内核源码版本:4.x
一、系统初始化
1. x86架构
1.1 8086的原理
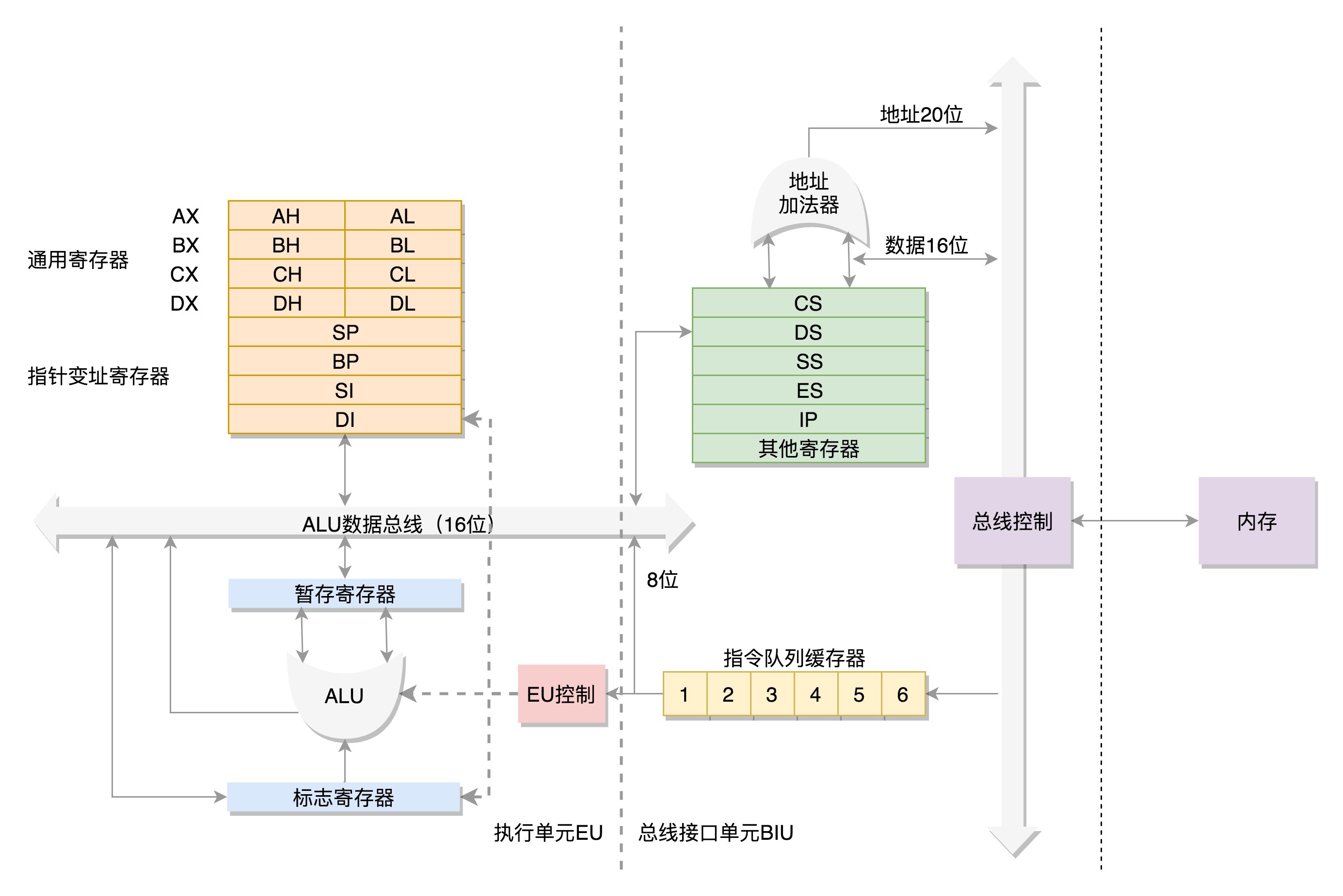
数据单元
为了暂存数据,8086处理器内部有8个16位的通用寄存器,分别是AX、BX、CX、DX、SP、BP、SI、DI。这些寄存器主要用于在计算过程中暂存数据。
其中AX、BX、CX、DX可以分成两个8位的寄存器来使用,分别是AH、AL、BH、BL、CH、CL、DH、DL,其中H就是High(高位),L就是Low(低位)的意思。
控制单元
IP寄存器就是指令指针寄存器(Instruction Pointer Register),指向代码段中下一条指令的位置。CPU会根据它来不断地将指令从内存的代码段中,加载到CPU的指令队列中,然后交给运算单元去执行。
如果需要切换进程呢?每个进程都分代码段和数据段,为了指向不同进程的地址空间,有四个16位的段寄存器,分别是CS、DS、SS、ES。
其中,CS就是代码段寄存器(Code Segment Register),通过它可以找到代码在内存中的位置;DS是数据段的寄存器,通过它可以找到数据在内存中的位置。
SS是栈寄存器(Stack Register)。栈是程序运行中一个特殊的数据结构,数据的存取只能从一端进行,秉承后进先出的原则,push就是入栈,pop就是出栈。
ES为扩展段寄存器。
在CS和DS中都存放着一个段的起始地址。代码段的偏移量在IP寄存器中,数据段的偏移量会放在通用寄存器中。
这时候问题来了,CS和DS都是16位的,也就是说,起始地址都是16位的,IP寄存器和通用寄存器都是16位的,偏移量也是16位的,但是8086的地址总线地址是20位。怎么凑够这20位呢?方法就是”起始地址*16+偏移量”,也就是把CS和DS中的值左移4位,变成20位的,加上16位的偏移量,这样就可以得到最终20位的数据地址。
因为偏移量只能是16位的,所以一个段最大的大小是2^16=64k。
1.2 32位处理器
在32位处理器中,有32根地址总线,可以访问2^32=4G的内存。
首先,通用寄存器有扩展,可以将8个16位的扩展到8个32位的,但是依然可以保留16位的和8位的使用方式。你可能会问,为什么高16位不分成两个8位使用呢?因为这样就不兼容了呀!
其中,指向下一条指令的指令指针寄存器IP,就会扩展成32位的,同样也兼容16位的。
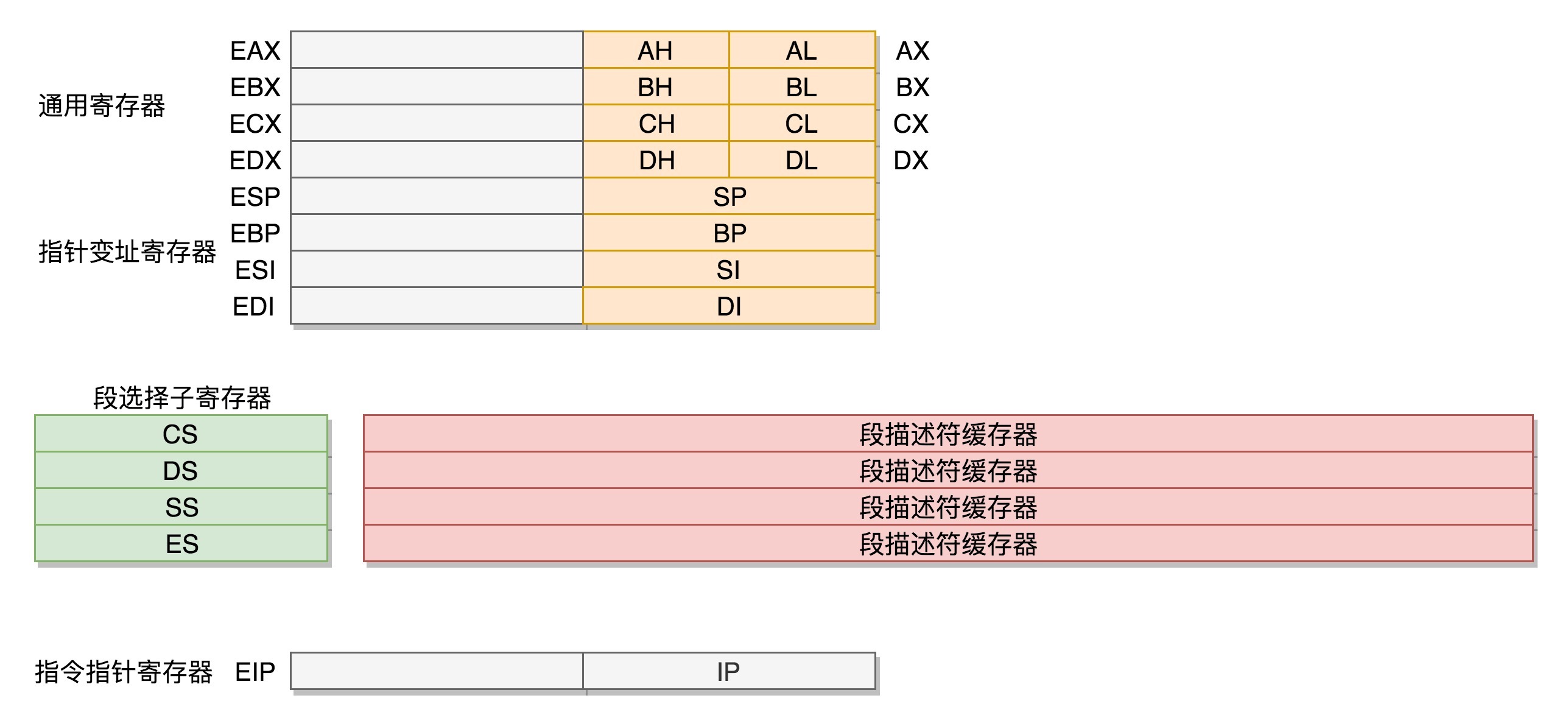
而改动比较大,有点不兼容的就是段寄存器(Segment Register)。
CS、SS、DS、ES仍然是16位的,但是不再是段的起始地址。段的起始地址放在内存的某个地方。这个地方是一个表格,表格中的一项一项是段描述符(Segment Descriptor)。这里面才是真正的段的起始地址。而段寄存器里面保存的是在这个表格中的哪一项,称为选择子(Selector)。
这样,将一个从段寄存器直接拿到的段起始地址,就变成了先间接地从段寄存器找到表格中的一项,再从表格中的一项中拿到段起始地址。
为了快速拿到段起始地址,段寄存器会从内存中拿到CPU的描述符高速缓存器中。
32位的系统架构下,我们将前一种模式称为实模式(Real Pattern),后一种模式称为保护模式(Protected Pattern)。
当系统刚刚启动的时候,CPU是处于实模式的。
1.3 总结
2. 系统启动过程
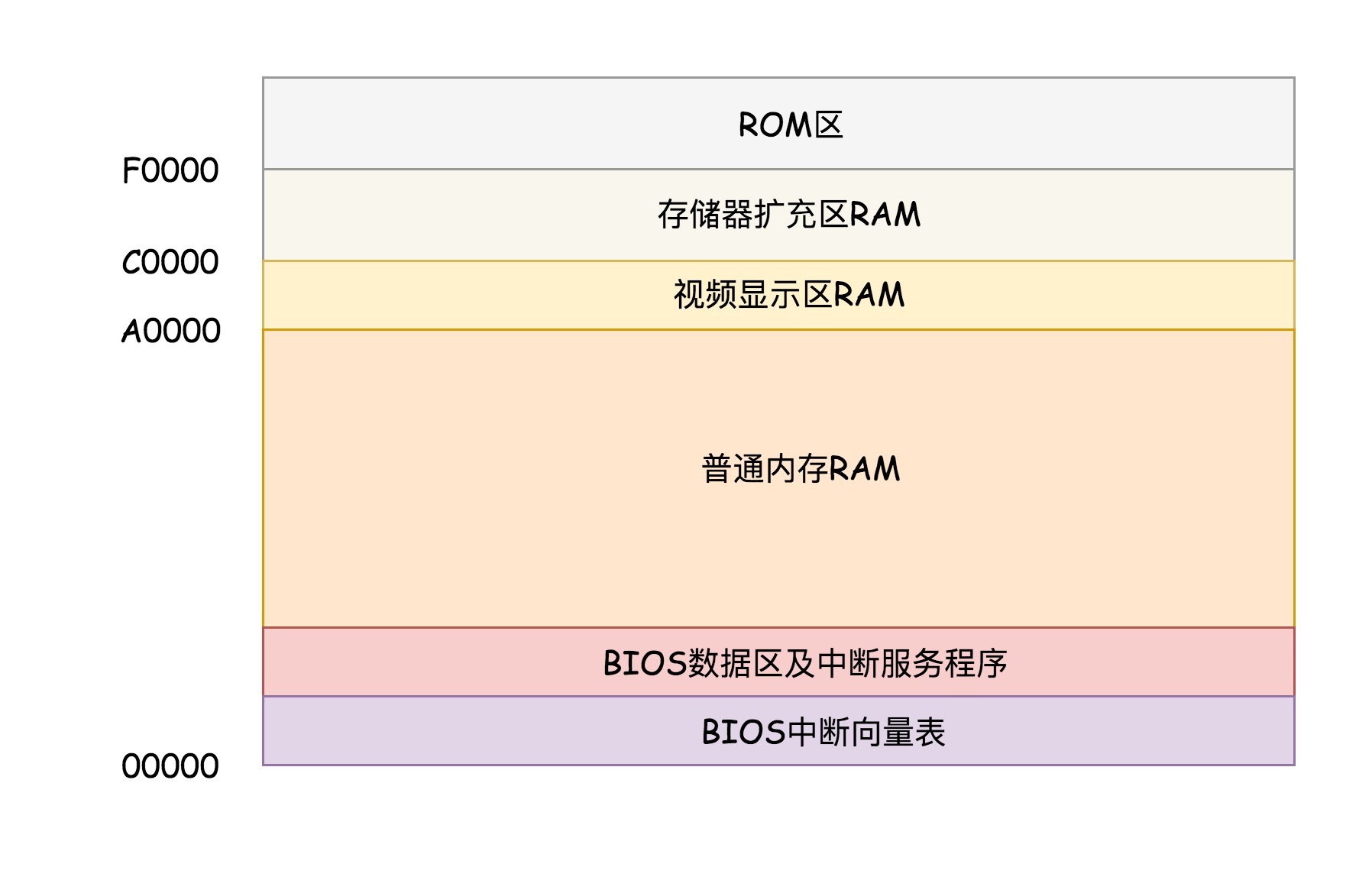
系统加电后,CPU 运行在实模式下,且 CS 重置为 0xFFFF ,IP 为 0x0000。
实模式下,内存地址的计算方式是:
段寄存器 * 16 + 偏移量。所以系统加电后运行的第一条指令在CS * 16 + IP = 0xFFFF0。实模式只有 1MB 内存寻址空间(X86)。
在 x86 系统中,内存
0xF0000-0xFFFFF映射到 BIOS 程序(存储在 ROM 中),BIOS 主要做三件事:- 检查硬件。
- 提供基本输入(中断)输出(显存映射)服务。
把 MBR(Master Boot Record,主引导记录/扇区)装载到内存 0x7C00 开始的 512 字节大小的内存区域,并设置 CS:IP 为 0x0000:7C00 。
MBR 指启动盘的第一个扇区,大小 512 字节,并且以 0xAA55 结束。
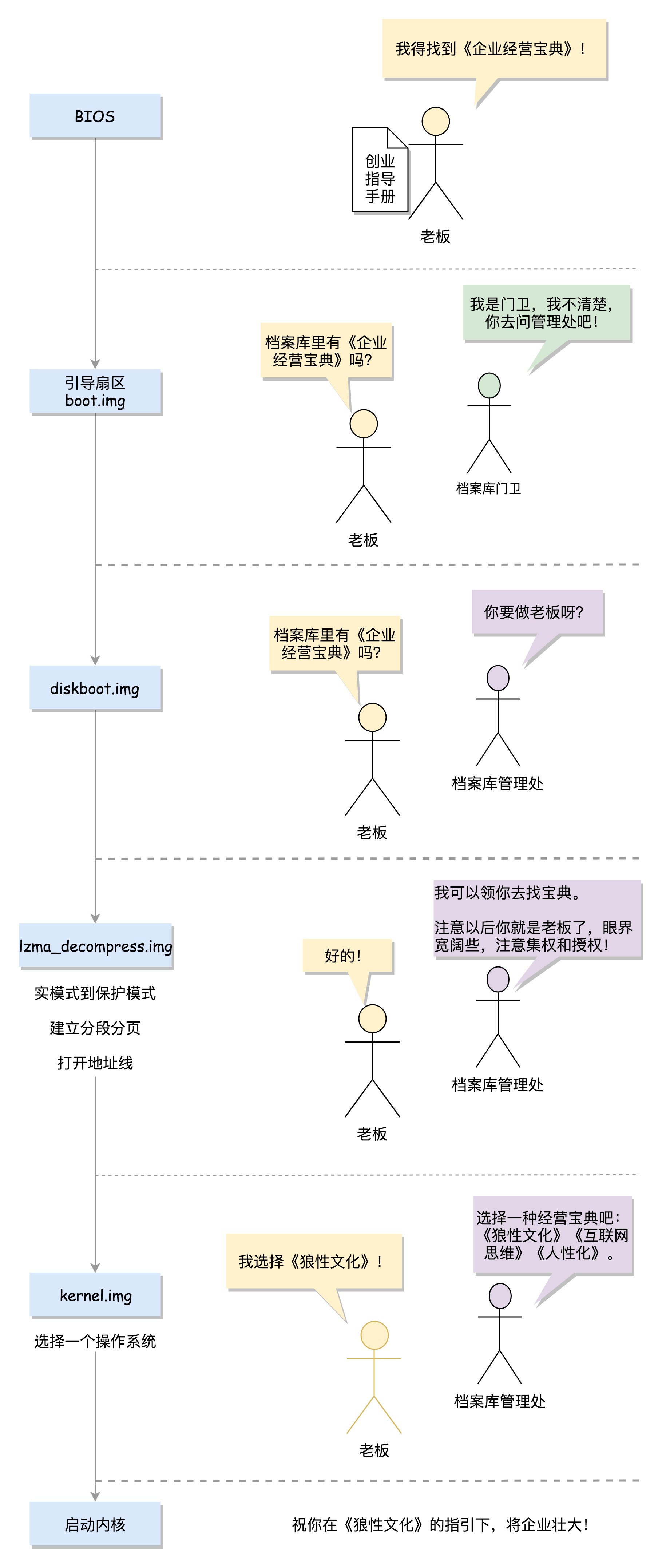
MBR中存放的一般是由 Grub2 写入的 boot.img。
boot.img 加载 Grub2 的 core.img 。
boot.img 由 boot.S 编译而成。
core.img 包括 diskroot.img, lzma_decompress.img, kernel.img 以及其他模块。
硬盘启动时,boot.img 先加载运行 diskroot.img, 再由 diskroot.img 加载 core.img 的其他内容。
diskroot.img 解压运行 lzma_compress.img 。
diskroot.img 由 diskboot.S 编译而成。
lzma_compress.img 首先切换到保护模式。然后再解压运行 grub 内核 kernel.img。
lzma_compress.img 由 startup_raw.S 编译而成。
调用
real_to_prot切换到保护模式需要做三件事:- 启用分段, 辅助进程管理。在内存里面建立段描述符表,将寄存器里面的段寄存器变成段选择子,指向某个段描述符,这样就能实现不同进程的切换了。
- 启动分页, 辅助内存管理;将内存分成相等大小的块。
- 打开其他地址线。打开Gate A20,也就是第21根地址线的控制线。
kernel.img 主要做的是根据配置信息,加载用户选择 linux kernel 并传递内核启动参数。
kernel.img 对应的代码是 startup.S 以及一堆 c 文件,在 startup.S 中会调用
grub_main,这是 grub kernel 的主函数。将真正的操作系统的 kernel 镜像加载执行,Linux Kernel的启动入口是
start_kernel()。start_kernel()中会进行一部分初始化工作,最后调用rest_init()来完成其他的初始化工作。rest_init()中会创建系统 1 号进程 kernel_init , kernel_init 会执行 ramdisk 中的 init 程序,并切换至用户态,加载驱动后执行真正的根文件系统中的 init 程序。rest_init()中会创建系统 2 号进程 kthread ,负责所有内核态线程的调度和管理,是内核态所有运行线程的祖先。
3. 内核初始化
内核的启动从入口函数start_kernel()开始。在init/main.c文件中,start_kernel相当于内核的main函数。
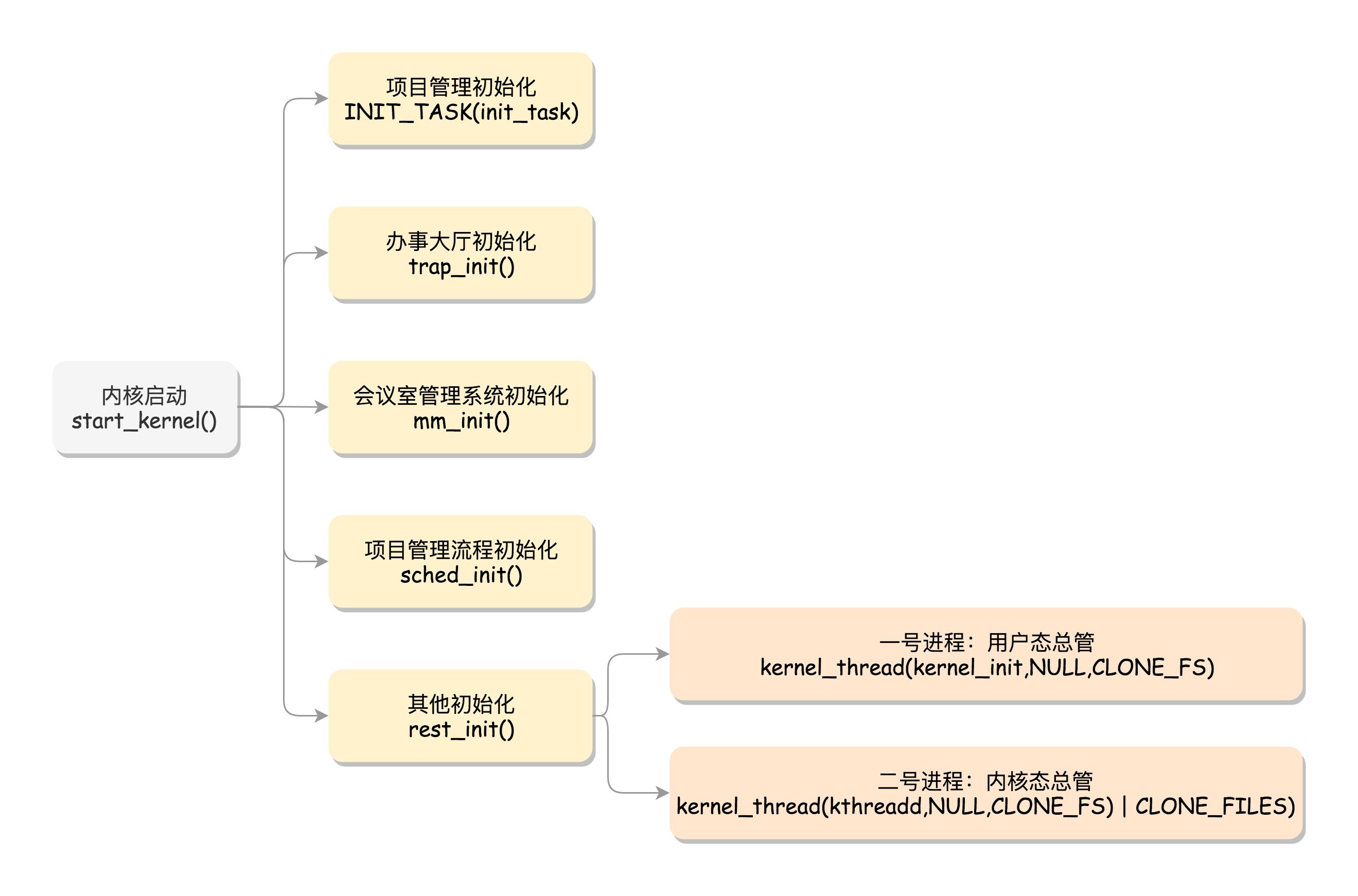
3.1 初始化任务管理
在操作系统里面,先要有个创始进程,有一行指令set_task_stack_end_magic(&init_task)。这里面有一个参数init_task,它的定义是struct task_struct init_task = INIT_TASK(init_task)。它是系统创建的第一个进程,我们称为 0号进程 。这是唯一一个没有通过fork或者kernel_thread产生的进程,是进程列表的第一个。
3.2 初始化中断处理
对应的函数是trap_init(),里面设置了很多中断门(Interrupt Gate),用于处理各种中断。其中有一个set_system_intr_gate(IA32_SYSCALL_VECTOR, entry_INT80_32),这是系统调用的中断门。系统调用也是通过发送中断的方式进行的。
64位的有另外的系统调用方法。
3.3 初始化内存管理
对应的,mm_init()就是用来初始化内存管理模块。
3.4 初始化调度模块
sched_init()就是用于初始化调度模块。
3.5 初始化 rootfs 文件系统
vfs_caches_init()会用来初始化基于内存的文件系统rootfs。在这个函数里面,会调用mnt_init()->init_rootfs()。这里面有一行代码,register_filesystem(&rootfs_fs_type)。在VFS虚拟文件系统里面注册了一种类型,我们定义为struct file_system_type rootfs_fs_type。
3.6 其他初始化
最后,start_kernel()调用的是rest_init(),用来做其他方面的初始化,这里面做了好多的工作。
3.6.1 初始化1号进程
rest_init的第一大工作是,用kernel_thread(kernel_init, NULL, CLONE_FS)创建第二个进程,这个是 1号进程 。
1号进程对于操作系统来讲,有”划时代”的意义。因为它将运行一个用户进程。
x86提供了分层的权限机制,把区域分成了四个Ring,越往里权限越高,越往外权限越低。
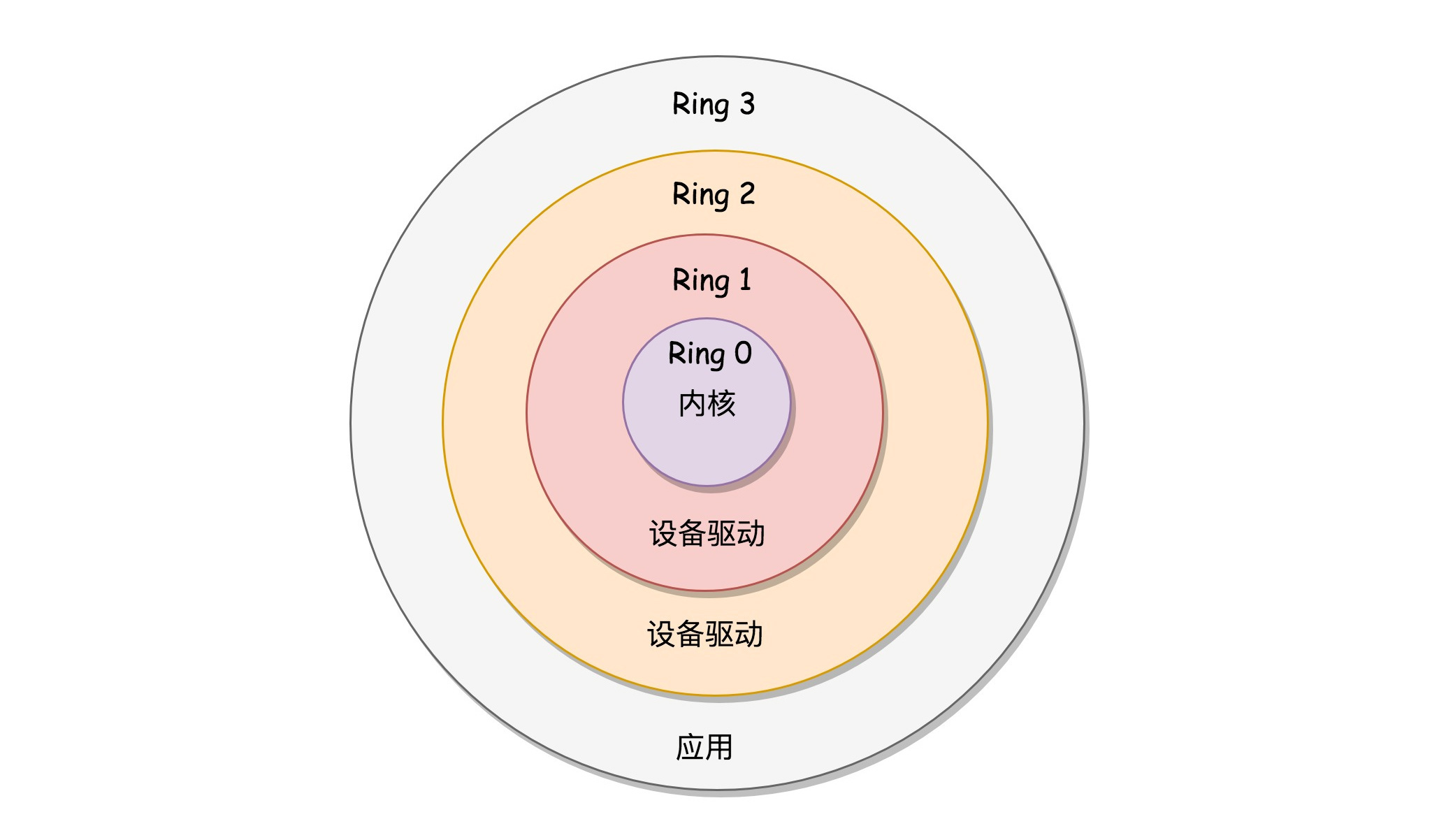
操作系统很好地利用了这个机制,将能够访问关键资源的代码放在Ring0,我们称为 内核态(Kernel Mode) ;将普通的程序代码放在Ring3,我们称为 用户态(User Mode) 。
从内核态到用户态
当执行kernel_thread这个函数的时候,系统在内核态。
kernel_thread的参数是一个函数kernel_init,也就是这个进程会运行这个函数。在kernel_init里面,会调用kernel_init_freeable(),里面有这样的代码:
if (!ramdisk_execute_command) ramdisk_execute_command = "/init";先不管ramdisk是啥,我们回到kernel_init里面。这里面有这样的代码块:
if (ramdisk_execute_command) { ret = run_init_process(ramdisk_execute_command); ...... } ...... if (!try_to_run_init_process("/sbin/init") || !try_to_run_init_process("/etc/init") || !try_to_run_init_process("/bin/init") || !try_to_run_init_process("/bin/sh")) return 0;这就说明,1号进程运行的是一个文件。如果我们打开run_init_process函数,会发现它调用的是do_execve。
static int run_init_process(const char *init_filename) { argv_init[0] = init_filename; return do_execve(getname_kernel(init_filename), (const char __user *const __user *)argv_init, (const char __user *const __user *)envp_init); }execve是一个系统调用,它的作用是运行一个执行文件。加一个do_的往往是内核系统调用的实现。没错,这就是一个系统调用,它会尝试运行ramdisk的”/init”,或者普通文件系统上的”/sbin/init””/etc/init””/bin/init””/bin/sh”。不同版本的Linux会选择不同的文件启动,但是只要有一个起来了就可以。
如何利用执行init文件的机会,从内核态回到用户态呢?
从系统调用的过程可以得到启发,”用户态-系统调用-保存寄存器-内核态执行系统调用-恢复寄存器-返回用户态”,然后接着运行。而咱们刚才运行init,是调用do_execve,正是上面的过程的后半部分,从内核态执行系统调用开始。
do_execve->do_execveat_common->exec_binprm->search_binary_handler,这里面会调用这段内容:
int search_binary_handler(struct linux_binprm *bprm) { ...... struct linux_binfmt *fmt; ...... retval = fmt->load_binary(bprm); ...... }要运行一个程序,需要加载这个二进制文件,它是有一定格式的。Linux下一个常用的格式是ELF(Executable and Linkable Format,可执行与可链接格式)。于是我们就有了下面这个定义:
static struct linux_binfmt elf_format = { .module = THIS_MODULE, .load_binary = load_elf_binary, .load_shlib = load_elf_library, .core_dump = elf_core_dump, .min_coredump = ELF_EXEC_PAGESIZE, };这其实就是先调用load_elf_binary,最后调用start_thread。
void start_thread(struct pt_regs *regs, unsigned long new_ip, unsigned long new_sp) { set_user_gs(regs, 0); regs->fs = 0; regs->ds = __USER_DS; regs->es = __USER_DS; regs->ss = __USER_DS; regs->cs = __USER_CS; regs->ip = new_ip; regs->sp = new_sp; regs->flags = X86_EFLAGS_IF; force_iret(); } EXPORT_SYMBOL_GPL(start_thread);struct pt_regs,看名字里的register,就是寄存器啊!这个结构就是在系统调用的时候,内核中保存用户态运行上下文的,里面将用户态的代码段CS设置为USER_CS,将用户态的数据段DS设置为USER_DS,以及指令指针寄存器IP、栈指针寄存器SP。这里相当于补上了原来系统调用里,保存寄存器的一个步骤。
最后的iret是用于从系统调用中返回。这个时候会恢复寄存器。从哪里恢复呢?按说是从进入系统调用的时候,保存的寄存器里面拿出。好在上面的函数补上了寄存器。CS和指令指针寄存器IP恢复了,指向用户态下一个要执行的语句。DS和函数栈指针SP也被恢复了,指向用户态函数栈的栈顶。所以,下一条指令,就从用户态开始运行了。
ramdisk的作用
init终于从内核到用户态了。一开始到用户态的是ramdisk的init,后来会启动真正根文件系统上的init,成为所有用户态进程的祖先。
为什么会有ramdisk这个东西呢?内核启动的时候,一般会配置参数:
initrd16 /boot/initramfs-3.10.0-862.el7.x86_64.img就是这个东西,这是一个基于内存的文件系统。为啥会有这个呢?
是因为刚才那个init程序是在文件系统上的,文件系统一定是在一个存储设备上的,例如硬盘。Linux访问存储设备,要有驱动才能访问。如果存储系统数目很有限,那驱动可以直接放到内核里面,反正前面我们加载过内核到内存里了,现在可以直接对存储系统进行访问。
但是存储系统越来越多了,如果所有市面上的存储系统的驱动都默认放进内核,内核就太大了。这该怎么办呢?
我们只好先弄一个基于内存的文件系统。内存访问是不需要驱动的,这个就是ramdisk。这个时候,ramdisk是根文件系统。
然后,我们开始运行ramdisk上的/init。等它运行完了就已经在用户态了。/init这个程序会先根据存储系统的类型加载驱动,有了驱动就可以设置真正的根文件系统了。有了真正的根文件系统,ramdisk上的/init会启动文件系统上的init。
接下来就是各种系统的初始化。启动系统的服务,启动控制台,用户就可以登录进来了。
先别忙着高兴,rest_init的第一个大事情才完成。我们仅仅形成了用户态所有进程的祖先。
3.6.2 创建2号进程
kernel_thread(kthreadd, NULL, CLONE_FS | CLONE_FILES)又一次使用kernel_thread函数创建进程。这里需要指出一点,函数名thread可以翻译成”线程”,这也是操作系统很重要的一个概念。它和进程有什么区别呢?为什么这里创建的是进程,函数名却是线程呢?
从用户态来看,创建进程其实就是立项,也就是启动一个项目。这个项目需要人去执行。有多个人并行执行不同的部分,这就叫 多线程(Multithreading) 。如果只有一个人,那它就是这个项目的主线程。
但是从内核态来看,无论是进程,还是线程,我们都可以统称为任务(Task),都使用相同的数据结构,平放在同一个链表中。
这里的函数kthreadd,负责所有内核态的线程的调度和管理,是内核态所有线程运行的祖先。
4. 系统调用
4.1 glibc对系统调用的封装
在glibc的源代码中,有个文件syscalls.list,里面列着所有glibc的函数对应的系统调用,就像下面这个样子:
# File name Caller Syscall name Args Strong name Weak names
open - open Ci:siv __libc_open __open open另外,glibc还有一个脚本make-syscall.sh,可以根据上面的配置文件,对于每一个封装好的系统调用,生成一个文件。这个文件里面定义了一些宏,例如#define SYSCALL_NAME open。
glibc还有一个文件syscall-template.S,使用上面这个宏,定义了这个系统调用的调用方式。
T_PSEUDO (SYSCALL_SYMBOL, SYSCALL_NAME, SYSCALL_NARGS)
ret
T_PSEUDO_END (SYSCALL_SYMBOL)
#define T_PSEUDO(SYMBOL, NAME, N) PSEUDO (SYMBOL, NAME, N)这里的PSEUDO也是一个宏,它的定义如下:
#define PSEUDO(name, syscall_name, args) \
.text; \
ENTRY (name) \
DO_CALL (syscall_name, args); \
cmpl $-4095, %eax; \
jae SYSCALL_ERROR_LABEL里面对于任何一个系统调用,会调用DO_CALL。这也是一个宏,这个宏32位和64位的定义是不一样的。
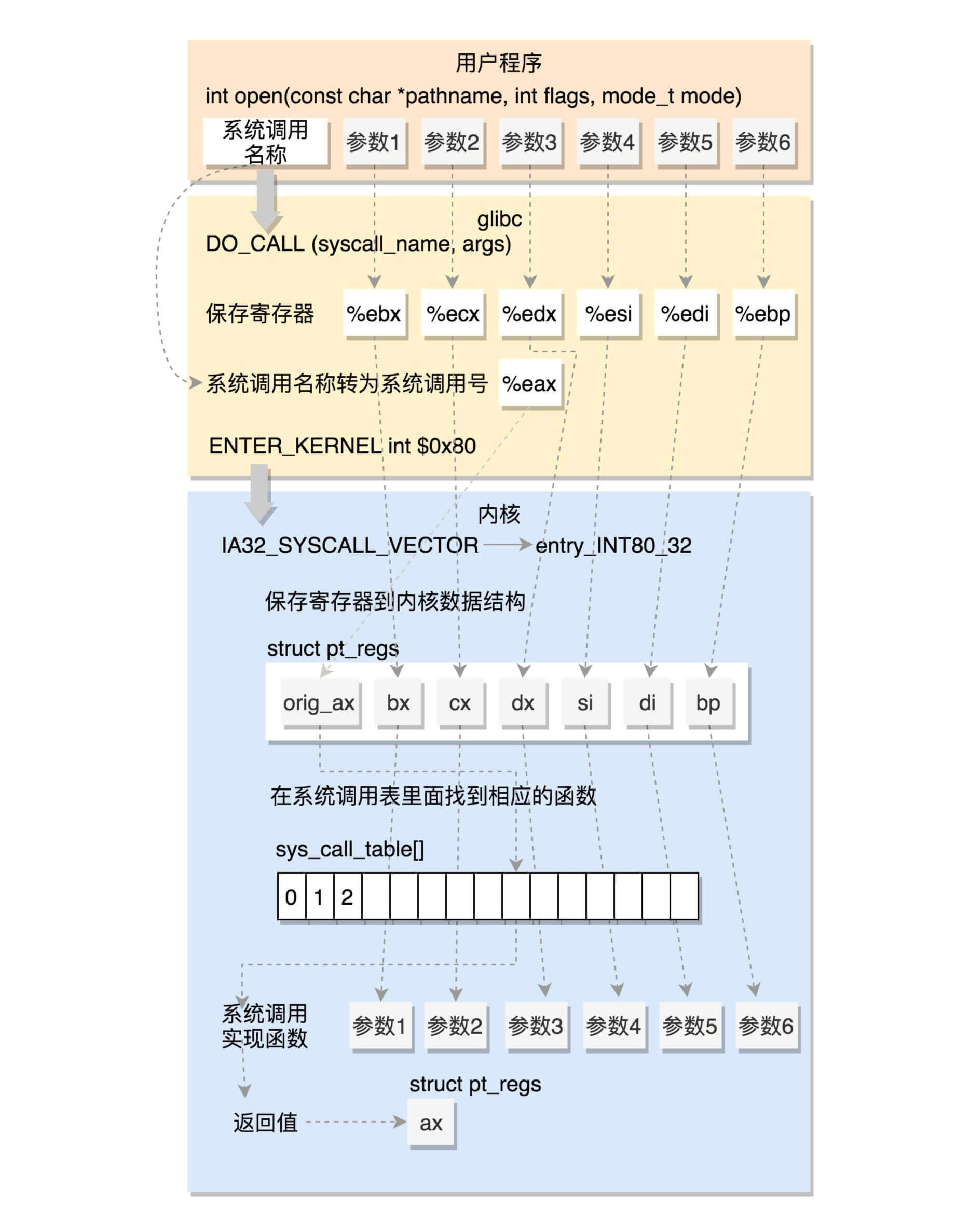
4.2 32位系统调用过程
我们先来看32位的情况(i386目录下的sysdep.h文件)。
/* Linux takes system call arguments in registers:
syscall number %eax call-clobbered
arg 1 %ebx call-saved
arg 2 %ecx call-clobbered
arg 3 %edx call-clobbered
arg 4 %esi call-saved
arg 5 %edi call-saved
arg 6 %ebp call-saved
......
*/
#define DO_CALL(syscall_name, args) \
PUSHARGS_##args \
DOARGS_##args \
movl $SYS_ify (syscall_name), %eax; \
ENTER_KERNEL \
POPARGS_##args这里,我们将请求参数放在寄存器里面,根据系统调用的名称,得到系统调用号,放在寄存器eax里面,然后执行ENTER_KERNEL。
在Linux的源代码注释里面,我们可以清晰地看到,这些寄存器是如何传递系统调用号和参数的。
这里面的ENTER_KERNEL是什么呢?
# define ENTER_KERNEL int $0x80int就是interrupt,也就是”中断”的意思。int $0x80就是触发一个软中断,通过它就可以陷入(trap)内核。
在内核启动的时候,还记得有一个trap_init(),其中有这样的代码:
set_system_intr_gate(IA32_SYSCALL_VECTOR, entry_INT80_32);这是一个软中断的陷入门。当接收到一个系统调用的时候,entry_INT80_32就被调用了。
ENTRY(entry_INT80_32)
ASM_CLAC
pushl %eax /* pt_regs->orig_ax */
SAVE_ALL pt_regs_ax=$-ENOSYS /* save rest */
movl %esp, %eax
call do_syscall_32_irqs_on
.Lsyscall_32_done:
......
.Lirq_return:
INTERRUPT_RETURN通过push和SAVE_ALL将当前用户态的寄存器,保存在pt_regs结构里面。
进入内核之前,保存所有的寄存器,然后调用do_syscall_32_irqs_on。它的实现如下:
static __always_inline void do_syscall_32_irqs_on(struct pt_regs *regs)
{
struct thread_info *ti = current_thread_info();
unsigned int nr = (unsigned int)regs->orig_ax;
......
if (likely(nr < IA32_NR_syscalls)) {
regs->ax = ia32_sys_call_table[nr](
(unsigned int)regs->bx, (unsigned int)regs->cx,
(unsigned int)regs->dx, (unsigned int)regs->si,
(unsigned int)regs->di, (unsigned int)regs->bp);
}
syscall_return_slowpath(regs);
}在这里,我们看到,将系统调用号从eax里面取出来,然后根据系统调用号,在系统调用表中找到相应的函数进行调用,并将寄存器中保存的参数取出来,作为函数参数。如果仔细比对,就能发现,这些参数所对应的寄存器,和Linux的注释是一样的。
根据宏定义,#define ia32_sys_call_table sys_call_table,系统调用就是放在这个表里面。至于这个表是如何形成的,我们后面讲。
当系统调用结束之后,在entry_INT80_32之后,紧接着调用的是INTERRUPT_RETURN,我们能够找到它的定义,也就是iret。
#define INTERRUPT_RETURN iretiret指令将原来用户态保存的现场恢复回来,包含代码段、指令指针寄存器等。这时候用户态进程恢复执行。
这里我总结一下32位的系统调用是如何执行的。
4.3 64位系统调用过程
我们再来看64位的情况(x86_64下的sysdep.h文件)。
/* The Linux/x86-64 kernel expects the system call parameters in
registers according to the following table:
syscall number rax
arg 1 rdi
arg 2 rsi
arg 3 rdx
arg 4 r10
arg 5 r8
arg 6 r9
......
*/
#define DO_CALL(syscall_name, args) \
lea SYS_ify (syscall_name), %rax; \
syscall和之前一样,还是将系统调用名称转换为系统调用号,放到寄存器rax。这里是真正进行调用,不是用中断了,而是改用syscall指令了。并且,通过注释我们也可以知道,传递参数的寄存器也变了。
syscall指令还使用了一种特殊的寄存器,我们叫 特殊模块寄存器(Model Specific Registers,简称MSR) 。这种寄存器是CPU为了完成某些特殊控制功能为目的的寄存器,其中就有系统调用。
在系统初始化的时候,trap_init除了初始化上面的中断模式,这里面还会调用cpu_init->syscall_init。这里面有这样的代码:
wrmsrl(MSR_LSTAR, (unsigned long)entry_SYSCALL_64);rdmsr 和 wrmsr 是用来读写特殊模块寄存器的。MSR_LSTAR就是这样一个特殊的寄存器,当syscall指令调用的时候,会从这个寄存器里面拿出函数地址来调用,也就是调用entry_SYSCALL_64。
在arch/x86/entry/entry_64.S中定义了entry_SYSCALL_64。
ENTRY(entry_SYSCALL_64)
/* Construct struct pt_regs on stack */
pushq $__USER_DS /* pt_regs->ss */
pushq PER_CPU_VAR(rsp_scratch) /* pt_regs->sp */
pushq %r11 /* pt_regs->flags */
pushq $__USER_CS /* pt_regs->cs */
pushq %rcx /* pt_regs->ip */
pushq %rax /* pt_regs->orig_ax */
pushq %rdi /* pt_regs->di */
pushq %rsi /* pt_regs->si */
pushq %rdx /* pt_regs->dx */
pushq %rcx /* pt_regs->cx */
pushq $-ENOSYS /* pt_regs->ax */
pushq %r8 /* pt_regs->r8 */
pushq %r9 /* pt_regs->r9 */
pushq %r10 /* pt_regs->r10 */
pushq %r11 /* pt_regs->r11 */
sub $(6*8), %rsp /* pt_regs->bp, bx, r12-15 not saved */
movq PER_CPU_VAR(current_task), %r11
testl $_TIF_WORK_SYSCALL_ENTRY|_TIF_ALLWORK_MASK, TASK_TI_flags(%r11)
jnz entry_SYSCALL64_slow_path
......
entry_SYSCALL64_slow_path:
/* IRQs are off. */
SAVE_EXTRA_REGS
movq %rsp, %rdi
call do_syscall_64 /* returns with IRQs disabled */
return_from_SYSCALL_64:
RESTORE_EXTRA_REGS
TRACE_IRQS_IRETQ
movq RCX(%rsp), %rcx
movq RIP(%rsp), %r11
movq R11(%rsp), %r11
......
syscall_return_via_sysret:
/* rcx and r11 are already restored (see code above) */
RESTORE_C_REGS_EXCEPT_RCX_R11
movq RSP(%rsp), %rsp
USERGS_SYSRET64这里先保存了很多寄存器到pt_regs结构里面,例如用户态的代码段、数据段、保存参数的寄存器,然后调用entry_SYSCALL64_slow_pat->do_syscall_64。
__visible void do_syscall_64(struct pt_regs *regs)
{
struct thread_info *ti = current_thread_info();
unsigned long nr = regs->orig_ax;
......
if (likely((nr & __SYSCALL_MASK) < NR_syscalls)) {
regs->ax = sys_call_table[nr & __SYSCALL_MASK](
regs->di, regs->si, regs->dx,
regs->r10, regs->r8, regs->r9);
}
syscall_return_slowpath(regs);
}在do_syscall_64里面,从rax里面拿出系统调用号,然后根据系统调用号,在系统调用表sys_call_table中找到相应的函数进行调用,并将寄存器中保存的参数取出来,作为函数参数。如果仔细比对,你就能发现,这些参数所对应的寄存器,和Linux的注释又是一样的。
所以,无论是32位,还是64位,都会到系统调用表sys_call_table这里来。
在研究系统调用表之前,我们看64位的系统调用返回的时候,执行的是USERGS_SYSRET64。定义如下:
#define USERGS_SYSRET64 \
swapgs; \
sysretq;这里,返回用户态的指令变成了sysretq。
我们这里总结一下64位的系统调用是如何执行的。
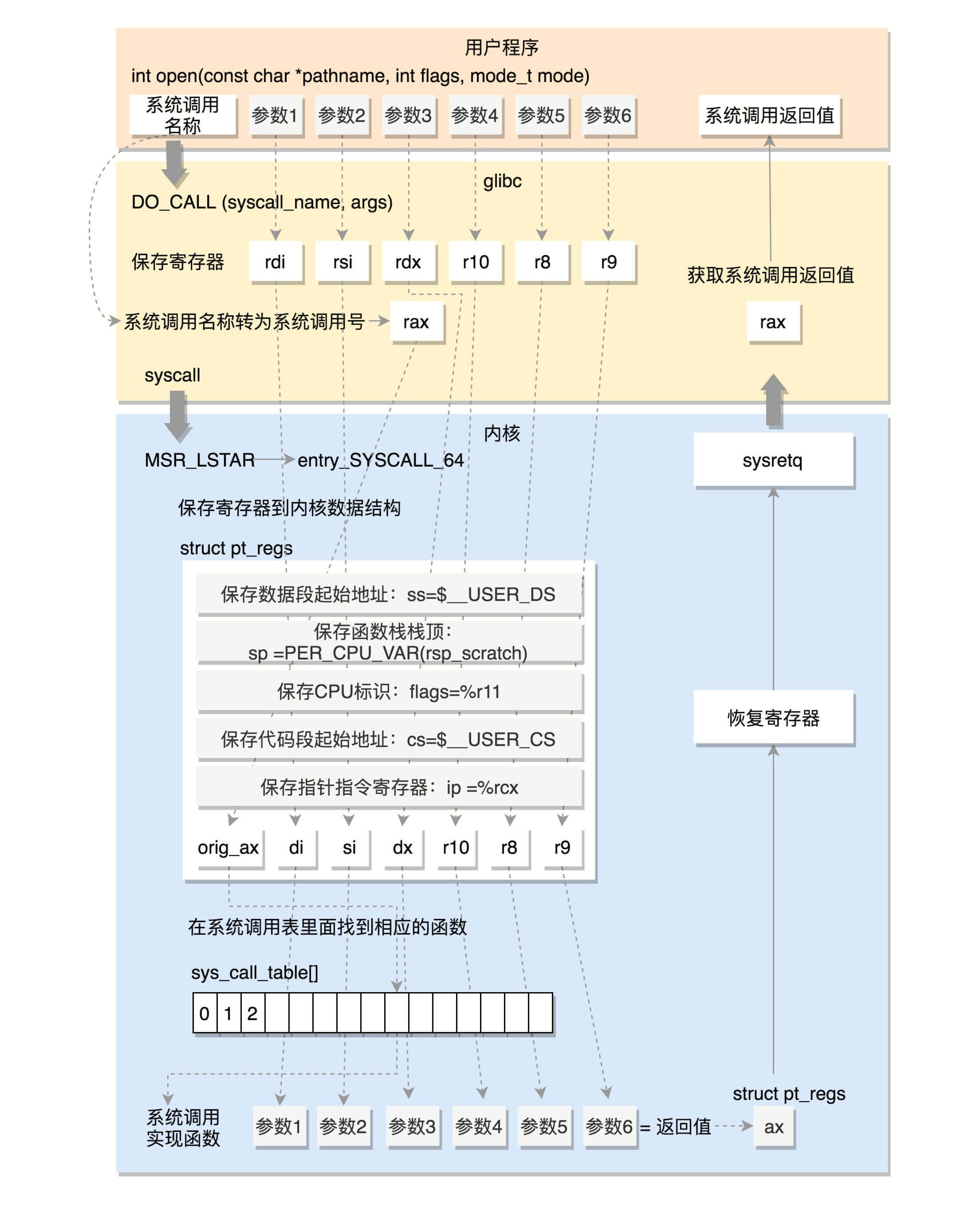
4.4 系统调用表
32位的系统调用表定义在面arch/x86/entry/syscalls/syscall_32.tbl文件里。例如open是这样定义的:
5 i386 open sys_open compat_sys_open64位的系统调用定义在另一个文件arch/x86/entry/syscalls/syscall_64.tbl里。例如open是这样定义的:
2 common open sys_open第一列的数字是系统调用号。可以看出,32位和64位的系统调用号是不一样的。第三列是系统调用的名字,第四列是系统调用在内核的实现函数。不过,它们都是以sys_开头。
系统调用在内核中的实现函数要有一个声明。声明往往在include/linux/syscalls.h文件中。例如sys_open是这样声明的:
asmlinkage long sys_open(const char __user *filename, int flags, umode_t mode);真正的实现这个系统调用,一般在一个.c文件里面,例如sys_open的实现在fs/open.c里面,但是你会发现样子很奇怪。
SYSCALL_DEFINE3(open, const char __user *, filename, int, flags, umode_t, mode)
{
if (force_o_largefile())
flags |= O_LARGEFILE;
return do_sys_open(AT_FDCWD, filename, flags, mode);
}SYSCALL_DEFINE3是一个宏系统调用最多六个参数,根据参数的数目选择宏。具体是这样定义的:
#define SYSCALL_DEFINE1(name, ...) SYSCALL_DEFINEx(1, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE2(name, ...) SYSCALL_DEFINEx(2, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE3(name, ...) SYSCALL_DEFINEx(3, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE4(name, ...) SYSCALL_DEFINEx(4, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE5(name, ...) SYSCALL_DEFINEx(5, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE6(name, ...) SYSCALL_DEFINEx(6, _##name, __VA_ARGS__)
#define SYSCALL_DEFINEx(x, sname, ...) \
SYSCALL_METADATA(sname, x, __VA_ARGS__) \
__SYSCALL_DEFINEx(x, sname, __VA_ARGS__)
#define __PROTECT(...) asmlinkage_protect(__VA_ARGS__)
#define __SYSCALL_DEFINEx(x, name, ...) \
asmlinkage long sys##name(__MAP(x,__SC_DECL,__VA_ARGS__)) \
__attribute__((alias(__stringify(SyS##name)))); \
static inline long SYSC##name(__MAP(x,__SC_DECL,__VA_ARGS__)); \
asmlinkage long SyS##name(__MAP(x,__SC_LONG,__VA_ARGS__)); \
asmlinkage long SyS##name(__MAP(x,__SC_LONG,__VA_ARGS__)) \
{ \
long ret = SYSC##name(__MAP(x,__SC_CAST,__VA_ARGS__)); \
__MAP(x,__SC_TEST,__VA_ARGS__); \
__PROTECT(x, ret,__MAP(x,__SC_ARGS,__VA_ARGS__)); \
return ret; \
} \
static inline long SYSC##name(__MAP(x,__SC_DECL,__VA_ARGS__)如果我们把宏展开之后,实现如下,和声明的是一样的。
asmlinkage long sys_open(const char __user * filename, int flags, int mode)
{
long ret;
if (force_o_largefile())
flags |= O_LARGEFILE;
ret = do_sys_open(AT_FDCWD, filename, flags, mode);
asmlinkage_protect(3, ret, filename, flags, mode);
return ret;
}声明和实现都好了。接下来,在编译的过程中,需要根据syscall_32.tbl和syscall_64.tbl生成自己的unistd_32.h和unistd_64.h。生成方式在arch/x86/entry/syscalls/Makefile中。
声明和实现都好了。接下来,在编译的过程中,需要根据syscall_32.tbl和syscall_64.tbl生成自己的unistd_32.h和unistd_64.h。生成方式在arch/x86/entry/syscalls/Makefile中。
这里面会使用两个脚本,其中第一个脚本arch/x86/entry/syscalls/syscallhdr.sh,会在文件中生成#define NR_open;第二个脚本arch/x86/entry/syscalls/syscalltbl.sh,会在文件中生成SYSCALL(__NR_open, sys_open)。这样,unistd_32.h和unistd_64.h是对应的系统调用号和系统调用实现函数之间的对应关系。
在文件arch/x86/entry/syscall_32.c,定义了这样一个表,里面include了这个头文件,从而所有的sys_系统调用都在这个表里面了。
__visible const sys_call_ptr_t ia32_sys_call_table[__NR_syscall_compat_max+1] = {
/*
* Smells like a compiler bug -- it doesn't work
* when the & below is removed.
*/
[0 ... __NR_syscall_compat_max] = &sys_ni_syscall,
#include <asm/syscalls_32.h>
};同理,在文件arch/x86/entry/syscall_64.c,定义了这样一个表,里面include了这个头文件,这样所有的sys_系统调用就都在这个表里面了。
/* System call table for x86-64. */
asmlinkage const sys_call_ptr_t sys_call_table[__NR_syscall_max+1] = {
/*
* Smells like a compiler bug -- it doesn't work
* when the & below is removed.
*/
[0 ... __NR_syscall_max] = &sys_ni_syscall,
#include <asm/syscalls_64.h>
};二、进程管理
5. 进程
5.1 源码编译
CPU是不能执行文本文件里面的指令的,这些指令只有人能看懂,CPU能够执行的命令是二进制的,比如”0101”这种,所以这些指令还需要翻译一下,这个翻译的过程就是编译(Compile)。
在Linux下面,二进制的程序也要有严格的格式,这个格式我们称为ELF(Executeable and Linkable Format,可执行与可链接格式)。这个格式可以根据编译的结果不同,分为不同的格式。
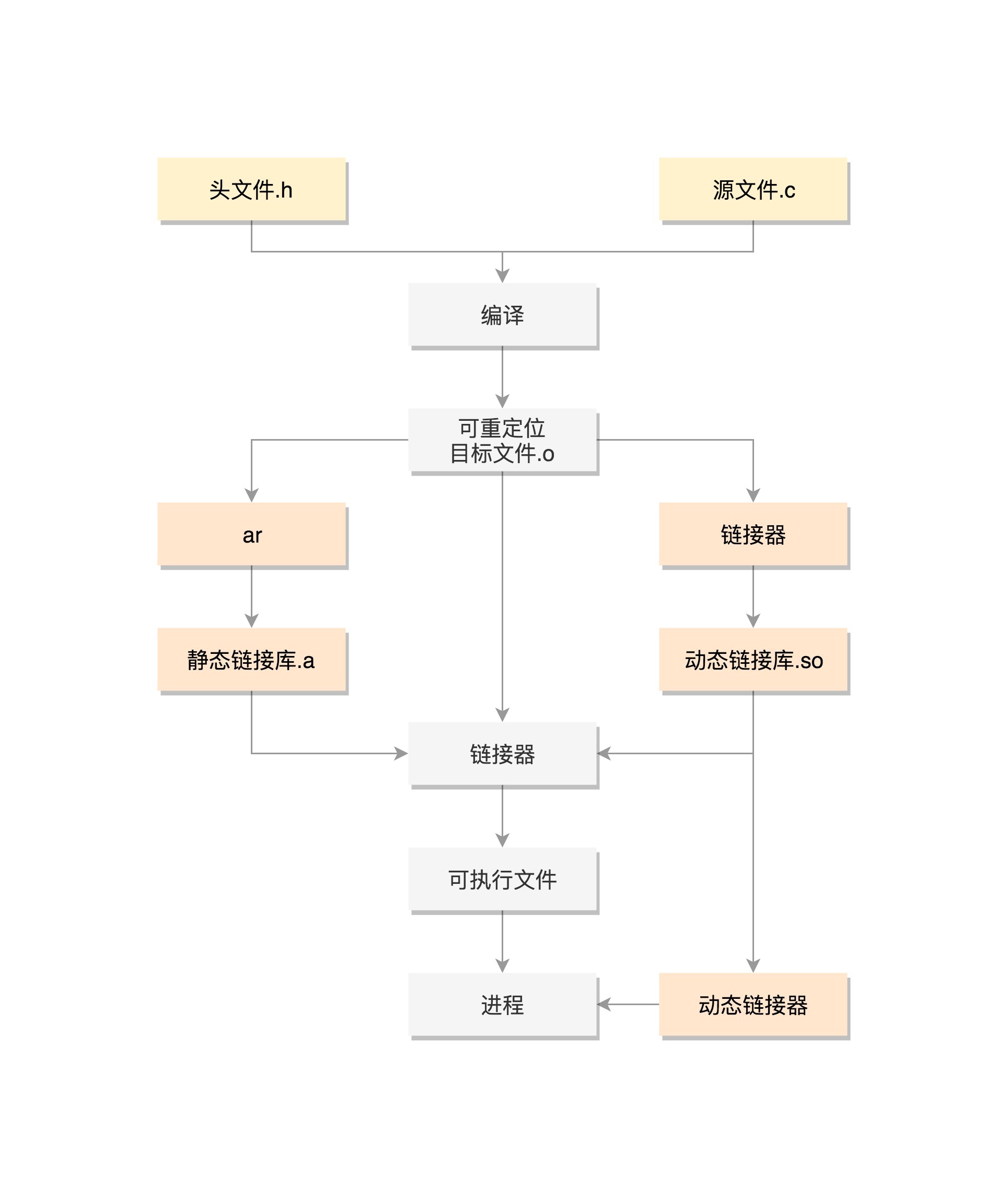
gcc -c -fPIC mylib.c
gcc -c -fPIC test_mylib.c可重定位文件
在编译的时候,先做预处理工作,例如将头文件嵌入到正文中,将定义的宏展开,然后就是真正的编译过程,最终编译成为.o文件,这就是ELF的第一种类型,可重定位文件(Relocatable File) 。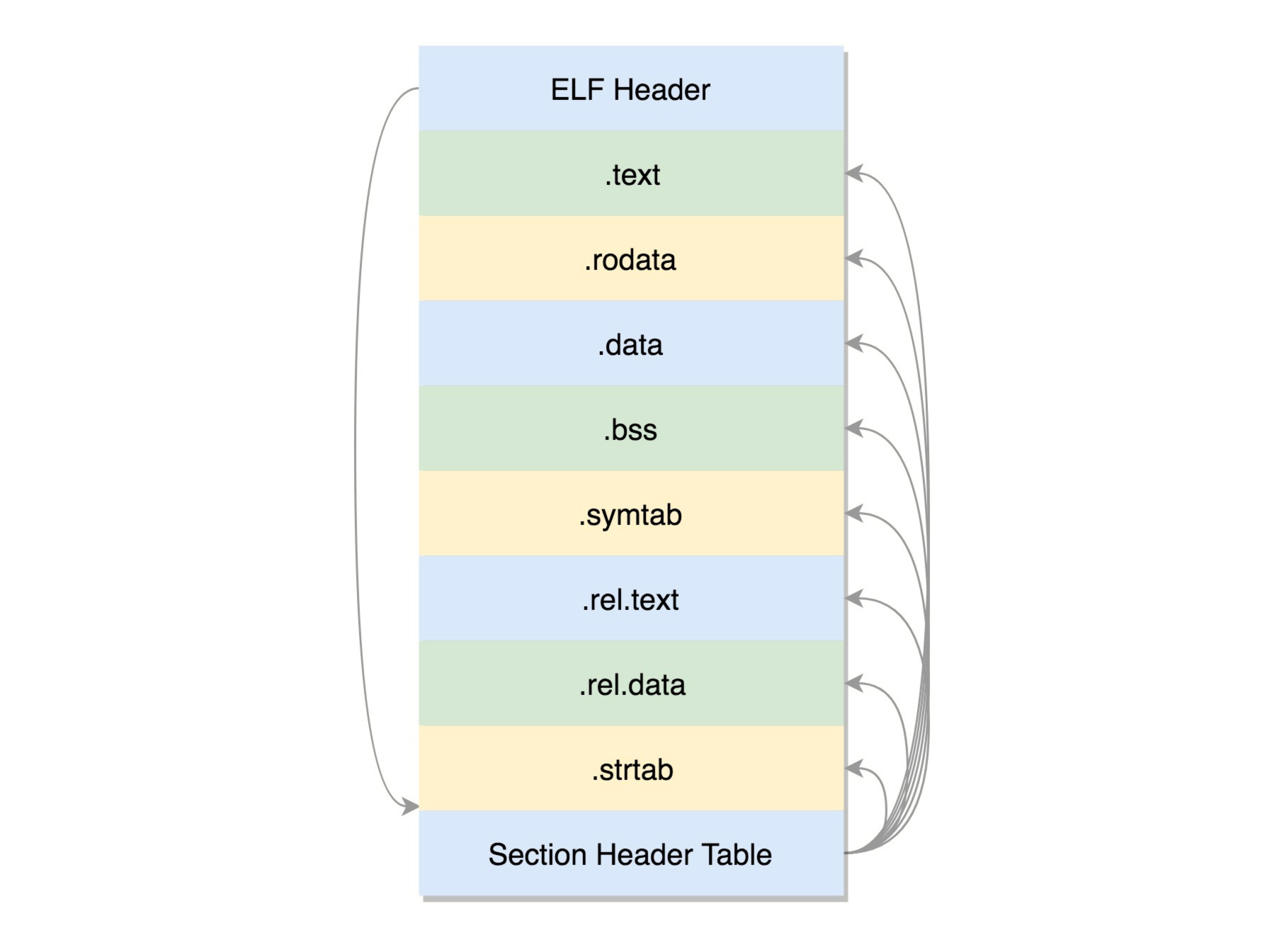
ELF文件的头是用于描述整个文件的。这个文件格式在内核中有定义,分别为struct elf32_hdr和struct elf64_hdr。
接下来来看一个一个的section,也叫节。
- .text:放编译好的二进制可执行代码
- .data:已经初始化好的全局变量
- .rodata:只读数据,例如字符串常量、const的变量
- .bss:未初始化全局变量,运行时会置0
- .symtab:符号表,记录的则是函数和变量
.strtab:字符串表、字符串常量和变量名
这些节的元数据信息也需要有一个地方保存,就是最后的节头部表(Section Header Table)。在这个表里面,每一个section都有一项,在代码里面也有定义struct elf32_shdr和struct elf64_shdr。在ELF的头里面,有描述这个文件的节头部表的位置,有多少个表项等等信息。
.o里面的位置是不确定的,但是必须是可重新定位的,因为它将来是要做函数库的。有的section,例如.rel.text, .rel.data就与重定位有关。
要想让代码被重用,不能以.o的形式存在,而是要形成库文件,最简单的类型是静态链接库.a文件(Archives),仅仅将一系列对象文件(.o)归档为一个文件,使用命令ar创建。
ar cr libstatic_mylib.a mylib.o虽然这里libstatic_mylib.a里面只有一个.o,但是实际情况可以有多个.o。当有程序要使用这个静态连接库的时候,会将.o文件提取出来,链接到程序中。
可执行文件
gcc -o static_test_mylib test_mylib.o -L. -lstatic_mylib在这个命令里,-L表示在当前目录下找.a文件,-lstatic_mylib会自动补全文件名,比如加前缀lib,后缀.a,变成libstatic_mylib.a,找到这个.a文件后,将里面的mylib.o取出来,和test_mylib.o做一个链接,形成二进制执行文件static_test_mylib。
形成的二进制文件叫可执行文件,是ELF的第二种格式,格式如下:
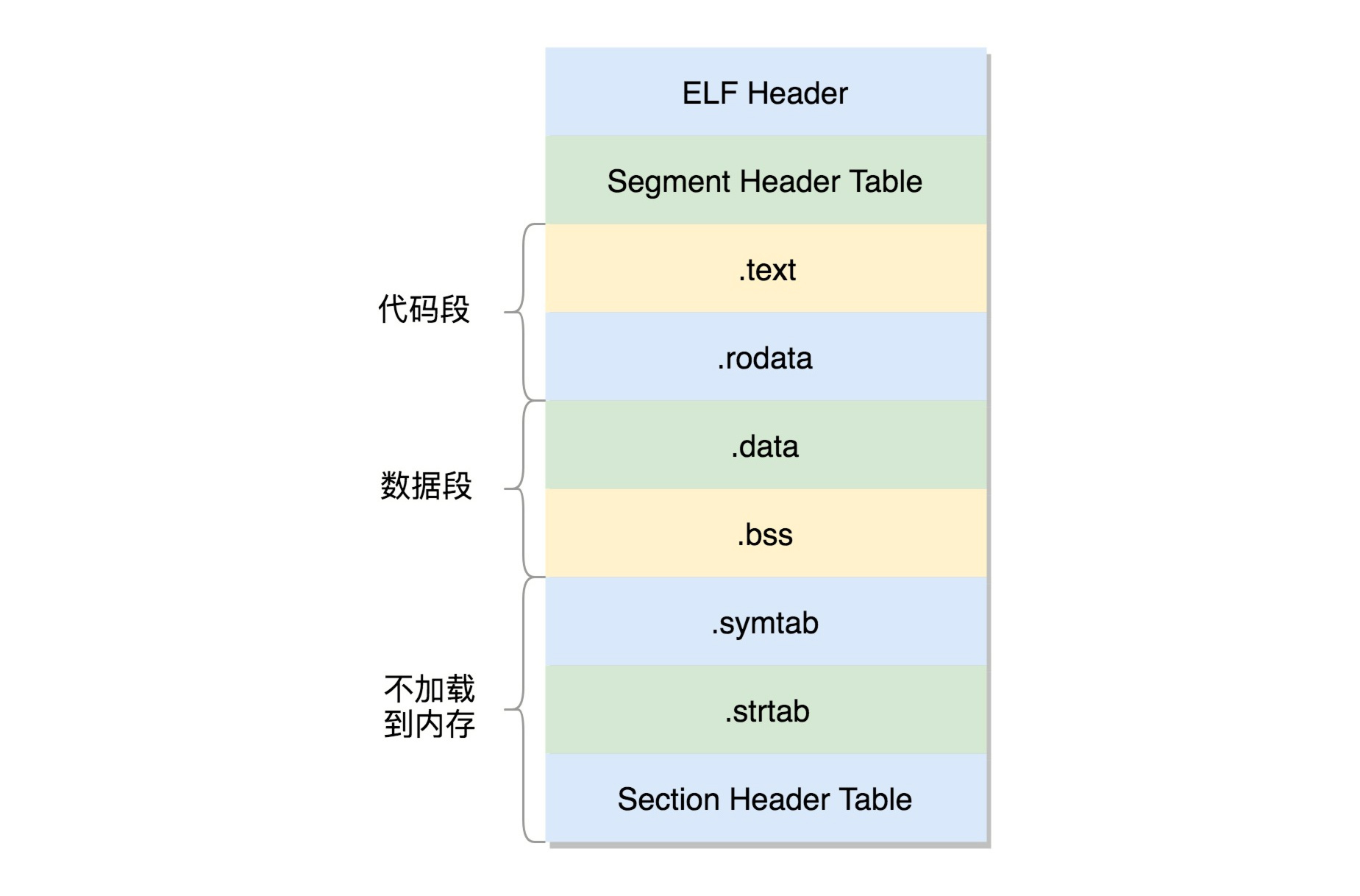
这个格式和.o文件大致相似,还是分成一个个的section,并且被节头表描述。只不过这些section是多个.o文件合并过的。但是这个时候,这个文件已经是马上就可以加载到内存里面执行的文件了,因而这些section被分成了需要加载到内存里面的代码段、数据段和不需要加载到内存里面的部分,将小的section合成了大的段segment,并且在最前面加一个段头表(Segment Header Table)。在代码里面的定义为struct elf32_phdr和struct elf64_phdr,这里面除了有对于段的描述之外,最重要的是p_vaddr,这个是这个段加载到内存的虚拟地址。
在ELF头里面,有一项e_entry,也是个虚拟地址,是这个程序运行的入口。
静态链接库一旦链接进去,代码和变量的section都合并了,因而程序运行的时候,就不依赖于这个库是否存在。但是这样有一个缺点,就是相同的代码段,如果被多个程序使用的话,在内存里面就有多份,而且一旦静态链接库更新了,如果二进制执行文件不重新编译,也不随着更新。
动态链接库
因而就出现了另一种,动态链接库(Shared Libraries),不仅仅是一组对象文件的简单归档,而是多个对象文件的重新组合,可被多个程序共享。
gcc -shared -fPIC -o libdynamic_mylib.so mylib.o当一个动态链接库被链接到一个程序文件中的时候,最后的程序文件并不包括动态链接库中的代码,而仅仅包括对动态链接库的引用,并且不保存动态链接库的全路径,仅仅保存动态链接库的名称。
gcc -o dynamic_test_mylib test_mylib.o -L. -ldynamic_mylib当运行这个程序的时候,首先寻找动态链接库,然后加载它。默认情况下,系统在/lib和/usr/lib文件夹下寻找动态链接库。如果找不到就会报错,我们可以设定LD_LIBRARY_PATH环境变量,程序运行时会在此环境变量指定的文件夹下寻找动态链接库。
动态链接库,就是ELF的第三种类型, 共享对象文件(Shared Object) 。
基于动态连接库创建出来的二进制文件格式还是ELF,但是稍有不同。
首先,多了一个.interp的Segment,这里面是ld-linux.so,这是动态链接器,也就是说,运行时的链接动作都是它做的。
另外,ELF文件中还多了两个section,一个是.plt,过程链接表(Procedure Linkage Table,PLT),一个是.got.plt,全局偏移量表(Global Offset Table,GOT)。
它们是怎么工作的,使得程序运行的时候,可以将so文件动态链接到进程空间的呢?
dynamic_test_mylib这个程序要调用libdynamic_mylib.so里的函数。由于是运行时才去找,编译的时候,压根不知道这个函数在哪里,所以就在PLT里面建立一项PLT[x]。这一项也是一些代码,有点像一个本地的代理,在二进制程序dynamic_test_mylib里面,不直接调用libdynamic_mylib.so里的函数,而是调用PLT[x]里面的代理代码,这个代理代码会在运行的时候找真正的函数。
去哪里找代理代码呢?这就用到了GOT,这里面也会为libdynamic_mylib.so中的函数创建一项GOT[y]。这一项是运行时libdynamic_mylib.so中的函数在内存中真正的地址。
如果这个地址在,dynamic_test_mylib调用PLT[x]里面的代理代码,代理代码调用GOT表中对应项GOT[y],调用的就是加载到内存中的libdynamic_mylib.so里面的对应函数了。
但是GOT怎么知道的呢?对于libdynamic_mylib.so中的函数,GOT一开始就会创建一项GOT[y],但是这里面没有真正的地址,因为它也不知道,但是它有办法,它又回调PLT,告诉它,你里面的代理代码来找我要libdynamic_mylib.so中函数的真实地址,我不知道,你想想办法吧。
PLT这个时候会转而调用PLT[0],也即第一项,PLT[0]转而调用GOT[2],这里面是ld-linux.so的入口函数,这个函数会找到加载到内存中的libdynamic_mylib.so里面的对应函数的地址,然后把这个地址放在GOT[y]里面。下次,PLT[x]的代理函数就能够直接调用了。
5.2 运行程序为进程
在内核中,有这样一个数据结构,用来定义加载二进制文件的方法。
struct linux_binfmt {
struct list_head lh;
struct module *module;
int (*load_binary)(struct linux_binprm *);
int (*load_shlib)(struct file *);
int (*core_dump)(struct coredump_params *cprm);
unsigned long min_coredump; /* minimal dump size */
} __randomize_layout;对于ELF文件格式,有对应的实现。
static struct linux_binfmt elf_format = {
.module = THIS_MODULE,
.load_binary = load_elf_binary,
.load_shlib = load_elf_library,
.core_dump = elf_core_dump,
.min_coredump = ELF_EXEC_PAGESIZE,
};load_elf_binary是不是你很熟悉?没错,我们加载内核镜像的时候,用的也是这种格式。
还记得当时是谁调用的load_elf_binary函数吗?具体是这样的:do_execve->do_execveat_common->exec_binprm->search_binary_handler。
那do_execve又是被谁调用的呢?我们看下面的代码。
SYSCALL_DEFINE3(execve,
const char __user *, filename,
const char __user *const __user *, argv,
const char __user *const __user *, envp)
{
return do_execve(getname(filename), argv, envp);
}学过了系统调用一节,你会发现,原理是exec这个系统调用最终调用的load_elf_binary。
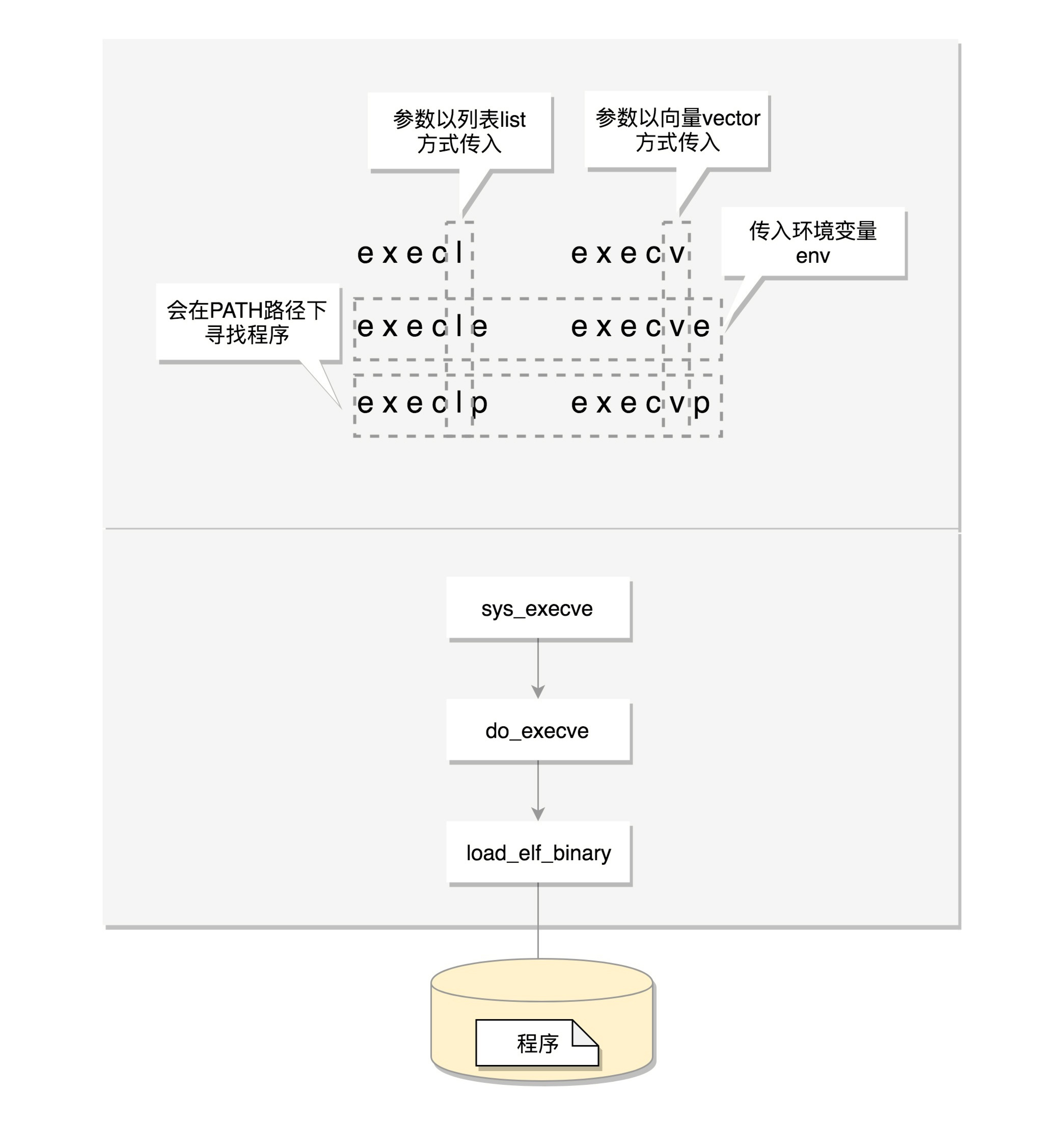
exec比较特殊,它是一组函数:
- 包含p的函数(execvp, execlp)会在PATH路径下面寻找程序;
- 不包含p的函数需要输入程序的全路径;
- 包含v的函数(execv, execvp, execve)以数组的形式接收参数;
- 包含l的函数(execl, execlp, execle)以列表的形式接收参数;
- 包含e的函数(execve, execle)以数组的形式接收环境变量。
5.3 进程树
既然所有的进程都是从父进程fork过来的,那总归有一个祖宗进程,这就是咱们系统启动的init进程。
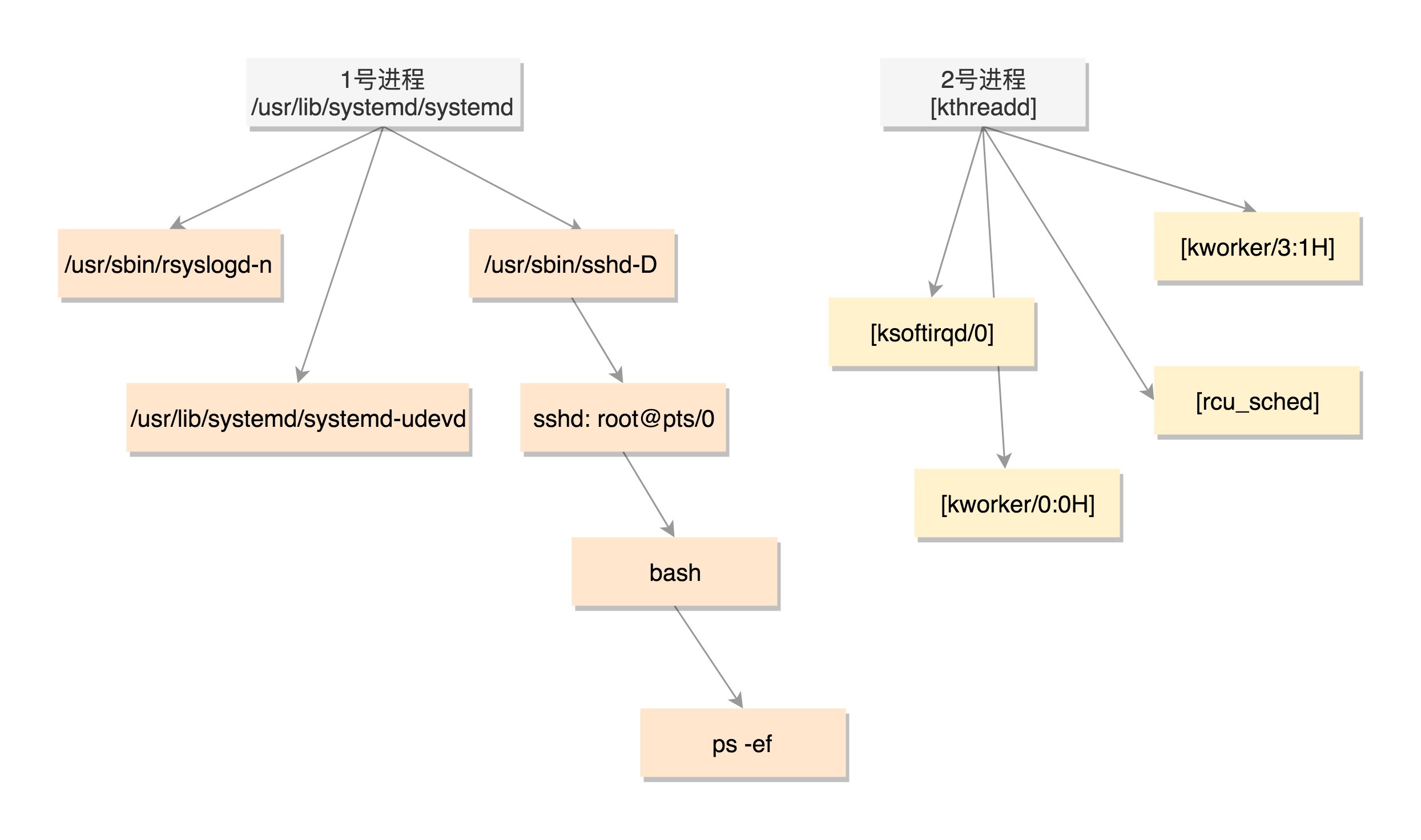
在解析Linux的启动过程的时候,1号进程是/sbin/init。如果在centOS 7里面,我们ls一下,可以看到,这个进程是被软链接到systemd的。
/sbin/init -> ../lib/systemd/systemd系统启动之后,init进程会启动很多的daemon进程,为系统运行提供服务,然后就是启动getty,让用户登录,登录后运行shell,用户启动的进程都是通过shell运行的,从而形成了一棵进程树。
我们可以通过ps -ef命令查看当前系统启动的进程,我们会发现有三类进程。
$ ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 2018 ? 00:00:29 /usr/lib/systemd/systemd --system --deserialize 21
root 2 0 0 2018 ? 00:00:00 [kthreadd]
root 3 2 0 2018 ? 00:00:00 [ksoftirqd/0]
root 5 2 0 2018 ? 00:00:00 [kworker/0:0H]
root 9 2 0 2018 ? 00:00:40 [rcu_sched]
......
root 337 2 0 2018 ? 00:00:01 [kworker/3:1H]
root 380 1 0 2018 ? 00:00:00 /usr/lib/systemd/systemd-udevd
root 415 1 0 2018 ? 00:00:01 /sbin/auditd
root 498 1 0 2018 ? 00:00:03 /usr/lib/systemd/systemd-logind
......
root 852 1 0 2018 ? 00:06:25 /usr/sbin/rsyslogd -n
root 2580 1 0 2018 ? 00:00:00 /usr/sbin/sshd -D
root 29058 2 0 Jan03 ? 00:00:01 [kworker/1:2]
root 29672 2 0 Jan04 ? 00:00:09 [kworker/2:1]
root 30467 1 0 Jan06 ? 00:00:00 /usr/sbin/crond -n
root 31574 2 0 Jan08 ? 00:00:01 [kworker/u128:2]
......
root 32792 2580 0 Jan10 ? 00:00:00 sshd: root@pts/0
root 32794 32792 0 Jan10 pts/0 00:00:00 -bash
root 32901 32794 0 00:01 pts/0 00:00:00 ps -ef你会发现,PID 1的进程就是我们的init进程systemd,PID 2的进程是内核线程kthreadd,这两个我们在内核启动的时候都见过。其中用户态的不带中括号,内核态的带中括号。
接下来进程号依次增大,但是你会看所有带中括号的内核态的进程,祖先都是2号进程。而用户态的进程,祖先都是1号进程。tty那一列,是问号的,说明不是前台启动的,一般都是后台的服务。
pts的父进程是sshd,bash的父进程是pts,ps -ef这个命令的父进程是bash。这样整个链条都比较清晰了。
5.4 总结
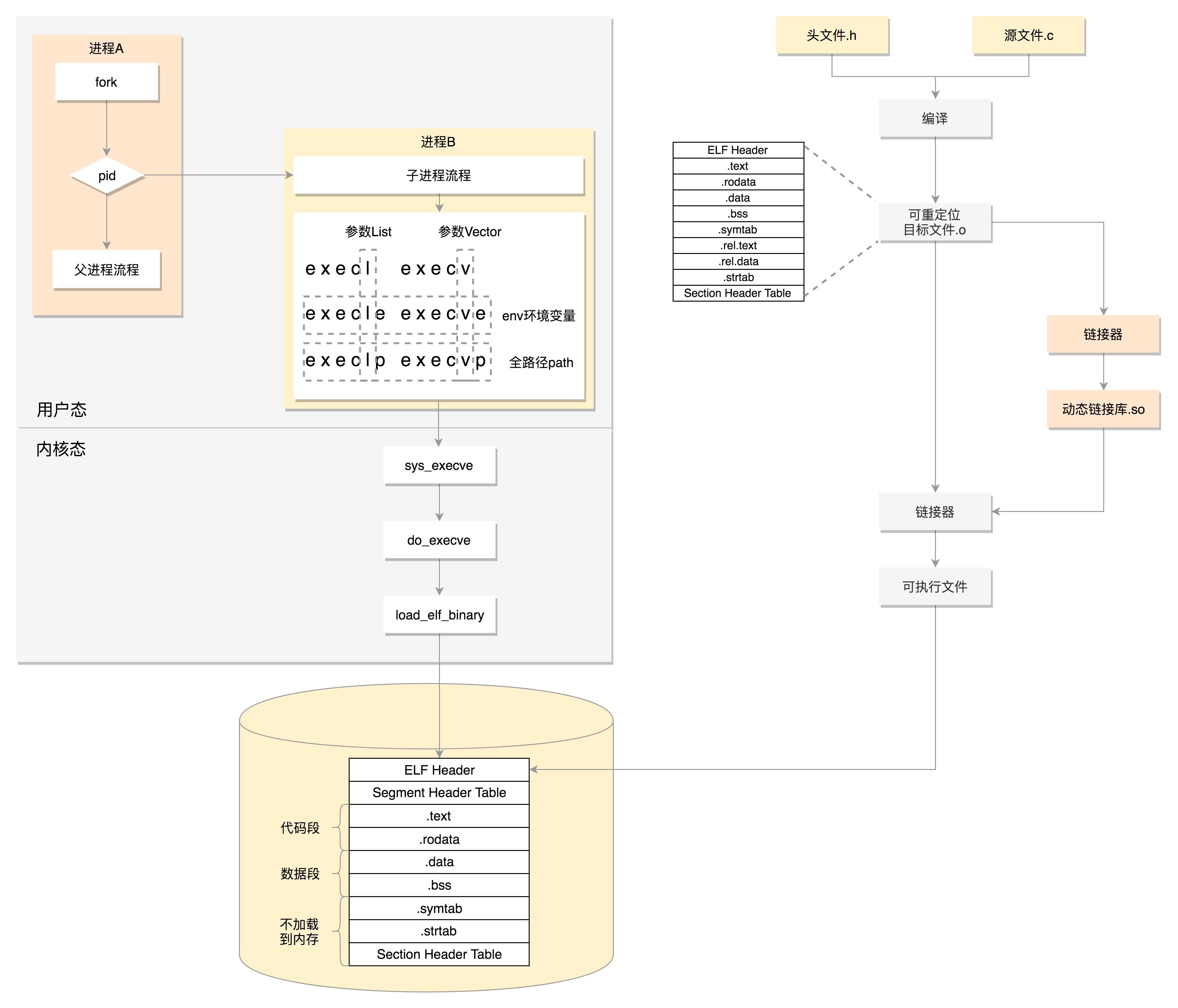
我们首先通过图右边的文件编译过程,生成so文件和可执行文件,放在硬盘上。下图左边的用户态的进程A执行fork,创建进程B,在进程B的处理逻辑中,执行exec系列系统调用。这个系统调用会通过load_elf_binary方法,将刚才生成的可执行文件,加载到进程B的内存中执行。
6. 线程
6.1 为什么要有线程?
对于任何一个进程来讲,即便我们没有主动去创建线程,进程也是默认有一个主线程的。线程是负责执行二进制指令的,一行一行执行下去。进程要比线程管的宽多了,除了执行指令之外,内存、文件系统等等都要它来管。
进程相当于一个项目,而线程就是为了完成项目需求,而建立的一个个开发任务。
使用进程实现并行执行的问题也有两个。第一,创建进程占用资源太多;第二,进程之间的通信需要数据在不同的内存空间传来传去,无法共享。
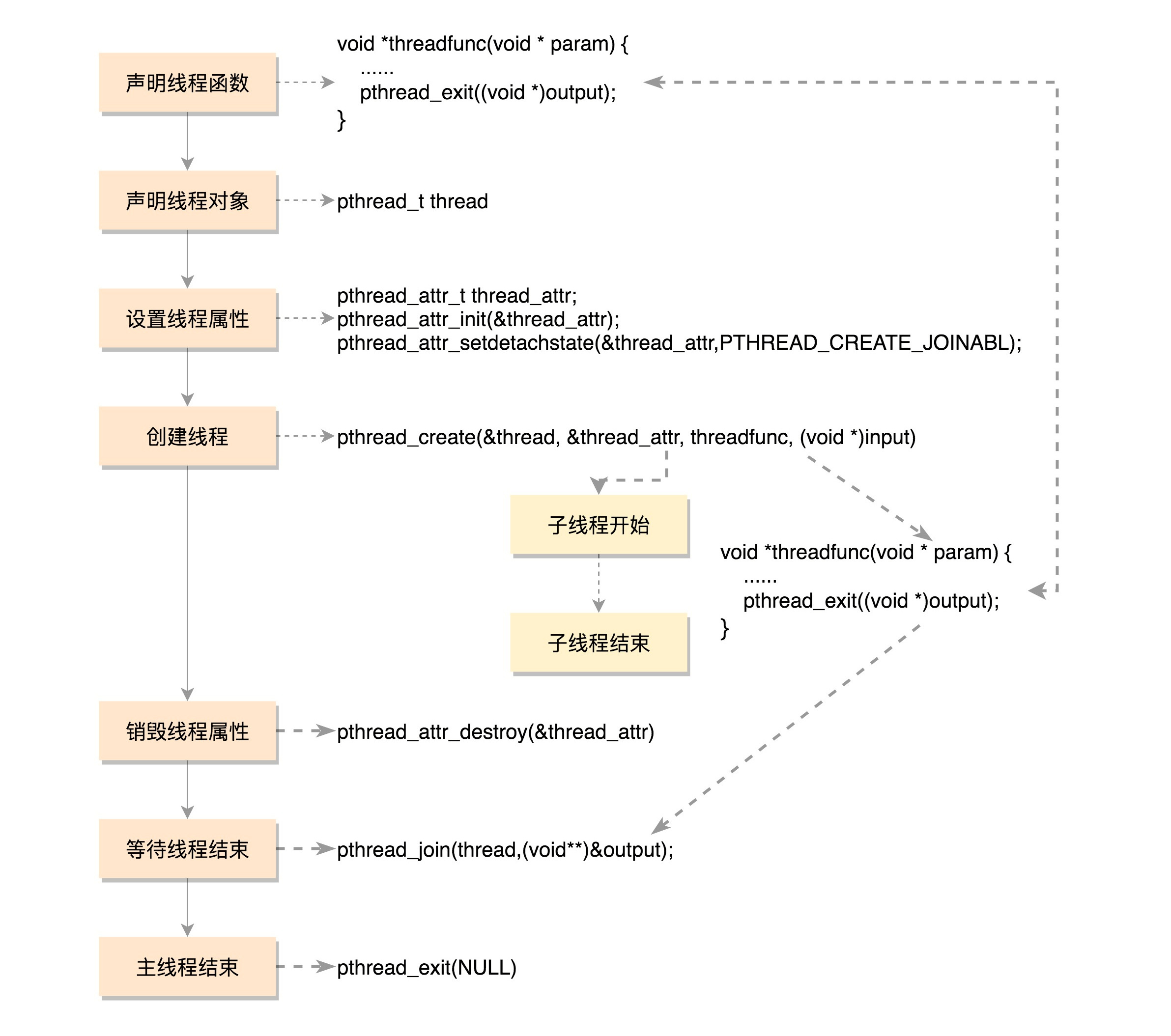
6.2 如何创建线程?
