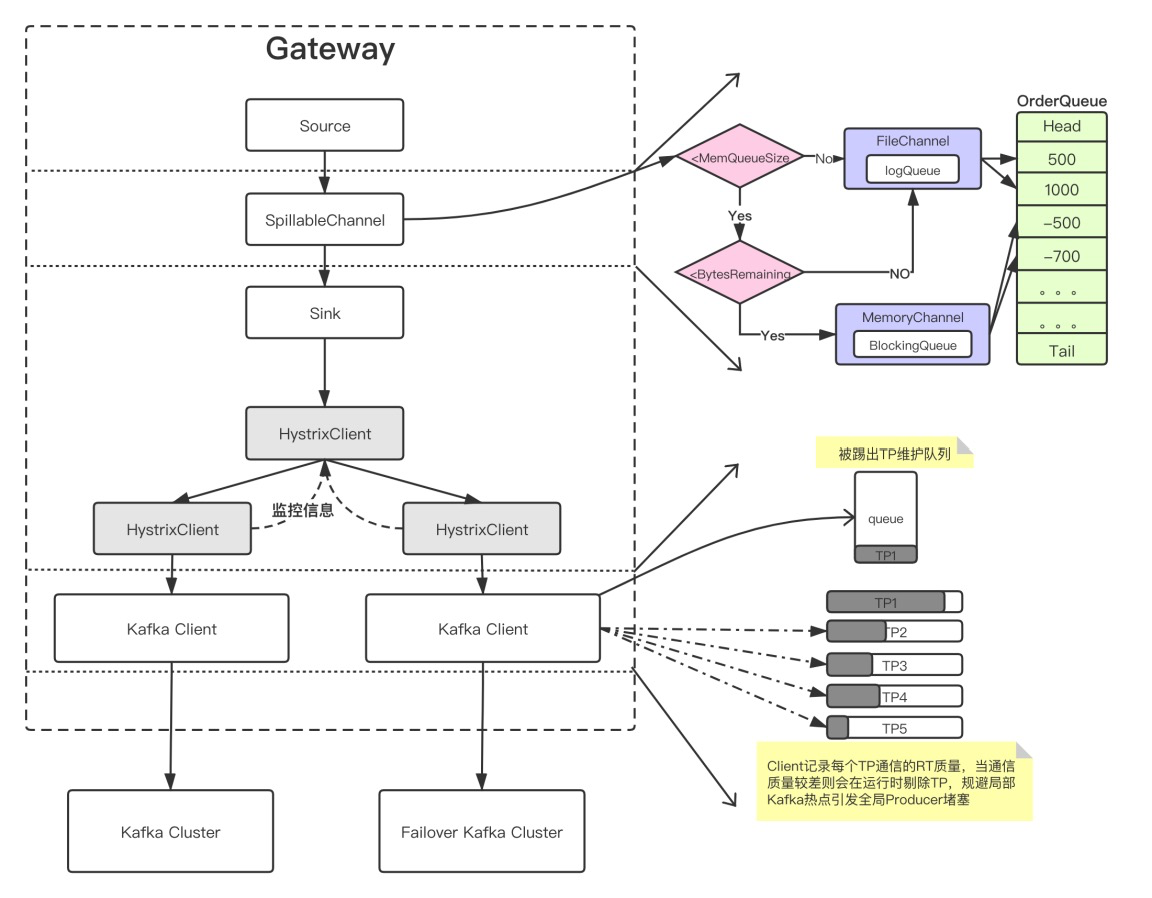
基于熔断的 gutter kafka ,用于接管自动修复系统运行过程中的负载,这样只需要付出10%的资源就能解决部分系统可用性问题。
我们经常使用 failover 的思路,但是完整的 failover 需要翻倍的机器资源,平常不接受流量时,资源浪费。高负载情况下接管流量又不一定完整能接住。所以这里核心利用熔断的思路,是把抛弃的流量转移到 gutter 集群,如果 gutter 也接受不住的流量,重新回抛到主集群,最大力度来接受。
6.4.9 客户端流控

positive feedback: 用户总是积极重试(失败时客户端自动重试),访问一个不可达的服务。
- 客户端需要限制请求频次,retry backoff 做一定的请求退让。
- 可以通过接口级别的 error_details,挂载到每个 API 返回的响应里(即把客户端自动重试的间隔设置在返回的错误信息中,客户端也需要有默认值)。
6.4.10 Case Study
- 二层缓存穿透、大量回源导致的核心服务故障。
- 异常客户端引起的服务故障(query of death)
- 请求放大。
- 资源数放大。
- 用户重试导致的大面积故障。
6.5 降级
6.5.1 介绍
通过降级回复来减少工作量,或者丢弃不重要的请求。而且需要了解哪些流量可以降级,并且有能力区分不同的请求。我们通常提供降低回复的质量来答复减少所需的计算量或者时间。我们自动降级通常需要考虑几个点:
- 确定具体采用哪个指标作为流量评估和优雅降级的决定性指标(如,CPU、延迟、队列长度、线程数量、错误等)。
- 当服务进入降级模式时,需要执行什么动作?
- 流量抛弃或者优雅降级应该在服务的哪一层实现?是否需要在整个服务的每一层都实现,还是可以选择某个高层面的关键节点来实现?
降级通常在 BFF 或者 API Gateway 中做。在下游做的话上游感觉不到降级,可能会污染缓存等,也需要做的很复杂。
同时我们要考虑一下几点:
- 优雅降级不应该被经常触发 - 通常触发条件现实了容量规划的失误,或者是意外的负载。
- 演练,代码平时不会触发和使用,需要定期针对一小部分的流量进行演练,保证模式的正常。
- 应该足够简单。
降级本质为: 提供有损服务。
UI 模块化,非核心模块降级。
- BFF 层聚合 API,模块降级。
页面上一次缓存副本。
- 默认值、热门推荐等。
- 流量拦截 + 定期数据缓存(过期副本策略)。
处理策略
- 页面降级、延迟服务、写/读降级、缓存降级
- 抛异常、返回约定协议、Mock 数据、Fallback 处理
6.5.2 Case Study
- 客户端解析协议失败,app 奔溃。
- 客户端部分协议不兼容,导致页面失败。
- local cache 数据源缓存,发版失效 + 依赖接口故障,引起的白屏。
- 没有 playbook(SOP),导致的平均修复时间(Mean time to repair,MTTR)上升。
6.6 重试
6.6.1 介绍
当请求返回错误(例: 配额不足、超时、内部错误等),对于 backend 部分节点过载的情况下,倾向于立刻重试,但是需要留意重试带来的流量放大:
- 限制重试次数和基于重试分布的策略(重试比率: 10%)。
- 随机化、指数型递增的重试周期: exponential ackoff + jitter。
- client 测记录重试次数直方图,传递到 server,进行分布判定,交由 server 判定拒绝。
- 只应该在失败的这层进行重试,当重试仍然失败,全局约定错误码”过载,无须重试”,避免级联重试。
6.6.2 Case Study
- Nginx upstream retry 过大,导致服务雪崩。
- 业务不幂等,导致的重试,数据重复。
- 全局唯一 ID: 根据业务生成一个全局唯一 ID,在调用接口时会传入该 ID,接口提供方会从相应的存储系统比如 redis 中去检索这个全局 ID 是否存在,如果存在则说明该操作已经执行过了,将拒绝本次服务请求;否则将相应该服务请求并将全局 ID 存入存储系统中,之后包含相同业务 ID 参数的请求将被拒绝。
- 去重表: 这种方法适用于在业务中有唯一标识的插入场景。比如在支付场景中,一个订单只会支付一次,可以建立一张去重表,将订单 ID 作为唯一索引。把支付并且写入支付单据到去重表放入一个事务中了,这样当出现重复支付时,数据库就会抛出唯一约束异常,操作就会回滚。这样保证了订单只会被支付一次。
- 多版本并发控制: 适合对更新请求作幂等性控制,比如要更新商品的名字,这是就可以在更新的接口中增加一个版本号来做幂等性控制。
- 多层级重试传递,放大流量引起雪崩。
6.7 负载均衡
数据中心内部的负载均衡
在理想情况下,某个服务的负载会完全均匀地分发给所有的后端任务。在任何时刻,最忙和最不忙的节点永远消耗同样数量的CPU。
目标:
- 均衡的流量分发。
- 可靠的识别异常节点。
- scale-out,增加同质节点扩容。
- 减少错误,提高可用性。
我们发现在 backend 之间的 load 差异比较大:
- 每个请求的处理成本不同。
- 物理机环境的差异:
- 服务器很难强同质性。
- 存在共享资源争用(内存缓存、带宽、IO等)。
- 性能因素:
- FullGC。
- JVM JIT。
参考JSQ(最闲轮训)负载均衡算法带来的问题,缺乏的是服务端全局视图,因此我们目标需要综合考虑:负载+可用性。
参考了《The power of two choices in randomized load balancing》的思路,我们使用 the choice-of-2 算法,随机选取的两个节点进行打分,选择更优的节点:
- 选择 backend:CPU,client:health、inflight、latency 作为指标,使用一个简单的线性方程进行打分。
- 对新启动的节点使用常量惩罚值(penalty),以及使用探针方式最小化放量,进行预热。
打分比较低的节点,避免进入”永久黑名单”而无法恢复,使用统计衰减的方式,让节点指标逐渐恢复到初始状态(即默认值)。
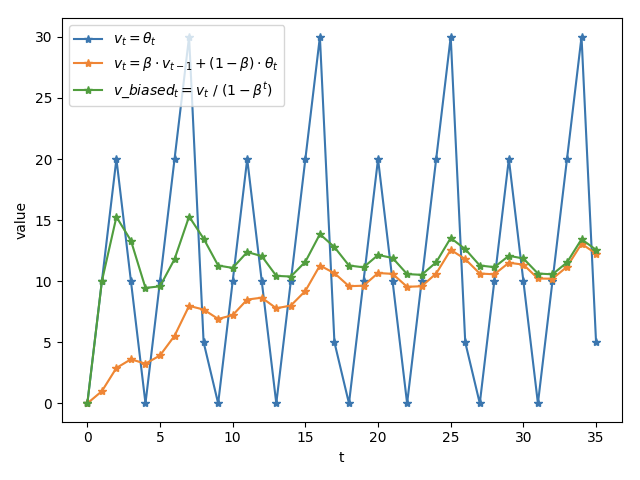
指标计算结合 moving average,使用时间衰减,计算
vt = v(t-1) * β + at * (1-β),β为若干次幂的倒数即: Math.Exp((-span) / 600ms)
6.8 最佳实践
- 变更管理:
- 70%的问题是由变更引起的,恢复可用代码并不总是坏事。
- 避免过载:
- 过载保护、流量调度等。
- 依赖管理:
- 任何依赖都可能故障,做 chaos monkey testing,注入故障测试。
- 优雅降级:
- 有损服务,避免核心链路依赖故障。
- 重试退避:
- 退让算法,冻结时间,API retry detail 控制策略。
- 超时控制:
- 进程内 + 服务间 超时控制。
- 极限压测 + 故障演练。
- 扩容 + 重启 + 消除有害流量。
6.9 References
http://www.360doc.com/content/16/1124/21/31263000_609259745.shtml
http://www.infoq.com/cn/articles/basis-frameworkto-implement-micro-service/
http://www.infoq.com/cn/news/2017/04/linkerd-celebrates-one-year
https://medium.com/netflix-techblog/netflix-edge-load-balancing-695308b5548c
https://mp.weixin.qq.com/s?__biz=MzAwNjQwNzU2NQ==&mid=402841629&idx=1&sn=f598fec9b370b8a6f2062233b31122e0&mpshare=1&scene=23&srcid=0404qP0fH8zRiIiFzQBiuzuU#rd
https://mp.weixin.qq.com/s?__biz=MzIzMzk2NDQyMw==&mid=2247486641&idx=1&sn=1660fb41b0c5b8d8d6eacdfc1b26b6a6&source=41#wechat_redirect
https://blog.acolyer.org/2018/11/16/overload-control-for-scaling-wechat-microservices/
https://www.cs.columbia.edu/~ruigu/papers/socc18-final100.pdf
https://github.com/alibaba/Sentinel/wiki/系统负载保护
https://blog.csdn.net/okiwilldoit/article/details/81738782
http://alex-ii.github.io/notes/2019/02/13/predictive_load_balancing.html
https://blog.csdn.net/m0_38106113/article/details/81542863
第7课 播放历史架构设计
7.1 功能模块
https://www.bilibili.com/account/history
为了大部分用户的基本功能体验,满足用户需求,例如播放历史查看、播放进度同步等。离线型用户,app 本地保留历史记录数据。
同样的,也要考虑平台化,视频、文章、漫画等业务扩展接入。
- 变更功能:添加记录、删除记录、清空历史。
- 读取功能:按照 timeline 返回 top N,点查获取进度信息。
- 其他功能:暂停/恢复记录,首次观察增加经验等。
历史记录类型的业务,是一个极高 tps 写入,高 qps 读取的业务服务。分析清楚系统的 hot path,投入优化,而不是哪哪都去优化。
7.2 架构设计
7.2.1 概览
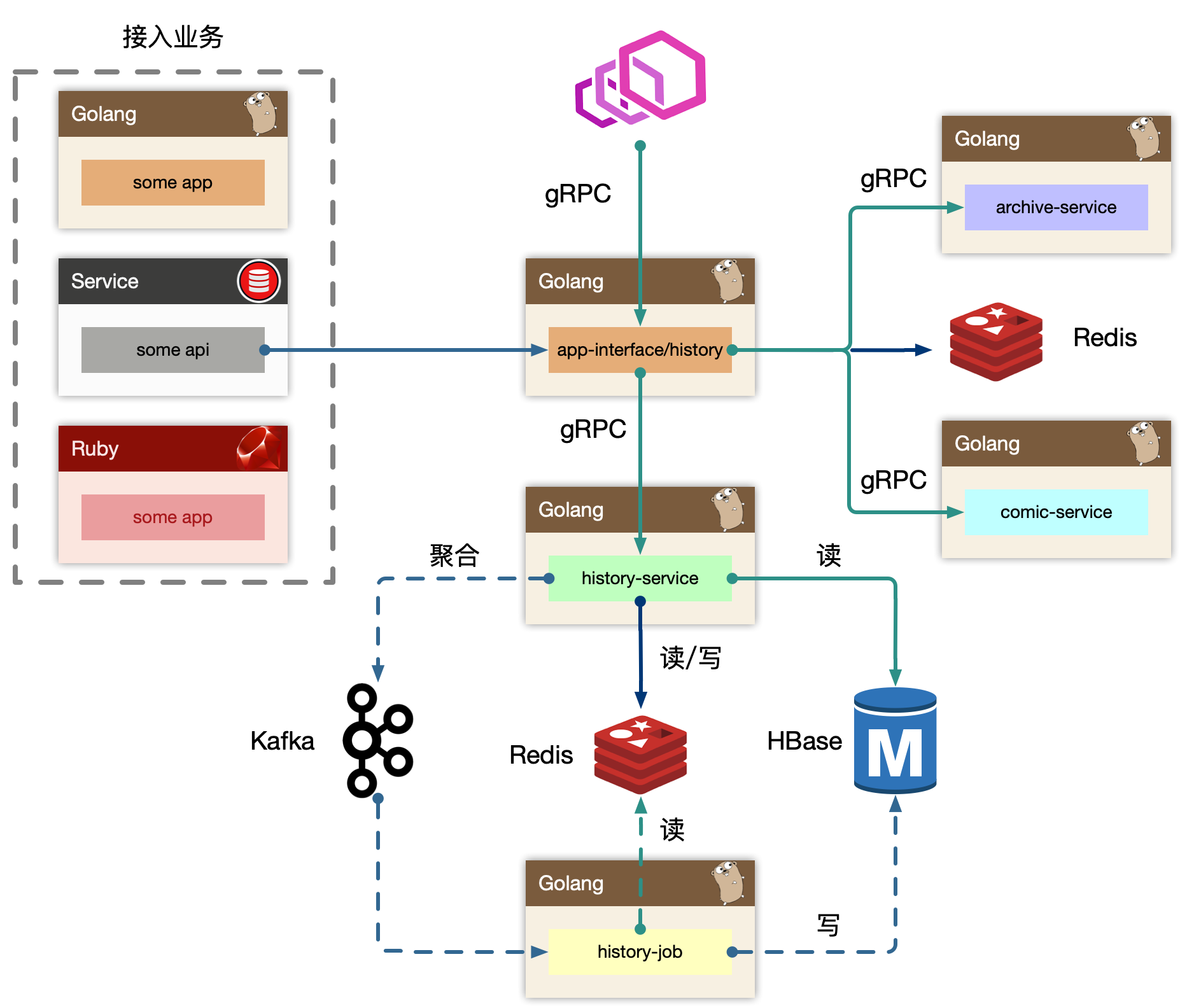
BFF: app-interface、history
历史 BFF 层接受来自外部用户的读请求,依赖其他例如稿件、漫画服务来组装完整的面向历史业务(页面)需要的数据的组合。同时接受来自内部其他业务线的写请求,通常都是业务方自己进行业务 ID 的判定,然后投递到历史服务的 BFF 写接口中。最终 BFF 是打包在 app-interface 大杂烩 BFF 中,考虑到隔离性,读写流量很大,独立成 history BFF 服务。Service: history-service
服务层,去平台业务的逻辑,专注在历史数据的持久化上(因为对于播放类业务,BFF 专注平台业务数据组织,service 负责数据的读、写、删、清理等操作。播放进度是非常高频同步的,需要考虑性能优化)。使用 write-back 的思路,把状态数据先入分布式缓存,再回写数据库。
Job: history-job
job 消费上游 kafka 的数据,利用消息队列的堆积能力,对于存储层的差速(消费能力跟不上生产速度时),可以进行一定的数据反压。配合上游 service 批量打包过来的数据持久化。Upstream: some-app,some-api
整个历史服务还会被一些外部 gRPC 服务所依赖,所以 history 还充当了内网的 gRPC Provider,这些上游服务,使用历史服务的写接口,把自己业务的数据进行持久化。
历史服务最重要的设计,就是批量打包(pipeline)聚合数据。将高频、密集的写请求先入缓存(write-back),批量消费减少对存储的直接压力,类似的设计随处可见。
7.2.2 history-service
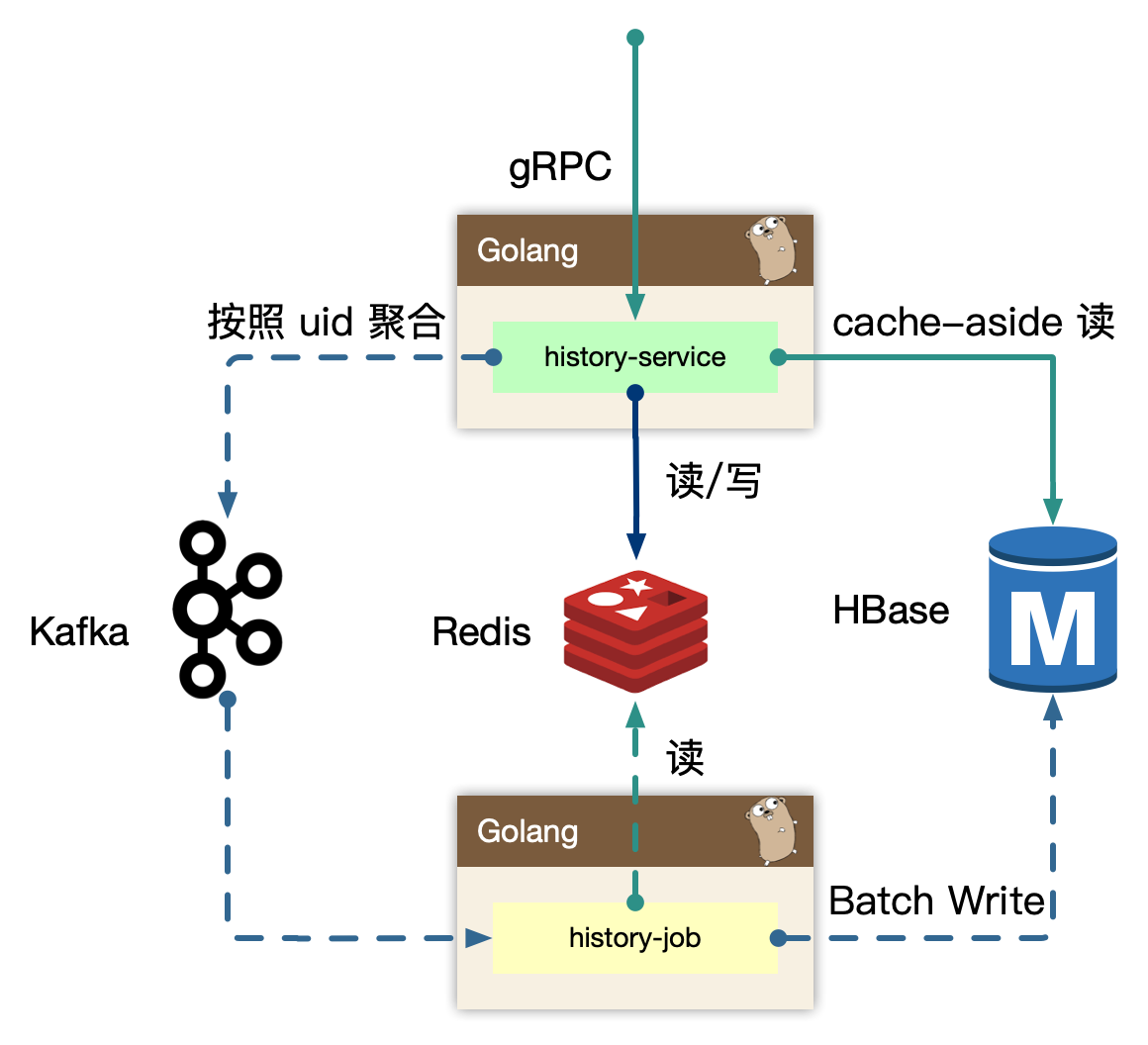
history-service,专注在历史数据处理。
写的核心逻辑:
用户观看的稿件、漫画等,带有进度信息的数据,同一个 id 最后一次的数据即可,即 last-write win,高频的用户端同步逻辑,只需要最后一次数据持久化即可。我们可以在 in-process 内存中,定时定量来聚合不同用户的”同一个对象的最后一次进度”,使用 kafka 消息队列来消除写入峰值。但同时我们需要保证用户数据可以实时被观察到,不能出现上报进度后,需要一阵子才能体现进度变化。所以我们即在内存中打包数据,同时实时写入到 redis 中,这样即保证了实时,又避免海量写入冲击存储。kafka 是为高吞吐设计,超高频的写入并不是最优,所以内存聚合和分片算法比较重要,按照 uid 来sharding 数据,写放大仍然很大,这里我们使用 region sharding,打包一组数据当作一个 kafka message(比如 uid % 100数据打包)。
写逻辑的数据流向: 实时写 redis -> 内存维护用户数据 -> 定时/定量写入到 kafka。
读的核心逻辑:
历史数据,实时写入 redis 后,不会无限制的存储,会按量截断,所以分布式缓存中数据不是完整数据,
历史数据从 redis sortedset 中读取后,如果发现尾部数据不足,会触发 cache-aside 模式,从存储中回捞数据,但是不会重新回填缓存,因为拉取过去更久远的数据,属于用户纬度的低频度行为。历史数据通常是按照 timeline 来组织,游标的 key 可以使用时间戳进行翻页或者下拉。
7.2.3 history-job
history-job,获取打包好的用户数据,进行批量持久化。
上游 history-service 按照 uid region sharding 聚合好的数据,在 job 中消费取出,为了节约传输过程,以及 history-service 的 in-process cache 的内存使用,我们只维护了用户的 uid 以及 id 列表,最小化存储和传输。因为数据是不完整的,我们额外需要从 redis 中按照 id 对应的数据内容,再持久化。从原来的 N 条记录变为一个用户一条记录。
对于存储的选型,我们认为 HBase 非常合适高密度写入。后续我们会单独讨论我们经历过的几次存储迭代和选型。
7.2.4 history
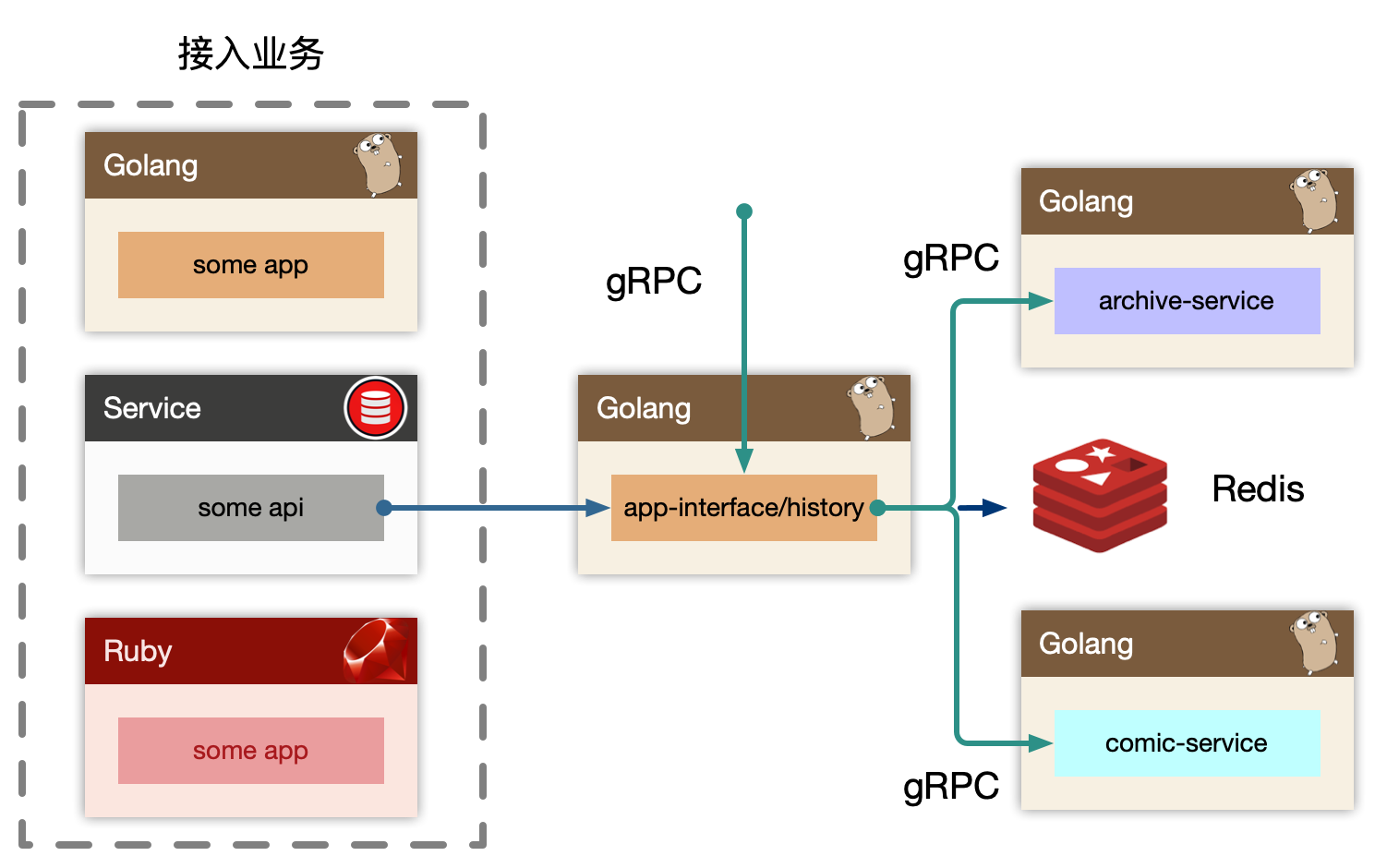
history 作为 BFF,对用户端提供统一的用户记录记录入口接口,同时也对内提供 gRPC 写入历史接口。如果业务场景中不存在统一的用户入口访问历史记录,可以去掉 BFF 层,直接使用 history-service 提供读接口,这样需要每个业务方自己实现自己的数据组装。
我们也有类似用户首次播放、观看等加经验或者奖励积分类似的操作,所以我们这里依赖 redis,进行判定用户当天是否是首次访问,我们比较容易想到使用 bitmap 或者 bloom filter 来进行判断,然后往下游 kafka 投递消息,而不直接依赖业务的某个服务。
因为我们有关闭历史记录的功能,这样每次写入操作都需要前置读取一次,是否打开了开关,同样的每次首次发送奖励也是一样,你有更好的办法吗?
