课程资源: https://github.com/kibaamor/101
代码走读:https://github.com/kibaamor/101/blob/master/source-code-reading/readme.MD, https://cncamp.notion.site/golang-843c958dafc54f0aab4fa1e4527da78a, https://cncamp.notion.site/kubernetes-8a9d48ee26284b3c8ddf9de4c62ea895, https://cncamp.notion.site/mesh-adf426d889f0448faa1671f5e05c9f12
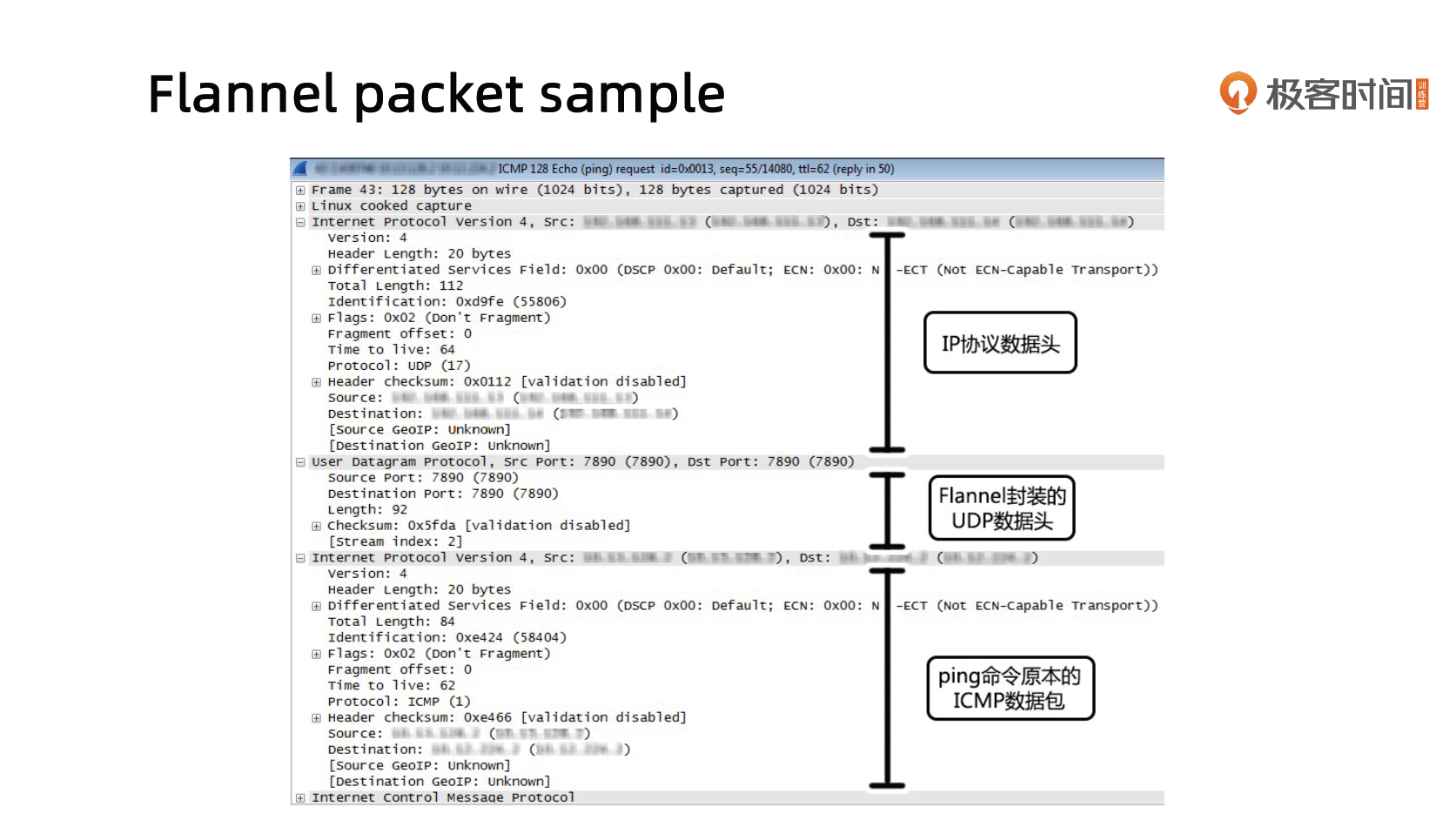
iptables: https://ipset.netfilter.org/iptables-extensions.man.html
Go 语言特性
多线程
并发和并行
- 并发(concurrency):两个或多个事件在同一时间间隔发生。
- 并行(parallellism):两个或者多个事件在同一时刻发生。
Go 语言进阶
线程调度
深入理解 Go 语言线程调度
- 进程:资源分配的基本单位
- 线程:调度的基本单位
- 无论是线程还是进程,在 linux 中都以 task_struct 描述,从内核角度看,与进程无本质区别
- Glibc 中的 pthread 库提供 NPTL(Native POSIX Threading Library)支持
进程切换开销
- 直接开销
- 切换页表全局目录(PGD)
- 切换内核态堆栈
- 切换硬件上下文(进程恢复前,必须装入寄存器的数据统称为硬件上下文)
- 刷新TLB
- 系统调度器的代码执行
- 间接开销
- CPU 缓存失效导致的进程需要到内存直接访问的IO 操作变多
线程切换开销
- 线程本质上只是一批共享资源的进程,线程切换本质上依然需要内核进行进程切换。
- 一组线程因为共享内存资源,因此一个进程的所有线程共享虚拟地址空间,线程切换相比进程切换,主要节省了虚拟地址空间的切换。
Goroutine
Go 语言基于 GMP 模型实现用户态线程
- G:表示 goroutine,每个 goroutine 都有自己的栈空间,定时器,初始化的栈空间在2k 左右,空间会随着需求增长。
- M:抽象化代表内核线程,记录内核线程栈信息,当 goroutine 调度到线程时,使用该 goroutine 自己的栈信息。
- P:代表调度器,负责调度 goroutine,维护一个本地 goroutine 队列,M 从 P 上获得 goroutine 并执行,同时还负责部分内存的管理。
GMP模型细节
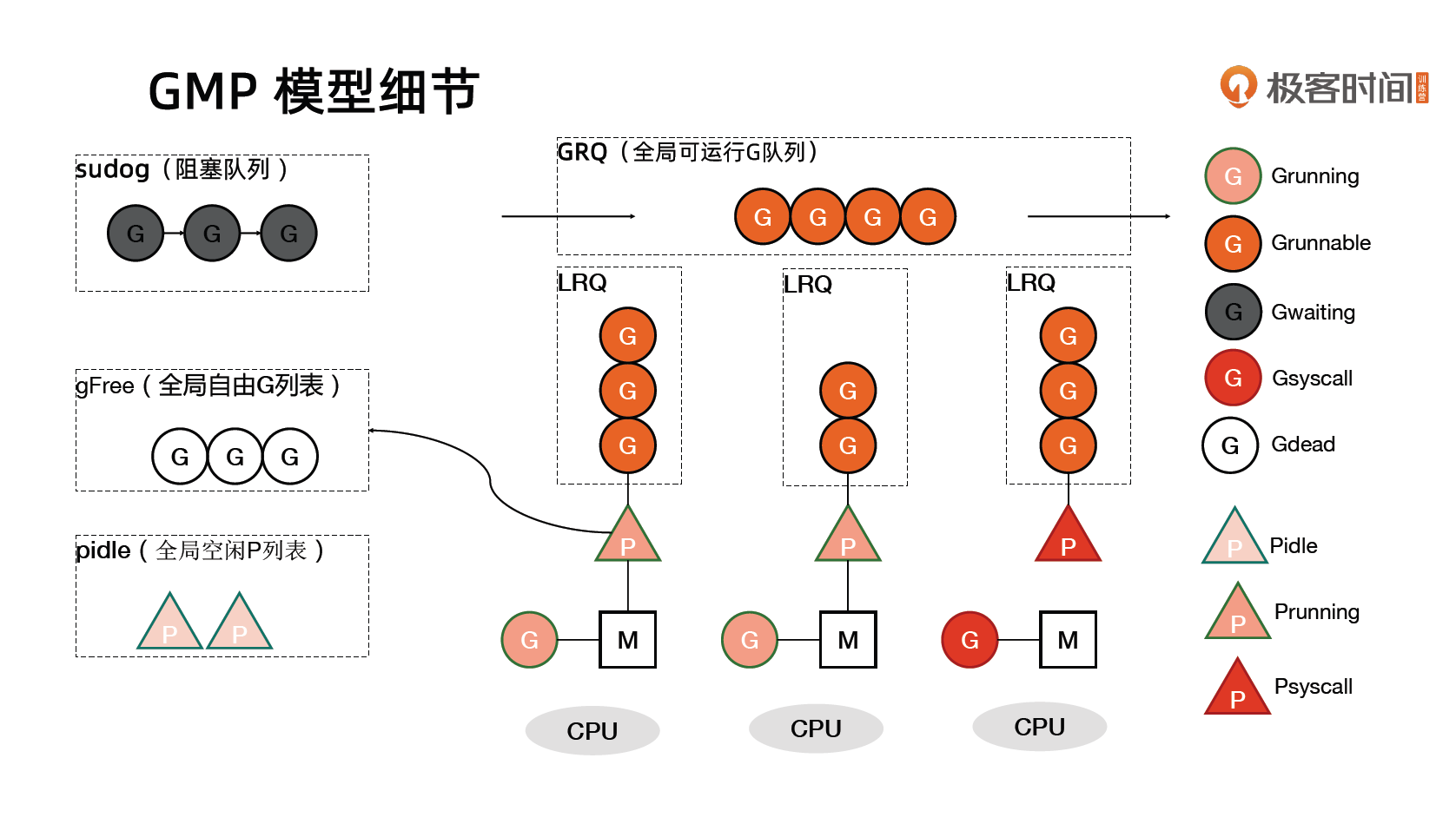
G 所处的位置
- 进程都有一个全局的 G 队列
- 每个 P 拥有自己的本地执行队列
- 有不在运行队列中的 G
- 处于 channel 阻塞态的 G 被放在 sudog
- 脱离 P 绑定在 M 上的 G,如系统调用
- 为了复用,执行结束进入 P 的 gFree 列表中的 G
Goroutine 创建过程
- 获取或者创建新的 Goroutine 结构体
- 从处理器的 gFree 列表中查找空闲的 Goroutine
- 如果不存在空闲的 Goroutine,会通过 runtime.malg 创建一个栈大小足够的新结构体
- 将函数传入的参数移到 Goroutine 的栈上
- 更新 Goroutine 调度相关的属性,更新状态为 _Grunnable
- 返回的 Goroutine 会存储到全局变量 allgs 中
将 Goroutine 放到运行队列上
关键函数
func runqput(pp *p, gp *g, next bool)
- Goroutine 设置到处理器的 runnext 作为下一个处理器执行的任务
- 当处理器的本地运行队列已经没有剩余空间时,就会把本地队列中的前一半 Goroutine 和待加入的 Goroutine 一起打乱顺序后通过
runtime.runqputslow添加到调度器持有的全局运行队列上
调度器行为
关键函数
func schedule()可以参考的资料《深入分析Go1.18 GMP调度器底层原理》
- 为了保证公平,当全局运行队列中有待执行的 Goroutine 时,通过 schedtick 保证有一定几率(1/61) 通过
runtime.globrunqget从全局的运行队列中查找一个的 Goroutine 来运行 - 从处理器本地的运行队列中查找待执行的 Goroutine
- 如果前两种方法都没有找到 Goroutine,会通过
runtime.findrunnable进行阻塞地查找 Goroutine - 从本地运行队列、全局运行队列中查找
- 从网络轮询器中查找是否有 Goroutine 等待运行
- 通过 runtime.runqsteal 尝试从其他随机的处理器中窃取待运行的 Goroutine
源码走读
关于M和P的数量的问题答疑昨天群里陷入了讨论,我看了一下代码把调用关系列在了这个文档里
设计考量
- 默认配置下,P的数量 = CPU个数,可通过GOMAXPROCS修改,上限是256
- M数量是内核线程数量,M大于P,上限是10000
- P的数量在调度器初始化的procresize中控制
- 当调度器进行调度,唤醒P的时候,会通过met获取idle m,如果获取不到,则创建新的M(也就是内核线程)
- 这样做的目的是,M可能陷入系统调用,而系统调用可能是阻塞的,比如磁盘读取,这个时候CPU是空闲的,创建新的M并与P关联,可以让更多的G被调度,充分利用CPU。
代码分析
/usr/local/go/src/runtime/proc.go
schedinit()-->
sched.maxmcount = 10000 // m count limit is 10000 by default
procs = atoi32(gogetenv("GOMAXPROCS"))
procresize(procs)-->
nallp := make([]*p, nprocs) // P count is read from environment variable GOMAXPROCS
pp.init(i)
p.m.set(mget()) // mget to associate p with idle m
schedule()-->
wakep()-->
startm()-->
nmp := mget()
if nmp == nil {
newm(fn, _p_, id)-->
mp := new(m)
mp.g0 = malg(8192 * sys.StackGuardMultiplier) // g0 is the maintainer for the m, like create other G
}
nmp.nextp.set(_p_)
notewakeup(&nmp.park)-->
semawakeup((*m)(unsafe.Pointer(v)))
pthread_cond_signal(&mp.cond) // wake up the kernel thread内存管理
TCMalloc
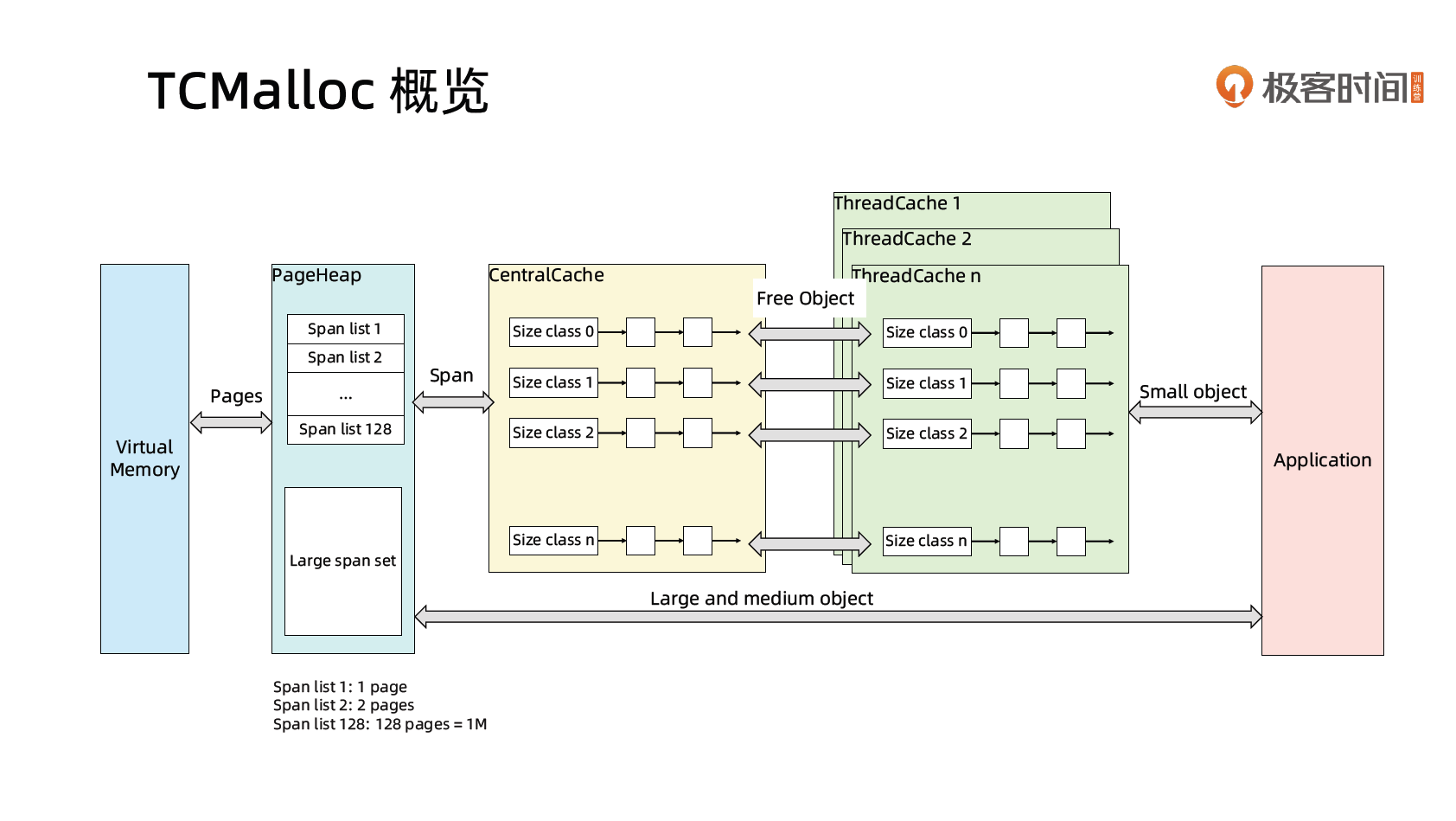
- page: 内存页,一块 8K 大小的内存空间。Go 与操作系统之间的内存申请和释放,都是以 page 为单位的
- span: 内存块,一个或多个连续的 page 组成一个 span
- sizeclass: 空间规格,每个 span 都带有一个 sizeclass ,标记着该 span 中的 page 应该如何使用
object: 对象,用来存储一个变量数据内存空间,一个 span 在初始化时,会被切割成一堆等大的 object ;假设 object 的大小是 16B ,span 大小是 8K ,那么就会把 span 中的 page 就会被初始化 8K / 16B = 512 个 object 。所谓内存分配,就是分配一个object 出去
对象大小定义
- 小对象大小:0~256KB
- 中对象大小:256KB~1MB
- 大对象大小:>1MB
- 小对象的分配流程
- ThreadCache -> CentralCache -> PageHeap,大部分时候,ThreadCache 缓存都是足够的,不需要去访问 CentralCache 和 PageHeap,无系统调用配合无锁分配,分配效率是非常高的
- 中对象分配流程
- 直接在 PageHeap 中选择适当的大小即可,128 Page 的 Span 所保存的最大内存就是 1MB
- 大对象分配流程
- 从 large span set 选择合适数量的页面组成 span,用来存储数据
Go 语言内存分配
关键函数
func mallocgcGo 语言内存分配可视化指南(A visual guide to Go Memory Allocator from scratch (Golang))
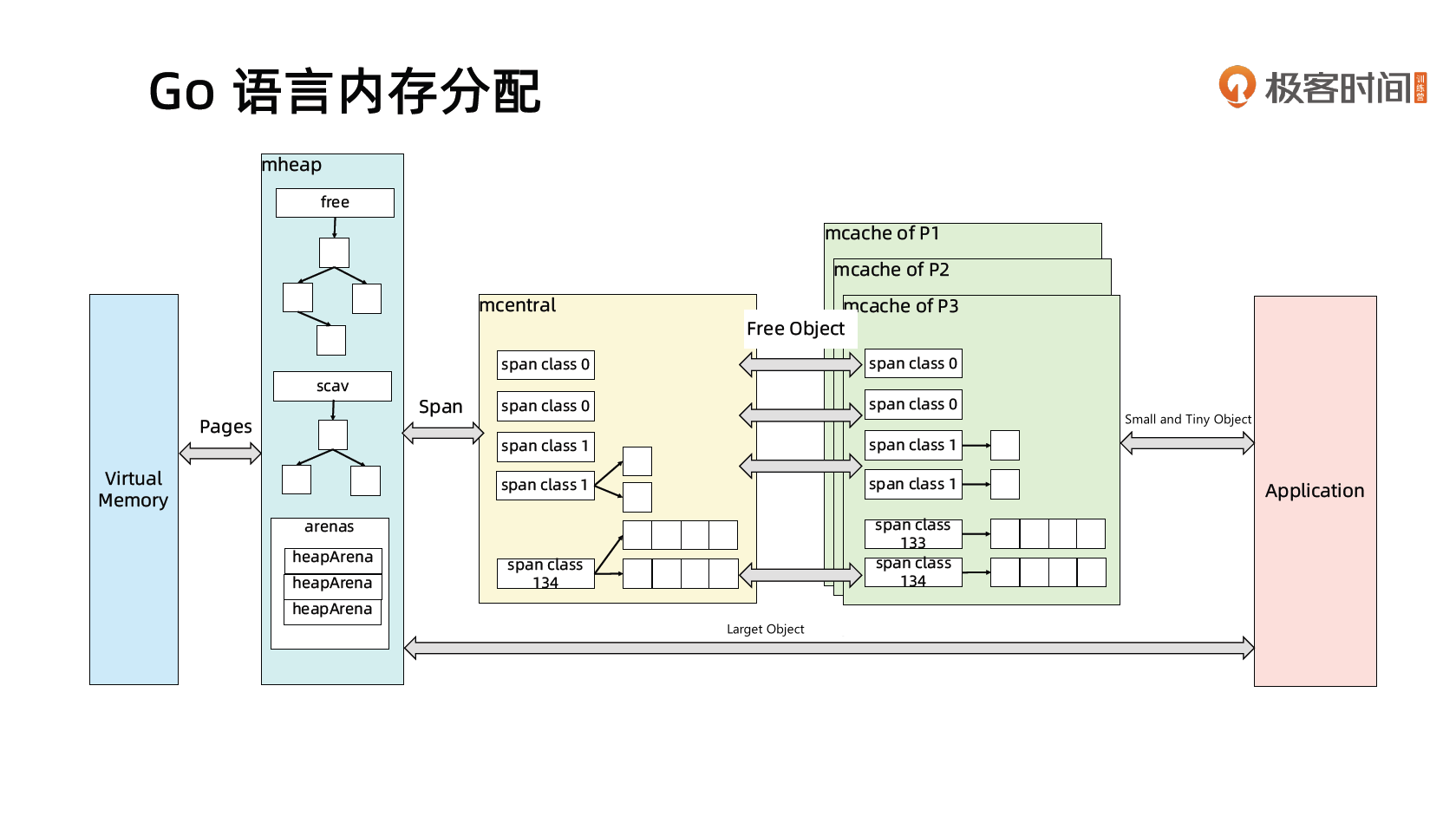
对象大小定义
- 小(Small)对象:<=32KB
- 其中大小 <16B 且不是指针的对象称为微(Tiny)对象
- 大(Large)对象:>32KB
- 小(Small)对象:<=32KB
mcache:小对象的内存分配直接走
- size class 从 1 到 66,每个 class 两个 span (scan 和 noscan)
- Span 大小是 8KB,按 span class 大小切分
- mcentral
- Span 内的所有内存块都被占用时,没有剩余空间继续分配对象,mcache 会向 mcentral 申请 1 个 span,mcache 拿到 span 后继续分配对象
- 当 mcentral 向 mcache 提供 span 时,如果没有符合条件的 span,mcentral 会向 mheap 申请 span
- mheap
- 当 mheap 没有足够的内存时,mheap 会向 OS 申请内存
- mheap 把 Span 组织成了树结构,而不是链表
- 然后把 Span 分配到 heapArena 进行管理,它包含地址映射和 span 是否包含指针等位图
- 为了更高效的分配、回收和再利用内存
- mspan
- allocBits
- 记录了每块内存分配的情况
- gcmarkBits
- 记录了每块内存的引用情况,标记阶段对每块内存进行标记,有对象引用的内存标记为 1,没有的标记为 0
- allocBits
Go 语言 GC
Golang 的汇编看不懂时可以看 A Quick Guide to Go’s Assembler
可以参考的资料《Golang 垃圾回收(一)概述》、《golang 垃圾回收(二)屏障技术》、《golang 垃圾回收(三)插入写屏障》、《golang 垃圾回收(四)删除写屏障》、《golang 垃圾回收(五)混合写屏障》
混合写屏障伪代码
// src/runtime/mbarrier.go
// Go uses a hybrid barrier that combines a Yuasa-style deletion
// barrier—which shades the object whose reference is being
// overwritten—with Dijkstra insertion barrier—which shades the object
// whose reference is being written. The insertion part of the barrier
// is necessary while the calling goroutine's stack is grey. In
// pseudocode, the barrier is:
writePointer(slot, ptr):
shade(*slot) // 删除写屏障(Yuasa-style 屏障)
if current stack is grey:
shade(ptr) // 插入写屏障(Dijkstra屏障)
*slot = ptrGo 实际实现为
writePointer(slot, ptr):
shade(*slot)
shade(ptr)
*slot = ptr垃圾回收触发机制
- 内存分配量达到阀值触发 GC
- 每次内存分配时都会检查当前内存分配量是否已达到阀值,如果达到阀值则立即启动 GC。
- 阀值 = 上次 GC 内存分配量 * 内存增长率
- 内存增长率由环境变量 GOGC 控制,默认为 100,即每当内存扩大一倍时启动 GC。
- 每次内存分配时都会检查当前内存分配量是否已达到阀值,如果达到阀值则立即启动 GC。
- 定期触发 GC
- 默认情况下,最长 2 分钟触发一次 GC,这个间隔在
src/runtime/proc.go:forcegcperiod变量中被声明
- 默认情况下,最长 2 分钟触发一次 GC,这个间隔在
- 手动触发
- 程序代码中也可以使用
runtime.GC()来手动触发 GC。这主要用于 GC 性能测试和统计。
- 程序代码中也可以使用
动手编写一个 HTTP Server
http.ListenAndServe()-->
server.ListenAndServe()-->
net.Listen("tcp", addr)-->
lc.Listen(context.Background(), network, address)-->
sl.listenTCP(ctx, la)-->
fd, err := internetSocket(ctx, sl.network, laddr, nil, syscall.SOCK_STREAM, 0, "listen", sl.ListenConfig.Control)-->
socket(ctx, net, family, sotype, proto, ipv6only, laddr, raddr, ctrlFn)-->
sysSocket(family, sotype, proto) // syscall.Socket and return fd
fd, err = newFD(s, family, sotype, net) // fd.pfd.sysfd = sysfd(socket fd)
fd.listenStream(laddr, listenerBacklog(), ctrlFn)-->
syscall.Bind(fd.pfd.Sysfd, lsa) // bind socket with address
listenFunc() // syscall.Listen
fd.init()-->
runtime_pollServerInit()--> // fd_poll_runtime.go
poll_runtime_pollServerInit()--> // netpoll.go
netpollGenericInit()-->
netpollinit()--> // netpoll_epoll.go
epollcreate1()
epollctl(epfd, _EPOLL_CTL_ADD, r, &ev)
runtime_pollOpen()-->
poll_runtime_pollOpen()--> // netpoll.go
netpollopen()--> // netpoll_epoll.go
var ev epollevent
ev.events = _EPOLLIN | _EPOLLOUT | _EPOLLRDHUP | _EPOLLET
*(**pollDesc)(unsafe.Pointer(&ev.data)) = pd
return -epollctl(epfd, _EPOLL_CTL_ADD, int32(fd), &ev)
srv.Serve(ln)-->
l.Accept()--> // tcpsocket.go
l.accept()--> // return TCPConn which holds the connection fd
fd := ln.fd.accept()-->
fd.pfd.Accept()--> // fd_unix.go syscall.Accept4
if err == nil {
return s, rsa, "", err
}
switch err {
case syscall.EAGAIN:
if fd.pd.pollable() {
fd.pd.waitRead()-->
runtime_pollWait()-->poll_runtime_pollWait()-->netpollblock()-->
atomic.Casuintptr(gpp, 0, pdWait)
gopark(netpollblockcommit, unsafe.Pointer(gpp), waitReasonIOWait, traceEvGoBlockNet, 5)-->
mcall(park_m) // put the go routine to park, schedule->findrunnable will wake it up
}
go c.serve(connCtx)-->c.readRequest(ctx)-->
req, err := readRequest(c.bufr, keepHostHeader)-->tp.ReadLine()-->r.readLineSlice()-->r.R.ReadLine()-->b.fill()-->
b.rd.Read(b.buf[b.w:])--> // fd_unix.go Read implements io.Reader.
ignoringEINTRIO(syscall.Read, fd.Sysfd, p) // syscall.Read// shedule parked go routine
schedule()-->findrunnable()-->
list := netpoll(0)--> //proc.go
n := epollwait(epfd, &events[0], int32(len(events)), waitms)
for i := int32(0); i < n; i++ {
netpollready(&toRun, pd, mode)-->
rg = netpollunblock(pd, 'r', true) // find related go routine of the epoll fd
toRun.push(rg)
}
startIdle(n)-->startmLinux epoll
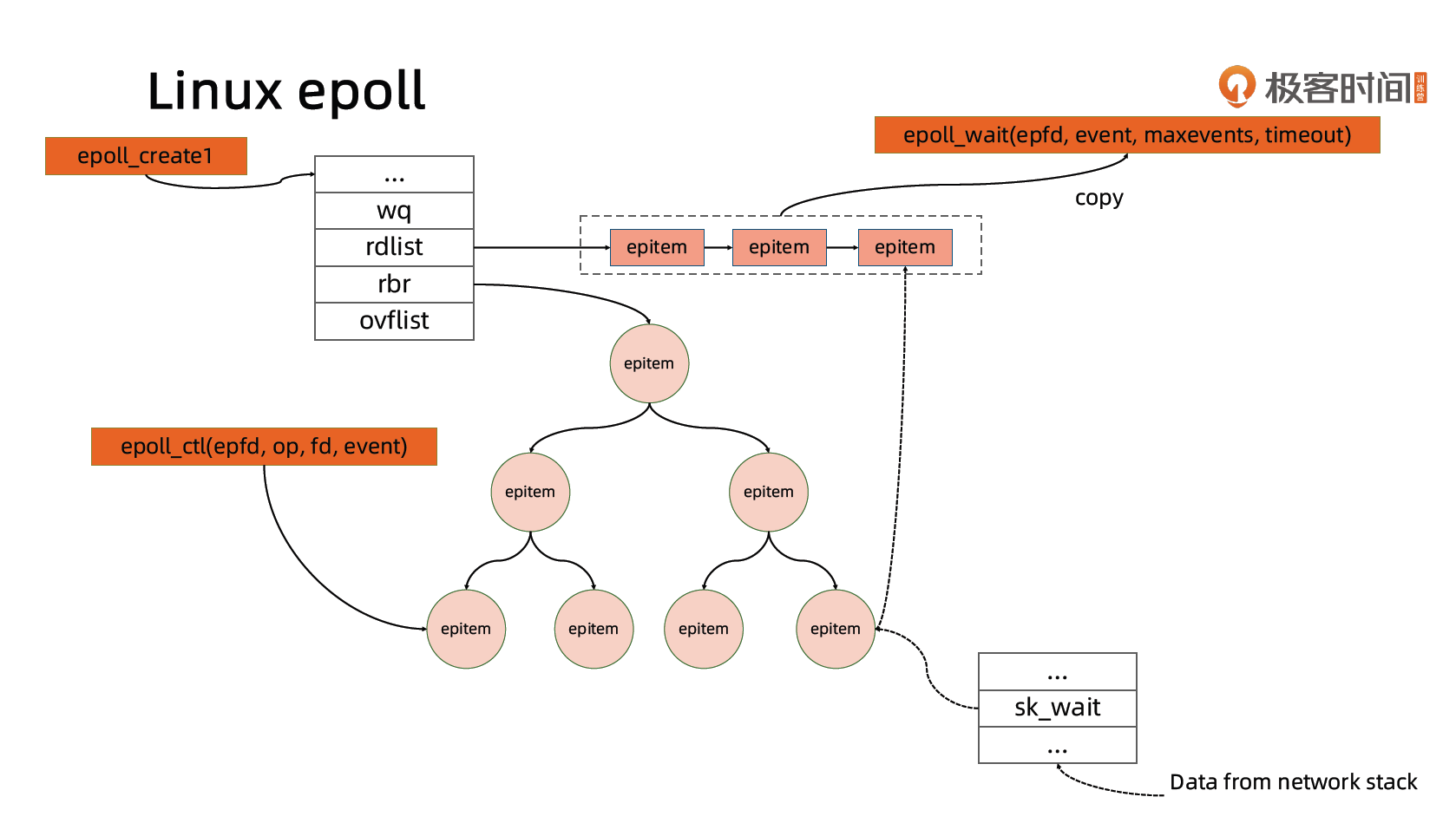
HttpServer 的实现细节
Go 语言将协程与 fd 资源绑定
- 一个 socket fd 与一个协程绑定
- 当 socket fd 未就绪时,将对应协程设置为 Gwaiting 状态,将 CPU 时间片让给其他协程
- Go 语言 runtime 调度器进行调度唤醒协程时,检查 fd 是否就绪,如果就绪则将协程置为 Grunnable 并加入执行队列
- 协程被调度后处理 fd 数据
Docker 核心技术
理解Docker
Linux 内核代码中 Namespace 的实现
进程数据结构
// include/linux/sched.h
struct task_struct {
//...
/* Namespaces: */
struct nsproxy *nsproxy;
//...
};Namespace 数据结构
// include/linux/nsproxy.h
/*
* A structure to contain pointers to all per-process
* namespaces - fs (mount), uts, network, sysvipc, etc.
*
* The pid namespace is an exception -- it's accessed using
* task_active_pid_ns. The pid namespace here is the
* namespace that children will use.
*
* 'count' is the number of tasks holding a reference.
* The count for each namespace, then, will be the number
* of nsproxies pointing to it, not the number of tasks.
*
* The nsproxy is shared by tasks which share all namespaces.
* As soon as a single namespace is cloned or unshared, the
* nsproxy is copied.
