http://service.qbjavawa.top/time/VIMPracticalSkills.html
https://github.com/adah1972/geek_time_vim
01|各平台下的 Vim 安装方法:上路前准备好你的宝马
02|基本概念和基础命令:应对简单的编辑任务
2.1 Vim 教程的内容概要
.webp)
图中的”•”表示,单个字母不是完整的命令,必须再有进一步的输入。比如,单个”g”没有意义,而”gg”表示跳转到文件开头。(对于命令后面明确跟一个动作的,如”c”,我们不使用”•”。)一个键最多有三排内容:最底下是直接按键的结果,中间是按下 Shift 的结果(变大写),上面偏右的小字是按下 Ctrl 的结果。
一些命令行命令:
- “:q!”:退出 Vim
- “:wq”:存盘退出
- “:s”:执行替换
- “:!”:执行外部命令
- “:edit”(一般缩写为 “:e”):编辑文件
- “:w”:写文件
- “:r”:读文件
- “:help”:查看帮助
- 使用键 Ctrl-D 和 Tab 来进行命令行补全
2.2 Vim 的模式
Vim 有以下四种主要模式:
- 正常(normal)模式(也称为普通模式),缺省的编辑模式;如果不加特殊说明,一般提到的命令都直接在正常模式下输入;在任何其他模式中,都可以通过键盘上的 Esc 键回到正常模式。
- 插入(insert)模式,输入文本时使用;比如在正常模式下键入 i(insert)或 a(append)即可进入插入模式。
- 可视(visual)模式,用于选定文本块;教程中已经提到可以用键 v(小写)来按字符选定,Vim 里也提供其他不同的选定方法,包括按行和按列块。
- 命令行(command-line)模式,用于执行较长、较复杂的命令;在正常模式下键入冒号(:)即可进入该模式;使用斜杠(/)和问号(?)开始搜索也算作命令行模式。命令行模式下的命令要输入回车键(Enter)才算完成。
此外,Vim 也有个选择(select)模式,与普通的 Windows 编辑器行为较为接近,选择内容后再输入任何内容,将会替换选择的内容。在以可视模式和选择模式之一选定文本块之后,可以使用 Ctrl-G 切换到另一模式。
2.3 Vim 的键描述体例
Vim 里的标准键描述方式:
<Esc>表示 Esc 键;显示为”⎋”<CR>表示回车键;显示为”↩”<Space>表示空格键;显示为”␣”<Tab>表示 Tab 键;显示为”⇥”<BS>表示退格键;显示为”⌫”<Del>表示删除键;显示为”⌦”<lt>表示 < 键;显示为”<”<Up>表示光标上移键;显示为”⇡”<Down>表示光标下移键;显示为”⇣”<Left>表示光标左移键;显示为”⇠”<Right>表示光标右移键;显示为”⇢”<PageUp>表示 Page Up 键;显示为”⇞”<PageDown>表示 Page Down 键;显示为”⇟”<Home>表示 Home 键;显示为”↖”<End>表示 End 键;显示为”↘”<F1> - <F12>表示功能键 1 到 12;显示为”F1”到”F12”<S-…>Shift 组合键;显示为”⇧”(较少使用,因为我们需要写!而不是<S-1>; 和特殊键组合时仍然有用)<C-…>Control 组合键;显示为”⌃”<M-…>Alt 组合键;显示为”⌥”(对于大部分用户,它的原始键名 Meta 应该只具有历史意义)<D-…>Command 组合键;显示为”⌘”(Mac 键盘)
Esc、Enter、v、V 和 Ctrl-V 以后就会写成 <Esc>、<CR>、v、V、<C-V>。这也是以后在 Vim 里对键进行重映射的写法。
这里我要强调一下,对”<”的特殊解释仅在描述输入时生效。在描述命令行和代码时,我们写”<CR>“仍表示四个字符,而非回车键。特别是,如果我们描述的命令行首是”:”,表示这是一个输入 : 开始的 Vim 命令行模式命令(以回车键结束);如果行首是”/“或”?”,表示这是一个输入 / 或 ? 开始的搜索命令(以回车键结束);如果行首是”$”,表示这是一个在 shell 命令行上输入的命令(以回车键结束),”$”(和后面的空格)不是命令的一部分,通常后续行也不是命令的一部分,除非行尾有”\”或”^”字符,或行首有”$”字符。
也就是说,下面的命令是在 Vim 里输入”:set ft?<CR>“(用来显示当前编辑文件的文件类型):
:set ft?
下面的命令则是在 shell 里输入”which vim<CR>“(用来检查 vim 命令的位置):
$ which vim
/usr/bin/vim
此外,当我用”:help“描述帮助命令时,你不仅可以在 Vim 里输入这个命令来得到帮助,也可以点击这个帮助的链接,直接在线查看相应的中文帮助页面。

这节内容不需要死记。建议使用”收藏”功能,这样,你可以在以后碰到不认识的符号标记的时候,返回来查看这一节的内容。
2.4 Vim 的选项和配置
Vim 的配置文件放在用户的主目录下,文件名通常是 .vimrc;而它在 Windows 下名字是 _vimrc。最基本的配置文件:
set enc=utf-8
set nocompatible
source $VIMRUNTIME/vimrc_example.vim这三行完成了下列功能:
- 设置编辑文件的内码是 UTF-8(非所有平台缺省,但为编辑多语言文件所必需)
- 设置 Vim 不需要和 vi 兼容(仅为万一起见,目前大部分情况下这是缺省情况)
- 导入 Vim 的示例配置(这会打开一些有用的选项,如语法加亮、搜索加亮、命令历史、记住上次的文件位置,等等)
对于现代 Unix 系统上的 Vim 8,实际上只需要最后一句就足够了。对于现代 Windows 系统上的 Vim 8,中间的这句 set nocompatible 也可以删除。如果你在较老的 Vim 版本上进行配置,那么把这三行全放进去会比较安全。
2.4.1 备份和撤销文件
上面的基本设置会产生一个有人喜欢、但也有很多人感到困惑的结果:你修改文件时会出现结尾为”~”的文件,有文件名后面直接加”~”的,还有前面加”.”后面加”.un~”的。这是因为在示例配置里,Vim 自动设置了下面两个选项:
set backup
set undofile前一个选项使得我们每次编辑会保留上一次的备份文件,后一个选项使得 Vim 在重新打开一个文件时,仍然能够撤销之前的编辑(undo),这就会产生一个保留编辑历史的”撤销文件”(undofile)了。

我的通常做法是,不产生备份文件,但保留跨会话撤销编辑的能力;因为有了撤销文件,备份其实也就没有必要了。同时,把撤销文件放在用户个人的特定目录下,既保证了安全,又免去了其他目录下出现不必要文件的麻烦。
要达到这个目的,我在 Linux/macOS 下会这么写:
set nobackup
set undodir=~/.vim/undodir在 Windows 下这么写:
set nobackup
set undodir=~\vimfiles\undodir无论哪种环境,你都需要创建这个目录。我们可以用下面的命令来让 Vim 在启动时自动创建这个目录:
if !isdirectory(&undodir)
call mkdir(&undodir, 'p', 0700)
endif其中 &undodir 代表 undodir 这个选项的值。相关的帮助文档:
这个跨会话撤销的能力,我还真不知道其他哪个编辑器也有。更妙的是,Vim 还有撤销树的概念,可以帮助你回到任一历史状态。
2.4.2 鼠标支持
在 Vim 的终端使用场景下,鼠标的选择有一定的歧义:你希望是使用 Vim 的可视模式选择内容,并且只能在 Vim 里使用呢,还是产生 Vim 外的操作系统的文本选择,用于跟其他应用程序的交互呢?这是一个基本的使用问题,两种情况都可能发生,都需要照顾。
如果你使用 xterm 兼容终端的话,通常的建议是:
- 在不按下修饰键时,鼠标选择产生 Vim 内部的可视选择。
- 在按下 Shift 时,鼠标选择产生操作系统的文本选择。
对于不兼容 xterm、不支持对 Shift 键做这样特殊处理的终端,我们一般会采用一种”绕过”方式,让 Vim 在某种情况下暂时不接管鼠标事件。通常的选择是在命令行模式下不使用鼠标。下面,我们就分这两种情况来配置。
虽然最新的 Vim 缺省配置文件(示例配置文件会包含缺省配置),在大部分情况下已经可以自动设置合适的鼠标选项了,不过为照顾我们课程的三种不同平台,我们还是手工设置一下:
if has('mouse')
if has('gui_running') || (&term =~ 'xterm' && !has('mac'))
set mouse=a
else
set mouse=nvi
endif
endif上面代码说的是,如果 Vim 有鼠标支持的话,那在以下任一条件满足时:
- 图形界面正在运行
- 终端是 xterm 兼容,并且不是 Mac(Mac 上的终端声称自己是 xterm,但行为并不完全相同)
我们将启用完全的鼠标支持(mouse=a)。特别是,此时鼠标拖拽就会在 Vim 里使用可视模式选择内容(只能在 Vim 里使用)。而当用户按下 Shift 键时,窗口系统接管鼠标事件,用户可以使用鼠标复制 Vim 窗口里的内容供其他应用程序使用。
否则(非图形界面的的终端,且终端类型不是 xterm),就只在正常模式(n)、可视模式(v)、插入模式(i)中使用鼠标。这意味着,当用户按下 : 键进入命令行模式时,Vim 将不对鼠标进行响应,这时,用户就可以使用鼠标复制 Vim 窗口里的内容到其他应用程序里去了。

非 xterm 的鼠标支持在 macOS 和 Windows 下都有效。但在 Windows 下需要注意的一点是,如果使用非图形界面的 Vim 的话,应当在命令提示符(Command Prompt)的属性里关闭”快速编辑模式”(QuickEdit Mode),否则 Vim 在运行时将无法对鼠标事件进行响应。
鉴于命令提示符的行为有很多怪异和不一致之处,强烈建议你在 Windows 下,要么使用图形界面的 Vim,要么使用 Cygwin/MSYS2 里、运行在 mintty 下的 Vim。
2.4.3 中文支持
完整的 Unicode 历史和原理从实用的角度可以简化成下面几条:
- 整个世界基本上在向 UTF-8 编码靠拢。
- 微软由于历史原因,内部使用 UTF-16;UTF-16 可以跟 UTF-8 无损转换。
- GB2312、GBK、GB18030 是一系列向后兼容的中文标准编码方式,GB2312 编码的文件是合法的 GBK 文件,GBK 编码的文件是合法的 GB18030 文件。但除了 GB18030,都不能做到跟 UTF-8 无损转换;目前非 UTF-8 的简体中文文本基本上都用 GBK/GB18030 编码(繁体中文文本则以 Big5 居多)。鉴于 GB18030 是国家标准,其他两种编码也和 GB18030 兼容,我们就重点讲如何在 Vim 中支持 GB18030 了。
举一个具体的例子,”你好😄”这个字符串,在 UTF-8 编码下是下面 10 个字节(我按字符进行了分组):
e4bda0 e5a5bd f09f9884如果使用 GB18030 编码(GB2312/GBK 不能支持表情字符)的话,会编码成 8 个字节:
c4e3 bac3 9439fd30这么看起来,GB18030 处理中文在存储效率上是优势的。但它也有缺点:
- GBK 外的 Unicode 字符一般需要四字节编码(非中文情况会劣化)
- GBK 外的 Unicode 字符跟 Unicode 码点需要查表才能转换(UTF-8 则可以用非常简单的条件判断、移位、与、或操作来转换)
- 一旦出现文件中有单字节发生损毁,后续的所有中文字符都可能发生紊乱(而 UTF-8 可以在一个字符之后恢复)
因此,GB18030 在国际化的软件中不会作为内码来使用,只会是读取/写入文件时使用的转换编码。我们要让 Vim 支持 GB18030 也同样是如此。由于 UTF-8 编码是有明显规律的,并非任意文件都能成功地当成 UTF-8 来解码,我们一般使用的解码顺序是:
- 首先,检查文件是不是有 Unicode 的 BOM(字节顺序标记)字符,有的话按照 BOM 字符来转换文件内容。
- 其次,检查文件能不能当作 UTF-8 来解码;如果可以,就当作 UTF-8 来解释。
- 否则,尝试用 GB18030 来解码;如果能成功,就当作 GB18030 来转换文件内容。
- 最后,如果上面的解码都不成功,就按 Latin1 字符集来解码;由于这是单字节的编码,转换必定成功。
事实上,Vim 缺省差不多就是按这样的顺序,但第三步使用何种编码跟系统配置有关。如果你明确需要处理中文,那在配置文件里最好明确写下下面的选项设定:
set fileencodings=ucs-bom,utf-8,gb18030,latin12.4.4 图形界面的字体配置
图形界面的 Vim 可以自行配置使用的字体,但在大部分环境里,这只是起到美化作用,而非必需项。不过,对于高分辨率屏幕的 Windows,这是一个必需项:Vim 在 Windows 下缺省使用的不是 TrueType 字体,不进行配置的话,字体会小得没法看。
在 Windows 的缺省字体里,一般而言,Consolas 和 Courier New 还比较合适。以 Courier New 为例,在 _vimrc 里可以这样配置(Windows 上的基本写法是字体名称加冒号、”h”加字号;用”_”取代空格,否则空格需要用”\”转义):
if has('gui_running')
set guifont=Courier_New:h10
endif
字体名称如何写是件平台相关的事(可参见帮助文档”:help gui-font“)。如果你不确定怎么写出你需要的字体配置,或者你怎么写都写不对的话,可以先使用图形界面的菜单来选择(通常是”编辑 > 选择字体”;在 MacVim 里是”Edit > Font > Show Fonts”),然后使用命令”:set guifont?”来查看。
注意,Vim 在设置选项时,空格需要用”\”进行转义。比如,如果我们要在 Ubuntu 下把字体设成 10 磅的 DejaVu Sans Mono,就需要写:
" Linux 和 Windows 不同,不能用 '_' 取代空格
set guifont=DejaVu\ Sans\ Mono\ 10此外,宽字符字体(对我们来讲,就是中文字体了)是可以单独配置的。这可能就更是一件仁者见仁、智者见智的事了。对于纯中文的操作系统,这一般反而是不需要配置的;但如果你的语言设定里,中文不是第一选择的话,就有可能在显示中文时出现操作系统误用日文字体的情况。这时你会想要手工选择一个中文字体,比如在 Ubuntu 下,可以用:
set guifontwide=Noto\ Sans\ Mono\ CJK\ SC\ 11注意,在不同的中英文字体搭配时,并不需要字号相同。事实上,在 Windows 和 Linux 上我通常都是使用不同字号的中英文字体的。

在上面的动图中,你可以观察到设了中文字体之后,不仅中文字变大,更美观了,”将”、”适”、”关”、”复”、”启”等字的字形也同时发生了变化。
由于字体在各平台上差异较大,字体配置我就不写到 Vim 的参考配置中去了,只把如何选择和配置的方法写出来供你参考。
2.4.5 内容小结
最终的 Vim 配置文件可以在 GitHub 上找到:
https://github.com/adah1972/geek_time_vim
关于这个配置文件,我这里做个备注说明:主(master)分支可以用在类 Unix 平台上,windows 分支则用在 Windows 上。适用于今天这一讲的内容标签是 l2-unix 和 l2-windows 。
03|更多常用命令:应对稍复杂的编辑任务
3.1 光标移动
Vim 里的基本光标移动是通过 h、j、k、l 四个键实现的。之所以使用这四个键,是有历史原因的。你看一下 Bill Joy 开发 vi 时使用的键盘就明白了:这个键盘上没有独立的光标键,而四个光标符号直接标注在 H、J、K、L 四个字母按键上。
.webp)
当然,除了历史原因外,这四个键一直使用至今,还是有其合理性的。它们都处于打字机的本位排(home row)上,这样打字的时候,手指基本不用移动就可以敲击到。
顺便提一句,你有没有注意到 ADM-3A 键盘上的 Esc 键在今天 Tab 的位置?在 Bill Joy 决定使用 Esc 来退出插入模式的时候,Esc 在键盘上的位置还没像今天那样跑到遥远的左上角去……
Vim 跳转到行首的命令是 0,跳转到行尾的命令是 $,它们与 <Home> 和 <End> 的区别可以参考帮助::help <Home> 。此外,我们也有 ^,用来跳转到行首的第一个非空白字符。
对于一次移动超过一个字符的情况,Vim 支持使用 b/w 和 B/W,来进行以单词为单位的跳转。它们的意思分别是 words Backward 和 Words forward,用来向后或向前跳转一个单词。小写和大写命令的区别在于,小写的跟编程语言里的标识符的规则相似,认为一个单词是由字母、数字、下划线组成的(不严格的说法),而大写的命令则认为非空格字符都是单词。

根据单个字符来进行选择也很常见。比如,现在光标在 if (frame->fr_child != NULL) 第五个字符上,如果我们想要修改括号里的所有内容,需要仔细考虑 w 的选词规则,然后输入 c5w 吗?这样显然不够方便。
这种情况下,我们就需要使用 f(find)和 t(till)了。它们的作用都是找到下一个(如果在输入它们之前先输入数字 n 的话,那就是下面第 n 个)紧接着输入的字符。两者的区别是,f 会包含这个字符,而 t 不会包含这个字符。在上面的情况下,我们用 t 就可以了:ct) 就可以达到目的。如果需要反方向搜索的话,使用大写的 F 和 T 就可以。
对于写文字的情况,比如给开源项目写英文的 README,下面的光标移动键也会比较有用:
- ( 和 ) 移到上一句和下一句
- { 和 } 移到上一段和下一段

在很多环境(特别是图形界面)里,Vim 支持使用 <C-Home> 和 <C-End> 跳转到文件的开头和结尾。如果遇到困难,则可以使用 vi 兼容的 gg 和 G 跳转到开头和结尾行(小区别:G 是跳转到最后一行的第一个字符,而不是最后一个字符)。
3.2 文本修改
Vim 中 c 和 d 配合方向键,可以对文本进行更改。本质上,我们可以认为 c(修改)的功能就是执行 d(删除)然后 i(插入)。在 Vim 里,一般的原则就是,常用的功能,按键应尽可能少。因此很多相近的功能在 Vim 里会有不同的按键。不仅如此,大写键也一般会重载一个相近但稍稍不同的含义:
- d 加动作来进行删除(dd 删除整行);D 则相当于 d$,删除到行尾。
- c 加动作来进行修改(cc 修改整行);C 则相当于 c$,删除到行尾然后进入插入模式。
- s 相当于 cl,删除一个字符然后进入插入模式;S 相当于 cc,替换整行的内容。
- i 在当前字符前面进入插入模式;I 则相当于 ^i,把光标移到行首非空白字符上然后进入插入模式。
- a 在当前字符后面进入插入模式;A 相当于 $a,把光标移到行尾然后进入插入模式。
- o 在当前行下方插入一个新行,然后在这行进入插入模式;O 在当前行上方插入一个新行,然后在这行进入插入模式。
- r 替换光标下的字符;R 则进入替换模式,每次按键(直到
<Esc>)替换一个字符。 - u 撤销最近的一个修改动作;U 撤销当前行上的所有修改。
3.3 文本对象选择
可以使用 c、d 加动作键对这个动作选定的文本块进行操作,也可以使用 v 加动作键来选定文本块(以便后续进行操作)。不过,还有几个动作只能在 c、d、v 这样命令之后用。
这些选择动作的基本附加键是 a 和 i。其中,a 可以简单理解为英文单词 a,表示选定后续动作要求的完整内容,而 i 可理解为英文单词 inner,代表后续动作要求的内容的”内部”。
具体的例子,假设有下面的文本内容:
if (message == "sesame open")我们进一步假设光标停在”sesame”的”a”上,那么:
- dw(理解为 delete word)会删除 ame␣,结果是 if (message == “sesopen”)
- diw(理解为 delete inside word)会删除 sesame,结果是 if (message == “ open”)
- daw(理解为 delete a word)会删除 sesame␣,结果是 if (message == “open”)
- diW 会删除 “sesame,结果是 if (message == open”)
- daW 会删除 “sesame␣,结果是 if (message == open”)
- di” 会删除 sesame open,结果是 if (message == “”)
- da” 会删除 “sesame open”,结果是 if (message ==)
- di( 或 di) 会删除 message == “sesame open”,结果是 if ()
- da( 或 da) 会删除 (message == “sesame open”),结果是 if␣
上面演示了 a、i 和 w、双引号、圆括号搭配使用,这些对于任何语言的代码编辑都是非常有用的。实际上,可以搭配的还有更多:
- 搭配 s(sentence)对句子进行操作——适合西文文本编辑
- 搭配 p(paragraph) 对段落进行操作——适合西文文本编辑,及带空行的代码编辑
- 搭配 t(tag)对 HTML/XML 标签进行操作——适合 HTML、XML 等语言的代码编辑
- 搭配 ` 和 ‘ 对这两种引号里的内容进行操作——适合使用这些引号的代码,如 shell 和 Python
- 搭配方括号(”[“和”]”)对方括号里的内容进行操作——适合各种语言(大部分都会用到方括号吧)
- 搭配花括号(”{“和”}”)对花括号里的内容进行操作——适合类 C 的语言
- 搭配角括号(”<”和”>”)对角括号里的内容进行操作——适合 C++ 的模板代码
再进一步,在 a 和 i 前可以加上数字,对多个(层)文本对象进行操作。下面图中是一个示例:

3.4 更快地移动
可以使用 <PageUp> 和 <PageDown> 来翻页,但 Vim 更传统的用法是 <C-B> 和 <C-F>,分别代表 Backward 和 Forward。
除了翻页,Vim 里还能翻半页,有时也许这种方式更方便,需要的键是 <C-U> 和 <C-D>,Up 和 Down。
如果你知道出错位置的行号,那你可以用数字加 G 来跳转到指定行。类似地,你可以用数字加 | 来跳转到指定列。这在调试代码的时候非常有用,尤其适合进行自动化。
下图中展示了 iTerm2 中捕获输出并执行 Vim 命令的过程(用 vim -c ‘normal 5G36|’ 来执行跳转到出错位置第 5 行第 36 列):

(如果你用 iTerm2 并对这个功能感兴趣,我设置的正则表达式是 ^([_a-zA-Z0-9+/.-]+):([0-9]+):([0-9]+): (?:fatal error|error|warning|note):,捕获输出后执行的命令是 echo "vim -c 'normal \2G\3|' \1"。)
你只关心当前屏幕的话,可以快速移动光标到屏幕的顶部、中间和底部:用 H(High)、M(Middle)和 L(Low)就可以做到。
顺便提一句,vimrc_example 有一个设定,我不太喜欢:它会设 set scrolloff=5,导致只要屏幕能滚动,光标就移不到最上面的 4 行和最下面的 4 行里,因为一移进去屏幕就会自动滚动。这同样也会导致 H 和 L 的功能发生变化:本来是移动光标到屏幕的最上面和最下面,现在则变成了移动到上数第 6 行和下数第 6 行,和没有这个设定时的 6H 与 6L 一样了。所以我一般会在 Vim 配置文件里设置 set scrolloff=1(你也可以考虑设成 0),减少这个设置的干扰。
只要光标还在屏幕上,你也可以滚动屏幕而不移动光标(不像某些其他编辑器,Vim 不允许光标在当前屏幕以外)。需要的按键是 <C-E> 和 <C-Y>。
另外一种可能更实用的滚动屏幕方式是,把当前行”滚动”到屏幕的顶部、中部或底部。Vim 里的对应按键是 zt、zz 和 zb。和上面的几个滚动相关的按键一样,它们同样受选项 scrolloff 的影响。

3.5 重复,重复,再重复
Vim 对很多简单操作已经定义了重复键:
- ; 重复最近的字符查找(f、t 等)操作
- , 重复最近的字符查找操作,反方向
- n 重复最近的字符串查找操作(/ 和 ?)
- N 重复最近的字符串查找操作(/ 和 ?),反方向
- . 重复执行最近的修改操作
04|初步定制:让你的 Vim 更顺手
4.1 Vim 的目录结构
Vim 的工作环境是由运行支持文件来设定的。Vim 比较有意思的一点的是,虽然运行支持文件是在 Vim 的安装目录下,但用户自己是可以”克隆”这个目录结构的。也就是说,你自己目录下的用户配置,到你深度定制的时候,也有相似的目录结构。
4.2 安装目录下的运行支持文件
Vim 的运行支持文件在不同的平台上有着相似的目录结构。以 Vim 8.2 为例,它们的标准安装位置分别在:
- 大部分 Unix 下面:/usr/share/vim/vim82
- macOS Homebrew 下:/usr/local/opt/macvim/MacVim.app/Contents/Resources/vim/runtime
- Windows 下:C:\Program Files (x86)\Vim\vim82
最常用的子目录:
- syntax:Vim 的语法加亮文件
- doc:Vim 的帮助文件
- colors:Vim 的配色方案
- plugin:Vim 的”插件”,即用来增强 Vim 功能的工具
这里面的文件去掉”.vim”后缀后,就是文件类型的名字,你可以用类似 :setfiletype java 这样的命令来设置文件的类型,从而进行语法加亮。
在图形界面的 Vim 里,你可以通过”语法 > 在菜单中显示文件类型”(”Syntax > Show File Types in Menu”)来展示 Vim 的所有文件类型,然后可以选择某一类型来对当前文件进行设置。这儿的菜单项,跟 syntax 目录下的文件就基本是一一对应的了。
在菜单中显示文件类型这个额外的步骤,可能是因为很久很久以前,加载所有文件类型的菜单是一个耗时的操作吧。在 menu.vim 里,目前有这样的代码:
" Skip setting up the individual syntax selection menus unless
" do_syntax_sel_menu is defined (it takes quite a bit of time).
if exists("do_syntax_sel_menu")
runtime! synmenu.vim
else
…
endif不知道这段注释是什么年代加上的……但显然,我们的电脑已经不会再在乎加载几百个菜单项所占的时间了。即使我不怎么用菜单,我也找不出不直接展示这个菜单的理由;我可不想在需要使用的时候再多点一次鼠标。
所以,我会在我的 vimrc 文件里写上:
let do_syntax_sel_menu = 1同理,我会加载其他一些可能会被 Vim 延迟加载的菜单,减少需要在菜单上点击的次数:
let do_no_lazyload_menus = 1我们用”:help”命令查看的帮助文件就放在 doc 目录下。我们可以用菜单”编辑 > 配色方案”(”Edit > Color Scheme”)浏览配色方案,相应的文件就在 colors 目录下。
在 plugin 目录下的系统内置插件不多,我们下面就快速讲解一下:
- getscriptPlugin:获得最新的 Vim 脚本的插件(在目前广泛使用 Git 的年代,这个插件过时了,我们不讲)
- gzip:编辑 .gz 压缩文件(能在编辑后缀为 .gz 的文件时自动解压和压缩,你会感觉不到这个文件是压缩的)
- logiPat:模式匹配的逻辑运算符(允许以逻辑运算、而非标准正则表达式的方式来写模式匹配表达式)
- manpager:使用 Vim 来查看 man 帮助(强烈建议试一下,记得使用 Vim 的跳转键C-] 和 C-T)
- matchparen:对括号进行高亮匹配(现代编辑器基本都有类似的功能)
- netrwPlugin:从网络上编辑文件和浏览(远程)目录(支持多种常见协议如 ftp 和scp,可直接打开目录来选择文件)
- rrhelper:用于支持 —remote-wait 编辑(Vim 的多服务器会用到这一功能)
- spellfile:在拼写文件缺失时自动下载(Vim 一般只安装了英文的拼写文件)
- tarPlugin:编辑(压缩的)tar 文件(注意,和 gzip 情况不同,这儿不支持写入)
- tohtml:把语法加亮的结果转成 HTML(自己打开个文件,输入命令”:TOhtml”就知道效果了)
- vimballPlugin:创建和解开 .vba 文件(这个目前也略过时了,我们不讲)
- zipPlugin:编辑 zip 文件(和 tar 文件不同,zip 文件可支持写入)
除了 rrhelper 和 spellfile 属于功能支持插件,没有自己的帮助页面,其他功能都可以使用”:help”命令来查看帮助。查看帮助时,插件名称中的”Plugin”后缀需要去掉:查看 zip 文件编辑的帮助时,应当使用”:help zip“而不是”:help zipPlugin”。


