架构风格和架构模式
架构风格(Architectural Styles)
架构风格的定义
Roy Thomas Fielding 在其 2000 年的博士论文 Architectural Styles and
the Design of Network-based Software Architectures 中指出:
An architectural style is a coordinated set of architectural constraints that restricts the roles/features of architectural elements and the allowed relationships among those elements within any architecture that conforms to that style.
架构风格是一组协调的架构约束,它限定了架构元素的角色、特性及在符合该风格的架构中这些元素之间所允许的相互关系。
这些约束不仅定义了系统的结构形态,也影响其非功能性特征,如可扩展性、可演化性和可维护性。
因此,架构风格可以被视为对系统架构中”设计约束集合”的抽象,不同的风格体现了不同的设计取舍与系统特征。
Vaughn Vernon 在其 2013 年出版的书籍 《Implementing Domain-Driven Design》 中指出:
An architectural style is to architecture what a design pattern is to a specific design. It is an abstraction of those aspects that are common to different concrete implementations, enabling discussion of their relevant benefits without getting lost in technical detail.
架构风格之于架构,如同设计模式之于具体设计。它将不同架构实现中的共性抽象出来,使讨论架构时能够关注其核心优势,而不陷入技术细节。
这一类比揭示了架构风格的抽象层次:正如设计模式体现了通用的设计思想,架构风格则概括了系统结构与交互机制的普遍特征。
换言之,架构风格通过约束系统元素的角色与关系,为架构提供可复用的结构范式。任何满足特定约束集合的架构实例,都可被视为该风格的具体化形式。
微服务架构风格
在分布式系统领域,微服务(Microservices) 是一种典型的架构风格。
James Lewis 和 Martin Fowler 在 2014 年发布的 Microservices Guide 一文中将其定义为:
In short, the microservice architectural style is an approach to developing a single application as a suite of small services, each running in its own process and communicating with lightweight mechanisms, often an HTTP resource API. These services are built around business capabilities and independently deployable by fully automated deployment machinery. There is a bare minimum of centralized management of these services, which may be written in different programming languages and use different data storage technologies.
简而言之,微服务架构风格 是一种将单个应用程序开发为一组小型服务的方法,每个服务都在自己的进程中运行并用轻量级机制(通常是 HTTP 资源 API)进行通信。 这些服务围绕业务功能构建,并可通过全自动部署机制独立部署。 这些服务的集中管理是最低限度的,这些服务可能用不同的编程语言编写并使用不同的数据存储技术。
基于 Fowler 与 Lewis 的总结,微服务架构风格的特征可归纳为以下三个层面:
组织层面特征
- 围绕业务能力构建(Organized around Business Capabilities):服务边界以业务领域为中心,而非技术分层。
- 产品化思维(Products not Projects):团队承担服务的全生命周期责任,形成长期维护的产品团队文化。
- 分散治理(Decentralized Governance):团队在技术选型与设计决策上保持自治,减少集中化控制带来的瓶颈。
技术层面特征
- 服务化组件化(Componentization via Services):系统通过服务实现高内聚、低耦合的组件化。
- 轻量级通信机制(Smart Endpoints and Dumb Pipes):服务间通信依赖轻量级协议(如 HTTP/REST、消息队列),避免复杂中间层。
- 数据去中心化(Decentralized Data Management):各服务独立拥有数据存储,以保障自治性与独立演化能力。
- 基础设施自动化(Infrastructure Automation):自动化的部署与运维机制支持服务的快速交付与弹性伸缩。
设计层面特征
- 容错性设计(Design for Failure):系统具备冗余与隔离机制,确保局部故障不会影响整体运行。
- 演进式设计(Evolutionary Design):系统结构允许随着业务变化持续演化,支持持续交付与渐进重构。
总结
综上,架构风格(Architectural Style) 是由一组协调约束所定义的结构与交互范式,这些约束决定了系统的结构形态及其非功能特征。
微服务作为一种特定的架构风格,通过在组织、技术与设计层面的多重约束,形成了以自治性、可演化性与持续交付为核心的架构特征。
因此,从架构理论角度而言,微服务不是一种具体技术,而是一种体现分布式自治思想的架构风格。
架构模式(Architectural Patterns)
Len Bass、Paul C. Clements 和 Rick Kazman 在 2012 年出版的书籍《Software Architecture in Practice》对架构模式的定义是:
An architectural pattern is a general, reusable resolution to a commonly occurring problem in software architecture within a given context.
