一、Page Cache管理问题
01 基础篇(一)| 如何用数据观测Page Cache?
在工作中,你可能遇见过与 Page Cache 有关的场景,比如:
- 服务器的 load 飙高;
- 服务器的 I/O 吞吐飙高;
- 业务响应时延出现大的毛刺;
- 业务平均访问时延明显增加。
这些问题,很可能是由于 Page Cache 管理不到位引起的,因为 Page Cache 管理不当除了会增加系统 I/O 吞吐外,还会引起业务性能抖动。
1.1 什么是 Page Cache?
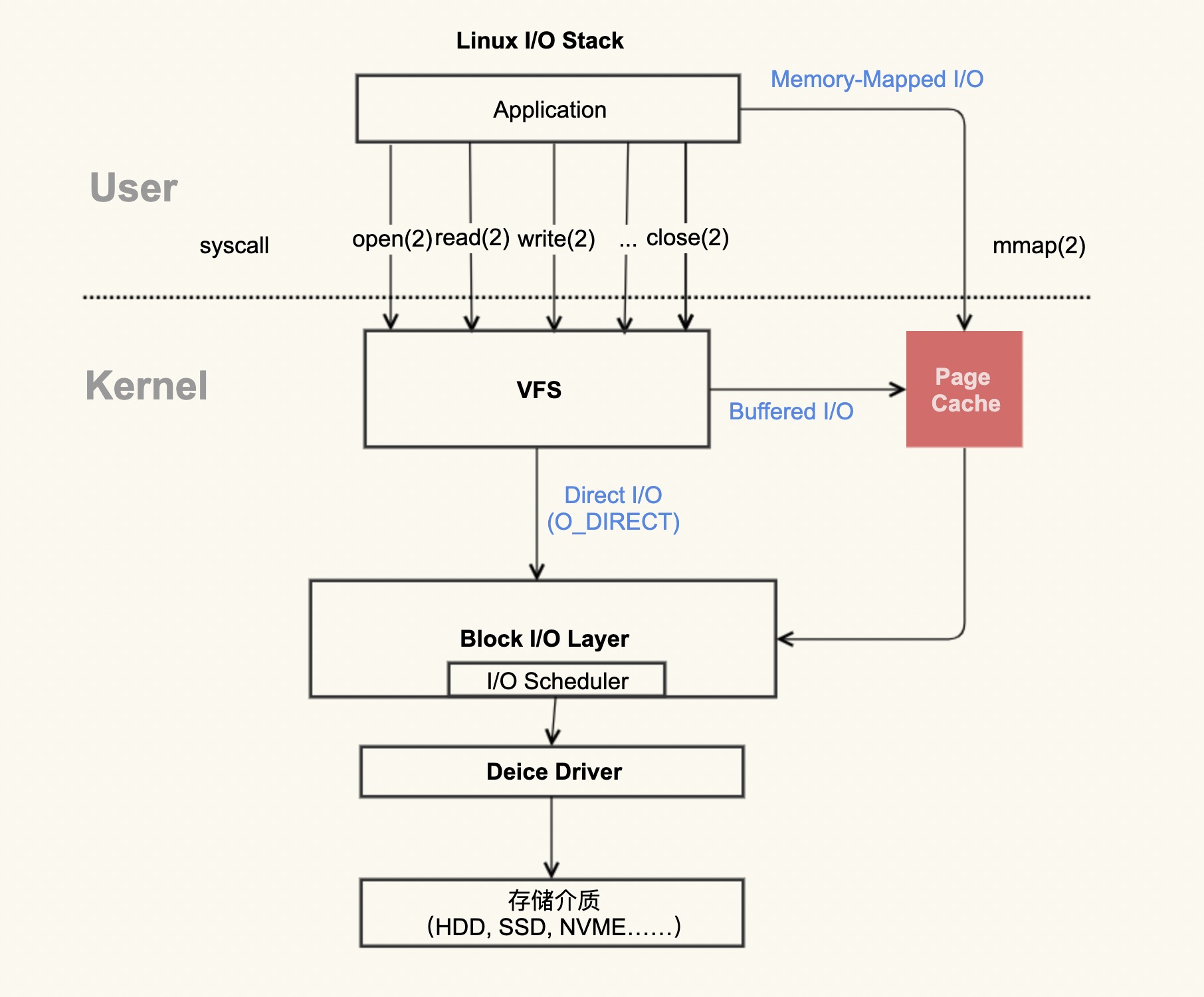
通过这张图片你可以清楚地看到,红色的地方就是 Page Cache,很明显,Page Cache 是内核管理的内存,也就是说,它属于内核不属于用户。
在 Linux 上直接查看 Page Cache 的方式有很多,包括 /proc/meminfo、free 、/proc/vmstat 命令等。
以 /proc/meminfo 命令为例:
如果你想了解 /proc/meminfo 中每一项具体含义的话,可以去看 Kernel Documentation 中 meminfo 这一节,它详细解释了每一项的具体含义,Kernel Documentation 是应用开发者想要了解内核最简单、直接的方式。
$ cat /proc/meminfo
...
Buffers: 1224 kB
Cached: 111472 kB
SwapCached: 36364 kB
Active: 6224232 kB
Inactive: 979432 kB
Active(anon): 6173036 kB
Inactive(anon): 927932 kB
Active(file): 51196 kB
Inactive(file): 51500 kB
...
Shmem: 10000 kB
...
SReclaimable: 43532 kB
...根据上面的数据,你可以简单得出这样的公式(等式两边之和都是 112696 KB):
Buffers + Cached + SwapCached = Active(file) + Inactive(file) + Shmem + SwapCached
那么等式两边的内容就是我们平时说的 Page Cache。请注意你没有看错,两边都有 SwapCached,之所以要把它放在等式里,就是说它也是 Page Cache 的一部分。
等式右边这些项把 Buffers 和 Cached 做了一下细分,分为了 Active(file),Inactive(file) 和 Shmem,因为 Buffers 更加依赖于内核实现,在不同内核版本中它的含义可能有些不一致,而等式右边和应用程序的关系更加直接,所以我们从等式右边来分析。
在 Page Cache 中,Active(file)+Inactive(file) 是 File-backed page(与文件对应的内存页),是你最需要关注的部分。因为你平时用的 mmap() 内存映射方式和 buffered I/O 来消耗的内存就属于这部分,最重要的是,这部分在真实的生产环境上也最容易产生问题,我们在接下来的课程案例篇会重点分析它。
而 SwapCached 是在打开了 Swap 分区后,把 Inactive(anon)+Active(anon) 这两项里的匿名页给交换到磁盘(swap out),然后再读入到内存(swap in)后分配的内存。由于读入到内存后原来的 Swap File 还在,所以 SwapCached 也可以认为是 File-backed page,即属于 Page Cache。 这样做的目的也是为了减少 I/O。
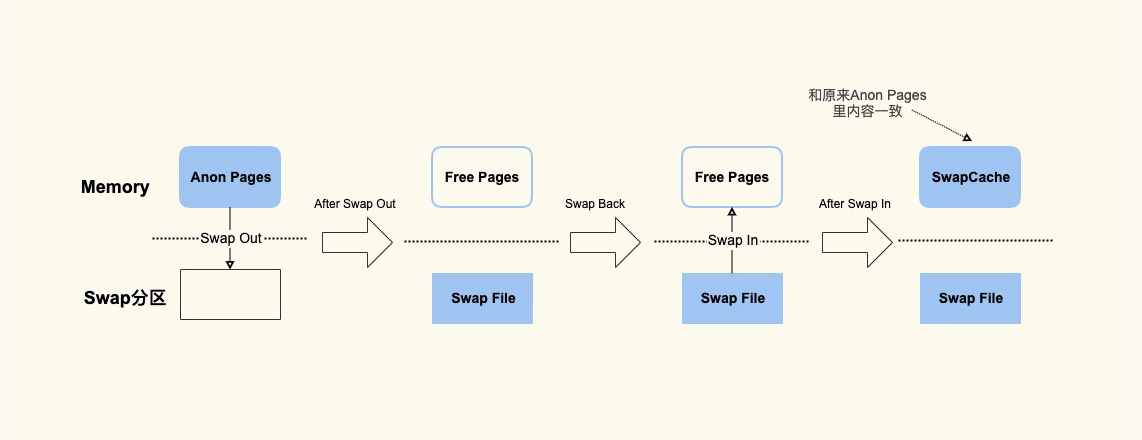
SwapCached 只在 Swap 分区打开的情况下才会有,而我建议你在生产环境中关闭 Swap 分区,因为 Swap 过程产生的 I/O 会很容易引起性能抖动。
除了 SwapCached,Page Cache 中的 Shmem 是指匿名共享映射这种方式分配的内存(free 命令中 shared 这一项),比如 tmpfs(临时文件系统),这部分在真实的生产环境中产生的问题比较少,不是我们今天的重点内容,我们这节课不对它做过多关注,你知道有这回事就可以了。
free 命令也是通过解析 /proc/meminfo 得出这些统计数据的,可以去看下 procfs 里的 free.c 文件。
free 命令中的 buff/cache 究竟是指什么呢?
$ free -k
total used free shared buff/cache available
Mem: 7926580 7277960 492392 10000 156228 430680
Swap: 8224764 380748 7844016通过 procfs 源码里面的 proc/sysinfo.c 这个文件,你可以发现 buff/cache 包括下面这几项:
buff/cache = Buffers + Cached + SReclaimable
通过前面的数据我们也可以验证这个公式: 1224 + 111472 + 43532 的和是 156228。
在做比较的过程中,这些数据是动态变化的,这个等式未必会严格相等,不过你不必怀疑它的正确性。
其中 SReclaimable 是指可以被回收的内核内存,包括 dentry 和 inode 等。
掌握了 Page Cache 具体由哪些部分构成之后,在它引发一些问题时,你就能够知道需要去观察什么。比如说,应用本身消耗内存(RSS)不多的情况下,整个系统的内存使用率还是很高,那不妨去排查下是不是 Shmem(共享内存) 消耗了太多内存导致的。
如果不用内核管理的 Page Cache,那有两种思路来进行处理:
第一种,应用程序维护自己的 Cache 做更加细粒度的控制,比如 MySQL 就是这样做的,你可以参考MySQL Buffer Pool ,它的实现复杂度还是很高的。对于大多数应用而言,实现自己的 Cache 成本还是挺高的,不如内核的 Page Cache 来得简单高效。
第二种,直接使用 Direct I/O 来绕过 Page Cache,不使用 Cache 了,省的去管它了。
1.2 为什么需要 Page Cache?
通过第一张图你其实已经可以直观地看到,标准 I/O 和内存映射会先把数据写入到 Page Cache,这样做会通过减少 I/O 次数来提升读写效率。
我们看一个具体的例子。首先,我们来生成一个 1G 大小的新文件,然后把 Page Cache 清空,确保文件内容不在内存中,以此来比较第一次读文件和第二次读文件耗时的差异。具体的流程如下。
先生成一个 1G 的文件:
dd if=/dev/zero of=dd.out bs=4096 count=256k其次,清空 Page Cache,需要先执行一下 sync 来将脏页(第二节课,我会解释一下什么是脏页)同步到磁盘再去 drop cache。
sync && echo 3 > /proc/sys/vm/drop_caches第一次读取文件的耗时如下:
$ time cat dd.out &> /dev/null
cat dd.out &> /dev/null 0.04s user 1.28s system 14% cpu 9.131 total再次读取文件的耗时如下:
$ time cat dd.out &> /dev/null
cat dd.out &> /dev/null 0.00s user 0.14s system 99% cpu 0.140 total可以看到,第二次读取文件的耗时远小于第一次的耗时,这是因为第一次是从磁盘来读取的内容,磁盘 I/O 是比较耗时的,而第二次读取的时候由于文件内容已经在第一次读取时被读到内存了,所以是直接从内存读取的数据,内存相比磁盘速度是快很多的。这就是 Page Cache 存在的意义:减少 I/O,提升应用的 I/O 速度。
Page Cache 不足之处主要体现在,它对应用程序太过于透明,以至于应用程序很难有好方法来控制它。
02 基础篇(二)| Page Cache是怎样产生和释放的?
2.1 Page Cache 是如何”诞生”的?
Page Cache 的产生有两种不同的方式:
- Buffered I/O(标准 I/O);
- Memory-Mapped I/O(存储映射 I/O)。
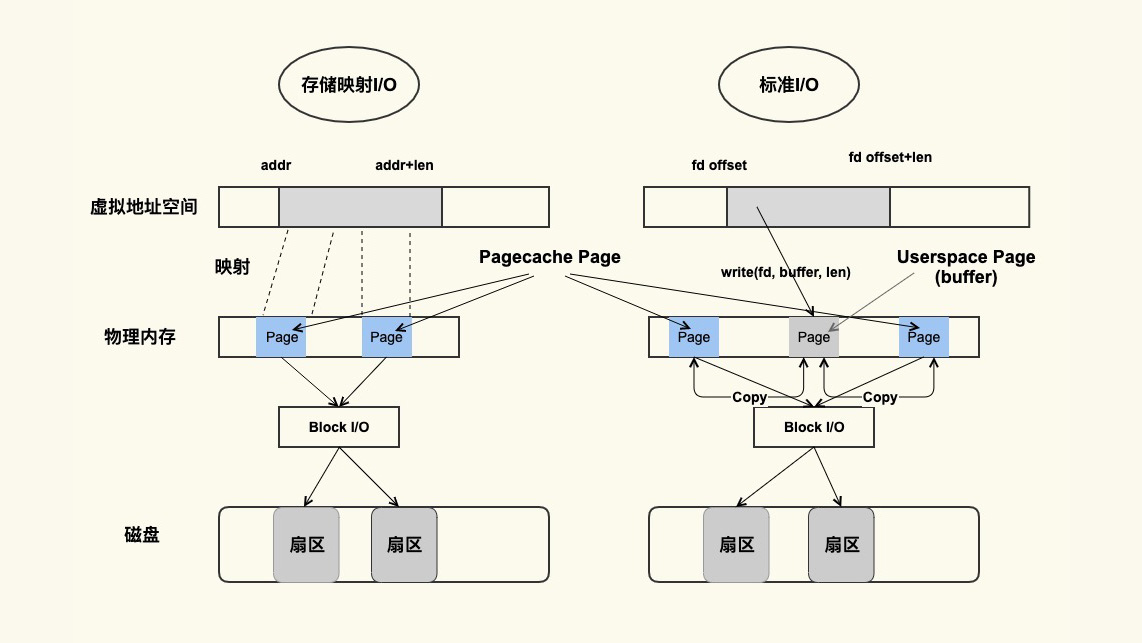
标准 I/O 是写的 (write(2)) 用户缓冲区 (Userpace Page 对应的内存),然后再将用户缓冲区里的数据拷贝到内核缓冲区 (Pagecache Page 对应的内存);如果是读的 (read(2)) 话则是先从内核缓冲区拷贝到用户缓冲区,再从用户缓冲区读数据,也就是 buffer 和文件内容不存在任何映射关系。
对于存储映射 I/O 而言,则是直接将 Pagecache Page 给映射到用户地址空间,用户直接读写 Pagecache Page 中内容。
显然,存储映射 I/O 要比标准 I/O 效率高一些,毕竟少了”用户空间到内核空间互相拷贝”的过程。这也是很多应用开发者发现,为什么使用内存映射 I/O 比标准 I/O 方式性能要好一些的主要原因。
我们来用具体的例子演示一下 Page Cache 是如何”诞生”的,就以其中的标准 I/O 为例,因为这是我们最常使用的一种方式,如下是一个简单的示例脚本 mem.sh :
#!/bin/bash
#这是我们用来解析的文件
MEM_FILE="/proc/meminfo"
#这是在该脚本中将要生成的一个新文件
NEW_FILE="/home/k/dd.write.out"
#我们用来解析的Page Cache的具体项
active=0
inactive=0
pagecache=0
IFS=' '
#从/proc/meminfo中读取File Page Cache的大小
function get_filecache_size() {
items=0
while read line
do
if [[ "$line" =~ "Active:" ]]; then
read -ra ADDR <<< "$line"
active=${ADDR[1]}
let "items=$items+1"
elif [[ "$line" =~ "Inactive:" ]]; then
read -ra ADDR <<< "$line"
inactive=${ADDR[1]}
let "items=$items+1"
fi
if [ $items -eq 2 ]; then
break
fi
done < $MEM_FILE
}
#读取File Page Cache的初始大小
get_filecache_size
let filecache="$active + $inactive"
#写一个新文件,该文件的大小为1048576 KB
dd if=/dev/zero of=$NEW_FILE bs=1024 count=1048576 &> /dev/null
#文件写完后,再次读取File Page Cache的大小
get_filecache_size
#两次的差异可以近似为该新文件内容对应的File Page Cache
#之所以用近似是因为在运行的过程中也可能会有其他Page Cache产生
let size_increased="$active + $inactive - $filecache"
#输出结果
echo "File size 1048576KB(1G), File Cache increased $size_increased KB"最终的测试结果是这样的:
$ sync && echo 3 > /proc/sys/vm/drop_caches
$ ./mem.sh
File size 1048576KB(1G), File Cache increased 1049764 KB通过这个脚本你可以看到,在创建一个文件的过程中,代码中 /proc/meminfo 里的 Active(file) 和 Inactive(file) 这两项会随着文件内容的增加而增加,它们增加的大小跟文件大小是一致的(这里之所以略有不同,是因为系统中还有其他程序在运行)。
用一张图简单描述下这个过程:
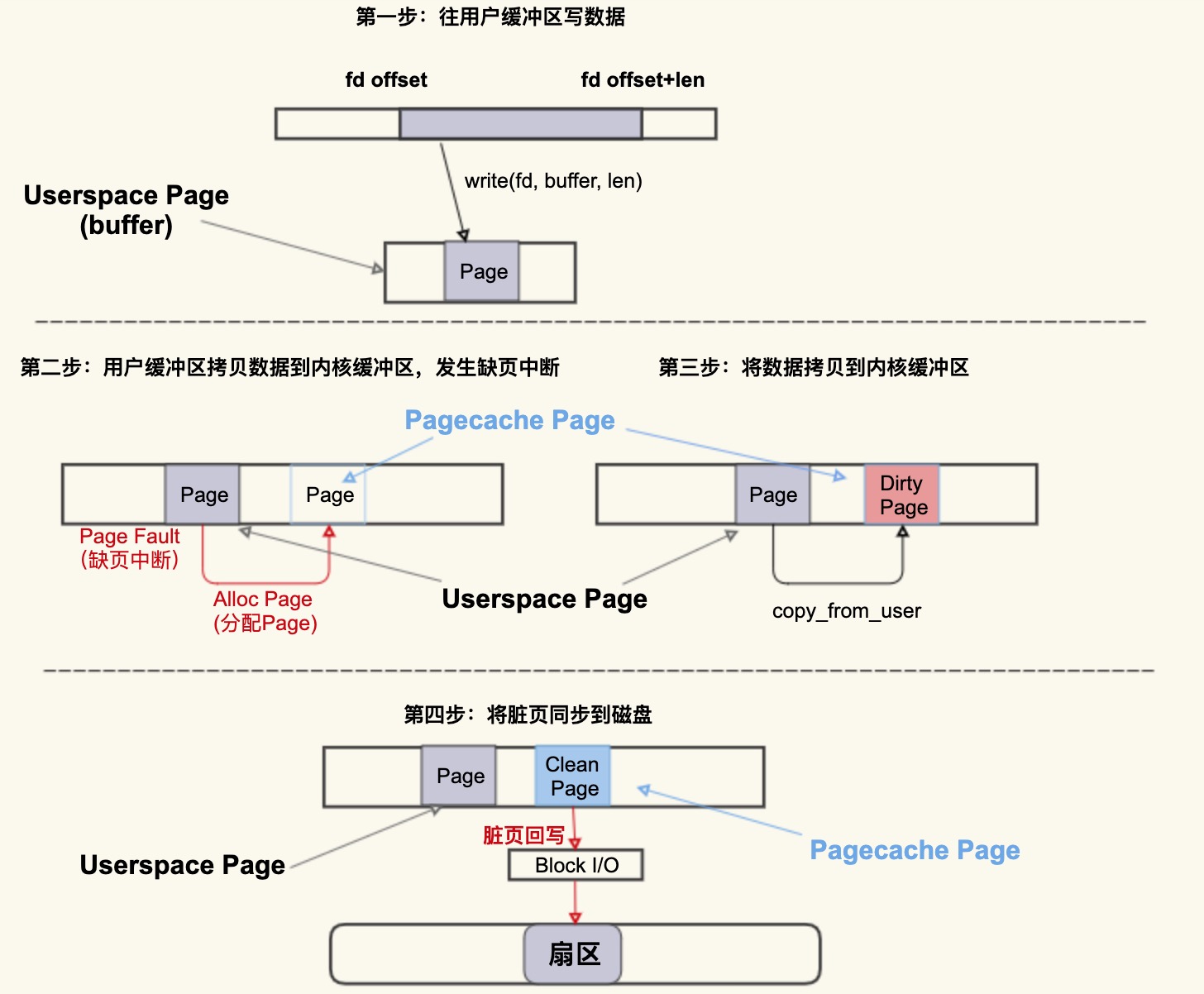
首先往用户缓冲区 buffer(这是 Userspace Page) 写入数据,然后 buffer 中的数据拷贝到内核缓冲区(这是 Pagecache Page),如果内核缓冲区中还没有这个 Page,就会发生 Page Fault 会去分配一个 Page,拷贝结束后该 Pagecache Page 是一个 Dirty Page(脏页),然后该 Dirty Page 中的内容会同步到磁盘,同步到磁盘后,该 Pagecache Page 变为 Clean Page 并且继续存在系统中。
可以将 Alloc Page 理解为 Page Cache 的”诞生”,将 Dirty Page 理解为 Page Cache 的婴幼儿时期(最容易生病的时期),将 Clean Page 理解为 Page Cache 的成年时期(在这个时期就很少会生病了)。
但是请注意,并不是所有人都有童年的,比如孙悟空,一出生就是成人了,Page Cache 也一样,如果是读文件产生的 Page Cache,它的内容跟磁盘内容是一致的,所以它一开始是 Clean Page,除非改写了里面的内容才会变成 Dirty Page(返老还童)。
就像我们为了让婴幼儿健康成长,要悉心照料他 / 她一样,为了提前发现或者预防婴幼儿时期的 Page Cache 发病,我们也需要一些手段来观测它:
$ cat /proc/vmstat | egrep "dirty|writeback"
nr_dirty 40
nr_writeback 2如上所示,nr_dirty 表示当前系统中积压了多少脏页,nr_writeback 则表示有多少脏页正在回写到磁盘中,他们两个的单位都是 Page(4KB)。
通常情况下,小朋友们(Dirty Pages)聚集在一起(脏页积压)不会有什么问题,但在非常时期比如流感期间,就很容易导致聚集的小朋友越多病症就会越严重。与此类似,Dirty Pages 如果积压得过多,在某些情况下也会容易引发问题,至于是哪些情况,又会出现哪些问题,我们会在案例篇中具体讲解。
2.2 Page Cache 是如何”死亡”的?
可以把 Page Cache 的回收行为 (Page Reclaim) 理解为 Page Cache 的”自然死亡”。
我们知道,服务器运行久了后,系统中 free 的内存会越来越少,用 free 命令来查看,大部分都会是 used 内存或者 buff/cache 内存,比如说下面这台生产环境中服务器的内存使用情况:
$ free -g
total used free shared buff/cache available
Mem: 125 41 6 0 79 82
Swap: 0 0 0free 命令中的 buff/cache 中的这些就是”活着”的 Page Cache,那它们什么时候会”死亡”(被回收)呢?我们来看一张图:
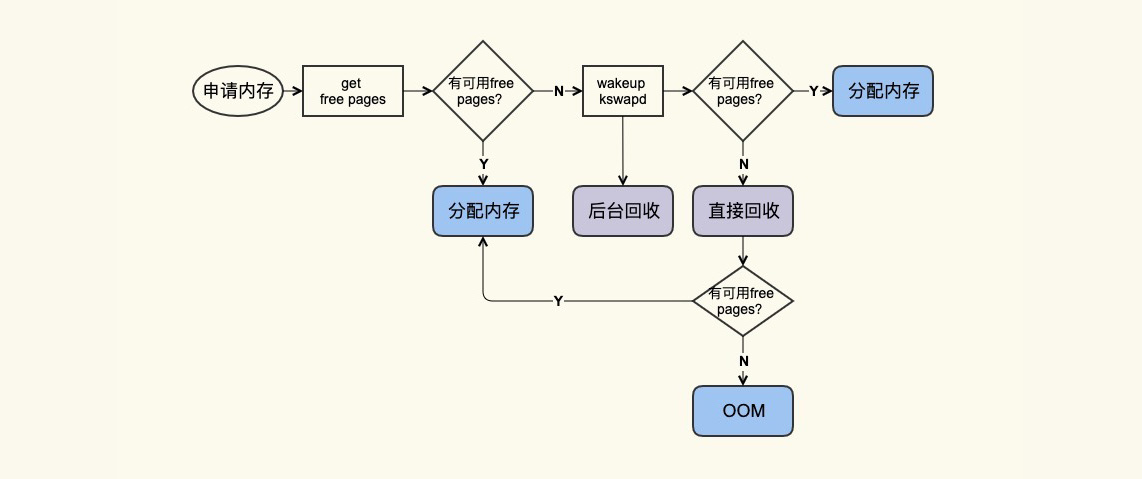
应用在申请内存的时候,即使没有 free 内存,只要还有足够可回收的 Page Cache,就可以通过回收 Page Cache 的方式来申请到内存,回收的方式主要是两种:直接回收和后台回收。
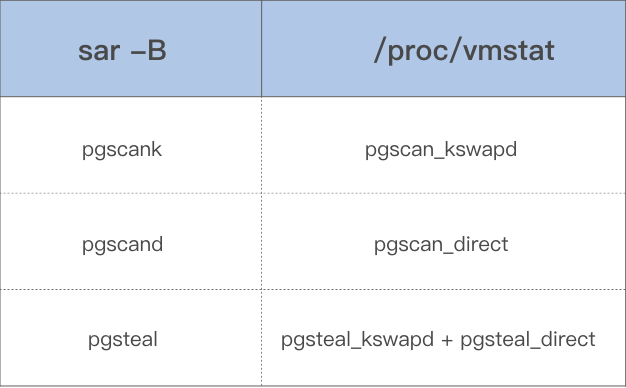
观察 Page Cache 直接回收和后台回收最简单方便的方式是使用 sar:
$ sar -B 1
02:14:01 PM pgpgin/s pgpgout/s fault/s majflt/s pgfree/s pgscank/s pgscand/s pgsteal/s %vmeff
02:14:01 PM 0.14 841.53 106745.40 0.00 41936.13 0.00 0.00 0.00 0.00
02:15:01 PM 5.84 840.97 86713.56 0.00 43612.15 717.81 0.00 717.66 99.98
02:16:01 PM 95.02 816.53 100707.84 0.13 46525.81 3557.90 0.00 3556.14 99.95
02:17:01 PM 10.56 901.38 122726.31 0.27 54936.13 8791.40 0.00 8790.17 99.99
02:18:01 PM 108.14 306.69 96519.75 1.15 67410.50 14315.98 31.48 14319.38 99.80
02:19:01 PM 5.97 489.67 88026.03 0.18 48526.07 1061.53 0.00 1061.42 99.99借助上面这些指标,你可以更加明确地观察内存回收行为,下面是这些指标的具体含义:
- pgscank/s : kswapd(后台回收线程) 每秒扫描的 page 个数。
- pgscand/s: Application 在内存申请过程中每秒直接扫描的 page 个数。
- pgsteal/s: 扫描的 page 中每秒被回收的个数。
- %vmeff: pgsteal/(pgscank+pgscand), 回收效率,越接近 100 说明系统越安全,越接近 0 说明系统内存压力越大。
这几个指标也是通过解析 /proc/vmstat 里面的数据来得出的,对应关系如下:
03 案例篇 | 如何处理Page Cache难以回收产生的load飙高问题?
在平时的工作中,应该会或多或少遇到过这些情形:系统很卡顿,敲命令响应非常慢;应用程序的 RT 变得很高,或者抖动得很厉害。在发生这些问题时,很有可能也伴随着系统 load 飙得很高。
那这是什么原因导致的呢?据我观察,大多是有三种情况:
- 直接内存回收引起的 load 飙高;
- 系统中脏页积压过多引起的 load 飙高;
- 系统 NUMA 策略配置不当引起的 load 飙高。
3.1 直接内存回收引起 load 飙高或者业务时延抖动
直接内存回收是指在进程上下文同步进行内存回收,那么直接内存回收具体是怎么引起 load 飙高的呢?
因为直接内存回收是在进程申请内存的过程中同步进行的回收,而这个回收过程可能会消耗很多时间,进而导致进程的后续行为都被迫等待,这样就会造成很长时间的延迟,以及系统的 CPU 利用率会升高,最终引起 load 飙高。
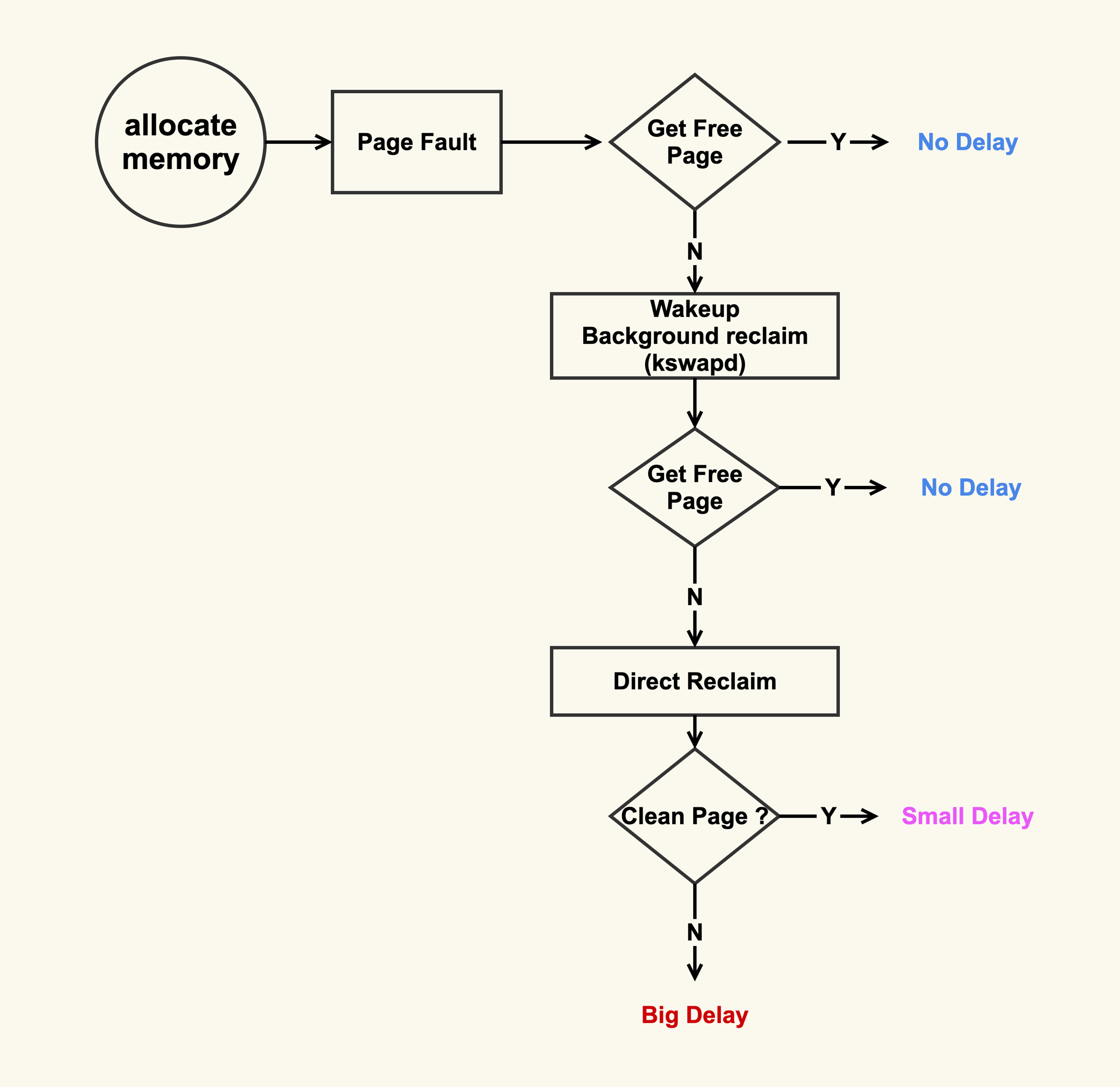
可以看到,在开始内存回收后,首先进行后台异步回收(上图中蓝色标记的地方),这不会引起进程的延迟;如果后台异步回收跟不上进行内存申请的速度,就会开始同步阻塞回收,导致延迟(上图中红色和粉色标记的地方,这就是引起 load 高的地址)。
一个解决方案就是及早地触发后台回收来避免应用程序进行直接内存回收,那具体要怎么做呢?
先来了解一下后台内存回收的原理,如图:
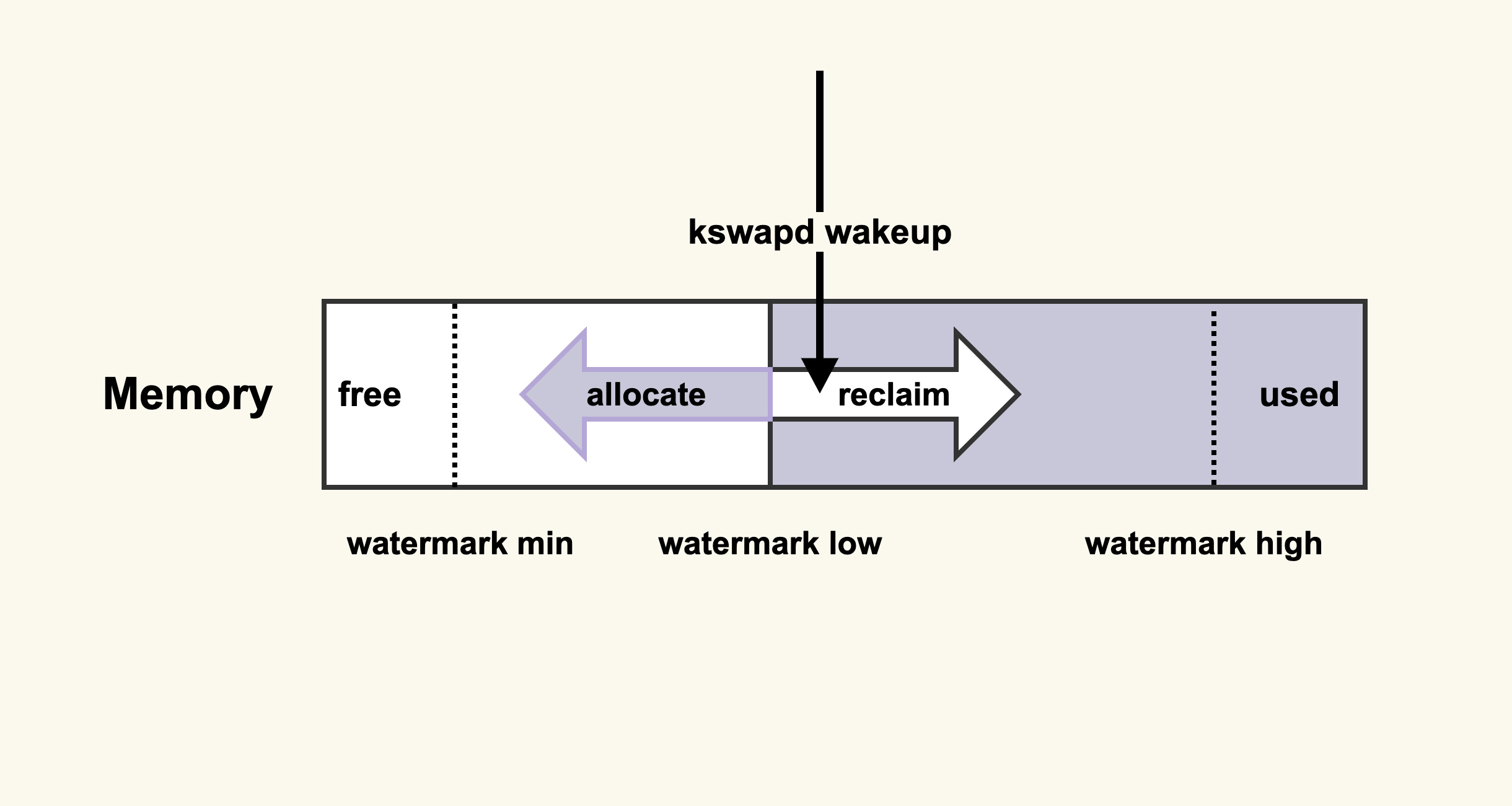
当内存水位低于 watermark low 时,就会唤醒 kswapd 进行后台回收,然后 kswapd 会一直回收到 watermark high。
内存中其他水位的值都是由最低水位 min_free_kbytes 的值计算而来,所以我们可以增大 min_free_kbytes 这个配置选项来及早地触发后台回收。
vm.min_free_kbytes = 4194304对于内存大于等于 128G 的系统而言,将 min_free_kbytes 设置为 4G 比较合理,这是我们在处理很多这种问题时总结出来的一个经验值,既不造成较多的内存浪费,又能避免掉绝大多数的直接内存回收。
该值的设置和总的物理内存并没有一个严格对应的关系,我们在前面也说过,如果配置不当会引起一些副作用,所以在调整该值之前,我的建议是:你可以渐进式地增大该值,比如先调整为 1G,观察 sar -B 中 pgscand 是否还有不为 0 的情况;如果存在不为 0 的情况,继续增加到 2G,再次观察是否还有不为 0 的情况来决定是否增大,以此类推。
在这里你需要注意的是,即使将该值增加得很大,还是可能存在 pgscand 不为 0 的情况(这个略复杂,涉及到内存碎片和连续内存申请,我们在此先不展开,你知道有这么回事儿就可以了)。那么这个时候你要考虑的是,业务是否可以容忍,如果可以容忍那就没有必要继续增加了,也就是说,增大该值并不是完全避免直接内存回收,而是尽量将直接内存回收行为控制在业务可以容忍的范围内。
这个方法可以用在 3.10.0 以后的内核上(对应的操作系统为 CentOS-7 以及之后更新的操作系统)。
当然了,这样做也有一些缺陷:提高了内存水位后,应用程序可以直接使用的内存量就会减少,这在一定程度上浪费了内存。所以在调整这一项之前,你需要先思考一下,应用程序更加关注什么,如果关注延迟那就适当地增大该值,如果关注内存的使用量那就适当地调小该值。
总的来说,通过调整内存水位,在一定程度上保障了应用的内存申请,但是同时也带来了一定的内存浪费,因为系统始终要保障有这么多的 free 内存,这就压缩了 Page Cache 的空间。调整的效果你可以通过 /proc/zoneinfo 来观察:
$ egrep "min|low|high" /proc/zoneinfo
...