7.3 存储设计
7.3.1 数据库设计

我们最早的主力存储选型是: HBase。
- 数据写入:
PUT mid, values,只需要写入到 column_family 的 info 列簇,rowkey 使用用户 id md5 以后的头两位 + 用户,避免 rowkey 热点密集到一个 region 中,导致写/读热点。 对于 column_family: info,存储一个列 obj_id + obj_type,例如 稿件业务:1、稿件ID: 100,100_1 作为列名,对于 value 使用 protobuf 序列化一个结构体接入。所以只需要单次更新 kv store。另外我们使用 HBase TTL 的能力,只需要保存90天的用户数据即可。(删除同理) - 数据读取:
列表获取为 GET mid,直接获取1000条,在内存中排序和翻页。点查 GET mid columns,在茫茫多视频查看当前视频的阅读进度,cache miss 会非常严重,虽然支持点查,但是对于上层 cache miss 后,不再回源请求 HBase。
7.3.2 缓存设计
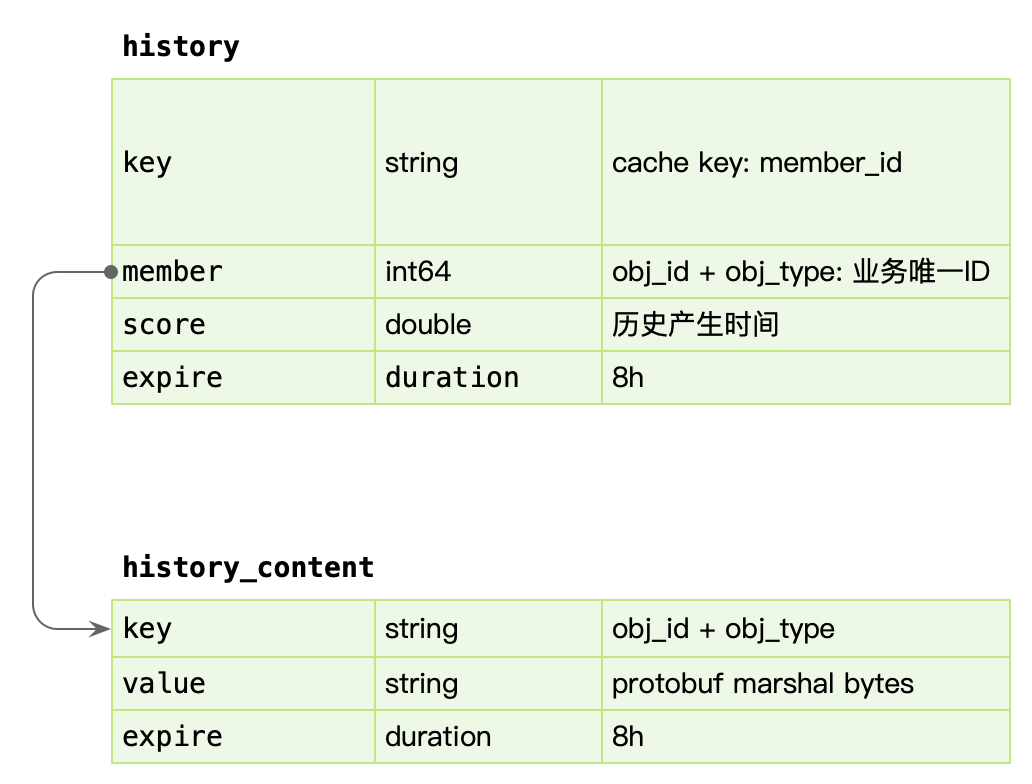
数据写入:
每次产生的历史数据,需要立马更新 redis,使用 sorted set 基于时间排序的列表,member 为业务 ID。同时存储一份数据到 redis string 中,使用 protobuf 序列化完整的数据内容。为了避免 redis 中单个用户数据无限增长,需要超过一定量后对数据进行截断。数据读取:
分为两个场景,一个是历史页面,这时候使用 sorted set,排序查找即可,拿到列表后,mget 批量获取 history_content 内容。
另外一个是点查进度,比如我们点击进入一个视频详情页,这时候直接查找 history_content 进行点查,不再回源 HBase,因为命中率太低。
首次触发某行为,增加经验的,我们在缓存设计中,经常使用 bitmap(roaring bitmap)、bloom filter 缓存加速访问,但是在使用缓存时,需要注意规避热点问题,某个key sharding 命中 node 是固定的,因此我们可以利用构建多组 bitmap 或 bloom filter,来进行打散。
prefix_key = hash(mid) % 1000
根据 prefix_key 找到对应的 cache 再进行操作,这样 1000 个 key 尽可能均匀的分布到更小集合的 node,而不会产生数据热点。
但是仍然每次触发行为,都为前置判定,有更好的优化方案吗?
7.4 可用性设计
7.4.1 Write-Back
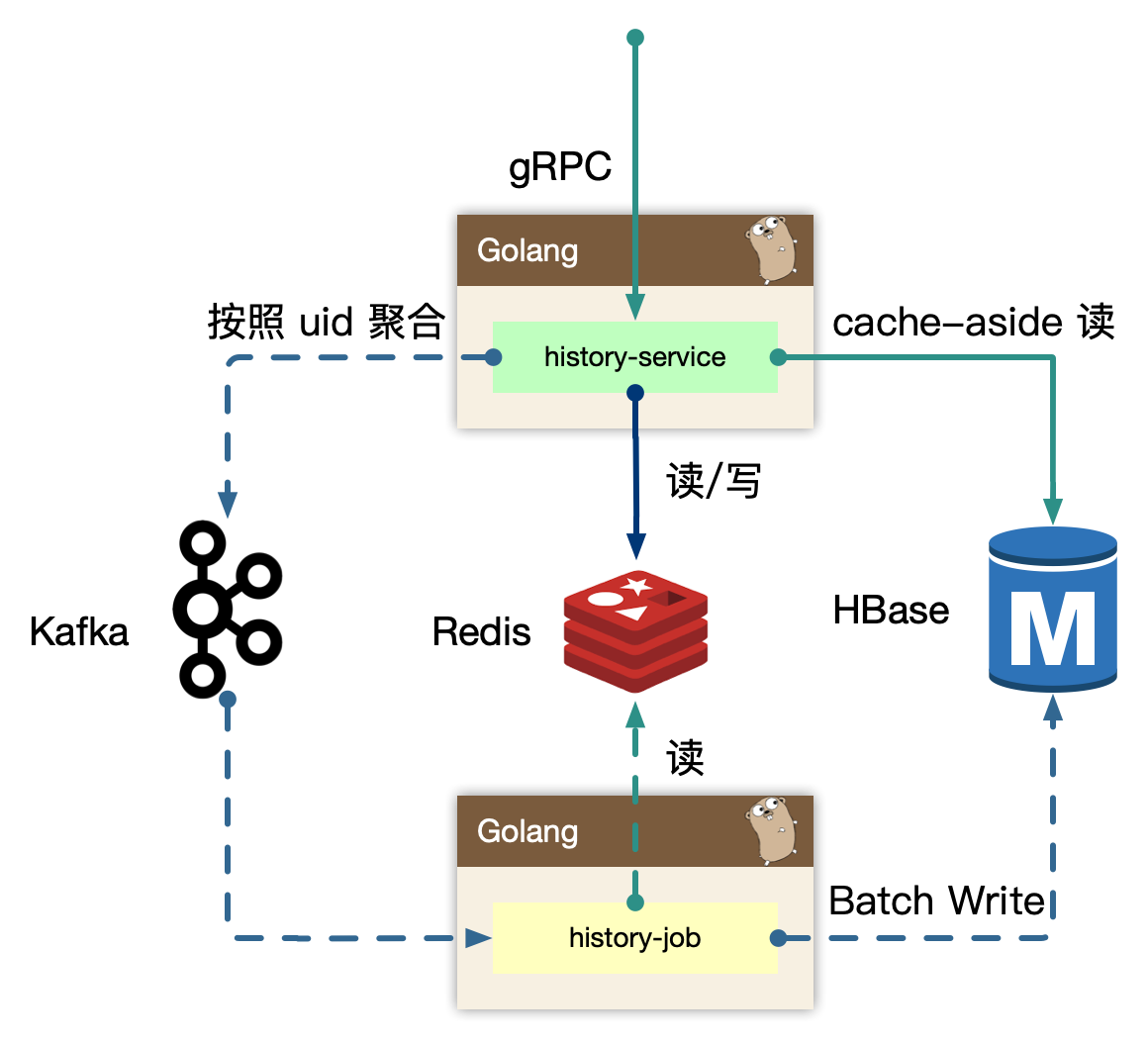
在 history-service 中实时写入 redis 数据,因此只需要重点优化缓存架构中,扛住峰值的流量写入。之后在服务内存中,使用 map[int]map[int]struct{} 聚合数据,之后利用 chan 在内部发送每个小消息,再聚合成一个大map,在 sendproc 中,使用 timer 和 定量判定逻辑,发送到下游 kafka 中。
在 history-job 中,获取消息后,重新去 redis 中回捞数据即: history-content,然后构建完整的数据批量写入到 HBase 中。
这里存在两个风险:
- history-service 重启过程中,预聚合的消息丢失;
- history-job 读取 redis 构建数据,但 redis 丢失;
我们在这里进行了 trade-off,高收敛比的设计,意味着存在数据丢失的风险,对于历史场景,非 L0 的业务服务/数据,我们认为极端情况下可接受。
7.4.2 聚合
经过 BFF history 的流量 per-request 都会发送给 history-service,我们最容易想到的优化就是聚合上移来减少发送给下游的 rpc。但是按照 mid region sharding 的思路非常具有业务的耦合性,所以不应该把逻辑上移,而只是数据上移,所以可以考虑简单 batch put 请求,做一个无逻辑的数据聚合再发送给 history-service,这样可以大大的减少内网的流量,节约资源。
我们发现经过 API Gateway 的流量都会触发高频的 per-rpc auth,给内网的 identify-service 带来了不少压力。我们认为大部分历史行为通过心跳的方式同步进度,为何不连接一个长连接,长连接服务再握手后先进行用户级的身份验证,之后维持身份信息,而不是每次发送 request 都进行验证,这样可以大大减少内网的 identify-service 的流量。
我们内网使用 boardcast(goim) 服务维护长连接,长连接一次验证,不断使用。
7.4.3 广播
用户首次触发的行为,需要发送消息给下游系统进行触发其他奖励等。如何减少这类一天只用一次的标记位缓存请求?
使用 in-process localcache,只有高频的用户访问,带来的收益就越大,我们很容易想到使用 LRU 维护这个集合,但用户分布很广,很难覆盖,命中率很低。
越源头解决架构问题,通常越简单,效率越高。
我们在写操作(高频请求)中,把当前的 flag 返回到 API 协议中,作为一个日期值,客户端保存到本地,下次请求的时候带上,如果发现该值在,获取以后直接使用不再请求缓存,例如: 2021-1-1,发现当前时间还是2021-1-1,直接不再请求 redis,如果发现当前时间是2021-1-2,需要触发一次 redis 访问,返回新的 flag 到客户端,这样把状态广播同步到任何其他设备,可以大大减少判定缓存。
实现成本在于,你认为的代价高低。
7.5 References
https://en.wikipedia.org/wiki/Cache#Writing_Policies
https://blog.csdn.net/jiaomeng/article/details/1495500
https://blog.csdn.net/yizishou/article/details/78342499
https://blog.csdn.net/caoshangpa/article/details/78783749
第8课 分布式缓存和分布式事务
8.1 缓存选型
8.1.1 memcache
memcache 提供简单的 kv cache 存储,value 大小不超过1mb。
我使用 memcache 作为大文本或者简单的 kv结构使用。
memcache 使用了slab 方式做内存管理,存在一定的浪费,如果大量接近的 item,建议调整 memcache 参数来优化每一个 slab 增长的 ratio、可以通过设置 slab_automove & slab_reassign 开启memcache 的动态/手动 move slab,防止某些 slab 热点导致内存足够的情况下引发 LRU。
大部分情况下,简单 KV 推荐使用 Memcache,吞吐和相应都足够好。
每个 slab 包含若干大小为1M的内存页,这些内存又被分割成多个 chunk,每个 chunk存储一个 item;
在 memcache 启动初始化时,每个 slab 都预分配一个 1M 的内存页,由slabs_preallocate 完成(也可将相应代码注释掉关闭预分配功能)。
chunk 的增长因子由 -f 指定,默认1.25,起始大小为48字节。
内存池有很多种设计,可以参考下: nginx ngx_pool_t,tcmalloc 的设计等等。
8.1.2 redis
redis 有丰富的数据类型,支持增量方式的修改部分数据,比如排行榜,集合,数组等。
比较常用的方式是使用 redis 作为数据索引,比如评论的列表 ID,播放历史的列表 ID 集合,我们的关系链列表 ID。
redis 因为没有使用内存池,所以是存在一定的内存碎片的,一般会使用 jemalloc 来优化内存分配,需要编译时候使用 jemalloc 库代替 glib 的 malloc 使用。
8.1.3 redis vs memcache
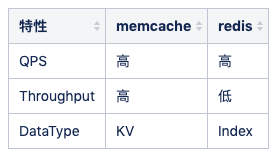
Redis 和 Memcache 最大的区别其实是 redis 单线程(新版本双线程),memcache 多线程,所以 QPS 可能两者差异不大,但是吞吐会有很大的差别,比如大数据 value 返回的时候,redis qps 会抖动下降的的很厉害,因为单线程工作,其他查询进不来(新版本有不少的改善)。
所以建议纯 kv 都走 memcache,比如我们的关系链服务中用了 hashs 存储双向关系,但是我们也会使用 memcache 档一层来避免hgetall 导致的吞吐下降问题。
我们系统中多次使用 memcache + redis 双缓存设计。
redis 6 已经支持了多线程的网络 IO 。
memcached 使用 slab 方式做内存管理,存在一定的浪费。如果有大量接近的 item,建议调整 memcache 参数来优化每一个 slab 增长的 ratio ,可以通过设置
slab_automove和slab_reassign开启 memcached 的动态/手动 move slab,防止某些 slab 热点导致内存足够的情况下引发 LRU 。
8.1.4 Proxy
早期使用 twemproxy 作为缓存代理,但是在使用上有如下一些痛点:
- 单进程单线程模型和 redis 类似,在处理一些大 key 的时候可能出现 io 瓶颈;
- 二次开发成本难度高,难以于公司运维平台进行深度集成;
- 不支持自动伸缩,不支持 autorebalance 增删节点需要重启才能生效;
- 运维不友好,没有控制面板;
业界开源的的其他代理工具:
- codis: 只支持 redis 协议,且需要使用 patch版本的 redis;
- mcrouter: 只支持 memcache 协议,C 开发,与运维集成开发难度高;
现在推荐直接用redis cluster。
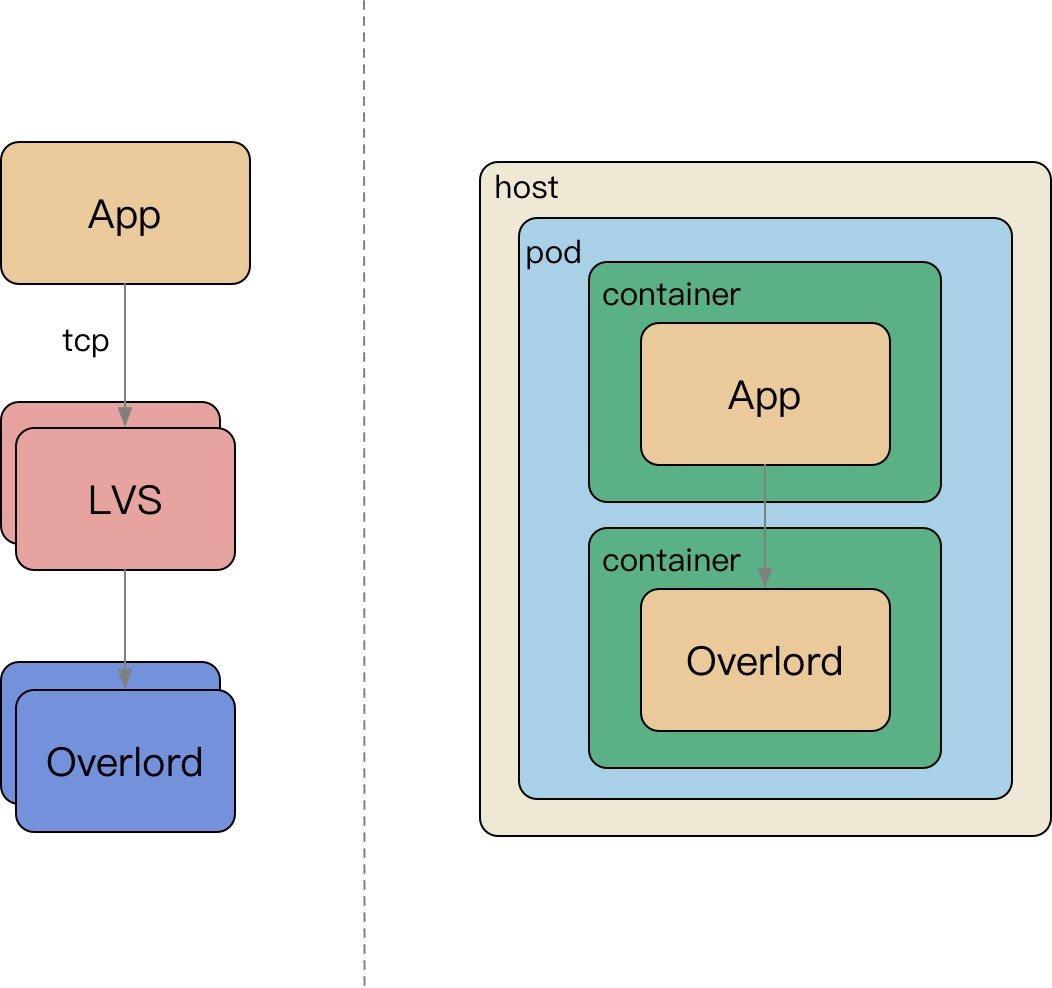
从集中式访问缓存到 Sidecar 访问缓存:
- 微服务强调去中心化;
- LVS 运维困难,容易流量热点,随下游扩容而扩容,连接不均衡等问题;
- Sidecar 伴生容器随 App 容器启动而启动,配置简化;
8.1.5 一致性Hash
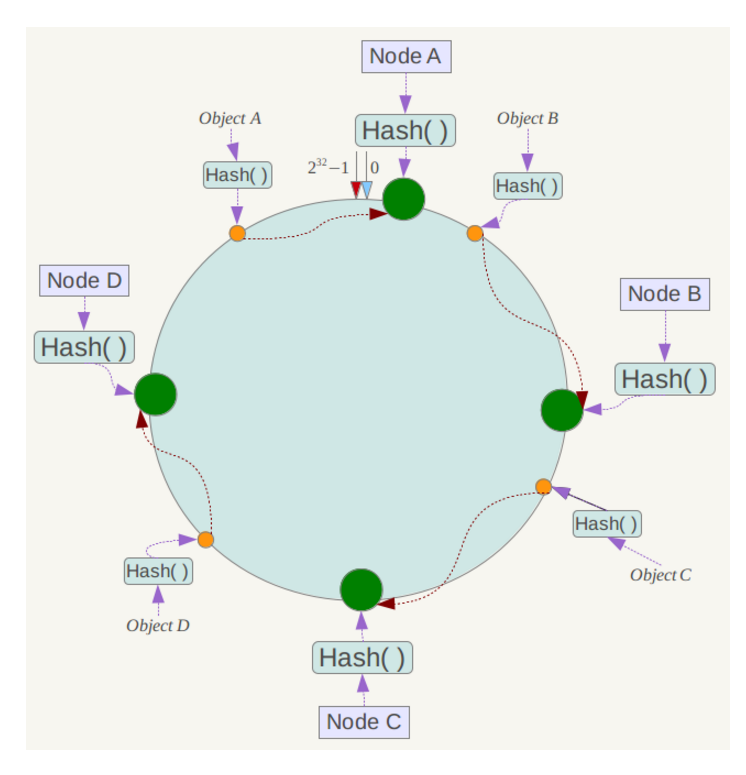
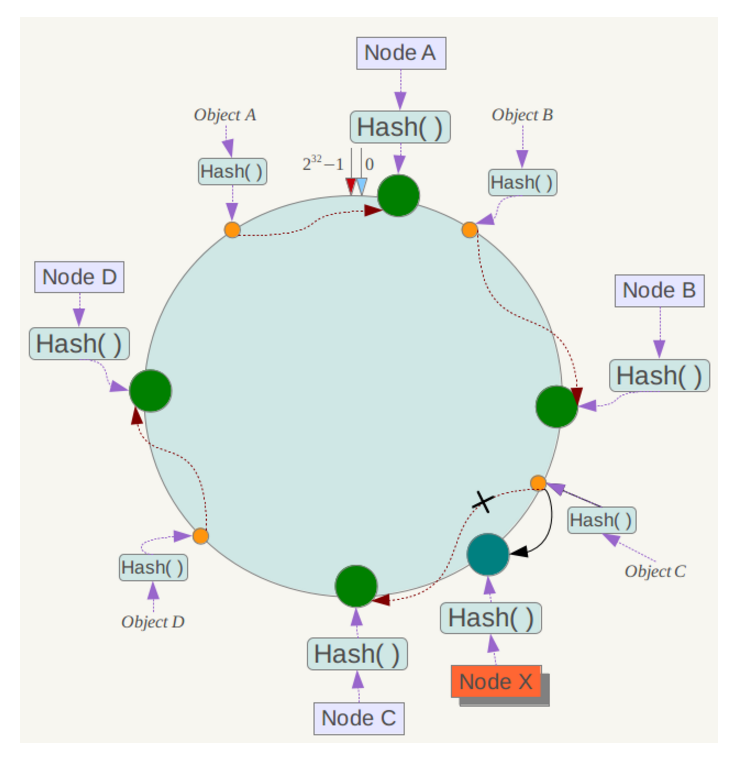
一致性 hash 是将数据按照特征值映射到一个首尾相接的 hash 环上,同时也将节点(按照 IP 地址或者机器名 hash)映射到这个环上。
对于数据,从数据在环上的位置开始,顺时针找到的第一个节点即为数据的存储节点。
余数分布式算法由于保存键的服务器会发生巨大变化而影响缓存的命中率,但Consistent Hashing 中,只有在园(continuum)上增加服务器的地点逆时针方向的第一台服务器上的键会受到影响。
- 平衡性(Balance):尽可能分布到所有的缓冲中去
- 单调性(Monotonicity):单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲区加入到系统中,那么哈希的结果应能够保证原有已分配的内容可以被映射到新的缓冲区中去,而不会被映射到旧的缓冲集合中的其他缓冲区。
- 分散性(Spread):相同内容被存储到不同缓冲中去,降低了系统存储的效率,需要尽量降低分散性。
- 负载(Load):哈希算法应能够尽量降低缓冲的负荷。
- 平滑性(Smoothness):缓存服务器的数目平滑改变和缓存对象的平滑改变是一致的。
一致性哈希算法在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜问题。
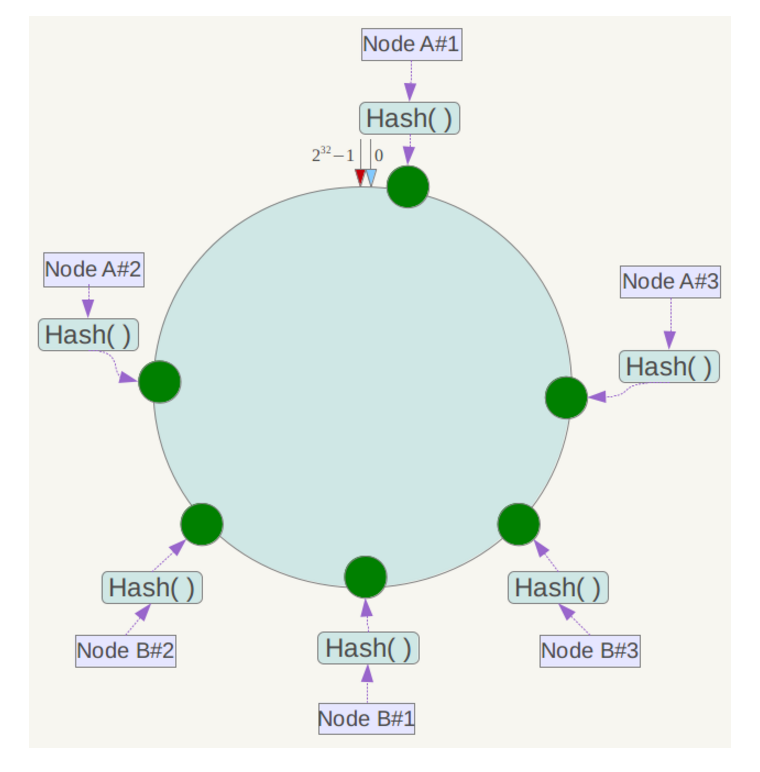
此时必然造成大量数据集中到 Node A 上,而只有极少量会定位到 Node B 上。为了解决这种数据倾斜问题,一致性哈希算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。
具体做法可以在服务器 ip 或主机名的后面增加编号来实现。
例如上面的情况,可以为每台服务器计算三个虚拟节点,于是可以分别计算 “Node A#1”、”Node A#2”、”Node A#3”、”Node B#1”、”Node B#2”、”Node B#3” 的哈希值,于是形成六个虚拟节点。
同时数据定位算法不变,只是多了一步虚拟节点到实际节点的映射,例如定位到 “Node A#1”、”Node A#2”、”Node A#3”三个虚拟节点的数据均定位到 Node A 上。这样就解决了服务节点少时数据倾斜的问题。
参考微信红包的写合并优化: https://www.cnblogs.com/chinanetwind/articles/9460820.html
在网关层,使用一致性 hash,对红包 id 进行分片,命中到某一个逻辑服务器处理,在进程内做写操作的合并,减少存储层的单行锁争用。
我认为更好的做法是 有界负载一致性 hash。
8.1.6 Hash
数据分片的 hash 方式也是这个思想,即按照数据的某一特征(key)来计算哈希值,并将哈希值与系统中的节点建立映射关系,从而将哈希值不同的数据分布到不同的节点上。
按照 hash 方式做数据分片,映射关系非常简单;需要管理的元数据也非常之少,只需要记录节点的数目以及 hash 方式就行了。
当加入或者删除一个节点的时候,大量的数据需要移动。比如在这里增加一个节点 N3,因此 hash 方式变为了 mod 4。
均衡问题:原始数据的特征值分布不均匀,导致大量的数据集中到一个物理节点上;第二,对于可修改的记录数据,单条记录的数据变大。
高级玩法是抽象 slot,基于 Hash 的 Slot Sharding,例如 Redis-Cluster。
8.1.7 Slot
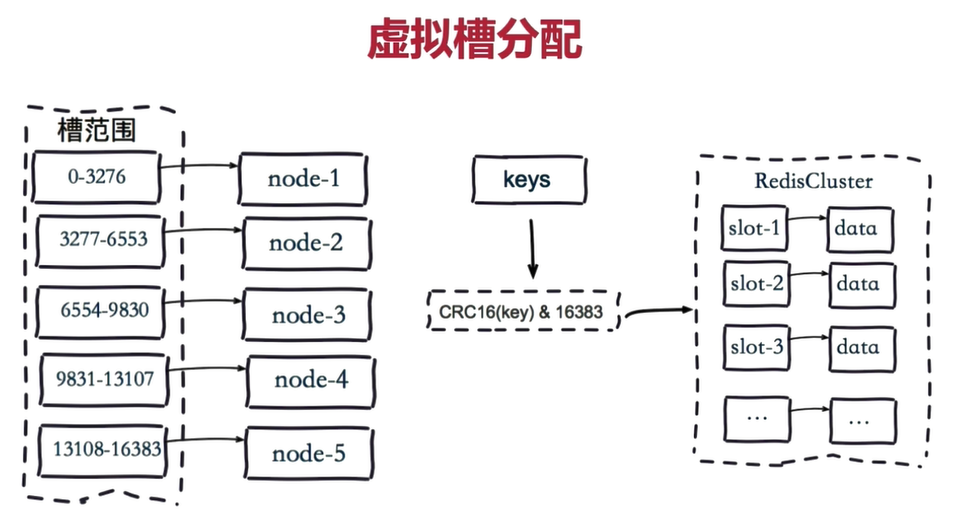
redis cluster 的做法:
1.把 16384 槽按照节点数量进行平均分配,由节点进行管理
2.对每个 key 按照 CRC16 规则进行 hash 运算
3.把 hash 结果对 16383 进行取余
4.把余数发送给 redis 节点
5.节点接收到数据,验证是否在自己管理的槽编号的范围
如果在自己管理的槽编号范围内,则把数据保存到数据槽中,然后返回执行结果
如果在自己管理的槽编号范围外,则会把数据发送给正确的节点,由正确的节点来把数据保存在对应的槽中
16384 = (1<<14)。Redis Cluster的节点之间会共享消息,每个节点都会知道是哪个节点负责哪个范围内的数据槽
8.2 缓存模式
8.2.1 数据一致性
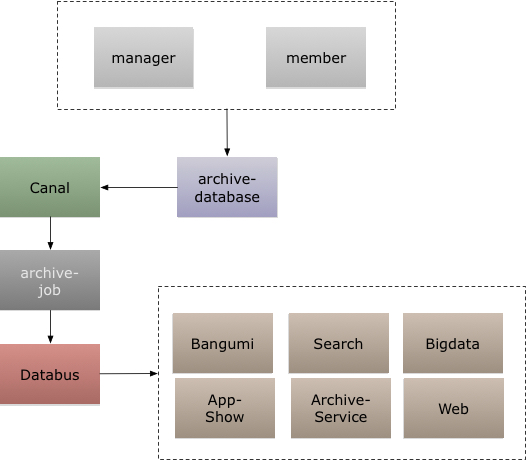
Storage 和 Cache 同步更新容易出现数据不一致。
模拟 MySQL Slave 做数据复制,再把消息投递到 Kafka,保证至少一次消费:
- 同步操作DB;
- 同步操作Cache;
- 利用Job消费消息,重新补偿一次缓存操作
保证时效性和一致性。
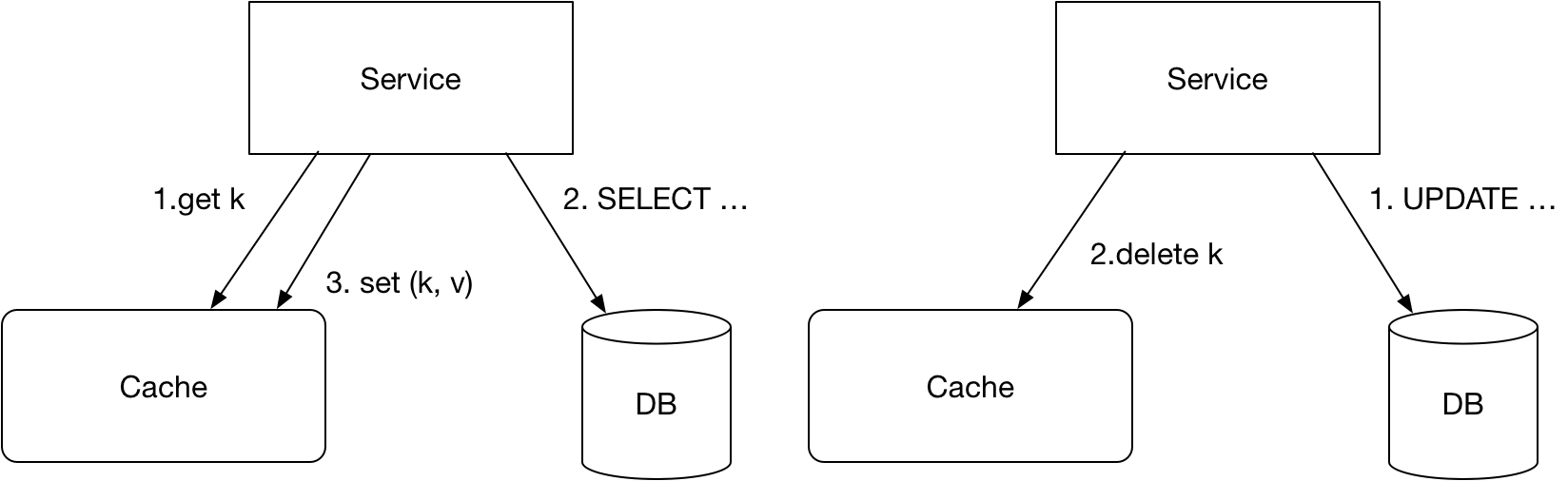
Cache Aside 模型中,读缓存 Miss 的回填操作,和修改数据同步更新缓存,包括消息队列的异步补偿缓存,都无法满足 “Happens Before”,会存在相互覆盖的情况。
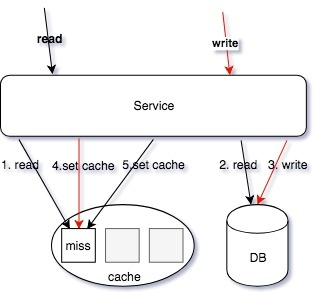
错误的使用:
- 读操作,读缓存,缓存 MISS
- 读操作,读 DB,读取到数据
- 写操作,更新 DB 数据
- 写操作 SET/DELETE Cache(可 Job 异步操作)
- 读操作,SET操作数据回写缓存(可 Job 异步操作)
