1. TIME_WAIT 会在什么情况下出现
如果处于 TIMEWAIT 状态,说明双方建立成功过连接,而且已经发送了最后的 ACK 之后,才会处于这个状态,而且是主动发起关闭的一方处于这个状态。
其次,当断开TCP的主动方收到了被动方发来的FIN包并回复对应的ACK包给被动方后,主动方就进入了TIME_WAIT状态。然后等待 2 * MSL 时间(此时间段内如果再次收到被动方发来的FIN消息,说明之前回复的ACK包丢失,需要重新发送给被动方,并重新开始计时)后,再进入CLOSED状态,此时才能完成的释放相关的资源。
如果存在大量的 TIMEWAIT,往往是因为短连接太多,不断的创建连接,然后释放连接,从而导致很多连接在这个状态,可能会导致无法发起新的连接。解决的方式往往是:
- 打开 tcp_tw_recycle 和 tcp_timestamps 选项;
- 打开 tcp_tw_reuse 和 tcp_timestamps 选项;
- 程序中使用 SO_LINGER,应用强制使用 rst 关闭。
当客户端收到 Connection Reset,往往是收到了 TCP 的 RST 消息,RST 消息一般在下面的情况下发送:
- 试图连接一个未被监听的服务端;
- 对方处于 TIMEWAIT 状态,或者连接已经关闭处于 CLOSED 状态,或者重新监听 seq num 不匹配;
- 发起连接时超时,重传超时,keepalive 超时;
- 在程序中使用 SO_LINGER,关闭连接时,放弃缓存中的数据,给对方发送 RST。
更多资料:
- TIME_WAIT and its design implications for protocols and scalable client server systems
- 系统调优,你所不知道的TIME_WAIT和CLOSE_WAIT
2. 什么是 MSL
MSL, Maximum Segment Lifetime,TCP Segment 在网络上的最长存活时间。
RFC793 将 MSL 定义为 2 分钟。Linux 下 MSL 默认是 30 秒,Windows 下 MSL 默认是 240 秒。Linux 下可以通过下面的命令查看实际的 MSL 值。
sysctl net.ipv4.tcp_fin_timeout
cat /proc/sys/net/ipv4/tcp_fin_timeout3. 为什么不直接进入 CLOSED 状态,还需要等待 2 * MSL 时间
主要原因有两个:
进入TIME_WAIT状态并等待
2 * MSL,保证了如果被动方没有收到主动方回复的 ACK,被动方至少有时间能重发一次之前 FIN 包。一回一重发,正好2 * MSL。如果主动方回的 ACK 包丢失,被动方重发的 FIN 包也丢失,那么就不管了。