min 7019
low 8773
high 10527
...其中 min、low、high 分别对应上图中的三个内存水位。你可以观察一下调整前后 min、low、high 的变化。需要提醒你的是,内存水位是针对每个内存 zone 进行设置的,所以 /proc/zoneinfo 里面会有很多 zone 以及它们的内存水位,你可以不用去关注这些细节。
3.2 系统中脏页过多引起 load 飙高
在前一个案例中我们也提到,直接回收过程中,如果存在较多脏页就可能涉及在回收过程中进行回写,这可能会造成非常大的延迟,而且因为这个过程本身是阻塞式的,所以又可能进一步导致系统中处于 D 状态的进程数增多,最终的表现就是系统的 load 值很高。
我们来看一下这张图,这是一个典型的脏页引起系统 load 值飙高的问题场景:
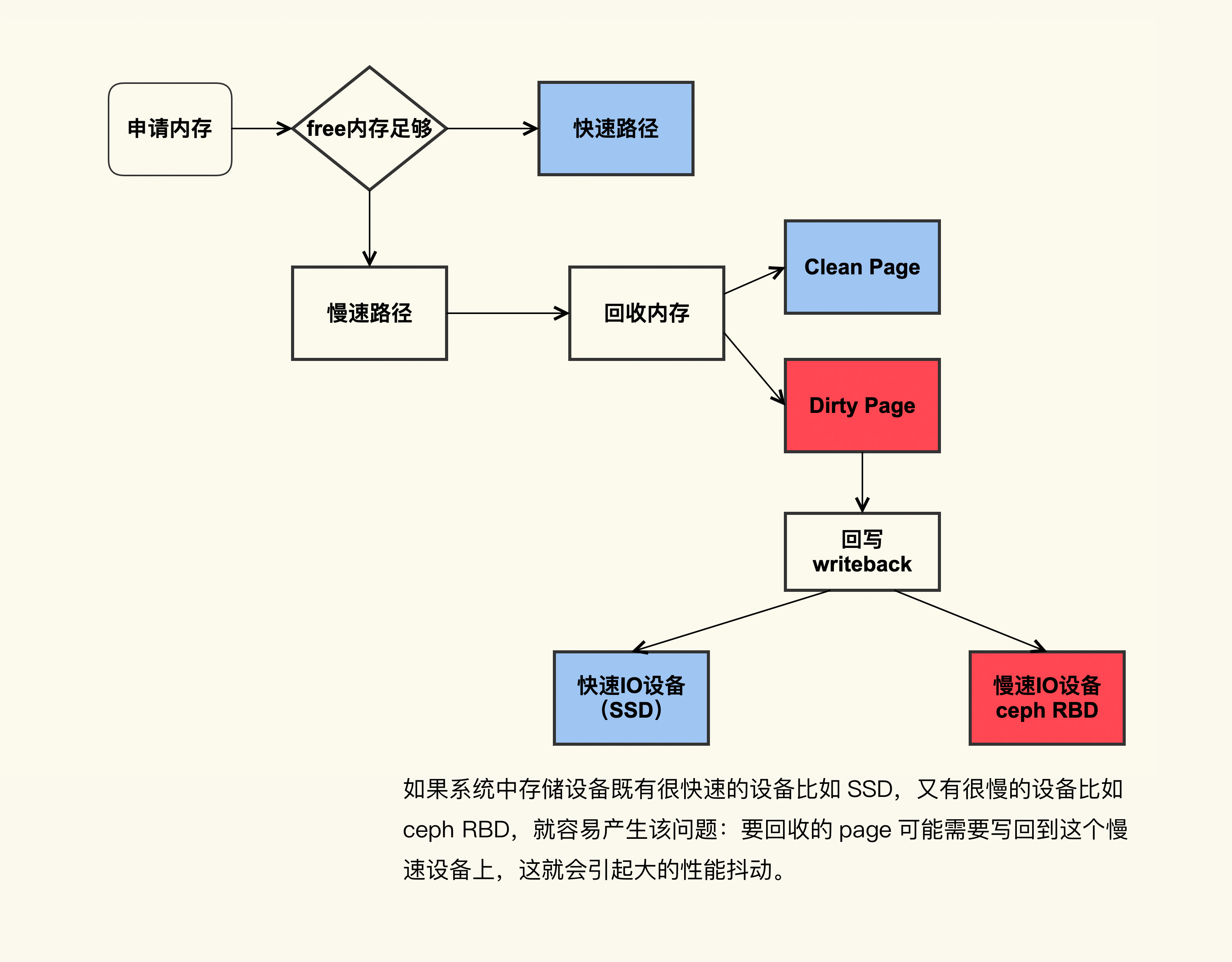
如图所示,如果系统中既有快速 I/O 设备,又有慢速 I/O 设备(比如图中的 ceph RBD 设备,或者其他慢速存储设备比如 HDD),直接内存回收过程中遇到了正在往慢速 I/O 设备回写的 page,就可能导致非常大的延迟。
一个比较省事的解决方案是控制好系统中积压的脏页数据。
首先通过 sar -r 来观察系统中的脏页个数:
$ sar -r 1
07:30:01 PM kbmemfree kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty
09:20:01 PM 5681588 2137312 27.34 0 1807432 193016 2.47 534416 1310876 4
09:30:01 PM 5677564 2141336 27.39 0 1807500 204084 2.61 539192 1310884 20
09:40:01 PM 5679516 2139384 27.36 0 1807508 196696 2.52 536528 1310888 20
09:50:01 PM 5679548 2139352 27.36 0 1807516 196624 2.51 536152 1310892 24kbdirty 就是系统中的脏页大小,它同样也是对 /proc/vmstat 中 nr_dirty 的解析。你可以通过调小如下设置来将系统脏页个数控制在一个合理范围:
vm.dirty_background_bytes = 0
vm.dirty_background_ratio = 10
vm.dirty_bytes = 0
vm.dirty_expire_centisecs = 3000
vm.dirty_ratio = 20调整这些配置项有利有弊,调大这些值会导致脏页的积压,但是同时也可能减少了 I/O 的次数,从而提升单次刷盘的效率;调小这些值可以减少脏页的积压,但是同时也增加了 I/O 的次数,降低了 I/O 的效率。
至于这些值调整大多少比较合适,也是因系统和业务的不同而异,我的建议也是一边调整一边观察,将这些值调整到业务可以容忍的程度就可以了,即在调整后需要观察业务的服务质量 (SLA),要确保 SLA 在可接受范围内。调整的效果你可以通过 /proc/vmstat 来查看:
$ grep "nr_dirty_" /proc/vmstat
nr_dirty_threshold 366998
nr_dirty_background_threshold 1832753.3 系统 NUMA 策略配置不当引起的 load 飙高
比如说,我们在生产环境上就曾经遇到这样的问题:系统中还有一半左右的 free 内存,但还是频频触发 direct reclaim,导致业务抖动得比较厉害。后来经过排查发现是由于设置了 zone_reclaim_mode,这是 NUMA 策略的一种。
设置 zone_reclaim_mode 的目的是为了增加业务的 NUMA 亲和性,但是在实际生产环境中很少会有对 NUMA 特别敏感的业务,这也是为什么内核将该配置从默认配置 1 修改为了默认配置 0: mm: disable zone_reclaim_mode by default ,配置为 0 之后,就避免了在其他 node 有空闲内存时,不去使用这些空闲内存而是去回收当前 node 的 Page Cache,也就是说,通过减少内存回收发生的可能性从而避免它引发的业务延迟。
那么如何来有效地衡量业务延迟问题是否由 zone reclaim 引起的呢?它引起的延迟究竟有多大呢?大致的思路就是利用 linux 的 tracepoint 来做这种量化分析,这是性能开销相对较小的一个方案。
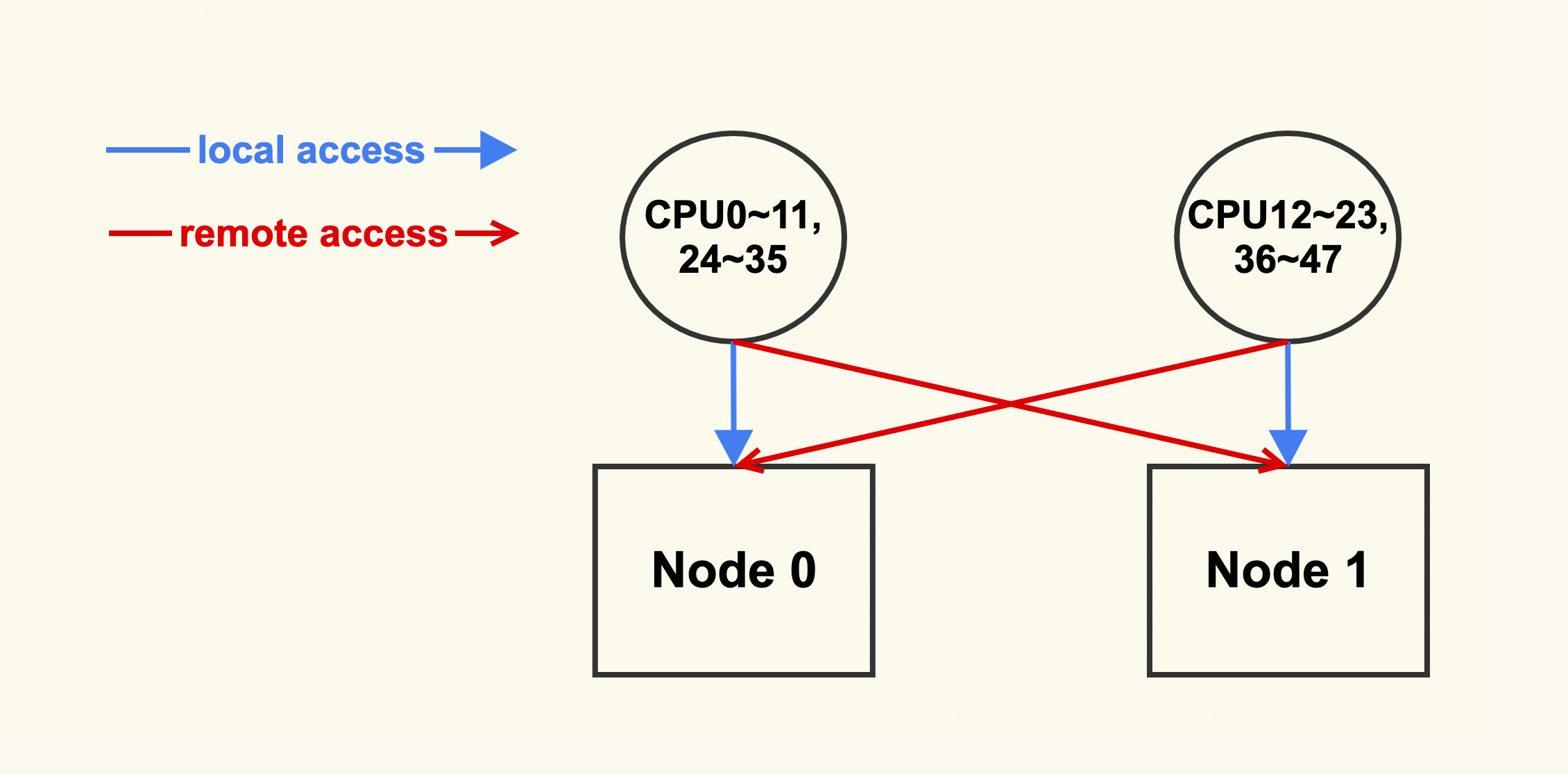
我们可以通过 numactl 来查看服务器的 NUMA 信息,如下是两个 node 的服务器:
$ numactl --hardware
available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 24 25 26 27 28 29 30 31 32 33 34 35
node 0 size: 130950 MB
node 0 free: 108256 MB
node 1 cpus: 12 13 14 15 16 17 18 19 20 21 22 23 36 37 38 39 40 41 42 43 44 45 46 47
node 1 size: 131072 MB
node 1 free: 122995 MB
node distances:
node 0 1
0: 10 21
1: 21 10其中 CPU0~11,24~35 的 local node 为 node 0;而 CPU12~23,36~47 的 local node 为 node 1。如下图所示:
推荐将 zone_reclaim_mode 配置为 0。
vm.zone_reclaim_mode = 0因为相比内存回收的危害而言,NUMA 带来的性能提升几乎可以忽略,所以配置为 0,利远大于弊。
04 案例篇 | 如何处理Page Cache容易回收引起的业务性能问题?
我把大家经常遇到的这类问题做个总结,大致可以分为两方面:
- 误操作而导致 Page Cache 被回收掉,进而导致业务性能下降明显;
- 内核的一些机制导致业务 Page Cache 被回收,从而引起性能下降。
4.1 对 Page Cache 操作不当产生的业务性能下降
我们先从一个相对简单的案例说起,一起分析下误操作导致 Page Cache 被回收掉的情况,它具体是怎样发生的。
我们知道,对于 Page Cache 而言,是可以通过 drop_cache 来清掉的,很多人在看到系统中存在非常多的 Page Cache 时会习惯使用 drop_cache 来清理它们,但是这样做是会有一些负面影响的,比如说这些 Page Cache 被清理掉后可能会引起系统性能下降。为什么?
其实这和 inode 有关,那 inode 是什么意思呢?inode 是内存中对磁盘文件的索引,进程在查找或者读取文件时就是通过 inode 来进行操作的,我们用下面这张图来表示一下这种关系:
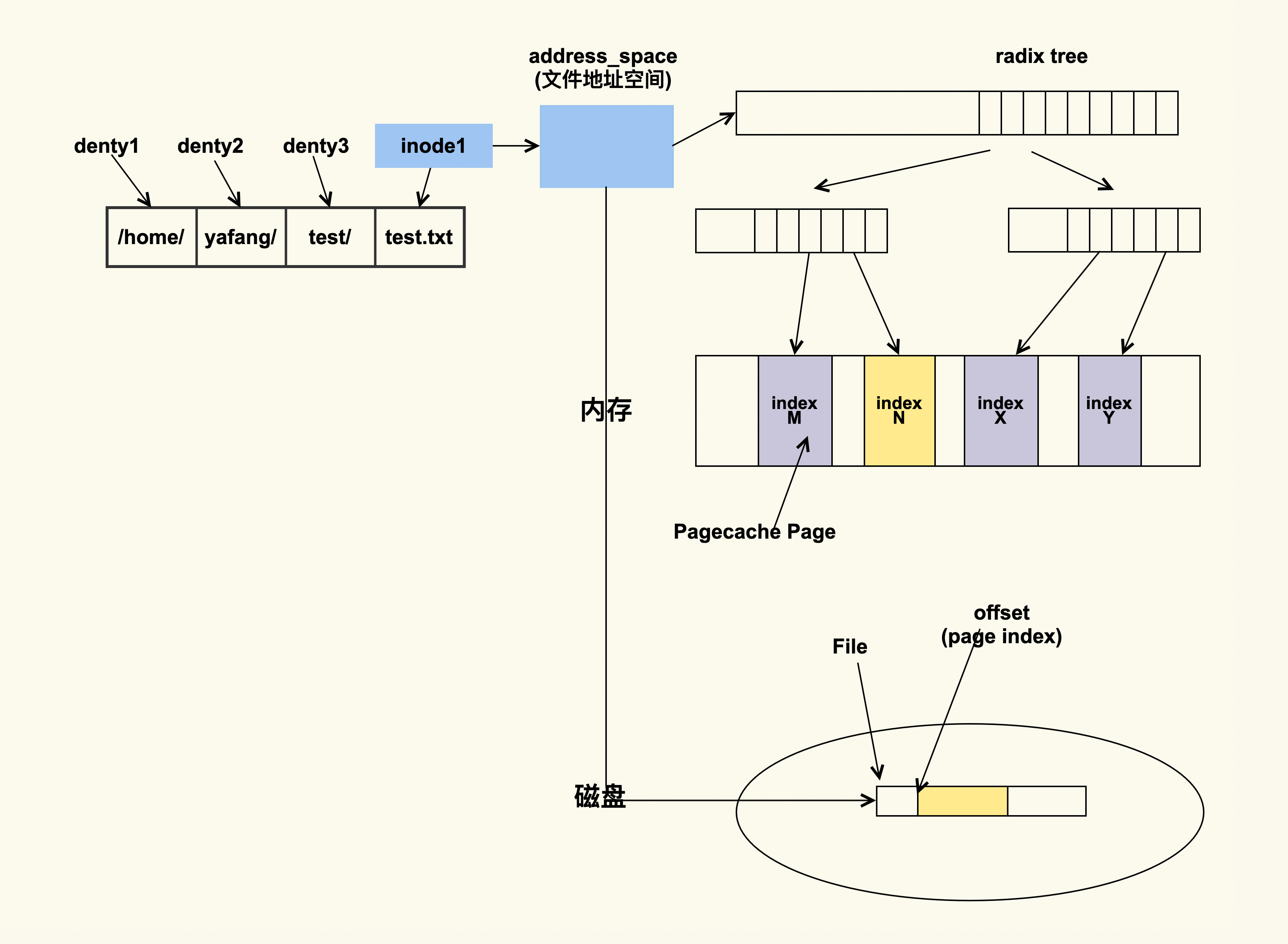
如上图所示,进程会通过 inode 来找到文件的地址空间(address_space),然后结合文件偏移(会转换成 page index)来找具体的 Page。如果该 Page 存在,那就说明文件内容已经被读取到了内存;如果该 Page 不存在那就说明不在内存中,需要到磁盘中去读取。你可以理解为 inode 是 Pagecache Page(页缓存的页)的宿主(host),如果 inode 不存在了,那么 PageCache Page 也就不存在了。
如果你使用过 drop_cache 来释放 inode 的话,应该会清楚它有几个控制选项,我们可以通过写入不同的数值来释放不同类型的 cache(用户数据 Page Cache,内核数据 Slab,或者二者都释放),这些选项你可以去看 Kernel Documentation 中 drop_caches 这一节 的描述。
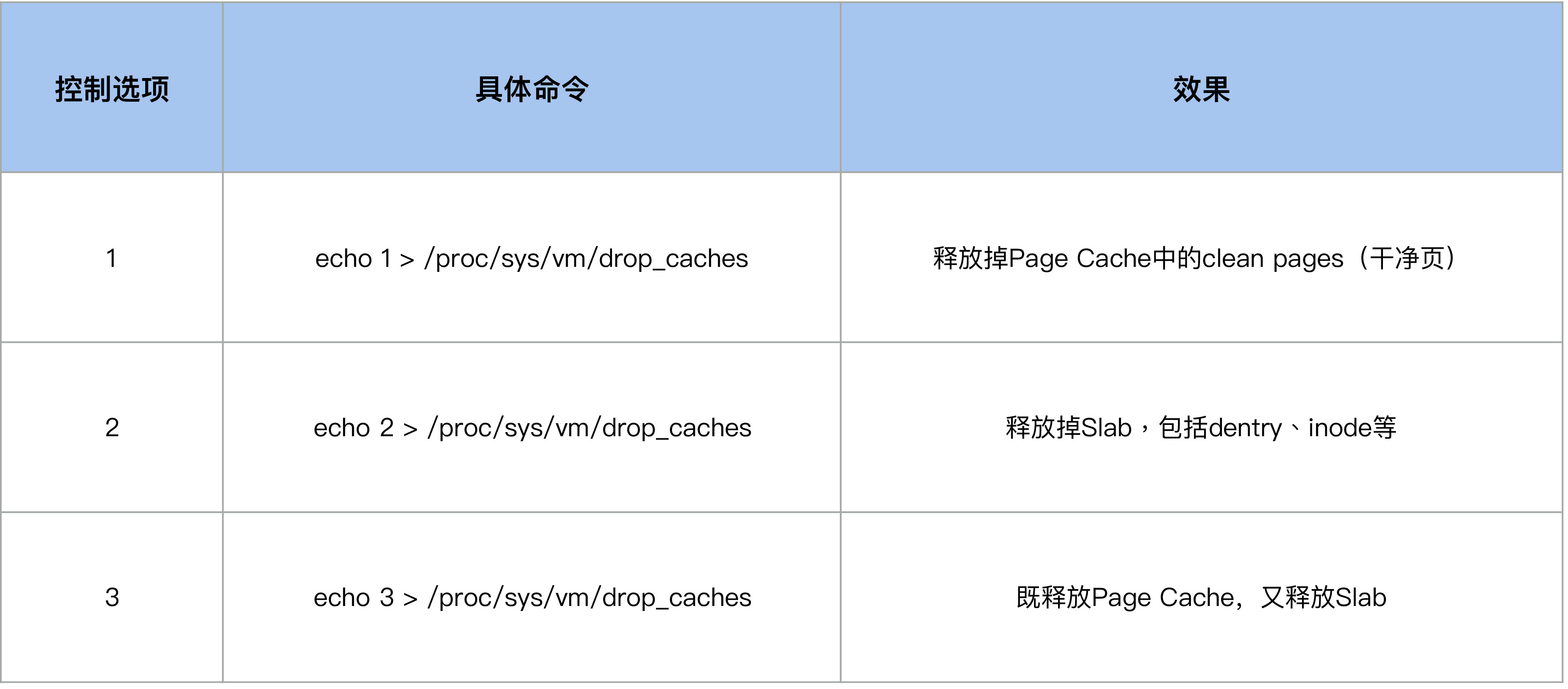
于是这样就引入了一个容易被我们忽略的问题:当我们执行 echo 2 来 drop slab 的时候,它也会把 Page Cache 给 drop 掉,很多运维人员都会忽视掉这一点。
由于 drop_caches 是一种内存事件,内核会在 /proc/vmstat 中来记录这一事件,所以我们可以通过 /proc/vmstat 来判断是否有执行过 drop_caches。
$ grep drop /proc/vmstat
drop_pagecache 3
drop_slab 2如上所示,它们分别意味着 pagecache 被 drop 了 3 次(通过 echo 1 或者 echo 3),slab 被 drop 了 2 次(通过 echo 2 或者 echo 3)。如果这两个值在问题发生前后没有变化,那就可以排除是有人执行了 drop_caches;否则可以认为是因为 drop_caches 引起的 Page Cache 被回收。
4.2 内核机制引起 Page Cache 被回收而产生的业务性能下降
我们在前面已经提到过,在内存紧张的时候会触发内存回收,内存回收会尝试去回收 reclaimable(可以被回收的)内存,这部分内存既包含 Page Cache 又包含 reclaimable kernel memory(比如 slab)。我们可以用下图来简单描述这个过程:
我简单来解释一下这个图。Reclaimer 是指回收者,它可以是内核线程(包括 kswapd)也可以是用户线程。回收的时候,它会依次来扫描 pagecache page 和 slab page 中有哪些可以被回收的,如果有的话就会尝试去回收,如果没有的话就跳过。在扫描可回收 page 的过程中回收者一开始扫描的较少,然后逐渐增加扫描比例直至全部都被扫描完。这就是内存回收的大致过程。
接下来我所要讲述的案例就发生在”reclaim slab”中,我们从前一个案例已然知道,如果 inode 被回收的话,那么它对应的 Page Cache 也都会被回收掉,所以如果业务进程读取的文件对应的 inode 被回收了,那么该文件所有的 Page Cache 都会被释放掉,这也是容易引起性能问题的地方。
可以通过 /proc/vmstat 来观察:
$ grep inodesteal /proc/vmstat
pginodesteal 114341
kswapd_inodesteal 1291853这个行为对应的事件是 inodesteal,就是上面这两个事件,其中 kswapd_inodesteal 是指在 kswapd 回收的过程中,因为回收 inode 而释放的 pagecache page 个数;pginodesteal 是指 kswapd 之外其他线程在回收过程中,因为回收 inode 而释放的 pagecache page 个数。所以在你发现业务的 Page Cache 被释放掉后,你可以通过观察来发现是否因为该事件导致的。
4.3 如何避免 Page Cache 被回收而引起的性能问题?
避免 Page Cache 里相对比较重要的数据被回收掉的思路也是有两种:
- 从应用代码层面来优化;
- 从系统层面来调整。
从应用程序代码层面来解决是相对比较彻底的方案,因为应用更清楚哪些 Page Cache 是重要的,哪些是不重要的,所以就可以明确地来对读写文件过程中产生的 Page Cache 区别对待。比如说,对于重要的数据,可以通过 mlock(2) 来保护它,防止被回收以及被 drop;对于不重要的数据(比如日志),那可以通过 madvise(2) 告诉内核来立即释放这些 Page Cache。
我们来看一个通过 mlock(2) 来保护重要数据防止被回收或者被 drop 的例子:
#include <fcntl.h>
#include <string.h>
#include <sys/mman.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <unistd.h>
#define FILE_NAME "/home/k/test_mmap_data"
#define SIZE (1024 * 1000 * 1000)
int main() {
int fd;
char *p;
int ret;
fd = open(FILE_NAME, O_CREAT | O_RDWR, S_IRUSR | S_IWUSR);
if (fd < 0)
return -1;
/* Set size of this file */
ret = ftruncate(fd, SIZE);
if (ret < 0)
return -1;
/* The current offset is 0, so we don't need to reset the offset. */
/* lseek(fd, 0, SEEK_CUR); */
/* Mmap virtual memory */
p = mmap(0, SIZE, PROT_READ | PROT_WRITE, MAP_FILE | MAP_SHARED, fd, 0);
if (!p)
return -1;
/* Alloc physical memory */
memset(p, 1, SIZE);
/* Lock these memory to prevent from being reclaimed */
mlock(p, SIZE);
/* Wait until we kill it specifically */
while (1) {
sleep(10);
}
/*
* Unmap the memory.
* Actually the kernel will unmap it automatically after the
* process exits, whatever we call munamp() specifically or not.
*/
munmap(p, SIZE);
return 0;
}在这个例子中,我们通过 mlock(2) 来锁住了读 FILE_NAME 这个文件内容对应的 Page Cache。在运行上述程序之后,我们来看下该如何来观察这种行为:确认这些 Page Cache 是否被保护住了,被保护了多大。这同样可以通过 /proc/meminfo 来观察:
$ egrep "Unevictable|Mlocked" /proc/meminfo
Unevictable: 1000000 kB
Mlocked: 1000000 kB然后你可以发现,drop_caches 或者内存回收是回收不了这些内容的,我们的目的也就达到了。
在有些情况下,对应用程序而言,修改源码是件比较麻烦的事,如果可以不修改源码来达到目的那就最好不过了。Linux 内核同样实现了这种不改应用程序的源码而从系统层面调整来保护重要数据的机制,这个机制就是 memory cgroup protection。
它大致的思路是,将需要保护的应用程序使用 memory cgroup 来保护起来,这样该应用程序读写文件过程中所产生的 Page Cache 就会被保护起来不被回收或者最后被回收。memory cgroup protection 大致的原理如下图所示:
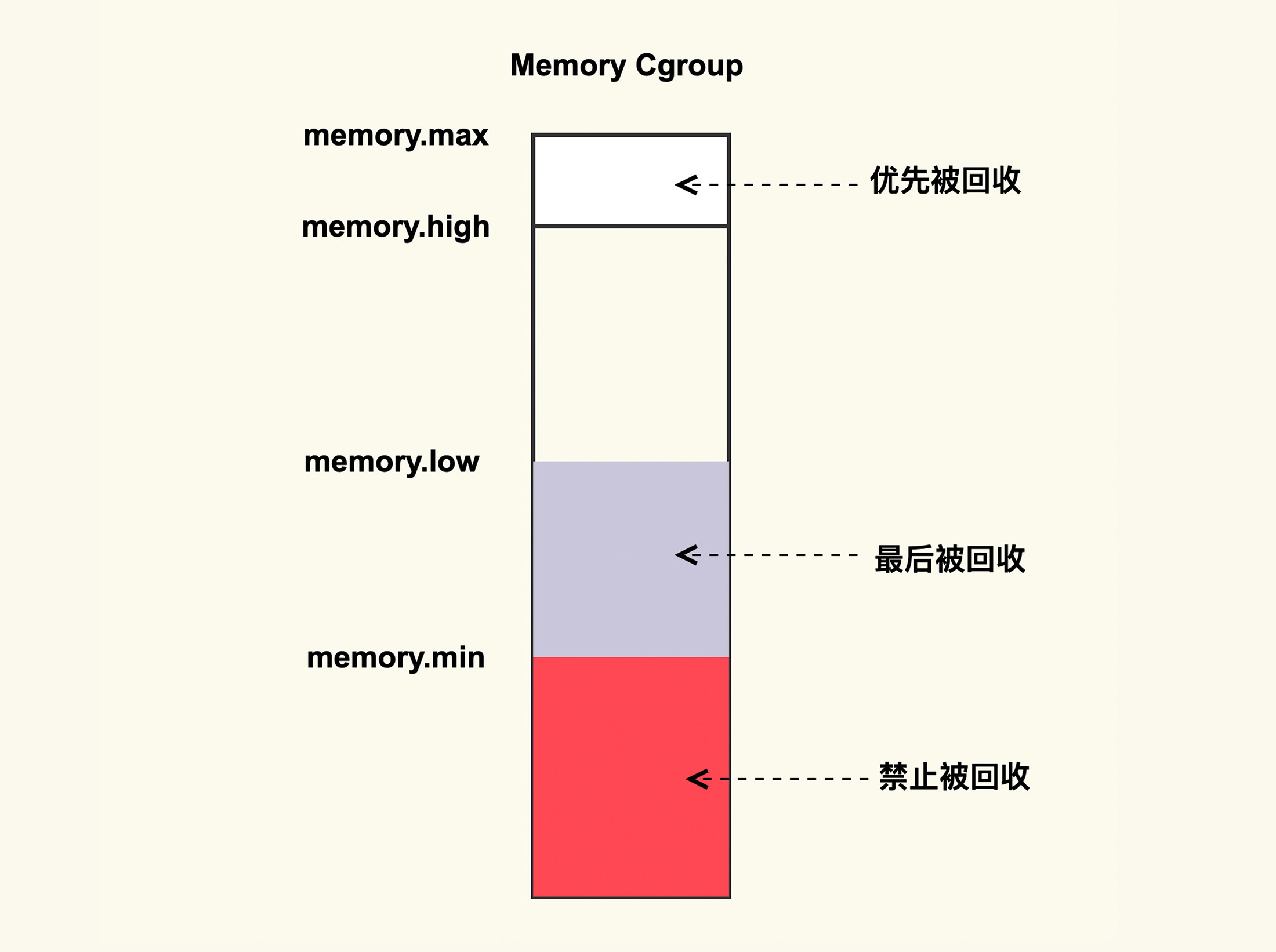
如上图所示,memory cgroup 提供了几个内存水位控制线 memory.{min, low, high, max} 。
memory.max
这是指 memory cgroup 内的进程最多能够分配的内存,如果不设置的话,就默认不做内存大小的限制。
memory.high
如果设置了这一项,当 memory cgroup 内进程的内存使用量超过了该值后就会立即被回收掉,所以这一项的目的是为了尽快的回收掉不活跃的 Page Cache。
memory.low
这一项是用来保护重要数据的,当 memory cgroup 内进程的内存使用量低于了该值后,在内存紧张触发回收后就会先去回收不属于该 memory cgroup 的 Page Cache,等到其他的 Page Cache 都被回收掉后再来回收这些 Page Cache。
memory.min
这一项同样是用来保护重要数据的,只不过与 memoy.low 有所不同的是,当 memory cgroup 内进程的内存使用量低于该值后,即使其他不在该 memory cgroup 内的 Page Cache 都被回收完了也不会去回收这些 Page Cache,可以理解为这是用来保护最高优先级的数据的。
如果你想要保护你的 Page Cache 不被回收,你就可以考虑将你的业务进程放在一个 memory cgroup 中,然后设置 memory.{min,low} 来进行保护;与之相反,如果你想要尽快释放你的 Page Cache,那你可以考虑设置 memory.high 来及时的释放掉不活跃的 Page Cache。
05 分析篇 | 如何判断问题是否由Page Cache产生的?
5.1 Linux 问题的典型分析手段
简单地归纳为下图:
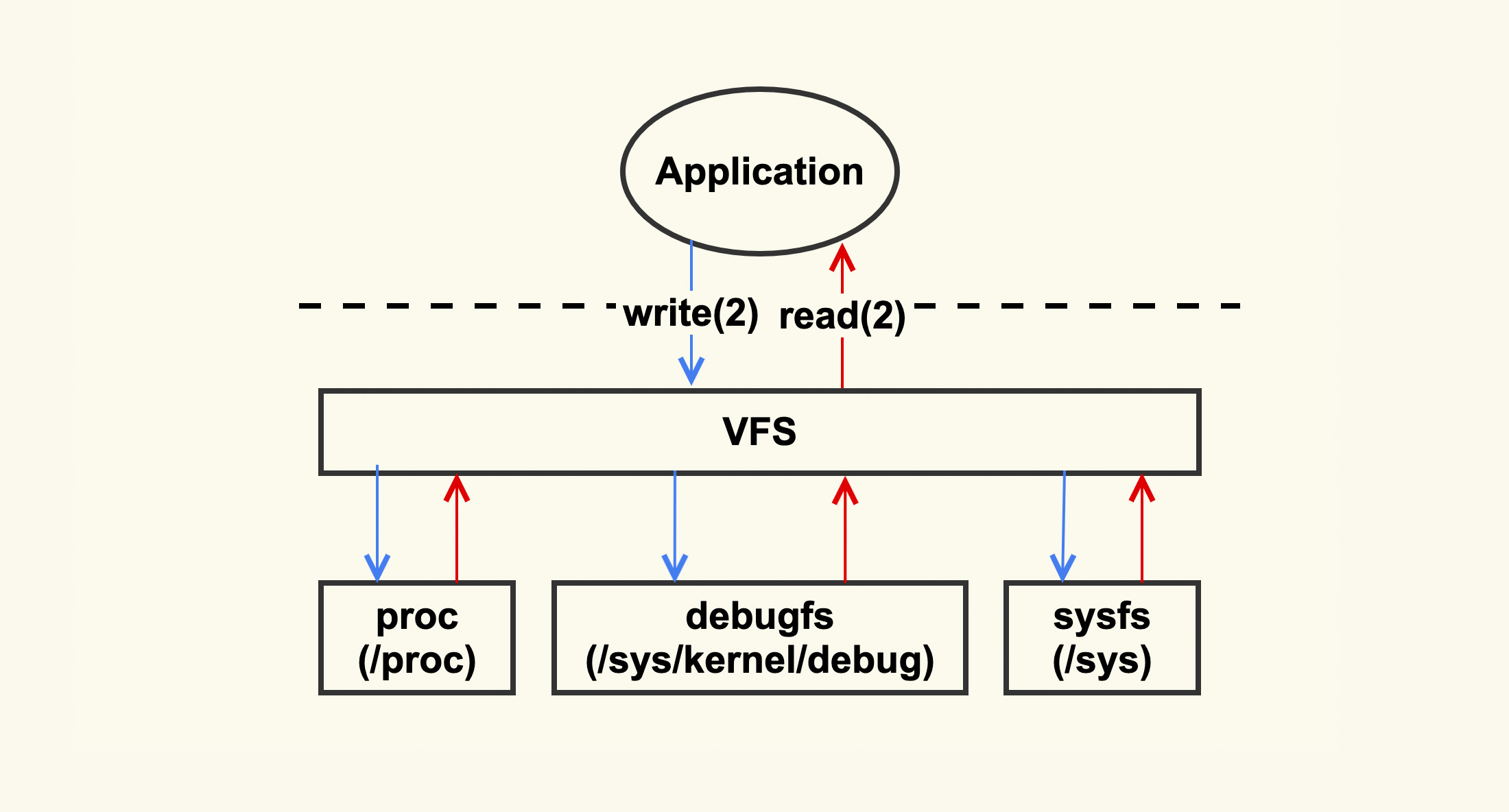
Linux 内核主要是通过 /proc 和 /sys 把系统信息导出给用户,当你不清楚问题发生的原因时,你就可以试着去这几个目录下读取一下系统信息,看看哪些指标异常。比如当你不清楚问题是否由 Page Cache 引起时,你可以试着去把 /proc/vmstat 里面的信息给读取出来,看看哪些指标单位时间内变化较大。如果 pgscan 相关指标变化较大,那就可能是 Page Cache 引起的,因为 pgscan 代表了 Page Cache 的内存回收行为,它变化较大往往意味着系统内存压力很紧张。
/proc 和 /sys 里面的信息可以给我们指出一个问题分析的大致方向,我们可以判断出问题是不是由 Page Cache 引起的,但是如果想要深入地分析问题,知道 Page Cache 是如何引起问题的,我们还需要掌握更加专业的分析手段,专业的分析工具有 ftrace,ebpf,perf 等。
为了让你在遇到问题时更加方便地找到合适的分析工具,我借用 Bredan Gregg 的一张图,并根据自己的经验,把这张图略作了一些改进,帮助你学习该如何使用这些分析工具:
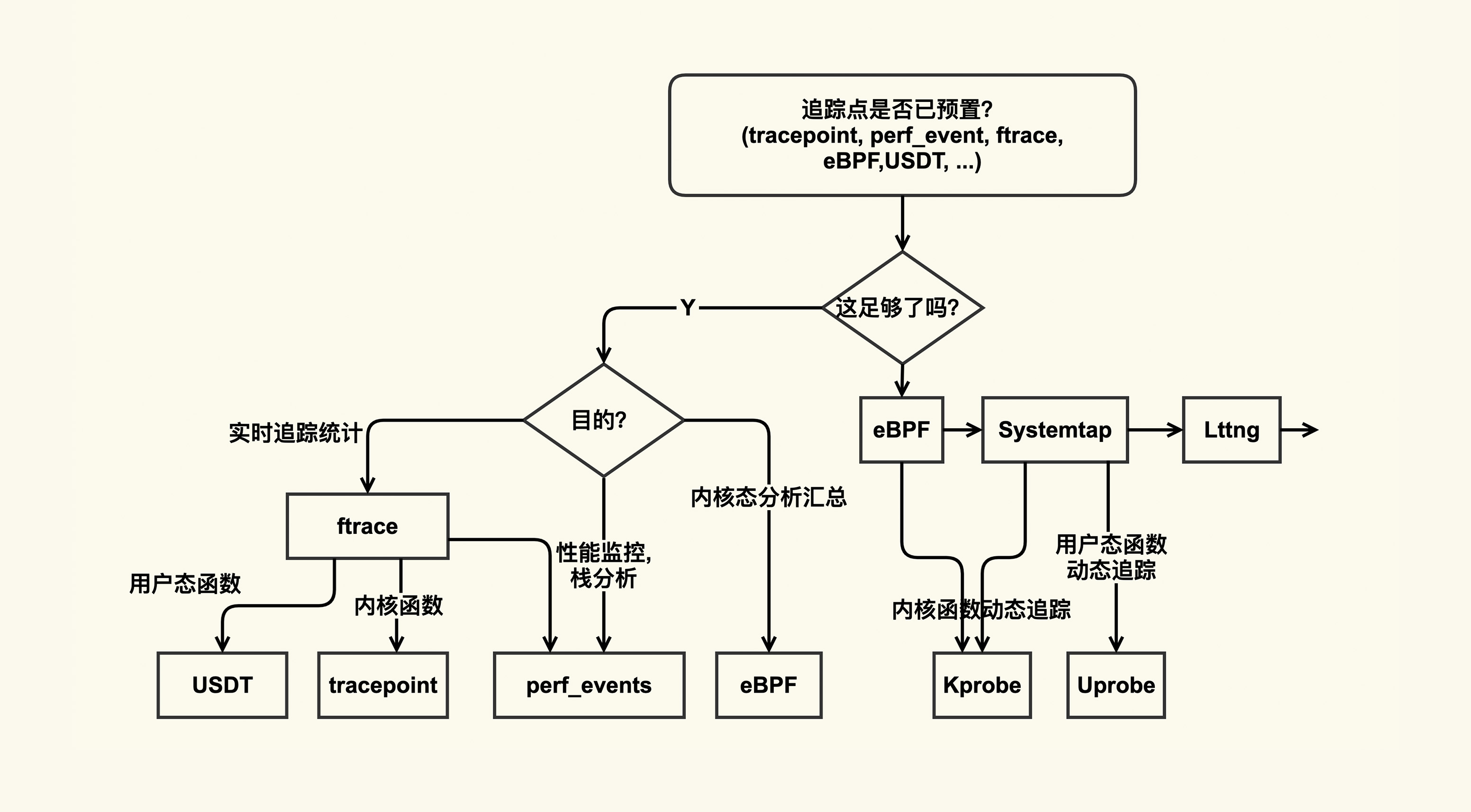
在这张图里,整体上追踪方式分为了静态追踪(预置了追踪点)和动态追踪(需要借助 probe):
- 如果你想要追踪的东西已经有了预置的追踪点,那你直接使用这些预置追踪点就可以了;
- 如果没有预置追踪点,那你就要看看是否可以使用 probe(包括 kprobe 和 uprobe) 来实现。
因为分析工具自身也会对业务造成一些影响(Heisenbug),比如说使用 strace 会阻塞进程的运行,再比如使用 systemtap 也会有加载编译的开销等,所以我们在使用这些工具之前也需要去详细了解下这些工具的副作用,以免引起意料之外的问题。
接下来我们一起分析两个具体问题。
5.2 系统现在 load 很高,是由 Page Cache 引起的吗?
我相信你肯定会遇到过这种场景:业务一直稳定运行着却忽然出现很大的性能抖动,或者系统一直稳定运行着却忽然出现较高的 load 值,那怎么去判断这个问题是不是由 Page Cache 引起的呢?
分析问题的第一步,就是需要对系统的概括做一个了解,对于 Page Cahe 相关的问题,我推荐你使用 sar 来采集 Page Cache 的概况。
我在课程的第 1 讲也提到了对 sar 的一些使用:比如通过 sar -B 来分析分页信息 (Paging statistics), 以及 sar -r 来分析内存使用情况统计 (Memory utilization statistics) 等。在这里,我特别推荐你使用 sar 里面记录的 PSI(Pressure-Stall Information)信息来查看 Page Cache 产生压力情况,尤其是给业务产生的压力,而这些压力最终都会体现在 load 上。不过该功能需要 4.20 以上的内核版本才支持,同时 sar 的版本也要更新到 12.3.3 版本以上。比如 PSI 中表示内存压力的如下输出:
$ cat /proc/pressure/memory
some avg10=45.49 avg60=10.23 avg300=5.41 total=76464318
full avg10=40.87 avg60=9.05 avg300=4.29 total=58141082你需要重点关注 avg10 这一列,它表示最近 10s 内存的平均压力情况,如果它很大(比如大于 40)那 load 飙高大概率是由于内存压力,尤其是 Page Cache 的压力引起的。
明白了概况之后,我们还需要进一步查看究竟是 Page Cache 的什么行为引起的系统压力。
因为 sar 采集的只是一些常用的指标,它并没有覆盖 Page Cache 的所有行为,比如说内存规整(memory compaction)、业务 workingset 等这些容易引起 load 飙高的问题点。在我们想要分析更加具体的原因时,就需要去采集这些指标了。通常在 Page Cache 出问题时,这些指标中的一个或多个都会有异常,这里我给你列出一些常见指标:
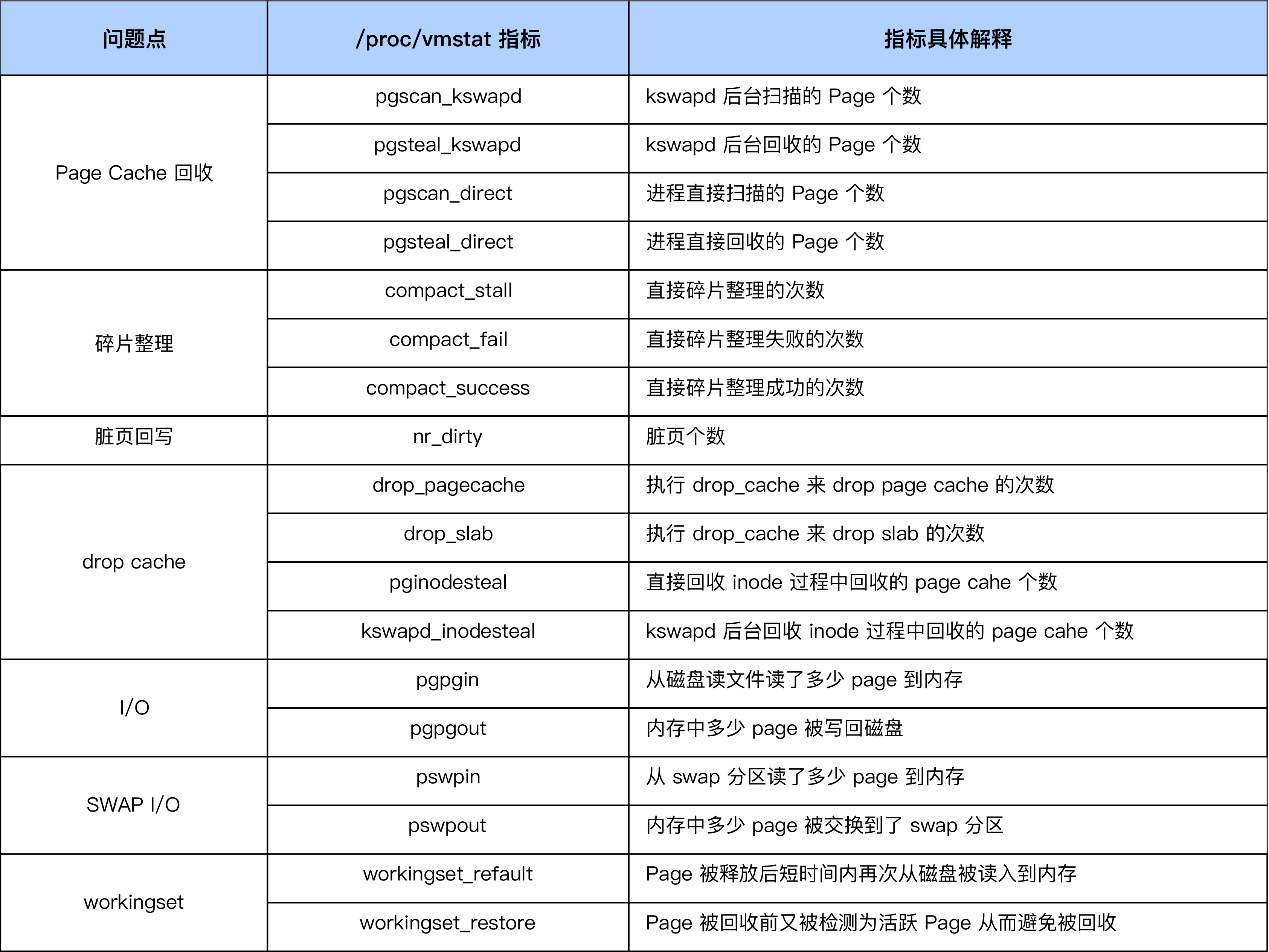
采集完这些指标后,我们就可以分析 Page Cache 异常是由什么引起的了。比如说,当我们发现,单位时间内 compact_fail 变化很大时,那往往意味着系统内存碎片很严重,已经很难申请到连续物理内存了,这时你就需要去调整碎片指数或者手动触发内存规整,来减缓因为内存碎片引起的压力了。
我们在前面的步骤中采集的数据指标,可以帮助我们来定位到问题点究竟是什么,比如下面这些问题点。但是有的时候,我们还需要知道是什么东西在进行连续内存的申请,从而来做更加有针对性的调整,这就需要进行进一步的观察了。我们可以利用内核预置的相关 tracepoint 来做更加细致的分析。
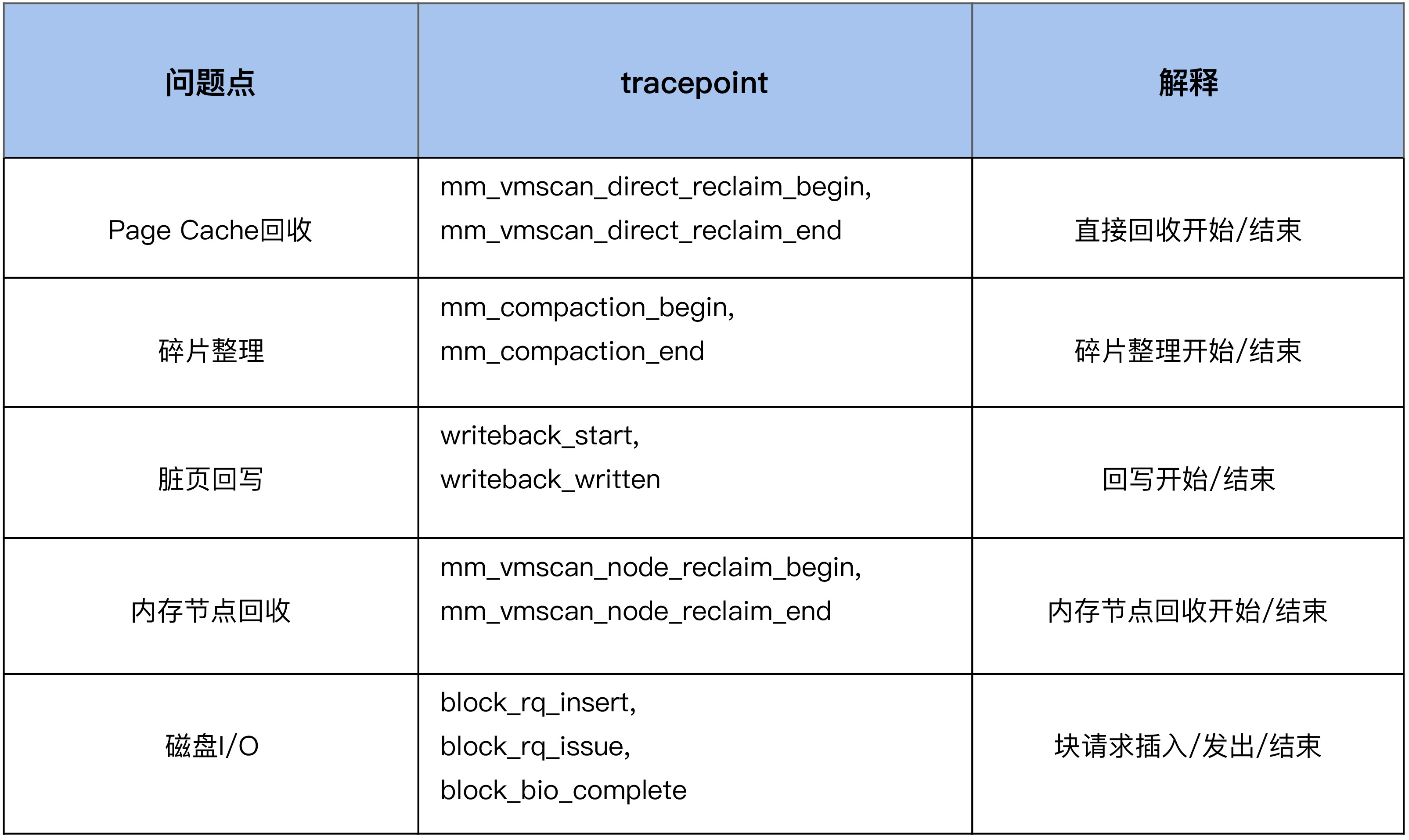
我们继续以内存规整 (memory compaction) 为例,来看下如何利用 tracepoint 来对它进行观察:
#首先来使能compcation相关的一些tracepoing
$ echo 1 >
/sys/kernel/debug/tracing/events/compaction/mm_compaction_begin/enable
$ echo 1 >
/sys/kernel/debug/tracing/events/compaction/mm_compaction_end/enable
#然后来读取信息,当compaction事件触发后就会有信息输出
$ cat /sys/kernel/debug/tracing/trace_pipe
<...>-49355 [037] .... 1578020.975159: mm_compaction_begin:
zone_start=0x2080000 migrate_pfn=0x2080000 free_pfn=0x3fe5800
zone_end=0x4080000, mode=async
<...>-49355 [037] .N.. 1578020.992136: mm_compaction_end:
zone_start=0x2080000 migrate_pfn=0x208f420 free_pfn=0x3f4b720
zone_end=0x4080000, mode=async status=contended从这个例子中的信息里,我们可以看到是 49355 这个进程触发了 compaction,begin 和 end 这两个 tracepoint 触发的时间戳相减,就可以得到 compaction 给业务带来的延迟,我们可以计算出这一次的延迟为 17ms。
5.3 系统 load 值在昨天飙得很高,是由 Page Cache 引起的吗?
