七、网络系统
38. Socket通信之网络协议基本原理
上一节我们讲的进程间通信,其实是通过内核的数据结构完成的,主要用于在一台Linux上两个进程之间的通信。但是,一旦超出一台机器的范畴,我们就需要一种跨机器的通信机制。
一台机器将自己想要表达的内容,按照某种约定好的格式发送出去,当另外一台机器收到这些信息后,也能够按照约定好的格式解析出来,从而准确、可靠地获得发送方想要表达的内容。这种约定好的格式就是网络协议(Networking Protocol)。
38.1 网络为什么要分层?
我们这里先构建一个相对简单的场景,之后几节内容,我们都要基于这个场景进行讲解。
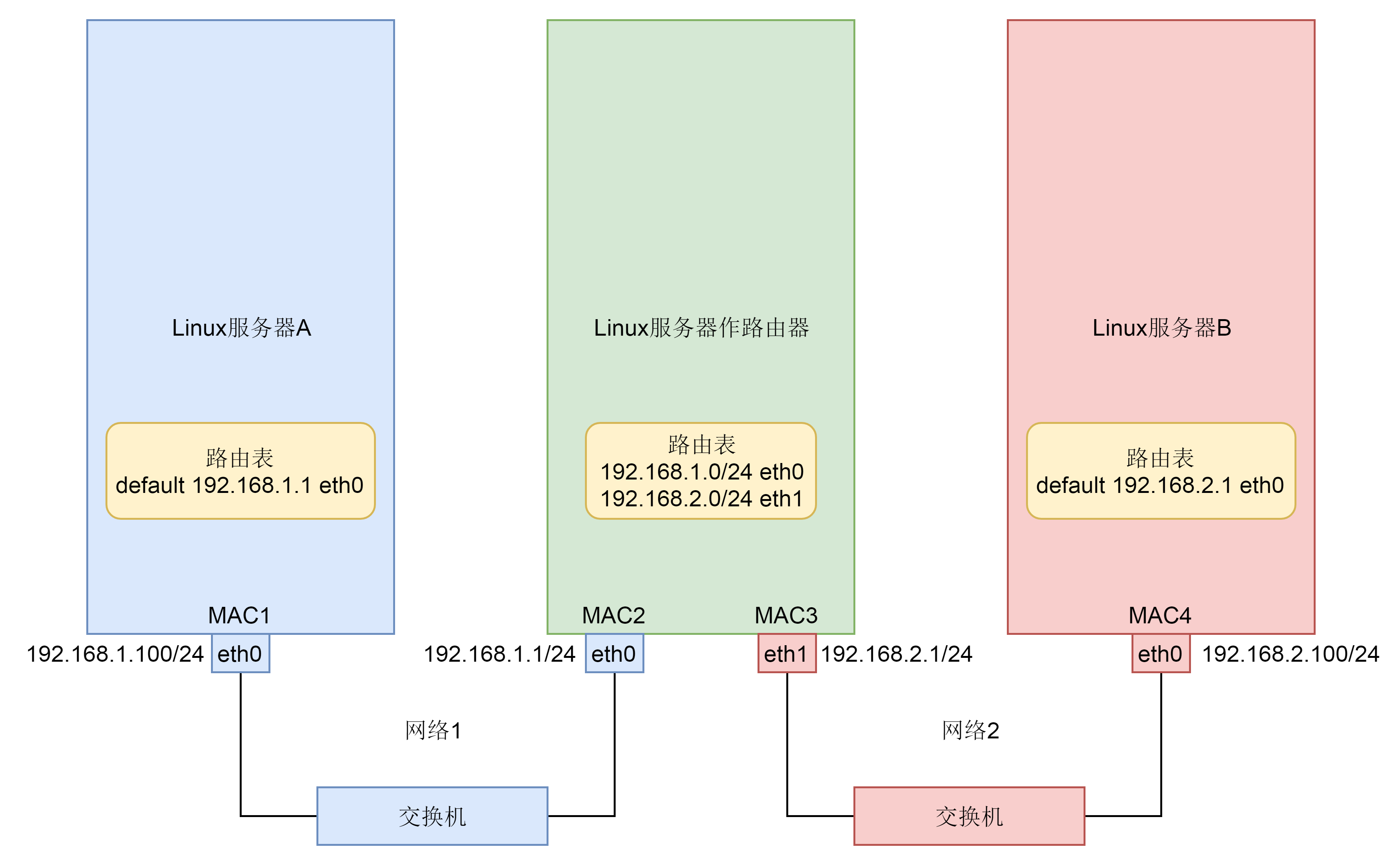
我们假设这里就涉及三台机器。Linux服务器A和Linux服务器B处于不同的网段,通过中间的Linux服务器作为路由器进行转发。
说到网络协议,我们还需要简要介绍一下两种网络协议模型,一种是OSI的标准七层模型,一种是业界标准的TCP/IP模型。它们的对应关系如下图所示:
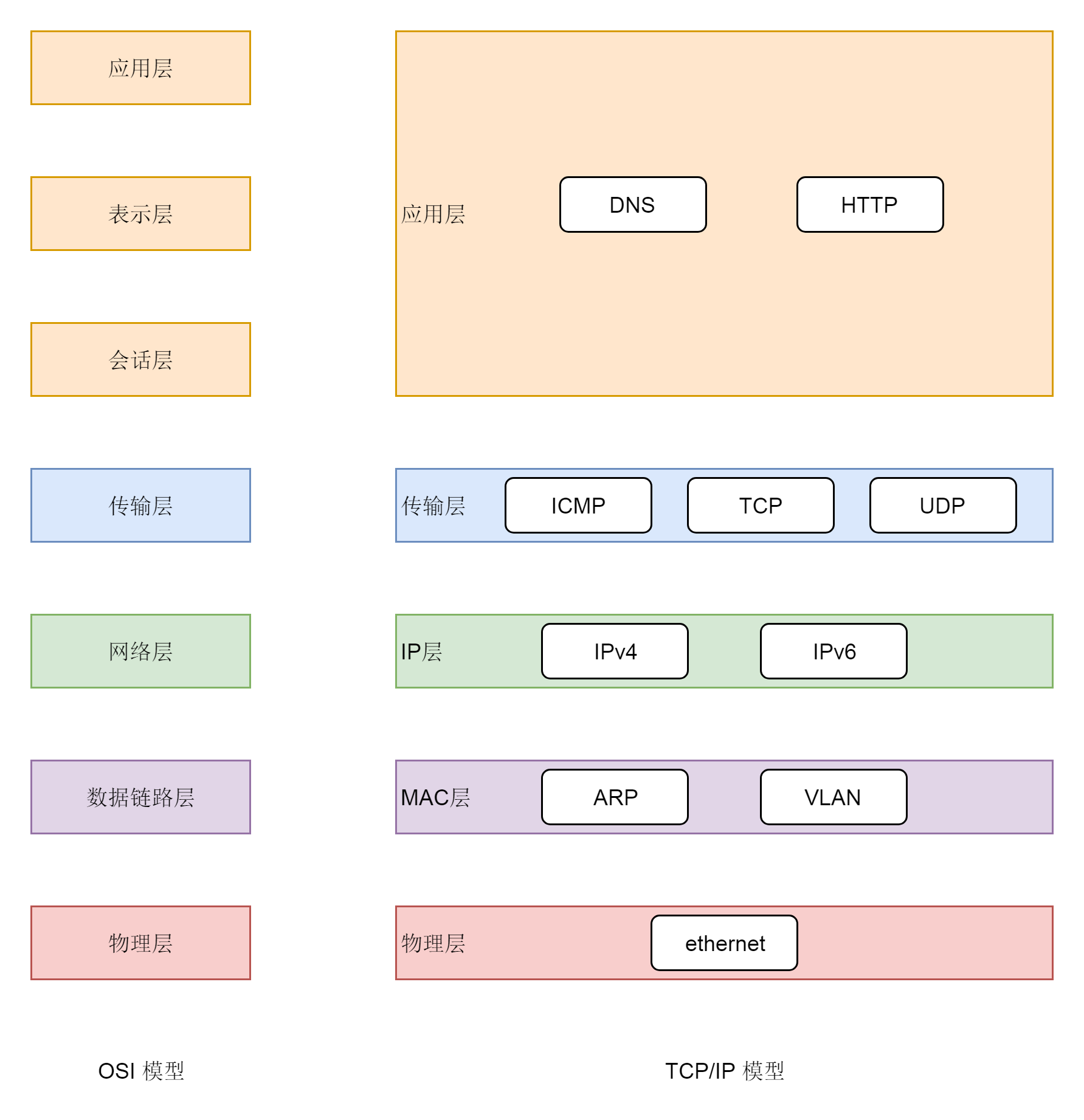
为什么网络要分层呢?因为网络环境过于复杂,不是一个能够集中控制的体系。全球数以亿记的服务器和设备各有各的体系,但是都可以通过同一套网络协议栈通过切分成多个层次和组合,来满足不同服务器和设备的通信需求。
我们这里简单介绍一下网络协议的几个层次。
我们从哪一个层次开始呢?从第三层,网络层开始,因为这一层有我们熟悉的IP地址。也因此,这一层我们也叫IP层。
我们通常看到的IP地址都是这个样子的:192.168.1.100/24。斜杠前面是IP地址,这个地址被点分隔为四个部分,每个部分8位,总共是32位。斜线后面24的意思是,32位中,前24位是网络号,后8位是主机号。
为什么要这样分呢?我们可以想象,虽然全世界组成一张大的互联网,美国的网站你也能够访问的,但是这个网络不是一整个的。你们小区有一个网络,你们公司也有一个网络,联通、移动、电信运营商也各有各的网络,所以一个大网络是被分成个小的网络。
那如何区分这些网络呢?这就是网络号的概念。一个网络里面会有多个设备,这些设备的网络号一样,主机号不一样。不信你可以观察一下你家里的手机、电视、电脑。
连接到网络上的每一个设备都至少有一个IP地址,用于定位这个设备。无论是近在咫尺的你旁边同学的电脑,还是远在天边的电商网站,都可以通过IP地址进行定位。因此,IP地址类似互联网上的邮寄地址,是有全局定位功能的。
就算你要访问美国的一个地址,也可以从你身边的网络出发,通过不断的打听道儿,经过多个网络,最终到达目的地址,和快递员送包裹的过程差不多。打听道儿的协议也在第三层,称为路由协议(Routing protocol),将网络包从一个网络转发给另一个网络的设备称为路由器。
路由器和路由协议十分复杂,我们这里就不详细讲解了,感兴趣可以去看我写的另一个专栏”趣谈网络协议”里的相关文章。
总而言之,第三层干的事情,就是网络包从一个起始的IP地址,沿着路由协议指的道儿,经过多个网络,通过多次路由器转发,到达目标IP地址。
从第三层,我们往下看,第二层是数据链路层。有时候我们简称为二层或者MAC层。所谓MAC,就是每个网卡都有的唯一的硬件地址(不绝对唯一,相对大概率唯一即可,类比UUID)。这虽然也是一个地址,但是这个地址是没有全局定位功能的。
就像给你送外卖的小哥,不可能根据手机尾号找到你家,但是手机尾号有本地定位功能的,只不过这个定位主要靠”吼”。外卖小哥到了你的楼层就开始大喊:”尾号xxxx的,你外卖到了!”
MAC地址的定位功能局限在一个网络里面,也即同一个网络号下的IP地址之间,可以通过MAC进行定位和通信。从IP地址获取MAC地址要通过ARP协议,是通过在本地发送广播包,也就是”吼”,获得的MAC地址。
由于同一个网络内的机器数量有限,通过MAC地址的好处就是简单。匹配上MAC地址就接收,匹配不上就不接收,没有什么所谓路由协议这样复杂的协议。当然坏处就是,MAC地址的作用范围不能出本地网络,所以一旦跨网络通信,虽然IP地址保持不变,但是MAC地址每经过一个路由器就要换一次。
我们看前面的图。服务器A发送网络包给服务器B,原IP地址始终是192.168.1.100,目标IP地址始终是192.168.2.100,但是在网络1里面,原MAC地址是MAC1,目标MAC地址是路由器的MAC2,路由器转发之后,原MAC地址是路由器的MAC3,目标MAC地址是MAC4。
所以第二层干的事情,就是网络包在本地网络中的服务器之间定位及通信的机制。
我们再往下看,第一层,物理层,这一层就是物理设备。例如连着电脑的网线,我们能连上的WiFi,这一层我们不打算进行分析。
从第三层往上看,第四层是传输层,这里面有两个著名的协议TCP和UDP。尤其是TCP,更是广泛使用,在IP层的代码逻辑中,仅仅负责数据从一个IP地址发送给另一个IP地址,丢包、乱序、重传、拥塞,这些IP层都不管。处理这些问题的代码逻辑写在了传输层的TCP协议里面。
我们常称,TCP是可靠传输协议,也是难为它了。因为从第一层到第三层都不可靠,网络包说丢就丢,是TCP这一层通过各种编号、重传等机制,让本来不可靠的网络对于更上层来讲,变得”看起来”可靠。哪有什么应用层岁月静好,只不过TCP层帮你负重前行。
传输层再往上就是应用层,例如咱们在浏览器里面输入的HTTP,Java服务端写的Servlet,都是这一层的。
二层到四层都是在Linux内核里面处理的,应用层例如浏览器、Nginx、Tomcat都是用户态的。内核里面对于网络包的处理是不区分应用的。
从四层再往上,就需要区分网络包发给哪个应用。在传输层的TCP和UDP协议里面,都有端口的概念,不同的应用监听不同的端口。例如,服务端Nginx监听80、Tomcat监听8080;再如客户端浏览器监听一个随机端口,FTP客户端监听另外一个随机端口。
应用层和内核互通的机制,就是通过Socket系统调用。所以经常有人会问,Socket属于哪一层,其实它哪一层都不属于,它属于操作系统的概念,而非网络协议分层的概念。只不过操作系统选择对于网络协议的实现模式是,二到四层的处理代码在内核里面,七层的处理代码让应用自己去做,两者需要跨内核态和用户态通信,就需要一个系统调用完成这个衔接,这就是Socket。
38.2 发送数据包
网络分完层之后,对于数据包的发送,就是层层封装的过程。
就像下面的图中展示的一样,在Linux服务器B上部署的服务端Nginx和Tomcat,都是通过Socket监听80和8080端口。这个时候,内核的数据结构就知道了。如果遇到发送到这两个端口的,就发送给这两个进程。
在Linux服务器A上的客户端,打开一个Firefox连接Ngnix。也是通过Socket,客户端会被分配一个随机端口12345。同理,打开一个Chrome连接Tomcat,同样通过Socket分配随机端口12346。
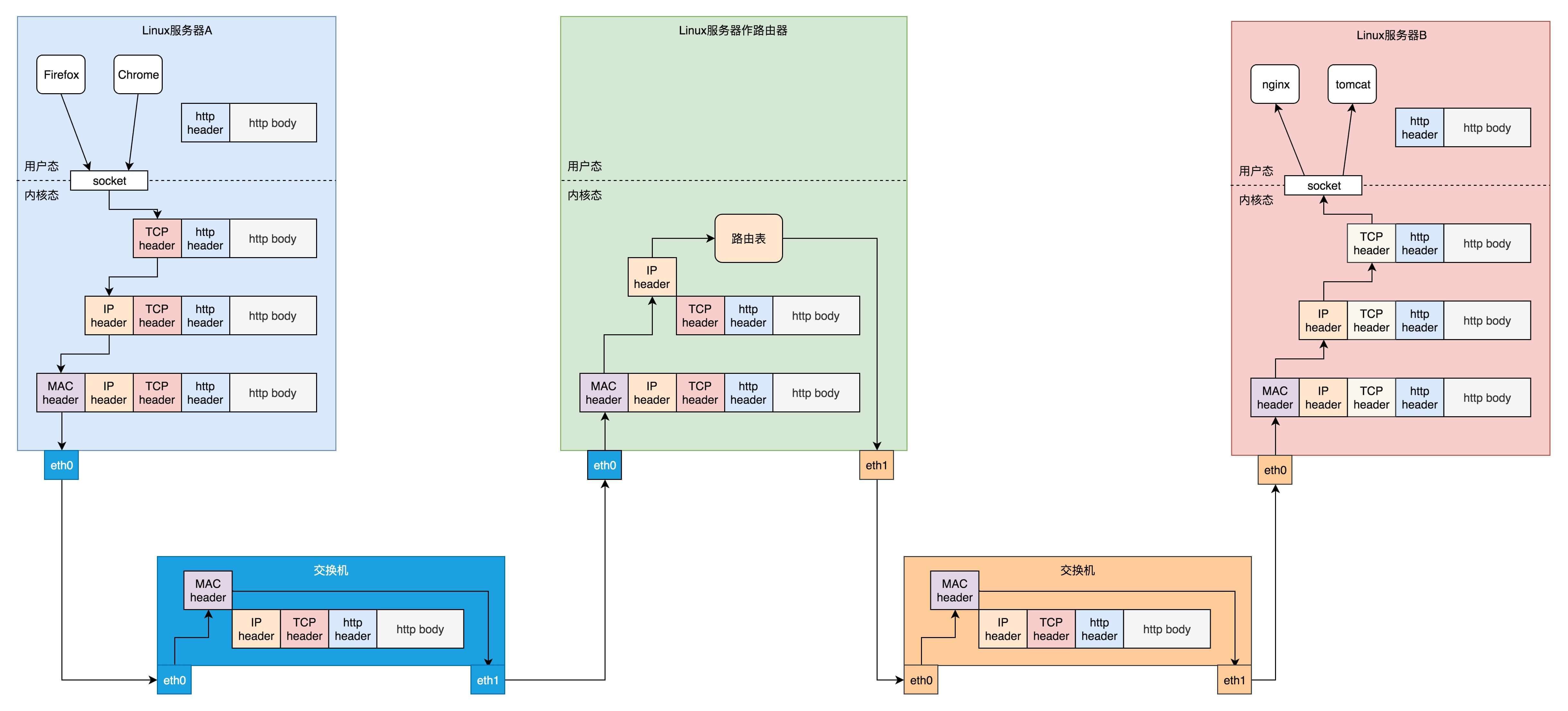
在客户端浏览器,我们将请求封装为HTTP协议,通过Socket发送到内核。内核的网络协议栈里面,在TCP层创建用于维护连接、序列号、重传、拥塞控制的数据结构,将HTTP包加上TCP头,发送给IP层,IP层加上IP头,发送给MAC层,MAC层加上MAC头,从硬件网卡发出去。
网络包会先到达网络1的交换机。我们常称交换机为二层设备,这是因为,交换机只会处理到第二层,然后它会将网络包的MAC头拿下来,发现目标MAC是在自己右面的网口,于是就从这个网口发出去。
网络包会到达中间的Linux路由器,它左面的网卡会收到网络包,发现MAC地址匹配,就交给IP层,在IP层根据IP头中的信息,在路由表中查找。下一跳在哪里,应该从哪个网口发出去?在这个例子中,最终会从右面的网口发出去。我们常把路由器称为三层设备,因为它只会处理到第三层。
从路由器右面的网口发出去的包会到网络2的交换机,还是会经历一次二层的处理,转发到交换机右面的网口。
最终网络包会被转发到Linux服务器B,它发现MAC地址匹配,就将MAC头取下来,交给上一层。IP层发现IP地址匹配,将IP头取下来,交给上一层。TCP层会根据TCP头中的序列号等信息,发现它是一个正确的网络包,就会将网络包缓存起来,等待应用层的读取。
应用层通过Socket监听某个端口,因而读取的时候,内核会根据TCP头中的端口号,将网络包发给相应的应用。
HTTP层的头和正文,是应用层来解析的。通过解析,应用层知道了客户端的请求,例如购买一个商品,还是请求一个网页。当应用层处理完HTTP的请求,会将结果仍然封装为HTTP的网络包,通过Socket接口,发送给内核。
内核会经过层层封装,从物理网口发送出去,经过网络2的交换机,Linux路由器到达网络1,经过网络1的交换机,到达Linux服务器A。在Linux服务器A上,经过层层解封装,通过socket接口,根据客户端的随机端口号,发送给客户端的应用程序,浏览器。于是浏览器就能够显示出一个绚丽多彩的页面了。
即便在如此简单的一个环境中,网络包的发送过程,竟然如此的复杂。不过这一章后面,我们还是会层层剖析每一层做的事情。
39. Socket通信
按照前一篇文章说的分层机制,我们可以想到,socket接口大多数情况下操作的是传输层,更底层的协议不用它来操心,这就是分层的好处。
在传输层有两个主流的协议TCP和UDP,所以我们的socket程序设计也是主要操作这两个协议。这两个协议的区别是什么呢?通常的答案是下面这样的。
- TCP是面向连接的,UDP是面向无连接的。
- TCP提供可靠交付,无差错、不丢失、不重复、并且按序到达;UDP不提供可靠交付,不保证不丢失,不保证按顺序到达。
- TCP是面向字节流的,发送时发的是一个流,没头没尾;UDP是面向数据报的,一个一个的发送。
- TCP是可以提供流量控制和拥塞控制的,既防止对端被压垮,也防止网络被压垮。
这些答案没有问题,但是没有到达本质,也经常让人产生错觉。例如,下面这些问题,你看看你是否了解?
- 所谓的连接,容易让人误以为,使用TCP会使得两端之间的通路和使用UDP不一样,那我们会在沿途建立一条线表示这个连接吗?
- 我从中国访问美国网站,中间这么多环节,我怎么保证连接不断呢?
- 中间有个网络管理员拔了一根网线不就断了吗?我不能控制它,它也不会通知我,我一个个人电脑怎么能够保持连接呢?
- 还让我做流量控制和拥塞控制,我既管不了中间的链路,也管不了对端的服务器呀,我怎么能够做到?
- 按照网络分层,TCP和UDP都是基于IP协议的,IP都不能保证可靠,说丢就丢,TCP怎么能够保证呢?
- IP层都是一个包一个包的发送,TCP怎么就变成流了?
从本质上来讲,所谓的建立连接,其实是为了在客户端和服务端维护连接,而建立一定的数据结构来维护双方交互的状态,并用这样的数据结构来保证面向连接的特性。TCP无法左右中间的任何通路,也没有什么虚拟的连接,中间的通路根本意识不到两端使用了TCP还是UDP。
所谓的连接,就是两端数据结构状态的协同,两边的状态能够对得上。符合TCP协议的规则,就认为连接存在;两面状态对不上,连接就算断了。
流量控制和拥塞控制其实就是根据收到的对端的网络包,调整两端数据结构的状态。TCP协议的设计理论上认为,这样调整了数据结构的状态,就能进行流量控制和拥塞控制了,其实在通路上是不是真的做到了,谁也管不着。
所谓的可靠,也是两端的数据结构做的事情。不丢失其实是数据结构在”点名”,顺序到达其实是数据结构在”排序”,面向数据流其实是数据结构将零散的包,按照顺序捏成一个流发给应用层。总而言之,”连接”两个字让人误以为功夫在通路,其实功夫在两端。
当然,无论是用socket操作TCP,还是UDP,我们首先都要调用socket函数。
int socket(int domain, int type, int protocol);socket函数用于创建一个socket的文件描述符,唯一标识一个socket。我们把它叫作文件描述符,因为在内核中,我们会创建类似文件系统的数据结构,并且后续的操作都有用到它。
socket函数有三个参数。
- domain:表示使用什么IP层协议。AF_INET表示IPv4,AF_INET6表示IPv6。
- type:表示socket类型。SOCK_STREAM,顾名思义就是TCP面向流的,SOCK_DGRAM就是UDP面向数据报的,SOCK_RAW可以直接操作IP层,或者非TCP和UDP的协议。例如ICMP。
- protocol表示的协议,包括IPPROTO_TCP、IPPTOTO_UDP。
通信结束后,我们还要像关闭文件一样,关闭socket。
39.1 针对TCP应该如何编程?
TCP的服务端要先监听一个端口,一般是先调用bind函数,给这个socket赋予一个端口和IP地址。
int bind(int sockfd, const struct sockaddr *addr,socklen_t addrlen);
struct sockaddr_in {
__kernel_sa_family_t sin_family; /* Address family */
__be16 sin_port; /* Port number */
struct in_addr sin_addr; /* Internet address */
/* Pad to size of `struct sockaddr'. */
unsigned char __pad[__SOCK_SIZE__ - sizeof(short int) -
sizeof(unsigned short int) - sizeof(struct in_addr)];
};
struct in_addr {
__be32 s_addr;
};其中,sockfd是上面我们创建的socket文件描述符。在sockaddr_in结构中,sin_family设置为AF_INET,表示IPv4;sin_port是端口号;sin_addr是IP地址。
服务端所在的服务器可能有多个网卡、多个地址,可以选择监听在一个地址,也可以监听0.0.0.0表示所有的地址都监听。服务端一般要监听在一个众所周知的端口上,例如,Nginx一般是80,Tomcat一般是8080。
客户端要访问服务端,肯定事先要知道服务端的端口。无论是电商,还是游戏,还是视频,如果你仔细观察,会发现都有一个这样的端口。可能你会发现,客户端不需要bind,因为浏览器嘛,随机分配一个端口就可以了,只有你主动去连接别人,别人不会主动连接你,没有人关心客户端监听到了哪里。
如果你看上面代码中的数据结构,里面的变量名称都有”be”两个字母,代表的意思是”big-endian”。如果在网络上传输超过1 Byte的类型,就要区分大端(Big Endian)和小端(Little Endian)。
假设,我们要在32位4 Bytes的一个空间存放整数1,很显然只要1 Byte放1,其他3 Bytes放0就可以了。那问题是,最后一个Byte放1呢,还是第一个Byte放1呢?或者说,1作为最低位,应该放在32位的最后一个位置呢,还是放在第一个位置呢?
最低位放在最后一个位置,我们叫作小端,最低位放在第一个位置,叫作大端。TCP/IP栈是按照大端来设计的,而x86机器多按照小端来设计,因而发出去时需要做一个转换。
接下来,就要建立TCP的连接了,也就是著名的三次握手,其实就是将客户端和服务端的状态通过三次网络交互,达到初始状态是协同的状态。下图就是三次握手的序列图以及对应的状态转换。
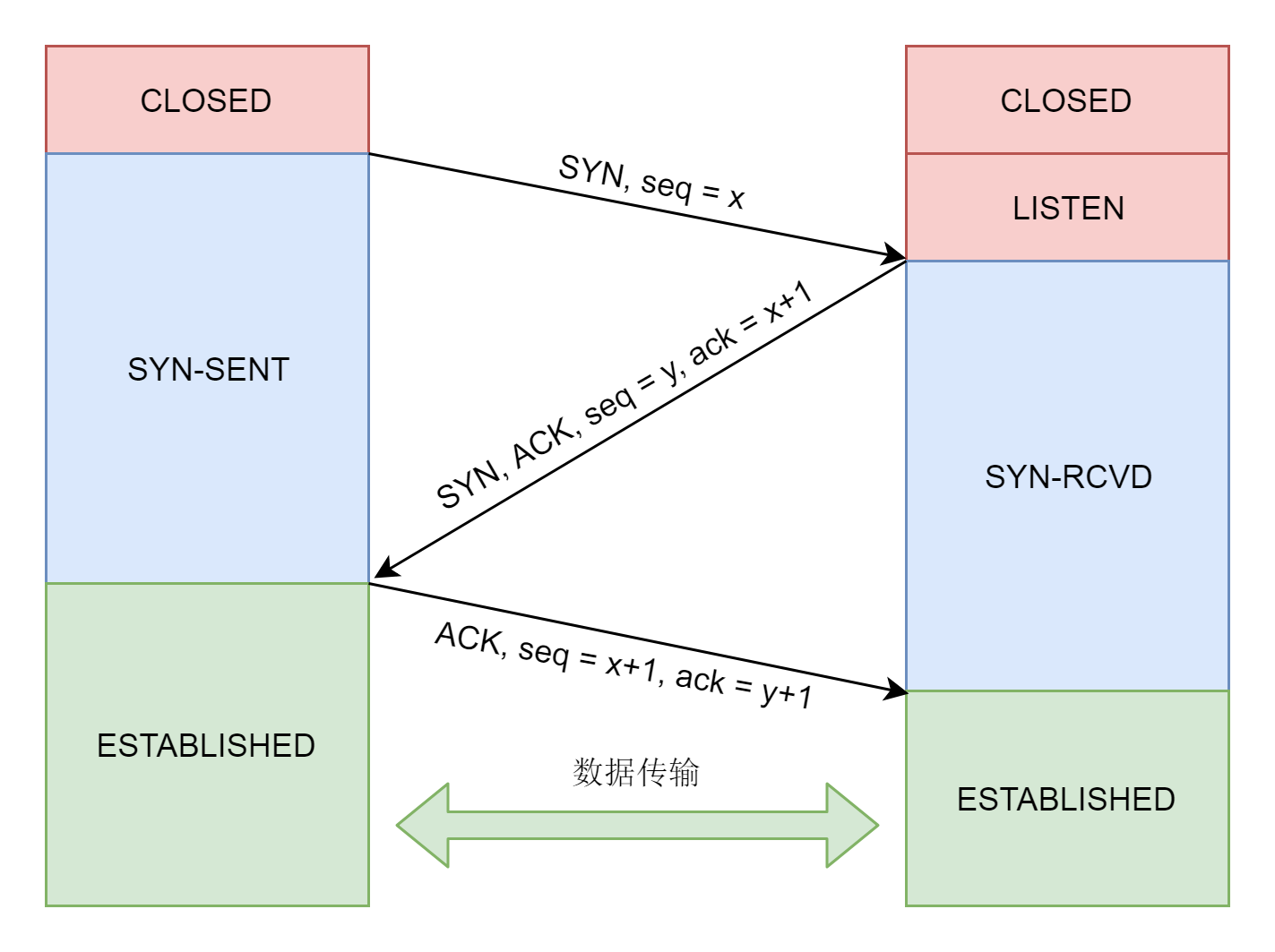
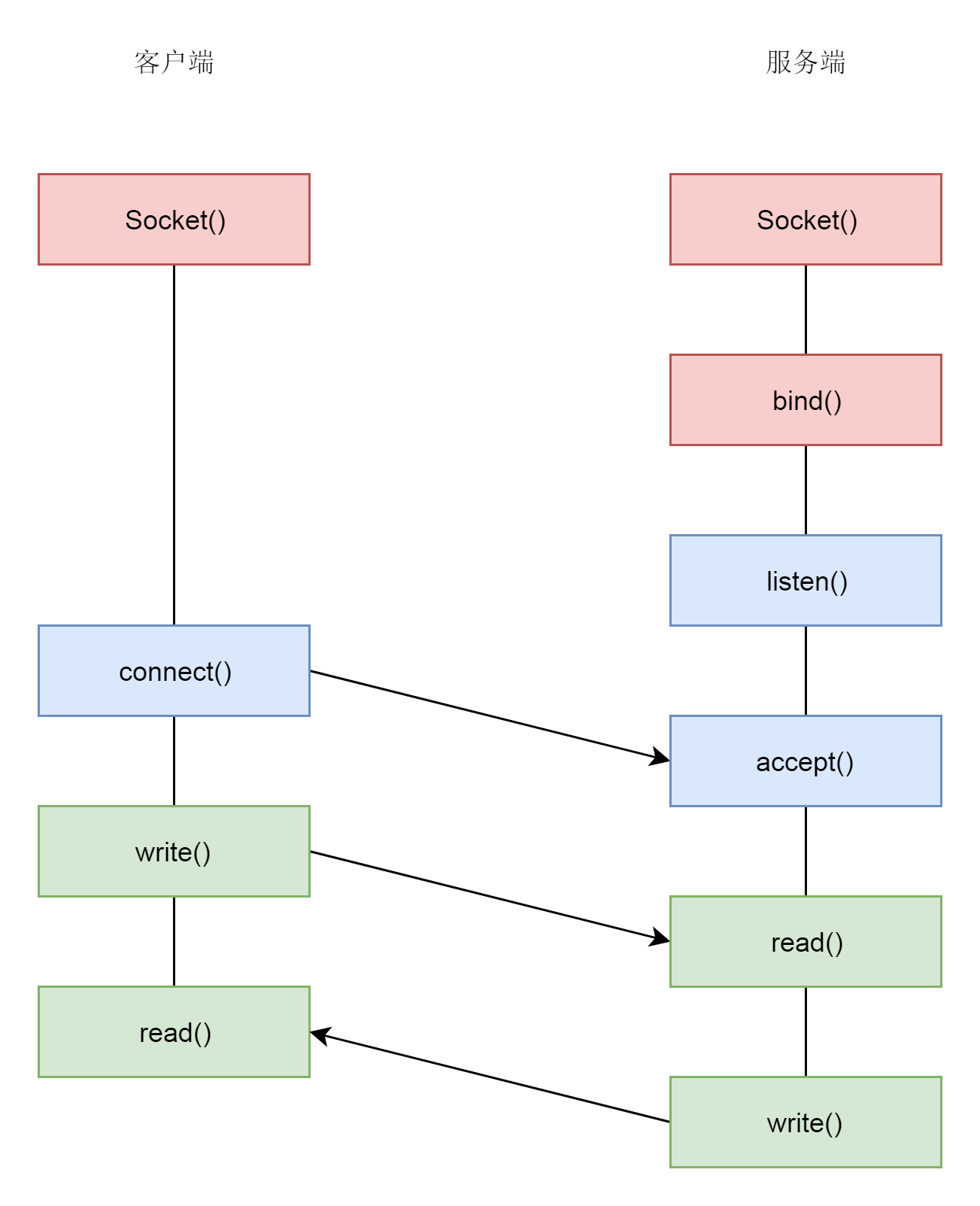
接下来,服务端要调用listen进入LISTEN状态,等待客户端进行连接。
int listen(int sockfd, int backlog);连接的建立过程,也即三次握手,是TCP层的动作,是在内核完成的,应用层不需要参与。
接着,服务端只需要调用accept,等待内核完成了至少一个连接的建立,才返回。如果没有一个连接完成了三次握手,accept就一直等待;如果有多个客户端发起连接,并且在内核里面完成了多个三次握手,建立了多个连接,这些连接会被放在一个队列里面。accept会从队列里面取出一个来进行处理。如果想进一步处理其他连接,需要调用多次accept,所以accept往往在一个循环里面。
int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);接下来,客户端可以通过connect函数发起连接。
int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen);我们先在参数中指明要连接的IP地址和端口号,然后发起三次握手。内核会给客户端分配一个临时的端口。一旦握手成功,服务端的accept就会返回另一个socket。
这里需要注意的是,监听的socket和真正用来传送数据的socket,是两个socket,一个叫作监听socket,一个叫作已连接socket。成功连接建立之后,双方开始通过read和write函数来读写数据,就像往一个文件流里面写东西一样。
39.2 针对UDP应该如何编程?
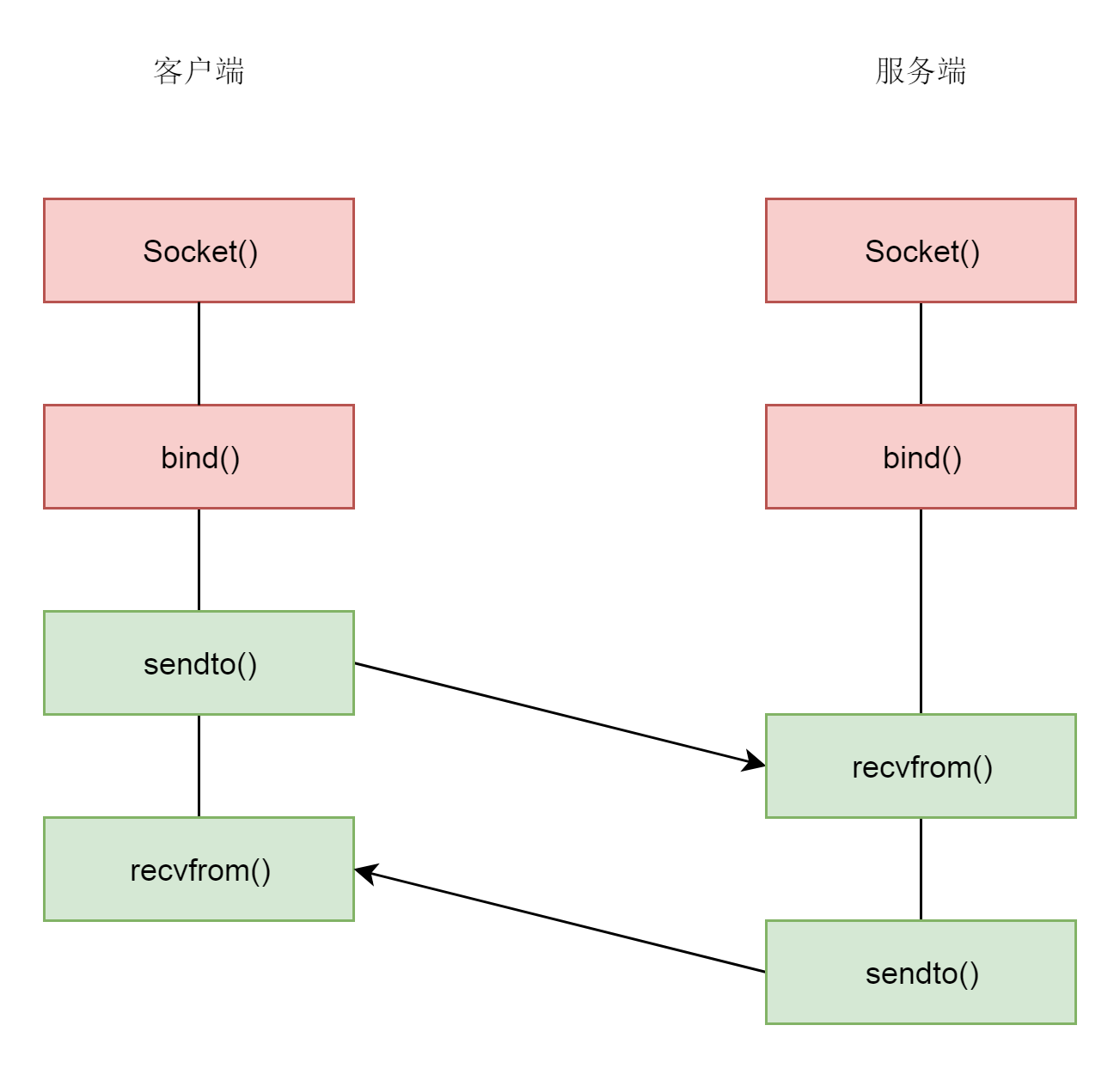
UDP是没有连接的,所以不需要三次握手,也就不需要调用listen和connect,但是UDP的交互仍然需要IP地址和端口号,因而也需要bind。
对于UDP来讲,没有所谓的连接维护,也没有所谓的连接的发起方和接收方,甚至都不存在客户端和服务端的概念,大家就都是客户端,也同时都是服务端。只要有一个socket,多台机器就可以任意通信,不存在哪两台机器是属于一个连接的概念。因此,每一个UDP的socket都需要bind。每次通信时,调用sendto和recvfrom,都要传入IP地址和端口。
ssize_t sendto(int sockfd, const void *buf, size_t len, int flags, const struct sockaddr *dest_addr, socklen_t addrlen);
ssize_t recvfrom(int sockfd, void *buf, size_t len, int flags, struct sockaddr *src_addr, socklen_t *addrlen);39.3 总结
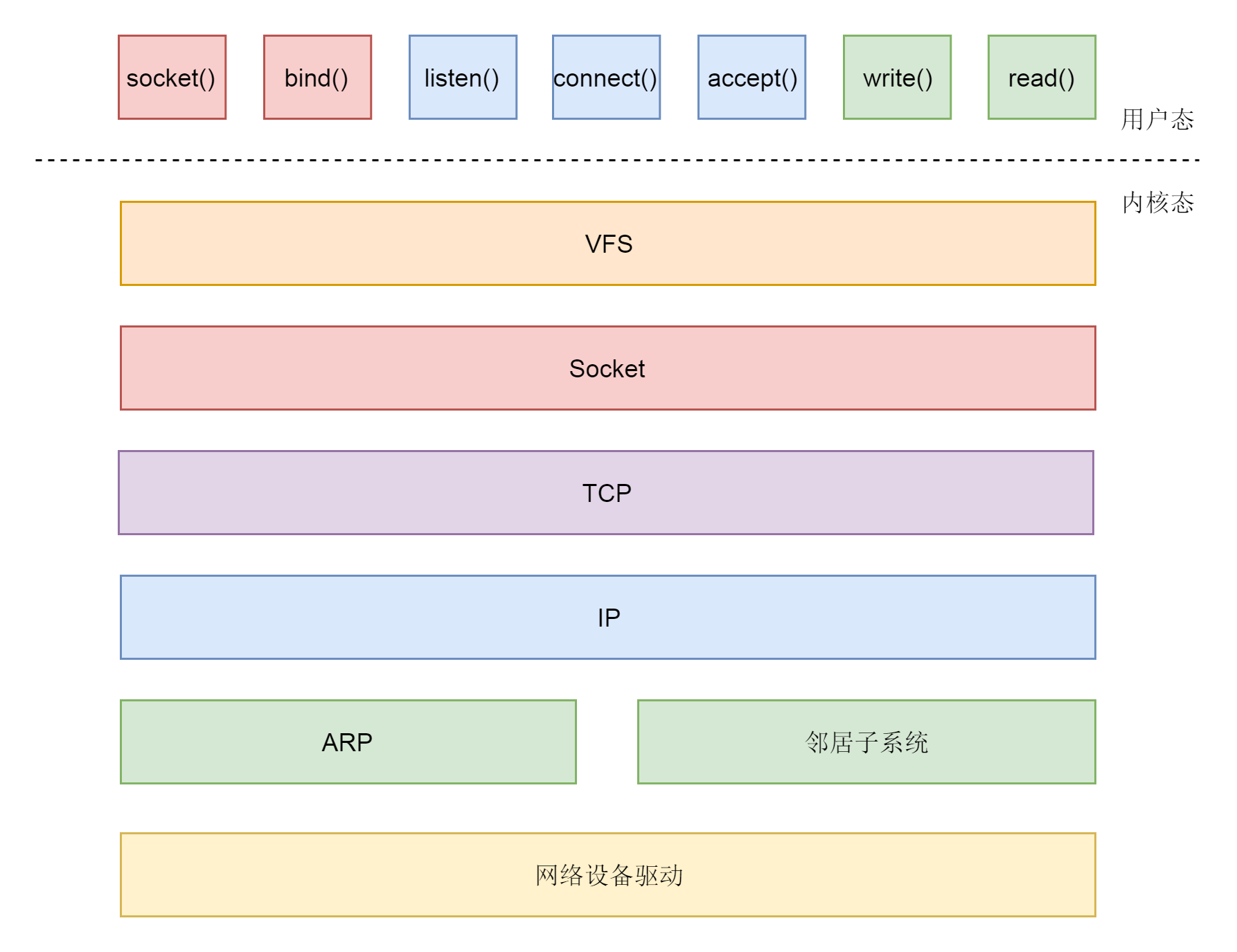
socket系统调用是用户态和内核态的接口,网络协议的四层以下都是在内核中的。
TCP协议的socket调用的过程:
- 服务端和客户端都调用socket,得到文件描述符;
- 服务端调用listen,进行监听;
- 服务端调用accept,等待客户端连接;
- 客户端调用connect,连接服务端;
- 服务端accept返回用于传输的socket的文件描述符;
- 客户端调用write写入数据;
- 服务端调用read读取数据。
40. Socket内核数据结构
40.1 解析socket函数
SYSCALL_DEFINE3(socket, int, family, int, type, int, protocol)
{
int retval;
struct socket *sock;
int flags;
......
if (SOCK_NONBLOCK != O_NONBLOCK && (flags & SOCK_NONBLOCK))
flags = (flags & ~SOCK_NONBLOCK) | O_NONBLOCK;
retval = sock_create(family, type, protocol, &sock);
......
retval = sock_map_fd(sock, flags & (O_CLOEXEC | O_NONBLOCK));
......
return retval;
}这里面的代码比较容易看懂,Socket系统调用会调用sock_create创建一个struct socket结构,然后通过sock_map_fd和文件描述符对应起来。
在创建Socket的时候,有三个参数。
一个是family,表示地址族。不是所有的Socket都要通过IP进行通信,还有其他的通信方式。例如,下面的定义中,domain sockets就是通过本地文件进行通信的,不需要IP地址。只不过,通过IP地址只是最常用的模式,所以我们这里着重分析这种模式。
第二个参数是type,也即Socket的类型。类型是比较少的。
第三个参数是protocol,是协议。协议数目是比较多的,也就是说,多个协议会属于同一种类型。
常用的Socket类型有三种,分别是SOCK_STREAM、SOCK_DGRAM和SOCK_RAW。
enum sock_type {
SOCK_STREAM = 1,
SOCK_DGRAM = 2,
SOCK_RAW = 3,
......
}SOCK_STREAM是面向数据流的,协议IPPROTO_TCP属于这种类型。SOCK_DGRAM是面向数据报的,协议IPPROTO_UDP属于这种类型。如果在内核里面看的话,IPPROTO_ICMP也属于这种类型。SOCK_RAW是原始的IP包,IPPROTO_IP属于这种类型。
这一节,我们重点看SOCK_STREAM类型和IPPROTO_TCP协议。
为了管理family、type、protocol这三个分类层次,内核会创建对应的数据结构。
接下来,我们打开sock_create函数看一下。它会调用__sock_create。
int __sock_create(struct net *net, int family, int type, int protocol,
struct socket **res, int kern)
{
int err;
struct socket *sock;
const struct net_proto_family *pf;
......
sock = sock_alloc();
......
sock->type = type;
......
pf = rcu_dereference(net_families[family]);
......
err = pf->create(net, sock, protocol, kern);
......
*res = sock;
return 0;
}这里先是分配了一个struct socket结构。接下来我们要用到family参数。这里有一个net_families数组,我们可以以family参数为下标,找到对应的struct net_proto_family。
/* Supported address families. */
#define AF_UNSPEC 0
#define AF_UNIX 1 /* Unix domain sockets */
#define AF_LOCAL 1 /* POSIX name for AF_UNIX */
#define AF_INET 2 /* Internet IP Protocol */
......
#define AF_INET6 10 /* IP version 6 */
......
#define AF_MPLS 28 /* MPLS */
......
#define AF_MAX 44 /* For now.. */
#define NPROTO AF_MAX
struct net_proto_family __rcu *net_families[NPROTO] __read_mostly;我们可以找到net_families的定义。每一个地址族在这个数组里面都有一项,里面的内容是net_proto_family。每一种地址族都有自己的net_proto_family,IP地址族的net_proto_family定义如下,里面最重要的就是,create函数指向inet_create。
//net/ipv4/af_inet.c
static const struct net_proto_family inet_family_ops = {
.family = PF_INET,
.create = inet_create,//这个用于socket系统调用创建
......
}我们回到函数__sock_create。接下来,在这里面,这个inet_create会被调用。
static int inet_create(struct net *net, struct socket *sock, int protocol, int kern)
{
struct sock *sk;
struct inet_protosw *answer;
struct inet_sock *inet;
struct proto *answer_prot;
unsigned char answer_flags;
int try_loading_module = 0;
int err;
/* Look for the requested type/protocol pair. */
lookup_protocol:
list_for_each_entry_rcu(answer, &inetsw[sock->type], list) {
err = 0;
/* Check the non-wild match. */
if (protocol == answer->protocol) {
if (protocol != IPPROTO_IP)
break;
} else {
/* Check for the two wild cases. */
if (IPPROTO_IP == protocol) {
protocol = answer->protocol;
break;
}
if (IPPROTO_IP == answer->protocol)
break;
}
err = -EPROTONOSUPPORT;
}
......
sock->ops = answer->ops;
answer_prot = answer->prot;
answer_flags = answer->flags;
......
sk = sk_alloc(net, PF_INET, GFP_KERNEL, answer_prot, kern);
......
inet = inet_sk(sk);
inet->nodefrag = 0;
if (SOCK_RAW == sock->type) {
inet->inet_num = protocol;
if (IPPROTO_RAW == protocol)
inet->hdrincl = 1;
}
inet->inet_id = 0;
sock_init_data(sock, sk);
sk->sk_destruct = inet_sock_destruct;
sk->sk_protocol = protocol;
sk->sk_backlog_rcv = sk->sk_prot->backlog_rcv;
inet->uc_ttl = -1;
inet->mc_loop = 1;
inet->mc_ttl = 1;
inet->mc_all = 1;
inet->mc_index = 0;
inet->mc_list = NULL;
inet->rcv_tos = 0;
if (inet->inet_num) {
inet->inet_sport = htons(inet->inet_num);
/* Add to protocol hash chains. */
err = sk->sk_prot->hash(sk);
}
if (sk->sk_prot->init) {
err = sk->sk_prot->init(sk);
}
......
}在inet_create中,我们先会看到一个循环list_for_each_entry_rcu。在这里,第二个参数type开始起作用。因为循环查看的是inetsw[sock->type]。
这里的inetsw也是一个数组,type作为下标,里面的内容是struct inet_protosw,是协议,也即inetsw数组对于每个类型有一项,这一项里面是属于这个类型的协议。
static struct list_head inetsw[SOCK_MAX];
static int __init inet_init(void)
{
......
/* Register the socket-side information for inet_create. */
for (r = &inetsw[0]; r < &inetsw[SOCK_MAX]; ++r)
INIT_LIST_HEAD(r);
for (q = inetsw_array; q < &inetsw_array[INETSW_ARRAY_LEN]; ++q)
inet_register_protosw(q);
......
}inetsw数组是在系统初始化的时候初始化的,就像下面代码里面实现的一样。
首先,一个循环会将inetsw数组的每一项,都初始化为一个链表。咱们前面说了,一个type类型会包含多个protocol,因而我们需要一个链表。接下来一个循环,是将inetsw_array注册到inetsw数组里面去。inetsw_array的定义如下,这个数组里面的内容很重要,后面会用到它们。
static struct inet_protosw inetsw_array[] =
{
{
.type = SOCK_STREAM,
.protocol = IPPROTO_TCP,
.prot = &tcp_prot,
.ops = &inet_stream_ops,
.flags = INET_PROTOSW_PERMANENT |
INET_PROTOSW_ICSK,
},
{
.type = SOCK_DGRAM,
.protocol = IPPROTO_UDP,
.prot = &udp_prot,
.ops = &inet_dgram_ops,
.flags = INET_PROTOSW_PERMANENT,
},
{
.type = SOCK_DGRAM,
.protocol = IPPROTO_ICMP,
.prot = &ping_prot,
.ops = &inet_sockraw_ops,
.flags = INET_PROTOSW_REUSE,
},
{
.type = SOCK_RAW,
.protocol = IPPROTO_IP, /* wild card */
.prot = &raw_prot,
.ops = &inet_sockraw_ops,
.flags = INET_PROTOSW_REUSE,
}
}我们回到inet_create的list_for_each_entry_rcu循环中。到这里就好理解了,这是在inetsw数组中,根据type找到属于这个类型的列表,然后依次比较列表中的struct inet_protosw的protocol是不是用户指定的protocol;如果是,就得到了符合用户指定的family->type->protocol的struct inet_protosw *answer对象。
接下来,struct socket *sock的ops成员变量,被赋值为answer的ops。对于TCP来讲,就是inet_stream_ops。后面任何用户对于这个socket的操作,都是通过inet_stream_ops进行的。
接下来,我们创建一个struct sock *sk对象。这里比较让人困惑。socket和sock看起来几乎一样,容易让人混淆,这里需要说明一下,socket是用于负责对上给用户提供接口,并且和文件系统关联。而sock,负责向下对接内核网络协议栈。
在sk_alloc函数中,struct inet_protosw *answer结构的tcp_prot赋值给了struct sock *sk的sk_prot成员。tcp_prot的定义如下,里面定义了很多的函数,都是sock之下内核协议栈的动作。
struct proto tcp_prot = {
.name = "TCP",
.owner = THIS_MODULE,
.close = tcp_close,
.connect = tcp_v4_connect,
.disconnect = tcp_disconnect,
.accept = inet_csk_accept,
.ioctl = tcp_ioctl,
.init = tcp_v4_init_sock,
.destroy = tcp_v4_destroy_sock,
.shutdown = tcp_shutdown,
.setsockopt = tcp_setsockopt,
.getsockopt = tcp_getsockopt,
.keepalive = tcp_set_keepalive,
.recvmsg = tcp_recvmsg,
.sendmsg = tcp_sendmsg,
.sendpage = tcp_sendpage,
.backlog_rcv = tcp_v4_do_rcv,
.release_cb = tcp_release_cb,
.hash = inet_hash,
.get_port = inet_csk_get_port,
......
}在inet_create函数中,接下来创建一个struct inet_sock结构,这个结构一开始就是struct sock,然后扩展了一些其他的信息,剩下的代码就填充这些信息。这一幕我们会经常看到,将一个结构放在另一个结构的开始位置,然后扩展一些成员,通过对于指针的强制类型转换,来访问这些成员。
socket的创建至此结束。
40.2 解析bind函数
SYSCALL_DEFINE3(bind, int, fd, struct sockaddr __user *, umyaddr, int, addrlen)
{
struct socket *sock;
struct sockaddr_storage address;
int err, fput_needed;
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (sock) {
err = move_addr_to_kernel(umyaddr, addrlen, &address);
if (err >= 0) {
err = sock->ops->bind(sock,
(struct sockaddr *)
&address, addrlen);
}
fput_light(sock->file, fput_needed);
}
return err;
}在bind中,sockfd_lookup_light会根据fd文件描述符,找到struct socket结构。然后将sockaddr从用户态拷贝到内核态,然后调用struct socket结构里面ops的bind函数。根据前面创建socket的时候的设定,调用的是inet_stream_ops的bind函数,也即调用inet_bind。
int inet_bind(struct socket *sock, struct sockaddr *uaddr, int addr_len)
{
struct sockaddr_in *addr = (struct sockaddr_in *)uaddr;
struct sock *sk = sock->sk;
struct inet_sock *inet = inet_sk(sk);
struct net *net = sock_net(sk);
unsigned short snum;
......
snum = ntohs(addr->sin_port);
......
inet->inet_rcv_saddr = inet->inet_saddr = addr->sin_addr.s_addr;
/* Make sure we are allowed to bind here. */
if ((snum || !inet->bind_address_no_port) &&
sk->sk_prot->get_port(sk, snum)) {
......
}
inet->inet_sport = htons(inet->inet_num);
inet->inet_daddr = 0;
inet->inet_dport = 0;
sk_dst_reset(sk);
}bind里面会调用sk_prot的get_port函数,也即inet_csk_get_port来检查端口是否冲突,是否可以绑定。如果允许,则会设置struct inet_sock的本方的地址inet_saddr和本方的端口inet_sport,对方的地址inet_daddr和对方的端口inet_dport都初始化为0。
bind的逻辑相对比较简单,就到这里了。
40.3 解析listen函数
SYSCALL_DEFINE2(listen, int, fd, int, backlog)
{
struct socket *sock;
int err, fput_needed;
int somaxconn;
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (sock) {
somaxconn = sock_net(sock->sk)->core.sysctl_somaxconn;
if ((unsigned int)backlog > somaxconn)
backlog = somaxconn;
err = sock->ops->listen(sock, backlog);
fput_light(sock->file, fput_needed);
}
return err;
}在listen中,我们还是通过sockfd_lookup_light,根据fd文件描述符,找到struct socket结构。接着,我们调用struct socket结构里面ops的listen函数。根据前面创建socket的时候的设定,调用的是inet_stream_ops的listen函数,也即调用inet_listen。
int inet_listen(struct socket *sock, int backlog)
{
struct sock *sk = sock->sk;
unsigned char old_state;
int err;
old_state = sk->sk_state;
/* Really, if the socket is already in listen state
* we can only allow the backlog to be adjusted.
*/
if (old_state != TCP_LISTEN) {
err = inet_csk_listen_start(sk, backlog);
}
sk->sk_max_ack_backlog = backlog;
}如果这个socket还不在TCP_LISTEN状态,会调用inet_csk_listen_start进入监听状态。
int inet_csk_listen_start(struct sock *sk, int backlog)
{
struct inet_connection_sock *icsk = inet_csk(sk);
struct inet_sock *inet = inet_sk(sk);
int err = -EADDRINUSE;
reqsk_queue_alloc(&icsk->icsk_accept_queue);
sk->sk_max_ack_backlog = backlog;
sk->sk_ack_backlog = 0;
inet_csk_delack_init(sk);
sk_state_store(sk, TCP_LISTEN);
if (!sk->sk_prot->get_port(sk, inet->inet_num)) {
......
}
......
}这里面建立了一个新的结构inet_connection_sock,这个结构一开始是struct inet_sock,inet_csk其实做了一次强制类型转换,扩大了结构,看到了吧,又是这个套路。
struct inet_connection_sock结构比较复杂。如果打开它,你能看到处于各种状态的队列,各种超时时间、拥塞控制等字眼。我们说TCP是面向连接的,就是客户端和服务端都是有一个结构维护连接的状态,就是指这个结构。我们这里先不详细分析里面的变量,因为太多了,后面我们遇到一个分析一个。
首先,我们遇到的是icsk_accept_queue。它是干什么的呢?
在TCP的状态里面,有一个listen状态,当调用listen函数之后,就会进入这个状态,虽然我们写程序的时候,一般要等待服务端调用accept后,等待在哪里的时候,让客户端就发起连接。其实服务端一旦处于listen状态,不用accept,客户端也能发起连接。其实TCP的状态中,没有一个是否被accept的状态,那accept函数的作用是什么呢?
在内核中,为每个Socket维护两个队列。一个是已经建立了连接的队列,这时候连接三次握手已经完毕,处于established状态;一个是还没有完全建立连接的队列,这个时候三次握手还没完成,处于syn_rcvd的状态。
服务端调用accept函数,其实是在第一个队列中拿出一个已经完成的连接进行处理。如果还没有完成就阻塞等待。这里的icsk_accept_queue就是第一个队列。
初始化完之后,将TCP的状态设置为TCP_LISTEN,再次调用get_port判断端口是否冲突。
至此,listen的逻辑就结束了。
40.4 解析accept函数
SYSCALL_DEFINE3(accept, int, fd, struct sockaddr __user *, upeer_sockaddr,
int __user *, upeer_addrlen)
{
return sys_accept4(fd, upeer_sockaddr, upeer_addrlen, 0);
}
SYSCALL_DEFINE4(accept4, int, fd, struct sockaddr __user *, upeer_sockaddr,
int __user *, upeer_addrlen, int, flags)
{
struct socket *sock, *newsock;
struct file *newfile;
int err, len, newfd, fput_needed;
struct sockaddr_storage address;
......
sock = sockfd_lookup_light(fd, &err, &fput_needed);
newsock = sock_alloc();
newsock->type = sock->type;
newsock->ops = sock->ops;
newfd = get_unused_fd_flags(flags);
newfile = sock_alloc_file(newsock, flags, sock->sk->sk_prot_creator->name);
err = sock->ops->accept(sock, newsock, sock->file->f_flags, false);
if (upeer_sockaddr) {
if (newsock->ops->getname(newsock, (struct sockaddr *)&address, &len, 2) < 0) {
}
err = move_addr_to_user(&address,
len, upeer_sockaddr, upeer_addrlen);
}
fd_install(newfd, newfile);
......
}accept函数的实现,印证了socket的原理中说的那样,原来的socket是监听socket,这里我们会找到原来的struct socket,并基于它去创建一个新的newsock。这才是连接socket。除此之外,我们还会创建一个新的struct file和fd,并关联到socket。
这里面还会调用struct socket的sock->ops->accept,也即会调用inet_stream_ops的accept函数,也即inet_accept。
int inet_accept(struct socket *sock, struct socket *newsock, int flags, bool kern)
{
struct sock *sk1 = sock->sk;
int err = -EINVAL;
struct sock *sk2 = sk1->sk_prot->accept(sk1, flags, &err, kern);
sock_rps_record_flow(sk2);
sock_graft(sk2, newsock);
newsock->state = SS_CONNECTED;
}inet_accept会调用struct sock的sk1->sk_prot->accept,也即tcp_prot的accept函数,inet_csk_accept函数。
/*
* This will accept the next outstanding connection.
*/
struct sock *inet_csk_accept(struct sock *sk, int flags, int *err, bool kern)
{
struct inet_connection_sock *icsk = inet_csk(sk);
struct request_sock_queue *queue = &icsk->icsk_accept_queue;
struct request_sock *req;
struct sock *newsk;
int error;
if (sk->sk_state != TCP_LISTEN)
goto out_err;
/* Find already established connection */
if (reqsk_queue_empty(queue)) {
long timeo = sock_rcvtimeo(sk, flags & O_NONBLOCK);
error = inet_csk_wait_for_connect(sk, timeo);
}
req = reqsk_queue_remove(queue, sk);
newsk = req->sk;
......
}
/*
* Wait for an incoming connection, avoid race conditions. This must be called
* with the socket locked.
*/
static int inet_csk_wait_for_connect(struct sock *sk, long timeo)
{
struct inet_connection_sock *icsk = inet_csk(sk);
DEFINE_WAIT(wait);
int err;
for (;;) {
prepare_to_wait_exclusive(sk_sleep(sk), &wait,
TASK_INTERRUPTIBLE);
release_sock(sk);
if (reqsk_queue_empty(&icsk->icsk_accept_queue))
timeo = schedule_timeout(timeo);
sched_annotate_sleep();
lock_sock(sk);
err = 0;
if (!reqsk_queue_empty(&icsk->icsk_accept_queue))
break;
err = -EINVAL;
if (sk->sk_state != TCP_LISTEN)
break;
err = sock_intr_errno(timeo);
if (signal_pending(current))
break;
err = -EAGAIN;
if (!timeo)
break;
}
finish_wait(sk_sleep(sk), &wait);
return err;
}inet_csk_accept的实现,印证了上面我们讲的两个队列的逻辑。如果icsk_accept_queue为空,则调用inet_csk_wait_for_connect进行等待;等待的时候,调用schedule_timeout,让出CPU,并且将进程状态设置为TASK_INTERRUPTIBLE。
如果再次CPU醒来,我们会接着判断icsk_accept_queue是否为空,同时也会调用signal_pending看有没有信号可以处理。一旦icsk_accept_queue不为空,就从inet_csk_wait_for_connect中返回,在队列中取出一个struct sock对象赋值给newsk。
40.5 解析connect函数
什么情况下,icsk_accept_queue才不为空呢?当然是三次握手结束才可以。接下来我们来分析三次握手的过程。
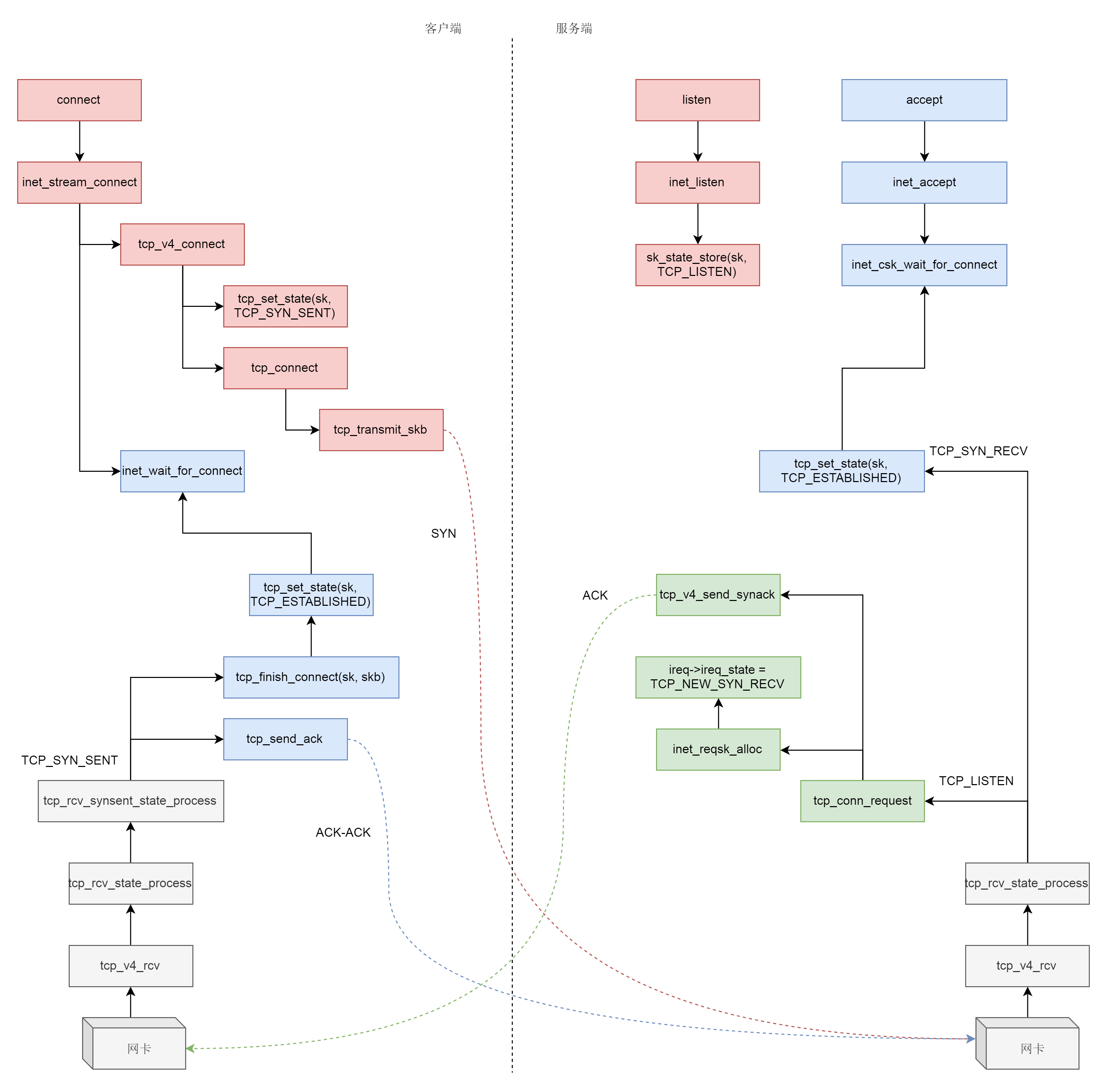
三次握手一般是由客户端调用connect发起。
SYSCALL_DEFINE3(connect, int, fd, struct sockaddr __user *, uservaddr,
int, addrlen)
{
struct socket *sock;
struct sockaddr_storage address;
int err, fput_needed;
sock = sockfd_lookup_light(fd, &err, &fput_needed);
err = move_addr_to_kernel(uservaddr, addrlen, &address);
err = sock->ops->connect(sock, (struct sockaddr *)&address, addrlen, sock->file->f_flags);
}connect函数的实现一开始你应该很眼熟,还是通过sockfd_lookup_light,根据fd文件描述符,找到struct socket结构。接着,我们会调用struct socket结构里面ops的connect函数,根据前面创建socket的时候的设定,调用inet_stream_ops的connect函数,也即调用inet_stream_connect。
/*
* Connect to a remote host. There is regrettably still a little
* TCP 'magic' in here.
*/
int __inet_stream_connect(struct socket *sock, struct sockaddr *uaddr,
int addr_len, int flags, int is_sendmsg)
{
struct sock *sk = sock->sk;
int err;
long timeo;
switch (sock->state) {
......
case SS_UNCONNECTED:
err = -EISCONN;
if (sk->sk_state != TCP_CLOSE)
goto out;
err = sk->sk_prot->connect(sk, uaddr, addr_len);
sock->state = SS_CONNECTING;
break;
}
timeo = sock_sndtimeo(sk, flags & O_NONBLOCK);
if ((1 << sk->sk_state) & (TCPF_SYN_SENT | TCPF_SYN_RECV)) {
......
if (!timeo || !inet_wait_for_connect(sk, timeo, writebias))
goto out;
err = sock_intr_errno(timeo);
if (signal_pending(current))
goto out;
}
sock->state = SS_CONNECTED;
}在__inet_stream_connect里面,我们发现,如果socket处于SS_UNCONNECTED状态,那就调用struct sock的sk->sk_prot->connect,也即tcp_prot的connect函数——tcp_v4_connect函数。
int tcp_v4_connect(struct sock *sk, struct sockaddr *uaddr, int addr_len)
{
struct sockaddr_in *usin = (struct sockaddr_in *)uaddr;
struct inet_sock *inet = inet_sk(sk);
struct tcp_sock *tp = tcp_sk(sk);
__be16 orig_sport, orig_dport;
__be32 daddr, nexthop;
struct flowi4 *fl4;
struct rtable *rt;
......
orig_sport = inet->inet_sport;
orig_dport = usin->sin_port;
rt = ip_route_connect(fl4, nexthop, inet->inet_saddr,
RT_CONN_FLAGS(sk), sk->sk_bound_dev_if,
IPPROTO_TCP,
orig_sport, orig_dport, sk);
......
tcp_set_state(sk, TCP_SYN_SENT);
err = inet_hash_connect(tcp_death_row, sk);
sk_set_txhash(sk);
rt = ip_route_newports(fl4, rt, orig_sport, orig_dport,
inet->inet_sport, inet->inet_dport, sk);
/* OK, now commit destination to socket. */
sk->sk_gso_type = SKB_GSO_TCPV4;
sk_setup_caps(sk, &rt->dst);
if (likely(!tp->repair)) {
if (!tp->write_seq)
tp->write_seq = secure_tcp_seq(inet->inet_saddr,
inet->inet_daddr,
inet->inet_sport,
usin->sin_port);
tp->tsoffset = secure_tcp_ts_off(sock_net(sk),
inet->inet_saddr,
inet->inet_daddr);
}
rt = NULL;
......
err = tcp_connect(sk);
......
}在tcp_v4_connect函数中,ip_route_connect其实是做一个路由的选择。为什么呢?因为三次握手马上就要发送一个SYN包了,这就要凑齐源地址、源端口、目标地址、目标端口。目标地址和目标端口是服务端的,已经知道源端口是客户端随机分配的,源地址应该用哪一个呢?这时候要选择一条路由,看从哪个网卡出去,就应该填写哪个网卡的IP地址。
接下来,在发送SYN之前,我们先将客户端socket的状态设置为TCP_SYN_SENT。然后初始化TCP的seq num,也即write_seq,然后调用tcp_connect进行发送。
/* Build a SYN and send it off. */
int tcp_connect(struct sock *sk)
{
struct tcp_sock *tp = tcp_sk(sk);
struct sk_buff *buff;
int err;
......
tcp_connect_init(sk);
......
buff = sk_stream_alloc_skb(sk, 0, sk->sk_allocation, true);
......
tcp_init_nondata_skb(buff, tp->write_seq++, TCPHDR_SYN);
tcp_mstamp_refresh(tp);
tp->retrans_stamp = tcp_time_stamp(tp);
tcp_connect_queue_skb(sk, buff);
tcp_ecn_send_syn(sk, buff);
/* Send off SYN; include data in Fast Open. */
err = tp->fastopen_req ? tcp_send_syn_data(sk, buff) :
tcp_transmit_skb(sk, buff, 1, sk->sk_allocation);
......
tp->snd_nxt = tp->write_seq;
tp->pushed_seq = tp->write_seq;
buff = tcp_send_head(sk);
if (unlikely(buff)) {
tp->snd_nxt = TCP_SKB_CB(buff)->seq;
tp->pushed_seq = TCP_SKB_CB(buff)->seq;
}
......
/* Timer for repeating the SYN until an answer. */
inet_csk_reset_xmit_timer(sk, ICSK_TIME_RETRANS,
inet_csk(sk)->icsk_rto, TCP_RTO_MAX);
return 0;
}在tcp_connect中,有一个新的结构struct tcp_sock,如果打开他,你会发现他是struct inet_connection_sock的一个扩展,struct inet_connection_sock在struct tcp_sock开头的位置,通过强制类型转换访问,故伎重演又一次。
struct tcp_sock里面维护了更多的TCP的状态,咱们同样是遇到了再分析。
接下来tcp_init_nondata_skb初始化一个SYN包,tcp_transmit_skb将SYN包发送出去,inet_csk_reset_xmit_timer设置了一个timer,如果SYN发送不成功,则再次发送。
发送网络包的过程,我们放到下一节讲解。这里我们姑且认为SYN已经发送出去了。
我们回到__inet_stream_connect函数,在调用sk->sk_prot->connect之后,inet_wait_for_connect会一直等待客户端收到服务端的ACK。而我们知道,服务端在accept之后,也是在等待中。
网络包是如何接收的呢?对于解析的详细过程,我们会在下下节讲解,这里为了解析三次握手,我们简单的看网络包接收到TCP层做的部分事情。
static struct net_protocol tcp_protocol = {
.early_demux = tcp_v4_early_demux,
.early_demux_handler = tcp_v4_early_demux,
.handler = tcp_v4_rcv,
.err_handler = tcp_v4_err,
.no_policy = 1,
.netns_ok = 1,
.icmp_strict_tag_validation = 1,
}我们通过struct net_protocol结构中的handler进行接收,调用的函数是tcp_v4_rcv。接下来的调用链为tcp_v4_rcv->tcp_v4_do_rcv->tcp_rcv_state_process。tcp_rcv_state_process,顾名思义,是用来处理接收一个网络包后引起状态变化的。
int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb)
{
struct tcp_sock *tp = tcp_sk(sk);
struct inet_connection_sock *icsk = inet_csk(sk);
const struct tcphdr *th = tcp_hdr(skb);
struct request_sock *req;
int queued = 0;
bool acceptable;
switch (sk->sk_state) {
......
case TCP_LISTEN:
......
if (th->syn) {
acceptable = icsk->icsk_af_ops->conn_request(sk, skb) >= 0;
if (!acceptable)
return 1;
consume_skb(skb);
return 0;
}
......
}目前服务端是处于TCP_LISTEN状态的,而且发过来的包是SYN,因而就有了上面的代码,调用icsk->icsk_af_ops->conn_request函数。struct inet_connection_sock对应的操作是inet_connection_sock_af_ops,按照下面的定义,其实调用的是tcp_v4_conn_request。
const struct inet_connection_sock_af_ops ipv4_specific = {
.queue_xmit = ip_queue_xmit,
.send_check = tcp_v4_send_check,
.rebuild_header = inet_sk_rebuild_header,
.sk_rx_dst_set = inet_sk_rx_dst_set,
.conn_request = tcp_v4_conn_request,
.syn_recv_sock = tcp_v4_syn_recv_sock,
.net_header_len = sizeof(struct iphdr),
.setsockopt = ip_setsockopt,
.getsockopt = ip_getsockopt,
.addr2sockaddr = inet_csk_addr2sockaddr,
.sockaddr_len = sizeof(struct sockaddr_in),
.mtu_reduced = tcp_v4_mtu_reduced,
};tcp_v4_conn_request会调用tcp_conn_request,这个函数也比较长,里面调用了send_synack,但实际调用的是tcp_v4_send_synack。具体发送的过程我们不去管它,看注释我们能知道,这是收到了SYN后,回复一个SYN-ACK,回复完毕后,服务端处于TCP_SYN_RECV。
int tcp_conn_request(struct request_sock_ops *rsk_ops,
const struct tcp_request_sock_ops *af_ops,
struct sock *sk, struct sk_buff *skb)
{
......
af_ops->send_synack(sk, dst, &fl, req, &foc,
!want_cookie ? TCP_SYNACK_NORMAL :
TCP_SYNACK_COOKIE);
......
}
/*
* Send a SYN-ACK after having received a SYN.
*/
static int tcp_v4_send_synack(const struct sock *sk, struct dst_entry *dst,
struct flowi *fl,
struct request_sock *req,
struct tcp_fastopen_cookie *foc,
enum tcp_synack_type synack_type)
{......}这个时候,轮到客户端接收网络包了。都是TCP协议栈,所以过程和服务端没有太多区别,还是会走到tcp_rcv_state_process函数的,只不过由于客户端目前处于TCP_SYN_SENT状态,就进入了下面的代码分支。
int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb)
{
struct tcp_sock *tp = tcp_sk(sk);
struct inet_connection_sock *icsk = inet_csk(sk);
const struct tcphdr *th = tcp_hdr(skb);
struct request_sock *req;
int queued = 0;
bool acceptable;
switch (sk->sk_state) {
......
case TCP_SYN_SENT:
tp->rx_opt.saw_tstamp = 0;
tcp_mstamp_refresh(tp);
queued = tcp_rcv_synsent_state_process(sk, skb, th);
if (queued >= 0)
return queued;
/* Do step6 onward by hand. */
tcp_urg(sk, skb, th);
__kfree_skb(skb);
tcp_data_snd_check(sk);
return 0;
}
......
}tcp_rcv_synsent_state_process会调用tcp_send_ack,发送一个ACK-ACK,发送后客户端处于TCP_ESTABLISHED状态。
又轮到服务端接收网络包了,我们还是归tcp_rcv_state_process函数处理。由于服务端目前处于状态TCP_SYN_RECV状态,因而又走了另外的分支。当收到这个网络包的时候,服务端也处于TCP_ESTABLISHED状态,三次握手结束。
int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb)
{
struct tcp_sock *tp = tcp_sk(sk);
struct inet_connection_sock *icsk = inet_csk(sk);
const struct tcphdr *th = tcp_hdr(skb);
struct request_sock *req;
int queued = 0;
bool acceptable;
......
switch (sk->sk_state) {
case TCP_SYN_RECV:
if (req) {
inet_csk(sk)->icsk_retransmits = 0;
reqsk_fastopen_remove(sk, req, false);
} else {
/* Make sure socket is routed, for correct metrics. */
icsk->icsk_af_ops->rebuild_header(sk);
tcp_call_bpf(sk, BPF_SOCK_OPS_PASSIVE_ESTABLISHED_CB);
tcp_init_congestion_control(sk);
tcp_mtup_init(sk);
tp->copied_seq = tp->rcv_nxt;
tcp_init_buffer_space(sk);
}
smp_mb();
tcp_set_state(sk, TCP_ESTABLISHED);
sk->sk_state_change(sk);
if (sk->sk_socket)
sk_wake_async(sk, SOCK_WAKE_IO, POLL_OUT);
tp->snd_una = TCP_SKB_CB(skb)->ack_seq;
tp->snd_wnd = ntohs(th->window) << tp->rx_opt.snd_wscale;
tcp_init_wl(tp, TCP_SKB_CB(skb)->seq);
break;
......
}40.6 总结
这一节除了网络包的接收和发送,其他的系统调用我们都分析到了。可以看出来,它们有一个统一的数据结构和流程。具体如下图所示:
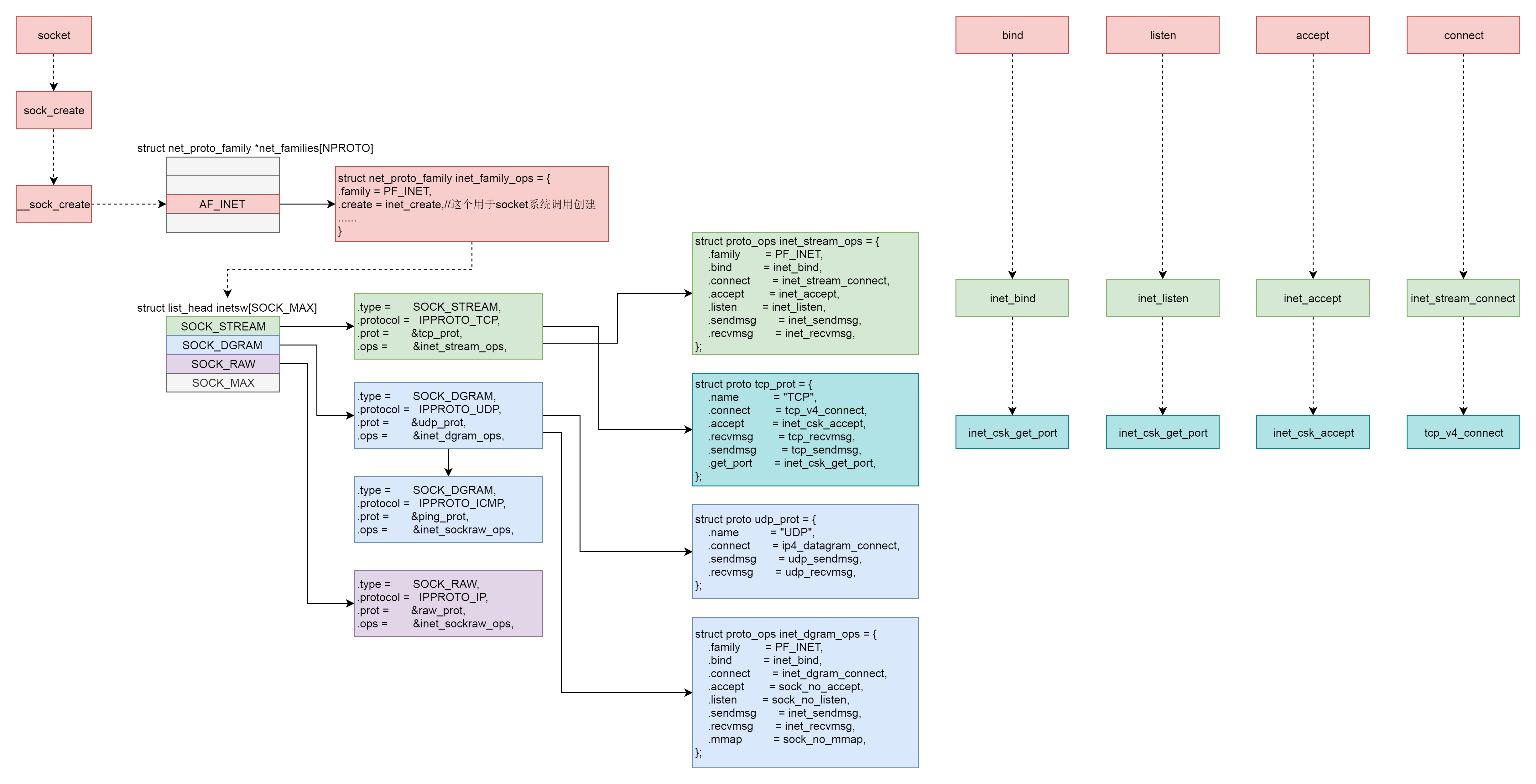
首先,Socket系统调用会有三级参数family、type、protocal,通过这三级参数,分别在net_proto_family表中找到type链表,在type链表中找到protocal对应的操作。这个操作分为两层,对于TCP协议来讲,第一层是inet_stream_ops层,第二层是tcp_prot层。
于是,接下来的系统调用规律就都一样了:
- bind第一层调用inet_stream_ops的inet_bind函数,第二层调用tcp_prot的inet_csk_get_port函数;
- listen第一层调用inet_stream_ops的inet_listen函数,第二层调用tcp_prot的inet_csk_get_port函数;
- accept第一层调用inet_stream_ops的inet_accept函数,第二层调用tcp_prot的inet_csk_accept函数;
- connect第一层调用inet_stream_ops的inet_stream_connect函数,第二层调用tcp_prot的tcp_v4_connect函数。
41. 发送网络包(上)
分析发送一个网络包的过程。
41.1 解析socket的Write操作
socket对于用户来讲,是一个文件一样的存在,拥有一个文件描述符。因而对于网络包的发送,我们可以使用对于socket文件的写入系统调用,也就是write系统调用。
write系统调用对于一个文件描述符的操作,大致过程都是类似的。在文件系统那一节,我们已经详细解析过,这里不再多说。对于每一个打开的文件都有一个struct file结构,write系统调用会最终调用stuct file结构指向的file_operations操作。
对于socket来讲,它的file_operations定义如下:
static const struct file_operations socket_file_ops = {
.owner = THIS_MODULE,
.llseek = no_llseek,
.read_iter = sock_read_iter,
.write_iter = sock_write_iter,
.poll = sock_poll,
.unlocked_ioctl = sock_ioctl,
.mmap = sock_mmap,
.release = sock_close,
.fasync = sock_fasync,
.sendpage = sock_sendpage,
.splice_write = generic_splice_sendpage,
.splice_read = sock_splice_read,
};按照文件系统的写入流程,调用的是sock_write_iter。
static ssize_t sock_write_iter(struct kiocb *iocb, struct iov_iter *from)
{
struct file *file = iocb->ki_filp;
struct socket *sock = file->private_data;
struct msghdr msg = {.msg_iter = *from,
.msg_iocb = iocb};
ssize_t res;
......
res = sock_sendmsg(sock, &msg);
*from = msg.msg_iter;
return res;
}在sock_write_iter中,我们通过VFS中的struct file,将创建好的socket结构拿出来,然后调用sock_sendmsg。而sock_sendmsg会调用sock_sendmsg_nosec。
static inline int sock_sendmsg_nosec(struct socket *sock, struct msghdr *msg)
{
int ret = sock->ops->sendmsg(sock, msg, msg_data_left(msg));
......