*/
struct nsproxy {
refcount_t count;
struct uts_namespace *uts_ns;
struct ipc_namespace *ipc_ns;
struct mnt_namespace *mnt_ns;
struct pid_namespace *pid_ns_for_children;
struct net *net_ns;
struct time_namespace *time_ns;
struct time_namespace *time_ns_for_children;
struct cgroup_namespace *cgroup_ns;
};Linux 对 Namespace 操作方法
clone
在创建新进程的系统调用时,可以通过 flags 参数指定需要新建的 Namespace 类型:
// CLONE_NEWCGROUP / CLONE_NEWIPC / CLONE_NEWNET / CLONE_NEWNS / CLONE_NEWPID / CLONE_NEWUSER / CLONE_NEWUTS
int clone(int (*fn)(void *), void *child_stack, int flags, void *arg)setns
该系统调用可以让调用进程加入某个已经存在的 Namespace 中:
Int setns(int fd, int nstype)unshare
该系统调用可以将调用进程移动到新的 Namespace 下:
int unshare(int flags)关于 namespace 的常用操作
- 查看当前系统的 namespace:
lsns -t <type> - 查看某进程的 namespace:
ls -la /proc/<pid>/ns/ - 查看某命令的 namespace:
sudo lsns | grep <command name> - 进入某 namespace 运行命令:
nsenter -t <pid> -n ip addr - 在新 network namespace 运行命令:
unshare -fn sleep 60
Linux 内核代码中 Cgroups 的实现
进程数据结构
// include/linux/sched.h
struct task_struct {
//...
#ifdef CONFIG_CGROUPS
/* Control Group info protected by css_set_lock: */
struct css_set __rcu *cgroups;
/* cg_list protected by css_set_lock and tsk->alloc_lock: */
struct list_head cg_list;
#endif
//...
};css_set 是 cgroup_subsys_state 对象的集合数据结构
// include/linux/cgroup-defs.h
/*
* A css_set is a structure holding pointers to a set of
* cgroup_subsys_state objects. This saves space in the task struct
* object and speeds up fork()/exit(), since a single inc/dec and a
* list_add()/del() can bump the reference count on the entire cgroup
* set for a task.
*/
struct css_set {
/*
* Set of subsystem states, one for each subsystem. This array is
* immutable after creation apart from the init_css_set during
* subsystem registration (at boot time).
*/
struct cgroup_subsys_state *subsys[CGROUP_SUBSYS_COUNT];
//...
};cgroups
cgroups 实现了对资源的配额和度量
- blkio: 这个子系统设置限制每个块设备的输入输出控制。例如:磁盘,光盘以及 USB 等等。
- CPU: 这个子系统使用调度程序为 cgroup 任务提供 CPU 的访问。
- cpuacct: 产生 cgroup 任务的CPU 资源报告。
- cpuset: 如果是多核心的 CPU,这个子系统会为 cgroup 任务分配单独的 CPU 和内存。
- devices: 允许或拒绝 cgroup 任务对设备的访问。
- freezer: 暂停和恢复 cgroup 任务。
- memory: 设置每个 cgroup 的内存限制以及产生内存资源报告。
- net_cls: 标记每个网络包以供 cgroup 方便使用。
- ns: 名称空间子系统。
- pid: 进程标识子系统。
CPU 子系统
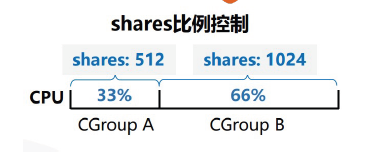
- cpu.shares: 可出让的能获得 CPU 使用时间的相对值。
- cpu.cfs_period_us:cfs_period_us 用来配置时间周期长度,单位为 us(微秒)。
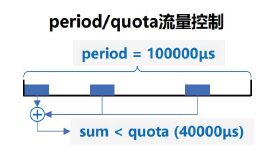
- cpu.cfs_quota_us:cfs_quota_us 用来配置当前 Cgroup 在 cfs_period_us 时间内最多能使用的 CPU 时间数,单位为 us(微秒)。
- cpu.stat : Cgroup 内的进程使用的 CPU 时间统计。
- nr_periods : 经过 cpu.cfs_period_us 的时间周期数量。
- nr_throttled : 在经过的周期内,有多少次因为进程在指定的时间周期内用光了配额时间而受到限制。
- throttled_time : Cgroup 中的进程被限制使用CPU 的总用时,单位是 ns(纳秒)
Linux 调度器
内核默认提供了 5 个调度器,Linux 内核使用 struct sched_class 来对调度器进行抽象:
- Stop 调度器,
stop_sched_class:优先级最高的调度类,可以抢占其他所有进程,不能被其他进程抢占; - Deadline 调度器,
dl_sched_class:使用红黑树,把进程按照绝对截止期限进行排序,选择最小进程进行调度运行; - RT 调度器,
rt_sched_class:实时调度器,为每个优先级维护一个队列; - CFS 调度器,
cfs_sched_class:完全公平调度器,采用完全公平调度算法,引入虚拟运行时间概念; - IDLE-Task 调度器,
idle_sched_class:空闲调度器,每个 CPU 都会有一个 idle 线程,当没有其他进程可以调度时,调度运行 idle 线程。
CFS 调度器
CFS 是 Completely Fair Scheduler 简称,即完全公平调度器。
- CFS 实现的主要思想是维护为任务提供处理器时间方面的平衡,这意味着应给进程分配相当数量的处理器。
- 分给某个任务的时间失去平衡时,应给失去平衡的任务分配时间,让其执行。
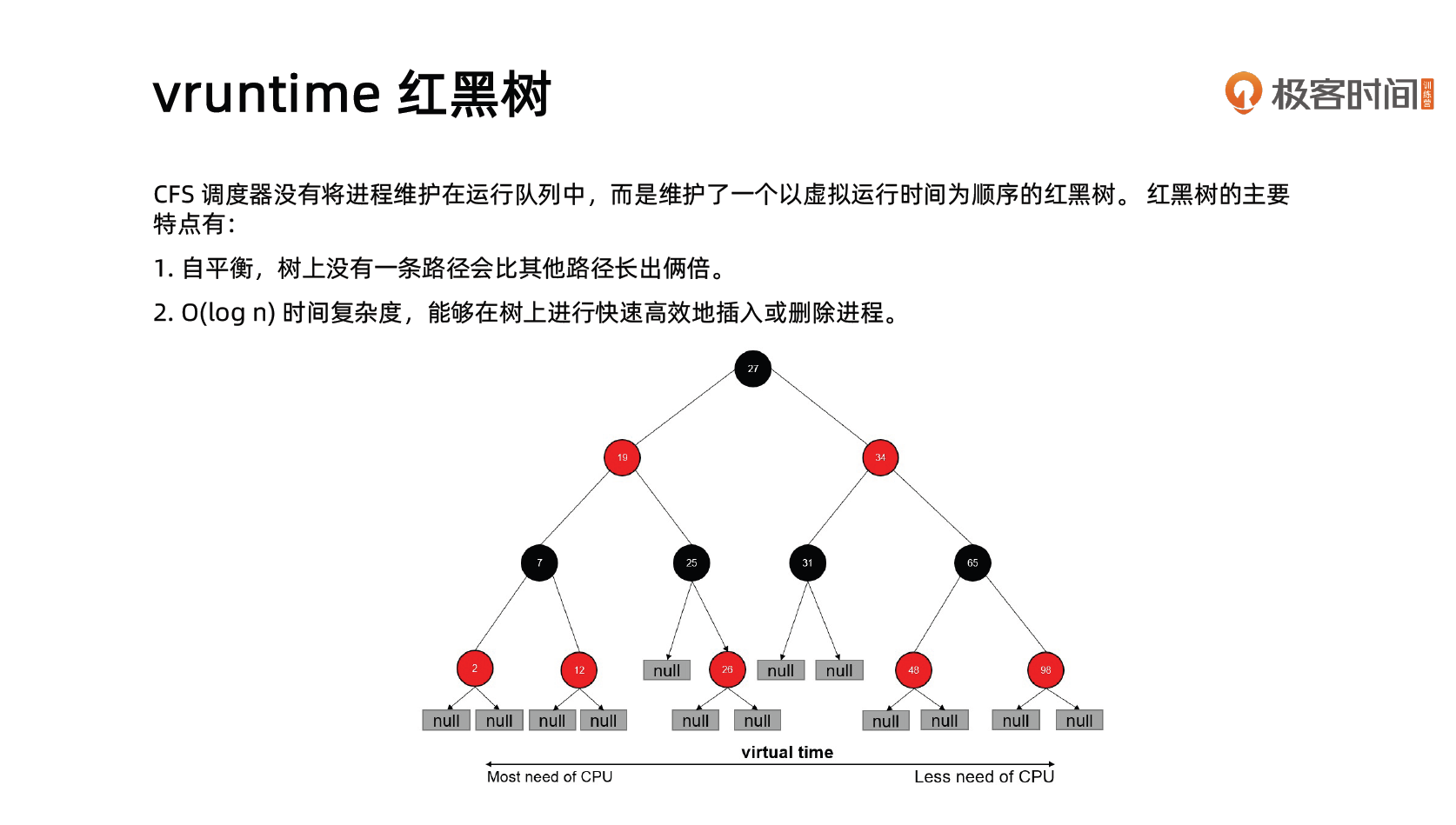
CFS 通过虚拟运行时间(vruntime)来实现平衡,维护提供给某个任务的时间量。
vruntime = 实际运行时间 * 1024 / 进程权重进程按照各自不同的速率在物理时钟节拍内前进,优先级高则权重大,其虚拟时钟比真实时钟跑得慢,但获得比较多的运行时间。
vruntime 红黑树
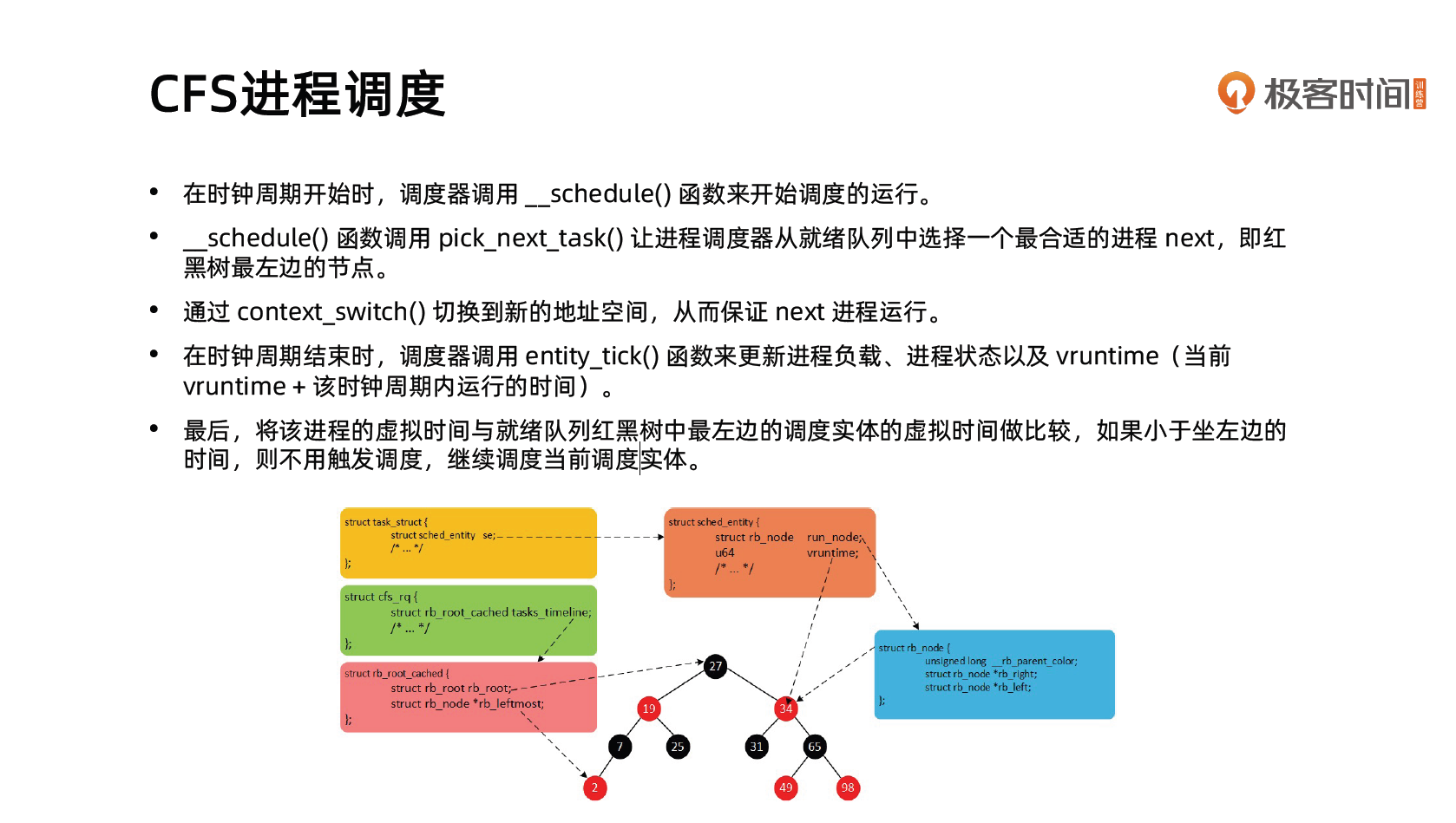
CFS进程调度
cpuacct 子系统
用于统计 Cgroup 及其子 Cgroup 下进程的 CPU 的使用情况。
- cpuacct.usage
包含该 Cgroup 及其子 Cgroup 下进程使用 CPU 的时间,单位是 ns(纳秒)。
- cpuacct.stat
包含该 Cgroup 及其子 Cgroup 下进程使用的 CPU 时间,以及用户态和内核态的时间。
Memory 子系统
memory.usage_in_bytes
cgroup 下进程使用的内存,包含 cgroup 及其子 cgroup 下的进程使用的内存
memory.max_usage_in_bytes
cgroup 下进程使用内存的最大值,包含子 cgroup 的内存使用量。
memory.limit_in_bytes
设置 Cgroup 下进程最多能使用的内存。如果设置为 -1,表示对该 cgroup 的内存使用不做限制。
memory.soft_limit_in_bytes
这个限制并不会阻止进程使用超过限额的内存,只是在系统内存足够时,会优先回收超过限额的内存,使之向限定值靠拢。
memory.oom_control
设置是否在 Cgroup 中使用 OOM(Out of Memory)Killer,默认为使用。当属于该 cgroup 的进程使用的内存超过最大的限定值时,会立刻被 OOM Killer 处理。
Cgroup driver
systemd:
- 当操作系统使用 systemd 作为 init system 时,初始化进程生成一个根 cgroup 目录结构并作为 cgroup 管理器。
- systemd 与 cgroup 紧密结合,并且为每个 systemd unit 分配 cgroup。
cgroupfs:
- docker 默认用 cgroupfs 作为 cgroup 驱动。
存在问题:
- 在 systemd 作为 init system 的系统中,默认并存着两套 groupdriver。
- 这会使得系统中 Docker 和 kubelet 管理的进程被 cgroupfs 驱动管,而 systemd 拉起的服务由 systemd 驱动管,让 cgroup 管理混乱且容易在资源紧张时引发问题。
因此 kubelet 会默认 —cgroup-driver=systemd,若运行时 cgroup 不一致时,kubelet 会报错。
Cgroup 的使用
可以使用 cgroup-tools 来管理 Cgroup
# 创建一个名为 k 的 CPU 子系统
$ cgcreate -g cpu:k
# 创建后的路径为
$ ls /sys/fs/cgroup/cpu/k
cgroup.clone_children cgroup.procs cpu.cfs_burst_us cpu.cfs_period_us cpu.cfs_quota_us cpu.idle cpu.rt_period_us cpu.rt_runtime_us cpu.shares cpu.stat notify_on_release tasks
# 获取 CPU 配额
$ cgget -r cpu.cfs_period_us -r cpu.cfs_quota_us k
k:
cpu.cfs_period_us: 100000
cpu.cfs_quota_us: -1
# 限制 CPU 使用率为 50%
$ cgset -r cpu.cfs_quota_us=50000 k
# 确认设置生效
$ cgget -r cpu.cfs_period_us -r cpu.cfs_quota_us k
k:
cpu.cfs_period_us: 100000
cpu.cfs_quota_us: 50000
# 测试
$ top -p $(ps -ef | grep 'bash -c while : ; do : ; done' | grep -v grep | awk '{print $2}') -b -n 1
top - 22:48:54 up 1:25, 2 users, load average: 1.54, 1.41, 1.21
Tasks: 1 total, 1 running, 0 sleeping, 0 stopped, 0 zombie
%Cpu(s): 8.4 us, 0.8 sy, 0.0 ni, 86.8 id, 0.0 wa, 0.0 hi, 4.0 si, 0.0 st
MiB Mem : 7898.4 total, 141.7 free, 2822.3 used, 4934.4 buff/cache
MiB Swap: 2048.0 total, 2042.7 free, 5.3 used. 4779.8 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
33693 root 20 0 4784 3224 2976 R 53.3 0.0 4:32.59 bash
# 删除 CPU 子系统 k
$ cgdelete cpu:k文件系统
Union FS
- 将不同目录挂载到同一个虚拟文件系统下(unite several directories into a single virtual filesystem)的文件系统
- 支持为每一个成员目录(类似 Git Branch)设定 readonly、readwrite 和 whiteout-able 权限
- 文件系统分层, 对 readonly 权限的 branch 可以逻辑上进行修改(增量地, 不影响 readonly 部分的)。
- 通常 Union FS 有两个用途, 一方面可以将多个 disk 挂到同一个目录下, 另一个更常用的就是将一个 readonly 的 branch 和一个 writeable 的 branch 联合在一起。
Docker 的文件系统
典型的 Linux 文件系统组成:
- Bootfs(boot file system)
- Bootloader - 引导加载 kernel,
- Kernel - 当 kernel 被加载到内存中后 umount bootfs。
- rootfs (root file system)
- /dev,/proc,/bin,/etc 等标准目录和文件。
- 对于不同的 linux 发行版, bootfs 基本是一致的,但 rootfs 会有差别。
Docker 启动
Linux
- 在启动后,首先将 rootfs 设置为 readonly, 进行一系列检查, 然后将其切换为 “readwrite” 供用户使用。
Docker 启动
- 初始化时也是将 rootfs 以 readonly 方式加载并检查,然而接下来利用 union mount 的方式将一个 readwrite 文件系统挂载在 readonly 的 rootfs 之上;
- 并且允许再次将下层的 FS(file system) 设定为 readonly 并且向上叠加。
- 这样一组 readonly 和一个 writeable 的结构构成一个 container 的运行时态, 每一个 FS 被称作一个 FS 层。
Docker 写操作
由于镜像具有共享特性,所以对容器可写层的操作需要依赖存储驱动提供的写时复制和用时分配机制,以此来支持对容器可写层的修改,进而提高对存储和内存资源的利用率。
- 写时复制
- 写时复制,即 Copy-on-Write。
- 一个镜像可以被多个容器使用,但是不需要在内存和磁盘上做多个拷贝。
- 在需要对镜像提供的文件进行修改时,该文件会从镜像的文件系统被复制到容器的可写层的文件系统进行修改,而镜像里面的文件不会改变。
- 不同容器对文件的修改都相互独立、互不影响。
- 用时分配
- 按需分配空间,而非提前分配,即当一个文件被创建出来后,才会分配空间。
Docker 引擎架构
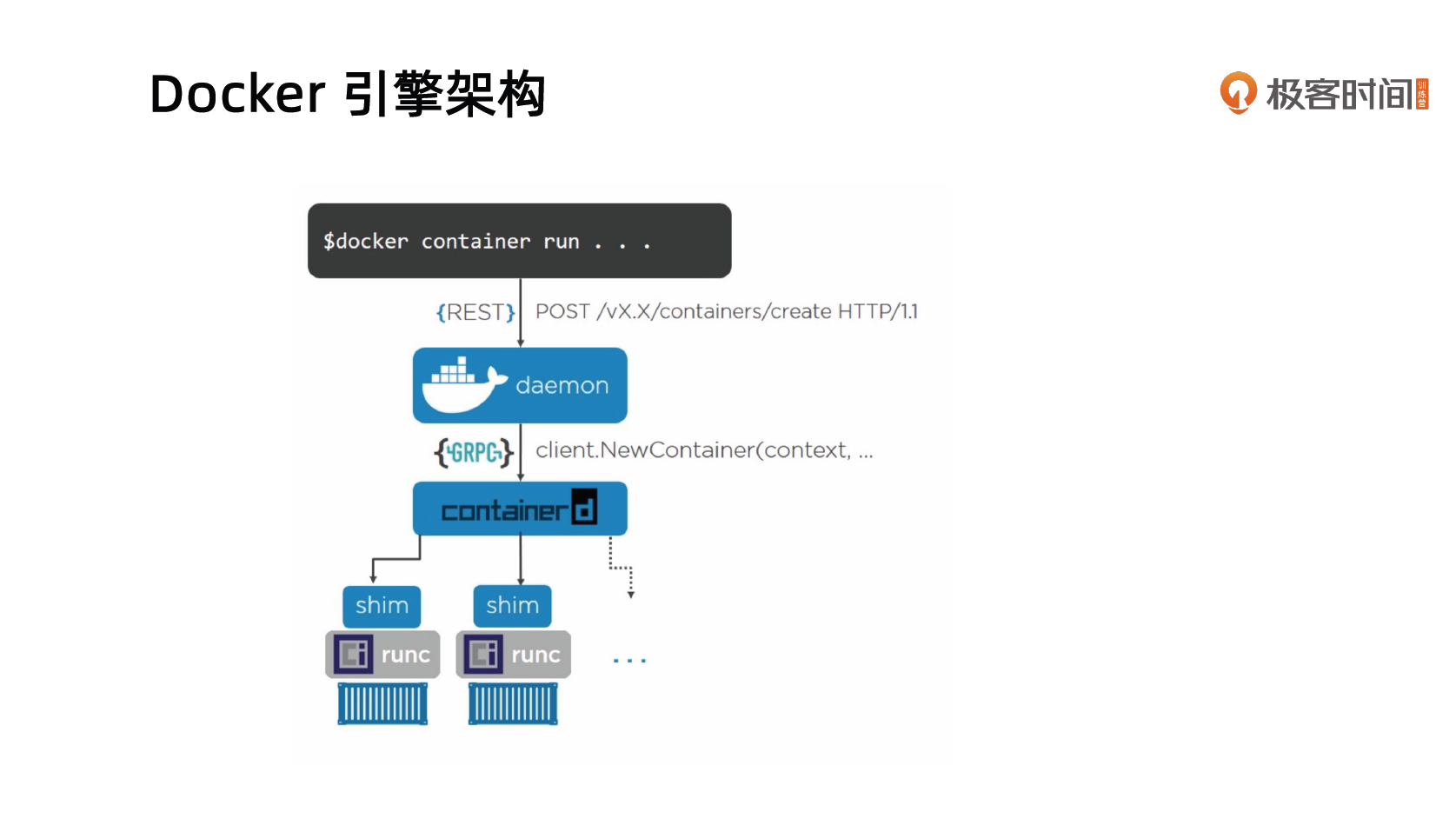
需要注意的是,在这个架构中,运行的 Docker 容器的父进程不是 Docker daemon ,这样就能避免重启 daemon 导致容器也必须重启。
$ docker inspect c07 | grep -i pid
"Pid": 5621,
"PidMode": "",
"PidsLimit": null,
$ ps -ef | grep 5621
root 5621 5600 0 11:45 pts/0 00:00:00 zsh
$ ps -ef | grep 5600
root 5600 1 0 11:45 ? 00:00:00 /snap/docker/2915/bin/containerd-shim-runc-v2 -namespace moby -id c07f841e7a66cb54f78f72445cb5baf7d479a3c27e8ea03966da1841e3605151 -address /run/snap.docker/containerd/containerd.sock
$ pstree -H 5600 -p -s -T
systemd(1)───containerd-shim(5600)───zsh(5621)Docker 网络
- Null(—net=None)
- 把容器放入独立的网络空间但不做任何网络配置;
- 用户需要通过运行 docker network 命令来完成网络配置。
- Host
- 使用主机网络名空间,复用主机网络。
- Container
- 重用其他容器的网络。
- Bridge(—net=bridge)
- 使用 Linux 网桥和 iptables 提供容器互联,Docker 在每台主机上创建一个名叫 docker0 的网桥,通过 veth pair 来连接该主机的每一个 EndPoint。
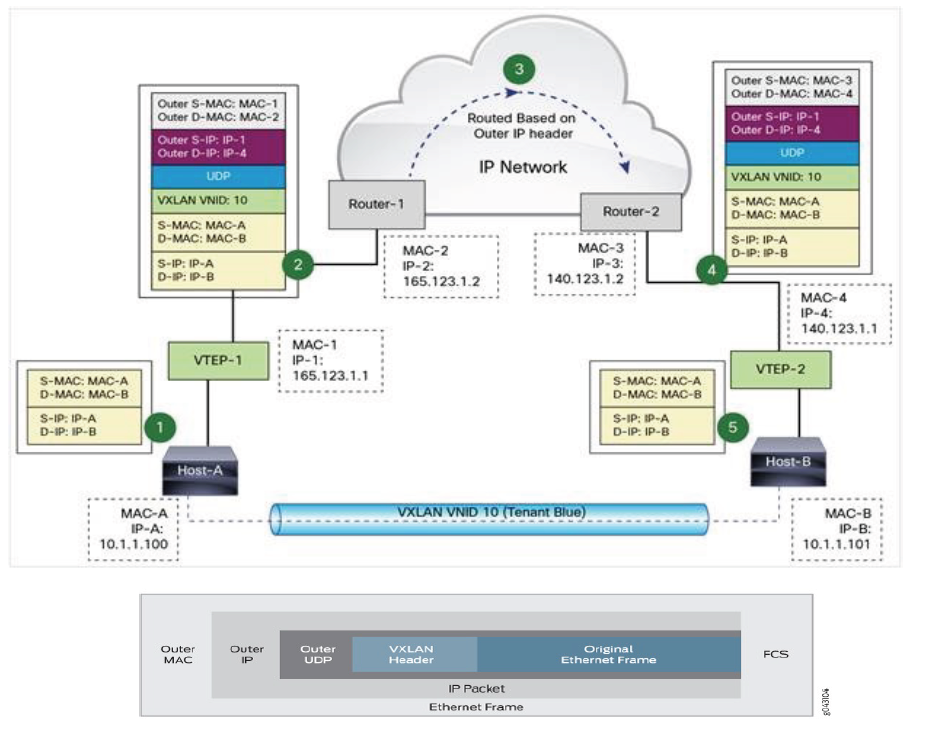
- Overlay(libnetwork, libkv)
- 通过网络封包实现。
- Remote(work with remote drivers)
- Underlay:使用现有底层网络,为每一个容器配置可路由的网络 IP。
- Overlay:通过网络封包实现。
Null 模式
- Null 模式是一个空实现;
- 可以通过 Null 模式启动容器并在宿主机上通过命令为容器配置网络。
https://github.com/kibaamor/101/blob/master/module3/setup-network.md
# 以后台的方式运行一个名为 nginx 的 nginx 容器,但不配置网络
$ docker run --network=none --name nginx -d nginx
# 获取刚刚运行的 nginx 容器中 nginx 进程在主机上的 Pid
$ docker inspect -f '{{.State.Pid}}' nginx
63648
# 查看 nginx 容器的网络配置
$ nsenter -t 63648 -n ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
# 将 nginx 容器进程所使用的 network namespace 连接到 /var/run/netns,这样才能使用 ip netns 命令查看和修改
# 创建目录
$ mkdir -p /var/run/netns
# 链接
$ ln -s /proc/63648/ns/net /var/run/netns/63648
# 确认链接成功
$ ip netns list