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
#define NUM_OF_TASKS 5
void *downloadfile(void *filename)
{
printf("I am downloading the file %s!\n", (char *)filename);
sleep(10);
long downloadtime = rand()%100;
printf("I finish downloading the file within %d minutes!\n", downloadtime);
pthread_exit((void *)downloadtime);
}
int main(int argc, char *argv[])
{
char files[NUM_OF_TASKS][20]={"file1.avi","file2.rmvb","file3.mp4","file4.wmv","file5.flv"};
pthread_t threads[NUM_OF_TASKS];
int rc;
int t;
int downloadtime;
pthread_attr_t thread_attr;
pthread_attr_init(&thread_attr);
pthread_attr_setdetachstate(&thread_attr,PTHREAD_CREATE_JOINABL);
for(t=0;t<NUM_OF_TASKS;t++){
printf("creating thread %d, please help me to download %s\n", t, files[t]);
rc = pthread_create(&threads[t], &thread_attr, downloadfile, (void *)files[t]);
if (rc){
printf("ERROR; return code from pthread_create() is %d\n", rc);
exit(-1);
}
}
pthread_attr_destroy(&thread_attr);
for(t=0;t<NUM_OF_TASKS;t++){
pthread_join(threads[t],(void**)&downloadtime);
printf("Thread %d downloads the file %s in %d minutes.\n",t,files[t],downloadtime);
}
pthread_exit(NULL);
}一个运行中的线程可以调用pthread_exit退出线程。这个函数可以传入一个参数转换为(void *)类型。这是线程退出的返回值。
接下来,我们来看主线程。在这里面,我列了五个文件名。接下来声明了一个数组,里面有五个pthread_t类型的线程对象。
接下来,声明一个线程属性pthread_attr_t。我们通过pthread_attr_init初始化这个属性,并且设置属性PTHREAD_CREATE_JOINABLE。这表示将来主线程程等待这个线程的结束,并获取退出时的状态。
接下来是一个循环。对于每一个文件和每一个线程,可以调用pthread_create创建线程。一共有四个参数,第一个参数是线程对象,第二个参数是线程的属性,第三个参数是线程运行函数,第四个参数是线程运行函数的参数。主线程就是通过第四个参数,将自己的任务派给子线程。
任务分配完毕,每个线程下载一个文件,接下来主线程要做的事情就是等待这些子任务完成。当一个线程退出的时候,就会发送信号给其他所有同进程的线程。有一个线程使用pthread_join获取这个线程退出的返回值。线程的返回值通过pthread_join传给主线程,这样子线程就将自己下载文件所耗费的时间,告诉给主线程。
好了,程序写完了,开始编译。多线程程序要依赖于libpthread.so。
gcc download.c -lpthread总结一下,一个普通线程的创建和运行过程。
6.3 线程的数据
我们把线程访问的数据细分成三类。
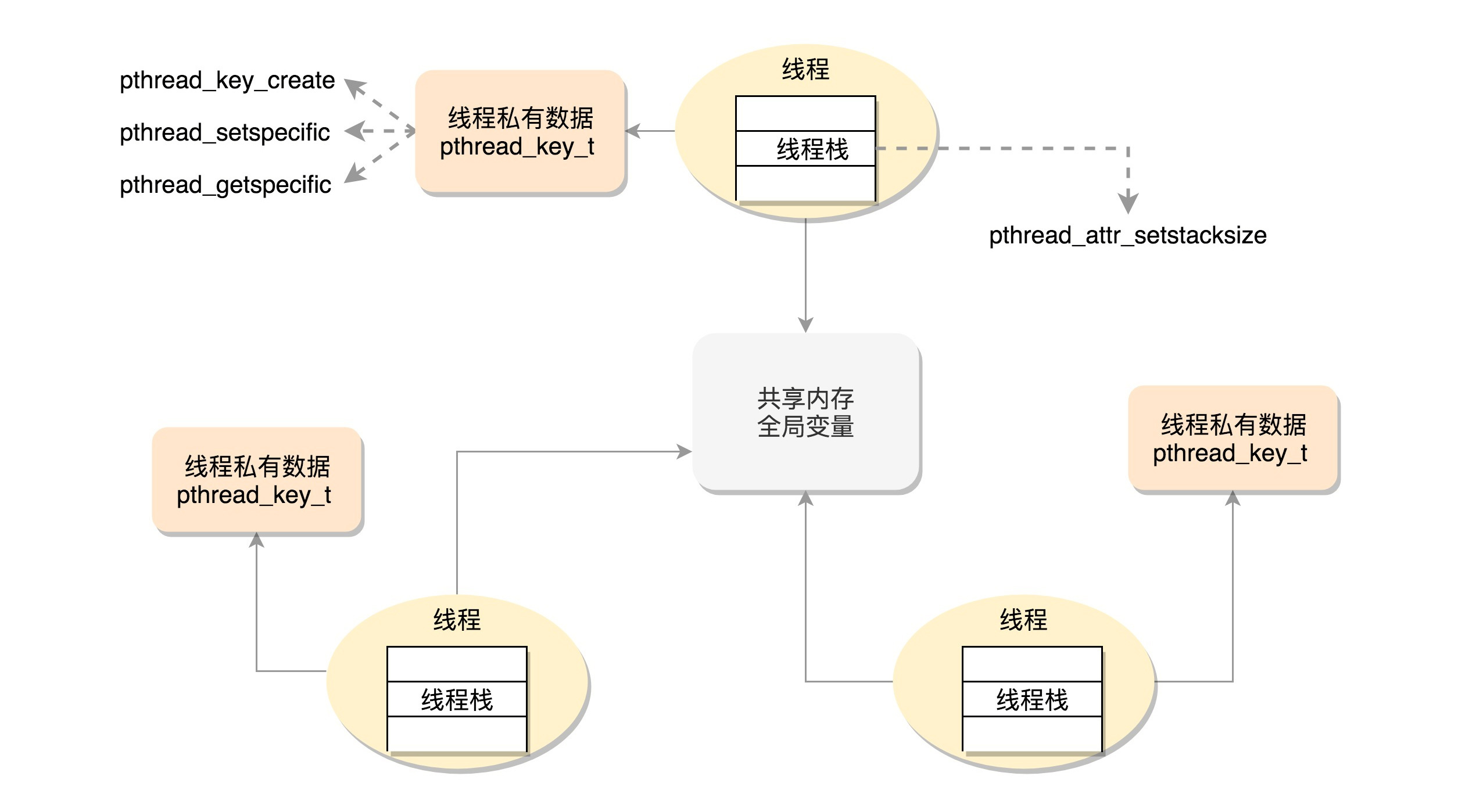
线程栈上的本地数据
比如函数执行过程中的局部变量。前面我们说过,函数的调用会使用栈的模型,这在线程里面是一样的。只不过每个线程都有自己的栈空间。
栈的大小可以通过命令ulimit -a查看,默认情况下线程栈大小为8192(8MB)。我们可以使用命令ulimit -s修改。
对于线程栈,可以通过下面这个函数pthread_attr_t,修改线程栈的大小。
int pthread_attr_setstacksize(pthread_attr_t *attr, size_t stacksize);主线程在内存中有一个栈空间,其他线程栈也拥有独立的栈空间。为了避免线程之间的栈空间踩踏,线程栈之间还会有小块区域,用来隔离保护各自的栈空间。一旦另一个线程踏入到这个隔离区,就会引发段错误。
在整个进程里共享的全局数据
例如全局变量,虽然在不同进程中是隔离的,但是在一个进程中是共享的。
线程私有数据(Thread Specific Data)
可以通过以下函数创建:
int pthread_key_create(pthread_key_t *key, void (*destructor)(void*))可以看到,创建一个key,伴随着一个析构函数。
key一旦被创建,所有线程都可以访问它,但各线程可根据自己的需要往key中填入不同的值,这就相当于提供了一个同名而不同值的全局变量。
我们可以通过下面的函数设置key对应的value。
int pthread_setspecific(pthread_key_t key, const void *value)我们还可以通过下面的函数获取key对应的value。
void *pthread_getspecific(pthread_key_t key)而等到线程退出的时候,就会调用析构函数释放value。
6.4 数据的保护
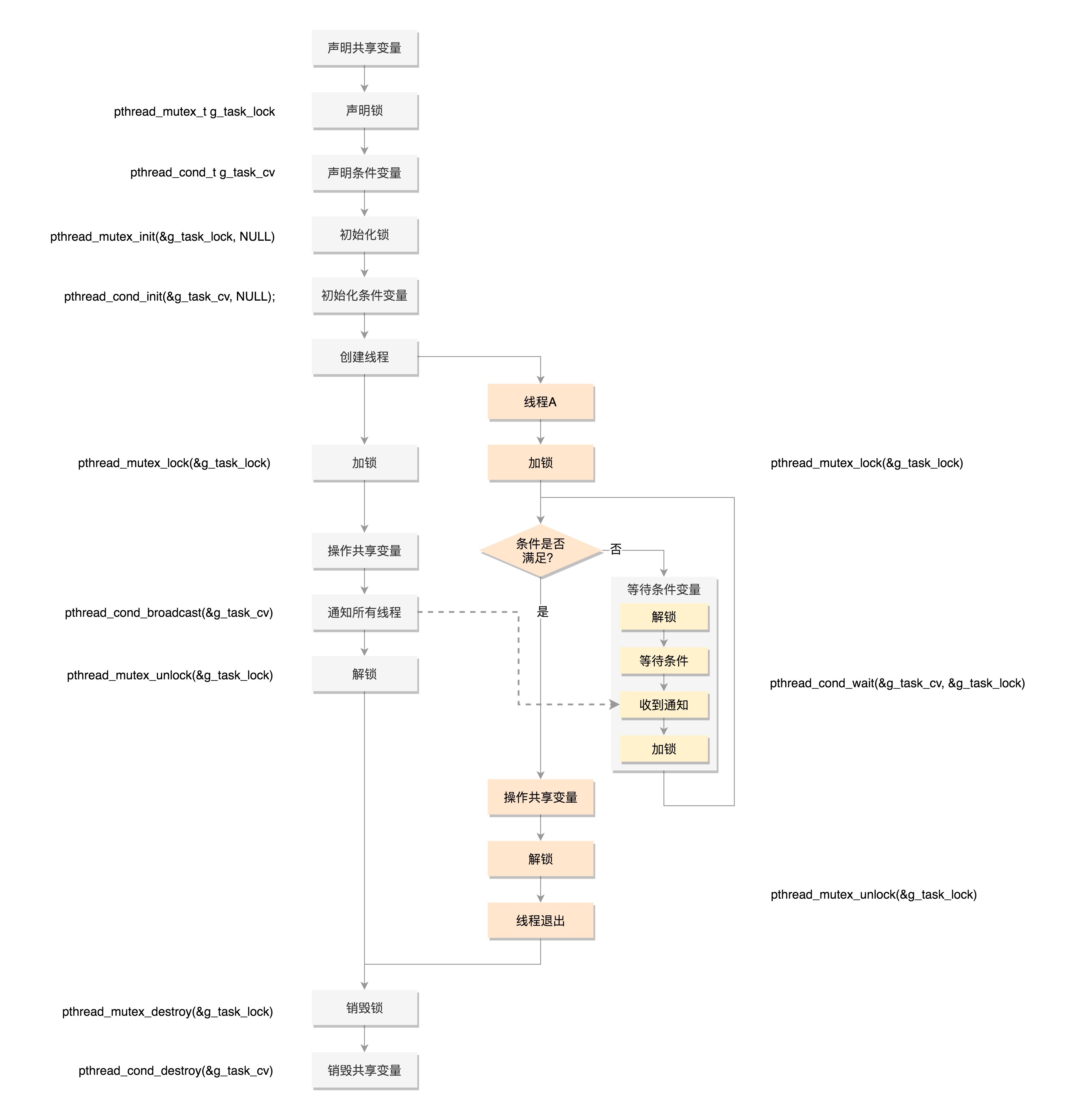
Mutex,全称Mutual Exclusion,中文叫互斥。顾名思义,有你没我,有我没你。它的模式就是在共享数据访问的时候,去申请加把锁,谁先拿到锁,谁就拿到了访问权限,其他人就只好在门外等着,等这个人访问结束,把锁打开,其他人再去争夺,还是遵循谁先拿到谁访问。
使用Mutex,首先要使用pthread_mutex_init函数初始化这个mutex,初始化后,就可以用它来保护共享变量了。
pthread_mutex_lock() 就是去抢那把锁的函数,如果抢到了,就可以执行下一行程序,对共享变量进行访;如果没抢到,就被阻塞在那里等待。
如果不想被阻塞,可以使用pthread_mutex_trylock去抢那把锁,如果抢到了,就可以执行下一行程序,对共享变量进行访问;如果没抢到,不会被阻塞,而是返回一个错误码。
当共享数据访问结束了,别忘了使用pthread_mutex_unlock释放锁,让给其他人使用,最终调用pthread_mutex_destroy销毁掉这把锁。

在使用Mutex的时候,有个问题是如果使用pthread_mutex_lock(),那就需要一直在那里等着。如果是pthread_mutex_trylock(),就可以不用等着,去干点儿别的,但是我怎么知道什么时候回来再试一下,是不是轮到我了呢?能不能在轮到我的时候,通知我一下呢?
这其实就是条件变量,也就是说如果没事儿,就让大家歇着,有事儿了就去通知,别让人家没事儿就来问问,浪费大家的时间。
但是当它接到了通知,来操作共享资源的时候,还是需要抢互斥锁,因为可能很多人都受到了通知,都来访问了,所以 条件变量和互斥锁是配合使用的 。
6.5 总结
7. 进程数据结构(上)
在Linux里面,无论是进程,还是线程,到了内核里面,我们统一都叫任务(Task),由一个统一的结构task_struct进行管理。
Linux内核有一个链表,将所有的task_struct串起来。
struct list_head tasks;接下来,我们来看每一个任务都应该包含哪些字段。
7.1 任务ID
每一个任务都应该有一个ID,作为这个任务的唯一标识。到时候排期啊、下发任务啊等等,都按ID来,就不会产生歧义。
task_struct里面涉及任务ID的,有下面几个:
pid_t pid;
pid_t tgid;
struct task_struct *group_leader;你可能觉得奇怪,既然是ID,有一个就足以做唯一标识了,这个怎么看起来这么麻烦?这是因为,上面的进程和线程到了内核这里,统一变成了任务,这就带来两个问题。
任务展示
前面我们学习命令行的时候,知道ps命令可以展示出所有的进程。但是如果你是这个命令的实现者,到了内核,按照上面的任务列表把这些命令都显示出来,把所有的线程全都平摊开来显示给用户。用户肯定觉得既复杂又困惑。复杂在于,列表这么长;困惑在于,里面出现了很多并不是自己创建的线程。
给任务下发指令
可以通过kill来给进程发信号,通知进程退出。如果发给了其中一个线程,我们就不能只退出这个线程,而是应该退出整个进程。当然,有时候,我们希望只给某个线程发信号。
所以在内核中,它们虽然都是任务,但是应该加以区分。其中,pid是process id,tgid是thread group ID。
任何一个进程,如果只有主线程,那pid是自己,tgid是自己,group_leader指向的还是自己。
但是,如果一个进程创建了其他线程,那就会有所变化了。线程有自己的pid,tgid就是进程的主线程的pid,group_leader指向的就是进程的主线程。
好了,有了tgid,我们就知道tast_struct代表的是一个进程还是代表一个线程了。
7.2 信号处理
task_struct里面关于信号处理的字段。
/* Signal handlers: */
struct signal_struct *signal;
struct sighand_struct *sighand;
sigset_t blocked;
sigset_t real_blocked;
sigset_t saved_sigmask;
struct sigpending pending;
unsigned long sas_ss_sp;
size_t sas_ss_size;
unsigned int sas_ss_flags;这里定义了哪些信号被阻塞暂不处理(blocked),哪些信号尚等待处理(pending),哪些信号正在通过信号处理函数进行处理(sighand)。处理的结果可以是忽略,可以是结束进程等等。
信号处理函数默认使用用户态的函数栈,当然也可以开辟新的栈专门用于信号处理,这就是sas_ss_xxx这三个变量的作用。
上面我说了下发信号的时候,需要区分进程和线程。从这里我们其实也能看出一些端倪。
task_struct里面有一个struct sigpending pending。如果我们进入struct signal_struct *signal去看的话,还有一个struct sigpending shared_pending。它们一个是本任务的,一个是线程组共享的。
7.3 任务状态
在task_struct里面,涉及任务状态的是下面这几个变量:
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
int exit_state;
unsigned int flags;state(状态)可以取的值定义在include/linux/sched.h头文件中。
/* Used in tsk->state: */
#define TASK_RUNNING 0
#define TASK_INTERRUPTIBLE 1
#define TASK_UNINTERRUPTIBLE 2
#define __TASK_STOPPED 4
#define __TASK_TRACED 8
/* Used in tsk->exit_state: */
#define EXIT_DEAD 16
#define EXIT_ZOMBIE 32
#define EXIT_TRACE (EXIT_ZOMBIE | EXIT_DEAD)
/* Used in tsk->state again: */
#define TASK_DEAD 64
#define TASK_WAKEKILL 128
#define TASK_WAKING 256
#define TASK_PARKED 512
#define TASK_NOLOAD 1024
#define TASK_NEW 2048
#define TASK_STATE_MAX 4096从定义的数值很容易看出来,flags是通过bitset的方式设置的也就是说,当前是什么状态,哪一位就置一。
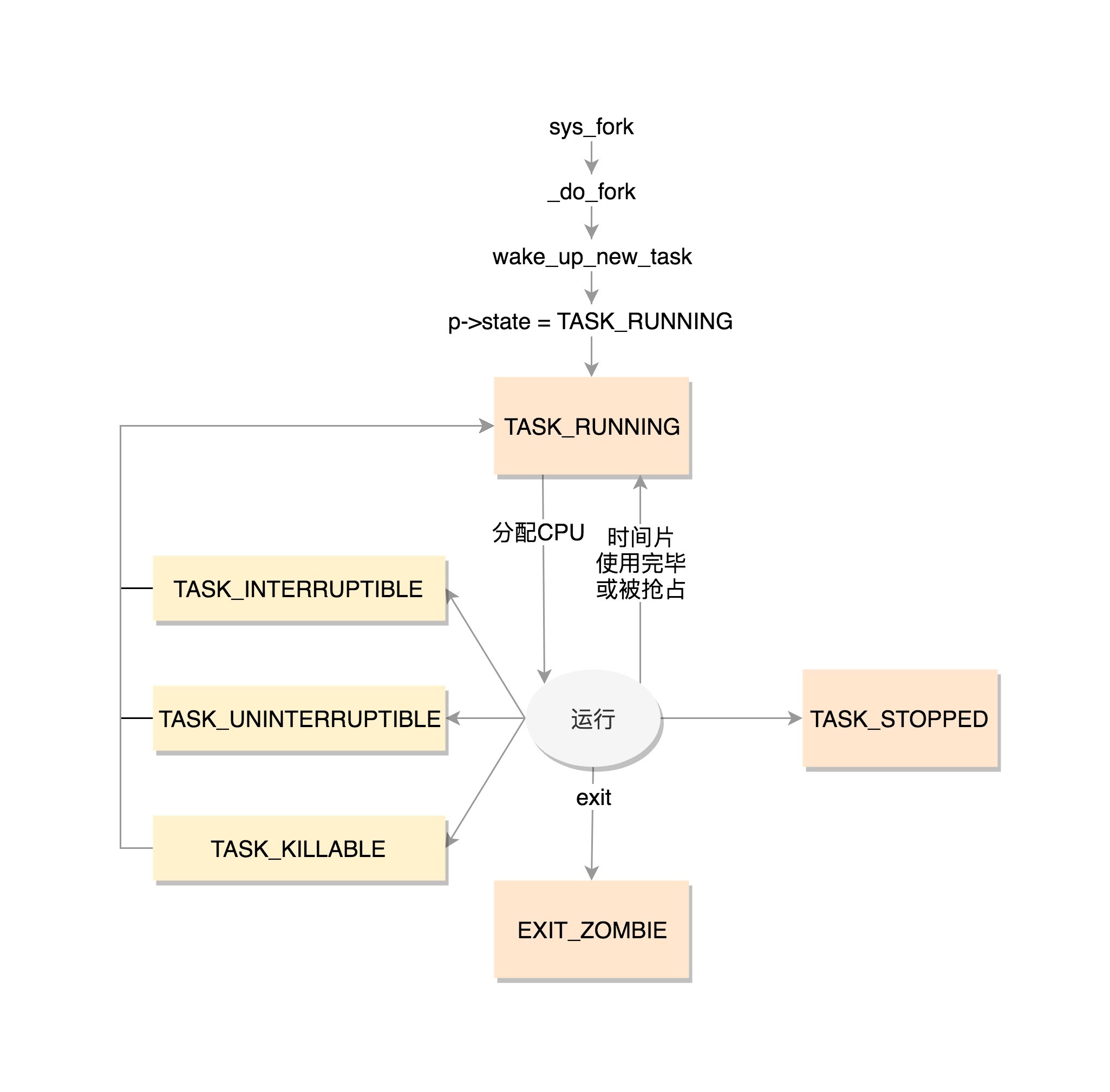
TASK_RUNNING并不是说进程正在运行,而是表示进程在时刻准备运行的状态。当处于这个状态的进程获得时间片的时候,就是在运行中;如果没有获得时间片,就说明它被其他进程抢占了,在等待再次分配时间片。
在运行中的进程,一旦要进行一些I/O操作,需要等待I/O完毕,这个时候会释放CPU,进入睡眠状态。
在Linux中,有两种睡眠状态。
TASK_INTERRUPTIBLE,可中断的睡眠状态。
这是一种浅睡眠的状态,也就是说,虽然在睡眠,等待I/O完成,但是这个时候一个信号来的时候,进程还是要被唤醒。只不过唤醒后,不是继续刚才的操作,而是进行信号处理。当然程序员可以根据自己的意愿,来写信号处理函数,例如收到某些信号,就放弃等待这个I/O操作完成,直接退出,也可也收到某些信息,继续等待。
TASK_UNINTERRUPTIBLE,不可中断的睡眠状态。
这是一种深度睡眠状态,不可被信号唤醒,只能死等I/O操作完成。一旦I/O操作因为特殊原因不能完成,这个时候,谁也叫不醒这个进程了。你可能会说,我kill它呢?别忘了,kill本身也是一个信号,既然这个状态不可被信号唤醒,kill信号也被忽略了。除非重启电脑,没有其他办法。
因此,这其实是一个比较危险的事情,除非程序员极其有把握,不然还是不要设置成TASK_UNINTERRUPTIBLE。
于是,我们就有了一种新的进程睡眠状态,TASK_KILLABLE,可以终止的新睡眠状态。进程处于这种状态中,它的运行原理类似TASK_UNINTERRUPTIBLE,只不过可以响应致命信号。
从定义可以看出,TASK_WAKEKILL用于在接收到致命信号时唤醒进程,而TASK_KILLABLE相当于这两位都设置了。
#define TASK_KILLABLE (TASK_WAKEKILL | TASK_UNINTERRUPTIBLE)TASK_STOPPED是在进程接收到SIGSTOP、SIGTTIN、SIGTSTP或者SIGTTOU信号之后进入该状态。
TASK_TRACED表示进程被debugger等进程监视,进程执行被调试程序所停止。当一个进程被另外的进程所监视,每一个信号都会让进程进入该状态。
一旦一个进程要结束,先进入的是EXIT_ZOMBIE状态,但是这个时候它的父进程还没有使用wait()等系统调用来获知它的终止信息,此时进程就成了僵尸进程。
EXIT_DEAD是进程的最终状态。
EXIT_ZOMBIE和EXIT_DEAD也可以用于exit_state。
上面的进程状态和进程的运行、调度有关系,还有其他的一些状态,我们称为标志。放在flags字段中,这些字段都被定义称为宏,以PF开头。我这里举几个例子。
#define PF_EXITING 0x00000004
#define PF_VCPU 0x00000010
#define PF_FORKNOEXEC 0x00000040- PF_EXITING 表示正在退出。当有这个flag的时候,在函数find_alive_thread中,找活着的线程,遇到有这个flag的,就直接跳过。
- PF_VCPU 表示进程运行在虚拟CPU上。在函数account_system_time中,统计进程的系统运行时间,如果有这个flag,就调用account_guest_time,按照客户机的时间进行统计。
- PF_FORKNOEXEC 表示fork完了,还没有exec。在_do_fork函数里面调用copy_process,这个时候把flag设置为PF_FORKNOEXEC。当exec中调用了load_elf_binary的时候,又把这个flag去掉。
7.4 进程调度
进程的状态切换往往涉及调度,下面这些字段都是用于调度的。为了让你理解task_struct进程管理的全貌,我先在这里列一下,咱们后面会有单独的章节讲解,这里你只要大概看一下里面的注释就好了。
//是否在运行队列上
int on_rq;
//优先级
int prio;
int static_prio;
int normal_prio;
unsigned int rt_priority;
//调度器类
const struct sched_class *sched_class;
//调度实体
struct sched_entity se;
struct sched_rt_entity rt;
struct sched_dl_entity dl;
//调度策略
unsigned int policy;
//可以使用哪些CPU
int nr_cpus_allowed;
cpumask_t cpus_allowed;
struct sched_info sched_info;7.5 总结
画一个图总结一下。这个图是进程管理task_struct的的结构图。其中红色的部分是今天讲的部分,你可以对着这张图说出它们的含义。
.webp)
8. 进程数据结构(中)
8.1 运行统计信息
在进程的运行过程中,会有一些统计量,具体你可以看下面的列表。这里面有进程在用户态和内核态消耗的时间、上下文切换的次数等等。
u64 utime;//用户态消耗的CPU时间
u64 stime;//内核态消耗的CPU时间
unsigned long nvcsw;//自愿(voluntary)上下文切换计数
unsigned long nivcsw;//非自愿(involuntary)上下文切换计数
u64 start_time;//进程启动时间,不包含睡眠时间
u64 real_start_time;//进程启动时间,包含睡眠时间8.2 进程亲缘关系
从我们之前讲的创建进程的过程,可以看出,任何一个进程都有父进程。所以,整个进程其实就是一棵进程树。而拥有同一父进程的所有进程都具有兄弟关系。
struct task_struct __rcu *real_parent; /* real parent process */
struct task_struct __rcu *parent; /* recipient of SIGCHLD, wait4() reports */
struct list_head children; /* list of my children */
struct list_head sibling; /* linkage in my parent's children list */- parent指向其父进程。当它终止时,必须向它的父进程发送信号。
- children表示链表的头部。链表中的所有元素都是它的子进程。
- sibling用于把当前进程插入到兄弟链表中。
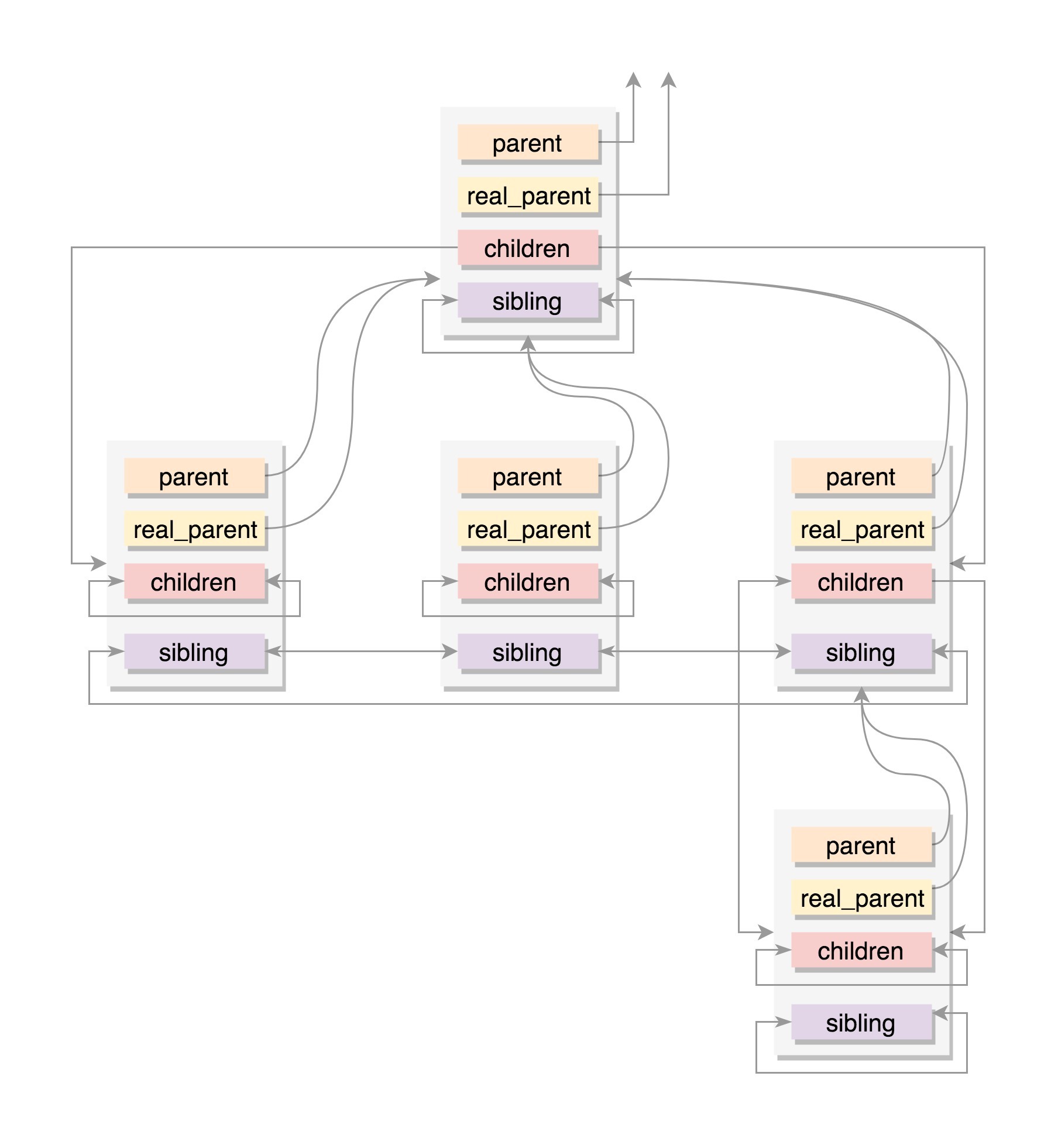
通常情况下,real_parent和parent是一样的,但是也会有另外的情况存在。例如,bash创建一个进程,那进程的parent和real_parent就都是bash。如果在bash上使用GDB来debug一个进程,这个时候GDB是real_parent,bash是这个进程的parent。
8.3 进程权限
在Linux里面,对于进程权限的定义如下:
/* Objective and real subjective task credentials (COW): */
const struct cred __rcu *real_cred;
/* Effective (overridable) subjective task credentials (COW): */
const struct cred __rcu *cred;这个结构的注释里,有两个名词比较拗口,Objective和Subjective。事实上,所谓的权限,就是我能操纵谁,谁能操纵我。
“谁能操作我”,很显然,这个时候我就是被操作的对象,就是Objective,那个想操作我的就是Subjective。”我能操作谁”,这个时候我就是Subjective,那个要被我操作的就是Objectvie。
“操作”,就是一个对象对另一个对象进行某些动作。当动作要实施的时候,就要审核权限,当两边的权限匹配上了,就可以实施操作。其中,real_cred就是说明谁能操作我这个进程,而cred就是说明我这个进程能够操作谁。
这里cred的定义如下:
struct cred {
......
kuid_t uid; /* real UID of the task */
kgid_t gid; /* real GID of the task */
kuid_t suid; /* saved UID of the task */
kgid_t sgid; /* saved GID of the task */
kuid_t euid; /* effective UID of the task */
kgid_t egid; /* effective GID of the task */
kuid_t fsuid; /* UID for VFS ops */
kgid_t fsgid; /* GID for VFS ops */
......
kernel_cap_t cap_inheritable; /* caps our children can inherit */
kernel_cap_t cap_permitted; /* caps we're permitted */
kernel_cap_t cap_effective; /* caps we can actually use */
kernel_cap_t cap_bset; /* capability bounding set */
kernel_cap_t cap_ambient; /* Ambient capability set */
......
} __randomize_layout;从这里的定义可以看出,大部分是关于 用户和用户所属的用户组信息 。
第一个是uid和gid,注释是real user/group id。一般情况下,谁启动的进程,就是谁的ID。但是权限审核的时候,往往不比较这两个,也就是说不大起作用。
第二个是euid和egid,注释是effective user/group id。一看这个名字,就知道这个是起”作用”的。当这个进程要操作消息队列、共享内存、信号量等对象的时候,其实就是在比较这个用户和组是否有权限。
第三个是fsuid和fsgid,也就是filesystem user/group id。这个是对文件操作会审核的权限。
一般说来,fsuid、euid,和uid是一样的,fsgid、egid,和gid也是一样的。因为谁启动的进程,就应该审核启动的用户到底有没有这个权限。
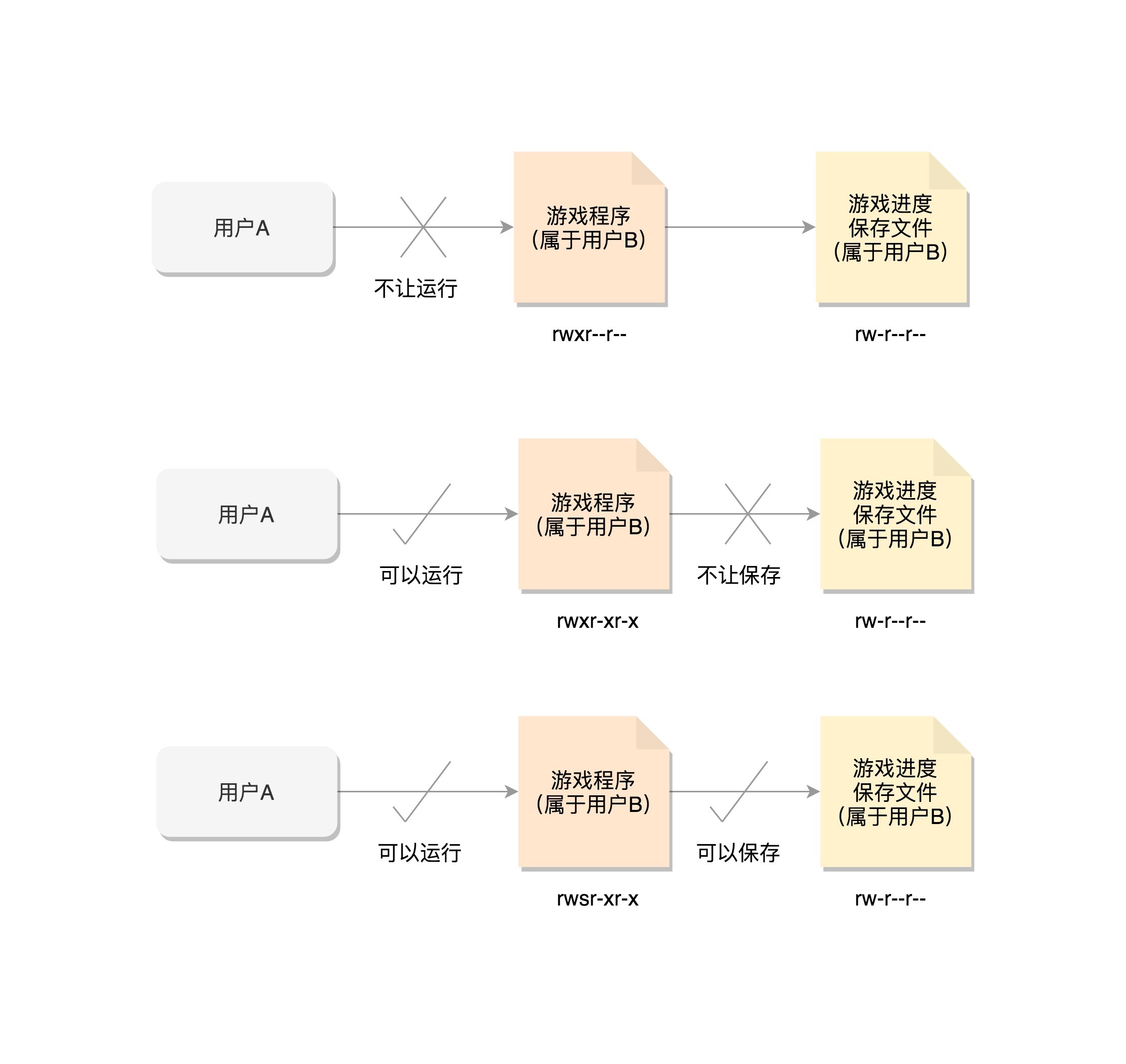
例如,用户A想玩一个游戏,这个游戏的程序是用户B安装的。游戏这个程序文件的权限为rwxr–r—。A是没有权限运行这个程序的,因而用户B要给用户A权限才行。用户B说没问题,都是朋友嘛,于是用户B就给这个程序设定了所有的用户都能执行的权限rwxr-xr-x,说兄弟你玩吧。
于是,用户A就获得了运行这个游戏的权限。当游戏运行起来之后,游戏进程的uid、euid、fsuid都是用户A。看起来没有问题,玩的很开心。
用户A好不容易通过一关,想保存通关数据的时候,发现坏了,这个游戏的玩家数据是保存在另一个文件里面的。这个文件权限rw———-,只给用户B开了写入权限,而游戏进程的euid和fsuid都是用户A,当然写不进去了。完了,这一局白玩儿了。
那怎么解决这个问题呢?我们可以通过chmod u+s program命令,给这个游戏程序设置set-user-ID的标识位,把游戏的权限变成rwsr-xr-x。这个时候,用户A再启动这个游戏的时候,创建的进程uid当然还是用户A,但是euid和fsuid就不是用户A了,因为看到了set-user-id标识,就改为文件的所有者的ID,也就是说,euid和fsuid都改成用户B了,这样就能够将通关结果保存下来。
在Linux里面,一个进程可以随时通过setuid设置用户ID,所以,游戏程序的用户B的ID还会保存在一个地方,这就是suid和sgid,也就是saved uid和save gid。这样就可以很方便地使用setuid,通过设置uid或者suid来改变权限。
除了以用户和用户组控制权限,Linux还有另一个机制就是 capabilities 。
原来控制进程的权限,要么是高权限的root用户,要么是一般权限的普通用户,这时候的问题是,root用户权限太大,而普通用户权限太小。有时候一个普通用户想做一点高权限的事情,必须给他整个root的权限。这个太不安全了。
于是,我们引入新的机制capabilities,用位图表示权限,在capability.h可以找到定义的权限。我这里列举几个。
#define CAP_CHOWN 0
#define CAP_KILL 5
#define CAP_NET_BIND_SERVICE 10
#define CAP_NET_RAW 13
#define CAP_SYS_MODULE 16
#define CAP_SYS_RAWIO 17
#define CAP_SYS_BOOT 22
#define CAP_SYS_TIME 25
#define CAP_AUDIT_READ 37
#define CAP_LAST_CAP CAP_AUDIT_READ对于普通用户运行的进程,当有这个权限的时候,就能做这些操作;没有的时候,就不能做,这样粒度要小很多。
cap_permitted表示进程能够使用的权限。但是真正起作用的是cap_effective。cap_permitted中可以包含cap_effective中没有的权限。一个进程可以在必要的时候,放弃自己的某些权限,这样更加安全。假设自己因为代码漏洞被攻破了,但是如果啥也干不了,就没办法进一步突破。
cap_inheritable表示当可执行文件的扩展属性设置了inheritable位时,调用exec执行该程序会继承调用者的inheritable集合,并将其加入到permitted集合。但在非root用户下执行exec时,通常不会保留inheritable集合,但是往往又是非root用户,才想保留权限,所以非常鸡肋。
cap_bset,也就是capability bounding set,是系统中所有进程允许保留的权限。如果这个集合中不存在某个权限,那么系统中的所有进程都没有这个权限。即使以超级用户权限执行的进程,也是一样的。
这样有很多好处。例如,系统启动以后,将加载内核模块的权限去掉,那所有进程都不能加载内核模块。这样,即便这台机器被攻破,也做不了太多有害的事情。
cap_ambient是比较新加入内核的,就是为了解决cap_inheritable鸡肋的状况,也就是,非root用户进程使用exec执行一个程序的时候,如何保留权限的问题。当执行exec的时候,cap_ambient会被添加到cap_permitted中,同时设置到cap_effective中。
8.4 内存管理
每个进程都有自己独立的虚拟内存空间,这需要有一个数据结构来表示,就是mm_struct。这个我们在内存管理那一节详细讲述。这里你先有个印象。
struct mm_struct *mm;
struct mm_struct *active_mm;8.5 文件与文件系统
每个进程有一个文件系统的数据结构,还有一个打开文件的数据结构。这个我们放到文件系统那一节详细讲述。
/* Filesystem information: */
struct fs_struct *fs;
/* Open file information: */
struct files_struct *files;8.6 总结
这一节,我们终于把进程管理复杂的数据结构基本讲完了,请你重点记住以下两点:
- 进程亲缘关系维护的数据结构,是一种很有参考价值的实现方式,在内核中会多个地方出现类似的结构;
- 进程权限中setuid的原理,这一点比较难理解,但是很重要,面试经常会考。
你可以对着下面这张图,看看自己是否真的理解了,进程树是如何组织的,以及如何控制进程的权限的。
.webp)
9. 进程数据结构(下)
在程序执行过程中,一旦调用到系统调用,就需要进入内核继续执行。那如何将用户态的执行和内核态的执行串起来呢?
这就需要以下两个重要的成员变量:
struct thread_info thread_info;
void *stack;9.1 用户态函数栈
在用户态中,程序的执行往往是一个函数调用另一个函数。函数调用都是通过栈来进行的。
在进程的内存空间里面,栈是一个从高地址到低地址,往下增长的结构,也就是上面是栈底,下面是栈顶,入栈和出栈的操作都是从下面的栈顶开始的。
以下栈操作,都是在进程的内存空间里面进行的。
9.1.1 32位操作系统
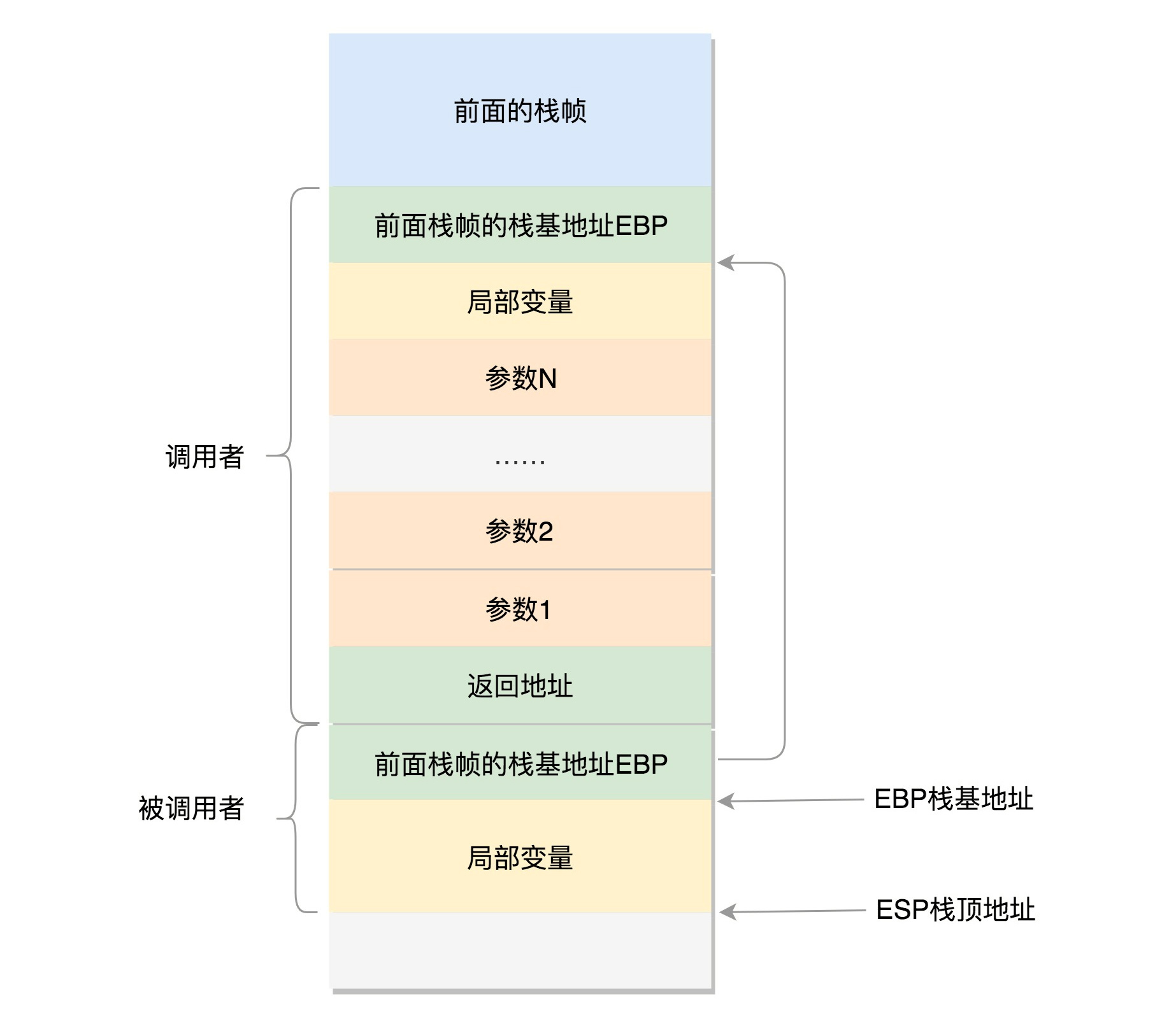
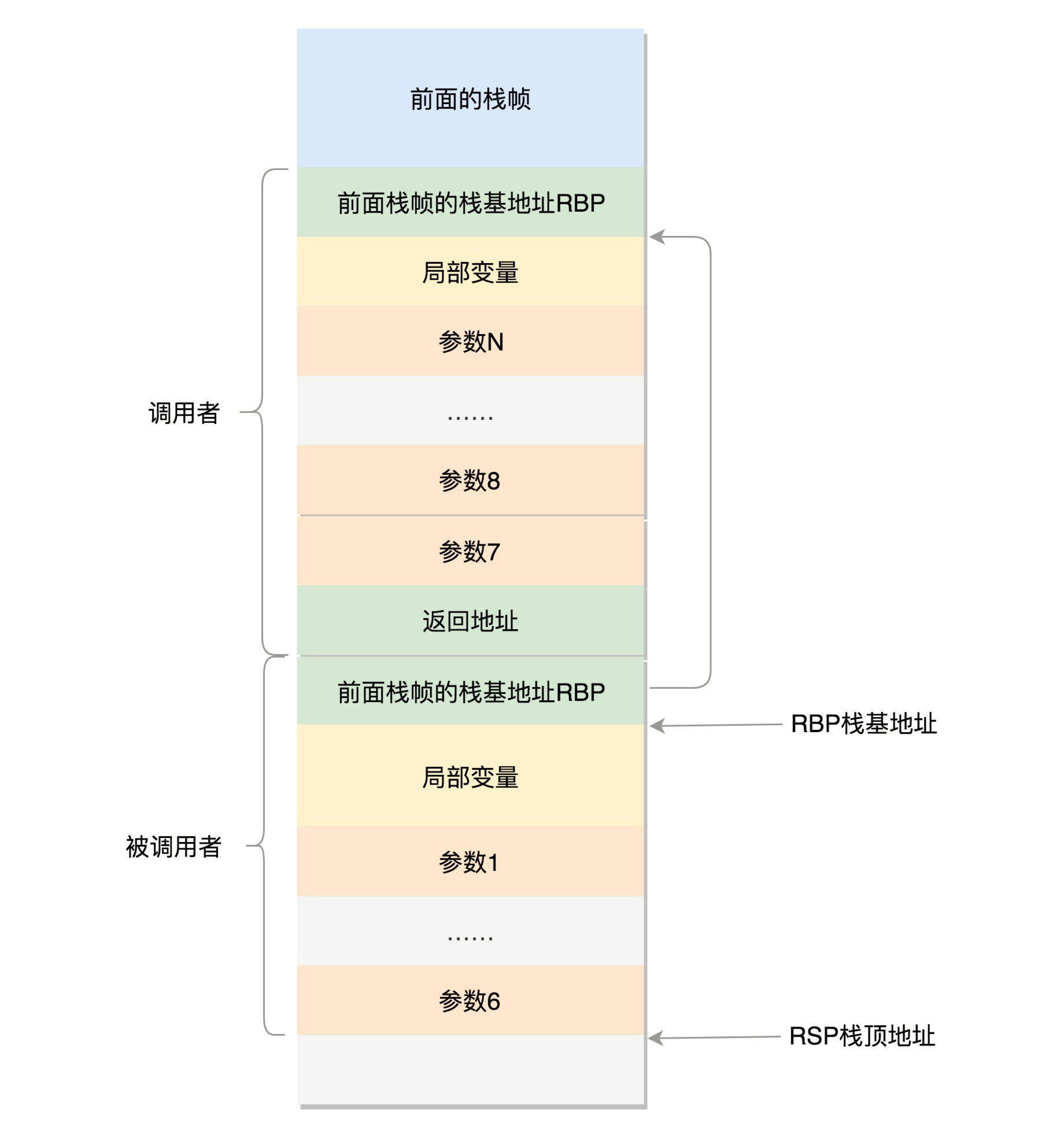
在CPU里,ESP(Extended Stack Pointer)是栈顶指针寄存器,入栈操作Push和出栈操作Pop指令,会自动调整ESP的值。另外有一个寄存器EBP(Extended Base Pointer),是栈基地址指针寄存器,指向当前栈帧的最底部。
例如,A调用B,A的栈里面包含A函数的局部变量,然后是调用B的时候要传给它的参数,然后返回A的地址,这个地址也应该入栈,这就形成了A的栈帧。接下来就是B的栈帧部分了,先保存的是A栈帧的栈底位置,也就是EBP。因为在B函数里面获取A传进来的参数,就是通过这个指针获取的,接下来保存的是B的局部变量等等。
当B返回的时候,返回值会保存在EAX寄存器中,从栈中弹出返回地址,将指令跳转回去,参数也从栈中弹出,然后继续执行A。
9.1.2 64位操作系统
对于64位操作系统,模式多少有些不一样。因为64位操作系统的寄存器数目比较多。rax用于保存函数调用的返回结果。栈顶指针寄存器变成了rsp,指向栈顶位置。堆栈的Pop和Push操作会自动调整rsp,栈基指针寄存器变成了rbp,指向当前栈帧的起始位置。
改变比较多的是参数传递。rdi、rsi、rdx、rcx、r8、r9这6个寄存器,用于传递存储函数调用时的6个参数。如果超过6的时候,还是需要放到栈里面。
然而,前6个参数有时候需要进行寻址,但是如果在寄存器里面,是没有地址的,因而还是会放到栈里面,只不过放到栈里面的操作是被调用函数做的。
9.2 内核态函数栈
接下来,我们通过系统调用,从进程的内存空间到内核中了。内核中也有各种各样的函数调用来调用去的,也需要这样一个机制,这该怎么办呢?
这时候,上面的成员变量stack,也就是内核栈,就派上了用场。
Linux给每个task都分配了内核栈。在32位系统上arch/x86/include/asm/page_32_types.h,是这样定义的:一个PAGE_SIZE是4K,左移一位就是乘以2,也就是8K。
#define THREAD_SIZE_ORDER 1
#define THREAD_SIZE (PAGE_SIZE << THREAD_SIZE_ORDER)内核栈在64位系统上arch/x86/include/asm/page_64_types.h,是这样定义的:在PAGE_SIZE的基础上左移两位,也即16K,并且要求起始地址必须是8192的整数倍。
#ifdef CONFIG_KASAN
#define KASAN_STACK_ORDER 1
#else
#define KASAN_STACK_ORDER 0
#endif
#define THREAD_SIZE_ORDER (2 + KASAN_STACK_ORDER)
#define THREAD_SIZE (PAGE_SIZE << THREAD_SIZE_ORDER)内核栈是一个非常特殊的结构,如下图所示:
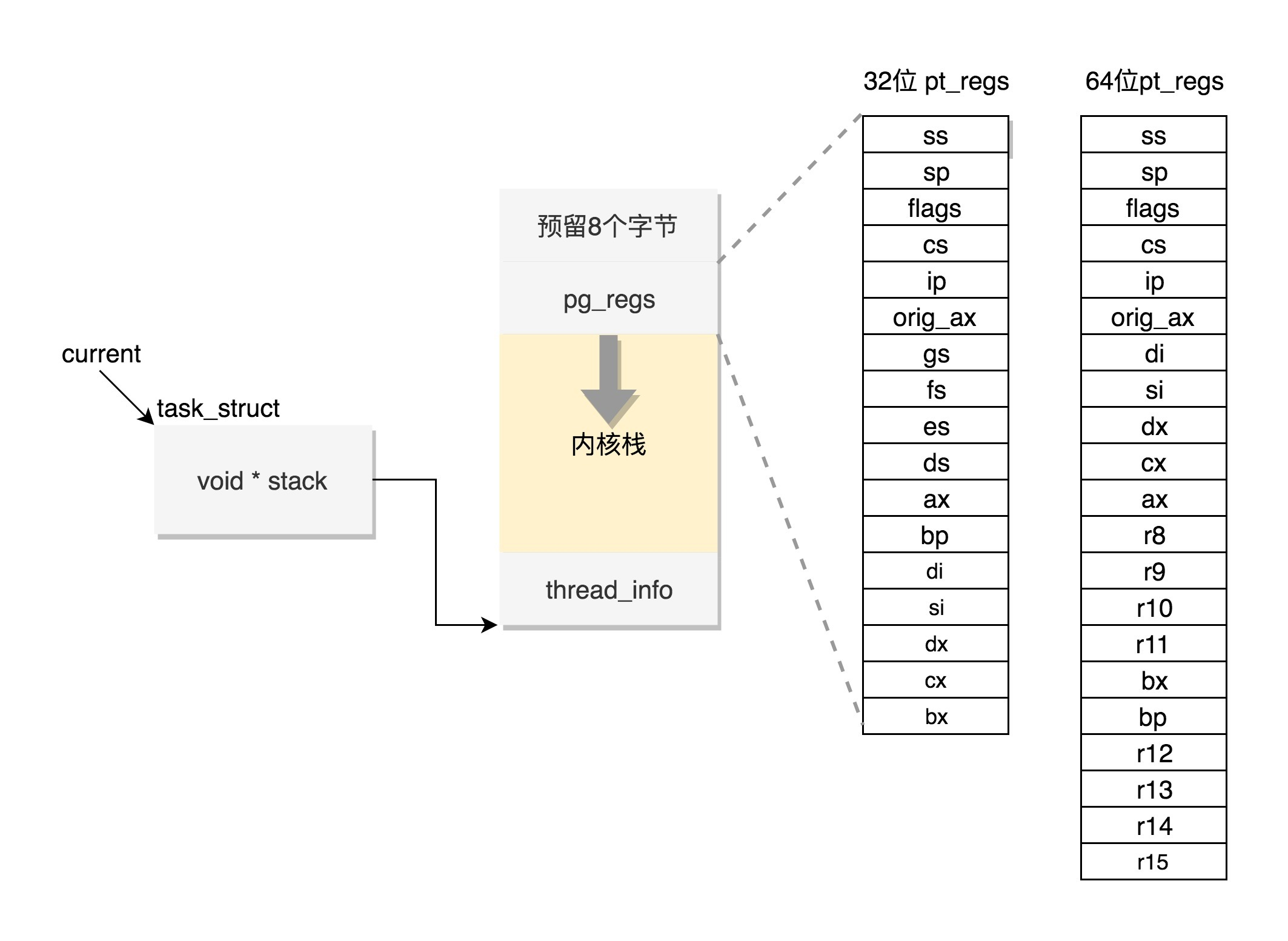
这段空间的最低位置,是一个thread_info结构。这个结构是对task_struct结构的补充。因为task_struct结构庞大但是通用,不同的体系结构就需要保存不同的东西,所以往往与体系结构有关的,都放在thread_info里面。
在内核代码里面有这样一个union,将thread_info和stack放在一起,在include/linux/sched.h文件中就有。
union thread_union {
#ifndef CONFIG_THREAD_INFO_IN_TASK
struct thread_info thread_info;
#endif
unsigned long stack[THREAD_SIZE/sizeof(long)];
};这个union就是这样定义的,开头是thread_info,后面是stack。
在内核栈的最高地址端,存放的是另一个结构pt_regs,定义如下。其中,32位和64位的定义不一样。
#ifdef __i386__
struct pt_regs {
unsigned long bx;
unsigned long cx;
unsigned long dx;
unsigned long si;
unsigned long di;
unsigned long bp;
unsigned long ax;
unsigned long ds;
unsigned long es;
unsigned long fs;
unsigned long gs;
unsigned long orig_ax;
unsigned long ip;
unsigned long cs;
unsigned long flags;
unsigned long sp;
unsigned long ss;
};
#else
struct pt_regs {
unsigned long r15;
unsigned long r14;
unsigned long r13;
unsigned long r12;
unsigned long bp;
unsigned long bx;
unsigned long r11;
unsigned long r10;
unsigned long r9;
unsigned long r8;
unsigned long ax;
unsigned long cx;
unsigned long dx;
unsigned long si;
unsigned long di;
unsigned long orig_ax;
unsigned long ip;
unsigned long cs;
unsigned long flags;
unsigned long sp;
unsigned long ss;
/* top of stack page */
};
#endif当系统调用从用户态到内核态的时候,首先要做的第一件事情,就是将用户态运行过程中的CPU上下文保存起来,其实主要就是保存在这个结构的寄存器变量里。这样当从内核系统调用返回的时候,才能让进程在刚才的地方接着运行下去。
如果我们对比系统调用那一节的内容,你会发现系统调用的时候,压栈的值的顺序和struct pt_regs中寄存器定义的顺序是一样的。
在内核中,CPU的寄存器ESP或者RSP,已经指向内核栈的栈顶,在内核态里的调用都有和用户态相似的过程。
9.3 通过task_struct找内核栈
如果有一个task_struct的stack指针在手,你可以通过下面的函数找到这个线程内核栈:
static inline void *task_stack_page(const struct task_struct *task)
{
return task->stack;
}从task_struct如何得到相应的pt_regs呢?我们可以通过下面的函数:
/*
* TOP_OF_KERNEL_STACK_PADDING reserves 8 bytes on top of the ring0 stack.
* This is necessary to guarantee that the entire "struct pt_regs"
* is accessible even if the CPU haven't stored the SS/ESP registers
* on the stack (interrupt gate does not save these registers
* when switching to the same priv ring).
* Therefore beware: accessing the ss/esp fields of the
* "struct pt_regs" is possible, but they may contain the
* completely wrong values.
*/
#define task_pt_regs(task) \
({ \
unsigned long __ptr = (unsigned long)task_stack_page(task); \
__ptr += THREAD_SIZE - TOP_OF_KERNEL_STACK_PADDING; \
((struct pt_regs *)__ptr) - 1; \
})你会发现,这是先从task_struct找到内核栈的开始位置。然后这个位置加上THREAD_SIZE就到了最后的位置,然后转换为struct pt_regs,再减一,就相当于减少了一个pt_regs的位置,就到了这个结构的首地址。
这里面有一个TOP_OF_KERNEL_STACK_PADDING,这个的定义如下:
#ifdef CONFIG_X86_32
# ifdef CONFIG_VM86
# define TOP_OF_KERNEL_STACK_PADDING 16
# else
# define TOP_OF_KERNEL_STACK_PADDING 8
# endif
#else
# define TOP_OF_KERNEL_STACK_PADDING 0
#endif也就是说,32位机器上是8,其他是0。这是为什么呢?因为压栈pt_regs有两种情况。我们知道,CPU用ring来区分权限,从而Linux可以区分内核态和用户态。
因此,第一种情况,我们拿涉及从用户态到内核态的变化的系统调用来说。因为涉及权限的改变,会压栈保存SS、ESP寄存器的,这两个寄存器共占用8个byte。
另一种情况是,不涉及权限的变化,就不会压栈这8个byte。这样就会使得两种情况不兼容。如果没有压栈还访问,就会报错,所以还不如预留在这里,保证安全。在64位上,修改了这个问题,变成了定长的。
好了,现在如果你task_struct在手,就能够轻松得到内核栈和内核寄存器。
9.4 通过内核栈找task_struct
那如果一个当前在某个CPU上执行的进程,想知道自己的task_struct在哪里,又该怎么办呢?
这个艰巨的任务要交给thread_info这个结构。
struct thread_info {
struct task_struct *task; /* main task structure */
__u32 flags; /* low level flags */
__u32 status; /* thread synchronous flags */
__u32 cpu; /* current CPU */
mm_segment_t addr_limit;
unsigned int sig_on_uaccess_error:1;
unsigned int uaccess_err:1; /* uaccess failed */
};这里面有个成员变量task指向task_struct,所以我们常用current_thread_info()->task来获取task_struct。
static inline struct thread_info *current_thread_info(void)
{
return (struct thread_info *)(current_top_of_stack() - THREAD_SIZE);
}而thread_info的位置就是内核栈的最高位置,减去THREAD_SIZE,就到了thread_info的起始地址。
但是现在变成这样了,只剩下一个flags。
struct thread_info {
unsigned long flags; /* low level flags */
};那这时候怎么获取当前运行中的task_struct呢?current_thread_info有了新的实现方式。
在include/linux/thread_info.h中定义了current_thread_info。
#include <asm/current.h>
#define current_thread_info() ((struct thread_info *)current)那current又是什么呢?在arch/x86/include/asm/current.h中定义了。
struct task_struct;
DECLARE_PER_CPU(struct task_struct *, current_task);
static __always_inline struct task_struct *get_current(void)
{
return this_cpu_read_stable(current_task);
}
#define current get_current到这里,你会发现,新的机制里面,每个CPU运行的task_struct不通过thread_info获取了,而是直接放在Per CPU 变量里面了。
多核情况下,CPU是同时运行的,但是它们共同使用其他的硬件资源的时候,我们需要解决多个CPU之间的同步问题。
Per CPU变量是内核中一种重要的同步机制。顾名思义,Per CPU变量就是为每个CPU构造一个变量的副本,这样多个CPU各自操作自己的副本,互不干涉。比如,当前进程的变量current_task就被声明为Per CPU变量。
要使用Per CPU变量,首先要声明这个变量,在arch/x86/include/asm/current.h中有:
DECLARE_PER_CPU(struct task_struct *, current_task);然后是定义这个变量,在arch/x86/kernel/cpu/common.c中有:
DEFINE_PER_CPU(struct task_struct *, current_task) = &init_task;也就是说,系统刚刚初始化的时候,current_task都指向init_task。
当某个CPU上的进程进行切换的时候,current_task被修改为将要切换到的目标进程。例如,进程切换函数__switch_to就会改变current_task。
__visible __notrace_funcgraph struct task_struct *
__switch_to(struct task_struct *prev_p, struct task_struct *next_p)
{
......
this_cpu_write(current_task, next_p);
......
return prev_p;
}当要获取当前的运行中的task_struct的时候,就需要调用this_cpu_read_stable进行读取。
#define this_cpu_read_stable(var) percpu_stable_op("mov", var)好了,现在如果你是一个进程,正在某个CPU上运行,就能够轻松得到task_struct了。
9.5 总结
这一节虽然只介绍了内核栈,但是内容更加重要。如果说task_struct的其他成员变量都是和进程管理有关的,内核栈是和进程运行有关系的。
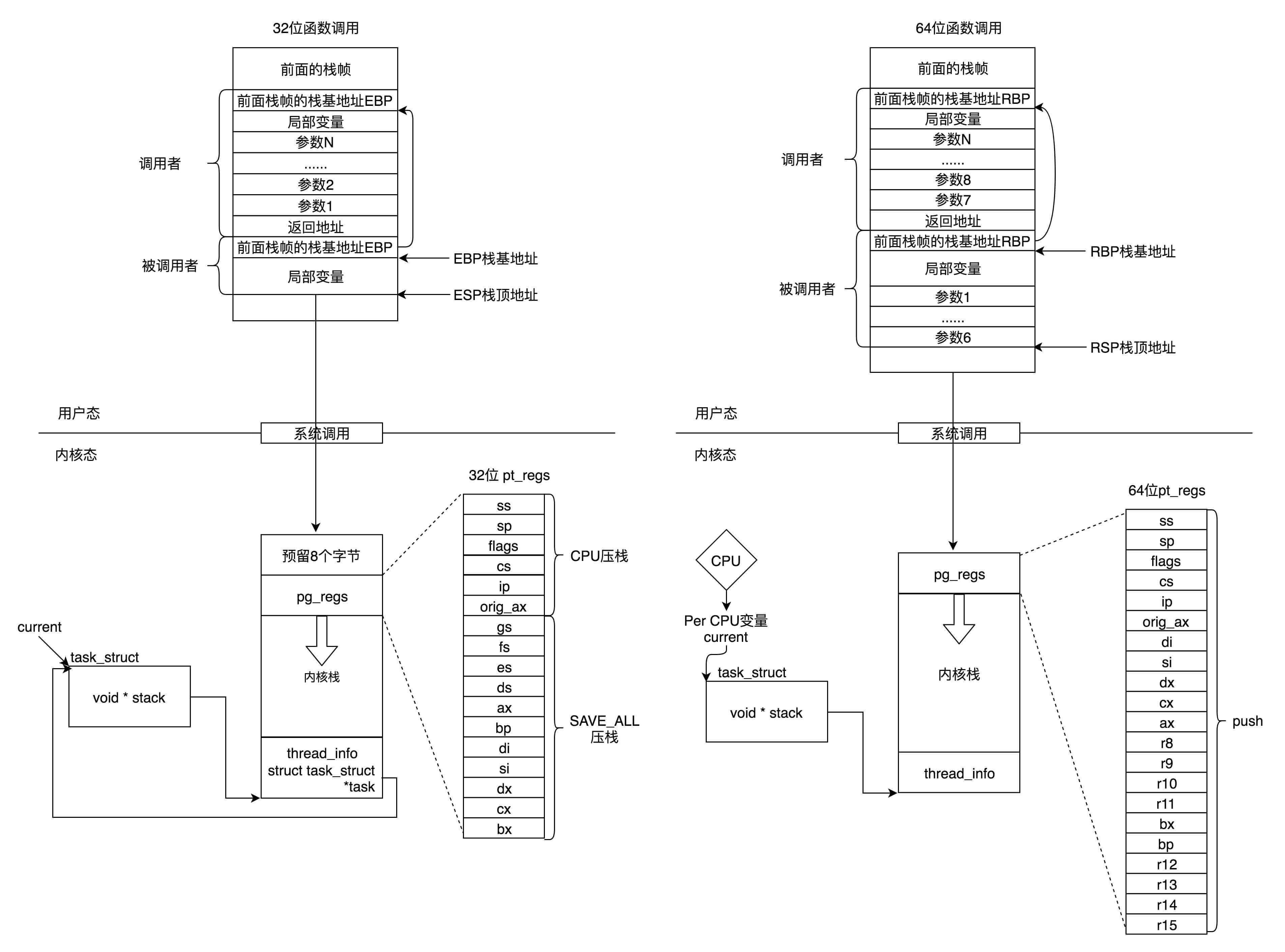
我这里画了一张图总结一下32位和64位的工作模式,左边是32位的,右边是64位的。
- 在用户态,应用程序进行了至少一次函数调用。32位和64的传递参数的方式稍有不同,32位的就是用函数栈,64位的前6个参数用寄存器,其他的用函数栈。
- 在内核态,32位和64位都使用内核栈,格式也稍有不同,主要集中在pt_regs结构上。
- 在内核态,32位和64位的内核栈和task_struct的关联关系不同。32位主要靠thread_info,64位主要靠Per-CPU变量。
10. 调度(上)
对于操作系统来讲,它面对的CPU的数量是有限的,干活儿都是它们,但是进程数目远远超过CPU的数目,因而就需要进行进程的调度,有效地分配CPU的时间,既要保证进程的最快响应,也要保证进程之间的公平。这也是一个非常复杂的、需要平衡的事情。
10.1 调度策略与调度类
在Linux里面,进程大概可以分成两种。
一种称为 实时进程 ,也就是需要尽快执行返回结果的那种。
另一种是 普通进程 ,大部分的进程其实都是这种。
对于这两种进程,我们的调度策略肯定是不同的。
在task_struct中,有一个成员变量,我们叫调度策略。
unsigned int policy;它有以下几个定义:
#define SCHED_NORMAL 0
#define SCHED_FIFO 1
#define SCHED_RR 2
#define SCHED_BATCH 3
#define SCHED_IDLE 5
#define SCHED_DEADLINE 6配合调度策略的,还有我们刚才说的优先级,也在task_struct中。
int prio, static_prio, normal_prio;
unsigned int rt_priority;优先级其实就是一个数值,对于实时进程,优先级的范围是0~99;对于普通进程,优先级的范围是100~139。数值越小,优先级越高。从这里可以看出,所有的实时进程都比普通进程优先级要高。
10.2 实时调度策略
对于调度策略,其中SCHED_FIFO、SCHED_RR、SCHED_DEADLINE是实时进程的调度策略。
- SCHED_FIFO 就是先来先服务,可以分配更高的优先级,也就是说,高优先级的进程可以抢占低优先级的进程,而相同优先级的进程,我们遵循先来先得。
- SCHED_RR 轮流调度算法。采用时间片,相同优先级的任务当用完时间片会被放到队列尾部,以保证公平性,而高优先级的任务也是可以抢占低优先级的任务。
- SCHED_DEADLINE 按照任务的deadline进行调度的。当产生一个调度点的时候,DL调度器总是选择其deadline距离当前时间点最近的那个任务,并调度它执行。
10.3 普通调度策略
对于普通进程的调度策略有,SCHED_NORMAL、SCHED_BATCH、SCHED_IDLE。
- SCHED_NORMAL 是普通的进程。
- SCHED_BATCH 是后台进程,几乎不需要和前端进行交互。不要影响需要交互的进程,可以降低他的优先级。
- SCHED_IDLE 是特别空闲的时候才跑的进程。
上面无论是policy还是priority,都设置了一个变量,变量仅仅表示了应该这样这样干,但事情总要有人去干,谁呢?在task_struct里面,还有这样的成员变量:
const struct sched_class *sched_class;调度策略的执行逻辑,就封装在这里面,它是真正干活的那个。
sched_class有几种实现:
- stop_sched_class 优先级最高的任务会使用这种策略,会中断所有其他线程,且不会被其他任务打断;
- dl_sched_class就对应上面的deadline调度策略;
- rt_sched_class就对应RR算法或者FIFO算法的调度策略,具体调度策略由进程的task_struct->policy指定;
- fair_sched_class就是普通进程的调度策略;
- idle_sched_class就是空闲进程的调度策略。
这里实时进程的调度策略RR和FIFO相对简单一些,而且由于咱们平时常遇到的都是普通进程,在这里,咱们就重点分析普通进程的调度问题。普通进程使用的调度策略是fair_sched_class,顾名思义,对于普通进程来讲,公平是最重要的。
10.4 完全公平调度算法
在Linux里面,实现了一个基于CFS的调度算法。CFS全称Completely Fair Scheduling,叫完全公平调度。听起来很”公平”。那这个算法的原理是什么呢?我们来看看。
首先,你需要记录下进程的运行时间。CPU会提供一个时钟,过一段时间就触发一个时钟中断。就像咱们的表滴答一下,这个我们叫Tick。CFS会为每一个进程安排一个虚拟运行时间vruntime。如果一个进程在运行,随着时间的增长,也就是一个个tick的到来,进程的vruntime将不断增大。没有得到执行的进程vruntime不变。
显然,那些vruntime少的,原来受到了不公平的对待,需要给它补上,所以会优先运行这样的进程。
这有点像让你把一筐球平均分到N个口袋里面,你看着哪个少,就多放一些;哪个多了,就先不放。这样经过多轮,虽然不能保证球完全一样多,但是也差不多公平。
你可能会说,不还有优先级呢?如何给优先级高的进程多分时间呢?
这个简单,就相当于N个口袋,优先级高的袋子大,优先级低的袋子小。这样球就不能按照个数分配了,要按照比例来,大口袋的放了一半和小口袋放了一半,里面的球数目虽然差很多,也认为是公平的。
在更新进程运行的统计量的时候,我们其实就可以看出这个逻辑。
/*
* Update the current task's runtime statistics.
*/
static void update_curr(struct cfs_rq *cfs_rq)
{
struct sched_entity *curr = cfs_rq->curr;
u64 now = rq_clock_task(rq_of(cfs_rq));
u64 delta_exec;
......
delta_exec = now - curr->exec_start;
......
curr->exec_start = now;
......
curr->sum_exec_runtime += delta_exec;
......
curr->vruntime += calc_delta_fair(delta_exec, curr);
update_min_vruntime(cfs_rq);
......
}
/*
* delta /= w
*/
static inline u64 calc_delta_fair(u64 delta, struct sched_entity *se)
{
if (unlikely(se->load.weight != NICE_0_LOAD))
/* delta_exec * weight / lw.weight */
delta = __calc_delta(delta, NICE_0_LOAD, &se->load);
return delta;
}在这里得到当前的时间,以及这次的时间片开始的时间,两者相减就是这次运行的时间delta_exec ,但是得到的这个时间其实是实际运行的时间,需要做一定的转化才作为虚拟运行时间vruntime。转化方法如下:
虚拟运行时间vruntime += 实际运行时间delta_exec * NICE_0_LOAD/权重
这就是说,同样的实际运行时间,给高权重的算少了,低权重的算多了,但是当选取下一个运行进程的时候,还是按照最小的vruntime来的,这样高权重的获得的实际运行时间自然就多了。这就相当于给一个体重(权重)200斤的胖子吃两个馒头,和给一个体重100斤的瘦子吃一个馒头,然后说,你们两个吃的是一样多。这样虽然总体胖子比瘦子多吃了一倍,但是还是公平的。
10.5 调度队列与调度实体
看来CFS需要一个数据结构来对vruntime进行排序,找出最小的那个。这个能够排序的数据结构不但需要查询的时候,能够快速找到最小的,更新的时候也需要能够快速的调整排序,要知道vruntime可是经常在变的,变了再插入这个数据结构,就需要重新排序。
能够平衡查询和更新速度的是树,在这里使用的是红黑树。
红黑树的的节点是应该包括vruntime的,称为调度实体。
在task_struct中有这样的成员变量:
struct sched_entity se;
struct sched_rt_entity rt;
struct sched_dl_entity dl;这里有实时调度实体sched_rt_entity,Deadline调度实体sched_dl_entity,以及完全公平算法调度实体sched_entity。
看来不光CFS调度策略需要有这样一个数据结构进行排序,其他的调度策略也同样有自己的数据结构进行排序,因为任何一个策略做调度的时候,都是要区分谁先运行谁后运行。
而进程根据自己是实时的,还是普通的类型,通过这个成员变量,将自己挂在某一个数据结构里面,和其他的进程排序,等待被调度。如果这个进程是个普通进程,则通过sched_entity,将自己挂在这棵红黑树上。
对于普通进程的调度实体定义如下,这里面包含了vruntime和权重load_weight,以及对于运行时间的统计。
struct sched_entity {
struct load_weight load;
struct rb_node run_node;
struct list_head group_node;
unsigned int on_rq;
u64 exec_start;
u64 sum_exec_runtime;
u64 vruntime;
u64 prev_sum_exec_runtime;
u64 nr_migrations;
struct sched_statistics statistics;
......
};下图是一个红黑树的例子。
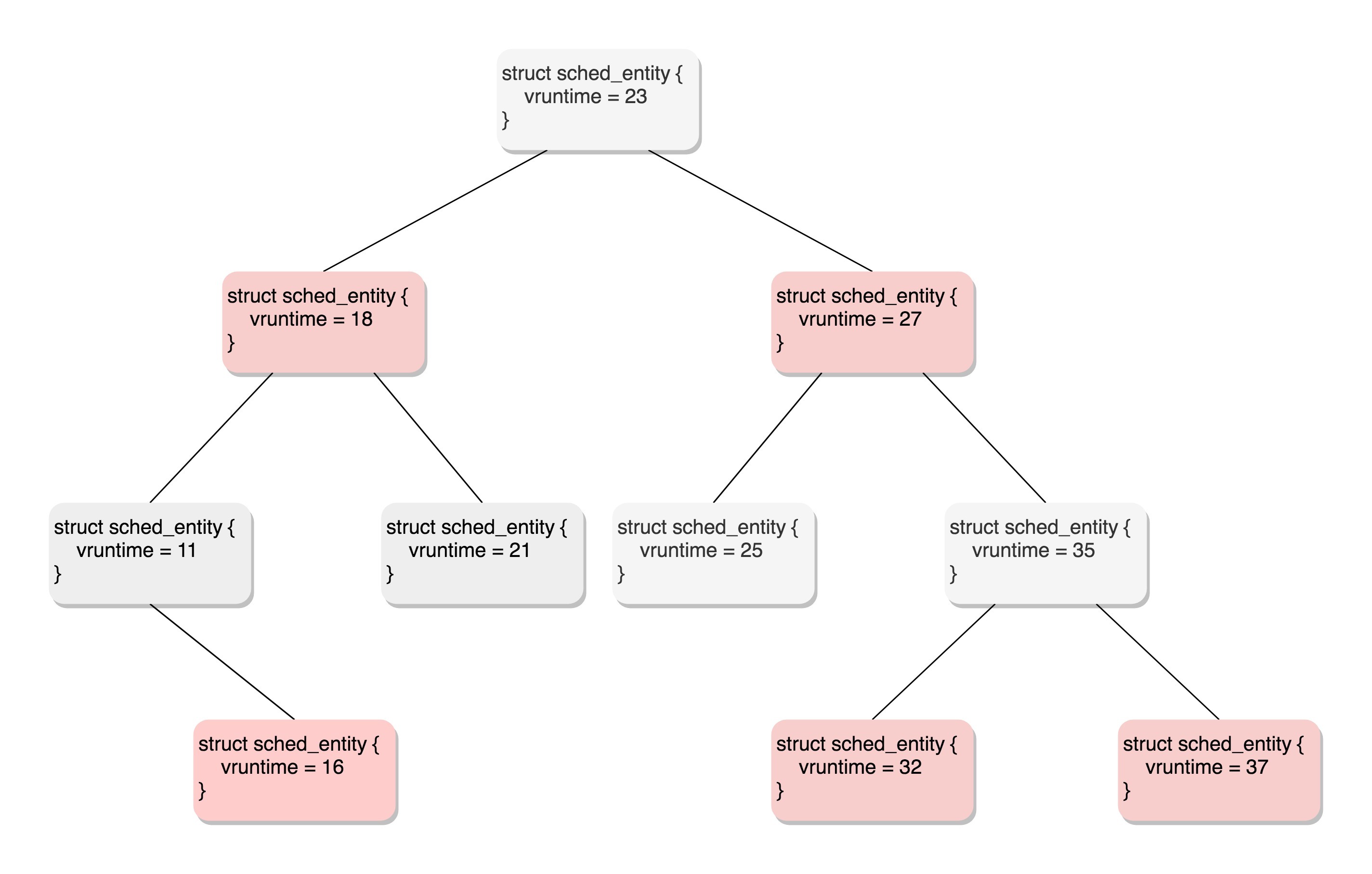
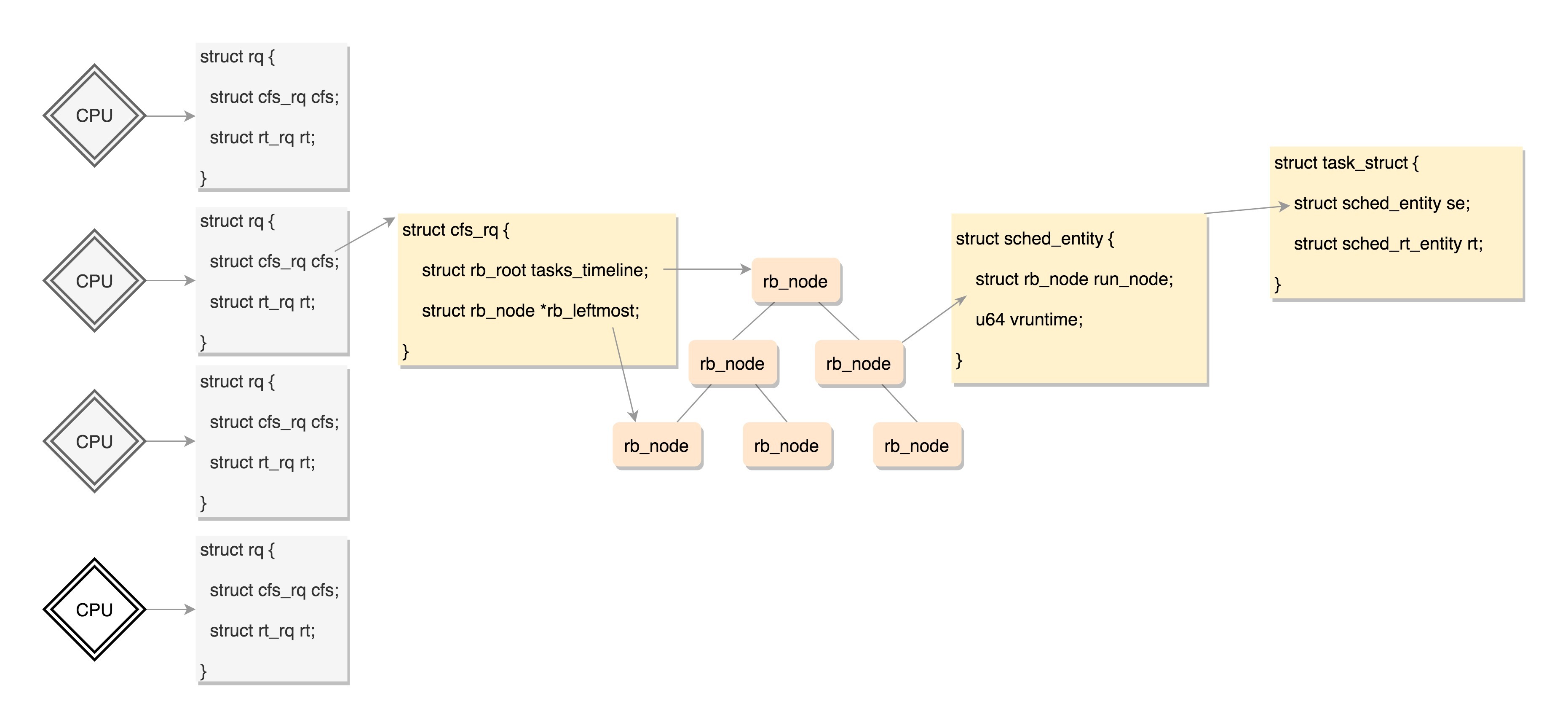
所有可运行的进程通过不断地插入操作最终都存储在以时间为顺序的红黑树中,vruntime最小的在树的左侧,vruntime最多的在树的右侧。 CFS调度策略会选择红黑树最左边的叶子节点作为下一个将获得cpu的任务。
每个CPU都有自己的 struct rq 结构,其用于描述在此CPU上所运行的所有进程,其包括一个实时进程队列rt_rq和一个CFS运行队列cfs_rq,在调度时,调度器首先会先去实时进程队列找是否有实时进程需要运行,如果没有才会去CFS运行队列找是否有进行需要运行。
struct rq {
/* runqueue lock: */
raw_spinlock_t lock;
unsigned int nr_running;
unsigned long cpu_load[CPU_LOAD_IDX_MAX];
......
struct load_weight load;
unsigned long nr_load_updates;
u64 nr_switches;
struct cfs_rq cfs;
struct rt_rq rt;
struct dl_rq dl;
......
struct task_struct *curr, *idle, *stop;
......
};对于普通进程公平队列cfs_rq,定义如下:
/* CFS-related fields in a runqueue */
struct cfs_rq {
struct load_weight load;
unsigned int nr_running, h_nr_running;
u64 exec_clock;
u64 min_vruntime;
#ifndef CONFIG_64BIT
u64 min_vruntime_copy;
#endif
struct rb_root tasks_timeline;
struct rb_node *rb_leftmost;
struct sched_entity *curr, *next, *last, *skip;
......
};这里面rb_root指向的就是红黑树的根节点,这个红黑树在CPU看起来就是一个队列,不断的取下一个应该运行的进程。rb_leftmost指向的是最左面的节点。
到这里终于凑够数据结构了,上面这些数据结构的关系如下图:
10.6 调度类是如何工作的?
调度类的定义如下:
struct sched_class {
const struct sched_class *next;
void (*enqueue_task) (struct rq *rq, struct task_struct *p, int flags);
void (*dequeue_task) (struct rq *rq, struct task_struct *p, int flags);
void (*yield_task) (struct rq *rq);
bool (*yield_to_task) (struct rq *rq, struct task_struct *p, bool preempt);
void (*check_preempt_curr) (struct rq *rq, struct task_struct *p, int flags);
struct task_struct * (*pick_next_task) (struct rq *rq,
struct task_struct *prev,
struct rq_flags *rf);
void (*put_prev_task) (struct rq *rq, struct task_struct *p);
void (*set_curr_task) (struct rq *rq);
void (*task_tick) (struct rq *rq, struct task_struct *p, int queued);
void (*task_fork) (struct task_struct *p);
void (*task_dead) (struct task_struct *p);
void (*switched_from) (struct rq *this_rq, struct task_struct *task);
void (*switched_to) (struct rq *this_rq, struct task_struct *task);
void (*prio_changed) (struct rq *this_rq, struct task_struct *task, int oldprio);
unsigned int (*get_rr_interval) (struct rq *rq,
struct task_struct *task);
void (*update_curr) (struct rq *rq)
}这个结构定义了很多种方法,用于在队列上操作任务。这里请大家注意第一个成员变量,是一个指针,指向下一个调度类。
上面我们讲了,调度类分为下面这几种:
extern const struct sched_class stop_sched_class;
extern const struct sched_class dl_sched_class;
extern const struct sched_class rt_sched_class;
extern const struct sched_class fair_sched_class;
extern const struct sched_class idle_sched_class;它们其实是放在一个链表上的。这里我们以调度最常见的操作,取下一个任务为例,来解析一下。可以看到,这里面有一个for_each_class循环,沿着上面的顺序,依次调用每个调度类的方法。
/*
* Pick up the highest-prio task:
*/
static inline struct task_struct *
pick_next_task(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
{
const struct sched_class *class;
struct task_struct *p;
......
for_each_class(class) {
p = class->pick_next_task(rq, prev, rf);
if (p) {
if (unlikely(p == RETRY_TASK))
goto again;
return p;
}
}
}这就说明,调度的时候是从优先级最高的调度类到优先级低的调度类,依次执行。而对于每种调度类,有自己的实现,例如,CFS就有fair_sched_class。
const struct sched_class fair_sched_class = {
.next = &idle_sched_class,
.enqueue_task = enqueue_task_fair,
.dequeue_task = dequeue_task_fair,
.yield_task = yield_task_fair,
.yield_to_task = yield_to_task_fair,
.check_preempt_curr = check_preempt_wakeup,
.pick_next_task = pick_next_task_fair,
.put_prev_task = put_prev_task_fair,
.set_curr_task = set_curr_task_fair,
.task_tick = task_tick_fair,
.task_fork = task_fork_fair,
.prio_changed = prio_changed_fair,
.switched_from = switched_from_fair,
.switched_to = switched_to_fair,
.get_rr_interval = get_rr_interval_fair,
.update_curr = update_curr_fair,
};对于同样的pick_next_task选取下一个要运行的任务这个动作,不同的调度类有自己的实现。fair_sched_class的实现是pick_next_task_fair,rt_sched_class的实现是pick_next_task_rt。
我们会发现这两个函数是操作不同的队列,pick_next_task_rt操作的是rt_rq,pick_next_task_fair操作的是cfs_rq。
static struct task_struct *
pick_next_task_rt(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
{
struct task_struct *p;
struct rt_rq *rt_rq = &rq->rt;
......
}
static struct task_struct *
pick_next_task_fair(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
{
struct cfs_rq *cfs_rq = &rq->cfs;
struct sched_entity *se;
struct task_struct *p;
......
}这样整个运行的场景就串起来了,在每个CPU上都有一个队列rq,这个队列里面包含多个子队列,例如rt_rq和cfs_rq,不同的队列有不同的实现方式,cfs_rq就是用红黑树实现的。
当有一天,某个CPU需要找下一个任务执行的时候,会按照优先级依次调用调度类,不同的调度类操作不同的队列。当然rt_sched_class先被调用,它会在rt_rq上找下一个任务,只有找不到的时候,才轮到fair_sched_class被调用,它会在cfs_rq上找下一个任务。这样保证了实时任务的优先级永远大于普通任务。
下面我们仔细看一下sched_class定义的与调度有关的函数。
- enqueue_task 向就绪队列中添加一个进程,当某个进程进入可运行状态时,调用这个函数;
- dequeue_task 将一个进程从就就绪队列中删除;
- pick_next_task 选择接下来要运行的进程;
- put_prev_task 用另一个进程代替当前运行的进程;
- set_curr_task 用于修改调度策略;
- task_tick 每次周期性时钟到的时候,这个函数被调用,可能触发调度。
在这里面,我们重点看fair_sched_class对于pick_next_task的实现pick_next_task_fair,获取下一个进程。调用路径如下:pick_next_task_fair->pick_next_entity->__pick_first_entity。
struct sched_entity *__pick_first_entity(struct cfs_rq *cfs_rq)
{
struct rb_node *left = rb_first_cached(&cfs_rq->tasks_timeline);
if (!left)
return NULL;
return rb_entry(left, struct sched_entity, run_node);
}从这个函数的实现可以看出,就是从红黑树里面取最左面的节点。
10.7 总结
一个CPU上有一个队列,CFS的队列是一棵红黑树,树的每一个节点都是一个sched_entity,每个sched_entity都属于一个task_struct,task_struct里面有指针指向这个进程属于哪个调度类。
.webp)
在调度的时候,依次调用调度类的函数,从CPU的队列中取出下一个进程。上面图中的调度器、上下文切换这一节我们没有讲,下一节我们讲讲基于这些数据结构,如何实现调度。
11. 调度(中)
所谓进程调度,其实就是一个人在做A项目,在某个时刻,换成做B项目去了。发生这种情况,主要有两种方式。
方式一:A项目做着做着,发现里面有一条指令sleep,也就是要休息一下,或者在等待某个I/O事件。那没办法了,就要主动让出CPU,然后可以开始做B项目。
方式二:A项目做着做着,旷日持久,实在受不了了。项目经理介入了,说这个项目A先停停,B项目也要做一下,要不然B项目该投诉了。
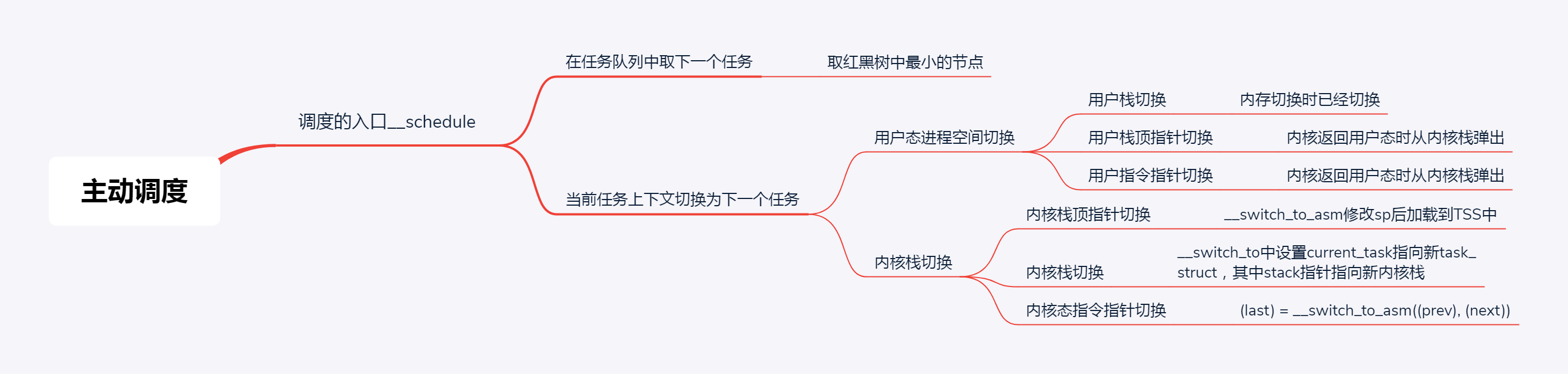
11.1 主动调度
我们这一节先来看方式一,主动调度。
这里我找了几个代码片段。 第一个片段是Btrfs,等待一个写入 。 Btrfs(B-Tree)是一种文件系统。
这个片段可以看作写入块设备的一个典型场景。写入需要一段时间,这段时间用不上CPU,还不如主动让给其他进程。
static void btrfs_wait_for_no_snapshoting_writes(struct btrfs_root *root)
{
......
do {
prepare_to_wait(&root->subv_writers->wait, &wait,
TASK_UNINTERRUPTIBLE);
writers = percpu_counter_sum(&root->subv_writers->counter);
if (writers)
schedule();
finish_wait(&root->subv_writers->wait, &wait);
} while (writers);
}另外一个例子是, 从Tap网络设备等待一个读取 。Tap网络设备是虚拟机使用的网络设备。当没有数据到来的时候,它也需要等待,所以也会选择把CPU让给其他进程。
static ssize_t tap_do_read(struct tap_queue *q,
struct iov_iter *to,
int noblock, struct sk_buff *skb)
{
......
while (1) {
if (!noblock)
prepare_to_wait(sk_sleep(&q->sk), &wait,
TASK_INTERRUPTIBLE);
......
/* Nothing to read, let's sleep */
schedule();
}
......
}接下来,我们就来看 schedule函数的调用过程。
asmlinkage __visible void __sched schedule(void)
{
struct task_struct *tsk = current;
sched_submit_work(tsk);
do {
preempt_disable();
__schedule(false);
sched_preempt_enable_no_resched();
} while (need_resched());
}这段代码的主要逻辑是在__schedule函数中实现的。这个函数比较复杂,我们分几个部分来讲解。
static void __sched notrace __schedule(bool preempt)
{
struct task_struct *prev, *next;
unsigned long *switch_count;
struct rq_flags rf;
struct rq *rq;
int cpu;
cpu = smp_processor_id();
rq = cpu_rq(cpu);
prev = rq->curr;
......首先,在当前的CPU上,我们取出任务队列rq。
task_struct *prev指向这个CPU的任务队列上面正在运行的那个进程curr。为啥是prev?因为一旦将来它被切换下来,那它就成了前任了。
接下来代码如下:
next = pick_next_task(rq, prev, &rf);
clear_tsk_need_resched(prev);
clear_preempt_need_resched();第二步,获取下一个任务,task_struct *next 指向下一个任务,这就是 继任 。
pick_next_task的实现如下:
static inline struct task_struct *
pick_next_task(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
{
const struct sched_class *class;
struct task_struct *p;
/*
* Optimization: we know that if all tasks are in the fair class we can call that function directly, but only if the @prev task wasn't of a higher scheduling class, because otherwise those loose the opportunity to pull in more work from other CPUs.
*/
if (likely((prev->sched_class == &idle_sched_class ||
prev->sched_class == &fair_sched_class) &&
rq->nr_running == rq->cfs.h_nr_running)) {
p = fair_sched_class.pick_next_task(rq, prev, rf);
if (unlikely(p == RETRY_TASK))
goto again;
/* Assumes fair_sched_class->next == idle_sched_class */
if (unlikely(!p))
p = idle_sched_class.pick_next_task(rq, prev, rf);
return p;
}
again:
for_each_class(class) {
p = class->pick_next_task(rq, prev, rf);
if (p) {
if (unlikely(p == RETRY_TASK))
goto again;
return p;
}
}
}我们来看again这里,就是咱们上一节讲的依次调用调度类。但是这里有了一个优化,因为大部分进程是普通进程,所以大部分情况下会调用上面的逻辑,调用的就是fair_sched_class.pick_next_task。
根据上一节对于fair_sched_class的定义,它调用的是pick_next_task_fair,代码如下:
static struct task_struct *
pick_next_task_fair(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
{
struct cfs_rq *cfs_rq = &rq->cfs;
struct sched_entity *se;
struct task_struct *p;
int new_tasks;对于CFS调度类,取出相应的队列cfs_rq,这就是我们上一节讲的那棵红黑树。
struct sched_entity *curr = cfs_rq->curr;
if (curr) {
if (curr->on_rq)
update_curr(cfs_rq);
else
curr = NULL;
......
}
se = pick_next_entity(cfs_rq, curr);取出当前正在运行的任务curr,如果依然是可运行的状态,也即处于进程就绪状态,则调用update_curr更新vruntime。update_curr咱们上一节就见过了,它会根据实际运行时间算出vruntime来。
接着,pick_next_entity从红黑树里面,取最左边的一个节点。这个函数的实现我们上一节也讲过了。
p = task_of(se);
if (prev != p) {
struct sched_entity *pse = &prev->se;
......
put_prev_entity(cfs_rq, pse);
set_next_entity(cfs_rq, se);
}
return ptask_of得到下一个调度实体对应的task_struct,如果发现继任和前任不一样,这就说明有一个更需要运行的进程了,就需要更新红黑树了。前面前任的vruntime更新过了,put_prev_entity放回红黑树,会找到相应的位置,然后set_next_entity将继任者设为当前任务。
第三步,当选出的继任者和前任不同,就要进行上下文切换,继任者进程正式进入运行。
if (likely(prev != next)) {
rq->nr_switches++;
rq->curr = next;
++*switch_count;
......
rq = context_switch(rq, prev, next, &rf);11.2 进程上下文切换
上下文切换主要干两件事情,一是切换进程空间,也即虚拟内存;二是切换寄存器和CPU上下文。
我们先来看context_switch的实现。
/*
* context_switch - switch to the new MM and the new thread's register state.
*/
static __always_inline struct rq *
context_switch(struct rq *rq, struct task_struct *prev,
struct task_struct *next, struct rq_flags *rf)
{
struct mm_struct *mm, *oldmm;
......
mm = next->mm;
oldmm = prev->active_mm;
......
switch_mm_irqs_off(oldmm, mm, next);
......
/* Here we just switch the register state and the stack. */
switch_to(prev, next, prev);
barrier();
return finish_task_switch(prev);
}这里首先是内存空间的切换,里面涉及内存管理的内容比较多。内存管理后面我们会有专门的章节来讲,这里你先知道有这么一回事就行了。
接下来,我们看switch_to。它就是寄存器和栈的切换,它调用到了__switch_to_asm。这是一段汇编代码,主要用于栈的切换。
对于32位操作系统来讲,切换的是栈顶指针esp。
/*
* %eax: prev task
* %edx: next task
*/
ENTRY(__switch_to_asm)
......
/* switch stack */
movl %esp, TASK_threadsp(%eax)
movl TASK_threadsp(%edx), %esp
......
jmp __switch_to
END(__switch_to_asm)对于64位操作系统来讲,切换的是栈顶指针rsp。
/*
* %rdi: prev task
* %rsi: next task
*/
ENTRY(__switch_to_asm)
......
/* switch stack */
movq %rsp, TASK_threadsp(%rdi)
movq TASK_threadsp(%rsi), %rsp
......
jmp __switch_to
END(__switch_to_asm)最终,都返回了__switch_to这个函数。这个函数对于32位和64位操作系统虽然有不同的实现,但里面做的事情是差不多的。所以我这里仅仅列出64位操作系统做的事情。
__visible __notrace_funcgraph struct task_struct *
__switch_to(struct task_struct *prev_p, struct task_struct *next_p)
{
struct thread_struct *prev = &prev_p->thread;
struct thread_struct *next = &next_p->thread;
......
int cpu = smp_processor_id();
struct tss_struct *tss = &per_cpu(cpu_tss, cpu);
......
load_TLS(next, cpu);
......
this_cpu_write(current_task, next_p);
/* Reload esp0 and ss1. This changes current_thread_info(). */
load_sp0(tss, next);
......
return prev_p;
}这里面有一个Per CPU的结构体tss。这是个什么呢?
在x86体系结构中,提供了一种以硬件的方式进行进程切换的模式,对于每个进程,x86希望在内存里面维护一个TSS(Task State Segment,任务状态段)结构。这里面有所有的寄存器。
另外,还有一个特殊的寄存器TR(Task Register,任务寄存器),指向某个进程的TSS。更改TR的值,将会触发硬件保存CPU所有寄存器的值到当前进程的TSS中,然后从新进程的TSS中读出所有寄存器值,加载到CPU对应的寄存器中。
下图就是32位的TSS结构。
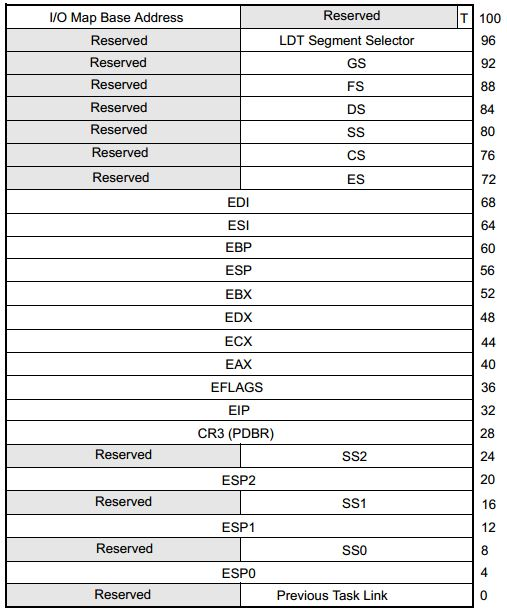
图片来自Intel® 64 and IA-32 Architectures Software Developer’s Manual Combined Volumes
但是这样有个缺点。我们做进程切换的时候,没必要每个寄存器都切换,这样每个进程一个TSS,就需要全量保存,全量切换,动作太大了。
于是,Linux操作系统想了一个办法。还记得在系统初始化的时候,会调用cpu_init吗?这里面会给每一个CPU关联一个TSS,然后将TR指向这个TSS,然后在操作系统的运行过程中,TR就不切换了,永远指向这个TSS。TSS用数据结构tss_struct表示,在x86_hw_tss中可以看到和上图相应的结构。
void cpu_init(void)
{
int cpu = smp_processor_id();
struct task_struct *curr = current;
struct tss_struct *t = &per_cpu(cpu_tss, cpu);
......
load_sp0(t, thread);
set_tss_desc(cpu, t);
load_TR_desc();
......