}这里调用了socket的ops的sendmsg,我们在上一节已经遇到它好几次了。根据inet_stream_ops的定义,我们这里调用的是inet_sendmsg。
int inet_sendmsg(struct socket *sock, struct msghdr *msg, size_t size)
{
struct sock *sk = sock->sk;
......
return sk->sk_prot->sendmsg(sk, msg, size);
}这里面,从socket结构中,我们可以得到更底层的sock结构,然后调用sk_prot的sendmsg方法。这个我们同样在上一节遇到好几次了。
41.2 解析tcp_sendmsg函数
根据tcp_prot的定义,我们调用的是tcp_sendmsg。
int tcp_sendmsg(struct sock *sk, struct msghdr *msg, size_t size)
{
struct tcp_sock *tp = tcp_sk(sk);
struct sk_buff *skb;
int flags, err, copied = 0;
int mss_now = 0, size_goal, copied_syn = 0;
long timeo;
......
/* Ok commence sending. */
copied = 0;
restart:
mss_now = tcp_send_mss(sk, &size_goal, flags);
while (msg_data_left(msg)) {
int copy = 0;
int max = size_goal;
skb = tcp_write_queue_tail(sk);
if (tcp_send_head(sk)) {
if (skb->ip_summed == CHECKSUM_NONE)
max = mss_now;
copy = max - skb->len;
}
if (copy <= 0 || !tcp_skb_can_collapse_to(skb)) {
bool first_skb;
new_segment:
/* Allocate new segment. If the interface is SG,
* allocate skb fitting to single page.
*/
if (!sk_stream_memory_free(sk))
goto wait_for_sndbuf;
......
first_skb = skb_queue_empty(&sk->sk_write_queue);
skb = sk_stream_alloc_skb(sk,
select_size(sk, sg, first_skb),
sk->sk_allocation,
first_skb);
......
skb_entail(sk, skb);
copy = size_goal;
max = size_goal;
......
}
/* Try to append data to the end of skb. */
if (copy > msg_data_left(msg))
copy = msg_data_left(msg);
/* Where to copy to? */
if (skb_availroom(skb) > 0) {
/* We have some space in skb head. Superb! */
copy = min_t(int, copy, skb_availroom(skb));
err = skb_add_data_nocache(sk, skb, &msg->msg_iter, copy);
......
} else {
bool merge = true;
int i = skb_shinfo(skb)->nr_frags;
struct page_frag *pfrag = sk_page_frag(sk);
......
copy = min_t(int, copy, pfrag->size - pfrag->offset);
......
err = skb_copy_to_page_nocache(sk, &msg->msg_iter, skb,
pfrag->page,
pfrag->offset,
copy);
......
pfrag->offset += copy;
}
......
tp->write_seq += copy;
TCP_SKB_CB(skb)->end_seq += copy;
tcp_skb_pcount_set(skb, 0);
copied += copy;
if (!msg_data_left(msg)) {
if (unlikely(flags & MSG_EOR))
TCP_SKB_CB(skb)->eor = 1;
goto out;
}
if (skb->len < max || (flags & MSG_OOB) || unlikely(tp->repair))
continue;
if (forced_push(tp)) {
tcp_mark_push(tp, skb);
__tcp_push_pending_frames(sk, mss_now, TCP_NAGLE_PUSH);
} else if (skb == tcp_send_head(sk))
tcp_push_one(sk, mss_now);
continue;
......
}
......
}tcp_sendmsg的实现还是很复杂的,这里面做了这样几件事情。
msg是用户要写入的数据,这个数据要拷贝到内核协议栈里面去发送;在内核协议栈里面,网络包的数据都是由struct sk_buff维护的,因而第一件事情就是找到一个空闲的内存空间,将用户要写入的数据,拷贝到struct sk_buff的管辖范围内。而第二件事情就是发送struct sk_buff。
在tcp_sendmsg中,我们首先通过强制类型转换,将sock结构转换为struct tcp_sock,这个是维护TCP连接状态的重要数据结构。
接下来是tcp_sendmsg的第一件事情,把数据拷贝到struct sk_buff。
我们先声明一个变量copied,初始化为0,这表示拷贝了多少数据。紧接着是一个循环,while (msg_data_left(msg)),也即如果用户的数据没有发送完毕,就一直循环。循环里声明了一个copy变量,表示这次拷贝的数值,在循环的最后有copied += copy,将每次拷贝的数量都加起来。
我们这里只需要看一次循环做了哪些事情。
第一步,tcp_write_queue_tail从TCP写入队列sk_write_queue中拿出最后一个struct sk_buff,在这个写入队列中排满了要发送的struct sk_buff,为什么要拿最后一个呢?这里面只有最后一个,可能会因为上次用户给的数据太少,而没有填满。
第二步,tcp_send_mss会计算MSS,也即Max Segment Size。这是什么呢?这个意思是说,我们在网络上传输的网络包的大小是有限制的,而这个限制在最底层开始就有。
MTU(Maximum Transmission Unit,最大传输单元)是二层的一个定义。以以太网为例,MTU为1500个Byte,前面有6个Byte的目标MAC地址,6个Byte的源MAC地址,2个Byte的类型,后面有4个Byte的CRC校验,共1518个Byte。
在IP层,一个IP数据报在以太网中传输,如果它的长度大于该MTU值,就要进行分片传输。
在TCP层有个MSS(Maximum Segment Size,最大分段大小),等于MTU减去IP头,再减去TCP头。也就是,在不分片的情况下,TCP里面放的最大内容。
在这里,max是struct sk_buff的最大数据长度,skb->len是当前已经占用的skb的数据长度,相减得到当前skb的剩余数据空间。
第三步,如果copy小于0,说明最后一个struct sk_buff已经没地方存放了,需要调用sk_stream_alloc_skb,重新分配struct sk_buff,然后调用skb_entail,将新分配的sk_buff放到队列尾部。
struct sk_buff是存储网络包的重要的数据结构,在应用层数据包叫data,在TCP层我们称为segment,在IP层我们叫packet,在数据链路层称为frame。在struct sk_buff,首先是一个链表,将struct sk_buff结构串起来。
接下来,我们从headers_start开始,到headers_end结束,里面都是各层次的头的位置。这里面有二层的mac_header、三层的network_header和四层的transport_header。
struct sk_buff {
union {
struct {
/* These two members must be first. */
struct sk_buff *next;
struct sk_buff *prev;
......
};
struct rb_node rbnode; /* used in netem & tcp stack */
};
......
/* private: */
__u32 headers_start[0];
/* public: */
......
__u32 priority;
int skb_iif;
__u32 hash;
__be16 vlan_proto;
__u16 vlan_tci;
......
union {
__u32 mark;
__u32 reserved_tailroom;
};
union {
__be16 inner_protocol;
__u8 inner_ipproto;
};
__u16 inner_transport_header;
__u16 inner_network_header;
__u16 inner_mac_header;
__be16 protocol;
__u16 transport_header;
__u16 network_header;
__u16 mac_header;
/* private: */
__u32 headers_end[0];
/* public: */
/* These elements must be at the end, see alloc_skb() for details. */
sk_buff_data_t tail;
sk_buff_data_t end;
unsigned char *head,
*data;
unsigned int truesize;
refcount_t users;
};最后几项, head指向分配的内存块起始地址。data这个指针指向的位置是可变的。它有可能随着报文所处的层次而变动。当接收报文时,从网卡驱动开始,通过协议栈层层往上传送数据报,通过增加 skb->data 的值,来逐步剥离协议首部。而要发送报文时,各协议会创建 sk_buff{},在经过各下层协议时,通过减少 skb->data的值来增加协议首部。tail指向数据的结尾,end指向分配的内存块的结束地址。
要分配这样一个结构,sk_stream_alloc_skb会最终调用到__alloc_skb。在这个函数里面,除了分配一个sk_buff结构之外,还要分配sk_buff指向的数据区域。这段数据区域分为下面这几个部分。
第一部分是连续的数据区域。紧接着是第二部分,一个struct skb_shared_info结构。这个结构是对于网络包发送过程的一个优化,因为传输层之上就是应用层了。按照TCP的定义,应用层感受不到下面的网络层的IP包是一个个独立的包的存在的。反正就是一个流,往里写就是了,可能一下子写多了,超过了一个IP包的承载能力,就会出现上面MSS的定义,拆分成一个个的Segment放在一个个的IP包里面,也可能一次写一点,一次写一点,这样数据是分散的,在IP层还要通过内存拷贝合成一个IP包。
为了减少内存拷贝的代价,有的网络设备支持分散聚合(Scatter/Gather)I/O,顾名思义,就是IP层没必要通过内存拷贝进行聚合,让散的数据零散的放在原处,在设备层进行聚合。如果使用这种模式,网络包的数据就不会放在连续的数据区域,而是放在struct skb_shared_info结构里面指向的离散数据,skb_shared_info的成员变量skb_frag_t frags[MAX_SKB_FRAGS],会指向一个数组的页面,就不能保证连续了。
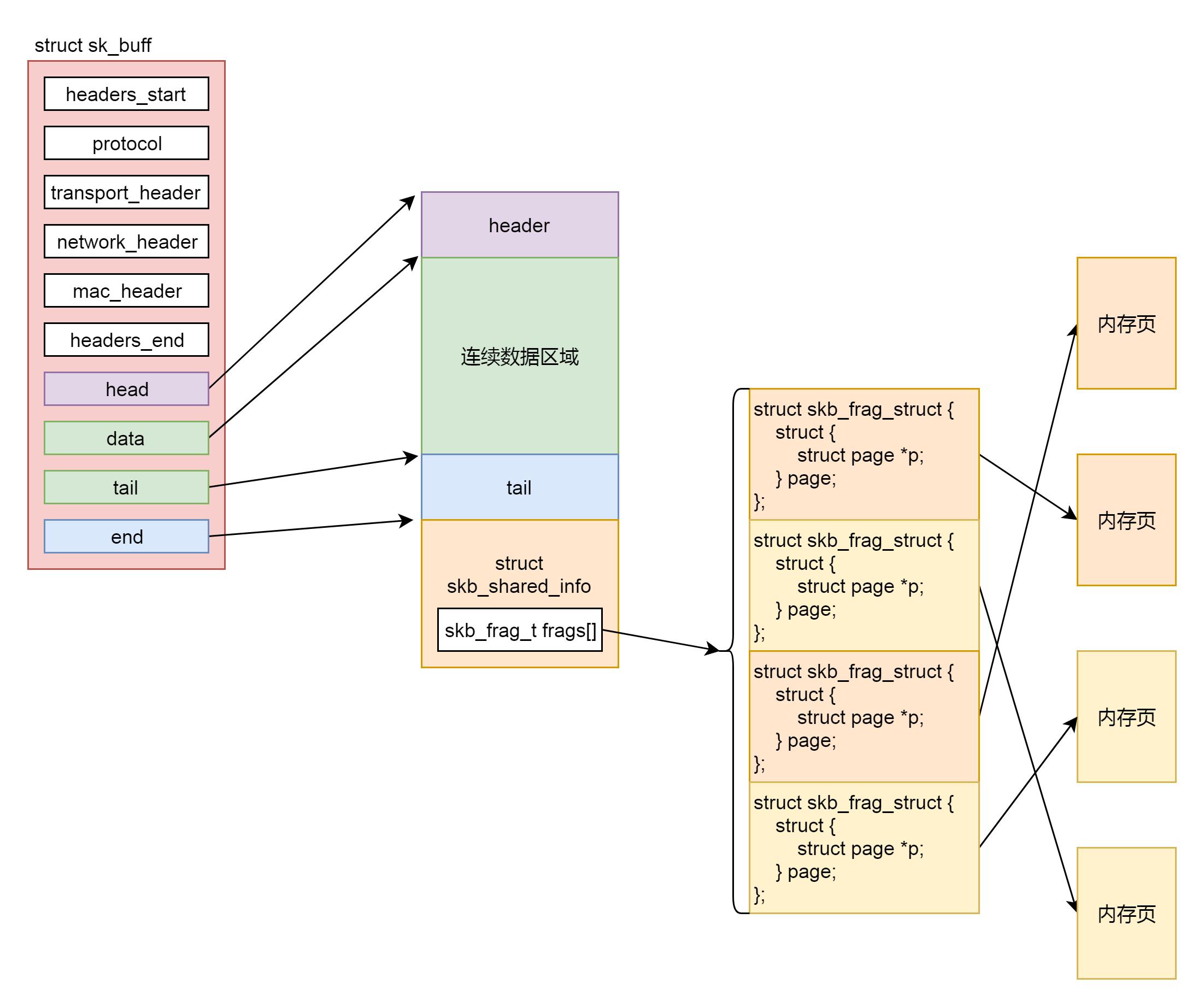
于是我们就有了第四步。在注释/* Where to copy to? */后面有个if-else分支。if分支就是skb_add_data_nocache将数据拷贝到连续的数据区域。else分支就是skb_copy_to_page_nocache将数据拷贝到struct skb_shared_info结构指向的不需要连续的页面区域。
第五步,就是要发生网络包了。第一种情况是积累的数据报数目太多了,因而我们需要通过调用__tcp_push_pending_frames发送网络包。第二种情况是,这是第一个网络包,需要马上发送,调用tcp_push_one。无论__tcp_push_pending_frames还是tcp_push_one,都会调用tcp_write_xmit发送网络包。
至此,tcp_sendmsg解析完了。
41.3 解析tcp_write_xmit函数
接下来我们来看,tcp_write_xmit是如何发送网络包的。
static bool tcp_write_xmit(struct sock *sk, unsigned int mss_now, int nonagle,
int push_one, gfp_t gfp)
{
struct tcp_sock *tp = tcp_sk(sk);
struct sk_buff *skb;
unsigned int tso_segs, sent_pkts;
int cwnd_quota;
......
max_segs = tcp_tso_segs(sk, mss_now);
while ((skb = tcp_send_head(sk))) {
unsigned int limit;
......
tso_segs = tcp_init_tso_segs(skb, mss_now);
......
cwnd_quota = tcp_cwnd_test(tp, skb);
......
if (unlikely(!tcp_snd_wnd_test(tp, skb, mss_now))) {
is_rwnd_limited = true;
break;
}
......
limit = mss_now;
if (tso_segs > 1 && !tcp_urg_mode(tp))
limit = tcp_mss_split_point(sk, skb, mss_now, min_t(unsigned int, cwnd_quota, max_segs), nonagle);
if (skb->len > limit &&
unlikely(tso_fragment(sk, skb, limit, mss_now, gfp)))
break;
......
if (unlikely(tcp_transmit_skb(sk, skb, 1, gfp)))
break;
repair:
/* Advance the send_head. This one is sent out.
* This call will increment packets_out.
*/
tcp_event_new_data_sent(sk, skb);
tcp_minshall_update(tp, mss_now, skb);
sent_pkts += tcp_skb_pcount(skb);
if (push_one)
break;
}
......
}这里面主要的逻辑是一个循环,用来处理发送队列,只要队列不空,就会发送。
在一个循环中,涉及TCP层的很多传输算法,我们来一一解析。
第一个概念是TSO(TCP Segmentation Offload)。如果发送的网络包非常大,就像上面说的一样,要进行分段。分段这个事情可以由协议栈代码在内核做,但是缺点是比较费CPU,另一种方式是延迟到硬件网卡去做,需要网卡支持对大数据包进行自动分段,可以降低CPU负载。
在代码中,tcp_init_tso_segs会调用tcp_set_skb_tso_segs。这里面有这样的语句:DIV_ROUND_UP(skb->len, mss_now)。也就是sk_buff的长度除以mss_now,应该分成几个段。如果算出来要分成多个段,接下来就是要看,是在这里(协议栈的代码里面)分好,还是等待到了底层网卡再分。
于是,调用函数tcp_mss_split_point,开始计算切分的limit。这里面会计算max_len = mss_now * max_segs,根据现在不切分来计算limit,所以下一步的判断中,大部分情况下tso_fragment不会被调用,等待到了底层网卡来切分。
第二个概念是拥塞窗口的概念(cwnd,congestion window),也就是说为了避免拼命发包,把网络塞满了,定义一个窗口的概念,在这个窗口之内的才能发送,超过这个窗口的就不能发送,来控制发送的频率。
那窗口大小是多少呢?就是遵循下面这个著名的拥塞窗口变化图。
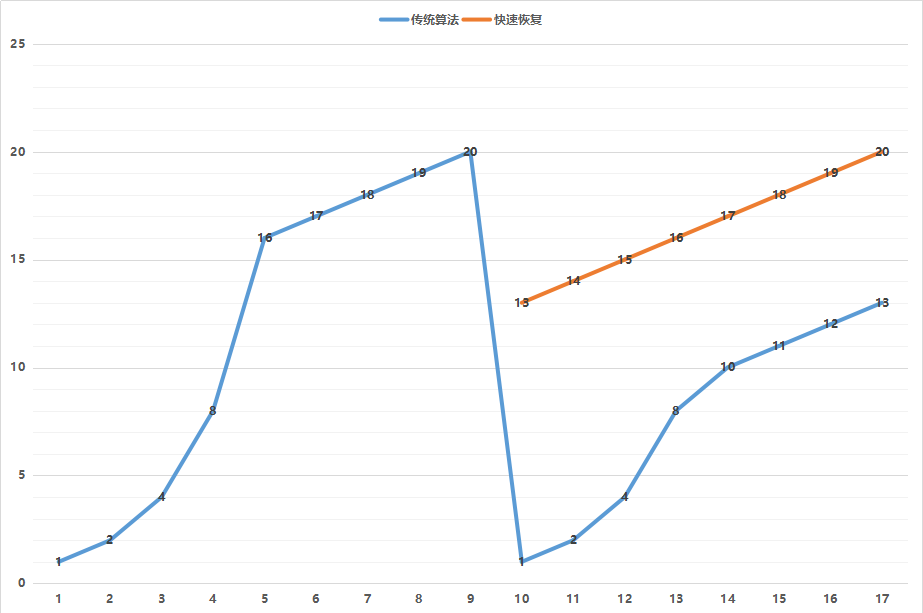
一开始的窗口只有一个mss大小叫作slow start(慢启动)。一开始的增长速度的很快的,翻倍增长。一旦到达一个临界值ssthresh,就变成线性增长,我们就称为拥塞避免。什么时候算真正拥塞呢?就是出现了丢包。一旦丢包,一种方法是马上降回到一个mss,然后重复先翻倍再线性对的过程。如果觉得太过激进,也可以有第二种方法,就是降到当前cwnd的一半,然后进行线性增长。
在代码中,tcp_cwnd_test会将当前的snd_cwnd,减去已经在窗口里面尚未发送完毕的网络包,那就是剩下的窗口大小cwnd_quota,也即就能发送这么多了。
第三个概念就是接收窗口rwnd的概念(receive window),也叫滑动窗口。如果说拥塞窗口是为了怕把网络塞满,在出现丢包的时候减少发送速度,那么滑动窗口就是为了怕把接收方塞满,而控制发送速度。
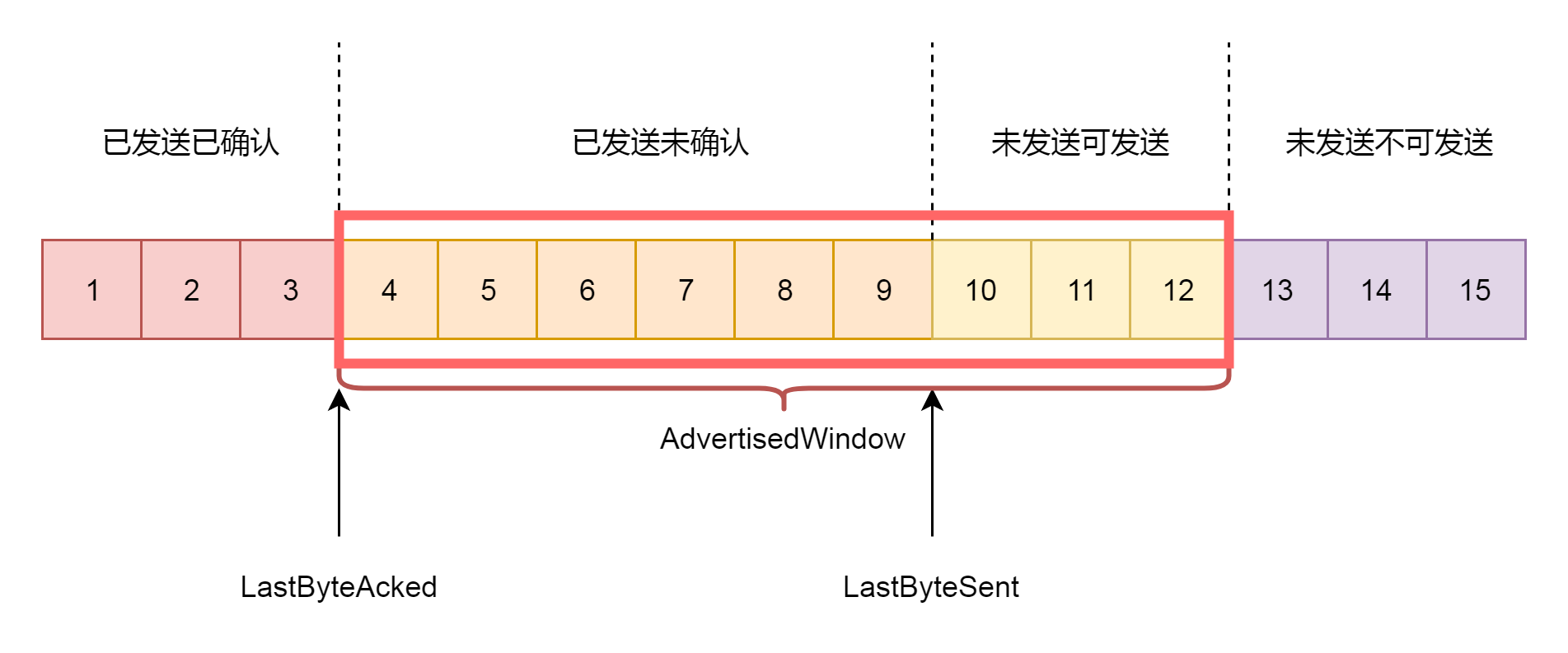
滑动窗口,其实就是接收方告诉发送方自己的网络包的接收能力,超过这个能力,我就受不了了。因为滑动窗口的存在,将发送方的缓存分成了四个部分。
- 第一部分:发送了并且已经确认的。这部分是已经发送完毕的网络包,这部分没有用了,可以回收。
- 第二部分:发送了但尚未确认的。这部分,发送方要等待,万一发送不成功,还要重新发送,所以不能删除。
- 第三部分:没有发送,但是已经等待发送的。这部分是接收方空闲的能力,可以马上发送,接收方收得了。
- 第四部分:没有发送,并且暂时还不会发送的。这部分已经超过了接收方的接收能力,再发送接收方就收不了了。
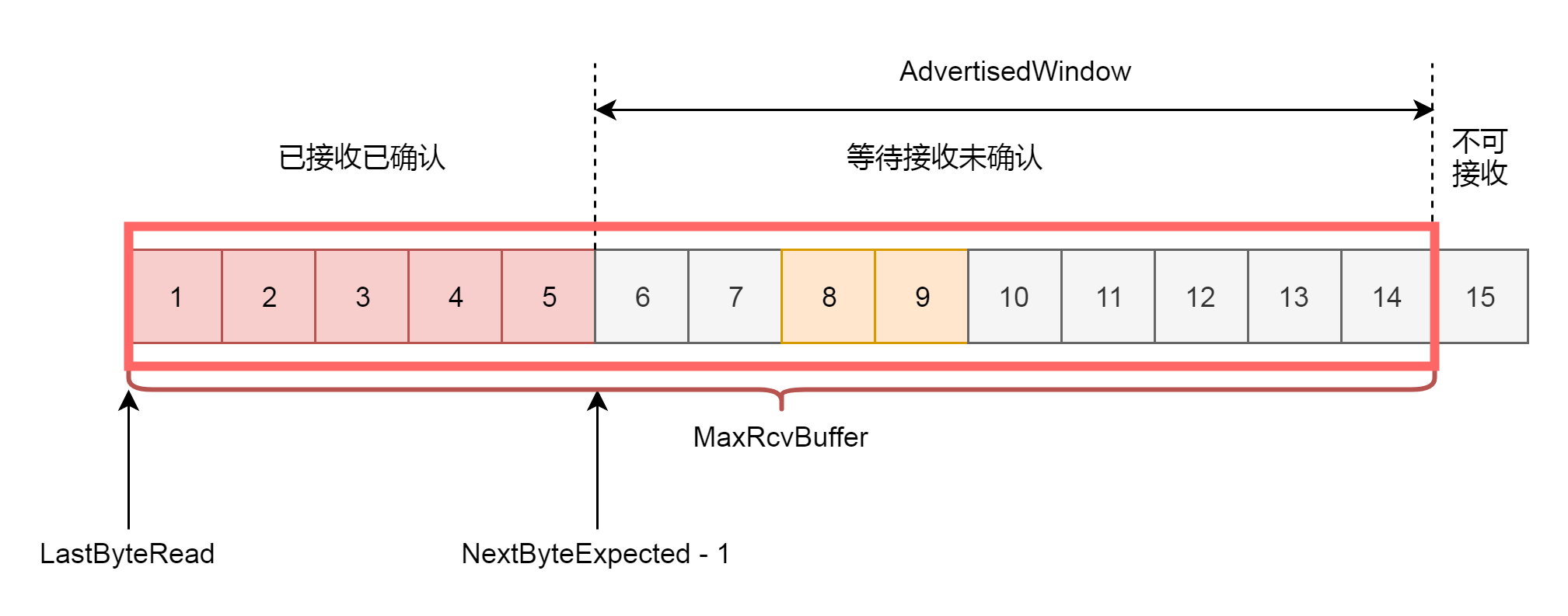
因为滑动窗口的存在,接收方的缓存也要分成了三个部分。
- 第一部分:接受并且确认过的任务。这部分完全接收成功了,可以交给应用层了。
- 第二部分:还没接收,但是马上就能接收的任务。这部分有的网络包到达了,但是还没确认,不算完全完毕,有的还没有到达,那就是接收方能够接受的最大的网络包数量。
- 第三部分:还没接收,也没法接收的任务。这部分已经超出接收方能力。
在网络包的交互过程中,接收方会将第二部分的大小,作为AdvertisedWindow发送给发送方,发送方就可以根据他来调整发送速度了。
在tcp_snd_wnd_test函数中,会判断sk_buff中的end_seq和tcp_wnd_end(tp)之间的关系,也即这个sk_buff是否在滑动窗口的允许范围之内。如果不在范围内,说明发送要受限制了,我们就要把is_rwnd_limited设置为true。
接下来,tcp_mss_split_point函数要被调用了。
static unsigned int tcp_mss_split_point(const struct sock *sk,
const struct sk_buff *skb,
unsigned int mss_now,
unsigned int max_segs,
int nonagle)
{
const struct tcp_sock *tp = tcp_sk(sk);
u32 partial, needed, window, max_len;
window = tcp_wnd_end(tp) - TCP_SKB_CB(skb)->seq;
max_len = mss_now * max_segs;
if (likely(max_len <= window && skb != tcp_write_queue_tail(sk)))
return max_len;
needed = min(skb->len, window);
if (max_len <= needed)
return max_len;
......
return needed;
}这里面除了会判断上面讲的,是否会因为超出mss而分段,还会判断另一个条件,就是是否在滑动窗口的运行范围之内,如果小于窗口的大小,也需要分段,也即需要调用tso_fragment。
在一个循环的最后,是调用tcp_transmit_skb,真的去发送一个网络包。
static int tcp_transmit_skb(struct sock *sk, struct sk_buff *skb, int clone_it,
gfp_t gfp_mask)
{
const struct inet_connection_sock *icsk = inet_csk(sk);
struct inet_sock *inet;
struct tcp_sock *tp;
struct tcp_skb_cb *tcb;
struct tcphdr *th;
int err;
tp = tcp_sk(sk);
skb->skb_mstamp = tp->tcp_mstamp;
inet = inet_sk(sk);
tcb = TCP_SKB_CB(skb);
memset(&opts, 0, sizeof(opts));
tcp_header_size = tcp_options_size + sizeof(struct tcphdr);
skb_push(skb, tcp_header_size);
/* Build TCP header and checksum it. */
th = (struct tcphdr *)skb->data;
th->source = inet->inet_sport;
th->dest = inet->inet_dport;
th->seq = htonl(tcb->seq);
th->ack_seq = htonl(tp->rcv_nxt);
*(((__be16 *)th) + 6) = htons(((tcp_header_size >> 2) << 12) |
tcb->tcp_flags);
th->check = 0;
th->urg_ptr = 0;
......
tcp_options_write((__be32 *)(th + 1), tp, &opts);
th->window = htons(min(tp->rcv_wnd, 65535U));
......
err = icsk->icsk_af_ops->queue_xmit(sk, skb, &inet->cork.fl);
......
}tcp_transmit_skb这个函数比较长,主要做了两件事情,第一件事情就是填充TCP头,如果我们对着TCP头的格式。

这里面有源端口,设置为inet_sport,有目标端口,设置为inet_dport;有序列号,设置为tcb->seq;有确认序列号,设置为tp->rcv_nxt。我们把所有的flags设置为tcb->tcp_flags。设置选项为opts。设置窗口大小为tp->rcv_wnd。
全部设置完毕之后,就会调用icsk_af_ops的queue_xmit方法,icsk_af_ops指向ipv4_specific,也即调用的是ip_queue_xmit函数。
const struct inet_connection_sock_af_ops ipv4_specific = {
.queue_xmit = ip_queue_xmit,
.send_check = tcp_v4_send_check,
.rebuild_header = inet_sk_rebuild_header,
.sk_rx_dst_set = inet_sk_rx_dst_set,
.conn_request = tcp_v4_conn_request,
.syn_recv_sock = tcp_v4_syn_recv_sock,
.net_header_len = sizeof(struct iphdr),
.setsockopt = ip_setsockopt,
.getsockopt = ip_getsockopt,
.addr2sockaddr = inet_csk_addr2sockaddr,
.sockaddr_len = sizeof(struct sockaddr_in),
.mtu_reduced = tcp_v4_mtu_reduced,
};41.4 总结
这一节,我们解析了发送一个网络包的一部分过程,如下图所示。
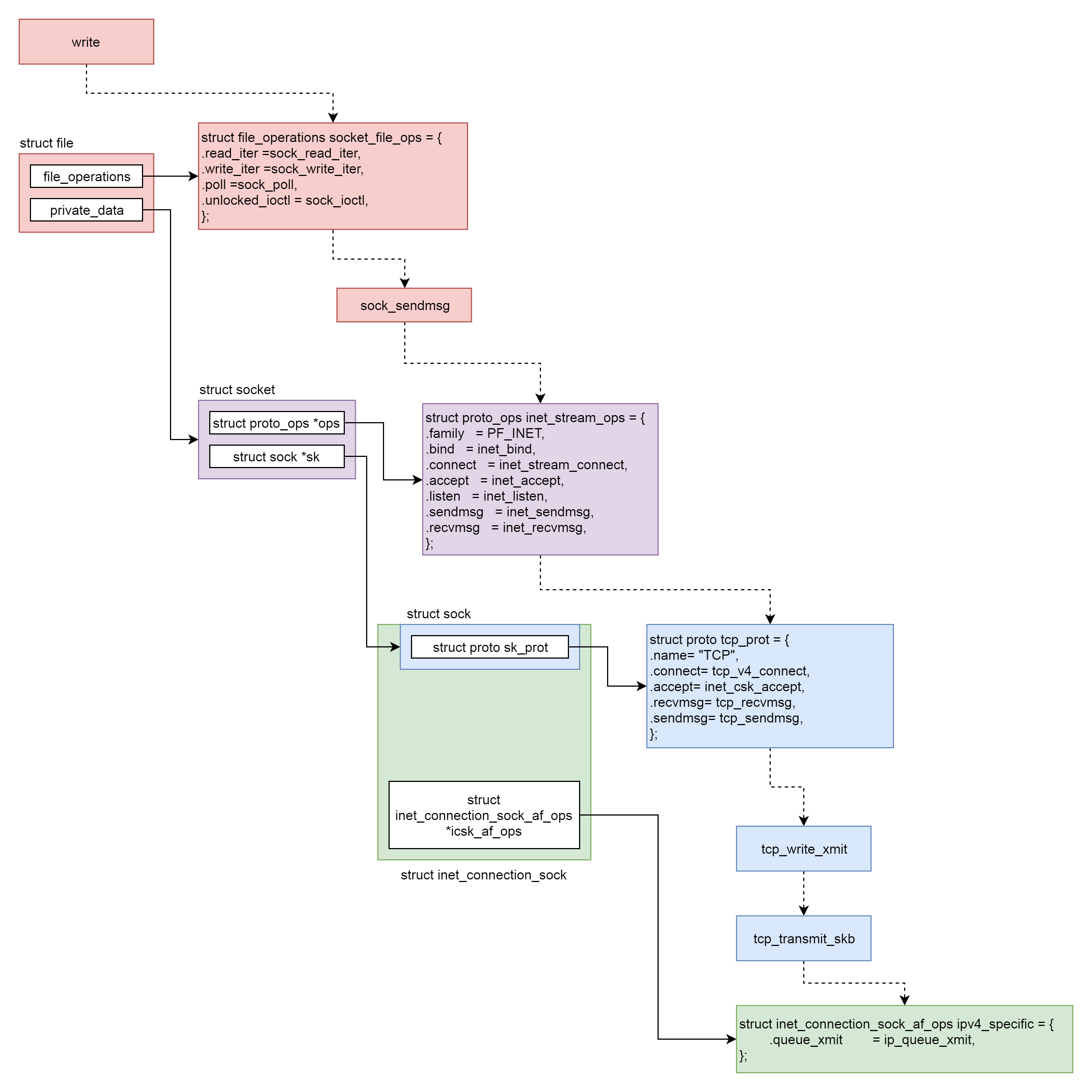
这个过程分成几个层次。
- VFS层:write系统调用找到struct file,根据里面的file_operations的定义,调用sock_write_iter函数。sock_write_iter函数调用sock_sendmsg函数。
- Socket层:从struct file里面的private_data得到struct socket,根据里面ops的定义,调用inet_sendmsg函数。
- Sock层:从struct socket里面的sk得到struct sock,根据里面sk_prot的定义,调用tcp_sendmsg函数。
- TCP层:tcp_sendmsg函数会调用tcp_write_xmit函数,tcp_write_xmit函数会调用tcp_transmit_skb,在这里实现了TCP层面向连接的逻辑。
- IP层:扩展struct sock,得到struct inet_connection_sock,根据里面icsk_af_ops的定义,调用ip_queue_xmit函数。
42. 发送网络包(下)
上一节我们讲网络包的发送,讲了上半部分,也即从VFS层一直到IP层,这一节我们接着看下去,看IP层和MAC层是如何发送数据的。
42.1 解析ip_queue_xmit函数
从ip_queue_xmit函数开始,我们就要进入IP层的发送逻辑了。
int ip_queue_xmit(struct sock *sk, struct sk_buff *skb, struct flowi *fl)
{
struct inet_sock *inet = inet_sk(sk);
struct net *net = sock_net(sk);
struct ip_options_rcu *inet_opt;
struct flowi4 *fl4;
struct rtable *rt;
struct iphdr *iph;
int res;
inet_opt = rcu_dereference(inet->inet_opt);
fl4 = &fl->u.ip4;
rt = skb_rtable(skb);
/* Make sure we can route this packet. */
rt = (struct rtable *)__sk_dst_check(sk, 0);
if (!rt) {
__be32 daddr;
/* Use correct destination address if we have options. */
daddr = inet->inet_daddr;
......
rt = ip_route_output_ports(net, fl4, sk,
daddr, inet->inet_saddr,
inet->inet_dport,
inet->inet_sport,
sk->sk_protocol,
RT_CONN_FLAGS(sk),
sk->sk_bound_dev_if);
if (IS_ERR(rt))
goto no_route;
sk_setup_caps(sk, &rt->dst);
}
skb_dst_set_noref(skb, &rt->dst);
packet_routed:
/* OK, we know where to send it, allocate and build IP header. */
skb_push(skb, sizeof(struct iphdr) + (inet_opt ? inet_opt->opt.optlen : 0));
skb_reset_network_header(skb);
iph = ip_hdr(skb);
*((__be16 *)iph) = htons((4 << 12) | (5 << 8) | (inet->tos & 0xff));
if (ip_dont_fragment(sk, &rt->dst) && !skb->ignore_df)
iph->frag_off = htons(IP_DF);
else
iph->frag_off = 0;
iph->ttl = ip_select_ttl(inet, &rt->dst);
iph->protocol = sk->sk_protocol;
ip_copy_addrs(iph, fl4);
/* Transport layer set skb->h.foo itself. */
if (inet_opt && inet_opt->opt.optlen) {
iph->ihl += inet_opt->opt.optlen >> 2;
ip_options_build(skb, &inet_opt->opt, inet->inet_daddr, rt, 0);
}
ip_select_ident_segs(net, skb, sk,
skb_shinfo(skb)->gso_segs ?: 1);
/* TODO : should we use skb->sk here instead of sk ? */
skb->priority = sk->sk_priority;
skb->mark = sk->sk_mark;
res = ip_local_out(net, sk, skb);
......
}在ip_queue_xmit中,也即IP层的发送函数里面,有三部分逻辑。
第一部分,选取路由,也即我要发送这个包应该从哪个网卡出去。
这件事情主要由ip_route_output_ports函数完成。接下来的调用链为:ip_route_output_ports->ip_route_output_flow->__ip_route_output_key->ip_route_output_key_hash->ip_route_output_key_hash_rcu。
struct rtable *ip_route_output_key_hash_rcu(struct net *net, struct flowi4 *fl4, struct fib_result *res, const struct sk_buff *skb)
{
struct net_device *dev_out = NULL;
int orig_oif = fl4->flowi4_oif;
unsigned int flags = 0;
struct rtable *rth;
......
err = fib_lookup(net, fl4, res, 0);
......
make_route:
rth = __mkroute_output(res, fl4, orig_oif, dev_out, flags);
......
}ip_route_output_key_hash_rcu先会调用fib_lookup。
FIB全称是Forwarding Information Base,转发信息表。其实就是咱们常说的路由表。
static inline int fib_lookup(struct net *net, const struct flowi4 *flp, struct fib_result *res, unsigned int flags)
{ struct fib_table *tb;
......
tb = fib_get_table(net, RT_TABLE_MAIN);
if (tb)
err = fib_table_lookup(tb, flp, res, flags | FIB_LOOKUP_NOREF);
......
}
路由表可以有多个,一般会有一个主表,RT_TABLE_MAIN。然后fib_table_lookup函数在这个表里面进行查找。
路由表是一个什么样的结构呢?
路由就是在Linux服务器上的路由表里面配置的一条一条规则。这些规则大概是这样的:想访问某个网段,从某个网卡出去,下一跳是某个IP。
之前我们讲过一个简单的拓扑图,里面的三台Linux机器的路由表都可以通过ip route命令查看。
# Linux服务器A
default via 192.168.1.1 dev eth0
192.168.1.0/24 dev eth0 proto kernel scope link src 192.168.1.100 metric 100
# Linux服务器B
default via 192.168.2.1 dev eth0
192.168.2.0/24 dev eth0 proto kernel scope link src 192.168.2.100 metric 100
# Linux服务器做路由器
192.168.1.0/24 dev eth0 proto kernel scope link src 192.168.1.1
192.168.2.0/24 dev eth1 proto kernel scope link src 192.168.2.1其实,对于两端的服务器来讲,我们没有太多路由可以选,但是对于中间的Linux服务器做路由器来讲,这里有两条路可以选,一个是往左面转发,一个是往右面转发,就需要路由表的查找。
fib_table_lookup的代码逻辑比较复杂,好在注释比较清楚。因为路由表要按照前缀进行查询,希望找到最长匹配的那一个,例如192.168.2.0/24和192.168.0.0/16都能匹配192.168.2.100/24。但是,我们应该使用192.168.2.0/24的这一条。
为了更方面的做这个事情,我们使用了Trie树这种结构。比如我们有一系列的字符串:{bcs#, badge#, baby#, back#, badger#, badness#}。之所以每个字符串都加上#,是希望不要一个字符串成为另外一个字符串的前缀。然后我们把它们放在Trie树中,如下图所示:
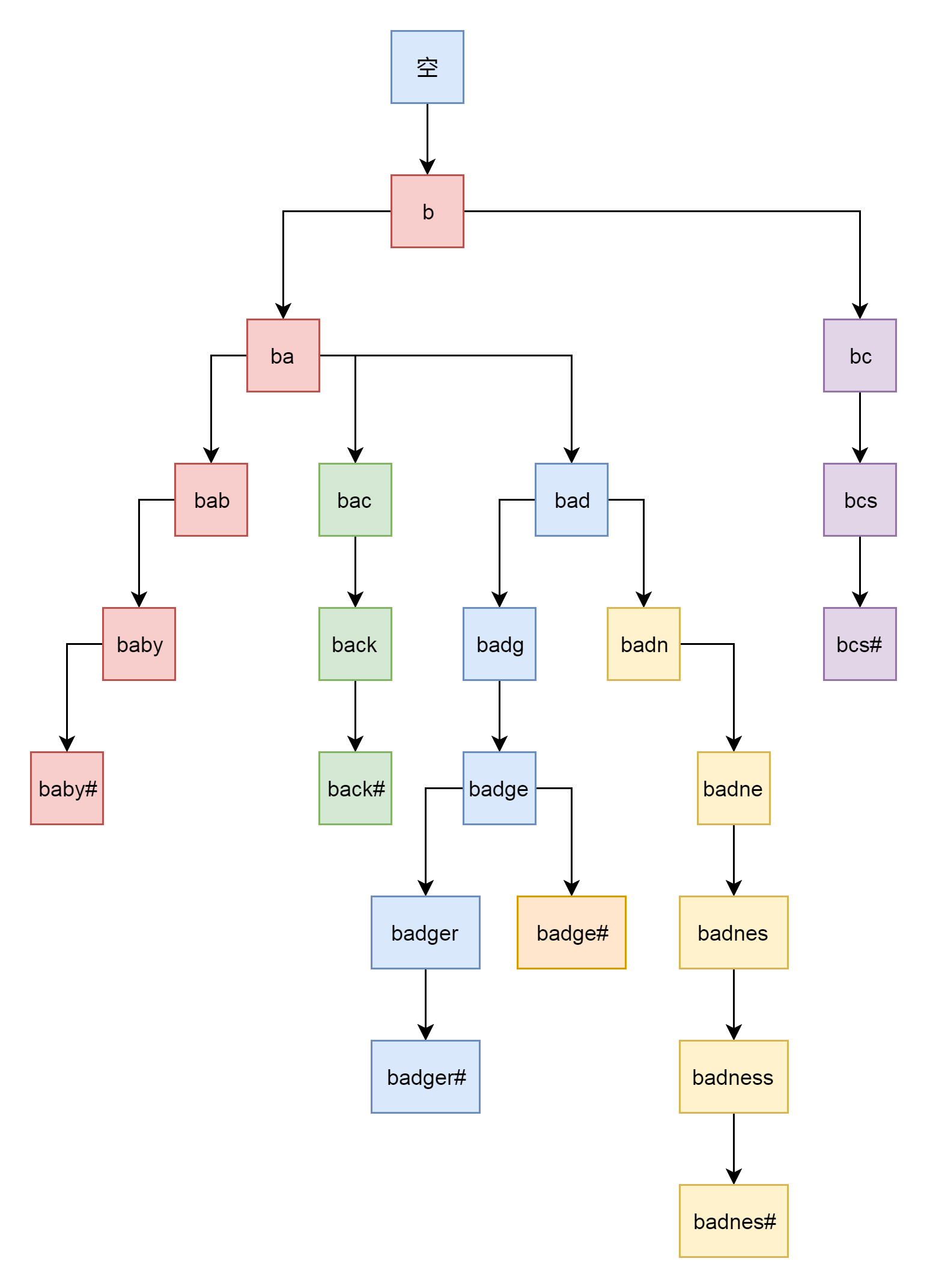
对于将IP地址转成二进制放入trie树,也是同样的道理,可以很快进行路由的查询。
找到了路由,就知道了应该从哪个网卡发出去。
然后,ip_route_output_key_hash_rcu会调用__mkroute_output,创建一个struct rtable,表示找到的路由表项。这个结构是由rt_dst_alloc函数分配的。
struct rtable *rt_dst_alloc(struct net_device *dev,
unsigned int flags, u16 type,
bool nopolicy, bool noxfrm, bool will_cache)
{
struct rtable *rt;
rt = dst_alloc(&ipv4_dst_ops, dev, 1, DST_OBSOLETE_FORCE_CHK,
(will_cache ? 0 : DST_HOST) |
(nopolicy ? DST_NOPOLICY : 0) |
(noxfrm ? DST_NOXFRM : 0));
if (rt) {
rt->rt_genid = rt_genid_ipv4(dev_net(dev));
rt->rt_flags = flags;
rt->rt_type = type;
rt->rt_is_input = 0;
rt->rt_iif = 0;
rt->rt_pmtu = 0;
rt->rt_gateway = 0;
rt->rt_uses_gateway = 0;
rt->rt_table_id = 0;
INIT_LIST_HEAD(&rt->rt_uncached);
rt->dst.output = ip_output;
if (flags & RTCF_LOCAL)
rt->dst.input = ip_local_deliver;
}
return rt;
}最终返回struct rtable实例,第一部分也就完成了。
第二部分,就是准备IP层的头,往里面填充内容。这就要对着IP层的头的格式进行理解。
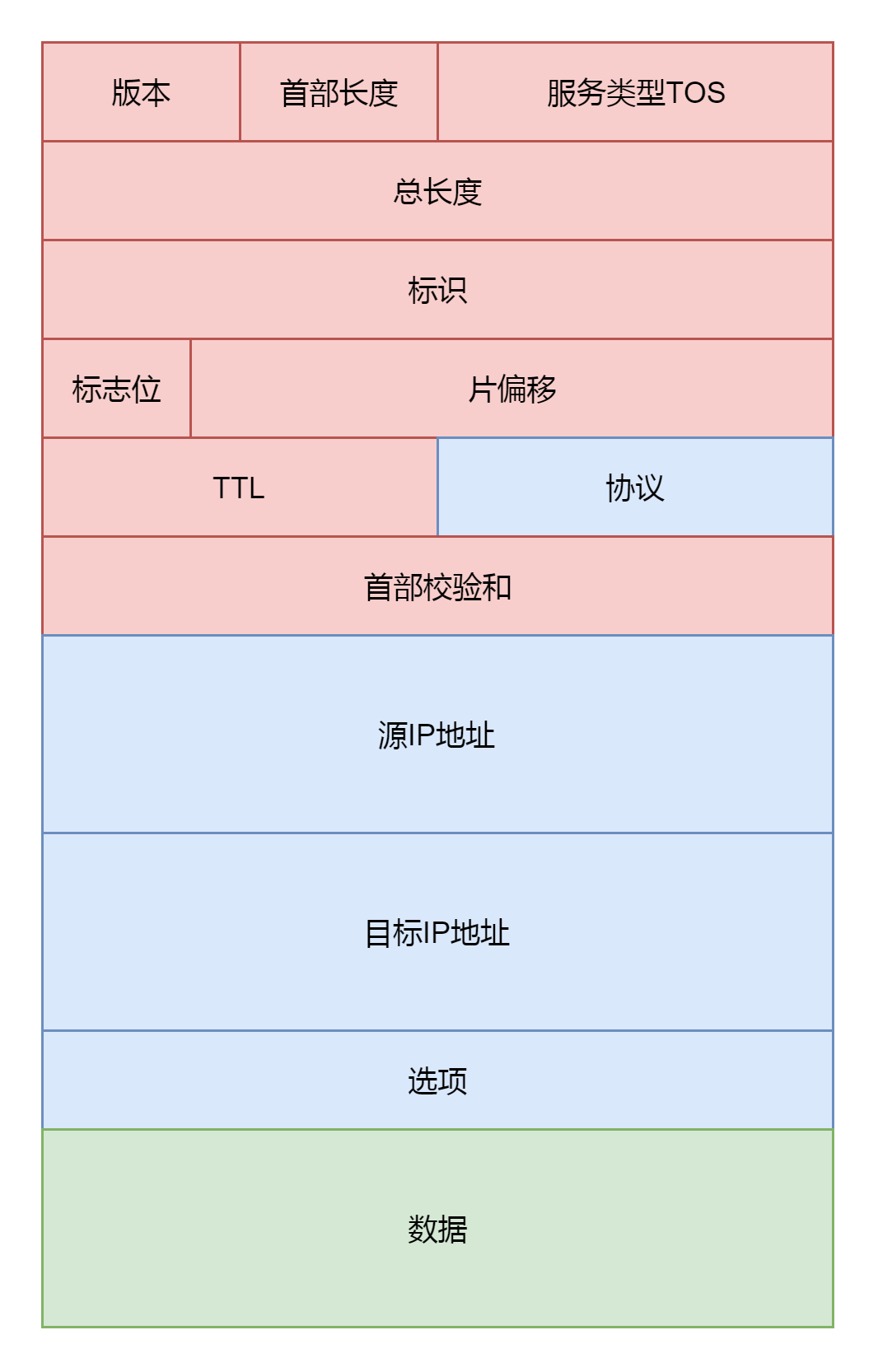
在这里面,服务类型设置为tos,标识位里面设置是否允许分片frag_off。如果不允许,而遇到MTU太小过不去的情况,就发送ICMP报错。TTL是这个包的存活时间,为了防止一个IP包迷路以后一直存活下去,每经过一个路由器TTL都减一,减为零则”死去”。设置protocol,指的是更上层的协议,这里是TCP。源地址和目标地址由ip_copy_addrs设置。最后,设置options。
第三部分,就是调用ip_local_out发送IP包。
int ip_local_out(struct net *net, struct sock *sk, struct sk_buff *skb)
{
int err;
err = __ip_local_out(net, sk, skb);
if (likely(err == 1))
err = dst_output(net, sk, skb);
return err;
}
int __ip_local_out(struct net *net, struct sock *sk, struct sk_buff *skb)
{
struct iphdr *iph = ip_hdr(skb);
iph->tot_len = htons(skb->len);
skb->protocol = htons(ETH_P_IP);
return nf_hook(NFPROTO_IPV4, NF_INET_LOCAL_OUT,
net, sk, skb, NULL, skb_dst(skb)->dev,
dst_output);
}ip_local_out先是调用__ip_local_out,然后里面调用了nf_hook。这是什么呢?nf的意思是Netfilter,这是Linux内核的一个机制,用于在网络发送和转发的关键节点上加上hook函数,这些函数可以截获数据包,对数据包进行干预。
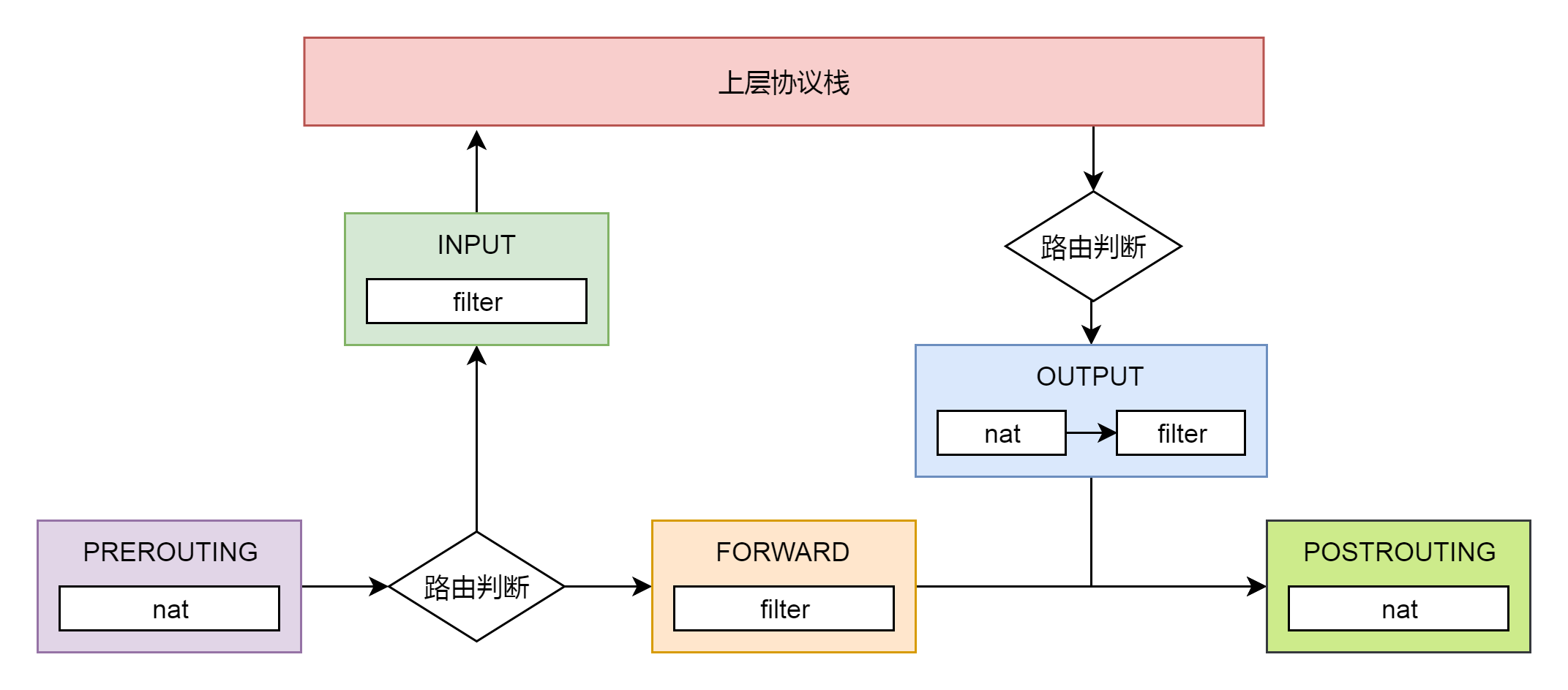
一个著名的实现,就是内核模块ip_tables。在用户态,还有一个客户端程序iptables,用命令行来干预内核的规则。
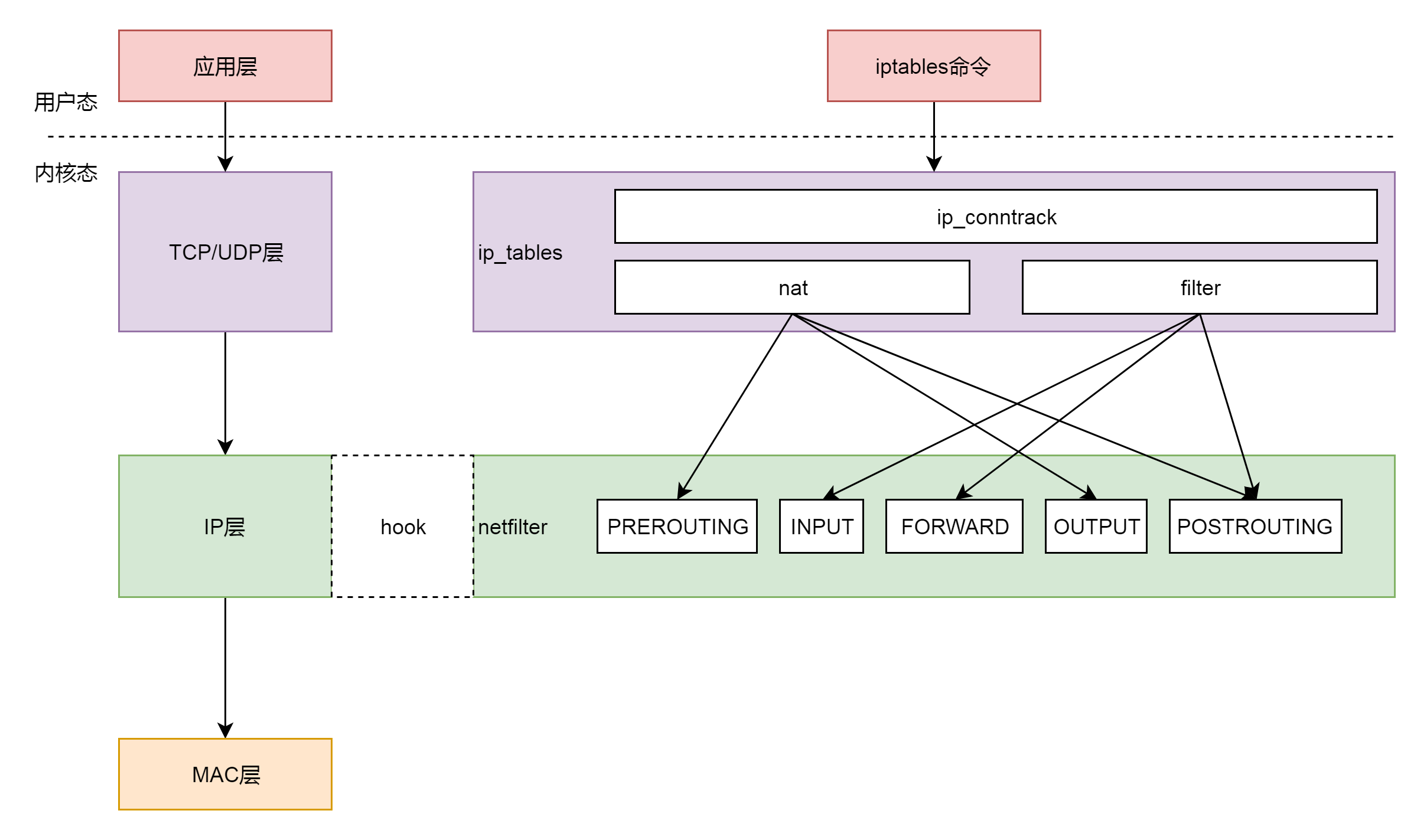
iptables有表和链的概念,最终要的是两个表。
filter表处理过滤功能,主要包含以下三个链。
- INPUT链:过滤所有目标地址是本机的数据包
- FORWARD链:过滤所有路过本机的数据包
- OUTPUT链:过滤所有由本机产生的数据包
nat表主要处理网络地址转换,可以进行SNAT(改变源地址)、DNAT(改变目标地址),包含以下三个链。
- PREROUTING链:可以在数据包到达时改变目标地址
- OUTPUT链:可以改变本地产生的数据包的目标地址
- POSTROUTING链:在数据包离开时改变数据包的源地址
在这里,网络包马上就要发出去了,因而是NF_INET_LOCAL_OUT,也即ouput链,如果用户曾经在iptables里面写过某些规则,就会在nf_hook这个函数里面起作用。
ip_local_out再调用dst_output,就是真正的发送数据。
/* Output packet to network from transport. */
static inline int dst_output(struct net *net, struct sock *sk, struct sk_buff *skb)
{
return skb_dst(skb)->output(net, sk, skb);
}这里调用的就是struct rtable成员dst的ouput函数。在rt_dst_alloc中,我们可以看到,output函数指向的是ip_output。
int ip_output(struct net *net, struct sock *sk, struct sk_buff *skb)
{
struct net_device *dev = skb_dst(skb)->dev;
skb->dev = dev;
skb->protocol = htons(ETH_P_IP);
return NF_HOOK_COND(NFPROTO_IPV4, NF_INET_POST_ROUTING,
net, sk, skb, NULL, dev,
ip_finish_output,
!(IPCB(skb)->flags & IPSKB_REROUTED));
}在ip_output里面,我们又看到了熟悉的NF_HOOK。这一次是NF_INET_POST_ROUTING,也即POSTROUTING链,处理完之后,调用ip_finish_output。
42.2 解析ip_finish_output函数
从ip_finish_output函数开始,发送网络包的逻辑由第三层到达第二层。ip_finish_output最终调用ip_finish_output2。
static int ip_finish_output2(struct net *net, struct sock *sk, struct sk_buff *skb)
{
struct dst_entry *dst = skb_dst(skb);
struct rtable *rt = (struct rtable *)dst;
struct net_device *dev = dst->dev;
unsigned int hh_len = LL_RESERVED_SPACE(dev);
struct neighbour *neigh;
u32 nexthop;
......
nexthop = (__force u32) rt_nexthop(rt, ip_hdr(skb)->daddr);
neigh = __ipv4_neigh_lookup_noref(dev, nexthop);
if (unlikely(!neigh))
neigh = __neigh_create(&arp_tbl, &nexthop, dev, false);
if (!IS_ERR(neigh)) {
int res;
sock_confirm_neigh(skb, neigh);
res = neigh_output(neigh, skb);
return res;
}
......
}在ip_finish_output2中,先找到struct rtable路由表里面的下一跳,下一跳一定和本机在同一个局域网中,可以通过二层进行通信,因而通过__ipv4_neigh_lookup_noref,查找如何通过二层访问下一跳。
static inline struct neighbour *__ipv4_neigh_lookup_noref(struct net_device *dev, u32 key)
{
return ___neigh_lookup_noref(&arp_tbl, neigh_key_eq32, arp_hashfn, &key, dev);
}__ipv4_neigh_lookup_noref是从本地的ARP表中查找下一跳的MAC地址。ARP表的定义如下:
struct neigh_table arp_tbl = {
.family = AF_INET,
.key_len = 4,
.protocol = cpu_to_be16(ETH_P_IP),
.hash = arp_hash,
.key_eq = arp_key_eq,
.constructor = arp_constructor,
.proxy_redo = parp_redo,
.id = "arp_cache",
......
.gc_interval = 30 * HZ,
.gc_thresh1 = 128,
.gc_thresh2 = 512,
.gc_thresh3 = 1024,
};如果在ARP表中没有找到相应的项,则调用__neigh_create进行创建。
struct neighbour *__neigh_create(struct neigh_table *tbl, const void *pkey, struct net_device *dev, bool want_ref)
{
u32 hash_val;
int key_len = tbl->key_len;
int error;
struct neighbour *n1, *rc, *n = neigh_alloc(tbl, dev);
struct neigh_hash_table *nht;
memcpy(n->primary_key, pkey, key_len);
n->dev = dev;
dev_hold(dev);
/* Protocol specific setup. */
if (tbl->constructor && (error = tbl->constructor(n)) < 0) {
......
}
......
if (atomic_read(&tbl->entries) > (1 << nht->hash_shift))
nht = neigh_hash_grow(tbl, nht->hash_shift + 1);
hash_val = tbl->hash(pkey, dev, nht->hash_rnd) >> (32 - nht->hash_shift);
for (n1 = rcu_dereference_protected(nht->hash_buckets[hash_val],
lockdep_is_held(&tbl->lock));
n1 != NULL;
n1 = rcu_dereference_protected(n1->next,
lockdep_is_held(&tbl->lock))) {
if (dev == n1->dev && !memcmp(n1->primary_key, pkey, key_len)) {
if (want_ref)
neigh_hold(n1);
rc = n1;
goto out_tbl_unlock;
}
}
......
rcu_assign_pointer(n->next,
rcu_dereference_protected(nht->hash_buckets[hash_val],
lockdep_is_held(&tbl->lock)));
rcu_assign_pointer(nht->hash_buckets[hash_val], n);
......
}__neigh_create先调用neigh_alloc,创建一个struct neighbour结构,用于维护MAC地址和ARP相关的信息。这个名字也很好理解,大家都是在一个局域网里面,可以通过MAC地址访问到,当然是邻居了。
static struct neighbour *neigh_alloc(struct neigh_table *tbl, struct net_device *dev)
{
struct neighbour *n = NULL;
unsigned long now = jiffies;
int entries;
......
n = kzalloc(tbl->entry_size + dev->neigh_priv_len, GFP_ATOMIC);
if (!n)
goto out_entries;
__skb_queue_head_init(&n->arp_queue);
rwlock_init(&n->lock);
seqlock_init(&n->ha_lock);
n->updated = n->used = now;
n->nud_state = NUD_NONE;
n->output = neigh_blackhole;
seqlock_init(&n->hh.hh_lock);
n->parms = neigh_parms_clone(&tbl->parms);
setup_timer(&n->timer, neigh_timer_handler, (unsigned long)n);
NEIGH_CACHE_STAT_INC(tbl, allocs);
n->tbl = tbl;
refcount_set(&n->refcnt, 1);
n->dead = 1;
......
}在neigh_alloc中,我们先分配一个struct neighbour结构并且初始化。这里面比较重要的有两个成员,一个是arp_queue,所以上层想通过ARP获取MAC地址的任务,都放在这个队列里面。另一个是timer定时器,我们设置成,过一段时间就调用neigh_timer_handler,来处理这些ARP任务。
__neigh_create然后调用了arp_tbl的constructor函数,也即调用了arp_constructor,在这里面定义了ARP的操作arp_hh_ops。
static int arp_constructor(struct neighbour *neigh)
{
__be32 addr = *(__be32 *)neigh->primary_key;
struct net_device *dev = neigh->dev;
struct in_device *in_dev;
struct neigh_parms *parms;
......
neigh->type = inet_addr_type_dev_table(dev_net(dev), dev, addr);
parms = in_dev->arp_parms;
__neigh_parms_put(neigh->parms);
neigh->parms = neigh_parms_clone(parms);
......
neigh->ops = &arp_hh_ops;
......
neigh->output = neigh->ops->output;
......
}
static const struct neigh_ops arp_hh_ops = {
.family = AF_INET,
.solicit = arp_solicit,
.error_report = arp_error_report,
.output = neigh_resolve_output,
.connected_output = neigh_resolve_output,
};__neigh_create最后是将创建的struct neighbour结构放入一个哈希表,从里面的代码逻辑比较容易看出,这是一个数组加链表的链式哈希表,先计算出哈希值hash_val,得到相应的链表,然后循环这个链表找到对应的项,如果找不到就在最后插入一项。
我们回到ip_finish_output2,在__neigh_create之后,会调用neigh_output发送网络包。
static inline int neigh_output(struct neighbour *n, struct sk_buff *skb)
{
......
return n->output(n, skb);
}按照上面对于struct neighbour的操作函数arp_hh_ops 的定义,output调用的是neigh_resolve_output。
int neigh_resolve_output(struct neighbour *neigh, struct sk_buff *skb)
{
if (!neigh_event_send(neigh, skb)) {
......
rc = dev_queue_xmit(skb);
}
......
}在neigh_resolve_output里面,首先neigh_event_send触发一个事件,看能否激活ARP。
int __neigh_event_send(struct neighbour *neigh, struct sk_buff *skb)
{
int rc;
bool immediate_probe = false;
if (!(neigh->nud_state & (NUD_STALE | NUD_INCOMPLETE))) {
if (NEIGH_VAR(neigh->parms, MCAST_PROBES) +
NEIGH_VAR(neigh->parms, APP_PROBES)) {
unsigned long next, now = jiffies;
atomic_set(&neigh->probes,
NEIGH_VAR(neigh->parms, UCAST_PROBES));
neigh->nud_state = NUD_INCOMPLETE;
neigh->updated = now;
next = now + max(NEIGH_VAR(neigh->parms, RETRANS_TIME),
HZ/2);
neigh_add_timer(neigh, next);
immediate_probe = true;
}
......
} else if (neigh->nud_state & NUD_STALE) {
neigh_dbg(2, "neigh %p is delayed\n", neigh);
neigh->nud_state = NUD_DELAY;
neigh->updated = jiffies;
neigh_add_timer(neigh, jiffies +
NEIGH_VAR(neigh->parms, DELAY_PROBE_TIME));
}
if (neigh->nud_state == NUD_INCOMPLETE) {
if (skb) {
.......
__skb_queue_tail(&neigh->arp_queue, skb);
neigh->arp_queue_len_Bytes += skb->truesize;
}
rc = 1;
}
out_unlock_bh:
if (immediate_probe)
neigh_probe(neigh);
.......
}在__neigh_event_send中,激活ARP分两种情况,第一种情况是马上激活,也即immediate_probe。另一种情况是延迟激活则仅仅设置一个timer。然后将ARP包放在arp_queue上。如果马上激活,就直接调用neigh_probe;如果延迟激活,则定时器到了就会触发neigh_timer_handler,在这里面还是会调用neigh_probe。
我们就来看neigh_probe的实现,在这里面会从arp_queue中拿出ARP包来,然后调用struct neighbour的solicit操作。
static void neigh_probe(struct neighbour *neigh)
__releases(neigh->lock)
{
struct sk_buff *skb = skb_peek_tail(&neigh->arp_queue);
......
if (neigh->ops->solicit)
neigh->ops->solicit(neigh, skb);
......
}按照上面对于struct neighbour的操作函数arp_hh_ops 的定义,solicit调用的是arp_solicit,在这里我们可以找到对于arp_send_dst的调用,创建并发送一个arp包,得到结果放在struct dst_entry里面。
static void arp_send_dst(int type, int ptype, __be32 dest_ip,
struct net_device *dev, __be32 src_ip,
const unsigned char *dest_hw,
const unsigned char *src_hw,
const unsigned char *target_hw,
struct dst_entry *dst)
{
struct sk_buff *skb;
......
skb = arp_create(type, ptype, dest_ip, dev, src_ip,
dest_hw, src_hw, target_hw);
......
skb_dst_set(skb, dst_clone(dst));
arp_xmit(skb);
}我们回到neigh_resolve_output中,当ARP发送完毕,就可以调用dev_queue_xmit发送二层网络包了。
/**
* __dev_queue_xmit - transmit a buffer
* @skb: buffer to transmit
* @accel_priv: private data used for L2 forwarding offload
*
* Queue a buffer for transmission to a network device.
*/
static int __dev_queue_xmit(struct sk_buff *skb, void *accel_priv)
{
struct net_device *dev = skb->dev;
struct netdev_queue *txq;
struct Qdisc *q;
......
txq = netdev_pick_tx(dev, skb, accel_priv);
q = rcu_dereference_bh(txq->qdisc);
if (q->enqueue) {
rc = __dev_xmit_skb(skb, q, dev, txq);
goto out;
}
......
}就像咱们在讲述硬盘块设备的时候讲过,每个块设备都有队列,用于将内核的数据放到队列里面,然后设备驱动从队列里面取出后,将数据根据具体设备的特性发送给设备。
网络设备也是类似的,对于发送来说,有一个发送队列struct netdev_queue *txq。
这里还有另一个变量叫做struct Qdisc,这个是什么呢?如果我们在一台Linux机器上运行ip addr,我们能看到对于一个网卡,都有下面的输出。
$ ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1400 qdisc pfifo_fast state UP group default qlen 1000
link/ether fa:16:3e:75:99:08 brd ff:ff:ff:ff:ff:ff
inet 10.173.32.47/21 brd 10.173.39.255 scope global noprefixroute dynamic eth0
valid_lft 67104sec preferred_lft 67104sec
inet6 fe80::f816:3eff:fe75:9908/64 scope link
valid_lft forever preferred_lft forever这里面有个关键字qdisc pfifo_fast是什么意思呢?qdisc全称是queueing discipline,中文叫排队规则。内核如果需要通过某个网络接口发送数据包,都需要按照为这个接口配置的qdisc(排队规则)把数据包加入队列。
最简单的qdisc是pfifo,它不对进入的数据包做任何的处理,数据包采用先入先出的方式通过队列。pfifo_fast稍微复杂一些,它的队列包括三个波段(band)。在每个波段里面,使用先进先出规则。
三个波段的优先级也不相同。band 0的优先级最高,band 2的最低。如果band 0里面有数据包,系统就不会处理band 1里面的数据包,band 1和band 2之间也是一样。
数据包是按照服务类型(Type of Service,TOS)被分配到三个波段里面的。TOS是IP头里面的一个字段,代表了当前的包是高优先级的,还是低优先级的。
pfifo_fast分为三个先入先出的队列,我们能称为三个Band。根据网络包里面的TOS,看这个包到底应该进入哪个队列。TOS总共四位,每一位表示的意思不同,总共十六种类型。
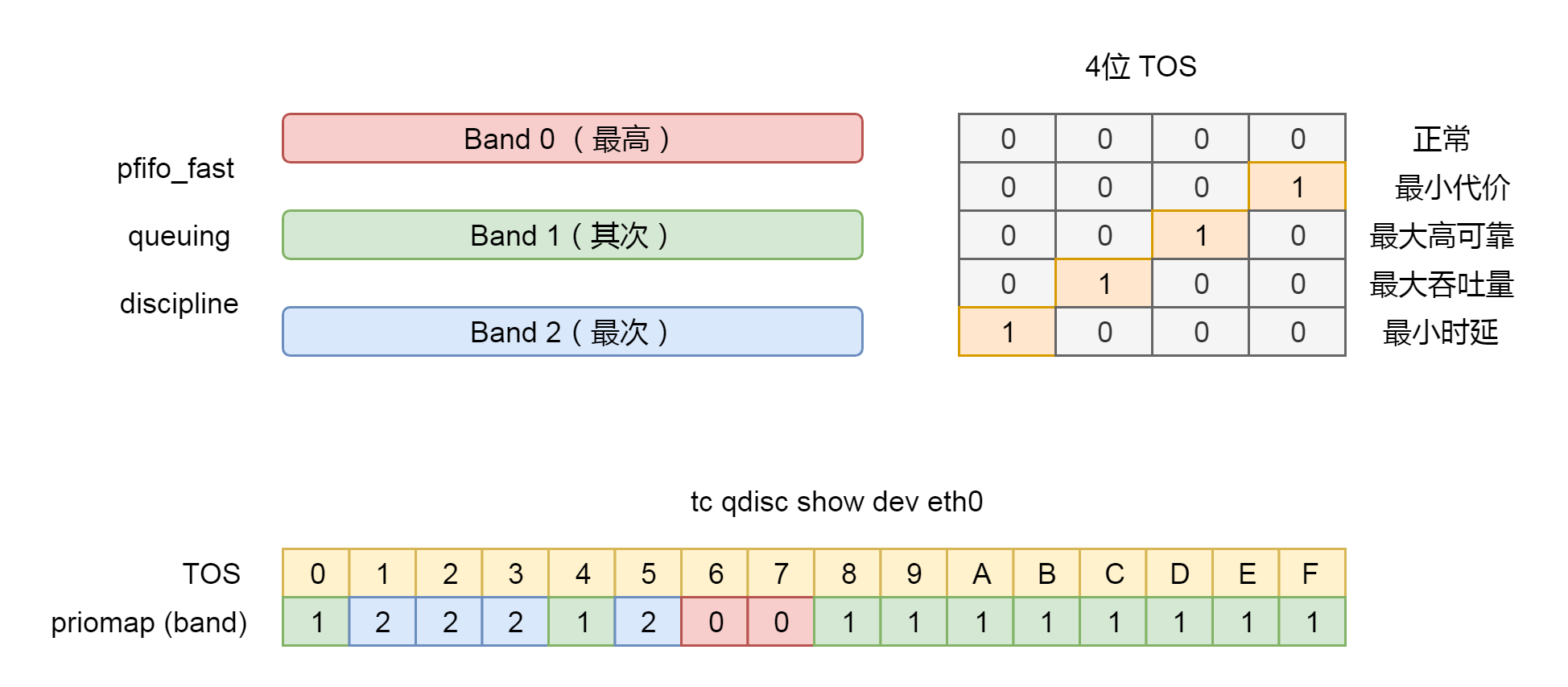
通过命令行tc qdisc show dev eth0,我们可以输出结果priomap,也是十六个数字。在0到2之间,和TOS的十六种类型对应起来。不同的TOS对应不同的队列。其中Band 0优先级最高,发送完毕后才轮到Band 1发送,最后才是Band 2。
$ tc qdisc show dev eth0
qdisc pfifo_fast 0: root refcnt 2 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1接下来,__dev_xmit_skb开始进行网络包发送。
static inline int __dev_xmit_skb(struct sk_buff *skb, struct Qdisc *q,
struct net_device *dev,
struct netdev_queue *txq)
{
......
rc = q->enqueue(skb, q, &to_free) & NET_XMIT_MASK;
if (qdisc_run_begin(q)) {
......
__qdisc_run(q);
}
......
}
void __qdisc_run(struct Qdisc *q)
{
int quota = dev_tx_weight;
int packets;
while (qdisc_restart(q, &packets)) {
/*
* Ordered by possible occurrence: Postpone processing if
* 1. we've exceeded packet quota
* 2. another process needs the CPU;
*/
quota -= packets;
if (quota <= 0 || need_resched()) {
__netif_schedule(q);
break;
}
}
qdisc_run_end(q);
}dev_xmit_skb会将请求放入队列,然后调用qdisc_run处理队列中的数据。qdisc_restart用于数据的发送。根据注释中的说法,qdisc的另一个功能是用于控制网络包的发送速度,因而如果超过速度,就需要重新调度,则会调用__netif_schedule。
static void __netif_reschedule(struct Qdisc *q)
{
struct softnet_data *sd;
unsigned long flags;
local_irq_save(flags);
sd = this_cpu_ptr(&softnet_data);
q->next_sched = NULL;
*sd->output_queue_tailp = q;
sd->output_queue_tailp = &q->next_sched;
raise_softirq_irqoff(NET_TX_SOFTIRQ);
local_irq_restore(flags);
}netif_schedule会调用netif_reschedule,发起一个软中断NET_TX_SOFTIRQ。咱们讲设备驱动程序的时候讲过,设备驱动程序处理中断,分两个过程,一个是屏蔽中断的关键处理逻辑,一个是延迟处理逻辑。当时说工作队列是延迟处理逻辑的处理方案,软中断也是一种方案。
在系统初始化的时候,我们会定义软中断的处理函数。例如,NET_TX_SOFTIRQ的处理函数是net_tx_action,用于发送网络包。还有一个NET_RX_SOFTIRQ的处理函数是net_rx_action,用于接收网络包。接收网络包的过程咱们下一节解析。
open_softirq(NET_TX_SOFTIRQ, net_tx_action);
open_softirq(NET_RX_SOFTIRQ, net_rx_action);这里我们来解析一下net_tx_action。
static __latent_entropy void net_tx_action(struct softirq_action *h)
{
struct softnet_data *sd = this_cpu_ptr(&softnet_data);
......
if (sd->output_queue) {
struct Qdisc *head;
local_irq_disable();
head = sd->output_queue;
sd->output_queue = NULL;
sd->output_queue_tailp = &sd->output_queue;
local_irq_enable();
while (head) {
struct Qdisc *q = head;
spinlock_t *root_lock;
head = head->next_sched;
......
qdisc_run(q);
}
}
}我们会发现,net_tx_action还是调用了qdisc_run,还是会调用__qdisc_run,然后调用qdisc_restart发送网络包。
我们来看一下qdisc_restart的实现。
static inline int qdisc_restart(struct Qdisc *q, int *packets)
{
struct netdev_queue *txq;
struct net_device *dev;
spinlock_t *root_lock;
struct sk_buff *skb;
bool validate;
/* Dequeue packet */
skb = dequeue_skb(q, &validate, packets);
if (unlikely(!skb))
return 0;
root_lock = qdisc_lock(q);
dev = qdisc_dev(q);
txq = skb_get_tx_queue(dev, skb);
return sch_direct_xmit(skb, q, dev, txq, root_lock, validate);
}qdisc_restart将网络包从Qdisc的队列中拿下来,然后调用sch_direct_xmit进行发送。
int sch_direct_xmit(struct sk_buff *skb, struct Qdisc *q,
struct net_device *dev, struct netdev_queue *txq,
spinlock_t *root_lock, bool validate)
{
int ret = NETDEV_TX_BUSY;
if (likely(skb)) {
if (!netif_xmit_frozen_or_stopped(txq))
skb = dev_hard_start_xmit(skb, dev, txq, &ret);
}
......
if (dev_xmit_complete(ret)) {
/* Driver sent out skb successfully or skb was consumed */
ret = qdisc_qlen(q);
} else {
/* Driver returned NETDEV_TX_BUSY - requeue skb */
ret = dev_requeue_skb(skb, q);
}
......
}在sch_direct_xmit中,调用dev_hard_start_xmit进行发送,如果发送不成功,会返回NETDEV_TX_BUSY。这说明网络卡很忙,于是就调用dev_requeue_skb,重新放入队列。
struct sk_buff *dev_hard_start_xmit(struct sk_buff *first, struct net_device *dev, struct netdev_queue *txq, int *ret)
{
struct sk_buff *skb = first;
int rc = NETDEV_TX_OK;
while (skb) {
struct sk_buff *next = skb->next;
rc = xmit_one(skb, dev, txq, next != NULL);
skb = next;
if (netif_xmit_stopped(txq) && skb) {
rc = NETDEV_TX_BUSY;
break;
}
}
......