避免断开的 TCP 连接不影响后面新建立的 TCP 连接。
如果主动方不等待
2*MSL直接进入 CLOSED 状态,然后再重新建立 TCP 连接,如果此时收到了之前关闭的被动方重发 FIN 消息,那么重新建立的 TCP 连接就会被断开。
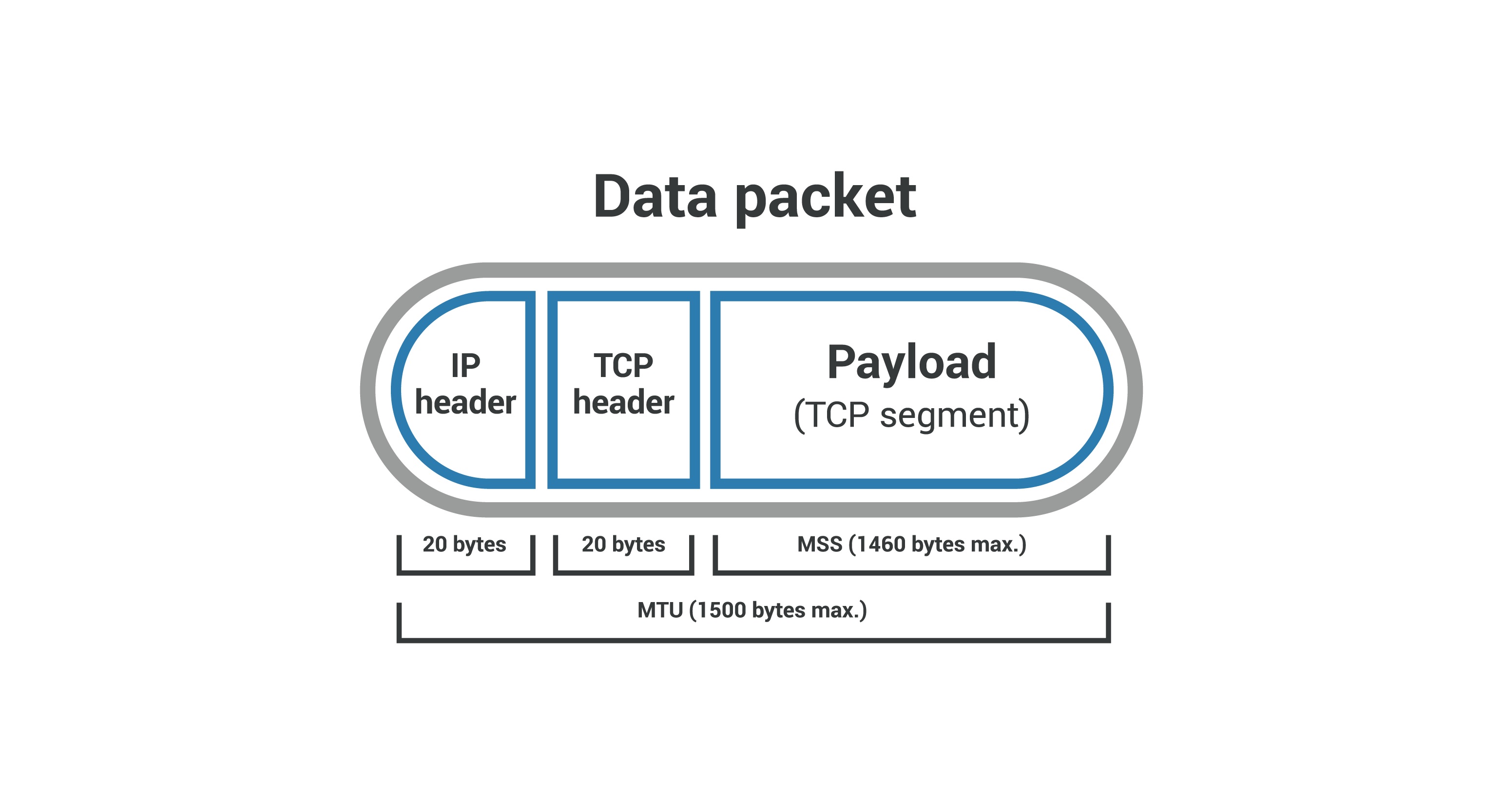
4. MTU 1500 和 MSS 1460
MTU(Maximum Transmission Unit,最大传输单元)是二层的一个定义。以以太网为例,MTU 为 1500 个 Byte,前面有 6 个 Byte 的目标 MAC 地址,6 个 Byte 的源 MAC 地址,2 个 Byte 的类型,后面有 4 个 Byte 的 CRC 校验,共 1518 个 Byte。
在 IP 层,一个 IP 数据报在以太网中传输,如果它的长度大于该 MTU 值,就要进行分片传输。如果不允许分片 DF,就会发送 ICMP 包,
在 TCP 层有个 MSS(Maximum Segment Size,最大分段大小),它等于 MTU 减去 IP 头,再减去 TCP 头,即 1460。即在不分片的情况下,TCP 里面放的最大内容。
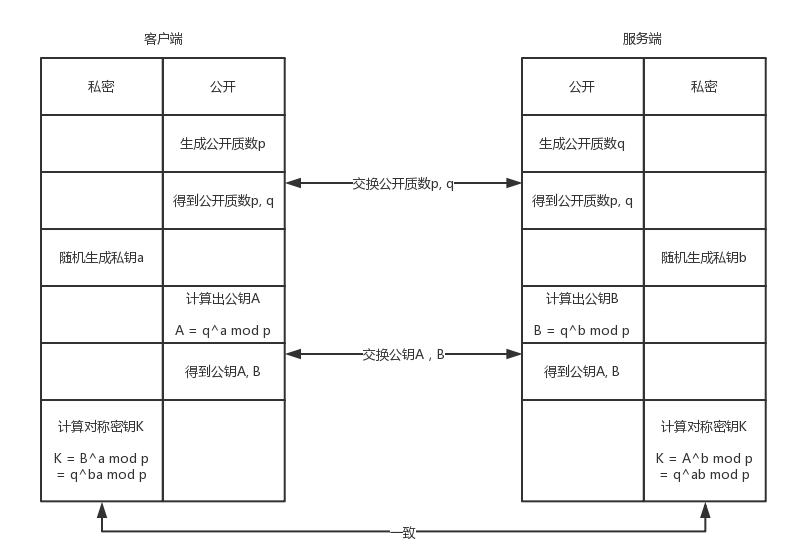
5. HTTPS 的双向认证流程
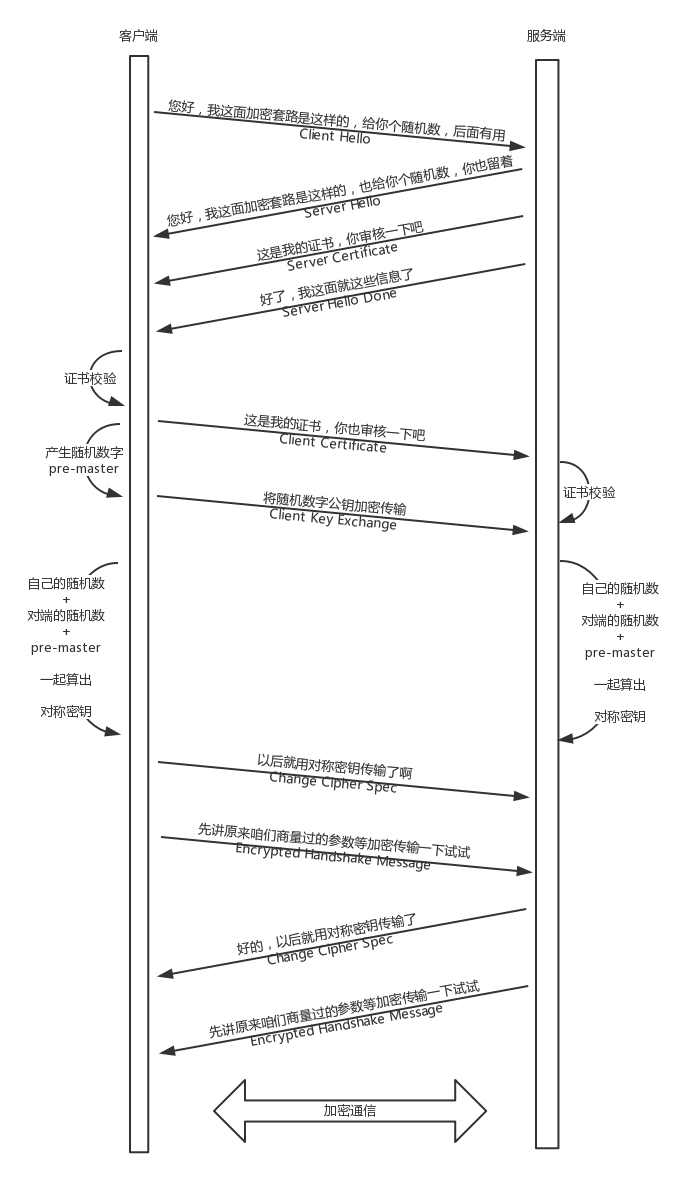
其中,随机数和 premaster 的含义是:
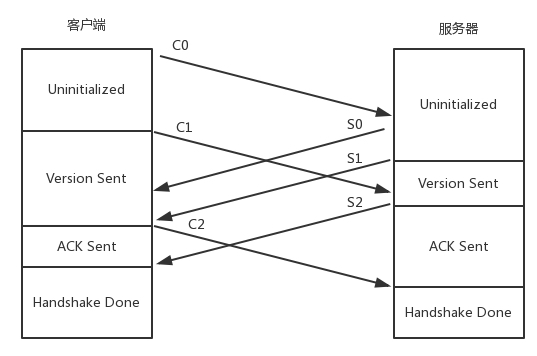
6. RTMP 连接建立的过程
- 首先,客户端发送 C0 表明自己的版本号,不必等对方的回复,然后发送 C1 表明自己的时间戳。
- 服务器只有在收到 C0 的时候,才能返回 S0,表明自己的版本号。如果版本不匹配,可以断开连接。
- 服务器发送完 S0 后,也不用等什么,就直接发送自己的时间戳 S1。客户端收到 S1 的时候,发一个知道了对方时间戳的 ACK C2。同理服务器收到 C1 的时候,发一个知道了对方时间戳的 ACK S2。
- 握手完成。
7. SO_RCVBUF 和 SO_SNDBUF 值设置的问题
在 Windows 和 MacOS 下,套接字选项 SO_RCVBUF 和 SO_SNDBUF 设置后的值 和 设置的值 相同。
但是在 Linux 下,设置后的值 是 设置值 的两倍。具体可以参考 man 7 socket:
SO_RCVBUF
Sets or gets the maximum socket receive buffer in bytes.
The kernel doubles this value (to allow space for
bookkeeping overhead) when it is set using setsockopt(2),
and this doubled value is returned by getsockopt(2). The
default value is set by the
/proc/sys/net/core/rmem_default file, and the maximum
allowed value is set by the /proc/sys/net/core/rmem_max
file. The minimum (doubled) value for this option is 256.
SO_SNDBUF
Sets or gets the maximum socket send buffer in bytes. The
kernel doubles this value (to allow space for bookkeeping
overhead) when it is set using setsockopt(2), and this
doubled value is returned by getsockopt(2). The default
value is set by the /proc/sys/net/core/wmem_default file
and the maximum allowed value is set by the
/proc/sys/net/core/wmem_max file. The minimum (doubled)
value for this option is 2048.8. SO_REUSEADDR 和 SO_REUSEPORT 的区别
参考 man 7 socket 的说明:
SO_REUSEADDR
Indicates that the rules used in validating addresses
supplied in a bind(2) call should allow reuse of local
addresses. For AF_INET sockets this means that a socket
may bind, except when there is an active listening socket
bound to the address. When the listening socket is bound
to INADDR_ANY with a specific port then it is not possible
to bind to this port for any local address. Argument is
an integer boolean flag.