63648
# 查看主机上网桥的配置
$ brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.0242b3da2420 no
# 显示主机上 docker0 网口的 ip 信息
$ ip address show dev docker0
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
link/ether 02:42:b3:da:24:20 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
inet6 fe80::42:b3ff:feda:2420/64 scope link
valid_lft forever preferred_lft forever
# 创建 veth pair
$ ip link add A type veth peer name B
# 配置 A
# 把 A 添加到网桥 docker0
$ brctl addif docker0 A
# 启动 A
$ ip link set A up
# 配置 B
# 将 B 的 network namespace 移动到进程 63648 中
$ ip link set B netns 63648
# 将 B 改名为 eth0
$ ip netns exec 63648 ip link set dev B name eth0
# 启动 eth0
$ ip netns exec 63648 ip link set eth0 up
# 设置 eth0 的 IP 和子网掩码(根据 docker0 信息来)
$ ip netns exec 63648 ip addr add 172.17.0.100/16 dev eth0
# 设置 eth0 的默认网关(即为 docker0 的 IP 地址)
$ ip netns exec 63648 ip route add default via 172.17.0.1
# 测试能访问 nginx(如果失败,检查一下 HTTP_PROXY 等配置)
$ curl 172.17.0.100
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>默认模式 - 网桥和 NAT

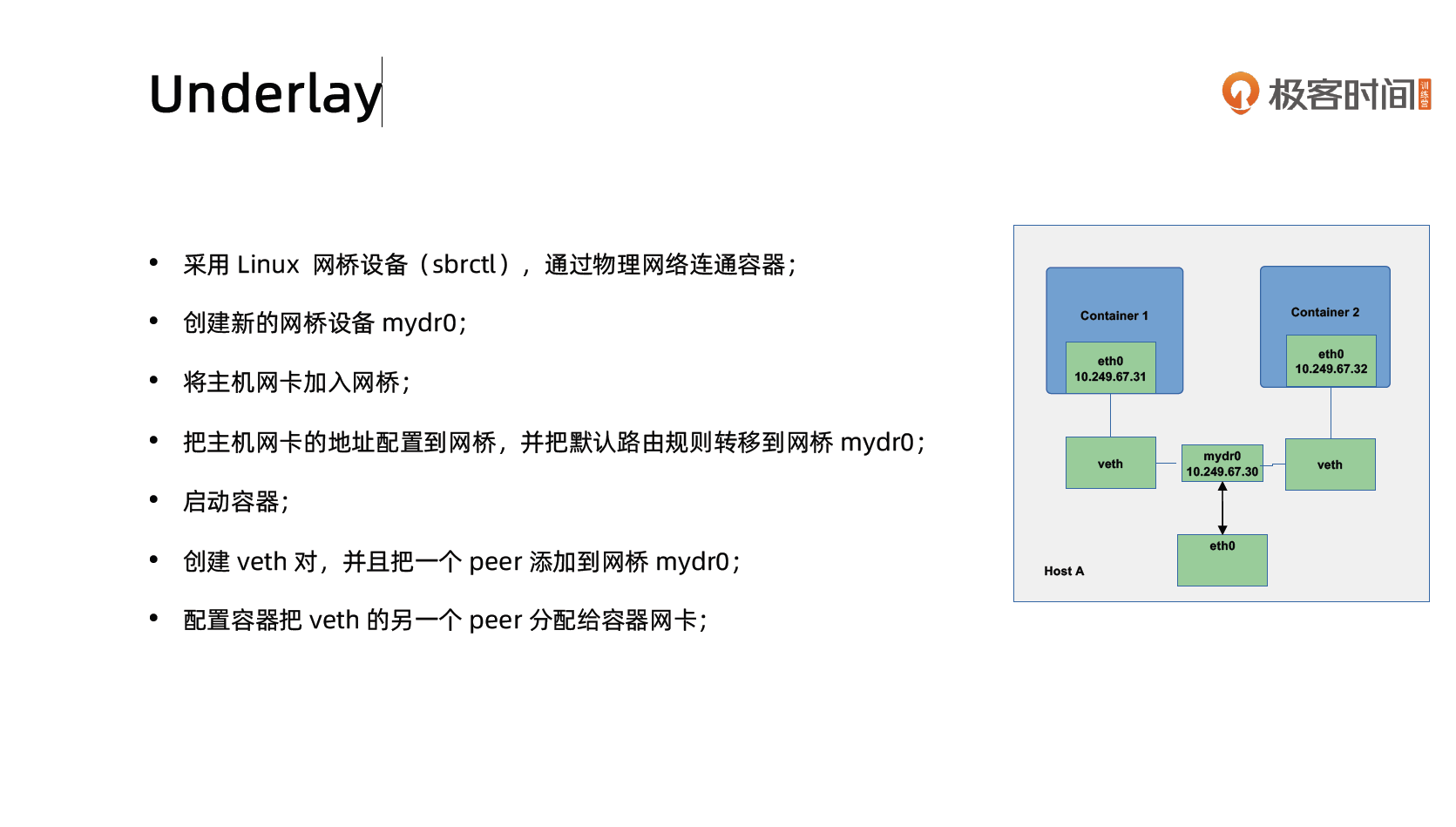
Underlay
Overlay
- Docker overlay 网络驱动原生支持多主机网络;
- Libnetwork 是一个内置的基于 VXLAN 的网络驱动。
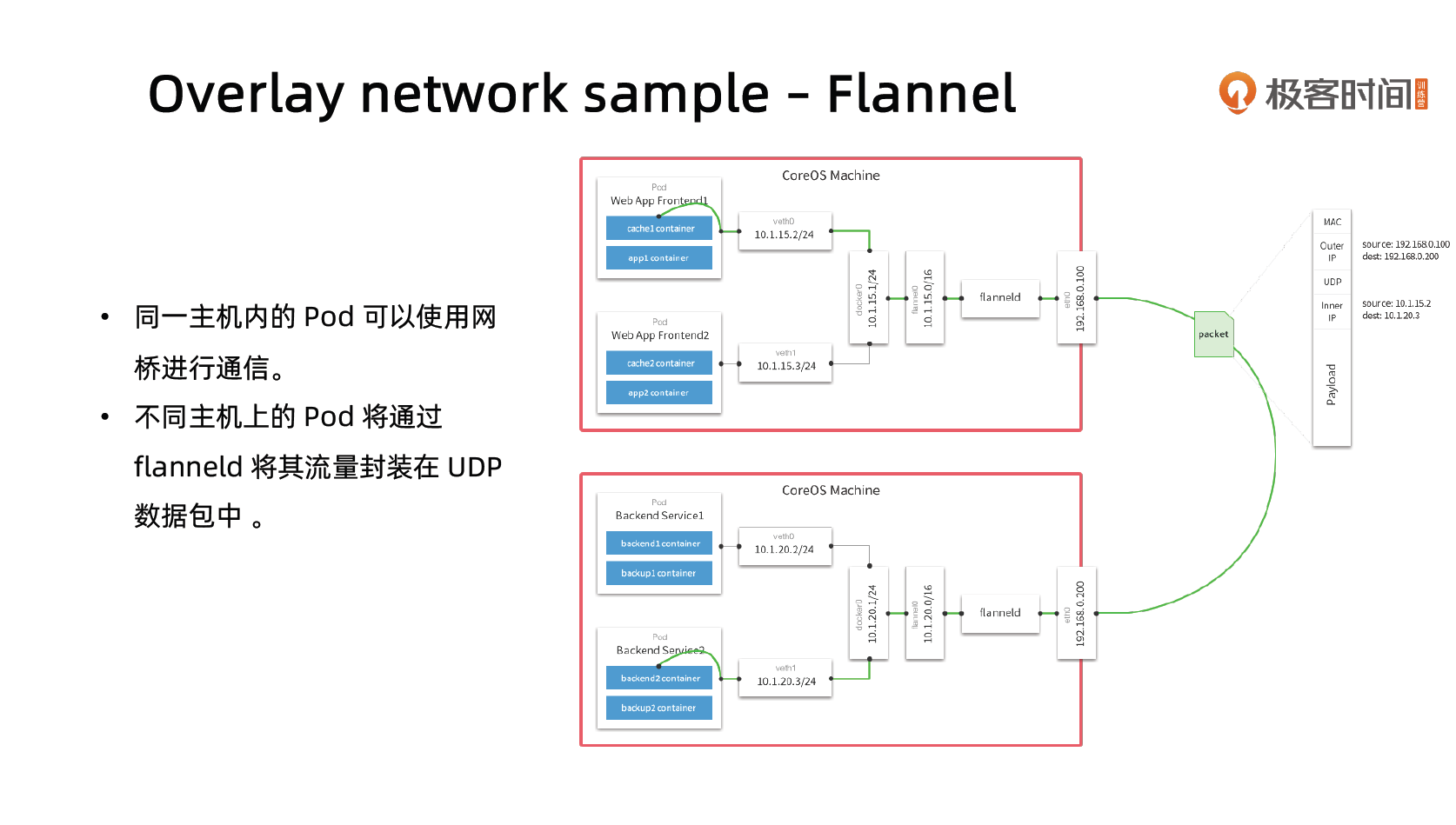
Dockerfile 的最佳实践
回顾12 Factor 之进程
- 运行环境中,应用程序通常是以一个和多个进程运行的。
- 12-Factor 应用的进程必须无状态(Stateless)且无共享(Share nothing)。
- 任何需要持久化的数据都要存储在后端服务内,比如数据库。
- 应在构建阶段将源代码编译成待执行应用。
- Session Sticky 是 12-Factor 极力反对的。
- Session 中的数据应该保存在诸如 Memcached 或 Redis 这样的带有过期时间的缓存中。
Docker 遵循以上原则管理和构建应用。
理解构建上下文(Build Context)
- 当运行docker build 命令时,当前工作目录被称为构建上下文。
- docker build 默认查找当前目录的Dockerfile 作为构建输入,也可以通过 -f 指定Dockerfile。
docker build -f ./Dockerfile
- 当docker build 运行时,首先会把构建上下文传输给 docker daemon,把没用的文件包含在构建上下文时,会导致传输时间长,构建需要的资源多,构建出的镜像大等问题。
- 试着到一个包含文件很多的目录运行下面的命令,会感受到差异;
docker build -f $GOPATH/src/github.com/cncamp/golang/httpserver/Dockerfile;docker build $GOPATH/src/github.com/cncamp/golang/httpserver/;- 可以通过
.dockerignore文件从编译上下文排除某些文件。
- 因此需要确保构建上下文清晰,比如创建一个专门的目录放置 Dockerfile,并在目录中运行
docker build。
Build Cache
构建容器镜像时,Docker 依次读取 Dockerfile 中的指令,并按顺序依次执行构建指令。
Docker 读取指令后,会先判断缓存中是否有可用的已存镜像,只有已存镜像不存在时才会重新构建。
- 通常 Docker 简单判断 Dockerfile 中的指令与镜像。
- 针对 ADD 和 COPY 指令,Docker 判断该镜像层每一个文件的内容并生成一个 checksum,与现存镜像比较时,Docker 比较的是二者的 checksum。
- 其他指令,比如
RUN apt-get -y update,Docker 简单比较与现存镜像中的指令字串是否一致。 - 当某一层 cache 失效以后,所有所有层级的 cache 均一并失效,后续指令都重新构建镜像。
Dockerfile 常用指令
FROM:选择基础镜像,推荐alpine
FROM [--platform=<platform>] <image>[@<digest>] [AS <name>]LABELS:按标签组织项目
LABEL multi.label1=”value1” multi.label2=”value2” other=”value3”
配合label filter 可过滤镜像查询结果
docker images -f label=multi.label1="value1"RUN:执行命令
最常见的用法是 RUN apt-get update && apt-get install,这两条命令应该永远用 && 连接,如果分开执行,RUN apt-get update 构建层被缓存,可能会导致新 package 无法安装
CMD:容器镜像中包含应用的运行命令,需要带参数
CMD [“executable”, “param1”, “param2”…]
EXPOSE:发布端口
EXPOSE <port> [<port>/<protocol>...]是镜像创建者和使用者的约定
在 docker run -P 时,docker 会自动映射 expose 的端口到主机大端口,如 0.0.0.0:32768->80/tcp
ENV 设置环境变量
ENV <key>=<value>…ADD:从源地址(文件,目录或者URL)复制文件到目标路径
ADD [--chown=<user>:<group>] <src>... <dest>ADD [--chown=<user>:<group>] ["<src>",... "<dest>"](路径中有空格时使用)ADD 支持 Go 风格的通配符,如 ADD check* /testdir/
src 如果是文件,则必须包含在编译上下文中,ADD 指令无法添加编译上下文之外的文件
src 如果是URL
- 如果 dest 结尾没有 /,那么 dest 是目标文件名,如果 dest 结尾有 /,那么 dest 是目标目录名
如果 src 是一个目录,则所有文件都会被复制至 dest
如果 src 是一个本地压缩文件,则在 ADD 的同时完整解压操作
如果 dest 不存在,则 ADD 指令会创建目标目录
应尽量减少通过 ADD URL 添加 remote 文件,建议使用 curl 或者 wget && untar (维护起来理解成本高)
COPY:从源地址(文件,目录或者URL)复制文件到目标路径
COPY [--chown=<user>:<group>] <src>... <dest>COPY [--chown=<user>:<group>] ["<src>",... "<dest>"]// 路径中有空格时使用COPY 的使用与 ADD 类似,但有如下区别
COPY 只支持本地文件的复制,不支持URL
COPY 不解压文件
COPY 可以用于多阶段编译场景,可以用前一个临时镜像中拷贝文件
COPY —from=build /bin/project /bin/project
COPY 语义上更直白,复制本地文件时,优先使用 COPY
ENTRYPOINT:定义可以执行的容器镜像入口命令
ENTRYPOINT [“executable”, “param1”, “param2”] // docker run参数追加模式
ENTRYPOINT command param1 param2 // docker run 参数替换模式
docker run -entrypoint 可替换 Dockerfile 中定义的 ENTRYPOINT
ENTRYPOINT 的最佳实践是用 ENTRYPOINT 定义镜像主命令,并通过 CMD 定义主要参数,如下所示
ENTRYPOINT [“s3cmd”]
CMD [“—help”]
VOLUME: 将指定目录定义为外挂存储卷,Dockerfile 中在该指令之后所有对同一目录的修改都无效
VOLUME [“/data”]
等价于docker run -v /data,可通过docker inspect 查看主机的mount point,
/var/lib/docker/volumes/<containerid>/_dataUSER:切换运行镜像的用户和用户组,因安全性要求,越来越多的场景要求容器应用要以 non-root 身份运行
USER <user>[:<group>]WORKDIR:等价于cd,切换工作目录
WORKDIR /path/to/workdir
其他非常用指令
- ARG
- ONBUILD
- STOPSIGNAL
- HEALTHCHECK
- SHELL
Dockerfile 最佳实践
目标:易管理、少漏洞、镜像小、层级少、利用缓存。
- 不要安装无效软件包。
- 应简化镜像中同时运行的进程数,理想状况下,每个镜像应该只有一个进程。
- 当无法避免同一镜像运行多进程时,应选择合理的初始化进程(init process)。
- 最小化层级数
- 最新的 docker 只有 RUN,COPY,ADD 创建新层,其他指令创建临时层,不会增加镜像大小。
- 比如 EXPOSE 指令就不会生成新层。
- 多条RUN 命令可通过连接符连接成一条指令集以减少层数。
- 通过多段构建减少镜像层数。
- 最新的 docker 只有 RUN,COPY,ADD 创建新层,其他指令创建临时层,不会增加镜像大小。
- 把多行参数按字母排序,可以减少可能出现的重复参数,并且提高可读性。
- 编写 dockerfile 的时候,应该把变更频率低的编译指令优先构建以便放在镜像底层以有效利用 build cache。
- 复制文件时,每个文件应独立复制,这确保某个文件变更时,只影响改文件对应的缓存。
多进程的容器镜像
- 选择适当的 init 进程
- 需要捕获 SIGTERM 信号并完成子进程的优雅终止
- 负责清理退出的子进程以避免僵尸进程
开源项目
https://github.com/krallin/tini
镜像仓库
创建私有镜像仓库
https://distribution.github.io/distribution/
docker run -d -p 5000:5000 registry
Kubernetes 架构原则和对象设计
云计算
什么是云计算
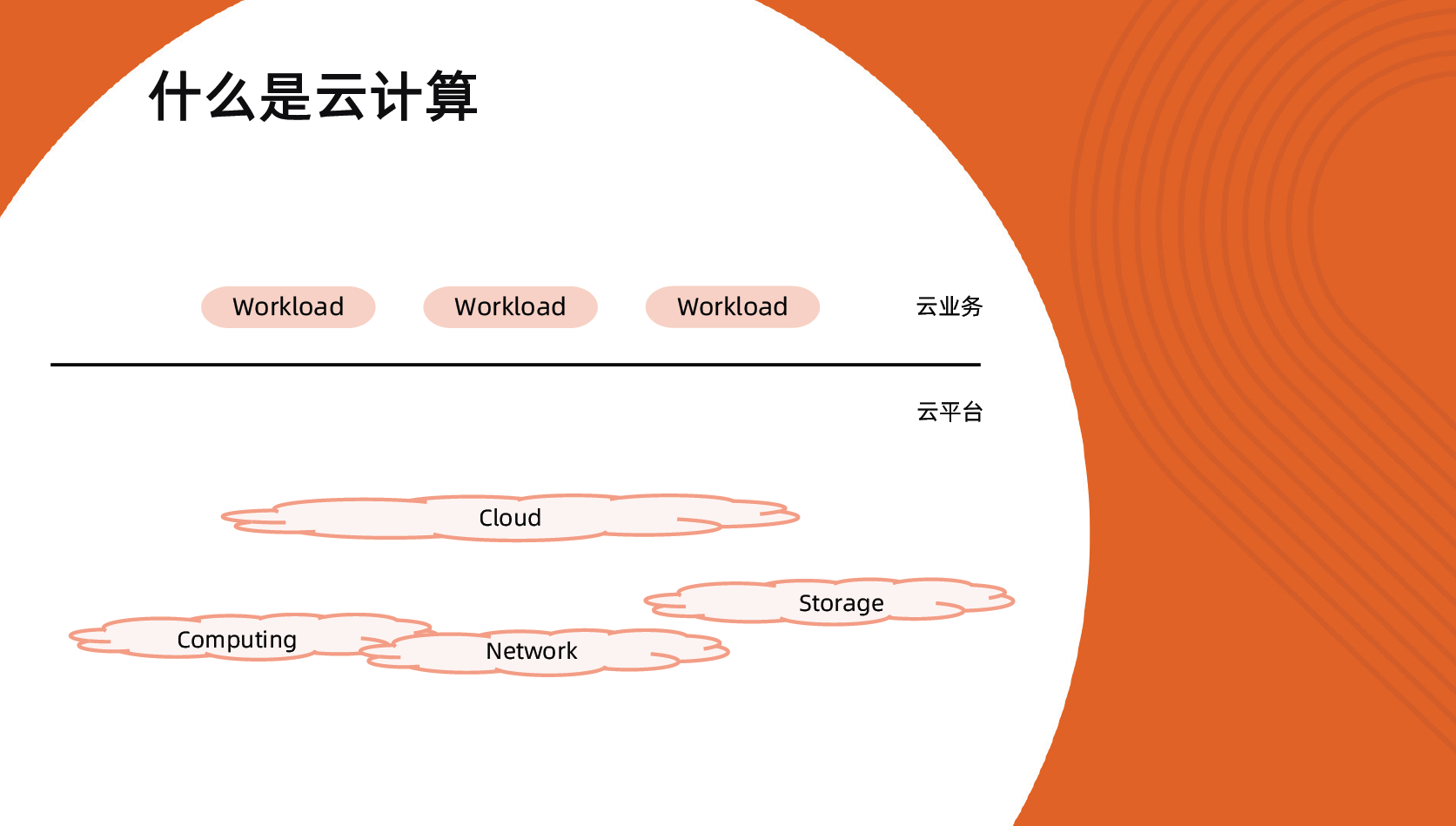
云计算是对所有计算资源、网络资源和存储资源的一种抽象。
怎么理解呢?
比如,有 5000 台机器。
- 我们可以从网络上打通,把它们形成一个集群。
- 我们可以有一个用于控制的控制平面,把这些计算资源抽象出来。
我们就能知道这 5000 个节点,每个节点上有多少 CPU、内存等。对于整个集群来说,我们也知道哪些节点是健康的,哪些节点是不健康的。谁能参与计算,谁不能参与计算等。这样我们就拥有了一个大的计算池。
上面是从云平台侧考虑的,做了资源的抽象。
另一方面,从业务的角度来说,业务也不用管作业实际部署在哪儿,只用告诉云平台某个业务需要多少实例,每个实例需要多少 CPU 和内存等资源信息即可。云平台会自动找合适节点来运行业务。
这就是云计算,对计算资源做一个抽象,让业务面向抽象的计算资源来部署应用。
云计算平台的分类
以 Openstack 为典型的虚拟化平台
- 虚拟机构建和业务代码部署分离。
- 可变的基础架构使后续维护风险变大。
以谷歌 borg 为典型的基于进程的作业调度平台
- 技术的迭代引发 borg 的换代需求。
- 早期的隔离依靠 chroot jail 实现,一些不合理的设计需要在新产品中改进。
- 对象之间的强依赖 job 和 task 是强包含关系,不利于重组。
- 所有容器共享 IP,会导致端口冲突,隔离困难等问题。
- 为超级用户添加复杂逻辑导致系统过于复杂。
Kubernetes 架构基础
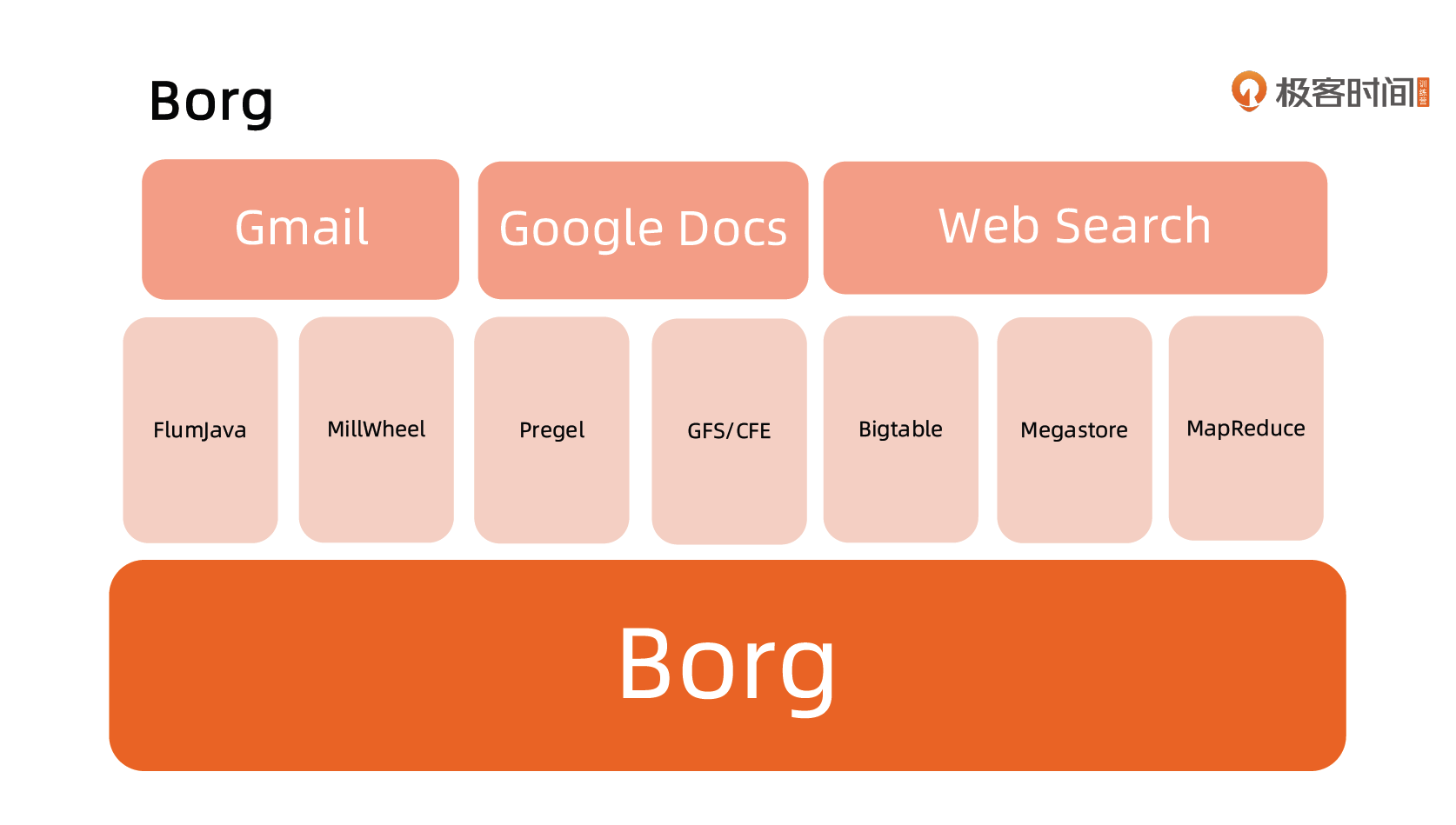
Google Borg
建议对原论文
特性
- 物理资源利用率高。
- 服务器共享,在进程级别做隔离。
- 应用高可用,故障恢复时间短。
- 调度策略灵活。
- 应用接入和使用方便,提供了完备的 Job 描述语言,服务发现,实时状态监控和诊断工具。
优势
- 对外隐藏底层资源管理和调度、故障处理等。
- 实现应用的高可靠和高可用。
- 足够弹性,支持应用跑在成千上万的机器上。
基本概念
Workload
- prod:在线任务,长期运行、对延时敏感、面向终端用户等,比如 Gmail, Google Docs,Web Search 服务等。
- non-prod : 离线任务,也称为批处理任务(Batch),比如一些分布式计算服务等。
Cell
相当于一个集群
- 一个 Cell 上跑一个集群管理系统 Borg。
- 通过定义 Cell 可以让 Borg 对服务器资源进行统一抽象,作为用户就无需知道自己的应用跑在哪台机器上,也不用关心资源分配、程序安装、依赖管理、健康检查及故障恢复等。
Job 和 Task
相当于 k8s 中的 pod 和 container
- 用户以 Job 的形式提交应用部署请求。一个 Job 包含一个或多个相同的 Task,每个 Task 运行相同的应用程序,Task 数量就是应用的副本数。
- 每个 Job 可以定义属性、元信息和优先级,优先级涉及到抢占式调度过程。
Naming
- Borg 的服务发现通过 BNS ( Borg NameService)来实现。
- 50.jfoo.ubar.cc.borg.google.com 可表示在一个名为 cc 的 Cell 中由用户 uBar 部署的一个名为 jFoo 的 Job下的第 50 个 Task。
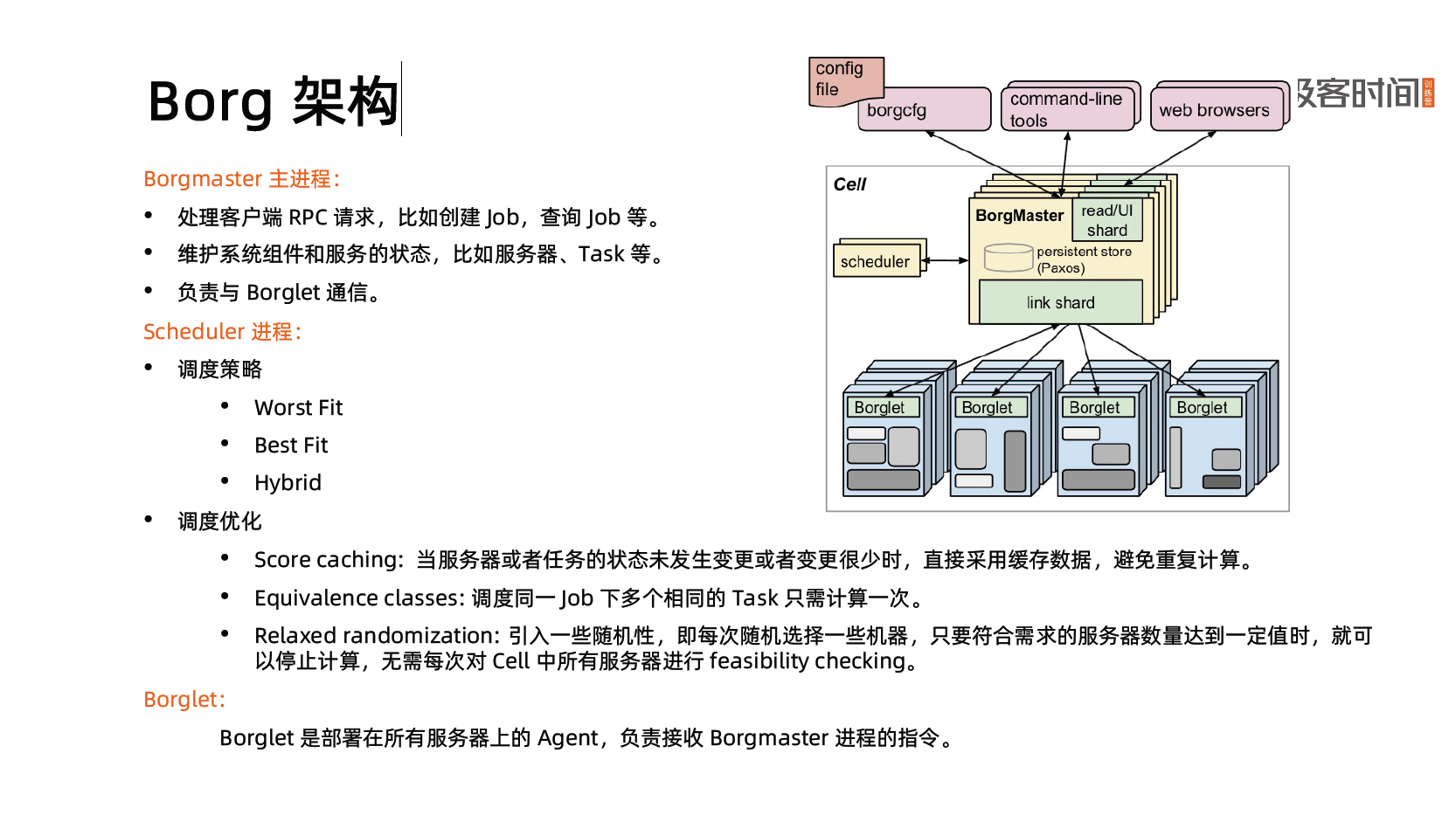
Borg 架构
应用高可用
- 被抢占的 non-prod 任务放回 pending queue,等待重新调度。
- 多副本应用跨故障域部署。所谓故障域有大有小,比如相同机器、相同机架或相同电源插座等,一挂全挂。
- 对于类似服务器或操作系统升级的维护操作,避免大量服务器同时进行。
- 支持幂等性,支持客户端重复操作。
- 当服务器状态变为不可用时,要控制重新调度任务的速率。因为 Borg 无法区分是节点故障还是出现了短暂的网络分区,如果是后者,静静地等待网络恢复更利于保障服务可用性。
- 当某种”任务 @ 服务器”的组合出现故障时,下次重新调度时需避免这种组合再次出现,因为极大可能会再次出现相同故障。
- 记录详细的内部信息,便于故障排查和分析。
- 保障应用高可用的关键性设计原则:无论何种原因,即使 Borgmaster 或者 Borglet 挂掉、失联,都不能杀掉正在运行的服务(Task)。
Borg 系统自身高可用
- Borgmaster 组件多副本设计。
- 采用一些简单的和底层(low-level)的工具来部署 Borg 系统实例,避免引入过多的外部依赖。
- 每个 Cell 的 Borg 均独立部署,避免不同 Borg 系统相互影响。
资源利用率
- 通过将在线任务(prod)和离线任务(non-prod,Batch)混合部署,空闲时,离线任务可以充分利用计算资源;繁忙时,在线任务通过抢占的方式保证优先得到执行,合理地利用资源。
- 98% 的服务器实现了混部。
- 90% 的服务器中跑了超过25 个 Task 和 4500 个线程。
- 在一个中等规模的 Cell 里,在线任务和离线任务独立部署比混合部署所需的服务器数量多出约20%-30%。
可以简单算一笔账,Google 的服务器数量在千万级别,按 20% 算也是百万级别,大概能省下的服务器采购费用就是百亿级别了,这还不包括省下的机房等基础设施和电费等费用。
Brog 调度原理
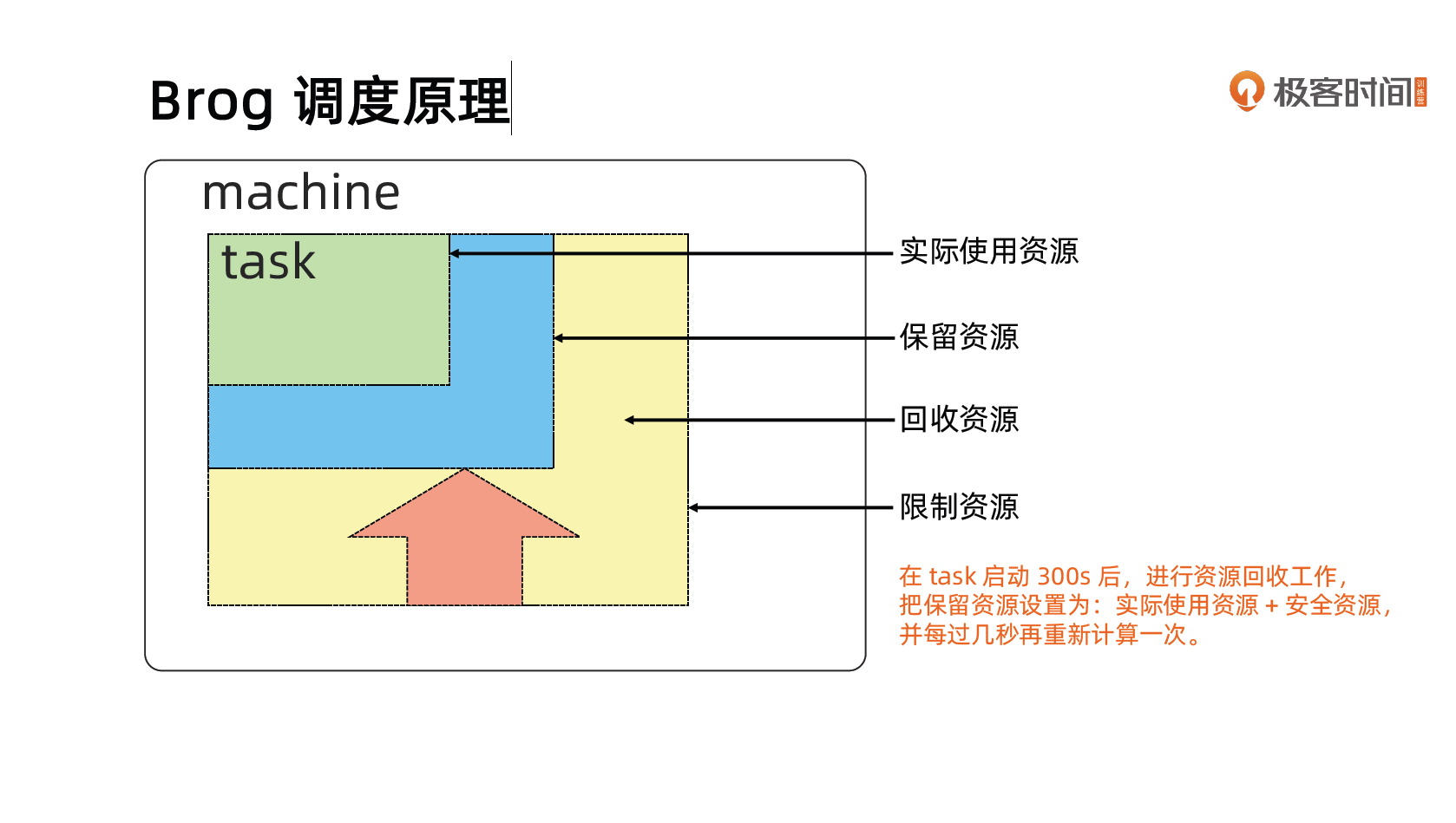
隔离性
安全性隔离:
- 早期采用 Chroot jail,后期版本基于 Namespace。
性能隔离:
- 采用基于 Cgroup 的容器技术实现。
- 在线任务(prod)是延时敏感(latency-sensitive)型的,优先级高,而离线任务(non-prod,Batch)优先级低。
- Borg 通过不同优先级之间的抢占式调度来优先保障在线任务的性能,牺牲离线任务。
- Borg 将资源类型分成两类:
- 可压榨的(compressible),CPU 是可压榨资源,资源耗尽不会终止进程;
- 不可压榨的(non-compressible),内存是不可压榨资源,资源耗尽进程会被终止。
什么是Kubernetes(K8s)
Kubernetes 是谷歌开源的容器集群管理系统,是 Google 多年大规模容器管理技术 Borg 的开源版本,主要功能包括:
- 基于容器的应用部署、维护和滚动升级;
- 负载均衡和服务发现;
- 跨机器和跨地区的集群调度;
- 自动伸缩;
- 无状态服务和有状态服务;
- 插件机制保证扩展性。
命令式( Imperative)vs 声明式( Declarative)

声明式(Declaritive)系统规范
命令式:
- 我要你做什么,怎么做,请严格按照我说的做。
声明式:
- 我需要你帮我做点事,但是我只告诉你我需要你做什么,不是你应该怎么做。
- 直接声明:我直接告诉你我需要什么。
- 间接声明:我不直接告诉你我的需求,我会把我的需求放在特定的地方,请在方便的时候拿出来处理。
幂等性:
- 状态固定,每次我要你做事,请给我返回相同结果。
面向对象的:
- 把一切抽象成对象。
Kubernetes:声明式系统
Kubernetes 的所有管理能力构建在对象抽象的基础上,核心对象包括:
- Node:计算节点的抽象,用来描述计算节点的资源抽象、健康状态等。
- Namespace:资源隔离的基本单位,可以简单理解为文件系统中的目录结构。
- Pod:用来描述应用实例,包括镜像地址、资源需求等。Kubernetes 中最核心的对象,也是打通应用和基础架构的秘密武器。
- Service:服务如何将应用发布成服务,本质上是负载均衡和域名服务的声明。
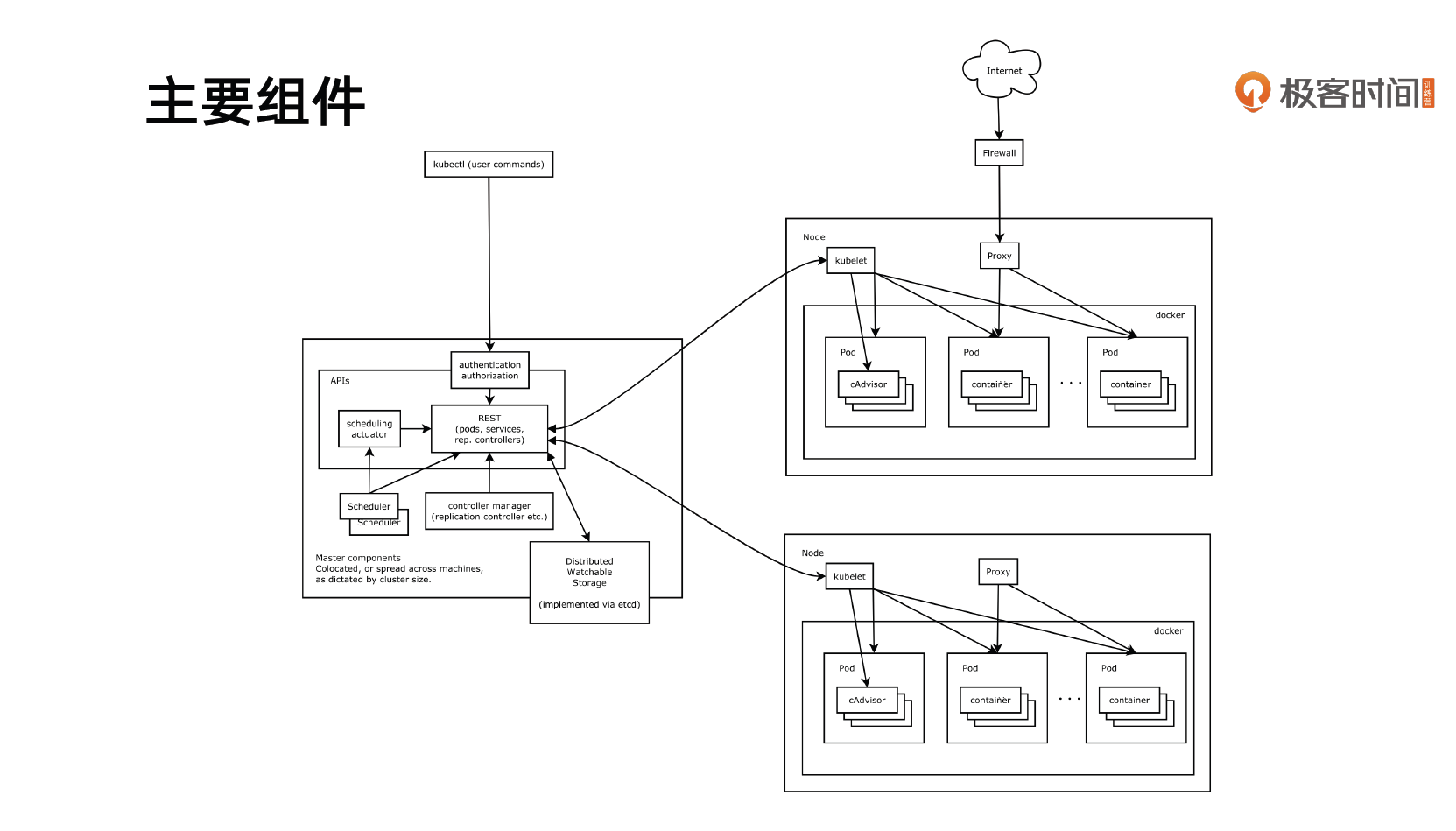
