01-开篇词
01 | 如何学习Linux性能优化?
1.1 性能指标是什么?
性能分析,其实就是找出应用或系统的瓶颈,并设法去避免或者缓解它们,从而更高效地利用系统资源处理更多的请求。这包含了一系列的步骤,比如下面这六个步骤:
- 选择指标评估应用程序和系统的性能;
- 为应用程序和系统设置性能目标;
- 进行性能基准测试;
- 性能分析定位瓶颈;
- 优化系统和应用程序;
- 性能监控和告警。
1.2 学习的重点是什么?
想要学习好性能分析和优化,建立整体系统性能的全局观是最核心的话题。因而,
- 理解最基本的几个系统知识原理;
- 掌握必要的性能工具;
- 通过实际的场景演练,贯穿不同的组件。
千万不要把性能工具当成学习的全部。工具只是解决问题的手段,关键在于你的用法。只有真正理解了它们背后的原理,并且结合具体场景,融会贯通系统的不同组件,你才能真正掌握它们。
1.3 怎么学更高效?
- 虽然系统的原理很重要,但在刚开始一定不要试图抓住所有的实现细节。
- 边学边实践,通过大量的案例演习掌握 Linux 性能的分析和优化。
- 勤思考,多反思,善总结,多问为什么。
02-CPU 性能篇
02 | 基础篇:到底应该怎么理解”平均负载”?
2.1 平均负载
$ uptime
02:34:03 up 2 days, 20:14, 1 user, load average: 0.63, 0.83, 0.88输出结果分别是:系统当前时间、系统运行时间、登录用户数、系统过去 1 分钟、5 分钟、15 分钟的平均负载(Load Average)。
关于平均负载的解释可以查看 man uptime。
平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数。
- 可运行状态的进程,是指正在使用 CPU 或者正在等待 CPU 的进程,也就是我们常用 ps 命令看到的,处于 R 状态(Running 或 Runnable)的进程。
- 不可中断状态的进程则是正处于内核态关键流程中的进程,并且这些流程是不可打断的,比如最常见的是等待硬件设备的 I/O 响应,也就是我们在 ps 命令中看到的 D 状态(Uninterruptible Sleep,也称为 Disk Sleep)的进程。
比如,当一个进程向磁盘读写数据时,为了保证数据的一致性,在得到磁盘回复前,它是不能被其他进程或者中断打断的,这个时候的进程就处于不可中断状态。
不可中断状态实际上是系统对进程和硬件设备的一种保护机制。
可以简单理解为,平均负载其实就是平均活跃进程数。平均活跃进程数,直观上的理解就是单位时间内的活跃进程数,但它实际上是活跃进程数的指数衰减平均值。
2.2 平均负载为多少时合理
平均负载最理想的情况是等于 CPU 个数。
分析系统负载趋势:
- 如果 1 分钟、5 分钟、15 分钟的三个值基本相同,或者相差不大,那就说明系统负载很平稳。
- 但如果 1 分钟的值远小于 15 分钟的值,就说明系统最近 1 分钟的负载在减少,而过去 15 分钟内却有很大的负载。
- 反过来,如果 1 分钟的值远大于 15 分钟的值,就说明最近 1 分钟的负载在增加,这种增加有可能只是临时性的,也有可能还会持续增加下去,所以就需要持续观察。一旦 1 分钟的平均负载接近或超过了 CPU 的个数,就意味着系统正在发生过载的问题,这时就得分析调查是哪里导致的问题,并要想办法优化了。
在实际生产环境中,当平均负载高于 CPU 数量 70% 的时候,就应该分析排查负载高的问题了。
2.3 平均负载与 CPU 使用率
平均负载是指单位时间内,处于可运行状态和不可中断状态的进程数。所以,它不仅包括了正在使用 CPU 的进程,还包括等待 CPU 和等待 I/O 的进程。
CPU 使用率,是单位时间内 CPU 繁忙情况的统计,跟平均负载并不一定完全对应。比如:
- CPU 密集型进程,使用大量 CPU 会导致平均负载升高,此时这两者是一致的;
- I/O 密集型进程,等待 I/O 也会导致平均负载升高,但 CPU 使用率不一定很高;
- 大量等待 CPU 的进程调度也会导致平均负载升高,此时的 CPU 使用率也会比较高。
2.4 平均负载案例分析
机器配置:2 CPU,8GB 内存。
安装软件:
apt install stress sysstat。
观察测试前的平均负载
$ uptime
..., load average: 0.11, 0.15, 0.09场景一:CPU 密集型进程
模拟高 CPU 使用率
stress --cpu 1 --timeout 600在第二个终端运行 uptime 查看平均负载的变化情况
# -d 参数表示高亮显示变化的区域 $ watch -d uptime ..., load average: 1.00, 0.75, 0.39在第三个终端运行 mpstat 查看 CPU 使用率的变化情况
# -P ALL 表示监控所有 CPU,后面数字 5 表示间隔 5 秒后输出一组数据 $ mpstat -P ALL 5 Linux 4.15.0 (ubuntu) 09/22/18 _x86_64_ (2 CPU) 13:30:06 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle 13:30:11 all 50.05 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 49.95 13:30:11 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 13:30:11 1 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00可以看到,1 分钟的平均负载会慢慢增加到 1.00,而从终端三中还可以看到,正好有一个 CPU 的使用率为 100%,但它的 iowait 只有 0。这说明,平均负载的升高正是由于 CPU 使用率为 100% 。
到底是哪个进程导致了 CPU 使用率为 100% 呢?你可以使用 pidstat 来查询
# 间隔 5 秒后输出一组数据 $ pidstat -u 5 1 13:37:07 UID PID %usr %system %guest %wait %CPU CPU Command 13:37:12 0 2962 100.00 0.00 0.00 0.00 100.00 1 stress可以明显看到,stress 进程的 CPU 使用率为 100%。
场景二:I/O 密集型进程
模拟 I/O 压力,即不停地执行 sync
stress -i 1 --timeout 600在第二个终端运行 uptime 查看平均负载的变化情况
$ watch -d uptime ..., load average: 1.06, 0.58, 0.37在第三个终端运行 mpstat 查看 CPU 使用率的变化情况
# 显示所有 CPU 的指标,并在间隔 5 秒输出一组数据 $ mpstat -P ALL 5 1 Linux 4.15.0 (ubuntu) 09/22/18 _x86_64_ (2 CPU) 13:41:28 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle 13:41:33 all 0.21 0.00 12.07 32.67 0.00 0.21 0.00 0.00 0.00 54.84 13:41:33 0 0.43 0.00 23.87 67.53 0.00 0.43 0.00 0.00 0.00 7.74 13:41:33 1 0.00 0.00 0.81 0.20 0.00 0.00 0.00 0.00 0.00 98.99可以看到,1 分钟的平均负载会慢慢增加到 1.06,其中一个 CPU 的系统 CPU 使用率升高到了 23.87,而 iowait 高达 67.53%。这说明,平均负载的升高是由于 iowait 的升高。
那么到底是哪个进程,导致 iowait 这么高呢?用 pidstat 来查询
# 间隔 5 秒后输出一组数据,-u 表示 CPU 指标 $ pidstat -u 5 1 Linux 4.15.0 (ubuntu) 09/22/18 _x86_64_ (2 CPU) 13:42:08 UID PID %usr %system %guest %wait %CPU CPU Command 13:42:13 0 104 0.00 3.39 0.00 0.00 3.39 1 kworker/1:1H 13:42:13 0 109 0.00 0.40 0.00 0.00 0.40 0 kworker/0:1H 13:42:13 0 2997 2.00 35.53 0.00 3.99 37.52 1 stress 13:42:13 0 3057 0.00 0.40 0.00 0.00 0.40 0 pidstat可以发现,还是 stress 进程导致的。
场景三:大量进程的场景
当系统中运行进程超出 CPU 运行能力时,就会出现等待 CPU 的进程。
使用 stress 模拟的是 8 个进程
stress -c 8 --timeout 600由于系统只有 2 个 CPU,明显比 8 个进程要少得多,因而,系统的 CPU 处于严重过载状态,平均负载高达 7.97。
$ uptime ..., load average: 7.97, 5.93, 3.02接着再运行 pidstat 来看一下进程的情况
# 间隔 5 秒后输出一组数据 $ pidstat -u 5 1 14:23:25 UID PID %usr %system %guest %wait %CPU CPU Command 14:23:30 0 3190 25.00 0.00 0.00 74.80 25.00 0 stress 14:23:30 0 3191 25.00 0.00 0.00 75.20 25.00 0 stress 14:23:30 0 3192 25.00 0.00 0.00 74.80 25.00 1 stress 14:23:30 0 3193 25.00 0.00 0.00 75.00 25.00 1 stress 14:23:30 0 3194 24.80 0.00 0.00 74.60 24.80 0 stress 14:23:30 0 3195 24.80 0.00 0.00 75.00 24.80 0 stress 14:23:30 0 3196 24.80 0.00 0.00 74.60 24.80 1 stress 14:23:30 0 3197 24.80 0.00 0.00 74.80 24.80 1 stress 14:23:30 0 3200 0.00 0.20 0.00 0.20 0.20 0 pidstat可以看出,8 个进程在争抢 2 个 CPU,每个进程等待 CPU 的时间(也就是代码块中的 %wait 列)高达 75%。这些超出 CPU 计算能力的进程,最终导致 CPU 过载。
2.5 小结
平均负载提供了一个快速查看系统整体性能的手段,反映了整体的负载情况。但只看平均负载本身,我们并不能直接发现,到底是哪里出现了瓶颈。所以,在理解平均负载时,也要注意:
- 平均负载高有可能是 CPU 密集型进程导致的;
- 平均负载高并不一定代表 CPU 使用率高,还有可能是 I/O 更繁忙了;
- 当发现负载高的时候,你可以使用 mpstat、pidstat 等工具,辅助分析负载的来源。
03 | 基础篇:经常说的 CPU 上下文切换是什么意思?(上)
进程在竞争 CPU 的时候并没有真正运行,但是 CPU 上下文切换会导致系统的负载升高。
根据任务的不同,CPU 的上下文切换就可以分为几个不同的场景,也就是进程上下文切换、线程上下文切换以及中断上下文切换。
3.1 进程上下文切换
系统调用
系统调用的过程会发生 CPU 上下文。
CPU 寄存器里原来用户态的指令位置,需要先保存起来。接着,为了执行内核态代码,CPU 寄存器需要更新为内核态指令的新位置。最后才是跳转到内核态运行内核任务。
而系统调用结束后,CPU 寄存器需要恢复原来保存的用户态,然后再切换到用户空间,继续运行进程。所以,一次系统调用的过程,其实是发生了两次 CPU 上下文切换。
需要注意的是,系统调用过程中,并不会涉及到虚拟内存等进程用户态的资源,也不会切换进程。这跟我们通常所说的进程上下文切换是不一样的:
- 进程上下文切换,是指从一个进程切换到另一个进程运行。
而系统调用过程中一直是同一个进程在运行。
所以,系统调用过程通常称为特权模式切换,而不是上下文切换。
进程上下文切换跟系统调用又有什么区别呢?
进程是由内核来管理和调度的,进程的切换只能发生在内核态。所以,进程的上下文不仅包括了虚拟内存、栈、全局变量等用户空间的资源,还包括了内核堆栈、寄存器等内核空间的状态。
因此,进程的上下文切换就比系统调用时多了一步:在保存当前进程的内核状态和 CPU 寄存器之前,需要先把该进程的虚拟内存、栈等保存下来;而加载了下一进程的内核态后,还需要刷新进程的虚拟内存和用户栈。

根据 How long does it take to make a context switch? 的测试报告,每次上下文切换都需要几十纳秒到数微秒的 CPU 时间。
另外, Linux 通过 TLB(Translation Lookaside Buffer)来管理虚拟内存到物理内存的映射关系。当虚拟内存更新后,TLB 也需要刷新,内存的访问也会随之变慢。特别是在多处理器系统上,缓存是被多个处理器共享的,刷新缓存不仅会影响当前处理器的进程,还会影响共享缓存的其他处理器的进程。
进程在什么时候才会被调度到 CPU 上运行呢?
- 进程执行完终止了,它之前使用的 CPU 会释放出来,这个时候再从就绪队列里,拿一个新的进程过来运行。
- 当某个进程的时间片耗尽了,就会被系统挂起,切换到其它正在等待 CPU 的进程运行。
- 进程在系统资源不足(比如内存不足)时,要等到资源满足后才可以运行,这个时候进程也会被挂起,并由系统调度其他进程运行。
- 当进程通过睡眠函数 sleep 这样的方法将自己主动挂起时,自然也会重新调度。
- 当有优先级更高的进程运行时,为了保证高优先级进程的运行,当前进程会被挂起,由高优先级进程来运行。
- 发生硬件中断时,CPU 上的进程会被中断挂起,转而执行内核中的中断服务程序。
3.2 线程上下文切换
线程与进程最大的区别在于,线程是调度的基本单位,而进程则是资源拥有的基本单位 。内核中的任务调度,实际上的调度对象是线程;而进程只是给线程提供了虚拟内存、全局变量等资源。所以,对于线程和进程,可以这么理解:
- 当进程只有一个线程时,可以认为进程就等于线程。
- 当进程拥有多个线程时,这些线程会共享相同的虚拟内存和全局变量等资源。这些资源在上下文切换时是不需要修改的。
- 另外,线程也有自己的私有数据,比如栈和寄存器等,这些在上下文切换时也是需要保存的。
这么一来,线程的上下文切换其实就可以分为两种情况:
- 前后两个线程属于不同进程。此时,因为资源不共享,所以切换过程就跟进程上下文切换是一样。
- 前后两个线程属于同一个进程。此时,因为虚拟内存是共享的,所以在切换时,虚拟内存这些资源就保持不动,只需要切换线程的私有数据、寄存器等不共享的数据。
虽然同为上下文切换,但同进程内的线程切换,要比多进程间的切换消耗更少的资源,而这,也正是多线程代替多进程的一个优势。
3.3 中断上下文切换
为了快速响应硬件的事件,中断处理会打断进程的正常调度和执行,转而调用中断处理程序,响应设备事件。
跟进程上下文不同,中断上下文切换并不涉及到进程的用户态。所以,即便中断过程打断了一个正处在用户态的进程,也不需要保存和恢复这个进程的虚拟内存、全局变量等用户态资源。中断上下文,其实只包括内核态中断服务程序执行所必需的状态,包括 CPU 寄存器、内核堆栈、硬件中断参数等。
对同一个 CPU 来说,中断处理比进程拥有更高的优先级,所以中断上下文切换并不会与进程上下文切换同时发生。
04 | 基础篇:经常说的 CPU 上下文切换是什么意思?(下)
4.1 怎么查看系统的上下文切换情况
查看系统总体的上下文切换情况
vmstat 是一个常用的系统性能分析工具,主要用来分析系统的内存使用情况,也常用来分析 CPU 上下文切换和中断的次数。
# 每隔 5 秒输出 1 组数据 $ vmstat 5 procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 0 0 0 7005360 91564 818900 0 0 0 0 25 33 0 0 100 0 0特别关注下面几列信息:
- cs(context switch)是每秒上下文切换的次数。
- in(interrupt)则是每秒中断的次数。
- r(Running or Runnable)是就绪队列的长度,也就是正在运行和等待 CPU 的进程数。
- b(Blocked)则是处于不可中断睡眠状态的进程数。
查看每个进程的上下文切换情况
vmstat 只给出了系统总体的上下文切换情况,要想查看每个进程的详细情况,就需要使用我们前面提到过的 pidstat 了。给它加上 -w 选项,你就可以查看每个进程上下文切换的情况了。
# 每隔 5 秒输出 1 组数据 $ pidstat -w 5 Linux 4.15.0 (ubuntu) 09/23/18 _x86_64_ (2 CPU) 08:18:26 UID PID cswch/s nvcswch/s Command 08:18:31 0 1 0.20 0.00 systemd 08:18:31 0 8 5.40 0.00 rcu_sched ...特别关注下面几列信息:
- cswch ,表示每秒自愿上下文切换(voluntary context switches)的次数。
nvcswch ,表示每秒非自愿上下文切换(non voluntary context switches)的次数。
它们会反应出不同的性能问题:
自愿上下文切换,是指进程无法获取所需资源,导致的上下文切换。比如说, I/O、内存等系统资源不足时,就会发生自愿上下文切换。
- 非自愿上下文切换,则是指进程由于时间片已到等原因,被系统强制调度,进而发生的上下文切换。比如说,大量进程都在争抢 CPU 时,就容易发生非自愿上下文切换。
4.2 案例分析
机器配置: 2 CPU, 8 GB 内存。
安装软件:
apt install sysbench sysstat。
先用 vmstat 看一下空闲系统的上下文切换次数
# 间隔 1 秒后输出 1 组数据
$ vmstat 1 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 6984064 92668 830896 0 0 2 19 19 35 1 0 99 0 0可以看到,现在的上下文切换次数 cs 是 35,而中断次数 in 是 19,r 和 b 都是 0。因为这会儿没有运行其他任务,所以它们就是空闲系统的上下文切换次数。
在第一个终端里运行 sysbench ,模拟系统多线程调度的瓶颈
# 以 10 个线程运行 5 分钟的基准测试,模拟多线程切换的问题 $ sysbench --threads=10 --max-time=300 threads run在第二个终端运行 vmstat ,观察上下文切换情况
# 每隔 1 秒输出 1 组数据(需要 Ctrl+C 才结束) $ vmstat 1 procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 6 0 0 6487428 118240 1292772 0 0 0 0 9019 1398830 16 84 0 0 0 8 0 0 6487428 118240 1292772 0 0 0 0 10191 1392312 16 84 0 0 0可以发现,cs 列的上下文切换次数从之前的 35 骤然上升到了 139 万。同时,注意观察其他几个指标:
- r 列:就绪队列的长度已经到了 8,远远超过了系统 CPU 的个数 2,所以肯定会有大量的 CPU 竞争。
- us(user)和 sy(system)列:这两列的 CPU 使用率加起来上升到了 100%,其中系统 CPU 使用率,也就是 sy 列高达 84%,说明 CPU 主要是被内核占用了。
in 列:中断次数也上升到了 1 万左右,说明中断处理也是个潜在的问题。
综合这几个指标,我们可以知道,系统的就绪队列过长,也就是正在运行和等待 CPU 的进程数过多,导致了大量的上下文切换,而上下文切换又导致了系统 CPU 的占用率升高。
那么到底是什么进程导致了这些问题呢?
在第三个终端再用 pidstat 来看一下, CPU 和进程上下文切换的情况
# 每隔 1 秒输出 1 组数据(需要 Ctrl+C 才结束) # -w 参数表示输出进程切换指标,而 -u 参数则表示输出 CPU 使用指标 $ pidstat -w -u 1 08:06:33 UID PID %usr %system %guest %wait %CPU CPU Command 08:06:34 0 10488 30.00 100.00 0.00 0.00 100.00 0 sysbench 08:06:34 0 26326 0.00 1.00 0.00 0.00 1.00 0 kworker/u4:2 08:06:33 UID PID cswch/s nvcswch/s Command 08:06:34 0 8 11.00 0.00 rcu_sched 08:06:34 0 16 1.00 0.00 ksoftirqd/1 08:06:34 0 471 1.00 0.00 hv_balloon 08:06:34 0 1230 1.00 0.00 iscsid 08:06:34 0 4089 1.00 0.00 kworker/1:5 08:06:34 0 4333 1.00 0.00 kworker/0:3 08:06:34 0 10499 1.00 224.00 pidstat 08:06:34 0 26326 236.00 0.00 kworker/u4:2 08:06:34 1000 26784 223.00 0.00 sshd从 pidstat 的输出你可以发现,CPU 使用率的升高果然是 sysbench 导致的,它的 CPU 使用率已经达到了 100%。但上下文切换则是来自其他进程,包括非自愿上下文切换频率最高的 pidstat ,以及自愿上下文切换频率最高的内核线程 kworker 和 sshd。
不过,细心的你肯定也发现了一个怪异的事儿:pidstat 输出的上下文切换次数,加起来也就几百,比 vmstat 的 139 万明显小了太多。
通过运行 man pidstat ,你会发现,pidstat 默认显示进程的指标数据,加上 -t 参数后,才会输出线程的指标。
所以,在第三个终端里, Ctrl+C 停止刚才的 pidstat 命令,再加上 -t 参数,重试一下看看:
# 每隔 1 秒输出一组数据(需要 Ctrl+C 才结束) # -wt 参数表示输出线程的上下文切换指标 $ pidstat -wt 1 08:14:05 UID TGID TID cswch/s nvcswch/s Command ... 08:14:05 0 10551 - 6.00 0.00 sysbench 08:14:05 0 - 10551 6.00 0.00 |__sysbench 08:14:05 0 - 10552 18911.00 103740.00 |__sysbench 08:14:05 0 - 10553 18915.00 100955.00 |__sysbench 08:14:05 0 - 10554 18827.00 103954.00 |__sysbench ...现在你就能看到了,虽然 sysbench 进程(也就是主线程)的上下文切换次数看起来并不多,但它的子线程的上下文切换次数却有很多。看来,上下文切换罪魁祸首,还是过多的 sysbench 线程。
在观察系统指标时,除了上下文切换频率骤然升高,还有一个指标也有很大的变化。是的,正是中断次数。中断次数也上升到了 1 万,但到底是什么类型的中断上升了?
既然是中断,我们都知道,它只发生在内核态,而 pidstat 只是一个进程的性能分析工具,并不提供任何关于中断的详细信息,怎样才能知道中断发生的类型呢?
没错,那就是从 /proc/interrupts 这个只读文件中读取。/proc 实际上是 Linux 的一个虚拟文件系统,用于内核空间与用户空间之间的通信。/proc/interrupts 就是这种通信机制的一部分,提供了一个只读的中断使用情况。
在第三个终端里, Ctrl+C 停止刚才的 pidstat 命令,然后运行下面的命令,观察中断的变化情况:
# -d 参数表示高亮显示变化的区域 $ watch -d cat /proc/interrupts CPU0 CPU1 ... RES: 2450431 5279697 Rescheduling interrupts ...观察一段时间,你可以发现,变化速度最快的是重调度中断(RES),这个中断类型表示,唤醒空闲状态的 CPU 来调度新的任务运行。这是多处理器系统(SMP)中,调度器用来分散任务到不同 CPU 的机制,通常也被称为处理器间中断(Inter-Processor Interrupts,IPI)。
所以,这里的中断升高还是因为过多任务的调度问题,跟前面上下文切换次数的分析结果是一致的。
通过这个案例,你应该也发现了多工具、多方面指标对比观测的好处。如果最开始时,我们只用了 pidstat 观测,这些很严重的上下文切换线程,压根儿就发现不了了。
现在再回到最初的问题,每秒上下文切换多少次才算正常呢?
这个数值其实取决于系统本身的 CPU 性能。在我看来,如果系统的上下文切换次数比较稳定,那么从数百到一万以内,都应该算是正常的。但当上下文切换次数超过一万次,或者切换次数出现数量级的增长时,就很可能已经出现了性能问题。
这时,你还需要根据上下文切换的类型,再做具体分析。比方说:
- 自愿上下文切换变多了,说明进程都在等待资源,有可能发生了 I/O 等其他问题;
- 非自愿上下文切换变多了,说明进程都在被强制调度,也就是都在争抢 CPU,说明 CPU 的确成了瓶颈;
- 中断次数变多了,说明 CPU 被中断处理程序占用,还需要通过查看 /proc/interrupts 文件来分析具体的中断类型。
05 | 基础篇:某个应用的CPU使用率居然达到100%,我该怎么办?
CPU 使用率是单位时间内 CPU 使用情况的统计,以百分比的方式展示。
5.1 CPU 使用率
Linux 作为一个多任务操作系统,将每个 CPU 的时间划分为很短的时间片,再通过调度器轮流分配给各个任务使用,因此造成多任务同时运行的错觉。
为了维护 CPU 时间,Linux 通过事先定义的节拍率(内核中表示为 HZ),触发时间中断,并使用全局变量 Jiffies 记录了开机以来的节拍数。每发生一次时间中断,Jiffies 的值就加 1。
节拍率 HZ 是内核的可配选项,可以设置为 100、250、1000 等。不同的系统可能设置不同数值,你可以通过查询 /boot/config 内核选项来查看它的配置值。比如在我的系统中,节拍率设置成了 250,也就是每秒钟触发 250 次时间中断。
$ grep 'CONFIG_HZ=' /boot/config-$(uname -r)
CONFIG_HZ=250同时,正因为节拍率 HZ 是内核选项,所以用户空间程序并不能直接访问。为了方便用户空间程序,内核还提供了一个用户空间节拍率 USER_HZ,它总是固定为 100,也就是 1/100 秒。这样,用户空间程序并不需要关心内核中 HZ 被设置成了多少,因为它看到的总是固定值 USER_HZ。
Linux 通过 /proc 虚拟文件系统,向用户空间提供了系统内部状态的信息,而 /proc/stat 提供的就是系统的 CPU 和任务统计信息。比方说,如果你只关注 CPU 的话,可以执行下面的命令:
# 只保留各个 CPU 的数据
$ cat /proc/stat | grep ^cpu
cpu 280580 7407 286084 172900810 83602 0 583 0 0 0
cpu0 144745 4181 176701 86423902 52076 0 301 0 0 0
cpu1 135834 3226 109383 86476907 31525 0 282 0 0 0输出结果是一个表格。其中,第一列表示的是 CPU 编号,如 cpu0、cpu1 ,而第一行没有编号的 cpu ,表示的是所有 CPU 的累加。其他列则表示不同场景下 CPU 的累加节拍数,它的单位是 USER_HZ,也就是 10 ms(1/100 秒),所以这其实就是不同场景下的 CPU 时间。
每个数字的意义可以通过 man proc 查询。要清楚 man proc 文档里每一列的涵义,它们都是 CPU 使用率相关的重要指标,你还会在很多其他的性能工具中看到它们。下面,我来依次解读一下。
- user(通常缩写为 us),代表用户态 CPU 时间。注意,它不包括下面的 nice 时间,但包括了 guest 时间。
- nice(通常缩写为 ni),代表低优先级用户态 CPU 时间,也就是进程的 nice 值被调整为 1-19 之间时的 CPU 时间。这里注意,nice 可取值范围是 -20 到 19,数值越大,优先级反而越低。
- system(通常缩写为 sys),代表内核态 CPU 时间。
- idle(通常缩写为 id),代表空闲时间。注意,它不包括等待 I/O 的时间(iowait)。
- iowait(通常缩写为 wa),代表等待 I/O 的 CPU 时间。
- irq(通常缩写为 hi),代表处理硬中断的 CPU 时间。
- softirq(通常缩写为 si),代表处理软中断的 CPU 时间。
- steal(通常缩写为 st),代表当系统运行在虚拟机中的时候,被其他虚拟机占用的 CPU 时间。
- guest(通常缩写为 guest),代表通过虚拟化运行其他操作系统的时间,也就是运行虚拟机的 CPU 时间。
- guest_nice(通常缩写为 gnice),代表以低优先级运行虚拟机的时间。
CPU 使用率,就是除了空闲时间外的其他时间占总 CPU 时间的百分比,用公式来表示就是:
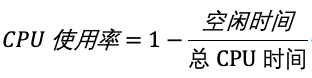
根据这个公式,我们就可以从 /proc/stat 中的数据,很容易地计算出 CPU 使用率。当然,也可以用每一个场景的 CPU 时间,除以总的 CPU 时间,计算出每个场景的 CPU 使用率。
不过先不要着急计算,你能说出,直接用 /proc/stat 的数据,算的是什么时间段的 CPU 使用率吗?
看到这里,你应该想起来了,这是开机以来的节拍数累加值,所以直接算出来的,是开机以来的平均 CPU 使用率,一般没啥参考价值。
事实上,为了计算 CPU 使用率,性能工具一般都会取间隔一段时间(比如 3 秒)的两次值,作差后,再计算出这段时间内的平均 CPU 使用率,即

这个公式,就是我们用各种性能工具所看到的 CPU 使用率的实际计算方法。
现在,我们知道了系统 CPU 使用率的计算方法,那进程的呢?跟系统的指标类似,Linux 也给每个进程提供了运行情况的统计信息,也就是 /proc/[pid]/stat。不过,这个文件包含的数据就比较丰富了,总共有 52 列的数据。
性能分析工具给出的都是间隔一段时间的平均 CPU 使用率,所以要注意间隔时间的设置,特别是用多个工具对比分析时,你一定要保证它们用的是相同的间隔时间。
比如,对比一下 top 和 ps 这两个工具报告的 CPU 使用率,默认的结果很可能不一样,因为 top 默认使用 3 秒时间间隔,而 ps 使用的却是进程的整个生命周期。
5.2 怎么查看 CPU 使用率
top 和 ps 是最常用的性能分析工具:
- top 显示了系统总体的 CPU 和内存使用情况,以及各个进程的资源使用情况。
- ps 则只显示了每个进程的资源使用情况。
top 的输出格式为:
# 默认每 3 秒刷新一次
$ top
top - 11:58:59 up 9 days, 22:47, 1 user, load average: 0.03, 0.02, 0.00
Tasks: 123 total, 1 running, 72 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.3 us, 0.3 sy, 0.0 ni, 99.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 8169348 total, 5606884 free, 334640 used, 2227824 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 7497908 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1 root 20 0 78088 9288 6696 S 0.0 0.1 0:16.83 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.05 kthreadd
4 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/0:0H
...输出结果中,第三行 %Cpu 就是系统的 CPU 使用率,具体每一列的含义上一节都讲过,只是把 CPU 时间变换成了 CPU 使用率。不过需要注意,top 默认显示的是所有 CPU 的平均值,这个时候你只需要按下数字 1 ,就可以切换到每个 CPU 的使用率了。
继续往下看,空白行之后是进程的实时信息,每个进程都有一个 %CPU 列,表示进程的 CPU 使用率。它是用户态和内核态 CPU 使用率的总和,包括进程用户空间使用的 CPU、通过系统调用执行的内核空间 CPU 、以及在就绪队列等待运行的 CPU。在虚拟化环境中,它还包括了运行虚拟机占用的 CPU。
可以发现, top 并没有细分进程的用户态 CPU 和内核态 CPU。可以使用 pidstat 专门分析每个进程 CPU 使用情况的工具。
比如,下面的 pidstat 命令,就间隔 1 秒展示了进程的 5 组 CPU 使用率,包括:
- 用户态 CPU 使用率 (%usr);
- 内核态 CPU 使用率(%system);
- 运行虚拟机 CPU 使用率(%guest);
- 等待 CPU 使用率(%wait);
- 以及总的 CPU 使用率(%CPU)。
最后的 Average 部分,还计算了 5 组数据的平均值。
# 每隔 1 秒输出一组数据,共输出 5 组
$ pidstat 1 5
15:56:02 UID PID %usr %system %guest %wait %CPU CPU Command
15:56:03 0 15006 0.00 0.99 0.00 0.00 0.99 1 dockerd
...
Average: UID PID %usr %system %guest %wait %CPU CPU Command
Average: 0 15006 0.00 0.99 0.00 0.00 0.99 - dockerd5.3 CPU 使用率过高怎么办?
通过 top、ps、pidstat 等工具,你能够轻松找到 CPU 使用率较高(比如 100% )的进程。接下来,你可能又想知道,占用 CPU 的到底是代码里的哪个函数呢?找到它,你才能更高效、更针对性地进行优化。
我猜你第一个想到的,应该是 GDB(The GNU Project Debugger), 这个功能强大的程序调试利器。的确,GDB 在调试程序错误方面很强大。但是,我又要来”挑刺”了。请你记住,GDB 并不适合在性能分析的早期应用。
为什么呢?因为 GDB 调试程序的过程会中断程序运行,这在线上环境往往是不允许的。所以,GDB 只适合用在性能分析的后期,当你找到了出问题的大致函数后,线下再借助它来进一步调试函数内部的问题。
那么哪种工具适合在第一时间分析进程的 CPU 问题呢?我的推荐是 perf。perf 是 Linux 2.6.31 以后内置的性能分析工具。它以性能事件采样为基础,不仅可以分析系统的各种事件和内核性能,还可以用来分析指定应用程序的性能问题。
使用 perf 分析 CPU 性能问题,我来说两种最常见、也是我最喜欢的用法。
第一种常见用法是 perf top,类似于 top,它能够实时显示占用 CPU 时钟最多的函数或者指令,因此可以用来查找热点函数,使用界面如下所示:
$ perf top
Samples: 833 of event 'cpu-clock', Event count (approx.): 97742399
Overhead Shared Object Symbol
7.28% perf [.] 0x00000000001f78a4
4.72% [kernel] [k] vsnprintf
4.32% [kernel] [k] module_get_kallsym
3.65% [kernel] [k] _raw_spin_unlock_irqrestore
...输出结果中,第一行包含三个数据,分别是采样数(Samples)、事件类型(event)和事件总数量(Event count)。比如这个例子中,perf 总共采集了 833 个 CPU 时钟事件,而总事件数则为 97742399。
再往下看是一个表格式样的数据,每一行包含四列,分别是:
- 第一列 Overhead ,是该符号的性能事件在所有采样中的比例,用百分比来表示。
- 第二列 Shared ,是该函数或指令所在的动态共享对象(Dynamic Shared Object),如内核、进程名、动态链接库名、内核模块名等。
- 第三列 Object ,是动态共享对象的类型。比如 [.] 表示用户空间的可执行程序、或者动态链接库,而 [k] 则表示内核空间。
- 最后一列 Symbol 是符号名,也就是函数名。当函数名未知时,用十六进制的地址来表示。
以上面的输出为例,我们可以看到,占用 CPU 时钟最多的是 perf 工具自身,不过它的比例也只有 7.28%,说明系统并没有 CPU 性能问题。 perf top 的使用你应该很清楚了吧。
接着再来看第二种常见用法,也就是 perf record 和 perf report。 perf top 虽然实时展示了系统的性能信息,但它的缺点是并不保存数据,也就无法用于离线或者后续的分析。而 perf record 则提供了保存数据的功能,保存后的数据,需要你用 perf report 解析展示。
$ perf record # 按 Ctrl+C 终止采样
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.452 MB perf.data (6093 samples) ]
$ perf report # 展示类似于 perf top 的报告在实际使用中,我们还经常为 perf top 和 perf record 加上 -g 参数,开启调用关系的采样,方便我们根据调用链来分析性能问题。
5.4 案例
下面我们就以 Nginx + PHP 的 Web 服务为例,来看看当你发现 CPU 使用率过高的问题后,要怎么使用 top 等工具找出异常的进程,又要怎么利用 perf 找出引发性能问题的函数。
机器配置:2 CPU,8GB 内存。
安装软件:
apt install docker.io sysstat linux-tools-common apache2-utils。ab(apache bench)是一个常用的 HTTP 服务性能测试工具,这里用来模拟 Ngnix 的客户端。
在第一个终端执行下面的命令来运行 Nginx 和 PHP 应用:
docker run --name nginx -p 10000:80 -itd feisky/nginx docker run --name phpfpm -itd --network container:nginx feisky/php-fpm在第二个终端使用 curl 访问
http://[VM1 的 IP]:10000,确认 Nginx 已正常启动。你应该可以看到 It works! 的响应。# 192.168.0.10 是第一台虚拟机的 IP 地址 $ curl http://192.168.0.10:10000/ It works!接着,我们来测试一下这个 Nginx 服务的性能。在第二个终端运行下面的 ab 命令:
# 并发 10 个请求测试 Nginx 性能,总共测试 100 个请求 $ ab -c 10 -n 100 http://192.168.0.10:10000/ This is ApacheBench, Version 2.3 <$Revision: 1706008 $> Copyright 1996 Adam Twiss, Zeus Technology Ltd, ... Requests per second: 11.63 [#/sec] (mean) Time per request: 859.942 [ms] (mean) ...从 ab 的输出结果我们可以看到,Nginx 能承受的每秒平均请求数只有 11.63。太少了,那到底是哪里出了问题呢?我们用 top 和 pidstat 再来观察下。
我们在第二个终端,将测试的请求总数增加到 10000。这样当你在第一个终端使用性能分析工具时, Nginx 的压力还是继续。继续在第二个终端,运行 ab 命令:
ab -c 10 -n 10000 http://10.240.0.5:10000/回到第一个终端运行 top 命令,并按下数字 1 ,切换到每个 CPU 的使用率:
$ top ... %Cpu0 : 98.7 us, 1.3 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st %Cpu1 : 99.3 us, 0.7 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st ... PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 21514 daemon 20 0 336696 16384 8712 R 41.9 0.2 0:06.00 php-fpm 21513 daemon 20 0 336696 13244 5572 R 40.2 0.2 0:06.08 php-fpm 21515 daemon 20 0 336696 16384 8712 R 40.2 0.2 0:05.67 php-fpm 21512 daemon 20 0 336696 13244 5572 R 39.9 0.2 0:05.87 php-fpm 21516 daemon 20 0 336696 16384 8712 R 35.9 0.2 0:05.61 php-fpm这里可以看到,系统中有几个 php-fpm 进程的 CPU 使用率加起来接近 200%;而每个 CPU 的用户使用率(us)也已经超过了 98%,接近饱和。这样,我们就可以确认,正是用户空间的 php-fpm 进程,导致 CPU 使用率骤升。
那再往下走,怎么知道是 php-fpm 的哪个函数导致了 CPU 使用率升高呢?我们来用 perf 分析一下。在第一个终端运行下面的 perf 命令:
# -g 开启调用关系分析,-p 指定 php-fpm 的进程号 21515 $ perf top -g -p 21515按方向键切换到 php-fpm,再按下回车键展开 php-fpm 的调用关系,你会发现,调用关系最终到了 sqrt 和 add_function。看来,我们需要从这两个函数入手了。
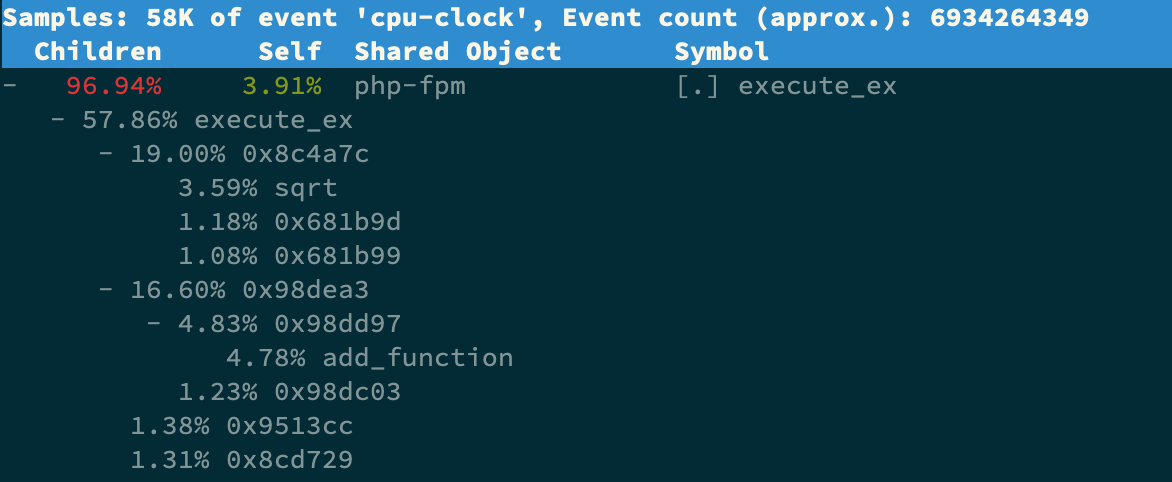
我们拷贝出 Nginx 应用的源码,看看是不是调用了这两个函数:
# 从容器 phpfpm 中将 PHP 源码拷贝出来 $ docker cp phpfpm:/app . # 使用 grep 查找函数调用 $ grep sqrt -r app/ # 找到了 sqrt 调用 app/index.php: $x += sqrt($x); $ grep add_function -r app/ # 没找到 add_function 调用,这其实是 PHP 内置函数OK,原来只有 sqrt 函数在 app/index.php 文件中调用了。那最后一步,我们就该看看这个文件的源码了:
$ cat app/index.php <?php // test only. $x = 0.0001; for ($i = 0; $i <= 1000000; $i++) { $x += sqrt($x); } echo "It works!"呀,有没有发现问题在哪里呢?我想你要笑话我了,居然犯了一个这么傻的错误,测试代码没删就直接发布应用了。为了方便你验证优化后的效果,我把修复后的应用也打包成了一个 Docker 镜像,你可以在第一个终端中执行下面的命令来运行它:
# 停止原来的应用 $ docker rm -f nginx phpfpm # 运行优化后的应用 $ docker run --name nginx -p 10000:80 -itd feisky/nginx:cpu-fix $ docker run --name phpfpm -itd --network container:nginx feisky/php-fpm:cpu-fix接着,到第二个终端来验证一下修复后的效果。首先 Ctrl+C 停止之前的 ab 命令后,再运行下面的命令:
$ ab -c 10 -n 10000 http://10.240.0.5:10000/ ... Complete requests: 10000 Failed requests: 0 Total transferred: 1720000 bytes HTML transferred: 90000 bytes Requests per second: 2237.04 [#/sec] (mean) Time per request: 4.470 [ms] (mean) Time per request: 0.447 [ms] (mean, across all concurrent requests) Transfer rate: 375.75 [Kbytes/sec] received ...从这里你可以发现,现在每秒的平均请求数,已经从原来的 11 变成了 2237。
5.5 小结
CPU 使用率是最直观和最常用的系统性能指标,更是我们在排查性能问题时,通常会关注的第一个指标。所以我们更要熟悉它的含义,尤其要弄清楚用户(%user)、Nice(%nice)、系统(%system) 、等待 I/O(%iowait) 、中断(%irq)以及软中断(%softirq)这几种不同 CPU 的使用率。比如说:
- 用户 CPU 和 Nice CPU 高,说明用户态进程占用了较多的 CPU,所以应该着重排查进程的性能问题。
- 系统 CPU 高,说明内核态占用了较多的 CPU,所以应该着重排查内核线程或者系统调用的性能问题。
- I/O 等待 CPU 高,说明等待 I/O 的时间比较长,所以应该着重排查系统存储是不是出现了 I/O 问题。
- 软中断和硬中断高,说明软中断或硬中断的处理程序占用了较多的 CPU,所以应该着重排查内核中的中断服务程序。
碰到 CPU 使用率升高的问题,你可以借助 top、pidstat 等工具,确认引发 CPU 性能问题的来源;再使用 perf 等工具,排查出引起性能问题的具体函数。
06 | 案例篇:系统的 CPU 使用率很高,但为啥却找不到高 CPU 的应用?
系统的 CPU 使用率,不仅包括进程用户态和内核态的运行,还包括中断处理、等待 I/O 以及内核线程等。所以,当你发现系统的 CPU 使用率很高的时候,不一定能找到相对应的高 CPU 使用率的进程。
今天,我就用一个 Nginx + PHP 的 Web 服务的案例,带你来分析这种情况。
6.1 案例分析
机器配置:2 CPU,8GB 内存。
安装软件:
apt install docker.io sysstat linux-tools-common apache2-utils。
在第一个终端,执行下面的命令运行 Nginx 和 PHP 应用:
docker run --name nginx -p 10000:80 -itd feisky/nginx:sp docker run --name phpfpm -itd --network container:nginx feisky/php-fpm:sp第二个终端,使用 curl 访问
http://[VM1 的 IP]:10000,确认 Nginx 已正常启动。你应该可以看到 It works! 的响应。# 192.168.0.10 是第一台虚拟机的 IP 地址 $ curl http://192.168.0.10:10000/ It works!来测试一下这个 Nginx 服务的性能。在第二个终端运行下面的 ab 命令。要注意,与上次操作不同的是,这次我们需要并发 100 个请求测试 Nginx 性能,总共测试 1000 个请求。
# 并发 100 个请求测试 Nginx 性能,总共测试 1000 个请求 $ ab -c 100 -n 1000 http://192.168.0.10:10000/ This is ApacheBench, Version 2.3 <$Revision: 1706008 $> Copyright 1996 Adam Twiss, Zeus Technology Ltd, ... Requests per second: 87.86 [#/sec] (mean) Time per request: 1138.229 [ms] (mean) ...从 ab 的输出结果我们可以看到,Nginx 能承受的每秒平均请求数,只有 87 多一点,是不是感觉它的性能有点差呀。那么,到底是哪里出了问题呢?我们再用 top 和 pidstat 来观察一下。
这次,我们在第二个终端,将测试的并发请求数改成 5,同时把请求时长设置为 10 分钟(-t 600)。这样,当你在第一个终端使用性能分析工具时, Nginx 的压力还是继续的。
继续在第二个终端运行 ab 命令:
ab -c 5 -t 600 http://192.168.0.10:10000/然后,我们在第一个终端运行 top 命令,观察系统的 CPU 使用情况:
$ top ... %Cpu(s): 80.8 us, 15.1 sy, 0.0 ni, 2.8 id, 0.0 wa, 0.0 hi, 1.3 si, 0.0 st ... PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 6882 root 20 0 8456 5052 3884 S 2.7 0.1 0:04.78 docker-containe 6947 systemd+ 20 0 33104 3716 2340 S 2.7 0.0 0:04.92 nginx 7494 daemon 20 0 336696 15012 7332 S 2.0 0.2 0:03.55 php-fpm 7495 daemon 20 0 336696 15160 7480 S 2.0 0.2 0:03.55 php-fpm 10547 daemon 20 0 336696 16200 8520 S 2.0 0.2 0:03.13 php-fpm 10155 daemon 20 0 336696 16200 8520 S 1.7 0.2 0:03.12 php-fpm 10552 daemon 20 0 336696 16200 8520 S 1.7 0.2 0:03.12 php-fpm 15006 root 20 0 1168608 66264 37536 S 1.0 0.8 9:39.51 dockerd 4323 root 20 0 0 0 0 I 0.3 0.0 0:00.87 kworker/u4:1 ...观察 top 输出的进程列表可以发现,CPU 使用率最高的进程也只不过才 2.7%,看起来并不高。
然而,再看系统 CPU 使用率( %Cpu )这一行,你会发现,系统的整体 CPU 使用率是比较高的:用户 CPU 使用率(us)已经到了 80%,系统 CPU 为 15.1%,而空闲 CPU (id)则只有 2.8%。
为什么用户 CPU 使用率这么高呢?我们再重新分析一下进程列表,看看有没有可疑进程:
- docker-containerd 进程是用来运行容器的,2.7% 的 CPU 使用率看起来正常;
- Nginx 和 php-fpm 是运行 Web 服务的,它们会占用一些 CPU 也不意外,并且 2% 的 CPU 使用率也不算高;
再往下看,后面的进程呢,只有 0.3% 的 CPU 使用率,看起来不太像会导致用户 CPU 使用率达到 80%。
看来 top 是不管用了,那还有其他工具可以查看进程 CPU 使用情况吗?
接下来,我们还是在第一个终端,运行 pidstat 命令:
# 间隔 1 秒输出一组数据(按 Ctrl+C 结束) $ pidstat 1 ... 04:36:24 UID PID %usr %system %guest %wait %CPU CPU Command 04:36:25 0 6882 1.00 3.00 0.00 0.00 4.00 0 docker-containe 04:36:25 101 6947 1.00 2.00 0.00 1.00 3.00 1 nginx 04:36:25 1 14834 1.00 1.00 0.00 1.00 2.00 0 php-fpm 04:36:25 1 14835 1.00 1.00 0.00 1.00 2.00 0 php-fpm 04:36:25 1 14845 0.00 2.00 0.00 2.00 2.00 1 php-fpm 04:36:25 1 14855 0.00 1.00 0.00 1.00 1.00 1 php-fpm 04:36:25 1 14857 1.00 2.00 0.00 1.00 3.00 0 php-fpm 04:36:25 0 15006 0.00 1.00 0.00 0.00 1.00 0 dockerd 04:36:25 0 15801 0.00 1.00 0.00 0.00 1.00 1 pidstat 04:36:25 1 17084 1.00 0.00 0.00 2.00 1.00 0 stress 04:36:25 0 31116 0.00 1.00 0.00 0.00 1.00 0 atopacctd ...观察一会儿,你是不是发现,所有进程的 CPU 使用率也都不高啊,最高的 Docker 和 Nginx 也只有 4% 和 3%,即使所有进程的 CPU 使用率都加起来,也不过是 21%,离 80% 还差得远呢!
后来我发现,会出现这种情况,很可能是因为前面的分析漏了一些关键信息。你可以先暂停一下,自己往上翻,重新操作检查一遍。或者,我们一起返回去分析 top 的输出,看看能不能有新发现。
现在,我们回到第一个终端,重新运行 top 命令,并观察一会儿:
$ top top - 04:58:24 up 14 days, 15:47, 1 user, load average: 3.39, 3.82, 2.74 Tasks: 149 total, 6 running, 93 sleeping, 0 stopped, 0 zombie %Cpu(s): 77.7 us, 19.3 sy, 0.0 ni, 2.0 id, 0.0 wa, 0.0 hi, 1.0 si, 0.0 st KiB Mem : 8169348 total, 2543916 free, 457976 used, 5167456 buff/cache KiB Swap: 0 total, 0 free, 0 used. 7363908 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 6947 systemd+ 20 0 33104 3764 2340 S 4.0 0.0 0:32.69 nginx 6882 root 20 0 12108 8360 3884 S 2.0 0.1 0:31.40 docker-containe 15465 daemon 20 0 336696 15256 7576 S 2.0 0.2 0:00.62 php-fpm 15466 daemon 20 0 336696 15196 7516 S 2.0 0.2 0:00.62 php-fpm 15489 daemon 20 0 336696 16200 8520 S 2.0 0.2 0:00.62 php-fpm 6948 systemd+ 20 0 33104 3764 2340 S 1.0 0.0 0:00.95 nginx 15006 root 20 0 1168608 65632 37536 S 1.0 0.8 9:51.09 dockerd 15476 daemon 20 0 336696 16200 8520 S 1.0 0.2 0:00.61 php-fpm 15477 daemon 20 0 336696 16200 8520 S 1.0 0.2 0:00.61 php-fpm 24340 daemon 20 0 8184 1616 536 R 1.0 0.0 0:00.01 stress 24342 daemon 20 0 8196 1580 492 R 1.0 0.0 0:00.01 stress 24344 daemon 20 0 8188 1056 492 R 1.0 0.0 0:00.01 stress 24347 daemon 20 0 8184 1356 540 R 1.0 0.0 0:00.01 stress ...这次从头开始看 top 的每行输出,咦?Tasks 这一行看起来有点奇怪,就绪队列中居然有 6 个 Running 状态的进程(6 running),是不是有点多呢?
回想一下 ab 测试的参数,并发请求数是 5。再看进程列表里, php-fpm 的数量也是 5,再加上 Nginx,好像同时有 6 个进程也并不奇怪。但真的是这样吗?
再仔细看进程列表,这次主要看 Running(R) 状态的进程。你有没有发现, Nginx 和所有的 php-fpm 都处于 Sleep(S)状态,而真正处于 Running(R)状态的,却是几个 stress 进程。这几个 stress 进程就比较奇怪了,需要我们做进一步的分析。
我们还是使用 pidstat 来分析这几个进程,并且使用 -p 选项指定进程的 PID。首先,从上面 top 的结果中,找到这几个进程的 PID。比如,先随便找一个 24344,然后用 pidstat 命令看一下它的 CPU 使用情况:
$ pidstat -p 24344 16:14:55 UID PID %usr %system %guest %wait %CPU CPU Command奇怪,居然没有任何输出。难道是 pidstat 命令出问题了吗?之前我说过,在怀疑性能工具出问题前,最好还是先用其他工具交叉确认一下。那用什么工具呢? ps 应该是最简单易用的。我们在终端里运行下面的命令,看看 24344 进程的状态:
# 从所有进程中查找 PID 是 24344 的进程 $ ps aux | grep 24344 root 9628 0.0 0.0 14856 1096 pts/0 S+ 16:15 0:00 grep --color=auto 24344还是没有输出。现在终于发现问题,原来这个进程已经不存在了,所以 pidstat 就没有任何输出。既然进程都没了,那性能问题应该也跟着没了吧。我们再用 top 命令确认一下:
$ top ... %Cpu(s): 80.9 us, 14.9 sy, 0.0 ni, 2.8 id, 0.0 wa, 0.0 hi, 1.3 si, 0.0 st ... PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 6882 root 20 0 12108 8360 3884 S 2.7 0.1 0:45.63 docker-containe 6947 systemd+ 20 0 33104 3764 2340 R 2.7 0.0 0:47.79 nginx 3865 daemon 20 0 336696 15056 7376 S 2.0 0.2 0:00.15 php-fpm 6779 daemon 20 0 8184 1112 556 R 0.3 0.0 0:00.01 stress ...好像又错了。结果还跟原来一样,用户 CPU 使用率还是高达 80.9%,系统 CPU 接近 15%,而空闲 CPU 只有 2.8%,Running 状态的进程有 Nginx、stress 等。
可是,刚刚我们看到 stress 进程不存在了,怎么现在还在运行呢?再细看一下 top 的输出,原来,这次 stress 进程的 PID 跟前面不一样了,原来的 PID 24344 不见了,现在的是 6779。
进程的 PID 在变,这说明什么呢?在我看来,要么是这些进程在不停地重启,要么就是全新的进程,这无非也就两个原因:
- 第一个原因,进程在不停地崩溃重启,比如因为段错误、配置错误等等,这时,进程在退出后可能又被监控系统自动重启了。
第二个原因,这些进程都是短时进程,也就是在其他应用内部通过 exec 调用的外面命令。这些命令一般都只运行很短的时间就会结束,你很难用 top 这种间隔时间比较长的工具发现(上面的案例,我们碰巧发现了)。
至于 stress,我们前面提到过,它是一个常用的压力测试工具。它的 PID 在不断变化中,看起来像是被其他进程调用的短时进程。要想继续分析下去,还得找到它们的父进程。
要怎么查找一个进程的父进程呢?没错,用 pstree 就可以用树状形式显示所有进程之间的关系:
$ pstree | grep stress |-docker-containe-+-php-fpm-+-php-fpm---sh---stress | |-3*[php-fpm---sh---stress---stress]从这里可以看到,stress 是被 php-fpm 调用的子进程,并且进程数量不止一个(这里是 3 个)。找到父进程后,我们能进入 app 的内部分析了。
首先,当然应该去看看它的源码。运行下面的命令,把案例应用的源码拷贝到 app 目录,然后再执行 grep 查找是不是有代码再调用 stress 命令:
# 拷贝源码到本地 $ docker cp phpfpm:/app . # grep 查找看看是不是有代码在调用 stress 命令 $ grep stress -r app app/index.php:// fake I/O with stress (via write()/unlink()). app/index.php:$result = exec("/usr/local/bin/stress -t 1 -d 1 2>&1", $output, $status);找到了,果然是 app/index.php 文件中直接调用了 stress 命令。
$ cat app/index.php <?php // fake I/O with stress (via write()/unlink()). $result = exec("/usr/local/bin/stress -t 1 -d 1 2>&1", $output, $status); if (isset($_GET["verbose"]) && $_GET["verbose"]==1 && $status != 0) { echo "Server internal error: "; print_r($output); } else { echo "It works!"; } ?>可以看到,源码里对每个请求都会调用一个 stress 命令,模拟 I/O 压力。从注释上看,stress 会通过 write() 和 unlink() 对 I/O 进程进行压测,看来,这应该就是系统 CPU 使用率升高的根源了。
不过,stress 模拟的是 I/O 压力,而之前在 top 的输出中看到的,却一直是用户 CPU 和系统 CPU 升高,并没见到 iowait 升高。这又是怎么回事呢?stress 到底是不是 CPU 使用率升高的原因呢?
我们还得继续往下走。从代码中可以看到,给请求加入 verbose=1 参数后,就可以查看 stress 的输出。你先试试看,在第二个终端运行:
$ curl http://192.168.0.10:10000?verbose=1 Server internal error: Array ( [0] => stress: info: [19607] dispatching hogs: 0 cpu, 0 io, 0 vm, 1 hdd [1] => stress: FAIL: [19608] (563) mkstemp failed: Permission denied [2] => stress: FAIL: [19607] (394) <-- worker 19608 returned error 1 [3] => stress: WARN: [19607] (396) now reaping child worker processes [4] => stress: FAIL: [19607] (400) kill error: No such process [5] => stress: FAIL: [19607] (451) failed run completed in 0s )看错误消息 mkstemp failed: Permission denied ,以及 failed run completed in 0s。原来 stress 命令并没有成功,它因为权限问题失败退出了。看来,我们发现了一个 PHP 调用外部 stress 命令的 bug:没有权限创建临时文件。
从这里我们可以猜测,正是由于权限错误,大量的 stress 进程在启动时初始化失败,进而导致用户 CPU 使用率的升高。
分析出问题来源,下一步是不是就要开始优化了呢?当然不是!既然只是猜测,那就需要再确认一下,这个猜测到底对不对,是不是真的有大量的 stress 进程。该用什么工具或指标呢?
我们前面已经用了 top、pidstat、pstree 等工具,没有发现大量的 stress 进程。那么,还有什么其他的工具可以用吗?
还记得上一期提到的 perf 吗?它可以用来分析 CPU 性能事件,用在这里就很合适。依旧在第一个终端中运行 perf record -g 命令 ,并等待一会儿(比如 15 秒)后按 Ctrl+C 退出。然后再运行 perf report 查看报告:
# 记录性能事件,等待大约 15 秒后按 Ctrl+C 退出 $ perf record -g # 查看报告 $ perf report这样,你就可以看到下图这个性能报告:
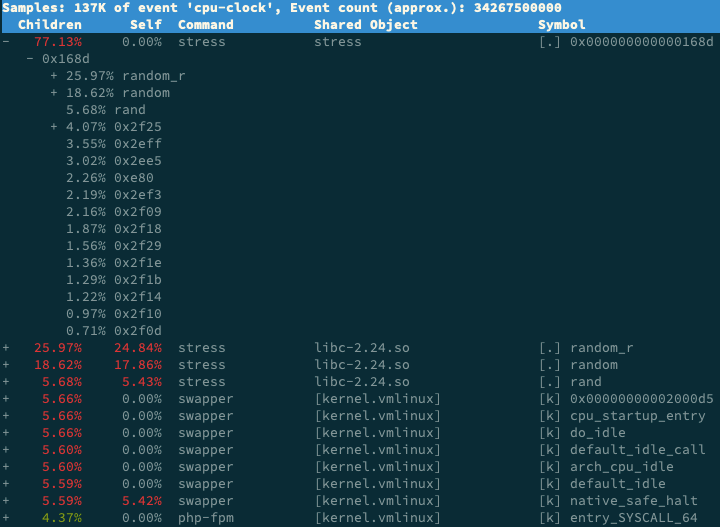
你看,stress 占了所有 CPU 时钟事件的 77%,而 stress 调用调用栈中比例最高的,是随机数生成函数 random(),看来它的确就是 CPU 使用率升高的元凶了。随后的优化就很简单了,只要修复权限问题,并减少或删除 stress 的调用,就可以减轻系统的 CPU 压力。
6.2 execsnoop
在这个案例中,我们使用了 top、pidstat、pstree 等工具分析了系统 CPU 使用率高的问题,并发现 CPU 升高是短时进程 stress 导致的,但是整个分析过程还是比较复杂的。对于这类问题,有没有更好的方法监控呢?
execsnoop 就是一个专为短时进程设计的工具。它通过 ftrace 实时监控进程的 exec() 行为,并输出短时进程的基本信息,包括进程 PID、父进程 PID、命令行参数以及执行的结果。
比如,用 execsnoop 监控上述案例,就可以直接得到 stress 进程的父进程 PID 以及它的命令行参数,并可以发现大量的 stress 进程在不停启动:
# 按 Ctrl+C 结束
$ execsnoop
PCOMM PID PPID RET ARGS
sh 30394 30393 0
stress 30396 30394 0 /usr/local/bin/stress -t 1 -d 1
sh 30398 30393 0
stress 30399 30398 0 /usr/local/bin/stress -t 1 -d 1
sh 30402 30400 0
stress 30403 30402 0 /usr/local/bin/stress -t 1 -d 1
sh 30405 30393 0
stress 30407 30405 0 /usr/local/bin/stress -t 1 -d 1
...execsnoop 所用的 ftrace 是一种常用的动态追踪技术,一般用于分析 Linux 内核的运行时行为,后面课程我也会详细介绍并带你使用。
6.3 小结
碰到常规问题无法解释的 CPU 使用率情况时,首先要想到有可能是短时应用导致的问题,比如有可能是下面这两种情况。
- 第一,应用里直接调用了其他二进制程序,这些程序通常运行时间比较短,通过 top 等工具也不容易发现。
- 第二,应用本身在不停地崩溃重启,而启动过程的资源初始化,很可能会占用相当多的 CPU。
对于这类进程,我们可以用 pstree 或者 execsnoop 找到它们的父进程,再从父进程所在的应用入手,排查问题的根源。
07 | 案例篇:系统中出现大量不可中断进程和僵尸进程怎么办?(上)
7.1 进程状态
当 iowait 升高时,进程很可能因为得不到硬件的响应,而长时间处于不可中断状态。从 ps 或者 top 命令的输出中,你可以发现它们都处于 D 状态,也就是不可中断状态(Uninterruptible Sleep)。
top 和 ps 是最常用的查看进程状态的工具,我们就从 top 的输出开始。下面是一个 top 命令输出的示例,S 列(也就是 Status 列)表示进程的状态。从这个示例里,你可以看到 R、D、Z、S、I 等几个状态,它们分别是什么意思呢?
$ top
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
28961 root 20 0 43816 3148 4040 R 3.2 0.0 0:00.01 top
620 root 20 0 37280 33676 908 D 0.3 0.4 0:00.01 app
1 root 20 0 160072 9416 6752 S 0.0 0.1 0:37.64 systemd
1896 root 20 0 0 0 0 Z 0.0 0.0 0:00.00 devapp
2 root 20 0 0 0 0 S 0.0 0.0 0:00.10 kthreadd
4 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/0:0H
6 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 mm_percpu_wq
7 root 20 0 0 0 0 S 0.0 0.0 0:06.37 ksoftirqd/0我们挨个来看一下:
- R 是 Running 或 Runnable 的缩写,表示进程在 CPU 的就绪队列中,正在运行或者正在等待运行。
- D 是 Disk Sleep 的缩写,也就是不可中断状态睡眠(Uninterruptible Sleep),一般表示进程正在跟硬件交互,并且交互过程不允许被其他进程或中断打断。
- Z 是 Zombie 的缩写,如果你玩过”植物大战僵尸”这款游戏,应该知道它的意思。它表示僵尸进程,也就是进程实际上已经结束了,但是父进程还没有回收它的资源(比如进程的描述符、PID 等)。
- S 是 Interruptible Sleep 的缩写,也就是可中断状态睡眠,表示进程因为等待某个事件而被系统挂起。当进程等待的事件发生时,它会被唤醒并进入 R 状态。
- I 是 Idle 的缩写,也就是空闲状态,用在不可中断睡眠的内核线程上。前面说了,硬件交互导致的不可中断进程用 D 表示,但对某些内核线程来说,它们有可能实际上并没有任何负载,用 Idle 正是为了区分这种情况。要注意,D 状态的进程会导致平均负载升高, I 状态的进程却不会。
当然了,上面的示例并没有包括进程的所有状态。除了以上 5 个状态,进程还包括下面这 2 个状态。
- 第一个是 T 或者 t,也就是 Stopped 或 Traced 的缩写,表示进程处于暂停或者跟踪状态。
向一个进程发送 SIGSTOP 信号,它就会因响应这个信号变成暂停状态(Stopped);再向它发送 SIGCONT 信号,进程又会恢复运行(如果进程是终端里直接启动的,则需要你用 fg 命令,恢复到前台运行)。
而当你用调试器(如 gdb)调试一个进程时,在使用断点中断进程后,进程就会变成跟踪状态,这其实也是一种特殊的暂停状态,只不过你可以用调试器来跟踪并按需要控制进程的运行。
- 另一个是 X,也就是 Dead 的缩写,表示进程已经消亡,所以你不会在 top 或者 ps 命令中看到它。
不可中断状态
先看不可中断状态,这其实是为了保证进程数据与硬件状态一致,并且正常情况下,不可中断状态在很短时间内就会结束。所以,短时的不可中断状态进程,我们一般可以忽略。
但如果系统或硬件发生了故障,进程可能会在不可中断状态保持很久,甚至导致系统中出现大量不可中断进程。这时,你就得注意下,系统是不是出现了 I/O 等性能问题。
僵尸进程
再看僵尸进程,这是多进程应用很容易碰到的问题。正常情况下,当一个进程创建了子进程后,它应该通过系统调用 wait() 或者 waitpid() 等待子进程结束,回收子进程的资源;而子进程在结束时,会向它的父进程发送 SIGCHLD 信号,所以,父进程还可以注册 SIGCHLD 信号的处理函数,异步回收资源。
如果父进程没这么做,或是子进程执行太快,父进程还没来得及处理子进程状态,子进程就已经提前退出,那这时的子进程就会变成僵尸进程。换句话说,父亲应该一直对儿子负责,善始善终,如果不作为或者跟不上,都会导致”问题少年”的出现。
通常,僵尸进程持续的时间都比较短,在父进程回收它的资源后就会消亡;或者在父进程退出后,由 init 进程回收后也会消亡。
一旦父进程没有处理子进程的终止,还一直保持运行状态,那么子进程就会一直处于僵尸状态。大量的僵尸进程会用尽 PID 进程号,导致新进程不能创建,所以这种情况一定要避免。
7.1 案例分析
机器配置: 2 CPU, 8 GB 内存。
安装软件:
apt install docker.io dstat sysstat。dstat 是一个新的性能工具,它吸收了 vmstat、iostat、ifstat 等几种工具的优点,可以同时观察系统的 CPU、磁盘 I/O、网络以及内存使用情况。
首先执行下面的命令运行案例应用:
docker run --privileged --name=app -itd feisky/app:iowait然后,输入 ps 命令,确认案例应用已正常启动。如果一切正常,你应该可以看到如下所示的输出:
$ ps aux | grep /app root 4009 0.0 0.0 4376 1008 pts/0 Ss+ 05:51 0:00 /app root 4287 0.6 0.4 37280 33660 pts/0 D+ 05:54 0:00 /app root 4288 0.6 0.4 37280 33668 pts/0 D+ 05:54 0:00 /app从这个界面,我们可以发现多个 app 进程已经启动,并且它们的状态分别是 Ss+ 和 D+。其中,S 表示可中断睡眠状态,D 表示不可中断睡眠状态,我们在前面刚学过,那后面的 s 和 + 是什么意思呢?不知道也没关系,查一下
man ps就可以。现在记住,s 表示这个进程是一个会话的领导进程,而 + 表示前台进程组。这里又出现了两个新概念,进程组和会话。它们用来管理一组相互关联的进程,意思其实很好理解。
- 进程组表示一组相互关联的进程,比如每个子进程都是父进程所在组的成员;
而会话是指共享同一个控制终端的一个或多个进程组。
比如,我们通过 SSH 登录服务器,就会打开一个控制终端(TTY),这个控制终端就对应一个会话。而我们在终端中运行的命令以及它们的子进程,就构成了一个个的进程组,其中,在后台运行的命令,构成后台进程组;在前台运行的命令,构成前台进程组。
明白了这些,我们再用 top 看一下系统的资源使用情况:
# 按下数字 1 切换到所有 CPU 的使用情况,观察一会儿按 Ctrl+C 结束 $ top top - 05:56:23 up 17 days, 16:45, 2 users, load average: 2.00, 1.68, 1.39 Tasks: 247 total, 1 running, 79 sleeping, 0 stopped, 115 zombie %Cpu0 : 0.0 us, 0.7 sy, 0.0 ni, 38.9 id, 60.5 wa, 0.0 hi, 0.0 si, 0.0 st %Cpu1 : 0.0 us, 0.7 sy, 0.0 ni, 4.7 id, 94.6 wa, 0.0 hi, 0.0 si, 0.0 st ... PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 4340 root 20 0 44676 4048 3432 R 0.3 0.0 0:00.05 top 4345 root 20 0 37280 33624 860 D 0.3 0.0 0:00.01 app 4344 root 20 0 37280 33624 860 D 0.3 0.4 0:00.01 app 1 root 20 0 160072 9416 6752 S 0.0 0.1 0:38.59 systemd ...从这里你能看出什么问题吗?
先看第一行的平均负载( Load Average),过去 1 分钟、5 分钟和 15 分钟内的平均负载在依次减小,说明平均负载正在升高;而 1 分钟内的平均负载已经达到系统的 CPU 个数,说明系统很可能已经有了性能瓶颈。
- 再看第二行的 Tasks,有 1 个正在运行的进程,但僵尸进程比较多,而且还在不停增加,说明有子进程在退出时没被清理。
- 接下来看两个 CPU 的使用率情况,用户 CPU 和系统 CPU 都不高,但 iowait 分别是 60.5% 和 94.6%,好像有点儿不正常。
最后再看每个进程的情况, CPU 使用率最高的进程只有 0.3%,看起来并不高;但有两个进程处于 D 状态,它们可能在等待 I/O,但光凭这里并不能确定是它们导致了 iowait 升高。
汇总一下:
第一点,iowait 太高了,导致系统的平均负载升高,甚至达到了系统 CPU 的个数。
- 第二点,僵尸进程在不断增多,说明有程序没能正确清理子进程的资源。
7.2 小结
进程的状态包括运行(R)、空闲(I)、不可中断睡眠(D)、可中断睡眠(S)、僵尸(Z)以及暂停(T)等。
其中,不可中断状态和僵尸状态,是我们今天学习的重点。
- 不可中断状态,表示进程正在跟硬件交互,为了保护进程数据和硬件的一致性,系统不允许其他进程或中断打断这个进程。进程长时间处于不可中断状态,通常表示系统有 I/O 性能问题。
- 僵尸进程表示进程已经退出,但它的父进程还没有回收子进程占用的资源。短暂的僵尸状态我们通常不必理会,但进程长时间处于僵尸状态,就应该注意了,可能有应用程序没有正常处理子进程的退出。
08 | 案例篇:系统中出现大量不可中断进程和僵尸进程怎么办?(下)
打开一个终端,登录到上次的机器中。然后执行下面的命令,重新运行这个案例:
# 先删除上次启动的案例
$ docker rm -f app
# 重新运行案例
$ docker run --privileged --name=app -itd feisky/app:iowait8.1 iowait 分析
一提到 iowait 升高,你首先会想要查询系统的 I/O 情况。我一般也是这种思路,那么什么工具可以查询系统的 I/O 情况呢?
这里,我推荐的正是上节课要求安装的 dstat ,它的好处是,可以同时查看 CPU 和 I/O 这两种资源的使用情况,便于对比分析。
在终端中运行 dstat 命令,观察 CPU 和 I/O 的使用情况:
# 间隔 1 秒输出 10 组数据 $ dstat 1 10 You did not select any stats, using -cdngy by default. --total-cpu-usage-- -dsk/total- -net/total- ---paging-- ---system-- usr sys idl wai stl| read writ| recv send| in out | int csw 0 0 96 4 0|1219k 408k| 0 0 | 0 0 | 42 885 0 0 2 98 0| 34M 0 | 198B 790B| 0 0 | 42 138 0 0 0 100 0| 34M 0 | 66B 342B| 0 0 | 42 135 0 0 84 16 0|5633k 0 | 66B 342B| 0 0 | 52 177 0 3 39 58 0| 22M 0 | 66B 342B| 0 0 | 43 144 0 0 0 100 0| 34M 0 | 200B 450B| 0 0 | 46 147 0 0 2 98 0| 34M 0 | 66B 342B| 0 0 | 45 134 0 0 0 100 0| 34M 0 | 66B 342B| 0 0 | 39 131 0 0 83 17 0|5633k 0 | 66B 342B| 0 0 | 46 168 0 3 39 59 0| 22M 0 | 66B 342B| 0 0 | 37 134从 dstat 的输出,我们可以看到,每当 iowait 升高(wai)时,磁盘的读请求(read)都会很大。这说明 iowait 的升高跟磁盘的读请求有关,很可能就是磁盘读导致的。
那到底是哪个进程在读磁盘呢?不知道你还记不记得,上节在 top 里看到的不可中断状态进程,我觉得它就很可疑,我们试着来分析下。
继续在刚才的终端中,运行 top 命令,观察 D 状态的进程:
# 观察一会儿按 Ctrl+C 结束 $ top ... PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 4340 root 20 0 44676 4048 3432 R 0.3 0.0 0:00.05 top 4345 root 20 0 37280 33624 860 D 0.3 0.0 0:00.01 app 4344 root 20 0 37280 33624 860 D 0.3 0.4 0:00.01 app ...我们从 top 的输出找到 D 状态进程的 PID,你可以发现,这个界面里有两个 D 状态的进程,PID 分别是 4344 和 4345。
一般要查看某一个进程的资源使用情况,都可以用我们的老朋友 pidstat,不过这次记得加上 -d 参数,以便输出 I/O 使用情况。
以 4344 为例,我们在终端里运行下面的 pidstat 命令,并用 -p 4344 参数指定进程号:
# -d 展示 I/O 统计数据,-p 指定进程号,间隔 1 秒输出 3 组数据 $ pidstat -d -p 4344 1 3 06:38:50 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command 06:38:51 0 4344 0.00 0.00 0.00 0 app 06:38:52 0 4344 0.00 0.00 0.00 0 app 06:38:53 0 4344 0.00 0.00 0.00 0 app在这个输出中, kB_rd 表示每秒读的 KB 数, kB_wr 表示每秒写的 KB 数,iodelay 表示 I/O 的延迟(单位是时钟周期)。它们都是 0,那就表示此时没有任何的读写,说明问题不是 4344 进程导致的。
可是,用同样的方法分析进程 4345,你会发现,它也没有任何磁盘读写。
那要怎么知道,到底是哪个进程在进行磁盘读写呢?我们继续使用 pidstat,但这次去掉进程号,干脆就来观察所有进程的 I/O 使用情况。
在终端中运行下面的 pidstat 命令:
# 间隔 1 秒输出多组数据 (这里是 20 组) $ pidstat -d 1 20 ... 06:48:46 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command 06:48:47 0 4615 0.00 0.00 0.00 1 kworker/u4:1 06:48:47 0 6080 32768.00 0.00 0.00 170 app 06:48:47 0 6081 32768.00 0.00 0.00 184 app 06:48:47 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command 06:48:48 0 6080 0.00 0.00 0.00 110 app 06:48:48 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command 06:48:49 0 6081 0.00 0.00 0.00 191 app 06:48:49 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command 06:48:50 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command 06:48:51 0 6082 32768.00 0.00 0.00 0 app 06:48:51 0 6083 32768.00 0.00 0.00 0 app 06:48:51 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command 06:48:52 0 6082 32768.00 0.00 0.00 184 app 06:48:52 0 6083 32768.00 0.00 0.00 175 app 06:48:52 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command 06:48:53 0 6083 0.00 0.00 0.00 105 app ...观察一会儿可以发现,的确是 app 进程在进行磁盘读,并且每秒读的数据有 32 MB,看来就是 app 的问题。不过,app 进程到底在执行啥 I/O 操作呢?
这里,我们需要回顾一下进程用户态和内核态的区别。进程想要访问磁盘,就必须使用系统调用,所以接下来,重点就是找出 app 进程的系统调用了。
strace 正是最常用的跟踪进程系统调用的工具。所以,我们从 pidstat 的输出中拿到进程的 PID 号,比如 6082,然后在终端中运行 strace 命令,并用 -p 参数指定 PID 号:
$ strace -p 6082 strace: attach: ptrace(PTRACE_SEIZE, 6082): Operation not permitted一般遇到这种问题时,我会先检查一下进程的状态是否正常。 比如,继续在终端中运行 ps 命令,并使用 grep 找出刚才的 6082 号进程:
$ ps aux | grep 6082 root 6082 0.0 0.0 0 0 pts/0 Z+ 13:43 0:00 [app] <defunct>果然,进程 6082 已经变成了 Z 状态,也就是僵尸进程。僵尸进程都是已经退出的进程,所以就没法儿继续分析它的系统调用。关于僵尸进程的处理方法,我们一会儿再说,现在还是继续分析 iowait 的问题。
到这一步,你应该注意到了,系统 iowait 的问题还在继续,但是 top、pidstat 这类工具已经不能给出更多的信息了。这时,我们就应该求助那些基于事件记录的动态追踪工具了。
你可以用 perf top 看看有没有新发现。再或者,可以像我一样,在终端中运行 perf record,持续一会儿(例如 15 秒),然后按 Ctrl+C 退出,再运行 perf report 查看报告:
perf record -g perf report接着,找到我们关注的 app 进程,按回车键展开调用栈,你就会得到下面这张调用关系图:
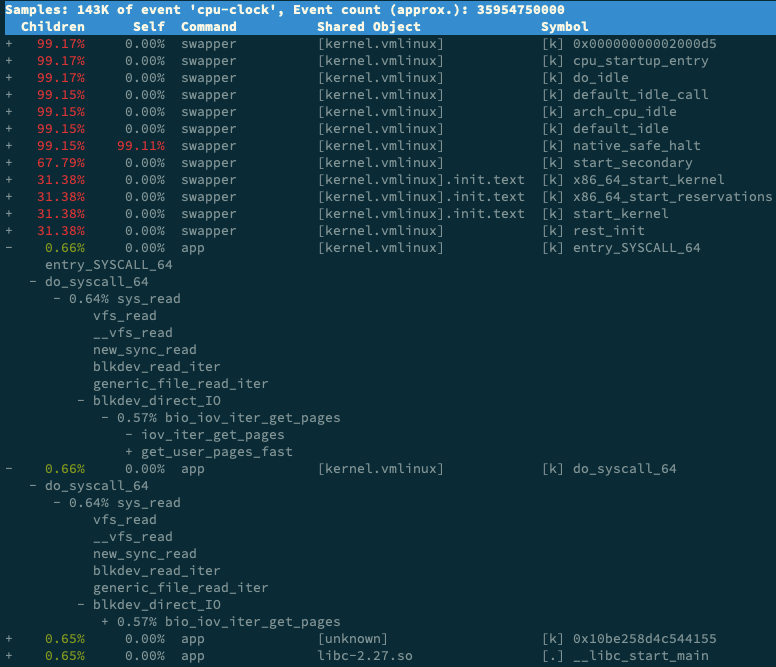
这个图里的 swapper 是内核中的调度进程,你可以先忽略掉。
我们来看其他信息,你可以发现, app 的确在通过系统调用 sys_read() 读取数据。并且从 new_sync_read 和 blkdev_direct_IO 能看出,进程正在对磁盘进行直接读,也就是绕过了系统缓存,每个读请求都会从磁盘直接读,这就可以解释我们观察到的 iowait 升高了。
看来,罪魁祸首是 app 内部进行了磁盘的直接 I/O 啊!
查看源码文件 app.c,你会发现它果然使用了 O_DIRECT 选项打开磁盘,于是绕过了系统缓存,直接对磁盘进行读写。
open(disk, O_RDONLY|O_DIRECT|O_LARGEFILE, 0755)直接读写磁盘,对 I/O 敏感型应用(比如数据库系统)是很友好的,因为你可以在应用中,直接控制磁盘的读写。但在大部分情况下,我们最好还是通过系统缓存来优化磁盘 I/O,换句话说,删除 O_DIRECT 这个选项就是了。
app-fix1.c 就是修改后的文件,我也打包成了一个镜像文件,运行下面的命令,你就可以启动它了:
# 首先删除原来的应用 $ docker rm -f app # 运行新的应用 $ docker run --privileged --name=app -itd feisky/app:iowait-fix1最后,再用 top 检查一下:
$ top top - 14:59:32 up 19 min, 1 user, load average: 0.15, 0.07, 0.05 Tasks: 137 total, 1 running, 72 sleeping, 0 stopped, 12 zombie %Cpu0 : 0.0 us, 1.7 sy, 0.0 ni, 98.0 id, 0.3 wa, 0.0 hi, 0.0 si, 0.0 st %Cpu1 : 0.0 us, 1.3 sy, 0.0 ni, 98.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st ... PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 3084 root 20 0 0 0 0 Z 1.3 0.0 0:00.04 app 3085 root 20 0 0 0 0 Z 1.3 0.0 0:00.04 app 1 root 20 0 159848 9120 6724 S 0.0 0.1 0:09.03 systemd 2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd 3 root你会发现, iowait 已经非常低了,只有 0.3%,说明刚才的改动已经成功修复了 iowait 高的问题。
8.2 僵尸进程
既然僵尸进程是因为父进程没有回收子进程的资源而出现的,那么,要解决掉它们,就要找到它们的根儿,也就是找出父进程,然后在父进程里解决。
父进程的找法我们前面讲过,最简单的就是运行 pstree 命令:
# -a 表示输出命令行选项 # p 表 PID # s 表示指定进程的父进程 $ pstree -aps 3084 systemd,1 └─dockerd,15006 -H fd:// └─docker-containe,15024 --config /var/run/docker/containerd/containerd.toml └─docker-containe,3991 -namespace moby -workdir... └─app,4009 └─(app,3084)运行完,你会发现 3084 号进程的父进程是 4009,也就是 app 应用。
所以,我们接着查看 app 应用程序的代码,看看子进程结束的处理是否正确,比如有没有调用 wait() 或 waitpid() ,抑或是,有没有注册 SIGCHLD 信号的处理函数。
现在我们查看修复 iowait 后的源码文件 app-fix1.c ,找到子进程的创建和清理的地方:
int status = 0; for (;;) { for (int i = 0; i < 2; i++) { if(fork()== 0) { sub_process(); } } sleep(5); } while(wait(&status)>0);循环语句本来就容易出错,你能找到这里的问题吗?这段代码虽然看起来调用了 wait() 函数等待子进程结束,但却错误地把 wait() 放到了 for 死循环的外面,也就是说,wait() 函数实际上并没被调用到,我们把它挪到 for 循环的里面就可以了。
修改后的文件我放到了 app-fix2.c 中,也打包成了一个 Docker 镜像,运行下面的命令,你就可以启动它:
# 先停止产生僵尸进程的 app $ docker rm -f app # 然后启动新的 app $ docker run --privileged --name=app -itd feisky/app:iowait-fix2启动后,再用 top 最后来检查一遍:
$ top top - 15:00:44 up 20 min, 1 user, load average: 0.05, 0.05, 0.04 Tasks: 125 total, 1 running, 72 sleeping, 0 stopped, 0 zombie %Cpu0 : 0.0 us, 1.7 sy, 0.0 ni, 98.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st %Cpu1 : 0.0 us, 1.3 sy, 0.0 ni, 98.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st ... PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 3198 root 20 0 4376 840 780 S 0.3 0.0 0:00.01 app 2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd 3 root 20 0 0 0 0 I 0.0 0.0 0:00.41 kworker/0:0 ...好了,僵尸进程(Z 状态)没有了, iowait 也是 0,问题终于全部解决了。
8.3 小结
虽然这个案例是磁盘 I/O 导致了 iowait 升高,不过, iowait 高不一定代表 I/O 有性能瓶颈。当系统中只有 I/O 类型的进程在运行时,iowait 也会很高,但实际上,磁盘的读写远没有达到性能瓶颈的程度。
因此,碰到 iowait 升高时,需要先用 dstat、pidstat 等工具,确认是不是磁盘 I/O 的问题,然后再找是哪些进程导致了 I/O。
等待 I/O 的进程一般是不可中断状态,所以用 ps 命令找到的 D 状态(即不可中断状态)的进程,多为可疑进程。但这个案例中,在 I/O 操作后,进程又变成了僵尸进程,所以不能用 strace 直接分析这个进程的系统调用。
这种情况下,我们用了 perf 工具,来分析系统的 CPU 时钟事件,最终发现是直接 I/O 导致的问题。这时,再检查源码中对应位置的问题,就很轻松了。
而僵尸进程的问题相对容易排查,使用 pstree 找出父进程后,去查看父进程的代码,检查 wait() / waitpid() 的调用,或是 SIGCHLD 信号处理函数的注册就行了。
09 | 基础篇:怎么理解Linux软中断?
9.1 从”取外卖”看中断
中断是系统用来响应硬件设备请求的一种机制,它会打断进程的正常调度和执行,然后调用内核中的中断处理程序来响应设备的请求。
为什么要有中断呢?
比如说你订了一份外卖,但是不确定外卖什么时候送到,也没有别的方法了解外卖的进度,但是,配送员送外卖是不等人的,到了你这儿没人取的话,就直接走人了。所以你只能苦苦等着,时不时去门口看看外卖送到没,而不能干其他事情。
不过呢,如果在订外卖的时候,你就跟配送员约定好,让他送到后给你打个电话,那你就不用苦苦等待了,就可以去忙别的事情,直到电话一响,接电话、取外卖就可以了。
这里的”打电话”,其实就是一个中断。没接到电话的时候,你可以做其他的事情;只有接到了电话(也就是发生中断),你才要进行另一个动作:取外卖。
可以发现,中断其实是一种异步的事件处理机制,可以提高系统的并发处理能力。
由于中断处理程序会打断其他进程的运行,所以,为了减少对正常进程运行调度的影响,中断处理程序就需要尽可能快地运行。如果中断本身要做的事情不多,那么处理起来也不会有太大问题;但如果中断要处理的事情很多,中断服务程序就有可能要运行很长时间。
特别是,中断处理程序在响应中断时,还会临时关闭中断。这就会导致上一次中断处理完成之前,其他中断都不能响应,也就是说中断有可能会丢失。
9.2 软中断
为了解决中断处理程序执行过长和中断丢失的问题,Linux 将中断处理过程分成了两个阶段,也就是上半部和下半部:
- 上半部用来快速处理中断,它在中断禁止模式下运行,主要处理跟硬件紧密相关的或时间敏感的工作。
- 下半部用来延迟处理上半部未完成的工作,通常以内核线程的方式运行。
举个最常见的网卡接收数据包的例子。
网卡接收到数据包后,会通过硬件中断的方式,通知内核有新的数据到了。这时,内核就应该调用中断处理程序来响应它。
对上半部来说,既然是快速处理,其实就是要把网卡的数据读到内存中,然后更新一下硬件寄存器的状态(表示数据已经读好了),最后再发送一个软中断信号,通知下半部做进一步的处理。
而下半部被软中断信号唤醒后,需要从内存中找到网络数据,再按照网络协议栈,对数据进行逐层解析和处理,直到把它送给应用程序。
所以,这两个阶段你也可以这样理解:
- 上半部直接处理硬件请求,也就是我们常说的硬中断,特点是快速执行;
- 而下半部则是由内核触发,也就是我们常说的软中断,特点是延迟执行。
实际上,上半部会打断 CPU 正在执行的任务,然后立即执行中断处理程序。而下半部以内核线程的方式执行,并且每个 CPU 都对应一个软中断内核线程,名字为 “ksoftirqd/CPU 编号”,比如说, 0 号 CPU 对应的软中断内核线程的名字就是 ksoftirqd/0。
不过要注意的是,软中断不只包括了刚刚所讲的硬件设备中断处理程序的下半部,一些内核自定义的事件也属于软中断,比如内核调度和 RCU 锁(Read-Copy Update 的缩写,RCU 是 Linux 内核中最常用的锁之一)等。
9.3 查看软中断和内核线程
proc 文件系统可以用来查看内核的数据结构,或者用来动态修改内核的配置。其中:
- /proc/softirqs 提供了软中断的运行情况;
- /proc/interrupts 提供了硬中断的运行情况。
运行下面的命令,查看 /proc/softirqs 文件的内容,你就可以看到各种类型软中断在不同 CPU 上的累积运行次数:
$ cat /proc/softirqs
CPU0 CPU1
HI: 0 0
TIMER: 811613 1972736
NET_TX: 49 7
NET_RX: 1136736 1506885
BLOCK: 0 0
IRQ_POLL: 0 0
TASKLET: 304787 3691
SCHED: 689718 1897539
HRTIMER: 0 0
RCU: 1330771 1354737在查看 /proc/softirqs 文件内容时,你要特别注意以下这两点。
- 第一,要注意软中断的类型,也就是这个界面中第一列的内容。从第一列你可以看到,软中断包括了 10 个类别,分别对应不同的工作类型。比如 NET_RX 表示网络接收中断,而 NET_TX 表示网络发送中断。
- 第二,要注意同一种软中断在不同 CPU 上的分布情况,也就是同一行的内容。正常情况下,同一种中断在不同 CPU 上的累积次数应该差不多。比如这个界面中,NET_RX 在 CPU0 和 CPU1 上的中断次数基本是同一个数量级,相差不大。
不过你可能发现,TASKLET 在不同 CPU 上的分布并不均匀。TASKLET 是最常用的软中断实现机制,每个 TASKLET 只运行一次就会结束 ,并且只在调用它的函数所在的 CPU 上运行。
因此,使用 TASKLET 特别简便,当然也会存在一些问题,比如说由于只在一个 CPU 上运行导致的调度不均衡,再比如因为不能在多个 CPU 上并行运行带来了性能限制。
另外,刚刚提到过,软中断实际上是以内核线程的方式运行的,每个 CPU 都对应一个软中断内核线程,这个软中断内核线程就叫做 ksoftirqd/CPU 编号。那要怎么查看这些线程的运行状况呢?