架构模式是针对给定上下文中软件架构中常见问题的通用的、可重用的解决方案。
与架构风格相比,架构模式侧重于解决问题的方法,而架构风格则描述系统的结构特征和交互机制。
换言之,架构风格回答”系统是什么样的”,架构模式回答”如何设计系统以满足这些特征”。
微服务架构模式
微服务(Microservices)作为一种分布式架构风格,其典型模式可以被抽象为一系列可复用的设计方案,用以解决分布式系统中的通用问题。
这些模式通常包括但不限于:
- 服务自治模式(Self-contained Service Pattern):每个服务独立部署和管理,实现高内聚、低耦合。
- 服务发现模式(Service Discovery Pattern):服务实例能够动态注册与发现,实现服务间的灵活调用。
- 网关模式(API Gateway Pattern):通过统一入口管理请求路由、负载均衡和安全控制。
- 熔断模式(Circuit Breaker Pattern):提供故障隔离,防止局部失败蔓延至整个系统。
- 事件驱动模式(Event-driven Pattern):通过消息或事件通信解耦服务,提高系统可伸缩性。
在实际微服务系统中,这些模式通常依赖于具体技术和基础设施实现,如:
- 弹性伸缩
- 服务发现
- 配置中心
- 服务网关
- 负载均衡
- 服务安全
- 跟踪监控
- 降级熔断
需要注意的是,这些实现细节并非模式本身,而是模式在工程实践中的具体落地方式。
架构风格与架构模式的关系
架构风格提供了系统结构和设计约束,而架构模式则为在这一风格下构建系统提供可复用的解决方案。风格决定了系统的结构特征(如自治性、演进性),模式指导如何在具体实现中解决相关问题(如服务发现、容错、监控)。
因此,从理论上讲:
- 架构风格(Architectural Style):描述系统高层结构特征与交互机制,如微服务强调自治性和演进性。
- 架构模式(Architectural Pattern):提供通用设计方案以实现风格特征,如服务发现、熔断、网关。
- 具体实现(Implementation / Technical Solution):利用具体技术手段落地模式,如服务注册中心、负载均衡器、监控系统。
常见软件架构
Boundary-Control-Entity
定义
Boundary-Control-Entity(BCE) 架构由 Ivar Jacobson 于 1992 年在 Object-Oriented Software Engineering: A use case driven approach 中提出。
Boundary-Control-Entity(BCE)也叫 Entity-Control-Boundary(ECB)或 Entity-Boundary-Control(EBC)。
Boundary
外界与系统交互的接口。
Control
包含所有不适合放在 Entity 和 Boundary 的行为。
Robert C. Martin 对 Interactor 的描述是包含特定于应用程序的业务规则(The interactors on the other hand, have application specific business rules)。
Entity
包含与问题域相关的数据和行为。
Robert C. Martin 对 Entity 的描述是包含与应用无关的的业务逻辑(contain application independent business rules)。
其他资料
分层架构(Layered Architecture)
定义
分层架构是一种经典的软件设计模式,其核心思想是通过分离关注点降低系统复杂性。
分层架构的基本原则是将系统划分为不同层,每层只关注特定职责,并通过依赖方向管理层间关系。
虽然 Eric Evans 在 2003 年的 《领域驱动设计:软件核心复杂性应对之道》 强调了分层思想在 DDD 中的应用,但分层架构概念本身则要早于 DDD,并广泛应用于软件开发实践中。
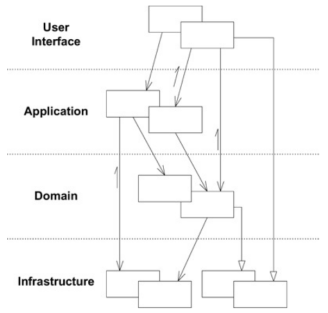
常见分层如下:
用户界面层(User Interface)
- 负责与用户交互,展示信息并接收用户请求。
- “用户”可以是人,也可以是其他应用或脚本。交互形式包括 GUI、CLI 或 API。
- UI 层仅负责交互,不包含业务逻辑或数据持久化逻辑。
应用层(Application Layer)
- 描述系统提供的用例和业务流程,包含用例逻辑、流程控制和业务编排。
- 主要职责是协调领域对象完成用例,不包含核心业务规则。
- 可执行操作包括调用微服务、事务管理、权限校验、发送领域事件等。
领域层(Domain Layer)
- 核心业务逻辑所在,表达业务概念和规则。
- 包含聚合根、实体、值对象、领域服务等。
- 任何业务规则或状态变化都应在此层实现。
基础设施层(Infrastructure)
- 提供通用技术服务,如数据库、缓存、消息中间件、外部 API 等。
- 实现领域层接口,支持持久化和外部通信。
实现规则:
- 依赖方向是从用户界面层(User Interface)到基础设施层(Infrastructure)。
- 每层只包含自身职责逻辑。
改进
Vaughn Vernon 在 《实现领域驱动设计》 书中提出了使用 依赖倒置原则 改进后的分层架构:
we would have a Repository implemented in Infrastructure for an interface defined in Domain. Focusing on the Domain Layer, using DIP enables both the Domain and Infrastructure to depend on abstractions (interfaces) defined by the domain model.
