1. cpupower
可以设置 CPU 为 performance 模式来提高性能。
查看 CPU 支持的模式。
cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_available_governors设置为 performance 模式。
cpupower frequency-set -g performance
2. top
top - 12:20:32 up 18:33, 0 users, load average: 0.00, 0.00, 0.00
Tasks: 9 total, 1 running, 8 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 16345516 total, 15938648 free, 273724 used, 133144 buff/cache
KiB Swap: 4194304 total, 4194304 free, 0 used. 15840516 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1 root 20 0 1744 1088 1016 S 0.0 0.0 0:00.00 init
7 root 20 0 1764 76 0 S 0.0 0.0 0:00.00 init
8 root 20 0 1764 92 0 S 0.0 0.0 0:00.05 init
9 k 20 0 75332 11712 4500 S 0.0 0.1 0:02.33 zsh
13 k 20 0 58876 5144 2092 S 0.0 0.0 0:00.00 zsh
53 k 20 0 75612 6764 1332 S 0.0 0.0 0:00.00 zsh
54 k 20 0 75596 5424 0 S 0.0 0.0 0:00.30 zsh
56 k 20 0 4536 1000 884 S 0.0 0.0 0:00.94 gitstatusd-linu
94 k 20 0 45728 3712 3228 R 0.0 0.0 0:00.00 top执行命令
uptime也能得到与命令top结果第一行一样的结果。命令w和命令cat /proc/loadavg也能得到类似的结果。
2.1 指标说明
A Guide to the Linux “Top” Command
2.1.1 系统时间、正常运行时间和用户会话
12:20:32 up 18:33, 0 users表示系统时间、正常运行时间和用户会话。
可以使用
who命令来查看当前那些用户在线。
2.1.2 内存使用情况