}
struct tss_struct {
/*
* The hardware state:
*/
struct x86_hw_tss x86_tss;
unsigned long io_bitmap[IO_BITMAP_LONGS + 1];
}在Linux中,真的参与进程切换的寄存器很少,主要的就是栈顶寄存器。
于是,在task_struct里面,还有一个我们原来没有注意的成员变量thread。这里面保留了要切换进程的时候需要修改的寄存器。
/* CPU-specific state of this task: */
struct thread_struct thread;所谓的进程切换,就是将某个进程的thread_struct里面的寄存器的值,写入到CPU的TR指向的tss_struct,对于CPU来讲,这就算是完成了切换。
例如__switch_to中的load_sp0,就是将下一个进程的thread_struct的sp0的值加载到tss_struct里面去。
11.3 指令指针的保存与恢复
你是不是觉得,这样真的就完成切换了吗?是的,不信我们来 盘点 一下。
从进程A切换到进程B,用户栈要不要切换呢?当然要,其实早就已经切换了,就在切换内存空间的时候。每个进程的用户栈都是独立的,都在内存空间里面。
那内核栈呢?已经在__switch_to里面切换了,也就是将current_task指向当前的task_struct。里面的void *stack指针,指向的就是当前的内核栈。
内核栈的栈顶指针呢?在switch_to_asm里面已经切换了栈顶指针,并且将栈顶指针在switch_to加载到了TSS里面。
用户栈的栈顶指针呢?如果当前在内核里面的话,它当然是在内核栈顶部的pt_regs结构里面呀。当从内核返回用户态运行的时候,pt_regs里面有所有当时在用户态的时候运行的上下文信息,就可以开始运行了。
唯一让人不容易理解的是指令指针寄存器,它应该指向下一条指令的,那它是如何切换的呢?这里有点绕,请你仔细看。
这里我先明确一点,进程的调度都最终会调用到__schedule函数。为了方便你记住,我姑且给它起个名字,就叫” 进程调度第一定律 “。后面我们会多次用到这个定律,你一定要记住。
我们用最前面的例子仔细分析这个过程。本来一个进程A在用户态是要写一个文件的,写文件的操作用户态没办法完成,就要通过系统调用到达内核态。在这个切换的过程中,用户态的指令指针寄存器是保存在pt_regs里面的,到了内核态,就开始沿着写文件的逻辑一步一步执行,结果发现需要等待,于是就调用__schedule函数。
这个时候,进程A在内核态的指令指针是指向schedule了。这里请记住,A进程的内核栈会保存这个schedule的调用,而且知道这是从btrfs_wait_for_no_snapshoting_writes这个函数里面进去的。
__schedule里面经过上面的层层调用,到达了context_switch的最后三行指令(其中barrier语句是一个编译器指令,用于保证switch_to和finish_task_switch的执行顺序,不会因为编译阶段优化而改变,这里咱们可以忽略它)。
switch_to(prev, next, prev);
barrier();
return finish_task_switch(prev);当进程A在内核里面执行switch_to的时候,内核态的指令指针也是指向这一行的。但是在switch_to里面,将寄存器和栈都切换到成了进程B的,唯一没有变的就是指令指针寄存器。当switch_to返回的时候,指令指针寄存器指向了下一条语句finish_task_switch。
但这个时候的finish_task_switch已经不是进程A的finish_task_switch了,而是进程B的finish_task_switch了。
这样合理吗?你怎么知道进程B当时被切换下去的时候,执行到哪里了?恢复B进程执行的时候一定在这里呢?这时候就要用到咱的”进程调度第一定律”了。
当年B进程被别人切换走的时候,也是调用__schedule,也是调用到switch_to,被切换成为C进程的,所以,B进程当年的下一个指令也是finish_task_switch,这就说明指令指针指到这里是没有错的。
接下来,我们要从finish_task_switch完毕后,返回__schedule的调用了。返回到哪里呢?按照函数返回的原理,当然是从内核栈里面去找,是返回到btrfs_wait_for_no_snapshoting_writes吗?当然不是了,因为btrfs_wait_for_no_snapshoting_writes是在A进程的内核栈里面的,它早就被切换走了,应该从B进程的内核栈里面找。
假设,B就是最前面例子里面调用tap_do_read读网卡的进程。它当年调用__schedule的时候,是从tap_do_read这个函数调用进去的。
当然,B进程的内核栈里面放的是tap_do_read。于是,从__schedule返回之后,当然是接着tap_do_read运行,然后在内核运行完毕后,返回用户态。这个时候,B进程内核栈的pt_regs也保存了用户态的指令指针寄存器,就接着在用户态的下一条指令开始运行就可以了。
假设,我们只有一个CPU,从B切换到C,从C又切换到A。在C切换到A的时候,还是按照”进程调度第一定律”,C进程还是会调用__schedule到达switch_to,在里面切换成为A的内核栈,然后运行finish_task_switch。
这个时候运行的finish_task_switch,才是A进程的finish_task_switch。运行完毕从__schedule返回的时候,从内核栈上才知道,当年是从btrfs_wait_for_no_snapshoting_writes调用进去的,因而应该返回btrfs_wait_for_no_snapshoting_writes继续执行,最后内核执行完毕返回用户态,同样恢复pt_regs,恢复用户态的指令指针寄存器,从用户态接着运行。
到这里你是不是有点理解为什么switch_to有三个参数呢?为啥有两个prev呢?其实我们从定义就可以看到。
#define switch_to(prev, next, last) \
do { \
prepare_switch_to(prev, next); \
\
((last) = __switch_to_asm((prev), (next))); \
} while (0)在上面的例子中,A切换到B的时候,运行到switch_to_asm这一行的时候,是在A的内核栈上运行的,prev是A,next是B。但是,A执行完switch_to_asm之后就被切换走了,当C再次切换到A的时候,运行到switch_to_asm,是从C的内核栈运行的。这个时候,prev是C,next是A,但是switch_to_asm里面切换成为了A当时的内核栈。
还记得当年的场景”prev是A,next是B”,__switch_to_asm里面return prev的时候,还没return的时候,prev这个变量里面放的还是C,因而它会把C放到返回结果中。但是,一旦return,就会弹出A当时的内核栈。这个时候,prev变量就变成了A,next变量就变成了B。这就还原了当年的场景,好在返回值里面的last还是C。
通过三个变量switch_to(prev = A, next=B, last=C),A进程就明白了,我当时被切换走的时候,是切换成B,这次切换回来,是从C回来的。
11.4 总结
这一节我们讲主动调度的过程,也即一个运行中的进程主动调用schedule让出CPU。在schedule里面会做两件事情,第一是选取下一个进程,第二是进行上下文切换。而上下文切换又分用户态进程空间的切换和内核态的切换。
12. 调度(下)
12.1 抢占式调度
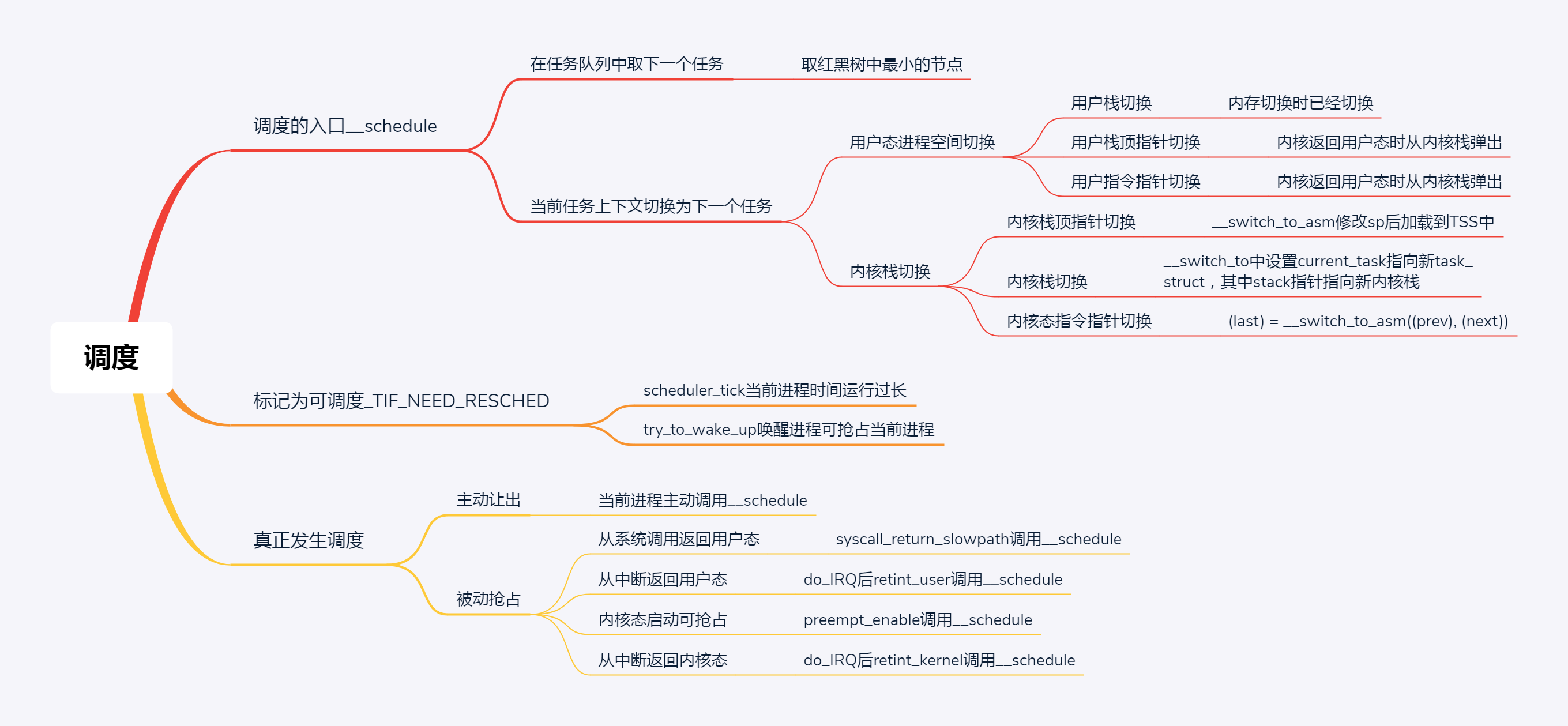
上一节我们讲的主动调度是第一种方式,第二种方式,就是抢占式调度。什么情况下会发生抢占呢?
最常见的现象就是 一个进程执行时间太长了,是时候切换到另一个进程了 。那怎么衡量一个进程的运行时间呢?在计算机里面有一个时钟,会过一段时间触发一次时钟中断,通知操作系统,时间又过去一个时钟周期,这是个很好的方式,可以查看是否是需要抢占的时间点。
时钟中断处理函数会调用scheduler_tick(),它的代码如下:
void scheduler_tick(void)
{
int cpu = smp_processor_id();
struct rq *rq = cpu_rq(cpu);
struct task_struct *curr = rq->curr;
......
curr->sched_class->task_tick(rq, curr, 0);
cpu_load_update_active(rq);
calc_global_load_tick(rq);
......
}这个函数先取出当前cpu的运行队列,然后得到这个队列上当前正在运行中的进程的task_struct,然后调用这个task_struct的调度类的task_tick函数,顾名思义这个函数就是来处理时钟事件的。
如果当前运行的进程是普通进程,调度类为fair_sched_class,调用的处理时钟的函数为task_tick_fair。我们来看一下它的实现。
static void task_tick_fair(struct rq *rq, struct task_struct *curr, int queued)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se = &curr->se;
for_each_sched_entity(se) {
cfs_rq = cfs_rq_of(se);
entity_tick(cfs_rq, se, queued);
}
......
}根据当前进程的task_struct,找到对应的调度实体sched_entity和cfs_rq队列,调用entity_tick。
static void
entity_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr, int queued)
{
update_curr(cfs_rq);
update_load_avg(curr, UPDATE_TG);
update_cfs_shares(curr);
.....
if (cfs_rq->nr_running > 1)
check_preempt_tick(cfs_rq, curr);
}在entity_tick里面,我们又见到了熟悉的update_curr。它会更新当前进程的vruntime,然后调用check_preempt_tick。顾名思义就是,检查是否是时候被抢占了。
static void
check_preempt_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr)
{
unsigned long ideal_runtime, delta_exec;
struct sched_entity *se;
s64 delta;
ideal_runtime = sched_slice(cfs_rq, curr);
delta_exec = curr->sum_exec_runtime - curr->prev_sum_exec_runtime;
if (delta_exec > ideal_runtime) {
resched_curr(rq_of(cfs_rq));
return;
}
......
se = __pick_first_entity(cfs_rq);
delta = curr->vruntime - se->vruntime;
if (delta < 0)
return;
if (delta > ideal_runtime)
resched_curr(rq_of(cfs_rq));
}check_preempt_tick先是调用sched_slice函数计算出的ideal_runtime,他是一个调度周期中,这个进程应该运行的实际时间。
sum_exec_runtime指进程总共执行的实际时间,prev_sum_exec_runtime指上次该进程被调度时已经占用的实际时间。每次在调度一个新的进程时都会把它的se->prev_sum_exec_runtime = se->sum_exec_runtime,所以sum_exec_runtime-prev_sum_exec_runtime就是这次调度占用实际时间。如果这个时间大于ideal_runtime,则应该被抢占了。
除了这个条件之外,还会通过__pick_first_entity取出红黑树中最小的进程。如果当前进程的vruntime大于红黑树中最小的进程的vruntime,且差值大于ideal_runtime,也应该被抢占了。
当发现当前进程应该被抢占,不能直接把它踢下来,而是把它标记为应该被抢占。为什么呢?因为进程调度第一定律呀,一定要等待正在运行的进程调用__schedule才行啊,所以这里只能先标记一下。
标记一个进程应该被抢占,都是调用resched_curr,它会调用set_tsk_need_resched,标记进程应该被抢占,但是此时此刻,并不真的抢占,而是打上一个标签TIF_NEED_RESCHED。
static inline void set_tsk_need_resched(struct task_struct *tsk)
{
set_tsk_thread_flag(tsk,TIF_NEED_RESCHED);
}另外一个可能抢占的场景是 当一个进程被唤醒的时候 。
我们前面说过,当一个进程在等待一个I/O的时候,会主动放弃CPU。但是当I/O到来的时候,进程往往会被唤醒。这个时候是一个时机。当被唤醒的进程优先级高于CPU上的当前进程,就会触发抢占。try_to_wake_up()调用ttwu_queue将这个唤醒的任务添加到队列当中。ttwu_queue再调用ttwu_do_activate激活这个任务。ttwu_do_activate调用ttwu_do_wakeup。这里面调用了check_preempt_curr检查是否应该发生抢占。如果应该发生抢占,也不是直接踢走当然进程,而也是将当前进程标记为应该被抢占。
static void ttwu_do_wakeup(struct rq *rq, struct task_struct *p, int wake_flags,
struct rq_flags *rf)
{
check_preempt_curr(rq, p, wake_flags);
p->state = TASK_RUNNING;
trace_sched_wakeup(p);
}到这里,你会发现,抢占问题只做完了一半。就是标识当前运行中的进程应该被抢占了,但是真正的抢占动作并没有发生。
12.2 抢占的时机
真正的抢占还需要时机,也就是需要那么一个时刻,让正在运行中的进程有机会调用一下__schedule。
你可以想象,不可能某个进程代码运行着,突然要去调用__schedule,代码里面不可能这么写,所以一定要规划几个时机,这个时机分为用户态和内核态。
12.2.1 用户态的抢占时机
对于用户态的进程来讲,从系统调用中返回的那个时刻,是一个被抢占的时机。
前面讲系统调用的时候,64位的系统调用的链路位do_syscall_64->syscall_return_slowpath->prepare_exit_to_usermode->exit_to_usermode_loop,当时我们还没关注exit_to_usermode_loop这个函数,现在我们来看一下。
static void exit_to_usermode_loop(struct pt_regs *regs, u32 cached_flags)
{
while (true) {
/* We have work to do. */
local_irq_enable();
if (cached_flags & _TIF_NEED_RESCHED)
schedule();
......
}
}现在我们看到在exit_to_usermode_loop函数中,上面打的标记起了作用,如果被打了_TIF_NEED_RESCHED,调用schedule进行调度,调用的过程和上一节解析的一样,会选择一个进程让出CPU,做上下文切换。
对于用户态的进程来讲,从中断中返回的那个时刻,也是一个被抢占的时机。
在arch/x86/entry/entry_64.S中有中断的处理过程。又是一段汇编语言代码,你重点领会它的意思就行,不要纠结每一行都看懂。
common_interrupt:
ASM_CLAC
addq $-0x80, (%rsp)
interrupt do_IRQ
ret_from_intr:
popq %rsp
testb $3, CS(%rsp)
jz retint_kernel
/* Interrupt came from user space */
GLOBAL(retint_user)
mov %rsp,%rdi
call prepare_exit_to_usermode
TRACE_IRQS_IRETQ
SWAPGS
jmp restore_regs_and_iret
/* Returning to kernel space */
retint_kernel:
#ifdef CONFIG_PREEMPT
bt $9, EFLAGS(%rsp)
jnc 1f
0: cmpl $0, PER_CPU_VAR(__preempt_count)
jnz 1f
call preempt_schedule_irq
jmp 0b中断处理调用的是do_IRQ函数,中断完毕后分为两种情况,一个是返回用户态,一个是返回内核态。这个通过注释也能看出来。
咱们先来来看返回用户态这一部分,先不管返回内核态的那部分代码,retint_user会调用prepare_exit_to_usermode,最终调用exit_to_usermode_loop,和上面的逻辑一样,发现有标记则调用schedule()。
12.2.2 内核态的抢占时机
对内核态的执行中,被抢占的时机一般发生在在preempt_enable()中。
在内核态的执行中,有的操作是不能被中断的,所以在进行这些操作之前,总是先调用preempt_disable()关闭抢占,当再次打开的时候,就是一次内核态代码被抢占的机会。
就像下面代码中展示的一样,preempt_enable()会调用preempt_count_dec_and_test(),判断preempt_count和TIF_NEED_RESCHED看是否可以被抢占。如果可以,就调用preempt_schedule->preempt_schedule_common->__schedule进行调度。还是满足进程调度第一定律的。
#define preempt_enable() \
do { \
if (unlikely(preempt_count_dec_and_test())) \
__preempt_schedule(); \
} while (0)
#define preempt_count_dec_and_test() \
({ preempt_count_sub(1); should_resched(0); })
static __always_inline bool should_resched(int preempt_offset)
{
return unlikely(preempt_count() == preempt_offset &&
tif_need_resched());
}
#define tif_need_resched() test_thread_flag(TIF_NEED_RESCHED)
static void __sched notrace preempt_schedule_common(void)
{
do {
......
__schedule(true);
......
} while (need_resched())
}在内核态也会遇到中断的情况,当中断返回的时候,返回的仍然是内核态。这个时候也是一个执行抢占的时机,现在我们再来上面中断返回的代码中返回内核的那部分代码,调用的是preempt_schedule_irq。
asmlinkage __visible void __sched preempt_schedule_irq(void)
{
......
do {
preempt_disable();
local_irq_enable();
__schedule(true);
local_irq_disable();
sched_preempt_enable_no_resched();
} while (need_resched());
......
}preempt_schedule_irq调用__schedule进行调度。还是满足进程调度第一定律的。
12.3 总结
第一条就是总结了进程调度第一定律的核心函数__schedule的执行过程,这是上一节讲的,因为要切换的东西比较多,需要你详细了解每一部分是如何切换的。
第二条总结了标记为可抢占的场景,第三条是所有的抢占发生的时机,这里是真正验证了进程调度第一定律的。
13. 进程的创建
fork是一个系统调用,根据咱们讲过的系统调用的流程,流程的最后会在sys_call_table中找到相应的系统调用sys_fork。
根据SYSCALL_DEFINE0这个宏的定义,下面这段代码就定义了sys_fork。
SYSCALL_DEFINE0(fork)
{
......
return _do_fork(SIGCHLD, 0, 0, NULL, NULL, 0);
}sys_fork会调用_do_fork。
long _do_fork(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr,
unsigned long tls)
{
struct task_struct *p;
int trace = 0;
long nr;
......
p = copy_process(clone_flags, stack_start, stack_size,
child_tidptr, NULL, trace, tls, NUMA_NO_NODE);
......
if (!IS_ERR(p)) {
struct pid *pid;
pid = get_task_pid(p, PIDTYPE_PID);
nr = pid_vnr(pid);
if (clone_flags & CLONE_PARENT_SETTID)
put_user(nr, parent_tidptr);
......
wake_up_new_task(p);
......
put_pid(pid);
}
......
}13.1 fork的第一件大事:复制结构
_do_fork里面做的第一件大事就是copy_process。
这里我们再把task_struct的结构图拿出来,对比着看如何一个个复制。

static __latent_entropy struct task_struct *copy_process(
unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *child_tidptr,
struct pid *pid,
int trace,
unsigned long tls,
int node)
{
int retval;
struct task_struct *p;
......
p = dup_task_struct(current, node);dup_task_struct主要做了下面几件事情:
- 调用alloc_task_struct_node分配一个task_struct结构;
- 调用alloc_thread_stack_node来创建内核栈,这里面调用__vmalloc_node_range分配一个连续的THREAD_SIZE的内存空间,赋值给task_struct的void *stack成员变量;
- 调用arch_dup_task_struct(struct task_struct dst, struct task_structsrc),将task_struct进行复制,其实就是调用memcpy;
- 调用setup_thread_stack设置thread_info。
到这里,整个task_struct复制了一份,而且内核栈也创建好了。
我们再接着看copy_process。
retval = copy_creds(p, clone_flags);轮到权限相关了,copy_creds主要做了下面几件事情:
- 调用prepare_creds,准备一个新的struct cred *new。如何准备呢?其实还是从内存中分配一个新的struct cred结构,然后调用memcpy复制一份父进程的cred;
- 接着p->cred = p->real_cred = get_cred(new),将新进程的”我能操作谁”和”谁能操作我”两个权限都指向新的cred。
接下来,copy_process重新设置进程运行的统计量。
p->utime = p->stime = p->gtime = 0;
p->start_time = ktime_get_ns();
p->real_start_time = ktime_get_boot_ns();接下来,copy_process开始设置调度相关的变量。
retval = sched_fork(clone_flags, p);sched_fork主要做了下面几件事情:
- 调用__sched_fork,在这里面将on_rq设为0,初始化sched_entity,将里面的exec_start、sum_exec_runtime、prev_sum_exec_runtime、vruntime都设为0。你还记得吗,这几个变量涉及进程的实际运行时间和虚拟运行时间。是否到时间应该被调度了,就靠它们几个;
- 设置进程的状态p->state = TASK_NEW;
- 初始化优先级prio、normal_prio、static_prio;
- 设置调度类,如果是普通进程,就设置为p->sched_class = &fair_sched_class;
- 调用调度类的task_fork函数,对于CFS来讲,就是调用task_fork_fair。在这个函数里,先调用update_curr,对于当前的进程进行统计量更新,然后把子进程和父进程的vruntime设成一样,最后调用place_entity,初始化sched_entity。这里有一个变量sysctl_sched_child_runs_first,可以设置父进程和子进程谁先运行。如果设置了子进程先运行,即便两个进程的vruntime一样,也要把子进程的sched_entity放在前面,然后调用resched_curr,标记当前运行的进程TIF_NEED_RESCHED,也就是说,把父进程设置为应该被调度,这样下次调度的时候,父进程会被子进程抢占。
接下来,copy_process开始初始化与文件和文件系统相关的变量。
retval = copy_files(clone_flags, p);
retval = copy_fs(clone_flags, p);copy_files主要用于复制一个进程打开的文件信息。这些信息用一个结构files_struct来维护,每个打开的文件都有一个文件描述符。在copy_files函数里面调用dup_fd,在这里面会创建一个新的files_struct,然后将所有的文件描述符数组fdtable拷贝一份。
copy_fs主要用于复制一个进程的目录信息。这些信息用一个结构fs_struct来维护。一个进程有自己的根目录和根文件系统root,也有当前目录pwd和当前目录的文件系统,都在fs_struct里面维护。copy_fs函数里面调用copy_fs_struct,创建一个新的fs_struct,并复制原来进程的fs_struct。
接下来,copy_process开始初始化与信号相关的变量。
init_sigpending(&p->pending);
retval = copy_sighand(clone_flags, p);
retval = copy_signal(clone_flags, p);copy_sighand会分配一个新的sighand_struct。这里最主要的是维护信号处理函数,在copy_sighand里面会调用memcpy,将信号处理函数sighand->action从父进程复制到子进程。
init_sigpending和copy_signal用于初始化,并且复制用于维护发给这个进程的信号的数据结构。copy_signal函数会分配一个新的signal_struct,并进行初始化。
接下来,copy_process开始复制进程内存空间。
retval = copy_mm(clone_flags, p);进程都自己的内存空间,用mm_struct结构来表示。copy_mm函数中调用dup_mm,分配一个新的mm_struct结构,调用memcpy复制这个结构。dup_mmap用于复制内存空间中内存映射的部分。前面讲系统调用的时候,我们说过,mmap可以分配大块的内存,其实mmap也可以将一个文件映射到内存中,方便可以像读写内存一样读写文件,这个在内存管理那节我们讲。
接下来,copy_process开始分配pid,设置tid,group_leader,并且建立进程之间的亲缘关系。
INIT_LIST_HEAD(&p->children);
INIT_LIST_HEAD(&p->sibling);
......
p->pid = pid_nr(pid);
if (clone_flags & CLONE_THREAD) {
p->exit_signal = -1;
p->group_leader = current->group_leader;
p->tgid = current->tgid;
} else {
if (clone_flags & CLONE_PARENT)
p->exit_signal = current->group_leader->exit_signal;
else
p->exit_signal = (clone_flags & CSIGNAL);
p->group_leader = p;
p->tgid = p->pid;
}
......
if (clone_flags & (CLONE_PARENT|CLONE_THREAD)) {
p->real_parent = current->real_parent;
p->parent_exec_id = current->parent_exec_id;
} else {
p->real_parent = current;
p->parent_exec_id = current->self_exec_id;
}好了,copy_process要结束了,上面图中的组件也初始化的差不多了。
13.2 fork的第二件大事:唤醒新进程
_do_fork做的第二件大事是wake_up_new_task。新任务刚刚建立,有没有机会抢占别人,获得CPU呢?
void wake_up_new_task(struct task_struct *p)
{
struct rq_flags rf;
struct rq *rq;
......
p->state = TASK_RUNNING;
......
activate_task(rq, p, ENQUEUE_NOCLOCK);
p->on_rq = TASK_ON_RQ_QUEUED;
trace_sched_wakeup_new(p);
check_preempt_curr(rq, p, WF_FORK);
......
}首先,我们需要将进程的状态设置为TASK_RUNNING。
activate_task函数中会调用enqueue_task。
static inline void enqueue_task(struct rq *rq, struct task_struct *p, int flags)
{
.....
p->sched_class->enqueue_task(rq, p, flags);
}如果是CFS的调度类,则执行相应的enqueue_task_fair。
static void
enqueue_task_fair(struct rq *rq, struct task_struct *p, int flags)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se = &p->se;
......
cfs_rq = cfs_rq_of(se);
enqueue_entity(cfs_rq, se, flags);
......
cfs_rq->h_nr_running++;
......
}在enqueue_task_fair中取出的队列就是cfs_rq,然后调用enqueue_entity。
在enqueue_entity函数里面,会调用update_curr,更新运行的统计量,然后调用__enqueue_entity,将sched_entity加入到红黑树里面,然后将se->on_rq = 1设置在队列上。
回到enqueue_task_fair后,将这个队列上运行的进程数目加一。然后,wake_up_new_task会调用check_preempt_curr,看是否能够抢占当前进程。
在check_preempt_curr中,会调用相应的调度类的rq->curr->sched_class->check_preempt_curr(rq, p, flags)。对于CFS调度类来讲,调用的是check_preempt_wakeup。
static void check_preempt_wakeup(struct rq *rq, struct task_struct *p, int wake_flags)
{
struct task_struct *curr = rq->curr;
struct sched_entity *se = &curr->se, *pse = &p->se;
struct cfs_rq *cfs_rq = task_cfs_rq(curr);
......
if (test_tsk_need_resched(curr))
return;
......
find_matching_se(&se, &pse);
update_curr(cfs_rq_of(se));
if (wakeup_preempt_entity(se, pse) == 1) {
goto preempt;
}
return;
preempt:
resched_curr(rq);
......
}在check_preempt_wakeup函数中,前面调用task_fork_fair的时候,设置sysctl_sched_child_runs_first了,已经将当前父进程的TIF_NEED_RESCHED设置了,则直接返回。
否则,check_preempt_wakeup还是会调用update_curr更新一次统计量,然后wakeup_preempt_entity将父进程和子进程PK一次,看是不是要抢占,如果要则调用resched_curr标记父进程为TIF_NEED_RESCHED。
如果新创建的进程应该抢占父进程,在什么时间抢占呢?别忘了fork是一个系统调用,从系统调用返回的时候,是抢占的一个好时机,如果父进程判断自己已经被设置为TIF_NEED_RESCHED,就让子进程先跑,抢占自己。
13.3 总结
fork系统调用的过程咱们就解析完了。它包含两个重要的事件,一个是将task_struct结构复制一份并且初始化,另一个是试图唤醒新创建的子进程。
这个过程我画了一张图,你可以对照着这张图回顾进程创建的过程。
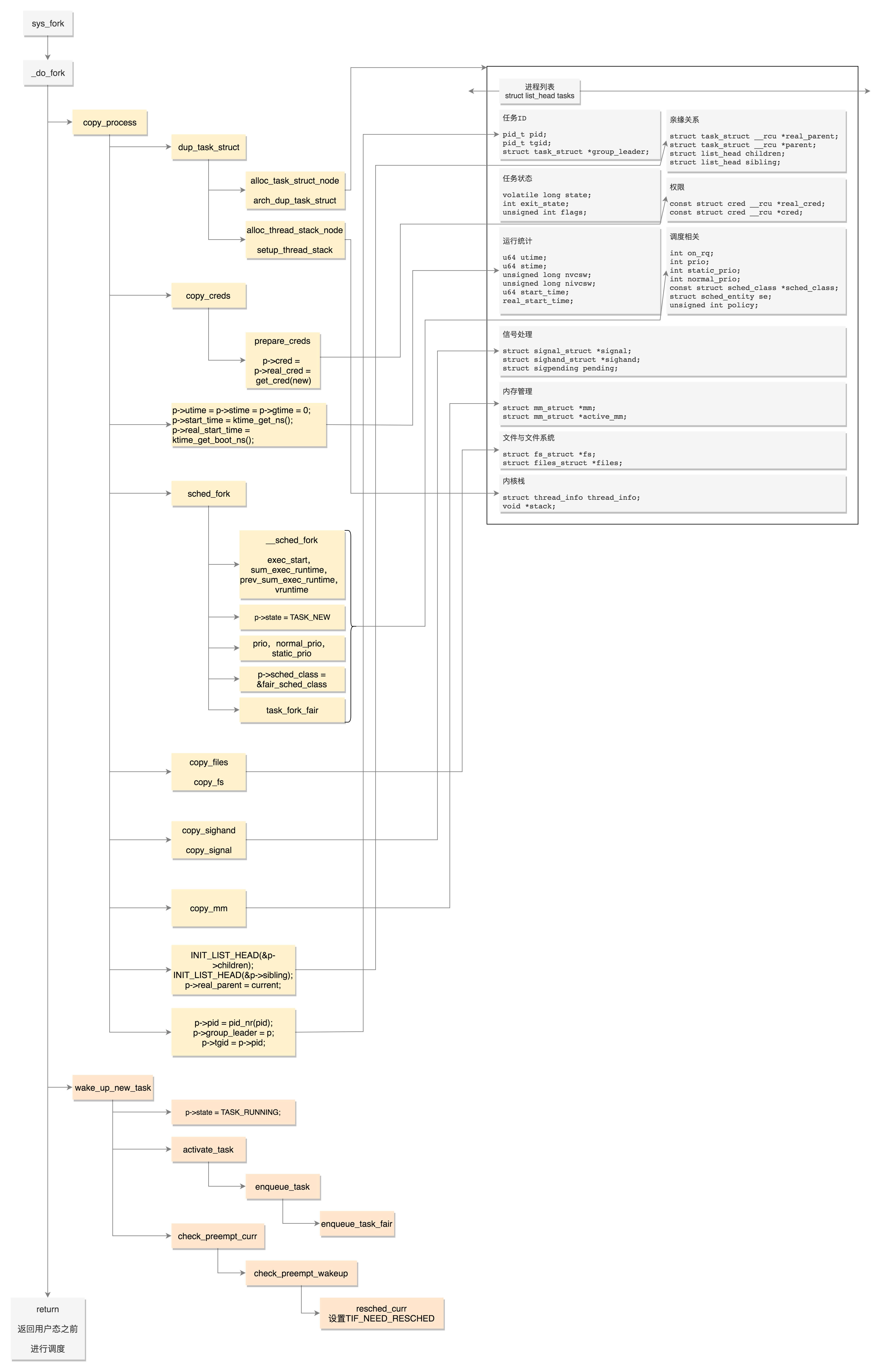
这个图的上半部分是复制task_struct结构,你可以对照着右面的task_struct结构图,看这里面的成员是如何一部分一部分的被复制的。图的下半部分是唤醒新创建的子进程,如果条件满足,就会将当前进程设置应该被调度的标识位,就等着当前进程执行__schedule了。
14. 线程的创建
14.1 用户态创建线程
无论是进程还是线程,在内核里面都是任务。
其实,线程不是一个完全由内核实现的机制,它是由内核态和用户态合作完成的。pthread_create不是一个系统调用,是Glibc库的一个函数,所以我们还要去Glibc里面去找线索。
在nptl/pthread_create.c里面可以找到这个函数:
int __pthread_create_2_1 (pthread_t *newthread, const pthread_attr_t *attr, void *(*start_routine) (void *), void *arg)
{
......
}
versioned_symbol (libpthread, __pthread_create_2_1, pthread_create, GLIBC_2_1);下面我们依次来看这个函数做了些啥。
首先处理的是线程的属性参数。例如前面写程序的时候,我们设置的线程栈大小。如果没有传入线程属性,就取默认值。
const struct pthread_attr *iattr = (struct pthread_attr *) attr;
struct pthread_attr default_attr;
if (iattr == NULL)
{
......
iattr = &default_attr;
}接下来,就像在内核里一样,每一个进程或者线程都有一个task_struct结构,在用户态也有一个用于维护线程的结构,就是这个pthread结构。
struct pthread *pd = NULL;凡是涉及函数的调用,都要使用到栈。每个线程也有自己的栈。那接下来就是创建线程栈了。
int err = ALLOCATE_STACK (iattr, &pd);ALLOCATE_STACK是一个宏,我们找到它的定义之后,发现它其实就是一个函数。只是,这个函数有些复杂,所以我这里把主要的代码列一下。
# define ALLOCATE_STACK(attr, pd) allocate_stack (attr, pd, &stackaddr)
static int
allocate_stack (const struct pthread_attr *attr, struct pthread **pdp,
ALLOCATE_STACK_PARMS)
{
struct pthread *pd;
size_t size;
size_t pagesize_m1 = __getpagesize () - 1;
......
size = attr->stacksize;
......
/* Allocate some anonymous memory. If possible use the cache. */
size_t guardsize;
void *mem;
const int prot = (PROT_READ | PROT_WRITE
| ((GL(dl_stack_flags) & PF_X) ? PROT_EXEC : 0));
/* Adjust the stack size for alignment. */
size &= ~__static_tls_align_m1;
/* Make sure the size of the stack is enough for the guard and
eventually the thread descriptor. */
guardsize = (attr->guardsize + pagesize_m1) & ~pagesize_m1;
size += guardsize;
pd = get_cached_stack (&size, &mem);
if (pd == NULL)
{
/* If a guard page is required, avoid committing memory by first
allocate with PROT_NONE and then reserve with required permission
excluding the guard page. */
mem = __mmap (NULL, size, (guardsize == 0) ? prot : PROT_NONE,
MAP_PRIVATE | MAP_ANONYMOUS | MAP_STACK, -1, 0);
/* Place the thread descriptor at the end of the stack. */
#if TLS_TCB_AT_TP
pd = (struct pthread *) ((char *) mem + size) - 1;
#elif TLS_DTV_AT_TP
pd = (struct pthread *) ((((uintptr_t) mem + size - __static_tls_size) & ~__static_tls_align_m1) - TLS_PRE_TCB_SIZE);
#endif
/* Now mprotect the required region excluding the guard area. */
char *guard = guard_position (mem, size, guardsize, pd, pagesize_m1);
setup_stack_prot (mem, size, guard, guardsize, prot);
pd->stackblock = mem;
pd->stackblock_size = size;
pd->guardsize = guardsize;
pd->specific[0] = pd->specific_1stblock;
/* And add to the list of stacks in use. */
stack_list_add (&pd->list, &stack_used);
}
*pdp = pd;
void *stacktop;
# if TLS_TCB_AT_TP
/* The stack begins before the TCB and the static TLS block. */
stacktop = ((char *) (pd + 1) - __static_tls_size);
# elif TLS_DTV_AT_TP
stacktop = (char *) (pd - 1);
# endif
*stack = stacktop;
......
}我们来看一下,allocate_stack主要做了以下这些事情:
- 如果你在线程属性里面设置过栈的大小,需要你把设置的值拿出来;
- 为了防止栈的访问越界,在栈的末尾会有一块空间guardsize,一旦访问到这里就错误了;
- 其实线程栈是在进程的堆里面创建的。如果一个进程不断地创建和删除线程,我们不可能不断地去申请和清除线程栈使用的内存块,这样就需要有一个缓存。get_cached_stack就是根据计算出来的size大小,看一看已经有的缓存中,有没有已经能够满足条件的;
- 如果缓存里面没有,就需要调用mmap创建一块新的,系统调用那一节我们讲过,如果要在堆里面malloc一块内存,比较大的话,用mmap;
- 线程栈也是自顶向下生长的,还记得每个线程要有一个pthread结构,这个结构也是放在栈的空间里面的。在栈底的位置,其实是地址最高位;
- 计算出guard内存的位置,调用setup_stack_prot设置这块内存的是受保护的;
- 接下来,开始填充pthread这个结构里面的成员变量stackblock、stackblock_size、guardsize、specific。这里的specific是用于存放Thread Specific Data的,也即属于线程的全局变量;
- 将这个线程栈放到stack_used链表中,其实管理线程栈总共有两个链表,一个是stack_used,也就是这个栈正被使用;另一个是stack_cache,就是上面说的,一旦线程结束,先缓存起来,不释放,等有其他的线程创建的时候,给其他的线程用。
搞定了用户态栈的问题,其实用户态的事情基本搞定了一半。
14.2 内核态创建任务
接下来,我们接着pthread_create看。其实有了用户态的栈,接着需要解决的就是用户态的程序从哪里开始运行的问题。
pd->start_routine = start_routine;
pd->arg = arg;
pd->schedpolicy = self->schedpolicy;
pd->schedparam = self->schedparam;
/* Pass the descriptor to the caller. */
*newthread = (pthread_t) pd;
atomic_increment (&__nptl_nthreads);
retval = create_thread (pd, iattr, &stopped_start, STACK_VARIABLES_ARGS, &thread_ran);start_routine就是咱们给线程的函数,start_routine,start_routine的参数arg,以及调度策略都要赋值给pthread。
接下来__nptl_nthreads加一,说明有多了一个线程。
真正创建线程的是调用create_thread函数,这个函数定义如下:
static int
create_thread (struct pthread *pd, const struct pthread_attr *attr,
bool *stopped_start, STACK_VARIABLES_PARMS, bool *thread_ran)
{
const int clone_flags = (CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SYSVSEM | CLONE_SIGHAND | CLONE_THREAD | CLONE_SETTLS | CLONE_PARENT_SETTID | CLONE_CHILD_CLEARTID | 0);
ARCH_CLONE (&start_thread, STACK_VARIABLES_ARGS, clone_flags, pd, &pd->tid, tp, &pd->tid);
/* It's started now, so if we fail below, we'll have to cancel it
and let it clean itself up. */
*thread_ran = true;
}这里面有很长的clone_flags,这些咱们原来一直没注意,不过接下来的过程,我们要特别的关注一下这些标志位。
然后就是ARCH_CLONE,其实调用的是__clone。看到这里,你应该就有感觉了,马上就要到系统调用了。
# define ARCH_CLONE __clone
/* The userland implementation is:
int clone (int (*fn)(void *arg), void *child_stack, int flags, void *arg),
the kernel entry is:
int clone (long flags, void *child_stack).
The parameters are passed in register and on the stack from userland:
rdi: fn
rsi: child_stack
rdx: flags
rcx: arg
r8d: TID field in parent
r9d: thread pointer
%esp+8: TID field in child
The kernel expects:
rax: system call number
rdi: flags
rsi: child_stack
rdx: TID field in parent
r10: TID field in child
r8: thread pointer */
.text
ENTRY (__clone)
movq $-EINVAL,%rax
......
/* Insert the argument onto the new stack. */
subq $16,%rsi
movq %rcx,8(%rsi)
/* Save the function pointer. It will be popped off in the
child in the ebx frobbing below. */
movq %rdi,0(%rsi)
/* Do the system call. */
movq %rdx, %rdi
movq %r8, %rdx
movq %r9, %r8
mov 8(%rsp), %R10_LP
movl $SYS_ify(clone),%eax
......
syscall
......
PSEUDO_END (__clone)能看到最后调用了syscall,这一点clone和我们原来熟悉的其他系统调用几乎是一致的。但是,也有少许不一样的地方。
如果在进程的主线程里面调用其他系统调用,当前用户态的栈是指向整个进程的栈,栈顶指针也是指向进程的栈,指令指针也是指向进程的主线程的代码。此时此刻执行到这里,调用clone的时候,用户态的栈、栈顶指针、指令指针和其他系统调用一样,都是指向主线程的。
但是对于线程来说,这些都要变。因为我们希望当clone这个系统调用成功的时候,除了内核里面有这个线程对应的task_struct,当系统调用返回到用户态的时候,用户态的栈应该是线程的栈,栈顶指针应该指向线程的栈,指令指针应该指向线程将要执行的那个函数。
所以这些都需要我们自己做,将线程要执行的函数的参数和指令的位置都压到栈里面,当从内核返回,从栈里弹出来的时候,就从这个函数开始,带着这些参数执行下去。
接下来我们就要进入内核了。内核里面对于clone系统调用的定义是这样的:
SYSCALL_DEFINE5(clone, unsigned long, clone_flags, unsigned long, newsp,
int __user *, parent_tidptr,
int __user *, child_tidptr,
unsigned long, tls)
{
return _do_fork(clone_flags, newsp, 0, parent_tidptr, child_tidptr, tls);
}看到这里,发现了熟悉的面孔_do_fork。
第一个是上面 复杂的标志位设定 ,我们来看都影响了什么。
对于copy_files,原来是调用dup_fd复制一个files_struct的,现在因为CLONE_FILES标识位变成将原来的files_struct引用计数加一。
static int copy_files(unsigned long clone_flags, struct task_struct *tsk)
{
struct files_struct *oldf, *newf;
oldf = current->files;
if (clone_flags & CLONE_FILES) {
atomic_inc(&oldf->count);
goto out;
}
newf = dup_fd(oldf, &error);
tsk->files = newf;
out:
return error;
}对于copy_fs,原来是调用copy_fs_struct复制一个fs_struct,现在因为CLONE_FS标识位变成将原来的fs_struct的用户数加一。
static int copy_fs(unsigned long clone_flags, struct task_struct *tsk)
{
struct fs_struct *fs = current->fs;
if (clone_flags & CLONE_FS) {
fs->users++;
return 0;
}
tsk->fs = copy_fs_struct(fs);
return 0;
}对于copy_sighand,原来是创建一个新的sighand_struct,现在因为CLONE_SIGHAND标识位变成将原来的sighand_struct引用计数加一。
static int copy_sighand(unsigned long clone_flags, struct task_struct *tsk)
{
struct sighand_struct *sig;
if (clone_flags & CLONE_SIGHAND) {
atomic_inc(¤t->sighand->count);
return 0;
}
sig = kmem_cache_alloc(sighand_cachep, GFP_KERNEL);
atomic_set(&sig->count, 1);
memcpy(sig->action, current->sighand->action, sizeof(sig->action));
return 0;
}对于copy_signal,原来是创建一个新的signal_struct,现在因为CLONE_THREAD直接返回了。
static int copy_signal(unsigned long clone_flags, struct task_struct *tsk)
{
struct signal_struct *sig;
if (clone_flags & CLONE_THREAD)
return 0;
sig = kmem_cache_zalloc(signal_cachep, GFP_KERNEL);
tsk->signal = sig;
init_sigpending(&sig->shared_pending);
......
}对于copy_mm,原来是调用dup_mm复制一个mm_struct,现在因为CLONE_VM标识位而直接指向了原来的mm_struct
static int copy_mm(unsigned long clone_flags, struct task_struct *tsk)
{
struct mm_struct *mm, *oldmm;
oldmm = current->mm;
if (clone_flags & CLONE_VM) {
mmget(oldmm);
mm = oldmm;
goto good_mm;
}
mm = dup_mm(tsk);
good_mm:
tsk->mm = mm;
tsk->active_mm = mm;
return 0;
}第二个就是 对于亲缘关系的影响 ,毕竟我们要识别多个线程是不是属于一个进程。
p->pid = pid_nr(pid);
if (clone_flags & CLONE_THREAD) {
p->exit_signal = -1;
p->group_leader = current->group_leader;
p->tgid = current->tgid;
} else {
if (clone_flags & CLONE_PARENT)
p->exit_signal = current->group_leader->exit_signal;
else
p->exit_signal = (clone_flags & CSIGNAL);
p->group_leader = p;
p->tgid = p->pid;
}
/* CLONE_PARENT re-uses the old parent */
if (clone_flags & (CLONE_PARENT|CLONE_THREAD)) {
p->real_parent = current->real_parent;
p->parent_exec_id = current->parent_exec_id;
} else {
p->real_parent = current;
p->parent_exec_id = current->self_exec_id;
}从上面的代码可以看出,使用了CLONE_THREAD标识位之后,使得亲缘关系有了一定的变化。
- 如果是新进程,那这个进程的group_leader就是他自己,tgid是它自己的pid,这就完全重打锣鼓另开张了,自己是线程组的头。如果是新线程,group_leader是当前进程的,group_leader,tgid是当前进程的tgid,也就是当前进程的pid,这个时候还是拜原来进程为老大。
- 如果是新进程,新进程的real_parent是当前的进程,在进程树里面又见一辈人;如果是新线程,线程的real_parent是当前的进程的real_parent,其实是平辈的。
第三, 对于信号的处理 ,如何保证发给进程的信号虽然可以被一个线程处理,但是影响范围应该是整个进程的。例如,kill一个进程,则所有线程都要被干掉。如果一个信号是发给一个线程的pthread_kill,则应该只有线程能够收到。
在copy_process的主流程里面,无论是创建进程还是线程,都会初始化struct sigpending pending,也就是每个task_struct,都会有这样一个成员变量。这就是一个信号列表。如果这个task_struct是一个线程,这里面的信号就是发给这个线程的;如果这个task_struct是一个进程,这里面的信号是发给主线程的。
init_sigpending(&p->pending);另外,上面copy_signal的时候,我们可以看到,在创建进程的过程中,会初始化signal_struct里面的struct sigpending shared_pending。但是,在创建线程的过程中,连signal_struct都共享了。也就是说,整个进程里的所有线程共享一个shared_pending,这也是一个信号列表,是发给整个进程的,哪个线程处理都一样。
init_sigpending(&sig->shared_pending);至此,clone在内核的调用完毕,要返回系统调用,回到用户态。
14.3 用户态执行线程
根据__clone的第一个参数,回到用户态也不是直接运行我们指定的那个函数,而是一个通用的start_thread,这是所有线程在用户态的统一入口。
#define START_THREAD_DEFN \
static int __attribute__ ((noreturn)) start_thread (void *arg)
START_THREAD_DEFN
{
struct pthread *pd = START_THREAD_SELF;
/* Run the code the user provided. */
THREAD_SETMEM (pd, result, pd->start_routine (pd->arg));
/* Call destructors for the thread_local TLS variables. */
/* Run the destructor for the thread-local data. */
__nptl_deallocate_tsd ();
if (__glibc_unlikely (atomic_decrement_and_test (&__nptl_nthreads)))
/* This was the last thread. */
exit (0);
__free_tcb (pd);
__exit_thread ();
}在start_thread入口函数中,才真正的调用用户提供的函数,在用户的函数执行完毕之后,会释放这个线程相关的数据。例如,线程本地数据thread_local variables,线程数目也减一。如果这是最后一个线程了,就直接退出进程,另外__free_tcb用于释放pthread。
void
internal_function
__free_tcb (struct pthread *pd)
{
......
__deallocate_stack (pd);
}
void
internal_function
__deallocate_stack (struct pthread *pd)
{
/* Remove the thread from the list of threads with user defined
stacks. */
stack_list_del (&pd->list);
/* Not much to do. Just free the mmap()ed memory. Note that we do
not reset the 'used' flag in the 'tid' field. This is done by
the kernel. If no thread has been created yet this field is
still zero. */
if (__glibc_likely (! pd->user_stack))
(void) queue_stack (pd);
}free_tcb会调用deallocate_stack来释放整个线程栈,这个线程栈要从当前使用线程栈的列表stack_used中拿下来,放到缓存的线程栈列表stack_cache中。
好了,整个线程的生命周期到这里就结束了。
14.4 总结
线程的调用过程解析完毕了,我画了一个图总结一下。这个图对比了创建进程和创建线程在用户态和内核态的不同。
创建进程的话,调用的系统调用是fork,在copy_process函数里面,会将五大结构files_struct、fs_struct、sighand_struct、signal_struct、mm_struct都复制一遍,从此父进程和子进程各用各的数据结构。而创建线程的话,调用的是系统调用clone,在copy_process函数里面, 五大结构仅仅是引用计数加一,也即线程共享进程的数据结构。
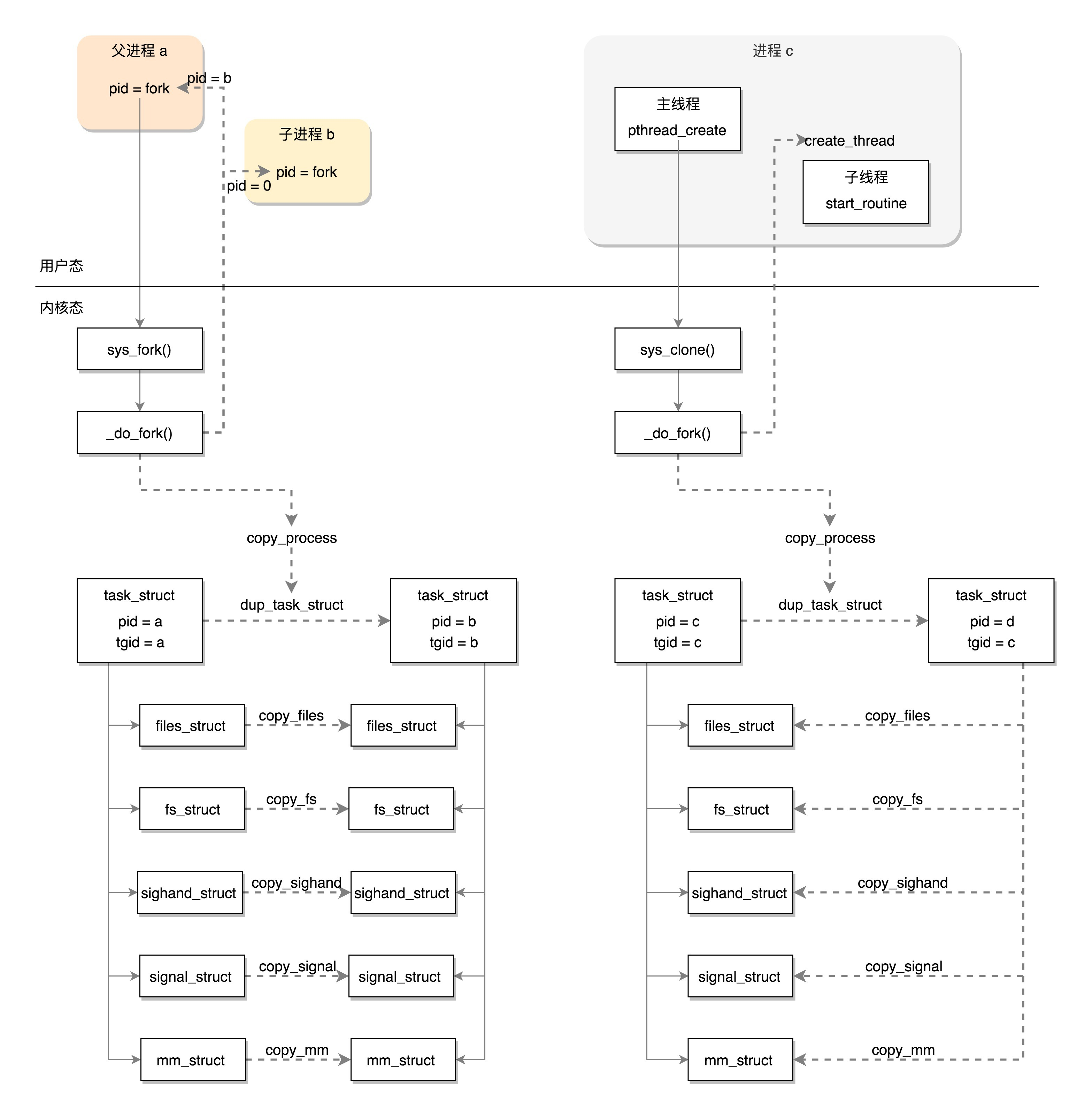
三、内存管理
15. 内存管理(上)
平时我们说计算机的”计算”两个字,其实说的就是两方面,第一,进程和线程对于CPU的使用;第二,对于内存的管理。
15.1 独享内存空间的原理
内存都被分成一块一块儿的,都编好了号。
操作系统会给进程分配一个虚拟地址。所有进程看到的这个地址都是一样的,里面的内存都是从0开始编号。
在程序里面,指令写入的地址是虚拟地址。例如,位置为10M的内存区域,操作系统会提供一种机制,将不同进程的虚拟地址和不同内存的物理地址映射起来。
当程序要访问虚拟地址的时候,由内核的数据结构进行转换,转换成不同的物理地址,这样不同的进程运行的时候,写入的是不同的物理地址,这样就不会冲突了。
15.2 规划虚拟地址空间
操作系统的内存管理,主要分为三个方面。
- 第一,物理内存的管理;
- 第二,虚拟地址的管理;
- 第三,虚拟地址和物理地址如何映射。
接下来,我们都会围绕虚拟地址和物理地址展开。这两个概念有点绕,很多时候你可能会犯糊涂:这个地方,我们用的是虚拟地址呢,还是物理地址呢?所以,请你在学习这一章节的时候,时刻问自己这个问题。
一个程序:
#include <stdio.h>
#include <stdlib.h>
int max_length = 128;
char * generate(int length){
int i;
char * buffer = (char*) malloc (length+1);
if (buffer == NULL)
return NULL;
for (i=0; i<length; i++){
buffer[i]=rand()%26+'a';
}
buffer[length]='\0';
return buffer;
}
int main(int argc, char *argv[])
{
int num;
char * buffer;
printf ("Input the string length : ");
scanf ("%d", &num);
if(num > max_length){
num = max_length;
}
buffer = generate(num);
printf ("Random string is: %s\n",buffer);
free (buffer);
return 0;
}这个程序比较简单,就是根据用户输入的整数来生成字符串,最长是128。由于字符串的长度不是固定的,因而不能提前知道,需要动态地分配内存,使用malloc函数。当然用完了需要释放内存,这就要使用free函数。
我们来总结一下,这个简单的程序使用哪些内存的几种方式:
- 代码需要放在内存里面;
- 全局变量,例如max_length;
- 常量字符串”Input the string length : “;
- 函数栈,例如局部变量num是作为参数传给generate函数的,这里面涉及了函数调用,局部变量,函数参数等都是保存在函数栈上面的;
- 堆,malloc分配的内存在堆里面;
- 这里面涉及对glibc的调用,所以glibc的代码是以so文件的形式存在的,也需要放在内存里面。
这就完了吗?还没有呢,别忘了malloc会调用系统调用,进入内核,所以这个程序一旦运行起来,内核部分还需要分配内存:
- 内核的代码要在内存里面;
- 内核中也有全局变量;
- 每个进程都要有一个task_struct;
- 每个进程还有一个内核栈;
- 在内核里面也有动态分配的内存;
- 虚拟地址到物理地址的映射表放在哪里?
对于内存的访问,用户态的进程使用虚拟地址,这点毫无疑问,内核态的也基本都是使用虚拟地址,只有最后一项容易让人产生疑问。虚拟地址到物理地址的映射表,这个感觉起来是内存管理模块的一部分,这个是”实”是”虚”呢?这个问题先保留,我们暂不讨论,放到内存映射那一节见分晓。
既然都是虚拟地址,我们就先不管映射到物理地址以后是如何布局的,反正现在至少从”虚”的角度来看,这一大片连续的内存空间都是我的了。
首先,这么大的虚拟空间一切二,一部分用来放内核的东西,称为 内核空间 ,一部分用来放进程的东西,称为 用户空间 。用户空间在下,在低地址,内核空间在上,在高地址。这两部分空间的分界线因为32位和64位的不同而不同。
对于普通进程来说,内核空间的那部分虽然虚拟地址在那里,但是不能访问。
我们从最低位开始排起,先是 Text Segment 、 Data Segment 和 BSS Segment 。Text Segment是存放二进制可执行代码的位置,Data Segment存放静态常量,BSS Segment存放未初始化的静态变量。是不是觉得这几个名字很熟悉?没错,咱们前面讲ELF格式的时候提到过,在二进制执行文件里面,就有这三个部分。这里就是把二进制执行文件的三个部分加载到内存里面。
接下来是 堆(Heap)段 。堆是往高地址增长的,是用来动态分配内存的区域,malloc就是在这里面分配的。
接下来的区域是 Memory Mapping Segment 。这块地址可以用来把文件映射进内存用的,如果二进制的执行文件依赖于某个动态链接库,就是在这个区域里面将so文件映射到了内存中。
再下面就是 栈(Stack)地址段 。主线程的函数调用的函数栈就是用这里的。
如果需要进行更高权限的工作,就需要调用系统调用,进入内核。
到了内核里面,无论是从哪个进程进来的,看到的都是同一个内核空间,看到的都是同一个进程列表。虽然内核栈是各用个的,但是如果想知道的话,还是能够知道每个进程的内核栈在哪里的。所以,如果要访问一些公共的数据结构,需要进行锁保护。
内核的代码访问内核的数据结构,大部分的情况下都是使用虚拟地址的,虽然内核代码权限很大,但是能够使用的虚拟地址范围也只能在内核空间,也即内核代码访问内核数据结构(不能访问用户空间)。
在内核里面也会有内核的代码,同样有Text Segment、Data Segment和BSS Segment,别忘了咱们讲内核启动的时候,内核代码也是ELF格式的。
16. 内存管理(下)
接下来,我们需要知道,如何将其映射成为物理地址呢?
你可能已经想到了,咱们前面讲x86 CPU的时候,讲过分段机制,咱们规划虚拟空间的时候,也是将空间分成多个段进行保存。
那就直接用分段机制呗。我们来看看分段机制的原理。
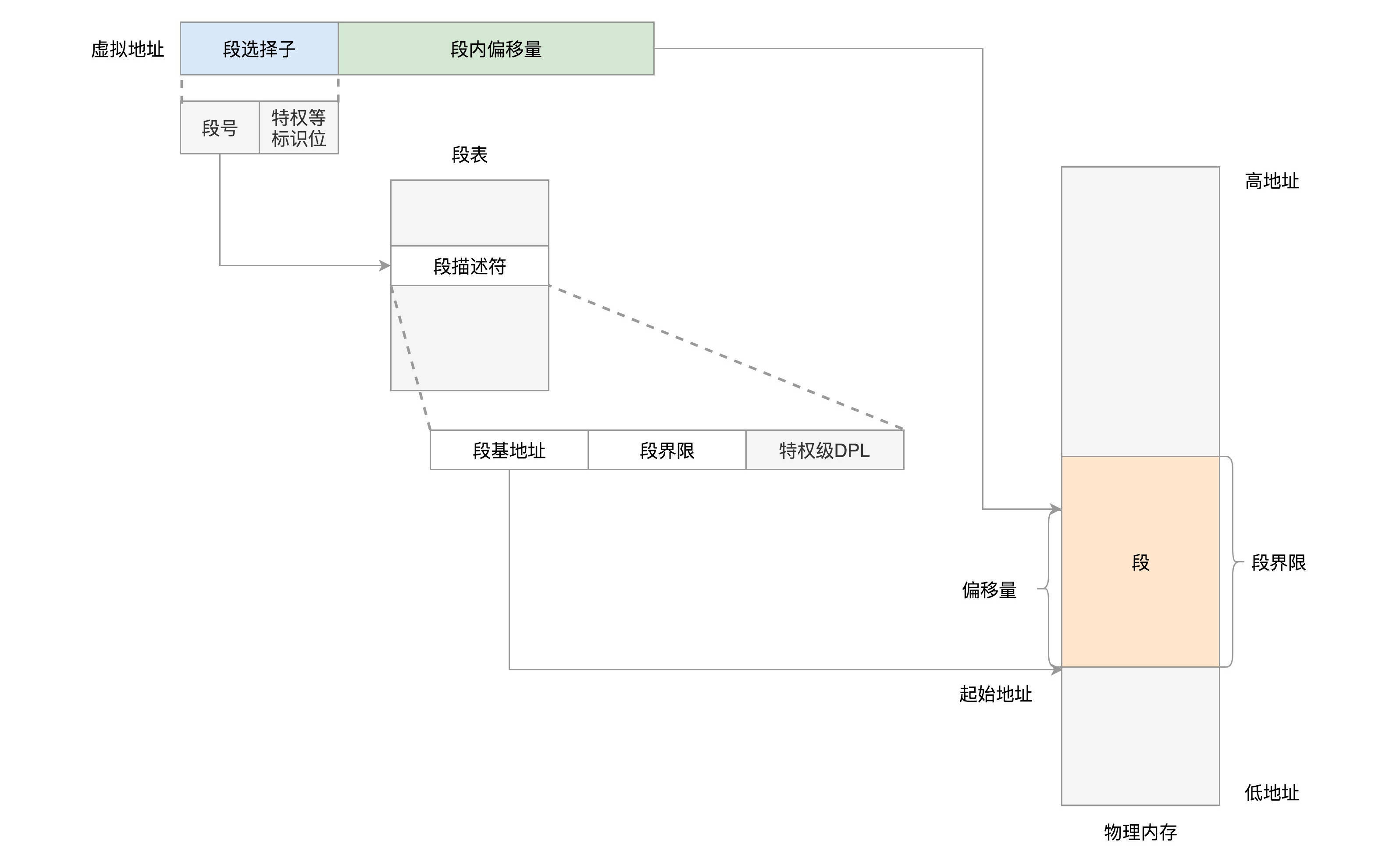
分段机制下的虚拟地址由两部分组成, 段选择子 和 段内偏移量 。段选择子就保存在咱们前面讲过的段寄存器里面。段选择子里面最重要的是段号,用作段表的索引。段表里面保存的是这个段的 基地址 、 段的界限 和 特权等级 等。虚拟地址中的段内偏移量应该位于0和段界限之间。如果段内偏移量是合法的,就将段基地址加上段内偏移量得到物理内存地址。
我们来看看Linux是如何使用这个机制的。
在Linux里面,段表全称 段描述符表(segment descriptors) ,放在 全局描述符表GDT(Global Descriptor Table) 里面,会有下面的宏来初始化段描述符表里面的表项。
#define GDT_ENTRY_INIT(flags, base, limit) { { { \
.a = ((limit) & 0xffff) | (((base) & 0xffff) << 16), \
.b = (((base) & 0xff0000) >> 16) | (((flags) & 0xf0ff) << 8) | \
((limit) & 0xf0000) | ((base) & 0xff000000), \
} } }一个段表项由段基地址base、段界限limit,还有一些标识符组成。
DEFINE_PER_CPU_PAGE_ALIGNED(struct gdt_page, gdt_page) = { .gdt = {
#ifdef CONFIG_X86_64
[GDT_ENTRY_KERNEL32_CS] = GDT_ENTRY_INIT(0xc09b, 0, 0xfffff),
[GDT_ENTRY_KERNEL_CS] = GDT_ENTRY_INIT(0xa09b, 0, 0xfffff),
[GDT_ENTRY_KERNEL_DS] = GDT_ENTRY_INIT(0xc093, 0, 0xfffff),
[GDT_ENTRY_DEFAULT_USER32_CS] = GDT_ENTRY_INIT(0xc0fb, 0, 0xfffff),
[GDT_ENTRY_DEFAULT_USER_DS] = GDT_ENTRY_INIT(0xc0f3, 0, 0xfffff),
[GDT_ENTRY_DEFAULT_USER_CS] = GDT_ENTRY_INIT(0xa0fb, 0, 0xfffff),
#else
[GDT_ENTRY_KERNEL_CS] = GDT_ENTRY_INIT(0xc09a, 0, 0xfffff),
[GDT_ENTRY_KERNEL_DS] = GDT_ENTRY_INIT(0xc092, 0, 0xfffff),
[GDT_ENTRY_DEFAULT_USER_CS] = GDT_ENTRY_INIT(0xc0fa, 0, 0xfffff),
[GDT_ENTRY_DEFAULT_USER_DS] = GDT_ENTRY_INIT(0xc0f2, 0, 0xfffff),
......
#endif
} };
EXPORT_PER_CPU_SYMBOL_GPL(gdt_page);这里面对于64位的和32位的,都定义了内核代码段、内核数据段、用户代码段和用户数据段。
另外,还会定义下面四个段选择子,指向上面的段描述符表项。这四个段选择子看着是不是有点眼熟?咱们讲内核初始化的时候,启动第一个用户态的进程,就是将这四个值赋值给段寄存器。
#define __KERNEL_CS (GDT_ENTRY_KERNEL_CS*8)
#define __KERNEL_DS (GDT_ENTRY_KERNEL_DS*8)
#define __USER_DS (GDT_ENTRY_DEFAULT_USER_DS*8 + 3)
#define __USER_CS (GDT_ENTRY_DEFAULT_USER_CS*8 + 3)通过分析,我们发现,所有的段的起始地址都是一样的,都是0。这算哪门子分段嘛!所以,在Linux操作系统中,并没有使用到全部的分段功能。那分段是不是完全没有用处呢?分段可以做权限审核,例如用户态DPL是3,内核态DPL是0。当用户态试图访问内核态的时候,会因为权限不足而报错。
其实Linux倾向于另外一种从虚拟地址到物理地址的转换方式,称为 分页(Paging) 。
对于物理内存,操作系统把它分成一块一块大小相同的页,这样更方便管理,例如有的内存页面长时间不用了,可以暂时写到硬盘上,称为 换出 。一旦需要的时候,再加载进来,叫作 换入 。这样可以扩大可用物理内存的大小,提高物理内存的利用率。
这个换入和换出都是以页为单位的。页面的大小一般为4KB。为了能够定位和访问每个页,需要有个页表,保存每个页的起始地址,再加上在页内的偏移量,组成线性地址,就能对于内存中的每个位置进行访问了。
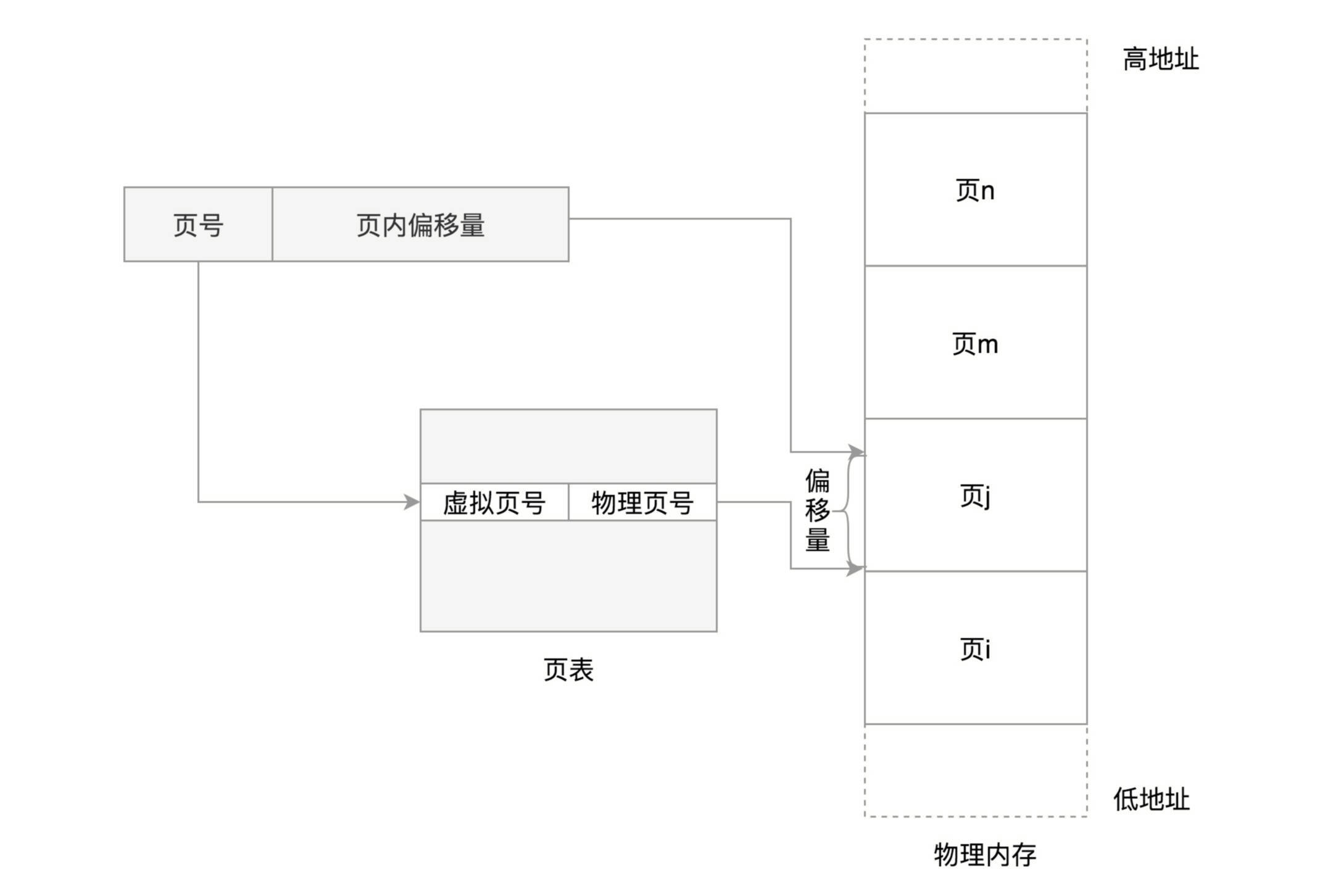
32位环境下,虚拟地址空间共4GB。如果分成4KB一个页,那就是1M个页。每个页表项需要4个字节来存储,那么整个4GB空间的映射就需要4MB的内存来存储映射表。如果每个进程都有自己的映射表,100个进程就需要400MB的内存。对于内核来讲,有点大了 。
页表中所有页表项必须提前建好,并且要求是连续的。如果不连续,就没有办法通过虚拟地址里面的页号找到对应的页表项了。
那怎么办呢?我们可以试着将页表再分页,4G的空间需要4M的页表来存储映射。我们把这4M分成1K(1024)个4K,每个4K又能放在一页里面,这样1K个4K就是1K个页,这1K个页也需要一个表进行管理,我们称为页目录表,这个页目录表里面有1K项,每项4个字节,页目录表大小也是4K。
页目录有1K项,用10位就可以表示访问页目录的哪一项。这一项其实对应的是一整页的页表项,也即4K的页表项。每个页表项也是4个字节,因而一整页的页表项是1K个。再用10位就可以表示访问页表项的哪一项,页表项中的一项对应的就是一个页,是存放数据的页,这个页的大小是4K,用12位可以定位这个页内的任何一个位置。
这样加起来正好32位,也就是用前10位定位到页目录表中的一项。将这一项对应的页表取出来共1k项,再用中间10位定位到页表中的一项,将这一项对应的存放数据的页取出来,再用最后12位定位到页中的具体位置访问数据。
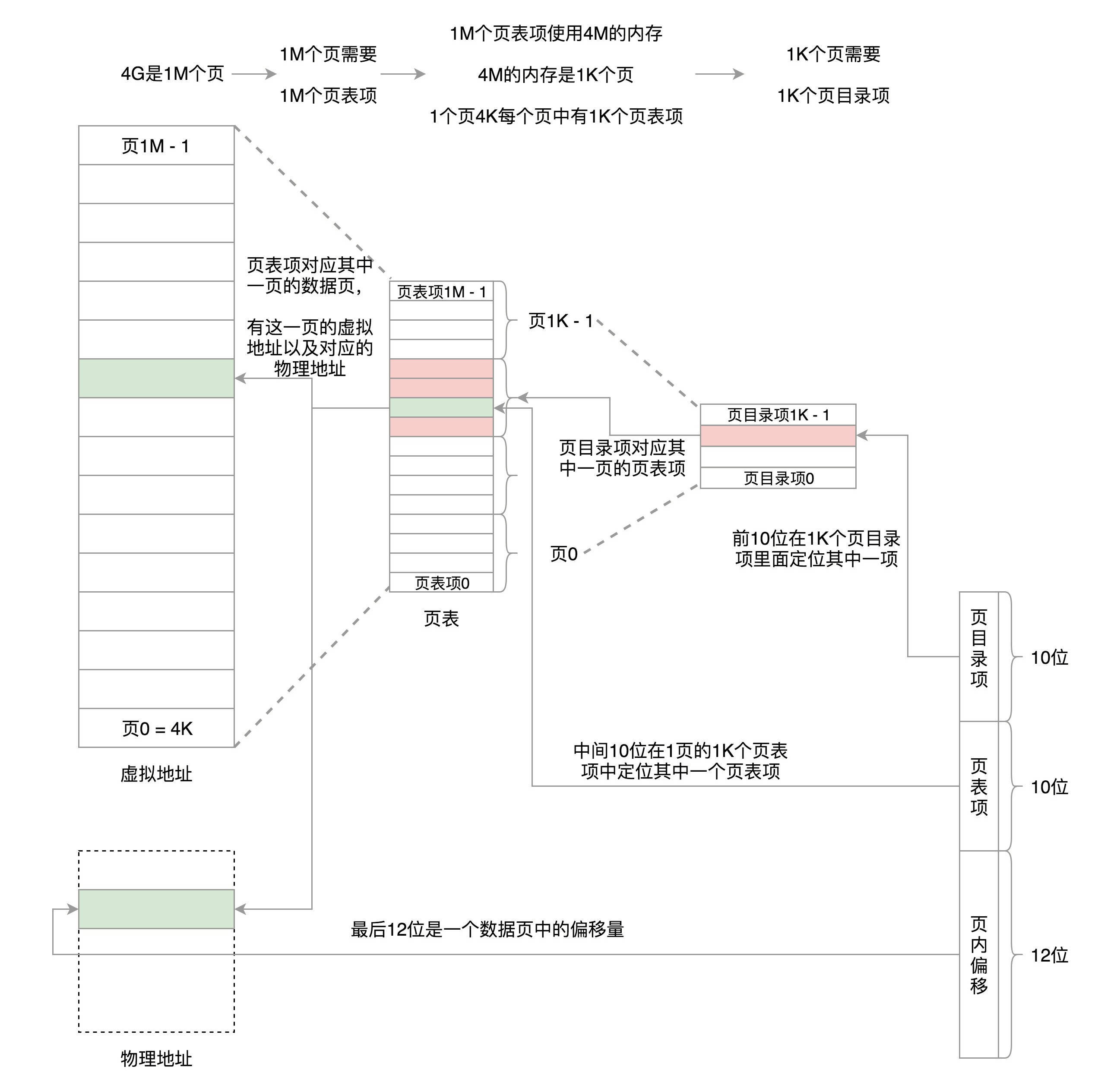
比如说,上面图中,我们假设只给这个进程分配了一个数据页。如果只使用页表,也需要完整的1M个页表项共4M的内存,但是如果使用了页目录,页目录需要1K个全部分配,占用内存4K,但是里面只有一项使用了。到了页表项,只需要分配能够管理那个数据页的页表项页就可以了,也就是说,最多4K,这样内存就节省多了。
当然对于64位的系统,两级肯定不够了,就变成了四级目录,分别是全局页目录项PGD(Page Global Directory)、上层页目录项PUD(Page Upper Directory)、中间页目录项PMD(Page Middle Directory)和页表项PTE(Page Table Entry)。
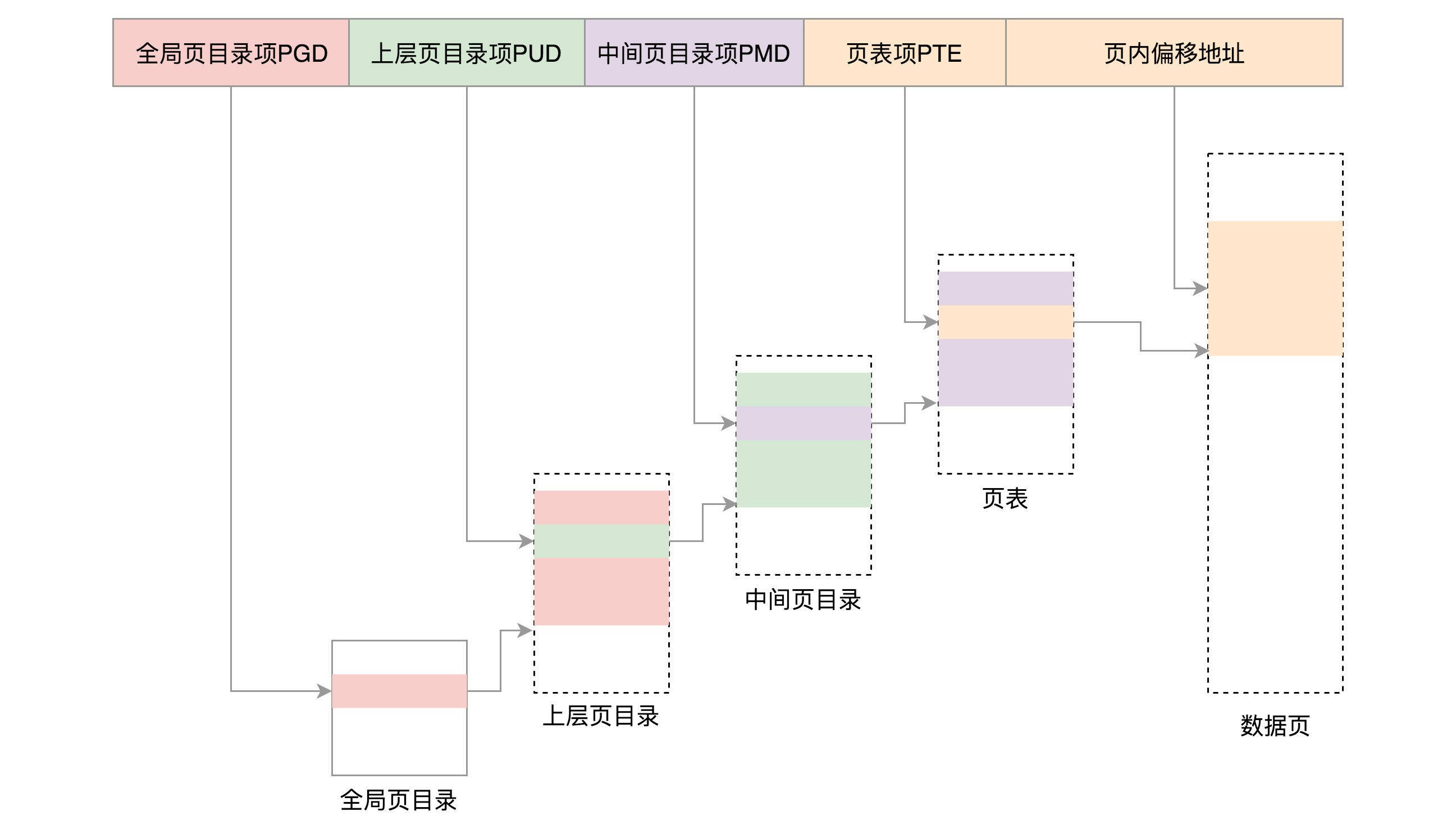
17. 进程空间管理
来详细看看进程的虚拟内存空间是如何管理的。
32位系统和64位系统的内存布局有的地方相似,有的地方差别比较大。
17.1 用户态和内核态的划分
task_struct里面有一个struct mm_struct结构来管理内存。
struct mm_struct *mm;在struct mm_struct里面,有这样一个成员变量:
unsigned long task_size; /* size of task vm space */我们之前讲过,整个虚拟内存空间要一分为二,一部分是用户态地址空间,一部分是内核态地址空间,那这两部分的分界线在哪里呢?这就要task_size来定义。
对于32位的系统,内核里面是这样定义TASK_SIZE的:
#ifdef CONFIG_X86_32
/*
* User space process size: 3GB (default).
*/
#define TASK_SIZE PAGE_OFFSET
#define TASK_SIZE_MAX TASK_SIZE
/*
config PAGE_OFFSET
hex
default 0xC0000000
depends on X86_32
*/
#else
/*
* User space process size. 47bits minus one guard page.
*/
#define TASK_SIZE_MAX ((1UL << 47) - PAGE_SIZE)
#define TASK_SIZE (test_thread_flag(TIF_ADDR32) ? \
IA32_PAGE_OFFSET : TASK_SIZE_MAX)
......当执行一个新的进程的时候,会做以下的设置:
current->mm->task_size = TASK_SIZE;对于32位系统,最大能够寻址2^32=4G,其中用户态虚拟地址空间是3G,内核态是1G。
对于64位系统,虚拟地址只使用了48位。就像代码里面写的一样,1左移了47位,就相当于48位地址空间一半的位置,0x0000800000000000,然后减去一个页,就是0x00007FFFFFFFF000,共128T。同样,内核空间也是128T。内核空间和用户空间之间隔着很大的空隙,以此来进行隔离。
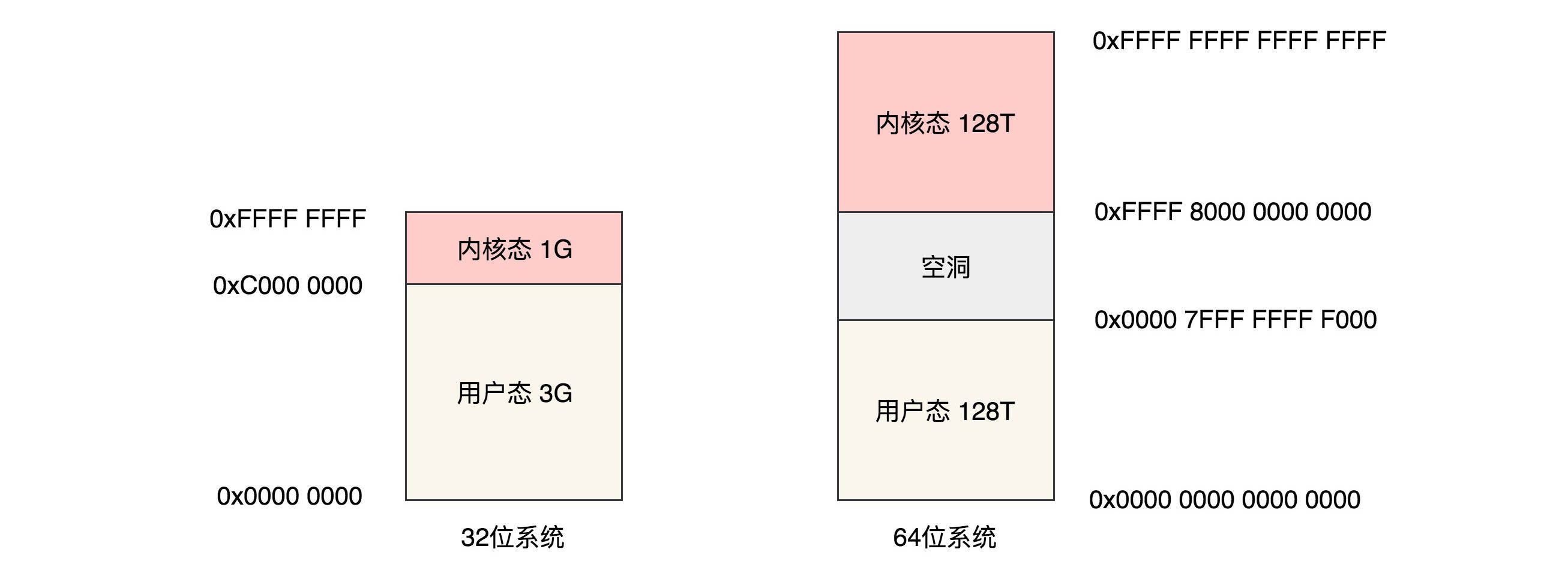
17.2 用户态布局
之前我们讲了用户态虚拟空间里面有几类数据,例如代码、全局变量、堆、栈、内存映射区等。在struct mm_struct里面,有下面这些变量定义了这些区域的统计信息和位置。
unsigned long mmap_base; /* base of mmap area */
unsigned long total_vm; /* Total pages mapped */
unsigned long locked_vm; /* Pages that have PG_mlocked set */
unsigned long pinned_vm; /* Refcount permanently increased */
unsigned long data_vm; /* VM_WRITE & ~VM_SHARED & ~VM_STACK */
unsigned long exec_vm; /* VM_EXEC & ~VM_WRITE & ~VM_STACK */
unsigned long stack_vm; /* VM_STACK */
unsigned long start_code, end_code, start_data, end_data;
unsigned long start_brk, brk, start_stack;
unsigned long arg_start, arg_end, env_start, env_end;其中,total_vm是总共映射的页的数目。我们知道,这么大的虚拟地址空间,不可能都有真实内存对应,所以这里是映射的数目。当内存吃紧的时候,有些页可以换出到硬盘上,有的页因为比较重要,不能换出。locked_vm就是被锁定不能换出,pinned_vm是不能换出,也不能移动。
data_vm是存放数据的页的数目,exec_vm是存放可执行文件的页的数目,stack_vm是栈所占的页的数目。
start_code和end_code表示可执行代码的开始和结束位置,start_data和end_data表示已初始化数据的开始位置和结束位置。
start_brk是堆的起始位置,brk是堆当前的结束位置。前面咱们讲过malloc申请一小块内存的话,就是通过改变brk位置实现的。
start_stack是栈的起始位置,栈的结束位置在寄存器的栈顶指针中。
arg_start和arg_end是参数列表的位置, env_start和env_end是环境变量的位置。它们都位于栈中最高地址的地方。
mmap_base表示虚拟地址空间中用于内存映射的起始地址。一般情况下,这个空间是从高地址到低地址增长的。前面咱们讲malloc申请一大块内存的时候,就是通过mmap在这里映射一块区域到物理内存。咱们加载动态链接库so文件,也是在这个区域里面,映射一块区域到so文件。
这下所有用户态的区域的位置基本上都描述清楚了。整个布局就像下面这张图这样。虽然32位和64位的空间相差很大,但是区域的类别和布局是相似的。

除了位置信息之外,struct mm_struct里面还专门有一个结构vm_area_struct,来描述这些区域的属性。
struct vm_area_struct *mmap; /* list of VMAs */
struct rb_root mm_rb;这里面一个是单链表,用于将这些区域串起来。另外还有一个红黑树。又是这个数据结构,在进程调度的时候我们用的也是红黑树。它的好处就是查找和修改都很快。这里用红黑树,就是为了快速查找一个内存区域,并在需要改变的时候,能够快速修改。
struct vm_area_struct {
/* The first cache line has the info for VMA tree walking. */
unsigned long vm_start; /* Our start address within vm_mm. */
unsigned long vm_end; /* The first byte after our end address within vm_mm. */
/* linked list of VM areas per task, sorted by address */
struct vm_area_struct *vm_next, *vm_prev;
struct rb_node vm_rb;
struct mm_struct *vm_mm; /* The address space we belong to. */
struct list_head anon_vma_chain; /* Serialized by mmap_sem &
* page_table_lock */
struct anon_vma *anon_vma; /* Serialized by page_table_lock */
/* Function pointers to deal with this struct. */
const struct vm_operations_struct *vm_ops;
struct file * vm_file; /* File we map to (can be NULL). */
void * vm_private_data; /* was vm_pte (shared mem) */
} __randomize_layout;vm_start和vm_end指定了该区域在用户空间中的起始和结束地址。vm_next和vm_prev将这个区域串在链表上。vm_rb将这个区域放在红黑树上。vm_ops里面是对这个内存区域可以做的操作的定义。
虚拟内存区域可以映射到物理内存,也可以映射到文件,映射到物理内存的时候称为匿名映射,anon_vma中,anoy就是anonymous,匿名的意思,映射到文件就需要有vm_file指定被映射的文件。
那这些vm_area_struct是如何和上面的内存区域关联的呢?
这个事情是在load_elf_binary里面实现的。没错,就是它。加载内核的是它,启动第一个用户态进程init的是它,fork完了以后,调用exec运行一个二进制程序的也是它。
当exec运行一个二进制程序的时候,除了解析ELF的格式之外,另外一个重要的事情就是建立内存映射。
static int load_elf_binary(struct linux_binprm *bprm)
{
......
setup_new_exec(bprm);
......
retval = setup_arg_pages(bprm, randomize_stack_top(STACK_TOP),
executable_stack);
......
error = elf_map(bprm->file, load_bias + vaddr, elf_ppnt,
elf_prot, elf_flags, total_size);
......
retval = set_brk(elf_bss, elf_brk, bss_prot);
......
elf_entry = load_elf_interp(&loc->interp_elf_ex,
interpreter,
&interp_map_addr,
load_bias, interp_elf_phdata);
......
current->mm->end_code = end_code;
current->mm->start_code = start_code;
current->mm->start_data = start_data;
current->mm->end_data = end_data;
current->mm->start_stack = bprm->p;
......
}load_elf_binary会完成以下的事情:
- 调用setup_new_exec,设置内存映射区mmap_base;
- 调用setup_arg_pages,设置栈的vm_area_struct,这里面设置了mm->arg_start是指向栈底的,current->mm->start_stack就是栈底;
- elf_map会将ELF文件中的代码部分映射到内存中来;
- set_brk设置了堆的vm_area_struct,这里面设置了current->mm->start_brk = current->mm->brk,也即堆里面还是空的;
- load_elf_interp将依赖的so映射到内存中的内存映射区域。
最终就形成下面这个内存映射图。
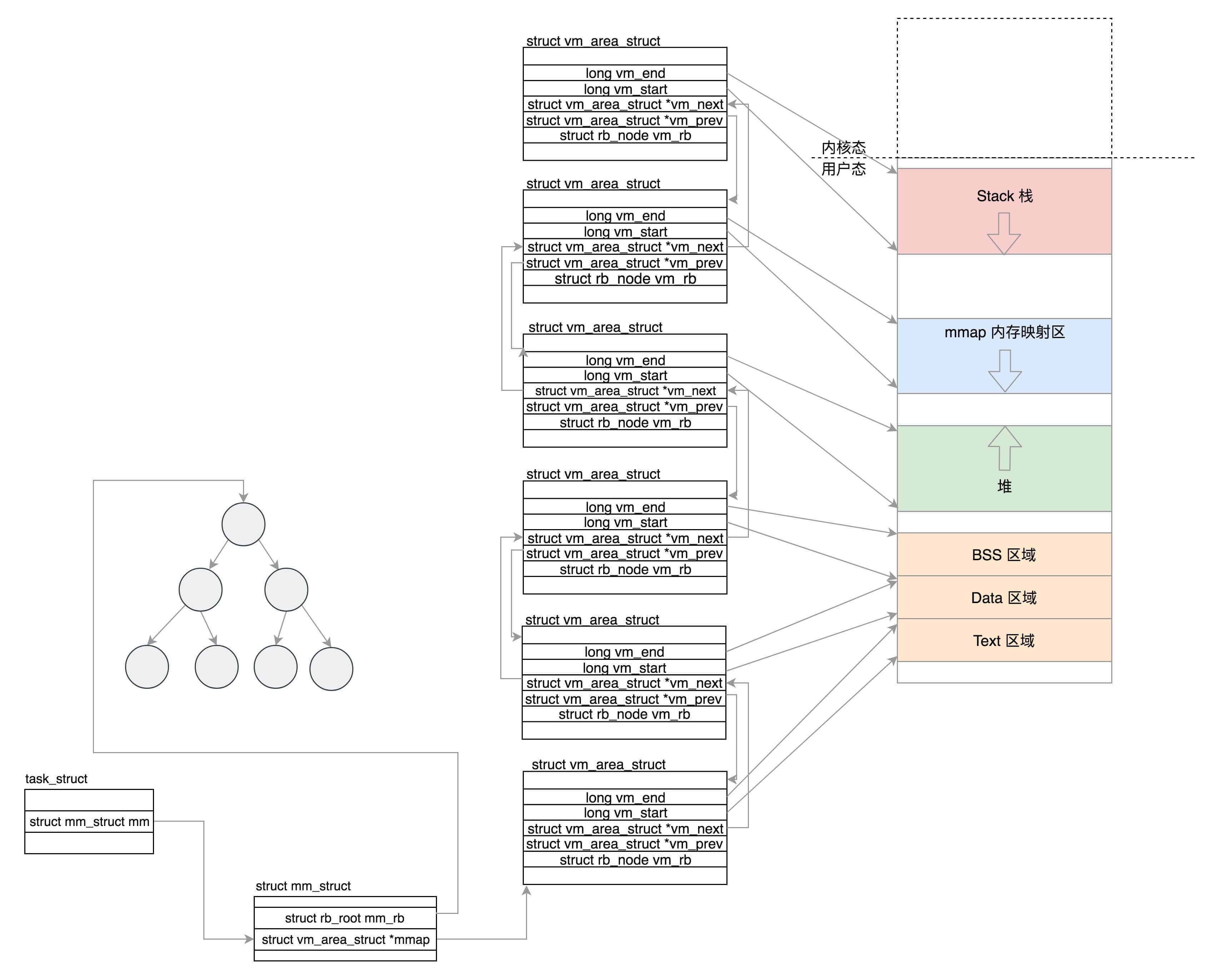
映射完毕后,什么情况下会修改呢?
第一种情况是函数的调用,涉及函数栈的改变,主要是改变栈顶指针。
第二种情况是通过malloc申请一个堆内的空间,当然底层要么执行brk,要么执行mmap。关于内存映射的部分,我们后面的章节讲,这里我们重点看一下brk是怎么做的。
brk系统调用实现的入口是sys_brk函数,就像下面代码定义的一样。
SYSCALL_DEFINE1(brk, unsigned long, brk)
{
unsigned long retval;
unsigned long newbrk, oldbrk;
struct mm_struct *mm = current->mm;
struct vm_area_struct *next;
......
newbrk = PAGE_ALIGN(brk);
oldbrk = PAGE_ALIGN(mm->brk);
if (oldbrk == newbrk)
goto set_brk;
/* Always allow shrinking brk. */
if (brk <= mm->brk) {
if (!do_munmap(mm, newbrk, oldbrk-newbrk, &uf))
goto set_brk;
goto out;
}
/* Check against existing mmap mappings. */
next = find_vma(mm, oldbrk);
if (next && newbrk + PAGE_SIZE > vm_start_gap(next))
goto out;
/* Ok, looks good - let it rip. */
if (do_brk(oldbrk, newbrk-oldbrk, &uf) < 0)
goto out;
set_brk:
mm->brk = brk;
......
return brk;
out:
retval = mm->brk;
return retval;
}前面我们讲过了,堆是从低地址向高地址增长的,sys_brk函数的参数brk是新的堆顶位置,而当前的mm->brk是原来堆顶的位置。
首先要做的第一个事情,将原来的堆顶和现在的堆顶,都按照页对齐地址,然后比较大小。如果两者相同,说明这次增加的堆的量很小,还在一个页里面,不需要另行分配页,直接跳到set_brk那里,设置mm->brk为新的brk就可以了。
如果发现新旧堆顶不在一个页里面,麻烦了,这下要跨页了。如果发现新堆顶小于旧堆顶,这说明不是新分配内存了,而是释放内存了,释放的还不小,至少释放了一页,于是调用do_munmap将这一页的内存映射去掉。
如果堆将要扩大,就要调用find_vma。如果打开这个函数,看到的是对红黑树的查找,找到的是原堆顶所在的vm_area_struct的下一个vm_area_struct,看当前的堆顶和下一个vm_area_struct之间还能不能分配一个完整的页。如果不能,没办法只好直接退出返回,内存空间都被占满了。
如果还有空间,就调用do_brk进一步分配堆空间,从旧堆顶开始,分配计算出的新旧堆顶之间的页数。
static int do_brk(unsigned long addr, unsigned long len, struct list_head *uf)
{
return do_brk_flags(addr, len, 0, uf);
}
static int do_brk_flags(unsigned long addr, unsigned long request, unsigned long flags, struct list_head *uf)
{
struct mm_struct *mm = current->mm;
struct vm_area_struct *vma, *prev;
unsigned long len;
struct rb_node **rb_link, *rb_parent;
pgoff_t pgoff = addr >> PAGE_SHIFT;
int error;
len = PAGE_ALIGN(request);
......
find_vma_links(mm, addr, addr + len, &prev, &rb_link,
&rb_parent);
......
vma = vma_merge(mm, prev, addr, addr + len, flags,
NULL, NULL, pgoff, NULL, NULL_VM_UFFD_CTX);
if (vma)
goto out;
......
vma = kmem_cache_zalloc(vm_area_cachep, GFP_KERNEL);
INIT_LIST_HEAD(&vma->anon_vma_chain);
vma->vm_mm = mm;
vma->vm_start = addr;
vma->vm_end = addr + len;
vma->vm_pgoff = pgoff;
vma->vm_flags = flags;
vma->vm_page_prot = vm_get_page_prot(flags);
vma_link(mm, vma, prev, rb_link, rb_parent);
out:
perf_event_mmap(vma);
mm->total_vm += len >> PAGE_SHIFT;
mm->data_vm += len >> PAGE_SHIFT;
if (flags & VM_LOCKED)
mm->locked_vm += (len >> PAGE_SHIFT);
vma->vm_flags |= VM_SOFTDIRTY;
return 0;
}在do_brk中,调用find_vma_links找到将来的vm_area_struct节点在红黑树的位置,找到它的父节点、前序节点。接下来调用vma_merge,看这个新节点是否能够和现有树中的节点合并。如果地址是连着的,能够合并,则不用创建新的vm_area_struct了,直接跳到out,更新统计值即可;如果不能合并,则创建新的vm_area_struct,既加到anon_vma_chain链表中,也加到红黑树中。
17.3 内核态的布局
内核态的虚拟空间和某一个进程没有关系,所有进程通过系统调用进入到内核之后,看到的虚拟地址空间都是一样的。
这里强调一下,千万别以为到了内核里面,咱们就会直接使用物理内存地址了,想当然地认为下面讨论的都是物理内存地址,不是的,这里讨论的还是虚拟内存地址,但是由于内核总是涉及管理物理内存,因而总是隐隐约约发生关系,所以这里必须思路清晰,分清楚物理内存地址和虚拟内存地址。
在内核态,32位和64位的布局差别比较大,主要是因为32位内核态空间太小了。
我们来看32位的内核态的布局。
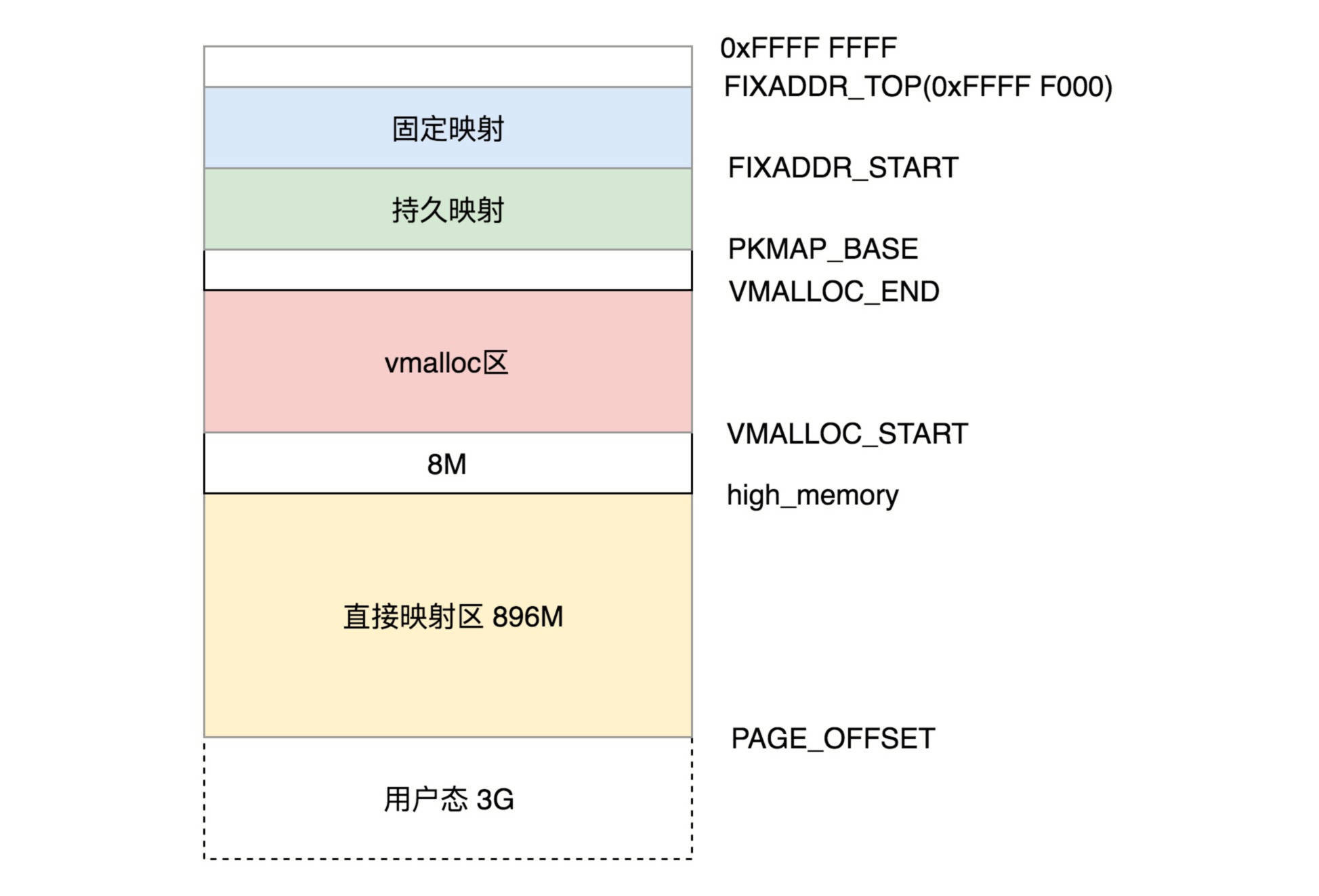
32位的内核态虚拟地址空间一共就1G,占绝大部分的前896M,我们称为 直接映射区 。
所谓的直接映射区,就是这一块空间是连续的,和物理内存是非常简单的映射关系,其实就是虚拟内存地址减去3G,就得到物理内存的位置。
在内核里面,有两个宏:
- __pa(vaddr) 返回与虚拟地址 vaddr 相关的物理地址;
- __va(paddr) 则计算出对应于物理地址 paddr 的虚拟地址。
#define __va(x) ((void *)((unsigned long)(x)+PAGE_OFFSET))
#define __pa(x) __phys_addr((unsigned long)(x))
#define __phys_addr(x) __phys_addr_nodebug(x)
#define __phys_addr_nodebug(x) ((x) - PAGE_OFFSET)但是你要注意,这里虚拟地址和物理地址发生了关联关系,在物理内存的开始的896M的空间,会被直接映射到3G至3G+896M的虚拟地址,这样容易给你一种感觉,是这些内存访问起来和物理内存差不多,别这样想,在大部分情况下,对于这一段内存的访问,在内核中,还是会使用虚拟地址的,并且将来也会为这一段空间建设页表,对这段地址的访问也会走上一节我们讲的分页地址的流程,只不过页表里面比较简单,是直接的一一对应而已。
这896M还需要仔细分解。在系统启动的时候,物理内存的前1M已经被占用了,从1M开始加载内核代码段,然后就是内核的全局变量、BSS等,也是ELF里面涵盖的。这样内核的代码段,全局变量,BSS也就会被映射到3G后的虚拟地址空间里面。具体的物理内存布局可以查看/proc/iomem。
在内核运行的过程中,如果碰到系统调用创建进程,会创建task_struct这样的实例,内核的进程管理代码会将实例创建在3G至3G+896M的虚拟空间中,当然也会被放在物理内存里面的前896M里面,相应的页表也会被创建。
在内核运行的过程中,会涉及内核栈的分配,内核的进程管理的代码会将内核栈创建在3G至3G+896M的虚拟空间中,当然也就会被放在物理内存里面的前896M里面,相应的页表也会被创建。
896M这个值在内核中被定义为high_memory,在此之上常称为”高端内存”。这是个很笼统的说法,到底是虚拟内存的3G+896M以上的是高端内存,还是物理内存896M以上的是高端内存呢?