4.3 用户的 Vim 配置目录
Vim 的安装目录你是不应该去修改的。首先,你可能没有权限去修改这个目录;其次,即使你有修改权限,这个目录会在 Vim 升级时被覆盖,你做的修改也会丢失。用户自己的配置应当放在自己的目录下,这也就是用户自己的主目录下的 Vim 配置目录(Unix 下的 .vim,Windows 下的 vimfiles)。这个目录应和 Vim 安装目录下的运行支持文件目录有相同的结构,但下面的子目录你在需要修改 Vim 的相关行为时才有必要创建。如果一个同名文件出现用户自己的 Vim 配置目录里和 Vim 的安装目录里,用户的文件优先。
4.4 Vim 8 新功能
站在我个人的角度看,从 Vim 7.4 到 Vim 8.2,最大的新功能是:
- Vim 软件包的支持(”:help packages“)
- 异步任务支持(”:help channel“、”:help job“和”:helptimers“)
- 终端支持(”:help terminal“)
4.5 Vim 软件包
Vim 的目录结构有点传统 Unix 式:一个功能用到的文件可能会分散在多个目录下。,一个 Vim 的插件(严格来讲,应该叫包)通常也会分散在多个目录下:
- 插件的主体通常在 plugin 目录下
- 插件的帮助文件在 doc 目录下
- 有些插件只对某些文件类型有效,会有文件放在 ftplugin 目录下
- 有些插件有自己的文件类型检测规则,会有文件放在 ftdetect 目录下
- 有些插件有特殊的语法加亮,会有文件放在 syntax 目录下
- ……
以前我们安装插件,一般是一次性安装后就不管了。安装过程基本上就是到 .vim 目录(Windows 上是 vimfiles 目录)下,解出压缩包的内容,然后执行 vim -c ‘helptags doc|q’ 生成帮助文件的索引。到了”互联网式更新”的年代,这种方式就显得落伍了。尤其糟糕的地方在于,它是按文件类型来组织目录的,而不是按相关性,这就没法用 Git 来管理了。
Vim 上后来就出现了一些包管理器,它们的基本模式都是相通的:每个包有自己的目录,然后这些目录会被加到 Vim 的运行时路径(runtimepath)选项里。最早的 runtimepath 较为简单,在 Unix 上缺省为:
- $HOME/.vim,
- $VIM/vimfiles,
- $VIMRUNTIME,
- $VIM/vimfiles/after,
- $HOME/.vim/after
而在有了包管理器之后,runtimepath 就会非常复杂,每个包都会增加一个自己的目录进去。但是,好处也是非常明显的,包的管理变得非常方便。从 Vim 8 开始,Vim 官方也采用了类似的体系。Vim 会在用户的配置目录(Unix 下是 $HOME/.vim ,Windows 下是 $HOME/vimfiles )下识别名字叫 pack 的目录,并在这个目录的子目录的 start 和 opt 目录下寻找包的目录。
听着有点绕吧?我们看一个实际的 Vim 配置目录的结构就清楚了:
.
├── colors
├── doc
├── pack
│ ├── minpac
│ │ ├── opt
│ │ │ ├── minpac
│ │ │ ├── vim-airline
│ │ │ └── vimcdoc
│ │ └── start
│ │ ├── VimExplorer
│ │ ├── asyncrun.vim
│ │ ├── fzf.vim
│ │ ├── gruvbox
│ │ ├── killersheep
│ │ ├── nerdcommenter
│ │ ├── nerdtree
│ │ ├── tagbar
│ │ ├── undotree
│ │ ├── vim-fugitive
│ │ ├── vim-matrix-screensaver
│ │ ├── vim-rainbow
│ │ ├── vim-repeat
│ │ ├── vim-rhubarb
│ │ └── vim-surround
│ └── my
│ ├── opt
│ │ ├── YouCompleteMe
│ │ ├── ale
│ │ ├── clang_complete
│ │ ├── cvsmenu
│ │ └── syntastic
│ └── start
│ ├── vim-gitgutter
│ └── ycmconf
├── plugin
├── syntax
└── undodir可以看到,pack 目录下有 minpac 和 my 两个子目录(这些名字 Vim 不关心),每个目录下面又有 opt 和 start 两个子目录,再下面就是每个包自己的目录了,里面又可以有自己的一套 colors、doc、plugin 这样的子目录,这样就方便管理了。Vim 8 在启动时会加载所有 pack/*/start 下面的包,而用户可以用 :packadd 命令来加载某个 opt 目录下的包,如 :packadd vimcdoc 命令可加载 vimcdoc 包,来显示中文帮助信息。
有了这样的目录结构,用户要自己安装、管理包就方便多了。不过,我们还是推荐使用一个包管理器。包管理器可以带来下面的好处:
- 根据文本的配置(一般写在 vimrc 配置文件里)决定要安装哪些包
- 自动化安装、升级和卸载,包括帮助文件的索引生成
在我们这门课程里,我会使用 minpac,一个利用 Vim 8 功能的小巧的包管理器。如果你已经在使用其他包管理器,我接下来讲的两个小节你可以考虑跳过。
4.6 安装 minpac
根据 minpac 网页上的说明,我们在 Windows 下可以使用下面的命令:
cd /d %USERPROFILE%
git clone https://github.com/k-takata/minpac.git ^
vimfiles\pack\minpac\opt\minpac在 Linux 和 macOS 下则可以使用下面的命令:
git clone https://github.com/k-takata/minpac.git \
~/.vim/pack/minpac/opt/minpac然后,我们在 vimrc 配置文件中加入以下内容(先不用理解其含义):
if exists('*minpac#init')
" Minpac is loaded.
call minpac#init()
call minpac#add('k-takata/minpac', {'type': 'opt'})
" Other plugins
endif
if has('eval')
" Minpac commands
command! PackUpdate packadd minpac | source $MYVIMRC | call minpac#update('', {'do': 'call minpac#status()'})
command! PackClean packadd minpac | source $MYVIMRC | call minpac#clean()
command! PackStatus packadd minpac | source $MYVIMRC | call minpac#status()
endif存盘、重启 Vim 之后,我们就有了三个新的命令,可以用来更新(安装)包、清理包和检查当前包的状态。
4.7 通过 minpac 安装扩展包
下面我们就来试验一下通过 minpac 来安装扩展包。我们在”Other plugins”那行下面加入以下内容:
call minpac#add('tpope/vim-eunuch')保存文件,然后我们使用 :PackUpdate 命令。略微等待之后,我们就能看到类似下面的界面:
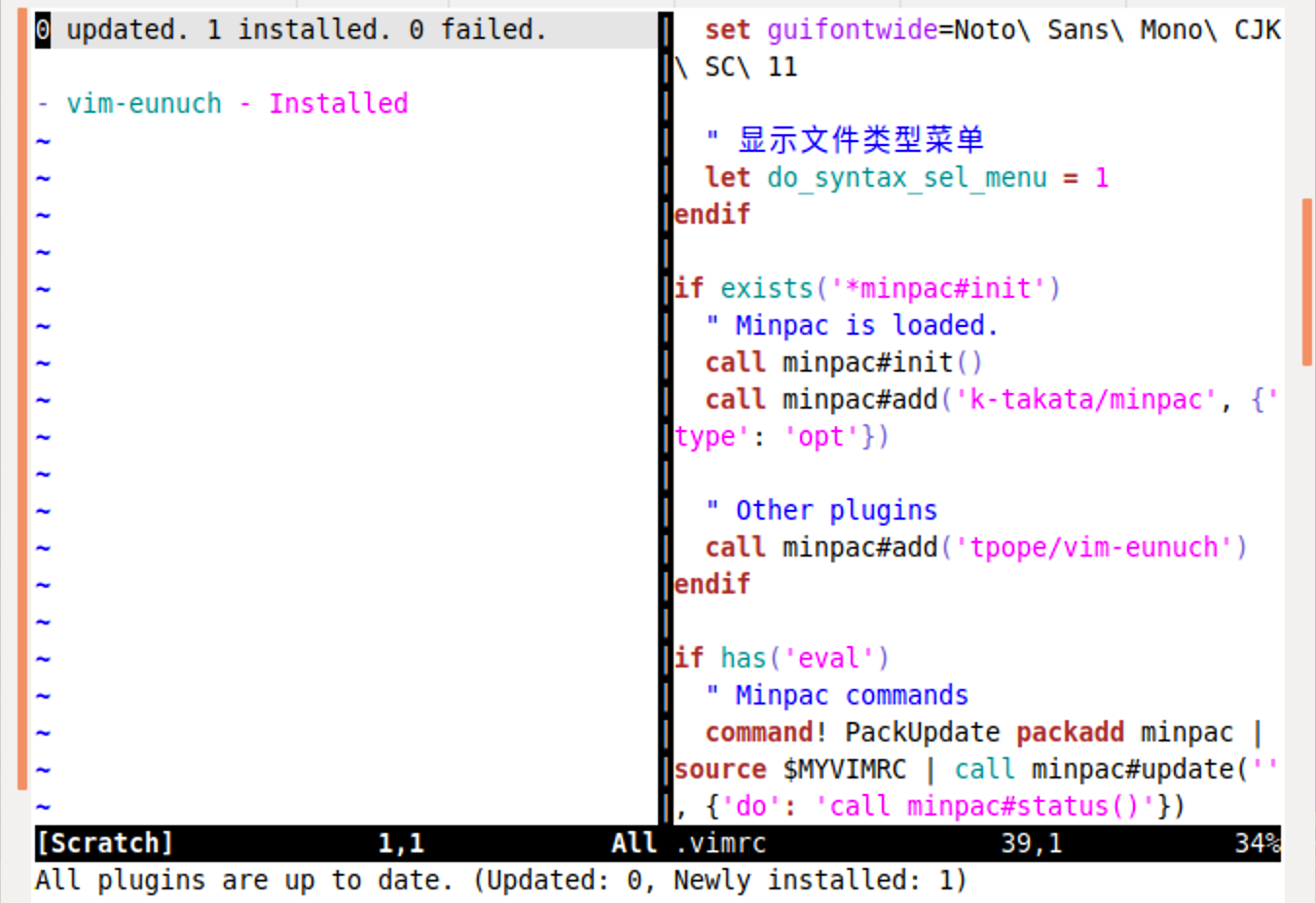
这就说明安装成功了。我们可以按 q 来退出这个状态窗口。我们也可以使用 :PackStatus 来重新打开这个状态窗口。要删除一个插件,在 vimrc 中删除对应的那行,保存,然后使用 :PackClean 命令就可以了。
4.8 最近使用的文件
安装好 Vim 软件包之后,我们进一步来实现一个小功能。
Vim 的缺省安装缺了一个很多编辑器都有的功能:最近使用的文件。
我们就把这个功能补上吧。你只需要按照上一节的步骤安装 yegappan/mru 包就可以了(MRU 代表 most recently used)。安装完之后,重新打开 vimrc 文件,你就可以在图形界面里看到下面的菜单了:
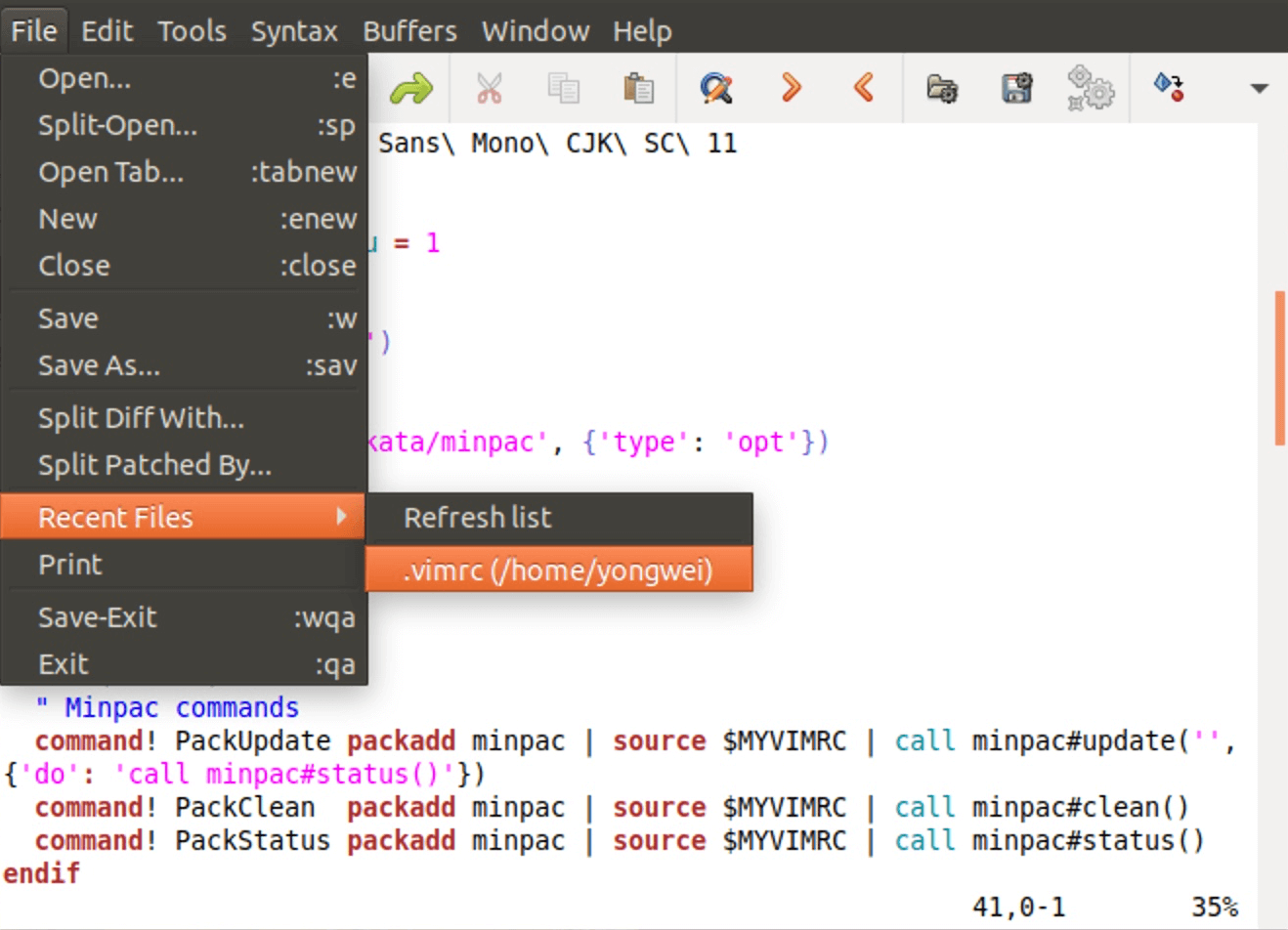
估计你很可能会问:如果是远程连接,没有图形界面怎么办?
我们仍可以在文本界面上唤起菜单,虽然美观程度会差点。你需要在 vimrc 配置文件中加入以下内容(同样,我们暂时先不用去理解其意义):
if !has('gui_running')
" 设置文本菜单
if has('wildmenu')
set wildmenu
set cpoptions-=<
set wildcharm=<C-Z>
nnoremap <F10> :emenu <C-Z>
inoremap <F10> <C-O>:emenu <C-Z>
endif
endif在增加上面的配置之后,你就可以使用键 <F10> (当然你也可以换用其他键)加 <Tab> 来唤起 Vim 的文本菜单了。如下图所示:

05|多文件打开与缓冲区:复制粘贴的正确姿势
今天,我们就来细细讨论一下这个话题,什么是编辑多个文件的正确姿势。
先来假设一个简单的使用场景,我们现在需要在某个目录下的所有 .cpp 和 .h 文件开头贴入一段版权声明,该如何操作?
5.1 单文件的打开方式
5.1.1 图形界面
使用图形界面的话,我们可以在操作系统的资源管理器里进入到合适的目录,然后逐个使用 Vim 来打开文件。我们可以使用右键菜单(”Edit with Vim”、”Open with…”等),也可以直接把文件拖拽到 Vim 里。使用”文件 > 打开”(File > Open)菜单当然也是一种选择,但这需要你记住上次打开到第几个文件,并不如使用资源管理器方便。
使用这几种编辑方式的话,你可以把需要粘贴的内容放到操作系统的剪贴板里,然后在图形界面的 Vim 里用以下方法之一粘贴进去(当然,如果光标不在开头的话,先用鼠标或用 gg 命令跳转到开头):
- 正常模式 Vim 命令 “+P(意义我们后面再解释)
- 快捷键
<D-V>(提醒:这是我们对 ⌘V 的标记方式;仅适用于 macOS)或<SInsert>(PC 键盘) - 鼠标右键加”粘贴”(Paste)
- 菜单”编辑 > 粘贴”(Edit > Paste)
注意,如果你通常使用 Ctrl-V 键粘贴的话,这个快捷键在 Vim 里并不适用。即使你使用的是图形界面的 Vim 也是如此,因为这个键在 Vim 里有其他用途。顺便说一句,这个键在 Unix 终端上也一样是不能用作粘贴的。
5.1.2 终端 Vim
如果直接把图形界面下的基本步骤,翻译成终端 Vim(非图形界面)的用法的话,应该是这样子的:
- 在终端里进入到目标目录下
- 使用 vim 文件名 来逐一打开需要编辑的文件
- 如果光标不在开头的话,用鼠标或 gg 命令跳转到开头
- 使用命令 i 进入插入模式
- 使用终端窗口的粘贴命令或快捷键(如
<S-Insert>)来粘贴内容 - 按
<Esc>回到正常模式并用 ZZ 存盘退出
或者,我们还可以采用下面的不退出 Vim 的处理方法:
- 打开文件使用 :e 文件名;可以使用
<C-D>来查看有哪些文件,及用<Tab>进行自动完成 - 存盘使用 :w
但是如果粘贴的内容含缩进、而 Vim 又不够新的话,我们还会有特殊的麻烦。请继续往下看。
5.1.3 Vim 老版本的特殊处理

上面的图片展示了 Vim 用户可能遇到的一种错误情况。这是因为对于终端 Vim 来说,一般而言,它是没法分辨用户输入和粘贴的。因此,在粘贴内容时,Vim 的很多功能,特别是和自动缩进相关的,就会和输入打架,导致最后的结果不对。
要解决这个问题,你就得让 Vim 知道,你到底是在输入还是在粘贴。Vim 有一个 paste 选项,就是用来切换输入 / 粘贴状态的。如果这个选项打开的话(:set paste),Vim 就认为你在粘贴,智能缩进、制表符转换等功能就不会修改粘贴的内容。
不过,手工设置该选项(及事后用 set nopaste 取消)是件烦人的事。所幸 xterm 里有一个”括号粘贴模式”(bracketed paste mode)可以帮 Vim 判断目前是输入还是粘贴。这个模式启用后,终端在发送剪贴板的内容之前和之后都会发送特殊的控制字符序列,来通知应用程序进行特殊的处理。
启用括号粘贴模式需要向 xterm 发送启用序列 <Esc>[?2004h,关闭括号粘贴模式需要向 xterm 发送关闭序列 <Esc>[?2004l;在启用了括号粘贴模式后,xterm 在发送剪贴板内容时会在前后分别加上开始粘贴序列 <Esc>[200~ 和结束粘贴序列 <Esc>[201~。
Vim 8.0.0210 开始引入了对括号粘贴模式的支持。在兼容 xterm 的终端里进行粘贴时,你不再需要使用 paste 这个选项了。更棒的是,目前你甚至都不需要进入插入模式就可以粘贴了。
如果你使用的是 Vim 8.0.0210 之前的版本的话,那我们至少也可以通过代码来使得手工设置 paste 选项变得不必要。你可以在 vimrc 里加入下面的代码:
if !has('patch-8.0.210')
" 进入插入模式时启用括号粘贴模式
let &t_SI .= "\<Esc>[?2004h"
" 退出插入模式时停用括号粘贴模式
let &t_EI .= "\<Esc>[?2004l"
" 见到 <Esc>[200~ 就调用 XTermPasteBegin
inoremap <special> <expr> <Esc>[200~ XTermPasteBegin()
function! XTermPasteBegin()
" 设置使用 <Esc>[201~ 关闭粘贴模式
set pastetoggle=<Esc>[201~
" 开启粘贴模式
set paste
return ""
endfunction
endif5.1.4 “已经存在交换文件!”
对每个文件单独使用一个 Vim 会话来编辑,很容易出现冲突的情况,所以你迟早会遇到”已经存在交换文件!”(Swap file “…” already exists!)的错误提示。出现这个提示,有两种可能的原因:
- 你上次编辑这个文件时,发生了意外崩溃。
- 你已经在使用另外一个 Vim 会话编辑这个文件了。
原因不同,我们处理的策略自然也不相同。当进程 ID(process ID)后面没有”STILL RUNNING”这样的字样时,那就是情况 1;否则,就是情况 2 了。
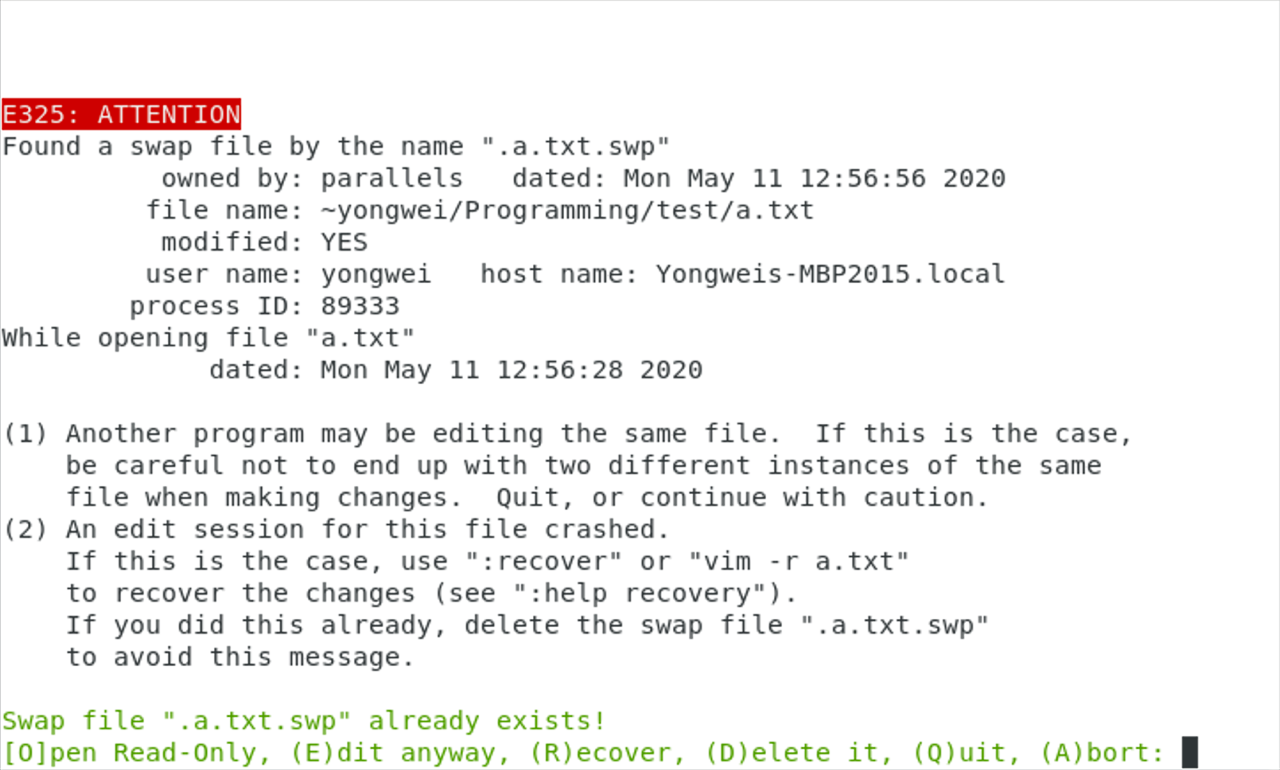
上图中没有”STILL RUNNING”的字样,说明是情况 1。这时你需要按 r 来恢复上次的编辑状态——Vim 支持即使在你没有存盘的情况下仍然保存你的编辑状态,因而这种方法可以恢复你上次没有存盘的内容。
需要注意的是,在恢复之后,Vim 仍然不会删除崩溃时保留下来的那个交换文件。因此,在确定内容无误、保存文件之后,你需要重新再打开文件,并按 d 键把交换文件删除。当然,如果你确定目前保存的文件版本就是你想要的,也可以直接按 d 把交换文件删除、重新编辑文件。
反过来,如果你已经在另一个 Vim 会话里编辑文件的话,我们就会在进程 ID 后面看到”STILL RUNNING”的字样;同时,Vim 界面上也没有了删除(Delete)交换文件这一选项。
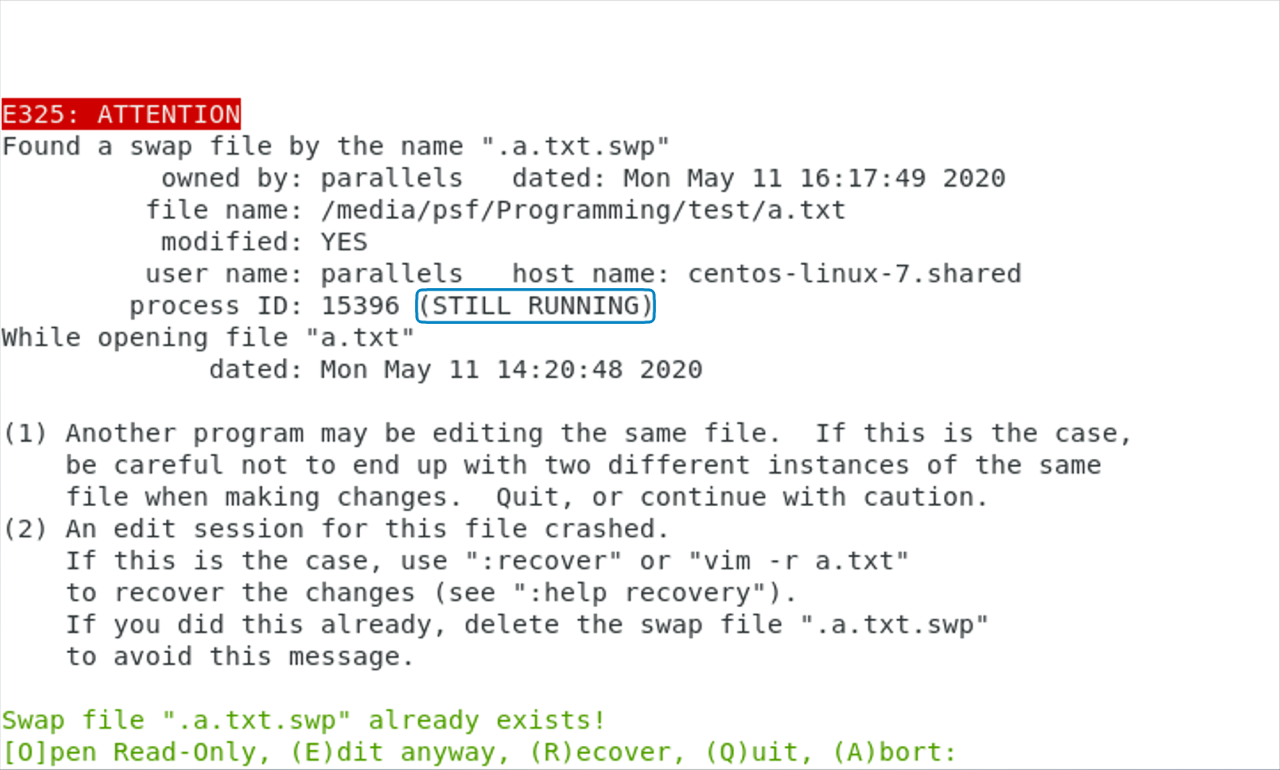
这时,大部分情况侠我们应当使用 q 或 a(绝大部分情况下没有区别)放弃编辑,并找到目前已经打开的 Vim 窗口,从那里继续。少数情况下,我们只是要查看文件,那也可以选择 o 只读打开文件。需要使用 e 强行编辑的情况很少,需要非常谨慎——比如,你确认另外有 Vim 会话,但里面不会去做任何修改,这是我目前想得出来的唯一的合理需求。
如果我们使用图形界面 Vim 8 的话,Vim 支持在文件已经打开时自动切换到已经打开的 Vim 窗口上。这个功能在文件处于一个不活跃的标签页(下一讲会讨论标签页支持)时特别有用,因为 Vim 能把这个标签页自动切到最前面。不过,这个功能不是默认激活的,我们需要在 vimrc 中加入以下内容:
if v:version >= 800
packadd! editexisting
endif5.2 多文件的打开方式
首先,我们需要知道,Vim 支持一次性打开多个文件,你只需要在命令行上写出多个文件即可,或者使用通配符。比如,就我们刚才所说的编辑场景,我们可以使用 vim *.cpp *.h 。
有可能让你吃惊的是,输入这个命令之后,Vim 只打开了一个文件,那就是所有文件中的第一个。
原来,为了确保在配置较差的环境里仍然能够正常工作,Vim 绝对不会不必要地消耗内存,包括打开不必要立即打开的文件。所以在上面的命令后,Vim 建立了一个文件列表,并且暂时只打开其中的第一个文件。接下来,用户可以决定,要编辑哪个文件,或者查看列表,或者提前退出,等等。
为此,Vim 提供了以下命令:
- :args:可以显示”参数”,即需要编辑的多个文件的列表
- :args 文件名:使用新的文件名替换参数列表
- :next(可缩写为 :n):打开下一个文件;如当前文件修改(未存盘)则会报错中止,但如果命令后面加 ! 则会放弃修改内容,其他命令也类似
- :Next(缩写 :N)或 :previous(缩写 :prev):打开上一个文件
- :first 或 :rewind:回到列表中的第一个文件
- :last:打开列表中的最后一个文件
使用这些命令,我们的工作流当然就会发生变化了:
- 在终端里进入到目标目录下
- 使用
vim *.cpp *.h或gvim *.cpp *.h来打开需要编辑的文件 - 对于第一个文件,使用之前的方法贴入所需的文本
- 使用 V 进入行选择的可视模式,移动光标选中所需的文本,然后使用 y 复制选中的各行
- 执行命令 :set autowrite,告诉 Vim 在切换文件时自动存盘
- 执行命令 :n|normal ggP,切换到下一个文件并执行正常模式命令 ggP,跳转到文件开头并贴入文本
- 确认修改无误后,键入 :、上箭头和回车,重复执行上面的命令
- 待 Vim 报错说已经在最后一个文件里,使用 :w 存盘,或 :wq(抑或更快的 ZZ)存盘退出
注意,第 6 步可以拆成 :n 和 ggP 两步,但文件数量较多时,反复手工敲 ggP 也挺累的。因此,我这儿使用了 normal 命令,在命令行模式下执行正常模式命令,下面就可以直接 重复切换命令加粘贴命令,我们的编辑效率也得以大大提升。
.webp)
另外,Vim 还能解决一个 shell 相关的不一致性问题。如果我们要编辑的文件除了当前目录下的,还有所有子目录下的,在大部分 shell 下,包括 Linux 上缺省的 Bash,我们需要使用”*.cpp *.h **/*.cpp **/*.h“来挑选这些文件,重复、麻烦。Vim 在此处采用了类似于 Zsh 的简化语法,”**”也包含了当前目录。这样,我们只需把上面第 2 步改成下面这样即可:
- 键入 vim 进入 Vim,然后使用
:args **/*.cpp **/*.h来打开需要编辑的文件
5.3 缓冲区的管理和切换
跟多文件相关又略微不同的一个概念是缓冲区(buffer)。它是 Vim 里的一个基本概念,和今天讲的很多其他内容有相关性和相似性。
Vim 里会对每一个已打开或要打开的文件创建一个缓冲区,这个缓冲区就是文件在 Vim 中的映射。在多文件编辑的时候你也会有同样数量的缓冲区。不过,缓冲区的数量常常会更高,因为你用 :e 等命令打开的文件不会改变”命令行参数”(只被命令行或 :args 命令修改),但同样会增加缓冲区的数量。
此外,:args 代表参数列表 / 文件列表,真的只是文件的列表而已。缓冲区中有更多信息的,最最基本的就是记忆了光标的位置。在 Vim 里,除了切换到下一个文件这样的批处理操作外,操作缓冲区的命令比简单操作文件的命令更为方便。
作为对比,我们来看一下文件列表和缓冲区列表的命令的结果。

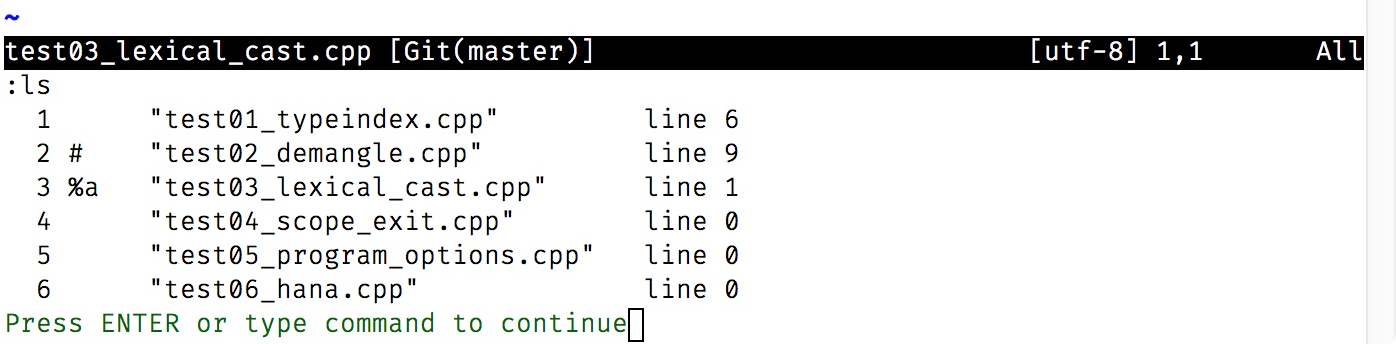
可以看到,两者都展示了文件,都标示出了当前编辑的文件(分别使用方括号和”%a”)。不过,缓冲区列表中明显有更多的信息:
- 文件名前面有编号;我们也马上就会说到利用编号的命令。
- 除了当前活跃文件的标记”%a”,还有个文件被标成了”#”,这表示最近的缓冲区;缓冲区列表里还可能有其他标记,如”+”表示缓冲区已经被修改。
- 文件名后面有行号,表示光标在文件中的位置。
常用的缓冲区命令跟前面文件列表相关的命令有很大的相似性,因此我在这儿一起讲,可以帮助你记忆:
- :buffers 或 :ls:可以显示缓冲区的列表
- :buffer 缓冲区列表里的编号(:buffer 可缩写为 :b):跳转到编号对应的缓冲区;如当前缓冲区已被修改(未存盘)则会报错中止,但如果命令后面加 ! 则会放弃修改内容;其他命令也类似
- :bdelete 缓冲区列表里的编号(:bdelete 可缩写为 :bd):删除编号对应的缓冲区;编号省略的话删除当前缓冲区
- :bnext(缩写 :bn):跳转到下一个缓冲区
- :bNext(缩写 :bN)或 :bprevious(缩写 :bp):跳转到上一个缓冲区
- :bfirst 或 :brewind:跳转到缓冲区列表中的第一个文件
- :blast:跳转到缓冲区列表中的最后一个文件
还有很常见的一种情况是,我们需要在两个文件之间切换。Vim 对最近编辑的文件(上面提到的列表里标有”#”的文件)有特殊的支持,使用快捷键 <C-^> 可以在最近的两个缓冲区之间来回切换。这个快捷键还有一个用法是在前面输入缓冲区的编号:比如,用 1<C-^> 可以跳转到第一个缓冲区(跟命令行模式的命令 :bfirst 或 :b1 效果相同)。
从实际使用的角度,使用缓冲区列表有点像打开最近使用的文件菜单(但缓冲区列表不会存盘),可以当作一种快速切换到最近使用的文件的方式。
缓冲区是文件在某个 Vim 会话里的映射。这意味着,如果某个 Vim 会话里不同的窗口或标签页(下一讲里会讨论)编辑的是同一个文件,它们对应到的也会是同一个缓冲区。更重要的是,文件 / 缓冲区的修改在同一个 Vim 会话里是完全同步的——这就不会像在多会话编辑时那样发生冲突和产生错误了。
06|窗口和标签页:修改、对比多个文件的正确姿势
6.1 多窗口编辑
Vim 有窗口的概念。事实上,如果你使用过 Vim 的帮助功能的话,那你就已经见过 Vim 的多窗口界面了。在那种情况下,Vim 自动打开了一个水平分割的帮助窗口。
那如果我们想要自己同时查看、编辑多个文件呢?最基本的命令就是 :split(缩写 :sp)了。这个命令后面如果有文件名,表示分割窗口并打开指定的文件;如果没有文件名,那就表示仅仅把当前窗口分割开,当前编辑的文件在两个窗口里都显示。跟显示帮助文件一样,:split 默认使用水平分割的方式。
可以在会产生分割的命令(如 help 和 split)之前加上 vertical(缩写 vert),来进行竖直分割。对于最常见的竖直分割操作,我们则可以直接写成 :vsplit(缩写 :vs)。
下面的动画展示了我们进行一次竖直分割后,再进行水平分割的过程:

多窗口编辑是一个比较适宜使用鼠标的情况。你可以使用鼠标来激活想要使用的窗口,也可以使用鼠标来拖拉窗口的大小——只要启用了鼠标支持,终端窗口(包括远程连接的 mintty、PuTTY 等)里的 Vim 的窗口分割线也是可以拖动的(上面动画里的分割线拖动就是在一个终端窗口里)。
当然,作为 Vim 用户,基本的键盘使用肯定是少不了的:
<C-W>加方向键(h、j、k、l、<Left>等等)可以在窗口之间跳转<C-W>w跳转到下一个(往右和往下)窗口,如果已经是右下角的窗口,则跳转到左上角的窗口<C-W>W跳转到上一个(往左和往上)窗口,如果已经是左上角的窗口,则跳转到右下角的窗口<C-W>n或 :new 打开一个新窗口<C-W>c或 :close 关闭当前窗口;当前窗口如果已经是最后一个则无效<C-W>q或 :quit 退出当前窗口,当最后一个窗口退出时则退出 Vim<C-W>o或 :only 只保留当前窗口,关闭其他所有窗口<C-W>s和 :split 作用相同,把当前窗口横向一分为二<C-W>v和 :vsplit 作用相同,把当前窗口纵向一分为二<C-W>=使得所有窗口大小相同(当调整过终端或图形界面 Vim 的窗口大小后特别有用)<C-W>_设置窗口高度,命令前的数字表示高度行数,默认为纵向占满(想专心编辑某个文件时很有用)<C-W>|设置窗口宽度,命令前的数字表示宽度列数,默认为横向占满<C-W>+增加窗口的高度,命令前的数字表示需要增加的行数,默认为 1<C-W>-减少窗口的高度,命令前的数字表示需要减少的行数,默认为 1<C-W>>增加窗口的宽度,命令前的数字表示需要增加的列数,默认为 1<C-W><lt>(提醒,我们用<lt>表示”<”键)减少窗口的宽度,命令前的数字表示需要增加的列数,默认为 1
由于切换窗口是一个非常常见的操作,我通常会映射一下快捷键。为了跟一般的图形界面程序一致,我使用了 Ctrl-Tab 和 Ctrl-Shift-Tab:
nnoremap <C-Tab> <C-W>w
inoremap <C-Tab> <C-O><C-W>w
nnoremap <C-S-Tab> <C-W>W
inoremap <C-S-Tab> <C-O><C-W>W简单解释一下:nnoremap 命令映射正常模式下的键盘,inoremap 命令映射插入模式下的键盘;正常模式的映射简单直白,应该不需要解释,插入模式的映射使用了临时模式切换键 <C-O>(:help i_CTRL-O),在正常模式下执行相应的窗口命令,然后返回插入模式。使用这样的键盘映射之后,这两个快捷键在正常模式和插入模式下就都可以使用了。
6.2 双窗口比较
多窗口编辑中有一个非常有用的使用方式,那就是比较两个文件,Vim 对此也有特殊的支持。使用 vimdiff 或 gvimdiff 命令,后面跟两个文件名,我们就可以对这两个文件进行比较。在比较时,Vim 会自动折叠相同的代码行,并加亮两边文本的不同部分。窗口的滚动也是联动的。一个实际的截图如下所示:
顺便说一句,因为使用双窗口比较功能要求 Vim 的宽度是平时的两倍左右,所以我通常都会对 Vim 窗口使用最大化、拖拉之类的操作。这些操作一般只影响右边的窗口的大小,因此,在放大窗口的操作后,我通常紧跟着就会执行 <C-W>= 来使两个窗口的宽度相同——事实上,我使用 <C-W>= 主要就在这种场合。你也可以试试。
当然了,在 Vim 内部也可以发起这样的比较。你需要做的是打开第一个文件,然后使用命令 :vert diffsplit 第二个文件。这一点只要了解一下就好,毕竟大部分情况下你不需要这样去做。
6.3 多标签页编辑
接下来我们继续讨论和多窗口编辑构成互补的另外一种方式,也就是多标签页。
这里我先给你一个结论:单窗口多文件编辑最适合的场景是批量修改具有相似性质的文件,多窗口编辑最适合的场景是需要对多个文件进行对比编辑,而其他的一些同时编辑多个文件的场景,就可以考虑多标签页的编辑方式。
多标签页的基本特性:
- 多标签页编辑允许在编辑器里同时修改多个(未存盘的)文件
- 多标签页编辑一次只展示一个文件
- 通过选择标签页(或使用键盘)可以方便地在多个标签页中进行切换
Vim 中的标签页在图形界面或终端模式下都能支持上面描述的这些特性。
和某些图形界面应用程序不同,Vim 里标签页可包含多个窗口(一个标签页里默认有一个窗口),而不是窗口可包含多个标签页——这也意味着,在标签页里关闭最后一个窗口就关闭了整个标签页。
此外,Vim 的标签页在纯文本的终端模式里也是可用的。在存在多个标签页的情况下,即使在终端里,你也可以用鼠标点击标签页来进行切换,双击标签栏的空白处添加新标签页,以及点击”X”标记来关闭标签页。
当然,Vim 用户更经常会使用键盘:
- 在已有命令行模式命令前加 tab␣ 可以在新标签页中展示命令的结果,如 :tab help 可以在新标签页中打开帮助,:tab split 可以在新标签页中打开当前缓冲区
- :tabs 展示所有标签页的列表
- :tabnew 或 :tabedit 可以打开一个空白的新标签页,后面有文件名的话则打开该文件
- :tabclose 可以关闭当前标签页(如果标签页里只有一个窗口,使用窗口关闭命令
<C-W>c应该更快) - :tabnext、gt 或
<C-PageDown>可以切换到下一个标签页 - :tabNext、:tabprevious 、gT 或
<C-PageUp>可以切换到上一个标签页 - :tabfirst 或 :tabrewind 切换到第一个标签页
- :tablast 切换到最后一个标签页
如果一开始用多窗口编辑,后来发现不需要一直参照这个文件了,或者屏幕空间不足了,该怎么办呢?Vim 提供了一个命令,可以把当前窗口转变成一个新标签页:按下 <C-W>T 即可(仅当当前屏幕上有多个窗口时有效)。
上一讲我们说过,如果某个 Vim 会话里不同的窗口(或标签页;以下略)编辑的是同一个文件,它们对应到的也会是同一个缓冲区。这意味着多个窗口编辑同一个文件不会有冲突,同时,如果缓冲区被修改了,但只要当前关闭的窗口不是包含这个缓冲区的唯一窗口,那关闭窗口不会有任何问题,也不会影响文件的状态。在任何一个瞬间,任何一个窗口都指向一个缓冲区,而任何一个缓冲区都属于一个或多个窗口。(例外情况是你使用了一个不那么常用的功能,隐藏缓冲区;这个功能在本课程中不会讨论。)
6.4 NERDTree 插件
来看几个利用这些特性的插件。我们讨论的第一个插件就是 NERDTree。
对于找文件这件事,NERDTree 就是你知道文件大概在哪里、但不知道文件具体名字时的一个好选择。跟很多 Vim 插件一样,NERDTree 会利用多窗口(少数情况下利用标签页)的特性。
6.4.1 安装
如果使用 minpac 的话,我们需要在 vimrc 中”Other plugins”那行下面加入下面的语句,并运行 :PackUpdate 来安装一下:
call minpac#add('preservim/nerdtree')NERDTree 缺省就会抢占 netrw 使用的路径形式,所以我们可以用 :e . 来打开 NERDTree。不过,更常用的方式仍然是使用 :NERDTreeToggle,NERDTree 窗口的切换命令。我们使用这个命令可以打开上面左侧的那个 NERDTree 窗口,也可以关闭。
6.4.2 使用
在打开 NERDTree 窗口之后,使用还是相当直观的,并且按下 ? 就可以查看帮助信息。提一下最重要的几个功能点:
- 顾名思义,这个插件以树形方式展示文件系统,在目录上敲回车或双击即可打开或关闭光标下的目录树。
- 在文件上敲回车或双击立即打开该文件,并且光标跳转到文件窗口中,这样你就可以立即开始编辑了。
- 在文件上使用 go 会预览该文件,也就是光标不会跳转到文件所在的窗口中,方便快速查看多个文件的内容。
- 按 i 会打开文件到一个新的水平分割的窗口中,按 s 会打开文件到一个新的竖直分割的窗口中,按 t 会打开文件到一个新的标签页中。
- NERDTree 会自动过滤隐藏文件和目录,但如果你需要看到它们的话,也可以用 I 来开启和关闭隐藏文件的显示。
- 按 m 会出现一个菜单,允许添加、删除、更名等操作。
6.5 类似插件
07|正则表达式:实现文件内容的搜索和替换
7.1 正则表达式搜索
通过 Vim 教程,你已经学到了搜索命令 / 和替换命令 :s 的基本用法。教程里没有提到的是,你输入的待查找的内容是被 Vim 当成正则表达式来看待的。下面我们会简单讨论的,是 Vim 里的正则表达式,重点是它和其他常用正则表达式(正则表达式还是有很多种不同的风格的)的区别之处。
在一个搜索表达式里,或者称为模式(pattern;注意不要和 Vim 的 mode 混淆)里,.、*、^、$、~、[]、\ 是有特殊含义的字符:
.可以匹配除换行符外的任何字符:如a.可以匹配”aa”、”ab”、”ac”等,但不能匹配”a”、”b”或”ba”。如果需要匹配换行符(跨行匹配)的话,则需要使用\_.。*表示之前的匹配原(最普通的情况为单个字符)重复零次或多次:如aa*可以匹配”a”、”aa”或”aaa”,a.*可以匹配”a”、”aa”、”abc”等等,但两者均不能匹配”b”。^匹配一行的开头,如果出现在模式的开头的话;在其他位置代表字符本身。$匹配一行的结尾,如果出现在模式的结尾的话;在其他位置代表字符本身。~匹配上一次替换的字符串,即如果上一次你把”foo”替换成了”bar”,那~就匹配”bar”。[…]匹配方括号内的任一字符;方括号内如果第一个字符是 ^,表示对结果取反;除开头之外的 - 表示范围:如[A-Za-z]表示任意一个拉丁字母,[^-+*/]表示除了”+”、”-“、”*”、”/“外的任意字符。\的含义取决于下一个字符,在大部分的情况下,包括上面的这几个(.、*、\、^、$、~、[ 和 ]),代表后面这个字符本身;在跟某些字符时则有特殊含义(后面我们会讨论最重要的那些)。
除此之外的字符都是普通字符,没有特殊含义。不过,需要注意的是,如果使用 / 开始一个搜索命令,或者在替换命令(:s)中使用 / 作为模式的分隔符,那模式中的 / 必须写作 \/ 才行,否则 Vim 看到 / 就会以为模式结束了,导致错误发生。
为了避免写模式的困扰,如果模式中使用”/“作为路径的分隔符,在替换命令中可以使用其他模式中没有的符号作为分隔符。比如,想把”/image/“全部替换成”/images/“的话,不要用 :%s/\/image\//\/images\//g,而应该用类似于 :%s!/image/!/images/!g 的写法。这只能适用于替换命令,而在使用 / 命令搜索时我们就没什么好办法了,只能把模式里的 / 写作 \/。不过我们也可以取巧一下,用 ? 向上、也就是反向搜索,只要记得 n、N 反过来用找下一个就行。
通过 \ 开始的特殊表达式有不少,如果你需要完整了解的话,可以去看看参考文档(:help pattern-overview)。我们下面先学习一下最基本的 6 个特殊模式项:
\?表示之前的匹配原重复零次或一次:如aa\?可以匹配”a”、”aa”,但不能完整匹配”aaa”(可以匹配其前两个字符、后两个或最后一个字符)。\+表示之前的匹配原重复一次或多次:如aa\+可以匹配”aa”、”aaa”,但不能匹配”a”或”b”。\{n,m}表示之前的匹配原重复 n 到 m 遍之间,两个数字可以省略部分或全部:如a\{3}(可读作:3 个”a”)可以匹配”aaa” ,a\{,3}(可读作:最多 3 个”a”)可以匹配””、”a”、”aa”和”aaa”;两个数字都省略时等价于*,也就是之前的匹配原可以重复零次或多次。\(和\)括起一个模式,将其组成为单个匹配原:如\(foo\)\?可以表示单词”foo”出现零次或一次。\(和\)还有一个附加作用,是捕获匹配的内容,按\(出现的先后顺序,可以用\1、\2到\9来引用。如果你不需要捕获匹配内容的话,用\%(和\)的性能更高。\&是分支内多个邻接(concat)的分隔符,概念上可以和与操作相比,表示每一项都需要匹配成功,然后取最后一项的结果返回:如.*foo.*\&.*bar.*匹配同时出现了”foo”和”bar”的完整行。相对来讲,\&没那么常用。\|是多个分支的分隔符,概念上可以和或操作相比,表示任意一项匹配成功即可:如foo\|bar可匹配”foo”或”bar”两单词之一。
接下来,我再和你分享 13 个特殊模式项。虽然它们相对来说不那么必需,但掌握它们可以大大地提高程序员的编辑效率。
\<匹配单词的开头\>匹配单词的结尾\s匹配空白字符<Space>和<Tab>\S匹配非空白字符\d匹配数字,相当于 [0-9]\D匹配非数字,相当于 0-9\x匹配十六进制数字,相当于 [0-9A-Fa-f]\X匹配非十六进制数字,相当于 0-9A-Fa-f\w匹配单词字符,相当于 [0-9A-Za-z_]\W匹配非单词字符,相当于 0-9A-Za-z_\h匹配单词首字符,相当于 [A-Za-z_]\H匹配非单词首字符,相当于 ^[A-Za-z_]\c忽略大小写进行匹配
以上我们讨论的实际上是 Vim 缺省设置下的正则表达式。通过选项(:help /magic),我们可以对哪些字符有特殊意义进行一定程度的调整。不过一般情况下,我认为修改这个选项只会造成混乱、增加心智负担,因此我也就不在这儿展开了。
7.2 搜索实例
抽象地讨论正则表达式恐怕你也不容易记住,我们还是拿一些具体的例子来看一下吧。
首先,如果我们要查找某个函数,该怎么做呢?简单,按下 /,然后输入函数名,回车,不就行了?
错。这种方式对函数名是部分匹配,你搜 begin 还会得到 begin1、_begin 之类的结果。正确的方法是,要在前后加上匹配单词头尾的标记,如,\<begin\>。
顺便说一句,被誉为最有用的 Vim 提示,是把光标移到希望搜索的关键字上,然后按下 *键。Vim 会提取光标下的关键字,并自动添加 \< 和 \> 进行搜索。

如果我要搜索 begin 或 end 呢?我想,你应该已经知道了,是:/\<\(begin\|end\)\>。注意,写成 /\<begin\|end\> 可是不对的。(为什么?你想明白了吗?)
对于 HTML,你应该多多少少有些了解。如果我们想匹配一下 HTML 标签的话,该怎么做呢?
一个标签以 < 开始,以 > 结束。所以,最简单的模式应该是 <.\+>,对吗?
不对,这个写法忽略了一行里可能有多个标签的事实:对于”<h1>title</h1>“这样一个字符串,上面这个简单的模式会匹配整个字符串,而不是”<h1>“和”</h1>“……
有一种解决方案是,排除不应该匹配的字符,把模式写成 <[^>]\+>:一对尖括号里有一个或多个不是”>”的字符。不过,这样的写法会让像 > 这样的结尾字符在模式中重复出现,因此这并不是最理想的写法。更好的方式是,使用最短匹配。
7.3 最长匹配和最短匹配
我们上面学到的 *、\?、\+ 和 \{} 都属于最长匹配(也叫贪婪匹配),也就是说,当模式既可以匹配一个较长的字符串,也可以匹配一个较短的字符串时,结果会是那个较长的字符串。
相应地,还有一种匹配叫做最短匹配,也就是在同时可以匹配较长的字符串和较短的字符串时,产生较短的匹配。在 Vim 里,最短匹配只有一种形式,{-n,m},其意义和之前说的 {n,m} 基本相同,但结果是较短而非较长的字符串。
以上面的 HTML 标签匹配为例,使用最短匹配的话,我们可以把模式写成 <.\{-1,}>,要求在一对尖括号里至少有一个字符,但越短越好。
7.4 搜索加亮和取消
Vim 缺省在你输入搜索模式时就会高亮跟你输入的模式匹配的文本。
Vim 有一个专门命令来取消搜索加亮,这个命令就是 :nohlsearch,不要高亮搜索。
鉴于这个命令使用的频度实在是太高了,我们需要给它专门分配一个快捷键。请在 vimrc 中加入:
" 停止搜索高亮的键映射
nnoremap <silent> <F2> :nohlsearch<CR>
inoremap <silent> <F2> <C-O>:nohlsearch<CR>这样一来,在搜索或替换工作完成之后,只要按下 <F2> 就可以取消搜索加亮了。
7.5 正则表达式替换
有些复杂的情况:
- 要保留匹配中的某些字符,而替换另外一些字符
- 要对匹配出的内容做大小写转换
- 需要”计算”出替换结果
- 需要决定一行里要替换单次还是多次,是自动替换还是要一一确认,等等
接下来,我们就分别看看这些复杂情况。
在这些情况里,最常用的显然就是在替换结果中保留匹配出的字符串了。前面说到 \(\) 除了将一个模式转变成匹配原外,还有一个作用是捕捉匹配的内容,按 \( 的出现顺序依次编号为 1 到 9,并可以在模式和替换字符串中用 \1 到 \9 来访问。如果要在替换字符串中完整使用匹配内容的话,则可以使用 \0 或 &(字符”&”也因此要在替换字符串中写成 \&)。
从搜索的角度,我们一般只关心匹配与否,而不关心匹配的大小。举个例子,如果我想找出作为函数调用的 begin,那我可以写成 \<begin(,虽然 ( 不是我想匹配的内容(函数名称)的一部分。但从替换的角度,我需要在替换时再处理一下多匹配的内容,也是件麻烦事;在非匹配的内容比较复杂或者会变化的时候,尤其会是这样。所以 Vim 里还有专门标识匹配开始和结束的匹配原,分别是 \zs 和 \ze。对于这个例子,搜索模式就应该是 \<begin\ze(。为了巩固前面学到的知识,你应该知道,这个模式也可以啰嗦地写成 \<begin(\&begin 或 \<begin(\&..... 。
\Vim 里还有一些大小写转换的特殊替换字符串。它们是:
\U把下面的字符变成大写,直到\E出现\u把下一个字符变成大写\L把下面的字符变成小写,直到\E出现\l把下一个字符变成小写\E结束大小写转换
Vim 还能用 \= 开始一个返回字符串的表达式,用来计算出一个替换结果。鉴于我们目前还没有讨论 Vim 脚本,这个我们就留到后面第 14 讲再说了。
跟常用的编程语言一样,Vim 的正则表达式中支持 \t、\r、\n 等特殊转义字符,但在替换表达式中,由于一些技术原因(:help NL-used-for-Nul),\n 插入的是空字符(NUL 或”\0”),而非在模式中出现时代表的 LF。如果要插入正常的行尾符 LF 的话,我们得使用 \r。这意味着如果想把一个回车变成两个的话,我们得别扭地写 :s/\n/\r\r/,略遗憾。如果有特殊需要得插入 CR 的话,就要更别扭地输入 \<C-V><CR> 才行。还好,我们基本不会在替换时遇到要插入 CR 的情况……
Vim 有很多用来控制替换的标志,你可以通过 :help s_flags 查看详细的介绍,我就不一一列举了。今天这一讲中,我们只会用到最常用的一个标志,g,代表可以在一行内进行多次替换;没有这个标志的话,Vim 在一行里只会对第一个成功的匹配进行替换。
7.6 替换实例
先来看一个简单的,删除行尾的”//“注释。我们可以用这个命令 :%s!\s*//.*$!! 把零到多个空白字符后面出现的”//“直到行尾全部删除。
如果要删除”/* */“注释,那就复杂多了。首先,匹配内容可以跨行;其次,有跟 HTML 标签类似的问题,需要使用最短匹配。我们需要使用的命令是 :%s!/\*\_.\{-}\*/!!g 。
由于一行里可以有多个”/* */“注释,我们在替换命令的尾部还加上了 g 标志,允许一行里进行多次替换。
假设我们目前的编码规范规定,所有的函数名应该首字母大写(简单起见,我们假设所有的类名已经是首字母大写了,因而构造函数自动符合该要求,不会发生冲突;但其他很多函数名称仍然是小写字母开头),那么 Vim 的替换命令是::%s/\<\(_*\)\([a-z]\w*\)\ze(/\1\u\2/g 。
08|基本编程支持:规避、解决编程时的常见问题
8.1 文件类型和关联设定
程序源代码通常由文件组成,每个文件都有一个关联的文件类型。这个文件类型决定了Vim 对其进行处理的一些基本设定,可能包括:
- 如何对文件进行高亮
- 制表符(tab)的宽度(空格数)
- 是否在键入
<Tab>时扩展为空格字符 - 每次缩进的空格数(是的,可以和制表符宽度不同)
- 采用何种自动缩进方法
- 其他可适用的选项
文件高亮通常需要一套相当复杂的规则,我们今天就只把它当成一个既成事实了,不讨论这些规则的细节。其他各项在 Vim 里一般以选项的形式出现。这些选项都是文件本地(local)选项,即可以在一个文件里修改其数值而不影响其他文件。对于这样的选项,可以用 :setlocal 和 :setglobal 命令分别访问本地值和全局值。一般的 :set 命令在读取数值时(如 :set tabstop?)返回本地值,在写入数值时(如 :set tabstop=4)同时设置本地值和全局值。
制表符宽度对应的选项是 tabstop。这在不同的语言里可能有不同的惯例,自然不必多说。它的缺省值是 8,但在不同的文件里可以不一样。不同的文件类型也可能会自动设定不同的数值。
是否 扩展 <Tab> 为空格 由 expandtab 选项控制。我们前面看到过,但没有讲过,Vim 选项有些是用等号赋值的,也有些不用等号,而只用选项名称或选项名称前面加 no,表示否定。这些就是布尔类型选项,expandtab 也是其中之一。如果打开了 expandtab 选项,那输入中的 tab 会被转变成空格;如果关闭的话,则 tab 字符会被保留。
让事情变得更复杂的是,Vim 还有个 softtabstop 选项,软制表符宽度。一旦设置了这个选项为非零值,再键入 <Tab> 和 <BS>(退格键),你就感觉像设置了这个宽度的 tabstop 一样,有相应数量的缩进或取消缩进,但实际插入的字符仍然受 expandtab 和 tabstop 两个选项控制。在设置软制表符宽度时,一种最常用的用法是同时设置 expandtab,这样,编辑时你感觉像使用了这个宽度的制表符一样,但你输入的内容里实际被保存的仍然是空格字符。
这些还不是 Vim 真正使用的”缩进”值。以 C 语言为例,当 Vim 看到你输入”{“和回车键时,会自动产生一个缩进,而这个缩进值跟 tabstop 和 softtabstop 都无关,是一个独立的选项 shiftwidth。
最后,Vim 还有很多精细的选项来控制如何进行缩进。默认情况下,Vim 没有特殊缩进,回车键回到行首。一般而言,使用选项 autoindent 可以使 Vim 至少记住上一行的缩进位置;而对于特定语言,Vim 可以设置更合适的选项,达到更佳的缩进效果——如对类 C 语言 Vim 会设置 cindent 选项,达到最优的缩进效果。我们下面还会提到,Vim 支持对类 C 语言的缩进有一些精调选项,你也可以自己进一步进行调整。
8.2 文件类型判断
Vim 的文件类型判断是在 filetype.vim 中执行的。我们可以用下面的命令来打开这个文件:
:e $VIMRUNTIME/filetype.vim其中最主要的逻辑仍然是通过后缀来进行判断,如:
" C++
au BufNewFile,BufRead *.cxx,*.c++,*.hh,*.hxx,*.hpp,*.ipp,*.moc,*.tcc,*.inl setf cpp其中 au 是 autocmd 的缩写,代表 Vim 在发生某事件时触发某一动作。上面说的就是在创建(BufNewFile)或读入(BufRead)跟指定文件名模式匹配的文件时,把文件类型设为 C++(setf cpp, setf 是 setfiletype 的缩写)。
但在后缀不足以唯一判断时,Vim 可以进一步执行代码,如:
au BufNewFile,BufRead *.h call dist#ft#FTheader()上面函数的定义在文件 $VIMRUNTIME/autoload/dist/ft.vim 里:
func dist#ft#FTheader()
if match(getline(1, min([line("$"), 200])), '^@\(interface\|end\|class\)') > -1
if exists("g:c_syntax_for_h")
setf objc
else
setf objcpp
endif
elseif exists("g:c_syntax_for_h")
setf c
elseif exists("g:ch_syntax_for_h")
setf ch
else
setf cpp
endif
endfunc它的大概意思是,如果在头 200 行里找到某行以 @interface 等内容开始,那就认为这是 Objective-C/C++,否则认为是 C/C++。具体是 C 还是 C++,则由全局变量 g:c_syntax_for_h 控制(我们忽略 Ch 这种小众情况)。
上面讲的是 Vim 的缺省行为。我们当然也可以定制 Vim 的行为。按照惯例,一般把定制放在用户 Vim 配置目录里的 filetype.vim 里。我的定制如下所示:
if exists("did_load_filetypes")
finish
endif
function! s:CheckCPP()
if expand('%:t') !~ '\.'
setfiletype cpp
endif
endfunction
augroup filetypedetect
au! BufRead,BufNewFile *.asm setfiletype masm
au! BufRead proxy.pac setfiletype javascript
au! BufRead */c++/* call s:CheckCPP()
au! BufRead */include/* call s:CheckCPP()
augroup END上面这段代码主要做了以下事情:
- 当读入或创建后缀为”.asm”的文件时,设置文件类型为微软宏汇编(默认为 GNU 的汇编格式)。
- 当读入名字为”proxy.pac”的文件时,把内容当成 JavaScript 解释。
- 当读入路径含”c++”或”include”的文件时,调用脚本内部函数 CheckCPP,检查文件名(% 代表文件名,:t 代表尾部,即去掉路径部分)是否不含”.”,是的话当成 C++ 文件类型。这是为了处理像”memory”这样的无后缀 C++ 头文件。
- 随后 Vim 会继续载入自带的 filetype.vim;如果文件类型还未确定的话,则继续使用 Vim 自带的规则进行判断。
8.3 文件类型选项
一旦确定了文件类型,Vim 会从运行支持文件目录下载入同名的文件。以 Python 为例:
- syntax/python.vim 包含了如何对 Python 进行语法加亮的设置
- indent/python.vim 包含了如何对 Python 代码进行缩进的设置(如在用户输入 if 时进行缩进等)
- ftplugin/python.vim 是文件类型插件,包含了其他跟文件类型相关的设置
文件类型插件中包含我们上面提到的制表符宽度方面的设定,具体来说,是下面这几行:
if !exists("g:python_recommended_style") || g:python_recommended_style != 0
" As suggested by PEP8.
setlocal expandtab shiftwidth=4 softtabstop=4 tabstop=8
endif默认情况下,该文件使用 PEP 8 推荐的设置:
- 把用户输入的制表符扩展成空格
- 缩进和软制表符宽度设为 4
- 如果文件中包含制表符的话,仍按宽度为 8 来解释
缩进和软制表符宽度设成 4 估计不需要解释,这应该是最常用的缩进值了。使用空格而不是制表符的最大好处是,在无论何种环境下,展示效果都可以完全一致,不会在 diff 时或制表符宽度不符合预期时代码就乱了。至于”硬”制表符宽度仍然是 8,则是为了确保显示文件的兼容性,尤其是在终端里 cat 文件时和在浏览器中浏览源代码时;这两种情况下,制表符宽度一般都是 8。
跟 Python 不同,很多其他文件类型没有推荐的风格设定,这时就应该用户自己进行设定了。我推荐在 vimrc 配置文件里进行设置,因为比较集中、容易管理。如:
au FileType c,cpp,objc setlocal expandtab shiftwidth=4 softtabstop=4 tabstop=4 cinoptions=:0,g0,(0,w1
au FileType json setlocal expandtab shiftwidth=2 softtabstop=2
au FileType vim setlocal expandtab shiftwidth=2 softtabstop=2上面设置了几种不同文件类型的编辑选项。大部分我们都已经知道了,下面这个则是新的:
- cinoptions 可以精调 C 风格缩进的方式;上面 :0 表示 switch 下面的 case 语句不进行额外缩进,g0 代表作用域声明(public:、private: 等)不额外缩进,(0 和 w1 配合代表没结束的圆括号里的内容折行时不额外缩进。
我们也可以根据文件类型以外的条件来进行设定,如下面设定是要把 /usr/include 目录下的文件按 GNU 编码风格来解释:
function! GnuIndent()
setlocal cinoptions=>4,n-2,{2,^-2,:2,=2,g0,h2,p5,t0,+2,(0,u0,w1,m1
setlocal shiftwidth=2
setlocal tabstop=8
endfunction
au BufRead /usr/include/* call GnuIndent().webp)
当然,除了设定选项,我们也可以做其他事情,比如下面的代码是在 Vim 帮助文件中,将 q 设定为关闭窗口的按键,映射中的 <buffer> 表示该映射只对这个缓冲区有效。
au FileType help nnoremap <buffer> q <C-W>c8.4 Tags 支持
Vim 对一种叫 tags 的文本索引格式有特殊支持。事实上,Vim 自己的帮助文件都是用 tags 来索引的。我们用过了 Vim 帮助,也就用过了 tags 文件。下面展示了 $VIMRUNTIME/doc/tags 文件中的一部分:
? pattern.txt /*?*
?<CR> pattern.txt /*?<CR>*
@ repeat.txt /*@*
@/ change.txt /*@\/*
@: repeat.txt /*@:*
@= change.txt /*@=*
@@ repeat.txt /*@@*
@r eval.txt /*@r*
A insert.txt /*A*
ACL editing.txt /*ACL*
ANSI-C develop.txt /*ANSI-C*我们可以清楚地看到,其中内容分为三列:第一列是关键字,第二列是文件名,第三列是在目标文件中的匹配文本。当你在 Vim 的帮助文件中使用双击或 <C-]> 等命令跳转时, Vim 就会在 tags 文件中搜索,寻找到匹配项的时候就跳转到指定的文件,并利用匹配文本跳转到指定的位置。
注意我们有不止一个 tags 文件。单单从 Vim 帮助的角度,个人 Vim 配置目录下的 doc目录里有一个 tags 文件;每当你装了一个新的带帮助文件的 Vim 插件时,你都需要到这个 doc 目录下运行 helptags . 来重新生成索引。每个 Vim 软件包的 doc 目录下也同样需要有 tags 文件,不过包管理器能够在安装、更新时自动帮我们在 doc 目录下生成 tags文件。Vim 在你使用 :help 命令查帮助时,会自动在你的所有运行时目录(可以使用 :set runtimepath? 查看)下的 doc/tags 里查找第一个匹配项。
8.5 生成 tags 文件的工具
我们需要使用下列两个工具之一:
Exuberant Ctags 是已经存在了好多年的老牌工具。Universal Ctags 还比较新。推荐 Universal Ctags,是因为虽然 Exuberant Ctags 和 Universal Ctags 都支持超过 40 种的常见编程语言,但 Exuberant Ctags 的最后一个版本 5.8,发布于 2009 年,之后就一直没有更新了。Universal Ctags 是基于 Exuberant Ctags 代码的改进版本,并把开发移到了 GitHub 上,项目一直处于活跃状态。想偷懒的话,可以直接使用 Exuberant Ctags;如果愿意折腾一下,或者明确遇到 Exuberant Ctags 的问题,则可以试试 Universal Ctags。
8.6 生成 tags 文件的命令
要生成 tags 文件时,你可以简单地进入到一个目录下,然后执行下面的语句对该目录及子目录下的程序源文件生成一个 tags 文件:
ctags -R .但根据场景和语言不同,你可能需要使用更多的选项。比如,对于 C++,我一般使用:
ctags --fields=+iaS --extra=+q -R .如果是对系统的头文件生成 tags 文件——可以用来查找函数的原型信息——那我们一般还需要加上 --c-kinds=+p 选项。为了一次性地对系统头文件简单地生成 tags 文件,我
还专门写了个脚本 gen_systags 来自动化这项工作。
8.7 使用 tags 文件
如果当前目录下或当前文件所在目录下存在 tags 文件,Vim 会自动使用这个文件,不需要你做额外的设定。你所需要做的就是在待搜索的关键字上(也可以在可视模式下选中需要的关键字)使用正常模式命令 <C-]>,或者按 g(g 可理解成 go)键加鼠标单击。你愿意的话,也可以手工输入命令 :tag 后面跟空格和待搜索的符号加回车键。这样 Vim 即会跳转到该符号的定义或声明位置。

如果待搜索的符号找不到,Vim 会报错”E426: tag not found”。如果存在一个或多个匹配项,Vim 会跳转到第一个匹配的位置。下面我列举一下其他相关的常用命令:
- :tnext(缩写 :tn)跳转到下一个标签匹配位置
- :tNext(缩写 :tN)或 :tprevious(缩写 :tp)跳转到上一个标签匹配位置
- :tfirst 或 :trewind 跳转到第一个标签匹配位置
- :tlast 跳转到最后一个标签匹配位置
- :tselect 名称(:tselect 可缩写为 :ts)跟 :tag 类似,但会列举可能的匹配项,让你自己选择(而非跳转到第一个匹配位置)
- g] 跟
<C-]>类似,但跟 :tselect 一样会给出一个列表而非直接跳转 - :tjump 名称(:tjump 可缩写为 :tj)跟 :tselect 类似,但在只有一个匹配项的时候会直接跳转到匹配位置
g<C-]>跟 g] 类似,但跟 :tjump 一样在只有一个匹配项时会直接跳转到匹配位置- :stselect 名称(:stselect 可缩写为 :sts)跟 :tselect 类似,但结果会打开到一个新分割的窗口中
- :stjump 名称(:stjump 可缩写为 :stj)跟 :tjump 类似,但结果会打开到一个新分割的窗口中
我们的标签跳转分为 :tag、:tselect 和 :tjump 三种不同方法,正常模式和可视模式的命令 <C-] 也同样有后两种方法的变体,对应的命令分别是 g] 和 g<C-]>。这三个命令前面也都可以额外加上 <C-W>,表示结果打开到新窗口中而非当前窗口。

Vim 默认只在当前目录下和文件所在目录下寻找 tags 文件。对于含多层目录的项目,这个设定就不合适了。解决方法是使用 Vim 的选项 tags。一个小技巧是根据项目的可能深度,检查上层存在的 tags 文件:
" 加入记录系统头文件的标签文件和上层的 tags 文件
set tags=./tags,../tags,../../tags,tags,/usr/local/etc/systags8.8 Tagbar 插件
Vim 的插件 tagbar 就可以利用 Ctags 来提取符号,生成源代码的结构图。只要 Ctags 能支持这种语言,插件就能”识别” 这种语言,来生成结构图;识别的好坏程度也视 Ctags 对其的支持程度而定。下面是一个示例:
跟之前类似,假设使用 minpac 的话,我们需要在 vimrc 中”Other plugins”那行下面加入下面的语句,并运行 :PackUpdate 来安装一下:
call minpac#add('majutsushi/tagbar')我给它映射了快捷键 <F9>,可以快速打开和关闭 Tagbar 的窗口:
" 开关 Tagbar 插件的键映射
nnoremap <F9> :TagbarToggle<CR>
inoremap <F9> <C-O>:TagbarToggle<CR>8.9 Quickfix 窗口
Vim 里有一种特殊类型的窗口,被称作 quickfix(快速修复)。这个窗口中会展示外部命令的结果,并可以通过这个窗口中的内容直接跳转到特定文件的特定位置。这个设计最初是用来加速”编辑 - 编译 - 编辑”这个循环的,但它的实际用处并不只是用来编译程序。
我们先来看一下 Vim 的 :make 命令。如果你的代码可以简单执行 make 来编译的话(也就是说,你已经写了或者生成了合适的 Makefile),你可以尝试直接在 Vim 里执行 :make。你会看到正常的执行过程。唯一不一样的地方是,如果编译失败了,Vim 会自动跳转到第一个出错的位置!