}在dev_hard_start_xmit中,是一个while循环。每次在队列中取出一个sk_buff,调用xmit_one发送。
接下来的调用链为:xmit_one->netdev_start_xmit->__netdev_start_xmit。
static inline netdev_tx_t __netdev_start_xmit(const struct net_device_ops *ops, struct sk_buff *skb, struct net_device *dev, bool more)
{
skb->xmit_more = more ? 1 : 0;
return ops->ndo_start_xmit(skb, dev);
}这个时候,已经到了设备驱动层了。我们能看到,drivers/net/ethernet/intel/ixgb/ixgb_main.c里面有对于这个网卡的操作的定义。
static const struct net_device_ops ixgb_netdev_ops = {
.ndo_open = ixgb_open,
.ndo_stop = ixgb_close,
.ndo_start_xmit = ixgb_xmit_frame,
.ndo_set_rx_mode = ixgb_set_multi,
.ndo_validate_addr = eth_validate_addr,
.ndo_set_mac_address = ixgb_set_mac,
.ndo_change_mtu = ixgb_change_mtu,
.ndo_tx_timeout = ixgb_tx_timeout,
.ndo_vlan_rx_add_vid = ixgb_vlan_rx_add_vid,
.ndo_vlan_rx_kill_vid = ixgb_vlan_rx_kill_vid,
.ndo_fix_features = ixgb_fix_features,
.ndo_set_features = ixgb_set_features,
};在这里面,我们可以找到对于ndo_start_xmit的定义,调用ixgb_xmit_frame。
static netdev_tx_t
ixgb_xmit_frame(struct sk_buff *skb, struct net_device *netdev)
{
struct ixgb_adapter *adapter = netdev_priv(netdev);
......
if (count) {
ixgb_tx_queue(adapter, count, vlan_id, tx_flags);
/* Make sure there is space in the ring for the next send. */
ixgb_maybe_stop_tx(netdev, &adapter->tx_ring, DESC_NEEDED);
}
......
return NETDEV_TX_OK;
}在ixgb_xmit_frame中,我们会得到这个网卡对应的适配器,然后将其放入硬件网卡的队列中。
至此,整个发送才算结束。
42.3 总结
这一节,我们继续解析了发送一个网络包的过程,我们整个过程的图画在了下面。
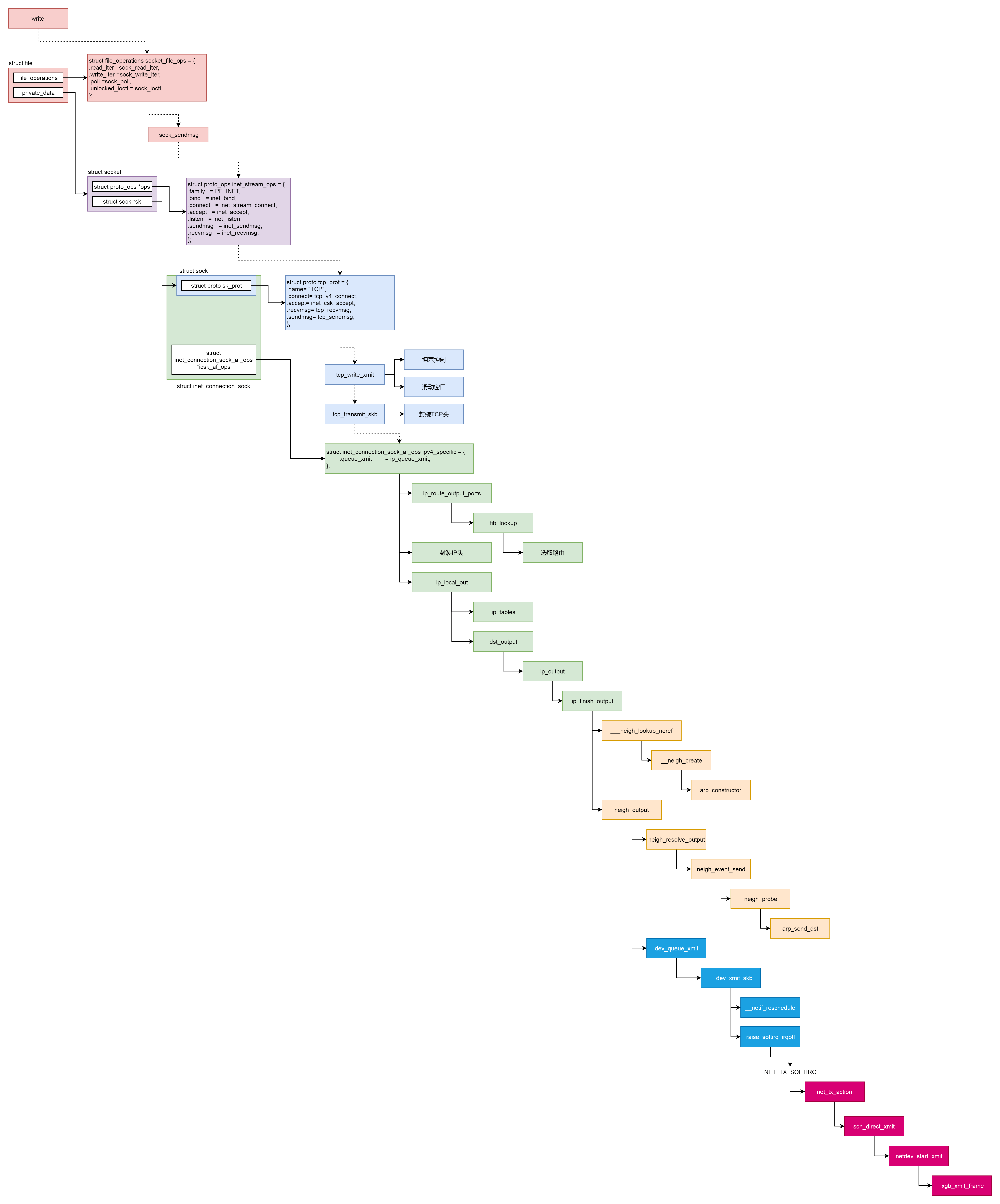
这个过程分成几个层次。
- VFS层:write系统调用找到struct file,根据里面的file_operations的定义,调用sock_write_iter函数。sock_write_iter函数调用sock_sendmsg函数。
- Socket层:从struct file里面的private_data得到struct socket,根据里面ops的定义,调用inet_sendmsg函数。
- Sock层:从struct socket里面的sk得到struct sock,根据里面sk_prot的定义,调用tcp_sendmsg函数。
- TCP层:tcp_sendmsg函数会调用tcp_write_xmit函数,tcp_write_xmit函数会调用tcp_transmit_skb,在这里实现了TCP层面向连接的逻辑。
- IP层:扩展struct sock,得到struct inet_connection_sock,根据里面icsk_af_ops的定义,调用ip_queue_xmit函数。
- IP层:ip_route_output_ports函数里面会调用fib_lookup查找路由表。FIB全称是Forwarding Information Base,转发信息表,也就是路由表。
- 在IP层里面要做的另一个事情是填写IP层的头。
- 在IP层还要做的一件事情就是通过iptables规则。
- MAC层:IP层调用ip_finish_output进行MAC层。
- MAC层需要ARP获得MAC地址,因而要调用___neigh_lookup_noref查找属于同一个网段的邻居,他会调用neigh_probe发送ARP。
- 有了MAC地址,就可以调用dev_queue_xmit发送二层网络包了,它会调用__dev_xmit_skb会将请求放入队列。
- 设备层:网络包的发送回触发一个软中断NET_TX_SOFTIRQ来处理队列中的数据。这个软中断的处理函数是net_tx_action。
- 在软中断处理函数中,会将网络包从队列上拿下来,调用网络设备的传输函数ixgb_xmit_frame,将网络包发的设备的队列上去。
43. 接收网络包(上)
如果说网络包的发送是从应用层开始,层层调用,一直到网卡驱动程序的话,网络包的结束过程,就是一个反过来的过程,我们不能从应用层的读取开始,而应该从网卡接收到一个网络包开始。我们用两节来解析这个过程,这一节我们从硬件网卡解析到IP层,下一节,我们从IP层解析到Socket层。
43.1 设备驱动层
网卡作为一个硬件,接收到网络包,应该怎么通知操作系统,这个网络包到达了呢?咱们学习过输入输出设备和中断。没错,我们可以触发一个中断。但是这里有个问题,就是网络包的到来,往往是很难预期的。网络吞吐量比较大的时候,网络包的到达会十分频繁。这个时候,如果非常频繁地去触发中断,想想就觉得是个灾难。
比如说,CPU正在做某个事情,一些网络包来了,触发了中断,CPU停下手里的事情,去处理这些网络包,处理完毕按照中断处理的逻辑,应该回去继续处理其他事情。这个时候,另一些网络包又来了,又触发了中断,CPU手里的事情还没捂热,又要停下来去处理网络包。能不能大家要来的一起来,把网络包好好处理一把,然后再回去集中处理其他事情呢?
网络包能不能一起来,这个我们没法儿控制,但是我们可以有一种机制,就是当一些网络包到来触发了中断,内核处理完这些网络包之后,我们可以先进入主动轮询poll网卡的方式,主动去接收到来的网络包。如果一直有,就一直处理,等处理告一段落,就返回干其他的事情。当再有下一批网络包到来的时候,再中断,再轮询poll。这样就会大大减少中断的数量,提升网络处理的效率,这种处理方式我们称为NAPI。
为了帮你了解设备驱动层的工作机制,我们还是以上一节发送网络包时的网卡drivers/net/ethernet/intel/ixgb/ixgb_main.c为例子,来进行解析。
static struct pci_driver ixgb_driver = {
.name = ixgb_driver_name,
.id_table = ixgb_pci_tbl,
.probe = ixgb_probe,
.remove = ixgb_remove,
.err_handler = &ixgb_err_handler
};
MODULE_AUTHOR("Intel Corporation, <linux.nics@intel.com>");
MODULE_DESCRIPTION("Intel(R) PRO/10GbE Network Driver");
MODULE_LICENSE("GPL");
MODULE_VERSION(DRV_VERSION);
/**
* ixgb_init_module - Driver Registration Routine
*
* ixgb_init_module is the first routine called when the driver is
* loaded. All it does is register with the PCI subsystem.
**/
static int __init
ixgb_init_module(void)
{
pr_info("%s - version %s\n", ixgb_driver_string, ixgb_driver_version);
pr_info("%s\n", ixgb_copyright);
return pci_register_driver(&ixgb_driver);
}
module_init(ixgb_init_module);在网卡驱动程序初始化的时候,我们会调用ixgb_init_module,注册一个驱动ixgb_driver,并且调用它的probe函数ixgb_probe。
static int
ixgb_probe(struct pci_dev *pdev, const struct pci_device_id *ent)
{
struct net_device *netdev = NULL;
struct ixgb_adapter *adapter;
......
netdev = alloc_etherdev(sizeof(struct ixgb_adapter));
SET_NETDEV_DEV(netdev, &pdev->dev);
pci_set_drvdata(pdev, netdev);
adapter = netdev_priv(netdev);
adapter->netdev = netdev;
adapter->pdev = pdev;
adapter->hw.back = adapter;
adapter->msg_enable = netif_msg_init(debug, DEFAULT_MSG_ENABLE);
adapter->hw.hw_addr = pci_ioremap_bar(pdev, BAR_0);
......
netdev->netdev_ops = &ixgb_netdev_ops;
ixgb_set_ethtool_ops(netdev);
netdev->watchdog_timeo = 5 * HZ;
netif_napi_add(netdev, &adapter->napi, ixgb_clean, 64);
strncpy(netdev->name, pci_name(pdev), sizeof(netdev->name) - 1);
adapter->bd_number = cards_found;
adapter->link_speed = 0;
adapter->link_duplex = 0;
......
}在ixgb_probe中,我们会创建一个struct net_device表示这个网络设备,并且netif_napi_add函数为这个网络设备注册一个轮询poll函数ixgb_clean,将来一旦出现网络包的时候,就是要通过他来轮询了。
当一个网卡被激活的时候,我们会调用函数ixgb_open->ixgb_up,在这里面注册一个硬件的中断处理函数。
int
ixgb_up(struct ixgb_adapter *adapter)
{
struct net_device *netdev = adapter->netdev;
......
err = request_irq(adapter->pdev->irq, ixgb_intr, irq_flags,
netdev->name, netdev);
......
}
/**
* ixgb_intr - Interrupt Handler
* @irq: interrupt number
* @data: pointer to a network interface device structure
**/
static irqreturn_t
ixgb_intr(int irq, void *data)
{
struct net_device *netdev = data;
struct ixgb_adapter *adapter = netdev_priv(netdev);
struct ixgb_hw *hw = &adapter->hw;
......
if (napi_schedule_prep(&adapter->napi)) {
IXGB_WRITE_REG(&adapter->hw, IMC, ~0);
__napi_schedule(&adapter->napi);
}
return IRQ_HANDLED;
}如果一个网络包到来,触发了硬件中断,就会调用ixgb_intr,这里面会调用__napi_schedule。
/**
* __napi_schedule - schedule for receive
* @n: entry to schedule
*
* The entry's receive function will be scheduled to run.
* Consider using __napi_schedule_irqoff() if hard irqs are masked.
*/
void __napi_schedule(struct napi_struct *n)
{
unsigned long flags;
local_irq_save(flags);
____napi_schedule(this_cpu_ptr(&softnet_data), n);
local_irq_restore(flags);
}
static inline void ____napi_schedule(struct softnet_data *sd,
struct napi_struct *napi)
{
list_add_tail(&napi->poll_list, &sd->poll_list);
__raise_softirq_irqoff(NET_RX_SOFTIRQ);
}__napi_schedule是处于中断处理的关键部分,在他被调用的时候,中断是暂时关闭的,但是处理网络包是个复杂的过程,需要到延迟处理部分,所以____napi_schedule将当前设备放到struct softnet_data结构的poll_list里面,说明在延迟处理部分可以接着处理这个poll_list里面的网络设备。
然后____napi_schedule触发一个软中断NET_RX_SOFTIRQ,通过软中断触发中断处理的延迟处理部分,也是常用的手段。
上一节,我们知道,软中断NET_RX_SOFTIRQ对应的中断处理函数是net_rx_action。
static __latent_entropy void net_rx_action(struct softirq_action *h)
{
struct softnet_data *sd = this_cpu_ptr(&softnet_data);
LIST_HEAD(list);
list_splice_init(&sd->poll_list, &list);
......
for (;;) {
struct napi_struct *n;
......
n = list_first_entry(&list, struct napi_struct, poll_list);
budget -= napi_poll(n, &repoll);
}
......
}在net_rx_action中,会得到struct softnet_data结构,这个结构在发送的时候我们也遇到过。当时它的output_queue用于网络包的发送,这里的poll_list用于网络包的接收。
struct softnet_data {
struct list_head poll_list;
......
struct Qdisc *output_queue;
struct Qdisc **output_queue_tailp;
......
}在net_rx_action中,接下来是一个循环,在poll_list里面取出网络包到达的设备,然后调用napi_poll来轮询这些设备,napi_poll会调用最初设备初始化的时候,注册的poll函数,对于ixgb_driver,对应的函数是ixgb_clean。
ixgb_clean会调用ixgb_clean_rx_irq。
static bool
ixgb_clean_rx_irq(struct ixgb_adapter *adapter, int *work_done, int work_to_do)
{
struct ixgb_desc_ring *rx_ring = &adapter->rx_ring;
struct net_device *netdev = adapter->netdev;
struct pci_dev *pdev = adapter->pdev;
struct ixgb_rx_desc *rx_desc, *next_rxd;
struct ixgb_buffer *buffer_info, *next_buffer, *next2_buffer;
u32 length;
unsigned int i, j;
int cleaned_count = 0;
bool cleaned = false;
i = rx_ring->next_to_clean;
rx_desc = IXGB_RX_DESC(*rx_ring, i);
buffer_info = &rx_ring->buffer_info[i];
while (rx_desc->status & IXGB_RX_DESC_STATUS_DD) {
struct sk_buff *skb;
u8 status;
status = rx_desc->status;
skb = buffer_info->skb;
buffer_info->skb = NULL;
prefetch(skb->data - NET_IP_ALIGN);
if (++i == rx_ring->count)
i = 0;
next_rxd = IXGB_RX_DESC(*rx_ring, i);
prefetch(next_rxd);
j = i + 1;
if (j == rx_ring->count)
j = 0;
next2_buffer = &rx_ring->buffer_info[j];
prefetch(next2_buffer);
next_buffer = &rx_ring->buffer_info[i];
......
length = le16_to_cpu(rx_desc->length);
rx_desc->length = 0;
......
ixgb_check_copybreak(&adapter->napi, buffer_info, length, &skb);
/* Good Receive */
skb_put(skb, length);
/* Receive Checksum Offload */
ixgb_rx_checksum(adapter, rx_desc, skb);
skb->protocol = eth_type_trans(skb, netdev);
netif_receive_skb(skb);
......
/* use prefetched values */
rx_desc = next_rxd;
buffer_info = next_buffer;
}
rx_ring->next_to_clean = i;
......
}在网络设备的驱动层,有一个用于接收网络包的rx_ring。它是一个环,从网卡硬件接收的包会放在这个环里面。这个环里面的buffer_info[]是一个数组,存放的是网络包的内容。i和j是这个数组的下标,在ixgb_clean_rx_irq里面的while循环中,依次处理环里面的数据。在这里面,我们看到了i和j加一之后,如果超过了数组的大小,就跳回下标0,就说明这是一个环。
ixgb_check_copybreak函数将buffer_info里面的内容,拷贝到struct sk_buff *skb,从而可以作为一个网络包进行后续的处理,然后调用netif_receive_skb。
43.2 网络协议栈的二层逻辑
从netif_receive_skb函数开始,我们就进入了内核的网络协议栈。
接下来的调用链为:netif_receive_skb->netif_receive_skb_internal->__netif_receive_skb->__netif_receive_skb_core。
在__netif_receive_skb_core中,我们先是处理了二层的一些逻辑。例如,对于VLAN的处理,接下来要想办法交给第三层。
static int __netif_receive_skb_core(struct sk_buff *skb, bool pfmemalloc)
{
struct packet_type *ptype, *pt_prev;
......
type = skb->protocol;
......
deliver_ptype_list_skb(skb, &pt_prev, orig_dev, type,
&orig_dev->ptype_specific);
if (pt_prev) {
ret = pt_prev->func(skb, skb->dev, pt_prev, orig_dev);
}
......
}
static inline void deliver_ptype_list_skb(struct sk_buff *skb,
struct packet_type **pt,
struct net_device *orig_dev,
__be16 type,
struct list_head *ptype_list)
{
struct packet_type *ptype, *pt_prev = *pt;
list_for_each_entry_rcu(ptype, ptype_list, list) {
if (ptype->type != type)
continue;
if (pt_prev)
deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype;
}
*pt = pt_prev;
}在网络包struct sk_buff里面,二层的头里面有一个protocol,表示里面一层,也即三层是什么协议。deliver_ptype_list_skb在一个协议列表中逐个匹配。如果能够匹配到,就返回。
这些协议的注册在网络协议栈初始化的时候, inet_init函数调用dev_add_pack(&ip_packet_type),添加IP协议。协议被放在一个链表里面。
void dev_add_pack(struct packet_type *pt)
{
struct list_head *head = ptype_head(pt);
list_add_rcu(&pt->list, head);
}
static inline struct list_head *ptype_head(const struct packet_type *pt)
{
if (pt->type == htons(ETH_P_ALL))
return pt->dev ? &pt->dev->ptype_all : &ptype_all;
else
return pt->dev ? &pt->dev->ptype_specific : &ptype_base[ntohs(pt->type) & PTYPE_HASH_MASK];
}假设这个时候的网络包是一个IP包,则在这个链表里面一定能够找到ip_packet_type,在__netif_receive_skb_core中会调用ip_packet_type的func函数。
static struct packet_type ip_packet_type __read_mostly = {
.type = cpu_to_be16(ETH_P_IP),
.func = ip_rcv,
};从上面的定义我们可以看出,接下来,ip_rcv会被调用。
43.3 网络协议栈的IP层
从ip_rcv函数开始,我们的处理逻辑就从二层到了三层,IP层。
int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt,
struct net_device *orig_dev)
{
const struct iphdr *iph;
struct net *net;
u32 len;
......
net = dev_net(dev);
......
iph = ip_hdr(skb);
len = ntohs(iph->tot_len);
skb->transport_header = skb->network_header + iph->ihl*4;
......
return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING,
net, NULL, skb, dev, NULL,
ip_rcv_finish);
......
}在ip_rcv中,得到IP头,然后又遇到了我们见过多次的NF_HOOK,这次因为是接收网络包,第一个hook点是NF_INET_PRE_ROUTING,也就是iptables的PREROUTING链。如果里面有规则,则执行规则,然后调用ip_rcv_finish。
static int ip_rcv_finish(struct net *net, struct sock *sk, struct sk_buff *skb)
{
const struct iphdr *iph = ip_hdr(skb);
struct net_device *dev = skb->dev;
struct rtable *rt;
int err;
......
rt = skb_rtable(skb);
.....
return dst_input(skb);
}
static inline int dst_input(struct sk_buff *skb)
{
return skb_dst(skb)->input(skb);
}ip_rcv_finish得到网络包对应的路由表,然后调用dst_input,在dst_input中,调用的是struct rtable的成员的dst的input函数。在rt_dst_alloc中,我们可以看到,input函数指向的是ip_local_deliver。
int ip_local_deliver(struct sk_buff *skb)
{
/*
* Reassemble IP fragments.
*/
struct net *net = dev_net(skb->dev);
if (ip_is_fragment(ip_hdr(skb))) {
if (ip_defrag(net, skb, IP_DEFRAG_LOCAL_DELIVER))
return 0;
}
return NF_HOOK(NFPROTO_IPV4, NF_INET_LOCAL_IN,
net, NULL, skb, skb->dev, NULL,
ip_local_deliver_finish);
}在ip_local_deliver函数中,如果IP层进行了分段,则进行重新的组合。接下来就是我们熟悉的NF_HOOK。hook点在NF_INET_LOCAL_IN,对应iptables里面的INPUT链。在经过iptables规则处理完毕后,我们调用ip_local_deliver_finish。
static int ip_local_deliver_finish(struct net *net, struct sock *sk, struct sk_buff *skb)
{
__skb_pull(skb, skb_network_header_len(skb));
int protocol = ip_hdr(skb)->protocol;
const struct net_protocol *ipprot;
ipprot = rcu_dereference(inet_protos[protocol]);
if (ipprot) {
int ret;
ret = ipprot->handler(skb);
......
}
......
}在IP头中,有一个字段protocol用于指定里面一层的协议,在这里应该是TCP协议。于是,从inet_protos数组中,找出TCP协议对应的处理函数。这个数组的定义如下,里面的内容是struct net_protocol。
struct net_protocol __rcu *inet_protos[MAX_INET_PROTOS] __read_mostly;
int inet_add_protocol(const struct net_protocol *prot, unsigned char protocol)
{
......
return !cmpxchg((const struct net_protocol **)&inet_protos[protocol],
NULL, prot) ? 0 : -1;
}
static int __init inet_init(void)
{
......
if (inet_add_protocol(&udp_protocol, IPPROTO_UDP) < 0)
pr_crit("%s: Cannot add UDP protocol\n", __func__);
if (inet_add_protocol(&tcp_protocol, IPPROTO_TCP) < 0)
pr_crit("%s: Cannot add TCP protocol\n", __func__);
......
}
static struct net_protocol tcp_protocol = {
.early_demux = tcp_v4_early_demux,
.early_demux_handler = tcp_v4_early_demux,
.handler = tcp_v4_rcv,
.err_handler = tcp_v4_err,
.no_policy = 1,
.netns_ok = 1,
.icmp_strict_tag_validation = 1,
};
static struct net_protocol udp_protocol = {
.early_demux = udp_v4_early_demux,
.early_demux_handler = udp_v4_early_demux,
.handler = udp_rcv,
.err_handler = udp_err,
.no_policy = 1,
.netns_ok = 1,
};在系统初始化的时候,网络协议栈的初始化调用的是inet_init,它会调用inet_add_protocol,将TCP协议对应的处理函数tcp_protocol、UDP协议对应的处理函数udp_protocol,放到inet_protos数组中。
在上面的网络包的接收过程中,会取出TCP协议对应的处理函数tcp_protocol,然后调用handler函数,也即tcp_v4_rcv函数。
43.4 总结
这一节我们讲了接收网络包的上半部分,分以下几个层次。
- 硬件网卡接收到网络包之后,通过DMA技术,将网络包放入Ring Buffer。
- 硬件网卡通过中断通知CPU新的网络包的到来。
- 网卡驱动程序会注册中断处理函数ixgb_intr。
- 中断处理函数处理完需要暂时屏蔽中断的核心流程之后,通过软中断NET_RX_SOFTIRQ触发接下来的处理过程。
- NET_RX_SOFTIRQ软中断处理函数net_rx_action,net_rx_action会调用napi_poll,进而调用ixgb_clean_rx_irq,从Ring Buffer中读取数据到内核struct sk_buff。
- 调用netif_receive_skb进入内核网络协议栈,进行一些关于VLAN的二层逻辑处理后,调用ip_rcv进入三层IP层。
- 在IP层,会处理iptables规则,然后调用ip_local_deliver,交给更上层TCP层。
- 在TCP层调用tcp_v4_rcv。
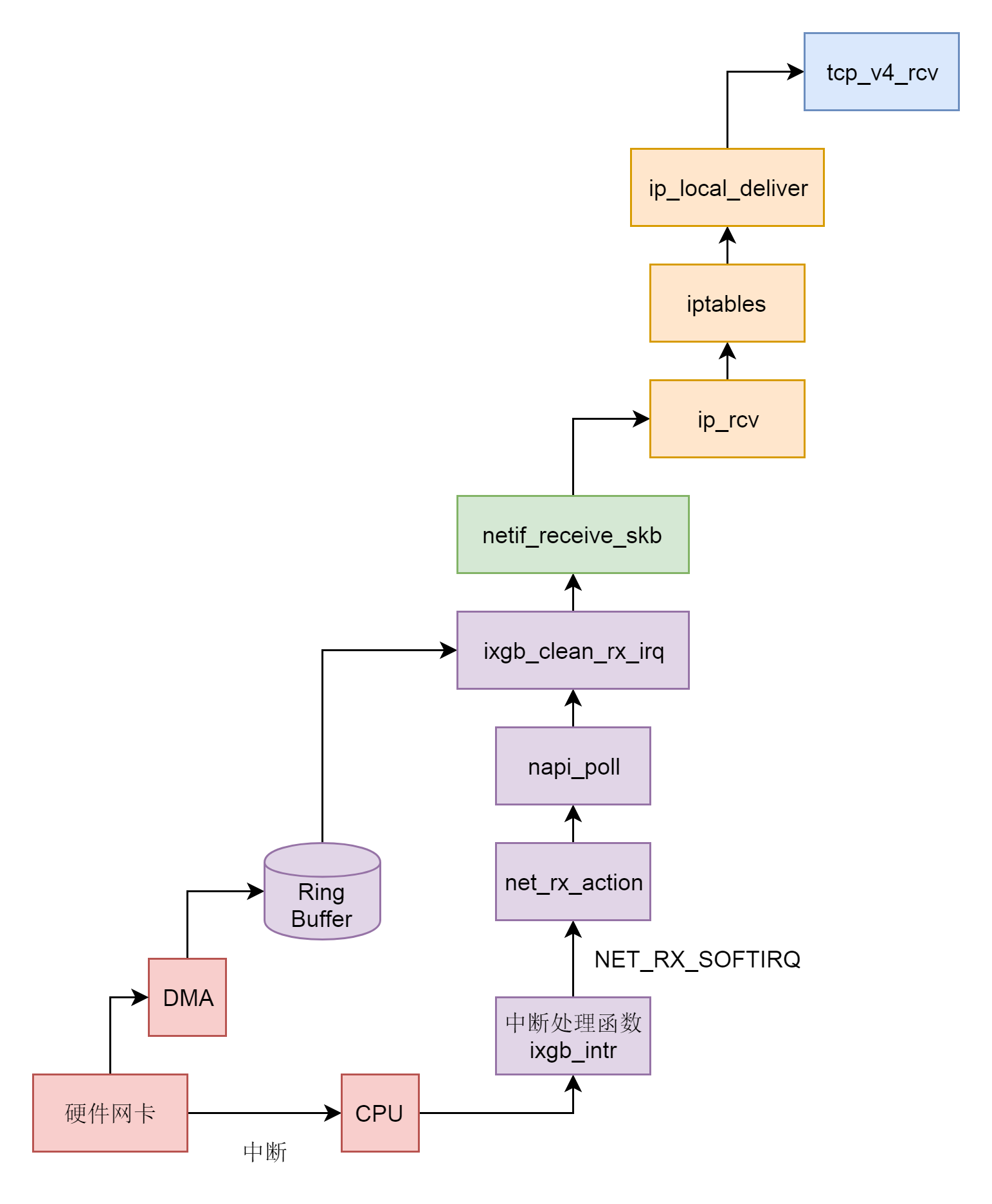
44. 接收网络包(下)
上一节,我们解析了网络包接收的上半部分,从硬件网卡到IP层。这一节,我们接着来解析TCP层和Socket层都做了哪些事情。
44.1 网络协议栈的TCP层
从tcp_v4_rcv函数开始,我们的处理逻辑就从IP层到了TCP层。
int tcp_v4_rcv(struct sk_buff *skb)
{
struct net *net = dev_net(skb->dev);
const struct iphdr *iph;
const struct tcphdr *th;
bool refcounted;
struct sock *sk;
int ret;
......
th = (const struct tcphdr *)skb->data;
iph = ip_hdr(skb);
......
TCP_SKB_CB(skb)->seq = ntohl(th->seq);
TCP_SKB_CB(skb)->end_seq = (TCP_SKB_CB(skb)->seq + th->syn + th->fin + skb->len - th->doff * 4);
TCP_SKB_CB(skb)->ack_seq = ntohl(th->ack_seq);
TCP_SKB_CB(skb)->tcp_flags = tcp_flag_byte(th);
TCP_SKB_CB(skb)->tcp_tw_isn = 0;
TCP_SKB_CB(skb)->ip_dsfield = ipv4_get_dsfield(iph);
TCP_SKB_CB(skb)->sacked = 0;
lookup:
sk = __inet_lookup_skb(&tcp_hashinfo, skb, __tcp_hdrlen(th), th->source, th->dest, &refcounted);
process:
if (sk->sk_state == TCP_TIME_WAIT)
goto do_time_wait;
if (sk->sk_state == TCP_NEW_SYN_RECV) {
......
}
......
th = (const struct tcphdr *)skb->data;
iph = ip_hdr(skb);
skb->dev = NULL;
if (sk->sk_state == TCP_LISTEN) {
ret = tcp_v4_do_rcv(sk, skb);
goto put_and_return;
}
......
if (!sock_owned_by_user(sk)) {
if (!tcp_prequeue(sk, skb))
ret = tcp_v4_do_rcv(sk, skb);
} else if (tcp_add_backlog(sk, skb)) {
goto discard_and_relse;
}
......
}在tcp_v4_rcv中,得到TCP的头之后,我们可以开始处理TCP层的事情。因为TCP层是分状态的,状态被维护在数据结构struct sock里面,因而我们要根据IP地址以及TCP头里面的内容,在tcp_hashinfo中找到这个包对应的struct sock,从而得到这个包对应的连接的状态。
接下来,我们就根据不同的状态做不同的处理,例如,上面代码中的TCP_LISTEN、TCP_NEW_SYN_RECV状态属于连接建立过程中。这个我们在讲三次握手的时候讲过了。再如,TCP_TIME_WAIT状态是连接结束的时候的状态,这个我们暂时可以不用看。
接下来,我们来分析最主流的网络包的接收过程,这里面涉及三个队列:
- backlog队列
- prequeue队列
- sk_receive_queue队列
为什么接收网络包的过程,需要在这三个队列里面倒腾过来、倒腾过去呢?这是因为,同样一个网络包要在三个主体之间交接。
第一个主体是软中断的处理过程。如果你没忘记的话,我们在执行tcp_v4_rcv函数的时候,依然处于软中断的处理逻辑里,所以必然会占用这个软中断。
第二个主体就是用户态进程。如果用户态触发系统调用read读取网络包,也要从队列里面找。
第三个主体就是内核协议栈。哪怕用户进程没有调用read,读取网络包,当网络包来的时候,也得有一个地方收着呀。
这时候,我们就能够了解上面代码中sock_owned_by_user的意思了,其实就是说,当前这个sock是不是正有一个用户态进程等着读数据呢,如果没有,内核协议栈也调用tcp_add_backlog,暂存在backlog队列中,并且抓紧离开软中断的处理过程。
如果有一个用户态进程等待读取数据呢?我们先调用tcp_prequeue,也即赶紧放入prequeue队列,并且离开软中断的处理过程。在这个函数里面,我们会看到对于sysctl_tcp_low_latency的判断,也即是不是要低时延地处理网络包。
如果把sysctl_tcp_low_latency设置为0,那就要放在prequeue队列中暂存,这样不用等待网络包处理完毕,就可以离开软中断的处理过程,但是会造成比较长的时延。如果把sysctl_tcp_low_latency设置为1,我们还是调用tcp_v4_do_rcv。
int tcp_v4_do_rcv(struct sock *sk, struct sk_buff *skb)
{
struct sock *rsk;
if (sk->sk_state == TCP_ESTABLISHED) { /* Fast path */
struct dst_entry *dst = sk->sk_rx_dst;
......
tcp_rcv_established(sk, skb, tcp_hdr(skb), skb->len);
return 0;
}
......
if (tcp_rcv_state_process(sk, skb)) {
......
}
return 0;
......
}在tcp_v4_do_rcv中,分两种情况,一种情况是连接已经建立,处于TCP_ESTABLISHED状态,调用tcp_rcv_established。另一种情况,就是其他的状态,调用tcp_rcv_state_process。
int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb)
{
struct tcp_sock *tp = tcp_sk(sk);
struct inet_connection_sock *icsk = inet_csk(sk);
const struct tcphdr *th = tcp_hdr(skb);
struct request_sock *req;
int queued = 0;
bool acceptable;
switch (sk->sk_state) {
case TCP_CLOSE:
......
case TCP_LISTEN:
......
case TCP_SYN_SENT:
......
}
......
switch (sk->sk_state) {
case TCP_SYN_RECV:
......
case TCP_FIN_WAIT1:
......
case TCP_CLOSING:
......
case TCP_LAST_ACK:
......
}
/* step 7: process the segment text */
switch (sk->sk_state) {
case TCP_CLOSE_WAIT:
case TCP_CLOSING:
case TCP_LAST_ACK:
......
case TCP_FIN_WAIT1:
case TCP_FIN_WAIT2:
......
case TCP_ESTABLISHED:
......
}
}在tcp_rcv_state_process中,如果我们对着TCP的状态图进行比对,能看到,对于TCP所有状态的处理,其中和连接建立相关的状态,咱们已经分析过,所以我们重点关注连接状态下的工作模式。
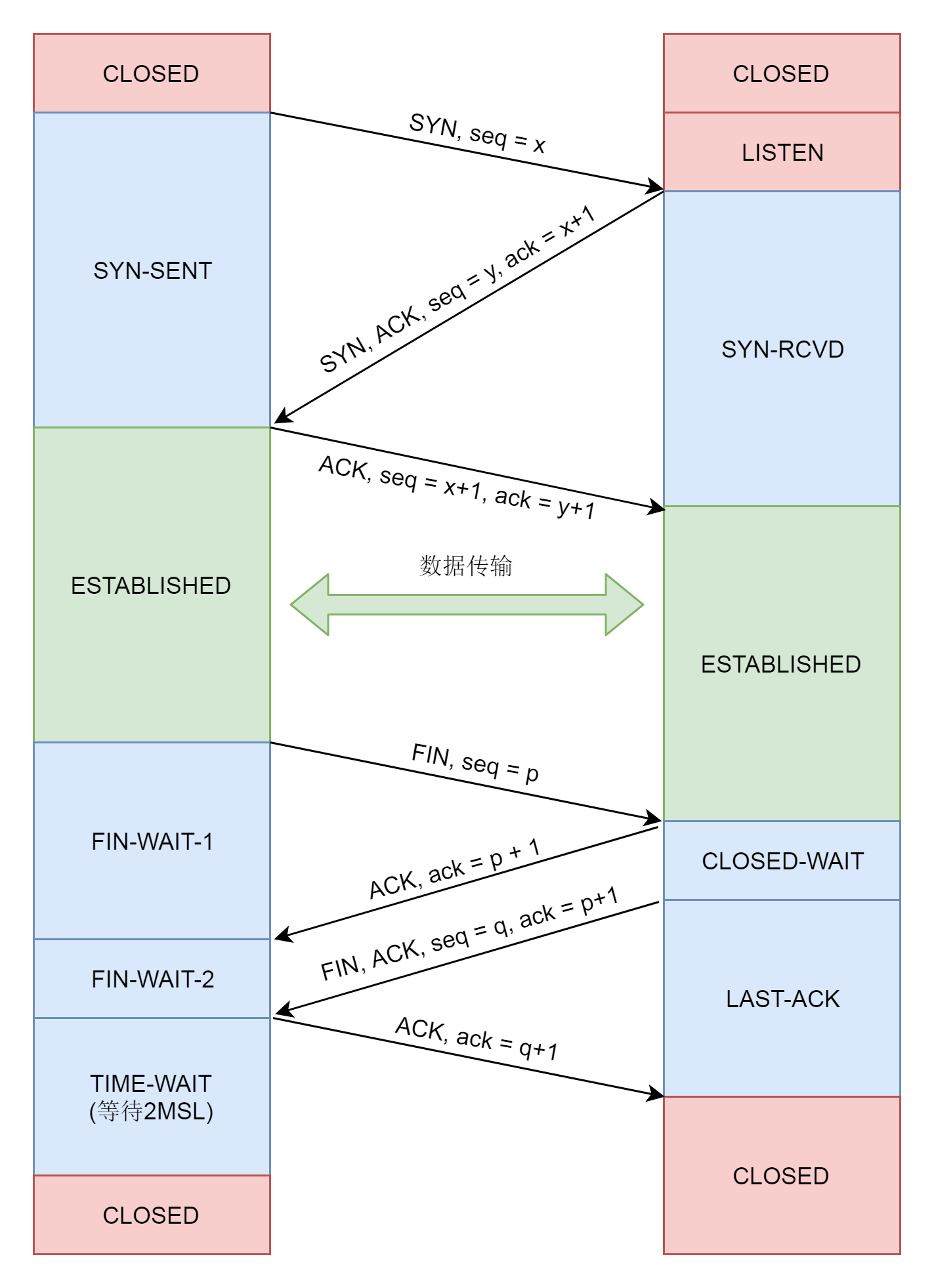
在连接状态下,我们会调用tcp_rcv_established。在这个函数里面,我们会调用tcp_data_queue,将其放入sk_receive_queue队列进行处理。
static void tcp_data_queue(struct sock *sk, struct sk_buff *skb)
{
struct tcp_sock *tp = tcp_sk(sk);
bool fragstolen = false;
......
if (TCP_SKB_CB(skb)->seq == tp->rcv_nxt) {
if (tcp_receive_window(tp) == 0)
goto out_of_window;
/* Ok. In sequence. In window. */
if (tp->ucopy.task == current &&
tp->copied_seq == tp->rcv_nxt && tp->ucopy.len &&
sock_owned_by_user(sk) && !tp->urg_data) {
int chunk = min_t(unsigned int, skb->len,
tp->ucopy.len);
__set_current_state(TASK_RUNNING);
if (!skb_copy_datagram_msg(skb, 0, tp->ucopy.msg, chunk)) {
tp->ucopy.len -= chunk;
tp->copied_seq += chunk;
eaten = (chunk == skb->len);
tcp_rcv_space_adjust(sk);
}
}
if (eaten <= 0) {
queue_and_out:
......
eaten = tcp_queue_rcv(sk, skb, 0, &fragstolen);
}
tcp_rcv_nxt_update(tp, TCP_SKB_CB(skb)->end_seq);
......
if (!RB_EMPTY_ROOT(&tp->out_of_order_queue)) {
tcp_ofo_queue(sk);
......
}
......
return;
}
if (!after(TCP_SKB_CB(skb)->end_seq, tp->rcv_nxt)) {
/* A retransmit, 2nd most common case. Force an immediate ack. */
tcp_dsack_set(sk, TCP_SKB_CB(skb)->seq, TCP_SKB_CB(skb)->end_seq);
out_of_window:
tcp_enter_quickack_mode(sk);
inet_csk_schedule_ack(sk);
drop:
tcp_drop(sk, skb);
return;
}
/* Out of window. F.e. zero window probe. */
if (!before(TCP_SKB_CB(skb)->seq, tp->rcv_nxt + tcp_receive_window(tp)))
goto out_of_window;
tcp_enter_quickack_mode(sk);
if (before(TCP_SKB_CB(skb)->seq, tp->rcv_nxt)) {
/* Partial packet, seq < rcv_next < end_seq */
tcp_dsack_set(sk, TCP_SKB_CB(skb)->seq, tp->rcv_nxt);
/* If window is closed, drop tail of packet. But after
* remembering D-SACK for its head made in previous line.
*/
if (!tcp_receive_window(tp))
goto out_of_window;
goto queue_and_out;
}
tcp_data_queue_ofo(sk, skb);
}在tcp_data_queue中,对于收到的网络包,我们要分情况进行处理。
第一种情况,seq == tp->rcv_nxt,说明来的网络包正是我服务端期望的下一个网络包。这个时候我们判断sock_owned_by_user,也即用户进程也是正在等待读取,这种情况下,就直接skb_copy_datagram_msg,将网络包拷贝给用户进程就可以了。
如果用户进程没有正在等待读取,或者因为内存原因没有能够拷贝成功,tcp_queue_rcv里面还是将网络包放入sk_receive_queue队列。
接下来,tcp_rcv_nxt_update将tp->rcv_nxt设置为end_seq,也即当前的网络包接收成功后,更新下一个期待的网络包。
这个时候,我们还会判断一下另一个队列,out_of_order_queue,也看看乱序队列的情况,看看乱序队列里面的包,会不会因为这个新的网络包的到来,也能放入到sk_receive_queue队列中。
例如,客户端发送的网络包序号为5、6、7、8、9。在5还没有到达的时候,服务端的rcv_nxt应该是5,也即期望下一个网络包是5。但是由于中间网络通路的问题,5、6还没到达服务端,7、8已经到达了服务端了,这就出现了乱序。
乱序的包不能进入sk_receive_queue队列。因为一旦进入到这个队列,意味着可以发送给用户进程。然而,按照TCP的定义,用户进程应该是按顺序收到包的,没有排好序,就不能给用户进程。所以,7、8不能进入sk_receive_queue队列,只能暂时放在out_of_order_queue乱序队列中。
当5、6到达的时候,5、6先进入sk_receive_queue队列。这个时候我们再来看out_of_order_queue乱序队列中的7、8,发现能够接上。于是,7、8也能进入sk_receive_queue队列了。tcp_ofo_queue函数就是做这个事情的。
至此第一种情况处理完毕。
第二种情况,end_seq不大于rcv_nxt,也即服务端期望网络包5。但是,来了一个网络包3,怎样才会出现这种情况呢?肯定是服务端早就收到了网络包3,但是ACK没有到达客户端,中途丢了,那客户端就认为网络包3没有发送成功,于是又发送了一遍,这种情况下,要赶紧给客户端再发送一次ACK,表示早就收到了。
第三种情况,seq不小于rcv_nxt + tcp_receive_window。这说明客户端发送得太猛了。本来seq肯定应该在接收窗口里面的,这样服务端才来得及处理,结果现在超出了接收窗口,说明客户端一下子把服务端给塞满了。
这种情况下,服务端不能再接收数据包了,只能发送ACK了,在ACK中会将接收窗口为0的情况告知客户端,客户端就知道不能再发送了。这个时候双方只能交互窗口探测数据包,直到服务端因为用户进程把数据读走了,空出接收窗口,才能在ACK里面再次告诉客户端,又有窗口了,又能发送数据包了。
第四种情况,seq小于rcv_nxt,但是end_seq大于rcv_nxt,这说明从seq到rcv_nxt这部分网络包原来的ACK客户端没有收到,所以重新发送了一次,从rcv_nxt到end_seq时新发送的,可以放入sk_receive_queue队列。
当前四种情况都排除掉了,说明网络包一定是一个乱序包了。这里有点儿难理解,我们还是用上面那个乱序的例子仔细分析一下rcv_nxt=5。
我们假设tcp_receive_window也是5,也即超过10服务端就接收不了了。当前来的这个网络包既不在rcv_nxt之前(不是3这种),也不在rcv_nxt + tcp_receive_window之后(不是11这种),说明这正在我们期望的接收窗口里面,但是又不是rcv_nxt(不是我们马上期望的网络包5),这正是上面的例子中网络包7、8的情况。
对于网络包7、8,我们只好调用tcp_data_queue_ofo进入out_of_order_queue乱序队列,但是没有关系,当网络包5、6到来的时候,我们会走第一种情况,把7、8拿出来放到sk_receive_queue队列中。
至此,网络协议栈的处理过程就结束了。
44.2 Socket层
当接收的网络包进入各种队列之后,接下来我们就要等待用户进程去读取它们了。
读取一个socket,就像读取一个文件一样,读取socket的文件描述符,通过read系统调用。
read系统调用对于一个文件描述符的操作,大致过程都是类似的,在文件系统那一节,我们已经详细解析过。最终它会调用到用来表示一个打开文件的结构stuct file指向的file_operations操作。
对于socket来讲,它的file_operations定义如下:
static const struct file_operations socket_file_ops = {
.owner = THIS_MODULE,
.llseek = no_llseek,
.read_iter = sock_read_iter,
.write_iter = sock_write_iter,
.poll = sock_poll,
.unlocked_ioctl = sock_ioctl,
.mmap = sock_mmap,
.release = sock_close,
.fasync = sock_fasync,
.sendpage = sock_sendpage,
.splice_write = generic_splice_sendpage,
.splice_read = sock_splice_read,
};按照文件系统的读取流程,调用的是sock_read_iter。
static ssize_t sock_read_iter(struct kiocb *iocb, struct iov_iter *to)
{
struct file *file = iocb->ki_filp;
struct socket *sock = file->private_data;
struct msghdr msg = {.msg_iter = *to,
.msg_iocb = iocb};
ssize_t res;
if (file->f_flags & O_NONBLOCK)
msg.msg_flags = MSG_DONTWAIT;
......
res = sock_recvmsg(sock, &msg, msg.msg_flags);
*to = msg.msg_iter;
return res;
}在sock_read_iter中,通过VFS中的struct file,将创建好的socket结构拿出来,然后调用sock_recvmsg,sock_recvmsg会调用sock_recvmsg_nosec。
static inline int sock_recvmsg_nosec(struct socket *sock, struct msghdr *msg, int flags)
{
return sock->ops->recvmsg(sock, msg, msg_data_left(msg), flags);
}这里调用了socket的ops的recvmsg,这个我们遇到好几次了。根据inet_stream_ops的定义,这里调用的是inet_recvmsg。
int inet_recvmsg(struct socket *sock, struct msghdr *msg, size_t size,
int flags)
{
struct sock *sk = sock->sk;
int addr_len = 0;
int err;
......
err = sk->sk_prot->recvmsg(sk, msg, size, flags & MSG_DONTWAIT,
flags & ~MSG_DONTWAIT, &addr_len);
......
}这里面,从socket结构,我们可以得到更底层的sock结构,然后调用sk_prot的recvmsg方法。这个同样遇到好几次了,根据tcp_prot的定义,调用的是tcp_recvmsg。
int tcp_recvmsg(struct sock *sk, struct msghdr *msg, size_t len, int nonblock,
int flags, int *addr_len)
{
struct tcp_sock *tp = tcp_sk(sk);
int copied = 0;
u32 peek_seq;
u32 *seq;
unsigned long used;
int err;
int target; /* Read at least this many bytes */
long timeo;
struct task_struct *user_recv = NULL;
struct sk_buff *skb, *last;
.....
do {
u32 offset;
......
/* Next get a buffer. */
last = skb_peek_tail(&sk->sk_receive_queue);
skb_queue_walk(&sk->sk_receive_queue, skb) {
last = skb;
offset = *seq - TCP_SKB_CB(skb)->seq;
if (offset < skb->len)
goto found_ok_skb;
......
}
......
if (!sysctl_tcp_low_latency && tp->ucopy.task == user_recv) {
/* Install new reader */
if (!user_recv && !(flags & (MSG_TRUNC | MSG_PEEK))) {
user_recv = current;
tp->ucopy.task = user_recv;
tp->ucopy.msg = msg;
}
tp->ucopy.len = len;
/* Look: we have the following (pseudo)queues:
*
* 1. packets in flight
* 2. backlog
* 3. prequeue
* 4. receive_queue
*
* Each queue can be processed only if the next ones
* are empty.
*/
if (!skb_queue_empty(&tp->ucopy.prequeue))
goto do_prequeue;
}
if (copied >= target) {
/* Do not sleep, just process backlog. */
release_sock(sk);
lock_sock(sk);
} else {
sk_wait_data(sk, &timeo, last);
}
if (user_recv) {
int chunk;
chunk = len - tp->ucopy.len;
if (chunk != 0) {
len -= chunk;
copied += chunk;
}
if (tp->rcv_nxt == tp->copied_seq &&
!skb_queue_empty(&tp->ucopy.prequeue)) {
do_prequeue:
tcp_prequeue_process(sk);
chunk = len - tp->ucopy.len;
if (chunk != 0) {
len -= chunk;
copied += chunk;
}
}
}
continue;
found_ok_skb:
/* Ok so how much can we use? */
used = skb->len - offset;
if (len < used)
used = len;
if (!(flags & MSG_TRUNC)) {
err = skb_copy_datagram_msg(skb, offset, msg, used);
......
}
*seq += used;
copied += used;
len -= used;
tcp_rcv_space_adjust(sk);
......
} while (len > 0);
......
}tcp_recvmsg这个函数比较长,里面逻辑也很复杂,好在里面有一段注释概扩了这里面的逻辑。注释里面提到了三个队列,receive_queue队列、prequeue队列和backlog队列。这里面,我们需要把前一个队列处理完毕,才处理后一个队列。
tcp_recvmsg的整个逻辑也是这样执行的:这里面有一个while循环,不断地读取网络包。
这里,我们会先处理sk_receive_queue队列。如果找到了网络包,就跳到found_ok_skb这里。这里会调用skb_copy_datagram_msg,将网络包拷贝到用户进程中,然后直接进入下一层循环。
直到sk_receive_queue队列处理完毕,我们才到了sysctl_tcp_low_latency判断。如果不需要低时延,则会有prequeue队列。于是,我们能就跳到do_prequeue这里,调用tcp_prequeue_process进行处理。
如果sysctl_tcp_low_latency设置为1,也即没有prequeue队列,或者prequeue队列为空,则需要处理backlog队列,在release_sock函数中处理。
release_sock会调用__release_sock,这里面会依次处理队列中的网络包。
void release_sock(struct sock *sk)
{
......
if (sk->sk_backlog.tail)
__release_sock(sk);
......
}
static void __release_sock(struct sock *sk)
__releases(&sk->sk_lock.slock)
__acquires(&sk->sk_lock.slock)
{
struct sk_buff *skb, *next;
while ((skb = sk->sk_backlog.head) != NULL) {
sk->sk_backlog.head = sk->sk_backlog.tail = NULL;
do {
next = skb->next;
prefetch(next);
skb->next = NULL;
sk_backlog_rcv(sk, skb);
cond_resched();
skb = next;
} while (skb != NULL);
}
......
}最后,哪里都没有网络包,我们只好调用sk_wait_data,继续等待在哪里,等待网络包的到来。
至此,网络包的接收过程到此结束。
44.3 总结
这一节我们讲完了接收网络包,我们来从头串一下,整个过程可以分成以下几个层次。
- 硬件网卡接收到网络包之后,通过DMA技术,将网络包放入Ring Buffer;
- 硬件网卡通过中断通知CPU新的网络包的到来;
- 网卡驱动程序会注册中断处理函数ixgb_intr;
- 中断处理函数处理完需要暂时屏蔽中断的核心流程之后,通过软中断NET_RX_SOFTIRQ触发接下来的处理过程;
- NET_RX_SOFTIRQ软中断处理函数net_rx_action,net_rx_action会调用napi_poll,进而调用ixgb_clean_rx_irq,从Ring Buffer中读取数据到内核struct sk_buff;
- 调用netif_receive_skb进入内核网络协议栈,进行一些关于VLAN的二层逻辑处理后,调用ip_rcv进入三层IP层;
- 在IP层,会处理iptables规则,然后调用ip_local_deliver交给更上层TCP层;
- 在TCP层调用tcp_v4_rcv,这里面有三个队列需要处理,如果当前的Socket不是正在被读;取,则放入backlog队列,如果正在被读取,不需要很实时的话,则放入prequeue队列,其他情况调用tcp_v4_do_rcv;
- 在tcp_v4_do_rcv中,如果是处于TCP_ESTABLISHED状态,调用tcp_rcv_established,其他的状态,调用tcp_rcv_state_process;
- 在tcp_rcv_established中,调用tcp_data_queue,如果序列号能够接的上,则放入sk_receive_queue队列;如果序列号接不上,则暂时放入out_of_order_queue队列,等序列号能够接上的时候,再放入sk_receive_queue队列。
至此内核接收网络包的过程到此结束,接下来就是用户态读取网络包的过程,这个过程分成几个层次。
- VFS层:read系统调用找到struct file,根据里面的file_operations的定义,调用sock_read_iter函数。sock_read_iter函数调用sock_recvmsg函数。
- Socket层:从struct file里面的private_data得到struct socket,根据里面ops的定义,调用inet_recvmsg函数。
- Sock层:从struct socket里面的sk得到struct sock,根据里面sk_prot的定义,调用tcp_recvmsg函数。
- TCP层:tcp_recvmsg函数会依次读取receive_queue队列、prequeue队列和backlog队列。
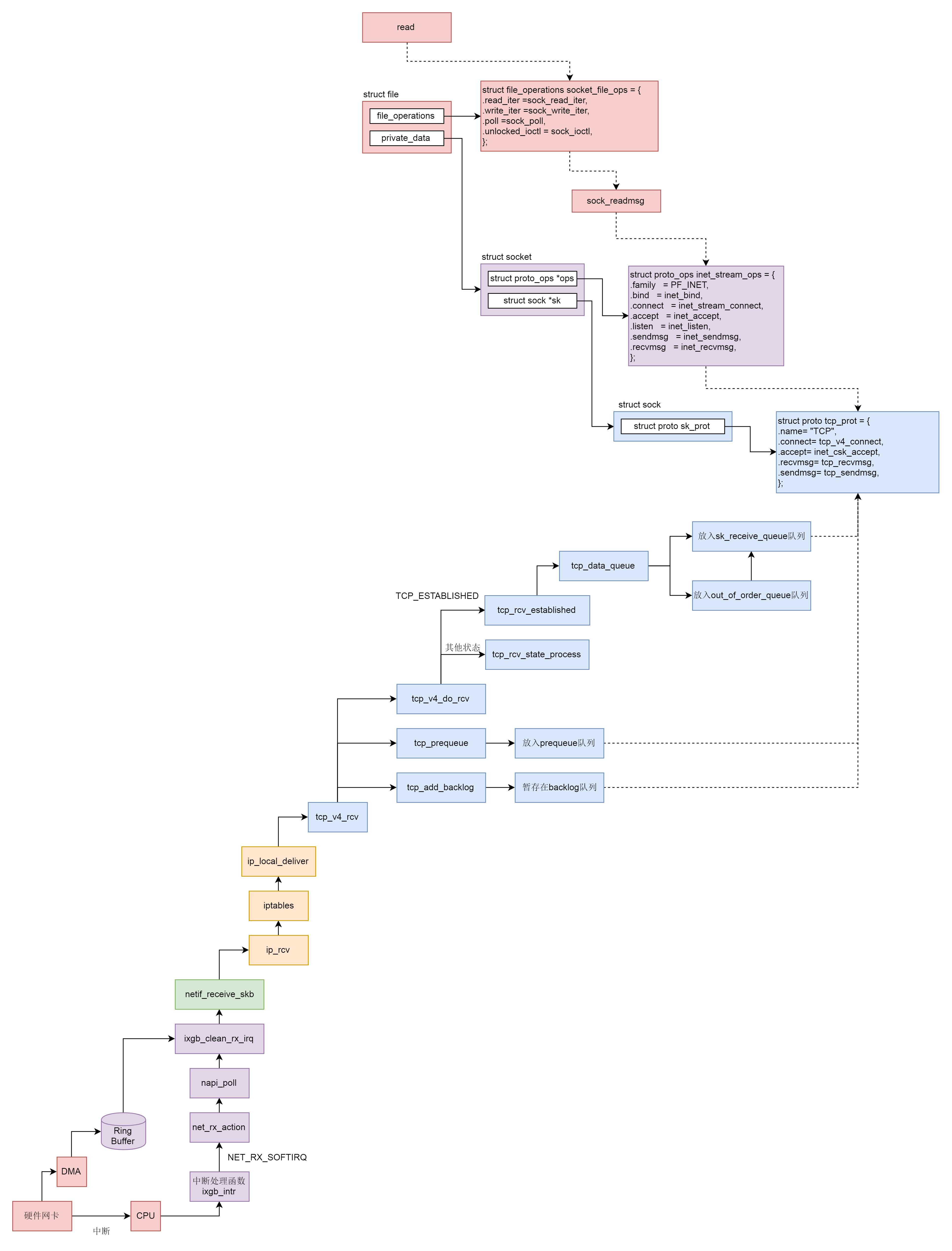
八、虚拟化
43. 虚拟机
我们前面所有章节涉及的Linux操作系统原理,都是在一台Linux服务器上工作的.在前面的原理阐述中,我们一直把Linux当作一家外包公司的老板来看待。想要管理这么复杂、这么大的一个公司,需要配备咱们前面讲过的所有机制。
Linux很强大,Linux服务器也随之变得越来越强大了。无论是计算、网络、存储,都越来越牛。例如,内存动不动就是百G内存,网络设备一个端口的带宽就能有几十G甚至上百G,存储在数据中心至少是PB级别的(一个P是1024个T,一个T是1024个G)。
公司大有大了的好处,自然也有大的毛病,也就是咱们常见的”大公司病”——不灵活。这里面的不灵活,有下面这几种,我列一下,你看看你是不是都见过。
- 资源大小不灵活:有时候我们不需要这么大规格的机器,可能只想尝试一下某些新业务,申请个4核8G的服务器试一下,但是不可能采购这么小规格的机器。无论每个项目需要多大规格的机器,公司统一采购就限制几种,全部是上面那种大规格的。
- 资源申请不灵活:规格定死就定死吧,可是每次申请机器都要重新采购,周期很长。
- 资源复用不灵活:反正我需要的资源不多,和别人共享一台机器吧,这样不同的进程可能会产生冲突,例如socket的端口冲突。另外就是别人用过的机器,不知道上面做过哪些操作,有很多的历史包袱,如果重新安装则代价太大。
这些是不是和咱们在大公司里面遇到的问题很像?按说,大事情流程严禁没问题,很多小事情也要被拖累走整个流程,而且很容易出现资源冲突,每天跨部门的协调很累人,历史包袱严重,创新没有办法轻装上阵。
很多公司处理这种问题采取的策略是成立独立的子公司,独立决策,独立运营,往往用于创新型的项目。
Linux也采取了这样的手段,就是在物理机上面创建虚拟机。每个虚拟机有自己单独的操作系统、灵活的规格,一个命令就能启动起来。每次创建都是新的操作系统,很好地解决了上面不灵活的问题。
但是要使用虚拟机,还有一些问题需要解决一下。
我们知道,操作系统上的程序分为两种,一种是用户态的程序,例如Word、Excel等,一种是内核态的程序,例如内核代码、驱动程序等。
为了区分内核态和用户态,CPU专门设置四个特权等级0、1、2、3来做这个事情。
当时写Linux内核的时候,估计大牛们还不知道将来虚拟机会大放异彩。大牛们想,一共两级特权,一个内核态,一个用户态,却有四个等级,好奢侈、好富裕,于是就敞开了用。内核态运行在第0等级,用户态运行在第3等级,占了两头,中间的都不用,太不会过日子了。
大牛们在写Linux内核的时候,如果用户态程序做事情,就将扳手掰到第3等级,一旦要申请使用更多的资源,就需要申请将扳手掰到第0等级,内核才能在高权限访问这些资源,申请完资源,返回到用户态,扳手再掰回去。
这个程序一直非常顺利地运行着,直到虚拟机出现了。
43.1 三种虚拟化方式
如果你安装VirtualBox桌面版,你可以用这个虚拟化软件创建虚拟机,在虚拟机里面安装一个Linux,外面的操作系统也可以是Linux。VirtualBox这个虚拟化软件,和你的Excel一样,都是在你的任务栏里面并排放着,是一个普通的应用。
当你进入虚拟机的时候,虚拟机里面的Excel也是一个普通的应用。
这个时候麻烦的事情出现了,当你设身处地地站在虚拟机的内核角度,去思考一下人生,你就会出现困惑了,会想,我到底是啥?
在硬件上的操作系统来看,我是一个普通的应用,只能运行在用户态。可是大牛们”生”我的时候,我的每一行代码都告诉我,我是个内核啊,应该运行在内核态。当虚拟机里面的Excel要访问网络的时候,向我请求,我的代码就要努力地去操作网卡。尽管我努力,但是我做不到啊,我没有权限!
我分裂了……
怎么办呢?虚拟化层,也就是Virtualbox会帮你解决这个问题,它有三种虚拟化的方式。
我们先来看第一种方式,完全虚拟化(Full virtualization)。其实说白了,这是一种”骗人”的方式。虚拟化软件会模拟假的CPU、内存、网络、硬盘给到我,让我自我感觉良好,感觉自己终于又像个内核了。
但是,真正的工作模式其实是下面这样的。
虚拟机内核说:我要在CPU上跑一个指令!
虚拟化软件说:没问题,你是内核嘛,可以跑!
虚拟化软件转过头去找物理机内核说:报告,我管理的虚拟机里面的一个要执行一个CPU指令,帮忙来一小段时间空闲的CPU时间,让我代它跑个指令。
物理机内核说:你等着,另一个跑着呢。(过了一会儿)它跑完了,该你了。
虚拟化软件说:我代它跑,终于跑完了,出来结果了。
虚拟化软件转头给虚拟机内核说:哥们儿,跑完了,结果是这个。我说你是内核吧,绝对有权限,没问题,下次跑指令找我啊!
虚拟机内核说:看来我真的是内核呢,可是,哥,好像这点儿指令跑得有点慢啊!
虚拟化软件说:这就不错啦,好几个排着队跑呢!
内存的申请模式是下面这样的。
虚拟机内核说:我启动需要4G内存,我好分给我上面的应用。
虚拟化软件说:没问题,才4G,你是内核嘛,我马上申请好。
虚拟化软件转头给物理机内核说:报告,我启动了一个虚拟机,需要4G内存,给我4个房间呗。
物理机内核:怎么又一个虚拟机啊!好吧,给你90、91、92、93四个房间。
虚拟化软件转头给虚拟机内核说:哥们,内存有了,0、1、2、3这个四个房间都是你的。你看,你是内核嘛,独占资源,从0编号的就是你的。
虚拟机内核说:看来我真的是内核啊,能从头开始用。那好,我就在房间2的第三个柜子里面放个东西吧!
虚拟化软件说:要放东西啊,没问题。但是,它心里想:我查查看,这个虚拟机是90号房间开头的,它要在房间2放东西,那就相当于在房间92放东西。
虚拟化软件转头给物理机内核说:报告,我上面的虚拟机要在92号房间的第三个柜子里面放个东西。
好了,说完了CPU和内存的例子,网络和硬盘就不细说了,情况也是类似的,都是虚拟化软件模拟一个给虚拟机内核看的,其实啥事儿都需要虚拟化软件转一遍。
这种方式一个坏处就是,慢,而且往往慢到不能忍受。
于是,虚拟化软件想,我能不能不当传话筒,要让虚拟机内核正视自己的身份。别说你是内核,你还真喘上了。你不是物理机,你是虚拟机!
但是,怎么解决权限等级的问题呢?于是,Intel的VT-x和AMD的AMD-V从硬件层面帮上了忙。当初谁让你们这些写内核的大牛用等级这么奢侈,用完了0,就是3,也不省着点儿用,没办法,只好另起炉灶弄一个新的标志位,表示当前是在虚拟机状态下,还是在真正的物理机内核下。
对于虚拟机内核来讲,只要将标志位设为虚拟机状态,我们就可以直接在CPU上执行大部分的指令,不需要虚拟化软件在中间转述,除非遇到特别敏感的指令,才需要将标志位设为物理机内核态运行,这样大大提高了效率。
所以,安装虚拟机的时候,我们务必要将物理CPU的这个标志位打开。想知道是否打开,对于Intel,你可以查看grep “vmx” /proc/cpuinfo;对于AMD,你可以查看grep “svm” /proc/cpuinfo
这叫作硬件辅助虚拟化(Hardware-Assisted Virtualization)。
另外就是访问网络或者硬盘的时候,为了取得更高的性能,也需要让虚拟机内核加载特殊的驱动,也是让虚拟机内核从代码层面就重新定位自己的身份,不能像访问物理机一样访问网络或者硬盘,而是用一种特殊的方式。
我知道我不是物理机内核,我知道我是虚拟机,我没那么高的权限,我很可能和很多虚拟机共享物理资源,所以我要学会排队,我写硬盘其实写的是一个物理机上的文件,那我的写文件的缓存方式是不是可以变一下。我发送网络包,根本就不是发给真正的网络设备,而是给虚拟的设备,我可不可以直接在内存里面拷贝给它,等等等等。
一旦我知道我不是物理机内核,痛定思痛,只好重新认识自己,反而能找出很多方式来优化我的资源访问。
这叫作半虚拟化(Paravirtualization)。
对于桌面虚拟化软件,我们多采用VirtualBox,如果使用服务器的虚拟化软件,则有另外的选型。
服务器上的虚拟化软件,多使用qemu,其中关键字emu,全称是emulator,模拟器。所以,单纯使用qemu,采用的是完全虚拟化的模式。
qemu向Guest OS模拟CPU,也模拟其他的硬件,GuestOS认为自己和硬件直接打交道,其实是同qemu模拟出来的硬件打交道,qemu会将这些指令转译给真正的硬件。由于所有的指令都要从qemu里面过一手,因而性能就会比较差。
按照上面的介绍,完全虚拟化是非常慢的,所以要使用硬件辅助虚拟化技术Intel-VT,AMD-V,所以需要CPU硬件开启这个标志位,一般在BIOS里面设置。
当确认开始了标志位之后,通过KVM,GuestOS的CPU指令不用经过Qemu转译,直接运行,大大提高了速度。
所以,KVM在内核里面需要有一个模块,来设置当前CPU是Guest OS在用,还是Host OS在用。
下面,我们来查看内核模块中是否含有kvm, lsmod | grep kvm。
KVM内核模块通过/dev/kvm暴露接口,用户态程序可以通过ioctl来访问这个接口。例如,你可以通过下面的流程编写程序。
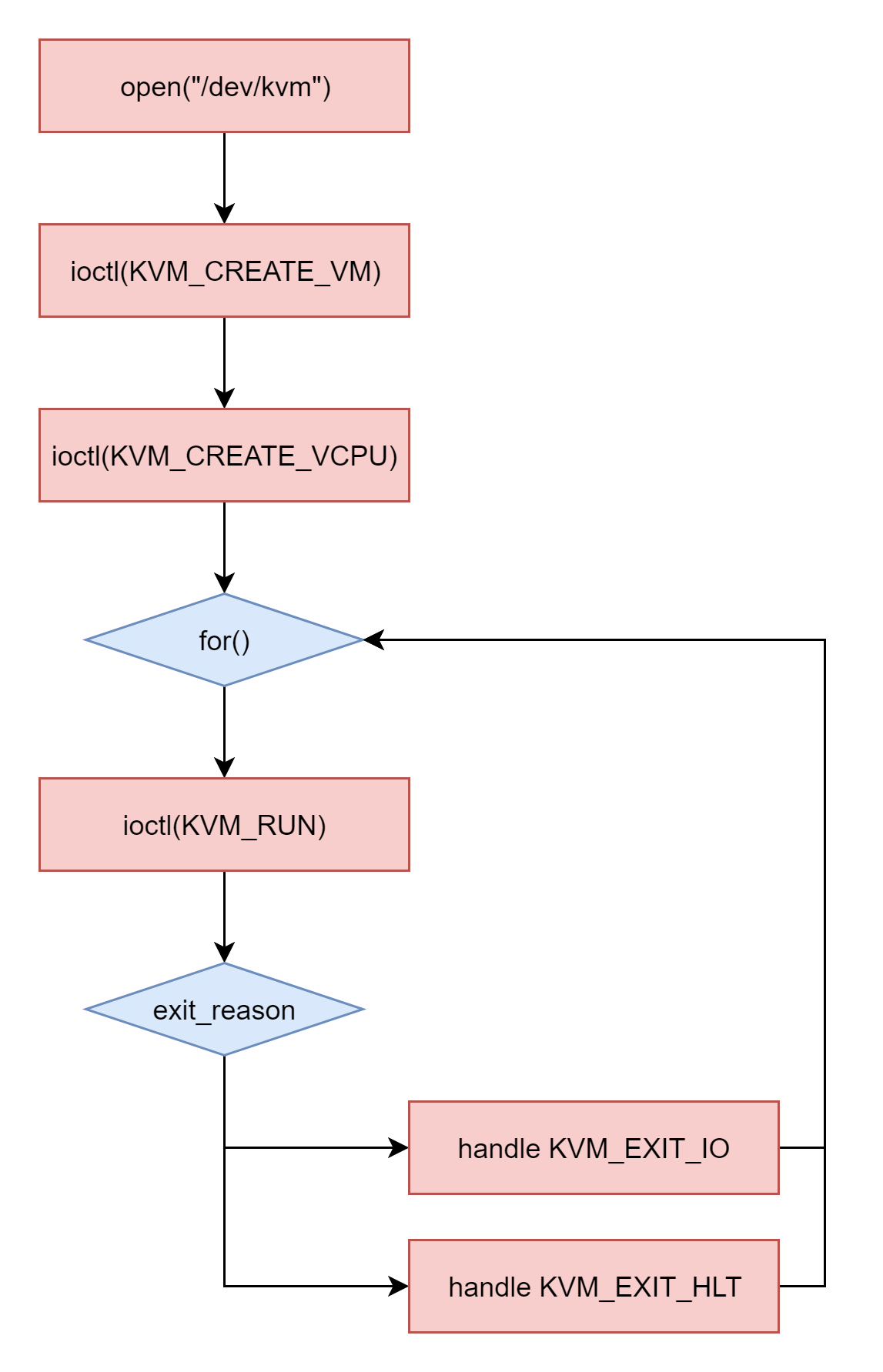
Qemu将KVM整合进来,将有关CPU指令的部分交由内核模块来做,就是qemu-kvm (qemu-system-XXX)。
qemu和kvm整合之后,CPU的性能问题解决了。另外Qemu还会模拟其他的硬件,如网络和硬盘。同样,全虚拟化的方式也会影响这些设备的性能。
于是,qemu采取半虚拟化的方式,让Guest OS加载特殊的驱动来做这件事情。
例如,网络需要加载virtio_net,存储需要加载virtio_blk,Guest需要安装这些半虚拟化驱动,GuestOS知道自己是虚拟机,所以数据会直接发送给半虚拟化设备,经过特殊处理(例如排队、缓存、批量处理等性能优化方式),最终发送给真正的硬件。这在一定程度上提高了性能。
至此,整个关系如下图所示。
43.2 创建虚拟机
了解了qemu-kvm的工作原理之后,下面我们来看一下,如何使用qemu-kvm创建一个能够上网的虚拟机。
如果使用VirtualBox创建过虚拟机,通过界面点点就能创建一个能够上网的虚拟机。如果使用qemu-kvm,就没有这么简单了。一切都得自己来做,不过这个过程可以了解KVM虚拟机的创建原理。
首先,我们要给虚拟机起一个名字,在KVM里面就是-name ubuntutest。
设置一个内存大小,在KVM里面就是-m 1024。
创建一个虚拟硬盘,对于VirtualBox是VDI格式,对于KVM则不同。
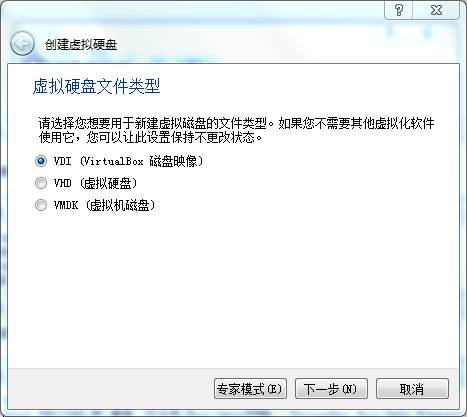
硬盘有两种格式,一个是动态分配,也即开始创建的时候,看起来很大,其实占用的空间很少,真实有多少数据,才真的占用多少空间。一个是固定大小,一开始就占用指定的大小。
比如,我这台电脑,硬盘的大小为8G。
在KVM中,创建一个虚拟机镜像,大小为8G,其中qcow2格式为动态分配,raw格式为固定大小。
qemu-img create -f qcow2 ubuntutest.img 8G我们将Ubuntu的ISO挂载为光盘,在KVM里面-cdrom ubuntu-xxx-server-amd64.iso
创建一个网络,有时候会选择桥接网络,有时候会选择NAT网络,这个在KVM里面只有自己配置了。
接下来Virtualbox就会有一个界面,可以看到安装的整个过程,在KVM里面,我们用VNC来做。参数为-vnc :19
于是,我们也可以创建KVM虚拟机了,可以用下面的命令:
qemu-system-x86_64 \
-enable-kvm \
-name ubuntutest \
-cpu host \
-m 2048 \
-hda ubuntutest.img \
-cdrom ubuntu-14.04-server-amd64.iso \
-boot d \
-vnc :19实际测试发现,直接运行上面的命令,在虚拟机里面就能正常访问网络。
启动了虚拟机后,连接VNC,我们也能看到安装的过程。
按照普通安装Ubuntu的流程安装好Ubuntu,然后shutdown -h now,关闭虚拟机。
接下来,我们可以对KVM创建桥接网络了。这个要模拟virtualbox的桥接网络模式。
如果在桌面虚拟化软件上选择桥接网络,在你的笔记本电脑上,就会形成下面的结构。
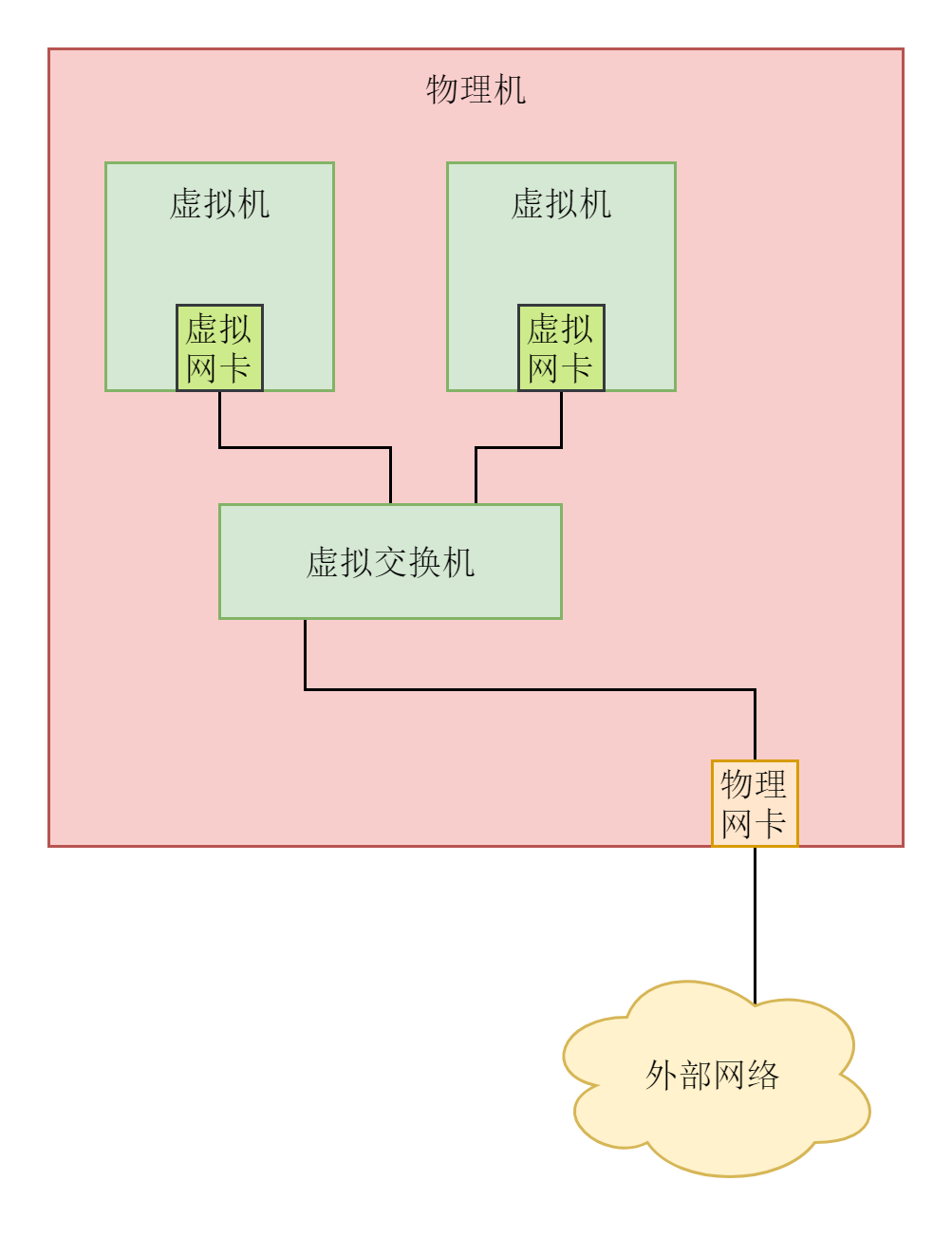
每个虚拟机都会有虚拟网卡,在你的笔记本电脑上,会发现多了几个网卡,其实是虚拟交换机。这个虚拟交换机将虚拟机连接在一起。在桥接模式下,物理网卡也连接到这个虚拟交换机上。物理网卡在桌面虚拟化软件的”界面名称”那里选定。
如果使用桥接网络,当你登录虚拟机里看IP地址时会发现,你的虚拟机的地址和你的笔记本电脑的地址,以及你旁边的同事的电脑的网段是一个网段。这是为什么呢?这其实相当于将物理机和虚拟机放在同一个网桥上,相当于这个网桥上有三台机器,是一个网段的,全部打平了。
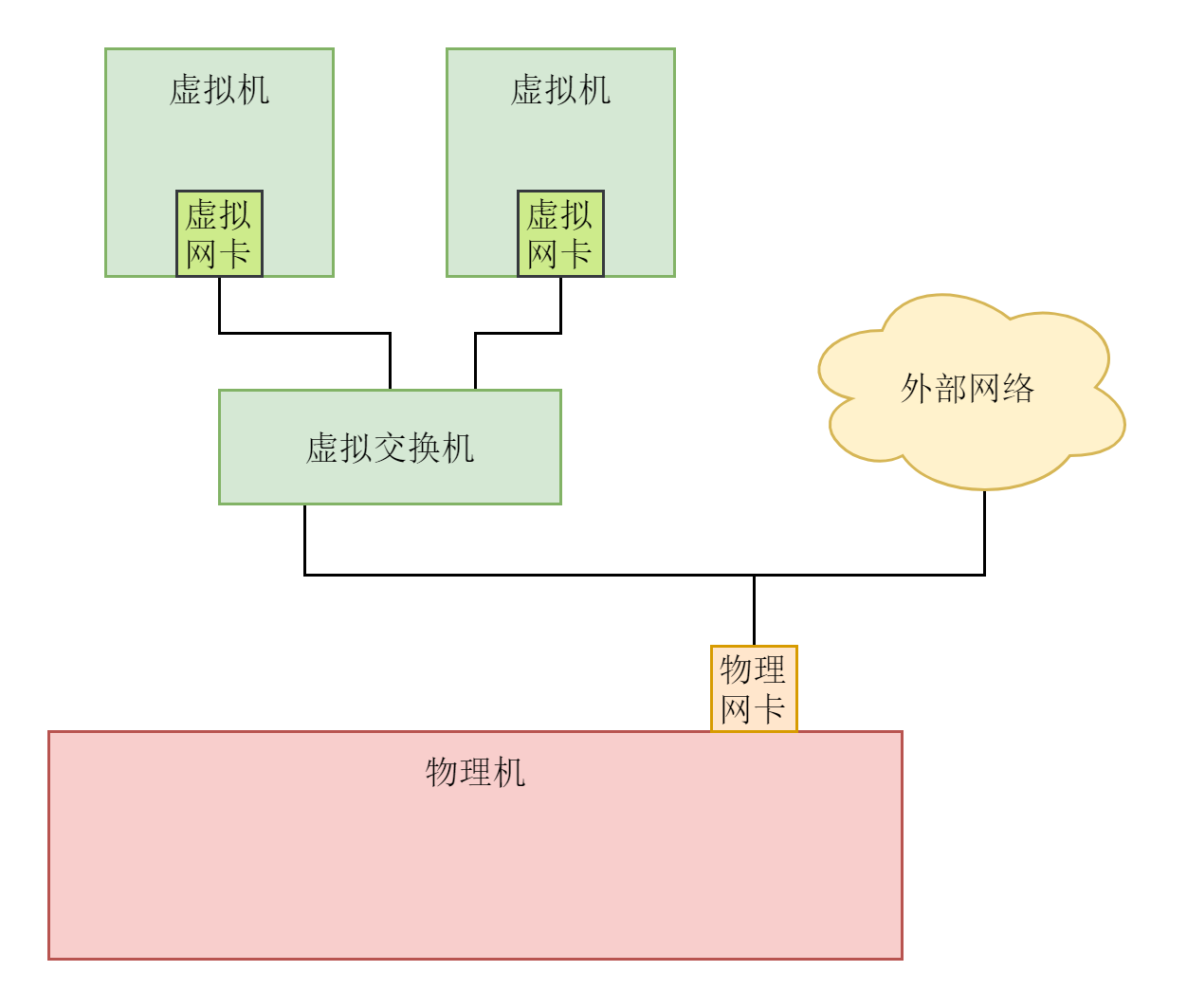
在数据中心里面,采取的也是类似的技术,连接方式如下图所示,只不过是Linux在每台机器上都创建网桥br0,虚拟机的网卡都连到br0上,物理网卡也连到br0上,所有的br0都通过物理网卡连接到物理交换机上。
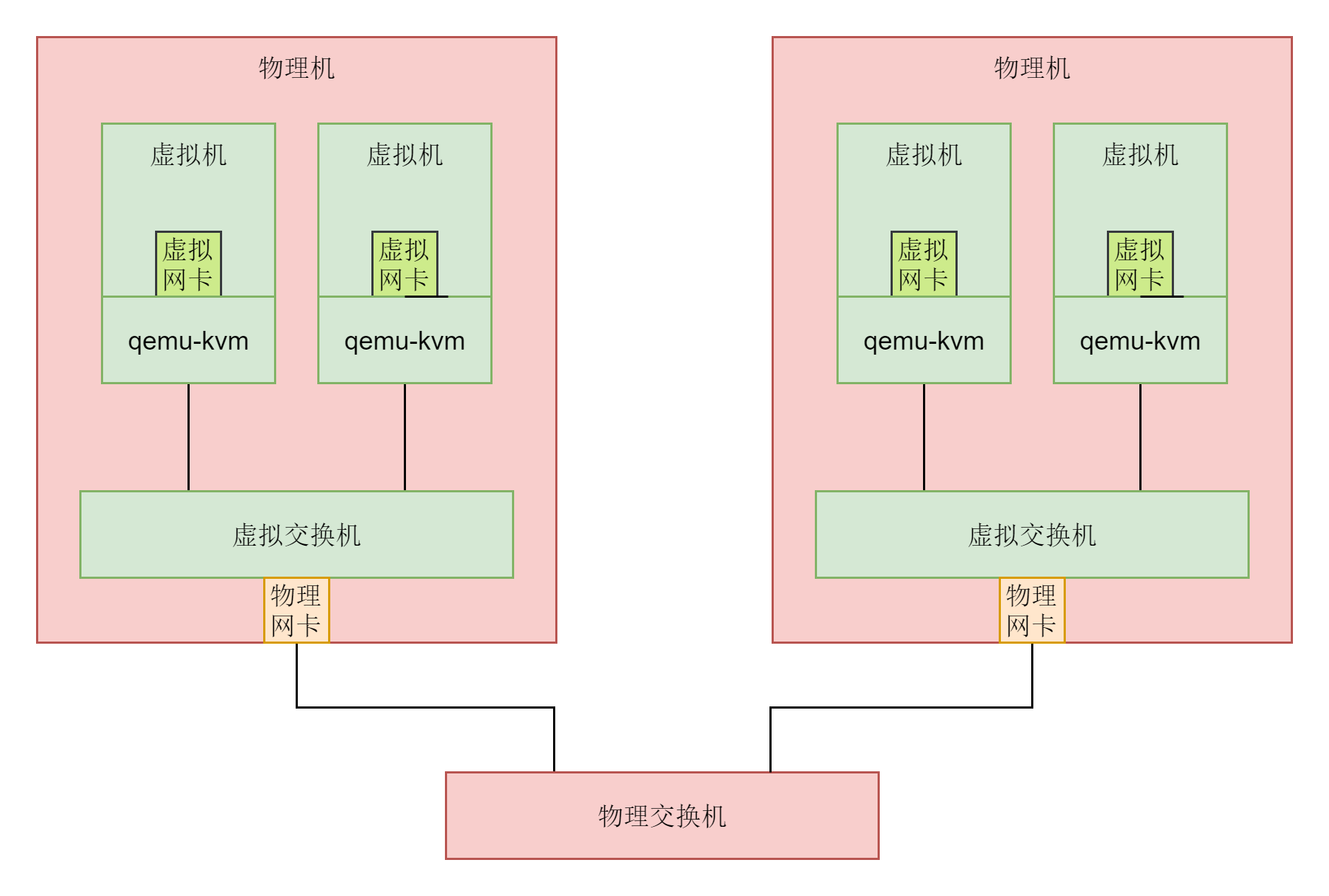
同样我们换一个角度看待这个拓扑图。同样是将网络打平,虚拟机会和物理网络具有相同的网段,就相当于两个虚拟交换机、一个物理交换机,一共三个交换机连在一起。两组四个虚拟机和两台物理机都是在一个二层网络里面的。
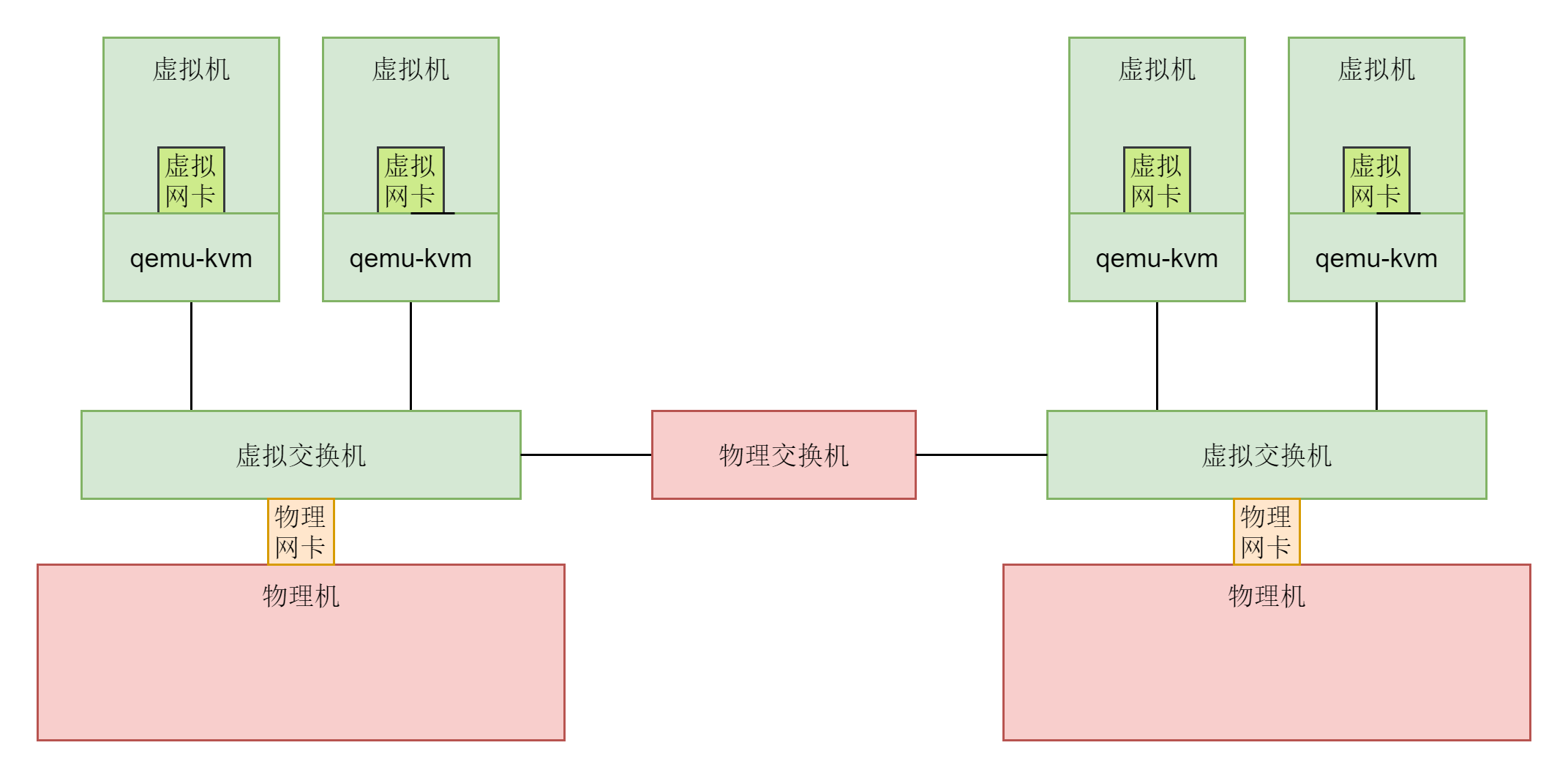
qemu-kvm如何才能创建一个这样的桥接网络呢?