这里仍然需要辨析一下,高端内存是物理内存的概念。它仅仅是内核中的内存管理模块看待物理内存的时候的概念。前面我们也说过,在内核中,除了内存管理模块直接操作物理地址之外,内核的其他模块,仍然要操作虚拟地址,而虚拟地址是需要内存管理模块分配和映射好的。
假设咱们的电脑有2G内存,现在如果内核的其他模块想要访问物理内存1.5G的地方,应该怎么办呢?如果你觉得,我有32位的总线,访问个2G还不小菜一碟,这就错了。
首先,你不能使用物理地址。你需要使用内存管理模块给你分配的虚拟地址,但是虚拟地址的0到3G已经被用户态进程占用去了,你作为内核不能使用。因为你写1.5G的虚拟内存位置,一方面你不知道应该根据哪个进程的页表进行映射;另一方面,就算映射了也不是你真正想访问的物理内存的地方,所以你发现你作为内核,能够使用的虚拟内存地址,只剩下1G减去896M的空间了。
于是,我们可以将剩下的虚拟内存地址分成下面这几个部分。
- 在896M到VMALLOC_START之间有8M的空间。
- VMALLOC_START到VMALLOC_END之间称为内核动态映射空间,也即内核想像用户态进程一样malloc申请内存,在内核里面可以使用vmalloc。假设物理内存里面,896M到1.5G之间已经被用户态进程占用了,并且映射关系放在了进程的页表中,内核vmalloc的时候,只能从分配物理内存1.5G开始,就需要使用这一段的虚拟地址进行映射,映射关系放在专门给内核自己用的页表里面。
- PKMAP_BASE到FIXADDR_START的空间称为持久内核映射。使用alloc_pages()函数的时候,在物理内存的高端内存得到struct page结构,可以调用kmap将其在映射到这个区域。
- FIXADDR_START到FIXADDR_TOP(0xFFFF F000)的空间,称为固定映射区域,主要用于满足特殊需求。
- 在最后一个区域可以通过kmap_atomic实现临时内核映射。假设用户态的进程要映射一个文件到内存中,先要映射用户态进程空间的一段虚拟地址到物理内存,然后将文件内容写入这个物理内存供用户态进程访问。给用户态进程分配物理内存页可以通过alloc_pages(),分配完毕后,按说将用户态进程虚拟地址和物理内存的映射关系放在用户态进程的页表中,就完事大吉了。这个时候,用户态进程可以通过用户态的虚拟地址,也即0至3G的部分,经过页表映射后访问物理内存,并不需要内核态的虚拟地址里面也划出一块来,映射到这个物理内存页。但是如果要把文件内容写入物理内存,这件事情要内核来干了,这就只好通过kmap_atomic做一个临时映射,写入物理内存完毕后,再kunmap_atomic来解映射即可。
32位的内核态布局我们看完了,接下来我们再来看64位的内核布局。
其实64位的内核布局反而简单,因为虚拟空间实在是太大了,根本不需要所谓的高端内存,因为内核是128T,根本不可能有物理内存超过这个值。
64位的内存布局如图所示。

64位的内核主要包含以下几个部分。
- 从0xffff800000000000开始就是内核的部分,只不过一开始有8T的空档区域。
- 从__PAGE_OFFSET_BASE(0xffff880000000000)开始的64T的虚拟地址空间是直接映射区域,也就是减去PAGE_OFFSET就是物理地址。虚拟地址和物理地址之间的映射在大部分情况下还是会通过建立页表的方式进行映射。
- 从VMALLOC_START(0xffffc90000000000)开始到VMALLOC_END(0xffffe90000000000)的32T的空间是给vmalloc的。
- 从VMEMMAP_START(0xffffea0000000000)开始的1T空间用于存放物理页面的描述结构struct page的。
- 从START_KERNEL_map(0xffffffff80000000)开始的512M用于存放内核代码段、全局变量、BSS等。这里对应到物理内存开始的位置,减去START_KERNEL_map就能得到物理内存的地址。这里和直接映射区有点像,但是不矛盾,因为直接映射区之前有8T的空当区域,早就过了内核代码在物理内存中加载的位置。
到这里内核中虚拟空间的布局就介绍完了。
17.4 总结
一个进程要运行起来需要以下的内存结构。
用户态:
- 代码段、全局变量、BSS
- 函数栈
- 堆
- 内存映射区
内核态:
- 内核的代码、全局变量、BSS
- 内核数据结构例如task_struct
- 内核栈
- 内核中动态分配的内存
我画了一个图,总结一下进程运行状态在32位下对应关系。
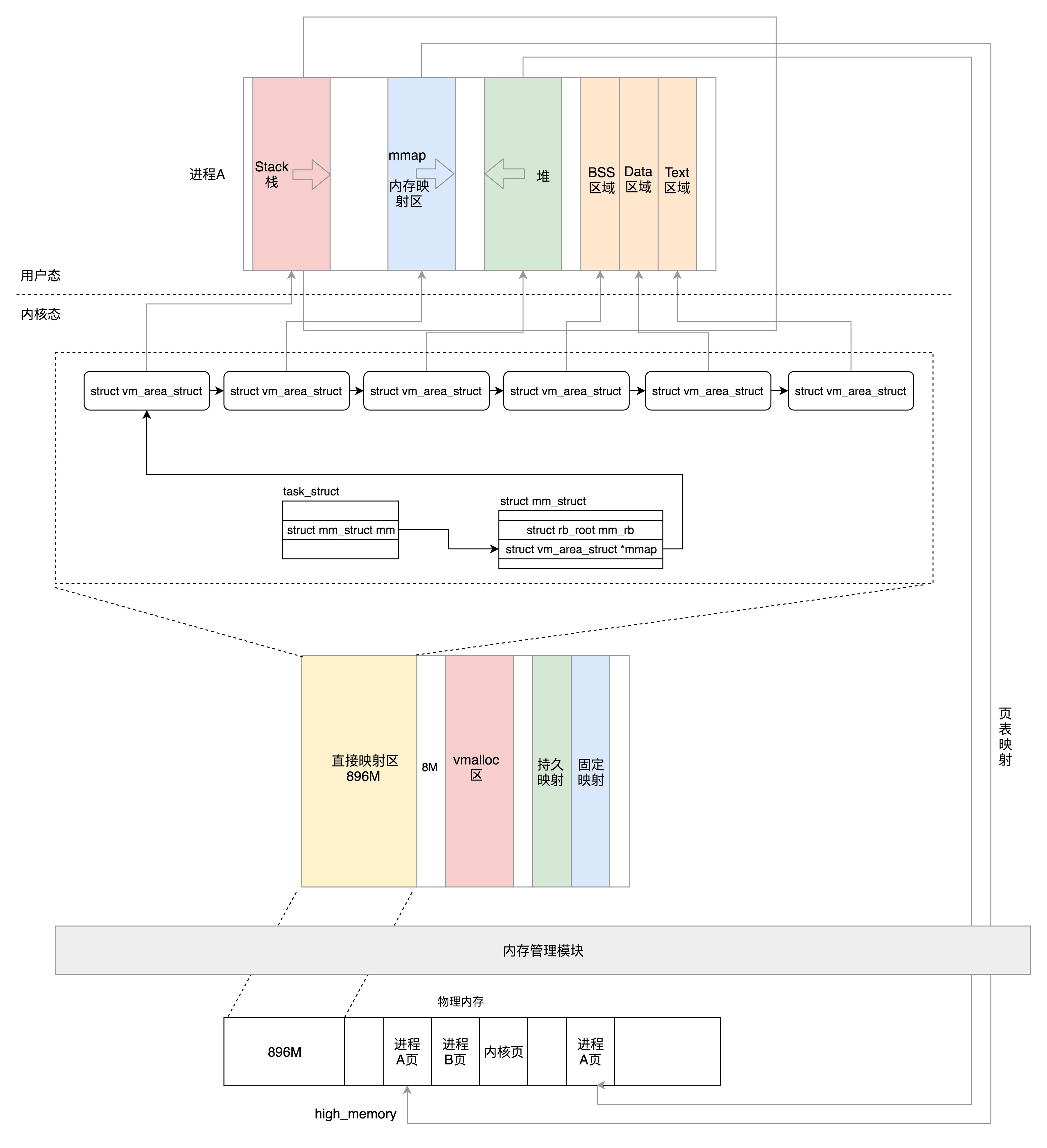
对于64位的对应关系,只是稍有区别,我这里也画了一个图,方便你对比理解。
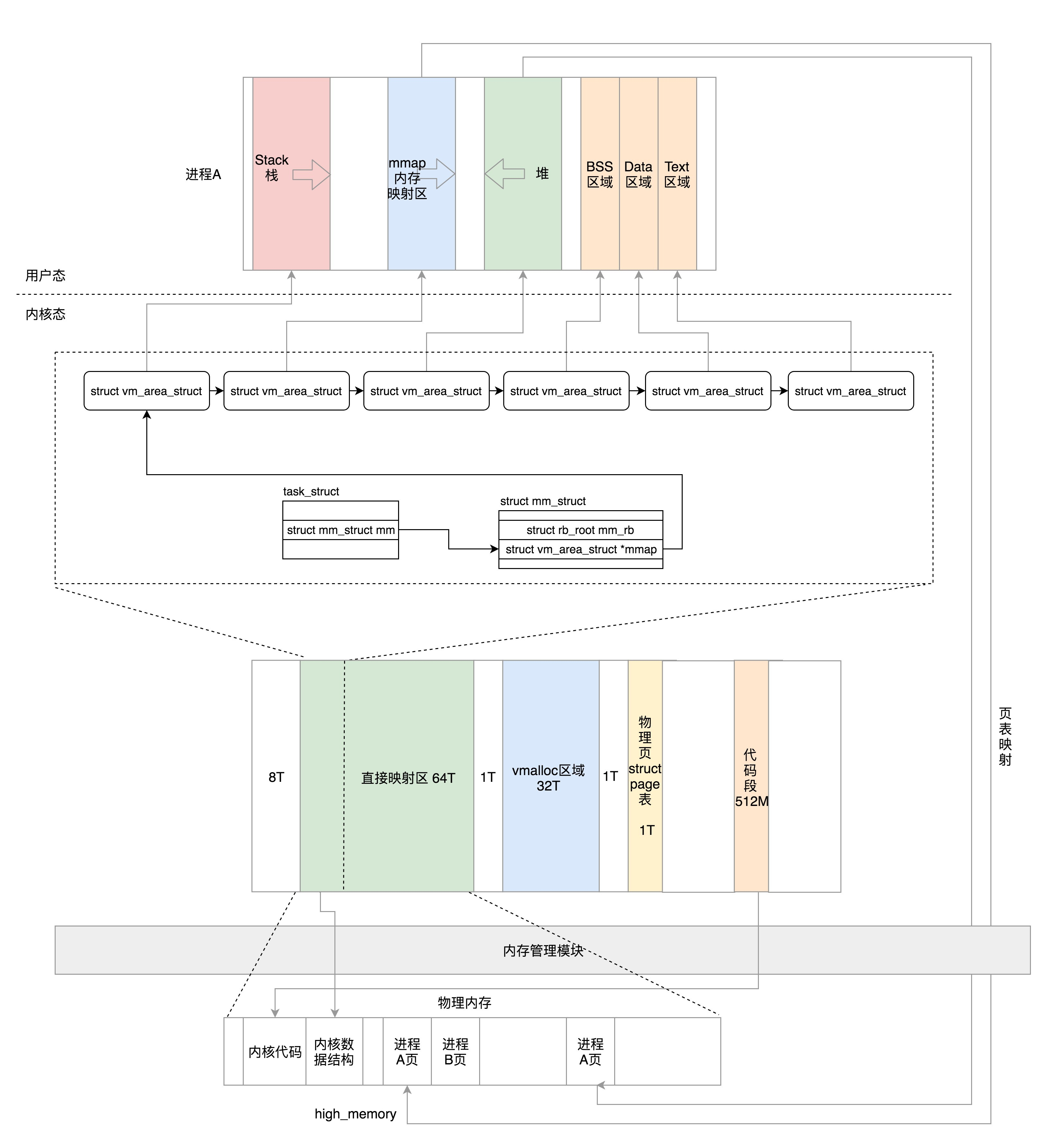
18. 物理内存管理(上)
18.1 物理内存的组织方式
前面咱们讲虚拟内存,涉及物理内存的映射的时候,我们总是把内存想象成它是由连续的一页一页的块组成的。我们可以从0开始对物理页编号,这样每个物理页都会有个页号。
由于物理地址是连续的,页也是连续的,每个页大小也是一样的。因而对于任何一个地址,只要直接除一下每页的大小,很容易直接算出在哪一页。每个页有一个结构struct page表示,这个结构也是放在一个数组里面,这样根据页号,很容易通过下标找到相应的struct page结构。
如果是这样,整个物理内存的布局就非常简单、易管理,这就是最经典的 平坦内存模型(Flat Memory Model) 。
我们讲x86的工作模式的时候,讲过CPU是通过总线去访问内存的,这就是最经典的内存使用方式。
在这种模式下,CPU也会有多个,在总线的一侧。所有的内存条组成一大片内存,在总线的另一侧,所有的CPU访问内存都要过总线,而且距离都是一样的,这种模式称为 SMP(Symmetric multiprocessing) ,即对称多处理器。当然,它也有一个显著的缺点,就是总线会成为瓶颈,因为数据都要走它。
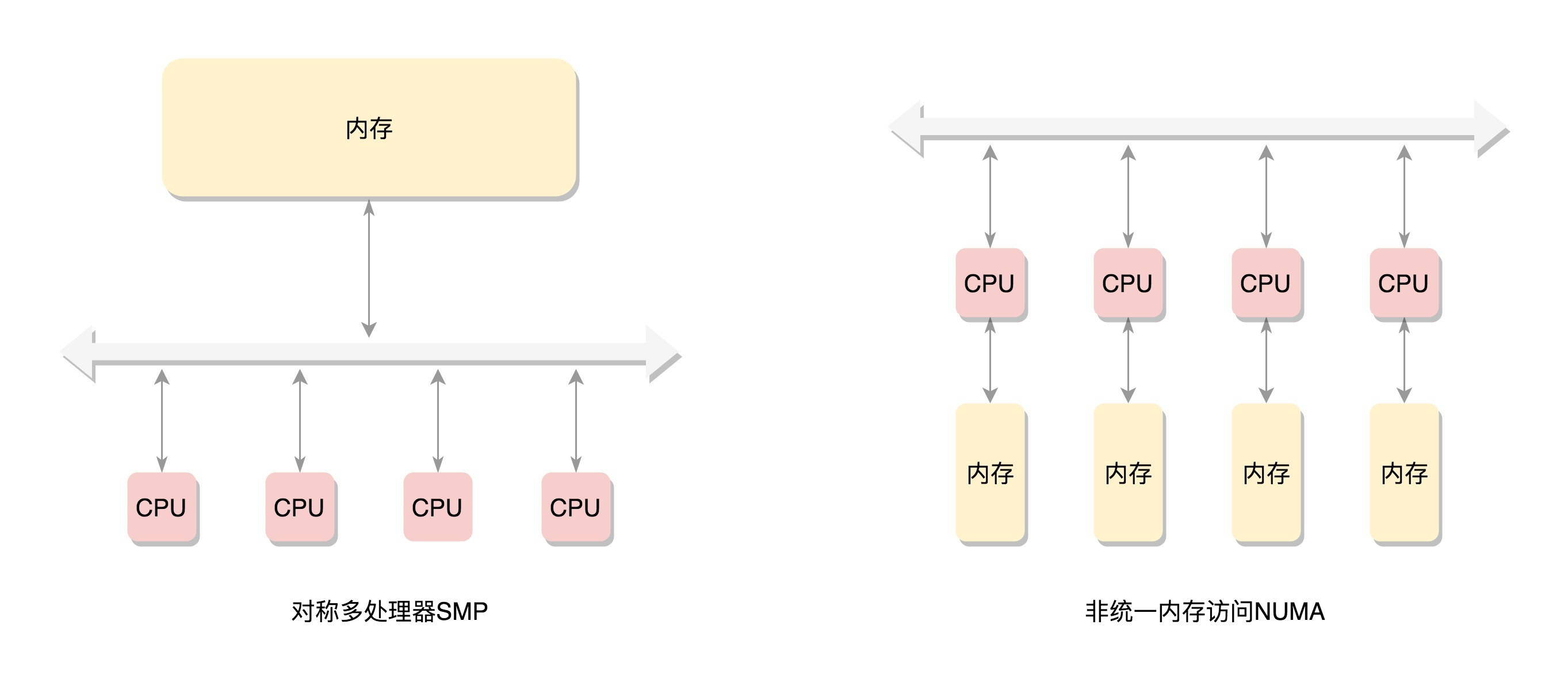
为了提高性能和可扩展性,后来有了一种更高级的模式, NUMA(Non-uniform memory access) ,非一致内存访问。在这种模式下,内存不是一整块。每个CPU都有自己的本地内存,CPU访问本地内存不用过总线,因而速度要快很多, 每个CPU和内存在一起,称为一个NUMA节点 。但是,在本地内存不足的情况下,每个CPU都可以去另外的NUMA节点申请内存,这个时候访问延时就会比较长。
这样,内存被分成了多个节点,每个节点再被分成一个一个的页面。由于页需要全局唯一定位,页还是需要有全局唯一的页号的。但是由于物理内存不是连起来的了,页号也就不再连续了。于是内存模型就变成了非连续内存模型,管理起来就复杂一些。
这里需要指出的是,NUMA往往是非连续内存模型。而非连续内存模型不一定就是NUMA,有时候一大片内存的情况下,也会有物理内存地址不连续的情况。
后来内存技术牛了,可以支持热插拔了。这个时候,不连续成为常态,于是就有了稀疏内存模型。
18.2 节点
我们主要解析当前的主流场景,NUMA方式。我们首先要能够表示NUMA节点的概念,于是有了下面这个结构typedef struct pglist_data pg_data_t,它里面有以下的成员变量:
- 每一个节点都有自己的ID:node_id;
- node_mem_map就是这个节点的struct page数组,用于描述这个节点里面的所有的页;
- node_start_pfn是这个节点的起始页号;
- node_spanned_pages是这个节点中包含不连续的物理内存地址的页面数;
- node_present_pages是真正可用的物理页面的数目。
例如,64M物理内存隔着一个4M的空洞,然后是另外的64M物理内存。这样换算成页面数目就是,16K个页面隔着1K个页面,然后是另外16K个页面。这种情况下,node_spanned_pages就是33K个页面,node_present_pages就是32K个页面。
typedef struct pglist_data {
struct zone node_zones[MAX_NR_ZONES];
struct zonelist node_zonelists[MAX_ZONELISTS];
int nr_zones;
struct page *node_mem_map;
unsigned long node_start_pfn;
unsigned long node_present_pages; /* total number of physical pages */
unsigned long node_spanned_pages; /* total size of physical page range, including holes */
int node_id;
......
} pg_data_t;每一个节点分成一个个区域zone,放在数组node_zones里面。这个数组的大小为MAX_NR_ZONES。我们来看区域的定义。
enum zone_type {
#ifdef CONFIG_ZONE_DMA
ZONE_DMA,
#endif
#ifdef CONFIG_ZONE_DMA32
ZONE_DMA32,
#endif
ZONE_NORMAL,
#ifdef CONFIG_HIGHMEM
ZONE_HIGHMEM,
#endif
ZONE_MOVABLE,
__MAX_NR_ZONES
};ZONE_DMA是指可用于作DMA(Direct Memory Access,直接内存存取)的内存。DMA是这样一种机制:要把外设的数据读入内存或把内存的数据传送到外设,原来都要通过CPU控制完成,但是这会占用CPU,影响CPU处理其他事情,所以有了DMA模式。CPU只需向DMA控制器下达指令,让DMA控制器来处理数据的传送,数据传送完毕再把信息反馈给CPU,这样就可以解放CPU。
对于64位系统,有两个DMA区域。除了上面说的ZONE_DMA,还有ZONE_DMA32。在这里你大概理解DMA的原理就可以,不必纠结,我们后面会讲DMA的机制。
ZONE_NORMAL是直接映射区,就是上一节讲的,从物理内存到虚拟内存的内核区域,通过加上一个常量直接映射。
ZONE_HIGHMEM是高端内存区,就是上一节讲的,对于32位系统来说超过896M的地方,对于64位没必要有的一段区域。
ZONE_MOVABLE是可移动区域,通过将物理内存划分为可移动分配区域和不可移动分配区域来避免内存碎片。
这里你需要注意一下,我们刚才对于区域的划分,都是针对物理内存的。
nr_zones表示当前节点的区域的数量。node_zonelists是备用节点和它的内存区域的情况。前面讲NUMA的时候,我们讲了CPU访问内存,本节点速度最快,但是如果本节点内存不够怎么办,还是需要去其他节点进行分配。毕竟,就算在备用节点里面选择,慢了点也比没有强。
既然整个内存被分成了多个节点,那pglist_data应该放在一个数组里面。每个节点一项,就像下面代码里面一样:
struct pglist_data *node_data[MAX_NUMNODES] __read_mostly;18.3 区域
到这里,我们把内存分成了节点,把节点分成了区域。接下来我们来看,一个区域里面是如何组织的。
表示区域的数据结构zone的定义如下:
struct zone {
......
struct pglist_data *zone_pgdat;
struct per_cpu_pageset __percpu *pageset;
unsigned long zone_start_pfn;
/*
* spanned_pages is the total pages spanned by the zone, including
* holes, which is calculated as:
* spanned_pages = zone_end_pfn - zone_start_pfn;
*
* present_pages is physical pages existing within the zone, which
* is calculated as:
* present_pages = spanned_pages - absent_pages(pages in holes);
*
* managed_pages is present pages managed by the buddy system, which
* is calculated as (reserved_pages includes pages allocated by the
* bootmem allocator):
* managed_pages = present_pages - reserved_pages;
*
*/
unsigned long managed_pages;
unsigned long spanned_pages;
unsigned long present_pages;
const char *name;
......
/* free areas of different sizes */
struct free_area free_area[MAX_ORDER];
/* zone flags, see below */
unsigned long flags;
/* Primarily protects free_area */
spinlock_t lock;
......
} ____cacheline_internodealigned_in_在一个zone里面,zone_start_pfn表示属于这个zone的第一个页。
如果我们仔细看代码的注释,可以看到,spanned_pages = zone_end_pfn - zone_start_pfn,也即spanned_pages指的是不管中间有没有物理内存空洞,反正就是最后的页号减去起始的页号。
present_pages = spanned_pages - absent_pages(pages in holes),也即present_pages是这个zone在物理内存中真实存在的所有page数目。
managed_pages = present_pages - reserved_pages,也即managed_pages是这个zone被伙伴系统管理的所有的page数目,伙伴系统的工作机制我们后面会讲。
per_cpu_pageset用于区分冷热页。什么叫冷热页呢?咱们讲x86体系结构的时候讲过,为了让CPU快速访问段描述符,在CPU里面有段描述符缓存。CPU访问这个缓存的速度比内存快得多。同样对于页面来讲,也是这样的。如果一个页被加载到CPU高速缓存里面,这就是一个热页(Hot Page),CPU读起来速度会快很多,如果没有就是冷页(Cold Page)。由于每个CPU都有自己的高速缓存,因而per_cpu_pageset也是每个CPU一个。
18.4 页
了解了区域zone,接下来我们就到了组成物理内存的基本单位,页的数据结构struct page。这是一个特别复杂的结构,里面有很多的union,union结构是在C语言中被用于同一块内存根据情况保存不同类型数据的一种方式。这里之所以用了union,是因为一个物理页面使用模式有多种。
第一种模式,要用就用一整页。这一整页的内存,或者直接和虚拟地址空间建立映射关系,我们把这种称为 匿名页(Anonymous Page) 。或者用于关联一个文件,然后再和虚拟地址空间建立映射关系,这样的文件,我们称为 内存映射文件(Memory-mapped File) 。
- struct address_space *mapping就是用于内存映射,如果是匿名页,最低位为1;如果是映射文件,最低位为0;
- pgoff_t index是在映射区的偏移量;
- atomic_t _mapcount,每个进程都有自己的页表,这里指有多少个页表项指向了这个页;
- struct list_head lru表示这一页应该在一个链表上,例如这个页面被换出,就在换出页的链表中;
- compound相关的变量用于复合页(Compound Page),就是将物理上连续的两个或多个页看成一个独立的大页。
第二种模式,仅需分配小块内存。有时候,我们不需要一下子分配这么多的内存,例如分配一个task_struct结构,只需要分配小块的内存,去存储这个进程描述结构的对象。为了满足对这种小内存块的需要,Linux系统采用了一种被称为 slab allocator 的技术,用于分配称为slab的一小块内存。它的基本原理是从内存管理模块申请一整块页,然后划分成多个小块的存储池,用复杂的队列来维护这些小块的状态(状态包括:被分配了/被放回池子/应该被回收)。
也正是因为slab allocator对于队列的维护过于复杂,后来就有了一种不使用队列的分配器slub allocator,后面我们会解析这个分配器。但是你会发现,它里面还是用了很多slab的字眼,因为它保留了slab的用户接口,可以看成slab allocator的另一种实现。
还有一种小块内存的分配器称为 slob ,非常简单,主要使用在小型的嵌入式系统。
如果某一页是用于分割成一小块一小块的内存进行分配的使用模式,则会使用union中的以下变量:
- s_mem是已经分配了正在使用的slab的第一个对象;
- freelist是池子中的空闲对象;
- rcu_head是需要释放的列表。
struct page {
unsigned long flags;
union {
struct address_space *mapping;
void *s_mem; /* slab first object */
atomic_t compound_mapcount; /* first tail page */
};
union {
pgoff_t index; /* Our offset within mapping. */
void *freelist; /* sl[aou]b first free object */
};
union {
unsigned counters;
struct {
union {
atomic_t _mapcount;
unsigned int active; /* SLAB */
struct { /* SLUB */
unsigned inuse:16;
unsigned objects:15;
unsigned frozen:1;
};
int units; /* SLOB */
};
atomic_t _refcount;
};
};
union {
struct list_head lru; /* Pageout list */
struct dev_pagemap *pgmap;
struct { /* slub per cpu partial pages */
struct page *next; /* Next partial slab */
int pages; /* Nr of partial slabs left */
int pobjects; /* Approximate # of objects */
};
struct rcu_head rcu_head;
struct {
unsigned long compound_head; /* If bit zero is set */
unsigned int compound_dtor;
unsigned int compound_order;
};
};
union {
unsigned long private;
struct kmem_cache *slab_cache; /* SL[AU]B: Pointer to slab */
};
......
}18.5 页的分配
对于要分配比较大的内存,例如到分配页级别的,可以使用 伙伴系统(Buddy System) 。
Linux中的内存管理的”页”大小为4KB。把所有的空闲页分组为11个页块链表,每个块链表分别包含很多个大小的页块,有1、2、4、8、16、32、64、128、256、512和1024个连续页的页块。最大可以申请1024个连续页,对应4MB大小的连续内存。每个页块的第一个页的物理地址是该页块大小的整数倍。
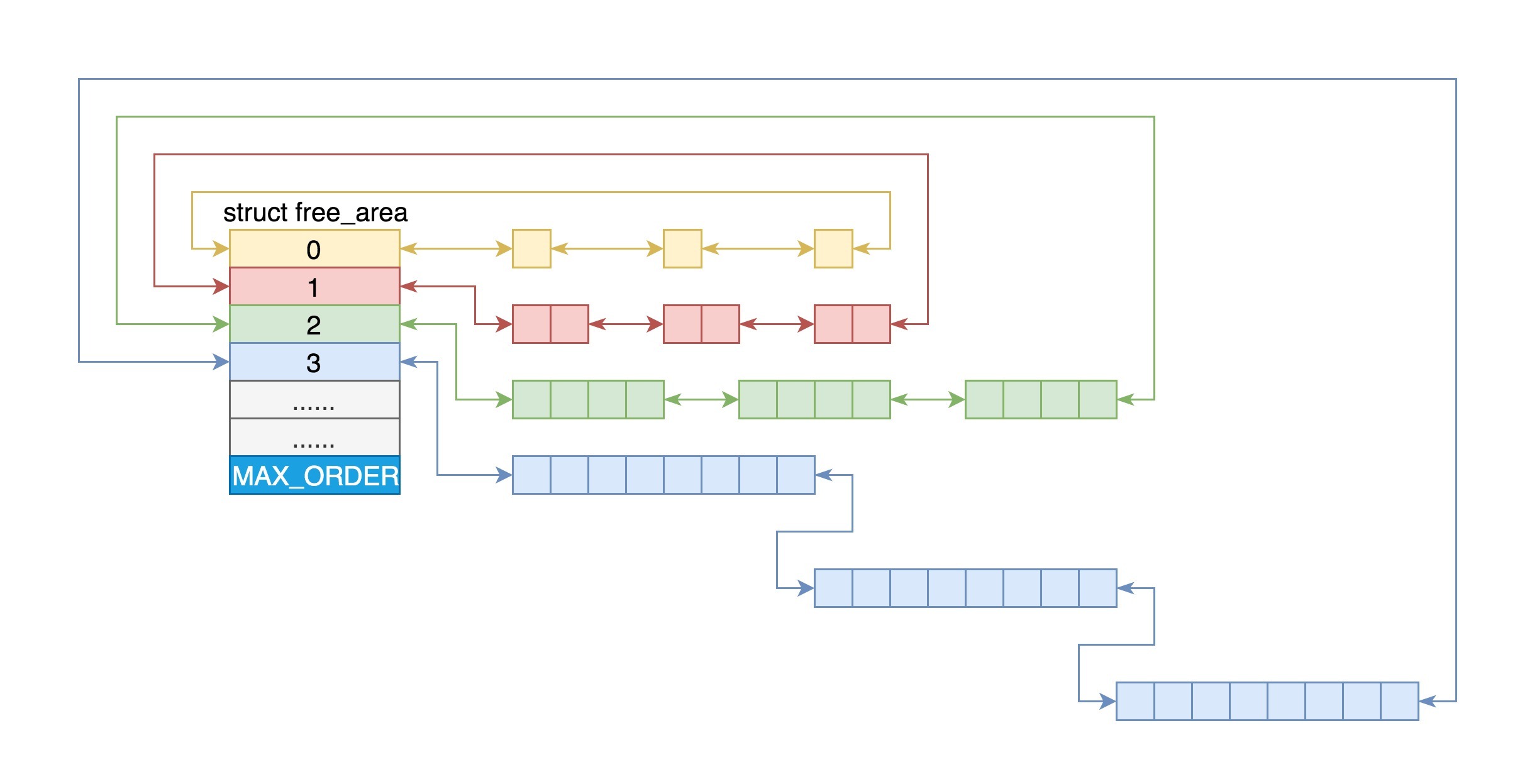
第i个页块链表中,页块中页的数目为2^i。
在struct zone里面有以下的定义:
struct free_area free_area[MAX_ORDER];MAX_ORDER就是指数。
#define MAX_ORDER 11当向内核请求分配(2^(i-1),2^i]数目的页块时,按照2^i页块请求处理。如果对应的页块链表中没有空闲页块,那我们就在更大的页块链表中去找。当分配的页块中有多余的页时,伙伴系统会根据多余的页块大小插入到对应的空闲页块链表中。
例如,要请求一个128个页的页块时,先检查128个页的页块链表是否有空闲块。如果没有,则查256个页的页块链表;如果有空闲块的话,则将256个页的页块分成两份,一份使用,一份插入128个页的页块链表中。如果还是没有,就查512个页的页块链表;如果有的话,就分裂为128、128、256三个页块,一个128的使用,剩余两个插入对应页块链表。
上面这个过程,我们可以在分配页的函数alloc_pages中看到。
static inline struct page *
alloc_pages(gfp_t gfp_mask, unsigned int order)
{
return alloc_pages_current(gfp_mask, order);
}
/**
* alloc_pages_current - Allocate pages.
*
* @gfp:
* %GFP_USER user allocation,
* %GFP_KERNEL kernel allocation,
* %GFP_HIGHMEM highmem allocation,
* %GFP_FS don't call back into a file system.
* %GFP_ATOMIC don't sleep.
* @order: Power of two of allocation size in pages. 0 is a single page.
*
* Allocate a page from the kernel page pool. When not in
* interrupt context and apply the current process NUMA policy.
* Returns NULL when no page can be allocated.
*/
struct page *alloc_pages_current(gfp_t gfp, unsigned order)
{
struct mempolicy *pol = &default_policy;
struct page *page;
......
page = __alloc_pages_nodemask(gfp, order,
policy_node(gfp, pol, numa_node_id()),
policy_nodemask(gfp, pol));
......
return page;
}alloc_pages会调用alloc_pages_current,这里面的注释比较容易看懂了,gfp表示希望在哪个区域中分配这个内存:
- GFP_USER用于分配一个页映射到用户进程的虚拟地址空间,并且希望直接被内核或者硬件访问,主要用于一个用户进程希望通过内存映射的方式,访问某些硬件的缓存,例如显卡缓存;
- GFP_KERNEL用于内核中分配页,主要分配ZONE_NORMAL区域,也即直接映射区;
- GFP_HIGHMEM,顾名思义就是主要分配高端区域的内存。
另一个参数order,就是表示分配2的order次方个页。
接下来调用__alloc_pages_nodemask。这是伙伴系统的核心方法。它会调用get_page_from_freelist。这里面的逻辑也很容易理解,就是在一个循环中先看当前节点的zone。如果找不到空闲页,则再看备用节点的zone。
static struct page *
get_page_from_freelist(gfp_t gfp_mask, unsigned int order, int alloc_flags,
const struct alloc_context *ac)
{
......
for_next_zone_zonelist_nodemask(zone, z, ac->zonelist, ac->high_zoneidx, ac->nodemask) {
struct page *page;
......
page = rmqueue(ac->preferred_zoneref->zone, zone, order,
gfp_mask, alloc_flags, ac->migratetype);
......
}
}每一个zone,都有伙伴系统维护的各种大小的队列,就像上面伙伴系统原理里讲的那样。这里调用rmqueue就很好理解了,就是找到合适大小的那个队列,把页面取下来。
接下来的调用链是rmqueue->rmqueue->rmqueue_smallest。在这里,我们能清楚看到伙伴系统的逻辑。
static inline
struct page *__rmqueue_smallest(struct zone *zone, unsigned int order,
int migratetype)
{
unsigned int current_order;
struct free_area *area;
struct page *page;
/* Find a page of the appropriate size in the preferred list */
for (current_order = order; current_order < MAX_ORDER; ++current_order) {
area = &(zone->free_area[current_order]);
page = list_first_entry_or_null(&area->free_list[migratetype],
struct page, lru);
if (!page)
continue;
list_del(&page->lru);
rmv_page_order(page);
area->nr_free--;
expand(zone, page, order, current_order, area, migratetype);
set_pcppage_migratetype(page, migratetype);
return page;
}
return NULL;
}从当前的order,也即指数开始,在伙伴系统的free_area找2^order大小的页块。如果链表的第一个不为空,就找到了;如果为空,就到更大的order的页块链表里面去找。找到以后,除了将页块从链表中取下来,我们还要把多余的的部分放到其他页块链表里面。expand就是干这个事情的。area–就是伙伴系统那个表里面的前一项,前一项里面的页块大小是当前项的页块大小除以2,size右移一位也就是除以2,list_add就是加到链表上,nr_free++就是计数加1。
static inline void expand(struct zone *zone, struct page *page,
int low, int high, struct free_area *area,
int migratetype)
{
unsigned long size = 1 << high;
while (high > low) {
area--;
high--;
size >>= 1;
......
list_add(&page[size].lru, &area->free_list[migratetype]);
area->nr_free++;
set_page_order(&page[size], high);
}
}18.6 总结
如果有多个CPU,那就有多个节点。每个节点用struct pglist_data表示,放在一个数组里面。
每个节点分为多个区域,每个区域用struct zone表示,也放在一个数组里面。
每个区域分为多个页。为了方便分配,空闲页放在struct free_area里面,使用伙伴系统进行管理和分配,每一页用struct page表示。
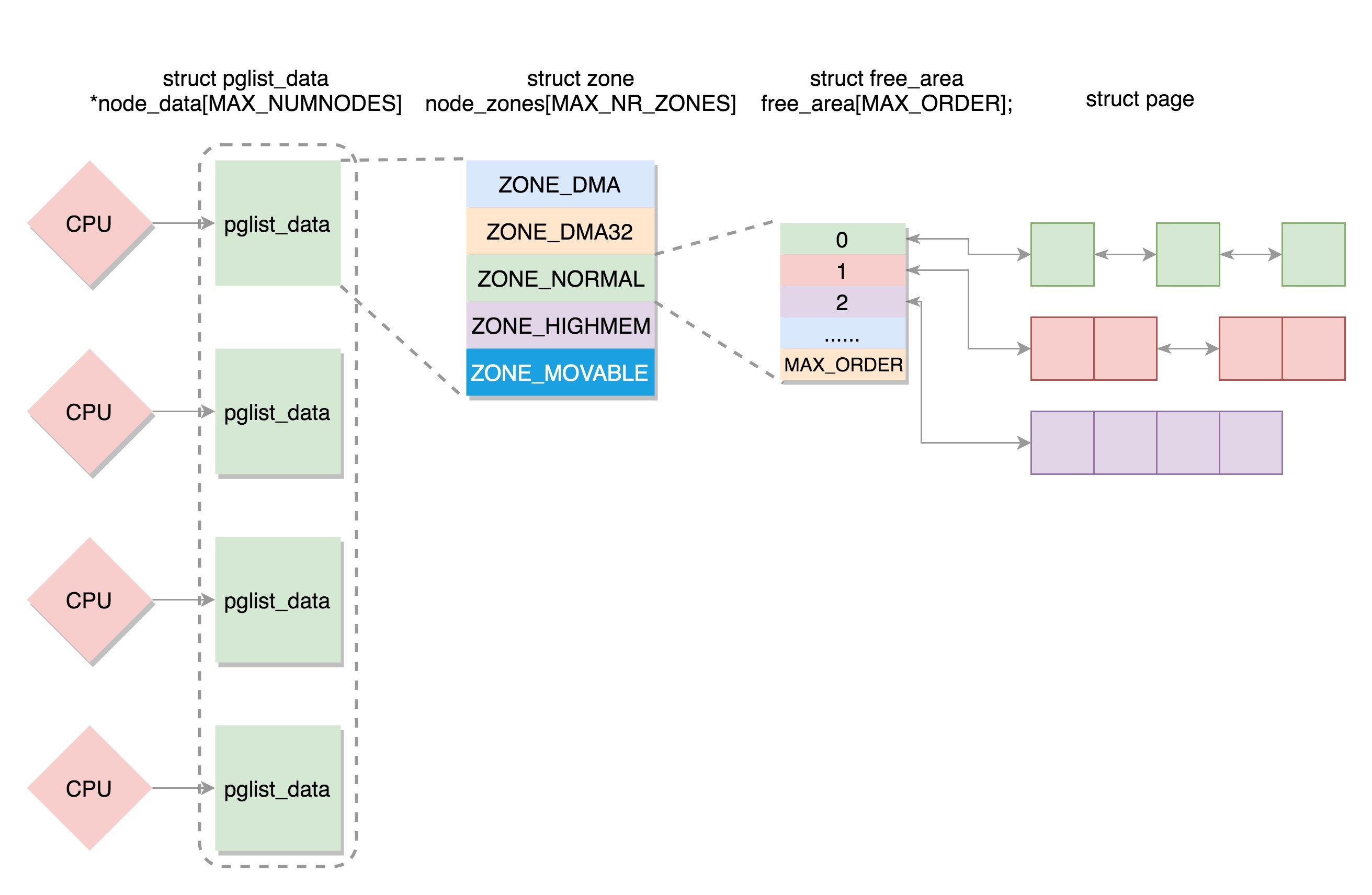
19. 物理内存管理(下)
19.1 小内存的分配
前面我们讲过,如果遇到小的对象,会使用slub分配器进行分配。那我们就先来解析它的工作原理。
还记得咱们创建进程的时候,会调用dup_task_struct,它想要试图复制一个task_struct对象,需要先调用alloc_task_struct_node,分配一个task_struct对象。
从这段代码可以看出,它调用了kmem_cache_alloc_node函数,在task_struct的缓存区域task_struct_cachep分配了一块内存。
static struct kmem_cache *task_struct_cachep;
task_struct_cachep = kmem_cache_create("task_struct",
arch_task_struct_size, align,
SLAB_PANIC|SLAB_NOTRACK|SLAB_ACCOUNT, NULL);
static inline struct task_struct *alloc_task_struct_node(int node)
{
return kmem_cache_alloc_node(task_struct_cachep, GFP_KERNEL, node);
}
static inline void free_task_struct(struct task_struct *tsk)
{
kmem_cache_free(task_struct_cachep, tsk);
}在系统初始化的时候,task_struct_cachep会被kmem_cache_create函数创建。这个函数也比较容易看懂,专门用于分配task_struct对象的缓存。这个缓存区的名字就叫task_struct。缓存区中每一块的大小正好等于task_struct的大小,也即arch_task_struct_size。
有了这个缓存区,每次创建task_struct的时候,我们不用到内存里面去分配,先在缓存里面看看有没有直接可用的,这就是 kmem_cache_alloc_node 的作用。
当一个进程结束,task_struct也不用直接被销毁,而是放回到缓存中,这就是 kmem_cache_free 的作用。这样,新进程创建的时候,我们就可以直接用现成的缓存中的task_struct了。
我们来仔细看看,缓存区struct kmem_cache到底是什么样子。
struct kmem_cache {
struct kmem_cache_cpu __percpu *cpu_slab;
/* Used for retriving partial slabs etc */
unsigned long flags;
unsigned long min_partial;
int size; /* The size of an object including meta data */
int object_size; /* The size of an object without meta data */
int offset; /* Free pointer offset. */
#ifdef CONFIG_SLUB_CPU_PARTIAL
int cpu_partial; /* Number of per cpu partial objects to keep around */
#endif
struct kmem_cache_order_objects oo;
/* Allocation and freeing of slabs */
struct kmem_cache_order_objects max;
struct kmem_cache_order_objects min;
gfp_t allocflags; /* gfp flags to use on each alloc */
int refcount; /* Refcount for slab cache destroy */
void (*ctor)(void *);
......
const char *name; /* Name (only for display!) */
struct list_head list; /* List of slab caches */
......
struct kmem_cache_node *node[MAX_NUMNODES];
};在struct kmem_cache里面,有个变量struct list_head list,这个结构我们已经看到过多次了。我们可以想象一下,对于操作系统来讲,要创建和管理的缓存绝对不止task_struct。难道mm_struct就不需要吗?fs_struct就不需要吗?都需要。因此,所有的缓存最后都会放在一个链表里面,也就是LIST_HEAD(slab_caches)。
对于缓存来讲,其实就是分配了连续几页的大内存块,然后根据缓存对象的大小,切成小内存块。
所以,我们这里有三个kmem_cache_order_objects类型的变量。这里面的order,就是2的order次方个页面的大内存块,objects就是能够存放的缓存对象的数量。
最终,我们将大内存块切分成小内存块,样子就像下面这样。
每一项的结构都是缓存对象后面跟一个下一个空闲对象的指针,这样非常方便将所有的空闲对象链成一个链。其实,这就相当于咱们数据结构里面学的, 用数组实现一个可随机插入和删除的链表 。
所以,这里面就有三个变量:size是包含这个指针的大小,object_size是纯对象的大小,offset就是把下一个空闲对象的指针存放在这一项里的偏移量。
那这些缓存对象哪些被分配了、哪些在空着,什么情况下整个大内存块都被分配完了,需要向伙伴系统申请几个页形成新的大内存块?这些信息该由谁来维护呢?
接下来就是最重要的两个成员变量出场的时候了。kmem_cache_cpu和kmem_cache_node,它们都是每个NUMA节点上有一个,我们只需要看一个节点里面的情况。
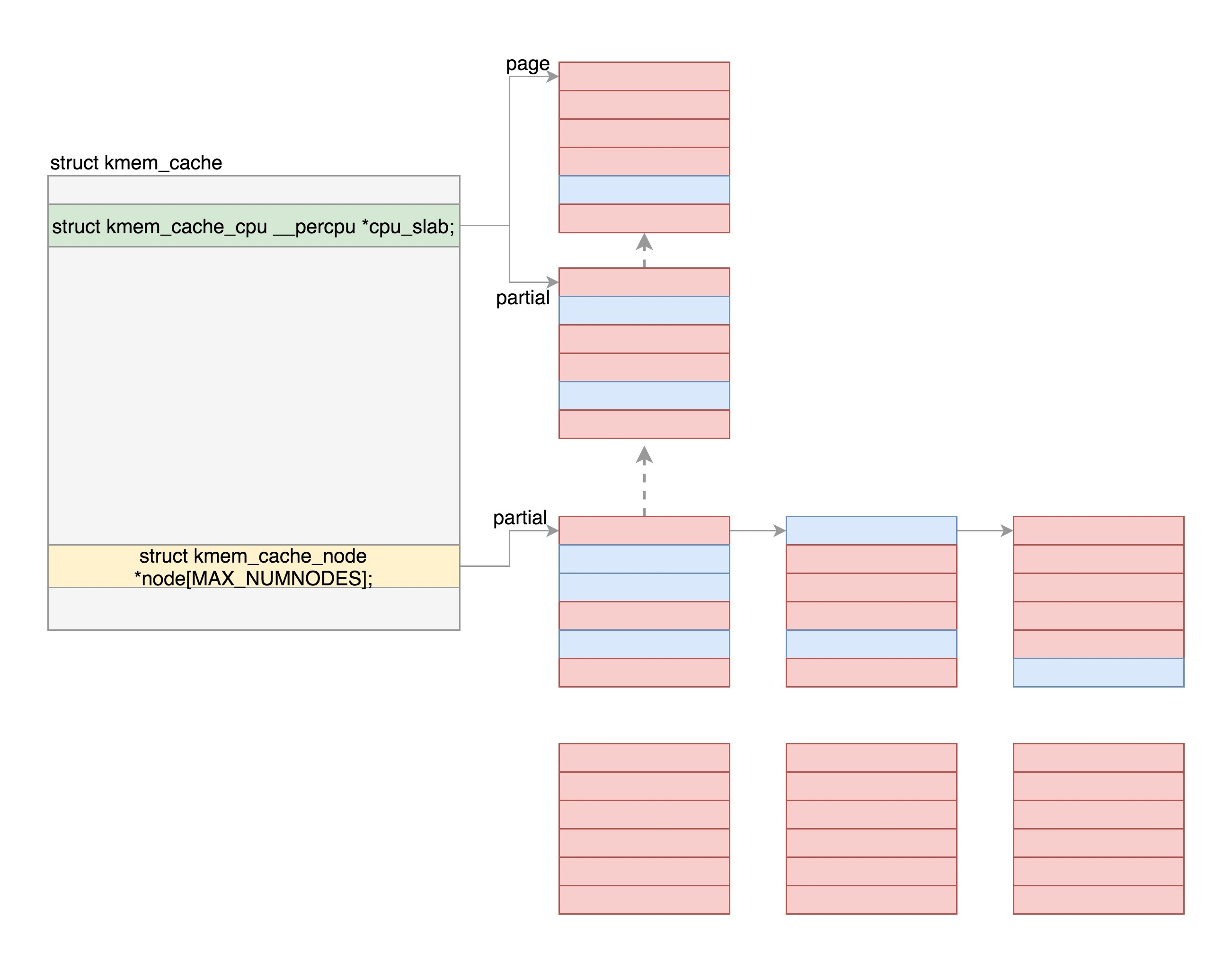
在分配缓存块的时候,要分两种路径,fast path和slow path,也就是快速通道和普通通道。其中kmem_cache_cpu就是快速通道,kmem_cache_node是普通通道。每次分配的时候,要先从kmem_cache_cpu进行分配。如果kmem_cache_cpu里面没有空闲的块,那就到kmem_cache_node中进行分配;如果还是没有空闲的块,才去伙伴系统分配新的页。
我们来看一下,kmem_cache_cpu里面是如何存放缓存块的。
struct kmem_cache_cpu {
void **freelist; /* Pointer to next available object */
unsigned long tid; /* Globally unique transaction id */
struct page *page; /* The slab from which we are allocating */
#ifdef CONFIG_SLUB_CPU_PARTIAL
struct page *partial; /* Partially allocated frozen slabs */
#endif
......
};在这里,page指向大内存块的第一个页,缓存块就是从里面分配的。freelist指向大内存块里面第一个空闲的项。按照上面说的,这一项会有指针指向下一个空闲的项,最终所有空闲的项会形成一个链表。
partial指向的也是大内存块的第一个页,之所以名字叫partial(部分),就是因为它里面部分被分配出去了,部分是空的。这是一个备用列表,当page满了,就会从这里找。
我们再来看kmem_cache_node的定义。
struct kmem_cache_node {
spinlock_t list_lock;
......
#ifdef CONFIG_SLUB
unsigned long nr_partial;
struct list_head partial;
......
#endif
};这里面也有一个partial,是一个链表。这个链表里存放的是部分空闲的大内存块。这是kmem_cache_cpu里面的partial的备用列表,如果那里没有,就到这里来找。
下面我们就来看看这个分配过程。kmem_cache_alloc_node会调用slab_alloc_node。你还是先重点看这里面的注释,这里面说的就是快速通道和普通通道的概念。
/*
* Inlined fastpath so that allocation functions (kmalloc, kmem_cache_alloc)
* have the fastpath folded into their functions. So no function call
* overhead for requests that can be satisfied on the fastpath.
*
* The fastpath works by first checking if the lockless freelist can be used.
* If not then __slab_alloc is called for slow processing.
*
* Otherwise we can simply pick the next object from the lockless free list.
*/
static __always_inline void *slab_alloc_node(struct kmem_cache *s,
gfp_t gfpflags, int node, unsigned long addr)
{
void *object;
struct kmem_cache_cpu *c;
struct page *page;
unsigned long tid;
......
tid = this_cpu_read(s->cpu_slab->tid);
c = raw_cpu_ptr(s->cpu_slab);
......
object = c->freelist;
page = c->page;
if (unlikely(!object || !node_match(page, node))) {
object = __slab_alloc(s, gfpflags, node, addr, c);
stat(s, ALLOC_SLOWPATH);
}
......
return object;
}快速通道很简单,取出cpu_slab也即kmem_cache_cpu的freelist,这就是第一个空闲的项,可以直接返回了。如果没有空闲的了,则只好进入普通通道,调用__slab_alloc。
static void *___slab_alloc(struct kmem_cache *s, gfp_t gfpflags, int node,
unsigned long addr, struct kmem_cache_cpu *c)
{
void *freelist;
struct page *page;
......
redo:
......
/* must check again c->freelist in case of cpu migration or IRQ */
freelist = c->freelist;
if (freelist)
goto load_freelist;
freelist = get_freelist(s, page);
if (!freelist) {
c->page = NULL;
stat(s, DEACTIVATE_BYPASS);
goto new_slab;
}
load_freelist:
c->freelist = get_freepointer(s, freelist);
c->tid = next_tid(c->tid);
return freelist;
new_slab:
if (slub_percpu_partial(c)) {
page = c->page = slub_percpu_partial(c);
slub_set_percpu_partial(c, page);
stat(s, CPU_PARTIAL_ALLOC);
goto redo;
}
freelist = new_slab_objects(s, gfpflags, node, &c);
......
return freeli;
}在这里,我们首先再次尝试一下kmem_cache_cpu的freelist。为什么呢?万一当前进程被中断,等回来的时候,别人已经释放了一些缓存,说不定又有空间了呢。如果找到了,就跳到load_freelist,在这里将freelist指向下一个空闲项,返回就可以了。
如果freelist还是没有,则跳到new_slab里面去。这里面我们先去kmem_cache_cpu的partial里面看。如果partial不是空的,那就将kmem_cache_cpu的page,也就是快速通道的那一大块内存,替换为partial里面的大块内存。然后redo,重新试下。这次应该就可以成功了。
如果真的还不行,那就要到new_slab_objects了。
static inline void *new_slab_objects(struct kmem_cache *s, gfp_t flags,
int node, struct kmem_cache_cpu **pc)
{
void *freelist;
struct kmem_cache_cpu *c = *pc;
struct page *page;
freelist = get_partial(s, flags, node, c);
if (freelist)
return freelist;
page = new_slab(s, flags, node);
if (page) {
c = raw_cpu_ptr(s->cpu_slab);
if (c->page)
flush_slab(s, c);
freelist = page->freelist;
page->freelist = NULL;
stat(s, ALLOC_SLAB);
c->page = page;
*pc = c;
} else
freelist = NULL;
return freelist;
}在这里面,get_partial会根据node id,找到相应的kmem_cache_node,然后调用get_partial_node,开始在这个节点进行分配。
/*
* Try to allocate a partial slab from a specific node.
*/
static void *get_partial_node(struct kmem_cache *s, struct kmem_cache_node *n,
struct kmem_cache_cpu *c, gfp_t flags)
{
struct page *page, *page2;
void *object = NULL;
int available = 0;
int objects;
......
list_for_each_entry_safe(page, page2, &n->partial, lru) {
void *t;
t = acquire_slab(s, n, page, object == NULL, &objects);
if (!t)
break;
available += objects;
if (!object) {
c->page = page;
stat(s, ALLOC_FROM_PARTIAL);
object = t;
} else {
put_cpu_partial(s, page, 0);
stat(s, CPU_PARTIAL_NODE);
}
if (!kmem_cache_has_cpu_partial(s)
|| available > slub_cpu_partial(s) / 2)
break;
}
......
return object;
}acquire_slab会从kmem_cache_node的partial链表中拿下一大块内存来,并且将freelist,也就是第一块空闲的缓存块,赋值给t。并且当第一轮循环的时候,将kmem_cache_cpu的page指向取下来的这一大块内存,返回的object就是这块内存里面的第一个缓存块t。如果kmem_cache_cpu也有一个partial,就会进行第二轮,再次取下一大块内存来,这次调用put_cpu_partial,放到kmem_cache_cpu的partial里面。
如果kmem_cache_node里面也没有空闲的内存,这就说明原来分配的页里面都放满了,就要回到new_slab_objects函数,里面new_slab函数会调用allocate_slab。
static struct page *allocate_slab(struct kmem_cache *s, gfp_t flags, int node)
{
struct page *page;
struct kmem_cache_order_objects oo = s->oo;
gfp_t alloc_gfp;
void *start, *p;
int idx, order;
bool shuffle;
flags &= gfp_allowed_mask;
......
page = alloc_slab_page(s, alloc_gfp, node, oo);
if (unlikely(!page)) {
oo = s->min;
alloc_gfp = flags;
/*
* Allocation may have failed due to fragmentation.
* Try a lower order alloc if possible
*/
page = alloc_slab_page(s, alloc_gfp, node, oo);
if (unlikely(!page))
goto out;
stat(s, ORDER_FALLBACK);
}
......
return page;
}在这里,我们看到了alloc_slab_page分配页面。分配的时候,要按kmem_cache_order_objects里面的order来。如果第一次分配不成功,说明内存已经很紧张了,那就换成min版本的kmem_cache_order_objects。
好了,这个复杂的层层分配机制,我们就讲到这里,你理解到这里也就够用了。
19.2 页面换出
另一个物理内存管理必须要处理的事情就是,页面换出。每个进程都有自己的虚拟地址空间,无论是32位还是64位,虚拟地址空间都非常大,物理内存不可能有这么多的空间放得下。所以,一般情况下,页面只有在被使用的时候,才会放在物理内存中。如果过了一段时间不被使用,即便用户进程并没有释放它,物理内存管理也有责任做一定的干预。例如,将这些物理内存中的页面换出到硬盘上去;将空出的物理内存,交给活跃的进程去使用。
什么情况下会触发页面换出呢?
可以想象,最常见的情况就是,分配内存的时候,发现没有地方了,就试图回收一下。例如,咱们解析申请一个页面的时候,会调用get_page_from_freelist,接下来的调用链为get_page_from_freelist->node_reclaim->__node_reclaim->shrink_node,通过这个调用链可以看出,页面换出也是以内存节点为单位的。
当然还有一种情况,就是作为内存管理系统应该主动去做的,而不能等真的出了事儿再做,这就是内核线程kswapd。这个内核线程,在系统初始化的时候就被创建。这样它会进入一个无限循环,直到系统停止。在这个循环中,如果内存使用没有那么紧张,那它就可以放心睡大觉;如果内存紧张了,就需要去检查一下内存,看看是否需要换出一些内存页。
/*
* The background pageout daemon, started as a kernel thread
* from the init process.
*
* This basically trickles out pages so that we have _some_
* free memory available even if there is no other activity
* that frees anything up. This is needed for things like routing
* etc, where we otherwise might have all activity going on in
* asynchronous contexts that cannot page things out.
*
* If there are applications that are active memory-allocators
* (most normal use), this basically shouldn't matter.
*/
static int kswapd(void *p)
{
unsigned int alloc_order, reclaim_order;
unsigned int classzone_idx = MAX_NR_ZONES - 1;
pg_data_t *pgdat = (pg_data_t*)p;
struct task_struct *tsk = current;
for ( ; ; ) {
......
kswapd_try_to_sleep(pgdat, alloc_order, reclaim_order,
classzone_idx);
......
reclaim_order = balance_pgdat(pgdat, alloc_order, classzone_idx);
......
}
}这里的调用链是balance_pgdat->kswapd_shrink_node->shrink_node,是以内存节点为单位的,最后也是调用shrink_node。
shrink_node会调用shrink_node_memcg。这里面有一个循环处理页面的列表,看这个函数的注释,其实和上面我们想表达的内存换出是一样的。
/*
* This is a basic per-node page freer. Used by both kswapd and direct reclaim.
*/
static void shrink_node_memcg(struct pglist_data *pgdat, struct mem_cgroup *memcg,
struct scan_control *sc, unsigned long *lru_pages)
{
......
unsigned long nr[NR_LRU_LISTS];
enum lru_list lru;
......
while (nr[LRU_INACTIVE_ANON] || nr[LRU_ACTIVE_FILE] ||
nr[LRU_INACTIVE_FILE]) {
unsigned long nr_anon, nr_file, percentage;
unsigned long nr_scanned;
for_each_evictable_lru(lru) {
if (nr[lru]) {
nr_to_scan = min(nr[lru], SWAP_CLUSTER_MAX);
nr[lru] -= nr_to_scan;
nr_reclaimed += shrink_list(lru, nr_to_scan,
lruvec, memcg, sc);
}
}
......
}
......
}这里面有个lru列表。从下面的定义,我们可以想象,所有的页面都被挂在LRU列表中。LRU是Least Recent Use,也就是最近最少使用。也就是说,这个列表里面会按照活跃程度进行排序,这样就容易把不怎么用的内存页拿出来做处理。
内存页总共分两类,一类是匿名页,和虚拟地址空间进行关联;一类是内存映射,不但和虚拟地址空间关联,还和文件管理关联。
它们每一类都有两个列表,一个是active,一个是inactive。顾名思义,active就是比较活跃的,inactive就是不怎么活跃的。这两个里面的页会变化,过一段时间,活跃的可能变为不活跃,不活跃的可能变为活跃。如果要换出内存,那就是从不活跃的列表中找出最不活跃的,换出到硬盘上。
enum lru_list {
LRU_INACTIVE_ANON = LRU_BASE,
LRU_ACTIVE_ANON = LRU_BASE + LRU_ACTIVE,
LRU_INACTIVE_FILE = LRU_BASE + LRU_FILE,
LRU_ACTIVE_FILE = LRU_BASE + LRU_FILE + LRU_ACTIVE,
LRU_UNEVICTABLE,
NR_LRU_LISTS
};
#define for_each_evictable_lru(lru) for (lru = 0; lru <= LRU_ACTIVE_FILE; lru++)
static unsigned long shrink_list(enum lru_list lru, unsigned long nr_to_scan,
struct lruvec *lruvec, struct mem_cgroup *memcg,
struct scan_control *sc)
{
if (is_active_lru(lru)) {
if (inactive_list_is_low(lruvec, is_file_lru(lru),
memcg, sc, true))
shrink_active_list(nr_to_scan, lruvec, sc, lru);
return 0;
}
return shrink_inactive_list(nr_to_scan, lruvec, sc, lru);
}从上面的代码可以看出,shrink_list会先缩减活跃页面列表,再压缩不活跃的页面列表。对于不活跃列表的缩减,shrink_inactive_list就需要对页面进行回收;对于匿名页来讲,需要分配swap,将内存页写入文件系统;对于内存映射关联了文件的,我们需要将在内存中对于文件的修改写回到文件中。
19.3 总结
对于物理内存来讲,从下层到上层的关系及分配模式如下:
- 物理内存分NUMA节点,分别进行管理;
- 每个NUMA节点分成多个内存区域;
- 每个内存区域分成多个物理页面;
- 伙伴系统将多个连续的页面作为一个大的内存块分配给上层;
- kswapd负责物理页面的换入换出;
- Slub Allocator将从伙伴系统申请的大内存块切成小块,分配给其他系统。
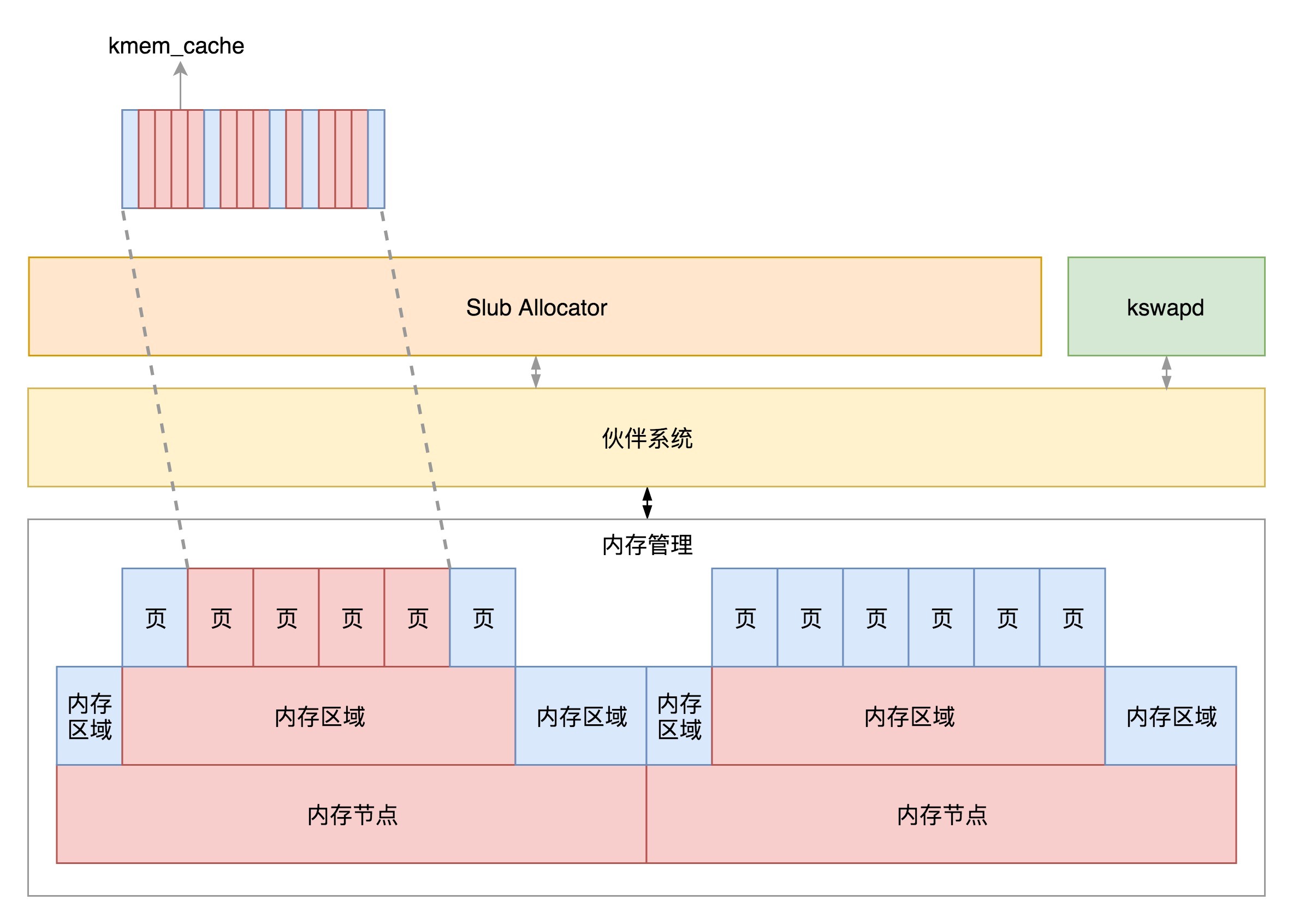
20. 用户态内存映射
20.1 mmap的原理
在虚拟地址空间那一节,我们知道,每一个进程都有一个列表vm_area_struct,指向虚拟地址空间的不同的内存块,这个变量的名字叫mmap。
struct mm_struct {
struct vm_area_struct *mmap; /* list of VMAs */
......
}
struct vm_area_struct {
/*
* For areas with an address space and backing store,
* linkage into the address_space->i_mmap interval tree.
*/
struct {
struct rb_node rb;
unsigned long rb_subtree_last;
} shared;
/*
* A file's MAP_PRIVATE vma can be in both i_mmap tree and anon_vma
* list, after a COW of one of the file pages. A MAP_SHARED vma
* can only be in the i_mmap tree. An anonymous MAP_PRIVATE, stack
* or brk vma (with NULL file) can only be in an anon_vma list.
*/
struct list_head anon_vma_chain; /* Serialized by mmap_sem &
* page_table_lock */
struct anon_vma *anon_vma; /* Serialized by page_table_lock */
/* Function pointers to deal with this struct. */
const struct vm_operations_struct *vm_ops;
/* Information about our backing store: */
unsigned long vm_pgoff; /* Offset (within vm_file) in PAGE_SIZE
units */
struct file * vm_file; /* File we map to (can be NULL). */
void * vm_private_data; /* was vm_pte (shared mem) */
}其实内存映射不仅仅是物理内存和虚拟内存之间的映射,还包括将文件中的内容映射到虚拟内存空间。这个时候,访问内存空间就能够访问到文件里面的数据。而仅有物理内存和虚拟内存的映射,是一种特殊情况。
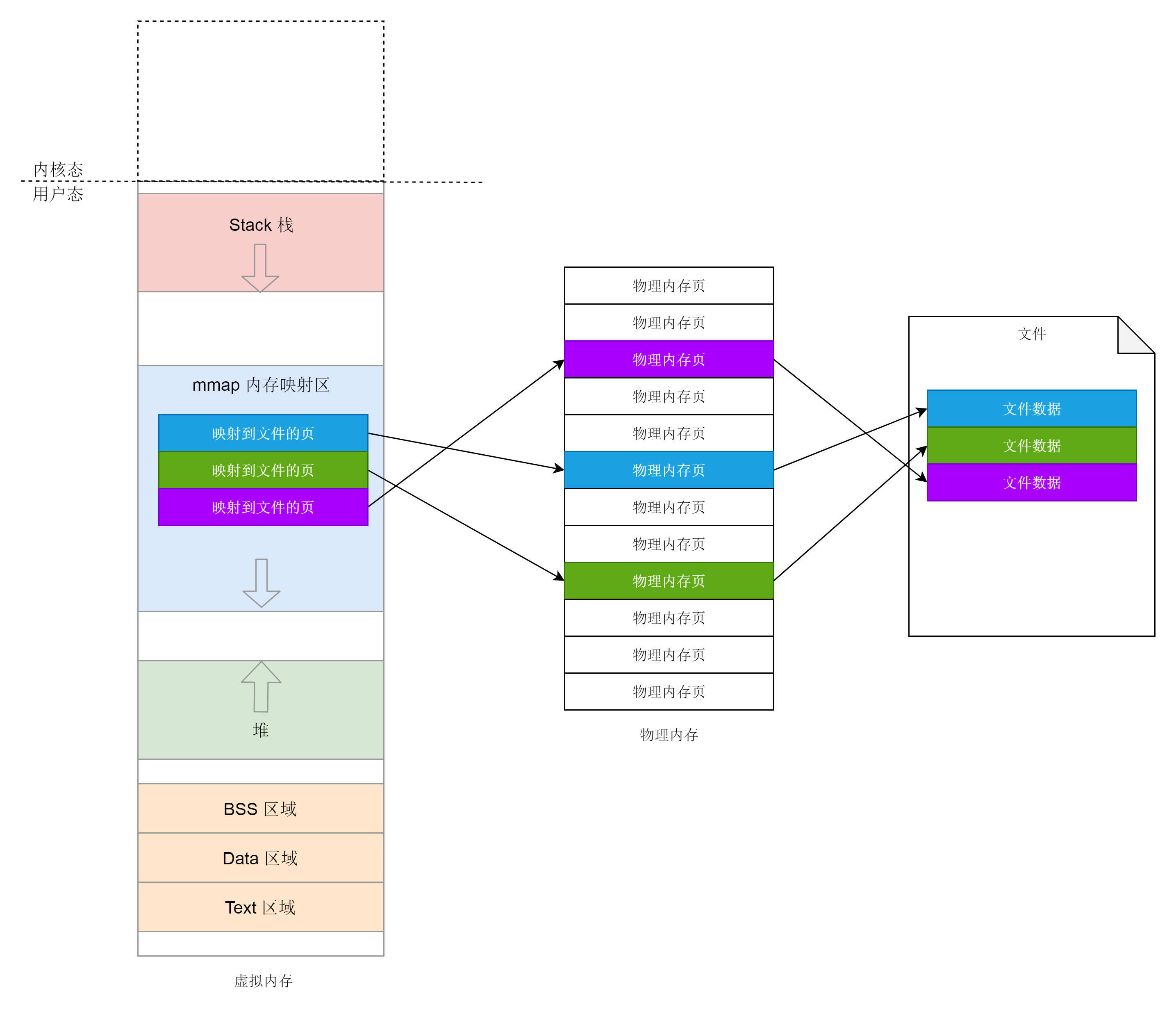
前面咱们讲堆的时候讲过,如果我们要申请小块内存,就用brk。brk函数之前已经解析过了,这里就不多说了。如果申请一大块内存,就要用mmap。对于堆的申请来讲,mmap是映射内存空间到物理内存。
另外,如果一个进程想映射一个文件到自己的虚拟内存空间,也要通过mmap系统调用。这个时候mmap是映射内存空间到物理内存再到文件。可见mmap这个系统调用是核心,我们现在来看mmap这个系统调用。
SYSCALL_DEFINE6(mmap, unsigned long, addr, unsigned long, len,
unsigned long, prot, unsigned long, flags,
unsigned long, fd, unsigned long, off)
{
......
error = sys_mmap_pgoff(addr, len, prot, flags, fd, off >> PAGE_SHIFT);
......
}
SYSCALL_DEFINE6(mmap_pgoff, unsigned long, addr, unsigned long, len,
unsigned long, prot, unsigned long, flags,
unsigned long, fd, unsigned long, pgoff)
{
struct file *file = NULL;
......
file = fget(fd);
......
retval = vm_mmap_pgoff(file, addr, len, prot, flags, pgoff);
return retval;
}如果要映射到文件,fd会传进来一个文件描述符,并且mmap_pgoff里面通过fget函数,根据文件描述符获得struct file。struct file表示打开的一个文件。
接下来的调用链是vm_mmap_pgoff->do_mmap_pgoff->do_mmap。这里面主要干了两件事情:
- 调用get_unmapped_area找到一个没有映射的区域;
- 调用mmap_region映射这个区域。
我们先来看get_unmapped_area函数。
unsigned long
get_unmapped_area(struct file *file, unsigned long addr, unsigned long len,
unsigned long pgoff, unsigned long flags)
{
unsigned long (*get_area)(struct file *, unsigned long,
unsigned long, unsigned long, unsigned long);
......
get_area = current->mm->get_unmapped_area;
if (file) {
if (file->f_op->get_unmapped_area)
get_area = file->f_op->get_unmapped_area;
}
......
}这里面如果是匿名映射,则调用mm_struct里面的get_unmapped_area函数。这个函数其实是arch_get_unmapped_area。它会调用find_vma_prev,在表示虚拟内存区域的vm_area_struct红黑树上找到相应的位置。之所以叫prev,是说这个时候虚拟内存区域还没有建立,找到前一个vm_area_struct。
如果不是匿名映射,而是映射到一个文件,这样在Linux里面,每个打开的文件都有一个struct file结构,里面有一个file_operations,用来表示和这个文件相关的操作。如果是我们熟知的ext4文件系统,调用的是thp_get_unmapped_area。如果我们仔细看这个函数,最终还是调用mm_struct里面的get_unmapped_area函数。殊途同归。
const struct file_operations ext4_file_operations = {
......
.mmap = ext4_file_mmap
.get_unmapped_area = thp_get_unmapped_area,
};
unsigned long __thp_get_unmapped_area(struct file *filp, unsigned long len,
loff_t off, unsigned long flags, unsigned long size)
{
unsigned long addr;
loff_t off_end = off + len;
loff_t off_align = round_up(off, size);
unsigned long len_pad;
len_pad = len + size;
......
addr = current->mm->get_unmapped_area(filp, 0, len_pad,
off >> PAGE_SHIFT, flags);
addr += (off - addr) & (size - 1);
return addr;
}我们再来看mmap_region,看它如何映射这个虚拟内存区域。
unsigned long mmap_region(struct file *file, unsigned long addr,
unsigned long len, vm_flags_t vm_flags, unsigned long pgoff,
struct list_head *uf)
{
struct mm_struct *mm = current->mm;
struct vm_area_struct *vma, *prev;
struct rb_node **rb_link, *rb_parent;
/*
* Can we just expand an old mapping?
*/
vma = vma_merge(mm, prev, addr, addr + len, vm_flags,
NULL, file, pgoff, NULL, NULL_VM_UFFD_CTX);
if (vma)
goto out;
/*
* Determine the object being mapped and call the appropriate
* specific mapper. the address has already been validated, but
* not unmapped, but the maps are removed from the list.
*/
vma = kmem_cache_zalloc(vm_area_cachep, GFP_KERNEL);
if (!vma) {
error = -ENOMEM;
goto unacct_error;
}
vma->vm_mm = mm;
vma->vm_start = addr;
vma->vm_end = addr + len;
vma->vm_flags = vm_flags;
vma->vm_page_prot = vm_get_page_prot(vm_flags);
vma->vm_pgoff = pgoff;
INIT_LIST_HEAD(&vma->anon_vma_chain);
if (file) {
vma->vm_file = get_file(file);
error = call_mmap(file, vma);
addr = vma->vm_start;
vm_flags = vma->vm_flags;
}
......
vma_link(mm, vma, prev, rb_link, rb_parent);
return addr;
.....
}还记得咱们刚找到了虚拟内存区域的前一个vm_area_struct,我们首先要看,是否能够基于它进行扩展,也即调用vma_merge,和前一个vm_area_struct合并到一起。
如果不能,就需要调用kmem_cache_zalloc,在Slub里面创建一个新的vm_area_struct对象,设置起始和结束位置,将它加入队列。如果是映射到文件,则设置vm_file为目标文件,调用call_mmap。其实就是调用file_operations的mmap函数。对于ext4文件系统,调用的是ext4_file_mmap。从这个函数的参数可以看出,这一刻文件和内存开始发生关系了。这里我们将vm_area_struct的内存操作设置为文件系统操作,也就是说,读写内存其实就是读写文件系统。
static inline int call_mmap(struct file *file, struct vm_area_struct *vma)
{
return file->f_op->mmap(file, vma);
}
static int ext4_file_mmap(struct file *file, struct vm_area_struct *vma)
{
......
vma->vm_ops = &ext4_file_vm_ops;
......
}我们再回到mmap_region函数。最终,vma_link函数将新创建的vm_area_struct挂在了mm_struct里面的红黑树上。
这个时候,从内存到文件的映射关系,至少要在逻辑层面建立起来。那从文件到内存的映射关系呢?vma_link还做了另外一件事情,就是__vma_link_file。这个东西要用于建立这层映射关系。
对于打开的文件,会有一个结构struct file来表示。它有个成员指向struct address_space结构,这里面有棵变量名为i_mmap的红黑树,vm_area_struct就挂在这棵树上。
struct address_space {
struct inode *host; /* owner: inode, block_device */
......
struct rb_root i_mmap; /* tree of private and shared mappings */
......
const struct address_space_operations *a_ops; /* methods */
......
}
static void __vma_link_file(struct vm_area_struct *vma)
{
struct file *file;
file = vma->vm_file;
if (file) {
struct address_space *mapping = file->f_mapping;
vma_interval_tree_insert(vma, &mapping->i_mmap);
}
}到这里,内存映射的内容要告一段落了。你可能会困惑,好像还没和物理内存发生任何关系,还是在虚拟内存里面折腾呀?
对的,因为到目前为止,我们还没有开始真正访问内存呀!这个时候,内存管理并不直接分配物理内存,因为物理内存相对于虚拟地址空间太宝贵了,只有等你真正用的那一刻才会开始分配。
20.2 用户态缺页异常
一旦开始访问虚拟内存的某个地址,如果我们发现,并没有对应的物理页,那就触发缺页中断,调用do_page_fault。
dotraplinkage void notrace
do_page_fault(struct pt_regs *regs, unsigned long error_code)
{
unsigned long address = read_cr2(); /* Get the faulting address */
......
__do_page_fault(regs, error_code, address);
......
}
/*
* This routine handles page faults. It determines the address,
* and the problem, and then passes it off to one of the appropriate
* routines.
*/
static noinline void
__do_page_fault(struct pt_regs *regs, unsigned long error_code,
unsigned long address)
{
struct vm_area_struct *vma;
struct task_struct *tsk;
struct mm_struct *mm;
tsk = current;
mm = tsk->mm;
if (unlikely(fault_in_kernel_space(address))) {
if (vmalloc_fault(address) >= 0)
return;
}
......
vma = find_vma(mm, address);
......
fault = handle_mm_fault(vma, address, flags);
......
}在__do_page_fault里面,先要判断缺页中断是否发生在内核。如果发生在内核则调用vmalloc_fault,这就和咱们前面学过的虚拟内存的布局对应上了。在内核里面,vmalloc区域需要内核页表映射到物理页。咱们这里把内核的这部分放放,接着看用户空间的部分。
接下来在用户空间里面,找到你访问的那个地址所在的区域vm_area_struct,然后调用handle_mm_fault来映射这个区域。
static int __handle_mm_fault(struct vm_area_struct *vma, unsigned long address,
unsigned int flags)
{
struct vm_fault vmf = {
.vma = vma,
.address = address & PAGE_MASK,
.flags = flags,
.pgoff = linear_page_index(vma, address),
.gfp_mask = __get_fault_gfp_mask(vma),
};
struct mm_struct *mm = vma->vm_mm;
pgd_t *pgd;
p4d_t *p4d;
int ret;
pgd = pgd_offset(mm, address);
p4d = p4d_alloc(mm, pgd, address);
......
vmf.pud = pud_alloc(mm, p4d, address);
......
vmf.pmd = pmd_alloc(mm, vmf.pud, address);
......
return handle_pte_fault(&vmf);
}到这里,终于看到了我们熟悉的PGD、P4G、PUD、PMD、PTE,这就是前面讲页表的时候,讲述的四级页表的概念,因为暂且不考虑五级页表,我们暂时忽略P4G。
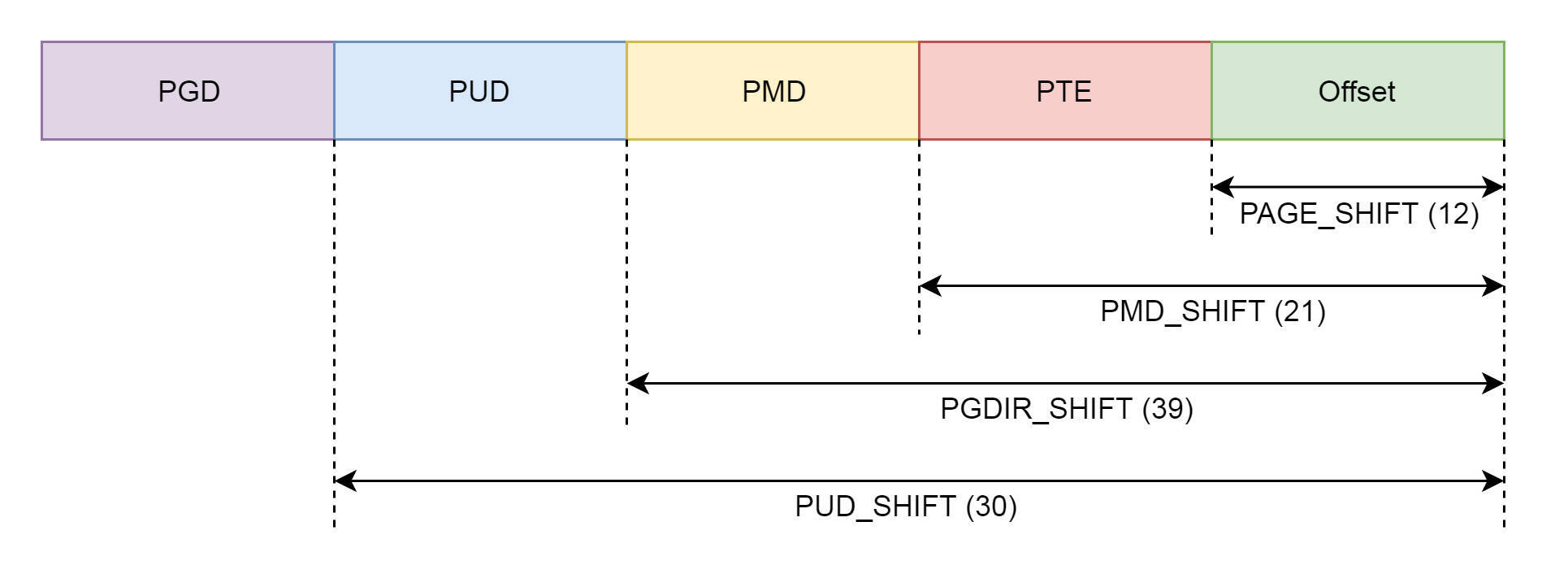
pgd_t 用于全局页目录项,pud_t 用于上层页目录项,pmd_t 用于中间页目录项,pte_t 用于直接页表项。
每个进程都有独立的地址空间,为了这个进程独立完成映射,每个进程都有独立的进程页表,这个页表的最顶级的pgd存放在task_struct中的mm_struct的pgd变量里面。
在一个进程新创建的时候,会调用fork,对于内存的部分会调用copy_mm,里面调用dup_mm。
/*
* Allocate a new mm structure and copy contents from the
* mm structure of the passed in task structure.
*/
static struct mm_struct *dup_mm(struct task_struct *tsk)
{
struct mm_struct *mm, *oldmm = current->mm;
mm = allocate_mm();
memcpy(mm, oldmm, sizeof(*mm));
if (!mm_init(mm, tsk, mm->user_ns))
goto fail_nomem;
err = dup_mmap(mm, oldmm);
return mm;
}在这里,除了创建一个新的mm_struct,并且通过memcpy将它和父进程的弄成一模一样之外,我们还需要调用mm_init进行初始化。接下来,mm_init调用mm_alloc_pgd,分配全局页目录项,赋值给mm_struct的pdg成员变量。
static inline int mm_alloc_pgd(struct mm_struct *mm)
{
mm->pgd = pgd_alloc(mm);
return 0;
}pgd_alloc里面除了分配PDG之外,还做了很重要的一个事情,就是调用pgd_ctor。
static void pgd_ctor(struct mm_struct *mm, pgd_t *pgd)
{
/* If the pgd points to a shared pagetable level (either the
ptes in non-PAE, or shared PMD in PAE), then just copy the
references from swapper_pg_dir. */
if (CONFIG_PGTABLE_LEVELS == 2 ||
(CONFIG_PGTABLE_LEVELS == 3 && SHARED_KERNEL_PMD) ||
CONFIG_PGTABLE_LEVELS >= 4) {
clone_pgd_range(pgd + KERNEL_PGD_BOUNDARY,
swapper_pg_dir + KERNEL_PGD_BOUNDARY,
KERNEL_PGD_PTRS);
}
......
}pgd_ctor干了什么事情呢?我们注意看里面的注释,它拷贝了对于swapper_pg_dir的引用。swapper_pg_dir是内核页表的最顶级的全局页目录。
一个进程的虚拟地址空间包含用户态和内核态两部分。为了从虚拟地址空间映射到物理页面,页表也分为用户地址空间的页表和内核页表,这就和上面遇到的vmalloc有关系了。在内核里面,映射靠内核页表,这里内核页表会拷贝一份到进程的页表。至于swapper_pg_dir是什么,怎么初始化的,怎么工作的,我们还是先放一放,放到下一节统一讨论。
至此,一个进程fork完毕之后,有了内核页表,有了自己顶级的pgd,但是对于用户地址空间来讲,还完全没有映射过。这需要等到这个进程在某个CPU上运行,并且对内存访问的那一刻了。
当这个进程被调度到某个CPU上运行的时候,咱们在 调度(上) 那一节讲过,要调用context_switch进行上下文切换。对于内存方面的切换会调用switch_mm_irqs_off,这里面会调用 load_new_mm_cr3。
cr3是CPU的一个寄存器,它会指向当前进程的顶级pgd。如果CPU的指令要访问进程的虚拟内存,它就会自动从cr3里面得到pgd在物理内存的地址,然后根据里面的页表解析虚拟内存的地址为物理内存,从而访问真正的物理内存上的数据。
这里需要注意两点。第一点,cr3里面存放当前进程的顶级pgd,这个是硬件的要求。cr3里面需要存放pgd在物理内存的地址,不能是虚拟地址。因而load_new_mm_cr3里面会使用__pa,将mm_struct里面的成员变量pdg(mm_struct里面存的都是虚拟地址)变为物理地址,才能加载到cr3里面去。
第二点,用户进程在运行的过程中,访问虚拟内存中的数据,会被cr3里面指向的页表转换为物理地址后,才在物理内存中访问数据,这个过程都是在用户态运行的,地址转换的过程无需进入内核态。
只有访问虚拟内存的时候,发现没有映射多物理内存,页表也没有创建过,才触发缺页异常。进入内核调用do_page_fault,一直调用到handle_mm_fault,这才有了上面解析到这个函数的时候,我们看到的代码。既然原来没有创建过页表,那只好补上这一课。于是,handle_mm_fault调用pud_alloc和pmd_alloc,来创建相应的页目录项,最后调用handle_pte_fault来创建页表项。
绕了一大圈,终于将页表整个机制的各个部分串了起来。但是咱们的故事还没讲完,物理的内存还没找到。我们还得接着分析handle_pte_fault的实现。
static int handle_pte_fault(struct vm_fault *vmf)
{
pte_t entry;
......
vmf->pte = pte_offset_map(vmf->pmd, vmf->address);
vmf->orig_pte = *vmf->pte;
......
if (!vmf->pte) {
if (vma_is_anonymous(vmf->vma))
return do_anonymous_page(vmf);
else
return do_fault(vmf);
}
if (!pte_present(vmf->orig_pte))
return do_swap_page(vmf);
......
}这里面总的来说分了三种情况。如果PTE,也就是页表项,从来没有出现过,那就是新映射的页。如果是匿名页,就是第一种情况,应该映射到一个物理内存页,在这里调用的是do_anonymous_page。如果是映射到文件,调用的就是do_fault,这是第二种情况。如果PTE原来出现过,说明原来页面在物理内存中,后来换出到硬盘了,现在应该换回来,调用的是do_swap_page。
我们来看第一种情况,do_anonymous_page。对于匿名页的映射,我们需要先通过pte_alloc分配一个页表项,然后通过alloc_zeroed_user_highpage_movable分配一个页。之后它会调用alloc_pages_vma,并最终调用__alloc_pages_nodemask。
这个函数你还记得吗?就是咱们伙伴系统的核心函数,专门用来分配物理页面的。do_anonymous_page接下来要调用mk_pte,将页表项指向新分配的物理页,set_pte_at会将页表项塞到页表里面。
static int do_anonymous_page(struct vm_fault *vmf)
{
struct vm_area_struct *vma = vmf->vma;
struct mem_cgroup *memcg;
struct page *page;
int ret = 0;
pte_t entry;
......
if (pte_alloc(vma->vm_mm, vmf->pmd, vmf->address))
return VM_FAULT_OOM;
......
page = alloc_zeroed_user_highpage_movable(vma, vmf->address);
......
entry = mk_pte(page, vma->vm_page_prot);
if (vma->vm_flags & VM_WRITE)
entry = pte_mkwrite(pte_mkdirty(entry));
vmf->pte = pte_offset_map_lock(vma->vm_mm, vmf->pmd, vmf->address,
&vmf->ptl);
......
set_pte_at(vma->vm_mm, vmf->address, vmf->pte, entry);
......
}第二种情况映射到文件do_fault,最终我们会调用__do_fault。
static int __do_fault(struct vm_fault *vmf)
{
struct vm_area_struct *vma = vmf->vma;
int ret;
......
ret = vma->vm_ops->fault(vmf);
......
return ret;
}
这里调用了struct vm_operations_struct vm_ops的fault函数。还记得咱们上面用mmap映射文件的时候,对于ext4文件系统,vm_ops指向了ext4_file_vm_ops,也就是调用了ext4_filemap_fault。
static const struct vm_operations_struct ext4_file_vm_ops = {
.fault = ext4_filemap_fault,
.map_pages = filemap_map_pages,
.page_mkwrite = ext4_page_mkwrite,
};
int ext4_filemap_fault(struct vm_fault *vmf)
{
struct inode *inode = file_inode(vmf->vma->vm_file);
......
err = filemap_fault(vmf);
......
return err;
}ext4_filemap_fault里面的逻辑我们很容易就能读懂。vm_file就是咱们当时mmap的时候映射的那个文件,然后我们需要调用filemap_fault。对于文件映射来说,一般这个文件会在物理内存里面有页面作为它的缓存,find_get_page就是找那个页。如果找到了,就调用do_async_mmap_readahead,预读一些数据到内存里面;如果没有,就跳到no_cached_page。
int filemap_fault(struct vm_fault *vmf)
{
int error;
struct file *file = vmf->vma->vm_file;
struct address_space *mapping = file->f_mapping;
struct inode *inode = mapping->host;
pgoff_t offset = vmf->pgoff;
struct page *page;
int ret = 0;
......
page = find_get_page(mapping, offset);
if (likely(page) && !(vmf->flags & FAULT_FLAG_TRIED)) {
do_async_mmap_readahead(vmf->vma, ra, file, page, offset);
} else if (!page) {
goto no_cached_page;
}
......
vmf->page = page;
return ret | VM_FAULT_LOCKED;
no_cached_page:
error = page_cache_read(file, offset, vmf->gfp_mask);
......
}如果没有物理内存中的缓存页,那我们就调用page_cache_read。在这里显示分配一个缓存页,将这一页加到lru表里面,然后在address_space中调用address_space_operations的readpage函数,将文件内容读到内存中。address_space的作用咱们上面也介绍过了。
static int page_cache_read(struct file *file, pgoff_t offset, gfp_t gfp_mask)
{
struct address_space *mapping = file->f_mapping;
struct page *page;
......
page = __page_cache_alloc(gfp_mask|__GFP_COLD);
......
ret = add_to_page_cache_lru(page, mapping, offset, gfp_mask & GFP_KERNEL);
......
ret = mapping->a_ops->readpage(file, page);
......
}struct address_space_operations对于ext4文件系统的定义如下所示。这么说来,上面的readpage调用的其实是ext4_readpage。因为我们还没讲到文件系统,这里我们不详细介绍ext4_readpage具体干了什么。你只要知道,最后会调用ext4_read_inline_page,这里面有部分逻辑和内存映射有关就行了。
static const struct address_space_operations ext4_aops = {
.readpage = ext4_readpage,
.readpages = ext4_readpages,
......
};
static int ext4_read_inline_page(struct inode *inode, struct page *page)
{
void *kaddr;
......
kaddr = kmap_atomic(page);
ret = ext4_read_inline_data(inode, kaddr, len, &iloc);
flush_dcache_page(page);
kunmap_atomic(kaddr);
......
}在ext4_read_inline_page函数里,我们需要先调用kmap_atomic,将物理内存映射到内核的虚拟地址空间,得到内核中的地址kaddr。 我们在前面提到过kmap_atomic,它是用来做临时内核映射的。本来把物理内存映射到用户虚拟地址空间,不需要在内核里面映射一把。但是,现在因为要从文件里面读取数据并写入这个物理页面,又不能使用物理地址,我们只能使用虚拟地址,这就需要在内核里面临时映射一把。临时映射后,ext4_read_inline_data读取文件到这个虚拟地址。读取完毕后,我们取消这个临时映射kunmap_atomic就行了。
至于kmap_atomic的具体实现,我们还是放到内核映射部分再讲。
我们再来看第三种情况,do_swap_page。之前我们讲过物理内存管理,你这里可以回忆一下。如果长时间不用,就要换出到硬盘,也就是swap,现在这部分数据又要访问了,我们还得想办法再次读到内存中来。
int do_swap_page(struct vm_fault *vmf)
{
struct vm_area_struct *vma = vmf->vma;
struct page *page, *swapcache;
struct mem_cgroup *memcg;
swp_entry_t entry;
pte_t pte;
......
entry = pte_to_swp_entry(vmf->orig_pte);
......
page = lookup_swap_cache(entry);
if (!page) {
page = swapin_readahead(entry, GFP_HIGHUSER_MOVABLE, vma,
vmf->address);
......
}
......
swapcache = page;
......
pte = mk_pte(page, vma->vm_page_prot);
......
set_pte_at(vma->vm_mm, vmf->address, vmf->pte, pte);
vmf->orig_pte = pte;
......
swap_free(entry);
......
}do_swap_page函数会先查找swap文件有没有缓存页。如果没有,就调用swapin_readahead,将swap文件读到内存中来,形成内存页,并通过mk_pte生成页表项。set_pte_at将页表项插入页表,swap_free将swap文件清理。因为重新加载回内存了,不再需要swap文件了。
swapin_readahead会最终调用swap_readpage,在这里,我们看到了熟悉的readpage函数,也就是说读取普通文件和读取swap文件,过程是一样的,同样需要用kmap_atomic做临时映射。
int swap_readpage(struct page *page, bool do_poll)
{
struct bio *bio;
int ret = 0;
struct swap_info_struct *sis = page_swap_info(page);
blk_qc_t qc;
struct block_device *bdev;
......
if (sis->flags & SWP_FILE) {
struct file *swap_file = sis->swap_file;
struct address_space *mapping = swap_file->f_mapping;
ret = mapping->a_ops->readpage(swap_file, page);
return ret;
}
......
}通过上面复杂的过程,用户态缺页异常处理完毕了。物理内存中有了页面,页表也建立好了映射。接下来,用户程序在虚拟内存空间里面,可以通过虚拟地址顺利经过页表映射的访问物理页面上的数据了。
为了加快映射速度,我们不需要每次从虚拟地址到物理地址的转换都走一遍页表。
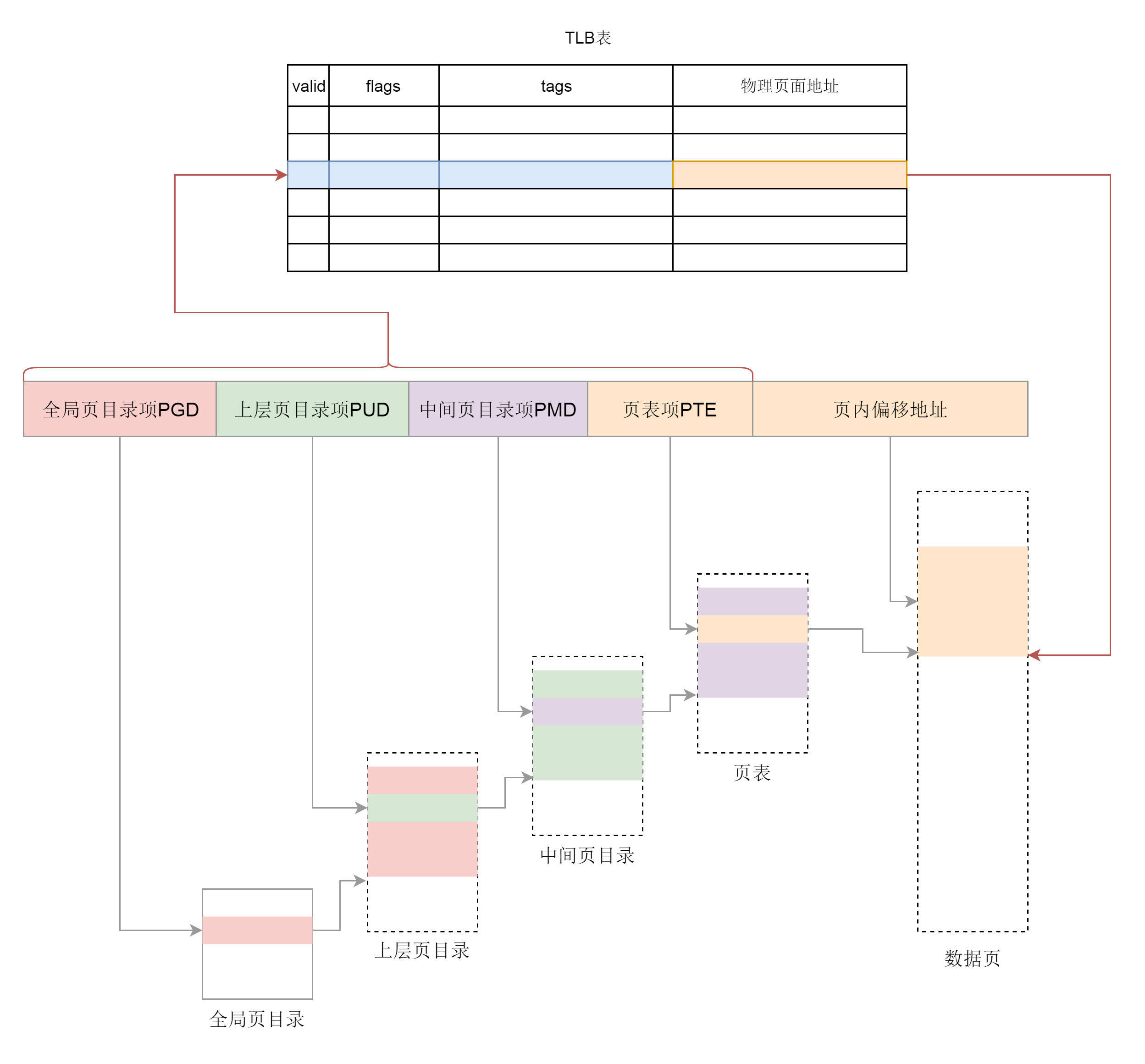
20.3 总结
总结一下,用户态的内存映射机制包含以下几个部分。
- 用户态内存映射函数mmap,包括用它来做匿名映射和文件映射。
- 用户态的页表结构,存储位置在mm_struct中。
- 在用户态访问没有映射的内存会引发缺页异常,分配物理页表、补齐页表。如果是匿名映射则分配物理内存;如果是swap,则将swap文件读入;如果是文件映射,则将文件读入。
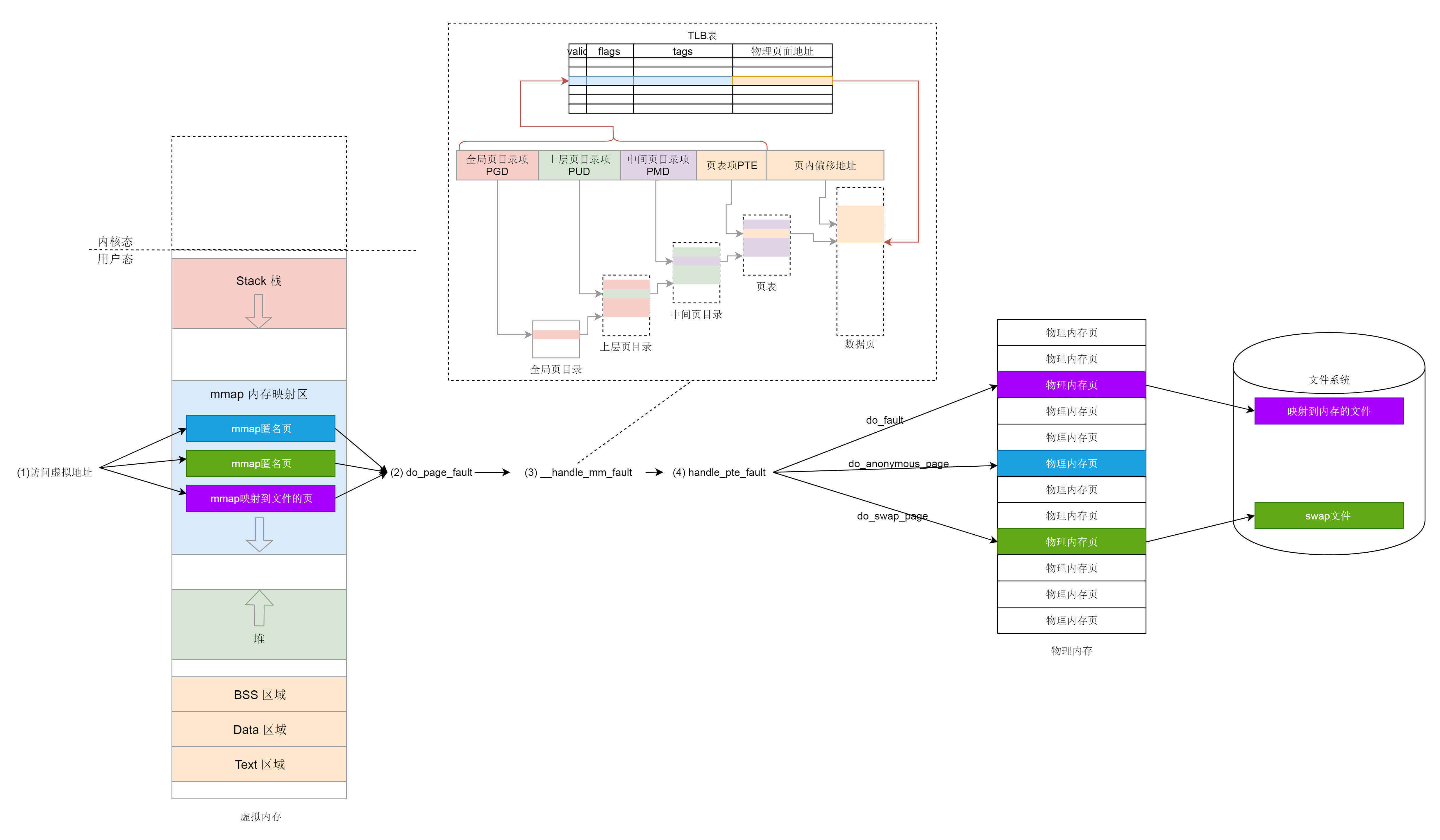
21. 内核态内存映射
内核态的内存映射机制,主要包含以下几个部分:
- 内核态内存映射函数vmalloc、kmap_atomic是如何工作的;
- 内核态页表是放在哪里的,如何工作的?swapper_pg_dir是怎么回事;
- 出现了内核态缺页异常应该怎么办?