SO_REUSEPORT (since Linux 3.9)
Permits multiple AF_INET or AF_INET6 sockets to be bound
to an identical socket address. This option must be set
on each socket (including the first socket) prior to
calling bind(2) on the socket. To prevent port hijacking,
all of the processes binding to the same address must have
the same effective UID. This option can be employed with
both TCP and UDP sockets.
For TCP sockets, this option allows accept(2) load
distribution in a multi-threaded server to be improved by
using a distinct listener socket for each thread. This
provides improved load distribution as compared to
traditional techniques such using a single accept(2)ing
thread that distributes connections, or having multiple
threads that compete to accept(2) from the same socket.
For UDP sockets, the use of this option can provide better
distribution of incoming datagrams to multiple processes
(or threads) as compared to the traditional technique of
having multiple processes compete to receive datagrams on
the same socket.更详细的区别:How do SO_REUSEADDR and SO_REUSEPORT differ?
SO_REUSEADDR- 对于相同的端口,允许两个 socket 绑定的 ip 范围有交集,但 ip 的值不同,比如:
0.0.0.0:8080和192.168.0.1:8080。 - 允许 socket 绑定到还有处于
TIME-WAIT状态的 socket 的地址端口。
- 对于相同的端口,允许两个 socket 绑定的 ip 范围有交集,但 ip 的值不同,比如:
SO_REUSEPORT- 允许不同的 socket 绑定到完全相同的地址端口,比如每个 socket 都绑定到
0.0.0.0:8080。
- 允许不同的 socket 绑定到完全相同的地址端口,比如每个 socket 都绑定到
9. SO_LINGER 选项的使用
SO_LINGER 选项用于控制在函数 close 关闭面向连接的套接字时,操作系统应该如何处理发送缓存中未发送完的数据?
struct linger {
int l_onoff; /* linger active */
int l_linger; /* how many seconds to linger for */
};设置
l_onoff为 0,l_linger值将被忽略。此时close调用会立即返回。操作系统将尽可能(并不保证)发送完任何未发送的数据。 这也是操作系统的默认处理方式。设置
l_onoff为非 0,l_linger为 0。此时close调用会立即返回。操作系统将会丢弃任何未发送完的数据,并发送一个 RST 给对方强制关闭连接。这种情况不会出现TIME_WAIT状态 。设置
l_onoff为非 0,同时l_linger也为非 0。此时close调用可能会阻塞一段时间。阻塞直到:- 所有未发送的数据都被发送完且被对方确认,之后进行正常的套接字断开流程。
l_linger指定的时间到了。如果在数据发送完且被确认前
l_linger指定时间到了,Windows、Linux、MacOS 都会在后台继续发送剩余的数据。套接字的状态变化为:FIN-WAIT-1->FIN-WAIT-2->TIME-WAIT。实际上在
close返回后但数据还未发送完时套接字状态就已经变成了FIN-WAIT-1,在剩余数据发送完和 FIN 发出后收到对于的 ACK 之前,套接字都是FIN-WAIT-1状态。分析 Linux 的源码可以看出,之所以出现这种情况是因为,发出 FIN 包也是排队发送的,而发送队列的前面还有那些缓存中未发送完成的数据包。
但是在 Windows 和 MacOS 下,
close调用一般不会阻塞,而在 Linux 下,close会阻塞指定的时间(即使是非阻塞的套接字也会阻塞指定的时间)。参考 Linux 源码中
tcp_close函数的实现。
10. tcp_tw_reuse 选项
首先看内核源码 (4.19.194) ip-sysctl.txt 文件中关于这两个选项的说明:
tcp_tw_reuse - INTEGER
Enable reuse of TIME-WAIT sockets for new connections when it is
safe from protocol viewpoint.
0 - disable
1 - global enable
2 - enable for loopback traffic only
It should not be changed without advice/request of technical
experts.
Default: 2tcp_tw_reuse 设置的是内核变量 sysctl_tcp_tw_reuse ,而这个变量仅在 tcp_twsk_unique 函数中使用。而这个函数的调用路径有且仅有一个:
net/ipv4/tcp_ipv4.c文件中的tcp_v4_connect函数。net/ipv4/inet_hashtables.c文件中的inet_hash_connect函数。net/ipv4/inet_hashtables.c文件中的__inet_check_established函数。include/net/timewait_sock.h文件中的twsk_unique函数。net/ipv4/tcp_ipv4.c文件中的tcp_twsk_unique函数。
tcp_twsk_unique 函数的主要实现如下:
int tcp_twsk_unique(struct sock *sk, struct sock *sktw, void *twp)
{
/* With PAWS, it is safe from the viewpoint
of data integrity. Even without PAWS it is safe provided sequence
spaces do not overlap i.e. at data rates <= 80Mbit/sec.
Actually, the idea is close to VJ's one, only timestamp cache is
held not per host, but per port pair and TW bucket is used as state
holder.
If TW bucket has been already destroyed we fall back to VJ's scheme
and use initial timestamp retrieved from peer table.