先安装
brctlapt install bridge-utils在Host机器上创建bridge br0。
brctl addbr br0 # or ip link add br0 type bridge将br0设为up。
ip link set dev br0 up创建tap device。
tunctl -b -t tap0 # or ip tuntap add dev tap0 mode tap user root将tap0设为up。
ip link set dev tap0 up将tap0加入到br0上。
brctl addif br0 tap0 # or ip link set tap0 master br0启动虚拟机, 虚拟机连接tap0、tap0连接br0。
qemu-system-x86_64 \ -enable-kvm \ -name ubuntutest \ -cpu host \ -m 2048 \ -hda ubuntutest.qcow2 \ -vnc :19 \ -nic user,model=virtio-net-pci -net nic,model=virtio \ -netdev tap,id=mynet0,ifname=tap0,script=no,downscript=no虚拟机启动后,网卡没有配置,所以无法连接外网,先给br0设置一个ip。
ifconfig br0 192.168.57.1/24 # or ip addr add 192.168.57.1/24 dev br0VNC连上虚拟机,给网卡设置地址,重启虚拟机,可ping通br0。
要想访问外网,在Host上设置NAT,并且enable ip forwarding,可以ping通外网网关。
$ sysctl -p net.ipv4.ip_forward = 1 $ sudo iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE- 如果DNS没配错,可以进行apt-get update。
在这里,请记住qemu-system-x86_64的启动命令,这里面有CPU虚拟化KVM,有内存虚拟化、硬盘虚拟化、网络虚拟化。接下来的章节,我们会看内核是如何进行虚拟化的。
43.3 总结
理解虚拟机启动的参数就是理解虚拟化技术的入口。学会创建虚拟机,在后面做内核相关实验的时候就会非常方便。
具体到知识点上,这一节你需要需要记住下面的这些知识点:
- 虚拟化的本质是用qemu的软件模拟硬件,但是模拟方式比较慢,需要加速;
- 虚拟化主要模拟CPU、内存、网络、存储,分别有不同的加速办法;
- CPU和内存主要使用硬件辅助虚拟化进行加速,需要配备特殊的硬件才能工作;
- 网络和存储主要使用特殊的半虚拟化驱动加速,需要加载特殊的驱动程序。
44. 计算虚拟化之CPU(上)
上一节,我们讲了一下虚拟化的基本原理,以及qemu、kvm之间的关系。这一节,我们就来看一下,用户态的qemu和内核态的kvm如何一起协作,来创建虚拟机,实现CPU和内存虚拟化。
这里是上一节我们讲的qemu启动时候的命令。
qemu-system-x86_64 -enable-kvm -name ubuntutest -m 2048 -hda ubuntutest.qcow2 -vnc :19 -net nic,model=virtio -nettap,ifname=tap0,script=no,downscript=no接下来,我们在这里下载qemu的代码。qemu的main函数在vl.c下面。这是一个非常非常长的函数,我们来慢慢地解析它。
44.1 初始化所有的Module
第一步,初始化所有的Module,调用下面的函数。
module_call_init(MODULE_INIT_QOM);上一节我们讲过,qemu作为中间人其实挺累的,对上面的虚拟机需要模拟各种各样的外部设备。当虚拟机真的要使用物理资源的时候,对下面的物理机上的资源要进行请求,所以它的工作模式有点儿类似操作系统对接驱动。驱动要符合一定的格式,才能算操作系统的一个模块。同理,qemu为了模拟各种各样的设备,也需要管理各种各样的模块,这些模块也需要符合一定的格式。
定义一个qemu模块会调用type_init。例如,kvm的模块要在accel/kvm/kvm-all.c文件里面实现。在这个文件里面,有一行下面的代码:
type_init(kvm_type_init);
#define type_init(function) module_init(function, MODULE_INIT_QOM)
#define module_init(function, type) \
static void __attribute__((constructor)) do_qemu_init_ ## function(void) \
{ \
register_module_init(function, type); \
}
void register_module_init(void (*fn)(void), module_init_type type)
{
ModuleEntry *e;
ModuleTypeList *l;
e = g_malloc0(sizeof(*e));
e->init = fn;
e->type = type;
l = find_type(type);
QTAILQ_INSERT_TAIL(l, e, node);
}从代码里面的定义我们可以看出来,type_init后面的参数是一个函数,调用type_init就相当于调用module_init,在这里函数就是kvm_type_init,类型就是MODULE_INIT_QOM。是不是感觉和驱动有点儿像?
module_init最终要调用register_module_init。属于MODULE_INIT_QOM这种类型的,有一个Module列表ModuleTypeList,列表里面是一项一项的ModuleEntry。KVM就是其中一项,并且会初始化每一项的init函数为参数表示的函数fn,也即KVM这个module的init函数就是kvm_type_init。
当然,MODULE_INIT_QOM这种类型会有很多很多的module,从后面的代码我们可以看到,所有调用type_init的地方都注册了一个MODULE_INIT_QOM类型的Module。
了解了Module的注册机制,我们继续回到main函数中module_call_init的调用。
void module_call_init(module_init_type type)
{
ModuleTypeList *l;
ModuleEntry *e;
l = find_type(type);
QTAILQ_FOREACH(e, l, node) {
e->init();
}
}在module_call_init中,我们会找到MODULE_INIT_QOM这种类型对应的ModuleTypeList,找出列表中所有的ModuleEntry,然后调用每个ModuleEntry的init函数。这里需要注意的是,在module_call_init调用的这一步,所有Module的init函数都已经被调用过了。
后面我们会看到很多的Module,当你看到它们的时候,你需要意识到,它的init函数在这里也被调用过了。这里我们还是以对于kvm这个module为例子,看看它的init函数都做了哪些事情。你会发现,其实它调用的是kvm_type_init。
static void kvm_type_init(void)
{
type_register_static(&kvm_accel_type);
}
TypeImpl *type_register_static(const TypeInfo *info)
{
return type_register(info);
}
TypeImpl *type_register(const TypeInfo *info)
{
assert(info->parent);
return type_register_internal(info);
}
static TypeImpl *type_register_internal(const TypeInfo *info)
{
TypeImpl *ti;
ti = type_new(info);
type_table_add(ti);
return ti;
}
static TypeImpl *type_new(const TypeInfo *info)
{
TypeImpl *ti = g_malloc0(sizeof(*ti));
int i;
if (type_table_lookup(info->name) != NULL) {
}
ti->name = g_strdup(info->name);
ti->parent = g_strdup(info->parent);
ti->class_size = info->class_size;
ti->instance_size = info->instance_size;
ti->class_init = info->class_init;
ti->class_base_init = info->class_base_init;
ti->class_data = info->class_data;
ti->instance_init = info->instance_init;
ti->instance_post_init = info->instance_post_init;
ti->instance_finalize = info->instance_finalize;
ti->abstract = info->abstract;
for (i = 0; info->interfaces && info->interfaces[i].type; i++) {
ti->interfaces[i].typename = g_strdup(info->interfaces[i].type);
}
ti->num_interfaces = i;
return ti;
}
static void type_table_add(TypeImpl *ti)
{
assert(!enumerating_types);
g_hash_table_insert(type_table_get(), (void *)ti->name, ti);
}
static GHashTable *type_table_get(void)
{
static GHashTable *type_table;
if (type_table == NULL) {
type_table = g_hash_table_new(g_str_hash, g_str_equal);
}
return type_table;
}
static const TypeInfo kvm_accel_type = {
.name = TYPE_KVM_ACCEL,
.parent = TYPE_ACCEL,
.class_init = kvm_accel_class_init,
.instance_size = sizeof(KVMState),
};每一个Module既然要模拟某种设备,那应该定义一种类型TypeImpl来表示这些设备,这其实是一种面向对象编程的思路,只不过这里用的是纯C语言的实现,所以需要变相实现一下类和对象。
kvm_type_init会注册kvm_accel_type,定义上面的代码,我们可以认为这样动态定义了一个类。这个类的名字是TYPE_KVM_ACCEL,这个类有父类TYPE_ACCEL,这个类的初始化应该调用函数kvm_accel_class_init(看,这里已经直接叫类class了)。如果用这个类声明一个对象,对象的大小应该是instance_size。是不是有点儿Java语言反射的意思,根据一些名称的定义,一个类就定义好了。
这里的调用链为:kvm_type_init->type_register_static->type_register->type_register_internal。
在type_register_internal中,我们会根据kvm_accel_type这个TypeInfo,创建一个TypeImpl来表示这个新注册的类,也就是说,TypeImpl才是我们想要声明的那个class。在qemu里面,有一个全局的哈希表type_table,用来存放所有定义的类。在type_new里面,我们先从全局表里面根据名字找这个类。如果找到,说明这个类曾经被注册过,就报错;如果没有找到,说明这是一个新的类,则将TypeInfo里面信息填到TypeImpl里面。type_table_add会将这个类注册到全局的表里面。到这里,我们注意,class_init还没有被调用,也即这个类现在还处于纸面的状态。
这点更加像Java的反射机制了。在Java里面,对于一个类,首先我们写代码的时候要写一个class xxx的定义,编译好就放在.class文件中,这也是出于纸面的状态。然后,Java会有一个Class对象,用于读取和表示这个纸面上的class xxx,可以生成真正的对象。
相同的过程在后面的代码中我们也可以看到,class_init会生成XXXClass,就相当于Java里面的Class对象,TypeImpl还会有一个instance_init函数,相当于构造函数,用于根据XXXClass生成Object,这就相当于Java反射里面最终创建的对象。和构造函数对应的还有instance_finalize,相当于析构函数。
这一套反射机制放在qom文件夹下面,全称QEMU Object Model,也即用C实现了一套面向对象的反射机制。
说完了初始化Module,我们还回到main函数接着分析。
44.2 解析qemu的命令行
第二步我们就要开始解析qemu的命令行了。qemu的命令行解析,就是下面这样一长串。还记得咱们自己写过一个解析命令行参数的程序吗?这里的opts是差不多的意思。
qemu_add_opts(&qemu_drive_opts);
qemu_add_opts(&qemu_chardev_opts);
qemu_add_opts(&qemu_device_opts);
qemu_add_opts(&qemu_netdev_opts);
qemu_add_opts(&qemu_nic_opts);
qemu_add_opts(&qemu_net_opts);
qemu_add_opts(&qemu_rtc_opts);
qemu_add_opts(&qemu_machine_opts);
qemu_add_opts(&qemu_accel_opts);
qemu_add_opts(&qemu_mem_opts);
qemu_add_opts(&qemu_smp_opts);
qemu_add_opts(&qemu_boot_opts);
qemu_add_opts(&qemu_name_opts);
qemu_add_opts(&qemu_numa_opts);为什么有这么多的opts呢?这是因为,我们上一节给的参数都是简单的参数,实际运行中创建的kvm参数会复杂N倍。这里我们贴一个开源云平台软件OpenStack创建出来的KVM的参数,如下所示。不要被吓坏,你不需要全部看懂,只需要看懂一部分就行了。具体我来给你解析。
qemu-system-x86_64
-enable-kvm
-name instance-00000024
-machine pc-i440fx-trusty,accel=kvm,usb=off
-cpu SandyBridge,+erms,+smep,+fsgsbase,+pdpe1gb,+rdrand,+f16c,+osxsave,+dca,+pcid,+pdcm,+xtpr,+tm2,+est,+smx,+vmx,+ds_cpl,+monitor,+dtes64,+pbe,+tm,+ht,+ss,+acpi,+ds,+vme
-m 2048
-smp 1,sockets=1,cores=1,threads=1
......
-rtc base=utc,driftfix=slew
-drive file=/var/lib/nova/instances/1f8e6f7e-5a70-4780-89c1-464dc0e7f308/disk,if=none,id=drive-virtio-disk0,format=qcow2,cache=none
-device virtio-blk-pci,scsi=off,bus=pci.0,addr=0x4,drive=drive-virtio-disk0,id=virtio-disk0,bootindex=1
-netdev tap,fd=32,id=hostnet0,vhost=on,vhostfd=37
-device virtio-net-pci,netdev=hostnet0,id=net0,mac=fa:16:3e:d1:2d:99,bus=pci.0,addr=0x3
-chardev file,id=charserial0,path=/var/lib/nova/instances/1f8e6f7e-5a70-4780-89c1-464dc0e7f308/console.log
-vnc 0.0.0.0:12
-device cirrus-vga,id=video0,bus=pci.0,addr=0x2- -enable-kvm:表示启用硬件辅助虚拟化。
- -name instance-00000024:表示虚拟机的名称。
- -machine pc-i440fx-trusty,accel=kvm,usb=off:machine是什么呢?其实就是计算机体系结构。不知道什么是体系结构的话,可以订阅极客时间的另一个专栏《深入浅出计算机组成原理》。qemu会模拟多种体系结构,常用的有普通PC机,也即x86的32位或者64位的体系结构、Mac电脑PowerPC的体系结构、Sun的体系结构、MIPS的体系结构,精简指令集。如果使用KVM hardware-assisted virtualization,也即BIOS中VD-T是打开的,则参数中accel=kvm。如果不使用hardware-assisted virtualization,用的是纯模拟,则有参数accel = tcg,-no-kvm。
- -cpu SandyBridge,+erms,+smep,+fsgsbase,+pdpe1gb,+rdrand,+f16c,…:表示设置CPU,SandyBridge是Intel处理器,后面的加号都是添加的CPU的参数,这些参数会显示在/proc/cpuinfo里面。
- -m 2048:表示内存。
- -smp 1,sockets=1,cores=1,threads=1:SMP我们解析过,叫对称多处理器,和NUMA对应。qemu仿真了一个具有1个vcpu,一个socket,一个core,一个threads的处理器。socket、core、threads是什么概念呢?socket就是主板上插cpu的槽的数目,也即常说的”路”,core就是我们平时说的”核”,即双核、4核等。thread就是每个core的硬件线程数,即超线程。举个具体的例子,某个服务器是:2路4核超线程(一般默认为2个线程),通过cat /proc/cpuinfo,我们看到的是242=16个processor,很多人也习惯成为16核了。
- -rtc base=utc,driftfix=slew:表示系统时间由参数-rtc指定。
- -device cirrus-vga,id=video0,bus=pci.0,addr=0x2:表示显示器用参数-vga设置,默认为cirrus,它模拟了CL-GD5446PCI VGA card。
- 有关网卡,使用-net参数和-device。
- 从HOST角度:-netdev tap,fd=32,id=hostnet0,vhost=on,vhostfd=37。
- 从GUEST角度:-device virtio-net-pci,netdev=hostnet0,id=net0,mac=fa:16:3e:d1:2d:99,bus=pci.0,addr=0x3。
- 有关硬盘,使用-hda -hdb,或者使用-drive和-device。
- 从HOST角度:-drive file=/var/lib/nova/instances/1f8e6f7e-5a70-4780-89c1-464dc0e7f308/disk,if=none,id=drive-virtio-disk0,format=qcow2,cache=none
- 从GUEST角度:-device virtio-blk-pci,scsi=off,bus=pci.0,addr=0x4,drive=drive-virtio-disk0,id=virtio-disk0,bootindex=1
- -vnc 0.0.0.0:12:设置VNC。
在main函数中,接下来的for循环和大量的switch case语句,就是对于这些参数的解析,我们不一一解析,后面真的用到这些参数的时候,我们再仔细看。
44.3 初始化machine
回到main函数,接下来是初始化machine。
machine_class = select_machine();
current_machine = MACHINE(object_new(object_class_get_name(
OBJECT_CLASS(machine_class))));这里面的machine_class是什么呢?这还得从machine参数说起。
-machine pc-i440fx-trusty,accel=kvm,usb=off这里的pc-i440fx是x86机器默认的体系结构。在hw/i386/pc_piix.c中,它定义了对应的machine_class。
DEFINE_I440FX_MACHINE(v4_0, "pc-i440fx-4.0", NULL,
pc_i440fx_4_0_machine_options);
#define DEFINE_I440FX_MACHINE(suffix, name, compatfn, optionfn) \
static void pc_init_##suffix(MachineState *machine) \
{ \
......
pc_init1(machine, TYPE_I440FX_PCI_HOST_BRIDGE, \
TYPE_I440FX_PCI_DEVICE); \
} \
DEFINE_PC_MACHINE(suffix, name, pc_init_##suffix, optionfn)
#define DEFINE_PC_MACHINE(suffix, namestr, initfn, optsfn) \
static void pc_machine_##suffix##_class_init(ObjectClass *oc, void *data
) \
{ \
MachineClass *mc = MACHINE_CLASS(oc); \
optsfn(mc); \
mc->init = initfn; \
} \
static const TypeInfo pc_machine_type_##suffix = { \
.name = namestr TYPE_MACHINE_SUFFIX, \
.parent = TYPE_PC_MACHINE, \
.class_init = pc_machine_##suffix##_class_init, \
}; \
static void pc_machine_init_##suffix(void) \
{ \
type_register(&pc_machine_type_##suffix); \
} \
type_init(pc_machine_init_##suffix)为了定义machine_class,这里有一系列的宏定义。入口是DEFINE_I440FX_MACHINE。这个宏有几个参数,v4_0是后缀,”pc-i440fx-4.0”是名字,pc_i440fx_4_0_machine_options是一个函数,用于定义machine_class相关的选项。这个函数定义如下:
static void pc_i440fx_4_0_machine_options(MachineClass *m)
{
pc_i440fx_machine_options(m);
m->alias = "pc";
m->is_default = 1;
}
static void pc_i440fx_machine_options(MachineClass *m)
{
PCMachineClass *pcmc = PC_MACHINE_CLASS(m);
pcmc->default_nic_model = "e1000";
m->family = "pc_piix";
m->desc = "Standard PC (i440FX + PIIX, 1996)";
m->default_machine_opts = "firmware=bios-256k.bin";
m->default_display = "std";
machine_class_allow_dynamic_sysbus_dev(m, TYPE_RAMFB_DEVICE);
}我们先不看pc_i440fx_4_0_machine_options,先来看DEFINE_I440FX_MACHINE。
这里面定义了一个pc_init_##suffix,也就是pc_init_v4_0。这里面转而调用pc_init1。注意这里这个函数只是定义了一下,没有被调用。
接下来,DEFINE_I440FX_MACHINE里面又定义了DEFINE_PC_MACHINE。它有四个参数,除了DEFINE_I440FX_MACHINE传进来的三个参数以外,多了一个initfn,也即初始化函数,指向刚才定义的pc_init_##suffix。
在DEFINE_PC_MACHINE中,我们定义了一个函数pc_machine_##suffix##class_init。从函数的名字class_init可以看出,这是machine_class从纸面上的class初始化为Class对象的方法。在这个函数里面,我们可以看到,它创建了一个MachineClass对象,这个就是Class对象。MachineClass对象的init函数指向上面定义的pc_init##suffix,说明这个函数是machine这种类型初始化的一个函数,后面会被调用。
接着,我们看DEFINE_PC_MACHINE。它定义了一个pc_machine_type_##suffix的TypeInfo。这是用于生成纸面上的class的原材料,果真后面调用了type_init。
看到了type_init,我们应该能够想到,既然它定义了一个纸面上的class,那上面的那句module_call_init,会和我们上面解析的type_init是一样的,在全局的表里面注册了一个全局的名字是”pc-i440fx-4.0”的纸面上的class,也即TypeImpl。
现在全局表中有这个纸面上的class了。我们回到select_machine。
static MachineClass *select_machine(void)
{
MachineClass *machine_class = find_default_machine();
const char *optarg;
QemuOpts *opts;
......
opts = qemu_get_machine_opts();
qemu_opts_loc_restore(opts);
optarg = qemu_opt_get(opts, "type");
if (optarg) {
machine_class = machine_parse(optarg);
}
......
return machine_class;
}
MachineClass *find_default_machine(void)
{
GSList *el, *machines = object_class_get_list(TYPE_MACHINE, false);
MachineClass *mc = NULL;
for (el = machines; el; el = el->next) {
MachineClass *temp = el->data;
if (temp->is_default) {
mc = temp;
break;
}
}
g_slist_free(machines);
return mc;
}
static MachineClass *machine_parse(const char *name)
{
MachineClass *mc = NULL;
GSList *el, *machines = object_class_get_list(TYPE_MACHINE, false);
if (name) {
mc = find_machine(name);
}
if (mc) {
g_slist_free(machines);
return mc;
}
......
}在select_machine中,有两种方式可以生成MachineClass。一种方式是find_default_machine,找一个默认的;另一种方式是machine_parse,通过解析参数生成MachineClass。无论哪种方式,都会调用object_class_get_list获得一个MachineClass的列表,然后在里面找。object_class_get_list定义如下:
GSList *object_class_get_list(const char *implements_type,
bool include_abstract)
{
GSList *list = NULL;
object_class_foreach(object_class_get_list_tramp,
implements_type, include_abstract, &list);
return list;
}
void object_class_foreach(void (*fn)(ObjectClass *klass, void *opaque), const char *implements_type, bool include_abstract,
void *opaque)
{
OCFData data = { fn, implements_type, include_abstract, opaque };
enumerating_types = true;
g_hash_table_foreach(type_table_get(), object_class_foreach_tramp, &data);
enumerating_types = false;
}在全局表type_table_get()中,对于每一项TypeImpl,我们都执行object_class_foreach_tramp。
static void object_class_foreach_tramp(gpointer key, gpointer value,
gpointer opaque)
{
OCFData *data = opaque;
TypeImpl *type = value;
ObjectClass *k;
type_initialize(type);
k = type->class;
......
data->fn(k, data->opaque);
}
static void type_initialize(TypeImpl *ti)
{
TypeImpl *parent;
......
ti->class_size = type_class_get_size(ti);
ti->instance_size = type_object_get_size(ti);
if (ti->instance_size == 0) {
ti->abstract = true;
}
......
ti->class = g_malloc0(ti->class_size);
......
ti->class->type = ti;
while (parent) {
if (parent->class_base_init) {
parent->class_base_init(ti->class, ti->class_data);
}
parent = type_get_parent(parent);
}
if (ti->class_init) {
ti->class_init(ti->class, ti->class_data);
}
}在object_class_foreach_tramp中,会调用将type_initialize,这里面会调用class_init将纸面上的class也即TypeImpl变为ObjectClass,ObjectClass是所有Class类的祖先,MachineClass是它的子类。
因为在machine的命令行里面,我们指定了名字为”pc-i440fx-4.0”,就肯定能够找到我们注册过了的TypeImpl,并调用它的class_init函数。
因而pc_machine_##suffix##class_init会被调用,在这里面,pc_i440fx_machine_options才真正被调用初始化MachineClass,并且将MachineClass的init函数设置为pc_init##suffix。也即,当select_machine执行完毕后,就有一个MachineClass了。
接着,我们回到object_new。这就很好理解了,MachineClass是一个Class类,接下来应该通过它生成一个Instance,也即对象,这就是object_new的作用。
Object *object_new(const char *typename)
{
TypeImpl *ti = type_get_by_name(typename);
return object_new_with_type(ti);
}
static Object *object_new_with_type(Type type)
{
Object *obj;
type_initialize(type);
obj = g_malloc(type->instance_size);
object_initialize_with_type(obj, type->instance_size, type);
obj->free = g_free;
return obj;
}object_new中,TypeImpl的instance_init会被调用,创建一个对象。current_machine就是这个对象,它的类型是MachineState。
至此,绕了这么大一圈,有关体系结构的对象才创建完毕,接下来很多的设备的初始化,包括CPU和内存的初始化,都是围绕着体系结构的对象来的,后面我们会常常看到current_machine。
44.4 总结
这一节,我们学到,虚拟机对于设备的模拟是一件非常复杂的事情,需要用复杂的参数模拟各种各样的设备。为了能够适配这些设备,qemu定义了自己的模块管理机制,只有了解了这种机制,后面看每一种设备的虚拟化的时候,才有一个整体的思路。
这里的MachineClass是我们遇到的第一个,我们需要掌握它里面各种定义之间的关系。
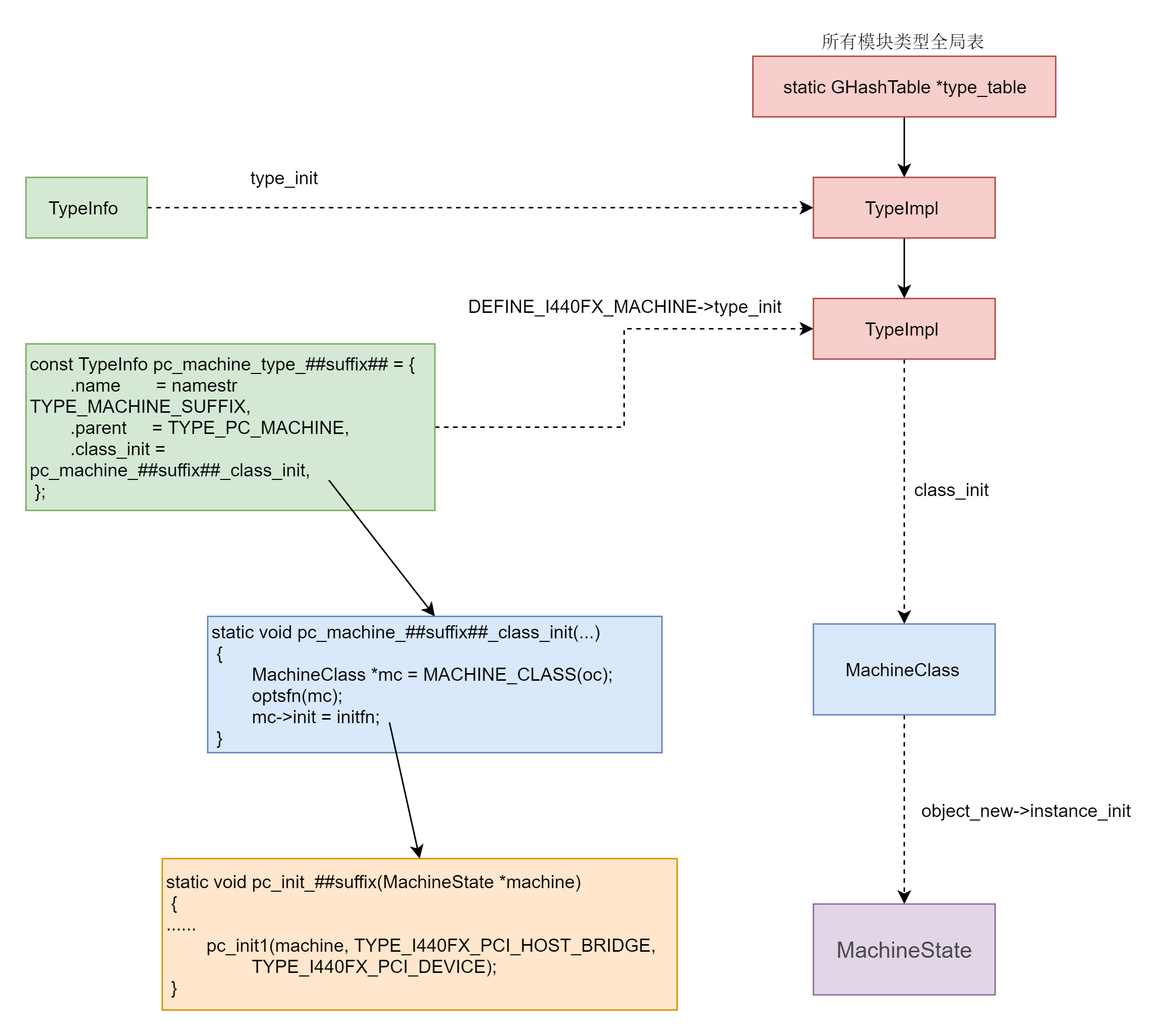
每个模块都会有一个定义TypeInfo,会通过type_init变为全局的TypeImpl。TypeInfo以及生成的TypeImpl有以下成员:
- name表示当前类型的名称
- parent表示父类的名称
- class_init用于将TypeImpl初始化为MachineClass
- instance_init用于将MachineClass初始化为MachineState
所以,以后遇到任何一个类型的时候,将父类和子类之间的关系,以及对应的初始化函数都要看好,这样就一目了然了。
45. 计算虚拟化之CPU(下)
上一节qemu初始化的main函数,我们解析了一个开头,得到了表示体系结构的MachineClass以及MachineState。
45.1 初始化块设备
我们接着回到main函数,接下来初始化的是块设备,调用的是configure_blockdev。这里我们需要重点关注上面参数中的硬盘,不过我们放在存储虚拟化那一节再解析。
configure_blockdev(&bdo_queue, machine_class, snapshot);45.2 初始化计算虚拟化的加速模式
接下来初始化的是计算虚拟化的加速模式,也即要不要使用KVM。根据参数中的配置是启用KVM。这里调用的是configure_accelerator。
configure_accelerator(current_machine, argv[0]);
void configure_accelerator(MachineState *ms, const char *progname)
{
const char *accel;
char **accel_list, **tmp;
int ret;
bool accel_initialised = false;
bool init_failed = false;
AccelClass *acc = NULL;
accel = qemu_opt_get(qemu_get_machine_opts(), "accel");
accel = "kvm";
accel_list = g_strsplit(accel, ":", 0);
for (tmp = accel_list; !accel_initialised && tmp && *tmp; tmp++) {
acc = accel_find(*tmp);
ret = accel_init_machine(acc, ms);
}
}
static AccelClass *accel_find(const char *opt_name)
{
char *class_name = g_strdup_printf(ACCEL_CLASS_NAME("%s"), opt_name);
AccelClass *ac = ACCEL_CLASS(object_class_by_name(class_name));
g_free(class_name);
return ac;
}
static int accel_init_machine(AccelClass *acc, MachineState *ms)
{
ObjectClass *oc = OBJECT_CLASS(acc);
const char *cname = object_class_get_name(oc);
AccelState *accel = ACCEL(object_new(cname));
int ret;
ms->accelerator = accel;
*(acc->allowed) = true;
ret = acc->init_machine(ms);
return ret;
}在configure_accelerator中,我们看命令行参数里面的accel,发现是kvm,则调用accel_find根据名字,得到相应的纸面上的class,并初始化为Class类。
MachineClass是计算机体系结构的Class类,同理,AccelClass就是加速器的Class类,然后调用accel_init_machine,通过object_new,将AccelClass这个Class类实例化为AccelState,类似对于体系结构的实例是MachineState。
在accel_find中,我们会根据名字kvm,找到纸面上的class,也即kvm_accel_type,然后调用type_initialize,里面调用kvm_accel_type的class_init方法,也即kvm_accel_class_init。
static void kvm_accel_class_init(ObjectClass *oc, void *data)
{
AccelClass *ac = ACCEL_CLASS(oc);
ac->name = "KVM";
ac->init_machine = kvm_init;
ac->allowed = &kvm_allowed;
}在kvm_accel_class_init中,我们创建AccelClass,将init_machine设置为kvm_init。在accel_init_machine中其实就调用了这个init_machine函数,也即调用kvm_init方法。
static int kvm_init(MachineState *ms)
{
MachineClass *mc = MACHINE_GET_CLASS(ms);
int soft_vcpus_limit, hard_vcpus_limit;
KVMState *s;
const KVMCapabilityInfo *missing_cap;
int ret;
int type = 0;
const char *kvm_type;
s = KVM_STATE(ms->accelerator);
s->fd = qemu_open("/dev/kvm", O_RDWR);
ret = kvm_ioctl(s, KVM_GET_API_VERSION, 0);
......
do {
ret = kvm_ioctl(s, KVM_CREATE_VM, type);
} while (ret == -EINTR);
......
s->vmfd = ret;
/* check the vcpu limits */
soft_vcpus_limit = kvm_recommended_vcpus(s);
hard_vcpus_limit = kvm_max_vcpus(s);
......
ret = kvm_arch_init(ms, s);
if (ret < 0) {
goto err;
}
if (machine_kernel_irqchip_allowed(ms)) {
kvm_irqchip_create(ms, s);
}
......
return 0;
}这里面的操作就从用户态到内核态的KVM了。就像前面原理讲过的一样,用户态使用内核态KVM的能力,需要打开一个文件/dev/kvm,这是一个字符设备文件,打开一个字符设备文件的过程我们讲过,这里不再赘述。
static struct miscdevice kvm_dev = {
KVM_MINOR,
"kvm",
&kvm_chardev_ops,
};
static struct file_operations kvm_chardev_ops = {
.unlocked_ioctl = kvm_dev_ioctl,
.compat_ioctl = kvm_dev_ioctl,
.llseek = noop_llseek,
};KVM这个字符设备文件定义了一个字符设备文件的操作函数kvm_chardev_ops,这里面只定义了ioctl的操作。
接下来,用户态就通过ioctl系统调用,调用到kvm_dev_ioctl这个函数。这个过程我们在字符设备那一节也讲了。
static long kvm_dev_ioctl(struct file *filp,
unsigned int ioctl, unsigned long arg)
{
long r = -EINVAL;
switch (ioctl) {
case KVM_GET_API_VERSION:
r = KVM_API_VERSION;
break;
case KVM_CREATE_VM:
r = kvm_dev_ioctl_create_vm(arg);
break;
case KVM_CHECK_EXTENSION:
r = kvm_vm_ioctl_check_extension_generic(NULL, arg);
break;
case KVM_GET_VCPU_MMAP_SIZE:
r = PAGE_SIZE; /* struct kvm_run */
break;
......
}
out:
return r;
}我们可以看到,在用户态qemu中,调用KVM_GET_API_VERSION查看版本号,内核就有相应的分支,返回版本号,如果能够匹配上,则调用KVM_CREATE_VM创建虚拟机。
创建虚拟机,需要调用kvm_dev_ioctl_create_vm。
static int kvm_dev_ioctl_create_vm(unsigned long type)
{
int r;
struct kvm *kvm;
struct file *file;
kvm = kvm_create_vm(type);
......
r = get_unused_fd_flags(O_CLOEXEC);
......
file = anon_inode_getfile("kvm-vm", &kvm_vm_fops, kvm, O_RDWR);
......
fd_install(r, file);
return r;
}在kvm_dev_ioctl_create_vm中,首先调用kvm_create_vm创建一个struct kvm结构。这个结构在内核里面代表一个虚拟机。
从下面结构的定义里,我们可以看到,这里面有vcpu,有mm_struct结构。这个结构本来用来管理进程的内存的。虚拟机也是一个进程,所以虚拟机的用户进程空间也是用它来表示。虚拟机里面的操作系统以及应用的进程空间不归它管。
在kvm_dev_ioctl_create_vm中,第二件事情就是创建一个文件描述符,和struct file关联起来,这个struct file的file_operations会被设置为kvm_vm_fops。
struct kvm {
struct mm_struct *mm; /* userspace tied to this vm */
struct kvm_memslots __rcu *memslots[KVM_ADDRESS_SPACE_NUM];
struct kvm_vcpu *vcpus[KVM_MAX_VCPUS];
atomic_t online_vcpus;
int created_vcpus;
int last_boosted_vcpu;
struct list_head vm_list;
struct mutex lock;
struct kvm_io_bus __rcu *buses[KVM_NR_BUSES];
......
struct kvm_vm_stat stat;
struct kvm_arch arch;
refcount_t users_count;
......
long tlbs_dirty;
struct list_head devices;
pid_t userspace_pid;
};
static struct file_operations kvm_vm_fops = {
.release = kvm_vm_release,
.unlocked_ioctl = kvm_vm_ioctl,
.llseek = noop_llseek,
};kvm_dev_ioctl_create_vm结束之后,对于一台虚拟机而言,只是在内核中有一个数据结构,对于相应的资源还没有分配,所以我们还需要接着看。
45.3 初始化网络设备
接下来,调用net_init_clients进行网络设备的初始化。我们可以解析net参数,也会在net_init_clients中解析netdev参数。这属于网络虚拟化的部分,我们先暂时放一下。
int net_init_clients(Error **errp)
{
QTAILQ_INIT(&net_clients);
if (qemu_opts_foreach(qemu_find_opts("netdev"),
net_init_netdev, NULL, errp)) {
return -1;
}
if (qemu_opts_foreach(qemu_find_opts("nic"), net_param_nic, NULL, errp)) {
return -1;
}
if (qemu_opts_foreach(qemu_find_opts("net"), net_init_client, NULL, errp)) {
return -1;
}
return 0;
}45.4 CPU虚拟化
接下来,我们要调用machine_run_board_init。这里面调用了MachineClass的init函数。盼啊盼才到了它,这才调用了pc_init1。
void machine_run_board_init(MachineState *machine)
{
MachineClass *machine_class = MACHINE_GET_CLASS(machine);
numa_complete_configuration(machine);
if (nb_numa_nodes) {
machine_numa_finish_cpu_init(machine);
}
......
machine_class->init(machine);
}在pc_init1里面,我们重点关注两件重要的事情,一个的CPU的虚拟化,主要调用pc_cpus_init;另外就是内存的虚拟化,主要调用pc_memory_init。这一节我们重点关注CPU的虚拟化,下一节,我们来看内存的虚拟化。
void pc_cpus_init(PCMachineState *pcms)
{
......
for (i = 0; i < smp_cpus; i++) {
pc_new_cpu(possible_cpus->cpus[i].type, possible_cpus->cpus[i].arch_id, &error_fatal);
}
}
static void pc_new_cpu(const char *typename, int64_t apic_id, Error **errp)
{
Object *cpu = NULL;
cpu = object_new(typename);
object_property_set_uint(cpu, apic_id, "apic-id", &local_err);
object_property_set_bool(cpu, true, "realized", &local_err);//调用 object_property_add_bool的时候,设置了用 device_set_realized 来设置
......
}在pc_cpus_init中,对于每一个CPU,都调用pc_new_cpu,在这里,我们又看到了object_new,这又是一个从TypeImpl到Class类再到对象的一个过程。
这个时候,我们就要看CPU的类是怎么组织的了。
在上面的参数里面,CPU的配置是这样的:
-cpu SandyBridge,+erms,+smep,+fsgsbase,+pdpe1gb,+rdrand,+f16c,+osxsave,+dca,+pcid,+pdcm,+xtpr,+tm2,+est,+smx,+vmx,+ds_cpl,+monitor,+dtes64,+pbe,+tm,+ht,+ss,+acpi,+ds,+vme在这里我们知道,SandyBridge是CPU的一种类型。在hw/i386/pc.c中,我们能看到这种CPU的定义。
{ "SandyBridge" "-" TYPE_X86_CPU, "min-xlevel", "0x8000000a" }接下来,我们就来看”SandyBridge”,也即TYPE_X86_CPU这种CPU的类,是一个什么样的结构。
static const TypeInfo device_type_info = {
.name = TYPE_DEVICE,
.parent = TYPE_OBJECT,
.instance_size = sizeof(DeviceState),
.instance_init = device_initfn,
.instance_post_init = device_post_init,
.instance_finalize = device_finalize,
.class_base_init = device_class_base_init,
.class_init = device_class_init,
.abstract = true,
.class_size = sizeof(DeviceClass),
};
static const TypeInfo cpu_type_info = {
.name = TYPE_CPU,
.parent = TYPE_DEVICE,
.instance_size = sizeof(CPUState),
.instance_init = cpu_common_initfn,
.instance_finalize = cpu_common_finalize,
.abstract = true,
.class_size = sizeof(CPUClass),
.class_init = cpu_class_init,
};
static const TypeInfo x86_cpu_type_info = {
.name = TYPE_X86_CPU,
.parent = TYPE_CPU,
.instance_size = sizeof(X86CPU),
.instance_init = x86_cpu_initfn,
.abstract = true,
.class_size = sizeof(X86CPUClass),
.class_init = x86_cpu_common_class_init,
};CPU这种类的定义是有多层继承关系的。TYPE_X86_CPU的父类是TYPE_CPU,TYPE_CPU的父类是TYPE_DEVICE,TYPE_DEVICE的父类是TYPE_OBJECT。到头了。
这里面每一层都有class_init,用于从TypeImpl生产xxxClass,也有instance_init将xxxClass初始化为实例。
在TYPE_X86_CPU这一层的class_init中,也即x86_cpu_common_class_init中,设置了DeviceClass的realize函数为x86_cpu_realizefn。这个函数很重要,马上就能用到。
static void x86_cpu_common_class_init(ObjectClass *oc, void *data)
{
X86CPUClass *xcc = X86_CPU_CLASS(oc);
CPUClass *cc = CPU_CLASS(oc);
DeviceClass *dc = DEVICE_CLASS(oc);
device_class_set_parent_realize(dc, x86_cpu_realizefn,
&xcc->parent_realize);
......
}在TYPE_DEVICE这一层的instance_init函数device_initfn,会为这个设备添加一个属性”realized”,要设置这个属性,需要用函数device_set_realized。
static void device_initfn(Object *obj)
{
DeviceState *dev = DEVICE(obj);
ObjectClass *class;
Property *prop;
dev->realized = false;
object_property_add_bool(obj, "realized",
device_get_realized, device_set_realized, NULL);
......
}我们回到pc_new_cpu函数,这里面就是通过object_property_set_bool设置这个属性为true,所以device_set_realized函数会被调用。
在device_set_realized中,DeviceClass的realize函数x86_cpu_realizefn会被调用。这里面qemu_init_vcpu会调用qemu_kvm_start_vcpu。
static void qemu_kvm_start_vcpu(CPUState *cpu)
{
char thread_name[VCPU_THREAD_NAME_SIZE];
cpu->thread = g_malloc0(sizeof(QemuThread));
cpu->halt_cond = g_malloc0(sizeof(QemuCond));
qemu_cond_init(cpu->halt_cond);
qemu_thread_create(cpu->thread, thread_name, qemu_kvm_cpu_thread_fn, cpu, QEMU_THREAD_JOINABLE);
}在这里面,为这个vcpu创建一个线程,也即虚拟机里面的一个vcpu对应物理机上的一个线程,然后这个线程被调度到某个物理CPU上。
我们来看这个vcpu的线程执行函数。
static void *qemu_kvm_cpu_thread_fn(void *arg)
{
CPUState *cpu = arg;
int r;
rcu_register_thread();
qemu_mutex_lock_iothread();
qemu_thread_get_self(cpu->thread);
cpu->thread_id = qemu_get_thread_id();
cpu->can_do_io = 1;
current_cpu = cpu;
r = kvm_init_vcpu(cpu);
kvm_init_cpu_signals(cpu);
/* signal CPU creation */
cpu->created = true;
qemu_cond_signal(&qemu_cpu_cond);
do {
if (cpu_can_run(cpu)) {
r = kvm_cpu_exec(cpu);
}
qemu_wait_io_event(cpu);
} while (!cpu->unplug || cpu_can_run(cpu));
qemu_kvm_destroy_vcpu(cpu);
cpu->created = false;
qemu_cond_signal(&qemu_cpu_cond);
qemu_mutex_unlock_iothread();
rcu_unregister_thread();
return NULL;
}在qemu_kvm_cpu_thread_fn中,先是kvm_init_vcpu初始化这个vcpu。
int kvm_init_vcpu(CPUState *cpu)
{
KVMState *s = kvm_state;
long mmap_size;
int ret;
......
ret = kvm_get_vcpu(s, kvm_arch_vcpu_id(cpu));
......
cpu->kvm_fd = ret;
cpu->kvm_state = s;
cpu->vcpu_dirty = true;
mmap_size = kvm_ioctl(s, KVM_GET_VCPU_MMAP_SIZE, 0);
......
cpu->kvm_run = mmap(NULL, mmap_size, PROT_READ | PROT_WRITE, MAP_SHARED, cpu->kvm_fd, 0);
......
ret = kvm_arch_init_vcpu(cpu);
err:
return ret;
}在kvm_get_vcpu中,我们会调用kvm_vm_ioctl(s, KVM_CREATE_VCPU, (void *)vcpu_id),在内核里面创建一个vcpu。在上面创建KVM_CREATE_VM的时候,我们已经创建了一个struct file,它的file_operations被设置为kvm_vm_fops,这个内核文件也是可以响应ioctl的。
如果我们切换到内核KVM,在kvm_vm_ioctl函数中,有对于KVM_CREATE_VCPU的处理,调用的是kvm_vm_ioctl_create_vcpu。
static long kvm_vm_ioctl(struct file *filp,
unsigned int ioctl, unsigned long arg)
{
struct kvm *kvm = filp->private_data;
void __user *argp = (void __user *)arg;
int r;
switch (ioctl) {
case KVM_CREATE_VCPU:
r = kvm_vm_ioctl_create_vcpu(kvm, arg);
break;
case KVM_SET_USER_MEMORY_REGION: {
struct kvm_userspace_memory_region kvm_userspace_mem;
if (copy_from_user(&kvm_userspace_mem, argp,
sizeof(kvm_userspace_mem)))
goto out;
r = kvm_vm_ioctl_set_memory_region(kvm, &kvm_userspace_mem);
break;
}
......
case KVM_CREATE_DEVICE: {
struct kvm_create_device cd;
if (copy_from_user(&cd, argp, sizeof(cd)))
goto out;
r = kvm_ioctl_create_device(kvm, &cd);
if (copy_to_user(argp, &cd, sizeof(cd)))
goto out;
break;
}
case KVM_CHECK_EXTENSION:
r = kvm_vm_ioctl_check_extension_generic(kvm, arg);
break;
default:
r = kvm_arch_vm_ioctl(filp, ioctl, arg);
}
out:
return r;
}在kvm_vm_ioctl_create_vcpu中,kvm_arch_vcpu_create调用kvm_x86_ops的vcpu_create函数来创建CPU。
static int kvm_vm_ioctl_create_vcpu(struct kvm *kvm, u32 id)
{
int r;
struct kvm_vcpu *vcpu;
kvm->created_vcpus++;
......
vcpu = kvm_arch_vcpu_create(kvm, id);
preempt_notifier_init(&vcpu->preempt_notifier, &kvm_preempt_ops);
r = kvm_arch_vcpu_setup(vcpu);
......
/* Now it's all set up, let userspace reach it */
kvm_get_kvm(kvm);
r = create_vcpu_fd(vcpu);
kvm->vcpus[atomic_read(&kvm->online_vcpus)] = vcpu;
......
}
struct kvm_vcpu *kvm_arch_vcpu_create(struct kvm *kvm,
unsigned int id)
{
struct kvm_vcpu *vcpu;
vcpu = kvm_x86_ops->vcpu_create(kvm, id);
return vcpu;
}
static int create_vcpu_fd(struct kvm_vcpu *vcpu)
{
return anon_inode_getfd("kvm-vcpu", &kvm_vcpu_fops, vcpu, O_RDWR | O_CLOEXEC);
}然后,create_vcpu_fd又创建了一个struct file,它的file_operations指向kvm_vcpu_fops。从这里可以看出,KVM的内核模块是一个文件,可以通过ioctl进行操作。基于这个内核模块创建的VM也是一个文件,也可以通过ioctl进行操作。在这个VM上创建的vcpu同样是一个文件,同样可以通过ioctl进行操作。
我们回过头来看,kvm_x86_ops的vcpu_create函数。kvm_x86_ops对于不同的硬件加速虚拟化指向不同的结构,如果是vmx,则指向vmx_x86_ops;如果是svm,则指向svm_x86_ops。我们这里看vmx_x86_ops。这个结构很长,里面有非常多的操作,我们用一个看一个。
static struct kvm_x86_ops vmx_x86_ops __ro_after_init = {
......
.vcpu_create = vmx_create_vcpu,
......
}
static struct kvm_vcpu *vmx_create_vcpu(struct kvm *kvm, unsigned int id)
{
int err;
struct vcpu_vmx *vmx = kmem_cache_zalloc(kvm_vcpu_cache, GFP_KERNEL);
int cpu;
vmx->vpid = allocate_vpid();
err = kvm_vcpu_init(&vmx->vcpu, kvm, id);
vmx->guest_msrs = kmalloc(PAGE_SIZE, GFP_KERNEL);
vmx->loaded_vmcs = &vmx->vmcs01;
vmx->loaded_vmcs->vmcs = alloc_vmcs();
vmx->loaded_vmcs->shadow_vmcs = NULL;
loaded_vmcs_init(vmx->loaded_vmcs);
cpu = get_cpu();
vmx_vcpu_load(&vmx->vcpu, cpu);
vmx->vcpu.cpu = cpu;
err = vmx_vcpu_setup(vmx);
vmx_vcpu_put(&vmx->vcpu);
put_cpu();
if (enable_ept) {
if (!kvm->arch.ept_identity_map_addr)
kvm->arch.ept_identity_map_addr =
VMX_EPT_IDENTITY_PAGETABLE_ADDR;
err = init_rmode_identity_map(kvm);
}
return &vmx->vcpu;
}vmx_create_vcpu创建用于表示vcpu的结构struct vcpu_vmx,并填写里面的内容。例如guest_msrs,咱们在讲系统调用的时候提过msr寄存器,虚拟机也需要有这样的寄存器。
enable_ept是和内存虚拟化相关的,EPT全称Extended Page Table,顾名思义,是优化内存虚拟化的,这个功能我们放到内存的那一节讲。
最最重要的就是loaded_vmcs了。VMCS是什么呢?它的全称是Virtual Machine Control Structure。它是来干什么呢?
前面咱们将进程调度的时候讲过,为了支持进程在CPU上的切换,CPU硬件要求有一个TSS结构,用于保存进程运行时的所有寄存器的状态,进程切换的时候,需要根据TSS恢复寄存器。
虚拟机也是一个进程,也需要切换,而且切换更加的复杂,可能是两个虚拟机之间切换,也可能是虚拟机切换给内核,虚拟机因为里面还有另一个操作系统,要保存的信息比普通的进程多得多。那就需要有一个结构来保存虚拟机运行的上下文,VMCS就是是Intel实现CPU虚拟化,记录vCPU状态的一个关键数据结构。
VMCS数据结构主要包含以下信息。
- Guest-state area,即vCPU的状态信息,包括vCPU的基本运行环境,例如寄存器等。
- Host-state area,是物理CPU的状态信息。物理CPU和vCPU之间也会来回切换,所以,VMCS中既要记录vCPU的状态,也要记录物理CPU的状态。
- VM-execution control fields,对vCPU的运行行为进行控制。例如,发生中断怎么办,是否使用EPT(Extended Page Table)功能等。
接下来,对于VMCS,有两个重要的操作。
VM-Entry,我们称为从根模式切换到非根模式,也即切换到guest上,这个时候CPU上运行的是虚拟机。VM-Exit我们称为CPU从非根模式切换到根模式,也即从guest切换到宿主机。例如,当要执行一些虚拟机没有权限的敏感指令时。
为了维护这两个动作,VMCS里面还有几项内容:
- VM-exit control fields,对VM Exit的行为进行控制。比如,VM Exit的时候对vCPU来说需要保存哪些MSR寄存器,对于主机CPU来说需要恢复哪些MSR寄存器。
- VM-entry control fields,对VM Entry的行为进行控制。比如,需要保存和恢复哪些MSR寄存器等。
- VM-exit information fields,记录下发生VM Exit发生的原因及一些必要的信息,方便对VM Exit事件进行处理。
至此,内核准备完毕。
我们再回到qemu的kvm_init_vcpu函数,这里面除了创建内核中的vcpu结构之外,还通过mmap将内核的vcpu结构,映射到qemu中CPUState的kvm_run中,为什么能用mmap呢,上面咱们不是说过了吗,vcpu也是一个文件。
我们再回到这个vcpu的线程函数qemu_kvm_cpu_thread_fn,他在执行kvm_init_vcpu创建vcpu之后,接下来是一个do-while循环,也即一直运行,并且通过调用kvm_cpu_exec,运行这个虚拟机。
int kvm_cpu_exec(CPUState *cpu)
{
struct kvm_run *run = cpu->kvm_run;
int ret, run_ret;
......
do {
......
run_ret = kvm_vcpu_ioctl(cpu, KVM_RUN, 0);
......
switch (run->exit_reason) {
case KVM_EXIT_IO:
kvm_handle_io(run->io.port, attrs,
(uint8_t *)run + run->io.data_offset,
run->io.direction,
run->io.size,
run->io.count);
break;
case KVM_EXIT_IRQ_WINDOW_OPEN:
ret = EXCP_INTERRUPT;
break;
case KVM_EXIT_SHUTDOWN:
qemu_system_reset_request(SHUTDOWN_CAUSE_GUEST_RESET);
ret = EXCP_INTERRUPT;
break;
case KVM_EXIT_UNKNOWN:
fprintf(stderr, "KVM: unknown exit, hardware reason %" PRIx64 "\n",(uint64_t)run->hw.hardware_exit_reason);
ret = -1;
break;
case KVM_EXIT_INTERNAL_ERROR:
ret = kvm_handle_internal_error(cpu, run);
break;
......
}
} while (ret == 0);
......
return ret;
}在kvm_cpu_exec中,我们能看到一个循环,在循环中,kvm_vcpu_ioctl(KVM_RUN)运行这个虚拟机,这个时候CPU进入VM-Entry,也即进入客户机模式。
如果一直是客户机的操作系统占用这个CPU,则会一直停留在这一行运行,一旦这个调用返回了,就说明CPU进入VM-Exit退出客户机模式,将CPU交还给宿主机。在循环中,我们会对退出的原因exit_reason进行分析处理,因为有了I/O,还有了中断等,做相应的处理。处理完毕之后,再次循环,再次通过VM-Entry,进入客户机模式。如此循环,直到虚拟机正常或者异常退出。
我们来看kvm_vcpu_ioctl(KVM_RUN)在内核做了哪些事情。
上面我们也讲了,vcpu在内核也是一个文件,也是通过ioctl进行用户态和内核态通信的,在内核中,调用的是kvm_vcpu_ioctl。
static long kvm_vcpu_ioctl(struct file *filp,
unsigned int ioctl, unsigned long arg)
{
struct kvm_vcpu *vcpu = filp->private_data;
void __user *argp = (void __user *)arg;
int r;
struct kvm_fpu *fpu = NULL;
struct kvm_sregs *kvm_sregs = NULL;
......
r = vcpu_load(vcpu);
switch (ioctl) {
case KVM_RUN: {
struct pid *oldpid;
r = kvm_arch_vcpu_ioctl_run(vcpu, vcpu->run);
break;
}
case KVM_GET_REGS: {
struct kvm_regs *kvm_regs;
kvm_regs = kzalloc(sizeof(struct kvm_regs), GFP_KERNEL);
r = kvm_arch_vcpu_ioctl_get_regs(vcpu, kvm_regs);
if (copy_to_user(argp, kvm_regs, sizeof(struct kvm_regs)))
goto out_free1;
break;
}
case KVM_SET_REGS: {
struct kvm_regs *kvm_regs;
kvm_regs = memdup_user(argp, sizeof(*kvm_regs));
r = kvm_arch_vcpu_ioctl_set_regs(vcpu, kvm_regs);
break;
}
......
}kvm_arch_vcpu_ioctl_run会调用vcpu_run,这里面也是一个无限循环。
static int vcpu_run(struct kvm_vcpu *vcpu)
{
int r;
struct kvm *kvm = vcpu->kvm;
for (;;) {
if (kvm_vcpu_running(vcpu)) {
r = vcpu_enter_guest(vcpu);
} else {
r = vcpu_block(kvm, vcpu);
}
....
if (signal_pending(current)) {
r = -EINTR;
vcpu->run->exit_reason = KVM_EXIT_INTR;
++vcpu->stat.signal_exits;
break;
}
if (need_resched()) {
cond_resched();
}
}
......
return r;
}在这个循环中,除了调用vcpu_enter_guest进入客户机模式运行之外,还有对于信号的响应signal_pending,也即一台虚拟机是可以被kill掉的,还有对于调度的响应,这台虚拟机可以被从当前的物理CPU上赶下来,换成别的虚拟机或者其他进程。
我们这里重点看vcpu_enter_guest。
static int vcpu_enter_guest(struct kvm_vcpu *vcpu)
{
r = kvm_mmu_reload(vcpu);
vcpu->mode = IN_GUEST_MODE;
kvm_load_guest_xcr0(vcpu);
......
guest_enter_irqoff();
kvm_x86_ops->run(vcpu);
vcpu->mode = OUTSIDE_GUEST_MODE;
......
kvm_put_guest_xcr0(vcpu);
kvm_x86_ops->handle_external_intr(vcpu);
++vcpu->stat.exits;
guest_exit_irqoff();
r = kvm_x86_ops->handle_exit(vcpu);
return r;
......
}
static struct kvm_x86_ops vmx_x86_ops __ro_after_init = {
......
.run = vmx_vcpu_run,
......
}在vcpu_enter_guest中,我们会调用vmx_x86_ops 的vmx_vcpu_run函数,进入客户机模式。
static void __noclone vmx_vcpu_run(struct kvm_vcpu *vcpu)
{
struct vcpu_vmx *vmx = to_vmx(vcpu);
unsigned long debugctlmsr, cr3, cr4;
......
cr3 = __get_current_cr3_fast();
......
cr4 = cr4_read_shadow();
......
vmx->__launched = vmx->loaded_vmcs->launched;
asm(
/* Store host registers */
"push %%" _ASM_DX "; push %%" _ASM_BP ";"
"push %%" _ASM_CX " \n\t" /* placeholder for guest rcx */
"push %%" _ASM_CX " \n\t"
......
/* Load guest registers. Don't clobber flags. */
"mov %crax, %%" _ASM_AX " \n\t"
"mov %crbx, %%" _ASM_BX " \n\t"
"mov %crdx, %%" _ASM_DX " \n\t"
"mov %crsi, %%" _ASM_SI " \n\t"
"mov %crdi, %%" _ASM_DI " \n\t"
"mov %crbp, %%" _ASM_BP " \n\t"
#ifdef CONFIG_X86_64
"mov %cr8, %%r8 \n\t"
"mov %cr9, %%r9 \n\t"
"mov %cr10, %%r10 \n\t"
"mov %cr11, %%r11 \n\t"
"mov %cr12, %%r12 \n\t"
"mov %cr13, %%r13 \n\t"
"mov %cr14, %%r14 \n\t"
"mov %cr15, %%r15 \n\t"
#endif
"mov %crcx, %%" _ASM_CX " \n\t" /* kills %0 (ecx) */
/* Enter guest mode */
"jne 1f \n\t"
__ex(ASM_VMX_VMLAUNCH) "\n\t"
"jmp 2f \n\t"
"1: " __ex(ASM_VMX_VMRESUME) "\n\t"
"2: "
/* Save guest registers, load host registers, keep flags */
"mov %0, %cwordsize \n\t"
"pop %0 \n\t"
"mov %%" _ASM_AX ", %crax \n\t"
"mov %%" _ASM_BX ", %crbx \n\t"
__ASM_SIZE(pop) " %crcx \n\t"
"mov %%" _ASM_DX ", %crdx \n\t"
"mov %%" _ASM_SI ", %crsi \n\t"
"mov %%" _ASM_DI ", %crdi \n\t"
"mov %%" _ASM_BP ", %crbp \n\t"
#ifdef CONFIG_X86_64
"mov %%r8, %cr8 \n\t"
"mov %%r9, %cr9 \n\t"
"mov %%r10, %cr10 \n\t"
"mov %%r11, %cr11 \n\t"
"mov %%r12, %cr12 \n\t"
"mov %%r13, %cr13 \n\t"
"mov %%r14, %cr14 \n\t"
"mov %%r15, %cr15 \n\t"
#endif
"mov %%cr2, %%" _ASM_AX " \n\t"
"mov %%" _ASM_AX ", %ccr2 \n\t"
"pop %%" _ASM_BP "; pop %%" _ASM_DX " \n\t"
"setbe %cfail \n\t"
".pushsection .rodata \n\t"
".global vmx_return \n\t"
"vmx_return: " _ASM_PTR " 2b \n\t"
......
);
......
vmx->loaded_vmcs->launched = 1;
vmx->exit_reason = vmcs_read32(VM_EXIT_REASON);
......
}在vmx_vcpu_run中,出现了汇编语言的代码,比较难看懂,但是没有关系呀,里面有注释呀,我们可以沿着注释来看。
- 首先是Store host registers,要从宿主机模式变为客户机模式了,所以原来宿主机运行时候的寄存器要保存下来。
- 接下来是Load guest registers,将原来客户机运行的时候的寄存器加载进来。
- 接下来是Enter guest mode,调用ASM_VMX_VMLAUNCH进入客户机模型运行,或者ASM_VMX_VMRESUME恢复客户机模型运行。
- 如果客户机因为某种原因退出,Save guest registers, load host registers,也即保存客户机运行的时候的寄存器,就加载宿主机运行的时候的寄存器。
- 最后将exit_reason保存在vmx结构中。
至此,CPU虚拟化就解析完了。
45.5 总结
CPU的虚拟化过程还是很复杂的,我画了一张图总结了一下。
- 首先,我们要定义CPU这种类型的TypeInfo和TypeImpl、继承关系,并且声明它的类初始化函数。
- 在qemu的main函数中调用MachineClass的init函数,这个函数既会初始化CPU,也会初始化内存。
- CPU初始化的时候,会调用pc_new_cpu创建一个虚拟CPU,它会调用CPU这个类的初始化函数。
- 每一个虚拟CPU会调用qemu_thread_create创建一个线程,线程的执行函数为qemu_kvm_cpu_thread_fn。
- 在虚拟CPU对应的线程执行函数中,我们先是调用kvm_vm_ioctl(KVM_CREATE_VCPU),在内核的KVM里面,创建一个结构struct vcpu_vmx,表示这个虚拟CPU。在这个结构里面,有一个VMCS,用于保存当前虚拟机CPU的运行时的状态,用于状态切换。
- 在虚拟CPU对应的线程执行函数中,我们接着调用kvm_vcpu_ioctl(KVM_RUN),在内核的KVM里面运行这个虚拟机CPU。运行的方式是保存宿主机的寄存器,加载客户机的寄存器,然后调用
__ex(ASM_VMX_VMLAUNCH)或者__ex(ASM_VMX_VMRESUME),进入客户机模式运行。一旦退出客户机模式,就会保存客户机寄存器,加载宿主机寄存器,进入宿主机模式运行,并且会记录退出虚拟机模式的原因。大部分的原因是等待I/O,因而宿主机调用kvm_handle_io进行处理。
46. 计算虚拟化之内存
上一节,我们解析了计算虚拟化之CPU。可以看到,CPU的虚拟化是用户态的qemu和内核态的KVM共同配合完成的。它们二者通过ioctl进行通信。对于内存管理来讲,也是需要这两者配合完成的。
咱们在内存管理的时候讲过,操作系统给每个进程分配的内存都是虚拟内存,需要通过页表映射,变成物理内存进行访问。当有了虚拟机之后,情况会变得更加复杂。因为虚拟机对于物理机来讲是一个进程,但是虚拟机里面也有内核,也有虚拟机里面跑的进程。所以有了虚拟机,内存就变成了四类:
- 虚拟机里面的虚拟内存(Guest OS Virtual Memory,GVA),这是虚拟机里面的进程看到的内存空间;
- 虚拟机里面的物理内存(Guest OS Physical Memory,GPA),这是虚拟机里面的操作系统看到的内存,它认为这是物理内存;
- 物理机的虚拟内存(Host Virtual Memory,HVA),这是物理机上的qemu进程看到的内存空间;
- 物理机的物理内存(Host Physical Memory,HPA),这是物理机上的操作系统看到的内存。
这下咱们内存管理那一章讲的两大内容,一个是内存管理变得非常复杂,另一个是内存映射,就都要转多手了。换句话说就是,从GVA到GPA,到HVA,再到HPA,性能会变得很差。当然,虚拟化技术成熟的今天,有了一些优化的手段,具体怎么优化呢?我们这一节就来一一解析。
46.1 内存管理
我们先来看内存管理的部分。
由于CPU和内存是紧密结合的,因而内存虚拟化的初始化过程,和CPU虚拟化的初始化是一起完成的。
上一节说CPU虚拟化初始化的时候,我们会调用kvm_init函数,这里面打开了”/dev/kvm”这个字符文件,并且通过ioctl调用到内核kvm的KVM_CREATE_VM操作,除了这些CPU相关的调用,接下来还有内存相关的。我们来看看。
static int kvm_init(MachineState *ms)
{
MachineClass *mc = MACHINE_GET_CLASS(ms);
......
kvm_memory_listener_register(s, &s->memory_listener,
&address_space_memory, 0);
memory_listener_register(&kvm_io_listener,
&address_space_io);
......
}
AddressSpace address_space_io;
AddressSpace address_space_memory;这里面有两个地址空间AddressSpace,一个是系统内存的地址空间address_space_memory,一个用于I/O的地址空间address_space_io。这里我们重点看address_space_memory。
struct AddressSpace {
/* All fields are private. */
struct rcu_head rcu;
char *name;
MemoryRegion *root;
/* Accessed via RCU. */
struct FlatView *current_map;
int ioeventfd_nb;
struct MemoryRegionIoeventfd *ioeventfds;
QTAILQ_HEAD(, MemoryListener) listeners;
QTAILQ_ENTRY(AddressSpace) address_spaces_link;
};对于一个地址空间,会有多个内存区域MemoryRegion组成树形结构。这里面,root是这棵树的根。另外,还有一个MemoryListener链表,当内存区域发生变化的时候,需要做一些动作,使得用户态和内核态能够协同,就是由这些MemoryListener完成的。
在kvm_init这个时候,还没有内存区域加入进来,root还是空的,但是我们可以先注册MemoryListener,这里注册的是KVMMemoryListener。
void kvm_memory_listener_register(KVMState *s, KVMMemoryListener *kml,
AddressSpace *as, int as_id)
{
int i;
kml->slots = g_malloc0(s->nr_slots * sizeof(KVMSlot));
kml->as_id = as_id;
for (i = 0; i < s->nr_slots; i++) {
kml->slots[i].slot = i;
}
kml->listener.region_add = kvm_region_add;
kml->listener.region_del = kvm_region_del;
kml->listener.priority = 10;
memory_listener_register(&kml->listener, as);
}在这个KVMMemoryListener中是这样配置的:当添加一个MemoryRegion的时候,region_add会被调用,这个我们后面会用到。
接下来,在qemu启动的main函数中,我们会调用cpu_exec_init_all->memory_map_init.
static void memory_map_init(void)
{
system_memory = g_malloc(sizeof(*system_memory));
memory_region_init(system_memory, NULL, "system", UINT64_MAX);
address_space_init(&address_space_memory, system_memory, "memory");
system_io = g_malloc(sizeof(*system_io));
memory_region_init_io(system_io, NULL, &unassigned_io_ops, NULL, "io",
65536);
address_space_init(&address_space_io, system_io, "I/O");
}在这里,对于系统内存区域system_memory和用于I/O的内存区域system_io,我们都进行了初始化,并且关联到了相应的地址空间AddressSpace。
void address_space_init(AddressSpace *as, MemoryRegion *root, const char *name)
{
memory_region_ref(root);
as->root = root;
as->current_map = NULL;
as->ioeventfd_nb = 0;
as->ioeventfds = NULL;
QTAILQ_INIT(&as->listeners);
QTAILQ_INSERT_TAIL(&address_spaces, as, address_spaces_link);
as->name = g_strdup(name ? name : "anonymous");
address_space_update_topology(as);
address_space_update_ioeventfds(as);
}对于系统内存地址空间address_space_memory,我们需要把它里面内存区域的根root设置为system_memory。
另外,在这里,我们还调用了address_space_update_topology。
static void address_space_update_topology(AddressSpace *as)
{
MemoryRegion *physmr = memory_region_get_flatview_root(as->root);
flatviews_init();
if (!g_hash_table_lookup(flat_views, physmr)) {
generate_memory_topology(physmr);
}
address_space_set_flatview(as);
}
static void address_space_set_flatview(AddressSpace *as)
{
FlatView *old_view = address_space_to_flatview(as);
MemoryRegion *physmr = memory_region_get_flatview_root(as->root);
FlatView *new_view = g_hash_table_lookup(flat_views, physmr);
if (old_view == new_view) {
return;
}
......
if (!QTAILQ_EMPTY(&as->listeners)) {
FlatView tmpview = { .nr = 0 }, *old_view2 = old_view;
if (!old_view2) {
old_view2 = &tmpview;
}
address_space_update_topology_pass(as, old_view2, new_view, false);
address_space_update_topology_pass(as, old_view2, new_view, true);
}
/* Writes are protected by the BQL. */
atomic_rcu_set(&as->current_map, new_view);
......
}这里面会生成AddressSpace的flatview。flatview是什么意思呢?
我们可以看到,在AddressSpace里面,除了树形结构的MemoryRegion之外,还有一个flatview结构,其实这个结构就是把这样一个树形的内存结构变成平的内存结构。因为树形内存结构比较容易管理,但是平的内存结构,比较方便和内核里面通信,来请求物理内存。虽然操作系统内核里面也是用树形结构来表示内存区域的,但是用户态向内核申请内存的时候,会按照平的、连续的模式进行申请。这里,qemu在用户态,所以要做这样一个转换。
在address_space_set_flatview中,我们将老的flatview和新的flatview进行比较。如果不同,说明内存结构发生了变化,会调用address_space_update_topology_pass->MEMORY_LISTENER_UPDATE_REGION->MEMORY_LISTENER_CALL。
这里面调用所有的listener。但是,这个逻辑这里不会执行的。这是因为这里内存处于初始化的阶段,全局的flat_views里面肯定找不到。因而generate_memory_topology第一次生成了FlatView,然后才调用了address_space_set_flatview。这里面,老的flatview和新的flatview一定是一样的。
但是,请你记住这个逻辑,到这里我们还没解析qemu有关内存的参数,所以这里添加的MemoryRegion虽然是一个根,但是是空的,是为了管理使用的,后面真的添加内存的时候,这个逻辑还会调用到。
我们再回到qemu启动的main函数中。接下来的初始化过程会调用pc_init1。在这里面,对于CPU虚拟化,我们会调用pc_cpus_init。这个我们在上一节已经讲过了。另外,pc_init1还会调用pc_memory_init,进行内存的虚拟化,我们这里解析这一部分。
void pc_memory_init(PCMachineState *pcms,
MemoryRegion *system_memory,
MemoryRegion *rom_memory,
MemoryRegion **ram_memory)
{
int linux_boot, i;
MemoryRegion *ram, *option_rom_mr;
MemoryRegion *ram_below_4g, *ram_above_4g;
FWCfgState *fw_cfg;
MachineState *machine = MACHINE(pcms);
PCMachineClass *pcmc = PC_MACHINE_GET_CLASS(pcms);
......
/* Allocate RAM. We allocate it as a single memory region and use
* aliases to address portions of it, mostly for backwards compatibility with older qemus that used qemu_ram_alloc().
*/
ram = g_malloc(sizeof(*ram));
memory_region_allocate_system_memory(ram, NULL, "pc.ram",
machine->ram_size);
*ram_memory = ram;
ram_below_4g = g_malloc(sizeof(*ram_below_4g));
memory_region_init_alias(ram_below_4g, NULL, "ram-below-4g", ram,
0, pcms->below_4g_mem_size);
memory_region_add_subregion(system_memory, 0, ram_below_4g);
e820_add_entry(0, pcms->below_4g_mem_size, E820_RAM);
if (pcms->above_4g_mem_size > 0) {
ram_above_4g = g_malloc(sizeof(*ram_above_4g));
memory_region_init_alias(ram_above_4g, NULL, "ram-above-4g", ram, pcms->below_4g_mem_size, pcms->above_4g_mem_size);
memory_region_add_subregion(system_memory, 0x100000000ULL,
ram_above_4g);
e820_add_entry(0x100000000ULL, pcms->above_4g_mem_size, E820_RAM);
}
......
}在pc_memory_init中,我们已经知道了虚拟机要申请的内存ram_size,于是通过memory_region_allocate_system_memory来申请内存。
接下来的调用链为:memory_region_allocate_system_memory->allocate_system_memory_nonnuma->memory_region_init_ram_nomigrate->memory_region_init_ram_shared_nomigrate。
void memory_region_init_ram_shared_nomigrate(MemoryRegion *mr,
Object *owner,
const char *name,
uint64_t size,
bool share,
Error **errp)
{
Error *err = NULL;
memory_region_init(mr, owner, name, size);
mr->ram = true;
mr->terminates = true;
mr->destructor = memory_region_destructor_ram;
mr->ram_block = qemu_ram_alloc(size, share, mr, &err);
......
}
static
RAMBlock *qemu_ram_alloc_internal(ram_addr_t size, ram_addr_t max_size, void (*resized)(const char*,uint64_t length,void *host),void *host, bool resizeable, bool share,MemoryRegion *mr, Error **errp)
{
RAMBlock *new_block;
size = HOST_PAGE_ALIGN(size);
max_size = HOST_PAGE_ALIGN(max_size);
new_block = g_malloc0(sizeof(*new_block));
new_block->mr = mr;
new_block->resized = resized;
new_block->used_length = size;
new_block->max_length = max_size;
new_block->fd = -1;
new_block->page_size = getpagesize();
new_block->host = host;
......
ram_block_add(new_block, &local_err, share);
return new_block;
}
static void ram_block_add(RAMBlock *new_block, Error **errp, bool shared)
{
RAMBlock *block;
RAMBlock *last_block = NULL;
ram_addr_t old_ram_size, new_ram_size;
Error *err = NULL;
old_ram_size = last_ram_page();
new_block->offset = find_ram_offset(new_block->max_length);
if (!new_block->host) {
new_block->host = phys_mem_alloc(new_block->max_length, &new_block->mr->align, shared);
......
}
}
......
}这里面,我们会调用qemu_ram_alloc,创建一个RAMBlock用来表示内存块。这里面调用ram_block_add->phys_mem_alloc。phys_mem_alloc是一个函数指针,指向函数qemu_anon_ram_alloc,这里面调用qemu_ram_mmap,在qemu_ram_mmap中调用mmap分配内存。
static void *(*phys_mem_alloc)(size_t size, uint64_t *align, bool shared) = qemu_anon_ram_alloc;
void *qemu_anon_ram_alloc(size_t size, uint64_t *alignment, bool shared)
{
size_t align = QEMU_VMALLOC_ALIGN;
void *ptr = qemu_ram_mmap(-1, size, align, shared);
......
if (alignment) {
*alignment = align;
}
return ptr;
}
void *qemu_ram_mmap(int fd, size_t size, size_t align, bool shared)
{
int flags;
int guardfd;
size_t offset;
size_t pagesize;
size_t total;
void *guardptr;
void *ptr;
......
total = size + align;
guardfd = -1;
pagesize = getpagesize();
flags = MAP_PRIVATE | MAP_ANONYMOUS;
guardptr = mmap(0, total, PROT_NONE, flags, guardfd, 0);
......
flags = MAP_FIXED;
flags |= fd == -1 ? MAP_ANONYMOUS : 0;
flags |= shared ? MAP_SHARED : MAP_PRIVATE;
offset = QEMU_ALIGN_UP((uintptr_t)guardptr, align) - (uintptr_t)guardptr;
ptr = mmap(guardptr + offset, size, PROT_READ | PROT_WRITE, flags, fd, 0);
......
return ptr;
}我们回到pc_memory_init,通过memory_region_allocate_system_memory申请到内存以后,为了兼容过去的版本,我们分成两个MemoryRegion进行管理,一个是ram_below_4g,一个是ram_above_4g。对于这两个MemoryRegion,我们都会初始化一个alias,也即别名,意思是说,两个MemoryRegion其实都指向memory_region_allocate_system_memory分配的内存,只不过分成两个部分,起两个别名指向不同的区域。
这两部分MemoryRegion都会调用memory_region_add_subregion,将这两部分作为子的内存区域添加到system_memory这棵树上。
接下来的调用链为:memory_region_add_subregion->memory_region_add_subregion_common->memory_region_update_container_subregions。
static void memory_region_update_container_subregions(MemoryRegion *subregion)
{
MemoryRegion *mr = subregion->container;
MemoryRegion *other;
memory_region_transaction_begin();
memory_region_ref(subregion);
QTAILQ_FOREACH(other, &mr->subregions, subregions_link) {
if (subregion->priority >= other->priority) {
QTAILQ_INSERT_BEFORE(other, subregion, subregions_link);
goto done;
}
}
QTAILQ_INSERT_TAIL(&mr->subregions, subregion, subregions_link);
done:
memory_region_update_pending |= mr->enabled && subregion->enabled;
memory_region_transaction_commit();
}在memory_region_update_container_subregions中,我们会将子区域放到链表中,然后调用memory_region_transaction_commit。在这里面,我们会调用address_space_set_flatview。因为内存区域变了,flatview也会变,就像上面分析过的一样,listener会被调用。
因为添加了一个MemoryRegion,region_add也即kvm_region_add。
static void kvm_region_add(MemoryListener *listener,
MemoryRegionSection *section)
{
KVMMemoryListener *kml = container_of(listener, KVMMemoryListener, listener);
kvm_set_phys_mem(kml, section, true);
}
static void kvm_set_phys_mem(KVMMemoryListener *kml,
MemoryRegionSection *section, bool add)
{
KVMSlot *mem;
int err;
MemoryRegion *mr = section->mr;
bool writeable = !mr->readonly && !mr->rom_device;
hwaddr start_addr, size;
void *ram;
......
size = kvm_align_section(section, &start_addr);
......
/* use aligned delta to align the ram address */
ram = memory_region_get_ram_ptr(mr) + section->offset_within_region + (start_addr - section->offset_within_address_space);
......
/* register the new slot */
mem = kvm_alloc_slot(kml);
mem->memory_size = size;
mem->start_addr = start_addr;
mem->ram = ram;
mem->flags = kvm_mem_flags(mr);
err = kvm_set_user_memory_region(kml, mem, true);
......
}kvm_region_add调用的是kvm_set_phys_mem,这里面分配一个用于放这块那内存的KVMSlot结构,就像一个内存条一样,当然这是在用户态模拟出来的内存条,放在KVMState结构里面。这个结构是我们上一节创建虚拟机的时候创建的。
接下来,kvm_set_user_memory_region就会将用户态模拟出来的内存条,和内核中的KVM模块关联起来。
static int kvm_set_user_memory_region(KVMMemoryListener *kml, KVMSlot *slot, bool new)
{
KVMState *s = kvm_state;
struct kvm_userspace_memory_region mem;
int ret;
mem.slot = slot->slot | (kml->as_id << 16);
mem.guest_phys_addr = slot->start_addr;
mem.userspace_addr = (unsigned long)slot->ram;
mem.flags = slot->flags;
......
mem.memory_size = slot->memory_size;
ret = kvm_vm_ioctl(s, KVM_SET_USER_MEMORY_REGION, &mem);
slot->old_flags = mem.flags;
......
return ret;
}终于,在这里,我们又看到了可以和内核通信的kvm_vm_ioctl。我们来看内核收到KVM_SET_USER_MEMORY_REGION会做哪些事情。
static long kvm_vm_ioctl(struct file *filp,
unsigned int ioctl, unsigned long arg)
{
struct kvm *kvm = filp->private_data;
void __user *argp = (void __user *)arg;
switch (ioctl) {
case KVM_SET_USER_MEMORY_REGION: {
struct kvm_userspace_memory_region kvm_userspace_mem;
if (copy_from_user(&kvm_userspace_mem, argp,
sizeof(kvm_userspace_mem)))
goto out;
r = kvm_vm_ioctl_set_memory_region(kvm, &kvm_userspace_mem);
break;
}
......
}接下来的调用链为:kvm_vm_ioctl_set_memory_region->kvm_set_memory_region->__kvm_set_memory_region。
int __kvm_set_memory_region(struct kvm *kvm,
const struct kvm_userspace_memory_region *mem)
{
int r;
gfn_t base_gfn;
unsigned long npages;
struct kvm_memory_slot *slot;
struct kvm_memory_slot old, new;
struct kvm_memslots *slots = NULL, *old_memslots;
int as_id, id;
enum kvm_mr_change change;
......
as_id = mem->slot >> 16;
id = (u16)mem->slot;
slot = id_to_memslot(__kvm_memslots(kvm, as_id), id);
base_gfn = mem->guest_phys_addr >> PAGE_SHIFT;
npages = mem->memory_size >> PAGE_SHIFT;
......
new = old = *slot;
new.id = id;
new.base_gfn = base_gfn;
new.npages = npages;
new.flags = mem->flags;
......
if (change == KVM_MR_CREATE) {
new.userspace_addr = mem->userspace_addr;
if (kvm_arch_create_memslot(kvm, &new, npages))
goto out_free;
}
......
slots = kvzalloc(sizeof(struct kvm_memslots), GFP_KERNEL);
memcpy(slots, __kvm_memslots(kvm, as_id), sizeof(struct kvm_memslots));
......
r = kvm_arch_prepare_memory_region(kvm, &new, mem, change);
update_memslots(slots, &new);
old_memslots = install_new_memslots(kvm, as_id, slots);
kvm_arch_commit_memory_region(kvm, mem, &old, &new, change);
return 0;
......
}在用户态每个KVMState有多个KVMSlot,在内核里面,同样每个struct kvm也有多个struct kvm_memory_slot,两者是对应起来的。
//用户态
struct KVMState
{
......
int nr_slots;
......
KVMMemoryListener memory_listener;
......