Kubernetes 架构
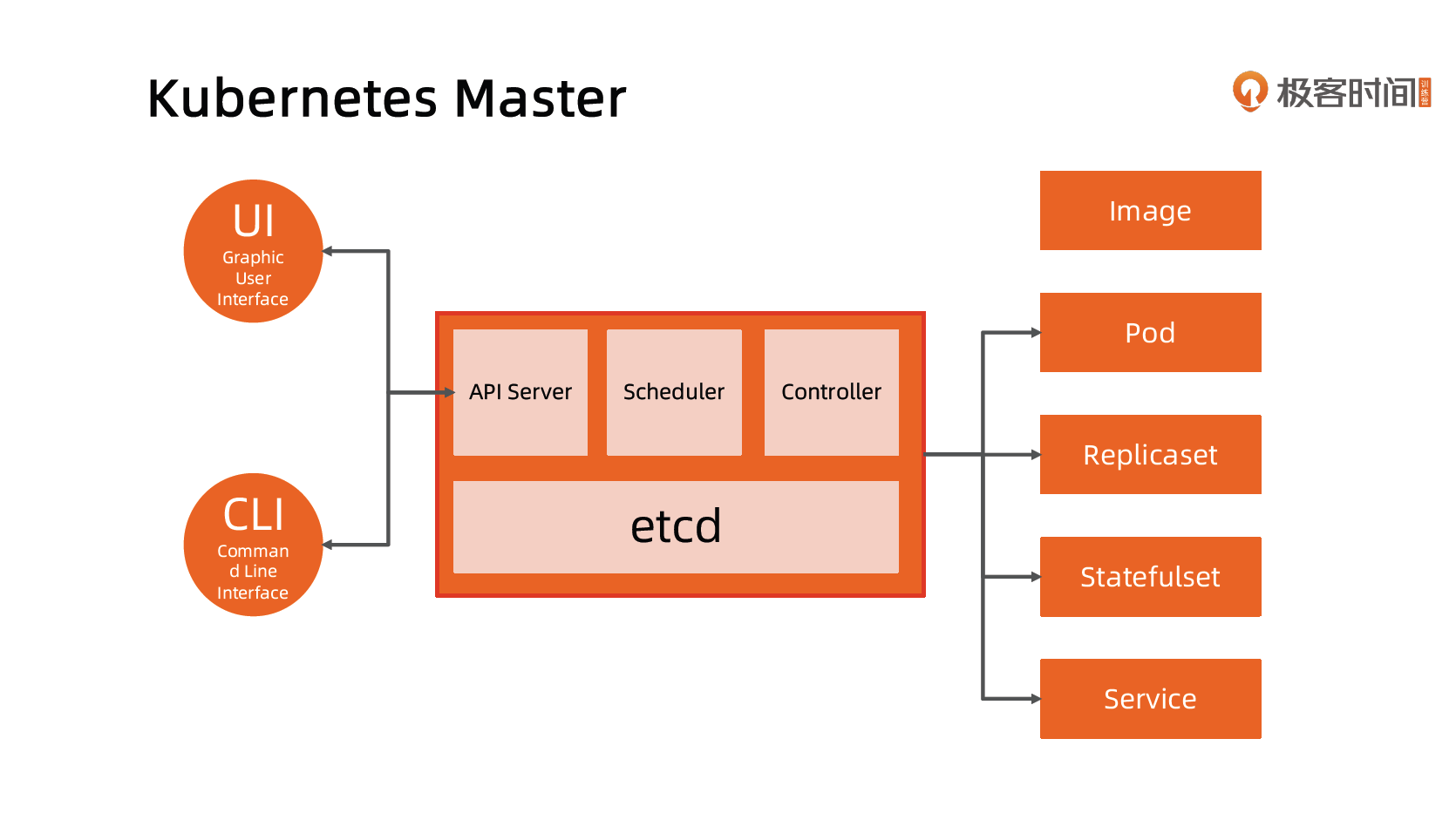
Kubernetes 采用与 Borg 类似的架构
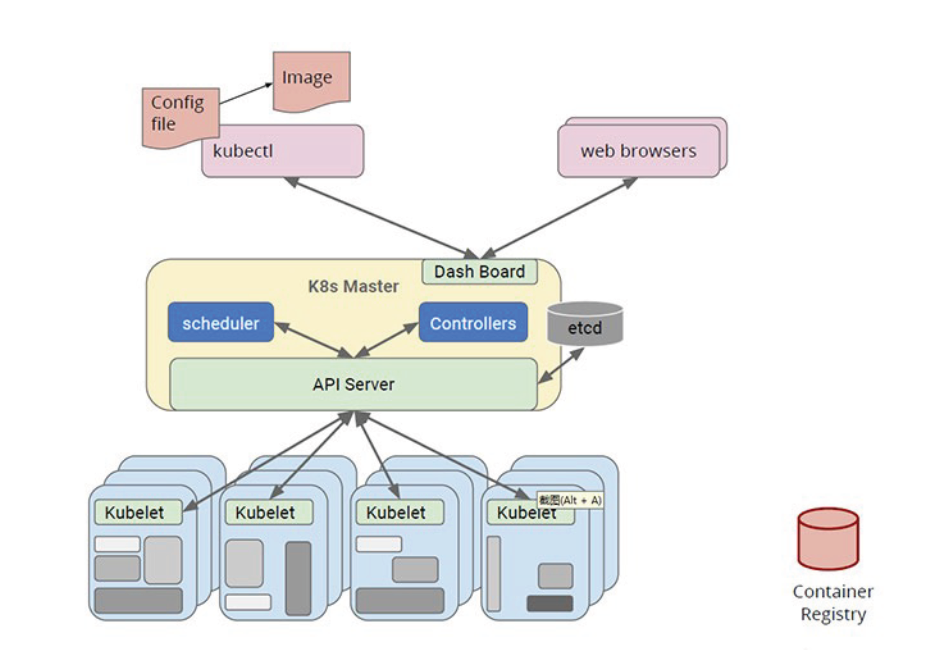
主要组件
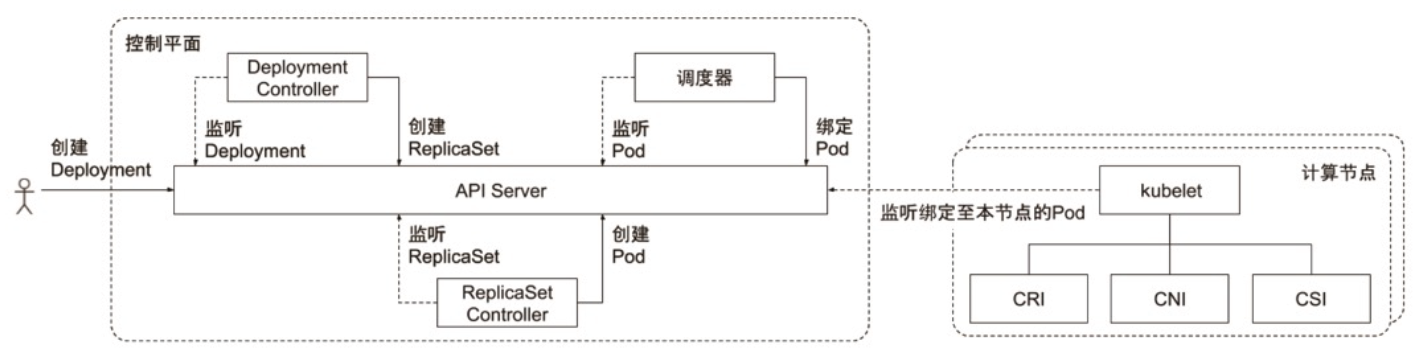
Kubernetes 的主节点(Master Node)
API 服务器(API Server)
API Server 的主要作用是对请求做认证、鉴权以及准入(验证请求内容的合法性),无其他逻辑。
这是Kubernetes 控制面板中唯一带有用户可访问API 以及用户可交互的组件。API 服务器会暴露一个RESTful 的Kubernetes API 并使用JSON 格式的清单文件(manifest files)。
群的数据存储(Cluster Data Store)
Kubernetes 使用 “etcd” 。这是一个强大的、稳定的、高可用的键值存储, 被 Kubernetes 用于长久储存所有的API 对象。
控制管理器(Controller Manager)
被称为 “kube-controller manager”,它运行着所有处理集群日常任务的控制器。包括了节点控制器、副本控制器、端点(endpoint)控制器以及服务账户等。
调度器(Scheduler)
调度器会监控新建的 pods(一组或一个容器)并将其分配给节点。
Kubernetes 的工作节点(Worker Node)
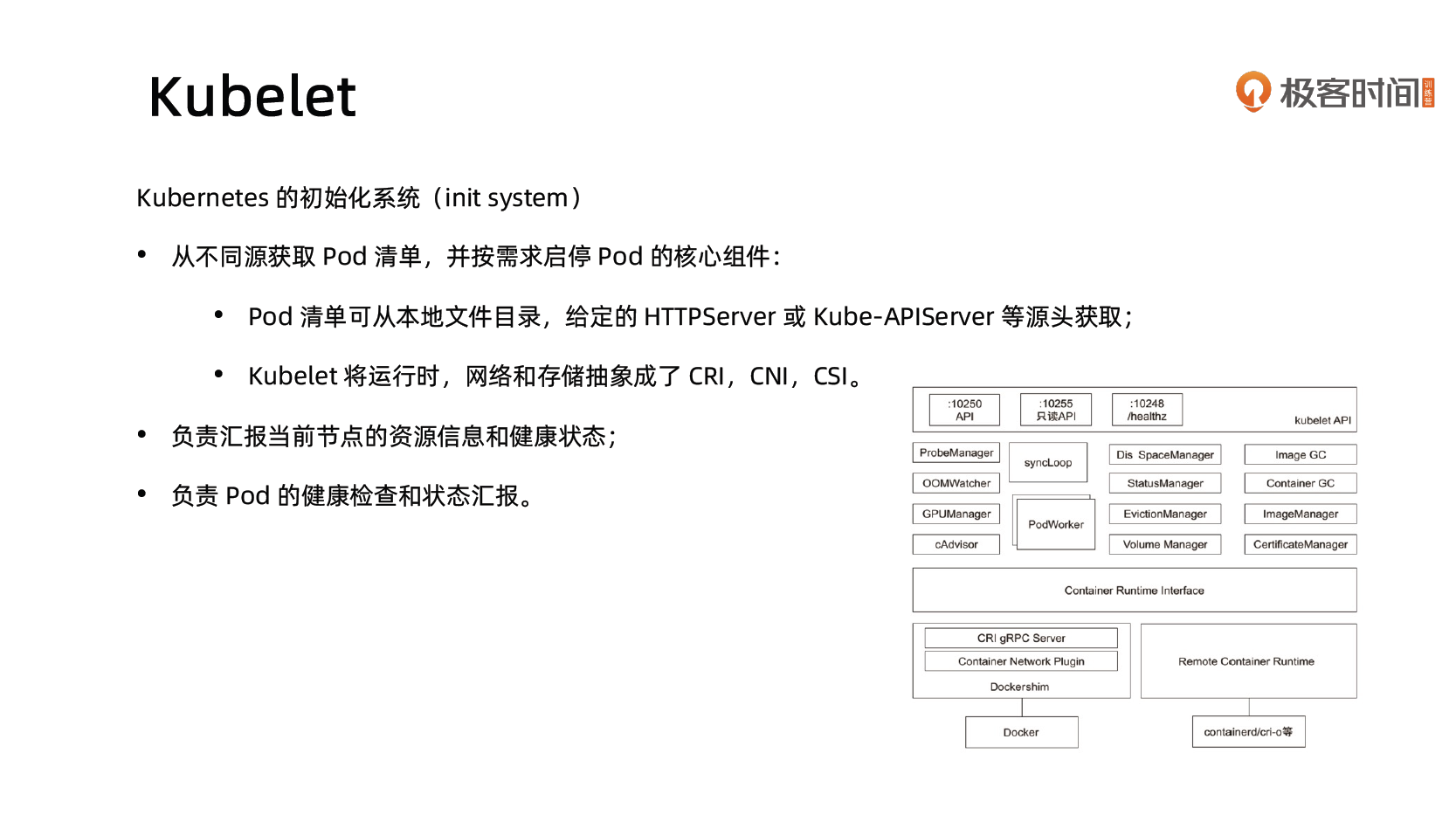
Kubelet
负责调度到对应节点的 Pod 的生命周期管理,执行任务并将 Pod 状态报告给主节点的渠道,通过容器运行时(拉取镜像、启动和停止容器等)来运行这些容器。它还会定期执行被请求的容器的健康探测程序。
Kube-proxy
它负责节点的网络,在主机上维护网络规则并执行连接转发。它还负责对正在服务的 pods 进行负载平衡。
etcd
直接访问 etcd 的数据
# 启动一个 minikube 集群
$ minikube start
# 获取 kube-system 中所有 pods
$ kubectl -n kube-system get pods
NAME READY STATUS RESTARTS AGE
coredns-7db6d8ff4d-z2rlw 1/1 Running 0 4h10m
etcd-minikube 1/1 Running 0 4h10m
kube-apiserver-minikube 1/1 Running 0 4h10m
kube-controller-manager-minikube 1/1 Running 0 4h10m
kube-proxy-m5fjm 1/1 Running 0 4h10m
kube-scheduler-minikube 1/1 Running 0 4h10m
storage-provisioner 1/1 Running 1 (4h9m ago) 4h10m
# 进入集群 etcd 所在的容器
$ kubectl -n kube-system exec -it etcd-minikube /bin/sh
$ alias etcdctl="etcdctl --endpoints https://localhost:2379 --cacert=/var/lib/minikube/certs/etcd/ca.crt --cert=/var/lib/minikube/certs/etcd/server.crt --key=/var/lib/minikube/certs/etcd/server.key"
# 查看 etcd 中的数据
$ etcdctl get --prefix / --keys-only
# 监听 default 命名空间中名为 nginx-svc 的 service 的变化
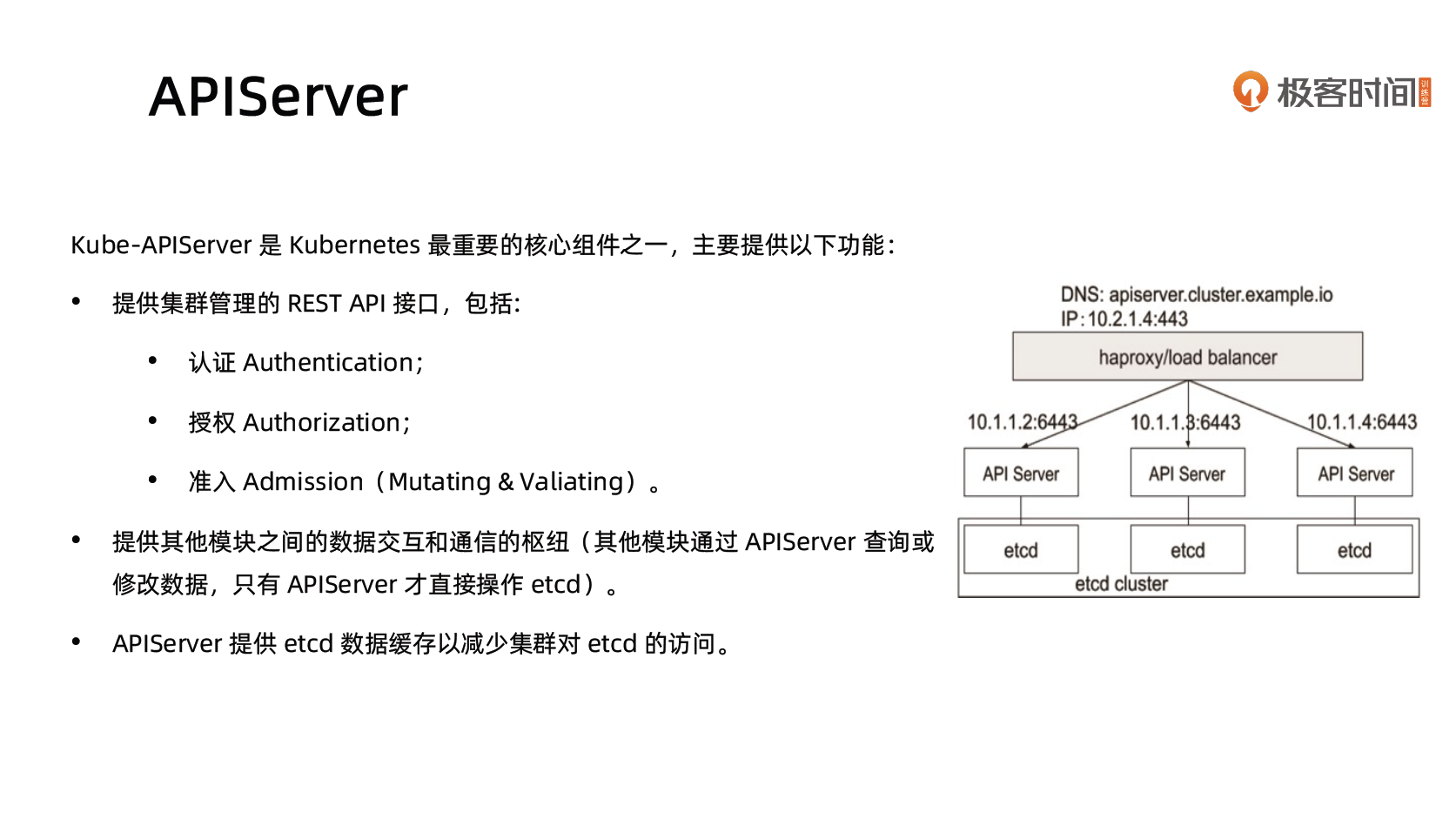
$ etcdctl watch --prefix /registry/services/specs/default/nginx-svcAPIServer
APIServer 展开
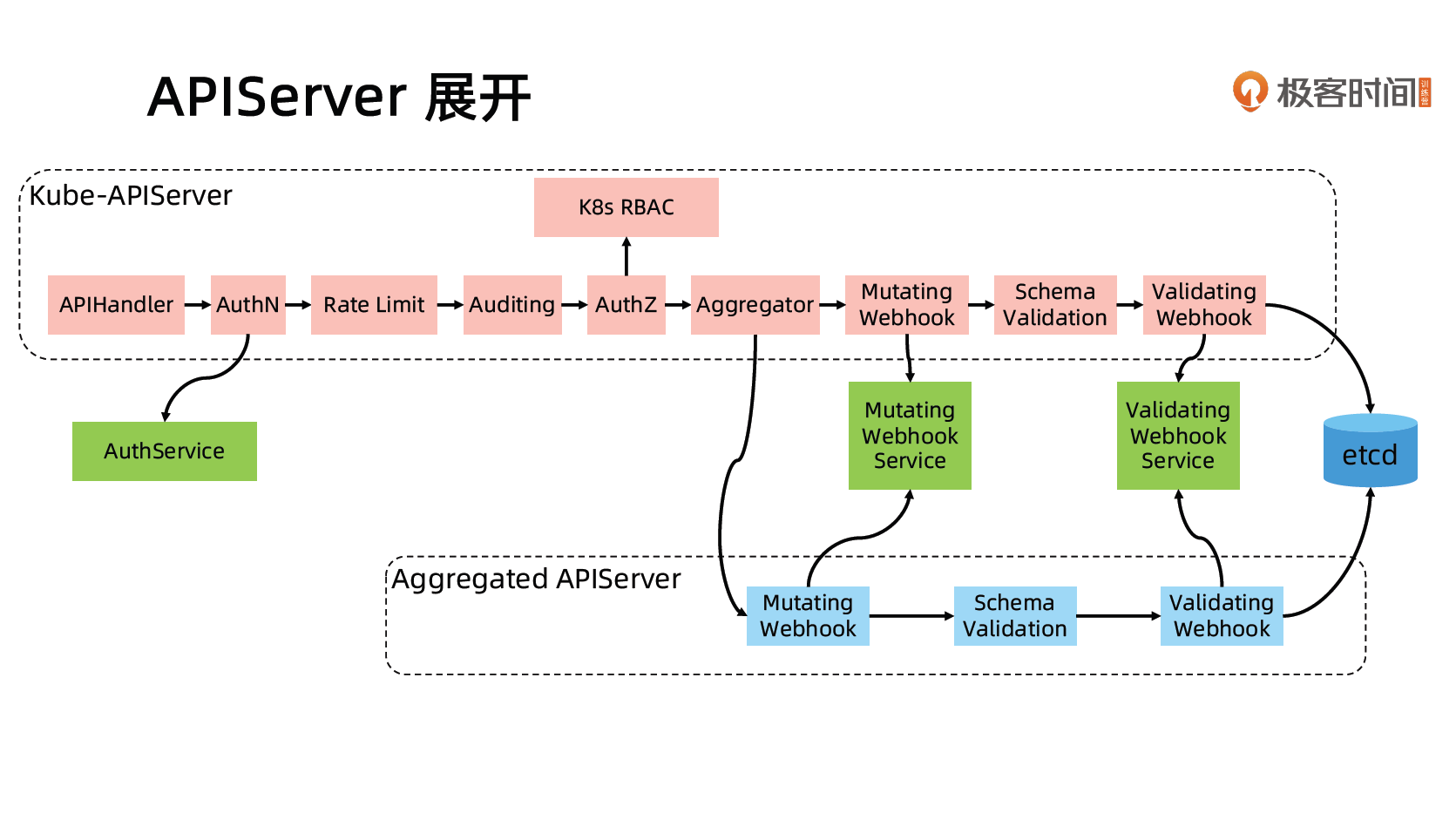
Controller Manager
- Controller Manager 是集群的大脑,是确保整个集群动起来的关键;
- 作用是确保 Kubernetes 遵循声明式系统规范,确保系统的真实状态(Actual State)与用户定义的期望状态(Desired State)一致;
- Controller Manager 是多个控制器的组合,每个 Controller 事实上都是一个 control loop,负责侦听其管控的对象,当对象发生变更时完成配置;
- Controller 配置失败通常会触发自动重试,整个集群会在控制器不断重试的机制下确保最终一致性( Eventual Consistency)。
控制器的工作流程
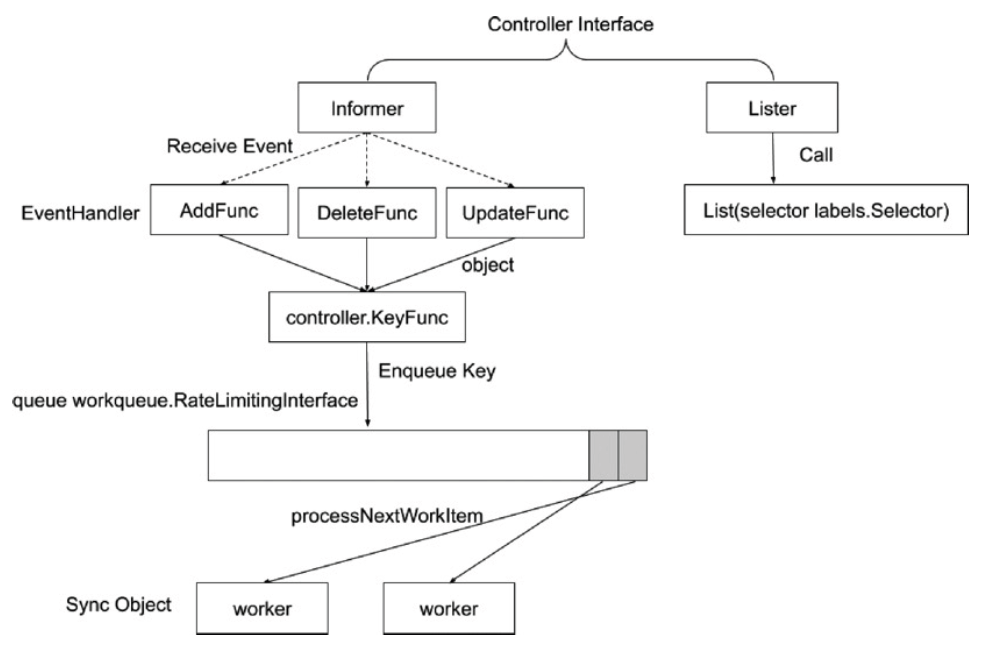
Informer 的内部机制
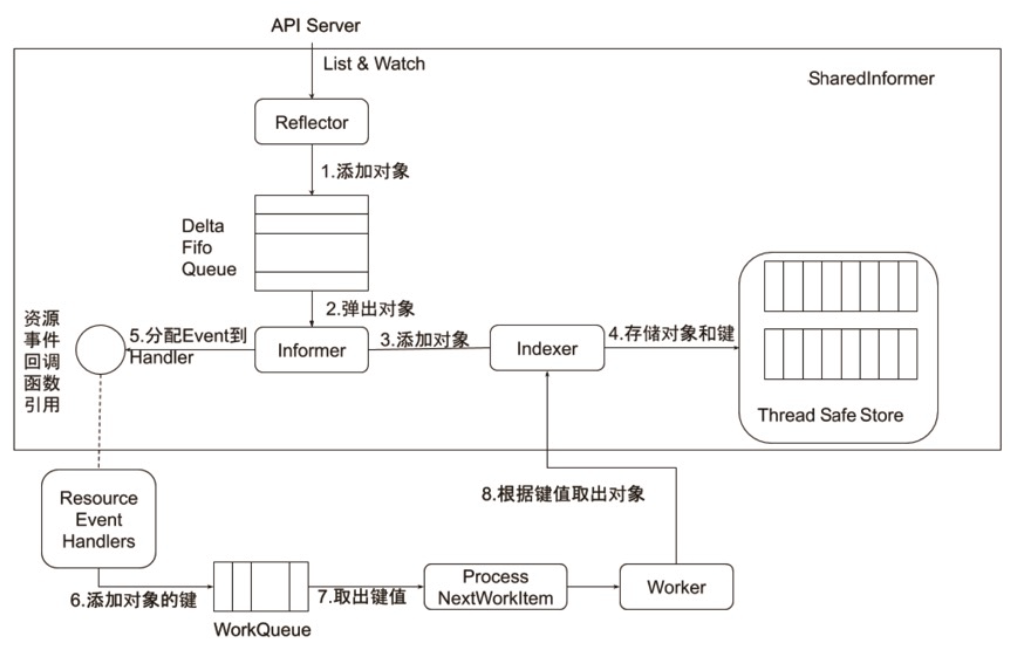
控制器的协同工作原理
Scheduler

Kubelet
Kube-Proxy

推荐的 Add-ons
- kube-dns:负责为整个集群提供 DNS 服务;
- Ingress Controller:为服务提供外网入口;
- MetricsServer:提供资源监控;
- Dashboard:提供GUI;
- Fluentd-Elasticsearch:提供集群日志采集、存储与查询。
了解 kubectl
Kubectl 命令和 kubeconfig
- kubectl 是一个 Kubernetes 的命令行工具,它允许 Kubernetes 用户以命令行的方式与 Kubernetes 交互,其默认读取配置文件 ~/.kube/config。
- kubectl 会将接收到的用户请求转化为 rest 调用以 rest client 的形式与 apiserver 通讯。
- apiserver 的地址,用户信息等配置在 kubeconfig。
可以在命令后加 -v 9 来开启详细的日志,如 kubectl get namespace default -v 9。
apiVersion: v1
clusters:
- cluster:
certificate-authority: /home/k/.minikube/ca.crt
extensions:
- extension:
last-update: Thu, 02 May 2024 21:50:24 CST
provider: minikube.sigs.k8s.io
version: v1.33.0
name: cluster_info
server: https://127.0.0.1:32774
name: minikube
contexts:
- context:
cluster: minikube
extensions:
- extension:
last-update: Thu, 02 May 2024 21:50:24 CST
provider: minikube.sigs.k8s.io
version: v1.33.0
name: context_info
namespace: default
user: minikube
name: minikube
current-context: minikube
kind: Config
preferences: {}
users:
- name: minikube
user:
client-certificate: /home/k/.minikube/profiles/minikube/client.crt
client-key: /home/k/.minikube/profiles/minikube/client.keykubectl 常用命令
kubectl get po -oyaml -w
- kubectl 可查看对象。
- -oyaml 输出详细信息为 yaml 格式。
- -w watch 该对象的后续变化。
- -owide 以详细列表的格式查看对象。
kubectl describe 展示资源的详细信息和相关 Event。
kubectl exec 提供进入运行容器的通道,可以进入容器进行 debug 操作。
Kubectl logs 可查看 pod 的标准输入(stdout, stderr),与 tail 用法类似。
深入理解 Kubernetes
云计算的传统分类
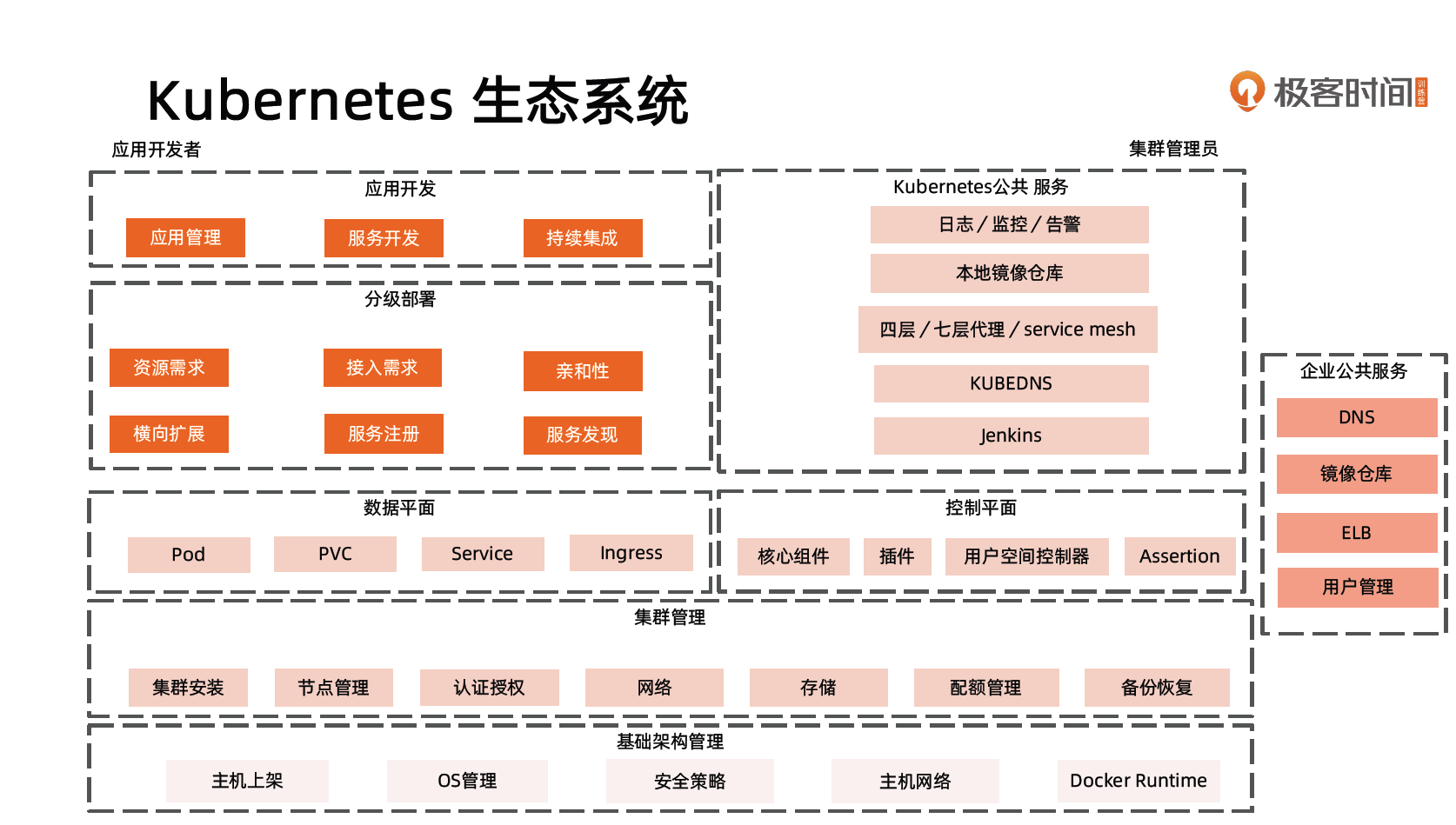
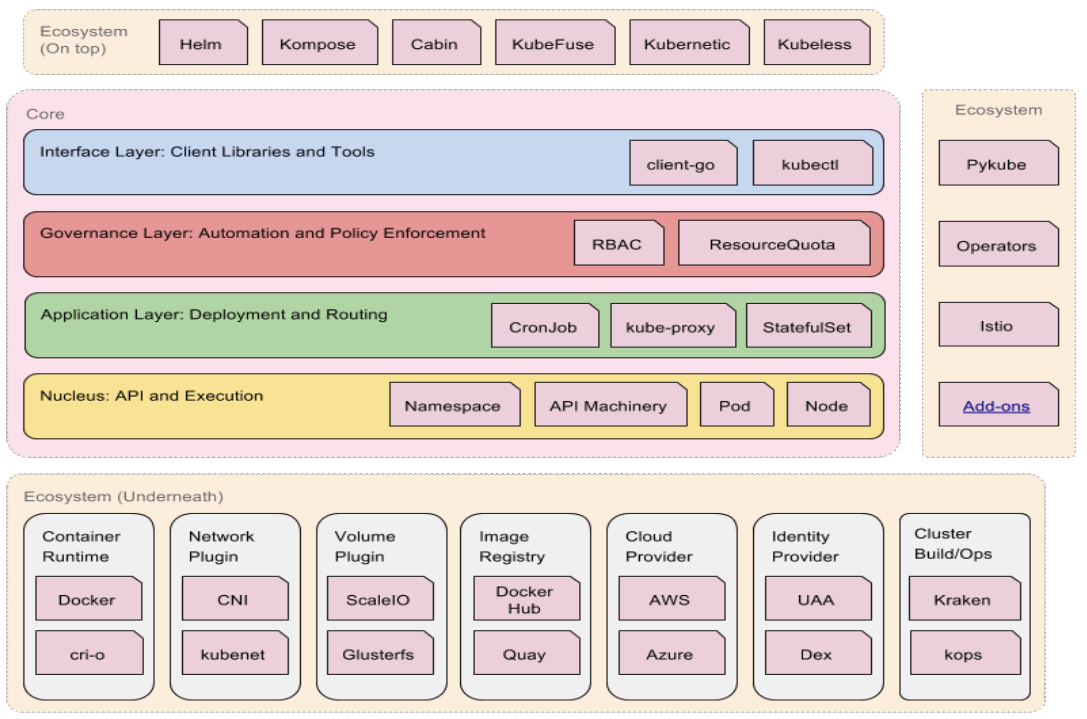
Kubernetes 生态系统
Kubernetes 设计理念
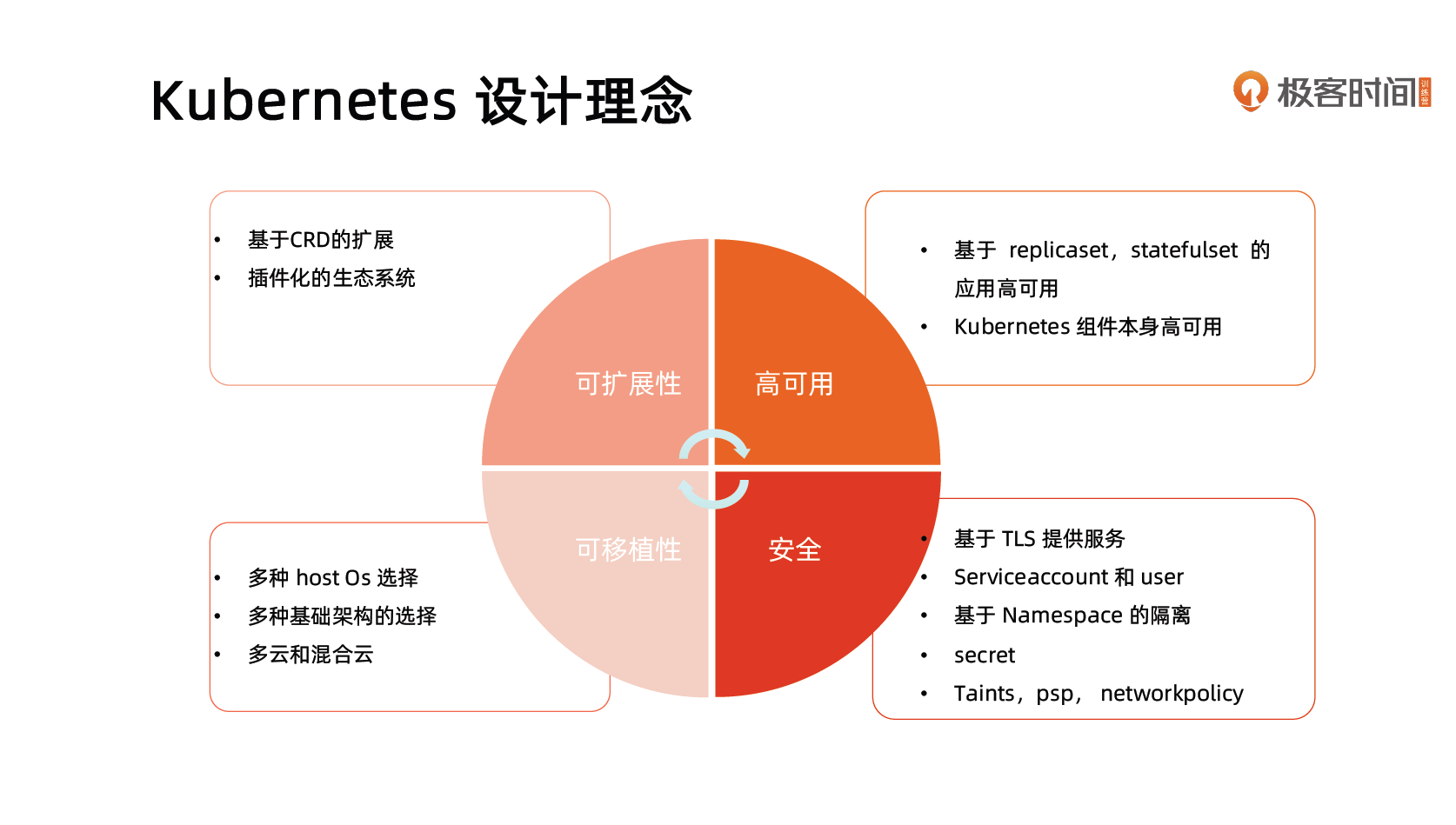
Kubernetes Master
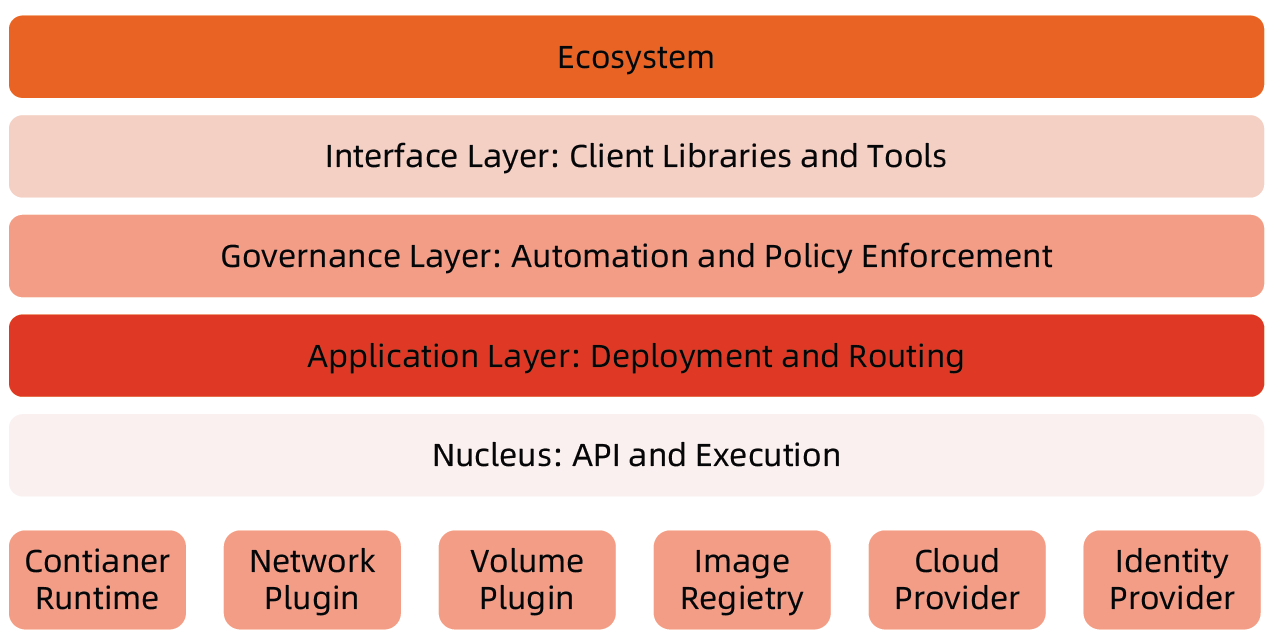
分层架构
- 核心层:Kubernetes 最核心的功能,对外提供 API 构建高层的应用,对内提供插件式应用执行环境。
- 应用层:部署(无状态应用、有状态应用、批处理任务、集群应用等)和路由(服务发现、DNS 解析等)。
- 管理层:系统度量(如基础设施、容器和网络的度量)、自动化(如自动扩展、动态 Provision 等)、策略管理(RBAC、Quota、PSP、NetworkPolicy 等)。
- 接口层:Kubectl 命令行工具、客户端 SDK 以及集群联邦。
- 生态系统:在接口层之上的庞大容器集群管理调度的生态系统,可以划分为两个范畴:
- Kubernetes 外部:日志、监控、配置管理、CI、CD、Workflow、FaaS、OTS 应用、ChatOps 等;
- Kubernetes 内部:CRI、CNI、CVI、镜像仓库、Cloud Provider、集群自身的配置和管理等。
API 设计原则
- 所有 API 都应是声明式的
- 相对于命令式操作,声明式操作对于重复操作的效果是稳定的,这对于容易出现数据丢失或重复的分布式环境来说是很重要的。
- 声明式操作更易被用户使用,可以使系统向用户隐藏实现的细节,同时也保留了系统未来持续优化的可能性。
- 此外,声明式的 API 还隐含了所有的 API 对象都是名词性质的,例如 Service、Volume 这些 API 都是名词,这些名词描述了用户所期望得到的一个目标对象。
- API 对象是彼此互补而且可组合的
- 这实际上鼓励 API 对象尽量实现面向对象设计时的要求,即”高内聚,松耦合”,对业务相关的概念有一个合适的分解,提高分解出来的对象的可重用性。
- 高层 API 以操作意图为基础设计
- 如何能够设计好 API,跟如何能用面向对象的方法设计好应用系统有相通的地方,高层设计一定是从业务出发,而不是过早的从技术实现出发。
- 因此,针对 Kubernetes 的高层 API 设计,一定是以 Kubernetes 的业务为基础出发,也就是以系统调度管理容器的操作意图为基础设计。
- 低层 API 根据高层 API 的控制需要设计
- 设计实现低层 API 的目的,是为了被高层 API 使用,考虑减少冗余、提高重用性的目的,低层 API 的设计也要以需求为基础,要尽量抵抗受技术实现影响的诱惑。
- 尽量避免简单封装,不要有在外部 API 无法显式知道的内部隐藏的机制
- 简单的封装,实际没有提供新的功能,反而增加了对所封装 API 的依赖性。
- 例如 StatefulSet 和 ReplicaSet,本来就是两种 Pod 集合,那么 Kubernetes 就用不同 API 对象来定义它们,而不会说只用同一个 ReplicaSet,内部通过特殊的算法再来区分这个 ReplicaSet 是有状态的还是无状态。
- API 操作复杂度与对象数量成正比
- API 的操作复杂度不能超过 O(N),否则系统就不具备水平伸缩性了。
- API 对象状态不能依赖于网络连接状态
- 由于众所周知,在分布式环境下,网络连接断开是经常发生的事情,因此要保证 API 对象状态能应对网络的不稳定,API 对象的状态就不能依赖于网络连接状态。
- 尽量避免让操作机制依赖于全局状态
- 因为在分布式系统中要保证全局状态的同步是非常困难的。
Kubernetes 如何通过对象的组合完成业务描述
引用依赖:一个对象中有个属性的名字指向了另一个对象。
基于命名规范:Deployment 根据 PodTemplate 的 hash 值来作为 Replicaset 名字的一部分,这个关系是写在代码中的。
基于标签:根据标签来筛选。

架构设计原则
- 只有 APIServer 可以直接访问 etcd 存储,其他服务必须通过 Kubernetes API 来访问集群状态;
- 单节点故障不应该影响集群的状态;
- 在没有新请求的情况下,所有组件应该在故障恢复后继续执行上次最后收到的请求(比如网络分区或服务重启等);
- 所有组件都应该在内存中保持所需要的状态,APIServer 将状态写入 etcd 存储,而其他组件则通过 API Server 更新并监听所有的变化;
- 优先使用事件监听而不是轮询。
引导(Bootstrapping)原则
- Self-hosting 是目标。
- 减少依赖,特别是稳态运行的依赖。
- 通过分层的原则管理依赖。
- 循环依赖问题的原则:
- 同时还接受其他方式的数据输入(比如本地文件等),这样在其他服务不可用时还可以手动配置引导服务;
- 状态应该是可恢复或可重新发现的;
- 支持简单的启动临时实例来创建稳态运行所需要的状态,使用分布式锁或文件锁等来协调不同状态的切换(通常称为 pivoting 技术);
- 自动重启异常退出的服务,比如副本或者进程管理器等。
核心技术概念和 API 对象
API 对象是 Kubernetes 集群中的管理操作单元。
Kubernetes 集群系统每支持一项新功能,引入一项新技术,一定会新引入对应的API 对象,支持对该功能的管理操作。
每个 API 对象都有四大类属性:
- TypeMeta
- MetaData
- Spec
- Status
TypeMeta
Kubernetes对象的最基本定义,它通过引入 GKV(Group,Kind,Version)模型定义了一个对象的类型。
- Group
Kubernetes 定义了非常多的对象,如何将这些对象进行归类是一门学问,将对象依据其功能范围归入不同的分组,比如把支撑最基本功能的对象归入 core 组,把与应用部署有关的对象归入 apps 组,会使这些对象的可维护性和可理解性更高。 - Kind
定义一个对象的基本类型,比如 Node、Pod、Deployment 等。 - Version
社区每个季度会推出一个 Kubernetes 版本,随着 Kubernetes 版本的演进,对象从创建之初到能够完全生产化就绪的版本是不断变化的。与软件版本类似,通常社区提出一个模型定义以后,随着该对象不断成熟,其版本可能会从 v1alpha1 到 v1alpha2,或者到 v1beta1,最终变成生产就绪版本 v1。
Metadata
Metadata 中有两个最重要的属性:Namespace 和 Name,分别定义了对象的 Namespace 归属及名字,这两个属性唯一定义了某个对象实例。
Label
顾名思义就是给对象打标签,一个对象可以有任意对标签,其存在形式是键值对。Label 定义了对象的可识别属性,Kubernetes API 支持以 Label 作为过滤条件查询对象。
Annotation
Annotation 与 Label 一样用键值对来定义,但 Annotation 是作为属性扩展,更多面向于系统管理员和开发人员,因此需要像其他属性一样做合理归类。
Finalizer
Finalizer 本质上是一个资源锁,Kubernetes 在接收某对象的删除请求时,会检查 Finalizer 是否为空,如果不为空则只对其做逻辑删除,即只会更新对象中的 metadata.deletionTimestamp 字段。
主要用于避免某个资源控制器意外终止,而无法监听到对应资源删除事件的情况。一旦某个资源设置了 Finalizer,那么这个资源删除时将不会消除,需要删除资源上的 Finalizer 后这个资源才会真正的删除,这就给了对应资源控制器处理的机会。
ResourceVersion
ResourceVersion 可以被看作一种乐观锁,每个对象在任意时刻都有其 ResourceVersion,当 Kubernetes 对象被客户端读取以后,ResourceVersion 信息也被一并读取。此机制确保了分布式系统中任意多线程能够无锁并发访问对象,极大提升了系统的整体效率。
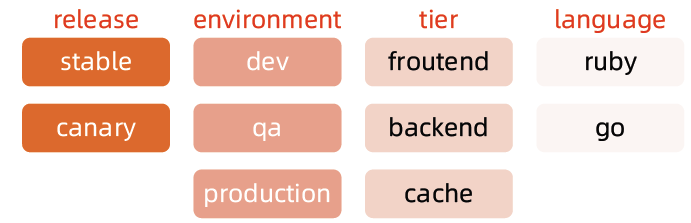
Label
- Label 是识别 Kubernetes 对象的标签,以 key/value 的方式附加到对象上。
- key 最长不能超过 63 字节,value 可以为空,也可以是不超过 253 字节的字符串。
- Label 不提供唯一性,并且实际上经常是很多对象(如 Pods)都使用相同的 label 来标志具体的应用。
- Label 定义好后其他对象可以使用 Label Selector 来选择一组相同 label 的对象
- Label Selector 支持以下几种方式:
- 等式,如 app=nginx 和 env!=production;
- 集合,如 env in (production, qa);
- 多个 label(它们之间是 AND 关系),如 app=nginx,env=test。
Annotations
- Annotations 是 key/value 形式附加于对象的注解。
- 不同于 Labels 用于标志和选择对象,Annotations 则是用来记录一些附加信息,用来辅助应用部署、安全策略以及调度策略等。
- 比如 deployment 使用 annotations 来记录 rolling update 的状态。
Spec 和 Status
- Spec 和 Status 才是对象的核心。
- Spec 是用户的期望状态,由创建对象的用户端来定义。
- Status 是对象的实际状态,由对应的控制器收集实际状态并更新。
- 与 TypeMeta 和 Metadata 等通用属性不同,Spec 和 Status 是每个对象独有的。
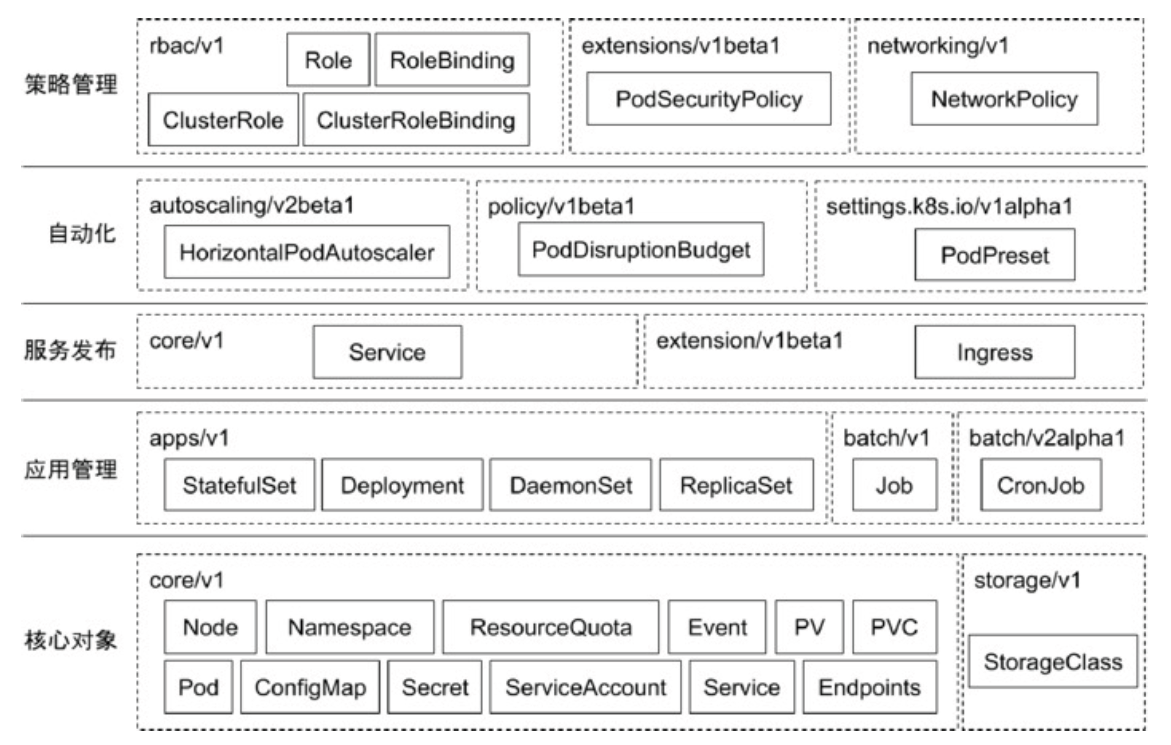
常用Kubernetes 对象及其分组
核心对象概览
Node
- Node 是 Pod 真正运行的主机,可以物理机,也可以是虚拟机。
- 为了管理 Pod,每个 Node 节点上至少要运行 container runtime(比如Docker 或者Rkt)、Kubelet 和 Kube-proxy 服务。
Namespace
Namespace 是对一组资源和对象的抽象集合,比如可以用来将系统内部的对象划分为不同的项目组或用户组。
常见的 pods, services, replication controllers 和 deployments 等都是属于某一个 Namespace 的(默认是 default),而 Node, persistentVolumes 等则不属于任何 Namespace。