21.1 内核页表
和用户态页表不同,在系统初始化的时候,我们就要创建内核页表了。
我们从内核页表的根swapper_pg_dir开始找线索,在arch/x86/include/asm/pgtable_64.h中就能找到它的定义。
extern pud_t level3_kernel_pgt[512];
extern pud_t level3_ident_pgt[512];
extern pmd_t level2_kernel_pgt[512];
extern pmd_t level2_fixmap_pgt[512];
extern pmd_t level2_ident_pgt[512];
extern pte_t level1_fixmap_pgt[512];
extern pgd_t init_top_pgt[];
#define swapper_pg_dir init_top_pgtswapper_pg_dir指向内核最顶级的目录pgd,同时出现的还有几个页表目录。我们可以回忆一下,64位系统的虚拟地址空间的布局,其中XXX_ident_pgt对应的是直接映射区,XXX_kernel_pgt对应的是内核代码区,XXX_fixmap_pgt对应的是固定映射区。
它们是在哪里初始化的呢?在汇编语言的文件里面的arch\x86\kernel\head_64.S。这段代码比较难看懂,你只要明白它是干什么的就行了。
__INITDATA
NEXT_PAGE(init_top_pgt)
.quad level3_ident_pgt - __START_KERNEL_map + _KERNPG_TABLE
.org init_top_pgt + PGD_PAGE_OFFSET*8, 0
.quad level3_ident_pgt - __START_KERNEL_map + _KERNPG_TABLE
.org init_top_pgt + PGD_START_KERNEL*8, 0
/* (2^48-(2*1024*1024*1024))/(2^39) = 511 */
.quad level3_kernel_pgt - __START_KERNEL_map + _PAGE_TABLE
NEXT_PAGE(level3_ident_pgt)
.quad level2_ident_pgt - __START_KERNEL_map + _KERNPG_TABLE
.fill 511, 8, 0
NEXT_PAGE(level2_ident_pgt)
/* Since I easily can, map the first 1G.
* Don't set NX because code runs from these pages.
*/
PMDS(0, __PAGE_KERNEL_IDENT_LARGE_EXEC, PTRS_PER_PMD)
NEXT_PAGE(level3_kernel_pgt)
.fill L3_START_KERNEL,8,0
/* (2^48-(2*1024*1024*1024)-((2^39)*511))/(2^30) = 510 */
.quad level2_kernel_pgt - __START_KERNEL_map + _KERNPG_TABLE
.quad level2_fixmap_pgt - __START_KERNEL_map + _PAGE_TABLE
NEXT_PAGE(level2_kernel_pgt)
/*
* 512 MB kernel mapping. We spend a full page on this pagetable
* anyway.
*
* The kernel code+data+bss must not be bigger than that.
*
* (NOTE: at +512MB starts the module area, see MODULES_VADDR.
* If you want to increase this then increase MODULES_VADDR
* too.)
*/
PMDS(0, __PAGE_KERNEL_LARGE_EXEC,
KERNEL_IMAGE_SIZE/PMD_SIZE)
NEXT_PAGE(level2_fixmap_pgt)
.fill 506,8,0
.quad level1_fixmap_pgt - __START_KERNEL_map + _PAGE_TABLE
/* 8MB reserved for vsyscalls + a 2MB hole = 4 + 1 entries */
.fill 5,8,0
NEXT_PAGE(level1_fixmap_pgt)
.fill 51内核页表的顶级目录init_top_pgt,定义在__INITDATA里面。咱们讲过ELF的格式,也讲过虚拟内存空间的布局。它们都有代码段,还有一些初始化了的全局变量,放在.init区域。这些说的就是这个区域。可以看到,页表的根其实是全局变量,这就使得我们初始化的时候,甚至内存管理还没有初始化的时候,很容易就可以定位到。
接下来,定义init_top_pgt包含哪些项,这个汇编代码比较难懂了。你可以简单地认为,quad是声明了一项的内容,org是跳到了某个位置。
所以,init_top_pgt有三项,上来先有一项,指向的是level3_ident_pgt,也即直接映射区页表的三级目录。为什么要减去__START_KERNEL_map呢?因为level3_ident_pgt是定义在内核代码里的,写代码的时候,写的都是虚拟地址,谁写代码的时候也不知道将来加载的物理地址是多少呀,对不对?
因为level3_ident_pgt是在虚拟地址的内核代码段里的,而START_KERNEL_map正是虚拟地址空间的内核代码段的起始地址,这在讲64位虚拟地址空间的时候都讲过了,要是想不起来就赶紧去回顾一下。这样,level3_ident_pgt减去START_KERNEL_map才是物理地址。
第一项定义完了以后,接下来我们跳到PGD_PAGE_OFFSET的位置,再定义一项。从定义可以看出,这一项就应该是PAGE_OFFSET_BASE对应的。PAGE_OFFSET_BASE是虚拟地址空间里面内核的起始地址。第二项也指向level3_ident_pgt,直接映射区。
PGD_PAGE_OFFSET = pgd_index(__PAGE_OFFSET_BASE)
PGD_START_KERNEL = pgd_index(__START_KERNEL_map)
L3_START_KERNEL = pud_index(__START_KERNEL_map)第二项定义完了以后,接下来跳到PGD_START_KERNEL的位置,再定义一项。从定义可以看出,这一项应该是START_KERNEL_map对应的项,START_KERNEL_map是虚拟地址空间里面内核代码段的起始地址。第三项指向level3_kernel_pgt,内核代码区。
接下来的代码就很类似了,就是初始化个表项,然后指向下一级目录,最终形成下面这张图。
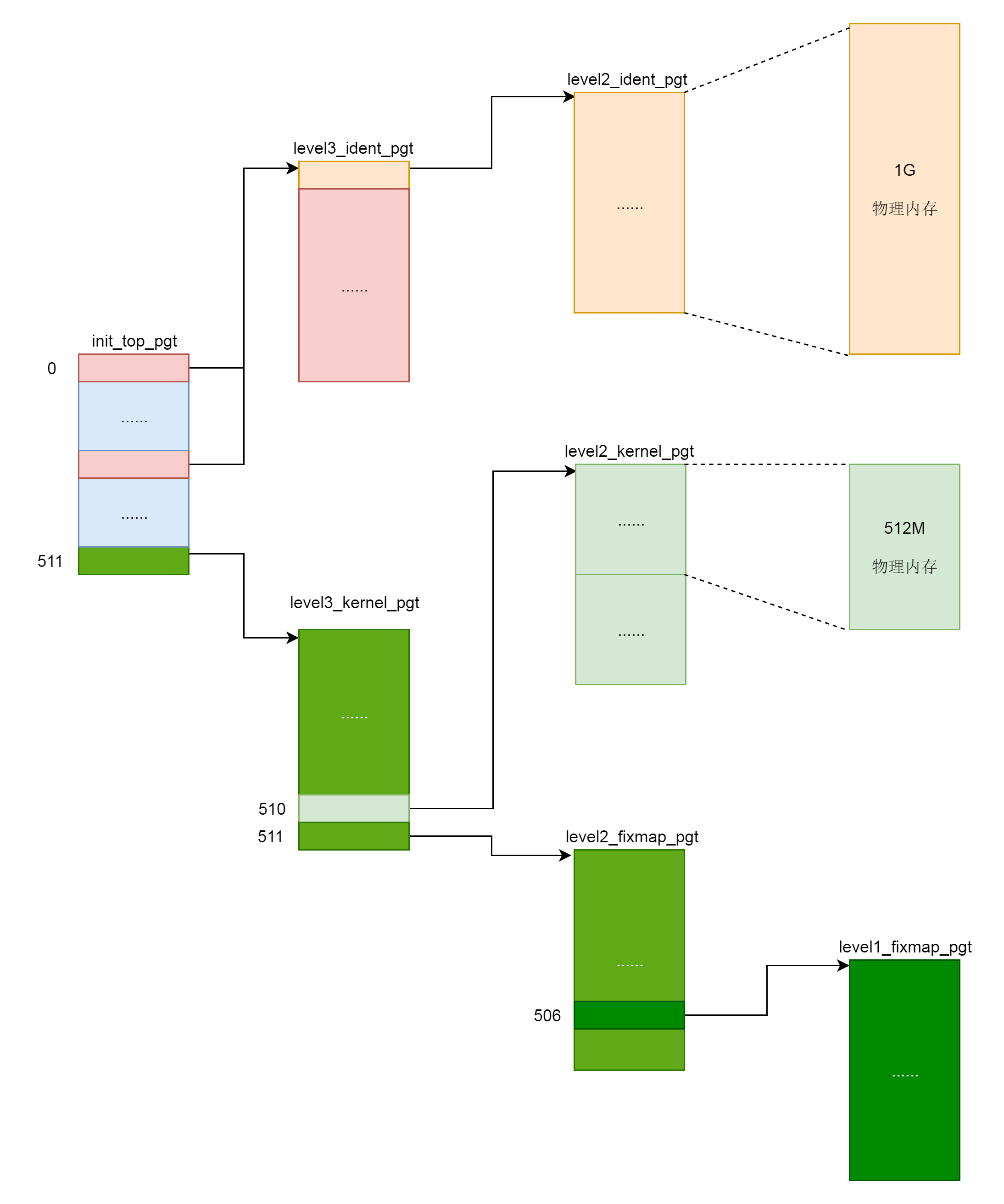
内核页表定义完了,一开始这里面的页表能够覆盖的内存范围比较小。例如,内核代码区512M,直接映射区1G。这个时候,其实只要能够映射基本的内核代码和数据结构就可以了。可以看出,里面还空着很多项,可以用于将来映射巨大的内核虚拟地址空间,等用到的时候再进行映射。
如果是用户态进程页表,会有mm_struct指向进程顶级目录pgd,对于内核来讲,也定义了一个mm_struct,指向swapper_pg_dir。
struct mm_struct init_mm = {
.mm_rb = RB_ROOT,
.pgd = swapper_pg_dir,
.mm_users = ATOMIC_INIT(2),
.mm_count = ATOMIC_INIT(1),
.mmap_sem = __RWSEM_INITIALIZER(init_mm.mmap_sem),
.page_table_lock = __SPIN_LOCK_UNLOCKED(init_mm.page_table_lock),
.mmlist = LIST_HEAD_INIT(init_mm.mmlist),
.user_ns = &init_user_ns,
INIT_MM_CONTEXT(init_mm)
};定义完了内核页表,接下来是初始化内核页表,在系统启动的时候start_kernel会调用setup_arch。
void __init setup_arch(char **cmdline_p)
{
/*
* copy kernel address range established so far and switch
* to the proper swapper page table
*/
clone_pgd_range(swapper_pg_dir + KERNEL_PGD_BOUNDARY,
initial_page_table + KERNEL_PGD_BOUNDARY,
KERNEL_PGD_PTRS);
load_cr3(swapper_pg_dir);
__flush_tlb_all();
......
init_mm.start_code = (unsigned long) _text;
init_mm.end_code = (unsigned long) _etext;
init_mm.end_data = (unsigned long) _edata;
init_mm.brk = _brk_end;
......
init_mem_mapping();
......
}在setup_arch中,load_cr3(swapper_pg_dir)说明内核页表要开始起作用了,并且刷新了TLB,初始化init_mm的成员变量,最重要的就是init_mem_mapping。最终它会调用kernel_physical_mapping_init。
/*
* Create page table mapping for the physical memory for specific physical
* addresses. The virtual and physical addresses have to be aligned on PMD level
* down. It returns the last physical address mapped.
*/
unsigned long __meminit
kernel_physical_mapping_init(unsigned long paddr_start,
unsigned long paddr_end,
unsigned long page_size_mask)
{
unsigned long vaddr, vaddr_start, vaddr_end, vaddr_next, paddr_last;
paddr_last = paddr_end;
vaddr = (unsigned long)__va(paddr_start);
vaddr_end = (unsigned long)__va(paddr_end);
vaddr_start = vaddr;
for (; vaddr < vaddr_end; vaddr = vaddr_next) {
pgd_t *pgd = pgd_offset_k(vaddr);
p4d_t *p4d;
vaddr_next = (vaddr & PGDIR_MASK) + PGDIR_SIZE;
if (pgd_val(*pgd)) {
p4d = (p4d_t *)pgd_page_vaddr(*pgd);
paddr_last = phys_p4d_init(p4d, __pa(vaddr),
__pa(vaddr_end),
page_size_mask);
continue;
}
p4d = alloc_low_page();
paddr_last = phys_p4d_init(p4d, __pa(vaddr), __pa(vaddr_end),
page_size_mask);
p4d_populate(&init_mm, p4d_offset(pgd, vaddr), (pud_t *) p4d);
}
__flush_tlb_all();
return paddr_l;
}在kernel_physical_mapping_init里,我们先通过__va将物理地址转换为虚拟地址,然后在创建虚拟地址和物理地址的映射页表。
你可能会问,怎么这么麻烦啊?既然对于内核来讲,我们可以用va和pa直接在虚拟地址和物理地址之间直接转来转去,为啥还要辛辛苦苦建立页表呢?因为这是CPU和内存的硬件的需求,也就是说,CPU在保护模式下访问虚拟地址的时候,就会用CR3这个寄存器,这个寄存器是CPU定义的,作为操作系统,我们是软件,只能按照硬件的要求来。
你可能又会问了,按照咱们将初始化的时候的过程,系统早早就进入了保护模式,到了setup_arch里面才load_cr3,如果使用cr3是硬件的要求,那之前是怎么办的呢?如果你仔细去看arch\x86\kernel\head_64.S,这里面除了初始化内核页表之外,在这之前,还有另一个页表early_top_pgt。看到关键字early了嘛?这个页表就是专门用在真正的内核页表初始化之前,为了遵循硬件的要求而设置的。早期页表不是我们这节的重点,这里我就不展开多说了。
21.2 vmalloc和kmap_atomic原理
在用户态可以通过malloc函数分配内存,当然malloc在分配比较大的内存的时候,底层调用的是mmap,当然也可以直接通过mmap做内存映射,在内核里面也有相应的函数。
在虚拟地址空间里面,有个vmalloc区域,从VMALLOC_START开始到VMALLOC_END,可以用于映射一段物理内存。
/**
* vmalloc - allocate virtually contiguous memory
* @size: allocation size
* Allocate enough pages to cover @size from the page level
* allocator and map them into contiguous kernel virtual space.
*
* For tight control over page level allocator and protection flags
* use __vmalloc() instead.
*/
void *vmalloc(unsigned long size)
{
return __vmalloc_node_flags(size, NUMA_NO_NODE,
GFP_KERNEL);
}
static void *__vmalloc_node(unsigned long size, unsigned long align,
gfp_t gfp_mask, pgprot_t prot,
int node, const void *caller)
{
return __vmalloc_node_range(size, align, VMALLOC_START, VMALLOC_END,
gfp_mask, prot, 0, node, caller);
}我们再来看内核的临时映射函数kmap_atomic的实现。从下面的代码我们可以看出,如果是32位有高端地址的,就需要调用set_pte通过内核页表进行临时映射;如果是64位没有高端地址的,就调用page_address,里面会调用lowmem_page_address。其实低端内存的映射,会直接使用__va进行临时映射。
void *kmap_atomic_prot(struct page *page, pgprot_t prot)
{
......
if (!PageHighMem(page))
return page_address(page);
......
vaddr = __fix_to_virt(FIX_KMAP_BEGIN + idx);
set_pte(kmap_pte-idx, mk_pte(page, prot));
......
return (void *)vaddr;
}
void *kmap_atomic(struct page *page)
{
return kmap_atomic_prot(page, kmap_prot);
}
static __always_inline void *lowmem_page_address(const struct page *page)
{
return page_to_virt(page);
}
#define page_to_virt(x) __va(PFN_PHYS(page_to_pfn(x)21.3 内核态缺页异常
可以看出,kmap_atomic和vmalloc不同。kmap_atomic发现,没有页表的时候,就直接创建页表进行映射了。而vmalloc没有,它只分配了内核的虚拟地址。所以,访问它的时候,会产生缺页异常。
内核态的缺页异常还是会调用do_page_fault,但是会走到咱们上面用户态缺页异常中没有解析的那部分vmalloc_fault。这个函数并不复杂,主要用于关联内核页表项。
/*
* 32-bit:
*
* Handle a fault on the vmalloc or module mapping area
*/
static noinline int vmalloc_fault(unsigned long address)
{
unsigned long pgd_paddr;
pmd_t *pmd_k;
pte_t *pte_k;
/* Make sure we are in vmalloc area: */
if (!(address >= VMALLOC_START && address < VMALLOC_END))
return -1;
/*
* Synchronize this task's top level page-table
* with the 'reference' page table.
*
* Do _not_ use "current" here. We might be inside
* an interrupt in the middle of a task switch..
*/
pgd_paddr = read_cr3_pa();
pmd_k = vmalloc_sync_one(__va(pgd_paddr), address);
if (!pmd_k)
return -1;
pte_k = pte_offset_kernel(pmd_k, address);
if (!pte_present(*pte_k))
return -1;
return 0
}21.4 总结
物理内存根据NUMA架构分节点。每个节点里面再分区域。每个区域里面再分页。
物理页面通过伙伴系统进行分配。分配的物理页面要变成虚拟地址让上层可以访问,kswapd可以根据物理页面的使用情况对页面进行换入换出。
对于内存的分配需求,可能来自内核态,也可能来自用户态。
对于内核态,kmalloc在分配大内存的时候,以及vmalloc分配不连续物理页的时候,直接使用伙伴系统,分配后转换为虚拟地址,访问的时候需要通过内核页表进行映射。
对于kmem_cache以及kmalloc分配小内存,则使用slub分配器,将伙伴系统分配出来的大块内存切成一小块一小块进行分配。
kmem_cache和kmalloc的部分不会被换出,因为用这两个函数分配的内存多用于保持内核关键的数据结构。内核态中vmalloc分配的部分会被换出,因而当访问的时候,发现不在,就会调用do_page_fault。
对于用户态的内存分配,或者直接调用mmap系统调用分配,或者调用malloc。调用malloc的时候,如果分配小的内存,就用sys_brk系统调用;如果分配大的内存,还是用sys_mmap系统调用。正常情况下,用户态的内存都是可以换出的,因而一旦发现内存中不存在,就会调用do_page_fault。
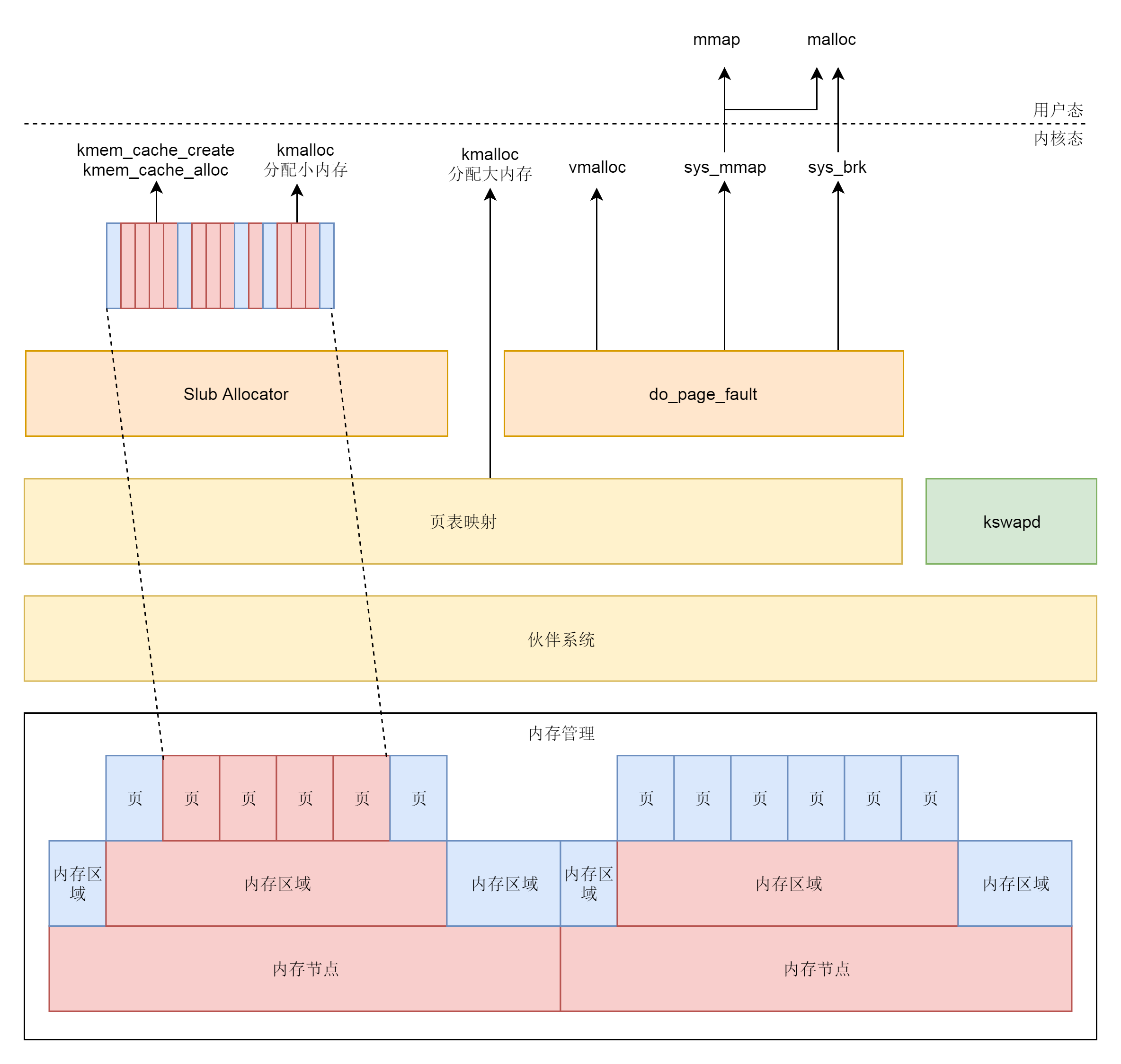
四、文件系统
22. 文件系统
22.1 文件系统的功能规划
在规划文件系统的时候,需要考虑到以下几点。
- 第一点,文件系统要有严格的组织形式,使得文件能够以块为单位进行存储。
- 第二点,文件系统中也要有索引区,用来方便查找一个文件分成的多个块都存放在了什么位置。
- 第三点,如果文件系统中有的文件是热点文件,近期经常被读取和写入,文件系统应该有缓存层。
- 第四点,文件应该用文件夹的形式组织起来,方便管理和查询。
- 第五点,Linux内核要在自己的内存里面维护一套数据结构,来保存哪些文件被哪些进程打开和使用。
22.2 文件系统相关命令行
22.3 文件系统相关系统调用
int stat(const char *pathname, struct stat *statbuf);
int fstat(int fd, struct stat *statbuf);
int lstat(const char *pathname, struct stat *statbuf);
struct stat {
dev_t st_dev; /* ID of device containing file */
ino_t st_ino; /* Inode number */
mode_t st_mode; /* File type and mode */
nlink_t st_nlink; /* Number of hard links */
uid_t st_uid; /* User ID of owner */
gid_t st_gid; /* Group ID of owner */
dev_t st_rdev; /* Device ID (if special file) */
off_t st_size; /* Total size, in bytes */
blksize_t st_blksize; /* Block size for filesystem I/O */
blkcnt_t st_blocks; /* Number of 512B blocks allocated */
struct timespec st_atim; /* Time of last access */
struct timespec st_mtim; /* Time of last modification */
struct timespec st_ctim; /* Time of last status change */
};函数stat和lstat返回的是通过文件名查到的状态信息。这两个方法区别在于,stat没有处理符号链接(软链接)的能力。如果一个文件是符号链接,stat会直接返回它所指向的文件的属性,而lstat返回的就是这个符号链接的内容,fstat则是通过文件描述符获取文件对应的属性。
23. 硬盘文件系统
这一节我们重点目前Linux下最主流的文件系统格式—— ext系列 的文件系统的格式。
23.1 inode与块的存储
硬盘分成相同大小的单元,我们称为 块(Block) 。一块的大小是扇区大小的整数倍,默认是4K。在格式化的时候,这个值是可以设定的。
一大块硬盘被分成了一个个小的块,用来存放文件的数据部分。这样一来,如果我们像存放一个文件,就不用给他分配一块连续的空间了。我们可以分散成一个个小块进行存放。这样就灵活得多,也比较容易添加、删除和插入数据。
但是这也带来一个新的问题,那就是文件的数据存放得太散,找起来就比较困难。有什么办法解决呢?我们是不是可以像图书馆那样,也设立一个索引区域,用来维护”某个文件分成几块、每一块在哪里”等等这些 基本信息 ?
另外,文件还有 元数据 部分,例如名字、权限等,这就需要一个结构inode来存放。
什么是inode呢?inode的”i”是index的意思,其实就是”索引”。既然如此,我们每个文件都会对应一个inode;一个文件夹就是一个文件,也对应一个inode。
至于inode里面有哪些信息,其实我们在内核中就有定义。你可以看下面这个数据结构。
struct ext4_inode {
__le16 i_mode; /* File mode */
__le16 i_uid; /* Low 16 bits of Owner Uid */
__le32 i_size_lo; /* Size in bytes */
__le32 i_atime; /* Access time */
__le32 i_ctime; /* Inode Change time */
__le32 i_mtime; /* Modification time */
__le32 i_dtime; /* Deletion Time */
__le16 i_gid; /* Low 16 bits of Group Id */
__le16 i_links_count; /* Links count */
__le32 i_blocks_lo; /* Blocks count */
__le32 i_flags; /* File flags */
......
__le32 i_block[EXT4_N_BLOCKS];/* Pointers to blocks */
__le32 i_generation; /* File version (for NFS) */
__le32 i_file_acl_lo; /* File ACL */
__le32 i_size_high;
......
};从这个数据结构中,我们可以看出,inode里面有文件的读写权限i_mode,属于哪个用户i_uid,哪个组i_gid,大小是多少i_size_io,占用多少个块i_blocks_io。咱们讲ls命令行的时候,列出来的权限、用户、大小这些信息,就是从这里面取出来的。
另外,这里面还有几个与文件相关的时间。i_atime是access time,是最近一次访问文件的时间;i_ctime是change time,是最近一次更改inode的时间;i_mtime是modify time,是最近一次更改文件的时间。
这里你需要注意区分几个地方。首先,访问了,不代表修改了,也可能只是打开看看,就会改变access time。其次,修改inode,有可能修改的是用户和权限,没有修改数据部分,就会改变change time。只有数据也修改了,才改变modify time。
我们刚才说的”某个文件分成几块、每一块在哪里”,这些在inode里面,应该保存在i_block里面。
具体如何保存的呢?EXT4_N_BLOCKS有如下的定义,计算下来一共有15项。
#define EXT4_NDIR_BLOCKS 12
#define EXT4_IND_BLOCK EXT4_NDIR_BLOCKS
#define EXT4_DIND_BLOCK (EXT4_IND_BLOCK + 1)
#define EXT4_TIND_BLOCK (EXT4_DIND_BLOCK + 1)
#define EXT4_N_BLOCKS (EXT4_TIND_BLOCK + 1)在ext2和ext3中,其中前12项直接保存了块的位置,也就是说,我们可以通过i_block[0-11],直接得到保存文件内容的块。
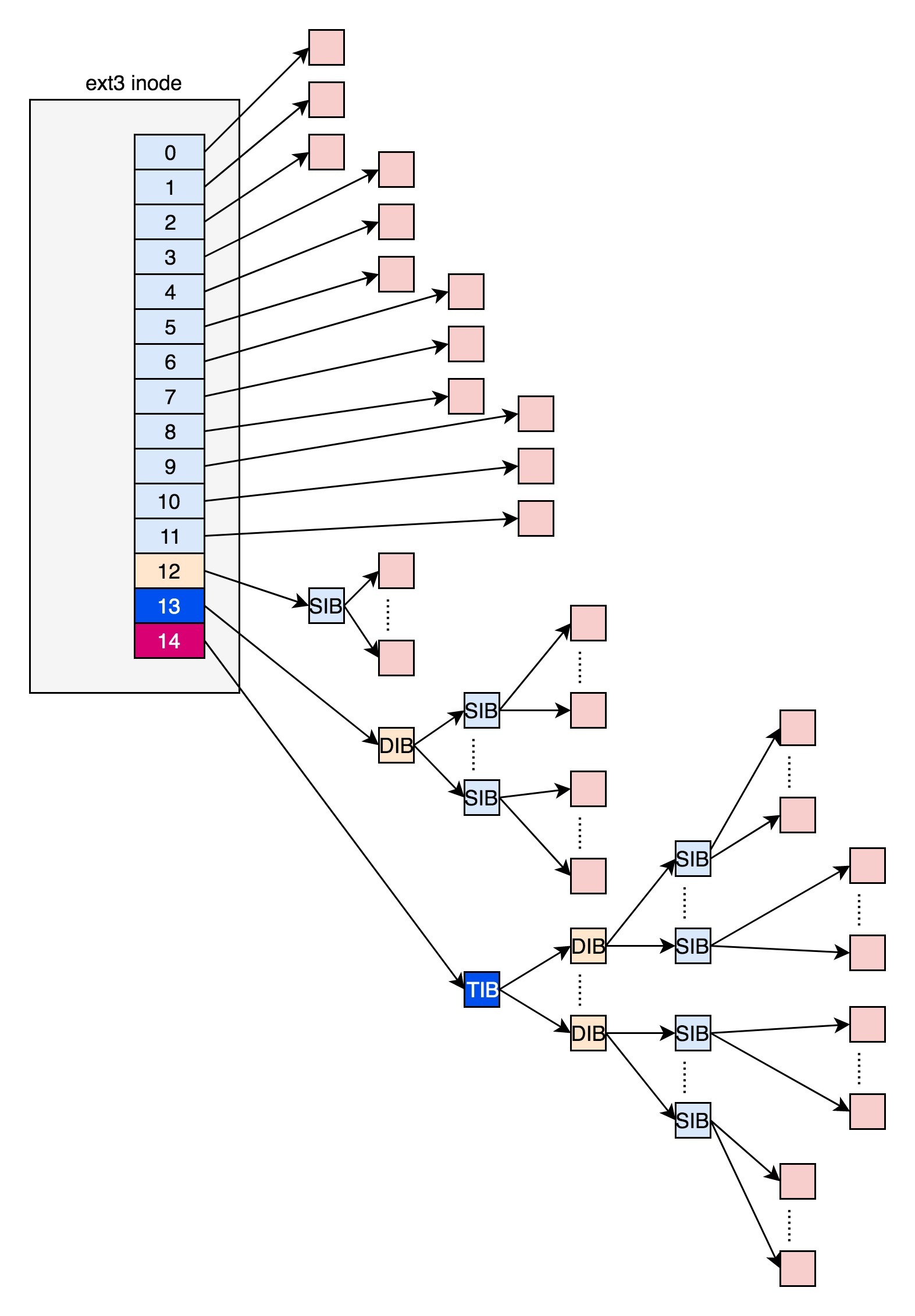
但是,如果一个文件比较大,12块放不下。当我们用到i_block[12]的时候,就不能直接放数据块的位置了,要不然i_block很快就会用完了。这该怎么办呢?我们需要想个办法。我们可以让i_block[12]指向一个块,这个块里面不放数据块,而是放数据块的位置,这个块我们称为间接块。也就是说,我们在i_block[12]里面放间接块的位置,通过i_block[12]找到间接块后,间接块里面放数据块的位置,通过间接块可以找到数据块。
如果文件再大一些,i_block[13]会指向一个块,我们可以用二次间接块。二次间接块里面存放了间接块的位置,间接块里面存放了数据块的位置,数据块里面存放的是真正的数据。如果文件再大一些,i_block[14]会指向三次间接块。原理和上面都是一样的,就像一层套一层的俄罗斯套娃,一层一层打开,才能拿到最中心的数据块。
如果你稍微有点经验,现在你应该能够意识到,这里面有一个非常显著的问题,对于大文件来讲,我们要多次读取硬盘才能找到相应的块,这样访问速度就会比较慢。
为了解决这个问题,ext4做了一定的改变。它引入了一个新的概念,叫作Extents。
我们来解释一下Extents。比方说,一个文件大小为128M,如果使用4k大小的块进行存储,需要32k个块。如果按照ext2或者ext3那样散着放,数量太大了。但是Extents可以用于存放连续的块,也就是说,我们可以把128M放在一个Extents里面。这样的话,对大文件的读写性能提高了,文件碎片也减少了。
Exents如何来存储呢?它其实会保存成一棵树。
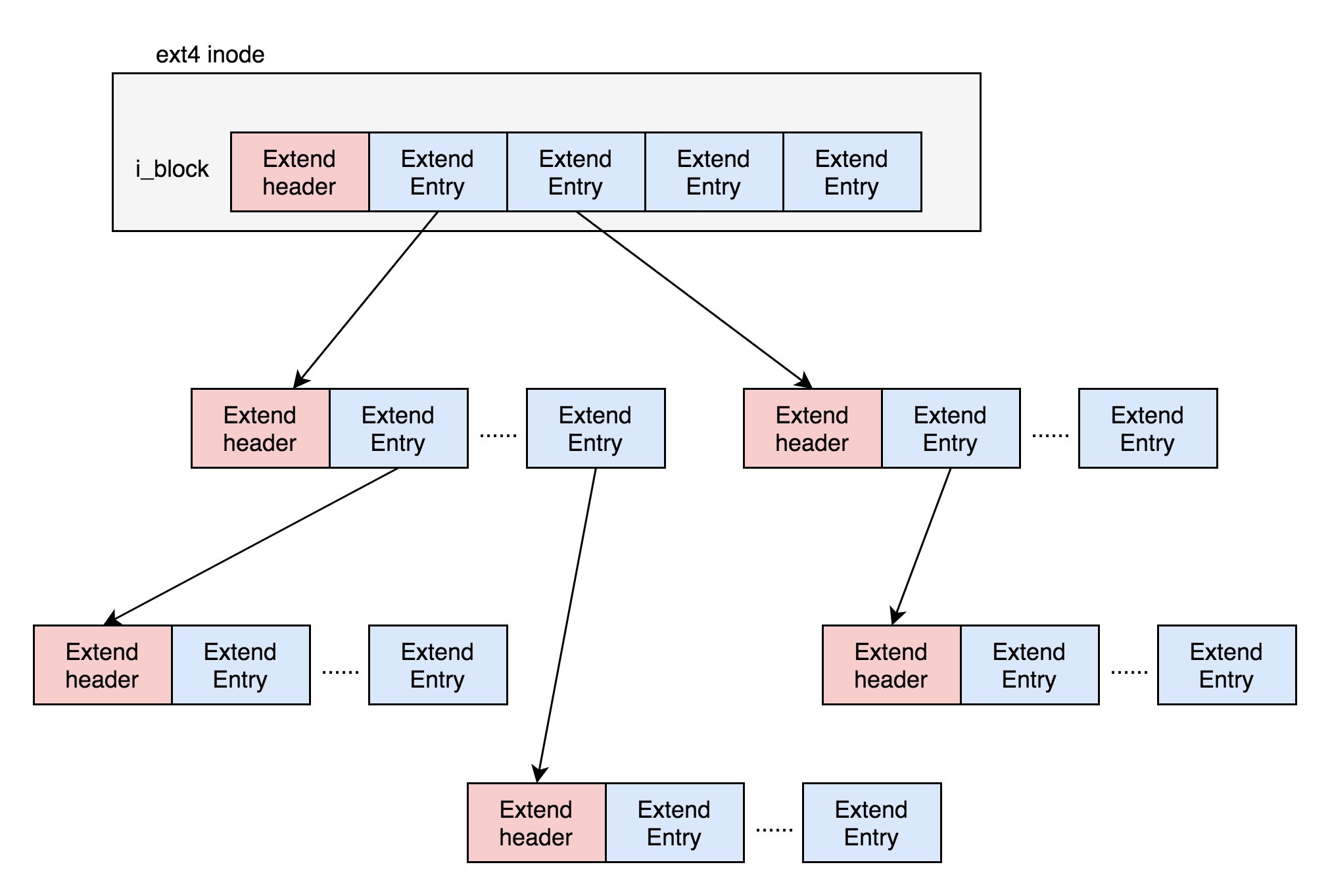
树有一个个的节点,有叶子节点,也有分支节点。每个节点都有一个头,ext4_extent_header可以用来描述某个节点。
struct ext4_extent_header {
__le16 eh_magic; /* probably will support different formats */
__le16 eh_entries; /* number of valid entries */
__le16 eh_max; /* capacity of store in entries */
__le16 eh_depth; /* has tree real underlying blocks? */
__le32 eh_generation; /* generation of the tree */
};eh_entries表示这个节点里面有多少项。这里的项分两种,如果是叶子节点,这一项会直接指向硬盘上的连续块的地址,我们称为数据节点ext4_extent;如果是分支节点,这一项会指向下一层的分支节点或者叶子节点,我们称为索引节点ext4_extent_idx。这两种类型的项的大小都是12个byte。
/*
* This is the extent on-disk structure.
* It's used at the bottom of the tree.
*/
struct ext4_extent {
__le32 ee_block; /* first logical block extent covers */
__le16 ee_len; /* number of blocks covered by extent */
__le16 ee_start_hi; /* high 16 bits of physical block */
__le32 ee_start_lo; /* low 32 bits of physical block */
};
/*
* This is index on-disk structure.
* It's used at all the levels except the bottom.
*/
struct ext4_extent_idx {
__le32 ei_block; /* index covers logical blocks from 'block' */
__le32 ei_leaf_lo; /* pointer to the physical block of the next *
* level. leaf or next index could be there */
__le16 ei_leaf_hi; /* high 16 bits of physical block */
__u16 ei_unused;
};如果文件不大,inode里面的i_block中,可以放得下一个ext4_extent_header和4项ext4_extent。所以这个时候,eh_depth为0,也即inode里面的就是叶子节点,树高度为0。
如果文件比较大,4个extent放不下,就要分裂成为一棵树,eh_depth>0的节点就是索引节点,其中根节点深度最大,在inode中。最底层eh_depth=0的是叶子节点。
除了根节点,其他的节点都保存在一个块4k里面,4k扣除ext4_extent_header的12个byte,剩下的能够放340项,每个extent最大能表示128MB的数据,340个extent会使你的表示的文件达到42.5GB。这已经非常大了,如果再大,我们可以增加树的深度。
23.2 inode位图和块位图
到这里,我们知道了,硬盘上肯定有一系列的inode和一系列的块排列起来。
在文件系统里面,我们专门弄了一个块来保存inode的位图。在这4k里面,每一位对应一个inode。如果是1,表示这个inode已经被用了;如果是0,则表示没被用。同样,我们也弄了一个块保存block的位图。
接下来,我们来看位图究竟是如何在Linux操作系统里面起作用的。前一节我们讲过,如果创建一个新文件,会调用open函数,并且参数会有O_CREAT。这表示当文件找不到的时候,我们就需要创建一个。open是一个系统调用,在内核里面会调用sys_open,定义如下:
SYSCALL_DEFINE3(open, const char __user *, filename, int, flags, umode_t, mode)
{
if (force_o_largefile())
flags |= O_LARGEFILE;
return do_sys_open(AT_FDCWD, filename, flags, mode);
}这里我们还是重点看对于inode的操作。其实open一个文件很复杂,下一节我们会详细分析整个过程。
我们来看接下来的调用链:do_sys_open-> do_filp_open->path_openat->do_last->lookup_open。这个调用链的逻辑是,要打开一个文件,先要根据路径找到文件夹。如果发现文件夹下面没有这个文件,同时又设置了O_CREAT,就说明我们要在这个文件夹下面创建一个文件,那我们就需要一个新的inode。
static int lookup_open(struct nameidata *nd, struct path *path,
struct file *file,
const struct open_flags *op,
bool got_write, int *opened)
{
......
if (!dentry->d_inode && (open_flag & O_CREAT)) {
......
error = dir_inode->i_op->create(dir_inode, dentry, mode,
open_flag & O_EXCL);
......
}
......
}想要创建新的inode,我们就要调用dir_inode,也就是文件夹的inode的create函数。它的具体定义是这样的:
const struct inode_operations ext4_dir_inode_operations = {
.create = ext4_create,
.lookup = ext4_lookup,
.link = ext4_link,
.unlink = ext4_unlink,
.symlink = ext4_symlink,
.mkdir = ext4_mkdir,
.rmdir = ext4_rmdir,
.mknod = ext4_mknod,
.tmpfile = ext4_tmpfile,
.rename = ext4_rename2,
.setattr = ext4_setattr,
.getattr = ext4_getattr,
.listxattr = ext4_listxattr,
.get_acl = ext4_get_acl,
.set_acl = ext4_set_acl,
.fiemap = ext4_fiemap,
};这里面定义了,如果文件夹inode要做一些操作,每个操作对应应该调用哪些函数。这里create操作调用的是ext4_create。
接下来的调用链是这样的:ext4_create->ext4_new_inode_start_handle->ext4_new_inode。在ext4_new_inode函数中,我们会创建新的inode。
struct inode *__ext4_new_inode(handle_t *handle, struct inode *dir,
umode_t mode, const struct qstr *qstr,
__u32 goal, uid_t *owner, __u32 i_flags,
int handle_type, unsigned int line_no,
int nblocks)
{
......
inode_bitmap_bh = ext4_read_inode_bitmap(sb, group);
......
ino = ext4_find_next_zero_bit((unsigned long *)
inode_bitmap_bh->b_data,
EXT4_INODES_PER_GROUP(sb), ino);
......
}这里面一个重要的逻辑就是,从文件系统里面读取inode位图,然后找到下一个为0的inode,就是空闲的inode。
对于block位图,在写入文件的时候,也会有这个过程,我就不展开说了。感兴趣的话,你可以自己去找代码看。
23.3 文件系统的格式
看起来,我们现在应该能够很顺利地通过inode位图和block位图创建文件了。如果仔细计算一下,其实还是有问题的。
数据块的位图是放在一个块里面的,共4k。每位表示一个数据块,共可以表示 4 * 1024 * 8 = 2^{15} 个数据块。如果每个数据块也是按默认的4K,最大可以表示空间为 2^{15} * 4 * 1024 = 2^{27} 个byte,也就是128M。
也就是说按照上面的格式,如果采用”一个块的位图+一系列的块“,外加”一个块的inode的位图+一系列的inode的结构“,最多能够表示128M。是不是太小了?现在很多文件都比这个大。我们先把这个结构称为一个块组。有N多的块组,就能够表示N大的文件。
对于块组,我们也需要一个数据结构来表示为ext4_group_desc。这里面对于一个块组里的inode位图bg_inode_bitmap_lo、块位图bg_block_bitmap_lo、inode列表bg_inode_table_lo,都有相应的成员变量。
这样一个个块组,就基本构成了我们整个文件系统的结构。因为块组有多个,块组描述符也同样组成一个列表,我们把这些称为块组描述符表。
当然,我们还需要有一个数据结构,对整个文件系统的情况进行描述,这个就是超级块。ext4_super_block。这里面有整个文件系统一共有多少inode,s_inodes_count;一共有多少块,s_blocks_count_lo,每个块组有多少inode,s_inodes_per_group,每个块组有多少块,s_blocks_per_group等。这些都是这类的全局信息。
对于整个文件系统,别忘了咱们讲系统启动的时候说的。如果是一个启动盘,我们需要预留一块区域作为引导区,所以第一个块组的前面要留1K,用于启动引导区。
最终,整个文件系统格式就是下面这个样子。
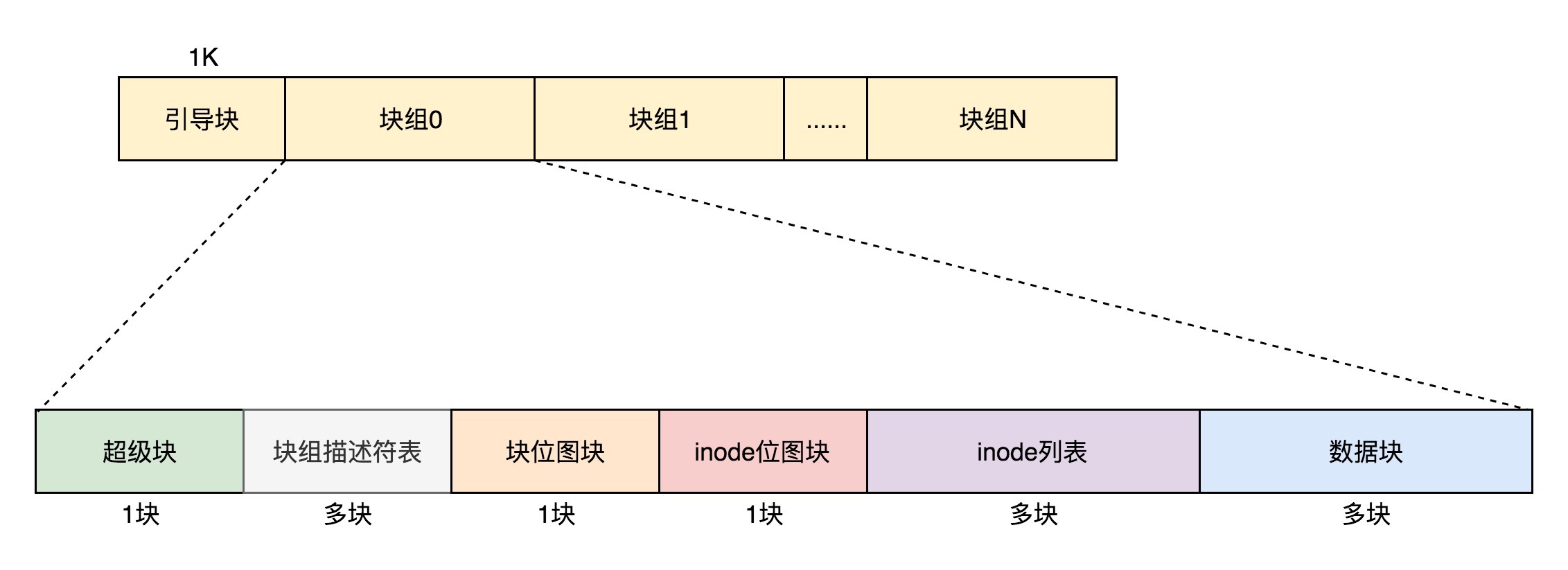
超级块和块组描述符表都是全局信息,而且这些数据很重要。如果这些数据丢失了,整个文件系统都打不开了,这比一个文件的一个块损坏更严重。所以,这两部分我们都需要备份,但是采取不同的策略。
默认情况下,超级块和块组描述符表都有副本保存在每一个块组里面。
如果开启了sparse_super特性,超级块和块组描述符表的副本只会保存在块组索引为0、3、5、7的整数幂里。除了块组0中存在一个超级块外,在块组1($3^0=1$)的第一个块中存在一个副本;在块组3(3^1=3)、块组5(5^1=5)、块组7(7^1=7)、块组9(3^2=9)、块组25(5^2=25)、块组27(3^3=27)的第一个block处也存在一个副本。
对于超级块来讲,由于超级块不是很大,所以就算我们备份多了也没有太多问题。但是,对于块组描述符表来讲,如果每个块组里面都保存一份完整的块组描述符表,一方面很浪费空间;另一个方面,由于一个块组最大128M,而块组描述符表里面有多少项,这就限制了有多少个块组,128M * 块组的总数目是整个文件系统的大小,就被限制住了。
我们的改进的思路就是引入Meta Block Groups特性。
首先,块组描述符表不会保存所有块组的描述符了,而是将块组分成多个组,我们称为元块组(Meta Block Group)。每个元块组里面的块组描述符表仅仅包括自己的,一个元块组包含64个块组,这样一个元块组中的块组描述符表最多64项。我们假设一共有256个块组,原来是一个整的块组描述符表,里面有256项,要备份就全备份,现在分成4个元块组,每个元块组里面的块组描述符表就只有64项了,这就小多了,而且四个元块组自己备份自己的。
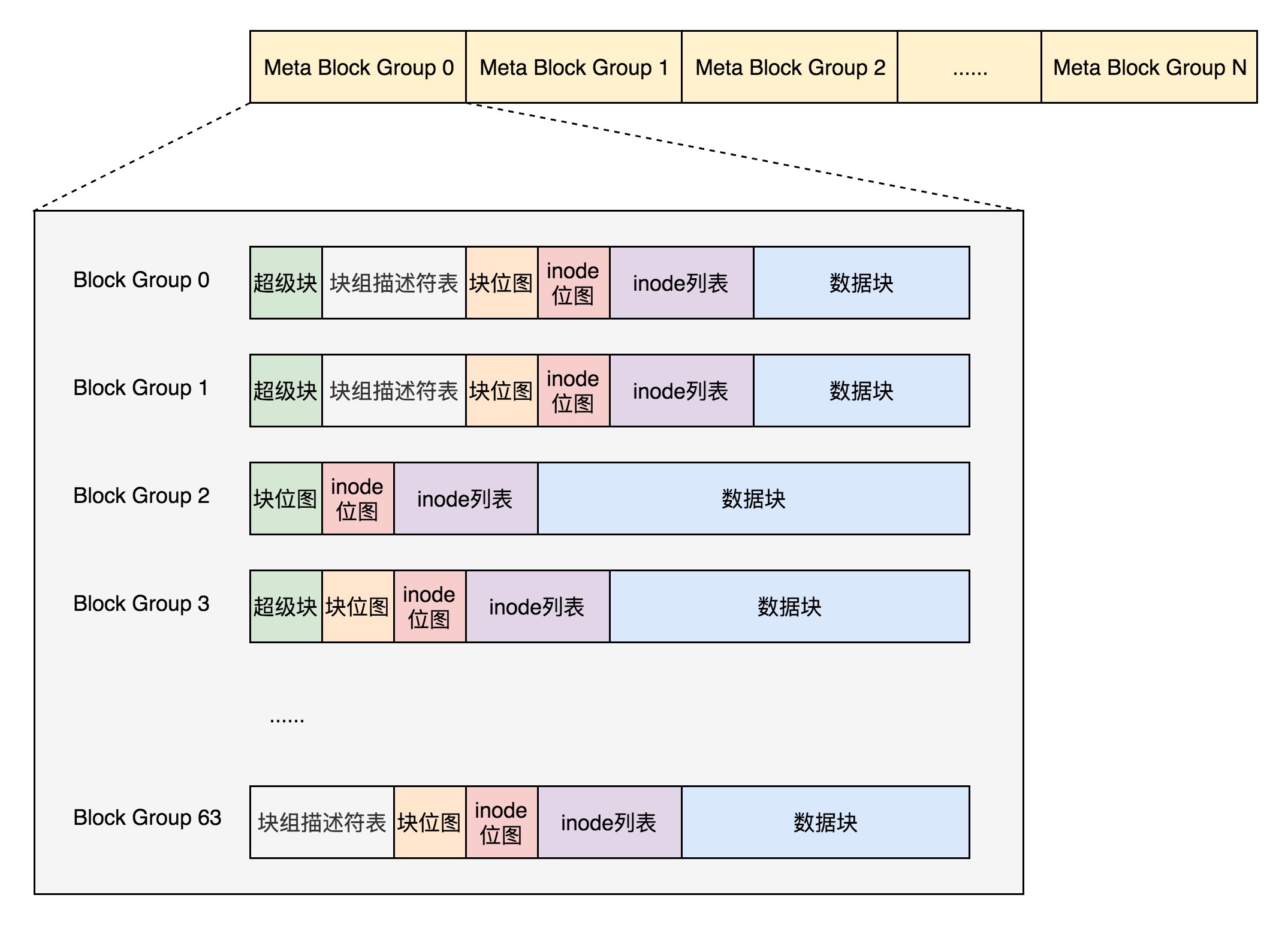
根据图中,每一个元块组包含64个块组,块组描述符表也是64项,备份三份,在元块组的第一个,第二个和最后一个块组的开始处。
这样化整为零,我们就可以发挥出ext4的48位块寻址的优势了,在超级块ext4_super_block的定义中,我们可以看到块寻址的分为高位和地位,均为32位,其中有用的是48位,2^48个块是1EB,足够用了。
struct ext4_super_block {
......
__le32 s_blocks_count_lo; /* Blocks count */
__le32 s_r_blocks_count_lo; /* Reserved blocks count */
__le32 s_free_blocks_count_lo; /* Free blocks count */
......
__le32 s_blocks_count_hi; /* Blocks count */
__le32 s_r_blocks_count_hi; /* Reserved blocks count */
__le32 s_free_blocks_count_hi; /* Free blocks count */
......
}23.4 目录的存储格式
其实目录本身也是个文件,也有inode。inode里面也是指向一些块。和普通文件不同的是,普通文件的块里面保存的是文件数据,而目录文件的块里面保存的是目录里面一项一项的文件信息。这些信息我们称为ext4_dir_entry。从代码来看,有两个版本,在成员来讲几乎没有差别,只不过第二个版本ext4_dir_entry_2是将一个16位的name_len,变成了一个8位的name_len和8位的file_type。
struct ext4_dir_entry {
__le32 inode; /* Inode number */
__le16 rec_len; /* Directory entry length */
__le16 name_len; /* Name length */
char name[EXT4_NAME_LEN]; /* File name */
};
struct ext4_dir_entry_2 {
__le32 inode; /* Inode number */
__le16 rec_len; /* Directory entry length */
__u8 name_len; /* Name length */
__u8 file_type;
char name[EXT4_NAME_LEN]; /* File name */
};在目录文件的块中,最简单的保存格式是列表,就是一项一项地将ext4_dir_entry_2列在哪里。
每一项都会保存这个目录的下一级的文件的文件名和对应的inode,通过这个inode,就能找到真正的文件。第一项是”.”,表示当前目录,第二项是”…”,表示上一级目录,接下来就是一项一项的文件名和inode。
有时候,如果一个目录下面的文件太多的时候,我们想在这个目录下找一个文件,按照列表一个个去找,太慢了,于是我们就添加了索引的模式。
如果在inode中设置EXT4_INDEX_FL标志,则目录文件的块的组织形式将发生变化,变成了下面定义的这个样子:
struct dx_root
{
struct fake_dirent dot;
char dot_name[4];
struct fake_dirent dotdot;
char dotdot_name[4];
struct dx_root_info
{
__le32 reserved_zero;
u8 hash_version;
u8 info_length; /* 8 */
u8 indirect_levels;
u8 unused_flags;
}
info;
struct dx_entry entries[0];
};当然,首先出现的还是差不多的,第一项是”.”,表示当前目录;第二项是”…”,表示上一级目录,这两个不变。接下来就开始发生改变了。是一个dx_root_info的结构,其中最重要的成员变量是indirect_levels,表示间接索引的层数。
接下来我们来看索引项dx_entry。这个也很简单,其实就是文件名的哈希值和数据块的一个映射关系。
struct dx_entry
{
__le32 hash;
__le32 block;
};如果我们要查找一个目录下面的文件名,可以通过名称取哈希。如果哈希能够匹配上,就说明这个文件的信息在相应的块里面。然后打开这个块,如果里面不再是索引,而是索引树的叶子节点的话,那里面还是ext4_dir_entry_2的列表,我们只要一项一项找文件名就行。通过索引树,我们可以将一个目录下面的N多的文件分散到很多的块里面,可以很快地进行查找。
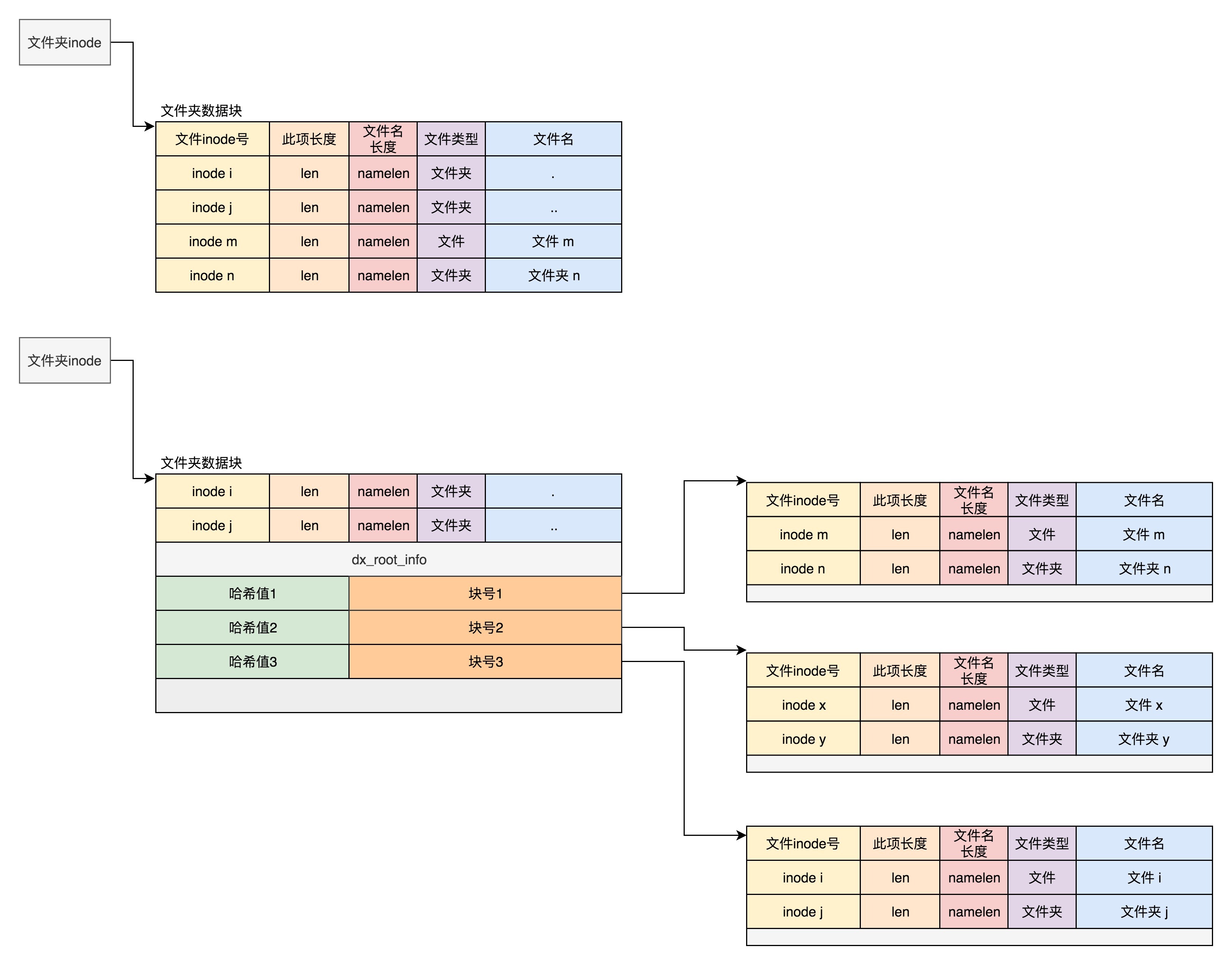
23.5 软链接和硬链接的存储格式
还有一种特殊的文件格式,硬链接(Hard Link)和软链接(Symbolic Link)。在讲操作文件的命令的时候,我们讲过软链接的概念。所谓的链接(Link),我们可以认为是文件的别名,而链接又可分为两种,硬链接与软链接。通过下面的命令可以创建。
ln [参数][源文件或目录][目标文件或目录]ln -s创建的是软链接,不带-s创建的是硬链接。它们有什么区别呢?在文件系统里面是怎么保存的呢?
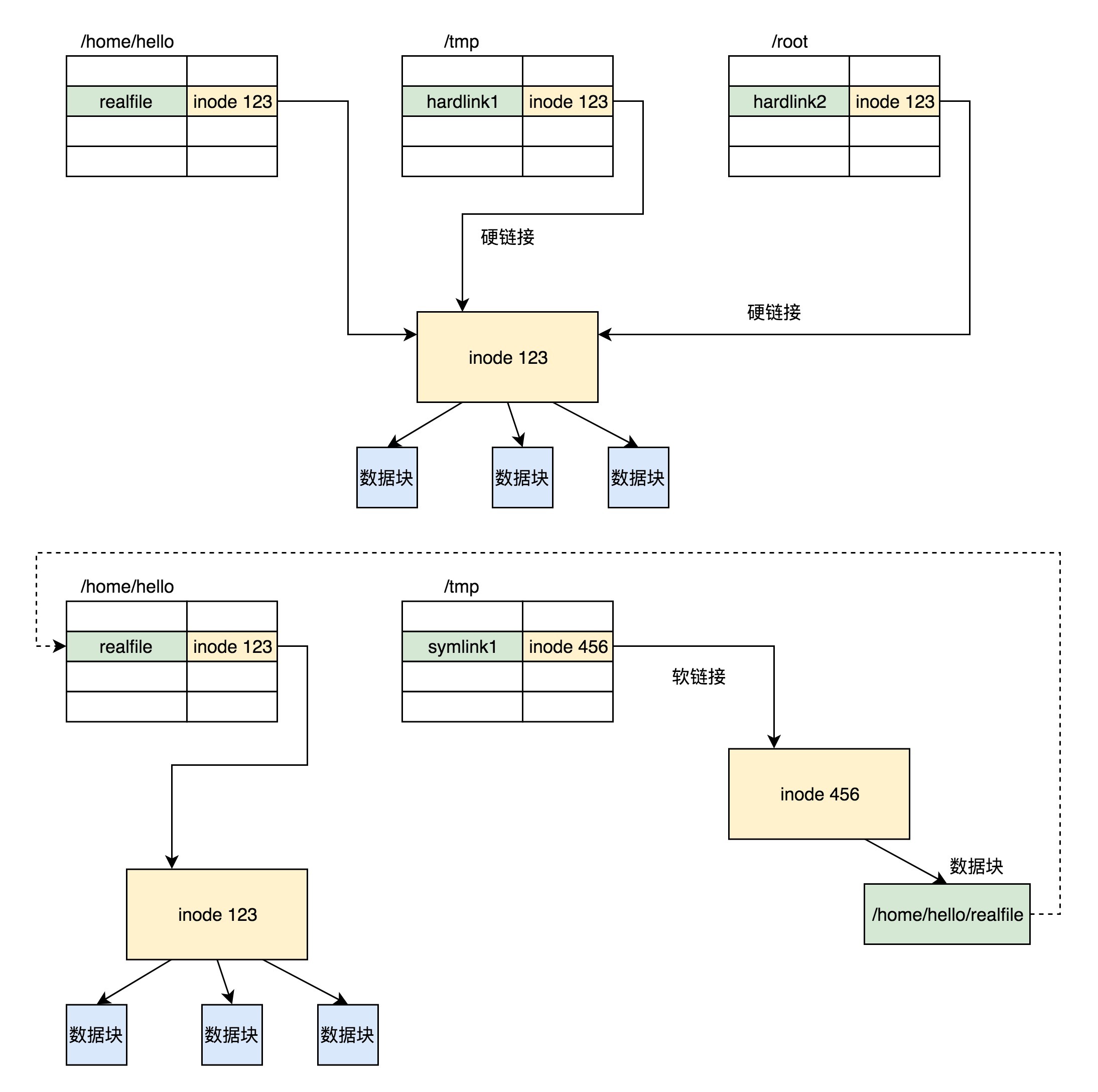
如图所示,硬链接与原始文件共用一个inode的,但是inode是不跨文件系统的,每个文件系统都有自己的inode列表,因而硬链接是没有办法跨文件系统的。
而软链接不同,软链接相当于重新创建了一个文件。这个文件也有独立的inode,只不过打开这个文件看里面内容的时候,内容指向另外的一个文件。这就很灵活了。我们可以跨文件系统,甚至目标文件被删除了,链接文件还是在的,只不过指向的文件找不到了而已。
23.6 总结
为了表示图中上半部分的那个简单的树形结构,在文件系统上的布局就像图的下半部分一样。无论是文件夹还是文件,都有一个inode。inode里面会指向数据块,对于文件夹的数据块,里面是一个表,是下一层的文件名和inode的对应关系,文件的数据块里面存放的才是真正的数据。
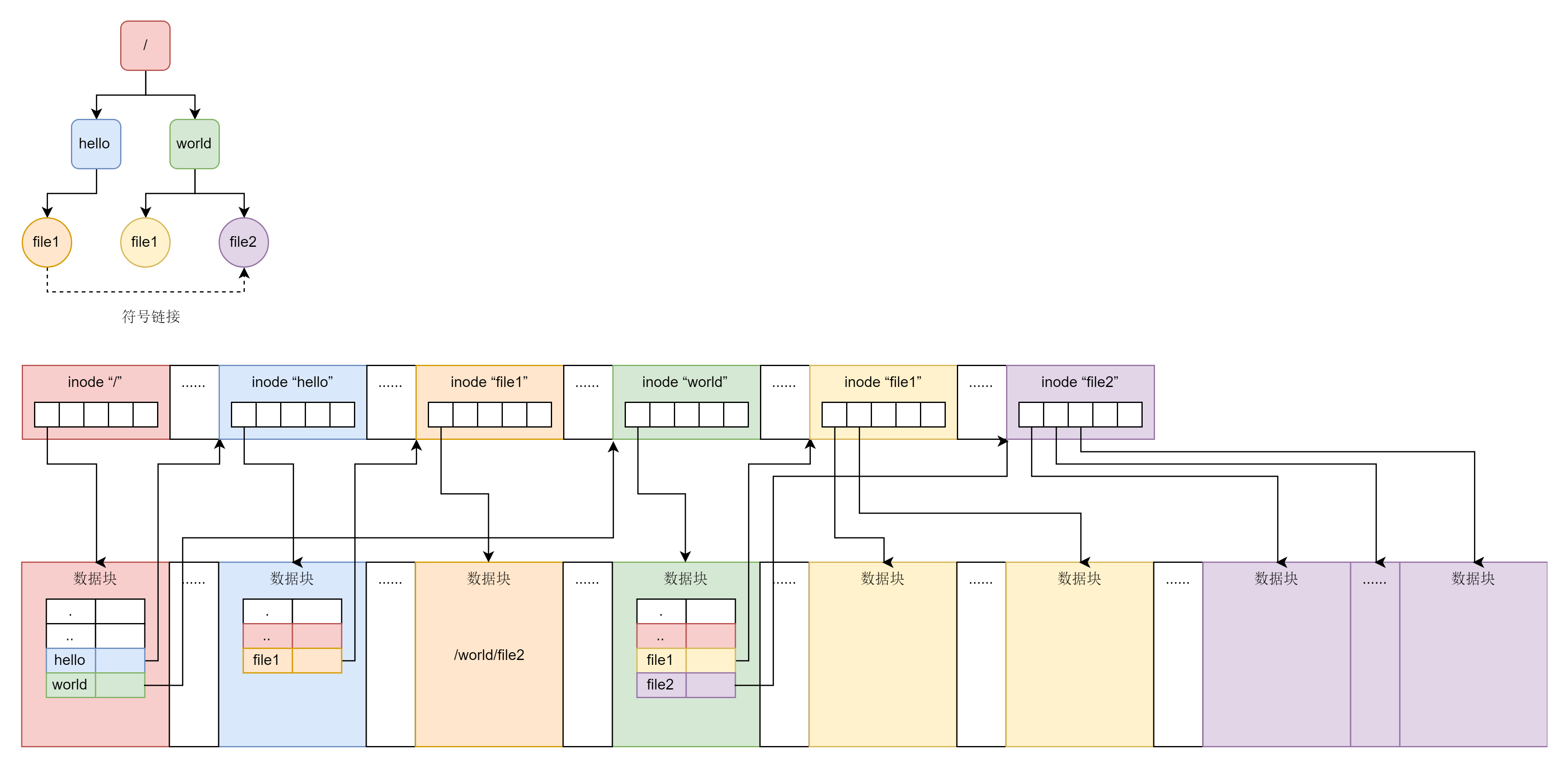
24. 虚拟文件系统
进程要想往文件系统里面读写数据,需要很多层的组件一起合作。具体是怎么合作的呢?我们一起来看一看。
- 在应用层,进程在进行文件读写操作时,可通过系统调用如sys_open、sys_read、sys_write等。
- 在内核,每个进程都需要为打开的文件,维护一定的数据结构。
- 在内核,整个系统打开的文件,也需要维护一定的数据结构。
- Linux可以支持多达数十种不同的文件系统。它们的实现各不相同,因此Linux内核向用户空间提供了虚拟文件系统这个统一的接口,来对文件系统进行操作。它提供了常见的文件系统对象模型,例如inode、directory entry、mount等,以及操作这些对象的方法,例如inode operations、directory operations、file operations等。
- 然后就是对接的是真正的文件系统,例如我们上节讲的ext4文件系统。
- 为了读写ext4文件系统,要通过块设备I/O层,也即BIO层。这是文件系统层和块设备驱动的接口。
- 为了加快块设备的读写效率,我们还有一个缓存层。
- 最下层是块设备驱动程序。
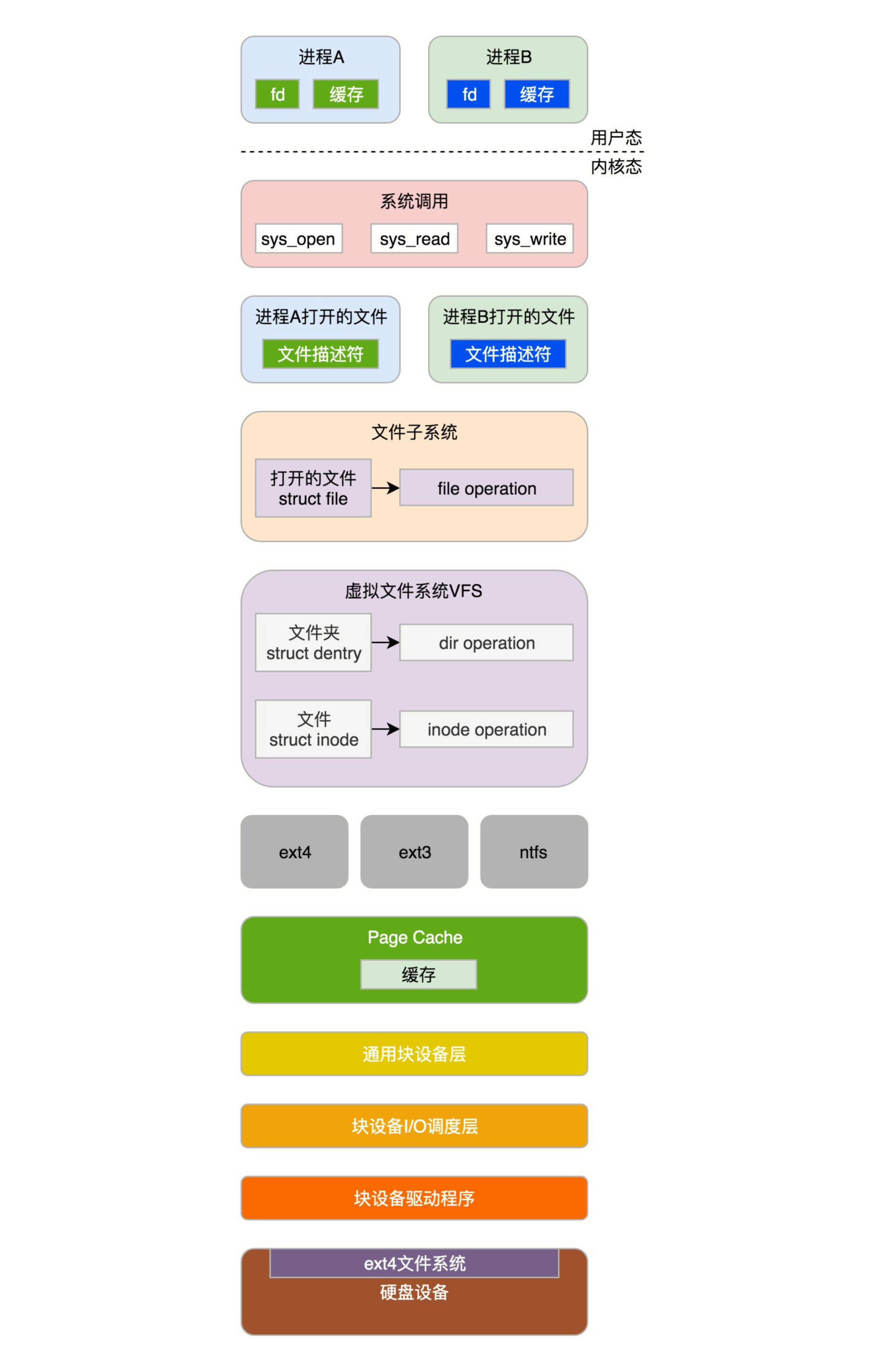
接下来我们逐层解析。
在这之前,有一点你需要注意。解析系统调用是了解内核架构最有力的一把钥匙,这里我们只要重点关注这几个最重要的系统调用就可以了:
- mount系统调用用于挂载文件系统;
- open系统调用用于打开或者创建文件,创建要在flags中设置O_CREAT,对于读写要设置flags为O_RDWR;
- read系统调用用于读取文件内容;
- write系统调用用于写入文件内容。
24.1 挂载文件系统
内核是不是支持某种类型的文件系统,需要我们进行注册才能知道。例如,咱们上一节解析的ext4文件系统,就需要通过register_filesystem进行注册,传入的参数是ext4_fs_type,表示注册的是ext4类型的文件系统。这里面最重要的一个成员变量就是ext4_mount。记住它,这个我们后面还会用。
register_filesystem(&ext4_fs_type);
static struct file_system_type ext4_fs_type = {
.owner = THIS_MODULE,
.name = "ext4",
.mount = ext4_mount,
.kill_sb = kill_block_super,
.fs_flags = FS_REQUIRES_DEV,
};如果一种文件系统的类型曾经在内核注册过,这就说明允许你挂载并且使用这个文件系统。
刚才我说了几个需要重点关注的系统调用,那我们就从第一个mount系统调用开始解析。mount系统调用的定义如下:
SYSCALL_DEFINE5(mount, char __user *, dev_name, char __user *, dir_name, char __user *, type, unsigned long, flags, void __user *, data)
{
......
ret = do_mount(kernel_dev, dir_name, kernel_type, flags, options);
......
}接下来的调用链为:do_mount->do_new_mount->vfs_kern_mount。
struct vfsmount *
vfs_kern_mount(struct file_system_type *type, int flags, const char *name, void *data)
{
......
mnt = alloc_vfsmnt(name);
......
root = mount_fs(type, flags, name, data);
......
mnt->mnt.mnt_root = root;
mnt->mnt.mnt_sb = root->d_sb;
mnt->mnt_mountpoint = mnt->mnt.mnt_root;
mnt->mnt_parent = mnt;
list_add_tail(&mnt->mnt_instance, &root->d_sb->s_mounts);
return &mnt->mnt;
}vfs_kern_mount先是创建struct mount结构,每个挂载的文件系统都对应于这样一个结构。
struct mount {
struct hlist_node mnt_hash;
struct mount *mnt_parent;
struct dentry *mnt_mountpoint;
struct vfsmount mnt;
union {
struct rcu_head mnt_rcu;
struct llist_node mnt_llist;
};
struct list_head mnt_mounts; /* list of children, anchored here */
struct list_head mnt_child; /* and going through their mnt_child */
struct list_head mnt_instance; /* mount instance on sb->s_mounts */
const char *mnt_devname; /* Name of device e.g. /dev/dsk/hda1 */
struct list_head mnt_list;
......
} __randomize_layout;
struct vfsmount {
struct dentry *mnt_root; /* root of the mounted tree */
struct super_block *mnt_sb; /* pointer to superblock */
int mnt_flags;
} __randomize_layout;其中,mnt_parent是装载点所在的父文件系统,mnt_mountpoint是装载点在父文件系统中的dentry;struct dentry表示目录,并和目录的inode关联;mnt_root是当前文件系统根目录的dentry,mnt_sb是指向超级块的指针。
接下来,我们来看调用mount_fs挂载文件系统。
struct dentry *
mount_fs(struct file_system_type *type, int flags, const char *name, void *data)
{
struct dentry *root;
struct super_block *sb;
......
root = type->mount(type, flags, name, data);
......
sb = root->d_sb;
......
}这里调用的是ext4_fs_type的mount函数,也就是咱们上面提到的ext4_mount,从文件系统里面读取超级块。在文件系统的实现中,每个在硬盘上的结构,在内存中也对应相同格式的结构。当所有的数据结构都读到内存里面,内核就可以通过操作这些数据结构,来操作文件系统了。
可以看出来,理解各个数据结构在这里的关系,非常重要。我这里举一个例子,来解析经过mount之后,刚刚那些数据结构之间的关系。
我们假设根文件系统下面有一个目录home,有另外一个文件系统A挂载在这个目录home下面。在文件系统A的根目录下面有另外一个文件夹hello。由于文件系统A已经挂载到了目录home下面,所以我们就有了目录/home/hello,然后有另外一个文件系统B挂在在/home/hello下面。在文件系统B的根目录下面有另外一个文件夹world,在world下面有个文件夹data。由于文件系统B已经挂载到了/home/hello下面,所以我们就有了目录/home/hello/world/data。
为了维护这些关系,操作系统创建了这一系列数据结构。具体你可以看下面的图。
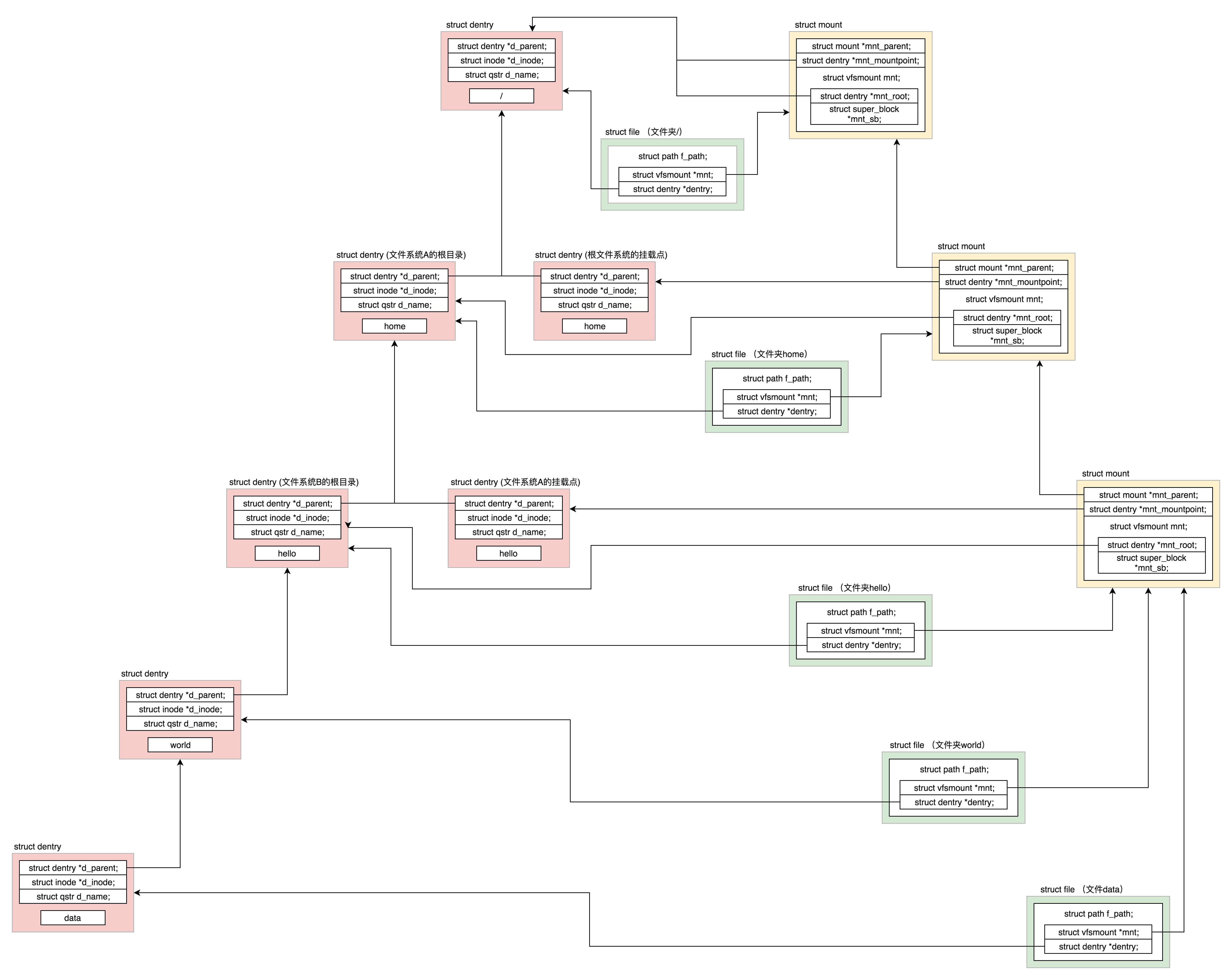
文件系统是树形关系。如果所有的文件夹都是几代单传,那就变成了一条线。你注意看图中的三条斜线。
第一条线是最左边的向左斜的dentry斜线。每一个文件和文件夹都有dentry,用于和inode关联。第二条线是最右面的向右斜的mount斜线,因为这个例子涉及两次文件系统的挂载,再加上启动的时候挂载的根文件系统,一共三个mount。第三条线是中间的向右斜的file斜线,每个打开的文件都有一个file结构,它里面有两个变量,一个指向相应的mount,一个指向相应的dentry。
我们从最上面往下看。根目录/对应一个dentry,根目录是在根文件系统上的,根文件系统是系统启动的时候挂载的,因而有一个mount结构。这个mount结构的mount point指针和mount root指针都是指向根目录的dentry。根目录对应的file的两个指针,一个指向根目录的dentry,一个指向根目录的挂载结构mount。
我们再来看第二层。下一层目录home对应了两个dentry,而且它们的parent都指向第一层的dentry。这是为什么呢?这是因为文件系统A挂载到了这个目录下。这使得这个目录有两个用处。一方面,home是根文件系统的一个挂载点;另一方面,home是文件系统A的根目录。
因为还有一次挂载,因而又有了一个mount结构。这个mount结构的mount point指针指向作为挂载点的那个dentry。mount root指针指向作为根目录的那个dentry,同时parent指针指向第一层的mount结构。home对应的file的两个指针,一个指向文件系统A根目录的dentry,一个指向文件系统A的挂载结构mount。
我们再来看第三层。目录hello又挂载了一个文件系统B,所以第三层的结构和第二层几乎一样。
接下来是第四层。目录world就是一个普通的目录。只要它的dentry的parent指针指向上一层就可以了。我们来看world对应的file结构。由于挂载点不变,还是指向第三层的mount结构。
接下来是第五层。对于文件data,是一个普通的文件,它的dentry的parent指向第四层的dentry。对于data对应的file结构,由于挂载点不变,还是指向第三层的mount结构。
24.2 打开文件
在进程里面通过open系统调用打开文件,最终对调用到内核的系统调用实现sys_open。
SYSCALL_DEFINE3(open, const char __user *, filename, int, flags, umode_t, mode)
{
......
return do_sys_open(AT_FDCWD, filename, flags, mode);
}
long do_sys_open(int dfd, const char __user *filename, int flags, umode_t mode)
{
......
fd = get_unused_fd_flags(flags);
if (fd >= 0) {
struct file *f = do_filp_open(dfd, tmp, &op);
if (IS_ERR(f)) {
put_unused_fd(fd);
fd = PTR_ERR(f);
} else {
fsnotify_open(f);
fd_install(fd, f);
}
}
putname(tmp);
return fd;
}要打开一个文件,首先要通过get_unused_fd_flags得到一个没有用的文件描述符。
在每一个进程的task_struct中,有一个指针files,类型是files_struct。
struct files_struct *files;files_struct里面最重要的是一个文件描述符列表,每打开一个文件,就会在这个列表中分配一项,下标就是文件描述符。
struct files_struct {
......
struct file __rcu * fd_array[NR_OPEN_DEFAULT];
};对于任何一个进程,默认情况下,文件描述符0表示stdin标准输入,文件描述符1表示stdout标准输出,文件描述符2表示stderr标准错误输出。另外,再打开的文件,都会从这个列表中找一个空闲位置分配给它。
文件描述符列表的每一项都是一个指向struct file的指针,也就是说,每打开一个文件,都会有一个struct file对应。
do_sys_open中调用do_filp_open,就是创建这个struct file结构,然后fd_install(fd, f)是将文件描述符和这个结构关联起来。
struct file *do_filp_open(int dfd, struct filename *pathname,
const struct open_flags *op)
{
......
set_nameidata(&nd, dfd, pathname);
filp = path_openat(&nd, op, flags | LOOKUP_RCU);
......
restore_nameidata();
return filp;
}do_filp_open里面首先初始化了struct nameidata这个结构。我们知道,文件都是一串的路径名称,需要逐个解析。这个结构就是解析和查找路径的时候做辅助作用。
在struct nameidata里面有一个关键的成员变量struct path。
struct path {
struct vfsmount *mnt;
struct dentry *dentry;
} __randomize_layout;其中,struct vfsmount和文件系统的挂载有关。另一个struct dentry,除了上面说的用于标识目录之外,还可以表示文件名,还会建立了文件名及其inode之间的关联。
接下来就调用path_openat,主要做了以下几件事情:
- get_empty_filp生成一个struct file结构;
- path_init初始化nameidata,准备开始节点路径查找;
- link_path_walk对于路径名逐层进行节点路径查找,这里面有一个大的循环,用”/“分隔逐层处理;
- do_last获取文件对应的inode对象,并且初始化file对象。
static struct file *path_openat(struct nameidata *nd,
const struct open_flags *op, unsigned flags)
{
......
file = get_empty_filp();
......
s = path_init(nd, flags);
......
while (!(error = link_path_walk(s, nd)) &&
(error = do_last(nd, file, op, &opened)) > 0) {
......
}
terminate_walk(nd);
......
return file;
}例如,文件”/root/hello/world/data”,link_path_walk会解析前面的路径部分”/root/hello/world”,解析完毕的时候nameidata的dentry为路径名的最后一部分的父目录”/root/hello/world”,而nameidata的filename为路径名的最后一部分”data”。
最后一部分的解析和处理,我们交给do_last。
static int do_last(struct nameidata *nd,
struct file *file, const struct open_flags *op,
int *opened)
{
......
error = lookup_fast(nd, &path, &inode, &seq);
......
error = lookup_open(nd, &path, file, op, got_write, opened);
......
error = vfs_open(&nd->path, file, current_cred());
......
}在这里面,我们需要先查找文件路径最后一部分对应的dentry。如何查找呢?
Linux为了提高目录项对象的处理效率,设计与实现了目录项高速缓存dentry cache,简称dcache。它主要由两个数据结构组成:
- 哈希表dentry_hashtable:dcache中的所有dentry对象都通过d_hash指针链到相应的dentry哈希链表中;
- 未使用的dentry对象链表s_dentry_lru:dentry对象通过其d_lru指针链入LRU链表中。LRU的意思是最近最少使用,我们已经好几次看到它了。只要有它,就说明长时间不使用,就应该释放了。
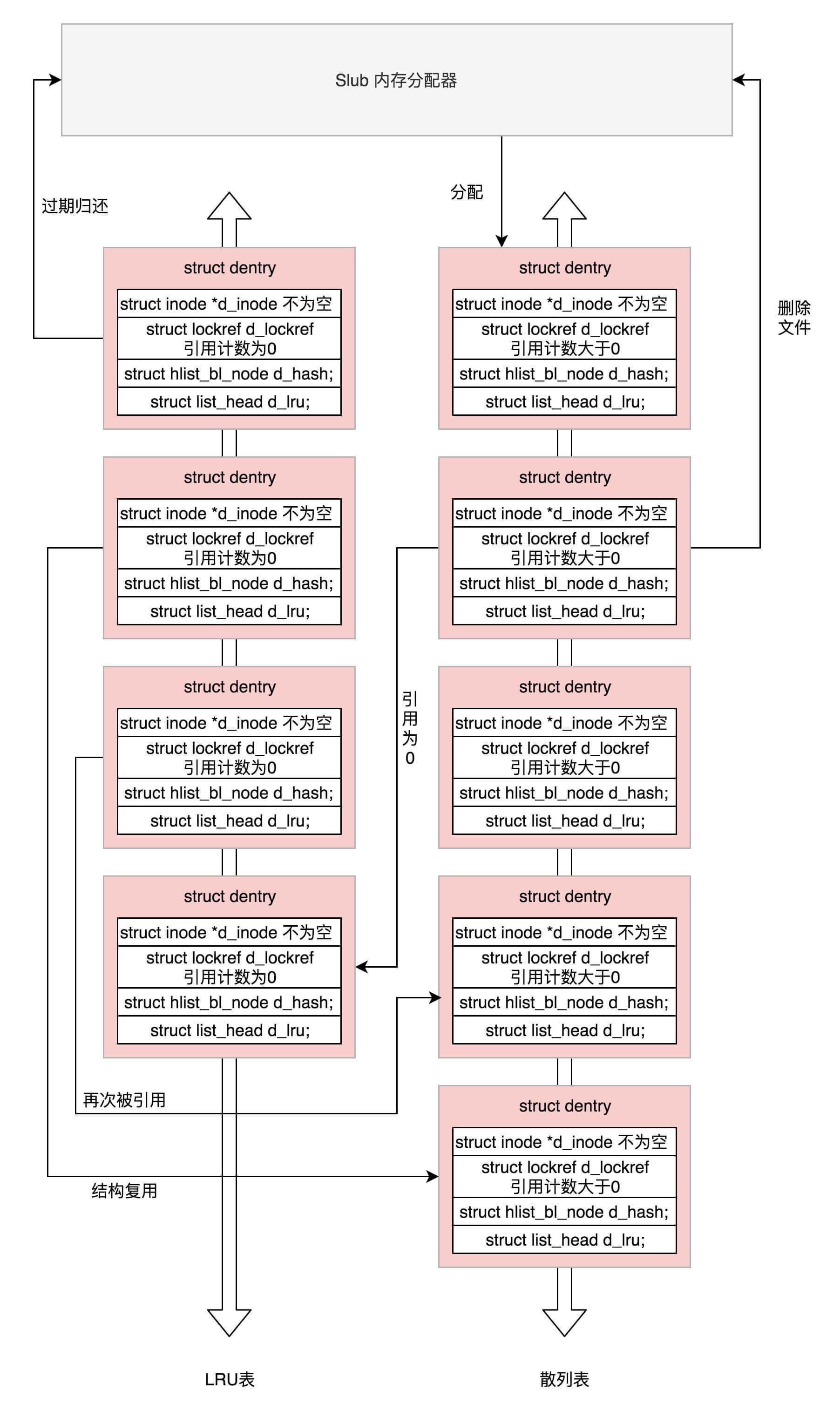
这两个列表之间会产生复杂的关系:
- 引用为0:一个在散列表中的dentry变成没有人引用了,就会被加到LRU表中去;
- 再次被引用:一个在LRU表中的dentry再次被引用了,则从LRU表中移除;
- 分配:当dentry在散列表中没有找到,则从Slub分配器中分配一个;
- 过期归还:当LRU表中最长时间没有使用的dentry应该释放回Slub分配器;
- 文件删除:文件被删除了,相应的dentry应该释放回Slub分配器;
- 结构复用:当需要分配一个dentry,但是无法分配新的,就从LRU表中取出一个来复用。
所以,do_last()在查找dentry的时候,当然先从缓存中查找,调用的是lookup_fast。
如果缓存中没有找到,就需要真的到文件系统里面去找了,lookup_open会创建一个新的dentry,并且调用上一级目录的Inode的inode_operations的lookup函数,对于ext4来讲,调用的是ext4_lookup,会到咱们上一节讲的文件系统里面去找inode。最终找到后将新生成的dentry付给path变量。
static int lookup_open(struct nameidata *nd, struct path *path,
struct file *file,
const struct open_flags *op,
bool got_write, int *opened)
{
......
dentry = d_alloc_parallel(dir, &nd->last, &wq);
......
struct dentry *res = dir_inode->i_op->lookup(dir_inode, dentry,
nd->flags);
......
path->dentry = dentry;
path->mnt = nd->path.mnt;
}
const struct inode_operations ext4_dir_inode_operations = {
.create = ext4_create,
.lookup = ext4_lookup,
...
}do_last()的最后一步是调用vfs_open真正打开文件。
int vfs_open(const struct path *path, struct file *file,
const struct cred *cred)
{
struct dentry *dentry = d_real(path->dentry, NULL, file->f_flags, 0);
......
file->f_path = *path;
return do_dentry_open(file, d_backing_inode(dentry), NULL, cred);
}
static int do_dentry_open(struct file *f,
struct inode *inode,
int (*open)(struct inode *, struct file *),
const struct cred *cred)
{
......
f->f_mode = OPEN_FMODE(f->f_flags) | FMODE_LSEEK |
FMODE_PREAD | FMODE_PWRITE;
path_get(&f->f_path);
f->f_inode = inode;
f->f_mapping = inode->i_mapping;
......
f->f_op = fops_get(inode->i_fop);
......
open = f->f_op->open;
......
error = open(inode, f);
......
f->f_flags &= ~(O_CREAT | O_EXCL | O_NOCTTY | O_TRUNC);
file_ra_state_init(&f->f_ra, f->f_mapping->host->i_mapping);
return 0;
......
}
const struct file_operations ext4_file_operations = {
......
.open = ext4_file_open,
......
};
vfs_open里面最终要做的一件事情是,调用f_op->open,也就是调用ext4_file_open。另外一件重要的事情是将打开文件的所有信息,填写到struct file这个结构里面。
struct file {
union {
struct llist_node fu_llist;
struct rcu_head fu_rcuhead;
} f_u;
struct path f_path;
struct inode *f_inode; /* cached value */
const struct file_operations *f_op;
spinlock_t f_lock;
enum rw_hint f_write_hint;
atomic_long_t f_count;
unsigned int f_flags;
fmode_t f_mode;
struct mutex f_pos_lock;
loff_t f_pos;
struct fown_struct f_owner;
const struct cred *f_cred;
......
struct address_space *f_mapping;
errseq_t f_wb_err;
}24.3 总结
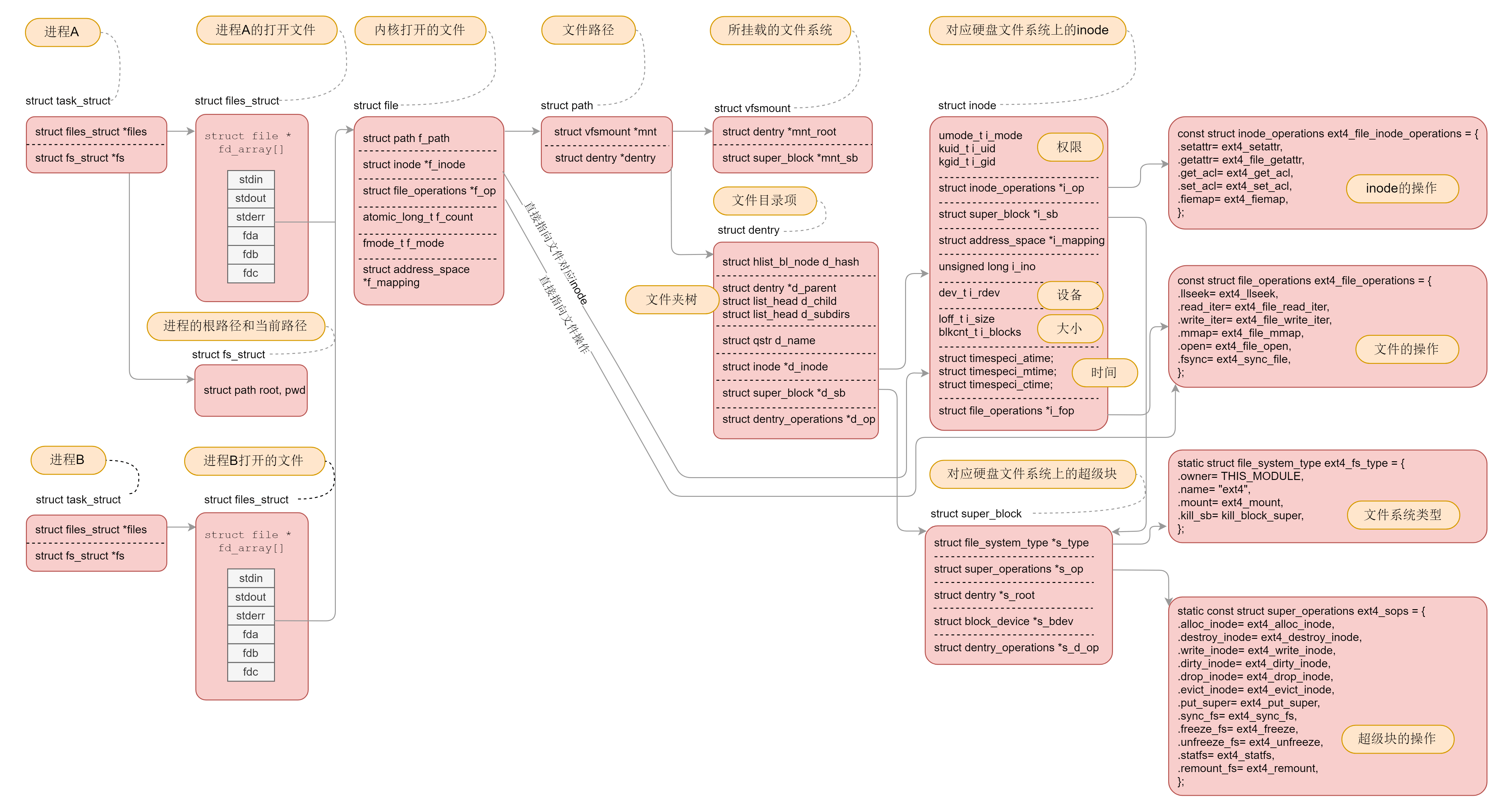
这张图十分重要,一定要掌握。因为我们后面的字符设备、块设备、管道、进程间通信、网络等等,全部都要用到这里面的知识。希望当你再次遇到它的时候,能够马上说出各个数据结构直接的关系。
这里我带你简单做一个梳理,帮助你理解记忆它。
对于每一个进程,打开的文件都有一个文件描述符,在files_struct里面会有文件描述符数组。每个一个文件描述符是这个数组的下标,里面的内容指向一个file结构,表示打开的文件。这个结构里面有这个文件对应的inode,最重要的是这个文件对应的操作file_operation。如果操作这个文件,就看这个file_operation里面的定义了。
对于每一个打开的文件,都有一个dentry对应,虽然叫作directory entry,但是不仅仅表示文件夹,也表示文件。它最重要的作用就是指向这个文件对应的inode。
如果说file结构是一个文件打开以后才创建的,dentry是放在一个dentry cache里面的,文件关闭了,他依然存在,因而他可以更长期的维护内存中的文件的表示和硬盘上文件的表示之间的关系。
inode结构就表示硬盘上的inode,包括块设备号等。
几乎每一种结构都有自己对应的operation结构,里面都是一些方法,因而当后面遇到对于某种结构进行处理的时候,如果不容易找到相应的处理函数,就先找这个operation结构,就清楚了。
25. 文件缓存
25.1 系统调用层和虚拟文件系统层
文件系统的读写,其实就是调用系统函数read和write。由于读和写的很多逻辑是相似的,这里我们一起来看一下这个过程。
下面的代码就是read和write的系统调用,在内核里面的定义。
SYSCALL_DEFINE3(read, unsigned int, fd, char __user *, buf, size_t, count)
{
struct fd f = fdget_pos(fd);
......
loff_t pos = file_pos_read(f.file);
ret = vfs_read(f.file, buf, count, &pos);
......