其实用 ps 命令就可以做到,比如执行下面的指令:
$ ps aux | grep softirq
root 7 0.0 0.0 0 0 ? S Oct10 0:01 [ksoftirqd/0]
root 16 0.0 0.0 0 0 ? S Oct10 0:01 [ksoftirqd/1]注意,这些线程的名字外面都有中括号,这说明 ps 无法获取它们的命令行参数(cmline)。一般来说,ps 的输出中,名字括在中括号里的,一般都是内核线程。
10 | 案例篇:系统的软中断CPU使用率升高,我该怎么办?
10.1 案例
机器配置: 2 CPU, 8 GB 内存。
安装软件:
apt-get install docker.io sysstat hping3 tcpdump。
- sar 是一个系统活动报告工具,既可以实时查看系统的当前活动,又可以配置保存和报告历史统计数据。
- hping3 是一个可以构造 TCP/IP 协议数据包的工具,可以对系统进行安全审计、防火墙测试等。
- tcpdump 是一个常用的网络抓包工具,常用来分析各种网络问题。
在第一个终端,执行下面的命令运行案例,也就是一个最基本的 Nginx 应用:
# 运行 Nginx 服务并对外开放 80 端口 $ docker run -itd --name=nginx -p 80:80 nginx在第二个终端,使用 curl 访问 Nginx 监听的端口,确认 Nginx 正常启动。假设 192.168.0.30 是 Nginx 所在虚拟机的 IP 地址,运行 curl 命令后你应该会看到下面这个输出界面:
$ curl http://192.168.0.30/ <!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> ...还是在第二个终端,我们运行 hping3 命令,来模拟 Nginx 的客户端请求:
# -S 参数表示设置 TCP 协议的 SYN(同步序列号),-p 表示目的端口为 80 # -i u100 表示每隔 100 微秒发送一个网络帧 # 注:如果你在实践过程中现象不明显,可以尝试把 100 调小,比如调成 10 甚至 1 $ hping3 -S -p 80 -i u100 192.168.0.30现在我们再回到第一个终端,你应该发现了异常。是不是感觉系统响应明显变慢了,即便只是在终端中敲几个回车,都得很久才能得到响应?这个时候应该怎么办呢?
先看看系统的整体资源使用情况应该是个不错的注意,比如执行下 top 看看是不是出现了 CPU 的瓶颈。我们在第一个终端运行 top 命令,看一下系统整体的资源使用情况。
# top 运行后按数字 1 切换到显示所有 CPU $ top top - 10:50:58 up 1 days, 22:10, 1 user, load average: 0.00, 0.00, 0.00 Tasks: 122 total, 1 running, 71 sleeping, 0 stopped, 0 zombie %Cpu0 : 0.0 us, 0.0 sy, 0.0 ni, 96.7 id, 0.0 wa, 0.0 hi, 3.3 si, 0.0 st %Cpu1 : 0.0 us, 0.0 sy, 0.0 ni, 95.6 id, 0.0 wa, 0.0 hi, 4.4 si, 0.0 st ... PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 7 root 20 0 0 0 0 S 0.3 0.0 0:01.64 ksoftirqd/0 16 root 20 0 0 0 0 S 0.3 0.0 0:01.97 ksoftirqd/1 2663 root 20 0 923480 28292 13996 S 0.3 0.3 4:58.66 docker-containe 3699 root 20 0 0 0 0 I 0.3 0.0 0:00.13 kworker/u4:0 3708 root 20 0 44572 4176 3512 R 0.3 0.1 0:00.07 top 1 root 20 0 225384 9136 6724 S 0.0 0.1 0:23.25 systemd 2 root 20 0 0 0 0 S 0.0 0.0 0:00.03 kthreadd ...我们从第一行开始,逐个看一下:
- 平均负载全是 0,就绪队列里面只有一个进程(1 running)。
- 每个 CPU 的使用率都挺低,最高的 CPU1 的使用率也只有 4.4%,并不算高。
再看进程列表,CPU 使用率最高的进程也只有 0.3%,还是不高呀。
仔细看 top 的输出,两个 CPU 的使用率虽然分别只有 3.3% 和 4.4%,但都用在了软中断上;而从进程列表上也可以看到,CPU 使用率最高的也是软中断进程 ksoftirqd。看起来,软中断有点可疑了。
根据上一期的内容,既然软中断可能有问题,那你先要知道,究竟是哪类软中断的问题。停下来想想,上一节我们用了什么方法,来判断软中断类型呢?没错,还是 proc 文件系统。观察 /proc/softirqs 文件的内容,你就能知道各种软中断类型的次数。
不过,这里的各类软中断次数,又是什么时间段里的次数呢?它是系统运行以来的累积中断次数。所以我们直接查看文件内容,得到的只是累积中断次数,对这里的问题并没有直接参考意义。因为,这些中断次数的变化速率才是我们需要关注的。
那什么工具可以观察命令输出的变化情况呢?我想你应该想起来了,在前面案例中用过的 watch 命令,就可以定期运行一个命令来查看输出;如果再加上 -d 参数,还可以高亮出变化的部分,从高亮部分我们就可以直观看出,哪些内容变化得更快。
在第一个终端,我们运行下面的命令:
$ watch -d cat /proc/softirqs CPU0 CPU1 HI: 0 0 TIMER: 1083906 2368646 NET_TX: 53 9 NET_RX: 1550643 1916776 BLOCK: 0 0 IRQ_POLL: 0 0 TASKLET: 333637 3930 SCHED: 963675 2293171 HRTIMER: 0 0 RCU: 1542111 1590625通过 /proc/softirqs 文件内容的变化情况,你可以发现, TIMER(定时中断)、NET_RX(网络接收)、SCHED(内核调度)、RCU(RCU 锁)等这几个软中断都在不停变化。
其中,NET_RX,也就是网络数据包接收软中断的变化速率最快。而其他几种类型的软中断,是保证 Linux 调度、时钟和临界区保护这些正常工作所必需的,所以它们有一定的变化倒是正常的。
那么接下来,我们就从网络接收的软中断着手,继续分析。既然是网络接收的软中断,第一步应该就是观察系统的网络接收情况。这里你可能想起了很多网络工具,不过,我推荐今天的主人公工具 sar 。
sar 可以用来查看系统的网络收发情况,还有一个好处是,不仅可以观察网络收发的吞吐量(BPS,每秒收发的字节数),还可以观察网络收发的 PPS,即每秒收发的网络帧数。
在第一个终端中运行 sar 命令,并添加 -n DEV 参数显示网络收发的报告:
# -n DEV 表示显示网络收发的报告,间隔 1 秒输出一组数据 $ sar -n DEV 1 15:03:46 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil 15:03:47 eth0 12607.00 6304.00 664.86 358.11 0.00 0.00 0.00 0.01 15:03:47 docker0 6302.00 12604.00 270.79 664.66 0.00 0.00 0.00 0.00 15:03:47 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 15:03:47 veth9f6bbcd 6302.00 12604.00 356.95 664.66 0.00 0.00 0.00 0.05对于 sar 的输出界面,我先来简单介绍一下,从左往右依次是:
- 第一列:表示报告的时间。
- 第二列:IFACE 表示网卡。
- 第三、四列:rxpck/s 和 txpck/s 分别表示每秒接收、发送的网络帧数,也就是 PPS。
第五、六列:rxkB/s 和 txkB/s 分别表示每秒接收、发送的千字节数,也就是 BPS。
后面的其他参数基本接近 0,显然跟今天的问题没有直接关系,你可以先忽略掉。
我们具体来看输出的内容,你可以发现:
对网卡 eth0 来说,每秒接收的网络帧数比较大,达到了 12607,而发送的网络帧数则比较小,只有 6304;每秒接收的千字节数只有 664 KB,而发送的千字节数更小,只有 358 KB。
docker0 和 veth9f6bbcd 的数据跟 eth0 基本一致,只是发送和接收相反,发送的数据较大而接收的数据较小。这是 Linux 内部网桥转发导致的,你暂且不用深究,只要知道这是系统把 eth0 收到的包转发给 Nginx 服务即可。具体工作原理,我会在后面的网络部分详细介绍。
既然怀疑是网络接收中断的问题,我们还是重点来看 eth0 :接收的 PPS 比较大,达到 12607,而接收的 BPS 却很小,只有 664 KB。直观来看网络帧应该都是比较小的,我们稍微计算一下,664*1024/12607 = 54 字节,说明平均每个网络帧只有 54 字节,这显然是很小的网络帧,也就是我们通常所说的小包问题。
那么,有没有办法知道这是一个什么样的网络帧,以及从哪里发过来的呢?
使用 tcpdump 抓取 eth0 上的包就可以了。我们事先已经知道, Nginx 监听在 80 端口,它所提供的 HTTP 服务是基于 TCP 协议的,所以我们可以指定 TCP 协议和 80 端口精确抓包。
接下来,我们在第一个终端中运行 tcpdump 命令,通过 -i eth0 选项指定网卡 eth0,并通过 tcp port 80 选项指定 TCP 协议的 80 端口:
# -i eth0 只抓取 eth0 网卡,-n 不解析协议名和主机名 # tcp port 80 表示只抓取 tcp 协议并且端口号为 80 的网络帧 $ tcpdump -i eth0 -n tcp port 80 15:11:32.678966 IP 192.168.0.2.18238 > 192.168.0.30.80: Flags [S], seq 458303614, win 512, length 0 ...从 tcpdump 的输出中,你可以发现:
- 192.168.0.2.18238 > 192.168.0.30.80 ,表示网络帧从 192.168.0.2 的 18238 端口发送到 192.168.0.30 的 80 端口,也就是从运行 hping3 机器的 18238 端口发送网络帧,目的为 Nginx 所在机器的 80 端口。
Flags [S] 则表示这是一个 SYN 包。
再加上前面用 sar 发现的, PPS 超过 12000 的现象,现在我们可以确认,这就是从 192.168.0.2 这个地址发送过来的 SYN FLOOD 攻击。
SYN FLOOD 问题最简单的解决方法,就是从交换机或者硬件防火墙中封掉来源 IP,这样 SYN FLOOD 网络帧就不会发送到服务器中。
10.2 终端卡顿的问题
这个是由于网络延迟增大(甚至是丢包)导致的。比如你可以再拿另外一台机器(也就是第三台)在 hping3 运行的前后 ping 一下案例机器,ping -c3 <ip>
hping3 运行前,你可能看到最长的也不超过 1 ms:
3 packets transmitted, 3 received, 0% packet loss, time 2028ms
rtt min/avg/max/mdev = 0.815/0.914/0.989/0.081 ms而 hping3 运行时,不仅平均延迟增长到了 245 ms,而且还会有丢包的发生:
3 packets transmitted, 2 received, 33% packet loss, time 2026ms
rtt min/avg/max/mdev = 240.637/245.758/250.880/5.145 ms11 | 套路篇:如何迅速分析出系统CPU的瓶颈在哪里?
11.1 CPU 性能指标
最容易想到的应该是 CPU 使用率。
CPU 使用率描述了非空闲时间占总 CPU 时间的百分比,根据 CPU 上运行任务的不同,又被分为用户 CPU、系统 CPU、等待 I/O CPU、软中断和硬中断等。
- 用户 CPU 使用率,包括用户态 CPU 使用率(user)和低优先级用户态 CPU 使用率(nice),表示 CPU 在用户态运行的时间百分比。用户 CPU 使用率高,通常说明有应用程序比较繁忙。
- 系统 CPU 使用率,表示 CPU 在内核态运行的时间百分比(不包括中断)。系统 CPU 使用率高,说明内核比较繁忙。
- 等待 I/O 的 CPU 使用率,通常也称为 iowait,表示等待 I/O 的时间百分比。iowait 高,通常说明系统与硬件设备的 I/O 交互时间比较长。
- 软中断和硬中断的 CPU 使用率,分别表示内核调用软中断处理程序、硬中断处理程序的时间百分比。它们的使用率高,通常说明系统发生了大量的中断。
- 除了上面这些,还有在虚拟化环境中会用到的窃取 CPU 使用率(steal)和客户 CPU 使用率(guest),分别表示被其他虚拟机占用的 CPU 时间百分比,和运行客户虚拟机的 CPU 时间百分比。
第二个比较容易想到的,应该是平均负载(Load Average)。
平均负载(Load Average),也就是系统的平均活跃进程数。它反应了系统的整体负载情况,主要包括三个数值,分别指过去 1 分钟、过去 5 分钟和过去 15 分钟的平均负载。
理想情况下,平均负载等于逻辑 CPU 个数,这表示每个 CPU 都恰好被充分利用。如果平均负载大于逻辑 CPU 个数,就表示负载比较重了。
第三个,也是在专栏学习前你估计不太会注意到的,进程上下文切换。
包括:
- 无法获取资源而导致的自愿上下文切换;
被系统强制调度导致的非自愿上下文切换。
上下文切换,本身是保证 Linux 正常运行的一项核心功能。但过多的上下文切换,会将原本运行进程的 CPU 时间,消耗在寄存器、内核栈以及虚拟内存等数据的保存和恢复上,缩短进程真正运行的时间,成为性能瓶颈。
还有一个指标,CPU 缓存的命中率。
由于 CPU 发展的速度远快于内存的发展,CPU 的处理速度就比内存的访问速度快得多。这样,CPU 在访问内存的时候,免不了要等待内存的响应。为了协调这两者巨大的性能差距,CPU 缓存(通常是多级缓存)就出现了。
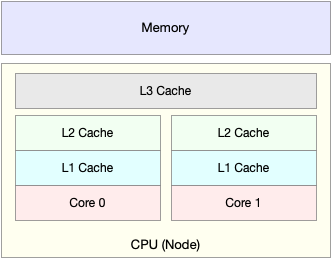
就像上面这张图显示的,CPU 缓存的速度介于 CPU 和内存之间,缓存的是热点的内存数据。根据不断增长的热点数据,这些缓存按照大小不同分为 L1、L2、L3 等三级缓存,其中 L1 和 L2 常用在单核中, L3 则用在多核中。
从 L1 到 L3,三级缓存的大小依次增大,相应的,性能依次降低(当然比内存还是好得多)。而它们的命中率,衡量的是 CPU 缓存的复用情况,命中率越高,则表示性能越好。
11.2 性能工具
平均负载的案例。
我们先用 uptime, 查看了系统的平均负载;而在平均负载升高后,又用 mpstat 和 pidstat ,分别观察了每个 CPU 和每个进程 CPU 的使用情况,进而找出了导致平均负载升高的进程,也就是我们的压测工具 stress。
上下文切换的案例。
我们先用 vmstat ,查看了系统的上下文切换次数和中断次数;然后通过 pidstat ,观察了进程的自愿上下文切换和非自愿上下文切换情况;最后通过 pidstat ,观察了线程的上下文切换情况,找出了上下文切换次数增多的根源,也就是我们的基准测试工具 sysbench。
进程 CPU 使用率升高的案例。
我们先用 top ,查看了系统和进程的 CPU 使用情况,发现 CPU 使用率升高的进程是 php-fpm;再用 perf top ,观察 php-fpm 的调用链,最终找出 CPU 升高的根源,也就是库函数 sqrt() 。
系统的 CPU 使用率升高的案例。
我们先用 top 观察到了系统 CPU 升高,但通过 top 和 pidstat ,却找不出高 CPU 使用率的进程。于是,我们重新审视 top 的输出,又从 CPU 使用率不高但处于 Running 状态的进程入手,找出了可疑之处,最终通过 perf record 和 perf report ,发现原来是短时进程在捣鬼。
另外,对于短时进程,我还介绍了一个专门的工具 execsnoop,它可以实时监控进程调用的外部命令。
不可中断进程和僵尸进程的案例。
我们先用 top 观察到了 iowait 升高的问题,并发现了大量的不可中断进程和僵尸进程;接着我们用 dstat 发现是这是由磁盘读导致的,于是又通过 pidstat 找出了相关的进程。但我们用 strace 查看进程系统调用却失败了,最终还是用 perf 分析进程调用链,才发现根源在于磁盘直接 I/O 。
软中断的案例。
我们通过 top 观察到,系统的软中断 CPU 使用率升高;接着查看 /proc/softirqs, 找到了几种变化速率较快的软中断;然后通过 sar 命令,发现是网络小包的问题,最后再用 tcpdump ,找出网络帧的类型和来源,确定是一个 SYN FLOOD 攻击导致的。
11.3 活学活用,把性能指标和性能工具联系起来
第一个维度,从 CPU 的性能指标出发。也就是说,当你要查看某个性能指标时,要清楚知道哪些工具可以做到。
根据不同的性能指标,对提供指标的性能工具进行分类和理解。这样,在实际排查性能问题时,你就可以清楚知道,什么工具可以提供你想要的指标,而不是毫无根据地挨个尝试,撞运气。
比如用 top 发现了软中断 CPU 使用率高后,下一步自然就想知道具体的软中断类型。那在哪里可以观察各类软中断的运行情况呢?当然是 proc 文件系统中的 /proc/softirqs 这个文件。
紧接着,比如说,我们找到的软中断类型是网络接收,那就要继续往网络接收方向思考。系统的网络接收情况是什么样的?什么工具可以查到网络接收情况呢?在我们案例中,用的正是 dstat。
.webp)
第二个维度,从工具出发。也就是当你已经安装了某个工具后,要知道这个工具能提供哪些指标。
.webp)
11.4 如何迅速分析 CPU 的性能瓶颈
虽然 CPU 的性能指标比较多,但要知道,既然都是描述系统的 CPU 性能,它们就不会是完全孤立的,很多指标间都有一定的关联。想弄清楚性能指标的关联性,就要通晓每种性能指标的工作原理。这也是为什么我在介绍每个性能指标时,都要穿插讲解相关的系统原理,希望你能记住这一点。
举个例子,用户 CPU 使用率高,我们应该去排查进程的用户态而不是内核态。因为用户 CPU 使用率反映的就是用户态的 CPU 使用情况,而内核态的 CPU 使用情况只会反映到系统 CPU 使用率上。
所以,为了缩小排查范围,我通常会先运行几个支持指标较多的工具,如 top、vmstat 和 pidstat。为什么是这三个工具呢?仔细看看下面这张图,你就清楚了。
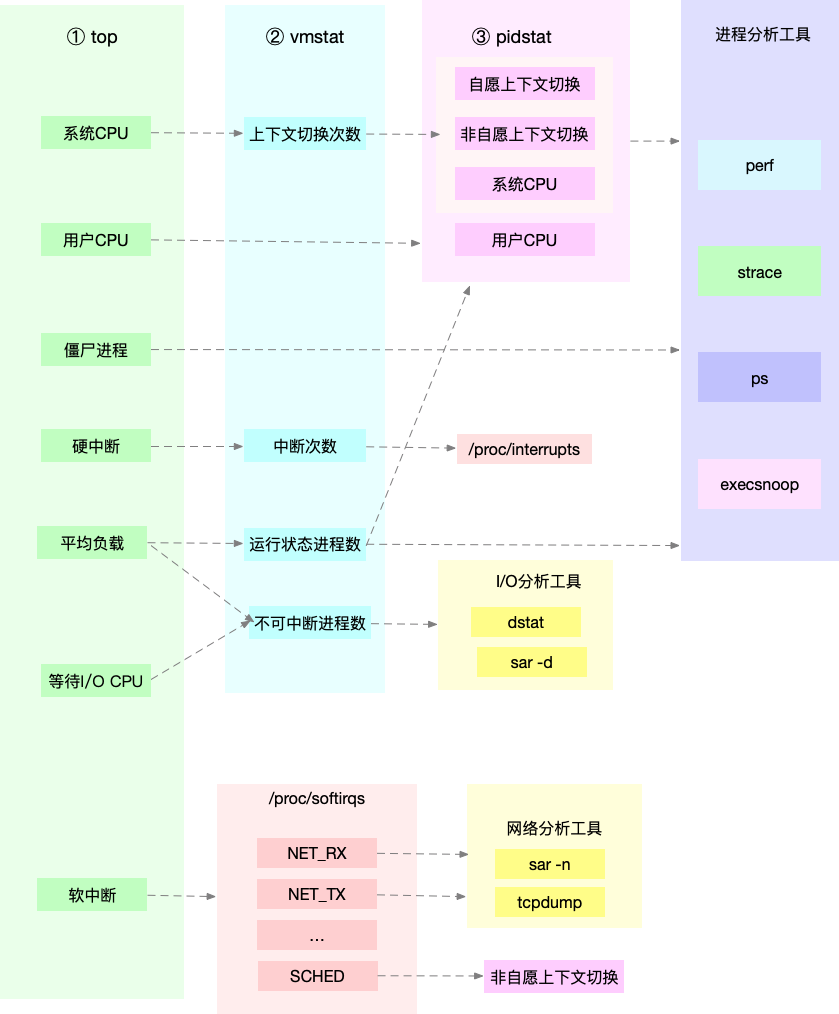
这张图里,我列出了 top、vmstat 和 pidstat 分别提供的重要的 CPU 指标,并用虚线表示关联关系,对应出了性能分析下一步的方向。
通过这张图你可以发现,这三个命令,几乎包含了所有重要的 CPU 性能指标,比如:
- 从 top 的输出可以得到各种 CPU 使用率以及僵尸进程和平均负载等信息。
- 从 vmstat 的输出可以得到上下文切换次数、中断次数、运行状态和不可中断状态的进程数。
- 从 pidstat 的输出可以得到进程的用户 CPU 使用率、系统 CPU 使用率、以及自愿上下文切换和非自愿上下文切换情况。
另外,这三个工具输出的很多指标是相互关联的,所以,我也用虚线表示了它们的关联关系,举几个例子你可能会更容易理解。
第一个例子,pidstat 输出的进程用户 CPU 使用率升高,会导致 top 输出的用户 CPU 使用率升高。所以,当发现 top 输出的用户 CPU 使用率有问题时,可以跟 pidstat 的输出做对比,观察是否是某个进程导致的问题。
而找出导致性能问题的进程后,就要用进程分析工具来分析进程的行为,比如使用 strace 分析系统调用情况,以及使用 perf 分析调用链中各级函数的执行情况。
第二个例子,top 输出的平均负载升高,可以跟 vmstat 输出的运行状态和不可中断状态的进程数做对比,观察是哪种进程导致的负载升高。
- 如果是不可中断进程数增多了,那么就需要做 I/O 的分析,也就是用 dstat 或 sar 等工具,进一步分析 I/O 的情况。
- 如果是运行状态进程数增多了,那就需要回到 top 和 pidstat,找出这些处于运行状态的到底是什么进程,然后再用进程分析工具,做进一步分析。
最后一个例子,当发现 top 输出的软中断 CPU 使用率升高时,可以查看 /proc/softirqs 文件中各种类型软中断的变化情况,确定到底是哪种软中断出的问题。比如,发现是网络接收中断导致的问题,那就可以继续用网络分析工具 sar 和 tcpdump 来分析。
12 | 套路篇:CPU 性能优化的几个思路
12.1 性能优化方法论
通过各种性能分析方法,终于找到引发性能问题的瓶颈后,是不是立刻就要开始优化了呢?别急,动手之前,你可以先看看下面这三个问题。
- 首先,既然要做性能优化,那要怎么判断它是不是有效呢?特别是优化后,到底能提升多少性能呢?
- 第二,性能问题通常不是独立的,如果有多个性能问题同时发生,你应该先优化哪一个呢?
- 第三,提升性能的方法并不是唯一的,当有多种方法可以选择时,你会选用哪一种呢?是不是总选那个最大程度提升性能的方法就行了呢?
如果你可以轻松回答这三个问题,那么二话不说就可以开始优化。
比如,在前面的不可中断进程案例中,通过性能分析,我们发现是因为一个进程的直接 I/O ,导致了 iowait 高达 90%。那是不是用”直接 I/O 换成缓存 I/O”的方法,就可以立即优化了呢?
按照上面讲的,你可以先自己思考下那三点。如果不能确定,我们一起来看看。
- 第一个问题,直接 I/O 换成缓存 I/O,可以把 iowait 从 90% 降到接近 0,性能提升很明显。
- 第二个问题,我们没有发现其他性能问题,直接 I/O 是唯一的性能瓶颈,所以不用挑选优化对象。
- 第三个问题,缓存 I/O 是我们目前用到的最简单的优化方法,而且这样优化并不会影响应用的功能。
好的,这三个问题很容易就能回答,所以立即优化没有任何问题。
12.2 怎么评估性能优化的效果?
我们解决性能问题的目的,自然是想得到一个性能提升的效果。为了评估这个效果,我们需要对系统的性能指标进行量化,并且要分别测试出优化前、后的性能指标,用前后指标的变化来对比呈现效果。我把这个方法叫做性能评估”三步走”。
确定性能的量化指标。
我的建议是不要局限在单一维度的指标上,你至少要从应用程序和系统资源这两个维度,分别选择不同的指标。比如,以 Web 应用为例:
- 应用程序的维度,我们可以用吞吐量和请求延迟来评估应用程序的性能。
系统资源的维度,我们可以用 CPU 使用率来评估系统的 CPU 使用情况。
之所以从这两个不同维度选择指标,主要是因为应用程序和系统资源这两者间相辅相成的关系。
好的应用程序是性能优化的最终目的和结果,系统优化总是为应用程序服务的。所以,必须要使用应用程序的指标,来评估性能优化的整体效果。
- 系统资源的使用情况是影响应用程序性能的根源。所以,需要用系统资源的指标,来观察和分析瓶颈的来源。
测试优化前的性能指标。
测试优化后的性能指标。
以刚刚的 Web 应用为例,对应上面提到的几个指标,我们可以选择 ab 等工具,测试 Web 应用的并发请求数和响应延迟。而测试的同时,还可以用 vmstat、pidstat 等性能工具,观察系统和进程的 CPU 使用率。这样,我们就同时获得了应用程序和系统资源这两个维度的指标数值。
不过,在进行性能测试时,有两个特别重要的地方你需要注意下。
第一,要避免性能测试工具干扰应用程序的性能。通常,对 Web 应用来说,性能测试工具跟目标应用程序要在不同的机器上运行。
比如,在之前的 Nginx 案例中,我每次都会强调要用两台虚拟机,其中一台运行 Nginx 服务,而另一台运行模拟客户端的工具,就是为了避免这个影响。
第二,避免外部环境的变化影响性能指标的评估。这要求优化前、后的应用程序,都运行在相同配置的机器上,并且它们的外部依赖也要完全一致。
比如还是拿 Nginx 来说,就可以运行在同一台机器上,并用相同参数的客户端工具来进行性能测试。
12.3 多个性能问题同时存在,要怎么选择?
系统性能总是牵一发而动全身,所以性能问题通常也不是独立存在的。那当多个性能问题同时发生的时候,应该先去优化哪一个呢?
在性能测试的领域,流传很广的一个说法是”二八原则”,也就是说 80% 的问题都是由 20% 的代码导致的。只要找出这 20% 的位置,你就可以优化 80% 的性能。所以,我想表达的是,并不是所有的性能问题都值得优化。
我的建议是,动手优化之前先动脑,先把所有这些性能问题给分析一遍,找出最重要的、可以最大程度提升性能的问题,从它开始优化。这样的好处是,不仅性能提升的收益最大,而且很可能其他问题都不用优化,就已经满足了性能要求。
那关键就在于,怎么判断出哪个性能问题最重要。这其实还是我们性能分析要解决的核心问题,只不过这里要分析的对象,从原来的一个问题,变成了多个问题,思路其实还是一样的。
所以,你依然可以用我前面讲过的方法挨个分析,分别找出它们的瓶颈。分析完所有问题后,再按照因果等关系,排除掉有因果关联的性能问题。最后,再对剩下的性能问题进行优化。
如果剩下的问题还是好几个,你就得分别进行性能测试了。比较不同的优化效果后,选择能明显提升性能的那个问题进行修复。这个过程通常会花费较多的时间,这里,我推荐两个可以简化这个过程的方法。
- 第一,如果发现是系统资源达到了瓶颈,比如 CPU 使用率达到了 100%,那么首先优化的一定是系统资源使用问题。完成系统资源瓶颈的优化后,我们才要考虑其他问题。
- 第二,针对不同类型的指标,首先去优化那些由瓶颈导致的,性能指标变化幅度最大的问题。比如产生瓶颈后,用户 CPU 使用率升高了 10%,而系统 CPU 使用率却升高了 50%,这个时候就应该首先优化系统 CPU 的使用。
12.4 有多种优化方法时,要如何选择?
一般情况下,我们当然想选能最大提升性能的方法,这其实也是性能优化的目标。
但要注意,现实情况要考虑的因素却没那么简单。最直观来说,性能优化并非没有成本。性能优化通常会带来复杂度的提升,降低程序的可维护性,还可能在优化一个指标时,引发其他指标的异常。也就是说,很可能你优化了一个指标,另一个指标的性能却变差了。
一个很典型的例子是我将在网络部分讲到的 DPDK(Data Plane Development Kit)。DPDK 是一种优化网络处理速度的方法,它通过绕开内核网络协议栈的方法,提升网络的处理能力。
不过它有一个很典型的要求,就是要独占一个 CPU 以及一定数量的内存大页,并且总是以 100% 的 CPU 使用率运行。所以,如果你的 CPU 核数很少,就有点得不偿失了。
所以,在考虑选哪个性能优化方法时,你要综合多方面的因素。切记,不要想着”一步登天”,试图一次性解决所有问题;也不要只会”拿来主义”,把其他应用的优化方法原封不动拿来用,却不经过任何思考和分析。
12.5 CPU 优化
清楚了性能优化最基本的三个问题后,我们接下来从应用程序和系统的角度,分别来看看如何才能降低 CPU 使用率,提高 CPU 的并行处理能力。
应用程序优化
首先,从应用程序的角度来说,降低 CPU 使用率的最好方法当然是,排除所有不必要的工作,只保留最核心的逻辑。比如减少循环的层次、减少递归、减少动态内存分配等等。
除此之外,应用程序的性能优化也包括很多种方法,我在这里列出了最常见的几种,你可以记下来。
- 编译器优化:很多编译器都会提供优化选项,适当开启它们,在编译阶段你就可以获得编译器的帮助,来提升性能。比如, gcc 就提供了优化选项 -O2,开启后会自动对应用程序的代码进行优化。
- 算法优化:使用复杂度更低的算法,可以显著加快处理速度。比如,在数据比较大的情况下,可以用 O(nlogn) 的排序算法(如快排、归并排序等),代替 O(n^2) 的排序算法(如冒泡、插入排序等)。
- 异步处理:使用异步处理,可以避免程序因为等待某个资源而一直阻塞,从而提升程序的并发处理能力。比如,把轮询替换为事件通知,就可以避免轮询耗费 CPU 的问题。
- 多线程代替多进程:前面讲过,相对于进程的上下文切换,线程的上下文切换并不切换进程地址空间,因此可以降低上下文切换的成本。
- 善用缓存:经常访问的数据或者计算过程中的步骤,可以放到内存中缓存起来,这样在下次用时就能直接从内存中获取,加快程序的处理速度。
系统优化
从系统的角度来说,优化 CPU 的运行,一方面要充分利用 CPU 缓存的本地性,加速缓存访问;另一方面,就是要控制进程的 CPU 使用情况,减少进程间的相互影响。
具体来说,系统层面的 CPU 优化方法也有不少,这里我同样列举了最常见的一些方法,方便你记忆和使用。
CPU 绑定:把进程绑定到一个或者多个 CPU 上,可以提高 CPU 缓存的命中率,减少跨 CPU 调度带来的上下文切换问题。
CPU 独占:跟 CPU 绑定类似,进一步将 CPU 分组,并通过 CPU 亲和性机制为其分配进程。这样,这些 CPU 就由指定的进程独占,换句话说,不允许其他进程再来使用这些 CPU。
优先级调整:使用 nice 调整进程的优先级,正值调低优先级,负值调高优先级。优先级的数值含义前面我们提到过,忘了的话及时复习一下。在这里,适当降低非核心应用的优先级,增高核心应用的优先级,可以确保核心应用得到优先处理。
为进程设置资源限制:使用 Linux cgroups 来设置进程的 CPU 使用上限,可以防止由于某个应用自身的问题,而耗尽系统资源。
NUMA(Non-Uniform Memory Access)优化:支持 NUMA 的处理器会被划分为多个 node,每个 node 都有自己的本地内存空间。NUMA 优化,其实就是让 CPU 尽可能只访问本地内存。
中断负载均衡:无论是软中断还是硬中断,它们的中断处理程序都可能会耗费大量的 CPU。开启 irqbalance 服务或者配置 smp_affinity,就可以把中断处理过程自动负载均衡到多个 CPU 上。
12.6 千万避免过早优化
“过早优化是万恶之源”。
因为,一方面,优化会带来复杂性的提升,降低可维护性;另一方面,需求不是一成不变的。针对当前情况进行的优化,很可能并不适应快速变化的新需求。这样,在新需求出现时,这些复杂的优化,反而可能阻碍新功能的开发。
所以,性能优化最好是逐步完善,动态进行,不追求一步到位,而要首先保证能满足当前的性能要求。当发现性能不满足要求或者出现性能瓶颈时,再根据性能评估的结果,选择最重要的性能问题进行优化。
13 | 答疑(一):无法模拟出 RES 中断的问题,怎么办?
13.1 问题 1:性能工具版本太低,导致指标不全
工具只是查找分析的手段,指标才是我们重点分析的对象。
proc 文件系统提供各项指标。
13.2 问题 2:使用 stress 命令,无法模拟 iowait 高的场景
使用 stress 无法模拟 iowait 升高,但是却看到了 sys 升高。这是因为案例中 的 stress -i 参数,它表示通过系统调用 sync() 来模拟 I/O 的问题,但这种方法实际上并不可靠。
因为 sync() 的本意是刷新内存缓冲区的数据到磁盘中,以确保同步。如果缓冲区内本来就没多少数据,那读写到磁盘中的数据也就不多,也就没法产生 I/O 压力。
这一点,在使用 SSD 磁盘的环境中尤为明显,很可能你的 iowait 总是 0,却单纯因为大量的系统调用,导致了系统 CPU 使用率 sys 升高。
推荐使用 stress-ng 来代替 stress。
# -i 的含义还是调用 sync,而—hdd 则表示读写临时文件
$ stress-ng -i 1 --hdd 1 --timeout 60013.3 问题 3:无法模拟出 RES 中断的问题
这个问题是说,即使运行了大量的线程,也无法模拟出重调度中断 RES 升高的问题。
其实我在 CPU 上下文切换的案例中已经提到,重调度中断是调度器用来分散任务到不同 CPU 的机制,也就是可以唤醒空闲状态的 CPU ,来调度新任务运行,而这通常借助处理器间中断(Inter-Processor Interrupts,IPI)来实现。
所以,这个中断在单核(只有一个逻辑 CPU)的机器上当然就没有意义了,因为压根儿就不会发生重调度的情况。
在这里顺便提一下,留言中很常见的一个错误。有些同学会拿 pidstat 中的 %wait 跟 top 中的 iowait% (缩写为 wa)对比,其实这是没有意义的,因为它们是完全不相关的两个指标。
- pidstat 中, %wait 表示进程等待 CPU 的时间百分比。
- top 中 ,iowait% 则表示等待 I/O 的 CPU 时间百分比。
13.4 问题 4:无法模拟出 I/O 性能瓶颈,以及 I/O 压力过大的问题
这个问题可以看成是上一个问题的延伸,只是把 stress 命令换成了一个在容器中运行的 app 应用。
事实上,在 I/O 瓶颈案例中,除了上面这个模拟不成功的留言,还有更多留言的内容刚好相反,说的是案例 I/O 压力过大,导致自己的机器出各种问题,甚至连系统都没响应了。
之所以这样,其实还是因为每个人的机器配置不同,既包括了 CPU 和内存配置的不同,更是因为磁盘的巨大差异。比如,机械磁盘(HDD)、低端固态磁盘(SSD)与高端固态磁盘相比,性能差异可能达到数倍到数十倍。
其实,我自己所用的案例机器也只是低端的 SSD,比机械磁盘稍微好一些,但跟高端固态磁盘还是比不了的。所以,相同操作下,我的机器上刚好出现 I/O 瓶颈,但换成一台使用机械磁盘的机器,可能磁盘 I/O 就被压死了(表现为使用率长时间 100%),而换上好一些的 SSD 磁盘,可能又无法产生足够的 I/O 压力。
另外,由于我在案例中只查找了 /dev/xvd 和 /dev/sd 前缀的磁盘,而没有考虑到使用其他前缀磁盘(比如 /dev/nvme)的同学。如果你正好用的是其他前缀,你可能会碰到跟 Vicky 类似的问题,也就是 app 启动后又很快退出,变成 exited 状态。
所以,在最新的案例中,我为 app 应用增加了三个选项。
- -d 设置要读取的磁盘,默认前缀为 /dev/sd 或者 /dev/xvd 的磁盘。
- -s 设置每次读取的数据量大小,单位为字节,默认为 67108864(也就是 64MB)。
- -c 设置每个子进程读取的次数,默认为 20 次,也就是说,读取 20*64MB 数据后,子进程退出。
你可以点击 Github 查看它的源码,使用方法我写在了这里:
docker run --privileged --name=app -itd feisky/app:iowait /app -d /dev/sdb -s 67108864 -c 20案例运行后,你可以执行 docker logs 查看它的日志。正常情况下,你可以看到下面的输出:
$ docker logs app
Reading data from disk /dev/sdb with buffer size 67108864 and count 2013.5 问题 5:性能工具(如 vmstat)输出中,第一行数据跟其他行差别巨大
这个问题主要是说,在执行 vmstat 时,第一行数据跟其他行相比较,数值相差特别大。我相信不少同学都注意到了这个现象,这里我简单解释一下。
首先还是要记住,我总强调的那句话,在碰到直观上解释不了的现象时,要第一时间去查命令手册。
比如,运行 man vmstat 命令,你可以在手册中发现下面这句话:
The first report produced gives averages since the last reboot. Additional reports give information on a sampling period of length delay. The process and memory reports are instantaneous in either case.也就是说,第一行数据是系统启动以来的平均值,其他行才是你在运行 vmstat 命令时,设置的间隔时间的平均值。另外,进程和内存的报告内容都是即时数值。
14 | 答疑(二):如何用perf工具分析Java程序?
14.1 问题 1: 使用 perf 工具时,看到的是 16 进制地址而不是函数名
这也是留言比较多的一个问题,在 CentOS 系统中,使用 perf 工具看不到函数名,只能看到一些 16 进制格式的函数地址。
其实,只要你观察一下 perf 界面最下面的那一行,就会发现一个警告信息:
Failed to open /opt/bitnami/php/lib/php/extensions/opcache.so, continuing without symbols这说明,perf 找不到待分析进程依赖的库。当然,实际上这个案例中有很多依赖库都找不到,只不过,perf 工具本身只在最后一行显示警告信息,所以你只能看到这一条警告。
这个问题,其实也是在分析 Docker 容器应用时,我们经常碰到的一个问题,因为容器应用依赖的库都在镜像里面。
针对这种情况,我总结了下面四个解决方法。
第一个方法,在容器外面构建相同路径的依赖库。这种方法从原理上可行,但是我并不推荐,一方面是因为找出这些依赖库比较麻烦,更重要的是,构建这些路径,会污染容器主机的环境。
第二个方法,在容器内部运行 perf。不过,这需要容器运行在特权模式下,但实际的应用程序往往只以普通容器的方式运行。所以,容器内部一般没有权限执行 perf 分析。
比方说,如果你在普通容器内部运行 perf record ,你将会看到下面这个错误提示:
$ perf_4.9 record -a -g perf_event_open(..., PERF_FLAG_FD_CLOEXEC) failed with unexpected error 1 (Operation not permitted) perf_event_open(..., 0) failed unexpectedly with error 1 (Operation not permitted)当然,其实你还可以通过配置 /proc/sys/kernel/perf_event_paranoid (比如改成 -1),来允许非特权用户执行 perf 事件分析。
不过还是那句话,为了安全起见,这种方法我也不推荐。
第三个方法,指定符号路径为容器文件系统的路径。比如对于第 05 讲的应用,你可以执行下面这个命令:
$ mkdir /tmp/foo $ PID=$(docker inspect --format {{.State.Pid}} phpfpm) $ bindfs /proc/$PID/root /tmp/foo $ perf report --symfs /tmp/foo # 使用完成后不要忘记解除绑定 $ umount /tmp/foo/不过这里要注意,bindfs 这个工具需要你额外安装。bindfs 的基本功能是实现目录绑定(类似于 mount —bind),这里需要你安装的是 1.13.10 版本(这也是它的最新发布版)。
如果你安装的是旧版本,你可以到 GitHub 上面下载源码,然后编译安装。
第四个方法,在容器外面把分析纪录保存下来,再去容器里查看结果。这样,库和符号的路径也就都对了。
比如,你可以这么做。先运行
perf record -g -p <pid>,执行一会儿(比如 15 秒)后,按 Ctrl+C 停止。然后,把生成的 perf.data 文件,拷贝到容器里面来分析:
docker cp perf.data phpfpm:/tmp docker exec -i -t phpfpm bash接下来,在容器的 bash 中继续运行下面的命令,安装 perf 并使用 perf report 查看报告:
cd /tmp/ apt-get update && apt-get install -y linux-tools linux-perf procps perf_4.9 report不过,这里也有两点需要你注意。
- 首先是 perf 工具的版本问题。在最后一步中,我们运行的工具是容器内部安装的版本 perf_4.9,而不是普通的 perf 命令。这是因为, perf 命令实际上是一个软连接,会跟内核的版本进行匹配,但镜像里安装的 perf 版本跟虚拟机的内核版本有可能并不一致。
- 另外,php-fpm 镜像是基于 Debian 系统的,所以安装 perf 工具的命令,跟 Ubuntu 也并不完全一样。
事实上,抛开我们的案例来说,即使是在非容器化的应用中,你也可能会碰到这个问题。假如你的应用程序在编译时,使用 strip 删除了 ELF 二进制文件的符号表,那么你同样也只能看到函数的地址。
14.2 问题 2:如何用 perf 工具分析 Java 程序
这两个问题,其实是上一个 perf 问题的延伸。 像是 Java 这种通过 JVM 来运行的应用程序,运行堆栈用的都是 JVM 内置的函数和堆栈管理。所以,从系统层面你只能看到 JVM 的函数堆栈,而不能直接得到 Java 应用程序的堆栈。
perf_events 实际上已经支持了 JIT,但还需要一个 /tmp/perf-PID.map 文件,来进行符号翻译。当然,开源项目 perf-map-agent 可以帮你生成这个符号表。
此外,为了生成全部调用栈,你还需要开启 JDK 的选项 -XX:+PreserveFramePointer。因为这里涉及到大量的 Java 知识,我就不再详细展开了。如果你的应用刚好基于 Java ,那么你可以参考 NETFLIX 的技术博客 Java in Flames,来查看详细的使用步骤。
说到这里,我也想强调一个问题,那就是学习性能优化时,不要一开始就把自己限定在具体的某个编程语言或者性能工具中,纠结于语言或工具的细节出不来。
掌握整体的分析思路,才是我们首先要做的。因为,性能优化的原理和思路,在任何编程语言中都是相通的。
14.3 问题 3:为什么 perf 的报告中,很多符号都不显示调用栈
perf report 是一个可视化展示 perf.data 的工具。在第 08 讲的案例中,我直接给出了最终结果,并没有详细介绍它的参数。估计很多同学的机器在运行时,都碰到了跟路过同学一样的问题,看到的是下面这个界面。
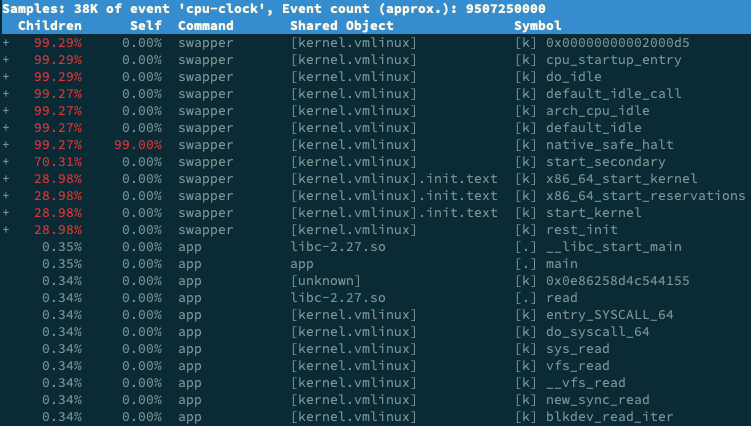
这个界面可以清楚看到,perf report 的输出中,只有 swapper 显示了调用栈,其他所有符号都不能查看堆栈情况,包括我们案例中的 app 应用。
这种情况我们以前也遇到过,当你发现性能工具的输出无法理解时,应该怎么办呢?当然还是查工具的手册。比如,你可以执行 man perf-report 命令,找到 -g 参数的说明:
-g, --call-graph=<print_type,threshold[,print_limit],order,sort_key[,branch],value>
Display call chains using type, min percent threshold, print limit, call order, sort key, optional branch and value. Note that
ordering is not fixed so any parameter can be given in an arbitrary order. One exception is the print_limit which should be
preceded by threshold.
print_type can be either:
- flat: single column, linear exposure of call chains.
- graph: use a graph tree, displaying absolute overhead rates. (default)
- fractal: like graph, but displays relative rates. Each branch of
the tree is considered as a new profiled object.
- folded: call chains are displayed in a line, separated by semicolons
- none: disable call chain display.
threshold is a percentage value which specifies a minimum percent to be
included in the output call graph. Default is 0.5 (%).
print_limit is only applied when stdio interface is used. It's to limit
number of call graph entries in a single hist entry. Note that it needs
to be given after threshold (but not necessarily consecutive).
Default is 0 (unlimited).
order can be either:
- callee: callee based call graph.
- caller: inverted caller based call graph.
Default is 'caller' when --children is used, otherwise 'callee'.
sort_key can be:
- function: compare on functions (default)
- address: compare on individual code addresses
- srcline: compare on source filename and line number
branch can be:
- branch: include last branch information in callgraph when available.
Usually more convenient to use --branch-history for this.
value can be:
- percent: diplay overhead percent (default)
- period: display event period
- count: display event count通过这个说明可以看到,-g 选项等同于 —call-graph,它的参数是后面那些被逗号隔开的选项,意思分别是输出类型、最小阈值、输出限制、排序方法、排序关键词、分支以及值的类型。
我们可以看到,这里默认的参数是 graph,0.5,caller,function,percent,具体含义文档中都有详细讲解,这里我就不再重复了。
现在再回过头来看我们的问题,堆栈显示不全,相关的参数当然就是最小阈值 threshold。通过手册中对 threshold 的说明,我们知道,当一个事件发生比例高于这个阈值时,它的调用栈才会显示出来。
threshold 的默认值为 0.5%,也就是说,事件比例超过 0.5% 时,调用栈才能被显示。再观察我们案例应用 app 的事件比例,只有 0.34%,低于 0.5%,所以看不到 app 的调用栈就很正常了。
这种情况下,你只需要给 perf report 设置一个小于 0.34% 的阈值,就可以显示我们想看到的调用图了。比如执行下面的命令:
perf report -g graph,0.314.4 问题 4:怎么理解 perf report 报告
看到这里,我估计你也曾嘀咕过,为啥不一上来就用 perf 工具解决,还要执行那么多其他工具呢? 这个问题其实就给出了很好的解释。
在问题 4 的 perf report 界面中,你也一定注意到了, swapper 高达 99% 的比例。直觉来说,我们应该直接观察它才对,为什么没那么做呢?
其实,当你清楚了 swapper 的原理后,就很容易理解我们为什么可以忽略它了。
看到 swapper,你可能首先想到的是 SWAP 分区。实际上, swapper 跟 SWAP 没有任何关系,它只在系统初始化时创建 init 进程,之后,它就成了一个最低优先级的空闲任务。也就是说,当 CPU 上没有其他任务运行时,就会执行 swapper 。所以,你可以称它为”空闲任务”。
回到我们的问题,在 perf report 的界面中,展开它的调用栈,你会看到, swapper 时钟事件都耗费在了 do_idle 上,也就是在执行空闲任务。
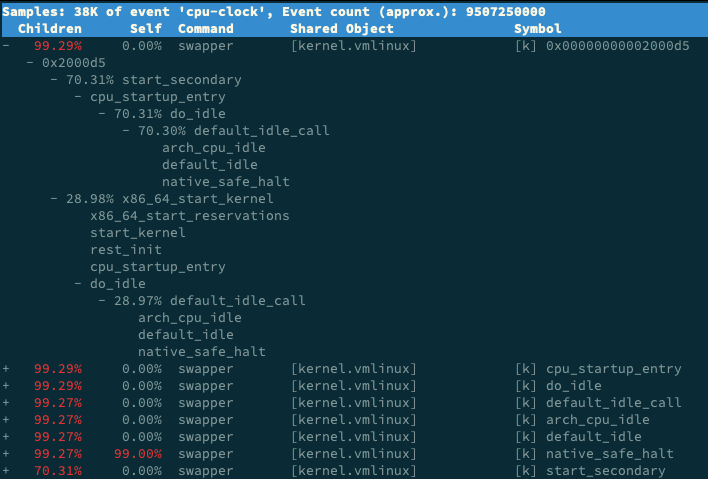
所以,分析案例时,我们直接忽略了前面这个 99% 的符号,转而分析后面只有 0.3% 的 app。其实从这里你也能理解,为什么我们一开始不先用 perf 分析。
因为在多任务系统中,次数多的事件,不一定就是性能瓶颈。所以,只观察到一个大数值,并不能说明什么问题。具体有没有瓶颈,还需要你观测多个方面的多个指标,来交叉验证。这也是我在套路篇中不断强调的一点。
另外,关于 Children 和 Self 的含义,手册里其实有详细说明,还很友好地举了一个例子,来说明它们的百分比的计算方法。简单来说,
- Self 是最后一列的符号(可以理解为函数)本身所占比例;
- Children 是这个符号调用的其他符号(可以理解为子函数,包括直接和间接调用)占用的比例之和。
所以,使用性能工具时,确实应该考虑工具本身对系统性能的影响。而这种情况,就需要你了解这些工具的原理。比如,
- perf 这种动态追踪工具,会给系统带来一定的性能损失。
- vmstat、pidstat 这些直接读取 proc 文件系统来获取指标的工具,不会带来性能损失。
14.5 问题 5:性能优化书籍和参考资料推荐
Brendan Gregg
《Systems Performance: Enterprise and the Cloud》
中文版 《性能之巅:洞悉系统、企业与云计算》
03-内存性能篇
15 | 基础篇:Linux内存是怎么工作的?
15.1 内存映射
通常所说的内存容量,其实指的是物理内存。物理内存也称为主存,大多数计算机用的主存都是动态随机访问内存(DRAM)。只有内核才可以直接访问物理内存。那么,进程要访问内存时,该怎么办呢?
Linux 内核给每个进程都提供了一个独立的虚拟地址空间,并且这个地址空间是连续的。这样,进程就可以很方便地访问内存,更确切地说是访问虚拟内存。
虚拟地址空间的内部又被分为内核空间和用户空间两部分,不同字长(也就是单个 CPU 指令可以处理数据的最大长度)的处理器,地址空间的范围也不同。比如最常见的 32 位和 64 位系统,我画了两张图来分别表示它们的虚拟地址空间,如下所示:
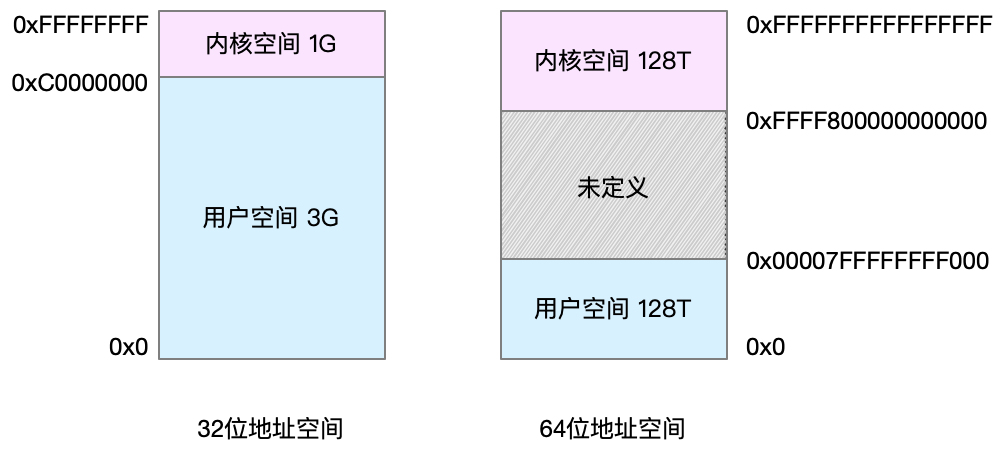
通过这里可以看出,32 位系统的内核空间占用 1G,位于最高处,剩下的 3G 是用户空间。而 64 位系统的内核空间和用户空间都是 128T,分别占据整个内存空间的最高和最低处,剩下的中间部分是未定义的。
还记得进程的用户态和内核态吗?进程在用户态时,只能访问用户空间内存;只有进入内核态后,才可以访问内核空间内存。虽然每个进程的地址空间都包含了内核空间,但这些内核空间,其实关联的都是相同的物理内存。这样,进程切换到内核态后,就可以很方便地访问内核空间内存。
既然每个进程都有一个这么大的地址空间,那么所有进程的虚拟内存加起来,自然要比实际的物理内存大得多。所以,并不是所有的虚拟内存都会分配物理内存,只有那些实际使用的虚拟内存才分配物理内存,并且分配后的物理内存,是通过内存映射来管理的。
内存映射,其实就是将虚拟内存地址映射到物理内存地址。为了完成内存映射,内核为每个进程都维护了一张页表,记录虚拟地址与物理地址的映射关系,如下图所示:
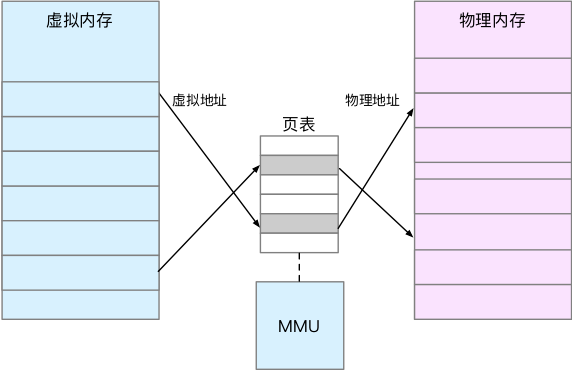
页表实际上存储在 CPU 的内存管理单元 MMU 中,这样,正常情况下,处理器就可以直接通过硬件,找出要访问的内存。
而当进程访问的虚拟地址在页表中查不到时,系统会产生一个缺页异常,进入内核空间分配物理内存、更新进程页表,最后再返回用户空间,恢复进程的运行。
TLB(Translation Lookaside Buffer,转译后备缓冲器)其实就是 MMU 中页表的高速缓存。由于进程的虚拟地址空间是独立的,而 TLB 的访问速度又比 MMU 快得多,所以,通过减少进程的上下文切换,减少 TLB 的刷新次数,就可以提高 TLB 缓存的使用率,进而提高 CPU 的内存访问性能。
不过要注意,MMU 并不以字节为单位来管理内存,而是规定了一个内存映射的最小单位,也就是页,通常是 4 KB 大小。这样,每一次内存映射,都需要关联 4 KB 或者 4KB 整数倍的内存空间。
页的大小只有 4 KB ,导致的另一个问题就是,整个页表会变得非常大。比方说,仅 32 位系统就需要 100 多万个页表项(4GB/4KB),才可以实现整个地址空间的映射。为了解决页表项过多的问题,Linux 提供了两种机制,也就是多级页表和大页(HugePage)。
多级页表就是把内存分成区块来管理,将原来的映射关系改成区块索引和区块内的偏移。由于虚拟内存空间通常只用了很少一部分,那么,多级页表就只保存这些使用中的区块,这样就可以大大地减少页表的项数。
Linux 用的正是四级页表来管理内存页,如下图所示,虚拟地址被分为 5 个部分,前 4 个表项用于选择页,而最后一个索引表示页内偏移。
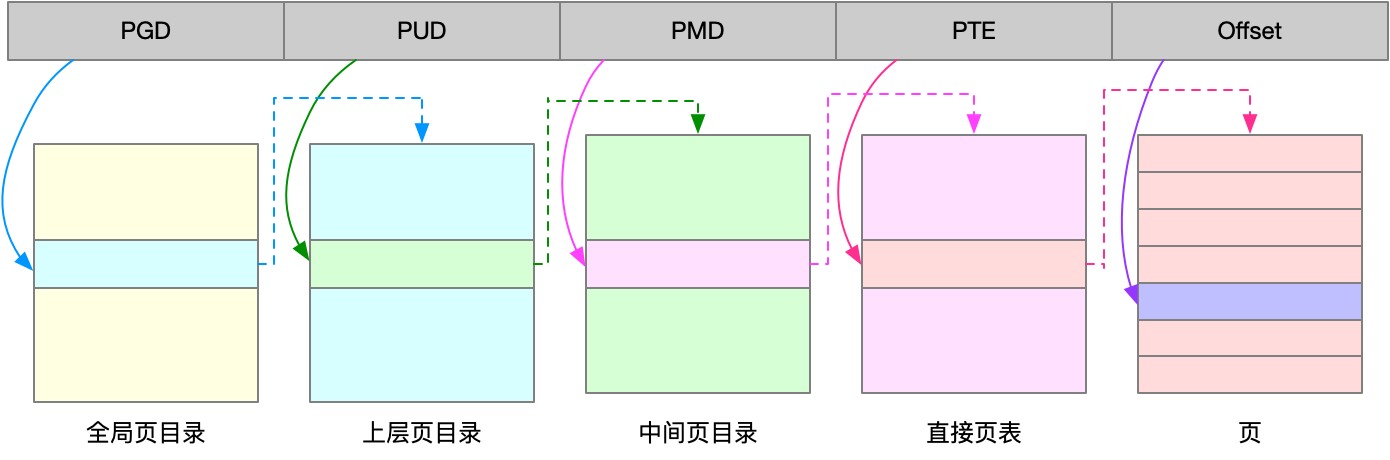
再看大页,顾名思义,就是比普通页更大的内存块,常见的大小有 2MB 和 1GB。大页通常用在使用大量内存的进程上,比如 Oracle、DPDK 等。
通过这些机制,在页表的映射下,进程就可以通过虚拟地址来访问物理内存了。那么具体到一个 Linux 进程中,这些内存又是怎么使用的呢?
15.2 虚拟内存空间分布
首先,我们需要进一步了解虚拟内存空间的分布情况。最上方的内核空间不用多讲,下方的用户空间内存,其实又被分成了多个不同的段。以 32 位系统为例,我画了一张图来表示它们的关系。
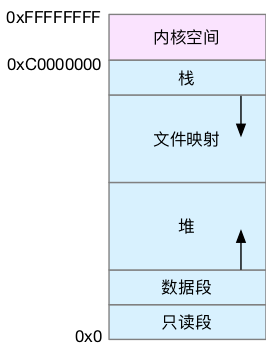
通过这张图你可以看到,用户空间内存,从低到高分别是五种不同的内存段。
- 只读段,包括代码和常量等。
- 数据段,包括全局变量等。
- 堆,包括动态分配的内存,从低地址开始向上增长。
- 文件映射段,包括动态库、共享内存等,从高地址开始向下增长。
- 栈,包括局部变量和函数调用的上下文等。栈的大小是固定的,一般是 8 MB。
在这五个内存段中,堆和文件映射段的内存是动态分配的。比如说,使用 C 标准库的 malloc() 或者 mmap() ,就可以分别在堆和文件映射段动态分配内存。
其实 64 位系统的内存分布也类似,只不过内存空间要大得多。那么,更重要的问题来了,内存究竟是怎么分配的呢?
15.3 内存分配与回收
malloc() 是 C 标准库提供的内存分配函数,对应到系统调用上,有两种实现方式,即 brk() 和 mmap()。
- 对小块内存(小于 128K),C 标准库使用 brk() 来分配,也就是通过移动堆顶的位置来分配内存。这些内存释放后并不会立刻归还系统,而是被缓存起来,这样就可以重复使用。
- 而大块内存(大于 128K),则直接使用内存映射 mmap() 来分配,也就是在文件映射段找一块空闲内存分配出去。
这两种方式,自然各有优缺点。
- brk() 方式的缓存,可以减少缺页异常的发生,提高内存访问效率。不过,由于这些内存没有归还系统,在内存工作繁忙时,频繁的内存分配和释放会造成内存碎片。
- 而 mmap() 方式分配的内存,会在释放时直接归还系统,所以每次 mmap 都会发生缺页异常。在内存工作繁忙时,频繁的内存分配会导致大量的缺页异常,使内核的管理负担增大。这也是 malloc 只对大块内存使用 mmap 的原因。
了解这两种调用方式后,我们还需要清楚一点,那就是,当这两种调用发生后,其实并没有真正分配内存。这些内存,都只在首次访问时才分配,也就是通过缺页异常进入内核中,再由内核来分配内存。
整体来说,Linux 使用伙伴系统来管理内存分配。前面我们提到过,这些内存在 MMU 中以页为单位进行管理,伙伴系统也一样,以页为单位来管理内存,并且会通过相邻页的合并,减少内存碎片化(比如 brk 方式造成的内存碎片)。
你可能会想到一个问题,如果遇到比页更小的对象,比如不到 1K 的时候,该怎么分配内存呢?
实际系统运行中,确实有大量比页还小的对象,如果为它们也分配单独的页,那就太浪费内存了。
所以,在用户空间,malloc 通过 brk() 分配的内存,在释放时并不立即归还系统,而是缓存起来重复利用。在内核空间,Linux 则通过 slab 分配器来管理小内存。你可以把 slab 看成构建在伙伴系统上的一个缓存,主要作用就是分配并释放内核中的小对象。
当然,系统也不会任由某个进程用完所有内存。在发现内存紧张时,系统就会通过一系列机制来回收内存,比如下面这三种方式:
- 回收缓存,比如使用 LRU(Least Recently Used)算法,回收最近使用最少的内存页面;
- 回收不常访问的内存,把不常用的内存通过交换分区直接写到磁盘中;
- 杀死进程,内存紧张时系统还会通过 OOM(Out of Memory),直接杀掉占用大量内存的进程。
其中,第二种方式回收不常访问的内存时,会用到交换分区(以下简称 Swap)。Swap 其实就是把一块磁盘空间当成内存来用。它可以把进程暂时不用的数据存储到磁盘中(这个过程称为换出),当进程访问这些内存时,再从磁盘读取这些数据到内存中(这个过程称为换入)。
所以,你可以发现,Swap 把系统的可用内存变大了。不过要注意,通常只在内存不足时,才会发生 Swap 交换。并且由于磁盘读写的速度远比内存慢,Swap 会导致严重的内存性能问题。
第三种方式提到的 OOM(Out of Memory),其实是内核的一种保护机制。它监控进程的内存使用情况,并且使用 oom_score 为每个进程的内存使用情况进行评分:
- 一个进程消耗的内存越大,oom_score 就越大;
- 一个进程运行占用的 CPU 越多,oom_score 就越小。
这样,进程的 oom_score 越大,代表消耗的内存越多,也就越容易被 OOM 杀死,从而可以更好保护系统。
当然,为了实际工作的需要,管理员可以通过 /proc 文件系统,手动设置进程的 oom_adj ,从而调整进程的 oom_score。
oom_adj 的范围是 [-17, 15],数值越大,表示进程越容易被 OOM 杀死;数值越小,表示进程越不容易被 OOM 杀死,其中 -17 表示禁止 OOM。
比如用下面的命令,你就可以把 sshd 进程的 oom_adj 调小为 -16,这样, sshd 进程就不容易被 OOM 杀死。
echo -16 > /proc/$(pidof sshd)/oom_adj15.4 如何查看内存使用情况
下面是一个 free 的输出示例:
# 注意不同版本的 free 输出可能会有所不同
$ free
total used free shared buff/cache available
Mem: 8169348 263524 6875352 668 1030472 7611064
Swap: 0 0 0free 输出的是一个表格,其中的数值都默认以字节为单位。表格总共有两行六列,这两行分别是物理内存 Mem 和交换分区 Swap 的使用情况,而六列中,每列数据的含义分别为:
- 第一列,total 是总内存大小;
- 第二列,used 是已使用内存的大小,包含了共享内存;
- 第三列,free 是未使用内存的大小;
- 第四列,shared 是共享内存的大小;
- 第五列,buff/cache 是缓存和缓冲区的大小;
- 最后一列,available 是新进程可用内存的大小。
available 不仅包含未使用内存,还包括了可回收的缓存,所以一般会比未使用内存更大。不过,并不是所有缓存都可以回收,因为有些缓存可能正在使用中。
如果你想查看进程的内存使用情况,可以用 top 或者 ps 等工具。比如,下面是 top 的输出示例:
# 按下 M 切换到内存排序
$ top
...
KiB Mem : 8169348 total, 6871440 free, 267096 used, 1030812 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 7607492 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
430 root 19 -1 122360 35588 23748 S 0.0 0.4 0:32.17 systemd-journal
1075 root 20 0 771860 22744 11368 S 0.0 0.3 0:38.89 snapd
1048 root 20 0 170904 17292 9488 S 0.0 0.2 0:00.24 networkd-dispat
1 root 20 0 78020 9156 6644 S 0.0 0.1 0:22.92 systemd
12376 azure 20 0 76632 7456 6420 S 0.0 0.1 0:00.01 systemd
12374 root 20 0 107984 7312 6304 S 0.0 0.1 0:00.00 sshd
...top 输出界面的顶端,也显示了系统整体的内存使用情况,这些数据跟 free 类似,我就不再重复解释。我们接着看下面的内容,跟内存相关的几列数据,比如 VIRT、RES、SHR 以及 %MEM 等。
这些数据,包含了进程最重要的几个内存使用情况,我们挨个来看。
- VIRT 是进程虚拟内存的大小,只要是进程申请过的内存,即便还没有真正分配物理内存,也会计算在内。
- RES 是常驻内存的大小,也就是进程实际使用的物理内存大小,但不包括 Swap 和共享内存。
- SHR 是共享内存的大小,比如与其他进程共同使用的共享内存、加载的动态链接库以及程序的代码段等。
- %MEM 是进程使用物理内存占系统总内存的百分比。
除了要认识这些基本信息,在查看 top 输出时,你还要注意两点。
- 第一,虚拟内存通常并不会全部分配物理内存。从上面的输出,你可以发现每个进程的虚拟内存都比常驻内存大得多。
- 第二,共享内存 SHR 并不一定是共享的,比方说,程序的代码段、非共享的动态链接库,也都算在 SHR 里。当然,SHR 也包括了进程间真正共享的内存。所以在计算多个进程的内存使用时,不要把所有进程的 SHR 直接相加得出结果。
16 | 基础篇:怎么理解内存中的Buffer和Cache?
16.1 free 数据的来源
用 man 命令查询 free 的文档,就可以找到 Buffer 和 Cache 指标的详细说明。比如,我们执行 man free ,就可以看到下面这个界面。
buffers
Memory used by kernel buffers (Buffers in /proc/meminfo)
cache Memory used by the page cache and slabs (Cached and SReclaimable in /proc/meminfo)
buff/cache
Sum of buffers and cache从 free 的手册中,你可以看到 buffer 和 cache 的说明。
- Buffers 是内核缓冲区用到的内存,对应的是 /proc/meminfo 中的 Buffers 值。
- Cache 是内核页缓存和 Slab 用到的内存,对应的是 /proc/meminfo 中的 Cached 与 SReclaimable 之和。
这里的说明告诉我们,这些数值都来自 /proc/meminfo,但更具体的 Buffers、Cached 和 SReclaimable 的含义,还是没有说清楚。
要弄明白它们到底是什么,我估计你第一反应就是去百度或者 Google 一下。虽然大部分情况下,网络搜索能给出一个答案。但是,且不说筛选信息花费的时间精力,对你来说,这个答案的准确性也是很难保证的。
要注意,网上的结论可能是对的,但是很可能跟你的环境并不匹配。最简单来说,同一个指标的具体含义,就可能因为内核版本、性能工具版本的不同而有挺大差别。这也是为什么,我总在专栏中强调通用思路和方法,而不是让你死记结论。对于案例实践来说,机器环境就是我们的最大限制。
那么,有没有更简单、更准确的方法,来查询它们的含义呢?
16.2 proc 文件系统
proc 文件系统同时也是很多性能工具的最终数据来源。比如我们刚才看到的 free ,就是通过读取 /proc/meminfo ,得到内存的使用情况。
执行 man proc ,你就可以得到 proc 文件系统的详细文档。
Buffers %lu
Relatively temporary storage for raw disk blocks that shouldn't get tremendously large (20MB or so).
Cached %lu
In-memory cache for files read from the disk (the page cache). Doesn't include SwapCached.
...
SReclaimable %lu (since Linux 2.6.19)
Part of Slab, that might be reclaimed, such as caches.
SUnreclaim %lu (since Linux 2.6.19)
Part of Slab, that cannot be reclaimed on memory pressure.通过这个文档,我们可以看到:
- Buffers 是对原始磁盘块的临时存储,也就是用来缓存磁盘的数据,通常不会特别大(20MB 左右)。这样,内核就可以把分散的写集中起来,统一优化磁盘的写入,比如可以把多次小的写合并成单次大的写等等。
- Cached 是从磁盘读取文件的页缓存,也就是用来缓存从文件读取的数据。这样,下次访问这些文件数据时,就可以直接从内存中快速获取,而不需要再次访问缓慢的磁盘。
- SReclaimable 是 Slab 的一部分。Slab 包括两部分,其中的可回收部分,用 SReclaimable 记录;而不可回收部分,用 SUnreclaim 记录。
不过,知道这个定义就真的理解了吗?这里我给你提了两个问题,你先想想能不能回答出来。
- 第一个问题,Buffer 的文档没有提到这是磁盘读数据还是写数据的缓存,而在很多网络搜索的结果中都会提到 Buffer 只是对将要写入磁盘数据的缓存。那反过来说,它会不会也缓存从磁盘中读取的数据呢?
- 第二个问题,文档中提到,Cache 是对从文件读取数据的缓存,那么它是不是也会缓存写文件的数据呢?
为了解答这两个问题,接下来,我将用几个案例来展示, Buffer 和 Cache 在不同场景下的使用情况。
16.3 案例
机器配置: 2 CPU, 8 GB 内存。
安装软件:
apt install sysstat。
为了减少缓存的影响,记得在第一个终端中,运行下面的命令来清理系统缓存:
# 清理文件页、目录项、Inodes 等各种缓存
$ echo 3 > /proc/sys/vm/drop_caches场景 1:磁盘和文件写案例
在第一个终端,运行下面这个 vmstat 命令:
# 每隔 1 秒输出 1 组数据 $ vmstat 1 procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 0 0 0 7743608 1112 92168 0 0 0 0 52 152 0 1 100 0 0 0 0 0 7743608 1112 92168 0 0 0 0 36 92 0 0 100 0 0输出界面里, 内存部分的 buff 和 cache ,以及 io 部分的 bi 和 bo 就是我们要关注的重点。
- buff 和 cache 就是我们前面看到的 Buffers 和 Cache,单位是 KB。
bi 和 bo 则分别表示块设备读取和写入的大小,单位为块 / 秒。因为 Linux 中块的大小是 1KB,所以这个单位也就等价于 KB/s。
man vmstat: All linux blocks are currently 1024 bytes.正常情况下,空闲系统中,你应该看到的是,这几个值在多次结果中一直保持不变。
接下来,到第二个终端执行 dd 命令,通过读取随机设备,生成一个 500MB 大小的文件:
dd if=/dev/urandom of=/tmp/file bs=1M count=500然后再回到第一个终端,观察 Buffer 和 Cache 的变化情况:
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 0 0 0 7499460 1344 230484 0 0 0 0 29 145 0 0 100 0 0 1 0 0 7338088 1752 390512 0 0 488 0 39 558 0 47 53 0 0 1 0 0 7158872 1752 568800 0 0 0 4 30 376 1 50 49 0 0 1 0 0 6980308 1752 747860 0 0 0 0 24 360 0 50 50 0 0 0 0 0 6977448 1752 752072 0 0 0 0 29 138 0 0 100 0 0 0 0 0 6977440 1760 752080 0 0 0 152 42 212 0 1 99 1 0 ... 0 1 0 6977216 1768 752104 0 0 4 122880 33 234 0 1 51 49 0 0 1 0 6977440 1768 752108 0 0 0 10240 38 196 0 0 50 50 0通过观察 vmstat 的输出,我们发现,在 dd 命令运行时, Cache 在不停地增长,而 Buffer 基本保持不变。
在 Cache 刚开始增长时,块设备 I/O 很少,bi 只出现了一次 488 KB/s,bo 则只有一次 4KB。而过一段时间后,才会出现大量的块设备写,比如 bo 变成了 122880。
当 dd 命令结束后,Cache 不再增长,但块设备写还会持续一段时间,并且,多次 I/O 写的结果加起来,才是 dd 要写的 500M 的数据。
把这个结果,跟我们刚刚了解到的 Cache 的定义做个对比,你可能会有点晕乎。为什么前面文档上说 Cache 是文件读的页缓存,怎么现在写文件也有它的份?
这个疑问,我们暂且先记下来,接着再来看另一个磁盘写的案例。两个案例结束后,我们再统一进行分析。
不过,对于接下来的案例,我必须强调一点:
下面的命令对环境要求很高,需要你的系统配置多块磁盘,并且磁盘分区 /dev/sdb1 还要处于未使用状态。如果你只有一块磁盘,千万不要尝试,否则将会对你的磁盘分区造成损坏。
如果你的系统符合标准,就可以继续在第二个终端中,运行下面的命令。清理缓存后,向磁盘分区 /dev/sdb1 写入 2GB 的随机数据:
# 首先清理缓存 $ echo 3 > /proc/sys/vm/drop_caches # 然后运行 dd 命令向磁盘分区 /dev/sdb1 写入 2G 数据 $ dd if=/dev/urandom of=/dev/sdb1 bs=1M count=2048然后,再回到终端一,观察内存和 I/O 的变化情况:
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 1 0 0 7584780 153592 97436 0 0 684 0 31 423 1 48 50 2 0 1 0 0 7418580 315384 101668 0 0 0 0 32 144 0 50 50 0 0 1 0 0 7253664 475844 106208 0 0 0 0 20 137 0 50 50 0 0 1 0 0 7093352 631800 110520 0 0 0 0 23 223 0 50 50 0 0 1 1 0 6930056 790520 114980 0 0 0 12804 23 168 0 50 42 9 0 1 0 0 6757204 949240 119396 0 0 0 183804 24 191 0 53 26 21 0 1 1 0 6591516 1107960 123840 0 0 0 77316 22 232 0 52 16 33 0从这里你会看到,虽然同是写数据,写磁盘跟写文件的现象还是不同的。写磁盘时(也就是 bo 大于 0 时),Buffer 和 Cache 都在增长,但显然 Buffer 的增长快得多。
这说明,写磁盘用到了大量的 Buffer,这跟我们在文档中查到的定义是一样的。
对比两个案例,我们发现,写文件时会用到 Cache 缓存数据,而写磁盘则会用到 Buffer 来缓存数据。所以,回到刚刚的问题,虽然文档上只提到,Cache 是文件读的缓存,但实际上,Cache 也会缓存写文件时的数据。
场景 2:磁盘和文件读案例
回到第二个终端,运行下面的命令。清理缓存后,从文件 /tmp/file 中,读取数据写入空设备:
# 首先清理缓存 $ echo 3 > /proc/sys/vm/drop_caches # 运行 dd 命令读取文件数据 $ dd if=/tmp/file of=/dev/null然后,再回到终端一,观察内存和 I/O 的变化情况:
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 0 1 0 7724164 2380 110844 0 0 16576 0 62 360 2 2 76 21 0 0 1 0 7691544 2380 143472 0 0 32640 0 46 439 1 3 50 46 0 0 1 0 7658736 2380 176204 0 0 32640 0 54 407 1 4 50 46 0 0 1 0 7626052 2380 208908 0 0 32640 40 44 422 2 2 50 46 0观察 vmstat 的输出,你会发现读取文件时(也就是 bi 大于 0 时),Buffer 保持不变,而 Cache 则在不停增长。这跟我们查到的定义”Cache 是对文件读的页缓存”是一致的。
那么,磁盘读又是什么情况呢?我们再运行第二个案例来看看。
首先,回到第二个终端,运行下面的命令。清理缓存后,从磁盘分区 /dev/sda1 中读取数据,写入空设备:
# 首先清理缓存 $ echo 3 > /proc/sys/vm/drop_caches # 运行 dd 命令读取文件 $ dd if=/dev/sda1 of=/dev/null bs=1M count=1024然后,再回到终端一,观察内存和 I/O 的变化情况:
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 0 0 0 7225880 2716 608184 0 0 0 0 48 159 0 0 100 0 0 0 1 0 7199420 28644 608228 0 0 25928 0 60 252 0 1 65 35 0 0 1 0 7167092 60900 608312 0 0 32256 0 54 269 0 1 50 49 0 0 1 0 7134416 93572 608376 0 0 32672 0 53 253 0 0 51 49 0 0 1 0 7101484 126320 608480 0 0 32748 0 80 414 0 1 50 49 0观察 vmstat 的输出,你会发现读磁盘时(也就是 bi 大于 0 时),Buffer 和 Cache 都在增长,但显然 Buffer 的增长快很多。这说明读磁盘时,数据缓存到了 Buffer 中。
当然,我想,经过上一个场景中两个案例的分析,你自己也可以对比得出这个结论:读文件时数据会缓存到 Cache 中,而读磁盘时数据会缓存到 Buffer 中。
到这里你应该发现了,虽然文档提供了对 Buffer 和 Cache 的说明,但是仍不能覆盖到所有的细节。比如说,今天我们了解到的这两点:
- Buffer 既可以用作”将要写入磁盘数据的缓存”,也可以用作”从磁盘读取数据的缓存”。
- Cache 既可以用作”从文件读取数据的页缓存”,也可以用作”写文件的页缓存”。
这样,我们就回答了案例开始前的两个问题。
简单来说,Buffer 是对磁盘数据的缓存,而 Cache 是文件数据的缓存,它们既会用在读请求中,也会用在写请求中。
17 | 案例篇:如何利用系统缓存优化程序的运行效率?
简单复习一下,Buffer 和 Cache 的设计目的,是为了提升系统的 I/O 性能。它们利用内存,充当起慢速磁盘与快速 CPU 之间的桥梁,可以加速 I/O 的访问速度。
Buffer 和 Cache 分别缓存的是对磁盘和文件系统的读写数据。
- 从写的角度来说,不仅可以优化磁盘和文件的写入,对应用程序也有好处,应用程序可以在数据真正落盘前,就返回去做其他工作。
- 从读的角度来说,不仅可以提高那些频繁访问数据的读取速度,也降低了频繁 I/O 对磁盘的压力。
既然 Buffer 和 Cache 对系统性能有很大影响,那我们在软件开发的过程中,能不能利用这一点,来优化 I/O 性能,提升应用程序的运行效率呢?
17.1 缓存命中率
缓存命中率,是指直接通过缓存获取数据的请求次数,占所有数据请求次数的百分比。
命中率越高,表示使用缓存带来的收益越高,应用程序的性能也就越好。
实际上,缓存是现在所有高并发系统必需的核心模块,主要作用就是把经常访问的数据(也就是热点数据),提前读入到内存中。这样,下次访问时就可以直接从内存读取数据,而不需要经过硬盘,从而加快应用程序的响应速度。
这些独立的缓存模块通常会提供查询接口,方便我们随时查看缓存的命中情况。不过 Linux 系统中并没有直接提供这些接口,所以这里我要介绍一下,cachestat 和 cachetop ,它们正是查看系统缓存命中情况的工具。
- cachestat 提供了整个操作系统缓存的读写命中情况。
- cachetop 提供了每个进程的缓存命中情况。
这两个工具都是 bcc 软件包的一部分,它们基于 Linux 内核的 eBPF(extended Berkeley Packet Filters)机制,来跟踪内核中管理的缓存,并输出缓存的使用和命中情况。
使用 cachestat 和 cachetop 前,我们首先要安装 bcc 软件包。比如,在 Ubuntu 系统中,你可以运行下面的命令来安装:
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 4052245BD4284CDD
echo "deb https://repo.iovisor.org/apt/xenial xenial main" | sudo tee /etc/apt/sources.list.d/iovisor.list
sudo apt-get update
sudo apt-get install -y bcc-tools libbcc-examples linux-headers-$(uname -r)注意:bcc-tools 需要内核版本为 4.1 或者更新的版本,如果你用的是 CentOS,那就需要手动 升级内核版本后再安装。
操作完这些步骤,bcc 提供的所有工具就都安装到 /usr/share/bcc/tools 这个目录中了。不过这里提醒你,bcc 软件包默认不会把这些工具配置到系统的 PATH 路径中,所以你得自己手动配置:
export PATH=$PATH:/usr/share/bcc/tools配置完,你就可以运行 cachestat 和 cachetop 命令了。比如,下面就是一个 cachestat 的运行界面,它以 1 秒的时间间隔,输出了 3 组缓存统计数据:
$ cachestat 1 3
TOTAL MISSES HITS DIRTIES BUFFERS_MB CACHED_MB
2 0 2 1 17 279
2 0 2 1 17 279
2 0 2 1 17 279你可以看到,cachestat 的输出其实是一个表格。每行代表一组数据,而每一列代表不同的缓存统计指标。这些指标从左到右依次表示:
- TOTAL ,表示总的 I/O 次数;
- MISSES ,表示缓存未命中的次数;
- HITS ,表示缓存命中的次数;
- DIRTIES, 表示新增到缓存中的脏页数;
- BUFFERS_MB 表示 Buffers 的大小,以 MB 为单位;
- CACHED_MB 表示 Cache 的大小,以 MB 为单位。
接下来我们再来看一个 cachetop 的运行界面:
$ cachetop
11:58:50 Buffers MB: 258 / Cached MB: 347 / Sort: HITS / Order: ascending
PID UID CMD HITS MISSES DIRTIES READ_HIT% WRITE_HIT%
13029 root python 1 0 0 100.0% 0.0%它的输出跟 top 类似,默认按照缓存的命中次数(HITS)排序,展示了每个进程的缓存命中情况。具体到每一个指标,这里的 HITS、MISSES 和 DIRTIES ,跟 cachestat 里的含义一样,分别代表间隔时间内的缓存命中次数、未命中次数以及新增到缓存中的脏页数。
而 READ_HIT 和 WRITE_HIT ,分别表示读和写的缓存命中率。
17.2 指定文件的缓存大小
除了缓存的命中率外,还有一个指标你可能也会很感兴趣,那就是指定文件在内存中的缓存大小。你可以使用 pcstat 这个工具,来查看文件在内存中的缓存大小以及缓存比例。
安装完 Go 语言,再运行下面的命令安装 pcstat:
export GOPATH=~/go
export PATH=~/go/bin:$PATH
go get golang.org/x/sys/unix
go get github.com/tobert/pcstat/pcstat全部安装完成后,你就可以运行 pcstat 来查看文件的缓存情况了。比如,下面就是一个 pcstat 运行的示例,它展示了 /bin/ls 这个文件的缓存情况:
$ pcstat /bin/ls
+---------+----------------+------------+-----------+---------+
| Name | Size (bytes) | Pages | Cached | Percent |
|---------+----------------+------------+-----------+---------|
| /bin/ls | 133792 | 33 | 0 | 000.000 |
+---------+----------------+------------+-----------+---------+这个输出中,Cached 就是 /bin/ls 在缓存中的大小,而 Percent 则是缓存的百分比。你看到它们都是 0,这说明 /bin/ls 并不在缓存中。
接着,如果你执行一下 ls 命令,再运行相同的命令来查看的话,就会发现 /bin/ls 都在缓存中了。
17.3 案例
机器配置: 2 CPU, 8 GB 内存。
安装软件:
apt install docker.io以及 bcc 和 pcstat。
dd 作为一个磁盘和文件的拷贝工具,经常被拿来测试磁盘或者文件系统的读写性能。不过,既然缓存会影响到性能,如果用 dd 对同一个文件进行多次读取测试,测试的结果会怎么样呢?
首先,打开两个终端,连接到 Ubuntu 机器上,确保 bcc 已经安装配置成功。
然后,使用 dd 命令生成一个临时文件,用于后面的文件读取测试:
# 生成一个 512MB 的临时文件 $ dd if=/dev/sda1 of=file bs=1M count=512 # 清理缓存 $ echo 3 > /proc/sys/vm/drop_caches继续在第一个终端,运行 pcstat 命令,确认刚刚生成的文件不在缓存中。如果一切正常,你会看到 Cached 和 Percent 都是 0:
$ pcstat file +-------+----------------+------------+-----------+---------+ | Name | Size (bytes) | Pages | Cached | Percent | |-------+----------------+------------+-----------+---------| | file | 536870912 | 131072 | 0 | 000.000 | +-------+----------------+------------+-----------+---------+在第一个终端中,现在运行 cachetop 命令:
# 每隔 5 秒刷新一次数据 $ cachetop 5第二个终端,运行 dd 命令测试文件的读取速度:
$ dd if=file of=/dev/null bs=1M 512+0 records in 512+0 records out 536870912 bytes (537 MB, 512 MiB) copied, 16.0509 s, 33.4 MB/s从 dd 的结果可以看出,这个文件的读性能是 33.4 MB/s。由于在 dd 命令运行前我们已经清理了缓存,所以 dd 命令读取数据时,肯定要通过文件系统从磁盘中读取。
不过,这是不是意味着, dd 所有的读请求都能直接发送到磁盘呢?
我们再回到第一个终端, 查看 cachetop 界面的缓存命中情况:
PID UID CMD HITS MISSES DIRTIES READ_HIT% WRITE_HIT% \.\.\. 3264 root dd 37077 37330 0 49.8% 50.2%从 cachetop 的结果可以发现,并不是所有的读都落到了磁盘上,事实上读请求的缓存命中率只有 50% 。
接下来,我们继续尝试相同的测试命令。先切换到第二个终端,再次执行刚才的 dd 命令:
$ dd if=file of=/dev/null bs=1M 512+0 records in 512+0 records out 536870912 bytes (537 MB, 512 MiB) copied, 0.118415 s, 4.5 GB/s看到这次的结果,有没有点小惊讶?磁盘的读性能居然变成了 4.5 GB/s,比第一次的结果明显高了太多。为什么这次的结果这么好呢?