什么是 Pod
- Pod 是一组紧密关联的容器集合,它们共享 PID、IPC、Network 和 UTS namespace,是 Kubernetes 调度的基本单位。
- Pod 的设计理念是支持多个容器在一个 Pod 中共享网络和文件系统,可以通过进程间通信和文件共享这种简单高效的方式组合完成服务。
- 同一个 Pod 中的不同容器可共享资源:
- 共享网络 Namespace;
- 可通过挂载存储卷共享存储;
- 共享 Security Context。
apiVersion: v1
kind: Pod
metadata:
name: hello
spec:
containers:
- image: nginx:1.15
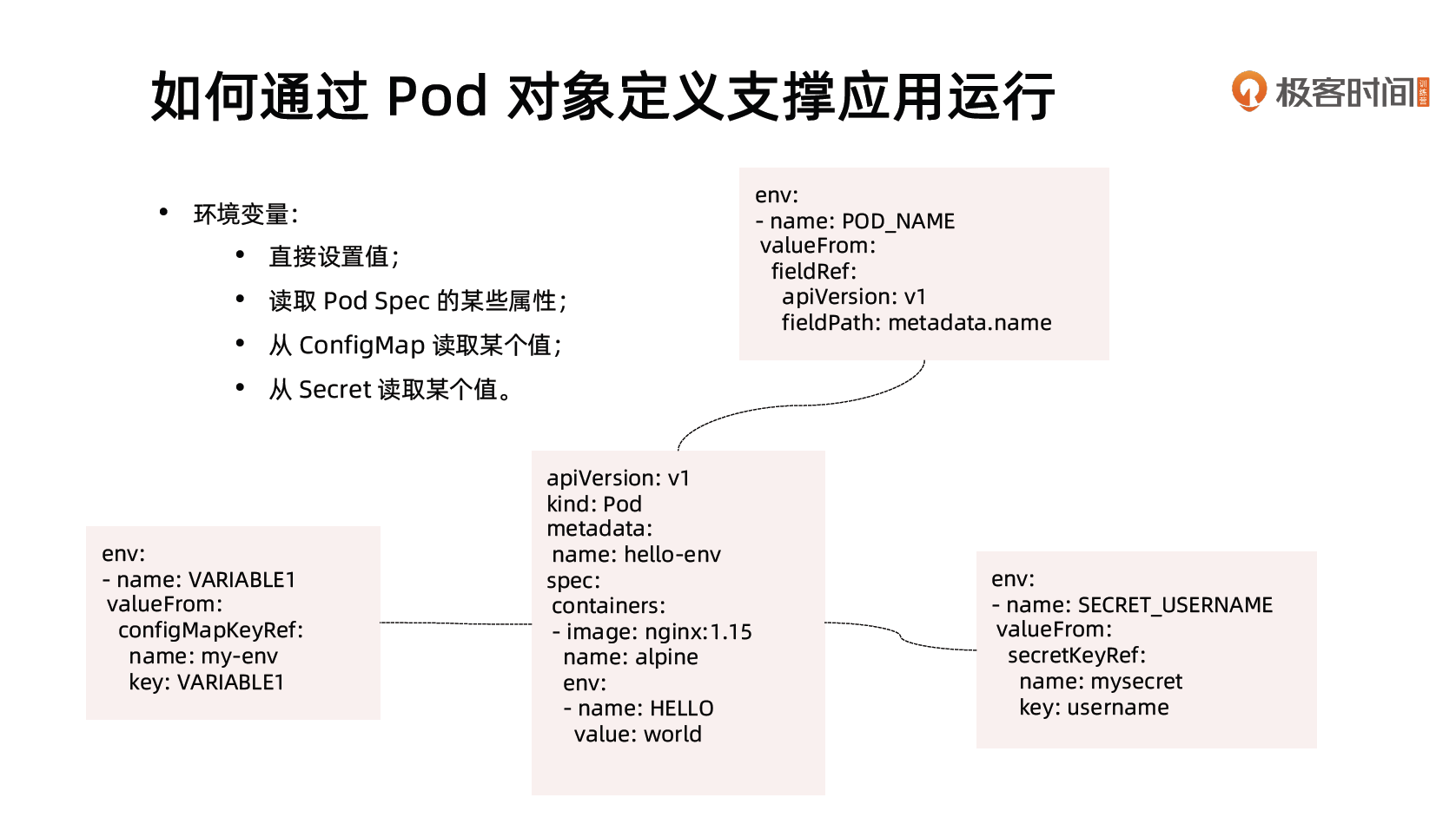
name: nginx如何通过Pod 对象定义支撑应用运行
存储卷
- 通过存储卷可以将外挂存储挂载到 Pod 内部使用。
- 存储卷定义包括两个部分: Volume 和 VolumeMounts。
- Volume:定义 Pod 可以使用的存储卷来源;
- VolumeMounts:定义存储卷如何 Mount 到容器内部。
apiVersion: v1
kind: Pod
metadata:
name: hello-volume
spec:
containers:
- image: nginx:1.15
name: nginx
volumeMounts:
- name: data
mountPath: /data
volumes:
- name: data
emptyDir: {}Pod 网络
Pod 的多个容器是共享网络 Namespace 的,这意味着:
- 同一个 Pod 中的不同容器可以彼此通过 Loopback 地址访问:
- 在第一个容器中起了一个服务 http://127.0.0.1 。
- 在第二个容器内,是可以通过 httpGet http://172.0.0.1 访问到该地址的。
- 这种方法常用于不同容器的互相协作。
资源限制
Kubernetes 通过 Cgroups 提供容器资源管理的功能,可以限制每个容器的 CPU 和内存使用,比如对于刚才创建的 deployment,可以通过下面的命令限制 nginx 容器最多只用 50% 的CPU 和 128MB 的内存:
$ kubectl set resources deployment nginx-app -c=nginx --limits=cpu=500m,memory=128Mi
deployment "nginx" resource requirements updated等同于在每个 Pod 中设置 resources limits
apiVersion: v1
kind: Pod
metadata:
labels:
app: nginx
name: nginx
spec:
containers:
- image: nginx
name: nginx
resources:
limits:
cpu: "500m"
memory: "128Mi"健康检查
Kubernetes 作为一个面向应用的集群管理工具,需要确保容器在部署后确实处在正常的运行状态。
- 探针类型:
- LivenessProbe
- 探测应用是否处于健康状态,如果不健康则删除并重新创建容器。
- ReadinessProbe
- 探测应用是否就绪并且处于正常服务状态,如果不正常则不会接收来自 Kubernetes Service 的流量。
- StartupProbe
- 探测应用是否启动完成,如果在
failureThreshold * periodSeconds周期内未就绪,则会应用进程会被重启。
- 探测应用是否启动完成,如果在
- 探活方式:
- Exec
- TCP socket
- HTTP

ConfigMap
- ConfigMap 用来将非机密性的数据保存到键值对中。
- 使用时, Pods 可以将其用作环境变量、命令行参数或者存储卷中的配置文件。
- ConfigMap 将环境配置信息和容器镜像解耦,便于应用配置的修改。
密钥对象(Secret)
- Secret 是用来保存和传递密码、密钥、认证凭证这些敏感信息的对象。
- 使用 Secret 的好处是可以避免把敏感信息明文写在配置文件里。
- Kubernetes 集群中配置和使用服务不可避免的要用到各种敏感信息实现登录、认证等功能,例\如访问 AWS 存储的用户名密码。
- 为了避免将类似的敏感信息明文写在所有需要使用的配置文件中,可以将这些信息存入一个 Secret 对象,而在配置文件中通过 Secret 对象引用这些敏感信息。
- 这种方式的好处包括:意图明确,避免重复,减少暴漏机会。
用户(User Account)& 服务帐户(Service Account)
- 顾名思义,用户帐户为人提供账户标识,而服务账户为计算机进程和 Kubernetes 集群中运行的 Pod 提供账户标识。
- 用户帐户和服务帐户的一个区别是作用范围:
- 用户帐户对应的是人的身份,人的身份与服务的 Namespace 无关,所以用户账户是跨 Namespace 的;
- 而服务帐户对应的是一个运行中程序的身份,与特定 Namespace 是相关的。
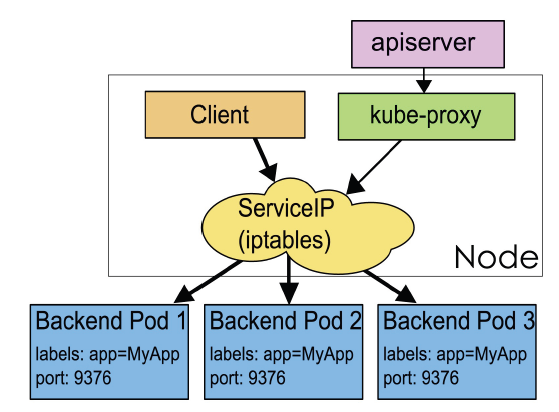
Service
Service 是应用服务的抽象,通过 labels 为应用提供负载均衡和服务发现。匹配 labels 的 Pod IP 和端口列表组成 endpoints,由 Kube-proxy 负责将服务 IP 负载均衡到这些 endpoints 上。
每个 Service 都会自动分配一个 cluster IP(仅在集群内部可访问的虚拟地址)和 DNS 名,其他容器可以通过该地址或 DNS 来访问服务,而不需要了解后端容器的运行。
apiVersion: v1
kind: Service
metadata:
name: nginx
spec:
ports:
- port: 8078 # the port that this service should serve on
name: http
# the container on each pod to connect to, can be a name
# (e.g. 'www') or a number (e.g. 80)
targetPort: 80
protocol: TCP
selector:
app: nginx副本集(Replica Set)
- Pod 只是单个应用实例的抽象,要构建高可用应用,通常需要构建多个同样的副本,提供同一个服务。
- Kubernetes 为此抽象出副本集 ReplicaSet,其允许用户定义 Pod 的副本数,每一个 Pod 都会被当作一个无状态的成员进行管理,Kubernetes 保证总是有用户期望的数量的 Pod 正常运行。
- 当某个副本宕机以后,控制器将会创建一个新的副本。
- 当因业务负载发生变更而需要调整扩缩容时,可以方便地调整副本数量。
RS 创建出来的名字分为三个部分,如:nginx-deploy-59dc7f9d89-k9rj9
- 第一个部分
nginx-deploy是 deployment 的名字。 - 第二个部分
59dc7f9d89是配置字符串的 hash 值。 - 第三个部分
k9rj9是随机值,因为是无状态的,所以给任何值都是可以的。
部署(Deployment)
- 部署表示用户对 Kubernetes 集群的一次更新操作。
- 部署是一个比 RS 应用模式更广的 API 对象,可以是创建一个新的服务,更新一个新的服务,也可以是滚动升级一个服务。
- 滚动升级一个服务,实际是创建一个新的 RS,然后逐渐将新 RS 中副本数增加到理想状态,将旧 RS 中的副本数减小到 0 的复合操作。
- 这样一个复合操作用一个 RS 是不太好描述的,所以用一个更通用的 Deployment 来描述。
- 以 Kubernetes 的发展方向,未来对所有长期伺服型的的业务的管理,都会通过 Deployment 来管理。

有状态服务集(StatefulSet)
- 对于 StatefulSet 中的 Pod,每个 Pod 挂载自己独立的存储,如果一个 Pod 出现故障,从其他节点启动一个同样名字的 Pod,要挂载上原来 Pod 的存储继续以它的状态提供服务。
- 适合于 StatefulSet 的业务包括数据库服务 MySQL 和 PostgreSQL,集群化管理服务 ZooKeeper、etcd 等有状态服务。
- 使用 StatefulSet,Pod 仍然可以通过漂移到不同节点提供高可用,而存储也可以通过外挂的存储来提供高可靠性,StatefulSet 做的只是将确定的 Pod 与确定的存储关联起来保证状态的连续性。
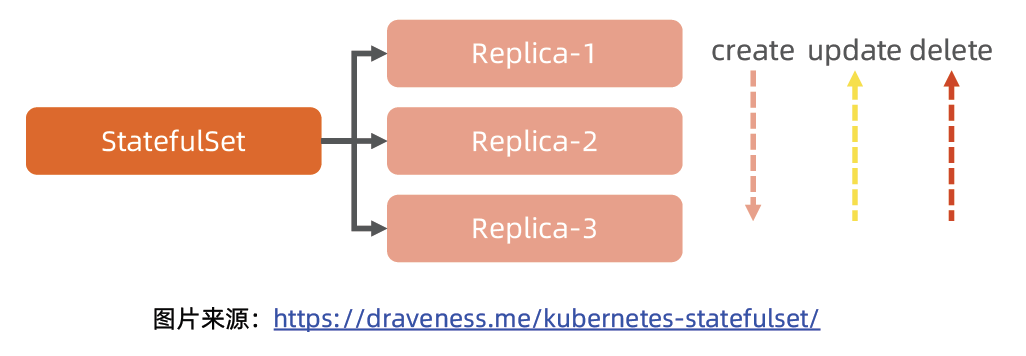
Statefulset 与Deployment 的差异
- 身份标识
- StatefulSet Controller 为每个 Pod 编号,序号从 0 开始。
- 数据存储
- StatefulSet 允许用户定义volumeClaimTemplates,Pod 被创建的同时,Kubernetes 会以 volumeClaimTemplates 中定义的模板创建存储卷,并挂载给Pod。
- StatefulSet 的升级策略不同
- onDelete
- 滚动升级
- 分片升级
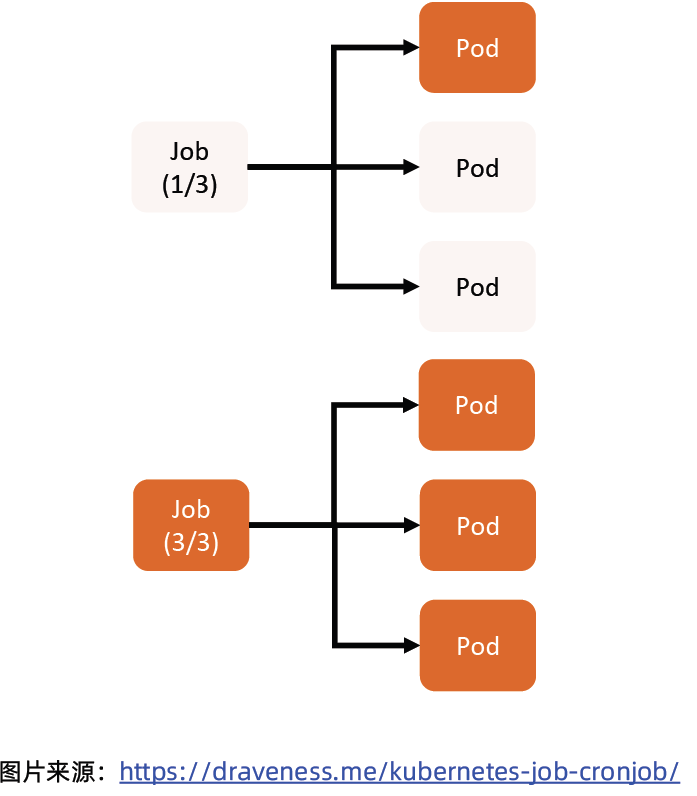
任务(Job)
- Job 是 Kubernetes 用来控制批处理型任务的 API 对象。
- Job 管理的 Pod 根据用户的设置把任务成功完成后就自动退出。
- 成功完成的标志根据不同的 spec.completions 策略而不同:
- 单 Pod 型任务有一个 Pod 成功就标志完成;
- 定数成功型任务保证有 N 个任务全部成功;
- 工作队列型任务根据应用确认的全局成功而标志成功。
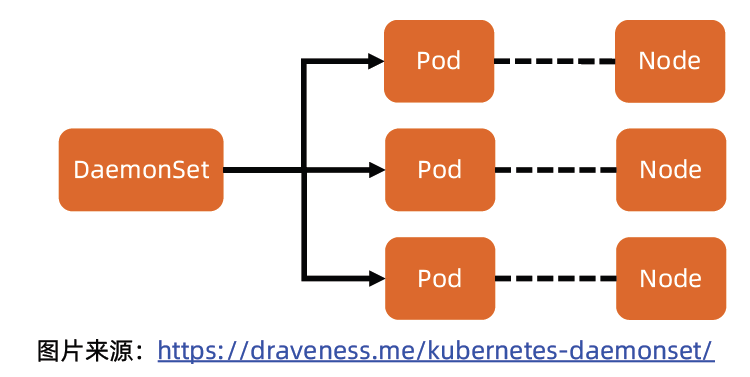
后台支撑服务集(DaemonSet)
- 长期伺服型和批处理型服务的核心在业务应用,可能有些节点运行多个同类业务的 Pod,有些节点上又没有这类 Pod 运行;
- 而后台支撑型服务的核心关注点在 Kubernetes 集群中的节点(物理机或虚拟机),要保证每个节点上都有一个此类 Pod 运行。
- 节点可能是所有集群节点也可能是通过 nodeSelector 选定的一些特定节点。
- 典型的后台支撑型服务包括存储、日志和监控等在每个节点上支撑 Kubernetes 集群运行的服务。
存储 PV 和 PVC
- PersistentVolume(PV)是集群中的一块存储卷,可以由管理员手动设置,或当用户创建 PersistentVolumeClaim(PVC)时根据 StorageClass 动态设置。
- PV 和 PVC 与 Pod 生命周期无关。也就是说,当 Pod 中的容器重新启动、Pod 重新调度或者删除时,PV 和 PVC 不会受到影响,Pod 存储于 PV 里的数据得以保留。
- 对于不同的使用场景,用户通常需要不同属性(例如性能、访问模式等)的 PV。
CustomResourceDefinition
- CRD 就像数据库的开放式表结构,允许用户自定义 Schema。
- 有了这种开放式设计,用户可以基于 CRD 定义一切需要的模型,满足不同业务的需求。
- 社区鼓励基于 CRD 的业务抽象,众多主流的扩展应用都是基于 CRD 构建的,比如 Istio、Knative。
- 甚至基于 CRD 推出了 Operator Mode 和 Operator SDK,可以以极低的开发成本定义新对象,并构建新对象的控制器。
Kubernetes 控制平面组件 etcd
etcd
Etcd是 CoreOS 基于 Raft 开发的分布式 key value 存储,可用于服务发现、共享配置以及一致性保障(如数据库选主、分布式锁等)。
在分布式系统中,如何管理节点间的状态一直是一个难题,etcd 像是专门为集群环境的服务发现和注册而设计,它提供了数据 TTL 失效、数据改变监视、多值、目录监听、分布式锁原子操作等功能,可以方便的跟踪并管理集群节点的状态。
- 键值对存储:将数据存储在分层组织的目录中,如同在标准文件系统中
- 监测变更:监测特定的键或目录以进行更改,并对值的更改做出反应
- 简单 curl 可访问的用户的 API HTTP+JSON
- 安全 : 可选的 SSL 客户端证书认证
- 快速 : 单实例每秒 1000 次写操作, 2000+ 次读操作
- 可靠 : 使用 Raft 算法保证一致性
主要功能
- 基本的 key value 存储
- 监听机制
- key 的过期及续约机制,用于监控和服务发现
- 原子 Compare And Swap 和 Compare And Delete ,用于分布式锁和 leader 选举
使用场景
- 也可以用于键值对存储,应用程序可以读取和写入 etcd 中的数据
- etcd 比较多的应用场景是用于服务注册与发现
- 基于监听机制的分布式异步系统
键值对存储
etcd 是一个 键值存储 的组件,其他的应用都是基于其键值存储的功能展开。
- 采用 kv 型数据存储,一般情况下比关系型数据库快。
- 支持动态存储(内存)以及静态存储(磁盘)。
- 分布式存储,可集成为多节点集群。
- 存储方式,采用类似目录结构。(B+tree)
- 只有叶子节点才能真正存储数据,相当于文件。
- 叶子节点的父节点一定是目录,目录不能存储数据。
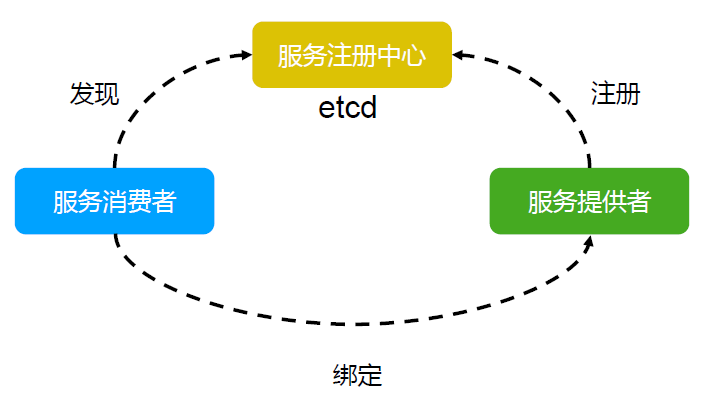
服务注册与发现
- 强一致性、高可用的服务存储目录。
- 基于 Raft 算法的 etcd 天生就是这样一个强一致性、高可用的服务存储目录。
- 一种注册服务和服务健康状况的机制。
- 用户可以在 etcd 中注册服务,并且对注册的服务配置 key TTL 定时保持服务的心跳以达到监控健康状态的效果。
消息发布与订阅
- 在分布式系统中,最适用的一种组件间通信方式就是消息发布与订阅。
- 即构建一个配置共享中心,数据提供者在这个配置中心发布消息,而消息使用者则订阅他们关心的主题,一旦主题有消息发布,就会实时通知订阅者。
- 通过这种方式可以做到分布式系统配置的集中式管理与动态更新。
- 应用中用到的一些配置信息放到 etcd 上进行集中管理。
- 应用在启动的时候主动从 etcd 获取一次配置信息,同时,在 etcd 节点上注册一个 Watcher 并等待,以后每次配置有更新的时候, etcd 都会实时通知订阅者,以此达到获取最新配置信息的目的。
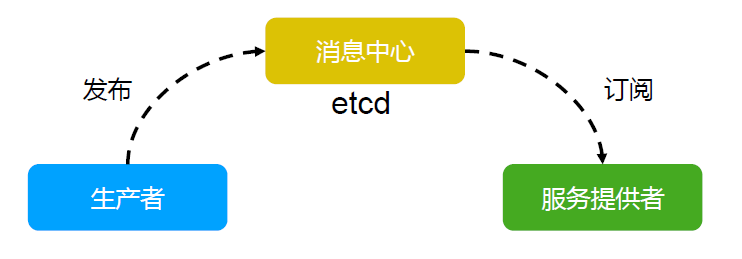
etcd 练习
查看集群成员状态
$ etcdctl member list write out=table
+------------------+---------+----------+---------------------------+---------------------------+------------+
| ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER |
+------------------+---------+----------+---------------------------+---------------------------+------------+
| aec36adc501070cc | started | minikube | https://192.168.49.2:2380 | https://192.168.49.2:2379 | false |
+------------------+---------+----------+---------------------------+---------------------------+------------+
# 写
$ etcdctl put /a b
OK
# 读
$ etcdctl get /a
/a
b
$ etcdctl get /a -wjson
{
"header": {
"cluster_id": 18038207397139143000,
"member_id": 12593026477526643000,
"revision": 23279, // 全局唯一的 revision, 每当 etcd 中有数据修改时,这个记录就会 +1
"raft_term": 4
},
"kvs": [
{
"key": "L2E=",
"create_revision": 11164, // key 创建时 revision 的值
"mod_revision": 11164, // key 上次修改时 revision 的值
"version": 1,
"value": "Yg=="
}
],
"count": 1
}
# 按 key 的前缀查询数据
$ etcdctl get --prefix /
$ etcdctl get --prefix / --keys-only --debug核心:TTL & CAS
TTL(time to live)指的是给一个 key 设置一个有效期,到期后这个 key 就会被自动删掉,这在很多分布式锁的实现上都会用到,可以保证锁的实时有效性。
Atomic Compare and Swap(CAS)指的是在对 key 进行赋值的时候,客户端需要提供一些条件,当这些条件满足后,才能赋值成功。这些条件包括:
- prevExist key 当前赋值前是否存在
- prevValue key 当前赋值前的值
- prevIndex key 当前赋值前的 Index
这样的话,key 的设置是有前提的,需要知道这个 key 当前的具体情况才可以对其设置。
Raft 协议
Raft 协议概览
Raft 协议基于 quorum 机制,即大多数同意原则,任何的变更都需超过半数的成员确认
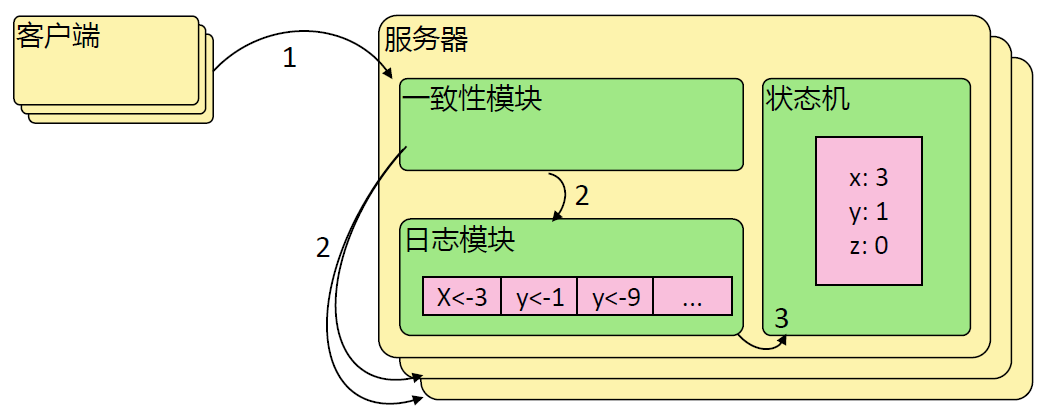
理解 Raft 协议
http://thesecretlivesofdata.com/raft/
learner
Raft 4.2.1 引入的新角色
当出现一个 etcd 集群 需要增加节点 时 ,新节点与 Leader 的数据差异较大,需要较多数据同步才能跟上 leader 的最新的数据。
此时 Leader 的网络带宽很可能被用尽,进而使得 leader 无法正常保持心跳。
进而导致 follower 重新发起投票 。
进而可能引发 etcd 集群不可用 。
Learner 角色只接收数据而不参与投票 ,因此增加 learner 节点时,集群的 quorum 不变 。
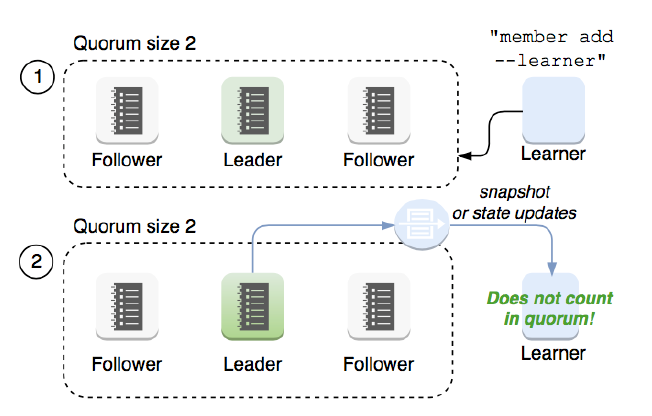
etcd 基于 Raft 的一致性
选举方法
- 初始启动时,节点处于 follower 状态并被设定一个 election timeout ,如果在这一时间周期内没有收到来自 leader 的 heartbeat ,节点将发起选举:将自己切换为 candidate 之后,向集群中其它 follower 节点发送请求,询问其是否选举自己成为 leader 。