}
SYSCALL_DEFINE3(write, unsigned int, fd, const char __user *, buf,
size_t, count)
{
struct fd f = fdget_pos(fd);
......
loff_t pos = file_pos_read(f.file);
ret = vfs_write(f.file, buf, count, &pos);
......
}对于read来讲,里面调用vfs_read->vfs_read。对于write来讲,里面调用vfs_write->vfs_write。
下面是vfs_read和vfs_write的代码。
ssize_t __vfs_read(struct file *file, char __user *buf, size_t count,
loff_t *pos)
{
if (file->f_op->read)
return file->f_op->read(file, buf, count, pos);
else if (file->f_op->read_iter)
return new_sync_read(file, buf, count, pos);
else
return -EINVAL;
}
ssize_t __vfs_write(struct file *file, const char __user *p, size_t count,
loff_t *pos)
{
if (file->f_op->write)
return file->f_op->write(file, p, count, pos);
else if (file->f_op->write_iter)
return new_sync_write(file, p, count, pos);
else
return -EINVAL;
}上一节,我们讲了,每一个打开的文件,都有一个struct file结构。这里面有一个struct file_operations f_op,用于定义对这个文件做的操作。vfs_read会调用相应文件系统的file_operations里面的read操作,vfs_write会调用相应文件系统file_operations里的write操作。
25.2 ext4文件系统层
对于ext4文件系统来讲,内核定义了一个ext4_file_operations。
const struct file_operations ext4_file_operations = {
......
.read_iter = ext4_file_read_iter,
.write_iter = ext4_file_write_iter,
......
}由于ext4没有定义read和write函数,于是会调用ext4_file_read_iter和ext4_file_write_iter。
ext4_file_read_iter会调用generic_file_read_iter,ext4_file_write_iter会调用__generic_file_write_iter。
ssize_t
generic_file_read_iter(struct kiocb *iocb, struct iov_iter *iter)
{
......
if (iocb->ki_flags & IOCB_DIRECT) {
......
struct address_space *mapping = file->f_mapping;
......
retval = mapping->a_ops->direct_IO(iocb, iter);
}
......
retval = generic_file_buffered_read(iocb, iter, retval);
}
ssize_t __generic_file_write_iter(struct kiocb *iocb, struct iov_iter *from)
{
......
if (iocb->ki_flags & IOCB_DIRECT) {
......
written = generic_file_direct_write(iocb, from);
......
} else {
......
written = generic_perform_write(file, from, iocb->ki_pos);
......
}
}generic_file_read_iter和__generic_file_write_iter有相似的逻辑,就是要区分是否用缓存。
缓存其实就是内存中的一块空间。因为内存比硬盘快的多,Linux为了改进性能,有时候会选择不直接操作硬盘,而是将读写都在内存中,然后批量读取或者写入硬盘。一旦能够命中内存,读写效率就会大幅度提高。
因此,根据是否使用内存做缓存,我们可以把文件的I/O操作分为两种类型。
第一种类型是缓存I/O。大多数文件系统的默认I/O操作都是缓存I/O。对于读操作来讲,操作系统会先检查,内核的缓冲区有没有需要的数据。如果已经缓存了,那就直接从缓存中返回;否则从磁盘中读取,然后缓存在操作系统的缓存中。对于写操作来讲,操作系统会先将数据从用户空间复制到内核空间的缓存中。这时对用户程序来说,写操作就已经完成。至于什么时候再写到磁盘中由操作系统决定,除非显式地调用了sync同步命令。
第二种类型是直接IO,就是应用程序直接访问磁盘数据,而不经过内核缓冲区,从而减少了在内核缓存和用户程序之间数据复制。
如果在读的逻辑generic_file_read_iter里面,发现设置了IOCB_DIRECT,则会调用address_space的direct_IO的函数,将数据直接读取硬盘。我们在mmap映射文件到内存的时候讲过address_space,它主要用于在内存映射的时候将文件和内存页产生关联。
同样,对于缓存来讲,也需要文件和内存页进行关联,这就要用到address_space。address_space的相关操作定义在struct address_space_operations结构中。对于ext4文件系统来讲, address_space的操作定义在ext4_aops,direct_IO对应的函数是ext4_direct_IO。
static const struct address_space_operations ext4_aops = {
......
.direct_IO = ext4_direct_IO,
......
};如果在写的逻辑__generic_file_write_iter里面,发现设置了IOCB_DIRECT,则调用generic_file_direct_write,里面同样会调用address_space的direct_IO的函数,将数据直接写入硬盘。
ext4_direct_IO最终会调用到__blockdev_direct_IO->do_blockdev_direct_IO,这就跨过了缓存层,直接到了文件系统的设备驱动层。由于文件系统是块设备,所以这个调用的是blockdev相关的函数,有关块设备驱动程序的原理我们下一章详细讲,这一节我们就讲到文件系统到块设备的分界线部分。
/*
* This is a library function for use by filesystem drivers.
*/
static inline ssize_t
do_blockdev_direct_IO(struct kiocb *iocb, struct inode *inode,
struct block_device *bdev, struct iov_iter *iter,
get_block_t get_block, dio_iodone_t end_io,
dio_submit_t submit_io, int flags)
{......}接下来,我们重点看带缓存的部分如果进行读写。
25.3 带缓存的写入操作
我们先来看带缓存写入的函数generic_perform_write。
ssize_t generic_perform_write(struct file *file,
struct iov_iter *i, loff_t pos)
{
struct address_space *mapping = file->f_mapping;
const struct address_space_operations *a_ops = mapping->a_ops;
do {
struct page *page;
unsigned long offset; /* Offset into pagecache page */
unsigned long bytes; /* Bytes to write to page */
status = a_ops->write_begin(file, mapping, pos, bytes, flags,
&page, &fsdata);
copied = iov_iter_copy_from_user_atomic(page, i, offset, bytes);
flush_dcache_page(page);
status = a_ops->write_end(file, mapping, pos, bytes, copied,
page, fsdata);
pos += copied;
written += copied;
balance_dirty_pages_ratelimited(mapping);
} while (iov_iter_count(i));
}这个函数里,是一个while循环。我们需要找出这次写入影响的所有的页,然后依次写入。对于每一个循环,主要做四件事情:
- 对于每一页,先调用address_space的write_begin做一些准备;
- 调用iov_iter_copy_from_user_atomic,将写入的内容从用户态拷贝到内核态的页中;
- 调用address_space的write_end完成写操作;
- 调用balance_dirty_pages_ratelimited,看脏页是否太多,需要写回硬盘。所谓脏页,就是写入到缓存,但是还没有写入到硬盘的页面。
我们依次来看这四个步骤。
static const struct address_space_operations ext4_aops = {
......
.write_begin = ext4_write_begin,
.write_end = ext4_write_end,
......
}第一步,对于ext4来讲,调用的是ext4_write_begin。
ext4是一种日志文件系统,是为了防止突然断电的时候的数据丢失,引入了日志(Journal)模式。日志文件系统比非日志文件系统多了一个Journal区域。文件在ext4中分两部分存储,一部分是文件的元数据,另一部分是数据。元数据和数据的操作日志Journal也是分开管理的。你可以在挂载ext4的时候,选择Journal模式。这种模式在将数据写入文件系统前,必须等待元数据和数据的日志已经落盘才能发挥作用。这样性能比较差,但是最安全。
另一种模式是order模式。这个模式不记录数据的日志,只记录元数据的日志,但是在写元数据的日志前,必须先确保数据已经落盘。这个折中,是默认模式。
还有一种模式是writeback,不记录数据的日志,仅记录元数据的日志,并且不保证数据比元数据先落盘。这个性能最好,但是最不安全。
在ext4_write_begin,我们能看到对于ext4_journal_start的调用,就是在做日志相关的工作。
在ext4_write_begin中,还做了另外一件重要的事情,就是调用grab_cache_page_write_begin来,得到应该写入的缓存页。
struct page *grab_cache_page_write_begin(struct address_space *mapping,
pgoff_t index, unsigned flags)
{
struct page *page;
int fgp_flags = FGP_LOCK|FGP_WRITE|FGP_CREAT;
page = pagecache_get_page(mapping, index, fgp_flags,
mapping_gfp_mask(mapping));
if (page)
wait_for_stable_page(page);
return page;
}在内核中,缓存以页为单位放在内存里面,那我们如何知道,一个文件的哪些数据已经被放到缓存中了呢?每一个打开的文件都有一个struct file结构,每个struct file结构都有一个struct address_space用于关联文件和内存,就是在这个结构里面,有一棵树,用于保存所有与这个文件相关的的缓存页。
我们查找的时候,往往需要根据文件中的偏移量找出相应的页面,而基数树radix tree这种数据结构能够快速根据一个长整型查找到其相应的对象,因而这里缓存页就放在radix基数树里面。
struct address_space {
struct inode *host; /* owner: inode, block_device */
struct radix_tree_root page_tree; /* radix tree of all pages */
spinlock_t tree_lock; /* and lock protecting it */
......
}pagecache_get_page就是根据pgoff_t index这个长整型,在这棵树里面查找缓存页,如果找不到就会创建一个缓存页。
第二步,调用iov_iter_copy_from_user_atomic。先将分配好的页面调用kmap_atomic映射到内核里面的一个虚拟地址,然后将用户态的数据拷贝到内核态的页面的虚拟地址中,调用kunmap_atomic把内核里面的映射删除。
第三步,调用ext4_write_end完成写入。这里面会调用ext4_journal_stop完成日志的写入,会调用block_write_end->__block_commit_write->mark_buffer_dirty,将修改过的缓存标记为脏页。可以看出,其实所谓的完成写入,并没有真正写入硬盘,仅仅是写入缓存后,标记为脏页。
但是这里有一个问题,数据很危险,一旦宕机就没有了,所以需要一种机制,将写入的页面真正写到硬盘中,我们称为回写(Write Back)。
第四步,调用 balance_dirty_pages_ratelimited,是回写脏页的一个很好的时机。
/**
* balance_dirty_pages_ratelimited - balance dirty memory state
* @mapping: address_space which was dirtied
*
* Processes which are dirtying memory should call in here once for each page
* which was newly dirtied. The function will periodically check the system's
* dirty state and will initiate writeback if needed.
*/
void balance_dirty_pages_ratelimited(struct address_space *mapping)
{
struct inode *inode = mapping->host;
struct backing_dev_info *bdi = inode_to_bdi(inode);
struct bdi_writeback *wb = NULL;
int ratelimit;
......
if (unlikely(current->nr_dirtied >= ratelimit))
balance_dirty_pages(mapping, wb, current->nr_dirtied);
......
}在balance_dirty_pages_ratelimited里面,发现脏页的数目超过了规定的数目,就调用balance_dirty_pages->wb_start_background_writeback,启动一个背后线程开始回写。
void wb_start_background_writeback(struct bdi_writeback *wb)
{
/*
* We just wake up the flusher thread. It will perform background
* writeback as soon as there is no other work to do.
*/
wb_wakeup(wb);
}
static void wb_wakeup(struct bdi_writeback *wb)
{
spin_lock_bh(&wb->work_lock);
if (test_bit(WB_registered, &wb->state))
mod_delayed_work(bdi_wq, &wb->dwork, 0);
spin_unlock_bh(&wb->work_lock);
}
/* bdi_wq serves all asynchronous writeback tasks */
struct workqueue_struct *bdi_wq;
/**
* mod_delayed_work - modify delay of or queue a delayed work
* @wq: workqueue to use
* @dwork: work to queue
* @delay: number of jiffies to wait before queueing
*
* mod_delayed_work_on() on local CPU.
*/
static inline bool mod_delayed_work(struct workqueue_struct *wq,
struct delayed_work *dwork,
unsigned long delay)
{....
}通过上面的代码,我们可以看出,bdi_wq是一个全局变量,所有回写的任务都挂在这个队列上。mod_delayed_work函数负责将一个回写任务bdi_writeback挂在这个队列上。bdi_writeback有个成员变量struct delayed_work dwork,bdi_writeback就是以delayed_work的身份挂到队列上的,并且把delay设置为0,意思就是一刻不等,马上执行。
那具体这个任务由谁来执行呢?这里的bdi的意思是backing device info,用于描述后端存储相关的信息。每个块设备都会有这样一个结构,并且在初始化块设备的时候,调用bdi_init初始化这个结构,在初始化bdi的时候,也会调用wb_init初始化bdi_writeback。
static int wb_init(struct bdi_writeback *wb, struct backing_dev_info *bdi,
int blkcg_id, gfp_t gfp)
{
wb->bdi = bdi;
wb->last_old_flush = jiffies;
INIT_LIST_HEAD(&wb->b_dirty);
INIT_LIST_HEAD(&wb->b_io);
INIT_LIST_HEAD(&wb->b_more_io);
INIT_LIST_HEAD(&wb->b_dirty_time);
wb->bw_time_stamp = jiffies;
wb->balanced_dirty_ratelimit = INIT_BW;
wb->dirty_ratelimit = INIT_BW;
wb->write_bandwidth = INIT_BW;
wb->avg_write_bandwidth = INIT_BW;
spin_lock_init(&wb->work_lock);
INIT_LIST_HEAD(&wb->work_list);
INIT_DELAYED_WORK(&wb->dwork, wb_workfn);
wb->dirty_sleep = jiffies;
......
}
#define __INIT_DELAYED_WORK(_work, _func, _tflags) \
do { \
INIT_WORK(&(_work)->work, (_func)); \
__setup_timer(&(_work)->timer, delayed_work_timer_fn, \
(unsigned long)(_work), \这里面最重要的是INIT_DELAYED_WORK。其实就是初始化一个timer,也即定时器,到时候我们就执行wb_workfn这个函数。
接下来的调用链为:wb_workfn->wb_do_writeback->wb_writeback->writeback_sb_inodes->__writeback_single_inode->do_writepages,写入页面到硬盘。
在调用write的最后,当发现缓存的数据太多的时候,会触发回写,这仅仅是回写的一种场景。另外还有几种场景也会触发回写:
- 用户主动调用sync,将缓存刷到硬盘上去,最终会调用wakeup_flusher_threads,同步脏页;
- 当内存十分紧张,以至于无法分配页面的时候,会调用free_more_memory,最终会调用wakeup_flusher_threads,释放脏页;
- 脏页已经更新了较长时间,时间上超过了timer,需要及时回写,保持内存和磁盘上数据一致性。
25.4 带缓存的读操作
带缓存的写分析完了,接下来,我们看带缓存的读,对应的是函数generic_file_buffered_read。
static ssize_t generic_file_buffered_read(struct kiocb *iocb,
struct iov_iter *iter, ssize_t written)
{
struct file *filp = iocb->ki_filp;
struct address_space *mapping = filp->f_mapping;
struct inode *inode = mapping->host;
for (;;) {
struct page *page;
pgoff_t end_index;
loff_t isize;
page = find_get_page(mapping, index);
if (!page) {
if (iocb->ki_flags & IOCB_NOWAIT)
goto would_block;
page_cache_sync_readahead(mapping,
ra, filp,
index, last_index - index);
page = find_get_page(mapping, index);
if (unlikely(page == NULL))
goto no_cached_page;
}
if (PageReadahead(page)) {
page_cache_async_readahead(mapping,
ra, filp, page,
index, last_index - index);
}
/*
* Ok, we have the page, and it's up-to-date, so
* now we can copy it to user space...
*/
ret = copy_page_to_iter(page, offset, nr, iter);
}
}读取比写入总体而言简单一些,主要涉及预读的问题。
在generic_file_buffered_read函数中,我们需要先找到page cache里面是否有缓存页。如果没有找到,不但读取这一页,还要进行预读,这需要在page_cache_sync_readahead函数中实现。预读完了以后,再试一把查找缓存页,应该能找到了。
如果第一次找缓存页就找到了,我们还是要判断,是不是应该继续预读;如果需要,就调用page_cache_async_readahead发起一个异步预读。
最后,copy_page_to_iter会将内容从内核缓存页拷贝到用户内存空间。
25.5 总结
在系统调用层我们需要仔细学习read和write。在VFS层调用的是vfs_read和vfs_write并且调用file_operation。在ext4层调用的是ext4_file_read_iter和ext4_file_write_iter。
接下来就是分叉。你需要知道缓存I/O和直接I/O。直接I/O读写的流程是一样的,调用ext4_direct_IO,再往下就调用块设备层了。缓存I/O读写的流程不一样。对于读,从块设备读取到缓存中,然后从缓存中拷贝到用户态。对于写,从用户态拷贝到缓存,设置缓存页为脏,然后启动一个线程写入块设备。
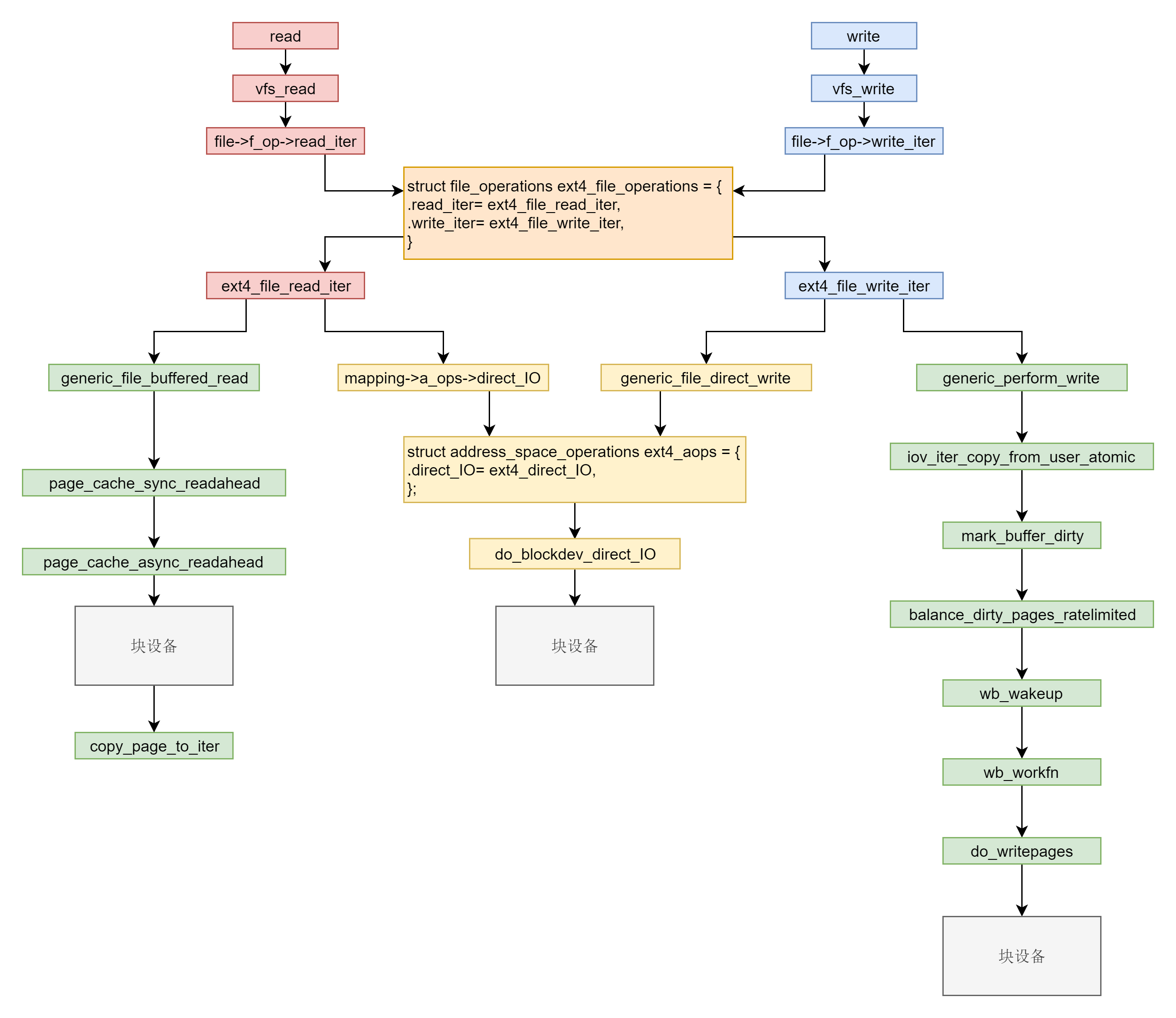
五、输入输出系统
26. 输入与输出
26.1 用设备控制器屏蔽设备差异
CPU并不直接和设备打交道,它们中间有一个叫作设备控制器(Device Control Unit)的组件,例如硬盘有磁盘控制器、USB有USB控制器、显示器有视频控制器等。这些控制器就像代理商一样,它们知道如何应对硬盘、鼠标、键盘、显示器的行为。
控制器其实有点儿像一台小电脑。它有它的芯片,类似小CPU,执行自己的逻辑。它也有它的寄存器。这样CPU就可以通过写这些寄存器,对控制器下发指令,通过读这些寄存器,查看控制器对于设备的操作状态。
CPU对于寄存器的读写,可比直接控制硬件,要标准和轻松很多。
输入输出设备我们大致可以分为两类:块设备(Block Device)和字符设备(Character Device)。
- 块设备将信息存储在固定大小的块中,每个块都有自己的地址。硬盘就是常见的块设备。
- 字符设备发送或接受的是字节流。而不用考虑任何块结构,没有办法寻址。鼠标就是常见的字符设备。
由于块设备传输的数据量比较大,控制器里往往会有缓冲区。CPU写入缓冲区的数据攒够一部分,才会发给设备。CPU读取的数据,也需要在缓冲区攒够一部分,才拷贝到内存。
CPU如何同控制器的寄存器和数据缓冲区进行通信呢?
- 每个控制寄存器被分配一个I/O端口,我们可以通过特殊的汇编指令(例如in/out类似的指令)操作这些寄存器。
- 数据缓冲区,可内存映射I/O,可以分配一段内存空间给它,就像读写内存一样读写数据缓冲区。如果你去看内存空间的话,有一个原来我们没有讲过的区域ioremap,就是做这个的。
对于CPU来讲,这些外部设备都有自己的大脑,可以自行处理一些事情,但是有个问题是,当你给设备发了一个指令,让它读取一些数据,它读完的时候,怎么通知你呢?
控制器的寄存器一般会有状态标志位,可以通过检测状态标志位,来确定输入或者输出操作是否完成。第一种方式就是轮询等待,就是一直查,一直查,直到完成。当然这种方式很不好,于是我们有了第二种方式,就是可以通过中断的方式,通知操作系统输入输出操作已经完成。
为了响应中断,我们一般会有一个硬件的中断控制器,当设备完成任务后出发中断到中断控制器,中断控制器就通知CPU,一个中断产生了,CPU需要停下当前手里的事情来处理中断。
中断有两种,一种软中断,例如代码调用INT指令触发,一种是硬件中断,就是硬件通过中断控制器触发的。
有的设备需要读取或者写入大量数据。如果所有过程都让CPU协调的话,就需要占用CPU大量的时间,比方说,磁盘就是这样的。这种类型的设备需要支持DMA功能,也就是说,允许设备在CPU不参与的情况下,能够自行完成对内存的读写。实现DMA机制需要有个DMA控制器帮你的CPU来做协调,就像下面这个图中显示的一样。
CPU只需要对DMA控制器下指令,说它想读取多少数据,放在内存的某个地方就可以了,接下来DMA控制器会发指令给磁盘控制器,读取磁盘上的数据到指定的内存位置,传输完毕之后,DMA控制器发中断通知CPU指令完成,CPU就可以直接用内存里面现成的数据了。还记得咱们讲内存的时候,有个DMA区域,就是这个作用。
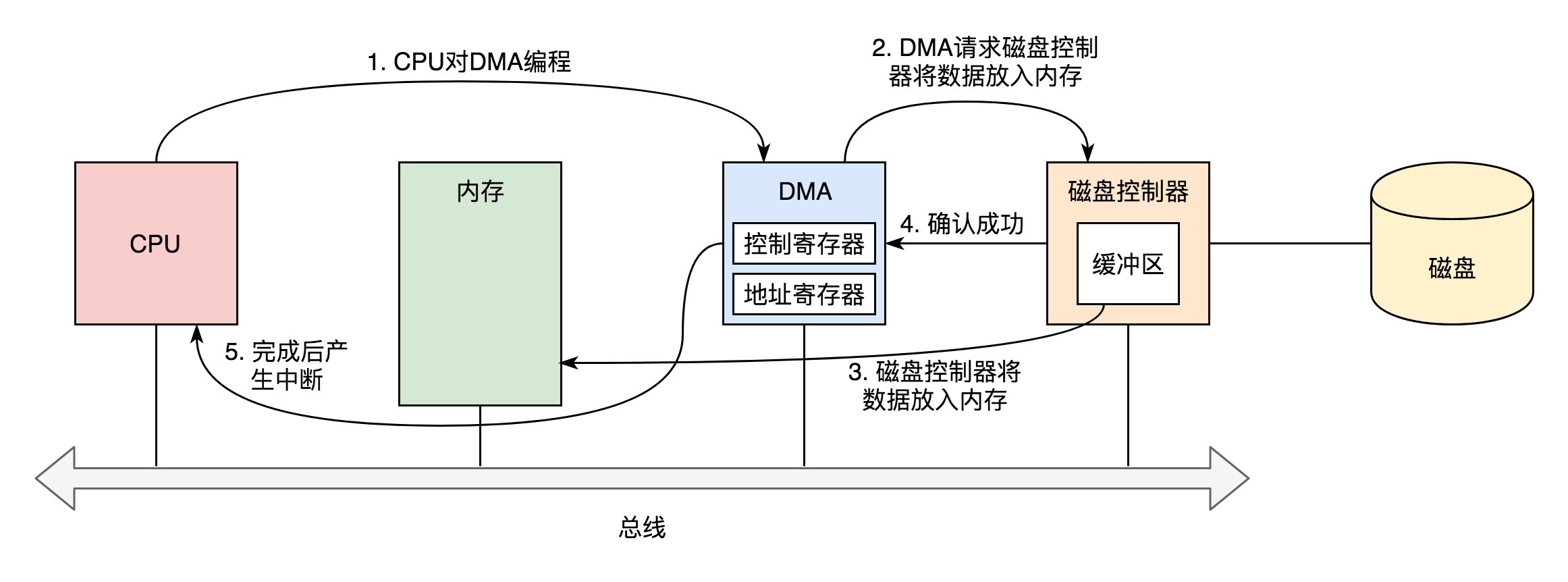
26.2 用驱动程序屏蔽设备控制器差异
虽然代理商机制能够帮我们屏蔽很多设备的细节,但是从上面的描述我们可以看出,由于每种设备的控制器的寄存器、缓冲区等使用模式,指令都不同,所以对于操作系统这家公司来讲,需要有个部门专门对接代理商,向其他部门屏蔽代理商的差异,类似公司的渠道管理部门。
那什么才是操作系统的渠道管理部门呢?就是用来对接各个设备控制器的设备驱动程序。
这里需要注意的是,设备控制器不属于操作系统的一部分,但是设备驱动程序属于操作系统的一部分。操作系统的内核代码可以像调用本地代码一样调用驱动程序的代码,而驱动程序的代码需要发出特殊的面向设备控制器的指令,才能操作设备控制器。
设备驱动程序中是一些面向特殊设备控制器的代码。不同的设备不同。但是对于操作系统其它部分的代码而言,设备驱动程序应该有统一的接口。不同的设备驱动程序,可以以同样的方式接入操作系统,而操作系统的其它部分的代码,也可以无视不同设备的区别,以同样的接口调用设备驱动程序。
接下来两节,我们会讲字符设备驱动程序和块设备驱动程序的模型,从那里我们也可以看出,所有设备驱动程序都要,按照同样的规则,实现同样的方法。
上面咱们说了,设备做完了事情要通过中断来通知操作系统。那操作系统就需要有一个地方处理这个中断,既然设备驱动程序是用来对接设备控制器的,中断处理也应该在设备驱动里面完成。
然而中断的触发最终会到达CPU,会中断操作系统当前运行的程序,所以操作系统也要有一个统一的流程来处理中断,使得不同设备的中断使用统一的流程。
一般的流程是,一个设备驱动程序初始化的时候,要先注册一个该设备的中断处理函数。咱们讲进程切换的时候说过,中断返回的那一刻是进程切换的时机。不知道你还记不记得,中断的时候,触发的函数是do_IRQ。这个函数是中断处理的统一入口。在这个函数里面,我们可以找到设备驱动程序注册的中断处理函数Handler,然后执行它进行中断处理。
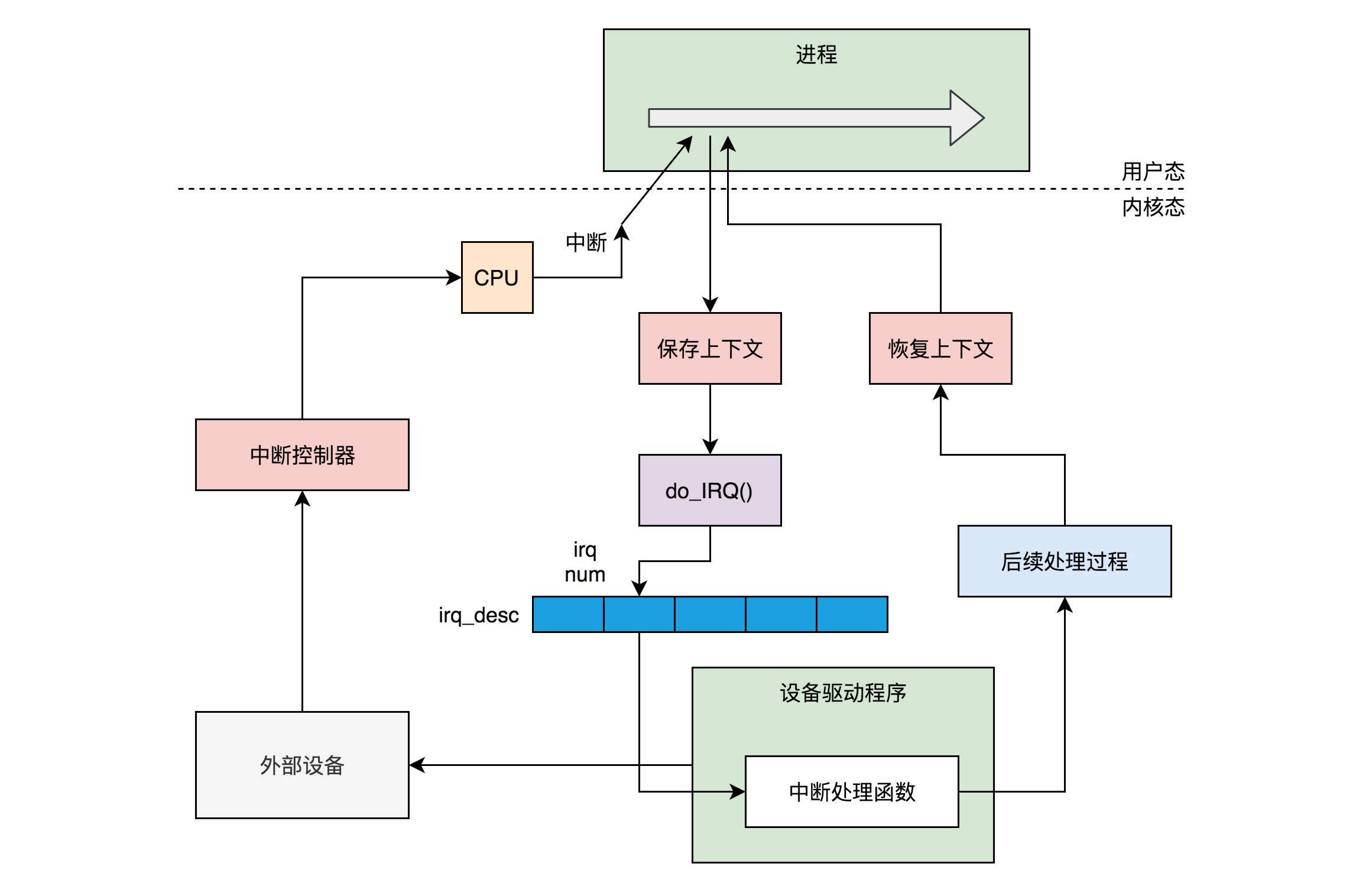
另外,对于块设备来讲,在驱动程序之上,文件系统之下,还需要一层通用设备层。比如咱们上一章讲的文件系统,里面的逻辑和磁盘设备没有什么关系,可以说是通用的逻辑。在写文件的最底层,我们看到了BIO字眼的函数,但是好像和设备驱动也没有什么关系。是的,因为块设备类型非常多,而Linux操作系统里面一切是文件。我们也不想文件系统以下,就直接对接各种各样的块设备驱动程序,这样会使得文件系统的复杂度非常高。所以,我们在中间加了一层通用块层,将与块设备相关的通用逻辑放在这一层,维护与设备无关的块的大小,然后通用块层下面对接各种各样的驱动程序。
26.3 用文件系统接口屏蔽驱动程序的差异
上面我们从硬件设备到设备控制器,到驱动程序,到通用块层,到文件系统,层层屏蔽不同的设备的差别,最终到这里涉及对用户使用接口,也要统一。
虽然我们操作设备,都是基于文件系统的接口,也要有一个统一的标准。
首先要统一的是设备名称。所有设备都在/dev/文件夹下面创建一个特殊的设备文件。这个设备特殊文件也有inode,但是它不关联到硬盘或任何其他存储介质上的数据,而是建立了与某个设备驱动程序的连接。
硬盘设备这里有一点绕。假设是/dev/sdb,这是一个设备文件。这个文件本身和硬盘上的文件系统没有任何关系。这个设备本身也不对应硬盘上的任何一个文件,/dev/sdb其实是在一个特殊的文件系统devtmpfs中。但是当我们将/dev/sdb格式化成一个文件系统ext4的时候,就会将它mount到一个路径下面。例如在/mnt/sdb下面。这个时候/dev/sdb还是一个设备文件在特殊文件系统devtmpfs中,而/mnt/sdb下面的文件才是在ext4文件系统中,只不这个设备是在/dev/sdb设备上的。
这里我们只关心设备文件,当我们用ls -l在/dev下面执行的时候,就会有这样的结果。
$ ls -l
crw------- 1 root root 5, 1 Dec 14 19:53 console
crw-r----- 1 root kmem 1, 1 Dec 14 19:53 mem
crw-rw-rw- 1 root root 1, 3 Dec 14 19:53 null
crw-r----- 1 root kmem 1, 4 Dec 14 19:53 port
crw-rw-rw- 1 root root 1, 8 Dec 14 19:53 random
crw--w---- 1 root tty 4, 0 Dec 14 19:53 tty0
crw--w---- 1 root tty 4, 1 Dec 14 19:53 tty1
crw-rw-rw- 1 root root 1, 9 Dec 14 19:53 urandom
brw-rw---- 1 root disk 253, 0 Dec 31 19:18 vda
brw-rw---- 1 root disk 253, 1 Dec 31 19:19 vda1
brw-rw---- 1 root disk 253, 16 Dec 14 19:53 vdb
brw-rw---- 1 root disk 253, 32 Jan 2 11:24 vdc
crw-rw-rw- 1 root root 1, 5 Dec 14 19:53 zero对于设备文件,ls出来的内容和我们原来讲过的稍有不同。
首先是第一位字符。如果是字符设备文件,则以c开头,如果是块设备文件,则以b开头。其次是这里面的两个号,一个是主设备号,一个是次设备号。主设备号定位设备驱动程序,次设备号作为参数传给启动程序,选择相应的单元。
从上面的列表我们可以看出来,mem、null、random、urandom、zero都是用同样的主设备号1,也就是它们使用同样的字符设备驱动,而vda、vda1、vdb、vdc也是同样的主设备号,也就是它们使用同样的块设备驱动。
有了设备文件,我们就可以使用对于文件的操作命令和API来操作文件了。例如,使用cat命令,可以读取/dev/random 和/dev/urandom的数据流,可以用od命令转换为十六进制后查看。
cat /dev/urandom | od -x这里还是要明确一下,如果用文件的操作作用于/dev/sdb的话,会无法操作文件系统上的文件,操作的这个设备。
如果Linux操作系统新添加了一个设备,应该做哪些事情呢?就像咱们使用Windows的时候,如果新添加了一种设备,首先要看这个设备有没有相应的驱动。如果没有就需要安装一个驱动,等驱动安装好了,设备就在Windows的设备列表中显示出来了。
在Linux上面,如果一个新的设备从来没有加载过驱动,也需要安装驱动。Linux的驱动程序已经被写成和操作系统有标准接口的代码,可以看成一个标准的内核模块。在Linux里面,安装驱动程序,其实就是加载一个内核模块。
我们可以用命令lsmod,查看有没有加载过相应的内核模块。这个列表很长,我这里列举了其中一部分。可以看到,这里面有网络和文件系统的驱动。
$ lsmod
Module Size Used by
iptable_filter 12810 1
bridge 146976 1 br_netfilter
vfat 17461 0
fat 65950 1 vfat
ext4 571716 1
cirrus 24383 1
crct10dif_pclmul 14307 0
crct10dif_common 12595 1 crct10dif_pclmul如果没有安装过相应的驱动,可以通过insmod安装内核模块。内核模块的后缀一般是ko。
例如,我们要加载openvswitch的驱动,就要通过下面的命令:
insmod openvswitch.ko一旦有了驱动,我们就可以通过命令mknod在/dev文件夹下面创建设备文件,就像下面这样:
mknod filename type major minor其中filename就是/dev下面的设备名称,type就是c为字符设备,b为块设备,major就是主设备号,minor就是次设备号。一旦执行了这个命令,新创建的设备文件就和上面加载过的驱动关联起来,这个时候就可以通过操作设备文件来操作驱动程序,从而操作设备。
你可能会问,人家Windows都说插上设备后,一旦安装了驱动,就直接在设备列表中出来了,你这里怎么还要人来执行命令创建呀,能不能智能一点?
当然可以,这里就要用到另一个管理设备的文件系统,也就是/sys路径下面的sysfs文件系统。它把实际连接到系统上的设备和总线组成了一个分层的文件系统。这个文件系统是当前系统上实际的设备数的真实反映。
在/sys路径下有下列的文件夹:
- /sys/devices是内核对系统中所有设备的分层次的表示;
- /sys/dev目录下一个char文件夹,一个block文件夹,分别维护一个按字符设备和块设备的主次号码(major:minor)链接到真实的设备(/sys/devices下)的符号链接文件;
- /sys/block是系统中当前所有的块设备;
- /sys/module有系统中所有模块的信息。
有了sysfs以后,我们还需要一个守护进程udev。当一个设备新插入系统的时候,内核会检测到这个设备,并会创建一个内核对象kobject 。 这个对象通过sysfs文件系统展现到用户层,同时内核还向用户空间发送一个热插拔消息。udevd会监听这些消息,在/dev中创建对应的文件。
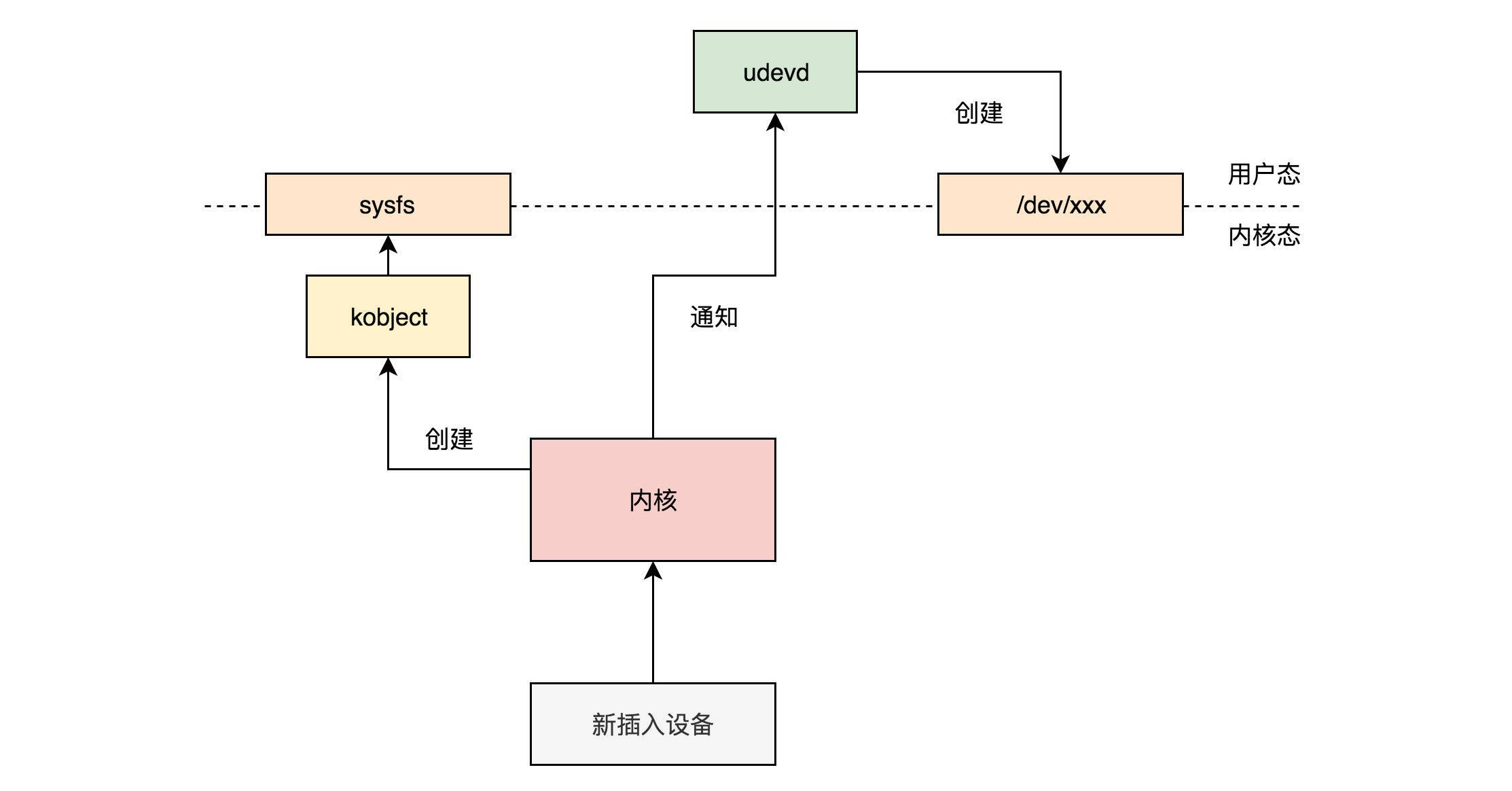
有了文件系统接口之后,我们不但可以通过文件系统的命令行操作设备,也可以通过程序,调用read、write函数,像读写文件一样操作设备。但是有些任务只使用读写很难完成,例如检查特定于设备的功能和属性,超出了通用文件系统的限制。所以,对于设备来讲,还有一种接口称为ioctl,表示输入输出控制接口,是用于配置和修改特定设备属性的通用接口,这个我们后面几节会详细说。
26.4 总结
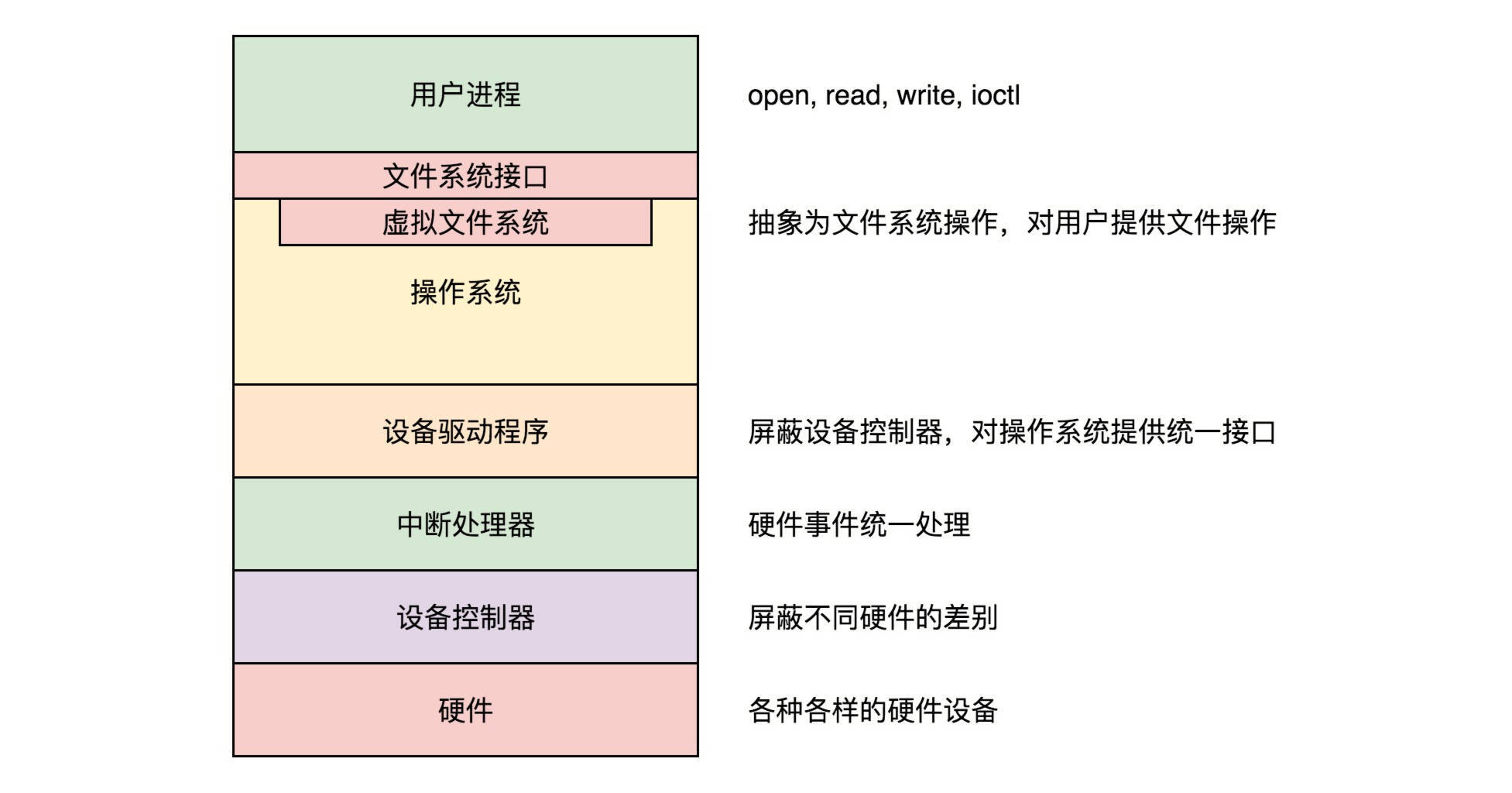
27. 字符设备(上)
先来讲稍微简单一点的字符设备驱动。
这一节,我找了两个比较简单的字符设备驱动来解析一下。一个是输入字符设备,鼠标。代码在drivers/input/mouse/logibm.c这里。
/*
* Logitech Bus Mouse Driver for Linux
*/
module_init(logibm_init);
module_exit(logibm_exit);另外一个是输出字符设备,打印机,代码drivers/char/lp.c这里。
/*
* Generic parallel printer driver
*/
module_init(lp_init_module);
module_exit(lp_cleanup_module);27.1 内核模块
设备驱动程序是一个内核模块,以ko的文件形式存在,可以通过insmod加载到内核中。那我们首先来看一下,怎么样才能构建一个内核模块呢?
一个内核模块应该由以下几部分组成。
第一部分,头文件部分。一般的内核模块,都需要include下面两个头文件:
#include <linux/module.h>
#include <linux/init.h>第二部分,定义一些函数,用于处理内核模块的主要逻辑。例如打开、关闭、读取、写入设备的函数或者响应中断的函数。
例如,logibm.c里面就定义了logibm_open。logibm_close就是处理打开和关闭的,定义了logibm_interrupt就是用来响应中断的。再如,lp.c里面就定义了lp_read,lp_write就是处理读写的。
第三部分,定义一个file_operations结构。前面我们讲过,设备是可以通过文件系统的接口进行访问的。咱们讲文件系统的时候说过,对于某种文件系统的操作,都是放在file_operations里面的。例如ext4就定义了这么一个结构,里面都是ext4_xxx之类的函数。设备要想被文件系统的接口操作,也需要定义这样一个结构。
例如,lp.c里面就定义了这样一个结构。
static const struct file_operations lp_fops = {
.owner = THIS_MODULE,
.write = lp_write,
.unlocked_ioctl = lp_ioctl,
#ifdef CONFIG_COMPAT
.compat_ioctl = lp_compat_ioctl,
#endif
.open = lp_open,
.release = lp_release,
#ifdef CONFIG_PARPORT_1284
.read = lp_read,
#endif
.llseek = noop_llseek,
};在logibm.c里面,我们找不到这样的结构,是因为它属于众多输入设备的一种,而输入设备的操作被统一定义在drivers/input/input.c里面,logibm.c只是定义了一些自己独有的操作。
static const struct file_operations input_devices_fileops = {
.owner = THIS_MODULE,
.open = input_proc_devices_open,
.poll = input_proc_devices_poll,
.read = seq_read,
.llseek = seq_lseek,
.release = seq_release,
};第四部分,定义整个模块的初始化函数和退出函数,用于加载和卸载这个ko的时候调用。
例如lp.c就定义了lp_init_module和lp_cleanup_module,logibm.c就定义了logibm_init和logibm_exit。
第五部分,调用module_init和module_exit,分别指向上面两个初始化函数和退出函数。
第六部分,声明一下lisense,调用MODULE_LICENSE。
有了这六部分,一个内核模块就基本合格了,可以工作了。
27.2 打开字符设备
字符设备可不是一个普通的内核模块,它有自己独特的行为。接下来,我们就沿着打开一个字符设备的过程,看看字符设备这个内核模块做了哪些特殊的事情。
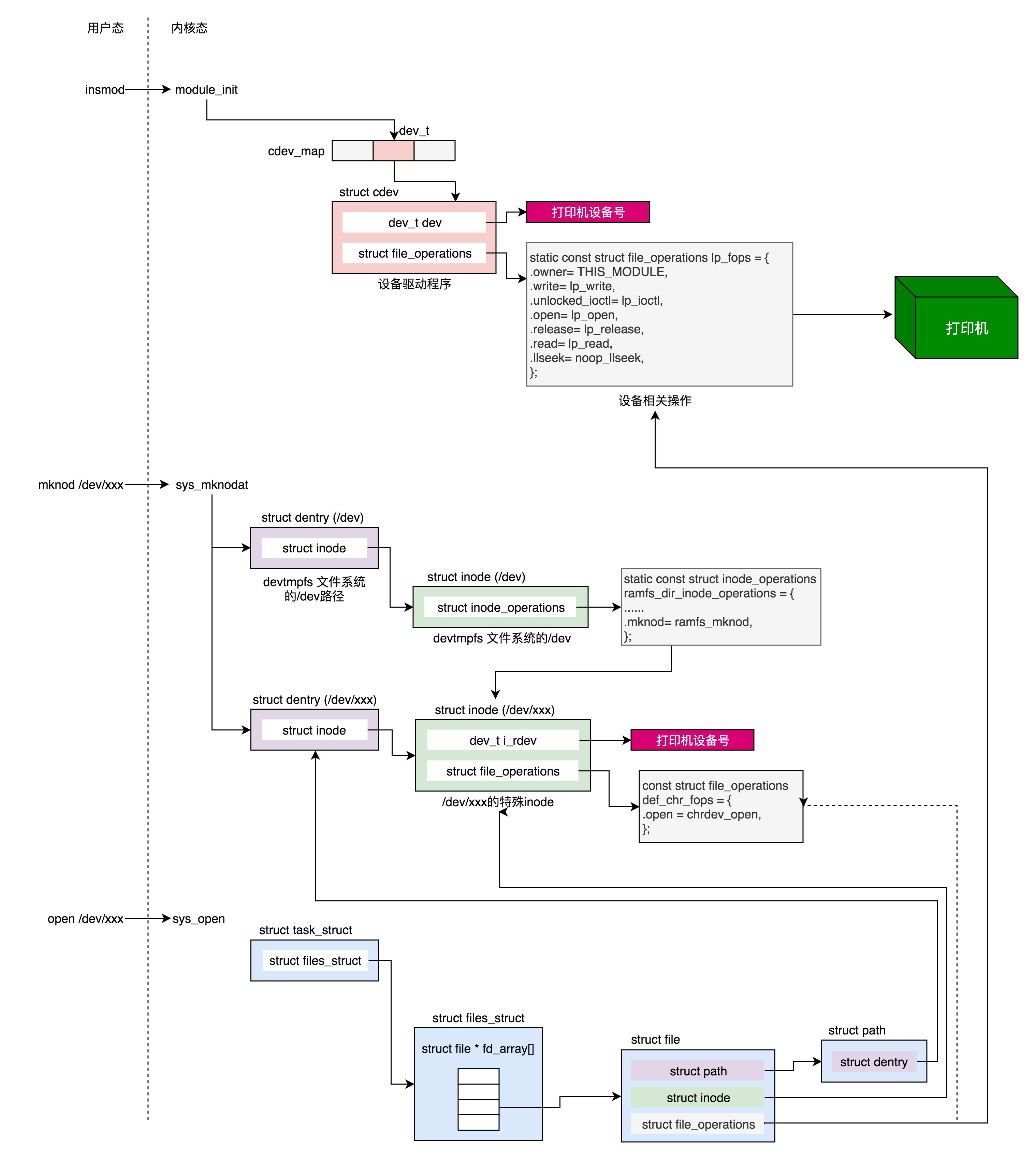
要使用一个字符设备,我们首先要把写好的内核模块,通过insmod加载进内核。这个时候,先调用的就是module_init调用的初始化函数。
例如,在lp.c的初始化函数lp_init对应的代码如下:
static int __init lp_init (void)
{
......
if (register_chrdev (LP_MAJOR, "lp", &lp_fops)) {
printk (KERN_ERR "lp: unable to get major %d\n", LP_MAJOR);
return -EIO;
}
......
}
int __register_chrdev(unsigned int major, unsigned int baseminor,
unsigned int count, const char *name,
const struct file_operations *fops)
{
struct char_device_struct *cd;
struct cdev *cdev;
int err = -ENOMEM;
......
cd = __register_chrdev_region(major, baseminor, count, name);
cdev = cdev_alloc();
cdev->owner = fops->owner;
cdev->ops = fops;
kobject_set_name(&cdev->kobj, "%s", name);
err = cdev_add(cdev, MKDEV(cd->major, baseminor), count);
cd->cdev = cdev;
return major ? 0 : cd->major;
}在字符设备驱动的内核模块加载的时候,最重要的一件事情就是,注册这个字符设备。注册的方式是调用__register_chrdev_region,注册字符设备的主次设备号和名称,然后分配一个struct cdev结构,将cdev的ops成员变量指向这个模块声明的file_operations。然后,cdev_add会将这个字符设备添加到内核中一个叫作struct kobj_map *cdev_map的结构,来统一管理所有字符设备。
其中,MKDEV(cd->major, baseminor)表示将主设备号和次设备号生成一个dev_t的整数,然后将这个整数dev_t和cdev关联起来。
/**
* cdev_add() - add a char device to the system
* @p: the cdev structure for the device
* @dev: the first device number for which this device is responsible
* @count: the number of consecutive minor numbers corresponding to this
* device
*
* cdev_add() adds the device represented by @p to the system, making it
* live immediately. A negative error code is returned on failure.
*/
int cdev_add(struct cdev *p, dev_t dev, unsigned count)
{
int error;
p->dev = dev;
p->count = count;
error = kobj_map(cdev_map, dev, count, NULL,
exact_match, exact_lock, p);
kobject_get(p->kobj.parent);
return 0;
}在logibm.c中,我们在logibm_init找不到注册字符设备,这是因为input.c里面的初始化函数input_init会调用register_chrdev_region,注册输入的字符设备,会在logibm_init中调用input_register_device,将logibm.c这个字符设备注册到input.c里面去,这就相当于input.c对多个输入字符设备进行统一的管理。
内核模块加载完毕后,接下来要通过mknod在/dev下面创建一个设备文件,只有有了这个设备文件,我们才能通过文件系统的接口,对这个设备文件进行操作。
mknod也是一个系统调用,定义如下:
SYSCALL_DEFINE3(mknod, const char __user *, filename, umode_t, mode, unsigned, dev)
{
return sys_mknodat(AT_FDCWD, filename, mode, dev);
}
SYSCALL_DEFINE4(mknodat, int, dfd, const char __user *, filename, umode_t, mode,
unsigned, dev)
{
struct dentry *dentry;
struct path path;
......
dentry = user_path_create(dfd, filename, &path, lookup_flags);
......
switch (mode & S_IFMT) {
......
case S_IFCHR: case S_IFBLK:
error = vfs_mknod(path.dentry->d_inode,dentry,mode,
new_decode_dev(dev));
break;
......
}
}我们可以在这个系统调用里看到,在文件系统上,顺着路径找到/dev/xxx所在的文件夹,然后为这个新创建的设备文件创建一个dentry。这是维护文件和inode之间的关联关系的结构。
接下来,如果是字符文件S_IFCHR或者设备文件S_IFBLK,我们就调用vfs_mknod。
int vfs_mknod(struct inode *dir, struct dentry *dentry, umode_t mode, dev_t dev)
{
......
error = dir->i_op->mknod(dir, dentry, mode, dev);
......
}这里需要调用对应的文件系统的inode_operations。应该调用哪个文件系统呢?
如果我们在linux下面执行mount命令,能看到下面这一行:
devtmpfs on /dev type devtmpfs (rw,nosuid,size=3989584k,nr_inodes=997396,mode=755)也就是说,/dev下面的文件系统的名称为devtmpfs,我们可以在内核中找到它。
static struct dentry *dev_mount(struct file_system_type *fs_type, int flags,
const char *dev_name, void *data)
{
#ifdef CONFIG_TMPFS
return mount_single(fs_type, flags, data, shmem_fill_super);
#else
return mount_single(fs_type, flags, data, ramfs_fill_super);
#endif
}
static struct file_system_type dev_fs_type = {
.name = "devtmpfs",
.mount = dev_mount,
.kill_sb = kill_litter_super,
};从这里可以看出,devtmpfs在挂载的时候,有两种模式,一种是ramfs,一种是shmem都是基于内存的文件系统。这里你先不用管,基于内存的文件系统具体是怎么回事儿。
static const struct inode_operations ramfs_dir_inode_operations = {
......
.mknod = ramfs_mknod,
};
static const struct inode_operations shmem_dir_inode_operations = {
#ifdef CONFIG_TMPFS
......
.mknod = shmem_mknod,
};这两个mknod虽然实现不同,但是都会调用到用一个函数init_special_inode。
void init_special_inode(struct inode *inode, umode_t mode, dev_t rdev)
{
inode->i_mode = mode;
if (S_ISCHR(mode)) {
inode->i_fop = &def_chr_fops;
inode->i_rdev = rdev;
} else if (S_ISBLK(mode)) {
inode->i_fop = &def_blk_fops;
inode->i_rdev = rdev;
} else if (S_ISFIFO(mode))
inode->i_fop = &pipefifo_fops;
else if (S_ISSOCK(mode))
; /* leave it no_open_fops */
}显然这个文件是个特殊文件,inode也是特殊的。这里这个inode可以关联字符设备、块设备、FIFO文件、Socket等。我们这里只看字符设备。
这里的inode的file_operations指向一个def_chr_fops,这里面只有一个open,就等着你打开它。
另外,inode的i_rdev指向这个设备的dev_t。还记得cdev_map吗?通过这个dev_t,可以找到我们刚在加载的字符设备cdev。
const struct file_operations def_chr_fops = {
.open = chrdev_open,
};到目前为止,我们只是创建了/dev下面的一个文件,并且和相应的设备号关联起来。但是,我们还没有打开这个/dev下面的设备文件。
现在我们来打开它。打开一个文件的流程,我们在 文件系统 那一节讲过了,这里不再重复。最终就像打开字符设备的图中一样,打开文件的进程的task_struct里,有一个数组代表它打开的文件,下标就是文件描述符fd,每一个打开的文件都有一个struct file结构,会指向一个dentry项。dentry可以用来关联inode。这个dentry就是咱们上面mknod的时候创建的。
在进程里面调用open函数,最终对调用到这个特殊的inode的open函数,也就是chrdev_open。
static int chrdev_open(struct inode *inode, struct file *filp)
{
const struct file_operations *fops;
struct cdev *p;
struct cdev *new = NULL;
int ret = 0;
p = inode->i_cdev;
if (!p) {
struct kobject *kobj;
int idx;
kobj = kobj_lookup(cdev_map, inode->i_rdev, &idx);
new = container_of(kobj, struct cdev, kobj);
p = inode->i_cdev;
if (!p) {
inode->i_cdev = p = new;
list_add(&inode->i_devices, &p->list);
new = NULL;
}
}
......
fops = fops_get(p->ops);
......
replace_fops(filp, fops);
if (filp->f_op->open) {
ret = filp->f_op->open(inode, filp);
......
}
......
}在这个函数里面,我们首先看这个inode的i_cdev,是否已经关联到cdev。如果第一次打开,当然没有。没有没关系,inode里面有i_rdev呀,也就是有dev_t。我们可以通过它在cdev_map中找cdev。咱们上面注册过了,所以肯定能够找到。找到后我们就将inode的i_cdev,关联到找到的cdev new。
找到cdev就好办了。cdev里面有file_operations,这是设备驱动程序自己定义的。我们可以通过它来操作设备驱动程序,把它付给struct file里面的file_operations。这样以后操作文件描述符,就是直接操作设备了。
最后,我们需要调用设备驱动程序的file_operations的open函数,真正打开设备。对于打印机,调用的是lp_open。对于鼠标调用的是input_proc_devices_open,最终会调用到logibm_open。这些多和设备相关,你不必看懂它们。
27.3 写入字符设备
当我们像打开一个文件一样打开一个字符设备之后,接下来就是对这个设备的读写。对于文件的读写咱们在文件系统那一章详细讲述过,读写的过程是类似的,所以这里我们只解析打印机驱动写入的过程。
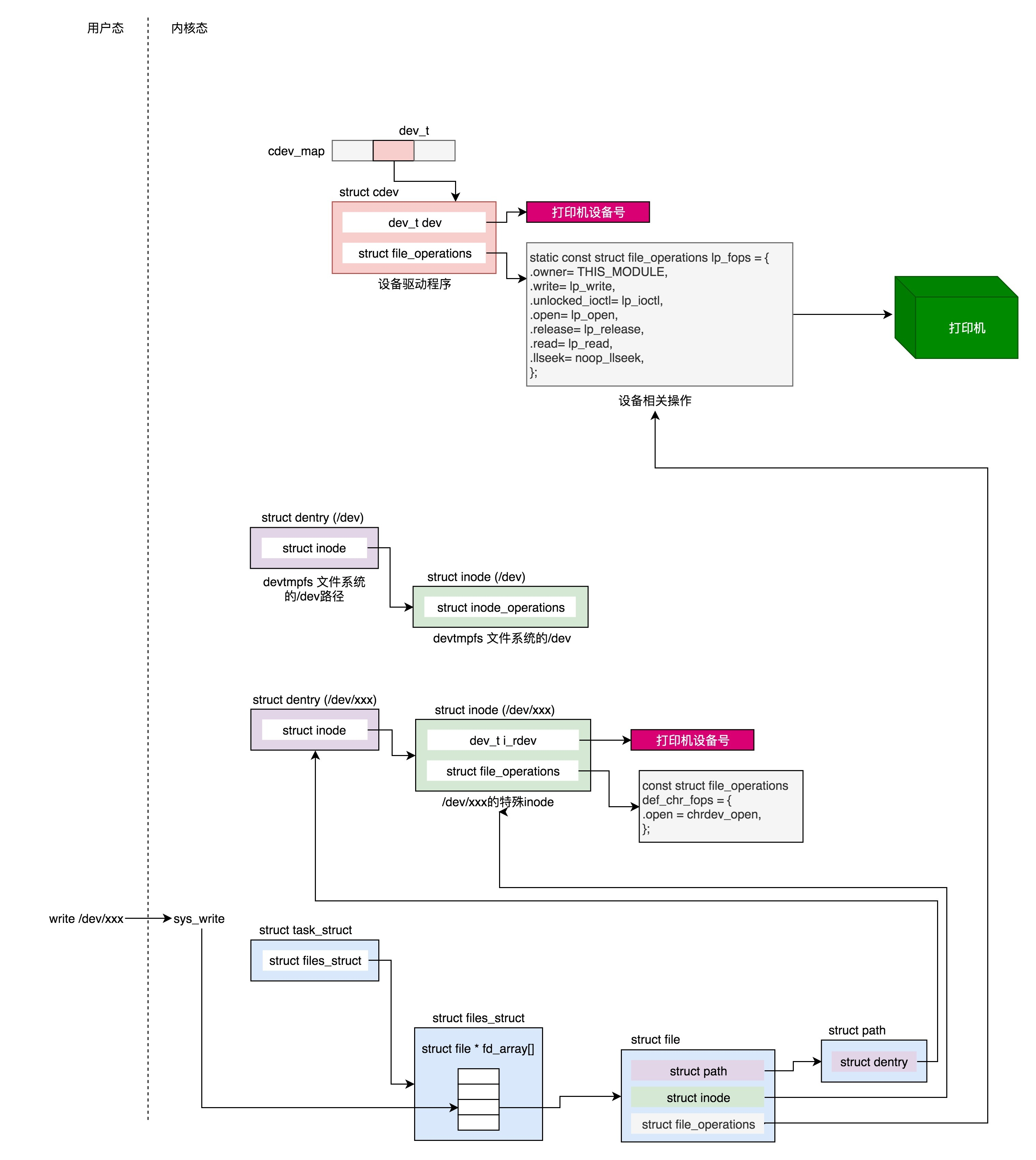
写入一个字符设备,就是用文件系统的标准接口write,参数文件描述符fd,在内核里面调用的sys_write,在sys_write里面根据文件描述符fd得到struct file结构。接下来再调用vfs_write。
ssize_t __vfs_write(struct file *file, const char __user *p, size_t count, loff_t *pos)
{
if (file->f_op->write)
return file->f_op->write(file, p, count, pos);
else if (file->f_op->write_iter)
return new_sync_write(file, p, count, pos);
else
return -EINVAL;
}我们可以看到,在__vfs_write里面,我们会调用struct file结构里的file_operations的write函数。上面我们打开字符设备的时候,已经将struct file结构里面的file_operations指向了设备驱动程序的file_operations结构,所以这里的write函数最终会调用到lp_write。
static ssize_t lp_write(struct file * file, const char __user * buf,
size_t count, loff_t *ppos)
{
unsigned int minor = iminor(file_inode(file));
struct parport *port = lp_table[minor].dev->port;
char *kbuf = lp_table[minor].lp_buffer;
ssize_t retv = 0;
ssize_t written;
size_t copy_size = count;
......
/* Need to copy the data from user-space. */
if (copy_size > LP_BUFFER_SIZE)
copy_size = LP_BUFFER_SIZE;
......
if (copy_from_user (kbuf, buf, copy_size)) {
retv = -EFAULT;
goto out_unlock;
}
......
do {
/* Write the data. */
written = parport_write (port, kbuf, copy_size);
if (written > 0) {
copy_size -= written;
count -= written;
buf += written;
retv += written;
}
......
if (need_resched())
schedule ();
if (count) {
copy_size = count;
if (copy_size > LP_BUFFER_SIZE)
copy_size = LP_BUFFER_SIZE;
if (copy_from_user(kbuf, buf, copy_size)) {
if (retv == 0)
retv = -EFAULT;
break;
}
}
} while (count > 0);
......
}这个设备驱动程序的写入函数的实现还是比较典型的。先是调用copy_from_user将数据从用户态拷贝到内核态的缓存中,然后调用parport_write写入外部设备。这里还有一个schedule函数,也即写入的过程中,给其他线程抢占CPU的机会。然后,如果count还是大于0,也就是数据还没有写完,那我们就接着copy_from_user,接着parport_write,直到写完为止。
27.4 使用IOCTL控制设备
对于I/O设备来讲,我们前面也说过,除了读写设备,还会调用ioctl,做一些特殊的I/O操作。

ioctl也是一个系统调用,它在内核里面的定义如下:
SYSCALL_DEFINE3(ioctl, unsigned int, fd, unsigned int, cmd, unsigned long, arg)
{
int error;
struct fd f = fdget(fd);
......
error = do_vfs_ioctl(f.file, fd, cmd, arg);
fdput(f);
return error;
}其中,fd是这个设备的文件描述符,cmd是传给这个设备的命令,arg是命令的参数。其中,对于命令和命令的参数,使用ioctl系统调用的用户和驱动程序的开发人员约定好行为即可。
其实cmd看起来是一个int,其实他的组成比较复杂,它由几部分组成:
- 最低八位为NR,是命令号;
- 然后八位是TYPE,是类型;
- 然后十四位是参数的大小;
- 最高两位是DIR,是方向,表示写入、读出,还是读写。
由于组成比较复杂,有一些宏是专门用于组成这个cmd值的。
由于组成比较复杂,有一些宏是专门用于组成这个cmd值的。
/*
* Used to create numbers.
*/
#define _IO(type,nr) _IOC(_IOC_NONE,(type),(nr),0)
#define _IOR(type,nr,size) _IOC(_IOC_READ,(type),(nr),(_IOC_TYPECHECK(size)))
#define _IOW(type,nr,size) _IOC(_IOC_WRITE,(type),(nr),(_IOC_TYPECHECK(size)))
#define _IOWR(type,nr,size) _IOC(_IOC_READ|_IOC_WRITE,(type),(nr),(_IOC_TYPECHECK(size)))
/* used to decode ioctl numbers.. */
#define _IOC_DIR(nr) (((nr) >> _IOC_DIRSHIFT) & _IOC_DIRMASK)
#define _IOC_TYPE(nr) (((nr) >> _IOC_TYPESHIFT) & _IOC_TYPEMASK)
#define _IOC_NR(nr) (((nr) >> _IOC_NRSHIFT) & _IOC_NRMASK)
#define _IOC_SIZE(nr) (((nr) >> _IOC_SIZESHIFT) & _IOC_SIZEMASK)在用户程序中,可以通过上面的”Used to create numbers”这些宏,根据参数生成cmd,在驱动程序中,可以通过下面的”used to decode ioctl numbers”这些宏,解析cmd后,执行指令。
ioctl中会调用do_vfs_ioctl,这里面对于已经定义好的cmd,进行相应的处理。如果不是默认定义好的cmd,则执行默认操作。对于普通文件,调用file_ioctl;对于其他文件调用vfs_ioctl。
int do_vfs_ioctl(struct file *filp, unsigned int fd, unsigned int cmd,
unsigned long arg)
{
int error = 0;
int __user *argp = (int __user *)arg;
struct inode *inode = file_inode(filp);
switch (cmd) {
......
case FIONBIO:
error = ioctl_fionbio(filp, argp);
break;
case FIOASYNC:
error = ioctl_fioasync(fd, filp, argp);
break;
......
case FICLONE:
return ioctl_file_clone(filp, arg, 0, 0, 0);
default:
if (S_ISREG(inode->i_mode))
error = file_ioctl(filp, cmd, arg);
else
error = vfs_ioctl(filp, cmd, arg);
break;
}
return error;
}由于咱们这里是设备驱动程序,所以调用的是vfs_ioctl。
/**
* vfs_ioctl - call filesystem specific ioctl methods
* @filp: open file to invoke ioctl method on
* @cmd: ioctl command to execute
* @arg: command-specific argument for ioctl
*
* Invokes filesystem specific ->unlocked_ioctl, if one exists; otherwise
* returns -ENOTTY.
*
* Returns 0 on success, -errno on error.
*/
long vfs_ioctl(struct file *filp, unsigned int cmd, unsigned long arg)
{
int error = -ENOTTY;
if (!filp->f_op->unlocked_ioctl)
goto out;
error = filp->f_op->unlocked_ioctl(filp, cmd, arg);
if (error == -ENOIOCTLCMD)
error = -ENOTTY;
out:
return error;
}这里面调用的是struct file里file_operations的unlocked_ioctl函数。我们前面初始化设备驱动的时候,已经将file_operations指向设备驱动的file_operations了。这里调用的是设备驱动的unlocked_ioctl。对于打印机程序来讲,调用的是lp_ioctl。可以看出来,这里面就是switch语句,它会根据不同的cmd,做不同的操作。
static long lp_ioctl(struct file *file, unsigned int cmd,
unsigned long arg)
{
unsigned int minor;
struct timeval par_timeout;
int ret;
minor = iminor(file_inode(file));
mutex_lock(&lp_mutex);
switch (cmd) {
......
default:
ret = lp_do_ioctl(minor, cmd, arg, (void __user *)arg);
break;
}
mutex_unlock(&lp_mutex);
return ret;
}
static int lp_do_ioctl(unsigned int minor, unsigned int cmd,
unsigned long arg, void __user *argp)
{
int status;
int retval = 0;
switch ( cmd ) {
case LPTIME:
if (arg > UINT_MAX / HZ)
return -EINVAL;
LP_TIME(minor) = arg * HZ/100;
break;
case LPCHAR:
LP_CHAR(minor) = arg;
break;
case LPABORT:
if (arg)
LP_F(minor) |= LP_ABORT;
else
LP_F(minor) &= ~LP_ABORT;
break;
case LPABORTOPEN:
if (arg)
LP_F(minor) |= LP_ABORTOPEN;
else
LP_F(minor) &= ~LP_ABORTOPEN;
break;
case LPCAREFUL:
if (arg)
LP_F(minor) |= LP_CAREFUL;
else
LP_F(minor) &= ~LP_CAREFUL;
break;
case LPWAIT:
LP_WAIT(minor) = arg;
break;
case LPSETIRQ:
return -EINVAL;
break;
case LPGETIRQ:
if (copy_to_user(argp, &LP_IRQ(minor),
sizeof(int)))
return -EFAULT;
break;
case LPGETSTATUS:
if (mutex_lock_interruptible(&lp_table[minor].port_mutex))
return -EINTR;
lp_claim_parport_or_block (&lp_table[minor]);
status = r_str(minor);
lp_release_parport (&lp_table[minor]);
mutex_unlock(&lp_table[minor].port_mutex);
if (copy_to_user(argp, &status, sizeof(int)))
return -EFAULT;
break;
case LPRESET:
lp_reset(minor);
break;
case LPGETFLAGS:
status = LP_F(minor);
if (copy_to_user(argp, &status, sizeof(int)))
return -EFAULT;
break;
default:
retval = -EINVAL;
}
return retval;
}27.5 总结
一个字符设备要能够工作,需要三部分配合。
第一,有一个设备驱动程序的ko模块,里面有模块初始化函数、中断处理函数、设备操作函数。这里面封装了对于外部设备的操作。加载设备驱动程序模块的时候,模块初始化函数会被调用。在内核维护所有字符设备驱动的数据结构cdev_map里面注册,我们就可以很容易根据设备号,找到相应的设备驱动程序。
第二,在/dev目录下有一个文件表示这个设备,这个文件在特殊的devtmpfs文件系统上,因而也有相应的dentry和inode。这里的inode是一个特殊的inode,里面有设备号。通过它,我们可以在cdev_map中找到设备驱动程序,里面还有针对字符设备文件的默认操作def_chr_fops。
第三,打开一个字符设备文件和打开一个普通的文件有类似的数据结构,有文件描述符、有struct file、指向字符设备文件的dentry和inode。字符设备文件的相关操作file_operations一开始指向def_chr_fops,在调用def_chr_fops里面的chrdev_open函数的时候,修改为指向设备操作函数,从而读写一个字符设备文件就会直接变成读写外部设备了。
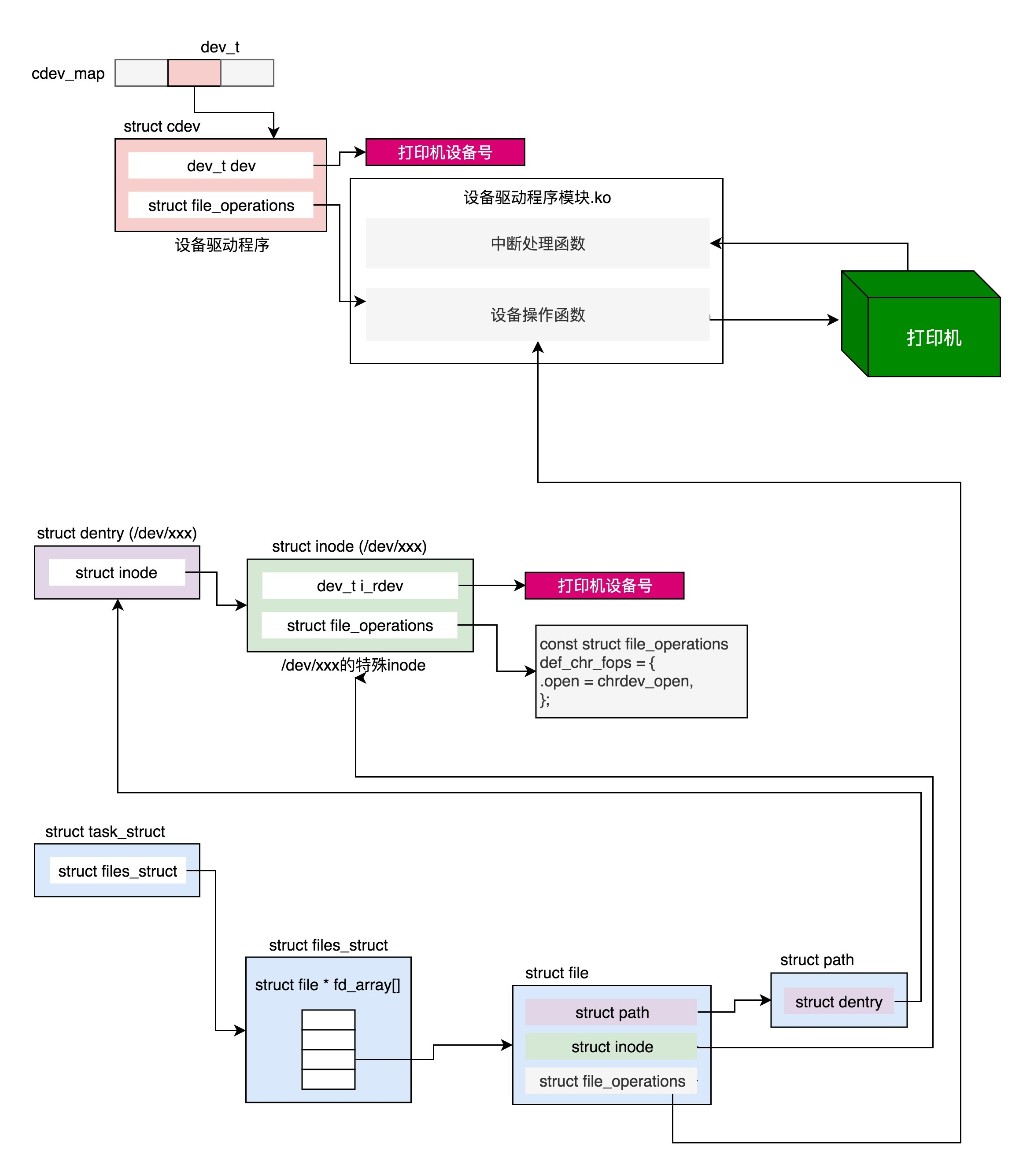
28. 字符设备(下)
28.1 中断处理机制
如果一个设备有事情需要通知操作系统,会通过中断和设备驱动程序进行交互,今天我们就来解析中断处理机制。
鼠标就是通过中断,将自己的位置和按键信息,传递给设备驱动程序。
static int logibm_open(struct input_dev *dev)
{
if (request_irq(logibm_irq, logibm_interrupt, 0, "logibm", NULL)) {
printk(KERN_ERR "logibm.c: Can't allocate irq %d\n", logibm_irq);
return -EBUSY;
}
outb(LOGIBM_ENABLE_IRQ, LOGIBM_CONTROL_PORT);
return 0;
}
static irqreturn_t logibm_interrupt(int irq, void *dev_id)
{
char dx, dy;
unsigned char buttons;
outb(LOGIBM_READ_X_LOW, LOGIBM_CONTROL_PORT);
dx = (inb(LOGIBM_DATA_PORT) & 0xf);
outb(LOGIBM_READ_X_HIGH, LOGIBM_CONTROL_PORT);
dx |= (inb(LOGIBM_DATA_PORT) & 0xf) << 4;
outb(LOGIBM_READ_Y_LOW, LOGIBM_CONTROL_PORT);
dy = (inb(LOGIBM_DATA_PORT) & 0xf);
outb(LOGIBM_READ_Y_HIGH, LOGIBM_CONTROL_PORT);
buttons = inb(LOGIBM_DATA_PORT);
dy |= (buttons & 0xf) << 4;
buttons = ~buttons >> 5;
input_report_rel(logibm_dev, REL_X, dx);
input_report_rel(logibm_dev, REL_Y, dy);
input_report_key(logibm_dev, BTN_RIGHT, buttons & 1);
input_report_key(logibm_dev, BTN_MIDDLE, buttons & 2);
input_report_key(logibm_dev, BTN_LEFT, buttons & 4);
input_sync(logibm_dev);
outb(LOGIBM_ENABLE_IRQ, LOGIBM_CONTROL_PORT);
return IRQ_HANDLED;
}要处理中断,需要有一个中断处理函数。定义如下:
irqreturn_t (*irq_handler_t)(int irq, void * dev_id);
/**
* enum irqreturn
* @IRQ_NONE interrupt was not from this device or was not handled
* @IRQ_HANDLED interrupt was handled by this device
* @IRQ_WAKE_THREAD handler requests to wake the handler thread
*/
enum irqreturn {
IRQ_NONE = (0 << 0),
IRQ_HANDLED = (1 << 0),
IRQ_WAKE_THREAD = (1 << 1),
};其中,irq是一个整数,是中断信号。dev_id是一个void *的通用指针,主要用于区分同一个中断处理函数对于不同设备的处理。
这里的返回值有三种:IRQ_NONE表示不是我的中断,不归我管;IRQ_HANDLED表示处理完了的中断;IRQ_WAKE_THREAD表示有一个进程正在等待这个中断,中断处理完了,应该唤醒它。
上面的例子中,logibm_interrupt这个中断处理函数,先是获取了x和y的移动坐标,以及左中右的按键,上报上去,然后返回IRQ_HANDLED,这表示处理完毕。
其实,写一个真正生产用的中断处理程序还是很复杂的。当一个中断信号A触发后,正在处理的过程中,这个中断信号A是应该暂时关闭的,这样是为了防止再来一个中断信号A,在当前的中断信号A的处理过程中插一杠子。但是,这个暂时关闭的时间应该多长呢?
如果太短了,应该原子化处理完毕的没有处理完毕,又被另一个中断信号A中断了,很多操作就不正确了;如果太长了,一直关闭着,新的中断信号A进不来,系统就显得很慢。所以,很多中断处理程序将整个中断要做的事情分成两部分,称为上半部和下半部,或者成为关键处理部分和延迟处理部分。在中断处理函数中,仅仅处理关键部分,完成了就将中断信号打开,使得新的中断可以进来,需要比较长时间处理的部分,也即延迟部分,往往通过工作队列等方式慢慢处理。
这个写起来可以是一本书了,推荐你好好读一读《Linux Device Drivers》这本书,这里我就不详细介绍了。
有了中断处理函数,接下来要调用request_irq来注册这个中断处理函数。request_irq有这样几个参数:
- unsigned int irq是中断信号;
- irq_handler_t handler是中断处理函数;
- unsigned long flags是一些标识位;
- const char *name是设备名称;
void *dev这个通用指针应该和中断处理函数的void *dev相对应。
static inline int __must_check
request_irq(unsigned int irq, irq_handler_t handler, unsigned long flags, const char *name, void *dev)
{
return request_threaded_irq(irq, handler, NULL, flags, name, dev);
}中断处理函数被注册到哪里去呢?让我们沿着request_irq看下去。request_irq调用的是request_threaded_irq。代码如下:
int request_threaded_irq(unsigned int irq, irq_handler_t handler,
irq_handler_t thread_fn, unsigned long irqflags,
const char *devname, void *dev_id)
{
struct irqaction *action;
struct irq_desc *desc;
int retval;
......
desc = irq_to_desc(irq);
......
action = kzalloc(sizeof(struct irqaction), GFP_KERNEL);
action->handler = handler;
action->thread_fn = thread_fn;
action->flags = irqflags;
action->name = devname;
action->dev_id = dev_id;
......
retval = __setup_irq(irq, desc, action);
......
}对于每一个中断,都有一个对中断的描述结构struct irq_desc。它有一个重要的成员变量是struct irqaction,用于表示处理这个中断的动作。如果我们仔细看这个结构,会发现,它里面有next指针,也就是说,这是一个链表,对于这个中断的所有处理动作,都串在这个链表上。
struct irq_desc {
......
struct irqaction *action; /* IRQ action list */
......
struct module *owner;
const char *name;
};
/**
* struct irqaction - per interrupt action descriptor
* @handler: interrupt handler function
* @name: name of the device
* @dev_id: cookie to identify the device
* @percpu_dev_id: cookie to identify the device
* @next: pointer to the next irqaction for shared interrupts
* @irq: interrupt number
* @flags: flags (see IRQF_* above)
* @thread_fn: interrupt handler function for threaded interrupts
* @thread: thread pointer for threaded interrupts
* @secondary: pointer to secondary irqaction (force threading)
* @thread_flags: flags related to @thread
* @thread_mask: bitmask for keeping track of @thread activity
* @dir: pointer to the proc/irq/NN/name entry
*/
struct irqaction {
irq_handler_t handler;
void *dev_id;
void __percpu *percpu_dev_id;
struct irqaction *next;
irq_handler_t thread_fn;
struct task_struct *thread;
struct irqaction *secondary;
unsigned int irq;
unsigned int flags;
unsigned long thread_flags;
unsigned long thread_mask;
const char *name;
struct proc_dir_entry *dir;
};每一个中断处理动作的结构struct irqaction,都有以下成员:
- 中断处理函数handler;
- void *dev_id为设备id;
- irq为中断信号;
- 如果中断处理函数在单独的线程运行,则有thread_fn是线程的执行函数,thread是线程的task_struct。
在request_threaded_irq函数中,irq_to_desc根据中断信号查找中断描述结构。如何查找呢?这就要区分情况。一般情况下,所有的struct irq_desc都放在一个数组里面,我们直接按下标查找就可以了。如果配置了CONFIG_SPARSE_IRQ,那中断号是不连续的,就不适合用数组保存了,
我们可以放在一棵基数树上。我们不是第一次遇到这个数据结构了。这种结构对于从某个整型key找到value速度很快,中断信号irq是这个整数。通过它,我们很快就能定位到对应的struct irq_desc。
#ifdef CONFIG_SPARSE_IRQ
static RADIX_TREE(irq_desc_tree, GFP_KERNEL);
struct irq_desc *irq_to_desc(unsigned int irq)
{
return radix_tree_lookup(&irq_desc_tree, irq);
}
#else /* !CONFIG_SPARSE_IRQ */
struct irq_desc irq_desc[NR_IRQS] __cacheline_aligned_in_smp = {
[0 ... NR_IRQS-1] = {
}
};
struct irq_desc *irq_to_desc(unsigned int irq)
{
return (irq < NR_IRQS) ? irq_desc + irq : NULL;
}
#endif /* !CONFIG_SPARSE_IRQ */为什么中断信号会有稀疏,也就是不连续的情况呢?这里需要说明一下,这里的irq并不是真正的、物理的中断信号,而是一个抽象的、虚拟的中断信号。因为物理的中断信号和硬件关联比较大,中断控制器也是各种各样的。
作为内核,我们不可能写程序的时候,适配各种各样的硬件中断控制器,因而就需要有一层中断抽象层。这里虚拟中断信号到中断描述结构的映射,就是抽象中断层的主要逻辑。
下面我们讲真正中断响应的时候,会涉及物理中断信号。可以想象,如果只有一个CPU,一个中断控制器,则基本能够保证从物理中断信号到虚拟中断信号的映射是线性的,这样用数组表示就没啥问题,但是如果有多个CPU,多个中断控制器,每个中断控制器各有各的物理中断信号,就没办法保证虚拟中断信号是连续的,所以就要用到基数树了。
接下来,request_threaded_irq函数分配了一个struct irqaction,并且初始化它,接着调用__setup_irq。在这个函数里面,如果struct irq_desc里面已经有struct irqaction了,我们就将新的struct irqaction挂在链表的末端。如果设定了以单独的线程运行中断处理函数,setup_irq_thread就会创建这个内核线程,wake_up_process会唤醒它。
static int
__setup_irq(unsigned int irq, struct irq_desc *desc, struct irqaction *new)
{
struct irqaction *old, **old_ptr;
unsigned long flags, thread_mask = 0;
int ret, nested, shared = 0;
......
new->irq = irq;
......
/*
* Create a handler thread when a thread function is supplied
* and the interrupt does not nest into another interrupt
* thread.
*/
if (new->thread_fn && !nested) {
ret = setup_irq_thread(new, irq, false);
}
......
old_ptr = &desc->action;
old = *old_ptr;
if (old) {
/* add new interrupt at end of irq queue */
do {
thread_mask |= old->thread_mask;
old_ptr = &old->next;
old = *old_ptr;
} while (old);
}
......
*old_ptr = new;
......
if (new->thread)
wake_up_process(new->thread);
......
}
static int
setup_irq_thread(struct irqaction *new, unsigned int irq, bool secondary)
{
struct task_struct *t;
struct sched_param param = {
.sched_priority = MAX_USER_RT_PRIO/2,
};
t = kthread_create(irq_thread, new, "irq/%d-%s", irq, new->name);
sched_setscheduler_nocheck(t, SCHED_FIFO, ¶m);
get_task_struct(t);
new->thread = t;
......
return 0;
}至此为止,request_irq完成了它的使命。总结来说,它就是根据中断信号irq,找到基数树上对应的irq_desc,然后将新的irqaction挂在链表上。
接下来,我们就来看,真正中断来了的时候,会发生一些什么。
真正中断的发生还是要从硬件开始。这里面有四个层次。
- 第一个层次是外部设备给中断控制器发送物理中断信号。
- 第二个层次是中断控制器将物理中断信号转换成为中断向量interrupt vector,发给各个CPU。
- 第三个层次是每个CPU都会有一个中断向量表,根据interrupt vector调用一个IRQ处理函数。注意这里的IRQ处理函数还不是咱们上面指定的irq_handler_t,到这一层还是CPU硬件的要求。
- 第四个层次是在IRQ处理函数中,将interrupt vector转化为抽象中断层的中断信号irq,调用中断信号irq对应的中断描述结构里面的irq_handler_t。
在这里,我们不解析硬件的部分,我们从CPU收到中断向量开始分析。
CPU收到的中断向量是什么样的呢?这个定义在文件arch/x86/include/asm/irq_vectors.h中。这里面的注释非常好,建议你仔细阅读。
/*
* Linux IRQ vector layout.
*
* There are 256 IDT entries (per CPU - each entry is 8 bytes) which can
* be defined by Linux. They are used as a jump table by the CPU when a
* given vector is triggered - by a CPU-external, CPU-internal or
* software-triggered event.
*
* Linux sets the kernel code address each entry jumps to early during
* bootup, and never changes them. This is the general layout of the
* IDT entries:
*
* Vectors 0 ... 31 : system traps and exceptions - hardcoded events
* Vectors 32 ... 127 : device interrupts
* Vector 128 : legacy int80 syscall interface
* Vectors 129 ... INVALIDATE_TLB_VECTOR_START-1 except 204 : device interrupts
* Vectors INVALIDATE_TLB_VECTOR_START ... 255 : special interrupts
*
* 64-bit x86 has per CPU IDT tables, 32-bit has one shared IDT table.
*
* This file enumerates the exact layout of them:
*/
#define FIRST_EXTERNAL_VECTOR 0x20
#define IA32_SYSCALL_VECTOR 0x80
#define NR_VECTORS 256
#define FIRST_SYSTEM_VECTOR NR_VECTORS通过这些注释,我们可以看出,CPU能够处理的中断总共256个,用宏NR_VECTOR或者FIRST_SYSTEM_VECTOR表示。
为了处理中断,CPU硬件要求每一个CPU都有一个中断向量表,通过load_idt加载,里面记录着每一个中断对应的处理方法,这个中断向量表定义在文件arch/x86/kernel/traps.c中。
gate_desc idt_table[NR_VECTORS] __page_aligned_bss;对于一个CPU可以处理的中断被分为几个部分,第一部分0到31的前32位是系统陷入或者系统异常,这些错误无法屏蔽,一定要处理。
这些中断的处理函数在系统初始化的时候,在start_kernel函数中调用过trap_init()。这个咱们讲系统初始化和系统调用的时候,都大概讲过这个函数,这里还需要仔细看一下。
void __init trap_init(void)
{
int i;
...
set_intr_gate(X86_TRAP_DE, divide_error);
//各种各样的set_intr_gate,不都贴在这里了,只贴一头一尾
...
set_intr_gate(X86_TRAP_XF, simd_coprocessor_error);
/* Reserve all the builtin and the syscall vector: */
for (i = 0; i < FIRST_EXTERNAL_VECTOR; i++)
set_bit(i, used_vectors);
#ifdef CONFIG_X86_32
set_system_intr_gate(IA32_SYSCALL_VECTOR, entry_INT80_32);
set_bit(IA32_SYSCALL_VECTOR, used_vectors);
#endif
/*
* Set the IDT descriptor to a fixed read-only location, so that the
* "sidt" instruction will not leak the location of the kernel, and
* to defend the IDT against arbitrary memory write vulnerabilities.
* It will be reloaded in cpu_init() */
__set_fixmap(FIX_RO_IDT, __pa_symbol(idt_table), PAGE_KERNEL_RO);
idt_descr.address = fix_to_virt(FIX_RO_IDT);
......
}我这里贴的代码省略了很多,在trap_init函数的一开始,调用了大量的set_intr_gate,最终都会调用_set_gate,代码如下:
static inline void _set_gate(int gate, unsigned type, void *addr,
unsigned dpl, unsigned ist, unsigned seg)
{
gate_desc s;
pack_gate(&s, type, (unsigned long)addr, dpl, ist, seg);
write_idt_entry(idt_table, gate, &s);
}从代码可以看出,set_intr_gate其实就是将每个中断都设置了中断处理函数,放在中断向量表idt_table中。
在trap_init中,由于set_intr_gate调用的太多,容易让人眼花缭乱。其实arch/x86/include/asm/traps.h文件中,早就定义好了前32个中断。如果仔细对比一下,你会发现,这些都在trap_init中使用set_intr_gate设置过了。
/* Interrupts/Exceptions */
enum {
X86_TRAP_DE = 0, /* 0, Divide-by-zero */
X86_TRAP_DB, /* 1, Debug */
X86_TRAP_NMI, /* 2, Non-maskable Interrupt */
X86_TRAP_BP, /* 3, Breakpoint */
X86_TRAP_OF, /* 4, Overflow */
X86_TRAP_BR, /* 5, Bound Range Exceeded */
X86_TRAP_UD, /* 6, Invalid Opcode */
X86_TRAP_NM, /* 7, Device Not Available */
X86_TRAP_DF, /* 8, Double Fault */
X86_TRAP_OLD_MF, /* 9, Coprocessor Segment Overrun */
X86_TRAP_TS, /* 10, Invalid TSS */
X86_TRAP_NP, /* 11, Segment Not Present */
X86_TRAP_SS, /* 12, Stack Segment Fault */
X86_TRAP_GP, /* 13, General Protection Fault */
X86_TRAP_PF, /* 14, Page Fault */
X86_TRAP_SPURIOUS, /* 15, Spurious Interrupt */
X86_TRAP_MF, /* 16, x87 Floating-Point Exception */
X86_TRAP_AC, /* 17, Alignment Check */
X86_TRAP_MC, /* 18, Machine Check */
X86_TRAP_XF, /* 19, SIMD Floating-Point Exception */
X86_TRAP_IRET = 32, /* 32, IRET Exception */
};我们回到trap_init中,当前32个中断都用set_intr_gate设置完毕。在中断向量表idt_table中填完了之后,接下来的for循环,for (i = 0; i < FIRST_EXTERNAL_VECTOR; i++),将前32个中断都在used_vectors中标记为1,表示这些都设置过中断处理函数了。
接下来,trap_init对单独调用set_intr_gate来设置32位系统调用的中断。IA32_SYSCALL_VECTOR,也即128,单独将used_vectors中的第128位标记为1。
在trap_init的最后,我们将idt_table放在一个固定的虚拟地址上。trap_init结束后,中断向量表中已经填好了前32位,外加一位32位系统调用,其他的都是用于设备中断。
在start_kernel调用完毕trap_init之后,还会调用init_IRQ()来初始化其他的设备中断,最终会调用到native_init_IRQ。
void __init native_init_IRQ(void)
{
int i;
i = FIRST_EXTERNAL_VECTOR;
#ifndef CONFIG_X86_LOCAL_APIC
#define first_system_vector NR_VECTORS
#endif
for_each_clear_bit_from(i, used_vectors, first_system_vector) {
/* IA32_SYSCALL_VECTOR could be used in trap_init already. */
set_intr_gate(i, irq_entries_start +
8 * (i - FIRST_EXTERNAL_VECTOR));
}
......
}这里面从第32个中断开始,到最后NR_VECTORS为止,对于used_vectors中没有标记为1的位置,都会调用set_intr_gate设置中断向量表。
其实used_vectors中没有标记为1的,都是设备中断的部分。
也即所有的设备中断的中断处理函数,在中断向量表里面都会设置为从irq_entries_start开始,偏移量为i - FIRST_EXTERNAL_VECTOR的一项。
看来中断处理函数是定义在irq_entries_start这个表里面的,我们在arch\x86\entry\entry_32.S和arch\x86\entry\entry_64.S都能找到这个函数表的定义。
这又是汇编语言,不需要完全看懂,但是我们还是能看出来,这里面定义了FIRST_SYSTEM_VECTOR - FIRST_EXTERNAL_VECTOR项。每一项都是中断处理函数,会跳到common_interrupt去执行。这里会最终调用do_IRQ,调用完毕后,就从中断返回。这里我们需要区分返回用户态还是内核态。这里会有一个几乎触发抢占,咱们讲进程切换的时候讲过的。
ENTRY(irq_entries_start)
vector=FIRST_EXTERNAL_VECTOR
.rept (FIRST_SYSTEM_VECTOR - FIRST_EXTERNAL_VECTOR)
pushl $(~vector+0x80) /* Note: always in signed byte range */
vector=vector+1
jmp common_interrupt /* 会调用到do_IRQ */
.align 8
.endr
END(irq_entries_start)
common_interrupt:
ASM_CLAC
addq $-0x80, (%rsp) /* Adjust vector to [-256, -1] range */
interrupt do_IRQ
/* 0(%rsp): old RSP */
ret_from_intr:
......
/* Interrupt came from user space */
GLOBAL(retint_user)
......
/* Returning to kernel space */
retint_kernel:
......这样任何一个中断向量到达任何一个CPU,最终都会走到do_IRQ。我们来看do_IRQ的实现。
/*
* do_IRQ handles all normal device IRQ's (the special
* SMP cross-CPU interrupts have their own specific
* handlers).
*/
__visible unsigned int __irq_entry do_IRQ(struct pt_regs *regs)
{
struct pt_regs *old_regs = set_irq_regs(regs);
struct irq_desc * desc;
/* high bit used in ret_from_ code */
unsigned vector = ~regs->orig_ax;
......
desc = __this_cpu_read(vector_irq[vector]);
if (!handle_irq(desc, regs)) {
......
}
......
set_irq_regs(old_regs);
return 1;
}在这里面,从AX寄存器里面拿到了中断向量vector,但是别忘了中断控制器发送给每个CPU的中断向量都是每个CPU局部的,而抽象中断处理层的虚拟中断信号irq以及它对应的中断描述结构irq_desc是全局的,也即这个CPU的200号的中断向量和另一个CPU的200号中断向量对应的虚拟中断信号irq和中断描述结构irq_desc可能不一样,这就需要一个映射关系。这个映射关系放在Per CPU变量vector_irq里面。
DECLARE_PER_CPU(vector_irq_t, vector_irq);在系统初始化的时候,我们会调用__assign_irq_vector,将虚拟中断信号irq分配到某个CPU上的中断向量。
static int __assign_irq_vector(int irq, struct apic_chip_data *d,
const struct cpumask *mask,
struct irq_data *irqdata)
{
static int current_vector = FIRST_EXTERNAL_VECTOR + VECTOR_OFFSET_START;
static int current_offset = VECTOR_OFFSET_START % 16;
int cpu, vector;
......
while (cpu < nr_cpu_ids) {
int new_cpu, offset;
......
vector = current_vector;
offset = current_offset;
next:
vector += 16;
if (vector >= first_system_vector) {
offset = (offset + 1) % 16;
vector = FIRST_EXTERNAL_VECTOR + offset;
}
/* If the search wrapped around, try the next cpu */
if (unlikely(current_vector == vector))
goto next_cpu;
if (test_bit(vector, used_vectors))
goto next;
......