KiB Mem : 16345516 total, 15938648 free, 273724 used, 133144 buff/cache
KiB Swap: 4194304 total, 4194304 free, 0 used. 15840516 avail MemKiB Mem 和 KiB Swap 后的 total 、 free 以及 used 分别表示系统内存和交换区总大小、可用大小、已使用的大小。
avail Mem 表示不使用交换分区的情况下,可以分配给进程使用的大小。
buff/cache 系统使用的缓冲区和缓存的总和。
buff表示内核缓冲区使用的内存,cache表示页缓存和 slab 使用的内存。可以通过
man free命令来获取详细的说明。
What do the “buff/cache” and “avail mem” fields in top mean?
2.1.3 任务
Tasks: 9 total, 1 running, 8 sleeping, 0 stopped, 0 zombie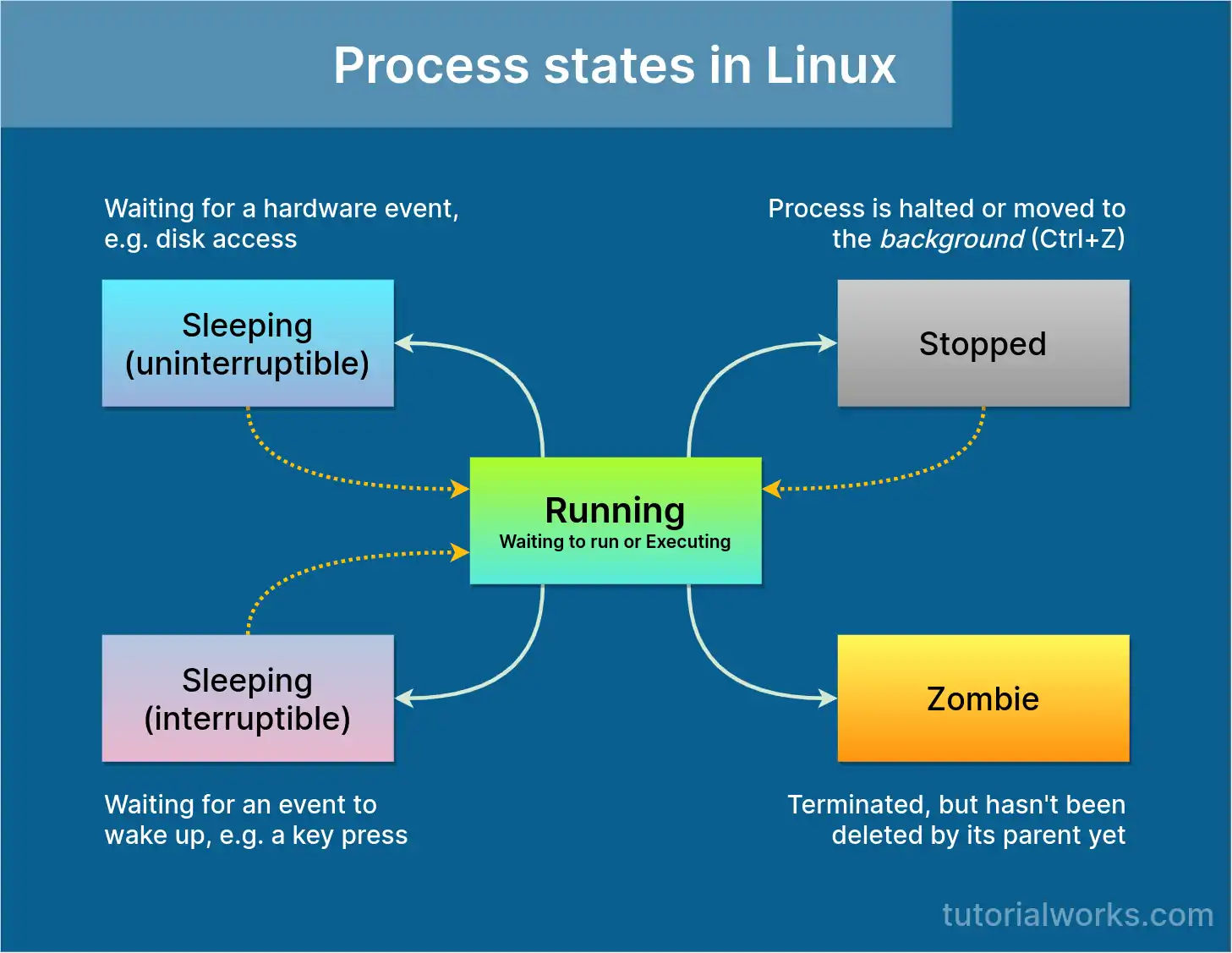
在 Linux 中,进程可能处于以下状态:
- 可运行 (R,Runnable):处于这种状态的进程要么在 CPU 上执行,要么出现在运行队列中,准备执行。
- 可中断睡眠 (S, Interruptible sleep):处于此状态的进程正在等待事件完成。
- 不间断睡眠 (D, Uninterruptible sleep):在这种情况下,进程正在等待 I/O 操作完成。
- 已停止 (T, Stopped):这些进程已被作业控制信号(例如按 Ctrl+Z)停止或因为它们正在被跟踪。
- 僵尸(Z, Zombie):内核在内存中维护各种数据结构以跟踪进程。一个进程可能会创建多个子进程,并且它们可能会在父进程还在时退出。但是,必须保留这些数据结构,直到父进程获得子进程的状态。这种数据结构仍然存在的终止进程称为僵尸进程。
D 和 S 状态的进程显示为 sleeping ,T状态的进程显示为 stopped 。僵尸的数量显示为 zombie 值。
top命令默认显示的是进程相关的信息,可以按SHIFT + H键切换到显示线程相关的信息。
2.1.4 CPU 使用率
%Cpu(s): 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 stCPU 使用率部分显示了用于各种任务的 CPU 时间百分比:
us, user是 CPU 在用户空间中执行进程所花费的时间(time running un-niced user processes)。sy, system是运行内核空间进程所花费的时间。ni, nice是使用手动设置的 nice 执行进程所花费的时间(time running niced user processes)。Linux 使用 nice 值来确定进程的优先级。具有高 nice 值的进程对其他进程更好,并获得低优先级。同样,具有较低 nice 的进程获得更高的优先级。可以手动更改默认的 nice 值。