这种交互下,由于4和5操作步骤都是设置缓存,导致写入的值互相覆盖;并且操作的顺序性不确定,从而导致 cache 存在脏缓存的情况。
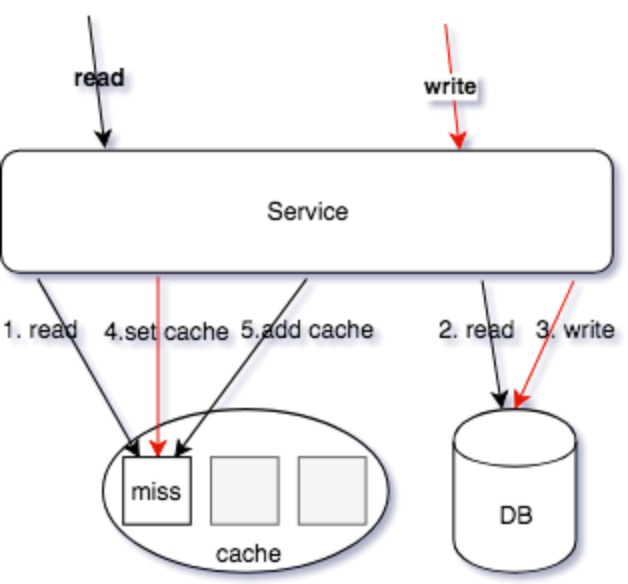
正确的使用:
- 读操作,读缓存,缓存 MISS
- 读操作,读 DB,读取到数据
- 写操作,更新 DB 数据
- 写操作 SET Cache(可异步 job 操作,Redis 可以使用 SETEX 操作)
- 读操作,ADD 操作数据回写缓存(可 Job异步操作,Redis 可以使用 SETNX 操作)
- 写操作使用 SET 操作命令,覆盖写缓存;读操作,使用 ADD 操作回写 MISS 数据,从而保证写操作的最新数据不会被读操作的回写数据覆盖。
读操作流程
- 从 Redis 读取数据,如果有就直接返回;
- 如果 Redis 中没有数据,从 MySQL 中读取数据;
- 将结果使用
SETNX回填到 Redis 中,并返回数据。写操作流程
- 直接更新 MySQL ;
删除或更新 Redis ;
用删除操作可能会导致缓存穿透问题,对热点数据不建议使用删除操作。
用更新操作可能会有 ABA 的问题,如:两次更新 v1 和 v2 ,缓存中的值会出现 v1 -> v2 -> v1 -> v2 。
使用 Canal 解析 MySQL 的 binlog,将解析的结果投递到一个消息队列中(如:kafka),然后再消费该消息队列更新 Redis 来保证最终一致性。
8.2.2 多级缓存
微服务拆分细粒度原子业务下的整合服务(聚合服务),用于提供粗粒度的接口,以及二级缓存加速,减少扇出的 rpc 网络请求,减少延迟。
最重要是保证多级缓存的一致性:
- 清理的优先级是有要求的,先优先清理下游再上游;
- 下游的缓存expire要大于上游,里面穿透回源;
天下大势分久必合,适当的微服务合并也是不错的做法,再使用 DDD 思路以及我们介绍的目录结构组织方式,区分不同的 Usecase。
8.2.3 热点缓存
对于热点缓存 Key,按照如下思路解决:
- 小表广播,从 RemoteCache 提升为LocalCache,App 定时更新,甚至可以让运营平台支持广播刷新 LocalCache;
- 主动监控防御预热,比如直播房间页高在线情况下直接外挂服务主动防御;
- 基础库框架支持热点发现,自动短时的 short-live cache;
- 多 Cluster 支持;
- 多 Key 设计: 使用多副本,减小节点热点的问题
- 使用多副本 ms_1,ms_2,ms_3 每个节点保存一份数据,使得请求分散到多个节点,避免单点热点问题。
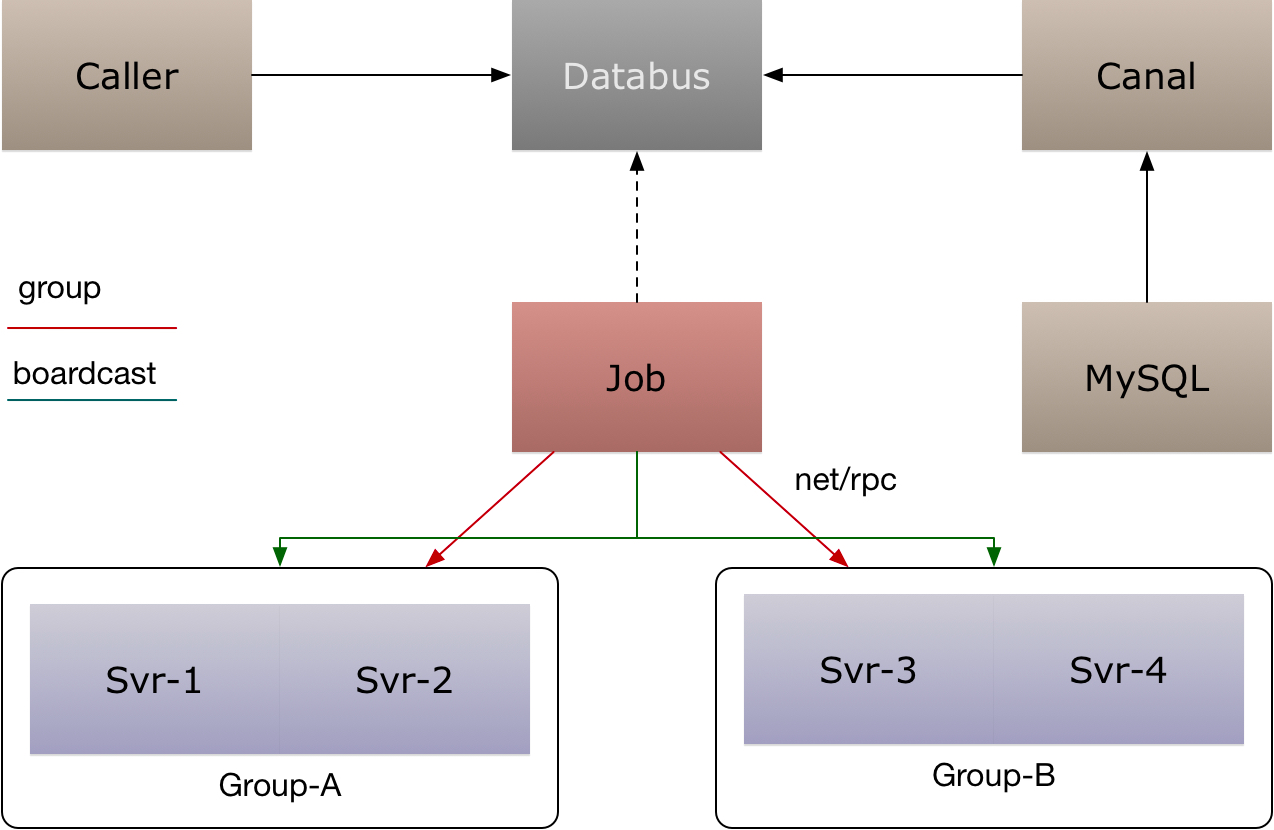
建立多个 Cluster ,和微服务、存储等一起组成一个 Region。
这样相当于是用空间换时间:
同一个 key 在每一个 frontend cluster 都可能有一个 copy,这样会带来 consistency 的问题,但是这样能够降低 latency 和提高 availability。利用 MySQL Binlog 消息 anycast 到不同集群的某个节点清理或者更新缓存;
当业务频繁更新时候,cache频繁过期,会导致命中率低: stale sets
如果应用程序层可以忍受稍微过期一点的数据,针对这点可以进一步降低系统负载。当一个key 被删除的时候(delete 请求或者 cache 爆棚清空间了),它被放倒一个临时的数据结构里,会再续上比较短的一段时间。当有请求进来的时候会返回这个数据并标记为”Stale”。对于大部分应用场景而言,Stale Value 是可以忍受的。(需要改 memcache、redis 源码,或者基础库支持);
最好通过改 Redis 源码来实现,因为要高效的处理边缘情况(比如:该数据本身的过期时间已经比 10 秒小了)。
8.2.4 穿透缓存
- singlefly
对关键字进行一致性 hash,使其某一个维度的 key 一定命中某个节点,然后在节点内使用互斥锁,保证归并回源,但是对于批量查询无解; - 分布式锁
设置一个 lock key,有且只有一个人成功,并且返回,交由这个人来执行回源操作,其他候选者轮训 cache 这个 lock key,如果不存在去读数据缓存,hit 就返回,miss 继续抢锁; - 队列
如果 cache miss,交由队列聚合一个key,来 load 数据回写缓存,对于 miss 当前请求可以使用 singlefly 保证回源,如评论架构实现。适合回源加载数据重的任务,比如评论 miss 只返回第一页,但是需要构建完成评论数据索引。 - lease
通过加入 lease 机制,可以很好避免这两个问题,lease 是 64-bit 的 token,与客户端请求的 key 绑定,对于过时设置,在写入时验证 lease,可以解决这个问题;对于 thundering herd,每个key 10s 分配一次,当 client 在没有获取到 lease 时,可以稍微等一下再访问 cache,这时往往cache 中已有数据。(基础库支持 & 修改 cache 源码);
8.3 缓存技巧
8.3.1 Incast Congestion
如果在网路中的包太多,就会发生 Incast Congestion 的问题(可以理解为,network 有很多switch,router 啥的,一旦一次性发一堆包,这些包同时到达 switch,这些 switch 就会忙不过来)。
应对这个问题就是不要让大量包在同一时间发送出去,在客户端限制每次发出去的包的数量(具体实现就是客户端弄个队列)。
每次发送的包的数量称为”Window size”。这个值太小的话,发送太慢,自然延迟会变高;这个值太大,发送的包太多把 network switch 搞崩溃了,就可能发生比如丢包之类的情况,可能被当作 cache miss,这样延迟也会变高。所以这个值需要调,一般会在 proxy 层面实现。
8.3.2 小技巧
- 易读性的前提下,key 设置尽可能小,减少资源的占用,redis value 可以用 int 就不要用string,对于小于 N 的 value,redis 内部有 shared_object 缓存。
- 拆分 key。主要是用在 redis 使用 hashes 情况下。同一个 hashes key 会落到同一个 redis 节点,hashes 过大的情况下会导致内存及请求分布的不均匀。考虑对 hash 进行拆分为小的hash,使得节点内存均匀及避免单节点请求热点。
- 空缓存设置。对于部分数据,可能数据库始终为空,这时应该设置空缓存,避免每次请求都缓存 miss 直接打到 DB。
- 空缓存保护策略。
- 读失败后的写缓存策略(降级后一般读失败不触发回写缓存)。
- 序列化使用 protobuf,尽可能减少 size。
- 工具化浇水代码
8.3.3 memcache 小技巧
- flag 使用:标识 compress、encoding、large value 等;
- memcache 支持 gets,尽量读取,尽可能的 pipeline,减少网络往返;
- 使用二进制协议,支持 pipeline delete,UDP 读取、TCP 更新;
8.3.4 redis 小技巧
- 增量更新一致性:EXPIRE、ZADD/HSET 等,保证索引结构体务必存在的情况下去操作新增数据;
- BITSET: 存储每日登陆用户,单个标记位置(boolean),为了避免单个 BITSET 过大或者热点,需要使用 region sharding,比如按照mid求余 %和/ 10000,商为 KEY、余数- 作为offset;
- List:抽奖的奖池、顶弹幕,用于类似 Stack PUSH/POP操作;
- Sortedset: 翻页、排序、有序的集合,杜绝 zrange 或者 zrevrange 返回的集合过大;
Sortedset 的 score 是 double 类型,不能存放下 int64,注意不要溢出了。
- Hashs: 过小的时候会使用压缩列表、过大的情况容易导致 rehash 内存浪费,也杜绝返回hgetall,对于小结构体,建议直接使用 memcache KV;
- String: SET 的 EX/NX 等 KV 扩展指令,SETNX 可以用于分布式锁、SETEX 聚合了SET + EXPIRE;
- Sets: 类似 Hashs,无 Value,去重等;
- 尽可能的 PIPELINE 指令,但是避免集合过大;
- 避免超大 Value;
8.4 References
https://blog.csdn.net/chen_kkw/article/details/82724330
https://zhuanlan.zhihu.com/p/328728595
https://www.cnblogs.com/chinanetwind/articles/9460820.html
https://medium.com/vimeo-engineering-blog/improving-load-balancing-with-a-new-consistent-hashing-algorithm-9f1bd75709ed
https://www.jianshu.com/p/5fa447c60327
https://writings.sh/post/consistent-hashing-algorithms-part-1-the-problem-and-the-concept
https://www.cnblogs.com/williamjie/p/11132211.html
8.5 分布式事务
8.5.1 转账问题
讲到事务,又得搬出经典的转账问题了:
- 支付宝账户表:A (id, user_id, amount)
- 余额宝账户表:B (id, user_id, amount)
用户的 user_id = 1,从支付宝转帐1万快到余额宝分为两个步骤:
- 支付宝表扣除1万:
UPDATE A SET amount = amount - 10000 WHERE user_id = 1; - 余额宝表增加1万:
UPDATE B SET amount = amount + 10000 WHERE user_id = 1;
如何保证数据一致性呢?
单个数据库,我们保证 ACID 使用 数据库事务。
8.5.2 微服务架构下转账问题
随着我们系统变大,我们进行了微服务架构的改造,因为每个微服务独占了一个数据库实例,从 user_id = 1 发起的转帐动作,跨越了两个微服务:pay 和 balance 服务。
我们需要保证,跨多个服务的步骤数据一致性:
- 微服务 pay 的支付宝表扣除1万;
- 微服务 balance 的余额宝表增加1万;
每个系统都对应一个独立的数据源,且可能位于不同机房,同时调用多个系统的服务很难保证同时成功,这就是跨服务分布式事务问题。
我们系统应该能保证每个服务自身的 ACID,基于这个假设,我们事务消息解决分布式事务问题。
8.5.3 事务消息
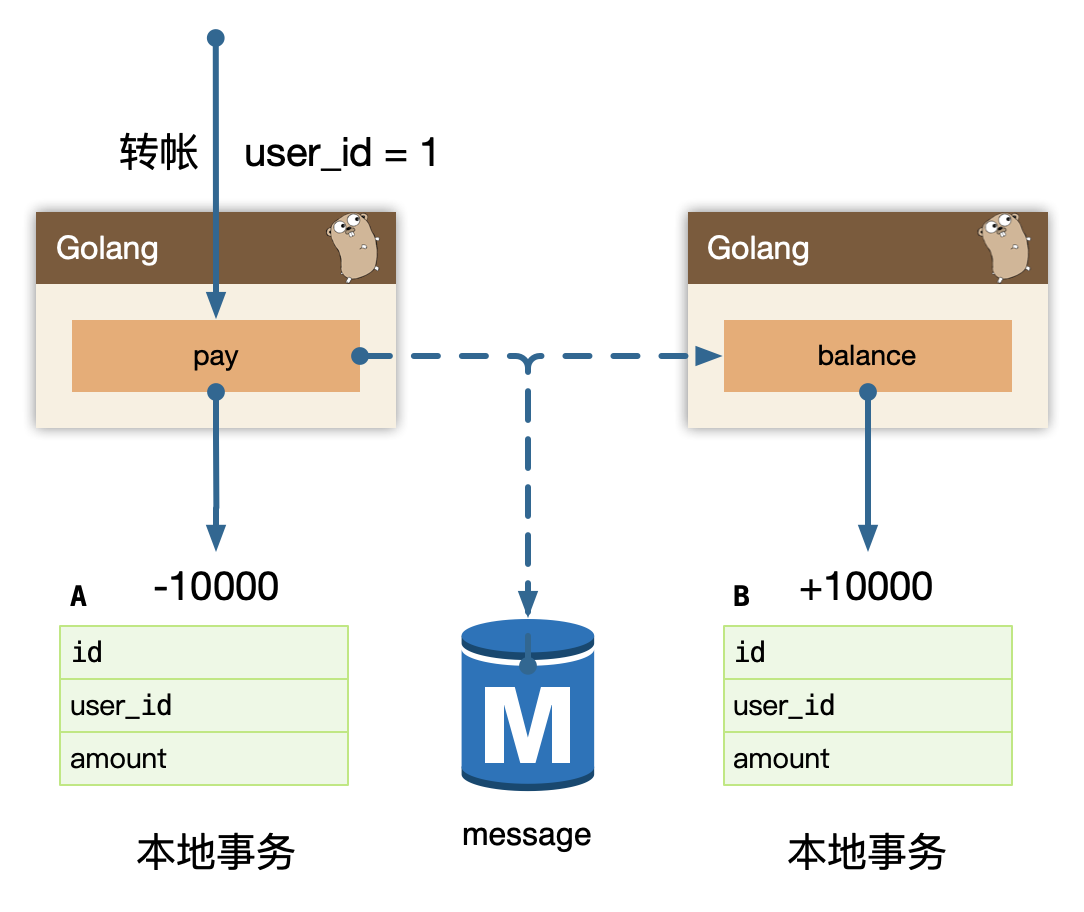
在北京很有名的姚记炒肝点了炒肝并付了钱后,他们并不会直接把你点的炒肝给你,往往是给你一张小票,然后让你拿着小票到出货区排队去取。
为什么他们要将付钱和取货两个动作分开呢?原因很多,其中一个很重要的原因是为了使他们接待能力增强(并发量更高)。
只要这张小票在,你最终是能拿到炒肝的。同理转账服务也是如此。
当支付宝账户扣除1万后,我们只要生成一个凭证(消息)即可,这个凭证(消息)上写着”让余额宝账户增加 1万”,只要这个凭证(消息)能可靠保存,我们最终是可以拿着这个凭证(消息)让余额宝账户增加1万的,即我们能依靠这个凭证(消息)完成最终一致性。
如何可靠的保存消息凭证?
要解决消息可靠存储,我们实际上需要解决的问题是,本地的 mysql 存储和 message 存储的一致性问题。
- Transactional outbox
- Polling publisher
- Transaction log tailing
- 2PC Message Queue
事务消息一旦被可靠的持久化,我们整个分布式事务,变为了最终一致性,消息的消费才能保障最终业务数据的完整性,所以我们要尽最大努力,把消息送达到下游的业务消费方,称为:Best Effort。只有消息被消费,整个交易才能算是完整完结。
8.5.4 Best Effort
即尽最大努力交付,主要用于在这样一种场景:不同的服务平台之间的事务性保证。
比如我们在电商购物,使用支付宝支付;又比如玩网游的时候,通过 App Store 充值。
拿购物为例,电商平台与支付平台是相互独立的,隶属于不同的公司,即使是同一个公司也很可能是独立的部门。
“ 做过支付宝交易接口的同学都知道,我们一般会在支付宝的回调页面和接口里,解密参数,然后调用系统中更新交易状态相关的服务,将订单更新为付款成功。
同时,只有当我们回调页面中输出了success 字样或者标识业务处理成功相应状态码时,支付宝才会停止回调请求。否则,支付宝会每间隔一段时间后,再向客户方发起回调请求,直到输出成功标识为止。”
8.5.5 Transactional outbox
Transactional outbox,支付宝在完成扣款的同时,同时记录消息数据,这个消息数据与业务数据保存在同一数据库实例里(消息记录表表名为 msg)。
BEGIN TRANSACTION
UPDATE A SET amount = amount - 10000 WHERE user_id = 1;
INSERT INTO msg(user_id, amount, status) VALUES(1, 10000, 1);
END TRANSACTION
COMMIT;上述事务能保证只要支付宝账户里被扣了钱,消息一定能保存下来。当上述事务提交成功后,我们想办法将此消息通知余额宝,余额宝处理成功后发送回复成功消息,支付宝收到回复后删除该条消息数据。
8.5.6 Polling publisher
Polling publisher,我们定时的轮训 msg 表,把 status = 1 的消息统统拿出来消费,可以按照自增 id 排序,保证顺序消费。在这里我们独立了一个 pay_task 服务,把拖出来的消息 publish 给我们消息队列,balance 服务自己来消费队列,或者直接 rpc 发送给 balance 服务。
实际我们第一个版本的 archive-service 在使用 CQRS 时,就用的这个模型,Pull 的模型,从延迟来说不够好,Pull 太猛对 Database 有一定压力,Pull 频次低了,延迟比较高。
8.5.6 Transaction log tailing
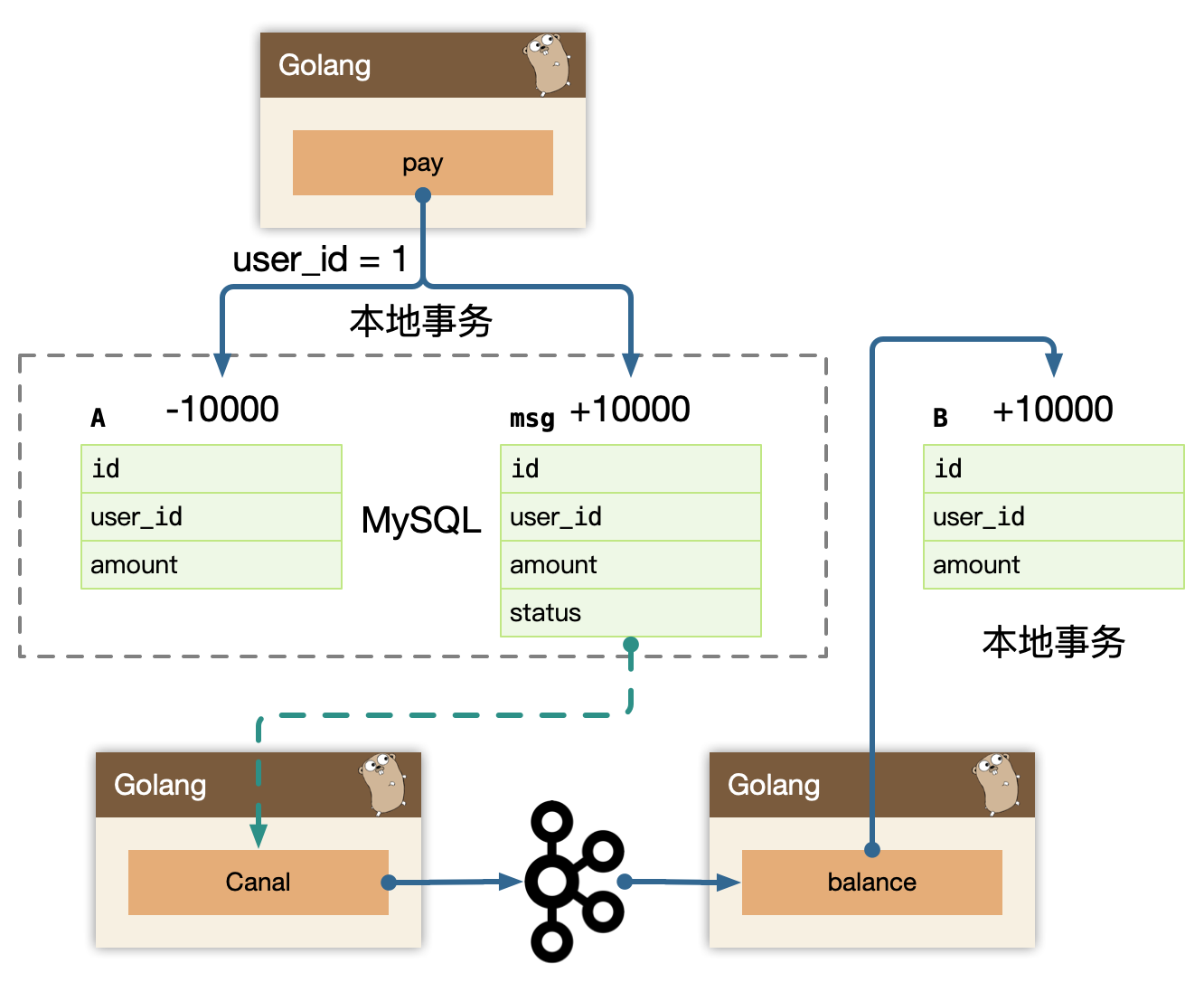
Transaction log tailing,上述保存消息的方式使得消息数据和业务数据紧耦合在一起,从架构上看不够优雅,而且容易诱发其他问题。
有一些业务场景,可以直接使用主表被 canal 订阅使用,有一些业务场景自带这类 message 表,比如订单或者交易流水,可以直接使用这类流水表作为 message 表使用。
使用 canal 订阅以后,是实时流式消费数据,在消费者 balance 或者 balance-job 必须努力送达到。
我们发现,所有努力送达的模型,必须是先预扣(预占资源)的做法。
8.5.7 幂等
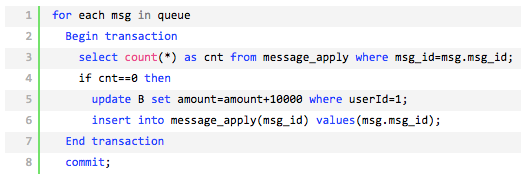
还有一个很严重的问题就是消息重复投递,如果相同的消息被重复投递两次,那么我们余额宝账户将会增加2万而不是1万了。
为什么相同的消息会被重复投递?比如余额宝处理完消息 msg 后,发送了处理成功的消息给支付宝,正常情况下支付宝应该要删除消息msg,但如果支付宝这时候悲剧的挂了,重启后一看消息 msg 还在,就会继续发送消息 msg。
- 全局唯一 ID+ 去重表