*/
if (tcptw->tw_ts_recent_stamp &&
(!twp || (reuse && time_after32(ktime_get_seconds(),
tcptw->tw_ts_recent_stamp)))) {
/* In case of repair and re-using TIME-WAIT sockets we still
* want to be sure that it is safe as above but honor the
* sequence numbers and time stamps set as part of the repair
* process.
*
* Without this check re-using a TIME-WAIT socket with TCP
* repair would accumulate a -1 on the repair assigned
* sequence number. The first time it is reused the sequence
* is -1, the second time -2, etc. This fixes that issue
* without appearing to create any others.
*/
if (likely(!tp->repair)) {
u32 seq = tcptw->tw_snd_nxt + 65535 + 2;
if (!seq)
seq = 1;
WRITE_ONCE(tp->write_seq, seq);
tp->rx_opt.ts_recent = tcptw->tw_ts_recent;
tp->rx_opt.ts_recent_stamp = tcptw->tw_ts_recent_stamp;
}
sock_hold(sktw);
return 1;
}
return 0;
}从源码实现中可以看出:
因为
tcp_twsk_unique函数最初只能由tcp_v4_connect函数调用,所以tcp_tw_reuse仅在 TCP 套接字作为客户端时起作用。因为
tcptw->tw_ts_recent_stamp的值要不为 0 , 所以服务端发回的包中要包含 timestamp 数据才有效,这个功能可以通过设置net.ipv4.tcp_timestamps = 1(默认为 1) 来开启。RFC 1323 引入了新的 TCP 选项:两个 4 字节的时间戳字段,用于记录 TCP 发送方的当前时间戳和从对端接收到的最新时间戳。此选项对应的解析代码在
net/ipv4/tcp_input.c文件tcp_parse_options函数中的case TCPOPT_TIMESTAMP:下。因为
time_after32(ktime_get_seconds(), tcptw->tw_ts_recent_stamp),所以套接字必须要处于TIME-WAIT状态 1 秒及以上才行。
11. close() 和 shutdown(SHUT_RDWR) 的区别
close函数- 把套接字的引用计数减 1,如果引用计数达到 0 时才进行后面的步骤。
- 在输入方向上,系统内核会将改套接字设置为不可读,任何读操作都会返回异常;
- 在输出方向上,系统内核尝试将发送缓冲区的数据发送给对端,并最后向对端发送一个 FIN 报文,接下来如果再对该套接字进行写操作就会返回异常;
- 如果对端没有检测到套接字已关闭,还继续发送报文,就会收到一个 RST 报文。
shutdown函数SHUT_RD:关闭连接的”读”,对该套接字进行读操作直接返回 EOF 。套接字上接收缓冲区已有的数据将会丢弃,如果还要新的数据流到达,会对数据进行 ACK ,然后悄悄地丢弃。SHUT_WR:关闭连接的”写”,这常被称为”半关闭”的连接。不管套接字引用计数的值是多少,都会直接关闭连接的写方向。套接字上发送缓冲区已有的数据将被立即发送出去,并发送一个 FIN 报文给对端。应用程序如果再对该套接字进行写操作会出错。SHUT_RDWR: 相当于SHUT_RD和SHUT_WR都操作一次。
