C++11 之后,C++ 以每三年一版的频度发布着新的语言标准,每一版都在基本保留向后兼容性的同时,提供着改进和新功能。本专栏主要就是讲这些新特性以及相关的编程实践。
作为专栏而非具体的工具参考书,我会重点讲是什么和为什么,而不是语法细节。
01丨基础篇
01 | 堆、栈、RAII:C++里该如何管理资源?
1.1 基本概念
堆,英文是 heap,在内存管理的语境下,指的是动态分配内存的区域。
C++ 标准里一个相关概念是自由存储区,英文是 free store,特指使用 new 和 delete 来分配和释放内存的区域。一般而言,这是堆的一个子集:
- new 和 delete 操作的区域是 free store
- malloc 和 free 操作的区域是 heap
但 new 和 delete 通常底层使用 malloc 和 free 来实现,所以 free store 也是 heap。鉴于对其区分的实际意义并不大,在本专栏里,除非另有特殊说明,我会只使用堆这一术语。
栈,英文是 stack,在内存管理的语境下,指的是函数调用过程中产生的本地变量和调用数据的区域。这个栈和数据结构里的栈高度相似,都满足”后进先出”(last-in-first-out 或 LIFO)。
RAII,完整的英文是 Resource Acquisition Is Initialization,是 C++ 所特有的资源管理方式。有少量其他语言,如 D、Ada 和 Rust 也采纳了 RAII,但主流的编程语言中, C++ 是唯一一个依赖 RAII 来做资源管理的。
1.2 堆
1.3 栈
编译器会自动调用析构函数,包括在函数执行发生异常的情况。在发生异常时对析构函数的调用,还有一个专门的术语,叫栈展开(stack unwinding)。
1.4 RAII
1.5 参考资料
- Wikipedia, “Memory management”. https://en.wikipedia.org/wiki/Memory_management
- Wikipedia, “Stack-based memory allocation”. https://en.wikipedia.org/wiki/Stack-based_memory_allocation
- Wikipedia, “Resource acquisition is initialization”. https://en.wikipedia.org/wiki/RAII
- Wikipedia, “Call stack”. https://en.wikipedia.org/wiki/Call_stack
- Wikipedia, “Object slicing”. https://en.wikipedia.org/wiki/Object_slicing
- Stack Overflow, “Why does the stack address grow towards decreasing memory addresses?” https://stackoverflow.com/questions/4560720/why-doesthe-stack-address-grow-towards-decreasing-memory-addresses
02 | 自己动手,实现C++的智能指针
2.1 回顾
上一讲给出了下面这个类:
class shape_wrapper {
public:
explicit shape_wrapper(shape* ptr = nullptr)
: ptr_(ptr)
{
}
~shape_wrapper() { delete ptr_; }
shape* get() const { return ptr_; }
private:
shape* ptr_;
};这个类可以完成智能指针的最基本的功能:对超出作用域的对象进行释放。但它缺了点东西:
- 这个类只适用于 shape 类
- 该类对象的行为不够像指针
- 拷贝该类对象会引发程序行为异常
下面我们来逐一看一下怎么弥补这些问题。
2.2 模板化和易用性
要让这个类能够包装任意类型的指针,我们需要把它变成一个类模板。
template <typename T>
class smart_ptr {
public:
explicit smart_ptr(T* ptr = nullptr)
: ptr_(ptr)
{
}
~smart_ptr()
{
delete ptr_;
}
T* get() const { return ptr_; }
T& operator*() const { return *ptr_; }
T* operator->() const { return ptr_; }
operator bool() const { return ptr_; }
private:
T* ptr_;
};2.3 拷贝构造和赋值
试试在拷贝时转移指针的所有权?大致实现如下:
template <typename T>
class smart_ptr {
//…
smart_ptr(smart_ptr& other)
{
ptr_ = other.release();
}
smart_ptr& operator=(smart_ptr& rhs)
{
smart_ptr(rhs).swap(*this);
return *this;
}
//…
T* release()
{
T* ptr = ptr_;
ptr_ = nullptr;
return ptr;
}
void swap(smart_ptr& rhs)
{
using std::swap;
swap(ptr_, rhs.ptr_);
}
//…
};在拷贝构造函数中,通过调用 other 的 release 方法来释放它对指针的所有权。在赋值函数中,则通过拷贝构造产生一个临时对象并调用 swap 来交换对指针的所有权。实现上是不复杂的。
如果你学到的赋值函数还有一个类似于 if (this != &rhs) 的判断的话,那种用法更啰嗦,而且异常安全性不够好——如果在赋值过程中发生异常的话,this 对象的内容可能已经被部分破坏了,对象不再处于一个完整的状态。
目前这种惯用法(见参考资料 [1])则保证了强异常安全性:赋值分为拷贝构造和交换两步,异常只可能在第一步发生;而第一步如果发生异常的话,this 对象完全不受任何影响。无论拷贝构造成功与否,结果只有赋值成功和赋值没有效果两种状态,而不会发生因为赋值破坏了当前对象这种场景。
上面实现的最大问题是,它的行为会让程序员非常容易犯错。一不小心把它传递给另外一个 smart_ptr,你就不再拥有这个对象了……
2.4 “移动”指针?
在下一讲我们将完整介绍一下移动语义。这一讲,我们先简单看一下 smart_ptr 可以如何使用”移动”来改善其行为。
template <typename T>
class smart_ptr {
//…
smart_ptr(smart_ptr&& other)
{
ptr_ = other.release();
}
smart_ptr& operator=(smart_ptr rhs)
{
rhs.swap(*this);
return *this;
}
//…
};改了两个地方:
- 把拷贝构造函数中的参数类型 smart_ptr& 改成了 smart_ptr&&;现在它成了移动构造函数。
- 把赋值函数中的参数类型 smart_ptr& 改成了 smart_ptr,在构造参数时直接生成新的智能指针,从而不再需要在函数体中构造临时对象。现在赋值函数的行为是移动还是拷贝,完全依赖于构造参数时走的是移动构造还是拷贝构造。
根据 C++ 的规则,如果我提供了移动构造函数而没有手动提供拷贝构造函数,那后者自动被禁用(记住,C++ 里那些复杂的规则也是为方便编程而设立的)。于是,我们自然地得到了以下结果:
smart_ptr<shape> ptr1{create_shape(shape_type::circle)};
smart_ptr<shape> ptr2{ptr1}; // 编译出错
smart_ptr<shape> ptr3;
ptr3 = ptr1; // 编译出错
ptr3 = std::move(ptr1); // OK,可以
smart_ptr<shape> ptr4{std::move(ptr3)}; // OK,可以这也是 C++11 的 unique_ptr 的基本行为。
2.5 子类指针向基类指针的转换
不知道你注意到没有,一个 circle* 是可以隐式转换成 shape* 的,但上面的 smart_ptr<circle> 却无法自动转换成 smart_ptr<shape>。
只需要修改我们的移动构造函数一处即可。
template <typename U>
smart_ptr(smart_ptr<U>&& other)
{
ptr_ = other.release();
}现在 smart_ptr<circle> 可以移动给 smart_ptr<shape>,但不能移动给 smart_ptr<triangle>。不正确的转换会在代码编译时直接报错。
至于非隐式的转换,因为本来就是要写特殊的转换函数的,我们留到这一讲的最后再讨论。
2.6 引用计数
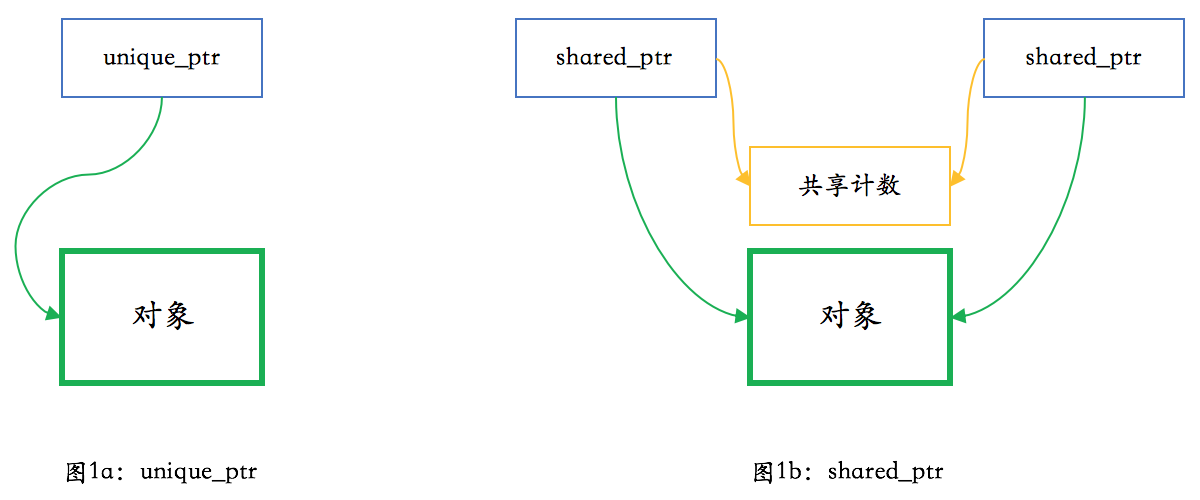
unique_ptr 和 shared_ptr 的主要区别如下图所示:
先来写出共享计数的接口:
class shared_count {
public:
shared_count();
void add_count();
long reduce_count();
long get_count() const;
};由于真正多线程安全的版本需要用到我们目前还没学到的知识,我们目前先实现一个简单化的版本:
class shared_count {
public:
shared_count()
: count_(1)
{
}
void add_count()
{
++count_;
}
long reduce_count()
{
return --count_;
}
long get_count() const
{
return count_;
}
private:
long count_;
};现在我们可以实现我们的引用计数智能指针了。首先是构造函数、析构函数和私有成员变量:
template <typename T>
class smart_ptr {
public:
explicit smart_ptr(T* ptr = nullptr)
: ptr_(ptr)
{
if (ptr) {
shared_count_ = new shared_count();
}
}
~smart_ptr()
{
if (ptr_ && !shared_count_->reduce_count()) {
delete ptr_;
delete shared_count_;
}
}
private:
T* ptr_;
shared_count* shared_count_;
};为了方便实现赋值(及其他一些惯用法),我们需要一个新的 swap 成员函数:
void swap(smart_ptr& rhs)
{
using std::swap;
swap(ptr_, rhs.ptr_);
swap(shared_count_, rhs.shared_count_);
}赋值函数可以跟前面一样,保持不变,但拷贝构造和移动构造函数是需要更新一下的:
smart_ptr(const smart_ptr& other) noexcept
{
ptr_ = other.ptr_;
if (ptr_) {
other.shared_count_->add_count();
shared_count_ = other.shared_count_;
}
}
template <typename U>
smart_ptr(const smart_ptr<U>& other)
{
ptr_ = other.ptr_;
if (ptr_) {
other.shared_count_->add_count();
shared_count_ = other.shared_count_;
}
}
template <typename U>
smart_ptr(smart_ptr<U>&& other)
{
ptr_ = other.ptr_;
if (ptr_) {
shared_count_ = other.shared_count_;
other.ptr_ = nullptr;
}
}不过,上面的代码有个问题:它不能正确编译。编译器会报错,像:
fatal error: 'ptr_' is a private member of 'smart_ptr<circle>'
错误原因是模板的各个实例间并不天然就有 friend 关系,因而不能互访私有成员 ptr_ 和 shared_count_。我们需要在 smart_ptr 的定义中显式声明:
template <typename U>
friend class smart_ptr;此外,我们之前的实现(类似于单一所有权的 unique_ptr )中用 release 来手工释放所有权。在目前的引用计数实现中,它就不太合适了,应当删除。但我们要加一个对调试非常有用的函数,返回引用计数值。定义如下:
long use_count() const
{
if (ptr_) {
return shared_count_->get_count();
} else {
return 0;
}
}2.7 指针类型转换
对应于 C++ 里的不同的类型强制转换:
- static_cast
- reinterpret_cast
- const_cast
- dynamic_cast
智能指针需要实现类似的函数模板。实现本身并不复杂,但为了实现这些转换,我们需要添加构造函数,允许在对智能指针内部的指针对象赋值时,使用一个现有的智能指针的共享计数。如下所示:
template <typename U>
smart_ptr(const smart_ptr<U>& other, T* ptr)
{
ptr_ = ptr;
if (ptr_) {
other.shared_count_->add_count();
shared_count_ = other.shared_count_;
}
}这样我们就可以实现转换所需的函数模板了。下面实现一个 dynamic_pointer_cast 来示例一下:
template <typename T, typename U>
smart_ptr<T> dynamic_pointer_cast(const smart_ptr<U>& other)
{
T* ptr = dynamic_cast<T*>(other.get());
return smart_ptr<T>(other, ptr);
}2.8 代码列表
完整的 smart_ptr 代码:
#include <utility> // std::swap
class shared_count {
public:
shared_count() noexcept
: count_(1)
{
}
void add_count() noexcept
{
++count_;
}
long reduce_count() noexcept
{
return --count_;
}
long get_count() const noexcept
{
return count_;
}
private:
long count_;
};
template <typename T>
class smart_ptr {
public:
template <typename U>
friend class smart_ptr;
explicit smart_ptr(T* ptr = nullptr)
: ptr_(ptr)
{
if (ptr) {
shared_count_ = new shared_count();
}
}
~smart_ptr()
{
printf("~smart_ptr(): %p\n", this);
if (ptr_ && !shared_count_->reduce_count()) {
delete ptr_;
delete shared_count_;
}
}
smart_ptr(const smart_ptr& other) noexcept
{
ptr_ = other.ptr_;
if (ptr_) {
other.shared_count_->add_count();
shared_count_ = other.shared_count_;
}
}
template <typename U>
smart_ptr(const smart_ptr<U>& other) noexcept
{
ptr_ = other.ptr_;
if (ptr_) {
other.shared_count_->add_count();
shared_count_ = other.shared_count_;
}
}
template <typename U>
smart_ptr(smart_ptr<U>&& other) noexcept
{
ptr_ = other.ptr_;
if (ptr_) {
shared_count_ = other.shared_count_;
other.ptr_ = nullptr;
}
}
template <typename U>
smart_ptr(const smart_ptr<U>& other, T* ptr) noexcept
{
ptr_ = ptr;
if (ptr_) {
other.shared_count_->add_count();
shared_count_ = other.shared_count_;
}
}
smart_ptr& operator=(smart_ptr rhs) noexcept
{
rhs.swap(*this);
return *this;
}
T* get() const noexcept
{
return ptr_;
}
long use_count() const noexcept
{
if (ptr_) {
return shared_count_->get_count();
} else {
return 0;
}
}
void swap(smart_ptr& rhs) noexcept
{
using std::swap;
swap(ptr_, rhs.ptr_);
swap(shared_count_, rhs.shared_count_);
}
T& operator*() const noexcept
{
return *ptr_;
}
T* operator->() const noexcept
{
return ptr_;
}
operator bool() const noexcept
{
return ptr_;
}
private:
T* ptr_;
shared_count* shared_count_;
};
template <typename T>
void swap(smart_ptr<T>& lhs, smart_ptr<T>& rhs) noexcept
{
lhs.swap(rhs);
}
template <typename T, typename U>
smart_ptr<T> static_pointer_cast(const smart_ptr<U>& other) noexcept
{
T* ptr = static_cast<T*>(other.get());
return smart_ptr<T>(other, ptr);
}
template <typename T, typename U>
smart_ptr<T> reinterpret_pointer_cast(const smart_ptr<U>& other) noexcept
{
T* ptr = reinterpret_cast<T*>(other.get());
return smart_ptr<T>(other, ptr);
}
template <typename T, typename U>
smart_ptr<T> const_pointer_cast(const smart_ptr<U>& other) noexcept
{
T* ptr = const_cast<T*>(other.get());
return smart_ptr<T>(other, ptr);
}
template <typename T, typename U>
smart_ptr<T> dynamic_pointer_cast(const smart_ptr<U>& other) noexcept
{
T* ptr = dynamic_cast<T*>(other.get());
return smart_ptr<T>(other, ptr);
}如果你足够细心的话,你会发现我在代码里加了不少 noexcept。这对这个智能指针在它的目标场景能正确使用是十分必要的。
2.9 参考资料
- Stack Overflow, GManNickG’s answer to “What is the copy-and-swapidiom?”. https://stackoverflow.com/a/3279550/816999
- cppreference.com, “std::shared_ptr”. https://en.cppreference.com/w/cpp/memory/shared_ptr
03 | 右值和移动究竟解决了什么问题?
移动语义是 C++11 里引入的一个重要概念;理解这个概念,是理解很多现代 C++ 里的优化的基础。
3.1 值分左右
C++标准里规定了下面这些值类别(value categories):
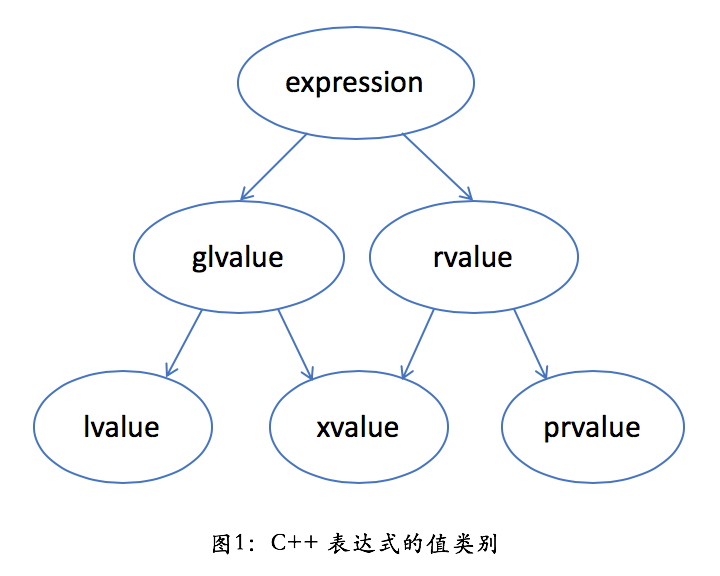
先理解一下这些名词的字面含义:
- 一个 lvalue 是通常可以放在等号左边的表达式,左值
- 一个 rvalue 是通常只能放在等号右边的表达式,右值
- 一个 glvalue 是 generalized lvalue,广义左值
- 一个 xvalue 是 expiring lvalue,将亡值
- 一个 prvalue 是 pure rvalue,纯右值
暂且抛开这些概念,只看其中两个:lvalue 和 prvalue。
左值 lvalue 是有标识符、可以取地址的表达式,最常见的情况有:
- 变量、函数或数据成员的名字
- 返回左值引用的表达式,如 ++x、x = 1、cout << ‘ ‘
- 字符串字面量如 “hello world”
在函数调用时,左值可以绑定到左值引用的参数,如 T&。一个常量只能绑定到常左值引用,如 const T&。
反之,纯右值 prvalue 是没有标识符、不可以取地址的表达式,一般也称之为”临时对象”。最常见的情况有:
- 返回非引用类型的表达式,如 x++、x + 1、
make_shared<int>(42) - 除字符串字面量之外的字面量,如 42、true
在 C++11 之前,右值可以绑定到常左值引用(const lvalue reference)的参数,如 const T&,但不可以绑定到非常左值引用(non-const lvalue reference),如 T&。从 C++11 开始,C++ 语言里多了一种引用类型——右值引用。右值引用的形式是 T&&,比左值引用多一个 & 符号。跟左值引用一样,我们可以使用 const 和 volatile 来进行修饰,但最常见的情况是,我们不会用 const 和 volatile 来修饰右值。本专栏就属于这种情况。
引入一种额外的引用类型当然增加了语言的复杂性,但也带来了很多优化的可能性。由于 C++ 有重载,我们就可以根据不同的引用类型,来选择不同的重载函数,来完成不同的行为。回想一下,在上一讲中,我们就利用了重载,让 smart_ptr 的构造函数可以有不同的行为:
template <typename U>
smart_ptr(const smart_ptr<U>& other)
{
ptr_ = other.ptr_;
if (ptr_) {
other.shared_count_->add_count();
shared_count_ = other.shared_count_;
}
}
template <typename U>
smart_ptr(smart_ptr<U>&& other)
{
ptr_ = other.ptr_;
if (ptr_) {
shared_count_ = other.shared_count_;
other.ptr_ = nullptr;
}
}使用右值引用的第二个重载函数中的变量 other 算是左值还是右值呢?根据定义,other 是个变量的名字,变量有标识符、有地址,所以它还是一个左值——虽然它的类型是右值引用。
尤其重要的是,拿这个 other 去调用函数时,它匹配的也会是左值引用。也就是说,类型是右值引用的变量是一个左值!这点可能有点反直觉,但跟 C++ 的其他方面是一致的。毕竟对于一个右值引用的变量,你是可以取地址的,这点上它和左值完全一致。稍后我们再回到这个话题上来。
再看一下下面的代码:
smart_ptr<shape> ptr1{new circle()};
smart_ptr<shape> ptr2 = std::move(ptr1);第一个表达式里的 new circle() 就是一个纯右值;但对于指针,我们通常使用值传递,并不关心它是左值还是右值。
第二个表达式里的 std::move(ptr) 就有趣点了。它的作用是把一个左值引用强制转换成一个右值引用,而并不改变其内容。从实用的角度,在我们这儿 std::move(ptr1) 等价于 static_cast<smart_ptr<shape>&&>(ptr1)。因此,std::move(ptr1) 的结果是指向 ptr1 的一个右值引用,这样构造 ptr2 时就会选择上面第二个重载。
我们可以把 std::move(ptr1) 看作是一个有名字的右值。为了跟无名的纯右值 prvalue 相区别,C++ 里目前就把这种表达式叫做 xvalue。跟左值 lvalue 不同,xvalue 仍然是不能取地址的——这点上,xvalue 和 prvalue 相同。所以,xvalue 和 prvalue 都被归为右值 rvalue。我们用下面的图来表示会更清楚一点:
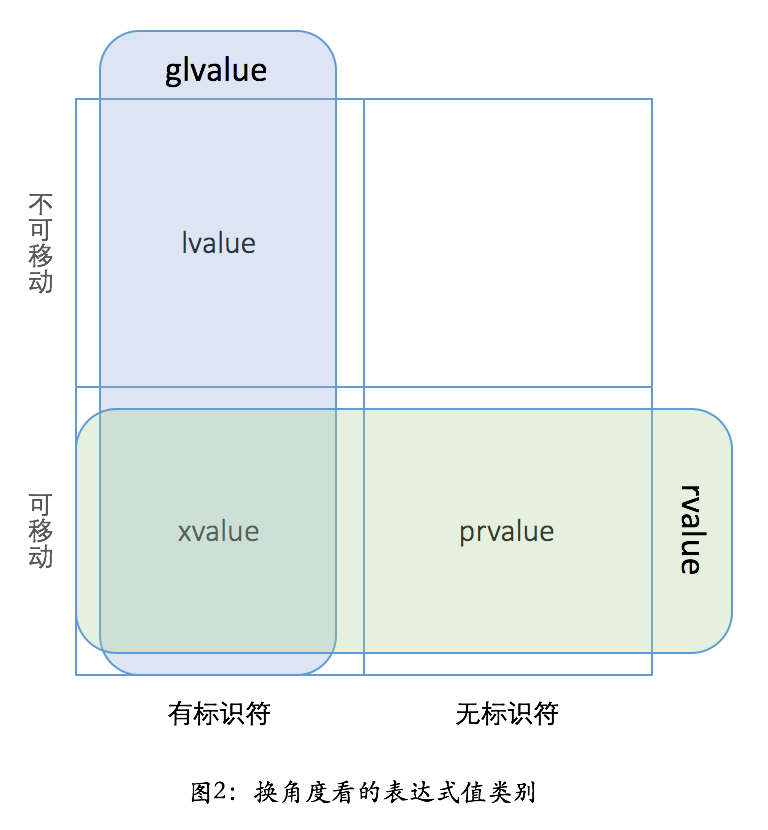
另外请注意,”值类别”(value category)和”值类型”(value type)是两个看似相似、却毫不相干的术语。前者指的是上面这些左值、右值相关的概念,后者则是与引用类型(reference type)相对而言,表明一个变量是代表实际数值,还是引用另外一个数值。在 C++ 里,所有的原生类型、枚举、结构、联合、类都代表值类型,只有引用(&)和指针(*)才是引用类型。在 Java 里,数字等原生类型是值类型,类则属于引用类型。在 Python 里,一切类型都是引用类型。
3.2 生命周期和表达式类型
一个变量的生命周期在超出作用域时结束。如果一个变量代表一个对象,当然这个对象的生命周期也在那时结束。那临时对象(prvalue)呢?在这儿,C++ 的规则是:一个临时对象会在包含这个临时对象的完整表达式估值完成后、按生成顺序的逆序被销毁,除非有生命周期延长发生。我们先看一个没有生命周期延长的基本情况:
#include <stdio.h>
class shape {
public:
virtual ~shape() { }
};
class circle : public shape {
public:
circle() { puts("circle()"); }
~circle() { puts("~circle()"); }
};
class triangle : public shape {
public:
triangle() { puts("triangle()"); }
~triangle() { puts("~triangle()"); }
};
class result {
public:
result() { puts("result()"); }
~result() { puts("~result()"); }
};
result process_shape(const shape& shape1, const shape& shape2)
{
puts("process_shape()");
return result();
}
int main()
{
puts("main()");
process_shape(circle(), triangle());
puts("something else");
}输出结果可能会是(circle 和 triangle 的顺序在标准中没有规定):
main()
circle()
triangle()
process_shape()
result()
~result()
~triangle()
~circle()
something else目前我让 process_shape 也返回了一个结果,这是为了下一步演示的需要。你可以看到结果的临时对象最后生成、最先析构。
为了方便对临时对象的使用,C++ 对临时对象有特殊的生命周期延长规则。这条规则是:
如果一个 prvalue 被绑定到一个引用上,它的生命周期则会延长到跟这个引用变量一样长。
我们对上面的代码只要改一行就能演示这个效果。把 process_shape 那行改成:
result&& r = process_shape(circle(), triangle());我们就能看到不同的结果了:
main()
circle()
triangle()
process_shape()
result()
~triangle()
~circle()
something else
~result()现在 result 的生成还在原来的位置,但析构被延到了 main 的最后。
需要万分注意的是,这条生命期延长规则只对 prvalue 有效,而对 xvalue 无效。如果由于某种原因,prvalue 在绑定到引用以前已经变成了 xvalue,那生命期就不会延长。不注意这点的话,代码就可能会产生隐秘的 bug。比如,我们如果这样改一下代码,结果就不对了:
#include <utility> // std::move
…
result&& r = std::move(process_shape(circle(), triangle()));这时的代码输出就回到了前一种情况。虽然执行到 something else 那儿我们仍然有一个有效的变量 r,但它指向的对象已经不存在了,对 r 的解引用是一个未定义行为。由于 r 指向的是栈空间,通常不会立即导致程序崩溃,而会在某些复杂的组合条件下才会引致问题……
对 C++ 的这条生命期延长规则,在后面讲到视图(view)的时候会十分有用。那时我们会看到,有些 C++ 的用法实际上会隐式地利用这条规则。
此外,参考资料 [5] 中提到了一个有趣的事实:你可以把一个没有虚析构函数的子类对象绑定到基类的引用变量上,这个子类对象的析构仍然是完全正常的——这是因为这条规则只是延后了临时对象的析构而已,不是利用引用计数等复杂的方法,因而只要引用绑定成功,其类型并没有什么影响。
3.3 移动的意义
对于 smart_ptr,我们使用右值引用的目的是实现移动,而实现移动的意义是减少运行的开销——在引用计数指针的场景下,这个开销并不大。移动构造和拷贝构造的差异仅在于:
- 少了一次 other.shared_count_->add_count() 的调用
- 被移动的指针被清空,因而析构时也少了一次 shared_count_->reduce_count() 的调用
在使用容器类的情况下,移动更有意义。我们可以尝试分析一下下面这个假想的语句(假设 name 是 string 类型):
string result = string("Hello, ") + name + ".";在 C++11 之前的年代里,这种写法是绝对不推荐的。因为它会引入很多额外开销,执行流程大致如下:
- 调用构造函数 string(const char*),生成临时对象 1;”Hello, “ 复制 1 次。
- 调用 operator+(const string&, const string&),生成临时对象 2;”Hello,” 复制 2 次,name 复制 1 次。
- 调用 operator+(const string&, const char*),生成对象 3;”Hello, “ 复制 3 次,name 复制 2 次,”.” 复制 1 次。
- 假设返回值优化能够生效(最佳情况),对象 3 可以直接在 result 里构造完成。
- 临时对象 2 析构,释放指向 string(“Hello, “) + name 的内存。
- 临时对象 1 析构,释放指向 string(“Hello, “) 的内存。
既然 C++ 是一门追求性能的语言,一个合格的 C++ 程序员会写:
string result = "Hello, ";
result += name;
result += ".";这样的话,只会调用构造函数一次和 string::operator+= 两次,没有任何临时对象需要生成和析构,所有的字符串都只复制了一次。但显然代码就啰嗦多了——尤其如果拼接的步骤比较多的话。从 C++11 开始,这不再是必须的。同样上面那个单行的语句,执行流程大致如下:
- 调用构造函数 string(const char*),生成临时对象 1;”Hello, “ 复制 1 次。
- 调用 operator+(string&&, const string&),直接在临时对象 1 上面执行追加操作,并把结果移动到临时对象 2;name 复制 1 次。
- 调用 operator+(string&&, const char*),直接在临时对象 2 上面执行追加操作,并把结果移动到 result;”.” 复制 1 次。
- 临时对象 2 析构,内容已经为空,不需要释放任何内存。
- 临时对象 1 析构,内容已经为空,不需要释放任何内存。
性能上,所有的字符串只复制了一次;虽然比啰嗦的写法仍然要增加临时对象的构造和析构,但由于这些操作不牵涉到额外的内存分配和释放,是相当廉价的。程序员只需要牺牲一点点性能,就可以大大增加代码的可读性。而且,所谓的性能牺牲,也只是相对于优化得很好的 C 或 C++ 代码而言——这样的 C++ 代码的性能仍然完全可以超越 Python 类的语言的相应代码。
一句话总结,移动语义使得在 C++ 里返回大对象(如容器)的函数和运算符成为现实,因而可以提高代码的简洁性和可读性,提高程序员的生产率。
3.4 如何实现移动?
要让你设计的对象支持移动的话,通常需要下面几步:
- 你的对象应该有分开的拷贝构造和移动构造函数(除非你只打算支持移动,不支持拷贝——如 unique_ptr)。
- 你的对象应该有 swap 成员函数,支持和另外一个对象快速交换成员。
- 在你的对象的名空间下,应当有一个全局的 swap 函数,调用成员函数 swap 来实现交换。支持这种用法会方便别人(包括你自己在将来)在其他对象里包含你的对象,并快速实现它们的 swap 函数。
- 实现通用的 operator=。
- 上面各个函数如果不抛异常的话,应当标为 noexcept。这对移动构造函数尤为重要。
具体写法可以参考我们当前已经实现的 smart_ptr:
- smart_ptr 有拷贝构造和移动构造函数(虽然此处我们的模板构造函数严格来说不算拷贝或移动构造函数)。移动构造函数应当从另一个对象获取资源,清空其资源,并将其置为一个可析构的状态。
3.5 不要返回本地变量的引用
在 C++11 之前,返回一个本地对象意味着这个对象会被拷贝,除非编译器发现可以做返回值优化(named return value optimization,或 NRVO),能把对象直接构造到调用者的栈上。从 C++11 开始,返回值优化仍可以发生,但在没有返回值优化的情况下,编译器将试图把本地对象移动出去,而不是拷贝出去。这一行为不需要程序员手工用 std::move 进行干预——使用std::move 对于移动行为没有帮助,反而会影响返回值优化。
下面是个例子:
#include <iostream> // std::cout/endl
#include <utility> // std::move
using namespace std;
class Obj {
public:
Obj()
{
cout << "Obj()" << endl;
}
Obj(const Obj&)
{
cout << "Obj(const Obj&)"
<< endl;
}
Obj(Obj&&)
{
cout << "Obj(Obj&&)" << endl;
}
};
Obj simple()
{
Obj obj;
// 简单返回对象;一般有 NRVO
return obj;
}
Obj simple_with_move()
{
Obj obj;
// move 会禁止 NRVO
return std::move(obj);
}
Obj complicated(int n)
{
Obj obj1;
Obj obj2;
// 有分支,一般无 NRVO
if (n % 2 == 0) {
return obj1;
} else {
return obj2;
}
}
int main()
{
cout << "*** 1 ***" << endl;
auto obj1 = simple();
cout << "*** 2 ***" << endl;
auto obj2 = simple_with_move();
cout << "*** 3 ***" << endl;
auto obj3 = complicated(42);
}输出通常为:
*** 1 ***
Obj()
*** 2 ***
Obj()
Obj(Obj&&)
*** 3 ***
Obj()
Obj()
Obj(Obj&&)也就是,用了 std::move 反而妨碍了返回值优化。
3.6 引用坍缩和完美转发
引用坍缩(又称”引用折叠”)。
我们已经讲了对于一个实际的类型 T,它的左值引用是 T&,右值引用是 T&&。那么:
- 是不是看到 T&,就一定是个左值引用?
- 是不是看到 T&&,就一定是个右值引用?
对于前者的回答是”是”,对于后者的回答为”否”。
关键在于,在有模板的代码里,对于类型参数的推导结果可能是引用。我们可以略过一些繁复的语法规则,要点是:
- 对于
template <typename T> foo(T&&)这样的代码,如果传递过去的参数是左值,T 的推导结果是左值引用;如果传递过去的参数是右值,T 的推导结果是参数的类型本身。 - 如果 T 是左值引用,那 T&& 的结果仍然是左值引用——即 type& && 坍缩成了 type&。
- 如果 T 是一个实际类型,那 T&& 的结果自然就是一个右值引用。
我们之前提到过,右值引用变量仍然会匹配到左值引用上去。下面的代码会验证这一行为:
void foo(const shape&)
{
puts("foo(const shape&)");
}
void foo(shape&&)
{
puts("foo(shape&&)");
}
void bar(const shape& s)
{
puts("bar(const shape&)");
foo(s);
}
void bar(shape&& s)
{
puts("bar(shape&&)");
foo(s);
}
int main()
{
bar(circle());
}输出为:
bar(shape&&)
foo(const shape&)如果我们要让 bar 调用右值引用的那个 foo 的重载,我们必须写成:
foo(std::move(s));或:
foo(static_cast<shape&&>(s));可如果两个 bar 的重载除了调用 foo 的方式不一样,其他都差不多的话,我们为什么要提供两个不同的 bar 呢?
事实上,很多标准库里的函数,连目标的参数类型都不知道,但我们仍然需要能够保持参数的值类型:左值的仍然是左值,右值的仍然是右值。这个功能在 C++ 标准库中已经提供了,叫 std::forward。它和 std::move 一样都是利用引用坍缩机制来实现。此处,我们不介绍其实现细节,而是重点展示其用法。我们可以把我们的两个 bar 函数简化成:
template <typename T>
void bar(T&& s)
{
foo(std::forward<T>(s));
}对于下面这样的代码:
circle temp;
bar(temp);
bar(circle());现在的输出是:
foo(const shape&)
foo(shape&&)因为在 T 是模板参数时,T&& 的作用主要是保持值类别进行转发,它有个名字就叫”转发引用”(forwarding reference)。因为既可以是左值引用,也可以是右值引用,它也曾经被叫做”万能引用”(universal reference)。
3.7 参考资料
- cppreference.com, “Value categories”. https://en.cppreference.com/w/cpp/language/value_category
- Anders Schau Knatten, “lvalues, rvalues, glvalues, prvalues, xvalues, help!”. https://blog.knatten.org/2018/03/09/lvalues-rvalues-glvalues-prvalues-xvalueshelp/
- Jeaye, “Value category cheat-sheet”. https://blog.jeaye.com/2017/03/19/xvalues/
- Thomas Becker, “C++ rvalue references explained”. http://thbecker.net/articles/rvalue_references/section_01.html
- Herb Sutter, “GotW #88: A candidate for the ‘most important const’”. https://herbsutter.com/2008/01/01/gotw-88-a-candidate-for-the-mostimportant-const/
04 | 容器汇编 I:比较简单的若干容器
4.1 string
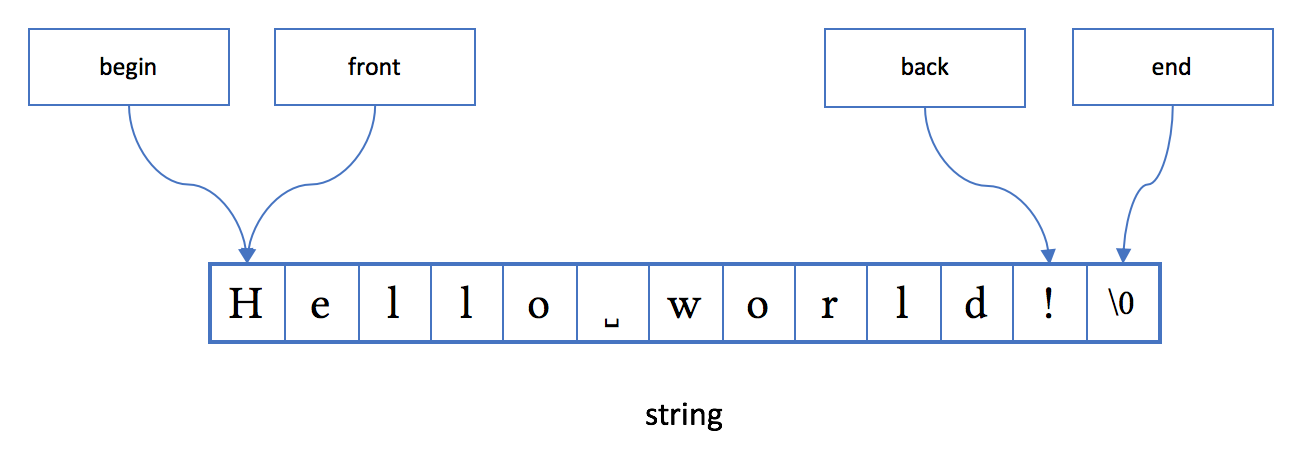
在 string 的情况下,由于考虑到和 C 字符串的兼容,end 指向代表字符串结尾的 \0 字符。
string 的内存布局大致如下图所示:
一些策略:
- 如果不修改字符串的内容,使用 const string& 或 C++17 的 string_view 作为参数类型。后者是最理想的情况,因为即使在只有 C 字符串的情况,也不会引发不必要的内存复制。
- 如果需要在函数内修改字符串内容、但不影响调用者的该字符串,使用 string 作为参数类型(自动拷贝)。
- 如果需要改变调用者的字符串内容,使用 string& 作为参数类型(通常不推荐)。
4.2 vector
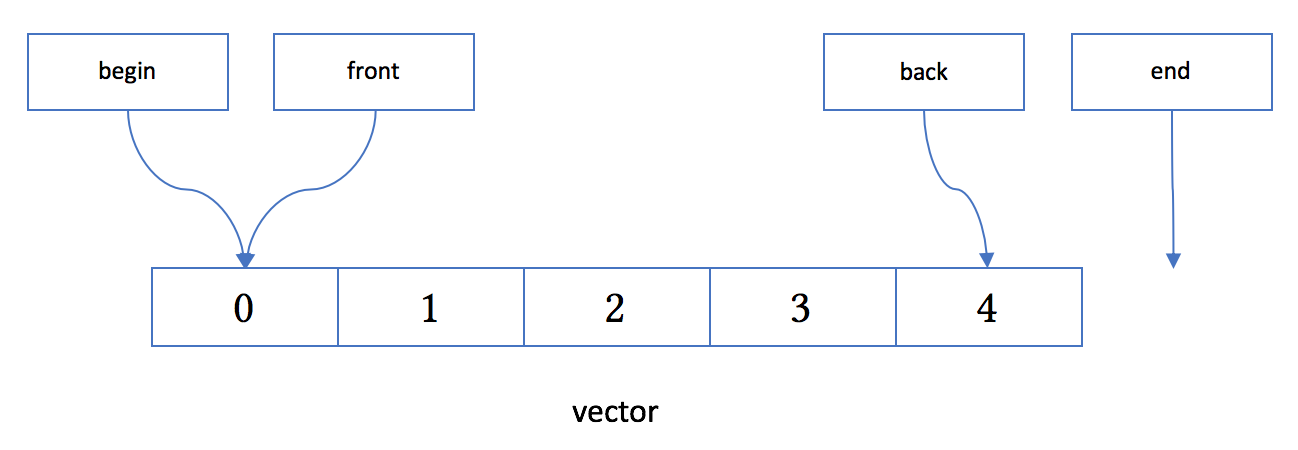
vector 通常保证强异常安全性,如果元素类型没有提供一个保证不抛异常的移动构造函数,vector 通常会使用拷贝构造函数。因此,对于拷贝代价较高的自定义元素类型,我们应当定义移动构造函数,并标其为 noexcept,或只在容器中放置对象的智能指针。这就是为什么我之前需要在 smart_ptr 的实现中标上 noexcept 的原因。
下面的代码可以演示这一行为:
#include <iostream>
#include <vector>
using namespace std;
class Obj1 {
public:
Obj1()
{
cout << "Obj1()\n";
}
Obj1(const Obj1&)
{
cout << "Obj1(const Obj1&)\n";
}
Obj1(Obj1&&)
{
cout << "Obj1(Obj1&&)\n";
}
};
class Obj2 {
public:
Obj2()
{
cout << "Obj2()\n";
}
Obj2(const Obj2&)
{
cout << "Obj2(const Obj2&)\n";
}
Obj2(Obj2&&) noexcept
{
cout << "Obj2(Obj2&&)\n";
}
};
int main()
{
vector<Obj1> v1;
v1.reserve(2);
v1.emplace_back();
v1.emplace_back();
v1.emplace_back();
vector<Obj2> v2;
v2.reserve(2);
v2.emplace_back();
v2.emplace_back();
v2.emplace_back();
}我们可以立即得到下面的输出:
Obj1()
Obj1()
Obj1()
Obj1(const Obj1&)
Obj1(const Obj1&)
Obj2()
Obj2()
Obj2()
Obj2(Obj2&&)
Obj2(Obj2&&)Obj1 和 Obj2 的定义只差了一个 noexcept,但这个小小的差异就导致了 vector 是否会移动对象。这点非常重要。
C++11 开始提供的 emplace… 系列函数是为了提升容器的性能而设计的。你可以试试把 v1.emplace_back() 改成 v1.push_back(Obj1())。对于 vector 里的内容,结果是一样的;但使用 push_back 会额外生成临时对象,多一次拷贝构造和一次析构。
4.3 deque
deque 的内存布局一般是这样的:
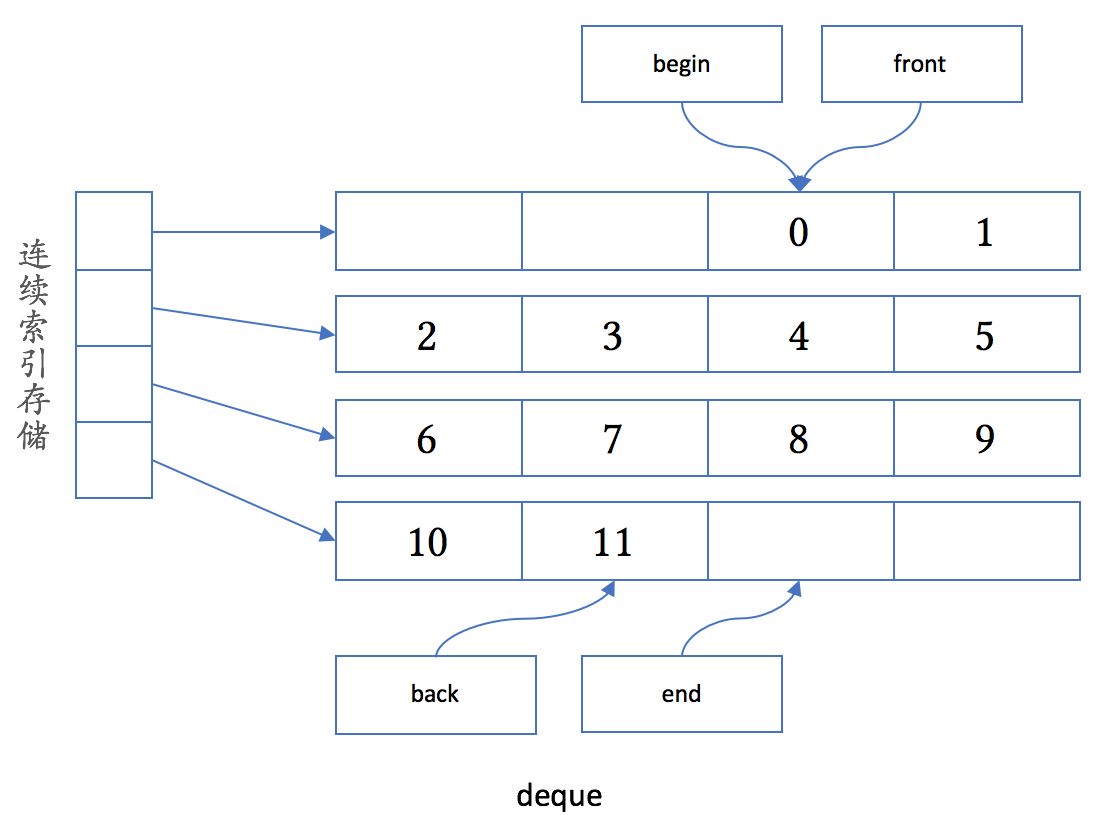
4.4 list
list 的内存布局一般是下图这个样子:
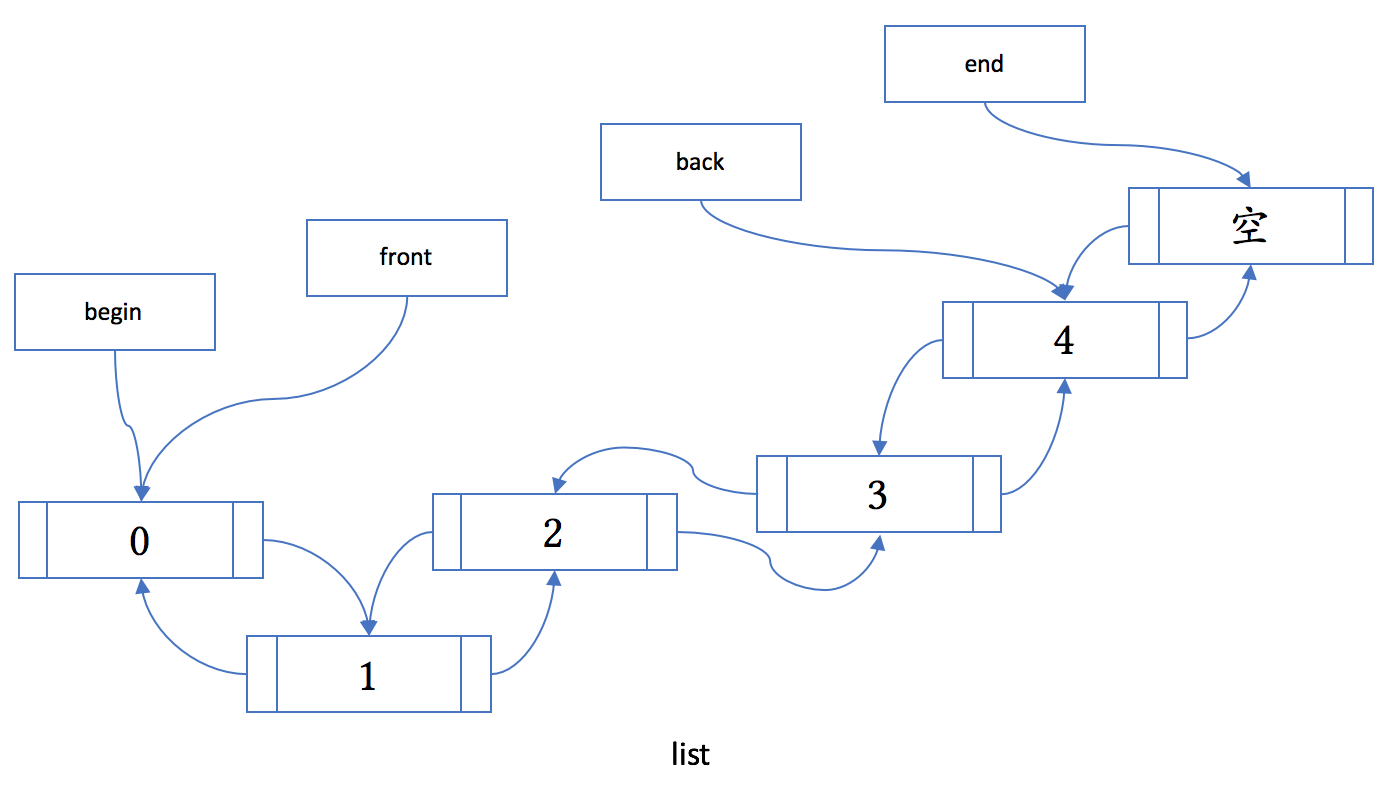
某些标准算法在 list 上会导致问题,list 提供了成员函数作为替代,包括下面几个:
- merge
- remove
- remove_if
- reverse
- sort
- unique
4.5 forward_list
从 C++11 开始,前向列表 forward_list 成了标准的一部分。
它的内存布局:
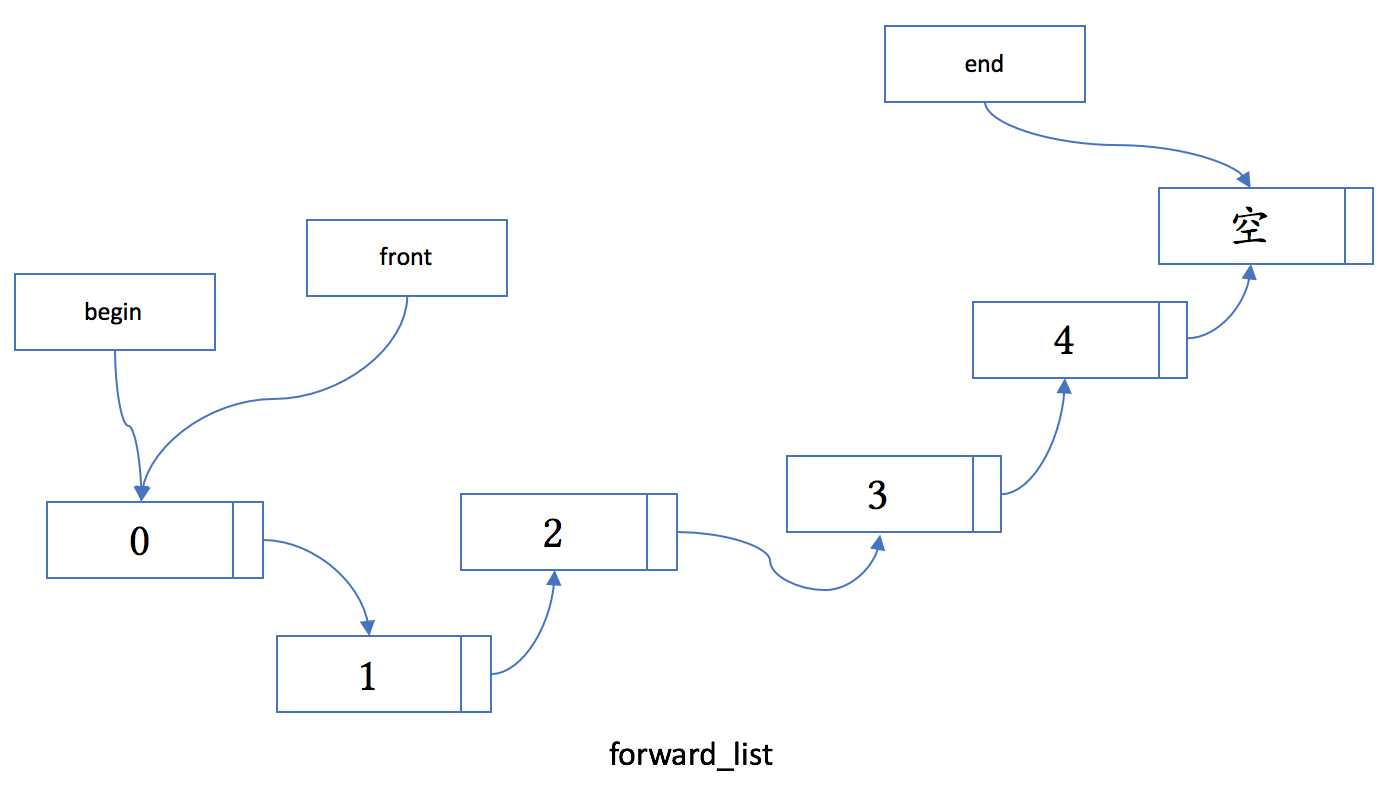
4.6 queue
queue 缺省用 deque 来实现。
从概念上讲,它的结构可如下所示:
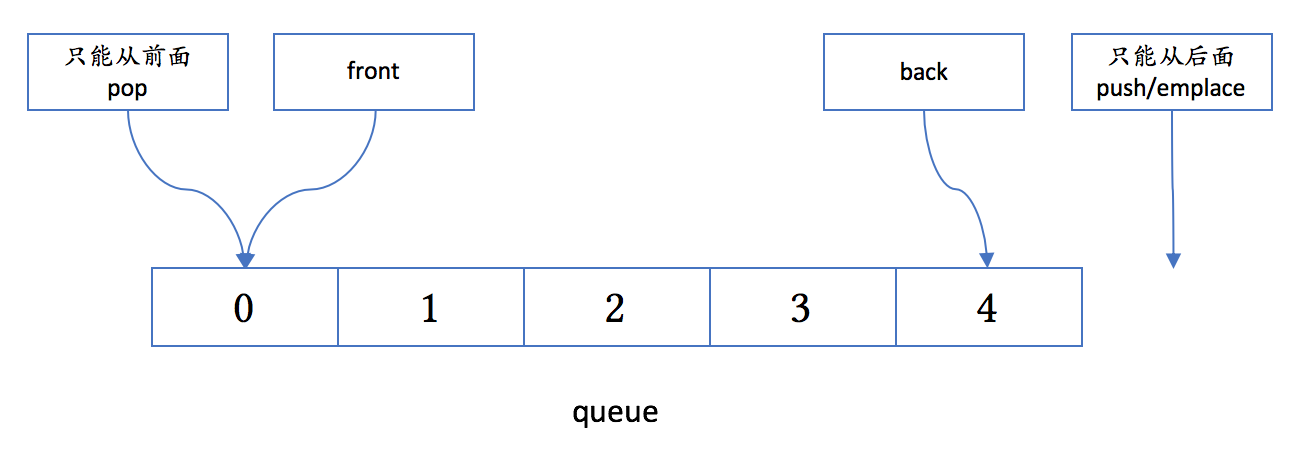
4.7 stack
queue 缺省也是用 deque 来实现。
一般图形表示法会把 stack 表示成一个竖起的 vector:
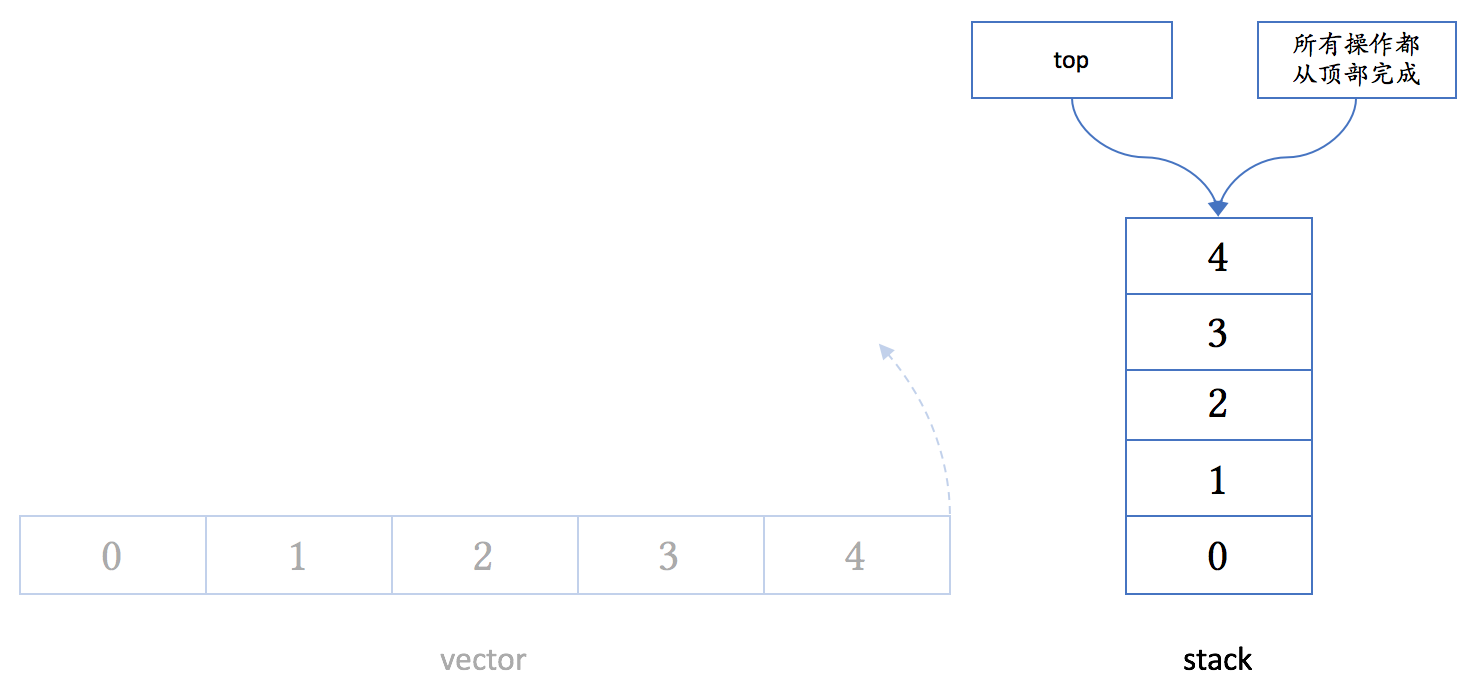
4.8 参考资料
- cppreference.com, “Containers library”. https://en.cppreference.com/w/cpp/container
- QuantStack, xeus-cling. https://github.com/QuantStack/xeus-cling
- 吴咏炜, output_container. https://github.com/adah1972/output_container/blob/master/output_container.h
05 | 容器汇编 II:需要函数对象的容器
5.1 函数对象及其特化
在讲容器之前,我们需要首先来讨论一下两个重要的函数对象,less 和 hash。
在标准库里,通用的 less 大致是这样定义的:
template <class T>
struct less : binary_function<T, T, bool> {
bool operator()(const T& x, const T& y) const
{
return x < y;
}
};也就是说,less 是一个函数对象,并且是个二元函数,执行对任意类型的值的比较,返回布尔类型。作为函数对象,它定义了函数调用运算符(operator()),并且缺省行为是对指定类型的对象进行 < 的比较操作。
在需要大小比较的场合,C++ 通常默认会使用 less,包括我们今天会讲到的若干容器和排序算法 sort。如果我们需要产生相反的顺序的话,则可以使用 greater,大于关系。
计算哈希值的函数对象 hash 的目的是把一个某种类型的值转换成一个无符号整数哈希值,类型为 size_t。它没有一个可用的默认实现。对于常用的类型,系统提供了需要的特化 [2],类似于:
template <class T>
struct hash;
template <>
struct hash<int> : public unary_function<int, size_t> {
size_t operator()(int v) const noexcept
{
return static_cast<size_t>(v);
}
};要点是,对于每个类,类的作者都可以提供 hash 的特化,使得对于不同的对象值,函数调用运算符都能得到尽可能均匀分布的不同数值。
用下面这个例子来加深一下理解:
#include <algorithm> // std::sort
#include <functional> // std::less/greater/hash
#include <iostream> // std::cout/endl
#include <string> // std::string
#include <vector> // std::vector
#include "output_container.h"
using namespace std;
int main()
{
// 初始数组
vector<int> v { 13, 6, 4, 11, 29 };
cout << v << endl;
// 从小到大排序
sort(v.begin(), v.end());
cout << v << endl;
// 从大到小排序
sort(v.begin(), v.end(), greater<int>());
cout << v << endl;
cout << hex;
auto hp = hash<int*>();
cout << "hash(nullptr) = "
<< hp(nullptr) << endl;
cout << "hash(v.data()) = "
<< hp(v.data()) << endl;
cout << "v.data() = "
<< static_cast<void*>(v.data())
<< endl;
auto hs = hash<string>();
cout << "hash(\"hello\") = "
<< hs(string("hello")) << endl;
cout << "hash(\"hellp\") = "
<< hs(string("hellp")) << endl;
}在 MSVC 下的某次运行结果如下所示:
{ 13, 6, 4, 11, 29 }
{ 4, 6, 11, 13, 29 }
{ 29, 13, 11, 6, 4 }
hash(nullptr) = a8c7f832281a39c5
hash(v.data()) = 7a0bdfd7df0923d2
v.data() = 000001EFFB10EAE0
hash("hello") = a430d84680aabd0b
hash("hellp") = a430e54680aad322可以看到,在这个实现里,空指针的哈希值是一个非零的数值,指针的哈希值也和指针的数值不一样。要注意不同的实现处理的方式会不一样。事实上,我的测试结果是 GCC、Clang 和 MSVC 对常见类型的哈希方式都各有不同。
在上面的例子里,我们同时可以看到,这两个函数对象的值不重要。我们甚至可以认为,每个 less(或 greater 或 hash)对象都是等价的。关键在于其类型。以 sort 为例,第三个参数的类型确定了其排序行为。
对于容器也是如此,函数对象的类型确定了容器的行为。
5.2 priority_queue
priority_queue 也是一个容器适配器。上一讲没有和其他容器适配器一起讲的原因就在于它用到了比较函数对象(默认是 less)。在使用缺省的 less 作为其 Compare 模板参数时,最大的数值会出现在容器的”顶部”。如果需要最小的数值出现在容器顶部,则可以传递 greater 作为其 Compare 模板参数。
5.3 关联容器
关联容器有 set(集合)、map(映射)、multiset(多重集)和 multimap(多重映射)。跳出 C++ 的语境,map(映射)的更常见的名字是关联数组和字典 [3],而在 JSON里直接被称为对象(object)。在 C++ 外这些容器常常是无序的;在 C++ 里关联容器则被认为是有序的。
关联容器都有 find、lower_bound、upper_bound 等查找函数,结果是一个迭代器:
- find(k) 可以找到任何一个等价于查找键 k 的元素(!(x < k || k < x))
- lower_bound(k) 找到第一个不小于查找键 k 的元素(!(x < k))
- upper_bound(k) 找到第一个大于查找键 k 的元素(k < x)
如果你需要在 multimap 里精确查找满足某个键的区间的话,建议使用 equal_range,可以一次性取得上下界(半开半闭)。
对于自定义类型,我推荐尽量使用标准的 less 实现,通过重载 <(及其他标准比较运算符)对该类型的对象进行排序。存储在关联容器中的键一般应满足严格弱序关系(strict weak ordering;[4]),即:
- 对于任何该类型的对象 x:!(x < x)(非自反)
- 对于任何该类型的对象 x 和 y:如果 x < y,则 !(y < x)(非对称)
- 对于任何该类型的对象 x、y 和 z:如果 x < y 并且 y < z,则 x < z(传递性)
- 对于任何该类型的对象 x、y 和 z:如果 x 和 y 不可比(!(x < y) 并且 !(y < x))并且 y 和 z 不可比,则 x 和 z 不可比(不可比的传递性)
5.4 无序关联容器
从 C++11 开始,每一个关联容器都有一个对应的无序关联容器,它们是:
- unordered_set
- unordered_map
- unordered_multiset
- unordered_multimap
一个示例:
#include <complex> // std::complex
#include <iostream> // std::cout/endl
#include <unordered_map> // std::unordered_map
#include <unordered_set> // std::unordered_set
#include "output_container.h"
using namespace std;
namespace std {
template <typename T>
struct hash<complex<T>> {
size_t operator()(const complex<T>& v) const noexcept
{
hash<T> h;
return h(v.real()) + h(v.imag());
}
};
} // namespace std
int main()
{
unordered_set<int> s {
1, 1, 2, 3, 5, 8, 13, 21
};
cout << s << endl;
unordered_map<complex<double>, double> umc {
{ { 1.0, 1.0 }, 1.4142 },
{ { 3.0, 4.0 }, 5.0 }
};
cout << umc << endl;
}输出可能是(顺序不能保证):
{ 21, 5, 8, 3, 13, 2, 1 }
{ (3,4) => 5, (1,1) => 1.4142 }请注意我们在 std 名空间中添加了特化,这是少数用户可以向 std 名空间添加内容的情况之一。正常情况下,向 std 名空间添加声明或定义是禁止的,属于未定义行为。
5.5 array
C 数组在 C++ 里继续存在,主要是为了保留和 C 的向后兼容性。C 数组本身和 C++ 的容器相差是非常大的:
- C 数组没有 begin 和 end 成员函数(虽然可以使用全局的 begin 和 end 函数)
- C 数组没有 size 成员函数(得用一些模板技巧来获取其长度)
- C 数组作为参数有退化行为,传递给另外一个函数后那个函数不再能获得 C 数组的长度和结束位置
在 C 的年代,大家有时候会定义这样一个宏来获得数组的长度:
#define ARRAY_LEN(a) (sizeof(a) / sizeof((a)[0]))如果在一个函数内部对数组参数使用这个宏,结果肯定是错的。现在 GCC 会友好地发出警告:
void test(int a[8])
{
cout << ARRAY_LEN(a) << endl;
}warning: sizeof on array function parameter will return size of ‘int *’ instead of ‘int [8]’ [-Wsizeof-array-argument]
cout << ARRAY_LEN(a) << endl;
C++17 直接提供了一个 size 方法,可以用于提供数组长度,并且在数组退化成指针的情况下会直接失败:
#include <iostream> // std::cout/endl
#include <iterator> // std::size
void test(int arr[])
{
// 不能编译
// std::cout << std::size(arr)
// << std::endl;
}
int main()
{
int arr[] = { 1, 2, 3, 4, 5 };
std::cout << "The array length is "
<< std::size(arr)
<< std::endl;
test(arr);
}此外,C 数组也没有良好的复制行为。
array 可以避免 C 数组的种种怪异行径。
5.6 参考资料
- cppreference.com, “Containers library”. https://en.cppreference.com/w/cpp/container
- cppreference.com, “Explicit (full) template specialization”. https://en.cppreference.com/w/cpp/language/template_specialization
- Wikipedia, “Associative array”. https://en.wikipedia.org/wiki/Associative_array
Wikipedia, “Weak ordering”. https://en.wikipedia.org/wiki/Weak_ordering
Wikipedia, “Hash table”. https://en.wikipedia.org/wiki/Hash_table
06 | 异常:用还是不用,这是个问题
首先,开宗明义,如果你不知道到底该不该用异常的话,那答案就是该用。如果你需要避免使用异常,原因必须是你有明确的需要避免使用异常的理由。
6.1 没有异常的世界
我们先来看看没有异常的世界是什么样子的。最典型的情况就是 C 了。
假设我们要做一些矩阵的操作,定义了下面这个矩阵的数据结构:
typedef struct {
float* data;
size_t nrows;
size_t ncols;
} matrix;我们至少需要有初始化和清理的代码:
enum matrix_err_code {
MATRIX_SUCCESS,
MATRIX_ERR_MEMORY_INSUFFICIENT,
//…
};
int matrix_alloc(matrix* ptr, size_t nrows, size_t ncols)
{
size_t size = nrows * ncols * sizeof(float);
float* data = malloc(size);
if (data == NULL) {
return MATRIX_ERR_MEMORY_INSUFFICIENT;
}
ptr->data = data;
ptr->nrows = nrows;
ptr->ncols = ncols;
}
void matrix_dealloc(matrix* ptr)
{
if (ptr->data == NULL) {
return;
}
free(ptr->data);
ptr->data = NULL;
ptr->nrows = 0;
ptr->ncols = 0;
}然后,我们做一下矩阵乘法吧。函数定义大概会是这个样子:
int matrix_multiply(matrix* result, const matrix* lhs, const matrix* rhs)
{
int errcode;
if (lhs->ncols != rhs->nrows) {
return MATRIX_ERR_MISMATCHED_MATRIX_SIZE;
// 呃,得把这个错误码添到 enum matrix_err_code 里
}
errcode = matrix_alloc(result, lhs->nrows, rhs->ncols);
if (errcode != MATRIX_SUCCESS) {
return errcode;
}
// 进行矩阵乘法运算
return MATRIX_SUCCESS;
}调用代码:
matrix c;
memset(c, 0, sizeof(matrix));
errcode = matrix_multiply(c, a, b);
if (errcode != MATRIX_SUCCESS) {
goto error_exit;
}
// 使用乘法的结果做其他处理
error_exit:
matrix_dealloc(&c);
return errcode;可以看到,我们有大量需要判断错误的代码,零散分布在代码各处。
可这是 C 啊。我们用 C++、不用异常可以吗?
当然可以,但你会发现结果好不了多少。毕竟,C++ 的构造函数是不能返回错误码的,所以你根本不能用构造函数来做可能出错的事情。你不得不定义一个只能清零的构造函数,再使用一个 init 函数来做真正的构造操作。C++ 虽然支持运算符重载,可你也不能使用,因为你没法返回一个新矩阵……
6.2 使用异常
如果使用异常的话,我们就可以在构造函数里做真正的初始化工作了。假设我们的矩阵类有下列的数据成员:
class matrix {
//…
private:
float* data_;
size_t nrows_;
size_t ncols_;
};构造函数和析构函数我们可以这样写:
matrix::matrix(size_t nrows, size_t ncols)
{
data_ = new float[nrows * ncols];
nrows_ = nrows;
ncols_ = ncols;
}
matrix::~matrix()
{
delete[] data_;
}乘法函数可以这样写:
class matrix {
//…
friend matrix operator*(const matrix&, const matrix&);
};
matrix operator*(const matrix& lhs, const matrix& rhs)
{
if (lhs.ncols != rhs.nrows) {
throw std::runtime_error("matrix sizes mismatch");
}
matrix result(lhs.nrows, rhs.ncols);
// 进行矩阵乘法运算
return result;
}使用乘法的代码则更是简单:
matrix c = a * b;你可能已经非常疑惑了:错误处理在哪儿呢?只有一个 throw,跟前面的 C 代码能等价吗?
异常处理并不意味着需要写显式的 try 和 catch。异常安全的代码,可以没有任何 try 和 catch。
如果你不确定什么是”异常安全”,我们先来温习一下概念:异常安全是指当异常发生时,既不会发生资源泄漏,系统也不会处于一个不一致的状态。
我们看看可能会出现错误 / 异常的地方:
- 首先是内存分配。如果 new 出错,按照 C++ 的规则,一般会得到异常 bad_alloc,对象的构造也就失败了。这种情况下,在 catch 捕捉到这个异常之前,所有的栈上对象会全部被析构,资源全部被自动清理。
- 如果是矩阵的长宽不合适不能做乘法呢?我们同样会得到一个异常,这样,在使用乘法的地方,对象 c 根本不会被构造出来。
- 如果在乘法函数里内存分配失败呢?一样,result 对象根本没有构造出来,也就没有 c 对象了。还是一切正常。
- 如果 a、b 是本地变量,然后乘法失败了呢?析构函数会自动释放其空间,我们同样不会有任何资源泄漏。
总而言之,只要我们适当地组织好代码、利用好 RAII,实现矩阵的代码和使用矩阵的代码都可以更短、更清晰。我们可以统一在外层某个地方处理异常——通常会记日志、或在界面上向用户报告错误了。
6.3 避免异常的风格指南?
但大名鼎鼎的 Google 的 C++ 风格指南不是说要避免异常吗 [1]?这又是怎么回事呢?
答案实际已经在 Google 的文档里了:
Given that Google’s existing code is not exception-tolerant, the costs of using
exceptions are somewhat greater than the costs in a new project. The conversion
process would be slow and error-prone. We don’t believe that the available
alternatives to exceptions, such as error codes and assertions, introduce a
significant burden.Our advice against using exceptions is not predicated on philosophical or moral
grounds, but practical ones. Because we’d like to use our open-source projects
at Google and it’s difficult to do so if those projects use exceptions, we need to
advise against exceptions in Google open-source projects as well. Things would
probably be different if we had to do it all over again from scratch.
我来翻译一下(我的加重):
鉴于 Google 的现有代码不能承受异常,使用异常的代价要比在全新的项目中使用异常
大一些。 转换 [代码来使用异常的] 过程会缓慢而容易出错。我们不认为可代替异常的方
法,如错误码或断言,会带来明显的负担。我们反对异常的建议并非出于哲学或道德的立场,而是出于实际考虑。因为我们希望在
Google 使用我们的开源项目,而如果这些项目使用异常的话就会对我们的使用带来困
难,我们也需要反对在 Google 的开源项目中使用异常。如果我们从头再来一次的话,
事情可能就会不一样了。
这个如果还比较官方、委婉的话,Reddit 上还能找到一个更个人化的表述 [2]:
I use [sic] to work at Google, and Craig Silverstein, who wrote the first draft of
the style guideline, said that he regretted the ban on exceptions, but he had no
choice; when he wrote it, it wasn’t only that the compiler they had at the time
did a very bad job on exceptions, but that they already had a huge volume of
non-exception-safe code.
我的翻译(同样,我的加重):
我过去在 Google 工作,写了风格指南初稿的 Craig Silverstein 说过 他对禁用异常感到
遗憾 ,但他当时别无选择。在他写风格指南的时候,不仅他们使用的编译器在异常上工
作得很糟糕,而且他们已经有了一大堆异常不安全的代码了。
当然,除了历史原因以外,也有出于性能等其他原因禁用异常的。美国国防部的联合攻击战斗机(JSF)项目的 C++ 编码规范就禁用异常,因为工具链不能保证抛出异常时的实时性能。不过在那种项目里,被禁用的 C++ 特性就多了,比如动态内存分配都不能使用。
一些游戏项目为了追求高性能,也禁用异常。这个实际上也有一定的历史原因,因为今天的主流 C++ 编译器,在异常关闭和开启时应该已经能够产生性能差不多的代码(在异常未抛出时)。代价是产生的二进制文件大小的增加,因为异常产生的位置决定了需要如何做栈展开,这些数据需要存储在表里。典型情况,使用异常和不使用异常比,二进制文件大小会有约百分之十到二十的上升。LLVM 项目的编码规范里就明确指出这是不使用 RTTI 和异常的原因 [3]:
In an effort to reduce code and executable size, LLVM does not use RTTI (e.g. dynamic_cast<>;) or exceptions.
6.4 异常的问题
异常当然不是一个完美的特性,否则也不会招来这些批评和禁用了。对它的批评主要有两条:
- 异常违反了”你不用就不需要付出代价”的 C++ 原则。只要开启了异常,即使不使用异常你编译出的二进制代码通常也会膨胀。
- 异常比较隐蔽,不容易看出来哪些地方会发生异常和发生什么异常。
对于第一条,开发者没有什么可做的。事实上,这也算是 C++ 实现的一个折中了。目前的主流异常实现中,都倾向于牺牲可执行文件大小、提高主流程(happy path)的性能。只要程序不抛异常,C++ 代码的性能比起完全不做错误检查的代码,都只有几个百分点的性能损失 [4]。除了非常有限的一些场景,可执行文件大小通常不会是个问题。
第二条可以算作是一个真正有效的批评。和 Java 不同,C++ 里不会对异常规约进行编译时的检查。从 C++17 开始,C++ 甚至完全禁止了以往的动态异常规约,你不再能在函数声明里写你可能会抛出某某异常。你唯一能声明的,就是某函数不会抛出异常—— noexcept、noexcept(true) 或 throw()。这也是 C++ 的运行时唯一会检查的东西了。如果一个函数声明了不会抛出异常、结果却抛出了异常,C++ 运行时会调用 std::terminate 来终止应用程序。不管是程序员的声明,还是编译器的检查,都不会告诉你哪些函数会抛出哪些异常。
当然,不声明异常是有理由的。特别是在泛型编程的代码里,几乎不可能预知会发生些什么异常。我个人对避免异常带来的问题有几点建议:
- 写异常安全的代码,尤其在模板里。可能的话,提供强异常安全保证 [5],在任何第三方代码发生异常的情况下,不改变对象的内容,也不产生任何资源泄漏。
- 如果你的代码可能抛出异常的话,在文档里明确声明可能发生的异常类型和发生条件。确保使用你的代码的人,能在不检查你的实现的情况,了解需要准备处理哪些异常。
- 对于肯定不会抛出异常的代码,将其标为 noexcept。注意类的特殊成员(构造函数、析构函数、赋值函数等)会自动成为 noexcept,如果它们调用的代码都是 noexcept 的话。所以,像 swap 这样的成员函数应当尽可能标成 noexcept。
6.5 使用异常的理由
虽然后面我们会描述到一些不使用异常、也不使用错误返回码的错误处理方式,但异常是渗透在 C++ 中的标准错误处理方式。标准库的错误处理方式就是异常。其中不仅包括运行时错误,甚至包括一些逻辑错误。比如,在说容器的时候,有一个我没提的地方是,在能使用 [] 运算符的地方,C++ 的标准容器也提供了 at 成员函数,能够在下标不存在的时候抛出异常,作为一种额外的帮助调试的手段。
C++ 的标准容器在大部分情况下提供了强异常保证,即,一旦异常发生,现场会恢复到调用函数之前的状态,容器的内容不会发生改变,也没有任何资源泄漏。前面提到过, vector 会在元素类型没有提供保证不抛异常的移动构造函数的情况下,在移动元素时会使用拷贝构造函数。这是因为一旦某个操作发生了异常,被移动的元素已经被破坏,处于只能析构的状态,异常安全性就不能得到保证了。
只要你使用了标准容器,不管你自己用不用异常,你都得处理标准容器可能引发的异常——至少有 bad_alloc,除非你明确知道你的目标运行环境不会产生这个异常。这对普通配置的 Linux 环境而言,倒确实是对的……这也算是 Google 这么规定的一个底气吧。
虽然对于运行时错误,开发者并没有什么选择余地;但对于代码中的逻辑错误,开发者则是可以选择不同的处理方式的:你可以使用异常,也可以使用 assert,在调试环境中报告错误并中断程序运行。由于测试通常不能覆盖所有的代码和分支,assert 在发布模式下一般被禁用,两者并不是完全的替代关系。在允许异常的情况下,使用异常可以获得在调试和发布模式下都良好、一致的效果。
标准 C++ 可能会产生哪些异常,可以查看参考资料 [6]。
6.6 参考资料
- Google, “Google C++ style guide”. https://google.github.io/styleguide/cppguide.html#Exceptions
- Reddit, Discussion on “Examples of C++ projects which embrace exceptions?”. https://www.reddit.com/r/cpp/comments/4wkkge/examples_of_c_projects_which_embrace_exceptions/
- LLVM Project, “LLVM coding standards”. https://llvm.org/docs/CodingStandards.html#do-not-use-rtti-or-exceptions
- Standard C++ Foundation, “FAQ—exceptions and error handling”. https://isocpp.org/wiki/faq/exceptions
- cppreference.com, “Exceptions”. https://en.cppreference.com/w/cpp/language/exceptions
- cppreference.com, “std::exception”. https://en.cppreference.com/w/cpp/error/exception
07 | 迭代器和好用的新for循环
7.1 什么是迭代器?
迭代器是一个很通用的概念,并不是一个特定的类型。它实际上是一组对类型的要求([1])。它的最基本要求就是从一个端点出发,下一步、下一步地到达另一个端点。
我在用 output_container.h 输出容器内容的时候,实际上就对容器的 begin 和 end 成员函数返回的对象类型提出了要求。假设前者返回的类型是 I,后者返回的类型是 S,这些要求是:
- I 对象支持
*操作,解引用取得容器内的某个对象。 - I 对象支持 ++,指向下一个对象。
- I 对象可以和 I 或 S 对象进行相等比较,判断是否遍历到了特定位置(在 S 的情况下是是否结束了遍历)。
注意在 C++17 之前,begin 和 end 返回的类型 I 和 S 必须是相同的。从 C++17 开始,I 和 S 可以是不同的类型。
上面的类型 I,多多少少就是一个满足输入迭代器(input iterator)的类型了。不过, output_container.h 只使用了前置 ++,但输入迭代器要求前置和后置 ++ 都得到支持。
输入迭代器不要求对同一迭代器可以多次使用 * 运算符,也不要求可以保存迭代器来重新遍历对象,换句话说,只要求可以单次访问。如果取消这些限制、允许多次访问的话,那迭代器同时满足了前向迭代器(forward iterator)。
一个前向迭代器的类型,如果同时支持 —(前置及后置),回到前一个对象,那它就是个双向迭代器(bidirectional iterator)。也就是说,可以正向遍历,也可以反向遍历。
一个双向迭代器,如果额外支持在整数类型上的 +、-、+=、-=,跳跃式地移动迭代器;支持 [],数组式的下标访问;支持迭代器的大小比较(之前只要求相等比较);那它就是个随机访问迭代器(random-access iterator)。
一个随机访问迭代器 i 和一个整数 n,在 *i 可解引用且 i + n 是合法迭代器的前提下,如果额外还满足 *(addressdof(*i) + n) 等价于 *(i + n),即保证迭代器指向的对象在内存里是连续存放的,那它(在 C++20 里)就是个连续迭代器(contiguous iterator)。
以上这些迭代器只考虑了读取。如果一个类型像输入迭代器,但 *i 只能作为左值来写而不能读,那它就是个输出迭代器(output iterator)。
而比输入迭代器和输出迭代器更底层的概念,就是迭代器了。基本要求是:
- 对象可以被拷贝构造、拷贝赋值和析构。
- 对象支持 * 运算符。
- 对象支持前置 ++ 运算符。
迭代器类型的关系可从下图中全部看到:
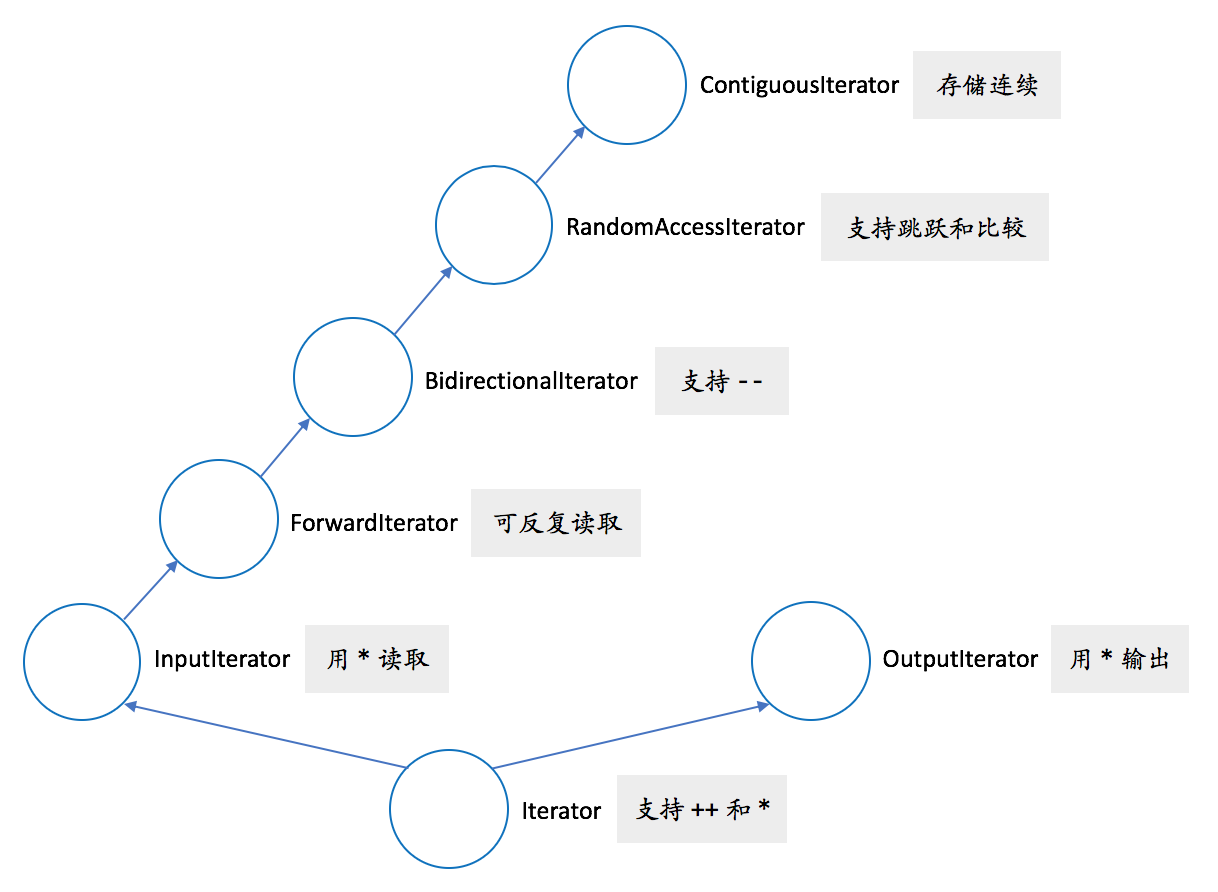
迭代器通常是对象。但需要注意的是,指针可以满足上面所有的迭代器要求,因而也是迭代器。这应该并不让人惊讶,因为本来迭代器就是根据指针的特性,对其进行抽象的结果。事实上,vector 的迭代器,在很多实现里就直接是使用指针的。
7.2 常用迭代器
最常用的迭代器就是容器的 iterator 类型了。一般而言,iterator 可写入,const_iterator 类型不可写入,但这些迭代器都被定义为输入迭代器或其派生类型:
- vector::iterator 和 array::iterator 可以满足到连续迭代器。
- deque::iterator 可以满足到随机访问迭代器(记得它的内存只有部分连续)。
- list::iterator 可以满足到双向迭代器(链表不能快速跳转)。
- forward_list::iterator 可以满足到前向迭代器(单向链表不能反向遍历)。
很常见的一个输出迭代器是 back_inserter 返回的类型 back_inserter_iterator 了;用它我们可以很方便地在容器的尾部进行插入操作。另外一个常见的输出迭代器是 ostream_iterator,方便我们把容器内容”拷贝”到一个输出流。
7.3 使用输入行迭代器
下面我们来看一下一个我写的输入迭代器。它的功能本身很简单,就是把一个输入流(istream)的内容一行行读进来。配上 C++11 引入的基于范围的 for 循环的语法,我们可以把遍历输入流的代码以一种自然、非过程式的方式写出来,如下所示:
for (const string& line : istream_line_reader(is)) {
// 示例循环体中仅进行简单输出
cout << line << endl;
}我们可以对比一下以传统的方式写的 C++ 代码,其中需要照顾不少细节:
string line;
for (;;) {
getline(is, line);
if (!is) {
break;
}
cout << line << endl;
}我们后面会分析一下这个输入迭代器。在此之前,我先解说一下基于范围的 for 循环这个语法。虽然这可以说是个语法糖,但它对提高代码的可读性真的非常重要。如果不用这个语法糖的话,简洁性上的优势就小多了。我们直接把这个循环改写成等价的普通 for 循环的样子。
{
auto&& r = istream_line_reader(is);
auto it = r.begin();
auto end = r.end();
for (; it != end; ++it) {
const string& line = *it;
cout << line << endl;
}
}可以看到,它做的事情也不复杂,就是:
- 获取冒号后边的范围表达式的结果,并隐式产生一个引用,在整个循环期间都有效。注意根据生命期延长规则,表达式结果如果是临时对象的话,这个对象要在循环结束后才被销毁。
- 自动生成遍历这个范围的迭代器。
- 循环内自动生成根据冒号左边的声明和 *it 来进行初始化的语句。
- 下面就是完全正常的循环体。
生成迭代器这一步有可能是——但不一定是——调用 r 的 begin 和 end 成员函数。具体规则是:
- 对于 C 数组(必须是没有退化为指针的情况),编译器会自动生成指向数组头尾的指针(相当于自动应用可用于数组的 std::begin 和 std::end 函数)。
- 对于有 begin 和 end 成员的对象,编译器会调用其 begin 和 end 成员函数(我们目前的情况)。
- 否则,编译器会尝试在 r 对象所在的名空间寻找可以用于 r 的 begin 和 end 函数,并
- 调用 begin(r) 和 end(r);找不到的话则失败报错。
7.4 定义输入行迭代器
C++ 里有些固定的类型要求规范。对于一个迭代器,我们需要定义下面的类型:
class istream_line_reader {
public:
class iterator { // 实现 InputIterator
public:
typedef ptrdiff_t difference_type;
typedef string value_type;
typedef const value_type* pointer;
typedef const value_type& reference;
typedef input_iterator_tag iterator_category;
// …
};
// …
};仿照一般的容器,我们把迭代器定义为 istream_line_reader 的嵌套类。它里面的这五个类型是必须定义的(其他泛型 C++ 代码可能会用到这五个类型;之前标准库定义了一个可以继承的类模板 std::iterator 来产生这些类型定义,但这个类目前已经被废弃[2])。其中:
- difference_type 是代表迭代器之间距离的类型,定义为 ptrdiff_t 只是种标准做法(指针间差值的类型),对这个类型没什么特别作用。
- value_type 是迭代器指向的对象的值类型,我们使用 string,表示迭代器指向的是字符串。
- pointer 是迭代器指向的对象的指针类型,这儿就平淡无奇地定义为 value_type 的常指针了(我们可不希望别人来更改指针指向的内容)。类似的,reference 是 value_type 的常引用。
- iterator_category 被定义为 input_iterator_tag,标识这个迭代器的类型是
- input iterator(输入迭代器)。
作为一个真的只能读一次的输入迭代器,有个特殊的麻烦(前向迭代器或其衍生类型没有):到底应该让 * 负责读取还是 ++ 负责读取。我们这儿采用常见、也较为简单的做法,让 ++ 负责读取,* 负责返回读取的内容(这个做法会有些副作用,但按我们目前的用法则没有问题)。这样的话,这个 iterator 类需要有一个数据成员指向输入流,一个数据成员来存放读取的结果。根据这个思路,我们定义这个类的基本成员函数和数据成员:
class istream_line_reader {
public:
class iterator {
//…
iterator() noexcept
: stream_(nullptr)
{
}
explicit iterator(istream& is)
: stream_(&is)
{
++*this;
}
reference operator*() const noexcept
{
return line_;
}
pointer operator->() const noexcept
{
return &line_;
}
iterator& operator++()
{
getline(*stream_, line_);
if (!*stream_) {
stream_ = nullptr;
}
return *this;
}
iterator operator++(int)
{
iterator temp(*this);
++*this;
return temp;
}
private:
istream* stream_;
string line_;
};
//…
};我们定义了默认构造函数,将 stream_ 清空;相应的,在带参数的构造函数里,我们根据传入的输入流来设置 stream_。我们也定义了 * 和 -> 运算符来取得迭代器指向的文本行的引用和指针,并用 ++ 来读取输入流的内容(后置 ++ 则以惯常方式使用前置 ++ 和拷贝构造来实现)。唯一”特别”点的地方,是我们在构造函数里调用了 ++,确保在构造后调用 * 运算符时可以读取内容,符合日常先使用 *、再使用 ++ 的习惯。一旦文件读取到尾部(或出错),则 stream_ 被清空,回到默认构造的情况。
对于迭代器之间的比较,我们则主要考虑文件有没有读到尾部的情况,简单定义为:
bool operator==(const iterator& rhs) const noexcept
{
return stream_ == rhs.stream_;
}
bool operator!=(const iterator& rhs) const noexcept
{
return !operator==(rhs);
}有了这个 iterator 的定义后,istream_line_reader 的定义就简单得很了:
class istream_line_reader {
public:
class iterator {
//…
};
istream_line_reader() noexcept
: stream_(nullptr)
{
}
explicit istream_line_reader(istream& is) noexcept
: stream_(&is)
{
}
iterator begin()
{
return iterator(*stream_);
}
iterator end() const noexcept
{
return iterator();
}
private:
istream* stream_;
};也就是说,构造函数只是简单地把输入流的指针赋给 stream_ 成员变量。begin 成员函数则负责构造一个真正有意义的迭代器;end 成员函数则只是返回一个默认构造的迭代器而已。
以上就是一个完整的基于输入流的行迭代器了。这个行输入模板的设计动机和性能测试结果可参见参考资料 [3] 和 [4];完整的工程可用代码,请参见参考资料 [5]。该项目中还提供了利用 C 文件接口的 file_line_reader 和基于内存映射文件的 mmap_line_reader。
7.5 参考资料
- cppreference.com, “Iterator library”. https://en.cppreference.com/w/cpp/iterator
- Jonathan Boccara, “std::iterator is deprecated: why, what it was, and what to use instead”. https://www.fluentcpp.com/2018/05/08/std-iterator-deprecated/
- 吴咏炜, “Python yield and C++ coroutines”. https://yongweiwu.wordpress.com/2016/08/16/python-yield-and-cpluspluscoroutines/
- 吴咏炜, “Performance of my line readers”. https://yongweiwu.wordpress.com/2016/11/12/performance-of-my-line-readers/
- 吴咏炜, nvwa. https://github.com/adah1972/nvwa/
08 | 易用性改进 I:自动类型推断和初始化
8.1 自动类型推断
auto
自动类型推断,顾名思义,就是编译器能够根据表达式的类型,自动决定变量的类型(从 C++14 开始,还有函数的返回类型),不再需要程序员手工声明([1])。但需要说明的是,auto 并没有改变 C++ 是静态类型语言这一事实——使用 auto 的变量(或函数返回值)的类型仍然是编译时就确定了,只不过编译器能自动帮你填充而已。
auto 实际使用的规则类似于函数模板参数的推导规则([3])。当你写了一个含 auto 的表达式时,相当于把 auto 替换为模板参数的结果。举具体的例子:
- auto a = expr; 意味着用 expr 去匹配一个假想的
template <typename T> f(T)函数模板,结果为值类型。 - const auto& a = expr; 意味着用 expr 去匹配一个假想的
template <typename T> f(const T&)函数模板,结果为常左值引用类型。 - auto&& a = expr; 意味着用 expr 去匹配一个假想的
template <typename T> f(T&&)函数模板,根据 [第 3 讲] 中我们讨论过的转发引用和引用坍缩规则,结果是一个跟 expr 值类别相同的引用类型。
- auto a = expr; 意味着用 expr 去匹配一个假想的
decltype
decltype 的用途是获得一个表达式的类型,结果可以跟类型一样使用。它有两个基本用法:
- decltype(变量名) 可以获得变量的精确类型。
decltype(表达式) (表达式不是变量名,但包括 decltype((变量名)) 的情况)可以获得表达式的引用类型;除非表达式的结果是个纯右值(prvalue),此时结果仍然是值类型。
如果我们有 int a;,那么:
decltype(a) 会获得 int(因为 a 是 int)。
- decltype((a)) 会获得 int&(因为 a 是 lvalue)。
- decltype(a + a) 会获得 int(因为 a + a 是 prvalue)。
decltype(auto)
通常情况下,能写 auto 来声明变量肯定是件比较轻松的事。但这儿有个限制,你需要在写下 auto 时就决定你写下的是个引用类型还是值类型。根据类型推导规则,auto 是值类型,auto& 是左值引用类型,auto&& 是转发引用(可以是左值引用,也可以是右值引用)。使用 auto 不能通用地根据表达式类型来决定返回值的类型。不过, decltype(expr) 既可以是值类型,也可以是引用类型。因此,我们可以这么写:
decltype(expr) a = expr;这种写法明显不能让人满意,特别是表达式很长的情况(而且,任何代码重复都是潜在的问题)。为此,C++14 引入了 decltype(auto) 语法。对于上面的情况,我们只需要像下面这样写就行了。
decltype(auto) a = expr;
8.2 函数返回值类型推断
从 C++14 开始,函数的返回值也可以用 auto 或 decltype(auto) 来声明了。同样的,用 auto 可以得到值类型,用 auto& 或 auto&& 可以得到引用类型;而用 decltype(auto) 可以根据返回表达式通用地决定返回的是值类型还是引用类型。
和这个形式相关的有另外一个语法,后置返回值类型声明。严格来说,这不算”类型推断”,不过我们也放在一起讲吧。它的形式是这个样子:
auto foo(参数) -> 返回值类型声明
{
// 函数体
}通常,在返回类型比较复杂、特别是返回类型跟参数类型有某种推导关系时会使用这种语法。以后我们会讲到一些实例。今天暂时不多讲了。
8.3 类模板的模板参数推导
如果你用过 pair 的话,一般都不会使用下面这种形式:
pair<int, int> pr{1, 42};使用 make_pair 显然更容易一些:
auto pr = make_pair(1, 42);这是因为函数模板有模板参数推导,使得调用者不必手工指定参数类型;但 C++17 之前的类模板却没有这个功能,也因而催生了像 make_pair 这样的工具函数。
在进入了 C++17 的世界后,这类函数变得不必要了。现在我们可以直接写:
pair pr{1, 42};在初次见到 array 时,我觉得它的主要缺点就是不能像 C 数组一样自动从初始化列表来推断数组的大小了:
int a1[] = {1, 2, 3};
array<int, 3> a2{1, 2, 3}; // 啰嗦
// array<int> a3{1, 2, 3}; 不行这个问题在 C++17 里也是基本不存在的。虽然不能只提供一个模板参数,但你可以两个参数全都不写:
array a{1, 2, 3}; // 得到 array<int, 3>这种自动推导机制,可以是编译器根据构造函数来自动生成:
template <typename T>
struct MyObj {
MyObj(T value);
//…
};
MyObj obj1 { string("hello") }; // 得到 MyObj<string>
MyObj obj2 { "hello" }; // 得到 MyObj<const char*>也可以是手工提供一个推导向导,达到自己需要的效果:
template <typename T>
struct MyObj {
MyObj(T value);
//…
};
MyObj(const char*) -> MyObj<string>;
MyObj obj1 { "hello" }; // 得到 MyObj<string>更多的技术细节请参见参考资料 [4]。
8.4 结构化绑定
一个例子:
multimap<string, int>::iterator lower, upper;
std::tie(lower, upper) = mmp.equal_range("four");这个例子里,返回值是个 pair,我们希望用两个变量来接收数值,就不得不声明了两个变量,然后使用 tie 来接收结果。在 C++11/14 里,这里是没法使用 auto 的。好在 C++17 引入了一个新语法,解决了这个问题。目前,我们可以把上面的代码简化为:
auto [lower, upper] = mmp.equal_range("four");这个语法使得我们可以用 auto 声明变量来分别获取 pair 或 tuple 返回值里各个子项,可以让代码的可读性更好。
关于这个语法的更多技术说明,请参见参考资料 [5]。
8.5 列表初始化
vector<int> v{1, 2, 3, 4, 5};这不是对标准库容器的特殊魔法,而是一个通用的、可以用于各种类的方法。从技术角度,编译器的魔法只是对 {1, 2, 3} 这样的表达式自动生成一个初始化列表,在这个例子里其类型是 initializer_list<int>。程序员只需要声明一个接受 initializer_list 的构造函数即可使用。从效率的角度,至少在动态对象的情况下,容器和数组也并无二致,都是通过拷贝(构造)进行初始化。
对于初始化列表在构造函数外的用法和更多的技术细节,请参见参考资料 [6]。
8.6 统一初始化
你可能已经注意到了,我在代码里使用了大括号 {} 来进行对象的初始化。这当然也是 C++11 引入的新语法,能够代替很多小括号 () 在变量初始化时使用。这被称为统一初始化(uniform initialization)。
大括号对于构造一个对象而言,最大的好处是避免了 C++ 里”最令人恼火的语法分析”(the most vexing parse)。我也遇到过。假设你有一个类,原型如下:
class utf8_to_wstring {
public:
utf8_to_wstring(const char*);
operator wchar_t*();
};然后你在 Windows 下想使用这个类来帮助转换文件名,打开文件:
ifstream ifs(utf8_to_wstring(filename));上面这个写法会被编译器认为是和下面的写法等价的:
ifstream ifs(utf8_to_wstring filename);换句话说,编译器认为你是声明了一个叫 ifs 的函数,而不是对象!