我们可以在领域层中定义资源库接口,然后在基础设施层中实现该接口。我们将关注点放在领域层上,采用依赖倒置原则,使领域层和基础设施层都只依赖于由领域模型定义的抽象接口。
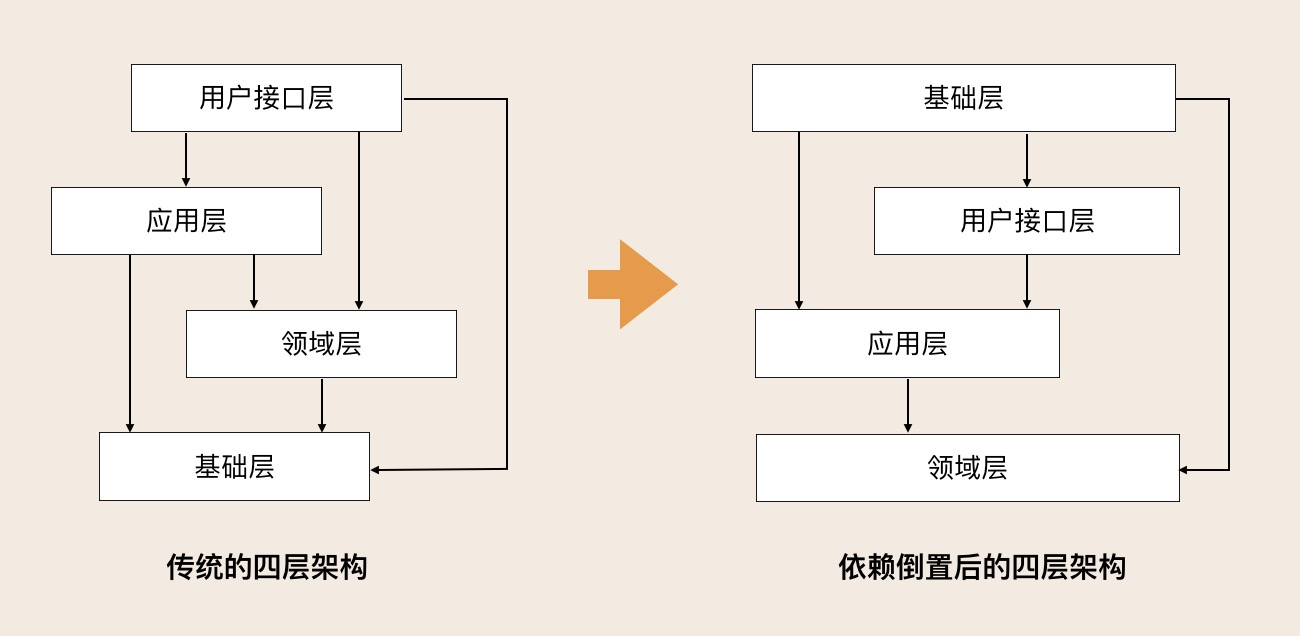
即领域层定义接口,基础设施层实现接口,实现了内层依赖抽象、外层实现抽象,使核心业务逻辑独立于外部技术,从而增强可测试性和可维护性。
总结
分层架构的目标是通过代码组织实现关注点分离,降低复杂性。
分层架构可以进一步细分为严格分层架构和松散分层架构。严格分层架构不允许跨层访问接口,而松散分层架构则允许跨层访问接口。
其他资料
六边形架构(Hexagonal Architecture)
六边形架构由 Alistair Cockburn 于 2005 年在其 个人博客 中提出,其核心思想是隔离业务逻辑与外部实现,强调系统核心独立性。
六边形架构之所以叫六边形是为了强调内部通过多个端口与外部连接,而避免大家像分层架构层层依赖那样一维的去思考。

特点:
- 内部(Core):核心业务逻辑(领域层 + 用例层/应用服务层)。
- 外部(Peripheral):外部系统实现(UI、数据库、消息队列等)。
- 连接方式:通过 端口(Ports) 与 适配器(Adapters) 实现内外交互。
- 核心业务不依赖外部实现,所有外部交互通过端口完成。
实现规则:
- 核心业务仅依赖抽象接口,不依赖外部实现。
- 外部实现通过适配器实现接口,不包含业务逻辑。
- 核心业务可独立测试与部署,支持外部实现替换。
其他资料
- Hexagonal Architecture Is Powerful
- Ports and Adapters Pattern (Hexagonal Architecture)
- Ports & Adapters Architecture
洋葱架构(Onion Architecture)
定义
洋葱架构由 Jeffrey Palermo 于 2008 年在其 个人博客 中提出。
洋葱架构并不是一个全新的架构,而是基于依赖倒置原则对传统分层架构与六边形架构的改进和优化。
它通过明确依赖方向、强化领域核心,帮助系统实现高内聚、低耦合的设计目标。
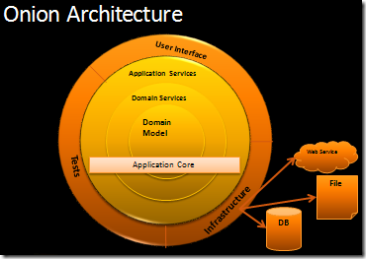
分层结构从内到外依次是:
领域模型层(Domain Model)
架构的核心,包含实体(Entity)和值对象(Value Object)等领域模型,封装了业务规则与行为。这一层完全独立,不依赖任何外部组件。
领域服务层(Domain Service)
封装那些不适合放入单个实体或值对象中的领域逻辑(例如跨实体操作的业务规则)。
领域服务通常依赖仓储(Repository)接口进行数据访问,但其职责是业务逻辑而非数据持久化。
仓储接口通常也在领域层中定义,用于抽象数据访问。
应用服务层(Application Service)
负责协调领域对象完成具体的业务用例。
它定义事务边界,调用领域模型和领域服务来实现功能,但不包含具体的业务规则。
应用服务层向外提供统一的接口,供用户界面或外部系统使用。
UI(User Interface)、基础设施(Infrastructure)以及测试用例(Tests)层
- UI(User Interface):调用应用服务层以响应用户请求并展示结果。
- 基础设施层(Infrastructure):实现领域层定义的仓储接口、消息总线、文件系统等外部资源访问逻辑。
- 测试(Tests):通过调用应用服务层或接口层,验证系统的整体行为。测试本身通常位于架构的最外层。
实现规则:
- 应用程序围绕独立的对象模型构建(The application is built around an independent object model)
- 内层定义接口,外层实现接口(Inner layers define interfaces. Outer layers implement interfaces)