在余额宝这边增加消息应用状态表 msg_apply,通俗来说就是个账本,用于记录消息的消费情况,每次来一个消息,在真正执行之前,先去消息应用状态表中查询一遍,如果找到说明是重复消息,丢弃即可,如果没找到才执行,同时插入到消息应用状态表(同一事务)。 - 版本号
8.5.8 2PC
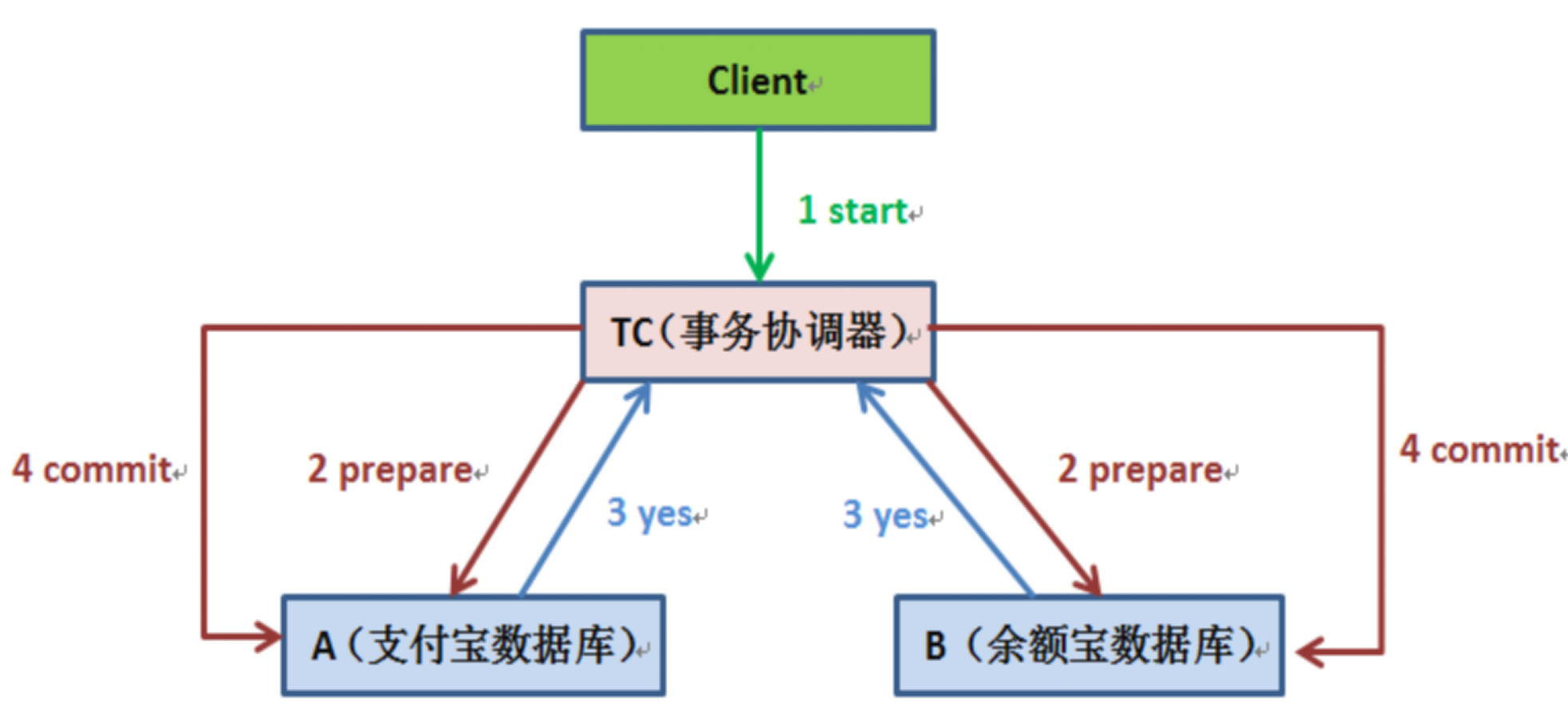
两阶段提交协议(Two Phase Commitment Protocol)中,涉及到两种角色
- 一个事务协调者(coordinator):负责协调多个参与者进行事务投票及提交(回滚)
- 多个事务参与者(participants):即本地事务执行者
总共处理步骤有两个
- 投票阶段(voting phase):协调者将通知事务参与者准备提交或取消事务,然后进入表决过程。参与者将告知协调者自己的决策:同意(事务参与者本地事务执行成功,但未提交)或取消(本地事务执行故障);
- 提交阶段(commit phase):收到参与者的通知后,协调者再向参与者发出通知,根据反馈情况决定各参与者是否要提交还是回滚;
8.5.9 2PC Message Queue
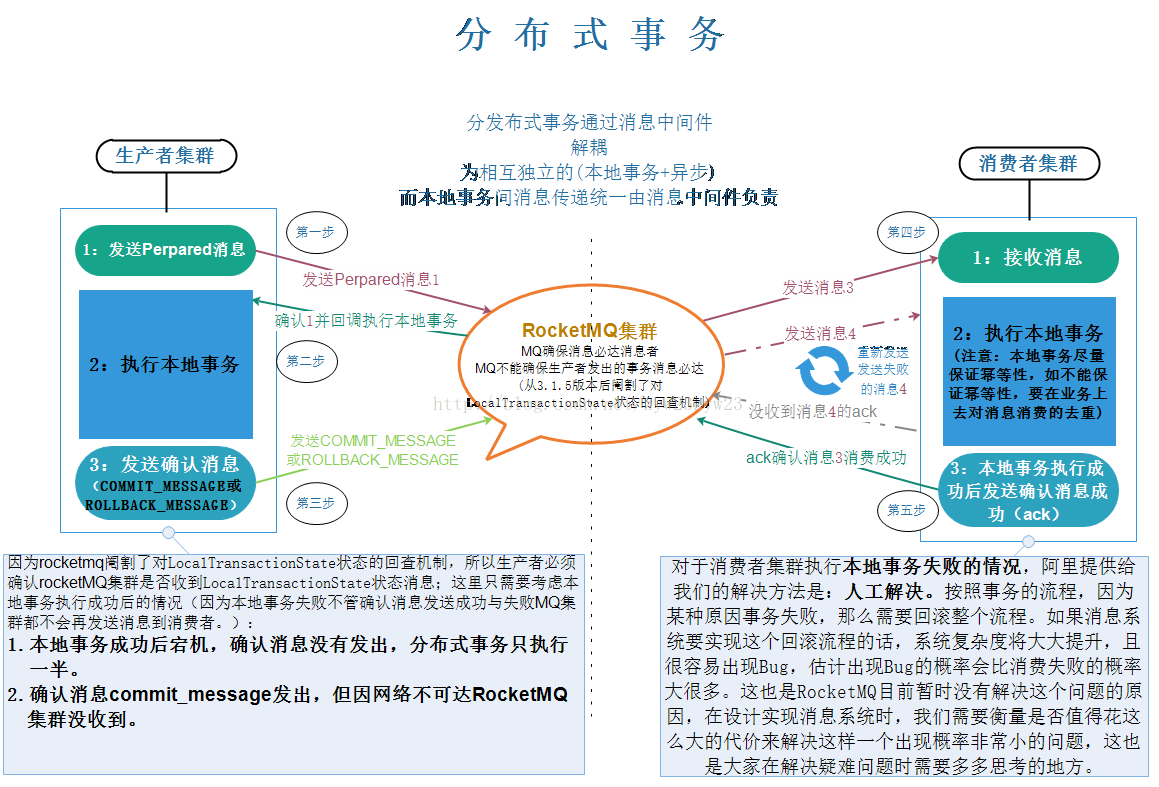
8.5.10 Seata 2PC
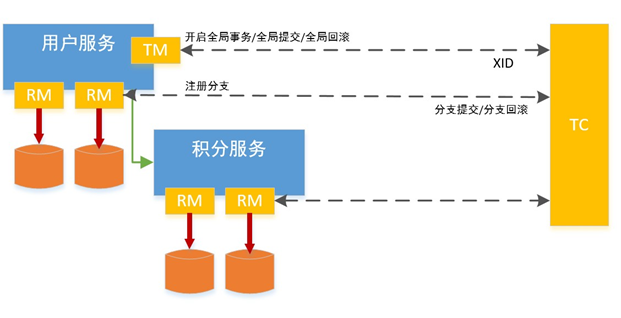
Seata 实现 2PC 与传统 2PC 的差别
- 架构层次方面:传统 2PC 方案的 RM 实际上是在数据库层,RM 本质上就是数据库自身,通过 XA 协议实现,而 Seata 的 RM 是以 jar 包的形式作为中间件层部署在应用程序这一侧的。
- 两阶段提交方面:传统 2PC无论第二阶段的决议是 commit 还是 rollback ,事务性资源的锁都要保持到 Phase2 完成才释放。而 Seata 的做法是在 Phase1 就将本地事务提交,这样就可以省去 Phase2 持锁的时间,整体提高效率。
8.5.11 TCC
TCC 是 Try、Confirm、Cancel 三个词语的缩写,TCC 要求每个分支事务实现三个操作:预处理 Try、确认 Confirm、撤销 Cancel。
Try 操作做业务检查及资源预留,Confirm 做业务确认操作,Cancel 实现一个与 Try 相反的操作即回滚操作。
TM 首先发起所有的分支事务的 Try 操作,任何一个分支事务的 Try 操作执行失败,TM 将会发起所有分支事务的 Cancel 操作,若 Try 操作全部成功,TM 将会发起所有分支事务的 Confirm 操作,其中 Confirm/Cancel 操作若执行失败,TM 会进行重试。
需要注意:
- 空回滚
- 防悬挂
8.6 微服务
- Event sourcing
- Saga
8.7 References
https://blog.csdn.net/hosaos/article/details/89136666
https://zhuanlan.zhihu.com/p/183753774
https://www.cnblogs.com/dyzcs/p/13780668.html
https://blog.csdn.net/bjweimengshu/article/details/79607522
https://microservices.io/patterns/data/event-sourcing.html
https://microservices.io/patterns/data/saga.html
https://microservices.io/patterns/data/polling-publisher.html
https://microservices.io/patterns/data/polling-publisher.html
https://microservices.io/patterns/data/transaction-log-tailing.html
第9课 网络编程
9.1 网络通信协议
互联网的核心是一系列协议,总称为”互联网协议”(Internet Protocol Suite),正是这一些协议规定了电脑如何连接和组网。
主要协议分为:
- Socket:接口抽象层
- TCP / UDP:面向连接(可靠) / 无连接(不可靠)
- HTTP1.1 / HTTP2 / QUIC(HTTP3):超文本传输协议
9.1.1 Socket 抽象层
应用程序通常通过”套接字”向网络发出请求或者应答网络请求。
一种通用的面向流的网络接口
主要操作:
- 建立、接受连接
- 读写、关闭、超时
- 获取地址、端口
9.1.2 TCP 可靠连接,面向连接的协议
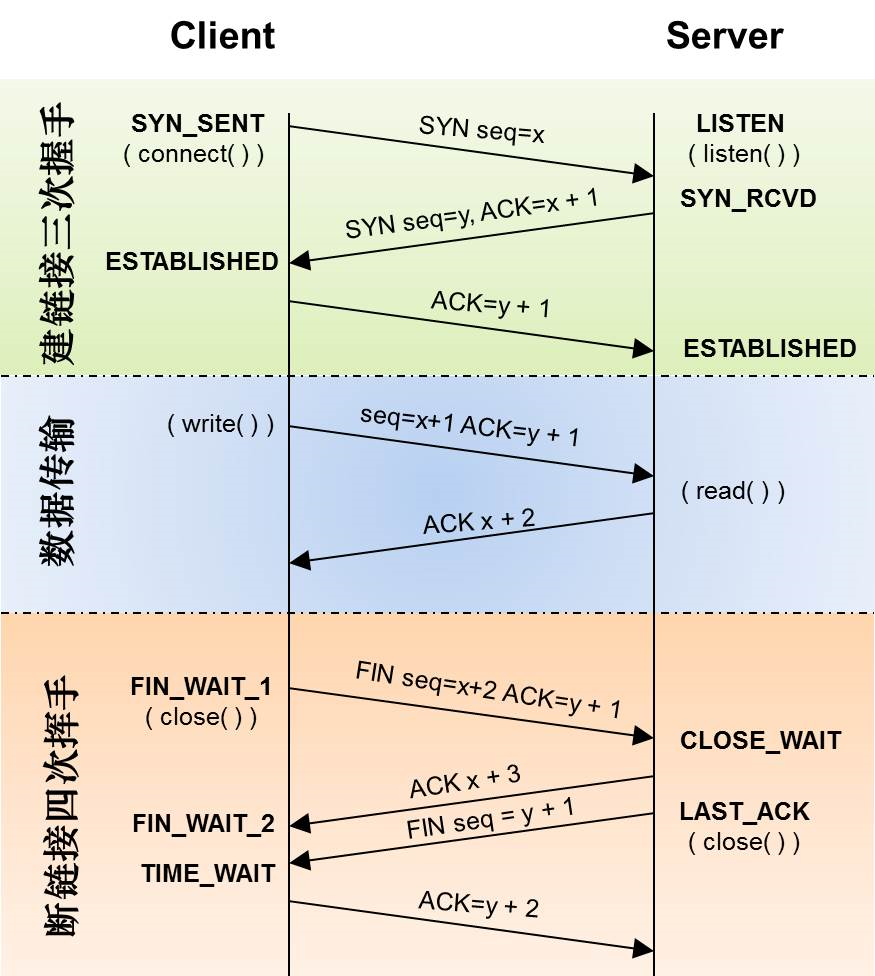
TCP/IP(Transmission Control Protocol/Internet Protocol)即传输控制协议/网间协议,是一种面向连接(连接导向)的、可靠的、基于字节流的传输层(Transport layer)通信协议,因为是面向连接的协议。
服务端流程:
- 监听端口
- 接收客户端请求建立连接
- 创建 goroutine 处理连接
客户端流程:
- 建立与服务端的连接
- 进行数据收发
- 关闭连接
9.1.3 UDP 不可靠连接,允许广播或多播
UDP 协议(User Datagram Protocol)中文名称是用户数据报协议,是 OSI(Open System Interconnection,开放式系统互联)参考模型中一种无连接的传输层协议。
一个简单的传输层协议:
- 不需要建立连接
- 不可靠的、没有时序的通信
- 数据报是有长度(65535-20=65515)
- 支持多播和广播
- 低延迟,实时性比较好
- 应用于用于视频直播、游戏同步
9.1.4 HTTP 超文本传输协议
HTTP(HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议,它详细规定了浏览器和万维网服务器之间互相通信的规则,通过因特网传送万维网文档的数据传送协议。
请求报文
- Method: HEAD/GET/POST/PUT/DELETE
- Accept:text/html、application/json
- Content-Type:
- application/json
- application/x-www-form-urlencoded
- 请求正文
响应报文
- 状态行(200/400/500)
- 响应头(Response Header)
- 响应正文
常用工具
- nload
- tcpflow
- ss
- netstat
- nmon
- top
9.1.5 gRPC 基于 HTTP2 协议扩展
请求
Headers :method = POST :scheme = https :path = /api.echo.v1.Echo/SayHello content-type = application/grpc+proto grpc-encoding = gzip Data <Length-Prefixed Message>响应
Headers :status = 200 grpc-encoding = gzip content-type = application/grpc+proto Data <Length-Prefixed Message> Trailers grpc-status = 0 grpc-message = OK grpc-details-bin = base64(pb)Data
1 byte of zero (not compressed). network order 4 bytes of proto message length. serialized proto message.
9.1.6 HTTP2 如何提升网络速度

HTTP/1.1 为网络效率做了几点优化:
- 增加了持久连接,每个请求进行串行请求。
- 浏览器为每个域名最多同时维护 6 个 TCP 持久连接。
- 使用 CDN 的实现域名分片机制。
HTTP/2 的多路复用:
- 请求数据二进制分帧层处理之后,会转换成请求 ID 编号的帧,通过协议栈将这些帧发送给服务器。
- 服务器接收到所有帧之后,会将所有相同 ID 的帧合并为一条完整的请求信息。
- 然后服务器处理该条请求,并将处理的响应行、响应头和响应体分别发送至二进制分帧层。
- 同样,二进制分帧层会将这些响应数据转换为一个个带有请求 ID 编号的帧,经过协议栈发送给浏览器。
- 浏览器接收到响应帧之后,会根据 ID 编号将帧的数据提交给对应的请求。
所以,HTTP2 通过引入二进制分帧层,就实现了 HTTP 的多路复用。
9.1.7 HTTP 超文本传输协议-演进
HTTP 发展史:
- 1991 年发布初代 HTTP/0.9 版
- 1996 年发布 HTTP/1.0 版
- 1997 年是 HTTP/1.1 版,是到今天为止传输最广泛的版本
- 2015 年发布了 HTTP/2.0 版,优化了 HTTP/1.1 的性能和安全性
- 2018 年发布的 HTTP/3.0 版,使用 UDP 取代 TCP 协议
HTTP2:
- 二进制分帧,按帧方式传输
- 多路复用,代替原来的序列和阻塞机制
- 头部压缩,通过 HPACK 压缩格式
- 服务器推送,服务端可以主动推送资源
HTTP3:
- 连接建立延时低,一次往返可建立HTTPS连接
- 改进的拥塞控制,高效的重传确认机制
- 切换网络保持连接,从4G切换到WIFI不用重建连接
9.1.8 HTTPS 超文本传输安全协议
HTTPS;常称为HTTP over TLS、HTTP over SSL或HTTP Secure)是一种通过计算机网络进行安全通信的传输协议。
SSL 1.0、2.0 和 3.0:
- SSL(Secure Sockets Layer)是网景公司(Netscape)设计的主要用于Web的安全传输协议,这种协议在Web上获得了广泛的应用。
TLS 1.0:
- IETF将SSL标准化,即 RFC 2246 ,并将其称为 TLS(Transport Layer Security)。
TLS 1.1:
- 添加对CBC攻击的保护、支持IANA登记的参数。
TLS 1.2:
- 增加 SHA-2 密码散列函数、增加 AEAD 加密算法,如 GCM 模式、添加 TLS 扩展定义和 AES 密码组合。
TLS 1.3:
- 较 TLS 1.2 速度更快,性能更好、更加安全。
9.1.9 SSL/TLS 重要概念
SSL/TLS 协议提供主要的作用有:
- 认证用户和服务器,确保数据发送到正确的客户端和服务器。
- 加密数据以防止数据中途被窃取。
- 维护数据的完整性,确保数据在传输过程中不被改变。
哈希算法:
- CA 用自己的私钥对指纹签名,浏览器通过内置 CA 跟证书公钥进行解密,如果解密成功就确定证书是 CA 颁发的。
对称加密:
- 指的就是加、解密使用的同是一串密钥,所以被称做对称加密。对称加密只有一个密钥作为私钥。
非对称加密:
- 指的是加、解密使用不同的密钥,一把作为公开的公钥,另一把作为私钥。公钥加密的信息,只有私钥才能解密。
CA 证书机构:
- CA 是负责签发证书、认证证书、管理已颁发证书的机关;
通常内置在操作系统,或者浏览器中,防止。
9.1.10 TLS 1.2 如何解决安全问题?
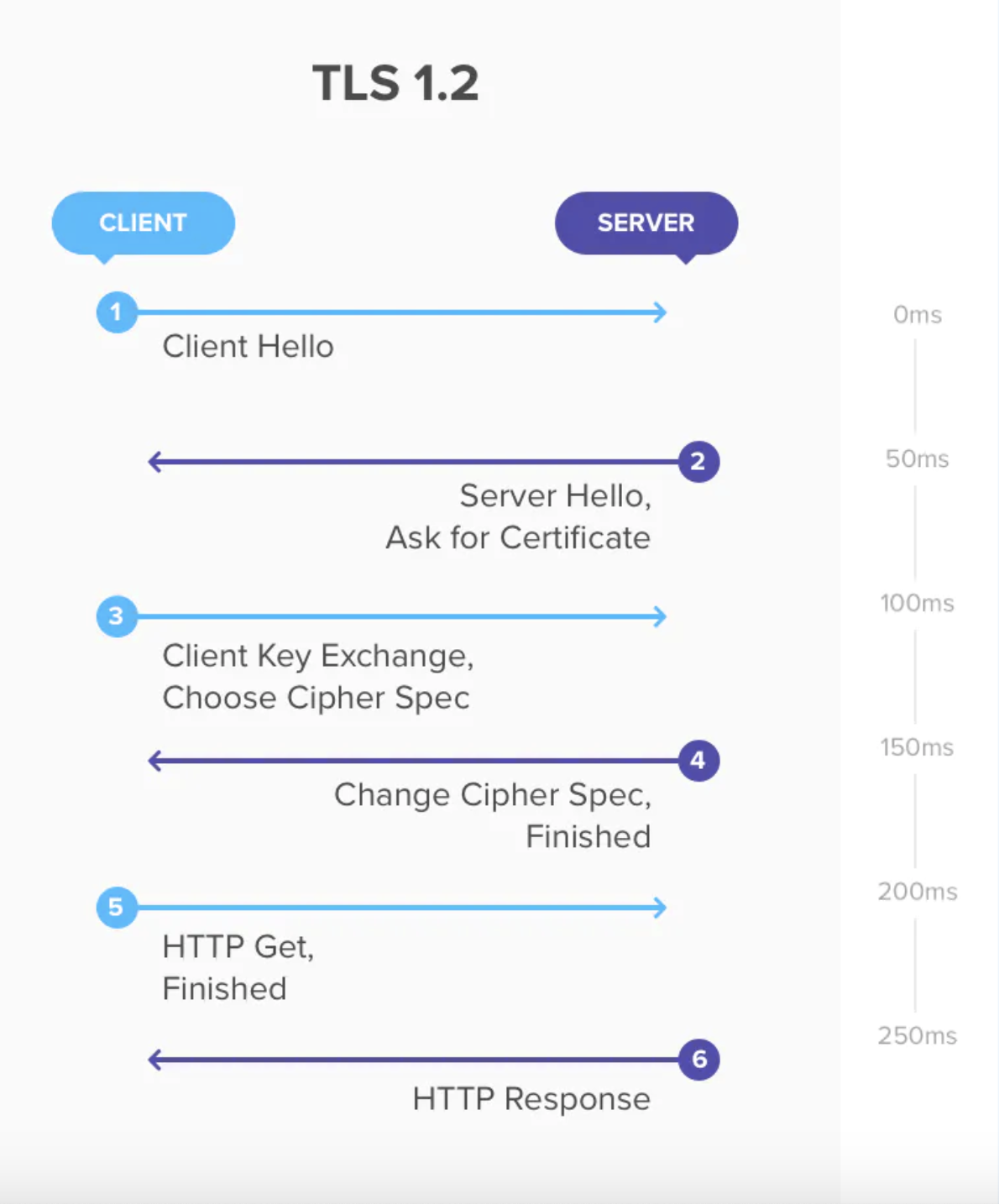
要解决的问题:
- 防窃听(eavesdropping),对应加密(Confidentiality)
- 防篡改(tampering),对应完整性校验(Integrity)
- 防伪造(forgery),对应认证过程(Authentication)
如何保证公钥不被篡改?
- 解决方法:将公钥放在数字证书中。只要证书是可信的,公钥就是可信的。
公钥加密计算量太大,如何减少耗用的时间?
- 解决方法:每一次对话(session),客户端和服务器端都生成一个”对话密钥”(session key),用它来加密信息。由于”对话密钥”是对称加密,所以运算速度非常快,而服务器公钥只用于加密”对话密钥”本身,这样就减少了加密运算的消耗时间。
因此,SSL/TLS协议的基本过程:
- 客户端向服务器端索要证书,并通过签名验证公钥。
- 双方协商生成”对话密钥”,加密类型、随机串(非对称加密)。
- 双方采用”对话密钥”进行加密通信(对称加密)。
9.1.11 TLS 1.3 Faster & More Secure

TLS 1.3 与之前的协议有较大差异,主要在于:
- RSA 密钥交换被废弃,引入新的密钥协商机制 PSK。
- 支持 0-RTT 数据传输,复用 PSK 无握手时间。
- 废弃若干加密组件,SHA1、MD5 等 hash 算法。
- 不再允许压缩加密报文,不允许重协商,不发 Change Cipher 了。
密钥协商机制:
- RSA 是常用且简单的一个交换密钥的算法,即客户端决定密钥后,用服务器的公钥加密传输给对方,这样通信双方就都有了后续通信的密钥。
- Diffie–Hellman(DH)是另一种交换密钥的算法,客户端和服务器都生成一对公私钥,然后将公钥发送给对方,双方得到对方的公钥后,用数字签名确保公钥没有被篡改,然后与自己的私钥结合,就可以计算得出相同的密钥。
为了保证前向安全,TLS 1.3 中 移除了 RSA 算法,Diffie–Hellman 是 唯一 的密钥交换算法。
9.2 Go 实现网络编程
9.2.1 基础概念
基础概念:
- Socket:数据传输
- Encoding:内容编码
- Session:连接会话状态
- C/S模式:通过客户端实现双端通信
- B/S模式:通过浏览器即可完成数据的传输
简单例子
- 通过TCP/UDP实现网络通信
网络轮询器
- 多路复用模型
- 多路复用模块
- 文件描述符
- Goroutine 唤醒
9.2.2 TCP简单例子
func handleConn(conn net.Conn) {
defer conn.Close()
// 读写缓冲区
rd := bufio.NewReader(conn)
wr := bufio.NewWriter(conn)
for {
line, _, err := rd.ReadLine()
if err != nil {
log.Printf("read error: %v\n", err)
return
}
wr.WriteString("hello ")
wr.Write(line)
wr.Flush() // 一次性syscall
}
}
func main() {
listen, err := net.Listen("tcp", "127.0.0.1:10000")
if err != nil {
log.Fatalf("listen error: %v\n", err)
}
for {
conn, err := listen.Accept()
if err != nil {
log.Printf("accept error: %v\n", err)
continue
}
// 开始goroutine监听连接
go handleConn(conn)
}
}9.2.3 UDP简单例子
func main() {
listen, err := net.ListenUDP("udp", &net.UDPAddr{Port: 20000})
if err != nil {
log.Fatalf("listen error: %v\n", err)
}
defer listen.Close()
for {
var buf [1024]byte
n, addr, err := listen.ReadFromUDP(buf[:])
if err != nil {
log.Printf("read udp error: %v\n", err)
continue
}
data := append([]byte("hello "), buf[:n]...)