如果你把任何一对小括号替换成大括号(或者都替换,如下),则可以避免此类问题:
ifstream ifs{utf8_to_wstring{filename}};推而广之,你几乎可以在所有初始化对象的地方使用大括号而不是小括号。它还有一个附带的特点:当一个构造函数没有标成 explicit 时,你可以使用大括号不写类名来进行构造,如果调用上下文要求那类对象的话。如:
Obj getObj()
{
return {1.0};
}如果 Obj 类可以使用浮点数进行构造的话,上面的写法就是合法的。如果有无参数、多参数的构造函数,也可以使用这个形式。除了形式上的区别,它跟 Obj(1.0) 的主要区别是,后者可以用来调用 Obj(int),而使用大括号时编译器会拒绝”窄”转换,不接受以 {1.0} 或 Obj{1.0} 的形式调用构造函数 Obj(int)。
这个语法主要的限制是,如果一个构造函数既有使用初始化列表的构造函数,又有不使用初始化列表的构造函数,那编译器会千方百计地试图调用使用初始化列表的构造函数,导致各种意外。所以,如果给一个推荐的话,那就是:
- 如果一个类没有使用初始化列表的构造函数时,初始化该类对象可全部使用统一初始化语法。
- 如果一个类有使用初始化列表的构造函数时,则只应用在初始化列表构造的情况。
关于这个语法的更多详细用法讨论,请参见参考资料 [7]。
8.7 类数据成员的默认初始化
按照 C++98 的语法,数据成员可以在构造函数里进行初始化。这本身不是问题,但实践中,如果数据成员比较多、构造函数又有多个的话,逐个去初始化是个累赘,并且很容易在增加数据成员时漏掉在某个构造函数中进行初始化。为此,C++11 增加了一个语法,允许在声明数据成员时直接给予一个初始化表达式。这样,当且仅当构造函数的初始化列表中不包含该数据成员时,这个数据成员就会自动使用初始化表达式进行初始化。
class Complex {
public:
Complex() { }
Complex(float re)
: re_(re)
{
}
Complex(float re, float im)
: re_(re)
, im_(im)
{
}
private:
float re_ { 0 };
float im_ { 0 };
};8.8 参考资料
- cppreference.com, “Placeholder type specifiers”. https://en.cppreference.com/w/cpp/language/auto
- Wikipedia, “Argument-dependent name lookup”. https://en.wikipedia.org/wiki/Argument-dependent_name_lookup
- cppreference.com, “Template argument deduction”. https://en.cppreference.com/w/cpp/language/template_argument_deduction
- cppreference.com, “Class template argument deduction”. https://en.cppreference.com/w/cpp/language/class_template_argument_deduction
- cppreference.com, “Structured binding declaration”. https://en.cppreference.com/w/cpp/language/structured_binding
- cppreference.com, “std::initializer_list”. https://en.cppreference.com/w/cpp/utility/initializer_list
- Scott Meyers,Effective Modern C++, item 7. O’Reilly Media, 2014. 有中文版(高博译,中国电力出版社,2018 年)
09 | 易用性改进 II:字面量、静态断言和成员函数说明符
9.1 自定义字面量
字面量(literal)是指在源代码中写出的固定常量,它们在 C++98 里只能是原生类型,如:
- “hello”,字符串字面量,类型是 const char[6]
- 1,整数字面量,类型是 int
- 0.0,浮点数字面量,类型是 double
- 3.14f,浮点数字面量,类型是 float
- 123456789ul,无符号长整数字面量,类型是 unsigned long
C++11 引入了自定义字面量,可以使用 operator”” 后缀 来将用户提供的字面量转换成实际的类型。C++14 则在标准库中加入了不少标准字面量。下面这个程序展示了它们的用法:
#include <chrono>
#include <complex>
#include <iostream>
#include <string>
#include <thread>
using namespace std;
int main()
{
cout << "i * i = " << 1i * 1i
<< endl;
cout << "Waiting for 500ms"
<< endl;
this_thread::sleep_for(500ms);
cout << "Hello world"s.substr(0, 5)
<< endl;
}上面这个例子展示了 C++ 标准里提供的帮助生成虚数、时间和 basic_string 字面量的后缀。一个需要注意的地方是,我在上面使用了 using namespace std,这会同时引入 std 名空间和里面的内联名空间(inline namespace),包括了上面的字面量运算符所在的三个名空间:
- std::literals::complex_literals
- std::literals::chrono_literals
- std::literals::string_literals
在产品项目中,一般不会(也不应该)全局使用 using namespace std(不过,为节约篇幅起见,专栏里的很多例子,特别是不完整的例子,还是默认使用了 using namespace std)。这种情况下,应当在使用到这些字面量的作用域里导入需要的名空间,以免发生冲突。在类似上面的例子里,就是在函数体的开头写:
using namespace std::literals::chrono_literals;等等。
要在自己的类里支持字面量也相当容易,唯一的限制是非标准的字面量后缀必须以下划线 _ 打头。比如,假如我们有下面的长度类:
struct length {
double value;
enum unit {
metre,
kilometre,
millimetre,
centimetre,
inch,
foot,
yard,
mile,
};
static constexpr double factors[] = {
1.0, 1000.0, 1e-3,
1e-2, 0.0254, 0.3048,
0.9144, 1609.344
};
explicit length(double v, unit u = metre)
{
value = v * factors[u];
}
};
length operator+(length lhs, length rhs)
{
return length(lhs.value + rhs.value);
}
// 可能有其他运算符我们可以手写 length(1.0, length::metre) 这样的表达式,但估计大部分开发人员都不愿意这么做吧。反过来,如果我们让开发人员这么写,大家应该还是基本乐意的:
1.0_m + 10.0_cm要允许上面这个表达式,我们只需要提供下面的运算符即可:
length operator"" _m(long double v)
{
return length(v, length::metre);
}
length operator"" _cm(long double v)
{
return length(v, length::centimetre);
}关于自定义字面量的进一步技术细节,请参阅参考资料 [2]。
9.2 二进制字面量
C++ 里有 0x 前缀,可以让开发人员直接写出像 0xFF 这样的十六进制字面量。另外一个目前使用得稍少的前缀就是 0 后面直接跟 0–7 的数字,表示八进制的字面量,在跟文件系统打交道的时候还会经常用到:有经验的 Unix 程序员可能会觉得 chmod(path, S_IRUSR|S_IWUSR|S_IRGRP|S_IROTH) 并不比 chmod(path, 0644) 更为直观。从 C++14 开始,我们对于二进制也有了直接的字面量:
unsigned mask = 0b111000000;遗憾的是, I/O streams 里只有 dec、hex、oct 三个操纵器(manipulator),而没有 bin,因而输出一个二进制数不能像十进制、十六进制、八进制那么直接。一个间接方式是使用 bitset,但调用者需要手工指定二进制位数:
#include <bitset>
cout << bitset<9>(mask) << endl; // 1110000009.3 数字分隔符
C++14 开始,允许在数字型字面量中任意添加 ‘ 来使其更可读。具体怎么添加,完全由程序员根据实际情况进行约定。某些常见的情况可能会是:
- 十进制数字使用三位的分隔,对应英文习惯的 thousand、million 等单位。
- 十进制数字使用四位的分隔,对应中文习惯的万、亿等单位。
- 十六进制数字使用两位或四位的分隔,对应字节或双字节。
- 二进制数字使用三位的分隔,对应文件系统的权限分组。
- 等等。
unsigned mask = 0b111'000'000;
long r_earth_equatorial = 6'378'137;
double pi = 3.14159'26535'89793;
const unsigned magic = 0x44'42'47'4E;9.4 静态断言
C++11 直接从语言层面提供了静态断言机制,不仅能输出更好的信息,而且适用性也更好,可以直接放在类的定义中。
静态断言语法上非常简单,就是:
static_assert(编译期条件表达式, 可选输出信息);9.5 default 和 delete 成员函数
在类的定义时,C++ 有一些规则决定是否生成默认的特殊成员函数。这些特殊成员函数可能包括:
- 默认构造函数
- 析构函数
- 拷贝构造函数
- 拷贝赋值函数
- 移动构造函数
- 移动赋值函数
生成这些特殊成员函数(或不生成)的规则比较复杂,感兴趣的话你可以查看参考资料[3]。每个特殊成员函数有几种不同的状态:
- 隐式声明还是用户声明
- 默认提供还是用户提供
- 正常状态还是删除状态
这三个状态是可组合的,虽然不是所有的组合都有效。隐式声明的必然是默认提供的;默认提供的才可能被删除;用户提供的也必然是用户声明的。
如果成员和父类没有特殊原因导致对象不可拷贝或移动,在用户不声明这些成员函数的情况下,编译器会自动产生这些成员函数,即隐式声明、默认提供、正常状态。有特殊成员、用户声明的话,情况就非常复杂了:
- 没有初始化的非静态 const 数据成员和引用类型数据成员会导致默认提供的默认构造函数被删除。
- 非静态的 const 数据成员和引用类型数据成员会导致默认提供的拷贝构造函数、拷贝赋值函数、移动构造函数和移动赋值函数被删除。
- 用户如果没有自己提供一个拷贝构造函数(必须形如 Obj(Obj&) 或 Obj(const Obj&);不是模板),编译器会隐式声明一个。
- 用户如果没有自己提供一个拷贝赋值函数(必须形如 Obj& operator=(Obj&) 或 Obj& operator=(const Obj&);不是模板),编译器会隐式声明一个。
- 用户如果自己声明了一个移动构造函数或移动赋值函数,则默认提供的拷贝构造函数和拷贝赋值函数被删除。
- 用户如果没有自己声明拷贝构造函数、拷贝赋值函数、移动赋值函数和析构函数,编译器会隐式声明一个移动构造函数。
- 用户如果没有自己声明拷贝构造函数、拷贝赋值函数、移动构造函数和析构函数,编译器会隐式声明一个移动赋值函数。
- ……
我不鼓励你去死记硬背这些规则,而是希望你在项目和测试中体会其缘由。我认为这些规则还相当合理,虽然有略偏保守之嫌。尤其是关于移动构造和赋值:只要用户声明了另外的特殊成员函数中的任何一个,编译器就不默认提供了。不过嘛,缺省慢点总比缺省不安全要好……
我们这儿主要要说的是,我们可以改变缺省行为,在编译器能默认提供特殊成员函数时将其删除,或在编译器不默认提供特殊成员函数时明确声明其需要默认提供(不过,要注意,即使用户要求默认提供,编译器也可能根据其他规则将特殊成员函数标为删除)。
另外注意一下,用户将构造函数声明成删除也是一种声明,因此编译器不会提供默认版本的移动构造和移动赋值函数。
9.6 override 和 final 说明符
override 和 final 是两个 C++11 引入的新说明符。它们不是关键词,仅在出现在函数声明尾部时起作用,不影响我们使用这两个词作变量名等其他用途。这两个说明符可以单个或组合使用,都是加在类成员函数声明的尾部。
override 显式声明了成员函数是一个虚函数且覆盖了基类中的该函数。如果有 override 声明的函数不是虚函数,或基类中不存在这个虚函数,编译器会报告错误。这个说明符的主要作用有两个:
- 给开发人员更明确的提示,这个函数覆写了基类的成员函数;
- 让编译器进行额外的检查,防止程序员由于拼写错误或代码改动没有让基类和派生类中的成员函数名称完全一致。
final 则声明了成员函数是一个虚函数,且该虚函数不可在派生类中被覆盖。如果有一点没有得到满足的话,编译器就会报错。
final 还有一个作用是标志某个类或结构不可被派生。同样,这时应将其放在被定义的类或结构名后面。
9.7 参考资料
- Wikipedia, “Mars Climate Orbiter”. https://en.wikipedia.org/wiki/Mars_Climate_Orbiter
- cppreference.com, “User-defined literals”. https://en.cppreference.com/w/cpp/language/user_literal
- cppreference.com, “Non-static member functions”, section “Special member functions”. https://en.cppreference.com/w/cpp/language/member_functions
02丨提高篇
10 | 到底应不应该返回对象?
10.1 F.20
《C++ 核心指南》的 F.20 这一条款是这么说的 [1]:
F.20: For “out” output values, prefer return values to output parameters
翻译一下:
在函数输出数值时,尽量使用返回值而非输出参数
10.2 如何返回一个对象?
一个用来返回的对象,通常应当是可移动构造 / 赋值的,一般也同时是可拷贝构造 / 赋值的。如果这样一个对象同时又可以默认构造,我们就称其为一个半正则(semiregular)的对象。如果可能的话,我们应当尽量让我们的类满足半正则这个要求。
半正则意味着我们的 matrix 类提供下面的成员函数:
class matrix {
public:
// 普通构造
matrix(size_t rows, size_t cols);
// 半正则要求的构造
matrix();
matrix(const matrix&);
matrix(matrix&&);
// 半正则要求的赋值
matrix& operator=(const matrix&);
matrix& operator=(matrix&&);
};我们先看一下在没有返回值优化的情况下 C++ 是怎样返回对象的。以矩阵乘法为例,代码应该像下面这样:
matrix operator*(const matrix& lhs, const matrix& rhs)
{
if (lhs.cols() != rhs.rows()) {
throw runtime_error("sizes mismatch");
}
matrix result(lhs.rows(), rhs.cols());
// 具体计算过程
return result;
}在 [第 3 讲] 里说过的,返回非引用类型的表达式结果是个纯右值(prvalue)。在执行 auto r = … 的时候,编译器会认为我们实际是在构造 matrix r(…),而”…”部分是一个纯右值。因此编译器会首先试图匹配 matrix(matrix&&),在没有时则试图匹配 matrix(const matrix&);也就是说,有移动支持时使用移动,没有移动支持时则拷贝。
10.3 返回值优化(拷贝消除)
我们再来看一个能显示生命期过程的对象的例子:
#include <iostream>
using namespace std;
// Can copy and move
class A {
public:
A() { cout << "Create A\n"; }
~A() { cout << "Destroy A\n"; }
A(const A&) { cout << "Copy A\n"; }
A(A&&) { cout << "Move A\n"; }
};
A getA_unnamed()
{
return A();
}
int main()
{
auto a = getA_unnamed();
}如果你认为执行结果里应当有一行”Copy A”或”Move A”的话,你就忽视了返回值优化的威力了。即使完全关闭优化,三种主流编译器(GCC、Clang 和 MSVC)都只输出两行:
Create A
Destroy A我们把代码稍稍改一下:
A getA_named()
{
A a;
return a;
}
int main()
{
auto a = getA_named();
}这回结果有了一点点小变化。虽然 GCC 和 Clang 的结果完全不变,但 MSVC 在非优化编译的情况下产生了不同的输出(优化编译——使用命令行参数 /O1、/O2 或 /Ox——则不变):
Create A
Move A
Destroy A
Destroy A也就是说,返回内容被移动构造了。
我们继续变形一下:
#include <stdlib.h>
A getA_duang()
{
A a1;
A a2;
if (rand() > 42) {
return a1;
} else {
return a2;
}
}
int main()
{
auto a = getA_duang();
}这回所有的编译器都被难倒了,输出是:
Create A
Create A
Move A
Destroy A
Destroy A
Destroy A关于返回值优化的实验我们就做到这里。下一步,我们试验一下把移动构造函数删除:
A(A&&) = delete;我们可以立即看到”Copy A”出现在了结果输出中,说明目前结果变成拷贝构造了。
如果再进一步,把拷贝构造函数也删除呢?是不是上面的 getA_unnamed、getA_named 和 getA_duang 都不能工作了?
在 C++14 及之前确实是这样的。但从 C++17 开始,对于类似于 getA_unnamed 这样的情况,即使对象不可拷贝、不可移动,这个对象仍然是可以被返回的!C++17 要求对于这种情况,对象必须被直接构造在目标位置上,不经过任何拷贝或移动的步骤 [3]。
10.4 回到 F.20
理解了 C++ 里的对返回值的处理和返回值优化之后,我们再回过头看一下 F.20 里陈述的理由的话,应该就显得很自然了:
A return value is self-documenting, whereas a & could be either in-out or outonly and is liable to be misused.
返回值是可以自我描述的;而 & 参数既可能是输入输出,也可能是仅输出,且很容易被误用。
我想我对返回对象的可读性,已经给出了充足的例子。对于其是否有性能影响这一问题,也给出了充分的说明。
我们最后看一下 F.20 里描述的例外情况:
- “对于非值类型,比如返回值可能是子对象的情况,使用 unique_ptr 或 shared_ptr 来返回对象。”也就是面向对象、工厂方法这样的情况,像 [第 1 讲] 里给出的 create_shape 应该这样改造。
- “对于移动代价很高的对象,考虑将其分配在堆上,然后返回一个句柄(如 unique_ptr),或传递一个非 const 的目标对象的引用来填充(用作输出参数)。”也就是说不方便移动的,那就只能使用一个 RAII 对象来管理生命周期,或者老办法输出参数了。
- “要在一个内层循环里在多次函数调用中重用一个自带容量的对象:将其当作输入 / 输出参数并将其按引用传递。”这也是个需要继续使用老办法的情况。
10.5 参考资料
- Bjarne Stroustrup and Herb Sutter (editors), “C++ core guidelines”, item F.20. https://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines#Rf-out (非官方中文版可参见 https://github.com/lynnboy/CppCoreGuidelines-zh-CN)
- Conrad Sanderson and Ryan Curtin, Armadillo. http://arma.sourceforge.net/
- cppreference.com, “Copy elision”. https://en.cppreference.com/w/cpp/language/copy_elision
11 | Unicode:进入多文字支持的世界
11.1 一些历史
ASCII [1] 是一种创立于 1963 年的 7 位编码,用 0 到 127 之间的数值来代表最常用的字符,包含了控制字符(很多在今天已不再使用)、数字、大小写拉丁字母、空格和基本标点。它在编码上具有简单性,字母和数字的编码位置非常容易记忆。时至今日,ASCII 可以看作是字符编码的基础,主要的编码方式都保持着与 ASCII 的兼容性。
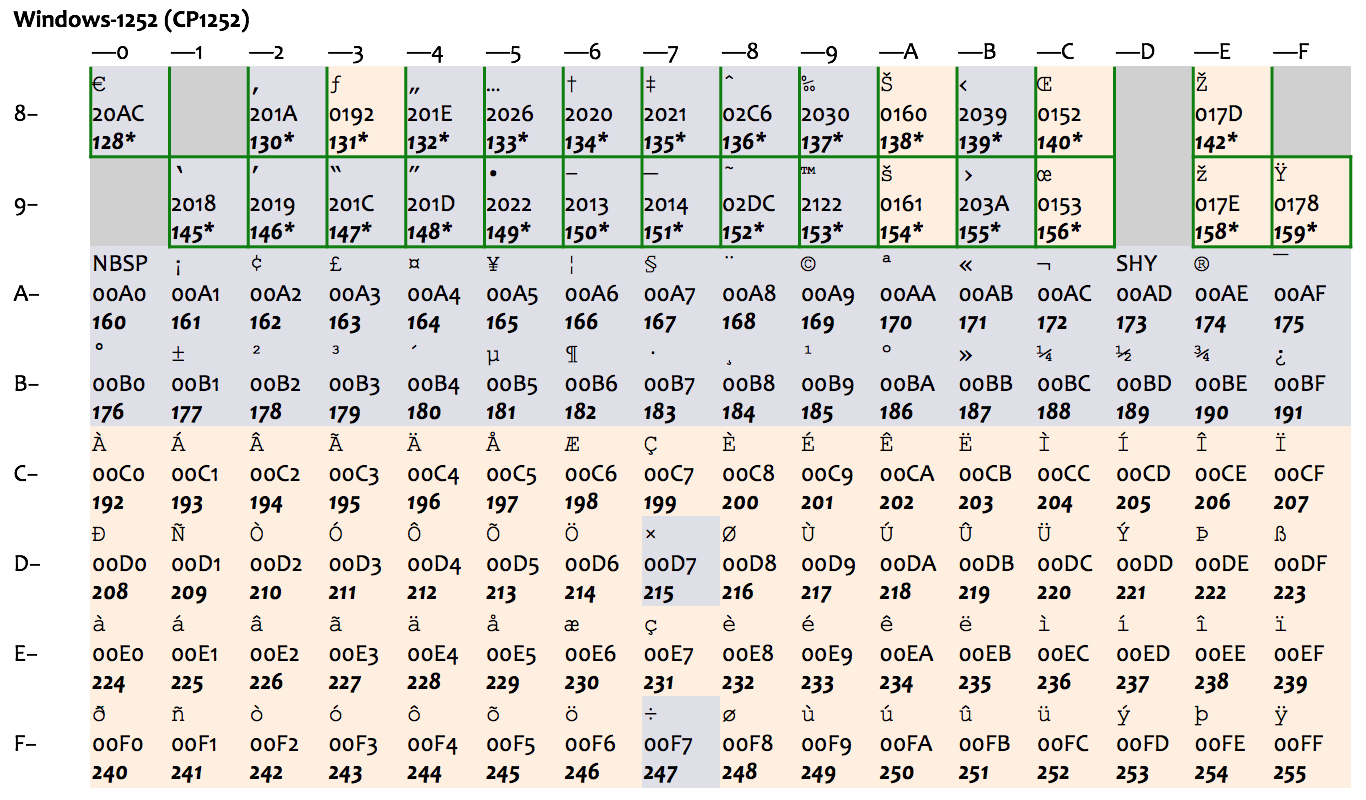
ASCII 里只有基本的拉丁字母,它既没有带变音符的拉丁字母(如 é 和 ä ),也不支持像希腊字母(如 α、β、γ)、西里尔字母(如 Пушкин)这样的其他欧洲文字(也难怪,毕竟它是 American Standard Code for Information Interchange)。很多其他编码方式纷纷应运而生,包括 ISO 646 系列、ISO/IEC 8859 系列等等;大部分编码方式都是头 128 个字符与 ASCII 兼容,后 128 个字符是自己的扩展,总共最多是 256 个字符。每次只有一套方式可以生效,称之为一个代码页(code page)。这种做法,只能适用于文字相近、且字符数不多的国家。比如,下图表示了 ISO-8859-1(也称作 Latin-1)和后面的 Windows 扩展代码页 1252(下图中绿框部分为 Windows 的扩展),就只能适用于西欧国家。
最早的中文字符集标准是 1980 年的国标 GB2312 [3],其中收录了 6763 个常用汉字和 682 个其他符号。我们平时会用到编码 GB2312,其实更正确的名字是 EUC-CN [4],它是一种与 ASCII 兼容的编码方式。它用单字节表示 ASCII 字符而用双字节表示 GB2312 中的字符;由于 GB2312 中本身也含有 ASCII 中包含的字符,在使用中逐渐就形成了”半角”和”全角”的区别。
国标字符集后面又有扩展,这个扩展后的字符集就是 GBK [5],是中文版 Windows 使用的标准编码方式。GB2312 和 GBK 所占用的编码位置可以参看下面的图(由 John M. Długosz 为 Wikipedia 绘制):
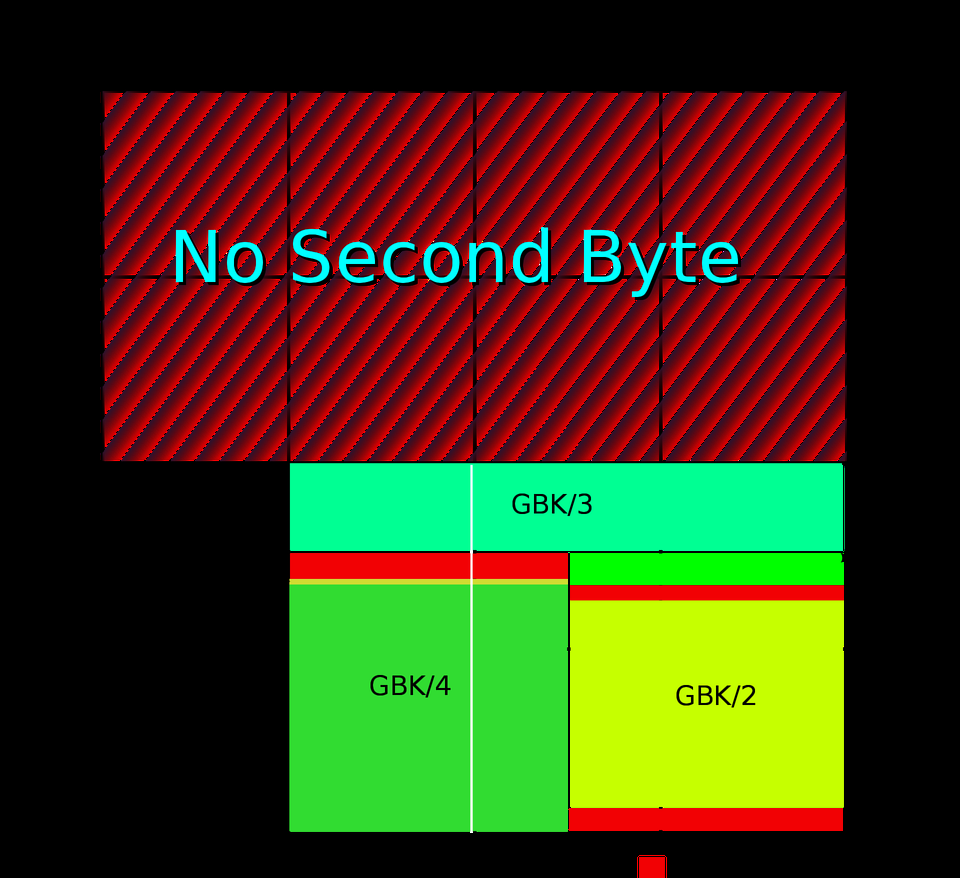
图中 GBK/1 和 GBK/2 为 GB2312 中已经定义的区域,其他的则是后面添加的字符,总共定义了两万多个编码点,支持了绝大部分现代汉语中还在使用的字。
Unicode [6] 作为一种统一编码的努力,诞生于八十年代末九十年代初,标准的第一版出版于 1991—1992 年。由于最初发明者的目标放得太低,只期望对活跃使用中的现代文字进行编码,他们认为 16 比特的”宽 ASCII”就够用了。这就导致了早期采纳 Unicode 的组织,特别是微软,在其操作系统和工具链中广泛采用了 16 比特的编码方式。在今天,微软的系统中宽字符类型 wchar_t 仍然是 16 位的,操作系统底层接口大量使用 16 位字符编码的 API,说到 Unicode 编码时仍然指的是 16 位的编码 UTF-16(这一不太正确的名字,跟中文 GBK 编码居然可以被叫做 ANSI 相比,实在是小巫见大巫了)。在微软以外的世界, Unicode 本身不作编码名称用,并且最主流的编码方式并不是 UTF-16,而是和 ASCII 全兼容的 UTF-8。
早期 Unicode 组织的另一个决定是不同语言里的同一个字符使用同一个编码点,来减少总编码点的数量。中日韩三国使用的汉字就这么被统一了:像”将”、”径”、”网”等字,每个字在 Unicode 中只占一个编码点。这对网页的字体选择也造成了不少麻烦,时至今日我们仍然可以看到这个问题 [10]。不过这和我们的主题无关,就不再多费笔墨了。
11.2 Unicode 简介
Unicode 在今天已经大大超出了最初的目标。到 Unicode 12.1 为止,Unicode 已经包含了 137,994 个字符,囊括所有主要语言(使用中的和已经不再使用的),并包含了表情符号、数学符号等各种特殊字符。仍然要指出一下,Unicode 字符是根据含义来区分的,而非根据字形。除了前面提到过中日韩汉字没有分开,像斜体(italics)、小大写字母(small caps)等排版效果在 Unicode 里也没有独立的对应。不过,因为 Unicode 里包含了很多数学、物理等自然科学中使用的特殊符号,某些情况下你也可以找到对应的符号,可以用在聊天中耍酷,如 𝒷𝒶𝒹(但不适合严肃的排版)。
Unicode 的编码点是从 0x0 到 0x10FFFF,一共 1,114,112 个位置。一般用”U+”后面跟 16 进制的数值来表示一个 Unicode 字符,如 U+0020 表示空格,U+6C49 表示”汉”,U+1F600 表示”😀”,等等(不足四位的一般写四位)。
Unicode 字符的常见编码方式有:
- UTF-32 [7]:32 比特,是编码点的直接映射。
- UTF-16 [8]:对于从 U+0000 到 U+FFFF 的字符,使用 16 比特的直接映射;对于大于 U+FFFF 的字符,使用 32 比特的特殊映射关系——在 Unicode 的 16 比特编码点中 0xD800–0xDFFF 是一段空隙,使得这种变长编码成为可能。在一个 UTF-16 的序列中,如果看到内容是 0xD800–0xDBFF,那这就是 32 比特编码的前 16 比特;如果看到内容是 0xDC00–0xDFFF,那这是 32 比特编码的后 16 比特;如果内容在 0xD800–0xDFFF 之外,那就是一个 16 比特的映射。
- UTF-8 [9]:1 到 4 字节的变长编码。在一个合法的 UTF-8 的序列中,如果看到一个字节的最高位是 0,那就是一个单字节的 Unicode 字符;如果一个字节的最高两比特是 10,那这是一个 Unicode 字符在编码后的后续字节;否则,这就是一个 Unicode 字符在编码后的首字节,且最高位开始连续 1 的个数表示了这个字符按 UTF-8 的方式编码有几个字节。
在上面三种编码方式里,只有 UTF-8 完全保持了和 ASCII 的兼容性,目前得到了最广泛的使用。在我们下面讲具体编码方式之前,我们先看一下上面提到的三个字符在这三种方式下的编码结果:
- UTF-32:U+0020 映射为 0x00000020,U+6C49 映射为 0x00006C49,U+1F600 映射为 0x0001F600。
- UTF-16:U+0020 映射为 0x0020,U+6C49 映射为 0x6C49,而 U+1F600 会映射为 0xD83D DE00。
- UTF-8:U+0020 映射为 0x20,U+6C49 映射为 0xE6 B1 89,而 U+1F600 会映射为 0xF0 9F 98 80。
Unicode 有好几种(上面还不是全部)不同的编码方式,上面的 16 比特和 32 比特编码方式还有小头党和大头党之争(”汉”按字节读取时是 6C 49 呢,还是 49 6C?);同时,任何一种编码方式还需要跟传统的编码方式容易区分。因此,Unicode 文本文件通常有一个使用 BOM(byte order mark)字符的约定,即字符 U+FEFF [11]。由于 Unicode 不使用 U+FFFE,在文件开头加一个 BOM 即可区分各种不同编码:
- 如果文件开头是 0x00 00 FE FF,那这是大头在前的 UTF-32 编码;
- 否则如果文件开头是 0xFF FE 00 00,那这是小头在前的 UTF-32 编码;
- 否则如果文件开头是 0xFE FF,那这是大头在前的 UTF-16 编码;
- 否则如果文件开头是 0xFF FE,那这是小头在前的 UTF-16 编码(注意,这条规则和第二条的顺序不能相反);
- 否则如果文件开头是 0xEF BB BF,那这是 UTF-8 编码;
- 否则,编码方式使用其他算法来确定。
在 UTF-8 编码下使用 BOM 字符并非必需,尤其在 Unix 上。但 Windows 上通常会使用 BOM 字符,以方便区分 UTF-8 和传统编码。
11.3 C++ 中的 Unicode 字符类型
C++98 中有 char 和 wchar_t 两种不同的字符类型,其中 char 的长度是单字节,而 wchar_t 的长度不确定。在 Windows 上它是双字节,只能代表 UTF-16,而在 Unix 上一般是四字节,可以代表 UTF-32。为了解决这种混乱,目前我们有了下面的改进:
- C++11 引入了 char16_t 和 char32_t 两个独立的字符类型(不是类型别名),分别代表 UTF-16 和 UTF-32。
- C++20 将引入 char8_t 类型,进一步区分了可能使用传统编码的窄字符类型和 UTF-8 字符类型。
- 除了 string 和 wstring,我们也相应地有了 u16string、u32string(和将来的 u8string)。
- 除了传统的窄字符 / 字符串字面量(如 “hi”)和宽字符 / 字符串字面量(如 L”hi”),引入了新的 UTF-8、UTF-16 和 UTF-32 字面量,分别形如 u8”hi”、u”hi” 和 U”hi”。
- 为了确保非 ASCII 字符在源代码中可以简单地输入,引入了新的 Unicode 换码序列。比如,我们前面说到的三个字符可以这样表达成一个 UTF-32 字符串字面量:U”\u6C49\U0001F600”。要生成 UTF-16 或 UTF-8 字符串字面量只需要更改前缀即可。
使用这些新的字符(串)类型,我们可以用下面的代码表达出 UTF-32 和其他两种 UTF 编码间是如何转换的:
#include <iomanip>
#include <iostream>
#include <stdexcept>
#include <string>
using namespace std;
const char32_t unicode_max = 0x10FFFF;
void to_utf_16(char32_t ch, u16string& result)
{
if (ch > unicode_max) {
throw runtime_error("invalid code point");
}
if (ch < 0x10000) {
result += char16_t(ch);
} else {
char16_t first = 0xD800 | ((ch - 0x10000) >> 10);
char16_t second = 0xDC00 | (ch & 0x3FF);
result += first;
result += second;
}
}
void to_utf_8(char32_t ch, string& result)
{
if (ch > unicode_max) {
throw runtime_error("invalid code point");
}
if (ch < 0x80) {
result += ch;
} else if (ch < 0x800) {
result += 0xC0 | (ch >> 6);
result += 0x80 | (ch & 0x3F);
} else if (ch < 0x10000) {
result += 0xE0 | (ch >> 12);
result += 0x80 | ((ch >> 6) & 0x3F);
result += 0x80 | (ch & 0x3F);
} else {
result += 0xF0 | (ch >> 18);
result += 0x80 | ((ch >> 12) & 0x3F);
result += 0x80 | ((ch >> 6) & 0x3F);
result += 0x80 | (ch & 0x3F);
}
}
int main()
{
char32_t str[] = U" \u6C49\U0001F600";
u16string u16str;
string u8str;
for (auto ch : str) {
if (ch == 0) {
break;
}
to_utf_16(ch, u16str);
to_utf_8(ch, u8str);
}
cout << hex << setfill('0');
for (char16_t ch : u16str) {
cout << setw(4) << unsigned(ch) << ' ';
}
cout << endl;
for (unsigned char ch : u8str) {
cout << setw(2) << unsigned(ch) << ' ';
}
cout << endl;
}输出结果是:
0020 6c49 d83d de00
20 e6 b1 89 f0 9f 98 8011.4 平台区别
下面我们看一下在两个主流的平台上一般是如何处理 Unicode 编码问题的。
Unix
现代 Unix 系统,包括 Linux 和 macOS 在内,已经全面转向了 UTF-8。这样的系统中一般直接使用 char[] 和 string 来代表 UTF-8 字符串,包括输入、输出和文件名,非常简单。不过,由于一个字符单位不能代表一个完整的 Unicode 字符,在需要真正进行文字处理的场合转换到 UTF-32 往往会更简单。在以前及需要和 C 兼容的场合,会使用 wchar_t、uint32_t 或某个等价的类型别名;在新的纯 C++ 代码里,就没有理由不使用 char32_t 和 u32string 了。
Unix 下输出宽字符串需要使用 wcout(这点和 Windows 相同),并且需要进行区域设置,通常使用 setlocale(LC_ALL, “en_US.UTF-8”); 即足够。由于没有什么额外好处,Unix 平台下一般只用 cout,不用 wcout。
Windows
Windows 由于历史原因和保留向后兼容性的需要(Windows 为了向后兼容性已经到了大规模放弃优雅的程度了),一直用 char 表示传统编码(如,英文 Windows 上是 Windows-1252,简体中文 Windows 上是 GBK),用 wchar_t 表示 UTF-16。由于传统编码一次只有一种、且需要重启才能生效,要得到好的多语言支持,在和操作系统交互时必须使用 UTF-16。
对于纯 Windows 编程,全面使用宽字符(串)是最简单的处理方式。当然,源代码和文本很少用 UTF-16 存储,通常还是 UTF-8(除非是纯 ASCII,否则需要加入 BOM 字符来和传统编码相区分)。这时可能会有一个小小的令人惊讶的地方:微软的编译器会把源代码里窄字符串字面量中的非 ASCII 字符转换成传统编码。换句话说,同样的源代码在不同编码的 Windows 下编译可能会产生不同的结果!如果你希望保留 UTF-8 序列的话,就应该使用 UTF-8 字面量(并在将来使用 char8_t 字符类型)。
#include <stdio.h> template <typename T> void dump(const T& str) { for (char ch : str) { printf("%.2x ", static_cast<unsigned char>(ch)); } putchar('\n'); } int main() { char str[] = "你好"; char u8str[] = u8"你好"; dump(str); dump(u8str); }下面展示的是以上代码在 Windows 下系统传统编码设置为简体中文时的编译、运行结果:
c4 e3 ba c3 00 e4 bd a0 e5 a5 bd 00Windows 下的 wcout 主要用在配合宽字符的输出,此外没什么大用处。原因一样,只有进行了正确的区域设置,才能输出含非 ASCII 字符的宽字符串。如果要输出中文,得写 setlocale(LC_ALL, “Chinese_China.936”);,这显然就让”统一码”输出失去意义了。
由于窄字符在大部分 Windows 系统上只支持传统编码,要打开一个当前编码不支持的文件名称,就必需使用宽字符的文件名。微软的 fstream 系列类及其 open 成员函数都支持 const wchar_t* 类型的文件名,这是 C++ 标准里所没有的。
11.5 统一化处理
要想写出跨平台的处理字符串的代码,我们一般考虑两种方式之一:
- 源代码级兼容,但内码不同
- 源代码和内码都完全兼容
微软推荐的方式一般是前者。做 Windows 开发的人很多都知道 tchar.h 和 _T 宏,它们就起着类似的作用(虽然目的不同)。根据预定义宏的不同,系统会在同一套代码下选择不同的编码方式及对应的函数。拿一个最小的例子来说:
#include <stdio.h>
#include <tchar.h>
int _tmain(int argc, TCHAR* argv[])
{
_putts(_T("Hello world!\n"));
}如果用缺省的命令行参数进行编译,上面的代码相当于:
#include <stdio.h>
int main(int argc, char* argv[])
{
puts("Hello world!\n");
}而如果在命令行上加上了 /D_UNICODE,那代码则相当于:
#include <stdio.h>
int wmain(int argc, wchar_t* argv[])
{
_putws(L"Hello world!\n");
}当然,这个代码还是只能在 Windows 上用,并且仍然不漂亮(所有的字符和字符串字面量都得套上 _T)。后者无解,前者则可以找到替代方案(甚至自己写也不复杂)。C++ REST SDK 中就提供了类似的封装,可以跨平台地开发网络应用。但可以说,这种方式是一种主要照顾 Windows 的开发方式。
相应的,对 Unix 开发者而言更自然的方式是全面使用 UTF-8,仅在跟操作系统、文件系统打交道时把字符串转换成需要的编码。利用临时对象的生命周期,我们可以像下面这样写帮助函数和宏。
utf8_to_native.hpp:
#ifndef UTF8_TO_NATIVE_HPP
#define UTF8_TO_NATIVE_HPP
#include <string>
#if defined(_WIN32) || defined(_UNICODE)
std::wstring utf8_to_wstring(const char* str);
std::wstring utf8_to_wstring(const std::string& str);
#define NATIVE_STR(s) utf8_to_wstring(s).c_str()
#else
inline const char* to_c_str(const char* str)
{
return str;
}
inline const char* to_c_str(const std::string& str)
{
return str.c_str();
}
#define NATIVE_STR(s) to_c_str(s)
#endif
#endif // UTF8_TO_NATIVE_HPPutf8_to_native.cpp:
#include "utf8_to_native.hpp"
#if defined(_WIN32) || defined(_UNICODE)
#include <windows.h>
#include <system_error>
namespace {
void throw_system_error(const char* reason)
{
std::string msg(reason);
msg += " failed";
std::error_code ec(GetLastError(), std::system_category());
throw std::system_error(ec, msg);
}
} /* unnamed namespace */
std::wstring utf8_to_wstring(const char* str)
{
int len = MultiByteToWideChar(CP_UTF8, 0, str, -1, nullptr, 0);
if (len == 0) {
throw_system_error("utf8_to_wstring");
}
std::wstring result(len - 1, L'\0');
if (MultiByteToWideChar(CP_UTF8, 0, str, -1, result.data(), len) == 0) {
throw_system_error("utf8_to_wstring");
}
return result;
}
std::wstring utf8_to_wstring(const std::string& str)
{
return utf8_to_wstring(str.c_str());
}
#endif在头文件里,定义了在 Windows 下会做 UTF-8 到 UTF-16 的转换;在其他环境下则不真正做转换,而是不管提供的是字符指针还是 string 都会转换成字符指针。在 Windows 下每次调用 NATIVE_STR 会生成一个临时对象,当前语句执行结束后这个临时对象会自动销毁。
使用该功能的代码是这样的:
#include <fstream>
#include "utf8_to_native.hpp"
int main()
{
using namespace std;
const char filename[] = u8"测试.txt";
ifstream ifs(NATIVE_STR(filename));
// 对 ifs 进行操作
}上面这样的代码可以同时适用于现代 Unix 和现代 Windows(任何语言设置下),用来读取名为”测试.txt”的文件。
11.6 编程支持
快速介绍一下其他的一些支持 Unicode 及其转换的 API。
Windows API
上一节的代码在 Windows 下用到了 MultiByteToWideChar [12],从某个编码转到 UTF-16。Windows 也提供了反向的 WideCharToMultiByte [13],从 UTF-16 转到某个编码。从上面可以看到,C 接口用起来并不方便,可以考虑自己封装一下。
iconv
Unix 下最常用的底层编码转换接口是 iconv [14],提供 iconv_open、iconv_close 和 iconv 三个函数。这同样是 C 接口,实践中应该封装一下。
ICU4C
ICU [15] 是一个完整的 Unicode 支持库,提供大量的方法,ICU4C 是其 C/C++ 的版本。ICU 有专门的字符串类型,内码是 UTF-16,但可以直接用于 IO streams 的输出。下面的程序应该在所有平台上都有同样的输出(但在 Windows 上要求当前系统传统编码能支持待输出的字符):
#include <iostream> #include <string> #include <unicode/unistr.h> #include <unicode/ustream.h> using namespace std; using icu::UnicodeString; int main() { auto str = UnicodeString::fromUTF8(u8"你好"); cout << str << endl; string u8str; str.toUTF8String(u8str); cout << "In UTF-8 it is " << u8str.size() << " bytes" << endl; }codecvt
C++11 曾经引入了一个头文件
<codecvt>[16] 用作 UTF 编码间的转换,但很遗憾,那个头文件目前已因为存在安全性和易用性问题被宣告放弃(deprecated)[17]。<locale>中有另外一个 codecvt 模板 [18],本身接口不那么好用,而且到 C++20 还会发生变化,这儿也不详细介绍了。有兴趣的话可以直接看参考资料。
11.7 参考资料
- Wikipedia, “ASCII”. https://en.wikipedia.org/wiki/ASCII
- Wikipedia, “EBCDIC”. https://en.wikipedia.org/wiki/EBCDIC
- Wikipedia, “GB 2312”. https://en.wikipedia.org/wiki/GB_2312
- Wikipedia, “EUC-CN”. https://en.wikipedia.org/wiki/Extended_Unix_Code#EUC-CN
- Wikipedia, “GBK”. https://en.wikipedia.org/wiki/GBK_(character_encoding)
- Wikipedia, “Unicode”. https://en.wikipedia.org/wiki/Unicode
- Wikipedia, “UTF-32”. https://en.wikipedia.org/wiki/UTF-32
- Wikipedia, “UTF-16”. https://en.wikipedia.org/wiki/UTF-16
- Wikipedia, “UTF-8”. https://en.wikipedia.org/wiki/UTF-8
- 吴咏炜, “Specify LANG in a UTF-8 web page”. http://wyw.dcweb.cn/lang_utf8.htm
- Wikipedia, “Byte order mark”. https://en.wikipedia.org/wiki/Byte_order_mark
- Microsoft, “MultiByteToWideChar function”.https://docs.microsoft.com/en-us/windows/win32/api/stringapiset/nfstringapiset-multibytetowidechar
- Microsoft, “WideCharToMultiByte function”.https://docs.microsoft.com/en-us/windows/win32/api/stringapiset/nfstringapiset-widechartomultibyte
- Wikipedia, “iconv”. https://en.wikipedia.org/wiki/Iconv
- ICU Technical Committee, ICU—International Components for Unicode. http://site.icu-project.org/
- cppreference.com, “
Standard library header <codecvt>“. https://en.cppreference.com/w/cpp/header/codecvt - Alisdair Meredith, “
Deprecating <codecvt>“. http://www.openstd.org/jtc1/sc22/wg21/docs/papers/2017/p0618r0.html - cppreference.com, “std::codecvt”. https://en.cppreference.com/w/cpp/locale/codecvt
12 | 编译期多态:泛型编程和模板入门
12.1 面向对象和多态
在面向对象的开发里,最基本的一个特性就是”多态” [1]——用相同的代码得到不同结果。
在很多动态类型语言里,有所谓的”鸭子”类型 [2]:
如果一只鸟走起来像鸭子、游起泳来像鸭子、叫起来也像鸭子,那么这只鸟就可以被当作鸭子。
鸭子类型使得开发者可以不使用继承体系来灵活地实现一些”约定”,尤其是使得混合不同来源、使用不同对象继承体系的代码成为可能。唯一的要求只是,这些不同的对象有”共通”的成员函数。这些成员函数应当有相同的名字和相同结构的参数(并不要求参数类型相同)。
来看一下 C++ 中的具体例子。
12.2 容器类的共性
容器类是有很多共性的。其中,一个最最普遍的共性就是,容器类都有 begin 和 end 成员函数——这使得通用地遍历一个容器成为可能。容器类不必继承一个共同的 Container 基类,而我们仍然可以写出通用的遍历容器的代码,如使用基于范围的循环。
大部分容器是有 size 成员函数的,在”泛型”编程中,我们同样可以取得一个容器的大小,而不要求容器继承一个叫 SizeableContainer 的基类。
很多容器具有 push_back 成员函数,可以在尾部插入数据。同样,我们不需要一个叫 BackPushableContainer 的基类。在这个例子里,push_back 函数的参数显然是都不一样的,但明显,所有的 push_back 函数都只接收一个参数。
我们可以清晰看到的是,虽然 C++ 的标准容器没有对象继承关系,但彼此之间有着很多的同构性。这些同构性很难用继承体系来表达,也完全不必要用继承来表达。C++ 的模板,已经足够表达这些鸭子类型。
12.3 C++ 模板
定义模板
template <typename E> E my_gcd(E a, E b) { while (b != E(0)) { E r = a % b; a = b; b = r; } return a; }我们对于”整数”这只鸭子的要求实际上是:
- 可以通过常量 0 来构造
- 可以拷贝(构造和赋值)
- 可以作不等于的比较
可以进行取余数的操作
对于标准的 int、long、long long 等类型及其对应的无符号类型,以上代码都能正常工作,并能得到正确的结果。
至于类模板的例子,我们可以直接参考 [第 2 讲] 中的智能指针。
实例化模板
不管是类模板还是函数模板,编译器在看到其定义时只能做最基本的语法检查,真正的类型检查要在实例化(instantiation)的时候才能做。一般而言,这也是编译器会报错的时候。
当我们在使用
vector<int>这样的表达式时,我们就在隐式地实例化vector<int>。我们同样也可以选择用template class vector<int>; 来显式实例化,或使用extern template class vector<int>; 来告诉编译器不需要实例化。显式实例化和外部实例化通常在大型项目中可以用来集中模板的实例化,从而加速编译过程——不需要在每个用到模板的地方都进行实例化了——但这种方式有额外的管理开销,如果实例化了不必要实例化的模板的话,反而会导致可执行文件变大。因而,显式实例化和外部实例化应当谨慎使用。特化模板
通用而言,Herb Sutter 给出了明确的建议:对函数使用重载,对类模板进行特化 [3]。
展示特化的更好的例子是 C++11 之前的静态断言。使用特化技巧可以大致实现 static_assert 的功能:
template <bool> struct compile_time_error; template <> struct compile_time_error<true> { }; #define STATIC_ASSERT(Expr, Msg) \ { \ compile_time_error<bool(Expr)> \ ERROR_##_Msg; \ (void)ERROR_##_Msg; \ }上面首先声明了一个 struct 模板,然后仅对 true 的情况进行了特化,产生了一个 struct 的定义。这样。如果遇到
compile_time_error<false>的情况——也就是下面静态断言里的 Expr 不为真的情况——编译就会失败报错,因为compile_time_error<false>从来就没有被定义过。
12.4 “动态”多态和”静态”多态的对比
我前面描述了面向对象的”动态”多态,也描述了 C++ 里基于泛型编程的”静态”多态。需要看到的是,两者解决的实际上是不太一样的问题。”动态”多态解决的是运行时的行为
变化。”静态”多态或者”泛型”——解决的是很不同的问题,让适用于不同类型的”同构”算法可以用同一套代码来实现,实际上强调的是对代码的复用。
C++ 里提供了很多标准算法,都一样只作出了基本的约定,然后对任何满足约定的类型都可以工作。以排序为例,C++ 里的标准 sort 算法(以两参数的重载为例)只要求:
- 参数满足随机访问迭代器的要求。
- 迭代器指向的对象之间可以使用 < 来比较大小,满足严格弱序关系。
- 迭代器指向的对象可以被移动。
它的性能超出 C 的 qsort,因为编译器可以内联(inline)对象的比较操作;而在 C 里面比较只能通过一个额外的函数调用来实现。此外,C 的 qsort 函数要求数组指向的内容是可按比特复制的,C++ 的 sort 则要求迭代器指向的内容是可移动的,可适用于更广的情况。
12.5 参考资料
[1] Wikipedia, “Polymorphism”. https://en.wikipedia.org/wiki/Polymorphism_(computer_science)
[2] Wikipedia, “Duck typing”. https://en.wikipedia.org/wiki/Duck_typing
[3] Herb Sutter, “Why not specialize function templates?”. http://www.gotw.ca/publications/mill17.htm
13 | 编译期能做些什么?一个完整的计算世界
模板的另外一种重要用途——编译期计算,也称作”模板元编程”。
13.1 编译期计算
首先,我们给出一个已经被证明的结论:C++ 模板是图灵完全的 [1]。这句话的意思是,使用 C++ 模板,你可以在编译期间模拟一个完整的图灵机,也就是说,可以完成任何的计算任务。
template <int n>
struct factorial {
static const int value = n * factorial<n - 1>::value;
};
template <>
struct factorial<0> {
static const int value = 1;
};上面定义了一个递归的阶乘函数。
那我们怎么知道这个计算是不是在编译时做的呢?我们可以直接看编译输出。下面直接贴出对上面这样的代码加输出(printf("%d\n", factorial<10>::value);)在 x86-64 下的编译结果:
.LC0:
.string "%d\n"
main:
push rbp
mov rbp, rsp
mov esi, 3628800
mov edi, OFFSET FLAT:.LC0
mov eax, 0
call printf
mov eax, 0
pop rbp
ret我们可以明确看到,编译结果里明明白白直接出现了常量 3628800。
可以看到,要进行编译期编程,最主要的一点,是需要把计算转变成类型推导。比如,下面的模板可以代表条件语句:
template <bool cond, typename Then, typename Else>
struct If;
template <typename Then, typename Else>
struct If<true, Then, Else> {
typedef Then type;
};
template <typename Then, typename Else>
struct If<false, Then, Else> {
typedef Else type;
};If 模板有三个参数,第一个是布尔值,后面两个则是代表不同分支计算的类型,这个类型可以是我们上面定义的任何一个模板实例,包括 If 和 factorial。第一个 struct 声明规定了模板的形式,然后我们不提供通用定义,而是提供了两个特化。第一个特化是真的情况,定义结果 type 为 Then 分支;第二个特化是假的情况,定义结果 type 为 Else 分支。
循环:
template <bool condition, typename Body>
struct WhileLoop;
template <typename Body>
struct WhileLoop<true, Body> {
typedef typename WhileLoop<Body::cond_value, typename Body::next_type>::typetype;
};
template <typename Body>
struct WhileLoop<false, Body> {
typedef typename Body::res_type type;
};
template <typename Body>
struct While {
typedef typename WhileLoop<Body::cond_value, Body>::type type;
};这个循环的模板定义稍复杂点。首先,我们对循环体类型有一个约定,它必须提供一个静态数据成员,cond_value,及两个子类型定义,res_type 和 next_type:
- cond_value 代表循环的条件(真或假)
- res_type 代表退出循环时的状态
- next_type 代表下面循环执行一次时的状态
如果你之前模板用得不多的话,还有一个需要了解的细节,就是用 :: 取一个成员类型、并且 :: 左边有模板参数的话,得额外加上 typename 关键字来标明结果是一个类型。上面循环模板的定义里就出现了多次这样的语法。MSVC 在这方面往往比较宽松,不写 typename 也不会报错,但这是不符合 C++ 标准的用法。
为了进行计算,我们还需要通用的代表数值的类型。下面这个模板可以通用地代表一个整数常数:
template <class T, T v>
struct integral_constant {
static const T value = v;
typedef T value_type;
typedef integral_constant type;
};integral_constant 模板同时包含了整数的类型和数值,而通过这个类型的 value 成员我们又可以重新取回这个数值。有了这个模板的帮忙,我们就可以进行一些更通用的计算了。下面这个模板展示了如何使用循环模板来完成从 1 加到 n 的计算:
template <int result, int n>
struct SumLoop {
static const bool cond_value = n != 0;
static const int res_value = result;
typedef integral_constant<int, res_value> res_type;
typedef SumLoop<result + n, n - 1> next_type;
};
template <int n>
struct Sum {
typedef SumLoop<0, n> type;
};然后你使用 While<Sum<10>::type>::type::value 就可以得到 1 加到 10 的结果。虽然有点绕,但代码实质就是在编译期间进行了以下的计算:
int result = 0;
while (n != 0) {
result = result + n;
n = n - 1;
}13.2 编译期类型推导
C++ 标准库在 <type_traits> 头文件里定义了很多工具类模板,用来提取某个类型(type)在某方面的特点(trait)[2]。和上一节给出的例子相似,这些特点既是类型,又是常值。
为了方便地在值和类型之间转换,标准库定义了一些经常需要用到的工具类。上面描述的 integral_constant 就是其中一个(我的定义有所简化)。为了方便使用,针对布尔值有两个额外的类型定义:
typedef std::integral_constant<bool, true> true_type;
typedef std::integral_constant<bool, false> false_type;这两个标准类型 true_type 和 false_type 经常可以在函数重载中见到。有一个工具函数常常会写成下面这个样子:
template <typename T>
class SomeContainer {
public:
//…
static void destroy(T* ptr)
{
_destroy(ptr, is_trivially_destructible<T>());
}
private:
static void _destroy(T* ptr, true_type)
{
}
static void _destroy(T* ptr, false_type)
{
ptr->~T();
}
};类似上面,很多容器类里会有一个 destroy 函数,通过指针来析构某个对象。为了确保最大程度的优化,常用的一个技巧就是用 is_trivially_destructible 模板来判断类是否是可平凡析构的——也就是说,不调用析构函数,不会造成任何资源泄漏问题。模板返回的结果还是一个类,要么是 true_type,要么是 false_type。如果要得到布尔值的话,当然使用 is_trivially_destructible<T>::value 就可以,但此处不需要。我们需要的是,使用 () 调用该类型的构造函数,让编译器根据数值类型来选择合适的重载。这样,在优化编译的情况下,编译器可以把不需要的析构操作彻底全部删除。
除了得到布尔值和相对应的类型的 trait 模板,我们还有另外一些模板,可以用来做一些类型的转换。以一个常见的模板 remove_const 为例(用来去除类型里的 const 修饰),它的定义大致如下:
template <class T>
struct remove_const {
typedef T type;
};
template <class T>
struct remove_const<const T> {
typedef T type;
};同样,它也是利用模板的特化,针对 const 类型去掉相应的修饰。比如,如果我们对 const string& 应用 remove_const,就会得到 string&,即, remove_const<const string&>::type 等价于 string&。
这里有一个细节你要注意一下,如果对 const char* 应用 remove_const 的话,结果还是 const char*。原因是,const char* 是指向 const char 的指针,而不是指向 char 的 const 指针。如果我们对 char * const 应用 remove_const 的话,还是可以得到 char* 的。
13.3 简易写法
如果你觉得写 is_trivially_destructible<T>::value 和 remove_const<T>::type 非常啰嗦的话,那你绝不是一个人。在当前的 C++ 标准里,前者有增加 _v 的编译时常量,后者有增加 _t 的类型别名:
template <class T>
inline constexpr bool is_trivially_destructible_v = is_trivially_destructible<T>::value;
template <class T>
using remove_const_t = typename remove_const<T>::type;至于什么是 constexpr,我们会单独讲。using 是现代 C++ 的新语法,功能大致与 typedef 相似,但 typedef 只能针对某个特定的类型,而 using 可以生成别名模板。目前我们只需要知道,在你需要 trait 模板的结果数值和类型时,使用带 _v 和 _t 后缀的模板可能会更方便,尤其是带 _t 后缀的类型转换模板。
13.4 通用的 fmap 函数模板
你应当多多少少听到过 map-reduce。抛开其目前在大数据应用中的具体方式不谈,从概念本源来看,map [3] 和 reduce [4] 都来自函数式编程。下面我们演示一个 map 函数(当然,在 C++ 里它的名字就不能叫 map 了),其中用到了目前为止我们学到的多个知识点:
template <
template <typename, typename>
class OutContainer = vector, typename F, class R>
auto fmap(F&& f, R&& inputs)
{
typedef decay_t<decltype(f(*inputs.begin()))> result_type;
OutContainer<result_type, allocator<result_type>> result;
for (auto&& item : inputs) {
result.push_back(f(item));
}
return result;
}我们:
- 用 decltype 来获得用 f 来调用 inputs 元素的类型(参考第 8 讲);
- 用 decay_t 来把获得的类型变成一个普通的值类型;
- 缺省使用 vector 作为返回值的容器,但可以通过模板参数改为其他容器;
- 使用基于范围的 for 循环来遍历 inputs,对其类型不作其他要求(参考第 7 讲);
- 存放结果的容器需要支持 push_back 成员函数(参考第 4 讲)。
下面的代码可以验证其功能:
vector<int> v { 1, 2, 3, 4, 5 };
int add_1(int x)
{
return x + 1;
}
auto result = fmap(add_1, v);在 fmap 执行之后,我们会在 result 里得到一个新容器,其内容是 2, 3, 4, 5, 6。
13.5 参考资料
- Todd L. Veldhuizen, “C++ templates are Turing complete”. http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.14.3670
- cppreference.com, “
Standard library header <type_traits>“. https://en.cppreference.com/w/cpp/header/type_traits - Wikipedia, “Map (higher-order function)”. https://en.wikipedia.org/wiki/Map_(higher-order_function)
- Wikipedia, “Fold (higher-order function)”. https://en.wikipedia.org/wiki/Fold_(higher-order_function)
14 | SFINAE:不是错误的替换失败是怎么回事?