有时候,我们没有办法及时地去搜集现场信息,比如问题发生在深夜时,我们没有来得及去采集现场信息,这个时候就只能查看历史记录了。
曾经有一个业务反馈说 RT 抖动得比较明显,让我帮他们分析一下抖动的原因,我把业务 RT 抖动的时间和 sar -B 里的 pgscand 不为 0 的时刻相比较后发现,二者在很多时候都是吻合的。于是,我推断业务抖动跟 Page Cache 回收存在一些关系,然后我让业务方调 vm.min_free_kbytes 来验证效果,业务方将该值从初始值 90112 调整为 4G 后效果立竿见影,就几乎没有抖动了。
如果你的 sysstat 版本较新并且内核版本较高,那你也可以观察 PSI 记录的日志信息是否跟业务抖动相吻合。根据 sar 的这些信息我们可以推断出故障是否跟 Page Cache 相关。
二、内存泄漏问题
06 基础篇 | 进程的哪些内存类型容易引起内存泄漏?
6.1 进程的地址空间
我们用一张图,来表示进程的地址空间。图的左侧是说进程可以通过什么方式来更改进程虚拟地址空间,而中间就是进程虚拟地址空间是如何划分的,右侧则是进程的虚拟地址空间所对应的物理内存或者说物理地址空间。
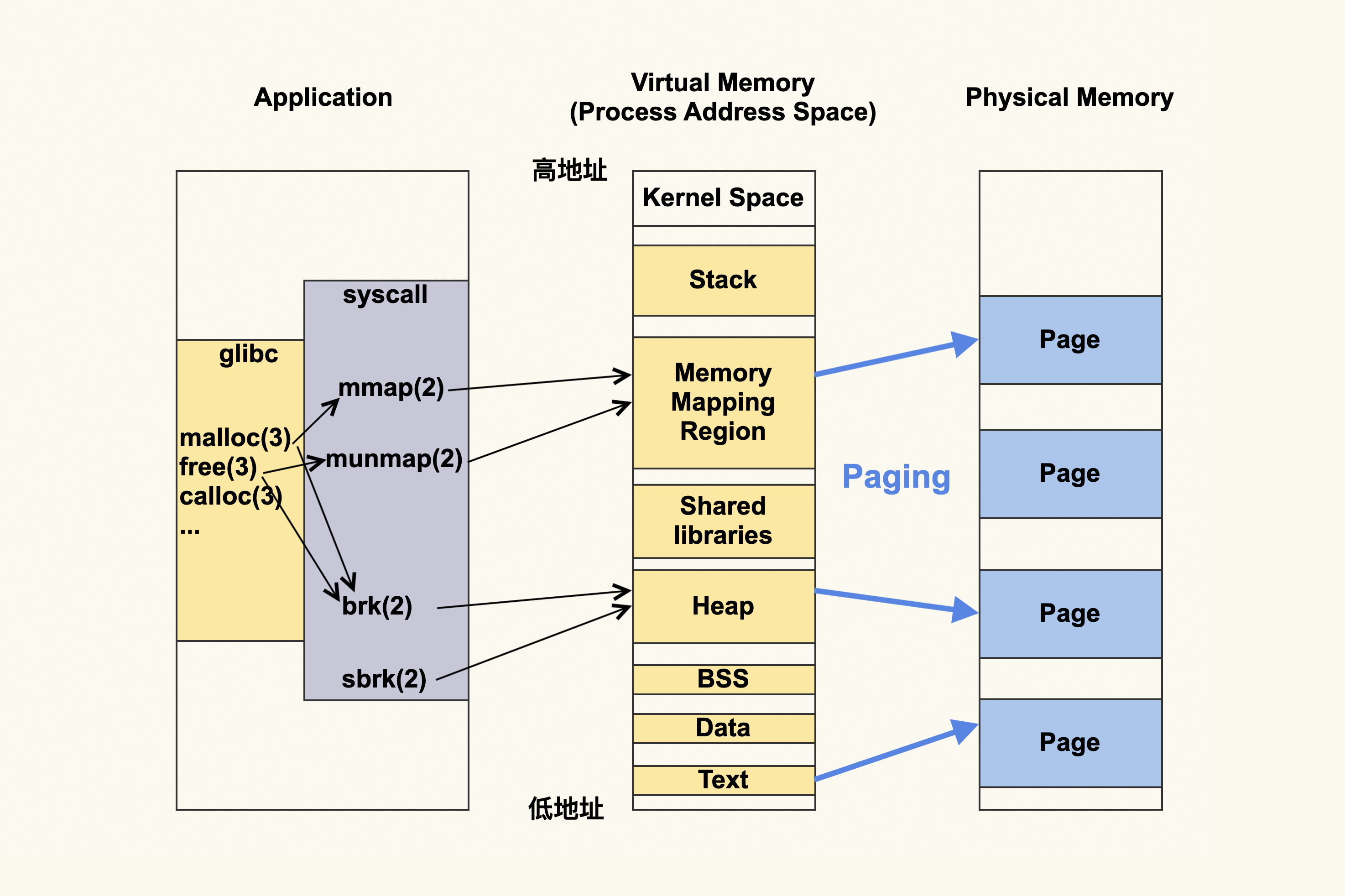
应用程序首先会调用内存申请释放相关的函数,比如 glibc 提供的 malloc(3)、 free(3)、calloc(3) 等;或者是直接使用系统调用 mmap(2)、munmap(2)、 brk(2)、sbrk(2) 等。
如果使用的是库函数,这些库函数其实最终也是对系统调用的封装,所以可以理解为是应用程序动态申请释放内存,最终是要经过 mmap(2)、munmap(2)、brk(2)、sbrk(2) 等这些系统调用。当然从库函数到系统调用,这其中还涉及到这些库本身进行的一些内存层面的优化,比如说,malloc(3) 既可能调用 mmap(2),又可能会调用 brk(2)。
然后这些内存申请和释放相关的系统调用会修改进程的地址空间 (address space),其中 brk(2) 和 sbrk(2) 修改的是 heap(堆),而 mmap(2) 和 munmap(2) 修改的是 Memory Mapping Region(内存映射区)。
请注意这些针对的都是虚拟地址,应用程序都是跟虚拟地址打交道,不会直接跟物理地址打交道。而虚拟地址最终都要转换为物理地址,由于 Linux 都是使用 Page(页)来进行管理的,所以这个过程叫 Paging(分页)。
我们用一张表格来简单汇总下这些不同的申请方式所对应的不同内存类型,这张表格也包含了我们在课程上一个模块讲的 Page Cache,所以你可以把它理解为是进程申请内存的类型大汇总:

进程运行所需要的内存类型有很多种,总的来说,这些内存类型可以从是不是文件映射,以及是不是私有内存这两个不同的维度来做区分,也就是可以划分为上面所列的四类内存。
私有匿名内存。
进程的堆、栈,以及 mmap(MAP_ANON | MAP_PRIVATE) 这种方式申请的内存都属于这种类型的内存。其中栈是由操作系统来进行管理的,应用程序无需关注它的申请和释放;堆和私有匿名映射则是由应用程序(程序员)来进行管理的,它们的申请和释放都是由应用程序来负责的,所以它们是容易产生内存泄漏的地方。
共享匿名内存。
进程通过 mmap(MAP_ANON | MAP_SHARED) 这种方式来申请的内存,比如说 tmpfs 和 shm。这个类型的内存也是由应用程序来进行管理的,所以也可能会发生内存泄漏。
私有文件映射。
进程通过 mmap(MAP_FILE | MAP_PRIVATE) 这种方式来申请的内存,比如进程将共享库(Shared libraries)和可执行文件的代码段(Text Segment)映射到自己的地址空间就是通过这种方式。对于共享库和可执行文件的代码段的映射,这是通过操作系统来进行管理的,应用程序无需关注它们的申请和释放。而应用程序直接通过 mmap(MAP_FILE | MAP_PRIVATE) 来申请的内存则是需要应用程序自己来进行管理,这也是可能会发生内存泄漏的地方。
共享文件映射。
进程通过 mmap(MAP_FILE | MAP_SHARED) 这种方式来申请的内存,我们在上一个模块课程中讲到的 File Page Cache 就属于这类内存。这部分内存也需要应用程序来申请和释放,所以也存在内存泄漏的可能性。
进程虚拟地址空间是通过 Paging(分页)这种方式来映射为物理内存的,进程调用 malloc() 或者 mmap() 来申请的内存都是虚拟内存,只有往这些内存中写入数据后(比如通过 memset),才会真正地分配物理内存 。
如果进程只是调用 malloc() 或者 mmap() 而不去写这些地址,即不去给它分配物理内存,是不是就不用担心内存泄漏了?
答案是这依然需要关注内存泄露,因为这可能导致进程虚拟地址空间耗尽,即虚拟地址空间同样存在内存泄露的问题。
接下来,我们继续用一张图片来细化一下分页的过程。
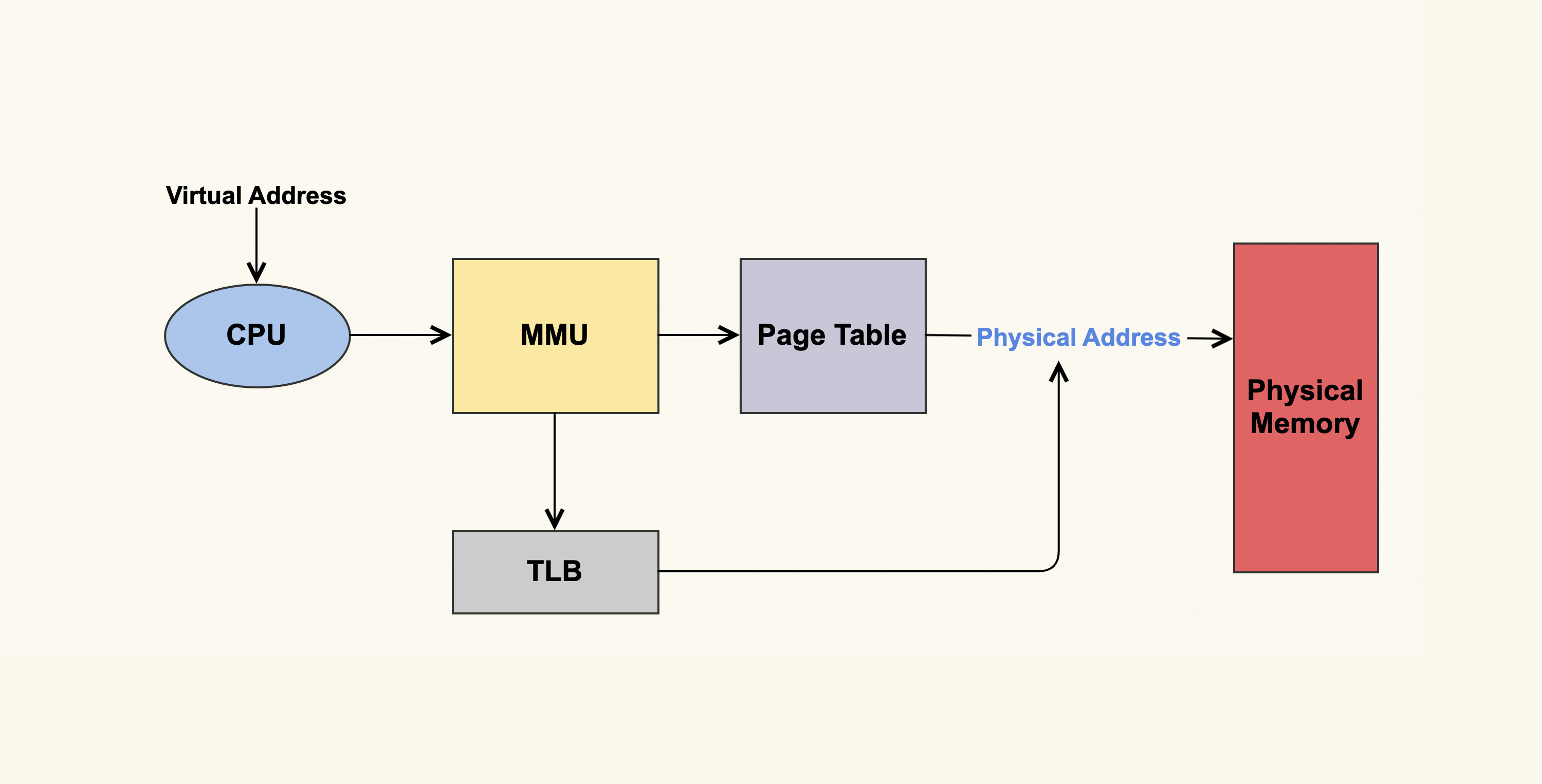
Paging 的大致过程是,CPU 将要请求的虚拟地址传给 MMU(Memory Management Unit,内存管理单元),然后 MMU 先在高速缓存 TLB(Translation Lookaside Buffer,页表缓存)中查找转换关系,如果找到了相应的物理地址则直接访问;如果找不到则在地址转换表(Page Table)里查找计算。最终进程访问的虚拟地址就对应到了实际的物理地址。
Linux 上最典型的规划进程地址空间的方式就是通过 ulimit,你可以通过调配它,来规划进程最大的虚拟地址空间、物理地址空间、栈空间是多少,等等。
6.2 用数据观察进程的内存
学会观察进程地址空间是分析内存泄漏问题的前提,当你怀疑内存有泄漏时,首先需要去观察哪些内存在持续增长,哪些内存特别大,这样才能够判断出内存泄漏大致是出在哪里,然后针对性地去做分析。
比如说 pmap、ps、top 等,都可以很好地来观察进程的内存。
首先我们可以使用 top 来观察系统所有进程的内存使用概况,打开 top 后,然后按 g 再输入 3,从而进入内存模式就可以了。在内存模式中,我们可以看到各个进程内存的 %MEM、VIRT、RES、CODE、DATA、SHR、nMaj、nDRT,这些信息通过 strace 来跟踪 top 进程,你会发现这些信息都是从 /proc/[pid]/statm 和 /proc/[pid]/stat 这个文件里面读取的:
$ strace -p `pidof top`
open("/proc/16348/statm", O_RDONLY) = 9
read(9, "40509 1143 956 24 0 324 0\n", 1024) = 26
close(9) = 0
...
open("/proc/16366/stat", O_RDONLY) = 9
read(9, "16366 (kworker/u16:1-events_unbo"..., 1024) = 182
close(9)
...除了 nMaj(Major Page Fault, 主缺页中断,指内容不在内存中然后从磁盘中来读取的页数)外,%MEM 则是从 RES 计算而来的,其余的内存信息都是从 statm 文件里面读取的,如下是 top 命令中的字段和 statm 中字段的对应关系:
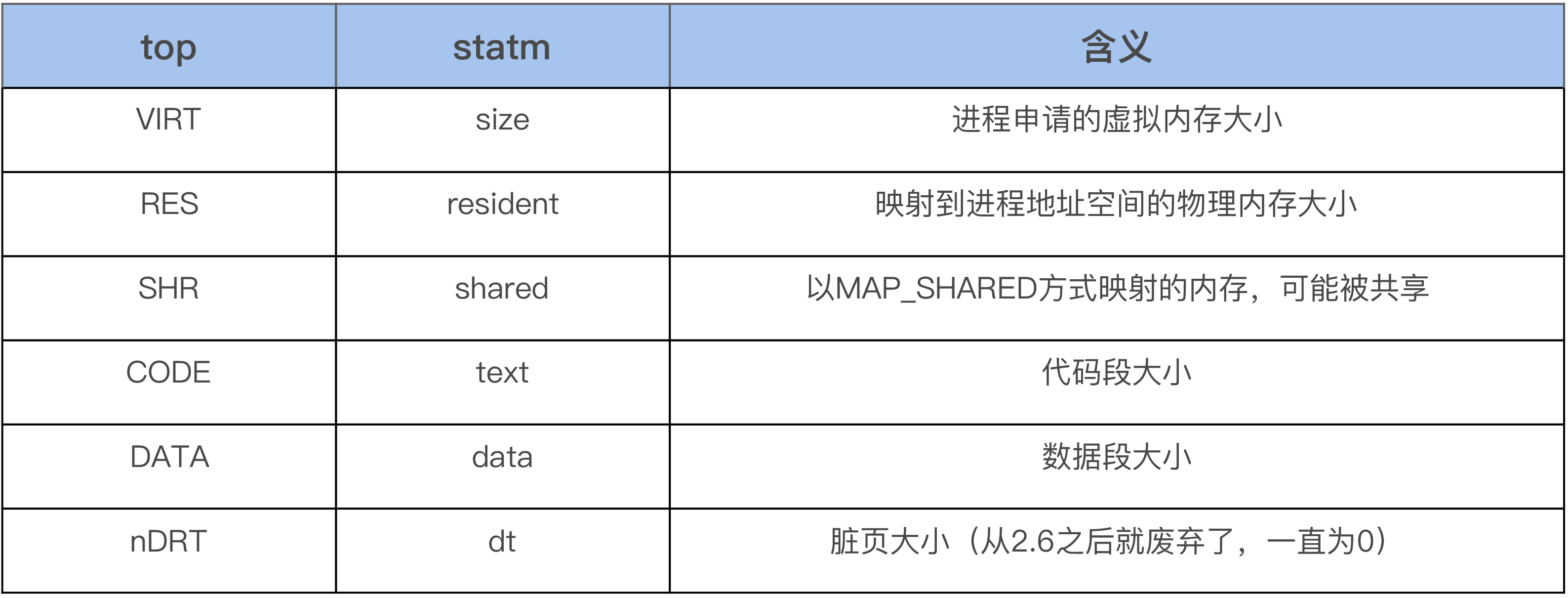
有些时候所有进程的 RES 相加起来要比系统总的物理内存大,这是因为 RES 中有一些内存是被一些进程给共享的。
在明白了系统中各个进程的内存使用概况后,如果想要继续看某个进程的内存使用细节,你可以使用 pmap。如下是 pmap 来展示 sshd 进程地址空间里的部分内容:
$ pmap -x `pidof sshd`
Address Kbytes RSS Dirty Mode Mapping
000055e798e1d000 768 652 0 r-x-- sshd
000055e7990dc000 16 16 16 r---- sshd
000055e7990e0000 4 4 4 rw--- sshd
000055e7990e1000 40 40 40 rw--- [ anon ]
...
00007f189613a000 1800 1624 0 r-x-- libc-2.17.so
00007f18962fc000 2048 0 0 ----- libc-2.17.so
00007f18964fc000 16 16 16 r---- libc-2.17.so
00007f1896500000 8 8 8 rw--- libc-2.17.so
...
00007ffd9d30f000 132 40 40 rw--- [ stack ]
...每一行表示一种类型的内存(Virtual Memory Area),每一列的含义如下。
Mapping,用来表示文件映射中占用内存的文件,比如 sshd 这个可执行文件,或者堆[heap],或者栈[stack],或者其他,等等。
Mode,它是该内存的权限,比如,”r-x”是可读可执行,它往往是代码段 (Text Segment);”rw-“是可读可写,这部分往往是数据段 (Data Segment);”r–”是只读,这往往是数据段中的只读部分。
Address、Kbytes、RSS、Dirty,Address 和 Kbytes 分别表示起始地址和虚拟内存的大小,RSS(Resident Set Size)则表示虚拟内存中已经分配的物理内存的大小,Dirty 则表示内存中数据未同步到磁盘的字节数。
可以看到,通过 pmap 我们能够清楚地观察一个进程的整个的地址空间,包括它们分配的物理内存大小,这非常有助于我们对进程的内存使用概况做一个大致的判断。比如说,如果地址空间中[heap]太大,那有可能是堆内存产生了泄漏;再比如说,如果进程地址空间包含太多的 vma(可以把 maps 中的每一行理解为一个 vma),那很可能是应用程序调用了很多 mmap 而没有 munmap;再比如持续观察地址空间的变化,如果发现某些项在持续增长,那很可能是那里存在问题。
pmap 同样也是解析的 /proc 里的文件,具体文件是 /proc/[pid]/maps 和 /proc/[pid]/smaps,其中 smaps 文件相比 maps 的内容更详细,可以理解为是对 maps 的一个扩展。你可以对比 /proc/[pid]/maps 和 pmaps 的输出,你会发现二者的内容是一致的。
除了观察进程自身的内存外,我们还可以观察进程分配的内存和系统指标的关联,我们就以常用的 /proc/meminfo 为例,来说明我们上面提到的四种内存类型(私有匿名,私有文件,共享匿名,共享文件)是如何体现在系统指标中的。
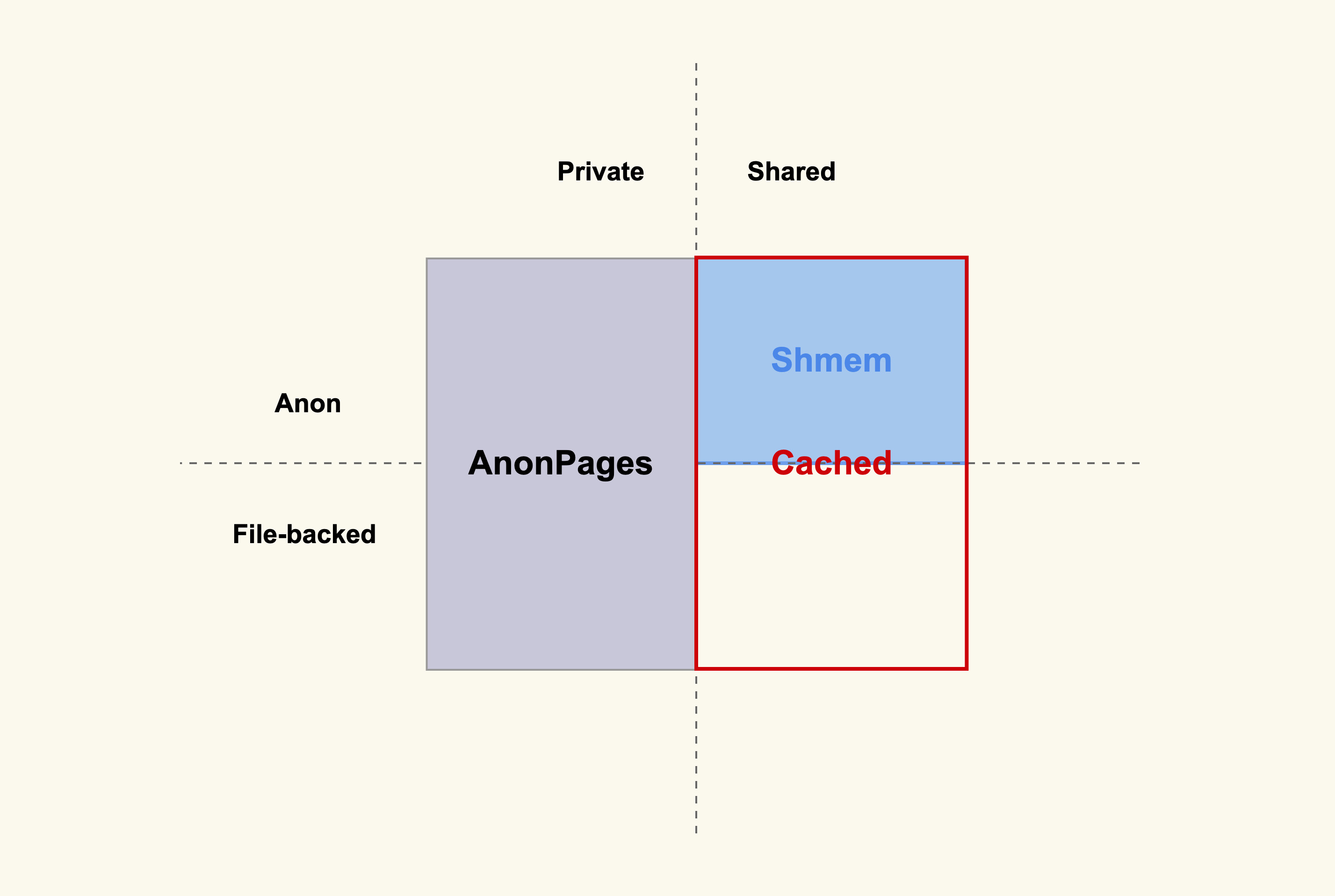
如上图所示,凡是私有的内存都会体现在 /proc/meminfo 中的 AnonPages 这一项,凡是共享的内存都会体现在 Cached 这一项,匿名共享的则还会体现在 Shmem 这一项。
$ cat /proc/meminfo
...
Cached: 3799380 kB
...
AnonPages: 1060684 kB
...
Shmem: 8724 kB
...07 案例篇 | 如何预防内存泄漏导致的系统假死?
7.1 什么样的内存泄漏是有危害的?
下面是一个内存泄漏的简单示例程序。
#include <stdlib.h>
#include <string.h>
#define SIZE (1024 * 1024 * 1024) /* 1G */
int main()
{
char *p = malloc(SIZE);
if (!p)
return -1;
memset(p, 1, SIZE);
/* 然后就再也不使用这块内存空间 */
/* 没有释放p所指向的内存进程就退出了 */
/* free(p); */
return 0;
}我们可以看到,这个程序里面申请了 1G 的内存后,没有进行释放就退出了,那这 1G 的内存空间是泄漏了吗?
我们可以使用一个简单的内存泄漏检查工具 (valgrind) 来看看。
$ valgrind --leak-check=full ./a.out
==20146== HEAP SUMMARY:
==20146== in use at exit: 1,073,741,824 bytes in 1 blocks
==20146== total heap usage: 1 allocs, 0 frees, 1,073,741,824 bytes allocated
==20146==
==20146== 1,073,741,824 bytes in 1 blocks are possibly lost in loss record 1 of 1
==20146== at 0x4C29F73: malloc (vg_replace_malloc.c:309)
==20146== by 0x400543: main (in /home/yafang/test/mmleak/a.out)
==20146==
==20146== LEAK SUMMARY:
==20146== definitely lost: 0 bytes in 0 blocks
==20146== indirectly lost: 0 bytes in 0 blocks
==20146== possibly lost: 1,073,741,824 bytes in 1 blocks
==20146== still reachable: 0 bytes in 0 blocks
==20146== suppressed: 0 bytes in 0 blocks从 valgrind 的检查结果里我们可以清楚地看到,申请的内存只被使用了一次(memset)就再没被使用,但是在使用完后却没有把这段内存空间给释放掉,这就是典型的内存泄漏。那这个内存泄漏是有危害的吗?
这就要从进程地址空间的分配和销毁来说起,下面是一个简单的示意图:
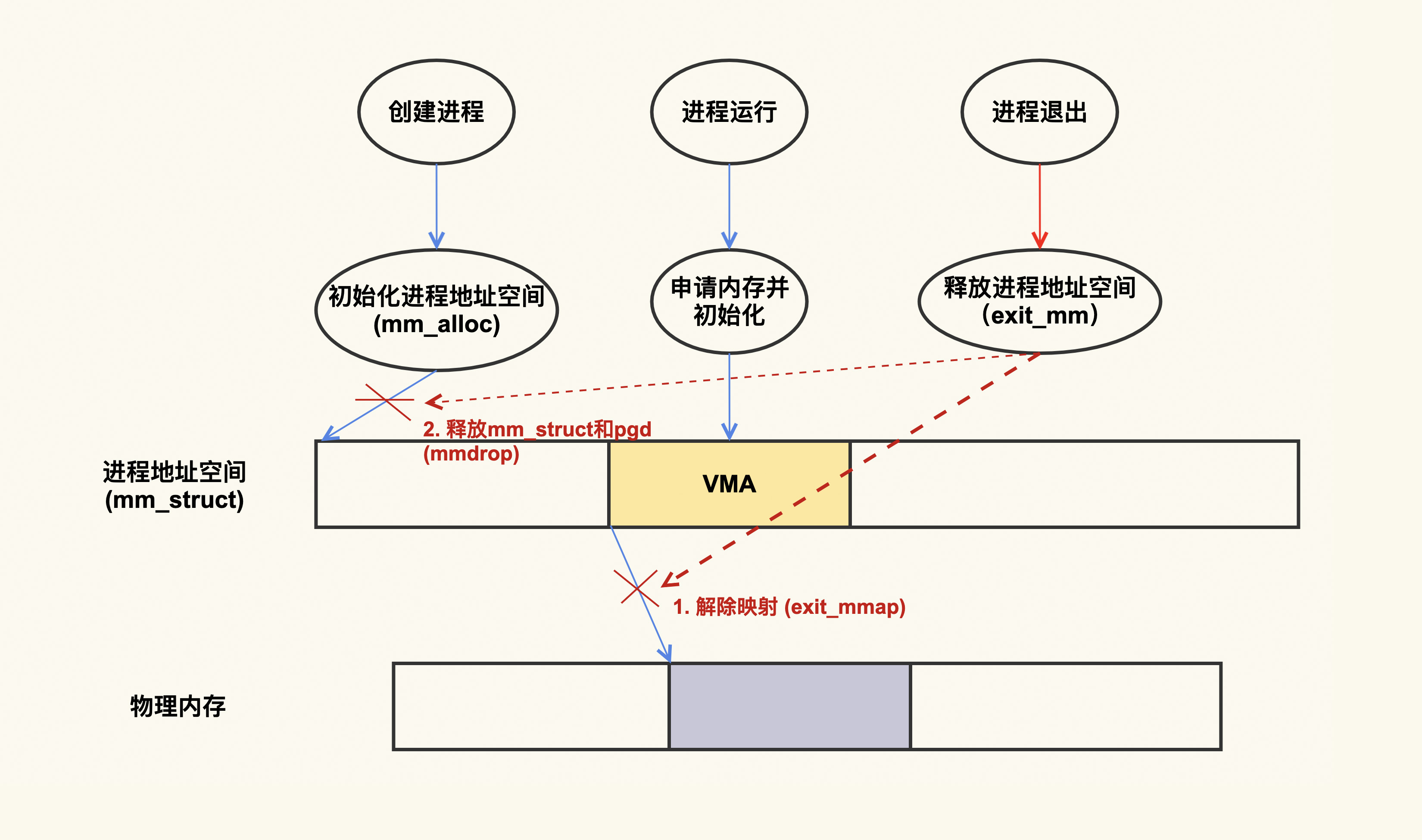
从上图可以看出,进程在退出的时候,会把它建立的映射都给解除掉。换句话说,进程退出时,会把它申请的内存都给释放掉,这个内存泄漏就是没危害的。
但是,对于后台服务型的业务而言,基本上都是需要长时间运行的程序,所以后台服务的内存泄漏会给系统造成实际的危害。
7.2 如何预防内存泄漏导致的危害?
我们还是以上面这个 malloc() 程序为例,在这个例子中,它只是申请了 1G 的内存,如果说持续不断地申请内存而不释放,你会发现,很快系统内存就会被耗尽,进而触发 OOM killer 去杀进程。这个信息可以通过 dmesg(该命令是用来查看内核日志的)这个命令来查看:
$ dmesg
[944835.029319] a.out invoked oom-killer: gfp_mask=0x100dca(GFP_HIGHUSER_MOVABLE|__GFP_ZERO), order=0, oom_score_adj=0
[...]
[944835.052448] Out of memory: Killed process 1426 (a.out) total-vm:8392864kB, anon-rss:7551936kB, file-rss:4kB, shmem-rss:0kB, UID:0 pgtables:14832kB oom_score_adj:0系统内存不足时会唤醒 OOM killer 来选择一个进程给杀掉,在我们这个例子中它杀掉了这个正在内存泄漏的程序,该进程被杀掉后,整个系统也就变得安全了。但是你要注意,OOM killer 选择进程是有策略的,它未必一定会杀掉正在内存泄漏的进程,很有可能是一个无辜的进程被杀掉。而且,OOM 本身也会带来一些副作用。
OOM 日志可以理解为是一个单生产者多消费者的模型,如下图所示:
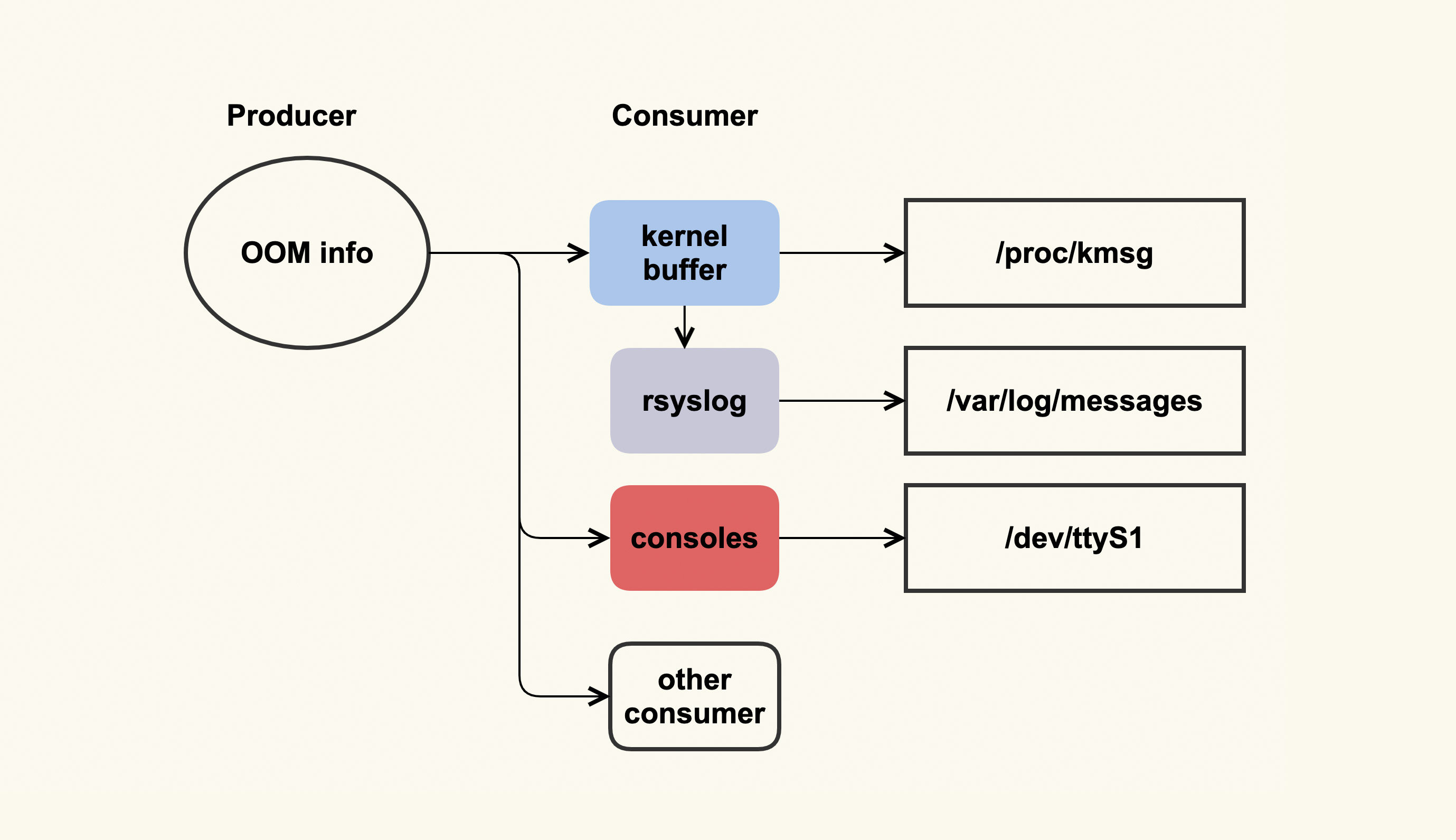
这个单生产者多消费者模型,其实是由 OOM killer 打印日志(OOM info)时所使用的 printk(类似于 userspace 的 printf)机制来决定的。printk 会检查这些日志需要输出给哪些消费者,比如写入到内核缓冲区(kernel buffer),然后通过 dmesg 命令来查看;我们通常也都会配置 rsyslog,然后 rsyslogd 会将内核缓冲区的内容给转储到日志文件(/var/log/messages)中;服务器也可能会连着一些控制台(console ),比如串口,这些日志也会输出到这些 console。
问题就出在 console 这里,如果 console 的速率很慢,输出太多日志会非常消耗时间,而当时我们配置了”console=ttyS1,19200”,即波特率为 19200 的串口,这是个很低速率的串口。一个完整的 OOM info 需要约 10s 才能打印完,这在系统内存紧张时就会成为一个瓶颈点,为什么会是瓶颈点呢?答案如下图所示:
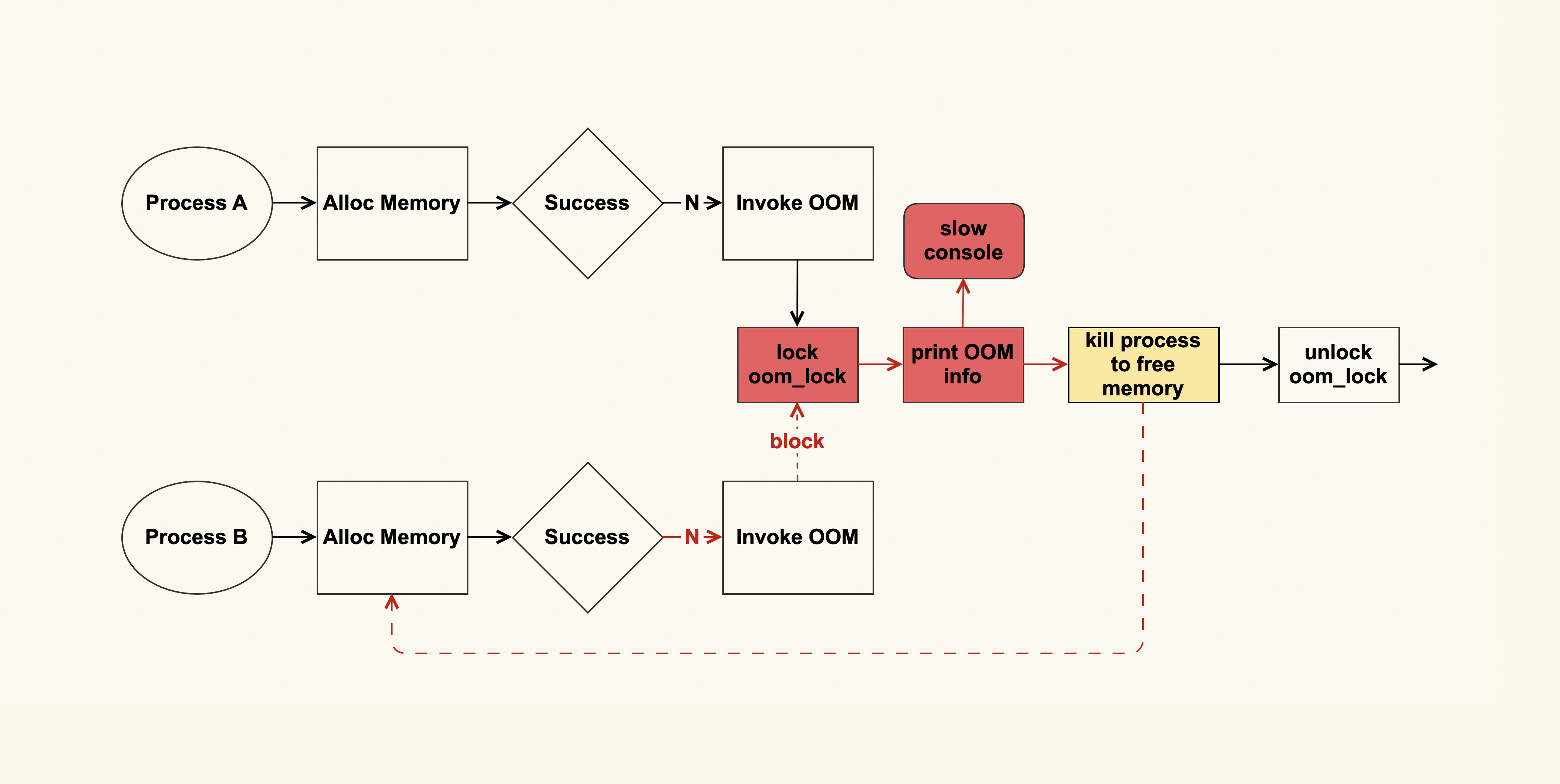
进程 A 在申请内存失败后会触发 OOM,在发生 OOM 的时候会打印很多很多日志(这些日志是为了方便分析为什么 OOM 会发生),然后会选择一个合适的进程来杀掉,从而释放出来空闲的内存,这些空闲的内存就可以满足后续内存申请了。
如果这个 OOM 的过程耗时很长(即打印到 slow console 所需的时间太长,如上图红色部分所示),其他进程(进程 B)也在此时申请内存,也会申请失败,于是进程 B 同样也会触发 OOM 来尝试释放内存,而 OOM 这里又有一个全局锁(oom_lock)来进行保护,进程 B 尝试获取(trylock)这个锁的时候会失败,就只能再次重试。
如果此时系统中有很多进程都在申请内存,那么这些申请内存的进程都会被阻塞在这里,这就形成了一个恶性循环,甚至会引发系统长时间无响应(假死)。
一些规避措施:
在发生 OOM 时尽可能少地打印信息
通过将vm.oom_dump_tasks调整为 0,可以不去备份(dump)当前系统中所有可被 kill 的进程信息,如果系统中有很多进程,这些信息的打印可能会非常消耗时间。在我们这个案例里,这部分耗时约为 6s 多,占 OOM 整体耗时 10s 的一多半,所以减少这部分的打印能够缓解这个问题。
但是,这并不是一个完美的方案,只是一个规避措施。因为当我们把 vm.oom_dump_tasks 配置为 1 时,是可以通过这些打印的信息来检查 OOM killer 是否选择了合理的进程,以及系统中是否存在不合理的 OOM 配置策略的。如果我们将它配置为 0,就无法得到这些信息了,而且这些信息不仅不会打印到串口,也不会打印到内核缓冲区,导致无法被转储到不会产生问题的日志文件中。
调整串口打印级别,不将 OOM 信息打印到串口
过调整/proc/sys/kernel/printk可以做到避免将 OOM 信息输出到串口,我们通过设置 console_loglevel 来将它的级别设置的比 OOM 日志级别(为 4)小,就可以避免 OOM 的信息打印到 console,比如将它设置为 3:
# 初始配置(为7):所有信息都会输出到console $ cat /proc/sys/kernel/printk 7 4 1 7 # 调整console_loglevel级别,不让OOM信息打印到console $ echo "3 4 1 7" > /proc/sys/kernel/printk # 查看调整后的配置 $ cat /proc/sys/kernel/printk 3 4 1但是这样做会导致所有低于默认级别(为 4)的内核日志都无法输出到 console,在系统出现问题时,我们有时候(比如无法登录到服务器上面时)会需要查看 console 信息来判断问题是什么引起的,如果某些信息没有被打印到 console,可能会影响我们的分析。
08 案例篇 | Shmem:进程没有消耗内存,内存哪去了?