- 层向中心耦合(Direction of coupling is toward the center)
- 所有应用程序核心代码都可以与基础设施分开编译和运行(All application core code can be compiled and run separate from infrastructure)
洋葱架构与其他架构之间的区别和联系:
- 在经典分层架构中,一个层只能调用其正下方的层。而在洋葱架构中,任何外层可以调用任何内层。
- 洋葱架构与六边形架构在思想上相近,都基于依赖倒置原则,强调领域核心与外部隔离。区别在于,洋葱架构通过多层同心结构更清晰地表达依赖关系和分层职责。各层的依赖方向均指向中心的领域模型层。
总结
洋葱架构的核心思想是依赖倒置原则的应用和内层不能对外层有直接的依赖。
其他资料
整洁架构(Clean Architecture)
整洁架构由 Robert C. Martin 于 2012 年提出,综合和提炼了以下几种架构思想:
- Hexagonal Architecture (a.k.a. Ports and Adapters)
- Onion Architecture
- Screaming Architecture
- DCI, The DCI Architecture: A New Vision of Object-Oriented Programming
- BCE
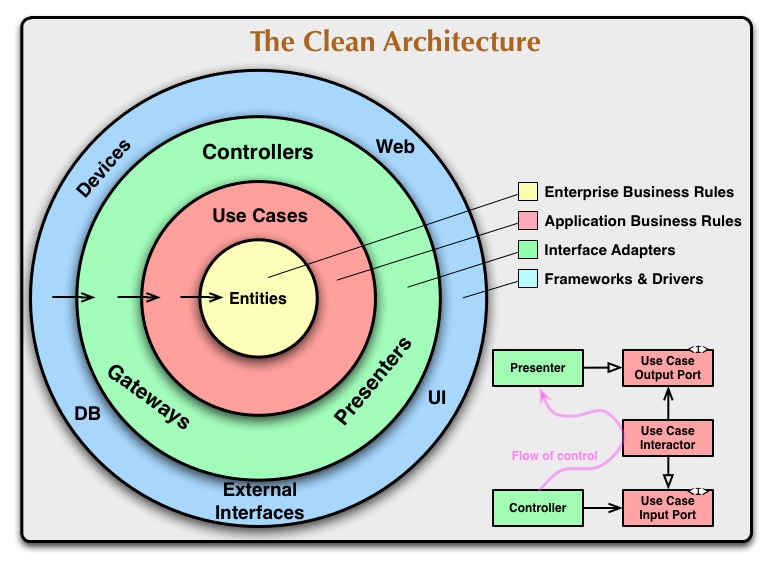
整洁架构通常由四层同心圆组成(层数可根据项目调整):
实体(Entities)
封装系统范围内最核心、最稳定的业务规则。
可以是带有方法的对象,也可以是函数集合。
类似于 DDD 中的”领域模型”,但范围更广,代表整个系统的企业级业务规则。
用例(Use Cases)
封装应用特定的业务逻辑,实现系统的业务用例场景。
每个用例应有独立实现,通常以单一职责类或交互器(Interactor)形式体现。
负责协调实体执行,定义事务边界。
接口适配器(Interface Adapters)
负责在内层(用例与实体)与外层(UI、数据库、外部系统)之间进行数据转换与适配。
MVC 模式中的 Controller、Presenter、View 通常位于此层。
框架和驱动(Frameworks and Drivers)
最外层包含数据库、Web 框架、UI 框架、第三方库等。
这一层主要提供基础设施支持,一般不包含核心业务逻辑。
圆圈之间存在很强的依赖规则:内层永远不依赖外层,所有通信通过接口进行。 这与洋葱架构和六边形架构的依赖方向一致。
除了层之外,Clean Architecture 还提供了一些有关需要实现的类的提示。在架构图的右下角:控制器通过 输入端口(Input Port) 调用用例,用例通过 输出端口(Output Port) 向演示器返回结果,从而实现 UI 与业务逻辑的完全解耦。
总结
整洁架构的核心思想有两点:
- 严格遵守依赖倒置原则。
- 用例驱动(Use Case Driven)。系统围绕业务用例组织代码。
- 框架独立(Framework Independence)。业务逻辑不依赖任何具体技术、框架或数据库。
其他资料
- DCI Architecture Is Visionary
- DCI - Data Context Interaction
- Clean Architecture Is Screaming
- Clean Architecture
- Clean Architecture: Standing on the shoulders of giants
几种架构之间的关系
传统分层架构(Layered)
↓ 改进依赖倒置
六边形架构(Hexagonal)
↓ 抽象为"内核+适配器"
洋葱架构(Onion)
↓ 用例中心化、框架无关
整洁架构(Clean)- 六边形架构解决了”应用如何与外界通信”的问题;
- 洋葱架构解决了”依赖如何反转,核心如何纯净”的问题;