讲模板里的一个特殊概念——替换失败非错(substituion failure is not an error),英文简称为SFINAE。
14.1 函数模板的重载决议
今天来着重看一个函数模板的情况。当一个函数名称和某个函数模板名称匹配时,重载决议过程大致如下:
- 根据名称找出所有适用的函数和函数模板
- 对于适用的函数模板,要根据实际情况对模板形参进行替换;替换过程中如果发生错误,这个模板会被丢弃
- 在上面两步生成的可行函数集合中,编译器会寻找一个最佳匹配,产生对该函数的调用
- 如果没有找到最佳匹配,或者找到多个匹配程度相当的函数,则编译器需要报错
一个具体的例子(改编自参考资料 [1]):
#include <stdio.h>
struct Test {
typedef int foo;
};
template <typename T>
void f(typename T::foo)
{
puts("1");
}
template <typename T>
void f(T)
{
puts("2");
}
int main()
{
f<Test>(10);
f<int>(10);
}输出为:
1
2我们来分析一下。首先看 f<Test>(10); 的情况:
- 我们有两个模板符合名字 f
- 替换结果为 f(Test::foo) 和 f(Test)
- 使用参数 10 去匹配,只有前者参数可以匹配,因而第一个模板被选择
再看一下 f<int>(10) 的情况:
- 还是两个模板符合名字 f
- 替换结果为 f(int::foo) 和 f(int);显然前者不是个合法的类型,被抛弃
- 使用参数 10 去匹配 f(int),没有问题,那就使用这个模板实例了
在这儿,体现的是 SFINAE 设计的最初用法:如果模板实例化中发生了失败,没有理由编译就此出错终止,因为还是可能有其他可用的函数重载的。
这儿的失败仅指函数模板的原型声明,即参数和返回值。函数体内的失败不考虑在内。如果重载决议选择了某个函数模板,而函数体在实例化的过程中出错,那我们仍然会得到一个编译错误。
14.2 编译期成员检测
编译期成员检测不过,很快人们就发现 SFINAE 可以用于其他用途。比如,根据某个实例化的成功或失败来在编译期检测类的特性。下面这个模板,就可以检测一个类是否有一个名叫 reserve、参数类型为 size_t 的成员函数:
template <typename T>
struct has_reserve {
struct good {
char dummy;
};
struct bad {
char dummy[2];
};
template <class U, void (U::*)(size_t)>
struct SFINAE {
};
template <class U>
static good reserve(SFINAE<U, &U::reserve>*);
template <class U>
static bad reserve(...);
static const bool value = sizeof(reserve<T>(nullptr)) == sizeof(good);
};在这个模板里:
- 我们首先定义了两个结构 good 和 bad;它们的内容不重要,我们只关心它们的大小必须不一样。
- 然后我们定义了一个 SFINAE 模板,内容也同样不重要,但模板的第二个参数需要是第一个参数的成员函数指针,并且参数类型是 size_t,返回值是 void。
- 随后,我们定义了一个要求
SFINAE*类型的 reserve 成员函数模板,返回值是 good;再定义了一个对参数类型无要求的 reserve 成员函数模板(不熟悉 … 语法的,可以看参考资料 [2]),返回值是 bad。 - 最后,我们定义常整型布尔值 value,结果是 true 还是 false,取决于 nullptr 能不能和
SFINAE*匹配成功,而这又取决于模板参数 T 有没有返回类型是 void、接受一个参数并且类型为 size_t 的成员函数 reserve。
那这样的模板有什么用处呢?
14.3 SFINAE 模板技巧
enable_if
C++11 开始,标准库里有了一个叫 enable_if 的模板(定义在
<type_traits>里),可以用它来选择性地启用某个函数的重载。假设我们有一个函数,用来往一个容器尾部追加元素。我们希望原型是这个样子的:
template <typename C, typename T> void append(C& container, T* ptr, size_t size);显然,container 有没有 reserve 成员函数,是对性能有影响的——如果有的话,我们通常应该预留好内存空间,以免产生不必要的对象移动甚至拷贝操作。利用 enable_if 和 上面的 has_reserve 模板,我们就可以这么写:
template <typename C, typename T> enable_if_t<has_reserve<C>::value, void> append(C& container, T* ptr, size_t size) { container.reserve(container.size() + size); for (size_t i = 0; i < size; ++i) { container.push_back(ptr[i]); } } template <typename C, typename T> enable_if_t<!has_reserve<C>::value, void> append(C& container, T* ptr, size_t size) { for (size_t i = 0; i < size; ++i) { container.push_back(ptr[i]); } }enable_if_t<has_reserve<C>::value, void>的意思可以理解成:如果类型 C 有 reserve 成员的话,那我们启用下面的成员函数,它的返回类型为 void。enable_if 的定义(其实非常简单)和它的进一步说明,请查看参考资料 [3]。参考资料里同时展示了一个通用技巧,可以用在构造函数(无返回值)或不想手写返回值类型的情况下。但那个写法更绕一些,不是必需要用的话,就采用上面那个写出返回值类型的写法吧。
decltype 返回值
如果只需要在某个操作有效的情况下启用某个函数,而不需要考虑相反的情况的话,有另外一个技巧可以用。对于上面的 append 的情况,如果我们想限制只有具有 reserve 成员函数的类可以使用这个重载,我们可以把代码简化成:
template <typename C, typename T> auto append(C& container, T* ptr, size_t size) -> decltype(declval<C&>().reserve(1U), void()) { container.reserve(container.size() + size); for (size_t i = 0; i < size; ++i) { container.push_back(ptr[i]); } }这是我们第一次用到 declval [4],需要简单介绍一下。这个模板用来声明一个某个类型的参数,但这个参数只是用来参加模板的匹配,不允许实际使用。使用这个模板,我们可以在某类型没有默认构造函数的情况下,假想出一个该类的对象来进行类型推导。
declval<C&>().reserve(1U)用来测试 C& 类型的对象是不是可以拿 1U 作为参数来调用 reserve 成员函数。此外,我们需要记得,C++ 里的逗号表达式的意思是按顺序逐个估值,并返回最后一项。所以,上面这个函数的返回值类型是 void。这个方式和 enable_if 不同,很难表示否定的条件。如果要提供一个专门给没有 reserve 成员函数的 C 类型的 append 重载,这种方式就不太方便了。因而,这种方式的主要用途是避免错误的重载。
void_t
void_t 是 C++17 新引入的一个模板 [5]。它的定义简单得令人吃惊:
template <typename...> using void_t = void;换句话说,这个类型模板会把任意类型映射到 void。它的特殊性在于,在这个看似无聊的过程中,编译器会检查那个”任意类型”的有效性。利用 decltype、declval 和模板特化,我们可以把 has_reserve 的定义大大简化:
template <typename T, typename = void_t<>> struct has_reserve : false_type { }; template <typename T> struct has_reserve<T, void_t<decltype(declval<T&>().reserve(1U))>> : true_type { };这里第二个 has_reserve 模板的定义实际上是一个偏特化 [6]。偏特化是类模板的特有功能,跟函数重载有些相似。编译器会找出所有的可用模板,然后选择其中最”特别”的一个。像上面的例子,所有类型都能满足第一个模板,但不是所有的类型都能满足第二个模板,所以第二个更特别。当第二个模板能被满足时,编译器就会选择第二个特化的模板;而只有第二个模板不能被满足时,才会回到第一个模板的通用情况。
有了这个 has_reserve 模板,我们就可以继续使用其他的技巧,如 enable_if 和下面的标签分发,来对重载进行限制。
标签分发
在上一讲,我们提到了用 true_type 和 false_type 来选择合适的重载。这种技巧有个专门的名字,叫标签分发(tag dispatch)。我们的 append 也可以用标签分发来实现:
template <typename C, typename T> void _append(C& container, T* ptr, size_t size, true_type) { container.reserve(container.size() + size); for (size_t i = 0; i < size; ++i) { container.push_back(ptr[i]); } } template <typename C, typename T> void _append(C& container, T* ptr, size_t size, false_type) { for (size_t i = 0; i < size; ++i) { container.push_back(ptr[i]); } } template <typename C, typename T> void append(C& container, T* ptr, size_t size) { _append(container, ptr, size, integral_constant<bool, has_reserve<C>::value> {}); }回想起上一讲里 true_type 和 false_type 的定义,你应该很容易看出这个代码跟使用 enable_if 是等价的。当然,在这个例子,标签分发并没有使用 enable_if 显得方便。作为一种可以替代 enable_if 的通用惯用法,你还是需要了解一下。
另外,如果我们用 void_t 那个版本的 has_reserve 模板的话,由于模板的实例会继承 false_type 或 true_type 之一,代码可以进一步简化为:
template <typename C, typename T> void append(C& container, T* ptr, size_t size) { _append(container, ptr, size, has_reserve<C> {}); }
14.4 静态多态的限制?
看到这儿,你可能会怀疑,为什么我们不能像在 Python 之类的语言里一样,直接写下面这样的代码呢?
template <typename C, typename T>
void append(C& container, T* ptr, size_t size)
{
if (has_reserve<C>::value) {
container.reserve(container.size() + size);
}
for (size_t i = 0; i < size; ++i) {
container.push_back(ptr[i]);
}
}如果你试验一下,就会发现,在 C 类型没有 reserve 成员函数的情况下,编译是不能通过的,会报错。这是因为 C++ 是静态类型的语言,所有的函数、名字必须在编译时被成功解析、确定。在动态类型的语言里,只要语法没问题,缺成员函数要执行到那一行上才会被发现。这赋予了动态类型语言相当大的灵活性;只不过,不能在编译时检查错误,同样也是很多人对动态类型语言的抱怨所在……
那在 C++ 里,我们有没有更好的办法呢?实际上是有的。具体方法,下回分解。
14.5 参考资料
[1] Wikipedia, “Substitution failure is not an error”. https://en.wikipedia.org/wiki/Substitution_failure_is_not_an_error
[2] cppreference.com, “Variadic functions”. https://en.cppreference.com/w/c/variadic
[3] cppreference.com, “std::enable_if”. https://en.cppreference.com/w/cpp/types/enable_if
[4] cppreference.com, “std::declval”. https://en.cppreference.com/w/cpp/utility/declval
[5] cppreference.com, “std::void_t”. https://en.cppreference.com/w/cpp/types/void_t
[6] cppreference.com, “Partial template specialization”. https://en.cppreference.com/w/cpp/language/partial_specialization
15 | constexpr:一个常态的世界
15.1 初识 constexpr
在 C++11 引入、在 C++14 得到大幅改进的 constexpr 关键字的字面意思是 constant expression,常量表达式。存在两类 constexpr 对象:
- constexpr 变量
- constexpr 函数
一个 constexpr 变量是一个编译时完全确定的常数。一个 constexpr 函数至少对于某一组实参可以在编译期间产生一个编译期常数。
注意一个 constexpr 函数不保证在所有情况下都会产生一个编译期常数(因而也是可以作为普通函数来使用的)。编译器也没法通用地检查这点。编译器唯一强制的是:
- constexpr 变量必须立即初始化
- 初始化只能使用字面量或常量表达式,后者不允许调用任何非 constexpr 函数
constexpr 的实际规则当然稍微更复杂些,而且随着 C++ 标准的演进也有着一些变化,特别是对 constexpr 函数如何实现的要求在慢慢放宽。要了解具体情况包括其在不同 C++ 标准中的限制,可以查看参考资料 [1]。下面我们也会回到这个问题略作展开。
要检验一个 constexpr 函数能不能产生一个真正的编译期常量,可以把结果赋给一个 constexpr 变量。成功的话,我们就确认了,至少在这种调用情况下,我们能真正得到一个编译期常量。
15.2 constexpr 和编译期计算
以 [第 13 讲] 提到的阶乘函数为例,和那个版本基本等价的写法是:
constexpr int factorial(int n)
{
if (n == 0) {
return 1;
} else {
return n * factorial(n - 1);
}
}这里有一个问题:在这个 constexpr 函数里,是不能写 static_assert(n >= 0) 的。一个 constexpr 函数仍然可以作为普通函数使用——显然,传入一个普通 int 是不能使用静态断言的。替换方法是在 factorial 的实现开头加入:
if (n < 0) {
throw std::invalid_argument("Arg must be non-negative");
}15.3 constexpr 和 const
const 的原本和基础的含义,自然是表示它修饰的内容不会变化,如:
const int n = 1:
n = 2; // 出错!本质上,const 用来表示一个运行时常量。
在 C++ 里,const 后面渐渐带上了现在的 constexpr 用法,也代表编译期常数。现在——在有了 constexpr 之后——我们应该使用 constexpr 在这些用法中替换 const 了。从编译器的角度,为了向后兼容性,const 和 constexpr 在很多情况下还是等价的。但有时候,它们也有些细微的区别,其中之一为是否内联的问题。
15.4 内联变量
C++17 引入了内联(inline)变量的概念,允许在头文件中定义内联变量,然后像内联函数一样,只要所有的定义都相同,那变量的定义出现多次也没有关系。对于类的静态数据成员,const 缺省是不内联的,而 constexpr 缺省就是内联的。这种区别在你用 & 去取一个 const int 值的地址、或将其传到一个形参类型为 const int& 的函数去的时候(这在 C++ 文档里的行话叫 ODR-use),就会体现出来。
下面是个合法的完整程序:
#include <iostream>
struct magic {
static const int number = 42;
};
int main()
{
std::cout << magic::number << std::endl;
}我们稍微改一点:
#include <iostream>
#include <vector>
struct magic {
static const int number = 42;
};
int main()
{
std::vector<int> v;
// 调用 push_back(const T&)
v.push_back(magic::number);
std::cout << v[0] << std::endl;
}程序在链接时就会报错了,说找不到 magic::number(注意:MSVC 缺省不报错,但使用标准模式——/Za 命令行选项——也会出现这个问题)。这是因为 ODR-use 的类静态常量也需要有一个定义,在没有内联变量之前需要在某一个源代码文件(非头文件)中这样写:
const int magic::number = 42;必须正正好好一个,多了少了都不行,所以叫 one definition rule。内联函数,现在又有了内联变量,以及模板,则不受这条规则限制。
修正这个问题的简单方法是把 magic 里的 static const 改成 static constexpr 或 static inline const。前者可行的原因是,类的静态 constexpr 成员变量默认就是内联的。const 常量和类外面的 constexpr 变量不默认内联,需要手工加 inline 关键字才会变成内联。
15.5 constexpr 变量模板
变量模板是 C++14 引入的新概念。之前我们需要用类静态数据成员来表达的东西,使用变量模板可以更简洁地表达。constexpr 很合适用在变量模板里,表达一个和某个类型相关的编译期常量。由此,type traits 都获得了一种更简单的表示方式。再看一下我们在 [第13 讲] 用过的例子:
template <class T>
inline constexpr bool is_trivially_destructible_v = is_trivially_destructible<T>::value;15.6 constexpr 变量仍是 const
一个 constexpr 变量仍然是 const 常类型。需要注意的是,就像 const char* 类型是指向常量的指针、自身不是 const 常量一样,下面这个表达式里的 const 也是不能缺少的:
constexpr int a = 42;
constexpr const int& b = a;第二行里,constexpr 表示 b 是一个编译期常量,const 表示这个引用是常量引用。去掉这个 const 的话,编译器就会认为你是试图将一个普通引用绑定到一个常数上,报一个类似下面的错误信息:
error: binding reference of type ‘int&’ to ‘const int’ discards qualifiers
如果按照 const 位置的规则,constexpr const int& b 实际该写成 const int& constexpr b。不过,constexpr 不需要像 const 一样有复杂的组合,因此永远是写在类型前面的。
15.7 constexpr 构造函数和字面类型
一个合理的 constexpr 函数,应当至少对于某一组编译期常量的输入,能得到编译期常量的结果。为此,对这个函数也是有些限制的:
- 最早,constexpr 函数里连循环都不能有,但在 C++14 放开了。
- 目前,constexpr 函数仍不能有 try … catch 语句和 asm 声明,但到 C++20 会放开。
- constexpr 函数里不能使用 goto 语句。
- 等等。
一个有意思的情况是一个类的构造函数。如果一个类的构造函数里面只包含常量表达式、满足对 constexpr 函数的限制的话(这也意味着,里面不可以有任何动态内存分配),并且类的析构函数是平凡的,那这个类就可以被称为是一个字面类型。换一个角度想,对 constexpr 函数——包括字面类型构造函数——的要求是,得让编译器能在编译期进行计算,而不会产生任何”副作用”,比如内存分配、输入、输出等等。
为了全面支持编译期计算,C++14 开始,很多标准类的构造函数和成员函数已经被标为 constexpr,以便在编译期使用。当然,大部分的容器类,因为用到了动态内存分配,不能成为字面类型。下面这些不使用动态内存分配的字面类型则可以在常量表达式中使用:
- array
- initializer_list
- pair
- tuple
- string_view
- optional
- variant
- bitset
- complex
- chrono::duration
- chrono::time_point
- shared_ptr(仅限默认构造和空指针构造)
- unique_ptr(仅限默认构造和空指针构造)
- …
15.8 if constexpr
上一讲的结尾,我们给出了一个在类型参数 C 没有 reserve 成员函数时不能编译的代码:
template <typename C, typename T>
void append(C& container, T* ptr, size_t size)
{
if (has_reserve<C>::value) {
container.reserve(container.size() + size);
}
for (size_t i = 0; i < size; ++i) {
container.push_back(ptr[i]);
}
}在 C++17 里,我们只要在 if 后面加上 constexpr,代码就能工作了 [2]。当然,它要求括号里的条件是个编译期常量。满足这个条件后,标签分发、enable_if 那些技巧就不那么有用了。显然,使用 if constexpr 能比使用其他那些方式,写出更可读的代码……
15.9 output_container.h 解读
到了今天,我们终于把 output_container.h([3])用到的 C++ 语法特性都讲过了,我们就拿里面的代码来讲解一下,让你加深对这些特性的理解。
// Type trait to detect std::pair
template <typename T>
struct is_pair : std::false_type {
};
template <typename T, typename U>
struct is_pair<std::pair<T, U>> : std::true_type {
};
template <typename T>
inline constexpr bool is_pair_v = is_pair<T>::value;这段代码利用模板特化([第 12 讲] 、[第 14 讲])和 false_type、true_type 类型([第 13 讲]),定义了 is_pair,用来检测一个类型是不是 pair。随后,我们定义了内联 constexpr 变量(本讲)is_pair_v,用来简化表达。
// Type trait to detect whether an
// output function already exists
template <typename T>
struct has_output_function {
template <class U>
static auto output(U* ptr) -> decltype(std::declval<std::ostream&>() << *ptr, std::true_type());
template <class U>
static std::false_type output(...);
static constexpr bool value = decltype(output<T>(nullptr))::value;
};
template <typename T>
inline constexpr bool has_output_function_v = has_output_function<T>::value;这段代码使用 SFINAE 技巧([第 14 讲]),来检测模板参数 T 的对象是否已经可以直接输出到 ostream。然后,一样用一个内联 constexpr 变量来简化表达。
// Output function for std::pair
template <typename T, typename U>
std::ostream& operator<<(std::ostream& os, const std::pair<T, U>& pr);再然后我们声明了一个 pair 的输出函数(标准库没有提供这个功能)。我们这儿只是声明,是因为我们这儿有两个输出函数,且可能互相调用。所以,我们要先声明其中之一。
下面会看到,pair 的通用输出形式是”(x, y)”。
// Element output function for
// containers that define a key_type
// and have its value type as
// std::pair
template <typename T, typename Cont>
auto output_element(std::ostream& os, const T& element, const Cont&, const std::true_type)
-> decltype(std::declval<typename Cont::key_type>(), os);
// Element output function for other
// containers
template <typename T, typename Cont>
auto output_element(std::ostream& os, const T& element, const Cont&, ...) -> decltype(os);对于容器成员的输出,我们也声明了两个不同的重载。我们的意图是,如果元素的类型是 pair 并且容器定义了一个 key_type 类型,我们就认为遇到了关联容器,输出形式为”x => y”(而不是”(x, y)”)。
// Main output function, enabled
// only if no output function
// already exists
template <typename T, typename = std::enable_if_t<!has_output_function_v<T>>>
auto operator<<(std::ostream& os, const T& container)
-> decltype(container.begin(), container.end(), os)主输出函数的定义。注意这儿这个函数的启用有两个不同的 SFINAE 条件:
- 用 decltype 返回值的方式规定了被输出的类型必须有 begin() 和 end() 成员函数。
- 用 enable_if_t 规定了只在被输出的类型没有输出函数时才启用这个输出函数。否则,对于 string 这样的类型,编译器发现有两个可用的输出函数,就会导致编译出错。
我们可以看到,用 decltype 返回值的方式比较简单,不需要定义额外的模板。但表达否定的条件还是要靠 enable_if。此外,因为此处是需要避免有二义性的重载,constexpr 条件语句帮不了什么忙。
using element_type = decay_t<decltype(*container.begin())>;
constexpr bool is_char_v = is_same_v<element_type, char>;
if constexpr (!is_char_v) {
os << "{ ";
}对非字符类型,我们在开始输出时,先输出”{ “。这儿使用了 decay_t,是为了把类型里的引用和 const/volatile 修饰去掉,只剩下值类型。如果容器里的成员是 char,这儿会把 char& 和 const char& 还原成 char。
后面的代码就比较简单了。可能唯一需要留意的是下面这句:
output_element(os, *it, container, is_pair<element_type>());这儿我们使用了标签分发技巧来输出容器里的元素。要记得,output_element 不纯粹使用标签分发,还会检查容器是否有 key_type 成员类型。
template <typename T, typename Cont>
auto output_element(std::ostream& os, const T& element, const Cont&, const std::true_type)
-> decltype(std::declval<typename Cont::key_type>(), os)
{
os << element.first << " => " << element.second;
return os;
}
template <typename T, typename Cont>
auto output_element(std::ostream& os, const T& element, const Cont&, ...) -> decltype(os)
{
os << element;
return os;
}output_element 的两个重载的实现都非常简单,应该不需要解释了。
template <typename T, typename U>
std::ostream& operator<<(std::ostream& os, const std::pair<T, U>& pr)
{
os << '(' << pr.first << ", " << pr.second << ')';
return os;
}同样,pair 的输出的实现也非常简单。
唯一需要留意的,是上面三个函数的输出内容可能还是容器,因此我们要将其实现放在后面,确保它能看到我们的通用输出函数。
要看一下用到 output_container 的例子,可以回顾 [第 4 讲] 和 [第 5 讲]。
15.10 参考资料
- cppreference.com, “constexpr specifier”. https://en.cppreference.com/w/cpp/language/constexpr
- cppreference.com, “if statement”, section “constexpr if”. https://en.cppreference.com/w/cpp/language/if
- 吴咏炜, output_container. https://github.com/adah1972/output_container/blob/master/output_container.h
16 | 函数对象和lambda:进入函数式编程
16.1 C++98 的函数对象
函数对象(function object)[1] 自 C++98 开始就已经被标准化了。从概念上来说,函数对象是一个可以被当作函数来用的对象。它有时也会被叫做 functor,但这个术语在范畴论里有着完全不同的含义,还是不用为妙——否则玩函数式编程的人可能会朝着你大皱眉头的。
下面的代码定义了一个简单的加 n 的函数对象类(根据一般的惯例,我们使用了 struct关键字而不是 class 关键字):
struct adder {
adder(int n)
: n_(n)
{
}
int operator()(int x) const
{
return x + n_;
}
private:
int n_;
};它看起来相当普通,唯一有点特别的地方就是定义了一个 operator(),这个运算符允许我们像调用函数一样使用小括号的语法。随后,我们可以定义一个实际的函数对象:
auto add_2 = adder(2); // C++11 风格
adder add_2(2); // C++98 风格得到的结果 add_2 就可以当作一个函数来用了。你如果写下 add_2(5) 的话,就会得到结果 7。
C++98 里也定义了少数高阶函数:你可以传递一个函数对象过去,结果得到一个新的函数对象。最典型的也许是目前已经从 C++17 标准里移除的 bind1st 和 bind2nd 了(在 <functional> 头文件中提供):
auto add_2 = bind2nd(plus<int>(), 2);这样产生的 add_2 功能和前面相同,是把参数 2 当作第二个参数绑定到函数对象 plus
binder2nd<plus<int> > add_2(plus<int>(), 2);16.2 函数的指针和引用
除非你用一个引用模板参数来捕捉函数类型,传递给一个函数的函数实参会退化成为一个函数指针。不管是函数指针还是函数引用,你也都可以当成函数对象来用。
假设我们有下面的函数定义:
int add_2(int x)
{
return x + 2;
}如果我们有下面的模板声明:
template <typename T>
auto test1(T fn)
{
return fn(2);
}
template <typename T>
auto test2(T& fn)
{
return fn(2);
}
template <typename T>
auto test3(T* fn)
{
return (*fn)(2);
}当我们拿 add_2 去调用这三个函数模板时,fn 的类型将分别被推导为 int (*)(int)、 int (&)(int) 和 int (*)(int)。不管我们得到的是指针还是引用,我们都可以直接拿它当普通的函数用。当然,在函数指针的情况下,我们直接写 *value 也可以。因而上面三个函数拿 add_2 作为实参调用的结果都是 4。
很多接收函数对象的地方,也可以接收函数的指针或引用。但在个别情况下,需要通过函数对象的类型来区分函数对象的时候,就不能使用函数指针或引用了——原型相同的函数,它们的类型也是相同的。
16.3 Lambda 表达式
看一下上一节给出的代码在使用 lambda 表达式时可以如何简化。
auto add_2 = [](int x) {
return x + 2;
};显然,定义 add_2 不再需要定义一个额外的类型了,我们可以直接写出它的定义。理解它只需要注意下面几点:
- Lambda 表达式以一对中括号开始(中括号中是可以有内容的;稍后我们再说)跟函数定义一样,我们有参数列表
- 跟正常的函数定义一样,我们会有一个函数体,里面会有 return 语句
- Lambda 表达式一般不需要说明返回值(相当于 auto);有特殊情况需要说明时,则应使用箭头语法的方式(参见[第 8 讲]):[] (int x) -> int { … }
- 每个 lambda 表达式都有一个全局唯一的类型,要精确捕捉 lambda 表达式到一个变量中,只能通过 auto 声明的方式
当然,我们想要定义一个通用的 adder 也不难:
auto adder = [](int n) {
return [n](int x) {
return x + n;
};
};这次我们直接返回了一个 lambda 表达式,并且中括号中写了 n 来捕获变量 n 的数值。这个函数的实际效果和前面的 adder 函数对象完全一致。也就是说,捕获 n 的效果相当于在一个函数对象中用成员变量存储其数值。
一个 lambda 表达式除了没有名字之外,还有一个特点是你可以立即进行求值。这就使得我们可以把一段独立的代码封装起来,达到更干净、表意的效果。
先看一个简单的例子:
[](int x) { return x * x; }(3)这个表达式的结果是 3 的平方 9。即使这个看似无聊的例子,都是有意义的,因为它免去了我们定义一个 constexpr 函数的必要。只要能满足 constexpr 函数的条件,一个 lambda 表达式默认就是 constexpr 函数。
16.4 变量捕获
变量捕获的开头是可选的默认捕获符 = 或 &,表示会自动按值或按引用捕获用到的本地变量,然后后面可以跟(逗号分隔):
- 本地变量名标明对其按值捕获(不能在默认捕获符 = 后出现;因其已自动按值捕获所有本地变量)
- & 加本地变量名标明对其按引用捕获(不能在默认捕获符 & 后出现;因其已自动按引用捕获所有本地变量)
- this 标明按引用捕获外围对象(针对 lambda 表达式定义出现在一个非静态类成员内的情况);注意默认捕获符 = 和 & 号可以自动捕获 this(并且在 C++20 之前,在 = 后写 this 会导致出错)
- *this 标明按值捕获外围对象(针对 lambda 表达式定义出现在一个非静态类成员内的情况;C++17 新增语法)
- 变量名 = 表达式 标明按值捕获表达式的结果(可理解为 auto 变量名 = 表达式)
- &变量名 = 表达式 标明按引用捕获表达式的结果(可理解为 auto& 变量名 = 表达式)
从工程的角度,大部分情况不推荐使用默认捕获符。更一般化的一条工程原则是:显式的代码比隐式的代码更容易维护。
一般而言,按值捕获是比较安全的做法。按引用捕获时则需要更小心些,必须能够确保被捕获的变量和 lambda 表达式的生命期至少一样长,并在有下面需求之一时才使用:
- 需要在 lambda 表达式中修改这个变量并让外部观察到
- 需要看到这个变量在外部被修改的结果
- 这个变量的复制代价比较高
如果希望以移动的方式来捕获某个变量的话,则应考虑 变量名 = 表达式 的形式。表达式可以返回一个 prvalue 或 xvalue,比如可以是 std::move(需移动捕获的变量)。
#include <chrono>
#include <iostream>
#include <sstream>
#include <thread>
using namespace std;
int get_count()
{
static int count = 0;
return ++count;
}
class task {
public:
task(int data)
: data_(data)
{
}
auto lazy_launch()
{
[*this, count = get_count()]() mutable {
ostringstream oss;
oss << "Done work " << data_
<< " (No. " << count
<< ") in thread "
<< this_thread::get_id()
<< '\n';
msg_ = oss.str();
calculate();
};
}
void calculate()
{
this_thread::sleep_for(100ms);
cout << msg_;
}
private:
int data_;
string msg_;
};
int main()
{
auto t = task { 37 };
thread t1 { t.lazy_launch() };
thread t2 { t.lazy_launch() };
t1.join();
t2.join();
}这个例子稍复杂,演示了好几个 lambda 表达式的特性:
- mutable 标记使捕获的内容可更改(缺省不可更改捕获的值,相当于定义了 operator()(…) const);
- [*this] 按值捕获外围对象(task);
- [count = get_count()] 捕获表达式可以在生成 lambda 表达式时计算并存储等号后表达式的结果。
这样,多个线程复制了任务对象,可以独立地进行计算。请自行运行一下代码,并把 *this 改成 this,看看输出会有什么不同。
16.5 泛型 lambda 表达式
函数的返回值可以 auto,但参数还是要一一声明的。在 lambda 表达式里则更进一步,在参数声明时就可以使用 auto(包括 auto&& 等形式)。不过,它的功能也不那么神秘,就是给你自动声明了模板而已。毕竟,在 lambda 表达式的定义过程中是没法写 template 关键字的。
template <typename T1, typename T2>
auto sum(T1 x, T2 y)
{
return x + y;
}跟上面的函数等价的 lambda 表达式是:
auto sum = [](auto x, auto y) {
return x + y;
}你可能要问,这么写有什么用呢?问得好。简单来说,答案是可组合性。上面这个 sum,就跟标准库里的 plus 模板一样,是可以传递给其他接受函数对象的函数的,而 + 本身则不行。下面的例子虽然略有点无聊,也可以演示一下:
#include <array> // std::array
#include <iostream> // std::cout/endl
#include <numeric> // std::accumulate
using namespace std;
int main()
{
array a { 1, 2, 3, 4, 5 };
auto s = accumulate(a.begin(), a.end(), 0,
[](auto x, auto y) {
return x + y;
});
cout << s << endl;
}虽然函数名字叫 accumulate——累加——但它的行为是通过第四个参数可修改的。我们把上面的加号 + 改成星号 *,上面的计算就从从 1 加到 5 变成了算 5 的阶乘了。
16.6 bind 模板
我们上面提到了 bind1st 和 bind2nd 目前已经从 C++ 标准里移除。原因实际上有两个:
- 它的功能可以被 lambda 表达式替代
- 有了一个更强大的 bind 模板 [5]
拿我们之前给出的例子:
transform(v.begin(), v.end(), v.begin(), bind2nd(plus<int>(), 2));现在我们可以写成:
using namespace std::placeholders; // for _1, _2...
transform(v.begin(), v.end(), v.begin(), bind(plus<>(), _1, 2));原先我们只能把一个给定的参数绑定到第一个参数或第二个参数上,现在则可以非常自由地适配各种更复杂的情况!当然,bind 的参数数量,必须是第一个参数(函数对象)所需的参数数量加一。而 bind 的结果的参数数量则没有限制——你可以无聊地写出 bind(plus<>(), _1, _3)(1, 2, 3),而结果是 4(完全忽略第二个参数)。
你可能会问,它的功能是不是可以被 lambda 表达式替代呢。回答是”是”。对 bind 只需要稍微了解一下就好——在 C++14 之后的年代里,已经没有什么地方必须要使用 bind 了。
16.7 function 模板
每一个 lambda 表达式都是一个单独的类型,所以只能使用 auto 或模板参数来接收结果。在很多情况下,我们需要使用一个更方便的通用类型来接收,这时我们就可以使用 function 模板 [6]。function 模板的参数就是函数的类型,一个函数对象放到 function 里之后,外界可以观察到的就只剩下它的参数、返回值类型和执行效果了。注意 function 对象的创建还是比较耗资源的,所以请你只在用 auto 等方法解决不了问题的时候使用这个模板。
map<string, function<int(int, int)>> op_dict {
{ "+", [](int x, int y) {
return x + y;
} },
{ "-", [](int x, int y) {
return x - y;
} },
{ "*", [](int x, int y) {
return x * y;
} },
{ "/", [](int x, int y) {
return x / y;
} },
};这儿,由于要把函数对象存到一个 map 里,我们必须使用 function 模板。随后,我们就可以用类似于 op_dict.at(“+”)(1, 6) 这样的方式来使用 function 对象。这种方式对表达式的解析处理可能会比较有用。
16.8 参考资料
[1] Wikipedia, “Function object”. https://en.wikipedia.org/wiki/Function_object
[2] Wikipedia, “Anonymous function”. https://en.wikipedia.org/wiki/Anonymous_function
[3] Wikipedia, “Lambda calculus”. https://en.wikipedia.org/wiki/Lambda_calculus
[4] Wikipedia, “Currying”. https://en.wikipedia.org/wiki/Currying
[5] cppreference.com, “std::bind”. https://en.cppreference.com/w/cpp/utility/functional/bind
[6] cppreference.com, “std::function”. https://en.cppreference.com/w/cpp/utility/functional/function
17 | 函数式编程:一种越来越流行的编程范式
17.1 一个小例子
想一下,如果给定一组文件名,要求数一下文件里的总文本行数,你会怎么做?
我们先规定一下函数的原型:
int count_lines(const char** begin, const char** end);也就是说,我们期待接受两个 C 字符串的迭代器,用来遍历所有的文件名;返回值代表文件中的总行数。
要测试行为是否正常,我们需要一个很小的 main 函数:
int main(int argc, const char** argv)
{
int total_lines = count_lines(argv + 1, argv + argc);
cout << "Total lines: " << total_lines << endl;
}最传统的命令式编程大概会这样写代码:
int count_file(const char* name)
{
int count = 0;
ifstream ifs(name);
string line;
for (;;) {
getline(ifs, line);
if (!ifs) {
break;
}
++count;
}
return count;
}
int count_lines(const char** begin, const char** end)
{
int count = 0;
for (; begin != end; ++begin) {
count += count_file(*begin);
}
return count;
}用 istream_line_reader 可以简化 count_file 成:
int count_file(const char* name)
{
int count = 0;
ifstream ifs(name);
for (auto&& line : istream_line_reader(ifs)) {
++count;
}
return count;
}如果我们使用之前已经出场过的两个函数,transform [1] 和 accumulate [2],代码可以进一步简化为:
int count_file(const char* name)
{
ifstream ifs(name);
istream_line_reader reader(ifs);
return distance(reader.begin(), reader.end());
}
int count_lines(const char** begin, const char** end)
{
vector<int> count(end - begin);
transform(begin, end, count.begin(), count_file);
return accumulate(count.begin(), count.end(), 0);
}这个就是一个非常函数式风格的结果了。上面这个处理方式恰恰就是 map-reduce。 transform 对应 map,accumulate 对应 reduce。而检查有多少行文本,也成了代表文件头尾两个迭代器之间的”距离”(distance)。
17.2 函数式编程的特点
在我们的代码里不那么明显的一点是,函数式编程期望函数的行为像数学上的函数,而非一个计算机上的子程序。这样的函数一般被称为纯函数(pure function),要点在于:
- 会影响函数结果的只是函数的参数,没有对环境的依赖
- 返回的结果就是函数执行的唯一后果,不产生对环境的其他影响
我们的代码中也体现了其他一些函数式编程的特点:
- 函数就像普通的对象一样被传递、使用和返回。
- 代码为说明式而非命令式。在熟悉函数式编程的基本范式后,你会发现说明式代码的可读性通常比命令式要高,代码还短。
- 一般不鼓励(甚至完全不使用)可变量。上面代码里只有 count 的内容在执行过程中被修改了,而且这种修改实际是 transform 接口带来的。如果接口像 [第 13 讲] 展示的 fmap 函数一样返回一个容器的话,就可以连这个问题都消除了。(C++ 毕竟不是一门函数式编程语言,对灵活性的追求压倒了其他考虑。)
17.3 高阶函数
既然函数(对象)可以被传递、使用和返回,自然就有函数会接受函数作为参数或者把函数作为返回值,这样的函数就被称为高阶函数。我们现在已经见过不少高阶函数了,如:
- sort
- transform
- accumulate
- fmap
- adder
事实上,C++ 里以 algorithm(算法)[3] 名义提供的很多函数都是高阶函数。
许多高阶函数在函数式编程中已成为基本的惯用法,在不同语言中都会出现,虽然可能是以不同的名字。我们在此介绍非常常见的三个,map(映射)、reduce(归并)和 filter(过滤)。
Map 在 C++ 中的直接映射是 transform(在 <algorithm> 头文件中提供)。它所做的事情也是数学上的映射,把一个范围里的对象转换成相同数量的另外一些对象。这个函数的基本实现非常简单,但这是一种强大的抽象,在很多场合都用得上。
Reduce 在 C++ 中的直接映射是 accumulate(在 <numeric> 头文件中提供)。它的功能是在指定的范围里,使用给定的初值和函数对象,从左到右对数值进行归并。在不提供函数对象作为第四个参数时,功能上相当于默认提供了加法函数对象,这时相当于做累加;提供了其他函数对象时,那当然就是使用该函数对象进行归并了。
Filter 的功能是进行过滤,筛选出符合条件的成员。它在当前 C++(C++20 之前)里的映射可以认为有两个:copy_if 和 partition。这是因为在 C++20 带来 ranges 之前,在 C++ 里实现惰性求值不太方便。上面说的两个函数里,copy_if 是把满足条件的元素拷贝到另外一个迭代器里;partition 则是根据过滤条件来对范围里的元素进行分组,把满足条件的放在返回值迭代器的前面。另外,remove_if 也有点相近,通常用于删除满足条件的元素。它确保把不满足条件的元素放在返回值迭代器的前面(但不保证满足条件的元素在函数返回后一定存在),然后你一般需要使用容器的 erase 成员函数来将待删除的元素真正删除。
17.4 命令式编程和说明式编程
传统上 C++ 属于命令式编程。命令式编程里,代码会描述程序的具体执行步骤。好处是代码显得比较直截了当;缺点就是容易让人只见树木、不见森林,只能看到代码啰嗦地怎么做(how),而不是做什么(what),更不用说为什么(why)了。
说明式编程则相反。以数据库查询语言 SQL 为例,SQL 描述的是类似于下面的操作:你想从什么地方(from)选择(select)满足什么条件(where)的什么数据,并可选指定排序(order by)或分组(group by)条件。你不需要告诉数据库引擎具体该如何去执行这个操作。事实上,在选择查询策略上,大部分数据库用户都不及数据库引擎”聪明”;正如大部分开发者在写出优化汇编代码上也不及编译器聪明一样。
这并不是说说明式编程一定就优于命令式编程。事实上,对于很多算法,命令式才是最自然的实现。
所以,我个人认为,说明式编程跟命令式编程可以结合起来产生既优雅又高效的代码。对于从命令式编程成长起来的大部分程序员,我的建议是:
- 写表意的代码,不要过于专注性能而让代码难以维护——记住高德纳的名言:”过早优化是万恶之源。”
- 使用有意义的变量,但尽量不要去修改变量内容——变量的修改非常容易导致程序员的思维错误。
- 类似地,尽量使用没有副作用的函数,并让你写的代码也尽量没有副作用,用返回值来代表状态的变化——没有副作用的代码更容易推理,更不容易出错。
- 代码的隐式依赖越少越好,尤其是不要使用全局变量——隐式依赖会让代码里的错误难以排查,也会让代码更难以测试。
- 使用知名的高级编程结构,如基于范围的 for 循环、映射、归并、过滤——这可以让你的代码更简洁,更易于推理,并减少类似下标越界这种低级错误的可能性。
这些跟函数式编程有什么关系呢?——这些差不多都是来自函数式编程的最佳实践。学习函数式编程,也是为了更好地体会如何从这些地方入手,写出易读而又高性能的代码。
17.5 不可变性和并发
在多核的时代里,函数式编程比以前更受青睐,一个重要的原因是函数式编程对并行并发天然友好。影响多核性能的一个重要因素是数据的竞争条件——由于共享内存数据需要加锁带来的延迟。函数式编程强调不可变性(immutability)、无副作用,天然就适合并发。更妙的是,如果你使用高层抽象的话,有时可以轻轻松松”免费”得到性能提升。
拿我们这一讲开头的例子来说,对代码做下面的改造,启用 C++17 的并行执行策略 [5],就能自动获得在多核环境下的性能提升:
int count_lines(const char** begin, const char** end)
{
vector<int> count(end - begin);
transform(execution::par, begin, end, count.begin(), count_file);
return reduce(execution::par, count.begin(), count.end());
}我们可以看到,两个高阶函数的调用中都加入了 execution::par,来启动自动并行计算。要注意的是,我把 accumulate 换成了 reduce [6],原因是前者已经定义成从左到右的归并,无法并行。reduce 则不同,初始值可以省略,操作上没有规定顺序,并反过来要求对元素的归并操作满足交换律和结合率(加法当然是满足的)。
17.6 Y 组合子
限于篇幅,这一讲我们只是很初浅地探讨了函数式编程。对于 C++ 的函数式编程的深入探讨是有整本书的(见参考资料 [8]),而今天讲的内容在书的最前面几章就覆盖完了。在后面,我们还会探讨部分的函数式编程话题;今天我们只再讨论一个有点有趣、也有点烧脑的话题,Y 组合子 [9]。第一次阅读的时候,如果觉得困难,可以跳过这一部分。
不过,我并不打算讨论 Haskell Curry 使用的 Y 组合子定义——这个比较复杂,需要写一篇完整的文章来讨论([10]),而且在 C++ 中的实用性非常弱。
17.7 参考资料
[1] cppreference.com, “std::transform”. https://en.cppreference.com/w/cpp/algorithm/transform
[2] cppreference.com, “std::accumulate”. https://en.cppreference.com/w/cpp/algorithm/accumulate
[3] cppreference.com, “Standard library header <algorithm>“. https://en.cppreference.com/w/cpp/header/algorithm
[4] 袁英杰, “Immutability: The Dark Side”. https://www.jianshu.com/p/13cd4c650125
[5] cppreference.com, “Standard library header <execution>“. https://en.cppreference.com/w/cpp/header/execution
[6] cppreference.com, “std::reduce”. https://en.cppreference.com/w/cpp/algorithm/reduce
[7] Intel, tbb. https://github.com/intel/tbb
[8] Ivan Čukić, Functional Programming in C++. Manning, 2019, https://www.manning.com/books/functional-programming-in-c-plus-plus
[9] Wikipedia, “Fixed-point combinator”. https://en.wikipedia.org/wiki/Fixedpoint_combinator
[10] 吴咏炜, “Y Combinator and C++”. https://yongweiwu.wordpress.com/2014/12/14/y-combinator-and-cplusplus/
18 | 应用可变模板和tuple的编译期技巧
如何使用可变模板和 tuple 来完成一些常见的功能,尤其是编译期计算。
18.1 可变模板
可变模板 [1] 是 C++11 引入的一项新功能,使我们可以在模板参数里表达不定个数和类型的参数。从实际的角度,它有两个明显的用途:
- 用于在通用工具模板中转发参数到另外一个函数
- 用于在递归的模板中表达通用的情况(另外会有至少一个模板特化来表达边界情况)
18.2 转发用法
以标准库里的 make_unique 为例,它的定义差不多是下面这个样子:
template <typename T, typename... Args>
inline unique_ptr<T> make_unique(Args&&... args)
{
return unique_ptr<T>(new T(forward<Args>(args)...));
}这样,它就可以把传递给自己的全部参数转发到模板参数类的构造函数上去。注意,在这种情况下,我们通常会使用 std::forward,确保参数转发时仍然保持正确的左值或右值引用类型。
稍微解释一下上面三处出现的 …:
- typename… Args 声明了一系列的类型——class… 或 typename… 表示后面的标识符代表了一系列的类型。
- Args&&… args 声明了一系列的形参 args,其类型是 Args&&。
forward<Args>(args)...会在编译时实际逐项展开 Args 和 args ,参数有多少项,展开后就是多少项。
举一个例子,如果我们需要在堆上传递一个 vector<int>,假设我们希望初始构造的大小为 100,每个元素都是 1,那我们可以这样写:
make_unique<vector<int>>(100, 1)模板实例化之后,会得到相当于下面的代码:
template <>
inline unique_ptr<vector<int>> make_unique(int&& arg1, int&& arg2)
{
return unique_ptr<vector<int>>(new vector<int>(forward<int>(arg1), forward<int>(arg2)));
}如前所述,forward<Args>(args)... 为每一项可变模板参数都以同样的形式展开。项数也允许为零,那样,我们在调用构造函数时也同样没有任何参数。
18.3 递归用法
我们也可以用可变模板来实现编译期递归。下面就是个小例子:
template <typename T>
constexpr auto sum(T x)
{
return x;
}
template <typename T1, typename T2, typename... Targ>
constexpr auto sum(T1 x, T2 y, Targ... args)
{
return sum(x + y, args...);
}在上面的定义里,如果 sum 得到的参数只有一个,会走到上面那个重载。如果有两个或更多参数,编译器就会选择下面那个重载,执行一次加法,随后你的参数数量就少了一个,因而递归总会终止到上面那个重载,结束计算。
注意我们都不必使用相同的数据类型:只要这些数据之间可以应用 +,它们的类型无关紧要……
再看另一个复杂些的例子,函数的组合 [2]。如果我们有函数 f 和 函数 g ,要得到函数的联用 g ∘ f ,其满足:
(g ∘ f )(x) = g(f (x))
我们能不能用一种非常简单的方式,写不包含变量 的表达式来表示函数组合呢?答案是肯定的。
跟上面类似,我们需要写出递归的终结情况,单个函数的”组合”:
template <typename F>
auto compose(F f)
{
return [f](auto&&... x) {
return f(forward<decltype(x)>(x)...);
};
}上面我们仅返回一个泛型 lambda 表达式,保证参数可以转发到 f。记得我们在 [第 16 讲] 讲过泛型 lambda 表达式,本质上就是一个模板,所以我们按转发用法的可变模板来理解上面的 … 部分就对了。
下面是正常有组合的情况:
template <typename F, typename... Args>
auto compose(F f, Args... other)
{
return [f, other...](auto&&... x) {
return f(compose(other...)(forward<decltype(x)>(x)...));
};
}在这个模板里,我们返回一个 lambda 表达式,然后用 f 捕捉第一个函数对象,用 args… 捕捉后面的函数对象。我们用 args… 继续组合后面的部分,然后把结果传到 f 里面。
上面的模板定义我实际上已经有所简化,没有保持值类别。完整的包含完美转发的版本,请看参考资料 [3] 中的 functional.h 实现。
下面我们来试验一下使用这个 compose 函数。我们先写一个对输入范围中每一项都进行平方的函数对象:
auto square_list = [](auto&& container) {
return fmap([](int x) { return x * x; }, container);
};我们这儿用了泛型 lambda 表达式,是因为组合的时候不能使用模板,只能是函数对象或函数(指针)——如果我们定义一个 square_list 模板的话,组合时还得显式实例化才行(写成 square_list<const vector<int>&> 的样子),很不方便。
我们再写一个求和的函数对象:
auto sum_list = [](auto&& container) {
return accumulate(container.begin(), container.end(), 0);
};那先平方再求和,就可以这样简单定义了:
auto squared_sum = compose(sum_list, square_list);我们可以验证这个定义是可以工作的:
vector v{1, 2, 3, 4, 5};
cout << squared_sum(v) << endl;我们会得到:
5518.4 tuple
上面的写法虽然看起来还不错,但实际上有个缺陷:被 compose 的函数除了第一个(最右边的),其他的函数只能接收一个参数。要想进一步推进类似的技巧,我们得首先解决这个问题。
在 C++ 里,要通用地用一个变量来表达多个值,那就得看多元组——tuple 模板了 [4]。tuple 算是 C++98 里的 pair 类型的一般化,可以表达任意多个固定数量、固定类型的值的组合。
- tuple 的成员数量由尖括号里写的类型数量决定。
- 可以使用 get 函数对 tuple 的内容进行读和写。(当一个类型在 tuple 中出现正好一次时,我们也可以传类型取内容,即,对我们上面的三元组,
get<int>是合法的,get<string>则不是。) - 可以用
tuple_size_v(在编译期)取得多元组里面的项数。
我们已经有了参数的项数(使用 tuple_size_v),所以我们下面要做的是生成从 0 到项数减一之间的整数序列。标准库里已经定义了相关的工具,我们需要的就是其中的 make_index_sequence [5],其简化实现如下所示:
template <class T, T... Ints>
struct integer_sequence {
};
template <size_t... Ints>
using index_sequence = integer_sequence<size_t, Ints...>;
template <size_t N, size_t... Ints>
struct index_sequence_helper {
typedef typename index_sequence_helper<N - 1, N - 1, Ints...>::type type;
};
template <size_t... Ints>
struct index_sequence_helper<0, Ints...> {
typedef index_sequence<Ints...> type;
};
template <size_t N>
using make_index_sequence = typename index_sequence_helper<N>::type;正如一般的模板代码,它看起来还是有点绕的。其要点是,如果我们给出 make_index_sequence<N>,则结果是 integer_sequence<size_t, 0, 1, 2, …, N - 1>(一下子想不清楚的话,可以拿纸笔来模拟一下模板的展开过程)。而有了这样一个模板的帮助之后,我们就可以写出下面这样的函数(同样,这是标准库里的 apply
函数模板 [6] 的简化版本):
template <class F, class Tuple, size_t... I>
constexpr decltype(auto) apply_impl(F&& f, Tuple&& t, index_sequence<I...>)
{
return f(get<I>(forward<Tuple>(t))...);
}
template <class F, class Tuple>
constexpr decltype(auto) apply(F&& f, Tuple&& t)
{
return apply_impl(
forward<F>(f),
forward<Tuple>(t),
make_index_sequence<tuple_size_v<remove_reference_t<Tuple>>> {});
}我们如果有一个三元组 t,类型为 tuple<int, string, string>,去 apply 到一个函数 f,展开后我们得到 apply_impl(f, t, index_sequence<0, 1, 2>{}),再展开后我们就得到了上面那个有 get<0>、get<1>、get<2> 的函数调用形式。换句话说,我们利用一个计数序列的类型,可以在编译时展开 tuple 里的各个成员,并用来调用函数。
完整可运行代码(可以使用 cppinsights 查看下面代码中模板展开的过程):
#include <string>
#include <vector>
#include <iostream>
#include <tuple>
#include <type_traits>
template <class T, T... Ints>
struct integer_sequence {
};
template <size_t... Ints>
using index_sequence = integer_sequence<size_t, Ints...>;
template <size_t N, size_t... Ints>
struct index_sequence_helper {
typedef typename index_sequence_helper<N - 1, N - 1, Ints...>::type type;
};
template <size_t... Ints>
struct index_sequence_helper<0, Ints...> {
typedef index_sequence<Ints...> type;
};
template <size_t N>
using make_index_sequence = typename index_sequence_helper<N>::type;
template <class F, class Tuple, size_t... I>
constexpr decltype(auto) apply_impl(F&& f, Tuple&& t, index_sequence<I...>)
{
return f(std::get<I>(std::forward<Tuple>(t))...);
}
template <class F, class Tuple>
constexpr decltype(auto) apply(F&& f, Tuple&& t)
{
return apply_impl(
std::forward<F>(f),
std::forward<Tuple>(t),
make_index_sequence<std::tuple_size_v<std::remove_reference_t<Tuple>>> {});
}
void k(std::string& s, int& n, std::vector<std::string>& v)
{
using namespace std;
cout << s << endl
<< n << endl;
}
int main()
{
std::tuple t = { std::string("k"), 10, std::vector<std::string> {} };
::apply(k, t);
}18.5 数值预算
我们下面看一个源自实际项目的例子。需求是,我们希望快速地计算一串二进制数中 1 比特的数量。举个例子,如果我们有十进制的 31 和 254,转换成二进制是 00011111 和 11111110,那我们应该得到 5 + 7 = 12。
显然,每个数字临时去数肯定会慢,我们应该预先把每个字节的 256 种情况记录下来。因而,如何得到这些计数值是个问题。在没有编译期编程时,我们似乎只能用另外一个程序先行计算,然后把结果填进去——这就很不方便很不灵活了。有了编译期编程,我们就不用写死,而让编译器在编译时帮我们计算数值。
利用 constexpr 函数,我们计算单个数值完全没有问题。快速定义如下:
constexpr int count_bits(unsigned char value)
{
if (value == 0) {
return 0;
} else {
return (value & 1) + count_bits(value >> 1);
}
}可 256 个,总不见得把计算语句写上 256 遍吧?这就需要用到我们上面讲到的 index_sequence 了。我们定义一个模板,它的参数是一个序列,在初始化时这个模板会对参数里的每一项计算比特数,并放到数组成员里。
template <size_t... V>
struct bit_count_t {
unsigned charcount[sizeof...(V)] = { static_cast<unsigned char>(count_bits(V))... };
};注意上面用 sizeof…(V) 可以获得参数的个数(在 tuple_size_v 的实现里实际也用到它了)。如果我们模板参数传 0, 1, 2, 3,结果里面就会有个含 4 项元素的数组,数值分别是对 0、1、2、3 的比特计数。
然后,我们当然就可以利用 make_index_sequence 来展开计算了,想产生几项就可以产生几项。不过,要注意到 make_index_sequence 的结果是个类型,不能直接用在 bit_count_t 的构造中。我们需要用模板匹配来中转一下:
template <size_t... V>
bit_count_t<V...> get_bit_count(index_sequence<V...>)
{
return bit_count_t<V...>();
}
auto bit_count = get_bit_count(make_index_sequence<256>());得到 bit_count 后,我们要计算一个序列里的比特数就只是轻松查表相加了,此处不再赘述。
18.6 参考资料
[1] cppreference.com, “Parameter pack”. https://en.cppreference.com/w/cpp/language/parameter_pack
[2] Wikipedia, “Function composition”. https://en.wikipedia.org/wiki/Function_composition
[3] 吴咏炜, nvwa. https://github.com/adah1972/nvwa
[4] cppreference.com, “std::tuple”. https://en.cppreference.com/w/cpp/utility/tuple
[5] cppreference.com, “std::integer_sequence”. https://en.cppreference.com/w/cpp/utility/integer_sequence
[6] cppreference.com, “std::apply”. https://en.cppreference.com/w/cpp/utility/apply
19 | thread和future:领略异步中的未来
19.1 为什么要使用并发编程?
