开篇词
开篇词 | 一个态度两个步骤,成为容器实战高手
我们可以结合 Linux 操作系统的主要模块,把容器的知识结构系统地串联起来,同时看到 Namespace 和 Cgroups 带来的特殊性。
在这个容器课程中,每一讲里都会有一些小例子,所以需要你有 一台安装有 Linux 的机器,或者用 VirtualBox 安装一个虚拟机来跑 Linux。Linux 的版本建议是 CentOS 8 或者是 Ubuntu 20.04。
容器是一个很好的技术窗口,它可以帮助你在这个瞬息万变的计算机世界里看到后面那些”不变”的技术,只有掌握好那些”不变”的技术,你才可以更加从容地去接受技术的瞬息万变。
01 | 认识容器:容器的基本操作和实现原理
说实话,容器这东西一点都不复杂,如果你只是想用的话,那跟着Docker 官网的说明,应该十来分钟就能搞定。
简单来说,它就是个小工具,可以把你想跑的程序,库文件啊,配置文件都一起”打包”。
然后,我们在任何一个计算机的节点上,都可以使用这个打好的包。有了容器,一个命令就能把你想跑的程序跑起来,做到了 一次打包,就可以到处使用。
今天是咱们整个课程的第一讲,我想和你来聊聊容器背后的实现机制。
当然,空讲原理也没什么感觉,所以我还是会先带着你启动一个容器玩玩,然后咱们再一起来探讨容器里面的两大关键技术—— Namespace 和 Cgroups。基本上理解了这两个概念,你就能彻底搞懂容器的核心原理了。
做个镜像
话不多说,咱们就先动手玩一玩。启动容器的工具有很多,在这里我们还是使用 Docker 这个最常用的容器管理工具。
如果你之前根本没用过 Docker 的话,那我建议你先去 官网 看看文档,一些基础的介绍我就不讲了,那些内容你随便在网上一搜就能找到。
安装完 Docker 之后,咱们先来用下面的命令运行一个 httpd 服务。
docker run -d centos/httpd:latest这命令也很简单,run 的意思就是要启动一个容器, -d 参数里 d 是 Daemon 的首字母,也就是让容器在后台运行。
最后一个参数 centos/httpd:latest 指定了具体要启动哪一个镜像,比如这里咱们启动的是 centos/httpd 这个镜像的 latest 版本。
镜像是 Docker 公司的创举,也是一个伟大的发明。你想想,在没有容器之前,你想安装 httpd 的话,会怎么做?是不是得运行一连串的命令?甚至不同的系统上操作方法也不一样?
但你看,有了容器之后,你只要运行一条命令就搞定了。其实所有的玄机都在这个镜像里面。
镜像这么神奇,那它到底是怎么一回事呢?其实,镜像就是一个特殊的文件系统,
它提供了容器中程序执行需要的所有文件。具体来说,就是应用程序想启动,需要三类文件:相关的程序可执行文件、库文件和配置文件,这三类文件都被容器打包做好了。
这样,在容器运行的时候就不再依赖宿主机上的文件操作系统类型和配置了,做到了想在哪个节点上运行,就可以在哪个节点上立刻运行。
那么我们怎么来做一个容器镜像呢?
刚才的例子里,我们用的 centos/httpd:latest 这个镜像是 Docker 镜像库 里直接提供的。当然,我们也可以自己做一个提供 httpd 服务的容器镜像,这里仍然可以用 Docker 这个工具来自定义镜像。
Docker 为用户自己定义镜像提供了一个叫做 Dockerfile 的文件,在这个 Dockerfile 文件里,你可以设定自己镜像的创建步骤。
如果我们自己来做一个 httpd 的镜像也不难,举个例子,我们可以一起来写一个 Dockerfile,体会一下整个过程。用 Dockerfile build image 的 Dockerfile 和对应的目录我放在 这里 了。
操作之前,我们首先要理解这个 Dockerfile 做了什么,其实它很简单,只有下面这 5 行:
$ cat Dockerfile
FROM centos:8.1.1911
RUN yum install -y httpd
COPY file1 /var/www/html/
ADD file2.tar.gz /var/www/html/
CMD ["/sbin/httpd", "-D", "FOREGROUND"]我们看下它做了哪几件事:在一个 centos 的基准镜像上安装好 httpd 的包,然后在 httpd 提供文件服务的配置目录下,把需要对外提供的文件 file1 和 file2 拷贝过去,最后指定容器启动以后,需要自动启动的 httpd 服务。
有了这个镜像,我们希望容器启动后,就运行这个 httpd 服务,让用户可以下载 file1 还有 file2 这两个文件。
我们具体来看这个 Dockerfile 的每一行,第一个大写的词都是 Dockerfile 专门定义的指令,也就是 FROM、RUN、COPY、ADD、CMD,这些指令都很基础,所以我们不做详细解释了,你可以参考 Dockerfile 的 官方文档 。
我们写完这个 Dockerfile 之后,想要让它变成一个镜像,还需要执行一下 docker build 命令。
下面这个命令中 -f ./Dockerfile 指定 Dockerfile 文件,-t registry/httpd:v1 指定了生成出来的镜像名,它的格式是”name:tag”,这个镜像名也是后面启动容器需要用到的。
docker build -t registry/httpd:v1 -f ./Dockerfile .docker build 执行成功之后,我们再运行 docker images 这个命令,就可以看到生成的镜像了。
$ docker images
REPOSITORY TAG IMAGEID CREATED SIZE
registry/httpd v1 c682fc3d4b9a 4 seconds ago 277MB启动一个容器 (Container)
做完一个镜像之后,你就可以用这个镜像来启动一个容器了,我们刚才做的镜像名字是 registry/httpd:v1,那么还是用 docker run 这个命令来启动容器。
docker run -d registry/httpd:v1容器启动完成后,我们可以用 docker ps 命令来查看这个已经启动的容器:
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
c5a9ff78d9c1 registry/httpd:v1 "/sbin/httpd -D FORE…" 2 seconds ago Up 2 seconds loving_jackson在前面介绍 Dockerfile 的时候,我们说过做这个镜像是用来提供 HTTP 服务的,也就是让用户可以下载 file1、file2 这两个文件。
那怎样来验证我们建起来的容器是不是正常工作的呢?可以通过这两步来验证:
- 第一步,我们可以进入容器的运行空间,查看 httpd 服务是不是启动了,配置文件是不是正确的。
- 第二步,对于 HTTP 文件服务,如果我们能用 curl 命令下载文件,就可以证明这个容器提供了我们预期的 httpd 服务。
我们先来做第一步验证,我们可以运行 docker exec 这个命令进入容器的运行空间,至于什么是容器的运行空间,它的标准说法是容器的命名空间(Namespace),这个概念我们等会儿再做介绍。
进入容器运行空间之后,我们怎么确认 httpd 的服务进程已经在容器里启动了呢?
我们运行下面这个 docker exec 命令,也就是执行 docker exec c5a9ff78d9c1 ps -ef ,可以看到 httpd 的服务进程正在容器的空间中运行。
$ docker exec c5a9ff78d9c1 ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 01:59 ? 00:00:00 /sbin/httpd -D FOREGROUND
apache 6 1 0 01:59 ? 00:00:00 /sbin/httpd -D FOREGROUND
apache 7 1 0 01:59 ? 00:00:00 /sbin/httpd -D FOREGROUND
apache 8 1 0 01:59 ? 00:00:00 /sbin/httpd -D FOREGROUND
apache 9 1 0 01:59 ? 00:00:00 /sbin/httpd -D FOREGROUND这里我解释一下,在这个 docker exec 后面紧跟着的 ID 表示容器的 ID,这个 ID 就是我们之前运行 docker ps 查看过那个容器,容器的 ID 值是 c5a9ff78d9c1 。在这个 ID 值的后面,就是我们要在容器空间里运行的 ps -ef 命令。
接下来我们再来确认一下,httpd 提供文件服务的目录中 file1 和 file2 文件是否存在。
我们同样可以用 docker exec 来查看一下容器的文件系统中,httpd 提供文件服务的目录 /var/www/html 是否有这两个文件。
很好,我们可以看到 file1、file2 这两个文件也都放在指定目录中了。
$ docker exec c5a9ff78d9c1 ls /var/www/html
file1
file2到这里我们完成了第一步的验证,进入到容器的运行空间里,验证了 httpd 服务已经启动,配置文件也是正确的。
那下面我们要做第二步的验证,用 curl 命令来验证是否可以从容器的 httpd 服务里下载到文件。
如果要访问 httpd 服务,我们就需要知道这个容器的 IP 地址。容器的网络空间也是独立的,有一个它自己的 IP。我们还是可以用 docker exec 进入到容器的网络空间,查看一下这个容器的 IP。
运行下面的这条 docker exec c5a9ff78d9c1 ip addr 命令,我们可以看到容器里网络接口 eth0 上配置的 IP 是 172.17.0.2 。
这个 IP 目前只能在容器的宿主机上访问,在别的机器上目前是不能访问的。关于容器网络的知识,我们会在后面的课程里介绍。
$ docker exec c5a9ff78d9c1 ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
168: eth0@if169: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever好了,获取了 httpd 服务的 IP 地址之后,我们随便下载一个文件试试,比如选 file2。
我们在宿主机上运行 curl ,就可以下载这个文件了,操作如下。很好,文件下载成功了,这证明了我们这个提供 httpd 服务的容器正常运行了。
$ curl -L -O http://172.17.0.2/file2
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 6 100 6 0 0 1500 0 --:--:-- --:--:-- --:--:-- 1500
$ ls
file2上面的步骤完成之后,我们的第二步验证,用 curl 下载 httpd 服务提供的文件也成功了。
好了,我们刚才自己做了容器镜像,用这个镜像启动了容器,并且用 docker exec 命令检查了容器运行空间里的进程、文件和网络设置。
通过这上面的这些操作练习,估计你已经初步感知到,容器的文件系统是独立的,运行的进程环境是独立的,网络的设置也是独立的。但是它们和宿主机上的文件系统,进程环境以及网络感觉都已经分开了。
我想和你说,这个感觉没错,的确是这样。我们刚才启动的容器,已经从宿主机环境里被分隔出来了,就像下面这张图里的描述一样。
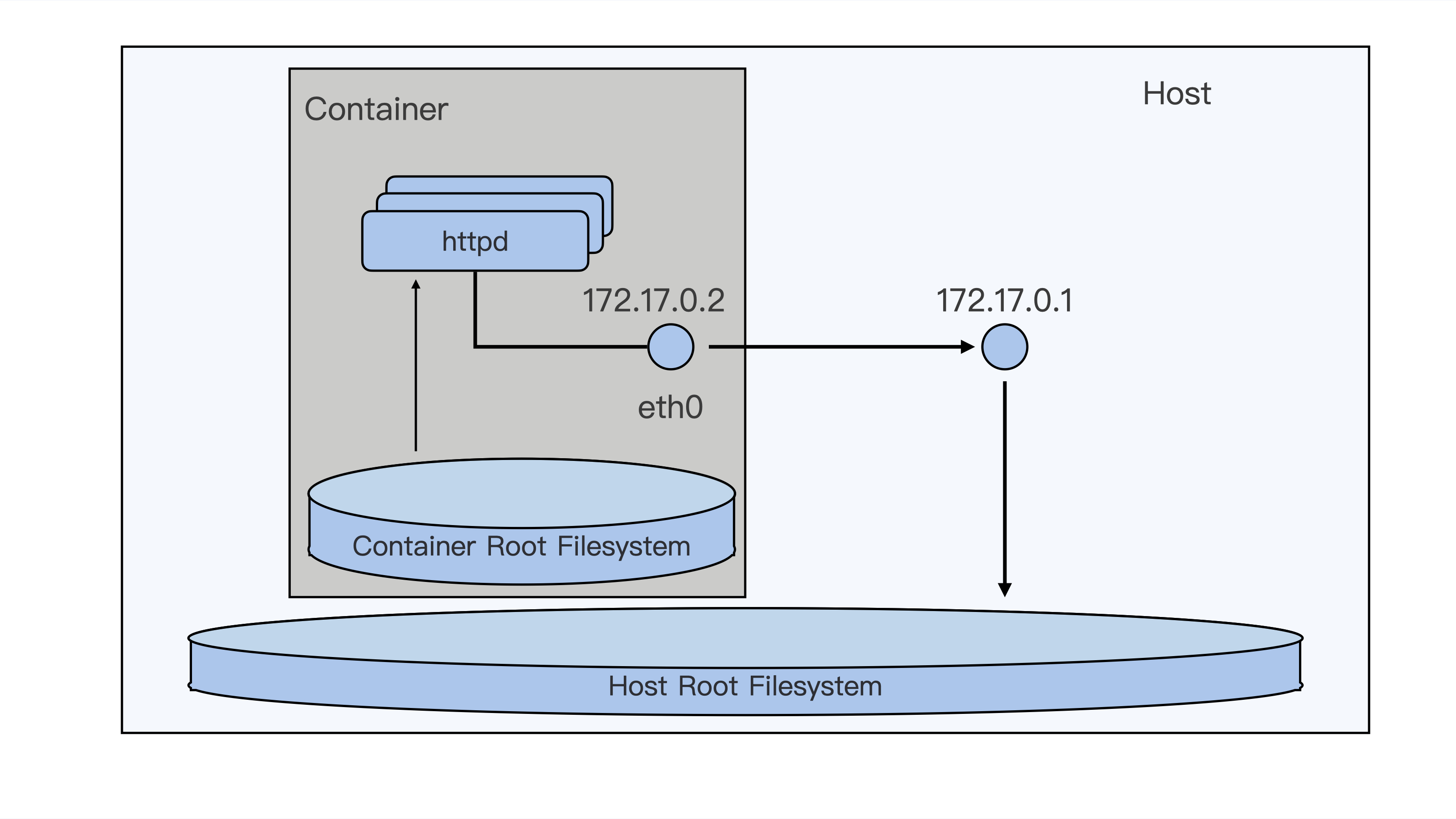
从用户使用的角度来看,容器和一台独立的机器或者虚拟机没有什么太大的区别,但是它和虚拟机相比,却没有各种复杂的硬件虚拟层,没有独立的 Linux 内核。
容器所有的进程调度,内存访问,文件的读写都直接跑在宿主机的内核之上,这是怎么做到的呢?
容器是什么
要回答这个问题,你可以先记住这两个术语 Namespace 和 Cgroups 。如果有人问你 Linux 上的容器是什么,最简单直接的回答就是 Namesapce 和 Cgroups。Namespace 和 Cgroups 可以让程序在一个资源可控的独立(隔离)环境中运行,这个就是容器了。
我们现在已经发现:容器的进程、网络还有文件系统都是独立的。那问题来了,容器的独立运行环境到底是怎么创造的呢?这就要提到 Namespace 这个概念了。所以接下来,就先从我们已经有点感觉的 Namespace 开始分析。
Namespace
接着前面的例子,我们正好有了一个正在运行的容器,那我们就拿这个运行的容器来看看 Namespace 到底是什么?
在前面我们运行 docker exec c5a9ff78d9c1 ps -ef,看到了 5 个 httpd 进程,而且也只有这 5 个进程。
$ docker exec c5a9ff78d9c1 ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 01:59 ? 00:00:00 /sbin/httpd -D FOREGROUND
apache 6 1 0 01:59 ? 00:00:00 /sbin/httpd -D FOREGROUND
apache 7 1 0 01:59 ? 00:00:00 /sbin/httpd -D FOREGROUND
apache 8 1 0 01:59 ? 00:00:00 /sbin/httpd -D FOREGROUND
apache 9 1 0 01:59 ? 00:00:00 /sbin/httpd -D FOREGROUND如果我们不用 docker exec,直接在宿主机上运行 ps -ef,就会看到很多进程。如果我们运行一下 grep httpd ,同样可以看到这 5 个 httpd 的进程:
$ ps -ef | grep httpd
UID PID PPID C STIME TTY TIME CMD
root 20731 20684 0 18:59 ? 00:00:01 /sbin/httpd -D FOREGROUND
48 20787 20731 0 18:59 ? 00:00:00 /sbin/httpd -D FOREGROUND
48 20788 20731 0 18:59 ? 00:00:06 /sbin/httpd -D FOREGROUND
48 20789 20731 0 18:59 ? 00:00:05 /sbin/httpd -D FOREGROUND
48 20791 20731 0 18:59 ? 00:00:05 /sbin/httpd -D FOREGROUN这两组输出结果到底有什么差别呢,你可以仔细做个对比,最大的不同就是 进程的 PID 不一样 。那为什么 PID 会不同呢?或者说,运行 docker exec c5a9ff78d9c1 ps -ef 和 ps -ef 实质的区别在哪里呢?
如果理解了 PID 为何不同,我们就能搞清楚 Linux Namespace 的概念了,为了方便后文的讲解,我们先用下面这张图来梳理一下我们看到的 PID。
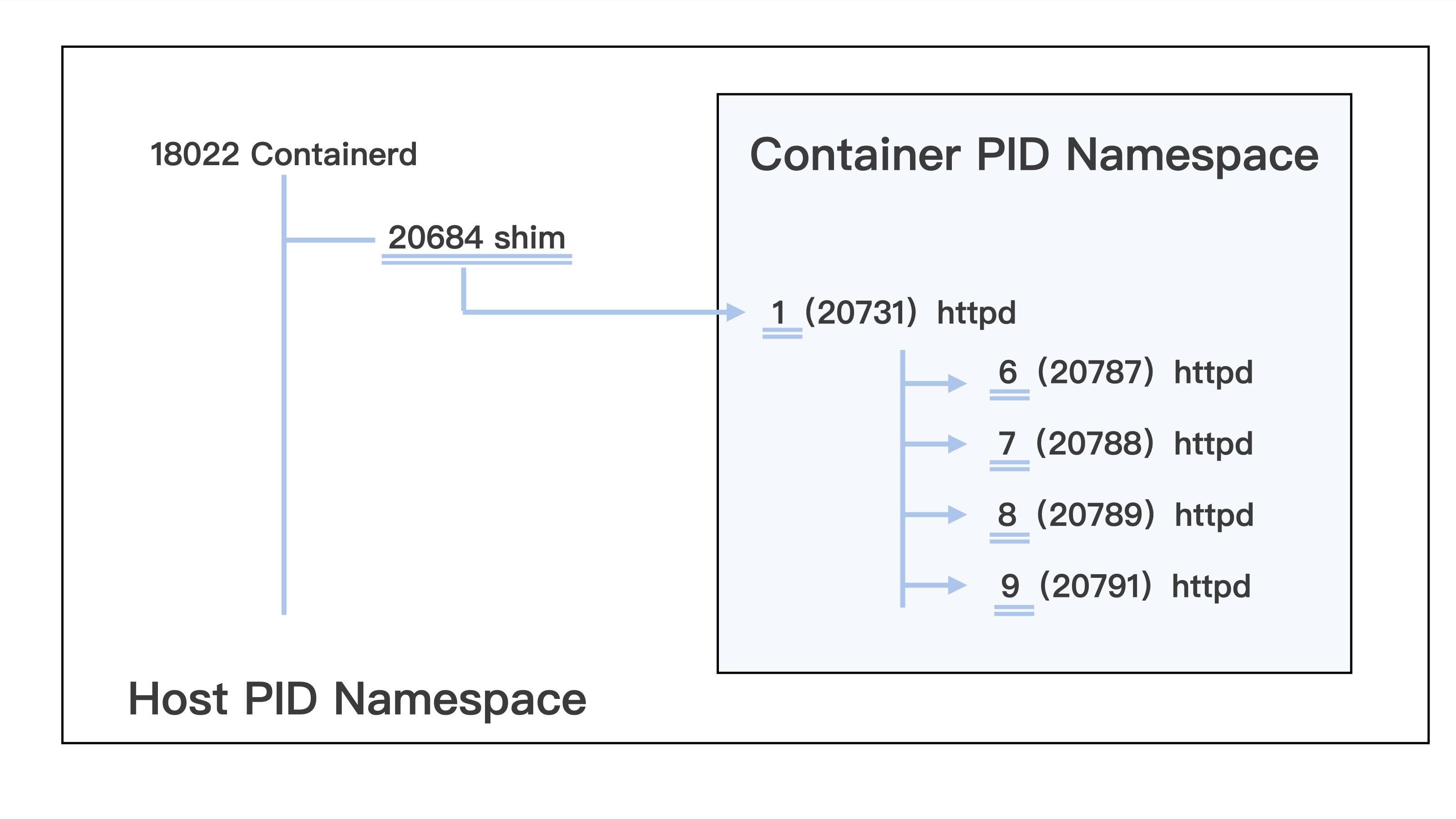
Linux 在创建容器的时候,就会建出一个 PID Namespace,PID 其实就是进程的编号。这个 PID Namespace,就是指每建立出一个 Namespace,就会单独对进程进行 PID 编号,每个 Namespace 的 PID 编号都从 1 开始。
同时在这个 PID Namespace 中也只能看到 Namespace 中的进程,而且看不到其他 Namespace 里的进程。
这也就是说,如果有另外一个容器,那么它也有自己的一个 PID Namespace,而这两个 PID Namespace 之间是不能看到对方的进程的,这里就体现出了 Namespace 的作用: 相互隔离 。
而在宿主机上的 Host PID Namespace,它是其他 Namespace 的父亲 Namespace,可以看到在这台机器上的所有进程,不过进程 PID 编号不是 Container PID Namespace 里的编号了,而是把所有在宿主机运行的进程放在一起,再进行编号。
讲了 PID Namespace 之后,我们了解到 Namespace 其实就是一种隔离机制,主要目的是隔离运行在同一个宿主机上的容器,让这些容器之间不能访问彼此的资源 。
这种隔离有两个作用: 第一是可以充分地利用系统的资源,也就是说在同一台宿主机上可以运行多个用户的容器;第二是保证了安全性,因为不同用户之间不能访问对方的资源 。
除了 PID Namespace,还有其他常见的 Namespace 类型,比如我们之前运行了 docker exec c5a9ff78d9c1 ip addr 这个命令去查看容器内部的 IP 地址,这里其实就是在查看 Network Namespace。
在 Network Namespace 中都有一套独立的网络接口比如这里的 lo,eth0,还有独立的 TCP/IP 的协议栈配置。
$ docker exec c5a9ff78d9c1 ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
168: eth0@if169: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever我们还可以运行 docker exec c5a9ff78d9c1 ls/ 查看容器中的根文件系统(rootfs)。然后,你会发现,它和宿主机上的根文件系统也是不一样的。 容器中的根文件系统,其实就是我们做的镜像。
那容器自己的根文件系统完全独立于宿主机上的根文件系统,这一点是怎么做到的呢?其实这里依靠的是 Mount Namespace ,Mount Namespace 保证了每个容器都有自己独立的文件目录结构。
Namespace 的类型还有很多,我们查看”Linux Programmer’s Manual”,可以看到 Linux 中所有的 Namespace:cgroup/ipc/network/mount/pid/time/user/uts。
在这里呢,你需要记住的是 Namespace 是 Linux 中实现容器的两大技术之一,它最重要的作用是保证资源的隔离。 在后面的课程,讲解到具体问题时,我会不断地提到 Namespace 这个概念。

好了,我们刚才说了 Namespace,这些 Namespace 尽管类型不同,其实都是为了隔离容器资源: PID Namespace 负责隔离不同容器的进程,Network Namespace 又负责管理网络环境的隔离,Mount Namespace 管理文件系统的隔离。
正是通过这些 Namespace,我们才隔离出一个容器,这里你也可以把它看作是一台”计算机”。
既然是一台”计算机”,你肯定会问这个”计算机”有多少 CPU,有多少 Memory 啊?那么 Linux 如何为这些”计算机”来定义 CPU,定义 Memory 的容量呢?
Cgroups
想要定义”计算机”各种容量大小,就涉及到支撑容器的第二个技术 Cgroups (Control Groups) 了。Cgroups 可以对指定的进程做各种计算机资源的限制,比如限制 CPU 的使用率,内存使用量,IO 设备的流量等等。
Cgroups 究竟有什么好处呢?要知道,在 Cgroups 出现之前,任意一个进程都可以创建出成百上千个线程,可以轻易地消耗完一台计算机的所有 CPU 资源和内存资源。
但是有了 Cgroups 这个技术以后,我们就可以对一个进程或者一组进程的计算机资源的消耗进行限制了。
Cgroups 通过不同的子系统限制了不同的资源,每个子系统限制一种资源。每个子系统限制资源的方式都是类似的,就是把相关的一组进程分配到一个控制组里,然后通过树结构进行管理,每个控制组都设有自己的资源控制参数。
完整的 Cgroups 子系统的介绍,你可以查看 Linux Programmer’s Manual 中 Cgroups 的定义。
这里呢,我们只需要了解几种比较常用的 Cgroups 子系统:
- CPU 子系统,用来限制一个控制组(一组进程,你可以理解为一个容器里所有的进程)可使用的最大 CPU。
- memory 子系统,用来限制一个控制组最大的内存使用量。
- pids 子系统,用来限制一个控制组里最多可以运行多少个进程。
- cpuset 子系统, 这个子系统来限制一个控制组里的进程可以在哪几个物理 CPU 上运行。
因为 memory 子系统的限制参数最简单,所以下面我们就用 memory 子系统为例,一起看看 Cgroups 是怎么对一个容器做资源限制的。
对于启动的每个容器,都会在 Cgroups 子系统下建立一个目录,在 Cgroups 中这个目录也被称作控制组,比如下图里的 docker-<id1> docker-<id2>等。然后我们设置这个控制组的参数,通过这个方式,来限制这个容器的内存资源。
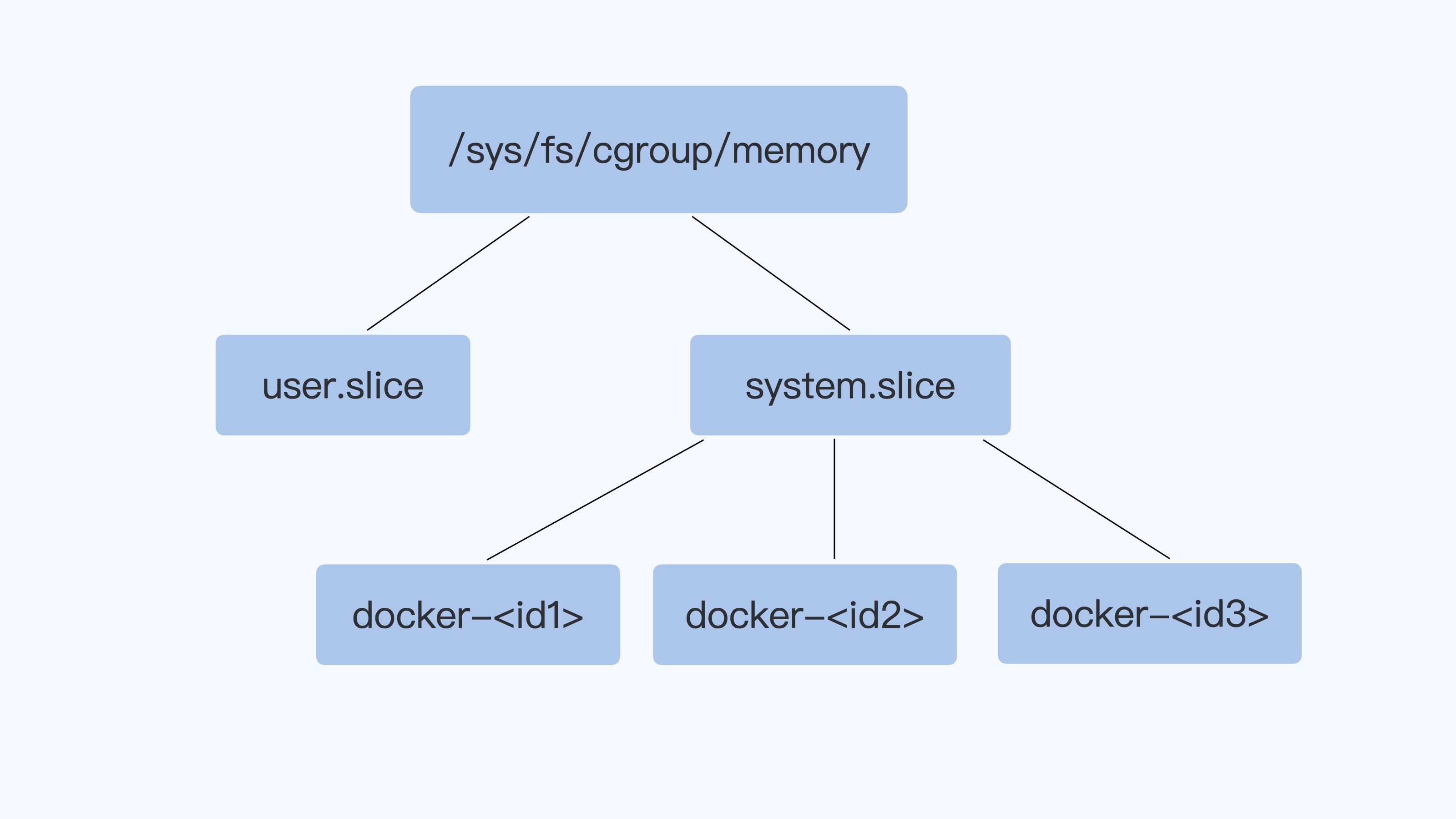
还记得,我们之前用 Docker 创建的那个容器吗?在每个 Cgroups 子系统下,对应这个容器就会有一个目录 docker-c5a9ff78d9c1……这个容器的 ID 号,容器中所有的进程都会储存在这个控制组中 cgroup.procs 这个参数里。
你看下面的这些进程号是不是很熟悉呢?没错,它们就是前面我们用 ps 看到的进程号。
我们实际看一下这个例子里的 memory Cgroups,它可以控制 Memory 的使用量。比如说,我们将这个控制组 Memory 的最大用量设置为 2GB。
具体操作是这样的,我们把(2 * 1024 * 1024 * 1024 = 2147483648)这个值,写入 memory Cgroup 控制组中的 memory.limit_in_bytes 里, 这样设置后,cgroup.procs 里面所有进程 Memory 使用量之和,最大也不会超过 2GB。
$ cd /sys/fs/cgroup/memory/system.slice/docker-c5a9ff78d9c1fedd52511e18fdbd26357250719fa0d128349547a50fad7c5de9.scope
$ cat cgroup.procs
20731
20787
20788
20789
20791
$ echo 2147483648 > memory.limit_in_bytes
$ cat memory.limit_in_bytes
2147483648ubuntu 20.04 上 docker 20.10.17 中目录变成了
/sys/fs/cgroup/memory/docker/c5a9ff78d9c1fedd52511e18fdbd26357250719fa0d128349547a50fad7c5de9。
刚刚我们通过 memory Cgroups 定义了容器的 memory 可以使用的最大值。其他的子系统稍微复杂一些,但用法也和 memory 类似,我们在后面的课程中会结合具体的实例来详细解释其他的 Cgroups。
这里我们还要提一下 Cgroups 有 v1 和 v2 两个版本:
如何检查系统中安装的 cgroup 版本: How do I check cgroup v2 is installed on my machine? .
Cgroups v1 在 Linux 中很早就实现了,各种子系统比较独立,每个进程在各个 Cgroups 子系统中独立配置,可以属于不同的 group。
虽然这样比较灵活,但是也存在问题,会导致 对同一进程的资源协调比较困难 (比如 memory Cgroup 与 blkio Cgroup 之间就不能协作)。虽然 v1 有缺陷,但是在主流的生产环境中,大部分使用的还是 v1。
Cgroups v2 做了设计改进, 解决了 v1 的问题,使各个子系统可以协调统一地管理资源。
不过 Cgroups v2 在生产环境的应用还很少,因为该版本很多子系统的实现需要较新版本的 Linux 内核,还有无论是主流的 Linux 发行版本还是容器云平台,比如 Kubernetes,对 v2 的支持也刚刚起步。
所以啊,我们在后面 Cgroups 的讲解里呢,主要还是用 Cgroups v1 这个版本 ,在磁盘 I/O 的这一章中,我们也会介绍一下 Cgroups v2。
好了,上面我们解读了 Namespace 和 Cgroups 两大技术,它们是 Linux 下实现容器的两个基石,后面课程中要讨论的容器相关问题,或多或少都和 Namespace 或者 Cgroups 相关,我们会结合具体问题做深入的分析。
目前呢,你只需要先记住这两个技术的作用,Namespace 帮助容器来实现各种计算资源的隔离,Cgroups 主要限制的是容器能够使用的某种资源量。
重点总结
这一讲,我们对容器有了一个大致的认识,包括它的”形”, 一些基本的容器操作 ;还有它的”神”,也就是 容器实现的原理 。
启动容器的基本操作是这样的,首先用 Dockerfile 来建立一个容器的镜像,然后再用这个镜像来启动一个容器。
那启动了容器之后,怎么检验它是不是正常工作了呢?
我们可以运行 docker exec 这个命令进入容器的运行空间,查看进程是否启动,检查配置文件是否正确,检验我们设置的服务是否能够正常提供。
我们用 docker exec 命令查看了容器的进程,网络和文件系统,就能体会到容器的文件系统、运行的进程环境和网络的设置都是独立的,所以从用户使用的角度看,容器和一台独立的机器或者虚拟机没有什么太大的区别。
最后,我们一起学习了 Namespace 和 Cgroups,它们是 Linux 的两大技术,用于实现容器的特性。
具体来说, Namespace 帮助容器实现各种计算资源的隔离,Cgroups 主要对容器使用某种资源量的多少做一个限制。
所以我们在这里可以直接记住: 容器其实就是 Namespace+Cgroups。
容器进程
02 | 理解进程(1):为什么我在容器中不能kill 1号进程?
今天,我们正式进入理解进程的模块。我会通过 3 讲内容,带你了解容器 init 进程的特殊之处,还有它需要具备哪些功能,才能保证容器在运行过程中不会出现类似僵尸进程,或者应用程序无法 graceful shutdown 的问题。
那么通过这一讲,我会带你掌握 init 进程和 Linux 信号的核心概念。
问题再现
接下来,我们一起再现用 kill 1 命令重启容器的问题。
我猜你肯定想问,为什么要在容器中执行 kill 1 或者 kill -9 1 的命令呢?其实这是我们团队里的一位同学提出的问题。
这位同学当时遇到的情况是这样的,他想修改容器镜像里的一个 bug,但因为网路配置的问题,这个同学又不想为了重建 pod 去改变 pod IP。
如果你用过 Kubernetes 的话,你也肯定知道,Kubernetes 上是没有 restart pod 这个命令的。这样看来,他似乎只能让 pod 做个原地重启了。 当时我首先想到的,就是在容器中使用 kill pid 1 的方式重启容器。
为了模拟这个过程,我们可以进行下面的这段操作。
如果你没有在容器中做过 kill 1 ,你可以下载我在 GitHub 上的这个 例子 ,运行 make image 来做一个容器镜像。
然后,我们用 Docker 构建一个容器,用例子中的 init.sh 脚本作为这个容器的 init 进程。
最后,我们在容器中运行 kill 1 和 kill -9 1 ,看看会发生什么。
$ docker stop sig-proc;docker rm sig-proc
$ docker run --name sig-proc -d registry/sig-proc:v1 /init.sh
$ docker exec -it sig-proc bash
[root@5cc69036b7b2 /]$ ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 07:23 ? 00:00:00 /bin/bash /init.sh
root 8 1 0 07:25 ? 00:00:00 /usr/bin/coreutils --coreutils-prog-shebang=sleep /usr/bin/sleep 100
root 9 0 6 07:27 pts/0 00:00:00 bash
root 22 9 0 07:27 pts/0 00:00:00 ps -ef
[root@5cc69036b7b2 /]$ kill 1
[root@5cc69036b7b2 /]$ kill -9 1
[root@5cc69036b7b2 /]$ ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 07:23 ? 00:00:00 /bin/bash /init.sh
root 9 0 0 07:27 pts/0 00:00:00 bash
root 23 1 0 07:27 ? 00:00:00 /usr/bin/coreutils --coreutils-prog-shebang=sleep /usr/bin/sleep 100
root 24 9 0 07:27 pts/0 00:00:00 ps -ef当我们完成前面的操作,就会发现无论运行 kill 1 (对应 Linux 中的 SIGTERM 信号)还是 kill -9 1(对应 Linux 中的 SIGKILL 信号),都无法让进程终止。
那么问题来了,这两个常常用来终止进程的信号,都对容器中的 init 进程不起作用,这是怎么回事呢?
要解释这个问题,我们就要回到容器的两个最基本概念——init 进程和 Linux 信号中寻找答案。
知识详解
如何理解 init 进程?
init 进程的意思并不难理解,你只要认真听我讲完,这块内容基本就不会有问题了。我们下面来看一看。
使用容器的理想境界是 一个容器只启动一个进程 ,但这在现实应用中有时是做不到的。
比如说,在一个容器中除了主进程之外,我们可能还会启动辅助进程,做监控或者 rotate logs;再比如说,我们需要把原来运行在虚拟机(VM)的程序移到容器里,这些原来跑在虚拟机上的程序本身就是多进程的。
一旦我们启动了多个进程,那么容器里就会出现一个 pid 1,也就是我们常说的 1 号进程或者 init 进程,然后 由这个进程创建出其他的子进程。
接下来,我带你梳理一下 init 进程是怎么来的。
一个 Linux 操作系统,在系统打开电源,执行 BIOS/boot-loader 之后,就会由 boot-loader 负责加载 Linux 内核。
Linux 内核执行文件一般会放在 /boot 目录下,文件名类似 vmlinuz。在内核完成了操作系统的各种初始化之后,*这个程序需要执行的第一个用户态程就是 init 进程。
内核代码启动 1 号进程的时候,在没有外面参数指定程序路径的情况下,一般会从几个缺省路径尝试执行 1 号进程的代码。这几个路径都是 Unix 常用的可执行代码路径。
系统启动的时候先是执行内核态的代码,然后在内核中调用 1 号进程的代码,从内核态切换到用户态。
目前主流的 Linux 发行版,无论是 RedHat 系的还是 Debian 系的,都会把 /sbin/init 作为符号链接指向 Systemd。Systemd 是目前最流行的 Linux init 进程,在它之前还有 SysVinit、UpStart 等 Linux init 进程。
但无论是哪种 Linux init 进程,它最基本的功能都是创建出 Linux 系统中其他所有的进程,并且管理这些进程。 具体在 kernel 里的代码实现如下:
// init/main.c
/*
* We try each of these until one succeeds.
*
* The Bourne shell can be used instead of init if we are
* trying to recover a really broken machine.
*/
if (execute_command) {
ret = run_init_process(execute_command);
if (!ret)
return 0;
panic("Requested init %s failed (error %d).",
execute_command, ret);
}
if (!try_to_run_init_process("/sbin/init") ||
!try_to_run_init_process("/etc/init") ||
!try_to_run_init_process("/bin/init") ||
!try_to_run_init_process("/bin/sh"))
return 0;
panic("No working init found. Try passing init= option to kernel. "
"See Linux Documentation/admin-guide/init.rst for guidance.");$ ls -l /sbin/init
lrwxrwxrwx 1 root root 20 Feb 5 01:07 /sbin/init -> /lib/systemd/systemd在 Linux 上有了容器的概念之后,一旦容器建立了自己的 Pid Namespace(进程命名空间),这个 Namespace 里的进程号也是从 1 开始标记的。所以,容器的 init 进程也被称为 1 号进程。
怎么样,1 号进程是不是不难理解?关于这个知识点,你只需要记住: 1 号进程是第一个用户态的进程,由它直接或者间接创建了 Namespace 中的其他进程。
如何理解 Linux 信号?
刚才我给你讲了什么是 1 号进程,要想解决”为什么我在容器中不能 kill 1 号进程”这个问题,我们还得看看 kill 命令起到的作用。
我们运行 kill 命令,其实在 Linux 里就是发送一个信号,那么信号到底是什么呢?这就涉及到 Linux 信号的概念了。
其实信号这个概念在很早期的 Unix 系统上就有了。它一般会从 1 开始编号,通常来说,信号编号是 1 到 31,这个编号在所有的 Unix 系统上都是一样的。
在 Linux 上我们可以用 kill -l 来看这些信号的编号和名字,具体的编号和名字我给你列在了下面,你可以看一看。
$ kill -l
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ
26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR
31) SIGSYS用一句话来概括, 信号(Signal)其实就是 Linux 进程收到的一个通知。 这些通知产生的源头有很多种,通知的类型也有很多种。
比如下面这几个典型的场景,你可以看一下:
- 如果我们按下键盘”Ctrl+C”,当前运行的进程就会收到一个信号 SIGINT 而退出;
- 如果我们的代码写得有问题,导致内存访问出错了,当前的进程就会收到另一个信号 SIGSEGV;
- 我们也可以通过命令
kill <pid>,直接向一个进程发送一个信号,缺省情况下不指定信号的类型,那么这个信号就是 SIGTERM。也可以指定信号类型,比如命令kill -9 <pid>, 这里的 9,就是编号为 9 的信号,SIGKILL 信号。
在这一讲中,我们主要用到 SIGTERM(15)和 SIGKILL(9)这两个信号 ,所以这里你主要了解这两个信号就可以了,其他信号以后用到时再做介绍。
进程在收到信号后,就会去做相应的处理。怎么处理呢?对于每一个信号,进程对它的处理都有下面三个选择。
第一个选择是 忽略(Ignore) ,就是对这个信号不做任何处理,但是有两个信号例外,对于 SIGKILL 和 SIGSTOP 这个两个信号,进程是不能忽略的。这是因为它们的主要作用是为 Linux kernel 和超级用户提供删除任意进程的特权。
第二个选择,就是 捕获(Catch) ,这个是指让用户进程可以注册自己针对这个信号的 handler。具体怎么做我们目前暂时涉及不到,你先知道就行,我们在后面课程会进行详细介绍。
对于捕获,SIGKILL 和 SIGSTOP 这两个信号也同样例外,这两个信号不能有用户自己的处理代码,只能执行系统的缺省行为。
还有一个选择是 缺省行为(Default) ,Linux 为每个信号都定义了一个缺省的行为,你可以在 Linux 系统中运行 man 7 signal来查看每个信号的缺省行为。
对于大部分的信号而言,应用程序不需要注册自己的 handler,使用系统缺省定义行为就可以了。

我刚才说了,SIGTERM(15)和 SIGKILL(9)这两个信号是我们重点掌握的。现在我们已经讲解了信号的概念和处理方式,我就拿这两个信号为例,再带你具体分析一下。
首先我们来看 SIGTERM(15),这个信号是 Linux 命令 kill 缺省发出的。前面例子里的命令 kill 1 ,就是通过 kill 向 1 号进程发送一个信号,在没有别的参数时,这个信号类型就默认为 SIGTERM。
SIGTERM 这个信号是可以被捕获的,这里的”捕获”指的就是用户进程可以为这个信号注册自己的 handler,而这个 handler,我们后面会看到,它可以处理进程的 graceful-shutdown 问题。
我们再来了解一下 SIGKILL (9),这个信号是 Linux 里两个 特权信号 之一。什么是特权信号呢?
前面我们已经提到过了,特权信号就是 Linux 为 kernel 和超级用户去删除任意进程所保留的,不能被忽略也不能被捕获。那么进程一旦收到 SIGKILL,就要退出。
在前面的例子里,我们运行的命令 kill -9 1 里的参数”-9”,其实就是指发送编号为 9 的这个 SIGKILL 信号给 1 号进程。
现象解释
现在,你应该理解 init 进程和 Linux 信号这两个概念了,让我们回到开头的问题上来:”为什么我在容器中不能 kill 1 号进程,甚至 SIGKILL 信号也不行?”
你还记得么,在课程的最开始,我们已经尝试过用 bash 作为容器 1 号进程,这样是无法把 1 号进程杀掉的。那么我们再一起来看一看,用别的编程语言写的 1 号进程是否也杀不掉。
我们现在 用 C 程序作为 init 进程 ,尝试一下杀掉 1 号进程。和 bash init 进程一样,无论 SIGTERM 信号还是 SIGKILL 信号,在容器里都不能杀死这个 1 号进程。
$ cat c-init-nosig.c
#include <stdio.h>
#include <unistd.h>
int main(int argc, char *argv[])
{
printf("Process is sleeping\n");
while (1) {
sleep(100);
}
return 0;
}$ docker stop sig-proc;docker rm sig-proc
$ docker run --name sig-proc -d registry/sig-proc:v1 /c-init-nosig
$ docker exec -it sig-proc bash
[root@5d3d42a031b1 /]$ ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 07:48 ? 00:00:00 /c-init-nosig
root 6 0 5 07:48 pts/0 00:00:00 bash
root 19 6 0 07:48 pts/0 00:00:00 ps -ef
[root@5d3d42a031b1 /]$ kill 1
[root@5d3d42a031b1 /]$ kill -9 1
[root@5d3d42a031b1 /]$ ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 07:48 ? 00:00:00 /c-init-nosig
root 6 0 0 07:48 pts/0 00:00:00 bash
root 20 6 0 07:49 pts/0 00:00:00 ps -ef我们是不是这样就可以得出结论——“容器里的 1 号进程,完全忽略了 SIGTERM 和 SIGKILL 信号了”呢?你先别着急,我们再拿其他语言试试。
接下来,我们用 Golang 程序作为 1 号进程 ,我们再在容器中执行 kill -9 1 和 kill 1 。
这次,我们发现 kill -9 1 这个命令仍然不能杀死 1 号进程,也就是说,SIGKILL 信号和之前的两个测试一样不起作用。
但是,我们执行 kill 1 以后,SIGTERM 这个信号把 init 进程给杀了,容器退出了。
$ cat go-init.go
package main
import (
"fmt"
"time"
)
func main() {
fmt.Println("Start app\n")
time.Sleep(time.Duration(100000) * time.Millisecond)
}$ docker stop sig-proc;docker rm sig-proc
$ docker run --name sig-proc -d registry/sig-proc:v1 /go-init
$ docker exec -it sig-proc bash
[root@234a23aa597b /]$ ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 1 08:04 ? 00:00:00 /go-init
root 10 0 9 08:04 pts/0 00:00:00 bash
root 23 10 0 08:04 pts/0 00:00:00 ps -ef
[root@234a23aa597b /]$ kill -9 1
[root@234a23aa597b /]$ kill 1
[root@234a23aa597b /]$
[~]$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES对于这个测试结果,你是不是反而觉得更加困惑了?
为什么使用不同程序,结果就不一样呢?接下来我们就看看 kill 命令下达之后,Linux 里究竟发生了什么事,我给你系统地梳理一下整个过程。
在我们运行 kill 1 这个命令的时候,希望把 SIGTERM 这个信号发送给 1 号进程,就像下面图里的 带箭头虚线 。
在 Linux 实现里,kill 命令调用了 kill() 的这个系统调用 (所谓系统调用就是内核的调用接口)而进入到了内核函数 sys_kill(), 也就是下图里的 实线箭头 。
而内核在决定把信号发送给 1 号进程的时候,会调用 sig_task_ignored() 这个函数来做个判断,这个判断有什么用呢?
它会决定内核在哪些情况下会把发送的这个信号给忽略掉。如果信号被忽略了,那么 init 进程就不能收到指令了。
所以,我们想要知道 init 进程为什么收到或者收不到信号,都要去看看 sig_task_ignored() 的这个内核函数的实现 。

在 sig_task_ignored() 这个函数中有三个 if{}判断,第一个和第三个 if{}判断和我们的问题没有关系,并且代码有注释,我们就不讨论了。
我们重点来看第二个 if{}。我来给你分析一下,在容器中执行 kill 1 或者 kill -9 1 的时候,这第二个 if{}里的三个子条件是否可以被满足呢?
我们来看下面这串代码,这里表示 一旦这三个子条件都被满足,那么这个信号就不会发送给进程。
// kernel/signal.c
static bool sig_task_ignored(struct task_struct *t, int sig, bool force)
{
void __user *handler;
handler = sig_handler(t, sig);
/* SIGKILL and SIGSTOP may not be sent to the global init */
if (unlikely(is_global_init(t) && sig_kernel_only(sig)))
return true;
if (unlikely(t->signal->flags & SIGNAL_UNKILLABLE) &&
handler == SIG_DFL && !(force && sig_kernel_only(sig)))
return true;
/* Only allow kernel generated signals to this kthread */
if (unlikely((t->flags & PF_KTHREAD) &&
(handler == SIG_KTHREAD_KERNEL) && !force))
return true;
return sig_handler_ignored(handler, sig);
}接下来,我们就逐一分析一下这三个子条件,我们来说说这个”!(force && sig_kernel_only(sig))” 。
第一个条件里 force 的值,对于同一个 Namespace 里发出的信号来说,调用值是 0,所以这个条件总是满足的。
我们再来看一下第二个条件 “handler == SIG_DFL”,第二个条件判断信号的 handler 是否是 SIG_DFL。
那么什么是 SIG_DFL 呢? 对于每个信号,用户进程如果不注册一个自己的 handler,就会有一个系统缺省的 handler,这个缺省的 handler 就叫作 SIG_DFL。
对于 SIGKILL,我们前面介绍过它是特权信号,是不允许被捕获的,所以它的 handler 就一直是 SIG_DFL。这第二个条件对 SIGKILL 来说总是满足的。
对于 SIGTERM,它是可以被捕获的。也就是说如果用户不注册 handler,那么这个条件对 SIGTERM 也是满足的。
最后再来看一下第三个条件,”t->signal->flags & SIGNAL_UNKILLABLE”,这里的条件判断是这样的,进程必须是 SIGNAL_UNKILLABLE 的。
这个 SIGNAL_UNKILLABLE flag 是在哪里置位的呢?
可以参考我们下面的这段代码,在每个 Namespace 的 init 进程建立的时候,就会打上 SIGNAL_UNKILLABLE 这个标签,也就是说只要是 1 号进程,就会有这个 flag,这个条件也是满足的。
// kernel/fork.c
if (is_child_reaper(pid)) {
ns_of_pid(pid)->child_reaper = p;
p->signal->flags |= SIGNAL_UNKILLABLE;
}
/*
* is_child_reaper returns true if the pid is the init process
* of the current namespace. As this one could be checked before
* pid_ns->child_reaper is assigned in copy_process, we check
* with the pid number.
*/
static inline bool is_child_reaper(struct pid *pid)
{
return pid->numbers[pid->level].nr == 1;
}我们可以看出来,其实 最关键的一点就是 handler == SIG_DFL 。Linux 内核针对每个 Namespace 里的 init 进程,把只有 default handler 的信号都给忽略了。
如果我们自己注册了信号的 handler(应用程序注册信号 handler 被称作”Catch the Signal”),那么这个信号 handler 就不再是 SIG_DFL 。即使是 init 进程在接收到 SIGTERM 之后也是可以退出的。
不过,由于 SIGKILL 是一个特例,因为 SIGKILL 是不允许被注册用户 handler 的(还有一个不允许注册用户 handler 的信号是 SIGSTOP),那么它只有 SIG_DFL handler。
所以 init 进程是永远不能被 SIGKILL 所杀,但是可以被 SIGTERM 杀死。
说到这里,我们该怎么证实这一点呢?我们可以做下面两件事来验证。
第一件事,你可以查看 1 号进程状态中 SigCgt Bitmap
我们可以看到,在 Golang 程序里,很多信号都注册了自己的 handler,当然也包括了 SIGTERM(15),也就是 bit 15。
而 C 程序里,缺省状态下,一个信号 handler 都没有注册;bash 程序里注册了两个 handler,bit 2 和 bit 17,也就是 SIGINT 和 SIGCHLD,但是没有注册 SIGTERM。
所以,C 程序和 bash 程序里 SIGTERM 的 handler 是 SIG_DFL(系统缺省行为),那么它们就不能被 SIGTERM 所杀。
具体我们可以看一下这段 /proc 系统的进程状态:
### golang init
$ cat /proc/1/status | grep -i SigCgt
SigCgt: fffffffe7fc1feff
### C init
$ cat /proc/1/status | grep -i SigCgt
SigCgt: 0000000000000000
### bash init
$ cat /proc/1/status | grep -i SigCgt
SigCgt: 0000000000010002SigCgt 掩码位的解释: How can I check what signals a process is listening to?
第二件事,给 C 程序注册一下 SIGTERM handler,捕获 SIGTERM
我们调用 signal() 系统调用注册 SIGTERM 的 handler,在 handler 里主动退出,再看看容器中 kill 1 的结果。
这次我们就可以看到,在进程状态的 SigCgt bitmap 里,bit 15 (SIGTERM) 已经置位了。同时,运行 kill 1 也可以把这个 C 程序的 init 进程给杀死了。
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
void sig_handler(int signo)
{
if (signo == SIGTERM) {
printf("received SIGTERM\n");
exit(0);
}
}
int main(int argc, char *argv[])
{
signal(SIGTERM, sig_handler);
printf("Process is sleeping\n");
while (1) {
sleep(100);
}
return 0;
}$ docker stop sig-proc;docker rm sig-proc
$ docker run --name sig-proc -d registry/sig-proc:v1 /c-init-sig
$ docker exec -it sig-proc bash
[root@043f4f717cb5 /]$ ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 09:05 ? 00:00:00 /c-init-sig
root 6 0 18 09:06 pts/0 00:00:00 bash
root 19 6 0 09:06 pts/0 00:00:00 ps -ef
[root@043f4f717cb5 /]$ cat /proc/1/status | grep SigCgt
SigCgt: 0000000000004000
[root@043f4f717cb5 /]$ kill 1
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES好了,到这里我们可以确定这两点:
- kill -9 1 在容器中是不工作的,内核阻止了 1 号进程对 SIGKILL 特权信号的响应。
- kill 1 分两种情况,如果 1 号进程没有注册 SIGTERM 的 handler,那么对 SIGTERM 信号也不响应,如果注册了 handler,那么就可以响应 SIGTERM 信号。
重点总结
这一讲我们主要讲了 init 进程。围绕这个知识点,我提出了一个真实发生的问题:”为什么我在容器中不能 kill 1 号进程?”。
想要解决这个问题,我们需要掌握两个基本概念。
第一个概念是 Linux 1 号进程。它是第一个用户态的进程。它直接或者间接创建了 Namespace 中的其他进程。
第二个概念是 Linux 信号。Linux 有 31 个基本信号,进程在处理大部分信号时有三个选择: 忽略、捕获和缺省行为。其中两个特权信号 SIGKILL 和 SIGSTOP 不能被忽略或者捕获。
只知道基本概念还不行,我们还要去解决问题。我带你尝试了用 bash, C 语言还有 Golang 程序作为容器 init 进程,发现它们对 kill 1 的反应是不同的。
因为信号的最终处理都是在 Linux 内核中进行的,因此,我们需要对 Linux 内核代码进行分析。
容器里 1 号进程对信号处理的两个要点,这也是这一讲里我想让你记住的两句话:
- 在容器中,1 号进程永远不会响应 SIGKILL 和 SIGSTOP 这两个特权信号;
- 对于其他的信号,如果用户自己注册了 handler,1 号进程可以响应。
思考题
这一讲的最开始,有这样一个 C 语言的 init 进程,它没有注册任何信号的 handler。如果我们从 Host Namespace 向它发送 SIGTERM,会发生什么情况呢?
答:SIGTERM不能杀掉,但是SIGKILL可以。
提示:此时 force 为 true 而 sig_kernel_only(SIGTERM) 为 false, sig_kernel_only(SIGKILL) 为 true 。
03|理解进程(2):为什么我的容器里有这么多僵尸进程?
说起僵尸进程,相信你并不陌生。很多面试官经常会问到这个知识点,用来考察候选人的操作系统背景。通过这个问题,可以了解候选人对 Linux 进程管理和信号处理这些基础知识的理解程度,他的基本功扎不扎实。
所以,今天我们就一起来看看容器里为什么会产生僵尸进程,然后去分析如何怎么解决。
通过这一讲,你就会对僵尸进程的产生原理有一个清晰的认识,也会更深入地理解容器 init 进程的特性。
问题再现
我们平时用容器的时候,有的同学会发现,自己的容器运行久了之后,运行 ps 命令会看到一些进程,进程名后面加了 <defunct> 标识。那么你自然会有这样的疑问,这些是什么进程呢?
你可以自己做个容器镜像来模拟一下,我们先下载这个 例子 ,运行 make image 之后,再启动容器。
在容器里我们可以看到,1 号进程 fork 出 1000 个子进程。当这些子进程运行结束后,它们的进程名字后面都加了标识。
从它们的 Z stat(进程状态)中我们可以知道,这些都是僵尸进程(Zombie Process)。运行 top 命令,我们也可以看到输出的内容显示有 1000 zombie 进程。
$ docker run --name zombie-proc -d registry/zombie-proc:v1
02dec161a9e8b18922bd3599b922dbd087a2ad60c9b34afccde7c91a463bde8a
$ docker exec -it zombie-proc bash
$ ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 4324 1436 ? Ss 01:23 0:00 /app-test 1000
root 6 0.0 0.0 0 0 ? Z 01:23 0:00 [app-test] <defunct>
root 7 0.0 0.0 0 0 ? Z 01:23 0:00 [app-test] <defunct>
root 8 0.0 0.0 0 0 ? Z 01:23 0:00 [app-test] <defunct>
root 9 0.0 0.0 0 0 ? Z 01:23 0:00 [app-test] <defunct>
root 10 0.0 0.0 0 0 ? Z 01:23 0:00 [app-test] <defunct>
…
root 999 0.0 0.0 0 0 ? Z 01:23 0:00 [app-test] <defunct>
root 1000 0.0 0.0 0 0 ? Z 01:23 0:00 [app-test] <defunct>
root 1001 0.0 0.0 0 0 ? Z 01:23 0:00 [app-test] <defunct>
root 1002 0.0 0.0 0 0 ? Z 01:23 0:00 [app-test] <defunct>
root 1003 0.0 0.0 0 0 ? Z 01:23 0:00 [app-test] <defunct>
root 1004 0.0 0.0 0 0 ? Z 01:23 0:00 [app-test] <defunct>
root 1005 0.0 0.0 0 0 ? Z 01:23 0:00 [app-test] <defunct>
root 1023 0.0 0.0 12020 3392 pts/0 Ss 01:39 0:00 bash
$ top
top - 02:18:57 up 31 days, 15:17, 0 users, load average: 0.00, 0.01, 0.00
Tasks: 1003 total, 1 running, 2 sleeping, 0 stopped, 1000 zombie
…那么问题来了,什么是僵尸进程?它们是怎么产生的?僵尸进程太多会导致什么问题?想要回答这些问题,我们就要从进程状态的源头学习,看看僵尸进程到底处于进程整个生命周期里的哪一环。
知识详解
Linux 的进程状态
无论进程还是线程,在 Linux 内核里其实都是用 task_struct{}这个结构来表示的。它其实就是任务(task),也就是 Linux 里基本的调度单位。为了方便讲解,我们在这里暂且称它为进程。
那一个进程从创建(fork)到退出(exit),这个过程中的状态转化还是很简单的。
下面这个图是 《Linux Kernel Development》这本书里的 Linux 进程状态转化图。
我们从这张图中可以看出来,在进程”活着”的时候就只有两个状态:运行态(TASK_RUNNING)和睡眠态(TASK_INTERRUPTIBLE,TASK_UNINTERRUPTIBLE)。