id, idle是 CPU 保持空闲的时间。wa, IO-wait是 CPU 等待 I/O 完成所花费的时间。hi, hardware interrupts是处理硬件所花费的时间。si, software interrupts是处理软件所花费的时间。st, stolen, timehypervisor 从这个 vm 窃取的时间 (time stolen from this vm by the hypervisor)。在虚拟化环境中,一部分 CPU 资源分配给每个虚拟机 (VM)。操作系统检测到它何时有工作要做,但它无法执行它们,因为 CPU 在某个其他 VM 上很忙。以这种方式损失的时间量是被窃取时间。
2.1.5 平均负载
load average: 0.00, 0.00, 0.00 表示一分钟、五分钟和十五分钟内的系统的平均负载。
在 Linux 上,负载是在任何给定时刻处于 R 和 D 状态的进程数。平均负载值提供了一个相对衡量 CPU 必须等待事情完成的时间。
平均负载的解释也可以通过命令
man uptime获得:System load averages is the average number of processes that are either in a runnable or uninterruptable state. A process in a runnable state is either using the CPU or waiting to use the CPU. A process in uninterruptable state is waiting for some I/O access, eg waiting for disk. The averages are taken over the three time intervals. Load averages are not normalized for the number of CPUs in a system, so a load average of 1 means a single CPU system is loaded all the time while on a 4 CPU system it means it was idle 75% of the time.
另外,平均负载是一个指数移动平均,意味着之前的负载平均值的一小部分被计入当前值。更多的细节:Examining Load Average。