如果你不熟悉进程和线程的话,我们就先来简单介绍一下它们的关系。我们编译完执行的 C++ 程序,那在操作系统看来就是一个进程了。而每个进程里可以有一个或多个线程:
- 每个进程有自己的独立地址空间,不与其他进程分享;一个进程里可以有多个线程,彼此共享同一个地址空间。
- 堆内存、文件、套接字等资源都归进程管理,同一个进程里的多个线程可以共享使用。每个进程占用的内存和其他资源,会在进程退出或被杀死时返回给操作系统。
- 并发应用开发可以用多进程或多线程的方式。多线程由于可以共享资源,效率较高;反之,多进程(默认)不共享地址空间和资源,开发较为麻烦,在需要共享数据时效率也较低。但多进程安全性较好,在某一个进程出问题时,其他进程一般不受影响;而在多线程的情况下,一个线程执行了非法操作会导致整个进程退出。
我们讲 C++ 里的并发,主要讲的就是多线程。它对开发人员的挑战是全方位的。从纯逻辑的角度,并发的思维模式就比单线程更为困难。在其之上,我们还得加上:
- 编译器和处理器的重排问题
- 原子操作和数据竞争
- 互斥锁和死锁问题
- 无锁算法
- 条件变量
- 信号量
- ……
即使对于专家,并发编程都是困难的,上面列举的也只是部分难点而已。对于并发的基本挑战,Herb Sutter 在他的 Effective Concurrency 专栏给出了一个较为全面的概述 [2]。要对 C++ 的并发编程有全面的了解,则可以阅读曼宁出版的 C++ Concurrency in Action(有中文版,但翻译口碑不好)[3]。而我们今天主要要介绍的,则是并发编程的基本概念,包括传统的多线程开发,以及高层抽象 future(姑且译为未来量)的用法。
19.2 基于 thread 的多线程开发
以下几个地方可能需要稍加留意一下:
- thread 的构造函数的第一个参数是函数(对象),后面跟的是这个函数所需的参数。
- thread 要求在析构之前要么 join(阻塞直到线程退出),要么 detach(放弃对线程的管理),否则程序会异常退出。
- sleep_for 是 this_thread 名空间下的一个自由函数,表示当前线程休眠指定的时间。
thread 不能在析构时自动 join 有点不那么自然,这可以算是一个缺陷吧。在 C++20 的 jthread [5] 到来之前,我们只能自己小小封装一下了。比如:
class scoped_thread {
public:
template <typename... Arg>
scoped_thread(Arg&&... arg)
: thread_(std::forward<Arg>(arg)...)
{
}
scoped_thread(scoped_thread&& other)
: thread_(std::move(other.thread_))
{
}
scoped_thread(const scoped_thread&) = delete;
~scoped_thread()
{
if (thread_.joinable()) {
thread_.join();
}
}
private:
thread thread_;
};这个实现里有下面几点需要注意:
- 我们使用了可变模板和完美转发来构造 thread 对象。
- thread 不能拷贝,但可以移动;我们也类似地实现了移动构造函数。
- 只有 joinable(已经 join 的、已经 detach 的或者空的线程对象都不满足 joinable)的 thread 才可以对其调用 join 成员函数,否则会引发异常。
19.3 mutex
互斥量的基本语义是,一个互斥量只能被一个线程锁定,用来保护某个代码块在同一时间只能被一个线程执行。
目前的 C++ 标准中,事实上提供了不止一个互斥量类。我们先看最简单、也最常用的mutex 类 [6]。mutex 只可默认构造,不可拷贝(或移动),不可赋值,主要提供的方法是:
- lock:锁定,锁已经被其他线程获得时则阻塞执行
- try_lock:尝试锁定,获得锁返回 true,在锁被其他线程获得时返回 false
- unlock:解除锁定(只允许在已获得锁时调用)
你可能会想到,如果一个线程已经锁定了某个互斥量,再次锁定会发生什么?对于 mutex,回答是危险的未定义行为。你不应该这么做。如果有特殊需要可能在同一线程对同一个互斥量多次加锁,就需要用到递归锁 recursive_mutex 了 [7]。除了允许同一线程可以无阻塞地多次加锁外(也必须有对应数量的解锁操作),recursive_mutex 的其他行为和 mutex 一致。
除了 mutex 和 recursive_mutex,C++ 标准库还提供了:
- timed_mutex:允许锁定超时的互斥量
- recursive_timed_mutex:允许锁定超时的递归互斥量
- shared_mutex:允许共享和独占两种获得方式的互斥量
- shared_timed_mutex:允许共享和独占两种获得方式的、允许锁定超时的互斥量
这些我们就不做讲解了,需要的请自行查看参考资料 [8]。另外,<mutex> 头文件中也定义了锁的 RAII 包装类,如我们上面用过的 lock_guard。为了避免手动加锁、解锁的麻烦,以及在有异常或出错返回时发生漏解锁,我们一般应当使用 lock_guard,而不是手工调用互斥量的 lock 和 unlock 方法。C++ 里另外还有 unique_lock(C++11)和 scoped_lock(C++17),提供了更多的功能,你在有更复杂的需求时应该检查一下它们是否合用。
19.4 执行任务,返回数据
如果我们要在某个线程执行一些后台任务,然后取回结果,我们该怎么做呢?
比较传统的做法是使用信号量或者条件变量。由于 C++17 还不支持信号量,我们要模拟传统的做法,只能用条件变量了。由于我的重点并不是传统的做法,条件变量 [9] 我就不展开讲了,而只是展示一下示例的代码。
#include <chrono>
#include <condition_variable>
#include <functional>
#include <iostream>
#include <mutex>
#include <thread>
#include <utility>
using namespace std;
class scoped_thread {
// 定义同上,略
};
void work(condition_variable& cv, int& result)
{
// 假装我们计算了很久
this_thread::sleep_for(2s);
result = 42;
cv.notify_one();
}
int main()
{
condition_variable cv;
mutex cv_mut;
int result;
scoped_thread th { work, ref(cv), ref(result) };
// 干一些其他事
cout << "I am waiting now\n";
unique_lock lock { cv_mut };
cv.wait(lock);
cout << "Answer: " << result << '\n';
}可以看到,为了这个小小的”计算”,我们居然需要定义 5 个变量:线程、条件变量、互斥量、单一锁和结果变量。我们也需要用 ref 模板来告诉 thread 的构造函数,我们需要传递条件变量和结果变量的引用,因为 thread 默认复制或移动所有的参数作为线程函数的参数。这种复杂性并非逻辑上的复杂性,而只是实现导致的,不是我们希望的写代码的方式。
下面,我们就看看更高层的抽象,未来量 future [10],可以如何为我们简化代码。
19.5 future
我们先把上面的代码直接翻译成使用 async [11](它会返回一个 future):
#include <chrono>
#include <future>
#include <iostream>
#include <thread>
using namespace std;
int work()
{
// 假装我们计算了很久
this_thread::sleep_for(2s);
return 42;
}
int main()
{
auto fut = async(launch::async, work);
// 干一些其他事
cout << "I am waiting now\n";
cout << "Answer: " << fut.get() << '\n';
}我们稍稍分析一下:
- work 函数现在不需要考虑条件变量之类的实现细节了,专心干好自己的计算活、老老实实返回结果就可以了。
- 调用 async 可以获得一个未来量,launch::async 是运行策略,告诉函数模板 async 应当在新线程里异步调用目标函数。在一些老版本的 GCC 里,不指定运行策略,默认不会起新线程。
- async 函数模板可以根据参数来推导出返回类型,在我们的例子里,返回类型是
future<int>。 - 在未来量上调用 get 成员函数可以获得其结果。这个结果可以是返回值,也可以是异常,即,如果 work 抛出了异常,那 main 里在执行 fut.get() 时也会得到同样的异常,需要有相应的异常处理代码程序才能正常工作。
这里有两个要点,从代码里看不出来,我特别说明一下:
- 一个 future 上只能调用一次 get 函数,第二次调用为未定义行为,通常导致程序崩溃。
- 这样一来,自然一个 future 是不能直接在多个线程里用的。
上面的第 1 点是 future 的设计,需要在使用时注意一下。第 2 点则是可以解决的。要么直接拿 future 来移动构造一个 shared_future [12],要么调用 future 的 share 方法来生成一个 shared_future,结果就可以在多个线程里用了——当然,每个 shared_future 上仍然还是只能调用一次 get 函数。
19.6 promise
我们上面用 async 函数生成了未来量,但这不是唯一的方式。另外有一种常用的方式是 promise [13],我称之为”承诺量”。我们同样看一眼上面的例子用 promise 该怎么写:
#include <chrono>
#include <future>
#include <iostream>
#include <thread>
using namespace std;
class scoped_thread {
// 定义同上,略
};
void work(promise<int> prom)
{
// 假装我们计算了很久
this_thread::sleep_for(2s);
prom.set_value(42);
}
int main()
{
promise<int> prom;
auto fut = prom.get_future();
scoped_thread th { work, move(prom) };
// 干一些其他事
cout << "I am waiting now\n";
cout << "Answer: " << fut.get() << '\n';
}promise 和 future 在这里成对出现,可以看作是一个一次性管道:有人需要兑现承诺,往 promise 里放东西(set_value);有人就像收期货一样,到时间去 future(写到这里想到,期货英文不就是 future 么,是不是该翻译成期货量呢?😝)里拿(get)就行了。我们把 prom 移动给新线程,这样老线程就完全不需要管理它的生命周期了。
就这个例子而言,使用 promise 没有 async 方便,但可以看到,这是一种非常灵活的方式,你不需要在一个函数结束的时候才去设置 future 的值。仍然需要注意的是,一组 promise 和 future 只能使用一次,既不能重复设,也不能重复取。
promise 和 future 还有个有趣的用法是使用 void 类型模板参数。这种情况下,两个线程之间不是传递参数,而是进行同步:当一个线程在一个 future<void> 上等待时(使用 get() 或 wait()),另外一个线程可以通过调用 promise<void> 上的 set_value() 让其结束等待、继续往下执行。有
19.7 packaged
我们最后要讲的一种 future 的用法是打包任务 packaged_task [14],我们同样给出完成相同功能的示例,让你方便对比一下:
#include <chrono>
#include <future>
#include <iostream>
#include <thread>
using namespace std;
class scoped_thread {
// 定义同上,略
};
int work()
{
// 假装我们计算了很久
this_thread::sleep_for(2s);
return 42;
}
int main()
{
packaged_task<int()> task { work };
auto fut = task.get_future();
scoped_thread th { move(task) };
// 干一些其他事
this_thread::sleep_for(1s);
cout << "I am waiting now\n";
cout << "Answer: " << fut.get()
<< '\n';
}打包任务里打包的是一个函数,模板参数就是一个函数类型。跟 thread、future、promise 一样,packaged_task 只能移动,不能复制。它是个函数对象,可以像正常函数一样被执行,也可以传递给 thread 在新线程中执行。它的特别地方,自然也是你可以从它得到一个未来量了。通过这个未来量,你可以得到这个打包任务的返回值,或者,至少知道这个打包任务已经执行结束了。
19.8 参考资料
- Herb Sutter, “The free lunch is over”. http://www.gotw.ca/publications/concurrency-ddj.htm
- Herb Sutter, “Effective concurrency”. https://herbsutter.com/2010/09/24/effective-concurrency-know-when-to-usean-active-object-instead-of-a-mutex/
- Anthony Williams, C++ Concurrency in Action (2nd ed.). Manning, 2019, https://www.manning.com/books/c-plus-plus-concurrency-in-action-secondedition
- cppreference.com, “std::thread”. https://en.cppreference.com/w/cpp/thread/thread
- cppreference.com, “std::jthread”. https://en.cppreference.com/w/cpp/thread/jthread
- cppreference.com, “std::mutex”. https://en.cppreference.com/w/cpp/thread/mutex
- cppreference.com, “std::recursive_mutex”. https://en.cppreference.com/w/cpp/thread/recursive_mutex
- cppreference.com, “
Standard library header <mutex>“. https://en.cppreference.com/w/cpp/header/mutex - cppreference.com, “std::recursive_mutex”. https://en.cppreference.com/w/cpp/thread/condition_variable
- cppreference.com, “std::future”. https://en.cppreference.com/w/cpp/thread/future
- cppreference.com, “std::async”. https://en.cppreference.com/w/cpp/thread/async
- cppreference.com, “std::shared_future”. https://en.cppreference.com/w/cpp/thread/shared_future
- cppreference.com, “std::promise”. https://en.cppreference.com/w/cpp/thread/promise
- cppreference.com, “std::packaged_task”. https://en.cppreference.com/w/cpp/thread/packaged_task
20 | 内存模型和atomic:理解并发的复杂性
20.1 C++98 的执行顺序问题
下面的事实可能会产生不符合直觉预期的结果:
- 为了优化的必要,编译器是可以调整代码的执行顺序的。唯一的要求是,程序的”可观测”外部行为是一致的。
- 处理器也会对代码的执行顺序进行调整(所谓的 CPU 乱序执行)。在单处理器的情况下,这种乱序无法被程序观察到;但在多处理器的情况下,在另外一个处理器上运行的另一个线程就可能会察觉到这种不同顺序的后果了。
对于上面的后一点,大部分开发者并没有意识到。原因有好几个方面:
- 多处理器的系统在那时还不常见
- 主流的 x86 体系架构仍保持着较严格的内存访问顺序
- 只有在数据竞争(data race)激烈的情况下才能看到”意外”的后果
举一个例子,假设我们有两个全局变量:
int x = 0;
int y = 0;然后我们在一个线程里执行:
x = 1;
y = 2;在另一个线程里执行:
if (y == 2) {
x = 3;
y = 4;
}想一下,你认为上面的代码运行完之后,x、y 的数值有几种可能?
你如果认为有两种可能,1、2 和 3、4 的话,那说明你是按典型程序员的思维模式看问题的——没有像编译器和处理器一样处理问题。事实上,1、4 也是一种结果的可能。有两个基本的原因可以造成这一后果:
- 编译器没有义务一定按代码里给出的顺序产生代码。事实上,跟据上下文调整代码的执行顺序,使其最有利于处理器的架构,是优化中很重要的一步。就单个线程而言,先执行 x = 1 还是先执行 y = 2 完全是件无关紧要的事:它们没有外部”可观察”的区别。
- 在多处理器架构中,各个处理器可能存在缓存不一致性问题。取决于具体的处理器类型、缓存策略和变量地址,对变量 y 的写入有可能先反映到主内存中去。之所以这个问题似乎并不常见,是因为常见的 x86 和 x86-64 处理器是在顺序执行方面做得最保守的——大部分其他处理器,如 ARM、DEC Alpha、PA-RISC、IBM Power、IBM z/ 架构和 Intel Itanium 在内存序问题上都比较”松散”。x86 使用的内存模型基本提供了顺序一致性(sequential consistency);相对的,ARM 使用的内存模型就只是松散一致性(relaxed consistency)。较为严格的描述,请查看参考资料 [1] 和里面提供的进一步资料。
虽说 Intel 架构处理器的顺序一致性比较好,但在多处理器(包括多核)的情况下仍然能够出现写读序列变成读写序列的情况,产生意料之外的后果。参考资料 [2] 中提供了完整的例子,包括示例代码。对于缓存不一致性问题的一般中文介绍,可以查看参考资料 [3]。
20.2 双重检查锁定
在多线程可能对同一个单件进行初始化的情况下,有一个双重检查锁定的技巧,可基本示意如下:
// 头文件
class singleton {
public:
static singleton* instance();
private:
static singleton* inst_ptr_;
};
// 实现文件
singleton* singleton::inst_ptr_ = nullptr;
singleton* singleton::instance()
{
if (inst_ptr_ == nullptr) {
lock_guard lock; // 加锁
if (inst_ptr_ == nullptr) {
inst_ptr_ = new singleton();
}
}
return inst_ptr_;
}这个代码的目的是消除大部分执行路径上的加锁开销。原本的意图是:如果 inst_ptr_没有被初始化,执行才会进入加锁的路径,防止单件被构造多次;如果 inst_ptr_ 已经被初始化,那它就会被直接返回,不会产生额外的开销。虽然看上去很美,但它一样有着上面提到的问题。Scott Meyers 和 Andrei Alexandrecu 详尽地分析了这个用法 [4],然后得出结论:即使花上再大的力气,这个用法仍然有着非常多的难以填补的漏洞。本质上还是上面说的,优化编译器会努力击败你试图想防止优化的努力,而多处理器会以令人意外的方式让代码走到错误的执行路径上去。他们分析得非常详细,建议你可以花时间学习一下。
20.3 volatile
在某些编译器里,使用 volatile 关键字可以达到内存同步的效果。但我们必须记住,这不是 volatile 的设计意图,也不能通用地达到内存同步的效果。volatile 的语义只是防止编译器”优化”掉对内存的读写而已。它的合适用法,目前主要是用来读写映射到内存地址上的 I/O 操作。
由于 volatile 不能在多处理器的环境下确保多个线程能看到同样顺序的数据变化,在今天的通用应用程序中,不应该再看到 volatile 的出现。
20.4 C++11 的内存模型
为了从根本上消除这些漏洞,C++11 里引入了适合多线程的内存模型。我们可以在参考资料 [5] 里了解更多的细节。跟我们开发密切相关的是:现在我们有了原子对象(atomic)和使用原子对象的获得(acquire)、释放(release)语义,可以真正精确地控制内存访问的顺序性,保证我们需要的内存序。
20.5 内存屏障和获得、释放语义
拿刚才的那个例子来说,如果我们希望结果只能是 1、2 或 3、4,即满足程序员心中的完全存储序(total store ordering),我们需要在 x = 1 和 y = 2 两句语句之间加入内存屏障,禁止这两句语句交换顺序。我们在此种情况下最常用的两个概念是”获得”和”释放”:
- 获得是一个对内存的读操作,当前线程的任何后面的读写操作都不允许重排到这个操作的前面去。
- 释放是一个对内存的写操作,当前线程的任何前面的读写操作都不允许重排到这个操作的后面去。
具体到我们上面的第一个例子,我们需要把 y 声明成 atomic<int>。然后,我们在线程 1需要使用释放语义:
x = 1;
y.store(2, memory_order_release);在线程 2 我们对 y 的读取应当使用获得语义,但存储只需要松散内存序即可:
if (y.load(memory_order_acquire) == 2) {
x = 3;
y.store(4, memory_order_relaxed);
}我们可以用下图示意一下,每一边的代码都不允许重排越过黄色区域,且如果 y 上的释放早于 y 上的获取的话,释放前对内存的修改都在另一个线程的获取操作后可见:
事实上,在我们把 y 改成 atomic<int> 之后,两个线程的代码一行不改,执行结果都会是符合我们的期望的。因为 atomic 变量的写操作缺省就是释放语义,读操作缺省就是获得语义。即
- y = 2 相当于 y.store(2, memory_order_release)
- y == 2 相当于 y.load(memory_order_acquire) == 2
但是,缺省行为可能是对性能不利的:我们并不需要在任何情况下都保证操作的顺序性。另外,我们应当注意一下,acquire 和 release 通常都是配对出现的,目的是保证如果对同一个原子对象的 release 发生在 acquire 之前的话,release 之前发生的内存修改能够被 acquire 之后的内存读取全部看到。
20.6 atomic
刚才是对 atomic 用法的一个非正式介绍。下面我们对 atomic 做一个稍完整些的说明(更完整的见 [6])。
C++11 在 <atomic> 头文件中引入了 atomic 模板,对原子对象进行了封装。我们可以将其应用到任何类型上去。当然对于不同的类型效果还是有所不同的:对于整型量和指针等简单类型,通常结果是无锁的原子对象;而对于另外一些类型,比如 64 位机器上大小不是 1、2、4、8(有些平台 / 编译器也支持对更大的数据进行无锁原子操作)的类型,编译器会自动为这些原子对象的操作加上锁。编译器提供了一个原子对象的成员函数 is_lock_free,可以检查这个原子对象上的操作是否是无锁的。
原子操作有三类:
- 读:在读取的过程中,读取位置的内容不会发生任何变动。
- 写:在写入的过程中,其他执行线程不会看到部分写入的结果。
- 读‐修改‐写:读取内存、修改数值、然后写回内存,整个操作的过程中间不会有其他写入操作插入,其他执行线程不会看到部分写入的结果。
<atomic> 头文件中还定义了内存序,分别是:
- memory_order_relaxed:松散内存序,只用来保证对原子对象的操作是原子的
- memory_order_consume:目前不鼓励使用,我就不说明了
- memory_order_acquire:获得操作,在读取某原子对象时,当前线程的任何后面的读写操作都不允许重排到这个操作的前面去,并且其他线程在对同一个原子对象释放之前的所有内存写入都在当前线程可见
- memory_order_release:释放操作,在写入某原子对象时,当前线程的任何前面的读写操作都不允许重排到这个操作的后面去,并且当前线程的所有内存写入都在对同一个原子对象进行获取的其他线程可见
- memory_order_acq_rel:获得释放操作,一个读‐修改‐写操作同时具有获得语义和释放语义,即它前后的任何读写操作都不允许重排,并且其他线程在对同一个原子对象释放之前的所有内存写入都在当前线程可见,当前线程的所有内存写入都在对同一个原子对象进行获取的其他线程可见
- memory_order_seq_cst:顺序一致性语义,对于读操作相当于获取,对于写操作相当于释放,对于读‐修改‐写操作相当于获得释放,是所有原子操作的默认内存序
atomic 有下面这些常用的成员函数:
- 默认构造函数(只支持零初始化)
- 拷贝构造函数被删除
- 使用内置对象类型的构造函数(不是原子操作)
- 可以从内置对象类型赋值到原子对象(相当于 store)
- 可以从原子对象隐式转换成内置对象(相当于 load)
- store,写入对象到原子对象里,第二个可选参数是内存序类型
- load,从原子对象读取内置对象,有个可选参数是内存序类型
- is_lock_free,判断对原子对象的操作是否无锁(是否可以用处理器的指令直接完成原子操作)
- exchange,交换操作,第二个可选参数是内存序类型(这是读‐修改‐写操作)
- compare_exchange_weak 和 compare_exchange_strong,两个比较加交换(CAS)的版本,你可以分别指定成功和失败时的内存序,也可以只指定一个,或使用默认的最安全内存序(这是读‐修改‐写操作)
- fetch_add 和 fetch_sub,仅对整数和指针内置对象有效,对目标原子对象执行加或减操作,返回其原始值,第二个可选参数是内存序类型(这是读‐修改‐写操作)
- ++ 和 —(前置和后置),仅对整数和指针内置对象有效,对目标原子对象执行增一或减一,操作使用顺序一致性语义,并注意返回的不是原子对象的引用(这是读‐修改‐写操作)
- += 和 -=,仅对整数和指针内置对象有效,对目标原子对象执行加或减操作,返回操作之后的数值,操作使用顺序一致性语义,并注意返回的不是原子对象的引用(这是读‐修改‐写操作)
20.7 is_lock_free 的可能问题
注意,macOS 上在使用 Clang 时似乎不支持对需要加锁的对象使用 is_lock_free 成员函数,此时链接会出错。而 GCC 在这种情况下,需要确保系统上装了 libatomic。以 CentOS 7 下的 GCC 7 为例,我们可以使用下面的语句来安装:
sudo yum install devtoolset-7-libatomic-devel然后,用下面的语句编译可以通过:
g++ -pthread test.cpp -latomicWindows 下使用 MSVC 则没有问题。
20.8 mutex
补充两点:
- 互斥量的加锁操作(lock)具有获得语义
- 互斥量的解锁操作(unlock)具有释放语义
实现一个真正安全的双重检查锁定了:
// 头文件
class singleton {
public:
static singleton* instance();
private:
static mutex lock_;
static atomic<singleton*> inst_ptr_;
};
// 实现文件
mutex singleton::lock_;
atomic<singleton*> singleton::inst_ptr_;
singleton* singleton::instance()
{
singleton* ptr = inst_ptr_.load(memory_order_acquire);
if (ptr == nullptr) {
lock_guard<mutex> guard { lock_ };
ptr = inst_ptr_.load(memory_order_relaxed);
if (ptr == nullptr) {
ptr = new singleton();
inst_ptr_.store(ptr, memory_order_release);
}
}
return inst_ptr_;
}
有个小地方注意一下:为了和 inst_ptr_.load 语句对称,我在 inst_ptr_.store 时使用了释放语义;不过,由于互斥量解锁本身具有释放语义,这么做并不是必需的。
20.9 并发队列的接口
并发安全的接口大概长下面这个样子:
template <typename T>
class queue {
public:
void wait_and_pop(T& dest);
bool try_pop(T& dest);
//…
}换句话说,要准备好位置去接收;然后如果接收成功了,才安安静静地在自己的线程里处理已经被弹出队列的对象。接收方式还得分两种,阻塞式的和非阻塞式的……
并发队列的实现,经常是用原子量来达到无锁和高性能的。单生产者、单消费者的并发队列,用原子量和获得、释放语义就能简单实现。对于多生产者或多消费者的情况,那实现就比较复杂了,一般会使用 compare_exchange_strong 或 compare_exchange_weak。讨论这个话题的复杂性,就大大超出了本专栏的范围了。你如果感兴趣的话,可以查看下面几项内容:
- nvwa::fc_queue [7] 给出了一个单生产者、单消费者的无锁并发定长环形队列,代码长度是几百行的量级。
- moodycamel::ConcurrentQueue [8] 给出了一个多生产者、多消费者的无锁通用并发队列,代码长度是几千行的量级。
- 陈皓给出了一篇很棒的对无锁队列的中文描述 [9],推荐阅读。
20.10 参考资料
[1] Wikipedia, “Memory ordering”. https://en.wikipedia.org/wiki/Memory_ordering
[2] Jeff Preshing, “Memory reordering caught in the act”. https://preshing.com/20120515/memory-reordering-caught-in-the-act/
[3] 王欢明, 《多处理器编程:从缓存一致性到内存模型》. https://zhuanlan.zhihu.com/p/35386457
[4] Scott Meyers and Andrei Alexandrescu, “C++ and the perils of double-checked locking”. https://www.aristeia.com/Papers/DDJ_Jul_Aug_2004_revised.pdf
[5] cppreference.com, “Memory model”. https://en.cppreference.com/w/cpp/language/memory_model
[6] cppreference.com, “std::atomic”. https://en.cppreference.com/w/cpp/atomic/atomic
[7] 吴咏炜, nvwa. https://github.com/adah1972/nvwa
[8] Cameron Desrochers, moodycamel::ConcurrentQueue. https://github.com/cameron314/concurrentqueue
[9] 陈皓, 《无锁队列的实现》. https://coolshell.cn/articles/8239.html
03丨实战篇
21 | 工具漫谈:编译、格式化、代码检查、排错各显身手
21.1 编译器
- MSVC
- GCC
- Clang
21.2 格式化工具
- Clang-Format
21.3 代码检查工具
Clang-Tidy
默认情况下,Clang-Tidy 只做基本的分析。你也可以告诉它你想现代化你的代码和提高代码的可读性:
clang-tidy --checks='clang-analyzer-*,modernize-*,readability-*' test.cpp以下面简单程序为例:
#include <iostream> #include <stddef.h> using namespace std; int sqr(int x) { return x * x; } int main() { int a[5] = { 1, 2, 3, 4, 5 }; int b[5]; for (int i = 0; i < 5; ++i) { b[i] = sqr(a[i]); } for (int i : b) { cout << i << endl; } char* ptr = NULL; *ptr = '\0'; }Clang-Tidy 会报告下列问题:
<stddef.h>应当替换成<cstddef>- 函数形式 int func(…) 应当修改成 auto func(…) -> int
- 不要使用 C 数组,应当改成 std::array
- 5 是魔术数,应当改成具名常数
NULL 应当改成 nullptr
前两条我不想听。这种情况下,使用配置文件来定制行为就必要了。配置文件叫 .clangtidy,应当放在你的代码目录下或者代码的一个父目录下。Clang-Tidy 会使用最”近”的那个配置文件。下面的配置文件反映了我的偏好:
Checks: 'clang-diagnostic-*,clang-analyzer-*,modernize-*,readability-*,-moderni使用 Clang-Tidy 还需要注意的地方是,额外的命令行参数应当跟在命令行最后的 — 后面。比如,如果我们要扫描一个 C++ 头文件 foo.h,我们就需要明确告诉 Clang-Tidy 这是 C++ 文件(默认 .h 是 C 文件)。然后,如果我们需要包含父目录下的 common 目录,语言标准使用了 C++17,命令行就应该是下面这个样子:
clang-tidy foo.h -- -x c++ -std=c++17 -I../common
- Cppcheck
21.4 排错工具
- Valgrind
nvwa::debug_new
在 nvwa [21] 项目里,我也包含了一个很小的内存泄漏检查工具。它的最大优点是小巧,并且对程序运行性能影响极小;缺点主要是不及 Valgrind 易用和强大,只能检查 new 导致的内存泄漏,并需要侵入式地对项目做修改。
需要检测内存泄漏时,你需要把 debug_new.cpp 加入到项目里。比如,可以简单地在命令行上加入这个文件:
c++ test.cpp ../nvwa/nvwa/debug_new.cpp下面是可能的运行时报错:
Leaked object at 0x100302760 (size 20, 0x1000018a4) *** 1 leaks found在使用 GCC 和 Clang 时,可以让它自动帮你找出内存泄漏点的位置。在命令行上需要加入可执行文件的名称,并产生调试信息:
c++ -D_DEBUG_NEW_PROGNAME=\"a.out\" -g test.cpp ../nvwa/nvwa/debug_new.cpp这样,我们就可以在运行时看到一个更明确的错误:
Leaked object at 0x100302760 (size 20, main (in a.out) (test.cpp:3)) *** 1 leaks found
21.5 网页工具
Compiler Explorer
这个网站,你不仅可以快速查看你的代码在不同编译器里的优化结果,还能快速分享结果。比如,下面这个链接,就可以展示我们之前讲过的一个模板元编程代码的编译结果: https://godbolt.org/z/zPNEJ4
C++ Insights
如果你在上面的链接里点击了”CppInsights”按钮的话,你就会跳转到 C++ Insights [24] 网站,并且你贴在 godbolt.org 的代码也会一起被带过去。这个网站提供了另外一个编译器目前没有提供、但十分有用的功能:展示模板的展开过程。
21.6 参考资料
- Visual Studio. https://visualstudio.microsoft.com/
- GCC, the GNU Compiler Collection. https://gcc.gnu.org/
- Clang: a C language family frontend for LLVM. https://clang.llvm.org/
- Jim Springfield, “Rejuvenating the Microsoft C/C++ compiler”. https://devblogs.microsoft.com/cppblog/rejuvenating-the-microsoft-cccompiler/
- Casey Carter, “Use the official range-v3 with MSVC 2017 version 15.9”. https://devblogs.microsoft.com/cppblog/use-the-official-range-v3-with-msvc-2017-version-15-9/
- cppreference.com, “std::regex”. https://en.cppreference.com/w/cpp/regex/basic_regex
- Microsoft, “Concurrency Runtime”. https://docs.microsoft.com/enus/cpp/parallel/concrt/concurrency-runtime
- ISO/IEC JTC1 SC22 WG21, “Programming languages—C++extensions for coroutines”. http://www.openstd.org/jtc1/sc22/wg21/docs/papers/2017/n4680.pdf
- Ulzii Luvsanbat, “Announcing: MSVC conforms to the C++ standard”. https://devblogs.microsoft.com/cppblog/announcing-msvc-conforms-to-the-cstandard/
- Jonathan Adamczewski, “The growth of modern C++ support”. http://brnz.org/hbr/?p=1404
- Vim Online. https://www.vim.org/
- Xavier Deguillard, clang_complete. https://github.com/xavierd/clang_complete
- “libc++” C++ Standard Library . https://libcxx.llvm.org/
- cppreference.com, “C++ compiler support”. https://en.cppreference.com/w/cpp/compiler_support
- Homebrew. https://brew.sh/
- 吴咏炜, “MSVCRT.DLL console I/O bug”. https://yongweiwu.wordpress.com/2016/05/27/msvcrt-dll-console-io-bug/
- ClangFormat. https://clang.llvm.org/docs/ClangFormat.html
- Clang-Tidy. https://clang.llvm.org/extra/clang-tidy/
- Daniel Marjamäki, Cppcheck. https://github.com/danmar/cppcheck
- Valgrind Home. https://valgrind.org/
- 吴咏炜, nvwa. https://github.com/adah1972/nvwa/
- Matt Godbolt, “Compiler Explorer”. https://godbolt.org/
- Matt Godbolt, compiler-explorer. https://github.com/mattgodbolt/compilerexplorer
- Andreas Fertig, “C++ Insights”. https://cppinsights.io/
22 | 处理数据类型变化和错误:optional、variant、expected 和Herbception
22.1 optional
在面向对象(引用语义)的语言里,我们有时候会使用空值 null 表示没有找到需要的对象。也有人推荐使用一个特殊的空对象,来避免空值带来的一些问题 [1]。可不管是空值,还是空对象,对于一个返回普通对象(值语义)的 C++ 函数都是不适用的——空值和空对象只能用在返回引用 / 指针的场合,一般情况下需要堆内存分配,在 C++ 里会引额外的开销。
C++17 引入的 optional 模板 [2] 可以(部分)解决这个问题。语义上来说,optional 代表一个”也许有效””可选”的对象。语法上来说,一个 optional 对象有点像一个指针,但它所管理的对象是直接放在 optional 里的,没有额外的内存分配。
构造一个 optional<T> 对象有以下几种方法:
- 不传递任何参数,或者使用特殊参数 std::nullopt(可以和 nullptr 类比),可以构造一个”空”的 optional 对象,里面不包含有效值。
- 第一个参数是 std::in_place,后面跟构造 T 所需的参数,可以在 optional 对象上直接构造出 T 的有效值。
- 如果 T 类型支持拷贝构造或者移动构造的话,那在构造
optional<T>时也可以传递一个 T 的左值或右值来将 T 对象拷贝或移动到 optional 中。
对于上面的第 1 种情况,optional 对象里是没有值的,在布尔值上下文里,会得到 false(类似于空指针的行为)。对于上面的第 2、3 两种情况,optional 对象里是有值的,在布尔值上下文里,会得到 true(类似于有效指针的行为)。类似的,在 optional 对象有值的情况下,你可以用 * 和 -> 运算符去解引用(没值的情况下,结果是未定义行为)。
虽然 optional 是 C++17 才标准化的,但实际上这个用法更早就通行了。因为 optional 的实现不算复杂,有些库里就自己实现了一个版本。比如 cpptoml [3] 就给出 了下面这样的示例(进行了翻译和重排版),用法跟标准的 optional 完全吻合。
cpptoml 里只是个缩微版的 optional,实现只有几十行,也不支持我们上面说的所有构造方式。标准库的 optional 为了方便程序员使用,除了我目前描述的功能,还支持下面的操作:
- 安全的析构行为
- 显式的 has_value 成员函数,判断 optional 是否有值
- value 成员函数,行为类似于
*,但在 optional 对象无值时会抛出异常 - std::bad_optional_access
- value_or 成员函数,在 optional 对象无值时返回传入的参数
- swap 成员函数,和另外一个 optional 对象进行交换
- reset 成员函数,清除 optional 对象包含的值
- emplace 成员函数,在 optional 对象上构造一个新的值(不管成功与否,原值会被丢弃)
- make_optional 全局函数,产生一个 optional 对象(类似 make_pair、
- make_unique 等)
- 全局比较操作
- 等等
如果我们认为无值就是数据无效,应当跳过剩下的处理,我们可以写出下面这样的高阶函数:
template <typename T>
constexpr bool has_value(const optional<T>& x) noexcept
{
return x.has_value();
}
template <typename T, typename... Args>
constexpr bool has_value(const optional<T>& first, const optional<Args>&... other) noexcept
{
return first.has_value() && has_value(other...);
}
template <typename F>
auto lift_optional(F&& f)
{
return [f = forward<F>(f)](auto&&... args) {
typedef decay_t<decltype(f(forward<decltype(args)>(args).value()...))> result_type;
if (has_value(args...)) {
return optional<result_type>(f(forward<decltype(args)>(args).value()...));
} else {
return optional<result_type>();
}
};
}has_value 比较简单,它可以有一个或多个 optional 参数,并在所有参数都有值时返回真,否则返回假。lift_optional 稍复杂些,它接受一个函数,返回另外一个函数。在返回的函数里,参数是一个或多个 optional 类型,result_type 是用参数的值(value())去调用原先函数时的返回值类型,最后返回的则是 result_type 的 optional 封装。函数内部会检查所有的参数是否都有值(通过调用 has_value):有值时会去拿参数的值去调用原先的函数,否则返回一个空的 optional 对象。
这个函数能把一个原本要求参数全部有效的函数抬升(lift)成一个接受和返回 optional 参数的函数,并且,只在参数全部有效时去调用原来的函数。这是一种非常函数式的编程方式。使用上面函数的示例代码如下:
#include <functional>
#include <optional>
#include <type_traits>
#include <utility>
using namespace std;
// 需包含 lift_optional 的定义
constexpr int increase(int n)
{
return n + 1;
}
// 标准库没有提供 optional 的输出
ostream& operator<<(ostream& os, optional<int>(x))
{
if (x) {
os << '(' << *x << ')';
} else {
os << "(Nothing)";
}
return os;
}
int main()
{
auto inc_opt = lift_optional(increase);
auto plus_opt = lift_optional(plus<int>());
cout << inc_opt(optional<int>()) << endl;
cout << inc_opt(make_optional(41)) << endl;
cout << plus_opt(make_optional(41), optional<int>()) << endl;
cout << plus_opt(make_optional(41), make_optional(1)) << endl;
}输出结果是:
(Nothing)
(42)
(Nothing)
(42)22.2 variant
optional 是一个非常简单而又好用的模板,很多情况下,使用它就足够解决问题了。在某种意义上,可以把它看作是允许有两种数值的对象:要么是你想放进去的对象,要么是 nullopt(再次提醒,联想 nullptr)。如果我们希望除了我们想放进去的对象,还可以是 nullopt 之外的对象怎么办呢(比如,某种出错的状态)?又比如,如果我希望有三种或更多不同的类型呢?这种情况下,variant [4] 可能就是一个合适的解决方案。
在没有 variant 类型之前,你要达到类似的目的,恐怕会使用一种叫做带标签的联合(tagged union)的数据结构。比如,下面就是一个可能的数据结构定义:
struct FloatIntChar {
enum {
Float,
Int,
Char
} type;
union {
float float_value;
int int_value;
char char_value;
};
};这个数据结构的最大问题,就是它实际上有很多复杂情况需要特殊处理。对于我们上面例子里的 POD 类型,这么写就可以了(但我们仍需小心保证我们设置的 type 和实际使用的类型一致)。如果我们把其中一个类型换成非 POD 类型,就会有复杂问题出现。比如,下面的代码是不能工作的:
struct StringIntChar {
enum { String,
Int,
Char
} type;
union {
string string_value;
int int_value;
char char_value;
};
};编译器会很合理地看到在 union 里使用 string 类型会带来构造和析构上的问题,所以会拒绝工作。要让这个代码工作,我们得手工加上析构函数,并且,在析构函数里得小心地判断存储的是什么数值,来决定是否应该析构(否则,默认不调用任何 union 里的析构函数,从而可能导致资源泄漏):
~StringIntChar()
{
if (type == String) {
string_value.~string();
}
}这样,我们才能安全地使用它(还是很麻烦):
StringIntChar obj {
.type = StringIntChar::String,
.string_value = "Hello world"
};
cout << obj.string_value << endl;这里用到了按成员初始化的语法,把类型设置成了字符串,同时设置了字符串的值。不用说,这是件麻烦、容易出错的事情。同时,细查之后我发现,这个语法虽然在 C99 里有,但在 C++ 里要在 C++20 才会被标准化,因此实际是有兼容性问题的——老版本的 MSVC,或最新版本的 MSVC 在没有开启 C++20 支持时,就不支持这个语法。
所以,目前的主流建议是,应该避免使用”裸” union 了。替换方式,就是这一节要说的 variant。上面的例子,如果用 variant 的话,会非常的干净利落:
variant<string, int, char> obj {"Hello world"};
cout << get<string>(obj) << endl;可以注意到我上面构造时使用的是 const char,但构造函数仍然能够正确地选择 string 类型,这是因为标准要求实现在没有一个完全匹配的类型的情况下,会选择成员类型中能够以传入的类型来构造的那个类型进行初始化(有且只有一个时)。string 类存在形式为 string(const char) 的构造函数(不精确地说),所以上面的构造能够正确进行。
跟 tuple 相似,variant 上可以使用 get 函数模板,其模板参数可以是代表序号的数字,也可以是类型。如果编译时可以确定序号或类型不合法,我们在编译时就会出错。如果序号或类型合法,但运行时发现 variant 里存储的并不是该类对象,我们则会得到一个异常 bad_variant_access。
variant 上还有一个重要的成员函数是 index,通过它我们能获得当前的数值的序号。就我们上面的例子而言,obj.index() 即为 1。正常情况下,variant 里总有一个有效的数值(缺省为第一个类型的默认构造结果),但如果 emplace 等修改操作中发生了异常, variant 里也可能没有任何有效数值,此时 index() 将会得到 variant_npos。
从基本概念来讲,variant 就是一个安全的 union,相当简单,我就不多做其他介绍了。你可以自己看文档来了解进一步的信息。其中比较有趣的一个非成员函数是 visit [5],文档里展示了一个非常简洁的、可根据当前包含的变量类型进行函数分发的方法。
平台细节:在老于 Mojave 的 macOS 上编译含有 optional 或 variant 的代码,需要在文件开头加上:
#if defined(__clang__) && defined(__APPLE__)
#include <__config>
#undef _LIBCPP_AVAILABILITY_BAD_OPTIONAL_ACCESS
#undef _LIBCPP_AVAILABILITY_BAD_VARIANT_ACCESS
#define _LIBCPP_AVAILABILITY_BAD_OPTIONAL_ACCESS
#define _LIBCPP_AVAILABILITY_BAD_VARIANT_ACCESS
#endif原因是苹果在头文件里把 optional 和 variant 在早期版本的 macOS 上禁掉了,而上面的代码去掉了这几个宏里对使用 bad_optional_access 和 bad_variant_access 的平台限制。
22.3 expected
和前面介绍的两个模板不同,expected 不是 C++ 标准里的类型。但概念上这三者有相关性,因此我们也放在一起讲一下。
我前面已经提到,optional 可以作为一种代替异常的方式:在原本该抛异常的地方,我们可以改而返回一个空的 optional 对象。当然,此时我们就只知道没有返回一个合法的对象,而不知道为什么没有返回合法对象了。我们可以考虑改用一个 variant,但我们此时需要给错误类型一个独特的类型才行,因为这是 variant 模板的要求。比如:
enum class error_code {
success,
operation_failure,
object_not_found,
//…
};
variant<Obj, error_code> get_object(…);这当然是一种可行的错误处理方式:我们可以判断返回值的 index(),来决定是否发生了错误。但这种方式不那么直截了当,也要求实现对允许的错误类型作出规定。Andrei Alexandrescu 在 2012 年首先提出的 Expected 模板 [6],提供了另外一种错误处理方式。他的方法的要点在于,把完整的异常信息放在返回值,并在必要的时候,可以”重放”出来,或者手工检查是不是某种类型的异常。
他的概念并没有被广泛推广,最主要的原因可能是性能。异常最被人诟病的地方是性能,而他的方式对性能完全没有帮助。不过,后面的类似模板都汲取了他的部分思想,至少会用一种显式的方式来明确说明当前是异常情况还是正常情况。在目前的 expected 的标准提案[7] 里,用法有点是 optional 和 variant 的某种混合:模板的声明形式像 variant,使用正常返回值像 optional。
下面的代码展示了一个 expected 实现 [8] 的基本用法。
#include <cstdint>
#include <iostream>
#include <string>
#include <tl/expected.hpp>
using namespace std;
using tl::expected;
using tl::unexpected;
// 返回 expected 的安全除法
expected<int, string> safe_divide(int i, int j)
{
if (j == 0)
return unexpected("divide by zero"s);
if (i == INT_MIN && j == -1)
return unexpected("integer divide overflows"s);
if (i % j != 0)
return unexpected("not integer division"s);
else
return i / j;
}
// 一个测试函数
expected<int, string> caller(int i, int j, int k)
{
auto q = safe_divide(j, k);
if (q)
return i + *q;
else
return q;
}
// 支持 expected 的输出函数
template <typename T, typename E>
ostream& operator<<(ostream& os, const expected<T, E>& exp)
{
if (exp) {
os << exp.value();
} else {
os << "unexpected: " << exp.error();
}
return os;
}
// 调试使用的检查宏
#define CHECK(expr) \
{ \
auto result = (expr); \
cout << result; \
if (result == unexpected("divide by zero"s)) { \
cout << ": Are you serious?"; \
} else if (result == 42) { \
cout << ": Ha, I got you!"; \
} \
cout << endl; \
}
int main()
{
CHECK(caller(2, 1, 0));
CHECK(caller(37, 20, 7));
CHECK(caller(39, 21, 7));
}输出是:
unexpected: divide by zero: Are you serious?