如果使用 :copen 命令,我们就可以打开 quickfix 窗口。在里面我们可以看到完整的出错信息,并能通过颜色看出 Vim 解析了文件名和行号。我们在带文件名的行上双击即可跳转到对应位置。另外,我们在 quickfix 窗口中也有跟之前类似的”next”类命令:
- :cnext(缩写 :cn)跳转到下一个出错位置
- :cNext(缩写 :cN)或 :cprevious(缩写 :cp)跳转到上一个出错位置
- :cfirst 或 :crewind 跳转到第一个出错位置
- :clast 跳转到最后一个出错位置
为了方便记忆,我对它们都映射了相似的快捷键。
" 用于 quickfix、标签和文件跳转的键映射
nmap <F11> :cn<CR>
nmap <F12> :cp<CR>
nmap <M-F11> :copen<CR>
nmap <M-F12> :cclose<CR>
nmap <C-F11> :tn<CR>
nmap <C-F12> :tp<CR>
nmap <S-F11> :n<CR>
nmap <S-F12> :prev<CR>8.10 :make 命令的其他细节
Vim 里的 :make 命令缺省会执行 make 命令,并且这是可以通过选项 makeprg 来进行配置的。比如,如果你希望启用四路并发编译,你就可以设置 :set makeprg=make\ -j4。你也可以使用 GNU Make 之外的构建工具,但需要注意的是,如果发现 Vim 不能识别你使用的构建工具产生的错误信息,你可能需要利用 errorformat(:helperrorformat)选项来告诉 Vim 如何处理错误信息。
8.11 :grep 命令
跟 :make 命令相似,Vim 会调用一个合适的外部程序(可通过 grepprg 选项来进行配置)来进行搜索,并从结果中找到文件名、行号等信息。注意:在 Windows 上如果 Vim 没找到 grep 的话,它会调用 Windows 自带的 findstr 命令行工具;为了获得跟其他平台相同的体验和跟 Vim 本身相似的正则表达式,我强烈推荐你在 Windows 上也安装 grep 工具。我们上一讲讲到的搜索模式,大部分在 grep 里可以原封不动地使用,尤其是对 \?、+、\< 和 \> 的解释。考虑到 vi 源自 Bill Joy,grep 源自 Ken Thompson,两者的老祖宗都是 ed,这自然也不是件令人意外的事。
如果使用 grep 命令的话,我们的命令大致如下所示:
:grep '要查找的符号' 文件名列表当然,grep 支持的复杂参数我们都可以用上。比如,下面的命令可以在所有的子目录里查找用到了 printf 的 .c 和 .h 文件:
:grep -R --include='*.c' --include='*.h' '\<printf\>' .小提示:在查看搜索结果时,适时使用 zz(或 zt、zb)重定位当前行在屏幕上的位置,可能可以更清晰地查看前后的相关代码。
8.12 异步支持
上面这些命令,都有一个缺点:在执行过程中你干不了其他事情。幸好,在 Vim 8 支持异步任务之后,这个问题也得到了解决。我们利用一个插件,就可以获得类似在一些集成开发环境中的体验,在构建过程中仍然可以继续做其他事情。
我们首先需要安装一个插件 asyncrun.vim。跟前面类似,假设我们使用 minpac 的话,我们需要在 vimrc 中的合适位置加入下面这行:
call minpac#add('skywind3000/asyncrun.vim')我们还需要一个跟 :make 相似的命令。我使用下面的命令定义(今天我们重点看使用,定义的细节就不讨论了):
" 和 asyncrun 一起用的异步 make 命令
command! -bang -nargs=* -complete=file Make AsyncRun -program=make @ <args>这个命令同样会使用 makeprg 选项。不过,还有个问题是默认情况下屏幕上看不到执行过程的信息。我们可以让 asyncrun 在执行命令时立即打开 quickfix 窗口:
" 异步运行命令时打开 quickfix 窗口,高度为 10 行
let g:asyncrun_open = 10对于 C/C++ 程序员来讲,启动和停止构建应该是一个很频繁的操作吧。所以,我也给它分配了一个快捷键:
" 映射按键来快速启停构建
nnoremap <F5> :if g:asyncrun_status != 'running'<bar>
\if &modifiable<bar>
\update<bar>
\endif<bar>
\exec 'Make'<bar>
\else<bar>
\AsyncStop<bar>
\endif<CR>上面的代码通过判断异步任务状态和窗口是否可修改,还会自动执行保存文件和终止构建等操作。

8.13 查看文档
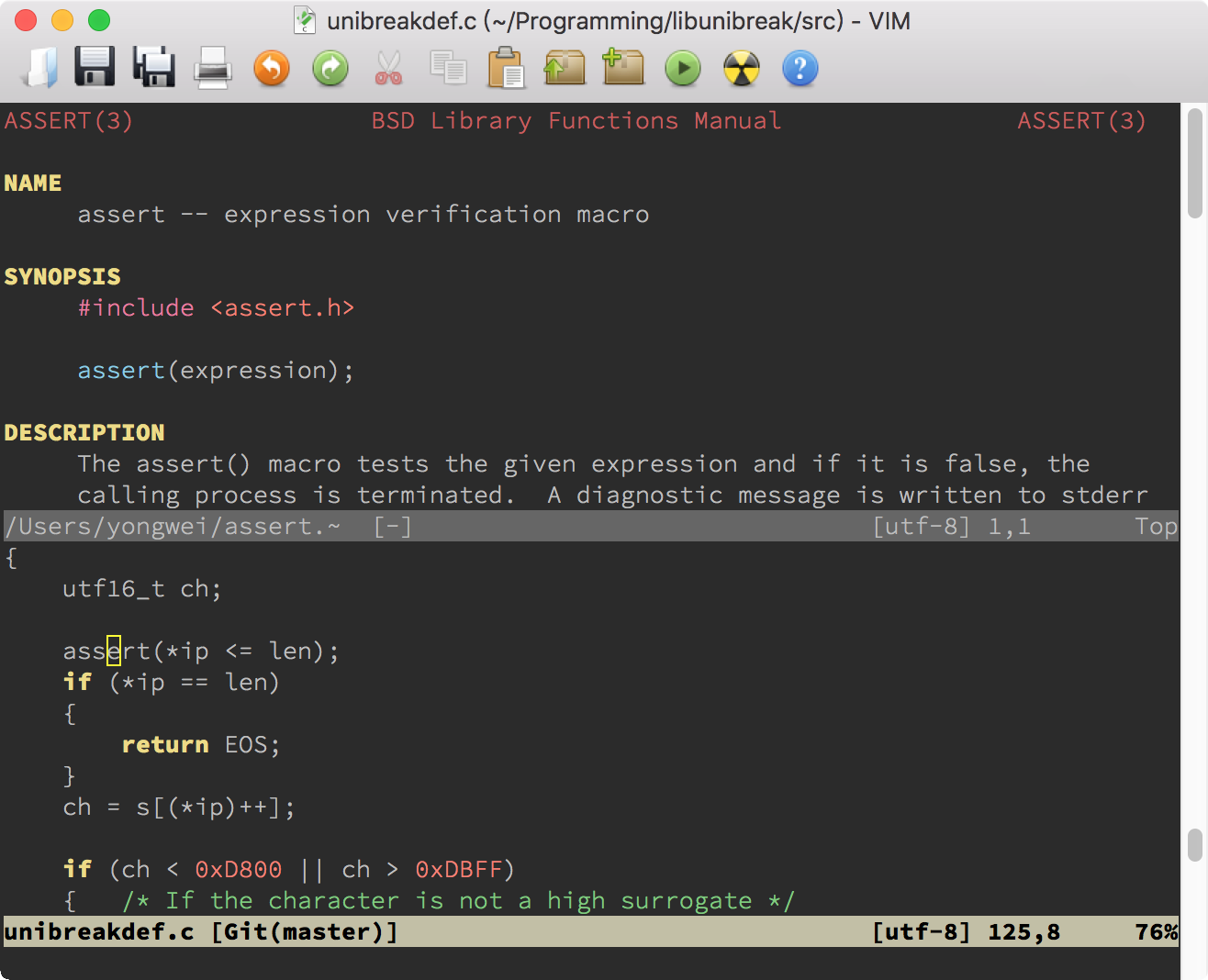
Vim 里快捷键 K 可以用来查看光标下关键字的相关文档。它的行为是由选项 keywordprg(:help ‘keywordprg’)控制的。这个选项的缺省值是 man,表示查看 Unix 的 man 手册,很多文件类型插件会对当前缓冲区设置一个更合适的值,如 Vim 脚本就会直接把行为改成调用 :help 命令。
查看 man 手册的默认行为通常只在终端工作良好,而在图形界面 Vim 里会出现显示问题。我推荐使用 Vim 内置的 man 插件,并把全局的 keywordprg 设成 :Man:
" 启用 man 插件
source $VIMRUNTIME/ftplugin/man.vim
set keywordprg=:Man这样,我们在使用 K 命令时,将在 Vim 里直接打开 man 手册,效果如下所示:
09|七大常用技巧:让编辑效率再上一个台阶
9.1 自动完成
Vim 内置有自动完成功能。最基本的自动完成功能有两种:
- 基于当前文件文本的自动完成
- 基于文件系统的自动完成
我们先说基于当前文件文本的自动完成。在当前文件里,或当前文件用 #include(C 类语言的情况)包含的文件里包含某个关键字时,你可以输入头若干个字母并按下 <CP>(表示 previous)或 <C-N>(表示 next)来进行自动完成。这两者的区别是,<C-P>是从当前位置往前找,而 <C-N> 是从当前位置往后找。当只有一个匹配项时,Vim 直接给出完成结果,再次按下 <C-P> 或 <C-N> 则取消自动完成。当存在多个匹配项时,Vim 会根据搜索顺序给出匹配项列表并使用第一个匹配项;再次按下 <C-P> 或 <C-N> 则可以在列表里进行选择。
Vim 的缺省选项能帮你在 Unix 系统上找到系统的头文件,利用里面出现的关键字来完成。想要在其他语言或平台里找到当前文件”包含”的文件里的关键字,请参考下列选项帮助:

我们再看一下基于文件系统的自动完成。当你在插入模式下输入一个绝对路径或者当前目录下的文件 / 目录名称的一部分时,你可以使用 <C-X><C-F> 来启动文件自动完成。在此之后,操作就和前面一样了,你可以使用 <C-P> 和 <C-N> 在匹配项中跳转和取消。
Vim 里还有其他一些以 <C-X> 开始的自动完成功能。比如,你可以用 <C-X><C-K> 从配置的词典中选择合适的单词,可以用 <C-X><C-O> 进行”代码自动完成”。但这些功能要么不常用,要么在缺省配置下工作得并不好。
最后,要注意任何自动完成功能都可能会重复你的错误。如果你一开始拼错了,后面又拼对了,很可能会发现前面的错误。而一旦使用自动完成,你要是一开始就拼错了,后面可能就会不断重复之前的错误。
9.2 文本目标跳转
当光标下的文件名可以在 path 选项标识的目录下找到时,我们可以很方便地跳转过去。你需要的是正常模式命令 gf 和 <C-W>f。前者是直接跳转到文件(理解为”goto file”),后者则会打开一个新窗口(window),在新窗口里打开该文件。

如果光标下面是一个链接,或者非文本文件,。这时候,最简单的解决方式是使用 netrw 插件提供的 gx 命令。它的缺省行为是使用操作系统提供的机制来打开光标下的文件或链接。
比较让人伤心的是,最新版本的 netrw 插件在打开链接时的行为不正常。这个问题已经报告有一年了,还没有解决。作为临时方案,我在 Vim 配置的目录放了一个可以工作的老版本,你可以把这个文件复制到你的 Vim 配置目录下的 plugin 子目录下来绕过这个问题。此外,gx 只适合本机,不适合在远程连接上使用。
9.3 Vim 寄存器 / 剪贴板
Vim 的删除和复制命令(如 d 和 y)会把内容存起来,以供粘贴命令(如p 和 P)使用。
估计你已经知道的是,Vim 把要粘贴的内容存在 Vim 内部的”寄存器”(register)里,而非系统的剪贴板。你不一定知道的是,Vim 里的寄存器有好多个。事实上,Vim 有超过 40 个不同的寄存器!我们挨个来看一下:
- 首先是无名寄存器。当操作没有用 “ 加寄存器名称指定寄存器时,我们默认使用无名寄存器。不过,我们仍可以使用 “” 来指定使用无名寄存器,也就是说,””p 和 p 效果相同。
- 其次是数字寄存器 0 到 9。0 号寄存器中放的永远是最近一次复制(yank)的内容。这和无名寄存器很不一样,它里面放的是最近操作的结果,也包括了 d、x、c 等命令,特别是包括了粘贴命令所替换的内容。1 到 9 号寄存器中放的则是上一次、倒数第二次、直到倒数第九次被删除或修改命令删除的文本。在做少量的用一个名字替换另一个名字、而又懒得使用替换命令时,”0p 是一个接近图形界面里的粘贴命令的常用选择。
- 然后有小删除寄存器 -。上面我说得不全,删除内容进入 1 到 9 号寄存器的前提条件是被删除的内容至少有一行,或者使用了移动命令 %、(、)、`、/、?、n、N、{ 和 } 进行删除。否则,删除的内容只会进入 - 而不是 1 到 9 号寄存器。
- 常用的有名寄存器 a 到 z。这些寄存器仅在用户手工指定时才会使用,内容在下一次打开 Vim 时仍然存在。比如,我们可以用 “ayy 代替 yy 把当前行复制到 a 寄存器中,以后就一直可以用 “ap 来进行粘贴了,直到 a 寄存器的内容被替换为止。
- 不常用的特殊寄存器 . 、:、# 和 %。这些相对来说不那么常用,请自行查看帮助文件 :help “. 等。
- 黑洞寄存器 _。专门用来删除,目的就是不要影响无名寄存器的内容。
- 搜索寄存器 /。存放是上一次搜索使用的模式。
- 表达式寄存器 =。可以把 Vim 表达式估值的结果作为寄存器的内容。
- 最后是图形界面剪贴板寄存器
+、*和~。一般而言,+ 寄存器代表操作系统的剪贴板,和图形界面应用程序交互用这个就好;你用图形界面 Vim 菜单里的拷贝和粘贴访问的也是系统剪贴板。*和~在 X11 和 GTK 环境下有一些特殊用途,我们目前就不展开了。想深入钻研的话,可以查看帮助文档 :help “+、:help “* 和 :help “~。
寄存器在正常模式下可以用 d、y、p 等命令来访问,你现在应当已经很清楚了。它们在插入模式和命令行模式下也可以用 C-R 加寄存器名来访问,这经常也会省去你很多打字的麻烦。
9.4 常用的寄存器使用场景
如果要交换两行内容,可以直接利用删除命令会把删除的内容放到无名寄存器这个特性。我们在第一行上面按下 dd,然后直接按 p 粘贴即可。
如果要交换两处文本内容,可以类似地使用删除和粘贴替换都会把内容放到无名寄存器这个特性。我们选中第一处文本,按下 d 进行删除;然后选中第二处文本,按下 p 进行粘贴;最后回到第一处文本的原来位置,使用 P 把文本粘贴回去即可。

如果要少量修改某一变量名称(多的话使用 :s 替换命令更合适),可以把光标移到变量名称上,用 * 进行开启自动搜索,然后编辑变量名称到合适;随后复制新的变量名称,反复使用 n 命令搜索,并用 ve"0p 进行替换即可。
当然,反复打 ve"0p 真的会感觉这个命令有点长。鉴于这个组合键使用的频度还挺高,我觉得映射一个更短的按键比较好,我的选择是 \v,同时,我做了点更通用的处理:
" 替换光标下单词的键映射
nnoremap <Leader>v viw"0p
vnoremap <Leader>v "0p关于 <Leader> 的含义,可查看帮助文档 :help <Leader>。

9.5 宏的录制和播放
Vim 里可以用 q 把动作记录到寄存器里,然后使用 @ 来播放这些动作。上面这个变量更名,如果用宏来做也可以:
- 用 * 开启搜索
- 键入 qa 开始录制宏到 a 寄存器;当然我们可以使用其他寄存器,只要被录制的命令不会修改这个寄存器即可,所以一般使用 a 到 z 这 26 个有名寄存器
- 键入 n 进行搜索;先行搜索的目的是,如果搜索不到内容,命令出错,宏的剩余部分就不会被执行
- 键入
eabar<Esc>把 foo 修改为 foobar - 键入 q 结束宏录制
- 键入 @a 播放录制的宏
- 重复上一步直到 Vim 报告找不到 foo 为止

关于宏的进一步细节可以查看帮助文件(:help q)。
9.6 文本对象增强
如果你安装了 tpope/vim-surround 插件,你可以实现下面这些功能:
- 在一个单词的外面加上引号,如把 word 变成 “word”,可以使用命令 ysiw”
- 把一个单词的外面的双引号变成单引号(有强迫症的 Python 程序员很可能有这样的需求),如把 “word” 变成 ‘word’,可以使用命令 cs”‘
- 把外面的引号或括号变成 HTML 标签也没有问题,如把 [my choice] 变成
<em>my choice</em>,可以使用命令cs[<em> - 可视模式也有类似的命令,如可以在选中 my choice 后,输入
S<em>把文本变成<em>my choice</em> - 当然,你也可以把加上的包围符号移除,命令是 ds 后面跟包围符号,如
ds"可以移除外围的双引号;要移除 HTML 标签则使用 t 来表达,即使用dst来移除文本外面的第一个 HTML 标签
注意 Vim 命令 . 只能用来重复 Vim 的内置命令,而不能用来重复上面这样的用户自定义命令。为了解决这个问题,我也会安装 tpope/vim-repeat 插件,使得重复命令对上面样的情况依然能够生效。

9.7 撤销树
Vim 不仅支持多级撤销,而且有撤销树的概念。利用撤销树,你可以转回到编辑中的任何一个历史状态。不过,问题是,Vim 用来管理撤销树的命令不那么直观。在使用撤销树的图形化插件之前,我自己也没有把相关的命令真正用好。
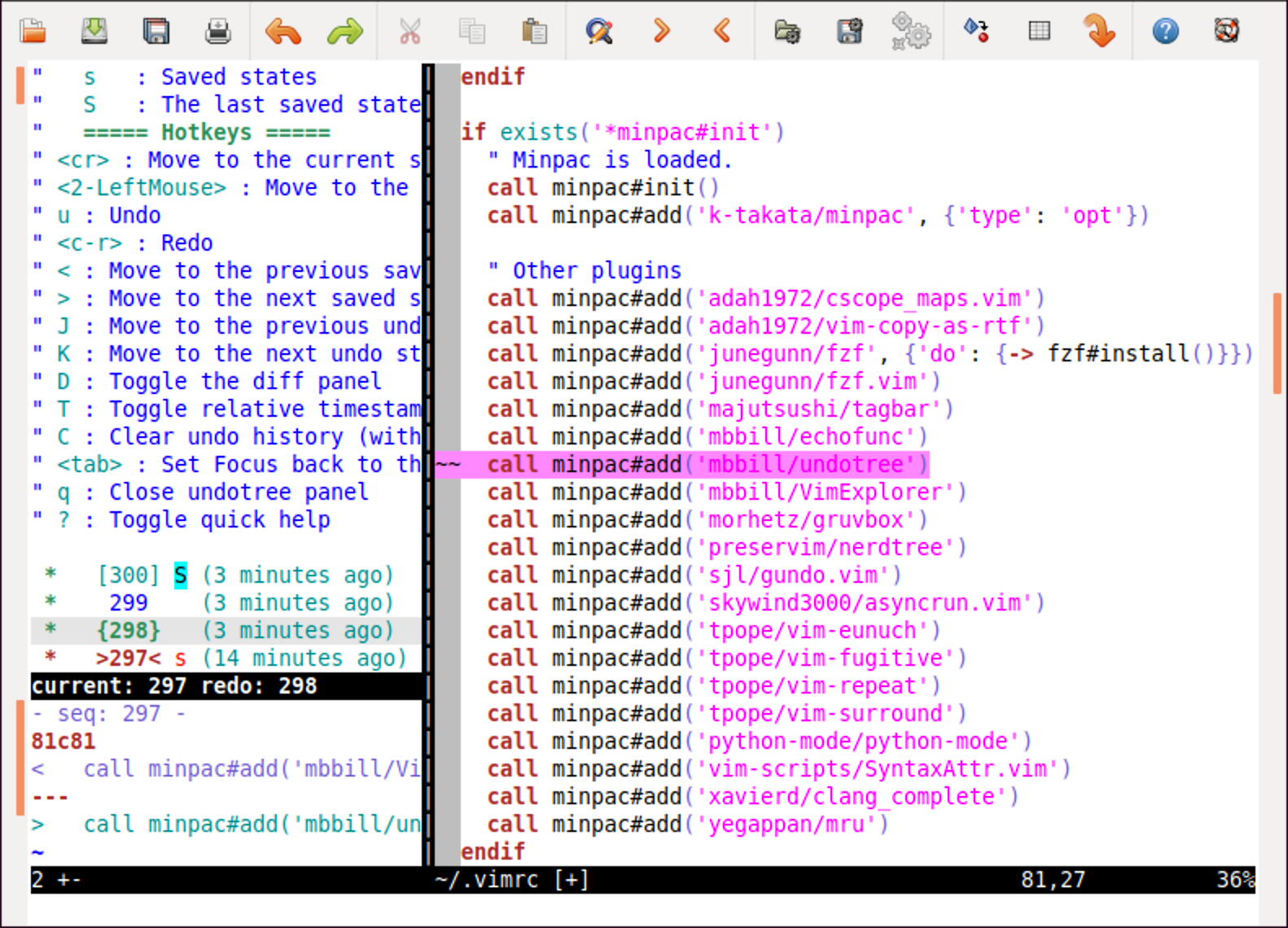
著名的撤销树插件我知道两个,一个是 mbbill/undotree,一个是 sjl/gundo.vim。两者功能相似,界面风格和快捷键有所不同。鉴于 undotree 功能更加丰富,我就以它为例来介绍一下。
从下图中可以看到,undotree 可以展示完整修改历史。你可以用 J 和 K 在历史中跳转,左下角的预览窗口中就会显示修改的内容,右侧文件直接会回到相应的历史状态,并加亮最近的那次修改。一旦用上这个插件,就真的回不到没有这个插件的环境了。
另外需要稍加注意的一点是,一旦这个文件在其他编辑器里修改了,Vim 发现内容对不上,就无法保留编辑的历史。有一个绕过方法是,当你需要使用其他编辑器修改前,确保你在 Vim 里打开了该文件并且所有修改已保存;这样,在修改完成之后,只要在 Vim 里用 :e 命令重新载入该文件,Vim 就可以把外部的修改也保存在撤销历史记录里,保留完整的编辑历史。此外要注意的是,最后得在 Vim 里使用 :w 存盘一次,才能把编辑历史真正保存下来——即使你在 Vim 里没有进行任何修改,也需要这样做一下才能保存修改的历史。
9.8 对当前缓冲区的更名和移动
你肯定遇见过文件需要更名或者移动吧。这当然很简单,你可以通过图形界面或命令行进行操作。但这样操作之后,有一个问题是 Vim 的撤销历史跟文件就再也对不上了,你也没法再继续撤销更名或移动前的编辑操作了。有一个 Vim 插件,也是 Tim Pope 写的 tpope/vim-eunuch,可以解决这个问题。
事实上,这个插件的功能远不止更名和移动。它实际上是把 Unix 的很多命令行工具搬到了 Vim 里(比较一下 Unix 和 eunuch 的发音你就知道这个插件的名字是什么意思了)。对我来说,最重要的就是它提供的 :Rename 和 :Move 命令,后面跟的参数就是新的名字或路径。这样操作之后,以后再打开这个更名或移动后的文件,仍然能够访问它的一切编辑历史。
9.9 模糊文件查找
使用 NERDTree 的话,你可以通过浏览目录来打开文件。这种方式,对于你知道文件在哪个目录下、但不知道文件名的时候特别有用。另外一种可能的情况是,你知道文件名或其中的关键部分,但你不知道或不关心文件在哪里。这种情况下,Fzf 的模糊匹配就非常有用了。我们先来看一下动画演示,有一个初步的印象:

从动画可以看到,插件使用的是模糊匹配的方式,可以动态展示搜索的结果,并能直接预览当前选中的文件内容(在窗口足够宽的情况下)。因而这种方式不仅快,而且非常直观。
跟其他插件不同的是,fzf.vim 插件依赖于 fzf 命令行工具。在 fzf 的页面上列出了具体安装方式,支持各个平台。
在安装了 fzf 后(可以执行 fzf 来验证一下,它会枚举当前目录下的所有文件,并在你输入字符时缩小匹配;按 <CR> 选择文件,按 <Esc> 取消选择),就可以安装插件了。使用minpac 的话,我们需要在 vimrc 中加入下面两行:
call minpac#add('junegunn/fzf', {'do': {-> fzf#install()}})
call minpac#add('junegunn/fzf.vim')在安装完成之后,你就可以像我前面展示的那样使用 :Files 命令了。更多高级用法可以查看 fzf.vim 的页面。
这个插件可以跟其他工具进一步配合。如果你安装了 ripgrep 和 bat 的话,可以获得更好的效果。动图中右下角文件预览的语法加亮的效果就依赖于系统里有 bat。如果你装了 ripgrep 的话,可以考虑设置下面的环境变量:
export FZF_DEFAULT_COMMAND='rg --files --sortr modified'这样的话,fzf 可以利用 ripgrep 来自动过滤掉被 Git 忽略的文件、隐藏文件、二进制文件等程序员通常不关心的内容,并将结果以修改时间倒排,确保最新修改的文件在最下面,大大提高了迅速找到你需要的文件的概率。
10|代码重构实验:在实战中提高编辑熟练度
11|文本的细节:关于字符、编码、行你所需要知道的一切
11.1 什么是文本
从二元论的角度看,计算机文件可以分为文本文件(text file)和二进制文件(binary file),但这个分法并没有对文本做出清晰的界定。从实用的角度,我们大致可以这么区分:
- 文本文件里存放的是用行结束符(EOL,即 End of Line)隔开的文本行,二进制文件里则没有这样的明确分隔符
- 文本文件可以通过简单、直接的算法转换为人眼能够识别的文字,而二进制文件里含有不能简单转化为文字的信息
事实上,计算机判定一个文件是不是文本文件,并不是件容易的事情,特别是在这个文件含有非 ASCII 字符的时候。
从实用的角度,我对文本文件的判定通常是:
一个文本文件可以直接输出到终端上,或在简单的编码转换后输出到终端上,显示为一行或多行可识别的字符,并且不包含乱码。
想要理解这句话,你得先知道什么是字符?什么是编码?什么是行和行结束符?
11.2 字符和编码
从文件系统的角度看,文件的内容就是一堆比特(bit)而已。把比特对应到字符的方法,就是编码(encoding)。在目前的主流操作系统里,通常八比特是一个基本单位,也就是字节(byte)。最基本的编码方式,就是把一个字节对应到一个字符。
目前的大部分编码方式,在 0-127 的范围里,字节值和字符的对应关系是基本相同的。除了个别字符外,编码的基本方式都和 ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)兼容,如下图所示:

注意,头 32 个字符和最后一个字符是控制字符,其中大部分现在已经很少有人使用了,但还有一些我们今天仍然会在不同的场合遇到,如马上就会讨论的 LF 和 CR。
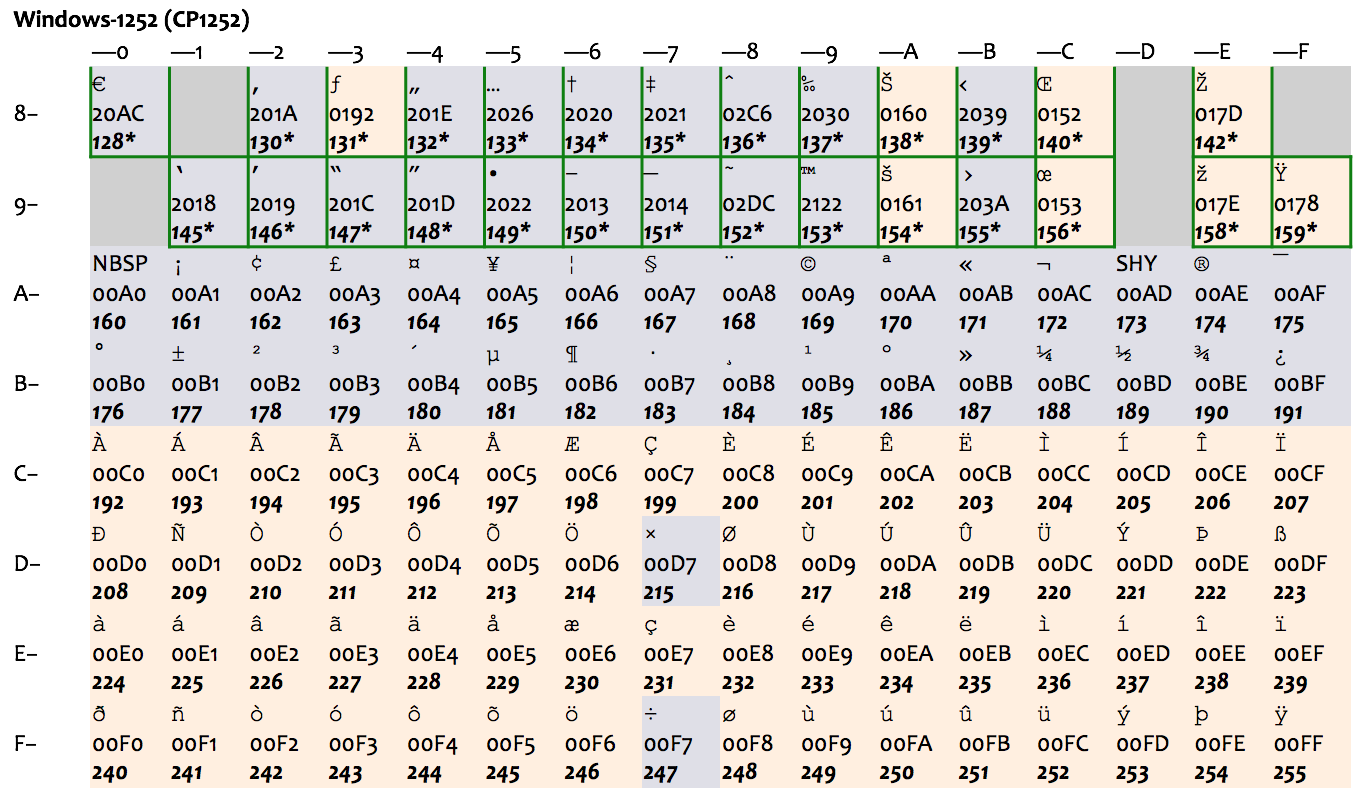
ASCII 是美国标准,里面只有基本的拉丁字母,对其他国家来讲可能就不合适。比如对欧洲国家来说,ASCII 既没有带变音符的拉丁字母(如 é 和 ä ),也不支持像希腊字母(如α、β、γ)、西里尔字母(如 Пушкин)这样的其他欧洲文字,使用起来很不方便。很多其他编码方式使用了 128-255 的字节值范围作为扩展,总共最多是 256 个字符,一次允许一套方式生效,称之为一个代码页(code page)。这种做法,只能适用于文字相近、且字符数不多的国家。比如,下图表示的 ISO-8859-1(也称作 Latin-1)和后面的 Windows 扩展代码页 1252(下图中绿框部分为 Windows 的扩展),就只能适用于西欧国家。
最早的中文字符集标准是 1980 年的国标 GB2312,其中收录了 6763 个常用汉字和 682 个其他符号。至于我们平时用到的编码 GB2312,它更准确的名字其实是 EUC-CN,是一种与 ASCII 兼容的编码方式。它用单字节表示 ASCII 字符而用双字节表示 GB2312 中的字符;由于 GB2312 中本身也含有 ASCII 中包含的字符,在使用中逐渐就形成了”半角”和”全角”的区别。
国标字符集后面又有扩展,这个扩展后的字符集就是 GBK,是中文版 Windows 使用的标准编码方式。GB2312 和 GBK 所占用的编码位置可以参看下面的图(由 John M. Długosz 为 Wikipedia 绘制):
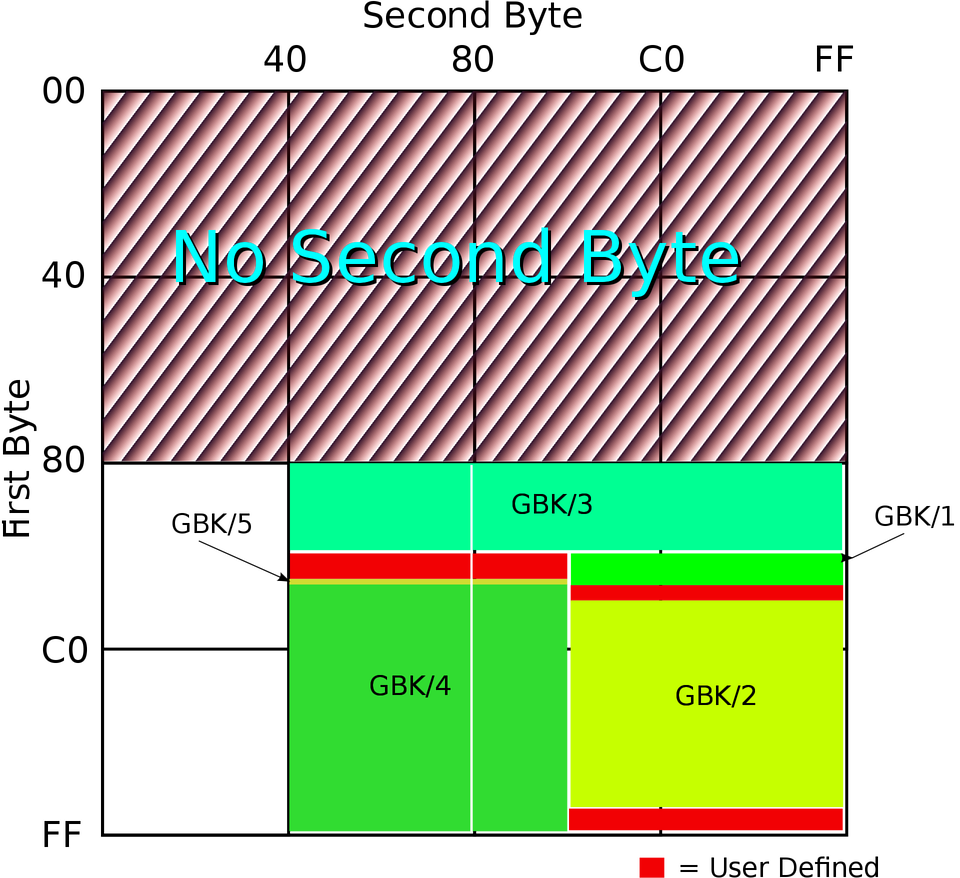
图中 GBK/1 和 GBK/2 为 GB2312 中已经定义的区域,其他的则是 GBK 后面添加的字符,总共定义了两万多个编码点,支持了绝大部分现代汉语中还在使用的字。
显然,多个不同的编码方式是不利于信息交换的。我们在打开文本文件时看到的”乱码”,最常见的情况就是文件的编码和打开文件的工具以为的编码不同。毕竟,只要出现了非 ASCII 字符,解释方式就多了。对我们来说,常见的情况是 Latin-1/Windows-1252(西欧文字)、GBK(简体中文)、Big5(繁体中文),今天还增加了 UTF-8。
UTF-8 的全称是 8-bit Unicode Transformation Format,8 比特的 Unicode 转换格式。Unicode 自发明伊始,就是为了统一编码问题,但它的最早编码方式,UCS-2,存在两个重大问题:
- 和 ASCII 不兼容,不能在现有软件和文件系统中直接使用
- 在储存 ASCII 为主的字符时,存在一字节变两字节的空间浪费
Ken Thompson 在 1992 年和 Rob Pike(罗勃 · 派克)一起发明了 UTF-8,解决了这两个问题(牛人就是牛人啊)。到了今天,UTF-8 已经成了互联网和 Unix 世界里文本文件(含 HTML 和 XHTML)的主流编码方式。但是,Windows 下的文本文件,由于历史原因,可能还大量使用着传统的编码方式(很错误地被叫做 ANSI);对于中文 Windows,这个传统编码就是 GBK 了。
抛开编码方式的细节(从网上你可以找到足够多的关于 Unicode 和 UTF-8 的资料),我们需要牢牢记住的是,UTF-8 是 Unicode 里最重要的编码方式,可以把一到四字节长度的字节序列映射成为一个 Unicode 字符。目前我们使用的任何字符都可以用 UTF-8 表示,因而 UTF-8 是我们在 Vim 中使用的内部编码(选项 encoding)。我们在第 2 讲中给出 fileencodings 选项设置,就是为了在读写文件时把文件内容进行适当的转换。这个选项表示的是自动检测使用的编码;而在文件被 Vim 载入后,文件的编码会出现在选项 fileencoding 里。如果 fileencoding 选项为空,则表示文件保存时不做任何转换。
11.3 字符和字形
Unicode 设计时的一个决定,目前看起来有点短视,那就是对中日韩文字中使用到的汉字进行了”统一”。如果字源相同,它们在 Unicode 中就只占据一个编码点。于是,一个字符可能就有多个字形。这个问题,我在第 2 讲中已经展示过了,它也是我们可能需要在图形界面 Vim 中单独设置宽字符字体(guifontwide)的原因。