那运行态和睡眠态这两种状态分别是什么意思呢?
运行态的意思是,无论进程是正在运行中(也就是获得了 CPU 资源),还是进程在 run queue 队列里随时可以运行,都处于这个状态。
我们想要查看进程是不是处于运行态,其实也很简单,比如使用 ps 命令,可以看到处于这个状态的进程显示的是 R stat。
睡眠态是指,进程需要等待某个资源而进入的状态,要等待的资源可以是一个信号量(Semaphore), 或者是磁盘 I/O,这个状态的进程会被放入到 wait queue 队列里。
这个睡眠态具体还包括两个子状态:一个是可以被打断的(TASK_INTERRUPTIBLE),我们用 ps 查看到的进程,显示为 S stat。还有一个是不可被打断的(TASK_UNINTERRUPTIBLE),用 ps 查看进程,就显示为 D stat。
这两个子状态,我们在后面的课程里碰到新的问题时,会再做详细介绍,这里你只要知道这些就行了。
除了上面进程在活的时候的两个状态,进程在调用 do_exit() 退出的时候,还有两个状态。
一个是 EXIT_DEAD,也就是进程在真正结束退出的那一瞬间的状态;第二个是 EXIT_ZOMBIE 状态,这是进程在 EXIT_DEAD 前的一个状态,而我们今天讨论的僵尸进程,也就是处于这个状态中。
限制容器中进程数目
理解了 Linux 进程状态之后,我们还需要知道,在 Linux 系统中怎么限制进程数目。因为弄清楚这个问题,我们才能更深入地去理解僵尸进程的危害。
一台 Linux 机器上的进程总数目是有限制的。如果超过这个最大值,那么系统就无法创建出新的进程了,比如你想 SSH 登录到这台机器上就不行了。
这个最大值可以我们在 /proc/sys/kernel/pid_max 这个参数中看到。
Linux 内核在初始化系统的时候,会根据机器 CPU 的数目来设置 pid_max 的值。
比如说,如果机器中 CPU 数目小于等于 32,那么 pid_max 就会被设置为 32768(32K);如果机器中的 CPU 数目大于 32,那么 pid_max 就被设置为 N*1024 (N 就是 CPU 数目)。
对于 Linux 系统而言,容器就是一组进程的集合。如果容器中的应用创建过多的进程或者出现 bug,就会产生类似 fork bomb 的行为。
这个 fork bomb 就是指在计算机中,通过不断建立新进程来消耗系统中的进程资源,它是一种黑客攻击方式。这样,容器中的进程数就会把整个节点的可用进程总数给消耗完。
这样,不但会使同一个节点上的其他容器无法工作,还会让宿主机本身也无法工作。所以对于每个容器来说,我们都需要限制它的最大进程数目,而这个功能由 pids Cgroup 这个子系统来完成。
而这个功能的实现方法是这样的:pids Cgroup 通过 Cgroup 文件系统的方式向用户提供操作接口,一般它的 Cgroup 文件系统挂载点在 /sys/fs/cgroup/pids。
在一个容器建立之后,创建容器的服务会在 /sys/fs/cgroup/pids 下建立一个子目录,就是一个控制组,控制组里 最关键的一个文件就是 pids.max 。我们可以向这个文件写入数值,而这个值就是这个容器中允许的最大进程数目。
我们对这个值做好限制,容器就不会因为创建出过多进程而影响到其他容器和宿主机了。思路讲完了,接下来我们就实际上手试一试。
下面是对一个 Docker 容器的 pids Cgroup 的操作,你可以跟着操作一下。
$ pwd
/sys/fs/cgroup/pids
$ df ./
Filesystem 1K-blocks Used Available Use% Mounted on
cgroup 0 0 0 - /sys/fs/cgroup/pids
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
7ecd3aa7fdc1 registry/zombie-proc:v1 "/app-test 1000" 37 hours ago Up 37 hours frosty_yalow
$ pwd
/sys/fs/cgroup/pids/system.slice/docker-7ecd3aa7fdc15a1e183813b1899d5d939beafb11833ad6c8b0432536e5b9871c.scope
$ ls
cgroup.clone_children cgroup.procs notify_on_release pids.current pids.events pids.max tasks
$ echo 1002 > pids.max
$ cat pids.max
1002解决问题
刚才我给你解释了两个基本概念,进程状态和进程数目限制,那我们现在就可以解决容器中的僵尸进程问题了。
在前面 Linux 进程状态的介绍里,我们知道了,僵尸进程是 Linux 进程退出状态的一种。
从内核进程的 do_exit() 函数我们也可以看到,这时候进程 task_struct 里的 mm/shm/sem/files 等文件资源都已经释放了,只留下了一个 stask_struct instance 空壳。
就像下面这段代码显示的一样,从进程对应的 /proc/<pid> 文件目录下,我们也可以看出来,对应的资源都已经没有了。
cat /proc/6/cmdline
cat /proc/6/smaps
cat /proc/6/maps
ls /proc/6/fd并且,这个进程也已经不响应任何的信号了,无论 SIGTERM(15) 还是 SIGKILL(9)。例如上面 pid 6 的僵尸进程,这两个信号都已经被响应了。
$ kill -15 6
$ kill -9 6
$ ps -ef | grep 6
root 6 1 0 13:59 ? 00:00:00 [app-test] <defunct>当多个容器运行在同一个宿主机上的时候,为了避免一个容器消耗完我们整个宿主机进程号资源,我们会配置 pids Cgroup 来限制每个容器的最大进程数目。也就是说,进程数目在每个容器中也是有限的,是一种很宝贵的资源。
既然进程号资源在宿主机上是有限的,显然残留的僵尸进程多了以后,给系统带来最大问题就是它占用了进程号。 这就意味着,残留的僵尸进程,在容器里仍然占据着进程号资源,很有可能会导致新的进程不能运转。
这里我再次借用开头的那个例子,也就是一个产生了 1000 个僵尸进程的容器,带你理解一下这个例子中进程数的上限。我们可以看一下,1 个 init 进程 +1000 个僵尸进程 +1 个 bash 进程 ,总共就是 1002 个进程。
如果 pids Cgroup 也限制了这个容器的最大进程号的数量,限制为 1002 的话,我们在 pids Cgroup 里可以看到,pids.current == pids.max,也就是已经达到了容器进程号数的上限。
这时候,如果我们在容器里想再启动一个进程,例如运行一下 ls 命令,就会看到 Resource temporarily unavailable 的错误消息。已经退出的无用进程,却阻碍了有用进程的启动,显然这样是不合理的。
具体代码如下:
### On host
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
09e6e8e16346 registry/zombie-proc:v1 "/app-test 1000" 29 minutes ago Up 29 minutes peaceful_ritchie
$ pwd
/sys/fs/cgroup/pids/system.slice/docker-09e6e8e1634612580a03dd3496d2efed2cf2a510b9688160b414ce1d1ea3e4ae.scope
$ cat pids.max
1002
$ cat pids.current
1002
### On Container
[root@09e6e8e16346 /]$ ls
bash: fork: retry: Resource temporarily unavailable
bash: fork: retry: Resource temporarily unavailable所以,接下来我们还要看看这些僵尸进程到底是怎么产生的。因为只有理解它的产生机制,我们才能想明白怎么避免僵尸进程的出现。
我们先看一下刚才模拟僵尸进程的那段小程序。这段程序里,父进程在创建完子进程之后就不管了,这就是造成子进程变成僵尸进程的原因。
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
int main(int argc, char *argv[])
{
int i;
int total;
if (argc < 2) {
total = 1;
} else {
total = atoi(argv[1]);
}
printf("To create %d processes\n", total);
for (i = 0; i < total; i++) {
pid_t pid = fork();
if (pid == 0) {
printf("Child => PPID: %d PID: %d\n", getppid(),
getpid());
sleep(60);
printf("Child process eixts\n");
exit(EXIT_SUCCESS);
} else if (pid > 0) {
printf("Parent created child %d\n", i);
} else {
printf("Unable to create child process. %d\n", i);
break;
}
}
printf("Paraent is sleeping\n");
while (1) {
sleep(100);
}
return EXIT_SUCCESS;
}前面我们通过分析,发现子进程变成僵尸进程的原因在于父进程”不负责”,那找到原因后,我们再想想,如何来解决。
其实解决思路很好理解,就好像熊孩子犯了事儿,你要去找他家长来管教,那子进程在容器里”赖着不走”,我们就需要让父进程出面处理了。
所以,在 Linux 中的进程退出之后,如果进入僵尸状态,我们就需要父进程调用 wait() 这个系统调用,去回收僵尸进程的最后的那些系统资源,比如进程号资源。
那么,我们在刚才那段代码里,主进程进入 sleep(100) 之前,加上一段 wait() 函数调用,就不会出现僵尸进程的残留了。
for (i = 0; i < total; i++) {
int status;
wait(&status);
}而容器中所有进程的最终父进程,就是我们所说的 init 进程,由它负责生成容器中的所有其他进程。因此,容器的 init 进程有责任回收容器中的所有僵尸进程。
前面我们知道了 wait() 系统调用可以回收僵尸进程,但是 wait() 系统调用有一个问题,需要你注意。
wait() 系统调用是一个阻塞的调用,也就是说,如果没有子进程是僵尸进程的话,这个调用就一直不会返回,那么整个进程就会被阻塞住,而不能去做别的事了。
不过这也没有关系,我们还有另一个方法处理。Linux 还提供了一个类似的系统调用 waitpid(),这个调用的参数更多。
其中就有一个参数 WNOHANG,它的含义就是,如果在调用的时候没有僵尸进程,那么函数就马上返回了,而不会像 wait() 调用那样一直等待在那里。
比如社区的一个 容器 init 项目 tini 。在这个例子中,它的主进程里,就是不断在调用带 WNOHANG 参数的 waitpid(),通过这个方式清理容器中所有的僵尸进程。
int reap_zombies(const pid_t child_pid, int* const child_exitcode_ptr) {
pid_t current_pid;
int current_status;
while (1) {
current_pid = waitpid(-1, ¤t_status, WNOHANG);
switch (current_pid) {
case -1:
if (errno == ECHILD) {
PRINT_TRACE("No child to wait");
break;
}
…
重点总结
首先,我们先用代码来模拟了这个情况,还原了在一个容器中大量的僵尸进程是如何产生的。为了理解它的产生原理和危害,我们先要掌握两个知识点:
- Linux 进程状态中,僵尸进程处于 EXIT_ZOMBIE 这个状态;
- 容器需要对最大进程数做限制。具体方法是这样的,我们可以向 Cgroup 中 pids.max 这个文件写入数值(这个值就是这个容器中允许的最大进程数目)。
掌握了基本概念之后,我们找到了僵尸进程的产生原因。父进程在创建完子进程之后就不管了。
所以,我们需要父进程调用 wait() 或者 waitpid() 系统调用来避免僵尸进程产生。
关于本节内容,你只要记住下面三个主要的知识点就可以了:
- 每一个 Linux 进程在退出的时候都会进入一个僵尸状态(EXIT_ZOMBIE);
- 僵尸进程如果不清理,就会消耗系统中的进程数资源,最坏的情况是导致新的进程无法启动;
- 僵尸进程一定需要父进程调用 wait() 或者 waitpid() 系统调用来清理,这也是容器中 init 进程必须具备的一个功能。
思考题
如果容器的 init 进程创建了子进程 B,B 又创建了自己的子进程 C。如果 C 运行完之后,退出成了僵尸进程,B 进程还在运行,而容器的 init 进程还在不断地调用 waitpid(),那 C 这个僵尸进程可以被回收吗?
C 应该不会被回收,waitpid 仅等待直接 children 的状态变化。
04 | 理解进程(3):为什么我在容器中的进程被强制杀死了?
今天我们来讲容器中 init 进程的最后一讲,为什么容器中的进程被强制杀死了。理解了这个问题,能够帮助你更好地管理进程,让容器中的进程可以 graceful shutdown。
我先给你说说,为什么进程管理中做到这点很重要。在实际生产环境中,我们有不少应用在退出的时候需要做一些清理工作,比如清理一些远端的链接,或者是清除一些本地的临时数据。
这样的清理工作,可以尽可能避免远端或者本地的错误发生,比如减少丢包等问题的出现。而这些退出清理的工作,通常是在 SIGTERM 这个信号用户注册的 handler 里进行的。
但是,如果我们的进程收到了 SIGKILL,那应用程序就没机会执行这些清理工作了。这就意味着,一旦进程不能 graceful shutdown,就会增加应用的出错率。
所以接下来,我们来重现一下,进程在容器退出时都发生了什么。
场景再现
在容器平台上,你想要停止一个容器,无论是在 Kubernetes 中去删除一个 pod,或者用 Docker 停止一个容器,最后都会用到 Containerd 这个服务。
而 Containerd 在停止容器的时候,就会向容器的 init 进程发送一个 SIGTERM 信号。
我们会发现,在 init 进程退出之后,容器内的其他进程也都立刻退出了。不过不同的是,init 进程收到的是 SIGTERM 信号,而其他进程收到的是 SIGKILL 信号。
在理解进程的第一讲中,我们提到过 SIGKILL 信号是不能被捕获的(catch)的,也就是用户不能注册自己的 handler,而 SIGTERM 信号却允许用户注册自己的 handler,这样的话差别就很大了。
那么,我们就一起来看看当容器退出的时候,如何才能让容器中的进程都收到 SIGTERM 信号,而不是 SIGKILL 信号。
延续前面课程中处理问题的思路,我们同样可以运行一个简单的容器,来重现这个问题,用这里的 代码 执行一下 make image ,然后用 Docker 启动这个容器镜像。
docker run -d --name fwd_sig registry/fwd_sig:v1 /c-init-sig你会发现,在我们用 docker stop 停止这个容器的时候,如果用 strace 工具来监控,就能看到容器里的 init 进程和另外一个进程收到的信号情况。
在下面的例子里,进程号为 15909 的就是容器里的 init 进程,而进程号为 15959 的是容器里另外一个进程。
在命令输出中我们可以看到,init 进程(15909)收到的是 SIGTERM 信号,而另外一个进程(15959)收到的果然是 SIGKILL 信号。
$ ps -ef | grep c-init-sig
root 15857 14391 0 06:23 pts/0 00:00:00 docker run -it registry/fwd_sig:v1 /c-init-sig
root 15909 15879 0 06:23 pts/0 00:00:00 /c-init-sig
root 15959 15909 0 06:23 pts/0 00:00:00 /c-init-sig
root 16046 14607 0 06:23 pts/3 00:00:00 grep --color=auto c-init-sig
$ strace -p 15909
strace: Process 15909 attached
restart_syscall(<... resuming interrupted read ...>) = ? ERESTART_RESTARTBLOCK (Interrupted by signal)
--- SIGTERM {si_signo=SIGTERM, si_code=SI_USER, si_pid=0, si_uid=0} ---
write(1, "received SIGTERM\n", 17) = 17
exit_group(0) = ?
+++ exited with 0 +++
$ strace -p 15959
strace: Process 15959 attached
restart_syscall(<... resuming interrupted read ...>) = ?
+++ killed by SIGKILL +++知识详解:信号的两个系统调用
我们想要理解刚才的例子,就需要搞懂信号背后的两个系统调用,它们分别是 kill() 系统调用和 signal() 系统调用。
这里呢,我们可以结合前面讲过的信号来理解这两个系统调用。在容器 init 进程的第一讲里,我们介绍过信号的基本概念了, 信号就是 Linux 进程收到的一个通知。
等你学完如何使用这两个系统调用之后,就会更清楚 Linux 信号是怎么一回事,遇到容器里信号相关的问题,你就能更好地理清思路了。
我还会再给你举个使用函数的例子,帮助你进一步理解进程是如何实现 graceful shutdown 的。
进程对信号的处理其实就包括两个问题, 一个是进程如何发送信号,另一个是进程收到信号后如何处理。
我们在 Linux 中发送信号的系统调用是 kill(),之前很多例子里面我们用的命令 kill ,它内部的实现就是调用了 kill() 这个函数。
下面是 Linux Programmer’s Manual 里对 kill() 函数的定义。
这个函数有两个参数,一个是 sig,代表需要发送哪个信号,比如 sig 的值是 15 的话,就是指发送 SIGTERM;另一个参数是 pid,也就是指信号需要发送给哪个进程,比如值是 1 的话,就是指发送给进程号是 1 的进程。
NAME
kill - send signal to a process
SYNOPSIS
#include <sys/types.h>
#include <signal.h>
int kill(pid_t pid, int sig);我们知道了发送信号的系统调用之后,再来看另一个系统调用,也就是 signal() 系统调用这个函数,它可以给信号注册 handler。
下面是 signal() 在 Linux Programmer’s Manual 里的定义,参数 signum 也就是信号的编号,例如数值 15,就是信号 SIGTERM;参数 handler 是一个函数指针参数,用来注册用户的信号 handler。
NAME
signal - ANSI C signal handling
SYNOPSIS
#include <signal.h>
typedef void (*sighandler_t)(int);
sighandler_t signal(int signum, sighandler_t handler);在容器 init 进程的第一讲里,我们学过 进程对每种信号的处理,包括三个选择:调用系统缺省行为、捕获、忽略 。而这里的选择,其实就是程序中如何去调用 signal() 这个系统调用。
第一个选择就是缺省,如果我们在代码中对某个信号,比如 SIGTERM 信号,不做任何 signal() 相关的系统调用,那么在进程运行的时候,如果接收到信号 SIGTERM,进程就会执行内核中 SIGTERM 信号的缺省代码。
对于 SIGTERM 这个信号来说,它的缺省行为就是进程退出(terminate)。
内核中对不同的信号有不同的缺省行为,一般会采用退出(terminate),暂停(stop),忽略(ignore)这三种行为中的一种。
那第二个选择捕获又是什么意思呢?
捕获指的就是我们在代码中为某个信号,调用 signal() 注册自己的 handler。这样进程在运行的时候,一旦接收到信号,就不会再去执行内核中的缺省代码,而是会执行通过 signal() 注册的 handler。
比如下面这段代码,我们为 SIGTERM 这个信号注册了一个 handler,在 handler 里只是做了一个打印操作。
那么这个程序在运行的时候,如果收到 SIGTERM 信号,它就不会退出了,而是只在屏幕上显示出”received SIGTERM”。
void sig_handler(int signo)
{
if (signo == SIGTERM) {
printf("received SIGTERM\n");
}
}
int main(int argc, char *argv[])
{
...
signal(SIGTERM, sig_handler);
...
}我们再来看看第三个选择,如果要让进程”忽略”一个信号,我们就要通过 signal() 这个系统调用,为这个信号注册一个特殊的 handler,也就是 SIG_IGN 。
比如下面的这段代码,就是为 SIGTERM 这个信号注册SIG_IGN。
这样操作的效果,就是在程序运行的时候,如果收到 SIGTERM 信号,程序既不会退出,也不会在屏幕上输出 log,而是什么反应也没有,就像完全没有收到这个信号一样。
int main(int argc, char *argv[])
{
...
signal(SIGTERM, SIG_IGN);
...
}好了,我们通过讲解 signal() 这个系统调用,帮助你回顾了信号处理的三个选择:缺省行为、捕获和忽略。
这里我还想要提醒你一点, SIGKILL 和 SIGSTOP 信号是两个特权信号,它们不可以被捕获和忽略,这个特点也反映在 signal() 调用上。
我们可以运行下面的 这段代码 ,如果我们用 signal() 为 SIGKILL 注册 handler,那么它就会返回 SIG_ERR,不允许我们做捕获操作。
$ cat reg_sigkill.c
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <errno.h>
#include <signal.h>
typedef void (*sighandler_t)(int);
void sig_handler(int signo)
{
if (signo == SIGKILL) {
printf("received SIGKILL\n");
exit(0);
}
}
int main(int argc, char *argv[])
{
sighandler_t h_ret;
h_ret = signal(SIGKILL, sig_handler);
if (h_ret == SIG_ERR) {
perror("SIG_ERR");
}
return 0;
}
$ ./reg_sigkill
SIG_ERR: Invalid argument最后,我用下面 这段代码 来做个小结。
这段代码里,我们用 signal() 对 SIGTERM 这个信号做了忽略,捕获以及恢复它的缺省行为,并且每一次都用 kill() 系统调用向进程自己发送 SIGTERM 信号,这样做可以确认进程对 SIGTERM 信号的选择。
#include <stdio.h>
#include <signal.h>
typedef void (*sighandler_t)(int);
void sig_handler(int signo)
{
if (signo == SIGTERM) {
printf("received SIGTERM\n\n");
// Set SIGTERM handler to default
signal(SIGTERM, SIG_DFL);
}
}
int main(int argc, char *argv[])
{
//Ignore SIGTERM, and send SIGTERM
// to process itself.
signal(SIGTERM, SIG_IGN);
printf("Ignore SIGTERM\n\n");
kill(0, SIGTERM);
//Catch SIGERM, and send SIGTERM
// to process itself.
signal(SIGTERM, sig_handler);
printf("Catch SIGTERM\n");
kill(0, SIGTERM);
//Default SIGTERM. In sig_handler, it sets
//SIGTERM handler back to default one.
printf("Default SIGTERM\n");
kill(0, SIGTERM);
return 0;
}我们一起来总结一下刚才讲的两个系统调用:
先说说 kill() 这个系统调用,它其实很简单,输入两个参数:进程号和信号,就把特定的信号发送给指定的进程了。
再说说 signal() 这个调用,它决定了进程收到特定的信号如何来处理,SIG_DFL 参数把对应信号恢复为缺省 handler,也可以用自定义的函数作为 handler,或者用 SIG_IGN 参数让进程忽略信号。
对于 SIGKILL 信号,如果调用 signal() 函数,为它注册自定义的 handler,系统就会拒绝。
解决问题
我们在学习了 kill() 和 signal() 这个两个信号相关的系统调用之后,再回到这一讲最初的问题上,为什么在停止一个容器的时候,容器 init 进程收到的 SIGTERM 信号,而容器中其他进程却会收到 SIGKILL 信号呢?
当 Linux 进程收到 SIGTERM 信号并且使进程退出,这时 Linux 内核对处理进程退出的入口点就是 do_exit() 函数,do_exit() 函数中会释放进程的相关资源,比如内存,文件句柄,信号量等等。
Linux 内核对处理进程退出的入口点就是 do_exit() 函数,do_exit() 函数中会释放进程的相关资源,比如内存,文件句柄,信号量等等。
在做完这些工作之后,它会调用一个 exit_notify() 函数,用来通知和这个进程相关的父子进程等。
对于容器来说,还要考虑 Pid Namespace 里的其他进程。这里调用的就是 zap_pid_ns_processes() 这个函数,而在这个函数中,如果是处于退出状态的 init 进程,它会向 Namespace 中的其他进程都发送一个 SIGKILL 信号。
整个流程如下图所示。
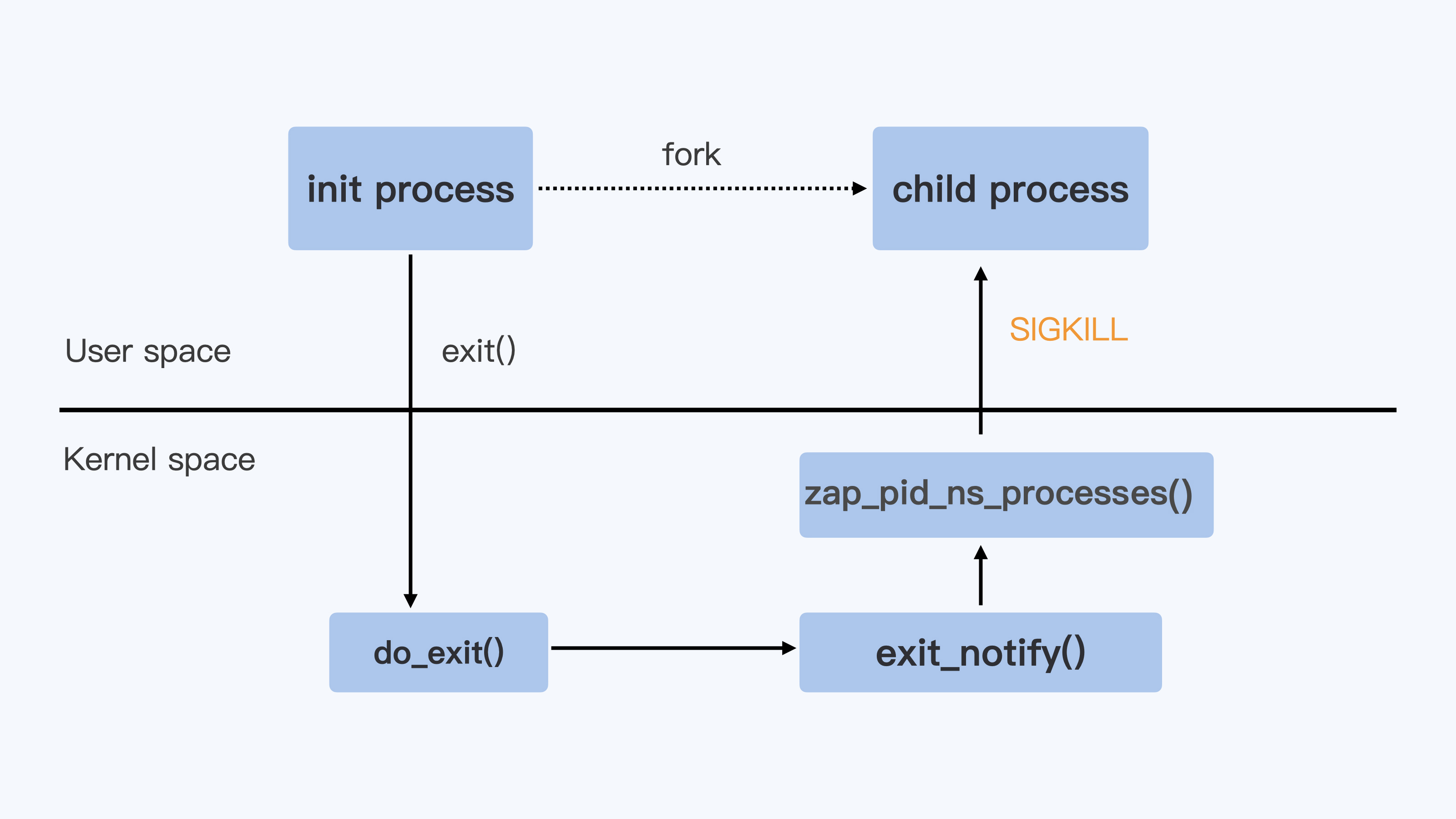
你还可以看一下, 内核代码 是这样的。
/*
* The last thread in the cgroup-init thread group is terminating.
* Find remaining pid_ts in the namespace, signal and wait for them
* to exit.
*
* Note: This signals each threads in the namespace - even those that
* belong to the same thread group, To avoid this, we would have
* to walk the entire tasklist looking a processes in this
* namespace, but that could be unnecessarily expensive if the
* pid namespace has just a few processes. Or we need to
* maintain a tasklist for each pid namespace.
*
*/
rcu_read_lock();
read_lock(&tasklist_lock);
nr = 2;
idr_for_each_entry_continue(&pid_ns->idr, pid, nr) {
task = pid_task(pid, PIDTYPE_PID);
if (task && !__fatal_signal_pending(task))
group_send_sig_info(SIGKILL, SEND_SIG_PRIV, task, PIDTYPE_MAX);
}说到这里,我们也就明白为什么容器 init 进程收到的 SIGTERM 信号,而容器中其他进程却会收到 SIGKILL 信号了。
前面我讲过,SIGKILL 是个特权信号(特权信号是 Linux 为 kernel 和超级用户去删除任意进程所保留的,不能被忽略也不能被捕获)。
所以进程收到这个信号后,就立刻退出了,没有机会调用一些释放资源的 handler 之后,再做退出动作。
而 SIGTERM 是可以被捕获的,用户是可以注册自己的 handler 的。因此,容器中的程序在 stop container 的时候,我们更希望进程收到 SIGTERM 信号而不是 SIGKILL 信号。
那在容器被停止的时候,我们该怎么做,才能让容器中的进程收到 SIGTERM 信号呢?
你可能已经想到了,就是让容器 init 进程来转发 SIGTERM 信号。的确是这样,比如 Docker Container 里使用的 tini 作为 init 进程,tini 的代码中就会调用 sigtimedwait() 这个函数来查看自己收到的信号,然后调用 kill() 把信号发给子进程。
我给你举个具体的例子说明,从下面的这段代码中,我们可以看到除了 SIGCHLD 这个信号外,tini 会把其他所有的信号都转发给它的子进程。
int wait_and_forward_signal(sigset_t const* const parent_sigset_ptr, pid_t const child_pid) {
siginfo_t sig;
if (sigtimedwait(parent_sigset_ptr, &sig, &ts) == -1) {
switch (errno) {
…
}
} else {
/* There is a signal to handle here */
switch (sig.si_signo) {
case SIGCHLD:
/* Special-cased, as we don't forward SIGCHLD. Instead, we'll
* fallthrough to reaping processes.
*/
PRINT_DEBUG("Received SIGCHLD");
break;
default:
PRINT_DEBUG("Passing signal: '%s'", strsignal(sig.si_signo));
/* Forward anything else */
if (kill(kill_process_group ? -child_pid : child_pid, sig.si_signo)) {
if (errno == ESRCH) {
PRINT_WARNING("Child was dead when forwarding signal");
} else {
PRINT_FATAL("Unexpected error when forwarding signal: '%s'", strerror(errno));
return 1;
}
}
break;
}
}
return 0;
}那么我们在这里明确一下,怎么解决停止容器的时候,容器内应用程序被强制杀死的问题呢?
解决的方法就是在容器的 init 进程中对收到的信号做个转发,发送到容器中的其他子进程,这样容器中的所有进程在停止时,都会收到 SIGTERM,而不是 SIGKILL 信号了。
重点小结
这一讲我们要解决的问题是让容器中的进程,在容器停止的时候,有机会 graceful shutdown,而不是收到 SIGKILL 信号而被强制杀死。
首先我们通过对 kill() 和 signal() 这个两个系统调用的学习,进一步理解了进程是怎样处理 Linux 信号的,重点是信号在接收处理的三个选择: 忽略,捕获和缺省行为。
通过代码例子,我们知道 SIGTERM 是可以被忽略和捕获的,但是 SIGKILL 是不可以被忽略和捕获的。
了解这一点以后,我们就找到了问题的解决方向,也就是我们需要在停止容器时,让容器中的应用收到 SIGTERM,而不是 SIGKILL。
具体怎么操作呢?我们可以在容器的 init 进程中对收到的信号做个转发,发送到容器中的其他子进程。这样一来,容器中的所有进程在停止容器时,都会收到 SIGTERM,而不是 SIGKILL 信号了。
我认为,解决 init 进程信号的这类问题其实并不难。
我们只需要先梳理一下和这个问题相关的几个知识点,再写个小程序,让它跑在容器里,稍微做几个试验。然后,我们再看一下内核和 Docker 的源代码,就可以很快得出结论了。
05|容器CPU(1):怎么限制容器的CPU使用?
我在第一讲中给你讲过,容器在 Linux 系统中最核心的两个概念是 Namespace 和 Cgroups。我们可以通过 Cgroups 技术限制资源。这个资源可以分为很多类型,比如 CPU,Memory,Storage,Network 等等。而计算资源是最基本的一种资源,所有的容器都需要这种资源。
那么,今天我们就先聊一聊,怎么限制容器的 CPU 使用?
我们拿 Kubernetes 平台做例子,具体来看下面这个 pod/container 里的 spec 定义,在 CPU 资源相关的定义中有两项内容,分别是 Request CPU 和 Limit CPU 。
apiVersion: v1
kind: Pod
metadata:
name: frontend
spec:
containers:
- name: app
image: images.my-company.example/app:v4
env:
resources:
requests:
memory: "64Mi"
cpu: "1"
limits:
memory: "128Mi"
cpu: "2"
…很多刚刚使用 Kubernetes 的同学,可能一开始并不理解这两个参数有什么作用。
这里我先给你说结论,在 Pod Spec 里的”Request CPU”和”Limit CPU”的值,最后会通过 CPU Cgroup 的配置,来实现控制容器 CPU 资源的作用。
那接下来我会先从进程的 CPU 使用讲起,然后带你在 CPU Cgroup 子系统中建立几个控制组,用这个例子为你讲解 CPU Cgroup 中的三个最重要的参数”cpu.cfs_quota_us””cpu.cfs_period_us””cpu.shares”。
相信理解了这三个参数后,你就会明白我们要怎样限制容器 CPU 的使用了。
如何理解 CPU 使用和 CPU Cgroup?
既然我们需要理解 CPU Cgroup,那么就有必要先来看一下 Linux 里的 CPU 使用的概念,这是因为 CPU Cgroup 最大的作用就是限制 CPU 使用。
CPU 使用的分类
如果你想查看 Linux 系统的 CPU 使用的话,会用什么方法呢?最常用的肯定是运行 Top 了。
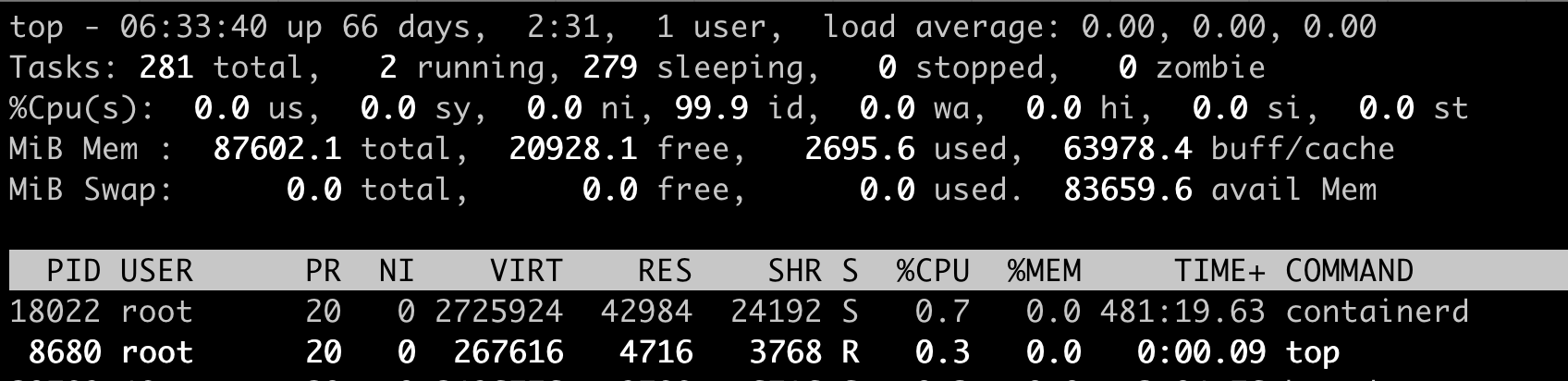
我们对照下图的 Top 运行界面,在截图第三行,”%Cpu(s)”开头的这一行,你会看到一串数值,也就是”0.0 us, 0.0 sy, 0.0 ni, 99.9 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st”,那么这里的每一项值都是什么含义呢?
下面这张图里最长的带箭头横轴,我们可以把它看成一个时间轴。同时,它的上半部分代表 Linux 用户态(User space),下半部分代表内核态(Kernel space)。这里为了方便你理解,我们先假设只有一个 CPU 吧。
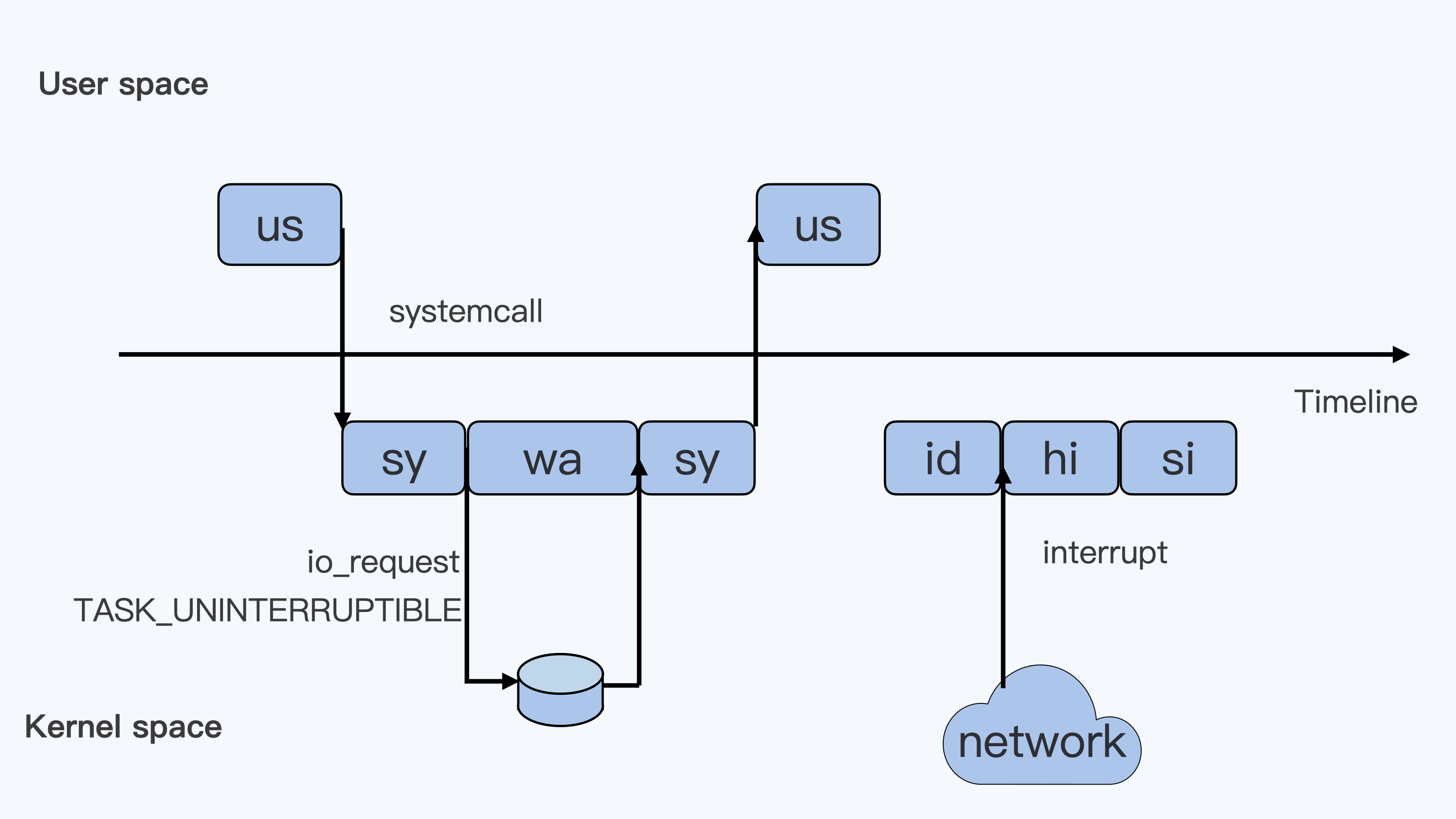
我们可以用上面这张图,把这些值挨个解释一下。
假设一个用户程序开始运行了,那么就对应着第一个”us”框,”us”是”user”的缩写,代表 Linux 的用户态 CPU Usage。普通用户程序代码中,只要不是调用系统调用(System Call),这些代码的指令消耗的 CPU 就都属于”us”。
当这个用户程序代码中调用了系统调用,比如说 read() 去读取一个文件,这时候这个用户进程就会从用户态切换到内核态。
内核态 read() 系统调用在读到真正 disk 上的文件前,就会进行一些文件系统层的操作。那么这些代码指令的消耗就属于”sy”,这里就对应上面图里的第二个框。”sy”是 “system”的缩写,代表内核态 CPU 使用。
接下来,这个 read() 系统调用会向 Linux 的 Block Layer 发出一个 I/O Request,触发一个真正的磁盘读取操作。
这时候,这个进程一般会被置为 TASK_UNINTERRUPTIBLE。而 Linux 会把这段时间标示成”wa”,对应图中的第三个框。”wa”是”iowait”的缩写,代表等待 I/O 的时间,这里的 I/O 是指 Disk I/O。
紧接着,当磁盘返回数据时,进程在内核态拿到数据,这里仍旧是内核态的 CPU 使用中的”sy”,也就是图中的第四个框。
然后,进程再从内核态切换回用户态,在用户态得到文件数据,这里进程又回到用户态的 CPU 使用,”us”,对应图中第五个框。
好,这里我们假设一下,这个用户进程在读取数据之后,没事可做就休眠了。并且我们可以进一步假设,这时在这个 CPU 上也没有其他需要运行的进程了,那么系统就会进入”id”这个步骤,也就是第六个框。”id”是”idle”的缩写,代表系统处于空闲状态。
如果这时这台机器在网络收到一个网络数据包,网卡就会发出一个中断(interrupt)。相应地,CPU 会响应中断,然后进入中断服务程序。
这时,CPU 就会进入”hi”,也就是第七个框。”hi”是”hardware irq”的缩写,代表 CPU 处理硬中断的开销。由于我们的中断服务处理需要关闭中断,所以这个硬中断的时间不能太长。
但是,发生中断后的工作是必须要完成的,如果这些工作比较耗时那怎么办呢?Linux 中有一个软中断的概念(softirq),它可以完成这些耗时比较长的工作。
你可以这样理解这个软中断,从网卡收到数据包的大部分工作,都是通过软中断来处理的。那么,CPU 就会进入到第八个框,”si”。这里”si”是”softirq”的缩写,代表 CPU 处理软中断的开销。
这里你要注意,无论是”hi”还是”si”,它们的 CPU 时间都不会计入进程的 CPU 时间。 这是因为本身它们在处理的时候就不属于任何一个进程。
好了,通过这个场景假设,我们介绍了大部分的 Linux CPU 使用。
不过,我们还剩两个类型的 CPU 使用没讲到,我想给你做个补充,一次性带你做个全面了解。这样以后你解决相关问题时,就不会再犹豫,这些值到底影不影响 CPU Cgroup 中的限制了。下面我给你具体讲一下。
一个是”ni”,是”nice”的缩写,这里表示如果进程的 nice 值是正值(1-19),代表优先级比较低的进程运行时所占用的 CPU。
另外一个是”st”,”st”是”steal”的缩写,是在虚拟机里用的一个 CPU 使用类型,表示有多少时间是被同一个宿主机上的其他虚拟机抢走的。
综合前面的内容,我再用表格为你总结一下:

CPU Cgroup
在第一讲中,我们提到过 Cgroups 是对指定进程做计算机资源限制的,CPU Cgroup 是 Cgroups 其中的一个 Cgroups 子系统,它是用来限制进程的 CPU 使用的。
对于进程的 CPU 使用, 通过前面的 Linux CPU 使用分类的介绍,我们知道它只包含两部分: 一个是用户态,这里的用户态包含了 us 和 ni;还有一部分是内核态,也就是 sy。
至于 wa、hi、si,这些 I/O 或者中断相关的 CPU 使用,CPU Cgroup 不会去做限制,那么接下来我们就来看看 CPU Cgoup 是怎么工作的?
每个 Cgroups 子系统都是通过一个虚拟文件系统挂载点的方式,挂到一个缺省的目录下,CPU Cgroup 一般在 Linux 发行版里会放在 /sys/fs/cgroup/cpu 这个目录下。
在这个子系统的目录下,每个控制组(Control Group) 都是一个子目录,各个控制组之间的关系就是一个树状的层级关系(hierarchy)。
比如说,我们在子系统的最顶层开始建立两个控制组(也就是建立两个目录)group1 和 group2,然后再在 group2 的下面再建立两个控制组 group3 和 group4。
这样操作以后,我们就建立了一个树状的控制组层级,你可以参考下面的示意图。
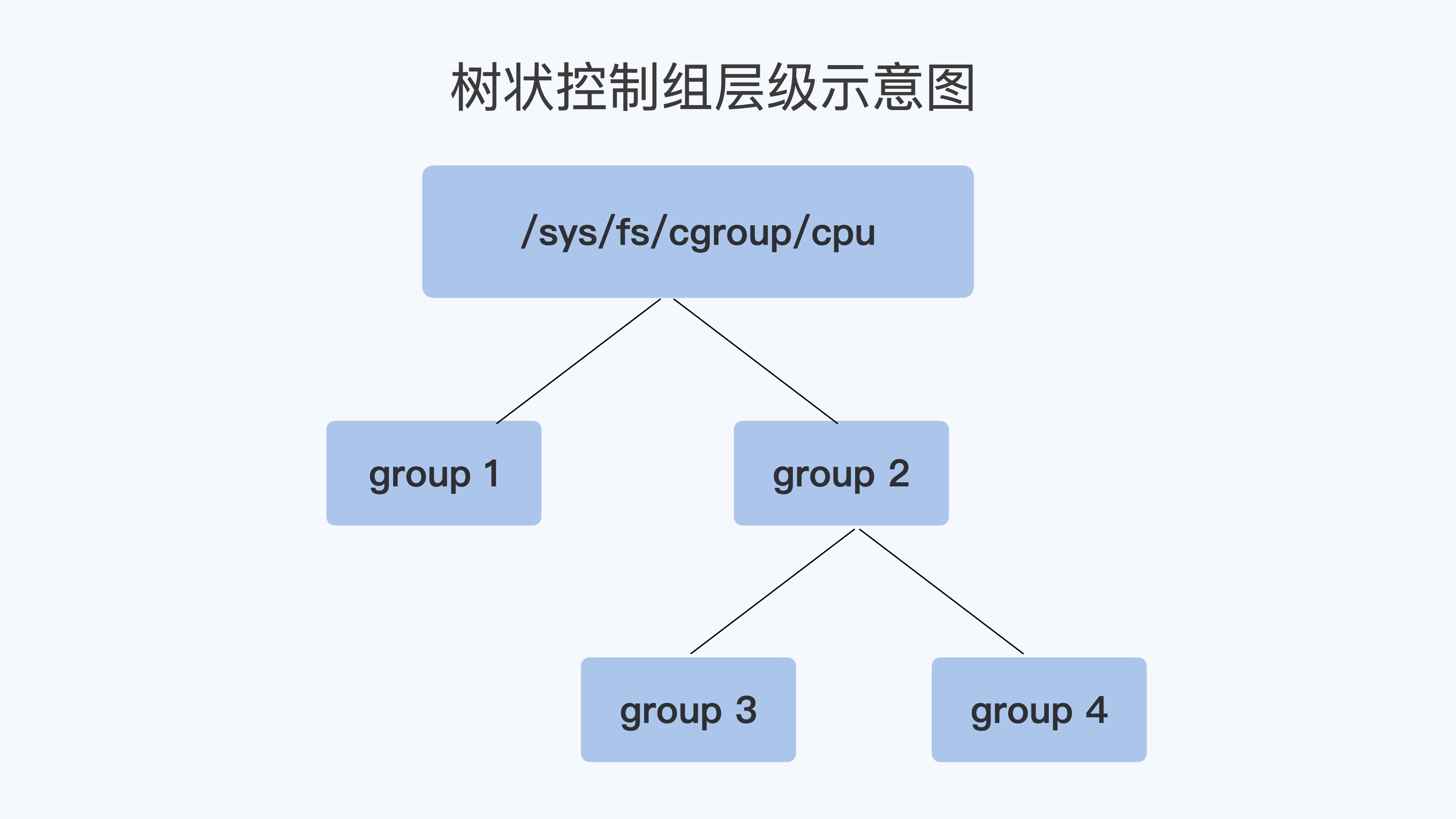
那么我们的每个控制组里,都有哪些 CPU Cgroup 相关的控制信息呢?这里我们需要看一下每个控制组目录中的内容:
$ pwd
/sys/fs/cgroup/cpu
$ mkdir group1 group2
$ cd group2
$ mkdir group3 group4
$ cd group3
$ ls cpu.*
cpu.cfs_period_us cpu.cfs_quota_us cpu.rt_period_us cpu.rt_runtime_us cpu.shares cpu.stat考虑到在云平台里呢,大部分程序都不是实时调度的进程,而是普通调度(SCHED_NORMAL)类型进程,那什么是普通调度类型呢?
因为普通调度的算法在 Linux 中目前是 CFS (Completely Fair Scheduler,即完全公平调度器)。为了方便你理解,我们就直接来看 CPU Cgroup 和 CFS 相关的参数,一共有三个。
第一个参数是 cpu.cfs_period_us ,它是 CFS 算法的一个调度周期,一般它的值是 100000,以 microseconds 为单位,也就 100ms。
第二个参数是 cpu.cfs_quota_us ,它”表示 CFS 算法中,在一个调度周期里这个控制组被允许的运行时间,比如这个值为 50000 时,就是 50ms。
如果用这个值去除以调度周期(也就是 cpu.cfs_period_us),50ms/100ms = 0.5,这样这个控制组被允许使用的 CPU 最大配额就是 0.5 个 CPU。
从这里能够看出,cpu.cfs_quota_us 是一个绝对值。如果这个值是 200000,也就是 200ms,那么它除以 period,也就是 200ms/100ms=2。
你看,结果超过了 1 个 CPU,这就意味着这时控制组需要 2 个 CPU 的资源配额。
我们再来看看第三个参数, cpu.shares 。这个值是 CPU Cgroup 对于控制组之间的 CPU 分配比例,它的缺省值是 1024。
假设我们前面创建的 group3 中的 cpu.shares 是 1024,而 group4 中的 cpu.shares 是 3072,那么 group3:group4=1:3。
这个比例是什么意思呢?我还是举个具体的例子来说明吧。
在一台 4 个 CPU 的机器上,当 group3 和 group4 都需要 4 个 CPU 的时候,它们实际分配到的 CPU 分别是这样的:group3 是 1 个,group4 是 3 个。
我们刚才讲了 CPU Cgroup 里的三个关键参数,接下来我们就通过几个例子来进一步理解一下,代码 你可以在这里找到。
第一个例子,我们启动一个消耗 2 个 CPU(200%)的程序 threads-cpu,然后把这个程序的 pid 加入到 group3 的控制组里:
./threads-cpu/threads-cpu 2 &
echo $! > /sys/fs/cgroup/cpu/group2/group3/cgroup.procs在我们没有修改 cpu.cfs_quota_us 前,用 top 命令可以看到 threads-cpu 这个进程的 CPU 使用是 199%,近似 2 个 CPU。

然后,我们更新这个控制组里的 cpu.cfs_quota_us,把它设置为 150000(150ms)。把这个值除以 cpu.cfs_period_us,计算过程是 150ms/100ms=1.5, 也就是 1.5 个 CPU,同时我们也把 cpu.shares 设置为 1024。
echo 150000 > /sys/fs/cgroup/cpu/group2/group3/cpu.cfs_quota_us
echo 1024 > /sys/fs/cgroup/cpu/group2/group3/cpu.shares这时候我们再运行 top,就会发现 threads-cpu 进程的 CPU 使用减小到了 150%。这是因为我们设置的 cpu.cfs_quota_us 起了作用,限制了进程 CPU 的绝对值。

但这时候 cpu.shares 的作用还没有发挥出来,因为 cpu.shares 是几个控制组之间的 CPU 分配比例,而且一定要到整个节点中所有的 CPU 都跑满的时候,它才能发挥作用。
好,下面我们再来运行第二个例子来理解 cpu.shares。我们先把第一个例子里的程序启动,同时按前面的内容,一步步设置好 group3 里 cpu.cfs_quota_us 和 cpu.shares。
group3:
./threads-cpu/threads-cpu 2 & # 启动一个消耗2个CPU的程序
echo $! > /sys/fs/cgroup/cpu/group2/group3/cgroup.procs #把程序的pid加入到控制组
echo 150000 > /sys/fs/cgroup/cpu/group2/group3/cpu.cfs_quota_us #限制CPU为1.5CPU
echo 1024 > /sys/fs/cgroup/cpu/group2/group3/cpu.shares设置完成后,我们再启动第二个程序,并且设置好 group4 里的 cpu.cfs_quota_us 和 cpu.shares。
group4:
./threads-cpu/threads-cpu 4 & # 启动一个消耗4个CPU的程序
echo $! > /sys/fs/cgroup/cpu/group2/group4/cgroup.procs #把程序的pid加入到控制组
echo 350000 > /sys/fs/cgroup/cpu/group2/group4/cpu.cfs_quota_us #限制CPU为3.5CPU
echo 3072 > /sys/fs/cgroup/cpu/group2/group4/cpu.shares # shares 比例 group4: group3 = 3:1好了,现在我们的节点上总共有 4 个 CPU,而 group3 的程序需要消耗 2 个 CPU,group4 里的程序要消耗 4 个 CPU。
即使 cpu.cfs_quota_us 已经限制了进程 CPU 使用的绝对值,group3 的限制是 1.5CPU,group4 是 3.5CPU,1.5+3.5=5,这个结果还是超过了节点上的 4 个 CPU。
好了,说到这里,我们发现在这种情况下,cpu.shares 终于开始起作用了。
在这里 shares 比例是 group4:group3=3:1,在总共 4 个 CPU 的节点上,按照比例,group4 里的进程应该分配到 3 个 CPU,而 group3 里的进程会分配到 1 个 CPU。
我们用 top 可以看一下,结果和我们预期的一样。

好了,我们对 CPU Cgroup 的参数做一个梳理。
第一点,cpu.cfs_quota_us 和 cpu.cfs_period_us 这两个值决定了 每个控制组中所有进程的可使用 CPU 资源的最大值。
第二点,cpu.shares 这个值决定了 CPU Cgroup 子系统下控制组可用 CPU 的相对比例 ,不过只有当系统上 CPU 完全被占满的时候,这个比例才会在各个控制组间起作用。
现象解释
在解释了 Linux CPU Usage 和 CPU Cgroup 这两个基本概念之后,我们再回到我们最初的问题 “怎么限制容器的 CPU 使用”。有了基础知识的铺垫,这个问题就比较好解释了。
首先,Kubernetes 会为每个容器都在 CPUCgroup 的子系统中建立一个控制组,然后把容器中进程写入到这个控制组里。
这时候”Limit CPU”就需要为容器设置可用 CPU 的上限。结合前面我们讲的几个参数么,我们就能知道容器的 CPU 上限具体如何计算了。
容器 CPU 的上限由 cpu.cfs_quota_us 除以 cpu.cfs_period_us 得出的值来决定的。而且,在操作系统里,cpu.cfs_period_us 的值一般是个固定值,Kubernetes 不会去修改它,所以我们就是只修改 cpu.cfs_quota_us。
而”Request CPU”就是无论其他容器申请多少 CPU 资源,即使运行时整个节点的 CPU 都被占满的情况下,我的这个容器还是可以保证获得需要的 CPU 数目,那么这个设置具体要怎么实现呢?
显然我们需要设置 cpu.shares 这个参数: 在 CPU Cgroup 中 cpu.shares == 1024 表示 1 个 CPU 的比例,那么 Request CPU 的值就是 n,给 cpu.shares 的赋值对应就是 n*1024。
重点总结
首先,我带你了解了 Linux 下 CPU Usage 的种类.
这里你要注意的是 每个进程的 CPU Usage 只包含用户态(us 或 ni)和内核态(sy)两部分,其他的系统 CPU 开销并不包含在进程的 CPU 使用中,而 CPU Cgroup 只是对进程的 CPU 使用做了限制。
其实这一讲我们开篇的问题”怎么限制容器的 CPU 使用”,这个问题背后隐藏了另一个问题,也就是容器是如何设置它的 CPU Cgroup 中参数值的?想解决这个问题,就要先知道 CPU Cgroup 都有哪些参数。
所以,我详细给你介绍了 CPU Cgroup 中的主要参数,包括这三个: cpu.cfs_quota_us,cpu.cfs_period_us 还有 cpu.shares。
其中,cpu.cfs_quota_us(一个调度周期里这个控制组被允许的运行时间)除以 cpu.cfs_period_us(用于设置调度周期)得到的这个值决定了 CPU Cgroup 每个控制组中 CPU 使用的上限值。
你还需要掌握一个 cpu.shares 参数,正是这个值决定了 CPU Cgroup 子系统下控制组可用 CPU 的相对比例,当系统上 CPU 完全被占满的时候,这个比例才会在各个控制组间起效。
最后,我们明白了 CPU Cgroup 关键参数是什么含义后,Kubernetes 中”Limit CPU”和 “Request CPU”也就很好解释了:
Limit CPU 就是容器所在 Cgroup 控制组中的 CPU 上限值,Request CPU 的值就是控制组中的 cpu.shares 的值。
思考题
我们还是按照文档中定义的控制组目录层次结构图,然后按序执行这几个脚本:
那么,在一个 4 个 CPU 的节点上,group1/group3/group4 里的进程,分别会被分配到多少 CPU 呢?
答:group1:group2是1比1,由于group1 limit是3.5,那group1分到的只能是两个核,剩余的2个核给group3和group4,group4:group3是3比1,那么得出group4与group3各分配的核就是1.5核与0.5核
06|容器CPU(2):如何正确地拿到容器CPU的开销?
无论是容器的所有者还是容器平台的管理者,我们想要精准地对运行着众多容器的云平台做监控,快速排查例如应用的处理能力下降,节点负载过高等问题,就绕不开容器 CPU 开销。因为 CPU 开销的异常,往往是程序异常最明显的一个指标。
在一台物理机器或者虚拟机里,如果你想得到这个节点的 CPU 使用率,最常用的命令就是 top 了吧?top 一下子就能看到整个节点当前的 CPU 使用情况。
那么在容器里,top 命令也可以做到这点吗?想要知道答案,我们还是得实际动手试一试。
问题重现
实际上,你在使用容器的时候,如果运行 top 命令来查看当前容器总共使用了多少 CPU,你肯定马上就会失望了。
这是因为我们在容器中运行 top 命令,虽然可以看到容器中每个进程的 CPU 使用率,但是 top 中”%Cpu(s)”那一行中显示的数值,并不是这个容器的 CPU 整体使用率,而是容器宿主机的 CPU 使用率。
就像下面的这个例子,我们在一个 12 个 CPU 的宿主机上,启动一个容器,然后在容器里运行 top 命令。
这时我们可以看到,容器里有两个进程 threads-cpu,总共消耗了 200% 的 CPU(2 CPU Usage),而”%Cpu(s)”那一行的”us cpu”是 58.5%。对于 12CPU 的系统来说,12 * 58.5%=7.02,也就是说这里显示总共消耗了 7 个 CPU,远远大于容器中 2 个 CPU 的消耗。
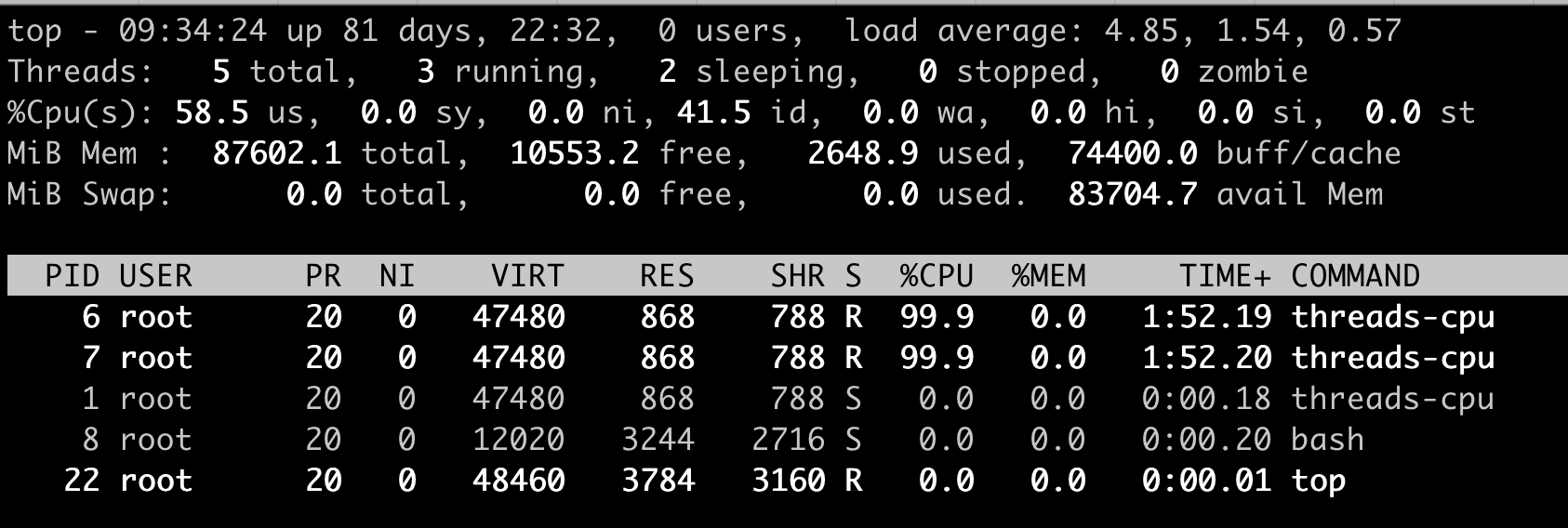
这个例子说明,top 这个工具虽然在物理机或者虚拟机上看得到系统 CPU 开销,但是如果是放在容器环境下,运行 top 就无法得到容器中总的 CPU 使用率。那么,我们还有什么其他的办法吗?
进程 CPU 使用率和系统 CPU 使用率
通过问题重现,我们发现 top 工具主要显示了宿主机系统整体的 CPU 使用率,以及单个进程的 CPU 使用率。既然没有现成的工具可以得到容器 CPU 开销,那我们需要自己开发一个工具来解决问题了。
其实我们自己推导,也没有那么难。我认为,最有效的思路还是从原理上去理解问题。
所以,在解决怎样得到单个容器整体的 CPU 使用率这个问题之前,我们先来学习一下,在 Linux 中到底是如何计算单个进程的 CPU 使用率,还有整个系统的 CPU 使用率的。
进程 CPU 使用率
Linux 中每个进程的 CPU 使用率,我们都可以用 top 命令查看。
对照我们前面的那张示意图,我们可以发现,每个进程在 top 命令输出中都有对应的一行,然后”%CPU”的那一列就是这个进程的实时 CPU 使用率了。
比如说,100% 就表示这个进程在这个瞬时使用了 1 个 CPU,200% 就是使用了 2 个 CPU。那么这个百分比的数值是怎么得到呢?
最直接的方法,就是从源头开始寻找答案。因为是 top 命令的输出,我们可以去看一下 top 命令的 源代码 。在代码中你会看到对于每个进程,top 都会从 proc 文件系统中每个进程对应的 stat 文件中读取 2 个数值。我们先来看这个文件,再来解读文件中具体的两个数值。
这个 stat 文件就是 /proc/[pid]/stat , [pid] 就是替换成具体一个进程的 PID 值。比如 PID 值为 1 的进程,这个文件就是 /proc/1/stat ,那么这个 /proc/[pid]/stat 文件里有什么信息呢?
其实这个 stat 文件实时输出了进程的状态信息,比如进程的运行态(Running 还是 Sleeping)、父进程 PID、进程优先级、进程使用的内存等等总共 50 多项。
完整的 stat 文件内容和格式在 proc 文件系统的 Linux programmer’s manual 里定义了。在这里,我们只需要重点关注这两项数值,stat 文件中的第 14 项 utime 和第 15 项 stime。

那么这两项数值 utime 和 stime 是什么含义呢?utime 是表示进程的用户态部分在 Linux 调度中获得 CPU 的 ticks,stime 是表示进程的内核态部分在 Linux 调度中获得 CPU 的 ticks。
看到这个解释,你可能又冒出一个新问题,疑惑 ticks 是什么? 这个 ticks 就是 Linux 操作系统中的一个时间单位,你可以理解成类似秒,毫秒的概念。
在 Linux 中有个自己的时钟,它会周期性地产生中断。每次中断都会触发 Linux 内核去做一次进程调度,而这一次中断就是一个 tick。因为是周期性的中断,比如 1 秒钟 100 次中断,那么一个 tick 作为一个时间单位看的话,也就是 1/100 秒。
我给你举个例子说明,假如进程的 utime 是 130ticks,就相当于 130 * 1/100=1.3 秒,也就是进程从启动开始在用户态总共运行了 1.3 秒钟。
这里需要你注意,utime 和 stime 都是一个累计值,也就是说从进程启动开始,这两个值就是一直在累积增长的。
那么我们怎么计算,才能知道某一进程在用户态和内核态中,分别获得了多少 CPU 的 ticks 呢?
首先,我们可以假设这个瞬时是 1 秒钟,这 1 秒是 T1 时刻到 T2 时刻之间的,那么这样我们就能获得 T1 时刻的 utime_1 和 stime_1,同时获得 T2 时刻的 utime_2 和 stime_2。
在这 1 秒的瞬时,进程用户态获得的 CPU ticks 就是 (utime_2 - utime_1), 进程内核态获得的 CPU ticks 就是 (stime_2 - stime_1)。
那么我们可以推导出,进程 CPU 总的开销就是用户态加上内核态,也就是在 1 秒瞬时进程总的 CPU ticks 等于 (utime_2 - utime_1) + (stime_2 - stime_1)。
好了,现在我们得到了进程以 ticks 为单位的 CPU 开销,接下来还要做个转化。我们怎样才能把这个值转化成我们熟悉的百分比值呢?其实也不难,我们还是可以去 top 的源代码里得到这个百分比的计算公式。
简单总结一下,这个公式是这样的:
进程的 CPU 使用率 =((utime_2 - utime_1) + (stime_2 - stime_1)) * 100.0 / (HZ * et * 1 )
接下来,我再给你讲一下,这个公式里每一个部分的含义。
首先, ((utime_2 - utime_1) + (stime_2 - stime_1)) 是瞬时进程总的 CPU ticks。这个我们已经在前面解释过了。
其次,我们来看 100.0,这里乘以 100.0 的目的是产生百分比数值。
最后,我再讲一下 (HZ * et * 1) 。这是被除数这里的三个参数,我给你详细解释一下。
第一个 HZ 是什么意思呢?前面我们介绍 ticks 里说了,ticks 是按照固定频率发生的,在我们的 Linux 系统里 1 秒钟是 100 次,那么 HZ 就是 1 秒钟里 ticks 的次数,这里值是 100。
第二个参数 et 是我们刚才说的那个”瞬时”的时间,也就是得到 utime_1 和 utime_2 这两个值的时间间隔。
第三个”1”, 就更容易理解了,就是 1 个 CPU。那么这三个值相乘,你是不是也知道了它的意思呢?就是在这”瞬时”的时间(et)里,1 个 CPU 所包含的 ticks 数目。
解释了这些参数,我们可以把这个公式简化一下,就是下面这样:
进程的 CPU 使用率 =(进程的 ticks/ 单个 CPU 总 ticks)*100.0
知道了这个公式,就需要上手来验证一下这个方法对不对,怎么验证呢?我们可以启动一个消耗 CPU 的小程序,然后读取一下进程对应的 /proc/[pid]/stat 中的 utime 和 stime,然后用这个方法来计算一下进程使用率这个百分比值,并且和 top 的输出对比一下,看看是否一致。
先启动一个消耗 200% 的小程序,它的 PID 是 10021,CPU 使用率是 200%。

然后,我们查看这个进程对应的 stat 文件 /proc/10021/stat,间隔 1 秒钟输出第二次,因为 stat 文件内容很多,我们知道 utime 和 stime 第 14 和 15 项,所以我们这里只截取了前 15 项的输出。这里可以看到,utime_1 = 399,stime_1=0,utime_2=600,stime_2=0。

根据前面的公式,我们计算一下进程 threads-cpu 的 CPU 使用率。套用前面的公式,计算的过程是:((600 - 399) + (0 - 0)) * 100.0 / (100 * 1 * 1) =201,也就是 201%。你会发现这个值和我们运行 top 里的值是一样的。同时,我们也就验证了这个公式是没问题的。
系统 CPU 使用率
前面我们介绍了 Linux 中如何获取单个进程的 CPU 使用率,下面我们再来看看 Linux 里是怎么计算系统的整体 CPU 使用率的。
其实知道了如何计算单个进程的 CPU 使用率之后,要理解系统整体的 CPU 使用率计算方法就简单多了。
同样,我们要计算 CPU 使用率,首先需要拿到数据,数据源也同样可以从 proc 文件系统里得到,对于整个系统的 CPU 使用率,这个文件就是 /proc/stat。
在 /proc/stat 文件的 cpu 这行有 10 列数据,同样我们可以在 proc 文件系统的 Linux programmer’s manual 里,找到每一列数据的定义,而前 8 列数据正好对应 top 输出中”%Cpu(s)”那一行里的 8 项数据,也就是在上一讲中,我们介绍过的 user/system/nice/idle/iowait/irq/softirq/steal 这 8 项。

而在 /proc/stat 里的每一项的数值,就是系统自启动开始的 ticks。那么要计算出”瞬时”的 CPU 使用率,首先就要算出这个”瞬时”的 ticks,比如 1 秒钟的”瞬时”,我们可以记录开始时刻 T1 的 ticks, 然后再记录 1 秒钟后 T2 时刻的 ticks,再把这两者相减,就可以得到这 1 秒钟的 ticks 了。

这里我们可以得到,在这 1 秒钟里每个 CPU 使用率的 ticks:
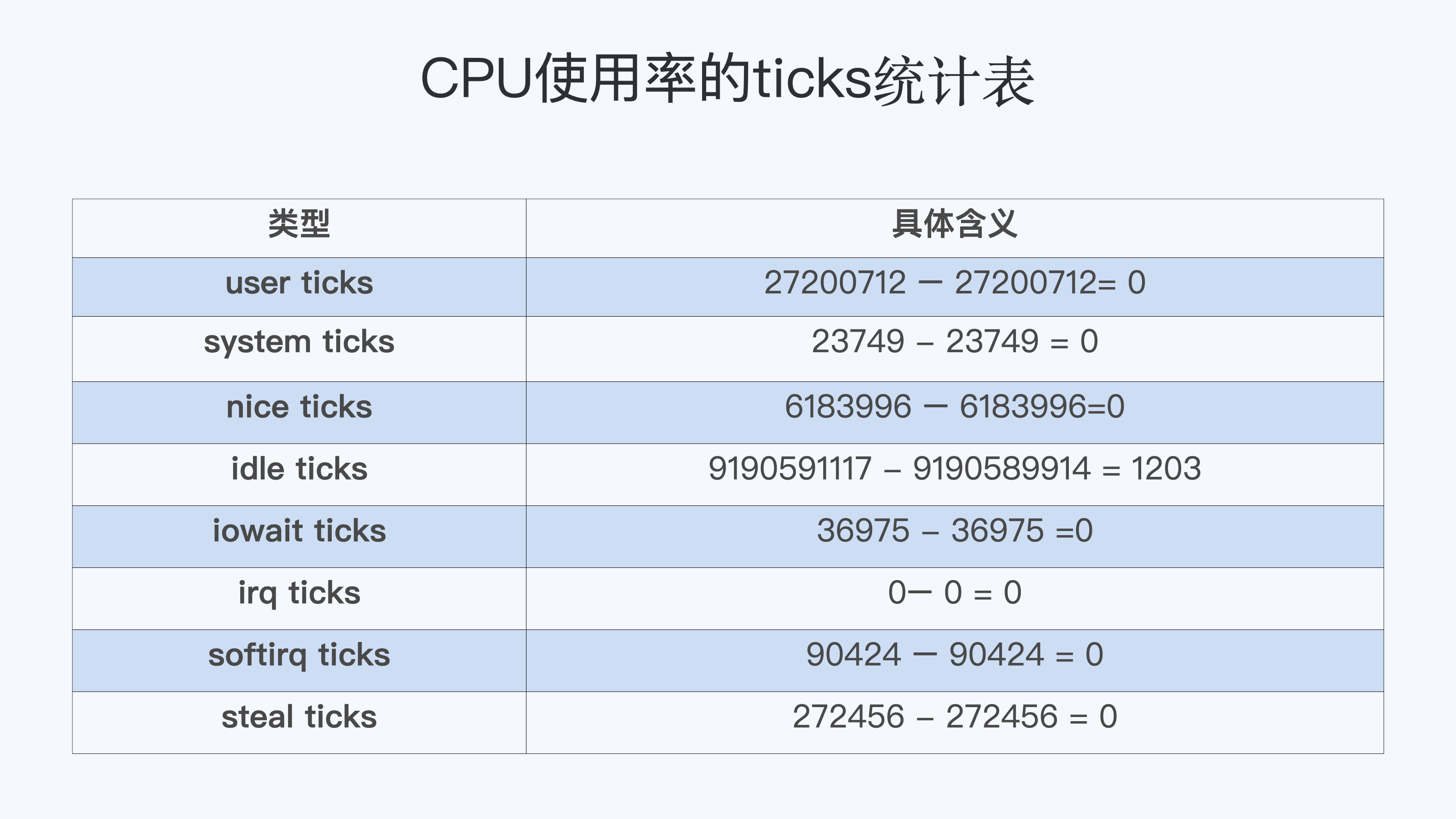
我们想要计算每一种 CPU 使用率的百分比,其实也很简单。我们只需要把所有在这 1 秒里的 ticks 相加得到一个总值,然后拿某一项的 ticks 值,除以这个总值。比如说计算 idle CPU 的使用率就是:
(1203 / 0 + 0 + 0 + 1203 + 0 + 0 + 0 + 0)=100%
好了,我们现在来整体梳理一下,我们通过 Linux 里的工具,要怎样计算进程的 CPU 使用率和系统的 CPU 使用率。
对于单个进程的 CPU 使用率计算,我们需要读取对应进程的 /proc/[pid]/stat 文件,将进程瞬时用户态和内核态的 ticks 数相加,就能得到进程的总 ticks。
然后我们运用公式 (进程的 ticks / 单个 CPU 总 ticks) * 100.0 计算出进程 CPU 使用率的百分比值。
对于系统的 CPU 使用率,需要读取 /proc/stat 文件,得到瞬时各项 CPU 使用率的 ticks 值,相加得到一个总值,单项值除以总值就是各项 CPU 的使用率。
解决问题
前面我们学习了在 Linux 中,top 工具是怎样计算每个进程的 CPU 使用率,以及系统总的 CPU 使用率。现在我们再来看最初的问题:为什么在容器中运行 top 命令不能得到容器中总的 CPU 使用率?
这就比较好解释了,对于系统总的 CPU 使用率,需要读取 /proc/stat 文件,但是这个文件中的各项 CPU ticks 是反映整个节点的,并且这个 /proc/stat 文件也不包含在任意一个 Namespace 里。
那么, 对于 top 命令来说,它只能显示整个节点中各项 CPU 的使用率,不能显示单个容器的各项 CPU 的使用率。 既然 top 命令不行,我们还有没有办法得到整个容器的 CPU 使用率呢?
我们之前已经学习过了 CPU Cgroup,每个容器都会有一个 CPU Cgroup 的控制组。在这个控制组目录下面有很多参数文件,有的参数可以决定这个控制组里最大的 CPU 可使用率外,除了它们之外,目录下面还有一个可读项 cpuacct.stat。
这里包含了两个统计值,这两个值分别是 这个控制组里所有进程的内核态 ticks 和用户态的 ticks,那么我们就可以用前面讲过的公式,也就是计算进程 CPU 使用率的公式,去计算整个容器的 CPU 使用率:
CPU 使用率 =((utime_2 - utime_1) + (stime_2 - stime_1)) * 100.0 / (HZ * et * 1 )
我们还是以问题重现中的例子说明,也就是最开始启动容器里的那两个容器 threads-cpu 进程。
就像下图显示的这样,整个容器的 CPU 使用率的百分比就是 ( (174021 - 173820) + (4 - 4)) * 100.0 / (100 * 1 * 1) = 201 , 也就是 201%。 所以,我们从每个容器的 CPU Cgroup 控制组里的 cpuacct.stat 的统计值中 ,可以比较快地得到整个容器的 CPU 使用率。