- 整洁架构解决了”系统如何围绕用例组织、框架如何可替换”的问题。
一些不错的总结
摘录自来自:Clean Architecture - Make Your Architecture Scream
Make Your Architecture Scream
Policy and Level
- A computer program is a statement of policy - known inputs and expected outputs
- Most systems have many statements of separate policies
-Business rules, formatting, ETL, etc - Policies that change for the same reasons should be grouped into the same components and vice versa
- Goal is to create acyclic dependency graphs where items with similar policies are at the same level, and dependencies are at the edges
- Direction of dependencies is based on the level of components they connect
- Level is the distance from the inputs and outputs
- The further the policy is from the inputs and outputs, the higher the level
- Direction of dependencies is based on the level of components they connect
- Data flows and source code dependencies do not always point in the same direction
- Dependencies should be decoupled from data flow but coupled to the level
- The importance of this is the fact that the higher level components are now reusable with different input and output sources
- Policies that change for the same reason or at the same time are bounded by the SRP or CCP
- Higher level components typically change less frequently than the lower level components
- Lower level components (those that change frequently) should be plugins to the higher level components
Business Rules
- “Business rules are rules or procedures that make or save the business money” (whether or not they were implemented on a computer)
- Critical business rules - rules critical to the business itself, with or without a computer, for example, calculating interest on a loan.