};
typedef struct KVMMemoryListener {
MemoryListener listener;
KVMSlot *slots;
int as_id;
} KVMMemoryListener
typedef struct KVMSlot
{
hwaddr start_addr;
ram_addr_t memory_size;
void *ram;
int slot;
int flags;
int old_flags;
} KVMSlot;
//内核态
struct kvm {
spinlock_t mmu_lock;
struct mutex slots_lock;
struct mm_struct *mm; /* userspace tied to this vm */
struct kvm_memslots __rcu *memslots[KVM_ADDRESS_SPACE_NUM];
......
}
struct kvm_memslots {
u64 generation;
struct kvm_memory_slot memslots[KVM_MEM_SLOTS_NUM];
/* The mapping table from slot id to the index in memslots[]. */
short id_to_index[KVM_MEM_SLOTS_NUM];
atomic_t lru_slot;
int used_slots;
};
struct kvm_memory_slot {
gfn_t base_gfn;//根据guest_phys_addr计算
unsigned long npages;
unsigned long *dirty_bitmap;
struct kvm_arch_memory_slot arch;
unsigned long userspace_addr;
u32 flags;
short id;
};并且,id_to_memslot函数可以根据用户态的slot号得到内核态的slot结构。
如果传进来的参数是KVM_MR_CREATE,表示要创建一个新的内存条,就会调用kvm_arch_create_memslot来创建kvm_memory_slot的成员kvm_arch_memory_slot。
接下来就是创建kvm_memslots结构,填充这个结构,然后通过install_new_memslots将这个新的内存条,添加到struct kvm结构中。
至此,用户态的内存结构和内核态的内存结构算是对应了起来。
46.2 页面分配和映射
上面对于内存的管理,还只是停留在元数据的管理。对于内存的分配与映射,我们还没有涉及,接下来,我们就来看看,页面是如何进行分配和映射的。
上面咱们说了,内存映射对于虚拟机来讲是一件非常麻烦的事情,从GVA到GPA到HVA到HPA,性能很差,为了解决这个问题,有两种主要的思路。
46.3 影子页表
第一种方式就是软件的方式,影子页表 (Shadow Page Table)。
按照咱们在内存管理那一节讲的,内存映射要通过页表来管理,页表地址应该放在cr3寄存器里面。本来的过程是,客户机要通过cr3找到客户机的页表,实现从GVA到GPA的转换,然后在宿主机上,要通过cr3找到宿主机的页表,实现从HVA到HPA的转换。
为了实现客户机虚拟地址空间到宿主机物理地址空间的直接映射。客户机中每个进程都有自己的虚拟地址空间,所以KVM需要为客户机中的每个进程页表都要维护一套相应的影子页表。
在客户机访问内存时,使用的不是客户机的原来的页表,而是这个页表对应的影子页表,从而实现了从客户机虚拟地址到宿主机物理地址的直接转换。而且,在TLB和CPU 缓存上缓存的是来自影子页表中客户机虚拟地址和宿主机物理地址之间的映射,也因此提高了缓存的效率。
但是影子页表的引入也意味着 KVM 需要为每个客户机的每个进程的页表都要维护一套相应的影子页表,内存占用比较大,而且客户机页表和和影子页表也需要进行实时同步。
46.4 扩展页表
于是就有了第二种方式,就是硬件的方式,Intel的EPT(Extent Page Table,扩展页表)技术。
EPT在原有客户机页表对客户机虚拟地址到客户机物理地址映射的基础上,又引入了 EPT页表来实现客户机物理地址到宿主机物理地址的另一次映射。客户机运行时,客户机页表被载入 CR3,而EPT页表被载入专门的EPT 页表指针寄存器 EPTP。
有了EPT,在客户机物理地址到宿主机物理地址转换的过程中,缺页会产生EPT 缺页异常。KVM首先根据引起异常的客户机物理地址,映射到对应的宿主机虚拟地址,然后为此虚拟地址分配新的物理页,最后 KVM 再更新 EPT 页表,建立起引起异常的客户机物理地址到宿主机物理地址之间的映射。
KVM 只需为每个客户机维护一套 EPT 页表,也大大减少了内存的开销。
这里,我们重点看第二种方式。因为使用了EPT之后,客户机里面的页表映射,也即从GVA到GPA的转换,还是用传统的方式,和在内存管理那一章讲的没有什么区别。而EPT重点帮我们解决的就是从GPA到HPA的转换问题。因为要经过两次页表,所以EPT又tdp(two dimentional paging)。
EPT的页表结构也是分为四层,EPT Pointer (EPTP)指向PML4的首地址。
管理物理页面的Page结构和咱们讲内存管理那一章是一样的。EPT页表也需要存放在一个页中,这些页要用kvm_mmu_page这个结构来管理。
当一个虚拟机运行,进入客户机模式的时候,我们上一节解析过,它会调用vcpu_enter_guest函数,这里面会调用kvm_mmu_reload->kvm_mmu_load。
int kvm_mmu_load(struct kvm_vcpu *vcpu)
{
......
r = mmu_topup_memory_caches(vcpu);
r = mmu_alloc_roots(vcpu);
kvm_mmu_sync_roots(vcpu);
/* set_cr3() should ensure TLB has been flushed */
vcpu->arch.mmu.set_cr3(vcpu, vcpu->arch.mmu.root_hpa);
......
}
static int mmu_alloc_roots(struct kvm_vcpu *vcpu)
{
if (vcpu->arch.mmu.direct_map)
return mmu_alloc_direct_roots(vcpu);
else
return mmu_alloc_shadow_roots(vcpu);
}
static int mmu_alloc_direct_roots(struct kvm_vcpu *vcpu)
{
struct kvm_mmu_page *sp;
unsigned i;
if (vcpu->arch.mmu.shadow_root_level == PT64_ROOT_LEVEL) {
spin_lock(&vcpu->kvm->mmu_lock);
make_mmu_pages_available(vcpu);
sp = kvm_mmu_get_page(vcpu, 0, 0, PT64_ROOT_LEVEL, 1, ACC_ALL);
++sp->root_count;
spin_unlock(&vcpu->kvm->mmu_lock);
vcpu->arch.mmu.root_hpa = __pa(sp->spt);
}
......
}这里构建的是页表的根部,也即顶级页表,并且设置cr3来刷新TLB。mmu_alloc_roots会调用mmu_alloc_direct_roots,因为我们用的是EPT模式,而非影子表。在mmu_alloc_direct_roots中,kvm_mmu_get_page会分配一个kvm_mmu_page,来存放顶级页表项。
接下来,当虚拟机真的要访问内存的时候,会发现有的页表没有建立,有的物理页没有分配,这都会触发缺页异常,在KVM里面会发送VM-Exit,从客户机模式转换为宿主机模式,来修复这个缺失的页表或者物理页。
static int (*const kvm_vmx_exit_handlers[])(struct kvm_vcpu *vcpu) = {
[EXIT_REASON_EXCEPTION_NMI] = handle_exception,
[EXIT_REASON_EXTERNAL_INTERRUPT] = handle_external_interrupt,
[EXIT_REASON_IO_INSTRUCTION] = handle_io,
......
[EXIT_REASON_EPT_VIOLATION] = handle_ept_violation,
......
}咱们前面讲过,虚拟机退出客户机模式有很多种原因,例如接收到中断、接收到I/O等,EPT的缺页异常也是一种类型,我们称为EXIT_REASON_EPT_VIOLATION,对应的处理函数是handle_ept_violation。
static int handle_ept_violation(struct kvm_vcpu *vcpu)
{
gpa_t gpa;
......
gpa = vmcs_read64(GUEST_PHYSICAL_ADDRESS);
......
vcpu->arch.gpa_available = true;
vcpu->arch.exit_qualification = exit_qualification;
return kvm_mmu_page_fault(vcpu, gpa, error_code, NULL, 0);
}
int kvm_mmu_page_fault(struct kvm_vcpu *vcpu, gva_t cr2, u64 error_code,
void *insn, int insn_len)
{
......
r = vcpu->arch.mmu.page_fault(vcpu, cr2, lower_32_bits(error_code),false);
......
}在handle_ept_violation里面,我们从VMCS中得到没有解析成功的GPA,也即客户机的物理地址,然后调用kvm_mmu_page_fault,看为什么解析不成功。kvm_mmu_page_fault会调用page_fault函数,其实是tdp_page_fault函数。tdp的意思就是EPT,前面我们解释过了。
static int tdp_page_fault(struct kvm_vcpu *vcpu, gva_t gpa, u32 error_code, bool prefault)
{
kvm_pfn_t pfn;
int r;
int level;
bool force_pt_level;
gfn_t gfn = gpa >> PAGE_SHIFT;
unsigned long mmu_seq;
int write = error_code & PFERR_WRITE_MASK;
bool map_writable;
r = mmu_topup_memory_caches(vcpu);
level = mapping_level(vcpu, gfn, &force_pt_level);
......
if (try_async_pf(vcpu, prefault, gfn, gpa, &pfn, write, &map_writable))
return 0;
if (handle_abnormal_pfn(vcpu, 0, gfn, pfn, ACC_ALL, &r))
return r;
make_mmu_pages_available(vcpu);
r = __direct_map(vcpu, write, map_writable, level, gfn, pfn, prefault);
......
}既然没有映射,就应该加上映射,tdp_page_fault就是干这个事情的。
在tdp_page_fault这个函数开头,我们通过gpa,也即客户机的物理地址得到客户机的页号gfn。接下来,我们要通过调用try_async_pf得到宿主机的物理地址对应的页号,也即真正的物理页的页号,然后通过__direct_map将两者关联起来。
static bool try_async_pf(struct kvm_vcpu *vcpu, bool prefault, gfn_t gfn, gva_t gva, kvm_pfn_t *pfn, bool write, bool *writable)
{
struct kvm_memory_slot *slot;
bool async;
slot = kvm_vcpu_gfn_to_memslot(vcpu, gfn);
async = false;
*pfn = __gfn_to_pfn_memslot(slot, gfn, false, &async, write, writable);
if (!async)
return false; /* *pfn has correct page already */
if (!prefault && kvm_can_do_async_pf(vcpu)) {
if (kvm_find_async_pf_gfn(vcpu, gfn)) {
kvm_make_request(KVM_REQ_APF_HALT, vcpu);
return true;
} else if (kvm_arch_setup_async_pf(vcpu, gva, gfn))
return true;
}
*pfn = __gfn_to_pfn_memslot(slot, gfn, false, NULL, write, writable);
return false;
}在try_async_pf中,要想得到pfn,也即物理页的页号,会先通过kvm_vcpu_gfn_to_memslot,根据客户机的物理地址对应的页号找到内存条,然后调用__gfn_to_pfn_memslot,根据内存条找到pfn。
kvm_pfn_t __gfn_to_pfn_memslot(struct kvm_memory_slot *slot, gfn_t gfn,bool atomic, bool *async, bool write_fault,bool *writable)
{
unsigned long addr = __gfn_to_hva_many(slot, gfn, NULL, write_fault);
......
return hva_to_pfn(addr, atomic, async, write_fault,
writable);
}在__gfn_to_pfn_memslot中,我们会调用__gfn_to_hva_many,从客户机物理地址对应的页号,得到宿主机虚拟地址hva,然后从宿主机虚拟地址到宿主机物理地址,调用的是hva_to_pfn。
hva_to_pfn会调用hva_to_pfn_slow。
static int hva_to_pfn_slow(unsigned long addr, bool *async, bool write_fault,
bool *writable, kvm_pfn_t *pfn)
{
struct page *page[1];
int npages = 0;
......
if (async) {
npages = get_user_page_nowait(addr, write_fault, page);
} else {
......
npages = get_user_pages_unlocked(addr, 1, page, flags);
}
......
*pfn = page_to_pfn(page[0]);
return npages;
}在hva_to_pfn_slow中,我们要先调用get_user_page_nowait,得到一个物理页面,然后再调用page_to_pfn将物理页面转换成为物理页号。
无论是哪一种get_user_pages_XXX,最终都会调用__get_user_pages函数。这里面会调用faultin_page,在faultin_page中我们会调用handle_mm_fault。看到这个是不是很熟悉?这就是咱们内存管理那一章讲的缺页异常的逻辑,分配一个物理内存。
至此,try_async_pf得到了物理页面,并且转换为对应的物理页号。
接下来,__direct_map会关联客户机物理页号和宿主机物理页号。
static int __direct_map(struct kvm_vcpu *vcpu, int write, int map_writable,
int level, gfn_t gfn, kvm_pfn_t pfn, bool prefault)
{
struct kvm_shadow_walk_iterator iterator;
struct kvm_mmu_page *sp;
int emulate = 0;
gfn_t pseudo_gfn;
if (!VALID_PAGE(vcpu->arch.mmu.root_hpa))
return 0;
for_each_shadow_entry(vcpu, (u64)gfn << PAGE_SHIFT, iterator) {
if (iterator.level == level) {
emulate = mmu_set_spte(vcpu, iterator.sptep, ACC_ALL,
write, level, gfn, pfn, prefault,
map_writable);
direct_pte_prefetch(vcpu, iterator.sptep);
++vcpu->stat.pf_fixed;
break;
}
drop_large_spte(vcpu, iterator.sptep);
if (!is_shadow_present_pte(*iterator.sptep)) {
u64 base_addr = iterator.addr;
base_addr &= PT64_LVL_ADDR_MASK(iterator.level);
pseudo_gfn = base_addr >> PAGE_SHIFT;
sp = kvm_mmu_get_page(vcpu, pseudo_gfn, iterator.addr,
iterator.level - 1, 1, ACC_ALL);
link_shadow_page(vcpu, iterator.sptep, sp);
}
}
return emulate;
}__direct_map首先判断页表的根是否存在,当然存在,我们刚才初始化了。
接下来是for_each_shadow_entry一个循环。每一个循环中,先是会判断需要映射的level,是否正是当前循环的这个iterator.level。如果是,则说明是叶子节点,直接映射真正的物理页面pfn,然后退出。接着是非叶子节点的情形,判断如果这一项指向的页表项不存在,就要建立页表项,通过kvm_mmu_get_page得到保存页表项的页面,然后将这一项指向下一级的页表页面。
至此,内存映射就结束了。
46.5 总结
我们这里来总结一下,虚拟机的内存管理也是需要用户态的qemu和内核态的KVM共同完成。为了加速内存映射,需要借助硬件的EPT技术。
在用户态qemu中,有一个结构AddressSpace address_space_memory来表示虚拟机的系统内存,这个内存可能包含多个内存区域struct MemoryRegion,组成树形结构,指向由mmap分配的虚拟内存。
在AddressSpace结构中,有一个struct KVMMemoryListener,当有新的内存区域添加的时候,会被通知调用kvm_region_add来通知内核。
在用户态qemu中,对于虚拟机有一个结构struct KVMState表示这个虚拟机,这个结构会指向一个数组的struct KVMSlot表示这个虚拟机的多个内存条,KVMSlot中有一个void *ram指针指向mmap分配的那块虚拟内存。
kvm_region_add是通过ioctl来通知内核KVM的,会给内核KVM发送一个KVM_SET_USER_MEMORY_REGION消息,表示用户态qemu添加了一个内存区域,内核KVM也应该添加一个相应的内存区域。
和用户态qemu对应的内核KVM,对于虚拟机有一个结构struct kvm表示这个虚拟机,这个结构会指向一个数组的struct kvm_memory_slot表示这个虚拟机的多个内存条,kvm_memory_slot中有起始页号,页面数目,表示这个虚拟机的物理内存空间。
虚拟机的物理内存空间里面的页面当然不是一开始就映射到物理页面的,只有当虚拟机的内存被访问的时候,也即mmap分配的虚拟内存空间被访问的时候,先查看EPT页表,是否已经映射过,如果已经映射过,则经过四级页表映射,就能访问到物理页面。
如果没有映射过,则虚拟机会通过VM-Exit指令回到宿主机模式,通过handle_ept_violation补充页表映射。先是通过handle_mm_fault为虚拟机的物理内存空间分配真正的物理页面,然后通过__direct_map添加EPT页表映射。
47. 存储虚拟化(上)
前面几节,我们讲了CPU和内存的虚拟化。我们知道,完全虚拟化是很慢的,而通过内核的KVM技术和EPT技术,加速虚拟机对于物理CPU和内存的使用,我们称为硬件辅助虚拟化。
对于一台虚拟机而言,除了要虚拟化CPU和内存,存储和网络也需要虚拟化,存储和网络都属于外部设备,这些外部设备应该如何虚拟化呢?
当然一种方式还是完全虚拟化。比如,有什么样的硬盘设备或者网卡设备,我们就用qemu模拟一个一模一样的软件的硬盘和网卡设备,这样在虚拟机里面的操作系统看来,使用这些设备和使用物理设备是一样的。当然缺点就是,qemu模拟的设备又是一个翻译官的角色。虽然这个时候虚拟机里面的操作系统,意识不到自己是运行在虚拟机里面的,但是这种每个指令都翻译的方式,实在是太慢了。
另外一种方式就是,虚拟机里面的操作系统不是一个通用的操作系统,它知道自己是运行在虚拟机里面的,使用的硬盘设备和网络设备都是虚拟的,应该加载特殊的驱动才能运行。这些特殊的驱动往往要通过虚拟机里面和外面配合工作的模式,来加速对于物理存储和网络设备的使用。
47.1 virtio的基本原理
在虚拟化技术的早期,不同的虚拟化技术会针对不同硬盘设备和网络设备实现不同的驱动,虚拟机里面的操作系统也要根据不同的虚拟化技术和物理存储和网络设备,选择加载不同的驱动。但是,由于硬盘设备和网络设备太多了,驱动纷繁复杂。
后来慢慢就形成了一定的标准,这就是virtio,就是虚拟化I/O设备的意思。virtio负责对于虚拟机提供统一的接口。也就是说,在虚拟机里面的操作系统加载的驱动,以后都统一加载virtio就可以了。
在虚拟机外,我们可以实现不同的virtio的后端,来适配不同的物理硬件设备。那virtio到底长什么样子呢?我们一起来看一看。
virtio的架构可以分为四层。
- 首先,在虚拟机里面的virtio前端,针对不同类型的设备有不同的驱动程序,但是接口都是统一的。例如,硬盘就是virtio_blk,网络就是virtio_net。
- 其次,在宿主机的qemu里面,实现virtio后端的逻辑,主要就是操作硬件的设备。例如通过写一个物理机硬盘上的文件来完成虚拟机写入硬盘的操作。再如向内核协议栈发送一个网络包完成虚拟机对于网络的操作。
- 在virtio的前端和后端之间,有一个通信层,里面包含virtio层和virtio-ring层。virtio这一层实现的是虚拟队列接口,算是前后端通信的桥梁。而virtio-ring则是该桥梁的具体实现。
virtio使用virtqueue进行前端和后端的高速通信。不同类型的设备队列数目不同。virtio-net使用两个队列,一个用于接受,另一个用于发送;而 virtio-blk仅使用一个队列。
如果客户机要向宿主机发送数据,宿主机会将数据的buffer添加到virtqueue中,然后通过写入寄存器通知宿主机。这样宿主机就可以从virtqueue 中收到的buffer里面的数据。
了解了virtio的基本原理,接下来,我们以硬盘写入为例,具体看一下存储虚拟化的过程。
47.2 初始化阶段的存储虚拟化
和咱们在学习CPU的时候看到的一样,Virtio Block Device也是一种类。它的继承关系如下:
static const TypeInfo device_type_info = {
.name = TYPE_DEVICE,
.parent = TYPE_OBJECT,
.instance_size = sizeof(DeviceState),
.instance_init = device_initfn,
.instance_post_init = device_post_init,
.instance_finalize = device_finalize,
.class_base_init = device_class_base_init,
.class_init = device_class_init,
.abstract = true,
.class_size = sizeof(DeviceClass),
};
static const TypeInfo virtio_device_info = {
.name = TYPE_VIRTIO_DEVICE,
.parent = TYPE_DEVICE,
.instance_size = sizeof(VirtIODevice),
.class_init = virtio_device_class_init,
.instance_finalize = virtio_device_instance_finalize,
.abstract = true,
.class_size = sizeof(VirtioDeviceClass),
};
static const TypeInfo virtio_blk_info = {
.name = TYPE_VIRTIO_BLK,
.parent = TYPE_VIRTIO_DEVICE,
.instance_size = sizeof(VirtIOBlock),
.instance_init = virtio_blk_instance_init,
.class_init = virtio_blk_class_init,
};
static void virtio_register_types(void)
{
type_register_static(&virtio_blk_info);
}
type_init(virtio_register_types)Virtio Block Device这种类的定义是有多层继承关系的。TYPE_VIRTIO_BLK的父类是TYPE_VIRTIO_DEVICE,TYPE_VIRTIO_DEVICE的父类是TYPE_DEVICE,TYPE_DEVICE的父类是TYPE_OBJECT。到头了。
type_init用于注册这种类。这里面每一层都有class_init,用于从TypeImpl生产xxxClass。还有instance_init,可以将xxxClass初始化为实例。
在TYPE_VIRTIO_BLK层的class_init函数virtio_blk_class_init中,定义了DeviceClass的realize函数为virtio_blk_device_realize,这一点在计算虚拟化之CPU(上)那一节也有类似的结构。
static void virtio_blk_device_realize(DeviceState *dev, Error **errp)
{
VirtIODevice *vdev = VIRTIO_DEVICE(dev);
VirtIOBlock *s = VIRTIO_BLK(dev);
VirtIOBlkConf *conf = &s->conf;
......
blkconf_blocksizes(&conf->conf);
virtio_blk_set_config_size(s, s->host_features);
virtio_init(vdev, "virtio-blk", VIRTIO_ID_BLOCK, s->config_size);
s->blk = conf->conf.blk;
s->rq = NULL;
s->sector_mask = (s->conf.conf.logical_block_size / BDRV_SECTOR_SIZE) - 1;
for (i = 0; i < conf->num_queues; i++) {
virtio_add_queue(vdev, conf->queue_size, virtio_blk_handle_output);
}
virtio_blk_data_plane_create(vdev, conf, &s->dataplane, &err);
s->change = qemu_add_vm_change_state_handler(virtio_blk_dma_restart_cb, s);
blk_set_dev_ops(s->blk, &virtio_block_ops, s);
blk_set_guest_block_size(s->blk, s->conf.conf.logical_block_size);
blk_iostatus_enable(s->blk);
}在virtio_blk_device_realize函数中,我们先是通过virtio_init初始化VirtIODevice结构。
void virtio_init(VirtIODevice *vdev, const char *name,
uint16_t device_id, size_t config_size)
{
BusState *qbus = qdev_get_parent_bus(DEVICE(vdev));
VirtioBusClass *k = VIRTIO_BUS_GET_CLASS(qbus);
int i;
int nvectors = k->query_nvectors ? k->query_nvectors(qbus->parent) : 0;
if (nvectors) {
vdev->vector_queues =
g_malloc0(sizeof(*vdev->vector_queues) * nvectors);
}
vdev->device_id = device_id;
vdev->status = 0;
atomic_set(&vdev->isr, 0);
vdev->queue_sel = 0;
vdev->config_vector = VIRTIO_NO_VECTOR;
vdev->vq = g_malloc0(sizeof(VirtQueue) * VIRTIO_QUEUE_MAX);
vdev->vm_running = runstate_is_running();
vdev->broken = false;
for (i = 0; i < VIRTIO_QUEUE_MAX; i++) {
vdev->vq[i].vector = VIRTIO_NO_VECTOR;
vdev->vq[i].vdev = vdev;
vdev->vq[i].queue_index = i;
}
vdev->name = name;
vdev->config_len = config_size;
if (vdev->config_len) {
vdev->config = g_malloc0(config_size);
} else {
vdev->config = NULL;
}
vdev->vmstate = qemu_add_vm_change_state_handler(virtio_vmstate_change,
vdev);
vdev->device_endian = virtio_default_endian();
vdev->use_guest_notifier_mask = true;
}从virtio_init中可以看出,VirtIODevice结构里面有一个VirtQueue数组,这就是virtio前端和后端互相传数据的队列,最多VIRTIO_QUEUE_MAX个。
我们回到virtio_blk_device_realize函数。接下来,根据配置的队列数目num_queues,对于每个队列都调用virtio_add_queue来初始化队列。
VirtQueue *virtio_add_queue(VirtIODevice *vdev, int queue_size,
VirtIOHandleOutput handle_output)
{
int i;
vdev->vq[i].vring.num = queue_size;
vdev->vq[i].vring.num_default = queue_size;
vdev->vq[i].vring.align = VIRTIO_PCI_VRING_ALIGN;
vdev->vq[i].handle_output = handle_output;
vdev->vq[i].handle_aio_output = NULL;
return &vdev->vq[i];
}在每个VirtQueue中,都有一个vring,用来维护这个队列里面的数据;另外还有一个函数virtio_blk_handle_output,用于处理数据写入,这个函数我们后面会用到。
至此,VirtIODevice,VirtQueue,vring之间的关系如下图所示。这是在qemu里面的对应关系,请你记好,后面我们还能看到类似的结构。
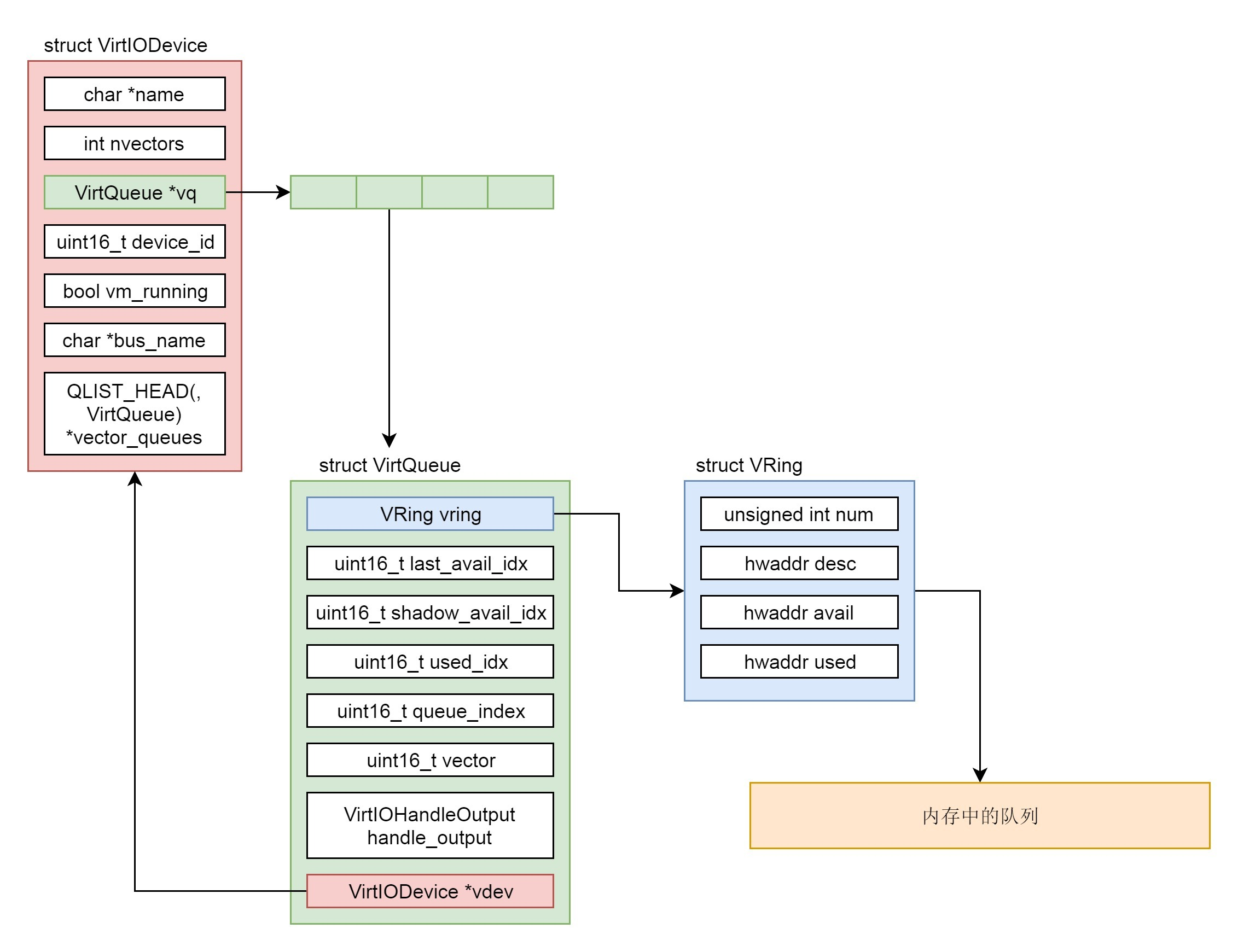
47.3 qemu启动过程中的存储虚拟化
初始化过程解析完毕以后,我们接下来从qemu的启动过程看起。
对于硬盘的虚拟化,qemu的启动参数里面有关的是下面两行:
-drive file=/var/lib/nova/instances/1f8e6f7e-5a70-4780-89c1-464dc0e7f308/disk,if=none,id=drive-virtio-disk0,format=qcow2,cache=none
-device virtio-blk-pci,scsi=off,bus=pci.0,addr=0x4,drive=drive-virtio-disk0,id=virtio-disk0,bootindex=1其中,第一行指定了宿主机硬盘上的一个文件,文件的格式是qcow2,这个格式我们这里不准备解析它,你只要明白,对于宿主机上的一个文件,可以被qemu模拟称为客户机上的一块硬盘就可以了。
而第二行说明了,使用的驱动是virtio-blk驱动。
configure_blockdev(&bdo_queue, machine_class, snapshot);在qemu启动的main函数里面,初始化块设备,是通过configure_blockdev调用开始的。
static void configure_blockdev(BlockdevOptionsQueue *bdo_queue, MachineClass *machine_class, int snapshot)
{
......
if (qemu_opts_foreach(qemu_find_opts("drive"), drive_init_func,
&machine_class->block_default_type, &error_fatal)) {
.....
}
}
static int drive_init_func(void *opaque, QemuOpts *opts, Error **errp)
{
BlockInterfaceType *block_default_type = opaque;
return drive_new(opts, *block_default_type, errp) == NULL;
}在configure_blockdev中,我们能看到对于drive这个参数的解析,并且初始化这个设备要调用drive_init_func函数,这里面会调用drive_new创建一个设备。
DriveInfo *drive_new(QemuOpts *all_opts, BlockInterfaceType block_default_type, Error **errp)
{
const char *value;
BlockBackend *blk;
DriveInfo *dinfo = NULL;
QDict *bs_opts;
QemuOpts *legacy_opts;
DriveMediaType media = MEDIA_DISK;
BlockInterfaceType type;
int max_devs, bus_id, unit_id, index;
const char *werror, *rerror;
bool read_only = false;
bool copy_on_read;
const char *filename;
Error *local_err = NULL;
int i;
......
legacy_opts = qemu_opts_create(&qemu_legacy_drive_opts, NULL, 0,
&error_abort);
......
/* Add virtio block device */
if (type == IF_VIRTIO) {
QemuOpts *devopts;
devopts = qemu_opts_create(qemu_find_opts("device"), NULL, 0,
&error_abort);
qemu_opt_set(devopts, "driver", "virtio-blk-pci", &error_abort);
qemu_opt_set(devopts, "drive", qdict_get_str(bs_opts, "id"),
&error_abort);
}
filename = qemu_opt_get(legacy_opts, "file");
......
/* Actual block device init: Functionality shared with blockdev-add */
blk = blockdev_init(filename, bs_opts, &local_err);
......
/* Create legacy DriveInfo */
dinfo = g_malloc0(sizeof(*dinfo));
dinfo->opts = all_opts;
dinfo->type = type;
dinfo->bus = bus_id;
dinfo->unit = unit_id;
blk_set_legacy_dinfo(blk, dinfo);
switch(type) {
case IF_IDE:
case IF_SCSI:
case IF_XEN:
case IF_NONE:
dinfo->media_cd = media == MEDIA_CDROM;
break;
default:
break;
}
......
}在drive_new里面,会解析qemu的启动参数。对于virtio来讲,会解析device参数,把driver设置为virtio-blk-pci;还会解析file参数,就是指向那个宿主机上的文件。
接下来,drive_new会调用blockdev_init,根据参数进行初始化,最后会创建一个DriveInfo来管理这个设备。
我们重点来看blockdev_init。在这里面,我们发现,如果file不为空,则应该调用blk_new_open打开宿主机上的硬盘文件,返回的结果是BlockBackend,对应我们上面讲原理的时候的virtio的后端。
BlockBackend *blk_new_open(const char *filename, const char *reference,
QDict *options, int flags, Error **errp)
{
BlockBackend *blk;
BlockDriverState *bs;
uint64_t perm = 0;
......
blk = blk_new(perm, BLK_PERM_ALL);
bs = bdrv_open(filename, reference, options, flags, errp);
blk->root = bdrv_root_attach_child(bs, "root", &child_root,
perm, BLK_PERM_ALL, blk, errp);
return blk;
}接下来的调用链为:bdrv_open->bdrv_open_inherit->bdrv_open_common.
static int bdrv_open_common(BlockDriverState *bs, BlockBackend *file,
QDict *options, Error **errp)
{
int ret, open_flags;
const char *filename;
const char *driver_name = NULL;
const char *node_name = NULL;
const char *discard;
QemuOpts *opts;
BlockDriver *drv;
Error *local_err = NULL;
......
drv = bdrv_find_format(driver_name);
......
ret = bdrv_open_driver(bs, drv, node_name, options, open_flags, errp);
......
}
static int bdrv_open_driver(BlockDriverState *bs, BlockDriver *drv,
const char *node_name, QDict *options,
int open_flags, Error **errp)
{
......
bs->drv = drv;
bs->read_only = !(bs->open_flags & BDRV_O_RDWR);
bs->opaque = g_malloc0(drv->instance_size);
if (drv->bdrv_open) {
ret = drv->bdrv_open(bs, options, open_flags, &local_err);
}
......
}在bdrv_open_common中,根据硬盘文件的格式,得到BlockDriver。因为虚拟机的硬盘文件格式有很多种,qcow2是一种,raw是一种,vmdk是一种,各有优缺点,启动虚拟机的时候,可以自由选择。
对于不同的格式,打开的方式不一样,我们拿qcow2来解析。它的BlockDriver定义如下:
BlockDriver bdrv_qcow2 = {
.format_name = "qcow2",
.instance_size = sizeof(BDRVQcow2State),
.bdrv_probe = qcow2_probe,
.bdrv_open = qcow2_open,
.bdrv_close = qcow2_close,
......
.bdrv_snapshot_create = qcow2_snapshot_create,
.bdrv_snapshot_goto = qcow2_snapshot_goto,
.bdrv_snapshot_delete = qcow2_snapshot_delete,
.bdrv_snapshot_list = qcow2_snapshot_list,
.bdrv_snapshot_load_tmp = qcow2_snapshot_load_tmp,
.bdrv_measure = qcow2_measure,
.bdrv_get_info = qcow2_get_info,
.bdrv_get_specific_info = qcow2_get_specific_info,
.bdrv_save_vmstate = qcow2_save_vmstate,
.bdrv_load_vmstate = qcow2_load_vmstate,
.supports_backing = true,
.bdrv_change_backing_file = qcow2_change_backing_file,
.bdrv_refresh_limits = qcow2_refresh_limits,
......
};根据上面的定义,对于qcow2来讲,bdrv_open调用的是qcow2_open。
static int qcow2_open(BlockDriverState *bs, QDict *options, int flags,
Error **errp)
{
BDRVQcow2State *s = bs->opaque;
QCow2OpenCo qoc = {
.bs = bs,
.options = options,
.flags = flags,
.errp = errp,
.ret = -EINPROGRESS
};
bs->file = bdrv_open_child(NULL, options, "file", bs, &child_file,
false, errp);
qemu_coroutine_enter(qemu_coroutine_create(qcow2_open_entry, &qoc));
......
}在qcow2_open中,我们会通过qemu_coroutine_enter进入一个协程coroutine。什么叫协程呢?我们可以简单地将它理解为用户态自己实现的线程。
前面咱们讲线程的时候说过,如果一个程序想实现并发,可以创建多个线程,但是线程是一个内核的概念,创建的每一个线程内核都能看到,内核的调度也是以线程为单位的。这对于普通的进程没有什么问题,但是对于qemu这种虚拟机,如果在用户态和内核态切换来切换去,由于还涉及虚拟机的状态,代价比较大。
但是,qemu的设备也是需要多线程能力的,怎么办呢?我们就在用户态实现一个类似线程的东西,也就是协程,用于实现并发,并且不被内核看到,调度全部在用户态完成。
从后面的读写过程可以看出,协程在后端经常使用。这里打开一个qcow2文件就是使用一个协程,创建一个协程和创建一个线程很像,也需要指定一个函数来执行,qcow2_open_entry就是协程的函数。
static void coroutine_fn qcow2_open_entry(void *opaque)
{
QCow2OpenCo *qoc = opaque;
BDRVQcow2State *s = qoc->bs->opaque;
qemu_co_mutex_lock(&s->lock);
qoc->ret = qcow2_do_open(qoc->bs, qoc->options, qoc->flags, qoc->errp);
qemu_co_mutex_unlock(&s->lock);
}我们可以看到,qcow2_open_entry函数前面有一个coroutine_fn,说明它是一个协程函数。在qcow2_do_open中,qcow2_do_open根据qcow2的格式打开硬盘文件。这个格式官网就有,我们这里就不花篇幅解析了。
总结
我们这里来总结一下,存储虚拟化的过程分为前端、后端和中间的队列。
- 前端有前端的块设备驱动Front-end driver,在客户机的内核里面,它符合普通设备驱动的格式,对外通过VFS暴露文件系统接口给客户机里面的应用。这一部分这一节我们没有讲,放在下一节解析。
- 后端有后端的设备驱动Back-end driver,在宿主机的qemu进程中,当收到客户机的写入请求的时候,调用文件系统的write函数,写入宿主机的VFS文件系统,最终写到物理硬盘设备上的qcow2文件。
- 中间的队列用于前端和后端之间传输数据,在前端的设备驱动和后端的设备驱动,都有类似的数据结构virt-queue来管理这些队列,这一部分这一节我们也没有讲,也放到下一节解析。
总结.webp)
48. 存储虚拟化(下)
上一节,我们讲了qemu启动过程中的存储虚拟化。好了,现在qemu启动了,硬盘设备文件已经打开了。那如果我们要往虚拟机的一个进程写入一个文件,该怎么做呢?最终这个文件又是如何落到宿主机上的硬盘文件的呢?这一节,我们一起来看一看。
48.1 前端设备驱动virtio_blk
虚拟机里面的进程写入一个文件,当然要通过文件系统。整个过程和咱们在文件系统那一节讲的过程没有区别。只是到了设备驱动层,我们看到的就不是普通的硬盘驱动了,而是virtio的驱动。
virtio的驱动程序代码在Linux操作系统的源代码里面,文件名叫drivers/block/virtio_blk.c。
static int __init init(void)
{
int error;
virtblk_wq = alloc_workqueue("virtio-blk", 0, 0);
major = register_blkdev(0, "virtblk");
error = register_virtio_driver(&virtio_blk);
......
}
module_init(init);
module_exit(fini);
MODULE_DEVICE_TABLE(virtio, id_table);
MODULE_DESCRIPTION("Virtio block driver");
MODULE_LICENSE("GPL");
static struct virtio_driver virtio_blk = {
......
.driver.name = KBUILD_MODNAME,
.driver.owner = THIS_MODULE,
.id_table = id_table,
.probe = virtblk_probe,
.remove = virtblk_remove,
......
};前面我们介绍过设备驱动程序,从这里的代码中,我们能看到非常熟悉的结构。它会创建一个workqueue,注册一个块设备,并获得一个主设备号,然后注册一个驱动函数virtio_blk。
当一个设备驱动作为一个内核模块被初始化的时候,probe函数会被调用,因而我们来看一下virtblk_probe。
static int virtblk_probe(struct virtio_device *vdev)
{
struct virtio_blk *vblk;
struct request_queue *q;
......
vdev->priv = vblk = kmalloc(sizeof(*vblk), GFP_KERNEL);
vblk->vdev = vdev;
vblk->sg_elems = sg_elems;
INIT_WORK(&vblk->config_work, virtblk_config_changed_work);
......
err = init_vq(vblk);
......
vblk->disk = alloc_disk(1 << PART_BITS);
memset(&vblk->tag_set, 0, sizeof(vblk->tag_set));
vblk->tag_set.ops = &virtio_mq_ops;
vblk->tag_set.queue_depth = virtblk_queue_depth;
vblk->tag_set.numa_node = NUMA_NO_NODE;
vblk->tag_set.flags = BLK_MQ_F_SHOULD_MERGE;
vblk->tag_set.cmd_size =
sizeof(struct virtblk_req) +
sizeof(struct scatterlist) * sg_elems;
vblk->tag_set.driver_data = vblk;
vblk->tag_set.nr_hw_queues = vblk->num_vqs;
err = blk_mq_alloc_tag_set(&vblk->tag_set);
......
q = blk_mq_init_queue(&vblk->tag_set);
vblk->disk->queue = q;
q->queuedata = vblk;
virtblk_name_format("vd", index, vblk->disk->disk_name, DISK_NAME_LEN);
vblk->disk->major = major;
vblk->disk->first_minor = index_to_minor(index);
vblk->disk->private_data = vblk;
vblk->disk->fops = &virtblk_fops;
vblk->disk->flags |= GENHD_FL_EXT_DEVT;
vblk->index = index;
......
device_add_disk(&vdev->dev, vblk->disk);
err = device_create_file(disk_to_dev(vblk->disk), &dev_attr_serial);
......
}在virtblk_probe中,我们首先看到的是struct request_queue,这是每一个块设备都有的一个队列。还记得吗?它有两个函数,一个是make_request_fn函数,用于生成request;另一个是request_fn函数,用于处理request。
这个request_queue的初始化过程在blk_mq_init_queue中。它会调用blk_mq_init_allocated_queue->blk_queue_make_request。在这里面,我们可以将make_request_fn函数设置为blk_mq_make_request,也就是说,一旦上层有写入请求,我们就通过blk_mq_make_request这个函数,将请求放入request_queue队列中。
另外,在virtblk_probe中,我们会初始化一个gendisk。前面我们也讲了,每一个块设备都有这样一个结构。
在virtblk_probe中,还有一件重要的事情就是,init_vq会来初始化virtqueue。
static int init_vq(struct virtio_blk *vblk)
{
int err;
int i;
vq_callback_t **callbacks;
const char **names;
struct virtqueue **vqs;
unsigned short num_vqs;
struct virtio_device *vdev = vblk->vdev;
......
vblk->vqs = kmalloc_array(num_vqs, sizeof(*vblk->vqs), GFP_KERNEL);
names = kmalloc_array(num_vqs, sizeof(*names), GFP_KERNEL);
callbacks = kmalloc_array(num_vqs, sizeof(*callbacks), GFP_KERNEL);
vqs = kmalloc_array(num_vqs, sizeof(*vqs), GFP_KERNEL);
......
for (i = 0; i < num_vqs; i++) {
callbacks[i] = virtblk_done;
names[i] = vblk->vqs[i].name;
}
/* Discover virtqueues and write information to configuration. */
err = virtio_find_vqs(vdev, num_vqs, vqs, callbacks, names, &desc);
for (i = 0; i < num_vqs; i++) {
vblk->vqs[i].vq = vqs[i];
}
vblk->num_vqs = num_vqs;
......
}按照上面的原理来说,virtqueue是一个介于客户机前端和qemu后端的一个结构,用于在这两端之间传递数据。这里建立的struct virtqueue是客户机前端对于队列的管理的数据结构,在客户机的linux内核中通过kmalloc_array进行分配。
而队列的实体需要通过函数virtio_find_vqs查找或者生成,所以这里我们还把callback函数指定为virtblk_done。当buffer使用发生变化的时候,我们需要调用这个callback函数进行通知。
static inline
int virtio_find_vqs(struct virtio_device *vdev, unsigned nvqs,
struct virtqueue *vqs[], vq_callback_t *callbacks[],
const char * const names[],
struct irq_affinity *desc)
{
return vdev->config->find_vqs(vdev, nvqs, vqs, callbacks, names, NULL, desc);
}
static const struct virtio_config_ops virtio_pci_config_ops = {
.get = vp_get,
.set = vp_set,
.generation = vp_generation,
.get_status = vp_get_status,
.set_status = vp_set_status,
.reset = vp_reset,
.find_vqs = vp_modern_find_vqs,
.del_vqs = vp_del_vqs,
.get_features = vp_get_features,
.finalize_features = vp_finalize_features,
.bus_name = vp_bus_name,
.set_vq_affinity = vp_set_vq_affinity,
.get_vq_affinity = vp_get_vq_affinity,
};根据virtio_config_ops的定义,virtio_find_vqs会调用vp_modern_find_vqs。
static int vp_modern_find_vqs(struct virtio_device *vdev, unsigned nvqs,
struct virtqueue *vqs[],
vq_callback_t *callbacks[],
const char * const names[], const bool *ctx,
struct irq_affinity *desc)
{
struct virtio_pci_device *vp_dev = to_vp_device(vdev);
struct virtqueue *vq;
int rc = vp_find_vqs(vdev, nvqs, vqs, callbacks, names, ctx, desc);
/* Select and activate all queues. Has to be done last: once we do
* this, there's no way to go back except reset.
*/
list_for_each_entry(vq, &vdev->vqs, list) {
vp_iowrite16(vq->index, &vp_dev->common->queue_select);
vp_iowrite16(1, &vp_dev->common->queue_enable);
}
return 0;
}在vp_modern_find_vqs中,vp_find_vqs会调用vp_find_vqs_intx。
static int vp_find_vqs_intx(struct virtio_device *vdev, unsigned nvqs,
struct virtqueue *vqs[], vq_callback_t *callbacks[],
const char * const names[], const bool *ctx)
{
struct virtio_pci_device *vp_dev = to_vp_device(vdev);
int i, err;
vp_dev->vqs = kcalloc(nvqs, sizeof(*vp_dev->vqs), GFP_KERNEL);
err = request_irq(vp_dev->pci_dev->irq, vp_interrupt, IRQF_SHARED,
dev_name(&vdev->dev), vp_dev);
vp_dev->intx_enabled = 1;
vp_dev->per_vq_vectors = false;
for (i = 0; i < nvqs; ++i) {
vqs[i] = vp_setup_vq(vdev, i, callbacks[i], names[i],
ctx ? ctx[i] : false,
VIRTIO_MSI_NO_VECTOR);
......
}
}在vp_find_vqs_intx中,我们通过request_irq注册一个中断处理函数vp_interrupt,当设备的配置信息发生改变,会产生一个中断,当设备向队列中写入信息时,也会会产生一个中断,我们称为vq中断,中断处理函数需要调用相应的队列的回调函数。
然后,我们根据队列的数目,依次调用vp_setup_vq,完成virtqueue、vring的分配和初始化。
static struct virtqueue *vp_setup_vq(struct virtio_device *vdev, unsigned index,
void (*callback)(struct virtqueue *vq),
const char *name,
bool ctx,
u16 msix_vec)
{
struct virtio_pci_device *vp_dev = to_vp_device(vdev);
struct virtio_pci_vq_info *info = kmalloc(sizeof *info, GFP_KERNEL);
struct virtqueue *vq;
unsigned long flags;
......
vq = vp_dev->setup_vq(vp_dev, info, index, callback, name, ctx,
msix_vec);
info->vq = vq;
if (callback) {
spin_lock_irqsave(&vp_dev->lock, flags);
list_add(&info->node, &vp_dev->virtqueues);
spin_unlock_irqrestore(&vp_dev->lock, flags);
} else {
INIT_LIST_HEAD(&info->node);
}
vp_dev->vqs[index] = info;
return vq;
}
static struct virtqueue *setup_vq(struct virtio_pci_device *vp_dev,
struct virtio_pci_vq_info *info,
unsigned index,
void (*callback)(struct virtqueue *vq),
const char *name,
bool ctx,
u16 msix_vec)
{
struct virtio_pci_common_cfg __iomem *cfg = vp_dev->common;
struct virtqueue *vq;
u16 num, off;
int err;
/* Select the queue we're interested in */
vp_iowrite16(index, &cfg->queue_select);
/* Check if queue is either not available or already active. */
num = vp_ioread16(&cfg->queue_size);
/* get offset of notification word for this vq */
off = vp_ioread16(&cfg->queue_notify_off);
info->msix_vector = msix_vec;
/* create the vring */
vq = vring_create_virtqueue(index, num,
SMP_CACHE_BYTES, &vp_dev->vdev,
true, true, ctx,
vp_notify, callback, name);
/* activate the queue */
vp_iowrite16(virtqueue_get_vring_size(vq), &cfg->queue_size);
vp_iowrite64_twopart(virtqueue_get_desc_addr(vq),
&cfg->queue_desc_lo, &cfg->queue_desc_hi);
vp_iowrite64_twopart(virtqueue_get_avail_addr(vq),
&cfg->queue_avail_lo, &cfg->queue_avail_hi);
vp_iowrite64_twopart(virtqueue_get_used_addr(vq),
&cfg->queue_used_lo, &cfg->queue_used_hi);
......
return vq;
}
struct virtqueue *vring_create_virtqueue(
unsigned int index,
unsigned int num,
unsigned int vring_align,
struct virtio_device *vdev,
bool weak_barriers,
bool may_reduce_num,
bool context,
bool (*notify)(struct virtqueue *),
void (*callback)(struct virtqueue *),
const char *name)
{
struct virtqueue *vq;
void *queue = NULL;
dma_addr_t dma_addr;
size_t queue_size_in_bytes;
struct vring vring;
/* TODO: allocate each queue chunk individually */
for (; num && vring_size(num, vring_align) > PAGE_SIZE; num /= 2) {
queue = vring_alloc_queue(vdev, vring_size(num, vring_align),
&dma_addr,
GFP_KERNEL|__GFP_NOWARN|__GFP_ZERO);
if (queue)
break;
}
if (!queue) {
/* Try to get a single page. You are my only hope! */
queue = vring_alloc_queue(vdev, vring_size(num, vring_align),
&dma_addr, GFP_KERNEL|__GFP_ZERO);
}
queue_size_in_bytes = vring_size(num, vring_align);
vring_init(&vring, num, queue, vring_align);
vq = __vring_new_virtqueue(index, vring, vdev, weak_barriers, context, notify, callback, name);
to_vvq(vq)->queue_dma_addr = dma_addr;
to_vvq(vq)->queue_size_in_bytes = queue_size_in_bytes;
to_vvq(vq)->we_own_ring = true;
return vq;
}在vring_create_virtqueue中,我们会调用vring_alloc_queue,来创建队列所需要的内存空间,然后调用vring_init初始化结构struct vring,来管理队列的内存空间,调用__vring_new_virtqueue,来创建struct vring_virtqueue。
这个结构的一开始,是struct virtqueue,它也是struct virtqueue的一个扩展,紧接着后面就是struct vring。
struct vring_virtqueue {
struct virtqueue vq;
/* Actual memory layout for this queue */
struct vring vring;
......
}至此我们发现,虚拟机里面的virtio的前端是这样的结构:struct virtio_device里面有一个struct vring_virtqueue,在struct vring_virtqueue里面有一个struct vring。
48.2 中间virtio队列的管理
还记不记得我们上面讲qemu初始化的时候,virtio的后端有数据结构VirtIODevice,VirtQueue和vring一模一样,前端和后端对应起来,都应该指向刚才创建的那一段内存。
现在的问题是,我们刚才分配的内存在客户机的内核里面,如何告知qemu来访问这段内存呢?
别忘了,qemu模拟出来的virtio block device只是一个PCI设备。对于客户机来讲,这是一个外部设备,我们可以通过给外部设备发送指令的方式告知外部设备,这就是代码中vp_iowrite16的作用。它会调用专门给外部设备发送指令的函数iowrite,告诉外部的PCI设备。
告知的有三个地址virtqueue_get_desc_addr、virtqueue_get_avail_addr,virtqueue_get_used_addr。从客户机角度来看,这里面的地址都是物理地址,也即GPA(Guest Physical Address)。因为只有物理地址才是客户机和qemu程序都认可的地址,本来客户机的物理内存也是qemu模拟出来的。
在qemu中,对PCI总线添加一个设备的时候,我们会调用virtio_pci_device_plugged。
static void virtio_pci_device_plugged(DeviceState *d, Error **errp)
{
VirtIOPCIProxy *proxy = VIRTIO_PCI(d);
......
memory_region_init_io(&proxy->bar, OBJECT(proxy),
&virtio_pci_config_ops,
proxy, "virtio-pci", size);
......
}
static const MemoryRegionOps virtio_pci_config_ops = {
.read = virtio_pci_config_read,
.write = virtio_pci_config_write,
.impl = {
.min_access_size = 1,
.max_access_size = 4,
},
.endianness = DEVICE_LITTLE_ENDIAN,
};在这里面,对于这个加载的设备进行I/O操作,会映射到读写某一块内存空间,对应的操作为virtio_pci_config_ops,也即写入这块内存空间,这就相当于对于这个PCI设备进行某种配置。
对PCI设备进行配置的时候,会有这样的调用链:virtio_pci_config_write->virtio_ioport_write->virtio_queue_set_addr。设置virtio的queue的地址是一项很重要的操作。
void virtio_queue_set_addr(VirtIODevice *vdev, int n, hwaddr addr)
{
vdev->vq[n].vring.desc = addr;
virtio_queue_update_rings(vdev, n);
}从这里我们可以看出,qemu后端的VirtIODevice的VirtQueue的vring的地址,被设置成了刚才给队列分配的内存的GPA。
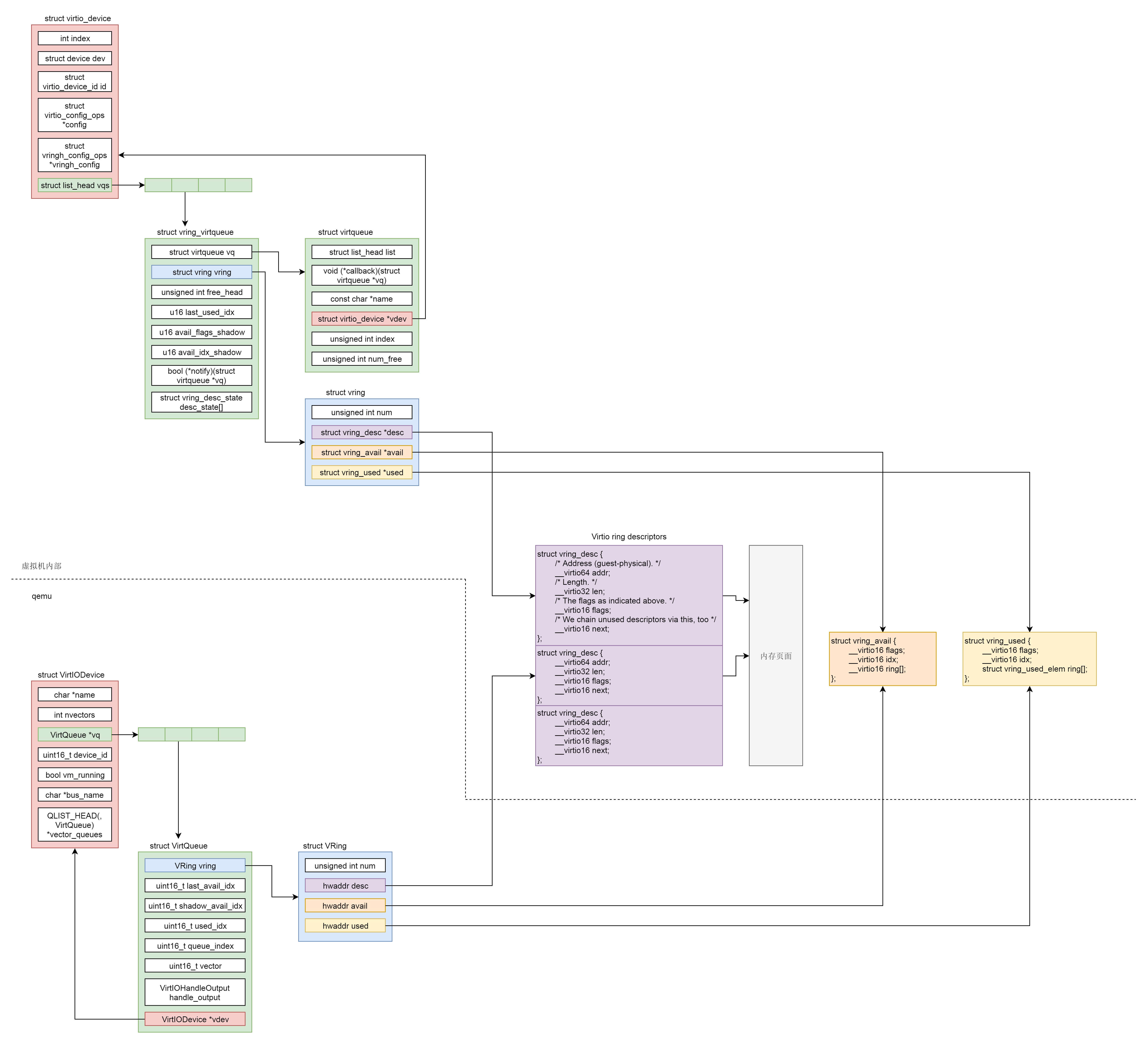
接着,我们来看一下这个队列的格式。
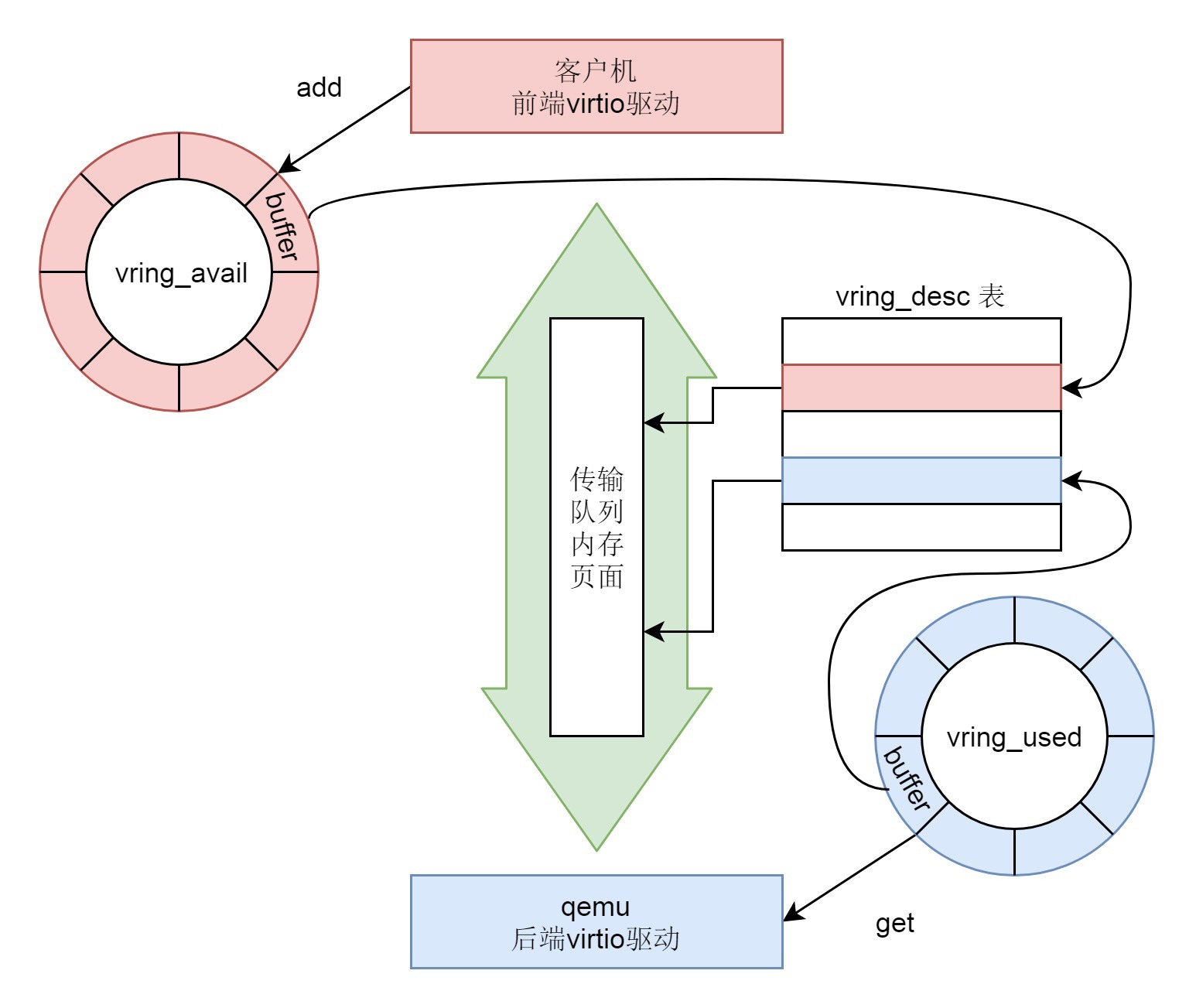
/* Virtio ring descriptors: 16 bytes. These can chain together via "next". */
struct vring_desc {
/* Address (guest-physical). */
__virtio64 addr;
/* Length. */
__virtio32 len;
/* The flags as indicated above. */
__virtio16 flags;
/* We chain unused descriptors via this, too */
__virtio16 next;
};
struct vring_avail {
__virtio16 flags;
__virtio16 idx;
__virtio16 ring[];
};
/* u32 is used here for ids for padding reasons. */
struct vring_used_elem {
/* Index of start of used descriptor chain. */
__virtio32 id;
/* Total length of the descriptor chain which was used (written to) */
__virtio32 len;
};
struct vring_used {
__virtio16 flags;
__virtio16 idx;
struct vring_used_elem ring[];
};
struct vring {
unsigned int num;
struct vring_desc *desc;
struct vring_avail *avail;
struct vring_used *used;
};vring包含三个成员:
- vring_desc指向分配的内存块,用于存放客户机和qemu之间传输的数据。
- avail->ring[]是发送端维护的环形队列,指向需要接收端处理的vring_desc。
- used->ring[]是接收端维护的环形队列,指向自己已经处理过了的vring_desc。
48.3 数据写入的流程
接下来,我们来看,真的写入一个数据的时候,会发生什么。
按照上面virtio驱动初始化的时候的逻辑,blk_mq_make_request会被调用。这个函数比较复杂,会分成多个分支,但是最终都会调用到request_queue的virtio_mq_ops的queue_rq函数。
struct request_queue *q = rq->q;
q->mq_ops->queue_rq(hctx, &bd);
static const struct blk_mq_ops virtio_mq_ops = {
.queue_rq = virtio_queue_rq,
.complete = virtblk_request_done,
.init_request = virtblk_init_request,
.map_queues = virtblk_map_queues,
};根据virtio_mq_ops的定义,我们现在要调用virtio_queue_rq。
static blk_status_t virtio_queue_rq(struct blk_mq_hw_ctx *hctx,
const struct blk_mq_queue_data *bd)
{
struct virtio_blk *vblk = hctx->queue->queuedata;
struct request *req = bd->rq;
struct virtblk_req *vbr = blk_mq_rq_to_pdu(req);
......
err = virtblk_add_req(vblk->vqs[qid].vq, vbr, vbr->sg, num);
......
if (notify)
virtqueue_notify(vblk->vqs[qid].vq);
return BLK_STS_OK;
}在virtio_queue_rq中,我们会将请求写入的数据,通过virtblk_add_req放入struct virtqueue。
因此,接下来的调用链为:virtblk_add_req->virtqueue_add_sgs->virtqueue_add。
static inline int virtqueue_add(struct virtqueue *_vq,
struct scatterlist *sgs[],
unsigned int total_sg,
unsigned int out_sgs,
unsigned int in_sgs,
void *data,
void *ctx,
gfp_t gfp)
{
struct vring_virtqueue *vq = to_vvq(_vq);
struct scatterlist *sg;
struct vring_desc *desc;
unsigned int i, n, avail, descs_used, uninitialized_var(prev), err_idx;
int head;
bool indirect;
......
head = vq->free_head;
indirect = false;
desc = vq->vring.desc;
i = head;
descs_used = total_sg;
for (n = 0; n < out_sgs; n++) {
for (sg = sgs[n]; sg; sg = sg_next(sg)) {
dma_addr_t addr = vring_map_one_sg(vq, sg, DMA_TO_DEVICE);
......
desc[i].flags = cpu_to_virtio16(_vq->vdev, VRING_DESC_F_NEXT);
desc[i].addr = cpu_to_virtio64(_vq->vdev, addr);
desc[i].len = cpu_to_virtio32(_vq->vdev, sg->length);
prev = i;
i = virtio16_to_cpu(_vq->vdev, desc[i].next);
}
}
/* Last one doesn't continue. */
desc[prev].flags &= cpu_to_virtio16(_vq->vdev, ~VRING_DESC_F_NEXT);
/* We're using some buffers from the free list. */
vq->vq.num_free -= descs_used;
/* Update free pointer */
vq->free_head = i;
/* Store token and indirect buffer state. */
vq->desc_state[head].data = data;
/* Put entry in available array (but don't update avail->idx until they do sync). */
avail = vq->avail_idx_shadow & (vq->vring.num - 1);
vq->vring.avail->ring[avail] = cpu_to_virtio16(_vq->vdev, head);
/* Descriptors and available array need to be set before we expose the new available array entries. */
virtio_wmb(vq->weak_barriers);
vq->avail_idx_shadow++;
vq->vring.avail->idx = cpu_to_virtio16(_vq->vdev, vq->avail_idx_shadow);
vq->num_added++;
......
return 0;
}在virtqueue_add函数中,我们能看到,free_head指向的整个内存块空闲链表的起始位置,用head变量记住这个起始位置。
接下来,i也指向这个起始位置,然后是一个for循环,将数据放到内存块里面,放的过程中,next不断指向下一个空闲位置,这样空闲的内存块被不断的占用。等所有的写入都结束了,i就会指向这次存放的内存块的下一个空闲位置,然后free_head就指向i,因为前面的都填满了。
至此,从head到i之间的内存块,就是这次写入的全部数据。
于是,在vring的avail变量中,在ring[]数组中分配新的一项,在avail的位置,avail的计算是avail_idx_shadow & (vq->vring.num - 1),其中,avail_idx_shadow是上一次的avail的位置。这里如果超过了ring[]数组的下标,则重新跳到起始位置,就说明是一个环。这次分配的新的avail的位置就存放新写入的从head到i之间的内存块。然后是avail_idx_shadow++,这说明这一块内存可以被接收方读取了。
接下来,我们回到virtio_queue_rq,调用virtqueue_notify通知接收方。而virtqueue_notify会调用vp_notify。
bool vp_notify(struct virtqueue *vq)
{
/* we write the queue's selector into the notification register to
* signal the other end */
iowrite16(vq->index, (void __iomem *)vq->priv);
return true;
}然后,我们写入一个I/O会触发VM exit。我们在解析CPU的时候看到过这个逻辑。
int kvm_cpu_exec(CPUState *cpu)
{
struct kvm_run *run = cpu->kvm_run;
int ret, run_ret;
......
run_ret = kvm_vcpu_ioctl(cpu, KVM_RUN, 0);
......
switch (run->exit_reason) {
case KVM_EXIT_IO:
DPRINTF("handle_io\n");
/* Called outside BQL */
kvm_handle_io(run->io.port, attrs,
(uint8_t *)run + run->io.data_offset,
run->io.direction,
run->io.size,
run->io.count);
ret = 0;
break;
}
......
}这次写入的也是一个I/O的内存空间,同样会触发virtio_ioport_write,这次会调用virtio_queue_notify。
void virtio_queue_notify(VirtIODevice *vdev, int n)
{
VirtQueue *vq = &vdev->vq[n];
......
if (vq->handle_aio_output) {
event_notifier_set(&vq->host_notifier);
} else if (vq->handle_output) {
vq->handle_output(vdev, vq);
}
}virtio_queue_notify会调用VirtQueue的handle_output函数,前面我们已经设置过这个函数了,是virtio_blk_handle_output。
接下来的调用链为:virtio_blk_handle_output->virtio_blk_handle_output_do->virtio_blk_handle_vq。
bool virtio_blk_handle_vq(VirtIOBlock *s, VirtQueue *vq)
{
VirtIOBlockReq *req;
MultiReqBuffer mrb = {};
bool progress = false;
......
do {
virtio_queue_set_notification(vq, 0);
while ((req = virtio_blk_get_request(s, vq))) {
progress = true;
if (virtio_blk_handle_request(req, &mrb)) {
virtqueue_detach_element(req->vq, &req->elem, 0);
virtio_blk_free_request(req);
break;
}
}
virtio_queue_set_notification(vq, 1);
} while (!virtio_queue_empty(vq));
if (mrb.num_reqs) {
virtio_blk_submit_multireq(s->blk, &mrb);
}
......
return progress;
}在virtio_blk_handle_vq中,有一个while循环,在循环中调用函数virtio_blk_get_request从vq中取出请求,然后调用virtio_blk_handle_request处理从vq中取出的请求。
我们先来看virtio_blk_get_request。
static VirtIOBlockReq *virtio_blk_get_request(VirtIOBlock *s, VirtQueue *vq)
{
VirtIOBlockReq *req = virtqueue_pop(vq, sizeof(VirtIOBlockReq));
if (req) {
virtio_blk_init_request(s, vq, req);
}
return req;
}
void *virtqueue_pop(VirtQueue *vq, size_t sz)
{
unsigned int i, head, max;
VRingMemoryRegionCaches *caches;
MemoryRegionCache *desc_cache;
int64_t len;
VirtIODevice *vdev = vq->vdev;
VirtQueueElement *elem = NULL;
unsigned out_num, in_num, elem_entries;
hwaddr addr[VIRTQUEUE_MAX_SIZE];
struct iovec iov[VIRTQUEUE_MAX_SIZE];
VRingDesc desc;
int rc;
......
/* When we start there are none of either input nor output. */
out_num = in_num = elem_entries = 0;
max = vq->vring.num;
i = head;
caches = vring_get_region_caches(vq);
desc_cache = &caches->desc;
vring_desc_read(vdev, &desc, desc_cache, i);
......
/* Collect all the descriptors */
do {
bool map_ok;
if (desc.flags & VRING_DESC_F_WRITE) {
map_ok = virtqueue_map_desc(vdev, &in_num, addr + out_num,
iov + out_num,
VIRTQUEUE_MAX_SIZE - out_num, true,
desc.addr, desc.len);
} else {
map_ok = virtqueue_map_desc(vdev, &out_num, addr, iov,
VIRTQUEUE_MAX_SIZE, false,
desc.addr, desc.len);
}
......
rc = virtqueue_read_next_desc(vdev, &desc, desc_cache, max, &i);
} while (rc == VIRTQUEUE_READ_DESC_MORE);
......
/* Now copy what we have collected and mapped */
elem = virtqueue_alloc_element(sz, out_num, in_num);
elem->index = head;
for (i = 0; i < out_num; i++) {
elem->out_addr[i] = addr[i];
elem->out_sg[i] = iov[i];
}
for (i = 0; i < in_num; i++) {
elem->in_addr[i] = addr[out_num + i];
elem->in_sg[i] = iov[out_num + i];
}
vq->inuse++;
......
return elem;
}我们可以看到,virtio_blk_get_request会调用virtqueue_pop。在这里面,我们能看到对于vring的操作,也即从这里面将客户机里面写入的数据读取出来,放到VirtIOBlockReq结构中。
接下来,我们就要调用virtio_blk_handle_request处理这些数据。所以接下来的调用链为:virtio_blk_handle_request->virtio_blk_submit_multireq->submit_requests。
static inline void submit_requests(BlockBackend *blk, MultiReqBuffer *mrb,int start, int num_reqs, int niov)
{
QEMUIOVector *qiov = &mrb->reqs[start]->qiov;
int64_t sector_num = mrb->reqs[start]->sector_num;
bool is_write = mrb->is_write;
if (num_reqs > 1) {
int i;
struct iovec *tmp_iov = qiov->iov;
int tmp_niov = qiov->niov;
qemu_iovec_init(qiov, niov);
for (i = 0; i < tmp_niov; i++) {
qemu_iovec_add(qiov, tmp_iov[i].iov_base, tmp_iov[i].iov_len);
}
for (i = start + 1; i < start + num_reqs; i++) {
qemu_iovec_concat(qiov, &mrb->reqs[i]->qiov, 0,
mrb->reqs[i]->qiov.size);
mrb->reqs[i - 1]->mr_next = mrb->reqs[i];
}
block_acct_merge_done(blk_get_stats(blk),
is_write ? BLOCK_ACCT_WRITE : BLOCK_ACCT_READ,
num_reqs - 1);
}
if (is_write) {
blk_aio_pwritev(blk, sector_num << BDRV_SECTOR_BITS, qiov, 0,
virtio_blk_rw_complete, mrb->reqs[start]);
} else {
blk_aio_preadv(blk, sector_num << BDRV_SECTOR_BITS, qiov, 0,
virtio_blk_rw_complete, mrb->reqs[start]);
}
}在submit_requests中,我们看到了BlockBackend。这是在qemu启动的时候,打开qcow2文件的时候生成的,现在我们可以用它来写入文件了,调用的是blk_aio_pwritev。
BlockAIOCB *blk_aio_pwritev(BlockBackend *blk, int64_t offset,
QEMUIOVector *qiov, BdrvRequestFlags flags,
BlockCompletionFunc *cb, void *opaque)
{
return blk_aio_prwv(blk, offset, qiov->size, qiov,
blk_aio_write_entry, flags, cb, opaque);
}
static BlockAIOCB *blk_aio_prwv(BlockBackend *blk, int64_t offset, int bytes,
void *iobuf, CoroutineEntry co_entry,
BdrvRequestFlags flags,
BlockCompletionFunc *cb, void *opaque)
{
BlkAioEmAIOCB *acb;
Coroutine *co;
acb = blk_aio_get(&blk_aio_em_aiocb_info, blk, cb, opaque);
acb->rwco = (BlkRwCo) {
.blk = blk,
.offset = offset,
.iobuf = iobuf,
.flags = flags,
.ret = NOT_DONE,
};
acb->bytes = bytes;
acb->has_returned = false;
co = qemu_coroutine_create(co_entry, acb);
bdrv_coroutine_enter(blk_bs(blk), co);
acb->has_returned = true;
return &acb->common;
}在blk_aio_pwritev中,我们看到,又是创建了一个协程来进行写入。写入完毕之后调用virtio_blk_rw_complete->virtio_blk_req_complete。
static void virtio_blk_req_complete(VirtIOBlockReq *req, unsigned char status)
{
VirtIOBlock *s = req->dev;
VirtIODevice *vdev = VIRTIO_DEVICE(s);
trace_virtio_blk_req_complete(vdev, req, status);
stb_p(&req->in->status, status);
virtqueue_push(req->vq, &req->elem, req->in_len);
virtio_notify(vdev, req->vq);
}在virtio_blk_req_complete中,我们先是调用virtqueue_push,更新vring中used变量,表示这部分已经写入完毕,空间可以回收利用了。但是,这部分的改变仅仅改变了qemu后端的vring,我们还需要通知客户机中virtio前端的vring的值,因而要调用virtio_notify。virtio_notify会调用virtio_irq发送一个中断。
还记得咱们前面注册过一个中断处理函数vp_interrupt吗?它就是干这个事情的。
static irqreturn_t vp_interrupt(int irq, void *opaque)
{
struct virtio_pci_device *vp_dev = opaque;
u8 isr;
/* reading the ISR has the effect of also clearing it so it's very
* important to save off the value. */
isr = ioread8(vp_dev->isr);
/* Configuration change? Tell driver if it wants to know. */
if (isr & VIRTIO_PCI_ISR_CONFIG)
vp_config_changed(irq, opaque);
return vp_vring_interrupt(irq, opaque);
}就像前面说的一样vp_interrupt这个中断处理函数,一是处理配置变化,二是处理I/O结束。第二种的调用链为:vp_interrupt->vp_vring_interrupt->vring_interrupt。
irqreturn_t vring_interrupt(int irq, void *_vq)
{
struct vring_virtqueue *vq = to_vvq(_vq);
......
if (vq->vq.callback)
vq->vq.callback(&vq->vq);
return IRQ_HANDLED;
}在vring_interrupt中,我们会调用callback函数,这个也是在前面注册过的,是virtblk_done。
接下来的调用链为:virtblk_done->virtqueue_get_buf->virtqueue_get_buf_ctx。
void *virtqueue_get_buf_ctx(struct virtqueue *_vq, unsigned int *len,
void **ctx)
{
struct vring_virtqueue *vq = to_vvq(_vq);
void *ret;
unsigned int i;
u16 last_used;
......
last_used = (vq->last_used_idx & (vq->vring.num - 1));
i = virtio32_to_cpu(_vq->vdev, vq->vring.used->ring[last_used].id);
*len = virtio32_to_cpu(_vq->vdev, vq->vring.used->ring[last_used].len);
......
/* detach_buf clears data, so grab it now. */
ret = vq->desc_state[i].data;
detach_buf(vq, i, ctx);
vq->last_used_idx++;
......
return ret;
}在virtqueue_get_buf_ctx中,我们可以看到,virtio前端的vring中的last_used_idx加一,说明这块数据qemu后端已经消费完毕。我们可以通过detach_buf将其放入空闲队列中,留给以后的写入请求使用。
至此,整个存储虚拟化的写入流程才全部完成。
48.4 总结
下面我们来总结一下存储虚拟化的场景下,整个写入的过程。
- 在虚拟机里面,应用层调用write系统调用写入文件。
- write系统调用进入虚拟机里面的内核,经过VFS,通用块设备层,I/O调度层,到达块设备驱动。
- 虚拟机里面的块设备驱动是virtio_blk,它和通用的块设备驱动一样,有一个request queue,另外有一个函数make_request_fn会被设置为blk_mq_make_request,这个函数用于将请求放入队列。
- 虚拟机里面的块设备驱动是virtio_blk会注册一个中断处理函数vp_interrupt。当qemu写入完成之后,它会通知虚拟机里面的块设备驱动。
- blk_mq_make_request最终调用virtqueue_add,将请求添加到传输队列virtqueue中,然后调用virtqueue_notify通知qemu。
- 在qemu中,本来虚拟机正处于KVM_RUN的状态,也即处于客户机状态。
- qemu收到通知后,通过VM exit指令退出客户机状态,进入宿主机状态,根据退出原因,得知有I/O需要处理。
- qemu调用virtio_blk_handle_output,最终调用virtio_blk_handle_vq。
- virtio_blk_handle_vq里面有一个循环,在循环中,virtio_blk_get_request函数从传输队列中拿出请求,然后调用virtio_blk_handle_request处理请求。
- virtio_blk_handle_request会调用blk_aio_pwritev,通过BlockBackend驱动写入qcow2文件。
- 写入完毕之后,virtio_blk_req_complete会调用virtio_notify通知虚拟机里面的驱动。数据写入完成,刚才注册的中断处理函数vp_interrupt会收到这个通知。
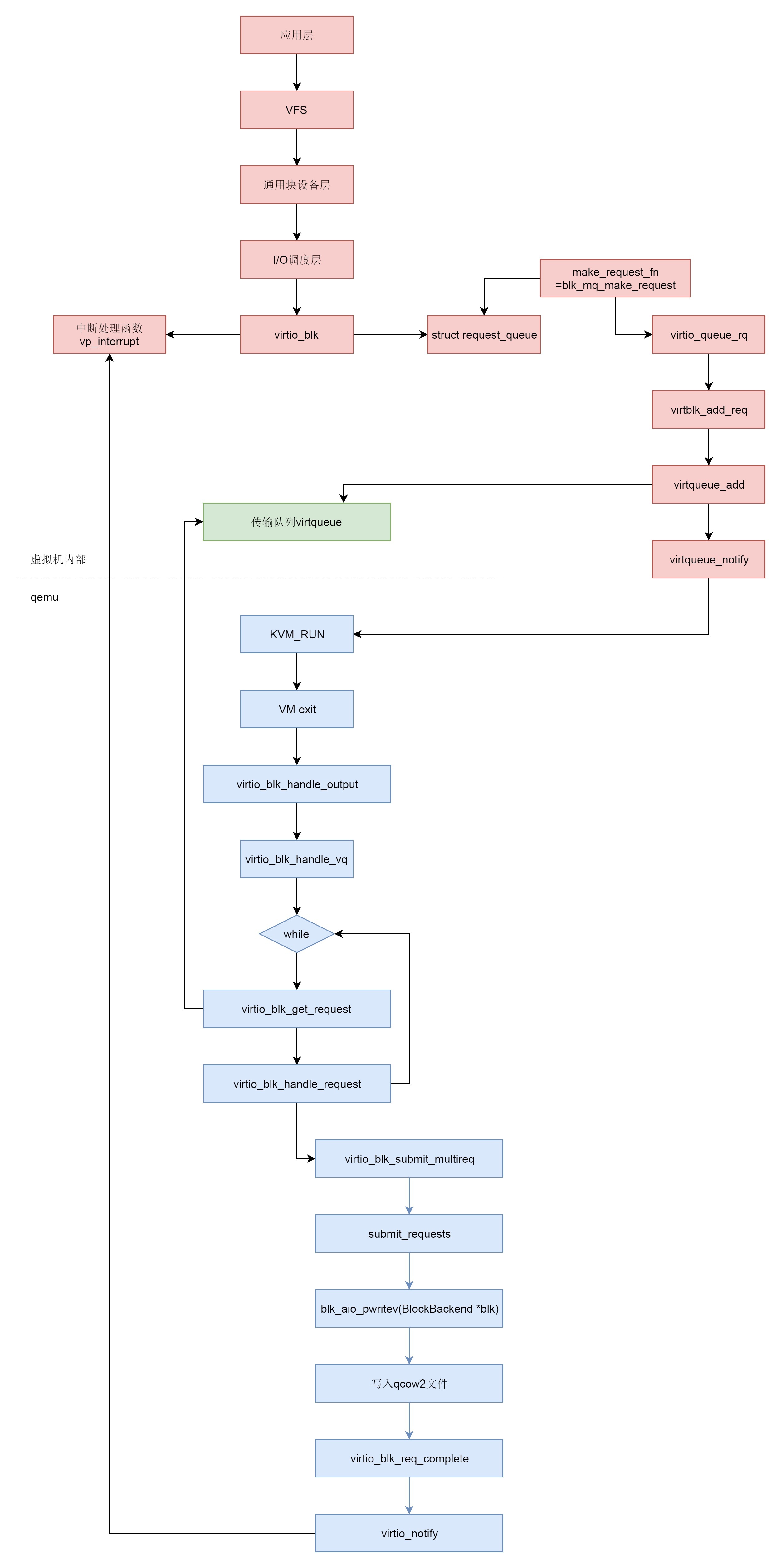
49. 网络虚拟化
上一节,我们讲了存储虚拟化,这一节我们来讲网络虚拟化。
网络虚拟化有和存储虚拟化类似的地方,例如,它们都是基于virtio的,因而我们在看网络虚拟化的过程中,会看到和存储虚拟化很像的数据结构和原理。但是,网络虚拟化也有自己的特殊性。例如,存储虚拟化是将宿主机上的文件作为客户机上的硬盘,而网络虚拟化需要依赖于内核协议栈进行网络包的封装与解封装。那怎么实现客户机和宿主机之间的互通呢?我们就一起来看一看。
49.1 解析初始化过程
我们还是从Virtio Network Device这个设备的初始化讲起。
static const TypeInfo device_type_info = {
.name = TYPE_DEVICE,
.parent = TYPE_OBJECT,
.instance_size = sizeof(DeviceState),
.instance_init = device_initfn,
.instance_post_init = device_post_init,
.instance_finalize = device_finalize,
.class_base_init = device_class_base_init,
.class_init = device_class_init,
.abstract = true,
.class_size = sizeof(DeviceClass),
};
static const TypeInfo virtio_device_info = {
.name = TYPE_VIRTIO_DEVICE,
.parent = TYPE_DEVICE,
.instance_size = sizeof(VirtIODevice),
.class_init = virtio_device_class_init,
.instance_finalize = virtio_device_instance_finalize,
.abstract = true,
.class_size = sizeof(VirtioDeviceClass),
};
static const TypeInfo virtio_net_info = {
.name = TYPE_VIRTIO_NET,
.parent = TYPE_VIRTIO_DEVICE,
.instance_size = sizeof(VirtIONet),
.instance_init = virtio_net_instance_init,
.class_init = virtio_net_class_init,
};
static void virtio_register_types(void)
{
type_register_static(&virtio_net_info);
}
type_init(virtio_register_types)Virtio Network Device这种类的定义是有多层继承关系的,TYPE_VIRTIO_NET的父类是TYPE_VIRTIO_DEVICE,TYPE_VIRTIO_DEVICE的父类是TYPE_DEVICE,TYPE_DEVICE的父类是TYPE_OBJECT,继承关系到头了。
type_init用于注册这种类。这里面每一层都有class_init,用于从TypeImpl生产xxxClass,也有instance_init,会将xxxClass初始化为实例。
TYPE_VIRTIO_NET层的class_init函数virtio_net_class_init,定义了DeviceClass的realize函数为virtio_net_device_realize,这一点和存储块设备是一样的。
static void virtio_net_device_realize(DeviceState *dev, Error **errp)
{
VirtIODevice *vdev = VIRTIO_DEVICE(dev);
VirtIONet *n = VIRTIO_NET(dev);
NetClientState *nc;
int i;
......
virtio_init(vdev, "virtio-net", VIRTIO_ID_NET, n->config_size);
/*
* We set a lower limit on RX queue size to what it always was.