8.1 进程没有消耗内存,内存哪去了?
我生产环境上就遇到过一个真实的案例。我们的运维人员发现某几台机器 used(已使用的)内存越来越多,但是通过 top 以及其他一些命令,却检查不出来到底是谁在占用内存。随着可用内存变得越来越少,业务进程也被 OOM killer 给杀掉,这给业务带来了比较严重的影响。于是他们向我寻求帮助,看看产生问题的原因是什么。
通过查看这几台服务器的 /proc/meminfo,发现是 Shmem 的大小有些异常:
$ cat /proc/meminfo
...
Shmem 16777216 kB
...我们在前面的基础篇里提到,Shmem 是指匿名共享内存,即进程以 mmap(MAP_ANON|MAP_SHARED)这种方式来申请的内存。你可能会有疑问,进程以这种方式来申请的内存不应该是属于进程的 RES(resident)吗?比如下面这个简单的示例:
#include <sys/mman.h>
#include <string.h>
#include <unistd.h>
#define SIZE (1024*1024*1024)
int main()
{
char *p;
p = mmap(NULL, SIZE, PROT_READ|PROT_WRITE, MAP_ANON|MAP_SHARED, -1, 0);
if (!p)
return -1;
memset(p, 1, SIZE);
while (1) {
sleep(1);
}
return 0;
}运行该程序后,通过 top 可以看到确实会体现在进程的 RES 里面,而且还同时体现在了进程的 SHR 里面,也就是说,如果进程是以 mmap 这种方式来申请内存的话,我们是可以通过进程的内存消耗来观察到的。
但是在我们生产环境上遇到的问题,各个进程的 RES 都不大,看起来和 /proc/meminfo 中的 Shmem 完全对应不起来,这又是为什么呢?
先说答案:这跟一种特殊的 Shmem 有关。我们知道,磁盘的速度是远远低于内存的,有些应用程序为了提升性能,会避免将一些无需持续化存储的数据写入到磁盘,而是把这部分临时数据写入到内存中,然后定期或者在不需要这部分数据时,清理掉这部分内容来释放出内存。在这种需求下,就产生了一种特殊的 Shmem:tmpfs。tmpfs 如下图所示:
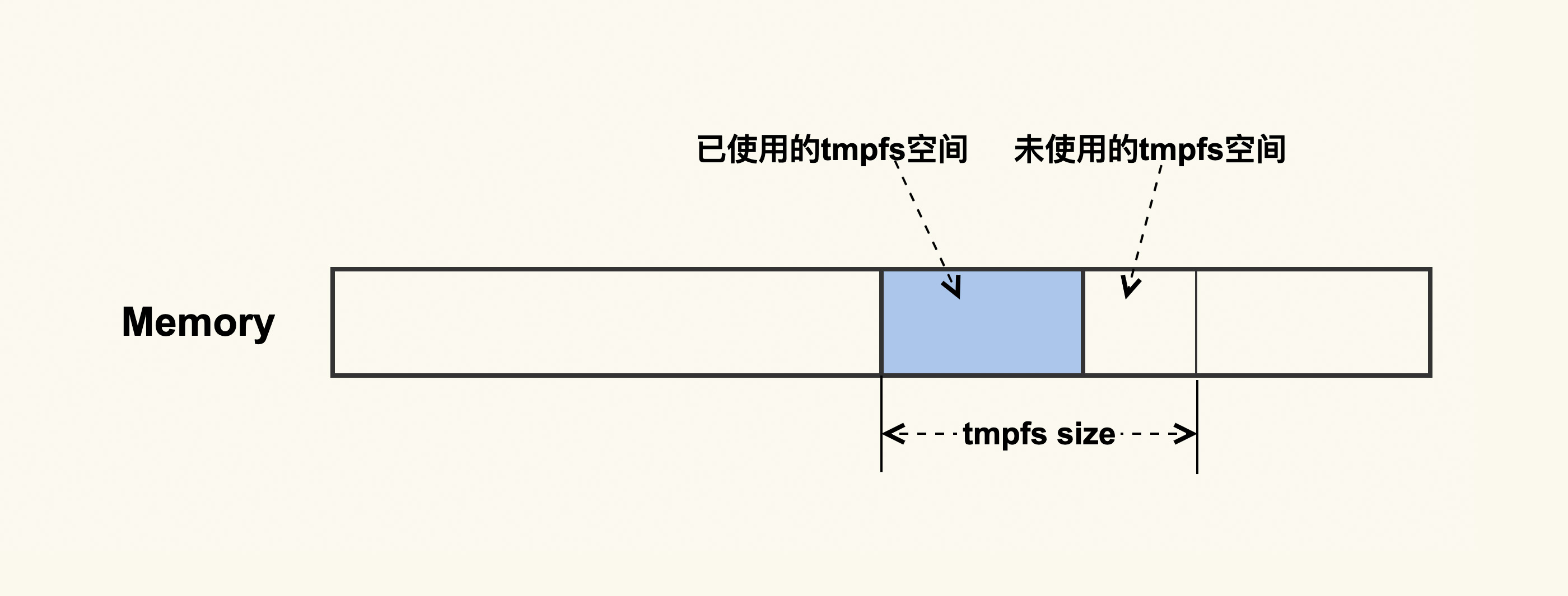
它是一种内存文件系统,只存在于内存中,它无需应用程序去申请和释放内存,而是操作系统自动来规划好一部分空间,应用程序只需要往这里面写入数据就可以了,这样会很方便。我们可以使用 moun 命令或者 df 命令来看系统中 tmpfs 的挂载点:
$ df -h
Filesystem Size Used Avail Use% Mounted on
...
tmpfs 16G 15G 1G 94% /run
...就像进程往磁盘写文件一样,进程写完文件之后就把文件给关闭掉了,这些文件和进程也就不再有关联,所以这些磁盘文件的大小不会体现在进程中。同样地,tmpfs 中的文件也一样,它也不会体现在进程的内存占用上。讲到这里,你大概已经猜到了,我们 Shmem 占用内存多,是不是因为 Shmem 中的 tmpfs 较大导致的呢?
tmpfs 是属于文件系统的一种。对于文件系统,我们都可以通过 df 来查看它的使用情况。所以呢,我们也可以通过 df 来看是不是 tmpfs 占用的内存较多,结果发现确实是它消耗了很多内存。这个问题就变得很清晰了,我们只要去分析 tmpfs 中存储的是什么文件就可以了。
我们在生产环境上还遇到过这样一个问题:systemd 不停地往 tmpfs 中写入日志但是没有去及时清理,而 tmpfs 配置的初始值又太大,这就导致 systemd 产生的日志量越来越多,最终可用内存越来越少。
针对这个问题,解决方案就是限制 systemd 所使用的 tmpfs 的大小,在日志量达到 tmpfs 大小限制时,自动地清理掉临时日志,或者定期清理掉这部分日志,这都可以通过 systemd 的配置文件来做到。tmpfs 的大小可以通过如下命令(比如调整为 2G)调整:
mount -o remount,size=2G /run8.1 OOM 杀进程的危害
OOM 杀进程的逻辑大致如下图所示:
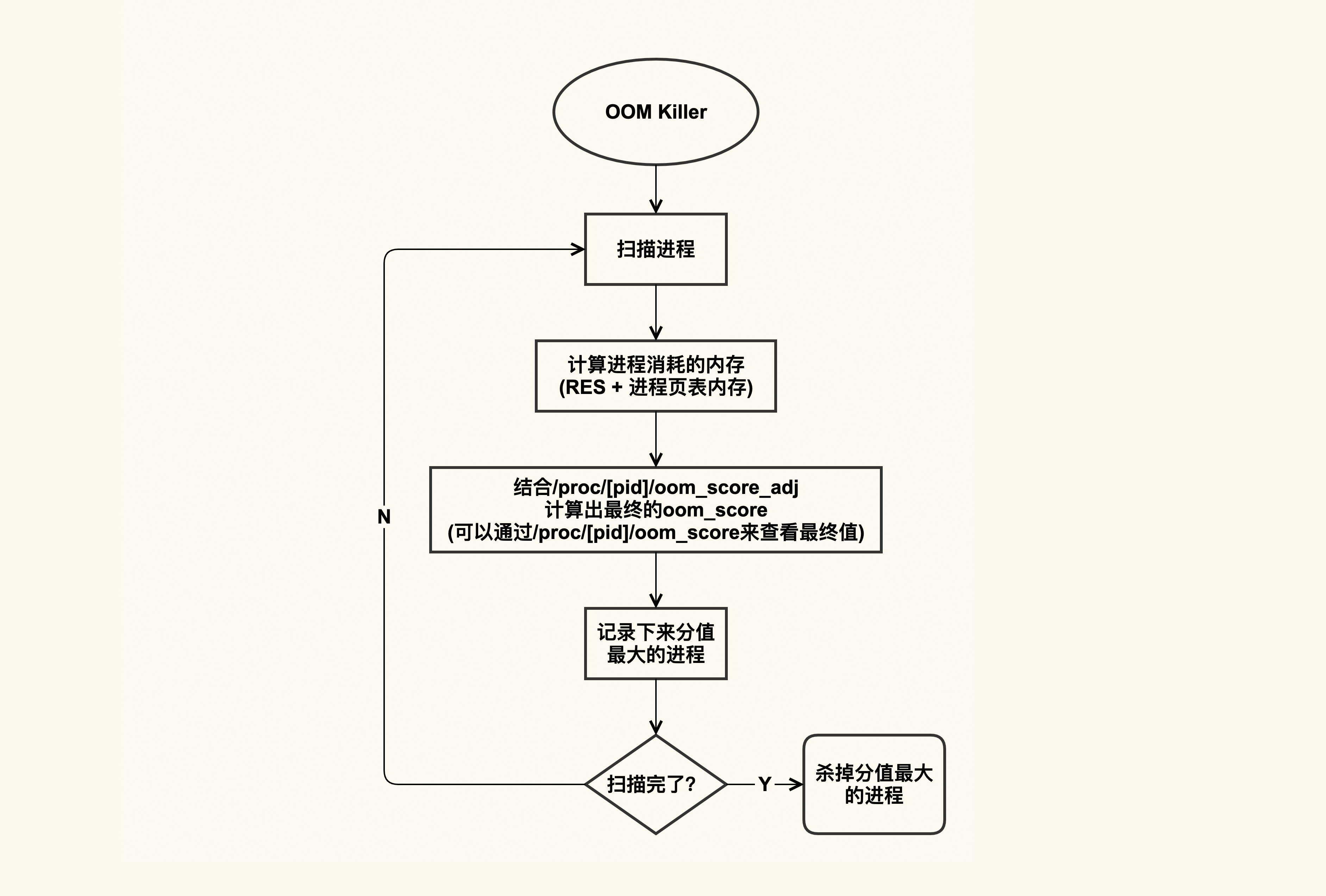
OOM killer 在杀进程的时候,会把系统中可以被杀掉的进程扫描一遍,根据进程占用的内存以及配置的 oom_score_adj 来计算出进程最终的得分,然后把得分(oom_score)最大的进程给杀掉,如果得分最大的进程有多个,那就把先扫描到的那个给杀掉。
进程的 oom_score 可以通过 /proc/[pid]/oom_score 来查看,你可以扫描一下你系统中所有进程的 oom_score,其中分值最大的那个就是在发生 OOM 时最先被杀掉的进程。不过你需要注意,由于 oom_score 和进程的内存开销有关,而进程的内存开销又是会动态变化的,所以该值也会动态变化。
如果你不想这个进程被首先杀掉,那你可以调整该进程的 oom_score_adj 改变这个 oom_score;如果你的进程无论如何都不能被杀掉,那你可以将 oom_score_adj 配置为 -1000。
通常而言,我们都需要将一些很重要的系统服务的 oom_score_adj 配置为 -1000,比如 sshd,因为这些系统服务一旦被杀掉,我们就很难再登陆进系统了。
09 分析篇 | 如何对内核内存泄漏做些基础的分析?
9.1 内核内存泄漏是什么?
在进行具体的分析之前,我们需要先对内核内存泄漏有个初步的概念,究竟内核内存泄漏是指什么呢?这得从内核空间内存分配的基本方法说起。
进程的虚拟地址空间(address space)既包括用户地址空间,也包括内核地址空间。这可以简单地理解为,进程运行在用户态申请的内存,对应的是用户地址空间,进程运行在内核态申请的内存,对应的是内核地址空间,如下图所示:
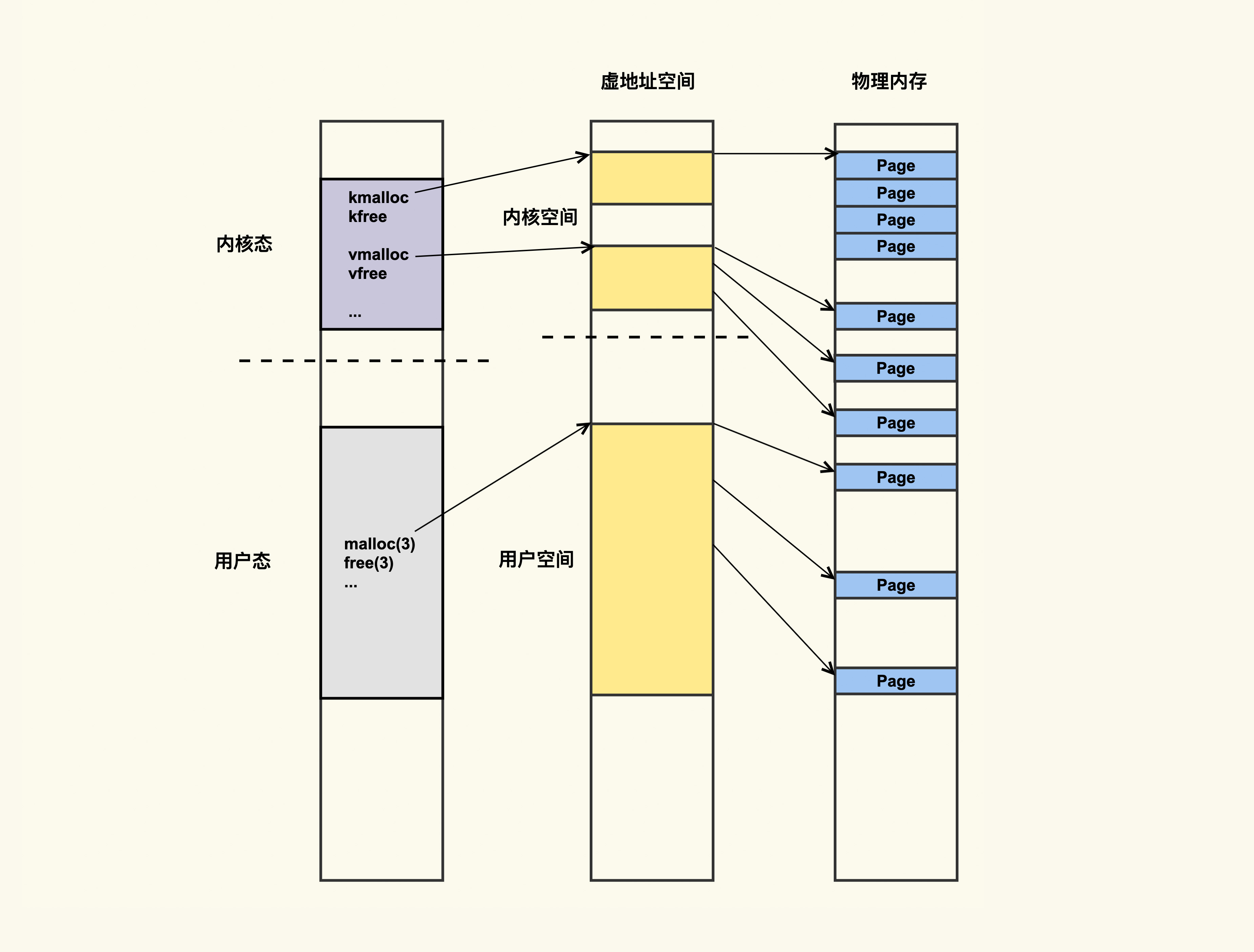
应用程序可以通过 malloc() 和 free() 在用户态申请和释放内存,与之对应,可以通过 kmalloc()/kfree() 以及 vmalloc()/vfree() 在内核态申请和释放内存。当然,还有其他申请和释放内存的方法,但大致可以分为这两类。
从最右侧的物理内存中你可以看出这两类内存申请方式的主要区别,kmalloc() 内存的物理地址是连续的,而 vmalloc() 内存的物理地址则是不连续的。这两种不同类型的内存也是可以通过 /proc/meminfo 来观察的:
$ cat /proc/meminfo
...
Slab: 2400284 kB
SReclaimable: 47248 kB
SUnreclaim: 2353036 kB
...
VmallocTotal: 34359738367 kB
VmallocUsed: 1065948 kB
...其中 vmalloc 申请的内存会体现在 VmallocUsed 这一项中,即已使用的 Vmalloc 区大小;而 kmalloc 申请的内存则是体现在 Slab 这一项中,它又分为两部分,其中 SReclaimable 是指在内存紧张的时候可以被回收的内存,而 SUnreclaim 则是不可以被回收只能主动释放的内存。
在讲述具体的案例以及排查方法之前,我们先以一个简单的程序来看下内核空间是如何进行内存申请和释放的。
/* kmem_test */
#include <linux/init.h>
#include <linux/vmalloc.h>
#define SIZE (1024 * 1024 * 1024)
char *kaddr;
char *kmem_alloc(unsigned long size) {
char *p;
p = vmalloc(size);
if (!p)
pr_info("[kmem_test]: vmalloc failed\n");
return p;
}
void kmem_free(const void *addr) {
if (addr)
vfree(addr);
}
int __init kmem_init(void) {
pr_info("[kmem_test]: kernel memory init\n");
kaddr = kmem_alloc(SIZE);
return 0;
}
void __exit kmem_exit(void) {
kmem_free(kaddr);
pr_info("[kmem_test]: kernel memory exit\n");
}
module_init(kmem_init)
module_exit(kmem_exit)
MODULE_LICENSE("GPLv2");这是一个典型的内核模块,在这个内核模块中,我们使用 vmalloc 来分配了 1G 的内存空间,然后在模块退出的时候使用 vfree 释放掉它。这在形式上跟应用申请 / 释放内存其实是一致的,只是申请和释放内存的接口函数不一样而已。
我们需要使用 Makefile 来编译这个内核模块:
obj-m = kmem_test.o
all:
make -C /lib/modules/`uname -r`/build M=`pwd`
clean:
rm -f *.o *.ko *.mod.c *.mod *.a modules.order Module.symvers执行 make 命令后就会生成一个 kmem_test 的内核模块,接着执行下面的命令就可以安装该模块了:
insmod kmem_test用 rmmod 命令则可以把它卸载掉:
rmmod kmem_test这个示例程序就是内核空间内存分配的基本方法。你可以在插入 / 卸载模块前后观察 VmallocUsed 的变化,以便于你更好地理解这一项的含义。
那么,在什么情况下会发生内核空间的内存泄漏呢?
跟用户空间的内存泄漏类似,内核空间的内存泄漏也是指只申请内存而不去释放该内存的情况,比如说,如果我们不在 kmem_exit() 这个函数中调用 kmem_free(),就会产生内存泄漏问题。
那么,内核空间的内存泄漏与用户空间的内存泄漏有什么不同呢?我们知道,用户空间内存的生命周期与用户进程是一致的,进程退出后这部分内存就会自动释放掉。但是,内核空间内存的生命周期是与内核一致的,却不是跟内核模块一致的,也就是说,在内核模块退出时,不会自动释放掉该内核模块申请的内存,只有在内核重启(即服务器重启)时才会释放掉这部分内存。
总之,一旦发生内核内存泄漏,你很难有很好的方法来优雅地解决掉它,很多时候唯一的解决方案就是重启服务器,这显然是件很严重的问题。
9.2 如何观察内核内存泄漏?
我们可以通过 /proc/meminfo 来观察内核内存的分配情况,这提供了一个观察内核内存的简便方法:
- 如果 /proc/meminfo 中内核内存(比如 VmallocUsed 和 SUnreclaim)太大,那很有可能发生了内核内存泄漏;
- 另外,你也可以周期性地观察 VmallocUsed 和 SUnreclaim 的变化,如果它们持续增长而不下降,也可能是发生了内核内存泄漏。
/proc/meminfo 只是提供了系统内存的整体使用情况,如果我们想要看具体是什么模块在使用内存,那该怎么办呢?
这也可以通过 /proc 来查看,所以再次强调一遍,当你不清楚该如何去分析时,你可以试着去查看 /proc 目录下的文件。以上面的程序为例,安装 kmem_test 这个内核模块后,我们可以通过 /proc/vmallocinfo 来看到该模块的内存使用情况:
$ cat /proc/vmallocinfo | grep kmem_test
0xffffc9008a003000-0xffffc900ca004000 1073745920 kmem_alloc+0x13/0x30 [kmem_test] pages=262144 vmalloc vpages N0=262144可以看到,在[kmem_test]这个模块里,通过 kmem_alloc 这个函数申请了 262144 个 pages,即总共 1G 大小的内存。
9.3 复杂场景下内核内存泄漏问题分析思路
如果我们想要对内核内存泄漏做些基础的分析,最好借助一些内核内存泄漏分析工具,其中最常用的分析工具就是kmemleak。
kmemleak 是内核内存泄漏检查的利器,但是,它的使用也存在一些不便性,因为打开该特性会给性能带来一些损耗,所以生产环境中的内核都会默认关闭该特性。该特性我们一般只用在测试环境中,然后在测试环境中运行需要分析的驱动程序以及其他内核模块。
与其他内存泄漏检查工具类似,kmemleak 也是通过检查内核内存的申请和释放,来判断是否存在申请的内存不再使用也不释放的情况。如果存在,就认为是内核内存泄漏,然后把这些泄漏的信息通过 /sys/kernel/debug/kmemleak 这个文件导出给用户分析。同样以我们上面的程序为例,检查结果如下:
unreferenced object 0xffffc9008a003000 (size 1073741824):
comm "insmod", pid 11247, jiffies 4344145825 (age 3719.606s)
hex dump (first 32 bytes):
38 40 18 ba 80 88 ff ff 00 00 00 00 00 00 00 00 8@..............
f0 13 c9 73 80 88 ff ff 18 40 18 ba 80 88 ff ff ...s.....@......
backtrace:
[<00000000fbd7cb65>] __vmalloc_node_range+0x22f/0x2a0
[<000000008c0afaef>] vmalloc+0x45/0x50
[<000000004f3750a2>] 0xffffffffa0937013
[<0000000078198a11>] 0xffffffffa093c01a
[<000000002041c0ec>] do_one_initcall+0x4a/0x200
[<000000008d10d1ed>] do_init_module+0x60/0x220
[<000000003c285703>] load_module+0x156c/0x17f0
[<00000000c428a5fe>] __do_sys_finit_module+0xbd/0x120
[<00000000bc613a5a>] __x64_sys_finit_module+0x1a/0x20
[<000000004b0870a2>] do_syscall_64+0x52/0x90
[<000000002f458917>] entry_SYSCALL_64_after_hwframe+0x44/0xa9由于该程序通过 vmalloc 申请的内存以后再也没有使用,所以被 kmemleak 标记为了”unreferenced object”,我们需要在使用完该内存空间后就释放它以节省内存。
如果我们想在生产环境上来观察内核内存泄漏,就无法使用 kmemleak 了,那还有没有其他的方法呢?
我们可以使用内核提供的内核内存申请释放的 tracepoint,来动态观察内核内存使用情况:
当我们使能这些 tracepoints 后,就可以观察内存的动态申请和释放情况了,只是这个分析过程不如 kmemleak 那么高效。
当我们想要观察某些内核结构体的申请和释放时,可能没有对应的 tracepiont。这个时候就需要使用 kprobe 或者 systemtap,来针对具体的内核结构体申请释放函数进行追踪了。
10 分析篇 | 内存泄漏时,我们该如何一步步找到根因?
10.1 如何定位出是谁在消耗内存 ?
首先,我们需要去找出到底是谁在消耗内存,/proc/meminfo 可以帮助我们来快速定位出问题所在。

总之,如果进程的内存有问题,那使用 top 就可以观察出来;如果进程的内存没有问题,那你可以从 /proc/meminfo 入手来一步步地去深入分析。
10.2 如何去分析进程的内存泄漏原因?
这是我多年以前帮助一个小伙伴分析的内存泄漏问题。这个小伙伴已经使用 top 排查出了业务进程的内存异常,但是不清楚该如何去进一步分析。
他遇到的这个异常是,业务进程的虚拟地址空间(VIRT)被消耗很大,但是物理内存(RES)使用得却很少,所以他怀疑是进程的虚拟地址空间有内存泄漏。
出现该现象时,可以用 top 命令观察:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
31108 app 20 0 285g 4.0g 19m S 60.6 12.7 10986:15 app_server继续用 pidstat 命令:
$ pidstat -r -p 31108 1
04:47:00 PM 31108 353.00 0.00 299029776 4182152 12.73 app_server
...
04:47:59 PM 31108 149.00 0.00 299029776 4181052 12.73 app_server
04:48:00 PM 31108 191.00 0.00 299040020 4181188 12.73 app_server
...
04:48:59 PM 31108 179.00 0.00 299040020 4181400 12.73 app_server
04:49:00 PM 31108 183.00 0.00 299050264 4181524 12.73 app_server
...
04:49:59 PM 31108 157.00 0.00 299050264 4181456 12.73 app_server
04:50:00 PM 31108 207.00 0.00 299060508 4181560 12.73 app_server
...
04:50:59 PM 31108 127.00 0.00 299060508 4180816 12.73 app_server
04:51:00 PM 31108 172.00 0.00 299070752 4180956 12.73 app_server如上所示,在每个整分钟的时候,VSZ 会增大 10244KB,这看起来是一个很有规律的现象。然后,我们再来看下增大的这个内存区域到底是什么,你可以通过 /proc/PID/smaps 来看。
$ cat /proc/31108/smaps
...
7faae0e49000-7faae1849000 rw-p 00000000 00:00 0
Size: 10240 kB
Rss: 80 kB
Pss: 80 kB
Shared_Clean: 0 kB
Shared_Dirty: 0 kB
Private_Clean: 0 kB
Private_Dirty: 80 kB
Referenced: 60 kB
Anonymous: 80 kB
AnonHugePages: 0 kB
Swap: 0 kB
KernelPageSize: 4 kB
MMUPageSize: 4 kB
7faae1849000-7faae184a000 ---p 00000000 00:00 0
Size: 4 kB
Rss: 0 kB
Pss: 0 kB
Shared_Clean: 0 kB
Shared_Dirty: 0 kB
Private_Clean: 0 kB
Private_Dirty: 0 kB
Referenced: 0 kB
Anonymous: 0 kB
AnonHugePages: 0 kB
Swap: 0 kB
KernelPageSize: 4 kB
MMUPageSize: 4 kB可以看到,它包括:一个私有地址空间,这从 rw-p 这个属性中的 private 可以看出来;以及一个保护页 ,这从—p 这个属性可以看出来,即进程无法访问。对于有经验的开发者而言,从这个 4K 的保护页就可以猜测出应该跟线程栈有关了。
然后我们跟踪下进程申请这部分地址空间的目的是什么,通过 strace 命令来跟踪系统调用就可以了。因为 VIRT 的增加,它的系统调用函数无非是 mmap 或者 brk,那么我们只需要 strace 的结果来看下 mmap 或 brk 就可以了。
用 strace 跟踪如下:
strace -t -f -p 31108 -o 31108.strace线程数较多,如果使用 -f 来跟踪线程,跟踪的信息量也很大,逐个搜索日志里面的 mmap 或者 brk 真是眼花缭乱, 所以我们来 grep 一下这个大小 (10489856 即 10244KB),然后过滤下就好了:
$ cat 31108.strace | grep 10489856
31152 23:00:00 mmap(NULL, 10489856, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS|MAP_STACK, -1, 0 <unfinished ...>
31151 23:01:00 mmap(NULL, 10489856, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS|MAP_STACK, -1, 0 <unfinished ...>
31157 23:02:00 mmap(NULL, 10489856, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS|MAP_STACK, -1, 0 <unfinished ...>
31158 23:03:00 mmap(NULL, 10489856, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS|MAP_STACK, -1, 0 <unfinished ...>
31165 23:04:00 mmap(NULL, 10489856, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS|MAP_STACK, -1, 0 <unfinished ...>
31163 23:05:00 mmap(NULL, 10489856, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS|MAP_STACK, -1, 0 <unfinished ...>
31153 23:06:00 mmap(NULL, 10489856, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS|MAP_STACK, -1, 0 <unfinished ...>
31155 23:07:00 mmap(NULL, 10489856, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS|MAP_STACK, -1, 0 <unfinished ...>
31149 23:08:00 mmap(NULL, 10489856, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS|MAP_STACK, -1, 0 <unfinished ...>
31147 23:09:00 mmap(NULL, 10489856, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS|MAP_STACK, -1, 0 <unfinished ...>
31159 23:10:00 mmap(NULL, 10489856, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS|MAP_STACK, -1, 0 <unfinished ...>
31157 23:11:00 mmap(NULL, 10489856, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS|MAP_STACK, -1, 0 <unfinished ...>
31148 23:12:00 mmap(NULL, 10489856, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS|MAP_STACK, -1, 0 <unfinished ...>
31150 23:13:00 mmap(NULL, 10489856, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS|MAP_STACK, -1, 0 <unfinished ...>
31173 23:14:00 mmap(NULL, 10489856, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS|MAP_STACK, -1, 0 <unfinished ...>从这个日志我们可以看到,出错的是 mmap() 这个系统调用,那我们再来看下 mmap 这个内存的目的:
31151 23:01:00 mmap(NULL, 10489856, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS|MAP_STACK, -1, 0 <unfinished ...>
31151 23:01:00 mprotect(0x7fa94bbc0000, 4096, PROT_NONE <unfinished ...> <<< 创建一个保护页
31151 23:01:00 clone( <unfinished ...> <<< 创建线程
31151 23:01:00 <... clone resumed> child_stack=0x7fa94c5afe50, flags=CLONE_VM|CLONE_FS|CLONE_FILES|CLONE_SIGHAND
|CLONE_THREAD|CLONE_SYSVSEM|CLONE_SETTLS|CLONE_PARENT_SETTID
|CLONE_CHILD_CLEARTID, parent_tidptr=0x7fa94c5c09d0, tls=0x7fa94c5c0700, child_tidptr=0x7fa94c5c09d0) = 20610可以看出,这是在 clone 时申请的线程栈。到这里你可能会有一个疑问:既然线程栈消耗了这么多的内存,那理应有很多才对啊?
但是实际上,系统中并没有很多 app_server 的线程,那这是为什么呢?答案其实比较简单:线程短暂执行完毕后就退出了,可是 mmap 的线程栈却没有被释放。
我们来写一个简单的程序复现这个现象,问题的复现是很重要的,如果很复杂的问题可以用简单的程序来复现,那就是最好的结果了。
如下是一个简单的复现程序:mmap 一个 40K 的线程栈,然后线程简单执行一下就退出。
#include <stdio.h>
#include <sys/mman.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
#define _SCHED_H
#define __USE_GNU
#include <bits/sched.h>
#define STACK_SIZE 40960
int func(void *arg) {
printf("thread enter.\n");
sleep(1);
printf("thread exit.\n");
return 0;
}
int main() {
int thread_pid;
int status;
int w;
while (1) {
void *addr = mmap(NULL, STACK_SIZE, PROT_READ | PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS | MAP_STACK, -1, 0);
if (addr == NULL) {
perror("mmap");
goto error;
}
printf("creat new thread...\n");
thread_pid = clone(&func, addr + STACK_SIZE,
CLONE_SIGHAND | CLONE_FS | CLONE_VM | CLONE_FILES, NULL);
printf("Done! Thread pid: %d\n", thread_pid);
if (thread_pid != -1) {
do {
w = waitpid(-1, NULL, __WCLONE | __WALL);
if (w == -1) {
perror("waitpid");
goto error;
}
} while (!WIFEXITED(status) && !WIFSIGNALED(status));
}
sleep(10);
}
error:
return 0;
}然后我们用 pidstat 观察该进程的执行,可以发现它的现象跟生产环境中的问题是一致的:
$ pidstat -r -p 535 5
11:56:51 PM UID PID minflt/s majflt/s VSZ RSS %MEM Command
11:56:56 PM 0 535 0.20 0.00 4364 360 0.00 a.out
11:57:01 PM 0 535 0.00 0.00 4364 360 0.00 a.out
11:57:06 PM 0 535 0.20 0.00 4404 360 0.00 a.out
11:57:11 PM 0 535 0.00 0.00 4404 360 0.00 a.out
11:57:16 PM 0 535 0.20 0.00 4444 360 0.00 a.out
11:57:21 PM 0 535 0.00 0.00 4444 360 0.00 a.out
11:57:26 PM 0 535 0.20 0.00 4484 360 0.00 a.out
11:57:31 PM 0 535 0.00 0.00 4484 360 0.00 a.out
11:57:36 PM 0 535 0.20 0.00 4524 360 0.00 a.out
^C
Average: 0 535 0.11 0.00 4435 360 0.00 a.out你可以看到,VSZ 每 10s 增大 40K,但是增加的那个线程只存在了 1s 就消失了。
至此我们就可以推断出 app_server 的代码哪里有问题了,然后小伙伴去修复该代码 Bug,很快就把该问题给解决了。
三、TCP重传问题
11 基础篇 | TCP连接的建立和断开受哪些系统配置影响?