如何理解 Linux 系统负荷呢?
为便于理解,把 CPU 想象成一个大桥,桥上只有一根车道(相当于 CPU 只有一个核),所有的车辆都要从这根到通过。
- 系统负载为 0,表示车道上一个车都没有。
- 系统负载为 0.5, 表示车道上一半的路段有车。
- 系统负载为 1,表示车道上全是车,但是所有车都能正常顺利的通行。
- 系统负载为 1.7,大桥已经被占满了(100%),后面等着上桥的车辆为桥面车辆的70%。
在多核系统上,需要将负载平均值除以 CPU 内核数以获得类似的度量。
区分 CPU 使用率和平均负载
High CPU utilization but low load average
- 平均负载是衡量一段时间内在内核运行队列中等待的任务数量。
- CPU 利用率是衡量当前 CPU 繁忙程度的指标。
单个 CPU 线程在 1 分钟内保持 100% 的 CPU 使用率可以让 1分钟平均负载 加 1。具有超线程(8 个虚拟内核)的 4 核 CPU 保持 100% 的 CPU 使用率 1 分钟可以让 1分钟平均负载 加 8。
2.1.6 任务区
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1 root 20 0 1744 1088 1016 S 0.0 0.0 0:00.00 init
7 root 20 0 1764 76 0 S 0.0 0.0 0:00.00 init
8 root 20 0 1764 92 0 S 0.0 0.0 0:00.05 init
9 k 20 0 75332 11712 4500 S 0.0 0.1 0:02.33 zsh
13 k 20 0 58876 5144 2092 S 0.0 0.0 0:00.00 zsh
53 k 20 0 75612 6764 1332 S 0.0 0.0 0:00.00 zsh
54 k 20 0 75596 5424 0 S 0.0 0.0 0:00.30 zsh
56 k 20 0 4536 1000 884 S 0.0 0.0 0:00.94 gitstatusd-linu
94 k 20 0 45728 3712 3228 R 0.0 0.0 0:00.00 topPID
进程 ID,一个唯一的正整数,用于标识进程。
USER
启动进程的用户的
有效(effective)用户名(映射到用户 ID)。Linux为进程分配一个真实用户ID(real user ID)和一个有效用户ID(effective user ID);后者允许进程代表另一个用户进行操作。(例如,非 root 用户可以提升为 root 以安装软件包。)PR 和 NI
NI 字段显示进程的 nice 值。PR 字段从内核的角度显示了进程的调度优先级。nice 值影响进程的优先级。