不妨再回到第一个终端,看看 cachetop 的情况:
10:45:22 Buffers MB: 4 / Cached MB: 719 / Sort: HITS / Order: ascending PID UID CMD HITS MISSES DIRTIES READ_HIT% WRITE_HIT% \.\.\. 32642 root dd 131637 0 0 100.0% 0.0%显然,cachetop 也有了不小的变化。你可以发现,这次的读的缓存命中率是 100.0%,也就是说这次的 dd 命令全部命中了缓存,所以才会看到那么高的性能。
然后,回到第二个终端,再次执行 pcstat 查看文件 file 的缓存情况:
$ pcstat file +-------+----------------+------------+-----------+---------+ | Name | Size (bytes) | Pages | Cached | Percent | |-------+----------------+------------+-----------+---------| | file | 536870912 | 131072 | 131072 | 100.000 | +-------+----------------+------------+-----------+---------+从 pcstat 的结果你可以发现,测试文件 file 已经被全部缓存了起来,这跟刚才观察到的缓存命中率 100% 是一致的。
这两次结果说明,系统缓存对第二次 dd 操作有明显的加速效果,可以大大提高文件读取的性能。
但同时也要注意,如果我们把 dd 当成测试文件系统性能的工具,由于缓存的存在,就会导致测试结果严重失真。
再来看一个文件读写的案例。这个案例类似于前面学过的不可中断状态进程的例子。它的基本功能比较简单,也就是每秒从磁盘分区 /dev/sda1 中读取 32MB 的数据,并打印出读取数据花费的时间。
为了方便你运行案例,我把它打包成了一个 Docker 镜像。 跟前面案例类似,我提供了下面两个选项,你可以根据系统配置,自行调整磁盘分区的路径以及 I/O 的大小。
- -d 选项,设置要读取的磁盘或分区路径,默认是查找前缀为 /dev/sd 或者 /dev/xvd 的磁盘。
-s 选项,设置每次读取的数据量大小,单位为字节,默认为 33554432(也就是 32MB)。
这个案例同样需要你开启两个终端。分别 SSH 登录到机器上后,先在第一个终端中运行 cachetop 命令:
# 每隔 5 秒刷新一次数据 $ cachetop 5接着,再到第二个终端,执行下面的命令运行案例:
docker run --privileged --name=app -itd feisky/app:io-direct案例运行后,我们还需要运行下面这个命令,来确认案例已经正常启动。如果一切正常,你应该可以看到类似下面的输出:
$ docker logs app Reading data from disk /dev/sdb1 with buffer size 33554432 Time used: 0.929935 s to read 33554432 bytes Time used: 0.949625 s to read 33554432 bytes从这里你可以看到,每读取 32 MB 的数据,就需要花 0.9 秒。这个时间合理吗?我想你第一反应就是,太慢了吧。那这是不是没用系统缓存导致的呢?
我们再来检查一下。回到第一个终端,先看看 cachetop 的输出,在这里,我们找到案例进程 app 的缓存使用情况:
16:39:18 Buffers MB: 73 / Cached MB: 281 / Sort: HITS / Order: ascending PID UID CMD HITS MISSES DIRTIES READ_HIT% WRITE_HIT% 21881 root app 1024 0 0 100.0% 0.0%这个输出似乎有点意思了。1024 次缓存全部命中,读的命中率是 100%,看起来全部的读请求都经过了系统缓存。但是问题又来了,如果真的都是缓存 I/O,读取速度不应该这么慢。
至于为什么只能看到 0.8 MB 的 HITS,我们后面再解释,这里你先知道怎么根据结果来分析就可以了。
这也进一步验证了我们的猜想,这个案例估计没有充分利用系统缓存。其实前面我们遇到过类似的问题,如果为系统调用设置直接 I/O 的标志,就可以绕过系统缓存。
那么,要判断应用程序是否用了直接 I/O,最简单的方法当然是观察它的系统调用,查找应用程序在调用它们时的选项。使用什么工具来观察系统调用呢?自然还是 strace。
继续在终端二中运行下面的 strace 命令,观察案例应用的系统调用情况。注意,这里使用了 pgrep 命令来查找案例进程的 PID 号:
# strace -p $(pgrep app) strace: Process 4988 attached restart_syscall(<\.\.\. resuming interrupted nanosleep \.\.\.>) = 0 openat(AT_FDCWD, "/dev/sdb1", O_RDONLY|O_DIRECT) = 4 mmap(NULL, 33558528, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f448d240000 read(4, "8vq\213\314\264u\373\4\336K\224\25@\371\1\252\2\262\252q\221\n0\30\225bD\252\266@J"\.\.\., 33554432) = 33554432 write(1, "Time used: 0.948897 s to read 33"\.\.\., 45) = 45 close(4) = 0从 strace 的结果可以看到,案例应用调用了 openat 来打开磁盘分区 /dev/sdb1,并且传入的参数为 O_RDONLY|O_DIRECT(中间的竖线表示或)。
O_RDONLY 表示以只读方式打开,而 O_DIRECT 则表示以直接读取的方式打开,这会绕过系统的缓存。
验证了这一点,就很容易理解为什么读 32 MB 的数据就都要那么久了。直接从磁盘读写的速度,自然远慢于对缓存的读写。这也是缓存存在的最大意义了。
找出问题后,我们还可以在再看看案例应用的源代码,再次验证一下:
int flags = O_RDONLY | O_LARGEFILE | O_DIRECT; int fd = open(disk, flags, 0755);上面的代码,很清楚地告诉我们:它果然用了直接 I/O。
找出了磁盘读取缓慢的原因,优化磁盘读的性能自然不在话下。修改源代码,删除 O_DIRECT 选项,让应用程序使用缓存 I/O ,而不是直接 I/O,就可以加速磁盘读取速度。
app-cached.c 就是修复后的源码,我也把它打包成了一个容器镜像。在第二个终端中,按 Ctrl+C 停止刚才的 strace 命令,运行下面的命令,你就可以启动它:
# 删除上述案例应用 $ docker rm -f app # 运行修复后的应用 $ docker run --privileged --name=app -itd feisky/app:io-cached还是第二个终端,再来运行下面的命令查看新应用的日志,你应该能看到下面这个输出:
$ docker logs app Reading data from disk /dev/sdb1 with buffer size 33554432 Time used: 0.037342 s s to read 33554432 bytes Time used: 0.029676 s to read 33554432 bytes现在,每次只需要 0.03 秒,就可以读取 32MB 数据,明显比之前的 0.9 秒快多了。所以,这次应该用了系统缓存。
我们再回到第一个终端,查看 cachetop 的输出来确认一下:
16:40:08 Buffers MB: 73 / Cached MB: 281 / Sort: HITS / Order: ascending PID UID CMD HITS MISSES DIRTIES READ_HIT% WRITE_HIT% 22106 root app 40960 0 0 100.0% 0.0%果然,读的命中率还是 100%,HITS (即命中数)却变成了 40960,同样的方法计算一下,换算成每秒字节数正好是 32 MB(即 40960*4k/5/1024=32M)。
这个案例说明,在进行 I/O 操作时,充分利用系统缓存可以极大地提升性能。 但在观察缓存命中率时,还要注意结合应用程序实际的 I/O 大小,综合分析缓存的使用情况。
案例的最后,再回到开始的问题,为什么优化前,通过 cachetop 只能看到很少一部分数据的全部命中,而没有观察到大量数据的未命中情况呢?这是因为,cachetop 工具并不把直接 I/O 算进来。这也又一次说明了,了解工具原理的重要。
cachetop 的计算方法涉及到 I/O 的原理以及一些内核的知识,如果你想了解它的原理的话,可以点击这里查看它的源代码。
18 | 案例篇:内存泄漏了,我该如何定位和处理?
18.1 内存的分配和回收
用户空间内存包括多个不同的内存段,比如只读段、数据段、堆、栈以及文件映射段等。这些内存段正是应用程序使用内存的基本方式。
栈内存由系统自动分配和管理。一旦程序运行超出了这个局部变量的作用域,栈内存就会被系统自动回收,所以不会产生内存泄漏的问题。
堆内存由应用程序自己来分配和管理。除非程序退出,这些堆内存并不会被系统自动释放,而是需要应用程序明确调用库函数 free() 来释放它们。如果应用程序没有正确释放堆内存,就会造成内存泄漏。
其他内存段是否也会导致内存泄漏呢?
- 只读段,包括程序的代码和常量,由于是只读的,不会再去分配新的内存,所以也不会产生内存泄漏。
- 数据段,包括全局变量和静态变量,这些变量在定义时就已经确定了大小,所以也不会产生内存泄漏。
- 最后一个内存映射段,包括动态链接库和共享内存,其中共享内存由程序动态分配和管理。所以,如果程序在分配后忘了回收,就会导致跟堆内存类似的泄漏问题。
内存泄漏的危害非常大,这些忘记释放的内存,不仅应用程序自己不能访问,系统也不能把它们再次分配给其他应用。内存泄漏不断累积,甚至会耗尽系统内存。
虽然,系统最终可以通过 OOM (Out of Memory)机制杀死进程,但进程在 OOM 前,可能已经引发了一连串的反应,导致严重的性能问题。
比如,其他需要内存的进程,可能无法分配新的内存;内存不足,又会触发系统的缓存回收以及 SWAP 机制,从而进一步导致 I/O 的性能问题等等。
如果你已经发现了内存泄漏,该如何定位和处理呢。
18.2 案例
机器配置: 2 CPU, 8 GB 内存。
安装软件:
apt install docker.io sysstat以及 bcc。
执行下面的命令来运行案例:
docker run --name=app -itd feisky/app:mem-leak案例成功运行后,你需要输入下面的命令,确认案例应用已经正常启动。如果一切正常,你应该可以看到下面这个界面:
$ docker logs app 2th => 1 3th => 2 4th => 3 5th => 5 6th => 8 7th => 13我们应该怎么检查内存情况,判断有没有泄漏发生呢?你首先想到的可能是 top 工具,不过,top 虽然能观察系统和进程的内存占用情况,但今天的案例并不适合。内存泄漏问题,我们更应该关注内存使用的变化趋势。
运行下面的 vmstat ,等待一段时间,观察内存的变化情况。如果忘了 vmstat 里各指标的含义,记得复习前面内容,或者执行 man vmstat 查询。
# 每隔 3 秒输出一组数据 $ vmstat 3 procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 0 0 0 6601824 97620 1098784 0 0 0 0 62 322 0 0 100 0 0 0 0 0 6601700 97620 1098788 0 0 0 0 57 251 0 0 100 0 0 0 0 0 6601320 97620 1098788 0 0 0 3 52 306 0 0 100 0 0 0 0 0 6601452 97628 1098788 0 0 0 27 63 326 0 0 100 0 0 2 0 0 6601328 97628 1098788 0 0 0 44 52 299 0 0 100 0 0 0 0 0 6601080 97628 1098792 0 0 0 0 56 285 0 0 100 0 0从输出中你可以看到,内存的 free 列在不停的变化,并且是下降趋势;而 buffer 和 cache 基本保持不变。
未使用内存在逐渐减小,而 buffer 和 cache 基本不变,这说明,系统中使用的内存一直在升高。但这并不能说明有内存泄漏,因为应用程序运行中需要的内存也可能会增大。比如说,程序中如果用了一个动态增长的数组来缓存计算结果,占用内存自然会增长。
那怎么确定是不是内存泄漏呢?或者换句话说,有没有简单方法找出让内存增长的进程,并定位增长内存用在哪儿呢?
根据前面内容,你应该想到了用 top 或 ps 来观察进程的内存使用情况,然后找出内存使用一直增长的进程,最后再通过 pmap 查看进程的内存分布。
但这种方法并不太好用,因为要判断内存的变化情况,还需要你写一个脚本,来处理 top 或者 ps 的输出。
这里,我介绍一个专门用来检测内存泄漏的工具,memleak。memleak 可以跟踪系统或指定进程的内存分配、释放请求,然后定期输出一个未释放内存和相应调用栈的汇总情况(默认 5 秒)。
memleak 是 bcc 软件包中的一个工具,我们一开始就装好了,执行 /usr/share/bcc/tools/memleak 就可以运行它。比如,我们运行下面的命令:
# -a 表示显示每个内存分配请求的大小以及地址 # -p 指定案例应用的 PID 号 $ /usr/share/bcc/tools/memleak -a -p $(pidof app) WARNING: Couldn't find .text section in /app WARNING: BCC can't handle sym look ups for /app addr = 7f8f704732b0 size = 8192 addr = 7f8f704772d0 size = 8192 addr = 7f8f704712a0 size = 8192 addr = 7f8f704752c0 size = 8192 32768 bytes in 4 allocations from stack [unknown] [app] [unknown] [app] start_thread+0xdb [libpthread-2.27.so]从 memleak 的输出可以看到,案例应用在不停地分配内存,并且这些分配的地址没有被回收。
这里有一个问题,Couldn’t find .text section in /app,所以调用栈不能正常输出,最后的调用栈部分只能看到 [unknown] 的标志。
为什么会有这个错误呢?实际上,这是由于案例应用运行在容器中导致的。memleak 工具运行在容器之外,并不能直接访问进程路径 /app。
类似的问题,我在 CPU 模块中的 perf 使用方法 中已经提到好几个解决思路。最简单的方法,就是在容器外部构建相同路径的文件以及依赖库。这个案例只有一个二进制文件,所以只要把案例应用的二进制文件放到 /app 路径中,就可以修复这个问题。
比如,你可以运行下面的命令,把 app 二进制文件从容器中复制出来,然后重新运行 memleak 工具:
$ /usr/share/bcc/tools/memleak -p $(pidof app) -a Attaching to pid 12512, Ctrl+C to quit. [03:00:41] Top 10 stacks with outstanding allocations: addr = 7f8f70863220 size = 8192 addr = 7f8f70861210 size = 8192 addr = 7f8f7085b1e0 size = 8192 addr = 7f8f7085f200 size = 8192 addr = 7f8f7085d1f0 size = 8192 40960 bytes in 5 allocations from stack fibonacci+0x1f [app] child+0x4f [app] start_thread+0xdb [libpthread-2.27.so]这一次,我们终于看到了内存分配的调用栈,原来是 fibonacci() 函数分配的内存没释放。
定位了内存泄漏的来源,下一步自然就应该查看源码,想办法修复它。我们一起来看案例应用的源代码 app.c:
$ docker exec app cat /app.c ... long long *fibonacci(long long *n0, long long *n1) { // 分配 1024 个长整数空间方便观测内存的变化情况 long long *v = (long long *) calloc(1024, sizeof(long long)); *v = *n0 + *n1; return v; } void *child(void *arg) { long long n0 = 0; long long n1 = 1; long long *v = NULL; for (int n = 2; n > 0; n++) { v = fibonacci(&n0, &n1); n0 = n1; n1 = *v; printf("%dth => %lld\n", n, *v); sleep(1); } } ...我把修复后的代码放到了 app-fix.c,也打包成了一
个 Docker 镜像。你可以运行下面的命令,验证一下内存泄漏是否修复:# 清理原来的案例应用 $ docker rm -f app # 运行修复后的应用 $ docker run --name=app -itd feisky/app:mem-leak-fix # 重新执行 memleak 工具检查内存泄漏情况 $ /usr/share/bcc/tools/memleak -a -p $(pidof app) Attaching to pid 18808, Ctrl+C to quit. [10:23:18] Top 10 stacks with outstanding allocations: [10:23:23] Top 10 stacks with outstanding allocations:
19 | 案例篇:为什么系统的Swap变高了(上)
当发生了内存泄漏时,或者运行了大内存的应用程序,导致系统的内存资源紧张时,系统又会如何应对呢?
这其实会导致两种可能结果,内存回收和 OOM 杀死进程。
内存资源紧张导致的 OOM(Out Of Memory),相对容易理解,指的是系统杀死占用大量内存的进程,释放这些内存,再分配给其他更需要的进程。
内存回收,也就是系统释放掉可以回收的内存,比如我前面讲过的缓存和缓冲区,就属于可回收内存。它们在内存管理中,通常被叫做文件页(File-backed Page)。
大部分文件页,都可以直接回收,以后有需要时,再从磁盘重新读取就可以了。而那些被应用程序修改过,并且暂时还没写入磁盘的数据(也就是脏页),就得先写入磁盘,然后才能进行内存释放。
这些脏页,一般可以通过两种方式写入磁盘。
- 可以在应用程序中,通过系统调用 fsync ,把脏页同步到磁盘中;
- 也可以交给系统,由内核线程 pdflush 负责这些脏页的刷新。
除了缓存和缓冲区,通过内存映射获取的文件映射页,也是一种常见的文件页。它也可以被释放掉,下次再访问的时候,从文件重新读取。
除了文件页外,还有没有其他的内存可以回收呢?比如,应用程序动态分配的堆内存,也就是我们在内存管理中说到的匿名页(Anonymous Page),是不是也可以回收呢?
我想,你肯定会说,它们很可能还要再次被访问啊,当然不能直接回收了。非常正确,这些内存自然不能直接释放。
但是,如果这些内存在分配后很少被访问,似乎也是一种资源浪费。是不是可以把它们暂时先存在磁盘里,释放内存给其他更需要的进程?
其实,这正是 Linux 的 Swap 机制。Swap 把这些不常访问的内存先写到磁盘中,然后释放这些内存,给其他更需要的进程使用。再次访问这些内存时,重新从磁盘读入内存就可以了。
19.1 Swap 原理
Swap 说白了就是把一块磁盘空间或者一个本地文件(以下讲解以磁盘为例),当成内存来使用。它包括换出和换入两个过程。
- 所谓换出,就是把进程暂时不用的内存数据存储到磁盘中,并释放这些数据占用的内存。
- 而换入,则是在进程再次访问这些内存的时候,把它们从磁盘读到内存中来。
Swap 其实是把系统的可用内存变大了。这样,即使服务器的内存不足,也可以运行大内存的应用程序。
现在的内存便宜多了,服务器一般也会配置很大的内存,那是不是说 Swap 就没有用武之地了呢?
当然不是。事实上,内存再大,对应用程序来说,也有不够用的时候。
一个很典型的场景就是,即使内存不足时,有些应用程序也并不想被 OOM 杀死,而是希望能缓一段时间,等待人工介入,或者等系统自动释放其他进程的内存,再分配给它。
除此之外,我们常见的笔记本电脑的休眠和快速开机的功能,也基于 Swap 。休眠时,把系统的内存存入磁盘,这样等到再次开机时,只要从磁盘中加载内存就可以。这样就省去了很多应用程序的初始化过程,加快了开机速度。
话说回来,既然 Swap 是为了回收内存,那么 Linux 到底在什么时候需要回收内存呢?前面一直在说内存资源紧张,又该怎么来衡量内存是不是紧张呢?
一个最容易想到的场景就是,有新的大块内存分配请求,但是剩余内存不足。这个时候系统就需要回收一部分内存(比如前面提到的缓存),进而尽可能地满足新内存请求。这个过程通常被称为直接内存回收。
除了直接内存回收,还有一个专门的内核线程用来定期回收内存,也就是kswapd0。为了衡量内存的使用情况,kswapd0 定义了三个内存阈值(watermark,也称为水位),分别是
页最小阈值(pages_min)、页低阈值(pages_low)和页高阈值(pages_high)。剩余内存,则使用 pages_free 表示。
这里,我画了一张图表示它们的关系。

kswapd0 定期扫描内存的使用情况,并根据剩余内存落在这三个阈值的空间位置,进行内存的回收操作。
- 剩余内存小于页最小阈值,说明进程可用内存都耗尽了,只有内核才可以分配内存。
- 剩余内存落在页最小阈值和页低阈值中间,说明内存压力比较大,剩余内存不多了。这时 kswapd0 会执行内存回收,直到剩余内存大于高阈值为止。
- 剩余内存落在页低阈值和页高阈值中间,说明内存有一定压力,但还可以满足新内存请求。
剩余内存大于页高阈值,说明剩余内存比较多,没有内存压力。
我们可以看到,一旦剩余内存小于页低阈值,就会触发内存的回收。这个页低阈值,其实可以通过内核选项 /proc/sys/vm/min_free_kbytes 来间接设置。min_free_kbytes 设置了页最小阈值,而其他两个阈值,都是根据页最小阈值计算生成的,计算方法如下 :
pages_low = pages_min*5/4 pages_high = pages_min*3/2
19.2 NUMA 与 Swap
很多情况下,你明明发现了 Swap 升高,可是在分析系统的内存使用时,却很可能发现,系统剩余内存还多着呢。为什么剩余内存很多的情况下,也会发生 Swap 呢?
看到上面的标题,你应该已经想到了,这正是处理器的 NUMA (Non-Uniform Memory Access)架构导致的。
在 NUMA 架构下,多个处理器被划分到不同 Node 上,且每个 Node 都拥有自己的本地内存空间。
而同一个 Node 内部的内存空间,实际上又可以进一步分为不同的内存域(Zone),比如直接内存访问区(DMA)、普通内存区(NORMAL)、伪内存区(MOVABLE)等,如下图所示:
先不用特别关注这些内存域的具体含义,我们只要会查看阈值的配置,以及缓存、匿名页的实际使用情况就够了。
既然 NUMA 架构下的每个 Node 都有自己的本地内存空间,那么,在分析内存的使用时,我们也应该针对每个 Node 单独分析。
你可以通过 numactl 命令,来查看处理器在 Node 的分布情况,以及每个 Node 的内存使用情况。比如,下面就是一个 numactl 输出的示例:
$ numactl --hardware
available: 1 nodes (0)
node 0 cpus: 0 1
node 0 size: 7977 MB
node 0 free: 4416 MB
...这个界面显示,我的系统中只有一个 Node,也就是 Node 0 ,而且编号为 0 和 1 的两个 CPU, 都位于 Node 0 上。另外,Node 0 的内存大小为 7977 MB,剩余内存为 4416 MB。
实际上,前面提到的三个内存阈值(页最小阈值、页低阈值和页高阈值),都可以通过内存域在 proc 文件系统中的接口 /proc/zoneinfo 来查看。
比如,下面就是一个 /proc/zoneinfo 文件的内容示例:
$ cat /proc/zoneinfo
...
Node 0, zone Normal
pages free 227894
min 14896
low 18620
high 22344
...
nr_free_pages 227894
nr_zone_inactive_anon 11082
nr_zone_active_anon 14024
nr_zone_inactive_file 539024
nr_zone_active_file 923986
...这个输出中有大量指标,我来解释一下比较重要的几个。
- pages 处的 min、low、high,就是上面提到的三个内存阈值,而 free 是剩余内存页数,它跟后面的 nr_free_pages 相同。
- nr_zone_active_anon 和 nr_zone_inactive_anon,分别是活跃和非活跃的匿名页数。
- nr_zone_active_file 和 nr_zone_inactive_file,分别是活跃和非活跃的文件页数。
从这个输出结果可以发现,剩余内存远大于页高阈值,所以此时的 kswapd0 不会回收内存。
当然,某个 Node 内存不足时,系统可以从其他 Node 寻找空闲内存,也可以从本地内存中回收内存。具体选哪种模式,你可以通过 /proc/sys/vm/zone_reclaim_mode 来调整。它支持以下几个选项:
- 默认的 0 ,也就是刚刚提到的模式,表示既可以从其他 Node 寻找空闲内存,也可以从本地回收内存。
- 1、2、4 都表示只回收本地内存,2 表示可以回写脏数据回收内存,4 表示可以用 Swap 方式回收内存。
19.3 swappiness
到这里,我们就可以理解内存回收的机制了。这些回收的内存既包括了文件页,又包括了匿名页。
- 对文件页的回收,当然就是直接回收缓存,或者把脏页写回磁盘后再回收。
- 而对匿名页的回收,其实就是通过 Swap 机制,把它们写入磁盘后再释放内存。
不过,你可能还有一个问题。既然有两种不同的内存回收机制,那么在实际回收内存时,到底该先回收哪一种呢?
其实,Linux 提供了一个 /proc/sys/vm/swappiness 选项,用来调整使用 Swap 的积极程度。
swappiness 的范围是 0-100,数值越大,越积极使用 Swap,也就是更倾向于回收匿名页;数值越小,越消极使用 Swap,也就是更倾向于回收文件页。
虽然 swappiness 的范围是 0-100,不过要注意,这并不是内存的百分比,而是调整 Swap 积极程度的权重,即使你把它设置成 0,当剩余内存 + 文件页小于页高阈值时,还是会发生 Swap。
A value of 0 instructs the kernel not to initiate swap until the amount of free and file-backed pages is less than the high water mark in a zone.
20 | 案例篇:为什么系统的Swap变高了?(下)
20.1 案例
机器配置: 2 CPU, 8 GB 内存。
安装软件:
apt install sysstat。
在终端中运行 free 命令,查看 Swap 的使用情况。比如,在我的机器中,输出如下:
$ free total used free shared buff/cache available Mem: 8169348 331668 6715972 696 1121708 7522896 Swap: 0 0 0从这个 free 输出你可以看到,Swap 的大小是 0,这说明我的机器没有配置 Swap。
要开启 Swap,我们首先要清楚,Linux 本身支持两种类型的 Swap,即 Swap 分区和 Swap 文件。以 Swap 文件为例,在第一个终端中运行下面的命令开启 Swap,我这里配置 Swap 文件的大小为 8GB:
# 创建 Swap 文件 $ fallocate -l 8G /mnt/swapfile # 修改权限只有根用户可以访问 $ chmod 600 /mnt/swapfile # 配置 Swap 文件 $ mkswap /mnt/swapfile # 开启 Swap $ swapon /mnt/swapfile然后,再执行 free 命令,确认 Swap 配置成功:
$ free total used free shared buff/cache available Mem: 8169348 331668 6715972 696 1121708 7522896 Swap: 8388604 0 8388604在第一个终端中,运行下面的 dd 命令,模拟大文件的读取:
# 写入空设备,实际上只有磁盘的读请求 $ dd if=/dev/sda1 of=/dev/null bs=1G count=2048接着,在第二个终端中运行 sar 命令,查看内存各个指标的变化情况。你可以多观察一会儿,查看这些指标的变化情况。
# 间隔 1 秒输出一组数据 # -r 表示显示内存使用情况,-S 表示显示 Swap 使用情况 $ sar -r -S 1 04:39:56 kbmemfree kbavail kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty 04:39:57 6249676 6839824 1919632 23.50 740512 67316 1691736 10.22 815156 841868 4 04:39:56 kbswpfree kbswpused %swpused kbswpcad %swpcad 04:39:57 8388604 0 0.00 0 0.00 04:39:57 kbmemfree kbavail kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty 04:39:58 6184472 6807064 1984836 24.30 772768 67380 1691736 10.22 847932 874224 20 04:39:57 kbswpfree kbswpused %swpused kbswpcad %swpcad 04:39:58 8388604 0 0.00 0 0.00 … 04:44:06 kbmemfree kbavail kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty 04:44:07 152780 6525716 8016528 98.13 6530440 51316 1691736 10.22 867124 6869332 0 04:44:06 kbswpfree kbswpused %swpused kbswpcad %swpcad 04:44:07 8384508 4096 0.05 52 1.27我们可以看到,sar 的输出结果是两个表格,第一个表格表示内存的使用情况,第二个表格表示 Swap 的使用情况。其中,各个指标名称前面的 kb 前缀,表示这些指标的单位是 KB。
几个新出现的指标,我来简单介绍一下。
- kbcommit,表示当前系统负载需要的内存。它实际上是为了保证系统内存不溢出,对需要内存的估计值。%commit,就是这个值相对总内存的百分比。
- kbactive,表示活跃内存,也就是最近使用过的内存,一般不会被系统回收。
kbinact,表示非活跃内存,也就是不常访问的内存,有可能会被系统回收。
清楚了界面指标的含义后,我们再结合具体数值,来分析相关的现象。你可以清楚地看到,总的内存使用率(%memused)在不断增长,从开始的 23% 一直长到了 98%,并且主要内存都被缓冲区(kbbuffers)占用。具体来说:
刚开始,剩余内存(kbmemfree)不断减少,而缓冲区(kbbuffers)则不断增大,由此可知,剩余内存不断分配给了缓冲区。
一段时间后,剩余内存已经很小,而缓冲区占用了大部分内存。这时候,Swap 的使用开始逐渐增大,缓冲区和剩余内存则只在小范围内波动。
你可能困惑了,为什么缓冲区在不停增大?这又是哪些进程导致的呢?
显然,我们还得看看进程缓存的情况。在前面缓存的案例中我们学过, cachetop 正好能满足这一点。那我们就来 cachetop 一下。
在第二个终端中,按下 Ctrl+C 停止 sar 命令,然后运行下面的 cachetop 命令,观察缓存的使用情况:
$ cachetop 5 12:28:28 Buffers MB: 6349 / Cached MB: 87 / Sort: HITS / Order: ascending PID UID CMD HITS MISSES DIRTIES READ_HIT% WRITE_HIT% 18280 root python 22 0 0 100.0% 0.0% 18279 root dd 41088 41022 0 50.0% 50.0%通过 cachetop 的输出,我们看到,dd 进程的读写请求只有 50% 的命中率,并且未命中的缓存页数(MISSES)为 41022(单位是页)。这说明,正是案例开始时运行的 dd,导致了缓冲区使用升高。
你可能接着会问,为什么 Swap 也跟着升高了呢?直观来说,缓冲区占了系统绝大部分内存,还属于可回收内存,内存不够用时,不应该先回收缓冲区吗?
这种情况,我们还得进一步通过 /proc/zoneinfo ,观察剩余内存、内存阈值以及匿名页和文件页的活跃情况。
你可以在第二个终端中,按下 Ctrl+C,停止 cachetop 命令。然后运行下面的命令,观察 /proc/zoneinfo 中这几个指标的变化情况:
# -d 表示高亮变化的字段 # -A 表示仅显示 Normal 行以及之后的 15 行输出 $ watch -d grep -A 15 'Normal' /proc/zoneinfo Node 0, zone Normal pages free 21328 min 14896 low 18620 high 22344 spanned 1835008 present 1835008 managed 1796710 protection: (0, 0, 0, 0, 0) nr_free_pages 21328 nr_zone_inactive_anon 79776 nr_zone_active_anon 206854 nr_zone_inactive_file 918561 nr_zone_active_file 496695 nr_zone_unevictable 2251 nr_zone_write_pending 0你可以发现,剩余内存(pages_free)在一个小范围内不停地波动。当它小于页低阈值(pages_low) 时,又会突然增大到一个大于页高阈值(pages_high)的值。
再结合刚刚用 sar 看到的剩余内存和缓冲区的变化情况,我们可以推导出,剩余内存和缓冲区的波动变化,正是由于内存回收和缓存再次分配的循环往复。
- 当剩余内存小于页低阈值时,系统会回收一些缓存和匿名内存,使剩余内存增大。其中,缓存的回收导致 sar 中的缓冲区减小,而匿名内存的回收导致了 Swap 的使用增大。
紧接着,由于 dd 还在继续,剩余内存又会重新分配给缓存,导致剩余内存减少,缓冲区增大。
其实还有一个有趣的现象,如果多次运行 dd 和 sar,你可能会发现,在多次的循环重复中,有时候是 Swap 用得比较多,有时候 Swap 很少,反而缓冲区的波动更大。
换句话说,系统回收内存时,有时候会回收更多的文件页,有时候又回收了更多的匿名页。
显然,系统回收不同类型内存的倾向,似乎不那么明显。你应该想到了上节课提到的 swappiness,正是调整不同类型内存回收的配置选项。
还是在第二个终端中,按下 Ctrl+C 停止 watch 命令,然后运行下面的命令,查看 swappiness 的配置:
$ cat /proc/sys/vm/swappiness 60swappiness 显示的是默认值 60,这是一个相对中和的配置,所以系统会根据实际运行情况,选择合适的回收类型,比如回收不活跃的匿名页,或者不活跃的文件页。
到这里,我们已经找出了 Swap 发生的根源。另一个问题就是,刚才的 Swap 到底影响了哪些应用程序呢?换句话说,Swap 换出的是哪些进程的内存?
这里我还是推荐 proc 文件系统,用来查看进程 Swap 换出的虚拟内存大小,它保存在 /proc/pid/status 中的 VmSwap 中(推荐你执行 man proc 来查询其他字段的含义)。
在第二个终端中运行下面的命令,就可以查看使用 Swap 最多的进程。注意 for、awk、sort 都是最常用的 Linux 命令,如果你还不熟悉,可以用 man 来查询它们的手册,或上网搜索教程来学习。
# 按 VmSwap 使用量对进程排序,输出进程名称、进程 ID 以及 SWAP 用量 $ for file in /proc/*/status ; do awk '/VmSwap|Name|^Pid/{printf $2 " " $3}END{ print ""}' $file; done | sort -k 3 -n -r | head dockerd 2226 10728 kB docker-containe 2251 8516 kB snapd 936 4020 kB networkd-dispat 911 836 kB polkitd 1004 44 kB也可以使用命令
smem --sort swap。这也说明了一点,虽然缓存属于可回收内存,但在类似大文件拷贝这类场景下,系统还是会用 Swap 机制来回收匿名内存,而不仅仅是回收占用绝大部分内存的文件页。
最后,如果你在一开始配置了 Swap,不要忘记在案例结束后关闭。你可以运行下面的命令,关闭 Swap:
swapoff -a实际上,关闭 Swap 后再重新打开,也是一种常用的 Swap 空间清理方法,比如:
swapoff -a && swapon -a
20.2 小结
在内存资源紧张时,Linux 会通过 Swap ,把不常访问的匿名页换出到磁盘中,下次访问的时候再从磁盘换入到内存中来。你可以设置 /proc/sys/vm/min_free_kbytes,来调整系统定期回收内存的阈值;也可以设置 /proc/sys/vm/swappiness,来调整文件页和匿名页的回收倾向。
当 Swap 变高时,你可以用 sar、/proc/zoneinfo、/proc/pid/status 等方法,查看系统和进程的内存使用情况,进而找出 Swap 升高的根源和受影响的进程。
反过来说,通常,降低 Swap 的使用,可以提高系统的整体性能。要怎么做呢?这里,我也总结了几种常见的降低方法。
- 禁止 Swap,现在服务器的内存足够大,所以除非有必要,禁用 Swap 就可以了。随着云计算的普及,大部分云平台中的虚拟机都默认禁止 Swap。
- 如果实在需要用到 Swap,可以尝试降低 swappiness 的值,减少内存回收时 Swap 的使用倾向。
- 响应延迟敏感的应用,如果它们可能在开启 Swap 的服务器中运行,你还可以用库函数 mlock() 或者 mlockall() 锁定内存,阻止它们的内存换出。
21 | 套路篇:如何”快准狠”找到系统内存的问题?
21.1 内存性能指标
为了分析内存的性能瓶颈,首先你要知道,怎样衡量内存的性能,也就是性能指标问题。
首先,你最容易想到的是系统内存使用情况,比如已用内存、剩余内存、共享内存、可用内存、缓存和缓冲区的用量等。
- 已用内存和剩余内存很容易理解,就是已经使用和还未使用的内存。
- 共享内存是通过 tmpfs 实现的,所以它的大小也就是 tmpfs 使用的内存大小。tmpfs 其实也是一种特殊的缓存。
- 可用内存是新进程可以使用的最大内存,它包括剩余内存和可回收缓存。
- 缓存包括两部分,一部分是磁盘读取文件的页缓存,用来缓存从磁盘读取的数据,可以加快以后再次访问的速度。另一部分,则是 Slab 分配器中的可回收内存。
- 缓冲区是对原始磁盘块的临时存储,用来缓存将要写入磁盘的数据。这样,内核就可以把分散的写集中起来,统一优化磁盘写入。
第二类很容易想到的,应该是进程内存使用情况,比如进程的虚拟内存、常驻内存、共享内存以及 Swap 内存等。
- 虚拟内存,包括了进程代码段、数据段、共享内存、已经申请的堆内存和已经换出的内存等。这里要注意,已经申请的内存,即使还没有分配物理内存,也算作虚拟内存。
- 常驻内存是进程实际使用的物理内存,不过,它不包括 Swap 和共享内存。
- 共享内存,既包括与其他进程共同使用的真实的共享内存,还包括了加载的动态链接库以及程序的代码段等。
Swap 内存,是指通过 Swap 换出到磁盘的内存。
当然,这些指标中,常驻内存一般会换算成占系统总内存的百分比,也就是进程的内存使用率。
除了这些很容易想到的指标外,我还想再强调一下,缺页异常。
在内存分配的原理中,我曾经讲到过,系统调用内存分配请求后,并不会立刻为其分配物理内存,而是在请求首次访问时,通过缺页异常来分配。缺页异常又分为下面两种场景。
- 可以直接从物理内存中分配时,被称为次缺页异常。
需要磁盘 I/O 介入(比如 Swap)时,被称为主缺页异常。
显然,主缺页异常升高,就意味着需要磁盘 I/O,那么内存访问也会慢很多。
除了系统内存和进程内存,第三类重要指标就是 Swap 的使用情况,比如 Swap 的已用空间、剩余空间、换入速度和换出速度等。
- 已用空间和剩余空间很好理解,就是字面上的意思,已经使用和没有使用的内存空间。
- 换入和换出速度,则表示每秒钟换入和换出内存的大小。
21.2 内存性能工具
所有的案例中都用到了 free。这是个最常用的内存工具,可以查看系统的整体内存和 Swap 使用情况。相对应的,你可以用 top 或 ps,查看进程的内存使用情况。
在缓存和缓冲区的原理篇中,我们通过 proc 文件系统,找到了内存指标的来源;并通过 vmstat,动态观察了内存的变化情况。与 free 相比,vmstat 除了可以动态查看内存变化,还可以区分缓存和缓冲区、Swap 换入和换出的内存大小。
在缓存和缓冲区的案例篇中,为了弄清楚缓存的命中情况,我们又用了 cachestat ,查看整个系统缓存的读写命中情况,并用 cachetop 来观察每个进程缓存的读写命中情况。
在内存泄漏的案例中,我们用 vmstat,发现了内存使用在不断增长,又用 memleak,确认发生了内存泄漏。通过 memleak 给出的内存分配栈,我们找到了内存泄漏的可疑位置。
在 Swap 的案例中,我们用 sar 发现了缓冲区和 Swap 升高的问题。通过 cachetop,我们找到了缓冲区升高的根源;通过对比剩余内存跟 /proc/zoneinfo 的内存阈,我们发现 Swap 升高是内存回收导致的。案例最后,我们还通过 /proc 文件系统,找出了 Swap 所影响的进程。
理解内存的工作原理,结合性能指标来记忆,拿下工具的使用方法并不难。
21.3 性能指标和工具的联系
同 CPU 性能分析一样,我的经验是两个不同维度出发,整理和记忆。
- 从内存指标出发,更容易把工具和内存的工作原理关联起来。
- 从性能工具出发,可以更快地利用工具,找出我们想观察的性能指标。特别是在工具有限的情况下,我们更得充分利用手头的每一个工具,挖掘出更多的问题。
从内存指标出发,列举了哪些性能工具可以提供这些指标。这样,在实际排查性能问题时,你就可以清楚知道,究竟要用什么工具来辅助分析,提供你想要的指标。
.webp)
从性能工具出发,整理了这些常见工具能提供的内存指标。掌握了这个表格,你可以最大化利用已有的工具,尽可能多地找到你要的指标。真正用到时, man 一下查它们的使用手册就可以了。
.webp)
21.4 如何迅速分析内存的性能瓶颈
为了迅速定位内存问题,我通常会先运行几个覆盖面比较大的性能工具,比如 free、top、vmstat、pidstat 等。
具体的分析思路主要有这几步。
- 先用 free 和 top,查看系统整体的内存使用情况。
- 再用 vmstat 和 pidstat,查看一段时间的趋势,从而判断出内存问题的类型。
- 最后进行详细分析,比如内存分配分析、缓存 / 缓冲区分析、具体进程的内存使用分析等。
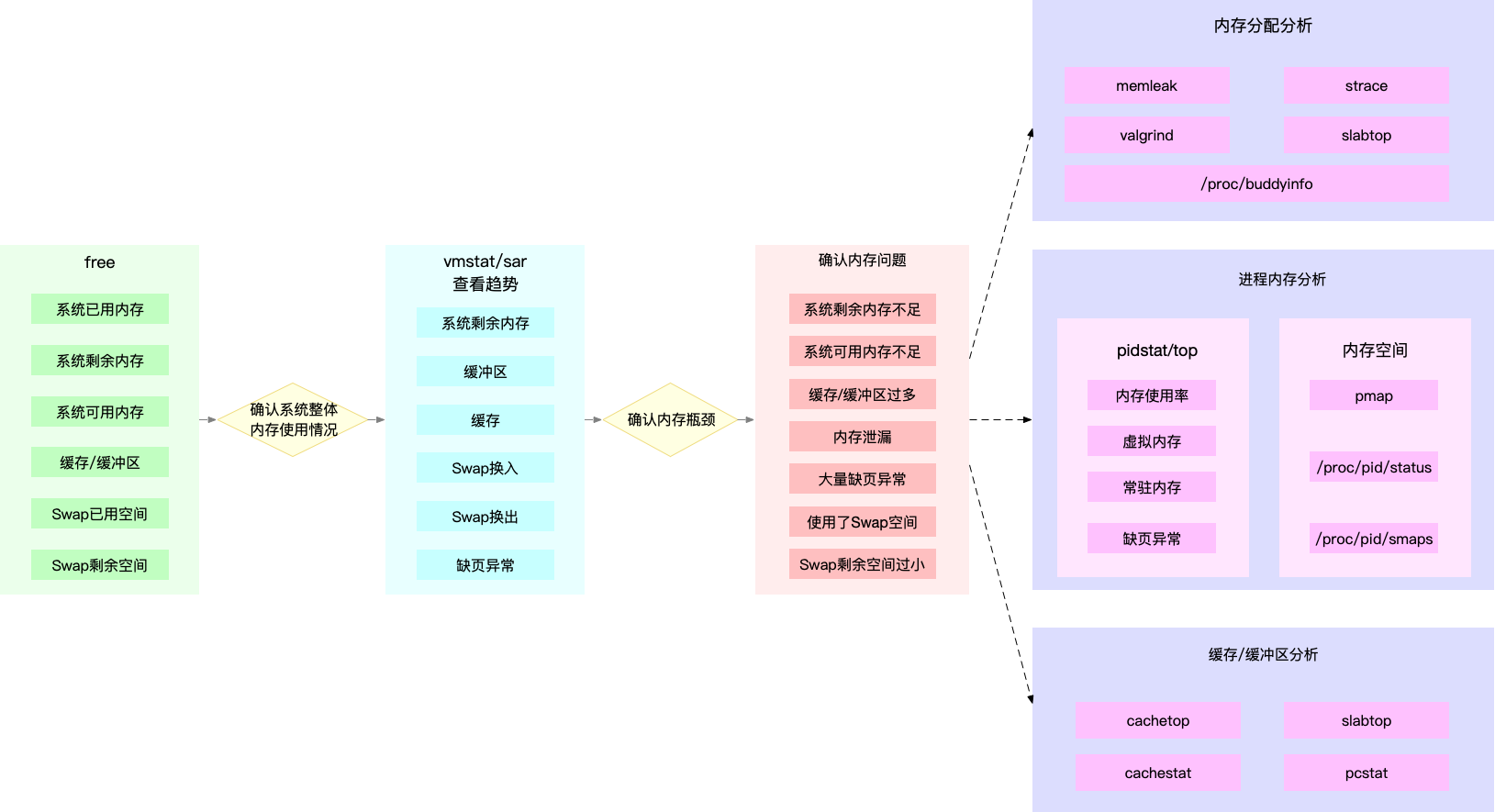
举几个例子你可能会更容易理解。
当你通过 free,发现大部分内存都被缓存占用后,可以使用 vmstat 或者 sar 观察一下缓存的变化趋势,确认缓存的使用是否还在继续增大。
如果继续增大,则说明导致缓存升高的进程还在运行,那你就能用缓存 / 缓冲区分析工具(比如 cachetop、slabtop 等),分析这些缓存到底被哪里占用。
当你 free 一下,发现系统可用内存不足时,首先要确认内存是否被缓存 / 缓冲区占用。排除缓存 / 缓冲区后,你可以继续用 pidstat 或者 top,定位占用内存最多的进程。
找出进程后,再通过进程内存空间工具(比如 pmap),分析进程地址空间中内存的使用情况就可以了。
当你通过 vmstat 或者 sar 发现内存在不断增长后,可以分析中是否存在内存泄漏的问题。
比如你可以使用内存分配分析工具 memleak ,检查是否存在内存泄漏。如果存在内存泄漏问题,memleak 会为你输出内存泄漏的进程以及调用堆栈。
注意,这个图里我没有列出所有性能工具,只给出了最核心的几个。这么做,一方面,确实不想让大量的工具列表吓到你。
另一方面,希望你能把重心先放在核心工具上,通过我提供的案例和真实环境的实践,掌握使用方法和分析思路。 毕竟熟练掌握它们,你就可以解决大多数的内存问题。
21.5 小结
找到内存问题的来源后,下一步就是相应的优化工作了。在我看来,内存调优最重要的就是,保证应用程序的热点数据放到内存中,并尽量减少换页和交换。
常见的优化思路有这么几种。
- 最好禁止 Swap。如果必须开启 Swap,降低 swappiness 的值,减少内存回收时 Swap 的使用倾向。
- 减少内存的动态分配。比如,可以使用内存池、大页(HugePage)等。
- 尽量使用缓存和缓冲区来访问数据。比如,可以使用堆栈明确声明内存空间,来存储需要缓存的数据;或者用 Redis 这类的外部缓存组件,优化数据的访问。
- 使用 cgroups 等方式限制进程的内存使用情况。这样,可以确保系统内存不会被异常进程耗尽。
- 通过 /proc/pid/oom_adj ,调整核心应用的 oom_score。这样,可以保证即使内存紧张,核心应用也不会被 OOM 杀死。
22 | 答疑(三):文件系统与磁盘的区别是什么?
22.1 问题 1:内存回收与 OOM
虎虎的这个问题,实际上包括四个子问题,即,
- 怎么理解 LRU 内存回收?
- 回收后的内存又到哪里去了?
- OOM 是按照虚拟内存还是实际内存来打分?
- 怎么估计应用程序的最小内存?
一旦发现内存紧张,系统会通过三种方式回收内存。
- 基于 LRU(Least Recently Used)算法,回收缓存;
- 基于 Swap 机制,回收不常访问的匿名页;
- 基于 OOM(Out of Memory)机制,杀掉占用大量内存的进程。
前两种方式,缓存回收和 Swap 回收,实际上都是基于 LRU 算法,也就是优先回收不常访问的内存。LRU 回收算法,实际上维护着 active 和 inactive 两个双向链表,其中:
- active 记录活跃的内存页;
- inactive 记录非活跃的内存页。
越接近链表尾部,就表示内存页越不常访问。这样,在回收内存时,系统就可以根据活跃程度,优先回收不活跃的内存。
活跃和非活跃的内存页,按照类型的不同,又分别分为文件页和匿名页,对应着缓存回收和 Swap 回收。
当然,你可以从 /proc/meminfo 中,查询它们的大小,比如:
# grep 表示只保留包含 active 的指标(忽略大小写)
# sort 表示按照字母顺序排序
$ cat /proc/meminfo | grep -i active | sort
Active(anon): 167976 kB
Active(file): 971488 kB
Active: 1139464 kB
Inactive(anon): 720 kB
Inactive(file): 2109536 kB
Inactive: 2110256 kB第三种方式,OOM 机制按照 oom_score 给进程排序。oom_score 越大,进程就越容易被系统杀死。
当系统发现内存不足以分配新的内存请求时,就会尝试直接内存回收。这种情况下,如果回收完文件页和匿名页后,内存够用了,当然皆大欢喜,把回收回来的内存分配给进程就可以了。但如果内存还是不足,OOM 就要登场了。
OOM 发生时,你可以在 dmesg 中看到 Out of memory 的信息,从而知道是哪些进程被 OOM 杀死了。比如,你可以执行下面的命令,查询 OOM 日志:
$ dmesg | grep -i "Out of memory"
Out of memory: Kill process 9329 (java) score 321 or sacrifice child当然了,如果你不希望应用程序被 OOM 杀死,可以调整进程的 oom_score_adj,减小 OOM 分值,进而降低被杀死的概率。或者,你还可以开启内存的 overcommit,允许进程申请超过物理内存的虚拟内存(这儿实际上假设的是,进程不会用光申请到的虚拟内存)。
这三种方式,我们就复习完了。接下来,我们回到开始的四个问题,相信你自己已经有了答案。
- LRU 算法的原理刚才已经提到了,这里不再重复。
- 内存回收后,会被重新放到未使用内存中。这样,新的进程就可以请求、使用它们。
- OOM 触发的时机基于虚拟内存。换句话说,进程在申请内存时,如果申请的虚拟内存加上服务器实际已用的内存之和,比总的物理内存还大,就会触发 OOM。
- 要确定一个进程或者容器的最小内存,最简单的方法就是让它运行起来,再通过 ps 或者 smap ,查看它的内存使用情况。不过要注意,进程刚启动时,可能还没开始处理实际业务,一旦开始处理实际业务,就会占用更多内存。所以,要记得给内存留一定的余量。
22.2 问题 2: 文件系统与磁盘的区别
在学习 Buffer 和 Cache 的原理时,我曾提到,Buffer 用于磁盘,而 Cache 用于文件。因此,有不少同学困惑了,比如 JJ 留言中的这两个问题。
- 读写文件最终也是读写磁盘,到底要怎么区分,是读写文件还是读写磁盘呢?
- 读写磁盘难道可以不经过文件系统吗?
磁盘是一个存储设备(确切地说是块设备),可以被划分为不同的磁盘分区。而在磁盘或者磁盘分区上,还可以再创建文件系统,并挂载到系统的某个目录中。这样,系统就可以通过这个挂载目录,来读写文件。
换句话说,磁盘是存储数据的块设备,也是文件系统的载体。所以,文件系统确实还是要通过磁盘,来保证数据的持久化存储。
你在很多地方都会看到这句话, Linux 中一切皆文件。换句话说,你可以通过相同的文件接口,来访问磁盘和文件(比如 open、read、write、close 等)。
- 我们通常说的”文件”,其实是指普通文件。
- 而磁盘或者分区,则是指块设备文件。
你可以执行 “ls -l < 路径 >“ 查看它们的区别。如果不懂 ls 输出的含义,别忘了 man 一下就可以。执行 man ls 命令,以及 info ‘(coreutils) ls invocation’ 命令,就可以查到了。
在读写普通文件时,I/O 请求会首先经过文件系统,然后由文件系统负责,来与磁盘进行交互。而在读写块设备文件时,会跳过文件系统,直接与磁盘交互,也就是所谓的”裸 I/O”。
这两种读写方式使用的缓存自然不同。文件系统管理的缓存,其实就是 Cache 的一部分。而裸磁盘的缓存,用的正是 Buffer。
22.3 问题 3: 如何统计所有进程的物理内存使用量
把所有进程的 RSS 全部累加这种方法,实际上导致不少地方会被重复计算。RSS 表示常驻内存,把进程用到的共享内存也算了进去。所以,直接累加会导致共享内存被重复计算,不能得到准确的答案。
可以通过 stackexchange 上的链接找到答案,不过,我还是更推荐,直接查 proc 文件系统的文档:
The "proportional set size" (PSS) of a process is the count of pages it has in memory, where each page is divided by the number of processes sharing it. So if a process has 1000 pages all to itself, and 1000 shared with one other process, its PSS will be 1500.解释一下,每个进程的 PSS ,是指把共享内存平分到各个进程后,再加上进程本身的非共享内存大小的和。
就像文档中的这个例子,一个进程的非共享内存为 1000 页,它和另一个进程的共享进程也是 1000 页,那么它的 PSS=1000/2+1000=1500 页。
这样,你就可以直接累加 PSS ,不用担心共享内存重复计算的问题了。
比如,你可以运行下面的命令来计算:
# 使用 grep 查找 Pss 指标后,再用 awk 计算累加值
$ grep Pss /proc/[1-9]*/smaps | awk '{total+=$2}; END {printf "%d kB\n", total }'
391266 kB22.4 问题 4: CentOS 系统中如何安装 bcc-tools
以 CentOS 7 为例,整个安装主要可以分两步。
第一步,升级内核。你可以运行下面的命令来操作:
# 升级系统
yum update -y
# 安装 ELRepo
rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
rpm -Uvh https://www.elrepo.org/elrepo-release-7.0-3.el7.elrepo.noarch.rpm
# 安装新内核
yum remove -y kernel-headers kernel-tools kernel-tools-libs
yum --enablerepo="elrepo-kernel" install -y kernel-ml kernel-ml-devel kernel-ml-headers kernel-ml-tools kernel-ml-tools-libs kernel-ml-tools-libs-devel
# 更新 Grub 后重启
grub2-mkconfig -o /boot/grub2/grub.cfg
grub2-set-default 0
reboot
# 重启后确认内核版本已升级为 4.20.0-1.el7.elrepo.x86_64
uname -r第二步,安装 bcc-tools:
# 安装 bcc-tools
yum install -y bcc-tools
# 配置 PATH 路径
export PATH=$PATH:/usr/share/bcc/tools
# 验证安装成功
cachestat22.5 问题 5: 内存泄漏案例的优化方法
这是我在 内存泄漏了,我该如何定位和处理 中留的一个思考题。这个问题是这样的:
在内存泄漏案例的最后,我们通过增加 free() 调用,释放了函数 fibonacci() 分配的内存,修复了内存泄漏的问题。就这个案例而言,还有没有其他更好的修复方法呢?
很多同学留言写下了自己的想法,都很不错。这里,我重点表扬下郭江伟同学,他给出的方法非常好:
他的思路是不用动态内存分配的方法,而是用数组来暂存计算结果。这样就可以由系统自动管理这些栈内存,也不存在内存泄漏的问题了。
这种减少动态内存分配的思路,除了可以解决内存泄漏问题,其实也是常用的内存优化方法。比如,在需要大量内存的场景中,你就可以考虑用栈内存、内存池、HugePage 等方法,来优化内存的分配和管理。
04-I-O 性能篇
23 | 基础篇:Linux 文件系统是怎么工作的?
23.1 索引节点和目录项
文件系统,本身是对存储设备上的文件,进行组织管理的机制。组织方式不同,就会形成不同的文件系统。
你要记住最重要的一点,在 Linux 中一切皆文件。不仅普通的文件和目录,就连块设备、套接字、管道等,也都要通过统一的文件系统来管理。
为了方便管理,Linux 文件系统为每个文件都分配两个数据结构,索引节点(index node)和目录项(directory entry)。它们主要用来记录文件的元信息和目录结构。
- 索引节点,简称为 inode,用来记录文件的元数据,比如 inode 编号、文件大小、访问权限、修改日期、数据的位置等。索引节点和文件一一对应,它跟文件内容一样,都会被持久化存储到磁盘中。所以记住,索引节点同样占用磁盘空间。
- 目录项,简称为 dentry,用来记录文件的名字、索引节点指针以及与其他目录项的关联关系。多个关联的目录项,就构成了文件系统的目录结构。不过,不同于索引节点,目录项是由内核维护的一个内存数据结构,所以通常也被叫做目录项缓存。
换句话说,索引节点是每个文件的唯一标志,而目录项维护的正是文件系统的树状结构。目录项和索引节点的关系是多对一,你可以简单理解为,一个文件可以有多个别名。
举个例子,通过硬链接为文件创建的别名,就会对应不同的目录项,不过这些目录项本质上还是链接同一个文件,所以,它们的索引节点相同。
索引节点和目录项纪录了文件的元数据,以及文件间的目录关系,那么具体来说,文件数据到底是怎么存储的呢?是不是直接写到磁盘中就好了呢?
实际上,磁盘读写的最小单位是扇区,然而扇区只有 512B 大小,如果每次都读写这么小的单位,效率一定很低。所以,文件系统又把连续的扇区组成了逻辑块,然后每次都以逻辑块为最小单元,来管理数据。常见的逻辑块大小为 4KB,也就是由连续的 8 个扇区组成。
为了帮助你理解目录项、索引节点以及文件数据的关系,我画了一张示意图。你可以对照着这张图,来回忆刚刚讲过的内容,把知识和细节串联起来。
不过,这里有两点需要你注意。
第一,目录项本身就是一个内存缓存,而索引节点则是存储在磁盘中的数据。在前面的 Buffer 和 Cache 原理中,我曾经提到过,为了协调慢速磁盘与快速 CPU 的性能差异,文件内容会缓存到页缓存 Cache 中。
那么,你应该想到,这些索引节点自然也会缓存到内存中,加速文件的访问。
第二,磁盘在执行文件系统格式化时,会被分成三个存储区域,超级块、索引节点区和数据块区。其中,
- 超级块,存储整个文件系统的状态。
- 索引节点区,用来存储索引节点。
- 数据块区,则用来存储文件数据。
23.2 虚拟文件系统
目录项、索引节点、逻辑块以及超级块,构成了 Linux 文件系统的四大基本要素。不过,为了支持各种不同的文件系统,Linux 内核在用户进程和文件系统的中间,又引入了一个抽象层,也就是虚拟文件系统 VFS(Virtual File System)。
VFS 定义了一组所有文件系统都支持的数据结构和标准接口。这样,用户进程和内核中的其他子系统,只需要跟 VFS 提供的统一接口进行交互就可以了,而不需要再关心底层各种文件系统的实现细节。
这里,我画了一张 Linux 文件系统的架构图,帮你更好地理解系统调用、VFS、缓存、文件系统以及块存储之间的关系。
通过这张图,你可以看到,在 VFS 的下方,Linux 支持各种各样的文件系统,如 Ext4、XFS、NFS 等等。按照存储位置的不同,这些文件系统可以分为三类。
- 第一类是基于磁盘的文件系统,也就是把数据直接存储在计算机本地挂载的磁盘中。常见的 Ext4、XFS、OverlayFS 等,都是这类文件系统。
- 第二类是基于内存的文件系统,也就是我们常说的虚拟文件系统。这类文件系统,不需要任何磁盘分配存储空间,但会占用内存。我们经常用到的 /proc 文件系统,其实就是一种最常见的虚拟文件系统。此外,/sys 文件系统也属于这一类,主要向用户空间导出层次化的内核对象。
- 第三类是网络文件系统,也就是用来访问其他计算机数据的文件系统,比如 NFS、SMB、iSCSI 等。
这些文件系统,要先挂载到 VFS 目录树中的某个子目录(称为挂载点),然后才能访问其中的文件。拿第一类,也就是基于磁盘的文件系统为例,在安装系统时,要先挂载一个根目录(/),在根目录下再把其他文件系统(比如其他的磁盘分区、/proc 文件系统、/sys 文件系统、NFS 等)挂载进来。
23.3 文件系统 I/O
把文件系统挂载到挂载点后,你就能通过挂载点,再去访问它管理的文件了。VFS 提供了一组标准的文件访问接口。这些接口以系统调用的方式,提供给应用程序使用。
就拿 cat 命令来说,它首先调用 open() ,打开一个文件;然后调用 read() ,读取文件的内容;最后再调用 write() ,把文件内容输出到控制台的标准输出中:
int open(const char *pathname, int flags, mode_t mode);
ssize_t read(int fd, void *buf, size_t count);
ssize_t write(int fd, const void *buf, size_t count);文件读写方式的各种差异,导致 I/O 的分类多种多样。最常见的有,缓冲与非缓冲 I/O、直接与非直接 I/O、阻塞与非阻塞 I/O、同步与异步 I/O 等。 接下来,我们就详细看这四种分类。
第一种,根据是否利用标准库缓存,可以把文件 I/O 分为缓冲 I/O 与非缓冲 I/O。
- 缓冲 I/O,是指利用标准库缓存来加速文件的访问,而标准库内部再通过系统调度访问文件。
非缓冲 I/O,是指直接通过系统调用来访问文件,不再经过标准库缓存。
注意,这里所说的”缓冲”,是指标准库内部实现的缓存。比方说,你可能见到过,很多程序遇到换行时才真正输出,而换行前的内容,其实就是被标准库暂时缓存了起来。
无论缓冲 I/O 还是非缓冲 I/O,它们最终还是要经过系统调用来访问文件。而根据上一节内容,我们知道,系统调用后,还会通过页缓存,来减少磁盘的 I/O 操作。
第二,根据是否利用操作系统的页缓存,可以把文件 I/O 分为直接 I/O 与非直接 I/O。
- 直接 I/O,是指跳过操作系统的页缓存,直接跟文件系统交互来访问文件。
非直接 I/O 正好相反,文件读写时,先要经过系统的页缓存,然后再由内核或额外的系统调用,真正写入磁盘。
想要实现直接 I/O,需要你在系统调用中,指定 O_DIRECT 标志。如果没有设置过,默认的是非直接 I/O。
不过要注意,直接 I/O、非直接 I/O,本质上还是和文件系统交互。如果是在数据库等场景中,你还会看到,跳过文件系统读写磁盘的情况,也就是我们通常所说的裸 I/O。
第三,根据应用程序是否阻塞自身运行,可以把文件 I/O 分为阻塞 I/O 和非阻塞 I/O:
- 所谓阻塞 I/O,是指应用程序执行 I/O 操作后,如果没有获得响应,就会阻塞当前线程,自然就不能执行其他任务。
所谓非阻塞 I/O,是指应用程序执行 I/O 操作后,不会阻塞当前的线程,可以继续执行其他的任务,随后再通过轮询或者事件通知的形式,获取调用的结果。
比方说,访问管道或者网络套接字时,设置 O_NONBLOCK 标志,就表示用非阻塞方式访问;而如果不做任何设置,默认的就是阻塞访问。
第四,根据是否等待响应结果,可以把文件 I/O 分为同步和异步 I/O:
- 所谓同步 I/O,是指应用程序执行 I/O 操作后,要一直等到整个 I/O 完成后,才能获得 I/O 响应。
所谓异步 I/O,是指应用程序执行 I/O 操作后,不用等待完成和完成后的响应,而是继续执行就可以。等到这次 I/O 完成后,响应会用事件通知的方式,告诉应用程序。
举个例子,在操作文件时,如果你设置了 O_SYNC 或者 O_DSYNC 标志,就代表同步 I/O。如果设置了 O_DSYNC,就要等文件数据写入磁盘后,才能返回;而 O_SYNC,则是在 O_DSYNC 基础上,要求文件元数据也要写入磁盘后,才能返回。
再比如,在访问管道或者网络套接字时,设置了 O_ASYNC 选项后,相应的 I/O 就是异步 I/O。这样,内核会再通过 SIGIO 或者 SIGPOLL,来通知进程文件是否可读写。
你也应该可以理解,”Linux 一切皆文件”的深刻含义。无论是普通文件和块设备、还是网络套接字和管道等,它们都通过统一的 VFS 接口来访问。
23.4 性能观测
观察一下文件系统的性能情况。
容量。
对文件系统来说,最常见的一个问题就是空间不足。当然,你可能本身就知道,用 df 命令,就能查看文件系统的磁盘空间使用情况。比如:
$ df /dev/sda1 Filesystem 1K-blocks Used Available Use% Mounted on /dev/sda1 30308240 3167020 27124836 11% /你可以看到,我的根文件系统只使用了 11% 的空间。这里还要注意,总空间用 1K-blocks 的数量来表示,你可以给 df 加上 -h 选项,以获得更好的可读性:
$ df -h /dev/sda1 Filesystem Size Used Avail Use% Mounted on /dev/sda1 29G 3.1G 26G 11% /不过有时候,明明你碰到了空间不足的问题,可是用 df 查看磁盘空间后,却发现剩余空间还有很多。这是怎么回事呢?
不知道你还记不记得,刚才我强调的一个细节。除了文件数据,索引节点也占用磁盘空间。你可以给 df 命令加上 -i 参数,查看索引节点的使用情况,如下所示:
$ df -i /dev/sda1 Filesystem Inodes IUsed IFree IUse% Mounted on /dev/sda1 3870720 157460 3713260 5% /索引节点的容量,(也就是 Inode 个数)是在格式化磁盘时设定好的,一般由格式化工具自动生成。当你发现索引节点空间不足,但磁盘空间充足时,很可能就是过多小文件导致的。
所以,一般来说,删除这些小文件,或者把它们移动到索引节点充足的其他磁盘中,就可以解决这个问题。
缓存
free 输出的 Cache,是页缓存和可回收 Slab 缓存的和,你可以从 /proc/meminfo ,直接得到它们的大小:
$ cat /proc/meminfo | grep -E "SReclaimable|Cached" Cached: 748316 kB SwapCached: 0 kB SReclaimable: 179508 kB话说回来,文件系统中的目录项和索引节点缓存,又该如何观察呢?
实际上,内核使用 Slab 机制,管理目录项和索引节点的缓存。/proc/meminfo 只给出了 Slab 的整体大小,具体到每一种 Slab 缓存,还要查看 /proc/slabinfo 这个文件。
比如,运行下面的命令,你就可以得到,所有目录项和各种文件系统索引节点的缓存情况:
$ cat /proc/slabinfo | grep -E '^#|dentry|inode' # name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <limit> <batchcount> <sharedfactor> : slabdata <active_slabs> <num_slabs> <sharedavail> xfs_inode 0 0 960 17 4 : tunables 0 0 0 : slabdata 0 0 0 ... ext4_inode_cache 32104 34590 1088 15 4 : tunables 0 0 0 : slabdata 2306 2306 0hugetlbfs_inode_cache 13 13 624 13 2 : tunables 0 0 0 : slabdata 1 1 0 sock_inode_cache 1190 1242 704 23 4 : tunables 0 0 0 : slabdata 54 54 0 shmem_inode_cache 1622 2139 712 23 4 : tunables 0 0 0 : slabdata 93 93 0 proc_inode_cache 3560 4080 680 12 2 : tunables 0 0 0 : slabdata 340 340 0 inode_cache 25172 25818 608 13 2 : tunables 0 0 0 : slabdata 1986 1986 0 dentry 76050 121296 192 21 1 : tunables 0 0 0 : slabdata 5776 5776 0这个界面中,dentry 行表示目录项缓存,inode_cache 行,表示 VFS 索引节点缓存,其余的则是各种文件系统的索引节点缓存。
/proc/slabinfo 的列比较多,具体含义你可以查询 man slabinfo。在实际性能分析中,我们更常使用 slabtop ,来找到占用内存最多的缓存类型。
比如,下面就是我运行 slabtop 得到的结果:
# 按下 c 按照缓存大小排序,按下 a 按照活跃对象数排序 $ slabtop Active / Total Objects (% used) : 277970 / 358914 (77.4%) Active / Total Slabs (% used) : 12414 / 12414 (100.0%) Active / Total Caches (% used) : 83 / 135 (61.5%) Active / Total Size (% used) : 57816.88K / 73307.70K (78.9%) Minimum / Average / Maximum Object : 0.01K / 0.20K / 22.88K OBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME 69804 23094 0% 0.19K 3324 21 13296K dentry 16380 15854 0% 0.59K 1260 13 10080K inode_cache 58260 55397 0% 0.13K 1942 30 7768K kernfs_node_cache 485 413 0% 5.69K 97 5 3104K task_struct 1472 1397 0% 2.00K 92 16 2944K kmalloc-2048从这个结果你可以看到,在我的系统中,目录项和索引节点占用了最多的 Slab 缓存。不过它们占用的内存其实并不大,加起来也只有 23MB 左右。
24 | 基础篇:Linux 磁盘I/O是怎么工作的(上)
回顾一下,文件系统是对存储设备上的文件,进行组织管理的一种机制。而 Linux 在各种文件系统实现上,又抽象了一层虚拟文件系统 VFS,它定义了一组,所有文件系统都支持的,数据结构和标准接口。
这样,对应用程序来说,只需要跟 VFS 提供的统一接口交互,而不需要关注文件系统的具体实现;对具体的文件系统来说,只需要按照 VFS 的标准,就可以无缝支持各种应用程序。
VFS 内部又通过目录项、索引节点、逻辑块以及超级块等数据结构,来管理文件。
- 目录项,记录了文件的名字,以及文件与其他目录项之间的目录关系。
- 索引节点,记录了文件的元数据。
- 逻辑块,是由连续磁盘扇区构成的最小读写单元,用来存储文件数据。
- 超级块,用来记录文件系统整体的状态,如索引节点和逻辑块的使用情况等。
其中,目录项是一个内存缓存;而超级块、索引节点和逻辑块,都是存储在磁盘中的持久化数据。
接下来,我就带你一起看看, Linux 磁盘 I/O 的工作原理。
24.1 磁盘
磁盘是可以持久化存储的设备,根据存储介质的不同,常见磁盘可以分为两类:机械磁盘和固态磁盘。
第一类,机械磁盘,也称为硬盘驱动器(Hard Disk Driver),通常缩写为 HDD。机械磁盘主要由盘片和读写磁头组成,数据就存储在盘片的环状磁道中。在读写数据前,需要移动读写磁头,定位到数据所在的磁道,然后才能访问数据。
显然,如果 I/O 请求刚好连续,那就不需要磁道寻址,自然可以获得最佳性能。这其实就是我们熟悉的,连续 I/O 的工作原理。与之相对应的,当然就是随机 I/O,它需要不停地移动磁头,来定位数据位置,所以读写速度就会比较慢。
第二类,固态磁盘(Solid State Disk),通常缩写为 SSD,由固态电子元器件组成。固态磁盘不需要磁道寻址,所以,不管是连续 I/O,还是随机 I/O 的性能,都比机械磁盘要好得多。
其实,无论机械磁盘,还是固态磁盘,相同磁盘的随机 I/O 都要比连续 I/O 慢很多,原因也很明显。
- 对机械磁盘来说,我们刚刚提到过的,由于随机 I/O 需要更多的磁头寻道和盘片旋转,它的性能自然要比连续 I/O 慢。
- 而对固态磁盘来说,虽然它的随机性能比机械硬盘好很多,但同样存在”先擦除再写入”的限制。随机读写会导致大量的垃圾回收,所以相对应的,随机 I/O 的性能比起连续 I/O 来,也还是差了很多。
- 此外,连续 I/O 还可以通过预读的方式,来减少 I/O 请求的次数,这也是其性能优异的一个原因。很多性能优化的方案,也都会从这个角度出发,来优化 I/O 性能。
此外,机械磁盘和固态磁盘还分别有一个最小的读写单位。
- 机械磁盘的最小读写单位是扇区,一般大小为 512 字节。
- 而固态磁盘的最小读写单位是页,通常大小是 4KB、8KB 等。
在上一节中,我也提到过,如果每次都读写 512 字节这么小的单位的话,效率很低。所以,文件系统会把连续的扇区或页,组成逻辑块,然后以逻辑块作为最小单元来管理数据。常见的逻辑块的大小是 4KB,也就是说,连续 8 个扇区,或者单独的一个页,都可以组成一个逻辑块。
除了可以按照存储介质来分类,另一个常见的分类方法,是按照接口来分类,比如可以把硬盘分为 IDE(Integrated Drive Electronics)、SCSI(Small Computer System Interface) 、SAS(Serial Attached SCSI) 、SATA(Serial ATA) 、FC(Fibre Channel) 等。
不同的接口,往往分配不同的设备名称。比如, IDE 设备会分配一个 hd 前缀的设备名,SCSI 和 SATA 设备会分配一个 sd 前缀的设备名。如果是多块同类型的磁盘,就会按照 a、b、c 等的字母顺序来编号。
除了磁盘本身的分类外,当你把磁盘接入服务器后,按照不同的使用方式,又可以把它们划分为多种不同的架构。
最简单的,就是直接作为独立磁盘设备来使用。这些磁盘,往往还会根据需要,划分为不同的逻辑分区,每个分区再用数字编号。比如我们前面多次用到的 /dev/sda ,还可以分成两个分区 /dev/sda1 和 /dev/sda2。
另一个比较常用的架构,是把多块磁盘组合成一个逻辑磁盘,构成冗余独立磁盘阵列,也就是 RAID(Redundant Array of Independent Disks),从而可以提高数据访问的性能,并且增强数据存储的可靠性。
根据容量、性能和可靠性需求的不同,RAID 一般可以划分为多个级别,如 RAID0、RAID1、RAID5、RAID10 等。
- RAID0 有最优的读写性能,但不提供数据冗余的功能。
- 而其他级别的 RAID,在提供数据冗余的基础上,对读写性能也有一定程度的优化。
最后一种架构,是把这些磁盘组合成一个网络存储集群,再通过 NFS、SMB、iSCSI 等网络存储协议,暴露给服务器使用。
其实在 Linux 中,磁盘实际上是作为一个块设备来管理的,也就是以块为单位读写数据,并且支持随机读写。每个块设备都会被赋予两个设备号,分别是主、次设备号。主设备号用在驱动程序中,用来区分设备类型;而次设备号则是用来给多个同类设备编号。
24.2 通用块层
跟我们上一节讲到的虚拟文件系统 VFS 类似,为了减小不同块设备的差异带来的影响,Linux 通过一个统一的通用块层,来管理各种不同的块设备。
通用块层,其实是处在文件系统和磁盘驱动中间的一个块设备抽象层。它主要有两个功能 。
- 第一个功能跟虚拟文件系统的功能类似。向上,为文件系统和应用程序,提供访问块设备的标准接口;向下,把各种异构的磁盘设备抽象为统一的块设备,并提供统一框架来管理这些设备的驱动程序。
- 第二个功能,通用块层还会给文件系统和应用程序发来的 I/O 请求排队,并通过重新排序、请求合并等方式,提高磁盘读写的效率。
其中,对 I/O 请求排序的过程,也就是我们熟悉的 I/O 调度。事实上,Linux 内核支持四种 I/O 调度算法,分别是 NONE、NOOP、CFQ 以及 DeadLine。这里我也分别介绍一下。
第一种 NONE ,更确切来说,并不能算 I/O 调度算法。因为它完全不使用任何 I/O 调度器,对文件系统和应用程序的 I/O 其实不做任何处理,常用在虚拟机中(此时磁盘 I/O 调度完全由物理机负责)。
第二种 NOOP ,是最简单的一种 I/O 调度算法。它实际上是一个先入先出的队列,只做一些最基本的请求合并,常用于 SSD 磁盘。
第三种 CFQ(Completely Fair Scheduler),也被称为完全公平调度器,是现在很多发行版的默认 I/O 调度器,它为每个进程维护了一个 I/O 调度队列,并按照时间片来均匀分布每个进程的 I/O 请求。
类似于进程 CPU 调度,CFQ 还支持进程 I/O 的优先级调度,所以它适用于运行大量进程的系统,像是桌面环境、多媒体应用等。
最后一种 DeadLine 调度算法,分别为读、写请求创建了不同的 I/O 队列,可以提高机械磁盘的吞吐量,并确保达到最终期限(deadline)的请求被优先处理。DeadLine 调度算法,多用在 I/O 压力比较重的场景,比如数据库等。
24.3. I/O 栈
可以把 Linux 存储系统的 I/O 栈,由上到下分为三个层次,分别是文件系统层、通用块层和设备层。这三个 I/O 层的关系如下图所示,这其实也是 Linux 存储系统的 I/O 栈全景图。
根据这张 I/O 栈的全景图,我们可以更清楚地理解,存储系统 I/O 的工作原理。
- 文件系统层,包括虚拟文件系统和其他各种文件系统的具体实现。它为上层的应用程序,提供标准的文件访问接口;对下会通过通用块层,来存储和管理磁盘数据。
- 通用块层,包括块设备 I/O 队列和 I/O 调度器。它会对文件系统的 I/O 请求进行排队,再通过重新排序和请求合并,然后才要发送给下一级的设备层。
- 设备层,包括存储设备和相应的驱动程序,负责最终物理设备的 I/O 操作。
存储系统的 I/O ,通常是整个系统中最慢的一环。所以, Linux 通过多种缓存机制来优化 I/O 效率。
比方说,为了优化文件访问的性能,会使用页缓存、索引节点缓存、目录项缓存等多种缓存机制,以减少对下层块设备的直接调用。
同样,为了优化块设备的访问效率,会使用缓冲区,来缓存块设备的数据。
24.4 小结
通用块层是 Linux 磁盘 I/O 的核心。向上,它为文件系统和应用程序,提供访问了块设备的标准接口;向下,把各种异构的磁盘设备,抽象为统一的块设备,并会对文件系统和应用程序发来的 I/O 请求进行重新排序、请求合并等,提高了磁盘访问的效率。
25 | 基础篇:Linux 磁盘I/O是怎么工作的(下)
25.1 磁盘性能指标
说到磁盘性能的衡量标准,必须要提到五个常见指标,也就是我们经常用到的,使用率、饱和度、IOPS、吞吐量以及响应时间等。这五个指标,是衡量磁盘性能的基本指标。
- 使用率,是指磁盘处理 I/O 的时间百分比。过高的使用率(比如超过 80%),通常意味着磁盘 I/O 存在性能瓶颈。
- 饱和度,是指磁盘处理 I/O 的繁忙程度。过高的饱和度,意味着磁盘存在严重的性能瓶颈。当饱和度为 100% 时,磁盘无法接受新的 I/O 请求。
- IOPS(Input/Output Per Second),是指每秒的 I/O 请求数。
- 吞吐量,是指每秒的 I/O 请求大小。
- 响应时间,是指 I/O 请求从发出到收到响应的间隔时间。
这里要注意的是,使用率只考虑有没有 I/O,而不考虑 I/O 的大小。换句话说,当使用率是 100% 的时候,磁盘依然有可能接受新的 I/O 请求。
这些指标,很可能是你经常挂在嘴边的,一讨论磁盘性能必定提起的对象。不过我还是要强调一点,不要孤立地去比较某一指标,而要结合读写比例、I/O 类型(随机还是连续)以及 I/O 的大小,综合来分析。
举个例子,在数据库、大量小文件等这类随机读写比较多的场景中,IOPS 更能反映系统的整体性能;而在多媒体等顺序读写较多的场景中,吞吐量才更能反映系统的整体性能。
一般来说,我们在为应用程序的服务器选型时,要先对磁盘的 I/O 性能进行基准测试,以便可以准确评估,磁盘性能是否可以满足应用程序的需求。
这一方面,我推荐用性能测试工具 fio ,来测试磁盘的 IOPS、吞吐量以及响应时间等核心指标。但还是那句话,因地制宜,灵活选取。在基准测试时,一定要注意根据应用程序 I/O 的特点,来具体评估指标。
当然,这就需要你测试出,不同 I/O 大小(一般是 512B 至 1MB 中间的若干值)分别在随机读、顺序读、随机写、顺序写等各种场景下的性能情况。
用性能工具得到的这些指标,可以作为后续分析应用程序性能的依据。一旦发生性能问题,你就可以把它们作为磁盘性能的极限值,进而评估磁盘 I/O 的使用情况。
25.2 磁盘 I/O 观测
第一个要观测的,是每块磁盘的使用情况。
iostat 是最常用的磁盘 I/O 性能观测工具,它提供了每个磁盘的使用率、IOPS、吞吐量等各种常见的性能指标,当然,这些指标实际上来自 /proc/diskstats。
iostat 的输出界面如下。
# -d -x 表示显示所有磁盘 I/O 的指标
$ iostat -d -x 1
Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
loop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
loop1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00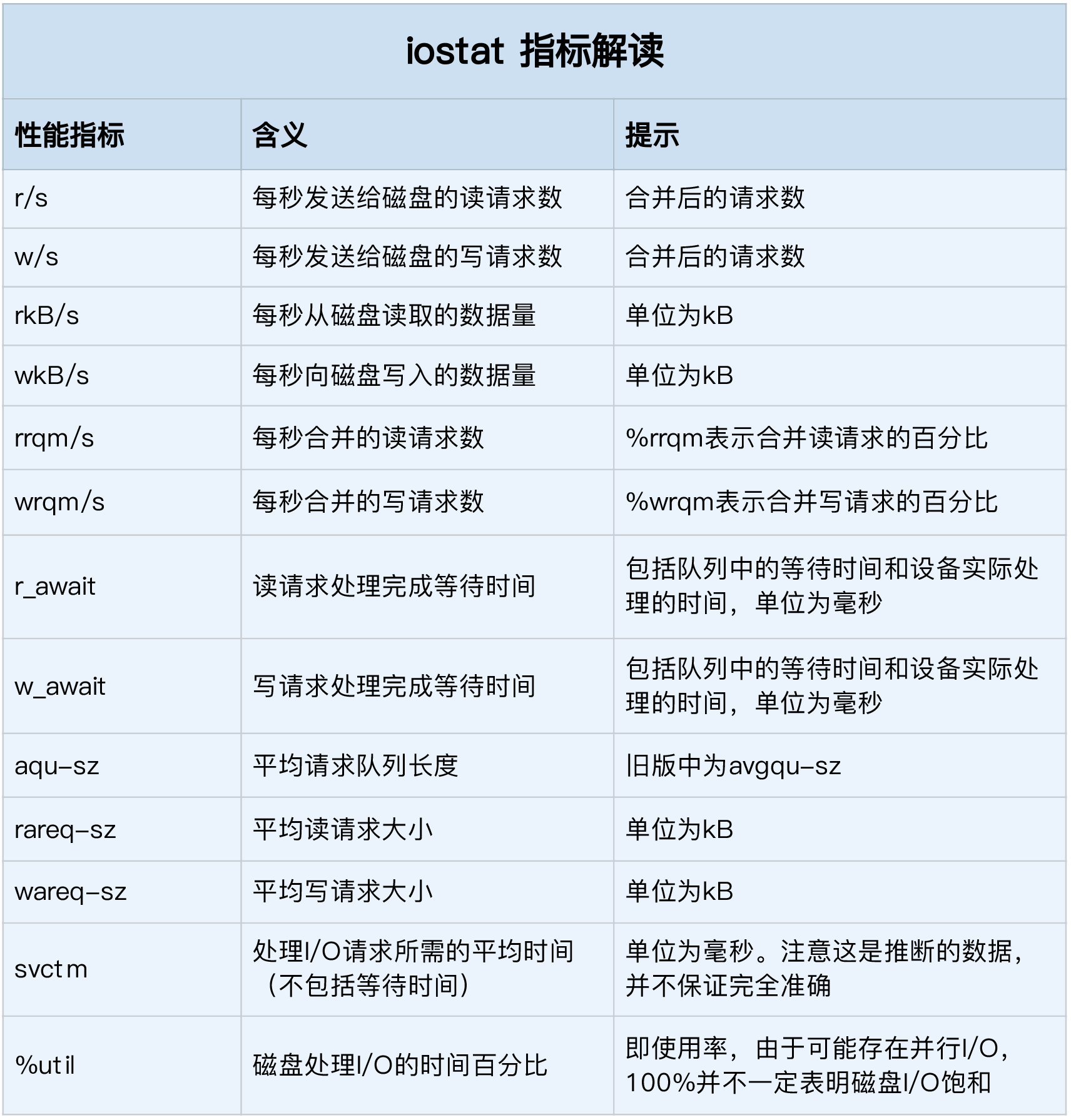
这些指标中,你要注意:
- %util ,就是我们前面提到的磁盘 I/O 使用率;
- r/s+ w/s ,就是 IOPS;
- rkB/s+wkB/s ,就是吞吐量;
- r_await+w_await ,就是响应时间。
在观测指标时,也别忘了结合请求的大小( rareq-sz 和 wareq-sz)一起分析。
你可能注意到,从 iostat 并不能直接得到磁盘饱和度。事实上,饱和度通常也没有其他简单的观测方法,不过,你可以把观测到的,平均请求队列长度或者读写请求完成的等待时间,跟基准测试的结果(比如通过 fio)进行对比,综合评估磁盘的饱和情况。
25.3 进程 I/O 观测
除了每块磁盘的 I/O 情况,每个进程的 I/O 情况也是我们需要关注的重点。
上面提到的 iostat 只提供磁盘整体的 I/O 性能数据,缺点在于,并不能知道具体是哪些进程在进行磁盘读写。要观察进程的 I/O 情况,你还可以使用 pidstat 和 iotop 这两个工具。
$ pidstat -d 1
13:39:51 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
13:39:52 102 916 0.00 4.00 0.00 0 rsyslogd从 pidstat 的输出你能看到,它可以实时查看每个进程的 I/O 情况,包括下面这些内容。
- 用户 ID(UID)和进程 ID(PID) 。
- 每秒读取的数据大小(kB_rd/s) ,单位是 KB。
- 每秒发出的写请求数据大小(kB_wr/s) ,单位是 KB。
- 每秒取消的写请求数据大小(kB_ccwr/s) ,单位是 KB。
- 块 I/O 延迟(iodelay),包括等待同步块 I/O 和换入块 I/O 结束的时间,单位是时钟周期。
除了可以用 pidstat 实时查看,根据 I/O 大小对进程排序,也是性能分析中一个常用的方法。这一点,我推荐另一个工具, iotop。它是一个类似于 top 的工具,你可以按照 I/O 大小对进程排序,然后找到 I/O 较大的那些进程。
iotop 的输出如下所示:
$ iotop
Total DISK READ : 0.00 B/s | Total DISK WRITE : 7.85 K/s
Actual DISK READ: 0.00 B/s | Actual DISK WRITE: 0.00 B/s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
15055 be/3 root 0.00 B/s 7.85 K/s 0.00 % 0.00 % systemd-journald从这个输出,你可以看到,前两行分别表示,进程的磁盘读写大小总数和磁盘真实的读写大小总数。因为缓存、缓冲区、I/O 合并等因素的影响,它们可能并不相等。
剩下的部分,则是从各个角度来分别表示进程的 I/O 情况,包括线程 ID、I/O 优先级、每秒读磁盘的大小、每秒写磁盘的大小、换入和等待 I/O 的时钟百分比等。
这两个工具,是我们分析磁盘 I/O 性能时最常用到的。你先了解它们的功能和指标含义,具体的使用方法,接下来的案例实战中我们一起学习。
26 | 案例篇:如何找出狂打日志的”内鬼”?
文件系统,是对存储设备上的文件进行组织管理的一种机制。为了支持各类不同的文件系统,Linux 在各种文件系统上,抽象了一层虚拟文件系统 VFS。
它定义了一组所有文件系统都支持的数据结构和标准接口。这样,应用程序和内核中的其他子系统,就只需要跟 VFS 提供的统一接口进行交互。
在文件系统的下层,为了支持各种不同类型的存储设备,Linux 又在各种存储设备的基础上,抽象了一个通用块层。
通用块层,为文件系统和应用程序提供了访问块设备的标准接口;同时,为各种块设备的驱动程序提供了统一的框架。此外,通用块层还会对文件系统和应用程序发送过来的 I/O 请求进行排队,并通过重新排序、请求合并等方式,提高磁盘读写的效率。
通用块层的下一层,自然就是设备层了,包括各种块设备的驱动程序以及物理存储设备。
文件系统、通用块层以及设备层,就构成了 Linux 的存储 I/O 栈。存储系统的 I/O ,通常是整个系统中最慢的一环。所以,Linux 采用多种缓存机制,来优化 I/O 的效率,比方说,
- 为了优化文件访问的性能,采用页缓存、索引节点缓存、目录项缓存等多种缓存机制,减少对下层块设备的直接调用。
- 同样的,为了优化块设备的访问效率,使用缓冲区来缓存块设备的数据。
不过,在碰到文件系统和磁盘的 I/O 问题时,具体应该怎么定位和分析呢?
26.1 案例
机器配置: 2 CPU, 8 GB 内存。
安装软件:
apt install docker.io sysstat。
在终端中执行下面的命令,运行今天的目标应用:
docker run -v /tmp:/tmp --name=app -itd feisky/logapp然后,在终端中运行 ps 命令,确认案例应用正常启动。如果操作无误,你应该可以在 ps 的输出中,看到一个 app.py 的进程:
$ ps -ef | grep /app.py root 18940 18921 73 14:41 pts/0 00:00:02 python /app.py接着,我们来看看系统有没有性能问题。要观察哪些性能指标呢?前面文章中,我们知道 CPU、内存和磁盘 I/O 等系统资源,很容易出现资源瓶颈,这就是我们观察的方向了。我们来观察一下这些资源的使用情况。
我的想法是,我们可以先用 top ,来观察 CPU 和内存的使用情况;然后再用 iostat ,来观察磁盘的 I/O 情况。
所以,接下来,你可以在终端中运行 top 命令,观察 CPU 和内存的使用情况:
# 按 1 切换到每个 CPU 的使用情况 $ top top - 14:43:43 up 1 day, 1:39, 2 users, load average: 2.48, 1.09, 0.63 Tasks: 130 total, 2 running, 74 sleeping, 0 stopped, 0 zombie %Cpu0 : 0.7 us, 6.0 sy, 0.0 ni, 0.7 id, 92.7 wa, 0.0 hi, 0.0 si, 0.0 st %Cpu1 : 0.0 us, 0.3 sy, 0.0 ni, 92.3 id, 7.3 wa, 0.0 hi, 0.0 si, 0.0 st KiB Mem : 8169308 total, 747684 free, 741336 used, 6680288 buff/cache KiB Swap: 0 total, 0 free, 0 used. 7113124 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 18940 root 20 0 656108 355740 5236 R 6.3 4.4 0:12.56 python 1312 root 20 0 236532 24116 9648 S 0.3 0.3 9:29.80 python3观察 top 的输出,你会发现,CPU0 的使用率非常高,它的系统 CPU 使用率(sys%)为 6%,而 iowait 超过了 90%。这说明 CPU0 上,可能正在运行 I/O 密集型的进程。
接着我们来看,进程部分的 CPU 使用情况。你会发现, python 进程的 CPU 使用率已经达到了 6%,而其余进程的 CPU 使用率都比较低,不超过 0.3%。看起来 python 是个可疑进程。
最后再看内存的使用情况,总内存 8G,剩余内存只有 730 MB,而 Buffer/Cache 占用内存高达 6GB 之多,这说明内存主要被缓存占用。虽然大部分缓存可回收,我们还是得了解下缓存的去处,确认缓存使用都是合理的。
到这一步,你基本可以判断出,CPU 使用率中的 iowait 是一个潜在瓶颈,而内存部分的缓存占比较大,那磁盘 I/O 又是怎么样的情况呢?