重点总结
Linux 里获取 CPU 使用率的工具,比如 top,都是通过读取 proc 文件系统下的 stat 文件来得到 CPU 使用了多少 ticks。而这里的 ticks,是 Linux 操作系统里的一个时间单位,可以理解成类似秒,毫秒的概念。
对于每个进程来说,它的 stat 文件是 /proc/[pid]/stat,里面包含了进程用户态和内核态的 ticks 数目;对于整个节点,它的 stat 文件是 /proc/stat,里面包含了 user/system/nice/idle/iowait 等不同 CPU 开销类型的 ticks。
由于 /proc/stat 文件是整个节点全局的状态文件,不属于任何一个 Namespace,因此在容器中无法通过读取 /proc/stat 文件来获取单个容器的 CPU 使用率。
所以要得到单个容器的 CPU 使用率,我们可以从 CPU Cgroup 每个控制组里的统计文件 cpuacct.stat 中获取。 单个容器 CPU 使用率 =((utime_2 - utime_1) + (stime_2 - stime_1)) * 100.0 / (HZ * et * 1 ) 。
得到单个容器的 CPU 的使用率,那么当宿主机上负载变高的时候,就可以很快知道是哪个容器引起的问题。同时,用户在管理自己成百上千的容器的时候,也可以很快发现 CPU 使用率异常的容器,这样就能及早地介入去解决问题。
07 | Load Average:加了CPU Cgroup限制,为什么我的容器还是很慢?
在上一讲中,我们提到过 CPU Cgroup 可以限制进程的 CPU 资源使用,但是 CPU Cgroup 对容器的资源限制是存在盲点的。
什么盲点呢?就是无法通过 CPU Cgroup 来控制 Load Average 的平均负载。而没有这个限制,就会影响我们系统资源的合理调度,很可能导致我们的系统变得很慢。
那么今天这一讲,我们要来讲一下为什么加了 CPU Cgroup 的配置后,即使保证了容器的 CPU 资源,容器中的进程还是会运行得很慢?
问题再现
在 Linux 的系统维护中,我们需要经常查看 CPU 使用情况,再根据这个情况分析系统整体的运行状态。有时候你可能会发现,明明容器里所有进程的 CPU 使用率都很低,甚至整个宿主机的 CPU 使用率都很低,而机器的 Load Average 里的值却很高,容器里进程运行得也很慢。
这么说有些抽象,我们一起动手再现一下这个情况,这样你就能更好地理解这个问题了。
比如说下面的 top 输出,第三行可以显示当前的 CPU 使用情况,我们可以看到整个机器的 CPU Usage 几乎为 0,因为”id”显示 99.9%,这说明 CPU 是处于空闲状态的。
但是请你注意,这里 1 分钟的”load average”的值却高达 9.09,这里的数值 9 几乎就意味着使用了 9 个 CPU 了,这样 CPU Usage 和 Load Average 的数值看上去就很矛盾了。

那问题来了,我们在看一个系统里 CPU 使用情况时,到底是看 CPU Usage 还是 Load Average 呢?
这里就涉及到今天要解决的两大问题:
- Load Average 到底是什么,CPU Usage 和 Load Average 有什么差别?
- 如果 Load Average 值升高,应用的性能下降了,这背后的原因是什么呢?
好了,这一讲我们就带着这两个问题,一起去揭开谜底。
什么是 Load Average?
要回答前面的问题,很显然我们要搞明白这个 Linux 里的”load average”这个值是什么意思,又是怎样计算的。
Load Average 这个概念,你可能在使用 Linux 的时候就已经注意到了,无论你是运行 uptime, 还是 top,都可以看到类似这个输出”load average:2.02, 1.83, 1.20”。那么这一串输出到底是什么意思呢?
最直接的办法当然是看手册了,如果我们用”Linux manual page”搜索 uptime 或者 top,就会看到对这个”load average”和后面三个数字的解释是”the system load averages for the past 1, 5, and 15 minutes”。
这个解释就是说,后面的三个数值分别代表过去 1 分钟,5 分钟,15 分钟在这个节点上的 Load Average,但是看了手册上的解释,我们还是不能理解什么是 Load Average。
这个时候,你如果再去网上找资料,就会发现 Load Average 是一个很古老的概念了。上个世纪 70 年代,早期的 Unix 系统上就已经有了这个 Load Average,IETF 还有一个 RFC546 定义了 Load Average,这里定义的 Load Average 是 一种 CPU 资源需求的度量。
举个例子,对于一个单个 CPU 的系统,如果在 1 分钟的时间里,处理器上始终有一个进程在运行,同时操作系统的进程可运行队列中始终都有 9 个进程在等待获取 CPU 资源。那么对于这 1 分钟的时间来说,系统的”load average”就是 1+9=10,这个定义对绝大部分的 Unix 系统都适用。
对于 Linux 来说,如果只考虑 CPU 的资源,Load Averag 等于单位时间内正在运行的进程加上可运行队列的进程,这个定义也是成立的。通过这个定义和我自己的观察,我给你归纳了下面三点对 Load Average 的理解。
第一,不论计算机 CPU 是空闲还是满负载,Load Average 都是 Linux 进程调度器中 可运行队列(Running Queue)里的一段时间的平均进程数目。
第二,计算机上的 CPU 还有空闲的情况下,CPU Usage 可以直接反映到”load average”上,什么是 CPU 还有空闲呢?具体来说就是可运行队列中的进程数目小于 CPU 个数,这种情况下,单位时间进程 CPU Usage 相加的平均值应该就是”load average”的值。
第三,计算机上的 CPU 满负载的情况下,计算机上的 CPU 已经是满负载了,同时还有更多的进程在排队需要 CPU 资源。这时”load average”就不能和 CPU Usage 等同了。
比如对于单个 CPU 的系统,CPU Usage 最大只是有 100%,也就 1 个 CPU;而”load average”的值可以远远大于 1,因为”load average”看的是操作系统中可运行队列中进程的个数。
这样的解释可能太抽象了,为了方便你理解,我们一起动手验证一下。
怎么验证呢?我们可以执行个程序来模拟一下, 先准备好一个可以消耗任意 CPU Usage 的程序,在执行这个程序的时候,后面加个数字作为参数。
比如下面的设置,参数是 2,就是说这个进程会创建出两个线程,并且每个线程都跑满 100% 的 CPU,2 个线程就是 2 * 100% = 200% 的 CPU Usage,也就是消耗了整整两个 CPU 的资源。
./threads-cpu 2准备好了这个 CPU Usage 的模拟程序,我们就可以用它来查看 CPU Usage 和 Load Average 之间的关系了。
接下来我们一起跑两个例子,第一个例子是执行 2 个满负载的线程,第二个例子执行 6 个满负载的线程,同样都是在一台 4 个 CPU 的节点上。
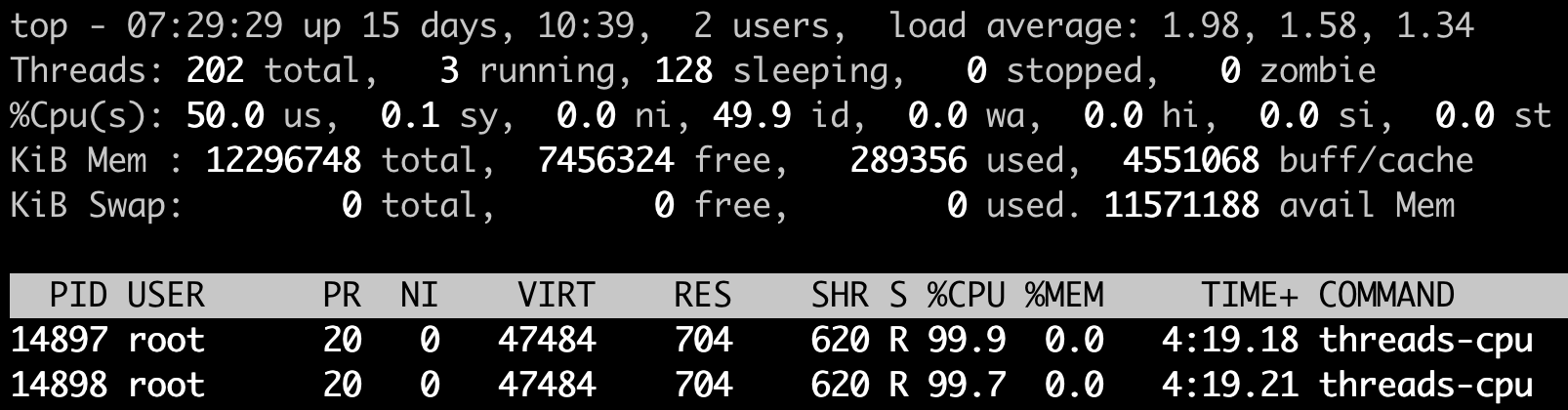
先来看第一个例子,我们在一台 4 个 CPU 的计算机节点上运行刚才这个模拟程序,还是设置参数为 2,也就是使用 2 个 CPU Usage。在这个程序运行了几分钟之后,我们运行 top 来查看一下 CPU Usage 和 Load Average。
我们可以看到两个 threads-cpu 各自都占了将近 100% 的 CPU,两个就是 200%,2 个 CPU,对于 4 个 CPU 的计算机来说,CPU Usage 占了 50%,空闲了一半,这个我们也可以从 idle (id):49.9% 得到印证。
这时候,Load Average 里第一项(也就是前 1 分钟的数值)为 1.98,近似于 2。这个值和我们一直运行的 200%CPU Usage 相对应,也验证了我们之前归纳的第二点—— CPU Usage 可以反映到 Load Average 上。
因为运行的时间不够,前 5 分钟,前 15 分钟的 Load Average 还没有到 2,而且后面我们的例子程序一般都只会运行几分钟,所以这里我们只看前 1 分钟的 Load Average 值就行。
另外,Linux 内核中不使用浮点计算,这导致 Load Average 里的 1 分钟,5 分钟,15 分钟的时间值并不精确,但这不影响我们查看 Load Average 的数值,所以先不用管这个时间的准确性。
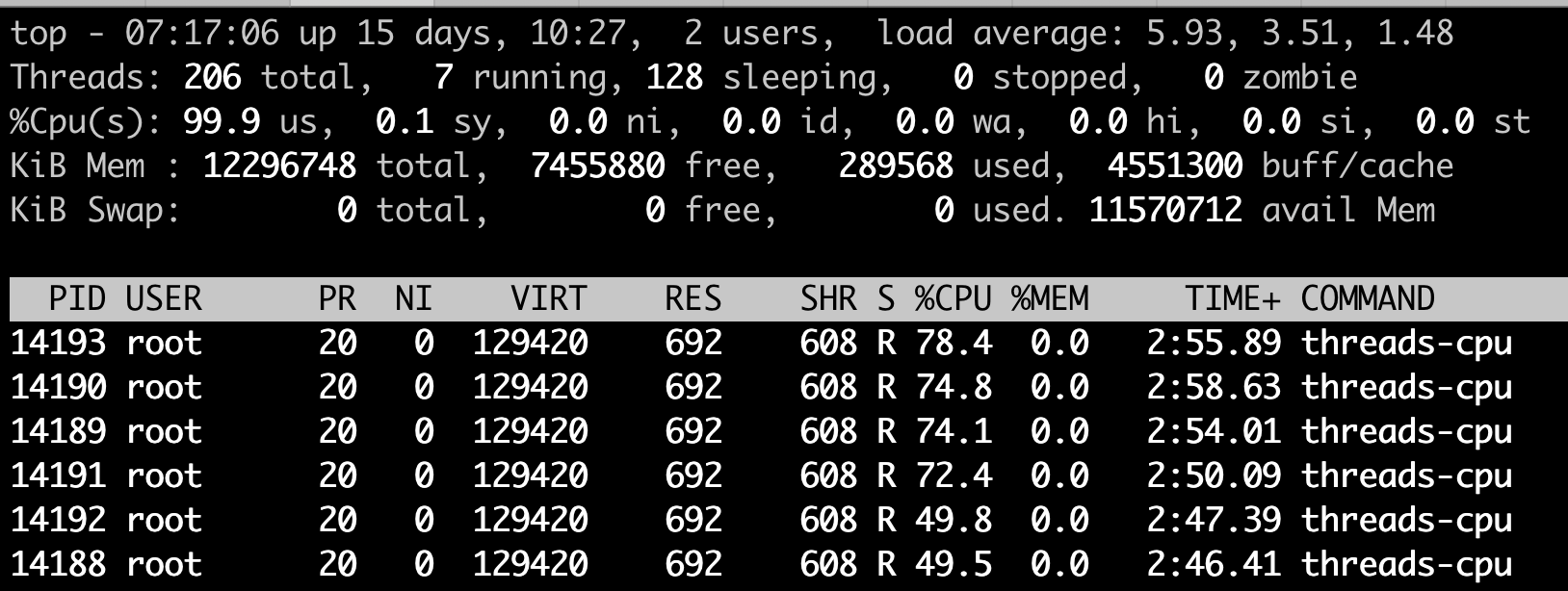
那我们再来跑第二个例子,同样在这个 4 个 CPU 的计算机节点上,如果我们执行 CPU Usage 模拟程序 threads-cpu,设置参数为 6,让这个进程建出 6 个线程,这样每个线程都会尽量去抢占 CPU,但是计算机总共只有 4 个 CPU,所以这 6 个线程的 CPU Usage 加起来只是 400%。
显然这时候 4 个 CPU 都被占满了,我们可以看到整个节点的 idle(id)也已经是 0.0% 了。
但这个时候,我们看看前 1 分钟的 Load Average,数值不是 4 而是 5.93 接近 6,我们正好模拟了 6 个高 CPU 需求的线程。这也告诉我们,Load Average 表示的是一段时间里运行队列中需要被调度的进程 / 线程平均数目。
讲到这里,我们是不是就可以认定 Load Average 就代表一段时间里运行队列中需要被调度的进程或者线程平均数目了呢? 或许对其他的 Unix 系统来说,这个理解已经够了,但是对于 Linux 系统还不能这么认定。
为什么这么说呢?故事还要从 Linux 早期的历史说起,那时开发者 Matthias 有这么一个发现,比如把快速的磁盘换成了慢速的磁盘,运行同样的负载,系统的性能是下降的,但是 Load Average 却没有反映出来。
他发现这是因为 Load Average 只考虑运行态的进程数目,而没有考虑等待 I/O 的进程。所以,他认为 Load Average 如果只是考虑进程运行队列中需要被调度的进程或线程平均数目是不够的,因为对于处于 I/O 资源等待的进程都是处于 TASK_UNINTERRUPTIBLE 状态的。
那他是怎么处理这件事的呢?估计你也猜到了,他给内核加一个 patch(补丁),把处于 TASK_UNINTERRUPTIBLE 状态的进程数目也计入了 Load Average 中。
在这里我们又提到了 TASK_UNINTERRUPTIBLE 状态的进程,在前面的章节中我们介绍过,我再给你强调一下, TASK_UNINTERRUPTIBLE 是 Linux 进程状态的一种,是进程为等待某个系统资源而进入了睡眠的状态,并且这种睡眠的状态是不能被信号打断的。
下面就是 1993 年 Matthias 的 kernel patch,你有兴趣的话,可以读一下。
From: Matthias Urlichs <urlichs@smurf.sub.org>
Subject: Load average broken ?
Date: Fri, 29 Oct 1993 11:37:23 +0200
The kernel only counts "runnable" processes when computing the load average.
I don't like that; the problem is that processes which are swapping or
waiting on "fast", i.e. noninterruptible, I/O, also consume resources.
It seems somewhat nonintuitive that the load average goes down when you
replace your fast swap disk with a slow swap disk...
Anyway, the following patch seems to make the load average much more
consistent WRT the subjective speed of the system. And, most important, the
load is still zero when nobody is doing anything. ;-)
--- kernel/sched.c.orig Fri Oct 29 10:31:11 1993
+++ kernel/sched.c Fri Oct 29 10:32:51 1993
@@ -414,7 +414,9 @@
unsigned long nr = 0;
for(p = &LAST_TASK; p > &FIRST_TASK; --p)
- if (*p && (*p)->state == TASK_RUNNING)
+ if (*p && ((*p)->state == TASK_RUNNING) ||
+ (*p)->state == TASK_UNINTERRUPTIBLE) ||
+ (*p)->state == TASK_SWAPPING))
nr += FIXED_1;
return nr;
}那么对于 Linux 的 Load Average 来说,除了可运行队列中的进程数目,等待队列中的 UNINTERRUPTIBLE 进程数目也会增加 Load Average。
为了验证这一点,我们可以模拟一下 UNINTERRUPTIBLE 的进程,来看看 Load Average 的变化。
这里我们做一个 kernel module ,通过一个 /proc 文件系统给用户程序提供一个读取的接口,只要用户进程读取了这个接口就会进入 UNINTERRUPTIBLE。这样我们就可以模拟两个处于 UNINTERRUPTIBLE 状态的进程,然后查看一下 Load Average 有没有增加。
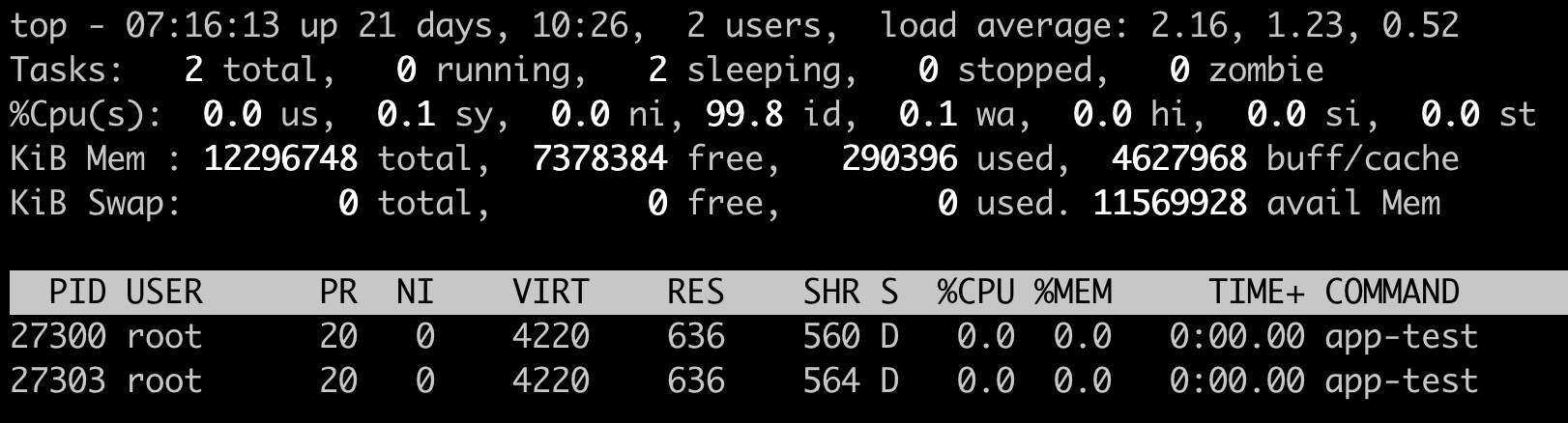
我们发现程序跑了几分钟之后,前 1 分钟的 Load Average 差不多从 0 增加到了 2.16,节点上 CPU Usage 几乎为 0,idle 为 99.8%。
可以看到,可运行队列(Running Queue)中的进程数目是 0,只有休眠队列(Sleeping Queue)中有两个进程,并且这两个进程显示为 D state 进程,这个 D state 进程也就是我们模拟出来的 TASK_UNINTERRUPTIBLE 状态的进程。
这个例子证明了 Linux 将 TASK_UNINTERRUPTIBLE 状态的进程数目计入了 Load Average 中,所以即使 CPU 上不做任何的计算,Load Average 仍然会升高。如果 TASK_UNINTERRUPTIBLE 状态的进程数目有几百几千个,那么 Load Average 的数值也可以达到几百几千。
好了,到这里我们就可以准确定义 Linux 系统里的 Load Average 了,其实也很简单,你只需要记住,平均负载统计了这两种情况的进程:
第一种是 Linux 进程调度器中可运行队列(Running Queue)一段时间(1 分钟,5 分钟,15 分钟)的进程平均数。
第二种是 Linux 进程调度器中休眠队列(Sleeping Queue)里的一段时间的 TASK_UNINTERRUPTIBLE 状态下的进程平均数。
所以,最后的公式就是: Load Average= 可运行队列进程平均数 + 休眠队列中不可打断的进程平均数
如果打个比方来说明 Load Average 的统计原理。你可以想象每个 CPU 就是一条道路,每个进程都是一辆车,怎么科学统计道路的平均负载呢?就是看单位时间通过的车辆,一条道上的车越多,那么这条道路的负载也就越高。
此外,Linux 计算系统负载的时候,还额外做了个补丁把 TASK_UNINTERRUPTIBLE 状态的进程也考虑了,这个就像道路中要把红绿灯情况也考虑进去。一旦有了红灯,汽车就要停下来排队,那么即使道路很空,但是红灯多了,汽车也要排队等待,也开不快。
现象解释:为什么 Load Average 会升高?
解释了 Load Average 这个概念,我们再回到这一讲最开始的问题,为什么对容器已经用 CPU Cgroup 限制了它的 CPU Usage,容器里的进程还是可以造成整个系统很高的 Load Average。
我们理解了 Load Average 这个概念之后,就能区分出 Load Averge 和 CPU 使用率的区别了。那么这个看似矛盾的问题也就很好回答了,因为 Linux 下的 Load Averge 不仅仅计算了 CPU Usage 的部分,它还计算了系统中 TASK_UNINTERRUPTIBLE 状态的进程数目。
讲到这里为止,我们找到了第一个问题的答案,那么现在我们再看第二个问题:如果 Load Average 值升高,应用的性能已经下降了,真正的原因是什么?问题就出在 TASK_UNINTERRUPTIBLE 状态的进程上了。
怎么验证这个判断呢?这时候我们只要运行 ps aux | grep D ,就可以看到容器中有多少 TASK_UNINTERRUPTIBLE 状态(在 ps 命令中这个状态的进程标示为”D”状态)的进程,为了方便理解,后面我们简称为 D 状态进程。而正是这些 D 状态进程引起了 Load Average 的升高。
找到了 Load Average 升高的问题出在 D 状态进程了,我们想要真正解决问题,还有必要了解 D 状态进程产生的本质是什么?
在 Linux 内核中有数百处调用点,它们会把进程设置为 D 状态,主要集中在 disk I/O 的访问和信号量(Semaphore)锁的访问上,因此 D 状态的进程在 Linux 里是很常见的。
无论是对 disk I/O 的访问还是对信号量的访问,都是对 Linux 系统里的资源的一种竞争。 当进程处于 D 状态时,就说明进程还没获得资源,这会在应用程序的最终性能上体现出来,也就是说用户会发觉应用的性能下降了。
那么 D 状态进程导致了性能下降,我们肯定是想方设法去做调试的。但目前 D 状态进程引起的容器中进程性能下降问题,Cgroups 还不能解决,这也就是为什么我们用 Cgroups 做了配置,即使保证了容器的 CPU 资源, 容器中的进程还是运行很慢的根本原因。
这里我们进一步做分析,为什么 CPU Cgroups 不能解决这个问题呢?就是因为 Cgroups 更多的是以进程为单位进行隔离,而 D 状态进程是内核中系统全局资源引入的,所以 Cgroups 影响不了它。
所以我们可以做的是,在生产环境中监控容器的宿主机节点里 D 状态的进程数量,然后对 D 状态进程数目异常的节点进行分析,比如磁盘硬件出现问题引起 D 状态进程数目增加,这时就需要更换硬盘。
重点总结
这一讲我们从 CPU Usage 和 Load Average 差异这个现象讲起,最主要的目的是讲清楚 Linux 下的 Load Average 这个概念。
在其他 Unix 操作系统里 Load Average 只考虑 CPU 部分,Load Average 计算的是进程调度器中可运行队列(Running Queue)里的一段时间(1 分钟,5 分钟,15 分钟)的平均进程数目,而 Linux 在这个基础上,又加上了进程调度器中休眠队列(Sleeping Queue)里的一段时间的 TASK_UNINTERRUPTIBLE 状态的平均进程数目。
这里你需要重点掌握 Load Average 的计算公式,如下图。

因为 TASK_UNINTERRUPTIBLE 状态的进程同样也会竞争系统资源,所以它会影响到应用程序的性能。我们可以在容器宿主机的节点对 D 状态进程做监控,定向分析解决。
最后,我还想强调一下,这一讲中提到的对 D 状态进程进行监控也很重要,因为这是通用系统性能的监控方法。
容器内存
08 | 容器内存:我的容器为什么被杀了?
从这一讲内容开始,我们进入容器内存这个模块。在使用容器的时候,一定会伴随着 Memory Cgroup。而 Memory Cgroup 给 Linux 原本就复杂的内存管理带来了新的变化,下面我们就一起来学习这一块内容。
今天这一讲,我们来解决容器在系统中消失的问题。
不知道你在使用容器时,有没有过这样的经历?一个容器在系统中运行一段时间后,突然消失了,看看自己程序的 log 文件,也没发现什么错误,不像是自己程序 Crash,但是容器就是消失了。
那么这是怎么回事呢?接下来我们就一起来”破案”。
问题再现
容器在系统中被杀掉,其实只有一种情况,那就是容器中的进程使用了太多的内存。具体来说,就是容器里所有进程使用的内存量,超过了容器所在 Memory Cgroup 里的内存限制。这时 Linux 系统就会主动杀死容器中的一个进程,往往这会导致整个容器的退出。
我们可以做个简单的容器,模拟一下这种容器被杀死的场景。做容器的 Dockerfile 和代码,你可以从 这里 获得。
接下来,我们用下面的这个脚本来启动容器,我们先把这个容器的 Cgroup 内存上限设置为 512MB(536870912 bytes)。
#!/bin/bash
docker stop mem_alloc;docker rm mem_alloc
docker run -d --name mem_alloc registry/mem_alloc:v1
sleep 2
CONTAINER_ID=$(sudo docker ps --format "{{.ID}}\t{{.Names}}" | grep -i mem_alloc | awk '{print $1}')
echo $CONTAINER_ID
CGROUP_CONTAINER_PATH=$(find /sys/fs/cgroup/memory/ -name "*$CONTAINER_ID*")
echo $CGROUP_CONTAINER_PATH
echo 536870912 > $CGROUP_CONTAINER_PATH/memory.limit_in_bytes
cat $CGROUP_CONTAINER_PATH/memory.limit_in_bytes好了,容器启动后,里面有一个小程序 mem_alloc 会不断地申请内存。当它申请的内存超过 512MB 的时候,你就会发现,我们启动的这个容器消失了。
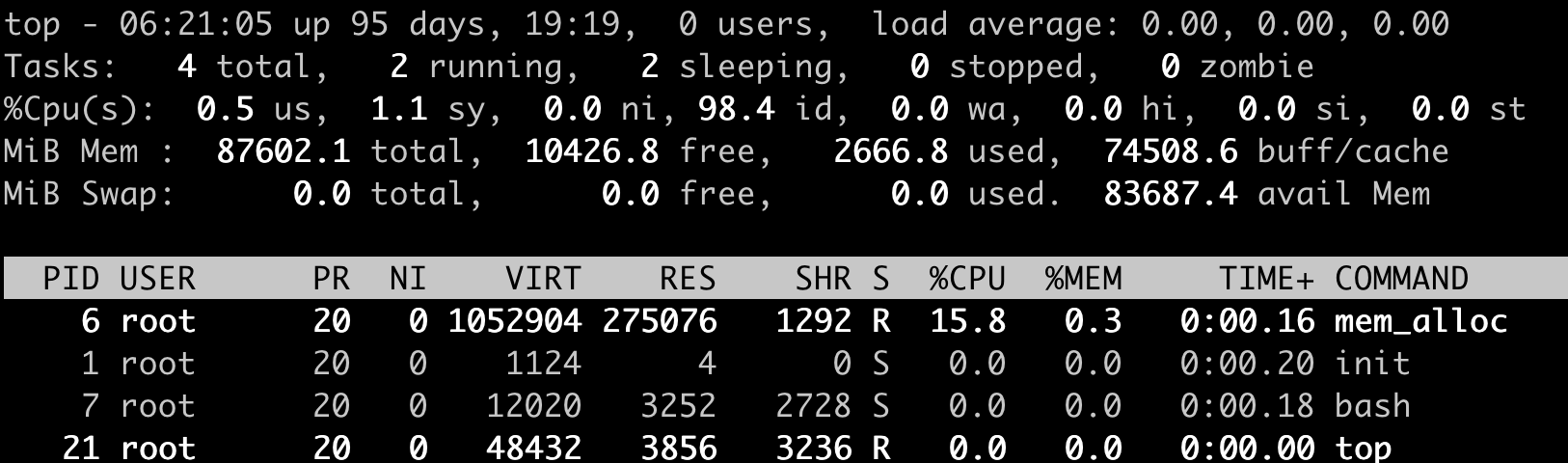
这时候,如果我们运行docker inspect 命令查看容器退出的原因,就会看到容器处于”exited”状态,并且”OOMKilled”是 true。
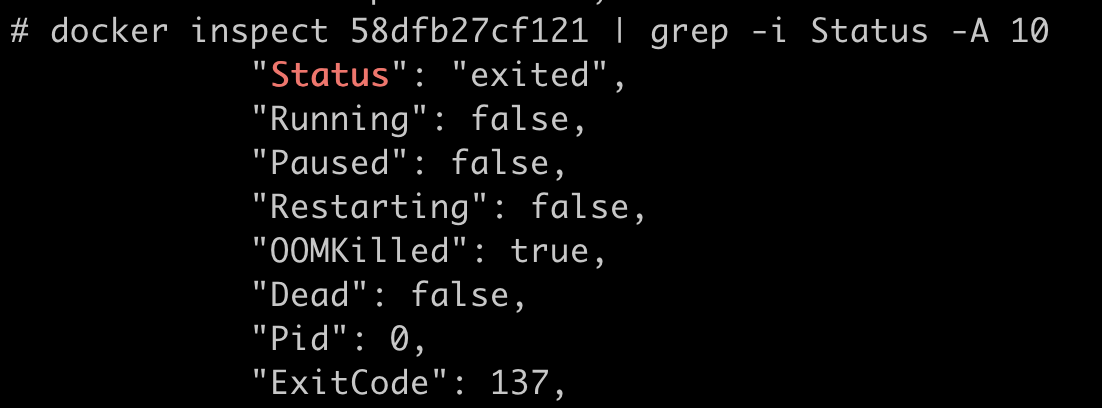
那么问题来了,什么是 OOM Killed 呢?它和之前我们对容器 Memory Cgroup 做的设置有什么关系,又是怎么引起容器退出的?想搞清楚这些问题,我们就需要先理清楚基本概念。
如何理解 OOM Killer?
我们先来看一看 OOM Killer 是什么意思。
OOM 是 Out of Memory 的缩写,顾名思义就是内存不足的意思,而 Killer 在这里指需要杀死某个进程。那么 OOM Killer 就是 在 Linux 系统里如果内存不足时,就需要杀死一个正在运行的进程来释放一些内存。
那么讲到这里,你可能会有个问题了,Linux 里的程序都是调用 malloc() 来申请内存,如果内存不足,直接 malloc() 返回失败就可以,为什么还要去杀死正在运行的进程呢?
其实,这个和 Linux 进程的内存申请策略有关,Linux 允许进程在申请内存的时候是 overcommit 的,这是什么意思呢?就是说允许进程申请超过实际物理内存上限的内存。
为了让你更好地理解,我给你举个例子说明。比如说,节点上的空闲物理内存只有 512MB 了,但是如果一个进程调用 malloc() 申请了 600MB,那么 malloc() 的这次申请还是被允许的。
这是因为 malloc() 申请的是内存的虚拟地址,系统只是给了程序一个地址范围,由于没有写入数据,所以程序并没有得到真正的物理内存。物理内存只有程序真的往这个地址写入数据的时候,才会分配给程序。
可以看得出来,这种 overcommit 的内存申请模式可以带来一个好处,它可以有效提高系统的内存利用率。不过这也带来了一个问题,也许你已经猜到了,就是物理内存真的不够了,又该怎么办呢?
为了方便你理解,我给你打个比方,这个有点像航空公司在卖飞机票。售卖飞机票的时候往往是超售的。比如说实际上有 100 个位子,航空公司会卖 105 张机票,在登机的时候如果实际登机的乘客超过了 100 个,那么就需要按照一定规则,不允许多出的几位乘客登机了。
同样的道理,遇到内存不够的这种情况,Linux 采取的措施就是杀死某个正在运行的进程。
那么你一定会问了,在发生 OOM 的时候,Linux 到底是根据什么标准来选择被杀的进程呢?这就要提到一个在 Linux 内核里有一个 oom_badness() 函数 ,就是它定义了选择进程的标准。其实这里的判断标准也很简单,函数中涉及两个条件:
第一,进程已经使用的物理内存页面数。
第二,每个进程的 OOM 校准值 oom_score_adj。在 /proc 文件系统中,每个进程都有一个 /proc//oom_score_adj 的接口文件。我们可以在这个文件中输入 -1000 到 1000 之间的任意一个数值,调整进程被 OOM Kill 的几率。
adj = (long)p->signal->oom_score_adj;
points = get_mm_rss(p->mm) + get_mm_counter(p->mm, MM_SWAPENTS) +mm_pgtables_bytes(p->mm) / PAGE_SIZE;
adj *= totalpages / 1000;
points += adj;结合前面说的两个条件,函数 oom_badness() 里的最终计算方法是这样的:
用系统总的可用页面数,去乘以 OOM 校准值 oom_score_adj,再加上进程已经使用的物理页面数,计算出来的值越大,那么这个进程被 OOM Kill 的几率也就越大。
如何理解 Memory Cgroup?
前面我们介绍了 OOM Killer,容器发生 OOM Kill 大多是因为 Memory Cgroup 的限制所导致的,所以在我们还需要理解 Memory Cgroup 的运行机制。
在这个专栏的第一讲中,我们讲过 Cgroups 是容器的两大支柱技术之一,在 CPU 的章节中,我们也讲到了 CPU Cgroups。那么按照同样的思路,我们想理解容器 Memory,自然要讨论一下 Memory Cgroup 了。
Memory Cgroup 也是 Linux Cgroups 子系统之一,它的作用是对一组进程的 Memory 使用做限制。Memory Cgroup 的虚拟文件系统的挂载点一般在”/sys/fs/cgroup/memory”这个目录下,这个和 CPU Cgroup 类似。我们可以在 Memory Cgroup 的挂载点目录下,创建一个子目录作为控制组。
每一个控制组下面有不少参数,在这一讲里,这里我们只讲跟 OOM 最相关的 3 个参数:memory.limit_in_bytes,memory.oom_control 和 memory.usage_in_bytes。其他参数如果你有兴趣了解,可以参考内核的 文档说明 。
首先我们来看第一个参数,叫作 memory.limit_in_bytes。请你注意,这个 memory.limit_in_bytes 是每个控制组里最重要的一个参数了。这是因为一个控制组里所有进程可使用内存的最大值,就是由这个参数的值来直接限制的。
那么一旦达到了最大值,在这个控制组里的进程会发生什么呢?
这就涉及到我要给你讲的第二个参数 memory.oom_control 了。这个 memory.oom_control 又是干啥的呢?当控制组中的进程内存使用达到上限值时,这个参数能够决定会不会触发 OOM Killer。
如果没有人为设置的话,memory.oom_control 的缺省值就会触发 OOM Killer。这是一个控制组内的 OOM Killer,和整个系统的 OOM Killer 的功能差不多,差别只是被杀进程的选择范围:控制组内的 OOM Killer 当然只能杀死控制组内的进程,而不能选节点上的其他进程。
如果我们要改变缺省值,也就是不希望触发 OOM Killer,只要执行 echo 1 > memory.oom_control 就行了,这时候即使控制组里所有进程使用的内存达到 memory.limit_in_bytes 设置的上限值,控制组也不会杀掉里面的进程。
但是,我想提醒你,这样操作以后,就会影响到控制组中正在申请物理内存页面的进程。这些进程会处于一个停止状态,不能往下运行了。
最后,我们再来学习一下第三个参数,也就是 memory.usage_in_bytes。这个参数是只读的,它里面的数值是当前控制组里所有进程实际使用的内存总和。
我们可以查看这个值,然后把它和 memory.limit_in_bytes 里的值做比较,根据接近程度来可以做个预判。这两个值越接近,OOM 的风险越高。通过这个方法,我们就可以得知,当前控制组内使用总的内存量有没有 OOM 的风险了。
控制组之间也同样是树状的层级结构,在这个结构中,父节点的控制组里的 memory.limit_in_bytes 值,就可以限制它的子节点中所有进程的内存使用。
我用一个具体例子来说明,比如像下面图里展示的那样,group1 里的 memory.limit_in_bytes 设置的值是 200MB,它的子控制组 group3 里 memory.limit_in_bytes 值是 500MB。那么,我们在 group3 里所有进程使用的内存总值就不能超过 200MB,而不是 500MB。
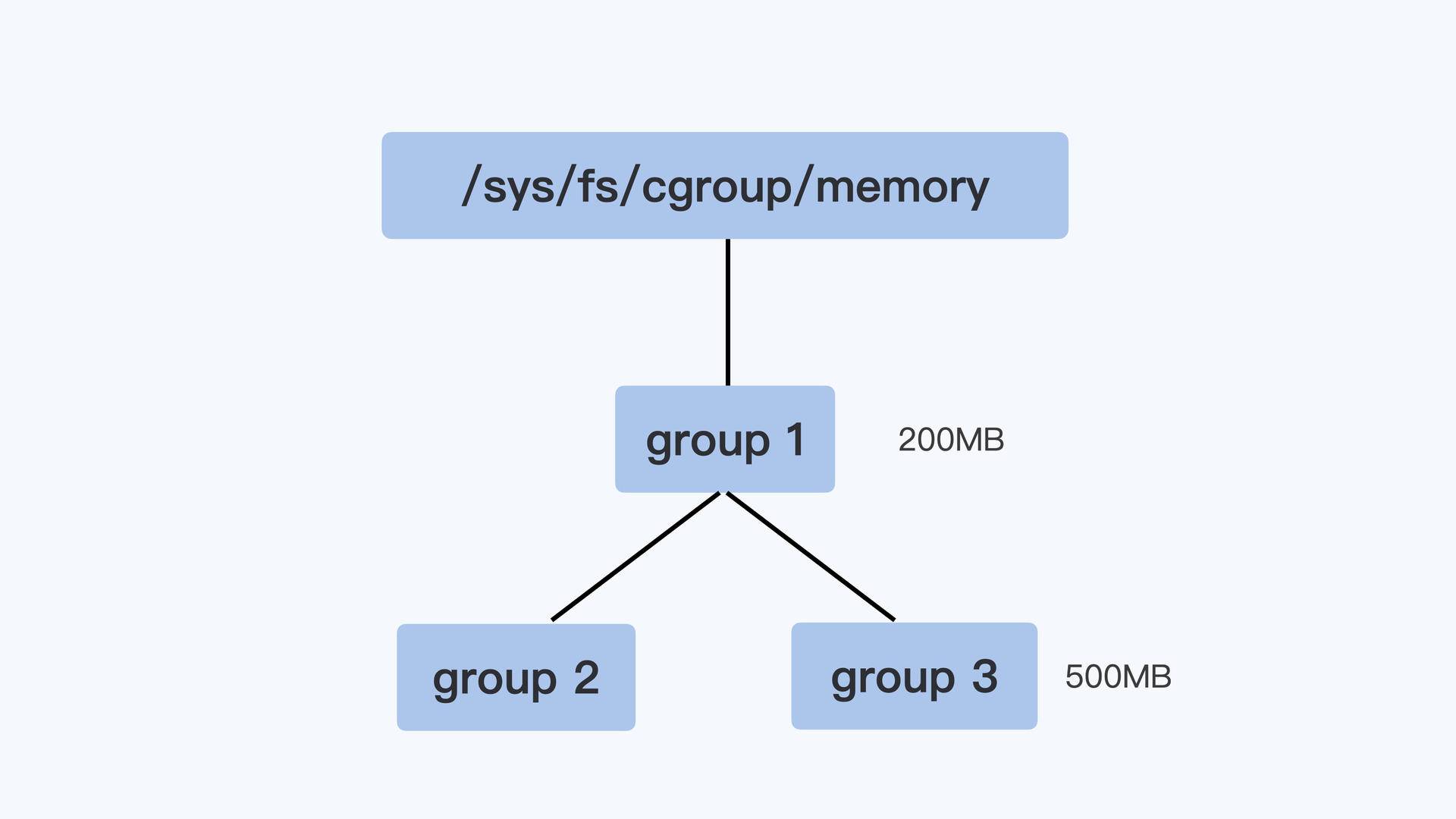
好了,我们这里介绍了 Memory Cgroup 最基本的概念,简单总结一下:
第一,Memory Cgroup 中每一个控制组可以为一组进程限制内存使用量,一旦所有进程使用内存的总量达到限制值,缺省情况下,就会触发 OOM Killer。这样一来,控制组里的”某个进程”就会被杀死。
第二,这里杀死”某个进程”的选择标准是, 控制组中总的可用页面乘以进程的 oom_score_adj,加上进程已经使用的物理内存页面,所得值最大的进程,就会被系统选中杀死。
解决问题
我们解释了 Memory Cgroup 和 OOM Killer 后,你应该明白了为什么容器在运行过程中会突然消失了。
对于每个容器创建后,系统都会为它建立一个 Memory Cgroup 的控制组,容器的所有进程都在这个控制组里。
一般的容器云平台,比如 Kubernetes 都会为容器设置一个内存使用的上限。这个内存的上限值会被写入 Cgroup 里,具体来说就是容器对应的 Memory Cgroup 控制组里 memory.limit_in_bytes 这个参数中。
所以,一旦容器中进程使用的内存达到了上限值,OOM Killer 会杀死进程使容器退出。
那么我们怎样才能快速确定容器发生了 OOM 呢?这个可以通过查看内核日志及时地发现。
还是拿我们这一讲最开始发生 OOM 的容器作为例子。我们通过查看内核的日志,使用用 journal -k 命令,或者直接查看日志文件 /var/log/message,我们会发现当容器发生 OOM Kill 的时候,内核会输出下面的这段信息,大致包含下面这三部分的信息:
第一个部分就是 容器里每一个进程使用的内存页面数量 。在”rss”列里,”rss’是 Resident Set Size 的缩写,指的就是进程真正在使用的物理内存页面数量。
比如下面的日志里,我们看到 init 进程的”rss”是 1 个页面,mem_alloc 进程的”rss”是 130801 个页面,内存页面的大小一般是 4KB,我们可以做个估算,130801 * 4KB 大致等于 512MB。

第二部分我们来看上面图片的 “ oom-kill: “ 这行,这一行里列出了发生 OOM 的 Memroy Cgroup 的控制组,我们可以从控制组的信息中知道 OOM 是在哪个容器发生的。
第三部分是图中 “ Killed process 7445 (mem_alloc) “ 这行,它显示了最终被 OOM Killer 杀死的进程。
我们通过了解内核日志里的这些信息,可以很快地判断出容器是因为 OOM 而退出的,并且还可以知道是哪个进程消耗了最多的 Memory。
那么知道了哪个进程消耗了最大内存之后,我们就可以有针对性地对这个进程进行分析了,一般有这两种情况:
第一种情况是 这个进程本身的确需要很大的内存 ,这说明我们给 memory.limit_in_bytes 里的内存上限值设置小了,那么就需要增大内存的上限值。
第二种情况是 进程的代码中有 Bug,会导致内存泄漏,进程内存使用到达了 Memory Cgroup 中的上限 。如果是这种情况,就需要我们具体去解决代码里的问题了。
重点总结
这一讲我们从容器在系统中被杀的问题,学习了 OOM Killer 和 Memory Cgroup 这两个概念。
OOM Killer 这个行为在 Linux 中很早就存在了,它其实是一种内存过载后的保护机制,通过牺牲个别的进程,来保证整个节点的内存不会被全部消耗掉。
在 Cgroup 的概念出现后,Memory Cgroup 中每一个控制组可以对一组进程限制内存使用量,一旦所有进程使用内存的总量达到限制值,在缺省情况下,就会触发 OOM Killer,控制组里的”某个进程”就会被杀死。
请注意,这里 Linux 系统肯定不能随心所欲地杀掉进程,那具体要用什么选择标准呢?
杀掉”某个进程”的选择标准,涉及到内核函数 oom_badness()。具体的计算方法是:系统总的可用页面数乘以进程的 OOM 校准值 oom_score_adj,再加上进程已经使用的物理页面数,计算出来的值越大,那么这个进程被 OOM Kill 的几率也就越大。
接下来,我给你讲解了 Memory Cgroup 里最基本的三个参数,分别是 memory.limit_in_bytes, memory.oom_control 和 memory.usage_in_bytes 。我把这三个参数的作用,给你总结成了一张图。第一个和第三个参数,下一讲中我们还会用到,这里你可以先有个印象。

容器因为 OOM 被杀,要如何处理呢?我们可以通过内核日志做排查,查看容器里内存使用最多的进程,然后对它进行分析。根据我的经验,解决思路要么是提高容器的最大内存限制,要么需要我们具体去解决进程代码的 BUG。
留言问答
k8s的memory的request,limit限制对应cgroup的参数是什么?
答:limit 对应 Memory Cgroup中的memory.limit_in_bytes。k8s request不修改Memory Cgroup里的参数。只是在kube scheduler里调度的时候看做个计算,看节点上是否还有内存给这个新的container。
09 | Page Cache:为什么我的容器内存使用量总是在临界点?
上一讲,我们讲了 Memory Cgroup 是如何控制一个容器的内存的。我们已经知道了,如果容器使用的物理内存超过了 Memory Cgroup 里的 memory.limit_in_bytes 值,那么容器中的进程会被 OOM Killer 杀死。
不过在一些容器的使用场景中,比如容器里的应用有很多文件读写,你会发现整个容器的内存使用量已经很接近 Memory Cgroup 的上限值了,但是在容器中我们接着再申请内存,还是可以申请出来,并且没有发生 OOM。
这是怎么回事呢?今天这一讲我就来聊聊这个问题。
问题再现
我们可以用这里的 代码 做个容器镜像,然后用下面的这个脚本启动容器,并且设置容器 Memory Cgroup 里的内存上限值是 100MB(104857600bytes)。
#!/bin/bash
docker stop page_cache;docker rm page_cache
if [ ! -f ./test.file ]
then
dd if=/dev/zero of=./test.file bs=4096 count=30000
echo "Please run start_container.sh again "
exit 0
fi
echo 3 > /proc/sys/vm/drop_caches
sleep 10
docker run -d --init --name page_cache -v $(pwd):/mnt registry/page_cache_test:v1
CONTAINER_ID=$(sudo docker ps --format "{{.ID}}\t{{.Names}}" | grep -i page_cache | awk '{print $1}')
echo $CONTAINER_ID
CGROUP_CONTAINER_PATH=$(find /sys/fs/cgroup/memory/ -name "*$CONTAINER_ID*")
echo 104857600 > $CGROUP_CONTAINER_PATH/memory.limit_in_bytes
cat $CGROUP_CONTAINER_PATH/memory.limit_in_bytes把容器启动起来后,我们查看一下容器的 Memory Cgroup 下的 memory.limit_in_bytes 和 memory.usage_in_bytes 这两个值。
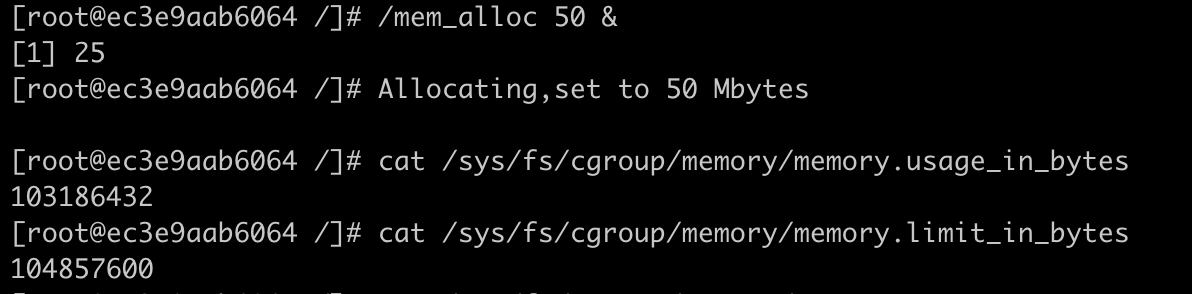
如下图所示,我们可以看到容器内存的上限值设置为 104857600bytes(100MB),而这时整个容器的已使用内存显示为 104767488bytes,这个值已经非常接近上限值了。
我们把容器内存上限值和已使用的内存数值做个减法,104857600-104767488= 90112bytes,只差大概 90KB 左右的大小。

但是,如果这时候我们继续启动一个程序,让这个程序申请并使用 50MB 的物理内存,就会发现这个程序还是可以运行成功,这时候容器并没有发生 OOM 的情况。
这时我们再去查看参数 memory.usage_in_bytes,就会发现它的值变成了 103186432bytes,比之前还少了一些。那这是怎么回事呢?
知识详解:Linux 系统有那些内存类型?
要解释刚才我们看到的容器里内存分配的现象,就需要先理解 Linux 操作系统里有哪几种内存的类型。
因为我们只有知道了内存的类型,才能明白每一种类型的内存,容器分别使用了多少。而且,对于不同类型的内存,一旦总内存增高到容器里内存最高限制的数值,相应的处理方式也不同。
Linux 内存类型
Linux 的各个模块都需要内存,比如内核需要分配内存给页表,内核栈,还有 slab,也就是内核各种数据结构的 Cache Pool;用户态进程里的堆内存和栈的内存,共享库的内存,还有文件读写的 Page Cache。
在这一讲里,我们讨论的 Memory Cgroup 里都不会对内核的内存做限制(比如页表,slab 等)。所以我们今天主要讨论 与用户态相关的两个内存类型,RSS 和 Page Cache。
RSS
先看什么是 RSS。RSS 是 Resident Set Size 的缩写,简单来说它就是指进程真正申请到物理页面的内存大小。这是什么意思呢?
应用程序在申请内存的时候,比如说,调用 malloc() 来申请 100MB 的内存大小,malloc() 返回成功了,这时候系统其实只是把 100MB 的虚拟地址空间分配给了进程,但是并没有把实际的物理内存页面分配给进程。
上一讲中,我给你讲过,当进程对这块内存地址开始做真正读写操作的时候,系统才会把实际需要的物理内存分配给进程。而这个过程中,进程真正得到的物理内存,就是这个 RSS 了。
比如下面的这段代码,我们先用 malloc 申请 100MB 的内存。
p = malloc(100 * MB);
if (p == NULL)
return 0;然后,我们运行 top 命令查看这个程序在运行了 malloc() 之后的内存,我们可以看到这个程序的虚拟地址空间(VIRT)已经有了 106728KB(~100MB),但是实际的物理内存 RSS(top 命令里显示的是 RES,就是 Resident 的简写,和 RSS 是一个意思)在这里只有 688KB。

接着我们在程序里等待 30 秒之后,我们再对这块申请的空间里写入 20MB 的数据。
sleep(30);
memset(p, 0x00, 20 * MB)当我们用 memset() 函数对这块地址空间写入 20MB 的数据之后,我们再用 top 查看,这时候可以看到虚拟地址空间(VIRT)还是 106728,不过物理内存 RSS(RES)的值变成了 21432(大小约为 20MB), 这里的单位都是 KB。

所以,通过刚才上面的小实验,我们可以验证 RSS 就是进程里真正获得的物理内存大小。
对于进程来说,RSS 内存包含了进程的代码段内存,栈内存,堆内存,共享库的内存, 这些内存是进程运行所必须的。刚才我们通过 malloc/memset 得到的内存,就是属于堆内存。
具体的每一部分的 RSS 内存的大小,你可以查看 /proc/[pid]/smaps 文件。
Page Cache
每个进程除了各自独立分配到的 RSS 内存外,如果进程对磁盘上的文件做了读写操作,Linux 还会分配内存,把磁盘上读写到的页面存放在内存中,这部分的内存就是 Page Cache。
Page Cache 的主要作用是提高磁盘文件的读写性能,因为系统调用 read() 和 write() 的缺省行为都会把读过或者写过的页面存放在 Page Cache 里。
还是用我们这一讲最开始的的例子:代码程序去读取 100MB 的文件,在读取文件前,系统中 Page Cache 的大小是 388MB,读取后 Page Cache 的大小是 506MB,增长了大约 100MB 左右,多出来的这 100MB,正是我们读取文件的大小。
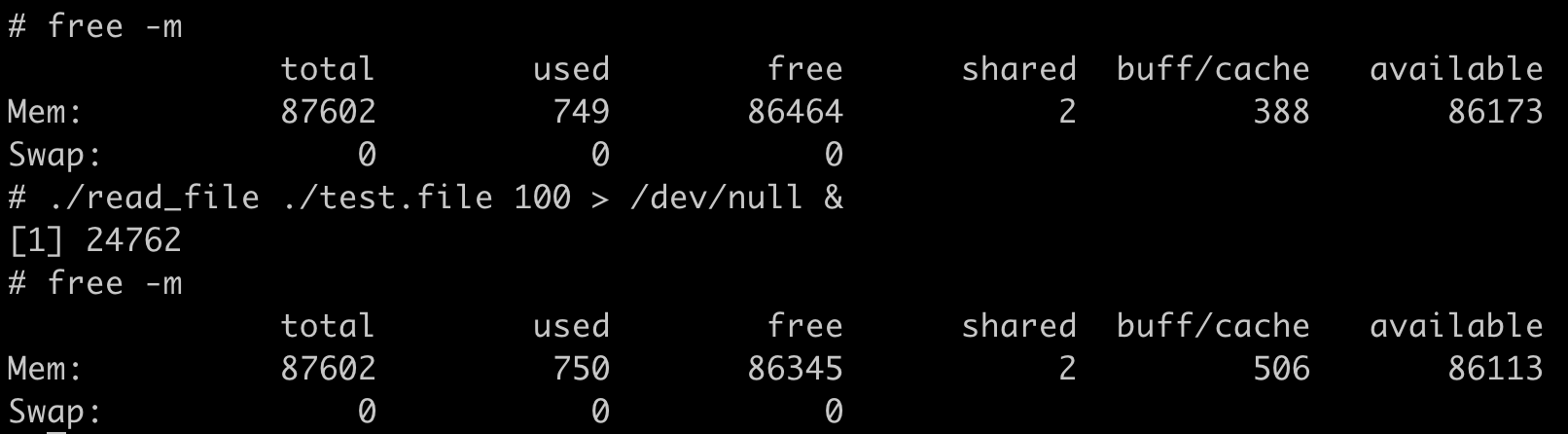
在 Linux 系统里只要有空闲的内存,系统就会自动地把读写过的磁盘文件页面放入到 Page Cache 里。那么这些内存都被 Page Cache 占用了,一旦进程需要用到更多的物理内存,执行 malloc() 调用做申请时,就会发现剩余的物理内存不够了,那该怎么办呢?
这就要提到 Linux 的内存管理机制了。 Linux 的内存管理有一种内存页面回收机制(page frame reclaim),会根据系统里空闲物理内存是否低于某个阈值(wartermark),来决定是否启动内存的回收。
内存回收的算法会根据不同类型的内存以及内存的最近最少用原则,就是 LRU(Least Recently Used)算法决定哪些内存页面先被释放。因为 Page Cache 的内存页面只是起到 Cache 作用,自然是会被优先释放的。
所以,Page Cache 是一种为了提高磁盘文件读写性能而利用空闲物理内存的机制。同时,内存管理中的页面回收机制,又能保证 Cache 所占用的页面可以及时释放,这样一来就不会影响程序对内存的真正需求了。
RSS & Page Cache in Memory Cgroup
学习了 RSS 和 Page Cache 的基本概念之后,我们下面来看不同类型的内存,特别是 RSS 和 Page Cache 是如何影响 Memory Cgroup 的工作的。
我们先从 Linux 的内核代码看一下,从 mem_cgroup_charge_statistics() 这个函数里,我们可以看到 Memory Cgroup 也的确只是统计了 RSS 和 Page Cache 这两部分的内存。
RSS 的内存,就是在当前 Memory Cgroup 控制组里所有进程的 RSS 的总和;而 Page Cache 这部分内存是控制组里的进程读写磁盘文件后,被放入到 Page Cache 里的物理内存。
static void mem_cgroup_charge_statistics(struct mem_cgroup *memcg,
struct page *page,
bool compound, int nr_pages)
{
/*
* Here, RSS means 'mapped anon' and anon's SwapCache. Shmem/tmpfs is
* counted as CACHE even if it's on ANON LRU.
*/
if (PageAnon(page))
__mod_memcg_state(memcg, MEMCG_RSS, nr_pages);
else {
__mod_memcg_state(memcg, MEMCG_CACHE, nr_pages);
if (PageSwapBacked(page))
__mod_memcg_state(memcg, NR_SHMEM, nr_pages);
}
...
}Memory Cgroup 控制组里 RSS 内存和 Page Cache 内存的和,正好是 memory.usage_in_bytes 的值。
当控制组里的进程需要申请新的物理内存,而且 memory.usage_in_bytes 里的值超过控制组里的内存上限值 memory.limit_in_bytes,这时我们前面说的 Linux 的内存回收(page frame reclaim)就会被调用起来。
那么在这个控制组里的 page cache 的内存会根据新申请的内存大小释放一部分,这样我们还是能成功申请到新的物理内存,整个控制组里总的物理内存开销 memory.usage_in_bytes 还是不会超过上限值 memory.limit_in_bytes。
解决问题
明白了 Memory Cgroup 中内存类型的统计方法,我们再回过头看这一讲开头的问题,为什么 memory.usage_in_bytes 与 memory.limit_in_bytes 的值只相差了 90KB,我们在容器中还是可以申请出 50MB 的物理内存?
我想你应该已经知道答案了,容器里肯定有大于 50MB 的内存是 Page Cache,因为作为 Page Cache 的内存在系统需要新申请物理内存的时候(作为 RSS)是可以被释放的。
知道了这个答案,那么我们怎么来验证呢?验证的方法也挺简单的,在 Memory Cgroup 中有一个参数 memory.stat,可以显示在当前控制组里各种内存类型的实际的开销。
那我们还是拿这一讲的容器例子,再跑一遍代码,这次要查看一下 memory.stat 里的数据。
第一步,我们还是用同样的 脚本 来启动容器,并且设置好容器的 Memory Cgroup 里的 memory.limit_in_bytes 值为 100MB。
启动容器后,这次我们不仅要看 memory.usage_in_bytes 的值,还要看一下 memory.stat。虽然 memory.stat 里的参数有不少,但我们目前只需要关注”cache”和”rss”这两个值。
我们可以看到,容器启动后,cache,也就是 Page Cache 占的内存是 99508224bytes,大概是 99MB,而 RSS 占的内存只有 1826816bytes,也就是 1MB 多一点。
这就意味着,在这个容器的 Memory Cgroup 里大部分的内存都被用作了 Page Cache,而这部分内存是可以被回收的。
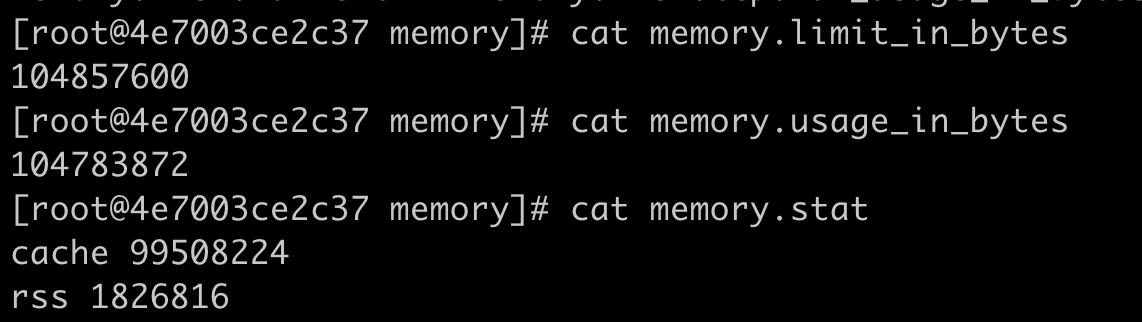
那么我们再执行一下我们的 mem_alloc 程序 ,申请 50MB 的物理内存。
我们可以再来查看一下 memory.stat,这时候 cache 的内存值降到了 46632960bytes,大概 46MB,而 rss 的内存值到了 54759424bytes,54MB 左右吧。总的 memory.usage_in_bytes 值和之前相比,没有太多的变化。
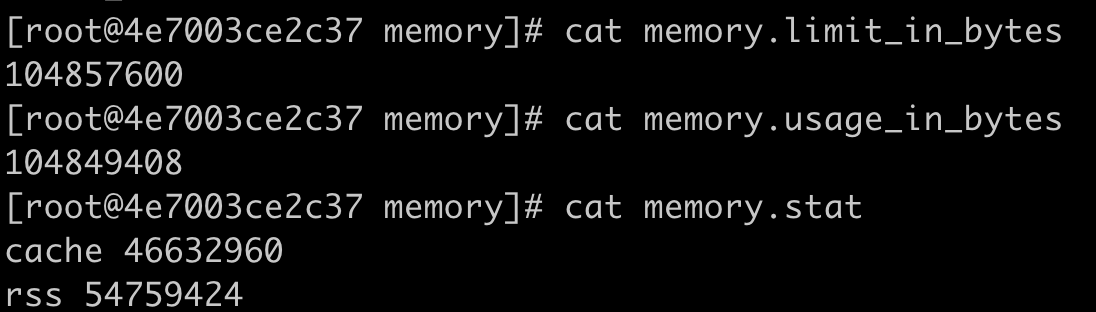
从这里我们发现,Page Cache 内存对我们判断容器实际内存使用率的影响,目前 Page Cache 完全就是 Linux 内核的一个自动的行为,只要读写磁盘文件,只要有空闲的内存,就会被用作 Page Cache。
所以,判断容器真实的内存使用量,我们不能用 Memory Cgroup 里的 memory.usage_in_bytes,而需要用 memory.stat 里的 rss 值。这个很像我们用 free 命令查看节点的可用内存,不能看”free”字段下的值,而要看除去 Page Cache 之后的”available”字段下的值。
重点总结
这一讲我想让你知道,每个容器的 Memory Cgroup 在统计每个控制组的内存使用时包含了两部分,RSS 和 Page Cache。
RSS 是每个进程实际占用的物理内存,它包括了进程的代码段内存,进程运行时需要的堆和栈的内存,这部分内存是进程运行所必须的。
Page Cache 是进程在运行中读写磁盘文件后,作为 Cache 而继续保留在内存中的,它的目的是为了提高磁盘文件的读写性能。
当节点的内存紧张或者 Memory Cgroup 控制组的内存达到上限的时候,Linux 会对内存做回收操作,这个时候 Page Cache 的内存页面会被释放,这样空出来的内存就可以分配给新的内存申请。
正是 Page Cache 内存的这种 Cache 的特性,对于那些有频繁磁盘访问容器,我们往往会看到它的内存使用率一直接近容器内存的限制值(memory.limit_in_bytes)。但是这时候,我们并不需要担心它内存的不够, 我们在判断一个容器的内存使用状况的时候,可以把 Page Cache 这部分内存使用量忽略,而更多的考虑容器中 RSS 的内存使用量。
10 | Swap:容器可以使用Swap空间吗?
用过 Linux 的同学应该都很熟悉 Swap 空间了,简单来说它就是就是一块磁盘空间。
当内存写满的时候,就可以把内存中不常用的数据暂时写到这个 Swap 空间上。这样一来,内存空间就可以释放出来,用来满足新的内存申请的需求。
它的好处是可以 应对一些瞬时突发的内存增大需求 ,不至于因为内存一时不够而触发 OOM Killer,导致进程被杀死。
那么对于一个容器,特别是容器被设置了 Memory Cgroup 之后,它还可以使用 Swap 空间吗?会不会出现什么问题呢?
问题再现
首先,我们在一个有 Swap 空间的节点上启动一个容器,设置好它的 Memory Cgroup 的限制,一起来看看接下来会发生什么。
如果你的节点上没有 Swap 分区,也没有关系,你可以用下面的 这组命令 来新建一个。
这个例子里,Swap 空间的大小是 20G,你可以根据自己磁盘空闲空间来决定这个 Swap 的大小。执行完这组命令之后,我们来运行 free 命令,就可以看到 Swap 空间有 20G。
输出的结果你可以参考下面的截图。
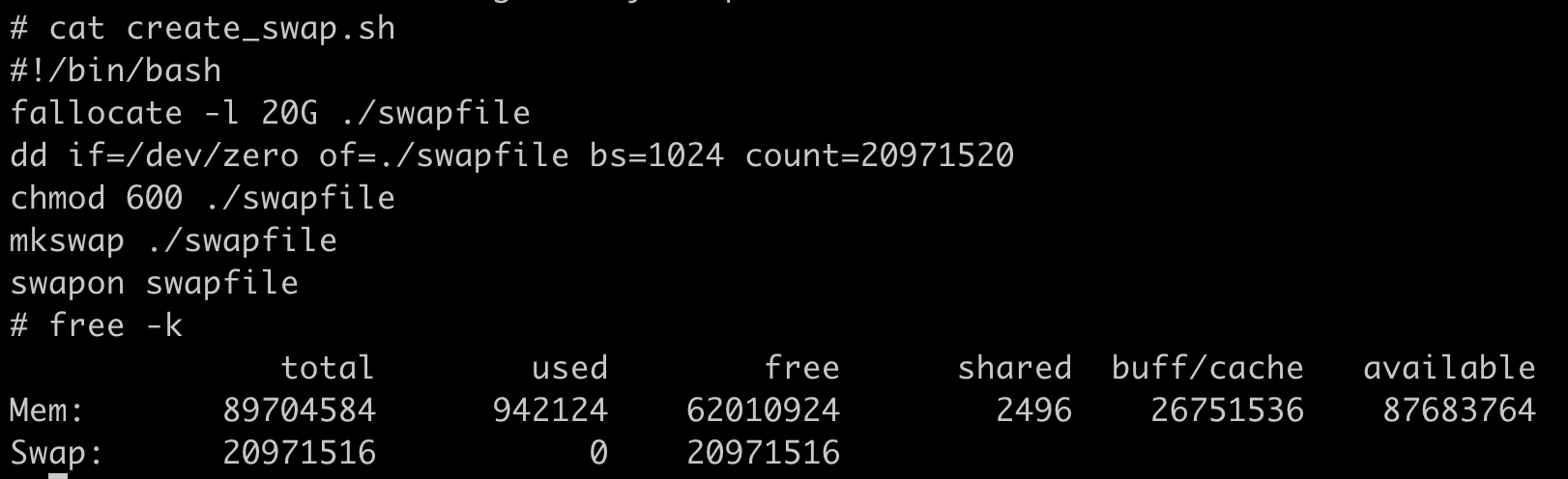
然后我们再启动一个容器,和 OOM 那一讲里的例子差不多,容器的 Memory Cgroup 限制为 512MB,容器中的 mem_alloc 程序去申请 2GB 内存。
你会发现,这次和上次 OOM 那一讲里的情况不一样了,并没有发生 OOM 导致容器退出的情况,容器运行得好好的。
从下面的图中,我们可以看到,mem_alloc 进程的 RSS 内存一直在 512MB(RES: 515596)左右。