VIRT、RES、SHR 和 %MEM
这三个字段与进程的内存消耗有关。
- VIRT 是进程消耗的内存总量。这包括程序代码、进程存储在内存中的数据以及已交换到磁盘的任何内存区域。
- RES 是进程在 RAM 中消耗的内存,%MEM 表示该值占可用 RAM 总量的百分比。
- SHR 是与其他进程共享的内存量。
S
一个进程可能处于不同的状态。此字段以单字母形式显示进程状态。
D – 不间断睡眠,I – 空闲,R – 运行,S – 睡眠,T – 被作业控制信号停止,t – 在跟踪期间被调试器停止, Z – 僵尸。
TIME+
进程自启动以来使用的总 CPU 时间,精确到百分之一秒。
COMMAND
进程的名称。
2.1.7 Linux 内存类型
下面的内容意译自 top(1) — Linux manual page 中 Linux Memory Types 部分。
Linux 中有三种类型的内存,其中一种是可选的。
- 物理内存:一种有限的资源,代码和数据在执行或引用时必须驻留在其中。
- 交换文件(可选的):当物理内存不足时,可以存放修改后的(脏)内存并在以后检索的地方。
- 虚拟内存:一种几乎无限的资源,用于以下目标。
- 抽象,不受物理内存地址/限制。
- 隔离,每个进程在一个单独的地址空间。
- 共享,单个映射可以满足多个需求。
- 灵活性,为文件分配一个虚拟地址。
无论内存采用哪种形式,都作为内存页(page)管理(通常 4096 字节)。
每个内存页都被限制为下表中的一个象限中。物理内存和虚拟内存都可以包含这四个中的任何一个,而交换文件只能包含象限 1 和象限 3。象限 4 中的内存在修改后会作为进程自己的专用交换文件。
Private | Shared
1 | 2
Anonymous . stack |
. malloc() |
. brk()/sbrk() | . POSIX shm*
. mmap(PRIVATE, ANON) | . mmap(SHARED, ANON)
-----------------------+----------------------
. mmap(PRIVATE, fd) | . mmap(SHARED, fd)
File-backed . pgms/shared libs |
3 | 4下面是对 top 命令中一些字段的解释:
%MEM:RES的值除以总物理内存。CODE:象限 3 中pgms的大小。DATA:整个象限 1 中的值加上象限 3 中显示mmap文件支持(File-backed)的内存页大小的和。RES:任何占用物理内存的东西。从 Linux-4.5 开始,是以下三个字段的总和:RSan:象限 1 中内存页的大小,包括象限 3 中之前修改过的内存页的大小。RSfd:象限 3 加上象限 4。RSsh:象限 2。