我们在终端中按 Ctrl+C ,停止 top 命令,再运行 iostat 命令,观察 I/O 的使用情况:
# -d 表示显示 I/O 性能指标,-x 表示显示扩展统计(即所有 I/O 指标) $ iostat -x -d 1 Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util loop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 sda 0.00 64.00 0.00 32768.00 0.00 0.00 0.00 0.00 0.00 7270.44 1102.18 0.00 512.00 15.50 99.20观察 iostat 的最后一列,你会看到,磁盘 sda 的 I/O 使用率已经高达 99%,很可能已经接近 I/O 饱和。
再看前面的各个指标,每秒写磁盘请求数是 64 ,写大小是 32 MB,写请求的响应时间为 7 秒,而请求队列长度则达到了 1100。
超慢的响应时间和特长的请求队列长度,进一步验证了 I/O 已经饱和的猜想。此时,sda 磁盘已经遇到了严重的性能瓶颈。
到这里,也就可以理解,为什么前面看到的 iowait 高达 90% 了,这正是磁盘 sda 的 I/O 瓶颈导致的。接下来的重点就是分析 I/O 性能瓶颈的根源了。那要怎么知道,这些 I/O 请求相关的进程呢?
使用 pidstat 加上 -d 参数,就可以显示每个进程的 I/O 情况。所以,你可以在终端中运行如下命令来观察:
$ pidstat -d 1 15:08:35 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command 15:08:36 0 18940 0.00 45816.00 0.00 96 python 15:08:36 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command 15:08:37 0 354 0.00 0.00 0.00 350 jbd2/sda1-8 15:08:37 0 18940 0.00 46000.00 0.00 96 python 15:08:37 0 20065 0.00 0.00 0.00 1503 kworker/u4:2从 pidstat 的输出,你可以发现,只有 python 进程的写比较大,而且每秒写的数据超过 45 MB,比上面 iostat 发现的 32MB 的结果还要大。很明显,正是 python 进程导致了 I/O 瓶颈。
再往下看 iodelay 项。虽然只有 python 在大量写数据,但你应该注意到了,有两个进程 (kworker 和 jbd2 )的延迟,居然比 python 进程还大很多。
这其中,kworker 是一个内核线程,而 jbd2 是 ext4 文件系统中,用来保证数据完整性的内核线程。他们都是保证文件系统基本功能的内核线程,所以具体细节暂时就不用管了,我们只需要明白,它们延迟的根源还是大量 I/O。
综合 pidstat 的输出来看,还是 python 进程的嫌疑最大。接下来,我们来分析 python 进程到底在写什么。
首先留意一下 python 进程的 PID 号, 18940。看到 18940 ,你有没有觉得熟悉?其实前面在使用 top 时,我们记录过的 CPU 使用率最高的进程,也正是它。不过,虽然在 top 中使用率最高,也不过是 6%,并不算高。所以,以 I/O 问题为分析方向还是正确的。
知道了进程的 PID 号,具体要怎么查看写的情况呢?
其实,我在系统调用的案例中讲过,读写文件必须通过系统调用完成。观察系统调用情况,就可以知道进程正在写的文件。想起 strace 了吗,它正是我们分析系统调用时最常用的工具。
接下来,我们在终端中运行 strace 命令,并通过 -p 18940 指定 python 进程的 PID 号:
$ strace -p 18940 strace: Process 18940 attached ... mmap(NULL, 314576896, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f0f7aee9000 mmap(NULL, 314576896, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f0f682e8000 write(3, "2018-12-05 15:23:01,709 - __main"..., 314572844 ) = 314572844 munmap(0x7f0f682e8000, 314576896) = 0 write(3, "\n", 1) = 1 munmap(0x7f0f7aee9000, 314576896) = 0 close(3) = 0 stat("/tmp/logtest.txt.1", {st_mode=S_IFREG|0644, st_size=943718535, ...}) = 0从 write() 系统调用上,我们可以看到,进程向文件描述符编号为 3 的文件中,写入了 300MB 的数据。看来,它应该是我们要找的文件。不过,write() 调用中只能看到文件的描述符编号,文件名和路径还是未知的。
再观察后面的 stat() 调用,你可以看到,它正在获取 /tmp/logtest.txt.1 的状态。 这种”点 + 数字格式”的文件,在日志回滚中非常常见。我们可以猜测,这是第一个日志回滚文件,而正在写的日志文件路径,则是 /tmp/logtest.txt。
接下来,我们在终端中运行下面的 lsof 命令,看看进程 18940 都打开了哪些文件:
$ lsof -p 18940 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME python 18940 root cwd DIR 0,50 4096 1549389 / python 18940 root rtd DIR 0,50 4096 1549389 / … python 18940 root 2u CHR 136,0 0t0 3 /dev/pts/0 python 18940 root 3w REG 8,1 117944320 303 /tmp/logtest.txt有几列我简单介绍一下,FD 表示文件描述符号,TYPE 表示文件类型,NAME 表示文件路径。这也是我们需要关注的重点。
再看最后一行,这说明,这个进程打开了文件 /tmp/logtest.txt,并且它的文件描述符是 3 号,而 3 后面的 w ,表示以写的方式打开。
这跟刚才 strace 完我们猜测的结果一致,看来这就是问题的根源:进程 18940 以每次 300MB 的速度,在”疯狂”写日志,而日志文件的路径是 /tmp/logtest.txt。
你可以运行 docker cp 命令,把案例应用的源代码拷贝出来,然后查看它的内容。(你也可以点击这里查看案例应用的源码):
# 拷贝案例应用源代码到当前目录 $ docker cp app:/app.py . # 查看案例应用的源代码 $ cat app.py logger = logging.getLogger(__name__) logger.setLevel(level=logging.INFO) rHandler = RotatingFileHandler("/tmp/logtest.txt", maxBytes=1024 * 1024 * 1024, backupCount=1) rHandler.setLevel(logging.INFO) def write_log(size): '''Write logs to file''' message = get_message(size) while True: logger.info(message) time.sleep(0.1) if __name__ == '__main__': msg_size = 300 * 1024 * 1024 write_log(msg_size)分析这个源码,我们发现,它的日志路径是 /tmp/logtest.txt,默认记录 INFO 级别以上的所有日志,而且每次写日志的大小是 300MB。这跟我们上面的分析结果是一致的。
一般来说,生产系统的应用程序,应该有动态调整日志级别的功能。继续查看源码,你会发现,这个程序也可以调整日志级别。如果你给它发送 SIGUSR1 信号,就可以把日志调整为 INFO 级;发送 SIGUSR2 信号,则会调整为 WARNING 级:
def set_logging_info(signal_num, frame): '''Set loging level to INFO when receives SIGUSR1''' logger.setLevel(logging.INFO) def set_logging_warning(signal_num, frame): '''Set loging level to WARNING when receives SIGUSR2''' logger.setLevel(logging.WARNING) signal.signal(signal.SIGUSR1, set_logging_info) signal.signal(signal.SIGUSR2, set_logging_warning)根据源码中的日志调用 logger. info(message) ,我们知道,它的日志是 INFO 级,这也正是它的默认级别。那么,只要把默认级别调高到 WARNING 级,日志问题应该就解决了。
接下来,我们就来检查一下,刚刚的分析对不对。在终端中运行下面的 kill 命令,给进程 18940 发送 SIGUSR2 信号:
kill -SIGUSR2 18940然后,再执行 top 和 iostat 观察一下:
$ top ... %Cpu(s): 0.3 us, 0.2 sy, 0.0 ni, 99.5 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st$ iostat -d -x 1 Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util loop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00观察 top 和 iostat 的输出,你会发现,稍等一段时间后,iowait 会变成 0,而 sda 磁盘的 I/O 使用率也会逐渐减少到 0。
26.2 问答区
“日志回滚文件”,打印日志的过程中从直觉来看很容易误认为日志是在”回滚”,我也犯过这样的错误;rotating英文直译为”旋转”或”轮流”,实际的日志打印过程中,日志名称是”旋转”的,例如log.1(当前打印的日志文件并且一直会打印这个文件),log.2(较早日志),log.3(更早日志),当触发”旋转”条件时,日志名称会发生变更,假如log.3是上限数,那么log.3发生”旋转”就被remove,log.2被rename为log.3。更形象一点的描述是,日志名称发生了滚动,log.1=>log.2=>log.3不断的更新。
27 | 案例篇:为什么我的磁盘I/O延迟很高?
27.1 案例
机器配置: 2 CPU, 8 GB 内存。
安装软件:
apt install docker.io sysstat。
在第一个终端中执行下面的命令,运行本次案例要分析的目标应用:
docker run --name=app -p 10000:80 -itd feisky/word-pop在第二个终端中运行 curl 命令,访问 http://192.168.0.10:1000/,确认案例正常启动。你应该可以在 curl 的输出界面里,看到一个 hello world 的输出:
$ curl http://192.168.0.10:10000/ hello world接下来,在第二个终端中,访问案例应用的单词热度接口,也就是 http://192.168.0.10:1000/popularity/word。
curl http://192.168.0.10:1000/popularity/word稍等一会儿,你会发现,这个接口居然这么长时间都没响应,究竟是怎么回事呢?我们先回到终端一来分析一下。
我们试试在第一个终端里,随便执行一个命令,比如执行 df 命令,查看一下文件系统的使用情况。奇怪的是,这么简单的命令,居然也要等好久才有输出。
$ df Filesystem 1K-blocks Used Available Use% Mounted on udev 4073376 0 4073376 0% /dev tmpfs 816932 1188 815744 1% /run /dev/sda1 30308240 8713640 21578216 29% /通过 df 我们知道,系统还有足够多的磁盘空间。那为什么响应会变慢呢?看来还是得观察一下,系统的资源使用情况,像是 CPU、内存和磁盘 I/O 等的具体使用情况。
这里的思路其实跟上一个案例比较类似,我们可以先用 top 来观察 CPU 和内存的使用情况,然后再用 iostat 来观察磁盘的 I/O 情况。
为了避免分析过程中 curl 请求突然结束,我们回到终端二,按 Ctrl+C 停止刚才的应用程序;然后,把 curl 命令放到一个循环里执行;这次我们还要加一个 time 命令,观察每次的执行时间:
while true; do time curl http://192.168.0.10:10000/popularity/word; sleep 1; done继续回到终端一来分析性能。我们在终端一中运行 top 命令,观察 CPU 和内存的使用情况:
$ top top - 14:27:02 up 10:30, 1 user, load average: 1.82, 1.26, 0.76 Tasks: 129 total, 1 running, 74 sleeping, 0 stopped, 0 zombie %Cpu0 : 3.5 us, 2.1 sy, 0.0 ni, 0.0 id, 94.4 wa, 0.0 hi, 0.0 si, 0.0 st %Cpu1 : 2.4 us, 0.7 sy, 0.0 ni, 70.4 id, 26.5 wa, 0.0 hi, 0.0 si, 0.0 st KiB Mem : 8169300 total, 3323248 free, 436748 used, 4409304 buff/cache KiB Swap: 0 total, 0 free, 0 used. 7412556 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 12280 root 20 0 103304 28824 7276 S 14.0 0.4 0:08.77 python 16 root 20 0 0 0 0 S 0.3 0.0 0:09.22 ksoftirqd/1 1549 root 20 0 236712 24480 9864 S 0.3 0.3 3:31.38 python3观察 top 的输出可以发现,两个 CPU 的 iowait 都非常高。特别是 CPU0, iowait 已经高达 94 %,而剩余内存还有 3GB,看起来也是充足的。
再往下看,进程部分有一个 python 进程的 CPU 使用率稍微有点高,达到了 14%。虽然 14% 并不能成为性能瓶颈,不过有点嫌疑——可能跟 iowait 的升高有关。
那这个 PID 号为 12280 的 python 进程,到底是不是我们的案例应用呢?
我们在第一个终端中,按下 Ctrl+C,停止 top 命令;然后执行下面的 ps 命令,查找案例应用 app.py 的 PID 号:
$ ps aux | grep app.py root 12222 0.4 0.2 96064 23452 pts/0 Ss+ 14:37 0:00 python /app.py root 12280 13.9 0.3 102424 27904 pts/0 Sl+ 14:37 0:09 /usr/local/bin/python /app.py从 ps 的输出,你可以看到,这个 CPU 使用率较高的进程,正是我们的案例应用。不过先别着急分析 CPU 问题,毕竟 iowait 已经高达 94%, I/O 问题才是我们首要解决的。
接下来,我们在终端一中,运行下面的 iostat 命令,其中:
- -d 选项是指显示出 I/O 的性能指标;
-x 选项是指显示出扩展统计信息(即显示所有 I/O 指标)。
$ iostat -d -x 1 Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util loop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 sda 0.00 71.00 0.00 32912.00 0.00 0.00 0.00 0.00 0.00 18118.31 241.89 0.00 463.55 13.86 98.40可以发现,磁盘 sda 的 I/O 使用率已经达到 98% ,接近饱和了。而且,写请求的响应时间高达 18 秒,每秒的写数据为 32 MB,显然写磁盘碰到了瓶颈。
那要怎么知道,这些 I/O 请求到底是哪些进程导致的呢?
在终端一中,运行下面的 pidstat 命令,观察进程的 I/O 情况:
$ pidstat -d 1 14:39:14 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command 14:39:15 0 12280 0.00 335716.00 0.00 0 python从 pidstat 的输出,我们再次看到了 PID 号为 12280 的结果。这说明,正是案例应用引发 I/O 的性能瓶颈。
走到这一步,你估计觉得,接下来就很简单了,上一个案例不刚刚学过吗?无非就是,先用 strace 确认它是不是在写文件,再用 lsof 找出文件描述符对应的文件即可。
到底是不是这样呢?我们不妨来试试。还是在终端一中,执行下面的 strace 命令:
$ strace -p 12280 strace: Process 12280 attached select(0, NULL, NULL, NULL, {tv_sec=0, tv_usec=567708}) = 0 (Timeout) stat("/usr/local/lib/python3.7/importlib/_bootstrap.py", {st_mode=S_IFREG|0644, st_size=39278, ...}) = 0 stat("/usr/local/lib/python3.7/importlib/_bootstrap.py", {st_mode=S_IFREG|0644, st_size=39278, ...}) = 0从 strace 中,你可以看到大量的 stat 系统调用,并且大都为 python 的文件,但是,请注意,这里并没有任何 write 系统调用。
由于 strace 的输出比较多,我们可以用 grep ,来过滤一下 write,比如:
strace -p 12280 2>&1 | grep write遗憾的是,这里仍然没有任何输出。
难道此时已经没有性能问题了吗?重新执行刚才的 top 和 iostat 命令,你会不幸地发现,性能问题仍然存在。
我们只好综合 strace、pidstat 和 iostat 这三个结果来分析了。很明显,你应该发现了这里的矛盾:iostat 已经证明磁盘 I/O 有性能瓶颈,而 pidstat 也证明了,这个瓶颈是由 12280 号进程导致的,但 strace 跟踪这个进程,却没有找到任何 write 系统调用。
这就奇怪了。难道因为案例使用的编程语言是 Python ,而 Python 是解释型的,所以找不到?还是说,因为案例运行在 Docker 中呢?这里留个悬念,你自己想想。
文件写,明明应该有相应的 write 系统调用,但用现有工具却找不到痕迹,这时就该想想换工具的问题了。怎样才能知道哪里在写文件呢?
这里我给你介绍一个新工具, filetop 。它是 bcc 软件包的一部分,基于 Linux 内核的 eBPF(extended Berkeley Packet Filters)机制,主要跟踪内核中文件的读写情况,并输出线程 ID(TID)、读写大小、读写类型以及文件名称。
首先,在终端一中运行下面的命令:
# 切换到工具目录 $ cd /usr/share/bcc/tools # -C 选项表示输出新内容时不清空屏幕 $ ./filetop -C TID COMM READS WRITES R_Kb W_Kb T FILE 514 python 0 1 0 2832 R 669.txt 514 python 0 1 0 2490 R 667.txt 514 python 0 1 0 2685 R 671.txt 514 python 0 1 0 2392 R 670.txt 514 python 0 1 0 2050 R 672.txt ... TID COMM READS WRITES R_Kb W_Kb T FILE 514 python 2 0 5957 0 R 651.txt 514 python 2 0 5371 0 R 112.txt 514 python 2 0 4785 0 R 861.txt 514 python 2 0 4736 0 R 213.txt 514 python 2 0 4443 0 R 45.txt你会看到,filetop 输出了 8 列内容,分别是线程 ID、线程命令行、读写次数、读写的大小(单位 KB)、文件类型以及读写的文件名称。
这些内容里,你可能会看到很多动态链接库,不过这不是我们的重点,暂且忽略即可。我们的重点,是一个 python 应用,所以要特别关注 python 相关的内容。
多观察一会儿,你就会发现,每隔一段时间,线程号为 514 的 python 应用就会先写入大量的 txt 文件,再大量地读。
线程号为 514 的线程,属于哪个进程呢?我们可以用 ps 命令查看。先在终端一中,按下 Ctrl+C ,停止 filetop ;然后,运行下面的 ps 命令。这个输出的第二列内容,就是我们想知道的进程号:
$ ps -efT | grep 514 root 12280 514 14626 33 14:47 pts/0 00:00:05 /usr/local/bin/python /app.py我们看到,这个线程正是案例应用 12280 的线程。终于可以先松一口气,不过还没完,filetop 只给出了文件名称,却没有文件路径,还得继续找啊。
我再介绍一个好用的工具,opensnoop 。它同属于 bcc 软件包,可以动态跟踪内核中的 open 系统调用。这样,我们就可以找出这些 txt 文件的路径。
接下来,在终端一中,运行下面的 opensnoop 命令:
$ opensnoop 12280 python 6 0 /tmp/9046db9e-fe25-11e8-b13f-0242ac110002/650.txt 12280 python 6 0 /tmp/9046db9e-fe25-11e8-b13f-0242ac110002/651.txt 12280 python 6 0 /tmp/9046db9e-fe25-11e8-b13f-0242ac110002/652.txt这次,通过 opensnoop 的输出,你可以看到,这些 txt 路径位于 /tmp 目录下。你还能看到,它打开的文件数量,按照数字编号,从 0.txt 依次增大到 999.txt,这可远多于前面用 filetop 看到的数量。
综合 filetop 和 opensnoop ,我们就可以进一步分析了。我们可以大胆猜测,案例应用在写入 1000 个 txt 文件后,又把这些内容读到内存中进行处理。我们来检查一下,这个目录中是不是真的有 1000 个文件:
$ ls /tmp/9046db9e-fe25-11e8-b13f-0242ac110002 | wc -l ls: cannot access '/tmp/9046db9e-fe25-11e8-b13f-0242ac110002': No such file or directory 0操作后却发现,目录居然不存在了。怎么回事呢?我们回到 opensnoop 再观察一会儿:
$ opensnoop 12280 python 6 0 /tmp/defee970-fe25-11e8-b13f-0242ac110002/261.txt 12280 python 6 0 /tmp/defee970-fe25-11e8-b13f-0242ac110002/840.txt 12280 python 6 0 /tmp/defee970-fe25-11e8-b13f-0242ac110002/136.txt原来,这时的路径已经变成了另一个目录。这说明,这些目录都是应用程序动态生成的,用完就删了。
结合前面的所有分析,我们基本可以判断,案例应用会动态生成一批文件,用来临时存储数据,用完就会删除它们。但不幸的是,正是这些文件读写,引发了 I/O 的性能瓶颈,导致整个处理过程非常慢。
当然,我们还需要验证这个猜想。老办法,还是查看应用程序的源码 app.py,
@app.route("/popularity/<word>") def word_popularity(word): dir_path = '/tmp/{}'.format(uuid.uuid1()) count = 0 sample_size = 1000 def save_to_file(file_name, content): with open(file_name, 'w') as f: f.write(content) try: # initial directory firstly os.mkdir(dir_path) # save article to files for i in range(sample_size): file_name = '{}/{}.txt'.format(dir_path, i) article = generate_article() save_to_file(file_name, article) # count word popularity for root, dirs, files in os.walk(dir_path): for file_name in files: with open('{}/{}'.format(dir_path, file_name)) as f: if validate(word, f.read()): count += 1 finally: # clean files shutil.rmtree(dir_path, ignore_errors=True) return jsonify({'popularity': count / sample_size * 100, 'word': word})源码中可以看到,这个案例应用,在每个请求的处理过程中,都会生成一批临时文件,然后读入内存处理,最后再把整个目录删除掉。
这是一种常见的利用磁盘空间处理大量数据的技巧,不过,本次案例中的 I/O 请求太重,导致磁盘 I/O 利用率过高。
要解决这一点,其实就是算法优化问题了。比如在内存充足时,就可以把所有数据都放到内存中处理,这样就能避免 I/O 的性能问题。
27.2 思考
今天的案例中,iostat 已经证明,磁盘 I/O 出现了性能瓶颈, pidstat 也证明了这个瓶颈是由 12280 号进程导致的。但是,strace 跟踪这个进程,却没有发现任何 write 系统调用。
答案:在strace -p PID后加上-f,多进程和多线程都可以跟踪。
28 | 案例篇:一个SQL查询要15秒,这是怎么回事?
28.1 案例
机器配置: 2 CPU, 8 GB 内存。
安装软件:
apt install docker.io sysstat make git。
案例总共由三个容器组成,包括一个 MySQL 数据库应用、一个商品搜索应用以及一个数据处理的应用。其中,商品搜索应用以 HTTP 的形式提供了一个接口:
- /:返回 Index Page;
- /db/insert/products/:插入指定数量的商品信息;
- /products/:查询指定商品的信息,并返回处理时间。
在第一个终端中执行下面命令,拉取本次案例所需脚本:
git clone https://github.com/feiskyer/linux-perf-examples cd linux-perf-examples/mysql-slow接着,执行下面的命令,运行本次的目标应用。正常情况下,你应该可以看到下面的输出:
# 注意下面的随机字符串是容器 ID,每次运行均会不同,并且你不需要关注它,因为我们只会用到名字 $ make run docker run --name=mysql -itd -p 10000:80 -m 800m feisky/mysql:5.6 WARNING: Your kernel does not support swap limit capabilities or the cgroup is not mounted. Memory limited without swap. 4156780da5be0b9026bcf27a3fa56abc15b8408e358fa327f472bcc5add4453f docker run --name=dataservice -itd --privileged feisky/mysql-dataservice f724d0816d7e47c0b2b1ff701e9a39239cb9b5ce70f597764c793b68131122bb docker run --name=app --network=container:mysql -itd feisky/mysql-slow 81d3392ba25bb8436f6151662a13ff6182b6bc6f2a559fc2e9d873cd07224ab6然后,再运行 docker ps 命令,确认三个容器都处在运行(Up)状态:
$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 9a4e3c580963 feisky/mysql-slow "python /app.py" 42 seconds ago Up 36 seconds app 2a47aab18082 feisky/mysql-dataservice "python /dataservice…" 46 seconds ago Up 41 seconds dataservice 4c3ff7b24748 feisky/mysql:5.6 "docker-entrypoint.s…" 47 seconds ago Up 46 seconds 3306/tcp, 0.0.0.0:10000->80/tcp mysqlMySQL 数据库的启动过程,需要做一些初始化工作,这通常需要花费几分钟时间。你可以运行 docker logs 命令,查看它的启动过程。
当你看到下面这个输出时,说明 MySQL 初始化完成,可以接收外部请求了:
$ docker logs -f mysql ... ... [Note] mysqld: ready for connections. Version: '5.6.42-log' socket: '/var/run/mysqld/mysqld.sock' port: 3306 MySQL Community Server (GPL)而商品搜索应用则是在 10000 端口监听。你可以按 Ctrl+C ,停止 docker logs 命令;然后,执行下面的命令,确认它也已经正常运行。如果一切正常,你会看到 Index Page 的输出:
$ curl http://127.0.0.1:10000/ Index Page接下来,运行 make init 命令,初始化数据库,并插入 10000 条商品信息。这个过程比较慢,比如在我的机器中,就花了十几分钟时间。耐心等待一段时间后,你会看到如下的输出:
$ make init docker exec -i mysql mysql -uroot -P3306 < tables.sql curl http://127.0.0.1:10000/db/insert/products/10000 insert 10000 lines接着,我们切换到第二个终端,访问一下商品搜索的接口,看看能不能找到想要的商品。执行如下的 curl 命令:
$ curl http://192.168.0.10:10000/products/geektime Got data: () in 15.364538192749023 sec稍等一会儿,你会发现,这个接口返回的是空数据,而且处理时间超过 15 秒。这么慢的响应速度让人无法忍受,到底出了什么问题呢?
既然今天用了 MySQL,你估计会猜到是慢查询的问题。
不过别急,在具体分析前,为了避免在分析过程中客户端的请求结束,我们把 curl 命令放到一个循环里执行。同时,为了避免给系统过大压力,我们设置在每次查询后,都先等待 5 秒,然后再开始新的请求。
所以,你可以在终端二中,继续执行下面的命令:
while true; do curl http://192.168.0.10:10000/products/geektime; sleep 5; done接下来,重新回到终端一中,分析接口响应速度慢的原因。不过,重回终端一后,你会发现系统响应也明显变慢了,随便执行一个命令,都得停顿一会儿才能看到输出。
首先,我们在终端一执行 top 命令,分析系统的 CPU 使用情况:
$ top top - 12:02:15 up 6 days, 8:05, 1 user, load average: 0.66, 0.72, 0.59 Tasks: 137 total, 1 running, 81 sleeping, 0 stopped, 0 zombie %Cpu0 : 0.7 us, 1.3 sy, 0.0 ni, 35.9 id, 62.1 wa, 0.0 hi, 0.0 si, 0.0 st %Cpu1 : 0.3 us, 0.7 sy, 0.0 ni, 84.7 id, 14.3 wa, 0.0 hi, 0.0 si, 0.0 st KiB Mem : 8169300 total, 7238472 free, 546132 used, 384696 buff/cache KiB Swap: 0 total, 0 free, 0 used. 7316952 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 27458 999 20 0 833852 57968 13176 S 1.7 0.7 0:12.40 mysqld 27617 root 20 0 24348 9216 4692 S 1.0 0.1 0:04.40 python 1549 root 20 0 236716 24568 9864 S 0.3 0.3 51:46.57 python3 22421 root 20 0 0 0 0 I 0.3 0.0 0:01.16 kworker/u观察 top 的输出,我们发现,两个 CPU 的 iowait 都比较高,特别是 CPU0,iowait 已经超过 60%。而具体到各个进程, CPU 使用率并不高,最高的也只有 1.7%。
既然 CPU 的嫌疑不大,那问题应该还是出在了 I/O 上。我们仍然在第一个终端,按下 Ctrl+C,停止 top 命令;然后,执行下面的 iostat 命令,看看有没有 I/O 性能问题:
$ iostat -d -x 1 Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util ... sda 273.00 0.00 32568.00 0.00 0.00 0.00 0.00 0.00 7.90 0.00 1.16 119.30 0.00 3.56 97.20iostat 的输出你应该非常熟悉。观察这个界面,我们发现,磁盘 sda 每秒的读数据为 32 MB, 而 I/O 使用率高达 97% ,接近饱和,这说明,磁盘 sda 的读取确实碰到了性能瓶颈。
那要怎么知道,这些 I/O 请求到底是哪些进程导致的呢?当然可以找我们的老朋友, pidstat。接下来,在终端一中,按下 Ctrl+C 停止 iostat 命令,然后运行下面的 pidstat 命令,观察进程的 I/O 情况:
# -d 选项表示展示进程的 I/O 情况 $ pidstat -d 1 12:04:11 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command 12:04:12 999 27458 32640.00 0.00 0.00 0 mysqld 12:04:12 0 27617 4.00 4.00 0.00 3 python 12:04:12 0 27864 0.00 4.00 0.00 0 systemd-journal从 pidstat 的输出可以看到,PID 为 27458 的 mysqld 进程正在进行大量的读,而且读取速度是 32 MB/s,跟刚才 iostat 的发现一致。两个结果一对比,我们自然就找到了磁盘 I/O 瓶颈的根源,即 mysqld 进程。
不过,这事儿还没完。我们自然要怀疑一下,为什么 mysqld 会去读取大量的磁盘数据呢?按照前面猜测,我们提到过,这有可能是个慢查询问题。
可是,回想一下,慢查询的现象大多是 CPU 使用率高(比如 100% ),但这里看到的却是 I/O 问题。看来,这并不是一个单纯的慢查询问题,我们有必要分析一下 MySQL 读取的数据。
要分析进程的数据读取,当然还要靠上一节用到过的 strace+ lsof 组合。
接下来,还是在终端一中,执行 strace 命令,并且指定 mysqld 的进程号 27458。我们知道,MySQL 是一个多线程的数据库应用,为了不漏掉这些线程的数据读取情况,你要记得在执行 stace 命令时,加上 -f 参数:
$ strace -f -p 27458 [pid 28014] read(38, "934EiwT363aak7VtqF1mHGa4LL4Dhbks"..., 131072) = 131072 [pid 28014] read(38, "hSs7KBDepBqA6m4ce6i6iUfFTeG9Ot9z"..., 20480) = 20480 [pid 28014] read(38, "NRhRjCSsLLBjTfdqiBRLvN9K6FRfqqLm"..., 131072) = 131072 [pid 28014] read(38, "AKgsik4BilLb7y6OkwQUjjqGeCTQTaRl"..., 24576) = 24576 [pid 28014] read(38, "hFMHx7FzUSqfFI22fQxWCpSnDmRjamaW"..., 131072) = 131072 [pid 28014] read(38, "ajUzLmKqivcDJSkiw7QWf2ETLgvQIpfC"..., 20480) = 20480观察一会,你会发现,线程 28014 正在读取大量数据,且读取文件的描述符编号为 38。这儿的 38 又对应着哪个文件呢?我们可以执行下面的 lsof 命令,并且指定线程号 28014 ,具体查看这个可疑线程和可疑文件:
lsof -p 28014奇怪的是,lsof 并没有给出任何输出。实际上,如果你查看 lsof 命令的返回值,就会发现,这个命令的执行失败了。
我们知道,在 SHELL 中,特殊标量 $? 表示上一条命令退出时的返回值。查看这个特殊标量,你会发现它的返回值是 1。可是别忘了,在 Linux 中,返回值为 0 ,才表示命令执行成功。返回值为 1,显然表明执行失败。
$ echo $? 1事实上,通过查询 lsof 的文档,你会发现,-p 参数需要指定进程号,而我们刚才传入的是线程号,所以 lsof 失败了。你看,任何一个细节都可能成为性能分析的”拦路虎”。
回过头我们看,mysqld 的进程号是 27458,而 28014 只是它的一个线程。而且,如果你观察 一下 mysqld 进程的线程,你会发现,mysqld 其实还有很多正在运行的其他线程:
# -t 表示显示线程,-a 表示显示命令行参数 $ pstree -t -a -p 27458 mysqld,27458 --log_bin=on --sync_binlog=1 ... ├─{mysqld},27922 ├─{mysqld},27923 └─{mysqld},28014找到了原因,lsof 的问题就容易解决了。把线程号换成进程号,继续执行 lsof 命令:
$ lsof -p 27458 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME ... mysqld 27458 999 38u REG 8,1 512440000 2601895 /var/lib/mysql/test/products.MYD这次我们得到了 lsof 的输出。从输出中可以看到, mysqld 进程确实打开了大量文件,而根据文件描述符(FD)的编号,我们知道,描述符为 38 的是一个路径为 /var/lib/mysql/test/products.MYD 的文件。这里注意, 38 后面的 u 表示, mysqld 以读写的方式访问文件。
看到这个文件,熟悉 MySQL 的你可能笑了:
- MYD 文件,是 MyISAM 引擎用来存储表数据的文件;
- 文件名就是数据表的名字;
- 而这个文件的父目录,也就是数据库的名字。
换句话说,这个文件告诉我们,mysqld 在读取数据库 test 中的 products 表。
实际上,你可以执行下面的命令,查看 mysqld 在管理数据库 test 时的存储文件。不过要注意,由于 MySQL 运行在容器中,你需要通过 docker exec 到容器中查看:
$ docker exec -it mysql ls /var/lib/mysql/test/ db.opt products.MYD products.MYI products.frm从这里你可以发现,/var/lib/mysql/test/ 目录中有四个文件,每个文件的作用分别是:
- MYD 文件用来存储表的数据;
- MYI 文件用来存储表的索引;
- frm 文件用来存储表的元信息(比如表结构);
- opt 文件则用来存储数据库的元信息(比如字符集、字符校验规则等)。
当然,看到这些,你可能还有一个疑问,那就是,这些文件到底是不是 mysqld 正在使用的数据库文件呢?有没有可能是不再使用的旧数据呢?其实,这个很容易确认,查一下 mysqld 配置的数据路径即可。
你可以在终端一中,继续执行下面的命令:
$ docker exec -i -t mysql mysql -e 'show global variables like "%datadir%";' +---------------+-----------------+ | Variable_name | Value | +---------------+-----------------+ | datadir | /var/lib/mysql/ | +---------------+-----------------+这里可以看到,/var/lib/mysql/ 确实是 mysqld 正在使用的数据存储目录。刚才分析得出的数据库 test 和数据表 products ,都是正在使用。
注:其实 lsof 的结果已经可以确认,它们都是 mysqld 正在访问的文件。再查询 datadir ,只是想换一个思路,进一步确认一下。
既然已经找出了数据库和表,接下来要做的,就是弄清楚数据库中正在执行什么样的 SQL 了。我们继续在终端一中,运行下面的 docker exec 命令,进入 MySQL 的命令行界面:
$ docker exec -i -t mysql mysql ... Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql>为了保证 SQL 语句不截断,这里我们可以执行 show full processlist 命令。如果一切正常,你应该可以看到如下输出:
mysql> show full processlist; +----+------+-----------------+------+---------+------+--------------+-----------------------------------------------------+ | Id | User | Host | db | Command | Time | State | Info | +----+------+-----------------+------+---------+------+--------------+-----------------------------------------------------+ | 27 | root | localhost | test | Query | 0 | init | show full processlist | | 28 | root | 127.0.0.1:42262 | test | Query | 1 | Sending data | select * from products where productName='geektime' | +----+------+-----------------+------+---------+------+--------------+-----------------------------------------------------+ 2 rows in set (0.00 sec)这个输出中,
- db 表示数据库的名字;
- Command 表示 SQL 类型;
- Time 表示执行时间;
- State 表示状态;
- 而 Info 则包含了完整的 SQL 语句。
多执行几次 show full processlist 命令,你可看到 select * from products where productName=’geektime’ 这条 SQL 语句的执行时间比较长。
再回忆一下,案例开始时,我们在终端二查询的产品名称 http://192.168.0.10:10000/products/geektime,其中的 geektime 也符合这条查询语句的条件。
我们知道,MySQL 的慢查询问题,很可能是没有利用好索引导致的,那这条查询语句是不是这样呢?我们又该怎么确认,查询语句是否利用了索引呢?
其实,MySQL 内置的 explain 命令,就可以帮你解决这个问题。继续在 MySQL 终端中,运行下面的 explain 命令:
# 切换到 test 库 mysql> use test; # 执行 explain 命令 mysql> explain select * from products where productName='geektime'; +----+-------------+----------+------+---------------+------+---------+------+-------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+----------+------+---------------+------+---------+------+-------+-------------+ | 1 | SIMPLE | products | ALL | NULL | NULL | NULL | NULL | 10000 | Using where | +----+-------------+----------+------+---------------+------+---------+------+-------+-------------+ 1 row in set (0.00 sec)观察这次的输出。这个界面中,有几个比较重要的字段需要你注意,我就以这个输出为例,分别解释一下:
- select_type 表示查询类型,而这里的 SIMPLE 表示此查询不包括 UNION 查询或者子查询;
- table 表示数据表的名字,这里是 products;
- type 表示查询类型,这里的 ALL 表示全表查询,但索引查询应该是 index 类型才对;
- possible_keys 表示可能选用的索引,这里是 NULL;
- key 表示确切会使用的索引,这里也是 NULL;
- rows 表示查询扫描的行数,这里是 10000。
根据这些信息,我们可以确定,这条查询语句压根儿没有使用索引,所以查询时,会扫描全表,并且扫描行数高达 10000 行。响应速度那么慢也就难怪了。
走到这一步,你应该很容易想到优化方法,没有索引那我们就自己建立,给 productName 建立索引就可以了。不过,增加索引前,你需要先弄清楚,这个表结构到底长什么样儿。
执行下面的 MySQL 命令,查询 products 表的结构,你会看到,它只有一个 id 主键,并不包括 productName 的索引:
mysql> show create table products; ... | products | CREATE TABLE `products` ( `id` int(11) NOT NULL, `productCode` text NOT NULL COMMENT '产品代码', `productName` text NOT NULL COMMENT '产品名称', ... PRIMARY KEY (`id`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC | ...接下来,我们就可以给 productName 建立索引了,也就是执行下面的 CREATE INDEX 命令:
mysql> CREATE INDEX products_index ON products (productName); ERROR 1170 (42000): BLOB/TEXT column 'productName' used in key specification without a key length不过,醒目的 ERROR 告诉我们,这条命令运行失败了。根据错误信息,productName 是一个 BLOB/TEXT 类型,需要设置一个长度。所以,想要创建索引,就必须为 productName 指定一个前缀长度。
那前缀长度设置为多大比较合适呢?这里其实有专门的算法,即通过计算前缀长度的选择性,来确定索引的长度。不过,我们可以稍微简化一下,直接使用一个固定数值(比如 64),执行下面的命令创建索引:
mysql> CREATE INDEX products_index ON products (productName(64)); Query OK, 10000 rows affected (14.45 sec) Records: 10000 Duplicates: 0 Warnings: 0我们切换到终端二中,查看还在执行的 curl 命令的结果:
Got data: ()in 15.383180141448975 sec Got data: ()in 15.384996891021729 sec Got data: ()in 0.0021054744720458984 sec Got data: ()in 0.003951072692871094 sec显然,查询时间已经从 15 秒缩短到了 3 毫秒。看来,没有索引果然就是这次性能问题的罪魁祸首,解决了索引,就解决了查询慢的问题。
28.2 案例思考
案例开始时,我们启动的几个容器应用。除了 MySQL 和商品搜索应用外,还有一个 DataService 应用。为什么这个案例开始时,要运行一个看起来毫不相关的应用呢?
实际上,DataService 是一个严重影响 MySQL 性能的干扰应用。抛开上述索引优化方法不说,这个案例还有一种优化方法,也就是停止 DataService 应用。
接下来,我们就删除数据库索引,回到原来的状态;然后停止 DataService 应用,看看优化效果如何。
在终端二中停止 curl 命令,然后回到终端一中,执行下面的命令删除索引:
# 删除索引 $ docker exec -i -t mysql mysql mysql> use test; mysql> DROP INDEX products_index ON products;在终端二中重新运行 curl 命令。当然,这次你会发现,处理时间又变慢了:
$ while true; do curl http://192.168.0.10:10000/products/geektime; sleep 5; done Got data: ()in 16.884345054626465 sec再次回到终端一中,执行下面的命令,停止 DataService 应用:
# 停止 DataService 应用 $ docker rm -f dataservice最后,我们回到终端二中,观察 curl 的结果:
Got data: ()in 16.884345054626465 sec Got data: ()in 15.238174200057983 sec Got data: ()in 0.12604427337646484 sec Got data: ()in 0.1101069450378418 sec Got data: ()in 0.11235237121582031 sec果然,停止 DataService 后,处理时间从 15 秒缩短到了 0.1 秒,虽然比不上增加索引后的 3 毫秒,但相对于 15 秒来说,优化效果还是非常明显的。
那么,这种情况下,还有没有 I/O 瓶颈了呢?
我们切换到终端一中,运行下面的 vmstat 命令(注意不是 iostat,稍后解释原因),观察 I/O 的变化情况:
$ vmstat 1 procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 0 1 0 6809304 1368 856744 0 0 32640 0 52 478 1 0 50 49 0 0 1 0 6776620 1368 889456 0 0 32640 0 33 490 0 0 50 49 0 0 0 0 6747540 1368 918576 0 0 29056 0 42 568 0 0 56 44 0 0 0 0 6747540 1368 918576 0 0 0 0 40 141 1 0 100 0 0 0 0 0 6747160 1368 918576 0 0 0 0 40 148 0 1 99 0 0在查看 I/O 情况时,我并没用 iostat 命令,而是用了 vmstat。其实,相对于 iostat 来说,vmstat 可以同时提供 CPU、内存和 I/O 的使用情况。
28.3 思考
停止 DataService 后,商品搜索应用的处理时间,从 15 秒缩短到了 0.1 秒。这是为什么呢?
我给个小小的提示。你可以先查看 dataservice.py,你会发现,DataService 实际上是在读写一个仅包括 “data” 字符串的小文件。不过在读取文件前,它会先把 /proc/sys/vm/drop_caches 改成 1。
答案:echo 1>/proc/sys/vm/drop_caches表示释放pagecache,也就是文件缓存,而mysql读取的数据就是文件缓存,dataservice不停的释放文件缓存,就导致MySQL都无法利用磁盘缓存,也就慢了。
29 | 案例篇:Redis响应严重延迟,如何解决?
29.1 案例
机器配置: 2 CPU, 8 GB 内存。
安装软件:
apt install docker.io sysstat。
今天的案例由 Python 应用 +Redis 两部分组成。其中,Python 应用是一个基于 Flask 的应用,它会利用 Redis ,来管理应用程序的缓存,并对外提供三个 HTTP 接口:
/:返回 hello redis;
/init/:插入指定数量的缓存数据,如果不指定数量,默认的是 5000 条;
缓存的键格式为 uuid;
缓存的值为 good、bad 或 normal 三者之一。
/get_cache/<type_name>:查询指定值的缓存数据,并返回处理时间。其中,type_name 参数只支持 good, bad 和 normal(也就是找出具有相同 value 的 key 列表)。
在第一个终端中,执行下面的命令,运行本次案例要分析的目标应用。正常情况下,你应该可以看到下面的输出:
# 注意下面的随机字符串是容器 ID,每次运行均会不同,并且你不需要关注它 $ docker run --name=redis -itd -p 10000:80 feisky/redis-server ec41cb9e4dd5cb7079e1d9f72b7cee7de67278dbd3bd0956b4c0846bff211803 $ docker run --name=app --network=container:redis -itd feisky/redis-app 2c54eb252d0552448320d9155a2618b799a1e71d7289ec7277a61e72a9de5fd0然后,再运行 docker ps 命令,确认两个容器都处于运行(Up)状态:
$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 2c54eb252d05 feisky/redis-app "python /app.py" 48 seconds ago Up 47 seconds app ec41cb9e4dd5 feisky/redis-server "docker-entrypoint.s…" 49 seconds ago Up 48 seconds 6379/tcp, 0.0.0.0:10000->80/tcp redis我们切换到第二个终端,使用 curl 工具,访问应用首页。如果你看到 hello redis 的输出,说明应用正常启动:
$ curl http://192.168.0.10:10000/ hello redis接下来,继续在终端二中,执行下面的 curl 命令,来调用应用的 /init 接口,初始化 Redis 缓存,并且插入 5000 条缓存信息。这个过程比较慢,比如我的机器就花了十几分钟时间。耐心等一会儿后,你会看到下面这行输出:
# 案例插入 5000 条数据,在实践时可以根据磁盘的类型适当调整,比如使用 SSD 时可以调大,而 HDD 可以适当调小 $ curl http://192.168.0.10:10000/init/5000 {"elapsed_seconds":30.26814079284668,"keys_initialized":5000}继续执行下一个命令,访问应用的缓存查询接口。如果一切正常,你会看到如下输出:
$ curl http://192.168.0.10:10000/get_cache {"count":1677,"data":["d97662fa-06ac-11e9-92c7-0242ac110002",...],"elapsed_seconds":10.545469760894775,"type":"good"}为了避免分析过程中客户端的请求结束,在进行性能分析前,我们先要把 curl 命令放到一个循环里来执行。你可以在终端二中,继续执行下面的命令:
while true; do curl http://192.168.0.10:10000/get_cache; done在终端一中执行 top 命令,分析系统的 CPU 使用情况:
$ top top - 12:46:18 up 11 days, 8:49, 1 user, load average: 1.36, 1.36, 1.04 Tasks: 137 total, 1 running, 79 sleeping, 0 stopped, 0 zombie %Cpu0 : 6.0 us, 2.7 sy, 0.0 ni, 5.7 id, 84.7 wa, 0.0 hi, 1.0 si, 0.0 st %Cpu1 : 1.0 us, 3.0 sy, 0.0 ni, 94.7 id, 0.0 wa, 0.0 hi, 1.3 si, 0.0 st KiB Mem : 8169300 total, 7342244 free, 432912 used, 394144 buff/cache KiB Swap: 0 total, 0 free, 0 used. 7478748 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 9181 root 20 0 193004 27304 8716 S 8.6 0.3 0:07.15 python 9085 systemd+ 20 0 28352 9760 1860 D 5.0 0.1 0:04.34 redis-server 368 root 20 0 0 0 0 D 1.0 0.0 0:33.88 jbd2/sda1-8 149 root 0 -20 0 0 0 I 0.3 0.0 0:10.63 kworker/0:1H 1549 root 20 0 236716 24576 9864 S 0.3 0.3 91:37.30 python3观察 top 的输出可以发现,CPU0 的 iowait 比较高,已经达到了 84%;而各个进程的 CPU 使用率都不太高,最高的 python 和 redis-server ,也分别只有 8% 和 5%。再看内存,总内存 8GB,剩余内存还有 7GB 多,显然内存也没啥问题。
综合 top 的信息,最有嫌疑的就是 iowait。所以,接下来还是要继续分析,是不是 I/O 问题。
还在第一个终端中,先按下 Ctrl+C,停止 top 命令;然后,执行下面的 iostat 命令,查看有没有 I/O 性能问题:
$ iostat -d -x 1 Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util ... sda 0.00 492.00 0.00 2672.00 0.00 176.00 0.00 26.35 0.00 1.76 0.00 0.00 5.43 0.00 0.00观察 iostat 的输出,我们发现,磁盘 sda 每秒的写数据(wkB/s)为 2.5MB,I/O 使用率(%util)是 0。看来,虽然有些 I/O 操作,但并没导致磁盘的 I/O 瓶颈。
排查一圈儿下来,CPU 和内存使用没问题,I/O 也没有瓶颈,接下来好像就没啥分析方向了?
回想一下,今天的案例问题是从 Redis 缓存中查询数据慢。对查询来说,对应的 I/O 应该是磁盘的读操作,但刚才我们用 iostat 看到的却是写操作。虽说 I/O 本身并没有性能瓶颈,但这里的磁盘写也是比较奇怪的。为什么会有磁盘写呢?那我们就得知道,到底是哪个进程在写磁盘。
要知道 I/O 请求来自哪些进程,还是要靠我们的老朋友 pidstat。在终端一中运行下面的 pidstat 命令,观察进程的 I/O 情况:
$ pidstat -d 1 12:49:35 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command 12:49:36 0 368 0.00 16.00 0.00 86 jbd2/sda1-8 12:49:36 100 9085 0.00 636.00 0.00 1 redis-server从 pidstat 的输出,我们看到,I/O 最多的进程是 PID 为 9085 的 redis-server,并且它也刚好是在写磁盘。这说明,确实是 redis-server 在进行磁盘写。
当然,光找到读写磁盘的进程还不够,我们还要再用 strace+lsof 组合,看看 redis-server 到底在写什么。
接下来,还是在终端一中,执行 strace 命令,并且指定 redis-server 的进程号 9085:
# -f 表示跟踪子进程和子线程,-T 表示显示系统调用的时长,-tt 表示显示跟踪时间 $ strace -f -T -tt -p 9085 [pid 9085] 14:20:16.826131 epoll_pwait(5, [{EPOLLIN, {u32=8, u64=8}}], 10128, 65, NULL, 8) = 1 <0.000055> [pid 9085] 14:20:16.826301 read(8, "*2\r\n$3\r\nGET\r\n$41\r\nuuid:5b2e76cc-"..., 16384) = 61 <0.000071> [pid 9085] 14:20:16.826477 read(3, 0x7fff366a5747, 1) = -1 EAGAIN (Resource temporarily unavailable) <0.000063> [pid 9085] 14:20:16.826645 write(8, "$3\r\nbad\r\n", 9) = 9 <0.000173> [pid 9085] 14:20:16.826907 epoll_pwait(5, [{EPOLLIN, {u32=8, u64=8}}], 10128, 65, NULL, 8) = 1 <0.000032> [pid 9085] 14:20:16.827030 read(8, "*2\r\n$3\r\nGET\r\n$41\r\nuuid:55862ada-"..., 16384) = 61 <0.000044> [pid 9085] 14:20:16.827149 read(3, 0x7fff366a5747, 1) = -1 EAGAIN (Resource temporarily unavailable) <0.000043> [pid 9085] 14:20:16.827285 write(8, "$3\r\nbad\r\n", 9) = 9 <0.000141> [pid 9085] 14:20:16.827514 epoll_pwait(5, [{EPOLLIN, {u32=8, u64=8}}], 10128, 64, NULL, 8) = 1 <0.000049> [pid 9085] 14:20:16.827641 read(8, "*2\r\n$3\r\nGET\r\n$41\r\nuuid:53522908-"..., 16384) = 61 <0.000043> [pid 9085] 14:20:16.827784 read(3, 0x7fff366a5747, 1) = -1 EAGAIN (Resource temporarily unavailable) <0.000034> [pid 9085] 14:20:16.827945 write(8, "$4\r\ngood\r\n", 10) = 10 <0.000288> [pid 9085] 14:20:16.828339 epoll_pwait(5, [{EPOLLIN, {u32=8, u64=8}}], 10128, 63, NULL, 8) = 1 <0.000057> [pid 9085] 14:20:16.828486 read(8, "*3\r\n$4\r\nSADD\r\n$4\r\ngood\r\n$36\r\n535"..., 16384) = 67 <0.000040> [pid 9085] 14:20:16.828623 read(3, 0x7fff366a5747, 1) = -1 EAGAIN (Resource temporarily unavailable) <0.000052> [pid 9085] 14:20:16.828760 write(7, "*3\r\n$4\r\nSADD\r\n$4\r\ngood\r\n$36\r\n535"..., 67) = 67 <0.000060> [pid 9085] 14:20:16.828970 fdatasync(7) = 0 <0.005415> [pid 9085] 14:20:16.834493 write(8, ":1\r\n", 4) = 4 <0.000250>事实上,从系统调用来看, epoll_pwait、read、write、fdatasync 这些系统调用都比较频繁。那么,刚才观察到的写磁盘,应该就是 write 或者 fdatasync 导致的了。
接着再来运行 lsof 命令,找出这些系统调用的操作对象:
$ lsof -p 9085 redis-ser 9085 systemd-network 3r FIFO 0,12 0t0 15447970 pipe redis-ser 9085 systemd-network 4w FIFO 0,12 0t0 15447970 pipe redis-ser 9085 systemd-network 5u a_inode 0,13 0 10179 [eventpoll] redis-ser 9085 systemd-network 6u sock 0,9 0t0 15447972 protocol: TCP redis-ser 9085 systemd-network 7w REG 8,1 8830146 2838532 /data/appendonly.aof redis-ser 9085 systemd-network 8u sock 0,9 0t0 15448709 protocol: TCP现在你会发现,描述符编号为 3 的是一个 pipe 管道,5 号是 eventpoll,7 号是一个普通文件,而 8 号是一个 TCP socket。
结合磁盘写的现象,我们知道,只有 7 号普通文件才会产生磁盘写,而它操作的文件路径是 /data/appendonly.aof,相应的系统调用包括 write 和 fdatasync。
如果你对 Redis 的持久化配置比较熟,看到这个文件路径以及 fdatasync 的系统调用,你应该能想到,这对应着正是 Redis 持久化配置中的 appendonly 和 appendfsync 选项。很可能是因为它们的配置不合理,导致磁盘写比较多。
接下来就验证一下这个猜测,我们可以通过 Redis 的命令行工具,查询这两个选项的配置。
继续在终端一中,运行下面的命令,查询 appendonly 和 appendfsync 的配置:
$ docker exec -it redis redis-cli config get 'append*' 1) "appendfsync" 2) "always" 3) "appendonly" 4) "yes"从这个结果你可以发现,appendfsync 配置的是 always,而 appendonly 配置的是 yes。这两个选项的详细含义,你可以从 Redis Persistence 的文档中查到,这里我做一下简单介绍。
Redis 提供了两种数据持久化的方式,分别是快照和追加文件。
快照方式,会按照指定的时间间隔,生成数据的快照,并且保存到磁盘文件中。为了避免阻塞主进程,Redis 还会 fork 出一个子进程,来负责快照的保存。这种方式的性能好,无论是备份还是恢复,都比追加文件好很多。
不过,它的缺点也很明显。在数据量大时,fork 子进程需要用到比较大的内存,保存数据也很耗时。所以,你需要设置一个比较长的时间间隔来应对,比如至少 5 分钟。这样,如果发生故障,你丢失的就是几分钟的数据。
追加文件,则是用在文件末尾追加记录的方式,对 Redis 写入的数据,依次进行持久化,所以它的持久化也更安全。
此外,它还提供了一个用 appendfsync 选项设置 fsync 的策略,确保写入的数据都落到磁盘中,具体选项包括 always、everysec、no 等。
- always 表示,每个操作都会执行一次 fsync,是最为安全的方式;
- everysec 表示,每秒钟调用一次 fsync ,这样可以保证即使是最坏情况下,也只丢失 1 秒的数据;
- 而 no 表示交给操作系统来处理。
回忆一下我们刚刚看到的配置,appendfsync 配置的是 always,意味着每次写数据时,都会调用一次 fsync,从而造成比较大的磁盘 I/O 压力。
当然,你还可以用 strace ,观察这个系统调用的执行情况。比如通过 -e 选项指定 fdatasync 后,你就会得到下面的结果:
$ strace -f -p 9085 -T -tt -e fdatasync strace: Process 9085 attached with 4 threads [pid 9085] 14:22:52.013547 fdatasync(7) = 0 <0.007112> [pid 9085] 14:22:52.022467 fdatasync(7) = 0 <0.008572> [pid 9085] 14:22:52.032223 fdatasync(7) = 0 <0.006769> ... [pid 9085] 14:22:52.139629 fdatasync(7) = 0 <0.008183>从这里你可以看到,每隔 10ms 左右,就会有一次 fdatasync 调用,并且每次调用本身也要消耗 7~8ms。
不管哪种方式,都可以验证我们的猜想,配置确实不合理。这样,我们就找出了 Redis 正在进行写入的文件,也知道了产生大量 I/O 的原因。
不过,回到最初的疑问,为什么查询时会有磁盘写呢?按理来说不应该只有数据的读取吗?这就需要我们再来审查一下 strace -f -T -tt -p 9085 的结果。
read(8, "*2\r\n$3\r\nGET\r\n$41\r\nuuid:53522908-"..., 16384) write(8, "$4\r\ngood\r\n", 10) read(8, "*3\r\n$4\r\nSADD\r\n$4\r\ngood\r\n$36\r\n535"..., 16384) write(7, "*3\r\n$4\r\nSADD\r\n$4\r\ngood\r\n$36\r\n535"..., 67) write(8, ":1\r\n", 4)细心的你应该记得,根据 lsof 的分析,文件描述符编号为 7 的是一个普通文件 /data/appendonly.aof,而编号为 8 的是 TCP socket。而观察上面的内容,8 号对应的 TCP 读写,是一个标准的”请求 - 响应”格式,即:
- 从 socket 读取 GET uuid:53522908-… 后,响应 good;
- 再从 socket 读取 SADD good 535… 后,响应 1。
对 Redis 来说,SADD 是一个写操作,所以 Redis 还会把它保存到用于持久化的 appendonly.aof 文件中。
观察更多的 strace 结果,你会发现,每当 GET 返回 good 时,随后都会有一个 SADD 操作,这也就导致了,明明是查询接口,Redis 却有大量的磁盘写。
到这里,我们就找出了 Redis 写磁盘的原因。不过,在下最终结论前,我们还是要确认一下,8 号 TCP socket 对应的 Redis 客户端,到底是不是我们的案例应用。
我们可以给 lsof 命令加上 -i 选项,找出 TCP socket 对应的 TCP 连接信息。不过,由于 Redis 和 Python 应用都在容器中运行,我们需要进入容器的网络命名空间内部,才能看到完整的 TCP 连接。
还是在终端一中,运行下面的命令:
注意:下面的命令用到的 nsenter 工具,可以进入容器命名空间。如果你的系统没有安装,请运行下面命令安装 nsenter:
docker run —rm -v /usr/local/bin:/target jpetazzo/nsenter
# 由于这两个容器共享同一个网络命名空间,所以我们只需要进入 app 的网络命名空间即可 $ PID=$(docker inspect --format {{.State.Pid}} app) # -i 表示显示网络套接字信息 $ nsenter --target $PID --net -- lsof -i COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME redis-ser 9085 systemd-network 6u IPv4 15447972 0t0 TCP localhost:6379 (LISTEN) redis-ser 9085 systemd-network 8u IPv4 15448709 0t0 TCP localhost:6379->localhost:32996 (ESTABLISHED) python 9181 root 3u IPv4 15448677 0t0 TCP *:http (LISTEN) python 9181 root 5u IPv4 15449632 0t0 TCP localhost:32996->localhost:6379 (ESTABLISHED)可以看到,redis-server 的 8 号文件描述符,对应 TCP 连接 localhost:6379->localhost:32996。其中, localhost:6379 是 redis-server 自己的监听端口,自然 localhost:32996 就是 redis 的客户端。再观察最后一行,localhost:32996 对应的,正是我们的 Python 应用程序(进程号为 9181)。
历经各种波折,我们总算找出了 Redis 响应延迟的潜在原因。总结一下,我们找到两个问题。
- 第一个问题,Redis 配置的 appendfsync 是 always,这就导致 Redis 每次的写操作,都会触发 fdatasync 系统调用。今天的案例,没必要用这么高频的同步写,使用默认的 1s 时间间隔,就足够了。
- 第二个问题,Python 应用在查询接口中会调用 Redis 的 SADD 命令,这很可能是不合理使用缓存导致的。
对于第一个配置问题,我们可以执行下面的命令,把 appendfsync 改成 everysec:
$ docker exec -it redis redis-cli config set appendfsync everysec OK改完后,切换到终端二中查看,你会发现,现在的请求时间,已经缩短到了 0.9s:
{..., "elapsed_seconds":0.9368953704833984,"type":"good"}而第二个问题,就要查看应用的源码了。点击 Github ,你就可以查看案例应用的源代码:
def get_cache(type_name): '''handler for /get_cache''' for key in redis_client.scan_iter("uuid:*"): value = redis_client.get(key) if value == type_name: redis_client.sadd(type_name, key[5:]) data = list(redis_client.smembers(type_name)) redis_client.delete(type_name) return jsonify({"type": type_name, 'count': len(data), 'data': data})果然,Python 应用把 Redis 当成临时空间,用来存储查询过程中找到的数据。不过我们知道,这些数据放内存中就可以了,完全没必要再通过网络调用存储到 Redis 中。
基于这个思路,我把修改后的代码也推送到了相同的源码文件中,你可以通过 http://192.168.0.10:10000/get_cache_data 这个接口来访问它。
我们切换到终端二,按 Ctrl+C 停止之前的 curl 命令;然后执行下面的 curl 命令,调用 http://192.168.0.10:10000/get_cache_data 新接口:
$ while true; do curl http://192.168.0.10:10000/get_cache_data; done {...,"elapsed_seconds":0.16034674644470215,"type":"good"}
30 | 套路篇:如何迅速分析出系统I/O的瓶颈在哪里?
30.1 性能指标
文件系统 I/O 性能指标
首先,最容易想到的是存储空间的使用情况,包括容量、使用量以及剩余空间等。
不过要注意,这些只是文件系统向外展示的空间使用,而非在磁盘空间的真实用量,因为文件系统的元数据也会占用磁盘空间。
而且,如果你配置了 RAID,从文件系统看到的使用量跟实际磁盘的占用空间,也会因为 RAID 级别的不同而不一样。比方说,配置 RAID10 后,你从文件系统最多也只能看到所有磁盘容量的一半。
除了数据本身的存储空间,还有一个容易忽略的是索引节点的使用情况,它也包括容量、使用量以及剩余量等三个指标。如果文件系统中存储过多的小文件,就可能碰到索引节点容量已满的问题。
其次,你应该想到的是前面多次提到过的缓存使用情况,包括页缓存、目录项缓存、索引节点缓存以及各个具体文件系统(如 ext4、XFS 等)的缓存。这些缓存会使用速度更快的内存,用来临时存储文件数据或者文件系统的元数据,从而可以减少访问慢速磁盘的次数。
除了以上这两点,文件 I/O 也是很重要的性能指标,包括 IOPS(包括 r/s 和 w/s)、响应时间(延迟)以及吞吐量(B/s)等。在考察这类指标时,通常还要考虑实际文件的读写情况。比如,结合文件大小、文件数量、I/O 类型等,综合分析文件 I/O 的性能。
磁盘 I/O 性能指标
在磁盘 I/O 原理的文章中,我曾提到过四个核心的磁盘 I/O 指标。
- 使用率,是指磁盘忙处理 I/O 请求的百分比。过高的使用率(比如超过 60%)通常意味着磁盘 I/O 存在性能瓶颈。
- IOPS(Input/Output Per Second),是指每秒的 I/O 请求数。
- 吞吐量,是指每秒的 I/O 请求大小。
响应时间,是指从发出 I/O 请求到收到响应的间隔时间。
考察这些指标时,一定要注意综合 I/O 的具体场景来分析,比如读写类型(顺序还是随机)、读写比例、读写大小、存储类型(有无 RAID 以及 RAID 级别、本地存储还是网络存储)等。
不过,这里有个大忌,就是把不同场景的 I/O 性能指标,直接进行分析对比。这是很常见的一个误区,你一定要避免。
30.2 性能工具
在文件系统的原理中,我介绍了查看文件系统容量的工具 df。它既可以查看文件系统数据的空间容量,也可以查看索引节点的容量。至于文件系统缓存,我们通过 /proc/meminfo、/proc/slabinfo 以及 slabtop 等各种来源,观察页缓存、目录项缓存、索引节点缓存以及具体文件系统的缓存情况。
在磁盘 I/O 的原理中,我们分别用 iostat 和 pidstat 观察了磁盘和进程的 I/O 情况。它们都是最常用的 I/O 性能分析工具。通过 iostat ,我们可以得到磁盘的 I/O 使用率、吞吐量、响应时间以及 IOPS 等性能指标;而通过 pidstat ,则可以观察到进程的 I/O 吞吐量以及块设备 I/O 的延迟等。
在狂打日志的案例中,我们先用 top 查看系统的 CPU 使用情况,发现 iowait 比较高;然后,又用 iostat 发现了磁盘的 I/O 使用率瓶颈,并用 pidstat 找出了大量 I/O 的进程;最后,通过 strace 和 lsof,我们找出了问题进程正在读写的文件,并最终锁定性能问题的来源——原来是进程在狂打日志。
在磁盘 I/O 延迟的单词热度案例中,我们同样先用 top、iostat ,发现磁盘有 I/O 瓶颈,并用 pidstat 找出了大量 I/O 的进程。可接下来,想要照搬上次操作的我们失败了。在随后的 strace 命令中,我们居然没看到 write 系统调用。于是,我们换了一个思路,用新工具 filetop 和 opensnoop ,从内核中跟踪系统调用,最终找出瓶颈的来源。
在 MySQL 和 Redis 的案例中,同样的思路,我们先用 top、iostat 以及 pidstat ,确定并找出 I/O 性能问题的瓶颈来源,它们正是 mysqld 和 redis-server。随后,我们又用 strace+lsof 找出了它们正在读写的文件。
关于 MySQL 案例,根据 mysqld 正在读写的文件路径,再结合 MySQL 数据库引擎的原理,我们不仅找出了数据库和数据表的名称,还进一步发现了慢查询的问题,最终通过优化索引解决了性能瓶颈。
至于 Redis 案例,根据 redis-server 读写的文件,以及正在进行网络通信的 TCP Socket,再结合 Redis 的工作原理,我们发现 Redis 持久化选项配置有问题;从 TCP Socket 通信的数据中,我们还发现了客户端的不合理行为。于是,我们修改 Redis 配置选项,并优化了客户端使用 Redis 的方式,从而减少网络通信次数,解决性能问题。
30.3 性能指标和工具的联系
同前面 CPU 和内存板块的学习一样,我建议从指标和工具两个不同维度出发,整理记忆。
- 从 I/O 指标出发,你更容易把性能工具同系统工作原理关联起来,对性能问题有宏观的认识和把握。
- 而从性能工具出发,可以让你更快上手使用工具,迅速找出我们想观察的性能指标。特别是在工具有限的情况下,我们更要充分利用好手头的每一个工具,少量工具也要尽力挖掘出大量信息。
第一个维度,从文件系统和磁盘 I/O 的性能指标出发。换句话说,当你想查看某个性能指标时,要清楚知道,哪些工具可以做到。
根据不同的性能指标,对提供指标的性能工具进行分类和理解。这样,在实际排查性能问题时,你就可以清楚知道,什么工具可以提供你想要的指标,而不是毫无根据地挨个尝试,撞运气。
.webp)
第二个维度,从工具出发。也就是当你已经安装了某个工具后,要知道这个工具能提供哪些指标。
这在实际环境中,特别是生产环境中也是非常重要的。因为很多情况下,你并没有权限安装新的工具包,只能最大化地利用好系统已有的工具,而这就需要你对它们有足够的了解。
具体到每个工具的使用方法,一般都支持丰富的配置选项。不过不用担心,这些配置选项并不用背下来。你只要知道有哪些工具,以及这些工具的基本功能是什么就够了。真正要用到的时候, 通过 man 命令,查它们的使用手册就可以了。
.webp)
30.4 如何迅速分析 I/O 的性能瓶颈
虽然文件系统和磁盘的 I/O 性能指标仍比较多,但核心的性能工具,其实就是那么几个。熟练掌握它们,再根据实际系统的现象,并配合系统和应用程序的原理, I/O 性能分析就很清晰了。
想弄清楚性能指标的关联性,就要通晓每种性能指标的工作原理。
以我们前面几期的案例为例,如果你仔细对比前面的几个案例,从 I/O 延迟的案例到 MySQL 和 Redis 的案例,就会发现,虽然这些问题千差万别,但从 I/O 角度来分析,最开始的分析思路基本上类似,都是:
- 先用 iostat 发现磁盘 I/O 性能瓶颈;
- 再借助 pidstat ,定位出导致瓶颈的进程;
- 随后分析进程的 I/O 行为;
- 最后,结合应用程序的原理,分析这些 I/O 的来源。
所以,为了缩小排查范围,我通常会先运行那几个支持指标较多的工具,如 iostat、vmstat、pidstat 等。然后再根据观察到的现象,结合系统和应用程序的原理,寻找下一步的分析方向。
图中列出了最常用的几个文件系统和磁盘 I/O 性能分析工具,以及相应的分析流程,箭头则表示分析方向。这其中,iostat、vmstat、pidstat 是最核心的几个性能工具,它们也提供了最重要的 I/O 性能指标。举几个例子你可能更容易理解。
例如,在前面讲过的 MySQL 和 Redis 案例中,我们就是通过 iostat 确认磁盘出现 I/O 性能瓶颈,然后用 pidstat 找出 I/O 最大的进程,接着借助 strace 找出该进程正在读写的文件,最后结合应用程序的原理,找出大量 I/O 的原因。
再如,当你用 iostat 发现磁盘有 I/O 性能瓶颈后,再用 pidstat 和 vmstat 检查,可能会发现 I/O 来自内核线程,如 Swap 使用大量升高。这种情况下,你就得进行内存分析了,先找出占用大量内存的进程,再设法减少内存的使用。
31 | 套路篇:磁盘 I/O 性能优化的几个思路
31.1 I/O 基准测试
按照我的习惯,优化之前,我会先问自己, I/O 性能优化的目标是什么?换句话说,我们观察的这些 I/O 性能指标(比如 IOPS、吞吐量、延迟等),要达到多少才合适呢?
事实上,I/O 性能指标的具体标准,每个人估计会有不同的答案,因为我们每个人的应用场景、使用的文件系统和物理磁盘等,都有可能不一样。
为了更客观合理地评估优化效果,我们首先应该对磁盘和文件系统进行基准测试,得到文件系统或者磁盘 I/O 的极限性能。
fio(Flexible I/O Tester)正是最常用的文件系统和磁盘 I/O 性能基准测试工具。它提供了大量的可定制化选项,可以用来测试,裸盘或者文件系统在各种场景下的 I/O 性能,包括了不同块大小、不同 I/O 引擎以及是否使用缓存等场景。
fio 的选项非常多, 我会通过几个常见场景的测试方法,介绍一些最常用的选项。这些常见场景包括随机读、随机写、顺序读以及顺序写等,你可以执行下面这些命令来测试:
# 随机读
fio -name=randread -direct=1 -iodepth=64 -rw=randread -ioengine=libaio -bs=4k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=/dev/sdb
# 随机写
fio -name=randwrite -direct=1 -iodepth=64 -rw=randwrite -ioengine=libaio -bs=4k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=/dev/sdb
# 顺序读
fio -name=read -direct=1 -iodepth=64 -rw=read -ioengine=libaio -bs=4k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=/dev/sdb
# 顺序写
fio -name=write -direct=1 -iodepth=64 -rw=write -ioengine=libaio -bs=4k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=/dev/sdb在这其中,有几个参数需要你重点关注一下。
- direct,表示是否跳过系统缓存。上面示例中,我设置的 1 ,就表示跳过系统缓存。
- iodepth,表示使用异步 I/O(asynchronous I/O,简称 AIO)时,同时发出的 I/O 请求上限。在上面的示例中,我设置的是 64。
- rw,表示 I/O 模式。我的示例中, read/write 分别表示顺序读 / 写,而 randread/randwrite 则分别表示随机读 / 写。
- ioengine,表示 I/O 引擎,它支持同步(sync)、异步(libaio)、内存映射(mmap)、网络(net)等各种 I/O 引擎。上面示例中,我设置的 libaio 表示使用异步 I/O。
- bs,表示 I/O 的大小。示例中,我设置成了 4K(这也是默认值)。
- filename,表示文件路径,当然,它可以是磁盘路径(测试磁盘性能),也可以是文件路径(测试文件系统性能)。示例中,我把它设置成了磁盘 /dev/sdb。不过注意,用磁盘路径测试写,会破坏这个磁盘中的文件系统,所以在使用前,你一定要事先做好数据备份。
下面就是我使用 fio 测试顺序读的一个报告示例。
read: (g=0): rw=read, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=libaio, iodepth=64
fio-3.1
Starting 1 process
Jobs: 1 (f=1): [R(1)][100.0%][r=16.7MiB/s,w=0KiB/s][r=4280,w=0 IOPS][eta 00m:00s]
read: (groupid=0, jobs=1): err= 0: pid=17966: Sun Dec 30 08:31:48 2018
read: IOPS=4257, BW=16.6MiB/s (17.4MB/s)(1024MiB/61568msec)
slat (usec): min=2, max=2566, avg= 4.29, stdev=21.76
clat (usec): min=228, max=407360, avg=15024.30, stdev=20524.39
lat (usec): min=243, max=407363, avg=15029.12, stdev=20524.26
clat percentiles (usec):
| 1.00th=[ 498], 5.00th=[ 1020], 10.00th=[ 1319], 20.00th=[ 1713],
| 30.00th=[ 1991], 40.00th=[ 2212], 50.00th=[ 2540], 60.00th=[ 2933],
| 70.00th=[ 5407], 80.00th=[ 44303], 90.00th=[ 45351], 95.00th=[ 45876],
| 99.00th=[ 46924], 99.50th=[ 46924], 99.90th=[ 48497], 99.95th=[ 49021],
| 99.99th=[404751]
bw ( KiB/s): min= 8208, max=18832, per=99.85%, avg=17005.35, stdev=998.94, samples=123
iops : min= 2052, max= 4708, avg=4251.30, stdev=249.74, samples=123
lat (usec) : 250=0.01%, 500=1.03%, 750=1.69%, 1000=2.07%
lat (msec) : 2=25.64%, 4=37.58%, 10=2.08%, 20=0.02%, 50=29.86%
lat (msec) : 100=0.01%, 500=0.02%
cpu : usr=1.02%, sys=2.97%, ctx=33312, majf=0, minf=75
IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=0.1%, >=64=100.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.1%, >=64=0.0%
issued rwt: total=262144,0,0, short=0,0,0, dropped=0,0,0
latency : target=0, window=0, percentile=100.00%, depth=64
Run status group 0 (all jobs):
READ: bw=16.6MiB/s (17.4MB/s), 16.6MiB/s-16.6MiB/s (17.4MB/s-17.4MB/s), io=1024MiB (1074MB), run=61568-61568msec
Disk stats (read/write):
sdb: ios=261897/0, merge=0/0, ticks=3912108/0, in_queue=3474336, util=90.09%这个报告中,需要我们重点关注的是, slat、clat、lat ,以及 bw 和 iops 这几行。
先来看刚刚提到的前三个参数。事实上,slat、clat、lat 都是指 I/O 延迟(latency)。不同之处在于:
- slat ,是指从 I/O 提交到实际执行 I/O 的时长(Submission latency);
- clat ,是指从 I/O 提交到 I/O 完成的时长(Completion latency);
- 而 lat ,指的是从 fio 创建 I/O 到 I/O 完成的总时长。
这里需要注意的是,对同步 I/O 来说,由于 I/O 提交和 I/O 完成是一个动作,所以 slat 实际上就是 I/O 完成的时间,而 clat 是 0。而从示例可以看到,使用异步 I/O(libaio)时,lat 近似等于 slat + clat 之和。
再来看 bw ,它代表吞吐量。在我上面的示例中,你可以看到,平均吞吐量大约是 16 MB(17005 KiB/1024)。
最后的 iops ,其实就是每秒 I/O 的次数,上面示例中的平均 IOPS 为 4250。
通常情况下,应用程序的 I/O 都是读写并行的,而且每次的 I/O 大小也不一定相同。所以,刚刚说的这几种场景,并不能精确模拟应用程序的 I/O 模式。那怎么才能精确模拟应用程序的 I/O 模式呢?
幸运的是,fio 支持 I/O 的重放。借助前面提到过的 blktrace,再配合上 fio,就可以实现对应用程序 I/O 模式的基准测试。你需要先用 blktrace ,记录磁盘设备的 I/O 访问情况;然后使用 fio ,重放 blktrace 的记录。
比如你可以运行下面的命令来操作:
# 使用 blktrace 跟踪磁盘 I/O,注意指定应用程序正在操作的磁盘
$ blktrace /dev/sdb
# 查看 blktrace 记录的结果
# ls
sdb.blktrace.0 sdb.blktrace.1
# 将结果转化为二进制文件
$ blkparse sdb -d sdb.bin
# 使用 fio 重放日志
$ fio --name=replay --filename=/dev/sdb --direct=1 --read_iolog=sdb.bin这样,我们就通过 blktrace+fio 的组合使用,得到了应用程序 I/O 模式的基准测试报告。
31.2 I/O 性能优化
得到 I/O 基准测试报告后,再用上我们上一节总结的性能分析套路,找出 I/O 的性能瓶颈并优化,就是水到渠成的事情了。当然, 想要优化 I/O 性能,肯定离不开 Linux 系统的 I/O 栈图的思路辅助。你可以结合下面的 I/O 栈图再回顾一下。
应用程序优化
应用程序处于整个 I/O 栈的最上端,它可以通过系统调用,来调整 I/O 模式(如顺序还是随机、同步还是异步), 同时,它也是 I/O 数据的最终来源。在我看来,可以有这么几种方式来优化应用程序的 I/O 性能。
- 第一,可以用追加写代替随机写,减少寻址开销,加快 I/O 写的速度。
- 第二,可以借助缓存 I/O ,充分利用系统缓存,降低实际 I/O 的次数。
第三,可以在应用程序内部构建自己的缓存,或者用 Redis 这类外部缓存系统。这样,一方面,能在应用程序内部,控制缓存的数据和生命周期;另一方面,也能降低其他应用程序使用缓存对自身的影响。
比如,在前面的 MySQL 案例中,我们已经见识过,只是因为一个干扰应用清理了系统缓存,就会导致 MySQL 查询有数百倍的性能差距(0.1s vs 15s)。
再如, C 标准库提供的 fopen、fread 等库函数,都会利用标准库的缓存,减少磁盘的操作。而你直接使用 open、read 等系统调用时,就只能利用操作系统提供的页缓存和缓冲区等,而没有库函数的缓存可用。
第四,在需要频繁读写同一块磁盘空间时,可以用 mmap 代替 read/write,减少内存的拷贝次数。
- 第五,在需要同步写的场景中,尽量将写请求合并,而不是让每个请求都同步写入磁盘,即可以用 fsync() 取代 O_SYNC。
- 第六,在多个应用程序共享相同磁盘时,为了保证 I/O 不被某个应用完全占用,推荐你使用 cgroups 的 I/O 子系统,来限制进程 / 进程组的 IOPS 以及吞吐量。
- 最后,在使用 CFQ 调度器时,可以用 ionice 来调整进程的 I/O 调度优先级,特别是提高核心应用的 I/O 优先级。ionice 支持三个优先级类:Idle、Best-effort 和 Realtime。其中, Best-effort 和 Realtime 还分别支持 0-7 的级别,数值越小,则表示优先级别越高。
文件系统优化
应用程序访问普通文件时,实际是由文件系统间接负责,文件在磁盘中的读写。所以,跟文件系统中相关的也有很多优化 I/O 性能的方式。
第一,你可以根据实际负载场景的不同,选择最适合的文件系统。比如 Ubuntu 默认使用 ext4 文件系统,而 CentOS 7 默认使用 xfs 文件系统。
相比于 ext4 ,xfs 支持更大的磁盘分区和更大的文件数量,如 xfs 支持大于 16TB 的磁盘。但是 xfs 文件系统的缺点在于无法收缩,而 ext4 则可以。
第二,在选好文件系统后,还可以进一步优化文件系统的配置选项,包括文件系统的特性(如 ext_attr、dir_index)、日志模式(如 journal、ordered、writeback)、挂载选项(如 noatime)等等。
比如, 使用 tune2fs 这个工具,可以调整文件系统的特性(tune2fs 也常用来查看文件系统超级块的内容)。 而通过 /etc/fstab ,或者 mount 命令行参数,我们可以调整文件系统的日志模式和挂载选项等。
第三,可以优化文件系统的缓存。
比如,你可以优化 pdflush 脏页的刷新频率(比如设置 dirty_expire_centisecs 和 dirty_writeback_centisecs)以及脏页的限额(比如调整 dirty_background_ratio 和 dirty_ratio 等)。
再如,你还可以优化内核回收目录项缓存和索引节点缓存的倾向,即调整 vfs_cache_pressure(/proc/sys/vm/vfs_cache_pressure,默认值 100),数值越大,就表示越容易回收。
- 最后,在不需要持久化时,你还可以用内存文件系统 tmpfs,以获得更好的 I/O 性能 。tmpfs 把数据直接保存在内存中,而不是磁盘中。比如 /dev/shm/ ,就是大多数 Linux 默认配置的一个内存文件系统,它的大小默认为总内存的一半。
磁盘优化
数据的持久化存储,最终还是要落到具体的物理磁盘中,同时,磁盘也是整个 I/O 栈的最底层。从磁盘角度出发,自然也有很多有效的性能优化方法。
第一,最简单有效的优化方法,就是换用性能更好的磁盘,比如用 SSD 替代 HDD。
第二,我们可以使用 RAID ,把多块磁盘组合成一个逻辑磁盘,构成冗余独立磁盘阵列。这样做既可以提高数据的可靠性,又可以提升数据的访问性能。
第三,针对磁盘和应用程序 I/O 模式的特征,我们可以选择最适合的 I/O 调度算法。比方说,SSD 和虚拟机中的磁盘,通常用的是 noop 调度算法。而数据库应用,我更推荐使用 deadline 算法。
第四,我们可以对应用程序的数据,进行磁盘级别的隔离。比如,我们可以为日志、数据库等 I/O 压力比较重的应用,配置单独的磁盘。
第五,在顺序读比较多的场景中,我们可以增大磁盘的预读数据,比如,你可以通过下面两种方法,调整 /dev/sdb 的预读大小。
- 调整内核选项 /sys/block/sdb/queue/read_ahead_kb,默认大小是 128 KB,单位为 KB。
- 使用 blockdev 工具设置,比如 blockdev —setra 8192 /dev/sdb,注意这里的单位是 512B(0.5KB),所以它的数值总是 read_ahead_kb 的两倍。
第六,我们可以优化内核块设备 I/O 的选项。比如,可以调整磁盘队列的长度 /sys/block/sdb/queue/nr_requests,适当增大队列长度,可以提升磁盘的吞吐量(当然也会导致 I/O 延迟增大)。
最后,要注意,磁盘本身出现硬件错误,也会导致 I/O 性能急剧下降,所以发现磁盘性能急剧下降时,你还需要确认,磁盘本身是不是出现了硬件错误。
比如,你可以查看 dmesg 中是否有硬件 I/O 故障的日志。 还可以使用 badblocks、smartctl 等工具,检测磁盘的硬件问题,或用 e2fsck 等来检测文件系统的错误。如果发现问题,你可以使用 fsck 等工具来修复。
32 | 答疑(四):阻塞、非阻塞 I/O 与同步、异步 I/O 的区别和联系
32.1 问题 1:阻塞、非阻塞 I/O 与同步、异步 I/O 的区别和联系
首先我们来看阻塞和非阻塞 I/O。根据应用程序是否阻塞自身运行,可以把 I/O 分为阻塞 I/O 和非阻塞 I/O。
- 所谓阻塞 I/O,是指应用程序在执行 I/O 操作后,如果没有获得响应,就会阻塞当前线程,不能执行其他任务。
- 所谓非阻塞 I/O,是指应用程序在执行 I/O 操作后,不会阻塞当前的线程,可以继续执行其他的任务。
再来看同步 I/O 和异步 I/O。根据 I/O 响应的通知方式的不同,可以把文件 I/O 分为同步 I/O 和异步 I/O。
- 所谓同步 I/O,是指收到 I/O 请求后,系统不会立刻响应应用程序;等到处理完成,系统才会通过系统调用的方式,告诉应用程序 I/O 结果。
- 所谓异步 I/O,是指收到 I/O 请求后,系统会先告诉应用程序 I/O 请求已经收到,随后再去异步处理;等处理完成后,系统再通过事件通知的方式,告诉应用程序结果。
你可以看出,阻塞 / 非阻塞和同步 / 异步,其实就是两个不同角度的 I/O 划分方式。它们描述的对象也不同,阻塞 / 非阻塞针对的是 I/O 调用者(即应用程序),而同步 / 异步针对的是 I/O 执行者(即系统)。
我举个例子来进一步解释下。比如在 Linux I/O 调用中,
- 系统调用 read 是同步读,所以,在没有得到磁盘数据前,read 不会响应应用程序。
- 而 aio_read 是异步读,系统收到 AIO 读请求后不等处理就返回了,而具体的 read 结果,再通过回调异步通知应用程序。
再如,在网络套接字的接口中,
- 使用 send() 直接向套接字发送数据时,如果套接字没有设置 O_NONBLOCK 标识,那么 send() 操作就会一直阻塞,当前线程也没法去做其他事情。
- 当然,如果你用了 epoll,系统会告诉你这个套接字的状态,那就可以用非阻塞的方式使用。当这个套接字不可写的时候,你可以去做其他事情,比如读写其他套接字。
32.2 “文件系统”课后思考
执行 find 命令时,会不会导致系统的缓存升高呢?如果会导致,升高的又是哪种类型的缓存呢?
通过学习 Linux 文件系统的原理,我们知道,文件名以及文件之间的目录关系,都放在目录项缓存中。而这是一个基于内存的数据结构,会根据需要动态构建。所以,查找文件时,Linux 就会动态构建不在缓存中的目录项结构,导致 dentry 缓存升高。


事实上,除了目录项缓存增加,Buffer 的使用也会增加。如果你用 vmstat 观察一下,会发现 Buffer 和 Cache 都在增长:
$ vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 1 0 7563744 6024 225944 0 0 3736 0 574 3249 3 5 89 3 0
1 0 0 7542792 14736 236856 0 0 8708 0 13494 32335 8 19 66 7 0
0 1 0 7494452 27280 272284 0 0 12544 0 4550 17084 5 15 68 13 0
0 1 0 7475084 42380 276320 0 0 15096 0 2541 14253 2 6 78 13 0
0 1 0 7455728 57600 280436 0 0 15220 0 2025 14518 2 6 70 22 0这里,Buffer 的增长是因为,构建目录项缓存所需的元数据(比如文件名称、索引节点等),需要从文件系统中读取。
32.3 问题 3:”磁盘 I/O 延迟”课后思考
我们通过 iostat ,确认磁盘 I/O 已经出现了性能瓶颈,还用 pidstat 找出了大量磁盘 I/O 的进程。但是,随后使用 strace 跟踪这个进程,却找不到任何 write 系统调用。这是为什么呢?
strace -p PID 后面需要加 -f 选项,以便跟踪多进程和多线程的系统调用情况。
32.4 问题 4:”MySQL 案例”课后思考
为什么 DataService 应用停止后,即使仍没有索引,MySQL 的查询速度还是快了很多,并且磁盘 I/O 瓶颈也消失了呢?
ninuxer 的留言基本解释了这个问题,不过还不够完善。
ninuxer 的留言:echo 1>/proc/sys/vm/drop_caches表示释放pagecache,也就是文件缓存,而mysql读书的数据就是文件缓存,dataservice不停的释放文件缓存,就导致MySQL都无法利用磁盘缓存,也就慢了。
事实上,当你看到 DataService 在修改 /proc/sys/vm/drop_caches 时,就应该想到前面学过的 Cache 的作用。
我们知道,案例应用访问的数据表,基于 MyISAM 引擎,而 MyISAM 的一个特点,就是只在内存中缓存索引,并不缓存数据。所以,在查询语句无法使用索引时,就需要数据表从数据库文件读入内存,然后再进行处理。
所以,如果你用 vmstat 工具,观察缓存和 I/O 的变化趋势,就会发现下面这样的结果:
$ vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
# 备注: DataService 正在运行
0 1 0 7293416 132 366704 0 0 32516 12 36 546 1 3 49 48 0
0 1 0 7260772 132 399256 0 0 32640 0 37 463 1 1 49 48 0
0 1 0 7228088 132 432088 0 0 32640 0 30 477 0 1 49 49 0
0 0 0 7306560 132 353084 0 0 20572 4 90 574 1 4 69 27 0
0 2 0 7282300 132 368536 0 0 15468 0 32 304 0 0 79 20 0
# 备注:DataService 从这里开始停止
0 0 0 7241852 1360 424164 0 0 864 320 133 1266 1 1 94 5 0
0 1 0 7228956 1368 437400 0 0 13328 0 45 366 0 0 83 17 0
0 1 0 7196320 1368 470148 0 0 32640 0 33 413 1 1 50 49 0
...