- 当收到来自集群中过半数节点的接受投票后,节点即成为 leader ,开始接收保存 client 的数据并向其它的 follower 节点同步日志。如果没有达成一致,则 candidate 随机选择一个等待间隔( 150ms ~ 300ms )再次发起投票,得到集群中半数以上 follower 接受的 candidate 将成为 leader
- leader 节点依靠定时向 follower 发送 heartbeat 来保持其地位。
- 任何时候如果其它 follower 在 election timeout 期间都没有收到来自 leader 的 heartbeat ,同样会将自己的状态切换为 candidate 并发起选举。每成功选举一次,新 leader 的任期( Term )都会比之前 leader 的任期大 1 。
日志复制
当接 Leader 收到客户端的日志(事务请求)后先把该日志追加到本地的 Log 中,然后通过 heartbeat 把该 Entry 同步给其他 Follower Follower 接收到日志后记录日志然后向 Leader 发送 ACK ,当 Leader 收到大多数( n/2+1 Follower 的 ACK 信息后将该日志设置为已提交并追加到本地磁盘中,通知客户端并在下个 heartbeat 中 Leader 将通知所有的 Follower 将该日志存储在自己的本地磁盘中。
安全性
安全性是用于保证每个节点都执行相同序列的安全机制,如当某个 Follower 在当前 Leader commit Log 时变得不可用了,稍后可能该 Follower 又会被选举为 Leader ,这时新 Leader 可能会用新的 Log 覆盖先前已 committed 的 Log ,这就是导致节点执行不同序列 Safety 就是用于保证选举出来的 Leader 一定包含先前 committed Log 的机制;
选举安全性(Election Safety ):每个任期(Term)只能选举出一个 Leader
Leader完整性( Leader Completeness ):指 Leader 日志的完整性,当 Log 在任期 Term1 被 Commit 后,那么以后任期 Term2 、 Term3… 等的 Leader 必须包含该 Log Raft 在选举阶段就使用 Term 的判断用于保证完整性:当请求投票的该 Candidate 的 Term 较大或 Term 相同 Index 更大则投票,否则拒绝该请求。
失效处理
- Leader 失效:其他没有收到 heartbeat 的节点会发起新的选举,而当 Leader 恢复后由于步进数小会自动成为 follower (日志也会被新 leader 的日志覆盖)
- follower 节点不可用: follower 节点不可用的情况相对容易解决。因为集群中的日志内容始终是从 leader 节点同步的,只要这一节点再次加入集群时重新从 leader 节点处制日志即可。
- 多个 candidate :冲突后 candidate 将随机选择一个等待间隔( 150ms ~ 300ms )再次发起投票,得到集群中半数以上 follower 接受的 candidate 将成为 leader
wal 日志
wal 日志是二进制的,解析出来后是以上数据结构 LogEntry 。其中第一个字段 type ,只有两种。一种是 0 表示 Normal 1 表示 ConfChange ConfChange 表示 Etcd 本身的配置变更同步,比如有新的节点加入等)。第二个字段是 term ,每个 term 代表一个主节点的任期,每次主节点变更 term 就会变化。第三个字段是 index ,这个序号是严格有序递增的,代表变更序号。第四个字段是二进制的 data ,将 raft request 对象的 pb 结构整个保存下。 etcd 源码下有个 tools/etcd dump logs ,可以将 wal 日志 dump 成文本查看,可以协助分析 Raft 协议。
Raft 协议本身不关心应用数据,也就是 data 中的部分,一致性都通过同步 wal 日志来实现,每个节点将从主节点收到的 data apply 到本地的存储, Raft 只关心日志的同步状态,如果本地存储实现的有 bug ,比如没有正确的将 data apply 到本地,也可能会导致数据不一致。
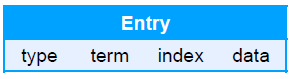
etcd v3 存储
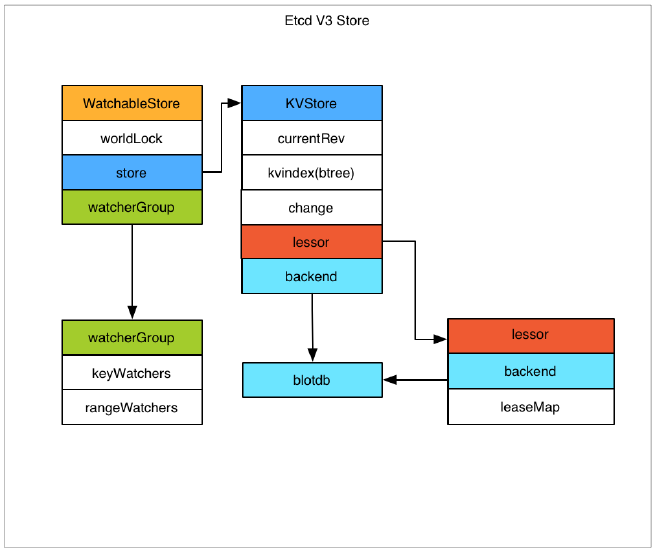
存储机制
etcd v3 store 分为两部分,一部分是内存中的索引, kvindex ,是基于 Google 开源的一个 Golang 的 btree 实现的,另外一部分是后端存储。按照它的设计, backend 可以对接多种存储,当前使用的 boltdb 。 boltdb 是一个单机的支持事务的 kv 存储, etcd 的事务是基于 boltdb 的事务实现的。 etcd 在 boltdb 中存储的 key 是 reversion value 是 etcd 自己的 key value 组合,也就是说 etcd 会在 boltdb 中把每个版本都保存下,从而实现了多版本机制。
reversion 主要由两部分组成,第一部分 main rev ,每次事务进行加一,第二部分 sub rev ,同一个事务中的每次操作加一。
etcd 提供了命令和设置选项来控制 compact ,同时支持 put 操作的参数来精确控制某个 key 的历史版本数。
内存 kvindex 保存的就是 key 和 reversion 之前的映射关系,用来加速查询。
每个 Etcd node 都有这些模块。
只有 Leader 能写,即使是 Follower 收到写请求,在做完 “预检查” 后,也会把请求转给 Leader。
Leader 收到请求后,先把修改放到
unstable,等收到超过半数的 Node 确认后移动到committed,最后把修改应用到内存中的 MVCC 模块后才会挪到applied。只有存在在 MVCC 模块中的数据才能被客户端查询到。
Watch 机制
etcd v3 的 watch 机制支持 watch 某个固定的 key ,也支持 watch 一个范围(可以用于模拟目录的结构的 watch ),所以 watchGroup 包含两种 watcher ,一种是 key watchers ,数据结构是每个 key 对应一组 watcher ,另外一种是 range watchers, 数据结构是一个 IntervalTree ,方便通过区间查找到对应的 watcher 。
同时,每个 WatchableStore 包含两种 watcherGroup ,一种是 synced ,一种是 unsynced 前者表示该 group 的 watcher 数据都已经同步完毕,在等待新的变更,后者表示该 group 的 watcher 数据同步落后于当前最新变更,还在追赶。
当 etcd 收到客户端的 watch 请求,如果请求携带了 revision 参数,则比较请求的 revision 和 store 当前的 revision ,如果大于当前 revision ,则放入 synced 组中,否则放入 unsynced 组。同时 etcd 会启动一个后台的 goroutine 持续同步 unsynced 的 watcher ,然后将其迁移到 synced 组。也就是这种机制下, etcd v3 支持从任意版本开始 watch ,没有 v2 的 1000 条历史 event 表限制的问题(当然这是指没有 compact 的情况下)
etcd 重要参数
成员相关参数
--name 'default'
Human-readable name for this member.
--data-dir '${name}.etcd'
Path to the data directory.
--listen-peer-urls 'http://localhost:2380'
List of URLs to listen on for peer traffic.
--listen-client-urls 'http://localhost:2379'
List of URLs to listen on for client grpc traffic and http as long as --listen-client-http-urls is not specified.
集群相关参数
--initial-advertise-peer-urls 'http://localhost:2380'
List of this member's peer URLs to advertise to the rest of the cluster.
--initial-cluster 'default=http://localhost:2380'
Initial cluster configuration for bootstrapping.
--initial-cluster-state 'new'
Initial cluster state ('new' when bootstrapping a new cluster or 'existing' when adding new members to an existing cluster).
After successful initialization (bootstrapping or adding), flag is ignored on restarts.
--initial-cluster-token 'etcd-cluster'
Initial cluster token for the etcd cluster during bootstrap.
Specifying this can protect you from unintended cross-cluster interaction when running multiple clusters.
--advertise-client-urls 'http://localhost:2379'
List of this member's client URLs to advertise to the public.
The client URLs advertised should be accessible to machines that talk to etcd cluster. etcd client libraries parse these URLs to connect to the cluster.
安全相关参数
--cert-file ''
Path to the client server TLS cert file.
--key-file ''
Path to the client server TLS key file.
--client-crl-file ''
Path to the client certificate revocation list file.
--trusted-ca-file ''
Path to the client server TLS trusted CA cert file.
--peer-cert-file ''
Path to the peer server TLS cert file.
--peer-key-file ''
Path to the peer server TLS key file.
--peer-trusted-ca-file ''
Path to the peer server TLS trusted CA file.灾备
创建 Snapshot:
etcdctl snapshot save snapshot.db恢复数据
etcdctl snapshot restore snapshot.db \
--name infra2 \
--data-dir=/tmp/etcd/infra2 \
--initial-cluster infra0=http://127.0.0.1:3380,infra1=http://127.0.0.1:4380,infra2=http://127.0.0.1:5380 \
--initial-cluster-token etcd-cluster-1 \
--initial-advertise-peer-urls http://127.0.0.1:5380容量管理
- 单个对象不建议超过 1.5M
- 默认容量 2G
- 不建议超过 8G
Alarm & Disarm Alarm
设置 etcd 存储大小
etcd --quota-backend-bytes=$((16*1024*1024))写爆磁盘
while [ 1 ]; do dd if=/dev/urandom bs=1024 count=1024 | ETCDCTL_API=3 etcdctl put key || break; done查看 endpoint 状态
ETCDCTL_API=3 etcdctl --write-out=table endpoint status查看 alarm
ETCDCTL_API=3 etcdctl alarm list清理碎片
ETCDCTL_API=3 etcdctl defrag清理 alarm
ETCDCTL_API=3 etcdctl alarm disarm碎片整理
Keep one hour of history
etcd --auto-compaction-retention=1Compact up to revision 3
$ etcdctl compact 3
$ etcdctl defrag
Finished defragmenting etcd member[127.0.0.1:2379]高可用 etcd 解决方案
https://github.com/cncamp/101/tree/master/module5/etcd-ha-demo

etcd operator: coreos 开源的 ,基于 kubernetes CRD 完成 etcd 集群配置。 Archived
https://github.com/coreos/etcd-operator
Etcd statefulset Helm chart: Bitnami (powered by vmware )
https://bitnami.com/stack/etcd/helm
https://github.com/bitnami/charts/blob/master/bitnami/etcd
Kubernetes 如何使用 etcd
etcd 是 kubernetes 的后端存储
对于每一个 kubernetes Object ,都有对应的 storage.go 负责对象的存储操作 pkg/registry/core/pod/storage/storage.go
API server 启动脚本中指定 etcd servers 集群
spec:
containers:
- command:
- etcd
- --advertise-client-urls=https://192.168.34.2:2379
- --cert-file=/etc/kubernetes/pki/etcd/server.crt
- --client-cert-auth=true
- --data-dir=/var/lib/etcd
- --initial-advertise-peer-urls=https://192.168.34.2:2380
- --initial-cluster=cadmin=https://192.168.34.2:2380
- --key-file=/etc/kubernetes/pki/etcd/server.key
- --listen-client-urls=https://127.0.0.1:2379,https://192.168.34.2:2379
- --listen-metrics-urls=http://127.0.0.1:2381
- --listen-peer-urls=https://192.168.34.2:2380
- --name=cadmin
- --peer-cert-file=/etc/kubernetes/pki/etcd/peer.crt
- --peer-client-cert-auth=true
- --peer-key-file=/etc/kubernetes/pki/etcd/peer.key
- --peer-trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
- --snapshot-count=10000
- --trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt早期 API server 对 etcd 做简单的 Ping check ,现在已经改为真实的 etcd api call
etcd 在集群中所处的位置
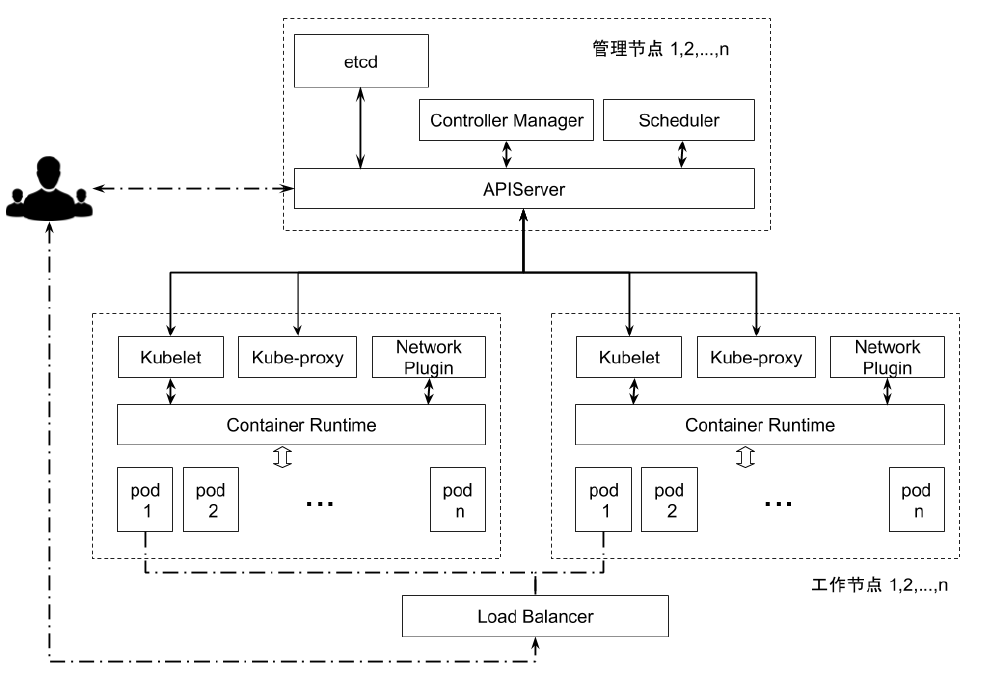
集群的高可用拓扑
堆叠式 etcd 集群的高可用拓扑
这种拓扑将相同节点上的控制平面和 etcd 成员耦合在一起。优点在于建立起来非常容易,并且对副本的管理也更容易。但是,堆叠式存在耦合失败的风险。如果一个节点发生故障,则 etcd 成员和控制平面实例都会丢失,并且集群冗余也会受到损害。可以通过添加更多控制平面节点来减轻这种风险。因此为实现集群高可用应该至少运行三个堆叠的 Master 节点。
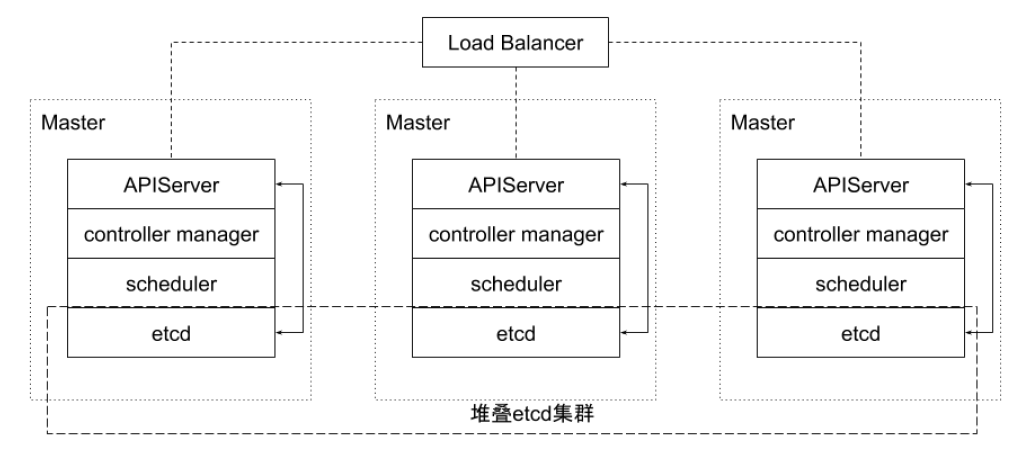
外部 etcd 集群的高可用拓扑
该拓扑将控制平面和 etcd 成员解耦。如果丢失一个 Master 节点,对 etcd 成员的影响较小,并且不会像堆叠式拓扑那样对集群冗余产生太大影响。但是,此拓扑所需的主机数量是堆叠式拓扑的两倍。具有此拓扑的群集至少需要三个主机用于控制平面节点,三个主机用于 etcd 集群。
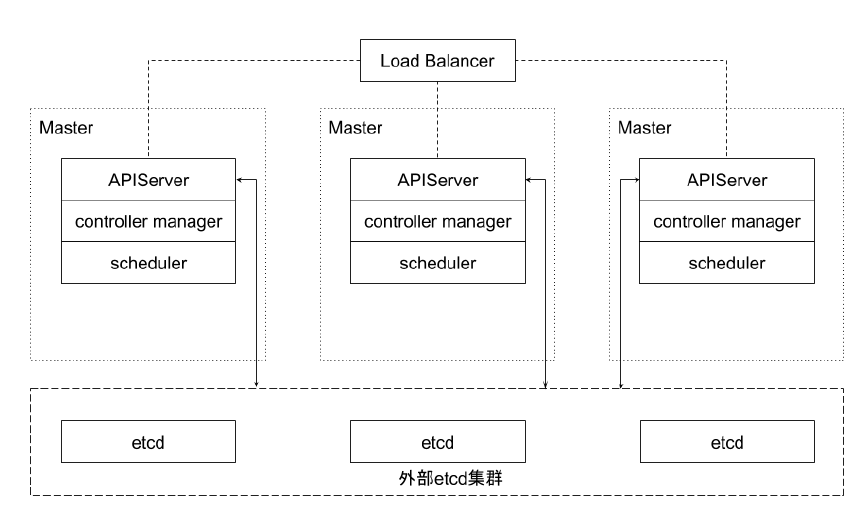
实践
etcd 集群高可用
多少个 peer 最适合?
- 1 个? 3 个? 5 个?
- 保证高可用是首要目标
- 所有写操作都要经过 leader
- peer 多了是否能提升集群并读操作的并发能力?
- apiserver 的配置只连本地的 etcd peer
- apiserver 的配置指定所有 etcd peers ,但只有当前连接的 etcd member 异常,apiserver 才会换目标
- 需要动态 flex up 吗?
保证 apiserver 和 etcd 之间的高效性通讯
- apiserver 和 etcd 部署在同一节点
- apiserver 和 etcd 之间的通讯基于 gRPC
- 针对每一个 object apiserver 和 etcd 之间的 Connection —> stream 共享
- http2 的特性
- Stream quota
- 带来的问题?对于大规模集群,会造成链路阻塞
- 10000 个 pod ,一次 list 操作需要返回的数据可能超过 100M
etcd 存储规划
- 本地 vs 远程?