RSlk:RES中不能被换出内存的部分(所有象限)。SHR:RES中排除象限 1 ,但包括象限 2 和象限 4 以及部分象限 3。SWAP:可能是除象限 4 外的其他象限中的任何内容。USED:RES和SWAP的和。VIRT:正在使用和/或保留的所有内容(所有象限)。
注意:虽然程序映像和共享库被认为是进程私有的,但在内核中被当做共享的(shared, SHR)。
2.2 关注指标
2.2.1 us 和 sy
us 低 和 sy 高的情况一般有两种:
- 用户态的代码写的很好,都压缩成了系统调用。
- 用户态的代码写的很差,导致全是小的系统调佣。
2.2.2 wa
wa 高表示硬盘或者网络 I/O wait 高。
2.2.3 si
网络压测时,很有可能会出现单个 CPU 的 si 很高的情况。优化思路就是让 si 均衡到多个 CPU 上,方式有:
RSS(Receive Side Scaling)
就是俗称的网卡多队列。需要网卡硬件支持。
把不同的流分散的不同的网卡多列中,至于网卡队列由哪个cpu处理还需要绑定网卡队列中断与 CPU。
队列应不超过机器上 CPU 物理核的数量。
还有一种叫XPS(Transmit Packet Steering)的技术:根据当前处理软中断的cpu选择网卡发包队列,适合于多队列网卡。主要是为了避免 CPU 由 RX 队列的中断进入到 TX 队列的中断时发生切换,导致 CPU cache 失效损失性能。
RPS(Receive Packet Steering)
网卡多队列的软件实现。
单队列网卡或者虚拟网卡,把该网卡上的数据流让多个 CPU 处理。
开启脚本:rps.sh
在 RPS 之上优化的版本叫 RFS(Receive Flow Steering)。
当流量需要传输到用户态处理时,用处理软中断的 CPU 去处理用户态的逻辑。主要是为了避免 CPU 由内核态进入到用户态的时候发生切换,导致 CPU cache 失效损失性能。
使用硬件加速版本的 RFS 叫 Accelerated RFS(Receive Flow Steering)。
Kernel Bypass
Kernel Bypass(内核旁路)是绕过Linux内核(TCPIP协议栈)的技术,不使用Linux内核子系统的功能,采用自己实现的相同功能的代码来处理,从用户空间直接访问和控制设备内存,避免数据从设备拷贝到内核,再从内核拷贝到用户空间。
Kernel Bypass目前主流实现方案有:DPDK、SolarFlare。
其他资料:
3. nmon
3.1 关注指标
3.1.1 内核指标(k)
Kernel and Load Average ---------------------------------------------------------|
