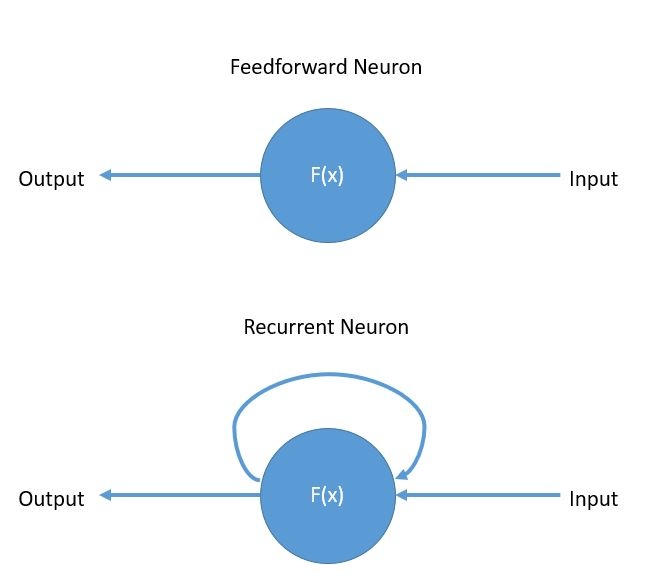
一、循环神经网络
循环神经网络(Recurrent neural network,RNN) 和前馈神经网络(Feedforward Neural Network)的主要区别是:
| 网络 | 输入 | 输出 |
|---|---|---|
| 前馈神经网络 | 训练数据 | 训练后的数据 |
| 循环神经网络 | 训练数据 + 上一层输出的隐状态 | 训练后的数据 + 新的隐状态 |
将上图的循环神经网络展开可以得到:
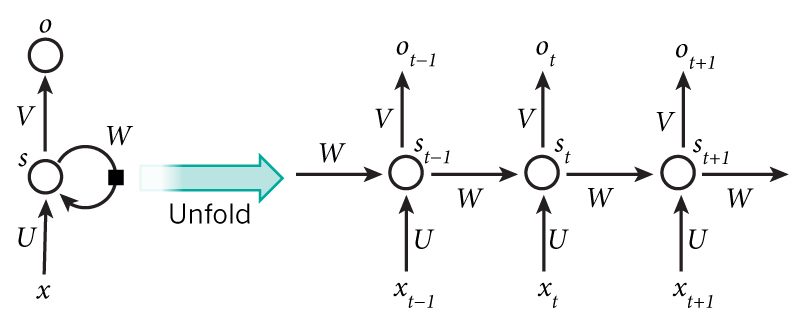
图片来源:Recurrent Neural Networks Tutorial, Part 1 – Introduction to RNNs
其中:
- $x_t$ 是 $t$ 时刻的输入。比如 $x_1$ 可以是一段话中与第 2 个单词对应的 one-hot 向量;
- $s_t$ 是 $t$ 时刻输出的隐状态,它是网络的”记忆”。 $s_t$ 根据前一个隐状态和当前时刻的输入计算得出:$s_t = f(U x_t + W s_{t-1})$,其中函数 $f$ 通常是非线性的,比如:$tanh$ 或 $ReLU$ 。当计算第一个隐状态时, $s_{-1}$ 通常初始化为全零;
- $o_t$ 是 $t$ 时刻的输出。比如,如果是预测一个句子的下一个单词,它就是词汇表中各个单词的概率向量: $o_t = softmax(V s_t)$ 。
注意:
- 隐状态 $s_t$ 可以看做是网络的记忆,它收集了 $t$ 时刻及之前所有输入的信息。
- 每一步中的神经网络参数 $U$ 、 $V$ 和 $W$ 都是相同的。