那我们再看一下 Swap 空间,使用了 1.5GB (used 1542144KB)。输出的结果如下图,简单计算一下,1.5GB + 512MB,结果正好是 mem_alloc 这个程序申请的 2GB 内存。

通过刚刚的例子,你也许会这么想,因为有了 Swap 空间,本来会被 OOM Kill 的容器,可以好好地运行了。初看这样似乎也挺好的,不过你仔细想想,这样一来,Memory Cgroup 对内存的限制不就失去了作用么?
我们再进一步分析,如果一个容器中的程序发生了内存泄漏(Memory leak),那么本来 Memory Cgroup 可以及时杀死这个进程,让它不影响整个节点中的其他应用程序。结果现在这个内存泄漏的进程没被杀死,还会不断地读写 Swap 磁盘,反而影响了整个节点的性能。
你看,这样一分析,对于运行容器的节点,你是不是又觉得应该禁止使用 Swap 了呢?
我想提醒你,不能一刀切地下结论,我们总是说,具体情况要具体分析,我们落地到具体的场景里,就会发现情况又没有原先我们想得那么简单。
比如说,某一类程序就是需要 Swap 空间,才能防止因为偶尔的内存突然增加而被 OOM Killer 杀死。因为这类程序重新启动的初始化时间会很长,这样程序重启的代价就很大了,也就是说,打开 Swap 对这类程序是有意义的。
这一类程序一旦放到容器中运行,就意味着它会和”别的容器”在同一个宿主机上共同运行,那如果这个”别的容器” 如果不需要 Swap,而是希望 Memory Cgroup 的严格内存限制。
这样一来,在这一个宿主机上的两个容器就会有冲突了,我们应该怎么解决这个问题呢?要解决这个问题,我们先来看看 Linux 里的 Swappiness 这个概念,后面它可以帮到我们。
如何正确理解 swappiness 参数?
在普通 Linux 系统上,如果你使用过 Swap 空间,那么你可能配置过 proc 文件系统下的 swappiness 这个参数 (/proc/sys/vm/swappiness)。swappiness 的定义在 Linux 内核文档 中可以找到,就是下面这段话。
swappiness
This control is used to define how aggressive the kernel will swap memory pages.
Higher values will increase aggressiveness, lower values decrease the amount of swap.
A value of 0 instructs the kernel not to initiate swap until the amount of free and
file-backed pages is less than the high water mark in a zone.
The default value is 60.前面两句话大致翻译过来,意思就是 swappiness 可以决定系统将会有多频繁地使用交换分区。
一个较高的值会使得内核更频繁地使用交换分区,而一个较低的取值,则代表着内核会尽量避免使用交换分区。swappiness 的取值范围是 0-100,缺省值 60。
我第一次读到这个定义,再知道了这个取值范围后,我觉得这是一个百分比值,也就是定义了使用 Swap 空间的频率。
当这个值是 100 的时候,哪怕还有空闲内存,也会去做内存交换,尽量把内存数据写入到 Swap 空间里;值是 0 的时候,基本上就不做内存交换了,也就不写 Swap 空间了。
后来再回顾的时候,我发现这个想法不能说是完全错的,但是想得简单了些。那这段 swappiness 的定义,应该怎么正确地理解呢?
你还记得,我们在上一讲里说过的两种内存类型 Page Cache 和 RSS 么?
在有磁盘文件访问的时候,Linux 会尽量把系统的空闲内存用作 Page Cache 来提高文件的读写性能。在没有打开 Swap 空间的情况下,一旦内存不够,这种情况下就只能把 Page Cache 释放了,而 RSS 内存是不能释放的。
在 RSS 里的内存,大部分都是没有对应磁盘文件的内存,比如用 malloc() 申请得到的内存,这种内存也被称为 匿名内存(Anonymous memory) 。那么当 Swap 空间打开后,可以写入 Swap 空间的,就是这些匿名内存。
所以在 Swap 空间打开的时候,问题也就来了,在内存紧张的时候,Linux 系统怎么决定是先释放 Page Cache,还是先把匿名内存释放并写入到 Swap 空间里呢?
我们一起来分析分析,都可能发生怎样的情况。最可能发生的是下面两种情况:
第一种情况是,如果系统先把 Page Cache 都释放了,那么一旦节点里有频繁的文件读写操作,系统的性能就会下降。
还有另一种情况,如果 Linux 系统先把匿名内存都释放并写入到 Swap,那么一旦这些被释放的匿名内存马上需要使用,又需要从 Swap 空间读回到内存中,这样又会让 Swap(其实也是磁盘)的读写频繁,导致系统性能下降。
显然,我们在释放内存的时候,需要平衡 Page Cache 的释放和匿名内存的释放,而 swappiness,就是用来定义这个平衡的参数。
那么 swappiness 具体是怎么来控制这个平衡的?我们看一下在 Linux 内核代码里是怎么用这个 swappiness 参数。
我们前面说了 swappiness 的这个值的范围是 0 到 100,但是请你一定要注意,它不是一个百分比,更像是一个权重。它是用来定义 Page Cache 内存和匿名内存的释放的一个比例。
我结合下面的这段代码具体给你讲一讲。
我们可以看到,这个比例是 anon_prio: file_prio,这里 anon_prio 的值就等于 swappiness。下面我们分三个情况做讨论:
第一种情况,当 swappiness 的值是 100 的时候,匿名内存和 Page Cache 内存的释放比例就是 100: 100,也就是等比例释放了。
第二种情况,就是 swappiness 缺省值是 60 的时候,匿名内存和 Page Cache 内存的释放比例就是 60 : 140,Page Cache 内存的释放要优先于匿名内存。
/*
* With swappiness at 100, anonymous and file have the same priority.
* This scanning priority is essentially the inverse of IO cost.
*/
anon_prio = swappiness;
file_prio = 200 - anon_prio;还有一种情况, 当 swappiness 的值是 0 的时候,会发生什么呢?这种情况下,Linux 系统是不允许匿名内存写入 Swap 空间了吗?
我们可以回到前面,再看一下那段 swappiness 的英文定义,里面特别强调了 swappiness 为 0 的情况。
当空闲内存少于内存一个 zone 的”high water mark”中的值的时候,Linux 还是会做内存交换,也就是把匿名内存写入到 Swap 空间后释放内存。
在这里 zone 是 Linux 划分物理内存的一个区域,里面有 3 个水位线(water mark),水位线可以用来警示空闲内存的紧张程度。
这里我们可以再做个试验来验证一下,先运行 echo 0 > /proc/sys/vm/swappiness 命令把 swappiness 设置为 0, 然后用我们之前例子里的 mem_alloc 程序来申请内存。
比如我们的这个节点上内存有 12GB,同时有 2GB 的 Swap,用 mem_alloc 申请 12GB 的内存,我们可以看到 Swap 空间在 mem_alloc 调用之前,used=0,输出结果如下图所示。
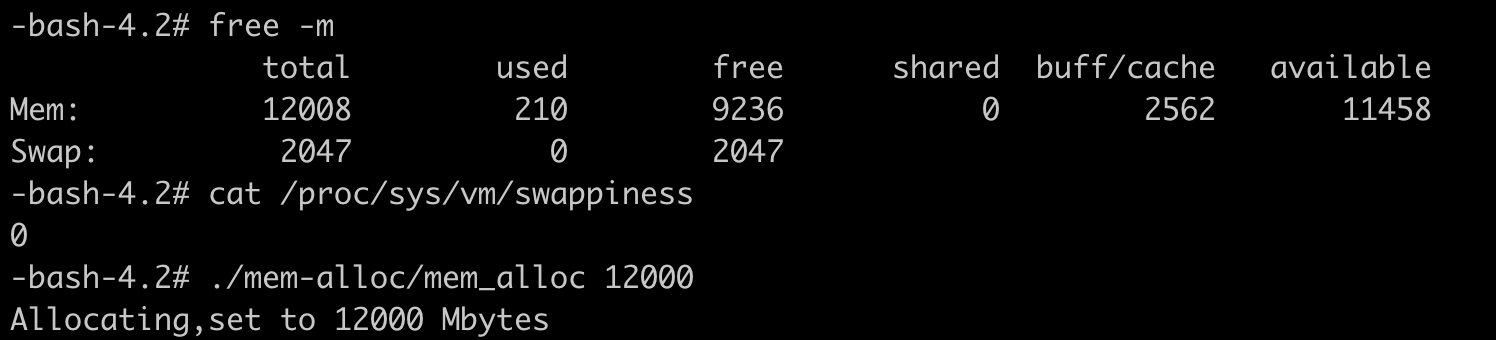
接下来,调用 mem_alloc 之后,Swap 空间就被使用了。

因为 mem_alloc 申请 12GB 内存已经和节点最大内存差不多了,我们如果查看 cat /proc/zoneinfo ,也可以看到 normal zone 里 high (water mark)的值和 free 的值差不多,这样在 free < high 的时候,系统就会回收匿名内存页面并写入 Swap 空间。
好了,在这里我们介绍了 Linux 系统里 swappiness 的概念,它是用来决定在内存紧张时候,回收匿名内存和 Page Cache 内存的比例。
swappiness 的取值范围在 0 到 100,值为 100 的时候系统平等回收匿名内存和 Page Cache 内存;一般缺省值为 60,就是优先回收 Page Cache;即使 swappiness 为 0,也不能完全禁止 Swap 分区的使用,就是说在内存紧张的时候,也会使用 Swap 来回收匿名内存。
解决问题
那么运行了容器,使用了 Memory Cgroup 之后,swappiness 怎么工作呢?
如果你查看一下 Memory Cgroup 控制组下面的参数,你会看到有一个 memory.swappiness 参数。这个参数是干啥的呢?
memory.swappiness 可以控制这个 Memroy Cgroup 控制组下面匿名内存和 page cache 的回收,取值的范围和工作方式和全局的 swappiness 差不多。这里有一个优先顺序,在 Memory Cgorup 的控制组里,如果你设置了 memory.swappiness 参数,它就会覆盖全局的 swappiness,让全局的 swappiness 在这个控制组里不起作用。
不过,这里有一点不同,需要你留意: 当 memory.swappiness = 0 的时候,对匿名页的回收是始终禁止的,也就是始终都不会使用 Swap 空间。
这时 Linux 系统不会再去比较 free 内存和 zone 里的 high water mark 的值,再决定一个 Memory Cgroup 中的匿名内存要不要回收了。
请你注意,当我们设置了”memory.swappiness=0 时,在 Memory Cgroup 中的进程,就不会再使用 Swap 空间,知道这一点很重要。
我们可以跑个容器试一试,还是在一个有 Swap 空间的节点上运行,运行和这一讲开始一样的容器,唯一不同的是把容器对应 Memory Cgroup 里的 memory.swappiness 设置为 0。
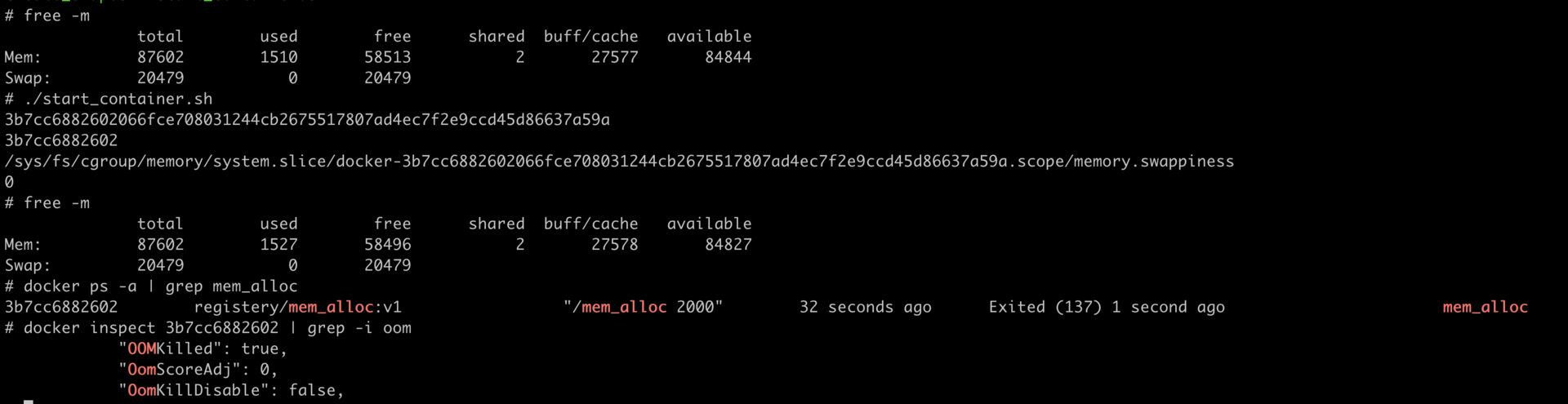
这次我们在容器中申请内存之后,Swap 空间就没有被使用了,而当容器申请的内存超过 memory.limit_in_bytes 之后,就发生了 OOM Kill。
好了,有了”memory.swappiness = 0”的配置和功能,就可以解决我们在这一讲里最开始提出的问题了。
在同一个宿主机上,假设同时存在容器 A 和其他容器,容器 A 上运行着需要使用 Swap 空间的应用,而别的容器不需要使用 Swap 空间。
那么,我们还是可以在宿主机节点上打开 Swap 空间,同时在其他容器对应的 Memory Cgroups 控制组里,把 memory.swappiness 这个参数设置为 0。这样一来,我们不但满足了容器 A 的需求,而且别的容器也不会受到影响,仍然可以严格按照 Memory Cgroups 里的 memory.limit_in_bytes 来限制内存的使用。
总之,memory.swappiness 这个参数很有用,通过它可以让需要使用 Swap 空间的容器和不需要 Swap 的容器,同时运行在同一个宿主机上。
重点总结
这一讲,我们主要讨论的问题是在容器中是否可以使用 Swap?
这个问题没有看起来那么简单。当然了,只要在宿主机节点上打开 Swap 空间,在容器中就是可以用到 Swap 的。但出现的问题是在同一个宿主机上,对于不需要使用 swap 的容器, 它的 Memory Cgroups 的限制也失去了作用。
针对这个问题,我们学习了 Linux 中的 swappiness 这个参数。swappiness 参数值的作用是,在系统里有 Swap 空间之后,当系统需要回收内存的时候,是优先释放 Page Cache 中的内存,还是优先释放匿名内存(也就是写入 Swap)。
swappiness 的取值范围在 0 到 100 之间,我们可以记住下面三个值:
- 值为 100 的时候, 释放 Page Cache 和匿名内存是同等优先级的。
- 值为 60,这是大多数 Linux 系统的缺省值,这时候 Page Cache 的释放优先级高于匿名内存的释放。
- 值为 0 的时候,当系统中空闲内存低于一个临界值的时候,仍然会释放匿名内存并把页面写入 Swap 空间。

swappiness 参数除了在 proc 文件系统下有个全局的值外,在每个 Memory Cgroup 控制组里也有一个 memory.swappiness,那它们有什么不同呢?
不同就是每个 Memory Cgroup 控制组里的 swappiness 参数值为 0 的时候,就可以让控制组里的内存停止写入 Swap。这样一来,有了 memory.swappiness 这个参数后,需要使用 Swap 和不需要 Swap 的容器就可以在同一个宿主机上同时运行了,这样对于硬件资源的利用率也就更高了。
容器存储
11 | 容器文件系统:我在容器中读写文件怎么变慢了?
这一模块我们所讲的内容,都和容器里的文件读写密切相关。因为所有的容器的运行都需要一个容器文件系统,那么我们就从容器文件系统先开始讲起。
那我们还是和以前一样,先来看看我之前碰到了什么问题。
这个问题具体是我们在宿主机上,把 Linux 从 ubuntu18.04 升级到 ubuntu20.04 之后发现的。
在我们做了宿主机的升级后,启动了一个容器,在容器里用 fio 这个磁盘性能测试工具,想看一下容器里文件的读写性能。结果我们很惊讶地发现,在 ubuntu 20.04 宿主机上的容器中文件读写的性能只有 ubuntu18.04 宿主机上的 1/8 左右了,那这是怎么回事呢?
问题再现
这里我提醒一下你,因为涉及到两个 Linux 的虚拟机,问题再现这里我为你列出了关键的结果输出截图,不方便操作的同学可以重点看其中的思路。
我们可以先启动一个 ubuntu18.04 的虚拟机,它的 Linux 内核版本是 4.15 的,然后在虚拟机上用命令 docker run -it ubuntu:18.04 bash 启动一个容器,接着在容器里运行 fio 这条命令,看一下在容器中读取文件的性能。
fio -direct=1 -iodepth=64 -rw=read -ioengine=libaio -bs=4k -size=10G -numjobs=1 -name=./fio.test这里我给你解释一下 fio 命令中的几个主要参数:
第一个参数是”-direct=1”,代表采用非 buffered I/O 文件读写的方式,避免文件读写过程中内存缓冲对性能的影响。
接着我们来看这”-iodepth=64”和”-ioengine=libaio”这两个参数,这里指文件读写采用异步 I/O(Async I/O)的方式,也就是进程可以发起多个 I/O 请求,并且不用阻塞地等待 I/O 的完成。稍后等 I/O 完成之后,进程会收到通知。
这种异步 I/O 很重要,因为它可以极大地提高文件读写的性能。在这里我们设置了同时发出 64 个 I/O 请求。
然后是”-rw=read,-bs=4k,-size=10G”,这几个参数指这个测试是个读文件测试,每次读 4KB 大小数块,总共读 10GB 的数据。
最后一个参数是”-numjobs=1”,指只有一个进程 / 线程在运行。
所以,这条 fio 命令表示我们通过异步方式读取了 10GB 的磁盘文件,用来计算文件的读取性能。
那我们看到在 ubuntu 18.04,内核 4.15 上的容器 I/O 性能是 584MB/s 的带宽,IOPS(I/O per second)是 150K 左右。

同样我们再启动一个 ubuntu 20.04,内核 5.4 的虚拟机,然后在它的上面也启动一个容器。
我们运行 docker run -it ubuntu:20.04 bash ,接着在容器中使用同样的 fio 命令,可以看到它的 I/O 性能是 70MB 带宽,IOPS 是 18K 左右。实践证明,这的确比老版本的 ubuntu 18.04 差了很多。

知识详解
如何理解容器文件系统?
刚才我们对比了升级前后的容器读写性能差异,那想要分析刚刚说的这个性能的差异,我们需要先理解容器的文件系统。
我们在容器里,运行 df 命令,你可以看到在容器中根目录 (/) 的文件系统类型是”overlay”,它不是我们在普通 Linux 节点上看到的 Ext4 或者 XFS 之类常见的文件系统。
那么看到这里你肯定想问,Overlay 是一个什么样的文件系统呢,容器为什么要用这种文件系统?别急,我会一步一步带你分析。

在说容器文件系统前,我们先来想象一下如果没有文件系统管理的话会怎样。假设有这么一个场景,在一个宿主机上需要运行 100 个容器。
在我们这个课程的第一讲里,我们就说过每个容器都需要一个镜像,这个镜像就把容器中程序需要运行的二进制文件,库文件,配置文件,其他的依赖文件等全部都打包成一个镜像文件。
如果没有特别的容器文件系统,只是普通的 Ext4 或者 XFS 文件系统,那么每次启动一个容器,就需要把一个镜像文件下载并且存储在宿主机上。
我举个例子帮你理解,比如说,假设一个镜像文件的大小是 500MB,那么 100 个容器的话,就需要下载 500MB*100= 50GB 的文件,并且占用 50GB 的磁盘空间。
如果你再分析一下这 50GB 里的内容,你会发现,在绝大部分的操作系统里,库文件都是差不多的。而且,在容器运行的时候,这类文件也不会被改动,基本上都是只读的。
特别是这样的情况:假如这 100 个容器镜像都是基于”ubuntu:18.04”的,每个容器镜像只是额外复制了 50MB 左右自己的应用程序到”ubuntu: 18.04”里,那么就是说在总共 50GB 的数据里,有 90% 的数据是冗余的。
讲到这里,你不难推测出理想的情况应该是什么样的?
没错,当然是在一个宿主机上只要下载并且存储存一份”ubuntu:18.04”,所有基于”ubuntu:18.04”镜像的容器都可以共享这一份通用的部分。这样设置的话,不同容器启动的时候,只需要下载自己独特的程序部分就可以。就像下面这张图展示的这样。
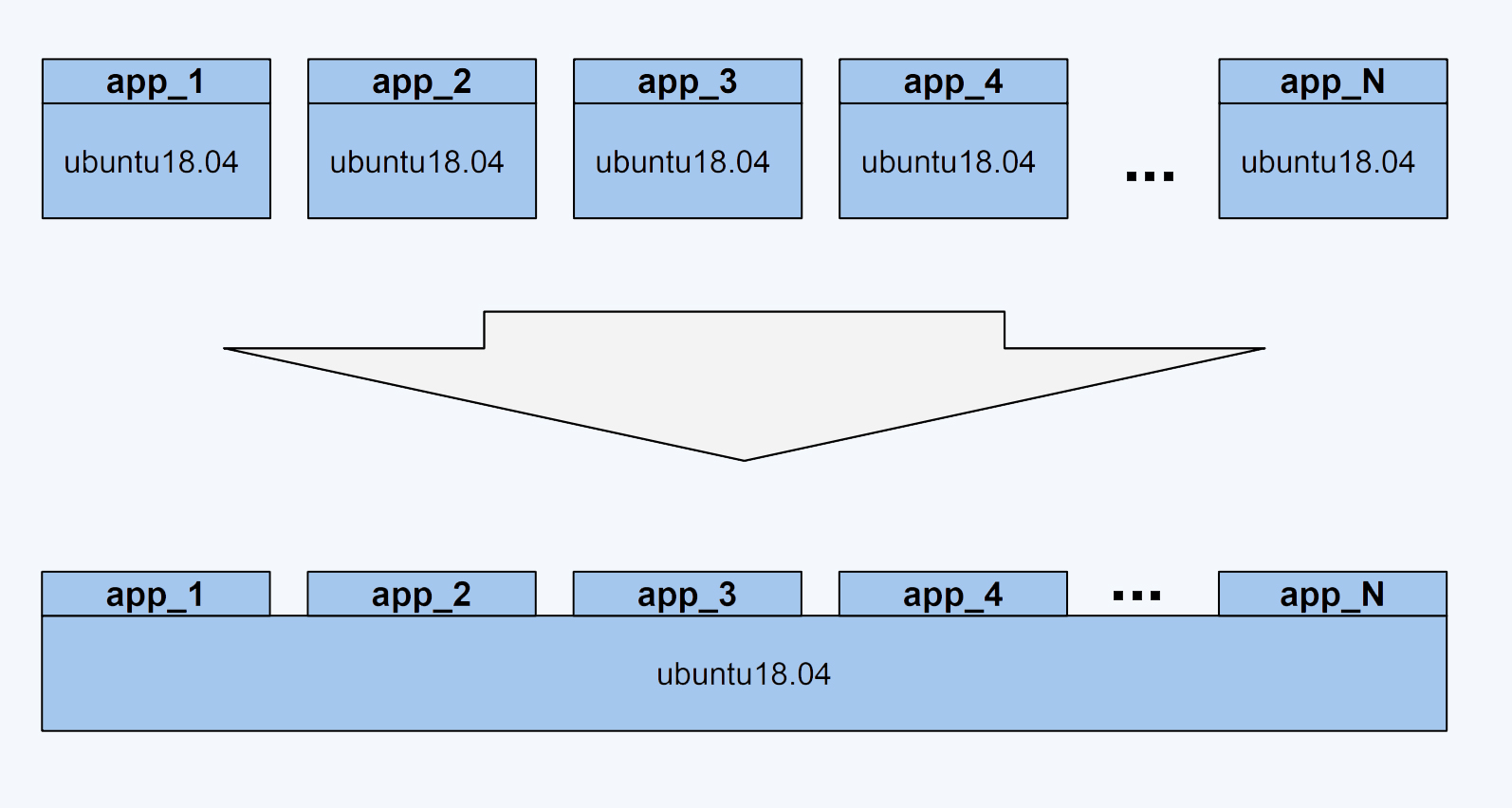
正是为了有效地减少磁盘上冗余的镜像数据,同时减少冗余的镜像数据在网络上的传输,选择一种针对于容器的文件系统是很有必要的,而这类的文件系统被称为 UnionFS。
UnionFS 这类文件系统实现的主要功能是把多个目录(处于不同的分区)一起挂载(mount)在一个目录下。这种多目录挂载的方式,正好可以解决我们刚才说的容器镜像的问题。
比如,我们可以把 ubuntu18.04 这个基础镜像的文件放在一个目录 ubuntu18.04/ 下,容器自己额外的程序文件 app_1_bin 放在 app_1/ 目录下。
然后,我们把这两个目录挂载到 container_1/ 这个目录下,作为容器 1 看到的文件系统;对于容器 2,就可以把 ubuntu18.04/ 和 app_2/ 两个目录一起挂载到 container_2 的目录下。
这样在节点上我们只要保留一份 ubuntu18.04 的文件就可以了。
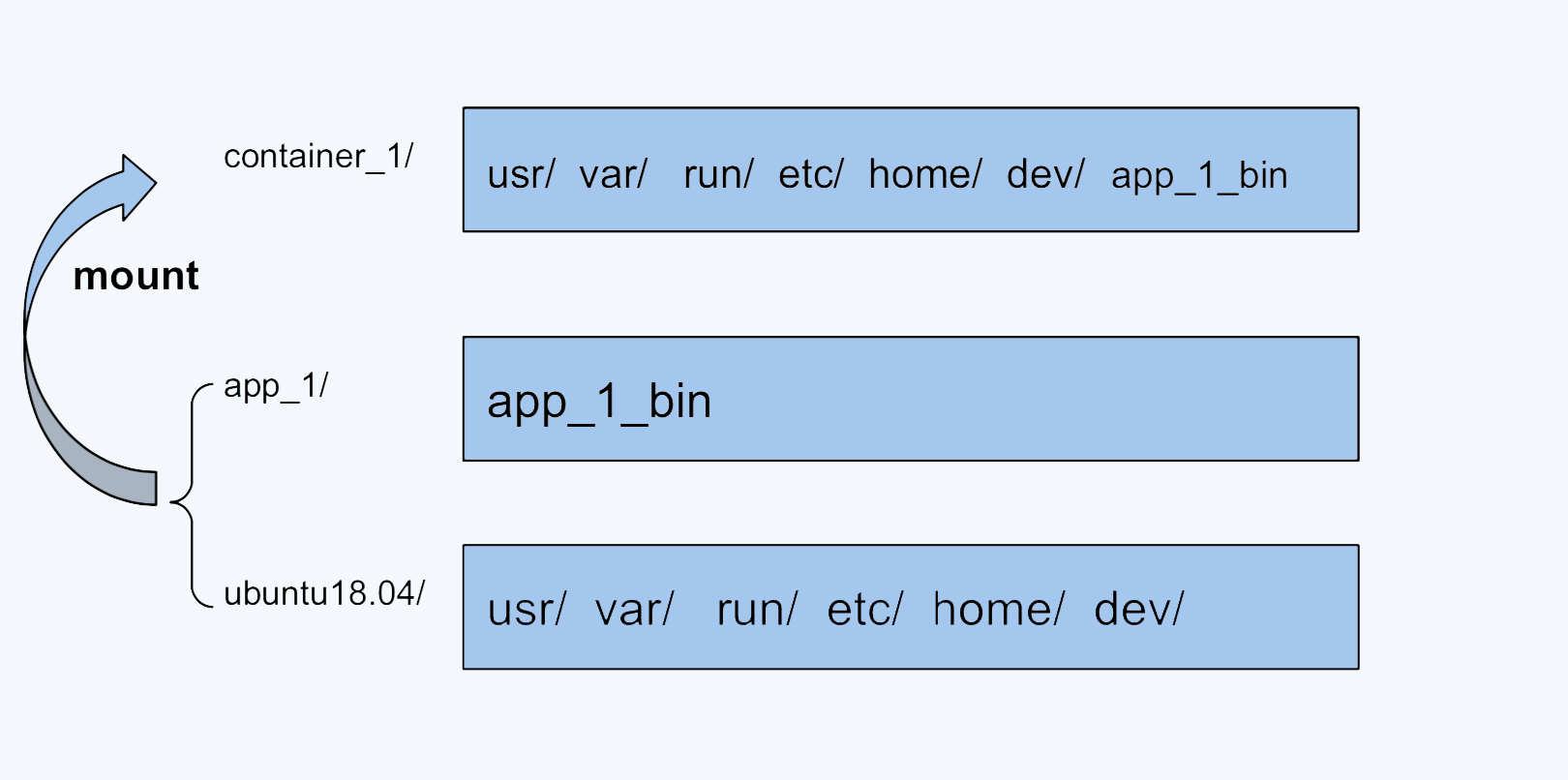
OverlayFS
UnionFS 类似的有很多种实现,包括在 Docker 里最早使用的 AUFS,还有目前我们使用的 OverlayFS。前面我们在运行df的时候,看到的文件系统类型”overlay”指的就是 OverlayFS。
在 Linux 内核 3.18 版本中,OverlayFS 代码正式合入 Linux 内核的主分支。在这之后,OverlayFS 也就逐渐成为各个主流 Linux 发行版本里缺省使用的容器文件系统了。
网上 Julia Evans 有个 blog ,里面有个的 OverlayFS 使用的例子,很简单,我们也拿这个例子来理解一下 OverlayFS 的一些基本概念。
你可以先执行一下这一组命令。
#!/bin/bash
umount ./merged
rm upper lower merged work -r
mkdir upper lower merged work
echo "I'm from lower!" > lower/in_lower.txt
echo "I'm from upper!" > upper/in_upper.txt
# `in_both` is in both directories
echo "I'm from lower!" > lower/in_both.txt
echo "I'm from upper!" > upper/in_both.txt
sudo mount -t overlay overlay -o lowerdir=./lower,upperdir=./upper,workdir=./work ./merged我们可以看到,OverlayFS 的一个 mount 命令牵涉到四类目录,分别是 lower,upper,merged 和 work,那它们是什么关系呢?
我们看下面这张图,这和前面 UnionFS 的工作示意图很像,也不奇怪,OverlayFS 就是 UnionFS 的一种实现。接下来,我们从下往上依次看看每一层的功能。
首先,最下面的”lower/“,也就是被 mount 两层目录中底下的这层(lowerdir)。
在 OverlayFS 中,最底下这一层里的文件是不会被修改的,你可以认为它是只读的。我还想提醒你一点,在这个例子里我们只有一个 lower/ 目录,不过 OverlayFS 是支持多个 lowerdir 的。
然后我们看”uppder/“,它是被 mount 两层目录中上面的这层 (upperdir)。在 OverlayFS 中,如果有文件的创建,修改,删除操作,那么都会在这一层反映出来,它是可读写的。
接着是最上面的”merged” ,它是挂载点(mount point)目录,也是用户看到的目录,用户的实际文件操作在这里进行。
其实还有一个”work/“,这个目录没有在这个图里,它只是一个存放临时文件的目录,OverlayFS 中如果有文件修改,就会在中间过程中临时存放文件到这里。

从这个例子我们可以看到,OverlayFS 会 mount 两层目录,分别是 lower 层和 upper 层,这两层目录中的文件都会映射到挂载点上。
从挂载点的视角看,upper 层的文件会覆盖 lower 层的文件,比如”in_both.txt”这个文件,在 lower 层和 upper 层都有,但是挂载点 merged/ 里看到的只是 upper 层里的 in_both.txt.
如果我们在 merged/ 目录里做文件操作,具体包括这三种。
第一种,新建文件,这个文件会出现在 upper/ 目录中。
第二种是删除文件,如果我们删除”in_upper.txt”,那么这个文件会在 upper/ 目录中消失。如果删除”in_lower.txt”, 在 lower/ 目录里的”in_lower.txt”文件不会有变化,只是在 upper/ 目录中增加了一个特殊文件来告诉 OverlayFS,”in_lower.txt’这个文件不能出现在 merged/ 里了,这就表示它已经被删除了。
还有一种操作是修改文件,类似如果修改”in_lower.txt”,那么就会在 upper/ 目录中新建一个”in_lower.txt”文件,包含更新的内容,而在 lower/ 中的原来的实际文件”in_lower.txt”不会改变。
通过这个例子,我们知道了 OverlayFS 是怎么工作了。那么我们可以再想一想,怎么把它运用到容器的镜像文件上?
其实也不难,从系统的 mounts 信息中,我们可以看到 Docker 是怎么用 OverlayFS 来挂载镜像文件的。容器镜像文件可以分成多个层(layer),每层可以对应 OverlayFS 里 lowerdir 的一个目录,lowerdir 支持多个目录,也就可以支持多层的镜像文件。
在容器启动后,对镜像文件中修改就会被保存在 upperdir 里了。

解决问题
在理解了容器使用的 OverlayFS 文件系统后,我们再回到开始的问题,为什么在宿主机升级之后,在容器里读写文件的性能降低了?现在我们至少应该知道,在容器中读写文件性能降低了,那么应该是 OverlayFS 的性能在新的 ubuntu20.04 中降低了。
要找到问题的根因,我们还需要进一步的 debug。对于性能问题,我们需要使用 Linux 下的 perf 工具来查看一下,具体怎么使用 perf 来解决问题,我们会在后面讲解。
这里你只要看一下结果就可以了,自下而上是函数的一个调用顺序。通过 perf 工具,我们可以比较在容器中运行 fio 的时候,ubuntu 18.04 和 ubuntu 20.04 在内核函数调用上的不同。

我们从系统调用框架之后的函数 aio_read() 开始比较:Linux 内核 4.15 里 aio_read() 之后调用的是 xfs_file_read_iter(),而在 Linux 内核 5.4 里,aio_read() 之后调用的是 ovl_read_iter() 这个函数,之后再调用 xfs_file_read_iter()。
这样我们就可以去查看一下,在内核 4.15 之后新加入的这个函数 ovl_read_iter() 的代码。
查看 代码 后我们就能明白,Linux 为了完善 OverlayFS,增加了 OverlayFS 自己的 read/write 函数接口,从而不再直接调用 OverlayFS 后端文件系统(比如 XFS,Ext4)的读写接口。但是它只实现了同步 I/O(sync I/O),并没有实现异步 I/O。
而在 fio 做文件系统性能测试的时候使用的是异步 I/O,这样才可以得到文件系统的性能最大值。所以,在内核 5.4 上就无法对 OverlayFS 测出最高的性能指标了。
在 Linux 内核 5.6 版本中,这个问题已经通过下面的这个补丁给解决了,有兴趣的同学可以看一下。
commit 2406a307ac7ddfd7effeeaff6947149ec6a95b4e
Author: Jiufei Xue <jiufei.xue@linux.alibaba.com>
Date: Wed Nov 20 17:45:26 2019 +0800
ovl: implement async IO routines
A performance regression was observed since linux v4.19 with aio test using
fio with iodepth 128 on overlayfs. The queue depth of the device was
always 1 which is unexpected.
After investigation, it was found that commit 16914e6fc7e1 ("ovl: add
ovl_read_iter()") and commit 2a92e07edc5e ("ovl: add ovl_write_iter()")
resulted in vfs_iter_{read,write} being called on underlying filesystem,
which always results in syncronous IO.
Implement async IO for stacked reading and writing. This resolves the
performance regresion.
This is implemented by allocating a new kiocb for submitting the AIO
request on the underlying filesystem. When the request is completed, the
new kiocb is freed and the completion callback is called on the original
iocb.
Signed-off-by: Jiufei Xue <jiufei.xue@linux.alibaba.com>
Signed-off-by: Miklos Szeredi <mszeredi@redhat.com>重点总结
这一讲,我们最主要的内容是理解容器文件系统。为什么要有容器自己的文件系统?很重要的一点是减少相同镜像文件在同一个节点上的数据冗余,可以节省磁盘空间,也可以减少镜像文件下载占用的网络资源。
作为容器文件系统,UnionFS 通过多个目录挂载的方式工作。OverlayFS 就是 UnionFS 的一种实现,是目前主流 Linux 发行版本中缺省使用的容器文件系统。
OverlayFS 也是把多个目录合并挂载,被挂载的目录分为两大类:lowerdir 和 upperdir。
lowerdir 允许有多个目录,在被挂载后,这些目录里的文件都是不会被修改或者删除的,也就是只读的;upperdir 只有一个,不过这个目录是可读写的,挂载点目录中的所有文件修改都会在 upperdir 中反映出来。
容器的镜像文件中各层正好作为 OverlayFS 的 lowerdir 的目录,然后加上一个空的 upperdir 一起挂载好后,就组成了容器的文件系统。
OverlayFS 在 Linux 内核中还在不断的完善,比如我们在这一讲看到的在 kenel 5.4 中对异步 I/O 操作的缺失,这也是我们在使用容器文件系统的时候需要注意的。
思考题
在这一讲 OverlayFS 的例子的基础上,建立 2 个 lowerdir 的目录,并且在目录中建立相同文件名的文件,然后一起做一个 overlay mount,看看会发生什么?
答:
$ cat test_overlayfs.sh
#!/bin/bash
umount ./merged
rm -fr upper lower lower2 merged work
mkdir upper lower lower2 merged work
echo "I'm from lower!" > lower/in_lower.txt
echo "I'm from lower2!" > lower2/in_lower.txt
echo "I'm from upper!" > upper/in_upper.txt
# `in_both` is in both directories
echo "I'm from lower!" > lower/in_both.txt
echo "I'm from lower2!" > lower2/in_both.txt
echo "I'm from upper!" > upper/in_both.txt
sudo mount -t overlay overlay -o lowerdir=./lower,lowerdir=./lower2,upperdir=./upper,workdir=./work ./merged
$ sudo ./test_overlayfs.sh
$ cat merged/in_lower.txt
I'm from lower2!
$ cat merged/in_both.txt
I'm from upper!12 | 容器文件Quota:容器为什么把宿主机的磁盘写满了?
上一讲,我们学习了容器文件系统 OverlayFS,这个 OverlayFS 有两层,分别是 lowerdir 和 upperdir。lowerdir 里是容器镜像中的文件,对于容器来说是只读的;upperdir 存放的是容器对文件系统里的所有改动,它是可读写的。
从宿主机的角度看,upperdir 就是一个目录,如果容器不断往容器文件系统中写入数据,实际上就是往宿主机的磁盘上写数据,这些数据也就存在于宿主机的磁盘目录中。
当然对于容器来说,如果有大量的写操作是不建议写入容器文件系统的,一般是需要给容器挂载一个 volume,用来满足大量的文件读写。
但是不能避免的是,用户在容器中运行的程序有错误,或者进行了错误的配置。
比如说,我们把 log 写在了容器文件系统上,并且没有做 log rotation,那么时间一久,就会导致宿主机上的磁盘被写满。这样影响的就不止是容器本身了,而是整个宿主机了。
那对于这样的问题,我们该怎么解决呢?
问题再现
我们可以自己先启动一个容器,一起试试不断地往容器文件系统中写入数据,看看是一个什么样的情况。
用 Docker 启动一个容器后,我们看到容器的根目录 (/) 也就是容器文件系统 OverlayFS,它的大小是 160G,已经使用了 100G。其实这个大小也是宿主机上的磁盘空间和使用情况。
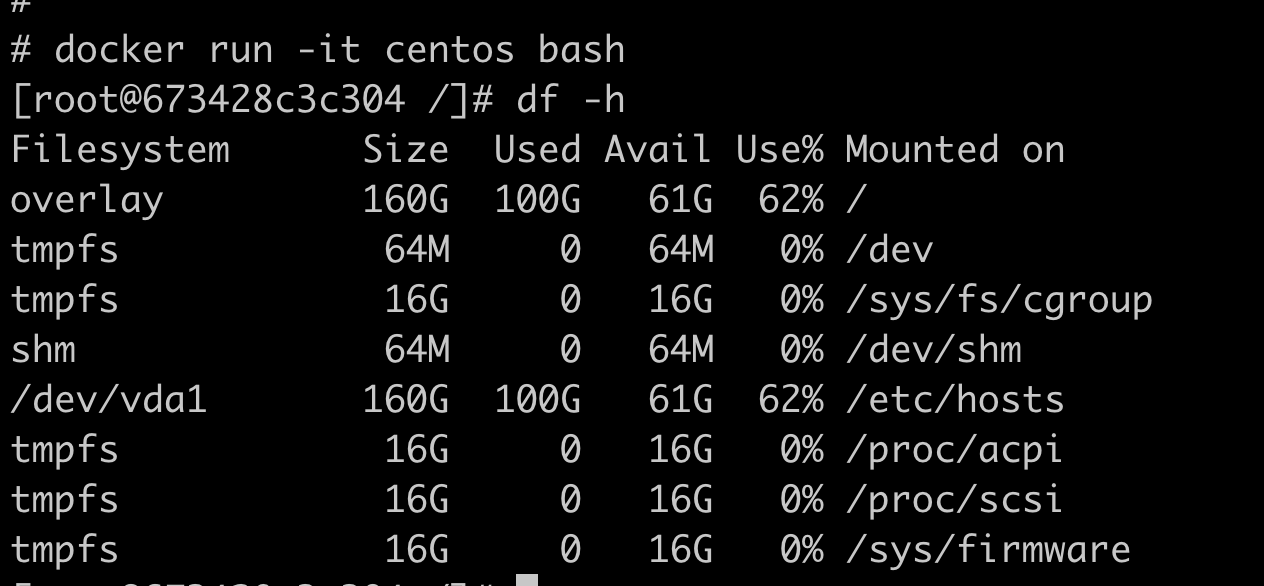
这时候,我们可以回到宿主机上验证一下,就会发现宿主机的根目录 (/) 的大小也是 160G,同样是使用了 100G。
好,那现在我们再往容器的根目录里写入 10GB 的数据。
这里我们可以看到容器的根目录使用的大小增加了,从刚才的 100G 变成现在的 110G。而多写入的 10G 大小的数据,对应的是 test.log 这个文件。
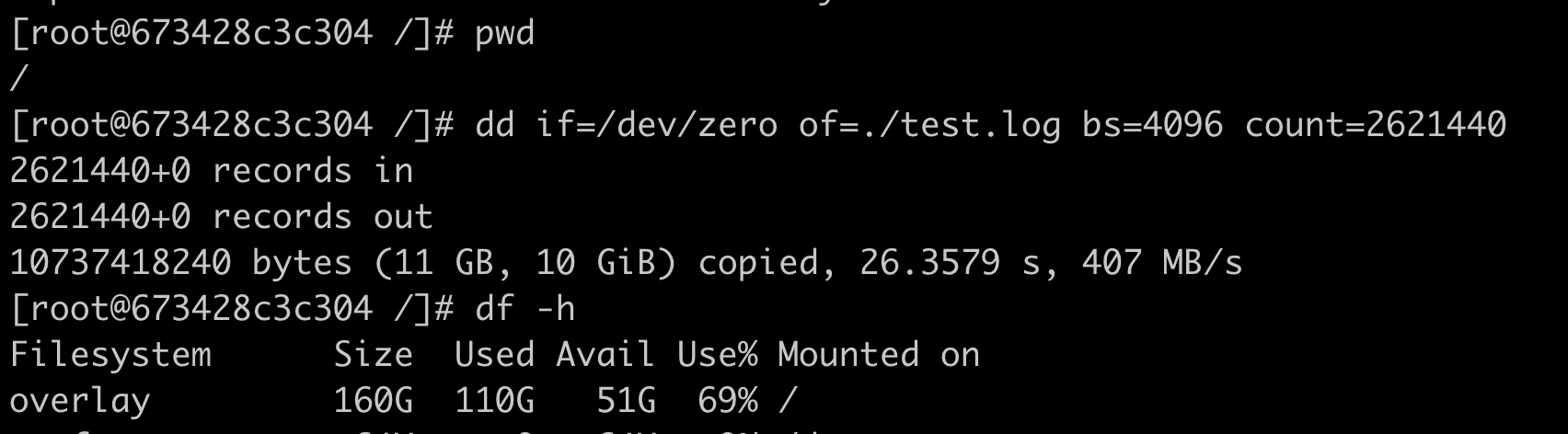
接下来,我们再回到宿主机上,可以看到宿主机上的根目录 (/) 里使用的大小也是 110G 了。
我们还是继续看宿主机,看看 OverlayFS 里 upperdir 目录中有什么文件?
这里我们仍然可以通过 /proc/mounts 这个路径,找到容器 OverlayFS 对应的 lowerdir 和 upperdir。因为写入的数据都在 upperdir 里,我们就只要看 upperdir 对应的那个目录就行了。果然,里面存放着容器写入的文件 test.log,它的大小是 10GB。
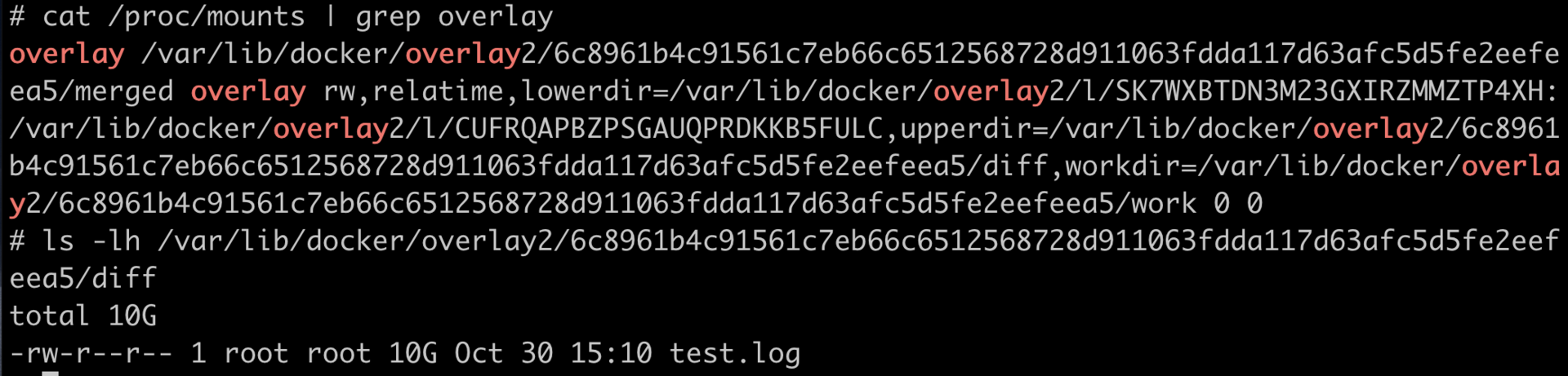
通过这个例子,我们已经验证了在容器中对于 OverlayFS 中写入数据,其实就是往宿主机的一个目录(upperdir)里写数据。我们现在已经写了 10GB 的数据,如果继续在容器中写入数据,结果估计你也知道了,就是会写满宿主机的磁盘。
那遇到这种情况,我们该怎么办呢?
知识详解
容器写自己的 OverlayFS 根目录,结果把宿主机的磁盘写满了。发生这个问题,我们首先就会想到需要对容器做限制,限制它写入自己 OverlayFS 的数据量,比如只允许一个容器写 100MB 的数据。
不过我们实际查看 OverlayFS 文件系统的特性,就会发现没有直接限制文件写入量的特性。别担心,在没有现成工具的情况下,我们只要搞懂了原理,就能想出解决办法。
所以我们再来分析一下 OverlayFS,它是通过 lowerdir 和 upperdir 两层目录联合挂载来实现的,lowerdir 是只读的,数据只会写在 upperdir 中。
那我们是不是可以通过限制 upperdir 目录容量的方式,来限制一个容器 OverlayFS 根目录的写入数据量呢?
沿着这个思路继续往下想,因为 upperdir 在宿主机上也是一个普通的目录,这样就要看 宿主机上的文件系统是否可以支持对一个目录限制容量 了。
对于 Linux 上最常用的两个文件系统 XFS 和 ext4,它们有一个特性 Quota,那我们就以 XFS 文件系统为例,学习一下这个 Quota 概念,然后看看这个特性能不能限制一个目录的使用量。
XFS Quota
在 Linux 系统里的 XFS 文件系统缺省都有 Quota 的特性,这个特性可以为 Linux 系统里的一个用户(user),一个用户组(group)或者一个项目(project)来限制它们使用文件系统的额度(quota),也就是限制它们可以写入文件系统的文件总量。
因为我们的目标是要限制一个目录中总体的写入文件数据量,那么显然给用户和用户组限制文件系统的写入数据量的模式,并不适合我们的这个需求。
因为同一个用户或者用户组可以操作多个目录,多个用户或者用户组也可以操作同一个目录,这样对一个用户或者用户组的限制,就很难用来限制一个目录。
那排除了限制用户或用户组的模式,我们再来看看 Project 模式。Project 模式是怎么工作的呢?
我举一个例子你会更好理解,对 Linux 熟悉的同学可以一边操作,一边体会一下它的工作方式。不熟悉的同学也没关系,可以重点关注我后面的讲解思路。
首先我们要使用 XFS Quota 特性,必须在文件系统挂载的时候加上对应的 Quota 选项,比如我们目前需要配置 Project Quota,那么这个挂载参数就是”pquota”。
对于根目录来说, 这个参数必须作为一个内核启动的参数”rootflags=pquota”,这样设置就可以保证根目录在启动挂载的时候,带上 XFS Quota 的特性并且支持 Project 模式。
我们可以从 /proc/mounts 信息里,看看根目录是不是带”prjquota”字段。如果里面有这个字段,就可以确保文件系统已经带上了支持 project 模式的 XFS quota 特性。

下一步,我们还需要给一个指定的目录打上一个 Project ID。这个步骤我们可以使用 XFS 文件系统自带的工具 xfs_quota 来完成,然后执行下面的这个命令就可以了。
执行命令之前,我先对下面的命令和输出做两点解释,让你理解这个命令的含义。
第一点,新建的目录 /tmp/xfs_prjquota,我们想对它做 Quota 限制。所以在这里要对它打上一个 Project ID。
第二点,通过 xfs_quota 这条命令,我们给 /tmp/xfs_prjquota 打上 Project ID 值 101,这个 101 是我随便选的一个数字,就是个 ID 标识,你先有个印象。在后面针对 Project 进行 Quota 限制的时候,我们还会用到这个 ID。
$ mkdir -p /tmp/xfs_prjquota
$ xfs_quota -x -c 'project -s -p /tmp/xfs_prjquota 101' /
Setting up project 101 (path /tmp/xfs_prjquota)...
Processed 1 (/etc/projects and cmdline) paths for project 101 with recursion depth infinite (-1).最后,我们还是使用 xfs_quota 命令,对 101(我们刚才建立的这个 Project ID)做 Quota 限制。
你可以执行下面这条命令,里面的”-p bhard=10m 101”就代表限制 101 这个 project ID,限制它的数据块写入量不能超过 10MB。
xfs_quota -x -c 'limit -p bhard=10m 101' /做好限制之后,我们可以尝试往 /tmp/xfs_prjquota 写数据,看看是否可以超过 10MB。比如说,我们尝试写入 20MB 的数据到 /tmp/xfs_prjquota 里。
我们可以看到,执行 dd 写入命令,就会有个出错返回信息”No space left on device”。这表示已经不能再往这个目录下写入数据了,而最后写入数据的文件 test.file 大小也停留在了 10MB。
$ dd if=/dev/zero of=/tmp/xfs_prjquota/test.file bs=1024 count=20000
dd: error writing '/tmp/xfs_prjquota/test.file': No space left on device
10241+0 records in
10240+0 records out
10485760 bytes (10 MB, 10 MiB) copied, 0.0357122 s, 294 MB/s
$ ls -l /tmp/xfs_prjquota/test.file
-rw-r--r-- 1 root root 10485760 Oct 31 10:00 /tmp/xfs_prjquota/test.file好了,做到这里,我们发现使用 XFS Quota 的 Project 模式,确实可以限制一个目录里的写入数据量,它实现的方式其实也不难,就是下面这两步。
第一步,给目标目录打上一个 Project ID,这个 ID 最终是写到目录对应的 inode 上。
这里我解释一下,inode 是文件系统中用来描述一个文件或者一个目录的元数据,里面包含文件大小,数据块的位置,文件所属用户 / 组,文件读写属性以及其他一些属性。
那么一旦目录打上这个 ID 之后,在这个目录下的新建的文件和目录也都会继承这个 ID。
第二步,在 XFS 文件系统中,我们需要给这个 project ID 设置一个写入数据块的限制。
有了 ID 和限制值之后,文件系统就可以统计所有带这个 ID 文件的数据块大小总和,并且与限制值进行比较。一旦所有文件大小的总和达到限制值,文件系统就不再允许更多的数据写入了。
用一句话概括,XFS Quota 就是通过前面这两步限制了一个目录里写入的数据量。
解决问题
我们理解了 XFS Quota 对目录限流的机制之后,再回到我们最开始的问题,如何确保容器不会写满宿主机上的磁盘。
你应该已经想到了,方法就是 对 OverlayFS 的 upperdir 目录做 XFS Quota 的限流 ,没错,就是这个解决办法!
其实 Docker 也已经实现了限流功能,也就是用 XFS Quota 来限制容器的 OverlayFS 大小。
我们在用 docker run 启动容器的时候,加上一个参数 --storage-opt size= <SIZE> ,就能限制住容器 OverlayFS 文件系统可写入的最大数据量了。
我们可以一起试一下,这里我们限制的 size 是 10MB。
进入容器之后,先运行 df -h 命令,这时候你可以看到根目录 (/)overlayfs 文件系统的大小就 10MB,而不是我们之前看到的 160GB 的大小了。这样容器在它的根目录下,最多只能写 10MB 数据,就不会把宿主机的磁盘给写满了。

完成了上面这个小试验之后,我们可以再看一下 Docker 的代码,看看它的实现是不是和我们想的一样。
Docker 里 SetQuota()函数 就是用来实现 XFS Quota 限制的,我们可以看到它里面最重要的两步,分别是 setProjectID 和 setProjectQuota 。
其实,这两步做的就是我们在基本概念中提到的那两步:
第一步,给目标目录打上一个 Project ID;第二步,为这个 Project ID 在 XFS 文件系统中,设置一个写入数据块的限制。
// SetQuota - assign a unique project id to directory and set the quota limits
// for that project id
func (q *Control) SetQuota(targetPath string, quota Quota) error {
projectID, ok := q.quotas[targetPath]
if !ok {
projectID = q.nextProjectID
//
// assign project id to new container directory
//
err := setProjectID(targetPath, projectID)
if err != nil {
return err
}
q.quotas[targetPath] = projectID
q.nextProjectID++
}
//
// set the quota limit for the container's project id
//
logrus.Debugf("SetQuota path=%s, size=%d, inodes=%d, projectID=%d", targetPath, quota.Size, quota.Inodes, projectID)
return setProjectQuota(q.backingFsBlockDev, projectID, quota)
}那 setProjectID 和 setProjectQuota 是如何实现的呢?
你可以进入到这两个函数里看一下,它们分别调用了 ioctl() 和 quotactl() 这两个系统调用来修改内核中 XFS 的数据结构,从而完成 project ID 的设置和 Quota 值的设置。具体的细节,我不在这里展开了,如果你有兴趣,可以继续去查看内核中对应的代码。
好了,Docker 里 XFS Quota 操作的步骤完全和我们先前设想的一样,那么还有最后一个问题要解决,XFS Quota 限制的目录是哪一个?
这个我们可以根据 /proc/mounts 中容器的 OverlayFS Mount 信息,再结合 Docker 的代码,就可以知道限制的目录是 /var/lib/docker/overlay2/<docker_id> 。那这个目录下有什么呢?果然 upperdir 目录中有对应的”diff”目录,就在里面!
讲到这里,我想你已经清楚了对于使用 OverlayFS 的容器,我们应该如何去防止它把宿主机的磁盘给写满了吧? 方法就是对 OverlayFS 的 upperdir 目录做 XFS Quota 的限流。
重点总结
我们这一讲的问题是,容器写了大量数据到 OverlayFS 文件系统的根目录,在这个情况下,就会把宿主机的磁盘写满。
由于 OverlayFS 自己没有专门的特性,可以限制文件数据写入量。这时我们通过实际试验找到了解决思路:依靠底层文件系统的 Quota 特性来限制 OverlayFS 的 upperdir 目录的大小,这样就能实现限制容器写磁盘的目的。
底层文件系统 XFS Quota 的 Project 模式,能够限制一个目录的文件写入量,这个功能具体是通过这两个步骤实现:
第一步,给目标目录打上一个 Project ID。
第二步,给这个 Project ID 在 XFS 文件系统中设置一个写入数据块的限制。
Docker 正是使用了这个方法,也就是 用 XFS Quota 来限制 OverlayFS 的 upperdir 目录 ,通过这个方式控制容器 OverlayFS 的根目录大小。
当我们理解了这个方法后,对于不是用 Docker 启动的容器,比如直接由 containerd 启动起来的容器,也可以自己实现 XFS Quota 限制 upperdir 目录。这样就能有效控制容器对 OverlayFS 的写数据操作,避免宿主机的磁盘被写满。
思考题
在正文知识详解的部分,我们使用”xfs_quota”给目录打了 project ID 并且限制了文件写入的数据量。那在做完这样的限制之后,我们是否能用 xfs_quota 命令,查询到被限制目录的 project ID 和限制的数据量呢?
答:
$ sudo xfs_quota -x -c 'report -h /tmp/xfs_prjquota'
Project quota on / (/dev/sda3)
Blocks
Project ID Used Soft Hard Warn/Grace
---------- ---------------------------------
#0 3.1G 0 0 00 [------]
#101 10M 0 10M 00 [------]13 | 容器磁盘限速:我的容器里磁盘读写为什么不稳定?
上一讲,我给你讲了如何通过 XFS Quota 来限制容器文件系统的大小,这是静态容量大小的一个限制。
你也许会马上想到,磁盘除了容量的划分,还有一个读写性能的问题。
具体来说,就是如果多个容器同时读写节点上的同一块磁盘,那么它们的磁盘读写相互之间影响吗?如果容器之间读写磁盘相互影响,我们有什么办法解决呢?
接下来,我们就带着问题一起学习今天的内容。
场景再现
我们先用这里的 代码 ,运行一下 make image 来做一个带 fio 的容器镜像,fio 在我们之前的课程里提到过,它是用来测试磁盘文件系统读写性能的工具。
有了这个带 fio 的镜像,我们可以用它启动一个容器,在容器中运行 fio,就可以得到只有一个容器读写磁盘时的性能数据。
mkdir -p /tmp/test1
docker stop fio_test1;docker rm fio_test1
docker run --name fio_test1 --volume /tmp/test1:/tmp registery/fio:v1 \
fio -direct=1 -rw=write -ioengine=libaio -bs=4k -size=1G -numjobs=1 -name=/tmp/fio_test1.log上面的这个 Docker 命令,我给你简单地解释一下:在这里我们第一次用到了”—volume”这个参数。之前我们讲过容器文件系统,比如 OverlayFS。
不过容器文件系统并不适合频繁地读写。对于频繁读写的数据,容器需要把他们到放到”volume”中。这里的 volume 可以是一个本地的磁盘,也可以是一个网络磁盘。
在这个例子里我们就使用了宿主机本地磁盘,把磁盘上的 /tmp/test1 目录作为 volume 挂载到容器的 /tmp 目录下。
然后在启动容器之后,我们直接运行 fio 的命令,这里的参数和我们第 11 讲最开始的例子差不多,只是这次我们运行的是 write,也就是写磁盘的操作,而写的目标盘就是挂载到 /tmp 目录的 volume。
可以看到,fio 的运行结果如下图所示,IOPS 是 18K,带宽 (BW) 是 70MB/s 左右。

好了,刚才我们模拟了一个容器写磁盘的性能。那么如果这时候有两个容器,都在往同一个磁盘上写数据又是什么情况呢?我们可以再用下面的这个脚本试一下:
mkdir -p /tmp/test1
mkdir -p /tmp/test2
docker stop fio_test1;docker rm fio_test1
docker stop fio_test2;docker rm fio_test2
docker run --name fio_test1 --volume /tmp/test1:/tmp registry/fio:v1 \
fio -direct=1 -rw=write -ioengine=libaio -bs=4k -size=1G -numjobs=1 -name=/tmp/fio_test1.log &
docker run --name fio_test2 --volume /tmp/test2:/tmp registry/fio:v1
fio -direct=1 -rw=write -ioengine=libaio -bs=4k -size=1G -numjobs=1 -name=/tmp/fio_test2.log &这时候,我们看到的结果,在容器 fio_test1 里,IOPS 是 15K 左右,带宽是 59MB/s 了,比之前单独运行的时候性能下降了不少。