* Guests that want a smaller ring can always resize it without
* help from us (using virtio 1 and up).
*/
if (n->net_conf.rx_queue_size < VIRTIO_NET_RX_QUEUE_MIN_SIZE ||
n->net_conf.rx_queue_size > VIRTQUEUE_MAX_SIZE ||
!is_power_of_2(n->net_conf.rx_queue_size)) {
......
return;
}
if (n->net_conf.tx_queue_size < VIRTIO_NET_TX_QUEUE_MIN_SIZE ||
n->net_conf.tx_queue_size > VIRTQUEUE_MAX_SIZE ||
!is_power_of_2(n->net_conf.tx_queue_size)) {
......
return;
}
n->max_queues = MAX(n->nic_conf.peers.queues, 1);
if (n->max_queues * 2 + 1 > VIRTIO_QUEUE_MAX) {
......
return;
}
n->vqs = g_malloc0(sizeof(VirtIONetQueue) * n->max_queues);
n->curr_queues = 1;
......
n->net_conf.tx_queue_size = MIN(virtio_net_max_tx_queue_size(n),
n->net_conf.tx_queue_size);
for (i = 0; i < n->max_queues; i++) {
virtio_net_add_queue(n, i);
}
n->ctrl_vq = virtio_add_queue(vdev, 64, virtio_net_handle_ctrl);
qemu_macaddr_default_if_unset(&n->nic_conf.macaddr);
memcpy(&n->mac[0], &n->nic_conf.macaddr, sizeof(n->mac));
n->status = VIRTIO_NET_S_LINK_UP;
if (n->netclient_type) {
n->nic = qemu_new_nic(&net_virtio_info, &n->nic_conf,
n->netclient_type, n->netclient_name, n);
} else {
n->nic = qemu_new_nic(&net_virtio_info, &n->nic_conf,
object_get_typename(OBJECT(dev)), dev->id, n);
}
......
}这里面创建了一个VirtIODevice,这一点和存储虚拟化也是一样的。virtio_init用来初始化这个设备。VirtIODevice结构里面有一个VirtQueue数组,这就是virtio前端和后端互相传数据的队列,最多有VIRTIO_QUEUE_MAX个。
刚才我们说的都是一样的地方,其实也有不一样的地方,我们下面来看。
你会发现,这里面有这样的语句n->max_queues * 2 + 1 > VIRTIO_QUEUE_MAX。为什么要乘以2呢?这是因为,对于网络设备来讲,应该分发送队列和接收队列两个方向,所以乘以2。
接下来,我们调用virtio_net_add_queue来初始化队列,可以看出来,这里面就有发送tx_vq和接收rx_vq两个队列。
typedef struct VirtIONetQueue {
VirtQueue *rx_vq;
VirtQueue *tx_vq;
QEMUTimer *tx_timer;
QEMUBH *tx_bh;
uint32_t tx_waiting;
struct {
VirtQueueElement *elem;
} async_tx;
struct VirtIONet *n;
} VirtIONetQueue;
static void virtio_net_add_queue(VirtIONet *n, int index)
{
VirtIODevice *vdev = VIRTIO_DEVICE(n);
n->vqs[index].rx_vq = virtio_add_queue(vdev, n->net_conf.rx_queue_size, virtio_net_handle_rx);
......
n->vqs[index].tx_vq = virtio_add_queue(vdev, n->net_conf.tx_queue_size, virtio_net_handle_tx_bh);
n->vqs[index].tx_bh = qemu_bh_new(virtio_net_tx_bh, &n->vqs[index]);
n->vqs[index].n = n;
}每个VirtQueue中,都有一个vring用来维护这个队列里面的数据;另外还有函数virtio_net_handle_rx用于处理网络包的接收;函数virtio_net_handle_tx_bh用于网络包的发送,这个函数我们后面会用到。
NICState *qemu_new_nic(NetClientInfo *info,
NICConf *conf,
const char *model,
const char *name,
void *opaque)
{
NetClientState **peers = conf->peers.ncs;
NICState *nic;
int i, queues = MAX(1, conf->peers.queues);
......
nic = g_malloc0(info->size + sizeof(NetClientState) * queues);
nic->ncs = (void *)nic + info->size;
nic->conf = conf;
nic->opaque = opaque;
for (i = 0; i < queues; i++) {
qemu_net_client_setup(&nic->ncs[i], info, peers[i], model, name, NULL);
nic->ncs[i].queue_index = i;
}
return nic;
}
static void qemu_net_client_setup(NetClientState *nc,
NetClientInfo *info,
NetClientState *peer,
const char *model,
const char *name,
NetClientDestructor *destructor)
{
nc->info = info;
nc->model = g_strdup(model);
if (name) {
nc->name = g_strdup(name);
} else {
nc->name = assign_name(nc, model);
}
QTAILQ_INSERT_TAIL(&net_clients, nc, next);
nc->incoming_queue = qemu_new_net_queue(qemu_deliver_packet_iov, nc);
nc->destructor = destructor;
QTAILQ_INIT(&nc->filters);
}接下来,qemu_new_nic会创建一个虚拟机里面的网卡。
49.2 qemu的启动过程中的网络虚拟化
初始化过程解析完毕以后,我们接下来从qemu的启动过程看起。
对于网卡的虚拟化,qemu的启动参数里面有关的是下面两行:
-netdev tap,fd=32,id=hostnet0,vhost=on,vhostfd=37
-device virtio-net-pci,netdev=hostnet0,id=net0,mac=fa:16:3e:d1:2d:99,bus=pci.0,addr=0x3qemu的main函数会调用net_init_clients进行网络设备的初始化,可以解析net参数,也可以在net_init_clients中解析netdev参数。
int net_init_clients(Error **errp)
{
QTAILQ_INIT(&net_clients);
if (qemu_opts_foreach(qemu_find_opts("netdev"),
net_init_netdev, NULL, errp)) {
return -1;
}
if (qemu_opts_foreach(qemu_find_opts("nic"), net_param_nic, NULL, errp)) {
return -1;
}
if (qemu_opts_foreach(qemu_find_opts("net"), net_init_client, NULL, errp)) {
return -1;
}
return 0;
}net_init_clients会解析参数。上面的参数netdev会调用net_init_netdev->net_client_init->net_client_init1。
net_client_init1会根据不同的driver类型,调用不同的初始化函数。
static int (* const net_client_init_fun[NET_CLIENT_DRIVER__MAX])(
const Netdev *netdev,
const char *name,
NetClientState *peer, Error **errp) = {
[NET_CLIENT_DRIVER_NIC] = net_init_nic,
[NET_CLIENT_DRIVER_TAP] = net_init_tap,
[NET_CLIENT_DRIVER_SOCKET] = net_init_socket,
[NET_CLIENT_DRIVER_HUBPORT] = net_init_hubport,
......
};由于我们配置的driver的类型是tap,因而这里会调用net_init_tap->net_tap_init->tap_open。
#define PATH_NET_TUN "/dev/net/tun"
int tap_open(char *ifname, int ifname_size, int *vnet_hdr,
int vnet_hdr_required, int mq_required, Error **errp)
{
struct ifreq ifr;
int fd, ret;
int len = sizeof(struct virtio_net_hdr);
unsigned int features;
TFR(fd = open(PATH_NET_TUN, O_RDWR));
memset(&ifr, 0, sizeof(ifr));
ifr.ifr_flags = IFF_TAP | IFF_NO_PI;
if (ioctl(fd, TUNGETFEATURES, &features) == -1) {
features = 0;
}
if (features & IFF_ONE_QUEUE) {
ifr.ifr_flags |= IFF_ONE_QUEUE;
}
if (*vnet_hdr) {
if (features & IFF_VNET_HDR) {
*vnet_hdr = 1;
ifr.ifr_flags |= IFF_VNET_HDR;
} else {
*vnet_hdr = 0;
}
ioctl(fd, TUNSETVNETHDRSZ, &len);
}
......
ret = ioctl(fd, TUNSETIFF, (void *) &ifr);
......
fcntl(fd, F_SETFL, O_NONBLOCK);
return fd;
}在tap_open中,我们打开一个文件”/dev/net/tun”,然后通过ioctl操作这个文件。这是Linux内核的一项机制,和KVM机制很像。其实这就是一种通过打开这个字符设备文件,然后通过ioctl操作这个文件和内核打交道,来使用内核的能力。
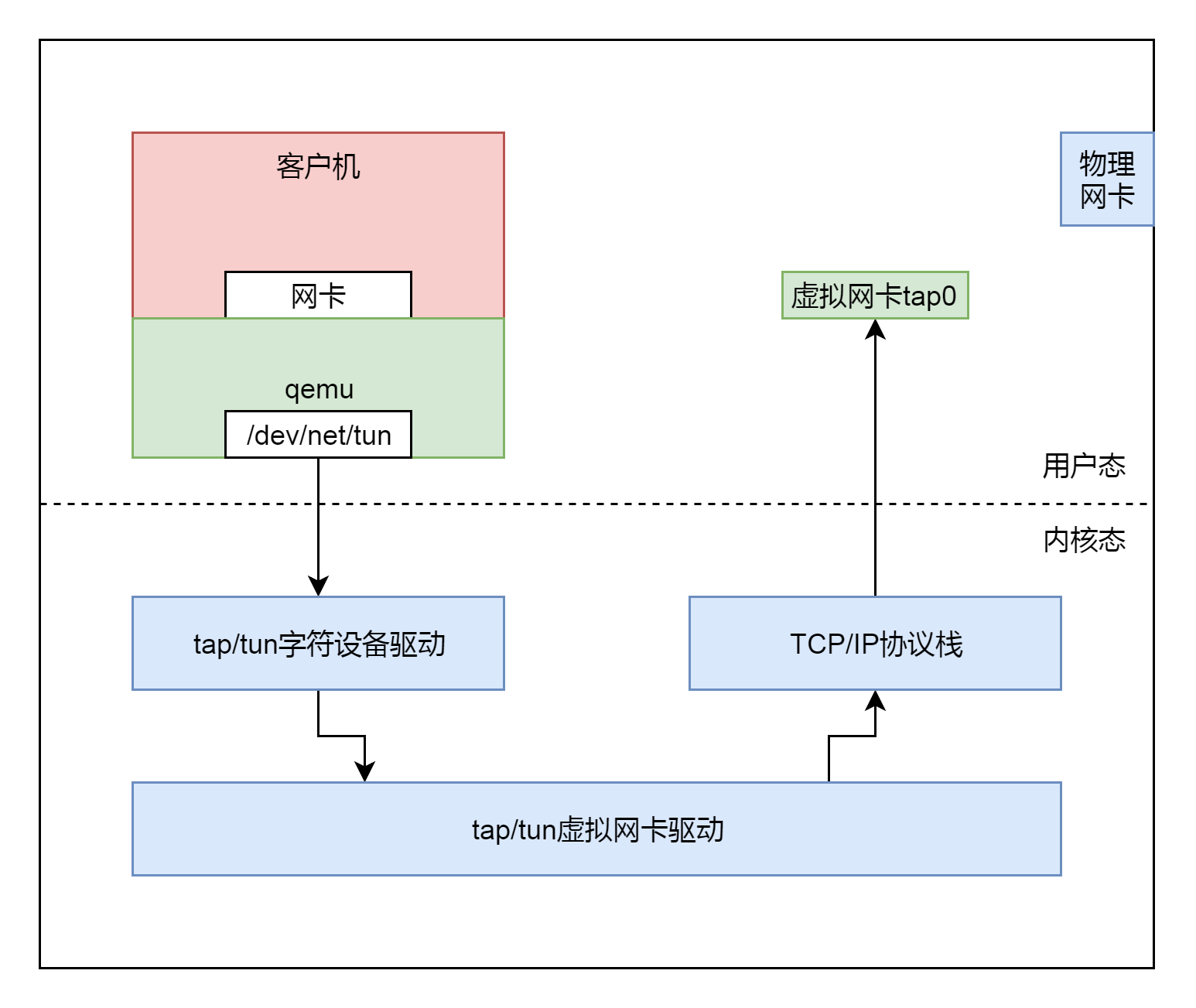
为什么需要使用内核的机制呢?因为网络包需要从虚拟机里面发送到虚拟机外面,发送到宿主机上的时候,必须是一个正常的网络包才能被转发。要形成一个网络包,我们那就需要经过复杂的协议栈,协议栈的复杂咱们在发送网络包那一节讲过了。
客户机会将网络包发送给qemu。qemu自己没有网络协议栈,现去实现一个也不可能,太复杂了。于是,它就要借助内核的力量。
qemu会将客户机发送给它的网络包,然后转换成为文件流,写入”/dev/net/tun”字符设备。就像写一个文件一样。内核中TUN/TAP字符设备驱动会收到这个写入的文件流,然后交给TUN/TAP的虚拟网卡驱动。这个驱动会将文件流再次转成网络包,交给TCP/IP栈,最终从虚拟TAP网卡tap0发出来,成为标准的网络包。后面我们会看到这个过程。
现在我们到内核里面,看一看打开”/dev/net/tun”字符设备后,内核会发生什么事情。内核的实现在drivers/net/tun.c文件中。这是一个字符设备驱动程序,应该符合字符设备的格式。
module_init(tun_init);
module_exit(tun_cleanup);
MODULE_DESCRIPTION(DRV_DESCRIPTION);
MODULE_AUTHOR(DRV_COPYRIGHT);
MODULE_LICENSE("GPL");
MODULE_ALIAS_MISCDEV(TUN_MINOR);
MODULE_ALIAS("devname:net/tun");
static int __init tun_init(void)
{
......
ret = rtnl_link_register(&tun_link_ops);
......
ret = misc_register(&tun_miscdev);
......
ret = register_netdevice_notifier(&tun_notifier_block);
......
}这里面注册了一个tun_miscdev字符设备,从它的定义可以看出,这就是”/dev/net/tun”字符设备。
static struct miscdevice tun_miscdev = {
.minor = TUN_MINOR,
.name = "tun",
.nodename = "net/tun",
.fops = &tun_fops,
};
static const struct file_operations tun_fops = {
.owner = THIS_MODULE,
.llseek = no_llseek,
.read_iter = tun_chr_read_iter,
.write_iter = tun_chr_write_iter,
.poll = tun_chr_poll,
.unlocked_ioctl = tun_chr_ioctl,
.open = tun_chr_open,
.release = tun_chr_close,
.fasync = tun_chr_fasync,
};qemu的tap_open函数会打开这个字符设备PATH_NET_TUN。打开字符设备的过程我们不再重复。我就说一下,到了驱动这一层,调用的是tun_chr_open。
static int tun_chr_open(struct inode *inode, struct file * file)
{
struct tun_file *tfile;
tfile = (struct tun_file *)sk_alloc(net, AF_UNSPEC, GFP_KERNEL,
&tun_proto, 0);
RCU_INIT_POINTER(tfile->tun, NULL);
tfile->flags = 0;
tfile->ifindex = 0;
init_waitqueue_head(&tfile->wq.wait);
RCU_INIT_POINTER(tfile->socket.wq, &tfile->wq);
tfile->socket.file = file;
tfile->socket.ops = &tun_socket_ops;
sock_init_data(&tfile->socket, &tfile->sk);
tfile->sk.sk_write_space = tun_sock_write_space;
tfile->sk.sk_sndbuf = INT_MAX;
file->private_data = tfile;
INIT_LIST_HEAD(&tfile->next);
sock_set_flag(&tfile->sk, SOCK_ZEROCOPY);
return 0;
}在tun_chr_open的参数里面,有一个struct file,这是代表什么文件呢?它代表的就是打开的字符设备文件”/dev/net/tun”,因而往这个字符设备文件中写数据,就会通过这个struct file写入。这个struct file里面的file_operations,按照字符设备打开的规则,指向的就是tun_fops。
另外,我们还需要在tun_chr_open创建了一个结构struct tun_file,并且将struct file的private_data指向它。
/* A tun_file connects an open character device to a tuntap netdevice. It
* also contains all socket related structures
* to serve as one transmit queue for tuntap device.
*/
struct tun_file {
struct sock sk;
struct socket socket;
struct socket_wq wq;
struct tun_struct __rcu *tun;
struct fasync_struct *fasync;
/* only used for fasnyc */
unsigned int flags;
union {
u16 queue_index;
unsigned int ifindex;
};
struct list_head next;
struct tun_struct *detached;
struct skb_array tx_array;
};
struct tun_struct {
struct tun_file __rcu *tfiles[MAX_TAP_QUEUES];
unsigned int numqueues;
unsigned int flags;
kuid_t owner;
kgid_t group;
struct net_device *dev;
netdev_features_t set_features;
int align;
int vnet_hdr_sz;
int sndbuf;
struct tap_filter txflt;
struct sock_fprog fprog;
/* protected by rtnl lock */
bool filter_attached;
spinlock_t lock;
struct hlist_head flows[TUN_NUM_FLOW_ENTRIES];
struct timer_list flow_gc_timer;
unsigned long ageing_time;
unsigned int numdisabled;
struct list_head disabled;
void *security;
u32 flow_count;
u32 rx_batched;
struct tun_pcpu_stats __percpu *pcpu_stats;
};
static const struct proto_ops tun_socket_ops = {
.peek_len = tun_peek_len,
.sendmsg = tun_sendmsg,
.recvmsg = tun_recvmsg,
};在struct tun_file中,有一个成员struct tun_struct,它里面有一个struct net_device,这个用来表示宿主机上的tuntap网络设备。在struct tun_file中,还有struct socket和struct sock,因为要用到内核的Socket通信之网络协议基本原理栈,所以就需要这两个结构,这在网络协议那一节已经分析过了。
所以,按照struct tun_file的注释说的,这是一个很重要的数据结构。”/dev/net/tun”对应的struct file的private_data指向它,因而可以接收qemu发过来的数据。除此之外,它还可以通过struct sock来操作内核协议栈,然后将网络包从宿主机上的tuntap网络设备发出去,宿主机上的tuntap网络设备对应的struct net_device也归它管。
在qemu的tap_open函数中,打开这个字符设备文件之后,接下来要做的事情是,通过ioctl来设置宿主机的网卡TUNSETIFF。
接下来,ioctl到了内核里面,会调用tun_chr_ioctl。
static long __tun_chr_ioctl(struct file *file, unsigned int cmd,
unsigned long arg, int ifreq_len)
{
struct tun_file *tfile = file->private_data;
struct tun_struct *tun;
void __user* argp = (void __user*)arg;
struct ifreq ifr;
kuid_t owner;
kgid_t group;
int sndbuf;
int vnet_hdr_sz;
unsigned int ifindex;
int le;
int ret;
if (cmd == TUNSETIFF || cmd == TUNSETQUEUE || _IOC_TYPE(cmd) == SOCK_IOC_TYPE) {
if (copy_from_user(&ifr, argp, ifreq_len))
return -EFAULT;
}
......
tun = __tun_get(tfile);
if (cmd == TUNSETIFF) {
ifr.ifr_name[IFNAMSIZ-1] = '\0';
ret = tun_set_iff(sock_net(&tfile->sk), file, &ifr);
......
if (copy_to_user(argp, &ifr, ifreq_len))
ret = -EFAULT;
}
......
}在__tun_chr_ioctl中,我们首先通过copy_from_user把配置从用户态拷贝到内核态,调用tun_set_iff设置tuntap网络设备,然后调用copy_to_user将配置结果返回。
static int tun_set_iff(struct net *net, struct file *file, struct ifreq *ifr)
{
struct tun_struct *tun;
struct tun_file *tfile = file->private_data;
struct net_device *dev;
......
char *name;
unsigned long flags = 0;
int queues = ifr->ifr_flags & IFF_MULTI_QUEUE ?
MAX_TAP_QUEUES : 1;
if (ifr->ifr_flags & IFF_TUN) {
/* TUN device */
flags |= IFF_TUN;
name = "tun%d";
} else if (ifr->ifr_flags & IFF_TAP) {
/* TAP device */
flags |= IFF_TAP;
name = "tap%d";
} else
return -EINVAL;
if (*ifr->ifr_name)
name = ifr->ifr_name;
dev = alloc_netdev_mqs(sizeof(struct tun_struct), name,
NET_NAME_UNKNOWN, tun_setup, queues,
queues);
err = dev_get_valid_name(net, dev, name);
dev_net_set(dev, net);
dev->rtnl_link_ops = &tun_link_ops;
dev->ifindex = tfile->ifindex;
dev->sysfs_groups[0] = &tun_attr_group;
tun = netdev_priv(dev);
tun->dev = dev;
tun->flags = flags;
tun->txflt.count = 0;
tun->vnet_hdr_sz = sizeof(struct virtio_net_hdr);
tun->align = NET_SKB_PAD;
tun->filter_attached = false;
tun->sndbuf = tfile->socket.sk->sk_sndbuf;
tun->rx_batched = 0;
tun_net_init(dev);
tun_flow_init(tun);
err = tun_attach(tun, file, false);
err = register_netdevice(tun->dev);
netif_carrier_on(tun->dev);
if (netif_running(tun->dev))
netif_tx_wake_all_queues(tun->dev);
strcpy(ifr->ifr_name, tun->dev->name);
return 0;
}tun_set_iff创建了struct tun_struct和struct net_device,并且将这个tuntap网络设备通过register_netdevice注册到内核中。这样,我们就能在宿主机上通过ip addr看到这个网卡了。
至此宿主机上的内核的数据结构也完成了。
49.3 关联前端设备驱动和后端设备驱动
下面,我们来解析在客户机中发送一个网络包的时候,会发生哪些事情。
虚拟机里面的进程发送一个网络包,通过文件系统和Socket调用网络协议栈,到达网络设备层。只不过这个不是普通的网络设备,而是virtio_net的驱动。
virtio_net的驱动程序代码在Linux操作系统的源代码里面,文件名为drivers/net/virtio_net.c。
static __init int virtio_net_driver_init(void)
{
ret = register_virtio_driver(&virtio_net_driver);
......
}
module_init(virtio_net_driver_init);
module_exit(virtio_net_driver_exit);
MODULE_DEVICE_TABLE(virtio, id_table);
MODULE_DESCRIPTION("Virtio network driver");
MODULE_LICENSE("GPL");
static struct virtio_driver virtio_net_driver = {
.driver.name = KBUILD_MODNAME,
.driver.owner = THIS_MODULE,
.id_table = id_table,
.validate = virtnet_validate,
.probe = virtnet_probe,
.remove = virtnet_remove,
.config_changed = virtnet_config_changed,
......
};在virtio_net的驱动程序的初始化代码中,我们需要注册一个驱动函数virtio_net_driver。
当一个设备驱动作为一个内核模块被初始化的时候,probe函数会被调用,因而我们来看一下virtnet_probe。
static int virtnet_probe(struct virtio_device *vdev)
{
int i, err;
struct net_device *dev;
struct virtnet_info *vi;
u16 max_queue_pairs;
int mtu;
/* Allocate ourselves a network device with room for our info */
dev = alloc_etherdev_mq(sizeof(struct virtnet_info), max_queue_pairs);
/* Set up network device as normal. */
dev->priv_flags |= IFF_UNICAST_FLT | IFF_LIVE_ADDR_CHANGE;
dev->netdev_ops = &virtnet_netdev;
dev->features = NETIF_F_HIGHDMA;
dev->ethtool_ops = &virtnet_ethtool_ops;
SET_NETDEV_DEV(dev, &vdev->dev);
......
/* MTU range: 68 - 65535 */
dev->min_mtu = MIN_MTU;
dev->max_mtu = MAX_MTU;
/* Set up our device-specific information */
vi = netdev_priv(dev);
vi->dev = dev;
vi->vdev = vdev;
vdev->priv = vi;
vi->stats = alloc_percpu(struct virtnet_stats);
INIT_WORK(&vi->config_work, virtnet_config_changed_work);
......
vi->max_queue_pairs = max_queue_pairs;
/* Allocate/initialize the rx/tx queues, and invoke find_vqs */
err = init_vqs(vi);
netif_set_real_num_tx_queues(dev, vi->curr_queue_pairs);
netif_set_real_num_rx_queues(dev, vi->curr_queue_pairs);
virtnet_init_settings(dev);
err = register_netdev(dev);
virtio_device_ready(vdev);
virtnet_set_queues(vi, vi->curr_queue_pairs);
......
}在virtnet_probe中,会创建struct net_device,并且通过register_netdev注册这个网络设备,这样在客户机里面,就能看到这个网卡了。
在virtnet_probe中,还有一件重要的事情就是,init_vqs会初始化发送和接收的virtqueue。
static int init_vqs(struct virtnet_info *vi)
{
int ret;
/* Allocate send & receive queues */
ret = virtnet_alloc_queues(vi);
ret = virtnet_find_vqs(vi);
......
get_online_cpus();
virtnet_set_affinity(vi);
put_online_cpus();
return 0;
}
static int virtnet_alloc_queues(struct virtnet_info *vi)
{
int i;
vi->sq = kzalloc(sizeof(*vi->sq) * vi->max_queue_pairs, GFP_KERNEL);
vi->rq = kzalloc(sizeof(*vi->rq) * vi->max_queue_pairs, GFP_KERNEL);
INIT_DELAYED_WORK(&vi->refill, refill_work);
for (i = 0; i < vi->max_queue_pairs; i++) {
vi->rq[i].pages = NULL;
netif_napi_add(vi->dev, &vi->rq[i].napi, virtnet_poll,
napi_weight);
netif_tx_napi_add(vi->dev, &vi->sq[i].napi, virtnet_poll_tx,
napi_tx ? napi_weight : 0);
sg_init_table(vi->rq[i].sg, ARRAY_SIZE(vi->rq[i].sg));
ewma_pkt_len_init(&vi->rq[i].mrg_avg_pkt_len);
sg_init_table(vi->sq[i].sg, ARRAY_SIZE(vi->sq[i].sg));
}
return 0;
}按照上一节的virtio原理,virtqueue是一个介于客户机前端和qemu后端的一个结构,用于在这两端之间传递数据,对于网络设备来讲有发送和接收两个方向的队列。这里建立的struct virtqueue是客户机前端对于队列的管理的数据结构。
队列的实体需要通过函数virtnet_find_vqs查找或者生成,这里还会指定接收队列的callback函数为skb_recv_done,发送队列的callback函数为skb_xmit_done。那当buffer使用发生变化的时候,我们可以调用这个callback函数进行通知。
static int virtnet_find_vqs(struct virtnet_info *vi)
{
vq_callback_t **callbacks;
struct virtqueue **vqs;
int ret = -ENOMEM;
int i, total_vqs;
const char **names;
/* Allocate space for find_vqs parameters */
vqs = kzalloc(total_vqs * sizeof(*vqs), GFP_KERNEL);
callbacks = kmalloc(total_vqs * sizeof(*callbacks), GFP_KERNEL);
names = kmalloc(total_vqs * sizeof(*names), GFP_KERNEL);
/* Allocate/initialize parameters for send/receive virtqueues */
for (i = 0; i < vi->max_queue_pairs; i++) {
callbacks[rxq2vq(i)] = skb_recv_done;
callbacks[txq2vq(i)] = skb_xmit_done;
names[rxq2vq(i)] = vi->rq[i].name;
names[txq2vq(i)] = vi->sq[i].name;
}
ret = vi->vdev->config->find_vqs(vi->vdev, total_vqs, vqs, callbacks, names, ctx, NULL);
......
for (i = 0; i < vi->max_queue_pairs; i++) {
vi->rq[i].vq = vqs[rxq2vq(i)];
vi->rq[i].min_buf_len = mergeable_min_buf_len(vi, vi->rq[i].vq);
vi->sq[i].vq = vqs[txq2vq(i)];
}
......
}这里的find_vqs是在struct virtnet_info里的struct virtio_device里的struct virtio_config_ops *config里面定义的。
根据virtio_config_ops的定义,find_vqs会调用vp_modern_find_vqs,到这一步和块设备是一样的了。
在vp_modern_find_vqs中,vp_find_vqs会调用vp_find_vqs_intx。在vp_find_vqs_intx中,通过request_irq注册一个中断处理函数vp_interrupt。当设备向队列中写入信息时,会产生一个中断,也就是vq中断。中断处理函数需要调用相应的队列的回调函数,然后根据队列的数目,依次调用vp_setup_vq完成virtqueue、vring的分配和初始化。
同样,这些数据结构会和virtio后端的VirtIODevice、VirtQueue、vring对应起来,都应该指向刚才创建的那一段内存。
客户机同样会通过调用专门给外部设备发送指令的函数iowrite告诉外部的pci设备,这些共享内存的地址。
至此前端设备驱动和后端设备驱动之间的两个收发队列就关联好了,这两个队列的格式和块设备是一样的。
49.4 发送网络包过程
接下来,我们来看当真的发送一个网络包的时候,会发生什么。
当网络包经过客户机的协议栈到达virtio_net驱动的时候,按照net_device_ops的定义,start_xmit会被调用。
static const struct net_device_ops virtnet_netdev = {
.ndo_open = virtnet_open,
.ndo_stop = virtnet_close,
.ndo_start_xmit = start_xmit,
.ndo_validate_addr = eth_validate_addr,
.ndo_set_mac_address = virtnet_set_mac_address,
.ndo_set_rx_mode = virtnet_set_rx_mode,
.ndo_get_stats64 = virtnet_stats,
.ndo_vlan_rx_add_vid = virtnet_vlan_rx_add_vid,
.ndo_vlan_rx_kill_vid = virtnet_vlan_rx_kill_vid,
.ndo_xdp = virtnet_xdp,
.ndo_features_check = passthru_features_check,
};接下来的调用链为:start_xmit->xmit_skb-> virtqueue_add_outbuf->virtqueue_add,将网络包放入队列中,并调用virtqueue_notify通知接收方。
static netdev_tx_t start_xmit(struct sk_buff *skb, struct net_device *dev)
{
struct virtnet_info *vi = netdev_priv(dev);
int qnum = skb_get_queue_mapping(skb);
struct send_queue *sq = &vi->sq[qnum];
int err;
struct netdev_queue *txq = netdev_get_tx_queue(dev, qnum);
bool kick = !skb->xmit_more;
bool use_napi = sq->napi.weight;
......
/* Try to transmit */
err = xmit_skb(sq, skb);
......
if (kick || netif_xmit_stopped(txq))
virtqueue_kick(sq->vq);
return NETDEV_TX_OK;
}
bool virtqueue_kick(struct virtqueue *vq)
{
if (virtqueue_kick_prepare(vq))
return virtqueue_notify(vq);
return true;
}写入一个I/O会使得qemu触发VM exit,这个逻辑我们在解析CPU的时候看到过。
接下来,我们那会调用VirtQueue的handle_output函数。前面我们已经设置过这个函数了,其实就是virtio_net_handle_tx_bh。
static void virtio_net_handle_tx_bh(VirtIODevice *vdev, VirtQueue *vq)
{
VirtIONet *n = VIRTIO_NET(vdev);
VirtIONetQueue *q = &n->vqs[vq2q(virtio_get_queue_index(vq))];
q->tx_waiting = 1;
virtio_queue_set_notification(vq, 0);
qemu_bh_schedule(q->tx_bh);
}virtio_net_handle_tx_bh调用了qemu_bh_schedule,而在virtio_net_add_queue中调用qemu_bh_new,并把函数设置为virtio_net_tx_bh。
virtio_net_tx_bh函数调用发送函数virtio_net_flush_tx。
static int32_t virtio_net_flush_tx(VirtIONetQueue *q)
{
VirtIONet *n = q->n;
VirtIODevice *vdev = VIRTIO_DEVICE(n);
VirtQueueElement *elem;
int32_t num_packets = 0;
int queue_index = vq2q(virtio_get_queue_index(q->tx_vq));
for (;;) {
ssize_t ret;
unsigned int out_num;
struct iovec sg[VIRTQUEUE_MAX_SIZE], sg2[VIRTQUEUE_MAX_SIZE + 1], *out_sg;
struct virtio_net_hdr_mrg_rxbuf mhdr;
elem = virtqueue_pop(q->tx_vq, sizeof(VirtQueueElement));
out_num = elem->out_num;
out_sg = elem->out_sg;
......
ret = qemu_sendv_packet_async(qemu_get_subqueue(n->nic, queue_index),out_sg, out_num, virtio_net_tx_complete);
}
......
return num_packets;
}virtio_net_flush_tx会调用virtqueue_pop。这里面,我们能看到对于vring的操作,也即从这里面将客户机里面写入的数据读取出来。
然后,我们调用qemu_sendv_packet_async发送网络包。接下来的调用链为:qemu_sendv_packet_async->qemu_net_queue_send_iov->qemu_net_queue_flush->qemu_net_queue_deliver。
在qemu_net_queue_deliver中,我们会调用NetQueue的deliver函数。前面qemu_new_net_queue会把deliver函数设置为qemu_deliver_packet_iov。它会调用nc->info->receive_iov。
static NetClientInfo net_tap_info = {
.type = NET_CLIENT_DRIVER_TAP,
.size = sizeof(TAPState),
.receive = tap_receive,
.receive_raw = tap_receive_raw,
.receive_iov = tap_receive_iov,
.poll = tap_poll,
.cleanup = tap_cleanup,
.has_ufo = tap_has_ufo,
.has_vnet_hdr = tap_has_vnet_hdr,
.has_vnet_hdr_len = tap_has_vnet_hdr_len,
.using_vnet_hdr = tap_using_vnet_hdr,
.set_offload = tap_set_offload,
.set_vnet_hdr_len = tap_set_vnet_hdr_len,
.set_vnet_le = tap_set_vnet_le,
.set_vnet_be = tap_set_vnet_be,
};根据net_tap_info的定义调用的是tap_receive_iov。他会调用tap_write_packet->writev写入这个字符设备。
在内核的字符设备驱动中,tun_chr_write_iter会被调用。
static ssize_t tun_chr_write_iter(struct kiocb *iocb, struct iov_iter *from)
{
struct file *file = iocb->ki_filp;
struct tun_struct *tun = tun_get(file);
struct tun_file *tfile = file->private_data;
ssize_t result;
result = tun_get_user(tun, tfile, NULL, from,
file->f_flags & O_NONBLOCK, false);
tun_put(tun);
return result;
}当我们使用writev()系统调用向tun/tap设备的字符设备文件写入数据时,tun_chr_write函数将被调用。它会使用tun_get_user,从用户区接收数据,将数据存入skb中,然后调用关键的函数netif_rx_ni(skb) ,将skb送给tcp/ip协议栈处理,最终完成虚拟网卡的数据接收。
至此,从虚拟机内部到宿主机的网络传输过程才算结束。
49.5 总结
最后,我们把网络虚拟化场景下网络包的发送过程总结一下。
- 在虚拟机里面的用户态,应用程序通过write系统调用写入socket。
- 写入的内容经过VFS层,内核协议栈,到达虚拟机里面的内核的网络设备驱动,也即virtio_net。
- virtio_net网络设备有一个操作结构struct net_device_ops,里面定义了发送一个网络包调用的函数为start_xmit。
- 在virtio_net的前端驱动和qemu中的后端驱动之间,有两个队列virtqueue,一个用于发送,一个用于接收。然后,我们需要在start_xmit中调用virtqueue_add,将网络包放入发送队列,然后调用virtqueue_notify通知qemu。
- qemu本来处于KVM_RUN的状态,收到通知后,通过VM exit指令退出客户机模式,进入宿主机模式。发送网络包的时候,virtio_net_handle_tx_bh函数会被调用。
- 接下来是一个for循环,我们需要在循环中调用virtqueue_pop,从传输队列中获取要发送的数据,然后调用qemu_sendv_packet_async进行发送。
- qemu会调用writev向字符设备文件写入,进入宿主机的内核。
- 在宿主机内核中字符设备文件的file_operations里面的write_iter会被调用,也即会调用tun_chr_write_iter。
- 在tun_chr_write_iter函数中,tun_get_user将要发送的网络包从qemu拷贝到宿主机内核里面来,然后调用netif_rx_ni开始调用宿主机内核协议栈进行处理。
- 宿主机内核协议栈处理完毕之后,会发送给tap虚拟网卡,完成从虚拟机里面到宿主机的整个发送过程。
九、容器化
50. 容器
上一章,我们讲了虚拟化的原理。从一台物理机虚拟化出很多的虚拟机这种方式,一定程度上实现了资源创建的灵活性。但是你同时会发现,虚拟化的方式还是非常复杂的。
那有没有一种更加灵活的方式,既可以隔离出一部分资源,专门用于某个进程,又不需要费劲周折的虚拟化这么多的硬件呢?毕竟最终我只想跑一个程序,而不是要一整个Linux系统。
在Linux操作系统中,有一项新的技术,称为容器,它就可以做到这一点。
容器的英文叫Container,Container的另一个意思是”集装箱”。其实容器就像船上的不同的集装箱装着不同的货物,有一定的隔离,但是隔离性又没有那么好,仅仅做简单的封装。当然封装也带来了好处,一个是打包,二是标准。
在没有集装箱的时代,假设我们要将货物从A运到B,中间要经过三个码头、换三次船。那么每次都要将货物卸下船来,弄得乱七八糟,然后还要再搬上船重新摆好。因此在没有集装箱的时候,每次换船,船员们都要在岸上待几天才能干完活。
有了尺寸全部都一样的集装箱以后,我们可以把所有的货物都打包在一起。每次换船的时候,把整个集装箱搬过去就行了,几个小时就能完成。船员换船时间大大缩短了。这是集装箱的”打包”和”标准”两大特点在生活中的应用。
其实容器的思想就是要变成软件交付的集装箱。那么容器如何对应用打包呢?
我们先来学习一下集装箱的打包过程。首先,我们得有个封闭的环境,将货物封装起来,让货物之间互不干扰,互相隔离,这样装货卸货才方便。
容器实现封闭的环境主要要靠两种技术,一种是看起来是隔离的技术,称为namespace(命名空间)。在每个namespace中的应用看到的,都是不同的 IP地址、用户空间、进程ID等。另一种是用起来是隔离的技术,称为cgroup(网络资源限制),即明明整台机器有很多的 CPU、内存,但是一个应用只能用其中的一部分。
有了这两项技术,就相当于我们焊好了集装箱。接下来的问题就是,如何”将这些集装箱标准化”,在哪艘船上都能运输。这里就要用到镜像了。
所谓镜像(Image),就是在你焊好集装箱的那一刻,将集装箱的状态保存下来。就像孙悟空说:”定!”,集装箱里的状态就被”定”在了那一刻,然后这一刻的状态会被保存成一系列文件。无论在哪里运行这个镜像,都能完整地还原当时的情况。
当程序员根据产品设计开发完毕之后,可以将代码连同运行环境打包成一个容器镜像。这个时候集装箱就焊好了。接下来,无论是在开发环境、测试环境,还是生产环境运行代码,都可以使用相同的镜像。就好像集装箱在开发、测试、生产这三个码头非常顺利地整体迁移,这样产品的发布和上线速度就加快了。
Docker可以限制对于CPU的使用,我们可以分几种的方式。
- Docker允许用户为每个容器设置一个数字,代表容器的 CPU share,默认情况下每个容器的 share 是 1024。这个数值是相对的,本身并不能代表任何确定的意义。当主机上有多个容器运行时,每个容器占用的 CPU 时间比例为它的 share 在总额中的比例。Docker为容器设置CPU share 的参数是 -c —cpu-shares。
- Docker提供了 —cpus 参数可以限定容器能使用的 CPU 核数。
- Docker可以通过 —cpuset 参数让容器只运行在某些核上
Docker会限制容器内存使用量,下面是一些具体的参数。
- -m —memory:容器能使用的最大内存大小。
- –memory-swap:容器能够使用的 swap 大小。
- –memory-swappiness:默认情况下,主机可以把容器使用的匿名页swap出来,你可以设置一个 0-100 之间的值,代表允许 swap 出来的比例。
- –memory-reservation:设置一个内存使用的 soft limit,如果 docker 发现主机内存不足,会执行 OOM (Out of Memory)操作。这个值必须小于 —memory 设置的值。
- –kernel-memory:容器能够使用的 kernel memory 大小。
- –oom-kill-disable:是否运行 OOM (Out of Memory)的时候杀死容器。只有设置了 -m,才可以把这个选项设置为 false,否则容器会耗尽主机内存,而且导致主机应用被杀死。
这就是用起来隔离的效果。
50.1 总结
这里我们来总结一下这一节的内容。无论是容器,还是虚拟机,都依赖于内核中的技术,虚拟机依赖的是KVM,容器依赖的是namespace和cgroup对进程进行隔离。
为了运行Docker,有一个daemon进程Docker Daemon用于接收命令行。
为了描述Docker里面运行的环境和应用,有一个Dockerfile,通过build命令称为容器镜像。容器镜像可以上传到镜像仓库,也可以通过pull命令从镜像仓库中下载现成的容器镜像。
通过Docker run命令将容器镜像运行为容器,通过namespace和cgroup进行隔离,容器里面不包含内核,是共享宿主机的内核的。对比虚拟机,虚拟机在qemu进程里面是有客户机内核的,应用运行在客户机的用户态。
51. Namespace技术
为了隔离不同类型的资源,Linux内核里面实现了以下几种不同类型的namespace。
- UTS,对应的宏为CLONE_NEWUTS,表示不同的namespace可以配置不同的hostname。
- User,对应的宏为CLONE_NEWUSER,表示不同的namespace可以配置不同的用户和组。
- Mount,对应的宏为CLONE_NEWNS,表示不同的namespace的文件系统挂载点是隔离的
- PID,对应的宏为CLONE_NEWPID,表示不同的namespace有完全独立的pid,也即一个namespace的进程和另一个namespace的进程,pid可以是一样的,但是代表不同的进程。
- Network,对应的宏为CLONE_NEWNET,表示不同的namespace有独立的网络协议栈。
还记得咱们启动的那个容器吗?
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
f604f0e34bc2 testnginx:1 "/bin/sh -c 'nginx -…" 17 hours ago Up 17 hours 0.0.0.0:8081->80/tcp youthful_torvalds我们可以看这个容器对应的entrypoint的pid。通过docker inspect命令,可以看到,进程号为58212。
$ docker inspect -f '{{.State.Pid}}' f604f0e34bc2
58212如果我们用ps查看机器上的nginx进程,可以看到master和worker,worker的父进程是master。
$ ps -ef |grep nginx
root 58212 58195 0 01:43 ? 00:00:00 /bin/sh -c nginx -g "daemon off;"
root 58244 58212 0 01:43 ? 00:00:00 nginx: master process nginx -g daemon off;
33 58250 58244 0 01:43 ? 00:00:00 nginx: worker process
33 58251 58244 0 01:43 ? 00:00:05 nginx: worker process
33 58252 58244 0 01:43 ? 00:00:05 nginx: worker process
33 58253 58244 0 01:43 ? 00:00:05 nginx: worker process在/proc/pid/ns里面,我们能够看到这个进程所属于的6种namespace。我们拿出两个进程来,应该可以看出来,它们属于同一个namespace。
$ ls -l /proc/58212/ns
lrwxrwxrwx 1 root root 0 Jul 16 19:19 ipc -> ipc:[4026532278]
lrwxrwxrwx 1 root root 0 Jul 16 19:19 mnt -> mnt:[4026532276]
lrwxrwxrwx 1 root root 0 Jul 16 01:43 net -> net:[4026532281]
lrwxrwxrwx 1 root root 0 Jul 16 19:19 pid -> pid:[4026532279]
lrwxrwxrwx 1 root root 0 Jul 16 19:19 user -> user:[4026531837]
lrwxrwxrwx 1 root root 0 Jul 16 19:19 uts -> uts:[4026532277]
$ ls -l /proc/58253/ns
lrwxrwxrwx 1 33 tape 0 Jul 16 19:20 ipc -> ipc:[4026532278]
lrwxrwxrwx 1 33 tape 0 Jul 16 19:20 mnt -> mnt:[4026532276]
lrwxrwxrwx 1 33 tape 0 Jul 16 19:20 net -> net:[4026532281]
lrwxrwxrwx 1 33 tape 0 Jul 16 19:20 pid -> pid:[4026532279]
lrwxrwxrwx 1 33 tape 0 Jul 16 19:20 user -> user:[4026531837]
lrwxrwxrwx 1 33 tape 0 Jul 16 19:20 uts -> uts:[4026532277]接下来,我们来看,如何操作namespace。这里我们重点关注pid和network。
操作namespace的常用指令nsenter,可以用来运行一个进程,进入指定的namespace。例如,通过下面的命令,我们可以运行/bin/bash,并且进入nginx所在容器的namespace。
$ nsenter --target 58212 --mount --uts --ipc --net --pid -- env --ignore-environment -- /bin/bash
root@f604f0e34bc2:/# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
23: eth0@if24: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:11:00:03 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.3/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever另一个命令是unshare,它会离开当前的namespace,创建且加入新的namespace,然后执行参数中指定的命令。
例如,运行下面这行命令之后,pid和net都进入了新的namespace。
unshare --mount --ipc --pid --net --mount-proc=/proc --fork /bin/bash如果从shell上运行上面这行命令的话,好像没有什么变化,但是因为pid和net都进入了新的namespace,所以我们查看进程列表和ip地址的时候应该会发现有所不同。
$ ip addr
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
$ ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 115568 2136 pts/0 S 22:55 0:00 /bin/bash
root 13 0.0 0.0 155360 1872 pts/0 R+ 22:55 0:00 ps aux果真,我们看不到宿主机上的IP地址和网卡了,也看不到宿主机上的所有进程了。
另外,我们还可以通过函数操作namespace。
第一个函数是clone,也就是创建一个新的进程,并把它放到新的namespace中。
int clone(int (*fn)(void *), void *child_stack, int flags, void *arg);clone函数我们原来介绍过。这里面有一个参数flags,原来我们没有注意它。其实它可以设置为CLONE_NEWUTS、CLONE_NEWUSER、CLONE_NEWNS、CLONE_NEWPID。CLONE_NEWNET会将clone出来的新进程放到新的namespace中。
第二个函数是setns,用于将当前进程加入到已有的namespace中。
int setns(int fd, int nstype);其中,fd指向/proc/[pid]/ns/目录里相应namespace对应的文件,表示要加入哪个namespace。nstype用来指定namespace的类型,可以设置为CLONE_NEWUTS、CLONE_NEWUSER、CLONE_NEWNS、CLONE_NEWPID和CLONE_NEWNET。
第三个函数是unshare,它可以使当前进程退出当前的namespace,并加入到新创建的namespace。
int unshare(int flags);其中,flags用于指定一个或者多个上面的CLONE_NEWUTS、CLONE_NEWUSER、CLONE_NEWNS、CLONE_NEWPID和CLONE_NEWNET。
clone和unshare的区别是,unshare是使当前进程加入新的namespace;clone是创建一个新的子进程,然后让子进程加入新的namespace,而当前进程保持不变。
这里我们尝试一下,通过clone函数来进入一个namespace。
#define _GNU_SOURCE
#include <sys/wait.h>
#include <sys/utsname.h>
#include <sched.h>
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#define STACK_SIZE (1024 * 1024)
static int childFunc(void *arg)
{
printf("In child process.\n");
execlp("bash", "bash", (char *) NULL);
return 0;
}
int main(int argc, char *argv[])
{
char *stack;
char *stackTop;
pid_t pid;
stack = malloc(STACK_SIZE);
if (stack == NULL)
{
perror("malloc");
exit(1);
}
stackTop = stack + STACK_SIZE;
pid = clone(childFunc, stackTop, CLONE_NEWNS|CLONE_NEWPID|CLONE_NEWNET|SIGCHLD, NULL);
if (pid == -1)
{
perror("clone");
exit(1);
}
printf("clone() returned %ld\n", (long) pid);
sleep(1);
if (waitpid(pid, NULL, 0) == -1)
{
perror("waitpid");
exit(1);
}
printf("child has terminated\n");
exit(0);
}在上面的代码中,我们调用clone的时候,给的参数是CLONE_NEWNS|CLONE_NEWPID|CLONE_NEWNET,也就是说,我们会进入一个新的pid、network,以及mount的namespace。
如果我们编译运行它,可以得到下面的结果。
$ echo $$
64267
$ ps aux | grep bash | grep -v grep
root 64267 0.0 0.0 115572 2176 pts/0 Ss 16:53 0:00 -bash
$ ./a.out
clone() returned 64360
In child process.
$ echo $$
1
$ ip addr
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
$ exit
exit
child has terminated
$ echo $$
64267通过echo $$,我们可以得到当前bash的进程号。一旦运行了上面的程序,我们就会进入一个新的pid的namespace。
当我们再次echo 的时候,就可以得到原来进程号。
clone系统调用我们在进程的创建那一节解析过,当时我们没有看关于namespace的代码,现在我们就来看一看,namespace在内核做了哪些事情。
在内核里面,clone会调用_do_fork->copy_process->copy_namespaces,也就是说,在创建子进程的时候,有一个机会可以复制和设置namespace。
namespace是在哪里定义的呢?在每一个进程的task_struct里面,有一个指向namespace结构体的指针nsproxy。
struct task_struct {
......
/* Namespaces: */
struct nsproxy *nsproxy;
......
}
/*
* A structure to contain pointers to all per-process
* namespaces - fs (mount), uts, network, sysvipc, etc.
*
* The pid namespace is an exception -- it's accessed using
* task_active_pid_ns. The pid namespace here is the
* namespace that children will use.
*/
struct nsproxy {
atomic_t count;
struct uts_namespace *uts_ns;
struct ipc_namespace *ipc_ns;
struct mnt_namespace *mnt_ns;
struct pid_namespace *pid_ns_for_children;
struct net *net_ns;
struct cgroup_namespace *cgroup_ns;
};我们可以看到在struct nsproxy结构里面,有我们上面讲过的各种namespace。
在系统初始化的时候,有一个默认的init_nsproxy。
struct nsproxy init_nsproxy = {
.count = ATOMIC_INIT(1),
.uts_ns = &init_uts_ns,
#if defined(CONFIG_POSIX_MQUEUE) || defined(CONFIG_SYSVIPC)
.ipc_ns = &init_ipc_ns,
#endif
.mnt_ns = NULL,
.pid_ns_for_children = &init_pid_ns,
#ifdef CONFIG_NET
.net_ns = &init_net,
#endif
#ifdef CONFIG_CGROUPS
.cgroup_ns = &init_cgroup_ns,
#endif
};下面,我们来看copy_namespaces的实现。
/*
* called from clone. This now handles copy for nsproxy and all
* namespaces therein.
*/
int copy_namespaces(unsigned long flags, struct task_struct *tsk)
{
struct nsproxy *old_ns = tsk->nsproxy;
struct user_namespace *user_ns = task_cred_xxx(tsk, user_ns);
struct nsproxy *new_ns;
if (likely(!(flags & (CLONE_NEWNS | CLONE_NEWUTS | CLONE_NEWIPC |
CLONE_NEWPID | CLONE_NEWNET |
CLONE_NEWCGROUP)))) {
get_nsproxy(old_ns);
return 0;
}
if (!ns_capable(user_ns, CAP_SYS_ADMIN))
return -EPERM;
......
new_ns = create_new_namespaces(flags, tsk, user_ns, tsk->fs);
tsk->nsproxy = new_ns;
return 0;
}如果clone的参数里面没有CLONE_NEWNS | CLONE_NEWUTS | CLONE_NEWIPC | CLONE_NEWPID | CLONE_NEWNET | CLONE_NEWCGROUP,就返回原来的namespace,调用get_nsproxy。
接着,我们调用create_new_namespaces。
/*
* Create new nsproxy and all of its the associated namespaces.
* Return the newly created nsproxy. Do not attach this to the task,
* leave it to the caller to do proper locking and attach it to task.
*/
static struct nsproxy *create_new_namespaces(unsigned long flags,
struct task_struct *tsk, struct user_namespace *user_ns,
struct fs_struct *new_fs)
{
struct nsproxy *new_nsp;
new_nsp = create_nsproxy();
......
new_nsp->mnt_ns = copy_mnt_ns(flags, tsk->nsproxy->mnt_ns, user_ns, new_fs);
......
new_nsp->uts_ns = copy_utsname(flags, user_ns, tsk->nsproxy->uts_ns);
......
new_nsp->ipc_ns = copy_ipcs(flags, user_ns, tsk->nsproxy->ipc_ns);
......
new_nsp->pid_ns_for_children =
copy_pid_ns(flags, user_ns, tsk->nsproxy->pid_ns_for_children);
......
new_nsp->cgroup_ns = copy_cgroup_ns(flags, user_ns,
tsk->nsproxy->cgroup_ns);
......
new_nsp->net_ns = copy_net_ns(flags, user_ns, tsk->nsproxy->net_ns);
......
return new_nsp;
......
}在create_new_namespaces中,我们可以看到对于各种namespace的复制。
我们来看copy_pid_ns对于pid namespace的复制。
struct pid_namespace *copy_pid_ns(unsigned long flags,
struct user_namespace *user_ns, struct pid_namespace *old_ns)
{
if (!(flags & CLONE_NEWPID))
return get_pid_ns(old_ns);
if (task_active_pid_ns(current) != old_ns)
return ERR_PTR(-EINVAL);
return create_pid_namespace(user_ns, old_ns);
}在copy_pid_ns中,如果没有设置CLONE_NEWPID,则返回老的pid namespace;如果设置了,就调用create_pid_namespace,创建新的pid namespace.
我们再来看copy_net_ns对于network namespace的复制。
struct net *copy_net_ns(unsigned long flags,
struct user_namespace *user_ns, struct net *old_net)
{
struct ucounts *ucounts;
struct net *net;
int rv;
if (!(flags & CLONE_NEWNET))
return get_net(old_net);
ucounts = inc_net_namespaces(user_ns);
......
net = net_alloc();
......
get_user_ns(user_ns);
net->ucounts = ucounts;
rv = setup_net(net, user_ns);
......
return net;
}在这里面,我们需要判断,如果flags中不包含CLONE_NEWNET,也就是不会创建一个新的network namespace,则返回old_net;否则需要新建一个network namespace。
然后,copy_net_ns会调用net = net_alloc(),分配一个新的struct net结构,然后调用setup_net对新分配的net结构进行初始化,之后调用list_add_tail_rcu,将新建的network namespace,添加到全局的network namespace列表net_namespace_list中。
我们来看一下setup_net的实现。
/*
* setup_net runs the initializers for the network namespace object.
*/
static __net_init int setup_net(struct net *net, struct user_namespace *user_ns)
{
/* Must be called with net_mutex held */
const struct pernet_operations *ops, *saved_ops;
LIST_HEAD(net_exit_list);
atomic_set(&net->count, 1);
refcount_set(&net->passive, 1);
net->dev_base_seq = 1;
net->user_ns = user_ns;
idr_init(&net->netns_ids);
spin_lock_init(&net->nsid_lock);
list_for_each_entry(ops, &pernet_list, list) {
error = ops_init(ops, net);
......
}
......
}在setup_net中,这里面有一个循环list_for_each_entry,对于pernet_list的每一项struct pernet_operations,运行ops_init,也就是调用pernet_operations的init函数。
这个pernet_list是怎么来的呢?在网络设备初始化的时候,我们要调用net_dev_init函数,这里面有下面的代码。
register_pernet_device(&loopback_net_ops)
int register_pernet_device(struct pernet_operations *ops)
{
int error;
mutex_lock(&net_mutex);
error = register_pernet_operations(&pernet_list, ops);
if (!error && (first_device == &pernet_list))
first_device = &ops->list;
mutex_unlock(&net_mutex);
return error;
}
struct pernet_operations __net_initdata loopback_net_ops = {
.init = loopback_net_init,
};register_pernet_device函数注册了一个loopback_net_ops,在这里面,把init函数设置为loopback_net_init.
static __net_init int loopback_net_init(struct net *net)
{
struct net_device *dev;
dev = alloc_netdev(0, "lo", NET_NAME_UNKNOWN, loopback_setup);
......
dev_net_set(dev, net);
err = register_netdev(dev);
......
net->loopback_dev = dev;
return 0;
......
}在loopback_net_init函数中,我们会创建并且注册一个名字为”lo”的struct net_device。注册完之后,在这个namespace里面就会出现一个这样的网络设备,称为loopback网络设备。
这就是为什么上面的实验中,创建出的新的network namespace里面有一个lo网络设备。
51.1 总结
这一节我们讲了namespace相关的技术,有六种类型,分别是UTS、User、Mount、Pid、Network和IPC。
还有两个常用的命令nsenter和unshare,主要用于操作Namespace,有三个常用的函数clone、setns和unshare。
在内核里面,对于任何一个进程task_struct来讲,里面都会有一个成员struct nsproxy,用于保存namespace相关信息,里面有 struct uts_namespace、struct ipc_namespace、struct mnt_namespace、struct pid_namespace、struct net net_ns和struct cgroup_namespacecgroup_ns。
创建namespace的时候,我们在内核中会调用copy_namespaces,调用顺序依次是copy_mnt_ns、copy_utsname、copy_ipcs、copy_pid_ns、copy_cgroup_ns和copy_net_ns,来复制namespace。
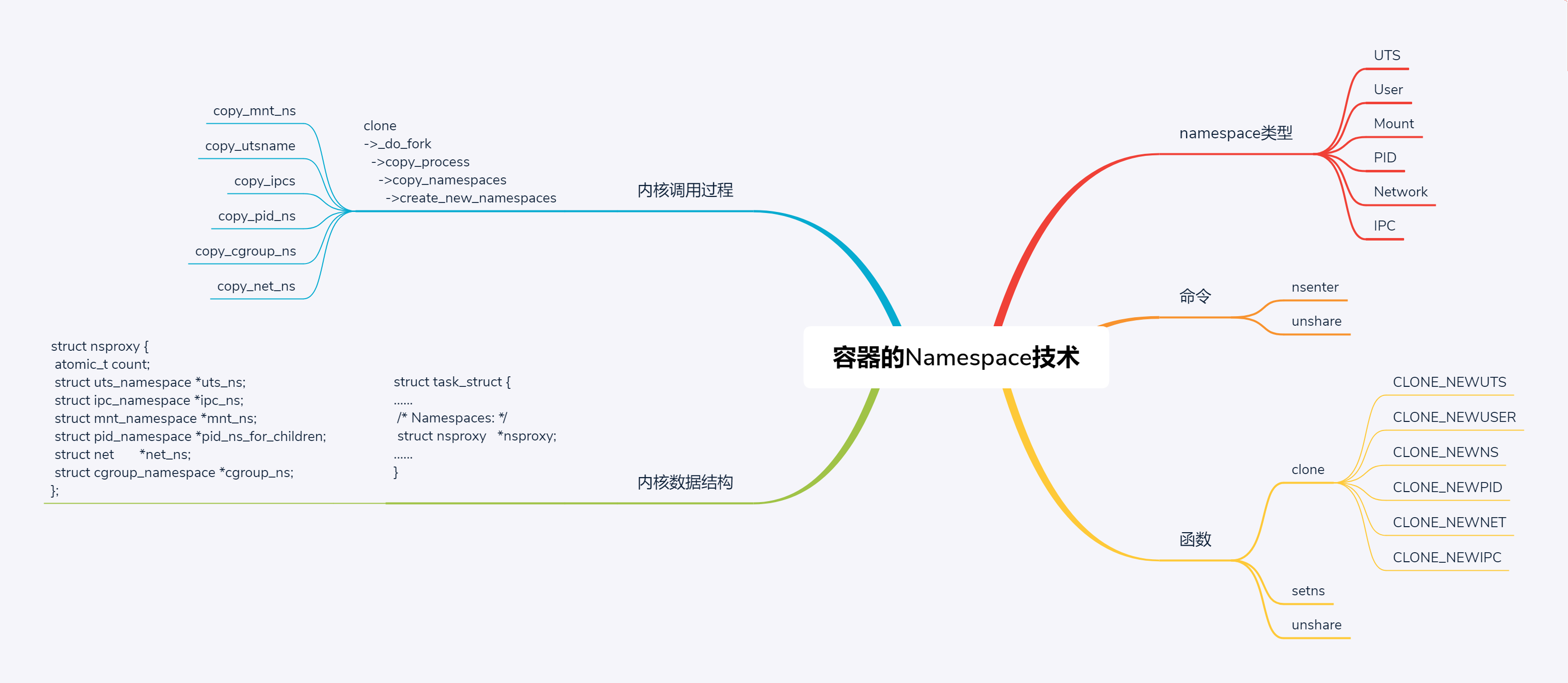
52. CGroup技术
我们前面说了,容器实现封闭的环境主要要靠两种技术,一种是”看起来是隔离”的技术Namespace,另一种是用起来是隔离的技术CGroup。
上一节我们讲了”看起来隔离”的技术Namespace,这一节我们就来看一下”用起来隔离”的技术CGroup。
CGroup全称是Control Group,顾名思义,它是用来做”控制”的。控制什么东西呢?当然是资源的使用了。那它都能控制哪些资源的使用呢?我们一起来看一看。
首先,cgroups定义了下面的一系列子系统,每个子系统用于控制某一类资源。
- cpu子系统,主要限制进程的cpu使用率。
- cpuacct 子系统,可以统计 cgroups 中的进程的 cpu 使用报告。
- cpuset 子系统,可以为 cgroups 中的进程分配单独的 cpu 节点或者内存节点。
- memory 子系统,可以限制进程的 memory 使用量。
- blkio 子系统,可以限制进程的块设备 io。
- devices 子系统,可以控制进程能够访问某些设备。
- net_cls 子系统,可以标记 cgroups 中进程的网络数据包,然后可以使用 tc 模块(traffic control)对数据包进行控制。
- freezer 子系统,可以挂起或者恢复 cgroups 中的进程。
这么多子系统,你可能要说了,那我们不用都掌握吧?没错,这里面最常用的是对于CPU和内存的控制,所以下面我们详细来说它。
在容器这一章的第一节,我们讲了,Docker有一些参数能够限制CPU和内存的使用,如果把它落地到Cgroup里面会如何限制呢?
为了验证Docker的参数与Cgroup的映射关系,我们运行一个命令特殊的docker run命令,这个命令比较长,里面的参数都会映射为cgroup的某项配置,然后我们运行docker ps,可以看到,这个容器的id为3dc0601189dd。
$ docker run -d --cpu-shares 513 --cpus 2 --cpuset-cpus 1,3 --memory 1024M --memory-swap 1234M --memory-swappiness 7 -p 8081:80 testnginx:1
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
3dc0601189dd testnginx:1 "/bin/sh -c 'nginx -…" About a minute ago Up About a minute 0.0.0.0:8081->80/tcp boring_cohen在Linux上,为了操作Cgroup,有一个专门的Cgroup文件系统,我们运行mount命令可以查看。
$ mount -t cgroup
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_prio,net_cls)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpuacct,cpu)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids)cgroup文件系统多挂载到/sys/fs/cgroup下,通过上面的命令行,我们可以看到我们可以用cgroup控制哪些资源。
对于CPU的控制,我在这一章的第一节讲过,Docker可以控制cpu-shares、cpus和cpuset。
我们在/sys/fs/cgroup/下面能看到下面的目录结构。
drwxr-xr-x 5 root root 0 May 30 17:00 blkio
lrwxrwxrwx 1 root root 11 May 30 17:00 cpu -> cpu,cpuacct
lrwxrwxrwx 1 root root 11 May 30 17:00 cpuacct -> cpu,cpuacct
drwxr-xr-x 5 root root 0 May 30 17:00 cpu,cpuacct
drwxr-xr-x 3 root root 0 May 30 17:00 cpuset
drwxr-xr-x 5 root root 0 May 30 17:00 devices
drwxr-xr-x 3 root root 0 May 30 17:00 freezer
drwxr-xr-x 3 root root 0 May 30 17:00 hugetlb
drwxr-xr-x 5 root root 0 May 30 17:00 memory
lrwxrwxrwx 1 root root 16 May 30 17:00 net_cls -> net_cls,net_prio
drwxr-xr-x 3 root root 0 May 30 17:00 net_cls,net_prio
lrwxrwxrwx 1 root root 16 May 30 17:00 net_prio -> net_cls,net_prio
drwxr-xr-x 3 root root 0 May 30 17:00 perf_event
drwxr-xr-x 5 root root 0 May 30 17:00 pids
drwxr-xr-x 5 root root 0 May 30 17:00 systemd我们可以想象,CPU的资源控制的配置文件,应该在cpu,cpuacct这个文件夹下面。
$ ls
cgroup.clone_children cpu.cfs_period_us notify_on_release
cgroup.event_control cpu.cfs_quota_us release_agent
cgroup.procs cpu.rt_period_us system.slice
cgroup.sane_behavior cpu.rt_runtime_us tasks
cpuacct.stat cpu.shares user.slice
cpuacct.usage cpu.stat
cpuacct.usage_percpu docker果真,这下面是对cpu的相关控制,里面还有一个路径叫docker。我们进入这个路径。
$ ls
cgroup.clone_children
cgroup.event_control
cgroup.procs
cpuacct.stat
cpuacct.usage
cpuacct.usage_percpu
cpu.cfs_period_us
cpu.cfs_quota_us
cpu.rt_period_us
cpu.rt_runtime_us
cpu.shares
cpu.stat
3dc0601189dd218898f31f9526a6cfae83913763a4da59f95ec789c6e030ecfd
notify_on_release
tasks这里面有个很长的id,是我们创建的docker的id。
[3dc0601189dd218898f31f9526a6cfae83913763a4da59f95ec789c6e030ecfd]$ ls
cgroup.clone_children cpuacct.usage_percpu cpu.shares
cgroup.event_control cpu.cfs_period_us cpu.stat
cgroup.procs cpu.cfs_quota_us notify_on_release
cpuacct.stat cpu.rt_period_us tasks
cpuacct.usage cpu.rt_runtime_us在这里,我们能看到cpu.shares,还有一个重要的文件tasks。这里面是这个容器里所有进程的进程号,也即所有这些进程都被这些cpu策略控制。
[3dc0601189dd218898f31f9526a6cfae83913763a4da59f95ec789c6e030ecfd]$ cat tasks
39487
39520
39526
39527
39528
39529如果我们查看cpu.shares,里面就是我们设置的513。
[3dc0601189dd218898f31f9526a6cfae83913763a4da59f95ec789c6e030ecfd]$ cat cpu.shares
513另外,我们还配置了cpus,这个值其实是由cpu.cfs_period_us和cpu.cfs_quota_us共同决定的。cpu.cfs_period_us是运行周期,cpu.cfs_quota_us是在周期内这些进程占用多少时间。我们设置了cpus为2,代表的意思是,在周期100000毫秒的运行周期内,这些进程要占用200000毫秒的时间,也即需要两个CPU同时运行一个整整的周期。
[3dc0601189dd218898f31f9526a6cfae83913763a4da59f95ec789c6e030ecfd]$ cat cpu.cfs_period_us
100000
[3dc0601189dd218898f31f9526a6cfae83913763a4da59f95ec789c6e030ecfd]$ cat cpu.cfs_quota_us
200000对于cpuset,也即cpu绑核的参数,在另外一个文件夹里面/sys/fs/cgroup/cpuset,这里面同样有一个docker文件夹,下面同样有docker id 也即3dc0601189dd218898f31f9526a6cfae83913763a4da59f95ec789c6e030ecfd文件夹,这里面的cpuset.cpus就是配置的绑定到1、3两个核。
[3dc0601189dd218898f31f9526a6cfae83913763a4da59f95ec789c6e030ecfd]$ cat cpuset.cpus
1,3这一章的第一节我们还讲了Docker可以限制内存的使用量,例如memory、memory-swap、memory-swappiness。这些在哪里控制呢?
/sys/fs/cgroup/下面还有一个memory路径,控制策略就是在这里面定义的。
[root@deployer memory]$ ls
cgroup.clone_children memory.memsw.failcnt
cgroup.event_control memory.memsw.limit_in_bytes
cgroup.procs memory.memsw.max_usage_in_bytes
cgroup.sane_behavior memory.memsw.usage_in_bytes
docker memory.move_charge_at_immigrate
memory.failcnt memory.numa_stat
memory.force_empty memory.oom_control
memory.kmem.failcnt memory.pressure_level
memory.kmem.limit_in_bytes memory.soft_limit_in_bytes
memory.kmem.max_usage_in_bytes memory.stat
memory.kmem.slabinfo memory.swappiness
memory.kmem.tcp.failcnt memory.usage_in_bytes
memory.kmem.tcp.limit_in_bytes memory.use_hierarchy
memory.kmem.tcp.max_usage_in_bytes notify_on_release
memory.kmem.tcp.usage_in_bytes release_agent
memory.kmem.usage_in_bytes system.slice
memory.limit_in_bytes tasks
memory.max_usage_in_bytes user.slice这里面全是对于memory的控制参数,在这里面我们可看到了docker,里面还有容器的id作为文件夹。
[docker]$ ls
3dc0601189dd218898f31f9526a6cfae83913763a4da59f95ec789c6e030ecfd
cgroup.clone_children
cgroup.event_control
cgroup.procs
memory.failcnt
memory.force_empty
memory.kmem.failcnt
memory.kmem.limit_in_bytes
memory.kmem.max_usage_in_bytes
memory.kmem.slabinfo
memory.kmem.tcp.failcnt
memory.kmem.tcp.limit_in_bytes
memory.kmem.tcp.max_usage_in_bytes
memory.kmem.tcp.usage_in_bytes
memory.kmem.usage_in_bytes
memory.limit_in_bytes
memory.max_usage_in_bytes
memory.memsw.failcnt
memory.memsw.limit_in_bytes
memory.memsw.max_usage_in_bytes
memory.memsw.usage_in_bytes
memory.move_charge_at_immigrate
memory.numa_stat
memory.oom_control
memory.pressure_level
memory.soft_limit_in_bytes
memory.stat
memory.swappiness
memory.usage_in_bytes
memory.use_hierarchy
notify_on_release
tasks
[3dc0601189dd218898f31f9526a6cfae83913763a4da59f95ec789c6e030ecfd]$ ls
cgroup.clone_children memory.memsw.failcnt
cgroup.event_control memory.memsw.limit_in_bytes
cgroup.procs memory.memsw.max_usage_in_bytes
memory.failcnt memory.memsw.usage_in_bytes
memory.force_empty memory.move_charge_at_immigrate
memory.kmem.failcnt memory.numa_stat
memory.kmem.limit_in_bytes memory.oom_control
memory.kmem.max_usage_in_bytes memory.pressure_level
memory.kmem.slabinfo memory.soft_limit_in_bytes
memory.kmem.tcp.failcnt memory.stat
memory.kmem.tcp.limit_in_bytes memory.swappiness
memory.kmem.tcp.max_usage_in_bytes memory.usage_in_bytes
memory.kmem.tcp.usage_in_bytes memory.use_hierarchy
memory.kmem.usage_in_bytes notify_on_release
memory.limit_in_bytes tasks
memory.max_usage_in_bytes在docker id的文件夹下面,有一个memory.limit_in_bytes,里面配置的就是memory。
[3dc0601189dd218898f31f9526a6cfae83913763a4da59f95ec789c6e030ecfd]$ cat memory.limit_in_bytes
1073741824还有memory.swappiness,里面配置的就是memory-swappiness。
[3dc0601189dd218898f31f9526a6cfae83913763a4da59f95ec789c6e030ecfd]$ cat memory.swappiness
7还有就是memory.memsw.limit_in_bytes,里面配置的是memory-swap。
[3dc0601189dd218898f31f9526a6cfae83913763a4da59f95ec789c6e030ecfd]$ cat memory.memsw.limit_in_bytes
1293942784我们还可以看一下tasks文件的内容,tasks里面是容器里面所有进程的进程号。
[3dc0601189dd218898f31f9526a6cfae83913763a4da59f95ec789c6e030ecfd]$ cat tasks
39487
39520
39526
39527
39528
39529至此,我们看到了cgroup对于Docker资源的控制,在用户态是如何表现的。我画了一张图总结一下。
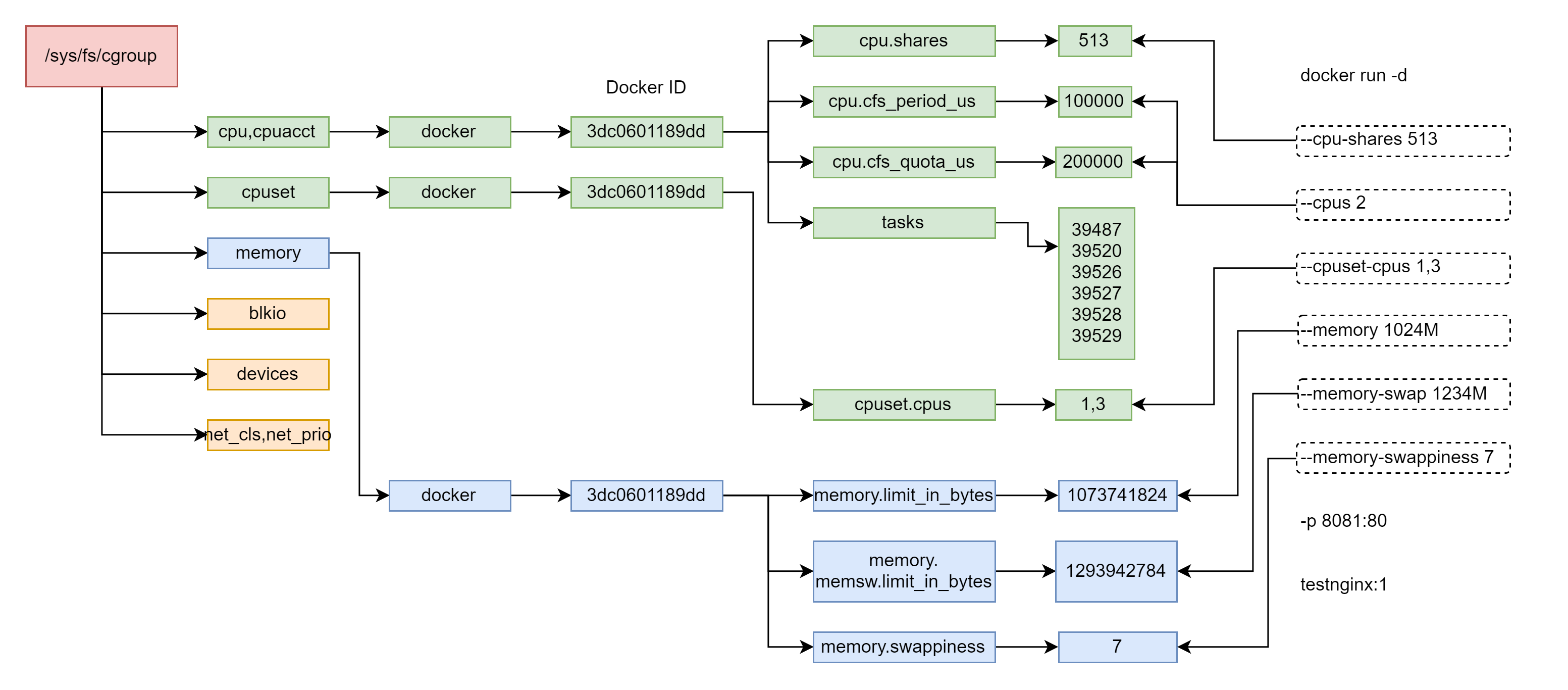
在内核中,cgroup是如何实现的呢?
首先,在系统初始化的时候,cgroup也会进行初始化,在start_kernel中,cgroup_init_early和cgroup_init都会进行初始化。
asmlinkage __visible void __init start_kernel(void)
{
......
cgroup_init_early();
......
cgroup_init();
......
}在cgroup_init_early和cgroup_init中,会有下面的循环。
for_each_subsys(ss, i) {
ss->id = i;
ss->name = cgroup_subsys_name[i];
......
cgroup_init_subsys(ss, true);
}
#define for_each_subsys(ss, ssid) \
for ((ssid) = 0; (ssid) < CGROUP_SUBSYS_COUNT && \
(((ss) = cgroup_subsys[ssid]) || true); (ssid)++)for_each_subsys会在cgroup_subsys数组中进行循环。这个cgroup_subsys数组是如何形成的呢?
#define SUBSYS(_x) [_x ## _cgrp_id] = &_x ## _cgrp_subsys,
struct cgroup_subsys *cgroup_subsys[] = {
#include <linux/cgroup_subsys.h>
};
#undef SUBSYSSUBSYS这个宏定义了这个cgroup_subsys数组,数组中的项定义在cgroup_subsys.h头文件中。例如,对于CPU和内存有下面的定义。
//cgroup_subsys.h
#if IS_ENABLED(CONFIG_CPUSETS)
SUBSYS(cpuset)
#endif
#if IS_ENABLED(CONFIG_CGROUP_SCHED)
SUBSYS(cpu)
#endif
#if IS_ENABLED(CONFIG_CGROUP_CPUACCT)
SUBSYS(cpuacct)
#endif
#if IS_ENABLED(CONFIG_MEMCG)
SUBSYS(memory)
#endif根据SUBSYS的定义,SUBSYS(cpu)其实是[cpu_cgrp_id] = &cpu_cgrp_subsys,而SUBSYS(memory)其实是[memory_cgrp_id] = &memory_cgrp_subsys。
我们能够找到cpu_cgrp_subsys和memory_cgrp_subsys的定义。
// cpuset_cgrp_subsys
struct cgroup_subsys cpuset_cgrp_subsys = {
.css_alloc = cpuset_css_alloc,
.css_online = cpuset_css_online,
.css_offline = cpuset_css_offline,
.css_free = cpuset_css_free,
.can_attach = cpuset_can_attach,
.cancel_attach = cpuset_cancel_attach,
.attach = cpuset_attach,
.post_attach = cpuset_post_attach,
.bind = cpuset_bind,
.fork = cpuset_fork,
.legacy_cftypes = files,
.early_init = true,
};
// cpu_cgrp_subsys
struct cgroup_subsys cpu_cgrp_subsys = {
.css_alloc = cpu_cgroup_css_alloc,
.css_online = cpu_cgroup_css_online,
.css_released = cpu_cgroup_css_released,
.css_free = cpu_cgroup_css_free,
.fork = cpu_cgroup_fork,
.can_attach = cpu_cgroup_can_attach,
.attach = cpu_cgroup_attach,
.legacy_cftypes = cpu_files,
.early_init = true,
};
// memory_cgrp_subsys
struct cgroup_subsys memory_cgrp_subsys = {
.css_alloc = mem_cgroup_css_alloc,
.css_online = mem_cgroup_css_online,
.css_offline = mem_cgroup_css_offline,
.css_released = mem_cgroup_css_released,
.css_free = mem_cgroup_css_free,
.css_reset = mem_cgroup_css_reset,
.can_attach = mem_cgroup_can_attach,
.cancel_attach = mem_cgroup_cancel_attach,
.post_attach = mem_cgroup_move_task,
.bind = mem_cgroup_bind,
.dfl_cftypes = memory_files,
.legacy_cftypes = mem_cgroup_legacy_files,
.early_init = 0,
};在for_each_subsys的循环里面,cgroup_subsys[]数组中的每一个cgroup_subsys,都会调用cgroup_init_subsys,对于cgroup_subsys对于初始化。
static void __init cgroup_init_subsys(struct cgroup_subsys *ss, bool early)
{
struct cgroup_subsys_state *css;
......
idr_init(&ss->css_idr);
INIT_LIST_HEAD(&ss->cfts);
/* Create the root cgroup state for this subsystem */
ss->root = &cgrp_dfl_root;
css = ss->css_alloc(cgroup_css(&cgrp_dfl_root.cgrp, ss));
......
init_and_link_css(css, ss, &cgrp_dfl_root.cgrp);
......
css->id = cgroup_idr_alloc(&ss->css_idr, css, 1, 2, GFP_KERNEL);
init_css_set.subsys[ss->id] = css;
......
BUG_ON(online_css(css));
......
}cgroup_init_subsys里面会做两件事情,一个是调用cgroup_subsys的css_alloc函数创建一个cgroup_subsys_state;另外就是调用online_css,也即调用cgroup_subsys的css_online函数,激活这个cgroup。
对于CPU来讲,css_alloc函数就是cpu_cgroup_css_alloc。这里面会调用 sched_create_group创建一个struct task_group。在这个结构中,第一项就是cgroup_subsys_state,也就是说,task_group是cgroup_subsys_state的一个扩展,最终返回的是指向cgroup_subsys_state结构的指针,可以通过强制类型转换变为task_group。
struct task_group {
struct cgroup_subsys_state css;
#ifdef CONFIG_FAIR_GROUP_SCHED
/* schedulable entities of this group on each cpu */
struct sched_entity **se;
/* runqueue "owned" by this group on each cpu */
struct cfs_rq **cfs_rq;
unsigned long shares;
#ifdef CONFIG_SMP
atomic_long_t load_avg ____cacheline_aligned;
#endif
#endif
struct rcu_head rcu;
struct list_head list;
struct task_group *parent;
struct list_head siblings;
struct list_head children;
struct cfs_bandwidth cfs_bandwidth;
};在task_group结构中,有一个成员是sched_entity,前面我们讲进程调度的时候,遇到过它。它是调度的实体,也即这一个task_group也是一个调度实体。
接下来,online_css会被调用。对于CPU来讲,online_css调用的是cpu_cgroup_css_online。它会调用sched_online_group->online_fair_sched_group。
void online_fair_sched_group(struct task_group *tg)
{
struct sched_entity *se;
struct rq *rq;
int i;
for_each_possible_cpu(i) {
rq = cpu_rq(i);
se = tg->se[i];
update_rq_clock(rq);
attach_entity_cfs_rq(se);
sync_throttle(tg, i);
}
}在这里面,对于每一个CPU,取出每个CPU的运行队列rq,也取出task_group的sched_entity,然后通过attach_entity_cfs_rq将sched_entity添加到运行队列中。
对于内存来讲,css_alloc函数就是mem_cgroup_css_alloc。这里面会调用 mem_cgroup_alloc,创建一个struct mem_cgroup。在这个结构中,第一项就是cgroup_subsys_state,也就是说,mem_cgroup是cgroup_subsys_state的一个扩展,最终返回的是指向cgroup_subsys_state结构的指针,我们可以通过强制类型转换变为mem_cgroup。
struct mem_cgroup {
struct cgroup_subsys_state css;
/* Private memcg ID. Used to ID objects that outlive the cgroup */
struct mem_cgroup_id id;
/* Accounted resources */
struct page_counter memory;
struct page_counter swap;
/* Legacy consumer-oriented counters */
struct page_counter memsw;
struct page_counter kmem;
struct page_counter tcpmem;
/* Normal memory consumption range */
unsigned long low;
unsigned long high;
/* Range enforcement for interrupt charges */
struct work_struct high_work;
unsigned long soft_limit;
......
int swappiness;
......
/*
* percpu counter.
*/
struct mem_cgroup_stat_cpu __percpu *stat;
int last_scanned_node;
/* List of events which userspace want to receive */
struct list_head event_list;
spinlock_t event_list_lock;
struct mem_cgroup_per_node *nodeinfo[0];
/* WARNING: nodeinfo must be the last member here */
};在cgroup_init函数中,cgroup的初始化还做了一件很重要的事情,它会调用cgroup_init_cftypes(NULL, cgroup1_base_files),来初始化对于cgroup文件类型cftype的操作函数,也就是将struct kernfs_ops *kf_ops设置为cgroup_kf_ops。
struct cftype cgroup1_base_files[] = {
......