- Critical business data - critical data that would exist even if there wasn’t an automated system.
- Critical business rules and data are tightly bound and therefore a good space for an object, also called…
Entity
- An object that contains critical business rules and critical business data
- These should be separated from every other concern in the application
- No dependencies on databases, 3rd party dependencies, user interfaces, etc.
- These objects are pure business.
Use Cases
- There are additional business rules that are not “critical” - they define how the automated system should work, but would have no impact on a manual business operation
- Use case - description of how an automated system is to be used
- These indicate how and when a critical business entity should be invoked
- These also indicate the inputs and outputs but not where they come from (database, UI, etc.)
- The how of data gets in and out is irrelevant to the use case
- Entities have no knowledge of how use cases use them
- Follows the Dependency Inversion Principle - higher level components know nothing of the lower level components - the direction is inverted
- Use cases are specific to a single application
- Entities are generalizations
Request and Response Models
- Use cases accept simple request objects for input and return simple response objects for outputs
- They SHOULD NOT depend on any frameworks or other dependencies - simple objects
- Seems like a good idea to return a reference to an entity object - do NOT do this
- Entity objects are higher level components that will change for different reasons so stick to the simple request / response objects
- Coupling them together violates the Common Closer and Single Responsibility Principles
So, Business Rules …
- “Business rules are the reason a software system exists”
- Should remain pristine
- Are independent and reusable
Screaming Architecture
- Upon initial inspection, does your application structure scream Spring, or does it scream Healthcare software?
- Architecture should scream the use cases of the application, not the frameworks or dependencies in the application
- “If your architecture is based on frameworks, then it cannot be based on your use cases”
- A house’s architecture is focused on usability, not whether the house is built of bricks or stucco
- Again, going back to deferring decisions like that until further down the road
- The “web” is a delivery mechanism - it’s your IO layer - much like a mobile app, desktop application or any other
The Theme and Purpose
- The architecture is all about structures that support the use cases of the application
- Architecture is not a framework nor is it supplied by a framework.
- Good architecture allows you to defer and delay decisions as well as make it easy to change your mind about those decisions.
Frameworks are Tools, NOT Ways of Life
- Look at frameworks with skepticism - you don’t want to adopt the be all end all position
- They should NOT dictate your application architecture
- How should you use it?
- How should you protect yourself from it?
Testable Architectures
- If you’ve done your job right, then unit testing should be easy to do as everything was decoupled properly
- Entity objects will be plain old objects with no external dependencies
- Use case objects will coordinate the use of entity objects, again with no infrastructure dependencies
Does your Architecture Scream?
- Your architecture should quickly identify the purpose of your system.