11.1 TCP 连接的建立过程会受哪些配置项的影响?
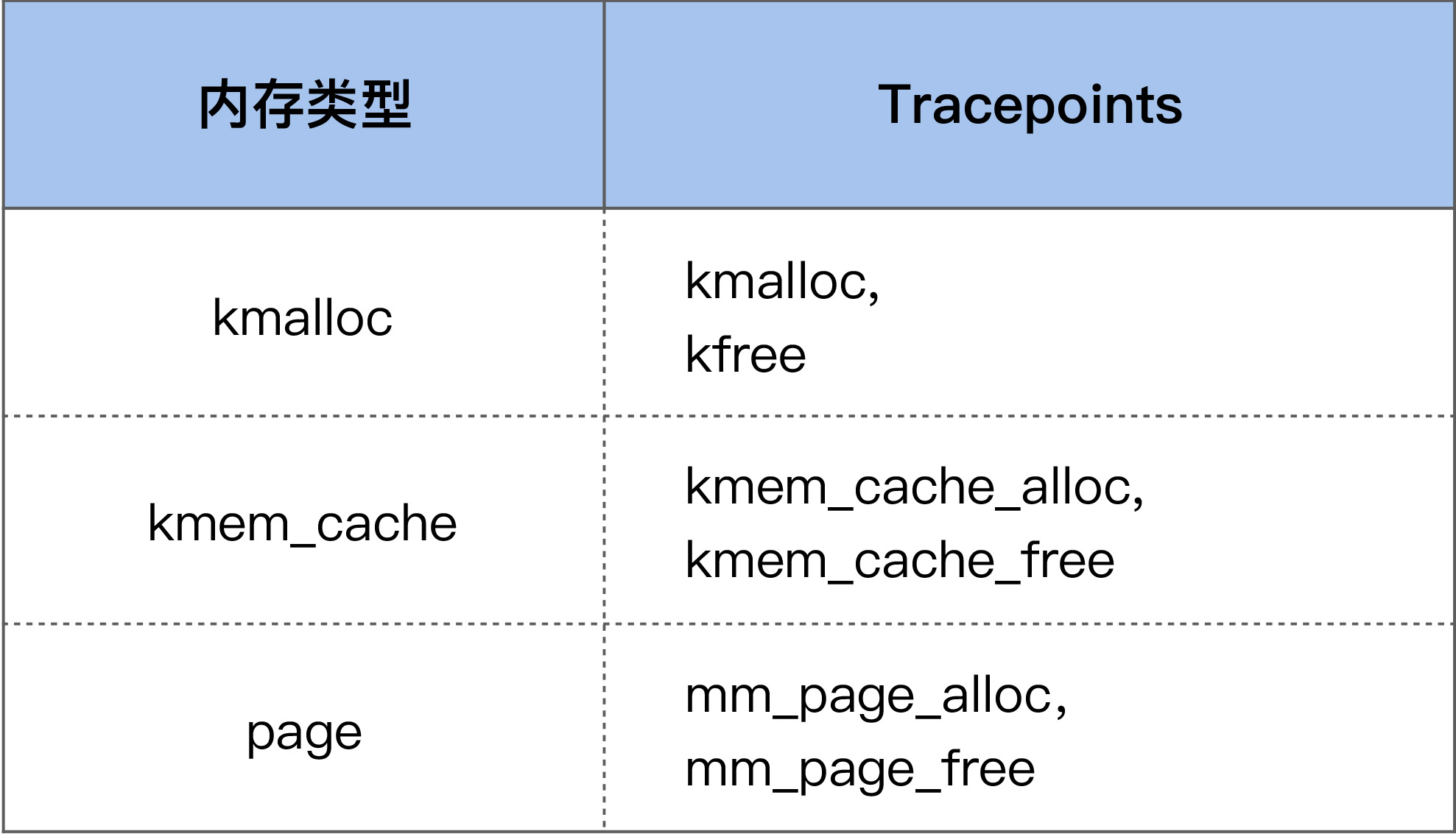
上图就是一个 TCP 连接的建立过程。TCP 连接的建立是一个从 Client 侧调用 connect(),到 Server 侧 accept() 成功返回的过程。你可以看到,在整个 TCP 建立连接的过程中,各个行为都有配置选项来进行控制。
Client 调用 connect() 后,Linux 内核就开始进行三次握手。
首先 Client 会给 Server 发送一个 SYN 包,但是该 SYN 包可能会在传输过程中丢失,或者因为其他原因导致 Server 无法处理,此时 Client 这一侧就会触发超时重传机制。但是也不能一直重传下去,重传的次数也是有限制的,这就是 tcp_syn_retries 这个配置项来决定的。
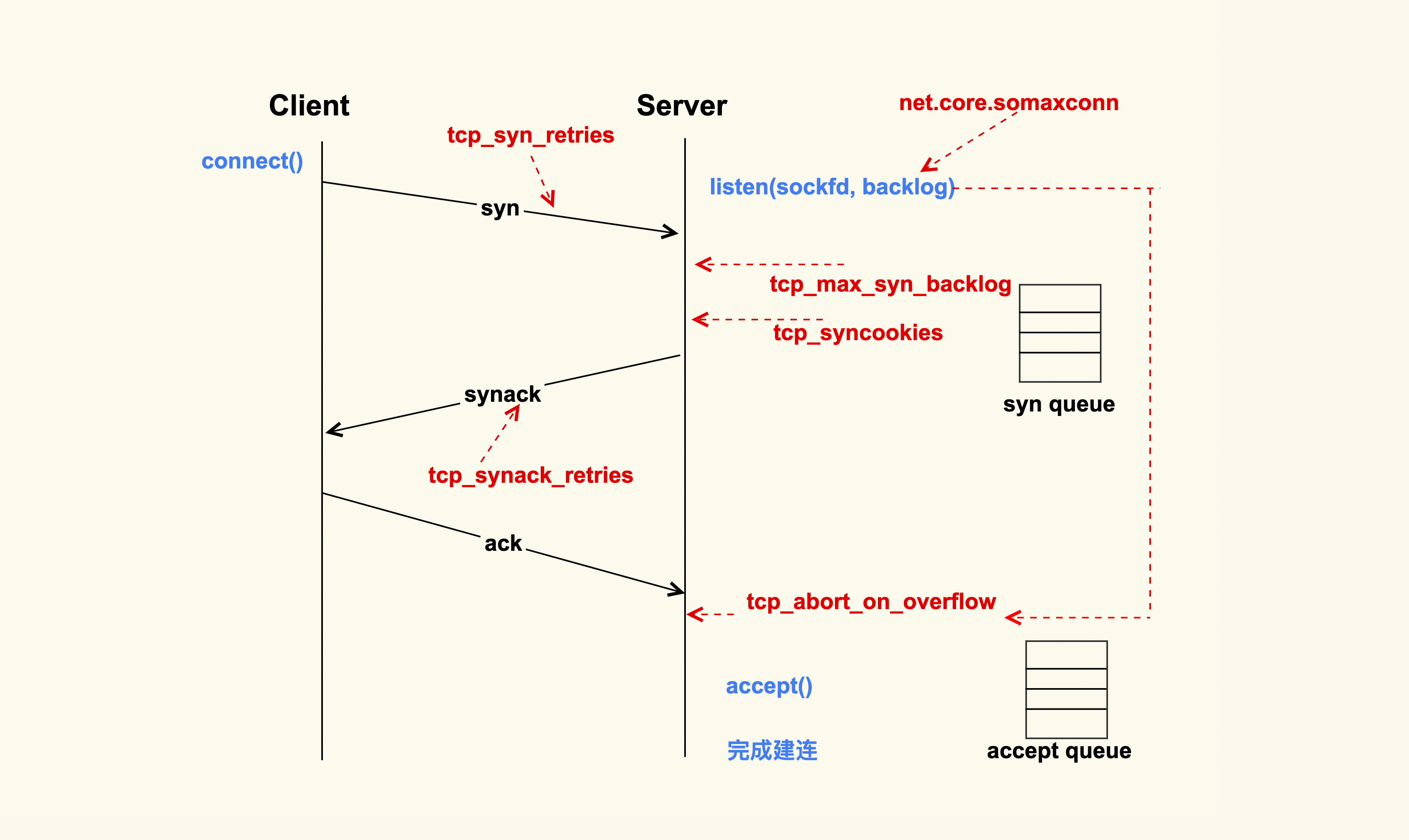
假设 tcp_syn_retires 为 3,那么 SYN 包重传的策略大致如下:
在 Client 发出 SYN 后,如果过了 1 秒 ,还没有收到 Server 的响应,那么就会进行第一次重传;如果经过 2s 的时间还没有收到 Server 的响应,就会进行第二次重传;一直重传 tcp_syn_retries 次。
tcp_syn_retries 的默认值是 6,也就是说如果 SYN 一直发送失败,会在(1 + 2 + 4 + 8 + 16+ 32 + 64)秒,即 127 秒后产生 ETIMEOUT 的错误。
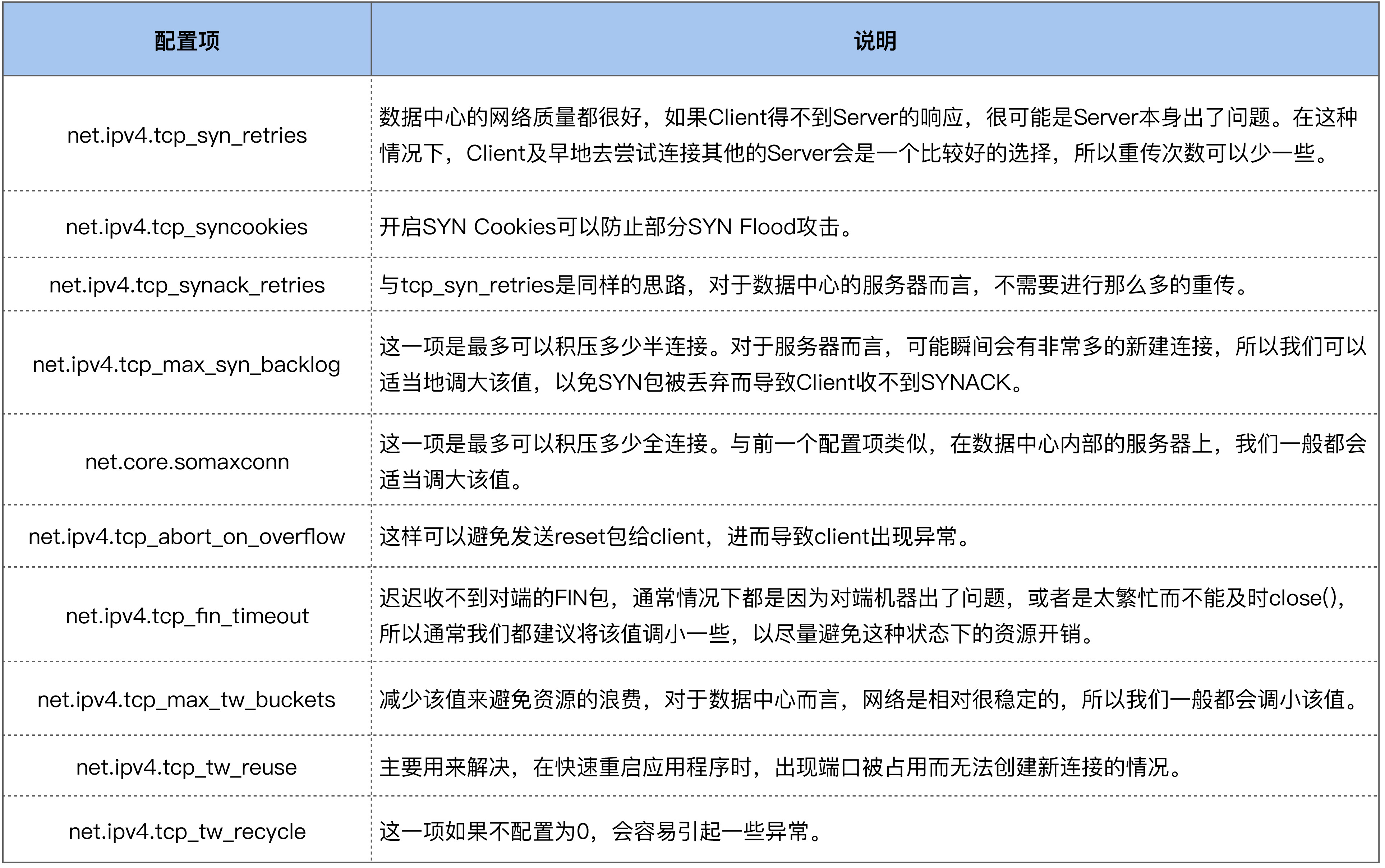
所以通常情况下,我们都会将数据中心内部服务器的 tcp_syn_retries 给调小,这里推荐设置为 2,来减少阻塞的时间。 因为对于数据中心而言,它的网络质量是很好的,如果得不到 Server 的响应,很可能是 Server 本身出了问题。在这种情况下,Client 及早地去尝试连接其他的 Server 会是一个比较好的选择,所以对于客户端而言,一般都会做如下调整:
net.ipv4.tcp_syn_retries = 2有些情况下 1s 的阻塞时间可能都很久,所以有的时候也会将三次握手的初始超时时间从默认值 1s 调整为一个较小的值,比如 100ms,这样整体的阻塞时间就会小很多。这也是数据中心内部经常进行一些网络优化的原因。
如果 Server 没有响应 Client 的 SYN,除了我们刚才提到的 Server 已经不存在了这种情况外,还有可能是因为 Server 太忙没有来得及响应,或者是 Server 已经积压了太多的半连接(incomplete)而无法及时去处理。
半连接,即收到了 SYN 后还没有回复 SYNACK 的连接,Server 每收到一个新的 SYN 包,都会创建一个半连接,然后把该半连接加入到半连接队列(syn queue)中。syn queue 的长度就是 tcp_max_syn_backlog 这个配置项来决定的,当系统中积压的半连接个数超过了该值后,新的 SYN 包就会被丢弃。对于服务器而言,可能瞬间会有非常多的新建连接,所以我们可以适当地调大该值,以免 SYN 包被丢弃而导致 Client 收不到 SYNACK:
net.ipv4.tcp_max_syn_backlog = 16384Server 中积压的半连接较多,也有可能是因为有些恶意的 Client 在进行 SYN Flood 攻击。
典型的 SYN Flood 攻击如下:Client 高频地向 Server 发 SYN 包,并且这个 SYN 包的源 IP 地址不停地变换,那么 Server 每次接收到一个新的 SYN 后,都会给它分配一个半连接,Server 的 SYNACK 根据之前的 SYN 包找到的是错误的 Client IP, 所以也就无法收到 Client 的 ACK 包,导致无法正确建立 TCP 连接,这就会让 Server 的半连接队列耗尽,无法响应正常的 SYN 包。
为了防止 SYN Flood 攻击,Linux 内核引入了 SYN Cookies 机制。SYN Cookie 的原理是什么样的呢?
在 Server 收到 SYN 包时,不去分配资源来保存 Client 的信息,而是根据这个 SYN 包计算出一个 Cookie 值,然后将 Cookie 记录到 SYNACK 包中发送出去。对于正常的连接,该 Cookies 值会随着 Client 的 ACK 报文被带回来。然后 Server 再根据这个 Cookie 检查这个 ACK 包的合法性,如果合法,才去创建新的 TCP 连接。通过这种处理,SYN Cookies 可以防止部分 SYN Flood 攻击。所以对于 Linux 服务器而言,推荐开启 SYN Cookies:
net.ipv4.tcp_syncookies = 1Server 向 Client 发送的 SYNACK 包也可能会被丢弃,或者因为某些原因而收不到 Client 的响应,这个时候 Server 也会重传 SYNACK 包。同样地,重传的次数也是由配置选项来控制的,该配置选项是 tcp_synack_retries。
tcp_synack_retries 的重传策略跟我们在前面讲的 tcp_syn_retries 是一致的,所以我们就不再画图来讲解它了。它在系统中默认是 5,对于数据中心的服务器而言,通常都不需要这么大的值,推荐设置为 2 :
net.ipv4.tcp_synack_retries = 2Client 在收到 Serve 的 SYNACK 包后,就会发出 ACK,Server 收到该 ACK 后,三次握手就完成了,即产生了一个 TCP 全连接(complete),它会被添加到全连接队列(accept queue)中。然后 Server 就会调用 accept() 来完成 TCP 连接的建立。
但是,就像半连接队列(syn queue)的长度有限制一样,全连接队列(accept queue)的长度也有限制,目的就是为了防止 Server 不能及时调用 accept() 而浪费太多的系统资源。
全连接队列(accept queue)的长度是由 listen(sockfd, backlog) 这个函数里的 backlog 控制的,而该 backlog 的最大值则是 somaxconn。somaxconn 在 5.4 之前的内核中,默认都是 128(5.4 开始调整为了默认 4096),建议将该值适当调大一些:
net.core.somaxconn = 16384当服务器中积压的全连接个数超过该值后,新的全连接就会被丢弃掉。Server 在将新连接丢弃时,有的时候需要发送 reset 来通知 Client,这样 Client 就不会再次重试了。不过,默认行为是直接丢弃不去通知 Client。至于是否需要给 Client 发送 reset,是由 tcp_abort_on_overflow 这个配置项来控制的,该值默认为 0,即不发送 reset 给 Client。推荐也是将该值配置为 0:
net.ipv4.tcp_abort_on_overflow = 0这是因为,Server 如果来不及 accept() 而导致全连接队列满,这往往是由瞬间有大量新建连接请求导致的,正常情况下 Server 很快就能恢复,然后 Client 再次重试后就可以建连成功了。也就是说,将 tcp_abort_on_overflow 配置为 0,给了 Client 一个重试的机会。当然,你可以根据你的实际情况来决定是否要使能该选项。
accept() 成功返回后,一个新的 TCP 连接就建立完成了,TCP 连接进入到了 ESTABLISHED 状态:
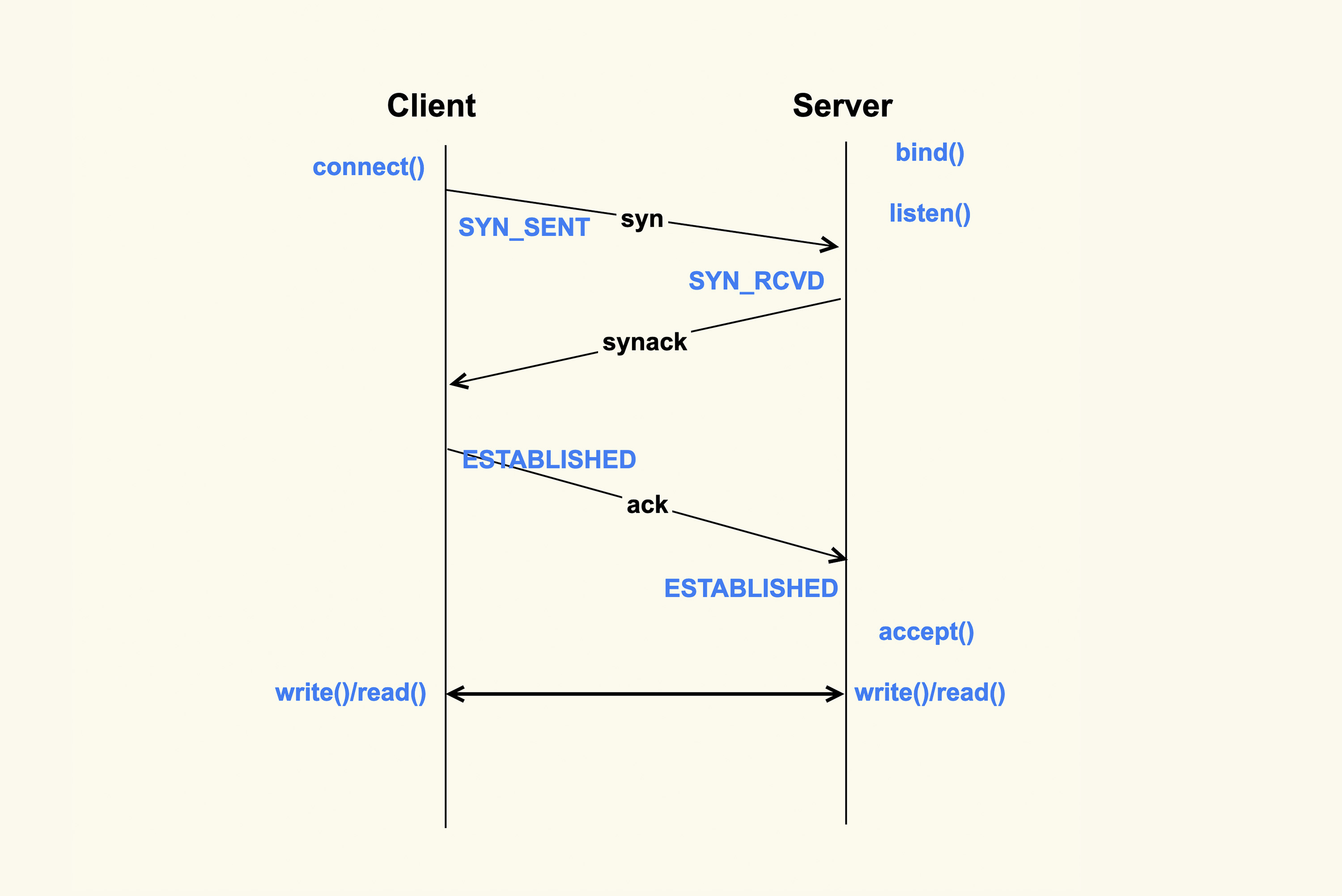
上图就是从 Client 调用 connect(),到 Server 侧 accept() 成功返回这一过程中的 TCP 状态转换。这些状态都可以通过 netstat 或者 ss 命令来看。至此,Client 和 Server 两边就可以正常通信了。
11.2 TCP 连接的断开过程会受哪些配置项的影响?
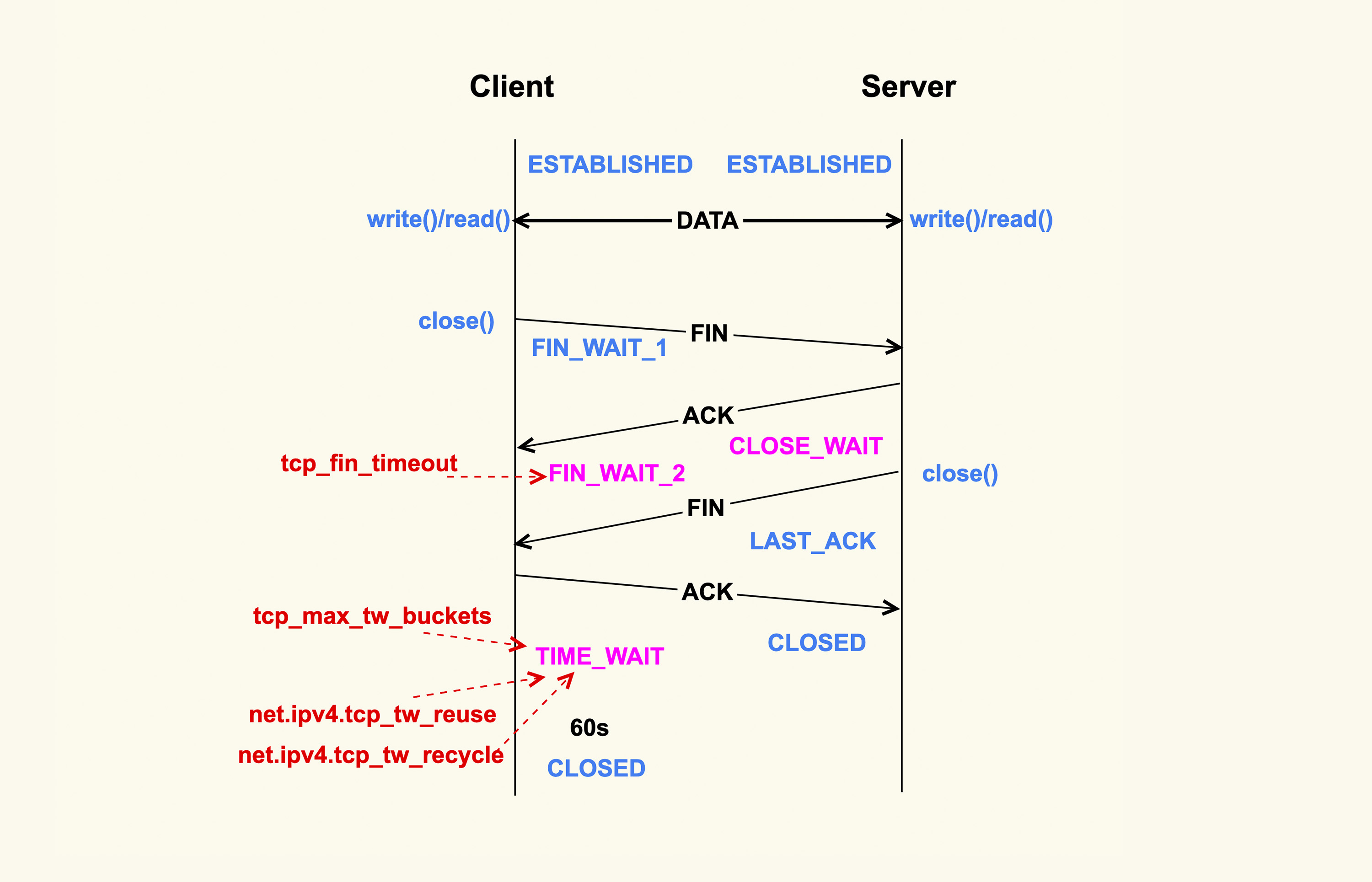
如上所示,当应用程序调用 close() 时,会向对端发送 FIN 包,然后会接收 ACK;对端也会调用 clsoe() 来发送 FIN,然后本端也会向对端回 ACK,这就是 TCP 的四次挥手过程。
首先调用 close() 的一侧是 active close(主动关闭);而接收到对端的 FIN 包后再调用 close() 来关闭的一侧,称之为 passive close(被动关闭)。在四次挥手的过程中,有三个 TCP 状态需要额外关注,就是上图中深红色的那三个状态:主动关闭方的 FIN_WAIT_2 和 TIME_WAIT,以及被动关闭方的 CLOSE_WAIT 状态。除了 CLOSE_WAIT 状态外,其余两个状态都有对应的系统配置项来控制。
我们首先来看 FIN_WAIT_2 状态,TCP 进入到这个状态后,如果本端迟迟收不到对端的 FIN 包,那就会一直处于这个状态,于是就会一直消耗系统资源。Linux 为了防止这种资源的开销,设置了这个状态的超时时间 tcp_fin_timeout,默认为 60s,超过这个时间后就会自动销毁该连接。
至于本端为何迟迟收不到对端的 FIN 包,通常情况下都是因为对端机器出了问题,或者是因为太繁忙而不能及时 close()。所以,通常我们都建议将 tcp_fin_timeout 调小一些,以尽量避免这种状态下的资源开销。对于数据中心内部的机器而言,将它调整为 2s 足以:
net.ipv4.tcp_fin_timeout = 2我们再来看 TIME_WAIT 状态,TIME_WAIT 状态存在的意义是:最后发送的这个 ACK 包可能会被丢弃掉或者有延迟,这样对端就会再次发送 FIN 包。如果不维持 TIME_WAIT 这个状态,那么再次收到对端的 FIN 包后,本端就会回一个 Reset 包,这可能会产生一些异常。
所以维持 TIME_WAIT 状态一段时间,可以保障 TCP 连接正常断开。TIME_WAIT 的默认存活时间在 Linux 上是 60s(TCP_TIMEWAIT_LEN),这个时间对于数据中心而言可能还是有些长了,所以有的时候也会修改内核做些优化来减小该值,或者将该值设置为可通过 sysctl 来调节。
TIME_WAIT 状态存在这么长时间,也是对系统资源的一个浪费,所以系统也有配置项来限制该状态的最大个数,该配置选项就是 tcp_max_tw_buckets。对于数据中心而言,网络是相对很稳定的,基本不会存在 FIN 包的异常,所以建议将该值调小一些:
net.ipv4.tcp_max_tw_buckets = 10000Client 关闭跟 Server 的连接后,也有可能很快再次跟 Server 之间建立一个新的连接,而由于 TCP 端口最多只有 65536 个,如果不去复用处于 TIME_WAIT 状态的连接,就可能在快速重启应用程序时,出现端口被占用而无法创建新连接的情况。所以建议你打开复用 TIME_WAIT 的选项:
net.ipv4.tcp_tw_reuse = 1还有另外一个选项 tcp_tw_recycle 来控制 TIME_WAIT 状态,但是该选项是很危险的,因为它可能会引起意料不到的问题,比如可能会引起 NAT 环境下的丢包问题。所以建议将该选项关闭:
net.ipv4.tcp_tw_recycle = 0对于 CLOSE_WAIT 状态而言,系统中没有对应的配置项。但是该状态也是一个危险信号,如果这个状态的 TCP 连接较多,那往往意味着应用程序有 Bug,在某些条件下没有调用 close() 来关闭连接。我们在生产环境上就遇到过很多这类问题。所以,如果你的系统中存在很多 CLOSE_WAIT 状态的连接,那你最好去排查一下你的应用程序,看看哪里漏掉了 close()。
11.3 总结
当然了,有些配置项也是可以根据你的服务器负载以及 CPU 和内存大小来做灵活配置的,比如 tcp_max_syn_backlog、somaxconn、tcp_max_tw_buckets 这三项,如果你的物理内存足够大、CPU 核数足够多,你可以适当地增大这些值,这些往往都是一些经验值。
12 基础篇 | TCP收发包过程会受哪些配置项影响?
12.1 TCP 数据包的发送过程会受什么影响?
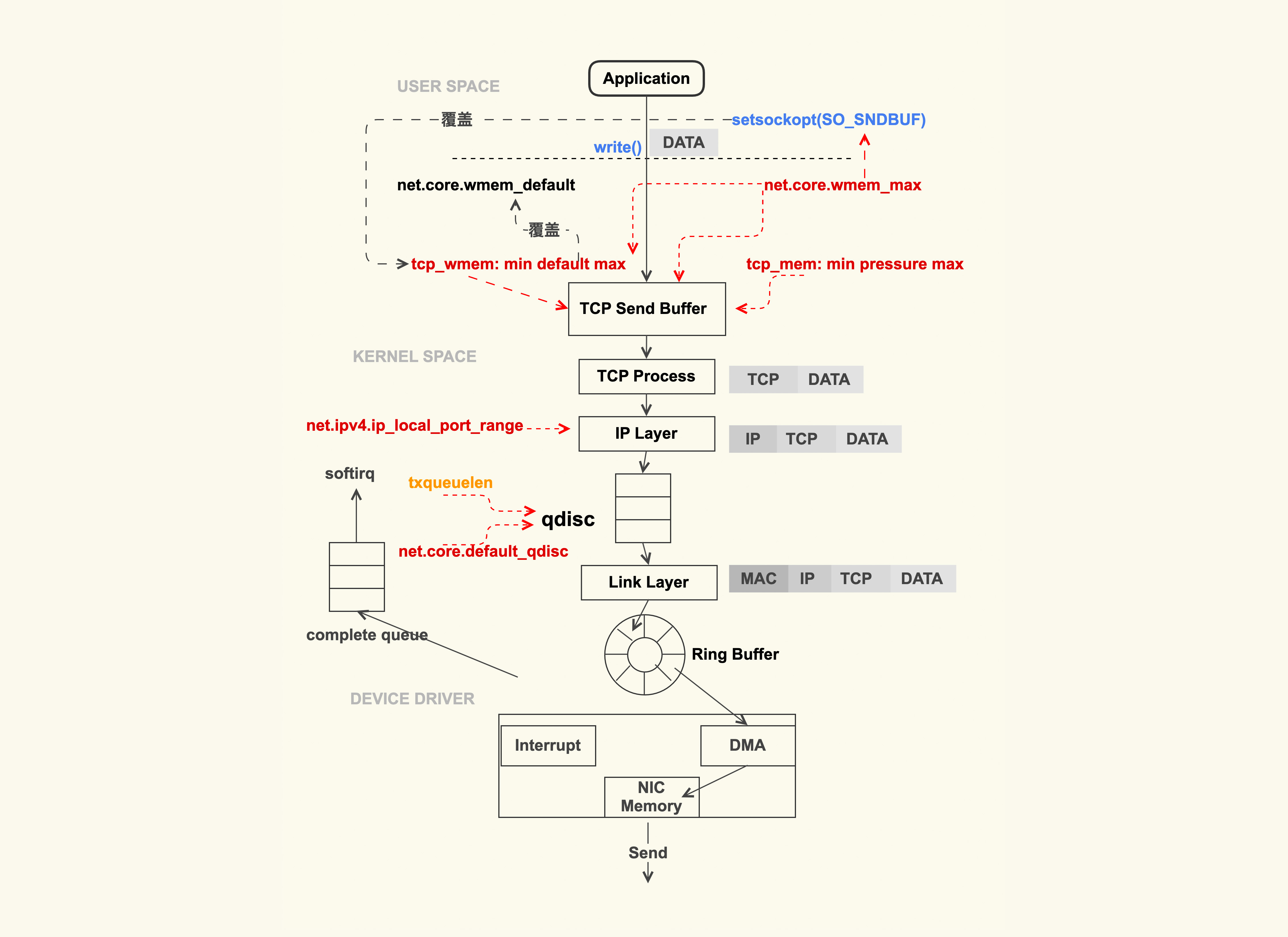
上图就是一个简略的 TCP 数据包的发送过程。应用程序调用 write(2) 或者 send(2) 系列系统调用开始往外发包时,这些系统调用会把数据包从用户缓冲区拷贝到 TCP 发送缓冲区(TCP Send Buffer),这个 TCP 发送缓冲区的大小是受限制的,这里也是容易引起问题的地方。
TCP 发送缓冲区的大小默认是受 net.ipv4.tcp_wmem 来控制:
net.ipv4.tcp_wmem = 8192 65536 16777216tcp_wmem 中这三个数字的含义分别为 min、default、max。TCP 发送缓冲区的大小会在 min 和 max 之间动态调整,初始的大小是 default,这个动态调整的过程是由内核自动来做的,应用程序无法干预。自动调整的目的,是为了在尽可能少的浪费内存的情况下来满足发包的需要。
tcp_wmem 中的 max 不能超过 net.core.wmem_max 这个配置项的值,如果超过了,TCP 发送缓冲区最大就是 net.core.wmem_max。通常情况下,我们需要设置 net.core.wmem_max 的值大于等于 net.ipv4.tcp_wmem 的 max:
net.core.wmem_max = 16777216对于 TCP 发送缓冲区的大小,我们需要根据服务器的负载能力来灵活调整。通常情况下我们需要调大它们的默认值,我上面列出的 tcp_wmem 的 min、default、max 这几组数值就是调大后的值,也是我们在生产环境中配置的值。
我之所以将这几个值给调大,是因为我们在生产环境中遇到过 TCP 发送缓冲区太小,导致业务延迟很大的问题,这类问题也是可以使用 systemtap 之类的工具在内核里面打点来进行观察的(观察 sk_stream_wait_memory 这个事件):
# sndbuf_overflow.stp
# Usage :
# $ stap sndbuf_overflow.stp
probe kernel.function("sk_stream_wait_memory")
{
printf("%d %s TCP send buffer overflow\n",
pid(), execname())
}如果你可以观察到 sk_stream_wait_memory 这个事件,就意味着 TCP 发送缓冲区太小了,你需要继续去调大 wmem_max 和 tcp_wmem:max 的值了。
应用程序有的时候会很明确地知道自己发送多大的数据,需要多大的 TCP 发送缓冲区,这个时候就可以通过 setsockopt(2) 里的 SO_SNDBUF 来设置固定的缓冲区大小。一旦进行了这种设置后,tcp_wmem 就会失效,而且这个缓冲区大小设置的是固定值,内核也不会对它进行动态调整。
但是,SO_SNDBUF 设置的最大值不能超过 net.core.wmem_max,如果超过了该值,内核会把它强制设置为 net.core.wmem_max。所以,如果你想要设置 SO_SNDBUF,一定要确认好 net.core.wmem_max 是否满足需求,否则你的设置可能发挥不了作用。通常情况下,我们都不会通过 SO_SNDBUF 来设置 TCP 发送缓冲区的大小,而是使用内核设置的 tcp_wmem,因为如果 SO_SNDBUF 设置得太大就会浪费内存,设置得太小又会引起缓冲区不足的问题。
另外,如果你关注过 Linux 的最新技术动态,你一定听说过 eBPF。你也可以通过 eBPF 来设置 SO_SNDBUF 和 SO_RCVBUF,进而分别设置 TCP 发送缓冲区和 TCP 接收缓冲区的大小。同样地,使用 eBPF 来设置这两个缓冲区时,也不能超过 wmem_max 和 rmem_max。
tcp_wmem 以及 wmem_max 的大小设置都是针对单个 TCP 连接的,这两个值的单位都是 Byte(字节)。系统中可能会存在非常多的 TCP 连接,如果 TCP 连接太多,就可能导致内存耗尽。因此,所有 TCP 连接消耗的总内存也有限制:
net.ipv4.tcp_mem = 8388608 12582912 16777216我们通常也会把这个配置项给调大。与前两个选项不同的是,该选项中这些值的单位是 Page(页数),也就是 4K。它也有 3 个值:min、pressure、max。当所有 TCP 连接消耗的内存总和达到 max 后,也会因达到限制而无法再往外发包。
因 tcp_mem 达到限制而无法发包或者产生抖动的问题,我们也是可以观测到的。为了方便地观测这类问题,Linux 内核里面预置了静态观测点:sock_exceed_buf_limit。观察时你只需要打开 tracepiont(需要 4.16+ 的内核版本):
echo 1 > /sys/kernel/debug/tracing/events/sock/sock_exceed_buf_limit/enable然后去看是否有该事件发生:
cat /sys/kernel/debug/tracing/trace_pipe如果有日志输出(即发生了该事件),就意味着你需要调大 tcp_mem 了,或者是需要断开一些 TCP 连接了。
TCP 层处理完数据包后,就继续往下来到了 IP 层。IP 层这里容易触发问题的地方是 net.ipv4.ip_local_port_range 这个配置选项,它是指和其他服务器建立 IP 连接时本地端口(local port)的范围。我们在生产环境中就遇到过默认的端口范围太小,以致于无法创建新连接的问题。所以通常情况下,我们都会扩大默认的端口范围:
net.ipv4.ip_local_port_range = 1024 65535为了能够对 TCP/IP 数据流进行流控,Linux 内核在 IP 层实现了 qdisc(排队规则)。我们平时用到的 TC 就是基于 qdisc 的流控工具。qdisc 的队列长度是我们用 ifconfig 来看到的 txqueuelen,我们在生产环境中也遇到过因为 txqueuelen 太小导致数据包被丢弃的情况,这类问题可以通过下面这个命令来观察:
$ ip -s -s link ls dev eth0
......
TX: bytes packets errors dropped carrier collsns
3263284 25060 0 0 0 0如果观察到 dropped 这一项不为 0,那就有可能是 txqueuelen 太小导致的。当遇到这种情况时,你就需要增大该值了,比如增加 eth0 这个网络接口的 txqueuelen:
ifconfig eth0 txqueuelen 2000或者使用 ip 这个工具:
ip link set eth0 txqueuelen 2000在调整了 txqueuelen 的值后,你需要持续观察是否可以缓解丢包的问题,这也便于你将它调整到一个合适的值。
Linux 系统默认的 qdisc 为 pfifo_fast(先进先出),通常情况下我们无需调整它。如果你想使用TCP BBR来改善 TCP 拥塞控制的话,那就需要将它调整为 fq(fair queue, 公平队列):
net.core.default_qdisc = fq经过 IP 层后,数据包再往下就会进入到网卡了,然后通过网卡发送出去。至此,你需要发送出去的数据就走完了 TCP/IP 协议栈,然后正常地发送给对端了。
12.2 TCP 数据包的接收过程会受什么影响?
TCP 数据包的接收过程,同样也可以用一张图来简单表示:
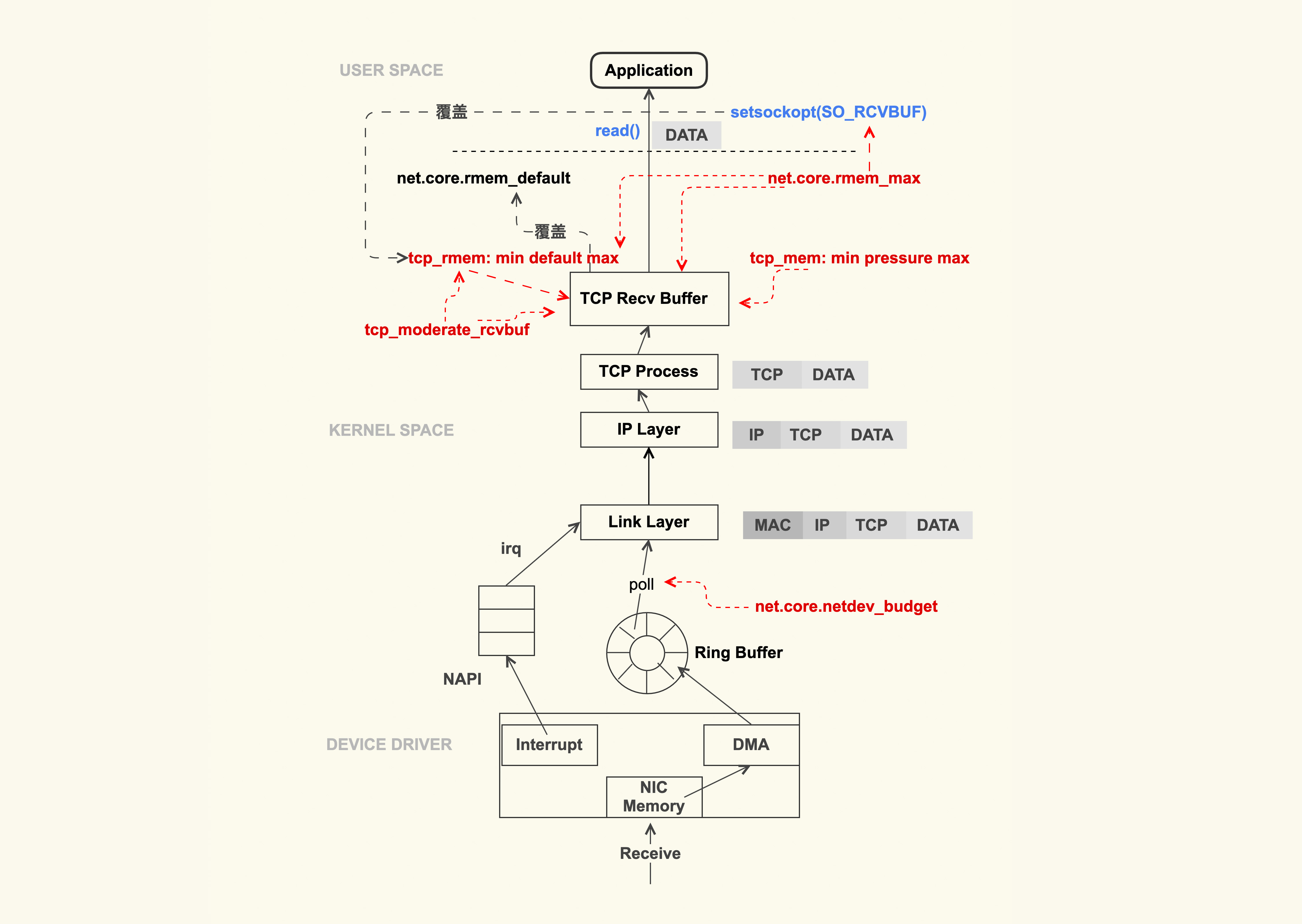
从上图可以看出,TCP 数据包的接收流程在整体上与发送流程类似,只是方向是相反的。数据包到达网卡后,就会触发中断(IRQ)来告诉 CPU 读取这个数据包。但是在高性能网络场景下,数据包的数量会非常大,如果每来一个数据包都要产生一个中断,那 CPU 的处理效率就会大打折扣,所以就产生了 NAPI(New API)这种机制让 CPU 一次性地去轮询(poll)多个数据包,以批量处理的方式来提升效率,降低网卡中断带来的性能开销。
那在 poll 的过程中,一次可以 poll 多少个呢?这个 poll 的个数可以通过 sysctl 选项来控制:
net.core.netdev_budget = 600该控制选项的默认值是 300,在网络吞吐量较大的场景中,我们可以适当地增大该值,比如增大到 600。增大该值可以一次性地处理更多的数据包。但是这种调整也是有缺陷的,因为这会导致 CPU 在这里 poll 的时间增加,如果系统中运行的任务很多的话,其他任务的调度延迟就会增加。
接下来继续看 TCP 数据包的接收过程。我们刚才提到,数据包到达网卡后会触发 CPU 去 poll 数据包,这些 poll 的数据包紧接着就会到达 IP 层去处理,然后再达到 TCP 层,这时就会面对另外一个很容易引发问题的地方了:TCP Receive Buffer(TCP 接收缓冲区)。
与 TCP 发送缓冲区类似,TCP 接收缓冲区的大小也是受控制的。通常情况下,默认都是使用 tcp_rmem 来控制缓冲区的大小。同样地,我们也会适当地增大这几个值的默认值,来获取更好的网络性能,调整为如下数值:
net.ipv4.tcp_rmem = 8192 87380 16777216它也有 3 个字段:min、default、max。TCP 接收缓冲区大小也是在 min 和 max 之间动态调整 ,不过跟发送缓冲区不同的是,这个动态调整是可以通过控制选项来关闭的,这个选项是 tcp_moderate_rcvbuf 。通常我们都是打开它,这也是它的默认值:
net.ipv4.tcp_moderate_rcvbuf = 1之所以接收缓冲区有选项可以控制自动调节,而发送缓冲区没有,那是因为 TCP 接收缓冲区会直接影响 TCP 拥塞控制,进而影响到对端的发包,所以使用该控制选项可以更加灵活地控制对端的发包行为。
除了 tcp_moderate_rcvbuf 可以控制 TCP 接收缓冲区的动态调节外,也可以通过 setsockopt() 中的配置选项 SO_RCVBUF 来控制,这与 TCP 发送缓冲区是类似的。如果应用程序设置了 SO_RCVBUF 这个标记,那么 TCP 接收缓冲区的动态调整就是关闭,即使 tcp_moderate_rcvbuf 为 1,接收缓冲区的大小始终就为设置的 SO_RCVBUF 这个值。
也就是说,只有在 tcp_moderate_rcvbuf 为 1,并且应用程序没有通过 SO_RCVBUF 来配置缓冲区大小的情况下,TCP 接收缓冲区才会动态调节。
同样地,与 TCP 发送缓冲区类似,SO_RCVBUF 设置的值最大也不能超过 net.core.rmem_max。通常情况下,我们也需要设置 net.core.rmem_max 的值大于等于 net.ipv4.tcp_rmem 的 max:
net.core.rmem_max = 1677721612.3 总结
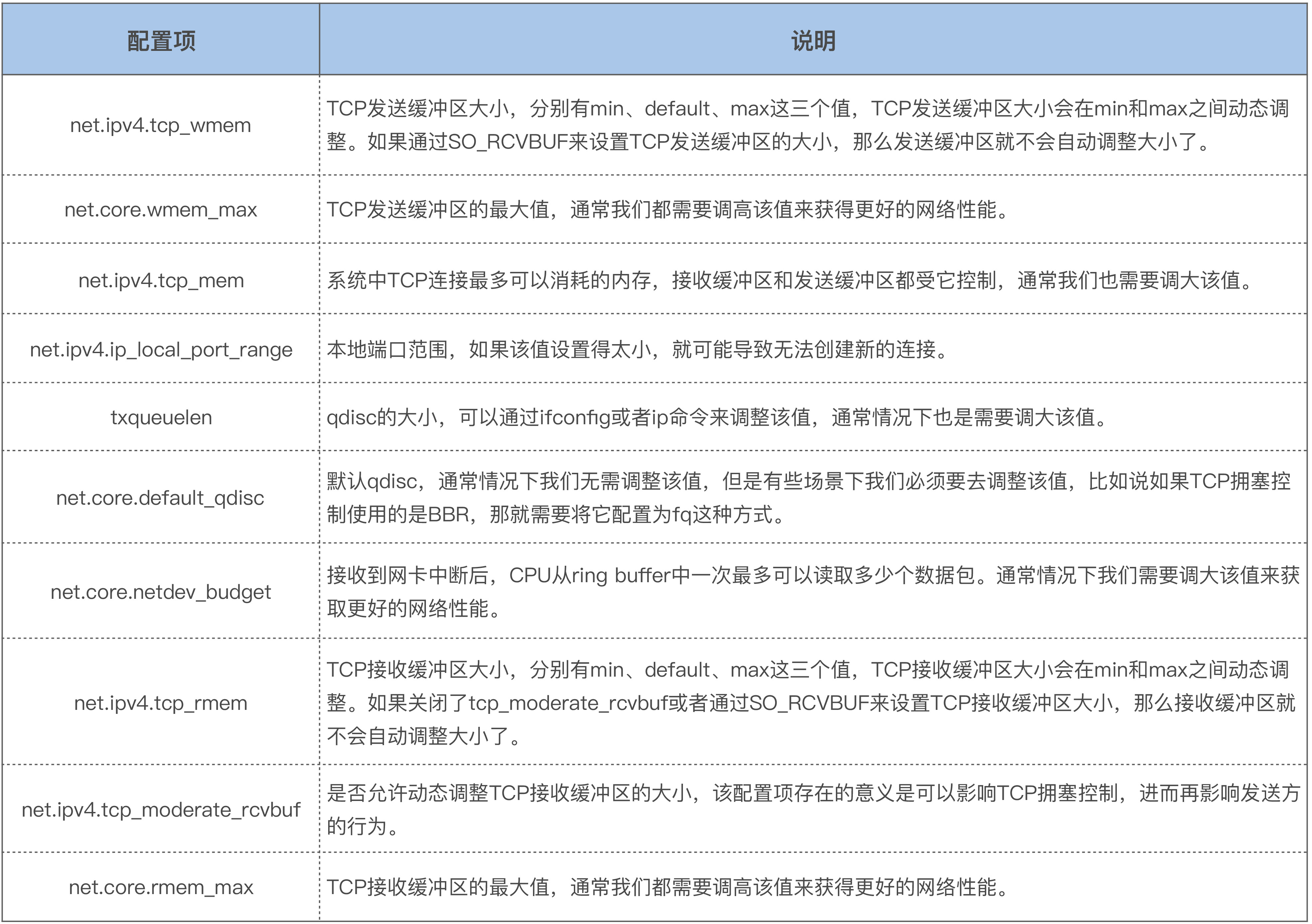
13 案例篇 | TCP拥塞控制是如何导致业务性能抖动的?