close()和shutdown(SHUT_RDWR)的区别close会关闭连接,并释放连接所对应的资源;而shutdown仅关闭连接,但不会释放连接所对应的资源。close存在引用计数的概念,并不一定导致该套接字不可用;shutdown则不管引用计数,直接使套接字不可用,如果有别的进程使用该套接字,将会受影响。close的引用计数导致不一定会发出 FIN 结束报文;shutdown总是会发送 FIN 结束报文。
12. 不会导致产生 ICMP 差错报文情况
- ICMP 差错报文(ICMP 查询报文可能会产生 ICMP 差错报文);
- 目的地址是广播地址或多播地址的 IP 数据报;
- 作为链路层广播的数据报;
- 不是 IP 分片的第一片;
- 源地址不是单个主机的数据报。这就是说,源地址不能为零地址、环回地址、广播地址或多播地址。
13. UDP connect 的作用
对 UDP 套接字进行 connect 操作的意义在于将该套接字和服务端的地址和端口绑定,如果操作系统收到了与该地址和端口匹配的网络错误(如 ICMP 不可达),后续在该套接字上的操作就能获取到这些错误。
14. 为什么推荐将监听套接字设置为非阻塞
因为当 accept 和 I/O 多路复用 select 、 poll 等一起配合使用时,如果在监听套接字上触发了事件,说明有连接建立完成。但是在调用 accept 获取已连接的套接字之前,该连接被关闭了(如客户端发送了 RST),那么再调用 accept 将会阻塞程序。
15. Reactor 和 Proactor 网络编程模式
Reactor 模式 基于待完成的 I/O 事件。每次感知到事件后再调用 read 、 write 方法完成数据的读写。如 epoll。
Proactor 模式 基于已完成的 I/O 事件。它只负责感知事件完成,并由对应的 handler 发起异步读写请求, I/O 读写操作本身由操作系统内核完成。如:IOCP。
无论是 Reactor 模式 还是 Proactor 模式 ,都是一种基于事件分发的网络编程模式。
16. 为什么 IPv4 协议的头中会需要一个 总长度 字段
下述内容摘自 《TCP/IP 详解 卷一: 协议 第2版》中 5.2.1 IP 头部字段 节中关于 总长度 字段的说明:
虽然以太网最小有效载荷为 46 字节(见第 3 章),但一个 IPv4 数据报也可能会更小( 20 字节)。如果没有提供 总长度 字段,IPv4 实现将无法知道一个 46 字节的以太网帧是一个 IP 数据报,还是经过填充的 IP 数据报,这样可能会导致混淆。
17. 为什么以太网帧会有最小帧是 64 字节的限制
下述内容摘自 《TCP/IP 详解 卷一: 协议 第2版》中 3.2.2.2 帧大小 节中关于最小帧的说明:
注意 最小长度对最初的 10Mb/s 以太网的 CSMA/CD 很重要。为了使传输数据的站能知道哪个帧发生了冲突,将一个以太网的最大长度限制为 2500m(通过 4 个中继器连接的 5 个 500m 的电缆段)。根据电子在铜缆中传播速度约为 0.77c (约2.31×10^8 m/s ),可得到 64 字节采用 10Mb/s 时的传输时间为 64×8/10000000 = 51.2us ,最小尺寸的帧能在电缆中传输约 11000m 。如果采用一条最长为 2500m的电缆,从一个站到另一个站之间的最大往返距离为 5000m 。以太网设计者确定最小帧长度基于安全困素,在完全兼容(和很多不兼容)的情况下,一个输出帧的最后位在所需时间后仍处于传输过程中,这个时间是信号到达位于最大距离的接收器并返回的时间。如果这时检测到一个冲突,传输中的站能知道哪个帧发生冲突,即当前正在传输中的那个帧。在这种情况下,该站发送一个干扰信号(高电压)提醒其他站,然后启动一个随机的二进制指数退避过程。
以太网帧最小帧为 64 字节时,对应的载荷大小就是 64 - 6(目的MAC) - 6(源MAC) - 2(类型或长度) - 4(帧校验序列) = 46 。
18. 网络编程的那些事儿
19. STUN 中定义的四种 NAT 类型
更多资料:Peer-to-Peer Communication Across Network Address Translators