跟中文字符集中”半角”和”全角”的概念有点像,Unicode 中也有字宽的概念。和简单的半角与全角的区别不同,Unicode 里除了窄字符和宽字符,还有模糊宽度(ambiguous width)字符。这些字符的宽度根据上下文而定:在东亚文字里一般是宽字符,而在西方文字里一般是窄字符。最常用的模糊宽度字符有(”U+”后面跟十六进制数值是用来表示 Unicode 字符所占编码点数值的通常方法):
- U+00B0:「°」
- U+00B7:「·」
- U+00D7:「×」
- U+00F7:「÷」
- U+2014:「—」
- U+2018:「‘」
- U+2019:「’」
- U+201C:「“」
- U+201D:「”」
- U+2103:「℃」
对于某一特定字体,它们的宽度当然就是确定的;尤其使用变宽字体(大部分英文字体,不同字符宽度不同)时,如在极客时间的正文里,这个模糊宽度没有什么意义。对于使用等宽字体(程序员一般使用的字体,Vim 只能用等宽字体)的文本编辑器,到底是把这些字符显示成跟 ASCII 字符一样的”单”宽度,还是显示成跟汉字一样的”双”宽度,就是一个需要考虑的问题了。
稍微展开一点点,这个模糊宽度,在我们日常生活中还是造成了一点麻烦的。非常常见的一个排版错误,就是由于使用的软件(在中文 Windows 下的)的字体选择规则,西文中的 「’」误用了中文字体展示,导致这个符号展示出来的字间距过宽。一个相反的麻烦,是中文中写「·」希望两侧留空很足,但在另外一些环境下,永远优先选择西文的字体(如大部分的手机操作系统),导致需要手工两侧加空格才能有比较理想的排版效果……
扯远了,这些毕竟不是 Vim 的问题。Vim 里的解决方式是提供选项 ambiwidth,可以设为 single(默认值)或 double,表示 Vim 到底把这些字符的宽度当成是占一个字符还是两个字符,你想怎么样都可以。对于终端 Vim,由于 Vim 不能决定显示的字体,这个选项只能决定光标在这些字符上应当移动的列数,用户必须自己保证在终端里的设定和 Vim的设定是一致的;否则,可能导致眼睛看到的编辑位置和实际编辑位置不一致。虽然 macOS 的终端应用、Linux 的 GNOME Terminal 和 Windows 下的 PuTTY 都提供了如何处理模糊宽度字体的设定(关键字是”模糊”或”ambiguous”),但鉴于这些软件的字体选择策略,选择”宽”容易导致显示问题,所以我的建议是保留缺省的”窄”设定。
对于图形界面的 Vim,ambiwidth 选项同时也决定了显示这些模糊宽度字符是使用 guifont 选项还是 guifontwide 的设定。在这种情况下,把 ambiwidth 设成 double 才比较有意义:

修改 ambiwidth 主要影响的是一行的长度,而 Vim 具有根据行长来进行断行的功能。下面,我们先来看一下什么是行。
11.4 行
从 Vim 和 Unix 的角度看,一个文本文件由多行构成,每一行都以一个行结束符(EOL)结束。根据传统习惯,这个 EOL 在存盘时使用的字符是 LF,编码值是 10(U+000A)。
这只是 Unix 格式。常用的还有 DOS 格式(也包括了 Windows),以及老的 Mac 格式。
在 DOS 格式里,行尾就不只使用 LF 这一个字符了,在 LF 前面会多一个 CR,编码值为 13(U+000D)。这个用法的来源是以前的打字机,CR 表示机架归位(carriage return),LF 表示换行(line feed)。在使用 CR LF 作为行结束符的系统里,CR 只负责光标回到第一列,而 LF 负责光标向下一行。
老的 Mac 则使用单个 CR 字符作为行结束符,但苹果从 Mac OS X(2001 年)开始就使用了 Unix 风格的行结束符。所以,目前我们遇到的文本文件,应当都使用 LF 或 CR LF 作为行结束符了。这也是 Vim 的 fileformats 选项的意义:它的默认值通常是 unix,dos(Unix 环境下)或 dos,unix(Windows 环境下),即会自动检测 Unix 和 DOS 行尾;如果检测不到,则以第一个风格设置作为默认值。
fileencodings 有一个对应的文件相关的 fileencoding 选项,跟它一样,fileformats 也对应有一个文件相关的 fileformat 选项,表示当前文件的行尾风格。需要注意的是,如果一个文件里既有 LF 行尾、又有 CR LF 行尾的话,Vim 会把文件当成 Unix 格式,于是文件里会出现最后一个字符显示成”^M”(通常为蓝色,表示是控制字符,跟正常文本不同)的情况。如果你想保留这种行尾,那不需要做任何事情。但绝大多数情况下,你会希望把行尾统一成 Unix 风格或 DOS 风格。此时,你可以使用下面两种方法之一:
- 使用 :e ++ff=dos 命令强制以 DOS 行尾加载文件;此时文件的行尾格式是 dos。
- 使用 :%s/\r$// 命令删除行尾多余的 CR 字符;此时文件的行尾格式保持 unix 不变。
此外,再说明一下,Unix/Vim 的传统是任何一行都以行结束符终结,包括最后一行。使用 Vim 编辑的文本文件,最后一个字符通常是 LF(除非使用 Mac 行尾风格,则结尾是 CR)。Windows 上大部分文本编辑器则允许最后一行不以行结束符结束;这样的文件在Vim 打开时,Vim 默认会给出一个”[noeol]“的提示。在存盘时,Vim 则会自动在最后添加一个行结束符。
除了 Vim,很多 Unix 工具都会有类似的要求。比如,用于文件比对的命令行工具 diff,它在文件比对时如果输出下面的信息,就是表示文件之一没有用行尾结束符来结束:
\ No newline at end of file
11.5 断行
中文文本文件的行文习惯,通常是在一段之中不空行,一段结束了再换行。文本编辑器需要做的,是在行长超过屏幕宽度时自动折行。Vim 虽然也能在这种情况下自动折行,但 Vim 的更惯常用法是欧洲字母文字和源代码的做法,行长有一定的限制(根据惯例,常用值是 72、80、120),到了指定的行长则应当进行断行,用一个空行来明确表示分段。这也是 Markdown 格式里的标准做法:单个换行符仅相当于空格而已。(这个额外插入的空格就是中文一段之中不换行的原因。)
Vim 有一个文本宽度的选项 textwidth,表示插入文字时的最大行宽度。这个选项的全局默认值为 0,表示不进行限制,但 Vim 脚本可能会设置它,你也可以自己在 vimrc 等地方对其进行设置。我自己的设置是文件相关的,如:
au FileType changelog setlocal textwidth=76这个设置,加上对行进行格式化的命令 gq,可以让你方便地对(英文)文本进行整理。gq 命令跟 c、d 等命令一样,可以先在可视模式下选定文本,也可以在命令之后跟动作键。对于源代码,它的妙处在于它知道什么是注释,什么是列表:

如果对这些功能有兴趣的话,请查看相关的帮助: :help gq 和 :help fo-table。我这儿特别要指出的是:
- 要能够在无空格的中文之中断行,我们需要有 :set formatoptions+=m
- 选项 ambiwidth 会影响行宽的判断,如左右弯引号的宽度算 1 还算 2
- 在 Vim 8.2.0901 之前,Vim 断行时不考虑中文标点符号的规则;要使用 gq 对中文文本断行,最好升级到这个版本或更高版本
11.6 编辑二进制文件
Vim 有个 binary 选项和一个 -b 命令行参数。当你通过 -b 命令行参数,或 :e ++binary … 命令来打开文件时,binary 选项会自动被设置(用户不应该手动设置该选项)。这个选项保证了,Vim 在读取和存储文件时,不会做会影响文件内容的转换和修改。
不过,即使有这个选项,二进制文件打开后仍然是一堆乱码,这当然是正常的。你除了可以在里面搜索文本之外,还可以利用 Vim 的 Tools(工具)菜单下的”Convert to HEX”(转换成十六进制)和”Convert Back”(转换回)两项,来对二进制文件进行编辑。下面的两张图显示了打开二进制文件后的样子和使用了”Convert to HEX”后的样子:
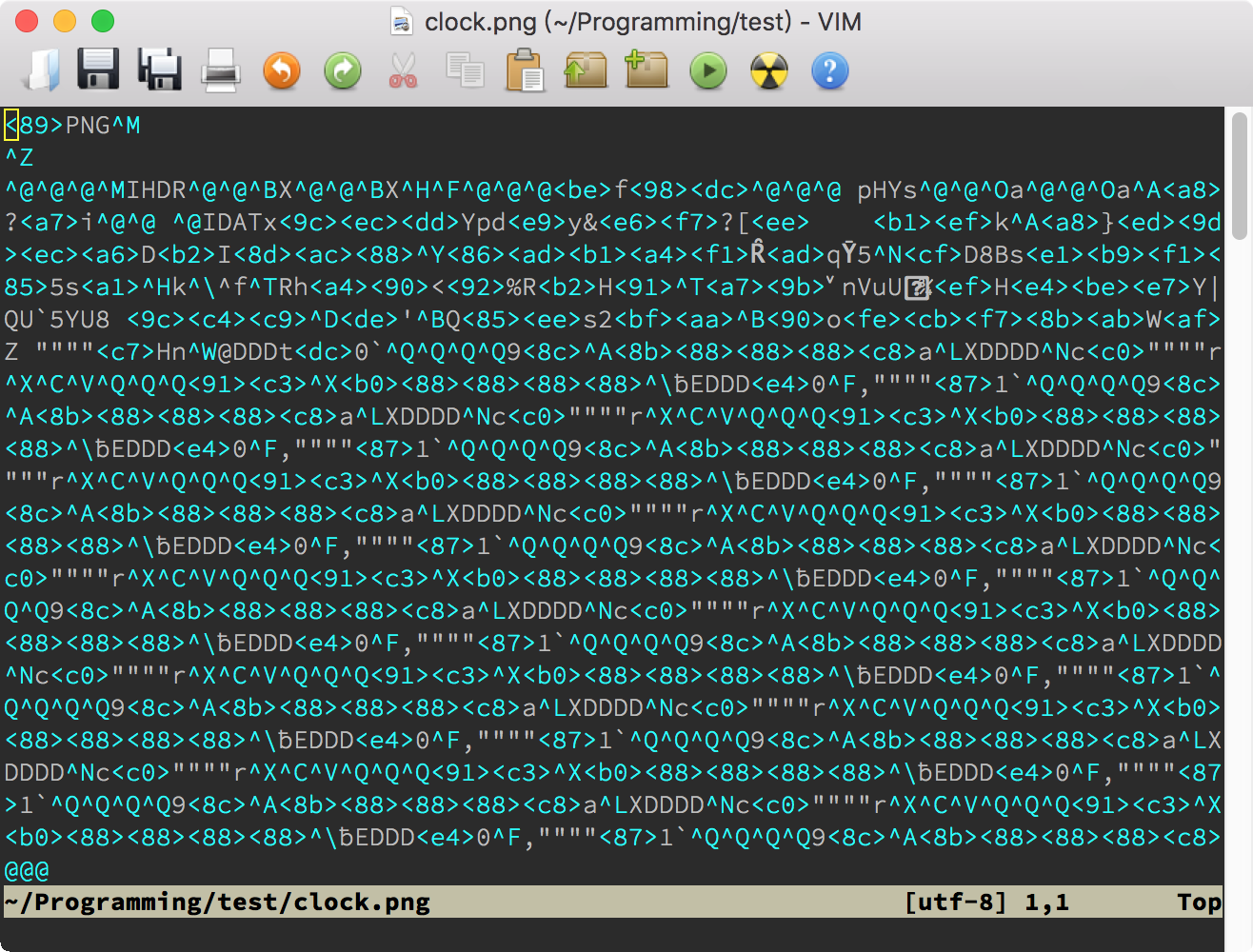
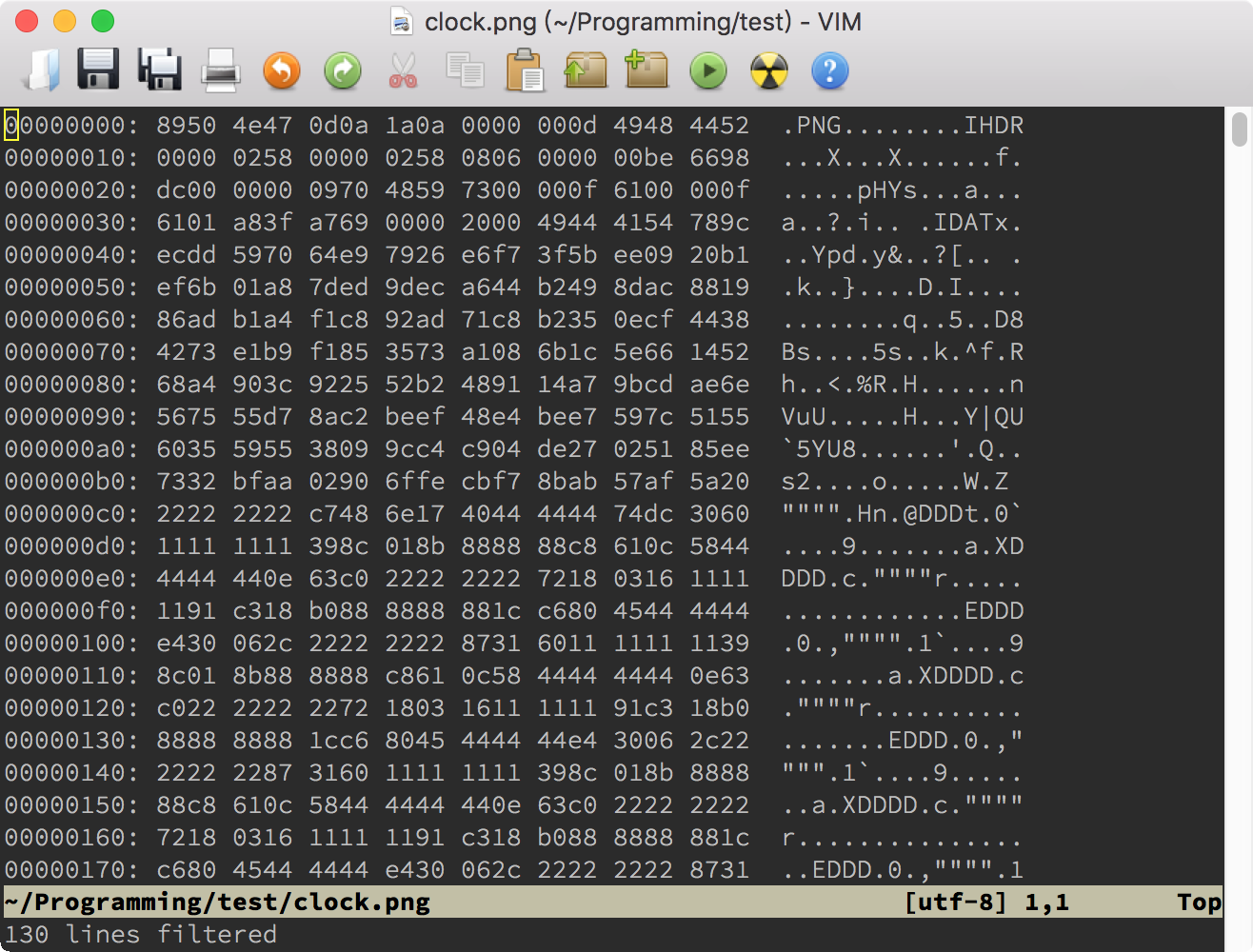
不管你是要检查文件中的具体字节内容,还是要修改某个字节,HEX 格式都更方便一些。当然,如果你要把修改写回硬盘的话,一定要先使用”Tools > Convert Back”。
要是你使用的不是图形界面,菜单里的这两个命令可以用 :%!xxd 和 :%!xxd -r 来手工替代。
12|语法加亮和配色方案:颜即正义
12.1 语法加亮
Vim 的语法加亮依靠的是在 syntax 目录下的运行支持文件。今天,我就通过例子给你解说一下,Vim 里如何实现语法加亮,然后语法加亮又如何映射到屏幕上的颜色和字体。
我们先来看一个比较简单的例子,xxd。
xxd 它是一个把二进制文件转换成地址加十六进制数值再加可读 ASCII 文本的工具,它的输出格式在 Vim 里也被称作 xxd。不过,在用菜单项或 :%!xxd 命令转换之后,Vim 并不会自动使用 xxd 格式。要应用 xxd 格式的语法加亮,我们需要使用自动命令(可以参考 :help using-xxd),或者手工使用命令 :setf xxd。下图是对上次的二进制文件使用了 xxd 语法加亮的效果:
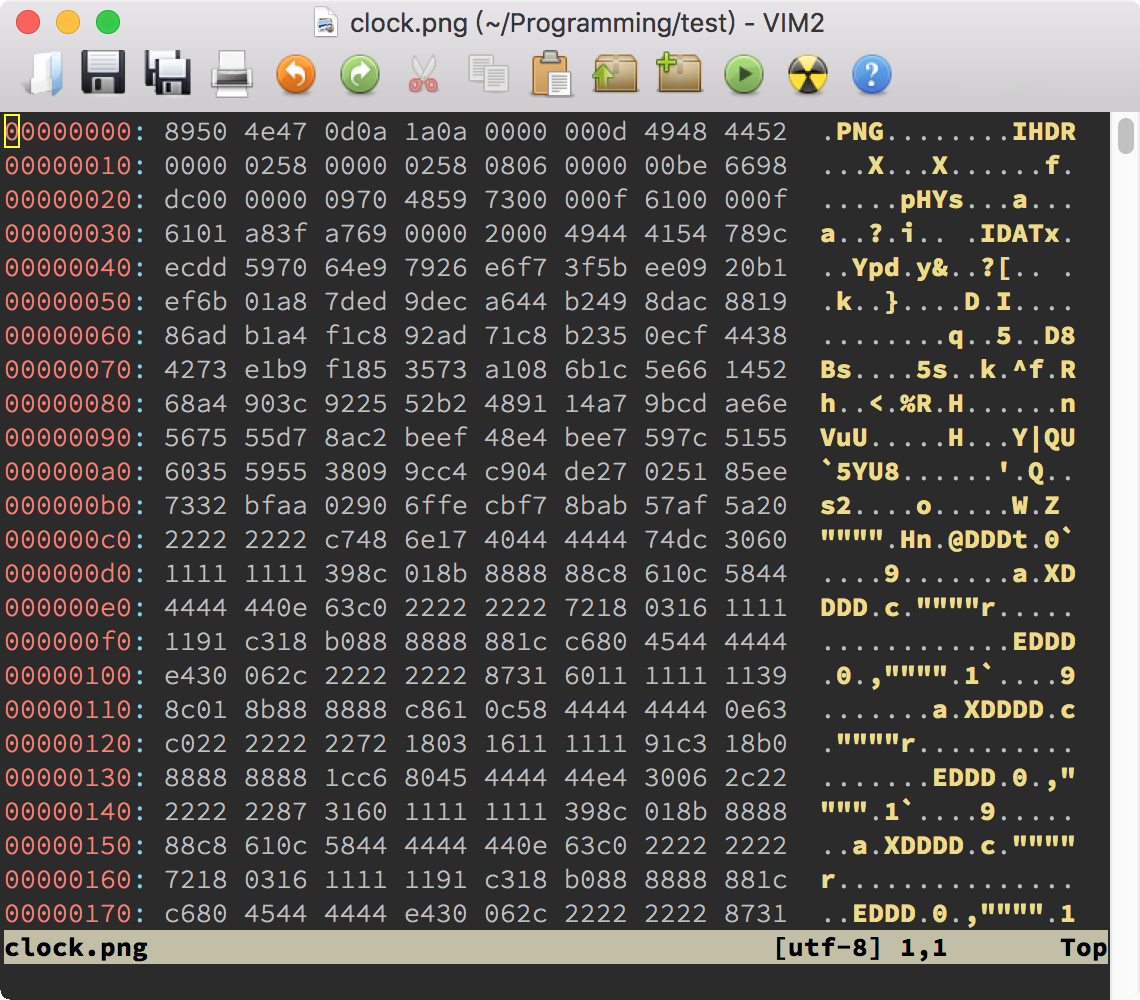
这个格式的语法加亮足够简单,我们就拿它来分析一下。不过,我有个小建议,你在看具体的语法加亮代码前,先花几秒钟的时间看一下图,自己分析一下里面有几种不同的语法加亮效果。
下面我们就来逐步看一下 syntax/xxd.vim 的内容。首先是开头和结尾部分:
" quit when a syntax file was already loaded
if exists("b:current_syntax")
finish
endif
…
let b:current_syntax = "xxd"
" vim: ts=4最后一行的模式行,设定了这个文件使用的 tab 宽度。剩余部分基本上算是语法文件的固定格式了,有一个检查缓冲区变量(使用前缀 b:)、防止语法文件重复载入的条件判断,并在结尾设定这个缓冲区变量为语法的名称。
剩余部分可以分为两段。第一段是语法匹配:
syn match xxdAddress "^[0-9a-f]\+:" contains=xxdSep
syn match xxdSep contained ":"
syn match xxdAscii " .\{,16\}\r\=$"hs=s+2 contains=xxdDot
syn match xxdDot contained "[.\r]"这儿定义了 4 种不同的”语法项目”,其中 1、2 和 3、4 还互相有包含(”contains”)和被包含(”contained”)的关系。
- xxdAddress。它是地址匹配,所以匹配条件是从行首开始的一个或更多的十六进制字符后面跟一个冒号。
- xxdSep。它是分隔符,仅匹配 xxdAddress 中的冒号部分,也算是地址的一部分。
- xxdAscii。它是右边的 ASCII 字符部分,条件是两个空格后面跟最多 16 个字符,然后是可选的 CR 字符(\= 和 \? 效果相同),然后必须是一行结束。
- xxdDot。它是对”.”和 CR 字符的特殊匹配,可以留意一下上面图里”.”和其他字符的加亮效果的不同之处。同样,这个句点也属于 ASCII 字符部分。
上面的正则表达式都比较简单,唯一之前没出现过的是第 3 个正则表达式后面的 hs=s+2:它的含义是语法加亮的起始位置是模式匹配部分的开始位置再加 2(可查看 :help :syn-pattern-offset),这是在语法加亮文件里的常用特殊语法。
上面的代码可以从 xxd 格式的内容中找出 4 种不同的语法格式。如何展示这些语法,就要看下面的第二段代码了:
" Define the default highlighting.
if !exists("skip_xxd_syntax_inits")
hi def link xxdAddress Constant
hi def link xxdSep Identifier
hi def link xxdAscii Statement
endif外面的条件语句不是惯用法,我们可以忽略。里面重要的是三个 hi def link 语句,拼写完整的话是 highlight default link(可参见帮助 :help :highlightlink)。这三个语句建立了默认的语法加亮链接组,也就是,在用户没有自己在 vimrc 配置文件中使用 highlight link 来修改语法加亮时,默认的语法项目和加亮组之间的关系。目前,地址 xxdAddress 使用常数 Constant 的加亮方式,冒号分隔符 xxdSep 使用标识符 Identifier 的加亮方式,ASCII 文本 xxdAscii 使用语句 Statement 的加亮方式。
那 xxdDot 到哪儿去了呢?答案是,它没有加亮组,因为我们不需要对其进行特殊加亮。虽然 Vim 会认出它使用了特殊的语法格式,在显示上它和中间的十六进制数值一样,没有任何语法加亮效果。
Constant、Identifier、Statement 这些加亮组,又应该以何种方式展示呢?这就是配色方案要做的事情了。如果说语法加亮是逻辑问题的话,那配色方案就是个审美问题。你要个性化的话,就靠配色方案了。
12.2 配色方案
类似地,配色方案里包含的也是一些模板语句加上色彩的定义。比如,在配色方案 koehler 里,跟 xxd 相关的核心色彩定义是:
set background=dark
hi Normal guifg=white guibg=black
hi Constant term=underline cterm=bold ctermfg=magenta guifg=#ffa0a0
hi Identifier term=underline ctermfg=brown guifg=#40ffff
hi Statement term=bold cterm=bold ctermfg=yellow gui=bold guifg=#ffff60首先,这个配色方案设定背景为 dark,深色(允许的另外一个值是 light,浅色背景)。这会调整缺省的颜色组,使得文字色彩在深色背景上显示比较友好。但这不会在终端里真正改变背景(仍要靠下面的背景色设定),因此,如果你在浅色背景的终端里使用这个配色方案,会显得不太友好。有些比较好的配色方案会采用相反的做法,根据目前是深色还是浅色背景,采用不同的配色。
对于”正常”(Normal)的加亮组,这个配色方案采用了最直截了当的前景白、背景黑。可以预见,这个配色会比较醒(cì)目(yǎn)。
对于 Constant 加亮组,这个配色方案就稍微复杂点了,分了单色终端、色彩终端和图形界面的不同配色。古老的单色终端里使用下划线(应该已经没人用吧,所以以后我就忽略这种设定了);色彩终端下使用粗体和紫色前景;图形界面指定了前景色为 RGB 色彩 #ffa0a0,亮棕色。
Identifier 加亮组也类似,色彩终端下使用棕色前景,图形界面下前景色则是 RGB 色彩 #40ffff,亮青色。
Statement 加亮组在色彩终端和图形界面下都使用粗体,色彩终端使用黄色前景色,图形界面使用前景色是 RGB 色彩 #ffff60,亮黄色。
使用这个配色方案在图形界面和色彩终端下的效果,如下面的截图所示:


12.3 配色方案在终端下的优化
说到这里,我们有必要来讨论一下 Vim 里允许使用的色彩数量。在图形界面 Vim 里,色彩是 Vim 本身调用系统的编程接口来控制的,可以使用 RGB 的所有 16,777,216 种不同颜色。但在终端里,Vim 会受到终端能力的限制,只能根据终端的能力来显示色彩。根据终端的类型,我们可以分为 4 种情况:
第 1 种是最古老的是单色终端,没有颜色,只能使用下划线、粗体等效果。效果定义使用 term=… 的形式。今天,我们应该基本碰不到这样的环境了。
第 2 种是 8/16 色终端,允许使用最基本的八种颜色(黑、红、绿、黄、蓝、紫、青、白),以及这些颜色的较亮变体(即使 8 色终端一般也能在前景色上使用加亮的变体)。我们可以使用 cterm=… 定义粗体等效果(由于兼容性问题,不常用),用 ctermfg=… 和 ctermbg=… 定义前景和背景色,其中可以使用英文色彩名称或序号(见 :help cterm-colors)。鉴于序号在不同的环境里可能是不同的,我们一般使用色彩名称。如果你使用非图形界面终端,可能会遇到这种情况,但这应当也很不常见了吧。
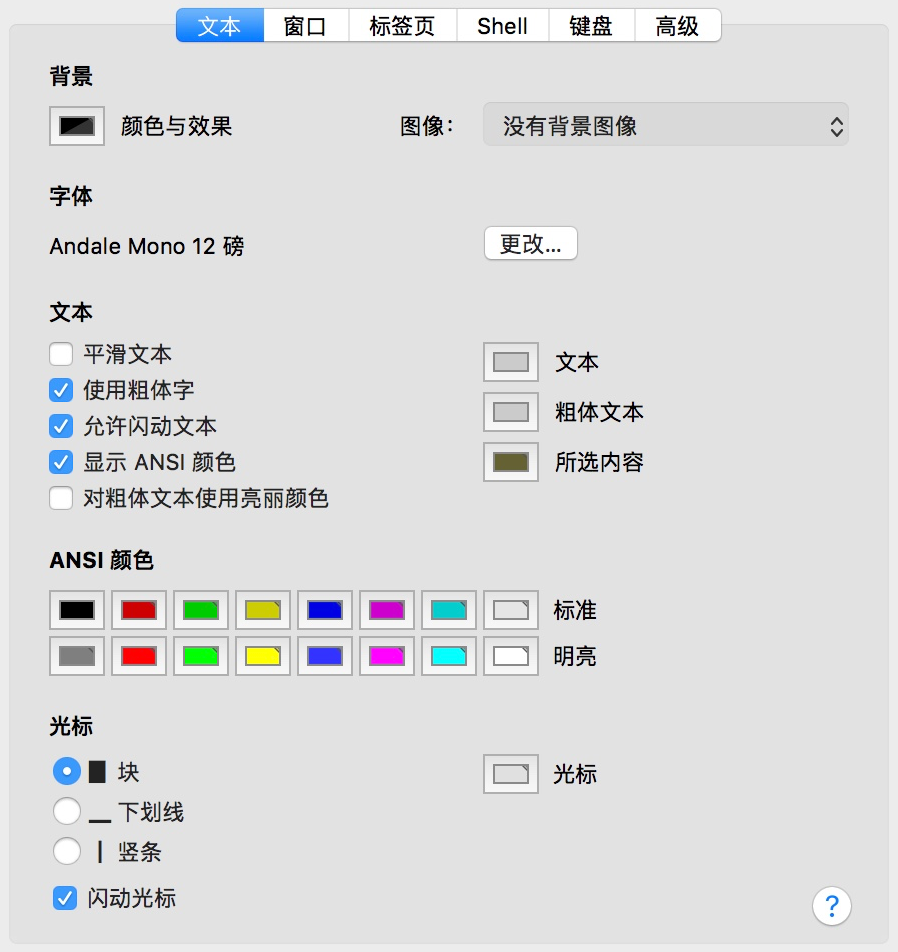
这些颜色虽然是标准的,但很多终端允许用户调整这些颜色,以达到最好的色彩组合效果。比如,下图是 macOS 里终端应用的一个设置界面,其中的”ANSI 颜色”就是用户可以调整的 16 种”标准色”:
第 3 种是 256 色终端,用户可以选择预先定义的 256 种颜色之一,这在目前的终端里是非常主流的方式了。你可以在网上很方便地找到脚本来输出这些颜色,效果如下图所示:

要选择这 256 种颜色中的一种,方式不太直观:你需要使用 ctermfg=… 和 ctermbg=…,并直接写出这 256 种颜色之一的编号。
这 256 种颜色都可以算是标准的,它们的标准 RGB 值有明确的定义。头 16 种颜色就是上面的”ANSI 颜色”,在终端里常常可以直接调整,图中也可以看到和前面图里的颜色已经有明显的不同。虽然界面只提供了头 16 种颜色的调整,但为了达到最佳的显示效果,你也可以编程修改这 256 种颜色的调色板。
第 4 种是支持真彩(truecolor)的终端,跟编程修改 256 色的调色板相比,这是更简单的做法。下面是部分比较常见的支持 RGB 真彩的终端( 此处是一个更完整的列表):
- GNOME-Terminal(Linux)
- iTerm2(macOS)
- mintty(Windows)
- 命令提示符(Windows 10 版本 1703 及以后;在命令提示符里使用 Vim,如果不启用真彩支持,颜色可能完全错误!)
在这些终端里,终端 Vim 就能显示跟图形界面 Vim 同样多的颜色数,因而能达到最佳色彩效果。你仍需手工打开(默认关闭的)Vim 选项 termguicolors。此后,Vim 就会使用你在 guifg 和 guibg 中写的 RGB 色彩,也就是说,把终端当图形界面一样看待(在色彩方面)。
鉴于真彩终端的一个惯例是设置环境变量 COLORTERM 为 truecolor 或 24bit,我们可以在 vimrc 配置文件中进行检查:
if has('termguicolors') &&
\($COLORTERM == 'truecolor' || $COLORTERM == '24bit')
set termguicolors
endif不过,这个检查方式仅限于类 Unix 平台。对于 Windows,Vim 提供了另外一个专门的特性检查项:
if has('vcon')
set termguicolors
endif12.4 推荐配色方案
- morhetz/gruvbox
- nanotech/jellybeans.vim
- mbbill/desertEx(作者用的就是这个)
12.5 检查 / 调试配色方案
如果你想自己对配色方案进行调整的话,有一个小工具肯定会非常有用,那就是 vimscripts/SyntaxAttr.vim。不过,这个插件不会自己添加键映射,需要你在用包管理器安装之后,自己在 vimrc 配置文件中加入类似下面的语句:
nnoremap <Leader>a :call SyntaxAttr()<CR>这样,我们就能用 \a 来检查光标下面的语法高亮详情了。下面是一个示例:
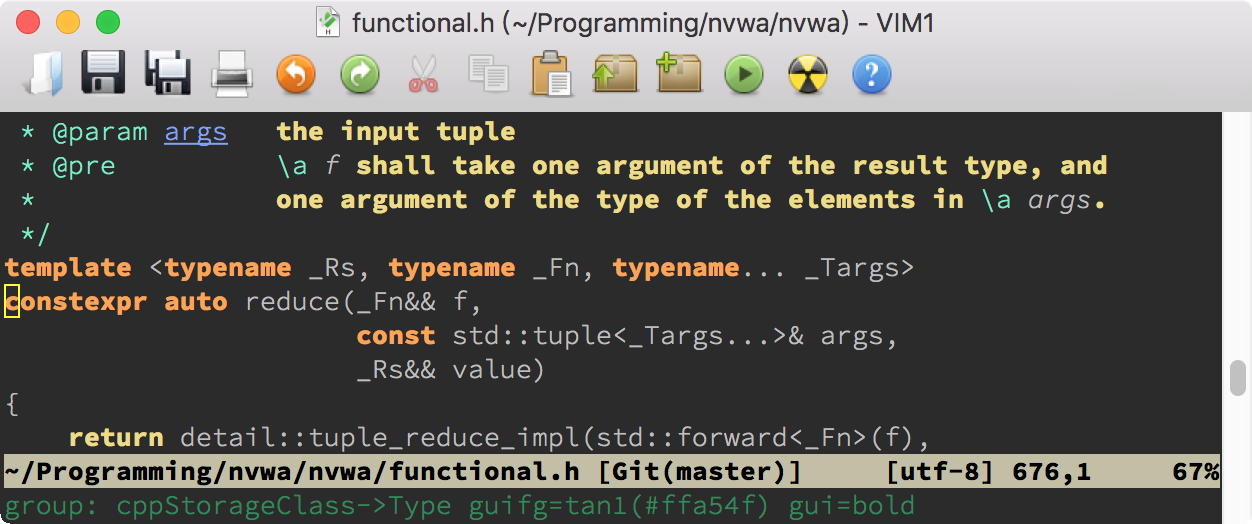
从上面可以看到,constexpr 属于 cppStorageClass 语法加亮组(这是在 syntax/cpp.vim 中定义的),并且被链接到了 Type 加亮组。后面的 guifg 和 gui 设定就是 Type 加亮组的内容:使用色彩 tan1(RGB 值为 #ffa54f),特殊效果为粗体(bold)。
12.6 输出加亮效果
作为一个文本编辑器,Vim 只接受文本的复制和粘贴。如果你想要在一个(非 Markdown)文档中展示有语法加亮的代码,Vim 也是可以用来产生这样的代码的——通过 HTML 输出。
Vim 默认就提供了 :TOhtml 命令,可以把当前展示的语法加亮效果输出为一个 HTML 文件。
我最近对一个 Vim 插件 vim-copy-as-rtf 作了点改造,使其可以在我们现在讲的三大主流平台(macOS、Linux 和 Windows)上都可以直接复制出带语法加亮的代码。在 macOS 和 Windows 上,没有特别的配置要求;在 Linux 桌面环境下,我们要求系统必须装有 xclip 工具。这样,我们只需要在使用 TOhtml 的地方,把命令改成 CopyRTF 就能把加亮的代码复制到系统的剪贴板中。
13|YouCompleteMe:Vim 里的自动完成
14|Vim 脚本简介:开始你的深度定制
14.1 语法概要
首先,我们需要知道,通过命令行模式执行的命令就是 Vim 脚本。它是一种图灵完全的脚本语言:图灵完全,说明它的功能够强大,理论上可以完成任何计算任务;脚本语言,说明它不需要编译,可以直接通过解释方式来执行。
当然,这并没有说出 Vim 脚本的真正特点。下面,我们就通过各个不同的角度,进行了解,把 Vim 脚本这头”大象”的基本形状完整地摸出来。
在这一讲里,我们改变一下惯例,除非明确说”正常模式命令”,否则用代码方式显示的都是脚本文件里的代码或者命令行模式命令,也就是说,它们前面都不会加 :。毕竟我们这一讲介绍的全是 Vim 脚本,而不是正常模式的快捷操作。
14.2 打印输出和字符串
Vim 脚本的”Hello world!”是下面这样的:
echo 'Hello world!'echo 是 Vim 用来显示信息的内置命令,而 ‘Hello world!’ 是一个字符串字面量。 Vim 里也可以使用 “ 来引起一个字符串。’ 和 “ 的区别和在 shell 里比较相似,前者里面不允许有任何转义字符,而后者则可以使用常见的转义字符序列,如 \n 和 \u…. 等。和 shell 不同的是,我们可以在 ‘ 括起的字符里把 ‘ 重复一次来得到这个字符本身,即 ‘It’’s’ 相当于 “It’s”。
因为 “ 还有开始注释的作用,一般情况下我推荐在 Vim 脚本里使用 ‘,除非你需要转义字符序列或者需要把 ‘ 本身放到字符串里。
字符串可以用 . 运算符来拼接。由于字典访问也可以用 . ,为了避免歧义,Bram 推荐开发者在新的 Vim 脚本中使用 .. 来拼接。但要注意,这个写法在 Vim 7 及之前的版本里不支持。我目前仍暂时使用 . 进行字符串拼接,并和其他大部分运算符一样,前后空一格。这样跟不空格的字典用法比起来,差异就相当明显了。
除了 echo,Vim 还可以用 echomsg(缩写 echom)命令,来显示一条消息。跟 echo 不同的是,这条消息不仅会显示在屏幕上,还会保留在消息历史里,可以在之后用 message 命令查看。
14.3 变量
变量可以用 let 命令来赋值,如下所示:
let answer = 42然后你当然就可以使用 answer 这个变量了,如:
echo 'The meaning of life, the universe and everything is ' . answerVim 的变量可以手工取消,需要的命令是 unlet。在你写了 unlet answer 之后,你就不能再读取 answer 这个变量了。
14.4 数字
Vim 脚本里的数字支持整数和浮点数,在大部分平台上,两者都是 64 位的有符号数字类型,基本对应于大部分 C 语言环境里的 int64_t 和 double。表示方式也和 C 里面差不多:整数可以使用 0(八进制)、0b(二进制)和 0x(十六进制)前缀;浮点数含小数点(不可省略),可选使用科学计数法。
14.5 复杂数据结构
Vim 脚本内置支持的复杂数据结构是列表(list)和字典(dictionary)。这两者都和 Python 里的对应数据结构一样。对于 C++ 的程序员来说,列表基本上就是数组 /array/vector,但大小可变,而且可以直接使用方括号表达式来初始化,如:
let primes = [2, 3, 5, 7, 11, 13, 17, 19]然后你可以用下标访问,比如用 primes[0] 就可以得到 2。
字典基本上就是 map,可以使用花括号来初始化,如:
let int_squares = {
\0: 0,
\1: 1,
\2: 4,
\3: 9,
\4: 16,
\}键会自动转换成字符串,而值会保留其类型。上面也用到了 Vim 脚本的续行——下一行的第一个非空白字符如果是 \,则表示这一行跟上一行在逻辑上是同一行,这一点和大部分其他语言是不同的。
访问字典里的某一个元素可以用方括号(跟大部分语言一样),如 int_squares[‘2’];或使用 .,如 int_squares.2。
14.6 表达式
跟大部分编程语言类似,Vim 脚本的表达式里可以使用括号,可以调用函数(形如 func(…)),支持加(+)、减(-)、乘(*)、除(/)和取模(%),支持逻辑操作(&&、|| 和 !),还支持三元条件表达式(a ? b : c)。前面我们已经学过,可以使用 [] 访问列表成员,可以使用 [] 或 . 访问字典的成员,也可以使用 . 或 .. 进行字符串拼接。== 和 != 运算符对所有类型都有效,而 <、>= 等运算符对整数、浮点数和字符串都有效。
对于文本处理,常见的情况是我们使用 =~ 和 !~ 进行正则表达式匹配,前者表示匹配的判断,后者表示不匹配的判断。比较操作符可以后面添加 # 或 ? 来强制进行大小写敏感或不敏感的匹配(缺省受 Vim 选项 ignorecase 影响)。表达式的左侧是待匹配的字符串,右侧则是用来匹配的正则表达式。
注意表达式不是一个合法的 Vim 命令或脚本语句。在表达式的左侧,需要有 echo 这样的命令。如果你只想调用一个函数,而不需要使用其返回的结果,则应使用 call func(…) 这样的写法。
此外,我们在插入模式和命令行模式下都可以使用按键 <C-R>=(两个键)后面跟一个表达式来使用表达式的结果。在替换命令中,我们在 \= 后面也同样可以跟一个表达式,来表示使用该表达式的结果。比如,下面的命令可以在当前编辑文件的每一行前面插入行号和空格:
:%s/^/\=line('.') . ' '/line 是 Vim 的一个内置函数,line(‘.’) 表示”当前”行的行号。
14.7 控制结构
Vim 支持标准的 if、while 和 for 语句。语法上,Vim 的写法有点老派,跟当前的主流语言不太一样,每种结构都要用一个对应的 endif、endwhile 和 endfor 来结束,如下面所示:
" 简单条件语句
if 表达式
语句
endif
" 有 else 分支的条件语句
if 表达式
语句
else
语句
endif
" 更复杂的条件语句
if 表达式
语句
elseif 表达式
语句
else
语句
endif
" 循环语句
while 表达式
语句
endwhile在 while 和 for 循环语句里,你可以使用 break 来退出循环,也可以使用 continue 来跳过循环体内的其他语句。
Vim 脚本的 for 语句跟 Python 非常相似,形式是:
for var in object
这儿可以使用 var
endfor表示遍历 object(通常是个列表)对象里面的所有元素。
跟 Python 一样,Vim 脚本也没有 switch/case 语句。
14.8 函数和匿名函数
Vim 脚本里定义函数使用下面的语法:
function 函数名(参数1, 参数2, ...)
函数内容
endfunctionVim 里用户自定义函数必须首字母大写(和内置函数相区别),或者使用 s: 表示该函数只在当前脚本文件有效。… 可以出现在参数列表的结尾,表示可以传递额外的无名参数。使用有名字的参数时,你需要加上 a: 前缀。要访问额外参数,则需要使用 a:1、a:2 这样的形式。特殊名字 a:0 表示额外参数的数量,a:000 表示把额外参数当成列表来使用,因而 a:000[0] 就相当于 a:1。
在函数里面,跟大部分语言一样,你可以使用 return 命令返回一个结果,或提前结束函数的执行。
Vim 脚本里允许匿名函数,形式是 {逗号分隔开的参数 -> 表达式}。在 Vim 脚本里可以使用类似下面的语句:
echo map(range(1, 5), {idx, val -> val * val})结果是 [1, 4, 9, 16, 25]。跟常见的 map 函数不同,Vim 会传过去两个参数,分别是列表索引和值;同时,它会修改列表的内容。不想修改的话,要把列表复制一份,如 copy(mylist)。
14.9 Vim 特性
14.9.1 变量的前缀
通用编程概念上很容易理解的是下面四个:
- a: 表示这个变量是函数参数,只能在函数内使用。
- g: 表示这个变量是全局变量,可以在任何地方访问。
- l: 表示这个变量是本地变量,但一般这个前缀不需要使用,除非你跟系统的某个名字发生了冲突。
- s: 表示这个变量(或函数,它也能用在函数上)只能用于当前脚本,有点像 C 里面的 static 变量和函数,只在当前脚本文件有效,因而不会影响其他脚本文件里定义的有冲突的名字。
一般编程语言里没有的,是下面这些前缀:
- b: 表示这个变量是当前缓冲区的,不同的缓冲区可以有同名的 b: 变量。比如,在 Vim 里,b:current_syntax 这个变量表示当前缓冲区使用的语法名字。
- w: 表示这个变量是当前窗口的,不同的窗口可以有同名的 w: 变量。
- t: 表示这个变量是当前标签页的,不同的标签页可以有同名的 t: 变量。
- v: 表示这个变量是特殊的 Vim 内置变量,如 v:version 是 Vim 的版本号,等等(详见 :help v:var)。
还有下面这些前缀,可以让我们像使用变量一样使用环境变量和 Vim 选项:
- $ 表示紧接着的名字是一个环境变量。注意,一些环境变量是由 Vim 自己设置的,如 $VIMRUNTIME。
- & 表示紧接着的名字是一个选项,比如, echo &filetype 和 set filetype? 效果相似,都能用来显示当前缓冲区的文件类型。
- &g: 表示访问一个选项的全局(global)值。对于有本地值的选项,如 tabstop,我们用 &tabstop 直接读到的是本地值了,要访问全局值就必须使用 &g:tabstop。
- &l: 表示访问一个选项的本地(local)值。对于有本地值的选项,如 tabstop,我们用 &tabstop 直接读到的已经是本地值了,但修改则和 set 一样,同时修改本地值和全局值。使用 &l: 前缀可以允许我们仅修改本地值,像 setlocal 命令一样。
你可能要问,什么时候我们会需要用变量形式来访问选项,而不是使用 set、setlocal 这样的命令呢?答案是,当我们需要计算出选项值的时候。set filetype=cpp 基本上和 let &filetype = ‘cpp’ 等效,我们需要注意到后者里面 cpp 是个字符串,可以是通过某种方式算出来的。光使用 set,就不方便做到这样的灵活性了。
14.9.2 重要命令
首先是 execute(缩写 exe),它能用来把后面跟的字符串当成命令来解释。跟上一节使用选项还是 & 变量一样,这样做可以增加脚本的灵活性。除此之外,它还有两种常见特殊用法:
- 在使用键盘映射等场合、需要在一行里放多个命令时,一般可以使用 | 来分隔,但某些命令会把 | 当成命令的一部分(如 !、command、nmap 和用户自定义命令),这种时候就可以使用 execute 把这样的命令包起来,如:exe ‘!ls’ | echo ‘See file list above’。
- normal 命令把后面跟的字符直接当成正常模式命令解释,但如果其中包含有特殊字符时就不方便了。这时可以用 execute 命令,然后在 “ 里可以使用转义字符。我们上面讲字符串时没说的是,按键也可以这样转义,比如,”
\<C-W>“ 就代表 Ctrl-W 这个按键。所以,如果你想在脚本中控制切换到下一个窗口,可以写成:exe "normal \<CW>w"。
然后,我要介绍一下 source(缩写 so)命令。它用来载入一个 Vim 脚本文件,并执行其中的内容。
source $VIMRUNTIME/vimrc_example.vim
…
command! PackUpdate packadd minpac | source $MYVIMRC | call minpac#update('', {'do': 'call minpac#status()'})
…这里要注意的地方是,要允许一个文件被 source 多次,是需要一些特殊处理的。我目前给出的 vimrc 配置文件由于需要被载入多次,进行了下面的特殊处理:
- 清除缺省自动命令组里当前的所有命令,以免定义的自动命令被执行超过一次
- 使用 command! 来定义命令,避免重复命令定义的错误
- 使用 function! 来定义函数,避免重复函数定义的错误
- 没有手工设置 set nocompatible,因为该设置可能会有较多的副作用(在 defaults.vim 里会确保只设置该选项一次)
上面我已经展示了一个 command 命令的例子。这个命令允许我们自定义 Vim 的命令,并允许用户来定制自动完成之类的效果(详见 :help user-commands)。注意这个命令的定义要写在一行里,所以如果命令很长,或者中间出现会吞掉 | 的命令的话,我们就会需要用上 execute 命令了。
最后,我再说明一下我们用过的 map 系列键映射命令(详见 :help keymapping)。这些命令的主干是 map,然后前面可以插入 nore 表示键映射的结果不再重新映射,最前面用 n、v、i 等字母表示适用的 Vim 模式。在绝大部分情况下,我们都会使用带 nore 这种方式,表示结果不再进行映射(排除偶尔偷懒的情况)。但是,如果我们的 map 命令的右侧用到了已有的(如某个插件带来的)键映射,我们就必须使用没有 nore 的版本了。
14.9.3 事件
和用户主动发起的命令相对应,Vim 里的自动处理依赖于 Vim 里的事件。迄今为止,我们已经遇到了下面这些事件:
- BufNewFile 事件在创建一个新文件时触发
- BufRead(跟 BufReadPost 相同)事件在读入一个文件后触发
- BufWritePost 事件在把整个缓冲区写回到文件之后触发
- FileType 事件在设置文件类型(filetype 选项)时被触发
Vim 里的事件还有很多(详见 :help autocmd-events-abc)。
14.9.4 内置函数
Vim 里内置了很多函数(列表见 :help function-list),可以实现编程语言所需要的基本功能。我们目前用得比较多的是下面这两个:
- exists 用来检测某一符号(变量、函数等)是否已经存在。在 Vim 脚本里最常见的用途是检测某一变量是否已经被定义。
- has 用来检测某一 Vim 特性(列表见 :help feature-list)是否存在。
在看 Vim 脚本时,在关键字上按下 K 就可以查看这个关键字的帮助,如下图所示:

14.9.5 风格指南
Google 出品的 Vim 脚本风格指南:Google Vimscript Style Guide。
14.9.5 Python 集成(选学)
Vim 脚本功能再强大,也还是一种小众的编程语言。所以,Vim 里内置了跟多种脚本语言的集成,包括:
- Python
- Perl
- Tcl
- Ruby
- Lua
- MzScheme
由于 Python 的高流行度,目前 Vim 插件里常常见到对 Python 的要求——至少我还没有用过哪个插件要求有其他语言的支持。所以,在这儿我就以 Python 为例,简单介绍一下 Vim 对其他脚本语言的支持。各个语言当然有不同的特性,但支持的方式非常相似,可以说是大同小异。
Vim 很早就支持了 Python 2,Vim 的命令 python(缩写 py)就是用来执行 Python 2 的代码的。后来,Vim 也支持了 Python 3,使用 python3(缩写 py3)来执行 Python 3 的代码。鉴于 Python 的代码还是有不少是 2、3 兼容的,Vim 还有命令 pythonx(缩写 pyx)可以自动选择一个可用的 Python 版本来执行。
我在 拓展 3 里给出了一段代码,用 Python 来检测当前目录是不是在一个 Git 库里。我们先用 pythonx 命令定义了一个 Python 函数,然后用 pyxeval 函数来调用该函数。这就是一种典型的使用方式:在 Python 里定义某个功能,然后在 Vim 脚本里调用该功能。这种情况下,Python 部分的代码一般不需要对 Vim 有任何特殊处理,只是简单实现某个特定功能。
下面是另一个小例子,通过 Python 来获得当前时区和协调世界时的时间差值(对于中国,应当返回 ␣+0800):
function! Timezone()
if has('pythonx')
pythonx << EOF
import time
def my_timezone():
is_dst = time.daylight and time.localtime().tm_isdst
offset = time.altzone if is_dst else time.timezone
(hours, seconds) = divmod(abs(offset), 3600)
if offset > 0: hours = -hours
minutes = seconds // 60
return '{:+03d}{:02d}'.format(hours, minutes)
EOF
return ' ' . pyxeval('my_timezone()')
else
return ''
endif
endfunction从 pythonx << EOF 到 EOF,中间是 Python 代码,定义了一个叫 my_timezone 的函数,我们然后调用该函数来获得结果。对于不支持 Python 的情况,我们就直接返回一个空字符串了。
另一种更复杂的情况是,我们的主干处理逻辑就放在 Python 里。这种情况下,我们就需要在 Python 里调用 Vim 的功能了。在 Vim 调用 Python 代码时,Python 可以访问 vim 模块,其中提供多个 Vim 的专门方法和对象,如:
- vim.command 可以执行 Vim 的命令
- vim.eval 可以对表达式进行估值
- vim.buffers 代表 Vim 里的缓冲区
- vim.windows 代表当前标签页里的 Vim 窗口
- vim.tabpages 代表 Vim 里的标签页
- vim.current 代表各种 Vim 的”当前”对象(详见 :help pythoncurrent),包括行、缓冲区、窗口等
此外,在 拓展 2 里我们给出的使用 pyxf 来执行一个 Python 脚本文件,也是一种在 Vim 里调用 Python 的方式(详见 :help pyxfile)。那段 clang-format 的代码,总体上也就是访问 vim.current.buffer 对象,调用外部命令格式化指定行,然后把修改的内容写回到 Vim 缓冲区里。
15|插件荟萃:不可或缺的插件
16|终端和 GDB 支持:不离开 Vim 完成开发任务
Emacs 有个功能可是 Vim 用户一直暗暗垂涎的,那就是可以集成 GDB 来调试程序。Emacs 之所以能够实现这个功能,是因为它可以模拟一个终端环境,像终端一样跟一个程序进行输入输出的交互。这样一来,我们不离开编辑器,也能调试程序,既可以方便地看到目前执行在源代码的第几行,也可以直接在编辑器里跟执行中的程序进行交互。
很多主流的开发环境都支持类似的功能。但 Vim 一直不支持这样的功能,直到 Vim 8。
16.1 终端窗口支持
16.1.1 基本用法
使用 :terminal(缩写 :term)命令,我们可以在 Vim 的窗口中运行终端模拟器。基本的用法就是下面两种:
- 使用 :terminal,后面不跟其他命令,分割一个新窗口,并使用默认的 shell 程序进行终端模拟;shell 退出后窗口自动关闭(可用使用命令参数 ++noclose 改变这一行为)。
- 使用 :terminal 命令 的方式,分割一个新窗口,在其中运行指定的命令并进行终端模拟;命令执行完成退出后窗口不自动关闭,保留执行中显示的信息(可用使用命令参数 ++close 改变这一行为)。
跟其他的多窗口命令一样,:terminal 默认会进行横向分割,但你也可以在 terminal 前面加上 vert 来进行纵向分割,或加上 tab 来把终端窗口打开到一个新的标签页里。
跟 quickfix 窗口里只能看到程序的输出不同,在终端模拟器里我们既可以看到程序的输出,也可以向程序提供输入。同时,这个终端模拟器像一个真正的终端一样,能够支持色彩和其他的文本控制。你甚至可以在里面运行 Vim,就像 Matrix 电影里层层嵌套的世界一样。

当然,从实用的角度,我并不建议你这么做——那样可能会让人头昏,并且容易在使用 <C-W> 和 :q 这样的命令时,出现结果跟自己预想不一致的情况。
终端模拟器的行为应当跟普通的终端一致;因此在 Vim 的终端模拟器里,你可以直接使用的命令跟一般的 Vim 窗口很不一样。毕竟,你在终端模拟器里输入 : 时,肯定不是想进入 Vim 的命令行模式吧?这时候,你需要知道下面这些在”终端作业模式”下的特殊命令(完整列表见 :help t_CTRL-W):
<C-W>N(注意大写)或<C-\><C-N>退出终端作业模式,进入终端普通模式。这时终端窗口变成一个普通的文本窗口(终端缓冲区),不再显示色彩,但可以像普通的只读窗口一样自由使用,只是不能修改其中的内容而已。按下 a 或 i 可重新激活终端模拟器,进入终端作业模式。<C-W>"后面跟寄存器号,表示粘贴该寄存器中的内容到终端里。<C-W>:相当于普通窗口中的 :,执行命令行模式的命令。<C-W>.可以给终端窗口发送一个普通的 Ctrl-W。<C-W><C-\>可以给终端窗口发送一个普通的 Ctrl-\。- 大部分的
<C-W>开始的命令仍然可以使用,如窗口跳转命令(后面跟 j、k 等)、窗口大小调整命令(后面跟 +、_ 等),等等。
需要注意,终端模拟器里的光标只能用正常终端里的光标移动键来移动,比如在 Bash 默认配置下,可以用 <C-A> 或 <Home> 移到行首,用 <C-E> 或 <End> 移到行尾等。在退出终端作业模式后,光标就只是普通文本窗口的光标,不会影响终端模式里的光标位置——在你按下 a 或 i 时,光标还是在原来的位置,而不是退出终端作业模式后你移动到的新位置。你也不能修改终端缓冲区中的内容。只要稍微仔细想一想,你就知道这些是完全符合逻辑的。
当你从终端窗口切到另外一个窗口时,终端窗口里面的程序仍然在继续运行;如果你不退出终端作业模式的话,终端窗口里面的内容也会持续更新,跟正常的终端行为一致。要结束终端运行的话(而不只是临时退出终端模式),也跟普通的终端情况一下,可使用 exit 命令或 <C-D>。如果由于某种原因无法正常退出终端的话,则可以使用 <C-W><C-C> 来强行退出。
16.2 使用提示
如果你觉得自己不会在终端里另外启动 Vim,似乎也就很少有机会用到 <Esc> 了,那我们干吗不把这个键用作退出终端作业模式呢?说干就干:
tnoremap <Esc> <C-\><C-N>
tnoremap <C-V><Esc> <Esc>前缀 t 表示在终端作业模式下的键映射。我们把 <Esc> 映射到我们上面说的退出终端作业模式的快捷键;同时,我们又把 <C-V><Esc> 这一在终端里等价于 <Esc> 的按键组合映射为 <Esc>,这样万一我们需要 <Esc>,仍然可以用一种较为自然的方式获得这个按键。
遗憾的是,在 Unix 终端的情况下,很多功能键本身包含 <Esc>,因而会误触发这个键映射。对于这种情况,我们使用下面的键映射,用连按两下 <Esc> 退出终端作业模式效果更好:
tnoremap <Esc><Esc> <C-\><C-N>此外,对于大部分人而言(像 Bram 这样,用 Vim 调试 Vim,不属于大众需求吧),在 Vim 的终端模式里启动 Vim,恐怕是失误的可能性最大。为了防止这样的失误发生,我们可以在 Vim 启动时检查一下,检测这种嵌套的 Vim 使用。你只需要把下面的代码加到 vimrc 配置文件的开头即可:
if exists('$VIM_TERMINAL')
echoerr 'Do not run Vim inside a Vim terminal'
quit
endif16.3 终端的用途
我是这么理解的:
方便。特别在远程连接的时候,有可能新开一个连接在某些环境里需要特别的认证,比较麻烦。即使连接没有任何障碍,你总还需要重新 cd 到工作目录里吧?而如果在一个现有的 Vim 会话里开一个新的终端,可以一个命令搞定,然后用你已经很熟悉的 Vim 命令在不同的窗口或标签页里切换。
文本。我们可以从终端作业模式切换到终端普通模式,然后用我们熟悉的 Vim 命令来对缓冲区中的文本进行搜索、复制等处理工作。
控制。你可以发送命令给终端,也可以读取终端屏幕上的信息。这样,事实上就打开了一片新天地,可以在 Vim 里做很多之前做不到的事情,比如,用 Vim 来比较两个屏幕输出的区别(:help terminal-diff)。
终端窗口相关的函数名称都以 term_ 打头(可以查看帮助文件:help terminalfunction-details)。比如,如果我们想要用程序向缓冲区编号为 2(可以用 :ls 和 :echo term_list() 等命令来检查)的终端发送 ls 命令来显示当前目录下的文件列表的话,我们可以使用(注意转义字符序列要求使用双引号):
call term_sendkeys(2, "ls\n")下面这个比较无聊的例子,可以用来获取 ~/.vim 目录下的文件清单:
let term_nbr = term_start('bash')
call term_wait(term_nbr, 100)
let line_pos1 = term_getcursor(term_nbr)[0]
call term_sendkeys(term_nbr, "ls ~/.vim|cat\n")
call term_wait(term_nbr, 500)
let line_pos2 = term_getcursor(term_nbr)[0]
let result = []
let line_pos1 += 1
while line_pos1 < line_pos2
call add(result, term_getline(term_nbr, line_pos1))
let line_pos1 += 1
endwhile
call term_sendkeys(term_nbr, "\<C-D>")
while term_getstatus(term_nbr) != 'finished'
call term_wait(term_nbr, 100)
endwhile
exe term_nbr . 'bd'
echo join(result, "\n")这当然不是完成这件任务的最好方法,但上面的代码展示了终端相关函数的一些基本用法:
- 我们用 term_start 命令创建一个新的终端,得到终端缓冲区的编号
- 我们用 term_wait 等待 100 毫秒,待其就绪
- 我们用 term_getcursor 获取光标的当前行号
- 我们用 term_sendkeys 发送一个命令到终端上;ls 之后用 cat 是为了防止 ls 看到输出是终端而产生多列的输出
- 然后我们等待命令执行完成并更新终端
- 我们获取光标的当前位置,然后用 term_getline 获得上一次的行号和这一次的行号之间的行的内容,放到变量 result 里
- 我们然后发送一个
<C-D>到终端,结束作业 - 然后我们等待到 term_getstaus 返回的状态成为 ‘finished’,即终端作业已经执行结束
- 最后我们用缓冲区编号加 bd 命令删除缓冲区(所以屏幕上我们看不到这个终端窗口),并用换行符作为分隔符打印 ls 返回的内容
你可以实际测试一下这个脚本,体会一下这些基本功能。比如,可以把脚本存盘为 test.vim,然后用 :so % 来运行。
16.4 GDB 支持
Vim 通过一个内置的插件,就可以提供 GDB 的调试支持了。我们可以通过 :packadd termdebug 命令来加载这个插件,然后通过 :Termdebug 可执行程序名称 来调试一个可执行程序。
下面这个动图可以说明最主要的流程:

我简要说明一下需要注意的几点:
- :Termdebug 命令会把屏幕分成三个区域,从上到下分别是 gdb 命令行,程序输出,以及含调试控制按钮的源代码窗口。
- 在最上面的 gdb 窗口中,我们可以输入 gdb 的命令,但程序的输出和纯终端使用 gdb 的情况不同,是在中间的窗口输出的。
- 最下面的的源代码窗口里,我们有五个按钮可以用,允许习惯图形界面的用户使用鼠标进行操作。我们也可以使用鼠标右键直接在源代码行上设置断点。(当然,我们仍然可以在最上面的 gdb 窗口用命令来完成这些任务。)
- 鼠标在变量上悬停时,可以显示变量的值。只要 gdb 能打印的信息,它就能用浮动提示显示出来。这比手工使用 gdb 的 p 命令还是要方便多了。
还有一个需要稍微注意的地方是,如果你在不同的作用域有两个同名变量,那浮动提示只能显示当前作用域的变量的信息,即使你把光标放到不在当前作用域的变量上也是如此。这点上,Vim 还是比较笨的——毕竟它不理解代码。
17 拓展1|纯文本编辑:使用 Vim 书写中英文文档
17.1 为什么不使用字处理器?
首先,Word 和 WPS 这些字处理器不是用来生成纯文本文件的。在处理纯文本文件上,它们反而会有诸多劣势,如:
- 只能本地使用,既不能在远程 Linux 服务器上运行,也不能用 SSH/SCP 的方式打开远程的文件(除非在服务器上启用 Samba 服务,但体验真的不好)
- 分段和分行一般没有很好的区分
- 如果存成纯文本的话,格式会全部丢失
最后一句话似乎是废话?还真不是,纯文本文件里面是可以存储格式的,但 Word 和其他字处理软件对于文本类型一般只能支持纯文本或富文本(Rich Text),而富文本虽然包含了格式信息,但却对直接阅读不友好。我想,没有人会去手写富文本文件吧。仍有一些带格式的文本文件比较适合手写,下面这些是其中较为流行的格式:
- Tex 和 LaTeX,著名的特别适合写公式的文档系统,在数学和物理学界尤其流行。
- DocBook,基于 SGML/XML 的文档系统,可以生成多种不同的输出格式;大量开源软件的文档是用 DocBook 写的。
- AsciiDoc,功能和 DocBook 等价、但使用非 XML 的简化语法的文档系统;有的国外技术书出版社接受作者用这种格式提交的稿件。
- HTML,HTML 的阅读友好性一般,但胜在熟悉的人多。
- Markdown,Markdown 的阅读体验非常友好,因而它虽然最”年轻”却最流行。接下来,我们就介绍一下这种文件类型。
17.2 Markdown 简介
Markdown 是由 John Gruber(约翰 · 格鲁伯)在 2004 年发明的,它不是一种标准化的格式,存在着多个实现,功能也并不完备。尽管如此,由于它轻量、易写、易读,很快就在互联网上流行开了。在 GitHub 上,现在 README 文件一般都使用 Markdown。
通过工具(很多是开源的,如 pandoc),Markdown 可以很容易地转成网页、PDF 等其他格式,同时也很适合以纯文本的形式阅读。而 HTML、DocBook 等格式实际上是不太适合人直接看源代码来阅读的。此外,极客时间,以及很多写作平台,用的也是 Markdown。
17.3 英文文本编辑
考虑到 Markdown 等标准在中文处理的标准化上面有先天不足,我们先学习文档的主语言为英文的情况。我们可以先看一眼下面的截图:

然后对比一下它的 Markdown 源代码在 Vim 中的展示效果:
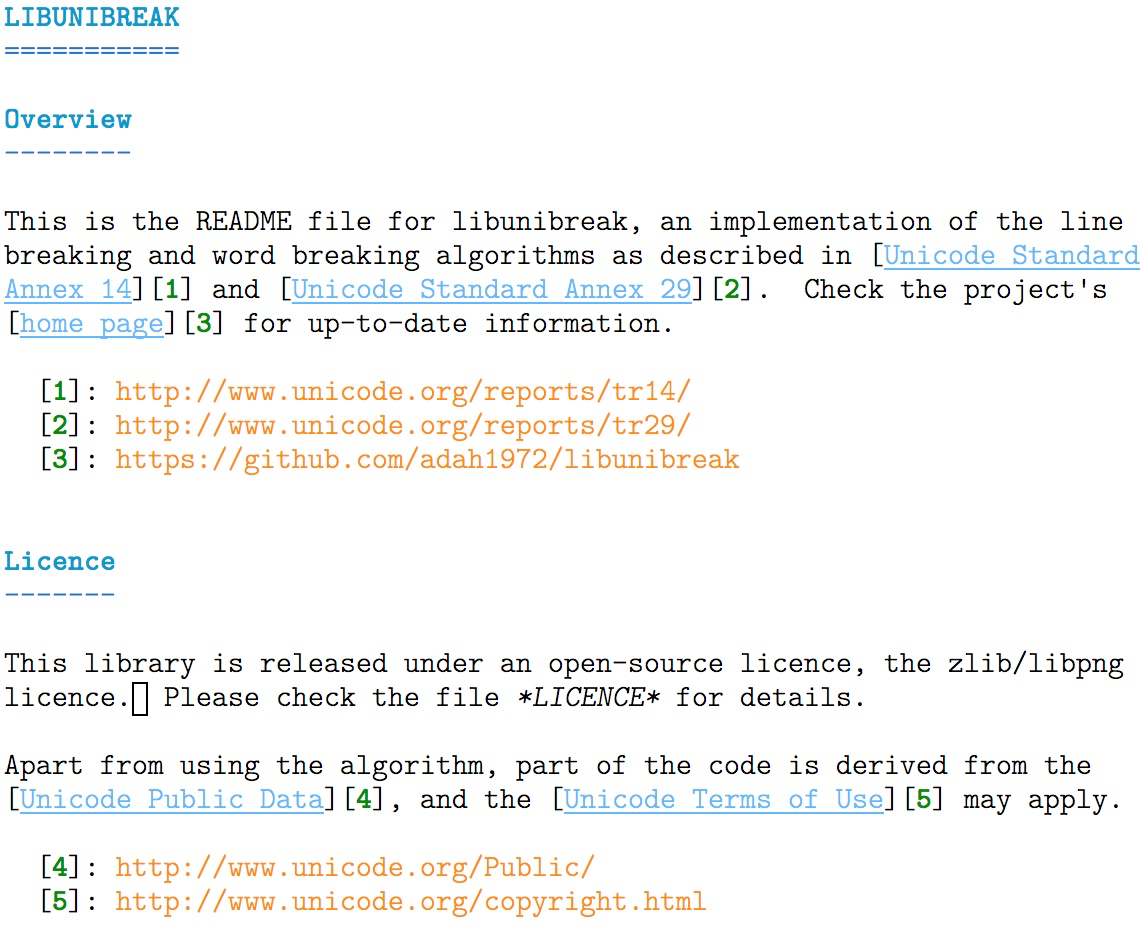
我们明显可以看到,用 Vim 编辑 Markdown 文件时,虽然没有浏览器里显示得那么美观,但在使用等宽字体的前提下仍有着合适的语法加亮。
有两个细节值得关注一下:
- 跨行的那个链接加亮正常(我在至少两种其他环境下看到在方括号跨行时链接就无法得到正确的处理)。
- 单词”LICENCE”在 Vim 展示时也使用了斜体(一对星号中间的内容在 Markdown 里就是使用斜体强调),并且如果光标移出该行,星号会被自动隐藏,更方便阅读。
需要注意,在网页中的换行位置和源代码中的换行位置是不一样的。源代码中存在真正的换行(上一讲提到的 LF 或 CR LF 构成的行尾结束符);而转换到网页显示之后,单个换行只相当于空格字符,浏览器里一行应当显示多少字符仍然由浏览器的宽度和样式表来决定。这就是标准的 Markdown 的行为了。
17.4 行宽设置
英文文本文件的惯例仍然是一行放不超过 80 个字符,所以在源代码中仍然是有手工断行的。这个习惯是为阅读”源代码”优化的:可以看到,上面这个 Markdown 文件虽然在浏览器里查看效果更好,以纯文本的形式查看也是非常干干净净、毫无问题——只要你的编辑器列宽大于等于 80 就行了。
我们上一讲已经提到了文本宽度选项 textwidth。在对英文文本编辑时,这个选项的推荐数值通常是 72,比标准列宽 80 稍窄。这个设置有历史原因,但更重要的是,这也是经过历史验证对人阅读比较舒适的设定:既不会产生频繁的换行而打乱阅读节奏,也不会因为行太长而发生寻找下一行起始位置的困难。
被誉为”排版圣经”的 The Elements of Typographic Style 对行宽有这样的描述:
Anything between 45 to 75 characters is widely regarded as a satisfactory length of line for a single-column page. . . . The 66-character line . . . is widely regarded as ideal.
我们说列宽 72,是指最大值,而使用 72 产生的实际文本宽度,差不多就是落在 66 这个理想值附近了。一些编码规范,如 Python 的 PEP 8,也约定对文档内容的列宽数值应当是 72。大部分编码规范对代码宽度的约定稍宽松些,一般是 79 或 80。
17.5 格式化选项
我们上一讲已经提到格式化选项 formatoptions(缩写 fo),今天我们来稍微展开一下,看看这些格式化选项对我们写文档有什么样的影响。
在 Vim 里,fo 选项的默认值是 tcq。根据 Vim 的帮助文档,它们的含义是:
- t:使用 textwidth 自动回绕文本。
- c:使用 textwidth 自动回绕注释,自动插入当前注释前导符。
- q:允许 gq 排版时排版注释。
不过,根据你编辑的内容的语法,这个选项内容可能会发生变化。如运行支持文件里的 ftplugin/c.vim 里有下面的语句:
" Set 'formatoptions' to break comment lines but not other lines,
" and insert the comment leader when hitting <CR> or using "o".
setlocal fo-=t fo+=croql即,正常输入非注释内容时,不进行回绕。但对注释还是要使用回绕的。另外几个我们还没检查过的选项是:
- r:在插入模式按回车时,自动插入当前注释前导符。
- o:在普通模式按 o 或者 O 时,自动插入当前注释前导符。
- l:插入模式不分行: 当一行已经超过 textwidth 时,插入命令不会自动排版。
上一讲我们用到的 n 则是:
- n:在对文本排版时,识别编号的列表。实际上,这里使用了 formatlistpat 选项,所以可以使用任何类型的列表。出现在数字之后的文本缩进距离被应用到后面的行。数字之后可以有可选的 .、:、)、] 或者 }。注意 autoindent 也必须同时置位。
formatlistpat 的缺省值是 ^\s*\d\+[\]:.)}\t ]\s*。也就是说,起始处有可选的空格,然后是至少一个数字,之后必须跟 .、:、)、]、}、制表符或空格中的一个,随后是可选的若干空格。
运行支持文件里的 ftplugin/markdown.vim 会对 formatlistpat 做额外的设定,使得 Vim 不仅可以识别数字列表,也能识别用 - 等字符开始的无序列表。有兴趣的同学可以自己分析一下。
如果你希望有比较接近字处理器的体验,不用自己手工断行,下面两个选项对英文文本编辑比较重要:
- w:拖尾的空格指示下一行继续同一个段落。而以非空白字符结束的行结束一个段落。
- a:自动排版段落。每当文本被插入或者删除时,段落都会自动进行排版。
这两个选项结合的效果,会让在 Vim 里编辑的效果在某种程度上接近字处理器:你会看到在某行增删内容会自动导致下面的行跟着卷动,你可以通过下面的动图看下效果(我使用了 Vim 的 listchars 选项来加亮行尾空格和行尾结束符):