/* Found one! */
current_vector = vector;
current_offset = offset;
/* Schedule the old vector for cleanup on all cpus */
if (d->cfg.vector)
cpumask_copy(d->old_domain, d->domain);
for_each_cpu(new_cpu, vector_searchmask)
per_cpu(vector_irq, new_cpu)[vector] = irq_to_desc(irq);
goto update;
next_cpu:
cpumask_or(searched_cpumask, searched_cpumask, vector_cpumask);
cpumask_andnot(vector_cpumask, mask, searched_cpumask);
cpu = cpumask_first_and(vector_cpumask, cpu_online_mask);
continue;
}
....
}在这里,一旦找到某个向量,就将CPU的此向量对应的向量描述结构irq_desc,设置为虚拟中断信号irq对应的向量描述结构irq_to_desc(irq)。
这样do_IRQ会根据中断向量vector得到对应的irq_desc,然后调用handle_irq。handle_irq会调用generic_handle_irq_desc,里面调用irq_desc的handle_irq。
static inline void generic_handle_irq_desc(struct irq_desc *desc)
{
desc->handle_irq(desc);
}这里的handle_irq,最终会调用__handle_irq_event_percpu。代码如下:
irqreturn_t __handle_irq_event_percpu(struct irq_desc *desc, unsigned int *flags)
{
irqreturn_t retval = IRQ_NONE;
unsigned int irq = desc->irq_data.irq;
struct irqaction *action;
record_irq_time(desc);
for_each_action_of_desc(desc, action) {
irqreturn_t res;
res = action->handler(irq, action->dev_id);
switch (res) {
case IRQ_WAKE_THREAD:
__irq_wake_thread(desc, action);
case IRQ_HANDLED:
*flags |= action->flags;
break;
default:
break;
}
retval |= res;
}
return retval;
}__handle_irq_event_percpu里面调用了irq_desc里每个hander,这些hander是我们在所有action列表中注册的,这才是我们设置的那个中断处理函数。如果返回值是IRQ_HANDLED,就说明处理完毕;如果返回值是IRQ_WAKE_THREAD就唤醒线程。
至此,中断的整个过程就结束了。
28.2 总结
中断是从外部设备发起的,会形成外部中断。外部中断会到达中断控制器,中断控制器会发送中断向量Interrupt Vector给CPU。
对于每一个CPU,都要求有一个idt_table,里面存放了不同的中断向量的处理函数。中断向量表中已经填好了前32位,外加一位32位系统调用,其他的都是用于设备中断。
硬件中断的处理函数是do_IRQ进行统一处理,在这里会让中断向量,通过vector_irq映射为irq_desc。
irq_desc是一个用于描述用户注册的中断处理函数的结构,为了能够根据中断向量得到irq_desc结构,会把这些结构放在一个基数树里面,方便查找。
irq_desc里面有一个成员是irqaction,指向设备驱动程序里面注册的中断处理函数。
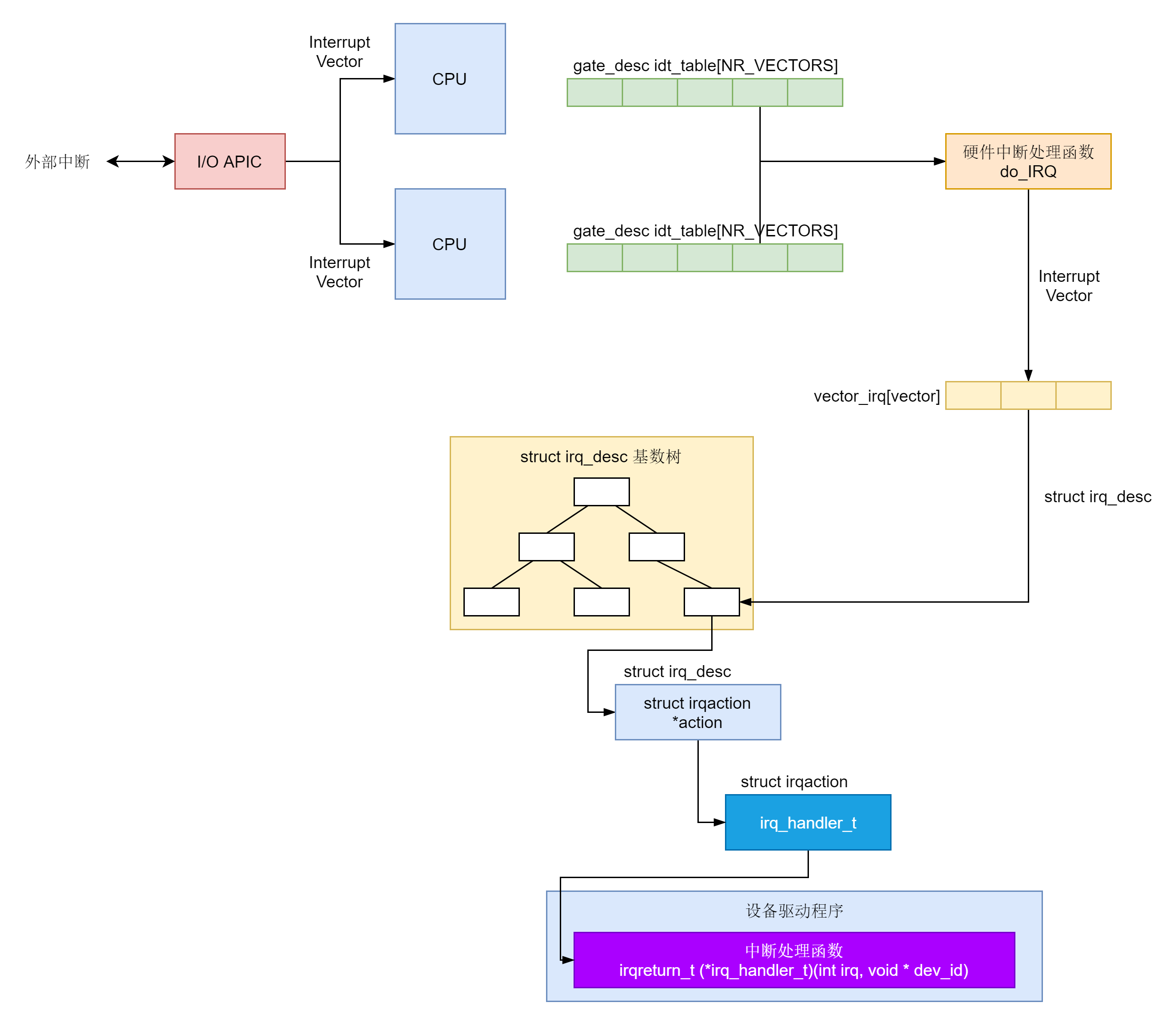
29. 块设备(上)
29.1 打开流程
块设备一般会被格式化为文件系统,但是,下面的讲述中,你可能会有一点困惑。你会看到各种各样的dentry和inode。块设备涉及三种文件系统,所以你看到的这些dentry和inode可能都不是一回事儿,请注意分辨。
块设备需要mknod吗?对于启动盘,你可能觉得,启动了就在那里了。可是如果我们要插进一块新的USB盘,还是要有这个操作的。
mknod还是会创建在/dev路径下面,这一点和字符设备一样。/dev路径下面是devtmpfs文件系统。这是块设备遇到的第一个文件系统。我们会为这个块设备文件,分配一个特殊的inode,这一点和字符设备也是一样的。只不过字符设备走S_ISCHR这个分支,对应inode的file_operations是def_chr_fops;而块设备走S_ISBLK这个分支,对应的inode的file_operations是def_blk_fops。这里要注意,inode里面的i_rdev被设置成了块设备的设备号dev_t,这个我们后面会用到,你先记住有这么一回事儿。
void init_special_inode(struct inode *inode, umode_t mode, dev_t rdev)
{
inode->i_mode = mode;
if (S_ISCHR(mode)) {
inode->i_fop = &def_chr_fops;
inode->i_rdev = rdev;
} else if (S_ISBLK(mode)) {
inode->i_fop = &def_blk_fops;
inode->i_rdev = rdev;
} else if (S_ISFIFO(mode))
inode->i_fop = &pipefifo_fops;
else if (S_ISSOCK(mode))
; /* leave it no_open_fops */
}特殊inode的默认file_operations是def_blk_fops,就像字符设备一样,有打开、读写这个块设备文件,但是我们常规操作不会这样做。我们会将这个块设备文件mount到一个文件夹下面。
const struct file_operations def_blk_fops = {
.open = blkdev_open,
.release = blkdev_close,
.llseek = block_llseek,
.read_iter = blkdev_read_iter,
.write_iter = blkdev_write_iter,
.mmap = generic_file_mmap,
.fsync = blkdev_fsync,
.unlocked_ioctl = block_ioctl,
.splice_read = generic_file_splice_read,
.splice_write = iter_file_splice_write,
.fallocate = blkdev_fallocate,
};不过,这里我们还是简单看一下,打开这个块设备的操作blkdev_open。它里面调用的是blkdev_get打开这个块设备,了解到这一点就可以了。
接下来,我们要调用mount,将这个块设备文件挂载到一个文件夹下面。如果这个块设备原来被格式化为一种文件系统的格式,例如ext4,那我们调用的就是ext4相应的mount操作。这是块设备遇到的第二个文件系统,也是向这个块设备读写文件,需要基于的主流文件系统。咱们在文件系统那一节解析的对于文件的读写流程,都是基于这个文件系统的。
还记得,咱们注册ext4文件系统的时候,有下面这样的结构:
static struct file_system_type ext4_fs_type = {
.owner = THIS_MODULE,
.name = "ext4",
.mount = ext4_mount,
.kill_sb = kill_block_super,
.fs_flags = FS_REQUIRES_DEV,
};在将一个硬盘的块设备mount成为ext4的时候,我们会调用ext4_mount->mount_bdev。
static struct dentry *ext4_mount(struct file_system_type *fs_type, int flags, const char *dev_name, void *data)
{
return mount_bdev(fs_type, flags, dev_name, data, ext4_fill_super);
}
struct dentry *mount_bdev(struct file_system_type *fs_type,
int flags, const char *dev_name, void *data,
int (*fill_super)(struct super_block *, void *, int))
{
struct block_device *bdev;
struct super_block *s;
fmode_t mode = FMODE_READ | FMODE_EXCL;
int error = 0;
if (!(flags & MS_RDONLY))
mode |= FMODE_WRITE;
bdev = blkdev_get_by_path(dev_name, mode, fs_type);
......
s = sget(fs_type, test_bdev_super, set_bdev_super, flags | MS_NOSEC, bdev);
......
return dget(s->s_root);
......
}mount_bdev主要做了两件大事情。第一,blkdev_get_by_path根据/dev/xxx这个名字,找到相应的设备并打开它;第二,sget根据打开的设备文件,填充ext4文件系统的super_block,从而以此为基础,建立一整套咱们在文件系统那一章讲的体系。
一旦这套体系建立起来以后,对于文件的读写都是通过ext4文件系统这个体系进行的,创建的inode结构也是指向ext4文件系统的。文件系统那一章我们只解析了这部分,由于没有到达底层,也就没有关注块设备相关的操作。这一章我们重新回过头来,一方面看mount的时候,对于块设备都做了哪些操作,另一方面看读写的时候,到了底层,对于块设备做了哪些操作。
这里我们先来看mount_bdev做的第一件大事情,通过blkdev_get_by_path,根据设备名/dev/xxx,得到struct block_device *bdev。
/**
* blkdev_get_by_path - open a block device by name
* @path: path to the block device to open
* @mode: FMODE_* mask
* @holder: exclusive holder identifier
*
* Open the blockdevice described by the device file at @path. @mode
* and @holder are identical to blkdev_get().
*
* On success, the returned block_device has reference count of one.
*/
struct block_device *blkdev_get_by_path(const char *path, fmode_t mode,
void *holder)
{
struct block_device *bdev;
int err;
bdev = lookup_bdev(path);
......
err = blkdev_get(bdev, mode, holder);
......
return bdev;
}blkdev_get_by_path干了两件事情。第一个,lookup_bdev根据设备路径/dev/xxx得到block_device。第二个,打开这个设备,调用blkdev_get。
咱们上面分析过def_blk_fops的默认打开设备函数blkdev_open,它也是调用blkdev_get的。块设备的打开往往不是直接调用设备文件的打开函数,而是调用mount来打开的。
/**
* lookup_bdev - lookup a struct block_device by name
* @pathname: special file representing the block device
*
* Get a reference to the blockdevice at @pathname in the current
* namespace if possible and return it. Return ERR_PTR(error)
* otherwise.
*/
struct block_device *lookup_bdev(const char *pathname)
{
struct block_device *bdev;
struct inode *inode;
struct path path;
int error;
if (!pathname || !*pathname)
return ERR_PTR(-EINVAL);
error = kern_path(pathname, LOOKUP_FOLLOW, &path);
if (error)
return ERR_PTR(error);
inode = d_backing_inode(path.dentry);
......
bdev = bd_acquire(inode);
......
goto out;
}lookup_bdev这里的pathname是设备的文件名,例如/dev/xxx。这个文件是在devtmpfs文件系统中的,kern_path可以在这个文件系统里面,一直找到它对应的dentry。接下来,d_backing_inode会获得inode。这个inode就是那个init_special_inode生成的特殊inode。
接下来,bd_acquire通过这个特殊的inode,找到struct block_device。
static struct block_device *bd_acquire(struct inode *inode)
{
struct block_device *bdev;
......
bdev = bdget(inode->i_rdev);
if (bdev) {
spin_lock(&bdev_lock);
if (!inode->i_bdev) {
/*
* We take an additional reference to bd_inode,
* and it's released in clear_inode() of inode.
* So, we can access it via ->i_mapping always
* without igrab().
*/
bdgrab(bdev);
inode->i_bdev = bdev;
inode->i_mapping = bdev->bd_inode->i_mapping;
}
}
return bdev;
}bd_acquire中最主要的就是调用bdget,它的参数是特殊inode的i_rdev。这里面在mknod的时候,放的是设备号dev_t。
struct block_device *bdget(dev_t dev)
{
struct block_device *bdev;
struct inode *inode;
inode = iget5_locked(blockdev_superblock, hash(dev),
bdev_test, bdev_set, &dev);
bdev = &BDEV_I(inode)->bdev;
if (inode->i_state & I_NEW) {
bdev->bd_contains = NULL;
bdev->bd_super = NULL;
bdev->bd_inode = inode;
bdev->bd_block_size = i_blocksize(inode);
bdev->bd_part_count = 0;
bdev->bd_invalidated = 0;
inode->i_mode = S_IFBLK;
inode->i_rdev = dev;
inode->i_bdev = bdev;
inode->i_data.a_ops = &def_blk_aops;
mapping_set_gfp_mask(&inode->i_data, GFP_USER);
spin_lock(&bdev_lock);
list_add(&bdev->bd_list, &all_bdevs);
spin_unlock(&bdev_lock);
unlock_new_inode(inode);
}
return bdev;
}在bdget中,我们遇到了第三个文件系统,bdev伪文件系统。 bdget函数根据传进来的dev_t,在blockdev_superblock这个文件系统里面找到inode。这里注意,这个inode已经不是devtmpfs文件系统的inode了。blockdev_superblock的初始化在整个系统初始化的时候,会调用bdev_cache_init进行初始化。它的定义如下:
struct super_block *blockdev_superblock __read_mostly;
static struct file_system_type bd_type = {
.name = "bdev",
.mount = bd_mount,
.kill_sb = kill_anon_super,
};
void __init bdev_cache_init(void)
{
int err;
static struct vfsmount *bd_mnt;
bdev_cachep = kmem_cache_create("bdev_cache",
sizeof(struct bdev_inode), 0,
(SLAB_HWCACHE_ALIGN|SLAB_RECLAIM_ACCOUNT|SLAB_MEM_SPREAD|SLAB_ACCOUNT|SLAB_PANIC),
init_once);
err = register_filesystem(&bd_type);
if (err)
panic("Cannot register bdev pseudo-fs");
bd_mnt = kern_mount(&bd_type);
if (IS_ERR(bd_mnt))
panic("Cannot create bdev pseudo-fs");
blockdev_superblock = bd_mnt->mnt_sb; /* For writeback */
}所有表示块设备的inode都保存在伪文件系统 bdev中,这些对用户层不可见,主要为了方便块设备的管理。Linux将块设备的block_device和bdev文件系统的块设备的inode,通过struct bdev_inode进行关联。所以,在bdget中,BDEV_I就是通过bdev文件系统的inode,获得整个struct bdev_inode结构的地址,然后取成员bdev,得到block_device。
struct bdev_inode {
struct block_device bdev;
struct inode vfs_inode;
};绕了一大圈,我们终于通过设备文件/dev/xxx,获得了设备的结构block_device。有点儿绕,我们再捋一下。设备文件/dev/xxx在devtmpfs文件系统中,找到devtmpfs文件系统中的inode,里面有dev_t。我们可以通过dev_t,在伪文件系统 bdev中找到对应的inode,然后根据struct bdev_inode找到关联的block_device。
接下来,blkdev_get_by_path开始做第二件事情,在找到block_device之后,要调用blkdev_get打开这个设备。blkdev_get会调用__blkdev_get。
在分析打开一个设备之前,我们先来看block_device这个结构是什么样的。
struct block_device {
dev_t bd_dev; /* not a kdev_t - it's a search key */
int bd_openers;
struct super_block * bd_super;
......
struct block_device * bd_contains;
unsigned bd_block_size;
struct hd_struct * bd_part;
unsigned bd_part_count;
int bd_invalidated;
struct gendisk * bd_disk;
struct request_queue * bd_queue;
struct backing_dev_info *bd_bdi;
struct list_head bd_list;
......
};你应该能发现,这个结构和其他几个结构有着千丝万缕的联系,比较复杂。这是因为块设备本身就比较复杂。
比方说,我们有一个磁盘/dev/sda,我们既可以把它整个格式化成一个文件系统,也可以把它分成多个分区/dev/sda1、 /dev/sda2,然后把每个分区格式化成不同的文件系统。如果我们访问某个分区的设备文件/dev/sda2,我们应该能知道它是哪个磁盘设备的。按说它们的驱动应该是一样的。如果我们访问整个磁盘的设备文件/dev/sda,我们也应该能知道它分了几个区域,所以就有了下图这个复杂的关系结构。
struct gendisk是用来描述整个设备的,因而上面的例子中,gendisk只有一个实例,指向/dev/sda。它的定义如下:
struct gendisk {
int major; /* major number of driver */
int first_minor;
int minors; /* maximum number of minors, =1 for disks that can't be partitioned. */
char disk_name[DISK_NAME_LEN]; /* name of major driver */
char *(*devnode)(struct gendisk *gd, umode_t *mode);
......
struct disk_part_tbl __rcu *part_tbl;
struct hd_struct part0;
const struct block_device_operations *fops;
struct request_queue *queue;
void *private_data;
int flags;
struct kobject *slave_dir;
......
};这里major是主设备号,first_minor表示第一个分区的从设备号,minors表示分区的数目。
disk_name给出了磁盘块设备的名称。
struct disk_part_tbl结构里是一个struct hd_struct的数组,用于表示各个分区。struct block_device_operations fops指向对于这个块设备的各种操作。struct request_queue queue是表示在这个块设备上的请求队列。
struct hd_struct是用来表示某个分区的,在上面的例子中,有两个hd_struct的实例,分别指向/dev/sda1、 /dev/sda2。它的定义如下:
struct hd_struct {
sector_t start_sect;
sector_t nr_sects;
......
struct device __dev;
struct kobject *holder_dir;
int policy, partno;
struct partition_meta_info *info;
......
struct disk_stats dkstats;
struct percpu_ref ref;
struct rcu_head rcu_head;
};在hd_struct中,比较重要的成员变量保存了如下的信息:从磁盘的哪个扇区开始,到哪个扇区结束。
而block_device既可以表示整个块设备,也可以表示某个分区,所以对于上面的例子,block_device有三个实例,分别指向/dev/sda1、/dev/sda2、/dev/sda。
block_device的成员变量bd_disk,指向的gendisk就是整个块设备。这三个实例都指向同一个gendisk。bd_part指向的某个分区的hd_struct,bd_contains指向的是整个块设备的block_device。
了解了这些复杂的关系,我们再来看打开设备文件的代码,就会清晰很多。
static int __blkdev_get(struct block_device *bdev, fmode_t mode, int for_part)
{
struct gendisk *disk;
struct module *owner;
int ret;
int partno;
int perm = 0;
if (mode & FMODE_READ)
perm |= MAY_READ;
if (mode & FMODE_WRITE)
perm |= MAY_WRITE;
......
disk = get_gendisk(bdev->bd_dev, &partno);
......
owner = disk->fops->owner;
......
if (!bdev->bd_openers) {
bdev->bd_disk = disk;
bdev->bd_queue = disk->queue;
bdev->bd_contains = bdev;
if (!partno) {
ret = -ENXIO;
bdev->bd_part = disk_get_part(disk, partno);
......
if (disk->fops->open) {
ret = disk->fops->open(bdev, mode);
......
}
if (!ret)
bd_set_size(bdev,(loff_t)get_capacity(disk)<<9);
if (bdev->bd_invalidated) {
if (!ret)
rescan_partitions(disk, bdev);
......
}
......
} else {
struct block_device *whole;
whole = bdget_disk(disk, 0);
......
ret = __blkdev_get(whole, mode, 1);
......
bdev->bd_contains = whole;
bdev->bd_part = disk_get_part(disk, partno);
......
bd_set_size(bdev, (loff_t)bdev->bd_part->nr_sects << 9);
}
}
......
bdev->bd_openers++;
if (for_part)
bdev->bd_part_count++;
.....
}在__blkdev_get函数中,我们先调用get_gendisk,根据block_device获取gendisk。具体代码如下:
/**
* get_gendisk - get partitioning information for a given device
* @devt: device to get partitioning information for
* @partno: returned partition index
*
* This function gets the structure containing partitioning
* information for the given device @devt.
*/
struct gendisk *get_gendisk(dev_t devt, int *partno)
{
struct gendisk *disk = NULL;
if (MAJOR(devt) != BLOCK_EXT_MAJOR) {
struct kobject *kobj;
kobj = kobj_lookup(bdev_map, devt, partno);
if (kobj)
disk = dev_to_disk(kobj_to_dev(kobj));
} else {
struct hd_struct *part;
part = idr_find(&ext_devt_idr, blk_mangle_minor(MINOR(devt)));
if (part && get_disk(part_to_disk(part))) {
*partno = part->partno;
disk = part_to_disk(part);
}
}
return disk;
}我们可以想象这里面有两种情况。第一种情况是,block_device是指向整个磁盘设备的。这个时候,我们只需要根据dev_t,在bdev_map中将对应的gendisk拿出来就好。
bdev_map是干什么的呢?前面咱们学习字符设备驱动的时候讲过,任何一个字符设备初始化的时候,都需要调用__register_chrdev_region,注册这个字符设备。对于块设备也是类似的,每一个块设备驱动初始化的时候,都会调用add_disk注册一个gendisk。
这里需要说明一下,gen的意思是general通用的意思,也就是说,所有的块设备,不仅仅是硬盘disk,都会用一个gendisk来表示,然后通过调用链add_disk->device_add_disk->blk_register_region,将dev_t和一个gendisk关联起来,保存在bdev_map中。
static struct kobj_map *bdev_map;
static inline void add_disk(struct gendisk *disk)
{
device_add_disk(NULL, disk);
}
/**
* device_add_disk - add partitioning information to kernel list
* @parent: parent device for the disk
* @disk: per-device partitioning information
*
* This function registers the partitioning information in @disk
* with the kernel.
*/
void device_add_disk(struct device *parent, struct gendisk *disk)
{
......
blk_register_region(disk_devt(disk), disk->minors, NULL,
exact_match, exact_lock, disk);
.....
}
/*
* Register device numbers dev..(dev+range-1)
* range must be nonzero
* The hash chain is sorted on range, so that subranges can override.
*/
void blk_register_region(dev_t devt, unsigned long range, struct module *module,
struct kobject *(*probe)(dev_t, int *, void *),
int (*lock)(dev_t, void *), void *data)
{
kobj_map(bdev_map, devt, range, module, probe, lock, data);
}get_gendisk要处理的第二种情况是,block_device是指向某个分区的。这个时候我们要先得到hd_struct,然后通过hd_struct,找到对应的整个设备的gendisk,并且把partno设置为分区号。
我们再回到__blkdev_get函数中,得到gendisk。接下来我们可以分两种情况。
如果partno为0,也就是说,打开的是整个设备而不是分区,那我们就调用disk_get_part,获取gendisk中的分区数组,然后调用block_device_operations里面的open函数打开设备。
如果partno不为0,也就是说打开的是分区,那我们就获取整个设备的block_device,赋值给变量struct block_device *whole,然后调用递归__blkdev_get,打开whole代表的整个设备,将bd_contains设置为变量whole。
block_device_operations就是在驱动层了。例如在drivers/scsi/sd.c里面,也就是MODULE_DESCRIPTION(“SCSI disk (sd) driver”)中,就有这样的定义。
static const struct block_device_operations sd_fops = {
.owner = THIS_MODULE,
.open = sd_open,
.release = sd_release,
.ioctl = sd_ioctl,
.getgeo = sd_getgeo,
#ifdef CONFIG_COMPAT
.compat_ioctl = sd_compat_ioctl,
#endif
.check_events = sd_check_events,
.revalidate_disk = sd_revalidate_disk,
.unlock_native_capacity = sd_unlock_native_capacity,
.pr_ops = &sd_pr_ops,
};
/**
* sd_open - open a scsi disk device
* @bdev: Block device of the scsi disk to open
* @mode: FMODE_* mask
*
* Returns 0 if successful. Returns a negated errno value in case
* of error.
**/
static int sd_open(struct block_device *bdev, fmode_t mode)
{
......
}在驱动层打开了磁盘设备之后,我们可以看到,在这个过程中,block_device相应的成员变量该填的都填上了,这才完成了mount_bdev的第一件大事,通过blkdev_get_by_path得到block_device。
接下来就是第二件大事情,我们要通过sget,将block_device塞进superblock里面。注意,调用sget的时候,有一个参数是一个函数set_bdev_super。这里面将block_device设置进了super_block。而sget要做的,就是分配一个super_block,然后调用set_bdev_super这个callback函数。这里的super_block是ext4文件系统的super_block。
sget(fs_type, test_bdev_super, set_bdev_super, flags | MS_NOSEC, bdev);
static int set_bdev_super(struct super_block *s, void *data)
{
s->s_bdev = data;
s->s_dev = s->s_bdev->bd_dev;
s->s_bdi = bdi_get(s->s_bdev->bd_bdi);
return 0;
}
/**
* sget - find or create a superblock
* @type: filesystem type superblock should belong to
* @test: comparison callback
* @set: setup callback
* @flags: mount flags
* @data: argument to each of them
*/
struct super_block *sget(struct file_system_type *type,
int (*test)(struct super_block *,void *),
int (*set)(struct super_block *,void *),
int flags,
void *data)
{
......
return sget_userns(type, test, set, flags, user_ns, data);
}
/**
* sget_userns - find or create a superblock
* @type: filesystem type superblock should belong to
* @test: comparison callback
* @set: setup callback
* @flags: mount flags
* @user_ns: User namespace for the super_block
* @data: argument to each of them
*/
struct super_block *sget_userns(struct file_system_type *type,
int (*test)(struct super_block *,void *),
int (*set)(struct super_block *,void *),
int flags, struct user_namespace *user_ns,
void *data)
{
struct super_block *s = NULL;
struct super_block *old;
int err;
......
if (!s) {
s = alloc_super(type, (flags & ~MS_SUBMOUNT), user_ns);
......
}
err = set(s, data);
......
s->s_type = type;
strlcpy(s->s_id, type->name, sizeof(s->s_id));
list_add_tail(&s->s_list, &super_blocks);
hlist_add_head(&s->s_instances, &type->fs_supers);
spin_unlock(&sb_lock);
get_filesystem(type);
register_shrinker(&s->s_shrink);
return s;
}好了,到此为止,mount中一个块设备的过程就结束了。设备打开了,形成了block_device结构,并且塞到了super_block中。
有了ext4文件系统的super_block之后,接下来对于文件的读写过程,就和文件系统那一章的过程一摸一样了。只要不涉及真正写入设备的代码,super_block中的这个block_device就没啥用处。这也是为什么文件系统那一章,我们丝毫感觉不到它的存在,但是一旦到了底层,就到了block_device起作用的时候了,这个我们下一节仔细分析。
29.2 总结
- 所有的块设备被一个map结构管理从dev_t到gendisk的映射;
- 所有的block_device表示的设备或者分区都在bdev文件系统的inode列表中;
- mknod创建出来的块设备文件在devtemfs文件系统里面,特殊inode里面有块设备号;
- mount一个块设备上的文件系统,调用这个文件系统的mount接口;
- 通过按照/dev/xxx在文件系统devtmpfs文件系统上搜索到特殊inode,得到块设备号;
- 根据特殊inode里面的dev_t在bdev文件系统里面找到inode;
- 根据bdev文件系统上的inode找到对应的block_device,根据dev_t在map中找到gendisk,将两者关联起来;
- 找到block_device后打开设备,调用和block_device关联的gendisk里面的block_device_operations打开设备;
- 创建被mount的文件系统的super_block。
30. 块设备(下)
在文件系统那一节,我们讲了文件的写入,到了设备驱动这一层,就没有再往下分析。上一节我们又讲了mount一个块设备,将block_device信息放到了ext4文件系统的super_block里面,有了这些基础,是时候把整个写入的故事串起来了。
还记得咱们在文件系统那一节分析写入流程的时候,对于ext4文件系统,最后调用的是ext4_file_write_iter,它将I/O的调用分成两种情况:
第一是直接I/O。最终我们调用的是generic_file_direct_write,这里调用的是mapping->a_ops->direct_IO,实际调用的是ext4_direct_IO,往设备层写入数据。
第二种是缓存I/O。最终我们会将数据从应用拷贝到内存缓存中,但是这个时候,并不执行真正的I/O操作。它们只将整个页或其中部分标记为脏。写操作由一个timer触发,那个时候,才调用wb_workfn往硬盘写入页面。
接下来的调用链为:wb_workfn->wb_do_writeback->wb_writeback->writeback_sb_inodes->__writeback_single_inode->do_writepages。在do_writepages中,我们要调用mapping->a_ops->writepages,但实际调用的是ext4_writepages,往设备层写入数据。
这一节,我们就沿着这两种情况分析下去。
30.1 直接I/O如何访问块设备?
我们先来看第一种情况,直接I/O调用到ext4_direct_IO。
static ssize_t ext4_direct_IO(struct kiocb *iocb, struct iov_iter *iter)
{
struct file *file = iocb->ki_filp;
struct inode *inode = file->f_mapping->host;
size_t count = iov_iter_count(iter);
loff_t offset = iocb->ki_pos;
ssize_t ret;
......
ret = ext4_direct_IO_write(iocb, iter);
......
}
static ssize_t ext4_direct_IO_write(struct kiocb *iocb, struct iov_iter *iter)
{
struct file *file = iocb->ki_filp;
struct inode *inode = file->f_mapping->host;
struct ext4_inode_info *ei = EXT4_I(inode);
ssize_t ret;
loff_t offset = iocb->ki_pos;
size_t count = iov_iter_count(iter);
......
ret = __blockdev_direct_IO(iocb, inode, inode->i_sb->s_bdev, iter,
get_block_func, ext4_end_io_dio, NULL,
dio_flags);
……
}在ext4_direct_IO_write调用__blockdev_direct_IO,有个参数你需要特别注意一下,那就是inode->i_sb->s_bdev。通过当前文件的inode,我们可以得到super_block。这个super_block中的s_bdev,就是咱们上一节填进去的那个block_device。
__blockdev_direct_IO会调用do_blockdev_direct_IO,在这里面我们要准备一个struct dio结构和struct dio_submit结构,用来描述将要发生的写入请求。
static inline ssize_t
do_blockdev_direct_IO(struct kiocb *iocb, struct inode *inode,
struct block_device *bdev, struct iov_iter *iter,
get_block_t get_block, dio_iodone_t end_io,
dio_submit_t submit_io, int flags)
{
unsigned i_blkbits = ACCESS_ONCE(inode->i_blkbits);
unsigned blkbits = i_blkbits;
unsigned blocksize_mask = (1 << blkbits) - 1;
ssize_t retval = -EINVAL;
size_t count = iov_iter_count(iter);
loff_t offset = iocb->ki_pos;
loff_t end = offset + count;
struct dio *dio;
struct dio_submit sdio = { 0, };
struct buffer_head map_bh = { 0, };
......
dio = kmem_cache_alloc(dio_cache, GFP_KERNEL);
dio->flags = flags;
dio->i_size = i_size_read(inode);
dio->inode = inode;
if (iov_iter_rw(iter) == WRITE) {
dio->op = REQ_OP_WRITE;
dio->op_flags = REQ_SYNC | REQ_IDLE;
if (iocb->ki_flags & IOCB_NOWAIT)
dio->op_flags |= REQ_NOWAIT;
} else {
dio->op = REQ_OP_READ;
}
sdio.blkbits = blkbits;
sdio.blkfactor = i_blkbits - blkbits;
sdio.block_in_file = offset >> blkbits;
sdio.get_block = get_block;
dio->end_io = end_io;
sdio.submit_io = submit_io;
sdio.final_block_in_bio = -1;
sdio.next_block_for_io = -1;
dio->iocb = iocb;
dio->refcount = 1;
sdio.iter = iter;
sdio.final_block_in_request =
(offset + iov_iter_count(iter)) >> blkbits;
......
sdio.pages_in_io += iov_iter_npages(iter, INT_MAX);
retval = do_direct_IO(dio, &sdio, &map_bh);
.....
}do_direct_IO里面有两层循环,第一层循环是依次处理这次要写入的所有块。对于每一块,取出对应的内存中的页page,在这一块中,有写入的起始地址from和终止地址to,所以,第二层循环就是依次处理from到to的数据,调用submit_page_section,提交到块设备层进行写入。
static int do_direct_IO(struct dio *dio, struct dio_submit *sdio,
struct buffer_head *map_bh)
{
const unsigned blkbits = sdio->blkbits;
const unsigned i_blkbits = blkbits + sdio->blkfactor;
int ret = 0;
while (sdio->block_in_file < sdio->final_block_in_request) {
struct page *page;
size_t from, to;
page = dio_get_page(dio, sdio);
from = sdio->head ? 0 : sdio->from;
to = (sdio->head == sdio->tail - 1) ? sdio->to : PAGE_SIZE;
sdio->head++;
while (from < to) {
unsigned this_chunk_bytes; /* # of bytes mapped */
unsigned this_chunk_blocks; /* # of blocks */
......
ret = submit_page_section(dio, sdio, page,
from,
this_chunk_bytes,
sdio->next_block_for_io,
map_bh);
......
sdio->next_block_for_io += this_chunk_blocks;
sdio->block_in_file += this_chunk_blocks;
from += this_chunk_bytes;
dio->result += this_chunk_bytes;
sdio->blocks_available -= this_chunk_blocks;
if (sdio->block_in_file == sdio->final_block_in_request)
break;
......
}
}
}submit_page_section会调用dio_bio_submit,进而调用submit_bio向块设备层提交数据。其中,参数struct bio是将数据传给块设备的通用传输对象。定义如下:
/**
* submit_bio - submit a bio to the block device layer for I/O
* @bio: The &struct bio which describes the I/O
*/
blk_qc_t submit_bio(struct bio *bio)
{
......
return generic_make_request(bio);
}30.2 缓存I/O如何访问块设备?
我们再来看第二种情况,缓存I/O调用到ext4_writepages。这个函数比较长,我们这里只截取最重要的部分来讲解。
static int ext4_writepages(struct address_space *mapping,
struct writeback_control *wbc)
{
......
struct mpage_da_data mpd;
struct inode *inode = mapping->host;
struct ext4_sb_info *sbi = EXT4_SB(mapping->host->i_sb);
......
mpd.do_map = 0;
mpd.io_submit.io_end = ext4_init_io_end(inode, GFP_KERNEL);
ret = mpage_prepare_extent_to_map(&mpd);
/* Submit prepared bio */
ext4_io_submit(&mpd.io_submit);
......
}这里比较重要的一个数据结构是struct mpage_da_data。这里面有文件的inode、要写入的页的偏移量,还有一个重要的struct ext4_io_submit,里面有通用传输对象bio。
struct mpage_da_data {
struct inode *inode;
......
pgoff_t first_page; /* The first page to write */
pgoff_t next_page; /* Current page to examine */
pgoff_t last_page; /* Last page to examine */
struct ext4_map_blocks map;
struct ext4_io_submit io_submit; /* IO submission data */
unsigned int do_map:1;
};
struct ext4_io_submit {
......
struct bio *io_bio;
ext4_io_end_t *io_end;
sector_t io_next_block;
};在ext4_writepages中,mpage_prepare_extent_to_map用于初始化这个struct mpage_da_data结构。接下来的调用链为:mpage_prepare_extent_to_map->mpage_process_page_bufs->mpage_submit_page->ext4_bio_write_page->io_submit_add_bh。
在io_submit_add_bh中,此时的bio还是空的,因而我们要调用io_submit_init_bio,初始化bio。
static int io_submit_init_bio(struct ext4_io_submit *io,
struct buffer_head *bh)
{
struct bio *bio;
bio = bio_alloc(GFP_NOIO, BIO_MAX_PAGES);
if (!bio)
return -ENOMEM;
wbc_init_bio(io->io_wbc, bio);
bio->bi_iter.bi_sector = bh->b_blocknr * (bh->b_size >> 9);
bio->bi_bdev = bh->b_bdev;
bio->bi_end_io = ext4_end_bio;
bio->bi_private = ext4_get_io_end(io->io_end);
io->io_bio = bio;
io->io_next_block = bh->b_blocknr;
return 0;
}我们再回到ext4_writepages中。在bio初始化完之后,我们要调用ext4_io_submit,提交I/O。在这里我们又是调用submit_bio,向块设备层传输数据。ext4_io_submit的实现如下:
void ext4_io_submit(struct ext4_io_submit *io)
{
struct bio *bio = io->io_bio;
if (bio) {
int io_op_flags = io->io_wbc->sync_mode == WB_SYNC_ALL ?
REQ_SYNC : 0;
io->io_bio->bi_write_hint = io->io_end->inode->i_write_hint;
bio_set_op_attrs(io->io_bio, REQ_OP_WRITE, io_op_flags);
submit_bio(io->io_bio);
}
io->io_bio = NULL;
}30.3 如何向块设备层提交请求?
既然无论是直接I/O,还是缓存I/O,最后都到了submit_bio里面,我们就来重点分析一下它。
submit_bio会调用generic_make_request。代码如下:
blk_qc_t generic_make_request(struct bio *bio)
{
/*
* bio_list_on_stack[0] contains bios submitted by the current
* make_request_fn.
* bio_list_on_stack[1] contains bios that were submitted before
* the current make_request_fn, but that haven't been processed
* yet.
*/
struct bio_list bio_list_on_stack[2];
blk_qc_t ret = BLK_QC_T_NONE;
......
if (current->bio_list) {
bio_list_add(¤t->bio_list[0], bio);
goto out;
}
bio_list_init(&bio_list_on_stack[0]);
current->bio_list = bio_list_on_stack;
do {
struct request_queue *q = bdev_get_queue(bio->bi_bdev);
if (likely(blk_queue_enter(q, bio->bi_opf & REQ_NOWAIT) == 0)) {
struct bio_list lower, same;
/* Create a fresh bio_list for all subordinate requests */
bio_list_on_stack[1] = bio_list_on_stack[0];
bio_list_init(&bio_list_on_stack[0]);
ret = q->make_request_fn(q, bio);
blk_queue_exit(q);
/* sort new bios into those for a lower level
* and those for the same level
*/
bio_list_init(&lower);
bio_list_init(&same);
while ((bio = bio_list_pop(&bio_list_on_stack[0])) != NULL)
if (q == bdev_get_queue(bio->bi_bdev))
bio_list_add(&same, bio);
else
bio_list_add(&lower, bio);
/* now assemble so we handle the lowest level first */
bio_list_merge(&bio_list_on_stack[0], &lower);
bio_list_merge(&bio_list_on_stack[0], &same);
bio_list_merge(&bio_list_on_stack[0], &bio_list_on_stack[1]);
}
......
bio = bio_list_pop(&bio_list_on_stack[0]);
} while (bio);
current->bio_list = NULL; /* deactivate */
out:
return ret;
}这里的逻辑有点复杂,我们先来看大的逻辑。在do-while中,我们先是获取一个请求队列request_queue,然后调用这个队列的make_request_fn函数。
30.4 块设备队列结构
如果再来看struct block_device结构和struct gendisk结构,我们会发现,每个块设备都有一个请求队列struct request_queue,用于处理上层发来的请求。
在每个块设备的驱动程序初始化的时候,会生成一个request_queue。
struct request_queue {
/*
* Together with queue_head for cacheline sharing
*/
struct list_head queue_head;
struct request *last_merge;
struct elevator_queue *elevator;
......
request_fn_proc *request_fn;
make_request_fn *make_request_fn;
......
}在请求队列request_queue上,首先是有一个链表list_head,保存请求request。
struct request {
struct list_head queuelist;
......
struct request_queue *q;
......
struct bio *bio;
struct bio *biotail;
......
}每个request包括一个链表的struct bio,有指针指向一头一尾。
struct bio {
struct bio *bi_next; /* request queue link */
struct block_device *bi_bdev;
blk_status_t bi_status;
......
struct bvec_iter bi_iter;
unsigned short bi_vcnt; /* how many bio_vec's */
unsigned short bi_max_vecs; /* max bvl_vecs we can hold */
atomic_t __bi_cnt; /* pin count */
struct bio_vec *bi_io_vec; /* the actual vec list */
......
};
struct bio_vec {
struct page *bv_page;
unsigned int bv_len;
unsigned int bv_offset;
}在bio中,bi_next是链表中的下一项,struct bio_vec指向一组页面。
在请求队列request_queue上,还有两个重要的函数,一个是make_request_fn函数,用于生成request;另一个是request_fn函数,用于处理request。
30.5 块设备的初始化
我们还是以scsi驱动为例。在初始化设备驱动的时候,我们会调用scsi_alloc_queue,把request_fn设置为scsi_request_fn。我们还会调用blk_init_allocated_queue->blk_queue_make_request,把make_request_fn设置为blk_queue_bio。
/**
* scsi_alloc_sdev - allocate and setup a scsi_Device
* @starget: which target to allocate a &scsi_device for
* @lun: which lun
* @hostdata: usually NULL and set by ->slave_alloc instead
*
* Description:
* Allocate, initialize for io, and return a pointer to a scsi_Device.
* Stores the @shost, @channel, @id, and @lun in the scsi_Device, and
* adds scsi_Device to the appropriate list.
*
* Return value:
* scsi_Device pointer, or NULL on failure.
**/
static struct scsi_device *scsi_alloc_sdev(struct scsi_target *starget,
u64 lun, void *hostdata)
{
struct scsi_device *sdev;
sdev = kzalloc(sizeof(*sdev) + shost->transportt->device_size,
GFP_ATOMIC);
......
sdev->request_queue = scsi_alloc_queue(sdev);
......
}
struct request_queue *scsi_alloc_queue(struct scsi_device *sdev)
{
struct Scsi_Host *shost = sdev->host;
struct request_queue *q;
q = blk_alloc_queue_node(GFP_KERNEL, NUMA_NO_NODE);
if (!q)
return NULL;
q->cmd_size = sizeof(struct scsi_cmnd) + shost->hostt->cmd_size;
q->rq_alloc_data = shost;
q->request_fn = scsi_request_fn;
q->init_rq_fn = scsi_init_rq;
q->exit_rq_fn = scsi_exit_rq;
q->initialize_rq_fn = scsi_initialize_rq;
//调用blk_queue_make_request(q, blk_queue_bio);
if (blk_init_allocated_queue(q) < 0) {
blk_cleanup_queue(q);
return NULL;
}
__scsi_init_queue(shost, q);
......
return q
}在blk_init_allocated_queue中,除了初始化make_request_fn函数,我们还要做一件很重要的事情,就是初始化I/O的电梯算法。
int blk_init_allocated_queue(struct request_queue *q)
{
q->fq = blk_alloc_flush_queue(q, NUMA_NO_NODE, q->cmd_size);
......
blk_queue_make_request(q, blk_queue_bio);
......
/* init elevator */
if (elevator_init(q, NULL)) {
......
}
......
}电梯算法有很多种类型,定义为elevator_type。下面我来逐一说一下。
struct elevator_type elevator_noop
Noop调度算法是最简单的IO调度算法,它将IO请求放入到一个FIFO队列中,然后逐个执行这些IO请求。
struct elevator_type iosched_deadline
Deadline算法要保证每个IO请求在一定的时间内一定要被服务到,以此来避免某个请求饥饿。为了完成这个目标,算法中引入了两类队列,一类队列用来对请求按起始扇区序号进行排序,通过红黑树来组织,我们称为sort_list,按照此队列传输性能会比较高;另一类队列对请求按它们的生成时间进行排序,由链表来组织,称为fifo_list,并且每一个请求都有一个期限值。
struct elevator_type iosched_cfq
又看到了熟悉的CFQ完全公平调度算法。所有的请求会在多个队列中排序。同一个进程的请求,总是在同一队列中处理。时间片会分配到每个队列,通过轮询算法,我们保证了I/O带宽,以公平的方式,在不同队列之间进行共享。
elevator_init中会根据名称来指定电梯算法,如果没有选择,那就默认使用iosched_cfq。
30.6 请求提交与调度
接下来,我们回到generic_make_request函数中。调用队列的make_request_fn函数,其实就是调用blk_queue_bio。
static blk_qc_t blk_queue_bio(struct request_queue *q, struct bio *bio)
{
struct request *req, *free;
unsigned int request_count = 0;
......
switch (elv_merge(q, &req, bio)) {
case ELEVATOR_BACK_MERGE:
if (!bio_attempt_back_merge(q, req, bio))
break;
elv_bio_merged(q, req, bio);
free = attempt_back_merge(q, req);
if (free)
__blk_put_request(q, free);
else
elv_merged_request(q, req, ELEVATOR_BACK_MERGE);
goto out_unlock;
case ELEVATOR_FRONT_MERGE:
if (!bio_attempt_front_merge(q, req, bio))
break;
elv_bio_merged(q, req, bio);
free = attempt_front_merge(q, req);
if (free)
__blk_put_request(q, free);
else
elv_merged_request(q, req, ELEVATOR_FRONT_MERGE);
goto out_unlock;
default:
break;
}
get_rq:
req = get_request(q, bio->bi_opf, bio, GFP_NOIO);
......
blk_init_request_from_bio(req, bio);
......
add_acct_request(q, req, where);
__blk_run_queue(q);
out_unlock:
......
return BLK_QC_T_NONE;
}blk_queue_bio首先做的一件事情是调用elv_merge来判断,当前这个bio请求是否能够和目前已有的request合并起来,成为同一批I/O操作,从而提高读取和写入的性能。
判断标准和struct bio的成员struct bvec_iter有关,它里面有两个变量,一个是起始磁盘簇bi_sector,另一个是大小bi_size。
enum elv_merge elv_merge(struct request_queue *q, struct request **req,
struct bio *bio)
{
struct elevator_queue *e = q->elevator;
struct request *__rq;
......
if (q->last_merge && elv_bio_merge_ok(q->last_merge, bio)) {
enum elv_merge ret = blk_try_merge(q->last_merge, bio);
if (ret != ELEVATOR_NO_MERGE) {
*req = q->last_merge;
return ret;
}
}
......
__rq = elv_rqhash_find(q, bio->bi_iter.bi_sector);
if (__rq && elv_bio_merge_ok(__rq, bio)) {
*req = __rq;
return ELEVATOR_BACK_MERGE;
}
if (e->uses_mq && e->type->ops.mq.request_merge)
return e->type->ops.mq.request_merge(q, req, bio);
else if (!e->uses_mq && e->type->ops.sq.elevator_merge_fn)
return e->type->ops.sq.elevator_merge_fn(q, req, bio);
return ELEVATOR_NO_MERGE;
}第一次,它先判断和上一次合并的request能不能再次合并,看看能不能赶上马上要走的这部电梯。在blk_try_merge主要做了这样的判断:如果blk_rq_pos(rq) + blk_rq_sectors(rq) == bio->bi_iter.bi_sector,也就是说这个request的起始地址加上它的大小(其实是这个request的结束地址),如果和bio的起始地址能接得上,那就把bio放在request的最后,我们称为ELEVATOR_BACK_MERGE。
如果blk_rq_pos(rq) - bio_sectors(bio) == bio->bi_iter.bi_sector,也就是说,这个request的起始地址减去bio的大小等于bio的起始地址,这说明bio放在request的最前面能够接得上,那就把bio放在request的最前面,我们称为ELEVATOR_FRONT_MERGE。否则,那就不合并,我们称为ELEVATOR_NO_MERGE。
enum elv_merge blk_try_merge(struct request *rq, struct bio *bio)
{
......
if (blk_rq_pos(rq) + blk_rq_sectors(rq) == bio->bi_iter.bi_sector)
return ELEVATOR_BACK_MERGE;
else if (blk_rq_pos(rq) - bio_sectors(bio) == bio->bi_iter.bi_sector)
return ELEVATOR_FRONT_MERGE;
return ELEVATOR_NO_MERGE;
}第二次,如果和上一个合并过的request无法合并,那我们就调用elv_rqhash_find。然后按照bio的起始地址查找request,看有没有能够合并的。如果有的话,因为是按照起始地址找的,应该接在人家的后面,所以是ELEVATOR_BACK_MERGE。
第三次,调用elevator_merge_fn试图合并。对于iosched_cfq,调用的是cfq_merge。在这里面,cfq_find_rq_fmerge会调用elv_rb_find函数,里面的参数是bio的结束地址。我们还是要看,能不能找到可以合并的。如果有的话,因为是按照结束地址找的,应该接在人家前面,所以是ELEVATOR_FRONT_MERGE。
static enum elv_merge cfq_merge(struct request_queue *q, struct request **req,
struct bio *bio)
{
struct cfq_data *cfqd = q->elevator->elevator_data;
struct request *__rq;
__rq = cfq_find_rq_fmerge(cfqd, bio);
if (__rq && elv_bio_merge_ok(__rq, bio)) {
*req = __rq;
return ELEVATOR_FRONT_MERGE;
}
return ELEVATOR_NO_MERGE;
}
static struct request *
cfq_find_rq_fmerge(struct cfq_data *cfqd, struct bio *bio)
{
struct task_struct *tsk = current;
struct cfq_io_cq *cic;
struct cfq_queue *cfqq;
cic = cfq_cic_lookup(cfqd, tsk->io_context);
if (!cic)
return NULL;
cfqq = cic_to_cfqq(cic, op_is_sync(bio->bi_opf));
if (cfqq)
return elv_rb_find(&cfqq->sort_list, bio_end_sector(bio));
return NUL
}等从elv_merge返回blk_queue_bio的时候,我们就知道,应该做哪种类型的合并,接着就要进行真的合并。如果没有办法合并,那就调用get_request,创建一个新的request,调用blk_init_request_from_bio,将bio放到新的request里面,然后调用add_acct_request,把新的request加到request_queue队列中。
至此,我们解析完了generic_make_request中最重要的两大逻辑:获取一个请求队列request_queue和调用这个队列的make_request_fn函数。
其实,generic_make_request其他部分也很令人困惑。感觉里面有特别多的struct bio_list,倒腾过来,倒腾过去的。这是因为,很多块设备是有层次的。
比如,我们用两块硬盘组成RAID,两个RAID盘组成LVM,然后我们就可以在LVM上创建一个块设备给用户用,我们称接近用户的块设备为高层次的块设备,接近底层的块设备为低层次(lower)的块设备。这样,generic_make_request把I/O请求发送给高层次的块设备的时候,会调用高层块设备的make_request_fn,高层块设备又要调用generic_make_request,将请求发送给低层次的块设备。虽然块设备的层次不会太多,但是对于代码generic_make_request来讲,这可是递归的调用,一不小心,就会递归过深,无法正常退出,而且内核栈的大小又非常有限,所以要比较小心。
这里你是否理解了struct bio_list bio_list_on_stack[2]的名字为什么叫stack呢?其实,将栈的操作变成对于队列的操作,队列不在栈里面,会大很多。每次generic_make_request被当前任务调用的时候,将current->bio_list设置为bio_list_on_stack,并在generic_make_request的一开始就判断current->bio_list是否为空。如果不为空,说明已经在generic_make_request的调用里面了,就不必调用make_request_fn进行递归了,直接把请求加入到bio_list里面就可以了,这就实现了递归的及时退出。
如果current->bio_list为空,那我们就将current->bio_list设置为bio_list_on_stack后,进入do-while循环,做咱们分析过的generic_make_request的两大逻辑。但是,当前的队列调用make_request_fn的时候,在make_request_fn的具体实现中,会生成新的bio。调用更底层的块设备,也会生成新的bio,都会放在bio_list_on_stack的队列中,是一个边处理还边创建的过程。
bio_list_on_stack[1] = bio_list_on_stack[0]这一句在make_request_fn之前,将之前队列里面遗留没有处理的保存下来,接着bio_list_init将bio_list_on_stack[0]设置为空,然后调用make_request_fn,在make_request_fn里面如果有新的bio生成,都会加到bio_list_on_stack[0]这个队列里面来。
make_request_fn执行完毕后,可以想象bio_list_on_stack[0]可能又多了一些bio了,接下来的循环中调用bio_list_pop将bio_list_on_stack[0]积攒的bio拿出来,分别放在两个队列lower和same中,顾名思义,lower就是更低层次的块设备的bio,same是同层次的块设备的bio。
接下来我们能将lower、same以及bio_list_on_stack[1] 都取出来,放在bio_list_on_stack[0]统一进行处理。当然应该lower优先了,因为只有底层的块设备的I/O做完了,上层的块设备的I/O才能做完。
到这里,generic_make_request的逻辑才算解析完毕。对于写入的数据来讲,其实仅仅到将bio请求放在请求队列上,设备驱动程序还没往设备里面写呢。
30.7 请求的处理
设备驱动程序往设备里面写,调用的是请求队列request_queue的另外一个函数request_fn。对于scsi设备来讲,调用的是scsi_request_fn。
static void scsi_request_fn(struct request_queue *q)
__releases(q->queue_lock)
__acquires(q->queue_lock)
{
struct scsi_device *sdev = q->queuedata;
struct Scsi_Host *shost;
struct scsi_cmnd *cmd;
struct request *req;
/*
* To start with, we keep looping until the queue is empty, or until
* the host is no longer able to accept any more requests.
*/
shost = sdev->host;
for (;;) {
int rtn;
/*
* get next queueable request. We do this early to make sure
* that the request is fully prepared even if we cannot
* accept it.
*/
req = blk_peek_request(q);
......
/*
* Remove the request from the request list.
*/
if (!(blk_queue_tagged(q) && !blk_queue_start_tag(q, req)))
blk_start_request(req);
.....
cmd = req->special;
......
/*
* Dispatch the command to the low-level driver.
*/
cmd->scsi_done = scsi_done;
rtn = scsi_dispatch_cmd(cmd);
......
}
return;
......
}在这里面是一个for无限循环,从request_queue中读取request,然后封装更加底层的指令,给设备控制器下指令,实施真正的I/O操作。
30.8 总结
对于块设备的I/O操作分为两种,一种是直接I/O,另一种是缓存I/O。无论是哪种I/O,最终都会调用submit_bio提交块设备I/O请求。
对于每一种块设备,都有一个gendisk表示这个设备,它有一个请求队列,这个队列是一系列的request对象。每个request对象里面包含多个BIO对象,指向page cache。所谓的写入块设备,I/O就是将page cache里面的数据写入硬盘。
对于请求队列来讲,还有两个函数,一个函数叫make_request_fn函数,用于将请求放入队列。submit_bio会调用generic_make_request,然后调用这个函数。
另一个函数往往在设备驱动程序里实现,我们叫request_fn函数,它用于从队列里面取出请求来,写入外部设备。
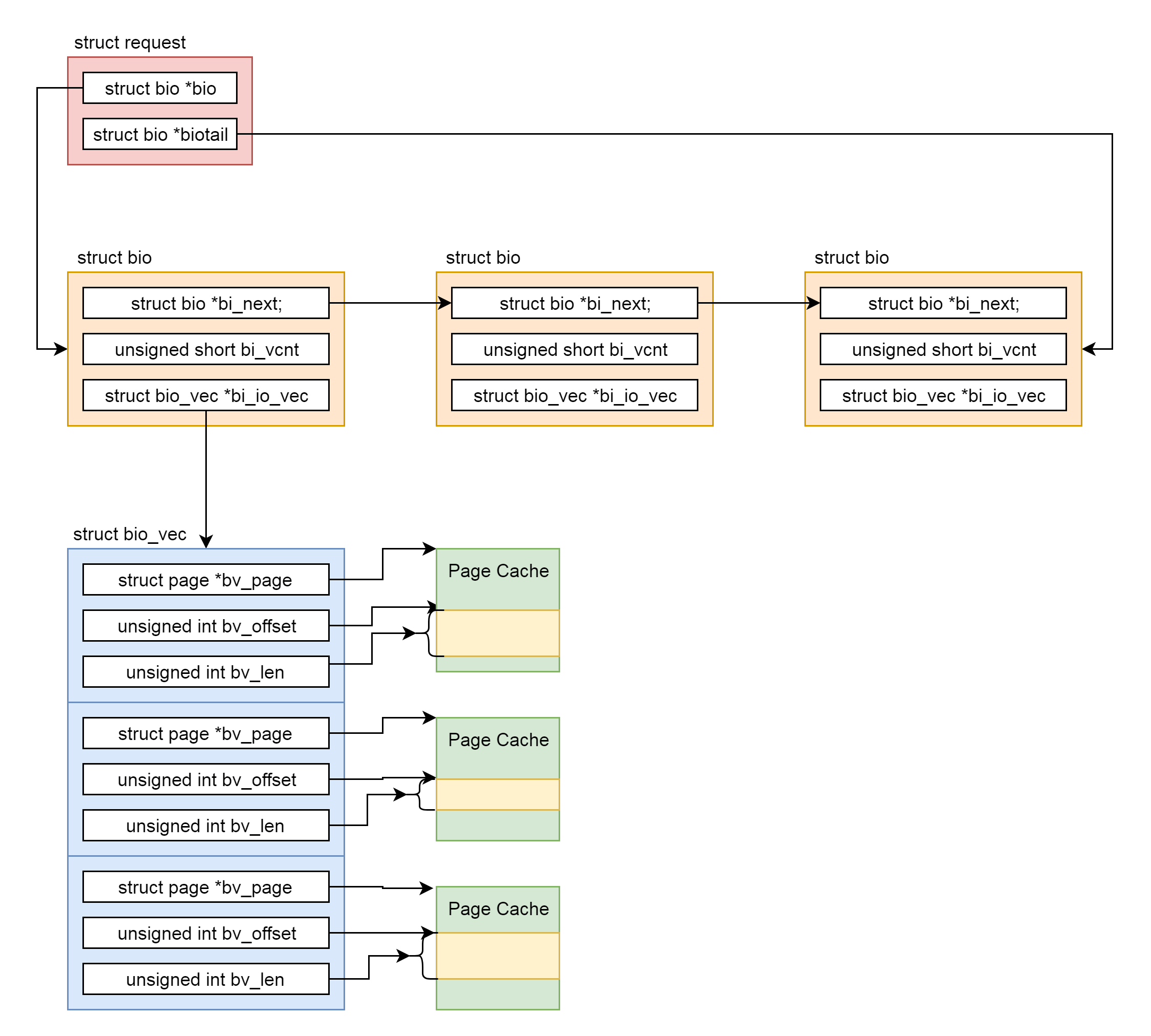
六、进程间通信
31. 进程间通信
31.1 管道模型
最最传统的模型就是软件开发的瀑布模型(Waterfall Model)。所谓的瀑布模型,其实就是将整个软件开发过程分成多个阶段,往往是上一个阶段完全做完,才将输出结果交给下一个阶段。
这种模型类似进程间通信的管道模型。还记得咱们最初学Linux命令的时候,有下面这样一行命令:
ps -ef | grep 关键字 | awk '{print $2}' | xargs kill -9这里面的竖线”|”就是一个管道。它会将前一个命令的输出,作为后一个命令的输入。从管道的这个名称可以看出来,管道是一种单向传输数据的机制,它其实是一段缓存,里面的数据只能从一端写入,从另一端读出。如果想互相通信,我们需要创建两个管道才行。
管道分为两种类型,”|” 表示的管道称为匿名管道,意思就是这个类型的管道没有名字,用完了就销毁了。就像上面那个命令里面的一样,竖线代表的管道随着命令的执行自动创建、自动销毁。用户甚至都不知道自己在用管道这种技术,就已经解决了问题。所以这也是面试题里面经常会问的,到时候千万别说这是竖线,而要回答背后的机制,管道。
另外一种类型是命名管道。这个类型的管道需要通过mkfifo命令显式地创建。
mkfifo hellohello就是这个管道的名称。管道以文件的形式存在,这也符合Linux里面一切皆文件的原则。这个时候,我们ls一下,可以看到,这个文件的类型是p,就是pipe的意思。
$ ls -l
prw-r--r-- 1 root root 0 May 21 23:29 hello接下来,我们可以往管道里面写入东西。例如,写入一个字符串。
echo "hello world" > hello这个时候,管道里面的内容没有被读出,这个命令就是停在这里的,这说明当一个项目组要把它的输出交接给另一个项目组做输入,当没有交接完毕的时候,前一个项目组是不能撒手不管的。
这个时候,我们就需要重新连接一个终端。在终端中,用下面的命令读取管道里面的内容:
$ cat < hello
hello world一方面,我们能够看到,管道里面的内容被读取出来,打印到了终端上;另一方面,echo那个命令正常退出了,也即交接完毕,前一个项目组就完成了使命,可以解散了。
我们可以看出,瀑布模型的开发流程效率比较低下,因为团队之间无法频繁地沟通。而且,管道的使用模式,也不适合进程间频繁的交换数据。
于是,我们还得想其他的办法,例如我们是不是可以借鉴传统外企的沟通方式——邮件。邮件有一定的格式,例如抬头,正文,附件等,发送邮件可以建立收件人列表,所有在这个列表中的人,都可以反复的在此邮件基础上回复,达到频繁沟通的目的。
31.2 消息队列模型
这种模型类似进程间通信的消息队列模型。和管道将信息一股脑儿地从一个进程,倒给另一个进程不同,消息队列有点儿像邮件,发送数据时,会分成一个一个独立的数据单元,也就是消息体,每个消息体都是固定大小的存储块,在字节流上不连续。
这个消息结构的定义我写在下面了。这里面的类型type和正文text没有强制规定,只要消息的发送方和接收方约定好即可。
struct msg_buffer {
long mtype;
char mtext[1024];
};接下来,我们需要创建一个消息队列,使用msgget函数。这个函数需要有一个参数key,这是消息队列的唯一标识,应该是唯一的。如何保持唯一性呢?这个还是和文件关联。
我们可以指定一个文件,ftok会根据这个文件的inode,生成一个近乎唯一的key。只要在这个消息队列的生命周期内,这个文件不要被删除就可以了。只要不删除,无论什么时刻,再调用ftok,也会得到同样的key。这种key的使用方式在这一章会经常遇到,这是因为它们都属于System V IPC进程间通信机制体系中。
#include <stdio.h>
#include <stdlib.h>
#include <sys/msg.h>
int main() {
int messagequeueid;
key_t key;
if((key = ftok("/root/messagequeue/messagequeuekey", 1024)) < 0)
{
perror("ftok error");
exit(1);
}
printf("Message Queue key: %d.\n", key);
if ((messagequeueid = msgget(key, IPC_CREAT|0777)) == -1)
{
perror("msgget error");
exit(1);
}
printf("Message queue id: %d.\n", messagequeueid);
}在运行上面这个程序之前,我们先使用命令touch messagequeuekey,创建一个文件,然后多次执行的结果就会像下面这样:
$ ./a.out
Message Queue key: 92536.
Message queue id: 32768.System V IPC体系有一个统一的命令行工具:ipcmk,ipcs和ipcrm用于创建、查看和删除IPC对象。
例如,ipcs -q就能看到上面我们创建的消息队列对象。
$ ipcs -q
------ Message Queues --------
key msqid owner perms used-bytes messages
0x00016978 32768 root 777 0 0接下来,我们来看如何发送信息。发送消息主要调用msgsnd函数。第一个参数是message queue的id,第二个参数是消息的结构体,第三个参数是消息的长度,最后一个参数是flag。这里IPC_NOWAIT表示发送的时候不阻塞,直接返回。
下面的这段程序,getopt_long、do-while循环以及switch,是用来解析命令行参数的。命令行参数的格式定义在long_options里面。每一项的第一个成员”id””type””message”是参数选项的全称,第二个成员都为1,表示参数选项后面要跟参数,最后一个成员’i’’t’’m’是参数选项的简称。
#include <stdio.h>
#include <stdlib.h>
#include <sys/msg.h>
#include <getopt.h>
#include <string.h>
struct msg_buffer {
long mtype;
char mtext[1024];
};
int main(int argc, char *argv[]) {
int next_option;
const char* const short_options = "i:t:m:";
const struct option long_options[] = {
{ "id", 1, NULL, 'i'},
{ "type", 1, NULL, 't'},
{ "message", 1, NULL, 'm'},
{ NULL, 0, NULL, 0 }
};
int messagequeueid = -1;
struct msg_buffer buffer;
buffer.mtype = -1;
int len = -1;
char * message = NULL;
do {
next_option = getopt_long (argc, argv, short_options, long_options, NULL);
switch (next_option)
{
case 'i':
messagequeueid = atoi(optarg);
break;
case 't':
buffer.mtype = atol(optarg);
break;
case 'm':
message = optarg;
len = strlen(message) + 1;
if (len > 1024) {
perror("message too long.");
exit(1);
}
memcpy(buffer.mtext, message, len);
break;
default:
break;
}
}while(next_option != -1);
if(messagequeueid != -1 && buffer.mtype != -1 && len != -1 && message != NULL){
if(msgsnd(messagequeueid, &buffer, len, IPC_NOWAIT) == -1){
perror("fail to send message.");
exit(1);
}
} else {
perror("arguments error");
}
return 0;
}接下来,我们可以编译并运行这个发送程序。
gcc -o send sendmessage.c
./send -i 32768 -t 123 -m "hello world"接下来,我们再来看如何收消息。收消息主要调用msgrcv函数,第一个参数是message queue的id,第二个参数是消息的结构体,第三个参数是可接受的最大长度,第四个参数是消息类型,最后一个参数是flag,这里IPC_NOWAIT表示接收的时候不阻塞,直接返回。
#include <stdio.h>
#include <stdlib.h>
#include <sys/msg.h>
#include <getopt.h>
#include <string.h>
struct msg_buffer {
long mtype;
char mtext[1024];
};
int main(int argc, char *argv[]) {
int next_option;
const char* const short_options = "i:t:";
const struct option long_options[] = {
{ "id", 1, NULL, 'i'},
{ "type", 1, NULL, 't'},
{ NULL, 0, NULL, 0 }
};
int messagequeueid = -1;
struct msg_buffer buffer;
long type = -1;
do {
next_option = getopt_long (argc, argv, short_options, long_options, NULL);
switch (next_option)
{
case 'i':
messagequeueid = atoi(optarg);
break;
case 't':
type = atol(optarg);
break;
default:
break;
}
}while(next_option != -1);
if(messagequeueid != -1 && type != -1){
if(msgrcv(messagequeueid, &buffer, 1024, type, IPC_NOWAIT) == -1){
perror("fail to recv message.");
exit(1);
}
printf("received message type : %d, text: %s.", buffer.mtype, buffer.mtext);
} else {
perror("arguments error");
}
return 0;
}接下来,我们可以编译并运行这个发送程序。可以看到,如果有消息,可以正确地读到消息;如果没有,则返回没有消息。
$ ./recv -i 32768 -t 123
received message type : 123, text: hello world.
$ ./recv -i 32768 -t 123
fail to recv message.: No message of desired type有了消息这种模型,两个进程之间的通信就像咱们平时发邮件一样,你来一封,我回一封,可以频繁沟通了。
31.3 共享内存模型
但是有时候,项目组之间的沟通需要特别紧密,而且要分享一些比较大的数据。如果使用邮件,就发现,一方面邮件的来去不及时;另外一方面,附件大小也有限制,所以,这个时候,我们经常采取的方式就是,把两个项目组在需要合作的期间,拉到一个会议室进行合作开发,这样大家可以直接交流文档呀,架构图呀,直接在白板上画或者直接扔给对方,就可以直接看到。
可以看出来,共享会议室这种模型,类似进程间通信的共享内存模型。前面咱们讲内存管理的时候,知道每个进程都有自己独立的虚拟内存空间,不同的进程的虚拟内存空间映射到不同的物理内存中去。这个进程访问A地址和另一个进程访问A地址,其实访问的是不同的物理内存地址,对于数据的增删查改互不影响。
但是,咱们是不是可以变通一下,拿出一块虚拟地址空间来,映射到相同的物理内存中。这样这个进程写入的东西,另外一个进程马上就能看到了,都不需要拷贝来拷贝去,传来传去。
共享内存也是System V IPC进程间通信机制体系中的,所以从它使用流程可以看到熟悉的面孔。
我们可以创建一个共享内存,调用shmget。在这个体系中,创建一个IPC对象都是xxxget,这里面第一个参数是key,和msgget里面的key一样,都是唯一定位一个共享内存对象,也可以通过关联文件的方式实现唯一性。第二个参数是共享内存的大小。第三个参数如果是IPC_CREAT,同样表示创建一个新的。
int shmget(key_t key, size_t size, int flag);创建完毕之后,我们可以通过ipcs命令查看这个共享内存。
$ ipcs --shmems
------ Shared Memory Segments ------
key shmid owner perms bytes nattch status
0x00000000 19398656 marc 600 1048576 2 dest接下来,如果一个进程想要访问这一段共享内存,需要将这个内存加载到自己的虚拟地址空间的某个位置,通过shmat函数,就是attach的意思。其中addr就是要指定attach到这个地方。但是这个地址的设定难度比较大,除非对于内存布局非常熟悉,否则可能会attach到一个非法地址。所以,通常的做法是将addr设为NULL,让内核选一个合适的地址。返回值就是真正被attach的地方。
void *shmat(int shm_id, const void *addr, int flag);如果共享内存使用完毕,可以通过shmdt解除绑定,然后通过shmctl,将cmd设置为IPC_RMID,从而删除这个共享内存对象。
int shmdt(void *addr);
int shmctl(int shm_id, int cmd, struct shmid_ds *buf);31.4 信号量
需要一种保护机制,使得同一个共享的资源,同时只能被一个进程访问。在System V IPC进程间通信机制体系中,早就想好了应对办法,就是信号量(Semaphore)。因此,信号量和共享内存往往要配合使用。
信号量其实是一个计数器,主要用于实现进程间的互斥与同步,而不是用于存储进程间通信数据。
我们可以将信号量初始化为一个数值,来代表某种资源的总体数量。对于信号量来讲,会定义两种原子操作,一个是P操作,我们称为申请资源操作。这个操作会申请将信号量的数值减去N,表示这些数量被他申请使用了,其他人不能用了。另一个是V操作,我们称为归还资源操作,这个操作会申请将信号量加上M,表示这些数量已经还给信号量了,其他人可以使用了。
如果想创建一个信号量,我们可以通过semget函数。看,又是xxxget,第一个参数key也是类似的,第二个参数num_sems不是指资源的数量,而是表示可以创建多少个信号量,形成一组信号量,也就是说,如果你有多种资源需要管理,可以创建一个信号量组。
int semget(key_t key, int num_sems, int sem_flags);接下来,我们需要初始化信号量的总的资源数量。通过semctl函数,第一个参数semid是这个信号量组的id,第二个参数semnum才是在这个信号量组中某个信号量的id,第三个参数是命令,如果是初始化,则用SETVAL,第四个参数是一个union。如果初始化,应该用里面的val设置资源总量。
int semctl(int semid, int semnum, int cmd, union semun args);
union semun
{
int val;
struct semid_ds *buf;
unsigned short int *array;
struct seminfo *__buf;
};无论是P操作还是V操作,我们统一用semop函数。第一个参数还是信号量组的id,一次可以操作多个信号量。第三个参数numops就是有多少个操作,第二个参数将这些操作放在一个数组中。
数组的每一项是一个struct sembuf,里面的第一个成员是这个操作的对象是哪个信号量。
第二个成员就是要对这个信号量做多少改变。如果sem_op < 0,就请求sem_op的绝对值的资源。如果相应的资源数可以满足请求,则将该信号量的值减去sem_op的绝对值,函数成功返回。
当相应的资源数不能满足请求时,就要看sem_flg了。如果把sem_flg设置为IPC_NOWAIT,也就是没有资源也不等待,则semop函数出错返回EAGAIN。如果sem_flg 没有指定IPC_NOWAIT,则进程挂起,直到当相应的资源数可以满足请求。若sem_op > 0,表示进程归还相应的资源数,将 sem_op 的值加到信号量的值上。如果有进程正在休眠等待此信号量,则唤醒它们。
int semop(int semid, struct sembuf semoparray[], size_t numops);
struct sembuf
{
short sem_num; // 信号量组中对应的序号,0~sem_nums-1
short sem_op; // 信号量值在一次操作中的改变量
short sem_flg; // IPC_NOWAIT, SEM_UNDO
}31.5 信号
上面讲的进程间通信的方式,都是常规状态下的工作模式,对应到咱们平时的工作交接,收发邮件、联合开发等,其实还有一种异常情况下的工作模式。
例如出现线上系统故障,这个时候,什么流程都来不及了,不可能发邮件,也来不及开会,所有的架构师、开发、运维都要被通知紧急出动。所以,7乘24小时不间断执行的系统都需要有告警系统,一旦出事情,就要通知到人,哪怕是半夜,也要电话叫起来,处理故障。
对应到操作系统中,就是信号。信号没有特别复杂的数据结构,就是用一个代号一样的数字。Linux提供了几十种信号,分别代表不同的意义。信号之间依靠它们的值来区分。这就像咱们看警匪片,对于紧急的行动,都是说,”1号作战任务”开始执行,警察就开始行动了。情况紧急,不能啰里啰嗦了。
信号可以在任何时候发送给某一进程,进程需要为这个信号配置信号处理函数。当某个信号发生的时候,就默认执行这个函数就可以了。这就相当于咱们运维一个系统应急手册,当遇到什么情况,做什么事情,都事先准备好,出了事情照着做就可以了。
32. 信号(上)
在Linux操作系统中,为了响应各种各样的事件,也是定义了非常多的信号。我们可以通过kill -l命令,查看所有的信号。
$ kill -l
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ
26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR
31) SIGSYS 34) SIGRTMIN 35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3
38) SIGRTMIN+4 39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8
43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12 47) SIGRTMIN+13
48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14 51) SIGRTMAX-13 52) SIGRTMAX-12
53) SIGRTMAX-11 54) SIGRTMAX-10 55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7
58) SIGRTMAX-6 59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2
63) SIGRTMAX-1 64) SIGRTMAX这些信号都是什么作用呢?我们可以通过man 7 signal命令查看,里面会有一个列表。
Signal Value Action Comment
──────────────────────────────────────────────────────────────────────
SIGHUP 1 Term Hangup detected on controlling terminal
or death of controlling process
SIGINT 2 Term Interrupt from keyboard
SIGQUIT 3 Core Quit from keyboard
SIGILL 4 Core Illegal Instruction
SIGABRT 6 Core Abort signal from abort(3)
SIGFPE 8 Core Floating point exception
SIGKILL 9 Term Kill signal
SIGSEGV 11 Core Invalid memory reference
SIGPIPE 13 Term Broken pipe: write to pipe with no
readers
SIGALRM 14 Term Timer signal from alarm(2)
SIGTERM 15 Term Termination signal
SIGUSR1 30,10,16 Term User-defined signal 1
SIGUSR2 31,12,17 Term User-defined signal 2
……一旦有信号产生,我们就有下面这几种,用户进程对信号的处理方式。
有下面这几种,用户进程对信号的处理方式。
执行默认操作。
Linux对每种信号都规定了默认操作,例如,上面列表中的Term,就是终止进程的意思。Core的意思是Core Dump,也即终止进程后,通过Core Dump将当前进程的运行状态保存在文件里面,方便程序员事后进行分析问题在哪里。
捕捉信号。
我们可以为信号定义一个信号处理函数。当信号发生时,我们就执行相应的信号处理函数。
忽略信号。
当我们不希望处理某些信号的时候,就可以忽略该信号,不做任何处理。有两个信号是应用进程无法捕捉和忽略的,即SIGKILL和SEGSTOP,它们用于在任何时候中断或结束某一进程。
接下来,我们来看一下信号处理最常见的流程。这个过程主要是分成两步,第一步是注册信号处理函数。第二步是发送信号。这一节我们主要看第一步。
如果我们不想让某个信号执行默认操作,一种方法就是对特定的信号注册相应的信号处理函数,设置信号处理方式的是signal函数。
typedef void (*sighandler_t)(int);
sighandler_t signal(int signum, sighandler_t handler);这其实就是定义一个方法,并且将这个方法和某个信号关联起来。当这个进程遇到这个信号的时候,就执行这个方法。
如果我们在Linux下面执行man signal的话,会发现Linux不建议我们直接用这个方法,而是改用sigaction。定义如下:
int sigaction(int signum, const struct sigaction *act,
struct sigaction *oldact);这两者的区别在哪里呢?其实它还是将信号和一个动作进行关联,只不过这个动作由一个结构struct sigaction表示了。
struct sigaction {
__sighandler_t sa_handler;
unsigned long sa_flags;
__sigrestore_t sa_restorer;
sigset_t sa_mask; /* mask last for extensibility */
};和signal类似的是,这里面还是有__sighandler_t。但是,其他成员变量可以让你更加细致地控制信号处理的行为。而signal函数没有给你机会设置这些。这里需要注意的是,signal不是系统调用,而是glibc封装的一个函数。这样就像man signal里面写的一样,不同的实现方式,设置的参数会不同,会导致行为的不同。
例如,我们在glibc里面会看到了这样一个实现:
#define signal __sysv_signal
__sighandler_t
__sysv_signal (int sig, __sighandler_t handler)
{
struct sigaction act, oact;
......
act.sa_handler = handler;
__sigemptyset (&act.sa_mask);
act.sa_flags = SA_ONESHOT | SA_NOMASK | SA_INTERRUPT;
act.sa_flags &= ~SA_RESTART;
if (__sigaction (sig, &act, &oact) < 0)
return SIG_ERR;
return oact.sa_handler;
}
weak_alias (__sysv_signal, sysv_signal)在这里面,sa_flags进行了默认的设置。SA_ONESHOT是什么意思呢?意思就是,这里设置的信号处理函数,仅仅起作用一次。用完了一次后,就设置回默认行为。这其实并不是我们想看到的。毕竟我们一旦安装了一个信号处理函数,肯定希望它一直起作用,直到我显式地关闭它。
另外一个设置就是SA_NOMASK。我们通过__sigemptyset,将sa_mask设置为空。这样的设置表示在这个信号处理函数执行过程中,如果再有其他信号,哪怕相同的信号到来的时候,这个信号处理函数会被中断。如果一个信号处理函数真的被其他信号中断,其实问题也不大,因为当处理完了其他的信号处理函数后,还会回来接着处理这个信号处理函数的,但是对于相同的信号就有点尴尬了,这就需要这个信号处理函数写的比较有技巧了。
例如,对于这个信号的处理过程中,要操作某个数据结构,因为是相同的信号,很可能操作的是同一个实例,这样的话,同步、死锁这些都要想好。其实一般的思路应该是,当某一个信号的信号处理函数运行的时候,我们暂时屏蔽这个信号。后面我们还会仔细分析屏蔽这个动作,屏蔽并不意味着信号一定丢失,而是暂存,这样能够做到信号处理函数对于相同的信号,处理完一个再处理下一个,这样信号处理函数的逻辑要简单得多。
还有一个设置就是设置了SA_INTERRUPT,清除了SA_RESTART。这是什么意思呢?我们知道,信号的到来时间是不可预期的,有可能程序正在调用某个漫长的系统调用的时候(你可以在一台Linux机器上运行man 7 signal命令,在这里找Interruption of system calls and library functions by signal handlers的部分,里面说的非常详细),这个时候一个信号来了,会中断这个系统调用,去执行信号处理函数,那执行完了以后呢?系统调用怎么办呢?
这时候有两种处理方法,一种就是SA_INTERRUPT,也即系统调用被中断了,就不再重试这个系统调用了,而是直接返回一个-EINTR常量,告诉调用方,这个系统调用被信号中断了,但是怎么处理你看着办。如果是这样的话,调用方可以根据自己的逻辑,重新调用或者直接返回,这会使得我们的代码非常复杂,在所有系统调用的返回值判断里面,都要特殊判断一下这个值。
另外一种处理方法是SA_RESTART。这个时候系统调用会被自动重新启动,不需要调用方自己写代码。当然也可能存在问题,例如从终端读入一个字符,这个时候用户在终端输入一个’a’字符,在处理’a’字符的时候被信号中断了,等信号处理完毕,再次读入一个字符的时候,如果用户不再输入,就停在那里了,需要用户再次输入同一个字符。
因而,建议你使用sigaction函数,根据自己的需要定制参数。
接下来,我们来看sigaction具体做了些什么。
还记得在学习系统调用那一节的时候,我们知道,glibc里面有个文件syscalls.list。这里面定义了库函数调用哪些系统调用,在这里我们找到了sigaction。
sigaction - sigaction i:ipp __sigaction sigaction接下来,在glibc中,sigaction会调用libc_sigaction,并最终调用的系统调用是rt_sigaction。
int
__sigaction (int sig, const struct sigaction *act, struct sigaction *oact)
{
......
return __libc_sigaction (sig, act, oact);
}
int
__libc_sigaction (int sig, const struct sigaction *act, struct sigaction *oact)
{
int result;
struct kernel_sigaction kact, koact;
if (act)
{
kact.k_sa_handler = act->sa_handler;
memcpy (&kact.sa_mask, &act->sa_mask, sizeof (sigset_t));
kact.sa_flags = act->sa_flags | SA_RESTORER;
kact.sa_restorer = &restore_rt;
}
result = INLINE_SYSCALL (rt_sigaction, 4,
sig, act ? &kact : NULL,
oact ? &koact : NULL, _NSIG / 8);
if (oact && result >= 0)
{
oact->sa_handler = koact.k_sa_handler;
memcpy (&oact->sa_mask, &koact.sa_mask, sizeof (sigset_t));
oact->sa_flags = koact.sa_flags;
oact->sa_restorer = koact.sa_restorer;
}
return result;
}这也是很多人看信号处理的内核实现的时候,比较困惑的地方。例如,内核代码注释里面会说,系统调用signal是为了兼容过去,系统调用sigaction也是为了兼容过去,连参数都变成了struct compat_old_sigaction,所以说,我们的库函数虽然调用的是sigaction,到了系统调用层,调用的可不是系统调用sigaction,而是系统调用rt_sigaction。
SYSCALL_DEFINE4(rt_sigaction, int, sig,
const struct sigaction __user *, act,
struct sigaction __user *, oact,
size_t, sigsetsize)
{
struct k_sigaction new_sa, old_sa;
int ret = -EINVAL;
......
if (act) {
if (copy_from_user(&new_sa.sa, act, sizeof(new_sa.sa)))
return -EFAULT;
}
ret = do_sigaction(sig, act ? &new_sa : NULL, oact ? &old_sa : NULL);
if (!ret && oact) {
if (copy_to_user(oact, &old_sa.sa, sizeof(old_sa.sa)))
return -EFAULT;
}
out:
return ret;
}在rt_sigaction里面,我们将用户态的struct sigaction结构,拷贝为内核态的k_sigaction,然后调用do_sigaction。do_sigaction也很简单,还记得进程内核的数据结构里,struct task_struct里面有一个成员sighand,里面有一个action。这是一个数组,下标是信号,内容就是信号处理函数,do_sigaction就是设置sighand里的信号处理函数。
int do_sigaction(int sig, struct k_sigaction *act, struct k_sigaction *oact)
{
struct task_struct *p = current, *t;
struct k_sigaction *k;
sigset_t mask;
......
k = &p->sighand->action[sig-1];
spin_lock_irq(&p->sighand->siglock);
if (oact)
*oact = *k;
if (act) {
sigdelsetmask(&act->sa.sa_mask,
sigmask(SIGKILL) | sigmask(SIGSTOP));
*k = *act;
......
}
spin_unlock_irq(&p->sighand->siglock);
return 0;
}至此,信号处理函数的注册已经完成了。
32.1 总结
这一节讲了如何通过API注册一个信号处理函数,整个过程如下图所示。
- 在用户程序里面,有两个函数可以调用,一个是signal,一个是sigaction,推荐使用sigaction。
- 用户程序调用的是Glibc里面的函数,signal调用的是sysv_signal,里面默认设置了一些参数,使得signal的功能受到了限制,sigaction调用的是sigaction,参数用户可以任意设定。
- 无论是sysv_signal还是sigaction,调用的都是统一的一个系统调用rt_sigaction。
- 在内核中,rt_sigaction调用的是do_sigaction设置信号处理函数。在每一个进程的task_struct里面,都有一个sighand指向struct sighand_struct,里面是一个数组,下标是信号,里面的内容是信号处理函数。
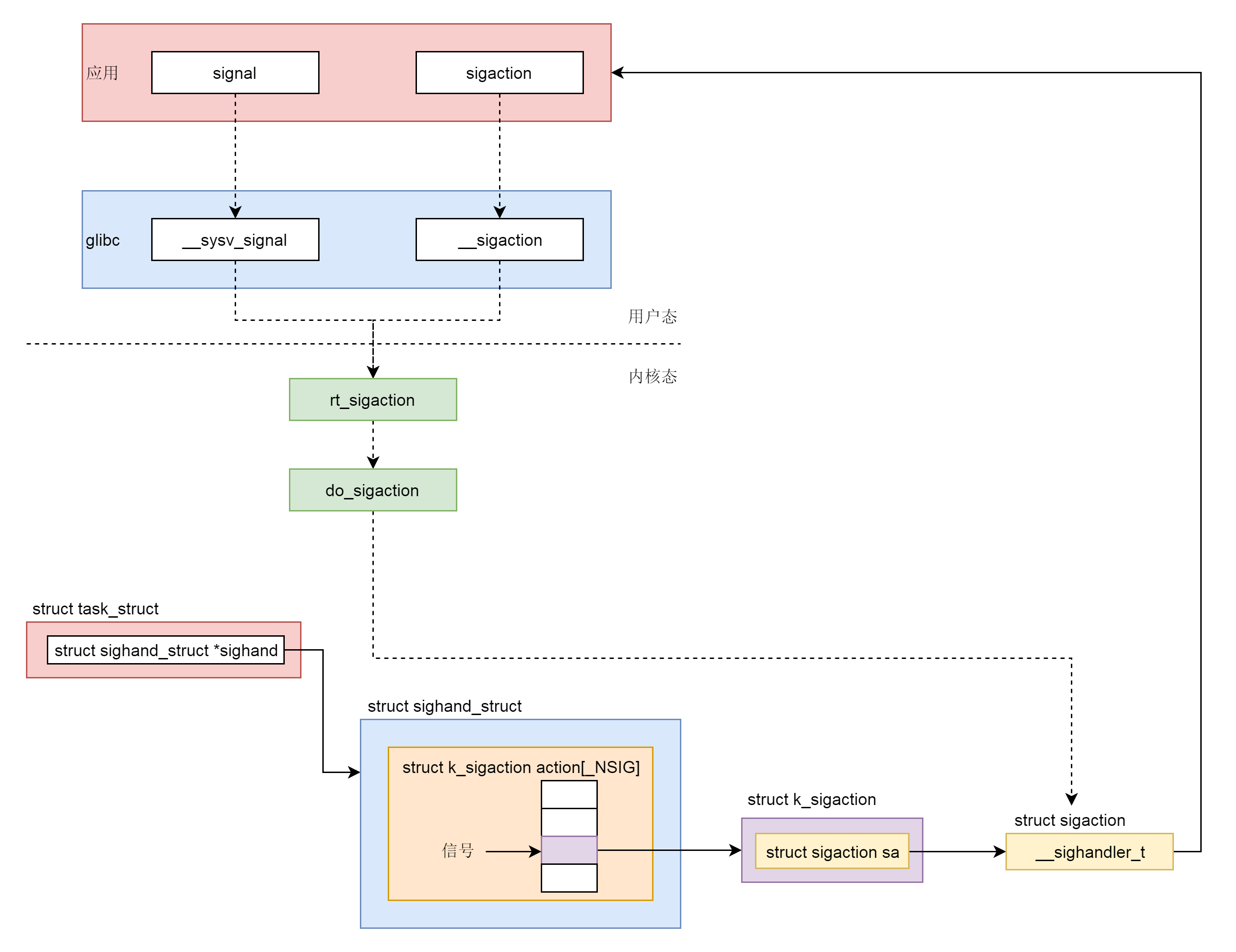
33. 信号(下)
33.1 信号的发送
有时候,我们在终端输入某些组合键的时候,会给进程发送信号,例如,Ctrl+C产生SIGINT信号,Ctrl+Z产生SIGTSTP信号。
有的时候,硬件异常也会产生信号。比如,执行了除以0的指令,CPU就会产生异常,然后把SIGFPE信号发送给进程。再如,进程访问了非法内存,内存管理模块就会产生异常,然后把信号SIGSEGV发送给进程。
这里同样是硬件产生的,对于中断和信号还是要加以区别。咱们前面讲过,中断要注册中断处理函数,但是中断处理函数是在内核驱动里面的,信号也要注册信号处理函数,信号处理函数是在用户态进程里面的。
对于硬件触发的,无论是中断,还是信号,肯定是先到内核的,然后内核对于中断和信号处理方式不同。一个是完全在内核里面处理完毕,一个是将信号放在对应的进程task_struct里信号相关的数据结构里面,然后等待进程在用户态去处理。当然有些严重的信号,内核会把进程干掉。但是,这也能看出来,中断和信号的严重程度不一样,信号影响的往往是某一个进程,处理慢了,甚至错了,也不过这个进程被干掉,而中断影响的是整个系统。一旦中断处理中有了bug,可能整个Linux都挂了。
有时候,内核在某些情况下,也会给进程发送信号。例如,向读端已关闭的管道写数据时产生SIGPIPE信号,当子进程退出时,我们要给父进程发送SIG_CHLD信号等。
最直接的发送信号的方法就是,通过命令kill来发送信号了。例如,我们都知道的kill -9 pid可以发送信号给一个进程,杀死它。
另外,我们还可以通过kill或者sigqueue系统调用,发送信号给某个进程,也可以通过tkill或者tgkill发送信号给某个线程。虽然方式多种多样,但是最终都是调用了do_send_sig_info函数,将信号放在相应的task_struct的信号数据结构中。
- kill->kill_something_info->kill_pid_info->group_send_sig_info->do_send_sig_info
- tkill->do_tkill->do_send_specific->do_send_sig_info
- tgkill->do_tkill->do_send_specific->do_send_sig_info
- rt_sigqueueinfo->do_rt_sigqueueinfo->kill_proc_info->kill_pid_info->group_send_sig_info->do_send_sig_info
do_send_sig_info会调用send_signal,进而调用__send_signal。
SYSCALL_DEFINE2(kill, pid_t, pid, int, sig)
{
struct siginfo info;
info.si_signo = sig;
info.si_errno = 0;
info.si_code = SI_USER;
info.si_pid = task_tgid_vnr(current);
info.si_uid = from_kuid_munged(current_user_ns(), current_uid());
return kill_something_info(sig, &info, pid);
}
static int __send_signal(int sig, struct siginfo *info, struct task_struct *t,
int group, int from_ancestor_ns)
{
struct sigpending *pending;
struct sigqueue *q;
int override_rlimit;
int ret = 0, result;
......
pending = group ? &t->signal->shared_pending : &t->pending;
......
if (legacy_queue(pending, sig))
goto ret;
if (sig < SIGRTMIN)
override_rlimit = (is_si_special(info) || info->si_code >= 0);
else
override_rlimit = 0;
q = __sigqueue_alloc(sig, t, GFP_ATOMIC | __GFP_NOTRACK_FALSE_POSITIVE,
override_rlimit);
if (q) {
list_add_tail(&q->list, &pending->list);
switch ((unsigned long) info) {
case (unsigned long) SEND_SIG_NOINFO:
q->info.si_signo = sig;
q->info.si_errno = 0;
q->info.si_code = SI_USER;
q->info.si_pid = task_tgid_nr_ns(current,
task_active_pid_ns(t));
q->info.si_uid = from_kuid_munged(current_user_ns(), current_uid());
break;
case (unsigned long) SEND_SIG_PRIV:
q->info.si_signo = sig;
q->info.si_errno = 0;
q->info.si_code = SI_KERNEL;
q->info.si_pid = 0;
q->info.si_uid = 0;
break;
default:
copy_siginfo(&q->info, info);
if (from_ancestor_ns)
q->info.si_pid = 0;
break;
}
userns_fixup_signal_uid(&q->info, t);
}
......
out_set:
signalfd_notify(t, sig);
sigaddset(&pending->signal, sig);
complete_signal(sig, t, group);
ret:
return ret;
}在这里,我们看到,在学习进程数据结构中task_struct里面的sigpending。在上面的代码里面,我们先是要决定应该用哪个sigpending。这就要看我们发送的信号,是给进程的还是线程的。如果是kill发送的,也就是发送给整个进程的,就应该发送给t->signal->shared_pending。这里面是整个进程所有线程共享的信号;如果是tkill发送的,也就是发给某个线程的,就应该发给t->pending。这里面是这个线程的task_struct独享的。
struct sigpending里面有两个成员,一个是一个集合sigset_t,表示都收到了哪些信号,还有一个链表,也表示收到了哪些信号。它的结构如下:
struct sigpending {
struct list_head list;
sigset_t signal;
};如果都表示收到了信号,这两者有什么区别呢?我们接着往下看__send_signal里面的代码。接下来,我们要调用legacy_queue。如果满足条件,那就直接退出。那legacy_queue里面判断的是什么条件呢?我们来看它的代码。
static inline int legacy_queue(struct sigpending *signals, int sig)
{
return (sig < SIGRTMIN) && sigismember(&signals->signal, sig);
}
#define SIGRTMIN 32
#define SIGRTMAX _NSIG
#define _NSIG 64当信号小于SIGRTMIN,也即32的时候,如果我们发现这个信号已经在集合里面了,就直接退出了。这样会造成什么现象呢?就是信号的丢失。例如,我们发送给进程100个SIGUSR1(对应的信号为10),那最终能够被我们的信号处理函数处理的信号有多少呢?这就不好说了,比如总共5个SIGUSR1,分别是A、B、C、D、E。
如果这五个信号来得太密。A来了,但是信号处理函数还没来得及处理,B、C、D、E就都来了。根据上面的逻辑,因为A已经将SIGUSR1放在sigset_t集合中了,因而后面四个都要丢失。 如果是另一种情况,A来了已经被信号处理函数处理了,内核在调用信号处理函数之前,我们会将集合中的标志位清除,这个时候B再来,B还是会进入集合,还是会被处理,也就不会丢。
这样信号能够处理多少,和信号处理函数什么时候被调用,信号多大频率被发送,都有关系,而且从后面的分析,我们可以知道,信号处理函数的调用时间也是不确定的。看小于32的信号如此不靠谱,我们就称它为不可靠信号。
如果大于32的信号是什么情况呢?我们接着看。接下来,__sigqueue_alloc会分配一个struct sigqueue对象,然后通过list_add_tail挂在struct sigpending里面的链表上。这样就靠谱多了是不是?如果发送过来100个信号,变成链表上的100项,都不会丢,哪怕相同的信号发送多遍,也处理多遍。因此,大于32的信号我们称为可靠信号。当然,队列的长度也是有限制的,如果我们执行ulimit命令,可以看到,这个限制pending signals (-i) 15408。
当信号挂到了task_struct结构之后,最后我们需要调用complete_signal。这里面的逻辑也很简单,就是说,既然这个进程有了一个新的信号,赶紧找一个线程处理一下吧。
static void complete_signal(int sig, struct task_struct *p, int group)
{
struct signal_struct *signal = p->signal;
struct task_struct *t;
/*
* Now find a thread we can wake up to take the signal off the queue.
*
* If the main thread wants the signal, it gets first crack.
* Probably the least surprising to the average bear.
*/
if (wants_signal(sig, p))
t = p;
else if (!group || thread_group_empty(p))
/*
* There is just one thread and it does not need to be woken.
* It will dequeue unblocked signals before it runs again.
*/
return;
else {
/*
* Otherwise try to find a suitable thread.
*/
t = signal->curr_target;
while (!wants_signal(sig, t)) {
t = next_thread(t);
if (t == signal->curr_target)
return;
}
signal->curr_target = t;
}
......
/*
* The signal is already in the shared-pending queue.
* Tell the chosen thread to wake up and dequeue it.
*/
signal_wake_up(t, sig == SIGKILL);
return;
}在找到了一个进程或者线程的task_struct之后,我们要调用signal_wake_up,来企图唤醒它,signal_wake_up会调用signal_wake_up_state。
void signal_wake_up_state(struct task_struct *t, unsigned int state)
{
set_tsk_thread_flag(t, TIF_SIGPENDING);
if (!wake_up_state(t, state | TASK_INTERRUPTIBLE))
kick_process(t);
}signal_wake_up_state里面主要做了两件事情。第一,就是给这个线程设置TIF_SIGPENDING,这就说明其实信号的处理和进程的调度是采取这样一种类似的机制。还记得咱们调度的时候是怎么操作的吗?
当发现一个进程应该被调度的时候,我们并不直接把它赶下来,而是设置一个标识位TIF_NEED_RESCHED,表示等待调度,然后等待系统调用结束或者中断处理结束,从内核态返回用户态的时候,调用schedule函数进行调度。信号也是类似的,当信号来的时候,我们并不直接处理这个信号,而是设置一个标识位TIF_SIGPENDING,来表示已经有信号等待处理。同样等待系统调用结束,或者中断处理结束,从内核态返回用户态的时候,再进行信号的处理。
signal_wake_up_state的第二件事情,就是试图唤醒这个进程或者线程。wake_up_state会调用try_to_wake_up方法。这个函数我们讲进程的时候讲过,就是将这个进程或者线程设置为TASK_RUNNING,然后放在运行队列中,这个时候,当随着时钟不断的滴答,迟早会被调用。如果wake_up_state返回0,说明进程或者线程已经是TASK_RUNNING状态了,如果它在另外一个CPU上运行,则调用kick_process发送一个处理器间中断,强制那个进程或者线程重新调度,重新调度完毕后,会返回用户态运行。这是一个时机会检查TIF_SIGPENDING标识位。
33.2 信号的处理
就是在从系统调用或者中断返回的时候,咱们讲调度的时候讲过,无论是从系统调用返回还是从中断返回,都会调用exit_to_usermode_loop,只不过我们上次主要关注了_TIF_NEED_RESCHED这个标识位,这次我们重点关注_TIF_SIGPENDING标识位。
static void exit_to_usermode_loop(struct pt_regs *regs, u32 cached_flags)
{
while (true) {
......
if (cached_flags & _TIF_NEED_RESCHED)
schedule();
......
/* deal with pending signal delivery */
if (cached_flags & _TIF_SIGPENDING)
do_signal(regs);
......
if (!(cached_flags & EXIT_TO_USERMODE_LOOP_FLAGS))
break;
}
}如果在前一个环节中,已经设置了_TIF_SIGPENDING,我们就调用do_signal进行处理。
void do_signal(struct pt_regs *regs)
{
struct ksignal ksig;
if (get_signal(&ksig)) {
/* Whee! Actually deliver the signal. */
handle_signal(&ksig, regs);
return;
}
/* Did we come from a system call? */
if (syscall_get_nr(current, regs) >= 0) {
/* Restart the system call - no handlers present */
switch (syscall_get_error(current, regs)) {
case -ERESTARTNOHAND:
case -ERESTARTSYS:
case -ERESTARTNOINTR:
regs->ax = regs->orig_ax;
regs->ip -= 2;
break;
case -ERESTART_RESTARTBLOCK:
regs->ax = get_nr_restart_syscall(regs);
regs->ip -= 2;
break;
}
}
restore_saved_sigmask();
}do_signal会调用handle_signal。按说,信号处理就是调用用户提供的信号处理函数,但是这事儿没有看起来这么简单,因为信号处理函数是在用户态的。
咱们又要来回忆系统调用的过程了。这个进程当时在用户态执行到某一行Line A,调用了一个系统调用,在进入内核的那一刻,在内核pt_regs里面保存了用户态执行到了Line A。现在我们从系统调用返回用户态了,按说应该从pt_regs拿出Line A,然后接着Line A执行下去,但是为了响应信号,我们不能回到用户态的时候返回Line A了,而是应该返回信号处理函数的起始地址。
static void
handle_signal(struct ksignal *ksig, struct pt_regs *regs)
{
bool stepping, failed;
......