显然从这个例子中,我们可以看到多个容器同时写一块磁盘的时候,它的性能受到了干扰。那么有什么办法可以保证每个容器的磁盘读写性能呢?
之前,我们讨论过用 Cgroups 来保证容器的 CPU 使用率,以及控制 Memroy 的可用大小。那么你肯定想到了,我们是不是也可以用 Cgroups 来保证每个容器的磁盘读写性能?
没错,在 Cgroup v1 中有 blkio 子系统,它可以来限制磁盘的 I/O。不过 blkio 子系统对于磁盘 I/O 的限制,并不像 CPU,Memory 那么直接,下面我会详细讲解。
知识详解
Blkio Cgroup
在讲解 blkio Cgroup 前,我们先简单了解一下衡量磁盘性能的两个常见的指标 IOPS 和吞吐量(Throughput)是什么意思,后面讲 Blkio Cgroup 的参数配置时会用到。
IOPS 是 Input/Output Operations Per Second 的简称,也就是每秒钟磁盘读写的次数,这个数值越大,当然也就表示性能越好。
吞吐量(Throughput)是指每秒钟磁盘中数据的读取量,一般以 MB/s 为单位。这个读取量可以叫作吞吐量,有时候也被称为带宽(Bandwidth)。刚才我们用到的 fio 显示结果就体现了带宽。
IOPS 和吞吐量之间是有关联的,在 IOPS 固定的情况下,如果读写的每一个数据块越大,那么吞吐量也越大,它们的关系大概是这样的:吞吐量 = 数据块大小 *IOPS。
好,那么我们再回到 blkio Cgroup 这个概念上,blkio Cgroup 也是 Cgroups 里的一个子系统。 在 Cgroups v1 里,blkio Cgroup 的虚拟文件系统挂载点一般在”/sys/fs/cgroup/blkio/“。
和我之前讲过的 CPU,memory Cgroup 一样,我们在这个”/sys/fs/cgroup/blkio/“目录下创建子目录作为控制组,再把需要做 I/O 限制的进程 pid 写到控制组的 cgroup.procs 参数中就可以了。
在 blkio Cgroup 中,有四个最主要的参数,它们可以用来限制磁盘 I/O 性能,我列在了下面。
blkio.throttle.read_iops_device
blkio.throttle.read_bps_device
blkio.throttle.write_iops_device
blkio.throttle.write_bps_device前面我们刚说了磁盘 I/O 的两个主要性能指标 IOPS 和吞吐量,在这里,根据这四个参数的名字,估计你已经大概猜到它们的意思了。
没错,它们分别表示:磁盘读取 IOPS 限制,磁盘读取吞吐量限制,磁盘写入 IOPS 限制,磁盘写入吞吐量限制。
对于每个参数写入值的格式,你可以参考内核blkio 的文档。为了让你更好地理解,在这里我给你举个例子。
如果我们要对一个控制组做限制,限制它对磁盘 /dev/vdb 的写入吞吐量不超过 10MB/s,那么我们对 blkio.throttle.write_bps_device 参数的配置就是下面这个命令。
echo "252:16 10485760" > $CGROUP_CONTAINER_PATH/blkio.throttle.write_bps_device在这个命令中,”252:16”是 /dev/vdb 的主次设备号,你可以通过 ls -l /dev/vdb 看到这两个值,而后面的”10485760”就是 10MB 的每秒钟带宽限制。
$ ls -l /dev/vdb -l
brw-rw---- 1 root disk 252, 16 Nov 2 08:02 /dev/vdb了解了 blkio Cgroup 的参数配置,我们再运行下面的这个例子,限制一个容器 blkio 的读写磁盘吞吐量,然后在这个容器里运行一下 fio,看看结果是什么。
mkdir -p /tmp/test1
rm -f /tmp/test1/*
docker stop fio_test1;docker rm fio_test1
docker run -d --name fio_test1 --volume /tmp/test1:/tmp registry/fio:v1 sleep 3600
sleep 2
CONTAINER_ID=$(sudo docker ps --format "{{.ID}}\t{{.Names}}" | grep -i fio_test1 | awk '{print $1}')
echo $CONTAINER_ID
CGROUP_CONTAINER_PATH=$(find /sys/fs/cgroup/blkio/ -name "*$CONTAINER_ID*")
echo $CGROUP_CONTAINER_PATH
# To get the device major and minor id from /dev for the device that /tmp/test1 is on.
echo "253:0 10485760" > $CGROUP_CONTAINER_PATH/blkio.throttle.read_bps_device
echo "253:0 10485760" > $CGROUP_CONTAINER_PATH/blkio.throttle.write_bps_device
docker exec fio_test1 fio -direct=1 -rw=write -ioengine=libaio -bs=4k -size=100MB -numjobs=1 -name=/tmp/fio_test1.log
docker exec fio_test1 fio -direct=1 -rw=read -ioengine=libaio -bs=4k -size=100MB -numjobs=1 -name=/tmp/fio_test1.log在这里,我的机器上 /tmp/test1 所在磁盘主次设备号是”253:0”,你在自己运行这组命令的时候,需要把主次设备号改成你自己磁盘的对应值。
还有一点我要提醒一下,不同数据块大小,在性能测试中可以适用于不同的测试目的。但因为这里不是我们要讲的重点,所以为了方便你理解概念,这里就用固定值。
在我们后面的例子里,fio 读写的数据块都固定在 4KB。所以对于磁盘的性能限制,我们在 blkio Cgroup 里就只设置吞吐量限制了。
在加了 blkio Cgroup 限制 10MB/s 后,从 fio 运行后的输出结果里,我们可以看到这个容器对磁盘无论是读还是写,它的最大值就不会再超过 10MB/s 了。

在给每个容器都加了 blkio Cgroup 限制,限制为 10MB/s 后,即使两个容器同时在一个磁盘上写入文件,那么每个容器的写入磁盘的最大吞吐量,也不会互相干扰了。
我们可以用下面的这个脚本来验证一下。
mkdir -p /tmp/test1
rm -f /tmp/test1/*
docker stop fio_test1;docker rm fio_test1
mkdir -p /tmp/test2
rm -f /tmp/test2/*
docker stop fio_test2;docker rm fio_test2
docker run -d --name fio_test1 --volume /tmp/test1:/tmp registry/fio:v1 sleep 3600
docker run -d --name fio_test2 --volume /tmp/test2:/tmp registry/fio:v1 sleep 3600
sleep 2
CONTAINER_ID1=$(sudo docker ps --format "{{.ID}}\t{{.Names}}" | grep -i fio_test1 | awk '{print $1}')
echo $CONTAINER_ID1
CGROUP_CONTAINER_PATH1=$(find /sys/fs/cgroup/blkio/ -name "*$CONTAINER_ID1*")
echo $CGROUP_CONTAINER_PATH1
# To get the device major and minor id from /dev for the device that /tmp/test1 is on.
echo "253:0 10485760" > $CGROUP_CONTAINER_PATH1/blkio.throttle.read_bps_device
echo "253:0 10485760" > $CGROUP_CONTAINER_PATH1/blkio.throttle.write_bps_device
CONTAINER_ID2=$(sudo docker ps --format "{{.ID}}\t{{.Names}}" | grep -i fio_test2 | awk '{print $1}')
echo $CONTAINER_ID2
CGROUP_CONTAINER_PATH2=$(find /sys/fs/cgroup/blkio/ -name "*$CONTAINER_ID2*")
echo $CGROUP_CONTAINER_PATH2
# To get the device major and minor id from /dev for the device that /tmp/test1 is on.
echo "253:0 10485760" > $CGROUP_CONTAINER_PATH2/blkio.throttle.read_bps_device
echo "253:0 10485760" > $CGROUP_CONTAINER_PATH2/blkio.throttle.write_bps_device
docker exec fio_test1 fio -direct=1 -rw=write -ioengine=libaio -bs=4k -size=100MB -numjobs=1 -name=/tmp/fio_test1.log &
docker exec fio_test2 fio -direct=1 -rw=write -ioengine=libaio -bs=4k -size=100MB -numjobs=1 -name=/tmp/fio_test2.log &我们还是看看 fio 运行输出的结果,这时候,fio_test1 和 fio_test2 两个容器里执行的结果都是 10MB/s 了。


那么做到了这一步,我们是不是就可以认为,blkio Cgroup 可以完美地对磁盘 I/O 做限制了呢?
你先别急,我们可以再做个试验,把前面脚本里 fio 命令中的 “-direct=1” 给去掉,也就是不让 fio 运行在 Direct I/O 模式了,而是用 Buffered I/O 模式再运行一次,看看 fio 执行的输出。
同时我们也可以运行 iostat 命令,查看实际的磁盘写入速度。
这时候你会发现,即使我们设置了 blkio Cgroup,也根本不能限制磁盘的吞吐量了。
Direct I/O 和 Buffered I/O
为什么会这样的呢?这就要提到 Linux 的两种文件 I/O 模式了:Direct I/O 和 Buffered I/O。
Direct I/O 模式,用户进程如果要写磁盘文件,就会通过 Linux 内核的文件系统层 (filesystem) -> 块设备层 (block layer) -> 磁盘驱动 -> 磁盘硬件,这样一路下去写入磁盘。
而如果是 Buffered I/O 模式,那么用户进程只是把文件数据写到内存中(Page Cache)就返回了,而 Linux 内核自己有线程会把内存中的数据再写入到磁盘中。 在 Linux 里,由于考虑到性能问题,绝大多数的应用都会使用 Buffered I/O 模式。

我们通过前面的测试,发现 Direct I/O 可以通过 blkio Cgroup 来限制磁盘 I/O,但是 Buffered I/O 不能被限制。
那通过上面的两种 I/O 模式的解释,你是不是可以想到原因呢?是的,原因就是被 Cgroups v1 的架构限制了。
我们已经学习过了 v1 的 CPU Cgroup,memory Cgroup 和 blkio Cgroup,那么 Cgroup v1 的一个整体结构,你应该已经很熟悉了。它的每一个子系统都是独立的,资源的限制只能在子系统中发生。
就像下面图里的进程 pid_y,它可以分别属于 memory Cgroup 和 blkio Cgroup。但是在 blkio Cgroup 对进程 pid_y 做磁盘 I/O 做限制的时候,blkio 子系统是不会去关心 pid_y 用了哪些内存,哪些内存是不是属于 Page Cache,而这些 Page Cache 的页面在刷入磁盘的时候,产生的 I/O 也不会被计算到进程 pid_y 上面。
就是这个原因,导致了 blkio 在 Cgroups v1 里不能限制 Buffered I/O。
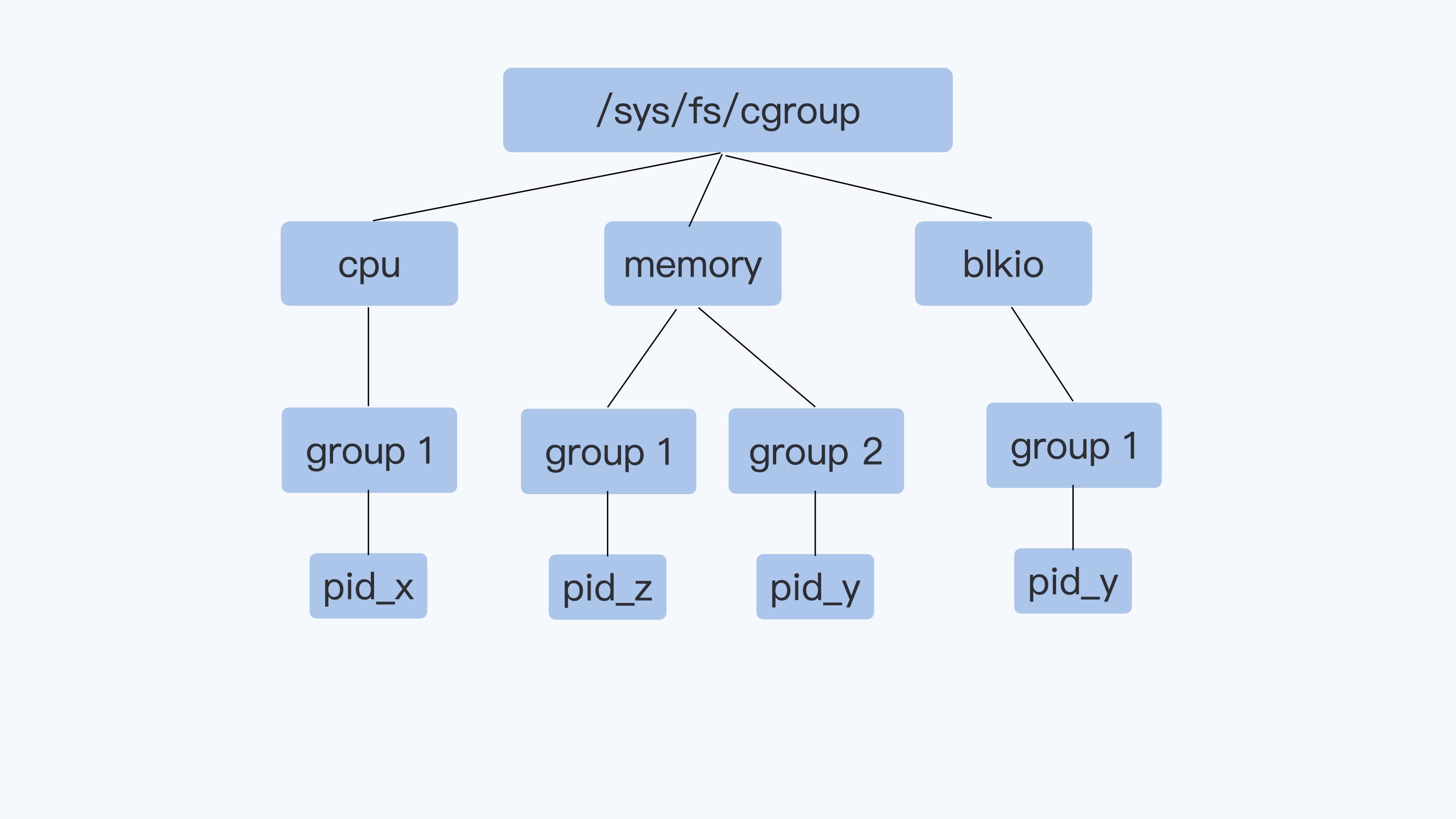
这个 Buffered I/O 限速的问题,在 Cgroup V2 里得到了解决,其实这个问题也是促使 Linux 开发者重新设计 Cgroup V2 的原因之一。
Cgroup V2
Cgroup v2 相比 Cgroup v1 做的最大的变动就是一个进程属于一个控制组,而每个控制组里可以定义自己需要的多个子系统。
比如下面的 Cgroup V2 示意图里,进程 pid_y 属于控制组 group2,而在 group2 里同时打开了 io 和 memory 子系统 (Cgroup V2 里的 io 子系统就等同于 Cgroup v1 里的 blkio 子系统)。
那么,Cgroup 对进程 pid_y 的磁盘 I/O 做限制的时候,就可以考虑到进程 pid_y 写入到 Page Cache 内存的页面了,这样 buffered I/O 的磁盘限速就实现了。
下面我们在 Cgroup v2 里,尝试一下设置了 blkio Cgroup+Memory Cgroup 之后,是否可以对 Buffered I/O 进行磁盘限速。
我们要做的第一步,就是在 Linux 系统里打开 Cgroup v2 的功能。因为目前即使最新版本的 Ubuntu Linux 或者 Centos Linux,仍然在使用 Cgroup v1 作为缺省的 Cgroup。
打开方法就是配置一个 kernel 参数”cgroup_no_v1=blkio,memory”,这表示把 Cgroup v1 的 blkio 和 Memory 两个子系统给禁止,这样 Cgroup v2 的 io 和 Memory 这两个子系统就打开了。
我们可以把这个参数配置到 grub 中,然后我们重启 Linux 机器,这时 Cgroup v2 的 io 还有 Memory 这两个子系统,它们的功能就打开了。
系统重启后,我们会看到 Cgroup v2 的虚拟文件系统被挂载到了 /sys/fs/cgroup/unified 目录下。
然后,我们用下面的这个脚本做 Cgroup v2 io 的限速配置,并且运行 fio,看看 buffered I/O 是否可以被限速。
# Create a new control group
mkdir -p /sys/fs/cgroup/unified/iotest
# enable the io and memory controller subsystem
echo "+io +memory" > /sys/fs/cgroup/unified/cgroup.subtree_control
# Add current bash pid in iotest control group.
# Then all child processes of the bash will be in iotest group too,
# including the fio
echo $$ >/sys/fs/cgroup/unified/iotest/cgroup.procs
# 256:16 are device major and minor ids, /mnt is on the device.
echo "252:16 wbps=10485760" > /sys/fs/cgroup/unified/iotest/io.max
cd /mnt
#Run the fio in non direct I/O mode
fio -iodepth=1 -rw=write -ioengine=libaio -bs=4k -size=1G -numjobs=1 -name=./fio.test运行 fio 写入 1GB 的数据后,你会发现 fio 马上就执行完了,因为系统上有足够的内存,fio 把数据写入内存就返回了,不过只要你再运行 “iostat -xz 10” 这个命令,你就可以看到磁盘 vdb 上稳定的写入速率是 10240wkB/s,也就是我们在 io Cgroup 里限制的 10MB/s。
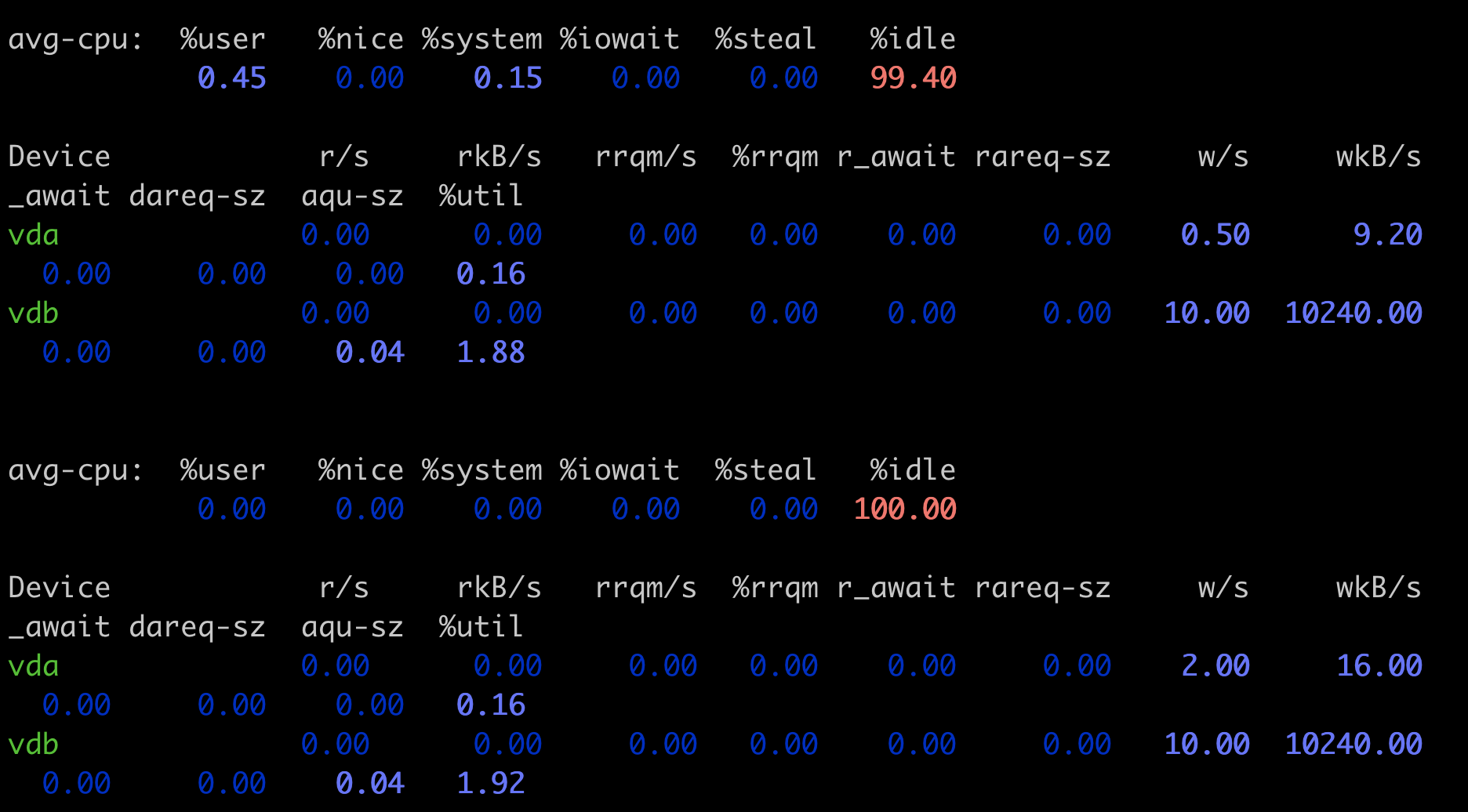
看到这个结果,我们证实了 Cgoupv2 io+Memory 两个子系统一起使用,就可以对 buffered I/O 控制磁盘写入速率。
重点总结
这一讲,我们主要想解决的问题是如何保证容器读写磁盘速率的稳定,特别是当多个容器同时读写同一个磁盘的时候,需要减少相互的干扰。
Cgroup V1 的 blkiio 控制子系统,可以用来限制容器中进程的读写的 IOPS 和吞吐量(Throughput),但是它只能对于 Direct I/O 的读写文件做磁盘限速,对 Buffered I/O 的文件读写,它无法进行磁盘限速。
这是因为 Buffered I/O 会把数据先写入到内存 Page Cache 中,然后由内核线程把数据写入磁盘,而 Cgroup v1 blkio 的子系统独立于 memory 子系统,无法统计到由 Page Cache 刷入到磁盘的数据量。
这个 Buffered I/O 无法被限速的问题,在 Cgroup v2 里被解决了。Cgroup v2 从架构上允许一个控制组里有多个子系统协同运行,这样在一个控制组里只要同时有 io 和 Memory 子系统,就可以对 Buffered I/O 作磁盘读写的限速。
虽然 Cgroup v2 解决了 Buffered I/O 磁盘读写限速的问题,但是在现实的容器平台上也不是能够立刻使用的,还需要等待一段时间。目前从 runC、containerd 到 Kubernetes 都是刚刚开始支持 Cgroup v2,而对生产环境中原有运行 Cgroup v1 的节点要迁移转化成 Cgroup v2 需要一个过程。
14 | 容器中的内存与I/O:容器写文件的延时为什么波动很大?
你应该还记得,我们上一讲中讲过 Linux 中的两种 I/O 模式,Direct I/O 和 Buffered I/O。
对于 Linux 的系统调用 write() 来说,Buffered I/O 是缺省模式,使用起来比较方便,而且从用户角度看,在大多数的应用场景下,用 Buffered I/O 的 write() 函数调用返回要快一些。所以,Buffered I/O 在程序中使用得更普遍一些。
当使用 Buffered I/O 的应用程序从虚拟机迁移到容器,这时我们就会发现多了 Memory Cgroup 的限制之后,write() 写相同大小的数据块花费的时间,延时波动会比较大。
这是怎么回事呢?接下来我们就带着问题开始今天的学习。
问题再现
我们可以先动手写一个 小程序 ,用来模拟刚刚说的现象。
这个小程序我们这样来设计:从一个文件中每次读取一个 64KB 大小的数据块,然后写到一个新文件中,它可以不断读写 10GB 大小的数据。同时我们在这个小程序中做个记录,记录写每个 64KB 的数据块需要花费的时间。
我们可以先在虚拟机里直接运行,虚拟机里内存大小是大于 10GB 的。接着,我们把这个程序放到容器中运行,因为这个程序本身并不需要很多的内存,我们给它做了一个 Memory Cgroup 的内存限制,设置为 1GB。
运行结束后,我们比较一下程序写数据块的时间。我把结果画了一张图,图里的纵轴是时间,单位 us;横轴是次数,在这里我们记录了 96 次。图中橘红色的线是在容器里运行的结果,蓝色的线是在虚拟机上运行的结果。
结果很明显,在容器中写入数据块的时间会时不时地增高到 200us;而在虚拟机里的写入数据块时间就比较平稳,一直在 30~50us 这个范围内。

通过这个小程序,我们再现了问题,那我们就来分析一下,为什么会产生这样的结果。
时间波动是因为 Dirty Pages 的影响么?
我们对文件的写入操作是 Buffered I/O。在前一讲中,我们其实已经知道了,对于 Buffer I/O,用户的数据是先写入到 Page Cache 里的。而这些写入了数据的内存页面,在它们没有被写入到磁盘文件之前,就被叫作 dirty pages。
Linux 内核会有专门的内核线程(每个磁盘设备对应的 kworker/flush 线程)把 dirty pages 写入到磁盘中。那我们自然会这样猜测,也许是 Linux 内核对 dirty pages 的操作影响了 Buffered I/O 的写操作?
想要验证这个想法,我们需要先来看看 dirty pages 是在什么时候被写入到磁盘的。这里就要用到 /proc/sys/vm 里和 dirty page 相关的内核参数 了,我们需要知道所有相关参数的含义,才能判断出最后真正导致问题发生的原因。
现在我们挨个来看一下。为了方便后面的讲述,我们可以设定一个比值 A, A 等于 dirty pages 的内存 / 节点可用内存 *100% 。
第一个参数,dirty_background_ratio,这个参数里的数值是一个百分比值,缺省是 10%。如果比值 A 大于 dirty_background_ratio 的话,比如大于默认的 10%,内核 flush 线程就会把 dirty pages 刷到磁盘里。
第二个参数,是和 dirty_background_ratio 相对应一个参数,也就是 dirty_background_bytes,它和 dirty_background_ratio 作用相同。区别只是 dirty_background_bytes 是具体的字节数,它用来定义的是 dirty pages 内存的临界值,而不是比例值。
这里你还要注意,dirty_background_ratio 和 dirty_background_bytes 只有一个可以起作用,如果你给其中一个赋值之后,另外一个参数就归 0 了。
接下来我们看第三个参数,dirty_ratio,这个参数的数值也是一个百分比值,缺省是 20%。
如果比值 A,大于参数 dirty_ratio 的值,比如大于默认设置的 20%,这时候正在执行 Buffered I/O 写文件的进程就会被阻塞住,直到它写的数据页面都写到磁盘为止。
同样,第四个参数 dirty_bytes 与 dirty_ratio 相对应,它们的关系和 dirty_background_ratio 与 dirty_background_bytes 一样。我们给其中一个赋值后,另一个就会归零。
然后我们来看 dirty_writeback_centisecs,这个参数的值是个时间值,以百分之一秒为单位,缺省值是 500,也就是 5 秒钟。它表示每 5 秒钟会唤醒内核的 flush 线程来处理 dirty pages。
最后还有 dirty_expire_centisecs,这个参数的值也是一个时间值,以百分之一秒为单位,缺省值是 3000,也就是 30 秒钟。它定义了 dirty page 在内存中存放的最长时间,如果一个 dirty page 超过这里定义的时间,那么内核的 flush 线程也会把这个页面写入磁盘。
好了,从这些 dirty pages 相关的参数定义,你会想到些什么呢?
进程写操作上的时间波动,只有可能是因为 dirty pages 的数量很多,已经达到了第三个参数 dirty_ratio 的值。这时执行写文件功能的进程就会被暂停,直到写文件的操作将数据页面写入磁盘,写文件的进程才能继续运行,所以进程里一次写文件数据块的操作时间会增加。
刚刚说的是我们的推理,那情况真的会是这样吗?其实我们可以在容器中进程不断写入数据的时候,查看节点上 dirty pages 的实时数目。具体操作如下:
watch -n 1 "cat /proc/vmstat | grep dirty"当我们的节点可用内存是 12GB 的时候,假设 dirty_ratio 是 20%,dirty_background_ratio 是 10%,那么我们在 1GB memory 容器中写 10GB 的数据,就会看到它实时的 dirty pages 数目,也就是 / proc/vmstat 里的 nr_dirty 的数值,这个数值对应的内存并不能达到 dirty_ratio 所占的内存值。
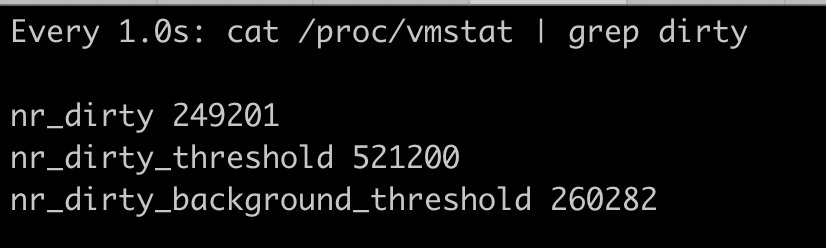
其实我们还可以再做个实验,就是在 dirty_bytes 和 dirty_background_bytes 里写入一个很小的值。
echo 8192 > /proc/sys/vm/dirty_bytes
echo 4096 > /proc/sys/vm/dirty_background_bytes然后再记录一下容器程序里每写入 64KB 数据块的时间,这时候,我们就会看到,时不时一次写入的时间就会达到 9ms,这已经远远高于我们之前看到的 200us 了。
因此,我们知道了这个时间的波动,并不是强制把 dirty page 写入到磁盘引起的。
调试问题
那接下来,我们还能怎么分析这个问题呢?
我们可以用 perf 和 ftrace 这两个工具,对容器里写数据块的进程做个 profile,看看到底是调用哪个函数花费了比较长的时间。顺便说一下,我们在专题加餐里会专门介绍如何使用 perf、ftrace 等工具以及它们的工作原理,在这里你只要了解我们的调试思路就行。
怎么使用这两个工具去定位耗时高的函数呢?我大致思路是这样的:我们发现容器中的进程用到了 write() 这个函数调用,然后写 64KB 数据块的时间增加了,而 write() 是一个系统调用,那我们需要进行下面这两步操作。
第一步,我们要找到内核中 write() 这个系统调用函数下,又调用了哪些子函数。 想找出主要的子函数我们可以查看代码,也可以用 perf 这个工具来得到。
然后是 第二步,得到了 write() 的主要子函数之后,我们可以用 ftrace 这个工具来 trace 这些函数的执行时间,这样就可以找到花费时间最长的函数了。
好,下面我们就按照刚才梳理的思路来做一下。首先是第一步,我们在容器启动写磁盘的进程后,在宿主机上得到这个进程的 pid,然后运行下面的 perf 命令。
perf record -a -g -p <pid>等写磁盘的进程退出之后,这个 perf record 也就停止了。
这时我们再执行 perf report 查看结果。把 vfs_write() 函数展开之后,我们就可以看到,write() 这个系统调用下面的调用到了哪些主要的子函数,到这里第一步就完成了。
下面再来做第二步,我们把主要的函数写入到 ftrace 的 set_ftrace_filter 里, 然后把 ftrace 的 tracer 设置为 function_graph,并且打开 tracing_on 开启追踪。
cd /sys/kernel/debug/tracing
echo vfs_write >> set_ftrace_filter
echo xfs_file_write_iter >> set_ftrace_filter
echo xfs_file_buffered_aio_write >> set_ftrace_filter
echo iomap_file_buffered_write >> set_ftrace_filter
echo pagecache_get_page >> set_ftrace_filter
echo try_to_free_mem_cgroup_pages >> set_ftrace_filter
echo try_charge >> set_ftrace_filter
echo mem_cgroup_try_charge >> set_ftrace_filter
echo function_graph > current_tracer
echo 1 > tracing_on这些设置完成之后,我们再运行一下容器中的写磁盘程序,同时从 ftrace 的 trace_pipe 中读取出追踪到的这些函数。
这时我们可以看到,当需要申请 Page Cache 页面的时候,write() 系统调用会反复地调用 mem_cgroup_try_charge(),并且在释放页面的时候,函数 do_try_to_free_pages() 花费的时间特别长,有 50+us(时间单位,micro-seconds)这么多。
1) | vfs_write() {
1) | xfs_file_write_iter [xfs]() {
1) | xfs_file_buffered_aio_write [xfs]() {
1) | iomap_file_buffered_write() {
1) | pagecache_get_page() {
1) | mem_cgroup_try_charge() {
1) 0.338 us | try_charge();
1) 0.791 us | }
1) 4.127 us | }
…
1) | pagecache_get_page() {
1) | mem_cgroup_try_charge() {
1) | try_charge() {
1) | try_to_free_mem_cgroup_pages() {
1) + 52.798 us | do_try_to_free_pages();
1) + 53.958 us | }
1) + 54.751 us | }
1) + 55.188 us | }
1) + 56.742 us | }
…
1) ! 109.925 us | }
1) ! 110.558 us | }
1) ! 110.984 us | }
1) ! 111.515 us | }看到这个 ftrace 的结果,你是不是会想到,我们在容器内存那一讲中提到的 Page Cahe 呢?
是的,这个问题的确和 Page Cache 有关,Linux 会把所有的空闲内存利用起来,一旦有 Buffered I/O,这些内存都会被用作 Page Cache。
当容器加了 Memory Cgroup 限制了内存之后,对于容器里的 Buffered I/O,就只能使用容器中允许使用的最大内存来做 Page Cache。
那么如果容器在做内存限制的时候,Cgroup 中 memory.limit_in_bytes 设置得比较小,而容器中的进程又有很大量的 I/O,这样申请新的 Page Cache 内存的时候,又会不断释放老的内存页面,这些操作就会带来额外的系统开销了。
重点总结
我们今天讨论的问题是在容器中用 Buffered I/O 方式写文件的时候,会出现写入时间波动的问题。
由于这是 Buffered I/O 方式,对于写入文件会先写到内存里,这样就产生了 dirty pages,所以我们先研究了一下 Linux 对 dirty pages 的回收机制是否会影响到容器中写入数据的波动。
在这里我们最主要的是理解这两个参数, dirty_background_ratio 和 dirty_ratio ,这两个值都是相对于节点可用内存的百分比值。
当 dirty pages 数量超过 dirty_background_ratio 对应的内存量的时候,内核 flush 线程就会开始把 dirty pages 写入磁盘 ; 当 dirty pages 数量超过 dirty_ratio 对应的内存量,这时候程序写文件的函数调用 write() 就会被阻塞住,直到这次调用的 dirty pages 全部写入到磁盘。
在节点是大内存容量,并且 dirty_ratio 为系统缺省值 20%,dirty_background_ratio 是系统缺省值 10% 的情况下,我们通过观察 /proc/vmstat 中的 nr_dirty 数值可以发现,dirty pages 不会阻塞进程的 Buffered I/O 写文件操作。
所以我们做了另一种尝试,使用 perf 和 ftrace 工具对容器中的写文件进程进行 profile。我们用 perf 得到了系统调用 write() 在内核中的一系列子函数调用,再用 ftrace 来查看这些子函数的调用时间。
根据 ftrace 的结果,我们发现写数据到 Page Cache 的时候,需要不断地去释放原有的页面,这个时间开销是最大的。造成容器中 Buffered I/O write() 不稳定的原因,正是容器在限制内存之后,Page Cache 的数量较小并且不断申请释放。
其实这个问题也提醒了我们:在对容器做 Memory Cgroup 限制内存大小的时候,不仅要考虑容器中进程实际使用的内存量,还要考虑容器中程序 I/O 的量,合理预留足够的内存作为 Buffered I/O 的 Page Cache。
比如,如果知道需要反复读写文件的大小,并且在内存足够的情况下,那么 Memory Cgroup 的内存限制可以超过这个文件的大小。
还有一个解决思路是,我们在程序中自己管理文件的 cache 并且调用 Direct I/O 来读写文件,这样才会对应用程序的性能有一个更好的预期。
容器网络
15 | 容器网络:我修改了/proc/sys/net下的参数,为什么在容器中不起效?
从这一讲开始,我们进入到了容器网络这个模块。容器网络最明显的一个特征就是它有自己的 Network Namespace 了。你还记得,在我们这个课程的第一讲里,我们就提到过 Network Namespace 负责管理网络环境的隔离。
今天呢,我们更深入地讨论一下和 Network Namespace 相关的一个问题——容器中的网络参数。
和之前的思路一样,我们先来看一个问题。然后在解决问题的过程中,更深入地理解容器的网络参数配置。
问题再现
在容器中运行的应用程序,如果需要用到 tcp/ip 协议栈的话,常常需要修改一些网络参数(内核中网络协议栈的参数)。
很大一部分网络参数都在 /proc 文件系统下的/proc/sys/net/目录里。
修改这些参数主要有两种方法:一种方法是直接到 /proc 文件系统下的”/proc/sys/net/“目录里对参数做修改;还有一种方法是使用sysctl这个工具来修改。
在启动容器之前呢,根据我们的需要我们在宿主机上已经修改过了几个参数,也就是说这些参数的值已经不是内核里原来的缺省值了.
比如我们改了下面的几个参数:
# # The default value:
$ cat /proc/sys/net/ipv4/tcp_congestion_control
cubic
$ cat /proc/sys/net/ipv4/tcp_keepalive_time
7200
$ cat /proc/sys/net/ipv4/tcp_keepalive_intvl
75
$ cat /proc/sys/net/ipv4/tcp_keepalive_probes
9
# # To update the value:
$ echo bbr > /proc/sys/net/ipv4/tcp_congestion_control
$ echo 600 > /proc/sys/net/ipv4/tcp_keepalive_time
$ echo 10 > /proc/sys/net/ipv4/tcp_keepalive_intvl
$ echo 6 > /proc/sys/net/ipv4/tcp_keepalive_probes
# # Double check the value after update:
$ cat /proc/sys/net/ipv4/tcp_congestion_control
bbr
$ cat /proc/sys/net/ipv4/tcp_keepalive_time
600
$ cat /proc/sys/net/ipv4/tcp_keepalive_intvl
10
$ cat /proc/sys/net/ipv4/tcp_keepalive_probes
6然后我们启动一个容器, 再来查看一下容器里这些参数的值。
你可以先想想,容器里这些参数的值会是什么?我最初觉得容器里参数值应该会继承宿主机 Network Namesapce 里的值,实际上是不是这样呢?
我们还是先按下面的脚本,启动容器,然后运行 docker exec 命令一起看一下:
$ docker run -d --name net_para centos:8.1.1911 sleep 3600
deec6082bac7b336fa28d0f87d20e1af21a784e4ef11addfc2b9146a9fa77e95
$ docker exec -it net_para bash
[root@deec6082bac7 /]$ cat /proc/sys/net/ipv4/tcp_congestion_control
bbr
[root@deec6082bac7 /]$ cat /proc/sys/net/ipv4/tcp_keepalive_time
7200
[root@deec6082bac7 /]$ cat /proc/sys/net/ipv4/tcp_keepalive_intvl
75
[root@deec6082bac7 /]$ cat /proc/sys/net/ipv4/tcp_keepalive_probes
9从这个结果我们看到,tcp_congestion_control 的值是 bbr,和宿主机 Network Namespace 里的值是一样的,而其他三个 tcp keepalive 相关的值,都不是宿主机 Network Namespace 里设置的值,而是原来系统里的缺省值了。
那为什么会这样呢?在分析这个问题之前,我们需要先来看看 Network Namespace 这个概念。
知识详解
如何理解 Network Namespace?
对于 Network Namespace,我们从字面上去理解的话,可以知道它是在一台 Linux 节点上对网络的隔离,不过它具体到底隔离了哪部分的网络资源呢?
我们还是先来看看操作手册,在 Linux Programmer’s Manual 里对 Network Namespace 有一个段简短的描述,在里面就列出了最主要的几部分资源,它们都是通过 Network Namespace 隔离的。
我把这些资源给你做了一个梳理:
第一种,网络设备,这里指的是 lo,eth0 等网络设备。你可以可以通过 ip link命令看到它们。
第二种是 IPv4 和 IPv6 协议栈。从这里我们可以知道,IP 层以及上面的 TCP 和 UPD 协议栈也是每个 Namespace 独立工作的。
所以 IP、TCP、UDP 的很多协议,它们的相关参数也是每个 Namespace 独立的,这些参数大多数都在 /proc/sys/net/ 目录下面,同时也包括了 TCP 和 UDP 的 port 资源。
第三种,IP 路由表,这个资源也是比较好理解的,你可以在不同的 Network Namespace 运行 ip route 命令,就能看到不同的路由表了。
第四种是防火墙规则,其实这里说的就是 iptables 规则了,每个 Namespace 里都可以独立配置 iptables 规则。
最后一种是网络的状态信息,这些信息你可以从 /proc/net 和 /sys/class/net 里得到,这里的状态基本上包括了前面 4 种资源的的状态信息。
Namespace 的操作
那我们怎么建立一个新的 Network Namespace 呢?
我们可以通过系统调用 clone() 或者 unshare() 这两个函数来建立新的 Network Namespace。
下面我们会讲两个例子,带你体会一下这两个方法具体怎么用。
第一种方法呢,是在新的进程创建的时候,伴随新进程建立,同时也建立出新的 Network Namespace。这个方法,其实就是通过 clone() 系统调用带上 CLONE_NEWNET flag 来实现的。
Clone 建立出来一个新的进程,这个新的进程所在的 Network Namespace 也是新的。然后我们执行 ip link 命令查看 Namespace 里的网络设备,就可以确认一个新的 Network Namespace 已经建立好了。
具体操作你可以看一下 这段代码 。
int new_netns(void *para)
{
printf("New Namespace Devices:\n");
system("ip link");
printf("\n\n");
sleep(100);
return 0;
}
int main(void)
{
pid_t pid;
printf("Host Namespace Devices:\n");
system("ip link");
printf("\n\n");
pid =
clone(new_netns, stack + STACK_SIZE, CLONE_NEWNET | SIGCHLD, NULL);
if (pid == -1)
errExit("clone");
if (waitpid(pid, NULL, 0) == -1)
errExit("waitpid");
return 0;
}第二种方法呢,就是调用 unshare() 这个系统调用来直接改变当前进程的 Network Namespace,你可以看一下 这段代码 。
int main(void)
{
pid_t pid;
printf("Host Namespace Devices:\n");
system("ip link");
printf("\n\n");
if (unshare(CLONE_NEWNET) == -1)
errExit("unshare");
printf("New Namespace Devices:\n");
system("ip link");
printf("\n\n");
return 0;
}其实呢,不仅是 Network Namespace,其它的 Namespace 也是通过 clone() 或者 unshare() 系统调用来建立的。
而创建容器的程序,比如runC也是用 unshare() 给新建的容器建立 Namespace 的。
这里我简单地说一下 runC 是什么,我们用 Docker 或者 containerd 去启动容器,最后都会调用 runC 在 Linux 中把容器启动起来。
除了在代码中用系统调用来建立 Network Namespace,我们也可以用命令行工具来建立 Network Namespace。比如用 ip netns 命令,在下一讲学习容器网络配置的时候呢,我们会用到 ip netns,这里你先有个印象就行。
在 Network Namespace 创建好了之后呢,我们可以在宿主机上运行 lsns -t net 这个命令来查看系统里已有的 Network Namespace。当然,lsns也可以用来查看其它 Namespace。
用 lsns 查看已有的 Namespace 后,我们还可以用 nsenter 这个命令进入到某个 Network Namespace 里,具体去查看这个 Namespace 里的网络配置。
比如下面的这个例子,用我们之前的 clone() 的例子里的代码,编译出 clone-ns 这个程序,运行后,再使用 lsns 查看新建的 Network Namespace,并且用nsenter进入到这个 Namespace,查看里面的 lo device。
具体操作你可以参考下面的代码:
$ ./clone-ns &
[1] 7732
$ Host Namespace Devices:
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000
link/ether 74:db:d1:80:54:14 brd ff:ff:ff:ff:ff:ff
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN mode DEFAULT group default
link/ether 02:42:0c:ff:2b:77 brd ff:ff:ff:ff:ff:ff
New Namespace Devices:
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
$ lsns -t net
NS TYPE NPROCS PID USER NETNSID NSFS COMMAND
4026531992 net 283 1 root unassigned /usr/lib/systemd/systemd --switched-root --system --deserialize 16
4026532241 net 1 7734 root unassigned ./clone-ns
$ nsenter -t 7734 -n ip addr
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00解决问题
那理解了 Network Namespace 之后,我们再来看看这一讲最开始的问题,我们应该怎么来设置容器里的网络相关参数呢?
首先你要避免走入误区。从我们一开始的例子里,也可以看到,容器里 Network Namespace 的网络参数并不是完全从宿主机 Host Namespace 里继承的,也不是完全在新的 Network Namespace 建立的时候重新初始化的。
其实呢,这一点我们只要看一下内核代码中对协议栈的初始化函数,很快就可以知道为什么会有这样的情况。
在我们的例子里 tcp_congestion_control 的值是从 Host Namespace 里继承的,而 tcp_keepalive 相关的几个值会被重新初始化了。
在函数 tcp_sk_init() 里,tcp_keepalive 的三个参数都是重新初始化的,而 tcp_congestion_control 的值是从 Host Namespace 里复制过来的。
static int __net_init tcp_sk_init(struct net *net)
{
…
net->ipv4.sysctl_tcp_keepalive_time = TCP_KEEPALIVE_TIME;
net->ipv4.sysctl_tcp_keepalive_probes = TCP_KEEPALIVE_PROBES;
net->ipv4.sysctl_tcp_keepalive_intvl = TCP_KEEPALIVE_INTVL;
…
/* Reno is always built in */
if (!net_eq(net, &init_net) &&
try_module_get(init_net.ipv4.tcp_congestion_control->owner))
net->ipv4.tcp_congestion_control = init_net.ipv4.tcp_congestion_control;
else
net->ipv4.tcp_congestion_control = &tcp_reno;
…
}那么我们现在知道 Network Namespace 的网络参数是怎么初始化的了,你可能会问了,我在容器里也可以修改这些参数吗?
我们可以启动一个普通的容器,这里的”普通”呢,我指的不是”privileged”的那种容器,也就是在这个容器中,有很多操作都是不允许做的,比如 mount 一个文件系统。这个 privileged 容器概念,我们会在后面容器安全这一讲里详细展开,这里你有个印象。
那么在启动完一个普通容器后,我们尝试一下在容器里去修改”/proc/sys/net/“下的参数。
这时候你会看到,容器中”/proc/sys/“是只读 mount 的,那么在容器里是不能修改”/proc/sys/net/“下面的任何参数了。
$ docker run -d --name net_para centos:8.1.1911 sleep 3600
977bf3f07da90422e9c1e89e56edf7a59fab5edff26317eeb253700c2fa657f7
$ docker exec -it net_para bash
[root@977bf3f07da9 /]$ echo 600 > /proc/sys/net/ipv4/tcp_keepalive_time
bash: /proc/sys/net/ipv4/tcp_keepalive_time: Read-only file system
[root@977bf3f07da9 /]$ cat /proc/mounts | grep "proc/sys"
proc /proc/sys proc ro,relatime 0 0为什么”/proc/sys/“ 在容器里是只读 mount 呢? 这是因为 runC 当初出于安全的考虑,把容器中所有 /proc 和 /sys 相关的目录缺省都做了 read-only mount 的处理。详细的说明你可以去看看这两个 commits:
- Mount /proc and /sys read-only, except in privileged containers
- Make /proc writable, but not /proc/sys and /proc/sysrq-trigger
那我们应该怎么来修改容器中 Network Namespace 的网络参数呢?
当然,如果你有宿主机上的 root 权限,最简单粗暴的方法就是用我们之前说的”nsenter”工具,用它修改容器里的网络参数的。不过这个方法在生产环境里显然是不会被允许的,因为我们不会允许用户拥有宿主机的登陆权限。
其次呢,一般来说在容器中的应用已经启动了之后,才会做这样的修改。也就是说,很多 tcp 链接已经建立好了,那么即使新改了参数,对已经建立好的链接也不会生效了。这就需要重启应用,我们都知道生产环境里通常要避免应用重启,那这样做显然也不合适。
通过刚刚的排除法,我们推理出了网络参数修改的”正确时机”:想修改 Network Namespace 里的网络参数,要选择容器刚刚启动,而容器中的应用程序还没启动之前进行。
其实,runC 也在对 /proc/sys 目录做 read-only mount 之前,预留出了修改接口,就是用来修改容器里 “/proc/sys”下参数的,同样也是 sysctl 的参数。
而 Docker 的 -sysctl 或者 Kubernetes 里的 allowed-unsafe-sysctls 特性也都利用了 runC 的 sysctl 参数修改接口,允许容器在启动时修改容器 Namespace 里的参数。
比如,我们可以试一下 docker -sysctl,这时候我们会发现,在容器的 Network Namespace 里,/proc/sys/net/ipv4/tcp_keepalive_time 这个网络参数终于被修改了!
$ docker run -d --name net_para --sysctl net.ipv4.tcp_keepalive_time=600 centos:8.1.1911 sleep 3600
7efed88a44d64400ff5a6d38fdcc73f2a74a7bdc3dbc7161060f2f7d0be170d1
$ docker exec net_para cat /proc/sys/net/ipv4/tcp_keepalive_time
600重点总结
今天我们讨论问题是容器中网络参数的问题,因为是问题发生在容器里,又是网络的参数,那么自然就和 Network Namespace 有关,所以我们首先要理解 Network Namespace。
Network Namespace 可以隔离网络设备,ip 协议栈,ip 路由表,防火墙规则,以及可以显示独立的网络状态信息。
我们可以通过 clone() 或者 unshare() 系统调用来建立新的 Network Namespace。
此外,还有一些工具”ip””netns””unshare””lsns”和”nsenter”,也可以用来操作 Network Namespace。
这些工具的适用条件,我用表格的形式整理如下,你可以做个参考。
接着我们分析了如何修改普通容器(非 privileged)的网络参数。
由于安全的原因,普通容器的 /proc/sys 是 read-only mount 的,所以在容器启动以后,我们无法在容器内部修改 /proc/sys/net 下网络相关的参数。
这时可行的方法是 通过 runC sysctl 相关的接口,在容器启动的时候对容器内的网络参数做配置。
这样一来,想要修改网络参数就可以这么做:如果是使用 Docker,我们可以加上”—sysctl”这个参数;而如果使用 Kubernetes 的话,就需要用到”allowed unsaft sysctl”这个特性了。
思考题
这一讲中,我们提到了可以使用”nsenter”这个工具,从宿主机上修改容器里的 /proc/sys/net/ 下的网络参数,你可以试试看具体怎么修改。
答:
# root 用户
$ nsenter -t <pid> -n bash -c 'echo 600 > /proc/sys/net/ipv4/tcp_keepalive_time'
# 非 root 用户
$ sudo nsenter -t <pid> -n sudo bash -c 'echo 600 > /proc/sys/net/ipv4/tcp_keepalive_time'其中,
<pid>表示容器 init 进程在宿主机上看到的 PID。
16 | 容器网络配置(1):容器网络不通了要怎么调试?
在上一讲,我们讲了 Network Namespace 隔离了网络设备,IP 协议栈和路由表,以及防火墙规则,那容器 Network Namespace 里的参数怎么去配置,我们现在已经很清楚了。
其实对于网络配置的问题,我们还有一个最需要关心的内容,那就是容器和外面的容器或者节点是怎么通讯的,这就涉及到了容器网络接口配置的问题了。
所以这一讲呢,我们就来聊一聊,容器 Network Namespace 里如何配置网络接口,还有当容器网络不通的时候,我们应该怎么去做一个简单调试。
问题再现
在前面的课程里,我们一直是用 docker run 这个命令来启动容器的。容器启动了之后,我们也可以看到,在容器里面有一个”eth0”的网络接口,接口上也配置了一个 IP 地址。
不过呢,如果我们想从容器里访问外面的一个 IP 地址,比如说 39.106.233.176(这个是极客时间网址对应的 IP),结果就发现是不能 ping 通的。
这时我们可能会想到,到底是不是容器内出了问题,在容器里无法访问,会不会宿主机也一样不行呢?
所以我们需要验证一下,首先我们退出容器,然后在宿主机的 Network Namespace 下,再运行 ping 39.106.233.176,结果就会发现在宿主机上,却是可以连通这个地址的。
$ docker run -d --name if-test centos:8.1.1911 sleep 36000
244d44f94dc2931626194c6fd3f99cec7b7c4bf61aafc6c702551e2c5ca2a371
$ docker exec -it if-test bash
[root@244d44f94dc2 /]$ ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
808: eth0@if809: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
[root@244d44f94dc2 /]$ ping 39.106.233.176 ### 容器中无法ping通
PING 39.106.233.176 (39.106.233.176) 56(84) bytes of data.
^C
--- 39.106.233.176 ping statistics ---
9 packets transmitted, 0 received, 100% packet loss, time 185ms
[root@244d44f94dc2 /]$ exit ###退出容器
exit
$ ping 39.106.233.176 ### 宿主机上可以ping通
PING 39.106.233.176 (39.106.233.176) 56(84) bytes of data.
64 bytes from 39.106.233.176: icmp_seq=1 ttl=78 time=296 ms
64 bytes from 39.106.233.176: icmp_seq=2 ttl=78 time=306 ms
64 bytes from 39.106.233.176: icmp_seq=3 ttl=78 time=303 ms
^C
--- 39.106.233.176 ping statistics ---
4 packets transmitted, 3 received, 25% packet loss, time 7ms
rtt min/avg/max/mdev = 296.059/301.449/305.580/4.037 ms那么碰到这种容器内网络不通的问题,我们应该怎么分析调试呢?我们还是需要先来理解一下,容器 Network Namespace 里的网络接口是怎么配置的。
基本概念
在讲解容器的网络接口配置之前,我们需要先建立一个整体的认识,搞清楚容器网络接口在系统架构中处于哪个位置。
你可以看一下我给你画的这张图,图里展示的是容器有自己的 Network Namespace,eth0 是这个 Network Namespace 里的网络接口。而宿主机上也有自己的 eth0,宿主机上的 eth0 对应着真正的物理网卡,可以和外面通讯。
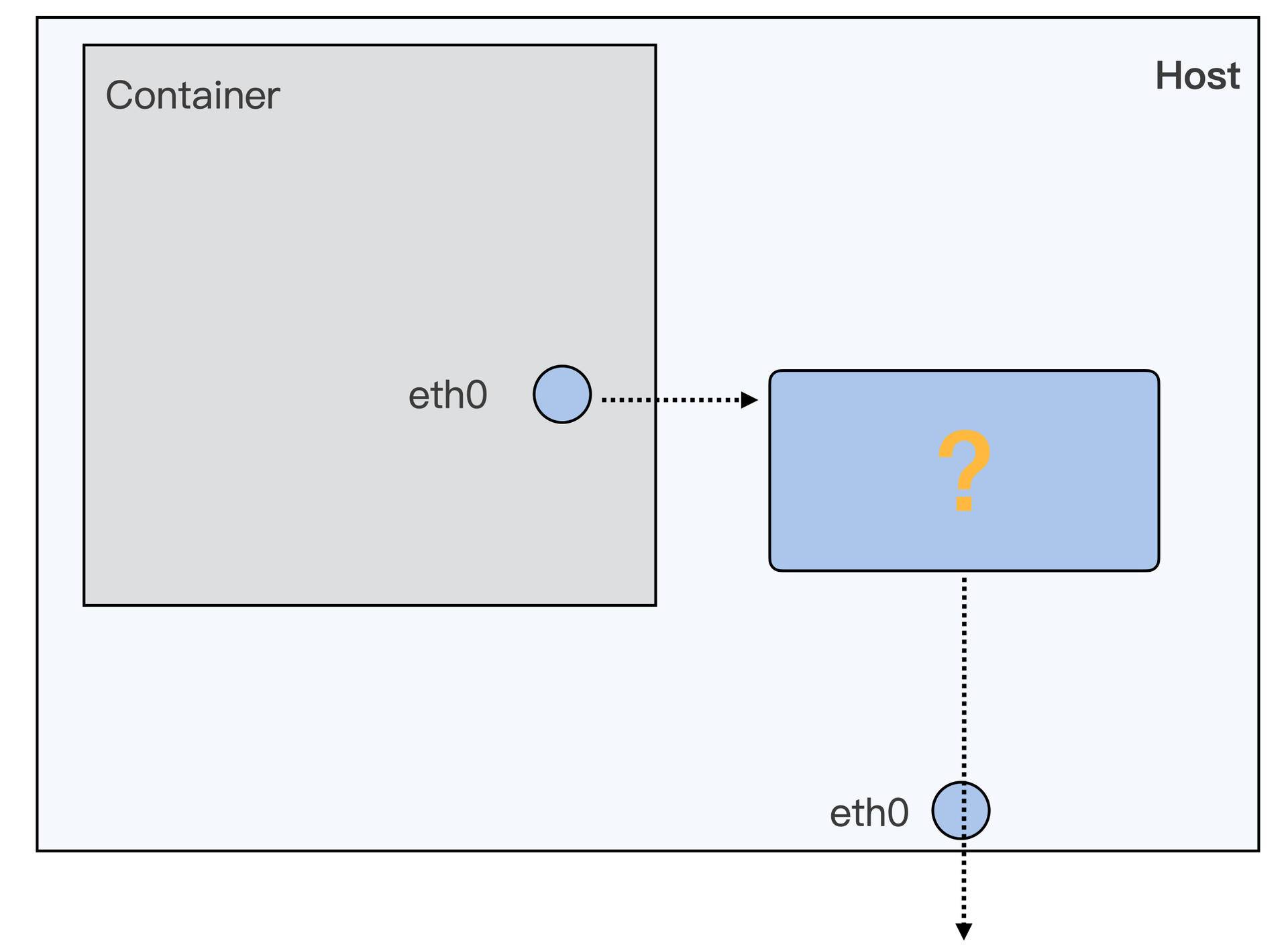
那你可以先想想,我们要让容器 Network Namespace 中的数据包最终发送到物理网卡上,需要完成哪些步骤呢?从图上看,我们大致可以知道应该包括这两步。
第一步,就是要让数据包从容器的 Network Namespace 发送到 Host Network Namespace 上。
第二步,数据包发到了 Host Network Namespace 之后,还要解决数据包怎么从宿主机上的 eth0 发送出去的问题。
好,整体的思路已经理清楚了,接下来我们做具体分析。我们先来看第一步,怎么让数据包从容器的 Network Namespace 发送到 Host Network Namespace 上面。
你可以查看一下 Docker 网络的文档 或者 Kubernetes 网络的文档 ,这些文档里面介绍了很多种容器网络配置的方式。
不过对于容器从自己的 Network Namespace 连接到 Host Network Namespace 的方法,一般来说就只有两类设备接口:一类是 veth ,另外一类是 macvlan/ipvlan。
在这些方法中,我们使用最多的就是 veth 的方式,用 Docker 启动的容器缺省的网络接口用的也是这个 veth。既然它这么常见,所以我们就用 veth 作为例子来详细讲解。至于另外一类 macvlan/ipvlan 的方式,我们在下一讲里会讲到。
那什么是 veth 呢?为了方便你更好地理解,我们先来模拟一下 Docker 为容器建立 eth0 网络接口的过程,动手操作一下,这样呢,你就可以很快明白什么是 veth 了。
对于这个模拟操作呢,我们主要用到的是 ip netns 这个命令,通过它来对 Network Namespace 做操作。
首先,我们先启动一个不带网络配置的容器,和我们之前的命令比较,主要是多加上了”—network none”参数。我们可以看到,这样在启动的容器中,Network Namespace 里就只有 loopback 一个网络设备,而没有了 eth0 网络设备了。
$ docker run -d --name if-test --network none centos:8.1.1911 sleep 36000
cf3d3105b11512658a025f5b401a09c888ed3495205f31e0a0d78a2036729472
$ docker exec -it if-test ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever完成刚才的设置以后,我们就在这个容器的 Network Namespace 里建立 veth,你可以执行一下后面的这个脚本。
pid=$(ps -ef | grep "sleep 36000" | grep -v grep | awk '{print $2}')
echo $pid
ln -s /proc/$pid/ns/net /var/run/netns/$pid
# Create a pair of veth interfaces
ip link add name veth_host type veth peer name veth_container
# Put one of them in the new net ns
ip link set veth_container netns $pid
# In the container, setup veth_container
ip netns exec $pid ip link set veth_container name eth0
ip netns exec $pid ip addr add 172.17.1.2/16 dev eth0
ip netns exec $pid ip link set eth0 up
ip netns exec $pid ip route add default via 172.17.0.1
# In the host, set veth_host up
ip link set veth_host up我在这里解释一下,这个 veth 的建立过程是什么样的。
首先呢,我们先找到这个容器里运行的进程”sleep 36000”的 pid,通过 “/proc/$pid/ns/net”这个文件得到 Network Namespace 的 ID,这个 Network Namespace ID 既是这个进程的,也同时属于这个容器。
然后我们在”/var/run/netns/“的目录下建立一个符号链接,指向这个容器的 Network Namespace。完成这步操作之后,在后面的”ip netns”操作里,就可以用 pid 的值作为这个容器的 Network Namesapce 的标识了。
接下来呢,我们用 ip link 命令来建立一对 veth 的虚拟设备接口,分别是 veth_container 和 veth_host。从名字就可以看出来,veth_container 这个接口会被放在容器 Network Namespace 里,而 veth_host 会放在宿主机的 Host Network Namespace。
所以我们后面的命令也很好理解了,就是用 ip link set veth_container netns $pid 把 veth_container 这个接口放入到容器的 Network Namespace 中。
再然后我们要把 veth_container 重新命名为 eth0,因为这时候接口已经在容器的 Network Namesapce 里了,eth0 就不会和宿主机上的 eth0 冲突了。
最后对容器内的 eht0,我们还要做基本的网络 IP 和缺省路由配置。因为 veth_host 已经在宿主机的 Host Network Namespace 了,就不需要我们做什么了,这时我们只需要 up 一下这个接口就可以了。
那刚才这些操作完成以后,我们就建立了一对 veth 虚拟设备接口。我给你画了一张示意图,图里直观展示了这对接口在容器和宿主机上的位置。
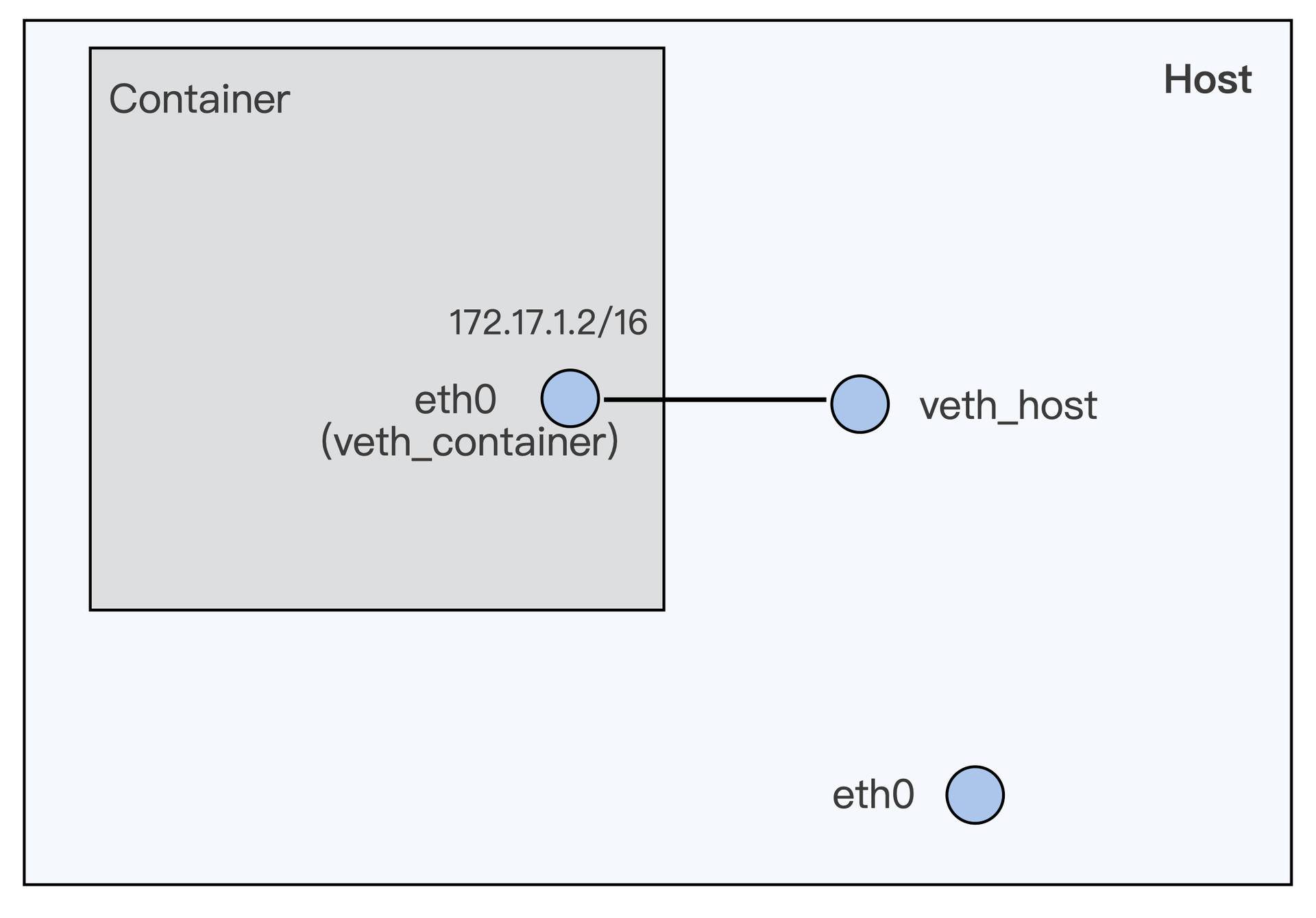
现在,我们再来看看 veth 的定义了,其实它也很简单。veth 就是一个虚拟的网络设备,一般都是成对创建,而且这对设备是相互连接的。当每个设备在不同的 Network Namespaces 的时候,Namespace 之间就可以用这对 veth 设备来进行网络通讯了。
比如说,你可以执行下面的这段代码,试试在 veth_host 上加上一个 IP,172.17.1.1/16,然后从容器里就可以 ping 通这个 IP 了。这也证明了从容器到宿主机可以利用这对 veth 接口来通讯了。
$ ip addr add 172.17.1.1/16 dev veth_host
$ docker exec -it if-test ping 172.17.1.1
PING 172.17.1.1 (172.17.1.1) 56(84) bytes of data.
64 bytes from 172.17.1.1: icmp_seq=1 ttl=64 time=0.073 ms
64 bytes from 172.17.1.1: icmp_seq=2 ttl=64 time=0.092 ms
^C
--- 172.17.1.1 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 30ms
rtt min/avg/max/mdev = 0.073/0.082/0.092/0.013 ms好了,这样我们完成了第一步,通过一对 veth 虚拟设备,可以让数据包从容器的 Network Namespace 发送到 Host Network Namespace 上。
那下面我们再来看第二步, 数据包到了 Host Network Namespace 之后呢,怎么把它从宿主机上的 eth0 发送出去?
其实这一步呢,就是一个普通 Linux 节点上数据包转发的问题了。这里我们解决问题的方法有很多种,比如说用 nat 来做个转发,或者建立 Overlay 网络发送,也可以通过配置 proxy arp 加路由的方法来实现。
因为考虑到网络环境的配置,同时 Docker 缺省使用的是 bridge + nat 的转发方式, 那我们就在刚才讲的第一步基础上,再手动实现一下 bridge+nat 的转发方式。对于其他的配置方法,你可以看一下 Docker 或者 Kubernetes 相关的文档。
Docker 程序在节点上安装完之后,就会自动建立了一个 docker0 的 bridge interface。所以我们只需要把第一步中建立的 veth_host 这个设备,接入到 docker0 这个 bridge 上。
这里我要提醒你注意一下,如果之前你在 veth_host 上设置了 IP 的,就需先运行一下”ip addr delete 172.17.1.1/16 dev veth_host”,把 IP 从 veth_host 上删除。
# ip addr delete 172.17.1.1/16 dev veth_host
ip link set veth_host master docker0这个命令执行完之后,容器和宿主机的网络配置就会发生变化,这种配置是什么样呢?你可以参考一下面这张图的描述。
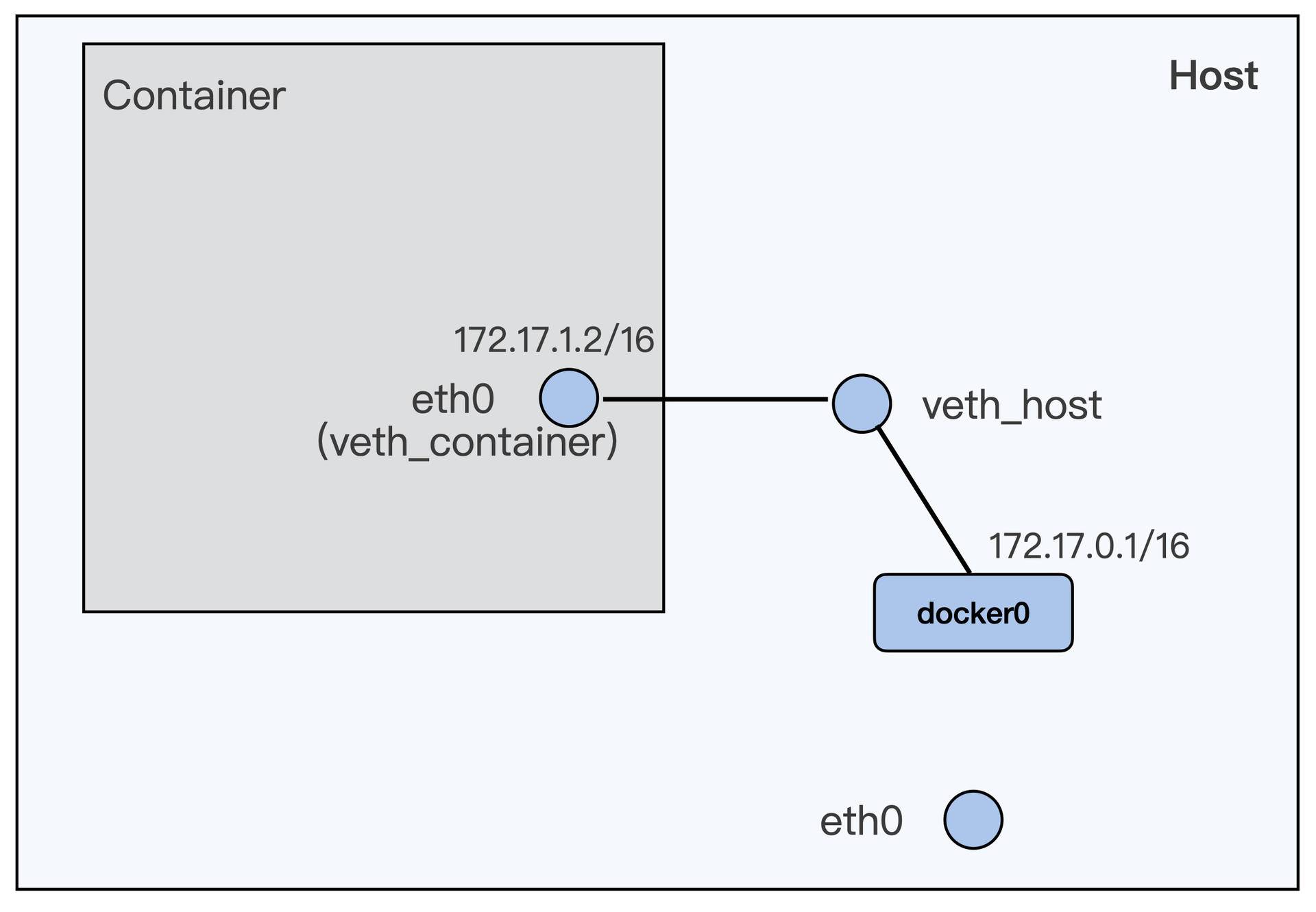
从这张示意图中,我们可以看出来,容器和 docker0 组成了一个子网,docker0 上的 IP 就是这个子网的网关 IP。
如果我们要让子网通过宿主机上 eth0 去访问外网的话,那么加上 iptables 的规则就可以了,也就是下面这条规则。
iptables -P FORWARD ACCEPT好了,进行到这里,我们通过 bridge+nat 的配置,似乎已经完成了第二步——让数据从宿主机的 eth0 发送出去。
那么我们这样配置,真的可以让容器里发送数据包到外网了吗?这需要我们做个测试,再重新尝试下这一讲开始的操作,从容器里 ping 外网的 IP,这时候,你会发现还是 ping 不通。
其实呢,做到这一步,我们通过自己的逐步操作呢,重现了这一讲了最开始的问题。
解决问题
既然现在我们清楚了,在这个节点上容器和宿主机上的网络配置是怎么一回事。那么要调试这个问题呢,也有了思路,关键就是找到数据包传到哪个环节时发生了中断。
那最直接的方法呢,就是在容器中继续 ping 外网的 IP 39.106.233.176,然后在容器的 eth0 (veth_container),容器外的 veth_host,docker0,宿主机的 eth0 这一条数据包的路径上运行 tcpdump。
这样就可以查到,到底在哪个设备接口上没有收到 ping 的 icmp 包。我把 tcpdump 运行的结果我列到了下面。
容器的 eth0:
$ ip netns exec $pid tcpdump -i eth0 host 39.106.233.176 -nn
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
00:47:29.934294 IP 172.17.1.2 > 39.106.233.176: ICMP echo request, id 71, seq 1, length 64
00:47:30.934766 IP 172.17.1.2 > 39.106.233.176: ICMP echo request, id 71, seq 2, length 64
00:47:31.958875 IP 172.17.1.2 > 39.106.233.176: ICMP echo request, id 71, seq 3, length 64veth_host:
$ tcpdump -i veth_host host 39.106.233.176 -nn
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on veth_host, link-type EN10MB (Ethernet), capture size 262144 bytes
00:48:01.654720 IP 172.17.1.2 > 39.106.233.176: ICMP echo request, id 71, seq 32, length 64
00:48:02.678752 IP 172.17.1.2 > 39.106.233.176: ICMP echo request, id 71, seq 33, length 64
00:48:03.702827 IP 172.17.1.2 > 39.106.233.176: ICMP echo request, id 71, seq 34, length 64docker0:
$ tcpdump -i docker0 host 39.106.233.176 -nn
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on docker0, link-type EN10MB (Ethernet), capture size 262144 bytes
00:48:20.086841 IP 172.17.1.2 > 39.106.233.176: ICMP echo request, id 71, seq 50, length 64
00:48:21.110765 IP 172.17.1.2 > 39.106.233.176: ICMP echo request, id 71, seq 51, length 64
00:48:22.134839 IP 172.17.1.2 > 39.106.233.176: ICMP echo request, id 71, seq 52, length 64host eth0:
$ tcpdump -i eth0 host 39.106.233.176 -nn
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
^C
0 packets captured
0 packets received by filter
0 packets dropped by kernel通过上面的输出结果,我们发现 icmp 包到达了 docker0,但是没有到达宿主机上的 eth0。
因为我们已经配置了 iptables nat 的转发,这个也可以通过查看 iptables 的 nat 表确认一下,是没有问题的,具体的操作命令如下:
$ iptables -L -t nat
Chain PREROUTING (policy ACCEPT)
target prot opt source destination
DOCKER all -- anywhere anywhere ADDRTYPE match dst-type LOCAL
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain POSTROUTING (policy ACCEPT)
target prot opt source destination
MASQUERADE all -- 172.17.0.0/16 anywhere
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
DOCKER all -- anywhere !127.0.0.0/8 ADDRTYPE match dst-type LOCAL
Chain DOCKER (2 references)
target prot opt source destination
RETURN all -- anywhere anywhere那么会是什么问题呢?因为这里需要做两个网络设备接口之间的数据包转发,也就是从 docker0 把数据包转发到 eth0 上,你可能想到了 Linux 协议栈里的一个常用参数 ip_forward。
我们可以看一下,它的值是 0,当我们把它改成 1 之后,那么我们就可以从容器中 ping 通外网 39.106.233.176 这个 IP 了!
$ cat /proc/sys/net/ipv4/ip_forward
0
$ echo 1 > /proc/sys/net/ipv4/ip_forward
$ docker exec -it if-test ping 39.106.233.176
PING 39.106.233.176 (39.106.233.176) 56(84) bytes of data.
64 bytes from 39.106.233.176: icmp_seq=1 ttl=77 time=359 ms
64 bytes from 39.106.233.176: icmp_seq=2 ttl=77 time=346 ms
^C
--- 39.106.233.176 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1ms
rtt min/avg/max/mdev = 345.889/352.482/359.075/6.593 ms重点小结
这一讲,我们主要解决的问题是如何给容器配置网络接口,让容器可以和外面通讯;同时我们还学习了当容器网络不通的时候,我们应该怎么来做一个简单调试。
解决容器与外界通讯的问题呢,一共需要完成两步。第一步是,怎么让数据包从容器的 Network Namespace 发送到 Host Network Namespace 上;第二步,数据包到了 Host Network Namespace 之后,还需要让它可以从宿主机的 eth0 发送出去。
我们想让数据从容器 Netowrk Namespace 发送到 Host Network Namespace,可以用配置一对 veth 虚拟网络设备的方法实现。而让数据包从宿主机的 eth0 发送出去,就用可 bridge+nat 的方式完成。
这里我讲的是最基本的一种配置,但它也是很常用的一个网络配置。针对其他不同需要,容器网络还有很多种。那你学习完这一讲,了解了基本的概念和操作之后呢,还可以查看更多的网上资料,学习不同的网络配置。
遇到容器中网络不通的情况,我们先要理解自己的容器以及容器在宿主机上的配置,通过对主要设备上做 tcpdump 可以找到具体在哪一步数据包停止了转发。
然后我们结合内核网络配置参数,路由表信息,防火墙规则,一般都可以定位出根本原因,最终解决这种网络完全不通的问题。
但是如果是网络偶尔丢包的问题,这个就需要用到其他的一些工具来做分析了,这个我们会在之后的章节做讲解。
17|容器网络配置(2):容器网络延时要比宿主机上的高吗?
在上一讲里,我们学习了在容器中的网络接口配置,重点讲解的是 veth 的接口配置方式,这也是绝大部分容器用的缺省的网络配置方式。
不过呢,从 veth 的这种网络接口配置上看,一个数据包要从容器里发送到宿主机外,需要先从容器里的 eth0 (veth_container) 把包发送到宿主机上 veth_host,然后再在宿主机上通过 nat 或者路由的方式,经过宿主机上的 eth0 向外发送。
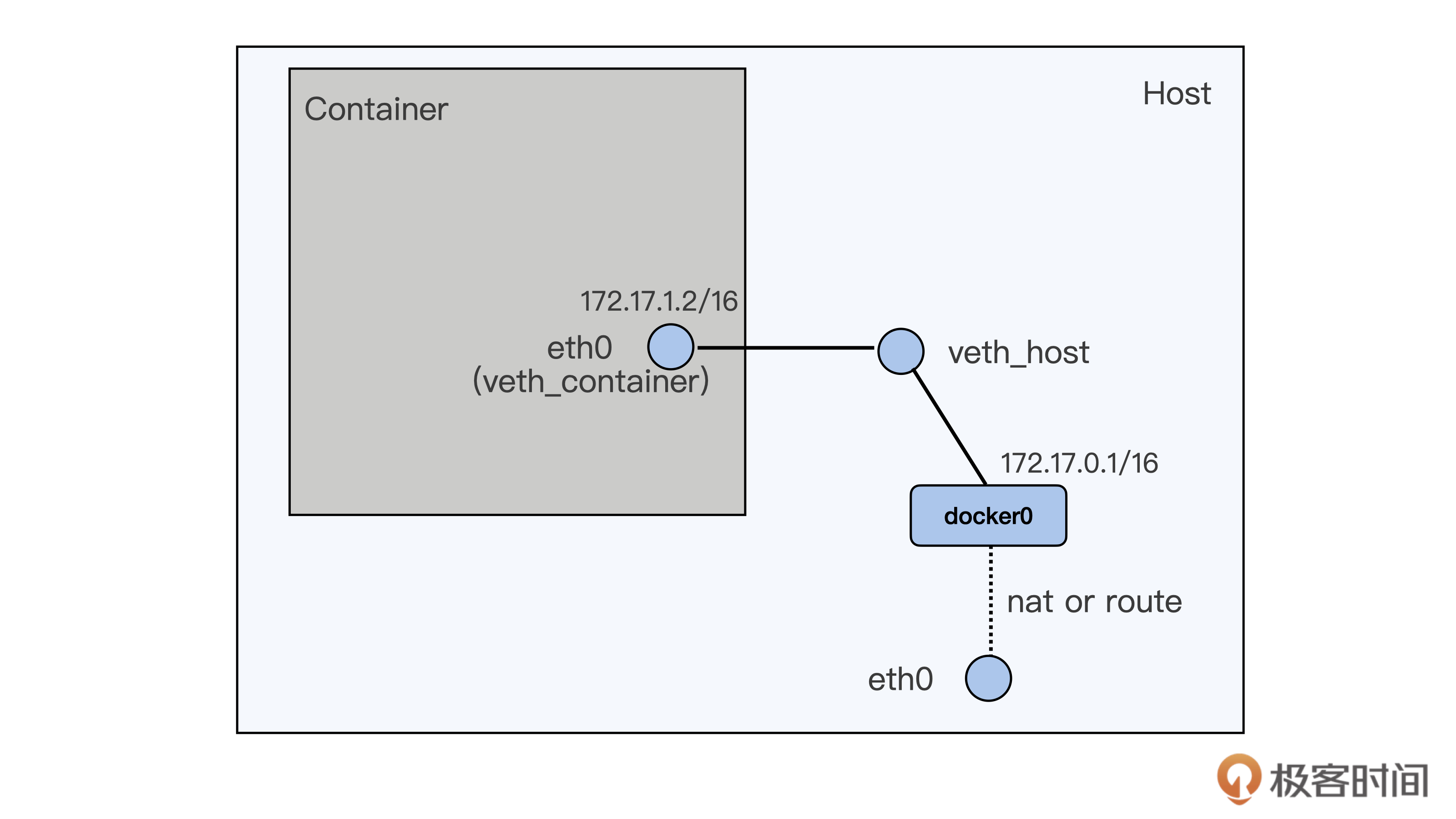
这种容器向外发送数据包的路径,相比宿主机上直接向外发送数据包的路径,很明显要多了一次接口层的发送和接收。尽管 veth 是虚拟网络接口,在软件上还是会增加一些开销。
如果我们的应用程序对网络性能有很高的要求,特别是之前运行在物理机器上,现在迁移到容器上的,如果网络配置采用 veth 方式,就会出现网络延时增加的现象。
那今天我们就来聊一聊,容器网络接口对于容器中应用程序网络延时有怎样的影响,还有这个问题应该怎么解决。
问题重现
对于这种 veth 接口配置导致网络延时增加的现象,我们可以通过运行netperf(Netperf 是一个衡量网络性能的工具,它可以提供单向吞吐量和端到端延迟的测试)来模拟一下。
这里我们需要两台虚拟机或者物理机,这两台机器需要同处于一个二层的网络中。
具体的配置示意图如下:
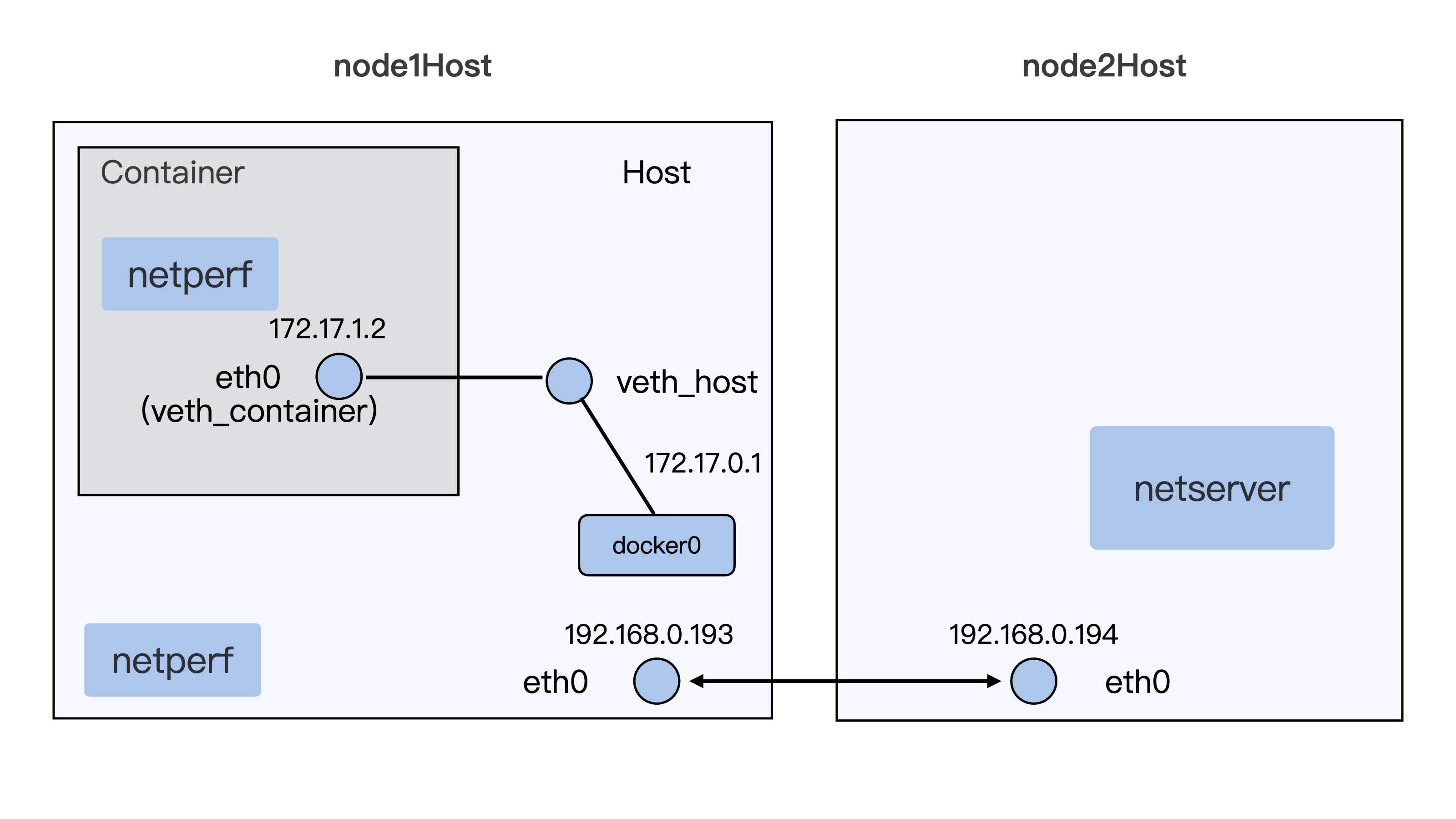
首先,我们需要在第一台机器上启动一个 veth 接口的容器,容器的启动和宿主机上的配置你可以参考一下这里的 脚本 。在第二台机器上,我们只要启动一个 netserver 就可以了。
然后呢,我们分别在容器里和宿主机上运行与 netserver 交互的 netperf,再比较一下它们延时的差异。
我们可以运行 netperf 的 TCP_RR 测试用例,TCP_RR 是 netperf 里专门用来测试网络延时的,缺省每次运行 10 秒钟。运行以后,我们还要计算平均每秒钟 TCP request/response 的次数,这个次数越高,就说明延时越小。
接下来,我们先在第一台机器的宿主机上直接运行 netperf 的 TCP_RR 测试用例 3 轮,得到的值分别是 2504.92,2410.14 和 2422.81,计算一下可以得到三轮 Transactions 平均值是 2446/s。
$ ./netperf -H 192.168.0.194 -t TCP_RR
MIGRATED TCP REQUEST/RESPONSE TEST from 0.0.0.0 (0.0.0.0) port 0 AF_INET to 192.168.0.194 () port 0 AF_INET : first burst 0
Local /Remote
Socket Size Request Resp. Elapsed Trans.
Send Recv Size Size Time Rate
bytes Bytes bytes bytes secs. per sec
16384 131072 1 1 10.00 2504.92
16384 131072
$ ./netperf -H 192.168.0.194 -t TCP_RR
MIGRATED TCP REQUEST/RESPONSE TEST from 0.0.0.0 (0.0.0.0) port 0 AF_INET to 192.168.0.194 () port 0 AF_INET : first burst 0
Local /Remote
Socket Size Request Resp. Elapsed Trans.
Send Recv Size Size Time Rate
bytes Bytes bytes bytes secs. per sec
16384 131072 1 1 10.00 2410.14
16384 131072
$ ./netperf -H 192.168.0.194 -t TCP_RR
MIGRATED TCP REQUEST/RESPONSE TEST from 0.0.0.0 (0.0.0.0) port 0 AF_INET to 192.168.0.194 () port 0 AF_INET : first burst 0
Local /Remote
Socket Size Request Resp. Elapsed Trans.
Send Recv Size Size Time Rate
bytes Bytes bytes bytes secs. per sec
16384 131072 1 1 10.00 2422.81
16384 131072同样,我们再在容器中运行一下 netperf 的 TCP_RR,也一样运行三轮,计算一下这三次的平均值,得到的值是 2141。
那么我们拿这次容器环境中的平均值和宿主机上得到的值 2446 做比较,会发现 Transactions 下降了大概 12.5%,也就是网络的延时超过了 10%。
[root@4150e2a842b5 /]$ ./netperf -H 192.168.0.194 -t TCP_RR
MIGRATED TCP REQUEST/RESPONSE TEST from 0.0.0.0 (0.0.0.0) port 0 AF_INET to 192.168.0.194 () port 0 AF_INET : first burst 0
Local /Remote
Socket Size Request Resp. Elapsed Trans.
Send Recv Size Size Time Rate
bytes Bytes bytes bytes secs. per sec
16384 131072 1 1 10.00 2104.68
16384 131072
[root@4150e2a842b5 /]$ ./netperf -H 192.168.0.194 -t TCP_RR
MIGRATED TCP REQUEST/RESPONSE TEST from 0.0.0.0 (0.0.0.0) port 0 AF_INET to 192.168.0.194 () port 0 AF_INET : first burst 0
Local /Remote
Socket Size Request Resp. Elapsed Trans.
Send Recv Size Size Time Rate
bytes Bytes bytes bytes secs. per sec
16384 131072 1 1 10.00 2146.34
16384 131072
[root@4150e2a842b5 /]$ ./netperf -H 192.168.0.194 -t TCP_RR
MIGRATED TCP REQUEST/RESPONSE TEST from 0.0.0.0 (0.0.0.0) port 0 AF_INET to 192.168.0.194 () port 0 AF_INET : first burst 0
Local /Remote
Socket Size Request Resp. Elapsed Trans.
Send Recv Size Size Time Rate
bytes Bytes bytes bytes secs. per sec
16384 131072 1 1 10.00 2173.79
16384 131072分析问题
刚才我们已经得到了测试的数值,我们发现 veth 方式的确带来了很高的网络延时。那现在我们先来分析一下,为什么 veth 会带来这么大的网络延时,然后再看看有什么方法可以降低容器里的网络延时。
我们先回顾一下容器里 veth 接口的配置,还是拿我们上一讲里容器 veth 的图作为例子。
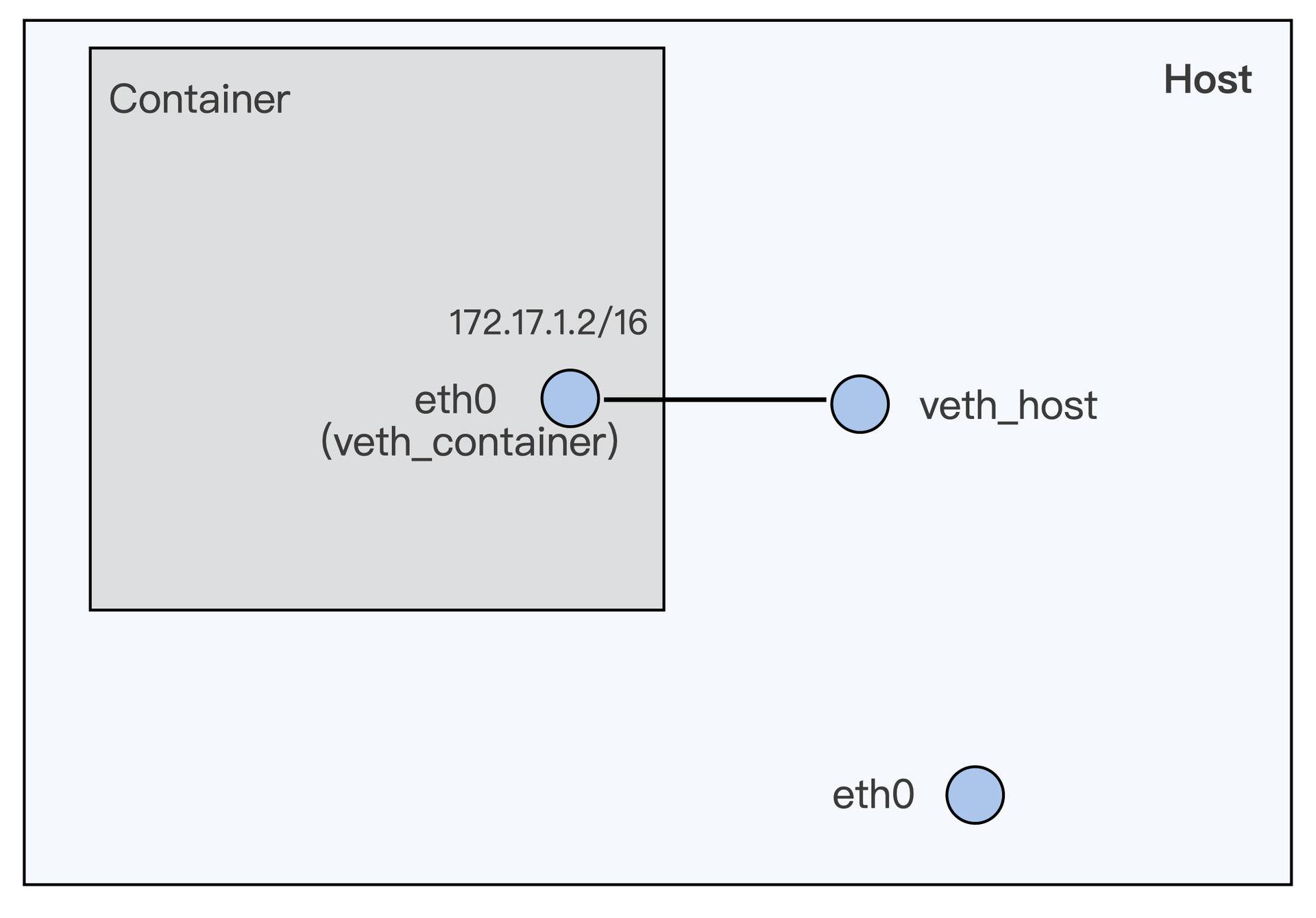
上一讲中我提到过,veth 的虚拟网络接口一般都是成对出现,就像上面图里的 veth_container 和 veth_host 一样。
在每次网络传输的过程中,数据包都需要通过 veth_container 这个接口向外发送,而且必须保证 veth_host 先接收到这个数据包。
虽然 veth 是一个虚拟的网络接口,但是在接收数据包的操作上,这个虚拟接口和真实的网路接口并没有太大的区别。这里除了没有硬件中断的处理,其他操作都差不多,特别是软中断(softirq)的处理部分其实就和真实的网络接口是一样的。
我们可以通过阅读 Linux 内核里的 veth 的驱动代码( drivers/net/veth.c )确认一下。
veth 发送数据的函数是 veth_xmit(),它里面的主要操作就是找到 veth peer 设备,然后触发 peer 设备去接收数据包。
比如 veth_container 这个接口调用了 veth_xmit() 来发送数据包,最后就是触发了它的 peer 设备 veth_host 去调用 netif_rx() 来接收数据包。主要的代码我列在下面了:
static netdev_tx_t veth_xmit(struct sk_buff *skb, struct net_device *dev)
{
…
/* 拿到veth peer设备的net_device */
rcv = rcu_dereference(priv->peer);
…
/* 将数据送到veth peer设备 */
if (likely(veth_forward_skb(rcv, skb, rq, rcv_xdp) == NET_RX_SUCCESS)) {
…
}
static int veth_forward_skb(struct net_device *dev, struct sk_buff *skb,
struct veth_rq *rq, bool xdp)
{
/* 这里最后调用了 netif_rx() */
return __dev_forward_skb(dev, skb) ?: xdp ?
veth_xdp_rx(rq, skb) :
netif_rx(skb);
}而 netif_rx() 是一个网络设备驱动里面标准的接收数据包的函数,netif_rx() 里面会为这个数据包 raise 一个 softirq。
__raise_softirq_irqoff(NET_RX_SOFTIRQ);其实 softirq 这个概念,我们之前在CPU 的模块中也提到过。在处理网络数据的时候,一些运行时间较长而且不能在硬中断中处理的工作,就会通过 softirq 来处理。
一般在硬件中断处理结束之后,网络 softirq 的函数才会再去执行没有完成的包的处理工作。即使这里 softirq 的执行速度很快,还是会带来额外的开销。
所以,根据 veth 这个虚拟网络设备的实现方式,我们可以看到它必然会带来额外的开销,这样就会增加数据包的网络延时。
解决问题
那么我们有什么方法可以减少容器的网络延时呢?你可能会想到,我们可不可以不使用 veth 这个方式配置网络接口,而是换成别的方式呢?
的确是这样,其实除了 veth 之外,容器还可以选择其他的网络配置方式。在 Docker 的文档中提到了 macvlan 的配置方式,和 macvlan 很类似的方式还有 ipvlan。
那我们先来简单看一下 macvlan 和 ipvlan 的异同点。
我们先来看这两个方式的相同之处,无论是 macvlan 还是 ipvlan,它们都是在一个物理的网络接口上再配置几个虚拟的网络接口。在这些虚拟的网络接口上,都可以配置独立的 IP,并且这些 IP 可以属于不同的 Namespace。
然后我再说说它们的不同点。 对于 macvlan,每个虚拟网络接口都有自己独立的 mac 地址;而 ipvlan 的虚拟网络接口是和物理网络接口共享同一个 mac 地址。 而且它们都有自己的 L2/L3 的配置方式,不过我们主要是拿 macvlan/ipvlan 来和 veth 做比较,这里可以先忽略 macvlan/ipvlan 这些详细的特性。
我们就以 ipvlan 为例,运行下面的这个脚本,为容器手动配置上 ipvlan 的网络接口。
docker run --init --name lat-test-1 --network none -d registry/latency-test:v1 sleep 36000
pid1=$(docker inspect lat-test-1 | grep -i Pid | head -n 1 | awk '{print $2}' | awk -F "," '{print $1}')
echo $pid1
ln -s /proc/$pid1/ns/net /var/run/netns/$pid1
ip link add link eth0 ipvt1 type ipvlan mode l2
ip link set dev ipvt1 netns $pid1
ip netns exec $pid1 ip link set ipvt1 name eth0
ip netns exec $pid1 ip addr add 172.17.3.2/16 dev eth0
ip netns exec $pid1 ip link set eth0 up在这个脚本里,我们先启动一个容器,这里我们用”—network none”的方式来启动,也就是在容器中没有配置任何的网络接口。
接着我们在宿主机 eth0 的接口上增加一个 ipvlan 虚拟网络接口 ipvt1,再把它加入到容器的 Network Namespace 里面,重命名为容器内的 eth0,并且配置上 IP。这样我们就配置好了第一个用 ipvlan 网络接口的容器。
我们可以用同样的方式配置第二个容器,这样两个容器可以相互 ping 一下 IP,看看网络是否配置成功了。脚本你可以在 这里 得到。
两个容器配置好之后,就像下面图中描述的一样了。从这张图里,你很容易就能看出 macvlan/ipvlan 与 veth 网络配置有什么不一样。容器的虚拟网络接口,直接连接在了宿主机的物理网络接口上了,形成了一个网络二层的连接。