17.6 段中不换行的文本
到现在为止,我们讨论的英文文本编辑,基本都是行尾结束符不代表真正分行的情况。这种方式最常见,但也存在例外,如有些网站不使用标准的 Markdown 规则,把行尾结束符直接就当成换行了。在这样的情况下,我们就不应该在一段中间手工插入换行符。不过,由于这种方式不是 Vim 的”自然”处理方式,我们需要修改一些选项和处理习惯来应对这种情况。
首先,Vim 在默认配置下会在窗口宽度不足时自动折行显示,但不会对折行的位置进行特殊挑选,很可能会在单词的中间折行。我们可以设置选项 linebreak,告诉 Vim 要在 breakat 的字符上才可以折行。默认的 breakat 设置包含了空白字符和英文标点符号,因此直接可以在英文环境中进行使用。下图展示了 linebreak 的效果:

在这种模式下进行编辑时,另外一个要注意的问题是 j 和 k 移动的是一个物理行,而非屏幕行。这和很多编辑器的行为是不同的。要让光标一次移动一个屏幕行,需要的按键是 gj 和 gk。如果你希望 <Up> 和 <Down> 的行为跟主流的编辑器一致,可以考虑以下的设定:
" 修改光标上下键一次移动一个屏幕行
nnoremap <Up> gk
inoremap <Up> <C-O>gk
nnoremap <Down> gj
inoremap <Down> <C-O>gj最后,如果之前换行符不代表分段,现在你希望换行即分段,你可以用 J(代表 join,连接)命令把多行重新连接成一行。这个命令在某种程度上可以看作是 gq 的逆命令。由于这个命令根据字符的类型来决定是否插入空格和插入几个空格(参考 :help ‘joinspaces’),它并不能简单地用替换命令来代替。如果考虑最简单的情况(:set nojoinspaces),那至少在 formatoptions 中含有 w 时,我们可以用下面的替换命令来连接同一段的所有行:
:%s/\([^\n]\)\s\+\n\s*\([^\n]\)/\1 \2/事实上,使用 joinspaces 和 Markdown 的双行尾空格代表换行是潜在会冲突的。在 Markdown 中使用 w 时,应当使用 nojoinspaces。
17.7 模式行
到现在为止,我们讨论的好些选项,不仅不适合作为全局选项,也不适合作为某一文件类型的选项,而更适合用作单个文件的选项。Vim 也确实提供了这样的功能,叫做模式行(:help modeline),能自己使用 :setlocal 仅对当前缓冲区设置本地选项。这个功能本身在帮助文件里说得挺清楚,我就不重复了。
在上面图里的那个文本文件中,我使用了下面的模式行:
vim:set et sts=2 tw=68 com-=mb\:* com+=fb\:* fo=tcqaw:上面这个模式行,除了设定了我们讨论过的 et 扩展 tab 为空格选项、sts 软 tabstop 选项、tw 行宽选项和 fo 格式化选项外,对 comments(缩写 com)选项进行了调整,不用星号作为注释中间部分的开始(mb),而用星号作为一个列表的开始(fb)。关于 comments 选项的详细解释可以参看帮助文档 :help format-comments,我这儿就不展开了。
17.8 拼写检查
写英文时启用自动拼写检查,这是一个写作的好习惯。哪怕你英语很好,也可能因为疏忽而拼错。Vim 从版本 7 开始,就内置了拼写检查的功能,可以通过选项 spell 来打开。

上面我存心写错了一个地方(”userz”),被 Vim 用红波浪线标了出来。标蓝波浪线的是 Vim 提醒我,句首一般需要首字母大写(此处没有错误)。另外,可以注意到单个换行是不会被 Vim 当作一段结束的,因此行首的”right”和”promise”等单词不会被 Vim 当成有拼写问题。
在 macOS 和 Windows 的图形界面 Vim 里,右键默认就可以弹出拼写纠正菜单,跟大部分其他有拼写检查功能的软件差不多。在 Linux 上,右键默认是 xterm 标准的扩展选择区域的行为。要让右键在 Linux 下也能弹出菜单,你需要手工在 vimrc 配置文件里加入:
set mousemodel=popup_setpos这可以算是图形界面的 Vim 跟终端 Vim 比起来的明显优势了:终端 Vim 显示不了波浪线,对右键的响应也通常有问题。在终端 Vim 里,你可能就需要去记拼写检查的命令了(见帮助 :help spell)。
Vim 拼写检查的默认语言是英语。对不同语言的支持,我们可以使用 Vim 选项 spelllang 来设定。比如,如果你希望按照英式英语的拼写,那你可以设置:
set spelllang=en_gb这样一来,Vim 就会把非英式英语的拼写方式用绿色波浪线(当然,这和色彩方案有关)标出来。在图形界面 Vim 里,你同样可以很方便地用右键点击来更改:
你如果希望使用美式英语,当然使用 :set spelllang=en_us 就可以了。同时使用英式和美式,可以用 :set spelllang=en_gb,en_us。如果任何英语拼写都能接受,那使用默认值或 en 就行。
作为东亚文字的特殊情况,如果你希望所有的东亚字符不被标成拼写错误的话,可以在 spelllang 选项里使用特殊值 cjk。作为中国人,我们可能会需要这么用:
set spelllang+=cjk17.9 拼写完成
我们之前提到了 Vim 支持用一个字典文件来进行拼写完成,你可以在帮助 :help ‘dictionary’ 里找到相关的信息。不过,这种方式需要你手工去寻找一个字典文件,并在 vimrc 里进行配置,不那么方便。更简单的方式,是先启用拼写检查,然后正常使用拼写完成的快捷键 <C-X><C-K> 即可。如果你完整拼出了单词,但 Vim 提示拼错了,你也可以使用快捷键 <C-X>s 来使用和查看拼写建议。
注意:虽然 <C-S> 在图形界面 Vim 里可以使用,但终端(不是 Vim)可能会解释 <C-S> 为特殊控制字符,因而我们一般不使用 <C-X><C-S>。如果你发现一不小心键入 <C-S> 导致终端表现得像失去响应一样,一般可以用 <C-Q> 来恢复。
17.10 中文文本编辑
跟英文文本编辑类似,中文处理同样有段中有断行和段中无断行两种方式。如果段中有断行,中文的主要处理麻烦是在转换成 HTML 或其他格式时通常不应该把行尾结束符转换成空格。我目前测下来,GitHub 的 Markdown 能有这样的合理行为,但很多其他工具,如 pandoc,则没有对中文作这样的特殊处理。因此,中文文档还是不在段中进行断行更保险一些。
这两种文本组织方式 Vim 都是能处理的,其方式和英文文本编辑差不多,差别主要表现在下面两点。
首先,英文段中不分行时我们推荐使用 linebreak 选项,但中文段中不分行时我们则不推荐启用这个选项。因为让 Vim 挑空格位置来折行,反而会让中文文本显得乱、不好看。下面的图展示了区别:


次,Vim 在处理中日韩(CJK)文字时在格式化选项 formatoptions 里是有些特殊设置的。我们重点关注下面 4 个:
- m:可以在任何值高于 255 的多字节字符上分行。这对 CJK 文本尤其有用,因为每个字符都是单独的单位。
- M:在连接行时,不要在多字节字符之前或之后插入空格。优先于 B 标志位。
- B:在连接行时,不要在两个多字节字符之间插入空格。有 M 标志位时无效。
- ]:严格遵循 textwidth 选项。当设定这个标志时,除非断行禁则使得行长不可能保留在限定的文本宽度以内,行长不允许超出限定的文本宽度。这个选项主要用于 CJK 文字,并且仅在 encoding 是 utf-8 时才生效。
如果文档的主语言是中文(或日文、韩文),那 m 肯定是需要设置的,这样才能在中文之中断行。M 和 B 一般我们也会设置其中一个,取决于行文规则,在中文和西文字符之间是否手工插一个空格。如果不插空格,那就用 M;如果用空格(就像本文一样),那就用 B。由于 Vim 不区别汉字和汉字标点,使用 B 时会导致全角标点前后出现空格,我一般仍然使用 M 而不是 B。
标志 ] 是和 CJK 断行规则一起在 Vim 8.2.0901 这个版本引入的。你可以通过下面的截图看下这个标志的效果:

换句话说,默认未使用 ] 标志时,Vim 的行为是允许 CJK 标点符号突出到 textwidth 限定的宽度以外;使用 ] 标志则不允许这样的特殊处理。你可以按照个人喜好和文本类型来酌情使用这个选项。
18 拓展 2|C 程序员的 Vim 工作环境:C 代码的搜索、提示和自动完成
18.1 语法加亮精调
在第 4 讲中我们已经学到了,Vim 能根据文件类型对代码进行加亮。在第 12 讲里,我们还进一步讨论了 Vim 实现语法加亮的细节,知道这些是如何通过代码来进行控制的。对于 C(含其他基于 C 的语言如 C++),语法加亮文件有一些精调选项,还挺有意思,能应对一些特殊场景的需求。我一般会设置以下几项:
let g:c_space_errors = 1
let g:c_gnu = 1
let g:c_no_cformat = 1
let g:c_no_curly_error = 1
if exists('g:c_comment_strings')
unlet g:c_comment_strings
endif第一项 c_space_errors 用来标记空格错误,包括了 tab 字符前的空格和行尾空格,这样设置之后 Vim 会把这样的空格加亮出来。
第二项 c_gnu 激活 GNU 扩展,这在 Unix 下一般是必要的。
第三项 c_no_cformat 不对 printf 或类似函数里的的格式化字串进行加亮。这条可能看个人需要了。我是对错误的加亮超级反感,所以关闭这种不分场合的加亮。
第四项 c_no_curly_error 也是为了让一些 GNU 的扩展能够正确显示,不会被标志成错误。
最后,Vim 默认会在注释中加亮字符串和数字(c_comment_strings)。虽然这种加亮有时候也能派上用场,但这种配置下我常常在注释中见到错误的加亮,所以我还是关闭这个功能。
关于这些选项的说明,以及其他的 C 语法加亮选项,你可以查看帮助:help ft-csyntax。
18.2 Tags
Exuberant/Universal Ctags 有大量的命令行参数,如果我们要对某个目录下的所有 C 代码生成 tags 文件,我们可以使用:
ctags --languages=c --langmap=c:.c.h --fields=+S -R .这儿我用了 —languages 选项来指定只检查 C 语言的文件;同时,因为 .h 文件默认被认为是 C++ 文件,所以我使用 —langmap 选项来告诉 ctags 这也是 C 文件。而 —fields=+S 的作用,是在 tags 文件里加入函数签名信息。我们后面会看到这类信息的作用。
这样生成的 tags 文件只考虑符号的定义,而不考虑符号的声明。对于大部分项目,这应该是合适的。如果你希望 Vim 能跳转到函数的声明处,则需要加上 —c-kinds=+p,让 tags 文件包含函数的原型声明。但是这样一来,一个函数就可能有原型声明和实际定义这两个不同的跳转位置,所以通常你不应该这样做。我只对系统的头文件生成 tags 文件时使用 —c-kinds=+p。
此外,一个可能的麻烦就是 tags 文件需要进行更新。对于一个更新不频繁的项目,最简单的方式就是在开始时运行一下上面的命令,然后就一直不管了。而对于活跃开发中的项目,我们需要更好的办法。
一个最简单的办法,显然就是在文件存盘后自动运行上面这样的命令。比如:
function! RunCtagsForC(root_path)
" 保存当前目录
let saved_path = getcwd()
" 进入到项目根目录
exe 'lcd ' . a:root_path
" 执行 ctags;silent 会抑制执行完的确认提示
silent !ctags --languages=c --langmap=c:.c.h --fields=+S -R .
" 恢复原先目录
exe 'lcd ' . saved_path
endfunction
" 当 /project/path/ 下文件改动时,更新 tags
au BufWritePost /project/path/* call
\ RunCtagsForC('/project/path')但这种方式对于大项目是不可行的,因为会在文件存盘时引入不可接受的时延。还好,Ctags 支持用 -a 选项对 tags 文件做渐进式更新。把上面的后两段代码换成下面这样就可以了:
function! AppendCtagsForC(file_path)
let saved_path = getcwd()
exe 'lcd ' . a:root_path
exe 'silent !ctags --languages=c --langmap=c:.c.h --fields=+S -a '
\. a:file_path
exe 'lcd ' . saved_path
endfunction
au BufWritePost /project/path/* call
\ AppendCtagsForC('/project/path/', expand('%'))在执行很多 Vim 命令时,可以用 % 指代当前文件;而在调用函数时,就得用 expand 函数了(可查看帮助文档 :help expand()))。
插件 ludovicchabant/vim-gutentags 可以完成 tags 文件的管理工作。如果你希望 tags 文件能自动更新的话,这个插件很可能可以满足你的所有需求:基本上你只需要配置它的选项,而不需要自己写 Vim 脚本代码。
不过,如果你在一个大项目上工作,代码很少发生结构性更动的话,也许在 shell/cron 里定期执行 ctags 命令,是个最简单、最不对开发者造成干扰的选项。毕竟,靠编辑器触发 ctags 命令也不那么可靠——因为很多其他操作(比如 git 切换分支)之后,你也同样需要更新 tags。
18.3 EchoFunc
EchoFunc 插件可以用来回显函数的原型。
首先我们需要安装 EchoFunc,使用包管理器安装 mbbill/echofunc 即可。然后,如果你有正确的 tags 文件,现在当你输入函数名加 ( 时,Vim 就会在屏幕底部自动提示函数的原型了:
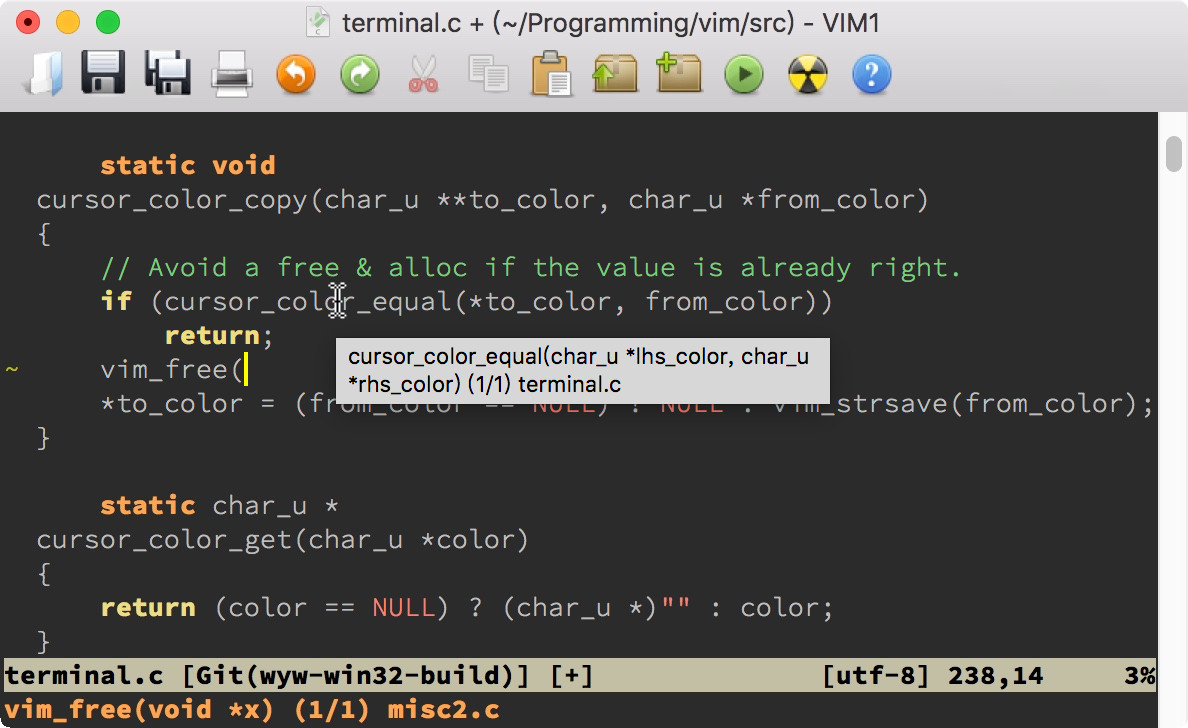
上图中实际上表现了 EchoFunc 的两个效果:一个是我们说的屏幕底部的原型回显,还有一个是鼠标移到符号上的气泡显示。后一个功能默认也是开启的(需要图形界面),但可以通过在 vimrc 配置文件中加入 let g:EchoFuncAutoStartBalloonDeclaration = 0 来禁用。
此外,当一个函数有多个原型声明时,可以用 Alt-= 和 Alt— 键来进行切换。但在 Mac 上,我和明白当年选择了把 Alt— 改成了 Alt-Shift-=。原因我现在想不起来了,估计是因为在 Mac 键盘上 Alt— 会产生短破折号(”–”),我们写文档时仍然可能会用到;而 Alt-= 和 Alt-Shift-= 产生的分别是不等号(”≠”)和正负号(”±”),基本上不会在 Vim 里使用。
18.4 Cscope
虽然 tags 是一个很有用的工具,但在我们常见的代码跳转操作里它只做到了一半:可以通过符号名称(从使用的地方)跳转到定义的地方,但不能通过符号名称查找所有使用的地方。这时候,我们有两种基本的应对策略:
- 使用搜索工具(第 8 讲讨论过的 :grep)
- 使用专门的检查使用位置的工具
诚然,第一种方式很常用、也很通用,但这毕竟是一种较”土”的办法,其主要缺点是容易有误匹配。第二种方法如果能支持的话,在完成大部分任务时会比第一种方法优越。
对于 C 代码,我们有这样的现成开源工具。由于 Vim 直接内置了对 Cscope 的支持,因此我们今天就讨论一下 Cscope。
根据 Cscope 的文档,它的定位是一个代码浏览工具,最主要的功能是代码搜索,包括查找符号的定义和符号的引用,查找函数调用的函数和调用该函数的函数,等等。查找引用某符号的地方、调用某函数的地方、包含某文件的地方,就是 Cscope 的独特之处了。
18.4.1 安装和配置
我们需要映射使用 Cscope 的按键。Cscope 的网站上提供了一个映射的脚本,不过,它里面用到了 <C-Space>,这个快捷键在很多系统上是会有问题的。因此我替换了一下,你可以安装 adah1972/cscope_maps.vim 来使用它。现在:
- 使用
<C-\>加 Cscope 命令是在当前窗口里执行 Cscope 命令 - 使用 |(Shift-\)加 Cscope 命令是横向分割一个窗口来执行 Cscope 命令
- 使用 || 加 Cscope 命令是纵向分割一个窗口来执行 Cscope 命令
Cscope 也可以配合 quickfix 窗口使用,这样,相应命令的结果就会放到 quickfix 窗口里,而不是直接在界面上提供一个可能有几千项的列表让你选择。一般推荐在 vimrc 配置文件里加入:
set cscopequickfix=s-,c-,d-,i-,t-,e-,ag18.4.2 创建 Cscope 数据库
要创建 Cscope 的数据库,只要在项目的根目录下运行 cscope -b 即可。拿 Vim 的约 50 万行代码为例,在我的笔记本上首次运行该命令需要四秒,产生了一个 13M 大小的 cscope.out。后面再运行该命令,Cscope 只会更新修改的部分,那就快得多了。不过,跟 Ctags 比,不管是首次创建,还是后面更新,Cscope 都要慢一点。这当然也很正常,毕竟 Cscope 要干的事情更多。
18.4.3 使用
Cscope 命令简要列表如下:
- g: 查找一个符号的全局定义(global definition)
- s:查找一个符号(symbol)的引用
- d:查找被这个函数调用(called)的函数
- c:查找调用(call)这个函数的函数
- t:查找这个文本(text)字符串的所有出现位置
- e:使用 egrep 搜索模式进行查找
- f:按照文件(file)名查找(和 Vim 的 gf、
<C-W>f命令相似) - i:查找包含(include)这个文件的文件
- a:查找一个符号被赋值(assigned)的地方
比如,我们在 Vim 的源代码里要查找 vim_free 函数的定义,只需要键入命令 :cscope find g vim_free,或者把光标移到符号 vim_free 上,然后按下 <C-\>g。在目前的配置下,使用 <C-]> 也可以,因为 cscope_maps.vim 脚本里设置了 :cscopetag 选项(参见帮助 :help cscopetag)。
如果我们想要使用分割窗口,那对应的命令是 :scscope find g vim_free,光标已经在符号上时的按键是 |g 或 <C-W>]。如果我们想要垂直分割窗口,那命令是 :vert scscope find g vim_free,光标已经在符号上时的按键是 ||g。
其他的 Cscope 命令也类似,把 g 替换成相应的命令即可。值得提一下,虽然 t 和 e 命令在 Vim 里可以用 :grep 命令替代,但这两个命令执行起来要比 :grep 快。当然, Cscope 的真正优势还是 s、c、i、a 这样的命令。下面展示的是在一个 Vim 源文件中执行符号引用查找(s)的结果,可以看到比 :grep 还是方便快捷了很多的:

18.5 ClangComplete
下面,我们来讨论一下一个新话题,C 代码的自动完成。
众所周知,Clang 是一个目前很流行的、模块化的 C/C++ 编译器。它跟其他 C/C++ 编译器最不一样的地方,是它让其他程序能够很容易利用 Clang 对源代码的处理结果。目前很多对 C/C++ 源代码进行处理的工具,都是基于 Clang 来开发的。ClangComplete 也是其中的一个,它在 Vim 中添加了对 C/C++ 代码的自动完成功能。
说到这里,我需要强调一下,ClangComplete 目前已经不是我最推荐的自动完成插件了——我更喜欢下一讲要讨论的 YouCompleteMe,它的功能更为强大,使用也更为方便。不过呢,ClangComplete 在某些环境里安装起来更加简单,如果出于某种原因,你的系统上安装 YouCompleteMe 不成功,那么 ClangComplete 也不失为一个后备方案。
此外,在我的配置方案里,ClangComplete 和 YouCompleteMe 是可以共用配置文件的,所以讲 ClangComplete 的功夫也不会完全白费。下面我就简单地介绍一下。
18.5.1 安装
ClangComplete 对系统的基本要求就是你已经安装了 LLVM/Clang。你需要告诉 ClangComplete,在哪里可以找到 libclang。
Windows 下默认是没有 Clang 的,如果你不是已经安装了 Clang,你可以直接跳过这节,直奔下一讲讨论 YouCompleteMe 的安装过程。
在 macOS 上,如果你安装了开发工具,那其中就应该有 libclang,通常你可以在 /Library/Developer/CommandLineTools/usr/lib 目录下找到 libclang.dylib,或者如果你用 Homebrew 安装了 llvm 的话,应该可以在 /usr/local/opt/llvm/lib 目录下找到 libclang.dylib。
在 Linux 上,这又是个跟发布版相关的问题了。我们一般可以通过关键字”libclang”、”clang”和”llvm”(从最特别到最通用)来查找。在 Ubuntu 18.04 上,我们可以在使用命令 sudo apt install libclang1-10 之后找到文件 /usr/lib/x86_64-linux-gnu/libclang-10.so.1。在 CentOS 7 上,我们可以在安装 LLVM Toolset 7.0 之后找到文件 /opt/rh/llvm-toolset-7.0/root/usr/lib64/libclang.so。这些路径我们等会儿就要用到。注意如果 libclang 的文件名不是”libclang”加平台的动态库后缀的话,我们需要使用 libclang 的完整名字。
有了 libclang 之后,ClangComplete 本身的安装很简单,就是在包管理器里安装 xavierd/clang_complete,然后在 vimrc 配置文件里加一个全局变量,告诉 ClangComplete 在哪儿可以找到 libclang。比如,在上面说的 Ubuntu 18.04 里,我们就应该在 vimrc 配置里加上:
let g:clang_library_path = '/usr/lib/x86_64-linux-gnu/libclang-10.so.1'下面就是我们在这样配置过后,在 Ubuntu 里得到的结果:

我们可以看到,现在 Vim 知道了 tm 是个结构的指针,并且知道指针的成员有哪些。
这个例子比较简单,如果我们在命令行上进行编译的话,不需要任何特殊参数。如果我们命令行上需要参数,那很可能 ClangComplete 也需要知道这些参数,才能正确工作。这些参数信息应该放在文件所在目录或其父目录下的名为 .clang_complete 的文件里。比如,我的极客时间 C++ 课程的示例代码里就有这个文件,内容也很简单:
-std=c++17
-D ELPP_FEATURE_CRASH_LOG
-D ELPP_FEATURE_PERFORMANCE_TRACKING
-D ELPP_NO_DEFAULT_LOG_FILE
-D ELPP_PERFORMANCE_MICROSECONDS
-D ELPP_UNICODE
-I common
-I 3rd-party/nvwa
-I 3rd-party/cmcstl2/include
-I 3rd-party/cppcoro/include
-I 3rd-party/expected/include由于只要能编译就可以工作,一般这个配置文件里只需要定义语言标准、预定义宏和头文件路径就可以了,优化选项、库路径和链接库名字则不需要。
18.6 Clang-Format
Clang-Format 是又一个 Clang 项目提供的工具,能够很”聪明”地格式化你的代码。作为 Clang 家族的一部分,它的代码格式化是在基于能够真正理解语言语法的基础上做的,因此比其他的格式化工具要智能、强大得多。在你安装了这个工具之后,它很容易和 Vim 集成,能大大提升代码格式化体验,因此我在这里也介绍一下。
在 Windows 上和 macOS 上,Clang-Format 一般作为 LLVM 安装的一部分提供。Windows 用户建议直接安装官方提供的下载版本。macOS 用户一般建议使用 Homebrew 安装:brew install llvm。
Linux 上就复杂点了,取决于不同的发布版,Clang-Format 可能作为 LLVM 大包的一部分提供,也可能是一个单独的工具。比如,在 Ubuntu 里,Clang-Format 是单独安装的:sudo apt install clang-format。而在 CentOS 7 里,Clang-Format 是 llvm-toolset-7.0 的一部分。所以你需要自己检查一下。
有了 clang-format 可执行程序之后,我们还需要一个 clang-format.py 脚本来和 Vim 集成。这个脚本文件的安装位置在不同环境是不同的,而且路径可能跟 LLVM 版本相关。比如,我在 Ubuntu 下从 /usr/share/clang/clang-format-10 下面找到了这个文件,在 macOS 上则是一个固定位置 /usr/local/opt/llvm/share/clang。但如果你在 LLVM 所在的目录下找不到的话,也没关系。你可以直接从网上下载,放到你自己知道的一个位置。
我们如果把这个脚本的位置记作 /path/to/clang-format.py,那我们现在在 vimrc 配置里加上这行以后就能工作了:
noremap <silent> <Tab> :pyxf /path/to/clang-format.py<CR>我是映射了 <Tab> 在正常模式和可视模式下对代码进行格式化。如果正常模式的话,我们是对当前语句执行格式化。如果可视模式,那就是对选定的行进行格式化了。这些应该都非常自然了。
Clang-Format 使用规则配置文件来确定如何进行格式化。首次配置觉得复杂的话,你可以参考我的配置文件。具体的效果你可以根据你的项目要求来调整。这个配置文件 .clang-format 同样是放在你的源代码文件目录下或其某一父目录下。
格式化的过程可以参考下面的动画:

19 拓展3|Python 程序员的 Vim 工作环境:完整的 Python 开发环境
19.1 功能简介
Python-mode 实际上是以 Vim 插件形式出现的一套工具,它包含了多个用于 Python 开发的工具。根据官网的介绍,它的主要功能点是:
- 支持 Python 3.6+
- 语法加亮
- 虚拟环境支持
- 运行 Python 代码(
<leader>r) - 添加 / 删除断点(
<leader>b) - 改善了的 Python 缩进
- Python 的移动命令和操作符(]], 3[[, ]]M, vaC, viM, daC, ciM, …)
- 改善了的 Python 折叠
- 同时运行多个代码检查器(:PymodeLint)
- 自动修正 PEP 8 错误(:PymodeLintAuto)
- 自动在 Python 文档里搜索(K)
- 代码重构
- 智能感知的代码完成
- 跳转到定义(
<C-c>g) - ……
不过,还是要提醒一句,它的功能虽然挺多,但作为非商业软件,全靠志愿者来贡献代码,并不是所有功能的完成度都很高。
19.2 安装
Python-mode 没有编译组件,全部由脚本代码组成,因而使用你的包管理器安装 python-mode/python-mode 即可,非常简单。
以 minpac 为例,你只需要在 vimrc 配置文件中”Other plugins”那行下面加入:
call minpac#add('python-mode/python-mode')然后执行 :PackUpdate 命令即可。
19.3 配置
在没有任何配置的情况下,python-mode 也是完全可用的。但如果你再做一些基本设置的话,就能够解决一些常见问题和规避一些常见陷阱。
我个人的设置是下面这个样子的:
function! IsGitRepo()
" This function requires GitPython
if has('pythonx')
pythonx << EOF
try:
import git
except ImportError:
pass
import vim
def is_git_repo():
try:
_ = git.Repo('.', search_parent_directories=True).git_dir
return 1
except:
return 0
EOF
return pyxeval('is_git_repo()')
else
return 0
endif
endfunction
let g:pymode_rope = IsGitRepo()
let g:pymode_rope_completion = 1
let g:pymode_rope_complete_on_dot = 0
let g:pymode_syntax_print_as_function = 1
let g:pymode_syntax_string_format = 0
let g:pymode_syntax_string_templates = 0稍微解释一下:
- IsGitRepo 是利用 Python 代码检测当前是不是在 Git 库目录下的一个函数,它要求你 在 Python 环境里安装了 GitPython(pip3 install GitPython)。
- 我们仅仅在当前目录是一个 Git 库下面才启用 rope 支持(pymode_rope)。Rope 是 python-mode 里提供语义识别和自动完成的主要工具,它会扫描所有子目录并创建 rope 工程目录。如果你一不小心在你的主目录(或子目录非常多的地方)执行 python-mode 的命令,可能会导致 Vim 卡顿(python-mode 并不是一个异步的插件)。所以我们在这儿特别限制一下,防止误操作。
- 我们启用 rope 的完成功能(pymode_rope_completion)。
- 我们禁用在输入 . 号时自动完成的功能(pymode_rope_complete_on_dot)。这是因为 rope 提供的自动完成会侵入式地影响正常输入流,即如果我想不理睬自动完成是不行的。这一点就不如 YCM 了。因此,我们的自动完成仍然使用 YCM。不过,需要的话,我们仍可以通过
<C-X><C-O>来使用 rope 的自动完成。 - Python-mode 对 Python 语法的加亮改善还不错,但它的默认行为是把 print 作为保留字显示,而不是普通函数。在写 Python 3 时,还是需要修改一下它的行为(pymode_syntax_print_as_function)。
- Python-mode 会试图对字符串中出现的格式化字串和模板替换字串做特殊的加亮(pymode_syntax_string_format 和 pymode_syntax_string_templates)。这儿主要的问题是,它会误匹配字符串中出现的 {} 和 $ 序列。我个人不习惯错误的加亮,不过你可以根据自己的喜好,来决定是不是要启用这个功能。
19.4 使用
19.4.1 语法加亮
Python-mode 提供了自己的语法加亮文件。除了上面提到的可以选择对 print 如何加亮,以及在字符串内部进行特殊加亮的选项外,它还提供了很多改进,并且可以由用户通过选项来微调(:help pymode-syntax),如对赋值号(=)的特殊高亮和对 self 的特殊高亮,等等。这些改进我觉得还挺有用。
19.4.2 代码折叠
我个人一直不怎么喜欢代码折叠(主要是觉得额外展开这个步骤非常有干扰,而更愿意一目十行式地快速浏览),所以 Vim 的这个功能我基本不用。如果你喜欢折叠的话,你应该会很高兴 python-mode 能帮你自动折叠 Python 代码。你只需要在 vimrc 配置文件中加入下面这行即可:
let g:pymode_folding = 1效果见下图:
这个功能会导致打开 Python 文件变慢。
19.4.3 快速文档查阅
Python-mode 默认映射了 K 对光标下的单词进行文档查阅。跟其他查阅文档的方式比起来,这还是非常快捷方便的。
19.4.4 缩进支持
在 Vim 的运行支持文件中,本来就包含了对 Python 缩进的支持,但默认的支持并没有把像 PEP 8 这样的 Python 编程规范考虑进去,缩进风格并不十分正确。安装了 pythonmode 后,缩进就能更好地自动遵循 PEP 8 规范了。
19.4.5 代码检查
不管 Vim 的缩进对不对,如果你在其他编辑器里编辑了 Python 代码,Vim 是不会修正其中的缩进或其他问题的——除非你启用代码检查器。
Python-mode 里带了好几个代码检查器,默认启用的是下面三个:
- pyflakes,一个很轻量的代码检查器,检查常见的 Python 编码问题,如未使用的变量和导入
- pep8,一个专门检查代码是否符合 PEP 8 的检查器
- mccabe,一个专门检查圈复杂度的代码检查器
默认启用哪些检查器,是通过下面的全局变量来控制的:
let g:pymode_lint_checkers = ['pyflakes', 'pep8', 'mccabe']我觉得默认的代码检查器还比较合适,因为执行真的很快,基本上可以在执行检查的瞬间帮你检查完代码并标记出问题。你可以手工执行 :PymodeLint 来检查代码,python-mode 也会自动在你保存文件时进行检查。