/* Are we from a system call? */
if (syscall_get_nr(current, regs) >= 0) {
/* If so, check system call restarting.. */
switch (syscall_get_error(current, regs)) {
case -ERESTART_RESTARTBLOCK:
case -ERESTARTNOHAND:
regs->ax = -EINTR;
break;
case -ERESTARTSYS:
if (!(ksig->ka.sa.sa_flags & SA_RESTART)) {
regs->ax = -EINTR;
break;
}
/* fallthrough */
case -ERESTARTNOINTR:
regs->ax = regs->orig_ax;
regs->ip -= 2;
break;
}
}
......
failed = (setup_rt_frame(ksig, regs) < 0);
......
signal_setup_done(failed, ksig, stepping);
}这个时候,我们就需要干预和自己来定制pt_regs了。这个时候,我们要看,是否从系统调用中返回。如果是从系统调用返回的话,还要区分我们是从系统调用中正常返回,还是在一个非运行状态的系统调用中,因为会被信号中断而返回。
我们这里解析一个最复杂的场景。还记得咱们解析进程调度的时候,我们举的一个例子,就是从一个tap网卡中读取数据。当时我们主要关注schedule那一行,也即如果当发现没有数据的时候,就调用schedule,自己进入等待状态,然后将CPU让给其他进程。具体的代码如下:
static ssize_t tap_do_read(struct tap_queue *q,
struct iov_iter *to,
int noblock, struct sk_buff *skb)
{
......
while (1) {
if (!noblock)
prepare_to_wait(sk_sleep(&q->sk), &wait,
TASK_INTERRUPTIBLE);
/* Read frames from the queue */
skb = skb_array_consume(&q->skb_array);
if (skb)
break;
if (noblock) {
ret = -EAGAIN;
break;
}
if (signal_pending(current)) {
ret = -ERESTARTSYS;
break;
}
/* Nothing to read, let's sleep */
schedule();
}
......
}这里我们关注和信号相关的部分。这其实是一个信号中断系统调用的典型逻辑。
首先,我们把当前进程或者线程的状态设置为TASK_INTERRUPTIBLE,这样才能是使这个系统调用可以被中断。
其次,可以被中断的系统调用往往是比较慢的调用,并且会因为数据不就绪而通过schedule让出CPU进入等待状态。在发送信号的时候,我们除了设置这个进程和线程的_TIF_SIGPENDING标识位之外,还试图唤醒这个进程或者线程,也就是将它从等待状态中设置为TASK_RUNNING。
当这个进程或者线程再次运行的时候,我们根据进程调度第一定律,从schedule函数中返回,然后再次进入while循环。由于这个进程或者线程是由信号唤醒的,而不是因为数据来了而唤醒的,因而是读不到数据的,但是在signal_pending函数中,我们检测到了_TIF_SIGPENDING标识位,这说明系统调用没有真的做完,于是返回一个错误ERESTARTSYS,然后带着这个错误从系统调用返回。
然后,我们到了exit_to_usermode_loop->do_signal->handle_signal。在这里面,当发现出现错误ERESTARTSYS的时候,我们就知道这是从一个没有调用完的系统调用返回的,设置系统调用错误码EINTR。
接下来,我们就开始折腾pt_regs了,主要通过调用setup_rt_frame->__setup_rt_frame。
static int __setup_rt_frame(int sig, struct ksignal *ksig,
sigset_t *set, struct pt_regs *regs)
{
struct rt_sigframe __user *frame;
void __user *fp = NULL;
int err = 0;
frame = get_sigframe(&ksig->ka, regs, sizeof(struct rt_sigframe), &fp);
......
put_user_try {
......
/* Set up to return from userspace. If provided, use a stub
already in userspace. */
/* x86-64 should always use SA_RESTORER. */
if (ksig->ka.sa.sa_flags & SA_RESTORER) {
put_user_ex(ksig->ka.sa.sa_restorer, &frame->pretcode);
}
} put_user_catch(err);
err |= setup_sigcontext(&frame->uc.uc_mcontext, fp, regs, set->sig[0]);
err |= __copy_to_user(&frame->uc.uc_sigmask, set, sizeof(*set));
/* Set up registers for signal handler */
regs->di = sig;
/* In case the signal handler was declared without prototypes */
regs->ax = 0;
regs->si = (unsigned long)&frame->info;
regs->dx = (unsigned long)&frame->uc;
regs->ip = (unsigned long) ksig->ka.sa.sa_handler;
regs->sp = (unsigned long)frame;
regs->cs = __USER_CS;
......
return 0;
}frame的类型是rt_sigframe。frame的意思是帧。我们只有在学习栈的时候,提到过栈帧的概念。对的,这个frame就是一个栈帧。
我们在get_sigframe中会得到pt_regs的sp变量,也就是原来这个程序在用户态的栈顶指针,然后get_sigframe中,我们会将sp减去sizeof(struct rt_sigframe),也就是把这个栈帧塞到了栈里面,然后我们又在__setup_rt_frame中把regs->sp设置成等于frame。这就相当于强行在程序原来的用户态的栈里面插入了一个栈帧,并在最后将regs->ip设置为用户定义的信号处理函数sa_handler。这意味着,本来返回用户态应该接着原来的代码执行的,现在不了,要执行sa_handler了。那执行完了以后呢?按照函数栈的规则,弹出上一个栈帧来,也就是弹出了frame。
那如果我们假设sa_handler成功返回了,怎么回到程序原来在用户态运行的地方呢?玄机就在frame里面。要想恢复原来运行的地方,首先,原来的pt_regs不能丢,这个没问题,是在setup_sigcontext里面,将原来的pt_regs保存在了frame中的uc_mcontext里面。
另外,很重要的一点,程序如何跳过去呢?在__setup_rt_frame中,还有一个不引起重视的操作,那就是通过put_user_ex,将sa_restorer放到了frame->pretcode里面,而且还是按照函数栈的规则。函数栈里面包含了函数执行完跳回去的地址。当sa_handler执行完之后,弹出的函数栈是frame,也就应该跳到sa_restorer的地址。这是什么地址呢?
咱们在sigaction介绍的时候就没有介绍它,在Glibc的__libc_sigaction函数中也没有注意到,它被赋值成了restore_rt。这其实就是sa_handler执行完毕之后,马上要执行的函数。从名字我们就能感觉到,它将恢复原来程序运行的地方。
在Glibc中,我们可以找到它的定义,它竟然调用了一个系统调用,系统调用号为__NR_rt_sigreturn。
RESTORE (restore_rt, __NR_rt_sigreturn)
#define RESTORE(name, syscall) RESTORE2 (name, syscall)
# define RESTORE2(name, syscall) \
asm \
( \
".LSTART_" #name ":\n" \
" .type __" #name ",@function\n" \
"__" #name ":\n" \
" movq $" #syscall ", %rax\n" \
" syscall\n" \
......我们可以在内核里面找到__NR_rt_sigreturn对应的系统调用。
asmlinkage long sys_rt_sigreturn(void)
{
struct pt_regs *regs = current_pt_regs();
struct rt_sigframe __user *frame;
sigset_t set;
unsigned long uc_flags;
frame = (struct rt_sigframe __user *)(regs->sp - sizeof(long));
if (__copy_from_user(&set, &frame->uc.uc_sigmask, sizeof(set)))
goto badframe;
if (__get_user(uc_flags, &frame->uc.uc_flags))
goto badframe;
set_current_blocked(&set);
if (restore_sigcontext(regs, &frame->uc.uc_mcontext, uc_flags))
goto badframe;
......
return regs->ax;
......
}在这里面,我们把上次填充的那个rt_sigframe拿出来,然后restore_sigcontext将pt_regs恢复成为原来用户态的样子。从这个系统调用返回的时候,应用还误以为从上次的系统调用返回的呢。
至此,整个信号处理过程才全部结束。
33.3 总结
信号的发送与处理是一个复杂的过程,这里来总结一下。
- 假设我们有一个进程A,main函数里面调用系统调用进入内核。
- 按照系统调用的原理,会将用户态栈的信息保存在pt_regs里面,也即记住原来用户态是运行到了line A的地方。
- 在内核中执行系统调用读取数据。
- 当发现没有什么数据可读取的时候,只好进入睡眠状态,并且调用schedule让出CPU,这是进程调度第一定律。
- 将进程状态设置为TASK_INTERRUPTIBLE,可中断的睡眠状态,也即如果有信号来的话,是可以唤醒它的。
- 其他的进程或者shell发送一个信号,有四个函数可以调用kill、tkill、tgkill、rt_sigqueueinfo。
- 四个发送信号的函数,在内核中最终都是调用do_send_sig_info。
- do_send_sig_info调用send_signal给进程A发送一个信号,其实就是找到进程A的task_struct,或者加入信号集合,为不可靠信号,或者加入信号链表,为可靠信号。
- do_send_sig_info调用signal_wake_up唤醒进程A。
- 进程A重新进入运行状态TASK_RUNNING,根据进程调度第一定律,一定会接着schedule运行。
- 进程A被唤醒后,检查是否有信号到来,如果没有,重新循环到一开始,尝试再次读取数据,如果还是没有数据,再次进入TASK_INTERRUPTIBLE,即可中断的睡眠状态。
- 当发现有信号到来的时候,就返回当前正在执行的系统调用,并返回一个错误表示系统调用被中断了。
- 系统调用返回的时候,会调用exit_to_usermode_loop。这是一个处理信号的时机。
- 调用do_signal开始处理信号。
- 根据信号,得到信号处理函数sa_handler,然后修改pt_regs中的用户态栈的信息,让pt_regs指向sa_handler。同时修改用户态的栈,插入一个栈帧sa_restorer,里面保存了原来的指向line A的pt_regs,并且设置让sa_handler运行完毕后,跳到sa_restorer运行。
- 返回用户态,由于pt_regs已经设置为sa_handler,则返回用户态执行sa_handler。
- sa_handler执行完毕后,信号处理函数就执行完了,接着根据第15步对于用户态栈帧的修改,会跳到sa_restorer运行。
- sa_restorer会调用系统调用rt_sigreturn再次进入内核。
- 在内核中,rt_sigreturn恢复原来的pt_regs,重新指向line A。
- 从rt_sigreturn返回用户态,还是调用exit_to_usermode_loop。
- 这次因为pt_regs已经指向line A了,于是就到了进程A中,接着系统调用之后运行,当然这个系统调用返回的是它被中断了,没有执行完的错误。
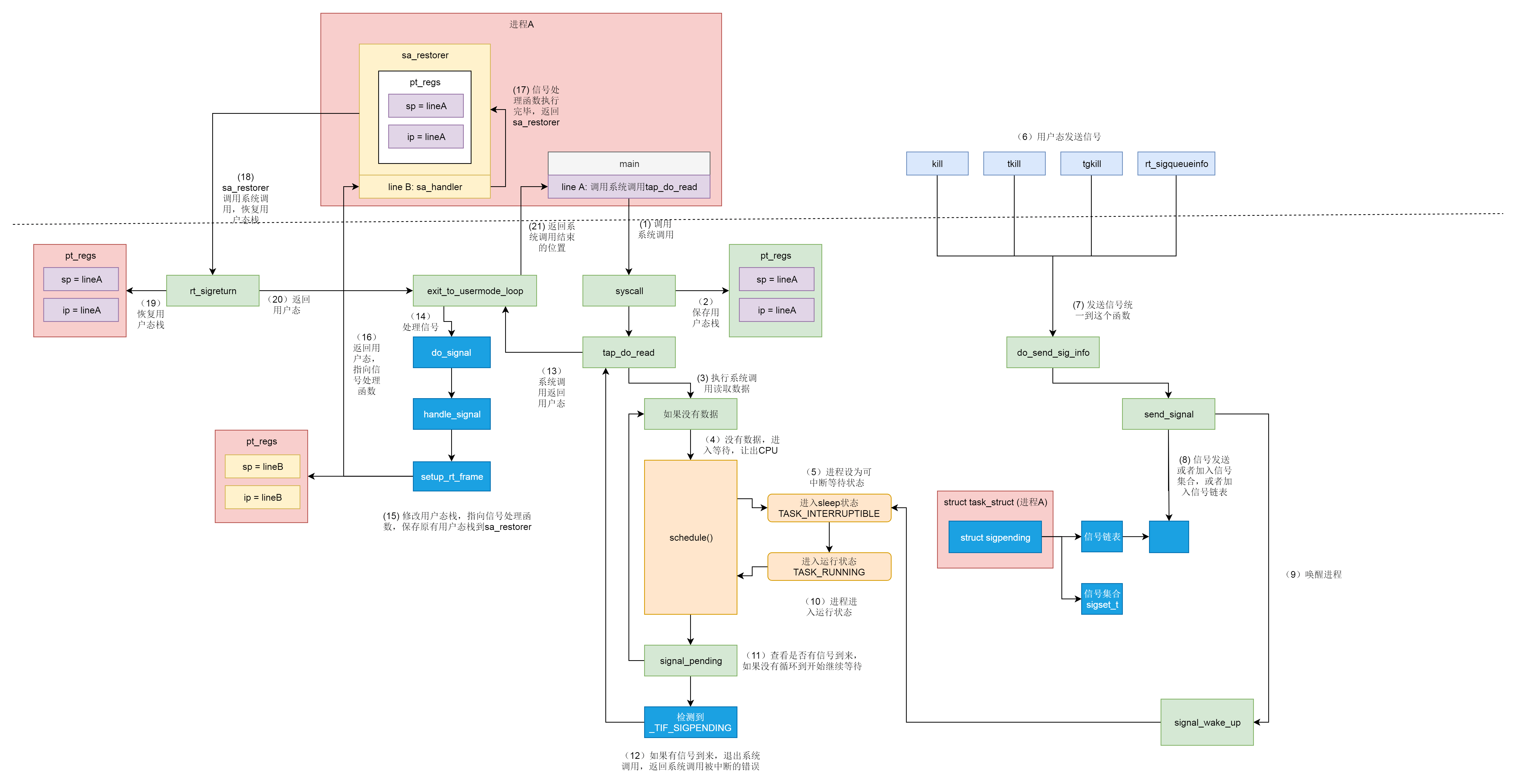
34. 管道
管道的创建,需要通过下面这个系统调用。
int pipe(int fd[2])在这里,我们创建了一个管道pipe,返回了两个文件描述符,这表示管道的两端,一个是管道的读取端描述符fd[0],另一个是管道的写入端描述符fd[1]。
我们来看在内核里面是如何实现的。
SYSCALL_DEFINE1(pipe, int __user *, fildes)
{
return sys_pipe2(fildes, 0);
}
SYSCALL_DEFINE2(pipe2, int __user *, fildes, int, flags)
{
struct file *files[2];
int fd[2];
int error;
error = __do_pipe_flags(fd, files, flags);
if (!error) {
if (unlikely(copy_to_user(fildes, fd, sizeof(fd)))) {
......
error = -EFAULT;
} else {
fd_install(fd[0], files[0]);
fd_install(fd[1], files[1]);
}
}
return error;
}在内核中,主要的逻辑在pipe2系统调用中。这里面要创建一个数组files,用来存放管道的两端的打开文件,另一个数组fd存放管道的两端的文件描述符。如果调用__do_pipe_flags没有错误,那就调用fd_install,将两个fd和两个struct file关联起来。这一点和打开一个文件的过程很像了。
我们来看__do_pipe_flags。这里面调用了create_pipe_files,然后生成了两个fd。从这里可以看出,fd[0]是用于读的,fd[1]是用于写的。
static int __do_pipe_flags(int *fd, struct file **files, int flags)
{
int error;
int fdw, fdr;
......
error = create_pipe_files(files, flags);
......
error = get_unused_fd_flags(flags);
......
fdr = error;
error = get_unused_fd_flags(flags);
......
fdw = error;
fd[0] = fdr;
fd[1] = fdw;
return 0;
......
}创建一个管道,大部分的逻辑其实都是在create_pipe_files函数里面实现的。这一章第一节的时候,我们说过,命名管道是创建在文件系统上的。从这里我们可以看出,匿名管道,也是创建在文件系统上的,只不过是一种特殊的文件系统,创建一个特殊的文件,对应一个特殊的inode,就是这里面的get_pipe_inode。
int create_pipe_files(struct file **res, int flags)
{
int err;
struct inode *inode = get_pipe_inode();
struct file *f;
struct path path;
......
path.dentry = d_alloc_pseudo(pipe_mnt->mnt_sb, &empty_name);
......
path.mnt = mntget(pipe_mnt);
d_instantiate(path.dentry, inode);
f = alloc_file(&path, FMODE_WRITE, &pipefifo_fops);
......
f->f_flags = O_WRONLY | (flags & (O_NONBLOCK | O_DIRECT));
f->private_data = inode->i_pipe;
res[0] = alloc_file(&path, FMODE_READ, &pipefifo_fops);
......
path_get(&path);
res[0]->private_data = inode->i_pipe;
res[0]->f_flags = O_RDONLY | (flags & O_NONBLOCK);
res[1] = f;
return 0;
......
}从get_pipe_inode的实现,我们可以看出,匿名管道来自一个特殊的文件系统pipefs。这个文件系统被挂载后,我们就得到了struct vfsmount *pipe_mnt。然后挂载的文件系统的superblock就变成了:pipe_mnt->mnt_sb。
static struct file_system_type pipe_fs_type = {
.name = "pipefs",
.mount = pipefs_mount,
.kill_sb = kill_anon_super,
};
static int __init init_pipe_fs(void)
{
int err = register_filesystem(&pipe_fs_type);
if (!err) {
pipe_mnt = kern_mount(&pipe_fs_type);
}
......
}
static struct inode * get_pipe_inode(void)
{
struct inode *inode = new_inode_pseudo(pipe_mnt->mnt_sb);
struct pipe_inode_info *pipe;
......
inode->i_ino = get_next_ino();
pipe = alloc_pipe_info();
......
inode->i_pipe = pipe;
pipe->files = 2;
pipe->readers = pipe->writers = 1;
inode->i_fop = &pipefifo_fops;
inode->i_state = I_DIRTY;
inode->i_mode = S_IFIFO | S_IRUSR | S_IWUSR;
inode->i_uid = current_fsuid();
inode->i_gid = current_fsgid();
inode->i_atime = inode->i_mtime = inode->i_ctime = current_time(inode);
return inode;
......
}我们从new_inode_pseudo函数创建一个inode。这里面开始填写Inode的成员,这里和文件系统的很像。这里值得注意的是struct pipe_inode_info,这个结构里面有个成员是struct pipe_buffer *bufs。我们可以知道,所谓的匿名管道,其实就是内核里面的一串缓存。
另外一个需要注意的是pipefifo_fops,将来我们对于文件描述符的操作,在内核里面都是对应这里面的操作。
const struct file_operations pipefifo_fops = {
.open = fifo_open,
.llseek = no_llseek,
.read_iter = pipe_read,
.write_iter = pipe_write,
.poll = pipe_poll,
.unlocked_ioctl = pipe_ioctl,
.release = pipe_release,
.fasync = pipe_fasync,
};我们回到create_pipe_files函数,创建完了inode,还需创建一个dentry和他对应。dentry和inode对应好了,我们就要开始创建struct file对象了。先创建用于写入的,对应的操作为pipefifo_fops;再创建读取的,对应的操作也为pipefifo_fops。然后把private_data设置为pipe_inode_info。这样从struct file这个层级上,就能直接操作底层的读写操作。
至此,一个匿名管道就创建成功了。如果对于fd[1]写入,调用的是pipe_write,向pipe_buffer里面写入数据;如果对于fd[0]的读入,调用的是pipe_read,也就是从pipe_buffer里面读取数据。
但是这个时候,两个文件描述符都是在一个进程里面的,并没有起到进程间通信的作用,怎么样才能使得管道是跨两个进程的呢?还记得创建进程调用的fork吗?在这里面,创建的子进程会复制父进程的struct files_struct,在这里面fd的数组会复制一份,但是fd指向的struct file对于同一个文件还是只有一份,这样就做到了,两个进程各有两个fd指向同一个struct file的模式,两个进程就可以通过各自的fd写入和读取同一个管道文件实现跨进程通信了。
由于管道只能一端写入,另一端读出,所以上面的这种模式会造成混乱,因为父进程和子进程都可以写入,也都可以读出,通常的方法是父进程关闭读取的fd,只保留写入的fd,而子进程关闭写入的fd,只保留读取的fd,如果需要双向通行,则应该创建两个管道。
一个典型的使用管道在父子进程之间的通信代码如下:
#include <unistd.h>
#include <fcntl.h>
#include <stdlib.h>
#include <stdio.h>
#include <errno.h>
#include <string.h>
int main(int argc, char *argv[])
{
int fds[2];
if (pipe(fds) == -1)
perror("pipe error");
pid_t pid;
pid = fork();
if (pid == -1)
perror("fork error");
if (pid == 0){
close(fds[0]);
char msg[] = "hello world";
write(fds[1], msg, strlen(msg) + 1);
close(fds[1]);
exit(0);
} else {
close(fds[1]);
char msg[128];
read(fds[0], msg, 128);
close(fds[0]);
printf("message : %s\n", msg);
return 0;
}
}
到这里,我们仅仅解析了使用管道进行父子进程之间的通信,但是我们在shell里面的不是这样的。在shell里面运行A|B的时候,A进程和B进程都是shell创建出来的子进程,A和B之间不存在父子关系。
不过,有了上面父子进程之间的管道这个基础,实现A和B之间的管道就方便多了。
我们首先从shell创建子进程A,然后在shell和A之间建立一个管道,其中shell保留读取端,A进程保留写入端,然后shell再创建子进程B。这又是一次fork,所以,shell里面保留的读取端的fd也被复制到了子进程B里面。这个时候,相当于shell和B都保留读取端,只要shell主动关闭读取端,就变成了一管道,写入端在A进程,读取端在B进程。
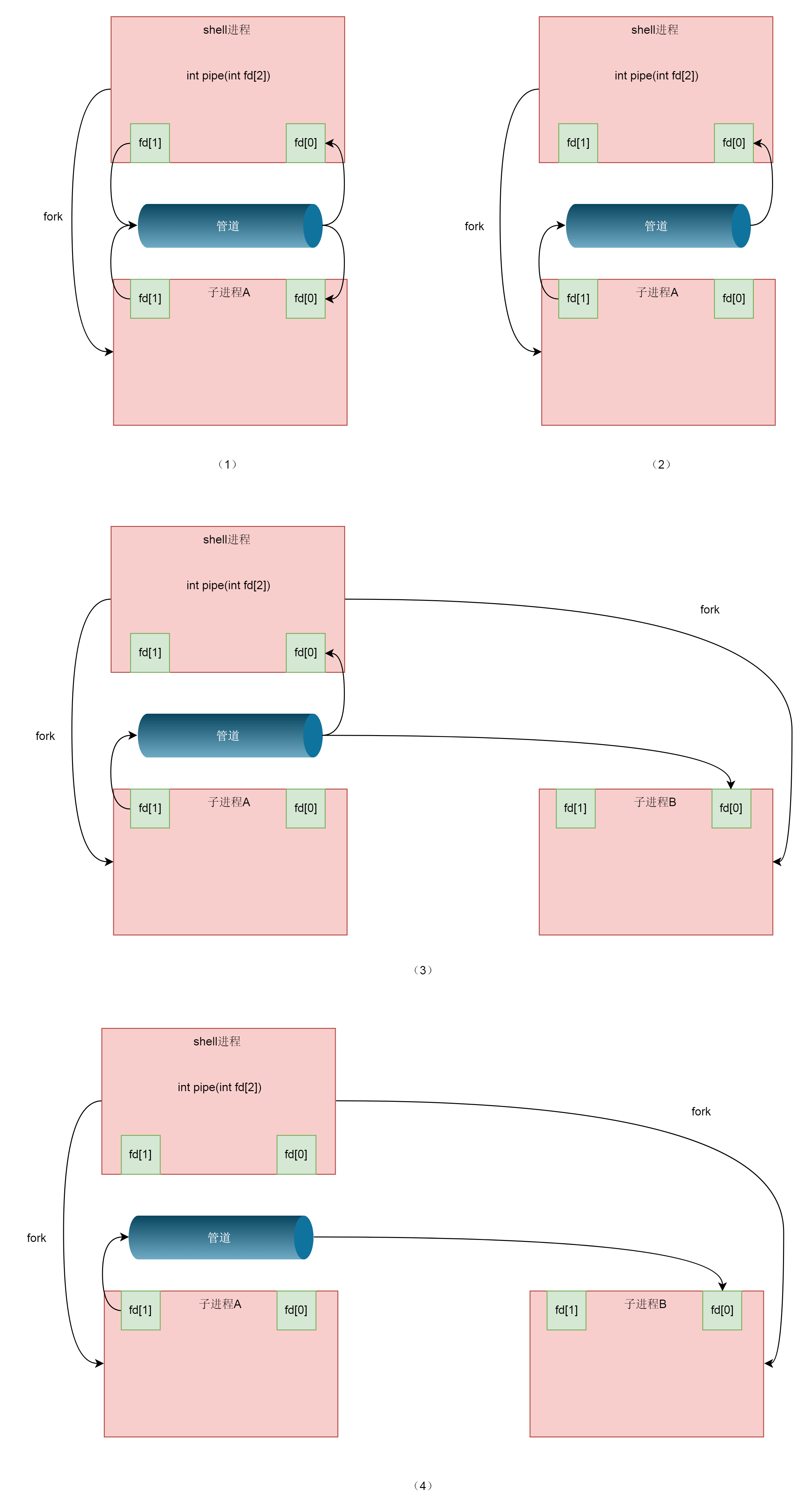
接下来我们要做的事情就是,将这个管道的两端和输入输出关联起来。这就要用到dup2系统调用了。
int dup2(int oldfd, int newfd);这个系统调用,将老的文件描述符赋值给新的文件描述符,让newfd的值和oldfd一样。
我们还是回忆一下,在files_struct里面,有这样一个表,下标是fd,内容指向一个打开的文件struct file。
struct files_struct {
struct file __rcu * fd_array[NR_OPEN_DEFAULT];
}在这个表里面,前三项是定下来的,其中第零项STDIN_FILENO表示标准输入,第一项STDOUT_FILENO表示标准输出,第三项STDERR_FILENO表示错误输出。
在A进程中,写入端可以做这样的操作:dup2(fd[1],STDOUT_FILENO),将STDOUT_FILENO(也即第一项)不再指向标准输出,而是指向创建的管道文件,那么以后往标准输出写入的任何东西,都会写入管道文件。
在B进程中,读取端可以做这样的操作,dup2(fd[0],STDIN_FILENO),将STDIN_FILENO也即第零项不再指向标准输入,而是指向创建的管道文件,那么以后从标准输入读取的任何东西,都来自于管道文件。
至此,我们才将A|B的功能完成。
为了模拟A|B的情况,我们可以将前面的那一段代码,进一步修改成为下面这样:
#include <unistd.h>
#include <fcntl.h>
#include <stdlib.h>
#include <stdio.h>
#include <errno.h>
#include <string.h>
int main(int argc, char *argv[])
{
int fds[2];
if (pipe(fds) == -1)
perror("pipe error");
pid_t pid;
pid = fork();
if (pid == -1)
perror("fork error");
if (pid == 0){
dup2(fds[1], STDOUT_FILENO);
close(fds[1]);
close(fds[0]);
execlp("ps", "ps", "-ef", NULL);
} else {
dup2(fds[0], STDIN_FILENO);
close(fds[0]);
close(fds[1]);
execlp("grep", "grep", "systemd", NULL);
}
return 0;
}接下来,我们来看命名管道。我们在讲命令的时候讲过,命名管道需要事先通过命令mkfifo,进行创建。如果是通过代码创建命名管道,也有一个函数,但是这不是一个系统调用,而是Glibc提供的函数。它的定义如下:
int
mkfifo (const char *path, mode_t mode)
{
dev_t dev = 0;
return __xmknod (_MKNOD_VER, path, mode | S_IFIFO, &dev);
}
int
__xmknod (int vers, const char *path, mode_t mode, dev_t *dev)
{
unsigned long long int k_dev;
......
/* We must convert the value to dev_t type used by the kernel. */
k_dev = (*dev) & ((1ULL << 32) - 1);
......
return INLINE_SYSCALL (mknodat, 4, AT_FDCWD, path, mode,
(unsigned int) k_dev);
}Glibc的mkfifo函数会调用mknodat系统调用,还记得咱们学字符设备的时候,创建一个字符设备的时候,也是调用的mknod。这里命名管道也是一个设备,因而我们也用mknod。
SYSCALL_DEFINE4(mknodat, int, dfd, const char __user *, filename, umode_t, mode, unsigned, dev)
{
struct dentry *dentry;
struct path path;
unsigned int lookup_flags = 0;
......
retry:
dentry = user_path_create(dfd, filename, &path, lookup_flags);
......
switch (mode & S_IFMT) {
......
case S_IFIFO: case S_IFSOCK:
error = vfs_mknod(path.dentry->d_inode,dentry,mode,0);
break;
}
......
}对于mknod的解析,我们在字符设备那一节已经解析过了,先是通过user_path_create对于这个管道文件创建一个dentry,然后因为是S_IFIFO,所以调用vfs_mknod。由于这个管道文件是创建在一个普通文件系统上的,假设是在ext4文件上,于是vfs_mknod会调用ext4_dir_inode_operations的mknod,也即会调用ext4_mknod。
const struct inode_operations ext4_dir_inode_operations = {
......
.mknod = ext4_mknod,
......
};
static int ext4_mknod(struct inode *dir, struct dentry *dentry,
umode_t mode, dev_t rdev)
{
handle_t *handle;
struct inode *inode;
......
inode = ext4_new_inode_start_handle(dir, mode, &dentry->d_name, 0,
NULL, EXT4_HT_DIR, credits);
handle = ext4_journal_current_handle();
if (!IS_ERR(inode)) {
init_special_inode(inode, inode->i_mode, rdev);
inode->i_op = &ext4_special_inode_operations;
err = ext4_add_nondir(handle, dentry, inode);
if (!err && IS_DIRSYNC(dir))
ext4_handle_sync(handle);
}
if (handle)
ext4_journal_stop(handle);
......
}
#define ext4_new_inode_start_handle(dir, mode, qstr, goal, owner, \
type, nblocks) \
__ext4_new_inode(NULL, (dir), (mode), (qstr), (goal), (owner), \
0, (type), __LINE__, (nblocks))
void init_special_inode(struct inode *inode, umode_t mode, dev_t rdev)
{
inode->i_mode = mode;
if (S_ISCHR(mode)) {
inode->i_fop = &def_chr_fops;
inode->i_rdev = rdev;
} else if (S_ISBLK(mode)) {
inode->i_fop = &def_blk_fops;
inode->i_rdev = rdev;
} else if (S_ISFIFO(mode))
inode->i_fop = &pipefifo_fops;
else if (S_ISSOCK(mode))
; /* leave it no_open_fops */
else
......
}在ext4_mknod中,ext4_new_inode_start_handle会调用__ext4_new_inode,在ext4文件系统上真的创建一个文件,但是会调用init_special_inode,创建一个内存中特殊的inode,这个函数我们在字符设备文件中也遇到过,只不过当时inode的i_fop指向的是def_chr_fops,这次换成管道文件了,inode的i_fop变成指向pipefifo_fops,这一点和匿名管道是一样的。
这样,管道文件就创建完毕了。
接下来,要打开这个管道文件,我们还是会调用文件系统的open函数。还是沿着文件系统的调用方式,一路调用到pipefifo_fops的open函数,也就是fifo_open。
static int fifo_open(struct inode *inode, struct file *filp)
{
struct pipe_inode_info *pipe;
bool is_pipe = inode->i_sb->s_magic == PIPEFS_MAGIC;
int ret;
filp->f_version = 0;
if (inode->i_pipe) {
pipe = inode->i_pipe;
pipe->files++;
} else {
pipe = alloc_pipe_info();
pipe->files = 1;
inode->i_pipe = pipe;
spin_unlock(&inode->i_lock);
}
filp->private_data = pipe;
filp->f_mode &= (FMODE_READ | FMODE_WRITE);
switch (filp->f_mode) {
case FMODE_READ:
pipe->r_counter++;
if (pipe->readers++ == 0)
wake_up_partner(pipe);
if (!is_pipe && !pipe->writers) {
if ((filp->f_flags & O_NONBLOCK)) {
filp->f_version = pipe->w_counter;
} else {
if (wait_for_partner(pipe, &pipe->w_counter))
goto err_rd;
}
}
break;
case FMODE_WRITE:
pipe->w_counter++;
if (!pipe->writers++)
wake_up_partner(pipe);
if (!is_pipe && !pipe->readers) {
if (wait_for_partner(pipe, &pipe->r_counter))
goto err_wr;
}
break;
case FMODE_READ | FMODE_WRITE:
pipe->readers++;
pipe->writers++;
pipe->r_counter++;
pipe->w_counter++;
if (pipe->readers == 1 || pipe->writers == 1)
wake_up_partner(pipe);
break;
......
}
......
}在fifo_open里面,创建pipe_inode_info,这一点和匿名管道也是一样的。这个结构里面有个成员是struct pipe_buffer *bufs。我们可以知道,所谓的命名管道,其实是也是内核里面的一串缓存。
接下来,对于命名管道的写入,我们还是会调用pipefifo_fops的pipe_write函数,向pipe_buffer里面写入数据。对于命名管道的读入,我们还是会调用pipefifo_fops的pipe_read,也就是从pipe_buffer里面读取数据。
34.1 总结
无论是匿名管道,还是命名管道,在内核都是一个文件。只要是文件就要有一个inode。这里我们又用到了特殊inode、字符设备、块设备,其实都是这种特殊的inode。
在这种特殊的inode里面,file_operations指向管道特殊的pipefifo_fops,这个inode对应内存里面的缓存。
当我们用文件的open函数打开这个管道设备文件的时候,会调用pipefifo_fops里面的方法创建struct file结构,他的inode指向特殊的inode,也对应内存里面的缓存,file_operations也指向管道特殊的pipefifo_fops。
写入一个pipe就是从struct file结构找到缓存写入,读取一个pipe就是从struct file结构找到缓存读出。
35. IPC(上)
有了进程之间共享内存的机制,两个进程可以像访问自己内存中的变量一样,访问共享内存的变量。但是同时问题也来了,当两个进程共享内存了,就会存在同时读写的问题,就需要对于共享的内存进行保护,就需要信号量这样的同步协调机制。这些也都是我们这节需要探讨的问题。下面我们就一一来看。
共享内存和信号量也是System V系列的进程间通信机制,所以很多地方和我们讲过的消息队列有点儿像。为了将共享内存和信号量结合起来使用,我这里定义了一个share.h头文件,里面放了一些共享内存和信号量在每个进程都需要的函数。
#include <stdio.h>
#include <stdlib.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/sem.h>
#include <string.h>
#define MAX_NUM 128
struct shm_data {
int data[MAX_NUM];
int datalength;
};
union semun {
int val;
struct semid_ds *buf;
unsigned short int *array;
struct seminfo *__buf;
};
int get_shmid(){
int shmid;
key_t key;
if((key = ftok("/root/sharememory/sharememorykey", 1024)) < 0){
perror("ftok error");
return -1;
}
shmid = shmget(key, sizeof(struct shm_data), IPC_CREAT|0777);
return shmid;
}
int get_semaphoreid(){
int semid;
key_t key;
if((key = ftok("/root/sharememory/semaphorekey", 1024)) < 0){
perror("ftok error");
return -1;
}
semid = semget(key, 1, IPC_CREAT|0777);
return semid;
}
int semaphore_init (int semid) {
union semun argument;
unsigned short values[1];
values[0] = 1;
argument.array = values;
return semctl (semid, 0, SETALL, argument);
}
int semaphore_p (int semid) {
struct sembuf operations[1];
operations[0].sem_num = 0;
operations[0].sem_op = -1;
operations[0].sem_flg = SEM_UNDO;
return semop (semid, operations, 1);
}
int semaphore_v (int semid) {
struct sembuf operations[1];
operations[0].sem_num = 0;
operations[0].sem_op = 1;
operations[0].sem_flg = SEM_UNDO;
return semop (semid, operations, 1);
}35.1 共享内存
首先,创建之前,我们要有一个key来唯一标识这个共享内存。这个key可以根据文件系统上的一个文件的inode随机生成。
然后,我们需要创建一个共享内存,就像创建一个消息队列差不多,都是使用xxxget来创建。其中,创建共享内存使用的是下面这个函数:
int shmget(key_t key, size_t size, int shmflag);其中,key就是前面生成的那个key,shmflag如果为IPC_CREAT,就表示新创建,还可以指定读写权限0777。
对于共享内存,需要指定一个大小size,这个一般要申请多大呢?一个最佳实践是,我们将多个进程需要共享的数据放在一个struct里面,然后这里的size就应该是这个struct的大小。这样每一个进程得到这块内存后,只要强制将类型转换为这个struct类型,就能够访问里面的共享数据了。
在这里,我们定义了一个struct shm_data结构。这里面有两个成员,一个是一个整型的数组,一个是数组中元素的个数。
生成了共享内存以后,接下来就是将这个共享内存映射到进程的虚拟地址空间中。我们使用下面这个函数来进行操作。
void *shmat(int shm_id, const void *addr, int shmflg);这里面的shm_id,就是上面创建的共享内存的id,addr就是指定映射在某个地方。如果不指定,则内核会自动选择一个地址,作为返回值返回。得到了返回地址以后,我们需要将指针强制类型转换为struct shm_data结构,就可以使用这个指针设置data和datalength了。
当共享内存使用完毕,我们可以通过shmdt解除它到虚拟内存的映射。
int shmdt(const void *shmaddr);35.2 信号量
信号量以集合的形式存在的。
首先,创建之前,我们同样需要有一个key,来唯一标识这个信号量集合。这个key同样可以根据文件系统上的一个文件的inode随机生成。
然后,我们需要创建一个信号量集合,同样也是使用xxxget来创建,其中创建信号量集合使用的是下面这个函数。
int semget(key_t key, int nsems, int semflg);这里面的key,就是前面生成的那个key,shmflag如果为IPC_CREAT,就表示新创建,还可以指定读写权限0777。
这里,nsems表示这个信号量集合里面有几个信号量,最简单的情况下,我们设置为1。
信号量往往代表某种资源的数量,如果用信号量做互斥,那往往将信号量设置为1。这就是上面代码中semaphore_init函数的作用,这里面调用semctl函数,将这个信号量集合的中的第0个信号量,也即唯一的这个信号量设置为1。
对于信号量,往往要定义两种操作,P操作和V操作。对应上面代码中semaphore_p函数和semaphore_v函数,semaphore_p会调用semop函数将信号量的值减一,表示申请占用一个资源,当发现当前没有资源的时候,进入等待。semaphore_v会调用semop函数将信号量的值加一,表示释放一个资源,释放之后,就允许等待中的其他进程占用这个资源。
我们可以用这个信号量,来保护共享内存中的struct shm_data,使得同时只有一个进程可以操作这个结构。
你是否记得咱们讲线程同步机制的时候,构建了一个老板分配活的场景。这里我们同样构建一个场景,分为producer.c和consumer.c,其中producer也即生产者,负责往struct shm_data塞入数据,而consumer.c负责处理struct shm_data中的数据。
下面我们来看producer.c的代码。
#include "share.h"
int main() {
void *shm = NULL;
struct shm_data *shared = NULL;
int shmid = get_shmid();
int semid = get_semaphoreid();
int i;
shm = shmat(shmid, (void*)0, 0);
if(shm == (void*)-1){
exit(0);
}
shared = (struct shm_data*)shm;
memset(shared, 0, sizeof(struct shm_data));
semaphore_init(semid);
while(1){
semaphore_p(semid);
if(shared->datalength > 0){
semaphore_v(semid);
sleep(1);
} else {
printf("how many integers to caculate : ");
scanf("%d",&shared->datalength);
if(shared->datalength > MAX_NUM){
perror("too many integers.");
shared->datalength = 0;
semaphore_v(semid);
exit(1);
}
for(i=0;i<shared->datalength;i++){
printf("Input the %d integer : ", i);
scanf("%d",&shared->data[i]);
}
semaphore_v(semid);
}
}
}在这里面,get_shmid创建了共享内存,get_semaphoreid创建了信号量集合,然后shmat将共享内存映射到了虚拟地址空间的shm指针指向的位置,然后通过强制类型转换,shared的指针指向放在共享内存里面的struct shm_data结构,然后初始化为0。semaphore_init将信号量进行了初始化。
接着,producer进入了一个无限循环。在这个循环里面,我们先通过semaphore_p申请访问共享内存的权利,如果发现datalength大于零,说明共享内存里面的数据没有被处理过,于是semaphore_v释放权利,先睡一会儿,睡醒了再看。如果发现datalength等于0,说明共享内存里面的数据被处理完了,于是开始往里面放数据。让用户输入多少个数,然后每个数是什么,都放在struct shm_data结构中,然后semaphore_v释放权利,等待其他的进程将这些数拿去处理。
我们再来看consumer的代码。
#include "share.h"
int main() {
void *shm = NULL;
struct shm_data *shared = NULL;
int shmid = get_shmid();
int semid = get_semaphoreid();
int i;
shm = shmat(shmid, (void*)0, 0);
if(shm == (void*)-1){
exit(0);
}
shared = (struct shm_data*)shm;
while(1){
semaphore_p(semid);
if(shared->datalength > 0){
int sum = 0;
for(i=0;i<shared->datalength-1;i++){
printf("%d+",shared->data[i]);
sum += shared->data[i];
}
printf("%d",shared->data[shared->datalength-1]);
sum += shared->data[shared->datalength-1];
printf("=%d\n",sum);
memset(shared, 0, sizeof(struct shm_data));
semaphore_v(semid);
} else {
semaphore_v(semid);
printf("no tasks, waiting.\n");
sleep(1);
}
}
}在这里面,get_shmid获得producer创建的共享内存,get_semaphoreid获得producer创建的信号量集合,然后shmat将共享内存映射到了虚拟地址空间的shm指针指向的位置,然后通过强制类型转换,shared的指针指向放在共享内存里面的struct shm_data结构。
接着,consumer进入了一个无限循环,在这个循环里面,我们先通过semaphore_p申请访问共享内存的权利,如果发现datalength等于0,就说明没什么活干,需要等待。如果发现datalength大于0,就说明有活干,于是将datalength个整型数字从data数组中取出来求和。最后将struct shm_data清空为0,表示任务处理完毕,通过semaphore_v释放权利。
通过程序创建的共享内存和信号量集合,我们可以通过命令ipcs查看。当然,我们也可以通过ipcrm进行删除。
$ ipcs
------ Message Queues --------
key msqid owner perms used-bytes messages
------ Shared Memory Segments --------
key shmid owner perms bytes nattch status
0x00016988 32768 root 777 516 0
------ Semaphore Arrays --------
key semid owner perms nsems
0x00016989 32768 root 777 1下面我们来运行一下producer和consumer,可以得到下面的结果:
$ ./producer
how many integers to caculate : 2
Input the 0 integer : 3
Input the 1 integer : 4
how many integers to caculate : 4
Input the 0 integer : 3
Input the 1 integer : 4
Input the 2 integer : 5
Input the 3 integer : 6
how many integers to caculate : 7
Input the 0 integer : 9
Input the 1 integer : 8
Input the 2 integer : 7
Input the 3 integer : 6
Input the 4 integer : 5
Input the 5 integer : 4
Input the 6 integer : 3
$ ./consumer
3+4=7
3+4+5+6=18
9+8+7+6+5+4+3=4235.3 总结
总结一下。共享内存和信号量的配合机制,如下图所示:
- 无论是共享内存还是信号量,创建与初始化都遵循同样流程,通过ftok得到key,通过xxxget创建对象并生成id;
- 生产者和消费者都通过shmat将共享内存映射到各自的内存空间,在不同的进程里面映射的位置不同;
- 为了访问共享内存,需要信号量进行保护,信号量需要通过semctl初始化为某个值;
- 接下来生产者和消费者要通过semop(-1)来竞争信号量,如果生产者抢到信号量则写入,然后通过semop(+1)释放信号量,如果消费者抢到信号量则读出,然后通过semop(+1)释放信号量;
- 共享内存使用完毕,可以通过shmdt来解除映射。
36. IPC(中)
不知道你有没有注意到,咱们讲消息队列、共享内存、信号量的机制的时候,我们其实能够从中看到一些统一的规律:它们在使用之前都要生成key,然后通过key得到唯一的id,并且都是通过xxxget函数。
内核里面,这三种进程间通信机制是使用统一的机制管理起来的,都叫ipcxxx。
为了维护这三种进程间通信进制,在内核里面,我们声明了一个有三项的数组。
我们通过这段代码,来具体看一看。
struct ipc_namespace {
......
struct ipc_ids ids[3];
......
}
#define IPC_SEM_IDS 0
#define IPC_MSG_IDS 1
#define IPC_SHM_IDS 2
#define sem_ids(ns) ((ns)->ids[IPC_SEM_IDS])
#define msg_ids(ns) ((ns)->ids[IPC_MSG_IDS])
#define shm_ids(ns) ((ns)->ids[IPC_SHM_IDS])根据代码中的定义,第0项用于信号量,第1项用于消息队列,第2项用于共享内存,分别可以通过sem_ids、msg_ids、shm_ids来访问。
这段代码里面有ns,全称叫namespace。可能不容易理解,你现在可以将它认为是将一台Linux服务器逻辑的隔离为多台Linux服务器的机制,它背后的原理是一个相当大的话题,我们需要在容器那一章详细讲述。现在,你就可以简单的认为没有namespace,整个Linux在一个namespace下面,那这些ids也是整个Linux只有一份。
接下来,我们再来看struct ipc_ids里面保存了什么。
首先,in_use表示当前有多少个ipc;其次,seq和next_id用于一起生成ipc唯一的id,因为信号量,共享内存,消息队列,它们三个的id也不能重复;ipcs_idr是一棵基数树,我们又碰到它了,一旦涉及从一个整数查找一个对象,它都是最好的选择。
struct ipc_ids {
int in_use;
unsigned short seq;
struct rw_semaphore rwsem;
struct idr ipcs_idr;
int next_id;
};
struct idr {
struct radix_tree_root idr_rt;
unsigned int idr_next;
};也就是说,对于sem_ids、msg_ids、shm_ids各有一棵基数树。那这棵树里面究竟存放了什么,能够统一管理这三类ipc对象呢?
通过下面这个函数ipc_obtain_object_idr,我们可以看出端倪。这个函数根据id,在基数树里面找出来的是struct kern_ipc_perm。
struct kern_ipc_perm *ipc_obtain_object_idr(struct ipc_ids *ids, int id)
{
struct kern_ipc_perm *out;
int lid = ipcid_to_idx(id);
out = idr_find(&ids->ipcs_idr, lid);
return out;
}如果我们看用于表示信号量、消息队列、共享内存的结构,就会发现,这三个结构的第一项都是struct kern_ipc_perm。
struct sem_array {
struct kern_ipc_perm sem_perm; /* permissions .. see ipc.h */
time_t sem_ctime; /* create/last semctl() time */
struct list_head pending_alter; /* pending operations */
/* that alter the array */
struct list_head pending_const; /* pending complex operations */
/* that do not alter semvals */
struct list_head list_id; /* undo requests on this array */
int sem_nsems; /* no. of semaphores in array */
int complex_count; /* pending complex operations */
unsigned int use_global_lock;/* >0: global lock required */
struct sem sems[];
} __randomize_layout;
struct msg_queue {
struct kern_ipc_perm q_perm;
time_t q_stime; /* last msgsnd time */
time_t q_rtime; /* last msgrcv time */
time_t q_ctime; /* last change time */
unsigned long q_cbytes; /* current number of bytes on queue */
unsigned long q_qnum; /* number of messages in queue */
unsigned long q_qbytes; /* max number of bytes on queue */
pid_t q_lspid; /* pid of last msgsnd */
pid_t q_lrpid; /* last receive pid */
struct list_head q_messages;
struct list_head q_receivers;
struct list_head q_senders;
} __randomize_layout;
struct shmid_kernel /* private to the kernel */
{
struct kern_ipc_perm shm_perm;
struct file *shm_file;
unsigned long shm_nattch;
unsigned long shm_segsz;
time_t shm_atim;
time_t shm_dtim;
time_t shm_ctim;
pid_t shm_cprid;
pid_t shm_lprid;
struct user_struct *mlock_user;
/* The task created the shm object. NULL if the task is dead. */
struct task_struct *shm_creator;
struct list_head shm_clist; /* list by creator */
} __randomize_layout;也就是说,我们完全可以通过struct kern_ipc_perm的指针,通过进行强制类型转换后,得到整个结构。做这件事情的函数如下:
static inline struct sem_array *sem_obtain_object(struct ipc_namespace *ns, int id)
{
struct kern_ipc_perm *ipcp = ipc_obtain_object_idr(&sem_ids(ns), id);
return container_of(ipcp, struct sem_array, sem_perm);
}
static inline struct msg_queue *msq_obtain_object(struct ipc_namespace *ns, int id)
{
struct kern_ipc_perm *ipcp = ipc_obtain_object_idr(&msg_ids(ns), id);
return container_of(ipcp, struct msg_queue, q_perm);
}
static inline struct shmid_kernel *shm_obtain_object(struct ipc_namespace *ns, int id)
{
struct kern_ipc_perm *ipcp = ipc_obtain_object_idr(&shm_ids(ns), id);
return container_of(ipcp, struct shmid_kernel, shm_perm);
}通过这种机制,我们就可以将信号量、消息队列、共享内存抽象为ipc类型进行统一处理。你有没有觉得,这有点儿面向对象编程中抽象类和实现类的意思?没错,如果你试图去了解C++中类的实现机制,其实也是这么干的。
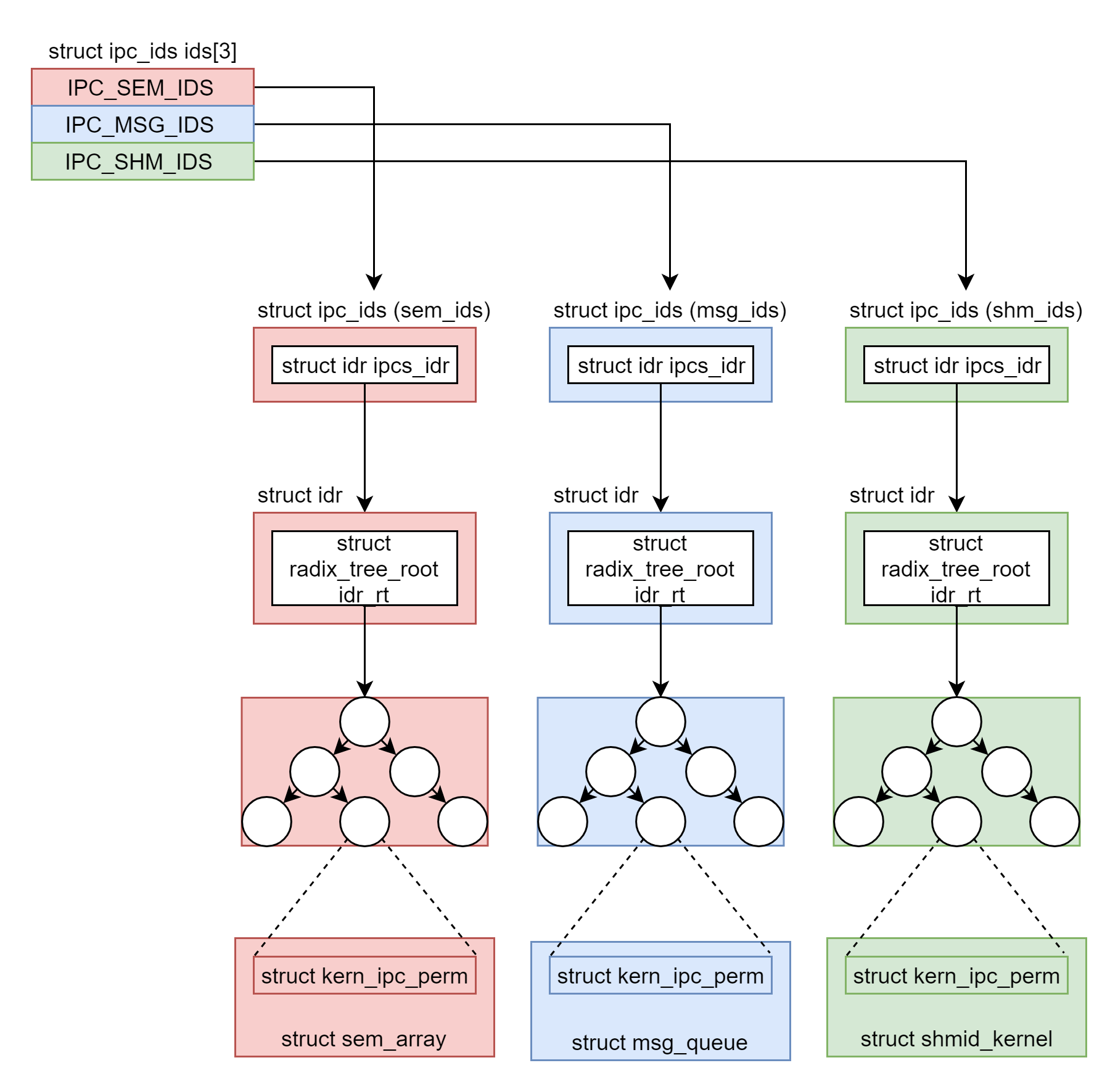
有了抽象类,接下来我们来看共享内存和信号量的具体实现。
36.1 如何创建共享内存?
首先,我们来看创建共享内存的的系统调用。
SYSCALL_DEFINE3(shmget, key_t, key, size_t, size, int, shmflg)
{
struct ipc_namespace *ns;
static const struct ipc_ops shm_ops = {
.getnew = newseg,
.associate = shm_security,
.more_checks = shm_more_checks,
};
struct ipc_params shm_params;
ns = current->nsproxy->ipc_ns;
shm_params.key = key;
shm_params.flg = shmflg;
shm_params.u.size = size;
return ipcget(ns, &shm_ids(ns), &shm_ops, &shm_params);
}这里面调用了抽象的ipcget、参数分别为共享内存对应的shm_ids、对应的操作shm_ops以及对应的参数shm_params。
如果key设置为IPC_PRIVATE则永远创建新的,如果不是的话,就会调用ipcget_public。ipcget的具体代码如下:
int ipcget(struct ipc_namespace *ns, struct ipc_ids *ids,
const struct ipc_ops *ops, struct ipc_params *params)
{
if (params->key == IPC_PRIVATE)
return ipcget_new(ns, ids, ops, params);
else
return ipcget_public(ns, ids, ops, params);
}
static int ipcget_public(struct ipc_namespace *ns, struct ipc_ids *ids, const struct ipc_ops *ops, struct ipc_params *params)
{
struct kern_ipc_perm *ipcp;
int flg = params->flg;
int err;
ipcp = ipc_findkey(ids, params->key);
if (ipcp == NULL) {
if (!(flg & IPC_CREAT))
err = -ENOENT;
else
err = ops->getnew(ns, params);
} else {
if (flg & IPC_CREAT && flg & IPC_EXCL)
err = -EEXIST;
else {
err = 0;
if (ops->more_checks)
err = ops->more_checks(ipcp, params);
......
}
}
return err;
}在ipcget_public中,我们会按照key,去查找struct kern_ipc_perm。如果没有找到,那就看是否设置了IPC_CREAT;如果设置了,就创建一个新的。如果找到了,就将对应的id返回。
我们这里重点看,如何按照参数shm_ops,创建新的共享内存,会调用newseg。
static int newseg(struct ipc_namespace *ns, struct ipc_params *params)
{
key_t key = params->key;
int shmflg = params->flg;
size_t size = params->u.size;
int error;
struct shmid_kernel *shp;
size_t numpages = (size + PAGE_SIZE - 1) >> PAGE_SHIFT;
struct file *file;
char name[13];
vm_flags_t acctflag = 0;
......
shp = kvmalloc(sizeof(*shp), GFP_KERNEL);
......
shp->shm_perm.key = key;
shp->shm_perm.mode = (shmflg & S_IRWXUGO);
shp->mlock_user = NULL;
shp->shm_perm.security = NULL;
......
file = shmem_kernel_file_setup(name, size, acctflag);
......
shp->shm_cprid = task_tgid_vnr(current);
shp->shm_lprid = 0;
shp->shm_atim = shp->shm_dtim = 0;
shp->shm_ctim = get_seconds();
shp->shm_segsz = size;
shp->shm_nattch = 0;
shp->shm_file = file;
shp->shm_creator = current;
error = ipc_addid(&shm_ids(ns), &shp->shm_perm, ns->shm_ctlmni);
......
list_add(&shp->shm_clist, ¤t->sysvshm.shm_clist);
......
file_inode(file)->i_ino = shp->shm_perm.id;
ns->shm_tot += numpages;
error = shp->shm_perm.id;
......
return error;
}newseg函数的第一步,通过kvmalloc在直接映射区分配一个struct shmid_kernel结构。这个结构就是用来描述共享内存的。这个结构最开始就是上面说的struct kern_ipc_perm结构。接下来就是填充这个struct shmid_kernel结构,例如key、权限等。
newseg函数的第二步,共享内存需要和文件进行关联。为什么要做这个呢?我们在讲内存映射的时候讲过,虚拟地址空间可以和物理内存关联,但是物理内存是某个进程独享的。虚拟地址空间也可以映射到一个文件,文件是可以跨进程共享的。
咱们这里的共享内存需要跨进程共享,也应该借鉴文件映射的思路。只不过不应该映射一个硬盘上的文件,而是映射到一个内存文件系统上的文件。mm/shmem.c里面就定义了这样一个基于内存的文件系统。这里你一定要注意区分shmem和shm的区别,前者是一个文件系统,后者是进程通信机制。
在系统初始化的时候,shmem_init注册了shmem文件系统shmem_fs_type,并且挂在到了shm_mnt下面。
int __init shmem_init(void)
{
int error;
error = shmem_init_inodecache();
error = register_filesystem(&shmem_fs_type);
shm_mnt = kern_mount(&shmem_fs_type);
......
return 0;
}
static struct file_system_type shmem_fs_type = {
.owner = THIS_MODULE,
.name = "tmpfs",
.mount = shmem_mount,
.kill_sb = kill_litter_super,
.fs_flags = FS_USERNS_MOUNT,
};接下来,newseg函数会调用shmem_kernel_file_setup,其实就是在shmem文件系统里面创建一个文件。
/**
* shmem_kernel_file_setup - get an unlinked file living in tmpfs which must be kernel internal.
* @name: name for dentry (to be seen in /proc/<pid>/maps
* @size: size to be set for the file
* @flags: VM_NORESERVE suppresses pre-accounting of the entire object size */
struct file *shmem_kernel_file_setup(const char *name, loff_t size, unsigned long flags)
{
return __shmem_file_setup(name, size, flags, S_PRIVATE);
}
static struct file *__shmem_file_setup(const char *name, loff_t size,
unsigned long flags, unsigned int i_flags)
{
struct file *res;
struct inode *inode;
struct path path;
struct super_block *sb;
struct qstr this;
......
this.name = name;
this.len = strlen(name);
this.hash = 0; /* will go */
sb = shm_mnt->mnt_sb;
path.mnt = mntget(shm_mnt);
path.dentry = d_alloc_pseudo(sb, &this);
d_set_d_op(path.dentry, &anon_ops);
......
inode = shmem_get_inode(sb, NULL, S_IFREG | S_IRWXUGO, 0, flags);
inode->i_flags |= i_flags;
d_instantiate(path.dentry, inode);
inode->i_size = size;
......
res = alloc_file(&path, FMODE_WRITE | FMODE_READ,
&shmem_file_operations);
return res;
}__shmem_file_setup会创建新的shmem文件对应的dentry和inode,并将它们两个关联起来,然后分配一个struct file结构,来表示新的shmem文件,并且指向独特的shmem_file_operations。
static const struct file_operations shmem_file_operations = {
.mmap = shmem_mmap,
.get_unmapped_area = shmem_get_unmapped_area,
#ifdef CONFIG_TMPFS
.llseek = shmem_file_llseek,
.read_iter = shmem_file_read_iter,
.write_iter = generic_file_write_iter,
.fsync = noop_fsync,
.splice_read = generic_file_splice_read,
.splice_write = iter_file_splice_write,
.fallocate = shmem_fallocate,
#endif
};newseg函数的第三步,通过ipc_addid将新创建的struct shmid_kernel结构挂到shm_ids里面的基数树上,并返回相应的id,并且将struct shmid_kernel挂到当前进程的sysvshm队列中。
至此,共享内存的创建就完成了。
36.2 如何将共享内存映射到虚拟地址空间?
从上面的代码解析中,我们知道,共享内存的数据结构struct shmid_kernel,是通过它的成员struct file *shm_file,来管理内存文件系统shmem上的内存文件的。无论这个共享内存是否被映射,shm_file都是存在的。
接下来,我们要将共享内存映射到虚拟地址空间中。调用的是shmat,对应的系统调用如下:
SYSCALL_DEFINE3(shmat, int, shmid, char __user *, shmaddr, int, shmflg)
{
unsigned long ret;
long err;
err = do_shmat(shmid, shmaddr, shmflg, &ret, SHMLBA);
force_successful_syscall_return();
return (long)ret;
}
long do_shmat(int shmid, char __user *shmaddr, int shmflg,
ulong *raddr, unsigned long shmlba)
{
struct shmid_kernel *shp;
unsigned long addr = (unsigned long)shmaddr;
unsigned long size;
struct file *file;
int err;
unsigned long flags = MAP_SHARED;
unsigned long prot;
int acc_mode;
struct ipc_namespace *ns;
struct shm_file_data *sfd;
struct path path;
fmode_t f_mode;
unsigned long populate = 0;
......
prot = PROT_READ | PROT_WRITE;
acc_mode = S_IRUGO | S_IWUGO;
f_mode = FMODE_READ | FMODE_WRITE;
......
ns = current->nsproxy->ipc_ns;
shp = shm_obtain_object_check(ns, shmid);
......
path = shp->shm_file->f_path;
path_get(&path);
shp->shm_nattch++;
size = i_size_read(d_inode(path.dentry));
......
sfd = kzalloc(sizeof(*sfd), GFP_KERNEL);
......
file = alloc_file(&path, f_mode,
is_file_hugepages(shp->shm_file) ?
&shm_file_operations_huge :
&shm_file_operations);
......
file->private_data = sfd;
file->f_mapping = shp->shm_file->f_mapping;
sfd->id = shp->shm_perm.id;
sfd->ns = get_ipc_ns(ns);
sfd->file = shp->shm_file;
sfd->vm_ops = NULL;
......
addr = do_mmap_pgoff(file, addr, size, prot, flags, 0, &populate, NULL);
*raddr = addr;
err = 0;
......
return err;
}在这个函数里面,shm_obtain_object_check会通过共享内存的id,在基数树中找到对应的struct shmid_kernel结构,通过它找到shmem上的内存文件。
接下来,我们要分配一个struct shm_file_data,来表示这个内存文件。将shmem中指向内存文件的shm_file赋值给struct shm_file_data中的file成员。
然后,我们创建了一个struct file,指向的也是shmem中的内存文件。
为什么要再创建一个呢?这两个的功能不同,shmem中shm_file用于管理内存文件,是一个中立的,独立于任何一个进程的角色。而新创建的struct file是专门用于做内存映射的,就像咱们在讲内存映射那一节讲过的,一个硬盘上的文件要映射到虚拟地址空间中的时候,需要在vm_area_struct里面有一个struct file *vm_file指向硬盘上的文件,现在变成内存文件了,但是这个结构还是不能少。
新创建的struct file的private_data,指向struct shm_file_data,这样内存映射那部分的数据结构,就能够通过它来访问内存文件了。
新创建的struct file的file_operations也发生了变化,变成了shm_file_operations。
static const struct file_operations shm_file_operations = {
.mmap = shm_mmap,
.fsync = shm_fsync,
.release = shm_release,
.get_unmapped_area = shm_get_unmapped_area,
.llseek = noop_llseek,
.fallocate = shm_fallocate,
};接下来,do_mmap_pgoff函数我们遇到过,原来映射硬盘上的文件的时候,也是调用它。这里我们不再详细解析了。它会分配一个vm_area_struct指向虚拟地址空间中没有分配的区域,它的vm_file指向这个内存文件,然后它会调用shm_file_operations的mmap函数,也即shm_mmap进行映射。
static int shm_mmap(struct file *file, struct vm_area_struct *vma)
{
struct shm_file_data *sfd = shm_file_data(file);
int ret;
ret = __shm_open(vma);
ret = call_mmap(sfd->file, vma);
sfd->vm_ops = vma->vm_ops;
vma->vm_ops = &shm_vm_ops;
return 0;
}shm_mmap中调用了shm_file_data中的file的mmap函数,这次调用的是shmem_file_operations的mmap,也即shmem_mmap。
static int shmem_mmap(struct file *file, struct vm_area_struct *vma)
{
file_accessed(file);
vma->vm_ops = &shmem_vm_ops;
return 0;
}这里面,vm_area_struct的vm_ops指向shmem_vm_ops。等从call_mmap中返回之后,shm_file_data的vm_ops指向了shmem_vm_ops,而vm_area_struct的vm_ops改为指向shm_vm_ops。
我们来看一下,shm_vm_ops和shmem_vm_ops的定义。
static const struct vm_operations_struct shm_vm_ops = {
.open = shm_open, /* callback for a new vm-area open */
.close = shm_close, /* callback for when the vm-area is released */
.fault = shm_fault,
};
static const struct vm_operations_struct shmem_vm_ops = {
.fault = shmem_fault,
.map_pages = filemap_map_pages,
};它们里面最关键的就是fault函数,也即访问虚拟内存的时候,访问不到应该怎么办。
当访问不到的时候,先调用vm_area_struct的vm_ops,也即shm_vm_ops的fault函数shm_fault。然后它会转而调用shm_file_data的vm_ops,也即shmem_vm_ops的fault函数shmem_fault。
static int shm_fault(struct vm_fault *vmf)
{
struct file *file = vmf->vma->vm_file;
struct shm_file_data *sfd = shm_file_data(file);
return sfd->vm_ops->fault(vmf);
}虽然基于内存的文件系统,已经为这个内存文件分配了inode,但是内存也却是一点儿都没分配,只有在发生缺页异常的时候才进行分配。
static int shmem_fault(struct vm_fault *vmf)
{
struct vm_area_struct *vma = vmf->vma;
struct inode *inode = file_inode(vma->vm_file);
gfp_t gfp = mapping_gfp_mask(inode->i_mapping);
......
error = shmem_getpage_gfp(inode, vmf->pgoff, &vmf->page, sgp,
gfp, vma, vmf, &ret);
......
}
/*
* shmem_getpage_gfp - find page in cache, or get from swap, or allocate
*
* If we allocate a new one we do not mark it dirty. That's up to the
* vm. If we swap it in we mark it dirty since we also free the swap
* entry since a page cannot live in both the swap and page cache.
*
* fault_mm and fault_type are only supplied by shmem_fault:
* otherwise they are NULL.
*/
static int shmem_getpage_gfp(struct inode *inode, pgoff_t index,
struct page **pagep, enum sgp_type sgp, gfp_t gfp,
struct vm_area_struct *vma, struct vm_fault *vmf, int *fault_type)
{
......
page = shmem_alloc_and_acct_page(gfp, info, sbinfo,
index, false);
......
}shmem_fault会调用shmem_getpage_gfp在page cache和swap中找一个空闲页,如果找不到就通过shmem_alloc_and_acct_page分配一个新的页,他最终会调用内存管理系统的alloc_page_vma在物理内存中分配一个页。
至此,共享内存才真的映射到了虚拟地址空间中,进程可以像访问本地内存一样访问共享内存。
36.3 总结
我们来总结一下共享内存的创建和映射过程。
- 调用shmget创建共享内存。
- 先通过ipc_findkey在基数树中查找key对应的共享内存对象shmid_kernel是否已经被创建过,如果已经被创建,就会被查询出来,例如producer创建过,在consumer中就会查询出来。
- 如果共享内存没有被创建过,则调用shm_ops的newseg方法,创建一个共享内存对象shmid_kernel。例如,在producer中就会新建。
- 在shmem文件系统里面创建一个文件,共享内存对象shmid_kernel指向这个文件,这个文件用struct file表示,我们姑且称它为file1。
- 调用shmat,将共享内存映射到虚拟地址空间。
- shm_obtain_object_check先从基数树里面找到shmid_kernel对象。
- 创建用于内存映射到文件的file和shm_file_data,这里的struct file我们姑且称为file2。
- 关联内存区域vm_area_struct和用于内存映射到文件的file,也即file2,调用file2的mmap函数。
- file2的mmap函数shm_mmap,会调用file1的mmap函数shmem_mmap,设置shm_file_data和vm_area_struct的vm_ops。
- 内存映射完毕之后,其实并没有真的分配物理内存,当访问内存的时候,会触发缺页异常do_page_fault。
- vm_area_struct的vm_ops的shm_fault会调用shm_file_data的vm_ops的shmem_fault。
- 在page cache中找一个空闲页,或者创建一个空闲页。
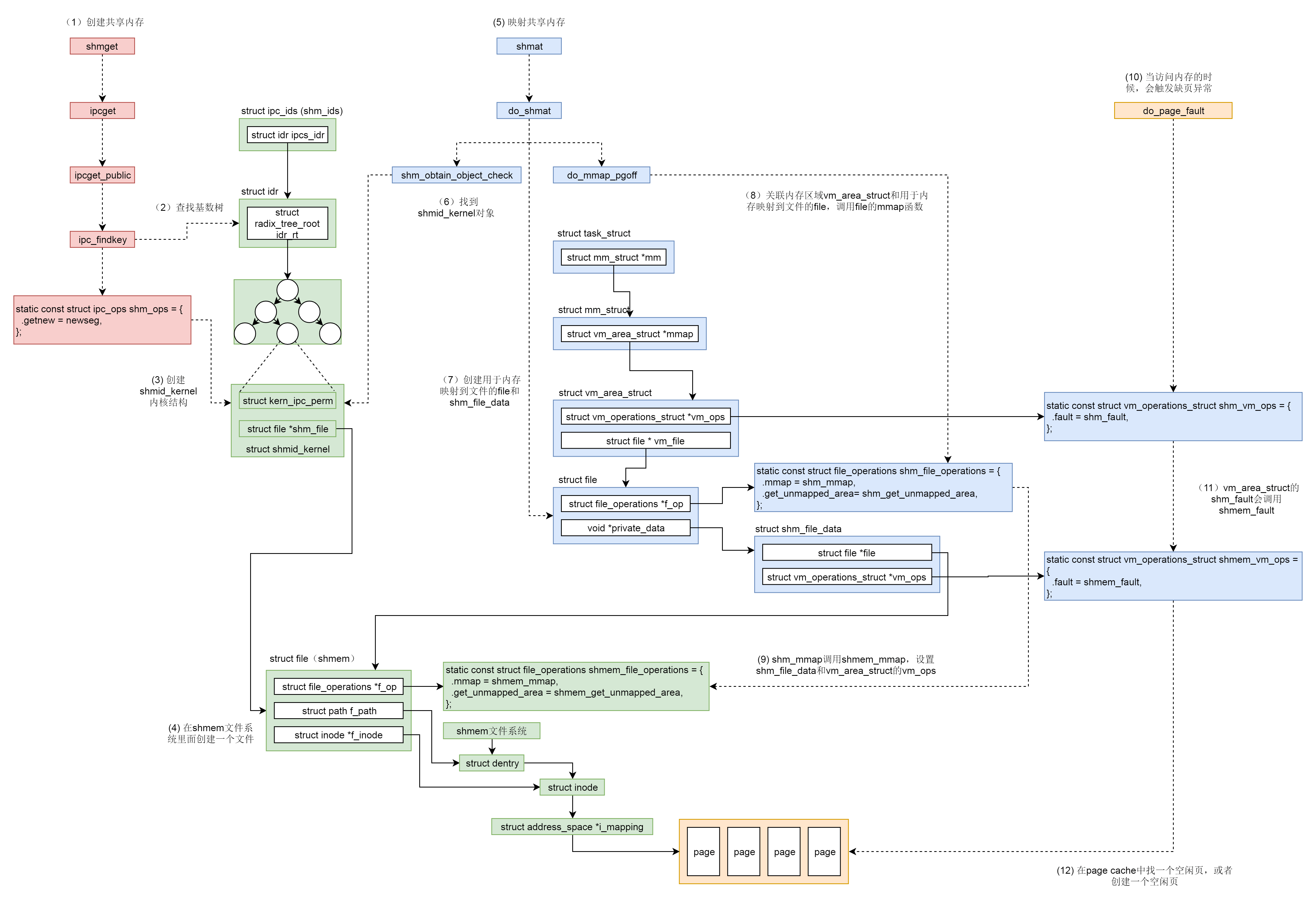
37. IPC(下)
今天我们来看最后一部分,信号量的内核机制。
首先,我们需要创建一个信号量,调用的是系统调用semget。代码如下:
SYSCALL_DEFINE3(semget, key_t, key, int, nsems, int, semflg)
{
struct ipc_namespace *ns;
static const struct ipc_ops sem_ops = {
.getnew = newary,
.associate = sem_security,
.more_checks = sem_more_checks,
};
struct ipc_params sem_params;
ns = current->nsproxy->ipc_ns;
sem_params.key = key;
sem_params.flg = semflg;
sem_params.u.nsems = nsems;
return ipcget(ns, &sem_ids(ns), &sem_ops, &sem_params);
}我们解析过了共享内存,再看信号量,就顺畅很多了。这里同样调用了抽象的ipcget,参数分别为信号量对应的sem_ids、对应的操作sem_ops以及对应的参数sem_params。
ipcget的代码我们已经解析过了。如果key设置为IPC_PRIVATE则永远创建新的;如果不是的话,就会调用ipcget_public。
在ipcget_public中,我们能会按照key,去查找struct kern_ipc_perm。如果没有找到,那就看看是否设置了IPC_CREAT。如果设置了,就创建一个新的。如果找到了,就将对应的id返回。
我们这里重点看,如何按照参数sem_ops,创建新的信号量会调用newary。
static int newary(struct ipc_namespace *ns, struct ipc_params *params)
{
int retval;
struct sem_array *sma;
key_t key = params->key;
int nsems = params->u.nsems;
int semflg = params->flg;
int i;
......
sma = sem_alloc(nsems);
......
sma->sem_perm.mode = (semflg & S_IRWXUGO);
sma->sem_perm.key = key;
sma->sem_perm.security = NULL;
......
for (i = 0; i < nsems; i++) {
INIT_LIST_HEAD(&sma->sems[i].pending_alter);
INIT_LIST_HEAD(&sma->sems[i].pending_const);
spin_lock_init(&sma->sems[i].lock);
}
sma->complex_count = 0;
sma->use_global_lock = USE_GLOBAL_LOCK_HYSTERESIS;
INIT_LIST_HEAD(&sma->pending_alter);
INIT_LIST_HEAD(&sma->pending_const);
INIT_LIST_HEAD(&sma->list_id);
sma->sem_nsems = nsems;
sma->sem_ctime = get_seconds();
retval = ipc_addid(&sem_ids(ns), &sma->sem_perm, ns->sc_semmni);
......
ns->used_sems += nsems;
......
return sma->sem_perm.id;
}newary函数的第一步,通过kvmalloc在直接映射区分配一个struct sem_array结构。这个结构是用来描述信号量的,这个结构最开始就是上面说的struct kern_ipc_perm结构。接下来就是填充这个struct sem_array结构,例如key、权限等。
struct sem_array里有多个信号量,放在struct sem sems[]数组里面,在struct sem里面有当前的信号量的数值semval。
struct sem {
int semval; /* current value */
/*
* PID of the process that last modified the semaphore. For
* Linux, specifically these are:
* - semop
* - semctl, via SETVAL and SETALL.
* - at task exit when performing undo adjustments (see exit_sem).
*/
int sempid;
spinlock_t lock; /* spinlock for fine-grained semtimedop */
struct list_head pending_alter; /* pending single-sop operations that alter the semaphore */
struct list_head pending_const; /* pending single-sop operations that do not alter the semaphore*/
time_t sem_otime; /* candidate for sem_otime */
} ____cacheline_aligned_in_smp;struct sem_array和struct sem各有一个链表struct list_head pending_alter,分别表示对于整个信号量数组的修改和对于某个信号量的修改。
newary函数的第二步,就是初始化这些链表。
newary函数的第三步,通过ipc_addid将新创建的struct sem_array结构,挂到sem_ids里面的基数树上,并返回相应的id。
信号量创建的过程到此结束,接下来我们来看,如何通过semctl对信号量数组进行初始化。
SYSCALL_DEFINE4(semctl, int, semid, int, semnum, int, cmd, unsigned long, arg)
{
int version;
struct ipc_namespace *ns;
void __user *p = (void __user *)arg;
ns = current->nsproxy->ipc_ns;
switch (cmd) {
case IPC_INFO:
case SEM_INFO:
case IPC_STAT:
case SEM_STAT:
return semctl_nolock(ns, semid, cmd, version, p);
case GETALL:
case GETVAL:
case GETPID:
case GETNCNT:
case GETZCNT:
case SETALL:
return semctl_main(ns, semid, semnum, cmd, p);
case SETVAL:
return semctl_setval(ns, semid, semnum, arg);
case IPC_RMID:
case IPC_SET:
return semctl_down(ns, semid, cmd, version, p);
default:
return -EINVAL;
}
}这里我们重点看,SETALL操作调用的semctl_main函数,以及SETVAL操作调用的semctl_setval函数。
对于SETALL操作来讲,传进来的参数为union semun里面的unsigned short *array,会设置整个信号量集合。
static int semctl_main(struct ipc_namespace *ns, int semid, int semnum,
int cmd, void __user *p)
{
struct sem_array *sma;
struct sem *curr;
int err, nsems;
ushort fast_sem_io[SEMMSL_FAST];
ushort *sem_io = fast_sem_io;
DEFINE_WAKE_Q(wake_q);
sma = sem_obtain_object_check(ns, semid);
nsems = sma->sem_nsems;
......
switch (cmd) {
......
case SETALL:
{
int i;
struct sem_undo *un;
......
if (copy_from_user(sem_io, p, nsems*sizeof(ushort))) {
......
}
......
for (i = 0; i < nsems; i++) {
sma->sems[i].semval = sem_io[i];
sma->sems[i].sempid = task_tgid_vnr(current);
}
......
sma->sem_ctime = get_seconds();
/* maybe some queued-up processes were waiting for this */
do_smart_update(sma, NULL, 0, 0, &wake_q);
err = 0;
goto out_unlock;
}
}
......
wake_up_q(&wake_q);
......
}在semctl_main函数中,先是通过sem_obtain_object_check,根据信号量集合的id在基数树里面找到struct sem_array对象,发现如果是SETALL操作,就将用户的参数中的unsigned short *array通过copy_from_user拷贝到内核里面的sem_io数组,然后是一个循环,对于信号量集合里面的每一个信号量,设置semval,以及修改这个信号量值的pid。
对于SETVAL操作来讲,传进来的参数union semun里面的int val,仅仅会设置某个信号量。
static int semctl_setval(struct ipc_namespace *ns, int semid, int semnum,
unsigned long arg)
{
struct sem_undo *un;
struct sem_array *sma;
struct sem *curr;
int err, val;
DEFINE_WAKE_Q(wake_q);
......
sma = sem_obtain_object_check(ns, semid);
......
curr = &sma->sems[semnum];
......
curr->semval = val;
curr->sempid = task_tgid_vnr(current);
sma->sem_ctime = get_seconds();
/* maybe some queued-up processes were waiting for this */
do_smart_update(sma, NULL, 0, 0, &wake_q);
......
wake_up_q(&wake_q);
return 0;
}在semctl_setval函数中,我们先是通过sem_obtain_object_check,根据信号量集合的id在基数树里面找到struct sem_array对象,对于SETVAL操作,直接根据参数中的val设置semval,以及修改这个信号量值的pid。
至此,信号量数组初始化完毕。接下来我们来看P操作和V操作。无论是P操作,还是V操作都是调用semop系统调用。
SYSCALL_DEFINE3(semop, int, semid, struct sembuf __user *, tsops,
unsigned, nsops)
{
return sys_semtimedop(semid, tsops, nsops, NULL);
}
SYSCALL_DEFINE4(semtimedop, int, semid, struct sembuf __user *, tsops,
unsigned, nsops, const struct timespec __user *, timeout)
{
int error = -EINVAL;
struct sem_array *sma;
struct sembuf fast_sops[SEMOPM_FAST];
struct sembuf *sops = fast_sops, *sop;
struct sem_undo *un;
int max, locknum;
bool undos = false, alter = false, dupsop = false;
struct sem_queue queue;
unsigned long dup = 0, jiffies_left = 0;
struct ipc_namespace *ns;
ns = current->nsproxy->ipc_ns;
......
if (copy_from_user(sops, tsops, nsops * sizeof(*tsops))) {
error = -EFAULT;
goto out_free;
}
if (timeout) {
struct timespec _timeout;
if (copy_from_user(&_timeout, timeout, sizeof(*timeout))) {
}
jiffies_left = timespec_to_jiffies(&_timeout);
}
......
/* On success, find_alloc_undo takes the rcu_read_lock */
un = find_alloc_undo(ns, semid);
......
sma = sem_obtain_object_check(ns, semid);
......
queue.sops = sops;
queue.nsops = nsops;
queue.undo = un;
queue.pid = task_tgid_vnr(current);
queue.alter = alter;
queue.dupsop = dupsop;
error = perform_atomic_semop(sma, &queue);
if (error == 0) { /* non-blocking succesfull path */
DEFINE_WAKE_Q(wake_q);
......
do_smart_update(sma, sops, nsops, 1, &wake_q);
......
wake_up_q(&wake_q);
goto out_free;
}
/*
* We need to sleep on this operation, so we put the current
* task into the pending queue and go to sleep.
*/
if (nsops == 1) {
struct sem *curr;
curr = &sma->sems[sops->sem_num];
......
list_add_tail(&queue.list,
&curr->pending_alter);
......
} else {
......
list_add_tail(&queue.list, &sma->pending_alter);
......
}
do {
queue.status = -EINTR;
queue.sleeper = current;
__set_current_state(TASK_INTERRUPTIBLE);
if (timeout)
jiffies_left = schedule_timeout(jiffies_left);
else
schedule();
......
/*
* If an interrupt occurred we have to clean up the queue.
*/
if (timeout && jiffies_left == 0)
error = -EAGAIN;
} while (error == -EINTR && !signal_pending(current)); /* spurious */
......
}semop会调用semtimedop,这是一个非常复杂的函数。
semtimedop做的第一件事情,就是将用户的参数,例如,对于信号量的操作struct sembuf,拷贝到内核里面来。另外,如果是P操作,很可能让进程进入等待状态,是否要为这个等待状态设置一个超时,timeout也是一个参数,会把它变成时钟的滴答数目。
semtimedop做的第二件事情,是通过sem_obtain_object_check,根据信号量集合的id,获得struct sem_array,然后,创建一个struct sem_queue表示当前的信号量操作。为什么叫queue呢?因为这个操作可能马上就能完成,也可能因为无法获取信号量不能完成,不能完成的话就只好排列到队列上,等待信号量满足条件的时候。semtimedop会调用perform_atomic_semop在实施信号量操作。
static int perform_atomic_semop(struct sem_array *sma, struct sem_queue *q)
{
int result, sem_op, nsops;
struct sembuf *sop;
struct sem *curr;
struct sembuf *sops;
struct sem_undo *un;
sops = q->sops;
nsops = q->nsops;
un = q->undo;
for (sop = sops; sop < sops + nsops; sop++) {
curr = &sma->sems[sop->sem_num];
sem_op = sop->sem_op;
result = curr->semval;
......
result += sem_op;
if (result < 0)
goto would_block;
......
if (sop->sem_flg & SEM_UNDO) {
int undo = un->semadj[sop->sem_num] - sem_op;
.....
}
}
for (sop = sops; sop < sops + nsops; sop++) {
curr = &sma->sems[sop->sem_num];
sem_op = sop->sem_op;
result = curr->semval;
if (sop->sem_flg & SEM_UNDO) {
int undo = un->semadj[sop->sem_num] - sem_op;
un->semadj[sop->sem_num] = undo;
}
curr->semval += sem_op;
curr->sempid = q->pid;
}
return 0;
would_block:
q->blocking = sop;
return sop->sem_flg & IPC_NOWAIT ? -EAGAIN : 1;
}在perform_atomic_semop函数中,对于所有信号量操作都进行两次循环。在第一次循环中,如果发现计算出的result小于0,则说明必须等待,于是跳到would_block中,设置q->blocking = sop表示这个queue是block在这个操作上,然后如果需要等待,则返回1。如果第一次循环中发现无需等待,则第二个循环实施所有的信号量操作,将信号量的值设置为新的值,并且返回0。
接下来,我们回到semtimedop,来看它干的第三件事情,就是如果需要等待,应该怎么办?
如果需要等待,则要区分刚才的对于信号量的操作,是对一个信号量的,还是对于整个信号量集合的。如果是对于一个信号量的,那我们就将queue挂到这个信号量的pending_alter中;如果是对于整个信号量集合的,那我们就将queue挂到整个信号量集合的pending_alter中。
接下来的do-while循环,就是要开始等待了。如果等待没有时间限制,则调用schedule让出CPU;如果等待有时间限制,则调用schedule_timeout让出CPU,过一段时间还回来。当回来的时候,判断是否等待超时,如果没有等待超时则进入下一轮循环,再次等待,如果超时则退出循环,返回错误。在让出CPU的时候,设置进程的状态为TASK_INTERRUPTIBLE,并且循环的结束会通过signal_pending查看是否收到过信号,这说明这个等待信号量的进程是可以被信号中断的,也即一个等待信号量的进程是可以通过kill杀掉的。
我们再来看,semtimedop要做的第四件事情,如果不需要等待,应该怎么办?
如果不需要等待,就说明对于信号量的操作完成了,也改变了信号量的值。接下来,就是一个标准流程。我们通过DEFINE_WAKE_Q(wake_q)声明一个wake_q,调用do_smart_update,看这次对于信号量的值的改变,可以影响并可以激活等待队列中的哪些struct sem_queue,然后把它们都放在wake_q里面,调用wake_up_q唤醒这些进程。其实,所有的对于信号量的值的修改都会涉及这三个操作,如果你回过头去仔细看SETALL和SETVAL操作,在设置完毕信号量之后,也是这三个操作。
我们来看do_smart_update是如何实现的。do_smart_update会调用update_queue。
static int update_queue(struct sem_array *sma, int semnum, struct wake_q_head *wake_q)
{
struct sem_queue *q, *tmp;
struct list_head *pending_list;
int semop_completed = 0;
if (semnum == -1)
pending_list = &sma->pending_alter;
else
pending_list = &sma->sems[semnum].pending_alter;
again:
list_for_each_entry_safe(q, tmp, pending_list, list) {
int error, restart;
......
error = perform_atomic_semop(sma, q);
/* Does q->sleeper still need to sleep? */
if (error > 0)
continue;
unlink_queue(sma, q);
......
wake_up_sem_queue_prepare(q, error, wake_q);
......
}
return semop_completed;
}
static inline void wake_up_sem_queue_prepare(struct sem_queue *q, int error,
struct wake_q_head *wake_q)
{
wake_q_add(wake_q, q->sleeper);
......
}update_queue会依次循环整个信号量集合的等待队列pending_alter,或者某个信号量的等待队列。试图在信号量的值变了的情况下,再次尝试perform_atomic_semop进行信号量操作。如果不成功,则尝试队列中的下一个;如果尝试成功,则调用unlink_queue从队列上取下来,然后调用wake_up_sem_queue_prepare,将q->sleeper加到wake_q上去。q->sleeper是一个task_struct,是等待在这个信号量操作上的进程。
接下来,wake_up_q就依次唤醒wake_q上的所有task_struct,调用的是我们在进程调度那一节学过的wake_up_process方法。
void wake_up_q(struct wake_q_head *head)
{
struct wake_q_node *node = head->first;
while (node != WAKE_Q_TAIL) {
struct task_struct *task;
task = container_of(node, struct task_struct, wake_q);
node = node->next;
task->wake_q.next = NULL;
wake_up_process(task);
put_task_struct(task);
}
}至此,对于信号量的主流操作都解析完毕了。
其实还有一点需要强调一下,信号量是一个整个Linux可见的全局资源,而不像咱们在线程同步那一节讲过的都是某个进程独占的资源,好处是可以跨进程通信,坏处就是如果一个进程通过P操作拿到了一个信号量,但是不幸异常退出了,如果没有来得及归还这个信号量,可能所有其他的进程都阻塞了。
那怎么办呢?Linux有一种机制叫SEM_UNDO,也即每一个semop操作都会保存一个反向struct sem_undo操作,当因为某个进程异常退出的时候,这个进程做的所有的操作都会回退,从而保证其他进程可以正常工作。
如果你回头看,我们写的程序里面的semaphore_p函数和semaphore_v函数,都把sem_flg设置为SEM_UNDO,就是这个作用。
等待队列上的每一个struct sem_queue,都有一个struct sem_undo,以此来表示这次操作的反向操作。
struct sem_queue {
struct list_head list; /* queue of pending operations */
struct task_struct *sleeper; /* this process */
struct sem_undo *undo; /* undo structure */
int pid; /* process id of requesting process */
int status; /* completion status of operation */
struct sembuf *sops; /* array of pending operations */
struct sembuf *blocking; /* the operation that blocked */
int nsops; /* number of operations */
bool alter; /* does *sops alter the array? */
bool dupsop; /* sops on more than one sem_num */
};在进程的task_struct里面对于信号量有一个成员struct sysv_sem,里面是一个struct sem_undo_list,将这个进程所有的semop所带来的undo操作都串起来。
struct task_struct {
......
struct sysv_sem sysvsem;
......
}
struct sysv_sem {
struct sem_undo_list *undo_list;
};
struct sem_undo {
struct list_head list_proc; /* per-process list: *
* all undos from one process
* rcu protected */
struct rcu_head rcu; /* rcu struct for sem_undo */
struct sem_undo_list *ulp; /* back ptr to sem_undo_list */
struct list_head list_id; /* per semaphore array list:
* all undos for one array */
int semid; /* semaphore set identifier */
short *semadj; /* array of adjustments */
/* one per semaphore */
};
struct sem_undo_list {
atomic_t refcnt;
spinlock_t lock;
struct list_head list_proc;
};为了让你更清楚地理解struct sem_undo的原理,我们这里举一个例子。
假设我们创建了两个信号量集合。一个叫semaphore1,它包含三个信号量,初始化值为3,另一个叫semaphore2,它包含4个信号量,初始化值都为4。初始化时候的信号量以及undo结构里面的值如图中(1)标号所示。
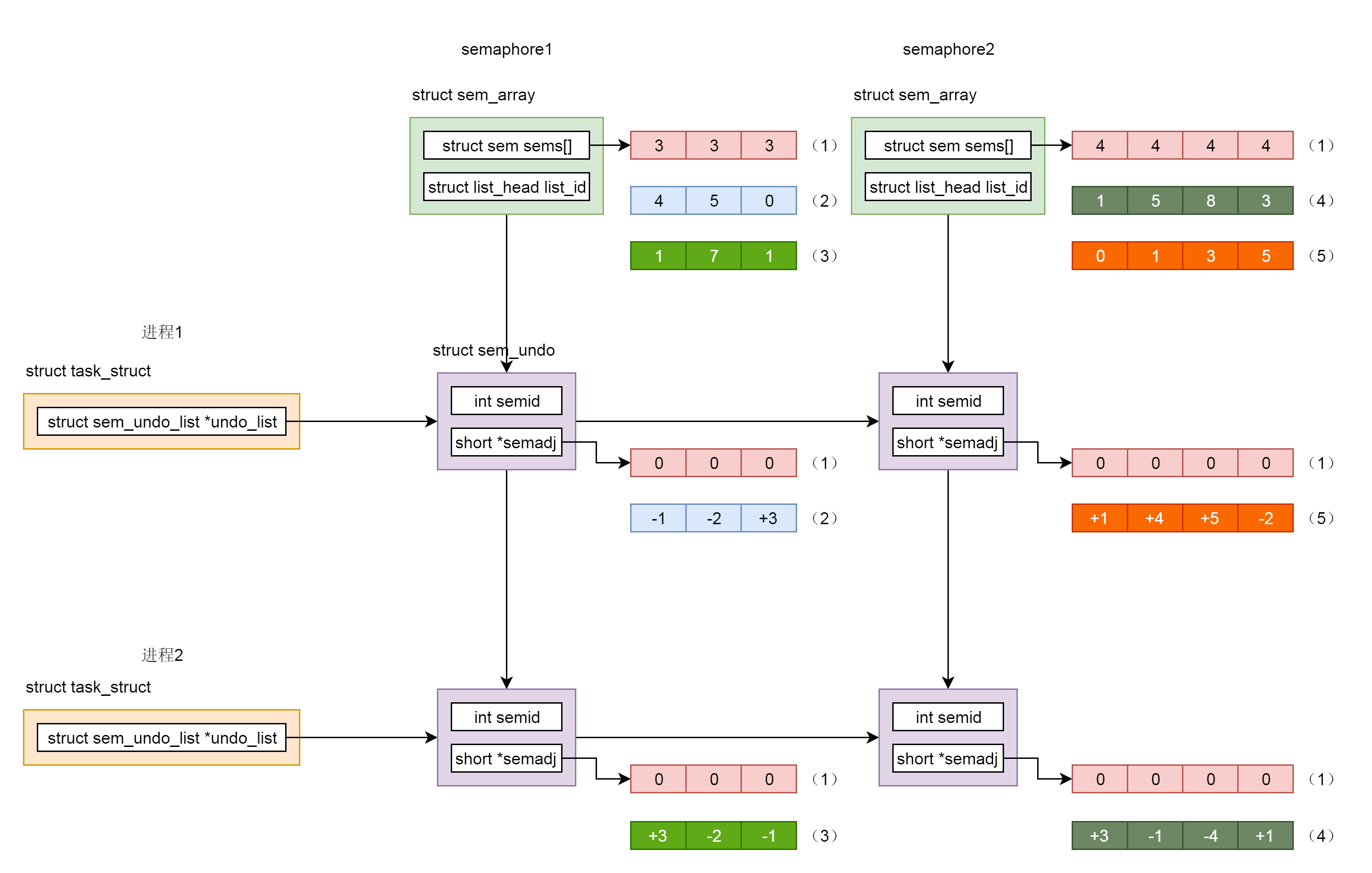
首先,我们来看进程1。我们调用semop,将semaphore1的三个信号量的值,分别加1、加2和减3,从而信号量的值变为4,5,0。于是在semaphore1和进程1链表交汇的undo结构里面,填写-1,-2,+3,是semop操作的反向操作,如图中(2)标号所示。
然后,我们来看进程2。我们调用semop,将semaphore1的三个信号量的值,分别减3、加2和加1,从而信号量的值变为1、7、1。于是在semaphore1和进程2链表交汇的undo结构里面,填写+3、-2、-1,是semop操作的反向操作,如图中(3)标号所示。
然后,我们接着看进程2。我们调用semop,将semaphore2的四个信号量的值,分别减3、加1、加4和减1,从而信号量的值变为1、5、8、3。于是,在semaphore2和进程2链表交汇的undo结构里面,填写+3、-1、-4、+1,是semop操作的反向操作,如图中(4)标号所示。
然后,我们再来看进程1。我们调用semop,将semaphore2的四个信号量的值,分别减1、减4、减5和加2,从而信号量的值变为0、1、3、5。于是在semaphore2和进程1链表交汇的undo结构里面,填写+1、+4、+5、-2,是semop操作的反向操作,如图中(5)标号所示。
从这个例子可以看出,无论哪个进程异常退出,只要将undo结构里面的值加回当前信号量的值,就能够得到正确的信号量的值,不会因为一个进程退出,导致信号量的值处于不一致的状态。
37.1 总结
信号量的机制也很复杂,我们对着下面这个图总结一下。
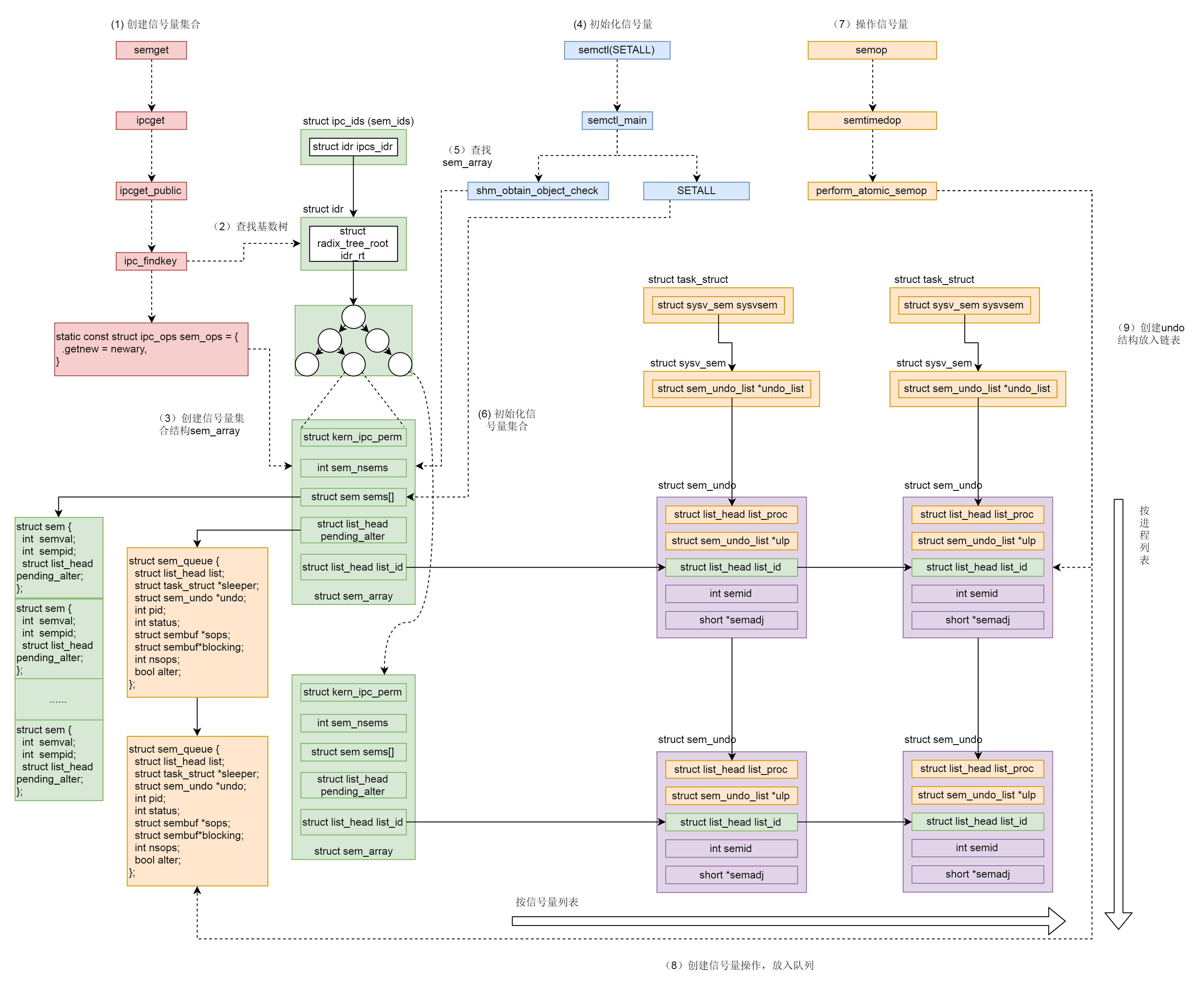
- 调用semget创建信号量集合。
- ipc_findkey会在基数树中,根据key查找信号量集合sem_array对象。如果已经被创建,就会被查询出来。例如producer被创建过,在consumer中就会查询出来。
- 如果信号量集合没有被创建过,则调用sem_ops的newary方法,创建一个信号量集合对象sem_array。例如,在producer中就会新建。
- 调用semctl(SETALL)初始化信号量。
- sem_obtain_object_check先从基数树里面找到sem_array对象。
- 根据用户指定的信号量数组,初始化信号量集合,也即初始化sem_array对象的struct sem sems[]成员。
- 调用semop操作信号量。
- 创建信号量操作结构sem_queue,放入队列。
- 创建undo结构,放入链表。