0 0 0 6747540 1368 918576 0 0 29056 0 42 568 0 0 56 44 0
0 0 0 6747540 1368 918576 0 0 0 0 40 141 1 0 100 0 0在 DataService 停止前,cache 会连续增长三次后再降回去,这正是因为 DataService 每隔 3 秒清理一次页缓存。而 DataService 停止后,cache 就会不停地增长,直到增长为 918576 后,就不再变了。
这时,磁盘的读(bi)降低到 0,同时,iowait(wa)也降低到 0,这说明,此时的所有数据都已经在系统的缓存中了。我们知道,缓存是内存的一部分,它的访问速度比磁盘快得多,这也就能解释,为什么 MySQL 的查询速度变快了很多。
从这个案例,你会发现,MySQL 的 MyISAM 引擎,本身并不缓存数据,而要依赖系统缓存来加速磁盘 I/O 的访问。一旦系统中还有其他应用同时运行,MyISAM 引擎就很难充分利用系统缓存。因为系统缓存可能被其他应用程序占用,甚至直接被清理掉。
所以,一般来说,我并不建议,把应用程序的性能优化完全建立在系统缓存上。还是那句话,最好能在应用程序的内部分配内存,构建完全自主控制的缓存,比如 MySQL 的 InnoDB 引擎,就同时缓存了索引和数据;或者,可以使用第三方的缓存应用,比如 Memcached、Redis 等。
05-网络性能篇
33 | 关于 Linux 网络,你必须知道这些(上)
33.1 网络模型
说到网络,我想你肯定经常提起七层负载均衡、四层负载均衡,或者三层设备、二层设备等等。那么,这里说的二层、三层、四层、七层又都是什么意思呢?
实际上,这些层都来自国际标准化组织制定的开放式系统互联通信参考模型(Open System Interconnection Reference Model),简称为 OSI 网络模型。
- 应用层,负责为应用程序提供统一的接口。
- 表示层,负责把数据转换成兼容接收系统的格式。
- 会话层,负责维护计算机之间的通信连接。
- 传输层,负责为数据加上传输表头,形成数据包。
- 网络层,负责数据的路由和转发。
- 数据链路层,负责 MAC 寻址、错误侦测和改错。
- 物理层,负责在物理网络中传输数据帧。
但是 OSI 模型还是太复杂了,也没能提供一个可实现的方法。所以,在 Linux 中,我们实际上使用的是另一个更实用的四层模型,即 TCP/IP 网络模型。
TCP/IP 模型,把网络互联的框架分为应用层、传输层、网络层、网络接口层等四层,其中,
- 应用层,负责向用户提供一组应用程序,比如 HTTP、FTP、DNS 等。
- 传输层,负责端到端的通信,比如 TCP、UDP 等。
- 网络层,负责网络包的封装、寻址和路由,比如 IP、ICMP 等。
- 网络接口层,负责网络包在物理网络中的传输,比如 MAC 寻址、错误侦测以及通过网卡传输网络帧等。
TCP/IP 模型包括了大量的网络协议,这些协议的原理,也是我们每个人必须掌握的核心基础知识。如果你不太熟练,推荐你去学《TCP/IP 详解》的卷一和卷二,或者学习极客时间出品的 《趣谈网络协议》 专栏。
33.2 Linux 网络栈
有了 TCP/IP 模型后,在进行网络传输时,数据包就会按照协议栈,对上一层发来的数据进行逐层处理;然后封装上该层的协议头,再发送给下一层。
当然,网络包在每一层的处理逻辑,都取决于各层采用的网络协议。比如在应用层,一个提供 REST API 的应用,可以使用 HTTP 协议,把它需要传输的 JSON 数据封装到 HTTP 协议中,然后向下传递给 TCP 层。
而封装做的事情就很简单了,只是在原来的负载前后,增加固定格式的元数据,原始的负载数据并不会被修改。
比如,以通过 TCP 协议通信的网络包为例,通过下面这张图,我们可以看到,应用程序数据在每个层的封装格式。
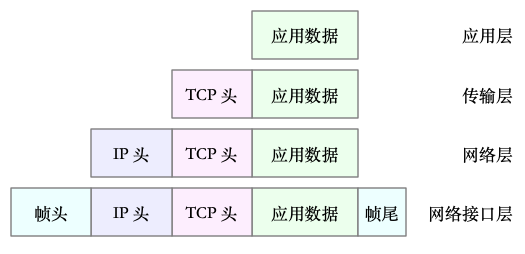
其中:
- 传输层在应用程序数据前面增加了 TCP 头;
- 网络层在 TCP 数据包前增加了 IP 头;
- 而网络接口层,又在 IP 数据包前后分别增加了帧头和帧尾。
这些新增的头部和尾部,都按照特定的协议格式填充,想了解具体格式,你可以查看协议的文档。 比如,你可以查看这里,了解 TCP 头的格式。
这些新增的头部和尾部,增加了网络包的大小,但我们都知道,物理链路中并不能传输任意大小的数据包。网络接口配置的最大传输单元(MTU),就规定了最大的 IP 包大小。在我们最常用的以太网中,MTU 默认值是 1500(这也是 Linux 的默认值)。
一旦网络包超过 MTU 的大小,就会在网络层分片,以保证分片后的 IP 包不大于 MTU 值。显然,MTU 越大,需要的分包也就越少,自然,网络吞吐能力就越好。
理解了 TCP/IP 网络模型和网络包的封装原理后,你很容易能想到,Linux 内核中的网络栈,其实也类似于 TCP/IP 的四层结构。如下图所示,就是 Linux 通用 IP 网络栈的示意图:
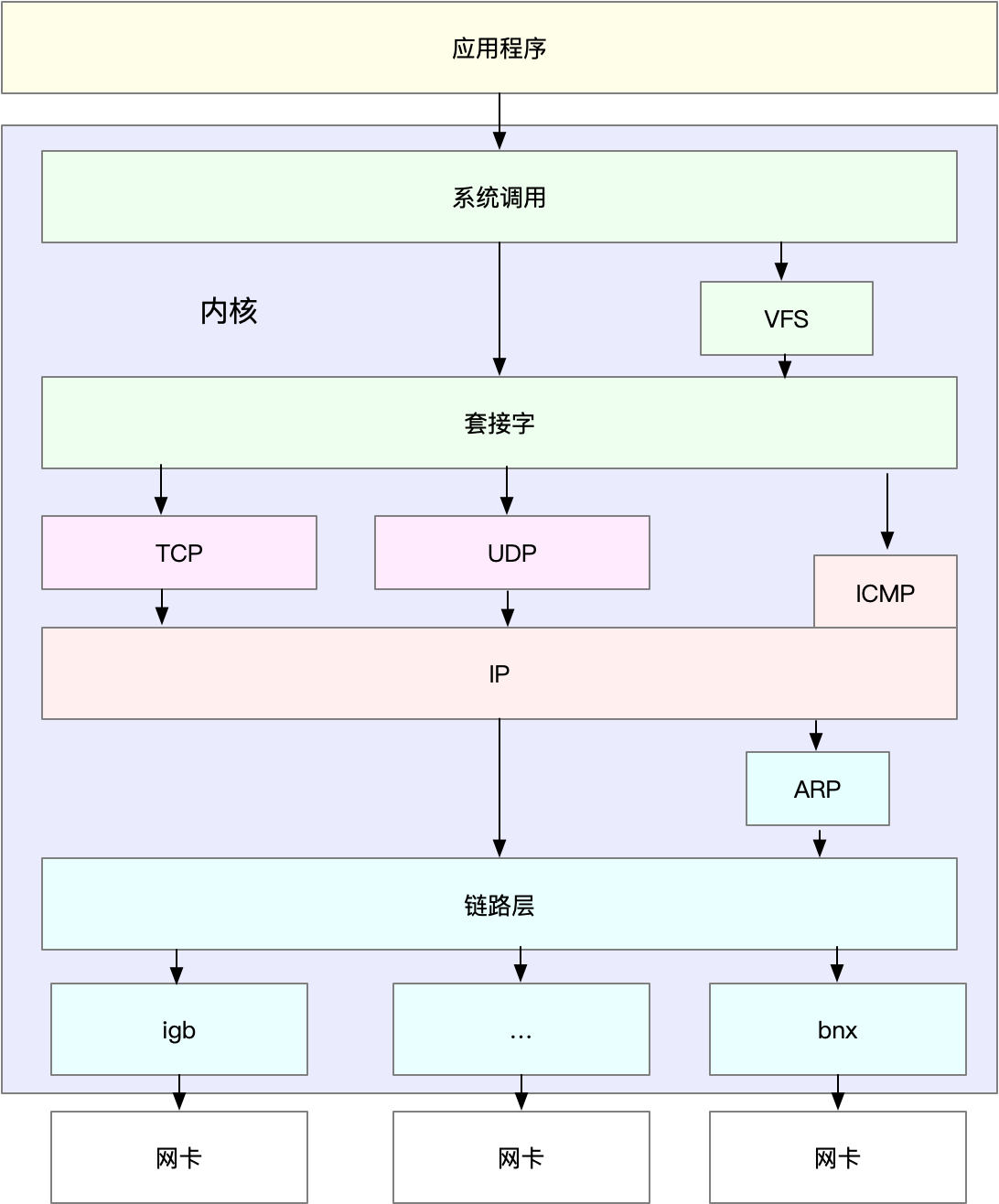
(图片参考《性能之巅》图 10.7 通用 IP 网络栈绘制)
我们从上到下来看这个网络栈,你可以发现,
- 最上层的应用程序,需要通过系统调用,来跟套接字接口进行交互;
- 套接字的下面,就是我们前面提到的传输层、网络层和网络接口层;
- 最底层,则是网卡驱动程序以及物理网卡设备。
网卡是发送和接收网络包的基本设备。在系统启动过程中,网卡通过内核中的网卡驱动程序注册到系统中。而在网络收发过程中,内核通过中断跟网卡进行交互。
再结合前面提到的 Linux 网络栈,可以看出,网络包的处理非常复杂。所以,网卡硬中断只处理最核心的网卡数据读取或发送,而协议栈中的大部分逻辑,都会放到软中断中处理。
33.3 Linux 网络收发流程
了解了 Linux 网络栈后,我们再来看看, Linux 到底是怎么收发网络包的。
注意,以下内容都以物理网卡为例。事实上,Linux 还支持众多的虚拟网络设备,而它们的网络收发流程会有一些差别。
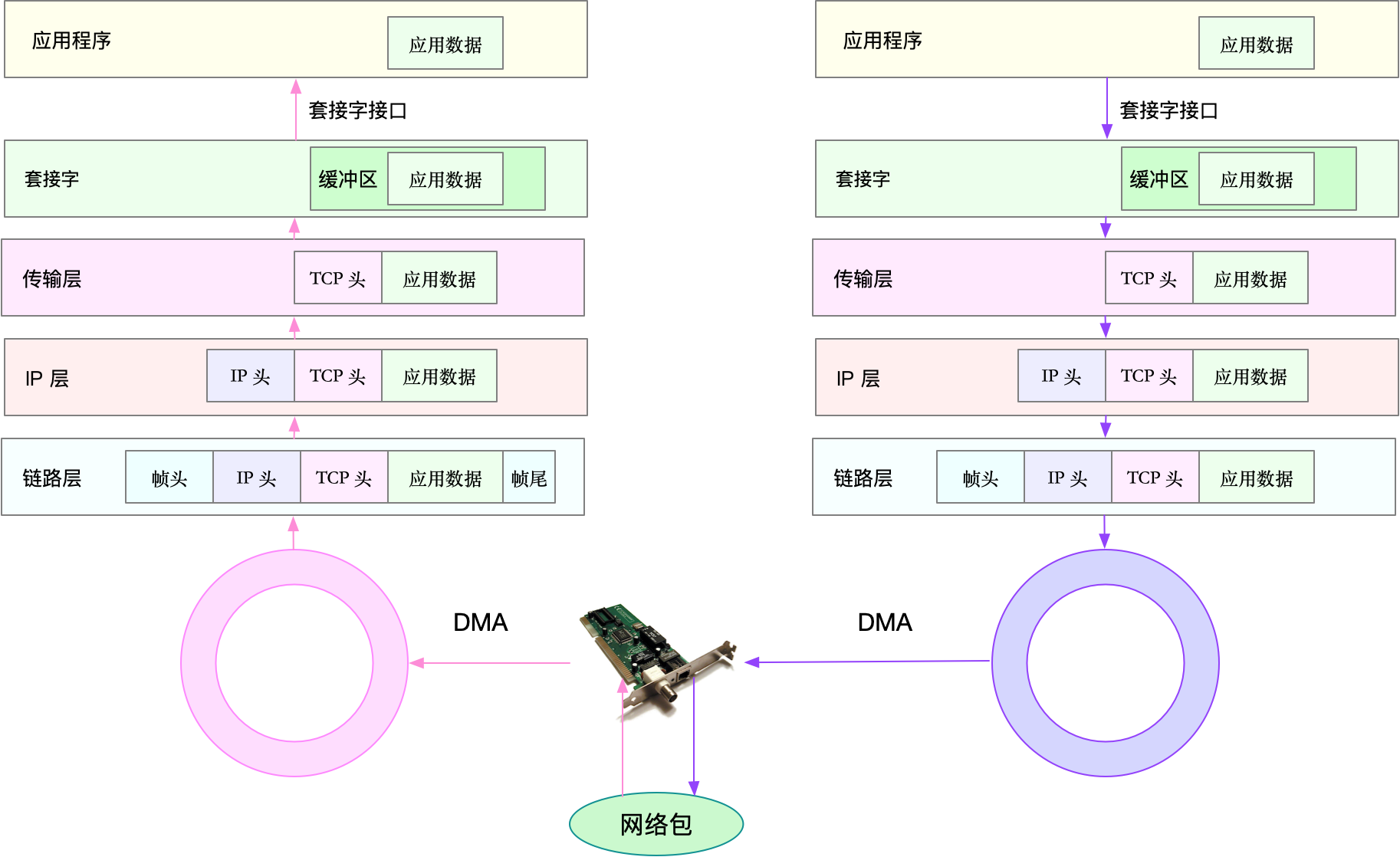
网络包的接收流程
当一个网络帧到达网卡后,网卡会通过 DMA 方式,把这个网络包放到收包队列中;然后通过硬中断,告诉中断处理程序已经收到了网络包。
接着,网卡中断处理程序会为网络帧分配内核数据结构(sk_buff),并将其拷贝到 sk_buff 缓冲区中;然后再通过软中断,通知内核收到了新的网络帧。
接下来,内核协议栈从缓冲区中取出网络帧,并通过网络协议栈,从下到上逐层处理这个网络帧。比如,
- 在链路层检查报文的合法性,找出上层协议的类型(比如 IPv4 还是 IPv6),再去掉帧头、帧尾,然后交给网络层。
- 网络层取出 IP 头,判断网络包下一步的走向,比如是交给上层处理还是转发。当网络层确认这个包是要发送到本机后,就会取出上层协议的类型(比如 TCP 还是 UDP),去掉 IP 头,再交给传输层处理。
传输层取出 TCP 头或者 UDP 头后,根据
< 源 IP、源端口、目的 IP、目的端口 >四元组作为标识,找出对应的 Socket,并把数据拷贝到 Socket 的接收缓存中。最后,应用程序就可以使用 Socket 接口,读取到新接收到的数据了。
网络包的发送流程
首先,应用程序调用 Socket API(比如 sendmsg)发送网络包。
由于这是一个系统调用,所以会陷入到内核态的套接字层中。套接字层会把数据包放到 Socket 发送缓冲区中。
接下来,网络协议栈从 Socket 发送缓冲区中,取出数据包;再按照 TCP/IP 栈,从上到下逐层处理。比如,传输层和网络层,分别为其增加 TCP 头和 IP 头,执行路由查找确认下一跳的 IP,并按照 MTU 大小进行分片。
分片后的网络包,再送到网络接口层,进行物理地址寻址,以找到下一跳的 MAC 地址。然后添加帧头和帧尾,放到发包队列中。这一切完成后,会有软中断通知驱动程序:发包队列中有新的网络帧需要发送。
最后,驱动程序通过 DMA ,从发包队列中读出网络帧,并通过物理网卡把它发送出去。
34 | 关于 Linux 网络,你必须知道这些(下)
34.1 性能指标
实际上,我们通常用带宽、吞吐量、延时、PPS(Packet Per Second)等指标衡量网络的性能。
- 带宽,表示链路的最大传输速率,单位通常为 b/s (比特 / 秒)。
- 吞吐量,表示单位时间内成功传输的数据量,单位通常为 b/s(比特 / 秒)或者 B/s(字节 / 秒)。吞吐量受带宽限制,而吞吐量 / 带宽,也就是该网络的使用率。
- 延时,表示从网络请求发出后,一直到收到远端响应,所需要的时间延迟。在不同场景中,这一指标可能会有不同含义。比如,它可以表示,建立连接需要的时间(比如 TCP 握手延时),或一个数据包往返所需的时间(比如 RTT)。
- PPS,是 Packet Per Second(包 / 秒)的缩写,表示以网络包为单位的传输速率。PPS 通常用来评估网络的转发能力,比如硬件交换机,通常可以达到线性转发(即 PPS 可以达到或者接近理论最大值)。而基于 Linux 服务器的转发,则容易受网络包大小的影响。
除了这些指标,网络的可用性(网络能否正常通信)、并发连接数(TCP 连接数量)、丢包率(丢包百分比)、重传率(重新传输的网络包比例)等也是常用的性能指标。
34.2 网络配置
可以使用 ifconfig 或者 ip 命令,来查看网络的配置。我个人更推荐使用 ip 工具,因为它提供了更丰富的功能和更易用的接口。
ifconfig 和 ip 分别属于软件包 net-tools 和 iproute2,iproute2 是 net-tools 的下一代。通常情况下它们会在发行版中默认安装。但如果你找不到 ifconfig 或者 ip 命令,可以安装这两个软件包。
以网络接口 eth0 为例,你可以运行下面的两个命令,查看它的配置和状态:
$ ifconfig eth0
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 10.240.0.30 netmask 255.240.0.0 broadcast 10.255.255.255
inet6 fe80::20d:3aff:fe07:cf2a prefixlen 64 scopeid 0x20<link>
ether 78:0d:3a:07:cf:3a txqueuelen 1000 (Ethernet)
RX packets 40809142 bytes 9542369803 (9.5 GB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 32637401 bytes 4815573306 (4.8 GB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
$ ip -s addr show dev eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 78:0d:3a:07:cf:3a brd ff:ff:ff:ff:ff:ff
inet 10.240.0.30/12 brd 10.255.255.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::20d:3aff:fe07:cf2a/64 scope link
valid_lft forever preferred_lft forever
RX: bytes packets errors dropped overrun mcast
9542432350 40809397 0 0 0 193
TX: bytes packets errors dropped carrier collsns
4815625265 32637658 0 0 0 0这些具体指标的含义,在文档中都有详细的说明,不过,这里有几个跟网络性能密切相关的指标,需要你特别关注一下。
第一,网络接口的状态标志。ifconfig 输出中的 RUNNING ,或 ip 输出中的 LOWER_UP ,都表示物理网络是连通的,即网卡已经连接到了交换机或者路由器中。如果你看不到它们,通常表示网线被拔掉了。
第二,MTU 的大小。MTU 默认大小是 1500,根据网络架构的不同(比如是否使用了 VXLAN 等叠加网络),你可能需要调大或者调小 MTU 的数值。
第三,网络接口的 IP 地址、子网以及 MAC 地址。这些都是保障网络功能正常工作所必需的,你需要确保配置正确。
第四,网络收发的字节数、包数、错误数以及丢包情况,特别是 TX 和 RX 部分的 errors、dropped、overruns、carrier 以及 collisions 等指标不为 0 时,通常表示出现了网络 I/O 问题。其中:
- errors 表示发生错误的数据包数,比如校验错误、帧同步错误等;
- dropped 表示丢弃的数据包数,即数据包已经收到了 Ring Buffer,但因为内存不足等原因丢包;
- overruns 表示超限数据包数,即网络 I/O 速度过快,导致 Ring Buffer 中的数据包来不及处理(队列满)而导致的丢包;
- carrier 表示发生 carrirer 错误的数据包数,比如双工模式不匹配、物理电缆出现问题等;
- collisions 表示碰撞数据包数。
34.3 套接字信息
使用 ss 来查询网络的连接信息,因为它比 netstat 提供了更好的性能(速度更快)。
# head -n 3 表示只显示前面 3 行
# -l 表示只显示监听套接字
# -n 表示显示数字地址和端口 (而不是名字)
# -p 表示显示进程信息
$ netstat -nlp | head -n 3
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 127.0.0.53:53 0.0.0.0:* LISTEN 840/systemd-resolve
# -l 表示只显示监听套接字
# -t 表示只显示 TCP 套接字
# -n 表示显示数字地址和端口 (而不是名字)
# -p 表示显示进程信息
$ ss -ltnp | head -n 3
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 127.0.0.53%lo:53 0.0.0.0:* users:(("systemd-resolve",pid=840,fd=13))
LISTEN 0 128 0.0.0.0:22 0.0.0.0:* users:(("sshd",pid=1459,fd=3))其中,接收队列(Recv-Q)和发送队列(Send-Q)需要你特别关注,它们通常应该是 0。当你发现它们不是 0 时,说明有网络包的堆积发生。当然还要注意,在不同套接字状态下,它们的含义不同。
当套接字处于连接状态(Established)时,
- Recv-Q 表示套接字缓冲还没有被应用程序取走的字节数(即接收队列长度)。
- 而 Send-Q 表示还没有被远端主机确认的字节数(即发送队列长度)。
当套接字处于监听状态(Listening)时,
- Recv-Q 表示 syn backlog 的当前值。
- 而 Send-Q 表示最大的 syn backlog 值。
而 syn backlog 是 TCP 协议栈中的半连接队列长度,相应的也有一个全连接队列(accept queue),它们都是维护 TCP 状态的重要机制。
顾名思义,所谓半连接,就是还没有完成 TCP 三次握手的连接,连接只进行了一半,而服务器收到了客户端的 SYN 包后,就会把这个连接放到半连接队列中,然后再向客户端发送 SYN+ACK 包。
而全连接,则是指服务器收到了客户端的 ACK,完成了 TCP 三次握手,然后就会把这个连接挪到全连接队列中。这些全连接中的套接字,还需要再被 accept() 系统调用取走,这样,服务器就可以开始真正处理客户端的请求了。
34.4 协议栈统计信息
$ netstat -s
...
Tcp:
3244906 active connection openings
23143 passive connection openings
115732 failed connection attempts
2964 connection resets received
1 connections established
13025010 segments received
17606946 segments sent out
44438 segments retransmitted
42 bad segments received
5315 resets sent
InCsumErrors: 42
...
$ ss -s
Total: 186 (kernel 1446)
TCP: 4 (estab 1, closed 0, orphaned 0, synrecv 0, timewait 0/0), ports 0
Transport Total IP IPv6
* 1446 - -
RAW 2 1 1
UDP 2 2 0
TCP 4 3 1
...这些协议栈的统计信息都很直观。ss 只显示已经连接、关闭、孤儿套接字等简要统计,而 netstat 则提供的是更详细的网络协议栈信息。
比如,上面 netstat 的输出示例,就展示了 TCP 协议的主动连接、被动连接、失败重试、发送和接收的分段数量等各种信息。
34.5 网络吞吐和 PPS
给 sar 增加 -n 参数就可以查看网络的统计信息,比如网络接口(DEV)、网络接口错误(EDEV)、TCP、UDP、ICMP 等等。执行下面的命令,你就可以得到网络接口统计信息:
# 数字 1 表示每隔 1 秒输出一组数据
$ sar -n DEV 1
Linux 4.15.0-1035-azure (ubuntu) 01/06/19 _x86_64_ (2 CPU)
13:21:40 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
13:21:41 eth0 18.00 20.00 5.79 4.25 0.00 0.00 0.00 0.00
13:21:41 docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
13:21:41 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00这儿输出的指标比较多,我来简单解释下它们的含义。
- rxpck/s 和 txpck/s 分别是接收和发送的 PPS,单位为包 / 秒。
- rxkB/s 和 txkB/s 分别是接收和发送的吞吐量,单位是 KB/ 秒。
- rxcmp/s 和 txcmp/s 分别是接收和发送的压缩数据包数,单位是包 / 秒。
- %ifutil 是网络接口的使用率,即半双工模式下为 (rxkB/s+txkB/s)/Bandwidth,而全双工模式下为 max(rxkB/s, txkB/s)/Bandwidth。
其中,Bandwidth 可以用 ethtool 来查询,它的单位通常是 Gb/s 或者 Mb/s,不过注意这里小写字母 b ,表示比特而不是字节。我们通常提到的千兆网卡、万兆网卡等,单位也都是比特。如下你可以看到,我的 eth0 网卡就是一个千兆网卡:
$ ethtool eth0 | grep Speed
Speed: 1000Mb/s34.6 连通性和延时
最后,我们通常使用 ping ,来测试远程主机的连通性和延时,而这基于 ICMP 协议。比如,执行下面的命令,你就可以测试本机到 114.114.114.114 这个 IP 地址的连通性和延时:
# -c3 表示发送三次 ICMP 包后停止
$ ping -c3 114.114.114.114
PING 114.114.114.114 (114.114.114.114) 56(84) bytes of data.
64 bytes from 114.114.114.114: icmp_seq=1 ttl=54 time=244 ms
64 bytes from 114.114.114.114: icmp_seq=2 ttl=47 time=244 ms
64 bytes from 114.114.114.114: icmp_seq=3 ttl=67 time=244 ms
--- 114.114.114.114 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2001ms
rtt min/avg/max/mdev = 244.023/244.070/244.105/0.034 msping 的输出,可以分为两部分。
- 第一部分,是每个 ICMP 请求的信息,包括 ICMP 序列号(icmp_seq)、TTL(生存时间,或者跳数)以及往返延时。
- 第二部分,则是三次 ICMP 请求的汇总。
比如上面的示例显示,发送了 3 个网络包,并且接收到 3 个响应,没有丢包发生,这说明测试主机到 114.114.114.114 是连通的;平均往返延时(RTT)是 244ms,也就是从发送 ICMP 开始,到接收到 114.114.114.114 回复的确认,总共经历 244ms。
35 | 基础篇:C10K 和 C1000K 回顾
回顾下经典的 C10K 和 C1000K 问题,以更好理解 Linux 网络的工作原理,并进一步分析,如何做到单机支持 C10M。
注意,C10K 和 C1000K 的首字母 C 是 Client 的缩写。C10K 就是单机同时处理 1 万个请求(并发连接 1 万)的问题,而 C1000K 也就是单机支持处理 100 万个请求(并发连接 100 万)的问题。
35.1 C10K
C10K 问题最早由 Dan Kegel 在 1999 年提出。那时的服务器还只是 32 位系统,运行着 Linux 2.2 版本(后来又升级到了 2.4 和 2.6,而 2.6 才支持 x86_64),只配置了很少的内存(2GB)和千兆网卡。
怎么在这样的系统中支持并发 1 万的请求呢?
从资源上来说,对 2GB 内存和千兆网卡的服务器来说,同时处理 10000 个请求,只要每个请求处理占用不到 200KB(2GB/10000)的内存和 100Kbit (1000Mbit/10000)的网络带宽就可以。所以,物理资源是足够的,接下来自然是软件的问题,特别是网络的 I/O 模型问题。
说到 I/O 的模型,我在文件系统的原理中,曾经介绍过文件 I/O,其实网络 I/O 模型也类似。在 C10K 以前,Linux 中网络处理都用同步阻塞的方式,也就是每个请求都分配一个进程或者线程。请求数只有 100 个时,这种方式自然没问题,但增加到 10000 个请求时,10000 个进程或线程的调度、上下文切换乃至它们占用的内存,都会成为瓶颈。
既然每个请求分配一个线程的方式不合适,那么,为了支持 10000 个并发请求,这里就有两个问题需要我们解决。
- 第一,怎样在一个线程内处理多个请求,也就是要在一个线程内响应多个网络 I/O。以前的同步阻塞方式下,一个线程只能处理一个请求,到这里不再适用,是不是可以用非阻塞 I/O 或者异步 I/O 来处理多个网络请求呢?
- 第二,怎么更节省资源地处理客户请求,也就是要用更少的线程来服务这些请求。是不是可以继续用原来的 100 个或者更少的线程,来服务现在的 10000 个请求呢?
当然,事实上,现在 C10K 的问题早就解决了,在继续学习下面的内容前,你可以先自己思考一下这两个问题。结合前面学过的内容,你是不是已经有了解决思路呢?
35.2 I/O 模型优化
异步、非阻塞 I/O 的解决思路,你应该听说过,其实就是我们在网络编程中经常用到的 I/O 多路复用(I/O Multiplexing)。I/O 多路复用是什么意思呢?
别急,详细了解前,我先来讲两种 I/O 事件通知的方式:水平触发和边缘触发,它们常用在套接字接口的文件描述符中。
- 水平触发:只要文件描述符可以非阻塞地执行 I/O ,就会触发通知。也就是说,应用程序可以随时检查文件描述符的状态,然后再根据状态,进行 I/O 操作。
- 边缘触发:只有在文件描述符的状态发生改变(也就是 I/O 请求达到)时,才发送一次通知。这时候,应用程序需要尽可能多地执行 I/O,直到无法继续读写,才可以停止。如果 I/O 没执行完,或者因为某种原因没来得及处理,那么这次通知也就丢失了。
接下来,我们再回过头来看 I/O 多路复用的方法。这里其实有很多实现方法,我带你来逐个分析一下。
第一种,使用非阻塞 I/O 和水平触发通知,比如使用 select 或者 poll。
这种方式的最大优点,是对应用程序比较友好,它的 API 非常简单。
但是,应用软件使用 select 和 poll 时,需要对这些文件描述符列表进行轮询,这样,请求数多的时候就会比较耗时。并且,select 和 poll 还有一些其他的限制。
select 使用固定长度的位相量,表示文件描述符的集合,因此会有最大描述符数量的限制。比如,在 32 位系统中,默认限制是 1024。并且,在 select 内部,检查套接字状态是用轮询的方法,再加上应用软件使用时的轮询,就变成了一个 O(n^2) 的关系。
而 poll 改进了 select 的表示方法,换成了一个没有固定长度的数组,这样就没有了最大描述符数量的限制(当然还会受到系统文件描述符限制)。但应用程序在使用 poll 时,同样需要对文件描述符列表进行轮询,这样,处理耗时跟描述符数量就是 O(N) 的关系。
除此之外,应用程序每次调用 select 和 poll 时,还需要把文件描述符的集合,从用户空间传入内核空间,由内核修改后,再传出到用户空间中。这一来一回的内核空间与用户空间切换,也增加了处理成本。
第二种,使用非阻塞 I/O 和边缘触发通知,比如 epoll。
既然 select 和 poll 有那么多的问题,就需要继续对其进行优化,而 epoll 就很好地解决了这些问题。
- epoll 使用红黑树,在内核中管理文件描述符的集合,这样,就不需要应用程序在每次操作时都传入、传出这个集合。
- epoll 使用事件驱动的机制,只关注有 I/O 事件发生的文件描述符,不需要轮询扫描整个集合。
第三种,使用异步 I/O(Asynchronous I/O,简称为 AIO)。
异步 I/O 允许应用程序同时发起很多 I/O 操作,而不用等待这些操作完成。而在 I/O 完成后,系统会用事件通知(比如信号或者回调函数)的方式,告诉应用程序。这时,应用程序才会去查询 I/O 操作的结果。
异步 I/O 也是到了 Linux 2.6 才支持的功能,并且在很长时间里都处于不完善的状态,比如 glibc 提供的异步 I/O 库,就一直被社区诟病。同时,由于异步 I/O 跟我们的直观逻辑不太一样,想要使用的话,一定要小心设计,其使用难度比较高。
35.3 工作模型优化
使用 I/O 多路复用后,就可以在一个进程或线程中处理多个请求,其中,又有下面两种不同的工作模型。
第一种,主进程 + 多个 worker 子进程,这也是最常用的一种模型。 这种方法的一个通用工作模式就是:
- 主进程执行 bind() + listen() 后,创建多个子进程;
然后,在每个子进程中,都通过 accept() 或 epoll_wait() ,来处理相同的套接字。
比如,最常用的反向代理服务器 Nginx 就是这么工作的。它也是由主进程和多个 worker 进程组成。主进程主要用来初始化套接字,并管理子进程的生命周期;而 worker 进程,则负责实际的请求处理。我画了一张图来表示这个关系。
这里要注意,accept() 和 epoll_wait() 调用,还存在一个惊群的问题。换句话说,当网络 I/O 事件发生时,多个进程被同时唤醒,但实际上只有一个进程来响应这个事件,其他被唤醒的进程都会重新休眠。
其中,accept() 的惊群问题,已经在 Linux 2.6 中解决了;
而 epoll 的问题,到了 Linux 4.5 ,才通过 EPOLLEXCLUSIVE 解决。
为了避免惊群问题, Nginx 在每个 worker 进程中,都增加一个了全局锁(accept_mutex)。这些 worker 进程需要首先竞争到锁,只有竞争到锁的进程,才会加入到 epoll 中,这样就确保只有一个 worker 子进程被唤醒。
不过,根据前面 CPU 模块的学习,你应该还记得,进程的管理、调度、上下文切换的成本非常高。那为什么使用多进程模式的 Nginx ,却具有非常好的性能呢?
这里最主要的一个原因就是,这些 worker 进程,实际上并不需要经常创建和销毁,而是在没任务时休眠,有任务时唤醒。只有在 worker 由于某些异常退出时,主进程才需要创建新的进程来代替它。
当然,你也可以用线程代替进程:主线程负责套接字初始化和子线程状态的管理,而子线程则负责实际的请求处理。由于线程的调度和切换成本比较低,实际上你可以进一步把 epoll_wait() 都放到主线程中,保证每次事件都只唤醒主线程,而子线程只需要负责后续的请求处理。
第二种,监听到相同端口的多进程模型。 在这种方式下,所有的进程都监听相同的接口,并且开启 SO_REUSEPORT 选项,由内核负责将请求负载均衡到这些监听进程中去。这一过程如下图所示。
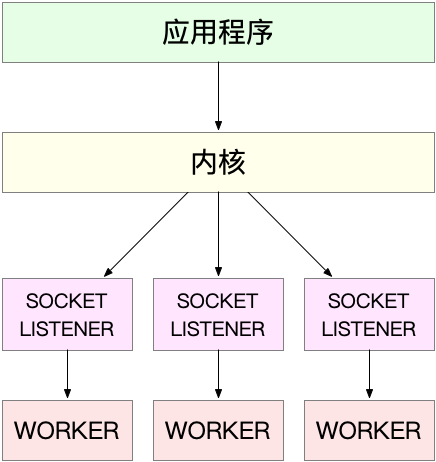
由于内核确保了只有一个进程被唤醒,就不会出现惊群问题了。比如,Nginx 在 1.9.1 中就已经支持了这种模式。
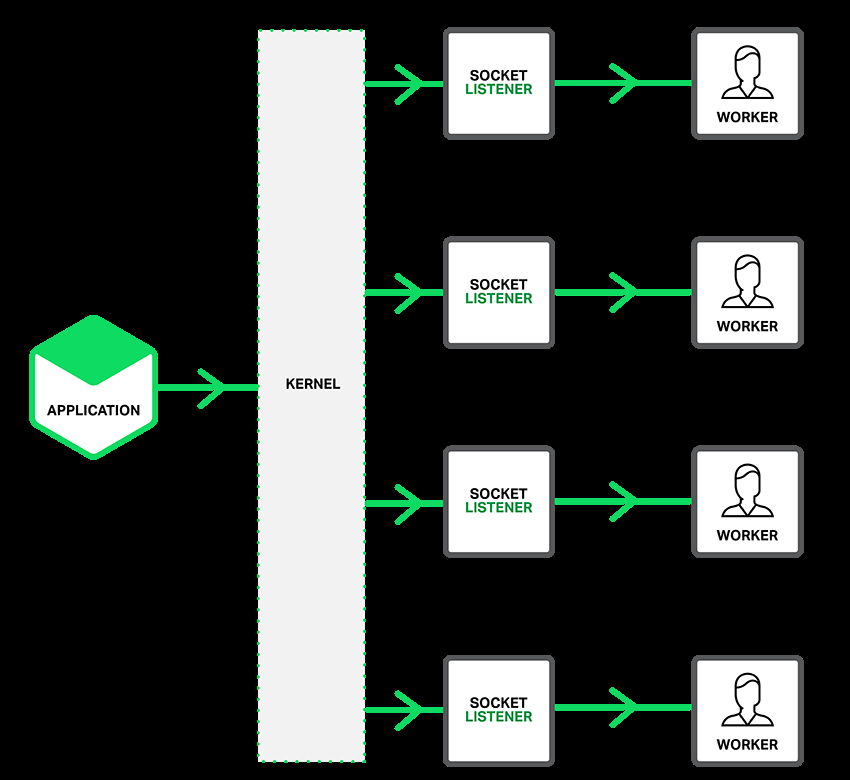
图片来自 Nginx 官网博客
35.4 C1000K
首先从物理资源使用上来说,100 万个请求需要大量的系统资源。比如,
- 假设每个请求需要 16KB 内存的话,那么总共就需要大约 15 GB 内存。
- 而从带宽上来说,假设只有 20% 活跃连接,即使每个连接只需要 1KB/s 的吞吐量,总共也需要 1.6 Gb/s 的吞吐量。千兆网卡显然满足不了这么大的吞吐量,所以还需要配置万兆网卡,或者基于多网卡 Bonding 承载更大的吞吐量。
其次,从软件资源上来说,大量的连接也会占用大量的软件资源,比如文件描述符的数量、连接状态的跟踪(CONNTRACK)、网络协议栈的缓存大小(比如套接字读写缓存、TCP 读写缓存)等等。
断负载均衡、CPU 绑定、RPS/RFS(软中断负载均衡到多个 CPU 核上),以及将网络包的处理卸载(Offload)到网络设备(如 TSO/GSO、LRO/GRO、VXLAN OFFLOAD)等各种硬件和软件的优化。
C1000K 的解决方法,本质上还是构建在 epoll 的非阻塞 I/O 模型上。只不过,除了 I/O 模型之外,还需要从应用程序到 Linux 内核、再到 CPU、内存和网络等各个层次的深度优化,特别是需要借助硬件,来卸载那些原来通过软件处理的大量功能。
35.5 C10M
显然,人们对于性能的要求是无止境的。再进一步,有没有可能在单机中,同时处理 1000 万的请求呢?这也就是 C10M 问题。
实际上,在 C1000K 问题中,各种软件、硬件的优化很可能都已经做到头了。特别是当升级完硬件(比如足够多的内存、带宽足够大的网卡、更多的网络功能卸载等)后,你可能会发现,无论你怎么优化应用程序和内核中的各种网络参数,想实现 1000 万请求的并发,都是极其困难的。
究其根本,还是 Linux 内核协议栈做了太多太繁重的工作。从网卡中断带来的硬中断处理程序开始,到软中断中的各层网络协议处理,最后再到应用程序,这个路径实在是太长了,就会导致网络包的处理优化,到了一定程度后,就无法更进一步了。
要解决这个问题,最重要就是跳过内核协议栈的冗长路径,把网络包直接送到要处理的应用程序那里去。这里有两种常见的机制,DPDK 和 XDP。
第一种机制,DPDK,是用户态网络的标准。它跳过内核协议栈,直接由用户态进程通过轮询的方式,来处理网络接收。
(图片来自 https://blog.selectel.com/introduction-dpdk-architecture-principles/)
说起轮询,你肯定会下意识认为它是低效的象征,但是进一步反问下自己,它的低效主要体现在哪里呢?是查询时间明显多于实际工作时间的情况下吧!那么,换个角度来想,如果每时每刻都有新的网络包需要处理,轮询的优势就很明显了。比如:
- 在 PPS 非常高的场景中,查询时间比实际工作时间少了很多,绝大部分时间都在处理网络包;
而跳过内核协议栈后,就省去了繁杂的硬中断、软中断再到 Linux 网络协议栈逐层处理的过程,应用程序可以针对应用的实际场景,有针对性地优化网络包的处理逻辑,而不需要关注所有的细节。
此外,DPDK 还通过大页、CPU 绑定、内存对齐、流水线并发等多种机制,优化网络包的处理效率。
第二种机制,XDP(eXpress Data Path),则是 Linux 内核提供的一种高性能网络数据路径。它允许网络包,在进入内核协议栈之前,就进行处理,也可以带来更高的性能。XDP 底层跟我们之前用到的 bcc-tools 一样,都是基于 Linux 内核的 eBPF 机制实现的。
XDP 的原理如下图所示:
你可以看到,XDP 对内核的要求比较高,需要的是 Linux 4.8 以上版本,并且它也不提供缓存队列。基于 XDP 的应用程序通常是专用的网络应用,常见的有 IDS(入侵检测系统)、DDoS 防御、 cilium 容器网络插件等。
35.4 小结
C10K 问题的根源,一方面在于系统有限的资源;另一方面,也是更重要的因素,是同步阻塞的 I/O 模型以及轮询的套接字接口,限制了网络事件的处理效率。Linux 2.6 中引入的 epoll ,完美解决了 C10K 的问题,现在的高性能网络方案都基于 epoll。
从 C10K 到 C100K ,可能只需要增加系统的物理资源就可以满足;但从 C100K 到 C1000K ,就不仅仅是增加物理资源就能解决的问题了。这时,就需要多方面的优化工作了,从硬件的中断处理和网络功能卸载、到网络协议栈的文件描述符数量、连接状态跟踪、缓存队列等内核的优化,再到应用程序的工作模型优化,都是考虑的重点。
再进一步,要实现 C10M ,就不只是增加物理资源,或者优化内核和应用程序可以解决的问题了。这时候,就需要用 XDP 的方式,在内核协议栈之前处理网络包;或者用 DPDK 直接跳过网络协议栈,在用户空间通过轮询的方式直接处理网络包。
当然了,实际上,在大多数场景中,我们并不需要单机并发 1000 万的请求。通过调整系统架构,把这些请求分发到多台服务器中来处理,通常是更简单和更容易扩展的方案。
36 | 套路篇:怎么评估系统的网络性能?
36.1 性能指标回顾
首先,带宽,表示链路的最大传输速率,单位是 b/s(比特 / 秒)。在你为服务器选购网卡时,带宽就是最核心的参考指标。常用的带宽有 1000M、10G、40G、100G 等。
第二,吞吐量,表示没有丢包时的最大数据传输速率,单位通常为 b/s (比特 / 秒)或者 B/s(字节 / 秒)。吞吐量受带宽的限制,吞吐量 / 带宽也就是该网络链路的使用率。
第三,延时,表示从网络请求发出后,一直到收到远端响应,所需要的时间延迟。这个指标在不同场景中可能会有不同的含义。它可以表示建立连接需要的时间(比如 TCP 握手延时),或者一个数据包往返所需时间(比如 RTT)。
最后,PPS,是 Packet Per Second(包 / 秒)的缩写,表示以网络包为单位的传输速率。PPS 通常用来评估网络的转发能力,而基于 Linux 服务器的转发,很容易受到网络包大小的影响(交换机通常不会受到太大影响,即交换机可以线性转发)。
这四个指标中,带宽跟物理网卡配置是直接关联的。一般来说,网卡确定后,带宽也就确定了(当然,实际带宽会受限于整个网络链路中最小的那个模块)。
另外,你可能在很多地方听说过”网络带宽测试”,这里测试的实际上不是带宽,而是网络吞吐量。Linux 服务器的网络吞吐量一般会比带宽小,而对交换机等专门的网络设备来说,吞吐量一般会接近带宽。
最后的 PPS,则是以网络包为单位的网络传输速率,通常用在需要大量转发的场景中。而对 TCP 或者 Web 服务来说,更多会用并发连接数和每秒请求数(QPS,Query per Second)等指标,它们更能反应实际应用程序的性能。
36.2 网络基准测试
测试之前,你应该弄清楚,你要评估的网络性能,究竟属于协议栈的哪一层?换句话说,你的应用程序基于协议栈的哪一层呢?
根据前面学过的 TCP/IP 协议栈的原理,这个问题应该不难回答。比如:
- 基于 HTTP 或者 HTTPS 的 Web 应用程序,显然属于应用层,需要我们测试 HTTP/HTTPS 的性能;
- 而对大多数游戏服务器来说,为了支持更大的同时在线人数,通常会基于 TCP 或 UDP ,与客户端进行交互,这时就需要我们测试 TCP/UDP 的性能;
- 当然,还有一些场景,是把 Linux 作为一个软交换机或者路由器来用的。这种情况下,你更关注网络包的处理能力(即 PPS),重点关注网络层的转发性能。
接下来,我就带你从下往上,了解不同协议层的网络性能测试方法。不过要注意,低层协议是其上的各层网络协议的基础。自然,低层协议的性能,也就决定了高层的网络性能。
36.3 各协议层的性能测试
转发性能
我们首先来看,网络接口层和网络层,它们主要负责网络包的封装、寻址、路由以及发送和接收。在这两个网络协议层中,每秒可处理的网络包数 PPS,就是最重要的性能指标。特别是 64B 小包的处理能力,值得我们特别关注。那么,如何来测试网络包的处理能力呢?
说到网络包相关的测试,你可能会觉得陌生。不过,其实在专栏开头的 CPU 性能篇中,我们就接触过一个相关工具,也就是软中断案例中的 hping3。
在那个案例中,hping3 作为一个 SYN 攻击的工具来使用。实际上, hping3 更多的用途,是作为一个测试网络包处理能力的性能工具。
今天我再来介绍另一个更常用的工具,Linux 内核自带的高性能网络测试工具 pktgen。pktgen 支持丰富的自定义选项,方便你根据实际需要构造所需网络包,从而更准确地测试出目标服务器的性能。
不过,在 Linux 系统中,你并不能直接找到 pktgen 命令。因为 pktgen 作为一个内核线程来运行,需要你加载 pktgen 内核模块后,再通过 /proc 文件系统来交互。下面就是 pktgen 启动的两个内核线程和 /proc 文件系统的交互文件:
$ modprobe pktgen $ ps -ef | grep pktgen | grep -v grep root 26384 2 0 06:17 ? 00:00:00 [kpktgend_0] root 26385 2 0 06:17 ? 00:00:00 [kpktgend_1] $ ls /proc/net/pktgen/ kpktgend_0 kpktgend_1 pgctrlpktgen 在每个 CPU 上启动一个内核线程,并可以通过 /proc/net/pktgen 下面的同名文件,跟这些线程交互;而 pgctrl 则主要用来控制这次测试的开启和停止。
如果 modprobe 命令执行失败,说明你的内核没有配置 CONFIG_NET_PKTGEN 选项。这就需要你配置 pktgen 内核模块(即 CONFIG_NET_PKTGEN=m)后,重新编译内核,才可以使用。
在使用 pktgen 测试网络性能时,需要先给每个内核线程 kpktgend_X 以及测试网卡,配置 pktgen 选项,然后再通过 pgctrl 启动测试。
以发包测试为例,假设发包机器使用的网卡是 eth0,而目标机器的 IP 地址为 192.168.0.30,MAC 地址为 11:11:11:11:11:11。
接下来,就是一个发包测试的示例。
# 定义一个工具函数,方便后面配置各种测试选项 function pgset() { local result echo $1 > $PGDEV result=`cat $PGDEV | fgrep "Result: OK:"` if [ "$result" = "" ]; then cat $PGDEV | fgrep Result: fi } # 为 0 号线程绑定 eth0 网卡 PGDEV=/proc/net/pktgen/kpktgend_0 pgset "rem_device_all" # 清空网卡绑定 pgset "add_device eth0" # 添加 eth0 网卡 # 配置 eth0 网卡的测试选项 PGDEV=/proc/net/pktgen/eth0 pgset "count 1000000" # 总发包数量 pgset "delay 5000" # 不同包之间的发送延迟 (单位纳秒) pgset "clone_skb 0" # SKB 包复制 pgset "pkt_size 64" # 网络包大小 pgset "dst 192.168.0.30" # 目的 IP pgset "dst_mac 11:11:11:11:11:11" # 目的 MAC # 启动测试 PGDEV=/proc/net/pktgen/pgctrl pgset "start"稍等一会儿,测试完成后,结果可以从 /proc 文件系统中获取。通过下面代码段中的内容,我们可以查看刚才的测试报告:
$ cat /proc/net/pktgen/eth0 Params: count 1000000 min_pkt_size: 64 max_pkt_size: 64 frags: 0 delay: 0 clone_skb: 0 ifname: eth0 flows: 0 flowlen: 0 ... Current: pkts-sofar: 1000000 errors: 0 started: 1534853256071us stopped: 1534861576098us idle: 70673us ... Result: OK: 8320027(c8249354+d70673) usec, 1000000 (64byte,0frags) 120191pps 61Mb/sec (61537792bps) errors: 0你可以看到,测试报告主要分为三个部分:
- 第一部分的 Params 是测试选项;
- 第二部分的 Current 是测试进度,其中, packts so far(pkts-sofar)表示已经发送了 100 万个包,也就表明测试已完成。
第三部分的 Result 是测试结果,包含测试所用时间、网络包数量和分片、PPS、吞吐量以及错误数。
根据上面的结果,我们发现,PPS 为 12 万,吞吐量为 61 Mb/s,没有发生错误。那么,12 万的 PPS 好不好呢?
作为对比,你可以计算一下千兆交换机的 PPS。交换机可以达到线速(满负载时,无差错转发),它的 PPS 就是 1000Mbit 除以以太网帧的大小,即 1000Mbps/((64+20)*8bit) = 1.5 Mpps(其中,20B 为以太网帧前导和帧间距的大小)。
你看,即使是千兆交换机的 PPS,也可以达到 150 万 PPS,比我们测试得到的 12 万大多了。所以,看到这个数值你并不用担心,现在的多核服务器和万兆网卡已经很普遍了,稍做优化就可以达到数百万的 PPS。而且,如果你用了上节课讲到的 DPDK 或 XDP ,还能达到千万数量级。
TCP/UDP 性能
掌握了 PPS 的测试方法,接下来,我们再来看 TCP 和 UDP 的性能测试方法。说到 TCP 和 UDP 的测试,我想你已经很熟悉了,甚至可能一下子就能想到相应的测试工具,比如 iperf 或者 netperf。
特别是现在的云计算时代,在你刚拿到一批虚拟机时,首先要做的,应该就是用 iperf ,测试一下网络性能是否符合预期。
iperf 和 netperf 都是最常用的网络性能测试工具,测试 TCP 和 UDP 的吞吐量。它们都以客户端和服务器通信的方式,测试一段时间内的平均吞吐量。
接下来,我们就以 iperf 为例,看一下 TCP 性能的测试方法。目前,iperf 的最新版本为 iperf3,你可以运行下面的命令来安装:
# Ubuntu apt-get install iperf3 # CentOS yum install iperf3然后,在目标机器上启动 iperf 服务端:
# -s 表示启动服务端,-i 表示汇报间隔,-p 表示监听端口 $ iperf3 -s -i 1 -p 10000接着,在另一台机器上运行 iperf 客户端,运行测试:
# -c 表示启动客户端,192.168.0.30 为目标服务器的 IP # -b 表示目标带宽 (单位是 bits/s) # -t 表示测试时间 # -P 表示并发数,-p 表示目标服务器监听端口 $ iperf3 -c 192.168.0.30 -b 1G -t 15 -P 2 -p 10000稍等一会儿(15 秒)测试结束后,回到目标服务器,查看 iperf 的报告:
[ ID] Interval Transfer Bandwidth ... [SUM] 0.00-15.04 sec 0.00 Bytes 0.00 bits/sec sender [SUM] 0.00-15.04 sec 1.51 GBytes 860 Mbits/sec receiver最后的 SUM 行就是测试的汇总结果,包括测试时间、数据传输量以及带宽等。按照发送和接收,这一部分又分为了 sender 和 receiver 两行。
从测试结果你可以看到,这台机器 TCP 接收的带宽(吞吐量)为 860 Mb/s, 跟目标的 1Gb/s 相比,还是有些差距的。
HTTP 性能
要测试 HTTP 的性能,也有大量的工具可以使用,比如 ab、webbench 等,都是常用的 HTTP 压力测试工具。其中,ab 是 Apache 自带的 HTTP 压测工具,主要测试 HTTP 服务的每秒请求数、请求延迟、吞吐量以及请求延迟的分布情况等。
运行下面的命令,你就可以安装 ab 工具:
# Ubuntu $ apt-get install -y apache2-utils # CentOS $ yum install -y httpd-tools接下来,在目标机器上,使用 Docker 启动一个 Nginx 服务,然后用 ab 来测试它的性能。首先,在目标机器上运行下面的命令:
docker run -p 80:80 -itd nginx而在另一台机器上,运行 ab 命令,测试 Nginx 的性能:
# -c 表示并发请求数为 1000,-n 表示总的请求数为 10000 $ ab -c 1000 -n 10000 http://192.168.0.30/ ... Server Software: nginx/1.15.8 Server Hostname: 192.168.0.30 Server Port: 80 ... Requests per second: 1078.54 [#/sec] (mean) Time per request: 927.183 [ms] (mean) Time per request: 0.927 [ms] (mean, across all concurrent requests) Transfer rate: 890.00 [Kbytes/sec] received Connection Times (ms) min mean[+/-sd] median max Connect: 0 27 152.1 1 1038 Processing: 9 207 843.0 22 9242 Waiting: 8 207 843.0 22 9242 Total: 15 233 857.7 23 9268 Percentage of the requests served within a certain time (ms) 50% 23 66% 24 75% 24 80% 26 90% 274 95% 1195 98% 2335 99% 4663 100% 9268 (longest request)可以看到,ab 的测试结果分为三个部分,分别是请求汇总、连接时间汇总还有请求延迟汇总。以上面的结果为例,我们具体来看。
在请求汇总部分,你可以看到:
- Requests per second 为 1074;
- 每个请求的延迟(Time per request)分为两行,第一行的 927 ms 表示平均延迟,包括了线程运行的调度时间和网络请求响应时间,而下一行的 0.927ms ,则表示实际请求的响应时间;
Transfer rate 表示吞吐量(BPS)为 890 KB/s。
连接时间汇总部分,则是分别展示了建立连接、请求、等待以及汇总等的各类时间,包括最小、最大、平均以及中值处理时间。
最后的请求延迟汇总部分,则给出了不同时间段内处理请求的百分比,比如, 90% 的请求,都可以在 274ms 内完成。
应用负载性能
当你用 iperf 或者 ab 等测试工具,得到 TCP、HTTP 等的性能数据后,这些数据是否就能表示应用程序的实际性能呢?我想,你的答案应该是否定的。
比如,你的应用程序基于 HTTP 协议,为最终用户提供一个 Web 服务。这时,使用 ab 工具,可以得到某个页面的访问性能,但这个结果跟用户的实际请求,很可能不一致。因为用户请求往往会附带着各种各种的负载(payload),而这些负载会影响 Web 应用程序内部的处理逻辑,从而影响最终性能。
那么,为了得到应用程序的实际性能,就要求性能工具本身可以模拟用户的请求负载,而 iperf、ab 这类工具就无能为力了。幸运的是,我们还可以用 wrk、TCPCopy、Jmeter 或者 LoadRunner 等实现这个目标。
以 wrk 为例,它是一个 HTTP 性能测试工具,内置了 LuaJIT,方便你根据实际需求,生成所需的请求负载,或者自定义响应的处理方法。
wrk 工具本身不提供 yum 或 apt 的安装方法,需要通过源码编译来安装。比如,你可以运行下面的命令,来编译和安装 wrk:
https://github.com/wg/wrk cd wrk apt-get install build-essential -y make sudo cp wrk /usr/local/bin/wrk 的命令行参数比较简单。比如,我们可以用 wrk ,来重新测一下前面已经启动的 Nginx 的性能。
# -c 表示并发连接数 1000,-t 表示线程数为 2 $ wrk -c 1000 -t 2 http://192.168.0.30/ Running 10s test @ http://192.168.0.30/ 2 threads and 1000 connections Thread Stats Avg Stdev Max +/- Stdev Latency 65.83ms 174.06ms 1.99s 95.85% Req/Sec 4.87k 628.73 6.78k 69.00% 96954 requests in 10.06s, 78.59MB read Socket errors: connect 0, read 0, write 0, timeout 179 Requests/sec: 9641.31 Transfer/sec: 7.82MB这里使用 2 个线程、并发 1000 连接,重新测试了 Nginx 的性能。你可以看到,每秒请求数为 9641,吞吐量为 7.82MB,平均延迟为 65ms,比前面 ab 的测试结果要好很多。
这也说明,性能工具本身的性能,对性能测试也是至关重要的。不合适的性能工具,并不能准确测出应用程序的最佳性能。
当然,wrk 最大的优势,是其内置的 LuaJIT,可以用来实现复杂场景的性能测试。wrk 在调用 Lua 脚本时,可以将 HTTP 请求分为三个阶段,即 setup、running、done,如下图所示:
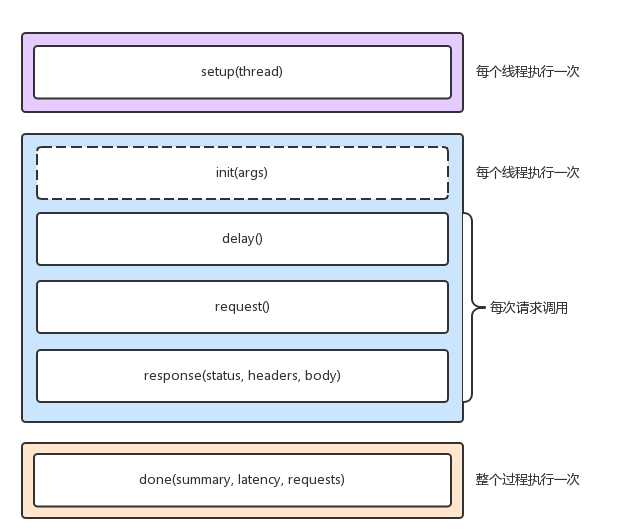
图片来自网易云博客
比如,你可以在 setup 阶段,为请求设置认证参数(来自于 wrk 官方示例):
-- example script that demonstrates response handling and -- retrieving an authentication token to set on all future -- requests token = nil path = "/authenticate" request = function() return wrk.format("GET", path) end response = function(status, headers, body) if not token and status == 200 then token = headers["X-Token"] path = "/resource" wrk.headers["X-Token"] = token end end而在执行测试时,通过 -s 选项,执行脚本的路径:
wrk -c 1000 -t 2 -s auth.lua http://192.168.0.30/wrk 需要你用 Lua 脚本,来构造请求负载。这对于大部分场景来说,可能已经足够了 。不过,它的缺点也正是,所有东西都需要代码来构造,并且工具本身不提供 GUI 环境。
像 Jmeter 或者 LoadRunner(商业产品),则针对复杂场景提供了脚本录制、回放、GUI 等更丰富的功能,使用起来也更加方便。
36.4 小结
性能评估是优化网络性能的前提,只有在你发现网络性能瓶颈时,才需要进行网络性能优化。根据 TCP/IP 协议栈的原理,不同协议层关注的性能重点不完全一样,也就对应不同的性能测试方法。比如,
- 在应用层,你可以使用 wrk、Jmeter 等模拟用户的负载,测试应用程序的每秒请求数、处理延迟、错误数等;
- 而在传输层,则可以使用 iperf 等工具,测试 TCP 的吞吐情况;
- 再向下,你还可以用 Linux 内核自带的 pktgen ,测试服务器的 PPS。
由于低层协议是高层协议的基础。所以,一般情况下,我们需要从上到下,对每个协议层进行性能测试,然后根据性能测试的结果,结合 Linux 网络协议栈的原理,找出导致性能瓶颈的根源,进而优化网络性能。
37 | 案例篇:DNS 解析时快时慢,我该怎么办?
37.1 域名与 DNS 解析
域名我们本身都比较熟悉,由一串用点分割开的字符组成,被用作互联网中的某一台或某一组计算机的名称,目的就是为了方便识别,互联网中提供各种服务的主机位置。
要注意,域名是全球唯一的,需要通过专门的域名注册商才可以申请注册。为了组织全球互联网中的众多计算机,域名同样用点来分开,形成一个分层的结构。而每个被点分割开的字符串,就构成了域名中的一个层级,并且位置越靠后,层级越高。
我们以极客时间的网站 time.geekbang.org 为例,来理解域名的含义。这个字符串中,最后面的 org 是顶级域名,中间的 geekbang 是二级域名,而最左边的 time 则是三级域名。
如下图所示,注意点(.)是所有域名的根,也就是说所有域名都以点作为后缀,也可以理解为,在域名解析的过程中,所有域名都以点结束。
域名主要是为了方便让人记住,而 IP 地址是机器间的通信的真正机制。把域名转换为 IP 地址的服务,也就是我们开头提到的,域名解析服务(DNS),而对应的服务器就是域名服务器,网络协议则是 DNS 协议。
这里注意,DNS 协议在 TCP/IP 栈中属于应用层,不过实际传输还是基于 UDP 或者 TCP 协议(UDP 居多) ,并且域名服务器一般监听在端口 53 上。
既然域名以分层的结构进行管理,相对应的,域名解析其实也是用递归的方式(从顶级开始,以此类推),发送给每个层级的域名服务器,直到得到解析结果。
不过不要担心,递归查询的过程并不需要你亲自操作,DNS 服务器会替你完成,你要做的,只是预先配置一个可用的 DNS 服务器就可以了。
当然,我们知道,通常来说,每级 DNS 服务器,都会有最近解析记录的缓存。当缓存命中时,直接用缓存中的记录应答就可以了。如果缓存过期或者不存在,才需要用刚刚提到的递归方式查询。
所以,系统管理员在配置 Linux 系统的网络时,除了需要配置 IP 地址,还需要给它配置 DNS 服务器,这样它才可以通过域名来访问外部服务。
比如,我的系统配置的就是 114.114.114.114 这个域名服务器。你可以执行下面的命令,来查询你的系统配置:
$ cat /etc/resolv.conf
nameserver 114.114.114.114另外,DNS 服务通过资源记录的方式,来管理所有数据,它支持 A、CNAME、MX、NS、PTR 等多种类型的记录。比如:
- A 记录,用来把域名转换成 IP 地址;
- CNAME 记录,用来创建别名;
- 而 NS 记录,则表示该域名对应的域名服务器地址。
简单来说,当我们访问某个网址时,就需要通过 DNS 的 A 记录,查询该域名对应的 IP 地址,然后再通过该 IP 来访问 Web 服务。
比如,还是以极客时间的网站 time.geekbang.org 为例,执行下面的 nslookup 命令,就可以查询到这个域名的 A 记录,可以看到,它的 IP 地址是 39.106.233.176:
$ nslookup time.geekbang.org
# 域名服务器及端口信息
Server: 114.114.114.114
Address: 114.114.114.114#53
# 非权威查询结果
Non-authoritative answer:
Name: time.geekbang.org
Address: 39.106.233.17这里要注意,由于 114.114.114.114 并不是直接管理 time.geekbang.org 的域名服务器,所以查询结果是非权威的。使用上面的命令,你只能得到 114.114.114.114 查询的结果。
前面还提到了,如果没有命中缓存,DNS 查询实际上是一个递归过程,那有没有方法可以知道整个递归查询的执行呢?
其实除了 nslookup,另外一个常用的 DNS 解析工具 dig ,就提供了 trace 功能,可以展示递归查询的整个过程。比如你可以执行下面的命令,得到查询结果:
# +trace 表示开启跟踪查询
# +nodnssec 表示禁止 DNS 安全扩展
$ dig +trace +nodnssec time.geekbang.org
; <<>> DiG 9.11.3-1ubuntu1.3-Ubuntu <<>> +trace +nodnssec time.geekbang.org
;; global options: +cmd
. 322086 IN NS m.root-servers.net.
. 322086 IN NS a.root-servers.net.
. 322086 IN NS i.root-servers.net.
. 322086 IN NS d.root-servers.net.
. 322086 IN NS g.root-servers.net.
. 322086 IN NS l.root-servers.net.
. 322086 IN NS c.root-servers.net.
. 322086 IN NS b.root-servers.net.
. 322086 IN NS h.root-servers.net.
. 322086 IN NS e.root-servers.net.
. 322086 IN NS k.root-servers.net.
. 322086 IN NS j.root-servers.net.
. 322086 IN NS f.root-servers.net.
;; Received 239 bytes from 114.114.114.114#53(114.114.114.114) in 1340 ms
org. 172800 IN NS a0.org.afilias-nst.info.
org. 172800 IN NS a2.org.afilias-nst.info.
org. 172800 IN NS b0.org.afilias-nst.org.
org. 172800 IN NS b2.org.afilias-nst.org.
org. 172800 IN NS c0.org.afilias-nst.info.
org. 172800 IN NS d0.org.afilias-nst.org.
;; Received 448 bytes from 198.97.190.53#53(h.root-servers.net) in 708 ms
geekbang.org. 86400 IN NS dns9.hichina.com.
geekbang.org. 86400 IN NS dns10.hichina.com.
;; Received 96 bytes from 199.19.54.1#53(b0.org.afilias-nst.org) in 1833 ms
time.geekbang.org. 600 IN A 39.106.233.176
;; Received 62 bytes from 140.205.41.16#53(dns10.hichina.com) in 4 msdig trace 的输出,主要包括四部分。
- 第一部分,是从 114.114.114.114 查到的一些根域名服务器(.)的 NS 记录。
- 第二部分,是从 NS 记录结果中选一个(h.root-servers.net),并查询顶级域名 org. 的 NS 记录。
- 第三部分,是从 org. 的 NS 记录中选择一个(b0.org.afilias-nst.org),并查询二级域名 geekbang.org. 的 NS 服务器。
- 最后一部分,就是从 geekbang.org. 的 NS 服务器(dns10.hichina.com)查询最终主机 time.geekbang.org. 的 A 记录。这个输出里展示的各级域名的 NS 记录,其实就是各级域名服务器的地址,可以让你更清楚 DNS 解析的过程。
当然,不仅仅是发布到互联网的服务需要域名,很多时候,我们也希望能对局域网内部的主机进行域名解析(即内网域名,大多数情况下为主机名)。Linux 也支持这种行为。
所以,你可以把主机名和 IP 地址的映射关系,写入本机的 /etc/hosts 文件中。这样,指定的主机名就可以在本地直接找到目标 IP。比如,你可以执行下面的命令来操作:
$ cat /etc/hosts
127.0.0.1 localhost localhost.localdomain
::1 localhost6 localhost6.localdomain6
192.168.0.100 domain.com或者,你还可以在内网中,搭建自定义的 DNS 服务器,专门用来解析内网中的域名。而内网 DNS 服务器,一般还会设置一个或多个上游 DNS 服务器,用来解析外网的域名。
37.2 案例
机器配置: 2 CPU, 8 GB 内存。
安装软件:
apt install docker.io。
你可以先打开一个终端,SSH 登录到 Ubuntu 机器中,然后执行下面的命令,拉取案例中使用的 Docker 镜像:
$ docker pull feisky/dnsutils
Using default tag: latest
...
Status: Downloaded newer image for feisky/dnsutils:latest然后,运行下面的命令,查看主机当前配置的 DNS 服务器:
$ cat /etc/resolv.conf
nameserver 114.114.114.114可以看到,我这台主机配置的 DNS 服务器是 114.114.114.114。
案例 1:DNS 解析失败
首先,执行下面的命令,进入今天的第一个案例。如果一切正常,你将可以看到下面这个输出:
# 进入案例环境的 SHELL 终端中 $ docker run -it --rm -v $(mktemp):/etc/resolv.conf feisky/dnsutils bash root@7e9ed6ed4974:/#注意,这儿 root 后面的 7e9ed6ed4974,是 Docker 生成容器的 ID 前缀,你的环境中很可能是不同的 ID,所以直接忽略这一项就可以了。
注意:下面的代码段中, /# 开头的命令都表示在容器内部运行的命令。
接着,继续在容器终端中,执行 DNS 查询命令,我们还是查询 time.geekbang.org 的 IP 地址:
/# nslookup time.geekbang.org ;; connection timed out; no servers could be reached你可以发现,这个命令阻塞很久后,还是失败了,报了 connection timed out 和 no servers could be reached 错误。
看到这里,估计你的第一反应就是网络不通了,到底是不是这样呢?我们用 ping 工具检查试试。执行下面的命令,就可以测试本地到 114.114.114.114 的连通性:
/# ping -c3 114.114.114.114 PING 114.114.114.114 (114.114.114.114): 56 data bytes 64 bytes from 114.114.114.114: icmp_seq=0 ttl=56 time=31.116 ms 64 bytes from 114.114.114.114: icmp_seq=1 ttl=60 time=31.245 ms 64 bytes from 114.114.114.114: icmp_seq=2 ttl=68 time=31.128 ms --- 114.114.114.114 ping statistics --- 3 packets transmitted, 3 packets received, 0% packet loss round-trip min/avg/max/stddev = 31.116/31.163/31.245/0.058 ms那要怎么知道 nslookup 命令失败的原因呢?这里其实有很多方法,最简单的一种,就是开启 nslookup 的调试输出,查看查询过程中的详细步骤,排查其中是否有异常。
比如,我们可以继续在容器终端中,执行下面的命令:
/# nslookup -debug time.geekbang.org ;; Connection to 127.0.0.1#53(127.0.0.1) for time.geekbang.org failed: connection refused. ;; Connection to ::1#53(::1) for time.geekbang.org failed: address not available.从这次的输出可以看到,nslookup 连接环回地址(127.0.0.1 和 ::1)的 53 端口失败。这里就有问题了,为什么会去连接环回地址,而不是我们的先前看到的 114.114.114.114 呢?
你可能已经想到了症结所在——有可能是因为容器中没有配置 DNS 服务器。那我们就执行下面的命令确认一下:
/# cat /etc/resolv.conf果然,这个命令没有任何输出,说明容器里的确没有配置 DNS 服务器。到这一步,很自然的,我们就知道了解决方法。在 /etc/resolv.conf 文件中,配置上 DNS 服务器就可以了。
/# echo "nameserver 114.114.114.114" > /etc/resolv.conf /# nslookup time.geekbang.org Server: 114.114.114.114 Address: 114.114.114.114#53 Non-authoritative answer: Name: time.geekbang.org Address: 39.106.233.176案例 2:DNS 解析不稳定
接下来,我们再来看第二个案例。执行下面的命令,启动一个新的容器,并进入它的终端中:
$ docker run -it --rm --cap-add=NET_ADMIN --dns 8.8.8.8 feisky/dnsutils bash root@0cd3ee0c8ecb:/#然后,跟上一个案例一样,还是运行 nslookup 命令,解析 time.geekbang.org 的 IP 地址。不过,这次要加一个 time 命令,输出解析所用时间。如果一切正常,你可能会看到如下输出:
/# time nslookup time.geekbang.org Server: 8.8.8.8 Address: 8.8.8.8#53 Non-authoritative answer: Name: time.geekbang.org Address: 39.106.233.176 real 0m10.349s user 0m0.004s sys 0m0.0可以看到,这次解析非常慢,居然用了 10 秒。如果你多次运行上面的 nslookup 命令,可能偶尔还会碰到下面这种错误:
/# time nslookup time.geekbang.org ;; connection timed out; no servers could be reached real 0m15.011s user 0m0.006s sys 0m0.006s换句话说,跟上一个案例类似,也会出现解析失败的情况。综合来看,现在 DNS 解析的结果不但比较慢,而且还会发生超时失败的情况。
这是为什么呢?碰到这种问题该怎么处理呢?
其实,根据前面的讲解,我们知道,DNS 解析,说白了就是客户端与服务器交互的过程,并且这个过程还使用了 UDP 协议。
那么,对于整个流程来说,解析结果不稳定,就有很多种可能的情况了。比方说:
- DNS 服务器本身有问题,响应慢并且不稳定;
- 或者是,客户端到 DNS 服务器的网络延迟比较大;
再或者,DNS 请求或者响应包,在某些情况下被链路中的网络设备弄丢了。
根据上面 nslookup 的输出,你可以看到,现在客户端连接的 DNS 是 8.8.8.8,这是 Google 提供的 DNS 服务。对 Google 我们还是比较放心的,DNS 服务器出问题的概率应该比较小。基本排除了 DNS 服务器的问题,那是不是第二种可能,本机到 DNS 服务器的延迟比较大呢?
前面讲过,ping 可以用来测试服务器的延迟。比如,你可以运行下面的命令:
/# ping -c3 8.8.8.8 PING 8.8.8.8 (8.8.8.8): 56 data bytes 64 bytes from 8.8.8.8: icmp_seq=0 ttl=31 time=137.637 ms 64 bytes from 8.8.8.8: icmp_seq=1 ttl=31 time=144.743 ms 64 bytes from 8.8.8.8: icmp_seq=2 ttl=31 time=138.576 ms --- 8.8.8.8 ping statistics --- 3 packets transmitted, 3 packets received, 0% packet loss round-trip min/avg/max/stddev = 137.637/140.319/144.743/3.152 ms从 ping 的输出可以看到,这里的延迟已经达到了 140ms,这也就可以解释,为什么解析这么慢了。实际上,如果你多次运行上面的 ping 测试,还会看到偶尔出现的丢包现象。
如果更改了 DNS 解析时间还是太长了,该怎么解决这个问题呢?我想你一定已经想到了,那就是使用 DNS 缓存。这样,只有第一次查询时需要去 DNS 服务器请求,以后的查询,只要 DNS 记录不过期,使用缓存中的记录就可以了。
不过要注意,我们使用的主流 Linux 发行版,除了最新版本的 Ubuntu (如 18.04 或者更新版本)外,其他版本并没有自动配置 DNS 缓存。
所以,想要为系统开启 DNS 缓存,就需要你做额外的配置。比如,最简单的方法,就是使用 dnsmasq。
dnsmasq 是最常用的 DNS 缓存服务之一,还经常作为 DHCP 服务来使用。它的安装和配置都比较简单,性能也可以满足绝大多数应用程序对 DNS 缓存的需求。
我们继续在刚才的容器终端中,执行下面的命令,就可以启动 dnsmasq:
/# /etc/init.d/dnsmasq start * Starting DNS forwarder and DHCP server dnsmasq [ OK ]然后,修改 /etc/resolv.conf,将 DNS 服务器改为 dnsmasq 的监听地址,这儿是 127.0.0.1。接着,重新执行多次 nslookup 命令:
/# echo nameserver 127.0.0.1 > /etc/resolv.conf /# time nslookup time.geekbang.org Server: 127.0.0.1 Address: 127.0.0.1#53 Non-authoritative answer: Name: time.geekbang.org Address: 39.106.233.176 real 0m0.492s user 0m0.007s sys 0m0.006s /# time nslookup time.geekbang.org Server: 127.0.0.1 Address: 127.0.0.1#53 Non-authoritative answer: Name: time.geekbang.org Address: 39.106.233.176 real 0m0.011s user 0m0.008s sys 0m0.003s现在我们可以看到,只有第一次的解析很慢,需要 0.5s,以后的每次解析都很快,只需要 11ms。并且,后面每次 DNS 解析需要的时间也都很稳定。
37.3 小结
在应用程序的开发过程中,我们必须考虑到 DNS 解析可能带来的性能问题,掌握常见的优化方法。这里,我总结了几种常见的 DNS 优化方法。
- 对 DNS 解析的结果进行缓存。缓存是最有效的方法,但要注意,一旦缓存过期,还是要去 DNS 服务器重新获取新记录。不过,这对大部分应用程序来说都是可接受的。
- 对 DNS 解析的结果进行预取。这是浏览器等 Web 应用中最常用的方法,也就是说,不等用户点击页面上的超链接,浏览器就会在后台自动解析域名,并把结果缓存起来。
- 使用 HTTPDNS 取代常规的 DNS 解析。这是很多移动应用会选择的方法,特别是如今域名劫持普遍存在,使用 HTTP 协议绕过链路中的 DNS 服务器,就可以避免域名劫持的问题。
- 基于 DNS 的全局负载均衡(GSLB)。这不仅为服务提供了负载均衡和高可用的功能,还可以根据用户的位置,返回距离最近的 IP 地址。
38 | 案例篇:怎么使用 tcpdump 和 Wireshark 分析网络流量?
# 禁止接收从 DNS 服务器发送过来并包含 googleusercontent 的包
$ iptables -I INPUT -p udp --sport 53 -m string --string googleusercontent --algo bm -j DROP当你发现针对相同的网络服务,使用 IP 地址快而换成域名却慢很多时,就要想到,有可能是 DNS 在捣鬼。DNS 的解析,不仅包括从域名解析出 IP 地址的 A 记录请求,还包括性能工具帮你,”聪明”地从 IP 地址反查域名的 PTR 请求。
实际上,根据 IP 地址反查域名、根据端口号反查协议名称,是很多网络工具默认的行为,而这往往会导致性能工具的工作缓慢。所以,通常,网络性能工具都会提供一个选项(比如 -n 或者 -nn),来禁止名称解析。
39 | 案例篇:怎么缓解 DDoS 攻击带来的性能下降问题?
39.1 DDoS 简介
从攻击的原理上来看,DDoS 可以分为下面几种类型。
- 第一种,耗尽带宽。无论是服务器还是路由器、交换机等网络设备,带宽都有固定的上限。带宽耗尽后,就会发生网络拥堵,从而无法传输其他正常的网络报文。
- 第二种,耗尽操作系统的资源。网络服务的正常运行,都需要一定的系统资源,像是 CPU、内存等物理资源,以及连接表等软件资源。一旦资源耗尽,系统就不能处理其他正常的网络连接。
- 第三种,消耗应用程序的运行资源。应用程序的运行,通常还需要跟其他的资源或系统交互。如果应用程序一直忙于处理无效请求,也会导致正常请求的处理变慢,甚至得不到响应。
39.2 案例
机器配置: 2 CPU, 8 GB 内存。
安装软件:
apt-get install docker.io hping3 tcpdump curl。
一台虚拟机运行 Nginx ,用来模拟待分析的 Web 服务器;而另外两台作为 Web 服务器的客户端,其中一台用作 DoS 攻击,而另一台则是正常的客户端。使用多台虚拟机的目的,自然还是为了相互隔离,避免”交叉感染”。
打开三个终端,分别 SSH 登录到三台机器上。
在终端一中,执行下面的命令运行案例,也就是启动一个最基本的 Nginx 应用:
# 运行 Nginx 服务并对外开放 80 端口 # --network=host 表示使用主机网络(这是为了方便后面排查问题) $ docker run -itd --name=nginx --network=host nginx在终端二和终端三中,使用 curl 访问 Nginx 监听的端口,确认 Nginx 正常启动。假设 192.168.0.30 是 Nginx 所在虚拟机的 IP 地址,那么运行 curl 命令后,你应该会看到下面这个输出界面:
# -w 表示只输出 HTTP 状态码及总时间,-o 表示将响应重定向到 /dev/null $ curl -s -w 'Http code: %{http_code}\nTotal time:%{time_total}s\n' -o /dev/null http://192.168.0.30/ ... Http code: 200 Total time:0.002s从这里可以看到,正常情况下,我们访问 Nginx 只需要 2ms(0.002s)。
在终端二中,运行 hping3 命令,来模拟 DoS 攻击:
# -S 参数表示设置 TCP 协议的 SYN(同步序列号),-p 表示目的端口为 80 # -i u10 表示每隔 10 微秒发送一个网络帧 $ hping3 -S -p 80 -i u10 192.168.0.30再回到终端一,你就会发现,现在不管执行什么命令,都慢了很多。不过,在实践时要注意:
- 如果你的现象不那么明显,那么请尝试把参数里面的 u10 调小(比如调成 u1),或者加上–flood 选项;
- 如果你的终端一完全没有响应了,那么请适当调大 u10(比如调成 u30),否则后面就不能通过 SSH 操作 VM1。
然后,到终端三中,执行下面的命令,模拟正常客户端的连接:
# --connect-timeout 表示连接超时时间 $ curl -w 'Http code: %{http_code}\nTotal time:%{time_total}s\n' -o /dev/null --connect-timeout 10 http://192.168.0.30 ... Http code: 000 Total time:10.001s curl: (28) Connection timed out after 10000 milliseconds你可以发现,在终端三中,正常客户端的连接超时了,并没有收到 Nginx 服务的响应。
这是发生了什么问题呢?我们再回到终端一中,检查网络状况。你应该还记得我们多次用过的 sar,它既可以观察 PPS(每秒收发的报文数),还可以观察 BPS(每秒收发的字节数)。
我们可以回到终端一中,执行下面的命令:
$ sar -n DEV 1 08:55:49 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil 08:55:50 docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 08:55:50 eth0 22274.00 629.00 1174.64 37.78 0.00 0.00 0.00 0.02 08:55:50 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00从这次 sar 的输出中,你可以看到,网络接收的 PPS 已经达到了 20000 多,但是 BPS 却只有 1174 kB,这样每个包的大小就只有 54B(1174*1024/22274=54)。
这明显就是个小包了,不过具体是个什么样的包呢?那我们就用 tcpdump 抓包看看吧。
在终端一中,执行下面的 tcpdump 命令:
# -i eth0 只抓取 eth0 网卡,-n 不解析协议名和主机名 # tcp port 80 表示只抓取 tcp 协议并且端口号为 80 的网络帧 $ tcpdump -i eth0 -n tcp port 80 09:15:48.287047 IP 192.168.0.2.27095 > 192.168.0.30: Flags [S], seq 1288268370, win 512, length 0 09:15:48.287050 IP 192.168.0.2.27131 > 192.168.0.30: Flags [S], seq 2084255254, win 512, length 0 09:15:48.287052 IP 192.168.0.2.27116 > 192.168.0.30: Flags [S], seq 677393791, win 512, length 0 09:15:48.287055 IP 192.168.0.2.27141 > 192.168.0.30: Flags [S], seq 1276451587, win 512, length 0 09:15:48.287068 IP 192.168.0.2.27154 > 192.168.0.30: Flags [S], seq 1851495339, win 512, length 0 ...这个输出中,Flags [S] 表示这是一个 SYN 包。大量的 SYN 包表明,这是一个 SYN Flood 攻击。实际上,SYN Flood 正是互联网中最经典的 DDoS 攻击方式。
它的原理:
- 即客户端构造大量的 SYN 包,请求建立 TCP 连接;
而服务器收到包后,会向源 IP 发送 SYN+ACK 报文,并等待三次握手的最后一次 ACK 报文,直到超时。
这种等待状态的 TCP 连接,通常也称为半开连接。由于连接表的大小有限,大量的半开连接就会导致连接表迅速占满,从而无法建立新的 TCP 连接。
参考下面这张 TCP 状态图,你能看到,此时,服务器端的 TCP 连接,会处于 SYN_RECEIVED 状态:
图片来自 Wikipedia
这其实提示了我们,查看 TCP 半开连接的方法,关键在于 SYN_RECEIVED 状态的连接。我们可以使用 netstat ,来查看所有连接的状态,不过要注意, SYN_RECEIVED 的状态,通常被缩写为 SYN_RECV。
我们继续在终端一中,执行下面的 netstat 命令:
# -n 表示不解析名字,-p 表示显示连接所属进程 $ netstat -n -p | grep SYN_REC tcp 0 0 192.168.0.30:80 192.168.0.2:12503 SYN_RECV - tcp 0 0 192.168.0.30:80 192.168.0.2:13502 SYN_RECV - tcp 0 0 192.168.0.30:80 192.168.0.2:15256 SYN_RECV - tcp 0 0 192.168.0.30:80 192.168.0.2:18117 SYN_RECV - ...从结果中,你可以发现大量 SYN_RECV 状态的连接,并且源 IP 地址为 192.168.0.2。
进一步,我们还可以通过 wc 工具,来统计所有 SYN_RECV 状态的连接数:
$ netstat -n -p | grep SYN_REC | wc -l 193找出源 IP 后,要解决 SYN 攻击的问题,只要丢掉相关的包就可以。这时,iptables 可以帮你完成这个任务。你可以在终端一中,执行下面的 iptables 命令:
iptables -I INPUT -s 192.168.0.2 -p tcp -j REJECT然后回到终端三中,再次执行 curl 命令,查看正常用户访问 Nginx 的情况:
$ curl -w 'Http code: %{http_code}\nTotal time:%{time_total}s\n' -o /dev/null --connect-timeout 10 http://192.168.0.30 Http code: 200 Total time:1.572171s现在,你可以发现,正常用户也可以访问 Nginx 了,只是响应比较慢,从原来的 2ms 变成了现在的 1.5s。
不过,一般来说,SYN Flood 攻击中的源 IP 并不是固定的。比如,你可以在 hping3 命令中,加入 —rand-source 选项,来随机化源 IP。不过,这时,刚才的方法就不适用了。
幸好,我们还有很多其他方法,实现类似的目标。比如,你可以用以下两种方法,来限制 syn 包的速率:
# 限制 syn 并发数为每秒 1 次 $ iptables -A INPUT -p tcp --syn -m limit --limit 1/s -j ACCEPT # 限制单个 IP 在 60 秒新建立的连接数为 10 $ iptables -I INPUT -p tcp --dport 80 --syn -m recent --name SYN_FLOOD --update --seconds 60 --hitcount 10 -j REJECT到这里,我们已经初步限制了 SYN Flood 攻击。不过这还不够,因为我们的案例还只是单个的攻击源。
如果是多台机器同时发送 SYN Flood,这种方法可能就直接无效了。因为你很可能无法 SSH 登录(SSH 也是基于 TCP 的)到机器上去,更别提执行上述所有的排查命令。
所以,这还需要你事先对系统做一些 TCP 优化。
比如,SYN Flood 会导致 SYN_RECV 状态的连接急剧增大。在上面的 netstat 命令中,你也可以看到 190 多个处于半开状态的连接。
不过,半开状态的连接数是有限制的,执行下面的命令,你就可以看到,默认的半连接容量只有 256:
$ sysctl net.ipv4.tcp_max_syn_backlog net.ipv4.tcp_max_syn_backlog = 256换句话说, SYN 包数再稍微增大一些,就不能 SSH 登录机器了。 所以,你还应该增大半连接的容量,比如,你可以用下面的命令,将其增大为 1024:
$ sysctl -w net.ipv4.tcp_max_syn_backlog=1024 net.ipv4.tcp_max_syn_backlog = 1024另外,连接每个 SYN_RECV 时,如果失败的话,内核还会自动重试,并且默认的重试次数是 5 次。你可以执行下面的命令,将其减小为 1 次:
$ sysctl -w net.ipv4.tcp_synack_retries=1 net.ipv4.tcp_synack_retries = 1除此之外,TCP SYN Cookies 也是一种专门防御 SYN Flood 攻击的方法。SYN Cookies 基于连接信息(包括源地址、源端口、目的地址、目的端口等)以及一个加密种子(如系统启动时间),计算出一个哈希值(SHA1),这个哈希值称为 cookie。
然后,这个 cookie 就被用作序列号,来应答 SYN+ACK 包,并释放连接状态。当客户端发送完三次握手的最后一次 ACK 后,服务器就会再次计算这个哈希值,确认是上次返回的 SYN+ACK 的返回包,才会进入 TCP 的连接状态。
因而,开启 SYN Cookies 后,就不需要维护半开连接状态了,进而也就没有了半连接数的限制。
注意,开启 TCP syncookies 后,内核选项 net.ipv4.tcp_max_syn_backlog 也就无效了。
可以通过下面的命令,开启 TCP SYN Cookies:
$ sysctl -w net.ipv4.tcp_syncookies=1 net.ipv4.tcp_syncookies = 1
29.3 DDoS 到底该怎么防御
当 DDoS 报文到达服务器后,Linux 提供的机制只能缓解,而无法彻底解决。即使像是 SYN Flood 这样的小包攻击,其巨大的 PPS ,也会导致 Linux 内核消耗大量资源,进而导致其他网络报文的处理缓慢。
所以,当时提到的 C10M 的方法,用到这里同样适合。比如,你可以基于 XDP 或者 DPDK,构建 DDoS 方案,在内核网络协议栈前,或者跳过内核协议栈,来识别并丢弃 DDoS 报文,避免 DDoS 对系统其他资源的消耗。
不过,对于流量型的 DDoS 来说,当服务器的带宽被耗尽后,在服务器内部处理就无能为力了。这时,只能在服务器外部的网络设备中,设法识别并阻断流量(当然前提是网络设备要能扛住流量攻击)。比如,购置专业的入侵检测和防御设备,配置流量清洗设备阻断恶意流量等。
既然 DDoS 这么难防御,这是不是说明, Linux 服务器内部压根儿就不关注这一点,而是全部交给专业的网络设备来处理呢?