- Remote Storage
- 优势是假设永远可用,现实真是如此吗?
- 劣势是 IO 效率,可能带来的问题?
- 最佳实践:
- Local SSD
- 利用 local volume 分配空间
- Remote Storage
- 多少空间?
- 与集群规模相关
思考:为什么每个 member 的 DB size 不一致?
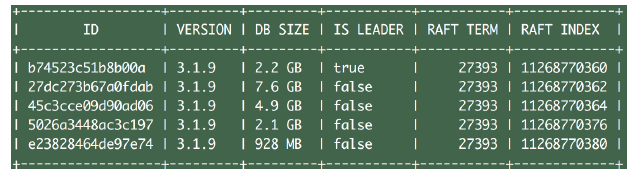
etcd
安全性
- peer 和 peer 之间的通讯加密
- 是否有需求
- TLS 的额外开销
- 运营复杂度增加
- 是否有需求
- 数据加密
- 是否有需求
- Kubernetes 提供了针对 secret 的加密 https://kubernetes.io/docs/tasks/administer-cluster/encrypt-data/
事件分离
- 对于大规模集群,大量的事件会对 etcd 造成压力
- API server 启动脚本中指定 etcd servers 集群
$ ks exec -it kube-apiserver-minikube -- kube-apiserver --help
--etcd-servers-overrides strings
Per-resource etcd servers overrides, comma separated. The individual override format: group/resource#servers, where servers are URLs, semicolon separated. Note that this applies only to resources compiled into this server binary.如何监控
减少网络延迟
- 数据中心内的 RTT 大概是数毫秒,国内的典型 RTT 约为 50ms ,两大洲之间的 RTT 可能慢至 400ms 。因此建议 etcd 集群尽量同地域部署。
- 当客户端到 Leader 的并发连接数量过多,可能会导致其他 Follower 节点发往 Leader 的请求因为网络拥塞而被延迟处理。在 Follower 节点上,可能会看到这样的错误:
- dropped MsgProp to 247ae21ff9436b2d since streamMsg’s sending buffer is full
- 可以在节点上通过流量控制工具( Traffic Control )提高 etcd 成员之间发送数据的优先级来避免。
减少磁盘 I/O 延迟
对于磁盘延迟,典型的旋转磁盘写延迟约为 10 毫秒。对于 SSD Solid State Drives ,固态硬盘),延迟通常低于 1 毫秒。 HDD Hard Disk Drive ,硬盘驱动器)或者网盘在大量数据读写操作的情况下延时会不稳定。因此强烈建议使用 SSD 。
同时为了降低其他应用程序的 I/O 操作对 etcd 的干扰,建议将 etcd 的数据存放在单独的磁盘内。也可以将不同类型的对象存储在不同的若干个 etcd 集群中,比如将频繁变更的 event 对象从主 etcd 集群中分离出来,以保证主集群的高性能。在 APIServer 处这是可以通过参数配置的。这些 etcd 集群最好也分别能有一块单独的存储磁盘。
如果不可避免地, etcd 和其他的业务共享存储磁盘,那么就需要通过下面 ionice 命令对 etcd 服务设置更高的磁盘 I/O 优先级,尽可能避免其他进程的影响。
ionice -c2 -n0 -p 'pgrep etcd'保持合理的日志文件大小
etcd 以日志的形式保存数据,无论是数据创建还是修改,它都将操作追加到日志文件,因此日志文件大小会随着数据修改次数而线性增长。
当 Kubernetes 集群规模较大时,其对 etcd 集群中的数据更改也会很频繁,集群日记文件会迅速增长。
为了有效降低日志文件大小,etcd 会以固定周期创建快照保存系统的当前状态,并移除旧日志文件。另外当修改次数累积到一定的数量(默认是 10000 ,通过参数 “—snapshot-count” 指定), etcd 也会创建快照文件。
如果 etcd 的内存使用和磁盘使用过高,可以先分析是否数据写入频度过大导致快照频度过高,确认后可通过调低快照触发的阈值来降低其对内存和磁盘的使用。
设置合理的存储配额
存储空间的配额用于控制 etcd 数据空间的大小。合理的存储配额可保证集群操作的可靠性。如果没有存储配额,也就是 etcd 可以利用整个磁盘空间, etcd 的性能会因为存储空间的持续增长而严重下降,甚至有耗完集群磁盘空间导致不可预测集群行为的风险。如果设置的存储配额太小,一旦其中一个节点的后台数据库的存储空间超出了存储配额, etcd 就会触发集群范围的告警,并将集群置于只接受读和删除请求的维护模式。只有在释放足够的空间、消除后端数据库的碎片和清除存储配额告警之后,集群才能恢复正常操作。
自动压缩历史版本
etcd 会为每个键都保存了历史版本。为了避免出现性能问题或存储空间消耗完导致写不进去的问题,这些历史版本需要进行周期性地压缩。压缩历史版本就是丢弃该键给定版本之前的所有信息,节省出来的空间可以用于后续的写操作。 etcd 支持自动压缩历史版本。在启动参数中指定参数 “—auto-compaction”,其值以小时为单位。也就是 etcd 会自动压缩该值设置的时间窗口之前的历史版本。
定期消除碎片化
压缩历史版本,相当于离散地抹去 etcd 存储空间某些数据, etcd 存储空间中将会出现碎片。这些碎片无法被后台存储使用,却仍占据节点的存储空间。因此定期消除存储碎片,将释放碎片化的存储空间,重新调整整个存储空间。
备份
- 备份方案
- etcd 备份:备份完整的集群信息,灾难恢复
- etcdctl snapshot save
- 备份 Kubernetes event
- etcd 备份:备份完整的集群信息,灾难恢复
- 频度?
- 时间间隔太长:
- 能否接受 user data lost
- 如果有外部资源配置,如负载均衡等,能否接受数据丢失导致的 leak
- 时间间隔太短:
- 对 etcd 的影响
- 做 snapshot 的时候, etcd 会锁住当前数据
- 并发的写操作需要开辟新的空间进行增量写,导致磁盘空间增长
- 对 etcd 的影响
- 时间间隔太长:
- 如何保证备份的时效性,同时防止磁盘爆掉?
- Auto defrag
优化运行参数
当网络延迟和磁盘延迟固定的情况下,可以优化 etcd 运行参数来提升集群的工作效率。 etcd 基于 Raft 协议进行 Leader 选举,当 Leader 选定以后才能开始数据读写操作,因此频繁的 Leader 选举会导致数据读写性能显著降低。可以通过调整心跳周期( Heatbeat Interval )和选举超时时间 Election Timeout ),来降低 Leader 选举的可能性。
心跳周期是控制 Leader 以何种频度向 Follower 发起心跳通知。心跳通知除表明 Leader 活跃状态之外,还带有待写入数据信息, Follower 依据心跳信息进行数据写入,默认心跳周期是 100ms 。选举超时时间定义了当 Follower 多久没有收到 Leader 心跳,则重新发起选举,该参数的默认设置是 1000ms 。
如果 etcd 集群的不同实例部署在延迟较低的相同数据中心,通常使用默认配置即可。如果不同实例部署在多数据中心或者网络延迟较高的集群环境,则需要对心跳周期和选举超时时间进行调整。建议心跳周期参数推荐设置为接近 etcd 多个成员之间平均数据往返周期的最大值,一般是平均 RTT 的 0.55 - 1.5 倍。如果心跳周期设置得过低, etcd 会发送很多不必要的心跳信息,从而增加 CPU 和网络的负担。如果设置得过高,则会导致选举频繁超时。选举超时时间也需要根据 etcd 成员之间的平均 RTT 时间来设置。选举超时时间最少设置为 etcd 成员之间 RTT 时间的 10 倍,以便对网络波动。
心跳间隔和选举超时时间的值必须对同一个 etcd 集群的所有节点都生效,如果各个节点配置不同,就会导致集群成员之间协商结果不可预知而不稳定。
etcd 备份存储
etcd 的默认工作目录下会生成两个子目录: wal 和 snap 。 wal 是用于存放预写式日志,其最大的作用是记录整个数据变化的全部历程。所有数据的修改在提交前,都要先写入 wal 中。
snap 是用于存放快照数据。为防止 wal 文件过多, etcd 会定期(当 wal 中数据超过 10000 条记录时,由参数 “—snapshot-count” 设置)创建快照。当快照生成后 wal 中数据就可以被删除了。
如果数据遭到破坏或错误修改需要回滚到之前某个状态时,方法就有两个:一是从快照中恢复数据主体,但是未被拍入快照的数据会丢失;而是执行所有 WAL 中记录的修改操作,从最原始的数据恢复到数据损坏之前的状态,但恢复的时间较长。
备份方案实践
官方推荐 etcd 集群的备份方式是定期创建快照。和 etcd 内部定期创建快照的目的不同,该备份方式依赖外部程序定期创建快照,并将快照上传到网络存储设备以实现 etcd 数据的冗余备份。上传到网络设备的数据,都应进行了加密。即使当所有 etcd 实例都丢失了数据,也能允许 etcd 集群从一个已知的良好状态的时间点在任一地方进行恢复。根据集群对 etcd 备份粒度的要求,可适当调节备份的周期。在生产环境中实测,拍摄快照通常会影响集群当时的性能,因此不建议频繁创建快照。但是备份周期太长,就可能导致大量数据的丢失。
这里可以使用增量备份的方式。如图所示,备份程序每 30 分钟触发一次快照的拍摄。紧接着它从快照结束的版本( Revision )开始,监听 etcd 集群的事件,并每 10 秒钟将事件保存到文件中,并将快照和事件文件上传到网络存储设备中。 30 分钟的快照周期对集群性能影响甚微。当大灾难来临时,也至多丢失 10 秒的数据。至于数据修复,首先把数据从网络存储设备中下载下来,然后从快照中恢复大块数据,并在此基础上依次应用存储的所有事件。这样就可以将集群数据恢复到灾难发生前。
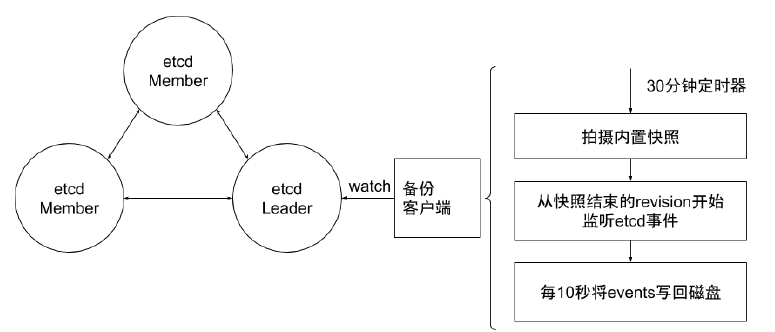
ResourceVersion
- 单个对象的 resourceVersion
- 对象的最后修改 resourceVersion
- List 对象的 resourceVersion
- 生成 list response 时的 resourceVersion
- List 行为
- List 对象时,如果不加 resourceVersion ,意味着需要 Most Recent 数据,请求会击穿 APIServer 缓存,直接发送至 etcd
- APIServer 通过 Label 过滤对象查询时,过滤动作是在 APIServer 端, APIServer 需要向 etcd 发起全量查询请求

遭遇到的陷阱
- 频繁的 leader election
- etcd 分裂
- etcd 不响应
- 与 apiserver 之间的链路阻塞
- 磁盘暴涨
Kubernetes 控制平面组件 API Server
API Server
kube-apiserver 是 Kubernetes 最重要的核心组件之一,主要提供以下的功能:
- 提供集群管理的 REST API 接口,包括认证授权、数据校验以及集群状态变更等
- 提供其他模块之间的数据交互和通信的枢纽(其他模块通过 API Server 查询或修改数据,只有 API Server 才直接操作 etcd)
访问控制概览
Kubernetes API的每个请求都会经过多阶段的访问控制之后才会被接受,这包括认证、授权以及准入控制(Admission Control)等。
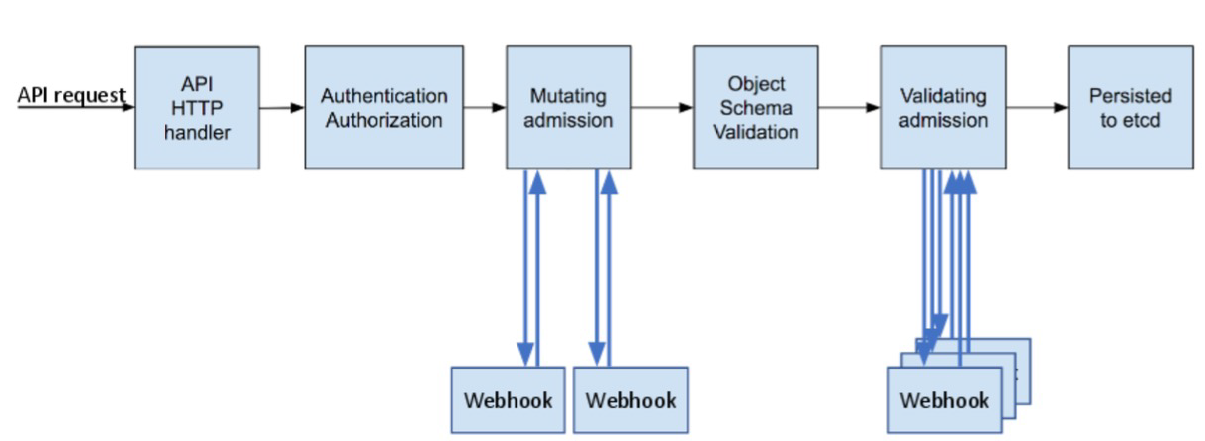
访问控制细节
认证
开启 TLS 时,所有的请求都需要首先认证。Kubernetes 支持多种认证机制,并支持同时开启多个认证插件(只要有一个认证通过即可)。如果认证成功,则用户的 username 会传入授权模块做进一步授权验证;而对于认证失败的请求则返回 HTTP 401。
认证插件
- X509证书
- https://github.com/kibaamor/101/blob/master/module6/basic-auth/x509.MD
- 使用 X509 客户端证书只需要 API Server 启动时配置
--client-ca-file=SOMEFILE。在证书认证时,其 CN 域用作用户名,而组织机构域则用作 group 名。
- 静态Token文件
- https://github.com/kibaamor/101/tree/master/module6/basic-auth
- 使用静态 Token 文件认证只需要 API Server 启动时配置
--token-auth-file=SOMEFILE。 - 该文件为csv格式,每行至少包括三列 token,username,user id,
- token,user,uid,”group1,group2,group3”
- 引导Token
- 为了支持平滑地启动引导新的集群,Kubernetes 包含了一种动态管理的持有者令牌类型, 称作启动引导令牌(Bootstrap Token)。
- 这些令牌以 Secret 的形式保存在 kube-system 名字空间中,可以被动态管理和创建。
- 控制器管理器包含的 TokenCleaner 控制器能够在启动引导令牌过期时将其删除。
- 在使用 kubeadm 部署 Kubernetes 时,可通过 kubeadm token list 命令查询。
- 静态密码文件
- 需要 API Server 启动时配置
--basic-auth-file=SOMEFILE,文件格式为 csv,每行至少三列 password, user, uid,后面是可选的 group 名- password,user,uid,”group1,group2,group3”
- 需要 API Server 启动时配置
- ServiceAccount
- ServiceAccount 是 Kubernetes 自动生成的,并会自动挂载到容器的
/run/secrets/kubernetes.io/serviceaccount目录中。
- ServiceAccount 是 Kubernetes 自动生成的,并会自动挂载到容器的
- OpenID
- OAuth 2.0的认证机制
- Webhook 令牌身份认证
- —authentication-token-webhook-config-file 指向一个配置文件,其中描述如何访问远程的Webhook 服务。
- —authentication-token-webhook-cache-ttl 用来设定身份认证决定的缓存时间。默认时长为2 分钟。
- 匿名请求
- 如果使用 AlwaysAllow 以外的认证模式,则匿名请求默认开启,但可用
--anonymous-auth=false禁止匿名请求。
- 如果使用 AlwaysAllow 以外的认证模式,则匿名请求默认开启,但可用
基于webhook的认证服务集成
构建符合Kubernetes规范的认证服务
需要依照 Kubernetes 规范,构建认证服务,用来认证 tokenreview request
构建认证服务需要满足如下Kubernetes的规范
URL: https://authn.example.com/authenticate
Method: POST
Input:
{
"apiVersion": "authentication.k8s.io/v1beta1",
"kind": "TokenReview",
"spec": {
"token": "(BEARERTOKEN)"
}
}Output:
{
"apiVersion": "authentication.k8s.io/v1beta1",
"kind": "TokenReview",
"status": {
"authenticated": true,
"user": {
"username": "janedoe@example.com",
"uid": "42",
"groups": [
"developers",
"qa"
]
}
}
}开发认证服务
https://github.com/kibaamor/101/tree/master/module6/authn-webhook
解码认证请求
decoder := json.NewDecoder(r.Body)
var tr authentication.TokenReview
err := decoder.Decode(&tr)
if err != nil {
log.Println("[Error]", err.Error())
w.WriteHeader(http.StatusBadRequest)
json.NewEncoder(w).Encode(map[string]interface{}{
"apiVersion": "authentication.k8s.io/v1beta1",
"kind": "TokenReview",
"status": authentication.TokenReviewStatus{
Authenticated: false,
},
})
return
}转发认证请求至认证服务器
// Check User
ts := oauth2.StaticTokenSource(
&oauth2.Token{AccessToken: tr.Spec.Token},
)
tc := oauth2.NewClient(context.Background(), ts)
client := github.NewClient(tc)
user, _, err := client.Users.Get(context.Background(), "")
if err != nil {
log.Println("[Error]", err.Error())
w.WriteHeader(http.StatusUnauthorized)
json.NewEncoder(w).Encode(map[string]interface{}{
"apiVersion": "authentication.k8s.io/v1beta1",
"kind": "TokenReview",
"status": authentication.TokenReviewStatus{
Authenticated: false,
},
})
return
}认证结果返回给 API Server
w.WriteHeader(http.StatusOK)
trs := authentication.TokenReviewStatus{
Authenticated: true,
User: authentication.UserInfo{
Username: *user.Login,
UID: *user.Login,
},
}
json.NewEncoder(w).Encode(map[string]interface{}{
"apiVersion": "authentication.k8s.io/v1beta1",
"kind": "TokenReview",
"status": trs,
})配置认证服务
{
"kind": "Config",
"apiVersion": "v1",
"preferences": {},
"clusters": [
{
"name": "github-authn",
"cluster": {
"server": "http://192.168.34.2:3000/authenticate"
}
}
],
"users": [
{
"name": "authn-apiserver",
"user": {
"token": "secret"
}
}
],
"contexts": [
{
"name": "webhook",
"context": {
"cluster": "github-authn",
"user": "authn-apiserver"
}
}
],
"current-context": "webhook"
}配置 apiserver
可以是任何认证系统
- 但在用户认证完成后,生成代表用户身份的 token
- 该 token 通常是有失效时间的
- 用户获取该 token 以后以后,将token配置进 kubeconfig
修改 apiserver 设置,开启认证服务,apiserver 保证将所有收到的请求中的 token 信息,发给认证服务进行验证
- --authentication-token-webhook-config-file,该文件描述如何访问认证服务
- --authentication-token-webhook-cache-ttl,默认 2 分钟
配置文件需要mount进Pod
配置文件中的服务器地址需要指向 authService
生产系统中遇到的陷阱
基于 Keystone 的认证插件导致 Keystone 故障且无法恢复
Keystone 是企业关键服务
Kubernetes 以 Keystone 作为认证插件
Keystone 在出现故障后会抛出 401 错误
Kubernetes 发现 401 错误后会尝试重新认证
大多数 controller 都有指数级 back off,重试间隔越来越慢
但 gophercloud 针对过期 token 会一直 retry
大量的 request 积压在 Keystone 导致服务无法恢复
Kubernetes 成为压死企业认证服务的最后一根稻草
解决方案?
- Circuit break
- Rate limit
鉴权
授权
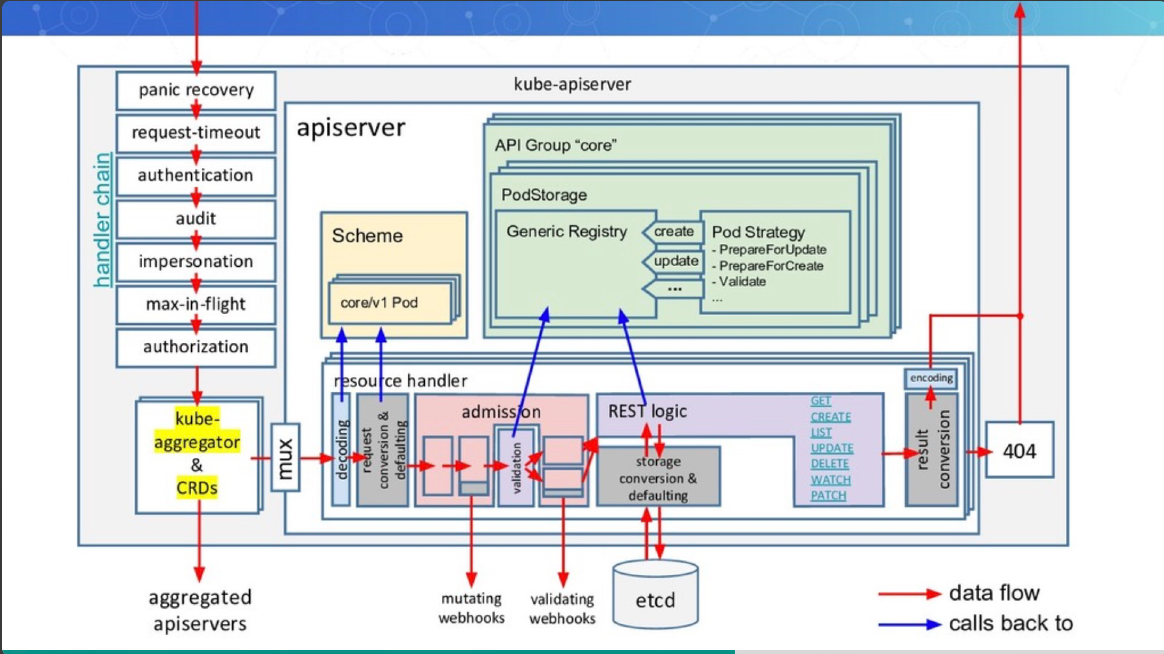
授权主要是用于对集群资源的访问控制,通过检查请求包含的相关属性值,与相对应的访问策略相比较,API 请求必须满足某些策略才能被处理。跟认证类似,Kubernetes 也支持多种授权机制,并支持同时开启多个授权插件(只要有一个验证通过即可)。如果授权成功,则用户的请求会发送到准入控制模块做进一步的请求验证;对于授权失败的请求则返回 HTTP 403。
Kubernetes 授权仅处理以下的请求属性:
- user, group, extra
- API、请求方法(如 get、post、update、patch 和 delete)和请求路径(如 /api)
- 请求资源和子资源
- Namespace
- API Group
目前,Kubernetes 支持以下授权插件:
- ABAC
- RBAC
- Webhook
- Node
RBAC vs ABAC
ABAC(Attribute Based Access Control)本来是不错的概念,但是在 Kubernetes 中的实现比较难于管理和理解,而且需要对 Master 所在节点的 SSH 和文件系统权限,要使得对授权的变更成功生效,还需要重新启动 API Server。
而 RBAC 的授权策略可以利用 kubectl 或者 Kubernetes API 直接进行配置。RBAC 可以授权给用户,让用户有权进行授权管理,这样就可以无需接触节点,直接进行授权管理。RBAC 在 Kubernetes 中被映射为 API 资源和操作。
RBAC 老图
RBAC 新解
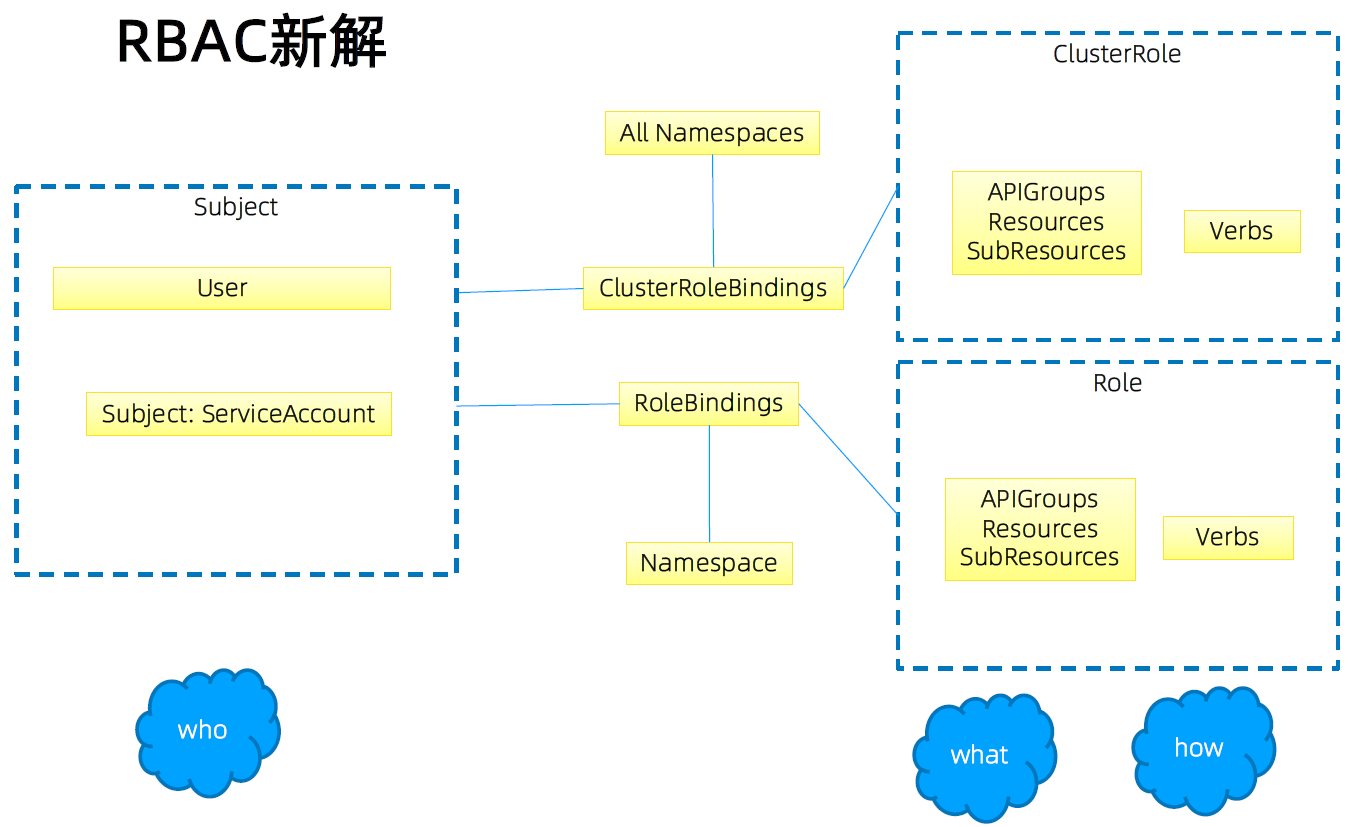
Role 与 ClusterRole
Role(角色)是一系列权限的集合,例如一个角色可以包含读取 Pod 的权限和列出 Pod 的权限。
Role 只能用来给某个特定 namespace 中的资源作鉴权,对多 namespace 和集群级的资源或者是非资源类的 API(如/healthz)使用 ClusterRole。
sub resource 可以单独控制权限(比如健康检查只能更新 status,不能更新 spec)
# Role示例
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
namespace: default
name: pod-reader
rules:
- apiGroups: [""] # "" indicates the core API group
resources: ["pods"]
verbs: ["get", "watch", "list"]
------
# ClusterRole示例
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
# "namespace" omitted since ClusterRoles are not namespaced
name: secret-reader
rules:
- apiGroups: [""]
resources: ["secrets"]
verbs: ["get", "watch", "list"]binding
# RoleBinding示例(引用ClusterRole)
# This role binding allows "dave" to read secrets in the "development"
namespace.
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: read-secrets
namespace: development # This only grants permissions within the "development" namespace.
subjects:
- kind: User
name: dave
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: ClusterRole
name: secret-reader
apiGroup: rbac.authorization.k8s.io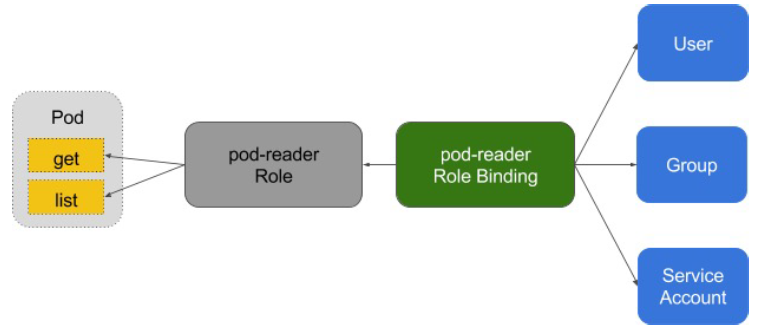
账户/组的管理
角色绑定(Role Binding)是将角色中定义的权限赋予一个或者一组用户。
它包含若干主体(用户、组或服务账户)的列表和对这些主体所获得的角色的引用。
组的概念:
- 当与外部认证系统对接时,用户信息(UserInfo)可包含 Group 信息,授权可针对用户群组
- 当对 ServiceAccount 授权时,Group 代表某个 Namespace 下的所有 ServiceAccount
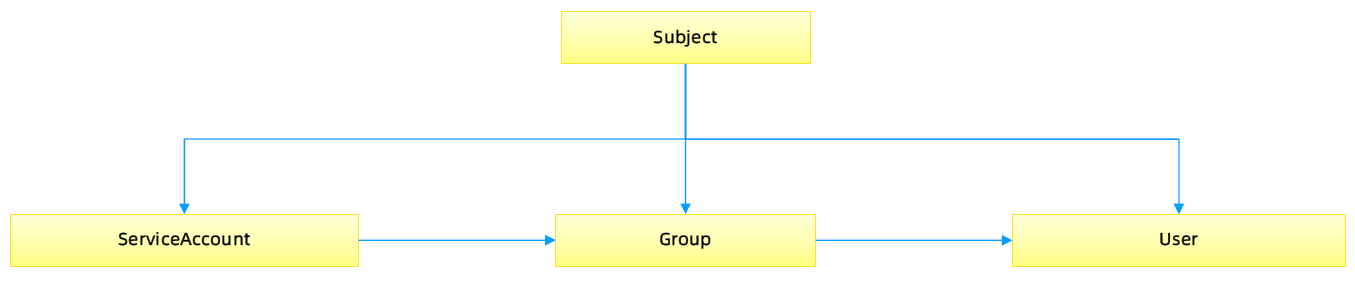
针对群租授权
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: read-secrets-global
subjects:
- kind: Group
name: manager # 'name' 是区分大小写的
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: ClusterRole
name: secret-reader
apiGroup: rbac.authorization.k8s.io
-------
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: read-secrets-global
subjects:
- kind: Group
name: system:serviceaccounts:qa
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: ClusterRole
name: secret-reader
apiGroup: rbac.authorization.k8s.io规划系统角色
User
- 管理员
- 所有资源的所有权限??
- 普通用户
- 是否有该用户创建的 namespace 下的所有 object 的操作权限?
- 对其他用户的 namespace 资源是否可读,是否可写?