13.1 TCP 拥塞控制是如何对业务网络性能产生影响的 ?
我们先来看下 TCP 拥塞控制的大致原理。
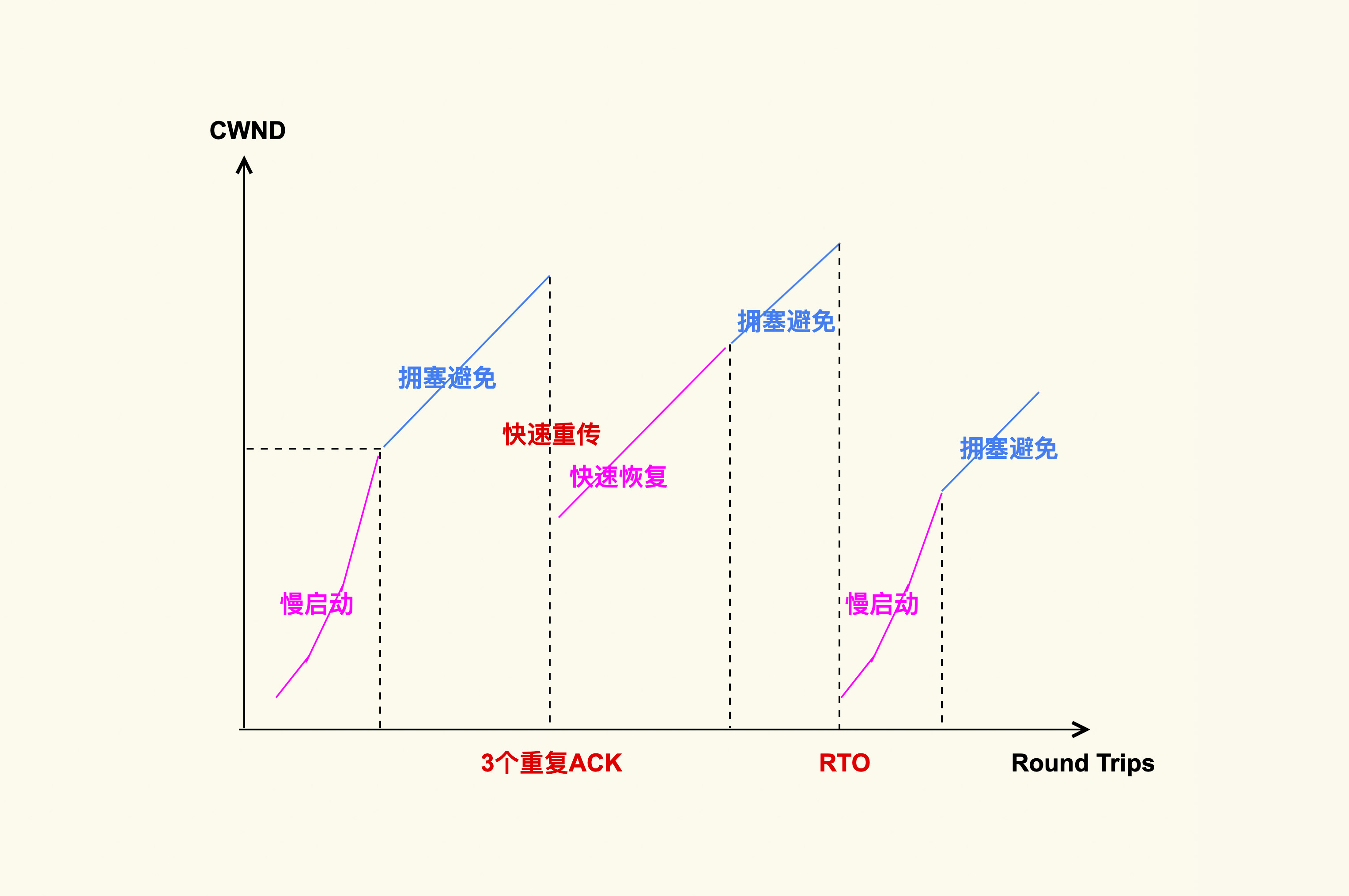
上图就是 TCP 拥塞控制的简单图示,它大致分为四个阶段。
慢启动
TCP 连接建立好后,发送方就进入慢速启动阶段,然后逐渐地增大发包数量(TCP Segments)。这个阶段每经过一个 RTT(round-trip time),发包数量就会翻倍。如下图所示:
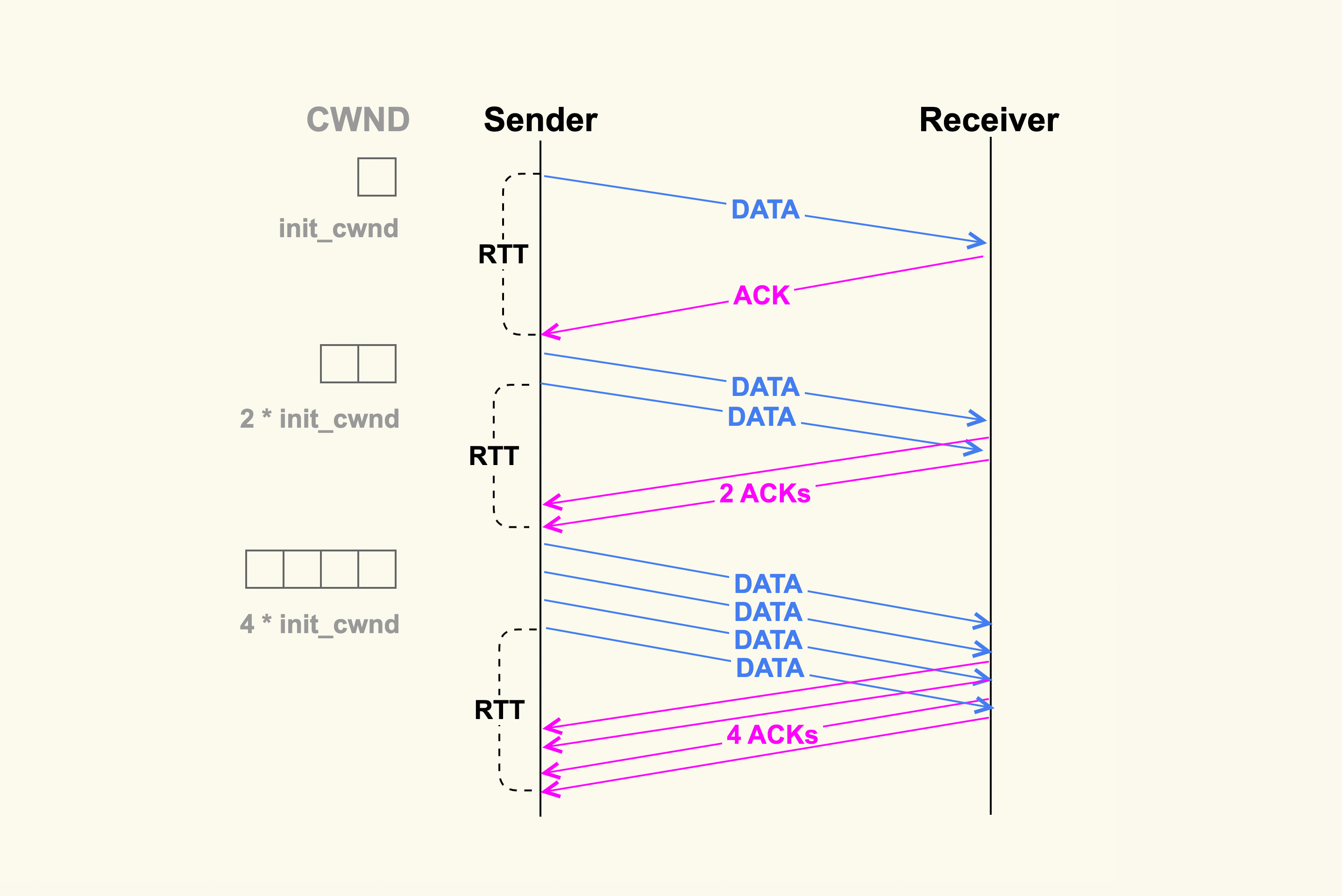
初始发送数据包的数量是由 init_cwnd(初始拥塞窗口)来决定的,该值在 Linux 内核中被设置为 10(TCP_INIT_CWND),这是由 Google 的研究人员总结出的一个经验值,这个经验值也被写入了RFC6928。并且,Linux 内核在 2.6.38 版本中也将它从默认值 3 修改为了 Google 建议的 10,你感兴趣的话可以看下这个 commit: tcp: Increase the initial congestion window to 10。
增大 init_cwnd 可以显著地提升网络性能,因为这样在初始阶段就可以一次性发送很多 TCP Segments,更加细节性的原因你可以参考RFC6928的解释。
增大 init_cwnd 的值对于提升短连接的网络性能会很有效,特别是数据量在慢启动阶段就能发送完的短连接,比如针对 http 这种服务,http 的短连接请求数据量一般不大,通常在慢启动阶段就能传输完,这些都可以通过 tcpdump 来进行观察。
在慢启动阶段,当拥塞窗口(cwnd)增大到一个阈值( ssthresh,慢启动阈值)后,TCP 拥塞控制就进入了下一个阶段:拥塞避免(Congestion Avoidance)。
拥塞避免
在这个阶段 cwnd 不再成倍增加,而是一个 RTT 增加 1,即缓慢地增加 cwnd,以防止网络出现拥塞。网络出现拥塞是难以避免的,由于网络链路的复杂性,甚至会出现乱序(Out of Order)报文。乱序报文产生原因之一如下图所示:
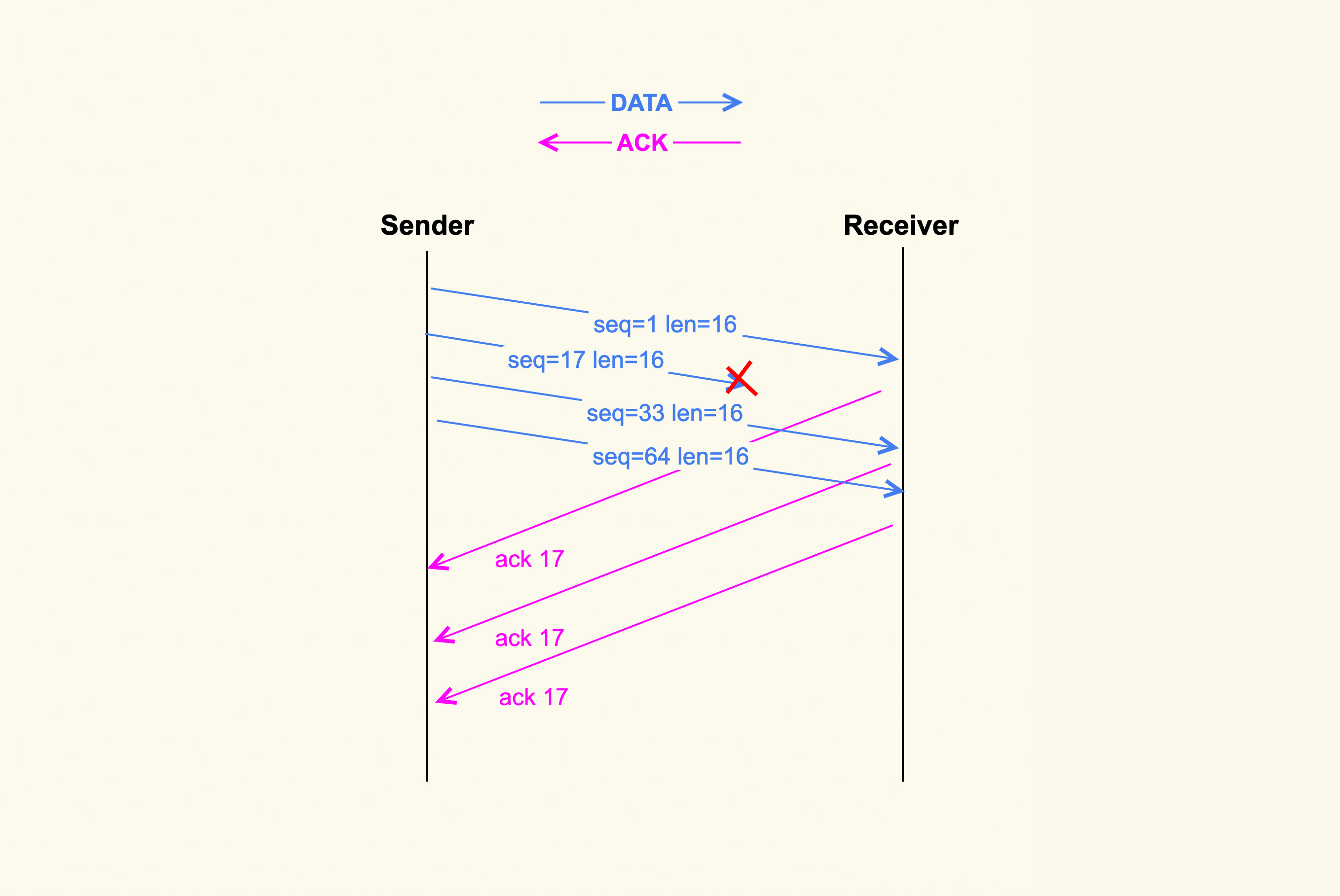
在上图中,发送端一次性发送了 4 个 TCP segments,但是第 2 个 segment 在传输过程中被丢弃掉了,那么接收方就接收不到该 segment 了。然而第 3 个 TCP segment 和第 4 个 TCP segment 能够被接收到,此时 3 和 4 就属于乱序报文,它们会被加入到接收端的 ofo queue(乱序队列)里。
丢包这类问题在移动网络环境中比较容易出现,特别是在一个网络状况不好的环境中,比如在电梯里丢包率就会很高,而丢包率高就会导致网络响应特别慢。在数据中心内部的服务上很少会有数据包在网络链路中被丢弃的情况,我说的这类丢包问题主要是针对网关服务这种和外部网络有连接的服务上。
针对我们的网关服务,我们自己也做过一些 TCP 单边优化工作,主要是优化 Cubic 拥塞控制算法,以缓解丢包引起的网络性能下降问题。另外,Google 前几年开源的一个新的拥塞控制算法 BBR在理论上也可以很好地缓解 TCP 丢包问题,但是在我们的实践中,BBR 的效果并不好,因此我们最终也没有使用它。
我们再回到上面这张图,因为接收端没有接收到第 2 个 segment,因此接收端每次收到一个新的 segment 后都会去 ack 第 2 个 segment,即 ack 17。紧接着,发送端就会接收到三个相同的 ack(ack 17)。连续出现了 3 个响应的 ack 后,发送端会据此判断数据包出现了丢失,于是就进入了下一个阶段:快速重传。
快速重传和快速恢复
快速重传和快速恢复是一起工作的,它们是为了应对丢包这种行为而做的优化,在这种情况下,由于网络并没有出现拥塞,所以拥塞窗口不必恢复到初始值。判断丢包的依据就是收到 3 个相同的 ack。
Google 的工程师同样对 TCP 快速重传提出了一个改进策略:tcp early retrans,它允许一些情况下的 TCP 连接可以绕过重传延时(RTO)来进行快速重传。
除了快速重传外,还有一种重传机制是超时重传。不过,这是非常糟糕的一种情况。如果发送出去一个数据包,超过一段时间(RTO)都收不到它的 ack,那就认为是网络出现了拥塞。这个时候就需要将 cwnd 恢复为初始值,再次从慢启动开始调整 cwnd 的大小。
RTO 一般发生在网络链路有拥塞的情况下,如果某一个连接数据量太大,就可能会导致其他连接的数据包排队,从而出现较大的延迟。我们在开头提到的,下载电影影响到别人玩网络游戏的例子就是这个原因。
关于 RTO,它也是一个优化点。如果 RTO 过大的话,那么业务就可能要阻塞很久,所以在 3.1 版本的内核里引入了一种改进来将 RTO 的初始值从 3s 调整为 1s,这可以显著节省业务的阻塞时间。不过,RTO=1s 在某些场景下还是有些大了,特别是在数据中心内部这种网络质量相对比较稳定的环境中。
我们在生产环境中发生过这样的案例:业务人员反馈说业务 RT 抖动得比较厉害,我们使用 strace 初步排查后发现,进程阻塞在了 send() 这类发包函数里。然后我们使用 tcpdump 来抓包,发现发送方在发送数据后,迟迟不能得到对端的响应,一直到 RTO 时间再次重传。与此同时,我们还尝试了在对端也使用 tcpdump 来抓包,发现对端是过了很长时间后才收到数据包。因此,我们判断是网络发生了拥塞,从而导致对端没有及时收到数据包。
那么,针对这种网络拥塞引起业务阻塞时间太久的情况,有没有什么解决方案呢?一种解决方案是,创建 TCP 连接,使用 SO_SNDTIMEO 来设置发送超时时间,以防止应用在发包的时候阻塞在发送端太久,如下所示:
ret = setsockopt(sockfd, SOL_SOCKET, SO_SNDTIMEO, &timeout, len);当业务发现该 TCP 连接超时后,就会主动断开该连接,然后尝试去使用其他的连接。
这种做法可以针对某个 TCP 连接来设置 RTO 时间,那么,有没有什么方法能够设置全局的 RTO 时间(设置一次,所有的 TCP 连接都能生效)呢?答案是有的,这就需要修改内核。针对这类需求,我们在生产环境中的实践是:将 TCP RTO min、TCP RTO max、TCP RTO init 更改为可以使用 sysctl 来灵活控制的变量,从而根据实际情况来做调整,比如说针对数据中心内部的服务器,我们可以适当地调小这几个值,从而减少业务阻塞时间。
上述这 4 个阶段是 TCP 拥塞控制的基础,总体来说,拥塞控制就是根据 TCP 的数据传输状况来灵活地调整拥塞窗口,从而控制发送方发送数据包的行为。换句话说,拥塞窗口的大小可以表示网络传输链路的拥塞情况。TCP 连接 cwnd 的大小可以通过 ss 这个命令来查看:
$ ss -nipt State Recv-Q Send-Q Local Address:Port Peer Address:Port Process ESTAB 0 36 172.23.245.7:22 172.30.16.162:60490 users:(("sshd",pid=19256,fd=3)) cubic wscale:5,7 rto:272 rtt:71.53/1.068 ato:40 mss:1248 rcvmss:1248 advmss:1448 cwnd:10 bytes_acked:19591 bytes_received:2817 segs_out:64 segs_in:80 data_segs_out:57 data_segs_in:28 send 1.4Mbps lastsnd:6 lastrcv:6 lastack:6 pacing_rate 2.8Mbps delivery_rate 1.5Mbps app_limited busy:2016ms unacked:1 rcv_space:14600 minrtt:69.402通过该命令,我们可以发现这个 TCP 连接的 cwnd 为 10。
如果你想要追踪拥塞窗口的实时变化信息,还有另外一个更好的办法:通过 tcp_probe 这个 tracepoint 来追踪:
/sys/kernel/debug/tracing/events/tcp/tcp_probe但是这个 tracepoint 只有 4.16 以后的内核版本才支持,如果你的内核版本比较老,你也可以使用 tcp_probe 这个内核模块(net/ipv4/tcp_probe.c)来进行追踪。
除了网络状况外,发送方还需要知道接收方的处理能力。如果接收方的处理能力差,那么发送方就必须要减缓它的发包速度,否则数据包都会挤压在接收方的缓冲区里,甚至被接收方给丢弃掉。接收方的处理能力是通过另外一个窗口——rwnd(接收窗口)来表示的。那么,接收方的 rwnd 又是如何影响发送方的行为呢?
13.2 接收方是如何影响发送方发送数据的?
同样地,我也画了一张简单的图,来表示接收方的 rwnd 是如何影响发送方的:
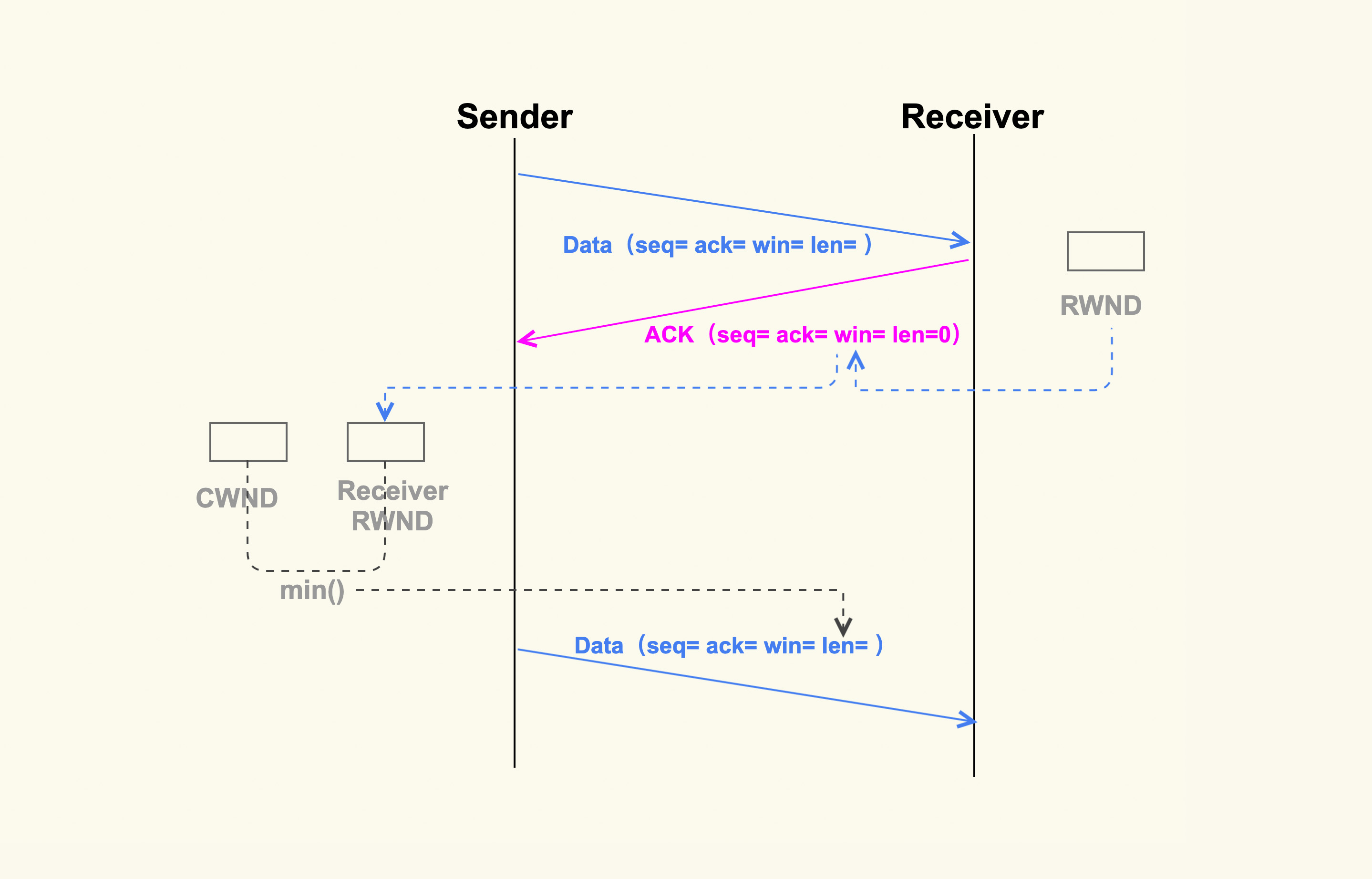
如上图所示,接收方在收到数据包后,会给发送方回一个 ack,然后把自己的 rwnd 大小写入到 TCP 头部的 win 这个字段,这样发送方就能根据这个字段来知道接收方的 rwnd 了。接下来,发送方在发送下一个 TCP segment 的时候,会先对比发送方的 cwnd 和接收方的 rwnd,得出这二者之间的较小值,然后控制发送的 TCP segment 个数不能超过这个较小值。
关于接收方的 rwnd 对发送方发送行为的影响,我们曾经遇到过这样的案例:业务反馈说 Server 向 Client 发包很慢,但是 Server 本身并不忙,而且网络看起来也没有问题,所以不清楚是什么原因导致的。对此,我们使用 tcpdump 在 server 上抓包后发现,Client 响应的 ack 里经常出现 win 为 0 的情况,也就是 Client 的接收窗口为 0。于是我们就去 Client 上排查,最终发现是 Client 代码存在 bug,从而导致无法及时读取收到的数据包。
如果系统中发生了接收窗口太小而无法收包的情况,就会产生TCPZeroWindowDrop事件,然后该事件可以通过 /proc/net/netstat 里的 TCPZeroWindowDrop 这个字段来查看。
因为 TCP 头部大小是有限制的,而其中的 win 这个字段只有 16bit,win 能够表示的大小最大只有 65535(64K),所以如果想要支持更大的接收窗口以满足高性能网络,我们就需要打开下面这个配置项,系统中也是默认打开了该选项:
net.ipv4.tcp_window_scaling = 1关于该选项更加详细的设计,你如果想了解的话,可以去参考RFC1323。
14 案例篇 | TCP端到端时延变大,怎样判断是哪里出现了问题?
14.1 如何分析 C/S 架构中的网络抖动问题?
上图就是一个典型的 C/S 架构,Client 和 Server 之间可能经过了很复杂的网络,但是对于服务器开发者或者运维人员而言,这些中间网络可以理解为是一个黑盒,很难去获取这些网络的详细信息,更不用说到这些网络设备上去做 debug 了。所以,我在这里把它们都简化为了一个 Router(路由器),然后 Client 和 Server 通过这个路由器来相互通信。比如互联网场景中的数据库服务(像 MySQL)、http 服务等都是这种架构。而当时给我们提需求来诊断网络抖动问题的也是 MySQL 业务。因此,接下来我们就以 MySQL 为例来进行具体讲解。
tcprstat 的大致原理是利用 MySQL 的 request-response 特征来简化对协议内容的处理。request-response 是指一个请求到达 MySQL 后,MySQL 处理完该请求,然后回 response,Client 侧收到 response 后再去发下一个 request,然后 MySQL 收到下一个 request 并处理。也就是说这种模型是典型的串行方式,处理完了一个再去处理下一个。所以 tcprstat 就可以以数据包到达 MySQL Server 侧作为起始时间点,以 MySQL 将最后一个数据包发出去作为结束时间点,然后这二者的时间差就是 RT(Response Time),这个过程大致如下图所示:
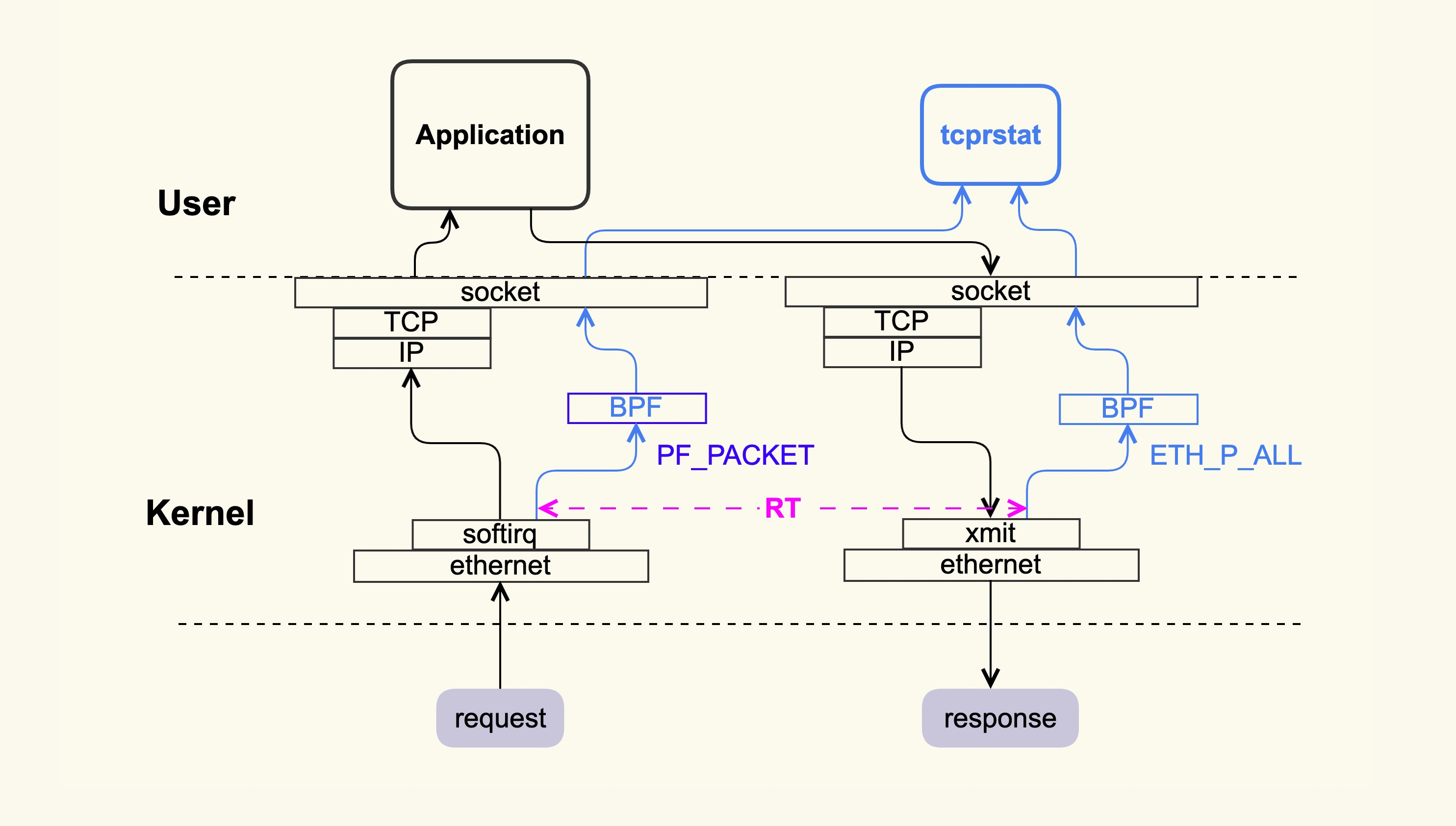
tcprstat 会记录 request 的到达时间点,以及 request 发出去的时间点,然后计算出 RT 并记录到日志中。当时我们把 tcprstat 部署到 MySQL server 侧后,发现每一个 RT 值都很小,并没有延迟很大的情况,所以看起来服务端并没有问题。那么问题是否发生在 Client 这里呢?
在我们想要把 tcprstat 也部署在 Client 侧抓取信息时,发现它只支持在 Server 侧部署,所以我们对 tcprstat 做了一些改造,让它也可以部署在 Client 侧。
在改造完成后,我们就开始部署 tcprstat 来抓取抖动现场了。在业务发生抖动时,通过我们抓取到的信息显示,Client 在收到响应包的时候就已经发生延迟了,也就是说问题同样也不是发生在 Client 侧。这就有些奇怪了,既然 Client 和 Server 都没有问题,难道是网络链路出现了问题?
为了明确这一点,我们就在业务低峰期使用 ping 包来检查网络是否存在问题。ping 了大概数小时后,我们发现 ping 响应时间忽然变得很大,从不到 1ms 的时间增大到了几十甚至上百 ms,然后很快又恢复正常。
据这个信息,我们推断某个交换机可能存在拥塞,于是就联系交换机管理人员来分析交换机。在交换机管理人员对这个链路上的交换机逐一排查后,最终定位到一台接入交换机确实有问题,它会偶然地出现排队很长的情况。而之所以 MySQL 反馈有抖动,其他业务没有反馈,只是因为这个接入交换机上的其他业务并不关心抖动。在交换机厂商帮忙修复了这个问题后,就再也没有出现过这种偶发性的抖动了。
14.2 如何轻量级地判断抖动发生在哪里?
我们的目标是在 10Gb 网卡的高并发场景下尽量地降低监控开销,最好可以控制在 1% 以内,而且不能给业务带来明显延迟。要想降低 CPU 开销,很多工作就需要在内核里面来完成,就跟现在很流行的 eBPF 这个追踪框架类似:内核处理完所有的数据,然后将结果返回给用户空间。
能够达到这个目标的方案大致有两种:一种是使用内核模块,另一种是使用轻量级的内核追踪框架。
使用内核模块的缺点是它的安装部署会很不方便,特别是在线上内核版本非常多的情况下。我们最终选择了基于 systemtap 这个追踪框架来开发。
基于 systemtap 实现的追踪框架大致如下图所示:
它会追踪每一个 TCP 流,TCP 流对应到内核里的实现就是一个 struct sock 实例,然后记录 TCP 流经过 A/B/C/D 这四个点的时刻,依据这几个时间点,我们就可以得到下面的结论:
- 如果 C-B 的时间差较大,那就说明 Server 侧有抖动,否则是 Client 或网络的问题;
- 如果 D-A 的时间差较小,那就说明是 Client 侧问题,否则是 Server 或者网络的问题。
这样在发生 RT 抖动时,我们就能够区分出抖动是发生在 Client,Server,还是网络中了,这会大大提升分析定位问题的效率。
在使用 systemtap 的过程中我们也踩了不少坑,在这里也分享给你,希望你可以避免:
- systemtap 的加载过程是一个开销很大的过程,主要是 CPU 的开销。因为 systemtap 的加载会编译 systemtap 脚本,这会比较耗时。你可以提前将你的 systemtap 脚本编译为内核模块,然后直接加载该模块来避免 CPU 开销;
- systemtap 有很多开销控制选项,你可以设置开销阈值来作为兜底方案,以防止异常情况下它占用太多 CPU;
- systemtap 进程异常退出后可能不会卸载 systemtap 模块,在你发现 systemtap 进程退出后,你需要检查它是否也把对应的内核模块给卸载了。如果没有,那你需要手动卸载一下,以免产生不必要的问题。
14.3 虚拟机场景下该如何判断抖动是发生在宿主机上还是虚拟机里?
随着云计算的发展,越来越多的业务开始部署在云上,很多企业或者使用自己定制的私有云,或者使用公有云。我们也有很多业务部署在自己的私有云中,既有基于 KVM 的虚拟机,也有基于 Kubernetes 和 Docker 的容器。以虚拟机为例,在 Server 侧发生抖动的时候,业务人员还想进一步知道,抖动是发生在 Server 侧的虚拟机内部,还是发生在 Server 侧的宿主机上。要想实现这个需求,我们只需要进一步扩展,再增加新的 hook 点,去记录 TCP 流经过虚拟机的时间点就好了,如下图所示:
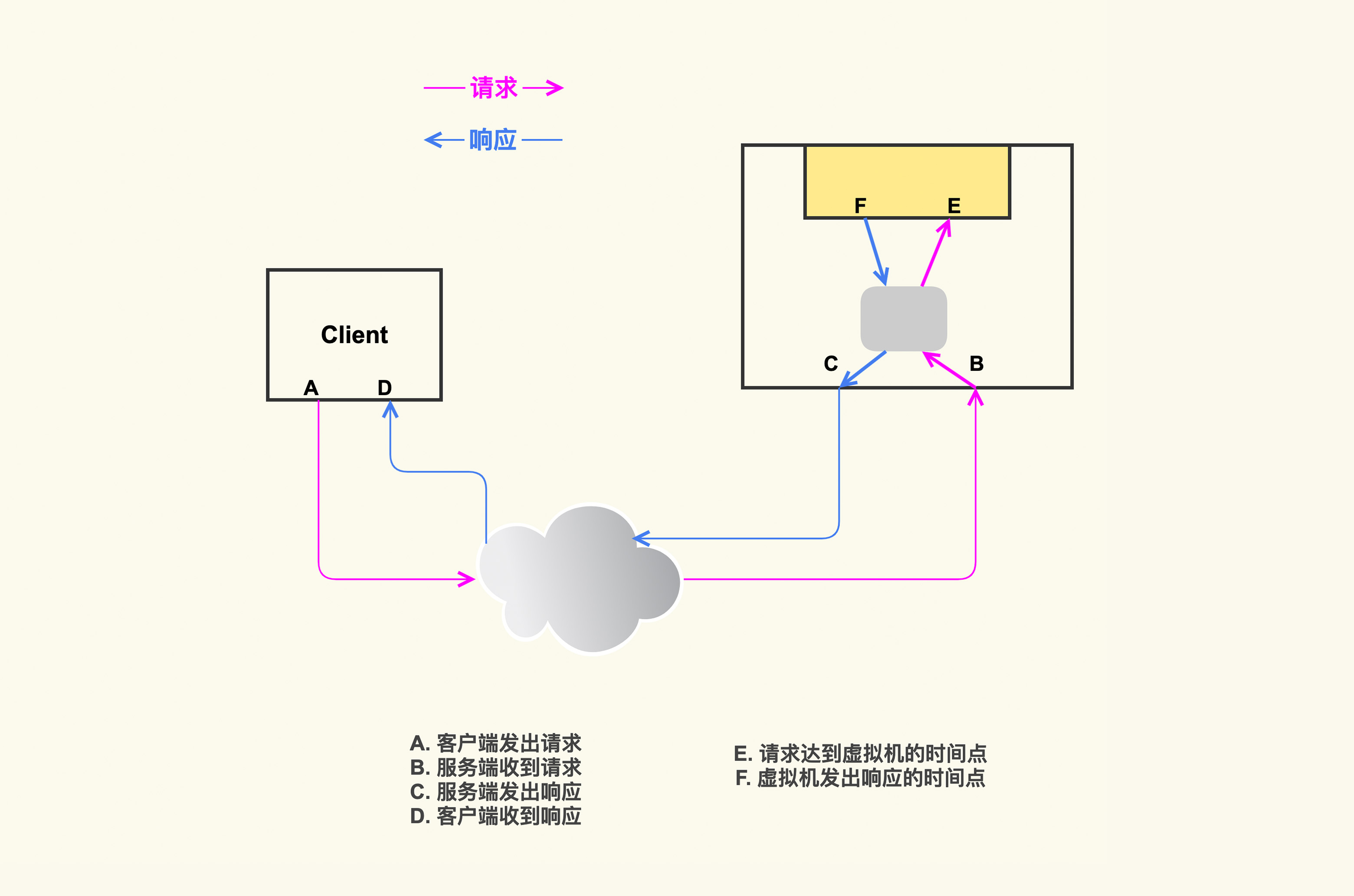
这样我们就可以根据 F 和 E 的时间差来判断抖动是否发生在虚拟机内部。针对这个需求,我们对 tcprstat 也做了类似的改造,让它可以识别出抖动是否发生在虚拟机内部。这个改造也不复杂,tcprstat 默认只处理目标地址为本机的数据包,不会处理转发包,所以我们让它支持混杂模式,然后就可以处理转发包了。当然,虚拟机的具体网络配置是千差万别的,你需要根据你的实际虚拟网络配置来做调整。
15 分析篇 | 如何高效地分析TCP重传问题?
15.1 什么是 TCP 重传 ?