|Global-CPU-Stats----> 0.5% user Load Average CPU use since boottime |
| /proc/stat line 1 0.0% user_nice 1 mins 0.00 Uptime Days Hours Mins |
|100 ticks per second 0.5% system 5 mins 0.00 Uptime 0 17 15 |
|100%=1 CPUcoreThread 1195.6% idle 15 mins 0.00 Idle 0 17 939 |
| 1 RunQueue 0.0% iowait Uptime has overflowed |
| 0 Blocked 0.0% irq |
| 1731.3 Context 0.0% softirq 12 CPU core threads |
| Switch 0.0% steal |
| 0.5 Forks 0.0% guest Boot time 1635930655 |
| 1743.8 Interrupts 0.0% guest_nice 05:10 PM 03-Nov-2021 |如果 Context Switch 比较高,可能代码中的 syscall 非常多,或者程序中线程非常多。
Interrupts 指标反应了中断的密集情况。
- 如果网络程序压测试,
Context Switch和Interrupts都非常高,说明网络发送的都是小包,没有批量发送(writev)。
4. nload
nload -u H 用于看网卡实时网速。
PageUp和PageDown切换网卡。
5. tcpflow
更方便的实时解析网络数据包。比如解析 HTTP 协议:sudo tcpflow -c -e http 。
6. ifconfig
6.1 关注指标
主要关注每个网络下的 RX errors 0 dropped 0 overruns 0 frame 0 和 TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 这几个指标,判断网络是否出现丢包错误之类的。
7. netstat
7.1 关注指标
7.1.1 网络栈统计信息
想看内核网络栈的统计信息应用命令 netstat -s ,其他的方式会有比较大的负担。
统计信息中主要关注的有统计数据中关于重传的数据:netstat -s | grep -i retran
23919133 segments retransmitted
TCPLostRetransmit: 6168959
12901177 fast retransmits