当然不是,因为 DDoS 并不一定是因为大流量或者大 PPS,有时候,慢速的请求也会带来巨大的性能下降(这种情况称为慢速 DDoS)。
比如,很多针对应用程序的攻击,都会伪装成正常用户来请求资源。这种情况下,请求流量可能本身并不大,但响应流量却可能很大,并且应用程序内部也很可能要耗费大量资源处理。
这时,就需要应用程序考虑识别,并尽早拒绝掉这些恶意流量,比如合理利用缓存、增加 WAF(Web Application Firewall)、使用 CDN 等等。
40 | 案例篇:网络请求延迟变大了,我该怎么办?
40.1 网络延迟
很多网络服务会把 ICMP 禁止掉,这也就导致我们无法用 ping ,来测试网络服务的可用性和往返延时。这时,你可以用 traceroute 或 hping3 的 TCP 和 UDP 模式,来获取网络延迟。
比如,以 baidu.com 为例,你可以执行下面的 hping3 命令,测试你的机器到百度搜索服务器的网络延迟:
# -c 表示发送 3 次请求,-S 表示设置 TCP SYN,-p 表示端口号为 80
$ hping3 -c 3 -S -p 80 baidu.com
HPING baidu.com (eth0 123.125.115.110): S set, 40 headers + 0 data bytes
len=46 ip=123.125.115.110 ttl=51 id=47908 sport=80 flags=SA seq=0 win=8192 rtt=20.9 ms
len=46 ip=123.125.115.110 ttl=51 id=6788 sport=80 flags=SA seq=1 win=8192 rtt=20.9 ms
len=46 ip=123.125.115.110 ttl=51 id=37699 sport=80 flags=SA seq=2 win=8192 rtt=20.9 ms
--- baidu.com hping statistic ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 20.9/20.9/20.9 ms当然,我们用 traceroute ,也可以得到类似结果:
# --tcp 表示使用 TCP 协议,-p 表示端口号,-n 表示不对结果中的 IP 地址执行反向域名解析
$ traceroute --tcp -p 80 -n baidu.com
traceroute to baidu.com (123.125.115.110), 30 hops max, 60 byte packets
1 * * *
2 * * *
3 * * *
4 * * *
5 * * *
6 * * *
7 * * *
8 * * *
9 * * *
10 * * *
11 * * *
12 * * *
13 * * *
14 123.125.115.110 20.684 ms * 20.798 mstraceroute 会在路由的每一跳发送三个包,并在收到响应后,输出往返延时。如果无响应或者响应超时(默认 5s),就会输出一个星号。
40.2 案例
机器配置: 2 CPU, 8 GB 内存。
安装软件:
apt-get install docker.io hping3 tcpdump curl。
打开两个终端,分别 SSH 登录到两台机器上。
为了对比得出延迟增大的影响,首先,我们来运行一个最简单的 Nginx,也就是用官方的 Nginx 镜像启动一个容器。在终端一中,执行下面的命令,运行官方 Nginx,它会在 80 端口监听:
$ docker run --network=host --name=good -itd nginx fb4ed7cb9177d10e270f8320a7fb64717eac3451114c9fab3c50e02be2e88ba2继续在终端一中,执行下面的命令,运行案例应用,它会监听 8080 端口:
$ docker run --name nginx --network=host -itd feisky/nginx:latency b99bd136dcfd907747d9c803fdc0255e578bad6d66f4e9c32b826d75b6812724然后,在终端二中执行 curl 命令,验证两个容器已经正常启动。如果一切正常,你将看到如下的输出:
# 80 端口正常 $ curl http://192.168.0.30 <!DOCTYPE html> <html> ... <p><em>Thank you for using nginx.</em></p> </body> </html> # 8080 端口正常 $ curl http://192.168.0.30:8080 ... <p><em>Thank you for using nginx.</em></p> </body> </html>接着,我们再用上面提到的 hping3 ,来测试它们的延迟,看看有什么区别。还是在终端二,执行下面的命令,分别测试案例机器 80 端口和 8080 端口的延迟:
# 测试 80 端口延迟 $ hping3 -c 3 -S -p 80 192.168.0.30 HPING 192.168.0.30 (eth0 192.168.0.30): S set, 40 headers + 0 data bytes len=44 ip=192.168.0.30 ttl=64 DF id=0 sport=80 flags=SA seq=0 win=29200 rtt=7.8 ms len=44 ip=192.168.0.30 ttl=64 DF id=0 sport=80 flags=SA seq=1 win=29200 rtt=7.7 ms len=44 ip=192.168.0.30 ttl=64 DF id=0 sport=80 flags=SA seq=2 win=29200 rtt=7.6 ms --- 192.168.0.30 hping statistic --- 3 packets transmitted, 3 packets received, 0% packet loss round-trip min/avg/max = 7.6/7.7/7.8 ms # 测试 8080 端口延迟 $ hping3 -c 3 -S -p 8080 192.168.0.30 HPING 192.168.0.30 (eth0 192.168.0.30): S set, 40 headers + 0 data bytes len=44 ip=192.168.0.30 ttl=64 DF id=0 sport=8080 flags=SA seq=0 win=29200 rtt=7.7 ms len=44 ip=192.168.0.30 ttl=64 DF id=0 sport=8080 flags=SA seq=1 win=29200 rtt=7.6 ms len=44 ip=192.168.0.30 ttl=64 DF id=0 sport=8080 flags=SA seq=2 win=29200 rtt=7.3 ms --- 192.168.0.30 hping statistic --- 3 packets transmitted, 3 packets received, 0% packet loss round-trip min/avg/max = 7.3/7.6/7.7 ms从这个输出你可以看到,两个端口的延迟差不多,都是 7ms。不过,这只是单个请求的情况。换成并发请求的话,又会怎么样呢?接下来,我们就用 wrk 试试。
这次在终端二中,执行下面的新命令,分别测试案例机器并发 100 时, 80 端口和 8080 端口的性能:
# 测试 80 端口性能 $ # wrk --latency -c 100 -t 2 --timeout 2 http://192.168.0.30/ Running 10s test @ http://192.168.0.30/ 2 threads and 100 connections Thread Stats Avg Stdev Max +/- Stdev Latency 9.19ms 12.32ms 319.61ms 97.80% Req/Sec 6.20k 426.80 8.25k 85.50% Latency Distribution 50% 7.78ms 75% 8.22ms 90% 9.14ms 99% 50.53ms 123558 requests in 10.01s, 100.15MB read Requests/sec: 12340.91 Transfer/sec: 10.00MB # 测试 8080 端口性能 $ wrk --latency -c 100 -t 2 --timeout 2 http://192.168.0.30:8080/ Running 10s test @ http://192.168.0.30:8080/ 2 threads and 100 connections Thread Stats Avg Stdev Max +/- Stdev Latency 43.60ms 6.41ms 56.58ms 97.06% Req/Sec 1.15k 120.29 1.92k 88.50% Latency Distribution 50% 44.02ms 75% 44.33ms 90% 47.62ms 99% 48.88ms 22853 requests in 10.01s, 18.55MB read Requests/sec: 2283.31 Transfer/sec: 1.85MB从上面两个输出可以看到,官方 Nginx(监听在 80 端口)的平均延迟是 9.19ms,而案例 Nginx 的平均延迟(监听在 8080 端口)则是 43.6ms。从延迟的分布上来看,官方 Nginx 90% 的请求,都可以在 9ms 以内完成;而案例 Nginx 50% 的请求,就已经达到了 44 ms。
在终端一中,执行下面的 tcpdump 命令,抓取 8080 端口上收发的网络包,并保存到 nginx.pcap 文件:
tcpdump -nn tcp port 8080 -w nginx.pcap然后切换到终端二中,重新执行 wrk 命令:
# 测试 8080 端口性能 $ wrk --latency -c 100 -t 2 --timeout 2 http://192.168.0.30:8080/当 wrk 命令结束后,再次切换回终端一,并按下 Ctrl+C 结束 tcpdump 命令。然后,再把抓取到的 nginx.pcap ,复制到装有 Wireshark 的机器中(如果 VM1 已经带有图形界面,那么可以跳过复制步骤),并用 Wireshark 打开它。
由于网络包的数量比较多,我们可以先过滤一下。比如,在选择一个包后,你可以单击右键并选择 “Follow” -> “TCP Stream”,如下图所示:
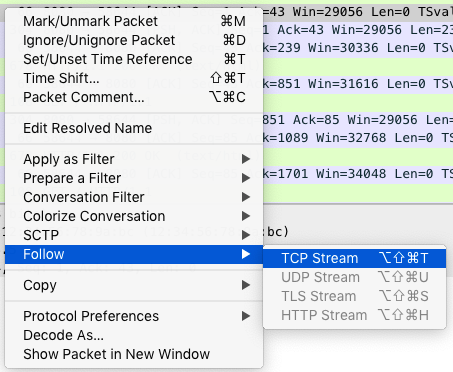
然后,关闭弹出来的对话框,回到 Wireshark 主窗口。这时候,你会发现 Wireshark 已经自动帮你设置了一个过滤表达式 tcp.stream eq 24。如下图所示(图中省去了源和目的 IP 地址):
从这里,你可以看到这个 TCP 连接从三次握手开始的每个请求和响应情况。当然,这可能还不够直观,你可以继续点击菜单栏里的 Statics -> Flow Graph,选中 “Limit to display filter” 并设置 Flow type 为 “TCP Flows”:
注意,这个图的左边是客户端,而右边是 Nginx 服务器。通过这个图就可以看出,前面三次握手,以及第一次 HTTP 请求和响应还是挺快的,但第二次 HTTP 请求就比较慢了,特别是客户端在收到服务器第一个分组后,40ms 后才发出了 ACK 响应(图中蓝色行)。
看到 40ms 这个值,你有没有想起什么东西呢?实际上,这是 TCP 延迟确认(Delayed ACK)的最小超时时间。
这里我解释一下延迟确认。这是针对 TCP ACK 的一种优化机制,也就是说,不用每次请求都发送一个 ACK,而是先等一会儿(比如 40ms),看看有没有”顺风车”。如果这段时间内,正好有其他包需要发送,那就捎带着 ACK 一起发送过去。当然,如果一直等不到其他包,那就超时后单独发送 ACK。
因为案例中 40ms 发生在客户端上,我们有理由怀疑,是客户端开启了延迟确认机制。而这儿的客户端,实际上就是前面运行的 wrk。
查询 TCP 文档(执行 man tcp),你就会发现,只有 TCP 套接字专门设置了 TCP_QUICKACK ,才会开启快速确认模式;否则,默认情况下,采用的就是延迟确认机制:
TCP_QUICKACK (since Linux 2.4.4) Enable quickack mode if set or disable quickack mode if cleared. In quickack mode, acks are sent imme‐ diately, rather than delayed if needed in accordance to normal TCP operation. This flag is not perma‐ nent, it only enables a switch to or from quickack mode. Subsequent operation of the TCP protocol will once again enter/leave quickack mode depending on internal protocol processing and factors such as delayed ack timeouts occurring and data transfer. This option should not be used in code intended to be portable.为了验证我们的猜想,确认 wrk 的行为,我们可以用 strace ,来观察 wrk 为套接字设置了哪些 TCP 选项。
比如,你可以切换到终端二中,执行下面的命令:
$ strace -f wrk --latency -c 100 -t 2 --timeout 2 http://192.168.0.30:8080/ ... setsockopt(52, SOL_TCP, TCP_NODELAY, [1], 4) = 0 ...这样,你可以看到,wrk 只设置了 TCP_NODELAY 选项,而没有设置 TCP_QUICKACK。这说明 wrk 采用的正是延迟确认,也就解释了上面这个 40ms 的问题。
不过,别忘了,这只是客户端的行为,按理来说,Nginx 服务器不应该受到这个行为的影响。那是不是我们分析网络包时,漏掉了什么线索呢?让我们回到 Wireshark 重新观察一下。
仔细观察 Wireshark 的界面,其中, 1173 号包,就是刚才说到的延迟 ACK 包;下一行的 1175 ,则是 Nginx 发送的第二个分组包,它跟 697 号包组合起来,构成一个完整的 HTTP 响应(ACK 号都是 85)。
第二个分组没跟前一个分组(697 号)一起发送,而是等到客户端对第一个分组的 ACK 后(1173 号)才发送,这看起来跟延迟确认有点像,只不过,这儿不再是 ACK,而是发送数据。
看到这里,我估计你想起了一个东西—— Nagle 算法(纳格算法)。进一步分析案例前,我先简单介绍一下这个算法。
Nagle 算法,是 TCP 协议中用于减少小包发送数量的一种优化算法,目的是为了提高实际带宽的利用率。
举个例子,当有效负载只有 1 字节时,再加上 TCP 头部和 IP 头部分别占用的 20 字节,整个网络包就是 41 字节,这样实际带宽的利用率只有 2.4%(1/41)。往大了说,如果整个网络带宽都被这种小包占满,那整个网络的有效利用率就太低了。
Nagle 算法正是为了解决这个问题。它通过合并 TCP 小包,提高网络带宽的利用率。Nagle 算法规定,一个 TCP 连接上,最多只能有一个未被确认的未完成分组;在收到这个分组的 ACK 前,不发送其他分组。这些小分组会被组合起来,并在收到 ACK 后,用同一个分组发送出去。
显然,Nagle 算法本身的想法还是挺好的,但是知道 Linux 默认的延迟确认机制后,你应该就不这么想了。因为它们一起使用时,网络延迟会明显。如下图所示:
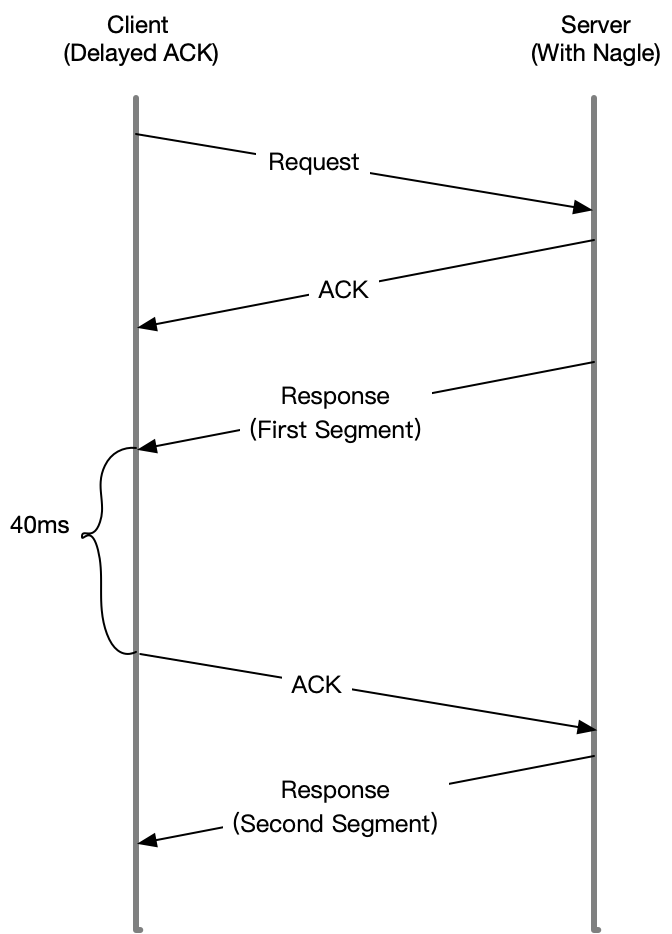
- 当 Sever 发送了第一个分组后,由于 Client 开启了延迟确认,就需要等待 40ms 后才会回复 ACK。
- 同时,由于 Server 端开启了 Nagle,而这时还没收到第一个分组的 ACK,Server 也会在这里一直等着。
直到 40ms 超时后,Client 才会回复 ACK,然后,Server 才会继续发送第二个分组。
既然可能是 Nagle 的问题,那该怎么知道,案例 Nginx 有没有开启 Nagle 呢?
查询 tcp 的文档,你就会知道,只有设置了 TCP_NODELAY 后,Nagle 算法才会禁用。所以,我们只需要查看 Nginx 的 tcp_nodelay 选项就可以了。
TCP_NODELAY If set, disable the Nagle algorithm. This means that segments are always sent as soon as possible, even if there is only a small amount of data. When not set, data is buffered until there is a sufficient amount to send out, thereby avoiding the frequent sending of small packets, which results in poor uti‐ lization of the network. This option is overridden by TCP_CORK; however, setting this option forces an explicit flush of pending output, even if TCP_CORK is currently set.
我们回到终端一中,执行下面的命令,查看案例 Nginx 的配置:
$ docker exec nginx cat /etc/nginx/nginx.conf | grep tcp_nodelay tcp_nodelay off;果然,你可以看到,案例 Nginx 的 tcp_nodelay 是关闭的,将其设置为 on ,应该就可以解决了。
改完后,问题是否就解决了呢?自然需要验证我们一下。修改后的应用,我已经打包到了 Docker 镜像中,在终端一中执行下面的命令,你就可以启动它:
# 删除案例应用 $ docker rm -f nginx # 启动优化后的应用 $ docker run --name nginx --network=host -itd feisky/nginx:nodelay接着,切换到终端二,重新执行 wrk 测试延迟:
$ wrk --latency -c 100 -t 2 --timeout 2 http://192.168.0.30:8080/ Running 10s test @ http://192.168.0.30:8080/ 2 threads and 100 connections Thread Stats Avg Stdev Max +/- Stdev Latency 9.58ms 14.98ms 350.08ms 97.91% Req/Sec 6.22k 282.13 6.93k 68.50% Latency Distribution 50% 7.78ms 75% 8.20ms 90% 9.02ms 99% 73.14ms 123990 requests in 10.01s, 100.50MB read Requests/sec: 12384.04 Transfer/sec: 10.04MB果然,现在延迟已经缩短成了 9ms,跟我们测试的官方 Nginx 镜像是一样的(Nginx 默认就是开启 tcp_nodelay 的) 。
作为对比,我们用 tcpdump ,抓取优化后的网络包(这儿实际上抓取的是官方 Nginx 监听的 80 端口)。你可以得到下面的结果:
从图中你可以发现,由于 Nginx 不用再等 ACK,536 和 540 两个分组是连续发送的;而客户端呢,虽然仍开启了延迟确认,但这时收到了两个需要回复 ACK 的包,所以也不用等 40ms,可以直接合并回复 ACK。
40.3 小结
在发现网络延迟增大后,你可以用 traceroute、hping3、tcpdump、Wireshark、strace 等多种工具,来定位网络中的潜在问题。比如,
- 使用 hping3 以及 wrk 等工具,确认单次请求和并发请求情况的网络延迟是否正常。
- 使用 traceroute,确认路由是否正确,并查看路由中每一跳网关的延迟。
- 使用 tcpdump 和 Wireshark,确认网络包的收发是否正常。
- 使用 strace 等,观察应用程序对网络套接字的调用情况是否正常。
41 | 案例篇:如何优化 NAT 性能?(上)
41.1 NAT 原理
NAT 技术可以重写 IP 数据包的源 IP 或者目的 IP,被普遍地用来解决公网 IP 地址短缺的问题。它的主要原理就是,网络中的多台主机,通过共享同一个公网 IP 地址,来访问外网资源。同时,由于 NAT 屏蔽了内网网络,自然也就为局域网中的机器提供了安全隔离。
你既可以在支持网络地址转换的路由器(称为 NAT 网关)中配置 NAT,也可以在 Linux 服务器中配置 NAT。如果采用第二种方式,Linux 服务器实际上充当的是”软”路由器的角色。
NAT 的主要目的,是实现地址转换。根据实现方式的不同,NAT 可以分为三类:
- 静态 NAT,即内网 IP 与公网 IP 是一对一的永久映射关系;
- 动态 NAT,即内网 IP 从公网 IP 池中,动态选择一个进行映射;
- 网络地址端口转换 NAPT(Network Address and Port Translation),即把内网 IP 映射到公网 IP 的不同端口上,让多个内网 IP 可以共享同一个公网 IP 地址。
NAPT 是目前最流行的 NAT 类型,我们在 Linux 中配置的 NAT 也是这种类型。而根据转换方式的不同,我们又可以把 NAPT 分为三类。
- 第一类是源地址转换 SNAT,即目的地址不变,只替换源 IP 或源端口。SNAT 主要用于,多个内网 IP 共享同一个公网 IP ,来访问外网资源的场景。
- 第二类是目的地址转换 DNAT,即源 IP 保持不变,只替换目的 IP 或者目的端口。DNAT 主要通过公网 IP 的不同端口号,来访问内网的多种服务,同时会隐藏后端服务器的真实 IP 地址。
第三类是双向地址转换,即同时使用 SNAT 和 DNAT。当接收到网络包时,执行 DNAT,把目的 IP 转换为内网 IP;而在发送网络包时,执行 SNAT,把源 IP 替换为外部 IP。
双向地址转换,其实就是外网 IP 与内网 IP 的一对一映射关系,所以常用在虚拟化环境中,为虚拟机分配浮动的公网 IP 地址。
41.2 iptables 与 NAT
Linux 内核提供的 Netfilter 框架,允许对网络数据包进行修改(比如 NAT)和过滤(比如防火墙)。在这个基础上,iptables、ip6tables、ebtables 等工具,又提供了更易用的命令行接口,以便系统管理员配置和管理 NAT、防火墙的规则。
其中,iptables 就是最常用的一种配置工具。要掌握 iptables 的原理和使用方法,最核心的就是弄清楚,网络数据包通过 Netfilter 时的工作流向,下面这张图就展示了这一过程。
在这张图中,绿色背景的方框,表示表(table),用来管理链。Linux 支持 4 种表,包括 filter(用于过滤)、nat(用于 NAT)、mangle(用于修改分组数据) 和 raw(用于原始数据包)等。
跟 table 一起的白色背景方框,则表示链(chain),用来管理具体的 iptables 规则。每个表中可以包含多条链,比如:
- filter 表中,内置 INPUT、OUTPUT 和 FORWARD 链;
- nat 表中,内置 PREROUTING、POSTROUTING、OUTPUT 等。
当然,你也可以根据需要,创建你自己的链。
灰色的 conntrack,表示连接跟踪模块。它通过内核中的连接跟踪表(也就是哈希表),记录网络连接的状态,是 iptables 状态过滤(-m state)和 NAT 的实现基础。
iptables 的所有规则,就会放到这些表和链中,并按照图中顺序和规则的优先级顺序来执行。
针对今天的主题,要实现 NAT 功能,主要是在 nat 表进行操作。而 nat 表内置了三个链:
- PREROUTING,用于路由判断前所执行的规则,比如,对接收到的数据包进行 DNAT。
- POSTROUTING,用于路由判断后所执行的规则,比如,对发送或转发的数据包进行 SNAT 或 MASQUERADE。
- OUTPUT,类似于 PREROUTING,但只处理从本机发送出去的包。
41.3 SNAT
SNAT 需要在 nat 表的 POSTROUTING 链中配置。我们常用两种方式来配置它。
第一种方法,是为一个子网统一配置 SNAT,并由 Linux 选择默认的出口 IP。这实际上就是经常说的 MASQUERADE:
iptables -t nat -A POSTROUTING -s 192.168.0.0/16 -j MASQUERADE第二种方法,是为具体的 IP 地址配置 SNAT,并指定转换后的源地址:
iptables -t nat -A POSTROUTING -s 192.168.0.2 -j SNAT --to-source 100.100.100.100
41.4 DNAT
再来看 DNAT,显然,DNAT 需要在 nat 表的 PREROUTING 或者 OUTPUT 链中配置,其中, PREROUTING 链更常用一些(因为它还可以用于转发的包)。
iptables -t nat -A PREROUTING -d 100.100.100.100 -j DNAT --to-destination 192.168.0.241.5 双向地址转换
双向地址转换,就是同时添加 SNAT 和 DNAT 规则,为公网 IP 和内网 IP 实现一对一的映射关系,即:
iptables -t nat -A POSTROUTING -s 192.168.0.2 -j SNAT --to-source 100.100.100.100
iptables -t nat -A PREROUTING -d 100.100.100.100 -j DNAT --to-destination 192.168.0.2在使用 iptables 配置 NAT 规则时,Linux 需要转发来自其他 IP 的网络包,所以你千万不要忘记开启 Linux 的 IP 转发功能。
你可以执行下面的命令,查看这一功能是否开启。如果输出的结果是 1,就表示已经开启了 IP 转发:
$ sysctl net.ipv4.ip_forward
net.ipv4.ip_forward = 1如果还没开启,你可以执行下面的命令,手动开启:
$ sysctl -w net.ipv4.ip_forward=1
net.ipv4.ip_forward = 142 | 案例篇:如何优化 NAT 性能?(下)
42.1 案例
机器配置: 2 CPU, 8 GB 内存。
安装软件:
apt-get install docker.io tcpdump curl apache2-utils以及 SystemTap。SystemTap 是 Linux 的一种动态追踪框架,它把用户提供的脚本,转换为内核模块来执行,用来监测和跟踪内核的行为。
打开两个终端,分别 SSH 登录到两台机器。
为了对比 NAT 带来的性能问题,我们首先运行一个不用 NAT 的 Nginx 服务,并用 ab 测试它的性能。
在终端一中,执行下面的命令,启动 Nginx,注意选项 —network=host ,表示容器使用 Host 网络模式,即不使用 NAT:
docker run --name nginx-hostnet --privileged --network=host -itd feisky/nginx:80终端二中,执行 curl 命令,确认 Nginx 正常启动:
$ curl http://192.168.0.30/ ... <p><em>Thank you for using nginx.</em></p> </body> </html>继续在终端二中,执行 ab 命令,对 Nginx 进行压力测试。不过在测试前要注意,Linux 默认允许打开的文件描述数比较小,比如在我的机器中,这个值只有 1024:
# open files $ ulimit -n 1024所以,执行 ab 前,先要把这个选项调大,比如调成 65536:
# 临时增大当前会话的最大文件描述符数 $ ulimit -n 65536接下来,再去执行 ab 命令,进行压力测试:
# -c 表示并发请求数为 5000,-n 表示总的请求数为 10 万 # -r 表示套接字接收错误时仍然继续执行,-s 表示设置每个请求的超时时间为 2s $ ab -c 5000 -n 100000 -r -s 2 http://192.168.0.30/ ... Requests per second: 6576.21 [#/sec] (mean) Time per request: 760.317 [ms] (mean) Time per request: 0.152 [ms] (mean, across all concurrent requests) Transfer rate: 5390.19 [Kbytes/sec] received Connection Times (ms) min mean[+/-sd] median max Connect: 0 177 714.3 9 7338 Processing: 0 27 39.8 19 961 Waiting: 0 23 39.5 16 951 Total: 1 204 716.3 28 7349 ...从这次的界面,你可以看出:
- 每秒请求数(Requests per second)为 6576;
- 每个请求的平均延迟(Time per request)为 760ms;
建立连接的平均延迟(Connect)为 177ms。
记住这几个数值,这将是接下来案例的基准指标。
注意,你的机器中,运行结果跟我的可能不一样,不过没关系,并不影响接下来的案例分析思路。
接着,回到终端一,停止这个未使用 NAT 的 Nginx 应用:
docker rm -f nginx-hostnet再执行下面的命令,启动今天的案例应用。案例应用监听在 8080 端口,并且使用了 DNAT ,来实现 Host 的 8080 端口,到容器的 8080 端口的映射关系:
docker run --name nginx --privileged -p 8080:8080 -itd feisky/nginx:natNginx 启动后,你可以执行 iptables 命令,确认 DNAT 规则已经创建:
$ iptables -nL -t nat Chain PREROUTING (policy ACCEPT) target prot opt source destination DOCKER all -- 0.0.0.0/0 0.0.0.0/0 ADDRTYPE match dst-type LOCAL ... Chain DOCKER (2 references) target prot opt source destination RETURN all -- 0.0.0.0/0 0.0.0.0/0 DNAT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:8080 to:172.17.0.2:8080你可以看到,在 PREROUTING 链中,目的为本地的请求,会转到 DOCKER 链;而在 DOCKER 链中,目的端口为 8080 的 tcp 请求,会被 DNAT 到 172.17.0.2 的 8080 端口。其中,172.17.0.2 就是 Nginx 容器的 IP 地址。
接下来,我们切换到终端二中,执行 curl 命令,确认 Nginx 已经正常启动:
$ curl http://192.168.0.30:8080/ ... <p><em>Thank you for using nginx.</em></p> </body> </html>然后,再次执行上述的 ab 命令,不过这次注意,要把请求的端口号换成 8080:
# -c 表示并发请求数为 5000,-n 表示总的请求数为 10 万 # -r 表示套接字接收错误时仍然继续执行,-s 表示设置每个请求的超时时间为 2s $ ab -c 5000 -n 100000 -r -s 2 http://192.168.0.30:8080/ ... apr_pollset_poll: The timeout specified has expired (70007) Total of 5602 requests completed果然,刚才正常运行的 ab ,现在失败了,还报了连接超时的错误。运行 ab 时的 -s 参数,设置了每个请求的超时时间为 2s,而从输出可以看到,这次只完成了 5602 个请求。
既然是为了得到 ab 的测试结果,我们不妨把超时时间延长一下试试,比如延长到 30s。延迟增大意味着要等更长时间,为了快点得到结果,我们可以同时把总测试次数,也减少到 10000:
$ ab -c 5000 -n 10000 -r -s 30 http://192.168.0.30:8080/ ... Requests per second: 76.47 [#/sec] (mean) Time per request: 65380.868 [ms] (mean) Time per request: 13.076 [ms] (mean, across all concurrent requests) Transfer rate: 44.79 [Kbytes/sec] received Connection Times (ms) min mean[+/-sd] median max Connect: 0 1300 5578.0 1 65184 Processing: 0 37916 59283.2 1 130682 Waiting: 0 2 8.7 1 414 Total: 1 39216 58711.6 1021 130682再重新看看 ab 的输出,这次的结果显示:
- 每秒请求数(Requests per second)为 76;
- 每个请求的延迟(Time per request)为 65s;
- 建立连接的延迟(Connect)为 1300ms。
显然,每个指标都比前面差了很多。
那么,碰到这种问题时,你会怎么办呢?你可以根据前面的讲解,先自己分析一下,再继续学习下面的内容。
在上一节,我们使用 tcpdump 抓包的方法,找出了延迟增大的根源。那么今天的案例,我们仍然可以用类似的方法寻找线索。不过,现在换个思路,因为今天我们已经事先知道了问题的根源——那就是 NAT。
回忆一下 Netfilter 中,网络包的流向以及 NAT 的原理,你会发现,要保证 NAT 正常工作,就至少需要两个步骤:
- 第一,利用 Netfilter 中的钩子函数(Hook),修改源地址或者目的地址。
- 第二,利用连接跟踪模块 conntrack ,关联同一个连接的请求和响应。
是不是这两个地方出现了问题呢?我们用前面提到的动态追踪工具 SystemTap 来试试。
由于今天案例是在压测场景下,并发请求数大大降低,并且我们清楚知道 NAT 是罪魁祸首。所以,我们有理由怀疑,内核中发生了丢包现象。
我们可以回到终端一中,创建一个 dropwatch.stp 的脚本文件,并写入下面的内容:
#! /usr/bin/env stap ############################################################ # Dropwatch.stp # Author: Neil Horman <nhorman@redhat.com> # An example script to mimic the behavior of the dropwatch utility # http://fedorahosted.org/dropwatch ############################################################ # Array to hold the list of drop points we find global locations # Note when we turn the monitor on and off probe begin { printf("Monitoring for dropped packets\n") } probe end { printf("Stopping dropped packet monitor\n") } # increment a drop counter for every location we drop at probe kernel.trace("kfree_skb") { locations[$location] <<< 1 } # Every 5 seconds report our drop locations probe timer.sec(5) { printf("\n") foreach (l in locations-) { printf("%d packets dropped at %s\n", @count(locations[l]), symname(l)) } delete locations }这个脚本,跟踪内核函数 kfree_skb() 的调用,并统计丢包的位置。文件保存好后,执行下面的 stap 命令,就可以运行丢包跟踪脚本。这里的 stap,是 SystemTap 的命令行工具:
$ stap --all-modules dropwatch.stp Monitoring for dropped packets当你看到 probe begin 输出的 “Monitoring for dropped packets” 时,表明 SystemTap 已经将脚本编译为内核模块,并启动运行了。
接着,我们切换到终端二中,再次执行 ab 命令:
ab -c 5000 -n 10000 -r -s 30 http://192.168.0.30:8080/然后,再次回到终端一中,观察 stap 命令的输出:
10031 packets dropped at nf_hook_slow 676 packets dropped at tcp_v4_rcv 7284 packets dropped at nf_hook_slow 268 packets dropped at tcp_v4_rcv你会发现,大量丢包都发生在 nf_hook_slow 位置。看到这个名字,你应该能想到,这是在 Netfilter Hook 的钩子函数中,出现丢包问题了。但是不是 NAT,还不能确定。接下来,我们还得再跟踪 nf_hook_slow 的执行过程,这一步可以通过 perf 来完成。
我们切换到终端二中,再次执行 ab 命令:
ab -c 5000 -n 10000 -r -s 30 http://192.168.0.30:8080/然后,再次切换回终端一,执行 perf record 和 perf report 命令
# 记录一会(比如 30s)后按 Ctrl+C 结束 $ perf record -a -g -- sleep 30 # 输出报告 $ perf report -g graph,0在 perf report 界面中,输入查找命令 / 然后,在弹出的对话框中,输入 nf_hook_slow;最后再展开调用栈,就可以得到下面这个调用图:
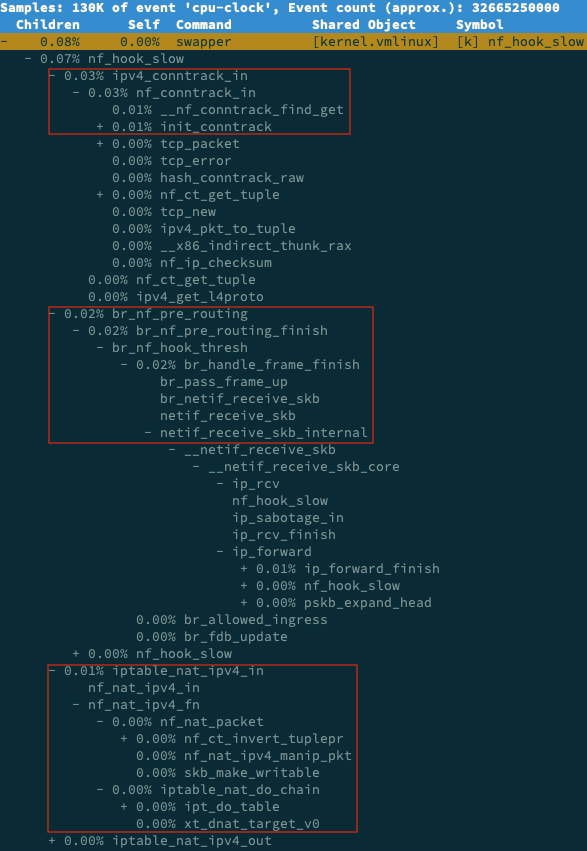
从这个图我们可以看到,nf_hook_slow 调用最多的有三个地方,分别是 ipv4_conntrack_in、br_nf_pre_routing 以及 iptable_nat_ipv4_in。换言之,nf_hook_slow 主要在执行三个动作。
- 第一,接收网络包时,在连接跟踪表中查找连接,并为新的连接分配跟踪对象(Bucket)。
- 第二,在 Linux 网桥中转发包。这是因为案例 Nginx 是一个 Docker 容器,而容器的网络通过网桥来实现;
- 第三,接收网络包时,执行 DNAT,即把 8080 端口收到的包转发给容器。
到这里,我们其实就找到了性能下降的三个来源。这三个来源,都是 Linux 的内核机制,所以接下来的优化,自然也是要从内核入手。
根据以前各个资源模块的内容,我们知道,Linux 内核为用户提供了大量的可配置选项,这些选项可以通过 proc 文件系统,或者 sys 文件系统,来查看和修改。除此之外,你还可以用 sysctl 这个命令行工具,来查看和修改内核配置。
比如,我们今天的主题是 DNAT,而 DNAT 的基础是 conntrack,所以我们可以先看看,内核提供了哪些 conntrack 的配置选项。
我们在终端一中,继续执行下面的命令:
$ sysctl -a | grep conntrack net.netfilter.nf_conntrack_count = 180 net.netfilter.nf_conntrack_max = 1000 net.netfilter.nf_conntrack_buckets = 65536 net.netfilter.nf_conntrack_tcp_timeout_syn_recv = 60 net.netfilter.nf_conntrack_tcp_timeout_syn_sent = 120 net.netfilter.nf_conntrack_tcp_timeout_time_wait = 120 ...你可以看到,这里最重要的三个指标:
- net.netfilter.nf_conntrack_count,表示当前连接跟踪数;
- net.netfilter.nf_conntrack_max,表示最大连接跟踪数;
- net.netfilter.nf_conntrack_buckets,表示连接跟踪表的大小。
所以,这个输出告诉我们,当前连接跟踪数是 180,最大连接跟踪数是 1000,连接跟踪表的大小,则是 65536。
回想一下前面的 ab 命令,并发请求数是 5000,而请求数是 100000。显然,跟踪表设置成,只记录 1000 个连接,是远远不够的。
实际上,内核在工作异常时,会把异常信息记录到日志中。比如前面的 ab 测试,内核已经在日志中报出了 “nf_conntrack: table full” 的错误。执行 dmesg 命令,你就可以看到:
$ dmesg | tail [104235.156774] nf_conntrack: nf_conntrack: table full, dropping packet [104243.800401] net_ratelimit: 3939 callbacks suppressed [104243.800401] nf_conntrack: nf_conntrack: table full, dropping packet [104262.962157] nf_conntrack: nf_conntrack: table full, dropping packet其中,net_ratelimit 表示有大量的日志被压缩掉了,这是内核预防日志攻击的一种措施。而当你看到 “nf_conntrack: table full” 的错误时,就表明 nf_conntrack_max 太小了。
那是不是,直接把连接跟踪表调大就可以了呢?调节前,你先得明白,连接跟踪表,实际上是内存中的一个哈希表。如果连接跟踪数过大,也会耗费大量内存。
其实,我们上面看到的 nf_conntrack_buckets,就是哈希表的大小。哈希表中的每一项,都是一个链表(称为 Bucket),而链表长度,就等于 nf_conntrack_max 除以 nf_conntrack_buckets。
比如,我们可以估算一下,上述配置的连接跟踪表占用的内存大小:
# 连接跟踪对象大小为 376,链表项大小为 16 nf_conntrack_max* 连接跟踪对象大小 +nf_conntrack_buckets* 链表项大小 = 1000*376+65536*16 B = 1.4 MB接下来,我们将 nf_conntrack_max 改大一些,比如改成 131072(即 nf_conntrack_buckets 的 2 倍):
sysctl -w net.netfilter.nf_conntrack_max=131072 sysctl -w net.netfilter.nf_conntrack_buckets=65536然后再切换到终端二中,重新执行 ab 命令。注意,这次我们把超时时间也改回原来的 2s:
$ ab -c 5000 -n 100000 -r -s 2 http://192.168.0.30:8080/ ... Requests per second: 6315.99 [#/sec] (mean) Time per request: 791.641 [ms] (mean) Time per request: 0.158 [ms] (mean, across all concurrent requests) Transfer rate: 4985.15 [Kbytes/sec] received Connection Times (ms) min mean[+/-sd] median max Connect: 0 355 793.7 29 7352 Processing: 8 311 855.9 51 14481 Waiting: 0 292 851.5 36 14481 Total: 15 666 1216.3 148 14645果然,现在你可以看到:
- 每秒请求数(Requests per second)为 6315(不用 NAT 时为 6576);
- 每个请求的延迟(Time per request)为 791ms(不用 NAT 时为 760ms);
- 建立连接的延迟(Connect)为 355ms(不用 NAT 时为 177ms)。
这个结果,已经比刚才的测试好了很多,也很接近最初不用 NAT 时的基准结果了。
不过,你可能还是很好奇,连接跟踪表里,到底都包含了哪些东西?这里的东西,又是怎么刷新的呢?
实际上,你可以用 conntrack 命令行工具,来查看连接跟踪表的内容。比如:
# -L 表示列表,-o 表示以扩展格式显示 $ conntrack -L -o extended | head ipv4 2 tcp 6 7 TIME_WAIT src=192.168.0.2 dst=192.168.0.96 sport=51744 dport=8080 src=172.17.0.2 dst=192.168.0.2 sport=8080 dport=51744 [ASSURED] mark=0 use=1 ipv4 2 tcp 6 6 TIME_WAIT src=192.168.0.2 dst=192.168.0.96 sport=51524 dport=8080 src=172.17.0.2 dst=192.168.0.2 sport=8080 dport=51524 [ASSURED] mark=0 use=1从这里你可以发现,连接跟踪表里的对象,包括了协议、连接状态、源 IP、源端口、目的 IP、目的端口、跟踪状态等。由于这个格式是固定的,所以我们可以用 awk、sort 等工具,对其进行统计分析。
比如,我们还是以 ab 为例。在终端二启动 ab 命令后,再回到终端一中,执行下面的命令:
# 统计总的连接跟踪数 $ conntrack -L -o extended | wc -l 14289 # 统计 TCP 协议各个状态的连接跟踪数 $ conntrack -L -o extended | awk '/^.*tcp.*$/ {sum[$6]++} END {for(i in sum) print i, sum[i]}' SYN_RECV 4 CLOSE_WAIT 9 ESTABLISHED 2877 FIN_WAIT 3 SYN_SENT 2113 TIME_WAIT 9283 # 统计各个源 IP 的连接跟踪数 $ conntrack -L -o extended | awk '{print $7}' | cut -d "=" -f 2 | sort | uniq -c | sort -nr | head -n 10 14116 192.168.0.2 172 192.168.0.96这里统计了总连接跟踪数,TCP 协议各个状态的连接跟踪数,以及各个源 IP 的连接跟踪数。你可以看到,大部分 TCP 的连接跟踪,都处于 TIME_WAIT 状态,并且它们大都来自于 192.168.0.2 这个 IP 地址(也就是运行 ab 命令的 VM2)。
这些处于 TIME_WAIT 的连接跟踪记录,会在超时后清理,而默认的超时时间是 120s,你可以执行下面的命令来查看:
$ sysctl net.netfilter.nf_conntrack_tcp_timeout_time_wait net.netfilter.nf_conntrack_tcp_timeout_time_wait = 120所以,如果你的连接数非常大,确实也应该考虑,适当减小超时时间。
除了上面这些常见配置,conntrack 还包含了其他很多配置选项,你可以根据实际需要,参考 nf_conntrack 的文档来配置。
43 | 套路篇:网络性能优化的几个思路(上)
43.1 确定优化目标
虽然网络性能优化的整体目标,是降低网络延迟(如 RTT)和提高吞吐量(如 BPS 和 PPS),但具体到不同应用中,每个指标的优化标准可能会不同,优先级顺序也大相径庭。
就拿上一节提到的 NAT 网关来说,由于其直接影响整个数据中心的网络出入性能,所以 NAT 网关通常需要达到或接近线性转发,也就是说, PPS 是最主要的性能目标。
再如,对于数据库、缓存等系统,快速完成网络收发,即低延迟,是主要的性能目标。
而对于我们经常访问的 Web 服务来说,则需要同时兼顾吞吐量和延迟。
所以,为了更客观合理地评估优化效果,我们首先应该明确优化的标准,即要对系统和应用程序进行基准测试,得到网络协议栈各层的基准性能。
在进行基准测试时,我们就可以按照协议栈的每一层来测试。由于底层是其上方各层的基础,底层性能也就决定了高层性能。所以我们要清楚,底层性能指标,其实就是对应高层的极限性能。我们从下到上来理解这一点。
首先是网络接口层和网络层,它们主要负责网络包的封装、寻址、路由,以及发送和接收。每秒可处理的网络包数 PPS,就是它们最重要的性能指标(特别是在小包的情况下)。你可以用内核自带的发包工具 pktgen ,来测试 PPS 的性能。
再向上到传输层的 TCP 和 UDP,它们主要负责网络传输。对它们而言,吞吐量(BPS)、连接数以及延迟,就是最重要的性能指标。你可以用 iperf 或 netperf ,来测试传输层的性能。
不过要注意,网络包的大小,会直接影响这些指标的值。所以,通常,你需要测试一系列不同大小网络包的性能。
最后,再往上到了应用层,最需要关注的是吞吐量(BPS)、每秒请求数以及延迟等指标。你可以用 wrk、ab 等工具,来测试应用程序的性能。
不过,这里要注意的是,测试场景要尽量模拟生产环境,这样的测试才更有价值。比如,你可以到生产环境中,录制实际的请求情况,再到测试中回放。
总之,根据这些基准指标,再结合已经观察到的性能瓶颈,我们就可以明确性能优化的目标。
43.2 网络性能工具
第一个维度,从网络性能指标出发,你更容易把性能工具同系统工作原理关联起来,对性能问题有宏观的认识和把握。这样,当你想查看某个性能指标时,就能清楚知道,可以用哪些工具。
.webp)
第二个维度,从性能工具出发。这可以让你更快上手使用工具,迅速找出想要观察的性能指标。特别是在工具有限的情况下,我们更要充分利用好手头的每一个工具,用少量工具也要尽力挖掘出大量信息。
.webp)
43.3 网络性能优化
应用程序
应用程序,通常通过套接字接口进行网络操作。由于网络收发通常比较耗时,所以应用程序的优化,主要就是对网络 I/O 和进程自身的工作模型的优化。
相关内容,其实我们在 C10K 和 C1000K 回顾 的文章中已经学过了。这里我们简单回顾一下。
从网络 I/O 的角度来说,主要有下面两种优化思路。
- 第一种是最常用的 I/O 多路复用技术 epoll,主要用来取代 select 和 poll。这其实是解决 C10K 问题的关键,也是目前很多网络应用默认使用的机制。
第二种是使用异步 I/O(Asynchronous I/O,AIO)。AIO 允许应用程序同时发起很多 I/O 操作,而不用等待这些操作完成。等到 I/O 完成后,系统会用事件通知的方式,告诉应用程序结果。不过,AIO 的使用比较复杂,你需要小心处理很多边缘情况。
而从进程的工作模型来说,也有两种不同的模型用来优化。
第一种,主进程 + 多个 worker 子进程。其中,主进程负责管理网络连接,而子进程负责实际的业务处理。这也是最常用的一种模型。
第二种,监听到相同端口的多进程模型。在这种模型下,所有进程都会监听相同接口,并且开启 SO_REUSEPORT 选项,由内核负责,把请求负载均衡到这些监听进程中去。
除了网络 I/O 和进程的工作模型外,应用层的网络协议优化,也是至关重要的一点。我总结了常见的几种优化方法。
使用长连接取代短连接,可以显著降低 TCP 建立连接的成本。在每秒请求次数较多时,这样做的效果非常明显。
- 使用内存等方式,来缓存不常变化的数据,可以降低网络 I/O 次数,同时加快应用程序的响应速度。
- 使用 Protocol Buffer 等序列化的方式,压缩网络 I/O 的数据量,可以提高应用程序的吞吐。
- 使用 DNS 缓存、预取、HTTPDNS 等方式,减少 DNS 解析的延迟,也可以提升网络 I/O 的整体速度。
套接字
套接字可以屏蔽掉 Linux 内核中不同协议的差异,为应用程序提供统一的访问接口。每个套接字,都有一个读写缓冲区。
- 读缓冲区,缓存了远端发过来的数据。如果读缓冲区已满,就不能再接收新的数据。
写缓冲区,缓存了要发出去的数据。如果写缓冲区已满,应用程序的写操作就会被阻塞。
所以,为了提高网络的吞吐量,你通常需要调整这些缓冲区的大小。比如:
增大每个套接字的缓冲区大小 net.core.optmem_max;
- 增大套接字接收缓冲区大小 net.core.rmem_max 和发送缓冲区大小 net.core.wmem_max;
增大 TCP 接收缓冲区大小 net.ipv4.tcp_rmem 和发送缓冲区大小 net.ipv4.tcp_wmem。
至于套接字的内核选项,我把它们整理成了一个表格,方便你在需要时参考:
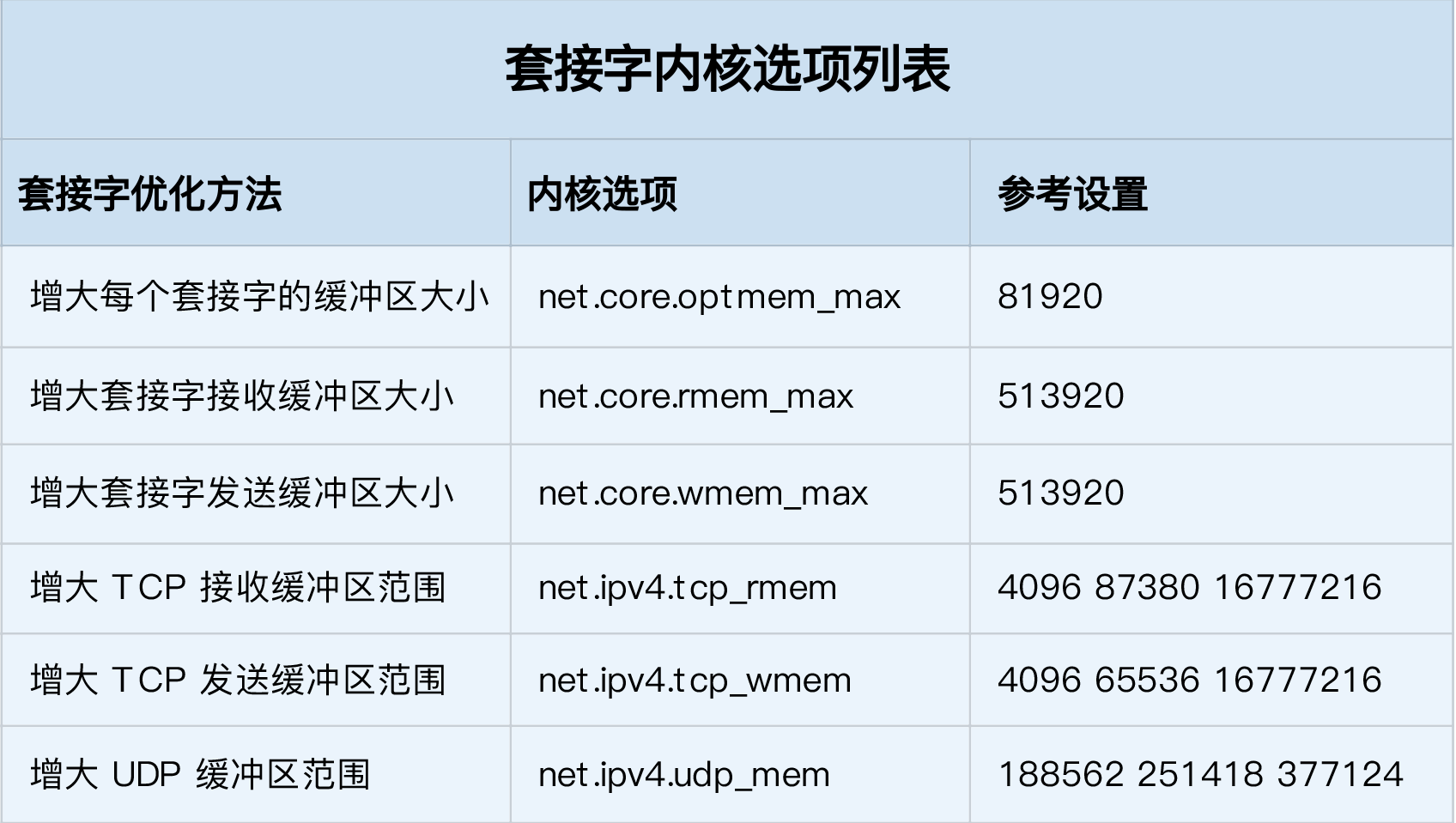
不过有几点需要你注意。
tcp_rmem 和 tcp_wmem 的三个数值分别是 min,default,max,系统会根据这些设置,自动调整 TCP 接收 / 发送缓冲区的大小。
udp_mem 的三个数值分别是 min,pressure,max,系统会根据这些设置,自动调整 UDP 发送缓冲区的大小。
当然,表格中的数值只提供参考价值,具体应该设置多少,还需要你根据实际的网络状况来确定。比如,发送缓冲区大小,理想数值是吞吐量 * 延迟,这样才可以达到最大网络利用率。
除此之外,套接字接口还提供了一些配置选项,用来修改网络连接的行为:
为 TCP 连接设置 TCP_NODELAY 后,就可以禁用 Nagle 算法;
- 为 TCP 连接开启 TCP_CORK 后,可以让小包聚合成大包后再发送(注意会阻塞小包的发送);
- 使用 SO_SNDBUF 和 SO_RCVBUF ,可以分别调整套接字发送缓冲区和接收缓冲区的大小。
44 | 套路篇:网络性能优化的几个思路(下)
44.1 网络性能优化
传输层
传输层最重要的是 TCP 和 UDP 协议,所以这儿的优化,其实主要就是对这两种协议的优化。
TCP 提供了面向连接的可靠传输服务。要优化 TCP,我们首先要掌握 TCP 协议的基本原理,比如流量控制、慢启动、拥塞避免、延迟确认以及状态流图(如下图所示)等。
掌握这些原理后,你就可以在不破坏 TCP 正常工作的基础上,对它进行优化。下面,我分几类情况详细说明。
第一类,在请求数比较大的场景下,你可能会看到大量处于 TIME_WAIT 状态的连接,它们会占用大量内存和端口资源。这时,我们可以优化与 TIME_WAIT 状态相关的内核选项,比如采取下面几种措施。
- 增大处于 TIME_WAIT 状态的连接数量 net.ipv4.tcp_max_tw_buckets ,并增大连接跟踪表的大小 net.netfilter.nf_conntrack_max。
- 减小 net.ipv4.tcp_fin_timeout 和 net.netfilter.nf_conntrack_tcp_timeout_time_wait ,让系统尽快释放它们所占用的资源。
- 开启端口复用 net.ipv4.tcp_tw_reuse。这样,被 TIME_WAIT 状态占用的端口,还能用到新建的连接中。
- 增大本地端口的范围 net.ipv4.ip_local_port_range 。这样就可以支持更多连接,提高整体的并发能力。
增加最大文件描述符的数量。你可以使用 fs.nr_open 和 fs.file-max ,分别增大进程和系统的最大文件描述符数;或在应用程序的 systemd 配置文件中,配置 LimitNOFILE ,设置应用程序的最大文件描述符数。
第二类,为了缓解 SYN FLOOD 等,利用 TCP 协议特点进行攻击而引发的性能问题,你可以考虑优化与 SYN 状态相关的内核选项,比如采取下面几种措施。
增大 TCP 半连接的最大数量 net.ipv4.tcp_max_syn_backlog ,或者开启 TCP SYN Cookies net.ipv4.tcp_syncookies ,来绕开半连接数量限制的问题(注意,这两个选项不可同时使用)。
减少 SYN_RECV 状态的连接重传 SYN+ACK 包的次数 net.ipv4.tcp_synack_retries。
第三类,在长连接的场景中,通常使用 Keepalive 来检测 TCP 连接的状态,以便对端连接断开后,可以自动回收。但是,系统默认的 Keepalive 探测间隔和重试次数,一般都无法满足应用程序的性能要求。所以,这时候你需要优化与 Keepalive 相关的内核选项,比如:
缩短最后一次数据包到 Keepalive 探测包的间隔时间 net.ipv4.tcp_keepalive_time;
- 缩短发送 Keepalive 探测包的间隔时间 net.ipv4.tcp_keepalive_intvl;
减少 Keepalive 探测失败后,一直到通知应用程序前的重试次数 net.ipv4.tcp_keepalive_probes。
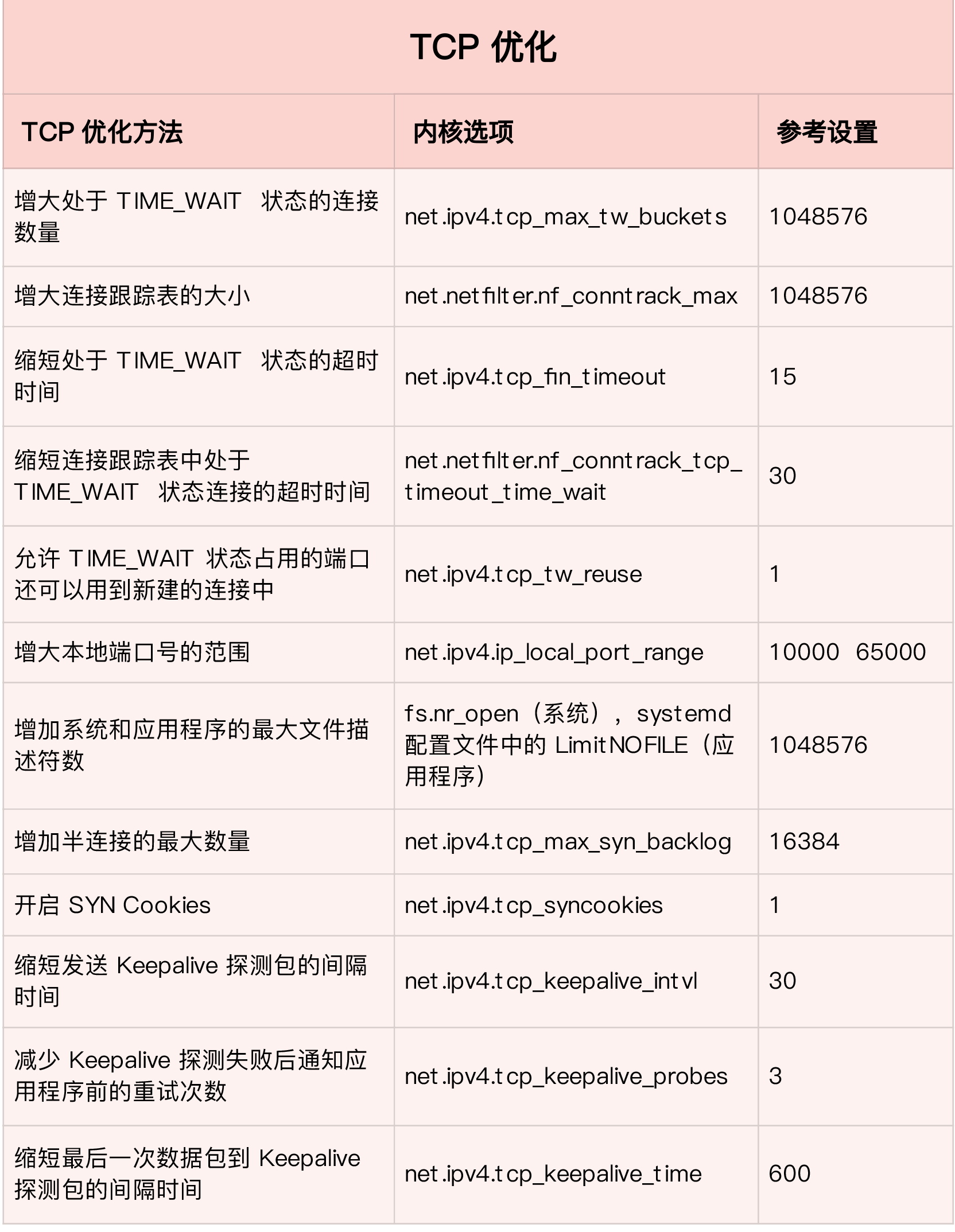
优化 TCP 性能时,你还要注意,如果同时使用不同优化方法,可能会产生冲突。
比如,就像网络请求延迟的案例中我们曾经分析过的,服务器端开启 Nagle 算法,而客户端开启延迟确认机制,就很容易导致网络延迟增大。
另外,在使用 NAT 的服务器上,如果开启 net.ipv4.tcp_tw_recycle ,就很容易导致各种连接失败。实际上,由于坑太多,这个选项在内核的 4.1 版本中已经删除了。
UDP 提供了面向数据报的网络协议,它不需要网络连接,也不提供可靠性保障。所以,UDP 优化,相对于 TCP 来说,要简单得多。这里我也总结了常见的几种优化方案。
- 跟上篇套接字部分提到的一样,增大套接字缓冲区大小以及 UDP 缓冲区范围;
- 跟前面 TCP 部分提到的一样,增大本地端口号的范围;
- 根据 MTU 大小,调整 UDP 数据包的大小,减少或者避免分片的发生。
网络层
网络层,负责网络包的封装、寻址和路由,包括 IP、ICMP 等常见协议。在网络层,最主要的优化,其实就是对路由、 IP 分片以及 ICMP 等进行调优。
第一种,从路由和转发的角度出发,你可以调整下面的内核选项。
- 在需要转发的服务器中,比如用作 NAT 网关的服务器或者使用 Docker 容器时,开启 IP 转发,即设置 net.ipv4.ip_forward = 1。
- 调整数据包的生存周期 TTL,比如设置 net.ipv4.ip_default_ttl = 64。注意,增大该值会降低系统性能。
- 开启数据包的反向地址校验,比如设置 net.ipv4.conf.eth0.rp_filter = 1。这样可以防止 IP 欺骗,并减少伪造 IP 带来的 DDoS 问题。
第二种,从分片的角度出发,最主要的是调整 MTU(Maximum Transmission Unit)的大小。
通常,MTU 的大小应该根据以太网的标准来设置。以太网标准规定,一个网络帧最大为 1518B,那么去掉以太网头部的 18B 后,剩余的 1500 就是以太网 MTU 的大小。
在使用 VXLAN、GRE 等叠加网络技术时,要注意,网络叠加会使原来的网络包变大,导致 MTU 也需要调整。
比如,就以 VXLAN 为例,它在原来报文的基础上,增加了 14B 的以太网头部、 8B 的 VXLAN 头部、8B 的 UDP 头部以及 20B 的 IP 头部。换句话说,每个包比原来增大了 50B。
所以,我们就需要把交换机、路由器等的 MTU,增大到 1550, 或者把 VXLAN 封包前(比如虚拟化环境中的虚拟网卡)的 MTU 减小为 1450。
另外,现在很多网络设备都支持巨帧,如果是这种环境,你还可以把 MTU 调大为 9000,以提高网络吞吐量。
第三种,从 ICMP 的角度出发,为了避免 ICMP 主机探测、ICMP Flood 等各种网络问题,你可以通过内核选项,来限制 ICMP 的行为。
- 比如,你可以禁止 ICMP 协议,即设置 net.ipv4.icmp_echo_ignore_all = 1。这样,外部主机就无法通过 ICMP 来探测主机。
- 或者,你还可以禁止广播 ICMP,即设置 net.ipv4.icmp_echo_ignore_broadcasts = 1。
链路层
链路层负责网络包在物理网络中的传输,比如 MAC 寻址、错误侦测以及通过网卡传输网络帧等。自然,链路层的优化,也是围绕这些基本功能进行的。接下来,我们从不同的几个方面分别来看。
由于网卡收包后调用的中断处理程序(特别是软中断),需要消耗大量的 CPU。所以,将这些中断处理程序调度到不同的 CPU 上执行,就可以显著提高网络吞吐量。这通常可以采用下面两种方法。
- 比如,你可以为网卡硬中断配置 CPU 亲和性(smp_affinity),或者开启 irqbalance 服务。
再如,你可以开启 RPS(Receive Packet Steering)和 RFS(Receive Flow Steering),将应用程序和软中断的处理,调度到相同 CPU 上,这样就可以增加 CPU 缓存命中率,减少网络延迟。
另外,现在的网卡都有很丰富的功能,原来在内核中通过软件处理的功能,可以卸载到网卡中,通过硬件来执行。
TSO(TCP Segmentation Offload)和 UFO(UDP Fragmentation Offload):在 TCP/UDP 协议中直接发送大包;而 TCP 包的分段(按照 MSS 分段)和 UDP 的分片(按照 MTU 分片)功能,由网卡来完成 。
- GSO(Generic Segmentation Offload):在网卡不支持 TSO/UFO 时,将 TCP/UDP 包的分段,延迟到进入网卡前再执行。这样,不仅可以减少 CPU 的消耗,还可以在发生丢包时只重传分段后的包。
- LRO(Large Receive Offload):在接收 TCP 分段包时,由网卡将其组装合并后,再交给上层网络处理。不过要注意,在需要 IP 转发的情况下,不能开启 LRO,因为如果多个包的头部信息不一致,LRO 合并会导致网络包的校验错误。
- GRO(Generic Receive Offload):GRO 修复了 LRO 的缺陷,并且更为通用,同时支持 TCP 和 UDP。
- RSS(Receive Side Scaling):也称为多队列接收,它基于硬件的多个接收队列,来分配网络接收进程,这样可以让多个 CPU 来处理接收到的网络包。
VXLAN 卸载:也就是让网卡来完成 VXLAN 的组包功能。
最后,对于网络接口本身,也有很多方法,可以优化网络的吞吐量。
比如,你可以开启网络接口的多队列功能。这样,每个队列就可以用不同的中断号,调度到不同 CPU 上执行,从而提升网络的吞吐量。
- 再如,你可以增大网络接口的缓冲区大小,以及队列长度等,提升网络传输的吞吐量(注意,这可能导致延迟增大)。
- 你还可以使用 Traffic Control 工具,为不同网络流量配置 QoS。
在单机并发 1000 万的场景中,对 Linux 网络协议栈进行的各种优化策略,基本都没有太大效果。因为这种情况下,网络协议栈的冗长流程,其实才是最主要的性能负担。
这时,我们可以用两种方式来优化。
- 第一种,使用 DPDK 技术,跳过内核协议栈,直接由用户态进程用轮询的方式,来处理网络请求。同时,再结合大页、CPU 绑定、内存对齐、流水线并发等多种机制,优化网络包的处理效率。
- 第二种,使用内核自带的 XDP 技术,在网络包进入内核协议栈前,就对其进行处理,这样也可以实现很好的性能。
45 | 答疑(五):网络收发过程中,缓冲区位置在哪里?
45.1 问题 1:网络收发过程中缓冲区的位置

这个流程涉及到了多个队列和缓冲区,包括:
- 网卡收发网络包时,通过 DMA 方式交互的环形缓冲区;
- 网卡中断处理程序为网络帧分配的,内核数据结构 sk_buff 缓冲区;
- 应用程序通过套接字接口,与网络协议栈交互时的套接字缓冲区。
不过相应的,就会有两个问题。
首先,这些缓冲区的位置在哪儿?是在网卡硬件中,还是在内存中?这个问题其实仔细想一下,就很容易明白——这些缓冲区都处于内核管理的内存中。
- 环形缓冲区,由于需要 DMA 与网卡交互,理应属于网卡设备驱动的范围。
- sk_buff 缓冲区,是一个维护网络帧结构的双向链表,链表中的每一个元素都是一个网络帧(Packet)。虽然 TCP/IP 协议栈分了好几层,但上下不同层之间的传递,实际上只需要操作这个数据结构中的指针,而无需进行数据复制。
- 套接字缓冲区,则允许应用程序,给每个套接字配置不同大小的接收或发送缓冲区。应用程序发送数据,实际上就是将数据写入缓冲区;而接收数据,其实就是从缓冲区中读取。至于缓冲区中数据的进一步处理,则由传输层的 TCP 或 UDP 协议来完成。
其次,这些缓冲区,跟前面内存部分讲到的 Buffer 和 Cache 有什么关联吗?
这个问题其实也不难回答。我在内存模块曾提到过,内存中提到的 Buffer ,都跟块设备直接相关;而其他的都是 Cache。
实际上,sk_buff、套接字缓冲、连接跟踪等,都通过 slab 分配器来管理。你可以直接通过 /proc/slabinfo,来查看它们占用的内存大小。
45.2 问题 2:内核协议栈,是通过一个内核线程的方式来运行的吗
说到网络收发,在中断处理文章中我曾讲过,其中的软中断处理,就有专门的内核线程 ksoftirqd。每个 CPU 都会绑定一个 ksoftirqd 内核线程,比如, 2 个 CPU 时,就会有 ksoftirqd/0 和 ksoftirqd/1 这两个内核线程。
不过要注意,并非所有网络功能,都在软中断内核线程中处理。内核中还有很多其他机制(比如硬中断、kworker、slab 等),这些机制一起协同工作,才能保证整个网络协议栈的正常运行。
45.3 问题 3:最大连接数是不是受限于 65535 个端口
我们知道,无论 TCP 还是 UDP,端口号都只占 16 位,也就说其最大值也只有 65535。那是不是说,如果使用 TCP 协议,在单台机器、单个 IP 地址时,并发连接数最大也只有 65535 呢?
对于这个问题,首先你要知道,Linux 协议栈,通过五元组来标志一个连接(即协议,源 IP、源端口、目的 IP、目的端口)。
明白了这一点,这个问题其实就有了思路。我们应该分客户端和服务器端,这两种场景来分析。
对客户端来说,每次发起 TCP 连接请求时,都需要分配一个空闲的本地端口,去连接远端的服务器。由于这个本地端口是独占的,所以客户端最多只能发起 65535 个连接。
对服务器端来说,其通常监听在固定端口上(比如 80 端口),等待客户端的连接。根据五元组结构,我们知道,客户端的 IP 和端口都是可变的。如果不考虑 IP 地址分类以及资源限制,服务器端的理论最大连接数,可以达到 2 的 48 次方(IP 为 32 位,端口号为 16 位),远大于 65535。
所以,综合来看,客户端最大支持 65535 个连接,而服务器端可支持的连接数是海量的。当然,由于 Linux 协议栈本身的性能,以及各种物理和软件的资源限制等,这么大的连接数,还是远远达不到的(实际上,C10M 就已经很难了)。
45.4 问题 4: “如何优化 NAT 性能”课后思考
MASQUERADE 是最常用的 SNAT 规则之一,通常用来为多个内网 IP 地址,提供共享的出口 IP。假设现在有一台 Linux 服务器,用了 MASQUERADE 方式,为内网所有 IP 提供出口访问功能。那么,
- 当多个内网 IP 地址的端口号相同时,MASQUERADE 还能正常工作吗?
- 内网 IP 地址数量或者请求数比较多的时候,这种使用方式有没有什么潜在问题呢?
先看第一点,当多个内网 IP 地址的端口号相同时,MASQUERADE 当然仍可以正常工作。不过,你肯定也听说过,配置 MASQUERADE 后,需要各个应用程序去手动配置修改端口号。
实际上,MASQUERADE 通过 conntrack 机制,记录了每个连接的信息。而在刚才第三个问题 中,我提到过,标志一个连接需要五元组,只要这五元组不是同时相同,网络连接就可以正常进行。
再看第二点,在内网 IP 地址和连接数比较小时,这种方式的问题不大。但在 IP 地址或并发连接数特别大的情况下,就可能碰到各种各样的资源限制。
比如,MASQUERADE 既然把内部多个 IP ,转换成了相同的外网 IP(即 SNAT),那么,为了确保发送出去的源端口不重复,原来网络包的源端口也可能会被重新分配。这样的话,转换后的外网 IP 的端口号,就成了限制连接数的一个重要因素。
除此之外,连接跟踪、MASQUERADE 机器的网络带宽等,都是潜在的瓶颈,并且还存在单点的问题。这些情况,在我们实际使用中都需要特别注意。
06-综合实战篇
46 | 案例篇:为什么应用容器化后,启动慢了很多?
46.1 案例
机器配置: 2 CPU, 8 GB 内存。
安装软件:
apt install docker.io curl jq sysstat。jq 工具专门用来在命令行中处理 json。为了更好的展示 json 数据,我们用这个工具,来格式化 json 输出。
打开两个终端,登录到同一台虚拟机中。
在终端一中,执行下面的命令,启动 Tomcat 应用,并监听 8080 端口。如果一切正常,你应该可以看到如下的输出:
# -m 表示设置内存为 512MB $ docker run --name tomcat --cpus 0.1 -m 512M -p 8080:8080 -itd feisky/tomcat:8 Unable to find image 'feisky/tomcat:8' locally 8: Pulling from feisky/tomcat 741437d97401: Pull complete ... 22cd96a25579: Pull complete Digest: sha256:71871cff17b9043842c2ec99f370cc9f1de7bc121cd2c02d8e2092c6e268f7e2 Status: Downloaded newer image for feisky/tomcat:8 WARNING: Your kernel does not support swap limit capabilities or the cgroup is not mounted. Memory limited without swap. 2df259b752db334d96da26f19166d662a82283057411f6332f3cbdbcab452249接着,在终端二中使用 curl,访问 Tomcat 监听的 8080 端口,确认案例已经正常启动:
$ curl localhost:8080 curl: (56) Recv failure: Connection reset by peer不过,很不幸,curl 返回了 “Connection reset by peer” 的错误,说明 Tomcat 服务,并不能正常响应客户端请求。
是不是 Tomcat 启动出问题了呢?我们切换到终端一中,执行 docker logs 命令,查看容器的日志。这里注意,需要加上 -f 参数,表示跟踪容器的最新日志输出:
$ docker logs -f tomcat Using CATALINA_BASE: /usr/local/tomcat Using CATALINA_HOME: /usr/local/tomcat Using CATALINA_TMPDIR: /usr/local/tomcat/temp Using JRE_HOME: /docker-java-home/jre Using CLASSPATH: /usr/local/tomcat/bin/bootstrap.jar:/usr/local/tomcat/bin/tomcat-juli.jar从这儿你可以看到,Tomcat 容器只打印了环境变量,还没有应用程序初始化的日志。也就是说,Tomcat 还在启动过程中,这时候去访问它,当然没有响应。
为了观察 Tomcat 的启动过程,我们在终端一中,继续保留 docker logs -f 命令,并在终端二中执行下面的命令,多次尝试访问 Tomcat:
$ for ((i=0;i<30;i++)); do curl localhost:8080; sleep 1; done curl: (56) Recv failure: Connection reset by peer curl: (56) Recv failure: Connection reset by peer # 这儿会阻塞一会 Hello, wolrd! curl: (52) Empty reply from server curl: (7) Failed to connect to localhost port 8080: Connection refused curl: (7) Failed to connect to localhost port 8080: Connection refused观察一会儿,可以看到,一段时间后,curl 终于给出了我们想要的结果 “Hello, wolrd!”。但是,随后又出现了 “Empty reply from server” ,和一直持续的 “Connection refused” 错误。换句话说,Tomcat 响应一次请求后,就再也不响应了。
这是怎么回事呢?我们回到终端一中,观察 Tomcat 的日志,看看能不能找到什么线索。
从终端一中,你应该可以看到下面的输出:
18-Feb-2019 12:43:32.719 INFO [localhost-startStop-1] org.apache.catalina.startup.HostConfig.deployDirectory Deploying web application directory [/usr/local/tomcat/webapps/docs] 18-Feb-2019 12:43:33.725 INFO [localhost-startStop-1] org.apache.catalina.startup.HostConfig.deployDirectory Deployment of web application directory [/usr/local/tomcat/webapps/docs] has finished in [1,006] ms 18-Feb-2019 12:43:33.726 INFO [localhost-startStop-1] org.apache.catalina.startup.HostConfig.deployDirectory Deploying web application directory [/usr/local/tomcat/webapps/manager] 18-Feb-2019 12:43:34.521 INFO [localhost-startStop-1] org.apache.catalina.startup.HostConfig.deployDirectory Deployment of web application directory [/usr/local/tomcat/webapps/manager] has finished in [795] ms 18-Feb-2019 12:43:34.722 INFO [main] org.apache.coyote.AbstractProtocol.start Starting ProtocolHandler ["http-nio-8080"] 18-Feb-2019 12:43:35.319 INFO [main] org.apache.coyote.AbstractProtocol.start Starting ProtocolHandler ["ajp-nio-8009"] 18-Feb-2019 12:43:35.821 INFO [main] org.apache.catalina.startup.Catalina.start Server startup in 24096 ms root@ubuntu:~#从内容上可以看到,Tomcat 在启动 24s 后完成初始化,并且正常启动。从日志上来看,没有什么问题。
不过,细心的你肯定注意到了最后一行,明显是回到了 Linux 的 SHELL 终端中,而没有继续等待 Docker 输出的容器日志。
输出重新回到 SHELL 终端,通常表示上一个命令已经结束。而我们的上一个命令,是 docker logs -f 命令。那么,它的退出就只有两种可能了,要么是容器退出了,要么就是 dockerd 进程退出了。
究竟是哪种情况呢?这就需要我们进一步确认了。我们可以在终端一中,执行下面的命令,查看容器的状态:
$ docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 0f2b3fcdd257 feisky/tomcat:8 "catalina.sh run" 2 minutes ago Exited (137) About a minute ago tomcat我们可以调用 Docker 的 API,查询容器的状态、退出码以及错误信息,然后确定容器退出的原因。这些可以通过 docker inspect 命令来完成,比如,你可以继续执行下面的命令,通过 -f 选项设置只输出容器的状态:
# 显示容器状态,jq 用来格式化 json 输出 $ docker inspect tomcat -f '{{json .State}}' | jq { "Status": "exited", "Running": false, "Paused": false, "Restarting": false, "OOMKilled": true, "Dead": false, "Pid": 0, "ExitCode": 137, "Error": "", ... }这次你可以看到,容器已经处于 exited 状态,OOMKilled 是 true,ExitCode 是 137。这其中,OOMKilled 表示容器被 OOM 杀死了。
我们前面提到过,OOM 表示内存不足时,某些应用会被系统杀死。可是,为什么内存会不足呢?我们的应用分配了 256 MB 的内存,而容器启动时,明明通过 -m 选项,设置了 512 MB 的内存,按说应该是足够的。
到这里,我估计你应该还记得,当 OOM 发生时,系统会把相关的 OOM 信息,记录到日志中。所以,接下来,我们可以在终端中执行 dmesg 命令,查看系统日志,并定位 OOM 相关的日志:
$ dmesg [193038.106393] java invoked oom-killer: gfp_mask=0x14000c0(GFP_KERNEL), nodemask=(null), order=0, oom_score_adj=0 [193038.106396] java cpuset=0f2b3fcdd2578165ea77266cdc7b1ad43e75877b0ac1889ecda30a78cb78bd53 mems_allowed=0 [193038.106402] CPU: 0 PID: 27424 Comm: java Tainted: G OE 4.15.0-1037 #39-Ubuntu [193038.106404] Hardware name: Microsoft Corporation Virtual Machine/Virtual Machine, BIOS 090007 06/02/2017 [193038.106405] Call Trace: [193038.106414] dump_stack+0x63/0x89 [193038.106419] dump_header+0x71/0x285 [193038.106422] oom_kill_process+0x220/0x440 [193038.106424] out_of_memory+0x2d1/0x4f0 [193038.106429] mem_cgroup_out_of_memory+0x4b/0x80 [193038.106432] mem_cgroup_oom_synchronize+0x2e8/0x320 [193038.106435] ? mem_cgroup_css_online+0x40/0x40 [193038.106437] pagefault_out_of_memory+0x36/0x7b [193038.106443] mm_fault_error+0x90/0x180 [193038.106445] __do_page_fault+0x4a5/0x4d0 [193038.106448] do_page_fault+0x2e/0xe0 [193038.106454] ? page_fault+0x2f/0x50 [193038.106456] page_fault+0x45/0x50 [193038.106459] RIP: 0033:0x7fa053e5a20d [193038.106460] RSP: 002b:00007fa0060159e8 EFLAGS: 00010206 [193038.106462] RAX: 0000000000000000 RBX: 00007fa04c4b3000 RCX: 0000000009187440 [193038.106463] RDX: 00000000943aa440 RSI: 0000000000000000 RDI: 000000009b223000 [193038.106464] RBP: 00007fa006015a60 R08: 0000000002000002 R09: 00007fa053d0a8a1 [193038.106465] R10: 00007fa04c018b80 R11: 0000000000000206 R12: 0000000100000768 [193038.106466] R13: 00007fa04c4b3000 R14: 0000000100000768 R15: 0000000010000000 [193038.106468] Task in /docker/0f2b3fcdd2578165ea77266cdc7b1ad43e75877b0ac1889ecda30a78cb78bd53 killed as a result of limit of /docker/0f2b3fcdd2578165ea77266cdc7b1ad43e75877b0ac1889ecda30a78cb78bd53 [193038.106478] memory: usage 524288kB, limit 524288kB, failcnt 77 [193038.106480] memory+swap: usage 0kB, limit 9007199254740988kB, failcnt 0 [193038.106481] kmem: usage 3708kB, limit 9007199254740988kB, failcnt 0 [193038.106481] Memory cgroup stats for /docker/0f2b3fcdd2578165ea77266cdc7b1ad43e75877b0ac1889ecda30a78cb78bd53: cache:0KB rss:520580KB rss_huge:450560KB shmem:0KB mapped_file:0KB dirty:0KB writeback:0KB inactive_anon:0KB active_anon:520580KB inactive_file:0KB active_file:0KB unevictable:0KB [193038.106494] [ pid ] uid tgid total_vm rss pgtables_bytes swapents oom_score_adj name [193038.106571] [27281] 0 27281 1153302 134371 1466368 0 0 java [193038.106574] Memory cgroup out of memory: Kill process 27281 (java) score 1027 or sacrifice child [193038.148334] Killed process 27281 (java) total-vm:4613208kB, anon-rss:517316kB, file-rss:20168kB, shmem-rss:0kB [193039.607503] oom_reaper: reaped process 27281 (java), now anon-rss:0kB, file-rss:0kB, shmem-rss:0kB从 dmesg 的输出,你就可以看到很详细的 OOM 记录了。你应该可以看到下面几个关键点。
- 第一,被杀死的是一个 java 进程。从内核调用栈上的 mem_cgroup_out_of_memory 可以看出,它是因为超过 cgroup 的内存限制,而被 OOM 杀死的。
- 第二,java 进程是在容器内运行的,而容器内存的使用量和限制都是 512M(524288kB)。目前使用量已经达到了限制,所以会导致 OOM。
第三,被杀死的进程,PID 为 27281,虚拟内存为 4.3G(total-vm:4613208kB),匿名内存为 505M(anon-rss:517316kB),页内存为 19M(20168kB)。换句话说,匿名内存是主要的内存占用。而且,匿名内存加上页内存,总共是 524M,已经超过了 512M 的限制。
综合这几点,可以看出,Tomcat 容器的内存主要用在了匿名内存中,而匿名内存,其实就是主动申请分配的堆内存。
不过,为什么 Tomcat 会申请这么多的堆内存呢?要知道,Tomcat 是基于 Java 开发的,所以应该不难想到,这很可能是 JVM 堆内存配置的问题。
我们知道,JVM 根据系统的内存总量,来自动管理堆内存,不明确配置的话,堆内存的默认限制是物理内存的四分之一。不过,前面我们已经限制了容器内存为 512 M,java 的堆内存到底是多少呢?