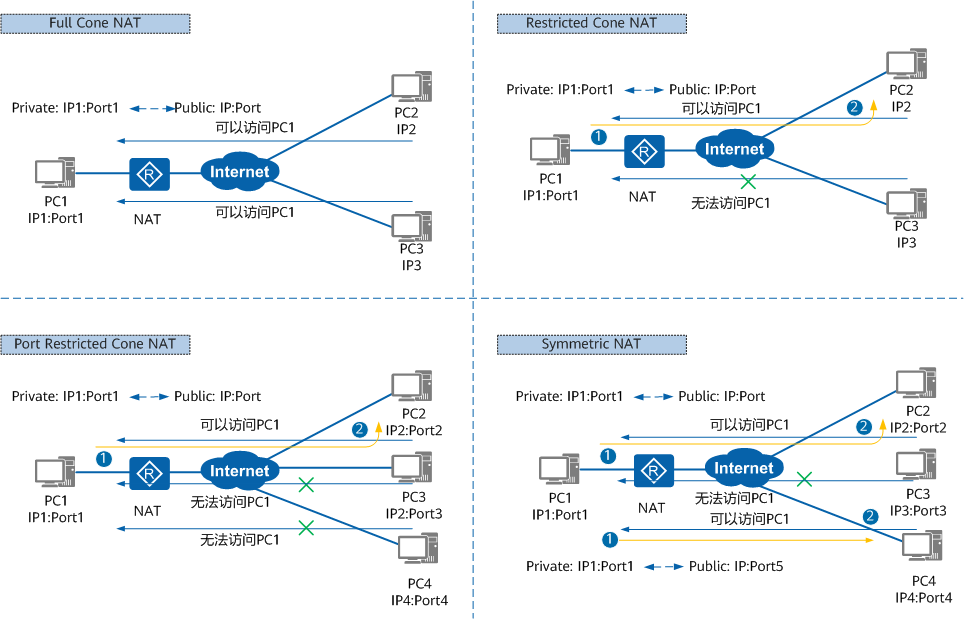
NAT1/Full Cone NAT/完全锥型 NAT
- 内网地址端口
IP1:Port1与外网任何地址任何端口通信都会映射到外网地址端口IP:Port。 - 在外网,
任何源地址:任何源端口发送给外网地址端口IP:Port的网络包都能在内网地址端口IP1:Port1上收到。 - 即发送给外网地址端口
IP:Port网络包的源地址源端口无限制。
- 内网地址端口
NAT2/(Address) Restricted Cone NAT/(地址)限制锥型NAT
- 内网地址端口
IP1:Port1与外网任何地址任何端口通信都会映射到外网地址端口IP:Port。 - 在外网,只有之前与内网地址端口
IP1:Port1通信过的外网地址IP2(任何端口都可以)发送给外网地址端口IP:Port的网络包才能在内网地址端口IP1:Port1上收到。而之前未与内网地址端口IP1:Port1通信过的任何外网地址IP3发送给外网地址端口IP:Port的网络包都不能在内网地址端口IP1:Port1上收到。 - 即发送给外网地址端口
IP:Port网络包的源地址有限制,而源端口无限制。
- 内网地址端口
NAT3/Port Restricted Cone NAT/端口限制锥型NAT
- 内网地址端口
IP1:Port1与外网任何地址任何端口通信都会映射到外网地址端口IP:Port。 - 在外网,只有之前与内网地址端口
IP1:Port1通信过的外网地址端口IP2:Port2发送给外网地址端口IP:Port的网络包才能在内网地址端口IP1:Port1上收到。而从外网地址IP2其他任何源端口Port3以及从其他之前未与内网地址端口IP1:Port1通信过的任何外网地址IP4发送给外网地址端口IP:Port的网络包都不能在内网地址端口IP1:Port1上收到。 - 即发送给外网地址端口
IP:Port网络包的源地址和源端口都有限制。
- 内网地址端口
NAT4/Symmetric NAT/对称NAT
- 内网地址端口
IP1:Port1与外网不同地址或者不同端口通信会映射到不同的外网地址端口。 - 在外网,只有之前与内网地址端口
IP1:Port1通信过的外网地址端口IP2:Port2和IP4:Port4发送给外网地址端口IP:Port的网络包才能在内网地址端口IP1:Port1上收到。而从其他之前未与内网地址端口IP1:Port1通信过的任何外网地址任何源端口IP3:Port3发送给外网地址端口IP:Port的网络包都不能在内网地址端口IP1:Port1上收到。 - 即发送给外网地址端口
IP:Port网络包的源地址和源端口都有限制。
- 内网地址端口
NAT 打洞(NAT Hole Punching)总结
| NAT | 全锥形 | 限制型锥形 | 端口限制型锥形 | 对称型 |
|---|---|---|---|---|
| 全锥形 | Direct | Direct | Direct | Direct |
| 限制型锥形 | Direct | Hole Punch | Hole Punch | HolePunch |
| 端口限制型锥形 | Direct | Hole Punch | Hole Punch | Hole Punch |
| 对称型 | Direct | Hole Punch | Hole Punch | Relay |
端口限制锥型NAT与端口限制锥型NAT打洞时,一方向对方外网地址:固定端口不停的发送网络包,另一方向对方外网地址:随机端口不停的发送网络包,根据 Birthday attack 理论,在有限次的尝试后就能成功的与对方建立通信。
20. 网络上字节传输的顺序
RFC1700规定网络上字节传输的顺序为大端字节序(Big Endian)。
int x = 0x12345678;
char *c = (char*)&x;
Big endian
------------------
Byte address | 0x01 | 0x02 | 0x03 | 0x04 |
+++++++++++++++++++++++++++++
Byte content | 0x12 | 0x34 | 0x56 | 0x78 |