4674395 retransmits in slow start
TCPSynRetrans: 31047.1.2 网卡 MTU 和统计信息
netstat -iKernel Interface table
Iface MTU RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
docker0 1500 0 0 0 0 0 0 0 0 BMU
enp4s0 1500 117099502 0 45104 0 109843615 0 0 0 BMRU
lo 65536 323529 0 0 0 323529 0 0 0 LRU8. ss
8.1 关注指标
8.1.1 连接的统计信息
想看 TCP 各个状态的连接数量:ss -s 。
8.1.2 TCP 连接的 timer 信息
命令 ss -et 可以看 TCP 上 keepalive 相关的信息。
8.1.3 TCP 连接上流量控制和拥塞控制的信息
命令 ss -it 可以看 TCP 连接上流量控制和拥塞控制的信息。
9. strace
sudo strace -p $pid 查看某个进程的系统调用。
10. perf
sudo perf top 是 on-cpu 系统分析工具。
on-cpu 时间即进程获得 CPU 使用权的时间,同理 off-cpu 即进程失去cpu使用权时度过的时间。
更多资料:
11. 其他工具
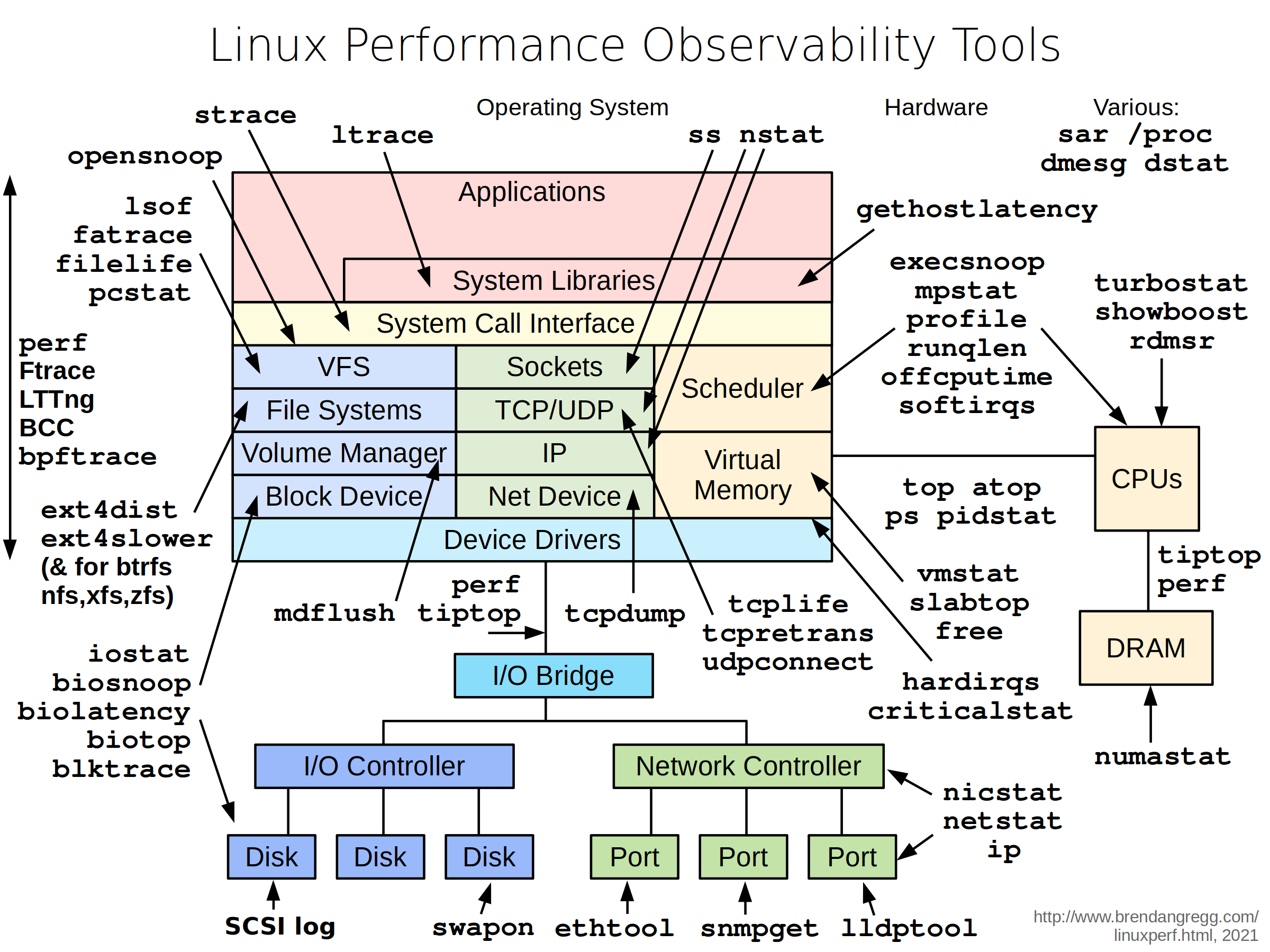
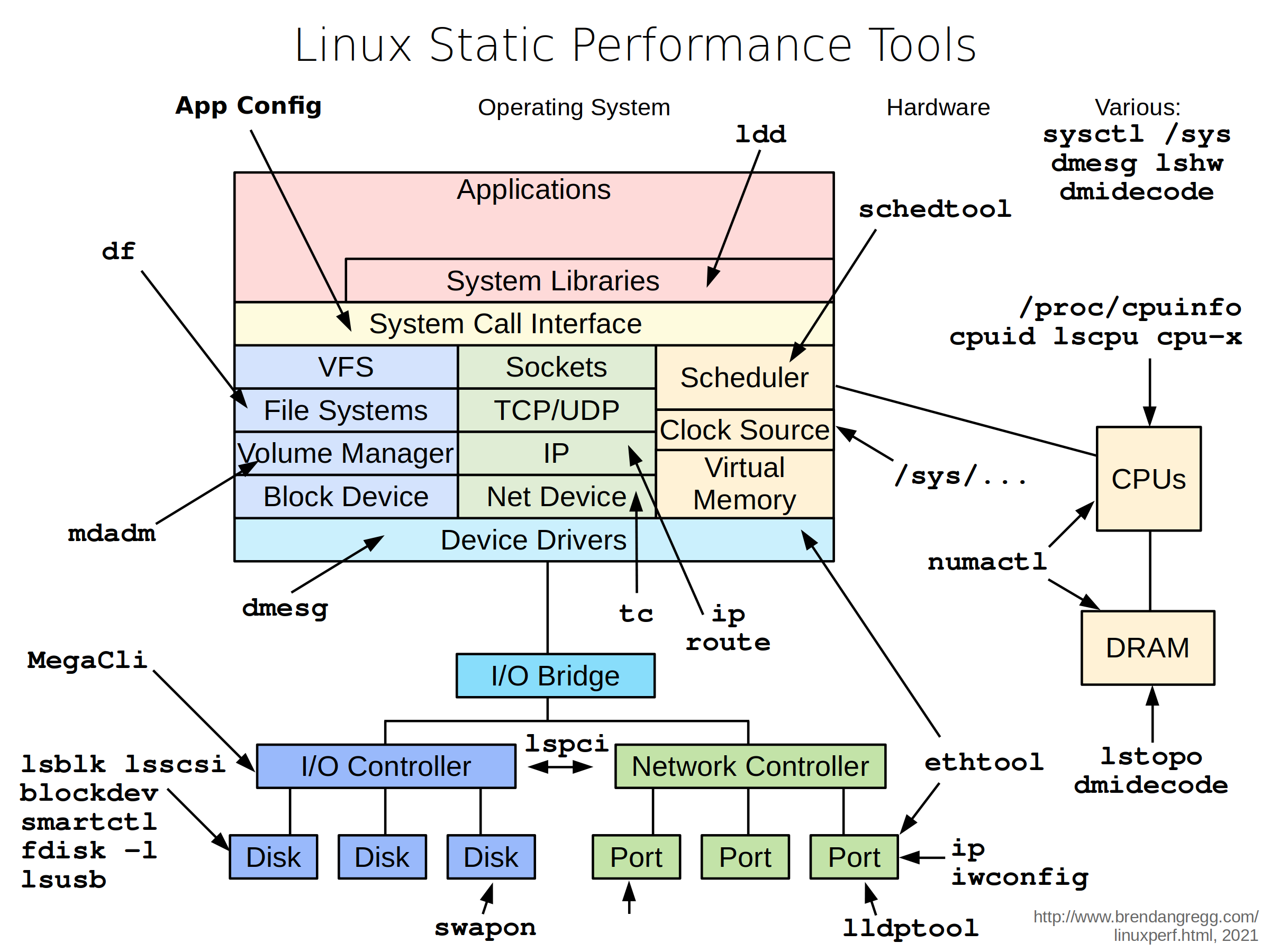
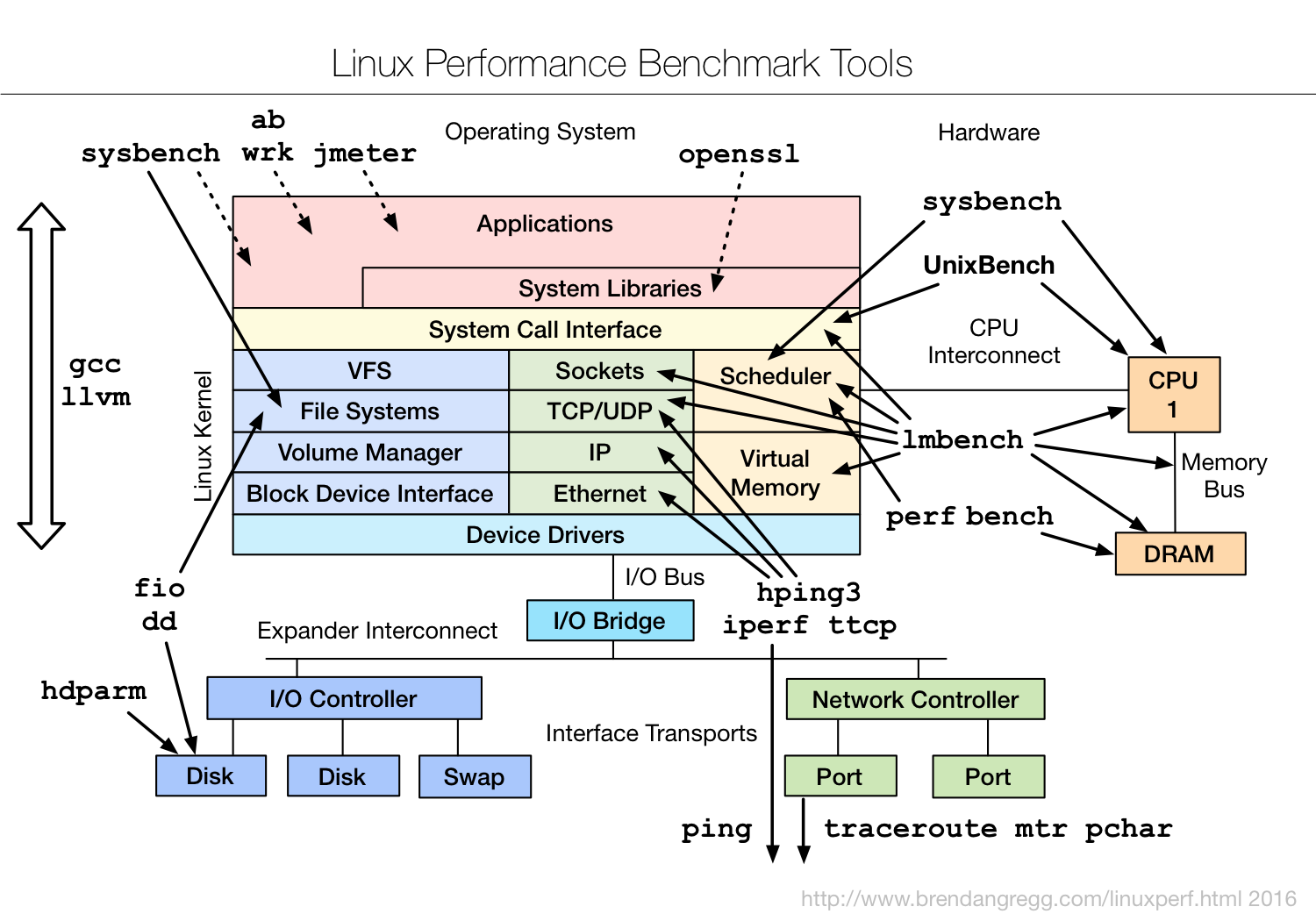
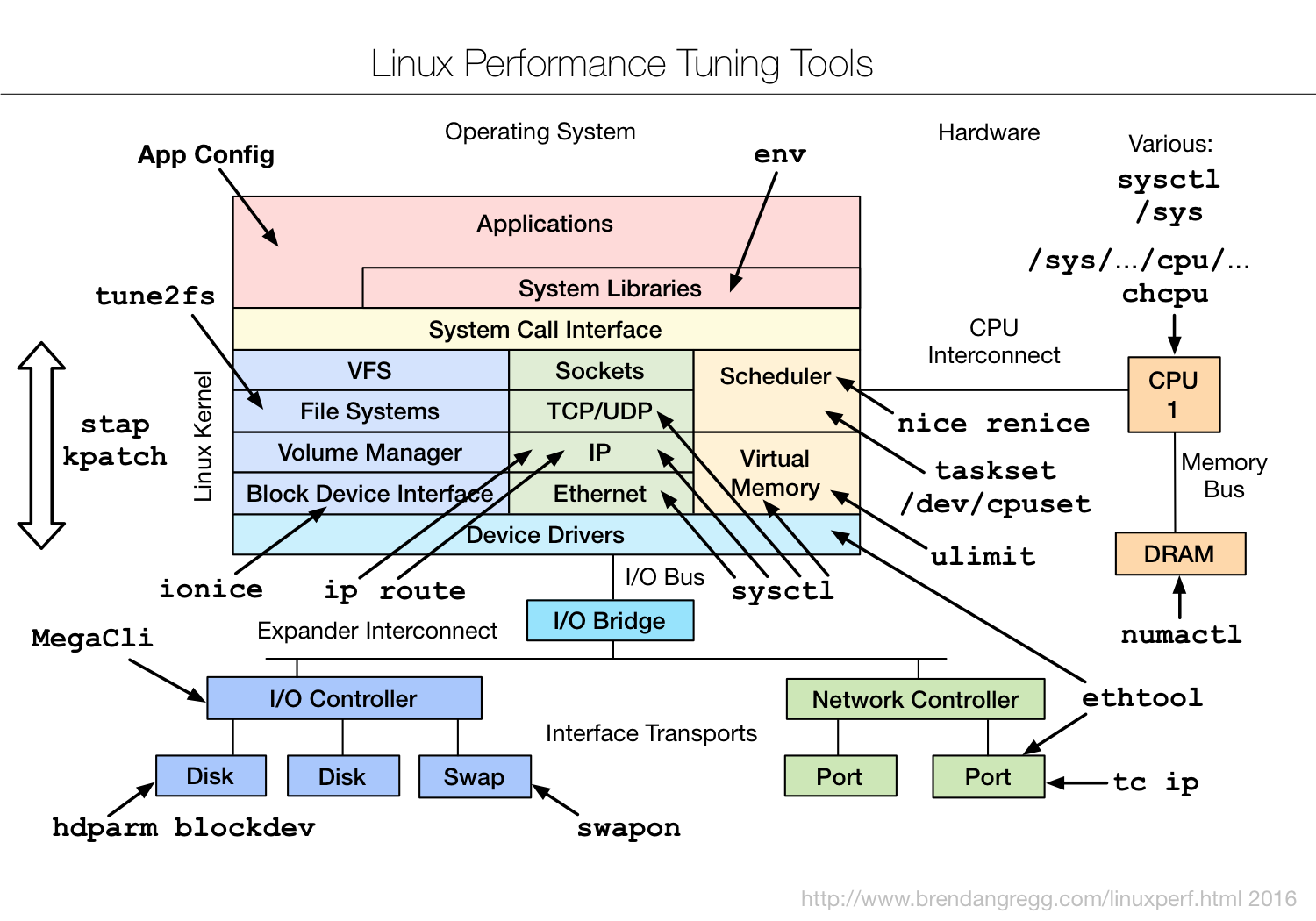
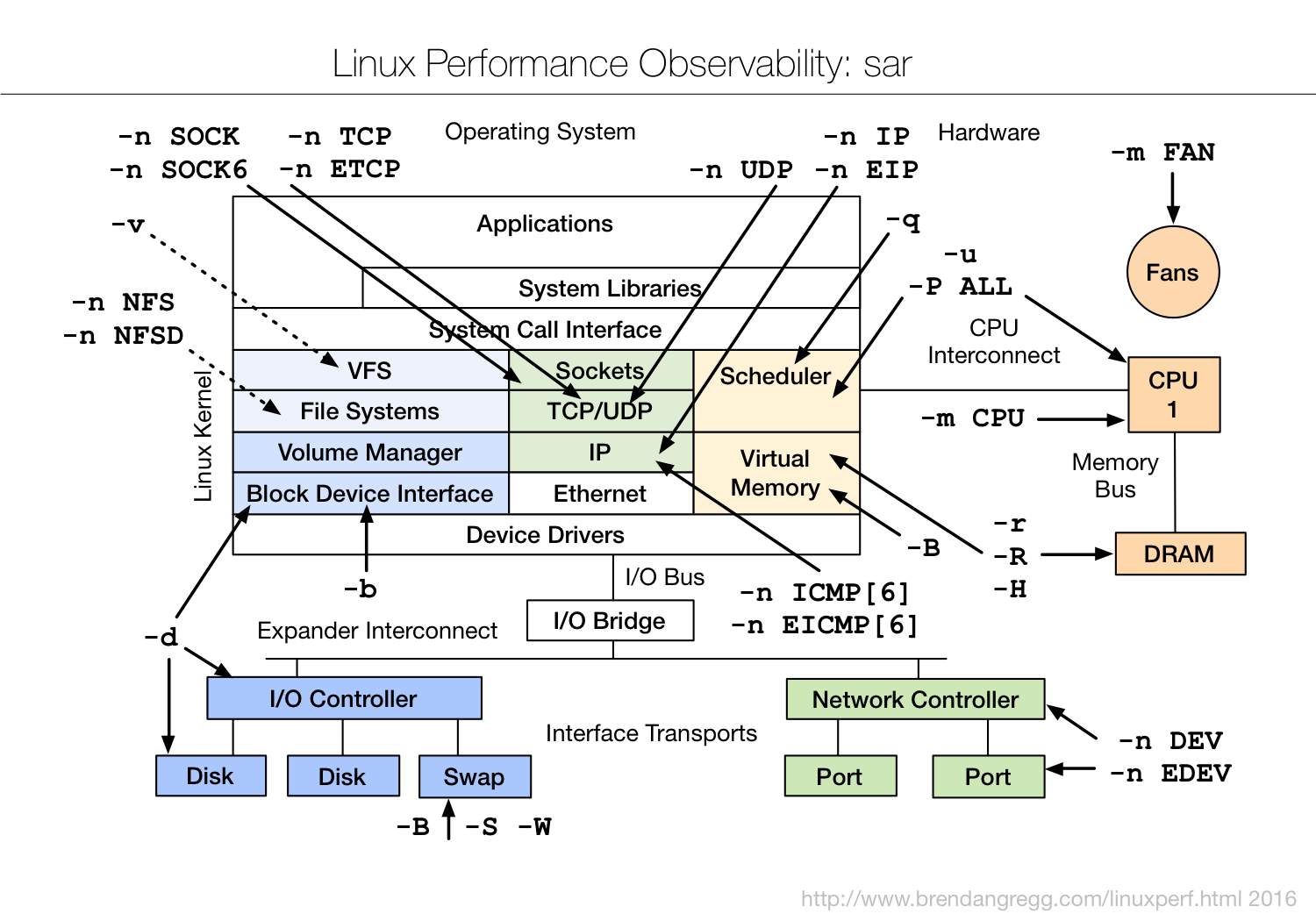
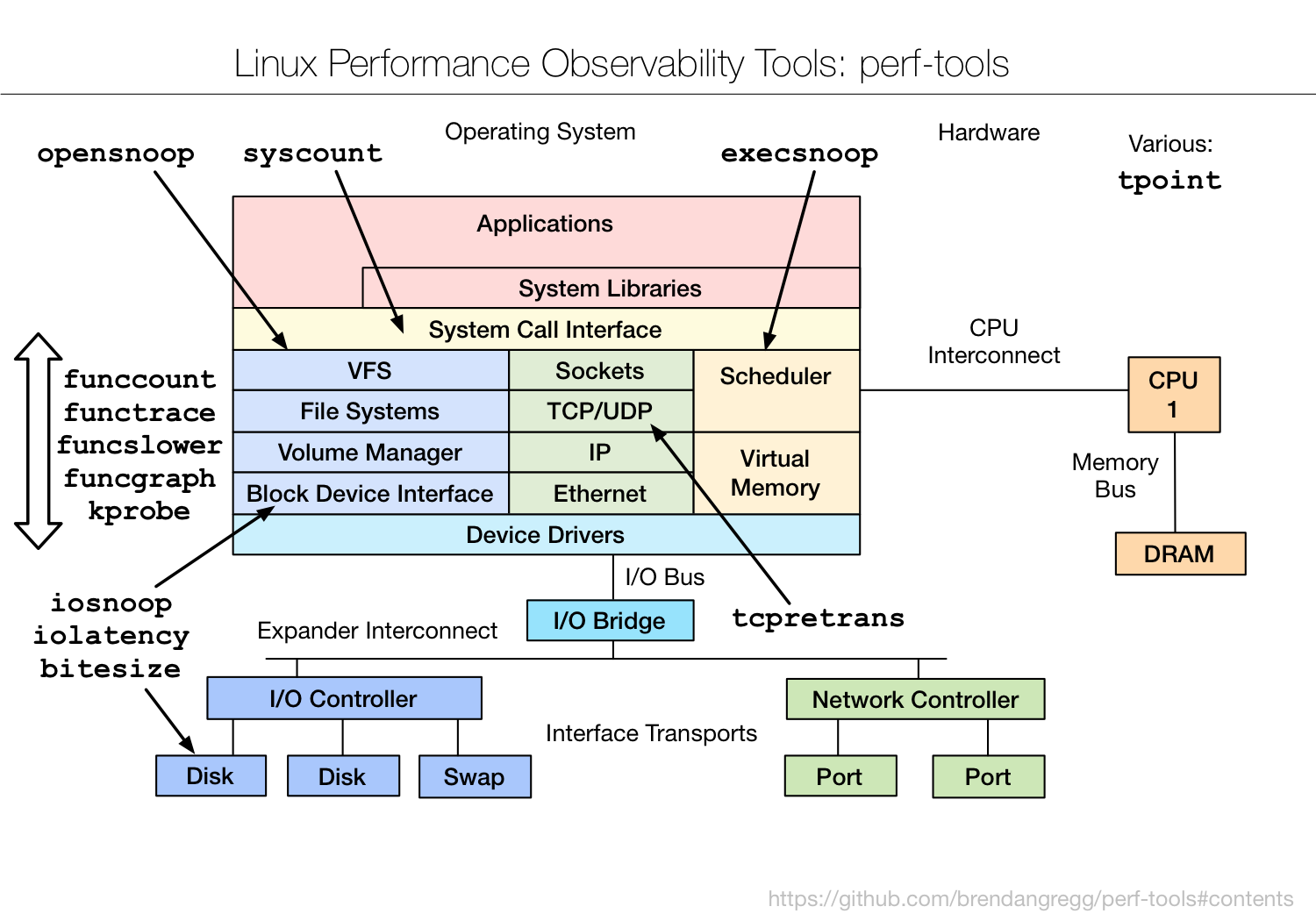
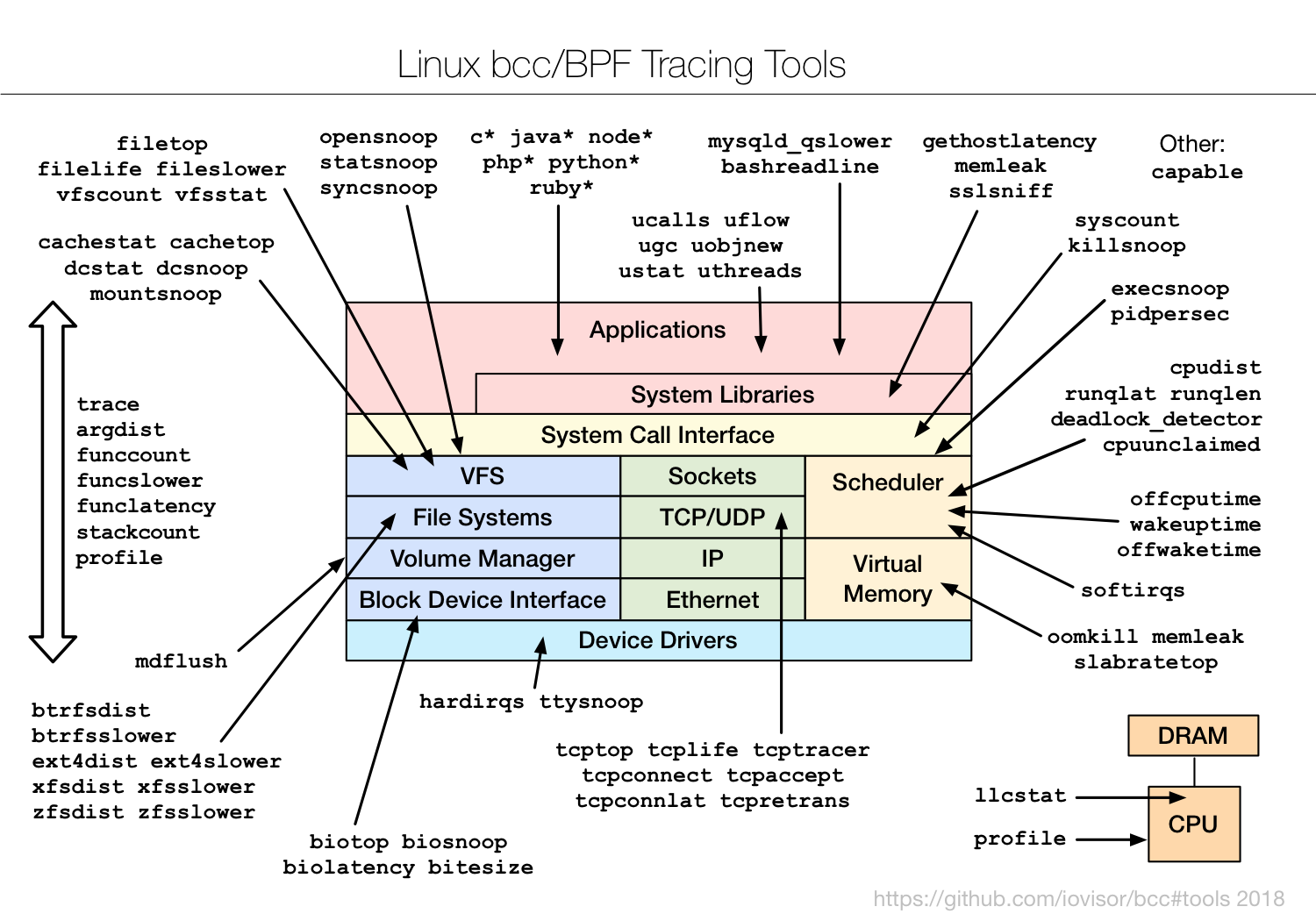
图片来源 Linux Performance
12. 查看指定进程使用的内存和有多少内存放在了 Swap 中
$ egrep '^(Swap|Size):' /proc/$pid/smaps
Size: 780 kB
Swap: 0 kB
Size: 8 kB
Swap: 0 kB
Size: 24 kB
Swap: 0 kB
Size: 80 kB
Swap: 0 kB
Size: 3460 kB
Swap: 0 kB
Size: 8 kB
Swap: 0 kB其中 Size 表示进程使用的某块内存的大小,Swap 和 SwapPss 表示该内存被交换到 Swap 中的大小。