我们继续在终端中,执行下面的命令,重新启动 tomcat 容器,并调用 java 命令行来查看堆内存大小:
# 重新启动容器 $ docker rm -f tomcat $ docker run --name tomcat --cpus 0.1 -m 512M -p 8080:8080 -itd feisky/tomcat:8 # 查看堆内存,注意单位是字节 $ docker exec tomcat java -XX:+PrintFlagsFinal -version | grep HeapSize uintx ErgoHeapSizeLimit = 0 {product} uintx HeapSizePerGCThread = 87241520 {product} uintx InitialHeapSize := 132120576 {product} uintx LargePageHeapSizeThreshold = 134217728 {product} uintx MaxHeapSize := 2092957696 {product}你可以看到,初始堆内存的大小(InitialHeapSize)是 126MB,而最大堆内存则是 1.95GB,这可比容器限制的 512 MB 大多了。
之所以会这么大,其实是因为,容器内部看不到 Docker 为它设置的内存限制。虽然在启动容器时,我们通过 -m 512M 选项,给容器设置了 512M 的内存限制。但实际上,从容器内部看到的限制,却并不是 512M。
我们在终端中,继续执行下面的命令:
$ docker exec tomcat free -m total used free shared buff/cache available Mem: 7977 521 1941 0 5514 7148 Swap: 0 0 0果然,容器内部看到的内存,仍是主机内存。
知道了问题根源,解决方法就很简单了,给 JVM 正确配置内存限制为 512M 就可以了。
比如,你可以执行下面的命令,通过环境变量 JAVA_OPTS=’-Xmx512m -Xms512m’ ,把 JVM 的初始内存和最大内存都设为 512MB:
# 删除问题容器 $ docker rm -f tomcat # 运行新的容器 $ docker run --name tomcat --cpus 0.1 -m 512M -e JAVA_OPTS='-Xmx512m -Xms512m' -p 8080:8080 -itd feisky/tomcat:8接着,再切换到终端二中,重新在循环中执行 curl 命令,查看 Tomcat 的响应:
$ for ((i=0;i<30;i++)); do curl localhost:8080; sleep 1; done curl: (56) Recv failure: Connection reset by peer curl: (56) Recv failure: Connection reset by peer Hello, wolrd! Hello, wolrd! Hello, wolrd!可以看到,刚开始时,显示的还是 “Connection reset by peer” 错误。不过,稍等一会儿后,就是连续的 “Hello, wolrd!” 输出了。这说明, Tomcat 已经正常启动。
这时,我们切换回终端一,执行 docker logs 命令,查看 Tomcat 容器的日志:
$ docker logs -f tomcat ... 18-Feb-2019 12:52:00.823 INFO [localhost-startStop-1] org.apache.catalina.startup.HostConfig.deployDirectory Deploying web application directory [/usr/local/tomcat/webapps/manager] 18-Feb-2019 12:52:01.422 INFO [localhost-startStop-1] org.apache.catalina.startup.HostConfig.deployDirectory Deployment of web application directory [/usr/local/tomcat/webapps/manager] has finished in [598] ms 18-Feb-2019 12:52:01.920 INFO [main] org.apache.coyote.AbstractProtocol.start Starting ProtocolHandler ["http-nio-8080"] 18-Feb-2019 12:52:02.323 INFO [main] org.apache.coyote.AbstractProtocol.start Starting ProtocolHandler ["ajp-nio-8009"] 18-Feb-2019 12:52:02.523 INFO [main] org.apache.catalina.startup.Catalina.start Server startup in 22798 ms这次,Tomcat 也正常启动了。不过,最后一行的启动时间,似乎比较刺眼。启动过程,居然需要 22 秒,这也太慢了吧。
由于这个时间是花在容器启动上的,要排查这个问题,我们就要重启容器,并借助性能分析工具来分析容器进程。至于工具的选用,回顾一下我们前面的案例,我觉得可以先用 top 看看。
我们切换到终端二中,运行 top 命令;然后再切换到终端一,执行下面的命令,重启容器:
# 删除旧容器 $ docker rm -f tomcat # 运行新容器 $ docker run --name tomcat --cpus 0.1 -m 512M -e JAVA_OPTS='-Xmx512m -Xms512m' -p 8080:8080 -itd feisky/tomcat:8接着,再切换到终端二,观察 top 的输出:
$ top top - 12:57:18 up 2 days, 5:50, 2 users, load average: 0.00, 0.02, 0.00 Tasks: 131 total, 1 running, 74 sleeping, 0 stopped, 0 zombie %Cpu0 : 3.0 us, 0.3 sy, 0.0 ni, 96.6 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st %Cpu1 : 5.7 us, 0.3 sy, 0.0 ni, 94.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st KiB Mem : 8169304 total, 2465984 free, 500812 used, 5202508 buff/cache KiB Swap: 0 total, 0 free, 0 used. 7353652 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 29457 root 20 0 2791736 73704 19164 S 10.0 0.9 0:01.61 java 27349 root 20 0 1121372 96760 39340 S 0.3 1.2 4:20.82 dockerd 27376 root 20 0 1031760 43768 21680 S 0.3 0.5 2:44.47 docker-containe 29430 root 20 0 7376 3604 3128 S 0.3 0.0 0:00.01 docker-containe 1 root 20 0 78132 9332 6744 S 0.0 0.1 0:16.12 systemd从 top 的输出,我们可以发现,
- 从系统整体来看,两个 CPU 的使用率分别是 3% 和 5.7% ,都不算高,大部分还是空闲的;可用内存还有 7GB(7353652 avail Mem),也非常充足。
- 具体到进程上,java 进程的 CPU 使用率为 10%,内存使用 0.9%,其他进程就都很低了。
这些指标都不算高,看起来都没啥问题。不过,事实究竟如何呢?我们还得继续找下去。由于 java 进程的 CPU 使用率最高,所以要把它当成重点,继续分析其性能情况。
说到进程的性能分析工具,你一定也想起了 pidstat。接下来,我们就用 pidstat 再来分析一下。我们回到终端一中,执行 pidstat 命令:
# -t 表示显示线程,-p 指定进程号 $ pidstat -t -p 29457 1 12:59:59 UID TGID TID %usr %system %guest %wait %CPU CPU Command 13:00:00 0 29457 - 0.00 0.00 0.00 0.00 0.00 0 java 13:00:00 0 - 29457 0.00 0.00 0.00 0.00 0.00 0 |__java 13:00:00 0 - 29458 0.00 0.00 0.00 0.00 0.00 1 |__java ... 13:00:00 0 - 29491 0.00 0.00 0.00 0.00 0.00 0 |__java结果中,各种 CPU 使用率全是 0,看起来不对呀。再想想,我们有没有漏掉什么线索呢?对了,这时候容器启动已经结束了,在没有客户端请求的情况下,Tomcat 本身啥也不用做,CPU 使用率当然是 0。
为了分析启动过程中的问题,我们需要再次重启容器。继续在终端一,按下 Ctrl+C 停止 pidstat 命令;然后执行下面的命令,重启容器。成功重启后,拿到新的 PID,再重新运行 pidstat 命令:
# 删除旧容器 $ docker rm -f tomcat # 运行新容器 $ docker run --name tomcat --cpus 0.1 -m 512M -e JAVA_OPTS='-Xmx512m -Xms512m' -p 8080:8080 -itd feisky/tomcat:8 # 查询新容器中进程的 Pid $ PID=$(docker inspect tomcat -f '{{.State.Pid}}') # 执行 pidstat $ pidstat -t -p $PID 1 12:59:28 UID TGID TID %usr %system %guest %wait %CPU CPU Command 12:59:29 0 29850 - 10.00 0.00 0.00 0.00 10.00 0 java 12:59:29 0 - 29850 0.00 0.00 0.00 0.00 0.00 0 |__java 12:59:29 0 - 29897 5.00 1.00 0.00 86.00 6.00 1 |__java ... 12:59:29 0 - 29905 3.00 0.00 0.00 97.00 3.00 0 |__java 12:59:29 0 - 29906 2.00 0.00 0.00 49.00 2.00 1 |__java 12:59:29 0 - 29908 0.00 0.00 0.00 45.00 0.00 0 |__java仔细观察这次的输出,你会发现,虽然 CPU 使用率(%CPU)很低,但等待运行的使用率(%wait)却非常高,最高甚至已经达到了 97%。这说明,这些线程大部分时间都在等待调度,而不是真正的运行。
注:如果你看不到 %wait 指标,请先升级 sysstat 后再试试。
为什么 CPU 使用率这么低,线程的大部分时间还要等待 CPU 呢?由于这个现象因 Docker 而起,自然的,你应该想到,这可能是因为 Docker 为容器设置了限制。
再回顾一下,案例开始时容器的启动命令。我们用 —cpus 0.1 ,为容器设置了 0.1 个 CPU 的限制,也就是 10% 的 CPU。这里也就可以解释,为什么 java 进程只有 10% 的 CPU 使用率,也会大部分时间都在等待了。
找出原因,最后的优化也就简单了,把 CPU 限制增大就可以了。比如,你可以执行下面的命令,将 CPU 限制增大到 1 ;然后再重启,并观察启动日志:
# 删除旧容器 $ docker rm -f tomcat # 运行新容器 $ docker run --name tomcat --cpus 1 -m 512M -e JAVA_OPTS='-Xmx512m -Xms512m' -p 8080:8080 -itd feisky/tomcat:8 # 查看容器日志 $ docker logs -f tomcat ... 18-Feb-2019 12:54:02.139 INFO [main] org.apache.catalina.startup.Catalina.start Server startup in 2001 ms现在可以看到,Tomcat 的启动过程,只需要 2 秒就完成了,果然比前面的 22 秒快多了。
46.2 小结
如果你在 Docker 容器中运行 Java 应用,一定要确保,在设置容器资源限制的同时,配置好 JVM 的资源选项(比如堆内存等)。当然,如果你可以升级 Java 版本,那么升级到 Java 10 ,就可以自动解决类似问题了。
当碰到容器化的应用程序性能时,你依然可以使用,我们前面讲过的各种方法来分析和定位。只不过要记得,容器化后的性能分析,跟前面内容稍微有些区别,比如下面这几点。
- 容器本身通过 cgroups 进行资源隔离,所以,在分析时要考虑 cgroups 对应用程序的影响。
- 容器的文件系统、网络协议栈等跟主机隔离。虽然在容器外面,我们也可以分析容器的行为,不过有时候,进入容器的命名空间内部,可能更为方便。
- 容器的运行可能还会依赖于其他组件,比如各种网络插件(比如 CNI)、存储插件(比如 CSI)、设备插件(比如 GPU)等,让容器的性能分析更加复杂。如果你需要分析容器性能,别忘了考虑它们对性能的影响。
47 | 案例篇:服务器总是时不时丢包,我该怎么办?(上)
丢包,是指在网络数据的收发过程中,由于种种原因,数据包还没传输到应用程序中,就被丢弃了。这些被丢弃包的数量,除以总的传输包数,也就是我们常说的丢包率。丢包率是网络性能中最核心的指标之一。
47.1 案例
机器配置: 2 CPU, 8 GB 内存。
安装软件:
apt install docker.io curl hping3。
在终端一中执行下面的命令,启动 Nginx 应用,并在 80 端口监听。如果一切正常,你应该可以看到如下的输出:
$ docker run --name nginx --hostname nginx --privileged -p 80:80 -itd feisky/nginx:drop dae0202cc27e5082b282a6aeeb1398fcec423c642e63322da2a97b9ebd7538e0然后,执行 docker ps 命令,查询容器的状态,你会发现容器已经处于运行状态(Up)了:
$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES dae0202cc27e feisky/nginx:drop "/start.sh" 4 minutes ago Up 4 minutes 0.0.0.0:80->80/tcp nginx切换到终端二中,执行下面的 hping3 命令,进一步验证 Nginx 是不是真的可以正常访问了。注意,这里我没有使用 ping,是因为 ping 基于 ICMP 协议,而 Nginx 使用的是 TCP 协议。
# -c 表示发送 10 个请求,-S 表示使用 TCP SYN,-p 指定端口为 80 $ hping3 -c 10 -S -p 80 192.168.0.30 HPING 192.168.0.30 (eth0 192.168.0.30): S set, 40 headers + 0 data bytes len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=3 win=5120 rtt=7.5 ms len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=4 win=5120 rtt=7.4 ms len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=5 win=5120 rtt=3.3 ms len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=7 win=5120 rtt=3.0 ms len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=6 win=5120 rtt=3027.2 ms --- 192.168.0.30 hping statistic --- 10 packets transmitted, 5 packets received, 50% packet loss round-trip min/avg/max = 3.0/609.7/3027.2 ms从 hping3 的输出中,我们可以发现,发送了 10 个请求包,却只收到了 5 个回复,50% 的包都丢了。再观察每个请求的 RTT 可以发现,RTT 也有非常大的波动变化,小的时候只有 3ms,而大的时候则有 3s。
根据这些输出,我们基本能判断,已经发生了丢包现象。可以猜测,3s 的 RTT ,很可能是因为丢包后重传导致的。那到底是哪里发生了丢包呢?
从图中你可以看出,可能发生丢包的位置,实际上贯穿了整个网络协议栈。换句话说,全程都有丢包的可能。比如我们从下往上看:
- 在两台 VM 连接之间,可能会发生传输失败的错误,比如网络拥塞、线路错误等;
- 在网卡收包后,环形缓冲区可能会因为溢出而丢包;
- 在链路层,可能会因为网络帧校验失败、QoS 等而丢包;
- 在 IP 层,可能会因为路由失败、组包大小超过 MTU 等而丢包;
- 在传输层,可能会因为端口未监听、资源占用超过内核限制等而丢包;
- 在套接字层,可能会因为套接字缓冲区溢出而丢包;
- 在应用层,可能会因为应用程序异常而丢包;
此外,如果配置了 iptables 规则,这些网络包也可能因为 iptables 过滤规则而丢包。
当然,上面这些问题,还有可能同时发生在通信的两台机器中。不过,由于我们没对 VM2 做任何修改,并且 VM2 也只运行了一个最简单的 hping3 命令,这儿不妨假设它是没有问题的。
为了简化整个排查过程,我们还可以进一步假设, VM1 的网络和内核配置也没问题。这样一来,有可能发生问题的位置,就都在容器内部了。
现在我们切换回终端一,执行下面的命令,进入容器的终端中:
$ docker exec -it nginx bash root@nginx:/#在这里简单说明一下,接下来的所有分析,前面带有 root@nginx:/# 的操作,都表示在容器中进行。
注意:实际环境中,容器内部和外部都有可能发生问题。不过不要担心,容器内、外部的分析步骤和思路都是一样的,只不过要花更多的时间而已。
那么, 接下来,我们就可以从协议栈中,逐层排查丢包问题。
链路层
首先,来看最底下的链路层。当缓冲区溢出等原因导致网卡丢包时,Linux 会在网卡收发数据的统计信息中,记录下收发错误的次数。
你可以通过 ethtool 或者 netstat ,来查看网卡的丢包记录。比如,可以在容器中执行下面的命令,查看丢包情况:
root@nginx:/# netstat -i Kernel Interface table Iface MTU RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg eth0 100 31 0 0 0 8 0 0 0 BMRU lo 65536 0 0 0 0 0 0 0 0 LRU输出中的 RX-OK、RX-ERR、RX-DRP、RX-OVR ,分别表示接收时的总包数、总错误数、进入 Ring Buffer 后因其他原因(如内存不足)导致的丢包数以及 Ring Buffer 溢出导致的丢包数。
TX-OK、TX-ERR、TX-DRP、TX-OVR 也代表类似的含义,只不过是指发送时对应的各个指标。
注意,由于 Docker 容器的虚拟网卡,实际上是一对 veth pair,一端接入容器中用作 eth0,另一端在主机中接入 docker0 网桥中。veth 驱动并没有实现网络统计的功能,所以使用 ethtool -S 命令,无法得到网卡收发数据的汇总信息。
从这个输出中,我们没有发现任何错误,说明容器的虚拟网卡没有丢包。不过要注意,如果用 tc 等工具配置了 QoS,那么 tc 规则导致的丢包,就不会包含在网卡的统计信息中。
所以接下来,我们还要检查一下 eth0 上是否配置了 tc 规则,并查看有没有丢包。我们继续容器终端中,执行下面的 tc 命令,不过这次注意添加 -s 选项,以输出统计信息:
root@nginx:/# tc -s qdisc show dev eth0 qdisc netem 800d: root refcnt 2 limit 1000 loss 30% Sent 432 bytes 8 pkt (dropped 4, overlimits 0 requeues 0) backlog 0b 0p requeues 0从 tc 的输出中可以看到, eth0 上面配置了一个网络模拟排队规则(qdisc netem),并且配置了丢包率为 30%(loss 30%)。再看后面的统计信息,发送了 8 个包,但是丢了 4 个。
看来,应该就是这里,导致 Nginx 回复的响应包,被 netem 模块给丢了。
既然发现了问题,解决方法也就很简单了,直接删掉 netem 模块就可以了。我们可以继续在容器终端中,执行下面的命令,删除 tc 中的 netem 模块:
root@nginx:/# tc qdisc del dev eth0 root netem loss 30%删除后,问题到底解决了没?我们切换到终端二中,重新执行刚才的 hping3 命令,看看现在还有没有问题:
$ hping3 -c 10 -S -p 80 192.168.0.30 HPING 192.168.0.30 (eth0 192.168.0.30): S set, 40 headers + 0 data bytes len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=0 win=5120 rtt=7.9 ms len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=2 win=5120 rtt=1003.8 ms len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=5 win=5120 rtt=7.6 ms len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=6 win=5120 rtt=7.4 ms len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=9 win=5120 rtt=3.0 ms --- 192.168.0.30 hping statistic --- 10 packets transmitted, 5 packets received, 50% packet loss round-trip min/avg/max = 3.0/205.9/1003.8 ms不幸的是,从 hping3 的输出中,我们可以看到,跟前面现象一样,还是 50% 的丢包;RTT 的波动也仍旧很大,从 3ms 到 1s。
网络层和传输层
我们知道,在网络层和传输层中,引发丢包的因素非常多。不过,其实想确认是否丢包,是非常简单的事,因为 Linux 已经为我们提供了各个协议的收发汇总情况。
我们继续在容器终端中,执行下面的 netstat -s 命令,就可以看到协议的收发汇总,以及错误信息了:
root@nginx:/# netstat -s Ip: Forwarding: 1 // 开启转发 31 total packets received // 总收包数 0 forwarded // 转发包数 0 incoming packets discarded // 接收丢包数 25 incoming packets delivered // 接收的数据包数 15 requests sent out // 发出的数据包数 Icmp: 0 ICMP messages received // 收到的 ICMP 包数 0 input ICMP message failed // 收到 ICMP 失败数 ICMP input histogram: 0 ICMP messages sent //ICMP 发送数 0 ICMP messages failed //ICMP 失败数 ICMP output histogram: Tcp: 0 active connection openings // 主动连接数 0 passive connection openings // 被动连接数 11 failed connection attempts // 失败连接尝试数 0 connection resets received // 接收的连接重置数 0 connections established // 建立连接数 25 segments received // 已接收报文数 21 segments sent out // 已发送报文数 4 segments retransmitted // 重传报文数 0 bad segments received // 错误报文数 0 resets sent // 发出的连接重置数 Udp: 0 packets received ... TcpExt: 11 resets received for embryonic SYN_RECV sockets // 半连接重置数 0 packet headers predicted TCPTimeouts: 7 // 超时数 TCPSynRetrans: 4 //SYN 重传数 ...netstat 汇总了 IP、ICMP、TCP、UDP 等各种协议的收发统计信息。不过,我们的目的是排查丢包问题,所以这里主要观察的是错误数、丢包数以及重传数。
根据上面的输出,你可以看到,只有 TCP 协议发生了丢包和重传,分别是:
- 11 次连接失败重试(11 failed connection attempts)
- 4 次重传(4 segments retransmitted)
- 11 次半连接重置(11 resets received for embryonic SYN_RECV sockets)
- 4 次 SYN 重传(TCPSynRetrans)
7 次超时(TCPTimeouts)
不过,虽然在这儿看到了这么多失败,但具体失败的根源还是无法确定。所以,我们还需要继续顺着协议栈来分析。
48 | 案例篇:服务器总是时不时丢包,我该怎么办?(下)
48.1 iptables
由于连接跟踪在 Linux 内核中是全局的(不属于网络命名空间),我们需要退出容器终端,回到主机中来查看。
在容器终端中,执行 exit ;然后执行下面的命令,查看连接跟踪数:
# 容器终端中执行 exit
root@nginx:/# exit
exit
# 主机终端中查询内核配置
$ sysctl net.netfilter.nf_conntrack_max
net.netfilter.nf_conntrack_max = 262144
$ sysctl net.netfilter.nf_conntrack_count
net.netfilter.nf_conntrack_count = 182从这儿你可以看到,连接跟踪数只有 182,而最大连接跟踪数则是 262144。显然,这里的丢包,不可能是连接跟踪导致的。
可以通过 iptables -nvL 命令,查看各条规则的统计信息。比如,你可以执行下面的 docker exec 命令,进入容器终端;然后再执行下面的 iptables 命令,就可以看到 filter 表的统计数据了:
# 在主机中执行
$ docker exec -it nginx bash
# 在容器中执行
root@nginx:/# iptables -t filter -nvL
Chain INPUT (policy ACCEPT 25 packets, 1000 bytes)
pkts bytes target prot opt in out source destination
6 240 DROP all -- * * 0.0.0.0/0 0.0.0.0/0 statistic mode random probability 0.29999999981
Chain FORWARD (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain OUTPUT (policy ACCEPT 15 packets, 660 bytes)
pkts bytes target prot opt in out source destination
6 264 DROP all -- * * 0.0.0.0/0 0.0.0.0/0 statistic mode random probability 0.29999999981从 iptables 的输出中,你可以看到,两条 DROP 规则的统计数值不是 0,它们分别在 INPUT 和 OUTPUT 链中。这两条规则实际上是一样的,指的是使用 statistic 模块,进行随机 30% 的丢包。
再观察一下它们的匹配规则。0.0.0.0/0 表示匹配所有的源 IP 和目的 IP,也就是会对所有包都进行随机 30% 的丢包。看起来,这应该就是导致部分丢包的”罪魁祸首”了。
既然找出了原因,接下来的优化就比较简单了。比如,把这两条规则直接删除就可以了。我们可以在容器终端中,执行下面的两条 iptables 命令,删除这两条 DROP 规则:
root@nginx:/# iptables -t filter -D INPUT -m statistic --mode random --probability 0.30 -j DROP
root@nginx:/# iptables -t filter -D OUTPUT -m statistic --mode random --probability 0.30 -j DROP删除后,问题是否就被解决了呢?我们可以切换到终端二中,重新执行刚才的 hping3 命令,看看现在是否正常:
$ hping3 -c 10 -S -p 80 192.168.0.30
HPING 192.168.0.30 (eth0 192.168.0.30): S set, 40 headers + 0 data bytes
len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=0 win=5120 rtt=11.9 ms
len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=1 win=5120 rtt=7.8 ms
...
len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=9 win=5120 rtt=15.0 ms
--- 192.168.0.30 hping statistic ---
10 packets transmitted, 10 packets received, 0% packet loss
round-trip min/avg/max = 3.3/7.9/15.0 ms这次输出你可以看到,现在已经没有丢包了,并且延迟的波动变化也很小。看来,丢包问题应该已经解决了。
不过,到目前为止,我们一直使用的 hping3 工具,只能验证案例 Nginx 的 80 端口处于正常监听状态,却还没有访问 Nginx 的 HTTP 服务。所以,不要匆忙下结论结束这次优化,我们还需要进一步确认,Nginx 能不能正常响应 HTTP 请求。
我们继续在终端二中,执行如下的 curl 命令,检查 Nginx 对 HTTP 请求的响应:
$ curl --max-time 3 http://192.168.0.30
curl: (28) Operation timed out after 3000 milliseconds with 0 bytes received从 curl 的输出中,你可以发现,这次连接超时了。可是,刚才我们明明用 hping3 验证了端口正常,现在却发现 HTTP 连接超时,是不是因为 Nginx 突然异常退出了呢?
48.2 tcpdump
在容器终端中,执行下面的 tcpdump 命令,抓取 80 端口的包:
root@nginx:/# tcpdump -i eth0 -nn port 80
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes然后,切换到终端二中,再次执行前面的 curl 命令:
$ curl --max-time 3 http://192.168.0.30/
curl: (28) Operation timed out after 3000 milliseconds with 0 bytes received等到 curl 命令结束后,再次切换回终端一,查看 tcpdump 的输出:
14:40:00.589235 IP 10.255.255.5.39058 > 172.17.0.2.80: Flags [S], seq 332257715, win 29200, options [mss 1418,sackOK,TS val 486800541 ecr 0,nop,wscale 7], length 0
14:40:00.589277 IP 172.17.0.2.80 > 10.255.255.5.39058: Flags [S.], seq 1630206251, ack 332257716, win 4880, options [mss 256,sackOK,TS val 2509376001 ecr 486800541,nop,wscale 7], length 0
14:40:00.589894 IP 10.255.255.5.39058 > 172.17.0.2.80: Flags [.], ack 1, win 229, options [nop,nop,TS val 486800541 ecr 2509376001], length 0
14:40:03.589352 IP 10.255.255.5.39058 > 172.17.0.2.80: Flags [F.], seq 76, ack 1, win 229, options [nop,nop,TS val 486803541 ecr 2509376001], length 0
14:40:03.589417 IP 172.17.0.2.80 > 10.255.255.5.39058: Flags [.], ack 1, win 40, options [nop,nop,TS val 2509379001 ecr 486800541,nop,nop,sack 1 {76:77}], length 0经过这么一系列的操作,从 tcpdump 的输出中,我们就可以看到:
- 前三个包是正常的 TCP 三次握手,这没问题;
- 但第四个包却是在 3 秒以后了,并且还是客户端(VM2)发送过来的 FIN 包,也就说明,客户端的连接关闭了。
我想,根据 curl 设置的 3 秒超时选项,你应该能猜到,这是因为 curl 命令超时后退出了。
我们可以重新执行 netstat -i 命令,确认一下网卡有没有丢包问题:
root@nginx:/# netstat -i
Kernel Interface table
Iface MTU RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
eth0 100 157 0 344 0 94 0 0 0 BMRU
lo 65536 0 0 0 0 0 0 0 0 LRU从 netstat 的输出中,你可以看到,接收丢包数(RX-DRP)是 344,果然是在网卡接收时丢包了。不过问题也来了,为什么刚才用 hping3 时不丢包,现在换成 GET 就收不到了呢?
还是那句话,遇到搞不懂的现象,不妨先去查查工具和方法的原理。我们可以对比一下这两个工具:
- hping3 实际上只发送了 SYN 包;
- 而 curl 在发送 SYN 包后,还会发送 HTTP GET 请求。
HTTP GET ,本质上也是一个 TCP 包,但跟 SYN 包相比,它还携带了 HTTP GET 的数据。
那么,通过这个对比,你应该想到了,这可能是 MTU 配置错误导致的。为什么呢?
其实,仔细观察上面 netstat 的输出界面,第二列正是每个网卡的 MTU 值。eth0 的 MTU 只有 100,而以太网的 MTU 默认值是 1500,这个 100 就显得太小了。
当然,MTU 问题是很好解决的,把它改成 1500 就可以了。我们继续在容器终端中,执行下面的命令,把容器 eth0 的 MTU 改成 1500:
root@nginx:/# ifconfig eth0 mtu 1500修改完成后,再切换到终端二中,再次执行 curl 命令,确认问题是否真的解决了:
$ curl --max-time 3 http://192.168.0.30/
<!DOCTYPE html>
<html>
...
<p><em>Thank you for using nginx.</em></p>
</body>49 | 案例篇:内核线程 CPU 利用率太高,我该怎么办?
49.1 内核线程
在 Linux 中,用户态进程的”祖先”,都是 PID 号为 1 的 init 进程。比如,现在主流的 Linux 发行版中,init 都是 systemd 进程;而其他的用户态进程,会通过 systemd 来进行管理。
实际上,Linux 在启动过程中,有三个特殊的进程,也就是 PID 号最小的三个进程。
- 0 号进程为 idle 进程,这也是系统创建的第一个进程,它在初始化 1 号和 2 号进程后,演变为空闲任务。当 CPU 上没有其他任务执行时,就会运行它。
- 1 号进程为 init 进程,通常是 systemd 进程,在用户态运行,用来管理其他用户态进程。
- 2 号进程为 kthreadd 进程,在内核态运行,用来管理内核线程。
所以,要查找内核线程,我们只需要从 2 号进程开始,查找它的子孙进程即可。比如,你可以使用 ps 命令,来查找 kthreadd 的子进程:
$ ps -f --ppid 2 -p 2
UID PID PPID C STIME TTY TIME CMD
root 2 0 0 12:02 ? 00:00:01 [kthreadd]
root 9 2 0 12:02 ? 00:00:21 [ksoftirqd/0]
root 10 2 0 12:02 ? 00:11:47 [rcu_sched]
root 11 2 0 12:02 ? 00:00:18 [migration/0]
...
root 11094 2 0 14:20 ? 00:00:00 [kworker/1:0-eve]
root 11647 2 0 14:27 ? 00:00:00 [kworker/0:2-cgr]从上面的输出,你能够看到,内核线程的名称(CMD)都在中括号里(这一点,我们前面内容也有提到过)。所以,更简单的方法,就是直接查找名称包含中括号的进程。比如:
$ ps -ef | grep "\[.*\]"
root 2 0 0 08:14 ? 00:00:00 [kthreadd]
root 3 2 0 08:14 ? 00:00:00 [rcu_gp]
root 4 2 0 08:14 ? 00:00:00 [rcu_par_gp]
...除了刚才看到的 kthreadd 和 ksoftirqd 外,还有很多常见的内核线程,我们在性能分析中都经常会碰到,比如下面这几个内核线程。
- kswapd0:用于内存回收。在 Swap 变高 案例中,我曾介绍过它的工作原理。
- kworker:用于执行内核工作队列,分为绑定 CPU (名称格式为 kworker/CPU86330)和未绑定 CPU(名称格式为 kworker/uPOOL86330)两类。
- migration:在负载均衡过程中,把进程迁移到 CPU 上。每个 CPU 都有一个 migration 内核线程。
- jbd2/sda1-8:jbd 是 Journaling Block Device 的缩写,用来为文件系统提供日志功能,以保证数据的完整性;名称中的 sda1-8,表示磁盘分区名称和设备号。每个使用了 ext4 文件系统的磁盘分区,都会有一个 jbd2 内核线程。
- pdflush:用于将内存中的脏页(被修改过,但还未写入磁盘的文件页)写入磁盘(已经在 3.10 中合并入了 kworker 中)。
49.2 案例
机器配置: 2 CPU, 8 GB 内存。
安装软件:
apt install docker.io linux-tools-common hping3。
打开两个终端,分别登录两台虚拟机。
在第一个终端,执行下面的命令运行案例,也就是一个最基本的 Nginx 应用:
# 运行 Nginx 服务并对外开放 80 端口 $ docker run -itd --name=nginx -p 80:80 nginx在第二个终端,使用 curl 访问 Nginx 监听的端口,确认 Nginx 正常启动。假设 192.168.0.30 是 Nginx 所在虚拟机的 IP 地址,运行 curl 命令后,你应该会看到下面这个输出界面:
$ curl http://192.168.0.30/ <!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> ...在第二个终端中,运行 hping3 命令,模拟 Nginx 的客户端请求:
# -S 参数表示设置 TCP 协议的 SYN(同步序列号),-p 表示目的端口为 80 # -i u10 表示每隔 10 微秒发送一个网络帧 # 注:如果你在实践过程中现象不明显,可以尝试把 10 调小,比如调成 5 甚至 1 $ hping3 -S -p 80 -i u10 192.168.0.30回到第一个终端,你应该就会发现异常——系统的响应明显变慢了。我们不妨执行 top,观察一下系统和进程的 CPU 使用情况:
$ top top - 08:31:43 up 17 min, 1 user, load average: 0.00, 0.00, 0.02 Tasks: 128 total, 1 running, 69 sleeping, 0 stopped, 0 zombie %Cpu0 : 0.3 us, 0.3 sy, 0.0 ni, 66.8 id, 0.3 wa, 0.0 hi, 32.4 si, 0.0 st %Cpu1 : 0.0 us, 0.3 sy, 0.0 ni, 65.2 id, 0.0 wa, 0.0 hi, 34.5 si, 0.0 st KiB Mem : 8167040 total, 7234236 free, 358976 used, 573828 buff/cache KiB Swap: 0 total, 0 free, 0 used. 7560460 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 9 root 20 0 0 0 0 S 7.0 0.0 0:00.48 ksoftirqd/0 18 root 20 0 0 0 0 S 6.9 0.0 0:00.56 ksoftirqd/1 2489 root 20 0 876896 38408 21520 S 0.3 0.5 0:01.50 docker-containe 3008 root 20 0 44536 3936 3304 R 0.3 0.0 0:00.09 top 1 root 20 0 78116 9000 6432 S 0.0 0.1 0:11.77 systemd ...从 top 的输出中,你可以看到,两个 CPU 的软中断使用率都超过了 30%;而 CPU 使用率最高的进程,正好是软中断内核线程 ksoftirqd/0 和 ksoftirqd/1。
虽然,我们已经知道了 ksoftirqd 的基本功能,可以猜测是因为大量网络收发,引起了 CPU 使用率升高;但它到底在执行什么逻辑,我们却并不知道。
对于普通进程,我们要观察其行为有很多方法,比如 strace、pstack、lsof 等等。但这些工具并不适合内核线程,比如,如果你用 pstack ,或者通过 /proc/pid/stack 查看 ksoftirqd/0(进程号为 9)的调用栈时,分别可以得到以下输出:
$ pstack 9 Could not attach to target 9: Operation not permitted. detach: No such process$ cat /proc/9/stack [<0>] smpboot_thread_fn+0x166/0x170 [<0>] kthread+0x121/0x140 [<0>] ret_from_fork+0x35/0x40 [<0>] 0xffffffffffffffff显然,pstack 报出的是不允许挂载进程的错误;而 /proc/9/stack 方式虽然有输出,但输出中并没有详细的调用栈情况。
那还有没有其他方法,来观察内核线程 ksoftirqd 的行为呢?
perf 可以对指定的进程或者事件进行采样,并且还可以用调用栈的形式,输出整个调用链上的汇总信息。 我们不妨就用 perf ,来试着分析一下进程号为 9 的 ksoftirqd。
继续在终端一中,执行下面的 perf record 命令;并指定进程号 9 ,以便记录 ksoftirqd 的行为:
# 采样 30s 后退出 $ perf record -a -g -p 9 -- sleep 30稍等一会儿,在上述命令结束后,继续执行 perf report命令,你就可以得到 perf 的汇总报告。按上下方向键以及回车键,展开比例最高的 ksoftirqd 后,你就可以得到下面这个调用关系链图:
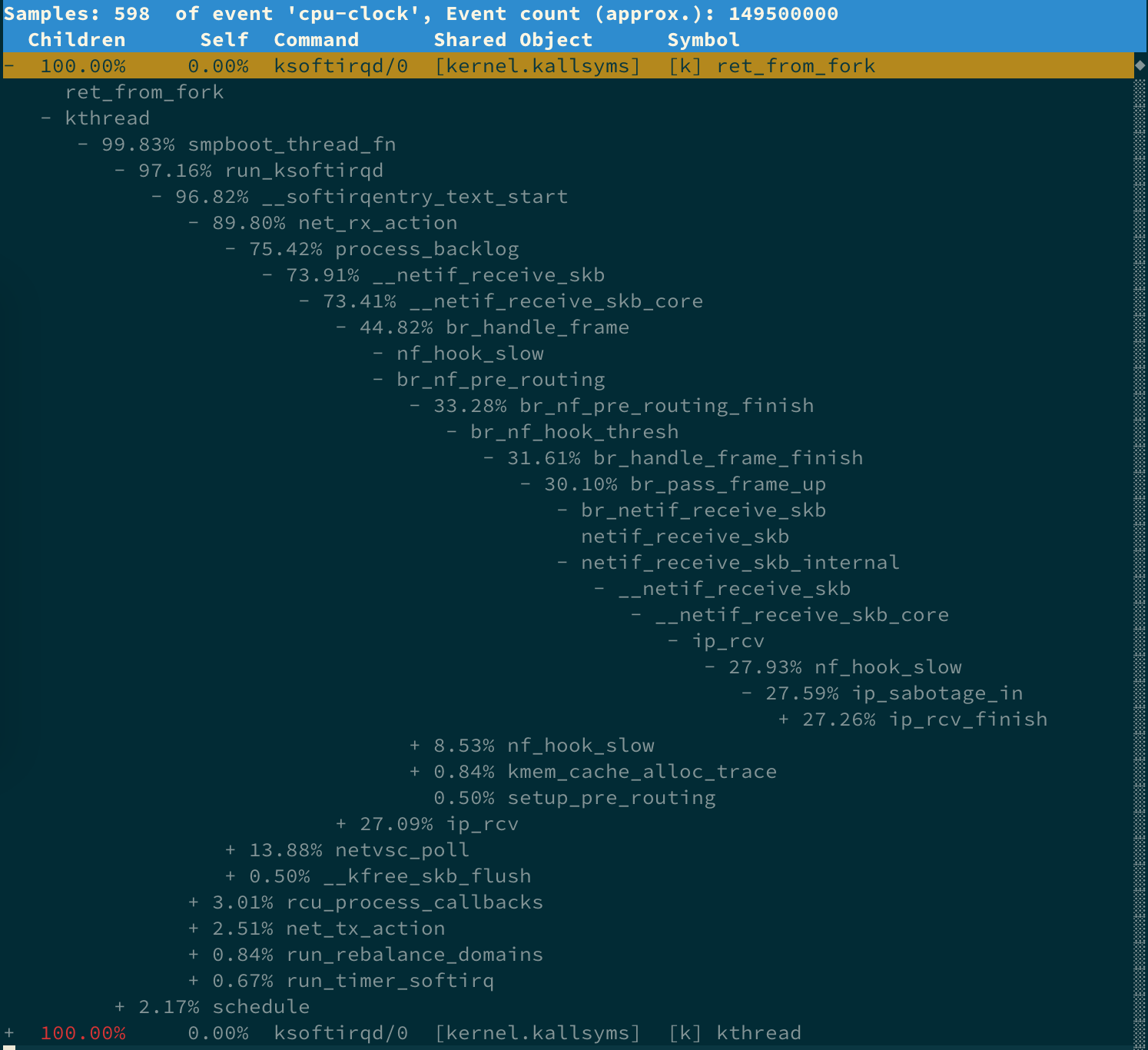
从这个图中,你可以清楚看到 ksoftirqd 执行最多的调用过程。虽然你可能不太熟悉内核源码,但通过这些函数,我们可以大致看出它的调用栈过程。
- net_rx_action 和 netif_receive_skb,表明这是接收网络包(rx 表示 receive)。
- br_handle_frame ,表明网络包经过了网桥(br 表示 bridge)。
- br_nf_pre_routing ,表明在网桥上执行了 netfilter 的 PREROUTING(nf 表示 netfilter)。而我们已经知道 PREROUTING 主要用来执行 DNAT,所以可以猜测这里有 DNAT 发生。
br_pass_frame_up,表明网桥处理后,再交给桥接的其他桥接网卡进一步处理。比如,在新的网卡上接收网络包、执行 netfilter 过滤规则等等。
我们的猜测对不对呢?实际上,我们案例最开始用 Docker 启动了容器,而 Docker 会自动为容器创建虚拟网卡、桥接到 docker0 网桥并配置 NAT 规则。这一过程,如下图所示:
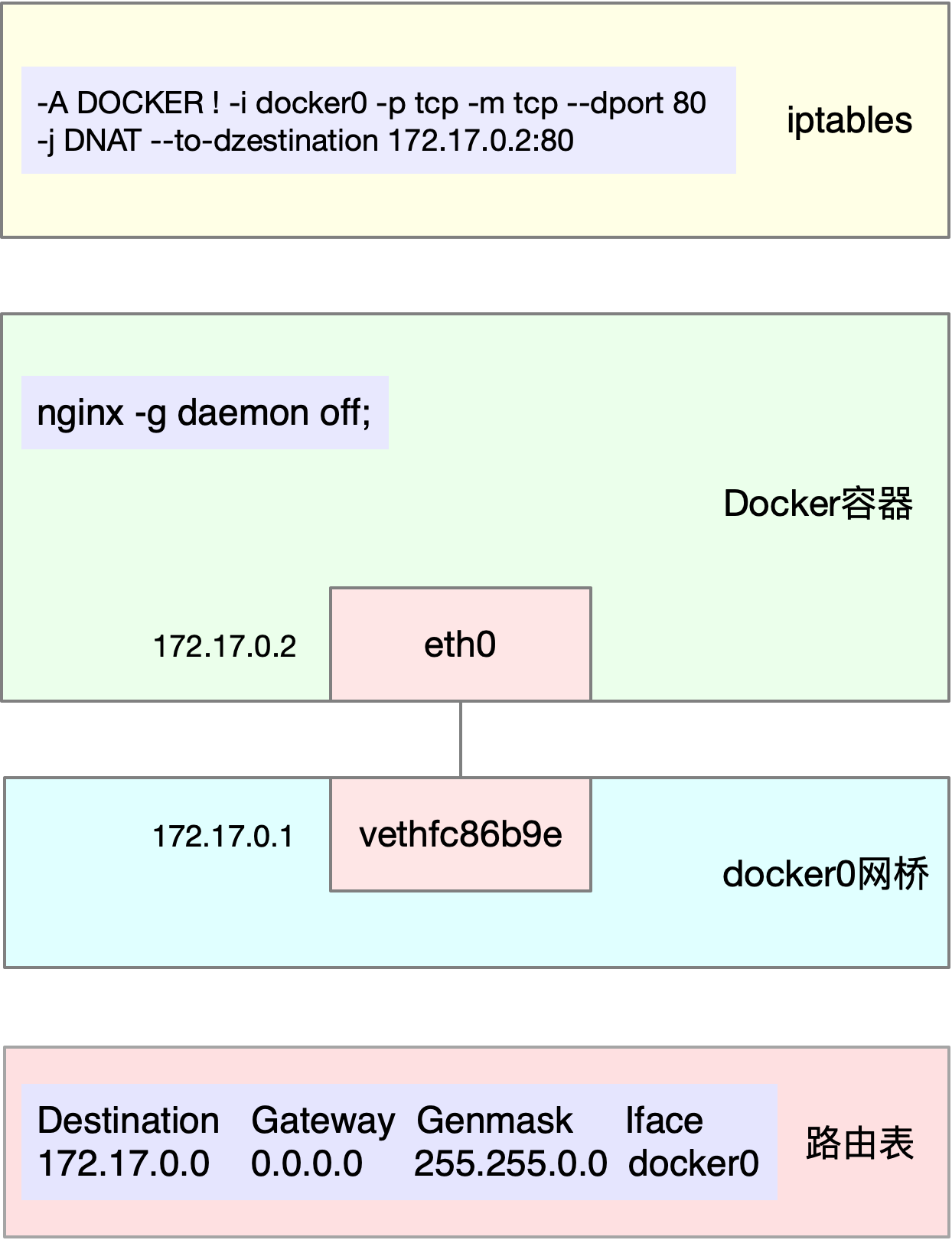
当然了,前面 perf report 界面的调用链还可以继续展开。但很不幸,我的屏幕不够大,如果展开更多的层级,最后几个层级会超出屏幕范围。这样,即使我们能看到大部分的调用过程,却也不能说明后面层级就没问题。
那么,有没有更好的方法,来查看整个调用栈的信息呢?
火焰图
针对 perf 汇总数据的展示问题,Brendan Gragg 发明了火焰图,通过矢量图的形式,更直观展示汇总结果。下图就是一个针对 mysql 的火焰图示例。
图片来自 Brendan Gregg 博客
这张图看起来像是跳动的火焰,因此也就被称为火焰图。要理解火焰图,我们最重要的是区分清楚横轴和纵轴的含义。
- 横轴表示采样数和采样比例。一个函数占用的横轴越宽,就代表它的执行时间越长。同一层的多个函数,则是按照字母来排序。
纵轴表示调用栈,由下往上根据调用关系逐个展开。换句话说,上下相邻的两个函数中,下面的函数,是上面函数的父函数。这样,调用栈越深,纵轴就越高。
另外,要注意图中的颜色,并没有特殊含义,只是用来区分不同的函数。
火焰图是动态的矢量图格式,所以它还支持一些动态特性。比如,鼠标悬停到某个函数上时,就会自动显示这个函数的采样数和采样比例。而当你用鼠标点击函数时,火焰图就会把该层及其上的各层放大,方便你观察这些处于火焰图顶部的调用栈的细节。
上面 mysql 火焰图的示例,就表示了 CPU 的繁忙情况,这种火焰图也被称为 on-CPU 火焰图。如果我们根据性能分析的目标来划分,火焰图可以分为下面这几种。
on-CPU 火焰图:表示 CPU 的繁忙情况,用在 CPU 使用率比较高的场景中。
- off-CPU 火焰图:表示 CPU 等待 I/O、锁等各种资源的阻塞情况。
- 内存火焰图:表示内存的分配和释放情况。
- 热 / 冷火焰图:表示将 on-CPU 和 off-CPU 结合在一起综合展示。
- 差分火焰图:表示两个火焰图的差分情况,红色表示增长,蓝色表示衰减。差分火焰图常用来比较不同场景和不同时期的火焰图,以便分析系统变化前后对性能的影响情况。
火焰图分析
首先,我们需要生成火焰图。我们先下载几个能从 perf record 记录生成火焰图的工具,这些工具都放在 https://github.com/brendangregg/FlameGraph 上面。你可以执行下面的命令来下载:
git clone https://github.com/brendangregg/FlameGraph cd FlameGraph安装好工具后,要生成火焰图,其实主要需要三个步骤:
- 执行 perf script ,将 perf record 的记录转换成可读的采样记录;
- 执行 stackcollapse-perf.pl 脚本,合并调用栈信息;
执行 flamegraph.pl 脚本,生成火焰图。
不过,在 Linux 中,我们可以使用管道,来简化这三个步骤的执行过程。假设刚才用 perf record 生成的文件路径为 /root/perf.data,执行下面的命令,你就可以直接生成火焰图:
perf script -i /root/perf.data | ./stackcollapse-perf.pl --all | ./flamegraph.pl > ksoftirqd.svg执行成功后,使用浏览器打开 ksoftirqd.svg ,你就可以看到生成的火焰图了。如下图所示:
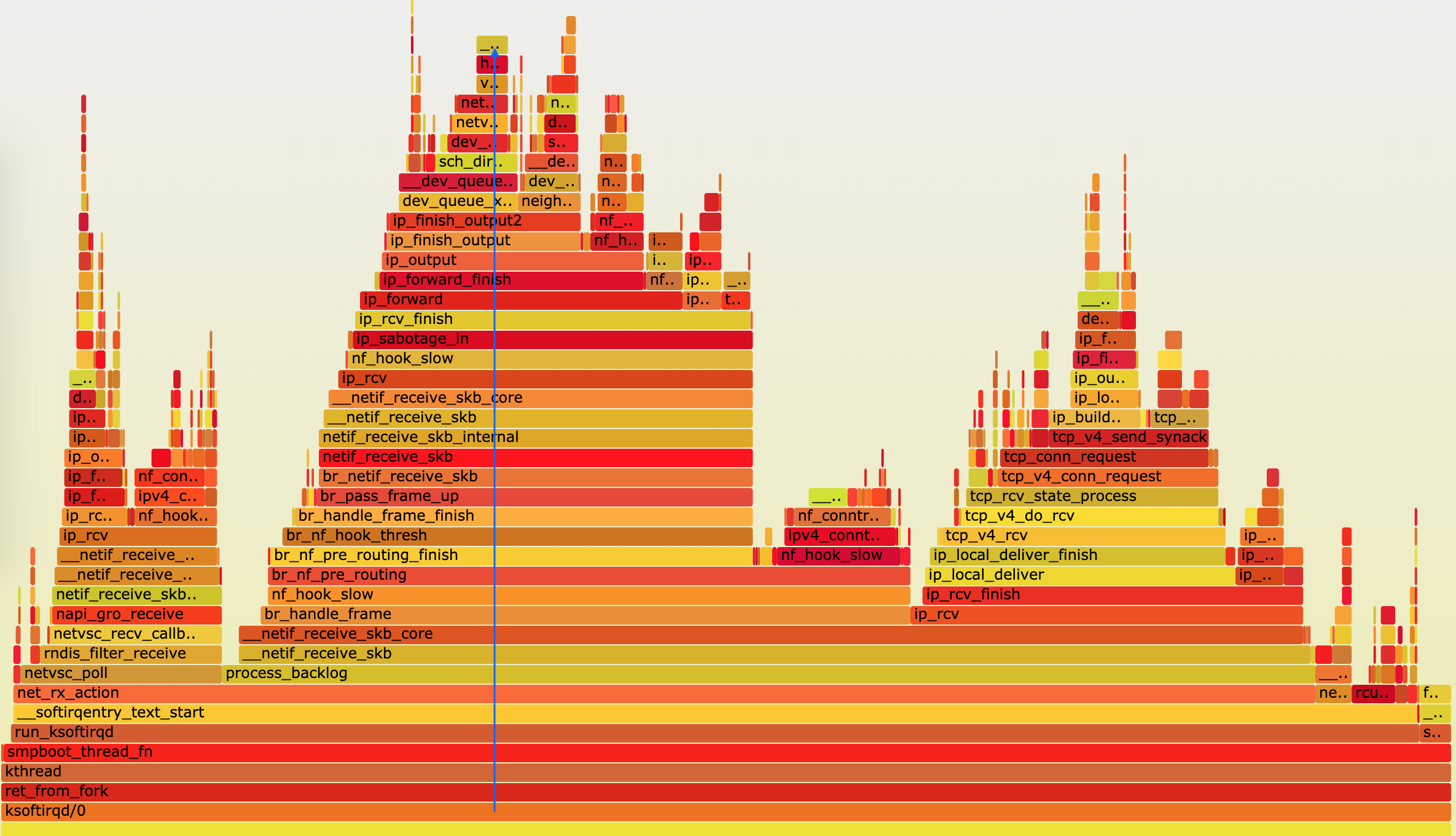
根据刚刚讲过的火焰图原理,这个图应该从下往上看,沿着调用栈中最宽的函数来分析执行次数最多的函数。这儿看到的结果,其实跟刚才的 perf report 类似,但直观了很多,中间这一团火,很明显就是最需要我们关注的地方。
我们顺着调用栈由下往上看(顺着图中蓝色箭头),就可以得到跟刚才 perf report 中一样的结果:
最开始,还是 net_rx_action 到 netif_receive_skb 处理网络收包;
- 然后, br_handle_frame 到 br_nf_pre_routing ,在网桥中接收并执行 netfilter 钩子函数;
再向上, br_pass_frame_up 到 netif_receive_skb ,从网桥转到其他网络设备又一次接收。
不过最后,到了 ip_forward 这里,已经看不清函数名称了。所以我们需要点击 ip_forward,展开最上面这一块调用栈:
这样,就可以进一步看到 ip_forward 后的行为,也就是把网络包发送出去。根据这个调用过程,再结合我们前面学习的网络收发和 TCP/IP 协议栈原理,这个流程中的网络接收、网桥以及 netfilter 调用等,都是导致软中断 CPU 升高的重要因素,也就是影响网络性能的潜在瓶颈。
不过,回想一下网络收发的流程,你可能会觉得它缺了好多步骤。
比如,这个堆栈中并没有 TCP 相关的调用,也没有连接跟踪 conntrack 相关的函数。实际上,这些流程都在其他更小的火焰中,你可以点击上图左上角的”Reset Zoom”,回到完整火焰图中,再去查看其他小火焰的堆栈。
所以,在理解这个调用栈时要注意。从任何一个点出发、纵向来看的整个调用栈,其实只是最顶端那一个函数的调用堆栈,而非完整的内核网络执行流程。
另外,整个火焰图不包含任何时间的因素,所以并不能看出横向各个函数的执行次序。
到这里,我们就找出了内核线程 ksoftirqd 执行最频繁的函数调用堆栈,而这个堆栈中的各层级函数,就是潜在的性能瓶颈来源。这样,后面想要进一步分析、优化时,也就有了根据。
50 | 案例篇:动态追踪怎么用?(上)
动态追踪技术,通过探针机制,来采集内核或者应用程序的运行信息,从而可以不用修改内核和应用程序的代码,就获得丰富的信息,帮你分析、定位想要排查的问题。
以往,在排查和调试性能问题时,我们往往需要先为应用程序设置一系列的断点(比如使用 GDB),然后以手动或者脚本(比如 GDB 的 Python 扩展)的方式,在这些断点处分析应用程序的状态。或者,增加一系列的日志,从日志中寻找线索。
不过,断点往往会中断应用的正常运行;而增加新的日志,往往需要重新编译和部署。这些方法虽然在今天依然广泛使用,但在排查复杂的性能问题时,往往耗时耗力,更会对应用的正常运行造成巨大影响。
此外,这类方式还有大量的性能问题。比如,出现的概率小,只有线上环境才能碰到。这种难以复现的问题,亦是一个巨大挑战。
而动态追踪技术的出现,就为这些问题提供了完美的方案:它既不需要停止服务,也不需要修改应用程序的代码;所有一切还按照原来的方式正常运行时,就可以帮你分析出问题的根源。
同时,相比以往的进程级跟踪方法(比如 ptrace),动态追踪往往只会带来很小的性能损耗(通常在 5% 或者更少)。
既然动态追踪有这么多好处,那么,都有哪些动态追踪的方法,又该如何使用这些动态追踪方法呢?今天,我就带你一起来看看这个问题。由于动态追踪涉及的知识比较多,我将分为上、下两篇为你讲解,先来看今天这部分内容。
50.1 动态追踪
说到动态追踪(Dynamic Tracing),就不得不提源于 Solaris 系统的 DTrace。DTrace 是动态追踪技术的鼻祖,它提供了一个通用的观测框架,并可以使用 D 语言进行自由扩展。
DTrace 的工作原理如下图所示。它的运行常驻在内核中,用户可以通过 dtrace 命令,把 D 语言编写的追踪脚本,提交到内核中的运行时来执行。DTrace 可以跟踪用户态和内核态的所有事件,并通过一些列的优化措施,保证最小的性能开销。
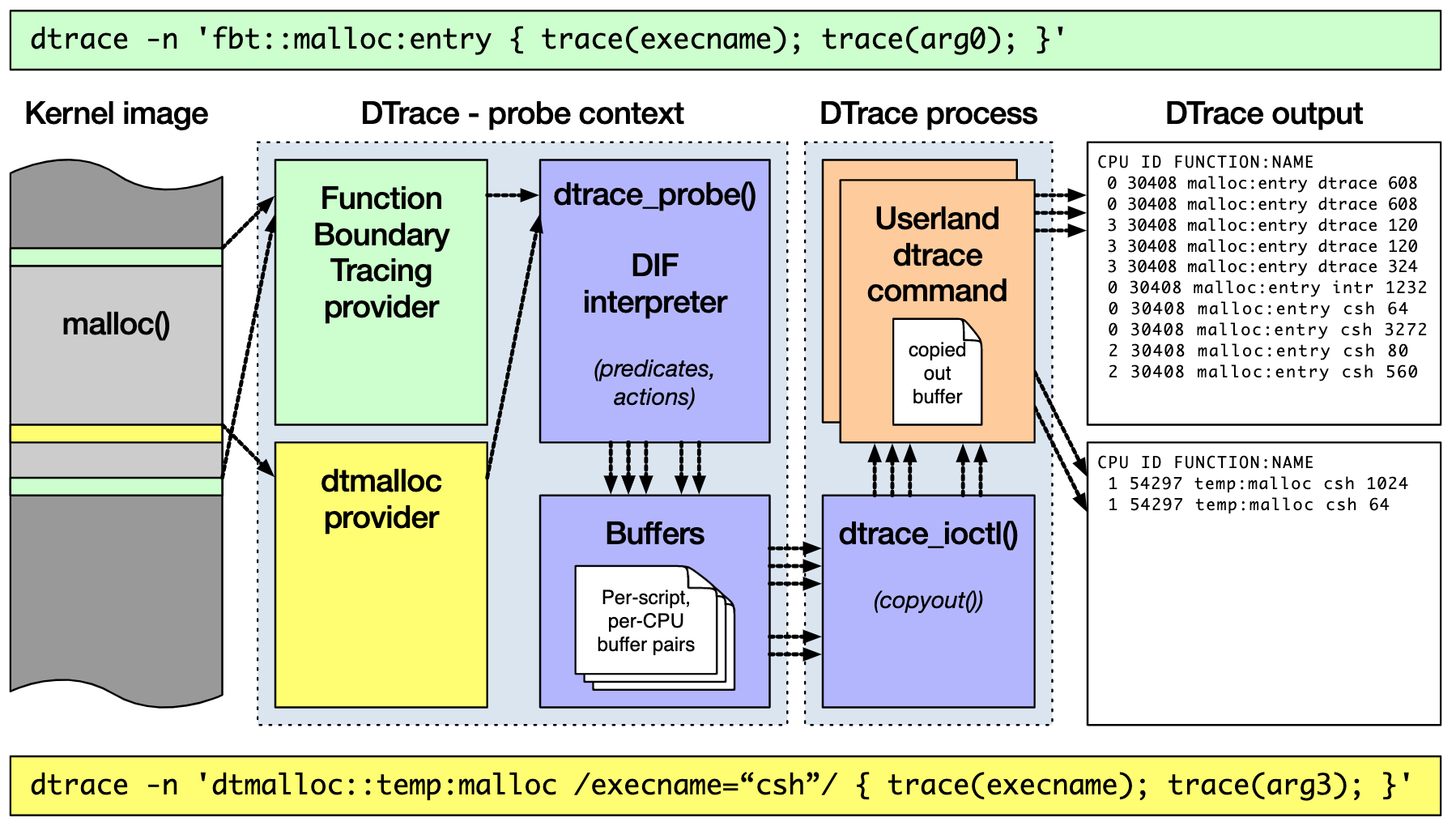
图片来自 BSDCan
虽然直到今天,DTrace 本身依然无法在 Linux 中运行,但它同样对 Linux 动态追踪产生了巨大的影响。很多工程师都尝试过把 DTrace 移植到 Linux 中,这其中,最著名的就是 RedHat 主推的 SystemTap。
同 DTrace 一样,SystemTap 也定义了一种类似的脚本语言,方便用户根据需要自由扩展。不过,不同于 DTrace,SystemTap 并没有常驻内核的运行时,它需要先把脚本编译为内核模块,然后再插入到内核中执行。这也导致 SystemTap 启动比较缓慢,并且依赖于完整的调试符号表。
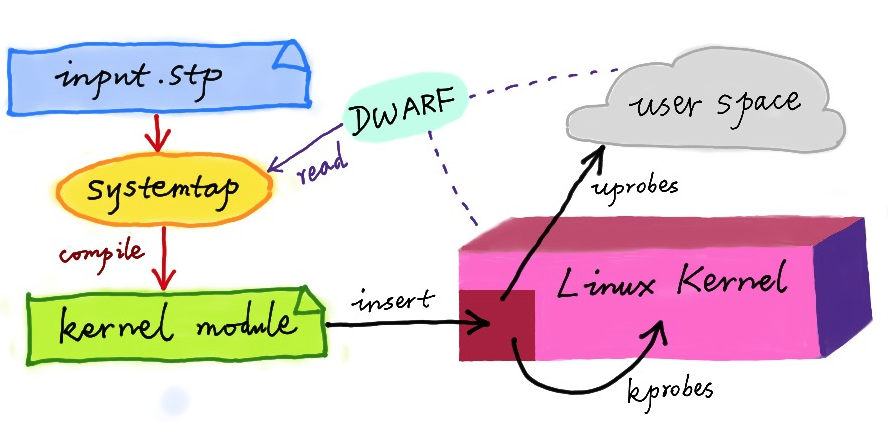
图片来自动态追踪技术漫谈
总的来说,为了追踪内核或用户空间的事件,Dtrace 和 SystemTap 都会把用户传入的追踪处理函数(一般称为 Action),关联到被称为探针的检测点上。这些探针,实际上也就是各种动态追踪技术所依赖的事件源。
50.2 动态追踪的事件源
根据事件类型的不同,动态追踪所使用的事件源,可以分为静态探针、动态探针以及硬件事件等三类。它们的关系如下图所示:
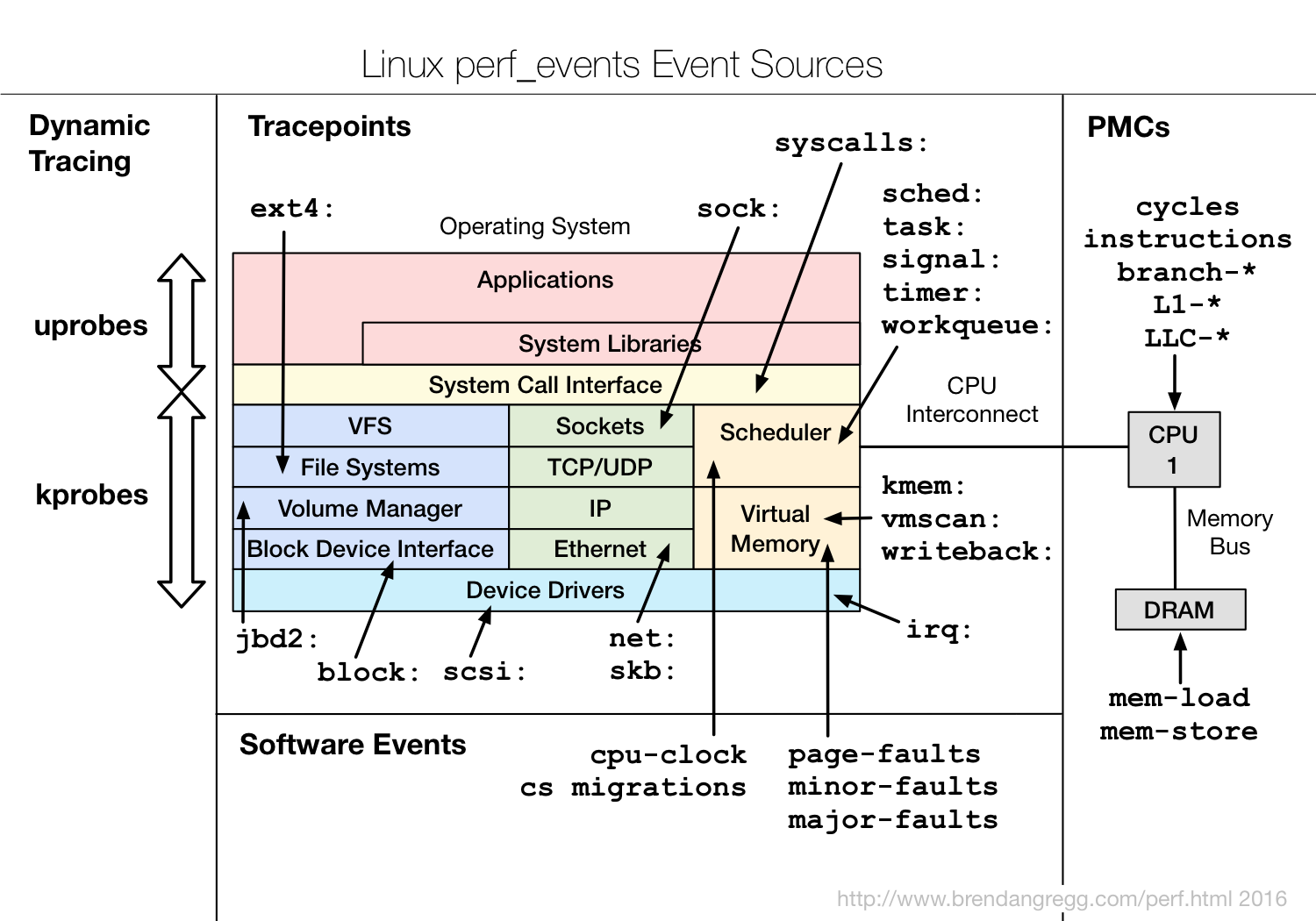
图片来自 Brendan Gregg Blog
其中,硬件事件通常由性能监控计数器 PMC(Performance Monitoring Counter)产生,包括了各种硬件的性能情况,比如 CPU 的缓存、指令周期、分支预测等等。
静态探针,是指事先在代码中定义好,并编译到应用程序或者内核中的探针。这些探针只有在开启探测功能时,才会被执行到;未开启时并不会执行。常见的静态探针包括内核中的跟踪点(tracepoints)和 USDT(Userland Statically Defined Tracing)探针。
跟踪点(tracepoints),实际上就是在源码中插入的一些带有控制条件的探测点,这些探测点允许事后再添加处理函数。比如在内核中,最常见的静态跟踪方法就是 printk,即输出日志。Linux 内核定义了大量的跟踪点,可以通过内核编译选项,来开启或者关闭。
USDT 探针,全称是用户级静态定义跟踪,需要在源码中插入 DTRACE_PROBE() 代码,并编译到应用程序中。不过,也有很多应用程序内置了 USDT 探针,比如 MySQL、PostgreSQL 等。
动态探针,则是指没有事先在代码中定义,但却可以在运行时动态添加的探针,比如函数的调用和返回等。动态探针支持按需在内核或者应用程序中添加探测点,具有更高的灵活性。常见的动态探针有两种,即用于内核态的 kprobes 和用于用户态的 uprobes。
- kprobes 用来跟踪内核态的函数,包括用于函数调用的 kprobe 和用于函数返回的 kretprobe。
- uprobes 用来跟踪用户态的函数,包括用于函数调用的 uprobe 和用于函数返回的 uretprobe。
注意,kprobes 需要内核编译时开启 CONFIG_KPROBE_EVENTS;而 uprobes 则需要内核编译时开启 CONFIG_UPROBE_EVENTS。
50.3 动态追踪机制
而在这些探针的基础上,Linux 也提供了一系列的动态追踪机制,比如 ftrace、perf、eBPF 等。
ftrace 最早用于函数跟踪,后来又扩展支持了各种事件跟踪功能。ftrace 的使用接口跟我们之前提到的 procfs 类似,它通过 debugfs(4.1 以后也支持 tracefs),以普通文件的形式,向用户空间提供访问接口。
这样,不需要额外的工具,你就可以通过挂载点(通常为 /sys/kernel/debug/tracing 目录)内的文件读写,来跟 ftrace 交互,跟踪内核或者应用程序的运行事件。
perf 是我们的老朋友了,我们在前面的好多案例中,都使用了它的事件记录和分析功能,这实际上只是一种最简单的静态跟踪机制。你也可以通过 perf ,来自定义动态事件(perf probe),只关注真正感兴趣的事件。
eBPF 则在 BPF(Berkeley Packet Filter)的基础上扩展而来,不仅支持事件跟踪机制,还可以通过自定义的 BPF 代码(使用 C 语言)来自由扩展。所以,eBPF 实际上就是常驻于内核的运行时,可以说就是 Linux 版的 DTrace。
除此之外,还有很多内核外的工具,也提供了丰富的动态追踪功能。最常见的就是前面提到的 SystemTap,我们之前多次使用过的 BCC(BPF Compiler Collection),以及常用于容器性能分析的 sysdig 等。
而在分析大量事件时,使用我们上节课提到的火焰图,可以将大量数据可视化展示,让你更直观发现潜在的问题。
接下来,我就通过几个例子,带你来看看,要怎么使用这些机制,来动态追踪内核和应用程序的执行情况。以下案例还是基于 Ubuntu 18.04 系统,同样适用于其他系统。
50.4 ftrace
我们先来看 ftrace。刚刚提到过,ftrace 通过 debugfs(或者 tracefs),为用户空间提供接口。所以使用 ftrace,往往是从切换到 debugfs 的挂载点开始。
$ cd /sys/kernel/debug/tracing
$ ls
README instances set_ftrace_notrace trace_marker_raw
available_events kprobe_events set_ftrace_pid trace_options
...如果这个目录不存在,则说明你的系统还没有挂载 debugfs,你可以执行下面的命令来挂载它:
mount -t debugfs nodev /sys/kernel/debugftrace 提供了多个跟踪器,用于跟踪不同类型的信息,比如函数调用、中断关闭、进程调度等。具体支持的跟踪器取决于系统配置,你可以执行下面的命令,来查询所有支持的跟踪器:
$ cat available_tracers
hwlat blk mmiotrace function_graph wakeup_dl wakeup_rt wakeup function nop这其中,function 表示跟踪函数的执行,function_graph 则是跟踪函数的调用关系,也就是生成直观的调用关系图。这便是最常用的两种跟踪器。
除了跟踪器外,使用 ftrace 前,还需要确认跟踪目标,包括内核函数和内核事件。其中,
- 函数就是内核中的函数名。
- 而事件,则是内核源码中预先定义的跟踪点。
同样地,你可以执行下面的命令,来查询支持的函数和事件:
cat available_filter_functions
cat available_events明白了这些基本信息,接下来,我就以 ls 命令为例,带你一起看看 ftrace 的使用方法。
为了列出文件,ls 命令会通过 open 系统调用打开目录文件,而 open 在内核中对应的函数名为 do_sys_open。 所以,我们要做的第一步,就是把要跟踪的函数设置为 do_sys_open:
echo do_sys_open > set_graph_function接下来,第二步,配置跟踪选项,开启函数调用跟踪,并跟踪调用进程:
echo function_graph > current_tracer
echo funcgraph-proc > trace_options接着,第三步,也就是开启跟踪:
$ echo 1 > tracing_on
第四步,执行一个 ls 命令后,再关闭跟踪:
ls
echo 0 > tracing_on第五步,也是最后一步,查看跟踪结果:
$ cat trace
# tracer: function_graph
#
# CPU TASK/PID DURATION FUNCTION CALLS
# | | | | | | | | |
0) ls-12276 | | do_sys_open() {
0) ls-12276 | | getname() {
0) ls-12276 | | getname_flags() {
0) ls-12276 | | kmem_cache_alloc() {
0) ls-12276 | | _cond_resched() {
0) ls-12276 | 0.049 us | rcu_all_qs();
0) ls-12276 | 0.791 us | }
0) ls-12276 | 0.041 us | should_failslab();
0) ls-12276 | 0.040 us | prefetch_freepointer();
0) ls-12276 | 0.039 us | memcg_kmem_put_cache();
0) ls-12276 | 2.895 us | }
0) ls-12276 | | __check_object_size() {
0) ls-12276 | 0.067 us | __virt_addr_valid();
0) ls-12276 | 0.044 us | __check_heap_object();
0) ls-12276 | 0.039 us | check_stack_object();
0) ls-12276 | 1.570 us | }
0) ls-12276 | 5.790 us | }
0) ls-12276 | 6.325 us | }
...在最后得到的输出中:
- 第一列表示运行的 CPU;
- 第二列是任务名称和进程 PID;
- 第三列是函数执行延迟;
- 最后一列,则是函数调用关系图。
当然,我想你应该也发现了 ftrace 的使用缺点——五个步骤实在是麻烦,用起来并不方便。不过,不用担心, trace-cmd 已经帮你把这些步骤给包装了起来。这样,你就可以在同一个命令行工具里,完成上述所有过程。
安装好后,原本的五步跟踪过程,就可以简化为下面这两步:
$ trace-cmd record -p function_graph -g do_sys_open -O funcgraph-proc ls
$ trace-cmd report
...
ls-12418 [000] 85558.075341: funcgraph_entry: | do_sys_open() {
ls-12418 [000] 85558.075363: funcgraph_entry: | getname() {
ls-12418 [000] 85558.075364: funcgraph_entry: | getname_flags() {
ls-12418 [000] 85558.075364: funcgraph_entry: | kmem_cache_alloc() {
ls-12418 [000] 85558.075365: funcgraph_entry: | _cond_resched() {
ls-12418 [000] 85558.075365: funcgraph_entry: 0.074 us | rcu_all_qs();
ls-12418 [000] 85558.075366: funcgraph_exit: 1.143 us | }
ls-12418 [000] 85558.075366: funcgraph_entry: 0.064 us | should_failslab();
ls-12418 [000] 85558.075367: funcgraph_entry: 0.075 us | prefetch_freepointer();
ls-12418 [000] 85558.075368: funcgraph_entry: 0.085 us | memcg_kmem_put_cache();
ls-12418 [000] 85558.075369: funcgraph_exit: 4.447 us | }
ls-12418 [000] 85558.075369: funcgraph_entry: | __check_object_size() {
ls-12418 [000] 85558.075370: funcgraph_entry: 0.132 us | __virt_addr_valid();
ls-12418 [000] 85558.075370: funcgraph_entry: 0.093 us | __check_heap_object();
ls-12418 [000] 85558.075371: funcgraph_entry: 0.059 us | check_stack_object();
ls-12418 [000] 85558.075372: funcgraph_exit: 2.323 us | }
ls-12418 [000] 85558.075372: funcgraph_exit: 8.411 us | }
ls-12418 [000] 85558.075373: funcgraph_exit: 9.195 us | }
...你会发现,trace-cmd 的输出,跟上述 cat trace 的输出是类似的。
通过这个例子我们知道,当你想要了解某个内核函数的调用过程时,使用 ftrace ,就可以跟踪到它的执行过程。
50.5 留言
Exploring USDT Probes on Linux
51 | 案例篇:动态追踪怎么用?(下)
51.1 perf
前面使用 perf record/top 时,都是先对事件进行采样,然后再根据采样数,评估各个函数的调用频率。实际上,perf 的功能远不止于此。比如,
perf 可以用来分析 CPU cache、CPU 迁移、分支预测、指令周期等各种硬件事件;
perf 也可以只对感兴趣的事件进行动态追踪。
接下来,我们还是以内核函数 do_sys_open,以及用户空间函数 readline 为例,看一看 perf 动态追踪的使用方法。
同 ftrace 一样,你也可以通过 perf list ,查询所有支持的事件:
perf list然后,在 perf 的各个子命令中添加 —event 选项,设置追踪感兴趣的事件。如果这些预定义的事件不满足实际需要,你还可以使用 perf probe 来动态添加。而且,除了追踪内核事件外,perf 还可以用来跟踪用户空间的函数。
第一个 perf 示例,内核函数 do_sys_open 的例子。
你可以执行 perf probe 命令,添加 do_sys_open 探针:
$ perf probe --add do_sys_open Added new event: probe:do_sys_open (on do_sys_open) You can now use it in all perf tools, such as: perf record -e probe:do_sys_open -aR sleep 1探针添加成功后,就可以在所有的 perf 子命令中使用。比如,上述输出就是一个 perf record 的示例,执行它就可以对 10s 内的 do_sys_open 进行采样:
$ perf record -e probe:do_sys_open -aR sleep 10 [ perf record: Woken up 1 times to write data ] [ perf record: Captured and wrote 0.148 MB perf.data (19 samples) ]而采样成功后,就可以执行 perf script ,来查看采样结果了:
$ perf script perf 12886 [000] 89565.879875: probe:do_sys_open: (ffffffffa807b290) sleep 12889 [000] 89565.880362: probe:do_sys_open: (ffffffffa807b290) sleep 12889 [000] 89565.880382: probe:do_sys_open: (ffffffffa807b290) sleep 12889 [000] 89565.880635: probe:do_sys_open: (ffffffffa807b290) sleep 12889 [000] 89565.880669: probe:do_sys_open: (ffffffffa807b290)输出中,同样也列出了调用 do_sys_open 的任务名称、进程 PID 以及运行的 CPU 等信息。不过,对于 open 系统调用来说,只知道它被调用了并不够,我们需要知道的是,进程到底在打开哪些文件。所以,实际应用中,我们还希望追踪时能显示这些函数的参数。
对于内核函数来说,你当然可以去查看内核源码,找出它的所有参数。不过还有更简单的方法,那就是直接从调试符号表中查询。执行下面的命令,你就可以知道 do_sys_open 的所有参数:
$ perf probe -V do_sys_open Available variables at do_sys_open @<do_sys_open+0> char* filename int dfd int flags struct open_flags op umode_t mode从这儿可以看出,我们关心的文件路径,就是第一个字符指针参数(也就是字符串),参数名称为 filename。如果这个命令执行失败,就说明调试符号表还没有安装。那么,你可以执行下面的命令,安装调试信息后重试:
# Ubuntu $ apt-get install linux-image-`uname -r`-dbgsym # CentOS $ yum --enablerepo=base-debuginfo install -y kernel-debuginfo-$(uname -r)找出参数名称和类型后,就可以把参数加到探针中了。不过由于我们已经添加过同名探针,所以在这次添加前,需要先把旧探针给删掉:
# 先删除旧的探针 perf probe --del probe:do_sys_open # 添加带参数的探针 $ perf probe --add 'do_sys_open filename:string' Added new event: probe:do_sys_open (on do_sys_open with filename:string) You can now use it in all perf tools, such as: perf record -e probe:do_sys_open -aR sleep 1新的探针添加后,重新执行 record 和 script 子命令,采样并查看记录:
# 重新采样记录 $ perf record -e probe:do_sys_open -aR ls # 查看结果 $ perf script perf 13593 [000] 91846.053622: probe:do_sys_open: (ffffffffa807b290) filename_string="/proc/13596/status" ls 13596 [000] 91846.053995: probe:do_sys_open: (ffffffffa807b290) filename_string="/etc/ld.so.cache" ls 13596 [000] 91846.054011: probe:do_sys_open: (ffffffffa807b290) filename_string="/lib/x86_64-linux-gnu/libselinux.so.1" ls 13596 [000] 91846.054066: probe:do_sys_open: (ffffffffa807b290) filename_string="/lib/x86_64-linux-gnu/libc.so.6" ... # 使用完成后不要忘记删除探针 $ perf probe --del probe:do_sys_open现在,你就可以看到每次调用 open 时打开的文件了。不过,这个结果是不是看着很熟悉呢?
其实,在我们使用 strace 跟踪进程的系统调用时,也经常会看到这些动态库的影子。比如,使用 strace 跟踪 ls 时,你可以得到下面的结果:
$ strace ls ... access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory) access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory) openat(AT_FDCWD, "/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3 ... access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory) openat(AT_FDCWD, "/lib/x86_64-linux-gnu/libselinux.so.1", O_RDONLY|O_CLOEXEC) = 3 ...你估计在想,既然 strace 也能得到类似结果,本身又容易操作,为什么我们还要用 perf 呢?
实际上,很多人只看到了 strace 简单易用的好处,却忽略了它对进程性能带来的影响。从原理上来说,strace 基于系统调用 ptrace 实现,这就带来了两个问题。
- 由于 ptrace 是系统调用,就需要在内核态和用户态切换。当事件数量比较多时,繁忙的切换必然会影响原有服务的性能;
ptrace 需要借助 SIGSTOP 信号挂起目标进程。这种信号控制和进程挂起,会影响目标进程的行为。
所以,在性能敏感的应用(比如数据库)中,我并不推荐你用 strace (或者其他基于 ptrace 的性能工具)去排查和调试。
在 strace 的启发下,结合内核中的 utrace 机制, perf 也提供了一个 trace 子命令,是取代 strace 的首选工具。相对于 ptrace 机制来说,perf trace 基于内核事件,自然要比进程跟踪的性能好很多。
perf trace 的使用方法如下所示,跟 strace 其实很像:
$ perf trace ls ? ( ): ls/14234 ... [continued]: execve()) = 0 0.177 ( 0.013 ms): ls/14234 brk( ) = 0x555d96be7000 0.224 ( 0.014 ms): ls/14234 access(filename: 0xad98082 ) = -1 ENOENT No such file or directory 0.248 ( 0.009 ms): ls/14234 access(filename: 0xad9add0, mode: R ) = -1 ENOENT No such file or directory 0.267 ( 0.012 ms): ls/14234 openat(dfd: CWD, filename: 0xad98428, flags: CLOEXEC ) = 3 0.288 ( 0.009 ms): ls/14234 fstat(fd: 3</usr/lib/locale/C.UTF-8/LC_NAME>, statbuf: 0x7ffd2015f230 ) = 0 0.305 ( 0.011 ms): ls/14234 mmap(len: 45560, prot: READ, flags: PRIVATE, fd: 3 ) = 0x7efe0af92000 0.324 Dockerfile test.sh ( 0.008 ms): ls/14234 close(fd: 3</usr/lib/locale/C.UTF-8/LC_NAME> ) = 0 ...不过,perf trace 还可以进行系统级的系统调用跟踪(即跟踪所有进程),而 strace 只能跟踪特定的进程。
第二个 perf 的例子是用户空间的库函数。
以 bash 调用的库函数 readline 为例,使用类似的方法,可以跟踪库函数的调用(基于 uprobes)。
readline 的作用,是从终端中读取用户输入,并把这些数据返回调用方。所以,跟 open 系统调用不同的是,我们更关注 readline 的调用结果。
我们执行下面的命令,通过 -x 指定 bash 二进制文件的路径,就可以动态跟踪库函数。这其实就是跟踪了所有用户在 bash 中执行的命令:
# 为 /bin/bash 添加 readline 探针 $ perf probe -x /bin/bash 'readline%return +0($retval):string’ # 采样记录 $ perf record -e probe_bash:readline__return -aR sleep 5 # 查看结果 $ perf script bash 13348 [000] 93939.142576: probe_bash:readline__return: (5626ffac1610 <- 5626ffa46739) arg1="ls" # 跟踪完成后删除探针 $ perf probe --del probe_bash:readline__return当然,如果你不确定探针格式,也可以通过下面的命令,查询所有支持的函数和函数参数:
# 查询所有的函数 $ perf probe -x /bin/bash —funcs # 查询函数的参数 $ perf probe -x /bin/bash -V readline Available variables at readline @<readline+0> char* prompt跟内核函数类似,如果你想要查看普通应用的函数名称和参数,那么在应用程序的二进制文件中,同样需要包含调试信息。
51.2 eBPF 和 BCC
ftrace 和 perf 的功能已经比较丰富了,不过,它们有一个共同的缺陷,那就是不够灵活,没法像 DTrace 那样通过脚本自由扩展。
而 eBPF 就是 Linux 版的 DTrace,可以通过 C 语言自由扩展(这些扩展通过 LLVM 转换为 BPF 字节码后,加载到内核中执行)。下面这张图,就表示了 eBPF 追踪的工作原理:
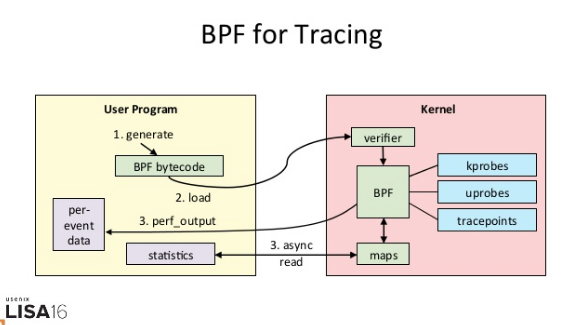
图片来自 THE NEW STACK
从图中你可以看到,eBPF 的执行需要三步:
- 从用户跟踪程序生成 BPF 字节码;
- 加载到内核中运行;
- 向用户空间输出结果。
所以,从使用上来说,eBPF 要比我们前面看到的 ftrace 和 perf ,都更加繁杂。
实际上,在 eBPF 执行过程中,编译、加载还有 maps 等操作,对所有的跟踪程序来说都是通用的。把这些过程通过 Python 抽象起来,也就诞生了 BCC(BPF Compiler Collection)。
BCC 把 eBPF 中的各种事件源(比如 kprobe、uprobe、tracepoint 等)和数据操作(称为 Maps),也都转换成了 Python 接口(也支持 lua)。这样,使用 BCC 进行动态追踪时,编写简单的脚本就可以了。
不过要注意,因为需要跟内核中的数据结构交互,真正核心的事件处理逻辑,还是需要我们用 C 语言来编写。
安装后,BCC 会把所有示例(包括 Python 和 lua),放到 /usr/share/bcc/examples 目录中:
$ ls /usr/share/bcc/examples
hello_world.py lua networking tracing接下来,还是以 do_sys_open 为例,我们一起来看看,如何用 eBPF 和 BCC 实现同样的动态跟踪。
通常,我们可以把 BCC 应用,拆分为下面这四个步骤。
第一,跟所有的 Python 模块使用方法一样,在使用之前,先导入要用到的模块:
from bcc import BPF第二,需要定义事件以及处理事件的函数。这个函数需要用 C 语言来编写,作用是初始化刚才导入的 BPF 对象。这些用 C 语言编写的处理函数,要以字符串的形式送到 BPF 模块中处理:
# define BPF program (""" is used for multi-line string).
# '#' indicates comments for python, while '//' indicates comments for C.
prog = """
#include <uapi/linux/ptrace.h>
#include <uapi/linux/limits.h>
#include <linux/sched.h>
// define output data structure in C
struct data_t {
u32 pid;
u64 ts;
char comm[TASK_COMM_LEN];
char fname[NAME_MAX];
};
BPF_PERF_OUTPUT(events);
// define the handler for do_sys_open.
// ctx is required, while other params depends on traced function.
int hello(struct pt_regs *ctx, int dfd, const char __user *filename, int flags){
struct data_t data = {};
data.pid = bpf_get_current_pid_tgid();
data.ts = bpf_ktime_get_ns();
if (bpf_get_current_comm(&data.comm, sizeof(data.comm)) == 0) {
bpf_probe_read(&data.fname, sizeof(data.fname), (void *)filename);
}
events.perf_submit(ctx, &data, sizeof(data));
return 0;
}
"""
# load BPF program
b = BPF(text=prog)
# attach the kprobe for do_sys_open, and set handler to hello
b.attach_kprobe(event="do_sys_open", fn_name="hello")第三步,是定义一个输出函数,并把输出函数跟 BPF 事件绑定:
# process event
start = 0
def print_event(cpu, data, size):
global start
# event’s type is data_t
event = b["events"].event(data)
if start == 0:
start = event.ts
time_s = (float(event.ts - start)) / 1000000000
print("%-18.9f %-16s %-6d %-16s" % (time_s, event.comm, event.pid, event.fname))
# loop with callback to print_event
b["events"].open_perf_buffer(print_event)最后一步,就是执行事件循环,开始追踪 do_sys_open 的调用:
# print header
print("%-18s %-16s %-6s %-16s" % ("TIME(s)", "COMM", "PID", "FILE"))
# start the event polling loop
while 1:
try:
b.perf_buffer_poll()
except KeyboardInterrupt:
exit()我们把上面几个步骤的代码,保存到文件 trace-open.py 中,然后就可以用 Python 来运行了。如果一切正常,你可以看到如下输出:
$ python trace-open.py
TIME(s) COMM PID FILE
0.000000000 irqbalance 1073 /proc/interrupts
0.000175401 irqbalance 1073 /proc/stat
0.000258802 irqbalance 1073 /proc/irq/9/smp_affinity
0.000290102 irqbalance 1073 /proc/irq/0/smp_affinity从输出中,你可以看到 irqbalance 进程(你的环境中可能还会有其他进程)正在打开很多文件,而 irqbalance 依赖这些文件中读取的内容,来执行中断负载均衡。
通过这个简单的示例,你也可以发现,eBPF 和 BCC 的使用,其实比 ftrace 和 perf 有更高的门槛。想用 BCC 开发自己的动态跟踪程序,至少要熟悉 C 语言、Python 语言、被跟踪事件或函数的特征(比如内核函数的参数和返回格式)以及 eBPF 提供的各种数据操作方法。
不过,因为强大的灵活性,虽然 eBPF 在使用上有一定的门槛,却也无法阻止它成为目前最热门、最受关注的动态追踪技术。
当然,BCC 软件包也内置了很多已经开发好的实用工具,默认安装到 /usr/share/bcc/tools/ 目录中,它们的使用场景如下图所示:
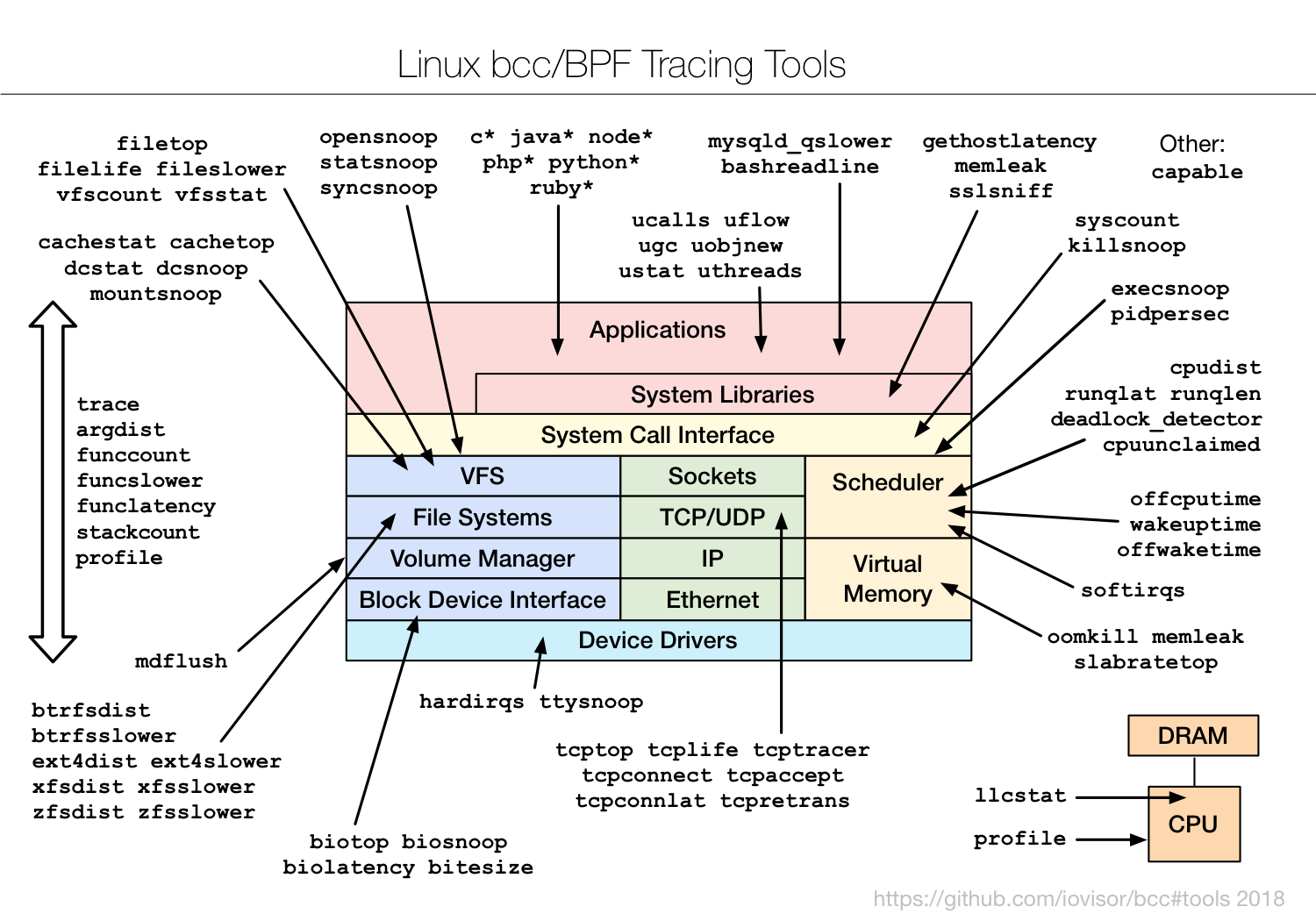
这些工具,一般都可以直接拿来用。而在编写其他的动态追踪脚本时,它们也是最好的参考资料。不过,有一点需要你特别注意,很多 eBPF 的新特性,都需要比较新的内核版本(如下图所示)。如果某些工具无法运行,很可能就是因为使用了当前内核不支持的特性。
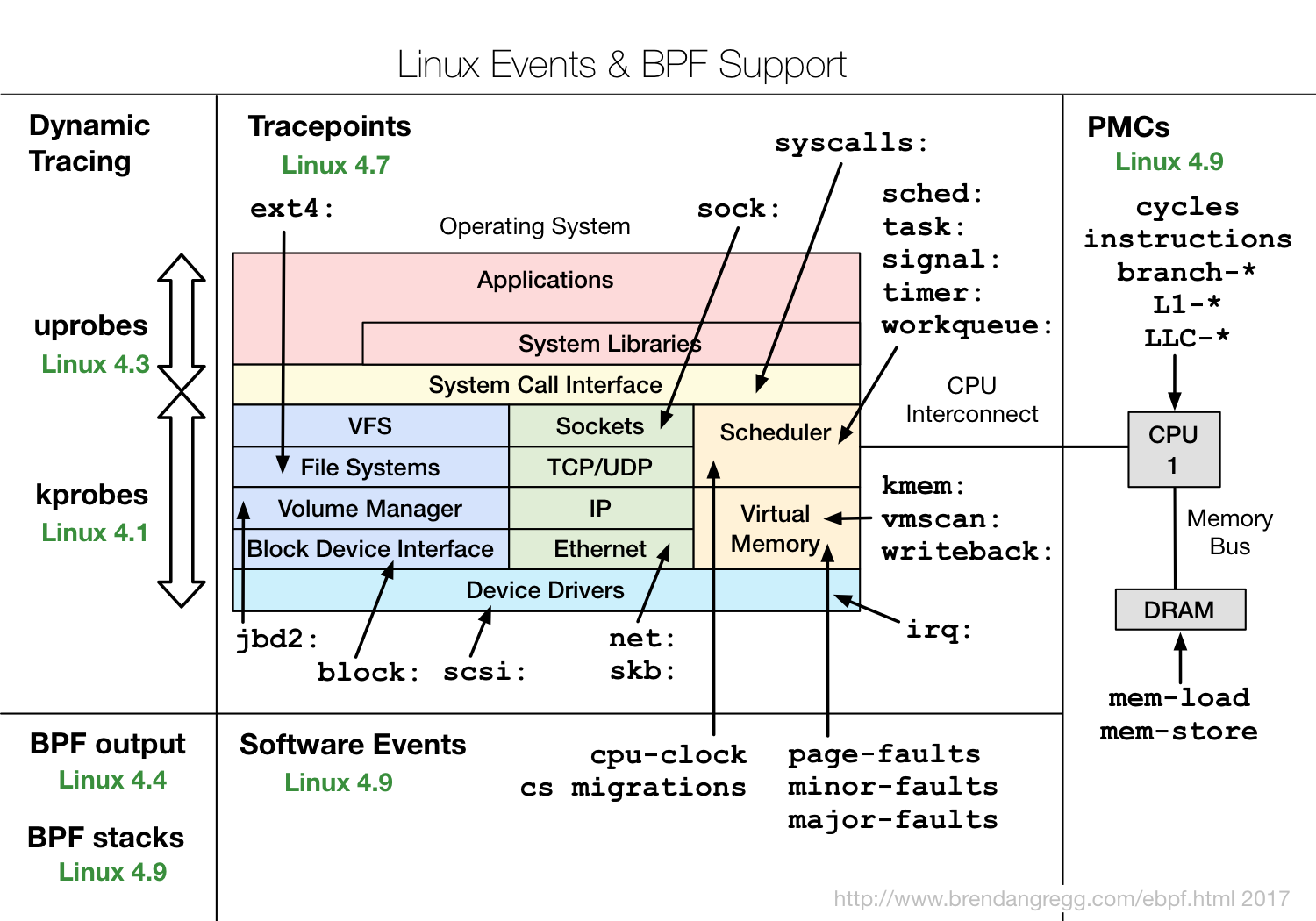
51.3 SystemTap 和 sysdig
除了前面提到的 ftrace、perf、eBPF 和 BCC 外,SystemTap 和 sysdig 也是常用的动态追踪工具。
SystemTap 也是一种可以通过脚本进行自由扩展的动态追踪技术。在 eBPF 出现之前,SystemTap 是 Linux 系统中,功能最接近 DTrace 的动态追踪机制。不过要注意,SystemTap 在很长时间以来都游离于内核之外(而 eBPF 自诞生以来,一直根植在内核中)。
所以,从稳定性上来说,SystemTap 只在 RHEL 系统中好用,在其他系统中则容易出现各种异常问题。当然,反过来说,支持 3.x 等旧版本的内核,也是 SystemTap 相对于 eBPF 的一个巨大优势。
sysdig 则是随着容器技术的普及而诞生的,主要用于容器的动态追踪。sysdig 汇集了一些列性能工具的优势,可以说是集百家之所长。我习惯用这个公式来表示 sysdig 的特点: sysdig = strace + tcpdump + htop + iftop + lsof + docker inspect。
而在最新的版本中(内核版本 >= 4.14),sysdig 还可以通过 eBPF 来进行扩展,所以,也可以用来追踪内核中的各种函数和事件。
51.4 如何选择追踪工具
不同场景的工具选择问题。比如:
- 在不需要很高灵活性的场景中,使用 perf 对性能事件进行采样,然后再配合火焰图辅助分析,就是最常用的一种方法;
- 而需要对事件或函数调用进行统计分析(比如观察不同大小的 I/O 分布)时,就要用 SystemTap 或者 eBPF,通过一些自定义的脚本来进行数据处理。
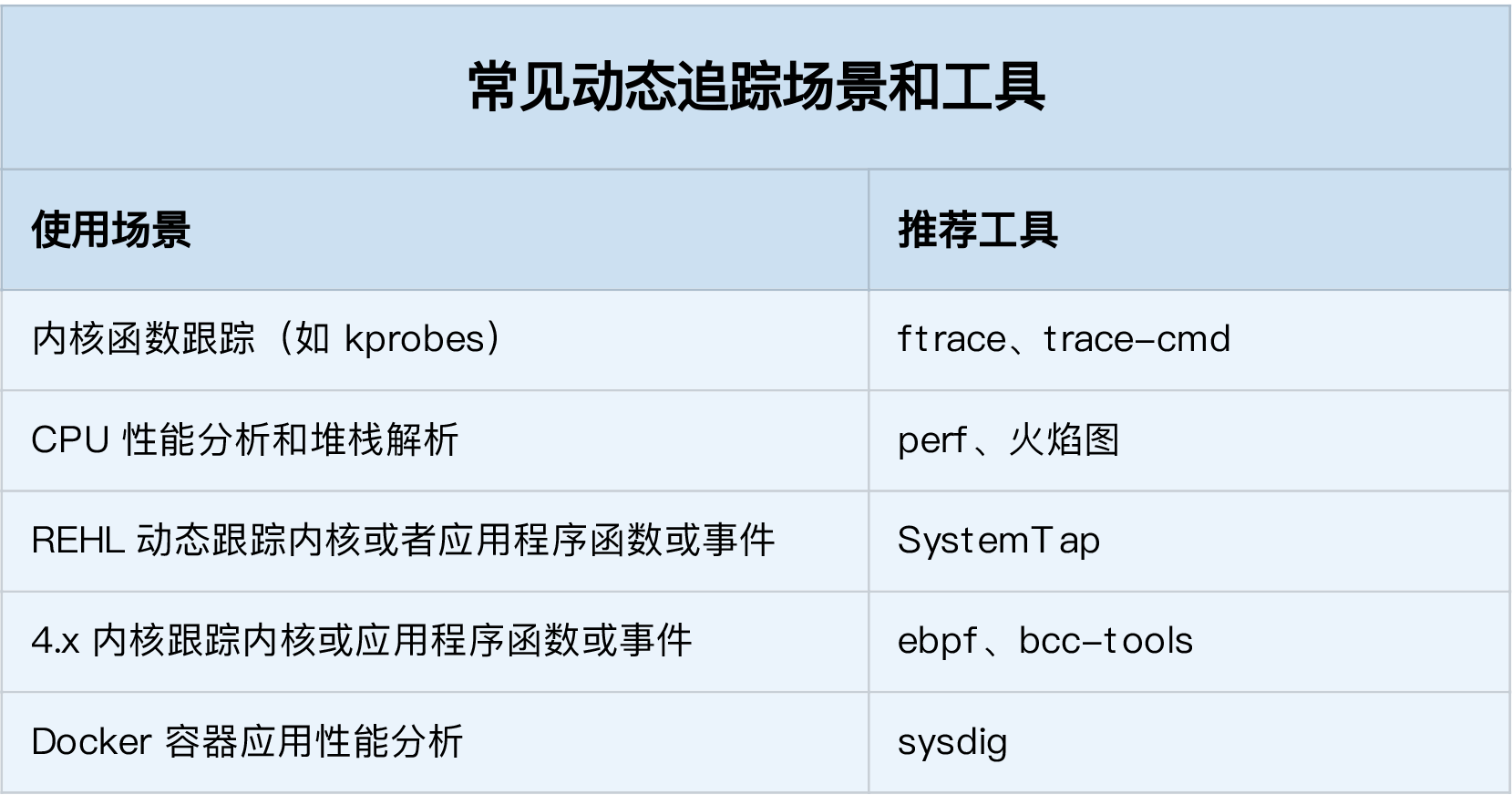
51.5 小结
在 Linux 系统中,常见的动态追踪方法,包括 ftrace、perf、eBPF 以及 SystemTap 等。在大多数性能问题中,使用 perf 配合火焰图是一个不错的方法。如果这满足不了你的要求,那么:
- 在新版的内核中,eBPF 和 BCC 是最灵活的动态追踪方法;
- 而在旧版本内核中,特别是在 RHEL 系统中,由于 eBPF 支持受限,SystemTap 往往是更好的选择。
此外,在使用动态追踪技术时,为了得到分析目标的详细信息,一般需要内核以及应用程序的调试符号表。动态追踪实际上也是在这些符号(包括函数和事件)上进行的,所以易读易理解的符号,有助于加快动态追踪的过程。
51.6 留言
https://docs.cilium.io/en/stable/bpf/
52 | 案例篇:服务吞吐量下降很厉害,怎么分析?