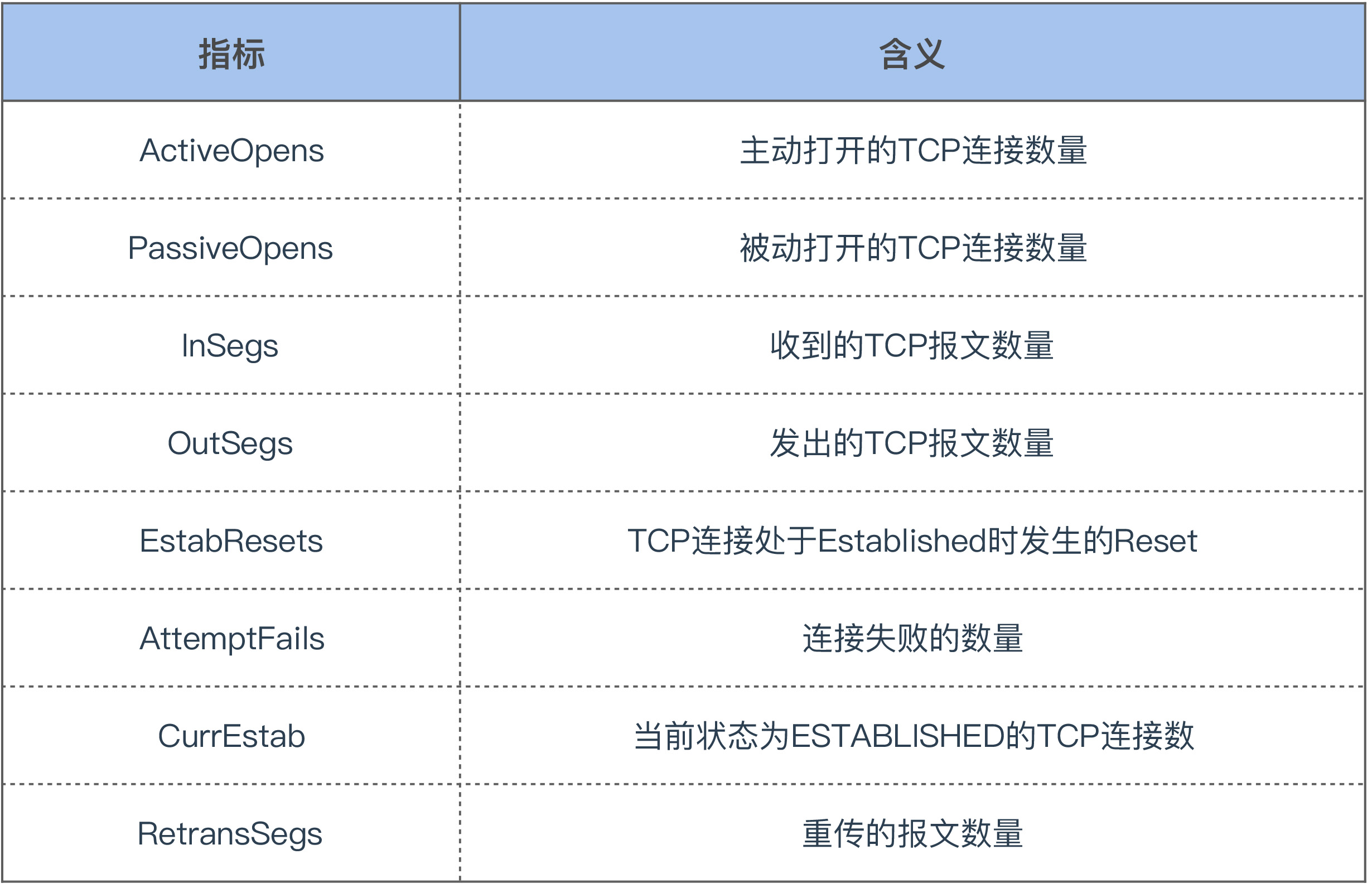
其实 TCP 重传率是通过解析 /proc/net/snmp 这个文件里的指标计算出来的,这个文件里面和 TCP 有关的关键指标如下:
TCP 重传率的计算公式如下:
retrans = (RetransSegs-last RetransSegs) / (OutSegs-last OutSegs) * 100
也就是说,单位时间内 TCP 重传包的数量除以 TCP 总的发包数量,就是 TCP 重传率。那我们继续看下这个公式中的 RetransSegs 和 OutSegs 是怎么回事,我画了两张示例图来演示这两个指标的变化:

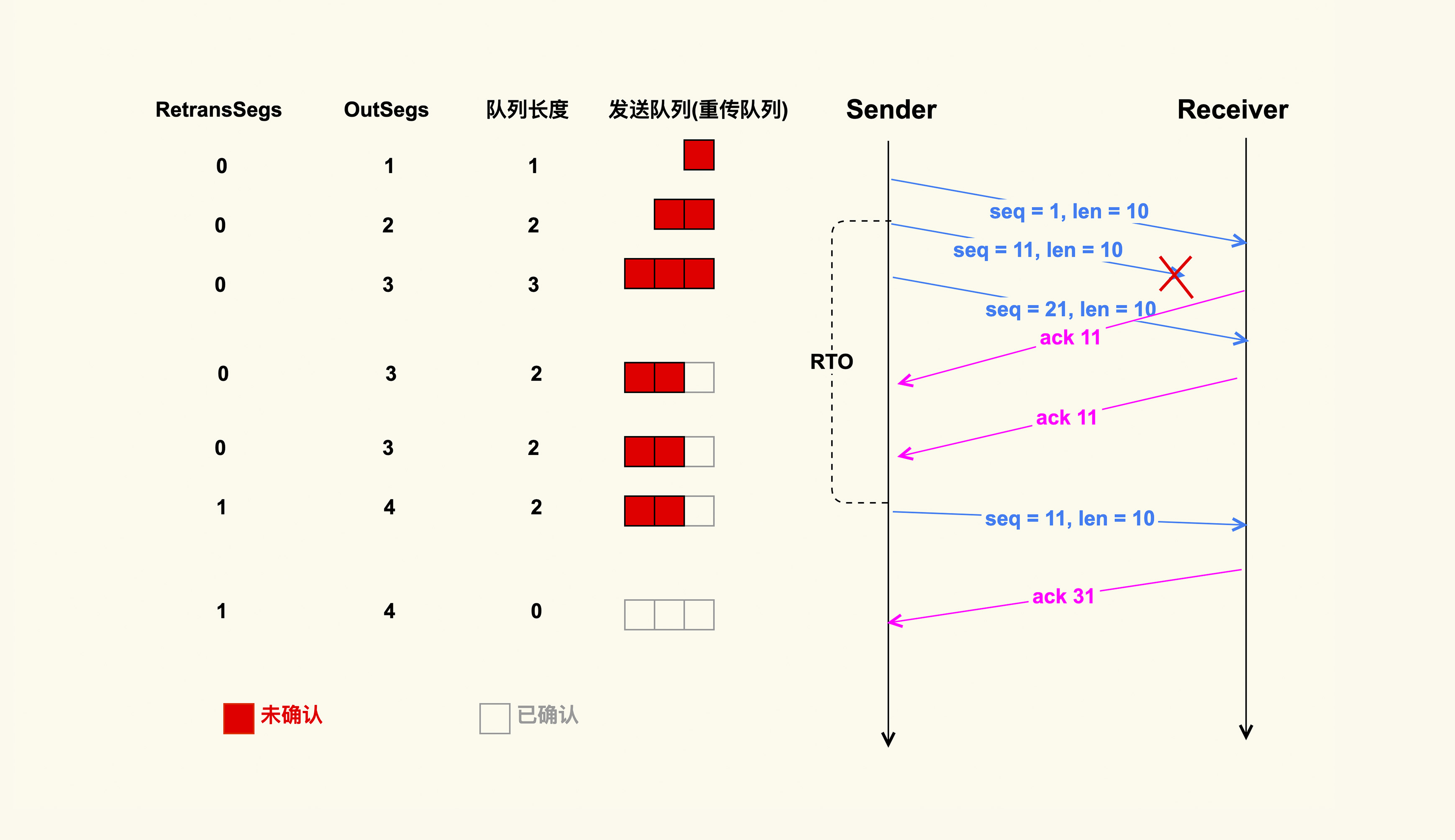
通过这两个示例图,你可以发现,发送端在发送一个 TCP 数据包后,会把该数据包放在发送端的发送队列里,也叫重传队列。此时,OutSegs 会相应地加 1,队列长度也为 1。如果可以收到接收端对这个数据包的 ACK,该数据包就会在发送队列中被删掉,然后队列长度变为 0;如果收不到这个数据包的 ACK,就会触发重传机制,我们在这里演示的就是超时重传这种情况,也就是说发送端在发送数据包的时候,会启动一个超时重传定时器(RTO),如果超过了这个时间,发送端还没有收到 ACK,就会重传该数据包,然后 OutSegs 加 1,同时 RetransSegs 也会加 1。
这就是 OutSegs 和 RetransSegs 的含义:每发出去一个 TCP 包(包括重传包),OutSegs 会相应地加 1;每发出去一个重传包,RetransSegs 会相应地加 1。同时,我也在图中展示了重传队列的变化,你可以仔细看下。
明白了 TCP 重传是如何定义的之后,我们继续来看下哪些情况会导致 TCP 重传。
引起 TCP 重传的情况在整体上可以分为如下两类。
丢包
TCP 数据包在网络传输过程中可能会被丢弃;接收端也可能会把该数据包给丢弃;接收端回的 ACK 也可能在网络传输过程中被丢弃;数据包在传输过程中发生错误而被接收端给丢弃……这些情况都会导致发送端重传该 TCP 数据包。
拥塞
TCP 数据包在网络传输过程中可能会在某个交换机 / 路由器上排队,比如臭名昭著的 Bufferbloat(缓冲膨胀);TCP 数据包在网络传输过程中因为路由变化而产生的乱序;接收端回的 ACK 在某个交换机 / 路由器上排队……这些情况都会导致发送端再次重传该 TCP 数据包。
总之,TCP 重传可以很好地作为通信质量的信号,我们需要去重视它。
15.2 分析 TCP 重传的常规手段
最常规的分析手段就是 tcpdump,我们可以使用它把进出某个网卡的数据包给保存下来:
tcpdump -s 0 -i eth0 -w tcpdumpfile然后在 Linux 上我们可以使用 tshark 这个工具(wireshark 的 Linux 版本)来过滤出 TCP 重传包:
tshark -r tcpdumpfile -R tcp.analysis.retransmission如果有重传包的话,就可以显示出来了,如下是一个 TCP 重传的示例:
3481 20.277303 10.17.130.20 -> 124.74.250.144 TCP 70 [TCP Retransmission] 35993 > https [SYN] Seq=0 Win=14600 Len=0 MSS=1460 SACK_PERM=1 TSval=3231504691 TSecr=0
3659 22.277070 10.17.130.20 -> 124.74.250.144 TCP 70 [TCP Retransmission] 35993 > https [SYN] Seq=0 Win=14600 Len=0 MSS=1460 SACK_PERM=1 TSval=3231506691 TSecr=0
8649 46.539393 58.216.21.165 -> 10.17.130.20 TLSv1 113 [TCP Retransmission] Change Cipher Spec, Encrypted Handshake Messag借助 tcpdump,我们就可以看到 TCP 重传的详细情况。从上面这几个 TCP 重传信息中,我们可以看到,这是发生在 10.17.130.20:35993 - 124.74.250.144: 443 这个 TCP 连接上的重传;通过[SYN]这个 TCP 连接状态,可以看到这是发生在三次握手阶段的重传。依据这些信息,我们就可以继续去 124.74.250.144 这个主机上分析 https 这个服务为什么无法建立新的连接了。
但是,我们都知道 tcpdump 很重,如果直接在生产环境上进行采集的话,难免会对业务造成性能影响。那有没有更加轻量级的一些分析方法呢?
15.3 如何高效地分析 TCP 重传 ?
其实,就像应用程序实现一些功能需要调用对应的函数一样,TCP 重传也需要调用特定的内核函数。这个内核函数就是 tcp_retransmit_skb()。你可以把这个函数名字里的 skb 理解为是一个需要发送的网络包。那么,如果我们想要高效地追踪 TCP 重传情况,那么直接追踪该函数就可以了。
追踪内核函数最通用的方法是使用 Kprobe,Kprobe 的大致原理如下:
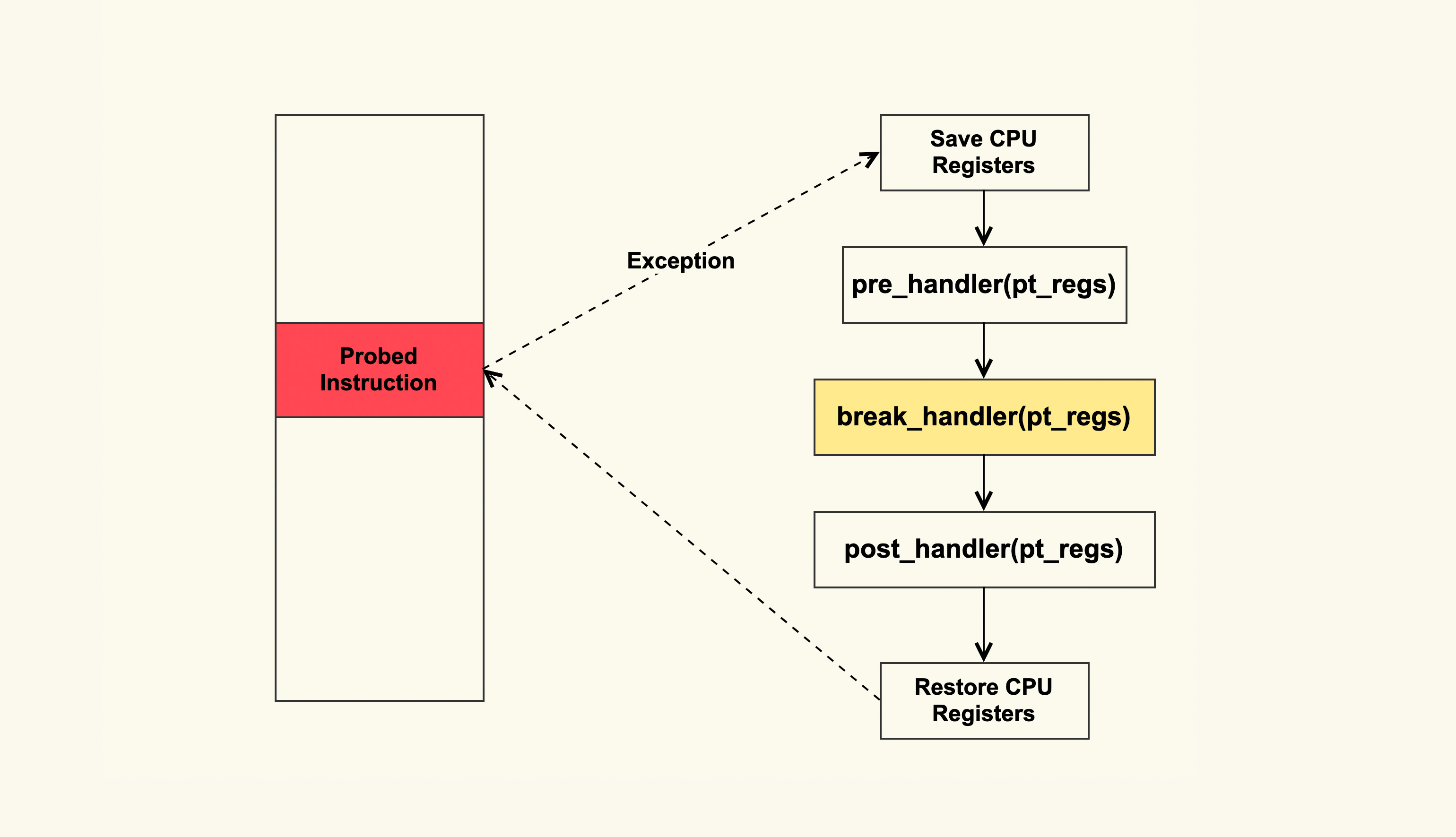
你可以实现一个内核模块,该内核模块中使用 Kprobe 在 tcp_retransmit_skb 这个函数入口插入一个 probe,然后注册一个 break_handler,这样在执行到 tcp_retransmit_skb 时就会异常跳转到注册的 break_handler 中,然后在 break_handler 中解析 TCP 报文(skb)就可以了,从而来判断是什么在重传。
如果你觉得实现内核模块比较麻烦,可以借助 ftrace 框架来使用 Kprobe。Brendan Gregg 实现的tcpretrans采用的就是这种方式,你也可以直接使用它这个工具来追踪 TCP 重传。不过,该工具也有一些缺陷,因为它是通过读取 /proc/net/tcp 这个文件来解析是什么在重传,所以它能解析的信息比较有限,而且如果 TCP 连接持续时间较短(比如短连接),那么该工具就无法解析出来了。另外,你在使用它时需要确保你的内核已经打开了 ftrace 的 tracing 功能,也就是 /sys/kernel/debug/tracing/tracing_on 中的内容需要为 1;在 CentOS-6 上,还需要 /sys/kernel/debug/tracing/tracing_enabled 也为 1。
$ cat /sys/kernel/debug/tracing/tracing_on
1如果为 0 的话,你需要打开它们,例如:
echo 1 > /sys/kernel/debug/tracing/tracing_on然后在追踪结束后,你需要来关闭他们:
echo 0 > /sys/kernel/debug/tracing/tracing_on由于 Kprobe 是通过异常(Exception)这种方式来工作的,所以它还是有一些性能开销的,在 TCP 发包快速路径上还是要避免使用 Kprobe。不过,由于重传路径是慢速路径,所以在重传路径上添加 Kprobe 也无需担心性能开销。
Kprobe 这种方式使用起来还是略有些不便,为了让 Linux 用户更方便地观察 TCP 重传事件,4.16 内核版本中专门添加了TCP tracepoint来解析 TCP 重传事件。如果你使用的操作系统是 CentOS-7 以及更老的版本,就无法使用该 Tracepoint 来观察了;如果你的版本是 CentOS-8 以及后续更新的版本,那你可以直接使用这个 Tracepoint 来追踪 TCP 重传,可以使用如下命令:
cd /sys/kernel/debug/tracing/events/
echo 1 > tcp/tcp_retransmit_skb/enable然后你就可以追踪 TCP 重传事件了:
$ cat trace_pipe
<idle>-0 [007] ..s. 265119.290232: tcp_retransmit_skb: sport=22 dport=62264 saddr=172.23.245.8 daddr=172.30.18.225 saddrv6=::ffff:172.23.245.8 daddrv6=::ffff:172.30.18.225 state=TCP_ESTABLISHED追踪结束后呢,你需要将这个 Tracepoint 给关闭:
echo 0 > tcp/tcp_retransmit_skb/enable16 套路篇 | 如何分析常见的TCP问题?
16.1 在 Linux 上检查网络的常用工具
当服务器产生问题,而我们又不清楚问题和什么有关时,就需要运行一些工具来检查系统的整体状况。其中,dstat 是我们常用的一种检查工具:
$ dstat
--total-cpu-usage-- -dsk/total- -net/total- ---paging-- ---system--
usr sys idl wai stl| read writ| recv send| in out | int csw
8 1 91 0 0| 0 4096B|7492B 7757B| 0 0 |4029 7399
8 1 91 0 0| 0 0 |7245B 7276B| 0 0 |4049 6967
8 1 91 0 0| 0 144k|7148B 7386B| 0 0 |3896 6971
9 2 89 0 0| 0 0 |7397B 7285B| 0 0 |4611 7426
8 1 91 0 0| 0 0 |7294B 7258B| 0 0 |3976 7062如上所示,dstat 会显示四类系统资源的整体使用情况和两个关键的系统指标。这四类系统资源分别是:CPU、磁盘 I/O、 网络和内存。两个关键的系统指标是中断次数(int)和上下文切换次数(csw)。而每个系统资源又会输出它的一些关键指标,这里你需要注意以下几点:

如果你发现某一类系统资源对应的指标比较高,你就需要进一步针对该系统资源做更深入的分析。假设你发现网络吞吐比较高,那就继续观察网络的相关指标,你可以用 dstat -h 来查看,比如针对 TCP,就可以使用 dstat --tcp :
$ dstat --tcp
------tcp-sockets-------
lis act syn tim clo
27 38 0 0 0
27 38 0 0 0它会统计并显示系统中所有的 TCP 连接状态,这些指标的含义如下:

在得到了 TCP 连接的整体状况后,如果你想要看 TCP 连接的详细信息,你可以使用 ss 这个命令来继续观察。通过 ss 你可以查看到每个 TCP 连接都是什么样的:
$ ss -natp
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN0 100 0.0.0.0:36457 0.0.0.0:* users:(("test",pid=11307,fd=17))
LISTEN0 5 0.0.0.0:33811 0.0.0.0:* users:(("test",pid=11307,fd=19))
ESTAB 0 0 127.0.0.1:57396 127.0.1.1:34751 users:(("test",pid=11307,fd=106))
ESTAB 0 0 127.0.0.1:57384 127.0.1.1:34751如上所示,我们能查看到每个 TCP 连接的状态(State)、接收队列大小(Recv-Q)、发送队列大小(Send-Q)、本地 IP 和端口(Local Address:Port )、远端 IP 和端口(Peer Address:Port)以及打开该 TCP 连接的进程信息。
除了 ss 命令外,你也可以使用 netstat 命令来查看所有 TCP 连接的详细信息:
netstat -natp不过,我不建议你使用 netstat,最好还是用 ss。因为 netstat 不仅比 ss 慢,而且开销也大。netstat 是通过直接读取 /proc/net/ 下面的文件来解析网络连接信息的;而 ss 使用的是 netlink 方式,这种方式的效率会高很多。
netlink 在解析时会依赖内核的一些诊断模块,比如解析 TCP 信息就需要 tcp_diag 这个诊断模块。如果诊断模块不存在,那么 ss 就无法使用 netlink 这种方式了,这个时候它就会退化到和 netstat 一样,也就是使用解析 /proc/net/ 这种方式,当然了,它的效率也会相应变差。
另外,如果你去看 netstat 手册,通过 man netstat,你会发现这样一句话”This program is obsolete. Replacement for netstat is ss”。所以,以后在分析网络连接问题时,我们尽量还是使用 ss,而不是 netstat。
netstat 属于 net-tools 这个比较古老的工具集,而 ss 属于 iproute2 这个工具集。net-tools 中的常用命令,几乎都可以用 iproute2 中的新命令来代替,比如:

除了查看系统中的网络连接信息外,我们有时候还需要去查看系统的网络状态,比如说系统中是否存在丢包,以及是什么原因引起了丢包,这时候我们就需要 netstat -s 或者它的替代工具 nstat 了:
$ nstat -z | grep -i drop
TcpExtLockDroppedIcmps 0 0.0
TcpExtListenDrops 0 0.0
TcpExtTCPBacklogDrop 0 0.0
TcpExtPFMemallocDrop 0 0.0
TcpExtTCPMinTTLDrop 0 0.0
TcpExtTCPDeferAcceptDrop 0 0.0
TcpExtTCPReqQFullDrop 0 0.0
TcpExtTCPOFODrop 0 0.0
TcpExtTCPZeroWindowDrop 0 0.0
TcpExtTCPRcvQDrop 0 0.0上面输出的这些信息就包括了常见的丢包原因,因为我的这台主机很稳定,所以你可以看到输出的结果都是 0。
16.2 分析网络问题你必须要掌握的工具:tcpdump
tcpdump 的大致原理如下图所示:
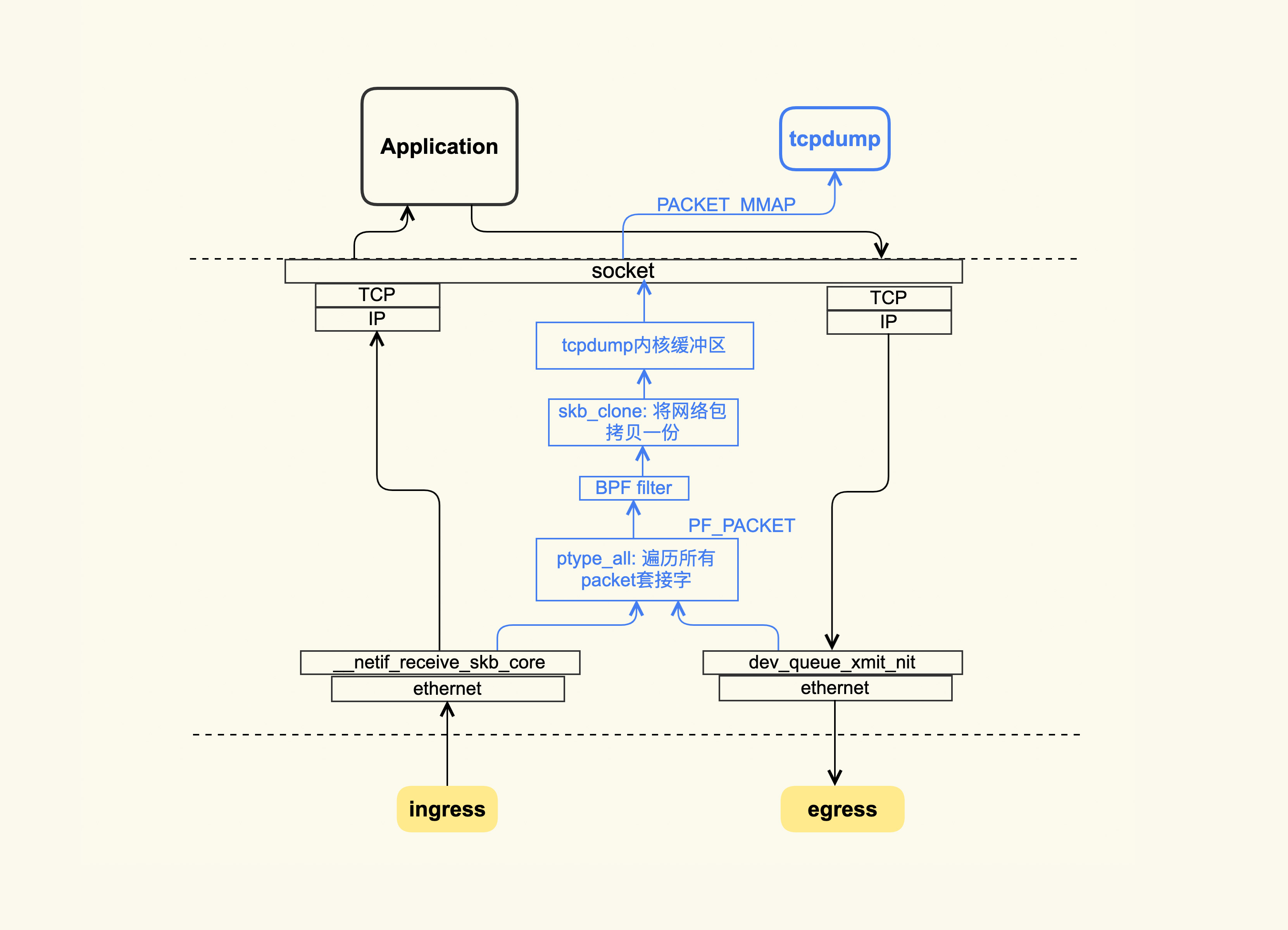
tcpdump 抓包使用的是 libpacp 这种机制。它的大致原理是:在收发包时,如果该包符合 tcpdump 设置的规则(BPF filter),那么该网络包就会被拷贝一份到 tcpdump 的内核缓冲区,然后以 PACKET_MMAP 的方式将这部分内存映射到 tcpdump 用户空间,解析后就会把这些内容给输出了。
通过上图你也可以看到,在收包的时候,如果网络包已经被网卡丢弃了,那么 tcpdump 是抓不到它的;在发包的时候,如果网络包在协议栈里被丢弃了,比如因为发送缓冲区满而被丢弃,tcpdump 同样抓不到它。我们可以将 tcpdump 的能力范围简单地总结为:网卡以内的问题可以交给 tcpdump 来处理;对于网卡以外(包括网卡上)的问题,tcpdump 可能就捉襟见肘了。这个时候,你需要在对端也使用 tcpdump 来抓包。
你还需要知道一点,那就是 tcpdump 的开销比较大,这主要在于 BPF 过滤器。如果系统中存在非常多的 TCP 连接,那么这个过滤的过程是非常耗时的,所以在生产环境中要慎用。但是,在出现网络问题时,如果你真的没有什么排查思路,那就想办法使用 tcpdump 来抓一下包吧,也许它的输出会给你带来一些意外的惊喜。
如果生产环境上运行着很重要的业务,你不敢使用 tcpdump 来抓包,那你就得去研究一些更加轻量级的追踪方式了。接下来,我给你推荐的轻量级追踪方式是 TCP Tracepoints。
16.3 TCP 疑难问题的轻量级分析手段:TCP Tracepoints
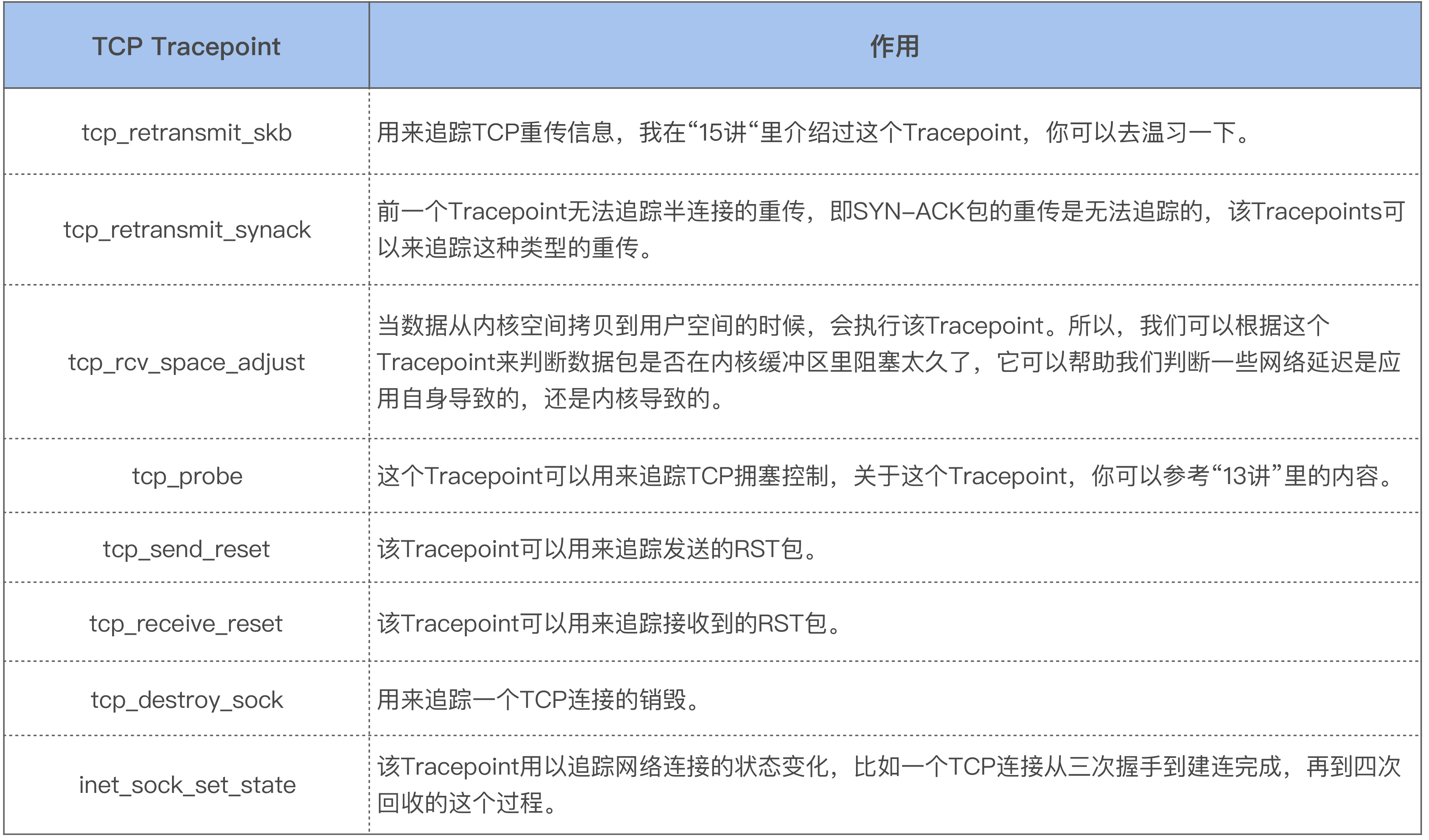
对于 TCP 的相关问题,我也习惯使用这些 TCP Tracepoints 来分析问题。要想使用这些 Tracepoints,你的内核版本需要为 4.16 及以上。这些常用的 TCP Tracepoints 路径位于 /sys/kernel/debug/tracing/events/tcp/ 和 /sys/kernel/debug/tracing/events/sock/,它们的作用如下表所示:
我们回到 TCP Tracepoints 这一轻量级的追踪方式。有一篇文章对它讲解得很好,就是 Brendan Gregg 写的TCP Tracepoints,这里面还详细介绍了基于 Tracepoints 的一些工具,如果你觉得用 Python 脚本解析 TCP Tracepoints 的输出有点麻烦,你可以直接使用里面推荐的那些工具。不过,你需要注意的是,这些工具都是基于 ebpf 来实现的,而 ebpf 有一个缺点,就是它在加载的时候 CPU 开销有些大。这是因为有一些编译工作比较消耗 CPU,所以你在使用这些命令时要先看下你的系统 CPU 使用情况。当 ebpf 加载起来后,CPU 开销就很小了,大致在 1% 以内。在停止 ebpf 工具的追踪时,也会有一些 CPU 开销,不过这个开销比加载时消耗的要小很多,但是你同样需要注意一下,以免影响到业务。
四、内核态CPU利用率飙高问题
17 基础篇 | CPU是如何执行任务的?
17.1 CPU 是如何读写数据的 ?
CPU 的架构图如下所示:
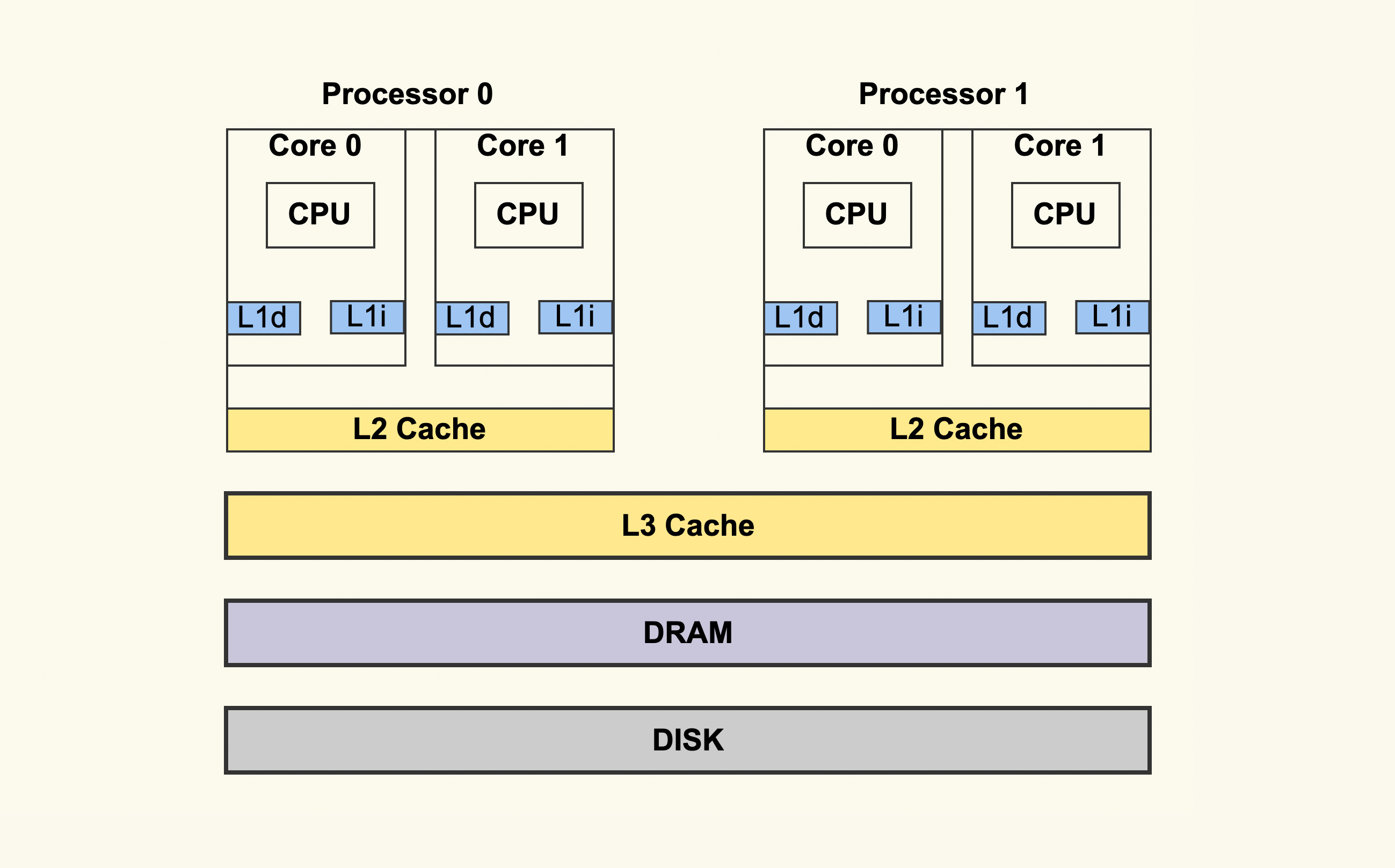
对于现代处理器而言,一个实体 CPU 通常会有两个逻辑线程,也就是上图中的 Core 0 和 Core 1。每个 Core 都有自己的 L1 Cache,L1 Cache 又分为 dCache 和 iCache,对应到上图就是 L1d 和 L1i。L1 Cache 只有 Core 本身可以看到,其他的 Core 是看不到的。同一个实体 CPU 中的这两个 Core 会共享 L2 Cache,其他的实体 CPU 是看不到这个 L2 Cache 的。所有的实体 CPU 会共享 L3 Cache。这就是典型的 CPU 架构。
相信你也看到,在 CPU 外还会有内存(DRAM)、磁盘等,这些存储介质共同构成了体系结构里的金字塔存储层次。如下所示:
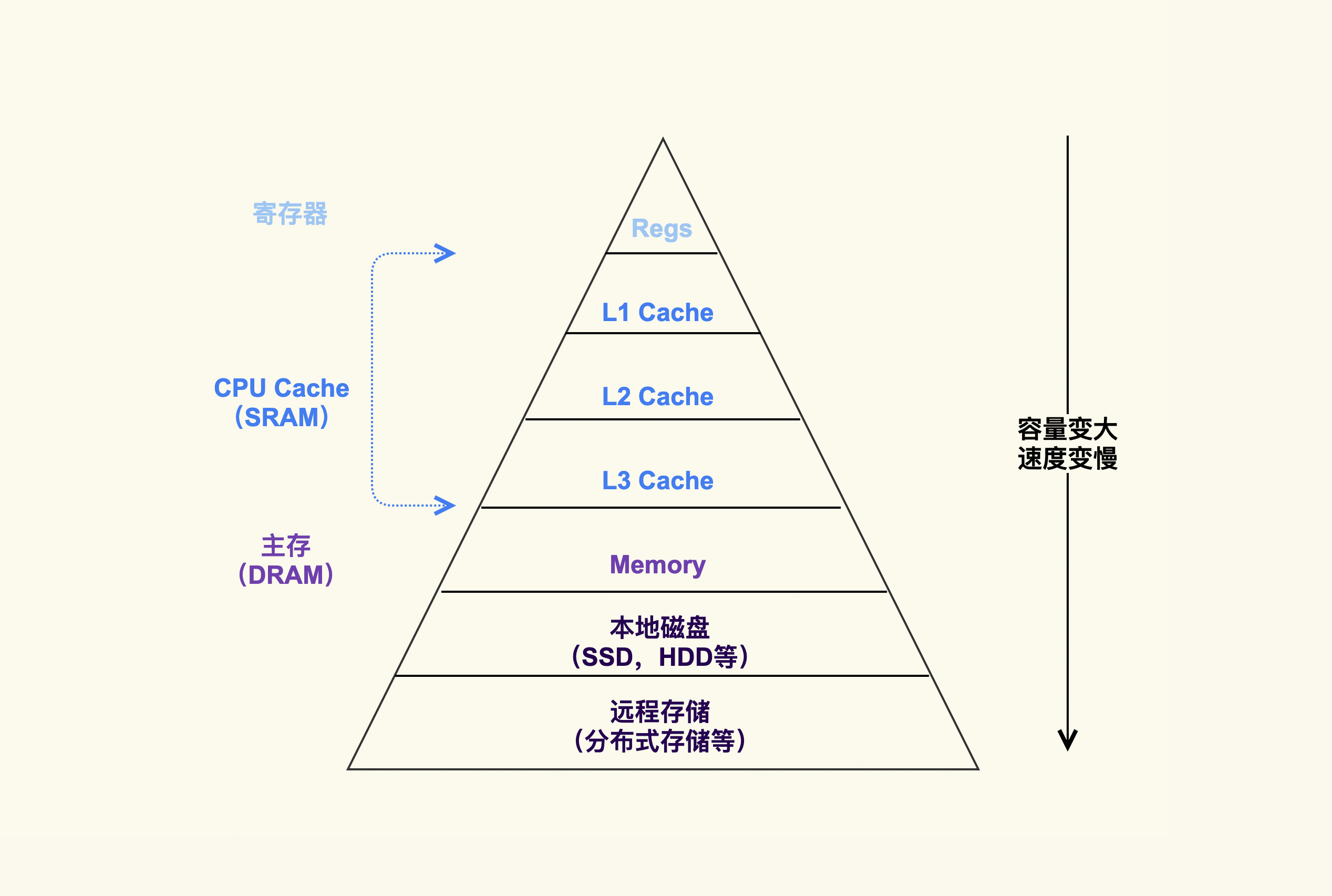
在这个”金字塔”中,越往下,存储容量就越大,它的速度也会变得越慢。
Cache 伪共享问题:
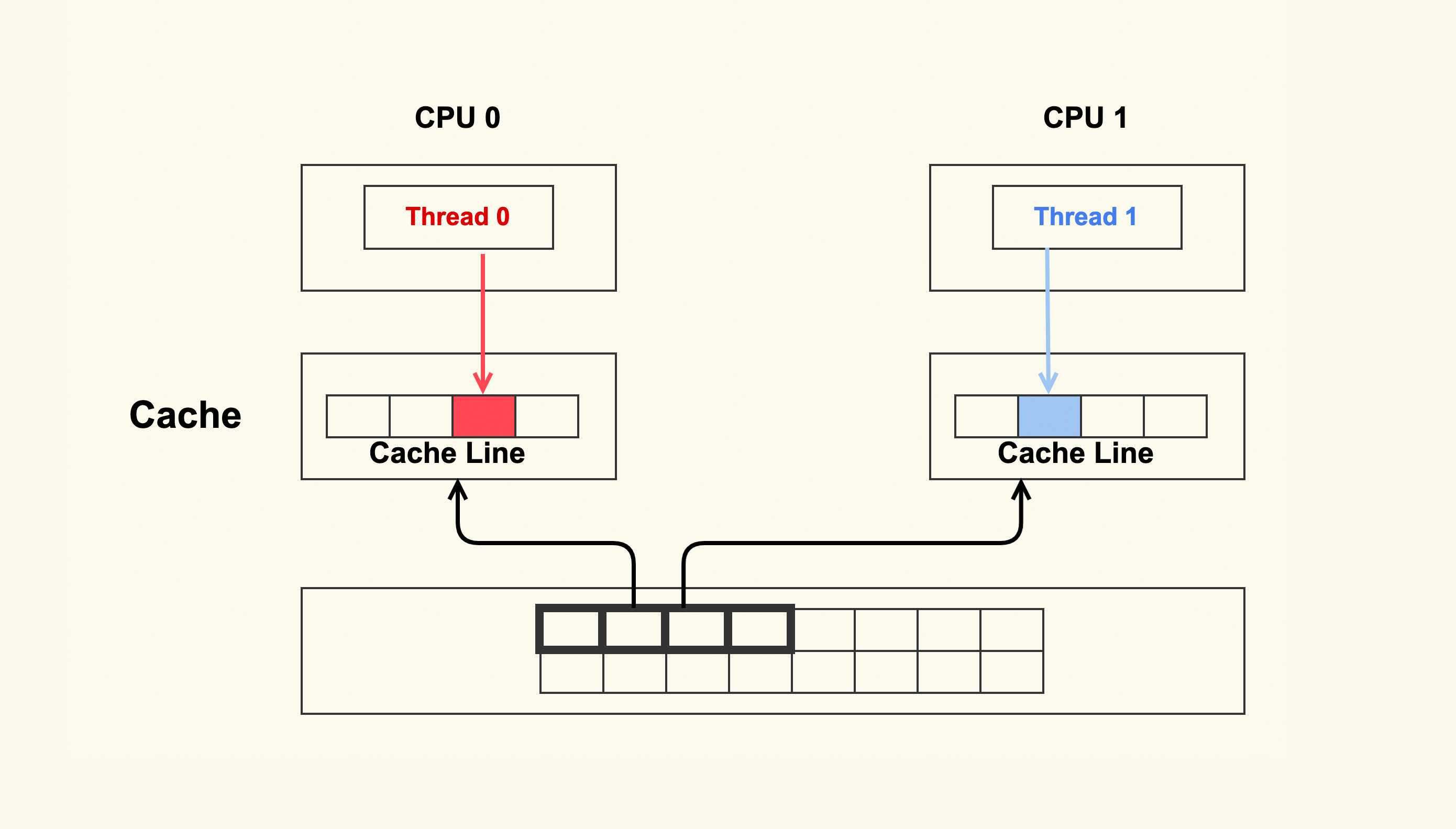
如上图所示,两个 CPU 上并行运行着两个不同线程,它们同时从内存中读取两个不同的数据,这两个数据的地址在物理内存上是连续的,它们位于同一个 Cache Line 中。CPU 从内存中读数据到 Cache 是以 Cache Line 为单位的,所以该 Cache Line 里的数据被同时读入到了这两个 CPU 的各自 Cache 中。紧接着这两个线程分别改写不同的数据,每次改写 Cache 中的数据都会将整个 Cache Line 置为无效。因此,虽然这两个线程改写的数据不同,但是由于它们位于同一个 Cache Line 中,所以一个 CPU 中的线程在写数据时会导致另外一个 CPU 中的 Cache Line 失效,而另外一个 CPU 中的线程在读写数据时就会发生 cache miss,然后去内存读数据,这就大大降低了性能。
Cache 伪共享问题可以说是性能杀手,我们在写代码时一定要留意那些频繁改写的共享数据,必要的时候可以将它跟其他的热数据放在不同的 Cache Line 中避免伪共享问题,就像我们在内核代码里经常看到的 ____cacheline_aligned 所做的那样。
那怎么来观测 Cache 伪共享问题呢?你可以使用perf c2c这个命令,但是这需要较新版本内核支持才可以。不过,perf 同样可以观察 cache miss 的现象,它对很多性能问题的分析还是很有帮助的。
我们再来看内存这个存储层次中的典型问题:并行计算时的竞争,即两个 CPU 同时去操作同一个物理内存地址时的竞争。关于这类问题,我举一些简单的例子给你说明一下。
以 C 语言为例:
struct foo {
int a;
int b;
};在这段示例代码里,我们定义了一个结构体,该结构体里的两个成员 a 和 b 在地址上是连续的。如果 CPU 0 去写 a,同时 CPU 1 去读 b 的话,此时不会有竞争,因为 a 和 b 是不同的地址。不过,a 和 b 由于在地址上是连续的,它们可能会位于同一个 Cache Line 中,所以为了防止前面提到的 Cache 伪共享问题,我们可以强制将 b 的地址设置为 Cache Line 对齐地址,如下:
struct foo {
int a;
int b ____cacheline_aligned;
};接下来,我们看下另外一种情况:
struct foo {
int a:1;
int b:1;
};这个示例程序定义了两个位域(bit field),a 和 b 的地址是一样的,只是属于该地址的不同 bit。在这种情况下,CPU 0 去写 a (a = 1),同时 CPU 1 去写 b (b = 1),就会产生竞争。在总线仲裁后,先写的数据就会被后写的数据给覆盖掉。这就是执行 RMW 操作时典型的竞争问题。在这种场景下,就需要同步原语了,比如使用 atomic 操作。
17.2 CPU 是如何选择线程执行的 ?
一个系统中可能会运行着非常多的线程,这些线程数可能远超系统中的 CPU 核数,这时候这些任务就需要排队,每个 CPU 都会维护着自己运行队列(runqueue)里的线程。这个运行队列的结构大致如下图所示:

每个 CPU 都有自己的运行队列(runqueue),需要运行的线程会被加入到这个队列中。因为有些线程的优先级高,Linux 内核为了保障这些高优先级任务的执行,设置了不同的调度类(Scheduling Class),如下所示:
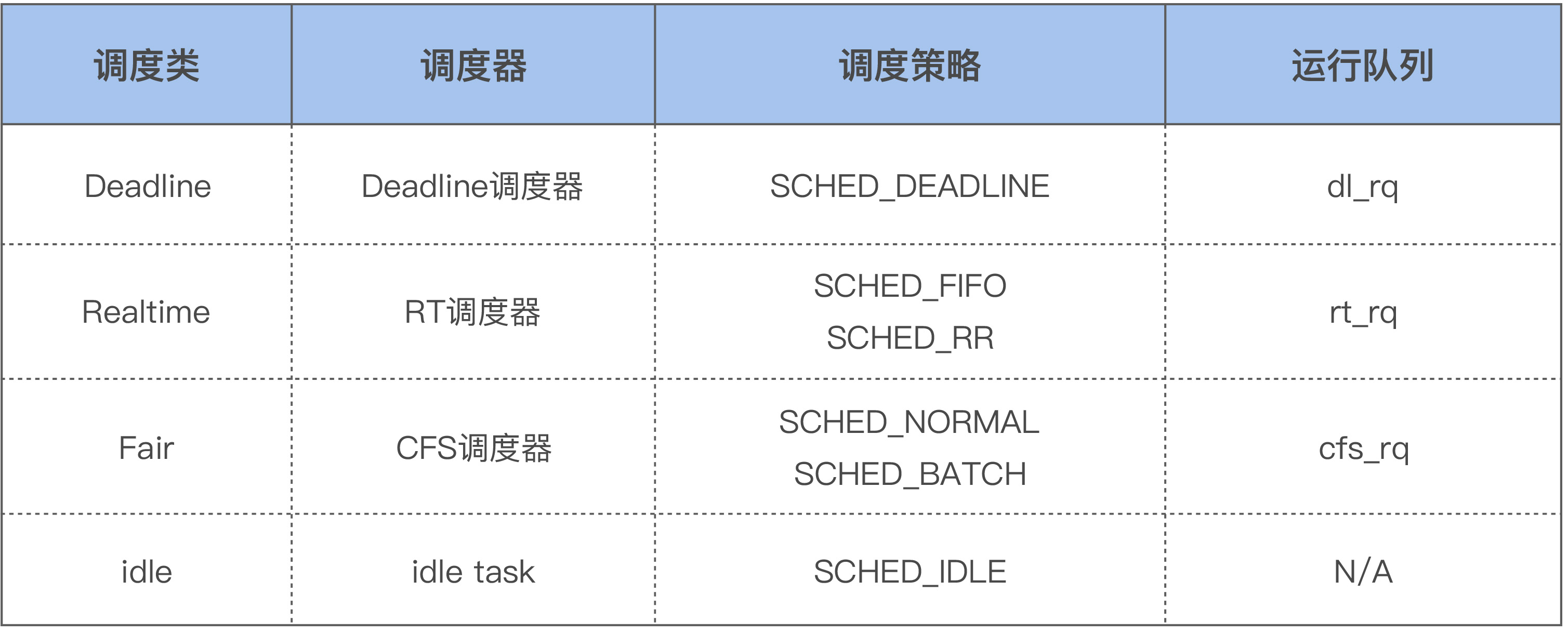
这几个调度类的优先级如下:Deadline > Realtime > Fair。Linux 内核在选择下一个任务执行时,会按照该顺序来进行选择,也就是先从 dl_rq 里选择任务,然后从 rt_rq 里选择任务,最后从 cfs_rq 里选择任务。所以实时任务总是会比普通任务先得到执行。
如果你的某些任务对延迟容忍度很低,比如说在嵌入式系统中就有很多这类任务,那就可以考虑将你的任务设置为实时任务,比如将它设置为 SCHED_FIFO 的任务:
chrt -f -p 1 1327如果你不做任何设置的话,用户线程在默认情况下都是普通线程,也就是属于 Fair 调度类,由 CFS 调度器来进行管理。CFS 调度器的目的是为了实现线程运行的公平性,举个例子,假设一个 CPU 上有两个线程需要执行,那么每个线程都将分配 50% 的 CPU 时间,以保障公平性。其实,各个线程之间执行时间的比例,也是可以人为干预的,比如在 Linux 上可以调整进程的 nice 值来干预,从而让优先级高一些的线程执行更多时间。这就是 CFS 调度器的大致思想。
18 案例篇 | 业务是否需要使用透明大页:水可载舟,亦可覆舟?