unexpected: not integer division
42: Ha, I got you一个 expected<T, E> 差不多可以看作是 T 和 unexpected<E> 的 variant。在学过上面的 variant 之后,我们应该很容易看明白上面的程序了。下面是几个需要注意一下的地方:
- 如果一个函数要正常返回数据,代码无需任何特殊写法;如果它要表示出现了异常,则可以返回一个 unexpected 对象。
- 这个返回值可以用来和一个正常值或 unexpected 对象比较,可以在布尔值上下文里检查是否有正常值,也可以用
*运算符来取得其中的正常值——与 optional 类似,在没有正常值的情况下使用*是未定义行为。 - 可以用 value 成员函数来取得其中的正常值,或使用 error 成员函数来取得其中的错误值——与 variant 类似,在 expected 中没有对应的值时产生异常 bad_expected_access。
- 返回错误跟抛出异常比较相似,但检查是否发生错误的代码还是要比异常处理啰嗦。
22.4 Herbception
上面的用法初看还行,但真正用起来,你会发现仍然没有使用异常方便。这只是为了解决异常在错误处理性能问题上的无奈之举。大部分试图替换 C++ 异常的方法都是牺牲编程方便性,来换取性能。只有 Herb Sutter 提出了一个基本兼容当前 C++ 异常处理方式的错误处理方式 [9],被戏称为 Herbception。
上面使用 expected 的示例代码,如果改用 Herbception 的话,可以大致如下改造(示意,尚无法编译):
int safe_divide(int i, int j) throws
{
if (j == 0)
throw arithmetic_errc::divide_by_zero;
if (i == INT_MIN && j == -1)
throw arithmetic_errc::integer_divide_overflows;
if (i % j != 0)
throw arithmetic_errc::not_integer_division;
else
return i / j;
}
int caller(int i, int j, int k) throws
{
return i + safe_divide(j, k);
}
#define CHECK(expr) \
try { \
int result = (expr); \
cout << result; \
if (result == 42) { \
cout << ": Ha, I got you!"; \
} \
} catch (error e) { \
if (e == arithmetic_errc::divide_by_zero) { \
cout << "Are you serious? "; \
} \
cout << "An error occurred"; \
} \
cout << endl
int main()
{
CHECK(caller(2, 1, 0));
CHECK(caller(37, 20, 7));
CHECK(caller(39, 21, 7));
}我们可以看到,上面的代码和普通使用异常的代码非常相似,区别有以下几点:
- 函数需要使用 throws(注意不是 throw)进行声明。
- 抛出异常的语法和一般异常语法相同,但抛出的是一个 std::error 值 [10]。
- 捕捉异常时不需要使用引用(因为 std::error 是个”小”对象),且使用一般的比较操作来检查异常”类型”,不再使用开销大的 RTTI。
虽然语法上基本是使用异常的样子,但 Herb 的方案却没有异常的不确定开销,性能和使用 expected 相仿。他牺牲了异常类型的丰富,但从实际编程经验来看,越是体现出异常优越性的地方——异常处理点和异常发生点距离较远的时候——越不需要异常有丰富的类型。因此,总体上看,这是一个非常吸引人的方案。不过,由于提案时间较晚,争议颇多,这个方案要进入标准至少要 C++23 了。我们目前稍稍了解一下就行。
22.5 参考资料
- Wikipedia, “Null object pattern”. https://en.wikipedia.org/wiki/Null_object_pattern
- cppreference.com, “std::optional”. https://en.cppreference.com/w/cpp/utility/optional
- Chase Geigle, cpptoml. https://github.com/skystrife/cpptoml
- cppreference.com, “std::optional”. https://en.cppreference.com/w/cpp/utility/variant
- cppreference.com, “std::visit”. https://en.cppreference.com/w/cpp/utility/variant/visit
- Andrei Alexandrescu, “Systematic error handling in C++”. https://channel9.msdn.com/Shows/Going+Deep/C-and-Beyond-2012-Andrei-Alexandrescu-Systematic-Error-Handling-in-C
- Vicente J. Botet Escribá and JF Bastien, “Utility class to represent expected object”. http://www.openstd.org/jtc1/sc22/wg21/docs/papers/2017/p0323r3.pdf
- Simon Brand, expected. https://github.com/TartanLlama/expected
- Herb Sutter, “P0709R0: Zero-overhead deterministic exceptions: Throwingvalues”. http://www.openstd.org/jtc1/sc22/wg21/docs/papers/2018/p0709r0.pdf
- Niall Douglas, “P1028R0: SG14 status_code and standard error object for P0709 Zero-overhead deterministic exceptions”. http://www.openstd.org/jtc1/sc22/wg21/docs/papers/2018/p1028r0.pdf
23 | 数字计算:介绍线性代数和数值计算库
23.1 Armadillo
23.2 Boost.Multiprecision
23.3 参考资料
- Wikipedia, “Basic Linear Algebra Subprograms”. https://en.wikipedia.org/wiki/Basic_Linear_Algebra_Subprograms
- Wikipedia, “LAPACK”. https://en.wikipedia.org/wiki/LAPACK
- Wikipedia, “ARPACK”. https://en.wikipedia.org/wiki/ARPACK
- Zhang Xianyi et al., OpenBLAS. https://github.com/xianyi/OpenBLAS
- Intel, Math Kernel Library. https://software.intel.com/mkl
- Ilya Yaroshenko, mir-glas. https://github.com/libmir/mir-glas
- Conrad Sanderson and Ryan Curtin, “Armadillo: C++ library for linear algebra & scientific computing”. http://arma.sourceforge.net/
- Wikipedia, “Expression templates”. https://en.wikipedia.org/wiki/Expression_templates
- John Maddock, Boost.Multiprecision. https://www.boost.org/doc/libs/release/libs/multiprecision/doc/html/index.html
- The GNU MP bignum library. https://gmplib.org/
- 吴咏炜, “Choosing a multi-precision library for C++—a critique”. https://yongweiwu.wordpress.com/2016/06/04/choosing-a-multi-precisionlibrary-for-c-a-critique/
24 | Boost:你需要的”瑞士军刀”
24.1 Boost 概览
Boost 的网站把 Boost 描述成为经过同行评审的、可移植的 C++ 源码库(peer-reviewed portable C++ source libraries)[1]。换句话说,它跟很多个人开源库不一样的地方在于,它的代码是经过评审的。事实上,Boost 项目的背后有很多 C++ 专家,比如发起人之一的 Dave Abarahams 是 C++ 标准委员会的成员,也是《C++ 模板元编程》一书 [2] 的作者。这也就使得 Boost 有了很不一样的特殊地位:它既是 C++ 标准库的灵感来源之一,也是 C++ 标准库的试验田。下面这些 C++ 标准库就源自 Boost:
- 智能指针
- thread
- regex
- random
- array
- bind
- tuple
- optional
- variant
- any
- string_view
- filesystem
- 等等
当然,将来还会有新的库从 Boost 进入 C++ 标准,如网络库的标准化就是基于 Boost.Asio 进行的。因此,即使相关的功能没有被标准化,我们也可能可以从 Boost 里看到某个功能可能会被标准化的样子——当然,最终标准化之后的样子还是经常有所变化的。
我们也可以在我们的编译器落后于标准、不能提供标准库的某个功能时使用 Boost 里的替代品。比如,我之前提到过老版本的 macOS 上苹果的编译器不支持 optional 和 variant。除了我描述的不正规做法,改用 Boost 也是方法之一。比如,对于 variant,所需的改动只是:
- 把包含
<variant>改成包含<boost/variant.hpp> - 把代码中的 std::variant 改成 boost::variant
这样,就基本大功告成了。
24.2 Boost 的安装
在主要的开发平台上,现在你都可以直接安装 Boost,而不需要自己从源代码编译了:
- 在 Windows 下使用 MSVC,我们可以使用 NuGet 安装(按需逐个安装)
- 在 Linux 下,我们可以使用系统的包管理器(如 apt 和 yum)安装(按需逐个安装,或一次性安装所有的开发需要的包)
- 在 macOS 下,我们可以使用 Homebrew 安装(一次性安装完整的 Boost)
24.3 Boost.TypeIndex
TypeIndex 是一个很轻量级的库,它不需要链接,解决的也是使用模板时的一个常见问题,如何精确地知道一个表达式或变量的类型。我们还是看一个例子:
#include <iostream>
#include <typeinfo>
#include <utility>
#include <vector>
#include <boost/type_index.hpp>
using namespace std;
using boost::typeindex::type_id;
using boost::typeindex::type_id_with_cvr;
int main()
{
vector<int> v;
auto it = v.cbegin();
cout << "*** Using typeid\n";
cout << typeid(const int).name() << endl;
cout << typeid(v).name() << endl;
cout << typeid(it).name() << endl;
cout << "*** Using type_id\n";
cout << type_id<const int>() << endl;
cout << type_id<decltype(v)>() << endl;
cout << type_id<decltype(it)>() << endl;
cout << "*** Using type_id_with_cvr\n";
cout << type_id_with_cvr<const int>() << endl;
cout << type_id_with_cvr<decltype((v))>() << endl;
cout << type_id_with_cvr<decltype(move((v)))>() << endl;
cout << type_id_with_cvr<decltype((it))>() << endl;
}上面的代码里,展示了标准的 typeid 和 Boost 的 type_id 和 type_id_with_cvr 的使用。它们的区别是:
- typeid 是标准 C++ 的关键字,可以应用到变量或类型上,返回一个 std::type_info。我们可以用它的 name 成员函数把结果转换成一个字符串,但标准不保证这个字符串的可读性和唯一性。
- type_id 是 Boost 提供的函数模板,必须提供类型作为模板参数——所以对于表达式和变量我们需要使用 decltype。结果可以直接输出到 IO 流上。
- type_id_with_cvr 和 type_id 相似,但它获得的结果会包含 const/volatile 状态及引用类型。
上面程序在 MSVC 下的输出为:
*** Using typeid
int
class std::vector<int,class std::allocator<int> >
class std::_Vector_const_iterator<class std::_Vector_val<struct
std::_Simple_types<int> > >
*** Using type_id
int
class std::vector<int,class std::allocator<int> >
class std::_Vector_const_iterator<class std::_Vector_val<struct
std::_Simple_types<int> > >
*** Using type_id_with_cvr
int const
class std::vector<int,class std::allocator<int> > &
class std::vector<int,class std::allocator<int> > &&
class std::_Vector_const_iterator<class std::_Vector_val<struct
std::_Simple_types<int> > > &在 GCC 下的输出为:
*** Using typeid
i
St6vectorIiSaIiEE
N9__gnu_cxx17__normal_iteratorIPKiSt6vectorIiSaIiEEEE
*** Using type_id
int
std::vector<int, std::allocator<int> >
__gnu_cxx::__normal_iterator<int const*, std::vector<int,
std::allocator<int> > >
*** Using type_id_with_cvr
int const
std::vector<int, std::allocator<int> >&
std::vector<int, std::allocator<int> >&&
__gnu_cxx::__normal_iterator<int const*, std::vector<int,
std::allocator<int> > >&我们可以看到 MSVC 下 typeid 直接输出了比较友好的类型名称,但 GCC 下没有。此外,我们可以注意到:
- typeid 的输出忽略了 const 修饰,也不能输出变量的引用类型。
- type_id 保证可以输出友好的类型名称,输出时也不需要调用成员函数,但例子里它忽略了 int 的 const 修饰,也和 typeid 一样不能输出表达式的引用类型。
- type_id_with_cvr 可以输出 const/volatile 状态和引用类型,注意这种情况下模板参数必须包含引用类型,所以我用了 decltype((v)) 这种写法,而不是 decltype(v)。如果你忘了这两者的区别,请复习一下 [第 8 讲] 的 decltype。
显然,除非你正在使用 MSVC,否则调试期 typeid 的用法完全应该用 Boost 的 type_id 来替代。另外,如果你的开发环境要求禁用 RTTI(运行时类型识别),那 typeid 在 Clang 和 GCC 下根本不能使用,而使用 Boost.TypeIndex 库仍然没有问题。
当然,上面说的前提都是你在调试中试图获得变量的类型,而不是要获得一个多态对象的运行时类型。后者还是离不开 RTTI 的——虽然你也可以用一些其他方式来模拟 RTTI,但我个人觉得一般的项目不太有必要这样做。下面的代码展示了 typeid 和 type_id 在获取对象类型上的差异:
#include <iostream>
#include <typeinfo>
#include <boost/type_index.hpp>
using namespace std;
using boost::typeindex::type_id;
class shape {
public:
virtual ~shape() { }
};
class circle : public shape {
};
#define CHECK_TYPEID(object, type) \
cout << "typeid(" #object << ")" \
<< (typeid(object) == typeid(type) \
? " is " \
: " is NOT ") \
<< #type << endl
#define CHECK_TYPE_ID(object, \
type) \
cout << "type_id(" #object \
<< ")" \
<< (type_id<decltype( \
object)>() \
== type_id<type>() \
? " is " \
: " is NOT ") \
<< #type << endl
int main()
{
shape* ptr = new circle();
CHECK_TYPEID(*ptr, shape);
CHECK_TYPEID(*ptr, circle);
CHECK_TYPE_ID(*ptr, shape);
CHECK_TYPE_ID(*ptr, circle);
delete ptr;
}输出为:
typeid(*ptr) is NOT shape
typeid(*ptr) is circle
type_id(*ptr) is shape
type_id(*ptr) is NOT circle24.4 Boost.Core
Core 里面提供了一些通用的工具,这些工具常常被 Boost 的其他库用到,而我们也可以使用,不需要链接任何库。在这些工具里,有些已经(可能经过一些变化后)进入了 C++ 标准,如:
- addressof,在即使用户定义了 operator& 时也能获得对象的地址
- enable_if,这个我们已经深入讨论过了([第 14 讲])
- is_same,判断两个类型是否相同,C++11 开始在
<type_traits>中定义 - ref,和标准库的相同,我们在 [第 19 讲] 讨论线程时用过
我们在剩下的里面来挑几个讲讲。
boost::core::demangle
boost::core::demangle 能够用来把 typeid 返回的内部名称”反粉碎”(demangle)成可读的形式,看代码和输出应该就非常清楚了:
#include <iostream> #include <typeinfo> #include <utility> #include <vector> #include <boost/core/demangle.hpp> using namespace std; using boost::core::demangle; int main() { vector<int> v; auto it = v.cbegin(); cout << "*** Using typeid\n"; cout << typeid(const int).name() << endl; cout << typeid(v).name() << endl; cout << typeid(it).name() << endl; cout << "*** Demangled\n"; cout << demangle(typeid(const int).name()) << endl; cout << demangle(typeid(v).name()) << endl; cout << demangle(typeid(it).name()) << endl; }GCC 下的输出为:
*** Using typeid i St6vectorIiSaIiEE N9__gnu_cxx17__normal_iteratorIPKiSt6vectorIiSaIiEEEE *** Demangled int std::vector<int, std::allocator<int> > __gnu_cxx::__normal_iterator<int const*, std::vector<int, std::allocator<int> > >如果你不使用 RTTI 的话,那直接使用 TypeIndex 应该就可以。如果你需要使用 RTTI、又不是(只)使用 MSVC 的话,demangle 就会给你不少帮助。
boost::noncopyable
boost::noncopyable 提供了一种非常简单也很直白的把类声明成不可拷贝的方式。比如,我们 [第 1 讲] 里的 shape_wrapper,用下面的写法就明确表示了它不允许被拷贝:
#include <boost/core/noncopyable.hpp> class shape_wrapper : private boost::noncopyable { //… };你当然也可以自己把拷贝构造和拷贝赋值函数声明成 = delete,不过,上面的写法是不是可读性更佳?
boost::swap
你有没有印象在通用的代码如何对一个不知道类型的对象执行交换操作?不记得的话,标准做法是这样的:
{ using std::swap; swap(lhs, rhs); }即,我们需要(在某个小作用域里)引入 std::swap,然后让编译器在”看得到” std::swap 的情况下去编译 swap 指令。根据 ADL,如果在被交换的对象所属类型的名空间下有 swap 函数,那个函数会被优先使用,否则,编译器会选择通用的 std::swap。似乎有点小啰嗦。使用 Boost 的话,你可以一行搞定:
boost::swap(lhs, rhs);当然,你需要包含头文件
<boost/core/swap.hpp>。
24.5 Boost.Conversion
Conversion 同样是一个不需要链接的轻量级的库。它解决了标准 C++ 里的另一个问题,标准类型之间的转换不够方便。在 C++11 之前,这个问题尤为严重。在 C++11 里,标准引入了一系列的函数,已经可以满足常用类型之间的转换。但使用 Boost.Conversion 里的 lexical_cast 更不需要去查阅方法名称或动脑子去努力记忆。
下面是一个例子:
#include <iostream>
#include <stdexcept>
#include <string>
#include <boost/lexical_cast.hpp>
using namespace std;
using boost::bad_lexical_cast;
using boost::lexical_cast;
int main()
{
// 整数到字符串的转换
int d = 42;
auto d_str = lexical_cast<string>(d);
cout << d_str << endl;
// 字符串到浮点数的转换
auto f = lexical_cast<float>(d_str) / 4.0;
cout << f << endl;
// 测试 lexical_cast 的转换异常
try {
int t = lexical_cast<int>("x");
cout << t << endl;
} catch (bad_lexical_cast& e) {
cout << e.what() << endl;
}
// 测试标准库 stoi 的转换异常
try {
int t = std::stoi("x");
cout << t << endl;
} catch (invalid_argument& e) {
cout << e.what() << endl;
}
}GCC 下的输出为:
42
10.5
bad lexical cast: source type value could not be interpreted as
target
stoi我觉得 GCC 里 stoi 的异常输出有点太言简意赅了……而 lexical_cast 的异常输出在不同的平台上有很好的一致性。
24.6 Boost.ScopeExit
我们说过 RAII 是推荐的 C++ 里管理资源的方式。不过,作为 C++ 程序员,跟 C 函数打交道也很正常。每次都写个新的 RAII 封装也有点浪费。Boost 里提供了一个简单的封装,你可以从下面的示例代码里看到它是如何使用的:
#include <stdio.h>
#include <boost/scope_exit.hpp>
void test()
{
FILE* fp = fopen("test.cpp", "r");
if (fp == NULL) {
perror("Cannot open file");
}
BOOST_SCOPE_EXIT(&fp)
{
if (fp) {
fclose(fp);
puts("File is closed");
}
}
BOOST_SCOPE_EXIT_END
puts("Faking an exception");
throw 42;
}
int main()
{
try {
test();
} catch (int) {
puts("Exception received");
}
}唯一需要说明的可能就是 BOOST_SCOPE_EXIT 里的那个 & 符号了——把它理解成 lambda 表达式的按引用捕获就对了(虽然 BOOST_SCOPE_EXIT 可以支持 C++98 的代码)。如果不需要捕获任何变量,BOOST_SCOPE_EXIT 的参数必须填为 void。
使用这个库也只需要头文件。注意实现类似的功能在 C++11 里相当容易,但由于 ScopeExit 可以支持 C++98 的代码,因而它的实现还是相当复杂的。
24.6 Boost.Program_options
传统上 C 代码里处理命令行参数会使用 getopt。我也用过,比如在下面的代码中:
https://github.com/adah1972/breaktext/blob/master/breaktext.c
这种方式有不少缺陷:
- 一个选项通常要在三个地方重复:说明文本里,getopt 的参数里,以及对 getopt 的返回结果进行处理时。不知道你觉得怎样,我反正发生过改了一处、漏改其他的错误。
- 对选项的附加参数需要手工写代码处理,因而常常不够严格(C 的类型转换不够方便,尤其是检查错误)。
Program_options 正是解决这个问题的。这个代码有点老了,不过还挺实用;懒得去找特别的处理库时,至少这个伸手可用。使用这个库需要链接 boost_program_options 库。
下面的代码展示了代替上面的 getopt 用法的代码:
#include <iostream>
#include <string>
#include <stdlib.h>
#include <boost/program_options.hpp>
namespace po = boost::program_options;
using std::cout;
using std::endl;
using std::string;
string locale;
string lang;
int width = 72;
bool keep_indent = false;
bool verbose = false;
int main(int argc, char* argv[])
{
po::options_description desc(
"Usage: breaktext [OPTION]... "
"<Input File> [Output File]\n"
"\n"
"Available options");
desc.add_options()(
"locale,L",
po::value<string>(&locale),
"Locale of the console (system locale by default)")(
"lang,l",
po::value<string>(&lang),
"Language of input (asssume no language by default)")(
"width,w",
po::value<int>(&width),
"Width of output text (72 by default)")("help,h", "Show this help message and exit")(
",i",
po::bool_switch(&keep_indent),
"Keep space indentation")(
",v",
po::bool_switch(&verbose),
"Be verbose");
po::variables_map vm;
try {
po::store(po::parse_command_line(argc, argv, desc), vm);
} catch (po::error& e) {
cout << e.what() << endl;
exit(1);
}
vm.notify();
if (vm.count("help")) {
cout << desc << "\n";
exit(1);
}
}略加说明一下:
- options_description 是基本的选项描述对象的类型,构造时我们给出对选项的基本描述。
- options_description 对象的 add_options 成员函数会返回一个函数对象,然后我们直接用括号就可以添加一系列的选项。
- 每个选项初始化时可以有两个或三个参数,第一项是选项的形式,使用长短选项用逗号隔开的字符串(可以只提供一种),最后一项是选项的文字描述,中间如果还有一项的话,就是选项的值描述。
- 选项的值描述可以用 value、bool_switch 等方法,参数是输出变量的指针。
- variables_map,变量映射表,用来存储对命令行的扫描结果;它继承了标准的 std::map。
- notify 成员函数用来把变量映射表的内容实际传送到选项值描述里提供的那些变量里去。
- count 成员函数继承自 std::map,只能得到 0 或 1 的结果。
24.7 Boost.Hana
Boost 里自然也有模板元编程相关的东西。但我不打算介绍 MPL、Fusion 和 Phoenix 那些,因为有些技巧,在 C++11 和 Lambda 表达式到来之后,已经略显得有点过时了。 Hana 则不同,它是一个使用了 C++11/14 实现技巧和惯用法的新库,也和一般的模板库一样,只要有头文件就能使用。
Hana 里定义了一整套供编译期使用的数据类型和函数。我们现在看一下它提供的部分类型:
- type:把类型转化成对象(我们在 [第 13 讲] 曾经示例过相反的动作,把数值转化成对象),来方便后续处理。
- integral_constant:跟 std::integral_constant 相似,但定义了更多的运算符和语法糖。特别的,你可以用字面量来生成一个 long long 类型的
integral_constant,如 1_c。 - string:一个编译期使用的字符串类型。
- tuple:跟 std::tuple 类似,意图是当作编译期的 vector 来使用。
- map:编译期使用的关联数组。
- set:编译期使用的集合。
Hana 里的算法的名称跟标准库的类似,我就不一一列举了。下面的例子展示了一个基本用法:
#include <boost/hana.hpp>
namespace hana = boost::hana;
class shape {
};
class circle {
};
class triangle {
};
int main()
{
using namespace hana::literals;
constexpr auto tup = hana::make_tuple(
hana::type_c<shape*>,
hana::type_c<circle>,
hana::type_c<triangle>);
constexpr auto no_pointers = hana::remove_if(
tup, [](auto a) {
return hana::traits::is_pointer(a);
});
static_assert(
no_pointers == hana::make_tuple(hana::type_c<circle>, hana::type_c<triangle>));
static_assert(
hana::reverse(no_pointers) == hana::make_tuple(hana::type_c<triangle>, hana::type_c<circle>));
static_assert(
tup[1_c] == hana::type_c<circle>);
}这个程序可以编译,但没有任何运行输出。在这个程序里,我们做了下面这几件事:
- 使用 type_c 把类型转化成 type 对象,并构造了类型对象的 tuple
- 使用 remove_if 算法移除了 tup 中的指针类型
- 使用静态断言确认了结果是我们想要的
- 使用静态断言确认了可以用 reverse 把 tup 反转一下
- 使用静态断言确认了可以用方括号运算符来获取 tup 中的某一项
可以看到,Hana 本质上以类似普通的运行期编程的写法,来做编译期的计算。上面展示的只是一些最基本的用法,而 Hana 的文档里展示了很多有趣的用法。尤其值得一看的是,文档中展示了如何利用 Hana 提供的机制,来自己定义 switch_、case_、default_,使得下面的代码可以通过编译:
boost::any a = 'x';
std::string r = switch_(a)(
case_<int>([](auto i) {
return "int: "s + std::to_string(i);
}),
case_<char>([](auto c) {
return "char: "s + std::string { c };
}),
default_([] { return "unknown"s; }));
assert(r == "char: x"s);我个人认为很有意思。
24.8 参考资料
- Boost C++ Libraries. https://www.boost.org/
- David Abarahams and Aleksey Gurtovoy, C++ Template Metaprogramming. Addison-Wesley, 2004. 有中文版(荣耀译,机械工业出版社,2010 年)
25 | 两个单元测试库:C++里如何进行单元测试?
25.1 Boost.Test
#define BOOST_TEST_MAIN
#include <boost/test/unit_test.hpp>
#include <stdexcept>
void test(int n)
{
if (n == 42) {
return;
}
throw std::runtime_error("Not the answer");
}
BOOST_AUTO_TEST_CASE(my_test)
{
BOOST_TEST_MESSAGE("Testing");
BOOST_TEST(1 + 1 == 2);
BOOST_CHECK_THROW(test(41), std::runtime_error);
BOOST_CHECK_NO_THROW(test(42));
int expected = 5;
BOOST_TEST(2 + 2 == expected);
BOOST_CHECK(2 + 2 == expected);
}
BOOST_AUTO_TEST_CASE(null_test)
{
}从代码里可以看到:
- 我们在包含单元测试的头文件之前定义了 BOOST_TEST_MAIN。如果编译时用到了多个源文件,只有一个应该定义该宏。多文件测试的时候,我一般会考虑把这个定义这个宏加包含放在一个单独的文件里(只有两行)。
- 我们用 BOOST_AUTO_TEST_CASE 来定义一个测试用例。一个测试用例里应当有多个测试语句(如 BOOST_CHECK)。
- 我们用 BOOST_CHECK 或 BOOST_TEST 来检查一个应当成立的布尔表达式(区别下面会讲)。
- 我们用 BOOST_CHECK_THROW 来检查一个应当抛出异常的语句。
- 我们用 BOOST_CHECK_NO_THROW 来检查一个不应当抛出异常的语句。
可以用下面的命令行来进行编译:
- MSVC:
cl /DBOOST_TEST_DYN_LINK /EHsc /MD test.cpp - GCC:
g++ -DBOOST_TEST_DYN_LINK test.cpp -lboost_unit_test_framework - Clang:
clang++ -DBOOST_TEST_DYN_LINK test.cpp -lboost_unit_test_framework
运行结果如下图所示:

我们现在能看到 BOOST_CHECK 和 BOOST_TEST 的区别了。后者是一个较新加入 Boost.Test 的宏,能利用模板技巧来输出表达式的具体内容。但在某些情况下, BOOST_TEST 试图输出表达式的内容会导致编译出错,这时可以改用更简单的 BOOST_CHECK。
不管是 BOOST_CHECK 还是 BOOST_TEST,在测试失败时,执行仍然会继续。在某些情况下,一个测试失败后继续执行后面的测试已经没有意义,这时,我们就可以考虑使用 BOOST_REQUIRE 或 BOOST_TEST_REQUIRE——表达式一旦失败,整个测试用例会停止执行(但其他测试用例仍会正常执行)。
缺省情况下单元测试的输出只包含错误信息和结果摘要,但输出的详细程度是可以通过命令行选项来进行控制的。如果我们在运行测试程序时加上命令行参数 —log_level=all(或 -l all),我们就可以得到下面这样更详尽的输出:
现在额外可以看到:
- 在进入、退出测试模块和用例时的提示
- BOOST_TEST_MESSAGE 的输出
- 正常通过的测试的输出
- 用例里无测试断言的警告
使用 Windows 的同学如果运行了测试程序的话,多半会惊恐地发现终端上的文字颜色已经发生了变化。这似乎是 Boost.Test 在 Windows 上特有的一个问题:建议你把单元测试的色彩显示关掉。你可以在系统高级设置里添加下面这个环境变量,也可以直接在命令行上输入:
set BOOST_TEST_COLOR_OUTPUT=0Boost.Test 产生的可执行代码支持很多命令行参数,可以用 —help 命令行选项来查看。常用的有:
- build_info 可用来展示构建信息
- color_output 可用来打开或关闭输出中的色彩
- log_format 可用来指定日志输出的格式,包括纯文本、XML、JUnit 等
- log_level 可指定日志输出的级别,有 all、test_suite、error、fatal_error、nothing等一共 11 个级别
- run_test 可选择只运行指定的测试用例
- show_progress 可在测试时显示进度,在测试数量较大时比较有用(见下图)

25.2 Catch2
优点:
- 只需要单个头文件即可使用,不需要安装和链接,简单方便
- 可选使用 BDD(Behavior-Driven Development)风格的分节形式
- 测试失败可选直接进入调试器(Windows 和 macOS 上)
拿前面 Boost.Test 的示例直接改造一下:
#define CATCH_CONFIG_MAIN
#include "catch.hpp"
#include <stdexcept>
void test(int n)
{
if (n == 42) {
return;
}
throw std::runtime_error("Not the answer");
}
TEST_CASE("My first test", "[my]")
{
INFO("Testing");
CHECK(1 + 1 == 2);
CHECK_THROWS_AS(test(41), std::runtime_error);
CHECK_NOTHROW(test(42));
int expected = 5;
CHECK(2 + 2 == expected);
}
TEST_CASE("A null test", "[null]")
{
}测试用例的参数:第一项是名字,第二项是标签,可以一个或多个。你除了可以直接在命令行上写测试的名字(不需要选项)来选择运行哪个测试外,也可以写测试的标签来选择运行哪些测试。
这是它在 Windows 下用 MSVC 编译的输出:
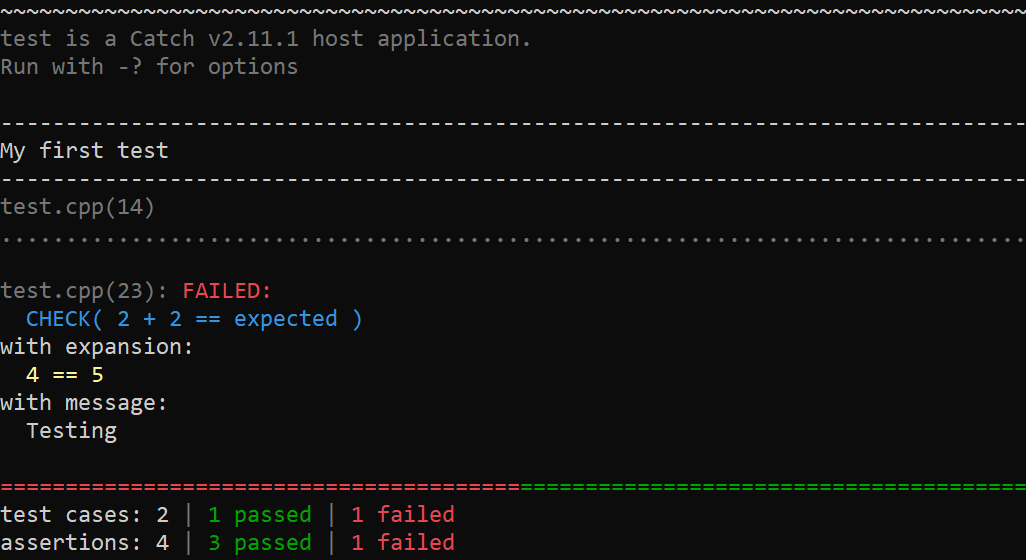
终端的色彩不会被搞乱。缺省的输出清晰程度相当不错。至少在 Windows 下,它看起来可能是个比 Boost.Test 更好的选择。但反过来,在浅色的终端里,Catch2 的色彩不太友好。Boost.Test 在 Linux 和 macOS 下则不管终端的色彩设定,都有比较友好的输出。
和 Boost.Test 类似,Catch2 的测试结果输出格式也是可以修改的。默认格式是纯文本,但你可以通过使用 -r junit 来设成跟 JUnit 兼容的格式,或使用 -r xml 输出成 Catch2 自己的 XML 格式。这方面,它比 Boost.Test 明显易用的一个地方是格式参数大小写不敏感,而在 Boost.Test 里你必须用全大写的形式,如 -f JUNIT,麻烦!
BDD 风格的测试一般采用这样的结构:
- Scenario:场景,我要做某某事
- Given:给定,已有的条件
- When:当,某个事件发生时
- Then:那样,就应该发生什么
如果我们要测试一个容器,那代码就应该是这个样子的:
SCENARIO("Int container can be accessed and modified", "[container]")
{
GIVEN("A container with initialized items")
{
IntContainer c { 1, 2, 3, 4, 5 };
REQUIRE(c.size() == 5);
WHEN("I access existing items")
{
THEN("The items can be retrieved intact")
{
CHECK(c[0] == 1);
CHECK(c[1] == 2);
CHECK(c[2] == 3);
CHECK(c[3] == 4);
CHECK(c[4] == 5);
}
}
WHEN("I modify items")
{
c[1] = -2;
c[3] = -4;
THEN("Only modified items are changed")
{
CHECK(c[0] == 1);
CHECK(c[1] == -2);
CHECK(c[2] == 3);
CHECK(c[3] == -4);
CHECK(c[4] == 5);
}
}
}
}你可以在程序前面加上类型定义来测试你自己的容器类或标准容器(如 vector<int>)。这是一种非常直观的写测试的方式。正常情况下,你当然应该看到:
All tests passed (12 assertions in 1 test case)
如果你没有留意到的话,在 GIVEN 里 WHEN 之前的代码是在每次 WHEN 之前都会执行一遍的。这也是 BDD 方式的一个非常方便的地方。
如果测试失败,我们就能看到类似下面这样的信息输出了(我存心制造了一个错误):
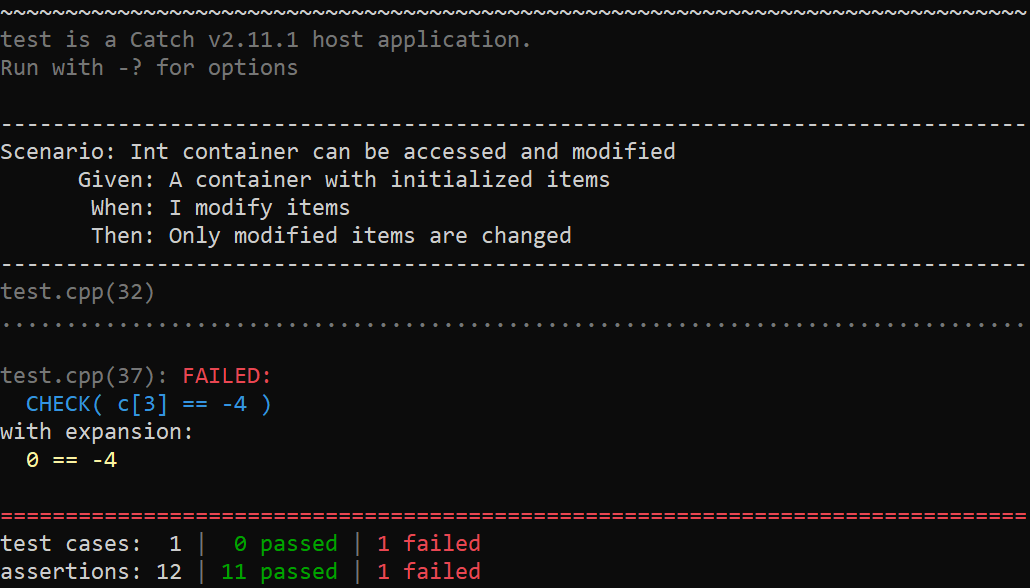
如果没有失败的情况下,想看到具体的测试内容,可以传递参数 —success(或 -s)。
25.3 参考资料
- Gennadiy Rozental and Raffi Enficiaud, Boost.Test. https://www.boost.org/doc/libs/release/libs/test/doc/html/index.html
- Two Blue Cubes Ltd., Catch2. https://github.com/catchorg/Catch2
- Wikipedia, “Behavior-driven development”. https://en.wikipedia.org/wiki/Behavior-driven_development
26 | Easylogging++和spdlog:两个好用的日志库
26.1 Easylogging++
事实上,我本来想只介绍 Easylogging++ 的。但在检查其 GitHub 页面时,我发现了一个问题:它在 2019 年基本没有更新,且目前上报的问题也没有人处理。
概述
Easylogging++ 一共只有两个文件,一个是头文件,一个是普通 C++ 源文件。事实上,它的一个较早版本只有一个文件。正如 Catch2 里一旦定义了 CATCH_CONFIG_MAIN 编译速度会大大减慢一样,把什么东西都放一起最终证明对编译速度还是相当不利的,因此,有人提交了一个补丁,把代码拆成了两个文件。使用 Easylogging++ 也只需要这两个文件——除此之外,就只有对标准和系统头文件的依赖了。
要使用 Easylogging++,推荐直接把这两个文件放到你的项目里。Easylogging++ 有很多的配置项会影响编译结果,我们先大致查看一下常用的可配置项:
- ELPP_UNICODE:启用 Unicode 支持,为在 Windows 上输出混合语言所必需
- ELPP_THREAD_SAFE:启用多线程支持
- ELPP_DISABLE_LOGS:全局禁用日志输出
- ELPP_DEFAULT_LOG_FILE:定义缺省日志文件名称
- ELPP_NO_DEFAULT_LOG_FILE:不使用缺省的日志输出文件
- ELPP_UTC_DATETIME:在日志里使用协调世界时而非本地时间
- ELPP_FEATURE_PERFORMANCE_TRACKING:开启性能跟踪功能
- ELPP_FEATURE_CRASH_LOG:启用 GCC 专有的崩溃日志功能
- ELPP_SYSLOG:允许使用系统日志(Unix 世界的 syslog)来记录日志
- ELPP_STL_LOGGING:允许在日志里输出常用的标准容器对象(std::vector 等)
- ELPP_QT_LOGGING:允许在日志里输出 Qt 的核心对象(QVector 等)
- ELPP_BOOST_LOGGING:允许在日志里输出某些 Boost 的容器(boost::container::vector 等)
- ELPP_WXWIDGETS_LOGGING:允许在日志里输出某些 wxWidgets 的模板对象(wxVector 等)
开始使用 Easylogging++
一个简单的例子:
#include "easylogging++.h" INITIALIZE_EASYLOGGINGPP int main() { LOG(INFO) << "My first info log"; }结果输出到终端和 myeasylog.log 文件里:
2020-01-25 20:47:50,990 INFO [default] My first info log
使用 Unicode
就我们日志输出而言,启用 Unicode 支持的好处是:
- 可以使用宽字符来输出
日志文件的格式是 UTF-8,而不是传统的字符集,只能支持一种文字
要启用 Unicode 支持,你需要定义宏 ELPP_UNICODE,并确保程序中有对 std::locale::global 或 setlocale 的调用(如 [第 11 讲] 中所述,只有进行了正确的区域设置,才能输出含非 ASCII 字符的宽字符串)。下面的程序给出了一个简单的示例:
#include <locale.h> #include "easylogging++.h" INITIALIZE_EASYLOGGINGPP int main() { setlocale(LC_ALL, ""); LOG(INFO) << L"测试 test"; }
改变输出文件名
Easylogging++ 的缺省输出日志名为 myeasylog.log,可以直接在命令行上使用宏定义来修改。只需要在命令行上加入下面的选项就可以:
-DELPP_DEFAULT_LOG_FILE=\"test.log\"使用配置文件设置日志选项
Easylogging++ 库自己支持配置文件。我自己使用的配置文件是这个样子的:
* GLOBAL: FORMAT = "%datetime{%Y-%M-%d %H:%m:%s.%g} %levshort %msg" FILENAME = "test.log" ENABLED = true TO_FILE = true ## 输出到文件 TO_STANDARD_OUTPUT = true ## 输出到标准输出 SUBSECOND_PRECISION = 6 ## 秒后面保留 6 位 MAX_LOG_FILE_SIZE = 2097152 ## 最大日志文件大小设为 2MB LOG_FLUSH_THRESHOLD = 10 ## 写 10 条日志刷新一次缓存 * DEBUG: FORMAT = "%datetime{%Y-%M-%d %H:%m:%s.%g} %levshort [%fbase:%line] %msg" TO_FILE = true TO_STANDARD_OUTPUT = false ## 调试日志不输出到标准输出假设这个配置文件的名字是 log.conf,我们在代码中可以这样使用:
#include "easylogging++.h" INITIALIZE_EASYLOGGINGPP int main() { el::Configurations conf { "log.conf" }; el::Loggers::reconfigureAllLoggers(conf); LOG(DEBUG) << "A debug message"; LOG(INFO) << "An info message"; }注意编译命令行上应当加上 -DELPP_NO_DEFAULT_LOG_FILE,否则 Easylogging++ 仍然会生成缺省的日志文件。
此外,我也推荐在编译时定义宏 ELPP_DEBUG_ASSERT_FAILURE,这样能在找不到配置文件时直接终止程序,而不是继续往下执行、在终端上以缺省的方式输出日志了。
性能跟踪
Easylogging++ 可以用来在日志中记录程序执行的性能数据。
#include <chrono> #include <thread> #include "easylogging++.h" INITIALIZE_EASYLOGGINGPP void foo() { TIMED_FUNC(timer); LOG(WARNING) << "A warning message"; } void bar() { using namespace std::literals; TIMED_SCOPE(timer1, "void bar()"); foo(); foo(); TIMED_BLOCK(timer2, "a block") { foo(); std::this_thread::sleep_for(100us); } } int main() { el::Configurations conf { "log.conf" }; el::Loggers::reconfigureAllLoggers(conf); bar(); }简单说明一下:
- TIMED_FUNC 接受一个参数,是用于性能跟踪的对象的名字。它能自动产生函数的名称。示例中的 TIMED_FUNC 和 TIMED_SCOPE 的作用是完全相同的。
- TIMED_SCOPE 接受两个参数,分别是用于性能跟踪的对象的名字,以及用于记录的名字。如果你不喜欢 TIMED_FUNC 生成的函数名字,可以用 TIMED_SCOPE 来代替。
TIMED_BLOCK 用于对下面的代码块进行性能跟踪,参数形式和 TIMED_SCOPE 相同。
在编译含有上面三个宏的代码时,需要定义宏 ELPP_FEATURE_PERFORMANCE_TRACKING。你一般也应该定义 ELPP_PERFORMANCE_MICROSECONDS,来获取微秒级的精度。下面是定义了上面两个宏编译的程序的某次执行的结果:
2020-01-26 15:00:11.99736 W A warning message 2020-01-26 15:00:11.99748 I Executed [void foo()] in [110 us] 2020-01-26 15:00:11.99749 W A warning message 2020-01-26 15:00:11.99750 I Executed [void foo()] in [5 us] 2020-01-26 15:00:11.99750 W A warning message 2020-01-26 15:00:11.99751 I Executed [void foo()] in [4 us] 2020-01-26 15:00:11.99774 I Executed [a block] in [232 us] 2020-01-26 15:00:11.99776 I Executed [void bar()] in [398 us]不过需要注意,由于 Easylogging++ 本身有一定开销,且开销有一定的不确定性,这种方式只适合颗粒度要求比较粗的性能跟踪。
性能跟踪产生的日志级别固定为 Info。性能跟踪本身可以在配置文件里的 GLOBAL 节下用 PERFORMANCE_TRACKING = false 来关闭。当然,关闭所有 Info 级别的输出也能达到关闭性能跟踪的效果。
记录崩溃日志
在 GCC 和 Clang 下,通过定义宏 ELPP_FEATURE_CRASH_LOG 我们可以启用崩溃日志。此时,当程序崩溃时,Easylogging++ 会自动在日志中记录程序的调用栈信息。通过记录下的信息,再利用 addr2line 这样的工具,我们就能知道是程序的哪一行引发了崩溃。下面的代码可以演示这一行为:
#include "easylogging++.h" INITIALIZE_EASYLOGGINGPP void boom() { char* ptr = nullptr; *ptr = '\0'; } int main() { el::Configurations conf { "log.conf" }; el::Loggers::reconfigureAllLoggers(conf); boom(); }使用 macOS 的需要特别注意一下:由于缺省方式产生的可执行文件是位置独立的,系统每次加载程序会在不同的地址,导致无法通过地址定位到程序行。在编译命令行尾部加上
-Wl,-no_pie可以解决这个问题。
26.2 spdlog
跟 Easylogging++ 比起来,spdlog 要新得多了:前者是 2012 年开始的项目,而后者是 2014 年开始的。我在 2016 年末开始在项目中使用 Easylogging++ 时,Easylogging++的版本是 9.85 左右,而 spdlog 大概是 0.11,成熟度和热度都不那么高。
功能点:
- 非常快(性能是其主要目标)
- 只需要头文件即可使用
- 没有其他依赖
- 跨平台
- 有单线程和多线程的日志记录器
- 日志文件旋转切换
- 每日日志文件
- 终端日志输出
- 可选异步日志
- 多个日志级别
- 通过用户自定义式样来定制输出格式
开始使用 spdlog
#include "spdlog/spdlog.h" int main() { spdlog::info("My first info log"); }代码里看不到的是,输出结果中的”info”字样是彩色的,方便快速识别日志的级别。这个功能在 Windows、Linux 和 macOS 上都能正常工作,对用户还是相当友好的。不过,和 Easylogging++ 缺省就会输出到文件中不同,spdlog 缺省只是输出到终端而已。
spdlog 不是使用 IO 流风格的输出了。它采用跟 Python 里的 str.format 一样的方式,使用大括号——可选使用序号和格式化要求——来对参数进行格式化。下面是一个很简单的例子:
spdlog::warn("Message with arg {}", 42); spdlog::error("{0:d}, {0:x}, {0:o}, {0:b}", 42);输出会像下面这样:
[2020-01-26 17:20:08.355] [warning] Message with arg 42 [2020-01-26 17:20:08.355] [error] 42, 2a, 52, 101010事实上,这就是 C++20 的 format 的风格了——spdlog 就是使用了一个 format 的库实现 fmt [3]。
设置输出文件
#include "spdlog/spdlog.h" #include "spdlog/sinks/basic_file_sink.h" int main() { auto file_logger = spdlog::basic_logger_mt("basic_logger", "test.log"); spdlog::set_default_logger(file_logger); spdlog::info("Into file: {1} {0}", "world", "hello"); }执行之后,终端上没有任何输出,但 test.log 文件里就会增加如下的内容:
[2020-01-26 17:47:37.864] [basic_logger] [info] Into file: hello world
如果同时输出到终端和文件:
#include <memory> #include "spdlog/spdlog.h" #include "spdlog/sinks/basic_file_sink.h" #include "spdlog/sinks/stdout_color_sinks.h" using namespace std; using namespace spdlog::sinks; void set_multi_sink() { auto console_sink = make_shared<stdout_color_sink_mt>(); console_sink->set_level(spdlog::level::warn); console_sink->set_pattern("%H:%M:%S.%e %^%L%$ %v"); auto file_sink = make_shared<basic_file_sink_mt>("test.log"); file_sink->set_level(spdlog::level::trace); file_sink->set_pattern("%Y-%m-%d %H:%M:%S.%f %L %v"); auto logger = shared_ptr<spdlog::logger>( new spdlog::logger("multi_sink", { console_sink, file_sink })); logger->set_level(spdlog::level::debug); spdlog::set_default_logger(logger); } int main() { set_multi_sink(); spdlog::warn("this should appear in both console and file"); spdlog::info("this message should not appear in the console, only in the file"); }大致说明一下:
- console_sink 是一个指向 stdout_color_sink_mt 的智能指针,我们设定让它只显示警告级别及以上的日志信息,并把输出式样调整成带毫秒的时间、有颜色的短级别以及信息本身。
- file_sink 是一个指向 basic_file_sink_mt 的智能指针,我们设定让它显示跟踪级别及以上(也就是所有级别了)的日志信息,并把输出式样调整成带微秒的日期时间、短级别以及信息本身。
- 然后我们创建了日志记录器,让它具有上面的两个日志槽。注意这儿的两个细节:
- 这儿的接口普遍使用 shared_ptr;
- 由于 make_shared 在处理 initializer_list 上的缺陷,对 spdlog::logger 的构造只能直接调用 shared_ptr 的构造函数,而不能使用 make_shared,否则编译会出错。
- 最后我们调用了 spdlog::set_default_logger 把缺省的日志记录器设置成刚创建的对象。这样,之后的日志缺省就会记录到这个新的日志记录器了(我们当然也可以手工调用这个日志记录器的 critical、error、warn 等日志记录方法)。
日志文件切换
在 Easylogging++ 里实现日志文件切换是需要写代码的,而且完善的多文件切换代码需要写上几十行代码才能实现。这项工作在 spdlog 则是超级简单的,因为 spdlog 直接提供了一个实现该功能的日志槽。把上面的例子改造成带日志文件切换我们只需要修改两处:
#include "spdlog/sinks/rotating_file_sink.h" // 替换 basic_file_sink.h auto file_sink = make_shared<rotating_file_sink_mt>("test.log", 1048576 * 5, 3); // 替换 basic_file_sink_mt,文件大 // 小为 5MB,一共保留 3 个日志文件适配用户定义的流输出
虽然 spdlog 缺省不支持容器的输出,但是,它是可以和用户提供的流 << 运算符协同工作的。如果我们要输出普通容器的话,我们只需要在代码开头加入:
#include "output_container.h" #include "spdlog/fmt/ostr.h"前一行包含了我们用于容器输出的代码,后一行包含了 spdlog 使用 ostream 来输出对象的能力。注意此处包含的顺序是重要的:spdlog 必须能看到用户的 << 的定义。在有了这两行之后,我们就可以像下面这样写代码了:
vector<int> v; spdlog::info("Content of vector: {}", v);只用头文件吗?