如果从容器里向宿主机外发送数据,看上去通过的接口要比 veth 少了,那么实际情况是不是这样呢?我们先来看一下 ipvlan 接口发送数据的代码。
从下面的 ipvlan 接口的发送代码中,我们可以看到,如果是往宿主机外发送数据,发送函数会直接找到 ipvlan 虚拟接口对应的物理网络接口。
比如在我们的例子中,这个物理接口就是宿主机上的 eth0,然后直接调用 dev_queue_xmit(),通过物理接口把数据直接发送出去。
static int ipvlan_xmit_mode_l2(struct sk_buff *skb, struct net_device *dev)
{
…
if (!ipvlan_is_vepa(ipvlan->port) &&
ether_addr_equal(eth->h_dest, eth->h_source)) {
…
} else if (is_multicast_ether_addr(eth->h_dest)) {
…
}
/*
* 对于普通的对外发送数据,上面的if 和 else if中的条件都不成立,
* 所以会执行到这一步,拿到ipvlan对应的物理网路接口设备,
* 然后直接从这个设备发送数据。
*/
skb->dev = ipvlan->phy_dev;
return dev_queue_xmit(skb);
}和 veth 接口相比,我们用 ipvlan 发送对外数据就要简单得多,因为这种方式没有内部额外的 softirq 处理开销。
现在我们还可以看一下,在实际生产环境中,一个应用程序跑在使用 veth 接口的容器中,跟这个应用程序跑在使用 ipvlan 接口的容器中,两者的网络延时差异是怎样的。
下面这张图是网络延时的监控图,图里蓝色的线表示程序运行在 veth 容器中,黄色线表示程序运行在 ipvlan 的容器里,绿色的线代表程序直接运行在物理机上。
从这张延时(Latency)图里,我们可以看到,在 veth 容器里程序的网络延时要明显高一些,而程序在 ipvlan 容器里的网络延时已经比较接近物理机上的网络延时了。
所以对于网络延时敏感的应用程序,我们可以考虑使用 ipvlan/macvlan 的容器网络配置方式来替换缺省的 veth 网络配置。
重点小结
好了,今天的内容讲完了,我们来做个总结。今天我们主要讨论了容器网络接口对容器中应用程序网络延时的影响。
容器通常缺省使用 veth 虚拟网络接口,不过 veth 接口会有比较大的网络延时。我们可以使用 netperf 这个工具来比较网络延时,相比物理机上的网络延时,使用 veth 接口容器的网络延时会增加超过 10%。
我们通过对 veth 实现的代码做分析,可以看到由于 veth 接口是成对工作, 在对外发送数据的时候,peer veth 接口都会 raise softirq 来完成一次收包操作,这样就会带来数据包处理的额外开销。
如果要减小容器网络延时,就可以给容器配置 ipvlan/macvlan 的网络接口来替代 veth 网络接口。Ipvlan/macvlan 直接在物理网络接口上虚拟出接口,在发送对外数据包的时候可以直接通过物理接口完成,没有节点内部类似 veth 的那种 softirq 的开销。 容器使用 ipvlan/maclan 的网络接口,它的网络延时可以非常接近物理网络接口的延时。
对于延时敏感的应用程序,我们可以考虑使用 ipvlan/macvlan 网络接口的容器。不过,由于 ipvlan/macvlan 网络接口直接挂载在物理网络接口上,对于需要使用 iptables 规则的容器,比如 Kubernetes 里使用 service 的容器,就不能工作了。这就需要你结合实际应用的需求做个判断,再选择合适的方案。
18 | 容器网络配置(3):容器中的网络乱序包怎么这么高?
这个问题也同样来自于工作实践,我们的用户把他们的应用程序从物理机迁移到容器之后,从网络监控中发现,容器中数据包的重传的数量要比在物理机里高了不少。
在网络的前面几讲里,我们已经知道了容器网络缺省的接口是 veth,veth 接口都是成对使用的。容器通过 veth 接口向外发送数据,首先需要从 veth 的一个接口发送给跟它成对的另一个接口。
那么这种接口会不会引起更多的网络重传呢?如果会引起重传,原因是什么,我们又要如何解决呢?接下来我们就带着这三个问题开始今天的学习。
问题重现
我们可以在容器里运行一下 iperf3 命令,向容器外部发送一下数据,从 iperf3 的输出”Retr”列里,我们可以看到有多少重传的数据包。
比如下面的例子里,我们可以看到有 162 个重传的数据包。
$ iperf3 -c 192.168.147.51
Connecting to host 192.168.147.51, port 5201
[ 5] local 192.168.225.12 port 51700 connected to 192.168.147.51 port 5201
[ ID] Interval Transfer Bitrate Retr Cwnd
[ 5] 0.00-1.00 sec 1001 MBytes 8.40 Gbits/sec 162 192 KBytes
…
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bitrate Retr
[ 5] 0.00-10.00 sec 9.85 GBytes 8.46 Gbits/sec 162 sender
[ 5] 0.00-10.04 sec 9.85 GBytes 8.42 Gbits/sec receiver
iperf Done.网络中发生了数据包的重传,有可能是数据包在网络中丢了,也有可能是数据包乱序导致的。 那么,我们怎么来判断到底是哪一种情况引起的重传呢?
最直接的方法就是用 tcpdump 去抓包,不过对于大流量的网络,用 tcpdump 抓包瞬间就会有几个 GB 的数据。可是这样做的话,带来的额外系统开销比较大,特别是在生产环境中这个方法也不太好用。
所以这里我们有一个简单的方法,那就是运行 netstat 命令来查看协议栈中的丢包和重传的情况。比如说,在运行上面的 iperf3 命令前后,我们都在容器的 Network Namespace 里运行一下 netstat 看看重传的情况。
我们会发现,一共发生了 162 次(604-442)快速重传(fast retransmits),这个数值和 iperf3 中的 Retr 列里的数值是一样的。
-bash-4.2 $ nsenter -t 51598 -n netstat -s | grep retran
454 segments retransmited
442 fast retransmits
-bash-4.2 $ nsenter -t 51598 -n netstat -s | grep retran
616 segments retransmited
604 fast retransmits问题分析
快速重传(fast retransmit)
在刚才的问题重现里,我们运行 netstat 命令后,统计了快速重传的次数。那什么是快速重传(fast retransmit)呢?这里我给你解释一下。
我们都知道 TCP 协议里,发送端(sender)向接受端(receiver)发送一个数据包,接受端(receiver)都回应 ACK。如果超过一个协议栈规定的时间(RTO),发送端没有收到 ACK 包,那么发送端就会重传(Retransmit)数据包,就像下面的示意图一样。

不过呢,这样等待一个超时之后再重传数据,对于实际应用来说太慢了,所以 TCP 协议又定义了快速重传 (fast retransmit)的概念。它的基本定义是这样的: 如果发送端收到 3 个重复的 ACK,那么发送端就可以立刻重新发送 ACK 对应的下一个数据包。
就像下面示意图里描述的那样,接受端没有收到 Seq 2 这个包,但是收到了 Seq 3-5 的数据包,那么接收端在回应 Ack 的时候,Ack 的数值只能是 2。这是因为按顺序来说收到 Seq 1 的包之后,后面 Seq 2 一直没有到,所以接收端就只能一直发送 Ack 2。
那么当发送端收到 3 个重复的 Ack 2 后,就可以马上重新发送 Seq 2 这个数据包了,而不用再等到重传超时之后了。

虽然 TCP 快速重传的标准定义是需要收到 3 个重复的 Ack,不过你会发现在 Linux 中常常收到一个 Dup Ack(重复的 Ack)后,就马上重传数据了。这是什么原因呢?
这里先需要提到 SACK 这个概念,SACK 也就是选择性确认(Selective Acknowledgement)。其实跟普通的 ACK 相比呢,SACK 会把接收端收到的所有包的序列信息,都反馈给发送端。
你看看下面这张图,就能明白这是什么意思了。
那有了 SACK,对于发送端来说,在收到 SACK 之后就已经知道接收端收到了哪些数据,没有收到哪些数据。
在 Linux 内核中会有个判断(你可以看看下面的这个函数),大概意思是这样的:如果在接收端收到的数据和还没有收到的数据之间,两者数据量差得太大的话(超过了 reordering*mss_cache),也可以马上重传数据。
这里你需要注意一下, 这里的数据量差是根据 bytes 来计算的,而不是按照包的数目来计算的,所以你会看到即使只收到一个 SACK,Linux 也可以重发数据包。
static bool tcp_force_fast_retransmit(struct sock *sk)
{
struct tcp_sock *tp = tcp_sk(sk);
return after(tcp_highest_sack_seq(tp),
tp->snd_una + tp->reordering * tp->mss_cache);
}好了,了解了快速重传的概念之后,我们再来看看,如果 netstat 中有大量的”fast retransmits”意味着什么?
如果你再用 netstat 查看”reordering”,就可以看到大量的 SACK 发现的乱序包。
-bash-4.2 $ nsenter -t 51598 -n netstat -s | grep reordering
Detected reordering 501067 times using SACK其实在云平台的这种网络环境里,网络包乱序 +SACK 之后,产生的数据包重传的量要远远高于网络丢包引起的重传。
比如说像下面这张图里展示的这样,Seq 2 与 Seq 3 这两个包如果乱序的话,那么就会引起 Seq 2 的立刻重传。
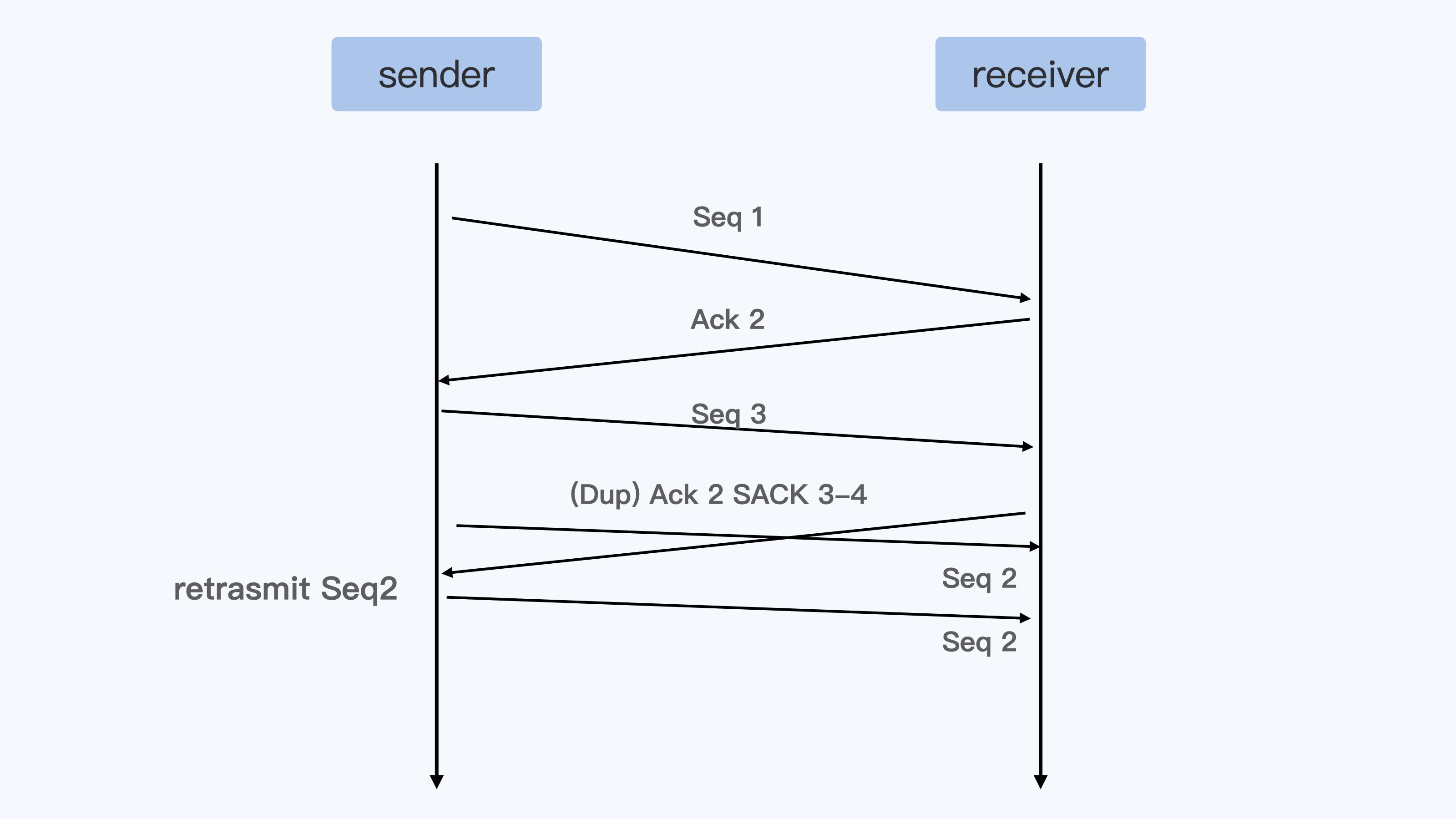
Veth 接口的数据包的发送
现在我们知道了网络包乱序会造成数据包的重传,接着我们再来看看容器的 veth 接口配置有没有可能会引起数据包的乱序。
在上一讲里,我们讲过通过 veth 接口从容器向外发送数据包,会触发 peer veth 设备去接收数据包,这个接收的过程就是一个网络的 softirq 的处理过程。
在触发 softirq 之前,veth 接口会模拟硬件接收数据的过程,通过 enqueue_to_backlog() 函数把数据包放到某个 CPU 对应的数据包队列里(softnet_data)。
static int netif_rx_internal(struct sk_buff *skb)
{
int ret;
net_timestamp_check(netdev_tstamp_prequeue, skb);
trace_netif_rx(skb);
#ifdef CONFIG_RPS
if (static_branch_unlikely(&rps_needed)) {
struct rps_dev_flow voidflow, *rflow = &voidflow;
int cpu;
preempt_disable();
rcu_read_lock();
cpu = get_rps_cpu(skb->dev, skb, &rflow);
if (cpu < 0)
cpu = smp_processor_id();
ret = enqueue_to_backlog(skb, cpu, &rflow->last_qtail);
rcu_read_unlock();
preempt_enable();
} else
#endif
{
unsigned int qtail;
ret = enqueue_to_backlog(skb, get_cpu(), &qtail);
put_cpu();
}
return ret;
}从上面的代码,我们可以看到,在缺省的状况下(也就是没有 RPS 的情况下),enqueue_to_backlog() 把数据包放到了”当前运行的 CPU”(get_cpu())对应的数据队列中。如果是从容器里通过 veth 对外发送数据包,那么这个”当前运行的 CPU”就是容器中发送数据的进程所在的 CPU。
对于多核的系统,这个发送数据的进程可以在多个 CPU 上切换运行。进程在不同的 CPU 上把数据放入队列并且 raise softirq 之后,因为每个 CPU 上处理 softirq 是个异步操作,所以两个 CPU network softirq handler 处理这个进程的数据包时,处理的先后顺序并不能保证。
所以,veth 对的这种发送数据方式增加了容器向外发送数据出现乱序的几率。
RSS 和 RPS
那么对于 veth 接口的这种发包方式,有办法减少一下乱序的几率吗?
其实,我们在上面 netif_rx_internal() 那段代码中,有一段在”#ifdef CONFIG_RPS”中的代码。
我们看到这段代码中在调用 enqueue_to_backlog() 的时候,传入的 CPU 并不是当前运行的 CPU,而是通过 get_rps_cpu() 得到的 CPU,那么这会有什么不同呢?这里的 RPS 又是什么意思呢?
要解释 RPS 呢,需要先看一下 RSS,这个 RSS 不是我们之前说的内存 RSS,而是和网卡硬件相关的一个概念,它是 Receive Side Scaling 的缩写。
现在的网卡性能越来越强劲了,从原来一条 RX 队列扩展到了 N 条 RX 队列,而网卡的硬件中断也从一个硬件中断,变成了每条 RX 队列都会有一个硬件中断。
每个硬件中断可以由一个 CPU 来处理,那么对于多核的系统,多个 CPU 可以并行的接收网络包,这样就大大地提高了系统的网络数据的处理能力.
同时,在网卡硬件中,可以根据数据包的 4 元组或者 5 元组信息来保证同一个数据流,比如一个 TCP 流的数据始终在一个 RX 队列中,这样也能保证同一流不会出现乱序的情况。
下面这张图,大致描述了一下 RSS 是怎么工作的。