可以看到,检查的结果会在屏幕的左侧标记出来,表示不同的问题类型;并且光标移到这样的行上,Vim 底部还会显示问题的描述信息。同时,python-mode 检查出问题时会自动打开一个位置列表,我们在第 13 讲提过,这是跟窗口关联的类似于快速修复窗口的信息窗口。由于我们可能在多个窗口/标签页编辑多个文件,位置列表确实比较合适。当 python-mode 认为你修复了所有问题时,这个位置列表也会自动关闭。
顺便提醒你注意一下屏幕右侧的红线(在某些配色方案里可能是其他颜色)。这条线在第 80 列上,也是提醒你写代码不能到那个位置,因为 PEP 8 规定 Python 代码行最长是 79 个字符。如果到达红线位置的话,那 pep8 检查的时候,一定跑不了,会报错的。
上面图中的错误都是 PEP 8 问题,绝大部分可以简单地执行 :PymodeLintAuto 命令来自动解决,用不着我们自己去动手修改代码。
Python-mode 还有两个没有默认启用的检查器:
- pylint,一个功能很强的代码检查器,它可以嗅出你的代码中的坏味道,除了性能,可以说是全面强于 pyflakes(使用它你得擦亮眼睛,做好被它虐的准备)
- pep257,一个检查文档串(docstring)是否符合 PEP 257 的工具(这个工具我个人感觉不成熟,给出的建议有点混乱)
由于 pylint 执行比较慢,我觉得还是先写完代码再专门来扫描并解决其报告的问题比较合适。上面的这个示例代码,跑 pylint 需要超过一秒才能执行完成,在存盘时自动执行检查基本属于不可忍受。这当然也是因为 python-mode 没有异步执行外部命令造成的。我们最后还会再看一下执行慢和异步的问题。
19.4.5 Rope 支持
Rope 是一个 Python 库,提供对 Python 代码的分析、重构和自动完成功能。由于我们使用 YCM 来进行自动完成,也能完成像跳转到定义这样的任务,rope 就略显鸡肋了。不过,它有重命名重构功能,而 YCM 并不支持对 Python 的重命名重构,所以两者功能还不算完全重叠。
你如果决定要用一下 rope 的话,需要了解以下几点:
- rope 会使用一个叫做 .ropeproject(默认名字)的目录,在里面缓存需要的信息;这个目录在当前目录下,或当前目录的一个父目录下;如果找不到,默认会在当前目录下创建这个目录
- 使用命令 :PymodeRopeNewProject 路径 可以在指定路径下创建这个 .ropeproject 目录
- 使用命令 :PymodeRopeRegenerate 可以重新产生项目数据的缓存
- 默认情况下(g:pymode_rope_regenerate_on_write 等于 1),在文件存盘时 python-mode 即会自动执行 :PymodeRopeRegenerate 命令
在启用 rope 之后,你就可以使用下面的命令了:
- 使用
<C-X><C-O>来启用自动完成(我们把 . 还是交给 YCM 了) - 使用
<C-C>g来跳转到定义(跟 YCM 的 \gt 比,大部分情况下没区别;rope 跳转更好和 YCM 跳转更好的情况都有,但都不多见) - 使用
<C-C>d来查看光标下符号的文档;和 K 键不同,这个命令可以查看当前项目代码里的文档字串 - 重构(refactor)功能以
<C-C>r开始,如<C-C>rr是重命名(rename)光标下的符号,这些功能还是比较强大的(可以使用 :help pymode-rope-refactoring 来查看完整的帮助信息)
下面的动图展示了 rope 的若干功能:

19.4.6 替换方案
如果你对 python-mode 的某些功能不满意,可以禁用其部分功能,用其他插件来代替。
首先,如果你如果觉得 rope 提供的额外功能对你用处不大的话,我们可以完全禁用 rope(let g:pymode_rope = 0),专心使用 YCM。这样,硬盘上也就不会出现 .ropeproject 那样的目录了。
其次,如果你真的希望能在写代码的时候自动进行 pylint 检查,那你也可以禁用 pythonmode 里的代码检查器功能(let g:pymode_lint = 0),转而使用 ALE 来进行异步检查。你需要安装它(包管理器需要的名字是 dense-analysis/ale),并在 vimrc 配置文件中加入:
let g:ale_linters = {
\'python': ['pylint'],
\}别忘了这种情况下,你需要自己用 pip 安装 pylint。这不像 python-mode 的情况,所有工具都已经打包在那一个套件里面了。
20 拓展4 | 插件样例分析:自己动手改进插件
虽说插件和其他 Vim 脚本之间的界限也并非泾渭分明,但我们一般把满足以下条件的 Vim 脚本称为插件:
- 功能独立,不依赖特殊的个性化配置
- 存在加载时即会执行的代码,一般放在 plugin 目录下(也有放在 ftplugin、ftdetect 等其他目录下的情况)
20.1 ycmconf
我们要看的第一个脚本,是在讲 YCM 时引入的 ycmconf。这是一个非常简单的插件,我们就拿它开始我们今天的课程。
如果你之前按我说的步骤安装的话,现在应该可以在 Vim 配置目录下的 pack/minpac/start/ycmconf 里找到它。你也可以自己用 Git 签出:
git clone https://github.com/adah1972/ycmconf.git除去一些文本说明文件,这个插件里只有两个真正的脚本文件:
- plugin/ycmconf.vim
- ycm_extra_conf.py
plugin 目录是 Vim 里主要放置无条件执行的脚本的地方,即”插件”的主体。打开 plugin/ycmconf.vim,我们看到里面只有一行注释加一行代码:
" Set the global extra configuration
let g:ycm_global_ycm_extra_conf=expand('<sfile>:p:h:h') . '/ycm_extra_conf.py'这个差不多是个最简单的插件了吧。Vim 脚本里只做了一件事,设置全局变量 g:ycm_global_ycm_extra_conf 给 YCM 用。关于脚本中的 expand 函数,我们稍微展开一下:
- expand 是用来展开文件名的。参数字符串里如果有 %,就代表当前编辑的文件名;如果有
<sfile>,代表当前执行的源代码文件(其他可展开的名字请参见 :help expand()))。 - :p 用来告诉 expand,我们需要得到完整的路径。比如,在我的机器上,这样展开的结果是 /Users/yongwei/.vim/pack/minpac/start/ycmconf/plugin/ycmconf.vim 。
- :h 用来告诉 expand,我们需要头部,即去掉路径的最后部分。我会得到 /Users/yongwei/.vim/pack/minpac/start/ycmconf/plugin 。
- 第二次使用 :h,我们再次去掉路径的最后部分,即 plugin。我会得到 /Users/yongwei/.vim/pack/minpac/start/ycmconf 。
随后,我们拿这个路径跟 ‘/ycm_extra_conf.py’ 进行拼接,就得到了 YCM 可以看到的 ycm_extra_conf.py 文件的路径。
这个插件的主体功能在 ycm_extra_conf.py 里。鉴于这是 Python 的代码,而不是 Vim 脚本,我就不再讲解了。你如果有兴趣的话,可以自己看一下。文件虽然总共要好几百行,但注释比较多,逻辑其实不复杂;如果你懂 Python,一定可以理解里面的内容。
20.2 cscope_maps.vim
拓展 2 里我给出了一个自己改过的 cscope_maps.vim,我们现在就来看看它的原始版本,然后看一下怎么修改它的行为。
原始版本在 Cscope 的网站上。可以看到,这也是一个比较简单的 Vim 脚本,应当直接放到 plugin 目录下。虽然文件总共有一百多行,倒有一大半是注释;实际代码行只有三十几行。我们可以细细地分析一下:
最外围,是一个条件语句,确保这个插件的内容仅在 Vim 支持 Cscope 时得到执行:
if has("cscope")
…
endif在条件语句里,有三行是设置 Vim 选项的:
set cscopetag
set csto=0
set cscopeverbose- 设置 cscopetag 使得我们在使用原先 tags 相关的命令时会同时查找 Cscope 数据库
- 设置 csto 为 0 是让 Vim 先查找 Cscope 数据库,找不到才查找 tags
- 设置 cscopeverbose 是让 Vim 在之后添加 Cscope 数据库时,告诉你结果成功与否
设置最后这个选项是在下面的语句之后:
if filereadable("cscope.out")
cs add cscope.out
elseif $CSCOPE_DB != ""
cs add $CSCOPE_DB
endif也就是说,Vim 会在启动时悄无声息地试图加载当前目录下的 cscope.out 数据库或环境变量 CSCOPE_DB 指定的数据库,并且不会报告结果。
剩下的代码就全部是……键映射了。我们就看其中的一个,其余的都大同小异:
nmap <C-\>s :cs find s <C-R>=expand("<cword>")<CR><CR>这个键映射把 <C-\>s 映射成了一个 :cs find s … 命令。值得注意的是命令的后半截:
- 脚本里使用
<C-R>=…<CR>来执行一个 Vim 表达式,并把结果填到命令里。 - 我们又一次见到了 expand 函数。这一次,要展开的是
<cword>,即当前光标下的单词。 - 注意结尾两个
<CR>里第一个是给<C-R>=的,第二个才是执行命令的回车键。
让我有意见的是下面这样的键映射:
nmap <C-@>s :scs find s <C-R>=expand("<cword>")<CR><CR>这儿用 <C-@> 代表 Ctrl- 空格,而这个组合键在很多系统上不可用。既然已经使用了 Ctrl-\ 作为 Cscope 的专用起始键,我觉得继续用 Shift-\ 就好。由于 | 在 Vim 里用来分隔多个语句,这儿我们要换个写法,改成:
nmap <bar>s :scs find s <C-R>=expand("<cword>")<CR><CR>我的完整修改过程,可以查看:https://github.com/adah1972/cscope_maps.vim/commits/master
20.3 EchoFunc
事实上,大部分行为良好的插件会允许用户通过一些全局变量来定制键映射之类的设定。不过,对于没有提供这种定制性的插件,我们自己找到代码里的键映射语句,手工修改一下,也是一种可能发生的常见情况。比如,EchoFunc 里查看下一个和上一个函数的按键分别可以用全局变量 g:EchoFuncKeyNext 和 g:EchoFuncKeyPrev 来修改。一般来说,插件的文档里会进行说明,你也可以在插件里通过搜索 exists 函数来找到插件提供出来的定制点。
以 EchoFunc 为例,它虽然简单到没有提供帮助文档,但插件的主文件(after/plugin/echofunc.vim)开头有大段的注释。同时,它有大量的 exists 的函数调用,来检查用户是否已经定义了某一全局变量来定制行为:
if !exists("g:EchoFuncMaxBalloonDeclarations")
let g:EchoFuncMaxBalloonDeclarations=20
endif
if !exists("g:EchoFuncKeyNext")
if has ("mac")
let g:EchoFuncKeyNext='≠'
else
let g:EchoFuncKeyNext='<M-=>'
endif
endif
if !exists("g:EchoFuncKeyPrev")
if has ("mac")
let g:EchoFuncKeyPrev='±'
else
let g:EchoFuncKeyPrev='<M-->'
endif
endif在我这儿给出的三个全局变量的相关定义里,第一个是对起泡提示的数量限制,第二个是下一个函数的键定义,第三个是上一个函数的键定义。在后两个键定义里,还分平台(Mac 或非 Mac)进行了不同的设置。这些都是非常直接了当的。
如果我们在 EchoFuncKeyNext 上面按下 * 来搜索这个变量的使用,我们就会发现它们是在函数 EchoFuncStart 里被真正使用的:
if maparg(g:EchoFuncKeyNext, "i") == '' && maparg(g:EchoFuncKeyPrev, "i") == ''
exec 'inoremap <silent> <buffer> ' . g:EchoFuncKeyNext . ' <c-r>=EchoFuncN()<cr>'
exec 'inoremap <silent> <buffer> ' . g:EchoFuncKeyPrev . ' <c-r>=EchoFuncP()<cr>'
endif这儿的代码说的是:
- 如果 g:EchoFuncKeyNext 和 g:EchoFuncKeyPrev 描述的键映射(:help maparg()))在插入模式(”i”)没有被占用(== ‘’)的话,那我们就执行(exec)针对当前缓冲区(
<buffer>)的插入模式键映射(inoremap),让其安静地(<silent>)执行(<c-r>=)函数中的语句。
注意,在键映射中使用 <C-R>= 来执行语句是一种常用技巧。这种情况下,我们常常不是要获得函数返回的结果(所以这些函数通常返回 ‘’),而只是需要执行一些指定的代码,产生需要的”副作用”。在这儿,我们需要的副作用就是选择函数列表里的下一项和上一项了。
EchoFunc 算是一个中等规模的 Vim 插件,也有好几百行代码了,我们没有必要全部讲一遍。它的初始化过程比较有特点,我们看一下:
augroup EchoFunc
autocmd BufRead,BufNewFile * call s:EchoFuncInitialize()
augroup END也就是说,在读入文件后,或创建新文件后,才调用 s:EchoFuncInitialize() 进行初始化。
那 s:EchoFuncInitialize() 究竟做了些什么呢?看下面:
function! s:EchoFuncInitialize()
augroup EchoFunc
autocmd!
autocmd InsertLeave * call EchoFuncRestoreSettings()
autocmd BufRead,BufNewFile * call CheckedEchoFuncStart()
if has('gui_running')
menu &Tools.Echo\ F&unction.Echo\ F&unction\ Start :call EchoFuncStart()<CR>
menu &Tools.Echo\ F&unction.Echo\ Function\ Sto&p :call EchoFuncStop()<CR>
endif
if has("balloon_eval")
autocmd BufRead,BufNewFile * call CheckedBalloonDeclarationStart()
if has('gui_running')
menu &Tools.Echo\ Function.&Balloon\ Declaration\ Start :call BalloonDeclarationStart()<CR>
menu &Tools.Echo\ Function.Balloon\ Declaration\ &Stop :call BalloonDeclarationStop()<CR>
endif
endif
augroup END
call CheckedEchoFuncStart()
if has("balloon_eval")
call CheckedBalloonDeclarationStart()
endif
endfunction我下面概要解说一下:
- 在 EchoFunc 自动命令组里,执行 autocmd!,清空已有的自动命令,即刚才的 call s:EchoFuncInitialize() 语句。
- 在 InsertLeave,离开插入模式事件里,调用 EchoFuncRestoreSettings 函数,停止函数回显。
- 在读入文件或创建新文件时,检查是否需要启用函数回显。
- 在图形界面下创建启停函数回显的菜单项。
- 如果 Vim 支持气泡显示,在读入文件或创建新文件时,检查是否需要启用气泡函数声明提示,并在图形界面下创建启停气泡函数声明提示的菜单项。
- 对当前文件,检查是否需要启用函数回显和起泡函数声明提示。
最后,如果你好奇为什么 EchoFunc 选择使用 after/plugin 目录而不是 plugin 目录,在它的 Git 日志里是有说明的:
1) fix key “(“ “)” mapping conflict with other plugins:
first, move plugin folder into after/ folder, so that echofunc will be load after most plugins have been loaded
Second, if during initialization time, if it find “(“ or “)” key have been mapped, it will try to append
<Plug>EchofuncXXfunction to it.
因为它用到 ( 和 ) 作为键映射,容易和其他插件冲突,因此它会最后加载,并尽量把自己键映射补充进去。
20.4 arm-syntax-vim
今天最后一个插件样例,是我最近的一个实际需求。由于我写的代码需要最终跑在 ARM 平台上,我偶尔需要检查一下产生的 ARM 汇编代码。在 Vim 的默认配置下,产生的汇编代码效果不太理想,如下图所示:
这里最糟糕的地方是,stmfd 那行里的 {r4, lr} 居然显示成了注释?是可忍,孰不可忍!
还好,我用不着从头开始自己搞。网上略加搜索,我就找到了 ARM9/arm-syntax-vim 这个 Vim 脚本,可以获得好得多的效果,如下所示:
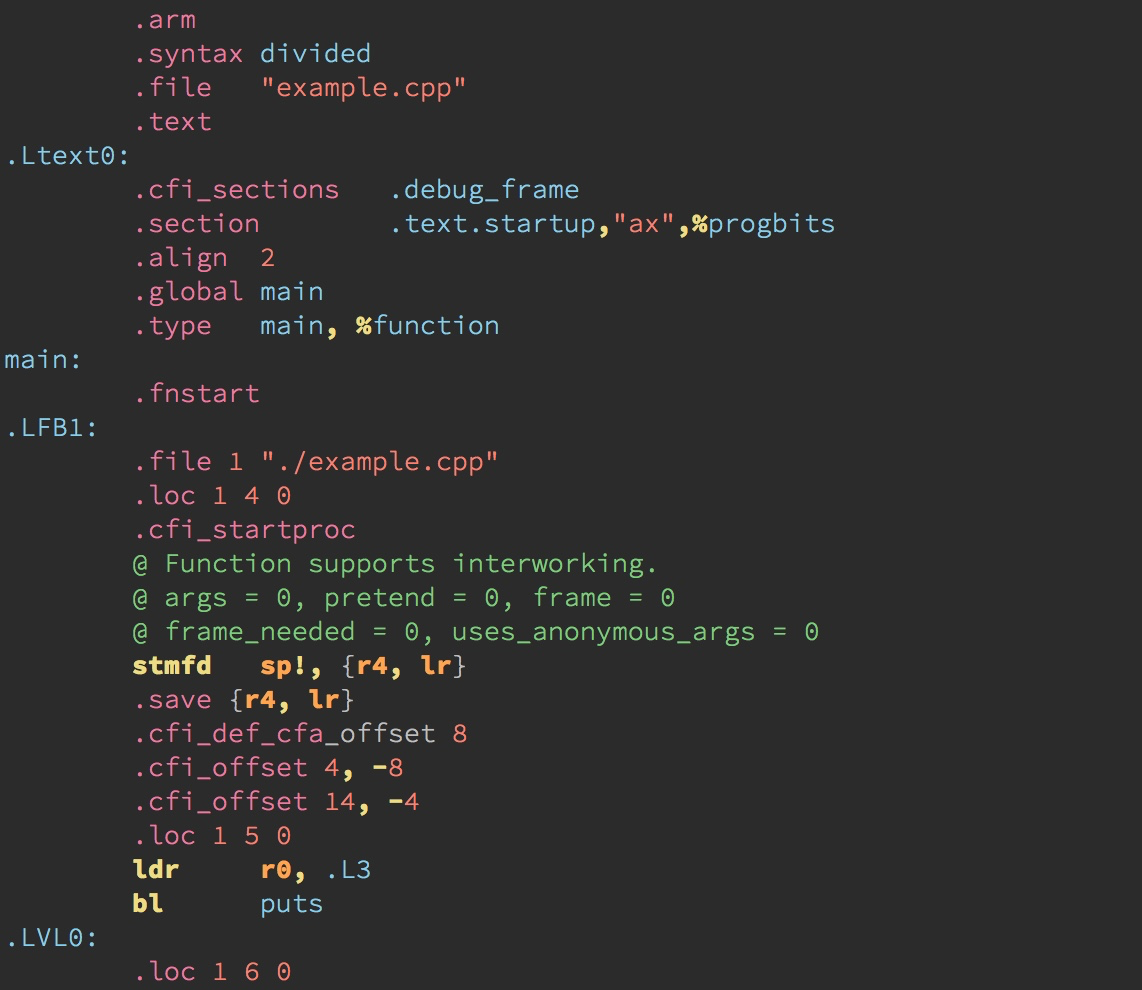
不过,这个脚本还是缺了点东西,它只包含了语法文件,不能把 GCC 产生的 .s 文件识别为它支持的 arm、armv4 和 armv5 格式。我要做的就是添加文件类型识别,让 Vim 把 ARM 的汇编文件识别成合适的 ARM 格式。
在 第 8 讲 讨论文件类型判断时,我已经说过,在 Vim 里后缀不是判断文件类型的唯一依据。既然我懒到不愿意在汇编文件里加帮助识别的文本,我当然也懒得去改汇编文件的后缀了。GCC 产生的汇编代码里的一些特定标识,也使得我利用文本判断变得相当容易:取决于不同的环境,汇编中一般会出现 .arch arm 和 .cpu arm 这样的明确行。
要让 Vim 进行文件类型判断,标准做法是在 ftdetect 目录下加入判断脚本。既然我们知道后缀是 .s,在这个文件中我会写入:
au BufRead *.[sS] call arm#ft#FTarm()为了加快 Vim 的启动速度,真正检测需要的代码一般推荐放到 autoload 目录下。这是 Vim 的专门机制,允许脚本”按需”加载,仅在用到函数的时候,才载入函数的定义(:help autoload)。在上面的写法下面,当 Vim 读入后缀为 .s 或 .S 的文件时, Vim 会自动在 autoload/arm 目录下载入 ft.vim,然后调用其中的 FTarm 函数。
下面我们来看一下 ft.vim 文件。这个文件不大,完整内容展示如下:
let s:cpo_save = &cpo
set cpo&vim
function! arm#ft#FTarm()
let head = ' '.getline(1).' '.getline(2).' '.getline(3).' '.getline(4).
\' '.getline(5).' '
" Can't use setf, as we need to overrule the default filetype setting
if matchstr(head, '\s\.arch\s\+armv4') != ''
set filetype=armv4
elseif matchstr(head, '\s\.arch\s\+armv5') != ''
set filetype=armv5
elseif matchstr(head, '\s\.arch\s\+arm') != ''
set filetype=arm
elseif matchstr(head, '\s\.cpu\s\+arm') != ''
set filetype=arm
endif
endfunction
let &cpo = s:cpo_save
unlet s:cpo_save开头和结尾的四行属于 Vim 脚本的标准模板写法:进入脚本时保存兼容性选项(:help ‘cpoptions’)的当前值,然后恢复其为默认值,免得其他地方的设置影响对脚本的解释;退出时则恢复原来保存的兼容性选项值。
中间主体部分就一个函数,做的事情也很简单,就是把文件的头五行内容拼到一起,然后看能不能找到满足条件的”.arch”和”.cpu”语句。找到的话,就设置合适的文件类型;找不到,就不做处理,留给其他的 Vim 脚本来继续判断。
这儿唯一比较特别点的地方是,一般设置文件类型推荐使用 :setfiletype 命令,它会避免重复设置,在一次 Vim 的自动事件触发过程中只执行一次。对于我们当前的目的,这是不够的:因为在我们的代码执行之前,当前缓冲区一般已经被系统的自动命令设置过类型了。具体来说,是运行支持文件里的 autoload/dist/ft.vim 里的 dist#ft#FTasm 函数。
所以,我们这儿需要强行覆盖已经设置的文件类型,用 set filetype=… 就可以做到。要注意,仅在你很有信心你设置的类型正确时才可以这么做,否则,你可能会干扰其他插件的结果。
这样,我就做到了在用 Vim 打开 GCC 产生的 ARM 汇编文件时,能自动检测并应用合适的 arm 语法。完整的代码可从 adah1972/arm-syntax-vim 下载。
21 拓展5 | 其他插件和技巧:吴咏炜的箱底私藏
21.1 插件
21.1.1 Syntastic 和 ALE
总体来说,我对代码检查的推荐顺序是:
- 使用 YCM、Python-mode、Vim-go 等有语言针对性的插件,如果你用的语言被支持,并且插件集成的代码检查功能够用的话
- 使用 ALE,如果你的语言和代码检查插件它能够支持的话
- 使用 Syntastic,如果其他选项不适用,或者你需要的检查执行够快的话
21.1.2 Renamer
Renamer
在需要对文件进行批量更名时,我会使用 qpkorr/vim-renamer 插件。它提供 :Renamer 命令,会打开当前目录下所有文件的列表。你随后就可以利用 Vim 强大的正则表达式和编辑功能来调整这些名字了。在调整完成后,执行 :Ren 命令即可。
.webp)
注意,图中的第二、三行提供了命令的说明,比如用 > 来多展开一层目录,等等。你应该只做行内的修改,而不去删除行或调整行的顺序,否则可能引致意外的后果。使用 <CDel> 可以删除当前行的文件,这算是一种例外情况。
在图中,我只是手工修改了”log.conf”那行的文件名。更常见的情况是利用 Vim 的编辑功能做批量操作。比如,你需要把文件名变成小写,可以选中要修改的部分然后使用 gu 命令。又比如,如果你的文件里有大量的编号,你希望对编号进行增减的操作,也可以利用 Vim 的 <C-A> 和 <C-X> 来对编号进行加减操作。当然,这时你可能需要使用可视模式的列选择(<C-V>)。
你还有可能需要注意一下选项 nrformats,因为如果其中含有 octal 的话,Vim 会把 0 打头的数字序列当成八进制来处理。还好,如果你按照我目前给出的方式来设置 vimrc 配置文件的话,缺省里面不含 octal,只会对 0b 和 0x 打头的数字做特别处理,这就不会跟普通的十进制数字编号有任何冲突了。
21.1.3 Undowarning
Vim 里有跨会话撤销修改的功能,这当然是它的强大的特色功能。不过,有时候也许你会发现,不小心多按了几下 u,你就退回到打开文件之前的版本去了。我想,这很有可能不是你想要的行为吧?如果你,像我一样,希望能够无限制地进行编辑撤销,同时还想在退回打开文件的状态之前能有一个提醒,那 undowarning.vim 可能就是你想要的。
这个插件不支持用包管理器自动安装。你需要自行下载 undowarning.vim,并把它放到你的 Vim 配置目录的 plugin 子目录下。下图是一个运行中的示例:

21.1.4 Rainbow
代码中括号多了,有时候眼睛就有点看不过来,需要有个更好的颜色提示。因此,就有了很多彩虹效果的 Vim 插件。在这些插件中,我最喜欢的是 frazrepo/vim-rainbow,它最妙的地方是,居然能把 C++ 代码中的尖括号也进行加亮,还能基本不会在出现小于、大于、流输入输出时进行错误的加亮。效果见下图:
效果默认不自动启用,可以用 :RainbowToggle 命令来切换,或用 :RainbowLoad 命令来加载。我觉得在括号多的时候按需启用挺好,推荐!
21.1.5 Auto-pairs
代码中永远有着大量成双成对的符号,输入一个,就自动出来另一个,会是一个非常有用的功能。但这样的功能,也需要处理一些特殊情况,比如,如果程序员输入了一对符号 (),结果千万不能是 ())。在很多现代的编辑器上,这已经是个标准功能了,但 Vim 一直没有类似的功能。
实际上,Vim 里已经有插件 jiangmiao/auto-pairs 支持了这个功能,并解决了大部分边角情况。我觉得可以推荐给大家。
这个插件,要不要推荐我还是犹豫了一下的。我一开始对它相当满意,但后来我发现仍然有一些边角情况处理不好,使用它就会导致无法编辑出我需要的效果。所以我又把它卸载了。但再后来,我又觉得,毕竟瑕不掩瑜,而且有问题时把它禁用不就得了!
所以,它的配置项我也只需要提一个,就是禁用的键映射。这个键映射由全局变量 g:AutoPairsShortcutToggle 控制,默认值是 <M-p>。如果你在 Mac 上,这个键多半就不工作了,除非你只在 Mac 终端里使用 Vim,并且在终端应用里配置了”将 Option 键用作 Meta 键”。对于大部分 Mac 用户,你需要进行类似下面的配置(因为 Mac 上按
Option-P 会产生”π”):
let g:AutoPairsShortcutToggle = 'π'其他内容就请自行查看它的帮助文件了。
21.1.6 Largefile
如果你经常打开很大的日志文件,那 Vim 的一些自动功能可能不仅帮不了什么忙,反而会拖慢你的编辑速度。有一个 Vim 插件能在文件较大时自动关闭事件处理、撤销、语法加亮等功能,用来换取更快的处理速度和更短的响应时间。这个插件就是 vimscripts/LargeFile。
这个插件的功能比较简单,唯一需要配置的就是多大算大。你只需要在 vimrc 配置文件中把你对大文件的阈值(以 MB 为单位)写到 g:LargeFile 变量里即可。比如,如果你认为超过 100MB 算大文件,那我们这样写就可以了:
let g:LargeFile = 10021.1.7 Markdown Preview
你如果像我一样常常写 Markdown 的话,你应该会喜欢 Markdown Preview 这个插件。Markdown 本来最适用的场景就是浏览器,纯文本的 Vim 只能编辑,没有好的预览终究是很不足的。Markdown Preview 解决了这个问题,让你在编辑的同时,可以在浏览器里看到实际的渲染效果。更令我吃惊的是,这个预览是完全实时、同步的,无需存盘,而且预览页面随着光标在 Vim 里移动而跟着滚动,效果相当酷。你可以直接到 Markdown Preview 的主页上看一下官方的示意图,我就不在这里放动图了。
这个插件唯一需要特别注意的是,你不能直接把 iamcco/markdown-preview.nvim 放到你的包管理器里了事。原因是它里面包含了需要编译的前端组件,需要下载或编译才行。在它的主页上描述了在不同包管理器里的安装方式,你只要跟着照做就行。
它的配置在主页上也有列表,但默认设置就已经完全可用了。如果有需求的话,你可以修改其中部分值,如 g:mkdp_browser 可以用来设定你希望打开页面的浏览器(我目前设的是 ‘firefox’)。
21.1.8 Calendar
Calendar 是一个很简单的显示日历的 Vim 插件,在包管理器里的名字是 mattn/calendar-vim。它的功能应该就不需要解释了,效果可以直接查看下图。
这个插件支持一些不同的样式和分割方式,上图中就是用 :CalendarH(或正常模式命令 caL)进行的横向分割,同时横向显示日历,你也可以用 :Calendar(或正常模式命令 cal)进行纵向分割和日历显示。此外,它还支持其他一些命令和组合。鉴于这个插件的的帮助文件也不长,如果你对相关功能有兴趣的话,就请你自己去看一下了。
21.2 技巧
21.2.1 行过滤
在编辑日志等类型的文本时,我们往往想过滤出我们感兴趣的内容。这时,我们可以用正则表达式,但使用 :s 命令并不是一种最高效的方式。如果你感兴趣的每一行都可以跟某个正则表达式模式匹配(如日期、某关键字等),最高效的命令应该是:
:v/匹配模式/d稍微解释一下,:v 命令(可以查看帮助 :help :v)可以用来找出不符合匹配模式的行(对比一下 grep -v 命令),然后执行后面的动作。所以上面的命令就是找出不满足匹配模式的行,然后执行删除(d)。
顺便说一下,如果你需要找出符合匹配模式的行,需要的命令是 :g(可以查看帮助 :help :g)。
21.2.2 自动关闭最后一个 quickfix 窗口
如果打开 quickfix 窗口后,你关闭了编辑的主窗口,那 quickfix 窗口可能就成为这个 Vim 会话里剩下的唯一窗口了,而这个窗口多半你完全不再需要。你会希望,此时 Vim 应该自动关闭这个窗口直接退出。这当然是个可以用程序自动化的事情,所以我们也应该这样做,用下面的脚本放到 vimrc 配置文件里就可以做到:
aug QFClose
au!
au WinEnter * if winnr('$') == 1 && &buftype == "quickfix"|q|endif
aug END你只要查一下 winnr 函数的帮助( :help winnr()))就很容易理解了,代码的意思还是非常清楚的:如果窗口的数量是 1 并且缓冲区类型是 quickfix 的话,那就退出 Vim。为了确保重复执行这段代码没有问题,它有一个自己的自动命令组,并会在清除这个自动命令组的所有自动命令后在进入窗口(WinEnter)这个事件中进行上面的检查。
(本技巧来自这个 Stack Overflow 回答。)
21.2.3 Home 键的行为
对于大部分现代的编辑器,Home 键的行为通常是:
- 当光标处于本行第一个非空白字符上时,跳转到行首
- 否则,跳转到本行第一个非空白字符上
虽然 Vim 的行为不是这样,但如果你希望配置出这样的行为,也不麻烦,把下面的代码加入到你的 vimrc 配置文件即可:
function! GoToFirstNonBlankOrFirstColumn()
let cur_col = col('.')
normal! ^
if cur_col != 1 && cur_col == col('.')
normal! 0
endif
return ''
endfunction
nnoremap <silent> <Home> :call GoToFirstNonBlankOrFirstColumn()<CR>
inoremap <silent> <Home> <C-R>=GoToFirstNonBlankOrFirstColumn()<CR>在这个代码里,col(‘.’) 用来获取光标所在的列号,然后我们跳转到第一个非空白字符处(^),随后检查是不是我们不在第 1 列并且列号没有变化。如果是的话,说明第一个非空白字符不在行首并且当前光标已经在第一个非空白字符处了,那我们就跳转到行首去(0)。
另外要注意,我们这儿使用了 normal! 而不是 normal。这两者的区别是,用了 ! 的 normal 命令会忽略键映射,否则 normal 就跟正常按键一样了。为了防止其他地方定义了键映射导致行为变化,一般推荐 normal! 命令而不是 normal 命令。
我们这样就修改了正常模式和插入模式下的 Home 键的行为。目前,在可视模式下这个方式不适用,你仍然只能手工选择合适的 0 或 ^ 命令。
21.2.4 查看光标下字符的内码
有很多字符是很相似的,在 Vim 使用的等宽字体中尤其如此。比如,光看字形,你能区分下面这些字符分别是什么吗?
- – — − ─
这些字符看起来虽然相似,但它们的意义是完全不同的。特别是在源代码中,如果你一不小心混入了一个相似的字符(字处理器有时候会自动替换一些 ASCII 字符,造成这种问题),代码运行就会出错了。这时,ga 命令就可以帮上忙。
下图展示了 ga 命令的一次执行结果:
我们可以看到这个字符实际上是 Unicode 字符 U+2013(十进制和八进制数值分别是 8211 和 20023),短破折号。这个字符在很多键盘上不能直接打出来,因而 Vim 提供了二合字母(digraph),可以用 <C-K>-N 的方式来输入。