18.1 细化 CPU 利用率监控
这里我们以常用的 top 命令为例,来看看 CPU 更加细化的利用率指标(不同版本的 top 命令显示可能会略有不同):
%Cpu(s): 12.5 us, 0.0 sy, 0.0 ni, 87.4 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 stCPU 利用率监控通常是去解析 /proc/stat 文件,而这些文件中就包含了这些细化的指标。
上述几个指标的具体含义,这些含义你也可以从top 手册里来查看:
us, user : time running un-niced user processes
sy, system : time running kernel processes
ni, nice : time running niced user processes
id, idle : time spent in the kernel idle handler
wa, IO-wait : time waiting for I/O completion
hi : time spent servicing hardware interrupts
si : time spent servicing software interrupts
st : time stolen from this vm by the hypervisor上述指标的具体含义以及注意事项如下:

在上面这几项中,idle 和 wait 是 CPU 不工作的时间,其余的项都是 CPU 工作的时间。idle 和 wait 的主要区别是,idle 是 CPU 无事可做,而 wait 则是 CPU 想做事却做不了。你也可以将 wait 理解为是一类特殊的 idle,即该 CPU 上有至少一个线程阻塞在 I/O 时的 idle。
18.2 抓取 sys 利用率飙高现场
我们在前面讲到,CPU 的 sys 利用率高,说明内核函数执行花费了太多的时间,所以我们需要采集 CPU 在 sys 飙高的瞬间所执行的内核函数。采集内核函数的方法有很多,比如:
- 通过 perf 可以采集 CPU 的热点,看看 sys 利用率高时,哪些内核耗时的 CPU 利用率高;
- 通过 perf 的 call-graph 功能可以查看具体的调用栈信息,也就是线程是从什么路径上执行下来的;
- 通过 perf 的 annotate 功能可以追踪到线程是在内核函数的哪些语句上比较耗时;
- 通过 ftrace 的 function-graph 功能可以查看这些内核函数的具体耗时,以及在哪个路径上耗时最大。
不过,这些常用的追踪方式在这种瞬间消失的问题上是不太适用的,因为它们更加适合采集一个时间段内的信息。
那么针对这种瞬时的状态,我希望有一个系统快照,把当前 CPU 正在做的工作记录下来,然后我们就可以结合内核源码分析为什么 sys 利用率会高了。
有一个工具就可以很好地追踪这种系统瞬时状态,即系统快照,它就是 sysrq。sysrq 是我经常用来分析内核问题的工具,用它可以观察当前的内存快照、任务快照,可以构造 vmcore 把系统的所有信息都保存下来,甚至还可以在内存紧张的时候用它杀掉内存开销最大的那个进程。sysrq 可以说是分析很多疑难问题的利器。
要想用 sysrq 来分析问题,首先需要使能 sysyrq。我建议你将 sysrq 的所有功能都使能,你无需担心会有什么额外开销,而且这也没有什么风险。使能方式如下:
sysctl -w kernel.sysrq = 1sysrq 的功能被使能后,你可以使用它的 -t 选项把当前的任务快照保存下来,看看系统中都有哪些任务,以及这些任务都在干什么。使用方式如下:
echo t > /proc/sysrq-trigger然后任务快照就会被打印到内核缓冲区,这些任务快照信息你可以通过 dmesg 命令来查看:
dmesg当时我为了抓取这种瞬时的状态,写了一个脚本来采集,如下就是一个简单的脚本示例:
#!/bin/sh
while [ 1 ]; do
top -bn2 | grep "Cpu(s)" | tail -1 | awk '{
# $2 is usr, $4 is sys.
if ($2 < 30.0 && $4 > 15.0) {
# save the current usr and sys into a tmp file
while ("date" | getline date) {
split(date, str, " ");
prefix=sprintf("%s_%s_%s_%s", str[2],str[3], str[4], str[5]);
}
sys_usr_file=sprintf("/tmp/%s_info.highsys", prefix);
print $2 > sys_usr_file;
print $4 >> sys_usr_file;
# run sysrq
system("echo t > /proc/sysrq-trigger");
}
}'
sleep 1m
done这个脚本会检测 sys 利用率高于 15% 同时 usr 较低的情况,也就是说检测 CPU 是否在内核里花费了太多时间。如果出现这种情况,就会运行 sysrq 来保存当前任务快照。你可以发现这个脚本设置的是 1 分钟执行一次,之所以这么做是因为不想引起很大的性能开销,而且当时业务团队里有几台机器差不多是一天出现两三次这种状况,有些机器每次可以持续几分钟,所以这已经足够了。不过,如果你遇到的问题出现的频率更低,持续时间更短,那就需要更加精确的方法了。
18.3 透明大页:水可载舟,亦可覆舟?
我们把脚本部署好后,就把问题现场抓取出来了。从 dmesg 输出的信息中,我们发现处于 R 状态的线程都在进行 compcation(内存规整),线程的调用栈如下所示(这是一个比较古老的内核,版本为 2.6.32):
java R running task 0 144305 144271 0x00000080
ffff88096393d788 0000000000000086 ffff88096393d7b8 ffffffff81060b13
ffff88096393d738 ffffea003968ce50 000000000000000e ffff880caa713040
ffff8801688b0638 ffff88096393dfd8 000000000000fbc8 ffff8801688b0640
Call Trace:
[<ffffffff81060b13>] ? perf_event_task_sched_out+0x33/0x70
[<ffffffff8100bb8e>] ? apic_timer_interrupt+0xe/0x20
[<ffffffff810686da>] __cond_resched+0x2a/0x40
[<ffffffff81528300>] _cond_resched+0x30/0x40
[<ffffffff81169505>] compact_checklock_irqsave+0x65/0xd0
[<ffffffff81169862>] compaction_alloc+0x202/0x460
[<ffffffff811748d8>] ? buffer_migrate_page+0xe8/0x130
[<ffffffff81174b4a>] migrate_pages+0xaa/0x480
[<ffffffff81169660>] ? compaction_alloc+0x0/0x460
[<ffffffff8116a1a1>] compact_zone+0x581/0x950
[<ffffffff8116a81c>] compact_zone_order+0xac/0x100
[<ffffffff8116a951>] try_to_compact_pages+0xe1/0x120
[<ffffffff8112f1ba>] __alloc_pages_direct_compact+0xda/0x1b0
[<ffffffff8112f80b>] __alloc_pages_nodemask+0x57b/0x8d0
[<ffffffff81167b9a>] alloc_pages_vma+0x9a/0x150
[<ffffffff8118337d>] do_huge_pmd_anonymous_page+0x14d/0x3b0
[<ffffffff8152a116>] ? rwsem_down_read_failed+0x26/0x30
[<ffffffff8114b350>] handle_mm_fault+0x2f0/0x300
[<ffffffff810ae950>] ? wake_futex+0x40/0x60
[<ffffffff8104a8d8>] __do_page_fault+0x138/0x480
[<ffffffff810097cc>] ? __switch_to+0x1ac/0x320
[<ffffffff81527910>] ? thread_return+0x4e/0x76e
[<ffffffff8152d45e>] do_page_fault+0x3e/0xa0
[<ffffffff8152a815>] page_fault+0x25/0x30从该调用栈我们可以看出,此时这个 java 线程在申请 THP(do_huge_pmd_anonymous_page)。THP 就是透明大页,它是一个 2M 的连续物理内存。但是,因为这个时候物理内存中已经没有连续 2M 的内存空间了,所以触发了 direct compaction(直接内存规整),内存规整的过程可以用下图来表示:
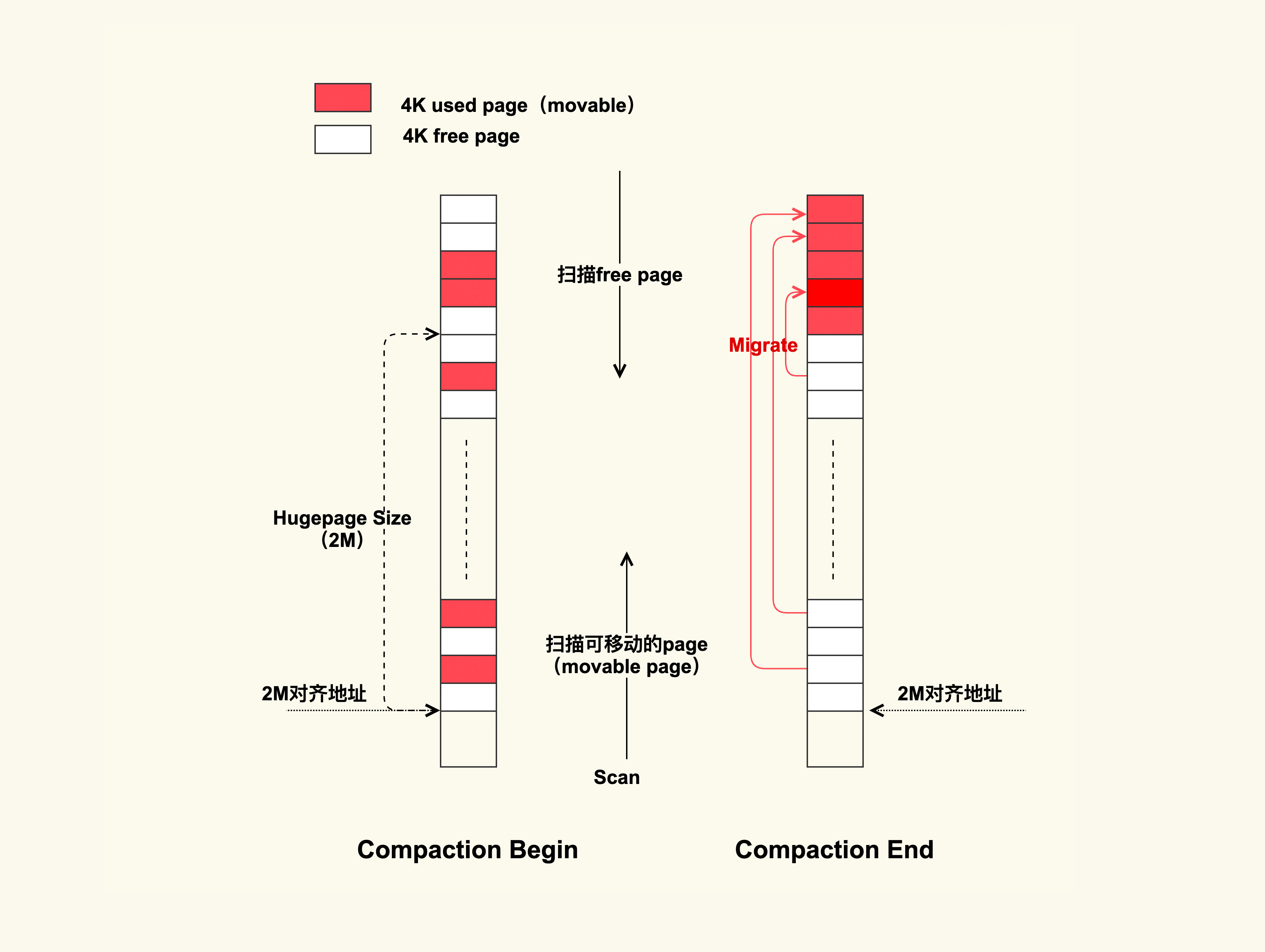
这个过程并不复杂,在进行 compcation 时,线程会从前往后扫描已使用的 movable page,然后从后往前扫描 free page,扫描结束后会把这些 movable page 给迁移到 free page 里,最终规整出一个 2M 的连续物理内存,这样 THP 就可以成功申请内存了。
direct compaction 这个过程是很耗时的,而且在 2.6.32 版本的内核上,该过程需要持有粗粒度的锁,所以在运行过程中线程还可能会主动检查(_cond_resched)是否有其他更高优先级的任务需要执行。如果有的话就会让其他线程先执行,这便进一步加剧了它的执行耗时。这也就是 sys 利用率飙高的原因。关于这些,你也都可以从内核源码的注释来看到:
/*
* Compaction requires the taking of some coarse locks that are potentially
* very heavily contended. Check if the process needs to be scheduled or
* if the lock is contended. For async compaction, back out in the event
* if contention is severe. For sync compaction, schedule.
* ...
*/在我们找到了原因之后,为了快速解决生产环境上的这些问题,我们就把该业务服务器上的 THP 关掉了,关闭后系统变得很稳定,再也没有出现过 sys 利用率飙高的问题。关闭 THP 可以使用下面这个命令:
echo never > /sys/kernel/mm/transparent_hugepage/enabled关闭了生产环境上的 THP 后,我们又在线下测试环境中评估了 THP 对该业务的性能影响,我们发现 THP 并不能给该业务带来明显的性能提升,即使是在内存不紧张、不会触发内存规整的情况下。这也引起了我的思考,THP 究竟适合什么样的业务呢?
这就要从 THP 的目的来说起了。我们长话短说,THP 的目的是用一个页表项来映射更大的内存(大页),这样可以减少 Page Fault,因为需要的页数少了。当然,这也会提升 TLB 命中率,因为需要的页表项也少了。如果进程要访问的数据都在这个大页中,那么这个大页就会很热,会被缓存在 Cache 中。而大页对应的页表项也会出现在 TLB 中,从上一讲的存储层次我们可以知道,这有助于性能提升。但是反过来,假设应用程序的数据局部性比较差,它在短时间内要访问的数据很随机地位于不同的大页上,那么大页的优势就会消失。
因此,我们基于大页给业务做性能优化的时候,首先要评估业务的数据局部性,尽量把业务的热点数据聚合在一起,以便于充分享受大页的优势。以我在华为任职期间所做的大页性能优化为例,我们将业务的热点数据聚合在一起,然后将这些热点数据分配到大页上,再与不使用大页的情况相比,最终发现这可以带来 20% 以上的性能提升。对于 TLB 较小的架构(比如 MIPS 这种架构),它可以带来 50% 以上的性能提升。当然了,我们在这个过程中也对内核的大页代码做了很多优化,这里就不展开说了。
针对 THP 的使用,我在这里给你几点建议:
- 不要将 /sys/kernel/mm/transparent_hugepage/enabled 配置为 always,你可以将它配置为 madvise。如果你不清楚该如何来配置,那就将它配置为 never;
- 如果你想要用 THP 优化业务,最好可以让业务以 madvise 的方式来使用大页,即通过修改业务代码来指定特定数据使用 THP,因为业务更熟悉自己的数据流;
- 很多时候修改业务代码会很麻烦,如果你不想修改业务代码的话,那就去优化 THP 的内核代码吧。
19 案例篇 | 网络吞吐高的业务是否需要开启网卡特性呢?
19.1 中断与业务进程之间是如何相互干扰的?
这是我多年以前遇到的一个案例,当时业务反馈说为了提升 QPS(Query per Second),他们开启了 RPS(Receivce Packet Steering)来模拟网卡多队列,没想到开启 RPS 反而导致了 QPS 明显下降,不知道是什么原因。
其实,这类特定行为改变引起的性能下降问题相对好分析一些。最简单的方式就是去对比这个行为前后的性能数据。即使你不清楚 RPS 是什么,也不知道它背后的机制,你也可以采集需要的性能指标进行对比分析,然后判断问题可能出在哪里。这些性能指标包括 CPU 指标,内存指标,I/O 指标,网络指标等,我们可以使用 dstat 来观察它们的变化。
在业务打开 RPS 之前的性能指标:
$ dstat
You did not select any stats, using -cdngy by default.
----total-cpu-usage---- -dsk/total- -net/total- ---paging-- ---system--
usr sys idl wai hiq siq| read writ| recv send| in out | int csw
64 23 6 0 0 7| 0 8192B|7917k 12M| 0 0 | 27k 1922
64 22 6 0 0 8| 0 0 |7739k 12M| 0 0 | 26k 2210
61 23 9 0 0 7| 0 0 |7397k 11M| 0 0 | 25k 2267打开了 RPS 之后的性能指标:
$ dstat
You did not select any stats, using -cdngy by default.
----total-cpu-usage---- -dsk/total- -net/total- ---paging-- ---system--
usr sys idl wai hiq siq| read writ| recv send| in out | int csw
62 23 4 0 0 12| 0 0 |7096k 11M| 0 0 | 49k 2261
74 13 4 0 0 9| 0 0 |4003k 6543k| 0 0 | 31k 2004
59 22 5 0 0 13| 0 4096B|6710k 10M| 0 0 | 48k 2220我们可以看到,打开 RPS 后,CPU 的利用率有所升高。其中,siq 即软中断利用率明显增加,int 即硬中断频率也明显升高,而 net 这一项里的网络吞吐数据则有所下降。也就是说,在网络吞吐不升反降的情况下,系统的硬中断和软中断都明显增加。由此我们可以推断出,网络吞吐的下降应该是中断增加导致的结果。
那么,接下来我们就需要分析到底是什么类型的软中断和硬中断增加了,以便于找到问题的源头。
系统中存在很多硬中断,这些硬中断及其发生频率我们都可以通过 /proc/interruptes 这个文件来查看:
cat /proc/interrupts如果你想要了解某个中断的详细情况,比如中断亲和性,那你可以通过 /proc/irq/[irq_num]来查看,比如:
cat /proc/irq/123/smp_affinity软中断可以通过 /proc/softirq 来查看:
cat /proc/softirqs软中断是用来处理硬中断在短时间内无法完成的任务的。硬中断由于执行时间短,所以如果它的发生频率不高的话,一般不会给业务带来明显影响。但是由于内核里关中断的地方太多,所以进程往往会给硬中断带来一些影响,比如进程关中断时间太长会导致网络报文无法及时处理,进而引起业务性能抖动。
我们在生产环境中就遇到过这种关中断时间太长引起的抖动案例,比如 cat /proc/slabinfo 这个操作里的逻辑关中断太长,它会致使业务 RT 抖动。这是因为该命令会统计系统中所有的 slab 数量,并显示出来,在统计的过程中会关中断。如果系统中的 slab 数量太多,就会导致关中断的时间太长,进而引起网络包阻塞,ping 延迟也会因此明显变大。所以,在生产环境中我们要尽量避免去采集 /proc/slabinfo,否则可能会引起业务抖动。
如果你要分析因中断关闭时间太长而引发的问题,有一种最简单的方式,就是使用 ftrace 的 irqsoff 功能。它不仅可以统计出中断被关闭了多长时间,还可以统计出为什么会关闭中断。不过,你需要注意的是,irqsoff 功能依赖于 CONFIG_IRQSOFF_TRACER 这个配置项,如果你的内核没有打开该配置项,那你就需要使用其他方式来去追踪了。
如何使用 irqsoff 呢?首先,你需要去查看你的系统是否支持了 irqsoff 这个 tracer:
cat /sys/kernel/debug/tracing/available_tracers如果显示的内容包含了 irqsoff,说明系统支持该功能,你就可以打开它进行追踪了:
echo irqsoff > /sys/kernel/debug/tracing/current_tracer接下来,你就可以通过 /sys/kernel/debug/tracing/trace_pipe 和 trace 这两个文件,来观察系统中的 irqsoff 事件了。
我们知道,相比硬中断,软中断的执行时间会长一些,而且它也会抢占正在执行进程的 CPU,从而导致进程在它运行期间只能等待。所以,相对而言它会更容易给业务带来延迟。那我们怎么对软中断的执行频率以及执行耗时进行观测呢?你可以通过如下两个 tracepoints 来进行观测:
/sys/kernel/debug/tracing/events/irq/softirq_entry
/sys/kernel/debug/tracing/events/irq/softirq_exit这两个 tracepoint 分别表示软中断的进入和退出,退出时间减去进入时间就是该软中断这一次的耗时。
如果你的内核版本比较新,支持 eBPF 功能,那你同样可以使用 bcc 里的softirqs.py这个工具来进行观测。它会统计软中断的次数和耗时,这对我们分析软中断引起的业务延迟来说,是比较方便的。
为了避免软中断太过频繁,进程无法得到 CPU 而被饿死的情况,内核引入了 ksoftirqd 这个机制。如果所有的软中断在短时间内无法被处理完,内核就会唤醒 ksoftirqd 处理接下来的软中断。ksoftirqd 与普通进程的优先级一样,也就是说它会和普通进程公平地使用 CPU,这在一定程度上可以避免用户进程被饿死的情况,特别是对于那些更高优先级的实时用户进程而言。
不过,这也会带来一些问题。如果 ksoftrirqd 长时间得不到 CPU,就会致使软中断的延迟变得很大,它引起的典型问题也是 ping 延迟。如果 ping 包无法在软中断里得到处理,就会被 ksoftirqd 处理。而 ksoftirqd 的实时性是很难得到保障的,可能需要等其他线程执行完,ksoftirqd 才能得到执行,这就会导致 ping 延迟变得很大。
要观测 ksoftirqd 延迟的问题,你可以使用 bcc 里的runqlat.py。这里我们以网卡中断为例,它唤醒 ksoftirqd 的逻辑大致如下图所示:
我们具体来看看这个过程:软中断被唤醒后会检查一遍软中断向量表,逐个处理这些软中断;处理完一遍后,它会再次检查,如果又有新的软中断要处理,就会唤醒 ksoftrqd 来处理。ksoftirqd 是 per-cpu 的内核线程,每个 CPU 都有一个。对于 CPU1 而言,它运行的是 ksoftirqd/1 这个线程。ksoftirqd/1 被唤醒后会检查软中断向量表并进行处理。如果你使用 ps 来查看 ksoftirqd/1 的优先级,会发现它其实就是一个普通线程(对应的 Nice 值为 0):
$ ps -eo "pid,comm,ni" | grep softirqd
9 ksoftirqd/0 0
16 ksoftirqd/1 0
21 ksoftirqd/2 0
26 ksoftirqd/3 019.2 softirq 是如何影响业务的?
在我们对硬中断和软中断进行观察后发现,使能 RPS 后增加了很多 CAL(Function Call Interrupts)硬中断。CAL 是通过软件触发硬中断的一种方式,可以指定 CPU 以及需要执行的中断处理程序。它也常被用来进行 CPU 间通信(IPI),当一个 CPU 需要其他 CPU 来执行特定中断处理程序时,就可以通过 CAL 中断来进行。
如果你对 RPS 的机制有所了解的话,应该清楚 RPS 就是通过 CAL 这种方式来让其他 CPU 去接收网络包的。为了验证这一点,我们可以通过 mpstat 这个命令来观察各个 CPU 利用率情况。
使能 RPS 之前的 CPU 利用率如下所示:
$ mpstat -P ALL 1
Average: CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
Average: all 70.18 0.00 19.28 0.00 0.00 5.86 0.00 0.00 0.00 4.68
Average: 0 73.25 0.00 21.50 0.00 0.00 0.00 0.00 0.00 0.00 5.25
Average: 1 58.85 0.00 14.46 0.00 0.00 23.44 0.00 0.00 0.00 3.24
Average: 2 74.50 0.00 20.00 0.00 0.00 0.00 0.00 0.00 0.00 5.50
Average: 3 74.25 0.00 21.00 0.00 0.00 0.00 0.00 0.00 0.00 4.75使能 RPS 之后各个 CPU 的利用率情况为:
$ mpstat -P ALL 1
Average: CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
Average: all 66.21 0.00 17.73 0.00 0.00 11.15 0.00 0.00 0.00 4.91
Average: 0 68.17 0.00 18.33 0.00 0.00 7.67 0.00 0.00 0.00 5.83
Average: 1 60.57 0.00 15.81 0.00 0.00 20.80 0.00 0.00 0.00 2.83
Average: 2 69.95 0.00 19.20 0.00 0.00 7.01 0.00 0.00 0.00 3.84
Average: 3 66.39 0.00 17.64 0.00 0.00 8.99 0.00 0.00 0.00 6.99我们可以看到,使能 RPS 之后,softirq 在各个 CPU 之间更加均衡了一些,本来只有 CPU1 在处理 softirq,使能后每个 CPU 都会处理 softirq,并且 CPU1 的 softirq 利用率降低了一些。这就是 RPS 的作用:让网络收包软中断处理在各个 CPU 间更加均衡,以防止其在某个 CPU 上达到瓶颈。你可以看到,使能 RPS 后整体的 %soft 比原来高了很多。
理论上,处理网络收包软中断的 CPU 变多,那么在单位时间内这些 CPU 应该可以处理更多的网络包,从而提升系统整体的吞吐。可是,在我们的案例中,为什么会引起业务的 QPS 不升反降呢?
其实,答案同样可以从 CPU 利用率中得出。我们可以看到在使能 RPS 之前,CPU 利用率已经很高了,达到了 90% 以上,也就是说 CPU 已经在超负荷工作了。而打开 RPS,RPS 又会消耗额外的 CPU 时间来模拟网卡多队列特性,这就会导致 CPU 更加超负荷地工作,从而进一步挤压用户进程的处理时间。因此,我们会发现,在打开 RPS 后 %usr 的利用率下降了一些。
我们知道 %usr 是衡量用户进程执行时间的一个指标,%usr 越高意味着业务代码的运行时间越多。如果 %usr 下降,那就意味着业务代码的运行时间变少了,在业务没有进行代码优化的前提下,这显然是一个危险的信号。
由此我们可以发现,RPS 的本质就是把网卡特性(网卡多队列)给 upload 到 CPU,通过牺牲 CPU 时间来提升网络吞吐。如果你的系统已经很繁忙了,那么再使用该特性无疑是雪上加霜。所以,你需要注意,使用 RPS 的前提条件是:系统的整体 CPU 利用率不能太高。
找到问题后,我们就把该系统的 RPS 特性关闭了。如果你的网卡比较新,它可能会支持硬件多队列。硬件多队列是在网卡里做负载均衡,在这种场景下硬件多队列会很有帮助。我们知道,与 upload 相反的方向是 offload,就是把 CPU 的工作给 offload 到网卡上去处理,这样可以把 CPU 解放出来,让它有更多的时间执行用户代码。关于网卡的 offload 特性,我们就不在此讨论了。
20 分析篇 | 如何分析CPU利用率飙高问题 ?
20.1 如何拓展你分析问题的边界?
我常用来追踪应用逻辑的工具之一就是 strace。strace 可以用来分析应用和内核的”边界”——系统调用。借助 strace,我们不仅能够了解应用执行的逻辑,还可以了解内核逻辑。那么,作为应用开发者的你,就可以借助这个工具来拓展你分析应用问题的边界。
strace 可以跟踪进程的系统调用、特定的系统调用以及系统调用的执行时间。很多时候,我们通过系统调用的执行时间,就能判断出业务延迟发生在哪里。比如我们想要跟踪一个多线程程序的系统调用情况,那就可以这样使用 strace:
strace -T -tt -ff -p pid -o strace.out20.2 了解工具的原理,不要局限于如何使用它
strace 工具的原理如下图所示(我们以上面的那个命令为例来说明):
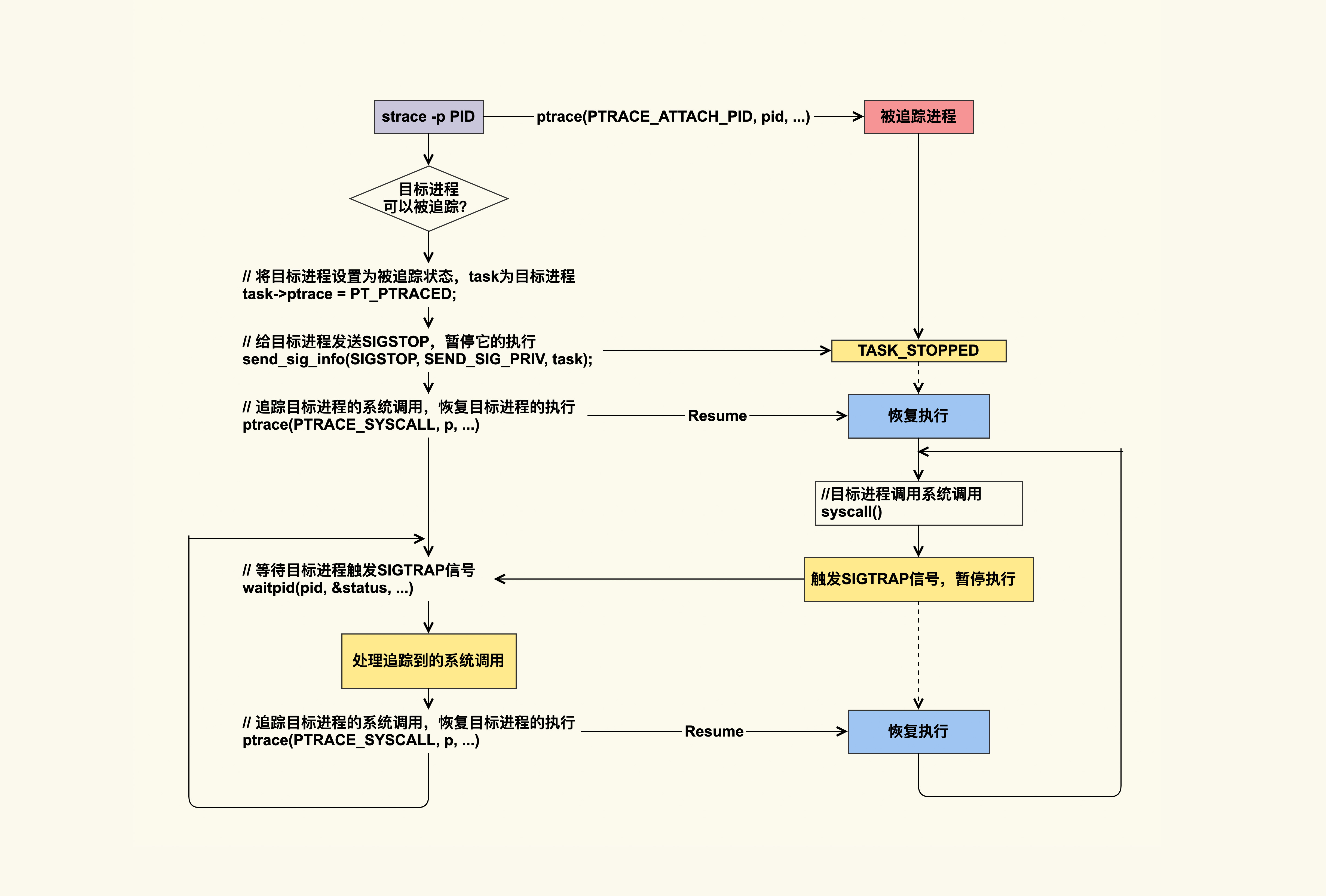
我们从图中可以看到,对于正在运行的进程而言,strace 可以 attach 到目标进程上,这是通过 ptrace 这个系统调用实现的(gdb 工具也是如此)。ptrace 的 PTRACE_SYSCALL 会去追踪目标进程的系统调用;目标进程被追踪后,每次进入 syscall,都会产生 SIGTRAP 信号并暂停执行;追踪者通过目标进程触发的 SIGTRAP 信号,就可以知道目标进程进入了系统调用,然后追踪者会去处理该系统调用,我们用 strace 命令观察到的信息输出就是该处理的结果;追踪者处理完该系统调用后,就会恢复目标进程的执行。被恢复的目标进程会一直执行下去,直到下一个系统调用。
你可以发现,目标进程每执行一次系统调用都会被打断,等 strace 处理完后,目标进程才能继续执行,这就会给目标进程带来比较明显的延迟。因此,在生产环境中我不建议使用该命令,如果你要使用该命令来追踪生产环境的问题,那就一定要做好预案。
假设我们使用 strace 跟踪到,线程延迟抖动是由某一个系统调用耗时长导致的,那么接下来我们该怎么继续追踪呢?这就到了应用开发者和运维人员需要拓展分析边界的时刻了,对内核开发者来说,这才算是分析问题的开始。
20.3 学会使用内核开发者常用的分析工具
我们以一个实际案例来说明吧。有一次,业务开发者反馈说他们用 strace 追踪发现业务的 pread(2) 系统调用耗时很长,经常会有几十毫秒(ms)的情况,甚至能够达到秒级,但是不清楚接下来该如何分析,因此让我帮他们分析一下。
因为已经明确了问题是由 pread(2) 这个系统调用引起的,所以对内核开发者而言,后续的分析就相对容易了。分析这类问题最合适的工具是 ftrace,我们可以使用 ftrace 的 function_trace 功能来追踪 pread(2) 这个系统调用到底是在哪里耗费了这么长的时间。
要想追踪 pread(2) 究竟在哪里耗时长,我们就需要知道该系统调用对应的内核函数是什么。我们有两种途径可以方便地获取到系统调用对应的内核函数:
查看include/linux/syscalls.h文件里的内核函数:
你可以看到,与 pread 有关的函数有多个,由于我们的系统是 64bit 的,只需关注 64bit 相关的系统调用就可以了,所以我们锁定在 ksys_pread64 和 sys_read64 这两个函数上。通过该头文件里的注释我们能知道,前者是内核使用的,后者是导出给用户的。那么在内核里,我们就需要去追踪前者。另外,请注意,不同内核版本对应的函数可能不一致,我们这里是以最新内核代码 (5.9-rc) 为例来说明的。
通过 /proc/kallsyms 这个文件来查找:
$ cat /proc/kallsyms | grep pread64 … ffffffffa02ef3d0 T ksys_pread64 …/proc/kallsyms 里的每一行都是一个符号,其中第一列是符号地址,第二列是符号的属性,第三列是符号名字,比如上面这个信息中的 T 就表示全局代码符号,我们可以追踪这类的符号。关于这些符号属性的含义,你可以通过man nm来查看。
接下来我们就使用 ftrace 的 function_graph 功能来追踪 ksys_pread64 这个函数,看看究竟是内核的哪里耗时这么久。function_graph 的使用方式如下:
# 首先设置要追踪的函数
$ echo ksys_pread64 > /sys/kernel/debug/tracing/set_graph_function
# 其次设置要追踪的线程的pid,如果有多个线程,那需要将每个线程都逐个写入
$ echo 6577 > /sys/kernel/debug/tracing/set_ftrace_pid
$ echo 6589 >> /sys/kernel/debug/tracing/set_ftrace_pid
# 将function_graph设置为当前的tracer,来追踪函数调用情况
$ echo function_graph > /sys/kernel/debug/tracing/current_trace然后我们就可以通过 /sys/kernel/debug/tracing/trace_pipe 来查看它的输出了,下面就是我追踪到的耗时情况:
我们可以发现 pread(2) 有 102ms 是阻塞在 io_schedule() 这个函数里的,io_schedule() 的意思是,该线程因 I/O 阻塞而被调度走,线程需要等待 I/O 完成才能继续执行。在 function_graph 里,我们同样也能看到 pread(2) 是如何一步步执行到 io_schedule 的,由于整个流程比较长,我在这里只把关键的调用逻辑贴出来:
21) | __lock_page_killable() {
21) 0.073 us | page_waitqueue();
21) | __wait_on_bit_lock() {
21) | prepare_to_wait_exclusive() {
21) 0.186 us | _raw_spin_lock_irqsave();
21) 0.051 us | _raw_spin_unlock_irqrestore();
21) 1.339 us | }
21) | bit_wait_io() {
21) | io_schedule() {我们可以看到,pread(2) 是从 __lock_page_killable 这个函数调用下来的。当 pread(2) 从磁盘中读文件到内存页(page)时,会先 lock 该 page,读完后再 unlock。如果该 page 已经被别的线程 lock 了,比如在 I/O 过程中被 lock,那么 pread(2) 就需要等待。等该 page 被 I/O 线程 unlock 后,pread(2) 才能继续把文件内容读到这个 page 中。我们当时遇到的情况是:在 pread(2) 从磁盘中读取文件内容到一个 page 中的时候,该 page 已经被 lock 了,于是调用 pread(2) 的线程就在这里等待。这其实是合理的内核逻辑,没有什么问题。接下来,我们就需要看看为什么该 page 会被 lock 了这么久。
因为线程是阻塞在磁盘 I/O 里的,所以我们需要查看一下系统的磁盘 I/O 情况,我们可以使用 iostat 来观察:
iostat -dxm 1追踪信息如下:
其中,sdb 是业务 pread(2) 读取的磁盘所在的文件,通常情况下它的读写量很小,但是我们从上图中可以看到,磁盘利用率(%util)会随机出现比较高的情况,接近 100%。而且 avgrq-sz 很大,也就是说出现了很多 I/O 排队的情况。另外,w/s 比平时也要高很多。我们还可以看到,由于此时存在大量的 I/O 写操作,磁盘 I/O 排队严重,磁盘 I/O 利用率也很高。根据这些信息我们可以判断,之所以 pread(2) 读磁盘文件耗时较长,很可能是因为被写操作饿死导致的。因此,我们接下来需要排查到底是谁在进行写 I/O 操作。
通过 iotop 观察 I/O 行为,我们发现并没有用户线程在进行 I/O 写操作,写操作几乎都是内核线程 kworker 来执行的,也就是说用户线程把内容写在了 Page Cache 里,然后 kwoker 将这些 Page Cache 中的内容再同步到磁盘中。这就涉及到了我们这门课程第一个模块的内容了:如何观测 Page Cache 的行为。
20.4 自己写分析工具
如果你现在还不清楚该如何来观测 Page Cache 的行为,那我建议你再从头仔细看一遍我们这门课程的第一个模块,我在这里就不细说了。不过,我要提一下在 Page Cache 模块中未曾提到的一些方法,这些方法用于判断内存中都有哪些文件以及这些文件的大小。
常规方式是用 fincore 和 mincore,不过它们都比较低效。这里有一个更加高效的方式:通过写一个内核模块遍历 inode 来查看 Page Cache 的组成。该模块的代码较多,我只说一下核心的思想,伪代码大致如下:
iterate_supers // 遍历super block
iterate_pagecache_sb // 遍历superblock里的inode
list_for_each_entry(inode, &sb->s_inodes, i_sb_list)
// 记录该inode的pagecache大小
nrpages = inode->i_mapping->nrpages;
/* 获取该inode对应的dentry,然后根据该dentry来查找文件路径;
* 请注意inode可能没有对应的dentry,因为dentry可能被回收掉了,
* 此时就无法查看该inode对应的文件名了。
*/
dentry = dentry_from_inode(inode);
dentry_path_raw(dentry, filename, PATH_MAX);使用这种方式不仅可以查看进程正在打开的文件,也能查看文件已经被进程关闭,但文件内容还在内存中的情况。所以这种方式分析起来会更全面。
通过查看 Page Cache 的文件内容,我们发现某些特定的文件占用的内存特别大,但是这些文件都是一些离线业务的文件,也就是不重要业务的文件。因为离线业务占用了大量的 Page Cache,导致该在线业务的 workingset 大大减小,所以 pread(2) 在读文件内容时经常命中不了 Page Cache,进而需要从磁盘来读文件,也就是说该在线业务存在大量的 pagein 和 pageout。
至此,问题的解决方案也就有了:我们可以通过限制离线业务的 Page Cache 大小,来保障在线业务的 workingset,防止它出现较多的 refault。经过这样调整后,业务再也没有出现这种性能抖动了。