RSS 的实现在网卡硬件和驱动里面,而 RPS(Receive Packet Steering)其实就是在软件层面实现类似的功能。它主要实现的代码框架就在上面的 netif_rx_internal() 代码里,原理也不难。
就像下面的这张示意图里描述的这样:在硬件中断后,CPU2 收到了数据包,再一次对数据包计算一次四元组的 hash 值,得到这个数据包与 CPU1 的映射关系。接着会把这个数据包放到 CPU1 对应的 softnet_data 数据队列中,同时向 CPU1 发送一个 IPI 的中断信号。
这样一来,后面 CPU1 就会继续按照 Netowrk softirq 的方式来处理这个数据包了。
RSS 和 RPS 的目的都是把数据包分散到更多的 CPU 上进行处理,使得系统有更强的网络包处理能力。在把数据包分散到各个 CPU 时,保证了同一个数据流在一个 CPU 上,这样就可以减少包的乱序。
明白了 RPS 的概念之后,我们再回头来看 veth 对外发送数据时候,在 enqueue_to_backlog() 的时候选择 CPU 的问题。显然,如果对应的 veth 接口上打开了 RPS 的配置以后,那么对于同一个数据流,就可以始终选择同一个 CPU 了。
其实我们打开 RPS 的方法挺简单的,只要去 /sys 目录下,在网络接口设备接收队列中修改队列里的 rps_cpus 的值,这样就可以了。rps_cpus 是一个 16 进制的数,每个 bit 代表一个 CPU。
比如说,我们在一个 12CPU 的节点上,想让 host 上的 veth 接口在所有的 12 个 CPU 上,都可以通过 RPS 重新分配数据包。那么就可以执行下面这段命令:
$ cat /sys/devices/virtual/net/veth57703b6/queues/rx-0/rps_cpus
000
$ echo fff > /sys/devices/virtual/net/veth57703b6/queues/rx-0/rps_cpus
$ cat /sys/devices/virtual/net/veth57703b6/queues/rx-0/rps_cpus
fff重点小结
由于在容器平台中看到大部分的重传是快速重传(fast retransmits),我们先梳理了什么是快速重传。快速重传的基本定义是: 如果发送端收到 3 个重复的 ACK,那么发送端就可以立刻重新发送 ACK 对应的下一个数据包,而不用等待发送超时。
不过我们在 Linux 系统上还会看到发送端收到一个重复的 ACK 就快速重传的,这是因为 Linux 下对 SACK 做了一个特别的判断之后,就可以立刻重传数据包。
我们再对容器云平台中的快速重传做分析,就会发现这些重传大部分是由包的乱序触发的。
通过对容器 veth 网络接口进一步研究,我们知道它可能会增加数据包乱序的几率。同时在这个分析过程中,我们也看到了 Linux 网络 RPS 的特性。
RPS 和 RSS 的作用类似,都是把数据包分散到更多的 CPU 上进行处理,使得系统有更强的网络包处理能力。它们的区别是 RSS 工作在网卡的硬件层,而 RPS 工作在 Linux 内核的软件层。
在把数据包分散到各个 CPU 时,RPS 保证了同一个数据流是在一个 CPU 上的,这样就可以有效减少包的乱序。那么我们可以把 RPS 的这个特性配置到 veth 网络接口上,来减少数据包乱序的几率。
不过,我这里还要说明的是,RPS 的配置还是会带来额外的系统开销,在某些网络环境中会引起 softirq CPU 使用率的增大。那接口要不要打开 RPS 呢?这个问题你需要根据实际情况来做个权衡。
同时你还要注意,TCP 的乱序包,并不一定都会产生数据包的重传。想要减少网络数据包的重传,我们还可以考虑协议栈中其他参数的设置,比如 /proc/sys/net/ipv4/tcp_reordering。
容器安全
19 | 容器安全(1):我的容器真的需要privileged权限吗?
容器安全是一个很大的话题,容器的安全性很大程度是由容器的架构特性所决定的。比如容器与宿主机共享 Linux 内核,通过 Namespace 来做资源的隔离,通过 shim/runC 的方式来启动等等。
这些容器架构特性,在你选择使用容器之后,作为使用容器的用户,其实你已经没有多少能力去对架构这个层面做安全上的改动了。你可能会说用 Kata Container 、 gVisor 就是安全”容器”了。不过,Kata 或者 gVisor 只是兼容了容器接口标准,而内部的实现完全是另外的技术了。
那么对于使用容器的用户,在运行容器的时候,在安全方面可以做些什么呢?我们主要可以从这两个方面来考虑:第一是赋予容器合理的 capabilities,第二是在容器中以非 root 用户来运行程序。
为什么是这两点呢?我通过两讲的内容和你讨论一下,这一讲我们先来看容器的 capabilities 的问题。
问题再现
刚刚使用容器的同学,往往会发现用缺省 docker run的方式启动容器后,在容器里很多操作都是不允许的,即使是以 root 用户来运行程序也不行。
我们用下面的 例子 来重现一下这个问题。我们先运行make image 做个容器镜像,然后运行下面的脚本:
$ docker run --name iptables -it registry/iptables:v1 bash
[root@0b88d6486149 /]$ iptables -L
iptables v1.8.4 (nf_tables): Could not fetch rule set generation id: Permission denied (you must be root)
[root@0b88d6486149 /]$ id
uid=0(root) gid=0(root) groups=0(root)在这里,我们想在容器中运行 iptables 这个命令,来查看一下防火墙的规则,但是执行命令之后,你会发现结果输出中给出了”Permission denied (you must be root)”的错误提示,这个提示要求我们用 root 用户来运行。
不过在容器中,我们现在已经是以 root 用户来运行了,么为什么还是不可以运行”iptables”这条命令呢?
你肯定会想到,是不是容器中又做了别的权限限制?如果你去查一下资料,就会看到启动容器有一个”privileged”的参数。我们可以试一下用上这个参数,没错,我们用了这个参数之后,iptables 这个命令就执行成功了。
$ docker stop iptables;docker rm iptables
iptables
iptables
$ docker run --name iptables --privileged -it registry/iptables:v1 bash
[root@44168f4b9b24 /]# iptables -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination看上去,我们用了一个配置参数就已经解决了问题,似乎很容易。不过这里我们可以进一步想想,用”privileged”参数来解决问题,是不是一个合理的方法呢?用它会有什么问题吗?
要回答这些问题,我们先来了解一下”privileged”是什么意思。从 Docker 的 代码 里,我们可以看到,如果配置了 privileged 的参数的话,就会获取所有的 capabilities,那什么是 capabilities 呢?
if ec.Privileged {
p.Capabilities = caps.GetAllCapabilities()
}基本概念
Linux capabilities
要了解 Linux capabilities 的定义,我们可以先查看一下”Linux Programmer’s Manual”中关于 Linux capabilities 的描述。
在 Linux capabilities 出现前,进程的权限可以简单分为两类,第一类是特权用户的进程(进程的有效用户 ID 是 0,简单来说,你可以认为它就是 root 用户的进程),第二类是非特权用户的进程(进程的有效用户 ID 是非 0,可以理解为非 root 用户进程)。
特权用户进程可以执行 Linux 系统上的所有操作,而非特权用户在执行某些操作的时候就会被内核限制执行。其实这个概念,也是我们通常对 Linux 中 root 用户与非 root 用户的理解。
从 kernel 2.2 开始,Linux 把特权用户所有的这些”特权”做了更详细的划分,这样被划分出来的每个单元就被称为 capability。
所有的 capabilities 都在 Linux capabilities 的手册列出来了,你也可以在内核的文件 capability.h 中看到所有 capabilities 的定义。
对于任意一个进程,在做任意一个特权操作的时候,都需要有这个特权操作对应的 capability。
比如说,运行 iptables 命令,对应的进程需要有 CAP_NET_ADMIN 这个 capability。如果要 mount 一个文件系统,那么对应的进程需要有 CAP_SYS_ADMIN 这个 capability。
我还要提醒你的是,CAP_SYS_ADMIN 这个 capability 里允许了大量的特权操作,包括文件系统,交换空间,还有对各种设备的操作,以及系统调试相关的调用等等。
在普通 Linux 节点上,非 root 用户启动的进程缺省没有任何 Linux capabilities,而 root 用户启动的进程缺省包含了所有的 Linux capabilities。
我们可以做个试验,对于 root 用户启动的进程,如果把 CAP_NET_ADMIN 这个 capability 移除,看看它是否还可以运行 iptables。
在这里我们要用到 capsh 这个工具,对这个工具不熟悉的同学可以查看超链接。接下来,我们就用 capsh 执行下面的这个命令:
$ sudo /usr/sbin/capsh --keep=1 --user=root --drop=cap_net_admin -- -c './iptables -L;sleep 100'
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
iptables: Permission denied (you must be root).这时候,我们可以看到即使是 root 用户,如果把”CAP_NET_ADMIN”给移除了,那么在执行 iptables 的时候就会看到”Permission denied (you must be root).”的提示信息。
同时,我们可以通过 /proc 文件系统找到对应进程的 status,这样就能确认进程中的 CAP_NET_ADMIN 是否已经被移除了。
$ ps -ef | grep sleep
root 22603 22275 0 19:44 pts/1 00:00:00 sudo /usr/sbin/capsh --keep=1 --user=root --drop=cap_net_admin -- -c ./iptables -L;sleep 100
root 22604 22603 0 19:44 pts/1 00:00:00 /bin/bash -c ./iptables -L;sleep 100
$ cat /proc/22604/status | grep Cap
CapInh: 0000000000000000
CapPrm: 0000003fffffefff
CapEff: 0000003fffffefff
CapBnd: 0000003fffffefff
CapAmb: 0000000000000000运行上面的命令查看 /proc//status 里 Linux capabilities 的相关参数之后,我们可以发现,输出结果中包含 5 个 Cap 参数。
这里我给你解释一下, 对于当前进程,直接影响某个特权操作是否可以被执行的参数,是”CapEff”,也就是”Effective capability sets”,这是一个 bitmap,每一个 bit 代表一项 capability 是否被打开。
在 Linux 内核 capability.h 里把 CAP_NET_ADMIN 的值定义成 12,所以我们可以看到”CapEff”的值是”0000003fffffefff”,第 4 个数值是 16 进制的”e”,而不是 f。
这表示 CAP_NET_ADMIN 对应的第 12-bit 没有被置位了(0xefff = 0xffff & (~(1 << 12))),所以这个进程也就没有执行 iptables 命令的权限了。
对于进程 status 中其他几个 capabilities 相关的参数,它们还需要和应用程序文件属性中的 capabilities 协同工作,这样才能得到新启动的进程最终的 capabilities 参数的值。
我们看下面的图,结合这张图看后面的讲解:
如果我们要新启动一个程序,在 Linux 里的过程就是先通过 fork() 来创建出一个子进程,然后调用 execve() 系统调用读取文件系统里的程序文件,把程序文件加载到进程的代码段中开始运行。
就像图片所描绘的那样,这个新运行的进程里的相关 capabilities 参数的值,是由它的父进程以及程序文件中的 capabilities 参数值计算得来的。
具体的计算过程你可以看 Linux capabilities 的手册中的描述,也可以读一下网上的这两篇文章:
我就不对所有的进程和文件的 capabilities 集合参数和算法挨个做解释了,感兴趣的话你可以自己详细去看看。
这里你只要记住最重要的一点, 文件中可以设置 capabilities 参数值,并且这个值会影响到最后运行它的进程。 比如,我们如果把 iptables 的应用程序加上 CAP_NET_ADMIN 的 capability,那么即使是非 root 用户也有执行 iptables 的权限了。
$ id
uid=1000(centos) gid=1000(centos) groups=1000(centos),10(wheel)
$ sudo setcap cap_net_admin+ep ./iptables
$ getcap ./iptables
./iptables = cap_net_admin+ep
$./iptables -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain FORWARD (policy ACCEPT)
target prot opt source destination
DOCKER-USER all -- anywhere anywhere
DOCKER-ISOLATION-STAGE-1 all -- anywhere anywhere
ACCEPT all -- anywhere anywhere ctstate RELATED,ESTABLISHED
DOCKER all -- anywhere anywhere
ACCEPT all -- anywhere anywhere
ACCEPT all -- anywhere anywhere
…好了,关于 Linux capabilities 的内容到这里我们就讲完了,其实它就是把 Linux root 用户原来所有的特权做了细化,可以更加细粒度地给进程赋予不同权限。
解决问题
我们搞懂了 Linux capabilities 之后,那么对 privileged 的容器也很容易理解了。 Privileged 的容器也就是允许容器中的进程可以执行所有的特权操作。
因为安全方面的考虑,容器缺省启动的时候,哪怕是容器中 root 用户的进程,系统也只允许了 15 个 capabilities。这个你可以查看 runC spec 文档中的 security 部分,你也可以查看容器 init 进程 status 里的 Cap 参数,看一下容器中缺省的 capabilities。
$ docker run --name iptables -it registry/iptables:v1 bash
[root@e54694652a42 /]$ cat /proc/1/status |grep Cap
CapInh: 00000000a80425fb
CapPrm: 00000000a80425fb
CapEff: 00000000a80425fb
CapBnd: 00000000a80425fb
CapAmb: 0000000000000000我想提醒你,当我们发现容器中运行某个程序的权限不够的时候,并不能”偷懒”把容器设置为”privileged”,也就是把所有的 capabilities 都赋予了容器。
因为容器中的权限越高,对系统安全的威胁显然也是越大的。比如说,如果容器中的进程有了 CAP_SYS_ADMIN 的特权之后,那么这些进程就可以在容器里直接访问磁盘设备,直接可以读取或者修改宿主机上的所有文件了。
所以,在容器平台上是基本不允许把容器直接设置为”privileged”的,我们需要根据容器中进程需要的最少特权来赋予 capabilities。
我们结合这一讲开始的例子来说说。在开头的例子中,容器里需要使用 iptables。因为使用 iptables 命令,只需要设置 CAP_NET_ADMIN 这个 capability 就行。那么我们只要在运行 Docker 的时候,给这个容器再多加一个 NET_ADMIN 参数就可以了。
$ docker run --name iptables --cap-add NET_ADMIN -it registry/iptables:v1 bash
[root@cfedf124dcf1 /]$ iptables -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination重点小结
这一讲我们主要学习了如何给容器赋予合理的 capabilities。
那么,我们自然需要先来理解什么是 Linux capabilities。 其实 Linux capabilities 就是把 Linux root 用户原来所有的特权做了细化,可以更加细粒度地给进程赋予不同权限。
对于 Linux 中的每一个特权操作都有一个对应的 capability,对于一个 capability,有的对应一个特权操作,有的可以对应很多个特权操作。
每个 Linux 进程有 5 个 capabilities 集合参数,其中 Effective 集合里的 capabilities 决定了当前进程可以做哪些特权操作,而其他集合参数会和应用程序文件的 capabilities 集合参数一起来决定新启动程序的 capabilities 集合参数。
对于容器的 root 用户,缺省只赋予了 15 个 capabilities。如果我们发现容器中进程的权限不够,就需要分析它需要的最小 capabilities 集合,而不是直接赋予容器”privileged”。
因为”privileged”包含了所有的 Linux capabilities, 这样”privileged”就可以轻易获取宿主机上的所有资源,这会对宿主机的安全产生威胁。所以,我们要根据容器中进程需要的最少特权来赋予 capabilities。
思考题
你可以查看一下你的 Linux 系统里 ping 程序文件有哪些 capabilities,看看有什么办法,能让 Linux 普通用户没有执行 ping 的能力。
答:
getcap $(which ping)
/usr/bin/ping = cap_net_raw+ep20 | 容器安全(2):在容器中,我不以root用户来运行程序可以吗?
在 上一讲 里,我们学习了 Linux capabilities 的概念,也知道了对于非 privileged 的容器,容器中 root 用户的 capabilities 是有限制的,因此容器中的 root 用户无法像宿主机上的 root 用户一样,拿到完全掌控系统的特权。
那么是不是让非 privileged 的容器以 root 用户来运行程序,这样就能保证安全了呢?这一讲,我们就来聊一聊容器中的 root 用户与安全相关的问题。
问题再现
说到容器中的用户(user),你可能会想到,在 Linux Namespace 中有一项隔离技术,也就是 User Namespace。
不过在容器云平台 Kubernetes 上目前还不支持 User Namespace,所以我们先来看看在没有 User Namespace 的情况下,容器中用 root 用户运行,会发生什么情况。
首先,我们可以用下面的命令启动一个容器,在这里,我们把宿主机上 /etc 目录以 volume 的形式挂载到了容器中的 /mnt 目录下面。
docker run -d --name root_example -v /etc:/mnt centos sleep 3600然后,我们可以看一下容器中的进程”sleep 3600”,它在容器中和宿主机上的用户都是 root,也就是说,容器中用户的 uid/gid 和宿主机上的完全一样。
$ docker exec -it root_example bash -c "ps -ef | grep sleep"
root 1 0 0 01:14 ? 00:00:00 /usr/bin/coreutils --coreutils-prog-shebang=sleep /usr/bin/sleep 3600
$ ps -ef | grep sleep
root 5473 5443 0 18:14 ? 00:00:00 /usr/bin/coreutils --coreutils-prog-shebang=sleep /usr/bin/sleep 3600虽然容器里 root 用户的 capabilities 被限制了一些,但是在容器中,对于被挂载上来的 /etc 目录下的文件,比如说 shadow 文件,以这个 root 用户的权限还是可以做修改的。
$ docker exec -it root_example bash
[root@9c7b76232c19 /]$ ls /mnt/shadow -l
---------- 1 root root 586 Nov 26 13:47 /mnt/shadow
[root@9c7b76232c19 /]$ echo "hello" >> /mnt/shadow接着我们看看后面这段命令输出,可以确认在宿主机上文件被修改了。
$ tail -n 3 /etc/shadow
grafana:!!:18437::::::
tcpdump:!!:18592::::::
hello这个例子说明容器中的 root 用户也有权限修改宿主机上的关键文件。
当然在云平台上,比如说在 Kubernetes 里,我们是可以限制容器去挂载宿主机的目录的。
不过,由于容器和宿主机是共享 Linux 内核的,一旦软件有漏洞,那么容器中以 root 用户运行的进程就有机会去修改宿主机上的文件了。比如 2019 年发现的一个 RunC 的漏洞 CVE-2019-5736 , 这导致容器中 root 用户有机会修改宿主机上的 RunC 程序,并且容器中的 root 用户还会得到宿主机上的运行权限。
问题分析
对于前面的问题,接下来我们就来讨论一下 解决办法 ,在讨论问题的过程中,也会涉及一些新的概念,主要有三个。
方法一:Run as non-root user(给容器指定一个普通用户)
我们如果不想让容器以 root 用户运行,最直接的办法就是给容器指定一个普通用户 uid。这个方法很简单,比如可以在 docker 启动容器的时候加上”-u”参数,在参数中指定 uid/gid。
具体的操作代码如下:
$ docker run -ti --name root_example -u 6667:6667 -v /etc:/mnt centos bash
bash-4.4$ id
uid=6667 gid=6667 groups=6667
bash-4.4$ ps -ef
UID PID PPID C STIME TTY TIME CMD
6667 1 0 1 01:27 pts/0 00:00:00 bash
6667 8 1 0 01:27 pts/0 00:00:00 ps -ef还有另外一个办法,就是我们在创建容器镜像的时候,用 Dockerfile 为容器镜像里建立一个用户。
为了方便你理解,我还是举例说明。就像下面例子中的 nonroot,它是一个用户名,我们用 USER 关键字来指定这个 nonroot 用户,这样操作以后,容器里缺省的进程都会以这个用户启动。
这样在运行 Docker 命令的时候就不用加”-u”参数来指定用户了。
$ cat Dockerfile
FROM centos
RUN adduser -u 6667 nonroot
USER nonroot
$ docker build -t registry/nonroot:v1 .
…
$ docker run -d --name root_example -v /etc:/mnt registry/nonroot:v1 sleep 3600
050809a716ab0a9481a6dfe711b332f74800eff5fea8b4c483fa370b62b4b9b3
$ docker exec -it root_example bash
[nonroot@050809a716ab /]$ id
uid=6667(nonroot) gid=6667(nonroot) groups=6667(nonroot)
[nonroot@050809a716ab /]$ ps -ef
UID PID PPID C STIME TTY TIME CMD
nonroot 1 0 0 01:43 ? 00:00:00 /usr/bin/coreutils --coreutils-prog-shebang=sleep /usr/bin/sleep 3600好,在容器中使用普通用户运行之后,我们再看看,现在能否修改被挂载上来的 /etc 目录下的文件? 显然,现在不可以修改了。
[nonroot@050809a716ab /]$ echo "hello" >> /mnt/shadow
bash: /mnt/shadow: Permission denied那么是不是只要给容器中指定了一个普通用户,这个问题就圆满解决了呢?其实在云平台上,这么做还是会带来别的问题,我们一起来看看。
由于用户 uid 是整个节点中共享的,那么在容器中定义的 uid,也就是宿主机上的 uid,这样就很容易引起 uid 的冲突。
比如说,多个客户在建立自己的容器镜像的时候都选择了同一个 uid 6667。那么当多个客户的容器在同一个节点上运行的时候,其实就都使用了宿主机上 uid 6667。
我们都知道,在一台 Linux 系统上,每个用户下的资源是有限制的,比如打开文件数目(open files)、最大进程数目(max user processes)等等。一旦有很多个容器共享一个 uid,这些容器就很可能很快消耗掉这个 uid 下的资源,这样很容易导致这些容器都不能再正常工作。
要解决这个问题,必须要有一个云平台级别的 uid 管理和分配,但选择这个方法也要付出代价。因为这样做是可以解决问题,但是用户在定义自己容器中的 uid 的时候,他们就需要有额外的操作,而且平台也需要新开发对 uid 平台级别的管理模块,完成这些事情需要的工作量也不少。
方法二:User Namespace(用户隔离技术的支持)
那么在没有使用 User Namespace 的情况,对于容器平台上的用户管理还是存在问题。你可能会想到,我们是不是应该去尝试一下 User Namespace?
好的,我们就一起来看看使用 User Namespace 对解决用户管理问题有没有帮助。首先,我们简单了解一下 User Namespace 的概念。
User Namespace 隔离了一台 Linux 节点上的 User ID(uid)和 Group ID(gid),它给 Namespace 中的 uid/gid 的值与宿主机上的 uid/gid 值建立了一个映射关系。经过 User Namespace 的隔离,我们在 Namespace 中看到的进程的 uid/gid,就和宿主机 Namespace 中看到的 uid 和 gid 不一样了。
你可以看下面的这张示意图,应该就能很快知道 User Namespace 大概是什么意思了。比如 namespace_1 里的 uid 值是 0 到 999,但其实它在宿主机上对应的 uid 值是 1000 到 1999。
还有一点你要注意的是,User Namespace 是可以嵌套的,比如下面图里的 namespace_2 里可以再建立一个 namespace_3,这个嵌套的特性是其他 Namespace 没有的。
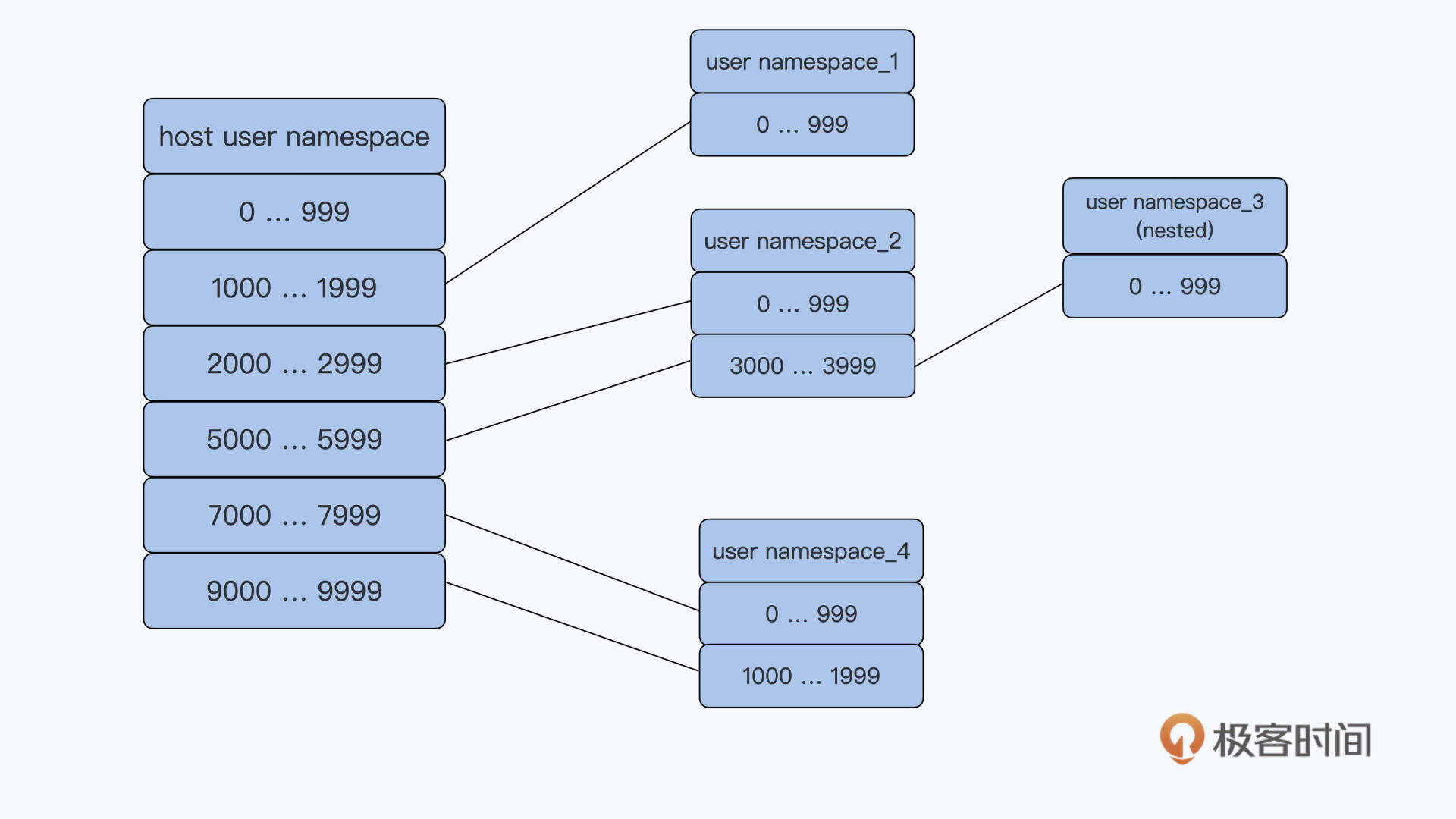
我们可以启动一个带 User Namespace 的容器来感受一下。这次启动容器,我们用一下 podman 这个工具,而不是 Docker。
跟 Docker 相比,podman 不再有守护进程 dockerd,而是直接通过 fork/execve 的方式来启动一个新的容器。这种方式启动容器更加简单,也更容易维护。
Podman 的命令参数兼容了绝大部分的 docker 命令行参数,用过 Docker 的同学也很容易上手 podman。你感兴趣的话,可以跟着这个 手册 在你自己的 Linux 系统上装一下 podman。
那接下来,我们就用下面的命令来启动一个容器:
我们可以看到,其他参数和前面的 Docker 命令是一样的。
这里我们在命令里增加一个参数,”—uidmap 0:2000:1000”,这个是标准的 User Namespace 中 uid 的映射格式:”ns_uid:host_uid:amount”。
那这个例子里的”0:2000:1000”是什么意思呢?我给你解释一下。
第一个 0 是指在新的 Namespace 里 uid 从 0 开始,中间的那个 2000 指的是 Host Namespace 里被映射的 uid 从 2000 开始,最后一个 1000 是指总共需要连续映射 1000 个 uid。
所以,我们可以得出,这个容器里的 uid 0 是被映射到宿主机上的 uid 2000 的。这一点我们可以验证一下。
首先,我们先在容器中以用户 uid 0 运行一下 sleep 这个命令:
$ id
uid=0(root) gid=0(root) groups=0(root)
$ sleep 3600然后就是第二步,到宿主机上查看一下这个进程的 uid。这里我们可以看到,进程 uid 的确是 2000 了。
$ ps -ef |grep sleep
2000 27021 26957 0 01:32 pts/0 00:00:00 /usr/bin/coreutils --coreutils-prog-shebang=sleep /usr/bin/sleep 3600第三步,我们可以再回到容器中,仍然以容器中的 root 对被挂载上来的 /etc 目录下的文件做操作,这时可以看到操作是不被允许的。
$ echo "hello" >> /mnt/shadow
bash: /mnt/shadow: Permission denied
$ id
uid=0(root) gid=0(root) groups=0(root)好了,通过这些操作以及和前面 User Namespace 的概念的解释,我们可以总结出容器使用 User Namespace 有两个好处。
第一,它把容器中 root 用户(uid 0)映射成宿主机上的普通用户。
作为容器中的 root,它还是可以有一些 Linux capabilities,那么在容器中还是可以执行一些特权的操作。而在宿主机上 uid 是普通用户,那么即使这个用户逃逸出容器 Namespace,它的执行权限还是有限的。
第二,对于用户在容器中自己定义普通用户 uid 的情况,我们只要为每个容器在节点上分配一个 uid 范围,就不会出现在宿主机上 uid 冲突的问题了。
因为在这个时候,我们只要在节点上分配容器的 uid 范围就可以了,所以从实现上说,相比在整个平台层面给容器分配 uid,使用 User Namespace 这个办法要方便得多。
这里我额外补充一下,前面我们说了 Kubernetes 目前还不支持 User Namespace,如果你想了解相关工作的进展,可以看一下社区的这个 PR 。
方法三:rootless container(以非 root 用户启动和管理容器)
前面我们已经讨论了,在容器中以非 root 用户运行进程可以降低容器的安全风险。除了在容器中使用非 root 用户,社区还有一个 rootless container 的概念。
这里 rootless container 中的”rootless”不仅仅指容器中以非 root 用户来运行进程,还指以非 root 用户来创建容器,管理容器。也就是说,启动容器的时候,Docker 或者 podman 是以非 root 用户来执行的。
这样一来,就能进一步提升容器中的安全性,我们不用再担心因为 containerd 或者 RunC 里的代码漏洞,导致容器获得宿主机上的权限。
我们可以参考 redhat blog 里的 这篇文档 , 在宿主机上用 redhat 这个用户通过 podman 来启动一个容器。在这个容器中也使用了 User Namespace,并且把容器中的 uid 0 映射为宿主机上的 redhat 用户了。
$ id
uid=1001(redhat) gid=1001(redhat) groups=1001(redhat)
$ podman run -it ubi7/ubi bash ### 在宿主机上以redhat用户启动容器
[root@206f6d5cb033 /]$ id ### 容器中的用户是root
uid=0(root) gid=0(root) groups=0(root)
[root@206f6d5cb033 /]$ sleep 3600 ### 在容器中启动一个sleep 进程$ ps -ef |grep sleep ###在宿主机上查看容器sleep进程对应的用户
redhat 29433 29410 0 05:14 pts/0 00:00:00 sleep 3600目前 Docker 和 podman 都支持了 rootless container,Kubernetes 对 rootless container 支持 的工作也在进行中。
重点小结
我们今天讨论的内容是 root 用户与容器安全的问题。
尽管容器中 root 用户的 Linux capabilities 已经减少了很多,但是在没有 User Namespace 的情况下,容器中 root 用户和宿主机上的 root 用户的 uid 是完全相同的,一旦有软件的漏洞,容器中的 root 用户就可以操控整个宿主机。
为了减少安全风险,业界都是建议在容器中以非 root 用户来运行进程。不过在没有 User Namespace 的情况下,在容器中使用非 root 用户,对于容器云平台来说,对 uid 的管理会比较麻烦。
所以,我们还是要分析一下 User Namespace,它带来的好处有两个。一个是把容器中 root 用户(uid 0)映射成宿主机上的普通用户,另外一个好处是在云平台里对于容器 uid 的分配要容易些。
除了在容器中以非 root 用户来运行进程外,Docker 和 podman 都支持了 rootless container,也就是说它们都可以以非 root 用户来启动和管理容器,这样就进一步降低了容器的安全风险。
专题加餐
加餐01 | 案例分析:怎么解决海量IPVS规则带来的网络延时抖动问题?
今天,我们进入到了加餐专题部分。我在结束语的彩蛋里就和你说过,在这个加餐案例中,我们会用到 perf、ftrace、bcc/ebpf 这几个 Linux 调试工具,了解它们的原理,熟悉它们在调试问题的不同阶段所发挥的作用。
加餐内容我是这样安排的,专题的第 1 讲我先完整交代这个案例的背景,带你回顾我们当时整个的调试过程和思路,然后用 5 讲内容,对这个案例中用到的调试工具依次进行详细讲解。
好了,话不多说。这一讲,我们先来整体看一下这个容器网络延时的案例。
问题的背景
在 2020 年初的时候,我们的一个用户把他们的应用从虚拟机迁移到了 Kubernetes 平台上。迁移之后,用户发现他们的应用在容器中的出错率很高,相比在之前虚拟机上的出错率要高出一个数量级。
那为什么会有这么大的差别呢?我们首先分析了应用程序的出错日志,发现在 Kubernetes 平台上,几乎所有的出错都是因为网络超时导致的。
经过网络环境排查和比对测试,我们排除了网络设备上的问题,那么这个超时就只能是容器和宿主机上的问题了。
这里要先和你说明的是,尽管应用程序的出错率在容器中比在虚拟机里高出一个数量级,不过这个出错比例仍然是非常低的,在虚拟机中的出错率是 0.001%,而在容器中的出错率是 0.01%~0.04%。
因为这个出错率还是很低,所以对于这种低概率事件,我们想复现和排查问题,难度就很大了。
当时我们查看了一些日常的节点监控数据,比如 CPU 使用率、Load Average、内存使用、网络流量和丢包数量、磁盘 I/O,发现从这些数据中都看不到任何的异常。
既然常规手段无效,那我们应该如何下手去调试这个问题呢?
你可能会想到用 tcpdump 看一看,因为它是网络抓包最常见的工具。其实我们当时也这样想过,不过马上就被自己否定了,因为这个方法存在下面三个问题。
第一,我们遇到的延时问题是偶尔延时,所以需要长时间地抓取数据,这样抓取的数据量就会很大。
第二,在抓完数据之后,需要单独设计一套分析程序来找到长延时的数据包。
第三,即使我们找到了长延时的数据包,也只是从实际的数据包层面证实了问题。但是这样做无法取得新进展,也无法帮助我们发现案例中网络超时的根本原因。
调试过程
对于这种非常偶然的延时问题,之前我们能做的是依靠经验,去查看一些可疑点碰碰”运气”。
不过这一次,我们想用更加系统的方法来调试这个问题。所以接下来,我会从 ebpf 破冰,perf 进一步定位以及用 ftrace 最终锁定这三个步骤,带你一步步去解决这个复杂的网络延时问题。
ebpf 的破冰
我们的想法是这样的:因为延时产生在节点上,所以可以推测,这个延时有很大的概率发生在 Linux 内核处理数据包的过程中。
沿着这个思路,还需要进一步探索。我们想到,可以给每个数据包在内核协议栈关键的函数上都打上时间戳,然后计算数据包在每两个函数之间的时间差,如果这个时间差比较大,就可以说明问题出在这两个内核函数之间。
要想找到内核协议栈中的关键函数,还是比较容易的。比如下面的这张示意图里,就列出了 Linux 内核在接收数据包和发送数据包过程中的主要函数:
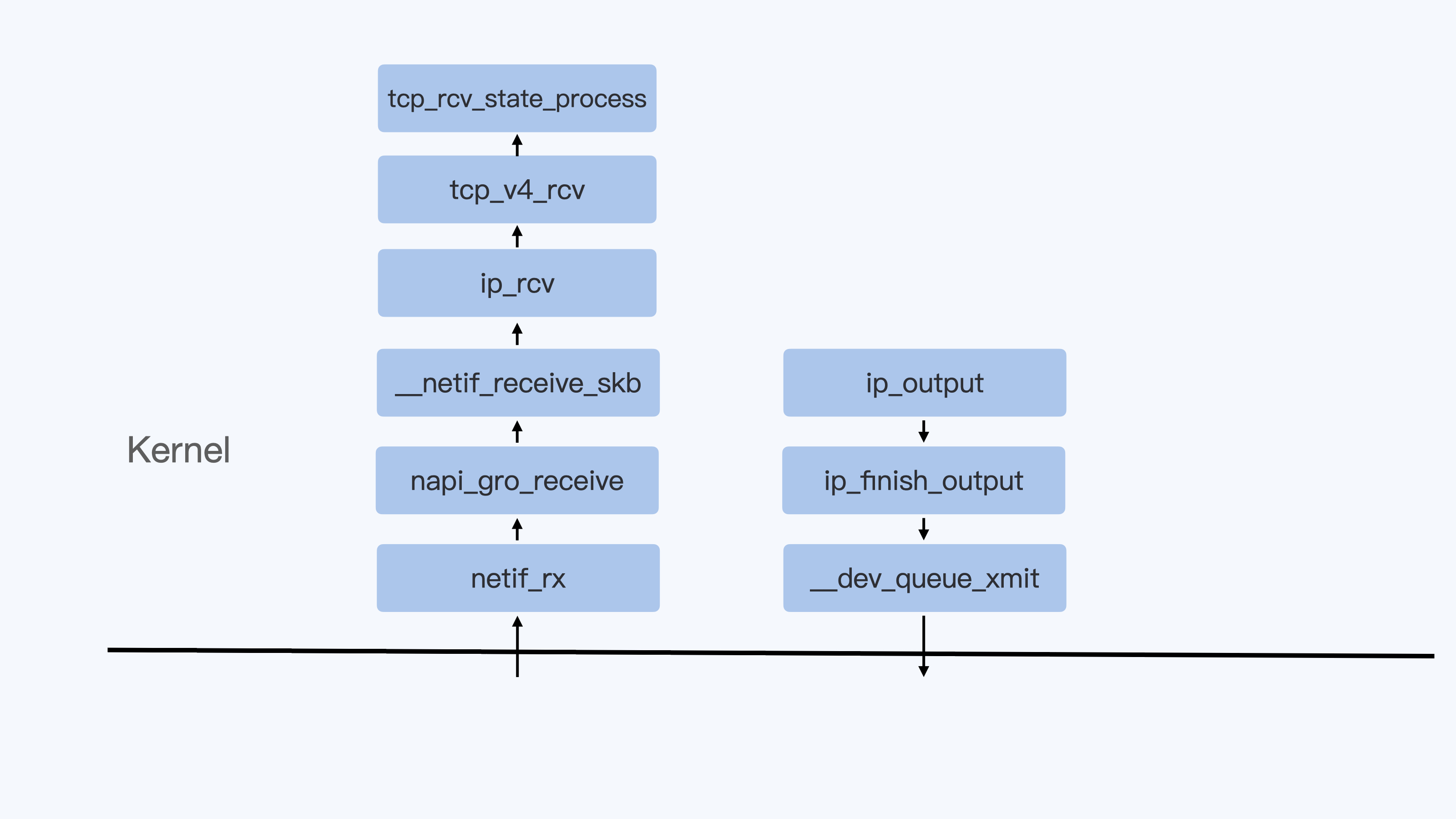
找到这些主要函数之后,下一个问题就是,想给每个数据包在经过这些函数的时候打上时间戳做记录,应该用什么方法呢?接下来我们一起来看看。
在不修改内核源代码的情况,要截获内核函数,我们可以利用kprobe或者tracepoint的接口。
使用这两种接口的方法也有两种:一是直接写 kernel module 来调用 kprobe 或者 tracepoint 的接口,第二种方法是通过ebpf的接口来调用它们。在后面的课程里,我还会详细讲解 ebpf、kprobe、tracepoint,这里你先有个印象就行。
在这里,我们选择了第二种方法,也就是使用 ebpf 来调用 kprobe 或者 tracepoint 接口,记录数据包处理过程中这些协议栈函数的每一次调用。
选择 ebpf 的原因主要是两个:一是 ebpf 的程序在内核中加载会做很严格的检查,这样在生产环境中使用比较安全;二是 ebpf map 功能可以方便地进行内核态与用户态的通讯,这样实现一个工具也比较容易。
决定了方法之后,这里我们需要先实现一个 ebpf 工具,然后用这个工具来对内核网络函数做 trace。
我们工具的具体实现是这样的,针对用户的一个 TCP/IP 数据流,记录这个流的数据发送包与数据接收包的传输过程,也就是数据发送包从容器的 Network Namespace 发出,一直到它到达宿主机的 eth0 的全过程,以及数据接收包从宿主机的 eth0 返回到容器 Network Namespace 的 eth0 的全程。
在收集了数十万条记录后,我们对数据做了分析,找出前后两步时间差大于 50 毫秒(ms)的记录。最后,我们终于发现了下面这段记录:
在这段记录中,我们先看一下”Network Namespace”这一列。编号 3 对应的 Namespace ID 4026535252 是容器里的,而 ID4026532057 是宿主机上的 Host Namespace。
数据包从 1 到 7 的数据表示了,一个数据包从容器里的 eth0 通过 veth 发到宿主机上的 peer veth cali29cf0fa56ce,然后再通过路由从宿主机的 obr0(openvswitch)接口和 eth0 接口发出。
为了方便你理解,我在下面画了一张示意图,描述了这个数据包的传输过程:
在这个过程里,我们发现了当数据包从容器的 eth0 发送到宿主机上的 cali29cf0fa56ce,也就是从第 3 步到第 4 步之间,花费的时间是 10865291752980718-10865291551180388=201800330。
因为时间戳的单位是纳秒 ns,而 201800330 超过了 200 毫秒(ms),这个时间显然是不正常的。
你还记得吗?我们在容器网络模块的第 17 讲说过 veth pair 之间数据的发送,它会触发一个 softirq,并且在我们 ebpf 的记录中也可以看到,当数据包到达 cali29cf0fa56ce 后,就是 softirqd 进程在 CPU32 上对它做处理。
那么这时候,我们就可以把关注点放到 CPU32 的 softirq 处理上了。我们再仔细看看 CPU32 上的 si(softirq)的 CPU 使用情况(运行 top 命令之后再按一下数字键 1,就可以列出每个 CPU 的使用率了),会发现在 CPU32 上时不时出现 si CPU 使用率超过 20% 的现象。
具体的输出情况如下:
%Cpu32 : 8.7 us, 0.0 sy, 0.0 ni, 62.1 id, 0.0 wa, 0.0 hi, 29.1 si, 0.0 st其实刚才说的这点,在最初的节点监控数据上,我们是不容易注意到的。这是因为我们的节点上有 80 个 CPU,单个 CPUsi 偶尔超过 20%,平均到 80 个 CPU 上就只有 0.25% 了。要知道,对于一个普通节点,1% 的 si 使用率都是很正常的。
好了,到这里我们已经缩小了问题的排查范围。可以看到,使用了 ebpf 帮助我们在毫无头绪的情况,找到了一个比较明确的方向。那么下一步,我们自然要顺藤摸瓜,进一步去搞清楚,为什么在 CPU32 上的 softirq CPU 使用率会时不时突然增高?
perf 定位热点
对于查找高 CPU 使用率情况下的热点函数,perf 显然是最有力的工具。我们只需要执行一下后面的这条命令,看一下 CPU32 上的函数调用的热度。
perf record -C 32 -g -- sleep 10为了方便查看,我们可以把 perf record 输出的结果做成一个火焰图,具体的方法我在下一讲里介绍,这里你需要先理解定位热点的整体思路。

结合前面的数据分析,我们已经知道了问题出现在 softirq 的处理过程中,那么在查看火焰图的时候,就要特别关注在 softirq 中被调用到的函数。
从上面这张图里,我们可以看到,run_timer_softirq 所占的比例是比较大的,而在 run_timer_softirq 中的绝大部分比例又是被一个叫作 estimation_timer() 的函数所占用的。
运行完 perf 之后,我们离真相又近了一步。现在,我们知道了 CPU32 上 softirq 的繁忙是因为 TIMER softirq 引起的,而 TIMER softirq 里又在不断地调用 estimation_timer() 这个函数。
沿着这个思路继续分析,对于 TIMER softirq 的高占比,一般有这两种情况,一是 softirq 发生的频率很高,二是 softirq 中的函数执行的时间很长。
那怎么判断具体是哪种情况呢?我们用 /proc/softirqs 查看 CPU32 上 TIMER softirq 每秒钟的次数,就会发现 TIMER softirq 在 CPU32 上的频率其实并不高。
这样第一种情况就排除了,那我们下面就来看看,Timer softirq 中的那个函数 estimation_timer(),是不是它的执行时间太长了?
ftrace 锁定长延时函数
我们怎样才能得到 estimation_timer() 函数的执行时间呢?
你还记得,我们在容器 I/O 与内存那一讲里用过的ftrace么?当时我们把 ftrace 的 tracer 设置为 function_graph,通过这个办法查看内核函数的调用时间。在这里我们也可以用同样的方法,查看 estimation_timer() 的调用时间。
这时候,我们会发现在 CPU32 上的 estimation_timer() 这个函数每次被调用的时间都特别长,比如下面图里的记录,可以看到 CPU32 上的时间高达 310 毫秒!

现在,我们可以确定问题就出在 estimation_timer() 这个函数里了。
接下来,我们需要读一下 estimation_timer() 在内核中的源代码,看看这个函数到底是干什么的,它为什么耗费了这么长的时间。其实定位到这一步,后面的工作就比较容易了。
estimation_timer() 是IPVS模块中每隔 2 秒钟就要调用的一个函数,它主要用来更新节点上每一条 IPVS 规则的状态。Kubernetes Cluster 里每建一个 service,在所有的节点上都会为这个 service 建立相应的 IPVS 规则。
通过下面这条命令,我们可以看到节点上 IPVS 规则的数目:
$ ipvsadm -L -n | wc -l
79004我们的节点上已经建立了将近 80K 条 IPVS 规则,而 estimation_timer() 每次都需要遍历所有的规则来更新状态,这样就导致 estimation_timer() 函数时间开销需要上百毫秒。
我们还有最后一个问题,estimation_timer() 是 TIMER softirq 里执行的函数,那它为什么会影响到网络 RX softirq 的延时呢?
这个问题,我们只要看一下 softirq 的处理函数do_softirq(),就会明白了。因为在同一个 CPU 上,do_softirq() 会串行执行每一种类型的 softirq,所以 TIMER softirq 执行的时间长了,自然会影响到下一个 RX softirq 的执行。
好了,分析这里,这个网络延时问题产生的原因我们已经完全弄清楚了。接下来,我带你系统梳理一下这个问题的解决思路。
问题小结
首先回顾一下今天这一讲的问题,我们分析了一个在容器平台的生产环境中,用户的应用程序网络延时的问题。这个延时只是偶尔发生,并且出错率只有 0.01%~0.04%,所以我们从常规的监控数据中无法看到任何异常。
那调试这个问题该如何下手呢?
我们想到的方法是使用 ebpf 调用 kprobe/tracepoint 的接口,这样就可以追踪数据包在内核协议栈主要函数中花费的时间。
我们实现了一个 ebpf 工具,并且用它缩小了排查范围,我们发现当数据包从容器的 veth 接口发送到宿主机上的 veth 接口,在某个 CPU 上的 softirq 的处理会有很长的延时。并且由此发现了,在对应的 CPU 上 si 的 CPU 使用率时不时会超过 20%。
找到了这个突破口之后,我们用 perf 工具专门查找了这个 CPU 上的热点函数,发现 TIMER softirq 中调用 estimation_timer() 的占比是比较高的。
接下来,我们使用 ftrace 进一步确认了,在这个特定 CPU 上 estimation_timer() 所花费的时间需要几百毫秒。
通过这些步骤,我们最终锁定了问题出在 IPVS 的这个 estimation_timer() 函数里,也找到了问题的根本原因: 在我们的节点上存在大量的 IPVS 规则,每次遍历这些规则都会消耗很多时间,最终导致了网络超时现象。
知道了原因之后,因为我们在生产环境中并不需要读取 IPVS 规则状态,所以为了快速解决生产环境上的问题,我们可以使用内核livepatch的机制在线地把 estimation_timer() 函数替换成了一个空函数。
这样,我们就暂时规避了因为 estimation_timer() 耗时长而影响其他 softirq 的问题。至于长期的解决方案,我们可以把 IPVS 规则的状态统计从 TIMER softirq 中转移到 kernel thread 中处理。
加餐02 | 理解perf:怎么用perf聚焦热点函数?
上一讲中,我们分析了一个生产环境里的一个真实例子,由于节点中的大量的 IPVS 规则导致了容器在往外发送网络包的时候,时不时会有很高的延时。在调试分析这个网络延时问题的过程中,我们会使用多种 Linux 内核的调试工具,利用这些工具,我们就能很清晰地找到这个问题的根本原因。
在后面的课程里,我们会挨个来讲解这些工具,其中 perf 工具的使用相对来说要简单些,所以这一讲我们先来看 perf 这个工具。
问题回顾
在具体介绍 perf 之前,我们先来回顾一下,上一讲中,我们是在什么情况下开始使用 perf 工具的,使用了 perf 工具之后给我们带来了哪些信息。
在调试网路延时的时候,我们使用了 ebpf 的工具之后,发现了节点上一个 CPU,也就是 CPU32 的 Softirq CPU Usage(在运行 top 时,%Cpu 那行中的 si 数值就是 Softirq CPU Usage)时不时地会增高一下。
在发现 CPU Usage 异常增高的时候,我们肯定想知道是什么程序引起了 CPU Usage 的异常增高,这时候我们就可以用到 perf 了。
具体怎么操作呢?我们可以通过 抓取数据、数据读取和异常聚焦 三个步骤来实现。
第一步,抓取数据。当时我们运行了下面这条 perf 命令,这里的参数 -C 32 是指定只抓取 CPU32 的执行指令;-g 是指 call-graph enable,也就是记录函数调用关系; sleep 10 主要是为了让 perf 抓取 10 秒钟的数据。
perf record -C 32 -g -- sleep 10执行完 perf record 之后,我们可以用 perf report 命令进行第二步,也就是读取数据。为了更加直观地看到 CPU32 上的函数调用情况,我给你生成了一个火焰图(火焰图的生产方法,我们在后面介绍)。
通过这个火焰图,我们发现了在 Softirq 里 TIMER softirq (run_timer_softirq)的占比很高,并且 timer 主要处理的都是 estimation_timer() 这个函数,也就是看火焰图 X 轴占比比较大的函数。这就是第三步异常聚焦,也就是说我们通过 perf 在 CPU Usage 异常的 CPU32 上,找到了具体是哪一个内核函数使用占比较高。这样在后面的调试分析中,我们就可以聚焦到这个内核函数 estimation_timer() 上了。
好了,通过回顾我们在网络延时例子中是如何使用 perf 的,我们知道了这一点, perf 可以在 CPU Usage 增高的节点上找到具体的引起 CPU 增高的函数,然后我们就可以有针对性地聚焦到那个函数做分析。
既然 perf 工具这么有用,想要更好地使用这个工具,我们就要好好认识一下它,那我们就一起看看 perf 的基本概念和常用的使用方法。
如何理解 Perf 的概念和工作机制?
Perf 这个工具最早是 Linux 内核著名开发者 Ingo Molnar 开发的,它的源代码在内核源码tools 目录下,在每个 Linux 发行版里都有这个工具,比如 CentOS 里我们可以运行 yum install perf 来安装,在 Ubuntu 里我们可以运行 apt install linux-tools-common 来安装。
Event
第一次上手使用 perf 的时候,我们可以先运行一下 perf list 这个命令,然后就会看到 perf 列出了大量的 event,比如下面这个例子就列出了常用的 event。
$ perf list
…
branch-instructions OR branches [Hardware event]
branch-misses [Hardware event]
bus-cycles [Hardware event]
cache-misses [Hardware event]
cache-references [Hardware event]
cpu-cycles OR cycles [Hardware event]
instructions [Hardware event]
ref-cycles [Hardware event]
alignment-faults [Software event]
bpf-output [Software event]
context-switches OR cs [Software event]
cpu-clock [Software event]
cpu-migrations OR migrations [Software event]
dummy [Software event]
emulation-faults [Software event]
major-faults [Software event]
minor-faults [Software event]
page-faults OR faults [Software event]
task-clock [Software event]
…
block:block_bio_bounce [Tracepoint event]
block:block_bio_complete [Tracepoint event]
block:block_bio_frontmerge [Tracepoint event]
block:block_bio_queue [Tracepoint event]
block:block_bio_remap [Tracepoint event]从这里我们可以了解到 event 都有哪些类型, perf list 列出的每个 event 后面都有一个”[]”,里面写了这个 event 属于什么类型,比如”Hardware event”、”Software event”等。完整的 event 类型,我们在内核代码枚举结构 perf_type_id 里可以看到。
接下来我们就说三个主要的 event,它们分别是 Hardware event、Software event 还有 Tracepoints event。
Hardware event
Hardware event 来自处理器中的一个 PMU(Performance Monitoring Unit),这些 event 数目不多,都是底层处理器相关的行为,perf 中会命名几个通用的事件,比如 cpu-cycles,执行完成的 instructions,Cache 相关的 cache-misses。
不同的处理器有自己不同的 PMU 事件,对于 Intel x86 处理器,PMU 的使用和编程都可以在”Intel 64 and IA-32 Architectures Developer’s Manual: Vol. 3B”(Intel 架构的开发者手册)里查到。
我们运行一下 perf stat ,就可以看到在这段时间里这些 Hardware event 发生的数目。
$ perf stat
^C
Performance counter stats for 'system wide':
58667.77 msec cpu-clock # 63.203 CPUs utilized
258666 context-switches # 0.004 M/sec
2554 cpu-migrations # 0.044 K/sec
30763 page-faults # 0.524 K/sec
21275365299 cycles # 0.363 GHz
24827718023 instructions # 1.17 insn per cycle
5402114113 branches # 92.080 M/sec
59862316 branch-misses # 1.11% of all branches
0.928237838 seconds time elapsedSoftware event
Software event 是定义在 Linux 内核代码中的几个特定的事件,比较典型的有进程上下文切换(内核态到用户态的转换)事件 context-switches、发生缺页中断的事件 page-faults 等。
为了让你更容易理解,这里我举个例子。就拿 page-faults 这个 perf 事件来说,我们可以看到,在内核代码处理缺页中断的函数里,就是调用了 perf_sw_event() 来注册了这个 page-faults。
/*
* Explicitly marked noinline such that the function tracer sees this as the
* page_fault entry point. __do_page_fault 是Linux内核处理缺页中断的主要函数
*/
static noinline void
__do_page_fault(struct pt_regs *regs, unsigned long hw_error_code,
unsigned long address)
{
prefetchw(¤t->mm->mmap_sem);
if (unlikely(kmmio_fault(regs, address)))
return;
/* Was the fault on kernel-controlled part of the address space? */
if (unlikely(fault_in_kernel_space(address)))
do_kern_addr_fault(regs, hw_error_code, address);
else
do_user_addr_fault(regs, hw_error_code, address);
/* 在do_user_addr_fault()里面调用了perf_sw_event() */
}
/* Handle faults in the user portion of the address space */
static inline
void do_user_addr_fault(struct pt_regs *regs,
unsigned long hw_error_code,
unsigned long address)
{
…
perf_sw_event(PERF_COUNT_SW_PAGE_FAULTS, 1, regs, address);
…
}Tracepoints event
你可以在 perf list 中看到大量的 Tracepoints event,这是因为内核中很多关键函数里都有 Tracepoints。它的实现方式和 Software event 类似,都是在内核函数中注册了 event。
不过,这些 tracepoints 不仅是用在 perf 中,它已经是 Linux 内核 tracing 的标准接口了,ftrace,ebpf 等工具都会用到它,后面我们还会再详细介绍 tracepoint。
好了,讲到这里,你要重点掌握的内容是, event 是 perf 工作的基础,主要有两种:有使用硬件的 PMU 里的 event,也有在内核代码中注册的 event。
那么在这些 event 都准备好了之后,perf 又是怎么去使用这些 event 呢?前面我也提到过,有计数和采样两种方式,下面我们分别来看看。
计数(count)
计数的这种工作方式比较好理解,就是统计某个 event 在一段时间里发生了多少次。
那具体我们怎么进行计数的呢?perf stat 这个命令就是来查看 event 的数目的,前面我们已经运行过 perf stat 来查看所有的 Hardware events。
这里我们可以加上”-e”参数,指定某一个 event 来看它的计数,比如 page-faults,这里我们看到在当前 CPU 上,这个 event 在 1 秒钟内发生了 49 次:
$ perf stat -e page-faults -- sleep 1
Performance counter stats for 'sleep 1':
49 page-faults
1.001583032 seconds time elapsed
0.001556000 seconds user
0.000000000 seconds sys采样(sample)
说完了计数,我们再来看看采样。在开头回顾网路延时问题的时候,我提到通过 perf record -C 32 -g — sleep 10 这个命令,来找到 CPU32 上 CPU 开销最大的 Softirq 相关函数。这里使用的 perf record 命令就是通过采样来得到热点函数的,我们来分析一下它是怎么做的。
perf record 在不加 -e 指定 event 的时候,它缺省的 event 就是 Hardware event cycles。我们先用 perf stat来查看 1 秒钟 cycles 事件的数量,在下面的例子里这个数量是 1878165 次。
我们可以想一下,如果每次 cycles event 发生的时候,我们都记录当时的 IP(就是处理器当时要执行的指令地址)、IP 所属的进程等信息的话,这样系统的开销就太大了。所以 perf 就使用了对 event 采样的方式来记录 IP、进程等信息。
$ perf stat -e cycles -- sleep 1
Performance counter stats for 'sleep 1':
1878165 cyclesPerf 对 event 的采样有两种模式:
第一种是按照 event 的数目(period),比如每发生 10000 次 cycles event 就记录一次 IP、进程等信息, perf record 中的 -c 参数可以指定每发生多少次,就做一次记录。
比如在下面的例子里,我们指定了每 10000 cycles event 做一次采样之后,在 1 秒里总共就做了 191 次采样,比我们之前看到 1 秒钟 1878165 次 cycles 的次数要少多了。
$ perf record -e cycles -c 10000 -- sleep 1
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.024 MB perf.data (191 samples) ]第二种是定义一个频率(frequency), perf record 中的 -F 参数就是指定频率的,比如 perf record -e cycles -F 99 — sleep 1 ,就是指采样每秒钟做 99 次。
在 perf record 运行结束后,会在磁盘的当前目录留下 perf.data 这个文件,里面记录了所有采样得到的信息。然后我们再运行 perf report 命令,查看函数或者指令在这些采样里的分布比例,后面我们会用一个例子说明。
好,说到这里,我们已经把 perf 的基本概念和使用机制都讲完了。接下来,我们看看在容器中怎么使用 perf?
容器中怎样使用 perf?
如果你的 container image 是基于 Ubuntu 或者 CentOS 等 Linux 发行版的,你可以尝试用它们的 package repo 安装 perf 的包。不过,这么做可能会有个问题,我们在前面介绍 perf 的时候提过,perf 是和 Linux kernel 一起发布的,也就是说 perf 版本最好是和 Linux kernel 使用相同的版本。
如果容器中 perf 包是独立安装的,那么容器中安装的 perf 版本可能会和宿主机上的内核版本不一致,这样有可能导致 perf 无法正常工作。
所以,我们在容器中需要跑 perf 的时候,最好从相应的 Linux kernel 版本的源代码里去编译,并且采用静态库(-static)的链接方式。然后,我们把编译出来的 perf 直接 copy 到容器中就可以使用了。
如何在 Linux kernel 源代码里编译静态链接的 perf,你可以参考后面的代码:
$ cd $(KERNEL_SRC_ROOT)/tools/perf
$ vi Makefile.perf
#### ADD "LDFLAGS=-static" in Makefile.perf
$ make clean; make
$ file perf
perf: ELF 64-bit LSB executable, x86-64, version 1 (GNU/Linux), statically linked, for GNU/Linux 3.2.0, BuildID[sha1]=9a42089e52026193fabf693da3c0adb643c2313e, with debug_info, not stripped, too many notes (256)
$ ls -lh perf
-rwxr-xr-x 1 root root 19M Aug 14 07:08 perf我这里给了一个带静态链接 perf(kernel 5.4)的 container image 例子 ,你可以运行 make image 来生成这个 image。
在容器中运行 perf,还要注意一个权限的问题,有两点注意事项需要你留意。
第一点,Perf 通过系统调用 perf_event_open() 来完成对 perf event 的计数或者采样。不过 Docker 使用 seccomp(seccomp 是一种技术,它通过控制系统调用的方式来保障 Linux 安全)会默认禁止 perf_event_open()。
所以想要让 Docker 启动的容器可以运行 perf,我们要怎么处理呢?
其实这个也不难,在用 Docker 启动容器的时候,我们需要在 seccomp 的 profile 里,允许 perf_event_open() 这个系统调用在容器中使用。在我们的例子中,启动 container 的命令里,已经加了这个参数允许了,参数是”—security-opt seccomp=unconfined”。
第二点,需要允许容器在没有 SYS_ADMIN 这个 capability(Linux capability 我们在第 19 讲说过)的情况下,也可以让 perf 访问这些 event。那么现在我们需要做的就是,在宿主机上设置出 echo -1 > /proc/sys/kernel/perf_event_paranoid,这样普通的容器里也能执行 perf 了。
完成了权限设置之后,在容器中运行 perf,就和在 VM/BM 上运行没有什么区别了。
最后,我们再来说一下我们在定位 CPU Uage 异常时最常用的方法,常规的步骤一般是这样的:
首先,调用 perf record 采样几秒钟,一般需要加 -g 参数,也就是 call-graph,还需要抓取函数的调用关系。在多核的机器上,还要记得加上 -a 参数,保证获取所有 CPU Core 上的函数运行情况。至于采样数据的多少,在讲解 perf 概念的时候说过,我们可以用 -c 或者 -F 参数来控制。
接着,我们需要运行 perf report 读取数据。不过很多时候,为了更加直观地看到各个函数的占比,我们会用 perf script 命令把 perf record 生成的 perf.data 转化成分析脚本,然后用 FlameGraph 工具来读取这个脚本,生成火焰图。
下面这组命令,就是刚才说过的使用 perf 的常规步骤:
perf record -a -g -- sleep 60
perf script > out.perf
git clone --depth 1 https://github.com/brendangregg/FlameGraph.git
FlameGraph/stackcollapse-perf.pl out.perf > out.folded
FlameGraph/flamegraph.pl out.folded > out.svg重点总结
我们这一讲学习了如何使用 perf,这里我来给你总结一下重点。
首先,我们在线上网络延时异常的那个实际例子中使用了 perf。我们发现可以用 perf 工具,通过 抓取数据、数据读取和异常聚焦 这三个步骤的操作,在 CPU Usage 增高的节点上找到具体引起 CPU 增高的函数。
之后我带你更深入地学习了 perf 是什么,它的工作方式是怎样的?这里我把 perf 的重点再给你强调一遍:
Perf 的实现基础是 event,有两大类,一类是基于硬件 PMU 的,一类是内核中的软件注册。而 Perf 在使用时的工作方式也是两大类,计数和采样。
先看一下计数,它执行的命令是 perf stat,用来查看每种 event 发生的次数;
采样执行的命令是perf record,它可以使用 period 方式,就是每 N 个 event 发生后记录一次 event 发生时的 IP/ 进程信息,或者用 frequency 方式,每秒钟以固定次数来记录信息。记录的信息会存在当前目录的 perf.data 文件中。
如果我们要在容器中使用 perf,要注意这两点:
容器中的 perf 版本要和宿主机内核版本匹配,可以直接从源代码编译出静态链接的 perf。
我们需要解决两个权限的问题,一个是 seccomp 对系统调用的限制,还有一个是内核对容器中没有 SYC_ADMIN capability 的限制。
在我们日常分析系统性能异常的时候,使用 perf 最常用的方式是perf record获取采样数据,然后用 FlameGraph 工具来生成火焰图。
加餐03 | 理解ftrace(1):怎么应用ftrace查看长延时内核函数?
上一讲里,我们一起学习了 perf 这个工具。在我们的案例里,使用 perf 找到了热点函数之后,我们又使用了 ftrace 这个工具,最终锁定了长延时的函数 estimation_timer()。
那么这一讲,我们就来学习一下 ftrace 这个工具,主要分为两个部分来学习。
第一部分讲解 ftrace 的最基本的使用方法,里面也会提到在我们的案例中是如何使用的。第二部分我们一起看看 Linux ftrace 是如何实现的,这样可以帮助你更好地理解 Linux 的 ftrace 工具。
ftrace 的基本使用方法
ftrace 这个工具在 2008 年的时候就被合入了 Linux 内核,当时的版本还是 Linux2.6.x。从 ftrace 的名字 function tracer,其实我们就可以看出,它最初就是用来 trace 内核中的函数的。
当然了,现在 ftrace 的功能要更加丰富了。不过,function tracer 作为 ftrace 最基本的功能,也是我们平常调试 Linux 内核问题时最常用到的功能。那我们就先来看看这个最基本,同时也是最重要的 function tracer 的功能。
ftrace 的操作都可以在 tracefs 这个虚拟文件系统中完成,对于 CentOS,这个 tracefs 的挂载点在 /sys/kernel/debug/tracing 下:
$ cat /proc/mounts | grep tracefs
tracefs /sys/kernel/debug/tracing tracefs rw,relatime 0 0你可以进入到 /sys/kernel/debug/tracing 目录下,看一下这个目录下的文件:
$ cd /sys/kernel/debug/tracing
$ ls
available_events dyn_ftrace_total_info kprobe_events saved_cmdlines_size set_graph_notrace trace_clock tracing_on
available_filter_functions enabled_functions kprobe_profile saved_tgids snapshot trace_marker tracing_thresh
available_tracers error_log max_graph_depth set_event stack_max_size trace_marker_raw uprobe_events
buffer_percent events options set_event_pid stack_trace trace_options uprobe_profile
buffer_size_kb free_buffer per_cpu set_ftrace_filter stack_trace_filter trace_pipe
buffer_total_size_kb function_profile_enabled printk_formats set_ftrace_notrace synthetic_events trace_stat
current_tracer hwlat_detector README set_ftrace_pid timestamp_mode tracing_cpumask
dynamic_events instances saved_cmdlines set_graph_function trace tracing_max_latencytracefs 虚拟文件系统下的文件操作,其实和我们常用的 Linux proc 和 sys 虚拟文件系统的操作是差不多的。通过对某个文件的 echo 操作,我们可以向内核的 ftrace 系统发送命令,然后 cat 某个文件得到 ftrace 的返回结果。
对于 ftrace,它的输出结果都可以通过 cat trace 这个命令得到。在缺省的状态下 ftrace 的 tracer 是 nop,也就是 ftrace 什么都不做。因此,我们从cat trace中也看不到别的,只是显示了 trace 输出格式。
$ pwd
/sys/kernel/debug/tracing
$ cat trace
# tracer: nop
#
# entries-in-buffer/entries-written: 0/0 #P:12
#
# _-----=> irqs-off
# / _----=> need-resched
# | / _---=> hardirq/softirq
# || / _--=> preempt-depth
# ||| / delay
# TASK-PID CPU# |||| TIMESTAMP FUNCTION
# | | | |||| | |下面,我们可以执行 echo function > current_tracer 来告诉 ftrace,我要启用 function tracer。
$ cat current_tracer
nop
$ cat available_tracers
hwlat blk mmiotrace function_graph wakeup_dl wakeup_rt wakeup function nop
$ echo function > current_tracer
$ cat current_tracer
function在启动了 function tracer 之后,我们再查看一下 trace 的输出。这时候我们就会看到大量的输出,每一行的输出就是当前内核中被调用到的内核函数,具体的格式你可以参考 trace 头部的说明。
$ cat trace | more
# tracer: function
#
# entries-in-buffer/entries-written: 615132/134693727 #P:12
#
# _-----=> irqs-off
# / _----=> need-resched
# | / _---=> hardirq/softirq
# || / _--=> preempt-depth
# ||| / delay
# TASK-PID CPU# |||| TIMESTAMP FUNCTION
# | | | |||| | |
systemd-udevd-20472 [011] .... 2148512.735026: lock_page_memcg <-page_remove_rmap
systemd-udevd-20472 [011] .... 2148512.735026: PageHuge <-page_remove_rmap
systemd-udevd-20472 [011] .... 2148512.735026: unlock_page_memcg <-page_remove_rmap
systemd-udevd-20472 [011] .... 2148512.735026: __unlock_page_memcg <-unlock_page_memcg
systemd-udevd-20472 [011] .... 2148512.735026: __tlb_remove_page_size <-unmap_page_range
systemd-udevd-20472 [011] .... 2148512.735027: vm_normal_page <-unmap_page_range
systemd-udevd-20472 [011] .... 2148512.735027: mark_page_accessed <-unmap_page_range
systemd-udevd-20472 [011] .... 2148512.735027: page_remove_rmap <-unmap_page_range
systemd-udevd-20472 [011] .... 2148512.735027: lock_page_memcg <-page_remove_rmap
…看到这个 trace 输出,你肯定会觉得输出的函数太多了,查看起来太困难了。别担心,下面我给你说个技巧,来解决输出函数太多的问题。
其实在实际使用的时候,我们可以利用 ftrace 里的 filter 参数做筛选,比如我们可以通过 set_ftrace_filter 只列出想看到的内核函数,或者通过 set_ftrace_pid 只列出想看到的进程。
为了让你加深理解,我给你举个例子,比如说,如果我们只是想看 do_mount 这个内核函数有没有被调用到,那我们就可以这么操作:
echo nop > current_tracer
echo do_mount > set_ftrace_filter
echo function > current_tracer在执行了 mount 命令之后,我们查看一下 trace。
这时候,我们就只会看到一条 do_mount() 函数调用的记录,我们一起来看看,输出结果里的几个关键参数都是什么意思。
输出里”do_mount <- ksys_mount”表示 do_mount() 函数是被 ksys_mount() 这个函数调用到的,”2159455.499195”表示函数执行时的时间戳,而”[005]”是内核函数 do_mount() 被执行时所在的 CPU 编号,还有”mount-20889”,它是 do_mount() 被执行时当前进程的 pid 和进程名。
$ mount -t tmpfs tmpfs /tmp/fs
$ cat trace
# tracer: function
#
# entries-in-buffer/entries-written: 1/1 #P:12
#
# _-----=> irqs-off
# / _----=> need-resched
# | / _---=> hardirq/softirq
# || / _--=> preempt-depth
# ||| / delay
# TASK-PID CPU# |||| TIMESTAMP FUNCTION
# | | | |||| | |
mount-20889 [005] .... 2159455.499195: do_mount <-ksys_mount这里我们只能判断出,ksys mount() 调用了 do mount() 这个函数,这只是一层调用关系,如果我们想要看更加完整的函数调用栈,可以打开 ftrace 中的 func_stack_trace 选项:
echo 1 > options/func_stack_trace打开以后,我们再来做一次 mount 操作,就可以更清楚地看到 do_mount() 是系统调用 (syscall) 之后被调用到的。
$ umount /tmp/fs
$ mount -t tmpfs tmpfs /tmp/fs
$ cat trace
# tracer: function
#
# entries-in-buffer/entries-written: 3/3 #P:12
#
# _-----=> irqs-off
# / _----=> need-resched
# | / _---=> hardirq/softirq
# || / _--=> preempt-depth
# ||| / delay
# TASK-PID CPU# |||| TIMESTAMP FUNCTION
# | | | |||| | |
mount-20889 [005] .... 2159455.499195: do_mount <-ksys_mount
mount-21048 [000] .... 2162013.660835: do_mount <-ksys_mount
mount-21048 [000] .... 2162013.660841: <stack trace>
=> do_mount
=> ksys_mount
=> __x64_sys_mount
=> do_syscall_64
=> entry_SYSCALL_64_after_hwframe结合刚才说的内容,我们知道了,通过 function tracer 可以帮我们判断内核中函数是否被调用到,以及函数被调用的整个路径 也就是调用栈。
这样我们就理清了整体的追踪思路:如果我们通过 perf 发现了一个内核函数的调用频率比较高,就可以通过 function tracer 工具继续深入,这样就能大概知道这个函数是在什么情况下被调用到的。
那如果我们还想知道,某个函数在内核中大致花费了多少时间,就像加餐第一讲案例中我们就拿到了 estimation_timer() 时间开销,又要怎么做呢?
这里需要用到 ftrace 中的另外一个 tracer,它就是 function_graph。我们可以在刚才的 ftrace 的设置基础上,把 current_tracer 设置为 function_graph,然后就能看到 do_mount() 这个函数调用的时间了。
$ echo function_graph > current_tracer
$ umount /tmp/fs
$ mount -t tmpfs tmpfs /tmp/fs
$ cat trace
# tracer: function_graph
#
# CPU DURATION FUNCTION CALLS
# | | | | | | |
0) ! 175.411 us | do_mount();通过 function_graph tracer,还可以让我们看到每个函数里所有子函数的调用以及时间,这对我们理解和分析内核行为都是很有帮助的。
比如说,我们想查看 kfree_skb() 这个函数是怎么执行的,就可以像下面这样配置:
echo '!do_mount ' >> set_ftrace_filter ### 先把之前的do_mount filter给去掉。
echo kfree_skb > set_graph_function ### 设置kfree_skb()
echo nop > current_tracer ### 暂时把current_tracer设置为nop, 这样可以清空trace
echo function_graph > current_tracer ### 把current_tracer设置为function_graph设置完成之后,我们再来看 trace 的输出。现在,我们就可以看到 kfree_skb() 下的所有子函数的调用,以及它们花费的时间了。
具体输出如下,你可以做个参考:
$ cat trace | more
# tracer: function_graph
#
# CPU DURATION FUNCTION CALLS
# | | | | | | |
0) | kfree_skb() {
0) | skb_release_all() {
0) | skb_release_head_state() {
0) | nf_conntrack_destroy() {
0) | destroy_conntrack [nf_conntrack]() {
0) 0.205 us | nf_ct_remove_expectations [nf_conntrack]();
0) | nf_ct_del_from_dying_or_unconfirmed_list [nf_conntrack]() {
0) 0.282 us | _raw_spin_lock();
0) 0.679 us | }
0) 0.193 us | __local_bh_enable_ip();
0) | nf_conntrack_free [nf_conntrack]() {
0) | nf_ct_ext_destroy [nf_conntrack]() {
0) 0.177 us | nf_nat_cleanup_conntrack [nf_nat]();
0) 1.377 us | }
0) | kfree_call_rcu() {
0) | __call_rcu() {
0) 0.383 us | rcu_segcblist_enqueue();
0) 1.111 us | }
0) 1.535 us | }
0) 0.446 us | kmem_cache_free();
0) 4.294 us | }
0) 6.922 us | }
0) 7.665 us | }
0) 8.105 us | }
0) | skb_release_data() {
0) | skb_free_head() {
0) 0.470 us | page_frag_free();
0) 0.922 us | }
0) 1.355 us | }
0) + 10.192 us | }
0) | kfree_skbmem() {
0) 0.669 us | kmem_cache_free();
0) 1.046 us | }
0) + 13.707 us | }好了,对于 ftrace 的最基本的、也是最重要的内核函数相关的 tracer,我们已经知道怎样操作了。那你有没有好奇过,这个 ftrace 又是怎么实现的呢?下面我们就来看一下。
ftrace 的实现机制
下面这张图描述了 ftrace 实现的 high level 的架构,用户通过 tracefs 向内核中的 function tracer 发送命令,然后 function tracer 把收集到的数据写入一个 ring buffer,再通过 tracefs 输出给用户。
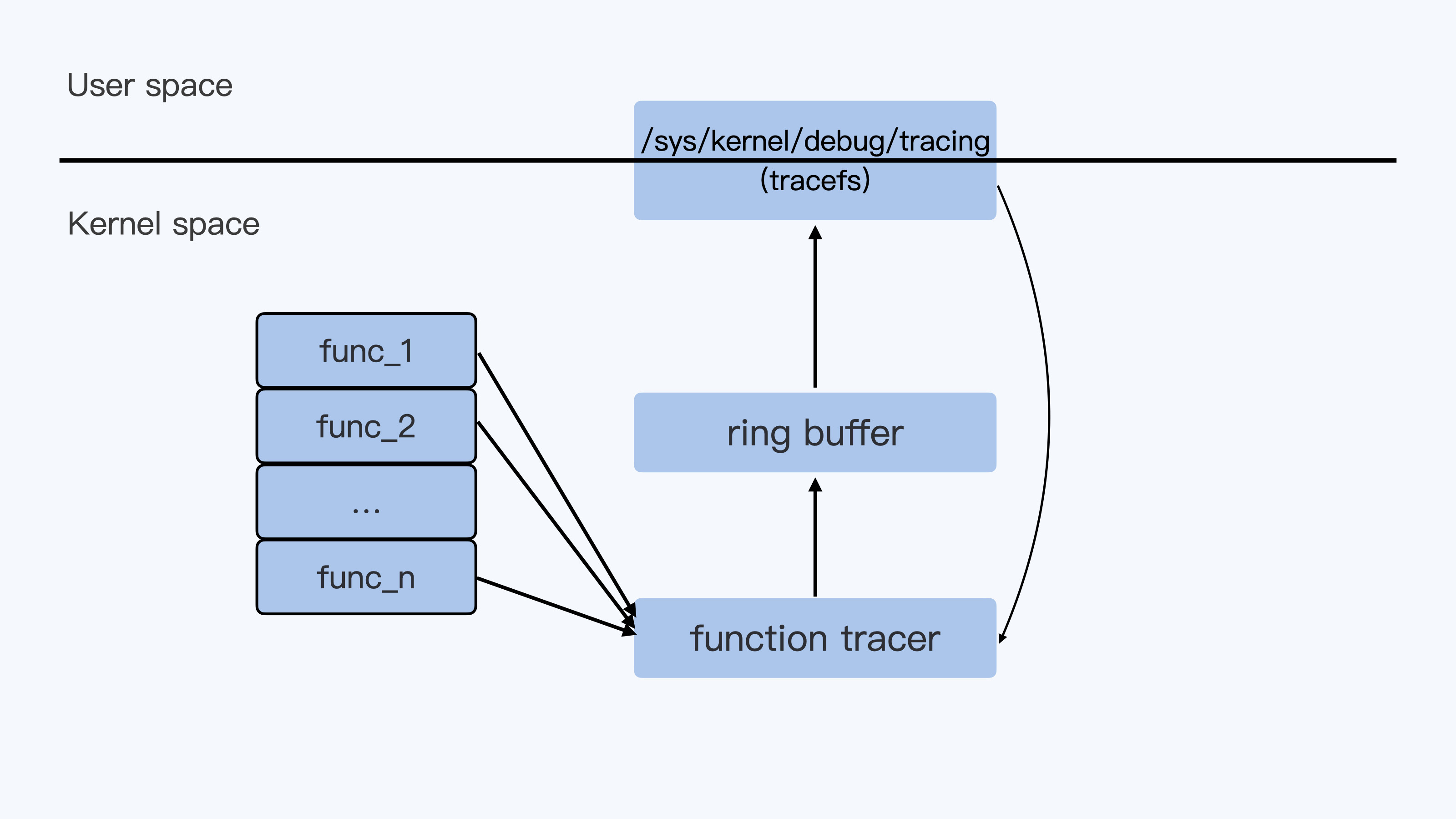
这里的整个过程看上去比较好理解。不过还是有一个问题,不知道你有没有思考过,
frace 可以收集到内核中任意一个函数被调用的情况,这点是怎么做到的?
你可能想到,这是因为在内核的每个函数中都加上了 hook 点了吗?这时我们来看一下内核的源代码,显然并没有这样的 hook 点。那 Linux 到底是怎么实现的呢?
其实这里 ftrace 是利用了 gcc 编译器的特性,再加上几步非常高明的代码段替换操作,就很完美地实现了对内核中所有函数追踪的接口(这里的”所有函数”不包括”inline 函数”)。下面我们一起看一下这个实现。
Linux 内核在编译的时候,缺省会使用三个 gcc 的参数”-pg -mfentry -mrecord-mcount”。
其中,”-pg -mfentry”这两个参数的作用是,给编译出来的每个函数开头都插入一条指令 callq <fentry>。
你如果编译过内核,那么你可以用”objdump -D vmlinux”来查看一下内核函数的汇编,比如 do_mount() 函数的开头几条汇编就是这样的:
ffffffff81309550 <do_mount>:
ffffffff81309550: e8 fb 83 8f 00 callq ffffffff81c01950 <__fentry__>
ffffffff81309555: 55 push %rbp
ffffffff81309556: 48 89 e5 mov %rsp,%rbp
ffffffff81309559: 41 57 push %r15
ffffffff8130955b: 49 89 d7 mov %rdx,%r15
ffffffff8130955e: ba 00 00 ed c0 mov $0xc0ed0000,%edx
ffffffff81309563: 41 56 push %r14
ffffffff81309565: 49 89 fe mov %rdi,%r14
ffffffff81309568: 41 55 push %r13
ffffffff8130956a: 4d 89 c5 mov %r8,%r13
ffffffff8130956d: 41 54 push %r12
ffffffff8130956f: 53 push %rbx
ffffffff81309570: 48 89 cb mov %rcx,%rbx
ffffffff81309573: 81 e1 00 00 ff ff and $0xffff0000,%ecx
ffffffff81309579: 48 83 ec 30 sub $0x30,%rsp而”-mrecord-mcount”参数在最后的内核二进制文件 vmlinux 中附加了一个 mcount_loc 的段,这个段里记录了所有 callq <fentry> 指令的地址。这样我们很容易就能找到每个函数的这个入口点。
为了方便你理解,我画了一张示意图,我们编译出来的 vmlinux 就像图里展示的这样:
不过你需要注意的是,尽管通过编译的方式,我们可以给每个函数都加上一个额外的 hook 点,但是这个额外”fentry”函数调用的开销是很大的。
即使”fentry”函数中只是一个 retq 指令,也会使内核性能下降 13%,这对于 Linux 内核来说显然是不可以被接受的。那我们应该怎么办呢?
ftrace 在内核启动的时候做了一件事,就是把内核每个函数里的第一条指令 callq <fentry>(5 个字节),替换成了”nop”指令(0F 1F 44 00 00),也就是一条空指令,表示什么都不做。
虽然是空指令,不过在内核的代码段里,这相当于给每个函数预留了 5 个字节。这样在需要的时候,内核可以再把这 5 个字节替换成 callq 指令,call 的函数就可以指定成我们需要的函数了。
同时,内核的 mcount_loc 段里,虽然已经记录了每个函数 callq <fentry> 的地址,不过对于 ftrace 来说,除了地址之外,它还需要一些额外的信息。
因此,在内核启动初始化的时候,ftrace 又申请了新的内存来存放 mcount_loc 段中原来的地址信息,外加对每个地址的控制信息,最后释放了原来的 mcount_loc 段。
所以 Linux 内核在机器上启动之后,在内存中的代码段和数据结构就会发生变化。你可以参考后面这张图,它描述了变化后的情况:
当我们需要用 function tracer 来 trace 某一个函数的时候,比如”echo do_mount > set_ftrace_filter”命令执行之后,do_mount() 函数的第一条指令就会被替换成调用 ftrace_caller 的指令。
你可以查看后面的示意图,结合这张图来理解刚才的内容。
这样,每调用一次 do_mount() 函数,它都会调用 function_trace_call() 函数,把 ftrace function trace 信息放入 ring buffer 里,再通过 tracefs 输出给用户。
重点小结
这一讲我们主要讲解了 Linux ftrace 这个工具。
首先我们学习了 ftrace 最基本的操作,对内核函数做 trace。在这里最重要的有两个 tracers,分别是 function 和 function_graph。
function tracer 可以用来记录内核中被调用到的函数的情况。在实际使用的时候,我们可以设置一些 ftrace 的 filter 来查看某些我们关心的函数,或者我们关心的进程调用到的函数。
我们还可以设置 func_stack_trace 选项,来查看被 trace 函数的完整调用栈。
而 function_graph tracer 可以用来查看内核函数和它的子函数调用关系以及调用时间,这对我们理解内核的行为非常有帮助。
讲完了 ftrace 的基本操作之后,我们又深入研究了 ftrace 在 Linux 中的实现机制。
在 ftrace 实现过程里,最重要的一个环节是利用 gcc 编译器的特性,为每个内核函数二进制码中预留了 5 个字节,这样内核函数就可以调用调试需要的函数,从而实现了 ftrace 的功能。
加餐04 | 理解ftrace(2):怎么理解ftrace背后的技术tracepoint和kprobe?
前面两讲,我们分别学习了 perf 和 ftrace 这两个最重要 Linux tracing 工具。在学习过程中,我们把重点放在了这两个工具最基本的功能点上。
不过你学习完这些之后,我们内核调试版图的知识点还没有全部点亮。
如果你再去查看一些 perf、ftrace 或者其他 Linux tracing 相关资料,你可能会常常看到两个单词,”tracepoint”和”kprobe”。你有没有好奇过,这两个名词到底是什么意思,它们和 perf、ftrace 这些工具又是什么关系呢?
这一讲,我们就来学习这两个在 Linux tracing 系统中非常重要的概念,它们就是 tracepoint 和 kprobe 。
tracepoint 和 kprobe 的应用举例
如果你深入地去看一些 perf 或者 ftrace 的功能,这时候你会发现它们都有跟 tracepoint、kprobe 相关的命令。我们先来看几个例子,通过这几个例子,你可以大概先了解一下 tracepoint 和 kprobe 的应用,这样我们后面做详细的原理介绍时,你也会更容易理解。
首先看看 tracepoint,tracepoint 其实就是在 Linux 内核的一些关键函数中埋下的 hook 点,这样在 tracing 的时候,我们就可以在这些固定的点上挂载调试的函数,然后查看内核的信息。
我们通过下面的这个 perf list 命令,就可以看到所有的 tracepoints:
$ perf list | grep Tracepoint
alarmtimer:alarmtimer_cancel [Tracepoint event]
alarmtimer:alarmtimer_fired [Tracepoint event]
alarmtimer:alarmtimer_start [Tracepoint event]
alarmtimer:alarmtimer_suspend [Tracepoint event]
block:block_bio_backmerge [Tracepoint event]
block:block_bio_bounce [Tracepoint event]
block:block_bio_complete [Tracepoint event]
block:block_bio_frontmerge [Tracepoint event]
block:block_bio_queue [Tracepoint event]至于 ftrace,你在 tracefs 文件系统中,也会看到一样的 tracepoints:
$ find /sys/kernel/debug/tracing/events -type d | sort
/sys/kernel/debug/tracing/events
/sys/kernel/debug/tracing/events/alarmtimer
/sys/kernel/debug/tracing/events/alarmtimer/alarmtimer_cancel
/sys/kernel/debug/tracing/events/alarmtimer/alarmtimer_fired
/sys/kernel/debug/tracing/events/alarmtimer/alarmtimer_start
/sys/kernel/debug/tracing/events/alarmtimer/alarmtimer_suspend
/sys/kernel/debug/tracing/events/block
/sys/kernel/debug/tracing/events/block/block_bio_backmerge
/sys/kernel/debug/tracing/events/block/block_bio_bounce
/sys/kernel/debug/tracing/events/block/block_bio_complete
/sys/kernel/debug/tracing/events/block/block_bio_frontmerge
…为了让你更好理解,我们就拿”do_sys_open”这个 tracepoint 做例子。在内核函数 do_sys_open() 中,有一个 trace_do_sys_open() 调用,其实它这就是一个 tracepoint:
long do_sys_open(int dfd, const char __user *filename, int flags, umode_t mode)
{
struct open_flags op;
int fd = build_open_flags(flags, mode, &op);
struct filename *tmp;
if (fd)
return fd;
tmp = getname(filename);
if (IS_ERR(tmp))
return PTR_ERR(tmp);
fd = get_unused_fd_flags(flags);
if (fd >= 0) {
struct file *f = do_filp_open(dfd, tmp, &op);
if (IS_ERR(f)) {
put_unused_fd(fd);
fd = PTR_ERR(f);
} else {
fsnotify_open(f);
fd_install(fd, f);
trace_do_sys_open(tmp->name, flags, mode);
}
}
putname(tmp);
return fd;
}
接下来,我们可以通过 perf 命令,利用 tracepoint 来查看一些内核函数发生的频率,比如在节点上,统计 10 秒钟内调用 do_sys_open 成功的次数,也就是打开文件的次数。
$ perf stat -a -e fs:do_sys_open -- sleep 10
Performance counter stats for 'system wide':
7 fs:do_sys_open
10.001954100 seconds time elapsed同时,如果我们把 tracefs 中 do_sys_open 的 tracepoint 打开,那么在 ftrace 的 trace 输出里,就可以看到具体 do_sys_open 每次调用成功时,打开的文件名、文件属性、对应的进程等信息。
$ pwd
/sys/kernel/debug/tracing
$ echo 1 > events/fs/do_sys_open/enable
$ cat trace
# tracer: nop
#
# _-----=> irqs-off
# / _----=> need-resched
# | / _---=> hardirq/softirq
# || / _--=> preempt-depth
# ||| / delay
# TASK-PID CPU# |||| TIMESTAMP FUNCTION
# | | | |||| | |
systemd-1 [011] .... 17133447.451839: do_sys_open: "/proc/22597/cgroup" 88000 666
bash-4118 [009] .... 17133450.076026: do_sys_open: "/" 98800 0
salt-minion-7101 [010] .... 17133450.478659: do_sys_open: "/etc/hosts" 88000 666
systemd-journal-2199 [011] .... 17133450.487930: do_sys_open: "/proc/6989/cgroup" 88000 666
systemd-journal-2199 [011] .... 17133450.488019: do_sys_open: "/var/log/journal/d4f76e4bf5414ac78e1c534ebe5d0a72" 98800 0
systemd-journal-2199 [011] .... 17133450.488080: do_sys_open: "/proc/6989/comm" 88000 666
systemd-journal-2199 [011] .... 17133450.488114: do_sys_open: "/proc/6989/cmdline" 88000 666
systemd-journal-2199 [011] .... 17133450.488143: do_sys_open: "/proc/6989/status" 88000 666
systemd-journal-2199 [011] .... 17133450.488185: do_sys_open: "/proc/6989/sessionid" 88000 666
…
请注意,Tracepoint 是在内核中固定的 hook 点,并不是在所有的函数中都有 tracepoint。
比如在上面的例子里,我们看到 do_sys_open() 调用到了 do_filp_open(),但是 do_filp_open() 函数里是没有 tracepoint 的。那如果想看到 do_filp_open() 函数被调用的频率,或者 do_filp_open() 在被调用时传入参数的情况,我们又该怎么办呢?
这时候,我们就需要用到 kprobe 了。kprobe 可以动态地在所有的内核函数(除了 inline 函数)上挂载 probe 函数。我们还是结合例子做理解,先看看 perf 和 ftraces 是怎么利用 kprobe 来做调试的。
比如对于 do_filp_open() 函数,我们可以通过perf probe添加一下,然后用perf stat 看看在 10 秒钟的时间里,这个函数被调用到的次数。
$ perf probe --add do_filp_open
$ perf stat -a -e probe:do_filp_open -- sleep 10
Performance counter stats for 'system wide':
11 probe:do_filp_open
10.001489223 seconds time elapsed我们也可以通过 ftrace 的 tracefs 给 do_filp_open() 添加一个 kprobe event,这样就能查看 do_filp_open() 每次被调用的时候,前面两个参数的值了。
这里我要给你说明一下,在写入 kprobe_event 的时候,对于参数的定义我们用到了”%di”和”%si”。这是 x86 处理器里的寄存器,根据 x86 的Application Binary Interface 的文档,在函数被调用的时候,%di 存放了第一个参数,%si 存放的是第二个参数。
echo 'p:kprobes/myprobe do_filp_open dfd=+0(%di):u32 pathname=+0(+0(%si)):string' > /sys/kernel/debug/tracing/kprobe_events完成上面的写入之后,我们再 enable 这个新建的 kprobe event。这样在 trace 中,我们就可以看到每次 do_filp_open()被调用时前两个参数的值了。
$ echo 1 > /sys/kernel/debug/tracing/events/kprobes/myprobe/enable
$ cat /sys/kernel/debug/tracing/trace
…
irqbalance-1328 [005] .... 2773211.189573: myprobe: (do_filp_open+0x0/0x100) dfd=4294967295 pathname="/proc/interrupts"
irqbalance-1328 [005] .... 2773211.189740: myprobe: (do_filp_open+0x0/0x100) dfd=638399 pathname="/proc/stat"
irqbalance-1328 [005] .... 2773211.189800: myprobe: (do_filp_open+0x0/0x100) dfd=638399 pathname="/proc/irq/8/smp_affinity"
bash-15864 [004] .... 2773211.219048: myprobe: (do_filp_open+0x0/0x100) dfd=14819 pathname="/sys/kernel/debug/tracing/"
bash-15864 [004] .... 2773211.891472: myprobe: (do_filp_open+0x0/0x100) dfd=6859 pathname="/sys/kernel/debug/tracing/"
bash-15864 [004] .... 2773212.036449: myprobe: (do_filp_open+0x0/0x100) dfd=4294967295 pathname="/sys/kernel/debug/tracing/"
bash-15864 [004] .... 2773212.197525: myprobe: (do_filp_open+0x0/0x100) dfd=638259 pathname="/sys/kernel/debug/tracing/
…好了,我们通过 perf 和 ftrace 的几个例子,简单了解了 tracepoint 和 kprobe 是怎么用的。那下面我们再来看看它们的实现原理。
Tracepoint
刚才,我们已经看到了内核函数 do_sys_open() 里调用了 trace_do_sys_open() 这个 treacepoint,那这个 tracepoint 是怎么实现的呢?我们还要再仔细研究一下。
如果你在内核代码中,直接搜索”trace_do_sys_open”字符串的话,并不能找到这个函数的直接定义。这是因为在 Linux 中,每一个 tracepoint 的相关数据结构和函数,主要是通过”DEFINE_TRACE”和”DECLARE_TRACE”这两个宏来定义的。
完整的”DEFINE_TRACE”和”DECLARE_TRACE”宏里,给每个 tracepoint 都定义了一组函数。在这里,我会选择最主要的几个函数,把定义一个 tracepoint 的过程给你解释一下。
首先,我们来看”trace_##name”这个函数(提示一下,这里的”##”是 C 语言的预编译宏,表示把两个字符串连接起来)。
对于每个命名为”name”的 tracepoint,这个宏都会帮助它定一个函数。这个函数的格式是这样的,以”trace_”开头,再加上 tracepoint 的名字。
我们举个例子吧。比如说,对于”do_sys_open”这个 tracepoint,它生成的函数名就是 trace_do_sys_open。而这个函数会被内核函数 do_sys_open() 调用,从而实现了一个内核的 tracepoint。
static inline void trace_##name(proto) \
{ \
if (static_key_false(&__tracepoint_##name.key)) \
__DO_TRACE(&__tracepoint_##name, \
TP_PROTO(data_proto), \
TP_ARGS(data_args), \
TP_CONDITION(cond), 0); \
if (IS_ENABLED(CONFIG_LOCKDEP) && (cond)) { \
rcu_read_lock_sched_notrace(); \
rcu_dereference_sched(__tracepoint_##name.funcs);\
rcu_read_unlock_sched_notrace(); \
} \
}在这个 tracepoint 函数里,主要的功能是这样实现的,通过 __DO_TRACE 来调用所有注册在这个 tracepoint 上的 probe 函数。
#define __DO_TRACE(tp, proto, args, cond, rcuidle) \
…
it_func_ptr = rcu_dereference_raw((tp)->funcs); \
\
if (it_func_ptr) { \
do { \
it_func = (it_func_ptr)->func; \
__data = (it_func_ptr)->data; \
((void(*)(proto))(it_func))(args); \
} while ((++it_func_ptr)->func); \
}
…
…而 probe 函数的注册,它可以通过宏定义的”register_trace_##name”函数完成。
static inline int \
register_trace_##name(void (*probe)(data_proto), void *data) \
{ \
return tracepoint_probe_register(&__tracepoint_##name, \
(void *)probe, data); \
}我们可以自己写一个简单 kernel module 来注册一个 probe 函数,把它注册到已有的 treacepoint 上。这样,这个 probe 函数在每次 tracepoint 点被调用到的时候就会被执行。你可以动手试一下。
好了,说到这里,tracepoint 的实现方式我们就讲完了。简单来说 就是在内核代码中需要被 trace 的地方显式地加上 hook 点,然后再把自己的 probe 函数注册上去,那么在代码执行的时候,就可以执行 probe 函数。
Kprobe
我们已经知道了,tracepoint 为内核 trace 提供了 hook 点,但是这些 hook 点需要在内核源代码中预先写好。如果在 debug 的过程中,我们需要查看的内核函数中没有 hook 点,就需要像前面 perf/ftrace 的例子中那样,要通过 Linux kprobe 机制来加载 probe 函数。
那我们要怎么来理解 kprobe 的实现机制呢?
你可以先从内核 samples 代码里,看一下
kprobe_example.c 代码。这段代码里实现了一个 kernel module,可以在内核中任意一个函数名 / 符号对应的代码地址上注册三个 probe 函数,分别是”pre_handler”、 “post_handler”和”fault_handler”。
#define MAX_SYMBOL_LEN 64
static char symbol[MAX_SYMBOL_LEN] = "_do_fork";
module_param_string(symbol, symbol, sizeof(symbol), 0644);
/* For each probe you need to allocate a kprobe structure */
static struct kprobe kp = {
.symbol_name = symbol,
};
…
static int __init kprobe_init(void)
{
int ret;
kp.pre_handler = handler_pre;
kp.post_handler = handler_post;
kp.fault_handler = handler_fault;
ret = register_kprobe(&kp);
if (ret < 0) {
pr_err("register_kprobe failed, returned %d\n", ret);
return ret;
}
pr_info("Planted kprobe at %p\n", kp.addr);
return 0;
}当这个内核函数被执行的时候,已经注册的 probe 函数也会被执行 (handler_fault 只有在发生异常的时候才会被调用到)。
比如,我们加载的这个 kernel module 不带参数,那么缺省的情况就是这样的:在”_do_fork”内核函数的入口点注册了这三个 probe 函数。
当 _do_fork() 函数被调用到的时候,换句话说,也就是创建新的进程时,我们通过 dmesg 就可以看到 probe 函数的输出了。
[8446287.087641] <_do_fork> pre_handler: p->addr = 0x00000000d301008e, ip = ffffffffb1e8c9d1, flags = 0x246
[8446287.087643] <_do_fork> post_handler: p->addr = 0x00000000d301008e, flags = 0x246
[8446288.019731] <_do_fork> pre_handler: p->addr = 0x00000000d301008e, ip = ffffffffb1e8c9d1, flags = 0x246
[8446288.019733] <_do_fork> post_handler: p->addr = 0x00000000d301008e, flags = 0x246
[8446288.022091] <_do_fork> pre_handler: p->addr = 0x00000000d301008e, ip = ffffffffb1e8c9d1, flags = 0x246
[8446288.022093] <_do_fork> post_handler: p->addr = 0x00000000d301008e, flags = 0x246kprobe 的基本工作原理其实也很简单。当 kprobe 函数注册的时候,其实就是把目标地址上内核代码的指令码,替换成了”cc”,也就是 int3 指令。这样一来,当内核代码执行到这条指令的时候,就会触发一个异常而进入到 Linux int3 异常处理函数 do_int3() 里。
在 do_int3() 这个函数里,如果发现有对应的 kprobe 注册了 probe,就会依次执行注册的 pre_handler(),原来的指令,最后是 post_handler()。
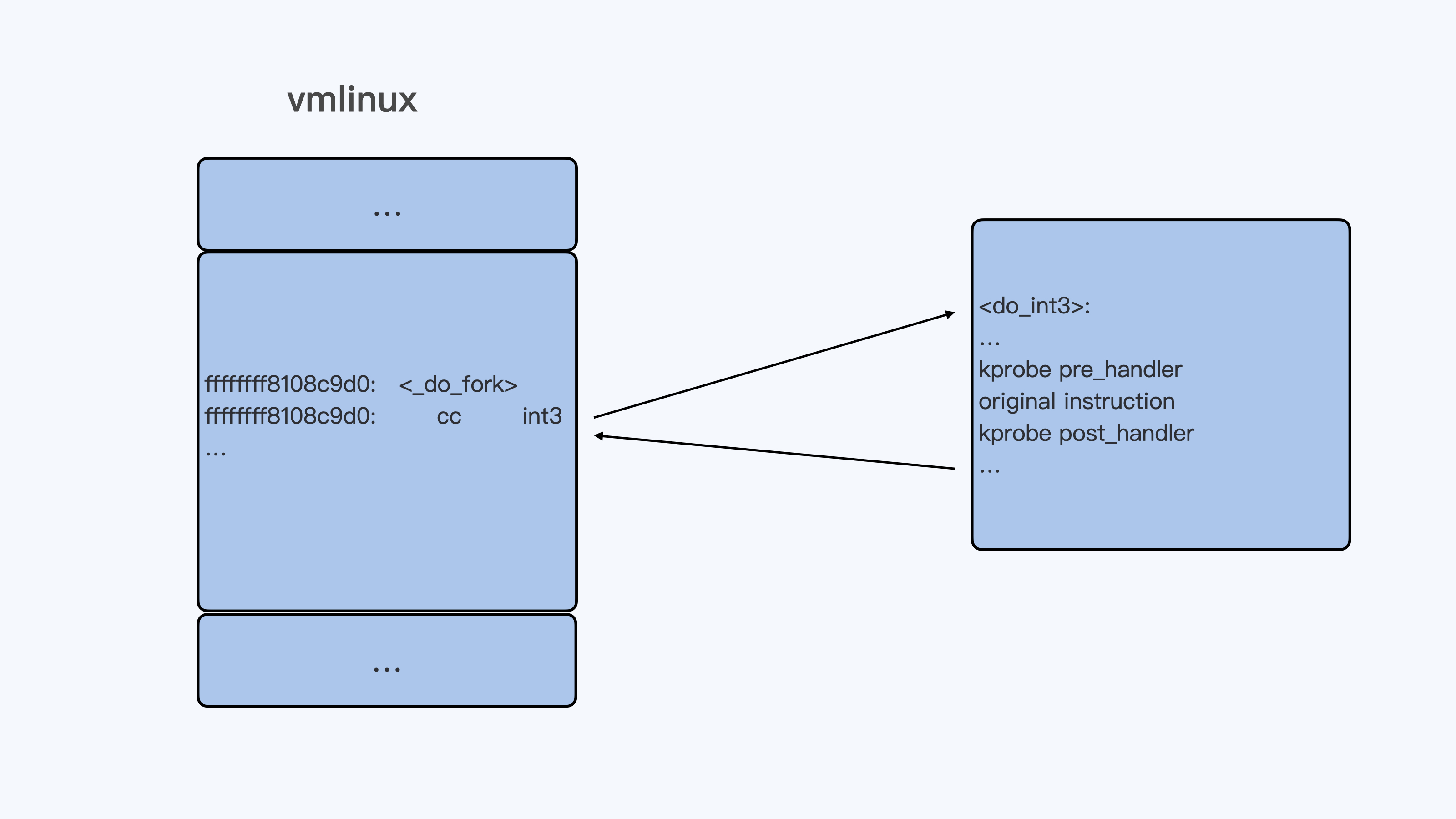
理论上 kprobe 其实只要知道内核代码中任意一条指令的地址,就可以为这个地址注册 probe 函数,kprobe 结构中的”addr”成员就可以接受内核中的指令地址。
static int __init kprobe_init(void)
{
int ret;
kp.addr = (kprobe_opcode_t *)0xffffffffb1e8ca02; /* 把一条指令的地址赋值给 kprobe.addr */
kp.pre_handler = handler_pre;
kp.post_handler = handler_post;
kp.fault_handler = handler_fault;
ret = register_kprobe(&kp);
if (ret < 0) {
pr_err("register_kprobe failed, returned %d\n", ret);
return ret;
}
pr_info("Planted kprobe at %p\n", kp.addr);
return 0;
}还要说明的是,如果内核可以使用我们上一讲 ftrace 对函数的 trace 方式,也就是函数头上预留了 callq <__fentry__> 的 5 个字节(在启动的时候被替换成了 nop)。Kprobe 对于函数头指令的 trace 方式,也会用”ftrace_caller”指令替换的方式,而不再使用 int3 指令替换。
不论是哪种替换方式,kprobe 的基本实现原理都是一样的,那就是把目标指令替换,替换的指令可以使程序跑到一个特定的 handler 里,去执行 probe 的函数。
重点小结
这一讲我们主要学习了 tracepoint 和 kprobe,这两个概念在 Linux tracing 系统中非常重要。
为什么说它们重要呢?因为从 Linux tracing 系统看,我的理解是可以大致分成大致这样三层。
第一层是最基础的提供数据的机制,这里就包含了 tracepoints、kprobes,还有一些别的 events,比如 perf 使用的 HW/SW events。
第二层是进行数据收集的工具,这里包含了 ftrace、perf,还有 ebpf。
第三层是用户层工具。虽然有了第二层,用户也可以得到数据。不过,对于大多数用户来说,第二层使用的友好程度还不够,所以又有了这一层。
很显然,如果要对 Linux 内核调试,很难绕过 tracepoint 和 kprobe。如果不刨根问底的话,前面我们讲的 perf、trace 工具对你来说还是黑盒。因为你只是知道了这些工具怎么用,但是并不知道它们依赖的底层技术。
在后面介绍 ebpf 的时候,我们还会继续学习 ebpf 是如何使用 tracepoint 和 kprobe 来做 Linux tracing 的,希望你可以把相关知识串联起来。
加餐05 | eBPF:怎么更加深入地查看内核中的函数?
今天这一讲,我们聊一聊 eBPF。在我们专题加餐第一讲的分析案例时就说过,当我们碰到网络延时问题,在毫无头绪的情况下,就是依靠了我们自己写的一个 eBPF 工具,找到了问题的突破口。
由此可见,eBPF 在内核问题追踪上的重要性是不言而喻的。那什么是 eBPF,它的工作原理是怎么样,它的编程模型又是怎样的呢?
在这一讲里,我们就来一起看看这几个问题。
eBPF 的概念
eBPF,它的全称是”Extended Berkeley Packet Filter”。从名字看,你可能会觉奇怪,似乎它就是一个用来做网络数据包过滤的模块。
其实这么想也没有错,eBPF 的概念最早源自于 BSD 操作系统中的 BPF(Berkeley Packet Filter),1992 伯克利实验室的一篇论文 “The BSD Packet Filter: A New Architecture for User-level Packet Capture”。这篇论文描述了,BPF 是如何更加高效灵活地从操作系统内核中抓取网络数据包的。
我们很熟悉的 tcpdump 工具,它就是利用了 BPF 的技术来抓取 Unix 操作系统节点上的网络包。Linux 系统中也沿用了 BPF 的技术。
那 BPF 是怎样从内核中抓取数据包的呢?我借用 BPF 论文中的图例来解释一下:
结合这张图,我们一起看看 BPF 实现有哪些特点。
第一,内核中实现了一个虚拟机,用户态程序通过系统调用,把数据包过滤代码载入到个内核态虚拟机中运行,这样就实现了内核态对数据包的过滤。这一块对应图中灰色的大方块,也就是 BPF 的核心。
第二,BPF 模块和网络协议栈代码是相互独立的,BPF 只是通过简单的几个 hook 点,就能从协议栈中抓到数据包。内核网络协议代码变化不影响 BPF 的工作,图中右边的”protocol stack”方块就是指内核网络协议栈。
第三,内核中的 BPF filter 模块使用 buffer 与用户态程序进行通讯,把 filter 的结果返回给用户态程序(例如图中的 network monitor),这样就不会产生内核态与用户态的上下文切换(context switch)。
在 BPF 实现的基础上,Linux 在 2014 年内核 3.18 的版本上实现了 eBPF,全名是 Extended BPF,也就是 BPF 的扩展。这个扩展主要做了下面这些改进。
首先,对虚拟机做了增强,扩展了寄存器和指令集的定义,提高了虚拟机的性能,并且可以处理更加复杂的程序。
其次,增加了 eBPF maps,这是一种存储类型,可以保存状态信息,从一个 BPF 事件的处理函数传递给另一个,或者保存一些统计信息,从内核态传递给用户态程序。
最后,eBPF 可以处理更多的内核事件,不再只局限在网络事件上。你可以这样来理解,eBPF 的程序可以在更多内核代码 hook 点上注册了,比如 tracepoints、kprobes 等。
在 Brendan Gregg 写的书《 BPF Performance Tools 》里有一张 eBPF 的架构图,这张图对 eBPF 内核部分的模块和工作流的描述还是挺完整的,我也推荐你阅读这本书。图书的网上预览部分也可以看到这张图,我把它放在这里,你可以先看一下。
这里我想提醒你,我们在后面介绍例子程序的时候,你可以回头再来看看这张图,那时你会更深刻地理解这张图里的模块。
当 BPF 增强为 eBPF 之后, 它的应用范围自然也变广了。从单纯的网络包抓取,扩展到了下面的几个领域:
- 网络领域,内核态网络包的快速处理和转发,你可以看一下XDP(eXpress Data Path)。
- 安全领域,通过LSM(Linux Security Module)的 hook 点,eBPF 可以对 Linux 内核做安全监控和访问控制,你可以参考KRSI(Kernel Runtime Security Instrumentation)的文档。
- 内核追踪 / 调试,eBPF 能通过 tracepoints、kprobes、 perf-events 等 hook 点来追踪和调试内核,这也是我们在调试生产环境中,解决容器相关问题时使用的方法。
eBPF 的编程模型
前面说了很多 eBPF 概念方面的内容,如果你是刚接触 eBPF,也许还不能完全理解。所以接下来,我们看一下 eBPF 编程模型,然后通过一个编程例子,再帮助你理解 eBPF。
eBPF 程序其实也是遵循了一个固定的模式,Daniel Thompson 的” Kernel analysis using eBPF “里的一张图解读得非常好,它很清楚地说明了 eBPF 的程序怎么编译、加载和运行的。