They: “We see some things that look like models - where are the views and controllers?“
You: “Oh, those are details that needn’t concern us at the moment. We’ll decide about them later.“
The Clean Architecture
Uncle Bob’s version of the Clean Architecture diagram:
Our re-imagining of it as a cone:
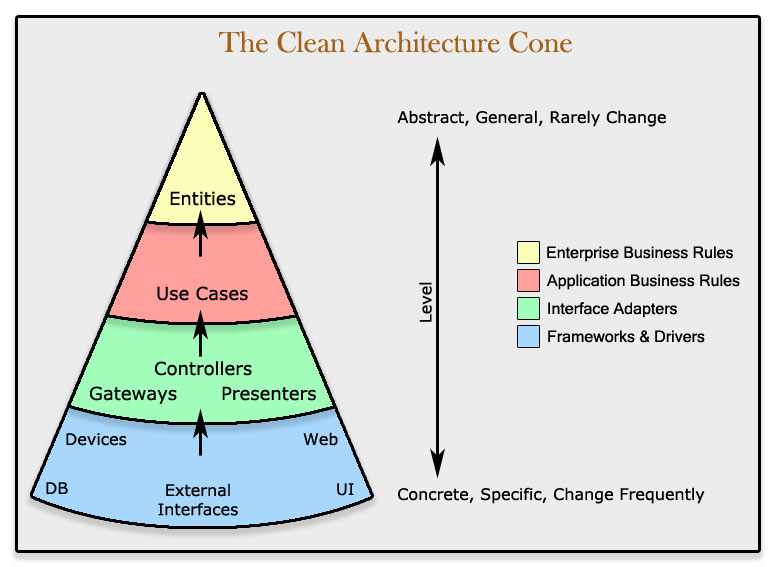
- It’s really about the Separation of Concerns
- Dividing software into layers
- Should be independent of frameworks
- They should be testable
- They should be independent of a UI
- They should be independent of a database
- They should be independent of interfaces to 3rd party dependencies
- The Clean Architecture Diagram
- Innermost: “Enterprise / Critical Business Rules” - Entities
- Next out: “Application business rules” - Use Cases
- Next out: “Interface adapters” - Gateways, Controllers, Presenters
- Outer: “Frameworks and drivers” - Devices, Web, UI, External Interfaces, DB
- Moving inward, the level of abstraction and policy increase
- The innermost circle is the most general/highest level
- Inner circles are policies
- Outer circles are mechanisms
- Inner circles cannot depend on outer circles
- Outer circles cannot influence inner circles
Entities
- Entities should be usable by many applications (critical business rules) and should not be impacted by anything other than a change to the critical business rule itself
- They encapsulate the most general/high-level rules.
Use Cases
- Use cases are application specific business rules
- Changes should not impact the Entities
- Changes should not be impacted by infrastructure such as a database
- The use cases orchestrate the flow of data in/out of the Entities and direct the Entities to use their Critical Business Rules to achieve the use case
Interface Adapters
- Converts data from data layers to use case or entity layers
- Presenters, views and controllers all belong here
- No code further in (use cases, entities) should have any knowledge of the db
Frameworks and Drivers
- These are the glue that hook the various layers up
- The infrastructure details live here
- You’re not writing much of this code, i.e. we use SQL Server, but we don’t write it.
Crossing Boundaries
- Flow of control went from the controller, through the application use case, then to the presenter
- Source code dependencies point in towards the use cases
- Dependency Inversion Principle
- Use case needs to call a presenter - doing so would violate the dependency rule - inner circles cannot call (or know about) outer circles….
- The use case would need to call an interface
- The implementation of that interface would be provided by the interface adapter layer - this is how the dependency is inverted
- This same type of inversion of control is used all throughout the architecture to invert the flow of control
- The implementation of that interface would be provided by the interface adapter layer - this is how the dependency is inverted
- The use case would need to call an interface
- Use case needs to call a presenter - doing so would violate the dependency rule - inner circles cannot call (or know about) outer circles….
Data Crossing Boundaries
- Typically data crossing the boundaries consist of simple data structures
- DO NOT PASS ENTITY OBJECTS OR DATA ROWS!
- This would violate the dependency rules
- Data is passed in the format that is most convenient to the inner circle / layer
- These are isolated, simple data structures
- Meaning our DTOs needed to cross the boundaries should belong in the inner circle, or at least their definition (interface, abstract class)
Conclusion
- Conforming to the rules is not difficult (but requires work) and will set you up to be able to plug and play pieces in the future
其他常见的术语
阻抗失衡(Impedance Mismatch)
Impedance mismatch is a term used in computer science to describe the problem that arises when two systems or components that are supposed to work together have different data models, structures, or interfaces that make communication difficult or inefficient.
In the context of databases, impedance mismatch refers to the discrepancy between the object-oriented programming (OOP) model used in application code and the relational model used in database management systems (DBMS). While OOP models are designed to represent data as objects with properties and methods, relational models represent data as tables with columns and rows.