{
.name = "tasks",
.seq_start = cgroup_pidlist_start,
.seq_next = cgroup_pidlist_next,
.seq_stop = cgroup_pidlist_stop,
.seq_show = cgroup_pidlist_show,
.private = CGROUP_FILE_TASKS,
.write = cgroup_tasks_write,
},
}
static struct kernfs_ops cgroup_kf_ops = {
.atomic_write_len = PAGE_SIZE,
.open = cgroup_file_open,
.release = cgroup_file_release,
.write = cgroup_file_write,
.seq_start = cgroup_seqfile_start,
.seq_next = cgroup_seqfile_next,
.seq_stop = cgroup_seqfile_stop,
.seq_show = cgroup_seqfile_show,
};在cgroup初始化完毕之后,接下来就是创建一个cgroup的文件系统,用了配置和操作cgroup。
cgroup是一种特殊的文件系统。它的定义如下:
struct file_system_type cgroup_fs_type = {
.name = "cgroup",
.mount = cgroup_mount,
.kill_sb = cgroup_kill_sb,
.fs_flags = FS_USERNS_MOUNT,
};当我们mount这个cgroup文件系统的时候,会调用cgroup_mount->cgroup1_mount。
struct dentry *cgroup1_mount(struct file_system_type *fs_type, int flags,
void *data, unsigned long magic,
struct cgroup_namespace *ns)
{
struct super_block *pinned_sb = NULL;
struct cgroup_sb_opts opts;
struct cgroup_root *root;
struct cgroup_subsys *ss;
struct dentry *dentry;
int i, ret;
bool new_root = false;
......
root = kzalloc(sizeof(*root), GFP_KERNEL);
new_root = true;
init_cgroup_root(root, &opts);
ret = cgroup_setup_root(root, opts.subsys_mask, PERCPU_REF_INIT_DEAD);
......
dentry = cgroup_do_mount(&cgroup_fs_type, flags, root,
CGROUP_SUPER_MAGIC, ns);
......
return dentry;
}cgroup被组织成为树形结构,因而有cgroup_root。init_cgroup_root会初始化这个cgroup_root。cgroup_root是cgroup的根,它有一个成员kf_root,是cgroup文件系统的根struct kernfs_root。kernfs_create_root就是用来创建这个kernfs_root结构的。
int cgroup_setup_root(struct cgroup_root *root, u16 ss_mask, int ref_flags)
{
LIST_HEAD(tmp_links);
struct cgroup *root_cgrp = &root->cgrp;
struct kernfs_syscall_ops *kf_sops;
struct css_set *cset;
int i, ret;
root->kf_root = kernfs_create_root(kf_sops,
KERNFS_ROOT_CREATE_DEACTIVATED,
root_cgrp);
root_cgrp->kn = root->kf_root->kn;
ret = css_populate_dir(&root_cgrp->self);
ret = rebind_subsystems(root, ss_mask);
......
list_add(&root->root_list, &cgroup_roots);
cgroup_root_count++;
......
kernfs_activate(root_cgrp->kn);
......
}就像在普通文件系统上,每一个文件都对应一个inode,在cgroup文件系统上,每个文件都对应一个struct kernfs_node结构,当然kernfs_root作为文件系的根也对应一个kernfs_node结构。
接下来,css_populate_dir会调用cgroup_addrm_files->cgroup_add_file->cgroup_add_file,来创建整棵文件树,并且为树中的每个文件创建对应的kernfs_node结构,并将这个文件的操作函数设置为kf_ops,也即指向cgroup_kf_ops 。
static int cgroup_add_file(struct cgroup_subsys_state *css, struct cgroup *cgrp,
struct cftype *cft)
{
char name[CGROUP_FILE_NAME_MAX];
struct kernfs_node *kn;
......
kn = __kernfs_create_file(cgrp->kn, cgroup_file_name(cgrp, cft, name),
cgroup_file_mode(cft), 0, cft->kf_ops, cft,
NULL, key);
......
}
struct kernfs_node *__kernfs_create_file(struct kernfs_node *parent,
const char *name,
umode_t mode, loff_t size,
const struct kernfs_ops *ops,
void *priv, const void *ns,
struct lock_class_key *key)
{
struct kernfs_node *kn;
unsigned flags;
int rc;
flags = KERNFS_FILE;
kn = kernfs_new_node(parent, name, (mode & S_IALLUGO) | S_IFREG, flags);
kn->attr.ops = ops;
kn->attr.size = size;
kn->ns = ns;
kn->priv = priv;
......
rc = kernfs_add_one(kn);
......
return kn;
}从cgroup_setup_root返回后,接下来,在cgroup1_mount中,要做的一件事情是cgroup_do_mount,调用kernfs_mount真的去mount这个文件系统,返回一个普通的文件系统都认识的dentry。这种特殊的文件系统对应的文件操作函数为kernfs_file_fops。
const struct file_operations kernfs_file_fops = {
.read = kernfs_fop_read,
.write = kernfs_fop_write,
.llseek = generic_file_llseek,
.mmap = kernfs_fop_mmap,
.open = kernfs_fop_open,
.release = kernfs_fop_release,
.poll = kernfs_fop_poll,
.fsync = noop_fsync,
};当我们要写入一个CGroup文件来设置参数的时候,根据文件系统的操作,kernfs_fop_write会被调用,在这里面会调用kernfs_ops的write函数,根据上面的定义为cgroup_file_write,在这里会调用cftype的write函数。对于CPU和内存的write函数,有以下不同的定义。
static struct cftype cpu_files[] = {
#ifdef CONFIG_FAIR_GROUP_SCHED
{
.name = "shares",
.read_u64 = cpu_shares_read_u64,
.write_u64 = cpu_shares_write_u64,
},
#endif
#ifdef CONFIG_CFS_BANDWIDTH
{
.name = "cfs_quota_us",
.read_s64 = cpu_cfs_quota_read_s64,
.write_s64 = cpu_cfs_quota_write_s64,
},
{
.name = "cfs_period_us",
.read_u64 = cpu_cfs_period_read_u64,
.write_u64 = cpu_cfs_period_write_u64,
},
}
static struct cftype mem_cgroup_legacy_files[] = {
{
.name = "usage_in_bytes",
.private = MEMFILE_PRIVATE(_MEM, RES_USAGE),
.read_u64 = mem_cgroup_read_u64,
},
{
.name = "max_usage_in_bytes",
.private = MEMFILE_PRIVATE(_MEM, RES_MAX_USAGE),
.write = mem_cgroup_reset,
.read_u64 = mem_cgroup_read_u64,
},
{
.name = "limit_in_bytes",
.private = MEMFILE_PRIVATE(_MEM, RES_LIMIT),
.write = mem_cgroup_write,
.read_u64 = mem_cgroup_read_u64,
},
{
.name = "soft_limit_in_bytes",
.private = MEMFILE_PRIVATE(_MEM, RES_SOFT_LIMIT),
.write = mem_cgroup_write,
.read_u64 = mem_cgroup_read_u64,
},
}如果设置的是cpu.shares,则调用cpu_shares_write_u64。在这里面,task_group的shares变量更新了,并且更新了CPU队列上的调度实体。
int sched_group_set_shares(struct task_group *tg, unsigned long shares)
{
int i;
shares = clamp(shares, scale_load(MIN_SHARES), scale_load(MAX_SHARES));
tg->shares = shares;
for_each_possible_cpu(i) {
struct rq *rq = cpu_rq(i);
struct sched_entity *se = tg->se[i];
struct rq_flags rf;
update_rq_clock(rq);
for_each_sched_entity(se) {
update_load_avg(se, UPDATE_TG);
update_cfs_shares(se);
}
}
......
}但是这个时候别忘了,我们还没有将CPU的文件夹下面的tasks文件写入进程号呢。写入一个进程号到tasks文件里面,按照cgroup1_base_files里面的定义,我们应该调用cgroup_tasks_write。
接下来的调用链为:cgroup_tasks_write->__cgroup_procs_write->cgroup_attach_task-> cgroup_migrate->cgroup_migrate_execute。将这个进程和一个cgroup关联起来,也即将这个进程迁移到这个cgroup下面。
static int cgroup_migrate_execute(struct cgroup_mgctx *mgctx)
{
struct cgroup_taskset *tset = &mgctx->tset;
struct cgroup_subsys *ss;
struct task_struct *task, *tmp_task;
struct css_set *cset, *tmp_cset;
......
if (tset->nr_tasks) {
do_each_subsys_mask(ss, ssid, mgctx->ss_mask) {
if (ss->attach) {
tset->ssid = ssid;
ss->attach(tset);
}
} while_each_subsys_mask();
}
......
}每一个cgroup子系统会调用相应的attach函数。而CPU调用的是cpu_cgroup_attach-> sched_move_task-> sched_change_group。
static void sched_change_group(struct task_struct *tsk, int type)
{
struct task_group *tg;
tg = container_of(task_css_check(tsk, cpu_cgrp_id, true),
struct task_group, css);
tg = autogroup_task_group(tsk, tg);
tsk->sched_task_group = tg;
#ifdef CONFIG_FAIR_GROUP_SCHED
if (tsk->sched_class->task_change_group)
tsk->sched_class->task_change_group(tsk, type);
else
#endif
set_task_rq(tsk, task_cpu(tsk));
}在sched_change_group中设置这个进程以这个task_group的方式参与调度,从而使得上面的cpu.shares起作用。
对于内存来讲,写入内存的限制使用函数mem_cgroup_write->mem_cgroup_resize_limit来设置struct mem_cgroup的memory.limit成员。
在进程执行过程中,申请内存的时候,我们会调用handle_pte_fault->do_anonymous_page()->mem_cgroup_try_charge()。
int mem_cgroup_try_charge(struct page *page, struct mm_struct *mm,
gfp_t gfp_mask, struct mem_cgroup **memcgp,
bool compound)
{
struct mem_cgroup *memcg = NULL;
......
if (!memcg)
memcg = get_mem_cgroup_from_mm(mm);
ret = try_charge(memcg, gfp_mask, nr_pages);
......
}在mem_cgroup_try_charge中,先是调用get_mem_cgroup_from_mm获得这个进程对应的mem_cgroup结构,然后在try_charge中,根据mem_cgroup的限制,看是否可以申请分配内存。
至此,cgroup对于内存的限制才真正起作用。
52.1 总结
内核中cgroup的工作机制,我们在这里总结一下。
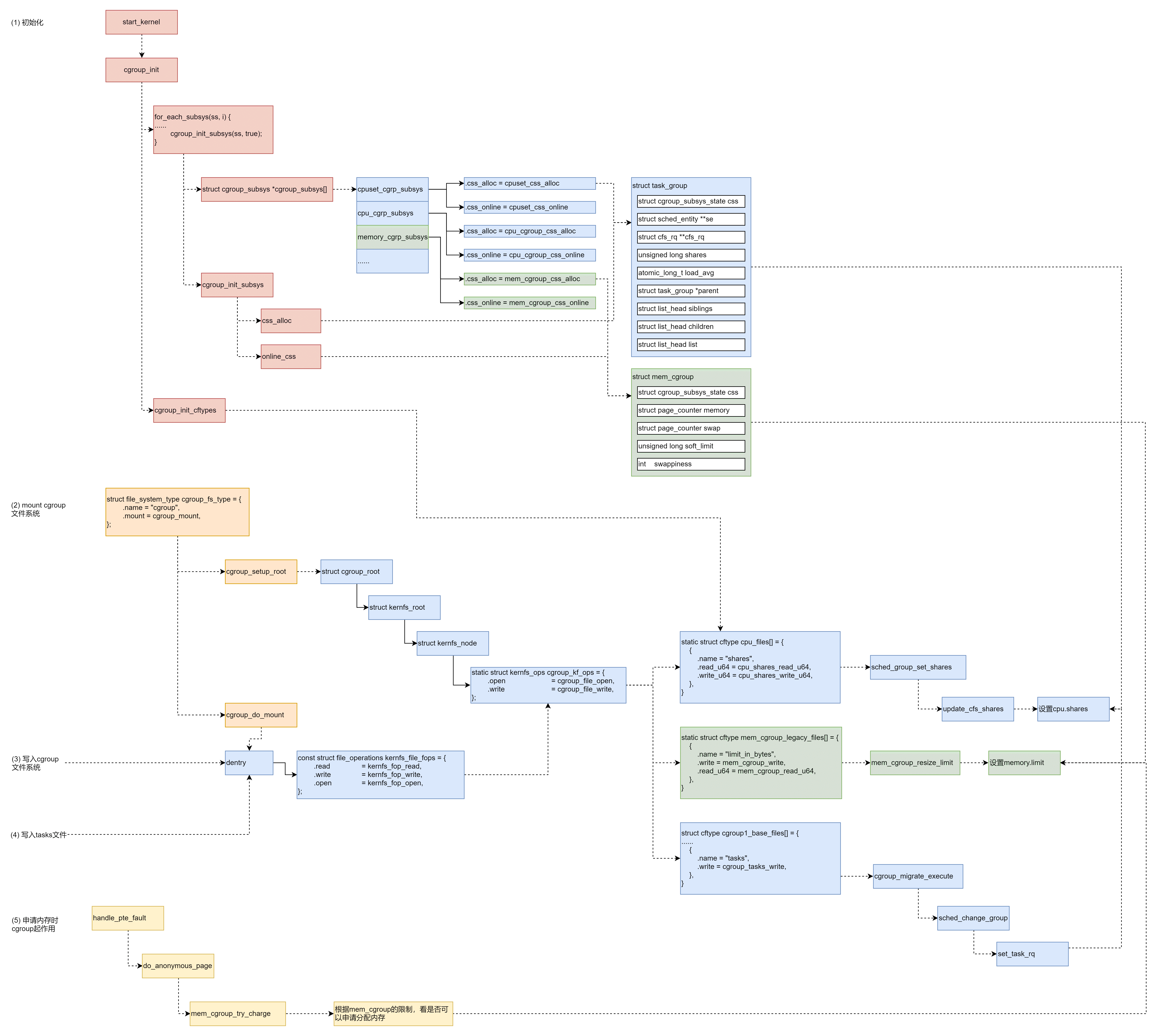
第一步,系统初始化的时候,初始化cgroup的各个子系统的操作函数,分配各个子系统的数据结构。
第二步,mount cgroup文件系统,创建文件系统的树形结构,以及操作函数。
第三步,写入cgroup文件,设置cpu或者memory的相关参数,这个时候文件系统的操作函数会调用到cgroup子系统的操作函数,从而将参数设置到cgroup子系统的数据结构中。
第四步,写入tasks文件,将进程交给某个cgroup进行管理,因为tasks文件也是一个cgroup文件,统一会调用文件系统的操作函数进而调用cgroup子系统的操作函数,将cgroup子系统的数据结构和进程关联起来。
第五步,对于cpu来讲,会修改scheduled entity,放入相应的队列里面去,从而下次调度的时候就起作用了。对于内存的cgroup设定,只有在申请内存的时候才起作用。
53. 数据中心操作系统
在这门课程里面,我们说了,在内核态有很多的模块,可以帮助我们管理硬件设备,最重要的四种硬件资源是CPU、内存、存储和网络。
最初使用汇编语言的前辈,在程序中需要指定使用的硬件资源,例如,指定使用哪个寄存器、放在内存的哪个位置、写入或者读取那个串口等等。对于这些资源的使用,需要程序员自己心里非常地清楚,要不然一旦jump错了位置,程序就无法运行。
为了将程序员从对硬件的直接操作中解放出来,提升程序设计的效率,于是,我们有了操作系统这一层,用来实现对于硬件资源的统一管理。某个程序使用哪个CPU、哪部分内存、哪部分硬盘,只需要调用API就可以了,这些都由操作系统自行分配和管理。
其实操作系统最重要的事情,就是调度。因此,在内核态就产生这些模块:进程管理子系统、内存管理子系统、文件子系统、设备子系统和网络子系统。
这些模块通过统一的API,也就是系统调用,对上提供服务。基于这些API,用户态有很多的工具可以帮我们使用好Linux操作系统,比如用户管理、软件安装、软件运行、周期性进程、文件管理、网络管理和存储管理。
但是到目前为止,我们能管理的还是少数几台机器。当我们面临数据中心成千上万台机器的时候,仍然非常”痛苦”。如果我们运维数据中心依然像的运维一台台物理机的前辈一样,天天关心哪个程序放在了哪台机器上,使用多少内存、多少硬盘,每台机器总共有多少内存、多少硬盘,还剩多少内存和硬盘,那头就大了。
因而对应到数据中心,我们也需要一个调度器,将运维人员从指定物理机或者虚拟机的痛苦中解放出来,实现对于物理资源的统一管理,这就是Kubernetes。
Kubernetes究竟有哪些功能,可以解放运维人员呢?为什么它能做数据中心的操作系统呢?
我列了两个表格,将操作系统的功能和模块与Kubernetes的功能和模块做了一个对比,你可以看看。
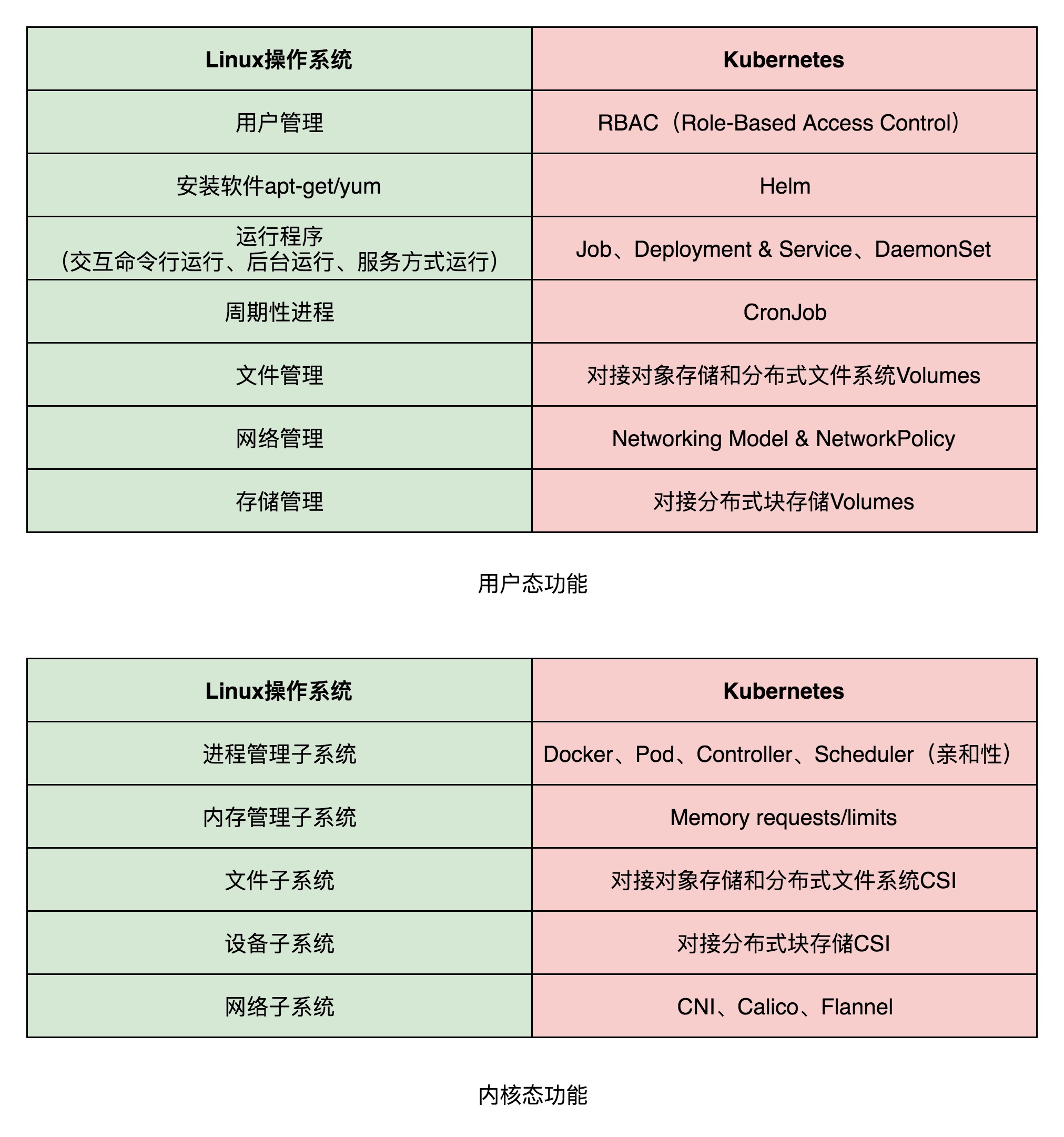
Kubernetes作为数据中心的操作系统还是主要管理数据中心里面的四种硬件资源:CPU、内存、存储、网络。
对于CPU和内存这两种计算资源的管理,我们可以通过Docker技术完成。它可以将CPU和内存资源,通过namespace和cgroup,从大的资源池里面隔离出来,并通过镜像技术,实现计算资源在数据中心里面的自由漂移。
就像我们上面说的一样,那没有操作系统的时候,汇编程序员需要指定程序运行的CPU和内存物理地址。同理,数据中心的管理员,原来还需要指定程序运行的服务器及使用的CPU和内存。现在,Kubernetes里面有一个调度器Scheduler,你只需要告诉它,你想运行10个4核8G的Java程序,它会自动帮你选择空闲的、有足够资源的服务器,去运行这些程序。
对于操作系统上的进程来讲,有主线程做主要的工作,还有其它线程做辅助的工作。对于数据中心里面的运行的程序来讲,可以也会有一个主要提供服务的程序,例如上面的Java程序,也会有一些提供辅助功能的程序;例如监控、环境预设值等。Kubernetes将多个Docker组装成一个Pod的概念,在一个Pod里面,往往有一个Docker为主,多个Docker为辅。
操作系统上的进程会在CPU上切换来切换去,它使用的内存也会换入换出。在数据中心里面,这些运行中的程序能不能在机器之间迁移呢?能不能在一台服务器故障的时候,选择其它的服务器运行呢?反正我关心的是运行10个4核8G的Java程序,又不在乎它在哪台上运行。Kubernetes里面有Controller的概念,可以控制Pod们的运行状态以及占用的资源,如果10个变9个就选一台机器添加一个,10个变11个,就随机删除一个。
操作系统上的进程有时候有亲和性的要求,比如它可能希望再某一个CPU上运行,不切换CPU从而提高运行效率,或者两个线程要求在一个CPU上,从而可以使用Per CPU变量不加锁,交互和协作比较方便。有的时候,一个线程想避开另一个线程,不要共用CPU,以防相互干扰。Kubernetes的Scheduler也是有亲和性功能的,你可以选择两个Pod永远运行在一台物理机上,这样本地通信就可以了,也可以选择两个Pod永远不要运行在同一台物理机上,这样一个挂了不影响另一个。
你可能会问,Docker可以将CPU内存资源进行抽象,在服务器之间迁移,那数据应该怎么办呢?如果数据放在每一台服务器上,其实就像散落在汪洋大海里面,用的时候根本找不到,所以必须要有统一的存储。正像一台操作系统上多个进程之间,要通过文件系统保存持久化的数据并且实现共享,在数据中心里面也需要一个这样的基础设施。
统一的存储常常有三种形式,我们分别来看。
第一种方式是对象存储。
顾名思义,这种方式是将文件作为一个完整对象的方式来保存。每一个文件对我们来说,都应该有一个唯一标识这个对象的key,而文件的内容就是value。对象可以分门别类地保存在一个叫作存储空间(Bucket)的地方,有点儿像文件夹。
对于任何一个文件对象,我们都可以通过HTTP RESTful API来远程获取对象。由于是简单的key-value模式,当需要保存大容量数据的时候,我们就比较容易根据唯一的key进行横向扩展,所以对象存储往往能够容纳的数据量非常大。在数据中心里面保存文档,视频等很好的方式,当然缺点就是,你没办法像操作文件一样操作它,而是要将value当成整个的来对待。
第二种方式是分布式文件系统。
这种是最容易习惯的,因为使用它和使用本地的文件系统几乎没有什么区别,只不过是通过网络的方式访问远程的文件系统。多个容器能看到统一的文件系统,一个容器写入文件系统的,另一个容器能够看到,可以实现共享。缺点是分布式文件系统的性能和规模是个矛盾,规模一大性能就难以保证,性能好则规模不会很大,所以不像对象存储一样能够保持海量的数据。
第三种方式是分布式块存储。
这是云硬盘,也即存储虚拟化的方式,只不过将盘挂载给容器而不是虚拟机。块存储没有分布式文件系统这一层,一旦挂载到某一个容器,可以有本地的文件系统,这样缺点是一般情况下,不同容器挂载的块存储都是不共享的,好处是在同样的规模的情况下,性能相对分布式文件系统要好。如果为了解决一个容器从一台服务器迁移到另一台服务器,如何保持存储的数据的问题,块存储是一个很好的选择。它不用解决多个容器共享数据的问题。
这三种形式,对象存储使用HTTP进行访问,当然任何容器都能访问到,不需要Kubernetes去管理它。而分布式文件系统和分布式块存储,就需要对接到Kubernetes,让Kubernetes可以管理它们。如何对接呢?Kubernetes提供Container Storage Interface (CSI)接口,这是一个标准接口,不同的存储可以实现这个接口来对接Kubernetes。是不是特别像设备驱动程序呀。操作系统只要定义统一的接口,不同的存储设备的驱动实现这些接口,就能被操作系统使用了。
存储的问题解决了,接下来是网络。因为不同的服务器上的Docker还是需要互相通信的。
Kubernetes有自己的网络模型,里面是这样规定的。
- IP-per-Pod,每个 Pod 都拥有一个独立 IP 地址,Pod 内所有容器共享一个网络命名空间。
- 集群内所有 Pod 都在一个直接连通的扁平网络中,可通过 IP 直接访问。
- 所有容器之间无需 NAT 就可以直接互相访问。
- 所有 Node 和所有容器之间无需 NAT 就可以直接互相访问。
- 容器自己看到的 IP 跟其它容器看到的一样。
这其实是说,里面的每一个Docker访问另一个Docker的时候,都是感觉在一个扁平的网络里面就可以了。
要实现这样的网络模型,有很多种方式,例如Kubernetes自己提供Calico、Flannel。当然,也可以对接Openvswitch这样的虚拟交换机,也可以使用brctl这种传统的桥接模式,也可以对接硬件交换机。
看,这又是一种类似驱动的模式,和操作系统面临的问题是一样的。Kubernetes同样是提供统一的接口Container Network Interface(CNI,容器网络接口)。无论你用哪种方式实现网络模型,只要对接这个统一的接口,Kubernetes就可以管理容器的网络。
至此,Kubernetes作为数据中心的操作系统,内核的问题解决了。
接下来是用户态的工具问题了。我们能不能像操作一台服务器那样操作数据中心呢?
使用操作系统,需要安装一些软件,于是,我们需要yum之类的包管理系统,使得软件的使用者和软件的编译者分隔开来,软件的编译者需要知道这个软件需要安装哪些包,包之间的依赖关系是什么,软件安装到什么地方,而软件的使用者仅仅需要yum install就可以了。Kubernetes就有这样一套包管理软件Helm,你可以用它来很方便的安装,升级,扩容一些数据中心里面的常用软件,例如数据库,缓存,消息队列。
使用操作系统,运行一个进程是最常见的需求。第一种进程是交互式命令行,运行起来就是执行一个任务,结束了马上返回结果。在Kubernetes里面有对应的概念叫做Job,Job 负责批量处理短暂的一次性任务 (Short Lived One-off Tasks),即仅执行一次的任务,它保证批处理任务的一个或多个 Pod 成功结束。
第二种进程是nohup长期运行的进程。在Kubernetes里对应的概念是Deployment,使用 Deployment 来创建 ReplicaSet。ReplicaSet 在后台创建 pod。也即Doployment里面会声明我希望某个进程以N的Pod副本的形式运行,并且长期运行,一但副本变少就会自动添加。
第三种进程是系统服务。在Kubernetes里面对应的概念是DaemonSet,它保证在每个节点上都运行一个容器副本,常用来部署一些集群的日志、监控或者其它系统管理应用。
第四种进程是周期性进程,也即crontab,常常用来设置一些周期性的任务。在Kubernetes里面对应的概念是CronJob定时任务,就类似于 Linux 系统的 crontab,在指定的时间周期运行指定的任务。
使用操作系统,我们还需使用文件系统,或者使用网络发送数据,虽然在Kubernetes里面有CSI和CNI来对接存储和网络,在用户态,不能让用户意识到后面具体设备,而是应该有抽象的概念。
对于存储来讲,Kubernetes有Volume的概念,Kubernetes Volume 的生命周期与 Pod 绑定,
容器挂掉后 Kubelet 再次重启容器时,Volume 的数据依然还在,而 Pod 删除时,Volume 才会清理。数据是否丢失取决于具体的 Volume 类型。Volume的概念是对具体存储设备的抽象,就像当我们使用ext4文件系统不用管它是基于什么硬盘一样。
对于网络来讲,Kubernetes有自己的DNS,有Service的概念,Kubernetes Service是一个 Pod 的逻辑分组,这一组 Pod 能够被 Service 访问。每一个Service都一个名字,Kubernetes会将Service的名字作为域名进行解析,称为一个虚拟的Cluster IP,然后通过负载均衡,转发到后端的Pod,虽然Pod可能漂移,IP会变,但是Service会一直不变。
对应到Linux操作系统的iptables,Kubernetes 在有个概念叫Network Policy,Network Policy 提供了基于策略的网络控制,用于隔离应用并减少攻击面。它使用标签选择器模拟传统的分段网络,并通过策略控制它们之间的流量以及来自外部的流量。
看,是不是很神奇?有了Kubernetes,我们就能像管理一台Linux服务器那样,去管理数据中心了。
如果想深入了解Kubernetes这个数据中心的操作系统,你可以订阅极客时间的专栏”深入剖析Kubernetes“。
53.1 总结
下面,你可以对照着这个图,来总结一下这个数据中心操作系统的功能。
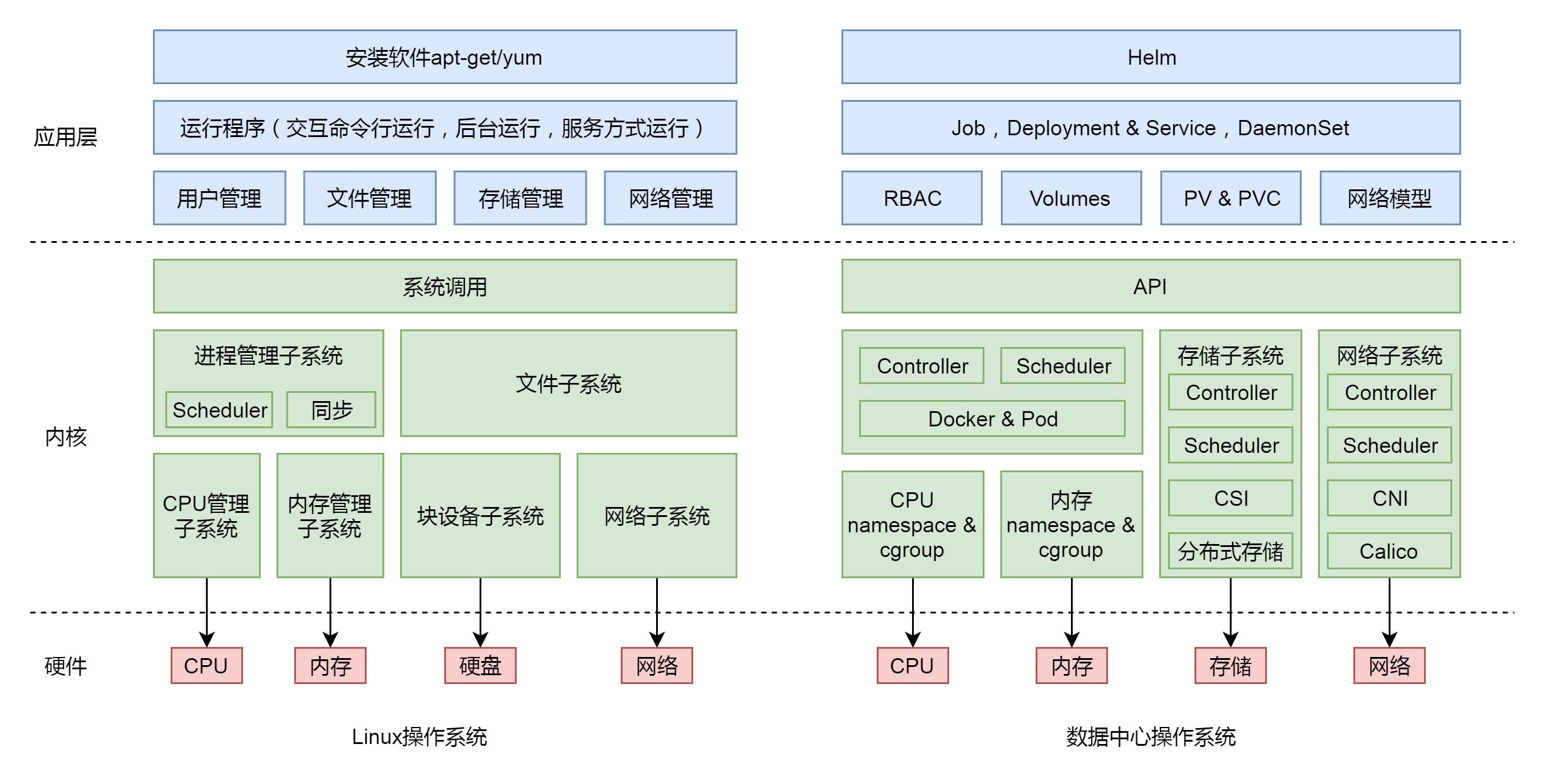
十、实战串讲篇
54. 搭建操作系统实验环境(上)
操作系统的理论部分我们就讲完了,但是计算机这门学科是实验性的。为了更加深入地了解操作系统的本质,我们必须能够做一些上手实验。操作系统的实验,相比其他计算机课程的实验要更加复杂一些。
我们做任何实验,都需要一个实验环境。这个实验环境要搭建在操作系统之上,但是,我们这个课程本身就是操作系统实验,难不成要自己debug自己?到底该咋整呢?
我们有一个利器,那就是qemu啊,不知道你还记得吗?它可以在操作系统之上模拟一个操作系统,就像一个普通的进程。那我们是否可以像debug普通进程那样,通过qemu来debug虚拟机里面的操作系统呢?
这一节和下一节,我们就按照这个思路,来试试看,搭建一个操作系统的实验环境。
运行一个qemu虚拟机,首先我们要有一个虚拟机的镜像。咱们在虚拟机那一节,已经制作了一个虚拟机的镜像。假设我们要基于 ubuntu-18.04.2-live-server-amd64.iso,它对应的内核版本是linux-source-4.15.0。
当时我们启动虚拟机的过程很复杂,设置参数的时候也很复杂,以至于解析这些参数就花了我们一章的时间。所以,这里我介绍一个简单的创建和管理虚拟机的方法。
在CPU虚拟化那一节,我留过一个思考题,OpenStack是如何创建和管理虚拟机的?当时我给了你一个提示,就是用libvirt。没错,这一节,我们就用libvirt来创建和管理虚拟机。
54.1 创建虚拟机
首先生成 /home/k/qemu/ubuntutest.img 文件。
qemu-img create -f qcow2 /home/k/qemu/ubuntutest.img 60G然后,使用下面的命令,安装libvirt。
apt install qemu-kvm libvirt-daemon-system libvirt-clients bridge-utils virtinst virt-managerlibvirt管理qemu虚拟机,是基于XML文件,这样容易维护。
<domain type='kvm'>
<name>ubuntutest</name>
<memory unit='GiB'>16</memory>
<currentMemory unit='GiB'>8</currentMemory>
<vcpu>8</vcpu>
<os>
<type arch='x86_64' machine='pc'>hvm</type>
<boot dev='hd'/>
<boot dev='cdrom'/>
<bootmenu enable='yes'/>
</os>
<features>
<acpi/>
<apic/>
<pae/>
</features>
<cpu mode='host-passthrough' />
<clock offset='utc'/>
<on_poweroff>destroy</on_poweroff>
<on_reboot>restart</on_reboot>
<on_crash>restart</on_crash>
<devices>
<emulator>/usr/bin/qemu-system-x86_64</emulator>
<disk type='file' device='disk'>
<driver name='qemu' type='qcow2'/>
<source file='/home/k/qemu/ubuntutest.img'/>
<target dev='vda' bus='virtio'/>
</disk>
<disk type='file' device='cdrom'>
<driver name='qemu' type='raw'/>
<source file='/home/k/qemu/ubuntu-18.04.5-desktop-amd64.iso'/>
<target dev='hdc' bus='ide'/>
</disk>
<interface type='bridge'>
<source bridge='virbr0'/>
</interface>
<graphics type='vnc' port='-1' autoport='yes' listen='0.0.0.0'>
<listen type='address' address='0.0.0.0'/>
</graphics>
<serial type='pty'>
<target port='0'/>
</serial>
<console type='pty'>
<target type='serial' port='0'/>
</console>
</devices>
</domain>在这个XML文件中,/home/k/qemu/ubuntu-18.04.5-desktop-amd64.iso 就是虚拟机的镜像,virbr0是安装libvirt后创建的网桥,连接到网桥上的网卡libvirt会自动帮我们创建。
接下来,需要将这个XML保存为domain.xml,然后调用下面的命令,交给libvirt进行管理。
sudo virsh define domain.xml接下来,运行sudo virsh list —all,我们就可以看到这个定义好的虚拟机了,然后我们调用 sudo virsh start ubuntutest,启动这个虚拟机。
$ sudo virsh list
Id Name State
----------------------------------------------------
1 ubuntutest running我们可以通过ps查看libvirt启动的qemu进程。这个命令行是不是很眼熟?我们之前花了一章来讲解。如果不记得了,你可以回去看看前面的内容。
$ ps aux | grep qemu
libvirt+ 307858 1 99 19:11 ? 00:01:45 /usr/bin/qemu-system-x86_64 -name guest=ubuntutest,debug-threads=on -S -object secret,id=masterKey0,format=raw,file=/var/lib/libvirt/qemu/domain-20-ubuntutest/master-key.aes -machine pc-i440fx-4.2,accel=kvm,usb=off,dump-guest-core=off -cpu host -m 16384 -overcommit mem-lock=off -smp 8,sockets=8,cores=1,threads=1 -uuid 54f20426-b436-49be-9063-cbbe37e5c7fa -no-user-config -nodefaults -chardev socket,id=charmonitor,fd=31,server,nowait -mon chardev=charmonitor,id=monitor,mode=control -rtc base=utc -no-shutdown -boot menu=on,strict=on -device piix3-usb-uhci,id=usb,bus=pci.0,addr=0x1.0x2 -blockdev {"driver":"file","filename":"/home/k/qemu/ubuntutest.img","node-name":"libvirt-2-storage","auto-read-only":true,"discard":"unmap"} -blockdev {"node-name":"libvirt-2-format","read-only":false,"driver":"qcow2","file":"libvirt-2-storage","backing":null} -device virtio-blk-pci,scsi=off,bus=pci.0,addr=0x4,drive=libvirt-2-format,id=virtio-disk0,bootindex=1 -blockdev {"driver":"file","filename":"/home/k/qemu/ubuntu-18.04.5-desktop-amd64.iso","node-name":"libvirt-1-storage","auto-read-only":true,"discard":"unmap"} -blockdev {"node-name":"libvirt-1-format","read-only":true,"driver":"raw","file":"libvirt-1-storage"} -device ide-cd,bus=ide.1,unit=0,drive=libvirt-1-format,id=ide0-1-0,bootindex=2 -netdev tap,fd=33,id=hostnet0 -device rtl8139,netdev=hostnet0,id=net0,mac=52:54:00:01:6d:1c,bus=pci.0,addr=0x3 -chardev pty,id=charserial0 -device isa-serial,chardev=charserial0,id=serial0 -vnc 0.0.0.0:0 -device cirrus-vga,id=video0,bus=pci.0,addr=0x2 -device virtio-balloon-pci,id=balloon0,bus=pci.0,addr=0x5 -sandbox on,obsolete=deny,elevateprivileges=deny,spawn=deny,resourcecontrol=deny -msg timestamp=on从这里,我们可以看到,VNC的设置为0.0.0.0:0。我们可以用VNCViewer工具登录到这个虚拟机的界面,但是这样实在是太麻烦了,其实virsh有一个特别好的工具,但是需要在虚拟机里面配置一些东西。
在虚拟机里面,我们修改文件/etc/default/grub:
- GRUB_CMDLINE_LINUX=""
+ GRUB_CMDLINE_LINUX="console=ttyS0,115200"然后更新grub
sudo update-grub接下来,我们重启虚拟机,重启后上面的配置就起作用了。这时候,我们可以通过下面的命令,进入机器的控制台,可以不依赖于SSH和IP地址进行登录。
$ sudo virsh console ubuntutest
Connected to domain ubuntutest
Escape character is ^]使用 sudo virsh console ubuntutest 获取控制台后,终端的大小可能与实际的终端大小不匹配,可以通过使用命令 resize 来手动更新终端的大小。
命令
resize可以通过安装包xterm来获取。
54.2 下载源代码
首先,打开源码仓库
sudo sed -i.bk 's/# deb-src/deb-src/g' /etc/apt/sources.list
sudo apt update
sudo apt full-upgrade
sudo apt autoremove下载源代码。
sudo apt install dpkg-dev
apt-get source linux-image-unsigned-$(uname -r)这行命令会将当前版本Ubuntu的内核代码下载到当前目录下,并解压缩。
$ uname -r
5.4.0-92-generic
$ ls
linux-hwe-5.4-5.4.0 linux-hwe-5.4_5.4.0-92.103~18.04.2.diff.gz linux-hwe-5.4_5.4.0-92.103~18.04.2.dsc linux-hwe-5.4_5.4.0.orig.tar.gz准备工作都做好了。这一节,我们先来做第一个实验,也就是,在原有内核代码的基础上加一个我们自己的系统调用。
在哪里加代码呢?如果你忘了,请出门左转,回顾一下系统调用那一节。
第一个要加的地方是arch/x86/entry/syscalls/syscall_64.tbl。这里面登记了所有的系统调用号以及相应的处理函数。
435 common clone3 __x64_sys_clone3/ptregs
436 common sayhelloworld __x64_sys_sayhelloworld在这里,我们找到435号系统调用x64_sys_clone3,然后照猫画虎,添加一个x64_sys_sayhelloworld。
第二个要加的地方是include/linux/syscalls.h,也就是系统调用的头文件,然后添加一个系统调用的声明。
asmlinkage long sys_clone3(struct clone_args __user *uargs, size_t size);
asmlinkage long sys_sayhelloworld(char __user *words, int count);同样,我们找到sys_clone3的声明,照猫画虎,声明一个sys_sayhelloworld。其中,words参数是用户态传递给内核态的文本的指针,count是数目。
第三个就是对于这个系统调用的实现,方便起见,我们直接在kernel/sys.c中实现。
SYSCALL_DEFINE2(sayhelloworld, char __user *, words, int, count)
{
char buffer[512];
if (count >= 512)
return -EINVAL;
if (copy_from_user(buffer, words, count))
return -EFAULT;
return printk("User Mode says %s to the Kernel Mode!", buffer);
}接下来就要开始编译内核了。
54.3 编译内核
编译之前,我们需要安装一些编译要依赖的包。
sudo apt install libncurses-dev bison flex libelf-dev libssl-dev dwarves首先,我们要定义编译选项。
make mrproper # 清理临时文件
make oldconfig # 将当前系统编译选项作为初始值,并修改编译选项
make menuconfig当前系统的内核编译选项可以通过命令
cat /boot/config-$(uname -r)获取。
然后,我们能通过选中下面的选项,激活CONFIG_DEBUG_INFO和CONFIG_FRAME_POINTER选项。
Kernel hacking --->
Compile-time checks and compiler options --->
[*] Compile the kernel with debug info
[*] Compile the kernel with frame pointers选择完毕之后,配置会保存在.config文件中。如果我们打开看,能看到这样的配置:
CONFIG_FRAME_POINTER=y
CONFIG_DEBUG_INFO=y接下来,我们编译内核。
make -j10 # 编译内核
sudo make modules_install # 把编译好的模块拷贝到系统目录下(一般是/lib/modules/)
sudo make install # 安装内核二进制映像, 生成并安装boot初始化文件系统映像文件下面,我们要做的就是重启虚拟机。进入的时候,会出现GRUB界面。我们选择Ubuntu高级选项,然后选择第一项进去,通过uname命令,我们就进入了新的内核。
$ uname -a
Linux k 5.4.157 #2 SMP Fri Jan 7 11:51:34 CST 2022 x86_64 x86_64 x86_64 GNU/Linux进入新的系统后,我们写一个测试程序 syscall.c 。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <linux/kernel.h>
#include <sys/syscall.h>
#include <string.h>
int main ()
{
char * words = "I am kibazen from user mode.";
int ret;
ret = syscall(436, words, strlen(words)+1);
printf("return %d from kernel mode.\n", ret);
return 0;
}然后,我们能利用gcc编译器编译后运行。
$ gcc syscall.c
$ ./a.out
return 63 from kernel mode.如果我们查看日志/var/log/syslog,就能够看到里面打印出来下面的日志,这说明我们的系统调用已经添加成功了。
$ grep kibazen /var/log/syslog
Jan 7 00:10:55 k kernel: [ 609.426453] User Mode says I am kibazen from user mode. to the Kernel Mode!54.4 总结
这一节是一节实战课,我们创建了一台虚拟机,在里面下载源代码,尝试修改了Linux内核,添加了一个自己的系统调用,并且进行了编译并安装了新内核。如果你按照这个过程做下来,你会惊喜地发现,原来令我们敬畏的内核,也是能够加以干预,为我而用的呢。没错,这就是你开始逐渐掌握内核的重要一步。
55. 搭建操作系统实验环境(下)
上一节我们做了一个实验,添加了一个系统调用,并且编译了内核。这一节,我们来尝试调试内核。这样,我们就可以一步一步来看,内核的代码逻辑执行到哪一步了,对应的变量值是什么。
55.1 了解gdb
在Linux下面,调试程序使用一个叫作gdb的工具。通过这个工具,我们可以逐行运行程序。
例如,上一节我们写的syscall.c这个程序,我们就可以通过下面的命令编译。
gcc -g syscall.c其中,参数-g的意思就是在编译好的二进制程序中,加入debug所需的信息。
接下来,我们安装一下gdb。
apt-get install gdb然后,我们就可以来调试这个程序了。
k@k:~$ gdb -q ./a.out
Reading symbols from ./a.out...done.
(gdb) l
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <unistd.h>
4 #include <linux/kernel.h>
5 #include <sys/syscall.h>
6 #include <string.h>
7
8 int main ()
9 {
10 char * words = "I am kibazen from user mode.";
(gdb) b 10
Breakpoint 1 at 0x6e2: file syscall.c, line 10.
(gdb) r
Starting program: /home/k/a.out
Breakpoint 1, main () at syscall.c:10
10 char * words = "I am kibazen from user mode.";
(gdb) n
12 ret = syscall(436, words, strlen(words)+1);
(gdb) p words
$1 = 0x5555555547c4 "I am kibazen from user mode."
(gdb) s
__strlen_avx2 () at ../sysdeps/x86_64/multiarch/strlen-avx2.S:55
55 ../sysdeps/x86_64/multiarch/strlen-avx2.S: No such file or directory.
(gdb) bt
#0 __strlen_avx2 () at ../sysdeps/x86_64/multiarch/strlen-avx2.S:55
#1 0x00005555555546f9 in main () at syscall.c:12
(gdb) c
Continuing.
return 63 from kernel mode.
[Inferior 1 (process 4049) exited normally]
(gdb) q在上面的例子中,我们只要掌握简单的几个gdb的命令就可以了。
- l,即list,用于显示多行源代码。
- b,即break,用于设置断点。
- r,即run,用于开始运行程序。
- n,即next,用于执行下一条语句。如果该语句为函数调用,则不会进入函数内部执行。
- p,即print,用于打印内部变量值。
- s,即step,用于执行下一条语句。如果该语句为函数调用,则进入函数,执行其中的第一条语句。
- c,即continue,用于继续程序的运行,直到遇到下一个断点。
- bt,即backtrace,用于产看函数调用信息。
- q,即quit,用于退出gdb环境。
55.2 Debug kernel
看了debug一个进程还是简单的,接下来,我们来试着debug整个kernel。
第一步,要想kernel能够被debug,需要向上面编译程序一样,将debug所需信息也放入二进制文件里面去。这个我们在编译内核的时候已经设置过了,也就是把”CONFIG_DEBUG_INFO”和”CONFIG_FRAME_POINTER”两个变量设置为yes。
第二步,就是安装gdb。kernel运行在qemu虚拟机里面,gdb运行在宿主机上,所以我们应该在宿主机上进行安装。
第三步,找到gdb要运行的那个内核的二进制文件。这个文件在哪里呢?根据grub里面的配置,它应该在/boot/vmlinuz-5.4.157这里。
另外,为了方便在debug的过程中查看源代码,我们可以将 linux-hwe-5.4-5.4.0 整个目录,都拷贝到宿主机上来。因为内核一旦进入debug模式,就不能运行了。
scp -r ./linux-hwe-5.4-5.4.0 k@192.168.104.113:/home/k/qemu/source在 linux-hwe-5.4-5.4.0 这个目录下面,vmlinux文件也是内核的二进制文件。
第四步,修改qemu的启动参数和qemu里面虚拟机的启动参数,从而使得gdb可以远程attach到qemu里面的内核上。
我们知道,gdb debug一个进程的时候,gdb会监控进程的运行,使得进程一行一行地执行二进制文件。如果像syscall.c的二进制文件a.out一样,就在本地,gdb可以通过attach到这个进程上,作为这个进程的父进程,来监控它的运行。
但是,gdb debug一个内核的时候,因为内核在qemu虚拟机里面,所以我们无法监控本地进程,而要通过qemu来监控qemu里面的内核,这就要借助qemu的机制。
qemu有个参数-s,它代表参数-gdb tcp::1234,意思是qemu监听1234端口,gdb可以attach到这个端口上来,debug qemu里面的内核。
为了完成这一点,我们需要修改ubuntutest这个虚拟机的定义文件。
在这里,我们能将虚拟机的定义文件修改成下面的样子,其中主要改了两项:
在domain的最后加上了qemu:commandline,里面指定了参数-s;
在domain中添加xmlns:qemu。没有这个XML的namespace,qemu:commandline这个参数libvirt不认。
<domain type='kvm' xmlns:qemu='http://libvirt.org/schemas/domain/qemu/1.0'> <name>ubuntutest</name> <memory unit='GiB'>16</memory> <currentMemory unit='GiB'>8</currentMemory> <vcpu>8</vcpu> <os> <type arch='x86_64' machine='pc'>hvm</type> <boot dev='hd'/> <boot dev='cdrom'/> <bootmenu enable='no'/> </os> <features> <acpi/> <apic/> <pae/> </features> <cpu mode='host-passthrough' /> <clock offset='utc'/> <on_poweroff>destroy</on_poweroff> <on_reboot>restart</on_reboot> <on_crash>restart</on_crash> <devices> <emulator>/usr/bin/qemu-system-x86_64</emulator> <disk type='file' device='disk'> <driver name='qemu' type='qcow2'/> <source file='/home/k/qemu/ubuntutest.img'/> <target dev='vda' bus='virtio'/> </disk> <disk type='file' device='cdrom'> <driver name='qemu' type='raw'/> <source file='/home/k/qemu/ubuntu-18.04.5-desktop-amd64.iso'/> <target dev='hdc' bus='ide'/> </disk> <interface type='bridge'> <source bridge='virbr0'/> </interface> <graphics type='vnc' port='-1' autoport='yes' listen='0.0.0.0'> <listen type='address' address='0.0.0.0'/> </graphics> <serial type='pty'> <target port='0'/> </serial> <console type='pty'> <target type='serial' port='0'/> </console> </devices> <qemu:commandline> <qemu:arg value='-s'/> </qemu:commandline> </domain>另外,为了远程debug成功,我们还需要修改qemu里面的虚拟机,在内核命令行中添加nokaslr,来关闭KASLR。KASLR会使得内核地址空间布局随机化,从而会造成我们打的断点不起作用。
在虚拟机里面,我们修改文件/etc/default/grub:
- GRUB_CMDLINE_LINUX="console=ttyS0,115200"
+ GRUB_CMDLINE_LINUX="nokaslr console=ttyS0,115200"更新虚拟机的grub启动
sudo update-grub修改完毕后,重新创建并启动虚拟机。
sudo virsh destroy ubuntutest
sudo virsh undefine ubuntutest
sudo virsh define domain.xml
sudo virsh start ubuntutest第五步,在宿主机中的目录 /home/k/qemu/source/linux-hwe-5.4-5.4.0 下使用gdb运行内核的二进制文件,执行gdb -q vmlinux。
$ gdb -q vmlinux
Reading symbols from vmlinux...
......
To enable execution of this file add
add-auto-load-safe-path /home/k/qemu/source/linux-hwe-5.4-5.4.0/vmlinux-gdb.py
......
(gdb) b __x64_sys_sayhelloworld
Breakpoint 1 at 0xffffffff810b7610: file kernel/sys.c, line 2663.
(gdb) target remote :1234
Remote debugging using :1234
native_safe_halt () at ./arch/x86/include/asm/irqflags.h:61
61 }
(gdb) c
Continuing.
[Switching to Thread 1.8]
Thread 8 hit Breakpoint 1, __x64_sys_sayhelloworld (regs=0xffffc900005c3f58) at kernel/sys.c:2663
2663 SYSCALL_DEFINE2(sayhelloworld, char __user *, words, int, count)
(gdb) bt
#0 __x64_sys_sayhelloworld (regs=0xffffc900005c3f58) at kernel/sys.c:2663
#1 0xffffffff81004207 in do_syscall_64 (nr=<optimized out>, regs=0xffffc900005c3f58) at arch/x86/entry/common.c:290
#2 0xffffffff81c0008c in entry_SYSCALL_64 () at arch/x86/entry/entry_64.S:175
#3 0x0000000000000000 in ?? ()
(gdb) x /s regs.di
0x5570f18bb7c4: "I am kibazen from user mode."
(gdb) p regs.si
$3 = 29
(gdb) n
do_syscall_64 (nr=18446612700050847944, regs=0xffffc900005c3f58) at arch/x86/entry/common.c:300
300 syscall_return_slowpath(regs);
(gdb) n
301 }
(gdb) n
entry_SYSCALL_64 () at arch/x86/entry/entry_64.S:184
184 movq RCX(%rsp), %rcx
......
(gdb) n
Cannot remove breakpoints because program is no longer writable.
Further execution is probably impossible.
entry_SYSCALL_64 () at arch/x86/entry/entry_64.S:275
275 USERGS_SYSRET64我们先设置一个断点在我们自己写的系统调用上b __x64_sys_sayhelloworld,通过执行target remote :1234,来attach到qemu上,然后,执行c,也即continue运行内核。这个时候内核始终在Continuing的状态,也即持续在运行中,这个时候我们可以远程登录到qemu里的虚拟机上,执行各种命令。
如果我们在虚拟机里面运行syscall.c编译好的a.out,这个时候肯定会调用到内核。内核肯定会经过系统调用的过程,到达__x64_sys_sayhelloworld这个函数,这就碰到了我们设置的那个断点。
如果执行bt,我们能看到,这个系统调用是从entry_64.S里面的entry_SYSCALL_64 ()函数,调用到do_syscall_64函数,再调用到 __x64_sys_sayhelloworld 函数的。这一点和我们在系统调用那一节分析的过程是一模一样的。
我们可以通过执行next命令,来看__x64_sys_sayhelloworld一步一步是怎么执行的,通过x /s regs.di查看第一个参数里面的内容。在这个过程中,由于内核是逐行运行的,因而我们在虚拟机里面的命令行是卡死的状态。
当我们不断地next,直到执行完毕__x64_sys_sayhelloworld的时候,会看到,do_syscall_64会调用syscall_return_slowpath。它然后会回到entry_SYSCALL_64,然后对于寄存器进行操作,最后调用指令USERGS_SYSRET64回到用户态。这个返回的过程和系统调用那一节也一模一样。
看,通过debug我们能够跟踪系统调用的整个过程。你可以将我们这一门课里面学得的所有的过程都debug一下,看看变量的值,从而对于内核的工作机制有更加深入的了解。
55.3 总结
在这个课程里面,我们写过一些程序,为了保证程序能够顺利运行,我一般会将代码完整地放到文本中,让你拷贝下来就能编译和运行。如果你运行的时候发现有问题,或者想了解一步一步运行的细节,这一节介绍的gdb是一个很好的工具。
这一节你尤其应该掌握的是,如何通过宿主机上的gdb来debug虚拟机里面的内核。这一点非常重要,会了这个,你就能够返回去,挨个研究每一章每一节的内核数据结构和运行逻辑了。
在这门课中,进程管理、内存管理、文件管理、设备管理网络管理,我们都介绍了从系统调用到底层的整个逻辑。如果你对我前面的代码解析还比较困惑,你可以尝试着去debug这些过程,只要把断点打在系统调用的入口位置就可以了。
从此,开启你的内核debug之旅吧!
十一、知识串讲
56. 用一个创业故事串起操作系统原理(一)
操作系统是一门体系复杂、知识点很多的课程,经过这么多节的讲解,你是否已经感觉自己被淹没在细节的汪洋大海里面了?没关系,从这一节开始,我们用五节的时间,通过一个创业故事,串起来操作系统的整个知识体系。
接下来,我们就来看主人公是如何从小马,变成马哥,再变成马总的吧!
56.1 小马创业选园区,开放标准是第一
小马最终还是决定走出大公司,自己去创业了。
创业首先要注册公司。注册公司就需要有一个办公地点。所以,小马需要选择一个适合创业的环境。他找了很多地方,发现有的地方政策倾斜大型企业,有的地方倾斜本地企业,有的地方鼓励金融创新。小马感觉这些地方都不太适合他这个IT男。
直到有一天,小马来到了位于杭州滨江的x86创业园区。他被深深地吸引住了,当然首要吸引他的就是园区工作人员的热情。
园区的工作人员向小马介绍了以下信息。
“首先,咱们这个x86园区,主要有三大特点,一是标准,二是开放,三是兼容。像您这种创业者还是非常多的。初次创业不一定有经验,园区提供标准的企业运行流程辅导。”
“另外,我们园区秉承完全开放的态度,对待各种各样的企业。不封闭,不保守。只要您符合国家的法律法规,我们都接纳。而且,整个园区是一种开放合作的生态,也有利于不同企业之间的协作。”
“再就是兼容。我们园区的流程和规则的设计都会兼容历史上的既有政策,既不会朝令夕改,也不会因为变化而影响您公司的运转。总而言之,来了咱们园区,您就埋头干业务就可以啦!”
小马显然对于x86园区的开放性十分满意,于是追问道:”您刚才说的企业运行流程辅导,能详细介绍一下吗?将来我这个企业在这个园区,应该怎么个运转法儿?”
工作人员接着说:”咱们这个园区毗邻全国知名高校,每年都有大量的优秀毕业生来园区找工作,这是企业非常重要的人才来源。葛优说了,二十一世纪了,人才是核心嘛。每年我们园区都会招聘大量的毕业生,先进行一个月的培训,合格毕业的可以推荐给您这种企业。这些人才啊,就是咱们企业的CPU。”
“经过我们园区培训过的’CPU人才’,具备了三种老板们喜欢的核心竞争力:
第一,实干能力强,干活快,我们称为运算才能——也即指令执行能力;
第二,记忆力好,记得又快又准,我们称为数据才能——也即数据寄存能力;
第三,听话,自控能力强,可以多任务并发执行,我们称为控制才能——也即指令寄存能力。
到时候,你可以根据需求,看雇佣多少个’CPU人才’。
另外,人才得有个办公的地方,这一片呢,就是我们的办公区域,称为也就是内存区域。您可以包几个工位,或者包一片区域,或者几个会议室,让您公司的人才在里面做项目就可以了。这里面有的是地方,同时运行多少各项目都行。”
1.webp)
跟着工作人员的介绍,小马走在x86园区中,看着这一片片的内存办公区,脑子里已经浮现出将来热火朝天的办公场景了。
“也许不到半年的时间,我肯定能够接两三个大项目,招聘十个八个CPU员工。那项目A的员工就坐在这片内存办公区,项目B的员工就坐在那片内存办公区。我根据积累的人脉,将接到的项目写成一个一个的项目执行计划书,里面是一行行项目执行的指令,这些指令操作数据产生一些结果,我们就可以叫程序啦。”小马这么想着。
“然后呢,我把不同的项目执行计划书,交给不同的项目组去执行。那项目组就叫进程吧!两个项目组,进程A和B,会有独立的内存办公空间,互相隔离,程序会分别加载到进程A和进程B的内存办公空间里面,形成各自的代码段。要操作的数据和产生的结果,就放在数据段里面。”
“除此之外,我应该找一个或者多个CPU员工来运行项目执行计划书,我只要告诉他下一条指令在内存办公区中的地址,经过训练的CPU员工就会很自觉地、不停地将代码段的指令拿进来进行处理。”
“指令一般是分两部分,一部分表示做什么操作,例如是加法还是位移;另一部分是操作哪些数据。数据的部分,CPU员工会从数据段里面读取出来,记在脑子里,然后进行处理,处理完毕的结果,在写回数据段。当项目执行计划书里面的所有指令都执行完毕之后,项目也就完成了,那就可以等着收钱啦。”
小马沉浸在思绪中久久不能自拔,直到工作人员打断了他的思绪:”您觉得园区如何?要不要入住呀?先租几个工位,招聘几个人呢?”
小马想了想,说道:”园区我很满意,以后就在您这里创业了,创业开始,我先不招人,自己先干吧。”
56.2 启动公司有手册,获取内核当宝典
工作人员说:”感谢您入驻咱们创业园区,由于您是初次创业,这里有一本《创业指导手册》,在这一本叫作BIOS的小册子上,有您启动一家公司的通用流程,你只要按照里面做就可以了。”
小马接过BIOS小册子,开始按照里面的指令启动公司了。
创业初期,小马的办公室肯定很小,只有有1M的内存办公空间。在1M空间最上面的0xF0000到0xFFFFF这64K映射给ROM,通过读这部分地址,可以访问这个BIOS小册子里面的指令。
创业指导手册第一条,BIOS要检查一些系统的硬件是不是都好着呢。创业指导手册第二条,要有个办事大厅,只不过小马自己就是办事员。因为一旦开张营业,就会有人来找到这家公司,因而基本的中断向量表和中断服务程序还是需要的,至少要能够使用键盘和鼠标。
BIOS这个手册空间有限,只能帮小马把公司建立起来,公司如何运转和经营,就需要另外一个东西——《企业经营宝典》,因而BIOS还要做的一件事情,就是帮助小马找到这个宝典,然后让小马以后根据这个宝典里面的方法来经营公司,这个《企业经营宝典》就是这家公司的内核。
运营一个企业非常的复杂,因而这本《企业经营宝典》也很厚,BIOS手册无法直接加载出来,而需要从门卫开始问起,不断打听这本内核的位置,然后才能加载他。
门卫只有巴掌大的一块地方,在启动盘的第一个扇区,512K的大小,我们通常称为MBR(Master Boot Record,主引导记录/扇区)。这里保存了boot.img,BIOS手册会将他加载到内存中的0x7c00来运行。
boot.img做不了太多的事情。他能做的最重要的一个事情,就是加载grub2的另一个镜像core.img。
引导扇区就是小马找到的门卫,虽然他看着档案库的大门,但是知道的事情很少。他不知道宝典在哪里,但是,他知道应该问谁。门卫说,档案库入口处有个管理处,然后把小马领到门口。
core.img就是管理处,他们知道的和能做的事情就多了一些。core.img由lzma_decompress.img、diskboot.img、kernel.img和一系列的模块组成,功能比较丰富,能做很多事情。
boot.img将控制权交给diskboot.img后,diskboot.img的任务就是将core.img的其他部分加载进来,先是解压缩程序lzma_decompress.img,再往下是kernel.img,最后是各个模块module对应的映像。
管理处听说小马要找宝典,知道他将来是要做老板的人。管理处就告诉小马,既然是老板,早晚都要雇人干活的。这不是个体户小打小闹,所以,你需要切换到老板角色,进入保护模式,把哪些是你的权限,哪些是你可以授权给别人的,都分得清清楚楚。
这些,小马都铭记在心,此时此刻,虽然公司还是只有他一个人,但是小马的眼界放宽了,能够管理的内存空间大多了,也开始区分哪些是用户态,哪些是内核态了。
接下来,kernel.img里面的grub_main会给小马展示一个《企业经营宝典》的列表,也即操作系统的列表,让小马进行选择。经营企业的方式也有很多种,到底是人性化的,还是强纪律的,这个时候你要做一个选择。
3.webp)
在这里,小马毫不犹豫地选择了《狼性文化》操作系统,至此grub才开始启动《狼性文化》操作系统内核。
拿到了宝典的小马,开始越来越像一个老板了。他要开始以老板的思维,来建立这家公司。
56.3 初创公司有章法,请来兄弟做臂膀
这注定是一个不眠夜,办公室里面一片漆黑中,唯一亮着的台灯下,小马独自捧着《企业经营宝典》仔细研读,读着读着,小马若有所思,开始书写公司内核的初始化计划。
4.webp)
公司首先应该有个项目管理部门,咱们将来肯定要接各种各样的项目,因此,项目管理体系和项目管理流程首先要建立起来。虽然现在还没有项目,但是小马还是弄了一个项目模板init_task。这是公司的第一个项目(进程),是项目管理系统里面的项目列表中的第一个,我们能称为0号进程。这个项目是虚拟的,不对应一个真实的项目(也就是进程)。
项目需要项目管理进行调度,还需要制定一些调度策略。
另外,为了快速响应客户需求,为了各个项目组能够方便地使用公司的公共资源,还应该有一个办事大厅。这里面可以设置了很多中断门(Interrupt Gate),用于处理各种中断,以便快速响应突发事件;还可以提供系统调用,为项目组服务。
如果项目接得多了,为了提高研发效率,对项目内容进行保密,就需要封闭开发,所以将来会有很多的会议室,因而还需要一个会议室管理系统。
项目的执行肯定会留下很多文档,这些是公司的积累,将来的核心竞争力,一定要好好管理,因而应该建立一个项目档案库,也即文件系统。
随着思绪的展开,小马奋笔疾书,已经写了满满的几页纸,小马顿感经营一个公司还是挺复杂的,一旦项目接多了肯定忙不过来。俗话说得好,”一个好汉三个帮”,小马准备找两个兄弟来一起创业。
小马想到的第一个人,是自己的大学室友,外号”周瑜”。大学一毕业,周瑜就转项目管理了,在一家大公司管理着大型项目。将来外部接了项目,可以让他来管。小马想到的第二个人,是自己上一家公司的同事,外号”张昭”,是他们总经理的好帮手,公司的流程、人事、财务打理得都轻轻楚楚,将来公司内部要运行的井井有条,也需要这样一个人。
第二天,小马请周瑜和张昭吃饭,邀请他们加入他的创业公司。小马说,公司要正规运转起来,应该分清内外,外部项目需要有人帮忙管理好——也就是用户态,内部公司的核心资源也需要管理好——也就是内核态。现在我一个人忙不过来,需要两位兄弟的加入,周瑜主外,张昭主内,正所谓,内事不决问张昭,外事不决问周郎嘛。
三个人相谈甚欢,谈及往日友谊、未来前景、上市敲钟……
第三天,周瑜早早就来到公司,开始了他的事业。小马拜托周瑜做的第一件事情是调用kernel_init运行1号项目(进程)。这个1号项目会在用户态运行init项目(进程)。这是第一个以外部项目的名义运行的,之所以叫init,就是做初始化的工作,周瑜根据自己多年的项目管理经验,将这个init项目立为标杆,以后所有外部项目的运行都要按照他来,是外部项目的祖先项目。
下午,张昭也来到了公司,小马拜托张昭做的第一件事情是调用kthreadd运行2号项目(进程)。这个2号项目是内核项目的祖先。将来所有的项目都有父项目、祖先项目,会形成一棵项目树。公司大了之后,周瑜和张昭做的公司VP级别的任务,就可以坐在塔尖上了。
好了,这一节小马终于将公司的架子搭起来了,兄弟三人如当年桃园三结义一样,开始自己的创业生涯,小马的这家公司能不能顺利接到项目呢?欲知后事,且听下回分解。
57. 用一个创业故事串起操作系统原理(二)
上一节说到小马同学的公司已经创立了,还请来了周瑜和张昭作为帮手,所谓”兄弟齐心,其利断金”。可是,现在这家公司,还得从接第一个外部项目开始。
57.1 首个项目虽简单,项目管理成体系
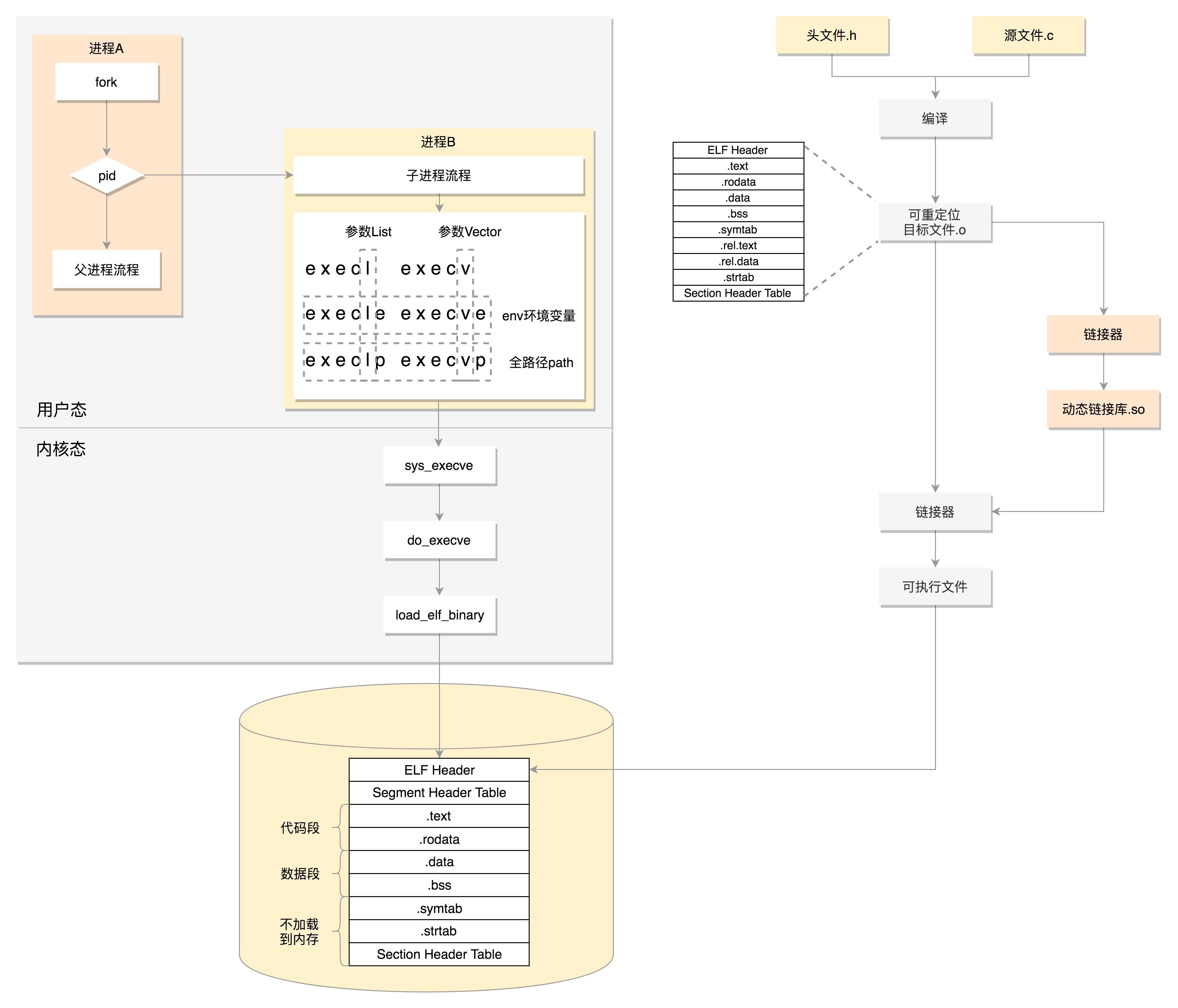
这第一个项目,还是小马亲自去谈的。其实软件公司了解客户需求还是比较难的,因为客户都说着接近人类的语言,例如C/C++。这些咱们公司招聘的CPU小伙伴们可听不懂,需要有一个人将客户需求,转换为项目执行计划书,CPU小伙伴们才能执行,这个过程我们称为编译。
编译其实是一个需求分析和需求转换的过程。这个过程会将接近人类的C/C++语言,转换为CPU小伙伴能够听懂的二进制语言,并且以一定的文档格式,写成项目执行计划书。这种文档格式是作为一个标准化的公司事先制定好的一种格式,是周瑜从大公司里面借鉴来的,称为ELF格式,这个项目执行计划书有总论ELF Header的部分,有包含指令的代码段的部分,有包含全局变量的数据段的部分。
小马和客户聊了整整一天,确认了项目的每一个细节,保证编译能够通过,才写成项目执行计划书ELF文件,放到档案库中。此时已经半夜了。
第二天,周瑜一到公司,小马就兴奋地给周瑜说,”我昨天接到了第一个项目,而且是一个大项目,项目执行计划书我都写好了,你帮我监督、执行、管理,记得按时交付哦!”
周瑜说,”没问题。”于是,周瑜从父项目开始,fork一个子项目,然后在子项目中,调用exec系统调用, 然后到了内核里面,通过load_elf_binary将项目执行计划书加载到子进程内存中,交给一个CPU执行。
虽然这是第一个项目,以周瑜的项目管理经验,他告诉小马,项目的执行要保质保量,需要有一套项目管理系统来管理项目的状态,而不能靠脑子记。”项目管理系统?当然应该有了”,小马说。他在《企业经营宝典》中看到过。
于是,项目管理系统就搭建起来了。在这里面,所有项目都放在一个task_struct列表中,对于每一个项目,都非常详细地登记了项目方方面面的信息。

每一个项目都应该有一个ID,作为这个项目的唯一标识。到时候排期啊、下发任务啊等等,都按ID来,就不会产生歧义。
项目应该有运行中的状态,TASK_RUNNING并不是说进程正在运行,而是表示进程在时刻准备运行的状态。这个时候,要看CPU小伙伴有没有空,有空就运行他,没空就得等着。
有时候,进程运行到一半,需要等待某个条件才能运行下去,这个时候只能睡眠。睡眠状态有两种。一种是TASK_INTERRUPTIBLE,可中断的睡眠状态。这是一种浅睡眠的状态,也就是说,虽然在睡眠,等条件成熟,进程可以被唤醒。
另一种睡眠是TASK_UNINTERRUPTIBLE,不可中断的睡眠状态。这是一种深度睡眠状态,不可被唤醒,只能死等条件满足。有了一种新的进程睡眠状态,TASK_KILLABLE,可以终止的新睡眠状态。进程处于这种状态中,他的运行原理类似TASK_UNINTERRUPTIBLE,只不过可以响应致命信号,也即虽然在深度睡眠,但是可以被干掉。
一旦一个进程要结束,先进入的是EXIT_ZOMBIE状态,但是这个时候他的父进程还没有使用wait()等系统调用来获知他的终止信息,此时进程就成了僵尸进程。
EXIT_DEAD是进程的最终状态。
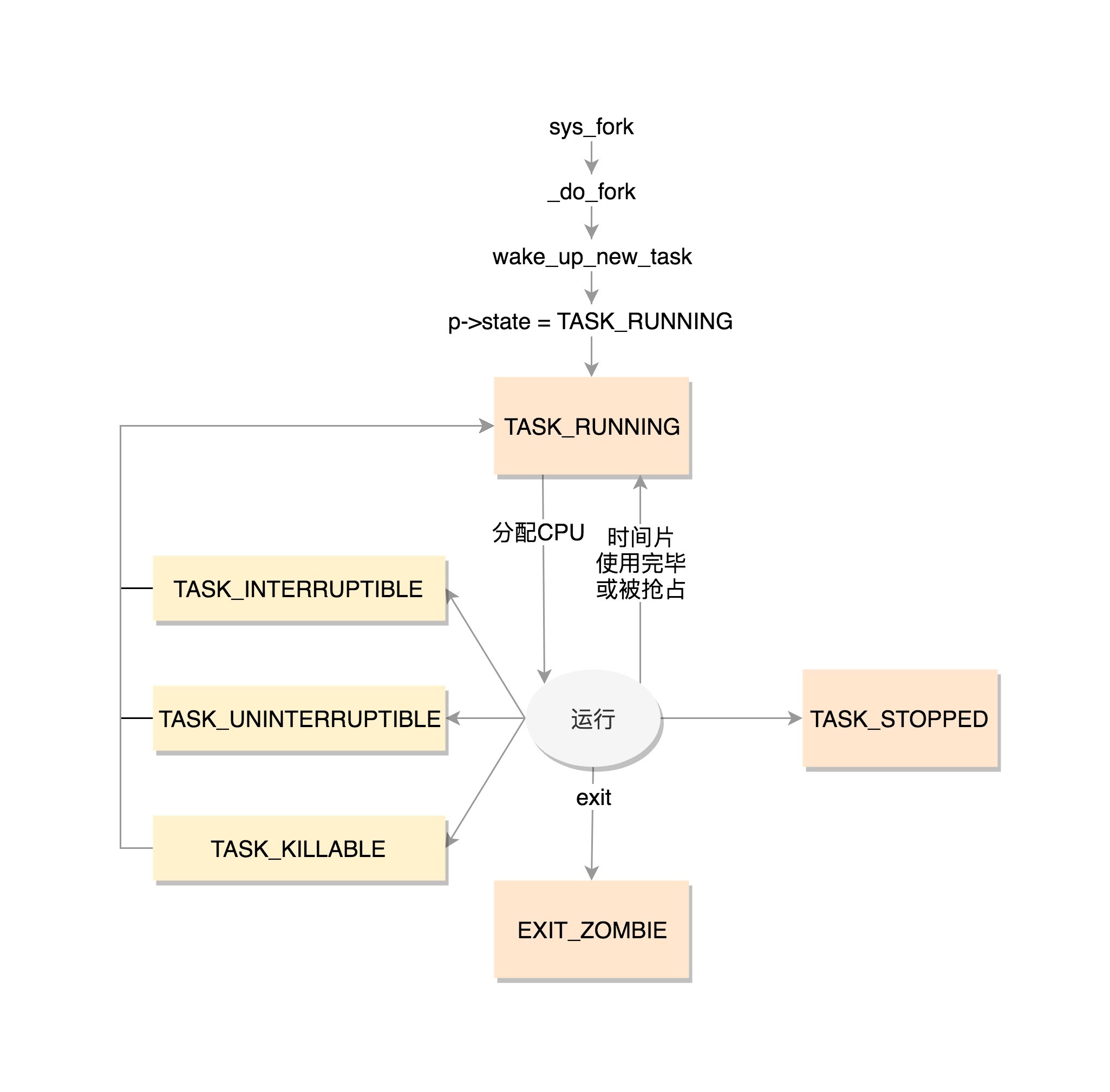
另外,项目运行的统计信息也非常重要。例如,有的员工很长时间都在做一个任务,这个时候你就需要特别关注一下;再如,有的员工的琐碎任务太多,这会大大影响他的工作效率。
那如何才能知道这些员工的工作情况呢?在进程的运行过程中,会有一些统计量,例如进程在用户态和内核态消耗的时间、上下文切换的次数等等。
项目之间的亲缘关系也需要维护,任何一个进程都有父进程。所以,整个进程其实就是一棵进程树。而拥有同一父进程的所有进程都具有兄弟关系。
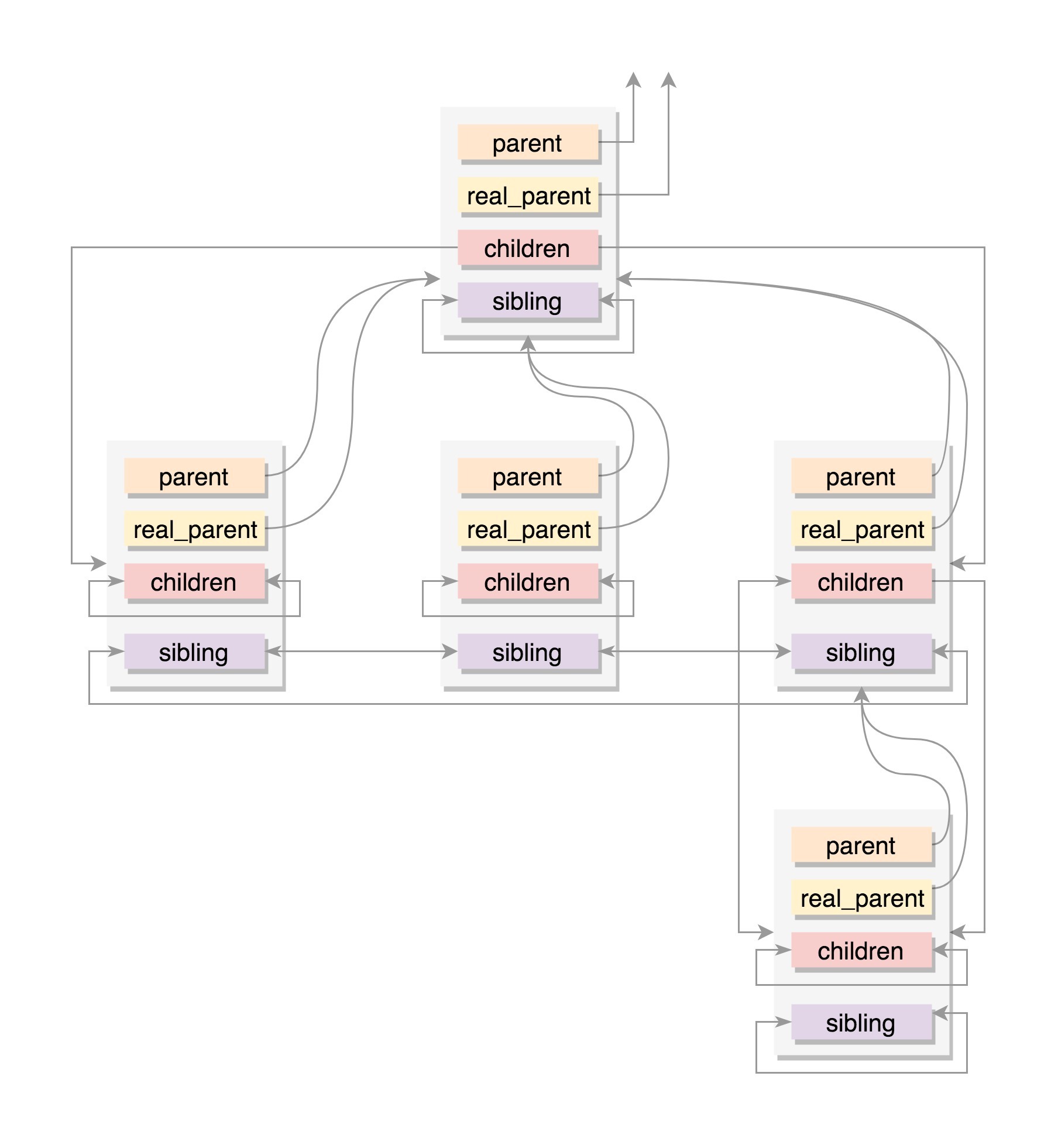
另外,对于项目来讲,项目组权限的控制也很重要。什么是项目组权限控制呢?这么说吧,我这个项目组能否访问某个文件,能否访问其他的项目组,以及我这个项目组能否被其他项目组访问等等
另外,项目运行过程中占用的公司的资源,例如会议室(内存)、档案库(文件系统)也需要在项目管理系统里面登记。
周瑜同学将项目登记好,然后就分配给CPU同学们说,开始执行吧。
好在第一个项目还是比较简单的,一个CPU同学按照项目执行计划书按部就班一条条的执行,很快就完成了,客户评价还不错,很快收到了回款。
57.2 项目大了要并行,项目多了要排期
小马很开心,可谓开门红。接着,第二个项目就到来了,这可是一个大项目,要帮一家知名公司开发一个交易网站,共200个页面,这下要赚翻了,就是时间要的比较急,要求两个星期搞定。
小马把项目带回来,周瑜同学说,这个项目有点大,估计一个CPU同学干不过来了,估计要多个CPU同学一起协作了。
为了完成这个大的项目(进程),就不能一个人从头干到尾了,这样肯定赶不上工期。于是,周瑜将一个大项目拆分成20个子项目,每个子项目完成10个页面,一个大项目组也分成20个小组,并行开发,都开发完了,再做一次整合,这肯定比依次开发200个页面快多了。如果项目叫进程,那子项目就叫线程。
在Linux里面,无论是进程,还是线程,到了内核里面,我们统一都叫任务,由一个统一的结构task_struct进行管理。
不知道是好消息,还是坏消息,这么大一个项目还没有做完,新的项目又找上门了。看来有了前面的标杆客户,名声算是打出去了,一个项目接一个地不停。
小马是既高兴,又犯愁,于是找周瑜和张昭商量应该咋办。要不多招人?多来几个CPU小伙伴,就不搞定了?可是咱们还是在创业阶段,养不起这么多人。另外的办法就是,人力复用,一个CPU小伙伴干多个项目,干不过来,就加加班,实在不行就996,这样应该就没问题了。
一旦涉及一个CPU小伙伴同时参与多个项目,就非常考验项目管理的水平了。如何排期、如何调度,是一个大学问。例如,有的项目比较紧急,应该先进行排期;有的项目可以缓缓,但是也不能让客户等太久。所以这个过程非常复杂,需要平衡。
对于操作系统来讲,他面对的CPU的数量是有限的,干活儿都是他们,但是进程数目远远超过CPU的数目,因而就需要进行进程的调度,有效地分配CPU的时间,既要保证进程的最快响应,也要保证进程之间的公平。
如何调度呢?周瑜能够想到的方式就是排队。每一个CPU小伙伴旁边都有一个白板,上面写着自己需要完成的任务,来了新任务就写到白板上,做完了就擦掉。
一个CPU上有一个队列,队列里面是一系列sched_entity,每个sched_entity都属于一个task_struct,代表进程或者线程。
调度要解决的第一个问题是,每一个CPU小伙伴每过一段时间,都要想一下,白板上这么多项目,我应该干哪一个?CPU的队列里面有这么多的进程或者线程,应该取出哪一个来执行?