listen.WriteToUDP(data, addr)
}
}9.2.4 I/O模型
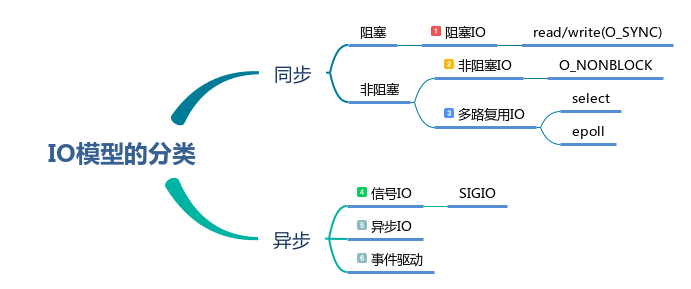
Linux下主要的IO模型分为:
- Blocking IO - 阻塞I O
- Nonblocking IO - 非阻塞IO
- IO multiplexing - IO 多路复用
- Signal-driven IO - 信号驱动式IO(异步阻塞)
- Asynchronous IO - 异步IO
同步:调用端会一直等待服务端响应,直到返回结果
异步:调用端发起调用之后不会立刻返回,不会等待服务端响应
阻塞:服务端返回结果之前,客户端线程会被挂起,此时线程不可被 CPU 调度,线程暂停运行
非阻塞:在服务端返回前,函数不会阻塞调用端线程,而会立刻返回
9.2.5 I/O多路复用
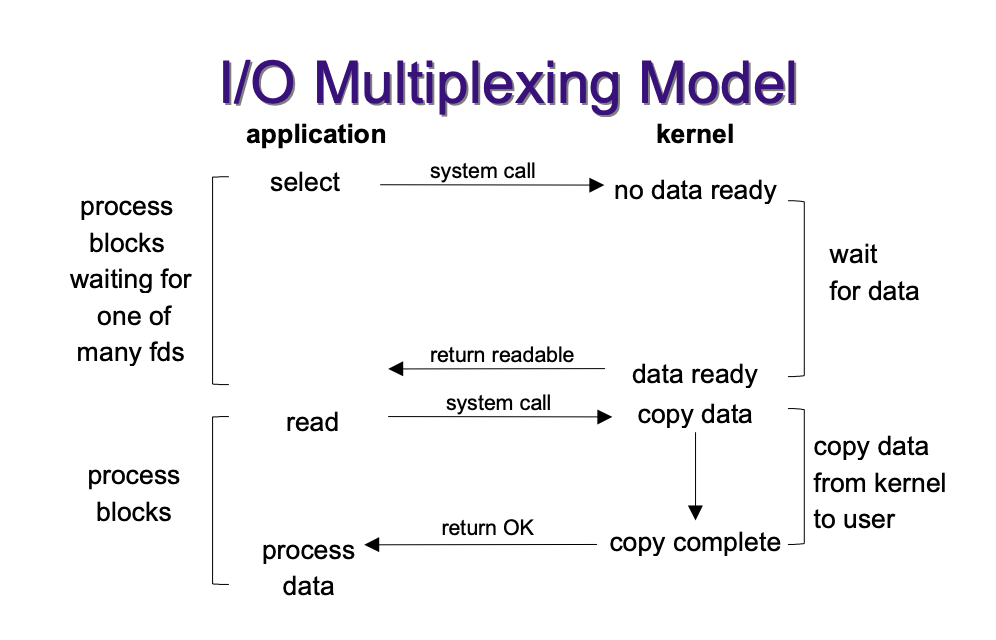
Go 语言在采用 I/O 多路复用 模型处理 I/O 操作,但是他没有选择最常见的系统调用 select。虽然 select 也可以提供 I/O 多路复用的能力,但是使用它有比较多的限制:
- 监听能力有限 — 最多只能监听 1024 个文件描述符;
- 内存拷贝开销大 — 需要维护一个较大的数据结构存储文件描述符,该结构需要拷贝到内核中;
- 时间复杂度 𝑂(𝑛) — 返回准备就绪的事件个数后,需要遍历所有的文件描述符;
I/O多路复用:进程阻塞于 select,等待多个 IO 中的任一个变为可读,select调 用返回,通知相应 IO 可以读。 它可以支持单线程响应多个请求这种模式。
9.2.6 多路复用模块
为了提高 I/O 多路复用的性能,不同的操作系统也都实现了自己的 I/O 多路复用函数,例如:epoll、kqueue 和 evport 等
Go 语言为了提高在不同操作系统上的 I/O 操作性能,使用平台特定的函数实现了多个版本的网络轮询模块:
- src/runtime/netpoll_epoll.go
- src/runtime/netpoll_kqueue.go
- src/runtime/netpoll_solaris.go
- src/runtime/netpoll_windows.go
- src/runtime/netpoll_aix.go
- src/runtime/netpoll_fake.go
9.3 Goim 长连接 TCP 编程
9.3.1 概览
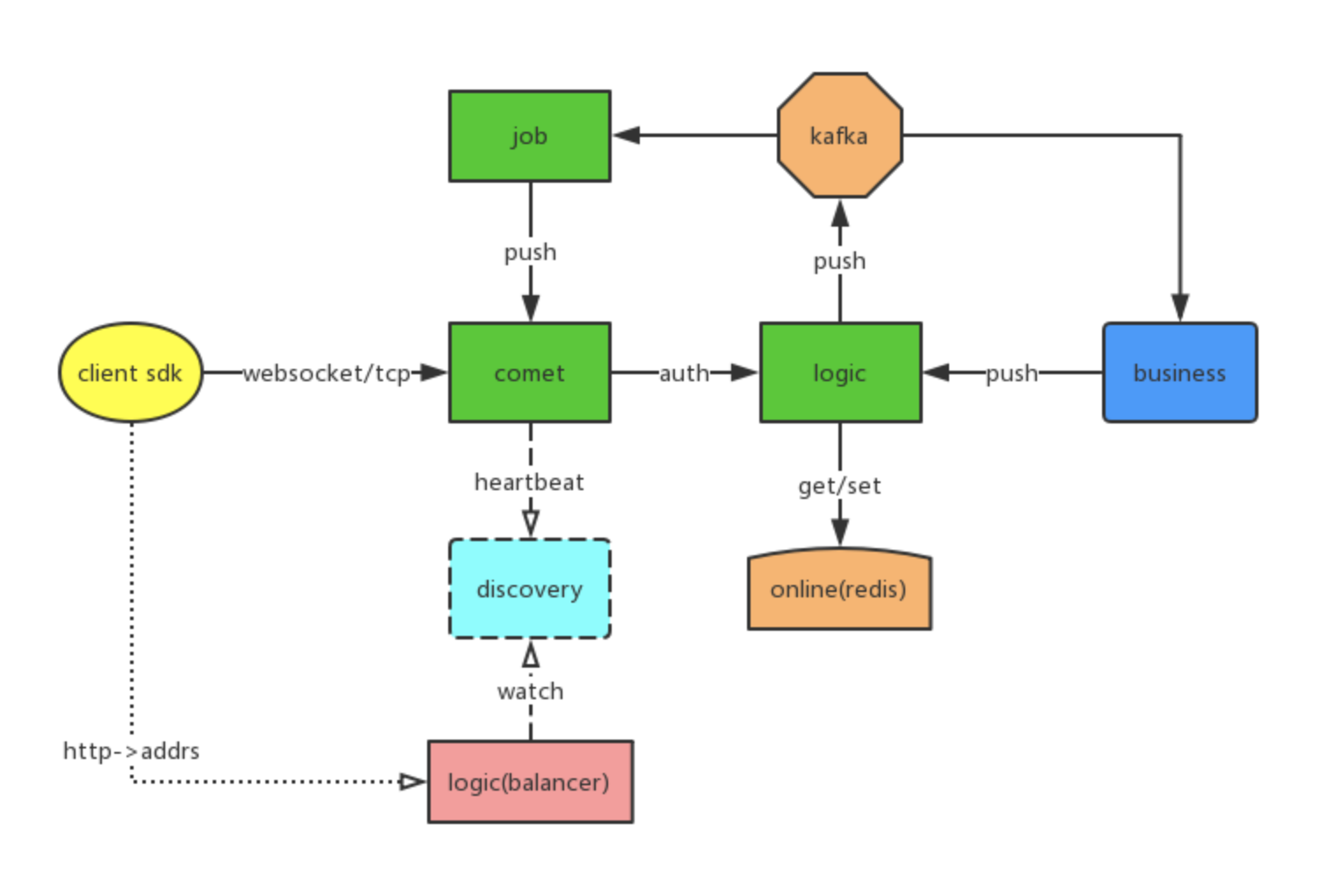
1.Comet
长连接管理层,主要是监控外网 TCP/Websocket端口,并且通过设备 ID 进行绑定 Channel实 现,以及实现了 Room 合适直播等大房间消息广播。
- Logic
逻辑层,监控连接 Connect、Disconnect 事件,可自定义鉴权,进行记录 Session 信息(设备 ID、ServerID、用户 ID),业务可通过设备 ID、用户 ID、RoomID、全局广播进行消息推送。 - Job
通过消息队列的进行推送消峰处理,并把消息推送到对应 Comet 节点。
各个模块之间通过 gRPC 进行通信。
9.3.2 协议设计
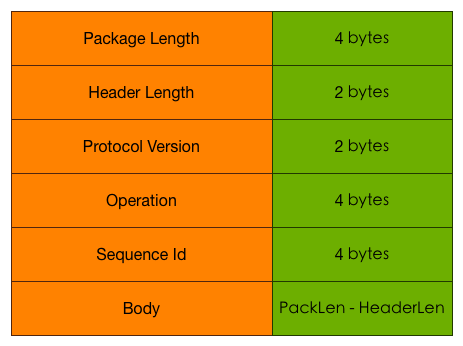
主要以包/针方式:
- Package Length,包长度
- Header Length,头长度
- Protocol Version,协议版本
- Operation,操作码
- Sequence 请求序号 ID
- Body,包内容
Operation:
- Auth
- Heartbeat
- Message
Sequence
- 按请求、响应对应递增 ID
9.3.3 边缘节点
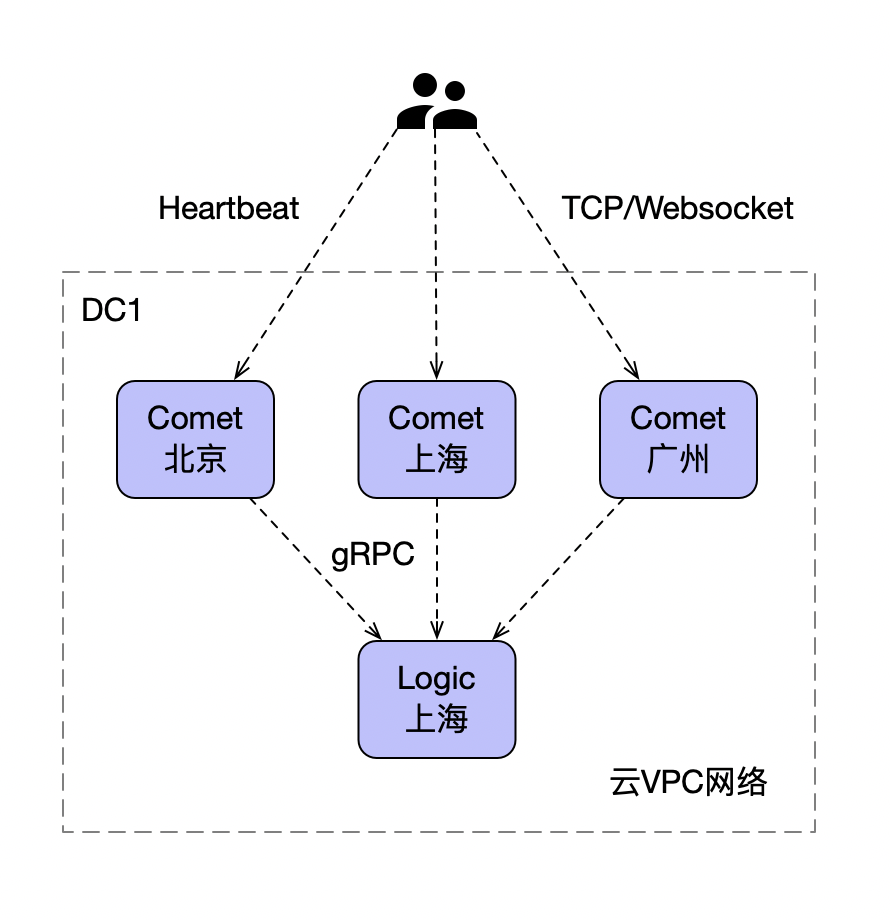
Comet 长连接连续节点,通常部署在距离用户比较近,通过 TCP 或者 Websocket 建立连接,并且通过应用层 Heartbeat 进行保活检测,保证连接可用性。
节点之间通过云 VPC 专线通信,按地区部署分布。
国内:
- 华北(北京)
- 华中(上海、杭州)
- 华南(广州、深圳)
- 华西(四川)
国外:
- 香港、日本、美国、欧洲
9.3.4 负载均衡
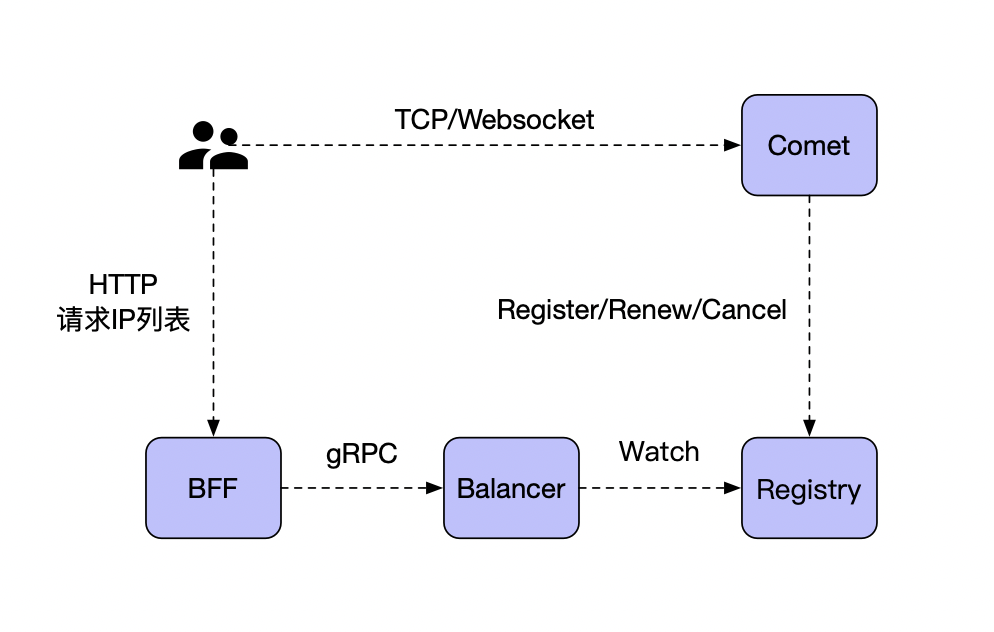
长连接负载均衡比较特殊,需要按一定的负载算法进行分配节点,可以通过 HTTPDNS 方式,请求获致到对应的节点 IP 列表,例如,返回固定数量 IP,按一定的权重或者最少连接数进行排序,客户端通过 IP 逐个重试连接;
- Comet 注册 IP 地址,以及节点权重,定时 Renew当前节点连接数量;
- Balancer 按地区经纬度计算,按最近地区(经纬度)提供 Comet 节点 IP 列表,以及权重计算排序;
- BFF 返回对应的长连接节点 IP,客户端可以通过 IP直接连;
- 客户端 按返回IP列表顺序,逐个连接尝试建立长连接
9.3.5 心跳保活机制
长连接断开的原因:
- 长连接所在进程被杀死
- NAT 超时
- 网络状态发生变化,如移动网络 & Wifi 切换、断开、重连
- 其他不可抗因素(网络状态差、DHCP 的租期等等 )
高效维持长连接方案
- 进程保活(防止进程被杀死)
- 心跳保活(阻止 NAT 超时)
- 断线重连(断网以后重新连接网络)
自适应心跳时间
- 心跳可选区间,[min=60s,max=300s]
- 心跳增加步长,step=30s
- 心跳周期探测,success=current + step、fail=current - step
9.3.6 用户鉴权和 Session 信息
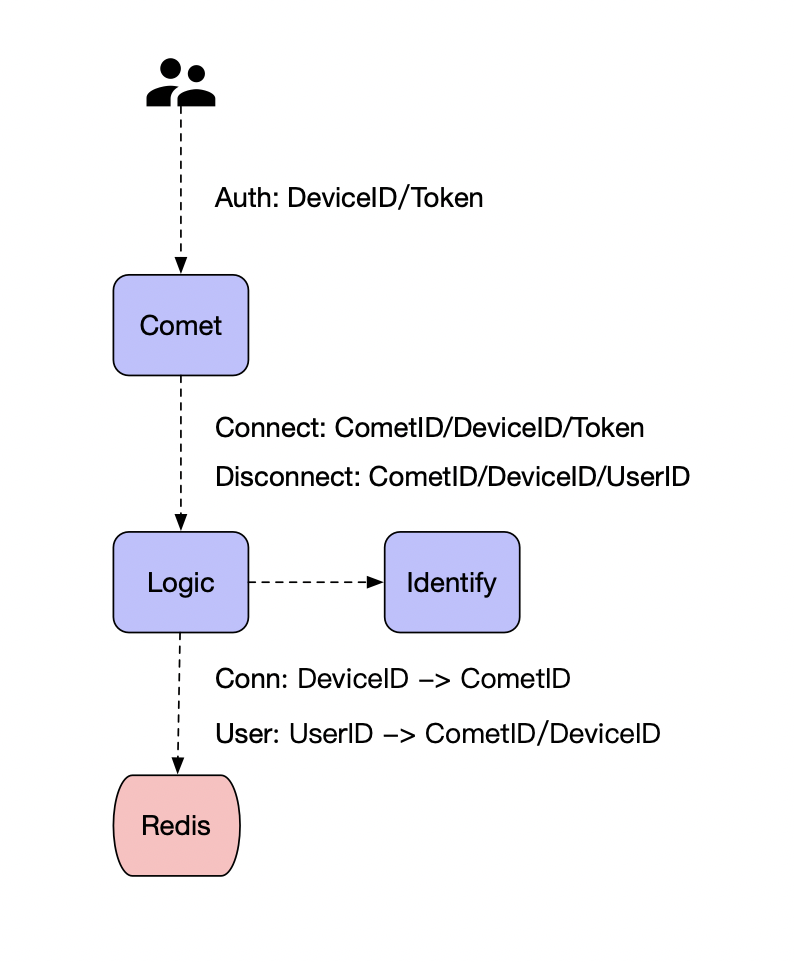
用户鉴权,在长连接建立成功后,需要先进行连接鉴权,并且绑定对应的会话信息;
Connect,建立连接进行鉴权,保存Session信息:
- DeviceID,设备唯一 ID
- Token,用户鉴权 Token,认证得到用户 ID
- CometID,连接所在 comet 节点
Disconnect,断开连接,删除对应Session信息:
- DeviceID,设备唯一 ID
- CometID,连接所在 Comet 节点
- UserID,用户 ID
Session,会话信息通过Redis保存连接路由信息:
- 连接维度,通过 设备 ID 找到所在 Comet 节点
- 用户维度,通过 用户 ID 找到对应的连接和 Comet所在节点
9.3.7 Comet
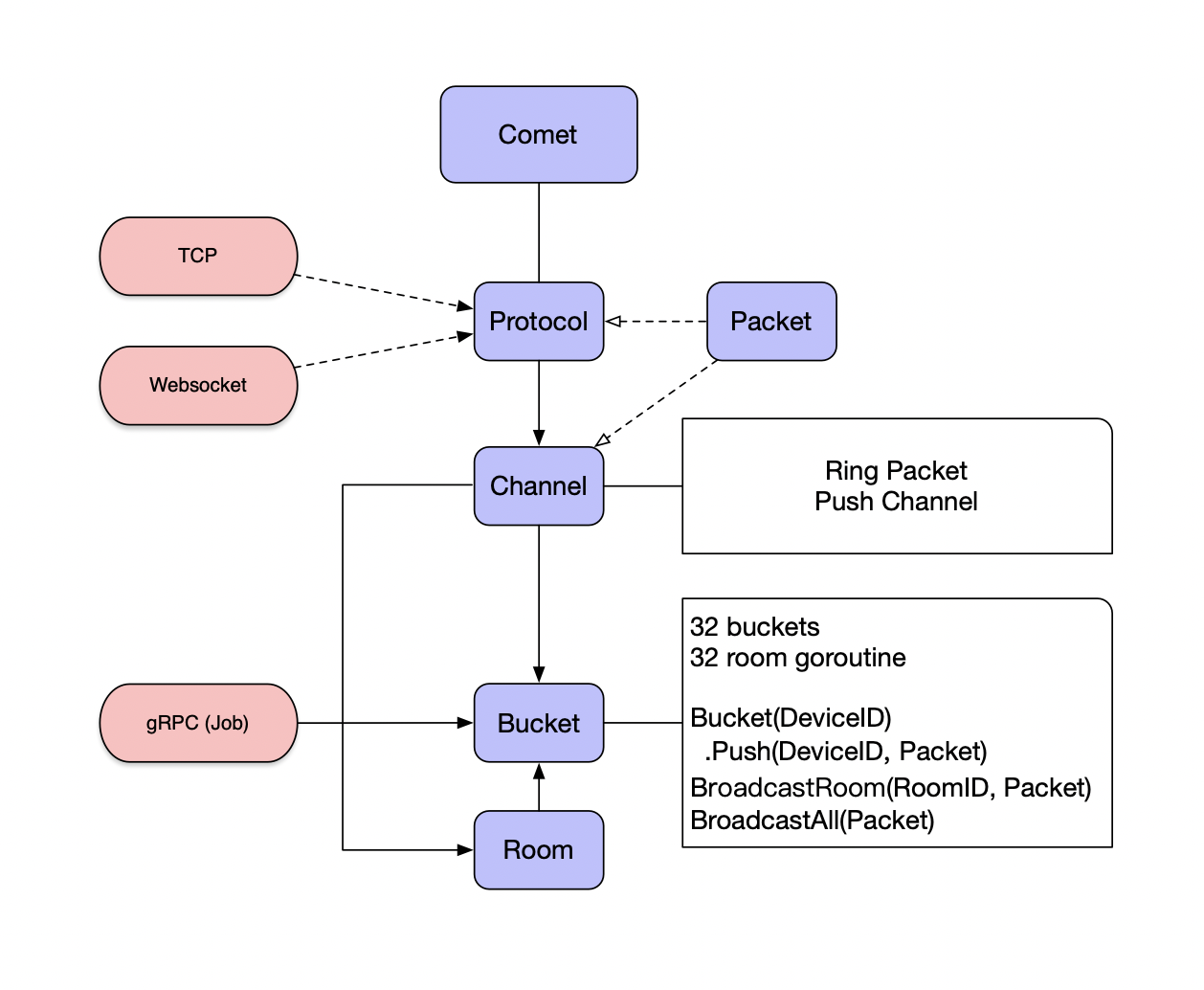
Comet 长连接层,实现连接管理和消息推送:
- Protocol,TCP/Websocket 协议监听;
- Packet,长连接消息包,每个包都有固定长度;
- Channel,消息管道相当于每个连接抽象,最终TCP/Websocket 中的封装,进行消息包的读写分发;
- Bucket,连接通过 DeviceID 进行管理,用于读写锁拆散,并且实现房间消息推送,类似 Nginx Worker;
- Room,房间管理通过 RoomID 进行管理,通过链表进行Channel遍历推送消息;
每个 Bucket 都有独立的 Goroutine 和读写锁优化。
Bucket
// Bucket is a channel holder. type Bucket struct { c *conf.Bucket cLock sync.RWMutex // protect the channels for chs chs map[string]*Channel // map sub key to a channel // room rooms map[string]*Room // bucket room channels routines []chan *pb.BroadcastRoomReq routinesNum uint64 ipCnts map[string]int32 }维护当前消息通道和房间的信息,有独立的 Goroutine 和 读写锁优化,用户可以自定义配置对应的 buckets 数量,在大并发业务上尤其明显。
Room
// Room is a room and store channel room info. type Room struct { ID string rLock sync.RWMutex next *Channel drop bool Online int32 // dirty read is ok AllOnline int32 }结构也比较简单,维护了的房间的通道 Channel, 推送消息进行了合并写,即 Batch Write, 如果不合并写,每来一个小的消息都通过长连接写出去,系统 Syscall 调用的开销会非常大,Pprof 的时候会看到网络 Syscall 是大头。
Channel
// Channel used by message pusher send msg to write goroutine. type Channel struct { Room *Room CliProto Ring signal chan *protocol.Proto Writer bufio.Writer Reader bufio.Reader Next *Channel Prev *Channel Mid int64 Key string IP string watchOps map[int32]struct{} mutex sync.RWMutex }一个连接通道。Writer/Reader 就是对网络 Conn 的封装,cliProto 是一个 Ring Buffer,保存 Room 广播或是直接发送过来的消息体。
内存优化
// Round used for connection round-robin get a reader/writer/timer for split big lock. type Round struct { readers []bytes.Pool writers []bytes.Pool timers []time.Timer options RoundOptions } // Get get a free memory buffer. func (p *Pool) Get() (b *Buffer) { p.lock.Lock() if b = p.free; b == nil { p.grow() b = p.free } p.free = b.next p.lock.Unlock() return } // Put put back a memory buffer to free. func (p *Pool) Put(b *Buffer) { p.lock.Lock() b.next = p.free p.free = b p.lock.Unlock() }一个消息一定只有一块内存:
使用 Job 聚合消息,Comet 指针引用。
一个用户的内存尽量放到栈上:
内存创建在对应的用户 Goroutine 中。
内存由自己控制:
主要是针对 Comet 模块所做的优化,可以查看模块中各个分配内存的地方,都使用了内存池。
模块优化
消息分发一定是并行的并且互不干扰:
要保证到每一个 Comet 的通讯通道必须是相互独立的,保证消息分发必须是完全并列的,并且彼此之间互不干扰。
并发数一定是可以进行控制的:
每个需要异步处理开启的 Goroutine(Go 协程)都必须预先创建好固定的个数,如果不提前进行控制,那么 Goroutine 就随时存在爆发的可能。
全局锁一定是被打散的:
Socket 链接池管理、用户在线数据管理都是多把锁;打散的个数通常取决于 CPU,往往需要考虑 CPU 切换时造成的负担,并非是越多越好。
9.3.8 Logic
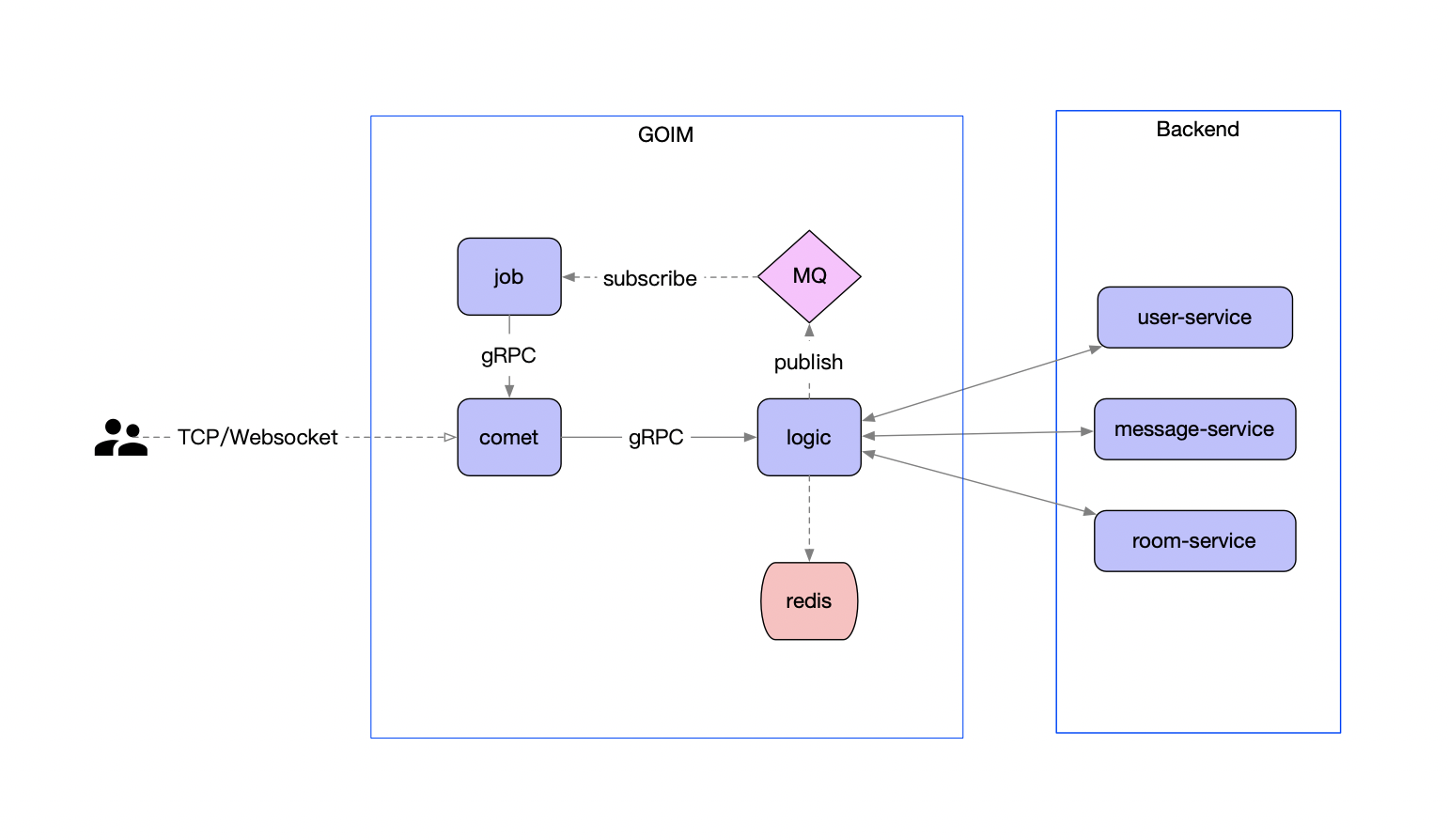
Logic 业务逻辑层,处理连接鉴权、消息路由,用户会话管理;
主要分为三层:
- sdk,通过 TCP/Websocket 建立长连接,进行重连、心跳保活;
- goim,主要负责连接管理,提供消息长连能力;
- backend,处理业务逻辑,对推送消息过虑,以及持久化相关等;
9.3.9 Job
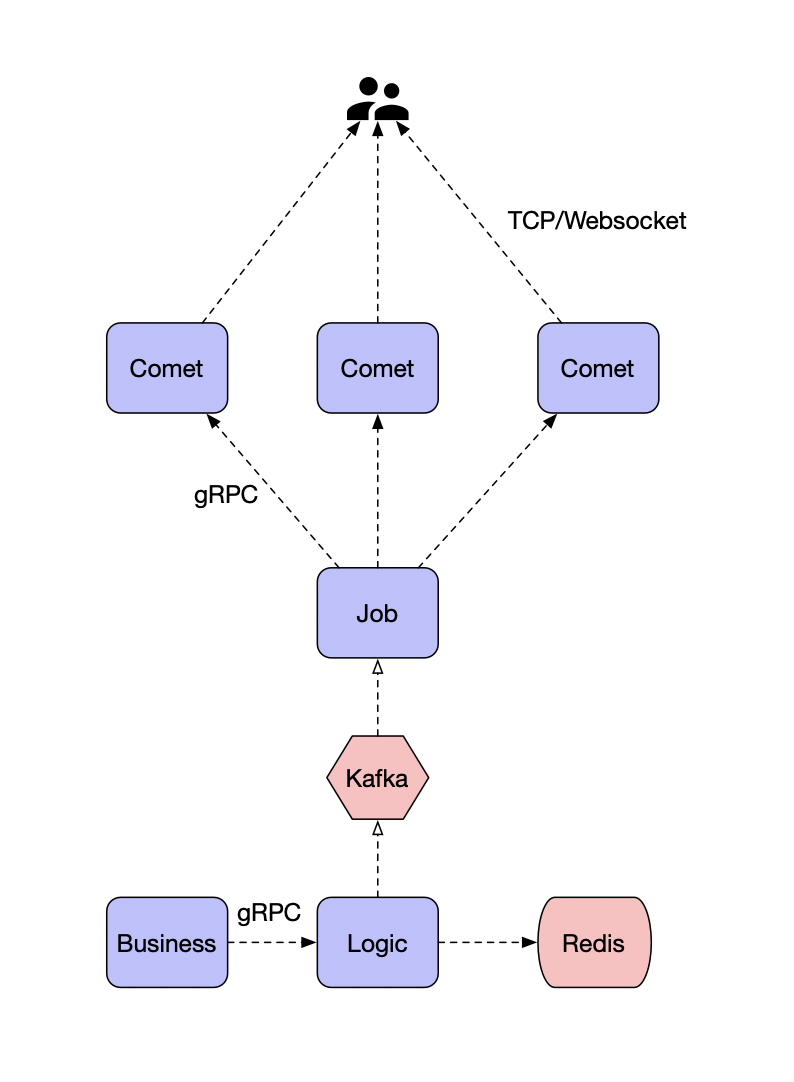
业务通过对应的推送方式,可以对连接设备、房间、用户ID进行推送,通过Session信息定位到所在的Comet连接节点,并通过Job推送消息;
通过Kafka进行推送消峰,保证消息逐步推送成功;
支持的多种推送方式:
- Push(DeviceID, Message)
- Push(UserID, Message)
- Push(RoomID, Message)
- Push(Message)
9.3.10 推拉结合
在长连接中,如果想把消息通知所有人,主要有两种模式:一种是自己拿广播通知所有人,这叫”推”模式;一种是有人主动来找你要,这叫”拉”模式。;
在业务系统中,通常会有三种可能的做法:
- 推模式,有新消息时服务器主动推给客户端;
- 拉模式,由前端主动发起拉取消息的请求;
- 推拉结合模式,有新消息实时通知,客户端再进行新的消息摘取;
9.3.11 读写扩散
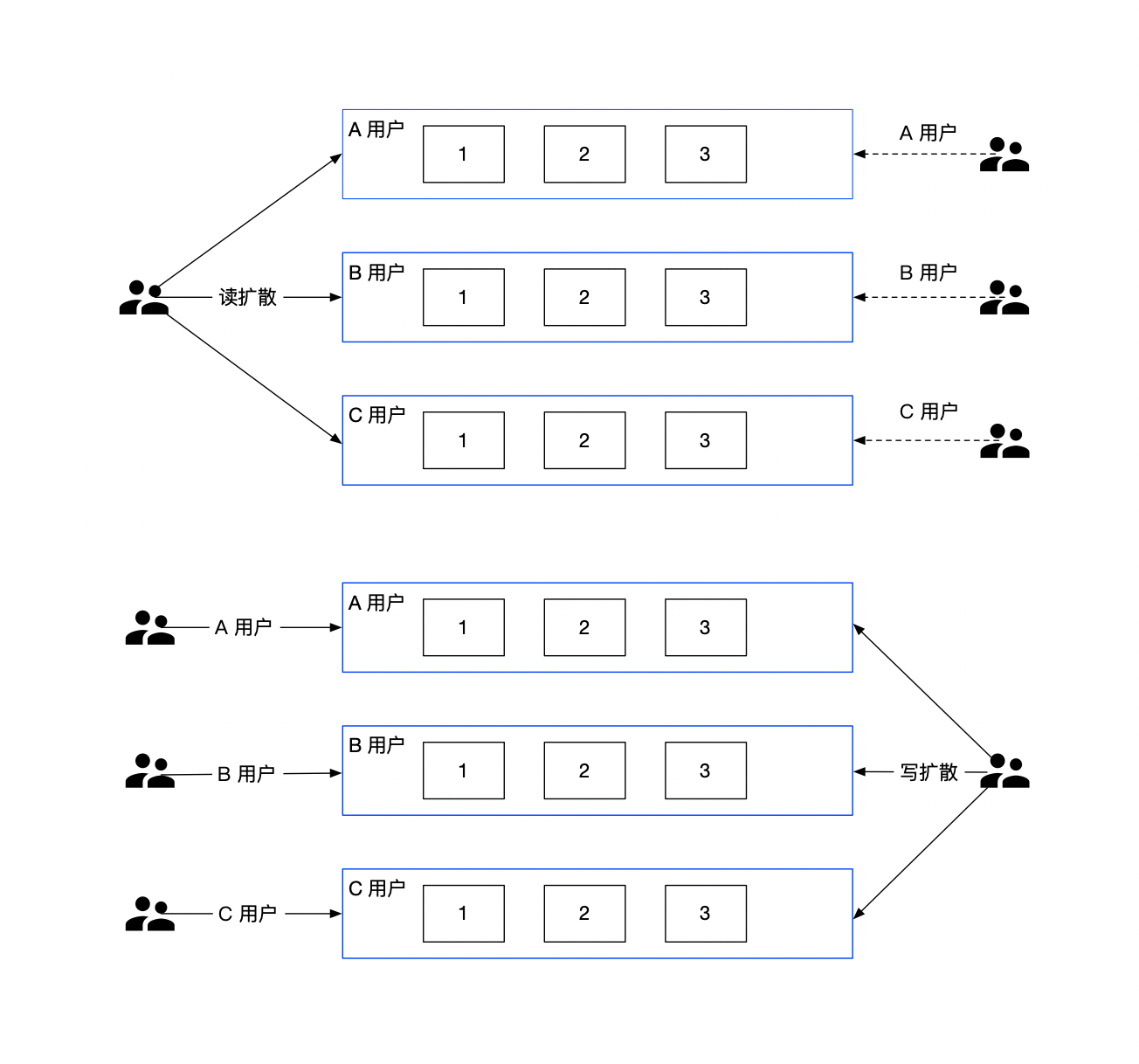
一般消息系统中,通常会比较关注消息存储;
主要进行考虑”读”、”写”扩散,也就是性能问题;
在不同场景,可能选择不同的方式:
读扩散,在IM系统里的读扩散通常是每两个相关联的人就有一个信箱,或者每个群一个信箱。
- 优点:写操作(发消息)很轻量,只用写自己信箱
- 缺点:读操作(读消息)很重,需要读所有人信箱
写扩散,每个人都只从自己的信箱里读取消息,但写(发消息)的时候需要所有人写一份
- 优点:读操作很轻量
- 缺点:写操作很重,尤其是对于群聊来说
9.3.12 唯一 ID 设计
唯一 ID,需要保证全局唯一,绝对不会出现重复的 ID,且 ID 整体趋势递增。
通常情况下,ID 的设计主要有以下几大类:
- UUID
- 基于 Snowflake 的 ID 生成方式
- 基于申请 DB 步长的生成方式
- 基于 Redis 或者 DB 的自增 ID生成方式
- 特殊的规则生成唯一 ID
Snowflake
Snowflake,is a network service for generating unique ID numbers at high scale with some simple guarantees.