- 每一步的输出 $o_t$ 不是必须需要使用的。比如,在预测一段话是积极的还是消极的时,只需要最后一步的输出即可。
- 每一步的输入 $x_t$ 也不是必须的,一个网络可以只需要另一个网络最后输出的隐状态作为该网络的初始隐状态即可产生一系列的输出。
理论上,不管输入的序列 $\{x_0, x_1, x_2, \cdots, x_t \}$ 多长,最后网络输出的隐状态 $s_t$ 应该都是包含了所有输入信息的。但是实际在使用时发现,循环神经网络对于比较长的输入序列来说,效果更差,这称之为长期依赖(Long-Term Dependencies)问题。
比如在一个根据之前的词预测下一个词的任务中,如果文本是 “I grew up in France… I speak fluent French”,如果第一句话与最后一句话隔得越远,循环神经网络就越难预测出最后的 “French”。
二、双向循环神经网络
标准的循环神经网络只考虑的过去输入,没有考虑未来的输入,而双向循环神经网络(Bi-directional Recurrent Neural Network,BRNN)则是都考虑了,其网络结构如下:
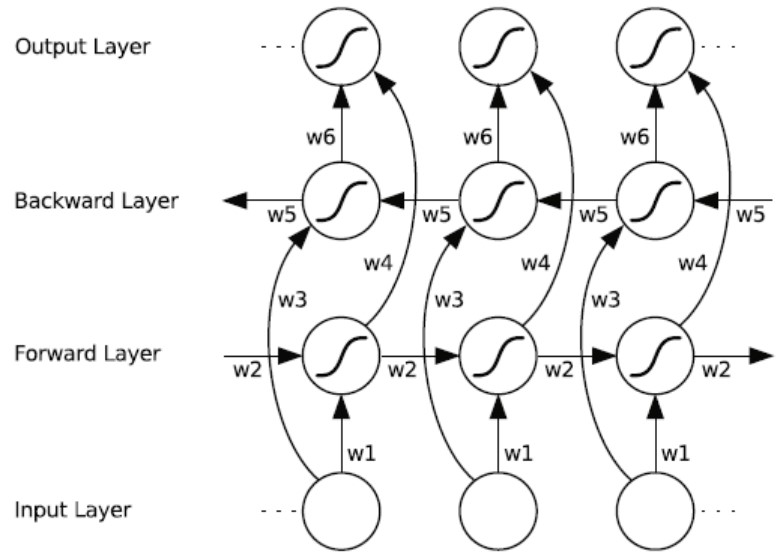
其中输出的值 $o_t$ 由下面的公式得到:
三、长短时记忆网络
长短时记忆(Long Short Term Memory,LSTM) 网络也属于循环神经网络,它较好的解决了循环神经网络有的长期依赖问题。其网络结构如下:
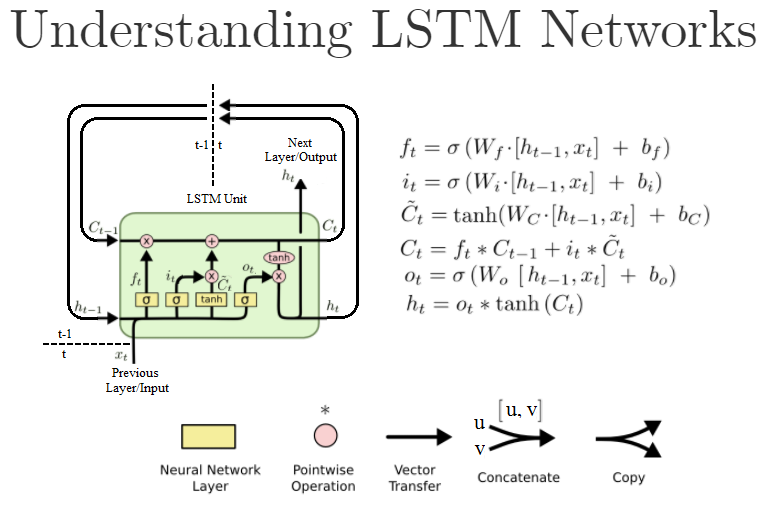
图片来源:In Keras, what exactly am I configuring when I create a stateful LSTM layer with N units?