使用 spdlog 可以使用只用头文件的方式,也可以使用预编译的方式。
其他
下面这些功能点值得提一下:
- 可以使用多个不同的日志记录器,用于不同的模块或功能。
- 可以使用异步日志,减少记日志时阻塞的可能性。
- 通过 spdlog::to_hex 可以方便地在日志里输出二进制信息。
- 可用的日志槽还有 syslog、systemd、Android、Windows 调试输出等;扩展新的日志槽较为容易。
26.3 参考资料
- Amrayn Web Services, easyloggingpp. https://github.com/amrayn/easyloggingpp
- Gabi Melman, spdlog. https://github.com/gabime/spdlog
- Victor Zverovich, fmt. https://github.com/fmtlib/fmt
- Andrey Semashev, Boost.Log v2. https://www.boost.org/doc/libs/release/libs/log/doc/html/index.html
- Kjell Hedström, g3log. https://github.com/KjellKod/g3log
- Stanford University, NanoLog. https://github.com/PlatformLab/NanoLog
27 | C++ REST SDK:使用现代C++开发网络应用
C++ REST SDK(也写作 cpprestsdk)[1],一个支持 HTTP 协议 [2]、主要用于 RESTful [3] 接口开发的 C++ 库。
27.1 初识 C++ REST SDK
使用 C++ REST SDK 只需要五十多行有效代码可以写出一个类似于 curl [4] 的 HTTP 客户端。
#include <iostream>
#ifdef _WIN32
#include <fcntl.h>
#include <io.h>
#endif
#include <cpprest/http_client.h>
using namespace utility;
using namespace web::http;
using namespace web::http::client;
using std::cerr;
using std::endl;
#ifdef _WIN32
#define tcout std::wcout
#else
#define tcout std::cout
#endif
auto get_headers(http_response resp)
{
auto headers = resp.to_string();
auto end = headers.find(U("\r\n\r\n"));
if (end != string_t::npos) {
headers.resize(end + 4);
};
return headers;
}
auto get_request(string_t uri)
{
http_client client { uri };
// 用 GET 方式发起一个客户端请求
auto request = client.request(methods::GET)
.then([](http_response resp) {
if (resp.status_code() != status_codes::OK) {
// 不 OK,显示当前响应信息
auto headers = get_headers(resp);
tcout << headers;
}
// 进一步取出完整响应
return resp.extract_string();
})
.then([](string_t str) {
// 输出到终端
tcout << str;
});
return request;
}
#ifdef _WIN32
int wmain(int argc, wchar_t* argv[])
#else
int main(int argc, char* argv[])
#endif
{
#ifdef _WIN32
_setmode(_fileno(stdout), _O_WTEXT);
#endif
if (argc != 2) {
cerr << "A URL is needed\n";
return 1;
}
// 等待请求及其关联处理全部完成
try {
auto request = get_request(argv[1]);
request.wait();
}
// 处理请求过程中产生的异常
catch (const std::exception& e) {
cerr << "Error exception: " << e.what() << endl;
return 1;
}
}虽然这种代码风格,对于之前没有接触过这种函数式编程风格的人来讲会有点奇怪——这被称作持续传递风格(continuation-passing style),显式地把上一段处理的结果传递到下一个函数中。
27.2 安装和编译
上面的代码本身虽然简单,但要把它编译成可执行文件比我们之前讲的代码都要复杂—— C++ REST SDK 有外部依赖,在 Windows 上和 Unix 上还不太一样。它的编译和安装也略复杂,如果你没有这方面的经验的话,建议尽量使用平台推荐的二进制包的安装方式。
由于其依赖较多,使用它的编译命令行也较为复杂。正式项目中绝对是需要使用项目管理软件的(如 cmake)。此处,我给出手工编译的典型命令行,仅供你尝试编译上面的例子作参考。
Windows MSVC:
cl /EHsc /std:c++17 test.cpp cpprest.lib zlib.lib libeay32.lib ssleay32.lib winhttp.lib httpapi.lib bcrypt.lib crypt32.lib advapi32.lib gdi32.lib user32.libLinux GCC:
g++ -std=c++17 -pthread test.cpp -lcpprest -lcrypto -lssl -lboost_thread -lboost_chrono -lboost_systemmacOS Clang:
clang++ -std=c++17 test.cpp -lcpprest -lcrypto -lssl -lboost_thread-mt -lboost_chrono-mt27.3 概述
特性(随平台不同会有所区别):
- HTTP 客户端
- HTTP 服务器
- 任务
- JSON
- URI
- 异步流
- WebSocket 客户端
- OAuth 客户端
27.4 异步流
C++ REST SDK 里实现了一套异步流,能够实现对文件的异步读写。下面的例子展示了我们如何把网络请求的响应异步地存储到文件 results.html 中:
#include <iostream>
#include <utility>
#ifdef _WIN32
#include <fcntl.h>
#include <io.h>
#endif
#include <stddef.h>
#include <cpprest/http_client.h>
#include <cpprest/filestream.h>
using namespace utility;
using namespace web::http;
using namespace web::http::client;
using namespace concurrency::streams;
using std::cerr;
using std::endl;
#ifdef _WIN32
#define tcout std::wcout
#else
#define tcout std::cout
#endif
auto get_headers(http_response resp)
{
auto headers = resp.to_string();
auto end = headers.find(U("\r\n\r\n"));
if (end != string_t::npos) {
headers.resize(end + 4);
};
return headers;
}
auto get_request(string_t uri)
{
http_client client { uri };
// 用 GET 方式发起一个客户端请求
auto request = client.request(methods::GET)
.then([](http_response resp) {
if (resp.status_code() == status_codes::OK) {
// 正常的话
tcout << U("Saving...\n");
ostream fs;
fstream::open_ostream(U("results.html"),
std::ios_base::out | std::ios_base::trunc)
.then([&fs, resp](ostream os) {
fs = os;
// 读取网页内容到流
return resp.body().read_to_end(fs.streambuf());
})
.then([&fs](size_t size) {
// 然后关闭流
fs.close();
tcout << size << U(" bytes saved\n");
})
.wait();
} else {
// 否则显示当前响应信息
auto headers = get_headers(resp);
tcout << headers;
tcout << resp.extract_string().get();
}
});
return request;
}
#ifdef _WIN32
int wmain(int argc, wchar_t* argv[])
#else
int main(int argc, char* argv[])
#endif
{
#ifdef _WIN32
_setmode(_fileno(stdout),
_O_WTEXT);
#endif
if (argc != 2) {
cerr << "A URL is needed\n";
return 1;
}
// 等待请求及其关联处理全部完成
try {
auto request = get_request(argv[1]);
request.wait();
}
// 处理请求过程中产生的异常
catch (const std::exception& e) {
cerr << "Error exception: " << e.what() << endl;
}
}跟上一个例子比,我们去掉了原先的第二段处理统一输出的异步处理代码,但加入了一段嵌套的异步代码。有几个地方需要注意一下:
- C++ REST SDK 的对象基本都是基于 shared_ptr 用引用计数实现的,因而可以轻松大胆地进行复制。
- 虽然 string_t 在 Windows 上是 wstring,但文件流无论在哪个平台上都是以 UTF-8 的方式写入,符合目前的主流处理方式(wofstream 的行为跟平台和环境相关)。
- extract_string 的结果这次没有传递到下一段,而是直接用 get 获得了最终结果(类似于 [第 19 讲] 中的 future)。
这个例子的代码是基于 cpprestsdk 官方的例子 改编的。但我做的下面这些更动值得提一下:
- 去除了不必要的 shared_ptr 的使用。
- fstream::open_ostream 缺省的文件打开方式是 std::ios_base::out,官方例子没有用 std::ios_base::trunc,导致不能清除文件中的原有内容。此处 C++ REST SDK 的 file_stream 行为跟标准 C++ 的 ofstream 是不一样的:后者缺省打开方式也是 std::ios_base::out,但此时文件内容会被自动清除。
- 沿用我的前一个例子,先进行请求再打开文件流,而不是先打开文件流再发送网络请求,符合实际流程。
- 这样做的一个结果就是 then 不完全是顺序的了,有嵌套,增加了复杂度,但展示了实际可能的情况。
27.5 JSON 支持
有几个 C++ 相关的关键点需要提一下:
- JSON 的基本类型是空值类型、布尔类型、数字类型和字符串类型。其中空值类型和数字类型在 C++ 里是没有直接对应物的。数字类型在 C++ 里可能映射到 double,也可能是 int32_t 或 int64_t。
- JSON 的复合类型是数组(array)和对象(object)。JSON 数组像 C++ 的 vector,但每个成员的类型可以是任意 JSON 类型,而不像 vector 通常是同质的——所有成员属于同一类型。JSON 对象像 C++ 的 map,键类型为 JSON 字符串,值类型则为任意 JSON 类型。JSON 标准不要求对象的各项之间有顺序,不过,从实际项目的角度,我个人觉得保持顺序还是非常有用的。
如果你去搜索”c++ json”的话,还是可以找到一些不同的 JSON 实现的。功能最完整、名声最响的目前似乎是 nlohmann/json [6],而腾讯释出的 RapidJSON [7] 则以性能闻名[8]。需要注意一下各个实现之间的区别:
- nlohmann/json 不支持对 JSON 的对象(object)保持赋值顺序;RapidJSON 保持赋值顺序;C++ REST SDK 可选保持赋值顺序(通过 web::json::keep_object_element_order 和 web::json::value::object 的参数)。
- nlohmann/json 支持最友好的初始化语法,可以使用初始化列表和 JSON 字面量; C++ REST SDK 只能逐项初始化,并且一般应显式调用 web::json::value 的构造函数(接受布尔类型和字符串类型的构造函数有 explicit 标注);RapidJSON 介于中间,不支持初始化列表和字面量,但赋值可以直接进行。
- nlohmann/json 和 C++ REST SDK 支持直接在用方括号 [] 访问不存在的 JSON 数组(array)成员时改变数组的大小;RapidJSON 的接口不支持这种用法,要向 JSON 数组里添加成员要麻烦得多。
- 作为性能的代价,RapidJSON 里在初始化字符串值时,只会传递指针值;用户需要保证字符串在 JSON 值使用过程中的有效性。要复制字符串的话,接口要麻烦得多。
- RapidJSON 的 JSON 对象没有 begin 和 end 方法,因而无法使用标准的基于范围的 for 循环。总体而言,RapidJSON 的接口显得最特别、不通用。
如果你使用 C++ REST SDK 的其他功能,你当然也没有什么选择;否则,你可以考虑一下其他的 JSON 实现。下面,我们就只讨论 C++ REST SDK 里的 JSON 了。
在 C++ REST SDK 里,核心的类型是 web::json::value,这就对应到我前面说的”任意 JSON 类型”了。还是拿例子说话(改编自 RapidJSON 的例子):
#include <iostream>
#include <string>
#include <utility>
#include <assert.h>
#ifdef _WIN32
#include <fcntl.h>
#include <io.h>
#endif
#include <cpprest/json.h>
using namespace std;
using namespace utility;
using namespace web;
#ifdef _WIN32
#define tcout std::wcout
#else
#define tcout std::cout
#endif
int main()
{
#ifdef _WIN32
_setmode(_fileno(stdout), _O_WTEXT);
#endif
// 测试的 JSON 字符串
string_t json_str = U(R"({
"s": "你好,世界",
"t": true,
"f": false,
"n": null,
"i": 123,
"d": 3.1416,
"a": [1, 2, 3]
})");
tcout << "Original JSON:" << json_str << endl;
// 保持元素顺序并分析 JSON 字符串
json::keep_object_element_order(true);
auto document = json::value::parse(json_str);
// 遍历对象成员并输出类型
static const char* type_names[] = {
"Number",
"Boolean",
"String",
"Object",
"Array",
"Null",
};
for (auto&& value : document.as_object()) {
tcout << "Type of member " << value.first << " is "
<< type_names[value.second.type()] << endl;
}
// 检查 document 是对象
assert(document.is_object());
// 检查 document["s"] 是字符串
assert(document.has_field(U("s")));
assert(document[U("s")].is_string());
tcout << "s = " << document[U("s")] << endl;
// 检查 document["t"] 是字符串
assert(document[U("t")].is_boolean());
tcout << "t = "
<< (document[U("t")].as_bool() ? "true" : "false")
<< endl;
// 检查 document["f"] 是字符串
assert(document[U("f")].is_boolean());
tcout << "f = "
<< (document[U("f")].as_bool() ? "true" : "false")
<< endl;
// 检查 document["f"] 是空值
tcout << "n = "
<< (document[U("n")].is_null() ? "null" : "?")
<< endl;
// 检查 document["i"] 是整数
assert(document[U("i")].is_number());
assert(document[U("i")].is_integer());
tcout << "i = " << document[U("i")] << endl;
// 检查 document["d"] 是浮点数
assert(document[U("d")].is_number());
assert(document[U("d")].is_double());
tcout << "d = " << document[U("d")] << endl;
{
// 检查 document["a"] 是数组
auto& a = document[U("a")];
assert(a.is_array());
// 测试读取数组元素并转换成整数
int y = a[0].as_integer();
(void)y;
// 遍历数组成员并输出
tcout << "a = ";
for (auto&& value : a.as_array()) {
tcout << value << ' ';
}
tcout << endl;
}
// 修改 document["i"] 为长整数
{
uint64_t bignum = 65000;
bignum *= bignum;
bignum *= bignum;
document[U("i")] = bignum;
assert(!document[U("i")].as_number().is_int32());
assert(document[U("i")].as_number().to_uint64() == bignum);
tcout << "i is changed to " << document[U("i")] << endl;
}
// 在数组里添加数值
{
auto& a = document[U("a")];
a[3] = 4;
a[4] = 5;
tcout << "a is changed to " << document[U("a")] << endl;
}
// 在 JSON 文档里添加布尔值:等号右侧 json::value 不能省
document[U("b")] = json::value(true);
// 构造新对象,保持多个值的顺序
auto temp = json::value::object(true);
// 在新对象里添加字符串:等号右侧 json::value 不能省
temp[U("from")] = json::value(U("rapidjson"));
temp[U("changed for")] = json::value(U("geekbang"));
// 把对象赋到文档里;json::value内部使用 unique_ptr,因而使用 move 可以减少拷贝
document[U("adapted")] = std::move(temp);
// 完整输出目前的 JSON 对象
tcout << document << endl;
}例子里我加了不少注释,应当可以帮助你看清 JSON 对象的基本用法了。唯一遗憾的是宏 U(类似于 [第 11 讲] 里提到过的 _T)的使用有点碍眼:要确保代码在 Windows 下和 Unix 下都能工作,目前这还是必要的。
C++ REST SDK 里的 http_request 和 http_response 都对 JSON 有原生支持,如可以使用 extract_json 成员函数来异步提取 HTTP 请求或响应体中的 JSON 内容。
27.6 HTTP 服务器
可以使用 C++ REST SDK 来快速搭建一个 HTTP 服务器。在三种主流的操作系统上,C++ REST SDK 的 http_listener 会通过调用 Boost.Asio [9] 和操作系统的底层接口(IOCP、epoll 或 kqueue)来完成功能,向使用者隐藏这些细节、提供一个简单的编程接口。
我们将搭建一个最小的 REST 服务器,只能处理一个 sayHi 请求。客户端应当向服务器发送一个 HTTP 请求,URI 是:
/sayHi?name=…
“…”部分代表一个名字,而服务器应当返回一个 JSON 的回复,形如:
{"msg": "Hi, …!"}这个服务器的有效代码行同样只有六十多行,如下所示:
#include <exception>
#include <iostream>
#include <map>
#include <string>
#ifdef _WIN32
#include <fcntl.h>
#include <io.h>
#endif
#include <cpprest/http_listener.h>
#include <cpprest/json.h>
using namespace std;
using namespace utility;
using namespace web;
using namespace web::http;
using namespace web::http::experimental::listener;
#ifdef _WIN32
#define tcout std::wcout
#else
#define tcout std::cout
#endif
void handle_get(http_request req)
{
auto& uri = req.request_uri();
if (uri.path() != U("/sayHi")) {
req.reply(status_codes::NotFound);
return;
}
tcout << uri::decode(uri.query()) << endl;
auto query = uri::split_query(uri.query());
auto it = query.find(U("name"));
if (it == query.end()) {
req.reply(status_codes::BadRequest, U("Missing query info"));
return;
}
auto answer = json::value::object(true);
answer[U("msg")] = json::value(string_t(U("Hi, ")) + uri::decode(it->second) + U("!"));
req.reply(status_codes::OK, answer);
}
int main()
{
#ifdef _WIN32
_setmode(_fileno(stdout), _O_WTEXT);
#endif
http_listener listener(U("http://127.0.0.1:8008/"));
listener.support(methods::GET, handle_get);
try {
listener.open().wait();
tcout << "Listening. Press ENTER to exit.\n";
string line;
getline(cin, line);
listener.close().wait();
} catch (const exception& e) {
cerr << e.what() << endl;
return 1;
}
}几个细节:
- 我们调用 http_request::reply 的第二个参数是 json::value 类型,这会让 HTTP 的内容类型(Content-Type)自动置成”application/json”。
- http_request::request_uri 函数返回的是 uri 的引用,因此我用 auto& 来接收。uri::split_query 函数返回的是一个普通的 std::map,因此我用 auto 来接收。
- http_listener::open 和 http_listener::close 返回的是
pplx::task<void>;当这个任务完成时(wait 调用返回),表示 HTTP 监听器上的对应操作(打开或关闭)真正完成了。
27.7 关于线程的细节
C++ REST SDK 使用异步的编程模式,使得写不阻塞的代码变得相当容易。不过,底层它是使用一个线程池来实现的——在 C++20 的协程能被使用之前,并没有什么更理想的跨平台方式可用。
C++ REST SDK 缺省会开启 40 个线程。在目前的实现里,如果这些线程全部被用完了,会导致系统整体阻塞。反过来,如果你只是用 C++ REST SDK 的 HTTP 客户端,你就不需要这么多线程。这个线程数量目前在代码里是可以控制的。比如,下面的代码会把线程池的大小设为 10:
#include <pplx/threadpool.h>
crossplat::threadpool::initialize_with_threads(10);如果你使用 C++ REST SDK 开发一个服务器,则不仅应当增加线程池的大小,还应当对并发数量进行统计,在并发数接近线程数时主动拒绝新的连接——一般可返回 status_codes::ServiceUnavailable——以免造成整个系统的阻塞。
27.8 参考资料
- Microsoft, cpprestsdk. https://github.com/microsoft/cpprestsdk
- Wikipedia, “Hypertext Transfer Protocol”. https://en.wikipedia.org/wiki/Hypertext_Transfer_Protocol
- RESTful. https://restfulapi.net/
- curl. https://curl.haxx.se/
- JSON. https://www.json.org/
- Niels Lohmann, json. https://github.com/nlohmann/json
- Tencent, rapidjson. https://github.com/Tencent/rapidjson
- Milo Yip, nativejson-benchmark. https://github.com/miloyip/nativejsonbenchmark
- Christopher Kohlhoff, Boost.Asio. https://www.boost.org/doc/libs/release/doc/html/boost_asio.html
04丨新年特别策划
新春福利 | C++好书荐读
入门介绍
Bjarne Stroustrup, A Tour of C++, 2nd ed. Addison-Wesley, 2018
中文版:王刚译,《C++ 语言导学》(第二版)。机械工业出版社,2019
推荐指数:★★★★★ (也有第一版的影印版,那就不推荐了。)
Michael Wong 和 IBM XL 编译器中国开发团队,《深入理解 C++11:C++11 新特性解析与应用》。机械工业出版社,2013
推荐指数:★★★☆
这本书我犹豫了好久是否应该推荐。Michael Wong 是 C++ 标准委员会委员,内容的权威性没有问题。但这本书,从电子书版本(Kindle 和微信读书上都有此书)看,排印错误不少——校对工作没有做好。我觉得,如果你已经熟悉 C++98,想很系统地检视一下 C++11 的新特性,这本书可能还比较适合。(我只讲了一些重点的现代 C++ 特性,完整性相差很远。)
最佳实践
Scott Meyers, Effective C++: 55 Specific Ways to Improve Your Programs and Designs, 3rd ed. Addison-Wesley, 2005
中文版:侯捷译《Effective C++ 中文版》(第三版)。电子工业出版社,2011
推荐指数:★★★★
Scott Meyers, Effective STL: 50 Specific Ways to Improve Your Use of the Standard Template Library. Addison-Wesley, 2001
中文版:潘爱民、陈铭、邹开红译《Effective STL 中文版》。清华大学出版社,2006
推荐指数:★★★★
Scott Meyers, Effective Modern C++: 42 Specific Ways to Improve Your Use o f C++11 and C++14. O’Reilly, 2014
中文版:高博译《Effective Modern C++ 中文版》。中国电力出版社,2018
推荐指数:★★★★★
之所以不推荐 More Effective C++,是因为那本没有出过新版,1996 年的内容有点太老了。
值得一提的是,这三本的译者在国内都是响当当的名家,翻译质量有保证。因此,这几本看看中文版就挺好。
深入学习
Herb Sutter, Exceptional C++: 47 Engineering Puzzles, Programming Problems, and Solutions. Addison-Wesley, 1999
中文版:卓小涛译《Exceptional C++ 中文版》。中国电力出版社,2003
推荐指数:★★★★
Herb Sutter and Andrei Alexandrescu, C++ Coding Standards: 101 Rules, Guidelines, and Best Practices. Addison-Wesley, 2004
中文版:刘基诚译《C++ 编程规范:101 条规则准则与最佳实践》。人民邮电出版社, 2006
推荐指数:★★★★
两个牛人制定的 C++ 编码规范。与其盲目追随网上的编码规范(比如,Google 的),不如仔细看看这两位大牛是怎么看待编码规范方面的问题的。
侯捷,《STL 源码剖析》。华中科技大学出版社,2002
推荐指数:★★★★☆
这本书有点老,也有些错误(比如,有人提到它对 std::copy 和 memmove 的说明是错的,但我已经不再有这本书了,没法确认),阅读时需要自己鉴别。但瑕不掩瑜,我还是认为这是本好书。
高级专题
Alexander A. Stepanov and Daniel E. Rose, From Mathematics to Generic Programming. Addison-Wesley, 2014
中文版:爱飞翔译《数学与泛型编程:高效编程的奥秘》。机械工业出版社,2017
推荐指数:★★★★★
Alexander Stepanov 是 STL 之父,这本书写的却不是具体的编程技巧或某个库,而是把泛型编程和抽象代数放在一起讨论了。说来惭愧,我是读了这本书之后才对群论稍稍有了点理解:之前看到的介绍材料都过于抽象,没能理解。事实上,Alexander 之前还写了一本同一题材、但使用公理推导风格的 Elements of Programming(裘宗燕译《编程原本》),那本就比较抽象艰深,从受欢迎程度上看远远不及这一本。我也只是买了放在书架上没看多少页😝。
除非抽象代数和模板编程你都已经了然于胸,否则这本书绝对会让你对编程的理解再上一个层次。相信我!
Andrei Alexandrescu, Modern C++ Design: Generic Programming and Design Patterns Applied. Addison-Wesley, 2001
中文版:侯捷、於春景译《C++ 设计新思维》。华中科技大学出版社,2003
推荐指数:★★★★☆
书里的技巧有些已经过时了(我也不推荐大家今天去使用 Loki 库),但理念没有过时,对思维的训练也仍然有意义。
Anthony Williams, C++ Concurrency in Action, 2nd ed. Manning, 2019
中文译本只有第一版,且有人评论”机器翻译的都比这个好”。因而不推荐中文版。
推荐指数:★★★★☆
C++ 在并发上出名的书似乎只此一本。这也不算奇怪:作者是 Boost.Thread 的主要作者之一,并且也直接参与了 C++ 跟线程相关的很多标准化工作;同时,这本书也非常全面,内容覆盖并发编程相关的所有主要内容,甚至包括在 Concurrency TS 里讨论的,尚未进入 C++17 标准(但应当会进入 C++20)的若干重要特性:barrier、latch 和 continuation。
除非你为一些老式的嵌入式系统开发 C++ 程序,完全不需要接触并发,否则我推荐你阅读这本书。
Ivan Čukić, Functional Programming in C++. Manning, 2019
中文版:程继洪、孙玉梅、娄山佑译《C++ 函数式编程》。机械工业出版社,2020
推荐指数:★★★★
如果你对函数式编程有兴趣,可以读一读这本书。如果你对函数式编程不感冒,可以跳过这一本。
参考书
Bjarne Stroustrup, The C++ Programming Language, 4th ed. Addison-Wesley, 2013
中文版:王刚、杨巨峰译《C++ 程序设计语言》。机械工业出版社, 2016
推荐指数:★★★★☆
C++ 之父亲自执笔写的 C++ 语言。主要遗憾是没有覆盖 C++14/17 的内容。中文版分为两卷出版,内容实在是有点多了。不过,如果你没有看过之前的版本,并且对 C++ 已经有一定经验的话,这个新版还是会让你觉得,姜还是老的辣!
Nicolai M. Josuttis, The C++ Standard Library: A Tutorial and Reference, 2nd ed. Addison-Wesley, 2012
中文版:侯捷译《C++ 标准库》。电子工业出版社,2015
推荐指数:★★★★☆
C++ 的设计哲学
Bjarne Stroustrup, The Design and Evolution of C++. Addison-Wesley, 1994
中文版:裘宗燕译《C++ 语言的设计与演化》。科学出版社, 2002
推荐指数:★★★☆
Bruce Eckel, Thinking in C++, Vol. 1: Introduction to Standard C++, 2nd ed. Prentice-Hall, 2000
Bruce Eckel and Chunk Allison, Thinking in C++, Vol. 2: Practical Programming.Pearson, 2003
中文版:刘宗田等译《C++ 编程思想》。机械工业出版社,2011
推荐指数:★★★
据说这套书翻译不怎么样,我没看过,不好评价。如果你英文没问题,还是看英文版吧——作者释出了英文的免费版本。这套书适合有一点编程经验的人,讲的是编程思想。推荐星级略低的原因是,书有点老,且据说存在一些错误。但 Bruce Eckel 对编程的理解非常深入,即使在 C++ 的细节上他有错误,通读此书肯定还是会对你大有益处的。
非 C++ 的经典书目
W. Richard Stevens, TCP/IP Illustrated Volume 1: The Protocols. Addison-Wesley, 1994
Gary R. Wright and W. Richard Stevens, TCP/IP Illustrated Volume 2: The Implementation. Addison-Wesley, 1995
W. Richard Stevens, TCP/IP Illustrated Volume 3: TCP for Transactions, HTTP, NNTP and the Unix Domain Protocols. Addison-Wesley 1996
中文版翻译不佳,不推荐。
推荐指数:★★★★☆
不是所有的书都是越新越好,《TCP/IP 详解》就是其中一例。W. Richard Stevens 写的卷一比后人补写的卷一第二版评价更高,就是其中一例。关于 TCP/IP 的编程,这恐怕是难以超越的经典了。不管你使用什么语言开发,如果你的工作牵涉到网络协议的话,这套书恐怕都值得一读——尤其是卷一。
W. Richard Stevens and Stephen A. Rago, Advanced Programming in the UNIX Environment, 3rd, ed… Addison-Wesley, 2013
中文版: 戚正伟、张亚英、尤晋元译《UNIX 环境高级编程》。人民邮电出版社,2014
推荐指数:★★★★
Erich Gamma, Richard Helm, Ralph Johson, John Vlissides, and Grady Booch, Design Patterns: Elements of Reusable Object-Oriented Software . Addison-Wesley, 1994
中文版:李英军、马晓星、蔡敏、刘建中等译《设计模式》。机械工业出版社,2000
推荐指数:★★★★☆
提示:如果你感觉这本书很枯燥、没用,那就等你有了更多的项目经验再回过头来看一下,也许就有了不同的体验。
Eric S. Raymond, The Art of UNIX Programming. Addison-Wesley, 2003
中文版:姜宏、何源、蔡晓骏译《UNIX 编程艺术》。电子工业出版社,2006
推荐指数:★★★★
如果你对 Unix 设计哲学有兴趣的话,那这本书仍然无可替代。如果你愿意看英文的话,这本书的英文一直是有在线免费版本的。
Pete McBreen, Software Craftsmanship: The New Imperative. Addison-Wesley, 2001
中文版:熊节译《软件工艺》。人民邮电出版社,2004
推荐指数:★★★★
这本书讲的是软件开发的过程,强调的是软件开发中人的作用。相比其他的推荐书,这本要”软”不少。但不等于这本书不重要。如果你之前只关注纯技术问题的话,那现在是时间关注一下软件开发中人的问题了。
Paul Graham, Hackers & Painters: Big Ideas From The Computer Age. O’Reilly, 2008
中文版:阮一峰译《黑客与画家》。人民邮电出版社,2011
推荐指数:★★★★
Robert C. Martin, Clean Code: A Handbook of Agile Software Craftsmanship. Prentice Hall, 2008
中文版:韩磊译《代码整洁之道》。人民邮电出版社,2010
推荐指数:★★★★☆
其他
- C++ Reference. https://en.cppreference.com
- C++ Core Guidelines. https://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines
新春寄语 | 35年码龄程序员:人生漫长,走点弯路在所难免
Larry Wall 认为程序员该有的三大美德:懒惰,急切,傲慢(laziness, impatience, hubris;初次阐释于 Programming Perl 第二版)。我翻译出完整的原文与你妙文共赏:
懒惰
使得你花费极大努力来减少总体能量开销的品质。懒惰使你去写能让别人觉得有用、并减少繁杂工作的程序;你也会用文档描述你的程序,免得你不得不去回答别人的问题。因此,这是程序员的第一大美德。
急切
当计算机不能满足你的需求时你所感到的愤怒。这使得你写的程序不仅满足自己的需求,还能预期其他需求。至少努力去这么做。因此,这是程序员的第二大美德。
傲慢
老天都受不了你的极度骄傲。这种品质使得你写程序(和维护程序)时不允许别人有机会来说三道四。因此这是程序员的第三大美德。
学习英语每天坚持:
- 每天阅读一篇英语的编程文章
- 每天看一条英文的 C++ Core Guideline
- 每天看 5 页 C++ 之父的 The C++ Programming Language(或其他的英文编程书籍)
- 每天在 Stack Overflow 上看 3 个问答
- 等等
05丨未来篇
28 | Concepts:如何对模板进行约束?
28.1 一个小例子
我们知道 C++ 里有重载,可以根据参数的类型来选择合适的函数。比如,我们可以定义 half 对于 int 和 string 有不同的作用:
int half(int n)
{
return n / 2;
}
string half(string s)
{
s.resize(s.size() / 2);
return s;
}初看,似乎重载可以解决问题,但细想,不对啊:除了 int,我们还有差不多的 short、 long 等类型,甚至还有 boost::multiprecision::cpp_int;除了 string,我们也还有 wstring、u16string、u32string 等等。上面的每个函数,实际上都适用于一族类型,而不是单个类型。重载在这方面并帮不了什么忙。
也许你现在已经反应过来了,我们有 SFINAE 啊!回答部分正确。可是,你告诉我你有没有想到一种很简单的方式能让 SFINAE 对整数类型可以工作?Type traits?嗯嗯,总是可以解决的是吧,但这会不会是一条把初学者劝退的道路呢?……
C++ 的概念就是用来解决这个问题的。对于上面的例子,我们只需要事先定义了 Integer 和 String 的概念(如何定义一个概念我们后面会说),我们就可以写出下面这样的代码:
template <Integer N>
N half(N n)
{
return n / 2;
}
template <String S>
S half(S s)
{
s.resize(s.size() / 2);
return s;
}我们应当了解一下,从概念上讲,上面这种形式的含义和下面的代码实质相同(以上面的第一个函数为例):
template <typename N>
requires Integer<N>
N half(N n)
{
return n / 2;
}即,这个 half 是一个函数模板,有一个模板参数,启用这个模板的前提条件是这个参数满足 Integer 这个约束。
28.2 Concepts 简史
虽然 C++ 的”概念”看起来是个挺简单的概念,但它的历史并不短——Bjarne 想把它加入 C++ 已经有好多年了 [1]。
从基本概念上来讲,”概念”就是一组对模板参数的约束条件。我们讨论过模板就是 C++ 里的鸭子类型,但我们没有提过,Bjarne 对模板的接口实际上是相当不满意的:他自己的用词直接就是 lousy,并认为这一糟糕的接口设计是后面导致了恐怖的模板编译错误信息的根源。
从另一方面讲,Alex Stepanov 设计的 STL 一开始就包含了”概念”的概念,如我们在 [第 7 讲] 中提到的各种不同类型的迭代器:
- Output Iterator
- Input Iterator
- Forward Iterator
- Bidirectional Iterator
- Random Access Iterator
- …
这些概念出现在了 STL 的文档中,有详细的定义;但它们只是落在纸面上,而没有在 C++ 语言中有真正的体现。后来,他还进一步把很多概念的形式描述写进了他于 2009 年(和 Paul McJones 一起)出版的”神作” Elements of Programming [2] 中,并给出了假想的实现代码——其中就有关键字 requires——即使那时没有任何编译器能够编译这样的代码。
在 C++ 第一次标准化(1998)之后,Bjarne 多次试图把”概念”引入 C++(根据我看到的文献,他在 03 到 09 年直接有至少九篇单独或合著的论文跟”概念”有关),但一直没有成功——魔鬼在细节,一旦进入细节,人们对一个看起来很美的点子的分歧就非常大了。一直到 C++11 标准化,”概念” 还是因为草案复杂、争议多、无成熟实现而没有进入 C++ 标准。
目前 C++20 里的”概念”的基础是 2009 年重新启动的 Concepts Lite,并在 2015 年出版成为技术规格书 Concepts TS(正式的 TS 文档需要花钱购买,我们需要进一步了解可以查看正式出版前的草案 [3])。很多人参与了相关工作,其中就包括了 Andrew Sutton、Bjarne Stroustrup 和 Alex Stepanov。这回,实现简化了,有了一个实现(GCC),争议也少多了。然而,”概念”还是没有进入 C++17,主要由于下面这些原因:
- 从 Concepts TS 出版到标准定稿只有不到四个⽉的时间(C++20 的内容也同样是在 2019 年就全部冻结了,到正式出版前的时间留个修正小问题和走批准流程)
- “概念”只有一个实现(GCC)
- Concepts TS 规格书的作者和 GCC 中的概念实现者是同⼀个⼈,没有⼈独⽴地从规格书出发实现概念
- Concepts TS ⾥没有实际定义概念,标准库也没有把概念用起来
当然,大家还是认可”概念”是个好功能,到了 2017 年 7 月,”概念”就正式并入 C++20 草案了。之后,小修订还是不少的(所以”概念”没有进入 C++20 也不完全是件坏事)。从用户的角度,最大的一个改变是”概念”的名字:目前,所有标准”概念”从全部由大写字母打头改成了”标准大小写”——即全部小写字母加下划线 [4]。比如,允许相等比较这个概念,原先写作 EqualityComparable,现在要写成 equality_comparable。
28.3 基本的 Concepts
下图中给出了 C++ 里对象相关的部分标准概念(不完整):
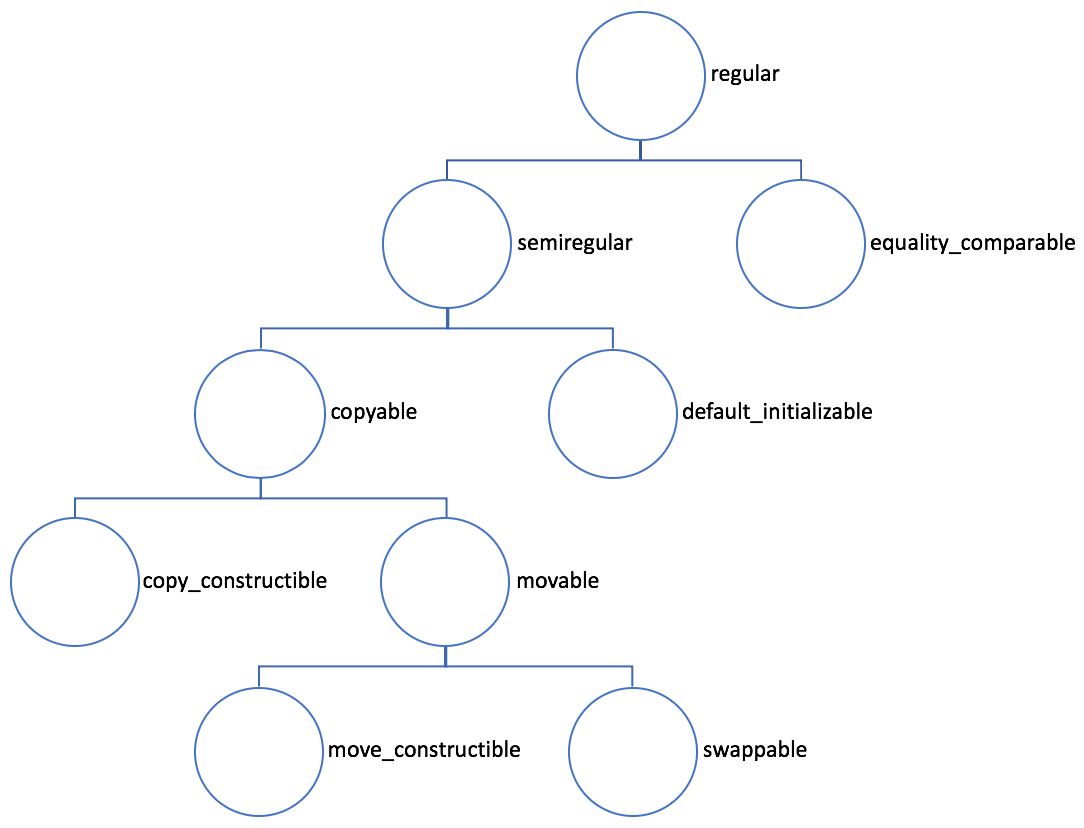
我们从下往上快速看一下:
- move_constructible:可移动构造
- swappable:可交换
- movable:可移动构造、可交换,合在一起就是可移动了
- copy_constructible:可拷贝构造
- copyable:可拷贝构造、可移动,合在一起就是可复制了(注:这儿”拷贝”和”复制”只是我在翻译中做的一点小区分,英文中没有区别)
- default_initializable:可默认初始化(名字不叫 default_constructible 是因为目前的 type traits 中有 is_default_constructible,且意义和
- default_initializable 有点微妙的区别;详见 问题报告 3338 )
- semiregular:可复制、可默认初始化,合在一起就是半正则了
- equality_comparable:可相等比较,即对象之间可以使用 == 运算符
- regular:半正则、可相等比较,合在一起就是正则了
这些”概念”现在不只是文字描述,绝大部分是可以真正在代码中定义的。现在,准标准的定义已经可以在 cppreference.com 上找到 [5]。从实际的角度,下面我们列举部分概念在 CMCSTL2 [6]——一个 Ranges(我们下一讲讨论)的参考实现——中的定义。
从简单性的角度,我们自上往下看,首先是 regular:
template <class T>
concept regular = semiregular<T> && equality_comparable<T>;很简单吧,定义一个 concept 此处只是一些针对类型的条件而已。可以看出,每个概念测试表达式(如 semiregular
然后是 semiregular:
template <class T>
concept semiregular = copyable<T> && default_initializable<T>;再看一眼 equality_comparable:
template <class T, class U>
concept WeaklyEqualityComparable =
requires(const remove_reference_t<T>& t, const remove_reference_t<U>& u) {
{ t == u } -> boolean;
{ t != u } -> boolean;
{ u == t } -> boolean;
{ u != t } -> boolean;
};
template <class T>
concept equality_comparable = WeaklyEqualityComparable<T, T>;这个稍复杂点,用到了 requires [7],但不需要我讲解,你也能看出来 equality_comparable 的要求就是类型的常左值引用之间允许进行 == 和 != 的比较,且返回类型为布尔类型吧。
注意上面的定义里写的是 boolean 而不是 bool。这个概念定义不要求比较运算符的结果类型是 bool,而是可以用在需要布尔值的上下文中。自然,boolean 也是有定义的,但这个定义可能比你想象的复杂,我这儿就不写出来了😜。
我们之前已经讲过了各种迭代器,每个迭代器也自然地满足一个”概念”——概念名称基本上就是之前给的,只是大小写要变化一下而已。最底下的 iterator 是个例外:因为这个名字在标准里已经被占用啦。所以现在它的名字是 input_or_output_iterator。
迭代器本身需要满足哪些概念呢?我们看下图:
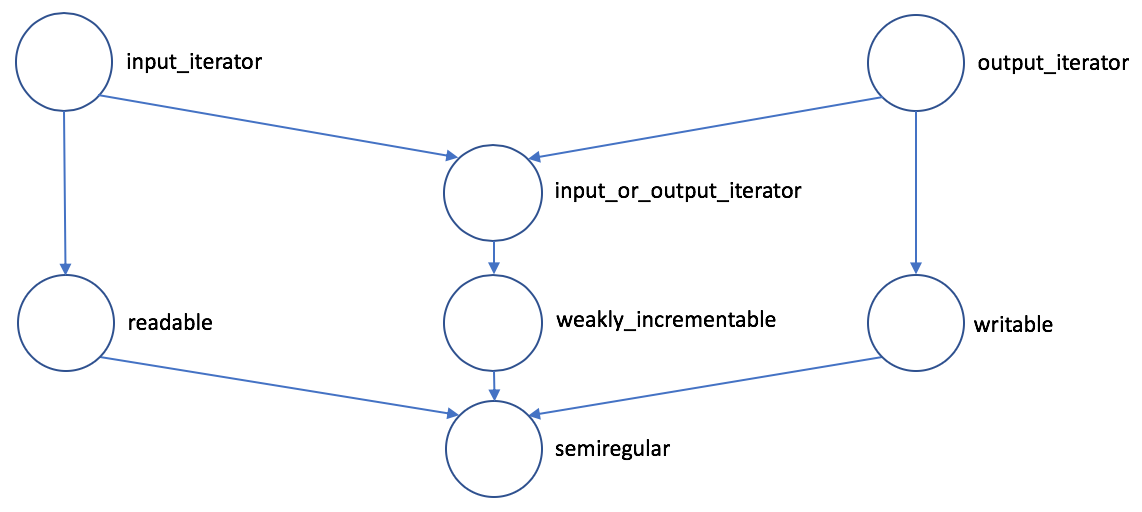
注意这张跟上面那张图不一样,概念之间不是简单的”合取”关系,而是一种”继承”关系:上面的概念比它指向的下面的概念有更多的要求。具体到代码:
template <class I>
concept weakly_incrementable = semiregular<I> && requires(I i)
{
typename iter_difference_t<I>;
requires signed_integral<iter_difference_t<I>>;
{ ++i } ->same_as<I&>;
i++;
};也就是说,weakly_incrementable 是 semiregular 再加一些额外的要求:
iter_difference_t<I>是一个类型iter_difference_t<I>是一个有符号的整数类型- ++i 的结果跟 I& 是完全相同的类型
- 能够执行 i++ 操作(不检查结果的类型)
input_or_output_iterator 也很简单:
template <class I>
concept input_or_output_iterator = __dereferenceable<I&> && weakly_incrementable<I>;就是要求可以解引用、可以执行 ++、可以使用 iter_difference_t 提取迭代器的 difference_type 而已。
剩下的概念的定义也不复杂,我这儿就不一一讲解了。感兴趣的话你可以自己去看 CMCSTL2 的源代码。
28.4 简单的概念测试
#include <armadillo>
#include <iostream>
#include <memory>
#include <string>
#include <type_traits>
using namespace std;
#if defined(__cpp_concepts)
#if __cpp_concepts < 201811
#include <experimental/ranges/concepts>
using namespace experimental::ranges;
#else
#include <concepts>
#endif
#else // defined(__cpp_concepts)
#error "No support for concepts!"
#endif
#define TEST_CONCEPT(Concept, Type) \
cout << #Concept << '<' << #Type \
<< ">: " \
<< Concept<Type> << endl
#define TEST_CONCEPT2( \
Concept, Type1, Type2) \
cout << #Concept << '<' \
<< #Type1 << ", " << #Type2 \
<< ">: " \
<< Concept<Type1, \
Type2> << endl
int main()
{
cout << boolalpha;
cout << "__cpp_concepts is " << __cpp_concepts << endl;
TEST_CONCEPT(regular, int);
TEST_CONCEPT(regular, char);
TEST_CONCEPT(integral, int);
TEST_CONCEPT(integral, char);
TEST_CONCEPT(readable, int);
TEST_CONCEPT(readable, unique_ptr<int>);
TEST_CONCEPT2(writable, unique_ptr<int>, int);
TEST_CONCEPT2(writable, unique_ptr<int>, double);
TEST_CONCEPT2(writable, unique_ptr<int>, int*);
TEST_CONCEPT(semiregular, unique_ptr<int>);
TEST_CONCEPT(semiregular, shared_ptr<int>);
TEST_CONCEPT(equality_comparable, unique_ptr<int>);
TEST_CONCEPT(semiregular, arma::imat);
TEST_CONCEPT2(assignable_from, arma::imat&, arma::imat&);
TEST_CONCEPT(semiregular, arma::imat22);
TEST_CONCEPT2(assignable_from, arma::imat22&, arma::imat22&);
}代码照顾了两种可能的环境:
- 最新的 MSVC(需要使用 /std:c++latest;我用的是 Visual Studio 2019 16.4.4)
- GCC(需要使用
-fconcepts;我测试了 7、8、9 三个版本都可以)和 CMCSTL2(需要将其 include 目录用-I选项加到命令行上)
程序在 MSVC 下的结果如下所示:
__cpp_concepts is 201811
regular<int>: true
regular<char>: true
integral<int>: true
integral<char>: true
readable<int>: false
readable<unique_ptr<int>>: true
writable<unique_ptr<int>, int>: true
writable<unique_ptr<int>, double>: true
writable<unique_ptr<int>, int*>: false
semiregular<unique_ptr<int>>: false
semiregular<shared_ptr<int>>: true
equality_comparable<unique_ptr<int>>: true
semiregular<arma::imat>: true
assignable_from<arma::imat&, arma::imat&>: true
semiregular<arma::imat22>: false
assignable_from<arma::imat22&, arma::imat22&>: false除了第一行 __cpp_concepts 的输出,GCC 的结果也是完全一致的。大部分的结果应当没有意外,但也需要注意,某些用起来没问题的类(如 arma::imat22),却因为一些实现上的特殊技术,不能满足 semiregular。——概念要比鸭子类型更为严格。
28.5 概念、出错信息和 SFINAE
显然,对于上面出现的这个例子:
template <Integer N>
N half(N n)
{
return n / 2;
}我们用 enable_if 也是能写出来的:
template <typename N>
enable_if_t<Integer<N>, N> half(N n)
{
return n / 2;
}不过,你不会觉得这种方式更好吧?而且,对于没有返回值的情况,要用对 enable_if 还是非常麻烦的(参见 [8] 里的 Notes / 注解部分)。
更重要的是,”概念”可以提供更为友好可读的代码,以及潜在更为友好的出错信息。拿 Andrew Sutton 的一个例子 [9](根据我们上节说的编译环境做了改编):
#include <string>
#include <vector>
using namespace std;
#if defined(__cpp_concepts)
#if __cpp_concepts < 201811
#include <experimental/ranges/concepts>
using namespace experimental::ranges;
#else
#include <concepts>
using namespace ranges;
#endif
#define REQUIRES(x) requires x
#else // defined(__cpp_concepts)
#define REQUIRES(x)
#endif
template <typename R, typename T>
REQUIRES((range<R> && equality_comparable_with<T, typename R::value_type>))
bool in(R const& r, T const& value)
{
for (auto const& x : r)
if (x == value)
return true;
return false;
}
int main()
{
vector<string> v { "Hello", "World" };
in(v, "Hello");
in(v, 0);
}以 GCC 8 为例,如果不使用概念约束,in(v, 0) 这行会产生 166 行出错信息;而启用了概念约束后,出错信息缩减到了 8 行。MSVC 上对于这个例子不使用概念错误信息也较短,但启用了概念后仍然能产生更短、更明确的出错信息:
test.cpp(46): error C2672: ‘in’: no matching overloaded function found
test.cpp(46): error C7602: ‘in’: the associated constraints are not satisfied
test.cpp(33): note: see declaration of ‘in’
随着编译器的改进,概念在出错信息上的优势在消减,但在代码表达上的优势仍然是实实在 在的。记得 [第 14 讲] 里我们费了好大的劲、用了几种不同的方法来定义 has_reserve 吗?在概念面前,那些就成了”回”字有几种写法了。我们可以飞快地定义下面的概念:
template <typename T>
concept has_reserve = requires(T& dest) {
dest.reserve(1U);
};在 [第 13 讲] 我给出过的 fmap,在实际代码中我也是用了 SFINAE 来进行约束的(略简化):
template <
template <typename, typename>
class OutContainer = vector, typename F, class R>
auto fmap(F&& f, R&& inputs) -> decltype(begin(inputs), end(inputs),
OutContainer<decay_t<decltype(f(*begin(inputs)))>>());我费了老大的劲,要把返回值写出来,实际上就是为了利用 SFINAE 而已。如果使用”概念”,那代码可以简化成:
template <
template <typename, typename>
class OutContainer = vector, typename F, class R>
requires requires(R&& r) { begin(r); end(r); }
auto fmap(F&& f, R&& inputs);上面的 requires requires 不是错误,正如 noexcept(noexcept(…)) 不是错误一样。第一个 requires 开始一个 requires 子句,后面跟一个常量表达式,结果的真假表示是否满足了模板的约束条件。第二个 requires 则开始了一个 requires 表达式:如果类型 R 满足约束——可以使用 begin 和 end 对 R&& 类型的变量进行调用——则返回真,否则返回假。
不过,在 C++20 里,上面这个条件我是不需要这么写出来的。有一个现成的概念可用,这么写就行了:
template <
template <typename, typename>
class OutContainer = vector, typename F, class R>
requires range<R>
auto fmap(F&& f, R&& inputs);28.6 参考资料
- Bjarne Stroustrup, “Concepts: the future of generic programming, or how to design good concepts and use them well”. http://www.stroustrup.com/good_concepts.pdf
- Alexander Stepanov and Paul McJones, Elements of Programming. Addison-Wesley, 2009. 有中文版(裘宗燕译《编程原本》,人民邮电出版社,2019 年)
- ISO/IEC JTC1 SC22 WG21, N4549, “Programming languages — C++ extensions for concepts”. http://www.openstd.org/jtc1/sc22/wg21/docs/papers/2015/n4549.pdf
- Herb Sutter et al., “Rename concepts to standard_case for C++20, while we still can”. http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2019/p1754r1.pdf
- cppreference.com, “
Standard library header <concepts>“. https://en.cppreference.com/w/cpp/header/concepts. - Casey Carter et al., cmcstl2. https://github.com/CaseyCarter/cmcstl2
- cppreference.com, “Constraints and concepts”. https://en.cppreference.com/w/cpp/language/constraints
- cppreference.com, “std::enable_if”. https://en.cppreference.com/w/cpp/types/enable_if
- Andrew Sutton, “Introducing concepts”. https://accu.org/index.php/journals/2157
29 | Ranges:无迭代器的迭代和更方便的组合
29.1 Ranges 简介
#include <experimental/ranges/algorithm>
#include <experimental/ranges/iterator>
#include <iostream>
int main()
{
using namespace std::experimental::ranges;
int a[] = { 1, 7, 3, 6, 5, 2, 4, 8 };
copy(a, ostream_iterator<int>(std::cout, " "));
std::cout << std::endl;
sort(a);
copy(a, ostream_iterator<int>(std::cout, " "));
std::cout << std::endl;
}这是真正可以编译的代码,用我们上一讲讲过的环境——最新版的 MSVC(编译命令行上需要额外加 /permissive- 选项)或 GCC 7+——都可以。不过,这一次即使最新版的 MSVC 也不能靠编译器本身支持 ranges 库的所有特性了:在两种环境下我们都必须使用 CMCSTL2 [1],也只能(在 C++20 之前临时)使用 std::experimental::ranges 而不是 std::ranges。注意我只引入了 ranges 名空间,而没有引入 std 名空间,这是因为 copy、sort 等名称同时出现在了这两个名空间里,同时引入两个名空间会在使用 sort 等名字时导致冲突。
下面我们看”视图”。比如下面的代码展示了一个反转的视图:
#include <experimental/ranges/algorithm>
#include <experimental/ranges/iterator>
#include <experimental/ranges/ranges>
#include <iostream>
int main()
{
using namespace std::experimental::ranges;
int a[] = { 1, 7, 3, 6, 5, 2, 4, 8 };
copy(a, ostream_iterator<int>(std::cout, " "));
std::cout << std::endl;
auto r = reverse_view(a);
copy(r, ostream_iterator<int>(std::cout, " "));
std::cout << std::endl;
}视图的大小也不一定跟原先的”范围”一样。下面是我们在 [第 17 讲] 讨论过的过滤视图在 ranges 里的实现的用法:
auto r = filter_view(a, [](int i) {
return i % 2 == 0;
});这些视图还能进行组合:我们可以写 reverse_view(filter_view(…))。不过,在组合的情况下,下面这样的写法(使用 | 和视图适配器)可能更清晰些:
auto r = a |
views::filter([](int i) {
return i % 2 == 0;
}) |
views::reverse;如果你用过 Unix 的管道符,你一定会觉得这种写法非常自然、容易组合吧……
29.2 范围相关的概念
整个 ranges 库是基于概念来定义的。下面这张图展示了 range 相关的概念:
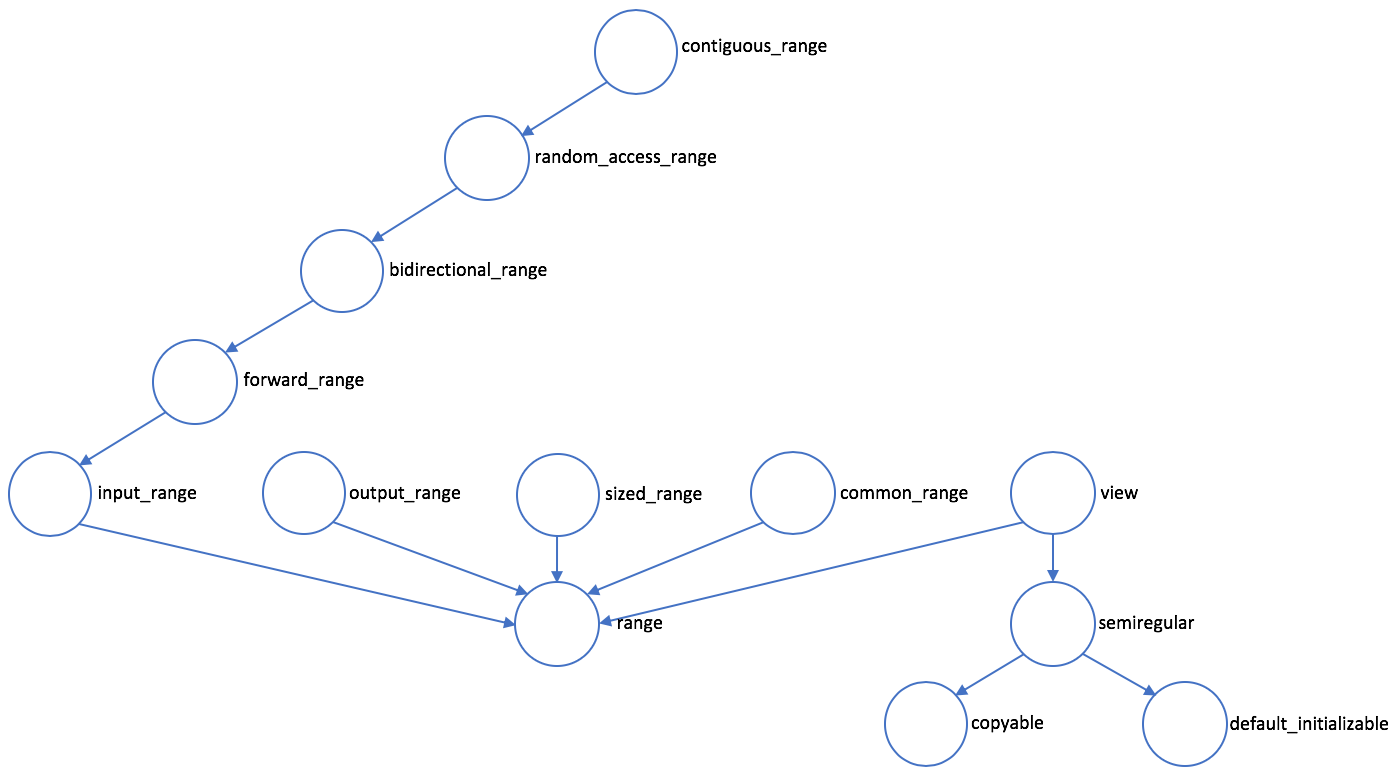
在 CMCSTL2 里,range 是这样定义的:
template <class T>
concept _RangeImpl = requires(T&& t) {
begin(static_cast<T&&>(t));
end(static_cast<T&&>(t));
};
template <class T>
concept range = _RangeImpl<T&>;换句话说,一个 range 允许执行 begin 和 end 操作(注意这是在 ranges 名空间下的 begin 和 end,和 std 下的有些小区别)。所以,一个数组,一个容器,通常也能当作一个 range。
view 的定义:
template <class T>
concept view = range<T> && semiregular<T> && enable_view<__uncvref<T>>;可以看到,view 首先是一个 range,其次它是 semiregular,也就是,可以被移动和复制(对 range 没有这个要求)。然后 enable_view 是个实现提供的概念,它的实际要求就是,视图应该不是一个容器,可以在 O(1) 复杂度完成拷贝或移动操作。我们常用的 string 满足 range,不满足 view;而 string_view 则同时满足 range 和 view。
下面,我们看 common_range,它的意思是这是个普通的 range,对其应用 begin() 和 end(),结果是同一类型:
template <class T>
concept common_range = range<T> && same_as<iterator_t<T>, sentinel_t<T>>;然后,sized_range 的意思就是这个 range 是有大小的,可以取出其大小(注意我们刚才的 filter_view 就是没有大小的):
template <class T>
concept sized_range = range<T> && requires(T& r) { size(r); };自然,output_range 的意思是这个 range 的迭代器满足输出迭代器的条件:
template <class R, class T>
concept output_range = range<R> && output_iterator<iterator_t<R>, T>;当然,input_range 的意思是这个 range 的迭代器满足输入迭代器的条件:
template <class T>
concept input_range = range<T> && input_iterator<iterator_t<T>>;29.3 Sentinel
我估计其他概念你理解起来应该问题不大,但 common_range 也许会让有些人迷糊:什么样的 range 会不是 common_range 呢?