结合这张图,我们一起分析一下 eBPF 的运行原理。
一个 eBPF 的程序分为两部分,第一部分是内核态的代码,也就是图中的 foo_kern.c,这部分的代码之后会在内核 eBPF 的虚拟机中执行。第二部分是用户态的代码,对应图中的 foo_user.c。它的主要功能是负责加载内核态的代码,以及在内核态代码运行后通过 eBPF maps 从内核中读取数据。
然后我们看看 eBPF 内核态程序的编译,因为内核部分的代码需要被编译成 eBPF bytecode 二进制文件,也就是 eBPF 的虚拟机指令,而在 Linux 里,最常用的 GCC 编译器不支持生成 eBPF bytecode,所以这里 必须要用 Clang/LLVM 来编译 ,编译后的文件就是 foo_kern.o。
foo_user.c 编译链接后就会生成一个普通的用户态程序,它会通过 bpf() 系统调用做两件事:第一是去加载 eBPF bytecode 文件 foo_kern.o,使 foo_kern.o 这个 eBPF bytecode 在内核 eBPF 的虚拟机中运行;第二是创建 eBPF maps,用于内核态与用户态的通讯。
接下来,在内核态,eBPF bytecode 会被加载到 eBPF 内核虚拟机中,这里你可以参考一下前面的 eBPF 架构图。
执行 BPF 程序之前,BPF Verifier 先要对 eBPF bytecode 进行很严格的指令检查。检查通过之后,再通过 JIT(Just In Time)编译成宿主机上的本地指令。
编译成本地指令之后,eBPF 程序就可以在内核中运行了,比如挂载到 tracepoints hook 点,或者用 kprobes 来对内核函数做分析,然后把得到的数据存储到 eBPF maps 中,这样 foo_user 这个用户态程序就可以读到数据了。
我们学习 eBPF 的编程的时候,可以从编译和执行 Linux 内核中 samples/bpf 目录下的例子开始。在这个目录下的例子里,包含了 eBPF 各种使用场景。每个例子都有两个.c 文件,命名规则都是 xxx_kern.c 和 xxx_user.c ,编译和运行的方式就和我们刚才讲的一样。
本来我想拿 samples/bpf 目录下的一个例子来具体说明的,不过后来我在 github 上看到了一个更好的例子,它就是 ebpf-kill-example 。下面,我就用这个例子来给你讲一讲,如何编写 eBPF 程序,以及 eBPF 代码需要怎么编译与运行。
我们先用 git clone 取一下代码:
$ git clone https://github.com/niclashedam/ebpf-kill-example
$ cd ebpf-kill-example/
$ ls
docs img LICENSE Makefile README.md src test这里你可以先看一下 Makefile,请注意编译 eBPF 程序需要 Clang/LLVM,以及由 Linux 内核源代码里的 tools/lib/bpf 中生成的 libbpf.so 库和相关的头文件。如果你的 OS 是 Ubuntu,可以运行make deps;make kernel-src这个命令,准备好编译的环境。
$ cat Makefile
…
deps:
sudo apt update
sudo apt install -y build-essential git make gcc clang libelf-dev gcc-multilib
kernel-src:
git clone --depth 1 --single-branch --branch ${LINUX_VERSION} https://github.com/torvalds/linux.git kernel-src
cd kernel-src/tools/lib/bpf && make && make install prefix=../../../../
…完成上面的步骤后,在 src/ 目录下,我们可以看到两个文件,分别是 bpf_program.c 和 loader.c。
在这个例子里,bpf_program.c 对应前面说的 foo_kern.c 文件,也就是说 eBPF 内核态的代码在 bpf_program.c 里面。而 loader.c 就是 eBPF 用户态的代码,它主要负责把 eBPF bytecode 加载到内核中,并且通过 eBPF Maps 读取内核中返回的数据。
$ ls src/
bpf_program.c loader.c我们先看一下 bpf_program.c 中的内容:
$ cat src/bpf_program.c
#include <linux/bpf.h>
#include <stdlib.h>
#include "bpf_helpers.h"
//这里定义了一个eBPF Maps
//Data in this map is accessible in user-space
struct bpf_map_def SEC("maps") kill_map = {
.type = BPF_MAP_TYPE_HASH,
.key_size = sizeof(long),
.value_size = sizeof(char),
.max_entries = 64,
};
// This is the tracepoint arguments of the kill functions
// /sys/kernel/debug/tracing/events/syscalls/sys_enter_kill/format
struct syscalls_enter_kill_args {
long long pad;
long syscall_nr;
long pid;
long sig;
};
// 这里定义了BPF_PROG_TYPE_TRACEPOINT类型的BPF Program
SEC("tracepoint/syscalls/sys_enter_kill")
int bpf_prog(struct syscalls_enter_kill_args *ctx) {
// Ignore normal program terminations
if(ctx->sig != 9) return 0;
// We can call glibc functions in eBPF
long key = labs(ctx->pid);
int val = 1;
// Mark the PID as killed in the map
bpf_map_update_elem(&kill_map, &key, &val, BPF_NOEXIST);
return 0;
}
// All eBPF programs must be GPL licensed
char _license[] SEC("license") = "GPL";在这一小段代码中包含了 eBPF 代码最重要的三个要素,分别是:
- BPF Program Types
- BPF Maps
- BPF Helpers
“BPF Program Types”定义了函数在 eBPF 内核态的类型,这个类型决定了这个函数会在内核中的哪个 hook 点执行,同时也决定了函数的输入参数的类型。在内核代码 bpf_prog_type 的枚举定义里,你可以看到 eBPF 支持的所有”BPF Program Types”。
比如在这个例子里的函数 bpf_prog(),通过 SEC() 这个宏,我们可以知道它的类型是 BPF_PROG_TYPE_TRACEPOINT,并且它注册在 syscalls subsystem 下的 sys_enter_kill 这个 tracepoint 上。
既然我们知道了具体的 tracepoint,那么这个 tracepoint 的注册函数的输入参数也就固定了。在这里,我们就把参数组织到 syscalls_enter_kill_args{} 这个结构里,里面最主要的信息就是 kill() 系统调用中,输入信号的 编号 sig 和信号发送目标进程的 pid 。
参数的结构来自于
sudo cat /sys/kernel/debug/tracing/events/syscalls/sys_enter_kill/format。
“BPF Maps”定义了 key/value 对的一个存储结构,它用于 eBPF 内核态程序之间,或者内核态程序与用户态程序之间的数据通讯。eBPF 中定义了不同类型的 Maps,在内核代码 bpf_map_type 的枚举定义中,你可以看到完整的定义。
在这个例子里,定义的 kill_map 是 BPF_MAP_TYPE_HASH 类型,这里也用到了 SEC() 这个宏,等会儿我们再解释,先看其他的。
kill_map 是 HASH Maps 里的一个 key,它是一个 long 数据类型,value 是一个 char 字节。bpf_prog() 函数在系统调用 kill() 的 tracepoint 上运行,可以得到目标进程的 pid 参数,Maps 里的 key 值就是这个 pid 参数来赋值的,而 val 只是简单赋值为 1。
然后,这段程序调用了一个函数 bpf_map_update_elem(),把这组新的 key/value 对写入了到 kill_map 中。这个函数 bpf_map_update_elem() 就是我们要说的第三个要素 BPF Helpers。
我们再看一下” BPF Helpers “,它定义了一组可以在 eBPF 内核态程序中调用的函数。
尽管 eBPF 程序在内核态运行,但是跟 kernel module 不一样,eBPF 程序不能调用普通内核 export 出来的函数,而是只能调用在内核中为 eBPF 事先定义好的一些接口函数。这些接口函数叫作 BPF Helpers,具体有哪些你可以在”Linux manual page”中查看。
看明白这段代码之后,我们就可以运行 make build 命令,把 C 代码编译成 eBPF bytecode 了。这里生成了 src/bpf_program.o 这个文件:
$ make build
clang -O2 -target bpf -c src/bpf_program.c -Ikernel-src/tools/testing/selftests/bpf -Ikernel-src/tools/lib/bpf -o src/bpf_program.o
$ ls -l src/bpf_program.o
-rw-r----- 1 root root 1128 Jan 24 00:50 src/bpf_program.o接下来,你可以用 LLVM 工具来看一下 eBPF bytecode 里的内容,这样做可以确认下面两点。
- 编译生成了 BPF 虚拟机的汇编指令,而不是 x86 的指令。
- 在代码中用 SEC 宏添加的”BPF Program Types”和”BPF Maps”信息也在后面的 section 里。
查看 eBPF bytecode 信息的操作如下:
### 用objdump来查看bpf_program.o里的汇编指令
$ llvm-objdump -D src/bpf_program.o
…
Disassembly of section tracepoint/syscalls/sys_enter_kill:
0000000000000000 <bpf_prog>:
0: 79 12 18 00 00 00 00 00 r2 = *(u64 *)(r1 + 24)
1: 55 02 10 00 09 00 00 00 if r2 != 9 goto +16 <LBB0_2>
2: 79 11 10 00 00 00 00 00 r1 = *(u64 *)(r1 + 16)
3: bf 12 00 00 00 00 00 00 r2 = r1
4: c7 02 00 00 3f 00 00 00 r2 s>>= 63
5: 0f 21 00 00 00 00 00 00 r1 += r2
6: af 21 00 00 00 00 00 00 r1 ^= r2
7: 7b 1a f8 ff 00 00 00 00 *(u64 *)(r10 - 8) = r1
8: b7 01 00 00 01 00 00 00 r1 = 1
9: 63 1a f4 ff 00 00 00 00 *(u32 *)(r10 - 12) = r1
10: bf a2 00 00 00 00 00 00 r2 = r10
11: 07 02 00 00 f8 ff ff ff r2 += -8
12: bf a3 00 00 00 00 00 00 r3 = r10
13: 07 03 00 00 f4 ff ff ff r3 += -12
14: 18 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r1 = 0 ll
16: b7 04 00 00 01 00 00 00 r4 = 1
17: 85 00 00 00 02 00 00 00 call 2
…
### 用readelf读到bpf_program.o中的ELF section信息。
$ llvm-readelf -sections src/bpf_program.o
There are 9 section headers, starting at offset 0x228:
Section Headers:
[Nr] Name Type Address Off Size ES Flg Lk Inf Al
…
[ 3] tracepoint/syscalls/sys_enter_kill PROGBITS 0000000000000000 000040 0000a0 00 AX 0 0 8
[ 4] .reltracepoint/syscalls/sys_enter_kill REL 0000000000000000 000190 000010 10 8 3 8
[ 5] maps PROGBITS 0000000000000000 0000e0 00001c 00 WA 0 0 4好了,看完了 eBPF 程序的内核态部分,我们再来看看它的用户态部分 loader.c:
$ cat src/loader.c
#include "bpf_load.h"
#include <unistd.h>
#include <stdio.h>
int main(int argc, char **argv) {
// Load our newly compiled eBPF program
if (load_bpf_file("src/bpf_program.o") != 0) {
printf("The kernel didn't load the BPF program\n");
return -1;
}
printf("eBPF will listen to force kills for the next 30 seconds!\n");
sleep(30);
// map_fd is a global variable containing all eBPF map file descriptors
int fd = map_fd[0], val;
long key = -1, prev_key;
// Iterate over all keys in the map
while(bpf_map_get_next_key(fd, &prev_key, &key) == 0) {
printf("%ld was forcefully killed!\n", key);
prev_key = key;
}
return 0;
}这部分的代码其实也很简单,主要就是做了两件事:
- 通过执行 load_bpf_file() 函数,加载内核态代码生成的 eBPF bytecode,也就是编译后得到的文件”src/bpf_program.o”。
- 等待 30 秒钟后,从 BPF Maps 读取 key/value 对里的值。这里的值就是前面内核态的函数 bpf_prog(),在 kill() 系统调用的 tracepoint 上执行这个函数以后,写入到 BPF Maps 里的值。
至于读取 BPF Maps 的部分,就不需要太多的解释了,这里我们主要看一下 load_bpf_file() 这个函数,load_bpf_file() 是 Linux 内核代码 samples/bpf/bpf_load.c 里封装的一个函数。
这个函数可以读取 eBPF bytecode 中的信息,然后决定如何在内核中加载 BPF Program,以及创建 BPF Maps。这里用到的都是 bpf() 这个系统调用,具体的代码你可以去看一下内核中 bpf_load.c 和 bpf.c 这两个文件。
理解了用户态的 load.c 这段代码后,我们最后编译一下,就生成了用户态的程序 ebpf-kill-example:
$ make
clang -O2 -target bpf -c src/bpf_program.c -Ikernel-src/tools/testing/selftests/bpf -Ikernel-src/tools/lib/bpf -o src/bpf_program.o
clang -O2 -o src/ebpf-kill-example -lelf -Ikernel-src/samples/bpf -Ikernel-src/tools/lib -Ikernel-src/tools/perf -Ikernel-src/tools/include -Llib64 -lbpf \
kernel-src/samples/bpf/bpf_load.c -DHAVE_ATTR_TEST=0 src/loader.c
$ ls -l src/ebpf-kill-example
-rwxr-x--- 1 root root 23400 Jan 24 01:28 src/ebpf-kill-example你可以运行一下这个程序,如果在 30 秒以内有别的程序执行了 kill -9 <pid> ,那么在内核中的 eBPF 代码就可以截获这个操作,然后通过 eBPF Maps 把信息传递给用户态进程,并且把这个信息打印出来了。
$ LD_LIBRARY_PATH=lib64/:$LD_LIBRARY_PATH ./src/ebpf-kill-example &
[1] 1963961
# eBPF will listen to force kills for the next 30 seconds!
$ kill -9 1
# 1 was forcefully killed!重点小结
今天我们一起学习了 eBPF,接下来我给你总结一下重点。
eBPF 对早年的 BPF 技术做了增强之后,为 Linux 网络, Linux 安全以及 Linux 内核的调试和跟踪这三个领域提供了强大的扩展接口。
虽然整个 eBPF 技术是很复杂的,不过对于用户编写 eBPF 的程序,还是有一个固定的模式。
eBPF 的程序都分为两部分,一是内核态的代码最后会被编译成 eBPF bytecode,二是用户态代码,它主要是负责加载 eBPF bytecode,并且通过 eBPF Maps 与内核态代码通讯。
这里我们重点要掌握 eBPF 程序里的三个要素, eBPF Program Types,eBPF Maps 和 eBPF Helpers。
eBPF Program Types 可以定义函数在 eBPF 内核态的类型。eBPF Maps 定义了 key/value 对的存储结构,搭建了 eBPF Program 之间以及用户态和内核态之间的数据交换的桥梁。eBPF Helpers 是内核事先定义好了接口函数,方便 eBPF 程序调用这些函数。
理解了这些概念后,你可以开始动手编写 eBPF 的程序了。不过,eBPF 程序的调试并不方便,基本只能依靠 bpf_trace_printk(),同时也需要我们熟悉 eBPF 虚拟机的汇编指令。这些就需要你在实际的操作中,不断去积累经验了。
思考题
请你在 ebpf-kill-example 这个例子的基础上,做一下修改,让用户态程序也能把调用 kill() 函数的进程所对应的进程号打印出来。
加餐06 | BCC:入门eBPF的前端工具
上一讲,我们学习了 eBPF 的基本概念,以及 eBPF 编程的一个基本模型。在理解了这些概念之后,从理论上来说,你就能自己写出 eBPF 的程序,对 Linux 系统上的一些问题做跟踪和调试了。
不过,从上一讲的例子里估计你也发现了,eBPF 的程序从编译到运行还是有些复杂。
为了方便我们用 eBPF 的程序跟踪和调试系统,社区有很多 eBPF 的前端工具。在这些前端工具中,BCC 提供了最完整的工具集,以及用于 eBPF 工具开发的 Python/Lua/C++ 的接口。那么今天我们就一起来看看,怎么使用 BCC 这个 eBPF 的前端工具。
如何使用 BCC 工具
BCC (BPF Compiler Collection)这个社区项目开始于 2015 年,差不多在内核中支持了 eBPF 的特性之后,BCC 这个项目就开始了。
BCC 的目标就是提供一个工具链,用于编写、编译还有内核加载 eBPF 程序,同时 BCC 也提供了大量的 eBPF 的工具程序,这些程序能够帮我们做 Linux 的性能分析和跟踪调试。
这里我们可以先尝试用几个 BCC 的工具,通过实际操作来了解一下 BCC。
大部分 Linux 发行版本都有 BCC 的软件包,你可以直接安装。比如我们可以在 Ubuntu 20.04 上试试,用下面的命令安装 BCC:
apt install bpfcc-tools安装完 BCC 软件包之后,你在 Linux 系统上就会看到多了 100 多个 BCC 的小工具 (在 Ubuntu 里,这些工具的名字后面都加了 bpfcc 的后缀):
$ ls -l /sbin/*-bpfcc | more
-rwxr-xr-x 1 root root 34536 Feb 7 2020 /sbin/argdist-bpfcc
-rwxr-xr-x 1 root root 2397 Feb 7 2020 /sbin/bashreadline-bpfcc
-rwxr-xr-x 1 root root 6231 Feb 7 2020 /sbin/biolatency-bpfcc
-rwxr-xr-x 1 root root 5524 Feb 7 2020 /sbin/biosnoop-bpfcc
-rwxr-xr-x 1 root root 6439 Feb 7 2020 /sbin/biotop-bpfcc
-rwxr-xr-x 1 root root 1152 Feb 7 2020 /sbin/bitesize-bpfcc
-rwxr-xr-x 1 root root 2453 Feb 7 2020 /sbin/bpflist-bpfcc
-rwxr-xr-x 1 root root 6339 Feb 7 2020 /sbin/btrfsdist-bpfcc
-rwxr-xr-x 1 root root 9973 Feb 7 2020 /sbin/btrfsslower-bpfcc
-rwxr-xr-x 1 root root 4717 Feb 7 2020 /sbin/cachestat-bpfcc
-rwxr-xr-x 1 root root 7302 Feb 7 2020 /sbin/cachetop-bpfcc
-rwxr-xr-x 1 root root 6859 Feb 7 2020 /sbin/capable-bpfcc
-rwxr-xr-x 1 root root 53 Feb 7 2020 /sbin/cobjnew-bpfcc
-rwxr-xr-x 1 root root 5209 Feb 7 2020 /sbin/cpudist-bpfcc
-rwxr-xr-x 1 root root 14597 Feb 7 2020 /sbin/cpuunclaimed-bpfcc
-rwxr-xr-x 1 root root 8504 Feb 7 2020 /sbin/criticalstat-bpfcc
-rwxr-xr-x 1 root root 7095 Feb 7 2020 /sbin/dbslower-bpfcc
-rwxr-xr-x 1 root root 3780 Feb 7 2020 /sbin/dbstat-bpfcc
-rwxr-xr-x 1 root root 3938 Feb 7 2020 /sbin/dcsnoop-bpfcc
-rwxr-xr-x 1 root root 3920 Feb 7 2020 /sbin/dcstat-bpfcc
-rwxr-xr-x 1 root root 19930 Feb 7 2020 /sbin/deadlock-bpfcc
-rwxr-xr-x 1 root root 7051 Dec 10 2019 /sbin/deadlock.c-bpfcc
-rwxr-xr-x 1 root root 6830 Feb 7 2020 /sbin/drsnoop-bpfcc
-rwxr-xr-x 1 root root 7658 Feb 7 2020 /sbin/execsnoop-bpfcc
-rwxr-xr-x 1 root root 10351 Feb 7 2020 /sbin/exitsnoop-bpfcc
-rwxr-xr-x 1 root root 6482 Feb 7 2020 /sbin/ext4dist-bpfcc这些工具几乎覆盖了 Linux 内核中各个模块,它们可以对 Linux 某个模块做最基本的 profile。你可以看看下面这张图,图里把 BCC 的工具与 Linux 中的各个模块做了一个映射。
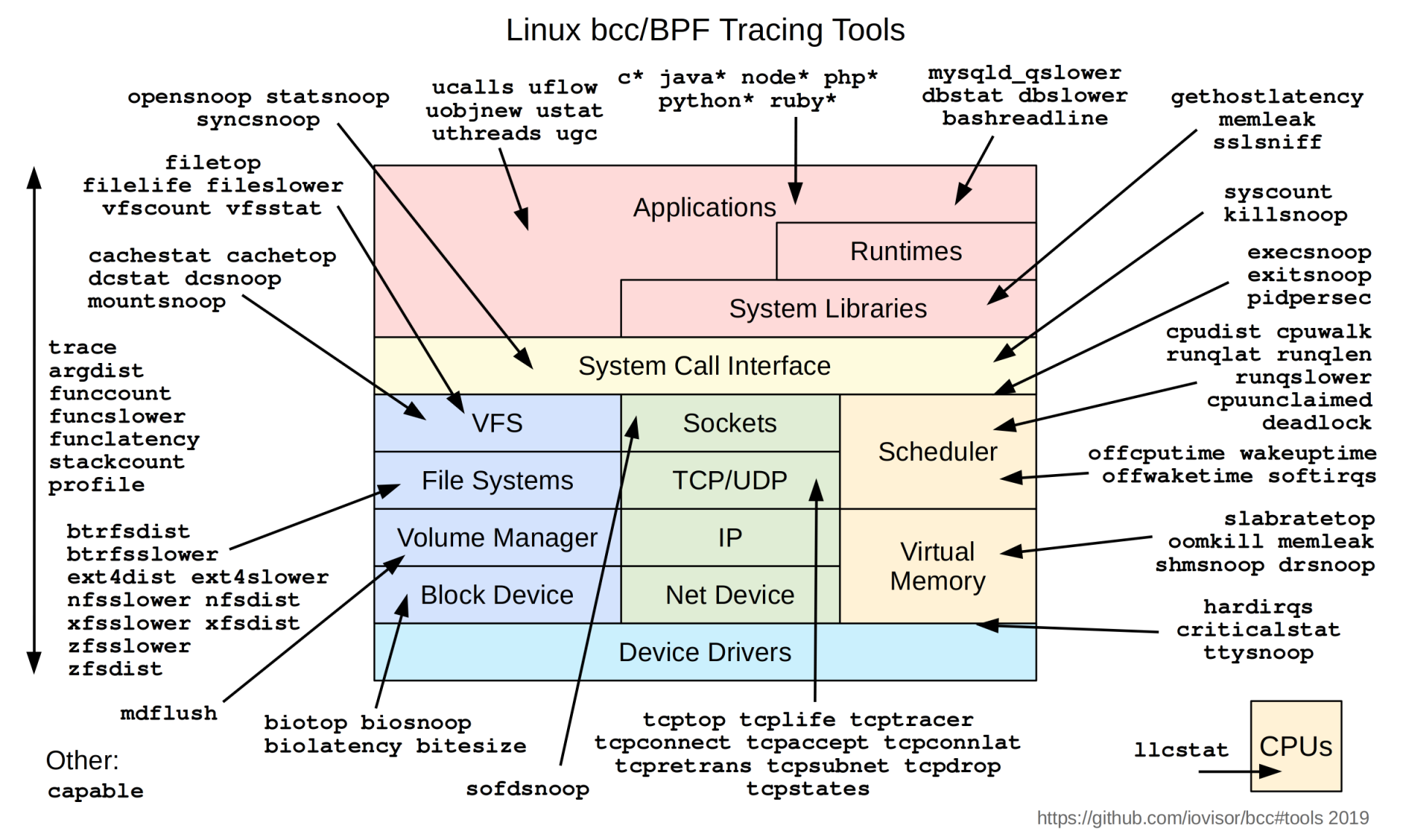
在 BCC 的 github repo 里,也有很完整的文档和例子来描述每一个工具。Brendan D. Gregg写了一本书,书名叫《BPF Performance Tools》(我们上一讲也提到过这本书),这本书从 Linux CPU/Memory/Filesystem/Disk/Networking 等角度介绍了如何使用 BCC 工具,感兴趣的你可以自行学习。
为了让你更容易理解,这里我给你举两个例子。
第一个是使用 opensnoop 工具,用它来监控节点上所有打开文件的操作。这个命令有时候也可以用来查看某个文件被哪个进程给动过。
比如说,我们先启动 opensnoop,然后在其他的 console 里运行 touch test-open 命令,这时候我们就会看到 touch 命令在启动时读取到的库文件和配置文件,以及最后建立的”test-open”这个文件。
$ opensnoop-bpfcc
PID COMM FD ERR PATH
2522843 touch 3 0 /etc/ld.so.cache
2522843 touch 3 0 /lib/x86_64-linux-gnu/libc.so.6
2522843 touch 3 0 /usr/lib/locale/locale-archive
2522843 touch 3 0 /usr/share/locale/locale.alias
2522843 touch 3 0 /usr/lib/locale/C.UTF-8/LC_IDENTIFICATION
2522843 touch 3 0 /usr/lib/x86_64-linux-gnu/gconv/gconv-modules.cache
2522843 touch 3 0 /usr/lib/locale/C.UTF-8/LC_MEASUREMENT
2522843 touch 3 0 /usr/lib/locale/C.UTF-8/LC_TELEPHONE
2522843 touch 3 0 /usr/lib/locale/C.UTF-8/LC_ADDRESS
2522843 touch 3 0 /usr/lib/locale/C.UTF-8/LC_NAME
2522843 touch 3 0 /usr/lib/locale/C.UTF-8/LC_PAPER
2522843 touch 3 0 /usr/lib/locale/C.UTF-8/LC_MESSAGES
2522843 touch 3 0 /usr/lib/locale/C.UTF-8/LC_MESSAGES/SYS_LC_MESSAGES
2522843 touch 3 0 /usr/lib/locale/C.UTF-8/LC_MONETARY
2522843 touch 3 0 /usr/lib/locale/C.UTF-8/LC_COLLATE
2522843 touch 3 0 /usr/lib/locale/C.UTF-8/LC_TIME
2522843 touch 3 0 /usr/lib/locale/C.UTF-8/LC_NUMERIC
2522843 touch 3 0 /usr/lib/locale/C.UTF-8/LC_CTYPE
2522843 touch 3 0 test-open第二个是使用 softirqs 这个命令,查看节点上各种类型的 softirqs 花费时间的分布图 (直方图模式)。
比如在下面这个例子里,每一次 timer softirq 执行时间在 0~1us 时间区间里的有 16 次,在 2-3us 时间区间里的有 49 次,以此类推。
在我们分析网络延时的时候,也用过这个 softirqs 工具,用它来确认 timer softirq 花费的时间。
$ softirqs-bpfcc -d
Tracing soft irq event time... Hit Ctrl-C to end.
^C
softirq = block
usecs : count distribution
0 -> 1 : 2 |******************** |
2 -> 3 : 3 |****************************** |
4 -> 7 : 2 |******************** |
8 -> 15 : 4 |****************************************|
softirq = rcu
usecs : count distribution
0 -> 1 : 189 |****************************************|
2 -> 3 : 52 |*********** |
4 -> 7 : 21 |**** |
8 -> 15 : 5 |* |
16 -> 31 : 1 | |
softirq = net_rx
usecs : count distribution
0 -> 1 : 1 |******************** |
2 -> 3 : 0 | |
4 -> 7 : 2 |****************************************|
8 -> 15 : 0 | |
16 -> 31 : 2 |****************************************|
softirq = timer
usecs : count distribution
0 -> 1 : 16 |************* |
2 -> 3 : 49 |****************************************|
4 -> 7 : 43 |*********************************** |
8 -> 15 : 5 |**** |
16 -> 31 : 13 |********** |
32 -> 63 : 13 |********** |
softirq = sched
usecs : count distribution
0 -> 1 : 18 |****** |
2 -> 3 : 107 |****************************************|
4 -> 7 : 20 |******* |
8 -> 15 : 1 | |
16 -> 31 : 1 | |BCC 中的工具数目虽然很多,但是你用过之后就会发现,它们的输出模式基本上就是上面我说的这两种。
第一种类似事件模式,就像 opensnoop 的输出一样,发生一次就输出一次;第二种是直方图模式,就是把内核中执行函数的时间做个统计,然后用直方图的方式输出,也就是 softirqs -d 的执行结果。
用过 BCC 工具之后,我们再来看一下 BCC 工具的工作原理,这样以后你有需要的时候,自己也可以编写和部署一个 BCC 工具了。
BCC 的工作原理
让我们来先看一下 BCC 工具的代码结构。
因为目前 BCC 的工具都是用 python 写的,所以你直接可以用文本编辑器打开节点上的一个工具文件。比如打开 /sbin/opensnoop-bpfcc 文件(也可在 github bcc 项目中查看 opensnoop.py ),这里你可以看到大概 200 行左右的代码,代码主要分成了两部分。
第一部分其实是一块 C 代码,里面定义的就是 eBPF 内核态的代码,不过它是以 python 字符串的形式加在代码中的。
我在下面列出了这段 C 程序的主干,其实就是定义两个 eBPF Maps 和两个 eBPF Programs 的函数:
# define BPF program
bpf_text = """
#include <uapi/linux/ptrace.h>
#include <uapi/linux/limits.h>
#include <linux/sched.h>
…
BPF_HASH(infotmp, u64, struct val_t); //BPF_MAP_TYPE_HASH
BPF_PERF_OUTPUT(events); // BPF_MAP_TYPE_PERF_EVENT_ARRAY
int trace_entry(struct pt_regs *ctx, int dfd, const char __user *filename, int flags)
{
…
}
int trace_return(struct pt_regs *ctx)
{
…
}
"""第二部分就是用 python 写的用户态代码,它的作用是加载内核态 eBPF 的代码,把内核态的函数 trace_entry() 以 kprobe 方式挂载到内核函数 do_sys_open(),把 trace_return() 以 kproberet 方式也挂载到 do_sys_open(),然后从 eBPF Maps 里读取数据并且输出。
…
# initialize BPF
b = BPF(text=bpf_text)
b.attach_kprobe(event="do_sys_open", fn_name="trace_entry")
b.attach_kretprobe(event="do_sys_open", fn_name="trace_return")
…
# loop with callback to print_event
b["events"].open_perf_buffer(print_event, page_cnt=64)
start_time = datetime.now()
while not args.duration or datetime.now() - start_time < args.duration:
try:
b.perf_buffer_poll()
except KeyboardInterrupt:
exit()
…从代码的结构看,其实这和我们上一讲介绍的 eBPF 标准的编程模式是差不多的,只是用户态的程序是用 python 来写的。不过这里有一点比较特殊,用户态在加载程序的时候,输入的是 C 程序的文本而不是 eBPF bytecode。
BCC 可以这么做,是因为它通过 pythonBPF() 加载 C 代码之后,调用 libbcc 库中的函数 bpf_module_create_c_from_string() 把 C 代码编译成了 eBPF bytecode。也就是说,libbcc 库中集成了 clang/llvm 的编译器。
def __init__(self, src_file=b"", hdr_file=b"", text=None, debug=0,
cflags=[], usdt_contexts=[], allow_rlimit=True, device=None):
"""Create a new BPF module with the given source code.
...
self.module = lib.bpf_module_create_c_from_string(text, self.debug,cflags_array, len(cflags_array), allow_rlimit, device)
...我们弄明白 libbcc 库的作用之后,再来整体看一下 BCC 工具的工作方式。为了让你理解,我给你画了一张示意图:

BCC 的这种设计思想是为了方便 eBPF 程序的开发和使用,特别是 eBPF 内核态的代码对当前运行的内核版本是有依赖的,比如在 4.15 内核的节点上编译好的 bytecode,放到 5.4 内核的节点上很有可能是运行不了的。
那么让编译和运行都在同一个节点,出现问题就可以直接修改源代码文件了。你有没有发现,这么做有点像把 C 程序的处理当成 python 的处理方式。
BCC 的这种设计思想虽然有好处,但是也带来了问题。其实问题也是很明显的,首先我们需要在运行 BCC 工具的节点上必须安装内核头文件,这个在编译内核态 eBPF C 代码的时候是必须要做的。
其次,在 libbcc 的库里面包含了 clang/llvm 的编译器,这不光占用磁盘空间,在运行程序前还需要编译,也会占用节点的 CPU 和 Memory,同时也让 BCC 工具的启动时间变长。这两个问题都会影响到 BCC 生产环境中的使用。
BCC 工具的发展
那么我们有什么办法来解决刚才说的问题呢?eBPF 的技术在不断进步,最新的 BPF CO-RE 技术可以解决这个问题。我们下面就来看 BPF CO-RE 是什么意思。
CO-RE 是”Compile Once – Run Everywhere”的缩写,BPF CO-RE 通过对 Linux 内核、用户态 BPF loader(libbpf 库)以及 Clang 编译器的修改,来实现编译出来的 eBPF 程序可以在不同版本的内核上运行。
不同版本的内核上,用 CO-RE 编译出来的 eBPF 程序都可以运行。在 Linux 内核和 BPF 程序之间,会通过BTF(BPF Type Format)来协调不同版本内核中数据结构的变量偏移或者变量长度变化等问题。
在 BCC 的 github repo 里,有一个目录 libbpf-tools,在这个目录下已经有一些重写过的 BCC 工具的源代码,它们并不是用 python+libbcc 的方式实现的,而是用到了 libbpf+BPF CO-RE 的方式。
如果你的系统上有高于版本 10 的 CLANG/LLVM 编译器,就可以尝试编译一下 libbpf-tools 下的工具。这里可以加一个”V=1”参数,这样我们就能清楚编译的步骤了。
# git remote -v
origin https://github.com/iovisor/bcc.git (fetch)
origin https://github.com/iovisor/bcc.git (push)
# cd libbpf-tools/
# make V=1
mkdir -p .output
mkdir -p .output/libbpf
make -C /root/bcc/src/cc/libbpf/src BUILD_STATIC_ONLY=1 \
OBJDIR=/root/bcc/libbpf-tools/.output//libbpf DESTDIR=/root/bcc/libbpf-tools/.output/ \
INCLUDEDIR= LIBDIR= UAPIDIR= \
Install
…
ar rcs /root/bcc/libbpf-tools/.output//libbpf/libbpf.a …
…
clang -g -O2 -target bpf -D__TARGET_ARCH_x86 \
-I.output -c opensnoop.bpf.c -o .output/opensnoop.bpf.o && \
llvm-strip -g .output/opensnoop.bpf.o
bin/bpftool gen skeleton .output/opensnoop.bpf.o > .output/opensnoop.skel.h
cc -g -O2 -Wall -I.output -c opensnoop.c -o .output/opensnoop.o
cc -g -O2 -Wall .output/opensnoop.o /root/bcc/libbpf-tools/.output/libbpf.a .output/trace_helpers.o .output/syscall_helpers.o .output/errno_helpers.o -lelf -lz -o opensnoop
…我们梳理一下编译的过程。首先这段代码生成了 libbpf.a 这个静态库,然后逐个的编译每一个工具。对于每一个工具的代码结构是差不多的,编译的方法也是差不多的。
我们拿 opensnoop 做例子来看一下,它的源代码分为两个文件。opensnoop.bpf.c 是内核态的 eBPF 代码,opensnoop.c 是用户态的代码,这个和我们之前学习的 eBPF 代码的标准结构是一样的。主要不同点有下面这些。
内核态的代码不再逐个 include 内核代码的头文件,而是只要 include 一个”vmlinux.h”就可以。在”vmlinux.h”中包含了所有内核的数据结构,它是由内核文件 vmlinux 中的 BTF 信息转化而来的。
$ cat opensnoop.bpf.c | head
// SPDX-License-Identifier: GPL-2.0
// Copyright (c) 2019 Facebook
// Copyright (c) 2020 Netflix
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include "opensnoop.h"
#define TASK_RUNNING 0
const volatile __u64 min_us = 0;我们使用 bpftool 这个工具,可以把编译出来的 opensnoop.bpf.o 重新生成为一个 C 语言的头文件 opensnoop.skel.h。这个头文件中定义了加载 eBPF 程序的函数,eBPF bytecode 的二进制流也直接写在了这个头文件中。
bin/bpftool gen skeleton .output/opensnoop.bpf.o > .output/opensnoop.skel.h用户态的代码 opensnoop.c 直接 include 这个 opensnoop.skel.h,并且调用里面的 eBPF 加载的函数。这样在编译出来的可执行程序 opensnoop,就可以直接运行了,不用再找 eBPF bytecode 文件或者 eBPF 内核态的 C 文件。并且这个 opensnoop 程序可以运行在不同版本内核的节点上(当然,这个内核需要打开 CONFIG_DEBUG_INFO_BTF 这个编译选项)。
比如,我们可以把在 kernel5.4 节点上编译好的 opensnoop 程序 copy 到一台 kernel5.10.4 的节点来运行:
$ uname -r
5.10.4
$ ls -lh opensnoop
-rwxr-x--- 1 root root 235K Jan 30 23:08 opensnoop
$ ./opensnoop
PID COMM FD ERR PATH
2637411 opensnoop 24 0 /etc/localtime
1 systemd 28 0 /proc/746/cgroup从上面的代码我们会发现,这时候的 opensnoop 不依赖任何的库函数,只有一个文件,strip 后的文件大小只有 235KB,启动运行的时候,既不不需要读取外部的文件,也不会做额外的编译。
重点小结
好了,今天我们主要讲了 eBPF 的一个前端工具 BCC,我来给你总结一下。
在我看来,对于把 eBPF 运用于 Linux 内核的性能分析和跟踪调试这个领域,BCC 是社区中最有影响力的一个项目。BCC 项目提供了 eBPF 工具开发的 Python/Lua/C++ 的接口,以及上百个基于 eBPF 的工具。
对不熟悉 eBPF 的同学来说,可以直接拿这些工具来调试 Linux 系统中的问题。而对于了解 eBPF 的同学,也可以利用 BCC 提供的接口,开发自己需要的 eBPF 工具。
BCC 工具目前主要通过 ptyhon+libbcc 的模式在目标节点上运行,但是这个模式需要节点有内核头文件以及内嵌在 libbcc 中的 Clang/LLVM 编译器,每次程序启动的时候还需要再做一次编译。
为了弥补这个缺点,BCC 工具开始向 libbpf+BPF CO-RE 的模式转变。用这种新模式编译出来的 BCC 工具程序,只需要很少的系统资源就可以在目标节点上运行,并且不受内核版本的限制。
除了 BCC 之外,你还可以看一下 bpftrace 、 ebpf-exporter 等 eBPF 的前端工具。
bpftrace 提供了类似 awk 和 C 语言混合的一种语言,在使用时也很类似 awk,可以用一两行的命令来完成一次 eBPF 的调用,它能做一些简单的内核事件的跟踪。当然它也可以编写比较复杂的 eBPF 程序。
ebpf-exporter 可以把 eBPF 程序收集到的 metrics 以Prometheus的格式对外输出,然后通过Grafana的 dashboard,可以对内核事件做长期的以及更加直观的监控。
总之,前面提到的这些工具,你都可以好好研究一下,它们可以帮助你对容器云平台上的节点做内核级别的监控与诊断。