长短时记忆网络的一个流行的变体是 GRU(Gated Recurrent Unit) ,其网络结构如下:

四、Seq2Seq
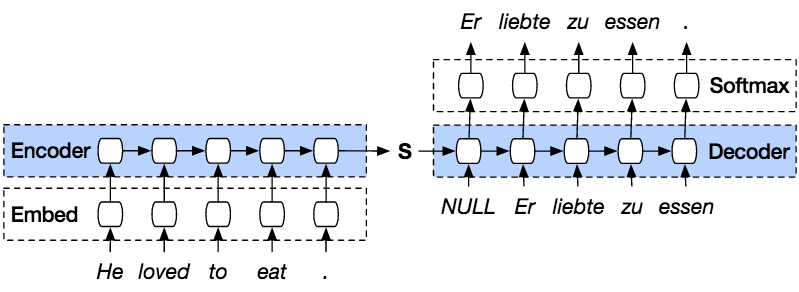
Seq2Seq 其实是指从一个序列生成另外一个序列的结构,这种结构由 Encoder 和 Decoder 组成。其中在 Encoder 和 Decoder 之间传递的只有输入序列最后一步得到的隐状态,如下图:
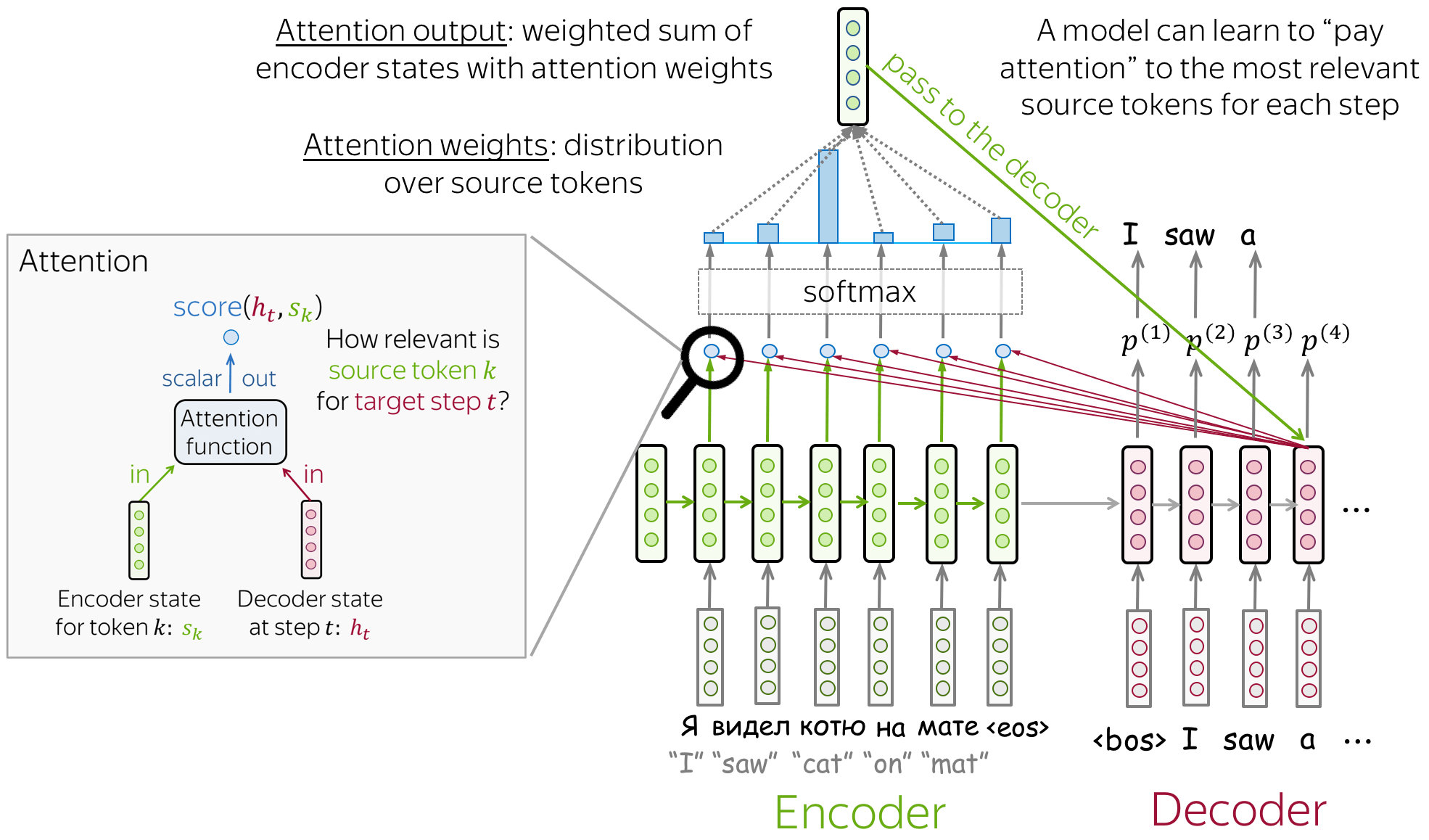
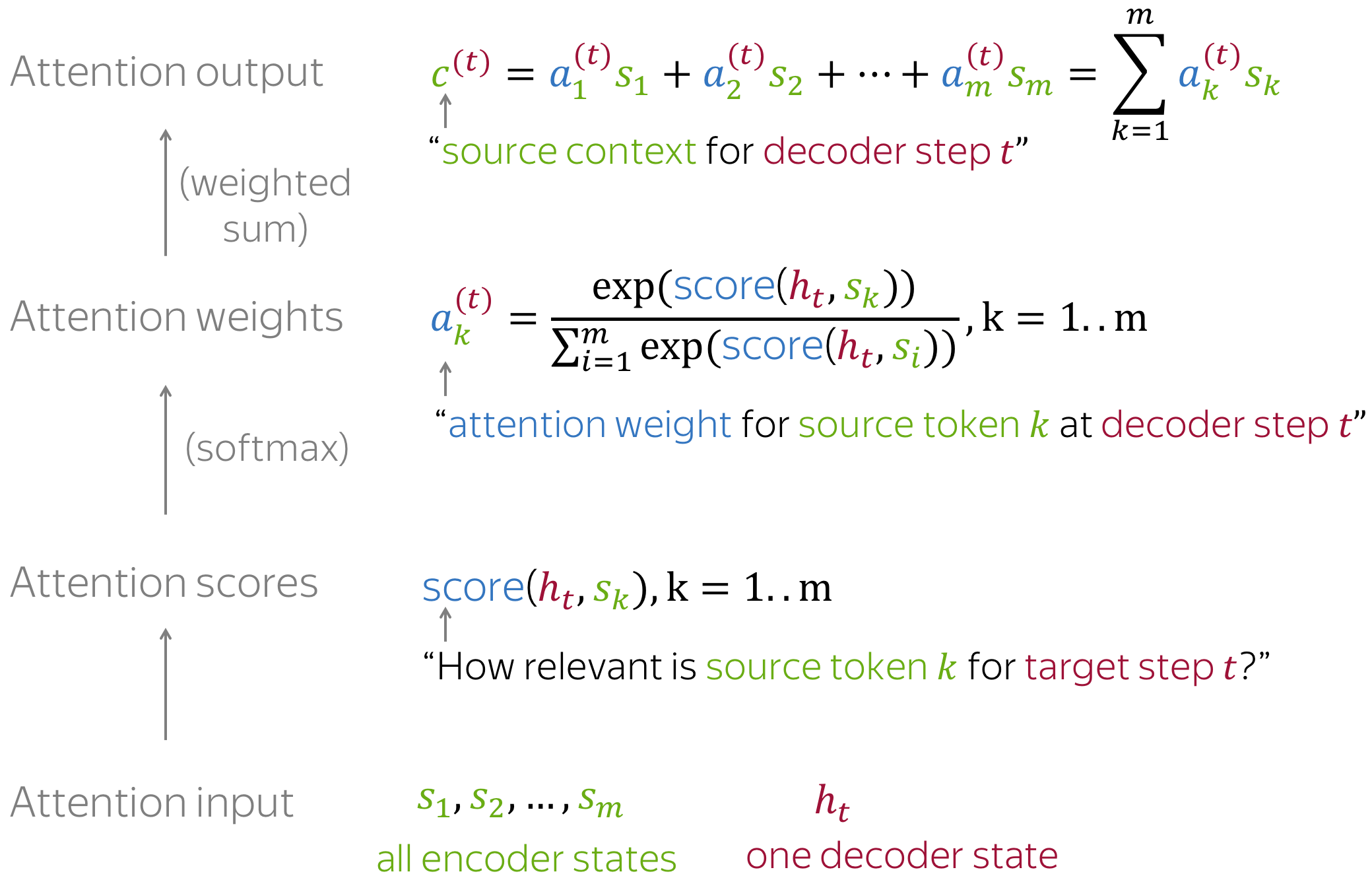
五、Attention
Attention 机制就是对输入的每个元素考虑不同的权重参数,从而更加关注与输入的元素相似的部分,而抑制其它无用的信息。