id is composed of:
- time - 41 bits (millisecond precision w/ a custom epoch gives us 69 years)
- configured machine id - 10 bits - gives us up to 1024 machines
- sequence number - 12 bits - rolls over every 4096 per machine (with protection to avoid rollover in the same ms)
Sonyflake
Sonyflake,is a distributed unique ID generator inspired by Twitter’s Snowflake.
id is composed of:
- 39 bits for time in units of 10 msec
- 8 bits for a sequence number
16 bits for a machine id
As a result, Sonyflake has the following advantages and disadvantages:
The lifetime (174 years) is longer than that of Snowflake (69 years)
- It can work in more distributed machines (2^16) than Snowflake (2^10)
- It can generate 2^8 IDs per 10 msec at most in a single machine/thread (slower than Snowflake)
基于步长递增的分布式 ID 生成器
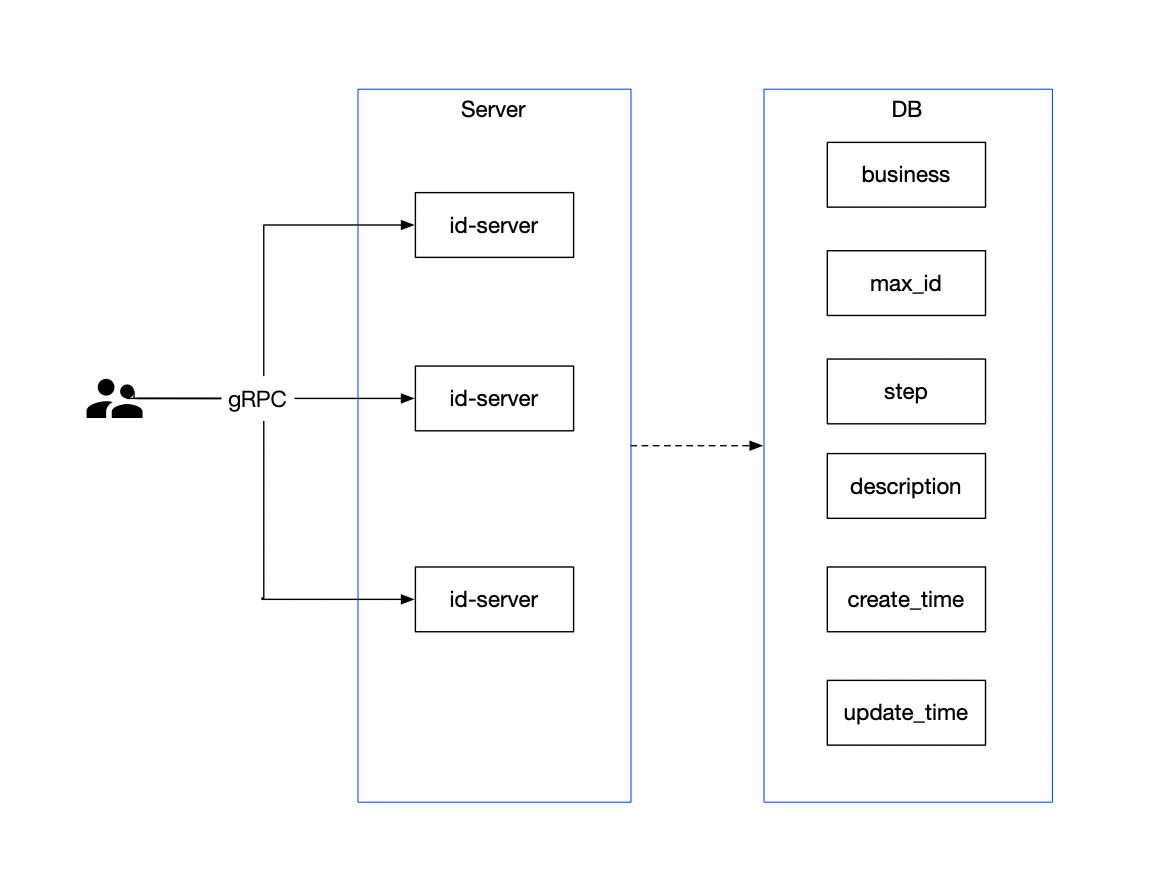
基于步长递增的分布式 ID 生成器,可以生成基于递增,并且比较小的唯一 ID;
服务主要分为:
- 通过 gRPC 通信,提供 ID 生成接口,并且携带业务标记,为不同业务分配 ID;
- 部署多个 id-server 服务,通过数据库进行申请 ID 步长,并且持久化最大的 ID,例如,每次批量取1000到内存中,可减少对 DB 的压力;
- 数据库记录分配的业务 MAX_ID 和对应 Step ,供Sequence 请求获取;
9.4 References
https://draveness.me/golang/docs/part3-runtime/ch06-concurrency/golang-netpoller/
https://www.liwenzhou.com/posts/Go/15_socket/
https://hit-alibaba.github.io/interview/basic/network/HTTP.html
https://cloud.tencent.com/developer/article/1030660
https://juejin.cn/post/6844903827536117774
https://xie.infoq.cn/article/19e95a78e2f5389588debfb1c
https://tech.meituan.com/2019/03/07/open-source-project-leaf.html
https://mp.weixin.qq.com/s/8WmASie_DjDDMQRdQi1FDg
https://www.imooc.com/article/265871
https://www.infoq.cn/article/the-road-of-the-growth-weixin-backgroundhttps://systeminterview.com/design-a-chat-system.php
https://blog.discord.com/how-discord-stores-billions-of-messages-7fa6ec7ee4c7
https://www.facebook.com/notes/facebook-engineering/the-underlying-technology-of-messages/454991608919/
https://www.infoq.cn/article/the-road-of-the-growth-weixin-background
https://slack.engineering/flannel-an-application-level-edge-cache-to-make-slack-scale/
https://www.infoq.cn/article/emrual7ttkl8xtr-dve4
http://www.91im.net/im/1130.html
https://xie.infoq.cn/article/19e95a78e2f5389588debfb1c
第10课 日志&指标&链路追踪
10.1 日志
10.1.1 日志级别
https://github.com/golang/glog,是 google 提供的一个不维护的日志库,glog 有其他语言的一些版本,对我当时使用 log 库有很大的影响。它包含如下日志级别:
- Info
- Warning
- Error
- Fatal(会中断程序执行)
还有类似 log4go,loggo,zap 等其他第三方日志库,他们还提供了设置日志级别的可见行,一般提供日志级别:
- Trace
- Debug
- Info
- Warning
- Error
- Critical
10.1.2 日志级别的说明
Warning
没人看警告,因为从定义上讲,没有什么出错。也许将来会出问题,但这听起来像是别人的问题。我们尽可能的消除警告级别,它要么是一条信息性消息,要么是一个错误。我们参考 Go 语言设计额哲学,所有警告都是错误,其他语言的 warning 都可以忽略,除非 IDE 或者在 CICD 流程中强制他们为 error,然后逼着程序员们尽可能去消除。同样的,如果想要最终消除 warning 可以记录为 error,让代码作者重视起来。
Fatal
记录消息后,直接调用 os.Exit(1),这意味着:- 在其他 goroutine defer 语句不会被执行;
- 各种 buffers 不会被 flush,包括日志的;
临时文件或者目录不会被移除;
不要使用 fatal 记录日志,而是向调用者返回错误。如果错误一直持续到 main.main。main.main 那就是在退出之前做处理任何清理操作的正确位置。
Error
也有很多人,在错误发生的地方要立马记录日志,尤其要使用 error 级别记录。
- 处理 error;
把 error 抛给调用者,在顶部打印日志;
如果您选择通过日志记录来处理错误,那么根据定义,它不再是一个错误 — 您已经处理了它。记录错误的行为会处理错误,因此不再适合将其记录为错误。
产生了降级行为时,本质属于有损服务,我更倾向在这里使用 Warning。
Debug
相信只有两件事你应该记录:
- 开发人员在开发或调试软件时关心的事情。
用户在使用软件时关心的事情。
显然,它们分别是调试和信息级别。
log.Info 只需将该行写入日志输出。不应该有关闭它的选项,因为用户只应该被告知对他们有用的事情。如果发生了一个无法处理的错误,它就会抛出到 main.main。main.main 程序终止的地方。在最后的日志消息前面插入 fatal 前缀,或者直接写入 os.Stderr。
log.Debug,是完全不同的事情。它由开发人员或支持工程师控制。在开发过程中,调试语句应该是丰富的,而不必求助于 trace 或 debug2(您知道自己是谁)级别。日志包应该支持细粒度控制,以启用或禁用调试,并且只在包或更精细的范围内启用或禁用调试语句。
我们如何设计和思考的:https://github.com/go-kratos/kratos/tree/v2.0.x/log
10.1.3 Logger
The package level logger anti pattern
在 package 使用的时候
package foo
import "mylogger"
var log = mylogger.GetLogger("github.com/project/foo")- foo 耦合了 mylogger
- 所有使用 foo 的其他库,被透明依赖了 mylogger
当我们使用 kit 时候
package foo
import "github.com/pkg/log"
type T struct {
logger log.Logger
}延迟需要打日志的类型与日志的实际类型之间的绑定。
10.1.4 日志选型
一个完整的集中式日志系统,需要包含以下几个主要特点:
- 收集-能够采集多种来源的日志数据;
- 传输-能够稳定的把日志数据传输到中央系统;
- 存储-如何存储日志数据;
- 分析-可以支持 UI 分析;
- 警告-能够提供错误报告,监控机制;
开源界鼎鼎大名 ELK stack,分别表示:Elasticsearch , Logstash, Kibana , 它们都是开源软件。新增了一个 FileBeat,它是一个轻量级的日志收集处理工具(Agent),Filebeat 占用资源少,适合于在各个服务器上搜集日志后传输给 Logstash,官方也推荐此工具。
此架构由 Logstash 分布于各个节点上搜集相关日志、数据,并经过分析、过滤后发送给远端服务器上的 Elasticsearch 进行存储。
Elasticsearch 将数据以分片的形式压缩存储并提供多种 API 供用户查询,操作。用户亦可以更直观的通过配置 Kibana Web方便的对日志查询,并根据数据生成报表。
因为 logstash 属于 server 角色,必然出现流量集中式的热点问题,因此我们不建议使用这种部署方式,同时因为 还需要做大量 match 操作(格式化日志),消耗的 CPU 也很多,不利于 scale out。
此种架构引入了消息队列机制,位于各个节点上的 Logstash Agent 先将数据/日志传递给 Kafka,并将队列中消息或数据间接传递给 Logstash,Logstash 过滤、分析后将数据传递给Elasticsearch 存储。最后由 Kibana 将日志和数据呈现给用户。因为引入了 Kafka,所以即使远端 Logstash server 因故障停止运行,数据将会先被存储下来,从而避免数据丢失。
更进一步的:
将收集端 logstash 替换为 beats,更灵活,消耗资源更少,扩展性更强。
10.1.5 日志系统:设计目标
- 接入方式收敛;
- 日志格式规范;
- 日志解析对日志系统透明;
- 系统高吞吐、低延迟;
- 系统高可用、容量可扩展、高可运维性;
10.1.6 日志系统:格式规范
JSON作为日志的输出格式:
- time: 日志产生时间,ISO8601格式;
- level: 日志等级,ERROR、WARN、 INFO、DEBUG;
- app_id: 应用id,用于标示日志来源;
- instance_id: 实例 id,用于区分同一应用不同实例,即 hostname;
10.1.7 日志系统 - 设计与实现
日志从产生到可检索,经历几个阶段:
- 生产 & 采集
- 传输 & 切分
- 存储 & 检索
10.1.8 日志系统:采集
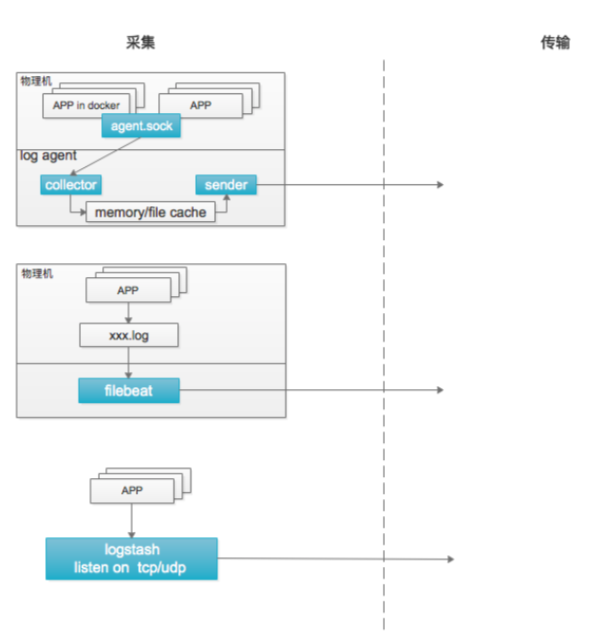
logstash:
- 监听tcp/udp
- 适用于通过网络上报日志的方式
filebeat:
- 直接采集本地生成的日志文件
- 适用于日志无法定制化输出的应用
logagent:
- 物理机部署,监听unixsocket
- 日志系统提供各种语言SDK
- 直接读取本地日志文件
10.1.9 日志系统 - logagent设计
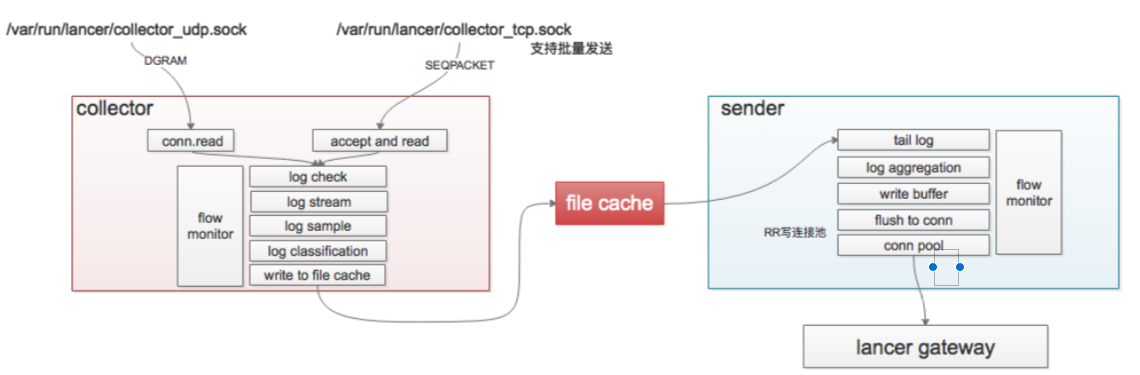
10.1.10 日志系统 - 传输
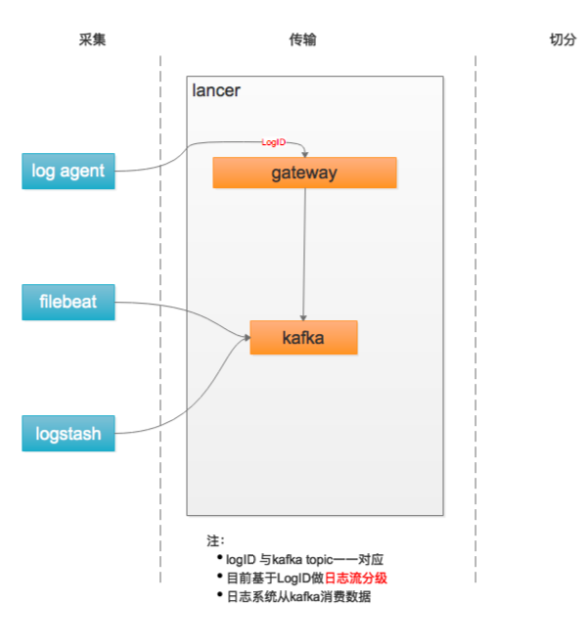
基于Flume + Kafka 统一传输平台
基于LogID做日志分流:
- 一般级别
- 低级别
- 高级别(ERROR)
10.1.11 日志系统 - 切分
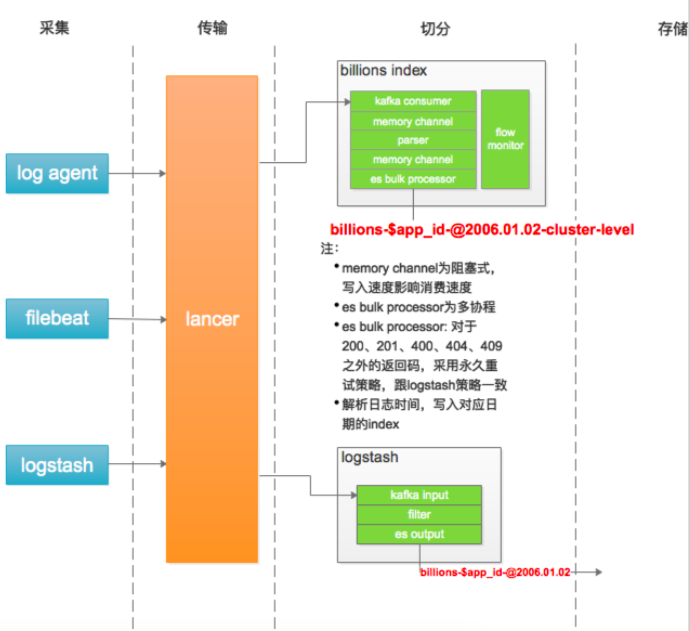
从kafka消费日志,解析日志,写入elasticsearch
bili-index: 自研,golang开发,逻辑简单,性能 高, 可定制化方便。
- 日志规范产生的日志(log agent收集)
logstash: es官方组件,基于jruby开发,功能强大, 资源消耗高,性能低。
- 处理未按照日志规范产生的日志(filebeat、logstash 收集),需配置各种日志解析规则。
10.1.12 日志系统 - 存储和检索
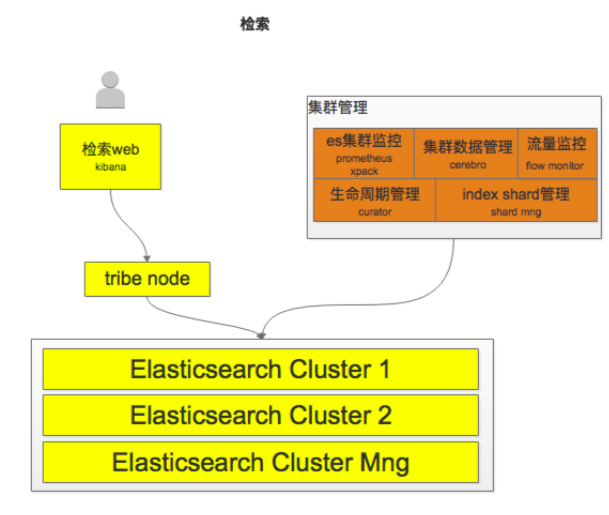
elasticsearch多集群架构:
- 日志分级、高可用
单数据集群内:
master node + data node(hot/stale) + client node
- 每日固定时间进行热->冷迁移
- Index 提前一天创建,基于 template 进行mapping 管理
- 检索基于 kibana
10.1.13 日志系统 - 文件
使用自定义协议,对 SDK 质量、版本升级都有比较高的要求,因此我们长期会使用”本地文件”的方案实现:
- 采集本地日志文件:位置不限,容器内 or 物理机
- 配置自描述:不做中心化配置,配置由 app/paas 自身提供,agent 读取配置并生效
- 日志不重不丢:多级队列,能够稳定地处理日志收集过程中各种异常
- 可监控:实时监控运行状态
- 完善的自我保护机制:限制自身对于宿主机资源的消耗,限制发送速度
10.1.14 日志系统 - 容器日志采集
容器内应用日志采集:
- 基于 overlay2,直接从物理机上查找对应日志文件
10.2 链路追踪
10.2.1 设计目标
- 无处不在的部署
- 持续的监控
- 低消耗
- 应用级的透明
- 延展性
- 低延迟
10.2.2 Dapper
参考 Google Dapper 论文实现,为每个请求都生成一个全局唯一的 traceid,端到端透传到上下游所有节点,每一层生成一个 spanid,通过traceid 将不同系统孤立的调用日志和异常信息串联一起,通过 spanid 和 level 表达节点的父子关系。