答案是,有些 range 的结束点,不是固定的位置,而是某个条件:如遇到 0,或者某个谓词满足了 10 次之后……从 C++17 开始,基于范围的 for 循环也接受 begin 和 end 的结果不是同一类型了——我们把前者返回的结果类型叫 iterator(迭代器),而把后者返回的结果类型叫 sentinel(标记)。
一个实际的例子:
#include <experimental/ranges/algorithm>
#include <experimental/ranges/iterator>
#include <iostream>
using namespace std::experimental::ranges;
struct null_sentinel {
};
template <input_iterator I>
bool operator==(I i, null_sentinel)
{
return *i == 0;
}
template <input_iterator I>
bool operator==(null_sentinel, I i)
{
return *i == 0;
}
template <input_iterator I>
bool operator!=(I i, null_sentinel)
{
return *i != 0;
}
template <input_iterator I>
bool operator!=(null_sentinel, I i)
{
return *i != 0;
}
int main(int argc, char* argv[])
{
if (argc != 2) {
std::cout << "Please provide an argument!" << std::endl;
return 1;
}
for_each(argv[1], null_sentinel(), [](char ch) {
std::cout << ch;
});
std::cout << std::endl;
}在这个程序里,null_sentinel 就是一个”空值标记”。这个类型存在的唯一意义,就是允许 == 和 != 根据重载规则做一些特殊的事情:在这里,就是判断当前迭代器指向的位置是否为 0。上面程序的执行结果是把命令行上传入的第一个参数输出到终端上。
29.4 概念测试
我们现在对概念来做一下检查,看看常用的一些容器和视图满足哪些 ranges 里的概念。
这张表里没有什么意外的东西。除了 view,vector<int> 满足所有的 range 概念。另外,const vector<int> 不能满足 output_range,不能往里写内容,也一切正常。
这张表,同样表达了我们已知的事实:list 不满足 random_access_range 和 contiguous_range。
这张表,说明了从 range 的角度,C 数组和 vector 是没啥区别的。
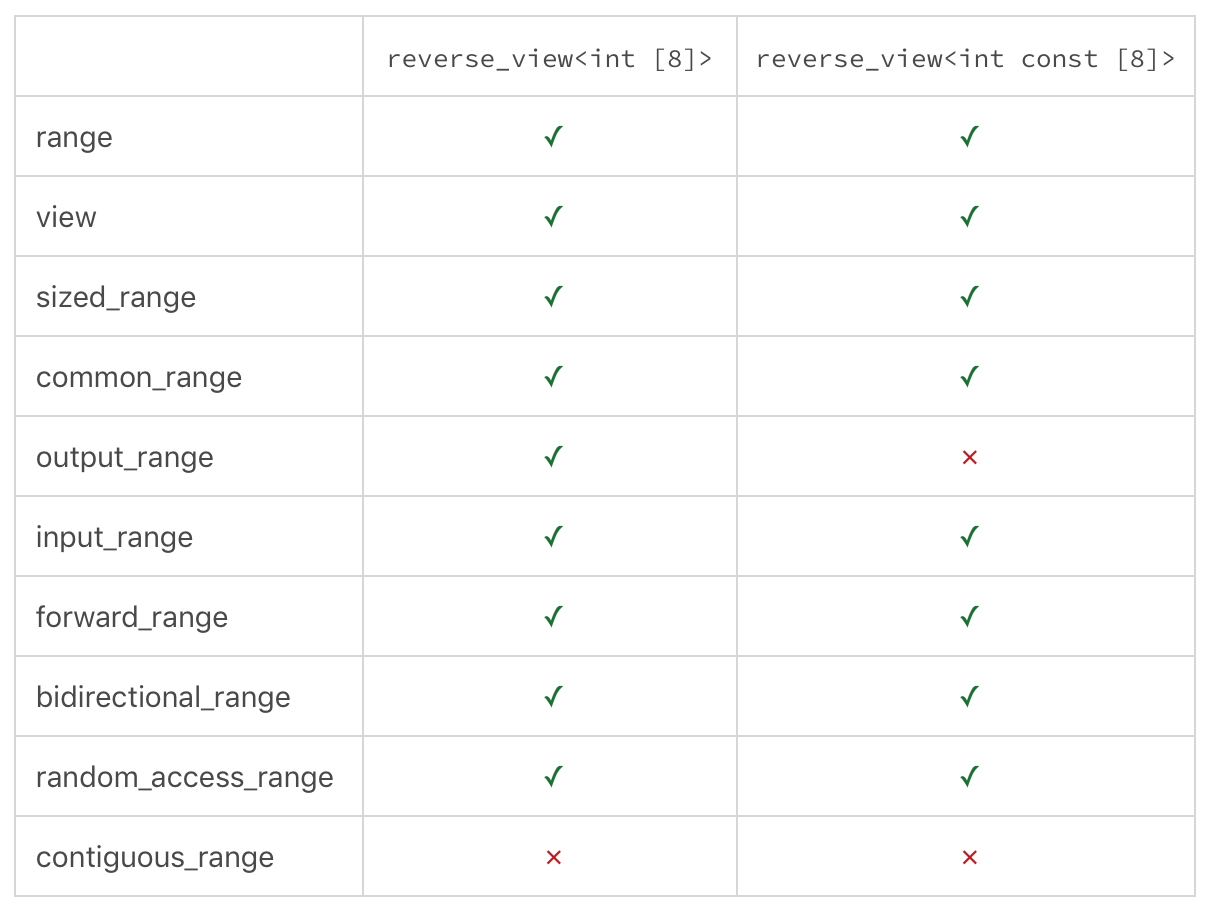
这张就有点意思了,展示了反转视图的特点。我们可以看到它几乎和原始容器可满足的概念一样,就多了 view,少了 contiguous_range。应该没有让你感到意外的内容吧。
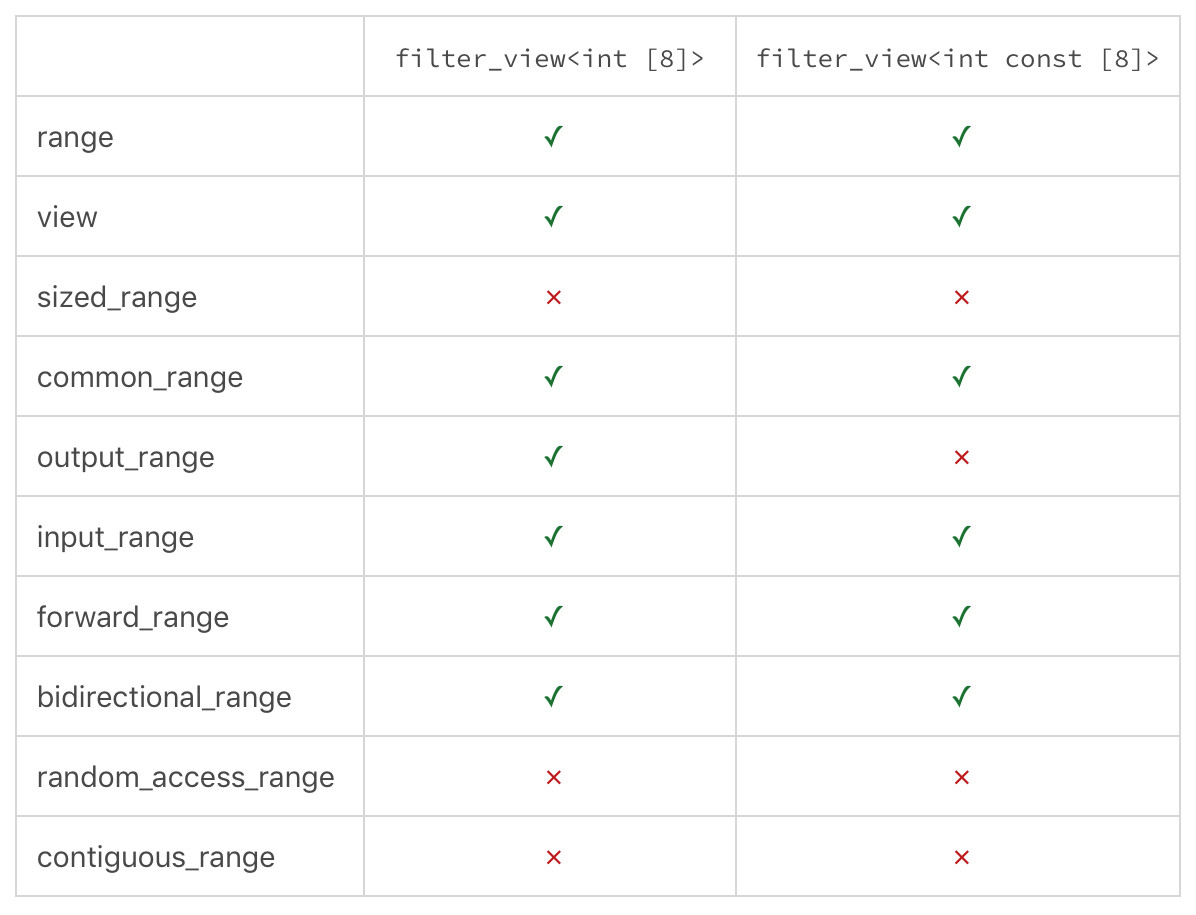
但过滤视图就不一样了:我们不能预知元素的数量,所以它不能满足 sized_range。

我们前面说过,istream_line_reader 的迭代器是输入迭代器,所以它也只能是个 input_range。我们在设计上对 begin() 和 end 的返回值采用了相同的类型,因此它仍是个 common_range。用 take_view 可以取一个范围的前若干项,它就不是一个 commom_range 了。因为输入可能在到达预定项数之前结束,所以它也不是 sized_range。
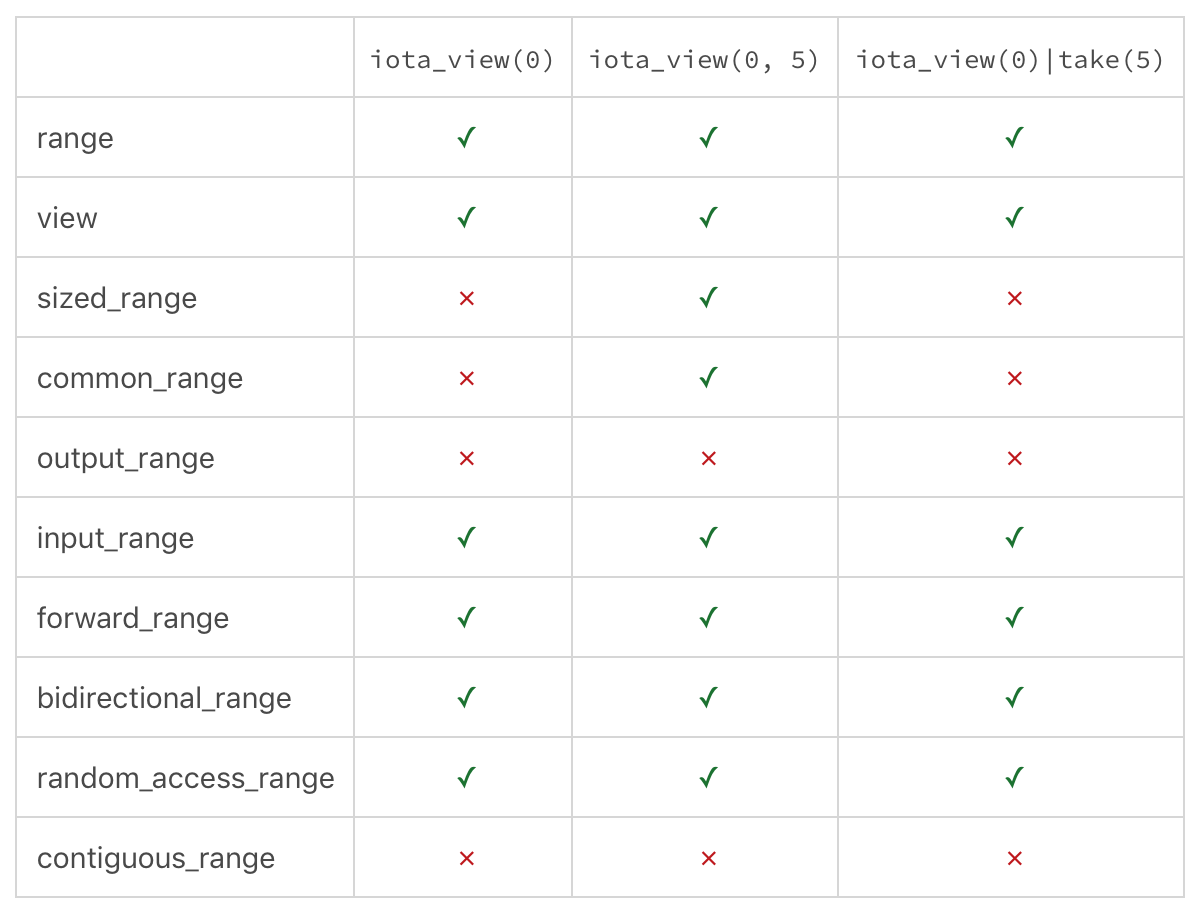
我们再来介绍一个新的视图,iota_view。它代表一个从某个数开始的递增序列。单参数的 iota_view 是无穷序列,双参数的是有限序列,从它们能满足的概念上就能看出来。这儿比较有趣的事实是,虽然 iota_view(0, 5) 和 iota_view(0) | take(5) 的结果相同,都是序列 {0, 1, 2, 3, 4},但编译器看起来,前者比后者要多满足两个概念。这应该也不难理解。
29.5 抽象和性能
Python 代码:
reduce(lambda x, y: x + y, map(lambda x: x * x, range(1, 101)))对应 C++ 代码:
int sum = nvwa::reduce(std::plus<int>(),
views::iota(1, 101) | views::transform([](int x) { return x * x; }));上面的代码性能很高……多高呢?看下面这行汇编输出的代码就知道了:
movl $338350, -4(%rbp)29.6 ranges 名空间
我们现在再来看一下 ranges 名空间(我们目前代码里的 std::experimental::ranges,C++20 的 std::ranges)。这个名空间有 ranges 特有的内容:
- 视图(如 reverse_view)和视图适配器(如 views::reverse)
- ranges 相关的概念(如 range、view 等)
但也有些名称是从 std 名空间”复制”过来的,包括:
- 标准算法(如 copy、transform、sort、all_of、for_each 等;但是,如前面所说,没有 accumulate 或 reduce)
- begin 和 end
std::copy 接受的是迭代器,而 ranges::copy 接受的是范围,似乎还有点道理。那 begin 和 end 呢?本来接受的参数就是一个范围啊……
Eric Niebler(Ranges TS 的作者)引入 ranges::begin 的目的是解决下面的代码可能产生的问题(他的例子 [3]):
extern std::vector<int> get_data();
auto it = std::begin(get_data());
int i = *it; // BOOM注意在读取 *it 的时候,get_data() 返回的 vector 已经被销毁了——所以这个读取操作是未定义行为(undefined behavior)。
Eric Niebler 和 Casey Carter(CMCSTL2 的主要作者)使用了一个特殊的技巧,把 begin 和 end 实现成了有特殊约束的函数对象,使得下面这样的代码无法通过编译:
extern std::vector<int> get_data();
auto it = ranges::begin(get_data());
int i = *it; // BOOM如果你对此有兴趣的话,可以看一下 CMCSTL2 里的 include/stl2/detail/range/access.hpp。
对一般的用户而言,记住 ranges::begin 和 ranges::end 是将来 std::begin 和 std::end 的更好的替代品就行了。
29.7 一点历史
对于标准算法里的迭代器的问题早就有人看到了,并且有不少人提出了改进的方案。最早在 2003 年,Boost.Range 就已经出现(但影响似乎不大)。Andrei Alexandresu 在 2009 年发了一篇很有影响力的文章,”Iterators must go” [4],讨论迭代器的问题,及他在 D 语言里实现 ranges 的经验,但在 C++ 界没有开花结果。Eric Niebler 在 2013 年开始了 range-v3 [5] 的工作,这才是目前的 ranges 的基础。他把 ranges 写成了一个标准提案[6],并在 2017 年被 ISO 出版成为正式的 Ranges TS。2018 年末,好消息传来,C++ 委员会通过了决议,Ranges 正式被并入了 C++20 的草案!
谁说程序员都是无趣的?这篇内容申请把 Ranges 并入 C++ 标准草案的纯技术文档 The One Ranges Proposal [7],开头绝对是激情四射啊。

29.8 批评和未来
如果我只说好的方面、问题一点不说,对于学习道路上的你,也不是件好事。最有名的对 C++ Ranges 的批评,就是 Unity 开发者 Aras Pranckevičius 发表的一篇文章 [8]。我不完全认同文中的观点,但我觉得读一下反面的意见也很重要。
此外,C++20 里的 ranges 不是一个概念的终点。即便在 range-v3 库里,也有很多东西仍然没有进入 C++ 标准。比如,看一眼下面的代码:
#include <iostream>
#include <string>
#include <vector>
#include <range/v3/all.hpp>
int main()
{
std::vector<int> vd { 1, 7, 3, 6, 5, 2, 4, 8 };
std::vector<std::string> vs {
"one", "seven", "three",
"six", "five", "two",
"four", "eight"
};
auto v = ranges::views::zip(vd, vs);
ranges::sort(v);
for (auto i : vs) {
std::cout << i << std::endl;
}
}这个非标的 range-v3 库的另外一个好处是,它不依赖于概念的支持,因而可以用在更多的环境中,包括目前还不支持概念的 Clang。
29.9 参考资料
- Casey Carter et al., cmcstl2. https://github.com/CaseyCarter/cmcstl2
- 吴咏炜, nvwa/functional.h. https://github.com/adah1972/nvwa/blob/master/nvwa/functional.h
- Eric Niebler, “Standard ranges”. http://ericniebler.com/2018/12/05/standard-ranges/
- Andrei Alexandrescu, “Iterators must go”, http://accu.org/content/conf2009/AndreiAlexandrescu_iterators-must-go.pdf
- Eric Niebler, range-v3. https://github.com/ericniebler/range-v3
- Eric Niebler and Casey Carter, “Working draft, C++ extensions for ranges”. http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2015/n4560.pdf
- Eric Niebler, Casey Carter, and Christopher Di Bella, “The one ranges proposal”. http://www.openstd.org/jtc1/sc22/wg21/docs/papers/2018/p0896r4.pdf
- Aras Pranckevičius, “ ‘Modern’ C++ lamentations”. https://arasp.info/blog/2018/12/28/Modern-C-Lamentations/ ;CSDN 的翻译见
https://blog.csdn.net/csdnnews/article/details/86386281
30 | Coroutines:协作式的交叉调度执行
30.1 什么是协程?
维基百科的定义 [1]:
协程是计算机程序的⼀类组件,推⼴了协作式多任务的⼦程序,允许执⾏被挂起与被恢复。相对⼦例程⽽⾔,协程更为⼀般和灵活……
在 C++ 里的标准协程有点小复杂。我们还是从……Python 开始。
def fibonacci():
a = 0
b = 1
while True:
yield b
a, b = b, a + byield 这种写法在 Python 里叫做”生成器”(generator),返回的是一个可迭代的对象,每次迭代就能得到一个 yield 出来的结果。这就是一种很常见的协程形式了。
如何使用这个生成器,请看下面的代码:
# 打印头 20 项
for i in islice(fibonacci(), 20):
print(i)
# 打印小于 10000 的数列项
for i in takewhile(lambda x: x < 10000, fibonacci()):
print(i)这些代码很容易理解:islice 相当于 [第 29 讲] 中的 take,取一个范围的头若干项;takewhile 则在范围中逐项取出内容,直到第一个参数的条件不能被满足。两个函数的结果都可以被看作是 C++ 中的视图。
在代码的执行过程中,fibonacci 和它的调用代码是交叉执行的。下面我们用代码行加注释的方式标一下:
a = 0 # fibonacci()
b = 0 # fibonacci()
yield b # fibonacci()
print(i) # 调用者
a, b = 1, 0 + 1 # fibonacci()
yield b # fibonacci()
print(i) # 调用者
a, b = 1, 1 + 1 # fibonacci()
yield b # fibonacci()
print(i) # 调用者
a, b = 2, 1 + 2 # fibonacci()
yield b # fibonacci()
print(i) # 调用者
…对应 C++ 代码:
#include <stddef.h>
#include <stdint.h>
class fibonacci {
public:
class sentinel;
class iterator;
iterator begin() noexcept;
sentinel end() noexcept;
};
class fibonacci::sentinel {
};
class fibonacci::iterator {
public:
// Required to satisfy iterator concept
typedef ptrdiff_t difference_type;
typedef uint64_t value_type;
typedef const uint64_t* pointer;
typedef const uint64_t& reference;
typedef std::input_iterator_tag iterator_category;
value_type operator*() const
{
return b_;
}
pointer operator->() const
{
return &b_;
}
iterator& operator++()
{
auto tmp = a_;
a_ = b_;
b_ += tmp;
return *this;
}
iterator operator++(int)
{
auto tmp = *this;
++*this;
return tmp;
}
bool operator==(const sentinel&) const
{
return false;
}
bool operator!=(const sentinel&) const
{
return true;
}
private:
uint64_t a_ { 0 };
uint64_t b_ { 1 };
};
// sentinel needs to be equality_comparable_with iterator
bool operator==(const fibonacci::sentinel& lhs, const fibonacci::iterator& rhs)
{
return rhs == lhs;
}
bool operator!=(const fibonacci::sentinel& lhs, const fibonacci::iterator& rhs)
{
return rhs != lhs;
}
inline fibonacci::iterator fibonacci::begin() noexcept
{
return iterator();
}
inline fibonacci::sentinel fibonacci::end() noexcept
{
return sentinel();
}调用代码跟 Python 的相似:
// 打印头 20 项
for (auto i : fibonacci() | take(20)) {
cout << i << endl;
}
// 打印小于 10000 的数列项
for (auto i : fibonacci() | take_while([](uint64_t x) {
return x < 10000;
})) {
cout << i << endl;
}这似乎还行。但 fibonacci 的定义差异就大了:在 Python 里是 6 行有效代码,在 C++ 里是 53 行。C++ 的生产率似乎有点低啊……
30.2 C++20 协程
C++20 协程的基础是微软提出的 Coroutines TS(可查看工作草案 [2]),它在 2019 年 7 月被批准加入到 C++20 草案中。目前,MSVC 和 Clang 已经支持协程。不过,需要提一下的是,目前被标准化的只是协程的底层语言支持,而不是上层的高级封装;稍后,我们会回到这个话题。
协程可以有很多不同的用途,下面列举了几种常见情况:
- 生成器
- 异步 I/O
- 惰性求值
- 事件驱动应用
这一讲中,我们主要还是沿用生成器的例子,向你展示协程的基本用法。异步 I/O 应当在协程得到广泛采用之后,成为最能有明显收益的使用场景;但目前,就我看到的,只有 Windows 平台上有较好的支持——微软目前还是做了很多努力的。
回到 Coroutines。我们今天采用 Coroutines TS 中的写法,包括 std::experimental 名空间,以确保你可以在 MSVC 和 Clang 下编译代码。首先,我们看一下协程相关的新关键字,有下面三个:
- co_await
- co_yield
- co_return
这三个关键字最初是没有 co_ 前缀的,但考虑到 await、yield 已经在很多代码里出现,就改成了目前这个样子。同时,return 和 co_return 也作出了明确的区分:一个协程里只能使用 co_return,不能使用 return。这三个关键字只要有一个出现在函数中,这个函数就是一个协程了——从外部则看不出来,没有用其他语言常用的 async 关键字来标记(async 也已经有其他用途了,见 [第 19 讲])。C++ 认为一个函数是否是一个协程是一个实现细节,不是对外接口的一部分。
我们看一下用协程实现的 fibonacci 长什么样子:
uint64_resumable fibonacci()
{
uint64_t a = 0;
uint64_t b = 1;
while (true) {
co_yield b;
auto tmp = a;
a = b;
b += tmp;
}
}这个形式跟 Python 的非常相似了吧,也非常简洁。我们稍后再讨论 uint64_resumable 的定义,先看一下调用代码的样子:
auto res = fibonacci();
while (res.resume()) {
auto i = res.get();
if (i >= 10000) {
break;
}
cout << i << endl;
}这个代码也非常简单,但我们需要留意 resume 和 get 两个函数调用——这就是我们的 uint64_resumable 类型需要提供的接口了。
30.3 co_await、co_yield、co_return 和协程控制
在讨论该如何定义 uint64_resumable 之前,我们需要先讨论一下协程的这三个新关键字。
首先是 co_await。对于下面这样一个表达式:
auto result = co_await 表达式;编译器会把它理解为:
auto&& __a = 表达式;
if (!__a.await_ready()) {
__a.await_suspend(协程句柄);
// 挂起/恢复点
}
auto result = __a.await_resume();也就是说,”表达式”需要支持 await_ready、await_suspend 和 await_resume 三个接口。如果 await_ready() 返回真,就代表不需要真正挂起,直接返回后面的结果就可以;否则,执行 await_suspend 之后即挂起协程,等待协程被唤醒之后再返回 await_resume() 的结果。这样一个表达式被称作是个 awaitable。
标准里定义了两个 awaitable,如下所示:
struct suspend_always {
bool await_ready() const noexcept
{
return false;
}
void await_suspend(coroutine_handle<>) const noexcept { }
void await_resume() const noexcept { }
};
struct suspend_never {
bool await_ready() const noexcept
{
return true;
}
void await_suspend(coroutine_handle<>) const noexcept { }
void await_resume() const noexcept { }
};也就是说,suspend_always 永远告诉调用者需要挂起,而 suspend_never 则永远告诉调用者不需要挂起。两者的 await_suspend 和 await_resume 都是平凡实现,不做任何实际的事情。一个 awaitable 可以自行实现这些接口,以定制挂起之前和恢复之后需要执行的操作。
上面的 coroutine_handle 是 C++ 标准库提供的类模板。这个类是用户代码跟系统协程调度真正交互的地方,有下面这些成员函数我们等会就会用到:
- destroy:销毁协程
- done:判断协程是否已经执行完成
- resume:让协程恢复执行
- promise:获得协程相关的 promise 对象(和 [第 19 讲] 中的”承诺量”有点相似,是协程和调用者的主要交互对象;一般类型名称为 promise_type)
- from_promise(静态):通过 promise 对象的引用来生成一个协程句柄
协程的执行过程大致是这个样子的:
- 为协程调用分配一个协程帧,含协程调用的参数、变量、状态、promise 对象等所需的空间。
- 调用 promise.get_return_object(),返回值会在协程第一次挂起时返回给协程的调用者。
- 执行 co_await promise.initial_suspsend();根据上面对 co_await 语义的描述,协程可能在此第一次挂起(但也可能此时不挂起,在后面的协程体执行过程中挂起)。
- 执行协程体中的语句,中间可能有挂起和恢复;如果期间发生异常没有在协程体中处理,则调用 promise.unhandled_exception()。
- 当协程执行到底,或者执行到 co_return 语句时,会根据是否有非 void 的返回值,调用 promise.return_value(…) 或 promise.return_void(),然后执行co_await promise.final_suspsend()。
用代码可以大致表示如下:
frame = operator new(…);
promise_type& promise = frame->promise;
// 在初次挂起时返回给调用者
auto return_value =promise.get_return_object();
co_await promise.initial_suspsend();
try {
执行协程体;
可能被 co_wait、co_yield 挂起;
恢复后继续执行,直到 co_return;
}
catch (...) {
promise.unhandled_exception();
}
final_suspend:
co_await promise.final_suspsend();上面描述了 co_await 和 co_return,那 co_yield 呢?也很简单,co_yield 表达式等价于:
co_await promise.yield_value(表达式);30.4 定义 uint64_resumable
class uint64_resumable {
public:
struct promise_type {
//…
};
using coro_handle = coroutine_handle<promise_type>;
explicit uint64_resumable(coro_handle handle)
: handle_(handle)
{
}
~uint64_resumable()
{
handle_.destroy();
}
uint64_resumable(const uint64_resumable&) = delete;
uint64_resumable(uint64_resumable&&) = default;
bool resume();
uint64_t get();
private:
coro_handle handle_;
};这个代码相当简单,我们的结构内部有个 promise_type(下面会定义),而私有成员只有一个协程句柄。协程构造需要一个协程句柄,析构时将使用协程句柄来销毁协程;为简单起见,我们允许结构被移动,但不可复制(以免重复调用 handle_.destroy())。除此之外,我们这个结构只提供了调用者需要的 resume 和 get 成员函数,分别定义如下:
bool uint64_resumable::resume()
{
if (!handle_.done()) {
handle_.resume();
}
return !handle_.done();
}
uint64_t uint64_resumable::get()
{
return handle_.promise().value_;
}也就是说,resume 会判断协程是否已经结束,没结束就恢复协程的执行;当协程再次挂起时(调用者恢复执行),返回协程是否仍在执行中的状态。而 get 简单地返回存储在 promise 对象中的数值。
现在我们需要看一下 promise 类型了,它里面有很多协程的定制点,可以修改协程的行为:
struct promise_type {
uint64_t value_;
using coro_handle = coroutine_handle<promise_type>;
auto get_return_object()
{
return uint64_resumable { coro_handle::from_promise(*this) };
}
constexpr auto initial_suspend()
{
return suspend_always();
}
constexpr auto final_suspend()
{
return suspend_always();
}
auto yield_value(uint64_t value)
{
value_ = value;
return suspend_always();
}
void return_void() { }
void unhandled_exception()
{
std::terminate();
}
};简单解说一下:
- 结构里面只有一个数据成员 value_,存放供 uint64_resumable::get 取用的数值。
- get_return_object 是第一个定制点。我们前面提到过,调用协程的返回值就是 get_return_object() 的结果。我们这儿就是使用 promise 对象来构造一个 uint64_resumable。
- initial_suspend 是第二个定制点。我们此处返回 suspend_always(),即协程立即挂起,调用者马上得到 get_return_object() 的结果。
- final_suspend 是第三个定制点。我们此处返回 suspend_always(),即使执行到了 co_return 语句,协程仍处于挂起状态。如果我们返回 suspend_never() 的话,那一旦执行了 co_return 或执行到协程结束,协程就会被销毁,连同已初始化的本地变量和 promise,并释放协程帧内存。
- yield_value 是第四个定制点。我们这儿仅对 value_ 进行赋值,然后让协程挂起(执行控制回到调用者)。
- return_void 是第五个定制点。我们的代码永不返回,这儿无事可做。
- unhandled_exception 是第六个定制点。我们这儿也不应该发生任何异常,所以我们简单地调用 terminate 来终结程序的执行。
好了,这样,我们就完成了协程相关的所有定义。有没有觉得轻松点?
没有?那就对了。正如我在这一节开头说的,C++20 标准化的只是协程的底层语言支持(我上面还并不是一个非常完整的描述)。要用这些底层直接写应用代码,那是非常痛苦的事。这些接口的目标用户实际上也不是普通开发者,而是库的作者。
幸好,我们并不是没有任何高层抽象,虽然这些实现不”标准”。
30.5 C++20 协程的高层抽象
cppcoro
我们首先看一下跨平台的 cppcoro 库 [3],它提供的高层接口就包含了 generator。如果使用 cppcoro,我们的 fibonacci 协程可以这样实现:
#include <cppcoro/generator.hpp> using cppcoro::generator; generator<uint64_t> fibonacci() { uint64_t a = 0; uint64_t b = 1; while (true) { co_yield b; auto tmp = a; a = b; b += tmp; } }使用 fibonacci 也比刚才的代码要方便:
for (auto i : fibonacci()) { if (i >= 10000) { break; } cout << i << endl; }除了生成器,cppcoro 还支持异步任务和异步 I/O——遗憾的是,异步 I/O 目前只有 Windows 平台上有,还没人实现 Linux 或 macOS 上的支持。
MSVC
作为协程的先行者和 Coroutines TS 的提出者,微软在协程上做了很多工作。生成器当然也在其中:
#include <experimental/generator> using std::experimental::generator; generator<uint64_t> fibonacci() { uint64_t a = 0; uint64_t b = 1; while (true) { co_yield b; auto tmp = a; a = b; b += tmp; } }微软还有一些有趣的私有扩展。比如,MSVC 把标准 C++ 的 future 改造成了 awaitable。下面的代码在 MSVC 下可以编译通过,简单地展示了基本用法:
#include <experimental/coroutine> using namespace std; future<int> compute_value() { int result = co_await async([] { this_thread::sleep_for(1s); return 42; }); co_return result; } int main() { auto value = compute_value(); cout << value.get() << endl; }代码中有一个地方我需要提醒一下:虽然上面 async 返回的是
future<int>,但 compute_value 的调用者得到的并不是这个 future——它得到的是另外一个独立的 future,并最终由 co_return 把结果数值填充了进去。
30.6 有栈协程和无栈协程
我们最后需要说一下有栈(stackful)协程和无栈(stackless)协程的区别。C++ 里很早就有了有栈的协程,概念上来讲,有栈的协程跟纤程、goroutines 基本是一个概念,都是由用户自行调度的、操作系统之外的运行单元。每个这样的运行单元都有自己独立的栈空间,缺点当然就是栈的空间占用和切换栈的开销了。而无栈的协程自己没有独立的栈空间,每个协程只需要一个很小的栈帧,空间占用小,也没有栈的切换开销。
C++20 的协程是无栈的。部分原因是有栈的协程可以使用纯库方式实现,而无栈的协程需要一点编译器魔法帮忙。毕竟,协程里面的变量都是要放到堆上而不是栈上的。
一个简单的无栈协程调用的内存布局如下图所示:
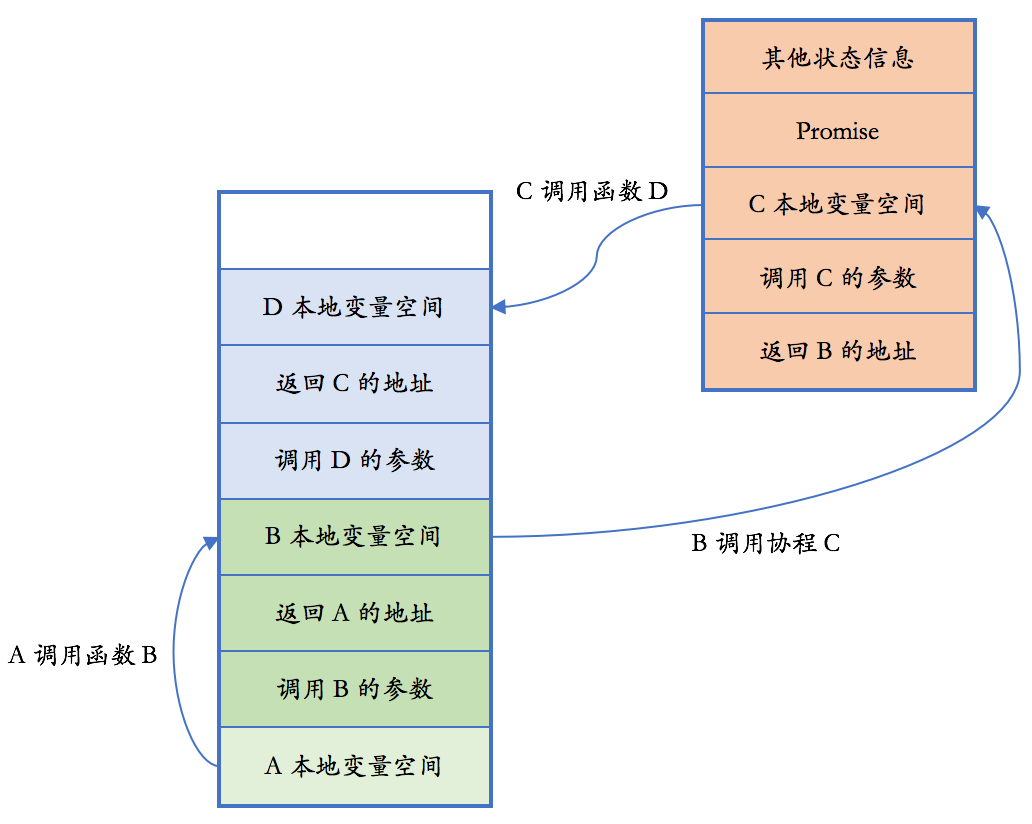
可以看到,协程 C 本身的本地变量不占用栈,但当它调用其他函数时,它会使用线程原先的栈空间。在上面的函数 D 的执行过程中,协程是不可以挂起的——如果控制回到 B 继续,B 可能会使用目前已经被 D 使用的栈空间!
因此,无栈的协程牺牲了一定的灵活性,换来了空间的节省和性能。有栈的协程你可能起几千个就占用不少内存空间,而无栈的协程可以轻轻松松起到亿级——毕竟,维持基本状态的开销我实测下来只有一百字节左右。
反过来,如果无栈的协程不满足需要——比如,你的协程里需要有递归调用,并在深层挂起——你就不得不寻找一个有栈的协程的解决方案。目前已经有一些成熟的方案,比如 Boost.Coroutine2 [4]。下面的代码展示如何在 Boost.Coroutine2 里实现 fibonacci,让你感受一点点小区别:
#include <iostream>
#include <stdint.h>
#include <boost/coroutine2/all.hpp>
typedef boost::coroutines2::coroutine<const uint64_t> coro_t;
void fibonacci(coro_t::push_type& yield)
{
uint64_t a = 0;
uint64_t b = 1;
while (true) {
yield(b);
auto tmp = a;
a = b;
b += tmp;
}
}
int main()
{
for (auto i : coro_t::pull_type(boost::coroutines2::fixedsize_stack(), fibonacci)) {
if (i >= 10000) {
break;
}
std::cout << i << std::endl;
}
}30.7 编译器支持
前面提到了,MSVC 和 Clang 目前支持协程。不过,它们都需要特殊的命令行选项来开启协程支持:
- MSVC 需要 /await 命令行选项
- Clang 需要 -fcoroutines-ts 命令行选项
为了满足使用 CMake 的同学的要求,也为了方便大家编译,我把示例代码放到了 GitHub 上:https://github.com/adah1972/geek_time_cpp
30.8 参考资料
- 维基百科, “协程”. https://zh.wikipedia.org/zh-cn/协程
- Gor Nishanov, “Working draft, C++ extensions for coroutines”. http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2018/n4775.pdf
- Lewis Baker, CppCoro. https://github.com/lewissbaker/cppcoro
- Oliver Kowalke, Boost.Coroutine2. https://www.boost.org/doc/libs/release/libs/coroutine2/doc/html/index.html
- Dawid Pilarski, “Coroutines introduction”. https://blog.panicsoftware.com/coroutines-introduction/
06丨加餐
加餐 | 部分课后思考题答案合集
本专栏部分课后思考题的答案,给你作为参考。
你觉得智能指针应该满足什么样的线程安全性?
答:(不是真正的回答,只是描述一下标准中的智能指针的线程安全性。)
- 多个不同线程同时访问不同的智能指针(不管是否指向同一个对象)是安全的。
- 多个不同线程同时读取同一个智能指针是安全的。
- 多个不同线程在同一个智能指针上执行原子操作(atomic_load 等)是安全的。
- 多个不同线程根据同一个智能指针创建新的智能指针(增加引用计数)是安全的。
只会有一个线程最后会(在引用计数表示已经无引用时)调用删除函数去销毁存储的对象。
其他操作潜在是不安全的,特别是在不同的线程对同一个智能指针执行 reset 等修改操作。
为什么 smart_ptr::operator= 对左值和右值都有效,而且不需要对等号两边是否引用同一对象进行判断?
答:我们使用值类型而非引用类型作为形参,这样实参永远会被移动(右值的情况)或复制(左值的情况),不可能和 *this 引用同一个对象。
为什么 stack(或 queue)的 pop 函数返回类型为 void,而不是直接返回容器的 top(或 front)成员?
答:这是 C++98 里、还没有移动语义时的设计。如果 pop 返回元素,而元素拷贝时发生异常的话,那这个元素就丢失了。因而容器设计成有分离的 top(或 front)和 pop 成员函数,分别执行访问和弹出的操作。
有一种可能的设计是把接口改成 void pop(T&),这增加了 T 必须支持默认构造和赋值的要求,在单线程为主的年代没有明显的好处,反而带来了对 T 的额外要求。
为什么大部分容器都提供了 begin、end 等方法?
答:容器提供了 begin 和 end 方法,就意味着是可以迭代(遍历)的。大部分容器都可以从头到尾遍历,因而也就需要提供这两个方法。
为什么容器没有继承一个公用的基类?
答:C++ 不是面向对象的语言,尤其在标准容器的设计上主要使用值语义,使用公共基类完全没有用处。
为什么说 UTF-32 处理会比较简单?
答:UTF-32 下,一个字符就是一个基本的处理单位,一般不会出现一个字符跨多个处理单位的情况(UTF-8 和 UTF-16 下会发生)。
你知道什么情况下 UTF-32 也并不那么简单吗?
答:Unicode 下有所谓的修饰字符,用来修饰前一个字符。按 Unicode 的处理规则,这些字符应该和基本字符一起处理(如断行之类)。所以 UTF-32 下也不可以在任意单位处粗暴断开处理。
哪种 UTF 编码方式空间存储效率比较高?
答:视存储的内容而定。比如,如果内容以 ASCII 为主(如源代码),那 UTF-8 效率最高。如果内容以一般的中文文本为主,那 UTF-16 效率最高。
想一想,你如何可以实现一个惰性的过滤器?
#include <iterator> using namespace std; template <typename I, typename F> class filter_view { public: class iterator { public: typedef ptrdiff_tdifference_type; typedef typename iterator_traits<I>::value_type value_type; typedef typename iterator_traits<I>::pointer pointer; typedef typename iterator_traits<I>::reference reference; typedef forward_iterator_tag iterator_category; iterator(I current, I end, F cond) : current_(current) , end_(end) , cond_(cond) { if (current_ != end_ && !cond_(*current_)) { ++*this; } } iterator& operator++() { while (current_ != end_) { ++current_; if (cond_(*current_)) { break; } } return *this; } iterator operator++(int) { auto temp = *this; ++*this; return temp; } reference operator*() const { return *current_; } pointer operator->() const { return &*current_; } bool operator==(const iterator& rhs) { return current_ == rhs.current_; } bool operator!=(const iterator& rhs) { return !operator==(rhs); } private: I current_; I end_; F cond_; }; filter_view(I begin, I end, F cond) : begin_(begin) , end_(end) , cond_(cond) { } iterator begin() const { return iterator(begin_, end_, cond_); } iterator end() const { return iterator(end_, end_, cond_); } private: I begin_; I end_; F cond_; };我展示了 compose 带一个或更多参数的情况。你觉得 compose 不带任何参数该如何定义?它有意义吗?
inline auto compose() { return [](auto&& x) -> decltype(auto) { return std::forward<decltype(x)>(x); }; }这个函数把参数原封不动地传回。它的意义相当于加法里的 0,乘法里的 1。
在普通的加法里,你可能不太需要 0;但在一个做加法的地方,如果别人想告诉你不要做任何操作,传给你一个 0 是最简单的做法。
有没有可能不用 index_sequence 来初始化 bit_count?如果行,应该如何实现?
答:似乎没有通用的办法,因为目前 constexpr 要求在构造时直接初始化对象的内容。
但是,到了 C++20,允许 constexpr 对象里存在平凡默认构造的成员之后,就可以使用下面的写法了:
template <size_t N> struct bit_count_t { constexpr bit_count_t() { for (auto i = 0U; i < N; ++i) { count[i] = count_bits(i); } } unsigned char count[N]; }; constexpr bit_count_t<256> bit_count;当前已经发布的编译器中,我测下来只有 Clang 能(在 C++17 模式下)编译通过此代码。GCC 10 能在使用命令行选项 -std=c++2a 时编译通过此代码。
作为一个挑战,你能自行实现出 make_integer_sequence 吗?
答 1:
template <class T, T... Ints> struct integer_sequence { }; template <class T> struct integer_sequence_ns { template <T N, T... Ints> struct integer_sequence_helper { using type = typename integer_sequence_helper<N - 1, N - 1, Ints...>::type; }; template <T... Ints> struct integer_sequence_helper<0, Ints...> { using type = integer_sequence<T, Ints...>; }; }; template <class T, T N> using make_integer_sequence = typename integer_sequence_ns<T>:: template integer_sequence_helper<N>::type;如果一开始写成
template <class T, T N, T... Ints> struct integer_sequence_helper的话,就会遇到错误”non-type template argument specializes a template parameter with dependent type ‘T’”(非类型的模板实参特化了一个使用依赖类型的’T’的模板形参)。这是目前的 C++ 标准所不允许的写法,改写成嵌套类形式可以绕过这个问题。答 2:
template <class T, T... Ints> struct integer_sequence { }; template <class T, T N, T... Is> auto make_integer_sequence_impl() { if constexpr (N == 0) { return integer_sequence<T, Is...>(); } else { return make_integer_sequence_impl<T, N - 1, N - 1, Is...>(); } } template <class T, T N> using make_integer_sequence = decltype(make_integer_sequence_impl<T, N>());这又是一个 constexpr 能简化表达的例子。
你觉得 C++ REST SDK 的接口好用吗?如果好用,原因是什么?如果不好用,你有什么样的改进意见?
答:举几个可能的改进点。
C++ REST SDK 的 uri::decode 接口设计有不少问题:
- 最严重的,不能对 query string 的等号左边的部分进行 decode;只能先 split_query 再 decode,此时等号左边已经在 map 里,不能修改——要修改需要建一个新的 map。
- 目前的实现对”+”不能重新还原成空格。
换个说法,目前的接口能正确处理”
/search?q=query%20string“这样的请求,但不能正确处理”/search?%71=query+string“这样的请求。应当有一个 split_query_and_decode 接口,同时执行分割和解码。
另外,json 的接口也还是不够好用,最主要是没有使用初始化列表的构造。构造复杂的 JSON 结构有点啰嗦了。
fstream::open_ostream 缺省行为跟 std::ofstream 不一样应该是个 bug。应当要么修正接口(接口缺省参数里带上 trunc),要么修正实现(跟 std::ofstream 一样把 out 当成 out|trunc)。
“概念”可以为开发具体带来哪些好处?反过来,负面的影响又可能会是什么?
答:对于代码严谨、具有形式化思维的人,”概念”是个福音,它不仅可以大量消除 SFINAE 的使用,还能以较为精确和形式化的形式在代码里写出对类型的要求,使得代码变得清晰、易读。
但反过来说,”概念”比鸭子类型更严格。在代码加上概念约束后,相关代码很可能需要修改才能满足概念的要求,即使之前在实际使用中可能已经完全没有问题。从迭代器的角度,实际使用中最小功能集是构造、可复制、
*、前置 ++、与 sentinel 类型对象的 !=(单一形式)。而为了满足迭代器概念,则要额外确保满足以下各点:- 可默认初始化
- 在 iterator 类型和 sentinel 类型之间,需要定义完整的四个 == 和 != 运算符
- 定义迭代器的标准内部类型,如 difference_type 等