c = 0x12
Little endian
---------------------
Byte address | 0x01 | 0x02 | 0x03 | 0x04 |
+++++++++++++++++++++++++++++
Byte content | 0x78 | 0x56 | 0x34 | 0x12 |
c = 0x7821. TCP 中 SYN 和 FIN 会消耗一个序列号
22. 网络利用率并不是越高越好
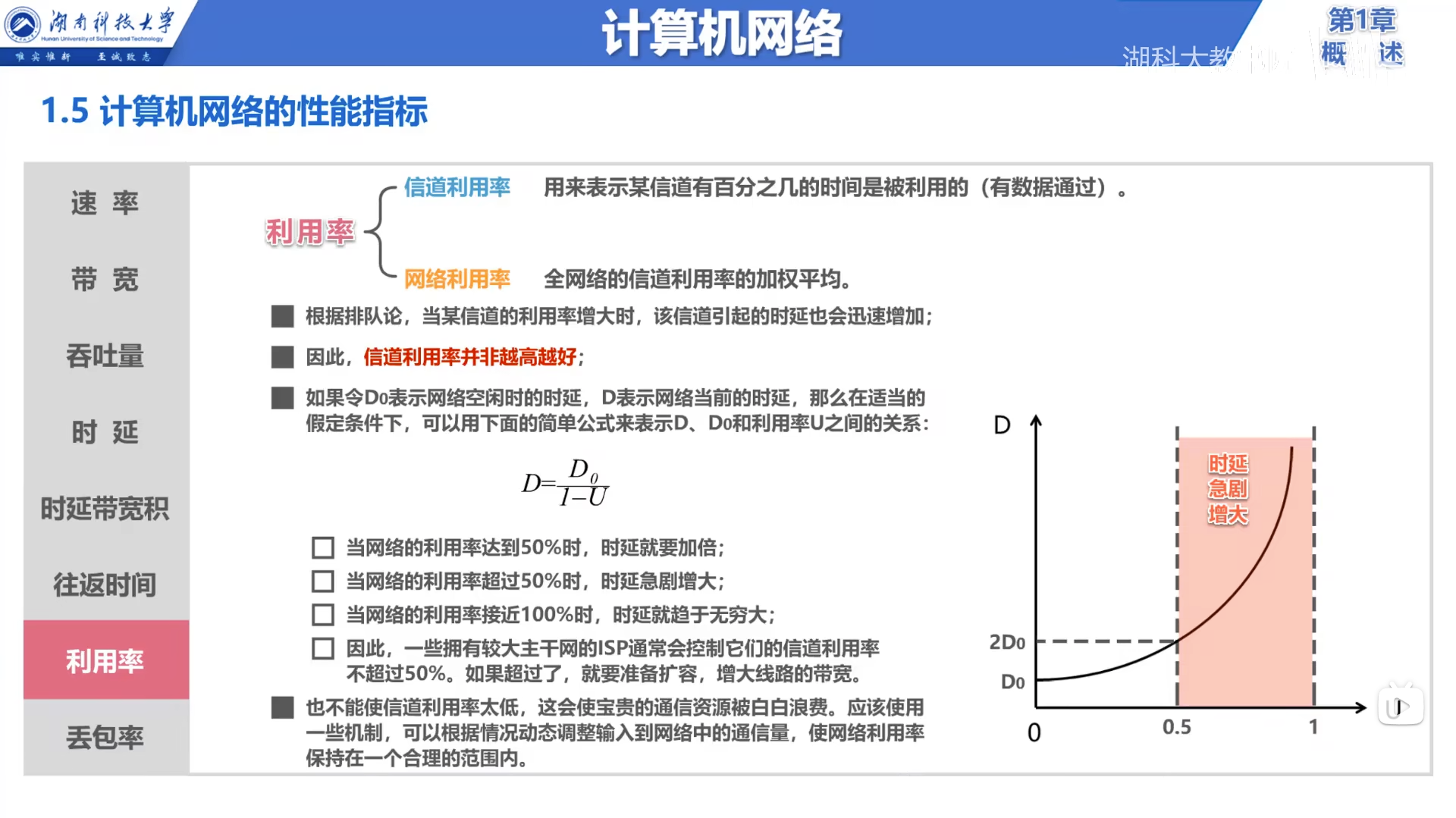
图片来源:计算机网络的性能指标(2)
23. TCP 为什么是 3 次握手,4 次挥手
TCP 是一个全双工(任何时刻数据都可以双向传输)的协议。
建立连接时,为了确保另一方已经准备好了开始接受数据,所以建立连接时双方都需要向对方发送 SYN(Synchronization)消息,另一方准备好接受数据后,发送 ACK(Acknowledgement)来进行确认。
由于被连接方返回 ACK 消息和发送 SYN 消息可以放到同一个 TCP 报文段(Segment)中,所以 TCP 建立连接的过程只需三个 TCP 报文段(Segment)即可完成,即 3 次握手。
断开连接时,为了确保另一方知道自己关闭了数据发送通道,所以需要向对方发送 SYN(Synchronization)消息,告知另一方自己不会再发送任何数据,另一方在收到消息后,发送 ACK(Acknowledgement)来进行确认。
由于 TCP 允许通信的一方关闭发送数据的通道,而能继续接受另一个方发送的数据(此时TCP 退化成 单工 的协议)。所以 TCP 断开连接(双方都关闭数据发送通道)的过程需要 4 个 TCP 报文段(Segment)来完成,即 4 次挥手。
24. 什么是权威 DNS
使用域名 NS 结果中的 DNS 服务器查询域名 IP 地址的结果。
DNS 中的 NS 记录指定哪台服务器是回答 DNS 查询的权威域名服务器。
$ nslookup bing.com
Server: 10.255.255.254
Address: 10.255.255.254#53
Non-authoritative answer:
Name: bing.com
Address: 204.79.197.200
Name: bing.com
Address: 13.107.21.200
Name: bing.com
Address: 2620:1ec:c11::200
$ nslookup -type=NS bing.com
Server: 10.255.255.254
Address: 10.255.255.254#53
Non-authoritative answer:
bing.com nameserver = ns3-204.azure-dns.org.
bing.com nameserver = ns4-204.azure-dns.info.
bing.com nameserver = dns1.p09.nsone.net.
bing.com nameserver = dns2.p09.nsone.net.
bing.com nameserver = dns3.p09.nsone.net.
bing.com nameserver = dns4.p09.nsone.net.
bing.com nameserver = ns1-204.azure-dns.com.
bing.com nameserver = ns2-204.azure-dns.net.
Authoritative answers can be found from:
$ nslookup bing.com ns3-204.azure-dns.org
Server: ns3-204.azure-dns.org
Address: 204.14.183.204#53
Name: bing.com
Address: 13.107.21.200
Name: bing.com
Address: 204.79.197.200
Name: bing.com
Address: 2620:1ec:c11::200

{kind=link}