.webp)
这就是调度规则或者调度算法的问题。
周瑜说,他原来在大公司的时候,调度算法常用是这样设计的。
一个是公平性,对于接到的多个项目,不能厚此薄彼。这个算法主要由fair_sched_class实现,fair就是公平的意思。
另一个是优先级,有的项目要急一点,客户出的钱多,所以应该多分配一些精力在高优先级的项目里面。
在Linux里面,讲究的公平可不是一般的公平,而是CFS调度算法,CFS全称是Completely Fair Scheduling,完全公平调度。
为了公平,项目经理需要记录下进程的运行时间。CPU会提供一个时钟,过一段时间就触发一个时钟中断。就像咱们的表滴答一下,这个我们叫Tick。CFS会为每一个进程安排一个虚拟运行时间vruntime。如果一个进程在运行,随着时间的增长,也就是一个个Tick的到来,进程的vruntime将不断增大。没有得到执行的进程vruntime不变。
显然,那些vruntime少的,原来受到了不公平的对待,需要给他补上,所以会优先运行这样的进程。
这有点儿像让你把一筐球平均分到N个口袋里面,你看着哪个少,就多放一些;哪个多了,就先不放。这样经过多轮,虽然不能保证球完全一样多,但是也差不多公平。
有时候,进程会分优先级,如何给优先级高的进程多分时间呢?
这个简单,就相当于N个口袋,优先级高的袋子大,优先级低的袋子小。这样球就不能按照个数分配了,要按照比例来,大口袋的放了一半和小口袋放了一半,里面的球数目虽然差很多,也认为是公平的。
函数update_curr用于更新进程运行的统计量vruntime ,CFS还需要一个数据结构来对vruntime进行排序,找出最小的那个。在这里使用的是红黑树。红黑树的的节点是sched_entity,里面包含vruntime。
调度算法的本质就是解决下一个进程应该轮到谁运行的问题,这个逻辑在fair_sched_class.pick_next_task中完成。
调度要解决的第二个问题是,什么时候切换任务?也即,什么时候,CPU小伙伴应该停下一个进程,换另一个进程运行?
一个人在做A项目,在某个时刻,换成做B项目去了。发生这种情况,主要有两种方式。
方式一,A项目做着做着,里面有一条指令sleep,也就是要休息一下,或者等待某个I/O事件。那没办法了,要主动让出CPU,然后可以开始做B项目。主动让出CPU的进程,会主动调用schedule()函数。
在schedule()函数中,会通过fair_sched_class.pick_next_task,在红黑树形成的队列上取出下一个进程,然后调用context_switch进行进程上下文切换。
进程上下文切换主要干两件事情,一是切换进程空间,也即进程的内存,也即CPU小伙伴不能A项目的会议室里面干活了,要跑到B项目的会议室去。二是切换寄存器和CPU上下文,也即CPU将当期在A项目中干到哪里了,记录下来,方便以后接着干。
方式二,A项目做着做着,旷日持久,实在受不了了。项目经理介入了,说这个项目A先停停,B项目也要做一下,要不然B项目该投诉了。最常见的现象就是,A进程执行时间太长了,是时候切换到B进程了。这个时候叫作A进程被被动抢占。
抢占还要通过CPU的时钟Tick,来衡量进程的运行时间。时钟Tick一下,是很好查看是否需要抢占的时间点。 时钟中断处理函数会调用scheduler_tick(),他会调用fair_sched_class的task_tick_fair,在这里面会调用update_curr更新运行时间。当发现当前进程应该被抢占,不能直接把他踢下来,而是把他标记为应该被抢占,打上一个标签TIF_NEED_RESCHED。
另外一个可能抢占的场景发生在,当一个进程被唤醒的时候。一个进程在等待一个I/O的时候,会主动放弃CPU。但是,当I/O到来的时候,进程往往会被唤醒。这个时候是一个时机。当被唤醒的进程优先级高于CPU上的当前进程,就会触发抢占。如果应该发生抢占,也不是直接踢走当然进程,而也是将当前进程标记为应该被抢占,打上一个标签TIF_NEED_RESCHED。
真正的抢占还是需要上下文切换,也就是需要那么一个时刻,让正在运行中的进程有机会调用一下schedule。调用schedule有以下四个时机。
- 对于用户态的进程来讲,从系统调用中返回的那个时刻,是一个被抢占的时机。
- 对于用户态的进程来讲,从中断中返回的那个时刻,也是一个被抢占的时机。
- 对内核态的执行中,被抢占的时机一般发生在preempt_enable()中。在内核态的执行中,有的操作是不能被中断的,所以在进行这些操作之前,总是先调用preempt_disable()关闭抢占。再次打开的时候,就是一次内核态代码被抢占的机会。
- 在内核态也会遇到中断的情况,当中断返回的时候,返回的仍然是内核态。这个时候也是一个执行抢占的时机。
周瑜和张昭商定了这个规则,然后给CPU小伙伴们交代之后,项目虽然越来越多,但是也井井有条起来。CPU小伙伴不会像原来一样火急火燎,不知所从了。
可是其实对于项目的开发,这家公司还是有严重漏洞的,就是项目的保密问题,不管哪家客户将系统外包出去,肯定也不想让其他公司知道详情。如果解决不好这个问题,没人敢把重要的项目交给这家公司,小马的公司也就永远只能接点边角系统,还是不能保证温饱问题。
那接下来,小马会怎么解决项目之间的保密问题呢?欲知后事,且听下回分解。
58. 用一个创业故事串起操作系统原理(三)
上一节我们说到,周瑜和张昭商定了调用schedule的时机。尽管项目越来越多,但是也井井有条。可是我们也说了,不管你的事情做得有多好,项目保密问题都是要解决的重要问题。怎么解决呢?今天我们就来看一看。
58.1 保密需封闭开发,空间小巧妙安排
慢慢地,小马发现,项目接的多了之后,CPU小伙伴的任务调度问题解决了之后,会议室的使用经常陷入混乱。不同的项目使用会议室的时候,经常冲突,一个项目组没用完,另一个项目组就在那里等着,十分耽误开发效率。
小马说:”要不咱们的项目别用会议室封闭开发了,原来总是说封闭开发,就是为了隔离,保密。这对于公司声誉来说很重要,但是能不能通过签订保密协议的方式来,干嘛非得封闭开发呢?”
周瑜说:”马哥,以我在大公司管理项目的经验来看,您还是想简单了。”
“你看,每次你接一个项目,总要写成项目执行计划书,CPU小伙伴们才能执行吧,项目计划书中的一行一行指令运行过程中,免不了要产生一些数据。这些数据要保存在一个地方,这个地方就是会议室(内存)。会议室(内存)被分成一块一块儿的,都编好了号。例如3F-10,就是三楼十号会议室。这个地址是实实在在的地址,通过这个地址我们就能够定位到物理内存的位置。”
“现在问题来了,写项目执行计划书的时候,里面的指令使用的地址是否可以使用物理地址呢?当然不行了,项目执行计划书,都是事先写好的,可以多次运行的。如果里面有个指令是,要把用户输入的数字保存在内存中,那就会有问题。”
“会产生什么问题呢?我举个例子你就明白了。如果我们使用那个实实在在的地址,3F-10,打开三个相同的程序,都执行到某一步。比方说,打开了三个计算器,用户在这三个程序的界面上分别输入了10、100、1000。如果内存中的这个位置只能保存一个数,那应该保存哪个呢?这不就冲突了吗?”
“如果不用这个实实在在的地址,那应该怎么办呢?那就必须用封闭开发的办法。
每个项目的物理地址对于进程不可见,谁也不能直接访问这个物理地址。操作系统会给进程分配一个虚拟地址。所有进程看到的这个地址都是一样的,里面的内存都是从0开始编号。
在程序里面,指令写入的地址是虚拟地址。例如,位置为10M的内存区域,操作系统会提供一种机制,将不同进程的虚拟地址和内存的物理地址映射起来。
当程序要访问虚拟地址的时候,由内核的数据结构进行转换,转换成不同的物理地址,这样不同的进程运行的时候,写入的是不同的物理地址,就不会冲突了。”
小马想想,对啊,这是个好办法,咱们得规划一套会议室管理系统(内存管理)。根据刚才的分析,这个系统应该包含以下三个部分:
第一,物理内存的管理,相当于会议室管理员管理会议室;
第二,虚拟地址的管理,也即在项目组的视角,会议室的虚拟地址应该如何组织;
第三,虚拟地址和物理地址如何映射的问题,也即会议室管理员如果管理映射表。
我们先来盘点一下物理内存的情况。
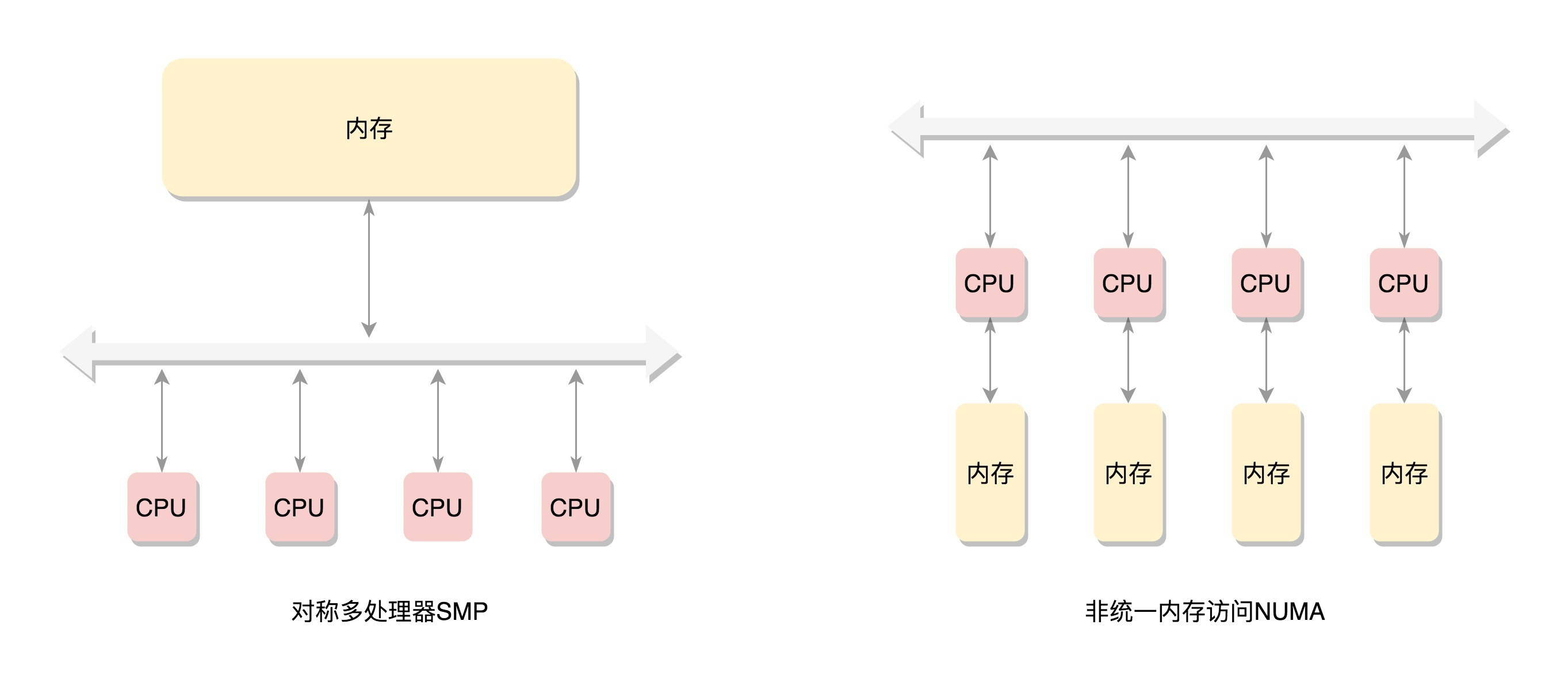
不同的园区工位的安排和会议室的布局各不相同。
第一种情况是,CPU小伙伴们坐在一起,会议室在楼层的另一面,大家到会议室里面去都要通过统一的过道,优点简单,缺点是通道会成为瓶颈。
第二种情况是,会议室分成多个节点,离散地分布在CPU小伙伴周围。有的小伙伴去这个会议室近一些,有的小伙伴离另外一些会议室近一些。这样做的优点是,如果CPU小伙伴干活总是能够去离他最近的会议室,则速度非常快,但是一旦离他最近的会议室被占用了,他只能去其他会议室,这样就比较远了。
现在的园区基本都设计成第二种样子,也即会议室(内存)要分节点,每个节点用struct pglist_data表示。
每个节点里面再分区域,用于区分内存不同部分的不同用法。ZONE_NORMAL是最常用的区域。ZONE_MOVABLE是可移动区域。我们通过将物理内存划分为,可移动分配区域和不可移动分配区域,来避免内存碎片。每个区域用struct zone表示,也放在一个数组里面。
每个区域里面再分页。默认的大小为4KB。这就相当于每个会议室的最小单位。
如果有项目要使用会议室,应该如何分配呢?不能任何项目来了,咱都给他整个会议室。会议室也是可以再分割的,例如在中间拼起一堵墙,这样一个会议室就可以分成两个,继续分,可以再分成四个1/4大小的会议室,直到不能再分,我们就能得到一页的大小。
物理页面分配的时候,也可以采取这样的思路,我们称为伙伴系统。
空闲页放在struct free_area里面,每一页用struct page表示。
把所有的空闲页分组为11个页块链表,每个块链表分别包含很多个大小的页块,有1、2、4、8、16、32、64、128、256、512和1024个连续页的页块。最大可以申请1024个连续页,对应4MB大小的连续内存。每个页块的第一个页的物理地址是该页块大小的整数倍。
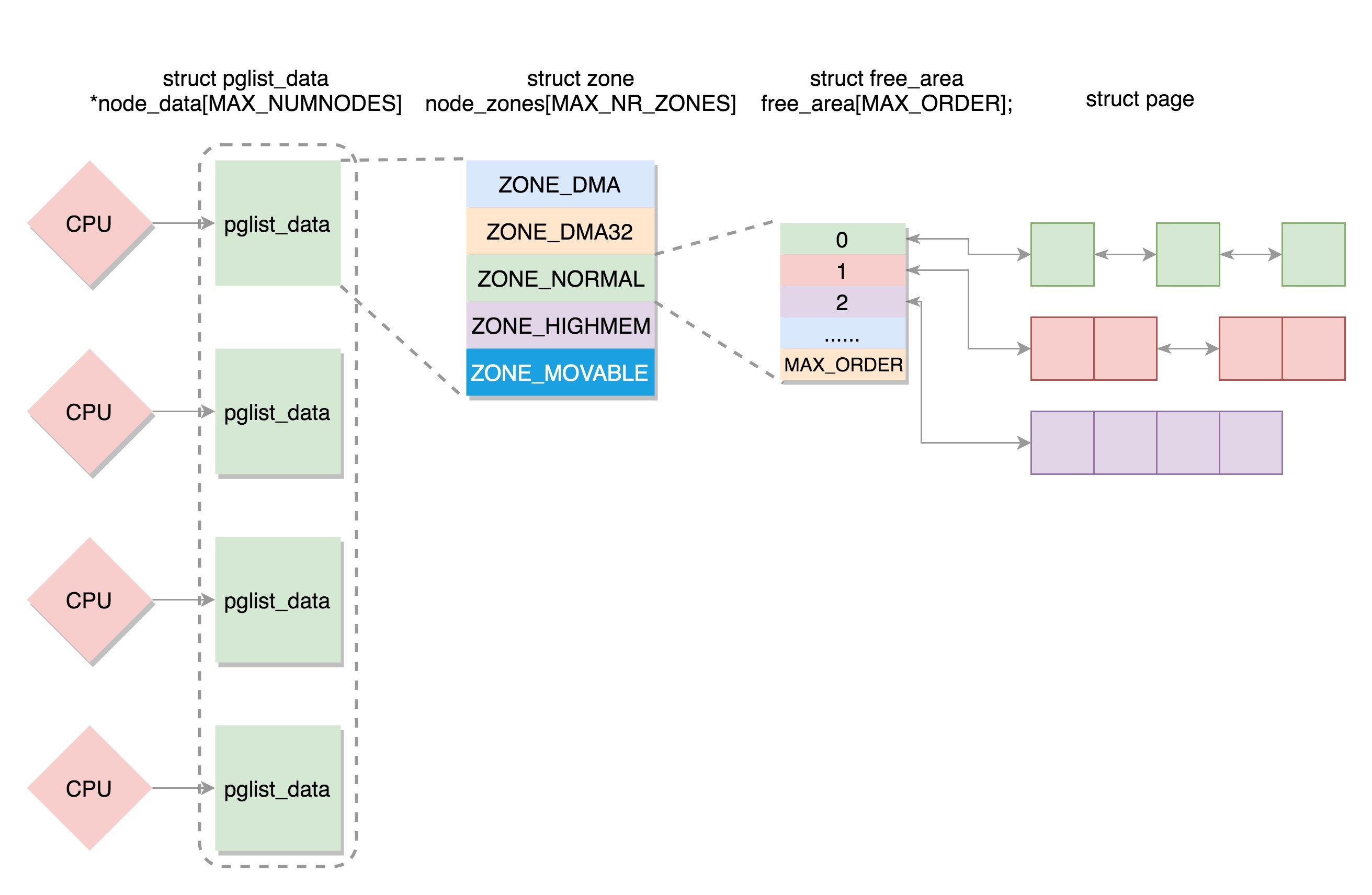
例如,要请求一个128个页的页块时,我们要先检查128个页的页块链表是否有空闲块。如果没有,则查256个页的页块链表;如果有空闲块的话,则将256个页的页块分成两份,一份使用,一份插入128个页的页块链表中。如果还是没有,就查512个页的页块链表;如果有的话,就分裂为128、128、256三个页块,一个128的使用,剩余两个插入对应页块链表。
把物理页面分成一块一块大小相同的页,这样带来的另一个好处是,当有的内存页面长时间不用了,可以暂时写到硬盘上,我们称为换出。一旦需要的时候,再加载进来,就叫作换入。这样可以扩大可用物理内存的大小,提高物理内存的利用率。在内核里面,也即张昭的管理下,有一个进程kswapd,可以根据物理页面的使用情况,对页面进行换入换出。
小马觉得这种方式太好了,如此高效地使用会议室,公司不用租用多少会议室,就能解决当前的项目问题了。
58.2 会议室排列有序,分视角各有洞天
周瑜说,”你先别急,这还仅仅是会议室物理地址的管理,每一个项目组能够看到的虚拟地址,咱还没规划呢!这个规划不好,执行项目还是会有问题的。”
每个项目组能看到的虚拟地址怎么规划呢?我们要给项目组这样一种感觉,从项目组的角度,也即从虚的角度来看,这一大片连续的内存空间都是他们的了。
如果是32位,有2^32 = 4G的内存空间都是他们的,不管内存是不是真的有4G。如果是64位,在x86_64下面,其实只使用了48位,那也挺恐怖的。48位地址长度也就是对应了256TB的地址空间。
小马说:”我都没怎么见过256T的硬盘,别说是内存了。”
周瑜接着说:”现在,一个项目组觉得,会议室可比世界首富房子还大。虽然是虚拟的,下面尽情地去排列咱们要放的东西吧!请记住,现在我们是站在一个进程的角度,去看这个虚拟的空间,不用管其他进程。”
首先,这么大的虚拟空间一切二,一部分用来放内核的东西,称为内核空间;一部分用来放进程的东西,称为用户空间。用户空间在下,在低地址,我们假设是0号到29号会议室;内核空间在上,在高地址,我们假设是30号到39号会议室。这两部分空间的分界线,因为32位和64位的不同而不同,我们这里不深究。
对于普通进程来说,内核空间的那部分,虽然虚拟地址在那里,但是不能访问。这就像作为普通员工,你明明知道财务办公室在这个30号会议室门里面,但是门上挂着”闲人免进”,你只能在自己的用户空间里面折腾。
3.webp)
我们从最低位开始排起,先是Text Segment、Data Segment和BSS Segment。Text Segment是存放二进制可执行代码的位置,Data Segment存放静态常量,BSS Segment存放未初始化的静态变量。这些都是在项目执行计划书里面有的。
接下来是堆段。堆是往高地址增长的,是用来动态分配内存的区域,malloc就是在这里面分配的。
接下来的区域是Memory Mapping Segment。这块地址可以用来把文件映射进内存用的,如果二进制的执行文件依赖于某个动态链接库,就是在这个区域里面将so文件映射到了内存中。
再下面就是栈地址段了,主线程的函数调用的函数栈就是用这里的。
如果普通进程还想进一步访问内核空间,是没办法的,只能眼巴巴地看着。如果需要进行更高权限的工作,就需要调用系统调用,进入内核。
一旦进入了内核,就换了一副视角。刚才是普通进程的视角,觉着整个空间是它独占的,没有其他进程存在。当然另一个进程也这样认为,因为它们互相看不到对方。这也就是说,不同进程的0号到29号会议室放的东西都不一样。
但是,到了内核里面,无论是从哪个进程进来的,看到的是同一个内核空间,看到的是同一个进程列表。虽然内核栈是各用个的,但是如果想知道的话,还是能够知道每个进程的内核栈在哪里的。所以,如果要访问一些公共的数据结构,需要进行锁保护。也就是说,不同的进程进入到内核后,进入的30号到39号会议室是同一批会议室。
4.webp)
内核的代码访问内核的数据结构,大部分的情况下都是使用虚拟地址的。虽然内核代码权限很大,但是能够使用的虚拟地址范围也只能在内核空间,也即内核代码访问内核数据结构,只能用30号到39号这些编号,不能用0到29号,因为这些是被进程空间占用的。而且,进程有很多个。你现在在内核,但是你不知道当前指的0号是哪个进程的0号。
在内核里面也会有内核的代码,同样有Text Segment、Data Segment和BSS Segment,内核代码也是ELF格式的。
不过有了这个规定以后,项目执行计划书要写入数据的时候,就需要符合里面的规定了,数据不能随便乱放了。
小马说,”没问题,这个作为项目章程,每一个新员工来了都培训。”
58.3 管理系统全搞定,至此生存无问题
周瑜接着说:”物理会议室和虚拟空间都分成大小相同的页,我们还得有一个会议室管理系统,将两者关联起来,这样项目组申请会议室的时候,也有个系统可以统一的管理,要不然会议室还不得老冲突呀。”
对于虚拟内存的访问,也是有一个地址的,我们需要找到一种策略,实现从虚拟地址到物理地址的转换。
为了能够定位和访问每个页,需要有个页表,保存每个页的起始地址,再加上在页内的偏移量,组成线性地址,就能对于内存中的每个位置进行访问了。
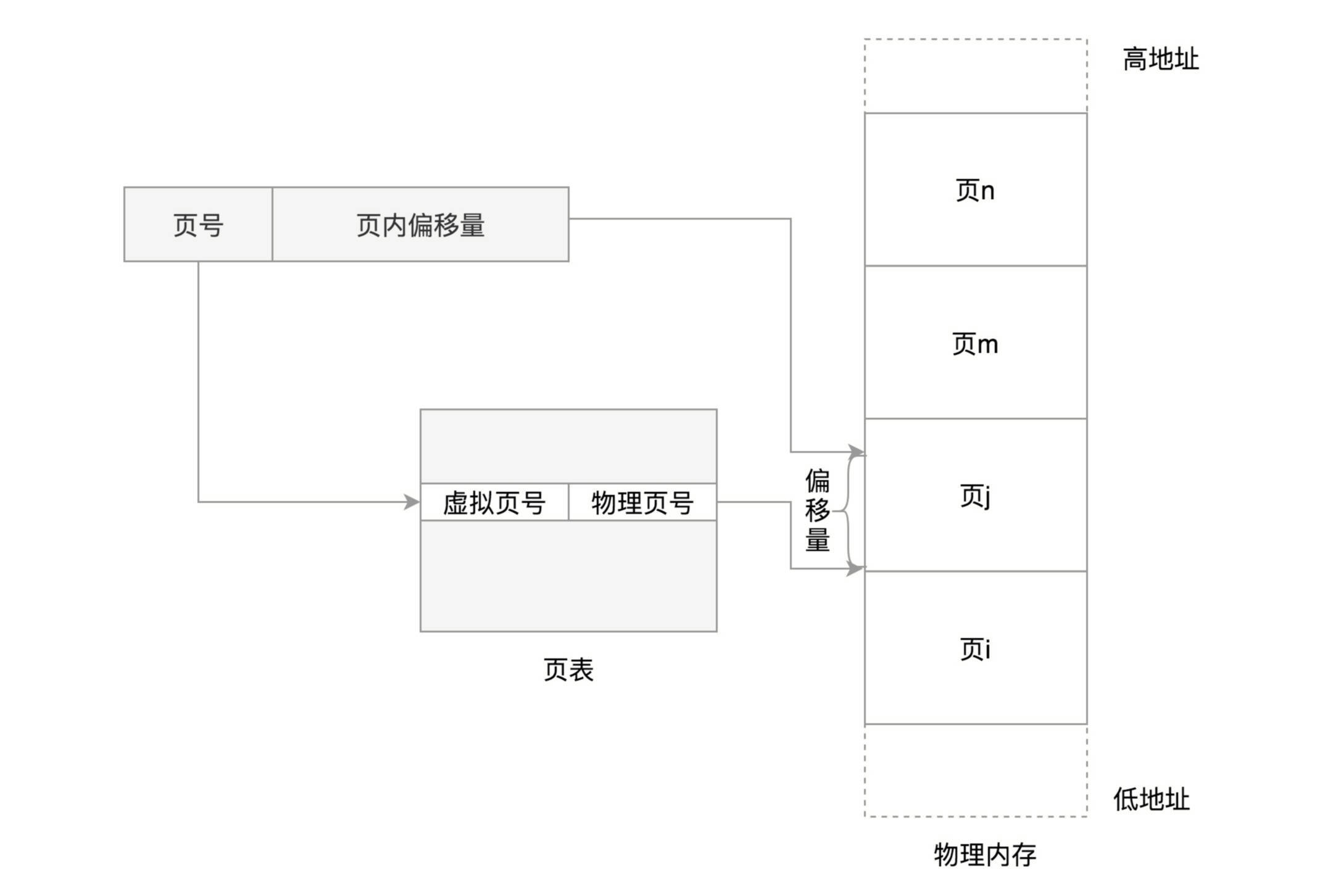
虚拟地址分为两部分,页号和页内偏移。页号作为页表的索引,页表包含物理页每页所在物理内存的基地址。这个基地址与页内偏移的组合就形成了物理内存地址。
下面的图,举了一个简单的页表的例子,虚拟内存中的页通过页表映射对应到物理内存中的页。
6.webp)
32位环境下,虚拟地址空间共4GB。如果分成4KB一个页,那就是1M个页。每个页表项需要4个字节来存储,那么整个4GB空间的映射就需要4MB的内存来存储映射表。如果每个进程都有自己的映射表,100个进程就需要400MB的内存。对于内核来讲,有点大了 。
页表中所有页表项必须提前建好,并且要求是连续的。如果不连续,就没有办法通过虚拟地址里面的页号找到对应的页表项了。
那怎么办呢?我们可以试着将页表再分页,4G的空间需要4M的页表来存储映射。我们把这4M分成1K(1024)个4K,每个4K又能放在一页里面,这样1K个4K就是1K个页,这1K个页也需要一个表进行管理,我们称为页目录表,这个页目录表里面有1K项,每项4个字节,页目录表大小也是4K。
页目录有1K项,用10位就可以表示访问页目录的哪一项。这一项其实对应的是一整页的页表项,也即4K的页表项。每个页表项也是4个字节,因而一整页的页表项是1k个。再用10位就可以表示访问页表项的哪一项,页表项中的一项对应的就是一个页,是存放数据的页,这个页的大小是4K,用12位可以定位这个页内的任何一个位置。
这样加起来正好32位,也就是用前10位定位到页目录表中的一项。将这一项对应的页表取出来共1k项,再用中间10位定位到页表中的一项,将这一项对应的存放数据的页取出来,再用最后12位定位到页中的具体位置访问数据。
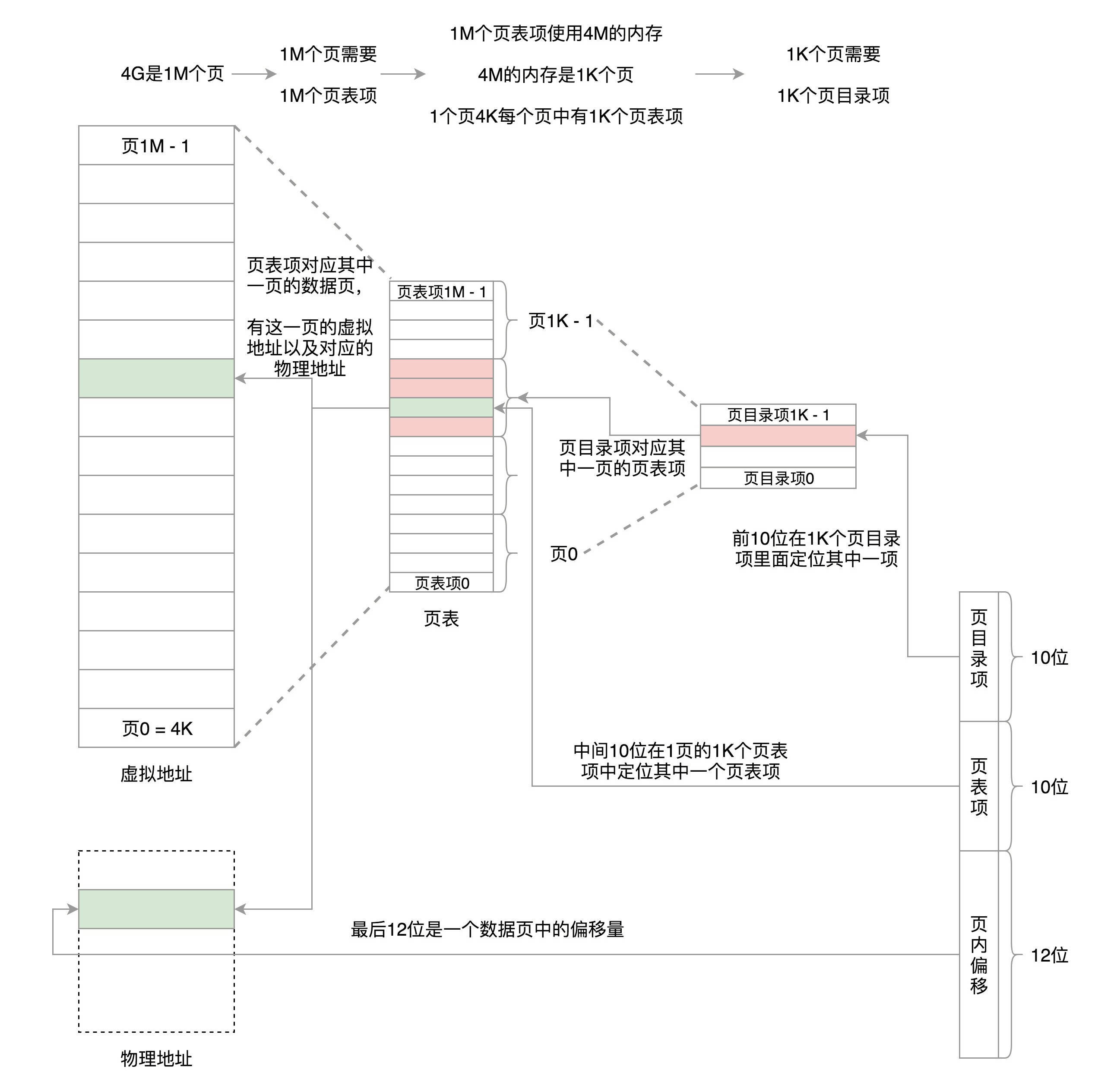
你可能会问,如果这样的话,映射4GB地址空间就需要4MB+4KB的内存,这样不是更大了吗? 当然如果页是满的,当时是更大了,但是,我们往往不会为一个进程分配那么多内存。
比如说,上面图中,我们假设只给这个进程分配了一个数据页。如果只使用页表,也需要完整的1M个页表项共4M的内存,但是如果使用了页目录,页目录需要1K个全部分配,占用内存4K,但是里面只有一项使用了。到了页表项,只需要分配能够管理那个数据页的页表项页就可以了,也就是说,最多4K,这样内存就节省多了。
当然对于64位的系统,两级肯定不够了,就变成了四级目录,分别是全局页目录项PGD(Page Global Directory)、上层页目录项PUD(Page Upper Directory)、中间页目录项PMD(Page Middle Directory)和页表项PTE(Page Table Entry)。
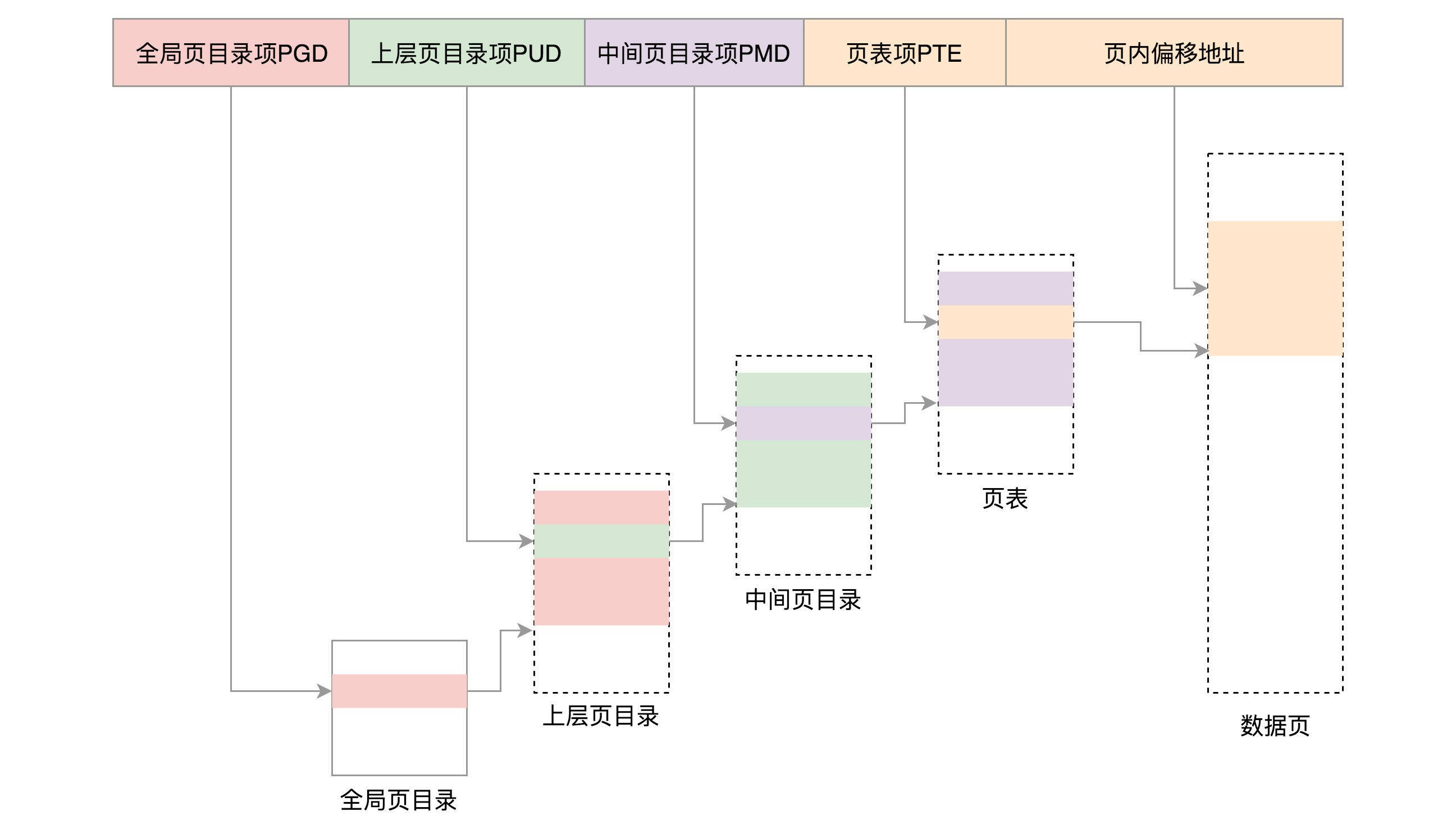
设计完毕会议室管理系统,再加上前面的项目管理系统,对于一家外包公司来讲,无论接什么样的项目都能轻松搞定了。我们常把CPU和内存合称为计算。至此,计算的问题就算搞定了。解决了这两大问题,一家外包公司的生存问题,就算解决了。
小马总算是可以松一口气了,他和周瑜、张昭好好地搓了一顿,喝得昏天黑地。周瑜和张昭纷纷感慨,幸亏当年跟了马哥,今日才有出头之日。
生存问题虽然解决了,马哥可非池中之物,接下来要解决的就是发展问题,马哥能想出什么办法进一步壮大企业呢?欲知后事,且听下回分解。
59. 用一个创业故事串起操作系统原理(四)
上一节,小马的公司已经解决了生存问题,成功从小马晋升马哥。
马哥是一个有危机意识的人。尽管公司开始不断盈利,项目像流水一样,一个接一个,赚了点儿钱,但是他感觉还是有点儿像狗熊掰棒子。因为公司没有积累,永远就都是在做小生意,无法实现成倍的增长。
马哥想,公司做了这么多的项目,应该有很多的共同点,能积累下来非常多的资料。如果能够把这些资料归档、总结、积累,形成核心竞争力,就可以随着行业的飞跃,深耕一个行业,实现快速增长。
59.1 公司发展需积累,马哥建立知识库
这就需要我们有一个存放资料的档案库(文件系统)。档案库应该不依赖于项目而独立存在,应该井井有条、利于查询;应该长久保存,不随人员流动而损失。
公司到了这个阶段,除了周瑜和张昭,应该专门请一个能够积累核心竞争力的人来主持大局了。马哥想到了,前一阵行业交流大会上,他遇到了一个很牛的架构师——鲁肃。他感觉鲁肃在这方面很有想法,于是就请他来主持大局。
鲁肃跟马哥说,构建公司的核心技术能力,这个档案库(文件系统)也可以叫作知识库,这个需要好好规划一下。规划文件系统的时候,需要考虑以下几点。
第一点,文件系统要有严格的组织形式,使得文件能够以块为单位进行存储。
这就像图书馆里,我们会给设置一排排书架,然后再把书架分成一个个小格子。有的项目存放的资料非常多,一个格子放不下,就需要多个格子来进行存放。我们把这个区域称为存放原始资料的仓库区。对于操作系统,硬盘分成相同大小的单元,我们称为块。一块的大小是扇区大小的整数倍,默认是4K,用来存放文件的数据部分。这样一来,如果我们像存放一个文件,就不用给他分配一块连续的空间了。我们可以分散成一个个小块进行存放。这样就灵活得多,也比较容易添加、删除和插入数据。
第二点,文件系统中也要有索引区,用来方便查找一个文件分成的多个块都存放在了什么位置。
这就好比,图书馆的书太多了,为了方便查找,我们需要专门设置一排书架,这里面会写清楚整个档案库有哪些资料,资料在哪个架子的哪个格子上。这样找资料的时候就不用跑遍整个档案库,只要在这个书架上找到后,直奔目标书架就可以了。
在Linux操作系统里面,每一个文件有一个Inode,inode的”i”是index的意思,其实就是”索引”。inode里面有文件的读写权限i_mode,属于哪个用户i_uid,哪个组i_gid,大小是多少i_size_io,占用多少个块i_blocks_io。”某个文件分成几块、每一块在哪里”,这些信息也在inode里面,保存在i_block里面。
1.webp)
第三点,如果文件系统中有的文件是热点文件,近期经常被读取和写入,文件系统应该有缓存层。
这就相当于图书馆里面的热门图书区,这里面的书都是畅销书或者是常常被借还的图书。因为借还的次数比较多,那就没必要每次有人还了之后,还放回遥远的货架,我们可以专门开辟一个区域,放置这些借还频次高的图书。这样借还的效率就会提高。
第四点,文件应该用文件夹的形式组织起来,方便管理和查询。
这就像在图书馆里面,你可以给这些资料分门别类,比如分成计算机类、文学类、历史类等等。这样你也容易管理,项目组借阅的时候只要在某个类别中去找就可以了。
在文件系统中,每个文件都有一个名字,我们访问一个文件,希望通过他的名字就可以找到。文件名就是一个普通的文本,所以文件名经常会冲突,不同用户取相同的名字的情况会经常出现的。
要想把很多的文件有序地组织起来,我们就需要把他们做成目录或者文件夹。这样,一个文件夹里可以包含文件夹,也可以包含文件,这样就形成了一种树形结构。我们可以将不同的用户放在不同的用户目录下,就可以一定程度上避免了命名的冲突问题。
2.webp)
第五点,Linux内核要在自己的内存里面维护一套数据结构,来保存哪些文件被哪些进程打开和使用。
这就好比,图书馆里会有个图书管理系统,记录哪些书被借阅了,被谁借阅了,借阅了多久,什么时候归还。
这个图书管理系统尤为重要,如果不是很方便使用,以后项目中积累了经验,就没有人愿意往知识库里面放了。
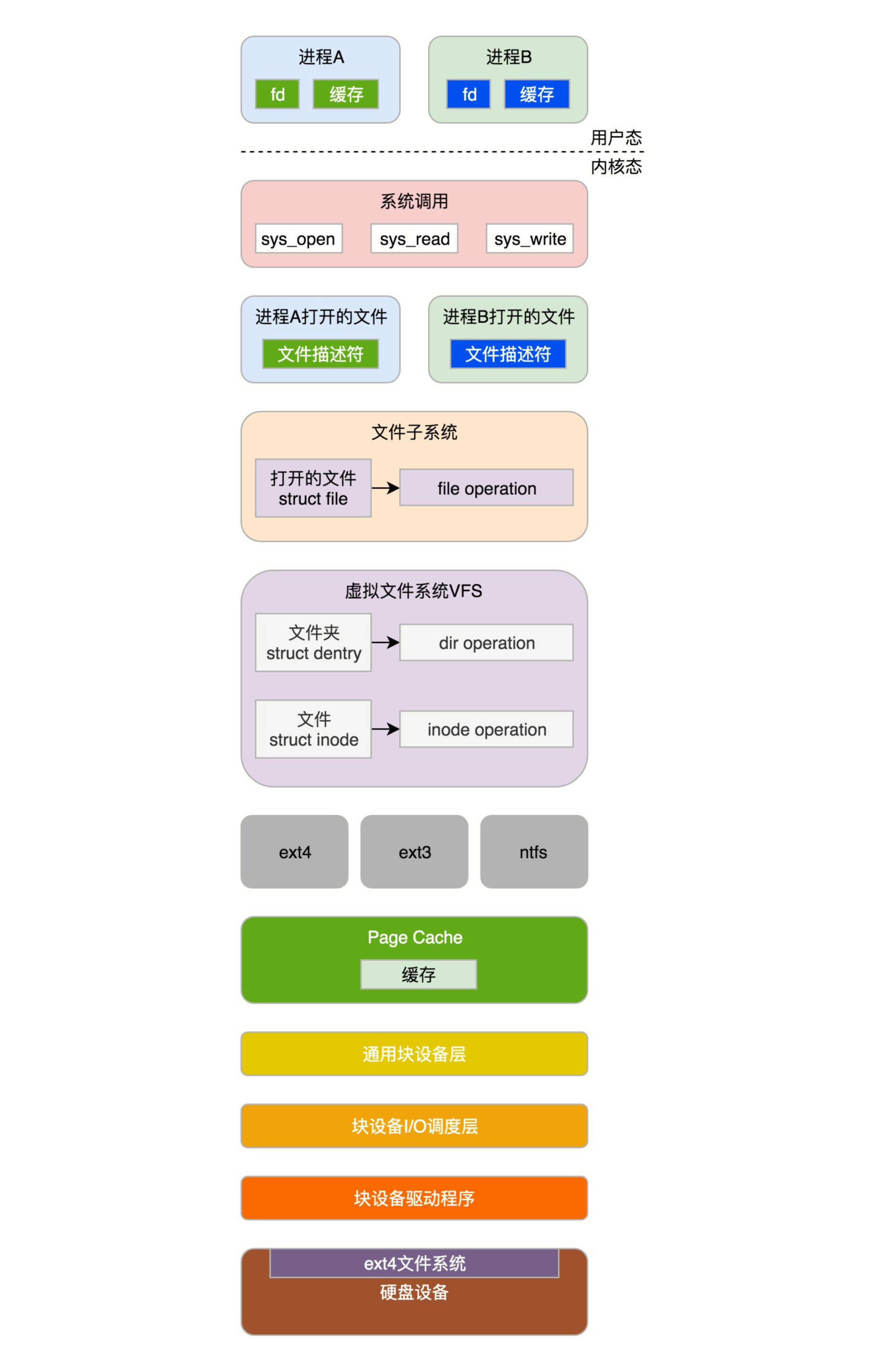
无论哪个项目(进程),都可以通过write系统调用写入知识库。
对于每一个进程,打开的文件都有一个文件描述符。files_struct里面会有文件描述符数组。每个一个文件描述符是这个数组的下标,里面的内容指向一个struct file结构,表示打开的文件。这个结构里面有这个文件对应的inode,最重要的是这个文件对应的操作file_operation。如果操作这个文件,就看这个file_operation里面的定义了。
每一个打开的文件,都有一个dentry对应,虽然我们叫作directory entry,但是他不仅仅表示文件夹,也表示文件。他最重要的作用就是指向这个文件对应的inode。
如果说file结构是一个文件打开以后才创建的,dentry是放在一个dentry cache里面的。文件关闭了,他依然存在,因而他可以更长期的维护内存中的文件的表示和硬盘上文件的表示之间的关系。
inode结构就表示硬盘上的inode,包括块设备号等。这个inode对应的操作保存在inode operations里面。真正写入数据,是写入硬盘上的文件系统,例如ext4文件系统。
马哥听了知识库和档案库的设计,非常开心,对鲁肃说,你这五大秘籍,可是帮了我大忙了。于是马上下令实施。
59.2 有了积累建生态,成立渠道管理部
有了知识库,公司的面貌果然大为改观。
马哥发现,当知识库积累到一定程度,公司接任何项目都能找到相似的旧项目作为参考,不用重新设计,效率大大提高。而且最重要的一点是,没有知识库的时候,原来项目做的好不好,完全取决于程序员,因为所有的知识都在程序员的脑子里,所以公司必须要招聘高质量的程序员,才能保证项目的质量。一方面优秀的程序员数量很少,这大大限制了公司能够接项目的规模,一方面优秀的程序员实在太贵,大大提高了公司的成本。
有了知识库,依赖于原来积累的体系,只要找到类似的旧项目,哪怕是普通的程序员,只要会照猫画虎,结果就不会太差。
于是,马哥马上想到,现在公司只有百十来号人,能赚这些钱,现在招人门槛降低了,我要是招聘一万人,这能赚多少钱啊!
鲁肃对马哥说,”你可先别急着招人,建立知识库,降低招人成本才是第一步。公司招聘太多人不容易管理。既然项目的执行可以照猫画虎,很多项目可以不用咱们公司来,我们可以建立渠道销售体系(输入和输出系统),让供应商、渠道帮我们卖,形成一个生态。这公司的盈利规模可就不是招一万人这么点儿了,这是指数级的增长啊!”
计算机系统的输入和输出系统都有哪些呢?我们能举出来的,例如键盘、鼠标、显示器、网卡、硬盘、打印机、CD/DVD等等,多种多样。这样,当然方便用户使用了,但是对于操作系统来讲,却是一件复杂的事情,因为这么多设备,形状、用法、功能都不一样,怎么才能统一管理起来呢?我们一层一层来看。
第一层,用设备控制器屏蔽设备差异。
马哥说,”把生意做到全国,我也想过,这个可不容易。咱们客户多种多样,众口难调,不同的地域不一样,不同的行业不一样。如果你不懂某个地方的规矩,根本卖不出去东西;如果你不懂某个具体行业的使用场景,也无法满足客户的需求。”
鲁肃说:”所以说,建议您建立生态,设置很多代理商,让各个地区和各个行业的代理商帮你屏蔽这些差异化。你和代理商之间只要进行简单的标准产品交付就可以了。”
计算机系统就是这样的。CPU并不直接和设备打交道,他们中间有一个叫作设备控制器(Device Control Unit)的组件。例如,硬盘有磁盘控制器、USB有USB控制器、显示器有视频控制器等。这些控制器就像代理商一样,他们知道如何应对硬盘、鼠标、键盘、显示器的行为。
你的代理商往往是小公司。控制器其实有点儿像一台小电脑。他有他的芯片,类似小CPU,执行自己的逻辑。他也有他的寄存器。这样CPU就可以通过写这些寄存器,对控制器下发指令,通过读这些寄存器,查看控制器对于设备的操作状态。
CPU对于寄存器的读写,可比直接控制硬件,要标准和轻松很多。这就相当于你和代理商的标准产品交付。
第二层,用驱动程序屏蔽设备控制器差异。
马哥说:”你这么一说,还真有道理,如果我们能够找到足够多的代理商,那就高枕无忧了。”
鲁肃说:”其实事情还没这么简单,虽然代理商机制能够帮我们屏蔽很多设备的细节,但是从上面的描述我们可以看出,由于每种设备的控制器的寄存器、缓冲区等使用模式,指令都不同。对于咱们公司来讲,就需要有个部门专门对接代理商,向其他部门屏蔽代理商的差异,成立公司的渠道管理部门。”
那对于操作系统来讲,渠道管理部门就是用来对接各个设备控制器的设备驱动程序。
这里需要注意的是,设备控制器不属于操作系统的一部分,但是设备驱动程序属于操作系统的一部分。操作系统的内核代码可以像调用本地代码一样调用驱动程序的代码,而驱动程序的代码需要发出特殊的面向设备控制器的指令,才能操作设备控制器。
设备驱动程序中是一些面向特殊设备控制器的代码。不同的设备不同。但是对于操作系统其他部分的代码而言,设备驱动程序应该有统一的接口。就像下面图中的一样,不同的设备驱动程序,可以以同样的方式接入操作系统,而操作系统的其他部分的代码,也可以无视不同设备的区别,以同样的接口调用设备驱动程序。
5.webp)
第三,用中断控制器统一外部事件处理。
马哥听了恍然大悟:”原来代理商也是五花八门,里面有这么多门道啊!”
鲁肃说:”当咱们对接的代理商多了,代理商可能会有各种各样的问题找到我们,例如代理商有了新客户,客户有了新需求,客户交付完毕等事件,都需要有一种机制通知你们公司,当然是中断,那操作系统就需要有一个地方处理这个中断,既然设备驱动程序是用来对接设备控制器的,中断处理也应该在设备驱动里面完成。”
然而,中断的触发最终会到达CPU,会中断操作系统当前运行的程序,所以操作系统也要有一个统一的流程来处理中断,使得不同设备的中断使用统一的流程。
一般的流程是,一个设备驱动程序初始化的时候,要先注册一个该设备的中断处理函数。咱们讲进程切换的时候说过,中断返回的那一刻是进程切换的时机。中断的时候,触发的函数是do_IRQ。这个函数是中断处理的统一入口。在这个函数里面,我们可以找到设备驱动程序注册的中断处理函数Handler,然后执行他进行中断处理。
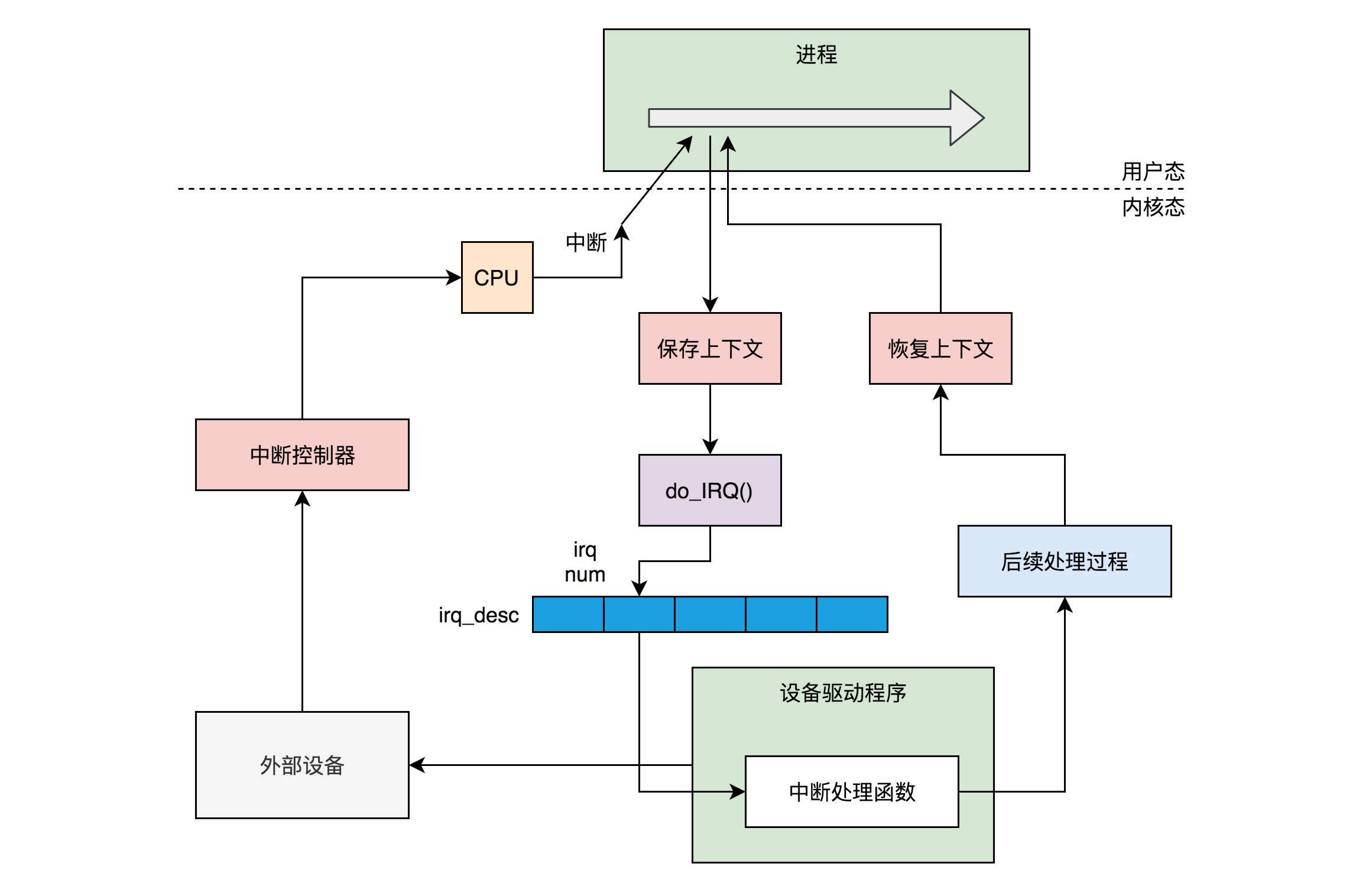
第四,用文件系统接口屏蔽驱动程序的差异。
马哥又问了:”对接了这么多代理商,如果咱们内部的工程师要和他们打交道,有没有一种统一的方式呢?”
鲁肃说:”当然应该了,我们内部员工操作外部设备,可以基于文件系统的接口,制定一个统一的标准。”
其实文件系统的机制是一个非常好的机制,咱们公司应该定下这样的规则,一切皆文件。
所有设备都在/dev/文件夹下面,创建一个特殊的设备文件。这个设备特殊文件也有inode,但是他不关联到硬盘或任何其他存储介质上的数据,而是建立了与某个设备驱动程序的连接。
有了文件系统接口之后,我们不但可以通过文件系统的命令行操作设备,也可以通过程序,调用read、write函数,像读写文件一样操作设备。
对于块设备来讲,在驱动程序之上,文件系统之下,还需要一层通用设备层。比如,咱们讲的文件系统,里面的逻辑和磁盘设备没有什么关系,可以说是通用的逻辑。在写文件的最底层,我们看到了BIO字眼的函数,但是好像和设备驱动也没有什么关系。
是的,因为块设备类型非常多,而Linux操作系统里面一切是文件。我们也不想文件系统以下,就直接对接各种各样的块设备驱动程序,这样会使得文件系统的复杂度非常高。所以,我们在中间加了一层通用块层,将与块设备相关的通用逻辑放在这一层,维护与设备无关的块的大小,然后通用块层下面对接各种各样的驱动程序。
7.webp)
鲁肃帮助马哥建立了这套体系之后,果真业务有了很大起色。原来公司只敢接华东区的项目,毕竟比较近,沟通交付都很方便。后来项目扩展到所有一线城市、二线城市、省会城市,项目数量实现了几十倍的增长。
59.3 千万项目难度大,集体合作可断金
项目接的多了,就不免有大型的项目,涉及多个行业多个领域,需要多个项目组进行合作才能完成。那两个项目组应该通过什么样的方式,进行沟通与合作呢?作为老板,马哥应该如何设计整个流程呢?
马哥叫来周瑜、张昭、鲁肃,一起商量团队间的合作模式。大家一起献计献策。好在有很多成熟的项目管理流程可以参考。
最最传统的模型就是软件开发的瀑布模型。所谓的瀑布模型,其实就是将整个软件开发过程分成多个阶段,往往是上一个阶段完全做完,才将输出结果交给下一个阶段。这种模型类似进程间通信的管道模型。
所谓的管道,就是在两个进程之间建立一条单向的通道,其实是一段缓存,它会将前一个命令的输出,作为后一个命令的输入。
张昭说,瀑布模型的开发流程效率比较低下,现在大部分公司都不使用这种开发模式了,因为团队之间无法频繁地沟通。而且,管道的使用模式,也不适合进程间频繁的交换数据。
于是,他们还得想其他的办法。是不是可以借鉴传统外企的沟通方式——邮件呢?邮件有一定的格式,例如抬头、正文、附件等。发送邮件可以建立收件人列表,所有在这个列表中的人,都可以反复地在此邮件基础上回复,达到频繁沟通的目的。这个啊,就是消息队列模型。
和管道将信息一股脑儿地从一个进程,倒给另一个进程不同,消息队列有点儿像邮件,发送数据时,会分成一个一个独立的数据单元,也就是消息体,每个消息体都是固定大小的存储块,在字节流上不连续。
有了消息这种模型,两个进程之间的通信就像咱们平时发邮件一样,你来一封,我回一封,可以频繁沟通了。
10.webp)
但是有时候,项目组之间的沟通需要特别紧密,而且要分享一些比较大的数据。如果使用邮件,就发现,一方面邮件的来去不及时;另外一方面,附件大小也有限制,所以,这个时候,我们经常采取的方式就是,把两个项目组在需要合作的期间,拉到一个会议室进行合作开发,这样大家可以直接交流文档呀,架构图呀,直接在白板上画或者直接扔给对方,就可以直接看到。
可以看出来,共享会议室这种模型,类似进程间通信的共享内存模型。前面咱们讲内存管理的时候,知道每个进程都有自己独立的虚拟内存空间,不同的进程的虚拟内存空间映射到不同的物理内存中去。这个进程访问A地址和另一个进程访问A地址,其实访问的是不同的物理内存地址,对于数据的增删查改互不影响。
但是,咱们是不是可以变通一下,拿出一块虚拟地址空间来,映射到相同的物理内存中。这样这个进程写入的东西,另外一个进程马上就能看到了,都不需要拷贝来拷贝去,传来传去。
马哥说:”共享内存也有问题呀。如果两个进程使用同一个共享内存,大家都往里面写东西,很有可能就冲突了。例如两个进程都同时写一个地址,那先写的那个进程会发现内容被别人覆盖了。”
张昭说:”当然,和共享内存配合的,有另一种保护机制,使得同一个共享的资源,同时只能被一个进程访问叫信号量。”
信号量其实是一个计数器,主要用于实现进程间的互斥与同步,而不是用于存储进程间通信数据。
我们可以将信号量初始化为一个数值,来代表某种资源的总体数量。对于信号量来讲,会定义两种原子操作,一个是P操作,我们称为申请资源操作。这个操作会申请将信号量的数值减去N,表示这些数量被他申请使用了,其他人不能用了。另一个是V操作,我们称为归还资源操作,这个操作会申请将信号量加上M,表示这些数量已经还给信号量了,其他人可以使用了。
例如,你有100元钱,就可以将信号量设置为100。其中A向你借80元,就会调用P操作,申请减去80。如果同时B向你借50元,但是B的P操作比A晚,那就没有办法,只好等待A归还钱的时候,B的P操作才能成功。之后,A调用V操作,申请加上30元,也就是还给你30元,这个时候信号量有50元了,这时候B的P操作才能成功,才能借走这50元。
所谓原子操作(Atomic Operation),就是任何一块钱,都只能通过P操作借给一个人,不能同时借给两个人。也就是说,当A的P操作(借80)和B的P操作(借50),几乎同时到达的时候,不能因为大家都看到账户里有100就都成功,必须分个先来后到。
马哥说:”有了上面的这些机制,基本常规状态下的工作模式,对应到咱们平时的工作交接,收发邮件、联合开发等。我还想到,如果发生了异常怎么办?例如出现线上系统故障,这个时候,什么流程都来不及了,不可能发邮件,也来不及开会,所有的架构师、开发、运维都要被通知紧急出动。所以,7乘24小时不间断执行的系统都需要有告警系统,一旦出事情,就要通知到人,哪怕是半夜,也要电话叫起来,处理故障。是不是应该还有一种异常情况下的工作模式。”
张昭说:”当然应该有,我们可以建立像操作系统里面的信号机制。信号没有特别复杂的数据结构,就是用一个代号一样的数字。Linux提供了几十种信号,分别代表不同的意义。信号之间依靠它们的值来区分。这就像咱们看警匪片,对于紧急的行动,都是说,’1号作战任务’开始执行,警察就开始行动了。情况紧急,不能啰里啰嗦了。”
信号可以在任何时候发送给某一进程,进程需要为这个信号配置信号处理函数。当某个信号发生的时候,就默认执行这个函数就可以了。这就相当于咱们运维一个系统应急手册,当遇到什么情况,做什么事情,都事先准备好,出了事情照着做就可以了。
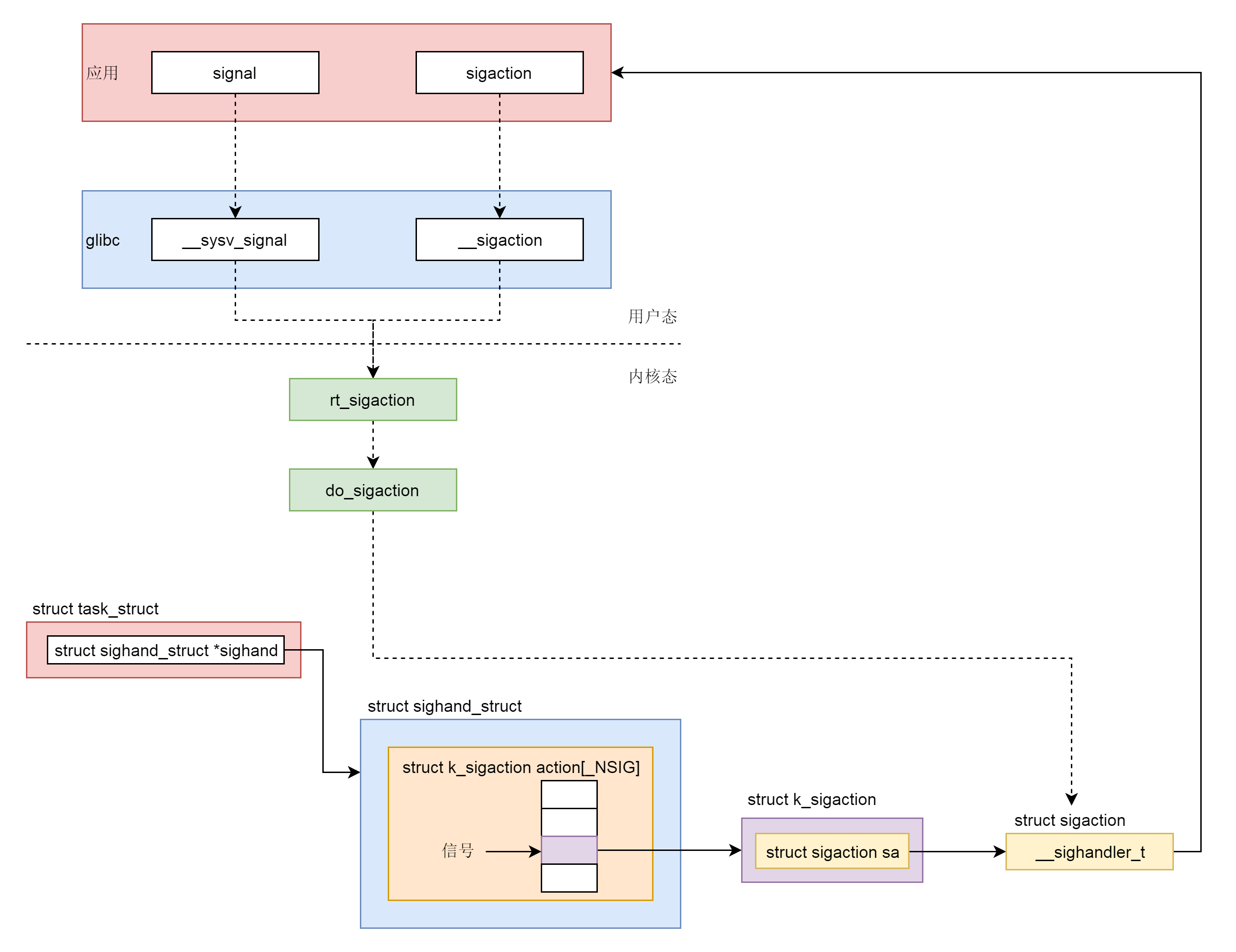
这些项目组合作的流程设计合理,因而推行起来十分顺畅,现在接个千万级别的项目没有任何问题,根据交易量估值市值,起码有十个亿。
马哥有些小激动,原来自己身价这么高了,是不是也能上个市啥的,实现亿万富翁的梦想呢?于是马哥找了一些投资人聊了聊,投资人说,要想冲一把上市,还差点劲,目前的项目虽然大,但是想象力不够丰富。
那接下来,马哥如何做才能满足市场的想象力,最终成功上市呢?预知后事,且听下回分解。
60. 用一个创业故事串起操作系统原理(五)
上一节我们说到,马哥的公司现在接个千万级别的项目没有任何问题,但是投资人说,要想冲一把上市,还差点劲,目前的项目虽然大,但是想象力不够丰富。
60.1 亿级项目创品牌,战略合作遵协议
马哥突然想到,西部有一个智慧城市的打单,金额几个亿,绝对标杆性质的。如果能够参与其中,应该是很有想象力的事情。
可是,甲方明确地说,”整个智慧城市的建设体系非常的大,一家公司做不下来,需要多家公司合作才能完成。你们有多家公司合作的经验和机制吗?”
马哥咬牙说道:”当然有!”先应下来再说呗,可是这心里是真没底。原来公司都是独自接单,现在要和其他公司合作,协议怎么签,价格怎么谈呢?
马哥找到鲁肃。鲁肃说:”我给你推荐一个人吧!这个人人脉广,项目运作能力强,叫陆逊,说不定能帮上忙。”
鲁肃找来陆逊。陆逊说:”这个好办。公司间合作嘛,就是条款谈好,利益分好就行,关键是大家要遵守行规。大家都按统一的规则来,事情就好办。”
这其实就像机器与机器之间合作,一台机器将自己想要表达的内容,按照某种约定好的格式发送出去。当另外一台机器收到这些信息后,也能够按照约定好的格式解析出来,从而准确、可靠地获得发送方想要表达的内容。这种约定好的格式就是网络协议。
现在业内知名的有两种网络协议模型,一种是OSI的标准七层模型,一种是业界标准的TCP/IP模型。它们的对应关系如下图所示:
我们先从第三层网络层开始,因为这一层有我们熟悉的IP地址,所以这一层我们也叫IP层。
连接到网络上的每一个设备都至少有一个IP地址,用于定位这个设备。无论是近在咫尺的、你旁边同学的电脑,还是远在天边的电商网站,都可以通过IP地址进行定位。因此,IP地址类似互联网上的邮寄地址,是有全局定位功能的。
就算你要访问美国的一个地址,也可以从你身边的网络出发,通过不断地打听道儿,经过多个网络,最终到达目的地址,和快递员送包裹的过程差不多。打听道儿的协议也在第三层,我们称为路由协议。将网络包从一个网络转发给另一个网络的设备,我们称为路由器。
总而言之,第三层干的事情,就是网络包从一个起始的IP地址,沿着路由协议指的道儿,经过多个网络,通过多次路由器转发,到达目标IP地址。
从第三层,我们往下看。第二层是数据链路层。有时候我们简称为二层或者MAC层。所谓MAC,就是每个网卡都有的唯一的硬件地址(不绝对唯一,相对大概率唯一即可,类比UUID)。这虽然也是一个地址,但是这个地址是没有全局定位功能的。
就像给你送外卖的小哥,不可能根据手机尾号找到你家,但是手机尾号有本地定位功能的,只不过这个定位主要靠”吼”。外卖小哥到了你的楼层就开始大喊:”尾号xxxx的,你外卖到了!”
MAC地址的定位功能局限在一个网络里面,也即同一个网络号下的IP地址之间,可以通过MAC进行定位和通信。从IP地址获取MAC地址要通过ARP协议,是通过在本地发送广播包,也就是”吼”,获得的MAC地址。
由于同一个网络内的机器数量有限,通过MAC地址的好处就是简单。匹配上MAC地址就接收,匹配不上就不接收,没有什么所谓路由协议这样复杂的协议。当然坏处就是,MAC地址的作用范围不能出本地网络,所以一旦跨网络通信,虽然IP地址保持不变,但是MAC地址每经过一个路由器就要换一次。
所以第二层干的事情,就是网络包在本地网络中的服务器之间定位及通信的机制。
我们再往下看第一层,物理层。这一层就是物理设备。例如,连着电脑的网线,我们能连上的WiFi。
从第三层往上看,第四层是传输层,这里面有两个著名的协议,TCP和UDP。尤其是TCP,更是广泛使用,在IP层的代码逻辑中,仅仅负责数据从一个IP地址发送给另一个IP地址,丢包、乱序、重传、拥塞,这些IP层都不管。处理这些问题的代码逻辑写在了传输层的TCP协议里面。
我们常说,TCP是可靠传输协议,也是难为它了。因为从第一层到第三层都不可靠,网络包说丢就丢,是TCP这一层通过各种编号、重传等机制,让本来不可靠的网络对于更上层来讲,变得”看起来”可靠。哪有什么应用层的岁月静好,只不过是TCP层在负重前行。
传输层再往上就是应用层,例如,咱们在浏览器里面输入的HTTP,Java服务端写的Servlet,都是这一层的。
二层到四层都是在Linux内核里面处理的,应用层例如浏览器、Nginx、Tomcat都是用户态的。内核里面对于网络包的处理是不区分应用的。
从四层再往上,就需要区分网络包发给哪个应用。在传输层的TCP和UDP协议里面,都有端口的概念,不同的应用监听不同的端口。例如,服务端Nginx监听80、Tomcat监听8080;再如客户端浏览器监听一个随机端口,FTP客户端监听另外一个随机端口。
应用层和内核互通的机制,就是通过Socket系统调用。所以经常有人会问,Socket属于哪一层,其实它哪一层都不属于,它属于操作系统的概念,而非网络协议分层的概念。
操作系统对于网络协议的实现模式是这样的:二到四层的处理代码在内核里面,七层的处理代码让应用自己去做。两者需要跨内核态和用户态通信,就需要一个系统调用完成这个衔接,这就是Socket。
如果公司想要和其他公司沟通,我们将请求封装为HTTP协议,通过Socket发送到内核。内核的网络协议栈里面,在TCP层创建用于维护连接、序列号、重传、拥塞控制的数据结构,将HTTP包加上TCP头,发送给IP层,IP层加上IP头,发送给MAC层,MAC层加上MAC头,从硬件网卡发出去。
最终网络包会被转发到目标服务器,它发现MAC地址匹配,就将MAC头取下来,交给上一层。IP层发现IP地址匹配,将IP头取下来,交给上一层。TCP层会根据TCP头中的序列号等信息,发现它是一个正确的网络包,就会将网络包缓存起来,等待应用层的读取。
应用层通过Socket监听某个端口,因而读取的时候,内核会根据TCP头中的端口号,将网络包发给相应的应用。
这样一个大项目中,各个公司都按协议来,别说两家公司合作,二十家也没有问题。
于是陆逊带着马哥,到甲方那里,将自己的方案,以及和其他公司的合作模式讲述清楚。马哥成功入围。
这次参与竞标的公司可不少,马哥公司的竞争力和专业性一点都不差,最后终于拿下了智慧生态合作平台的建设部分。这下不得了,一提马哥的公司,业内无人不知,无人不晓,大家纷纷称呼他为”马总”。
60.2 公司大了不灵活,鼓励创新有妙招
慢慢地,马总发现,公司大有大的好处,自然也有大的毛病,也就是咱们常见的”大公司病”——不灵活。
这里面的不灵活,就像Linux服务器,越来越强大的时候,无论是计算、网络、存储,都越来越牛。例如,内存动不动就是百G内存,网络设备一个端口的带宽就能有几十G甚至上百G。存储在数据中心至少是PB级别的,自然也有不灵活的毛病。
资源大小不灵活:有时候我们不需要这么大规格的机器,可能只想尝试一下某些新业务,申请个4核8G的服务器试一下,但是不可能采购这么小规格的机器。无论每个项目需要多大规格的机器,公司统一采购就限制几种,全部是上面那种大规格的。
资源申请不灵活:规格定死就定死吧,可是每次申请机器都要重新采购,周期很长。
资源复用不灵活:反正我需要的资源不多,和别人共享一台机器吧,这样不同的进程可能会产生冲突,例如socket的端口冲突。另外就是别人用过的机器,不知道上面做过哪些操作,有很多的历史包袱,如果重新安装则代价太大。
按说,大事情流程严禁没问题,很多小事情也要被拖累走整个流程,而且很容易出现资源冲突,每天跨部门的协调很累人,历史包袱严重,创新没有办法轻装上阵。
很多公司处理这种问题采取的策略是成立独立的子公司,独立决策,独立运营。这种办法往往会用在创新型的项目上。
Linux也采取了这样的手段,就是在物理机上面创建虚拟机。每个虚拟机有自己单独的操作系统、灵活的规格,一个命令就能启动起来。每次创建都是新的操作系统,很好地解决了上面不灵活的问题。
在物理机上的操作系统看来,虚拟机是一个普通的应用,他和Excel一样,只能运行在用户态。但是对于虚拟机里面的操作系统内核来讲,运行在内核态,应该有高的权限。
要做到这件事情,第一种方式,完全虚拟化。其实说白了,这是一种”骗人”的方式。虚拟化软件会模拟假的CPU、内存、网络、硬盘给到虚拟机,让虚拟机里面的内核自我感觉良好,感觉他终于又像个内核了。在Linux上,一个叫作qemu的工具可以做到这一点。
qemu向虚拟机里面的客户机操作系统模拟CPU和其他的硬件,骗客户机,GuestOS认为自己和硬件直接打交道,其实是同qemu模拟出来的硬件打交道,qemu会将这些指令转译给真正的硬件。由于所有的指令都要从qemu里面过一手,因而性能就会比较差。
第二种方式,硬件辅助虚拟化。可以使用硬件CPU的Intel-VT和AMD-V技术,需要CPU硬件开启这个标志位(一般在BIOS里面设置)。当确认开始了标志位之后,通过内核模块KVM,GuestOS的CPU指令将不用经过Qemu转译,直接运行,大大提高了速度。qemu和KVM融合以后,就是qemu-kvm。
第三种方式称为半虚拟化。对于网络或者硬盘的访问,我们让虚拟机内核加载特殊的驱动,重新定位自己的身份。虚拟机操作系统的内核知道自己不是物理机内核,没那么高的权限。他很可能要和很多虚拟机共享物理资源,所以学会了排队。虚拟机写硬盘其实写的是一个物理机上的文件,那我的写文件的缓存方式是不是可以变一下。我发送网络包,根本就不是发给真正的网络设备,而是给虚拟的设备,我可不可以直接在内存里面拷贝给它,等等等等。
网络半虚拟化方式是virtio_net,存储是virtio_blk。客户机需要安装这些半虚拟化驱动。客户机内核知道自己是虚拟机,所以会直接把数据发送给半虚拟化设备,然后经过特殊处理(例如排队、缓存、批量处理等性能优化方式),最终发送给真正的硬件。这在一定程度上提高了性能。
有了虚拟化的技术,公司的状态改观了不少,在主要的经营方向之外,公司还推出了很多新的创新方向,都是通过虚拟机创建子公司的方式进行的,例如跨境电商、工业互联网、社交等。一方面,能够享受大公司的支持;一方面,也可以和灵活的创业公司进行竞争。
于是,公司就变成集团公司了。
60.3 独占鳌头定格局,上市敲钟责任重
随着公司越来越大,钱赚的越来越多,马总的公司慢慢从行业的追随者,变成了领导者。这一方面,让马总觉得”会当凌绝顶,一览众山小”;另一方面,马总也觉得”高处不胜寒”。原来公司总是追着别人跑,产业格局,市场格局从来不用自己操心,只要自己的公司能赚钱就行。现在做了领头羊,马总也就慢慢成了各种政府论坛、产业论坛,甚至国际论坛的座上宾。
穷则独善其身,达则兼济天下。马总的决策可能关系到产业的发展、地方的GDP和就业,甚至未来的国际竞争力。因此,即便是和原来相同的事情,现在来做,方式和层次都不一样了。
就像对于单台Linux服务器,最重要的四种硬件资源是CPU、内存、存储和网络。面对整个数据中心成千上万台机器,我们只要重点关注这四种硬件资源就可以了。如果运维数据中心依然像的运维一台台物理机的前辈一样,天天关心哪个程序放在了哪台机器上,使用多少内存、多少硬盘,每台机器总共有多少内存、多少硬盘,还剩多少内存和硬盘,那头就大了。
对于数据中心,我们需要一个调度器,将运维人员从指定物理机或者虚拟机的痛苦中解放出来,实现对于物理资源的统一管理,这就是Kubernetes,也就是数据中心的操作系统。
对于CPU和内存这两种计算资源的管理,我们可以通过Docker技术完成。
容器实现封闭的环境主要要靠两种技术,一种是看起来是隔离的技术,称为namespace。在每个namespace中的应用看到的,都是不同的 IP地址、用户空间、进程ID等。另一种是用起来是隔离的技术,称为cgroup,即明明整台机器有很多的 CPU、内存,但是一个应用只能用其中的一部分。
另外,容器里还有镜像。也就是说,在你焊好集装箱的那一刻,将集装箱的状态保存下来的样子。就像孙悟空说”定!”,集装箱里的状态就被”定”在了那一刻。然后,这一刻的状态会被保存成一系列文件。无论在哪里运行这个镜像,都能完整地还原当时的情况。
通过容器,我们可以将CPU和内存资源,从大的资源池里面隔离出来,并通过镜像技术,在数据中心里面实现计算资源的自由漂移。
没有操作系统的时候,汇编程序员需要指定程序运行的CPU和内存物理地址。同理,数据中心的管理员,原来也需要指定程序运行的服务器以及使用的CPU和内存。现在,Kubernetes里面有一个调度器Scheduler,你只需要告诉它,你想运行10个4核8G的Java程序,它会自动帮你选择空闲的、有足够资源的服务器,去运行这些程序。
对于存储,无论是分布式文件系统和分布式块存储,需要对接到Kubernetes,让Kubernetes管理它们。如何对接呢?Kubernetes会提供CSI接口。这是一个标准接口,不同的存储可以实现这个接口来对接Kubernetes。是不是特别像设备驱动程序呀?操作系统只要定义统一的接口,不同的存储设备的驱动实现这些接口,就能被操作系统使用了。
对于网络,也是类似的机制,Kubernetes同样是提供统一的接口CNI。无论你用哪种方式实现网络模型,只要对接这个统一的接口,Kubernetes就可以管理容器的网络。
到此,有了这套鼎定市场格局的策略,作为龙头企业,马总的公司终于可以顺利上市敲钟,走向人生巅峰。从此,江湖人称”马爸爸”。
好了,马同学的创业故事就讲到这里了,操作系统的原理也给你串了一遍。你是否真的记住了这些原理呢?试着将这个创业故事讲给你的朋友听吧!
十二、其他资料
- 《自己动手写操作系统》
- 《UNIX 环境高级编程》
- 《一个操作系统的实现》
- 《系统虚拟化原理与实现》
- 《深入理解Linux虚拟内存管理》
- 《深入理解Linux内核》
- 《深入Linux内核架构》
- 《穿越计算机的迷雾》
- 《程序员的自我修养:链接、装载与库》
- 《操作系统真象还原》
- 《操作系统设计与实现》
- 《x86汇编语言:从实模式到保护模式》
- 《linux内核设计的艺术图解》
- 《Linux设备驱动开发详解》
- 《Linux内核完全注释》
- 《Linux内核设计与实现》
- 《Linux多线程服务端编程》
- 《Linux 内核分析及编程》
- 《IBM PC汇编语言程序设计》
- 《深入理解计算机系统》
- 《性能之巅:洞悉系统、企业与云计算》
- 《Linux内核协议栈源代码解析》
- 《UNIX网络编程》
- 《Linux/UNIX系统编程手册》
- 《深入Linux设备驱动程序内核机制》
- 《深入理解Linux驱动程序设计》
- 《Linux Device Drivers》
- 《TCP/IP详解卷》
- 《The TCP/IP Guide》
- 《深入理解LINUX网络技术内幕》
- 《Linux内核源代码情景分析》
- 《UNIX/Linux系统管理技术手册》