核心概念:
- Tree
- Span
- Annotation
10.2.3 调用链
跟踪树结构中,树节点是整个架构的基本单元,而每一个节点又是对 span 的引用。虽然 span 在日志文件中只是简单的代表 span 的开始和结束时间,他们在整个树形结构中却是相对独立的。
核心概念:
- TraceID
- SpanID
- ParentID
- Family & Title
10.2.4 追踪信息
追踪信息包含时间戳、事件、方法名(Family+Title)、注释(TAG/Comment)。
客户端和服务器上的时间戳来自不同的主机,我们必须考虑到时间偏差,RPC 客户端发送一个请求之后,服务器端才能接收到,对于响应也是一样的(服务器先响应,然后客户端才能接收到这个响应)。这样一来,服务器端的 RPC 就有一个时间戳的一个上限和下限。
10.2.5 植入点
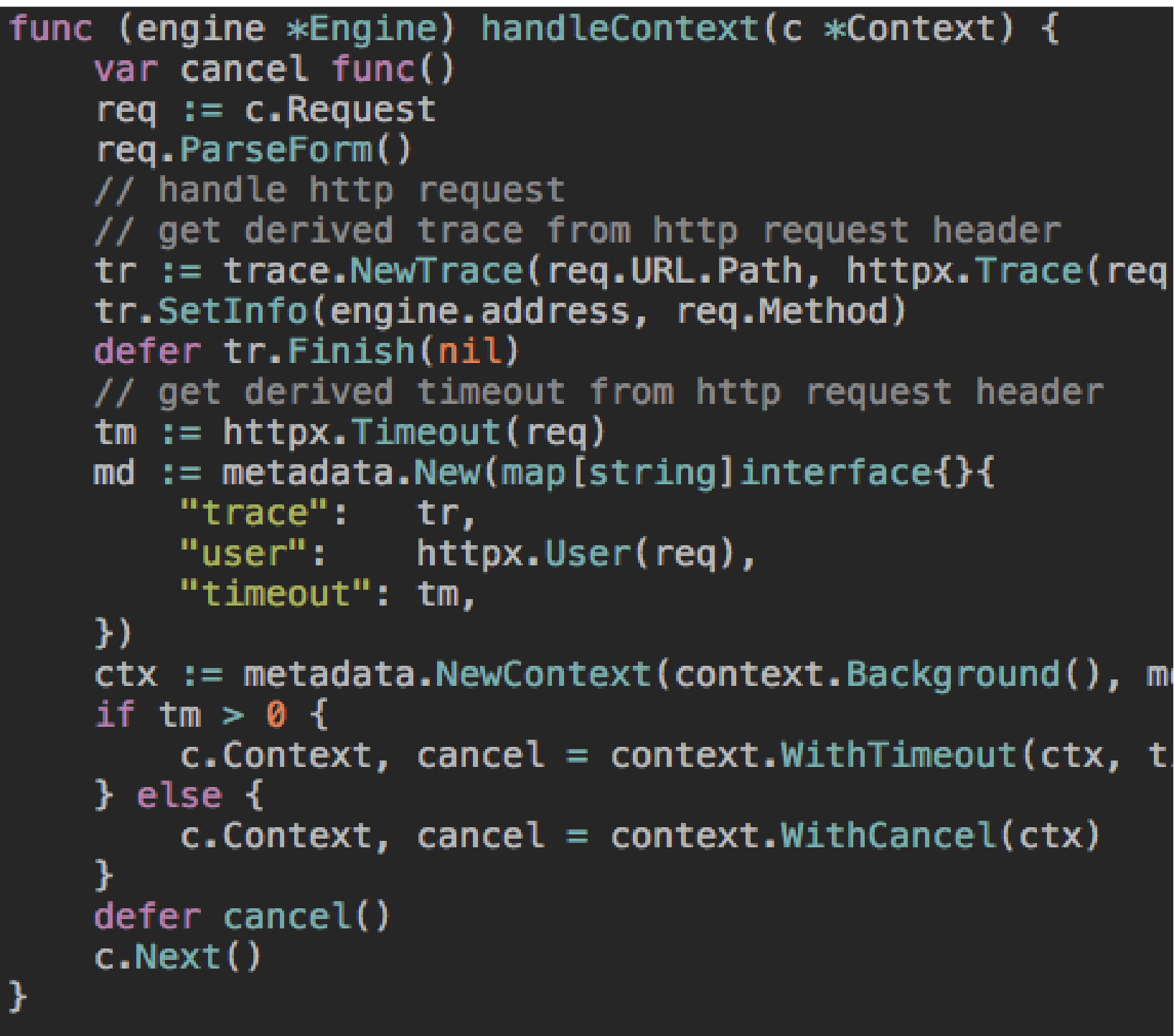
Dapper 可以以对应用开发者近乎零浸入的成本对分布式控制路径进行跟踪,几乎完全依赖于基于少量通用组件库的改造。如下:
- 当一个线程在处理跟踪控制路径的过程中,Dapper 把这次跟踪的上下文的在 ThreadLocal中进行存储,在 Go 语言中,约定每个方法首参数为 context(上下文)
- 覆盖通用的中间件&通讯框架、不限于:redis、memcache、rpc、http、database、queue。
10.2.6 架构图
10.2.7 跟踪消耗
处理跟踪消耗:
- 正在被监控的系统在生成追踪和收集追踪数据的消耗导致系统性能下降,
- 需要使用一部分资源来存储和分析跟踪数据,是Dapper性能影响中最关键的部分:
- 因为收集和分析可以更容易在紧急情况下被关闭,ID生成耗时、创建Span等;
- 修改agent nice值,以防在一台高负载的服务器上发生cpu竞争;
采样:
- 如果一个显着的操作在系统中出现一次,他就会出现上千次,基于这个事情我们不全量收集数据。
有意思的论文:Uncertainty in Aggregate Estimates from Sampled Distributed Traces
10.2.8 跟踪采样
固定采样,1/1024:
这个简单的方案是对我们的高吞吐量的线上服务来说是非常有用,因为那些感兴趣的事件(在大吞吐量的情况下)仍然很有可能经常出现,并且通常足以被捕捉到。然而,在较低的采样率和较低的传输负载下可能会导致错过重要事件,而想用较高的采样率就需要能接受的性能损耗。对于这样的系统的解决方案就是覆盖默认的采样率,这需要手动干预的,这种情况是我们试图避免在 Dapper 中出现的。
应对积极采样:
我们理解为单位时间期望采集样本的条目,在高 QPS 下,采样率自然下降,在低 QPS 下,采样率自然增加;比如1s内某个接口采集1条。
二级采样
容器节点数量多,即使使用积极采样仍然会导致采样样本非常多,所以需要控制写入中央仓库的数据的总规模,利用所有 span 都来自一个特定的跟踪并分享同一个 traceid 这个事实,虽然这些 span 有可能横跨了数千个主机。
对于在收集系统中的每一个 span,我们用hash算法把 traceid 转成一个标量Z ,这里0<=Z<=1,我们选择了运行期采样率,这样就可以优雅的去掉我们无法写入到仓库中的多余数据,我们还可以通过调节收集系统中的二级采样率系数来调整这个运行期采样率,最终我们通过后端存储压力把策略下发给 agent采集系统,实现精准的二级采样。
下游采样
越被依赖多的服务,网关层使用积极采样以后,对于 downstream 的服务采样率仍然很高。
10.2.9 API
搜索:
按照 Family(服务名)、Title(接口)、时间、调用者等维度进行搜索
详情:
根据单个 traceid,查看整体链路信息,包含 span、level 统计,span 详情,依赖的服务、组件信息等;
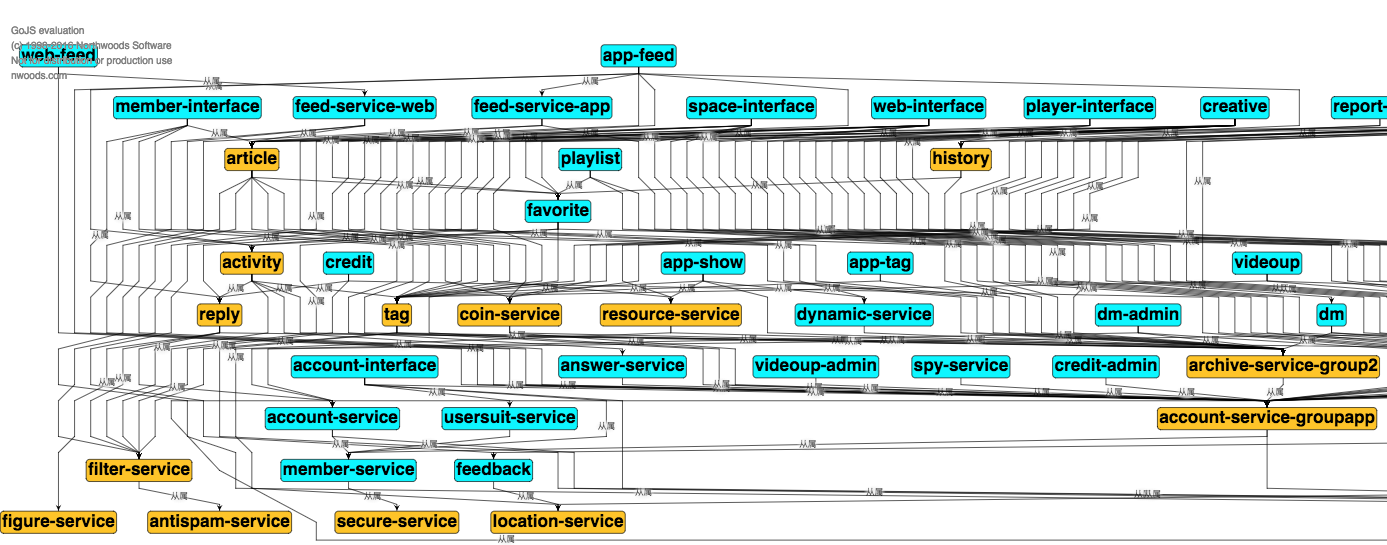
全局依赖图:
由于服务之间的依赖是动态改变的,所以不可能仅从配置信息上推断出所有这些服务之间的依赖关系,能够推算出任务各自之间的依赖,以及任务和其他软件组件之间的依赖。
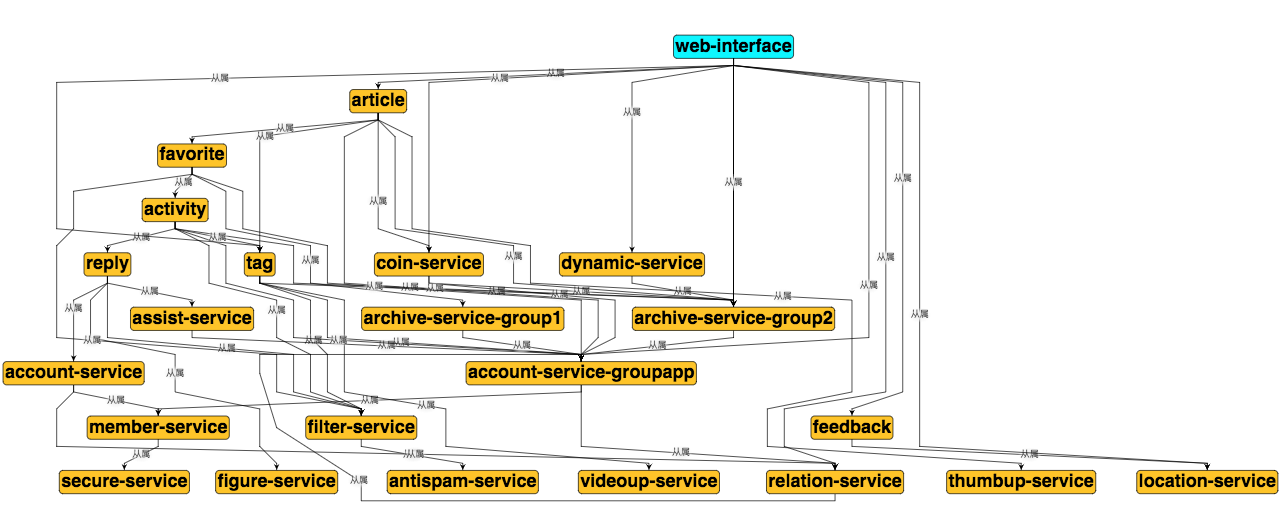
依赖搜索:
搜索单个服务的依赖情况,方便我们做”异地多活”时候来全局考虑资源的部署情况,以及区分服务是否属于多活范畴,也可以方便我们经常性的梳理依赖服务和层级来优化我们的整体架构可用性。
推断环依赖:
一个复杂的业务架构,很难避免全部是层级关系的调用,但是我们要尽可能保证一点:调用栈永远向下,即:不产生环依赖。
10.2.10 经验&优化
性能优化:
- 不必要的串行调用;
- 缓存读放大;
- 数据库写放大;
- 服务接口聚合调用;
异常日志系统集成:
- 如果这些异常发生在 Dapper 跟踪采样的上下文中,那么相应的 traceid 和 spanid 也会作为元数据记录在异常日志中。异常监测服务的前端会提供一个链接,从特定的异常信息的报告直接导向到他们各自的分布式跟踪;
用户日志集成:
- 在请求的头中返回 traceid,当用户遇到故障或者上报客服我们可以根据 traceid 作为整个请求链路的关键字,再根据接口级的服务依赖接口所涉及的服务并行搜索 ES Index,聚合排序数据,就比较直观的诊断问题了;
容量预估:
- 根据入口网关服务,推断整体下游服务的调用扇出来精确预估流量再各个系统的占比;
网络热点&易故障点:
- 我们内部 RPC 框架还不够统一,以及基础库的组件部分还没解决拿到应用层协议大小,如果我们收集起来,可以很简单的实现流量热点、机房热点、异常流量等情况。同理容易失败的 span,很容易统计出来,方便我们辨识服务的易故障点;
opentraceing:
- 标准化的推广,上面几个特性,都依赖 span TAG 来进行计算,因此我们会逐步完成标准化协议,也更方便我们开源,而不是一个内部”特殊系统”;
10.3 监控
10.3.1 监控指标

Monitoring:
- 延迟、流量、错误、饱和度
- 长尾问题
- 依赖资源 (Client/Server ‘s view)
opentracing (Google Dapper)
Logging:
- traceid关联
Prometheus + Granfana
10.3.2 日志级别
涉及到 net、cache、db、rpc 等资源类型的基础库,首先监控维度4个黄金指标:
- 延迟(耗时,需要区分正常还是异常)
- 流量(需要覆盖来源,即:caller)
- 错误(覆盖错误码或者 HTTP Status Code)
- 饱和度(服务容量有多”满”)
系统层面:
- CPU,Memory,IO,Network,TCP/IP状态等,FD(等其他),Kernel:Context Switch
- Runtime:各类 GC、Mem 内部状态等
10.3.3 在线监控操作
- 线上打开 Profiling 的端口;
- 使用服务发现找到节点信息,以及提供快捷的方式快速可以 WEB 化查看进程的 Profiling 信息(火焰图等);
- watchdog,使用内存、CPU等信号量触发自动采集;
10.4 References
https://dave.cheney.net/2015/11/05/lets-talk-about-logging
https://www.ardanlabs.com/blog/2013/11/using-log-package-in-go.html
https://www.ardanlabs.com/blog/2017/05/design-philosophy-on-logging.html
https://dave.cheney.net/2017/01/23/the-package-level-logger-anti-pattern
https://help.aliyun.com/document_detail/28979.html?spm=a2c4g.11186623.2.10.3b0a729amtsBZe
https://developer.aliyun.com/article/703229
https://developer.aliyun.com/article/204554
https://developer.aliyun.com/article/251629
https://www.elastic.co/cn/what-is/elk-stack
https://my.oschina.net/itblog/blog/547250
https://www.cnblogs.com/aresxin/p/8035137.html
https://www.elastic.co/cn/products/beats/filebeat
https://www.elastic.co/guide/en/beats/filebeat/5.6/index.html
https://www.elastic.co/cn/products/logstash
https://www.elastic.co/guide/en/logstash/5.6/index.html
https://www.elastic.co/cn/products/kibana
https://www.elastic.co/guide/en/kibana/5.5/index.html
https://www.elastic.co/guide/en/elasticsearch/reference/5.6/index.html
https://elasticsearch.cn/
https://blog.aliasmee.com/post/graylog-log-system-architecture/
第11课 DNS & CDN & 多活架构
11.1 DNS
11.1.1 DNS 介绍
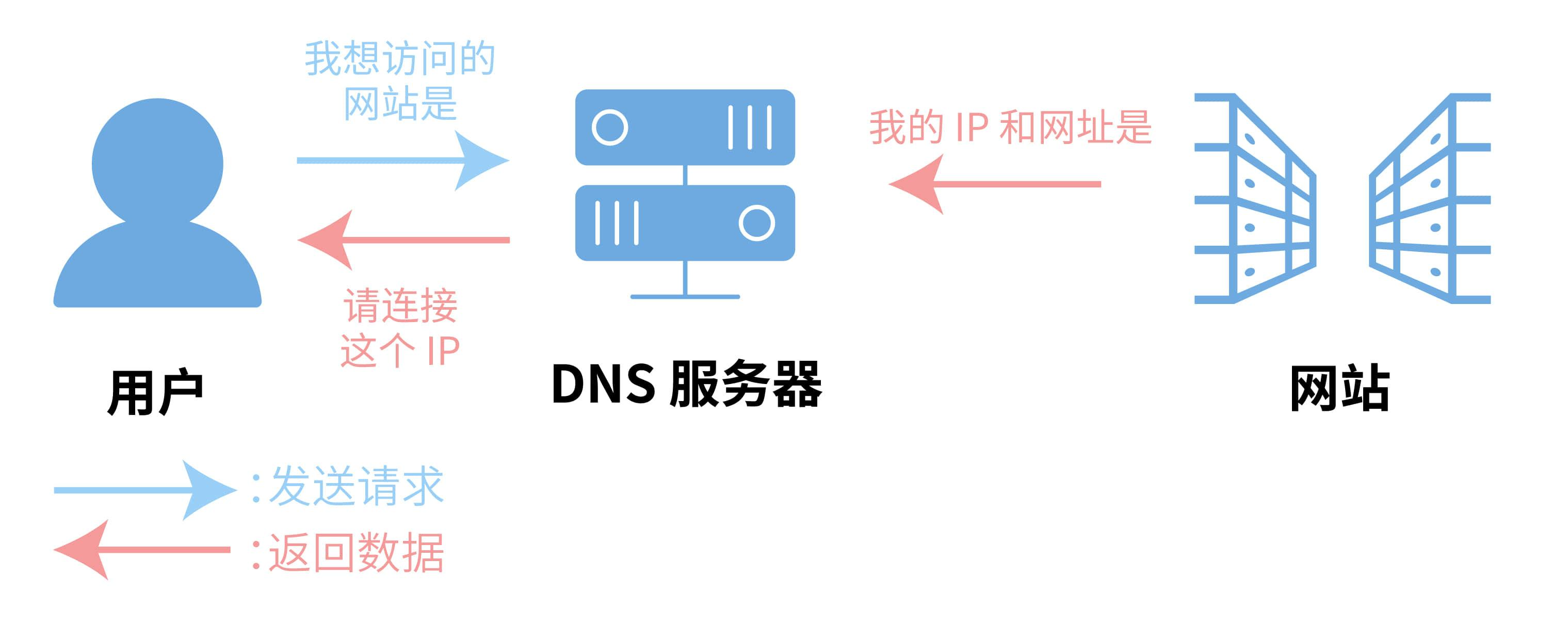
DNS(Domain Name System,域名系统),DNS 服务用于在网络请求时,将域名转为 IP 地址。能够使用户更方便的访问互联网,而不用去记住能够被机器直接读取的 IP 数串。
传统的基于 UDP 协议的公共 DNS 服务极易发生 DNS 劫持,从而造成安全问题。
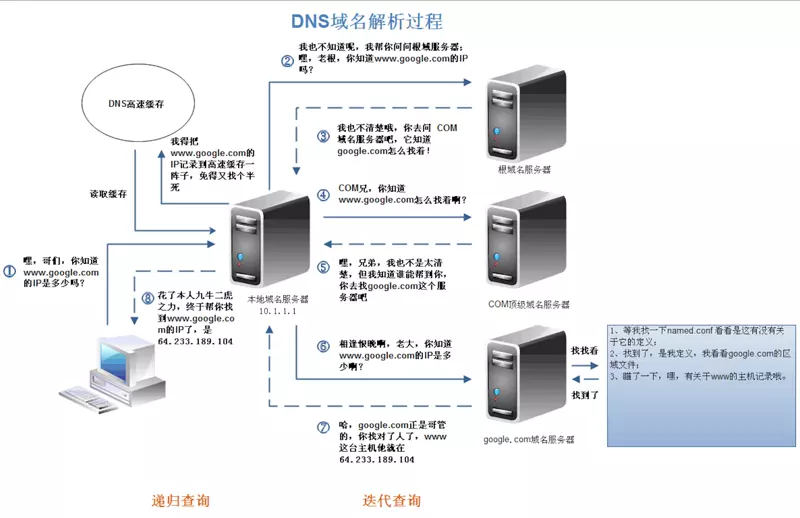
递归查询
如果主机所询问的本地域名服务器不知道被查询域名的 IP 地址,那么本地域名服务器就以 DNS 客户的身份,向其他根域名服务器继续发出查询请求报文,而不是让该主机自己进行下一步的查询。
迭代查询
当根域名服务器收到本地域名服务器发出的迭代查询请求报文时,要么给出所要查询的 IP 地址,要么告诉本地域名服务器:你下一步应当向哪一个域名服务器进行查询。然后让本地域名服务器进行后续的查询,而不是替本地域名服务器进行后续的查询。
由此可见,客户端到 Local DNS 服务器,Local DNS 与上级 DNS 服务器之间属于递归查询;DNS 服务器与根 DNS 服务器之前属于迭代查询。
11.1.2 DNS 问题
Local DNS 劫持:
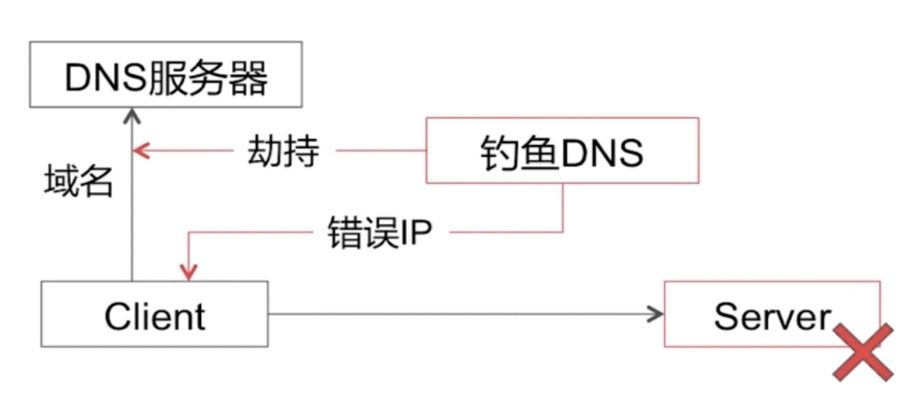
Local DNS 把域名劫持到其他域名,实现其不可告人的目的。
域名缓存
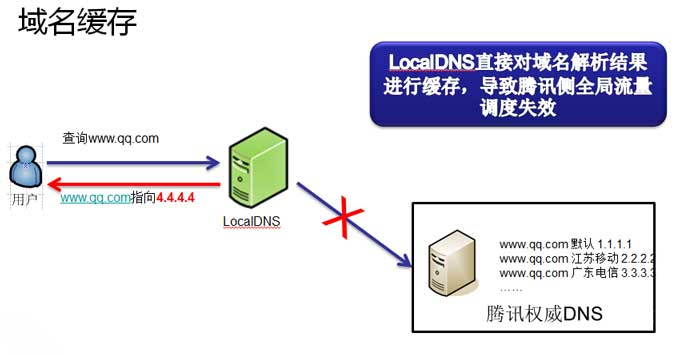
域名缓存就是 LocalDNS 缓存了业务的域名的解析结果,不向权威 DNS 发起递归。
- 保证用户访问流量在本网内消化:国内的各互联网接入运营商的带宽资源、网间结算费用、IDC机房分布、网内 ICP 资源分布等存在较大差异。为了保证网内用户的访问质量,同时减少跨网结算,运营商在网内搭建了内容缓存服务器,通过把域名强行指向内容缓存服务器的 IP 地址,就实现了把本地本网流量完全留在了本地的目的。
- 推送广告:有部分 LocalDNS 会把部分域名解析结果的所指向的内容缓存,并替换成第三方广告联盟的广告。
解析转发
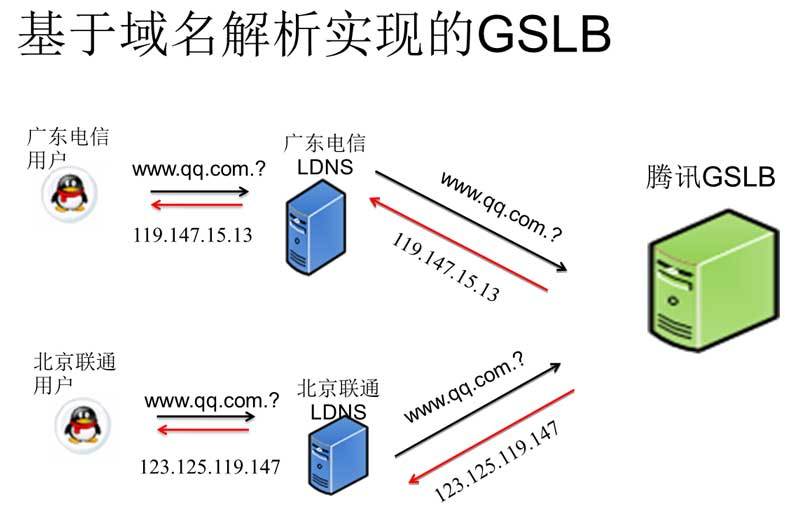
除了域名缓存以外,运营商的 LocalDNS 还存在解析转发的现象。
解析转发是指运营商自身不进行域名递归解析,而是把域名解析请求转发到其它运营商的递归 DNS 上的行为。
而部分小运营商为了节省资源,就直接将解析请求转发到了其它运营的递归 LocalDNS 上去了。
这样的直接后果就是权威 DNS 收到的域名解析请求的来源 IP 就成了其它运营商的 IP,最终导致用户流量被导向了错误的 IDC,用户访问变慢。
多NAT出口导致DNS解析错误
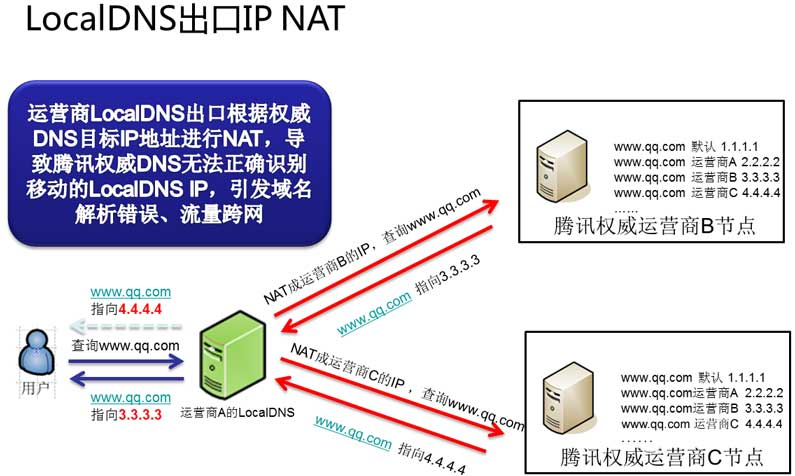
LocalDNS 递归出口 NAT 指的是运营商的 LocalDNS 按照标准的 DNS 协议进行递归,但是因为在网络上存在多出口且配置了目标路由 NAT,结果导致 LocalDNS 最终进行递归解析的时候的出口 IP 就有概率不为本网的 IP 地址。
这样的直接后果就是 DNS 收到的域名解析请求的来源 IP 还是成了其它运营商的 IP,最终导致用户流量被导向了错误的 IDC,用户访问变慢。
11.1.3 高可用的 DNS 设计
实时监控 + 商务推动:
这种方案就是周期比较长,毕竟通过行政手段来推动运营商来解决这个问题是比较耗时的。
另外我们通过大数据分析,得出的结论是 Top3 的问题用户均为移动互联网用户。对于这部分用户,我们有什么技术手段可以解决以上的问题呢?
绕过自动分配 DNS,使用 114DNS 或 Google public DNS:
如何在用户侧构造域名请求:对于 PC 端的客户端来说,构造一个标准的 DNS 请求包并不算什么难事。但在移动端要向一个指定的 LocalDNS 上发送标准的 DNS 请求包,而且要兼容各种 iOS 和 Android 的版本的话,技术上是可行的,只是兼容的成本会很高。
推动用户修改配置极高:如果要推动用户手动修改 PC 的 DNS 配置的话,在 PC 端和手机客户端的 WiFi 下面还算勉强可行。但是要用户修改在移动互联网环境下的 DNS 配置,其难度不言而喻。
完全抛弃域名,自建 HTTPDNS 进行流量调度:
如果要采用这种这种方案的话,首先你就得要拿到一份准确的 IP 地址库来判断用户的归属,然后再制定个协议搭个服务来做调度,然后再对接入层做调度改造。
这种方案和2种方案一样,不是不能做,只是成本会比较高,尤其对于大体量业务规模如此庞大的公司而言。
当前主流的解决方案:HTTPDNS出现了!