机器配置: 2 CPU, 8 GB 内存。
安装软件: docker、curl、wrk、perf、FlameGraph。
打开两个终端,分别登录到两台虚拟机。
在终端一中,执行下面的命令,启动 Nginx 应用,并监听在 80 端口。如果一切正常,你应该可以看到如下的输出:
$ docker run --name nginx --network host --privileged -itd feisky/nginx-tp 6477c607c13b37943234755a14987ffb3a31c33a7f04f75bb1c190e710bce19e $ docker run --name phpfpm --network host --privileged -itd feisky/php-fpm-tp 09e0255159f0c8a647e22cd68bd097bec7efc48b21e5d91618ff29b882fa7c1f执行 docker ps 命令,查询容器的状态,你会发现,容器已经处于运行状态(Up)了:
$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 09e0255159f0 feisky/php-fpm-tp "php-fpm -F --pid /o…" 28 seconds ago Up 27 seconds phpfpm 6477c607c13b feisky/nginx-tp "/init.sh" 29 seconds ago Up 28 seconds nginx从 docker ps 的输出,我们只能知道容器处于运行状态。至于 Nginx 能不能正常处理外部的请求,还需要我们进一步确认。
切换到终端二中,执行下面的 curl 命令,进一步验证 Nginx 能否正常访问。如果你看到 “Hello World!” 的输出,说明 Nginx+PHP 的应用已经正常启动了:
$ curl http://192.168.0.30 Hello World!在终端二中,执行 wrk 命令,来测试 Nginx 的性能:
# 默认测试时间为 10s,请求超时 2s $ wrk --latency -c 1000 http://192.168.0.30 Running 10s test @ http://192.168.0.30 2 threads and 1000 connections Thread Stats Avg Stdev Max +/- Stdev Latency 14.82ms 42.47ms 874.96ms 98.43% Req/Sec 550.55 1.36k 5.70k 93.10% Latency Distribution 50% 11.03ms 75% 15.90ms 90% 23.65ms 99% 215.03ms 1910 requests in 10.10s, 573.56KB read Non-2xx or 3xx responses: 1910 Requests/sec: 189.10 Transfer/sec: 56.78KB从 wrk 的结果中,你可以看到吞吐量(也就是每秒请求数)只有 189,并且所有 1910 个请求收到的都是异常响应(非 2xx 或 3xx)。这些数据显然表明,吞吐量太低了,并且请求处理都失败了。这是怎么回事呢?
根据 wrk 输出的统计结果,我们可以看到,总共传输的数据量只有 573 KB,那就肯定不会是带宽受限导致的。所以,我们应该从请求数的角度来分析。
分析请求数,特别是 HTTP 的请求数,有什么好思路吗?当然就要从 TCP 连接数入手。
连接数优化
要查看 TCP 连接数的汇总情况,首选工具自然是 ss 命令。为了观察 wrk 测试时发生的问题,我们在终端二中再次启动 wrk,并且把总的测试时间延长到 30 分钟:
# 测试时间 30 分钟 $ wrk --latency -c 1000 -d 1800 http://192.168.0.30回到终端一中,观察 TCP 连接数:
$ ss -s Total: 177 (kernel 1565) TCP: 1193 (estab 5, closed 1178, orphaned 0, synrecv 0, timewait 1178/0), ports 0 Transport Total IP IPv6 * 1565 - - RAW 1 0 1 UDP 2 2 0 TCP 15 12 3 INET 18 14 4 FRAG 0 0 0从这里看出,wrk 并发 1000 请求时,建立连接数只有 5,而 closed 和 timewait 状态的连接则有 1100 多 。其实从这儿你就可以发现两个问题:
- 一个是建立连接数太少了;
另一个是 timewait 状态连接太多了。
分析问题,自然要先从相对简单的下手。我们先来看第二个关于 timewait 的问题。在之前的 NAT 案例中,我已经提到过,内核中的连接跟踪模块,有可能会导致 timewait 问题。我们今天的案例还是基于 Docker 运行,而 Docker 使用的 iptables ,就会使用连接跟踪模块来管理 NAT。那么,怎么确认是不是连接跟踪导致的问题呢?
其实,最简单的方法,就是通过 dmesg 查看系统日志,如果有连接跟踪出了问题,应该会看到 nf_conntrack 相关的日志。
我们可以继续在终端一中,运行下面的命令,查看系统日志:
$ dmesg | tail [88356.354329] nf_conntrack: nf_conntrack: table full, dropping packet [88356.354374] nf_conntrack: nf_conntrack: table full, dropping packet从日志中,你可以看到 nf_conntrack: table full, dropping packet 的错误日志。这说明,正是连接跟踪导致的问题。
这种情况下,我们应该想起前面学过的两个内核选项——连接跟踪数的最大限制 nf_conntrack_max ,以及当前的连接跟踪数 nf_conntrack_count。执行下面的命令,你就可以查询这两个选项:
$ sysctl net.netfilter.nf_conntrack_max net.netfilter.nf_conntrack_max = 200 $ sysctl net.netfilter.nf_conntrack_count net.netfilter.nf_conntrack_count = 200这次的输出中,你可以看到最大的连接跟踪限制只有 200,并且全部被占用了。200 的限制显然太小,不过相应的优化也很简单,调大就可以了。
我们执行下面的命令,将 nf_conntrack_max 增大:
# 将连接跟踪限制增大到 1048576 $ sysctl -w net.netfilter.nf_conntrack_max=1048576连接跟踪限制增大后,对 Nginx 吞吐量的优化效果如何呢?我们不妨再来测试一下。你可以切换到终端二中,按下 Ctrl+C ;然后执行下面的 wrk 命令,重新测试 Nginx 的性能:
# 默认测试时间为 10s,请求超时 2s $ wrk --latency -c 1000 http://192.168.0.30 ... 54221 requests in 10.07s, 15.16MB read Socket errors: connect 0, read 7, write 0, timeout 110 Non-2xx or 3xx responses: 45577 Requests/sec: 5382.21 Transfer/sec: 1.50MB从 wrk 的输出中,你可以看到,连接跟踪的优化效果非常好,吞吐量已经从刚才的 189 增大到了 5382。看起来性能提升了将近 30 倍,
不过,这是不是就能说明,我们已经把 Nginx 的性能优化好了呢?
别急,我们再来看看 wrk 汇报的其他数据。果然,10s 内的总请求数虽然增大到了 5 万,但是有 4 万多响应异常,说白了,真正成功的只有 8000 多个(54221-45577=8644)。
很明显,大部分请求的响应都是异常的。那么,该怎么分析响应异常的问题呢?
工作进程优化
由于这些响应并非 Socket error,说明 Nginx 已经收到了请求,只不过,响应的状态码并不是我们期望的 2xx (表示成功)或 3xx(表示重定向)。所以,这种情况下,搞清楚 Nginx 真正的响应就很重要了。
不过这也不难,我们切换回终端一,执行下面的 docker 命令,查询 Nginx 容器日志就知道了:
$ docker logs nginx --tail 3 192.168.0.2 - - [15/Mar/2019:2243:27 +0000] "GET / HTTP/1.1" 499 0 "-" "-" "-" 192.168.0.2 - - [15/Mar/2019:22:43:27 +0000] "GET / HTTP/1.1" 499 0 "-" "-" "-" 192.168.0.2 - - [15/Mar/2019:22:43:27 +0000] "GET / HTTP/1.1" 499 0 "-" "-" "-"499 并非标准的 HTTP 状态码,而是由 Nginx 扩展而来,表示服务器端还没来得及响应时,客户端就已经关闭连接了。换句话说,问题在于服务器端处理太慢,客户端因为超时(wrk 超时时间为 2s),主动断开了连接。
既然问题出在了服务器端处理慢,而案例本身是 Nginx+PHP 的应用,那是不是可以猜测,是因为 PHP 处理过慢呢?
我么可以在终端中,执行下面的 docker 命令,查询 PHP 容器日志:
$ docker logs phpfpm --tail 5 [15-Mar-2019 22:28:56] WARNING: [pool www] server reached max_children setting (5), consider raising it [15-Mar-2019 22:43:17] WARNING: [pool www] server reached max_children setting (5), consider raising it bash从这个日志中,我们可以看到两条警告信息,server reached max_children setting (5),并建议增大 max_children。
max_children 表示 php-fpm 子进程的最大数量,当然是数值越大,可以同时处理的请求数就越多。不过由于这是进程问题,数量增大,也会导致更多的内存和 CPU 占用。所以,我们还不能设置得过大。
一般来说,每个 php-fpm 子进程可能会占用 20 MB 左右的内存。所以,你可以根据内存和 CPU 个数,估算一个合理的值。这儿我把它设置成了 20,并将优化后的配置重新打包成了 Docker 镜像。你可以执行下面的命令来执行它:
# 停止旧的容器 $ docker rm -f nginx phpfpm # 使用新镜像启动 Nginx 和 PHP $ docker run --name nginx --network host --privileged -itd feisky/nginx-tp:1 $ docker run --name phpfpm --network host --privileged -itd feisky/php-fpm-tp:1然后我们切换到终端二,再次执行下面的 wrk 命令,重新测试 Nginx 的性能:
# 默认测试时间为 10s,请求超时 2s $ wrk --latency -c 1000 http://192.168.0.30 ... 47210 requests in 10.08s, 12.51MB read Socket errors: connect 0, read 4, write 0, timeout 91 Non-2xx or 3xx responses: 31692 Requests/sec: 4683.82 Transfer/sec: 1.24MB从 wrk 的输出中,可以看到,虽然吞吐量只有 4683,比刚才的 5382 少了一些;但是测试期间成功的请求数却多了不少,从原来的 8000,增长到了 15000(47210-31692=15518)。
不过,虽然性能有所提升,可 4000 多的吞吐量显然还是比较差的,并且大部分请求的响应依然还是异常。接下来,该怎么去进一步提升 Nginx 的吞吐量呢?
套接字优化
切换到终端二中,重新运行测试,这次还是要用 -d 参数延长测试时间,以便模拟性能瓶颈的现场:
# 测试时间 30 分钟 $ wrk --latency -c 1000 -d 1800 http://192.168.0.30回到终端一中,观察有没有发生套接字的丢包现象:
# 只关注套接字统计 $ netstat -s | grep socket 73 resets received for embryonic SYN_RECV sockets 308582 TCP sockets finished time wait in fast timer 8 delayed acks further delayed because of locked socket 290566 times the listen queue of a socket overflowed 290566 SYNs to LISTEN sockets dropped # 稍等一会,再次运行 $ netstat -s | grep socket 73 resets received for embryonic SYN_RECV sockets 314722 TCP sockets finished time wait in fast timer 8 delayed acks further delayed because of locked socket 344440 times the listen queue of a socket overflowed 344440 SYNs to LISTEN sockets dropped根据两次统计结果中 socket overflowed 和 sockets dropped 的变化,你可以看到,有大量的套接字丢包,并且丢包都是套接字队列溢出导致的。所以,接下来,我们应该分析连接队列的大小是不是有异常。
你可以执行下面的命令,查看套接字的队列大小:
$ ss -ltnp State Recv-Q Send-Q Local Address:Port Peer Address:Port LISTEN 10 10 0.0.0.0:80 0.0.0.0:* users:(("nginx",pid=10491,fd=6),("nginx",pid=10490,fd=6),("nginx",pid=10487,fd=6)) LISTEN 7 10 *:9000 *:* users:(("php-fpm",pid=11084,fd=9),...,("php-fpm",pid=10529,fd=7))这次可以看到,Nginx 和 php-fpm 的监听队列 (Send-Q)只有 10,而 nginx 的当前监听队列长度 (Recv-Q)已经达到了最大值,php-fpm 也已经接近了最大值。很明显,套接字监听队列的长度太小了,需要增大。
关于套接字监听队列长度的设置,既可以在应用程序中,通过套接字接口调整,也支持通过内核选项来配置。我们继续在终端一中,执行下面的命令,分别查询 Nginx 和内核选项对监听队列长度的配置:
# 查询 nginx 监听队列长度配置 $ docker exec nginx cat /etc/nginx/nginx.conf | grep backlog listen 80 backlog=10; # 查询 php-fpm 监听队列长度 $ docker exec phpfpm cat /opt/bitnami/php/etc/php-fpm.d/www.conf | grep backlog ; Set listen(2) backlog. ;listen.backlog = 511 # somaxconn 是系统级套接字监听队列上限 $ sysctl net.core.somaxconn net.core.somaxconn = 10从输出中可以看到,Nginx 和 somaxconn 的配置都是 10,而 php-fpm 的配置也只有 511,显然都太小了。那么,优化方法就是增大这三个配置,比如,可以把 Nginx 和 php-fpm 的队列长度增大到 8192,而把 somaxconn 增大到 65536。
同样地,我也把这些优化后的 Nginx ,重新打包成了两个 Docker 镜像,你可以执行下面的命令来运行它:
# 停止旧的容器 $ docker rm -f nginx phpfpm # 使用新镜像启动 Nginx 和 PHP $ docker run --name nginx --network host --privileged -itd feisky/nginx-tp:2 $ docker run --name phpfpm --network host --privileged -itd feisky/php-fpm-tp:2然后,切换到终端二中,重新测试 Nginx 的性能:
$ wrk --latency -c 1000 http://192.168.0.30 ... 62247 requests in 10.06s, 18.25MB read Non-2xx or 3xx responses: 62247 Requests/sec: 6185.65 Transfer/sec: 1.81MB现在的吞吐量已经增大到了 6185,并且在测试的时候,如果你在终端一中重新执行 netstat -s | grep socket,还会发现,现在已经没有套接字丢包问题了。
不过,这次 Nginx 的响应,再一次全部失败了,都是 Non-2xx or 3xx。这是怎么回事呢?我们再去终端一中,查看 Nginx 日志:
$ docker logs nginx --tail 10 2019/03/15 16:52:39 [crit] 15#15: *999779 connect() to 127.0.0.1:9000 failed (99: Cannot assign requested address) while connecting to upstream, client: 192.168.0.2, server: localhost, request: "GET / HTTP/1.1", upstream: "fastcgi://127.0.0.1:9000", host: "192.168.0.30"你可以看到,Nginx 报出了无法连接 fastcgi 的错误,错误消息是 Connect 时, Cannot assign requested address。这个错误消息对应的错误代码为 EADDRNOTAVAIL,表示 IP 地址或者端口号不可用。
在这里,显然只能是端口号的问题。接下来,我们就来分析端口号的情况。
端口号优化
根据网络套接字的原理,当客户端连接服务器端时,需要分配一个临时端口号,而 Nginx 正是 PHP-FPM 的客户端。端口号的范围并不是无限的,最多也只有 6 万多。
我们执行下面的命令,就可以查询系统配置的临时端口号范围:
$ sysctl net.ipv4.ip_local_port_range net.ipv4.ip_local_port_range=20000 20050你可以看到,临时端口的范围只有 50 个,显然太小了 。优化方法很容易想到,增大这个范围就可以了。比如,你可以执行下面的命令,把端口号范围扩展为 “10000 65535”:
$ sysctl -w net.ipv4.ip_local_port_range="10000 65535" net.ipv4.ip_local_port_range = 10000 65535优化完成后,我们再次切换到终端二中,测试性能:
$ wrk --latency -c 1000 http://192.168.0.30/ ... 32308 requests in 10.07s, 6.71MB read Socket errors: connect 0, read 2027, write 0, timeout 433 Non-2xx or 3xx responses: 30 Requests/sec: 3208.58 Transfer/sec: 682.15KB这次,异常的响应少多了 ,不过,吞吐量也下降到了 3208。并且,这次还出现了很多 Socket read errors。显然,还得进一步优化。
火焰图
在终端二中,执行下面的命令,重新启动长时间测试:
# 测试时间 30 分钟 $ wrk --latency -c 1000 -d 1800 http://192.168.0.30切换回终端一中,执行 top ,观察 CPU 和内存的使用:
$ top ... %Cpu0 : 30.7 us, 48.7 sy, 0.0 ni, 2.3 id, 0.0 wa, 0.0 hi, 18.3 si, 0.0 st %Cpu1 : 28.2 us, 46.5 sy, 0.0 ni, 2.0 id, 0.0 wa, 0.0 hi, 23.3 si, 0.0 st KiB Mem : 8167020 total, 5867788 free, 490400 used, 1808832 buff/cache KiB Swap: 0 total, 0 free, 0 used. 7361172 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 20379 systemd+ 20 0 38068 8692 2392 R 36.1 0.1 0:28.86 nginx 20381 systemd+ 20 0 38024 8700 2392 S 33.8 0.1 0:29.29 nginx 1558 root 20 0 1118172 85868 39044 S 32.8 1.1 22:55.79 dockerd 20313 root 20 0 11024 5968 3956 S 27.2 0.1 0:22.78 docker-containe 13730 root 20 0 0 0 0 I 4.0 0.0 0:10.07 kworker/u4:0-ev从 top 的结果中可以看到,可用内存还是很充足的,但系统 CPU 使用率(sy)比较高,两个 CPU 的系统 CPU 使用率都接近 50%,且空闲 CPU 使用率只有 2%。再看进程部分,CPU 主要被两个 Nginx 进程和两个 docker 相关的进程占用,使用率都是 30% 左右。
CPU 使用率上升了,该怎么进行分析呢?我想,你已经还记得我们多次用到的 perf,再配合前两节讲过的火焰图,很容易就能找到系统中的热点函数。
我们保持终端二中的 wrk 继续运行;在终端一中,执行 perf 和 flamegraph 脚本,生成火焰图:
# 执行 perf 记录事件 $ perf record -g # 切换到 FlameGraph 安装路径执行下面的命令生成火焰图 $ perf script -i ~/perf.data | ./stackcollapse-perf.pl --all | ./flamegraph.pl > nginx.svg然后,使用浏览器打开生成的 nginx.svg ,你就可以看到下面的火焰图:
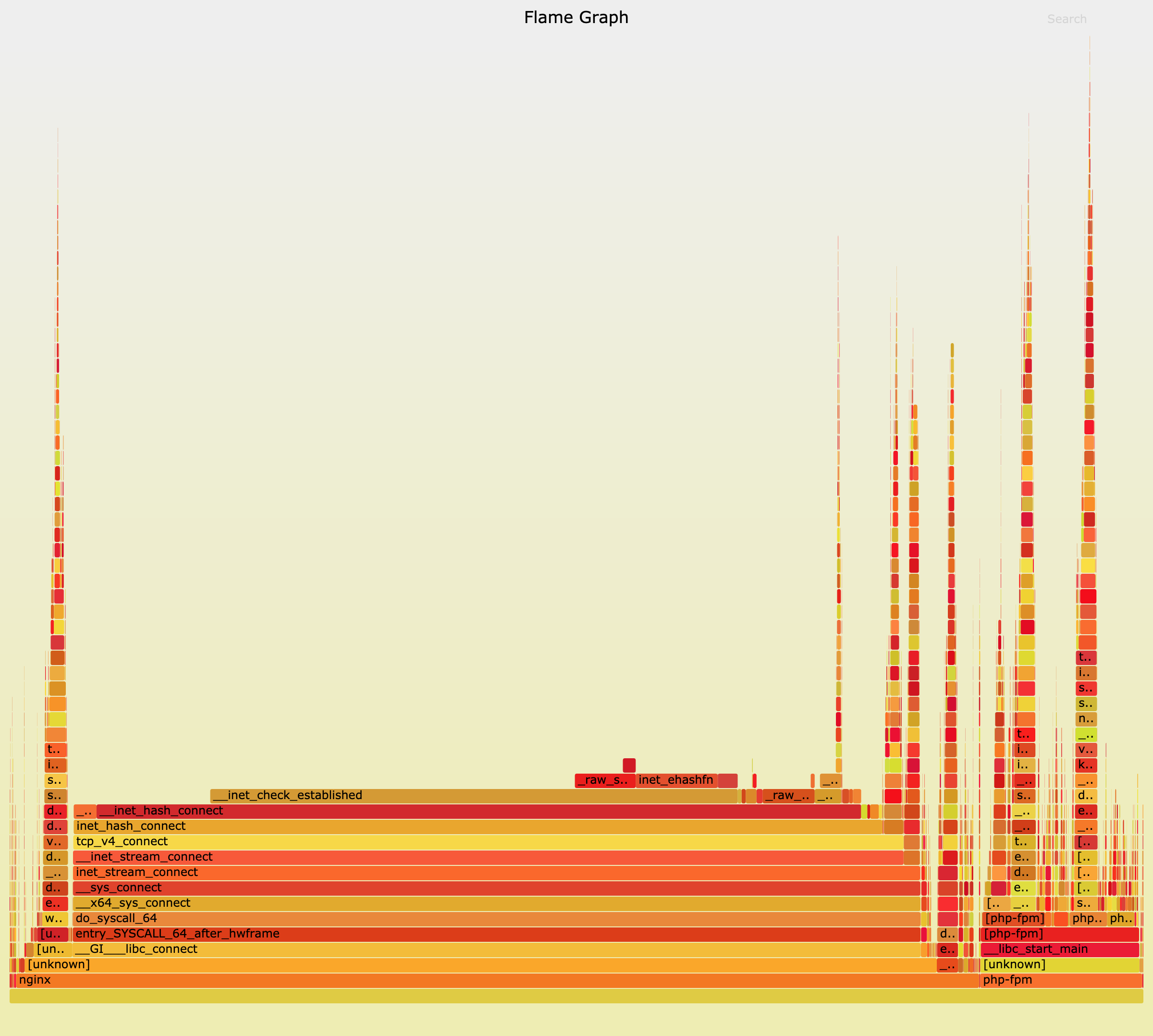
根据我们讲过的火焰图原理,这个图应该从下往上、沿着调用栈中最宽的函数,来分析执行次数最多的函数。
这儿中间的 do_syscall_64、tcp_v4_connect、inet_hash_connect 这个堆栈,很明显就是最需要关注的地方。inet_hash_connect() 是 Linux 内核中负责分配临时端口号的函数。所以,这个瓶颈应该还在临时端口的分配上。
在上一步的”端口号”优化中,临时端口号的范围,已经优化成了 “10000 65535”。这显然是一个非常大的范围,那么,端口号的分配为什么又成了瓶颈呢?
一时想不到也没关系,我们可以暂且放下,先看看其他因素的影响。再顺着 inet_hash_connect 往堆栈上面查看,下一个热点是 __init_check_established 函数。而这个函数的目的,是检查端口号是否可用。结合这一点,你应该可以想到,如果有大量连接占用着端口,那么检查端口号可用的函数,不就会消耗更多的 CPU 吗?
实际是否如此呢?我们可以继续在终端一中运行 ss 命令, 查看连接状态统计:
$ ss -s TCP: 32775 (estab 1, closed 32768, orphaned 0, synrecv 0, timewait 32768/0), ports 0 ...这回可以看到,有大量连接(这儿是 32768)处于 timewait 状态,而 timewait 状态的连接,本身会继续占用端口号。如果这些端口号可以重用,那么自然就可以缩短 __init_check_established 的过程。而 Linux 内核中,恰好有一个 tcp_tw_reuse 选项,用来控制端口号的重用。
我们在终端一中,运行下面的命令,查询它的配置:
$ sysctl net.ipv4.tcp_tw_reuse net.ipv4.tcp_tw_reuse = 0你可以看到,tcp_tw_reuse 是 0,也就是禁止状态。其实看到这里,我们就能理解,为什么临时端口号的分配会是系统运行的热点了。当然,优化方法也很容易,把它设置成 1 就可以开启了。
我把优化后的应用,也打包成了两个 Docker 镜像,你可以执行下面的命令来运行:
# 停止旧的容器 $ docker rm -f nginx phpfpm # 使用新镜像启动 Nginx 和 PHP $ docker run --name nginx --network host --privileged -itd feisky/nginx-tp:3 $ docker run --name phpfpm --network host --privileged -itd feisky/php-fpm-tp:3容器启动后,切换到终端二中,再次测试优化后的效果:
$ wrk --latency -c 1000 http://192.168.0.30/ ... 52119 requests in 10.06s, 10.81MB read Socket errors: connect 0, read 850, write 0, timeout 0 Requests/sec: 5180.48 Transfer/sec: 1.07MB现在的吞吐量已经达到了 5000 多,并且只有少量的 Socket errors,也不再有 Non-2xx or 3xx 的响应了。说明一切终于正常了。
53 | 套路篇:系统监控的综合思路
搭建监控系统,把系统和应用程序的运行状况监控起来,并定义一系列的策略,在发生问题时第一时间告警通知。一个好的监控系统,不仅可以实时暴露系统的各种问题,更可以根据这些监控到的状态,自动分析和定位大致的瓶颈来源,从而更精确地把问题汇报给相关团队处理。
要做好监控,最核心的就是全面的、可量化的指标,这包括系统和应用两个方面。
从系统来说,监控系统要涵盖系统的整体资源使用情况,比如我们前面讲过的 CPU、内存、磁盘和文件系统、网络等各种系统资源。
而从应用程序来说,监控系统要涵盖应用程序内部的运行状态,这既包括进程的 CPU、磁盘 I/O 等整体运行状况,更需要包括诸如接口调用耗时、执行过程中的错误、内部对象的内存使用等应用程序内部的运行状况。
53.1 USE 法
USE 法把系统资源的性能指标,简化成了三个类别,即使用率、饱和度以及错误数。
- 使用率,表示资源用于服务的时间或容量百分比。100% 的使用率,表示容量已经用尽或者全部时间都用于服务。
- 饱和度,表示资源的繁忙程度,通常与等待队列的长度相关。100% 的饱和度,表示资源无法接受更多的请求。
- 错误数表示发生错误的事件个数。错误数越多,表明系统的问题越严重。
这三个类别的指标,涵盖了系统资源的常见性能瓶颈,所以常被用来快速定位系统资源的性能瓶颈。这样,无论是对 CPU、内存、磁盘和文件系统、网络等硬件资源,还是对文件描述符数、连接数、连接跟踪数等软件资源,USE 方法都可以帮你快速定位出,是哪一种系统资源出现了性能瓶颈。
.webp)
不过,需要注意的是,USE 方法只关注能体现系统资源性能瓶颈的核心指标,但这并不是说其他指标不重要。诸如系统日志、进程资源使用量、缓存使用量等其他各类指标,也都需要我们监控起来。只不过,它们通常用作辅助性能分析,而 USE 方法的指标,则直接表明了系统的资源瓶颈。
53.2 监控系统
一个完整的监控系统通常由数据采集、数据存储、数据查询和处理、告警以及可视化展示等多个模块组成。所以,要从头搭建一个监控系统,其实也是一个很大的系统工程。
不过,幸运的是,现在已经有很多开源的监控工具可以直接使用,比如最常见的 Zabbix、Nagios、Prometheus 等等。
下面,我就以 Prometheus 为例,为你介绍这几个组件的基本原理。如下图所示,就是 Prometheus 的基本架构:
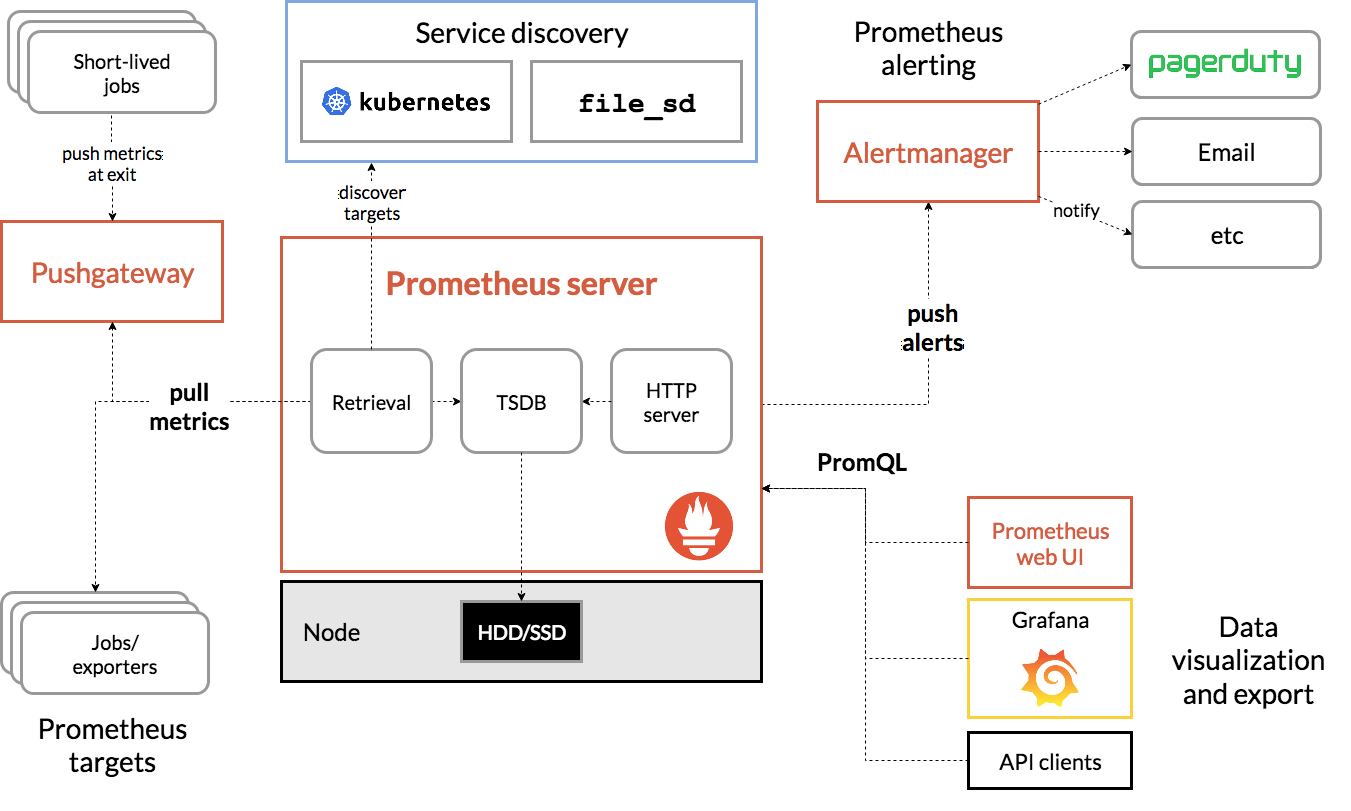
图片来自 prometheus.io
先看数据采集模块。最左边的 Prometheus targets 就是数据采集的对象,而 Retrieval 则负责采集这些数据。从图中你也可以看到,Prometheus 同时支持 Push 和 Pull 两种数据采集模式。
- Pull 模式,由服务器端的采集模块来触发采集。只要采集目标提供了 HTTP 接口,就可以自由接入(这也是最常用的采集模式)。
Push 模式,则是由各个采集目标主动向 Push Gateway(用于防止数据丢失)推送指标,再由服务器端从 Gateway 中拉取过去(这是移动应用中最常用的采集模式)。
由于需要监控的对象通常都是动态变化的,Prometheus 还提供了服务发现的机制,可以自动根据预配置的规则,动态发现需要监控的对象。这在 Kubernetes 等容器平台中非常有效。
第二个是数据存储模块。为了保持监控数据的持久化,图中的 TSDB(Time series database)模块,负责将采集到的数据持久化到 SSD 等磁盘设备中。TSDB 是专门为时间序列数据设计的一种数据库,特点是以时间为索引、数据量大并且以追加的方式写入。
第三个是数据查询和处理模块。刚才提到的 TSDB,在存储数据的同时,其实还提供了数据查询和基本的数据处理功能,而这也就是 PromQL 语言。PromQL 提供了简洁的查询、过滤功能,并且支持基本的数据处理方法,是告警系统和可视化展示的基础。
第四个是告警模块。右上角的 AlertManager 提供了告警的功能,包括基于 PromQL 语言的触发条件、告警规则的配置管理以及告警的发送等。不过,虽然告警是必要的,但过于频繁的告警显然也不可取。所以,AlertManager 还支持通过分组、抑制或者静默等多种方式来聚合同类告警,并减少告警数量。
最后一个是可视化展示模块。Prometheus 的 web UI 提供了简单的可视化界面,用于执行 PromQL 查询语句,但结果的展示比较单调。不过,一旦配合 Grafana,就可以构建非常强大的图形界面了。
介绍完了这些组件,想必你对每个模块都有了比较清晰的认识。接下来,我们再来继续深入了解这些组件结合起来的整体功能。
比如,以刚才提到的 USE 方法为例,我使用 Prometheus,可以收集 Linux 服务器的 CPU、内存、磁盘、网络等各类资源的使用率、饱和度和错误数指标。然后,通过 Grafana 以及 PromQL 查询语句,就可以把它们以图形界面的方式直观展示出来。
54 | 套路篇:应用监控的一般思路
系统监控的核心是资源的使用情况,这既包括 CPU、内存、磁盘、文件系统、网络等硬件资源,也包括文件描述符数、连接数、连接跟踪数等软件资源。而要描述这些资源瓶颈,最简单有效的方法就是 USE 法。
USE 法把系统资源的性能指标,简化为了三个类别:使用率、饱和度以及错误数。 当这三者之中任一类别的指标过高时,都代表相对应的系统资源可能存在性能瓶颈。
基于 USE 法建立性能指标后,我们还需要通过一套完整的监控系统,把这些指标从采集、存储、查询、处理,再到告警和可视化展示等贯穿起来。这样,不仅可以将系统资源的瓶颈快速暴露出来,还可以借助监控的历史数据,来追踪定位性能问题的根源。
54.1 指标监控
跟系统监控一样,在构建应用程序的监控系统之前,首先也需要确定,到底需要监控哪些指标。特别是要清楚,有哪些指标可以用来快速确认应用程序的性能问题。
对系统资源的监控,USE 法简单有效,却不代表其适合应用程序的监控。举个例子,即使在 CPU 使用率很低的时候,也不能说明应用程序就没有性能瓶颈。因为应用程序可能会因为锁或者 RPC 调用等,导致响应缓慢。
应用程序的核心指标,不再是资源的使用情况,而是请求数、错误率和响应时间。这些指标不仅直接关系到用户的使用体验,还反映应用整体的可用性和可靠性。
有了请求数、错误率和响应时间这三个黄金指标之后,我们就可以快速知道,应用是否发生了性能问题。但是,只有这些指标显然还是不够的,因为发生性能问题后,我们还希望能够快速定位”性能瓶颈区”。所以,在我看来,下面几种指标,也是监控应用程序时必不可少的。
第一个,是应用进程的资源使用情况,比如进程占用的 CPU、内存、磁盘 I/O、网络等。使用过多的系统资源,导致应用程序响应缓慢或者错误数升高,是一个最常见的性能问题。
第二个,是应用程序之间调用情况,比如调用频率、错误数、延时等。由于应用程序并不是孤立的,如果其依赖的其他应用出现了性能问题,应用自身性能也会受到影响。
第三个,是应用程序内部核心逻辑的运行情况,比如关键环节的耗时以及执行过程中的错误等。由于这是应用程序内部的状态,从外部通常无法直接获取到详细的性能数据。所以,应用程序在设计和开发时,就应该把这些指标提供出来,以便监控系统可以了解其内部运行状态。
- 有了应用进程的资源使用指标,你就可以把系统资源的瓶颈跟应用程序关联起来,从而迅速定位因系统资源不足而导致的性能问题;
- 有了应用程序之间的调用指标,你可以迅速分析出一个请求处理的调用链中,到底哪个组件才是导致性能问题的罪魁祸首;
- 而有了应用程序内部核心逻辑的运行性能,你就可以更进一步,直接进入应用程序的内部,定位到底是哪个处理环节的函数导致了性能问题。
除此之外,由于业务系统通常会涉及到一连串的多个服务,形成一个复杂的分布式调用链。为了迅速定位这类跨应用的性能瓶颈,你还可以使用 Zipkin、Jaeger、Pinpoint 等各类开源工具,来构建全链路跟踪系统。
全链路跟踪可以帮你迅速定位出,在一个请求处理过程中,哪个环节才是问题根源。比如,从上图中,你就可以很容易看到,这是 Redis 超时导致的问题。
全链路跟踪除了可以帮你快速定位跨应用的性能问题外,还可以帮你生成线上系统的调用拓扑图。这些直观的拓扑图,在分析复杂系统(比如微服务)时尤其有效。
54.2 日志监控
性能指标的监控,可以让你迅速定位发生瓶颈的位置,不过只有指标的话往往还不够。比如,同样的一个接口,当请求传入的参数不同时,就可能会导致完全不同的性能问题。所以,除了指标外,我们还需要对这些指标的上下文信息进行监控,而日志正是这些上下文的最佳来源。
对比来看,
- 指标是特定时间段的数值型测量数据,通常以时间序列的方式处理,适合于实时监控。
- 而日志则完全不同,日志都是某个时间点的字符串消息,通常需要对搜索引擎进行索引后,才能进行查询和汇总分析。
对日志监控来说,最经典的方法,就是使用 ELK 技术栈,即使用 Elasticsearch、Logstash 和 Kibana 这三个组件的组合。
图片来自elastic.co
- Logstash 负责对从各个日志源采集日志,然后进行预处理,最后再把初步处理过的日志,发送给 Elasticsearch 进行索引。
- Elasticsearch 负责对日志进行索引,并提供了一个完整的全文搜索引擎,这样就可以方便你从日志中检索需要的数据。
- Kibana 则负责对日志进行可视化分析,包括日志搜索、处理以及绚丽的仪表板展示等。
值得注意的是,ELK 技术栈中的 Logstash 资源消耗比较大。所以,在资源紧张的环境中,我们往往使用资源消耗更低的 Fluentd,来替代 Logstash(也就是所谓的 EFK 技术栈)。
55 | 套路篇:分析性能问题的一般步骤
55.1 系统资源瓶颈
系统监控的综合思路篇中,我曾经介绍过,系统资源的瓶颈,可以通过 USE 法,即使用率、饱和度以及错误数这三类指标来衡量。系统的资源,可以分为硬件资源和软件资源两类。
- 如 CPU、内存、磁盘和文件系统以及网络等,都是最常见的硬件资源。
- 而文件描述符数、连接跟踪数、套接字缓冲区大小等,则是典型的软件资源。
这样,在你收到监控系统告警时,就可以对照这些资源列表,再根据指标的不同来进行定位。
实际上,咱们专栏前四大模块的核心,正是学会去分析这些资源瓶颈导致的性能问题。所以,当你碰到了系统资源的性能瓶颈时,前面模块的所有思路、方法以及工具,都完全可以照用。
接下来,我就从 CPU 性能、内存性能、磁盘和文件系统 I/O 性能以及网络性能等四个方面,带你回顾一下它们的分析步骤。
55.2 CPU 性能分析
55.3 内存性能分析
55.4 磁盘和文件系统 I/O 性能分析
55.5 网络性能分析
55.6 应用程序瓶颈
应用程序性能问题虽然各种各样,但就其本质来源,实际上只有三种,也就是资源瓶颈、依赖服务瓶颈以及应用自身的瓶颈。
第一种资源瓶颈,其实还是指刚才提到的 CPU、内存、磁盘和文件系统 I/O、网络以及内核资源等各类软硬件资源出现了瓶颈,从而导致应用程序的运行受限。对于这种情况,我们就可以用前面系统资源瓶颈模块提到的各种方法来分析。
第二种依赖服务的瓶颈,也就是诸如数据库、分布式缓存、中间件等应用程序,直接或者间接调用的服务出现了性能问题,从而导致应用程序的响应变慢,或者错误率升高。这说白了就是跨应用的性能问题,使用全链路跟踪系统,就可以帮你快速定位这类问题的根源。
最后一种,应用程序自身的性能问题,包括了多线程处理不当、死锁、业务算法的复杂度过高等等。对于这类问题,在我们前面讲过的应用程序指标监控以及日志监控中,观察关键环节的耗时和内部执行过程中的错误,就可以帮你缩小问题的范围。
不过,由于这是应用程序内部的状态,外部通常不能直接获取详细的性能数据,所以就需要应用程序在设计和开发时,就提供出这些指标,以便监控系统可以了解应用程序的内部运行状态。
如果这些手段过后还是无法找出瓶颈,你还可以用系统资源模块提到的各类进程分析工具,来进行分析定位。比如:
- 你可以用 strace,观察系统调用;
- 使用 perf 和火焰图,分析热点函数;
- 甚至使用动态追踪技术,来分析进程的执行状态。
当然,系统资源和应用程序本来就是相互影响、相辅相成的一个整体。实际上,很多资源瓶颈,也是应用程序自身运行导致的。比如,进程的内存泄漏,会导致系统内存不足;进程过多的 I/O 请求,会拖慢整个系统的 I/O 请求等。
55.7 小结
值得注意的是,虽然我把瓶颈分为了系统和应用两个角度,但在实际运行时,这两者往往是相辅相成、相互影响的。系统是应用的运行环境,系统的瓶颈会导致应用的性能下降;而应用的不合理设计,也会引发系统资源的瓶颈。我们做性能分析,就是要结合应用程序和操作系统的原理,揪出引发问题的真凶。
56 | 套路篇:优化性能问题的一般方法
56.1 CPU 优化
首先来看 CPU 性能的优化方法。在CPU 性能优化的几个思路中,我曾经介绍过,CPU 性能优化的核心,在于排除所有不必要的工作、充分利用 CPU 缓存并减少进程调度对性能的影响。
从这几个方面出发,我相信你已经想到了很多的优化方法。这里,我主要强调一下,最典型的三种优化方法。
- 第一种,把进程绑定到一个或者多个 CPU 上,充分利用 CPU 缓存的本地性,并减少进程间的相互影响。
- 第二种,为中断处理程序开启多 CPU 负载均衡,以便在发生大量中断时,可以充分利用多 CPU 的优势分摊负载。
- 第三种,使用 Cgroups 等方法,为进程设置资源限制,避免个别进程消耗过多的 CPU。同时,为核心应用程序设置更高的优先级,减少低优先级任务的影响。
56.2 内存优化
说完了 CPU 的性能优化,我们再来看看,怎么优化内存的性能。在如何”快准狠”找到系统内存的问题中,我曾经为你梳理了常见的一些内存问题,比如可用内存不足、内存泄漏、Swap 过多、缺页异常过多以及缓存过多等等。所以,说白了,内存性能的优化,也就是要解决这些内存使用的问题。
在我看来,你可以通过以下几种方法,来优化内存的性能。
- 第一种,除非有必要,Swap 应该禁止掉。这样就可以避免 Swap 的额外 I/O ,带来内存访问变慢的问题。
- 第二种,使用 Cgroups 等方法,为进程设置内存限制。这样就可以避免个别进程消耗过多内存,而影响了其他进程。对于核心应用,还应该降低 oom_score,避免被 OOM 杀死。
- 第三种,使用大页、内存池等方法,减少内存的动态分配,从而减少缺页异常。
56.3 磁盘和文件系统 I/O 优化
接下来,我们再来看第三类系统资源,即磁盘和文件系统 I/O 的优化方法。在磁盘 I/O 性能优化的几个思路 中,我已经为你梳理了一些常见的优化思路,这其中有三种最典型的方法。
- 第一种,也是最简单的方法,通过 SSD 替代 HDD、或者使用 RAID 等方法,提升 I/O 性能。
- 第二种,针对磁盘和应用程序 I/O 模式的特征,选择最适合的 I/O 调度算法。比如,SSD 和虚拟机中的磁盘,通常用的是 noop 调度算法;而数据库应用,更推荐使用 deadline 算法。
- 第三,优化文件系统和磁盘的缓存、缓冲区,比如优化脏页的刷新频率、脏页限额,以及内核回收目录项缓存和索引节点缓存的倾向等等。
除此之外,使用不同磁盘隔离不同应用的数据、优化文件系统的配置选项、优化磁盘预读、增大磁盘队列长度等,也都是常用的优化思路。
56.4 网络优化
最后一个是网络的性能优化。在网络性能优化的几个思路中,我也已经为你梳理了一些常见的优化思路。这些优化方法都是从 Linux 的网络协议栈出发,针对每个协议层的工作原理进行优化。这里,我同样强调一下,最典型的几种网络优化方法。
首先,从内核资源和网络协议的角度来说,我们可以对内核选项进行优化,比如:
- 你可以增大套接字缓冲区、连接跟踪表、最大半连接数、最大文件描述符数、本地端口范围等内核资源配额;
- 也可以减少 TIMEOUT 超时时间、SYN+ACK 重传数、Keepalive 探测时间等异常处理参数;
- 还可以开启端口复用、反向地址校验,并调整 MTU 大小等降低内核的负担。
其次,从网络接口的角度来说,我们可以考虑对网络接口的功能进行优化,比如:
- 你可以将原来 CPU 上执行的工作,卸载到网卡中执行,即开启网卡的 GRO、GSO、RSS、VXLAN 等卸载功能;
- 也可以开启网络接口的多队列功能,这样,每个队列就可以用不同的中断号,调度到不同 CPU 上执行;
- 可以增大网络接口的缓冲区大小以及队列长度等,提升网络传输的吞吐量。
最后,在极限性能情况(比如 C10M)下,内核的网络协议栈可能是最主要的性能瓶颈,所以,一般会考虑绕过内核协议栈。
- 你可以使用 DPDK 技术,跳过内核协议栈,直接由用户态进程用轮询的方式,来处理网络请求。同时,再结合大页、CPU 绑定、内存对齐、流水线并发等多种机制,优化网络包的处理效率。
-你还可以使用内核自带的 XDP 技术,在网络包进入内核协议栈前,就对其进行处理。这样,也可以达到目的,获得很好的性能。
56.5. 应用程序优化
性能优化的最佳位置,还是应用程序内部。 为什么这么说呢?我简单举两个例子你就明白了。
第一个例子,是系统 CPU 使用率(sys%)过高的问题。有时候出现问题,虽然表面现象是系统 CPU 使用率过高,但待你分析过后,很可能会发现,应用程序的不合理系统调用才是罪魁祸首。这种情况下,优化应用程序内部系统调用的逻辑,显然要比优化内核要简单也有用得多。
再比如说,数据库的 CPU 使用率高、I/O 响应慢,也是最常见的一种性能问题。这种问题,一般来说,并不是因为数据库本身性能不好,而是应用程序不合理的表结构或者 SQL 查询语句导致的。这时候,优化应用程序中数据库表结构的逻辑或者 SQL 语句,显然要比优化数据库本身,能带来更大的收益。
所以,在观察性能指标时,你应该先查看应用程序的响应时间、吞吐量以及错误率等指标,因为它们才是性能优化要解决的终极问题。以终为始,从这些角度出发,你一定能想到很多优化方法,而我比较推荐下面几种方法。
- 第一,从 CPU 使用的角度来说,简化代码、优化算法、异步处理以及编译器优化等,都是常用的降低 CPU 使用率的方法,这样可以利用有限的 CPU 处理更多的请求。
- 第二,从数据访问的角度来说,使用缓存、写时复制、增加 I/O 尺寸等,都是常用的减少磁盘 I/O 的方法,这样可以获得更快的数据处理速度。
- 第三,从内存管理的角度来说,使用大页、内存池等方法,可以预先分配内存,减少内存的动态分配,从而更好地内存访问性能。
- 第四,从网络的角度来说,使用 I/O 多路复用、长连接代替短连接、DNS 缓存等方法,可以优化网络 I/O 并减少网络请求数,从而减少网络延时带来的性能问题。
- 第五,从进程的工作模型来说,异步处理、多线程或多进程等,可以充分利用每一个 CPU 的处理能力,从而提高应用程序的吞吐能力。
除此之外,你还可以使用消息队列、CDN、负载均衡等各种方法,来优化应用程序的架构,将原来单机要承担的任务,调度到多台服务器中并行处理。这样也往往能获得更好的整体性能。
57 | 套路篇:Linux 性能工具速查
关于工具手册的查看,man 应该是我们最熟悉的方法,我在专栏中多次介绍过。实际上,除了 man 之外,还有另外一个查询命令手册的方法,也就是 info。
info 可以理解为 man 的详细版本,提供了诸如节点跳转等更强大的功能。相对来说,man 的输出比较简洁,而 info 的输出更详细。所以,我们通常使用 man 来查询工具的使用方法,只有在 man 的输出不太好理解时,才会再去参考 info 文档。
所以,在选择性能工具时,除了要考虑性能指标这个目的外,还要结合待分析的环境来综合考虑。比如,实际环境是否允许安装软件包,是否需要新的内核版本等。
明白了工具选择的基本原则后,我们来看 Linux 的性能工具。首先还是要推荐下面这张图,也就是 Brendan Gregg 整理的性能工具谱图。我在专栏中多次提到过,你肯定也已经参考过。
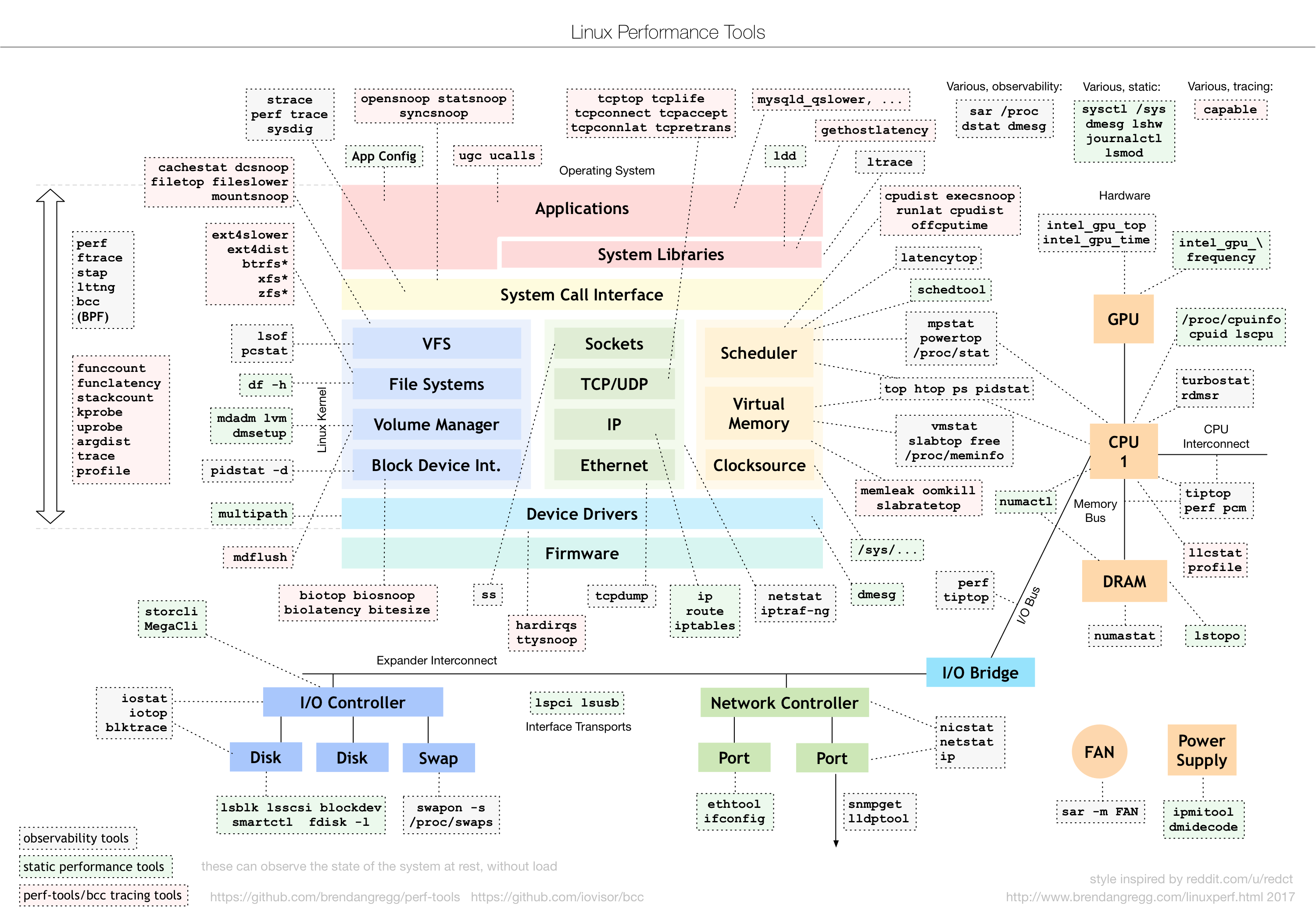
图片来自 brendangregg.com
这张图从 Linux 内核的各个子系统出发,汇总了对各个子系统进行性能分析时,你可以选择的工具。不过,虽然这个图是性能分析最好的参考资料之一,它其实还不够具体。
比如,当你需要查看某个性能指标时,这张图里对应的子系统部分,可能有多个性能工具可供选择。但实际上,并非所有这些工具都适用,具体要用哪个,还需要你去查找每个工具的手册,对比分析做出选择。
那么,有没有更好的方法来理解这些工具呢?我的建议,还是从性能指标出发,根据性能指标的不同,将性能工具划分为不同类型。比如,最常见的就是可以根据 CPU、内存、磁盘 I/O 以及网络的各类性能指标,将这些工具进行分类。
57.1 CPU 性能工具
首先,从 CPU 的角度来说,主要的性能指标就是 CPU 的使用率、上下文切换以及 CPU Cache 的命中率等。下面这张图就列出了常见的 CPU 性能指标。
从这些指标出发,再把 CPU 使用率,划分为系统和进程两个维度,我们就可以得到,下面这个 CPU 性能工具速查表。
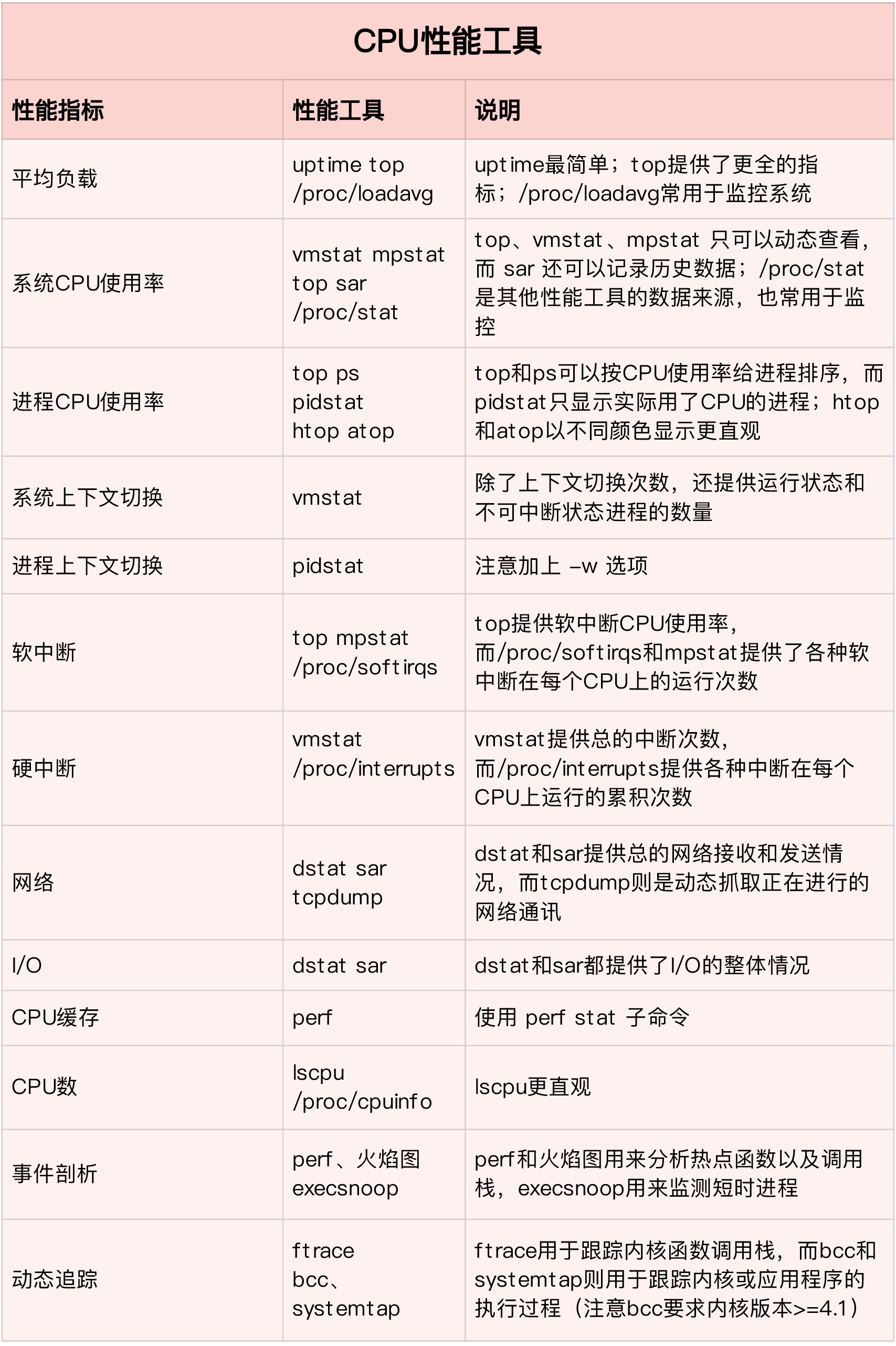
57.2 内存性能工具
接着我们来看内存方面。从内存的角度来说,主要的性能指标,就是系统内存的分配和使用、进程内存的分配和使用以及 SWAP 的用量。下面这张图列出了常见的内存性能指标。
从这些指标出发,我们就可以得到如下表所示的内存性能工具速查表。同 CPU 性能工具一样,这儿我也帮你梳理了,常见工具的特点和注意事项。
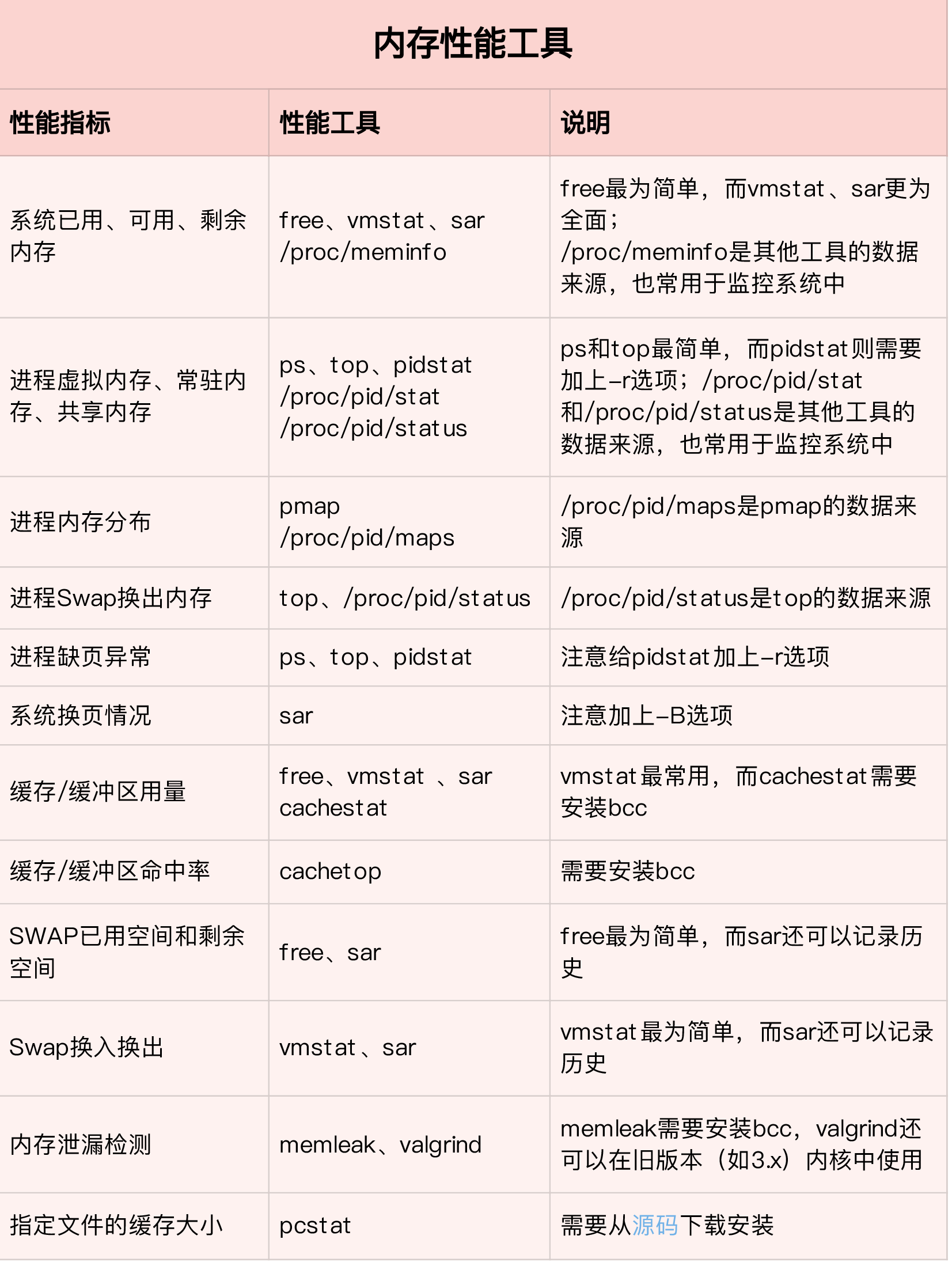
注:最后一行 pcstat 的源码链接为 https://github.com/tobert/pcstat
57.3 磁盘 I/O 性能工具
接下来,从文件系统和磁盘 I/O 的角度来说,主要性能指标,就是文件系统的使用、缓存和缓冲区的使用,以及磁盘 I/O 的使用率、吞吐量和延迟等。下面这张图列出了常见的 I/O 性能指标。
从这些指标出发,我们就可以得到,下面这个文件系统和磁盘 I/O 性能工具速查表。同 CPU 和内存性能工具一样,我也梳理出了这些工具的特点和注意事项。
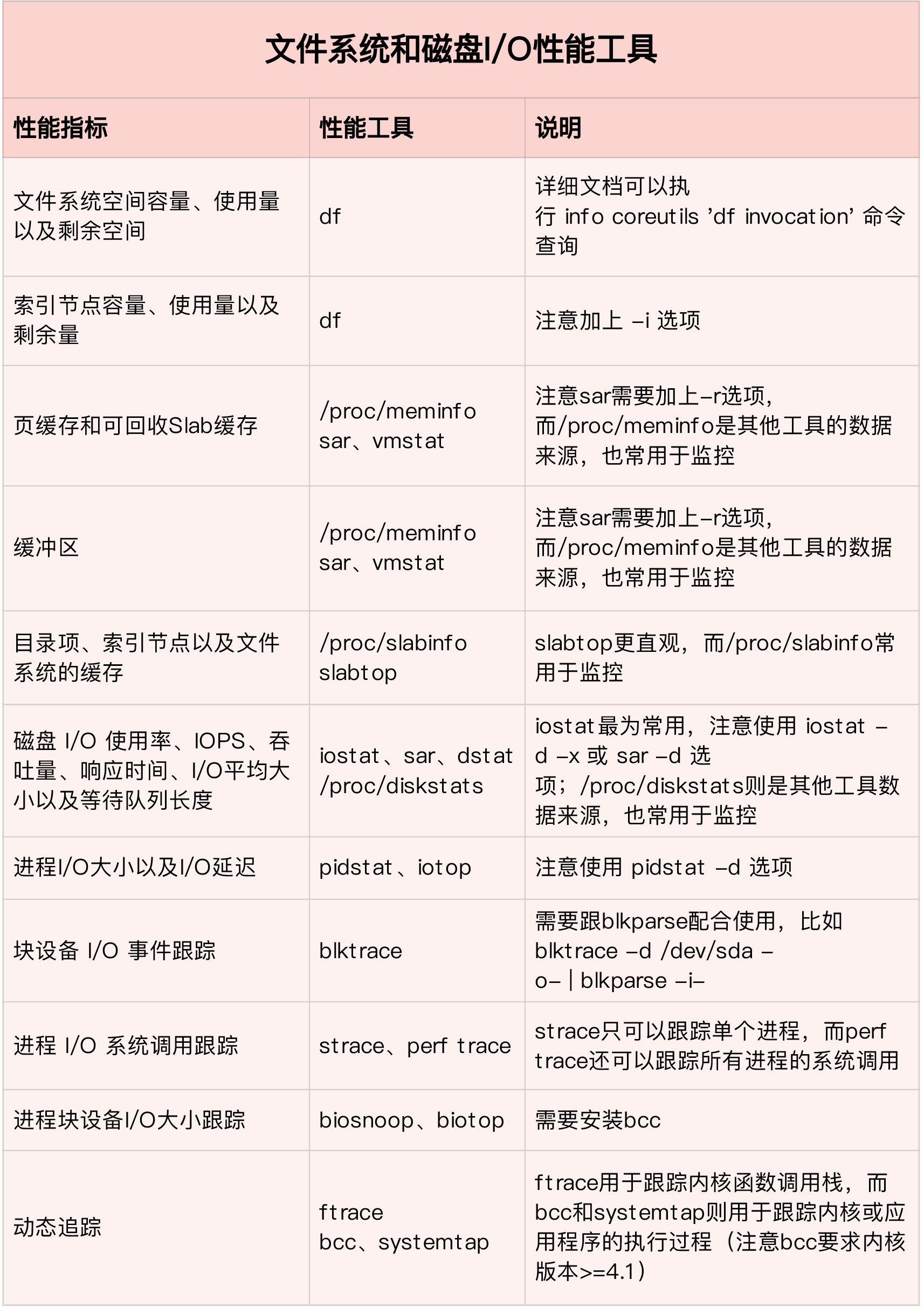
57.4 网络性能工具
最后,从网络的角度来说,主要性能指标就是吞吐量、响应时间、连接数、丢包数等。根据 TCP/IP 网络协议栈的原理,我们可以把这些性能指标,进一步细化为每层协议的具体指标。这里我同样用一张图,分别从链路层、网络层、传输层和应用层,列出了各层的主要指标。
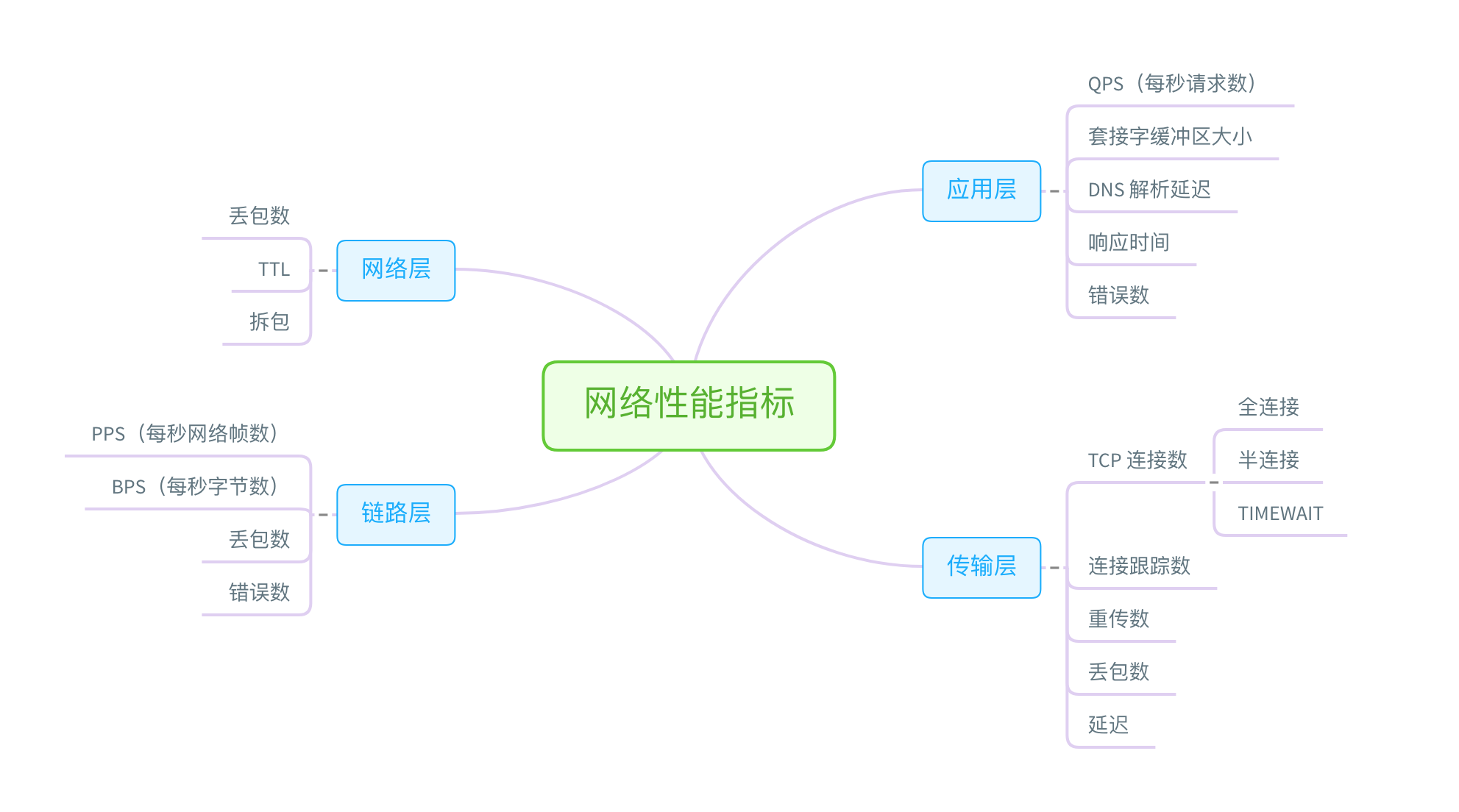
从这些指标出发,我们就可以得到下面的网络性能工具速查表。同样的,我也帮你梳理了各种工具的特点和注意事项。
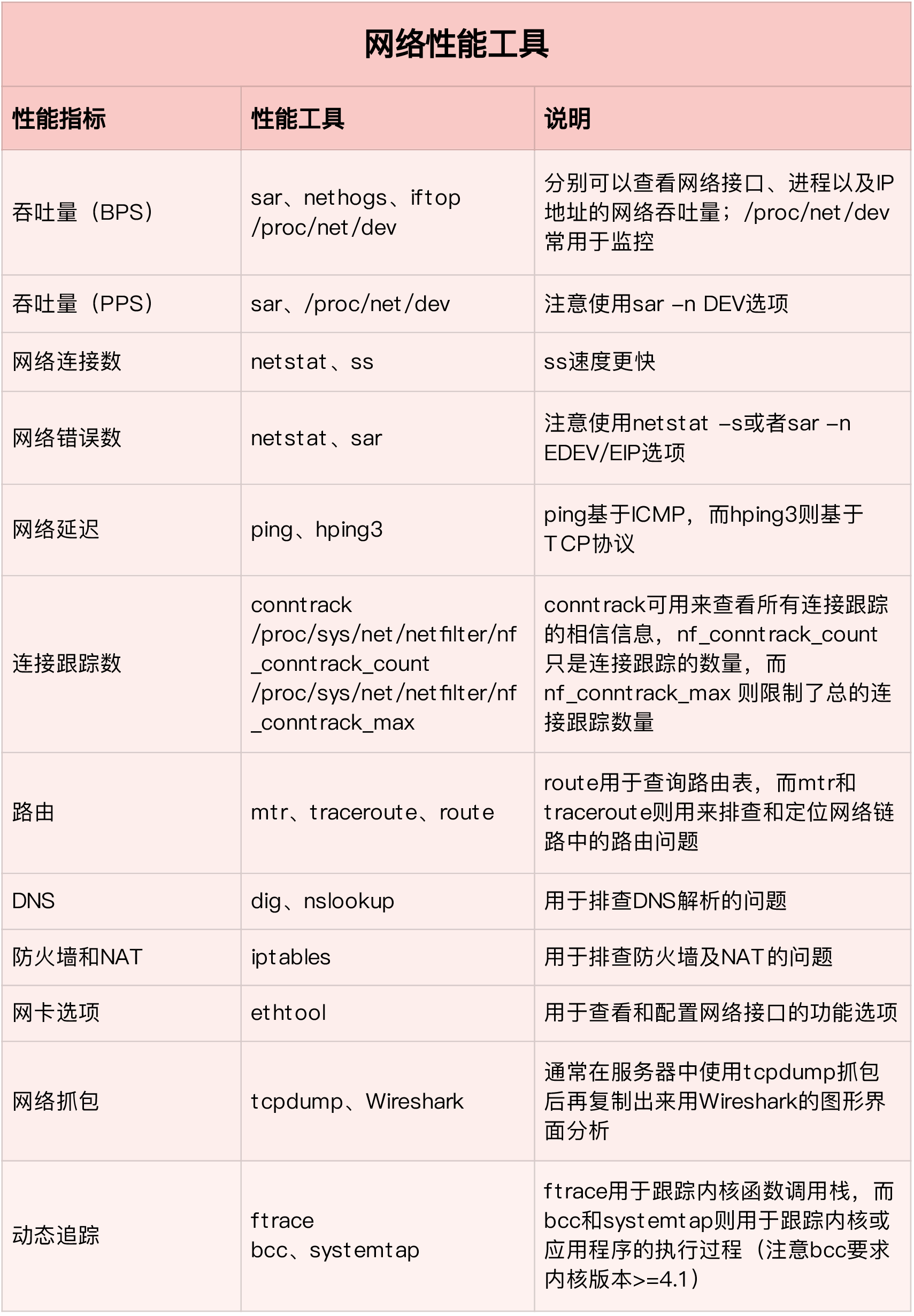
57.5 基准测试工具
除了性能分析外,很多时候,我们还需要对系统性能进行基准测试。比如,
- 在文件系统和磁盘 I/O 模块中,我们使用 fio 工具,测试了磁盘 I/O 的性能。
- 在网络模块中,我们使用 iperf、pktgen 等,测试了网络的性能。
- 而在很多基于 Nginx 的案例中,我们则使用 ab、wrk 等,测试 Nginx 应用的性能。
除了专栏里介绍过的这些工具外,对于 Linux 的各个子系统来说,还有很多其他的基准测试工具可能会用到。下面这张图,是 Brendan Gregg 整理的 Linux 基准测试工具图谱,你可以保存下来,在需要时参考。
图片来自 brendangregg.com
58 | 答疑(六):容器冷启动如何性能分析?
58.1 问题 1:容器冷启动性能分析
我们知道,容器为应用程序的管理带来了巨大的便捷,诸如 Serverless(只关注应用的运行,而无需关注服务器)、FaaS(Function as a Service)等新型的软件架构,也都基于容器技术来构建。不过,虽然容器启动已经很快了,但在启动新容器,也就是冷启动的时候,启动时间相对于应用程序的性能要求来说,还是过长了。
那么,应该怎么来分析和优化冷启动的性能呢?
这个问题最核心的一点,其实就是要弄清楚,启动时间到底都花在哪儿了。一般来说,一个 Serverless 服务的启动,包括:
- 事件触发(比如收到新的 HTTP 调用请求);
- 资源调度;
- 镜像拉取;
- 网络配置;
- 启动应用等几个过程。
这几个过程所消耗的时间,都可以通过链路跟踪的方式来监控,进而就可以定位出耗时最多的一个或者多个流程。
紧接着,针对耗时最多的流程,我们可以通过应用程序监控或者动态追踪的方法,定位出耗时最多的字模块,这样也就找出了要优化的瓶颈点。
比如,镜像拉取流程,可以通过缓存热点镜像来减少镜像拉取时间;网络配置流程,可以通过网络资源预分配进行加速;而资源调度和容器启动,也可以通过复用预先创建好的容器来进行优化。
58.2 问题 2:CPU 火焰图和内存火焰图有什么不同?
CPU 火焰图和内存火焰图,最大的差别其实就是数据来源的不同,也就是函数堆栈不同,而火焰图的格式还是完全一样的。
- 对 CPU 火焰图来说,采集的数据主要是消耗 CPU 的函数;
- 而对内存火焰图来说,采集的数据主要是内存分配、释放、换页等内存管理函数。
举个例子,我们在使用 perf record 时,默认的采集事件 cpu-cycles ,就是采集 on-CPU 数据,而生成的火焰图就是 CPU 火焰图。通过 perf record -e page-fault 将采集事件换成 page-fault 后,就可以采集内存缺页的数据,生成的火焰图自然就成了内存火焰图。
58.3 问题 3:perf probe 失败怎么办?
在使用动态追踪工具时,由于十六进制格式的函数地址并不容易理解,就需要我们借助调试信息,将它们转换为更直观的函数名。对于内核来说,我已经多次提到过,需要安装 debuginfo。不过,针对应用程序又该怎么办呢?
这里其实有两种方法。
第一种方法,假如应用程序提供了调试信息软件包,那你就可以直接安装来使用。比如,对于我们案例中的 bash 来说,就可以通过下面的命令,来安装它的调试信息:
# Ubuntu
apt-get install -y bash-dbgsym
# Centos
debuginfo-install bash第二种方法,使用源码重新编译应用程序,并开启编译器的调试信息开关,比如可以为 gcc 增加 -g 选项。
58.4 问题 4:RED 法监控微服务应用
在系统监控的综合思路中,我为你介绍了监控系统资源性能时常用的 USE 法。USE 法把系统资源的性能指标,简化成了三类:使用率、饱和度以及错误数。三者之中任一类别的指标过高时,都代表相应的系统资源可能有性能瓶颈。
不过,对应用程序的监控来说,这些指标显然就不合适了。因为应用程序的核心指标,是请求数、错误数和响应时间。那该怎么办呢?这其实,正是 Adam 同学在留言中提到的 RED 方法。
RED 方法,是 Weave Cloud 在监控微服务性能时,结合 Prometheus 监控,所提出的一种监控思路——即对微服务来说,监控它们的请求数(Rate)、错误数(Errors)以及响应时间(Duration)。所以,RED 方法适用于微服务应用的监控,而 USE 方法适用于系统资源的监控。
58.5 问题 5:深入内核的方法
在定位性能问题时,我们通过 perf、ebpf、systemtap 等各种方法排查时,很可能会发现,问题的热点在内核中的某个函数中。而青石和 xfan 的问题,就是如何去了解、深入 Linux 内核的原理,特别是想弄清楚,性能工具展示的内核函数到底是什么含义。
其实,要了解内核函数的含义,最好的方法,就是去查询所用内核版本的源代码。这里,我推荐 https://elixir.bootlin.com 这个网站。使用方法也很简单,从左边选择内核版本,再通过内核函数名称去搜索就可以了。
之所以推荐这个网站,是因为它不仅可以让你快速搜索函数定位,还为所有的函数、变量、宏定义等,都提供了快速跳转的功能。这样,当你看到不明白的函数或变量时,点击就可以跳转到相应的定义处。
此外,对于 eBPF 来说,除了可以通过内核源码来了解,我更推荐你从 BPF Compiler Collection (BCC) 这个项目开始。BCC 提供了很多短小的示例,可以帮你快速了解 eBPF 的工作原理,并熟悉 eBPF 程序的开发思路。了解这些基本的用法后,再去深入 eBPF 的内部,就会轻松很多。
07-加餐篇
59 加餐(一) | 书单推荐:性能优化和Linux 系统原理
Linux 系统原理和性能优化涉及的面很广,相关的书籍自然也很多。学习咱们专栏,你先要了解 Linux 系统的工作原理,基于此,再去分析、理解各类性能瓶颈,最终找出方法、优化性能。围绕这几个方面,我来推荐一些相应书籍。
Linux 基础入门书籍:《鸟哥的 Linux 私房菜》
另外,这本书的大部分内容,还可以在其繁体中文官方网站上在线学习.
计算机原理书籍:《深入理解计算机系统》
此外,这本书的官方网站上还提供了丰富的资源,可以帮你进一步理解、深入书里的内容,还提供了多个实验操作,助你加深掌握。
Linux 编程书籍:《Linux 程序设计》和《UNIX 环境高级编程》
Linux 内核书籍:《深入 Linux 内核架构》
性能优化书籍:《性能之巅:洞悉系统、企业与云计算》
60 加餐(二) | 书单推荐:网络原理和 Linux 内核实现
今天,我就来给你推荐一些,关于网络的原理,以及 Linux 内核实现的书籍。
- 计算机网络经典教材《计算机网络(第 5 版)》
- 网络协议必读书籍《TCP/IP 详解 卷 1:协议》
- Wireshark 书籍《Wireshark 网络分析就这么简单》和《Wireshark 网络分析的艺术》
- 网络编程书籍《UNIX 网络编程》