11.1.4 高可用 DNS 的最佳实践
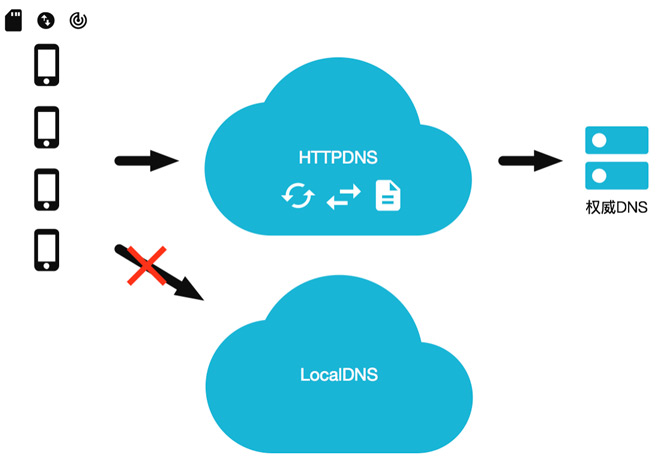
HTTPDNS 利用 HTTP 协议与 DNS 服务器交互,代替了传统的基于 UDP 协议的 DNS 交互,绕开了运营商的 Local DNS,有效防止了域名劫持,提高域名解析效率。
另外,由于 DNS 服务器端获取的是真实客户端 IP 而非 Local DNS 的 IP,能够精确定位客户端地理位置、运营商信息,从而有效改进调度精确性。
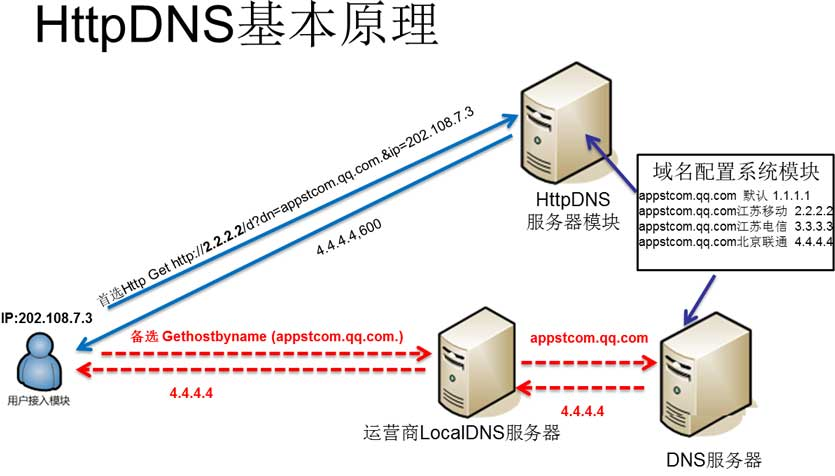
由于 HTTP DNS 是通过 ip 直接请求 http获取服务器 A 记录地址,不存在向本地运营商询问 domain 解析过程,所以从根本避免了劫持问题。
平均访问延迟下降:
- 由于是 ip 直接访问省掉了一次 domain 解析过程。
用户连接失败率下降:
- 通过算法降低以往失败率过高的服务器排序
- 通过时间近期访问过的数据提高服务器排序
- 通过历史访问成功记录提高服务器排序
根治域名解析异常:由于绕过了运营商的LocalDNS,用户解析域名的请求通过 HTTP 协议直接透传到了 HTTPDNS 服务器 IP 上,用户在客户端的域名解析请求将不会遭受到域名解析异常的困扰。
调度精准:HTTPDNS 能直接获取到用户 IP,通过结合 IP 地址库以及测速系统,可以保证将用户引导的访问最快的 IDC 节点上;
实现成本低廉:接入 HTTPDNS 的业务仅需要对客户端接入层做少量改造,无需用户手机进行 root 或越狱;而且由于 HTTP 协议请求构造非常简单,兼容各版本的移动操作系统更不成问题;另外 HTTPDNS 的后端配置完全复用现有权威 DNS 配置,管理成本也非常低。
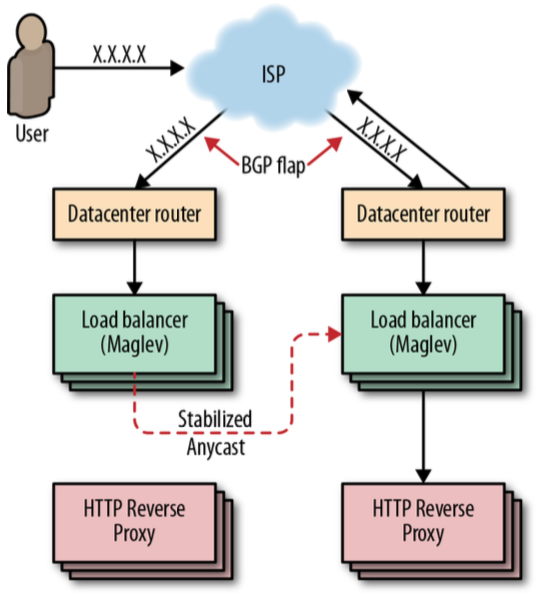
如果只有一个 VIP,即可以增加 DNS 记录的TTL,减少解析的延迟。
Anycast 可以使用一个 IP,将数据路由到最近的一组服务器,通过 BGP 宣告这个 IP,但是这存在两个问题:
- 如果某个节点承载过多的用户会过载
- BGP 路由计算可能会导致连接重置
因此需要一个 “稳定 Anycast” 技术来实现。
11.2 CDN
11.2.1 CDN 系统架构
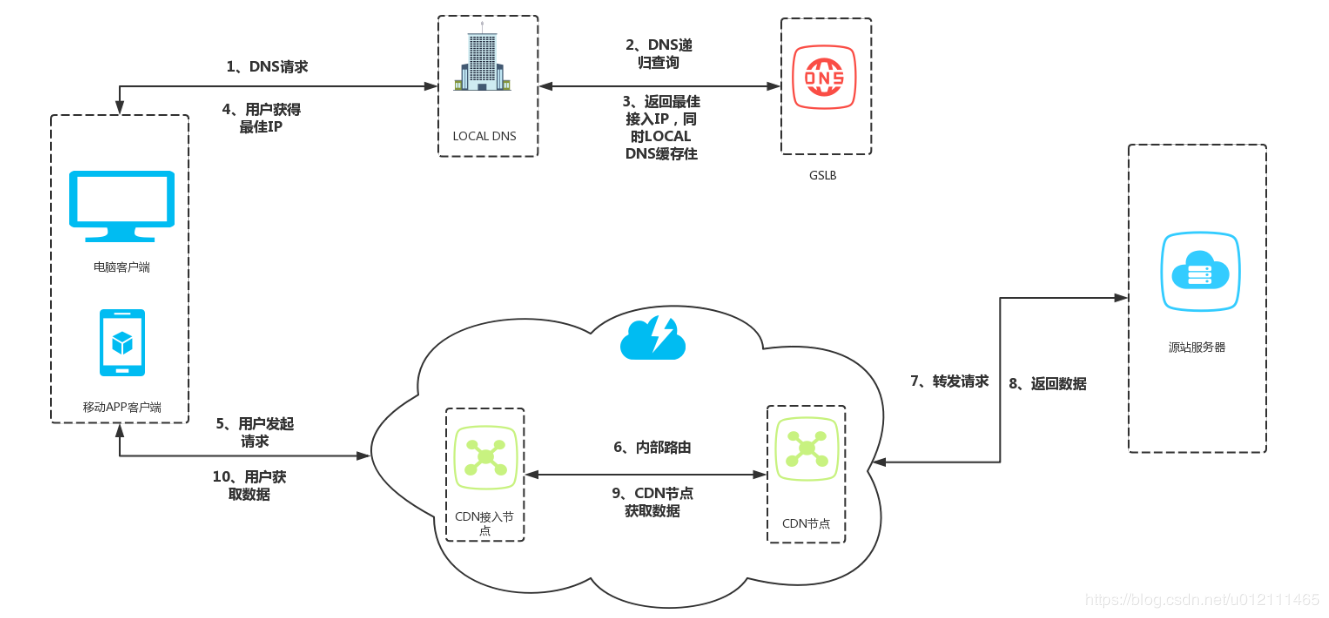
缓存代理
- 通过智能 DNS 的筛选,用户的请求被透明地指向离他最近的省内骨干节点,最大限度的缩短用户信息的传输距离。
路由加速
- 利用接入节点和中继节点或者多线节点互联互通。
安全保护
- 无论面对是渗透还是 DDoS攻击,攻击的目标大都会被指向到了 CDN,进而保护了用户源站。
节省成本
- CDN 节点机房只需要在当地运营商的单线机房,或者带宽相对便宜的城市,采购成本低。
内容路由
- DNS系统、应用层重定向,传输层重定向。
内容分发
- PUSH:主动分发,内容管理系统发起,将内容从源分发到 CDN 的 Cache 节点。
- PULL:被动分发技术,用户请求驱动,用户请求内容中 miss,从源中或者其他 CDN 节点中实时获取内容。
内容存储
- 随机读、顺序写、小文件的分布式存储。
内容管理
- 提高内容服务的效率,提高CDN的缓存利用率。
11.2.2 CDN 数据一致性
PUSH
不存在数据一致性问题。
PULL
缓存更新不及时,数据一致性问题,可设置缓存的失效时间,可以达到最终一致性。如果用户对一致性要求比较高也可以使用 ?version=xx 的技术,也可以每次上传图片返回的url是不同的方式来代替版本号。CDN 存储的资源复本指定过期时间,因而缓存图像文件可在一个小时,一个月有效的。任何资源缓存在 CDN 上,是潜在历史版本,因为在源数据与副本之间总是有一个更新与传输的延迟。
Expires
即在 HTTP 头中指明具体失效的时间(HTTP/1.0)
Cache Control
max-age 在 HTTP 头中按秒指定失效的时间,优先级高于Expires(HTTP/1.1)
Last-Modified / If-Modified-Since 文件最后一次修改的时间(精度是秒,HTTP/1.0),需要 Cache-Control 过期。
Etag 当前资源在服务器的唯一标识(生成规则由服务器决定)优先级高于Last-Modified
11.2.3 静/动态 CDN 加速
静态 CDN 加速
地理位置分散的用户最小化接收静态内容所需的跳数,直接从附近边缘的缓存中获取内容。 结果是显着降低了延迟和数据包丢失,加快了页面加载速度,并大大降低了原始基础架构的负载。
- 静态域名非主域名
- 静态多域名和收敛
- 静态资源版本化管理
动态 CDN 加速
TCP 优化
设计算法来处理网络拥堵和包丢失,加快这些情况下的数据从cdn的恢复以及一些常见的 TCP 瓶颈。
Route optimization
就是优化从源到用户端的请求的线路,以及可靠性,就是不断的测量计算得到更快更可靠的路线。
Connection management
就是边缘和源之间,包括 CDN 之前的线路,采用长连接,而不是每一个请求一个连接
On-the-fly compression
就是数据在刚刚离开源的时候就进行压缩,可以缩短在整个网络之中的流通时间。
SSL offload
加速或者说减少一些安全监测,减少原服务器执行这种计算密集型的压力。
11.3 多活架构
11.3.1 多活系统
业务分级
按照一定的标准将业务进行分级,挑选出核心的业务,只为核心业务核心场景设计异地多活,降低方案整体复杂度和实现成本。例如:1、访问量;2、核心场景;3、收入;避免进入所有业务都要全部多活,分阶段分场景推进。
数据分类
挑选出核心业务后,需要对核心业务相关的数据进一步分析,目的在于识别所有的数据及数据特征,这些数据特征会影响后面的方案设计。
常见的数据特征分析维度有:
- 数据量;
- 唯一性;
- 实时性;
- 可丢失性;
- 可恢复性;
数据同步
确定数据的特点后,我们可以根据不同的数据设计不同的同步方案。
常见的数据同步方案有:
- 存储系统同步;
- 消息队列同步;
- 重复生成;
异常处理
无论数据同步方案如何设计,一旦出现极端异常的情况,总是会有部分数据出现异常的。例如,同步延迟、数据丢失、数据不一致等。异常处理就是假设在出现这些问题时,系统将采取什么措施来应对。
常见的异常处理措施:
- 多通道同步;
- 同步和异步访问;
- 日志记录;
- 补偿;
多活不是整个体系业务的多活,而是分成不同维度,不同重要性的多活,比如我们业务观看体验为主(淘宝以交易单元,买家为维度),那么第一大前提就是浏览、观看上的多活。我们将资源分为三类:
- Global 资源:多个 Zone(机房)共享访问的资源,每个 Zone 访问本 Zone 的资源,但是 Global 层面来说是单写 Core Zone(核心机房),即:单写+多读、利用数据复制(写Zone 单向)实现最终一致性方案实现;
- Multi Zone 资源:多个 Zone 分片部署,每个 Zone 拥有部分的 Shard 数据,比如我们按照用户维度拆分,用户 A 可能在 ZoneA,用户 B 可能在 ZoneB,即:多写+多读、利用数据复制(写 Zone 双向复制)方案实现;
- Single Zone 资源:单机房部署业务;
核心主要围绕:PC/APP 首页可观看、视频详情页可打开、账号可登陆、鉴权来开展,我们认为最合适我们观看类业务最合适的场景就是采用 Global 资源策略,对于社区类(评论、弹幕)可能会采用 Multi Zone 的策略。
11.3.2 大厂做法
饿了么多活
业务过程中包含3个最重要的角色,分别是用户、商家和骑手,一个订单包含3个步骤:
- 用户打开我们的APP,系统会推荐出用户位置附近的各种美食,推荐顺序中结合了用户习惯,推荐排序,商户的推广等。用户找到中意的食物 ,下单并支付,订单会流转到商家。
- 商家接单并开始制作食物,制作完成后,系统调度骑手赶到店面,取走食物。
骑手按照配送地址,把食物送到客户手中。
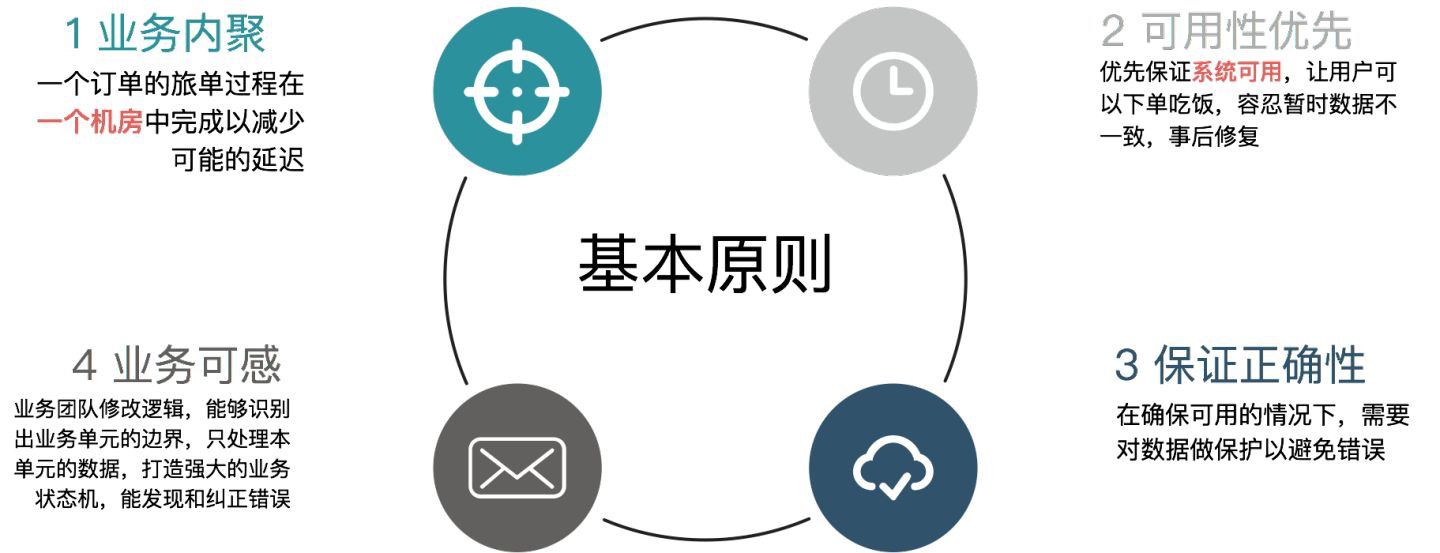
业务内聚
单个订单的旅单过程,要在一个机房中完成,不允许跨机房调用。这个原则是为了保证实时性,旅单过程中不依赖另外一个机房的服务,才能保证没有延迟。我们称每个机房为一个 ezone,一个 ezone 包含了饿了么需要的各种服务。一笔业务能够内聚在一个 ezone 中,那么一个定单涉及的用户,商家,骑手,都会在相同的机房,这样订单在各个角色之间流转速度最快,不会因为各种异常情况导致延时。恰好我们的业务是地域化的,通过合理的地域划分,也能够实现业务内聚。
可用性优先
当发生故障切换机房时,优先保证系统可用,首先让用户可以下单吃饭,容忍有限时间段内的数据不一致,在事后修复。每个 ezone 都会有全量的业务数据,当一个 ezone 失效后,其他的 ezone 可以接管用户。用户在一个ezone的下单数据,会实时的复制到其他ezone。
保证数据正确
在确保可用的情况下,需要对数据做保护以避免错误,在切换和故障时,如果发现某些订单的状态在两个机房不一致,会锁定该笔订单,阻止对它进行更改,保证数据的正确。
业务可感
因为基础设施还没有强大到可以抹去跨机房的差异,需要让业务感知多活逻辑,业务代码要做一些改造,包括:需要业务代码能够识别出业务数据的归属,只处理本 ezone 的数据,过滤掉无关的数据。完善业务状态机,能够在数据出现不一致的时候,通过状态机发现和纠正。
为了实现业务内聚,我们首先要选择一个划分方法(Sharding Key),对服务进行分区,让用户,商户,骑手能够正确的内聚到同一个 ezone 中。分区方案是整个多活的基础,它决定了之后的所有逻辑。
根据饿了么的业务特点,我们自然的选择地理位置(地理围栏,地理围栏主体按照省界划分,再加上局部微调)作为划分业务的单元,把地理位置上接近的用户,商户,骑手划分到同一个ezone,这样一个订单的履单流程就会在一个机房完成,能够保证最小的延时,在某个机房出现问题的时候,也可以按照地理位置把用户,商户,骑手打包迁移到别的机房即可。
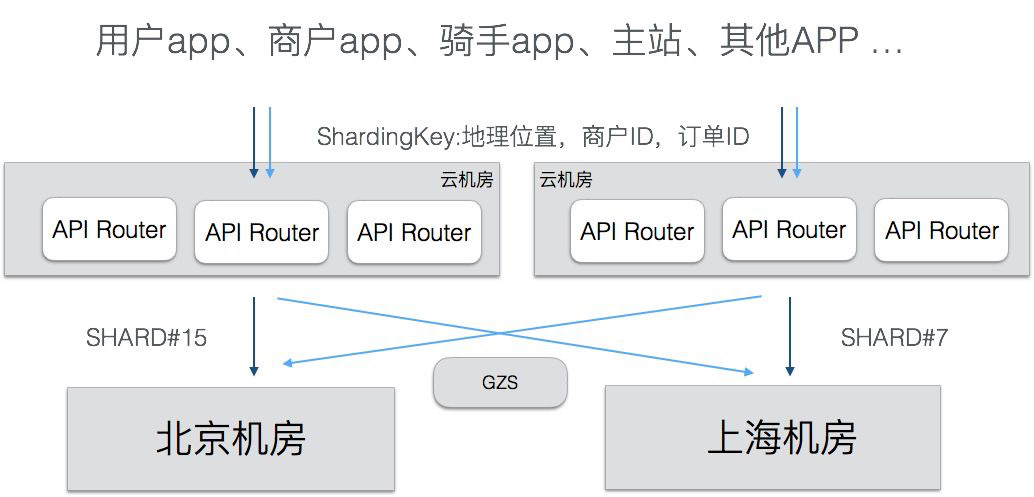
基于地理位置划分规则,开发了统一的流量路由层(API Router),这一层负责对客户端过来的 API 调用进行路由,把流量导向到正确的 ezone。API Router 部署在多个公有云机房中,用户就近接入到公有云的API Router,还可以提升接入质量。
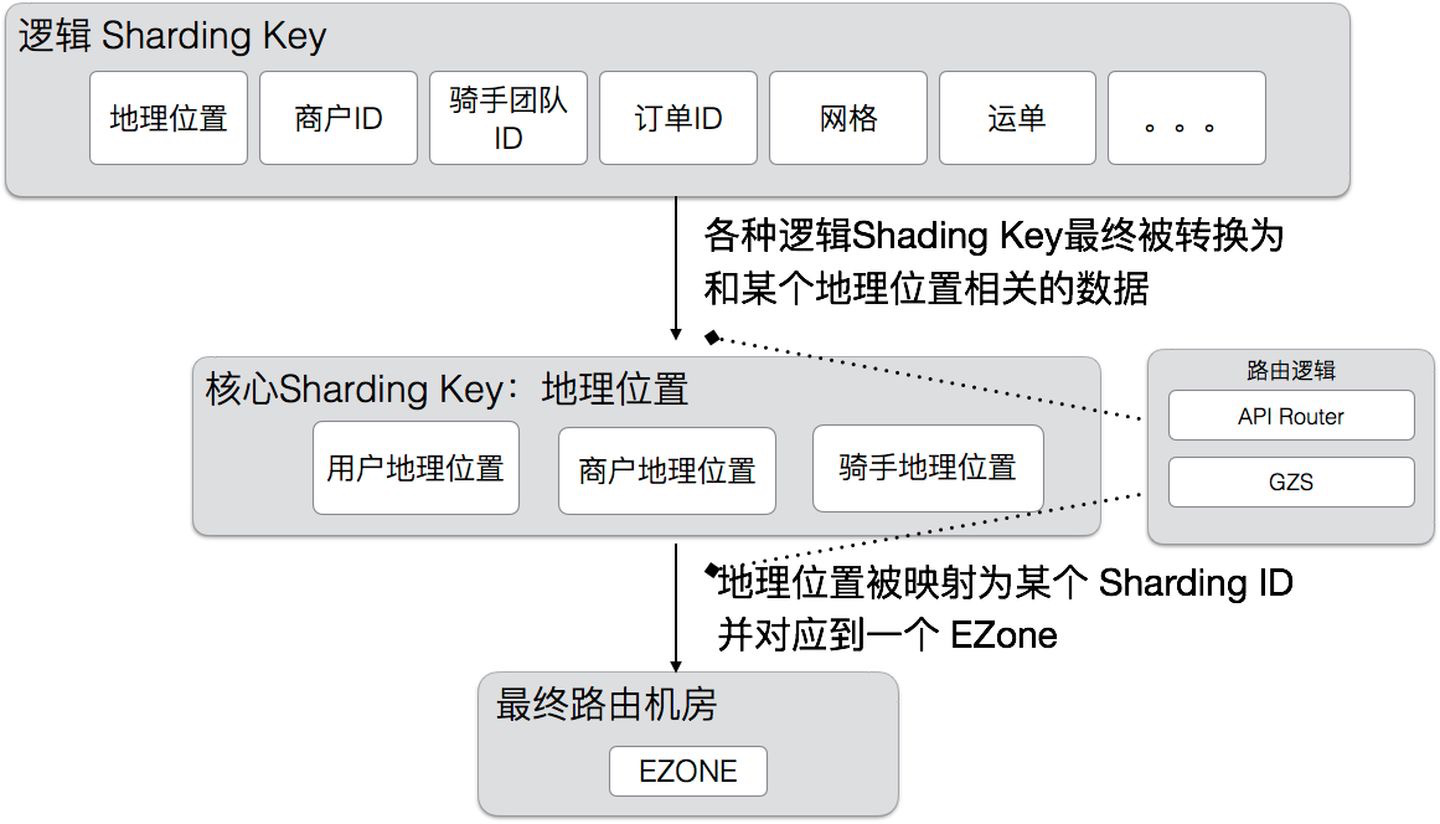
最基础的分流标签是地理位置,有了地理位置,AR 就能计算出正确的 shard 归属。但业务是很复杂的,并不是所有的调用都能直接关联到某个地理位置上,我们使用了一种分层的路由方案,核心的路由逻辑是地理位置,但是也支持其他的一些 High Level Sharding Key,这些 Sharding Key 由 APIRouter 转换为核心的 Sharding Key,具体如下图。这样既减少了业务的改造工作量,也可以扩展出更多的分区方法。除了入口处的路由,我们还开发了 SOA Proxy,用于路由SOA调用的,和API Router基于相同的路由规则。
阿里多活

苏宁多活
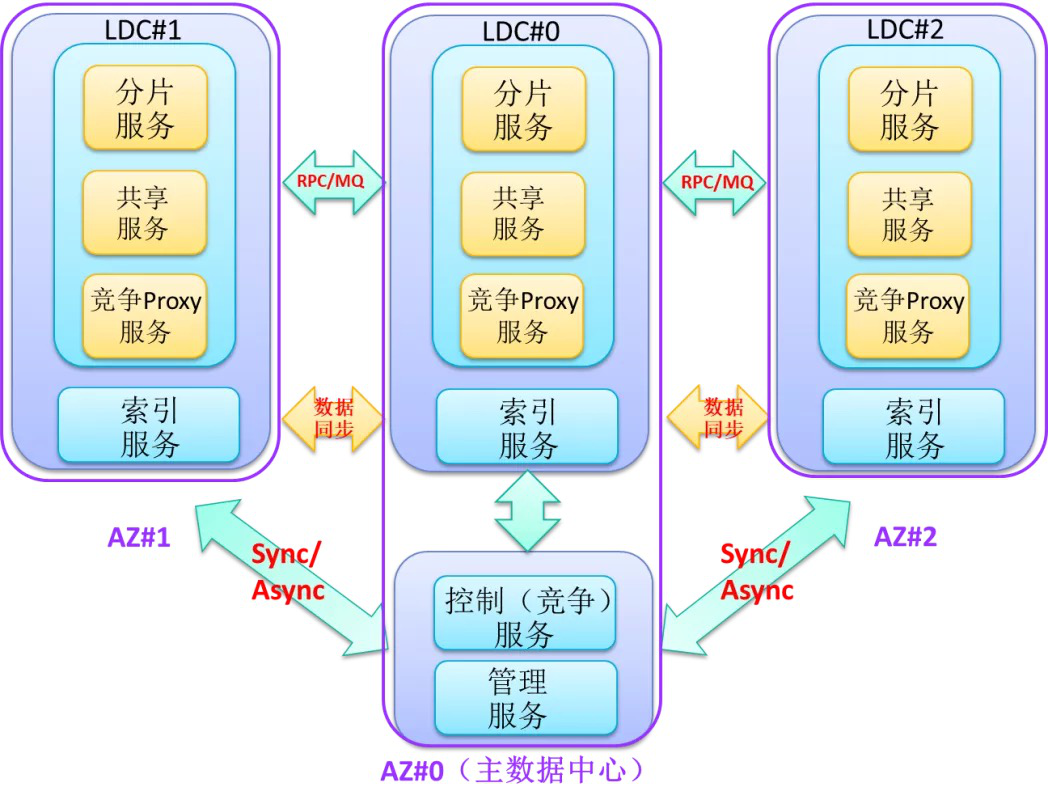
Facebook Memcache一致性
11.3.3 账号多活
11.3.4 稿件多活
11.4 References
https://zhuanlan.zhihu.com/p/32009822
https://zhuanlan.zhihu.com/p/32587960
https://zhuanlan.zhihu.com/p/33430869
https://zhuanlan.zhihu.com/p/34958596
https://mp.weixin.qq.com/s/ooPLV039BAGBsiDZagWNHw
https://mp.weixin.qq.com/s/VPkQhJLl_ULwklP1sqF79g
https://mp.weixin.qq.com/s/ty5GltO9M648OXSWgLe_Sg
https://mp.weixin.qq.com/s/GdfYsuUajWP-OWo6lbmjVQ
https://developer.aliyun.com/article/57715
https://mp.weixin.qq.com/s/RQiurTi_pLkmIg_PSpZtvA
https://mp.weixin.qq.com/s/LCn71j3hgm5Ij5tHYe8uoA
http://afghl.github.io/2018/02/11/distributed-system-multi-datacenter-1.html
https://zhuanlan.zhihu.com/p/42150666
https://zhuanlan.zhihu.com/p/20827183
https://myslide.cn/slides/733
https://blog.csdn.net/u012422829/article/details/83718296
https://blog.csdn.net/u012422829/article/details/83932829
https://www.cnblogs.com/king0101/p/11908305.html
https://mp.weixin.qq.com/s/WK8N4xFxCoUvSpXOwCVIXw
https://mp.weixin.qq.com/s/jd9Os1OAyCXZ8rXw8ZIQmg
https://cloud.tencent.com/developer/article/1441455
https://mp.weixin.qq.com/s/RQiurTi_pLkmIg_PSpZtvA
https://help.aliyun.com/document_detail/72721.html
https://mp.weixin.qq.com/s/h_KWwzPzszrdGq5kcCudRA
https://www.cnblogs.com/davidwang456/articles/8192860.html
bilibili SRE
SRE方法论
确保长期关注研发工作
- 所有的产品事故都应该有总结,无论有没有触发报警
在保障服务SLO的前提下最大化迭代速度
- 错误预算,发布策略
监控系统
- alert、ticket、logging
应急事件处理
- MTTF + MTTR
- 预案 playbook 最佳方法
变更管理:70%的生产事故来自变更而触发
- 采用渐进式的发布机制
- 迅速而准确地检测到问题的发生
- 当发现问题时,安全迅速地回退变动
需求预测和容量规划:自然增长 + 非自然增长
- 必须有一个准确的自然增长需求预测模型,需求预测的时间应该超过资源获取的时间
- 规划中必须有准备的非自然增长需求来源的统计
- 必须有周期性的压力测试,以便准备地将系统原始资源与业务容量对应起来
资源部署
变更管理与容量规划的结合物
效率与性能持续的优化资源利用率,有效地降低系统的总成本
- 根据一个预设的延迟目标部署和维护足够的容量
“我是一名软件工程师,这是我如何来应付重复劳动的办法”
Oncall
面向终端用户的服务,时间为5分钟。而非敏感的业务通常来说是30分钟
多个渠道可以收到报警(不限于邮件、短信、自动电话呼叫)
响应时间和业务的可靠性有关,如果服务为99.99%,那么每个季度有13分钟的不可用时间,所以oncall工程师要分钟级响应生产事故
一旦收到报警信息,工程师必须确认(ack),要能够及时定位问题并且尝试解决问题,必要的话要升级(escalate)请求支援
一般主oncall人值班,副oncall作为辅助,通常团队也可以彼此作为副oncall,互相值班,共同分担工作压力
oncall值班过程中,轮值工程师必须有足够的时间处理紧急事件和后续跟进工作,例如写事故报告
在面临挑战时,一个人会主动或者非主动选择下联方式处理:
- 依赖直觉,自动化、快速行动
- 理性、专注、有意识的进行认知类活动
当处理负载系统问题时,第二种行事方式是更好的,可能产生更好的处理结果,以及计划更周全的执行过程
凭直觉操作和快速响应看起来都是很有用的方法,但是这些方法都有自己的缺点。在有足够数据支撑的时候按步骤解决问题,同时不停地审核和验证目前所有的假设
Oncall可以寻求外部帮助
- 清晰的问题升级路线
- 清晰定义应急事件处理步骤
- 无指责,对事不对人的文化氛围
系统太稳定,容易松懈,定期轮值以及进行灾难恢复演习
有效的故障排查手段
通用的故障排查过程 + 发生故障的系统足够了解
排查过程反复采用”假设- 排除”
收到报警时,先搞清问题的严重程度
- 对于大型问题,立即声明一个全员参与的会议
- 大不多数的人第一反应是立即开始故障排除过程,试图尽快找到问题根源,正确做法是:尽最大可能让系统恢复服务,止损
- 快速定位问题时:保存问题现场,比如日志、监控等
监控系统记录了整个系统的监控指标,良好的Dashboard可以方便快速定位问题,比如Moni
日志是另外一个无价之宝,日志记录每个操作的信息和对应的系统状态可以让你了解在某一个时刻整个组件究竟在做什么,比如Billions
链路追踪工具,比如Dapper
Debug客户端,以便了解这个组件在收到请求后具体返回了什么信息
最后一个修改:一个正常工作的系统,直到某种外力因素出现。
- 一个配置文件修改,用户流量的改变,检查最近对系统的修改可能对查找问题根源很有帮助
紧急事件响应
不要慌,你不是一个人在战斗!
如果你感到自己难以应付,就去找更多人参与
- 通知公司内的其他部门目前情况
经常性的进行灾难处理和应急响应演习
- 大型测试中一定先测试回滚机制
应急响应要让其他人得到清晰和及时的事态更新
如果你想不到解决办法,那么就再更大的范围内需求帮助。找到更多的团队成员,寻求更多的帮助,但是要快。
紧急事件过后,别忘了留出一些时间书写事故报告。
向过去学习,而不是重复它
- 没有什么比过去的事故记录是更好的学习材料了,公布和维护时候报告
- 在记录中请务必诚实,事务巨细,时刻寻找如何能在战术以及战略上避免这项事故的发生。
= 确保自己和其他人切实完成事故中总结的代办事项。
紧急事故管理
无流程管理的紧急事故
- 过于关注技术问题
- 沟通不畅
- 不请自来
事故总控、事务处理团队、发言人
什么时候对外宣布事故
- 是否需要引入第二个团队来帮助处理问题?
- 这次事故是否正在影响最终用户?
- 在集中分析一小时后,这个问题是否依然没有得到解决?
划分优先级:控制影响范围,恢复服务,同时为根源调查保存现场
事前准备:事先和所有事故处理参与者一起准备一套流程
信任:充分相信每个事故处理参与者,分配职责后让他们主动行动
反思:在事故处理过程中注意自己的情绪和精神状态。如果发现自己开始惊慌失措或者干到压力难以承受,应该需求更多的帮助
考虑替代方案:周期性地重新审视目前的情况,重新评估目前的工作是否应该继续执行,还是需要执行其他更要要或者更紧急的事情
练习:平时不断地使用这项流程,知道习惯成自然
换位思考:上次你是事故总控负责人吗?鼓励每个团队成员熟悉流程中的其他角色
事后总结:从失败中学习
避免指责,提供建设性意见
用户可见的宕机时间或者服务质量降低程度达到一定标准
任何类型的数据丢失
on-call工程师需要人工介入的事故(包括回滚,切换用户流量等)
问题解决耗时超过一定时间
监控问题(预示着问题是由人工发现的,而非报警系统)