SystemAccount
- SystemAccount 是开发者(kubernetes developer 或者 domain developer)创建应用后,应用于 apiserver 通讯需要的身份
- 用户可以创建自定的 ServiceAccount,kubernetes 也为每个 namespace 创建 default ServiceAccount
- Default ServiceAccount 通常需要给定权限以后才能对 apiserver 做写操作
实现方案
在 cluster 创建时,创建自定义的 clusterrole,比如 namespace-creator
Namespace-creator role 定义用户可操作的对象和对应的读写操作。
创建自定义的 namespace admission controller
- 当 namespace 创建请求被处理时,获取当前用户信息并 annotate 到 namespace
创建 RBAC controller
- Watch namespace 的创建事件
- 获取当前 namespace 的创建者信息
- 在当前 namespace 创建 rolebinding 对象,并将 namespace-creator 角色和用户绑定
与权限相关的其他最佳实践
ClusterRole 是非 namespace 绑定的,针对整个集群生效
通常需要创建一个管理员角色,并且绑定给开发运营团队成员
ThirdPartyResource 和 CustomResourceDefinition 是全局资源,普通用户创建 ThirdPartyResource 以后,需要管理员授予相应权限后才能真正操作该对象
针对所有的角色管理,建议创建 spec,用源代码驱动
虽然可以通过edit操作来修改权限,但后期会导致权限管理混乱,可能会有很多临时创建出来的角色和角色绑定对象,重复绑定某一个资源权限
权限是可以传递的,用户 A 可以将其对某对象的某操作,抽取成一个权限,并赋给用户 B
防止海量的角色和角色绑定对象,因为大量的对象会导致鉴权效率低,同时给 apiserver 增加负担
ServiceAccount 也需要授权的,否则你的 component 可能无法操作某对象
Tips:SSH 到 master 节点通过 insecure port 访问 apiserver 可绕过鉴权,当需要做管理操作又没有权限时可以使用(不推荐)
运营过程中出现的陷阱
案例1:
- 研发人员为提高系统效率,将 update 方法修改为 patch
- 研发人员本地非安全测试环境测试通过
- 上生产,发现不 work
- 原因:忘记更新 rolebinding,对应的 serviceaccount 没有 patch 权限
案例2:
- 研发人员创建 CRD,并针对该 CRD 编程
- 上生产后不工作
- 原因,该 CRD 未授权,对应的组件 get 不到对应的 CRD 资源
准入
准入控制
为资源增加自定义属性
- 作为多租户集群方案中的一环,我们需要在 namespace 的准入控制中,获取用户信息,并将用户信息更新的 namespace 的 annotation
只有当 namespace 中有有效用户信息时,我们才可以在 namespace 创建时,自动绑定用户权限,namespace 才可用。
准入控制(Admission Control)在授权后对请求做进一步的验证或添加默认参数。不同于授权和认证只关心请求的用户和操作,准入控制还处理请求的内容,并且仅对创建、更新、删除或连接(如代理)等有效,而对读操作无效。
准入控制支持同时开启多个插件,它们依次调用,只有全部插件都通过的请求才可以放过进入系统。
准入控制插件
- AlwaysAdmit: 接受所有请求。
- AlwaysPullImages: 总是拉取最新镜像。在多租户场景下非常有用。
- DenyEscalatingExec: 禁止特权容器的 exec 和 attach 操作。
- ImagePolicyWebhook: 通过 webhook 决定 image 策略,需要同时配置
--admission-controlconfig-file - ServiceAccount:自动创建默认 ServiceAccount,并确保 Pod 引用的 ServiceAccount 已经存在
- SecurityContextDeny:拒绝包含非法 SecurityContext 配置的容器
- ResourceQuota:限制 Pod 的请求不会超过配额,需要在 namespace 中创建一个 ResourceQuota 对象
- LimitRanger:为 Pod 设置默认资源请求和限制,需要在 namespac 中创建一个 LimitRange 对象
- InitialResources:根据镜像的历史使用记录,为容器设置默认资源请求和限制
- NamespaceLifecycle:确保处于 termination 状态的 namespace 不再接收新的对象创建请求,并拒绝请求不存在的 namespace
- DefaultStorageClass:为 PVC 设置默认 StorageClass
- DefaultTolerationSeconds:设置 Pod 的默认 forgiveness toleration 为 5 分钟
- PodSecurityPolicy:使用 Pod Security Policies 时必须开启
- NodeRestriction:限制 kubelet 仅可访问 node、endpoint、pod、service 以及 secret、configmap、PV 和PVC 等相关的资源
准入控制插件的开发
https://github.com/kibaamor/101/blob/master/module6/mutatingwebhook/readme.MD
https://github.com/kibaamor/admission-controller-webhook-demo
准入控制插件
除默认的准入控制插件以外,Kubernetes 预留了准入控制插件的扩展点,用户可自定义准入控制插件实现自定义准入功能
- MutatingWebhookConfiguration:变形插件,支持对准入对象的修改
- ValidatingWebhookConfiguration:校验插件,只能对准入对象合法性进行校验,不能修改
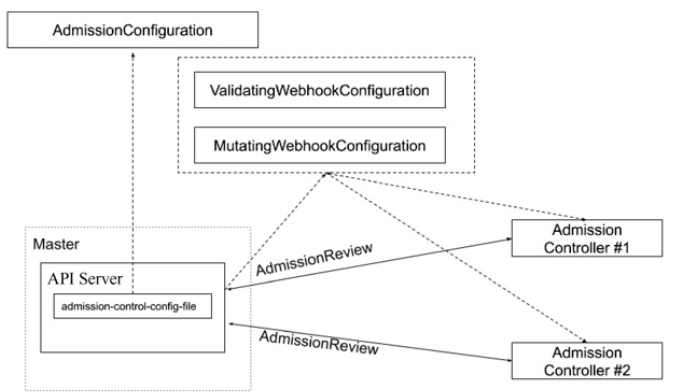
# {{if eq .k8snode_validating "enabled"}}
apiVersion: admissionregistration.k8s.io/v1beta1
kind: MutatingWebhookConfiguration
metadata:
name: ns-mutating.webhook.k8s.io
webhooks:
- clientConfig:
caBundle: {{.serverca_base64}}
url: https://admission.local.tess.io/apis/admission.k8s.io/v1alpha1/ns-mutating
failurePolicy: Fail
name: ns-mutating.webhook.k8s.io
namespaceSelector: {}
rules:
- apiGroups:
- ""
apiVersions:
- '*'
operations:
- CREATE
resources:
- nodes
sideEffects: Unknown
# {{end}}配额管理
https://github.com/kibaamor/101/tree/master/module6/quota
配额管理
- 原因:资源有限,如何限定某个用户有多少资源?
方案: - 预定义每个 Namespace 的 ResourceQuota,并把 spec 保存为 configmap
- 用户可以创建多少个 Pod
- BestEffortPod
- QoSPod
- 用户可以创建多少个 service
- 用户可以创建多少个 ingress
- 用户可以创建多少个 service VIP
- 用户可以创建多少个 Pod
- 创建 ResourceQuota Controller
- 监控 namespace 创建事件,当 namespace 创建时,在该 namespace 创建对应的 ResourceQuota 对象
- apiserver 中开启 ResourceQuota 的 admission plugin
限流
计数器固定窗口算法
原理就是对一段固定时间窗口内的请求进行计数,如果请求数超过了阈值,则舍弃该请求;
如果没有达到设定的阈值,则接受该请求,且计数加 1 。
当时间窗口结束时,重置计数器为 0 。
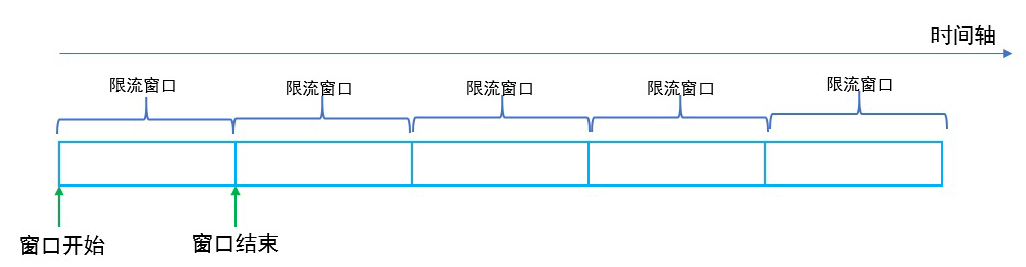
计数器滑动窗口算法
在固定窗口的基础上,将一个计时窗口分成了若干个小窗口,然后每个小窗口维护一个独立的计数器。
当请求的时间大于当前窗口的最大时间时,则将计时窗口向前平移一个小窗口。
平移时,将第一个小窗口的数据丢弃,然后将第二个小窗口设置为第一个小窗口,同时在最后面新增一个小窗口,将新的请求放在新增的小窗口中。
同时要保证整个窗口中所有小窗口的请求数目之后不能超过设定的阈值。
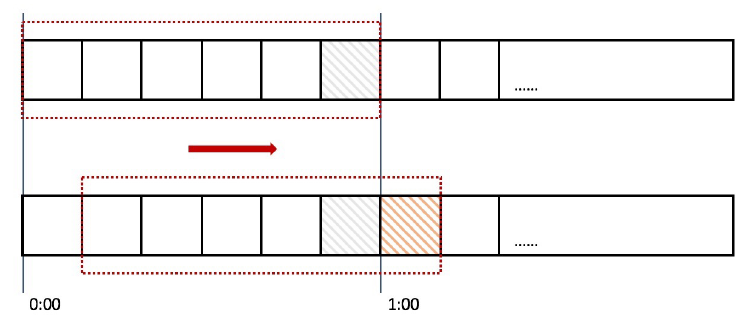
漏斗算法
漏斗算法的原理也很容易理解。请求来了之后会首先进到漏斗里,然后漏斗以恒定的速率将请求流出进行处理,从而起到平滑流量的作用。
当请求的流量过大时,漏斗达到最大容量时会溢出,此时请求被丢弃。
在系统看来,请求永远是以平滑的传输速率过来,从而起到了保护系统的作用。
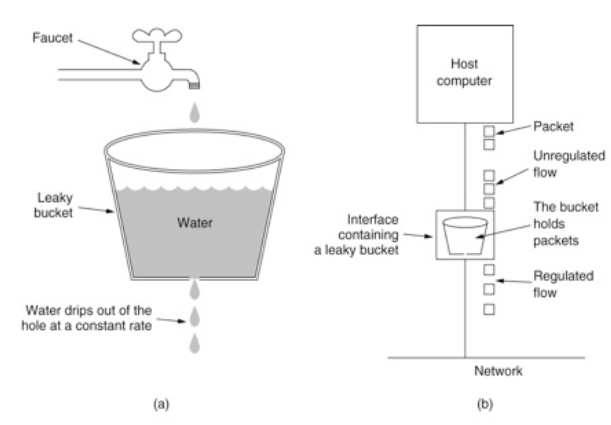
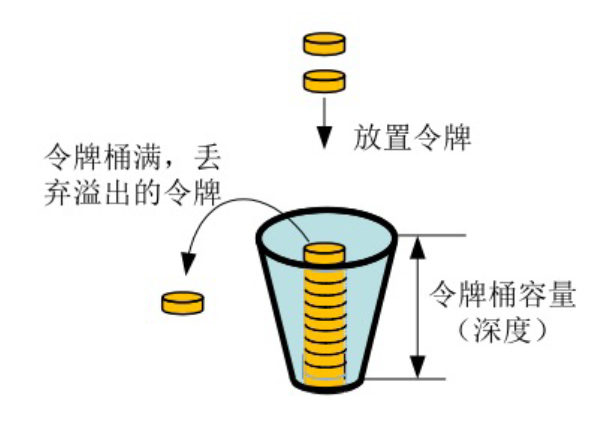
令牌桶算法
令牌桶算法是对漏斗算法的一种改进,除了能够起到限流的作用外,还允许一定程度的流量突发。
在令牌桶算法中,存在一个令牌桶,算法中存在一种机制以恒定的速率向令牌桶中放入令牌。
令牌桶也有一定的容量,如果满了令牌就无法放进去了。
当请求来时,会首先到令牌桶中去拿令牌,如果拿到了令牌,则该请求会被处理,并消耗掉拿到的令牌;
如果令牌桶为空,则该请求会被丢弃。
API Server 中的限流
max-requests-inflight: 在给定时间内的最大 non-mutating 请求数
max-mutating-requests-inflight: 在给定时间内的最大 mutating 请求数,调整 apiserver 的流控 qos
代码 staging/src/k8s.io/apiserver/pkg/server/filters/maxinflight.go:WithMaxInFlightLimit()

传统限流方法的局限性
- 粒度粗
- 无法为不同用户,不同场景设置不通的限流
- 单队列
- 共享限流窗口/桶,一个坏用户可能会将整个系统堵塞,其他正常用户的请求无法被及时处理
- 不公平
- 正常用户的请求会被排到队尾,无法及时处理而饿死
- 无优先级
- 重要的系统指令一并被限流,系统故障难以恢复
API Priority and Fairness
APF 以更细粒度的方式对请求进行分类和隔离。
- 它还引入了空间有限的排队机制,因此在非常短暂的突发情况下,API 服务器不会拒绝任何请求。
- 通过使用公平排队技术从队列中分发请求,这样, 一个行为不佳的控制器就不会饿死其他控制器(即使优先级相同)。
APF的核心
- 多等级
- 多队列
APF 的实现依赖两个非常重要的资源 FlowSchema, PriorityLevelConfiguration
- APF 对请求进行更细粒度的分类,每一个请求分类对应一个 FlowSchema (FS)
- FS 内的请求又会根据 distinguisher 进一步划分为不同的 Flow.
- FS 会设置一个优先级(Priority Level, PL),不同优先级的并发资源是隔离的。所以不同优先级的资源不会相互排挤。特定优先级的请求可以被高优处理。
- 一个 PL 可以对应多个 FS,PL 中维护了一个 QueueSet,用于缓存不能及时处理的请求,请求不会因为超出 PL 的并发限制而被丢弃。
- FS 中的每个 Flow 通过 shuffle sharding 算法从 QueueSet 选取特定的 queues 缓存请求。
- 每次从 QueueSet 中取请求执行时,会先应用 fair queuing 算法从 QueueSet 中选中一个 queue,然后从这个 queue 中取出 oldest 请求执行。所以即使是同一个 PL 内的请求,也不会出现一个 Flow 内的请求一直占用资源的不公平现象。
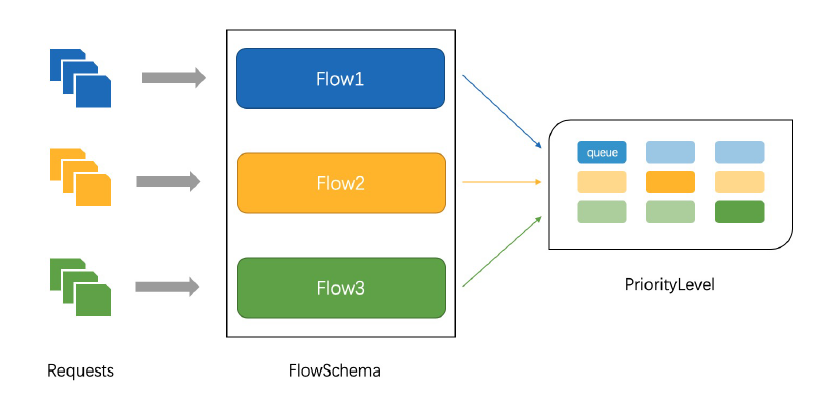
概念
- 传入的请求通过FlowSchema 按照其属性分类,并分配优先级。
- 每个优先级维护自定义的并发限制,加强了隔离度,这样不同优先级的请求,就不会相互饿死。
- 在同一个优先级内,公平排队算法可以防止来自不同flow 的请求相互饿死。
- 该算法将请求排队,通过排队机制,防止在平均负载较低时,通信量突增而导致请求失败。
优先级
- 如果未启用 APF,API 服务器中的整体并发量将受到 kube-apiserver 的参数
--maxrequests-inflight和--max-mutating-requests-inflight的限制。 - 启用 APF 后,将对这些参数定义的并发限制进行求和,然后将总和分配到一组可配置的优先级中。每个传入的请求都会分配一个优先级;
- 每个优先级都有各自的配置,设定允许分发的并发请求数。
- 例如,默认配置包括针对领导者选举请求、内置控制器请求和 Pod 请求都单独设置优先级。这表示即使异常的 Pod 向 API 服务器发送大量请求,也无法阻止领导者选举或内置控制器的操作执行成功。
排队
- 即使在同一优先级内,也可能存在大量不同的流量源。
- 在过载情况下,防止一个请求流饿死其他流是非常有价值的(尤其是在一个较为常见的场景中,一个有故障的客户端会疯狂地向 kube-apiserver 发送请求, 理想情况下,这个有故障的客户端不应对其他客户端产生太大的影响)。
- 公平排队算法在处理具有相同优先级的请求时,实现了上述场景。
- 每个请求都被分配到某个流中,该流由对应的 FlowSchema 的名字加上一个流区分项(Flow Distinguisher)来标识。
- 这里的流区分项可以是发出请求的用户、目标资源的名称空间或什么都不是。
- 系统尝试为不同流中具有相同优先级的请求赋予近似相等的权重。
- 将请求划分到流中之后,APF 功能将请求分配到队列中。
- 分配时使用一种称为混洗分片(Shuffle-Sharding) 的技术。该技术可以相对有效地利用队列隔离低强度流与高强度流。
- 排队算法的细节可针对每个优先等级进行调整,并允许管理员在内存占用、公平性(当总流量超标时,各个独立的流将都会取得进展)、突发流量的容忍度以及排队引发的额外延迟之间进行权衡。
豁免请求
某些特别重要的请求不受制于此特性施加的任何限制。这些豁免可防止不当的流控配置完全禁用 API 服务器。
默认配置
- system
- 用于 system:nodes 组(即 kubelets)的请求; kubelets 必须能连上API 服务器,以便工作负载能够调度到其上。
- leader-election
- 用于内置控制器的领导选举的请求(特别是来自 kube-system 名称空间中 system:kubecontroller-manager 和 system:kube-scheduler 用户和服务账号,针对 endpoints、configmaps 或leases 的请求)。
- 将这些请求与其他流量相隔离非常重要,因为领导者选举失败会导致控制器发生故障并重新启动,这反过来会导致新启动的控制器在同步信息时,流量开销更大。
- workload-high
- 优先级用于内置控制器的请求。
- workload-low
- 优先级适用于来自任何服务帐户的请求,通常包括来自Pods 中运行的控制器的所有请求。
- global-default
- 优先级可处理所有其他流量,例如:非特权用户运行的交互式 kubectl 命令。
- exempt
- 优先级的请求完全不受流控限制:它们总是立刻被分发。特殊的 exempt FlowSchema 把 system:masters 组的所有请求都归入该优先级组。
- catch-all
- 优先级与特殊的 catch-all FlowSchema 结合使用,以确保每个请求都分类。
- 一般不应该依赖于 catch-all 的配置,而应适当地创建自己的 catch-all FlowSchema 和 PriorityLevelConfigurations(或使用默认安装的 global-default 配置)。
- 为了帮助捕获部分请求未分类的配置错误,强制要求 catch-all 优先级仅允许5个并发份额,并且不对请求进行排队,使得仅与 catch-all FlowSchema 匹配的流量被拒绝的可能性更高,并显示 HTTP 429 错误。
PriorityLevelConfiguration
一个 PriorityLevelConfiguration 表示单个隔离类型。
每个 PriorityLevelConfigurations 对未完成的请求数有各自的限制,对排队中的请求数也有限制。

FlowSchema
FlowSchema 匹配一些入站请求,并将它们分配给优先级。
每个入站请求都会对所有 FlowSchema 测试是否匹配, 首先从 matchingPrecedence 数值最低的匹配开始(我们认为这是逻辑上匹配度最高), 然后依次进行,直到首个匹配出现
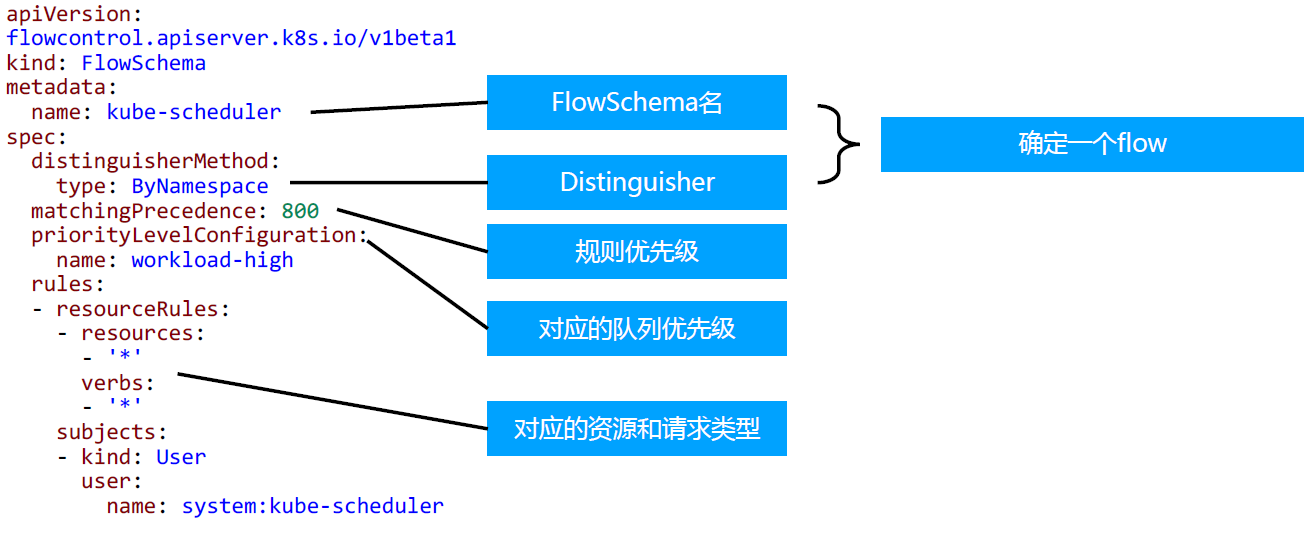
调试
- /debug/api_priority_and_fairness/dump_priority_levels —— 所有优先级及其当前状态的列表。
kubectl get --raw /debug/api_priority_and_fairness/dump_priority_levels - /debug/api_priority_and_fairness/dump_queues —— 所有队列及其当前状态的列表。
kubectl get --raw /debug/api_priority_and_fairness/dump_queues - /debug/api_priority_and_fairness/dump_requests ——当前正在队列中等待的所有请求的列表。
kubectl get --raw /debug/api_priority_and_fairness/dump_requests
高可用 API Server
构建高可用的多副本apiserver
apiserver 是无状态的 Rest Server
无状态所以方便 Scale Up/down
负载均衡
- 在多个 apiserver 实例之上,配置负载均衡
- 证书可能需要加上 Loadbalancer VIP 重新生成
预留充足的 CPU、内存资源
随着集群中节点数量不断增多,APIServer 对 CPU 和内存的开销也不断增大。过少的 CPU 资源会降低其处理效率,过少的内存资源会导致 Pod 被 OOMKilled,直接导致服务不可用。在规划 APIServer 资源时,不能仅看当下需求,也要为未来预留充分。
善用速率限制(RateLimit)
APIServer 的参数 --max-requests-inflight 和 --max-mutating-requests-inflight 支持在给定时间内限制并行处理读请求(包括 Get、List 和 Watch 操作)和写请求(包括 Create、Delete、Update 和 Patch 操作)的最大数量。当 APIServer 接收到的请求超过这两个参数设定的值时,再接收到的请求将会被直接拒绝。通过速率限制机制,可以有效地控 APIServer 内存的使用。如果该值配置过低,会经常出现请求超过限制的错误,如果配置过高,则 APIServer 可能会因为占用过多内存而被强制终止,因此需要根据实际的运行环境,结合实时用户请求数量和 APIServer 的资源配置进行调优。
客户端在接收到拒绝请求的返回值后,应等待一段时间再发起重试,无间隔的重试会加重 APIServer 的压力,导致性能进一步降低。针对并行处理请求数的过滤颗粒度太大,在请求数量比较多的场景,重要的消息可能会被拒绝掉,自 1.18 版本开始,社区引入了优先级和公平保证(Priority and Fairness)功能,以提供更细粒度地客户端请求控制。该功能支持将不同用户或不同类型的请求进行优先级归类,保证高优先级的请求总是能够更快得到处理,从而不受低优先级请求的影响。
设置合适的缓存大小
APIServer 与 etcd 之间基于 gRPC 协议进行通信,gRPC 协议保证了二者在大规模集群中的数据高速传输。gRPC 基于连接复用的 HTTP/2 协议,即针对相同分组的对象,APIServer 和 etcd 之间共享相同的 TCP 连接,不同请求由不同的 stream 传输。
一个 HTTP/2 连接有其 stream 配额,配额的大小限制了能支持的并发请求。APIServer 提供了集群对象的缓存机制,当客户端发起查询请求时,APIServer 默认会将其缓存直接返回给客户端。缓存区大小可以通过参数 --watch-cache-sizes 设置。针对访问请求比较多的对象,适当设置缓存的大小,极大降低对 etcd 的访问频率,节省了网络调用,降低了对 etcd 集群的读写压力,从而提高对象访问的性能。
但是 APIServer 也是允许客户端忽略缓存的,例如客户端请求中 ListOption 中没有设置 resourceVersion,这时 APIServer 直接从 etcd 拉取最新数据返回给客户端。客户端应尽量避免此操作,应在 ListOption 中设置 resourceVersion 为 0,APIServer 则将从缓存里面读取数据,而不会直接访问 etcd。
客户端尽量使用长连接
当查询请求的返回数据较大且此类请求并发量较大时,容易引发 TCP 链路的阻塞,导致其他查询操作超时。因此基于 Kubernetes 开发组件时,例如某些 DaemonSet 和 Controller,如果要查询某类对象,应尽量通过长连接 ListWatch 监听对象变更,避免全量从 APIServer 获取资源。如果在同一应用程序中,如果有多个 Informer 监听 APIServer 资源变化,可以将这些Informer 合并,减少和 APIServer 的长连接数,从而降低对 APIServer 的压力。
如何访问 APIServer
对外部客户(user/client/admin),永远只通过 LoadBalancer 访问
只有当负载均衡出现故障时,管理员才切换到 apiserver IP 进行管理
内部客户端,优先访问 cluster IP?(是否一定如此?)

搭建多租户的 Kubernetes 集群
授信
- 认证:
- 禁止匿名访问,只允许可信用户做操作。
- 授权:
- 基于授信的操作,防止多用户之间互相影响,比如普通用户删除 Kubernetes 核心服务,或者 A 用户删除或修改 B 用户的应用。
隔离
- 可见行隔离:
- 用户只关心自己的应用,无需看到其他用户的服务和部署。
- 资源隔离:
- 有些关键项目对资源需求较高,需要专有设备,不与其他人共享。
- 应用访问隔离:
- 用户创建的服务,按既定规则允许其他用户访问。
资源管理
- Quota 管理
- 谁能用多少资源?
认证
与企业现有认证系统集成
- 很多企业基于 Microsoft Active Directory 提供认证服务
选择认证插件
- 选择 webhook 作为认证插件(*以此为例展开)
- 也可以选择 Keystone 作为认证插件,以 Microsoft Ad 作为 backend 搭建 keystone 服务
一旦认证完成,Kubernetes 即可获取当前用户信息(主要是用户名),并针对该用户做授权。授权和准入控制完成后,该用户的请求完成。
$ kubectl get apiservices v1. -oyaml
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:
creationTimestamp: "2024-05-02T13:50:21Z"
labels:
kube-aggregator.kubernetes.io/automanaged: onstart
name: v1.
resourceVersion: "5"
uid: 0510b743-30fc-4aab-96b9-cd9cc6d309d2
spec:
groupPriorityMinimum: 18000
version: v1
versionPriority: 1
status:
conditions:
- lastTransitionTime: "2024-05-02T13:50:21Z"
message: Local APIServices are always available
reason: Local
status: "True"
type: Available授权
ABAC 有期局限性,针对每个 account 都需要做配置,并且需要重启 apiserver
RBAC 更灵活,更符合我们通常熟知的权限管理
apimachinery
https://github.com/kubernetes/apimachinery
https://github.com/kubernetes/kubernetes/tree/master/staging/src/k8s.io/apimachinery
包含了 kubernetes 核心 API 对象的定义。
回顾 GKV
Group
Kind
Version
- Internel version 和 External version(还有一个 storage version)
- External version:面向用户。版本演进时,照顾版本的兼容性。(kubernetes 只承诺向前兼容 3 个版本)
staging/src/k8s.io/api/core/v1/types.go中就是 core group 的 External version 的定义
- Internal version:API Service 在存数据时会把数据先转成 Internal version
pkg/apis/core/types.go中就是 core group 的 Internal version 的定义
- 对比 External version 和 Internal version 的定义
- External version 的定义会有 json/patchStrategy/patchMergeKey/protobuf tag
- External version:面向用户。版本演进时,照顾版本的兼容性。(kubernetes 只承诺向前兼容 3 个版本)
- 版本转换
如何定义 Group
pkg/apis/core/register.go
定义 group
const GroupName = ""定义 groupversion
var SchemeGroupVersion = schema.GroupVersion{Group: GroupName, Version: runtime.APIVersionInternal}定义 SchemeBuilder
var (
SchemeBuilder = runtime.NewSchemeBuilder(addKnownTypes)
AddToScheme = SchemeBuilder.AddToScheme
)将对象加入SchemeBuild
func addKnownTypes(scheme *runtime.Scheme) error {
if err := scheme.AddIgnoredConversionType(&metav1.TypeMeta{}, &metav1.TypeMeta{}); err != nil {
return err
}
scheme.AddKnownTypes(SchemeGroupVersion,
&Pod{},
&PodList{},
//...
}}定义对象类型 types.go
List
单一对象数据结构
- TypeMeta
- ObjectMeta
- Spec
- Status
代码生成 Tags
Global Tags
定义在 doc.go 中
// +k8s:deepcopy-gen=packageLocal Tags
定义在 types.go 中的每个对象里
// +k8s:deepcopy-gen:interfaces=k8s.io/apimachinery/pkg/runtime.Object
// +genclient
// +genclient:nonNamespaced
// +genclient:noVerbs
// +genclient:onlyVerbs=create,delete
// +genclient:skipVerbs=get,list,create,update,patch,delete,deleteCollection,watch
// +genclient:method=Create,verb=create,result=k8s.io/apimachinery/pkg/apis/meta/v1.Status实现 etcd storage
// pkg/registry/core/configmap/storage/storage.go
// NewREST returns a RESTStorage object that will work with ConfigMap objects.
func NewREST(optsGetter generic.RESTOptionsGetter) (*REST, error) {
store := &genericregistry.Store{
NewFunc: func() runtime.Object { return &api.ConfigMap{} },
NewListFunc: func() runtime.Object { return &api.ConfigMapList{} },
PredicateFunc: configmap.Matcher,
DefaultQualifiedResource: api.Resource("configmaps"),
SingularQualifiedResource: api.Resource("configmap"),
CreateStrategy: configmap.Strategy,
UpdateStrategy: configmap.Strategy,
DeleteStrategy: configmap.Strategy,
TableConvertor: printerstorage.TableConvertor{TableGenerator: printers.NewTableGenerator().With(printersinternal.AddHandlers)},
}
options := &generic.StoreOptions{
RESTOptions: optsGetter,
AttrFunc: configmap.GetAttrs,
}
if err := store.CompleteWithOptions(options); err != nil {
return nil, err
}
return &REST{store}, nil
}创建和更新对象时的业务逻辑 - Strategy
// pkg/registry/core/configmap/strategy.go
func (strategy) PrepareForCreate(ctx context.Context, obj runtime.Object) {
configMap := obj.(*api.ConfigMap)
dropDisabledFields(configMap, nil)
}
func (strategy) Validate(ctx context.Context, obj runtime.Object) field.ErrorList {
cfg := obj.(*api.ConfigMap)
return validation.ValidateConfigMap(cfg)
}
func (strategy) PrepareForUpdate(ctx context.Context, newObj, oldObj runtime.Object) {
oldConfigMap := oldObj.(*api.ConfigMap)
newConfigMap := newObj.(*api.ConfigMap)
dropDisabledFields(newConfigMap, oldConfigMap)
}
func (strategy) ValidateUpdate(ctx context.Context, newObj, oldObj runtime.Object) field.ErrorList {
oldCfg, newCfg := oldObj.(*api.ConfigMap), newObj.(*api.ConfigMap)
return validation.ValidateConfigMapUpdate(newCfg, oldCfg)
}subresource
什么是 subresource,内嵌在 kubernetes 对象中,有独立的操作逻辑的属性集合,如 podstatus
subresource 可以单独的 listandwatch
// pkg/registry/core/pod/strategy.go
statusStore.UpdateStrategy = pod.StatusStrategy
var StatusStrategy = podStatusStrategy{Strategy}
func (podStatusStrategy) PrepareForUpdate(ctx context.Context, obj, old runtime.Object)
{
newPod := obj.(*api.Pod)
oldPod := old.(*api.Pod)
newPod.Spec = oldPod.Spec
newPod.DeletionTimestamp = nil
// don't allow the pods/status endpoint to touch owner references since old kubelets corrupt them in a way
// that breaks garbage collection
newPod.OwnerReferences = oldPod.OwnerReferences
}注册 APIGroup
定义 Storage
configMapStorage := configmapstore.NewREST(restOptionsGetter)
restStorageMap := map[string]rest.Storage{
"configMaps": configMapStorage,
}定义对象的 StorageMap
apiGroupInfo.VersionedResourcesStorageMap["v1"] = restStorageMap将对象注册至 APIServer(挂载handler)
if err := m.GenericAPIServer.InstallLegacyAPIGroup(genericapiserver.DefaultLegacyAPIPrefix, &apiGroupInfo); err != nil {
klog.Fatalf("Error in registering group versions: %v", err)
}代码生成
https://github.com/kubernetes/code-generator
deepcopy-gen
- 为对象生成 DeepCopy 方法,用于创建对象副本
client-gen
- 创建 Clientset,用于操作对象的 CRUD
informer-gen
- 为对象创建 Informer 框架,用于监听对象变化
lister-gen
- 为对象构建 Lister 框架,用于为 Get 和 List 操作,构建客户端缓存
coversion-gen
- 为对象构建 Conversion 方法,用于内外版本转换以及不同版本号的转换
hack/update-codegen.sh
依赖
BUILD_TARGETS=(
vendor/k8s.io/code-generator/cmd/client-gen
vendor/k8s.io/code-generator/cmd/lister-gen
vendor/k8s.io/code-generator/cmd/informer-gen
)生成命令
${GOPATH}/bin/deepcopy-gen --input-dirs {versioned-package-pach}
-O zz_generated.deepcopy \
--bounding-dirs {output-package-path} \
--go-header-file ${SCRIPT_ROOT}/hack/boilerplate.go.txtAPIServer 代码走读
https://cncamp.notion.site/kube-apiserver-10d5695cbbb14387b60c6d622005583d
建议先读 controller 的源码,比如 deployment controller 的源码
cmd/kube-apiserver/app/server.go:NewAPIServerCommand()-->
completedOptions, err := Complete(s)-->
s.Etcd.WatchCacheSizes, err = serveroptions.WriteWatchCacheSizes(sizes)
Run(completedOptions, genericapiserver.SetupSignalHandler())-->CreateServerChain()-->
CreateServerChain()-->
CreateKubeAPIServerConfig-->
buildGenericConfig(s.ServerRunOptions, proxyTransport)-->
genericapiserver.NewConfig(legacyscheme.Codecs) // create codec factory for encoding/decoding
controlplane.DefaultAPIResourceConfigSource() // group version: enabled/disabled
storageFactoryConfig.Complete(s.Etcd)
completedStorageFactoryConfig.New()--> // register access path in etcd for all k8s objects
storageFactory.AddCohabitatingResources(networking.Resource("networkpolicies"), extensions.Resource("networkpolicies"))
s.Etcd.ApplyWithStorageFactoryTo(storageFactory, genericConfig)-->
c.AddHealthChecks()
c.RESTOptionsGetter = &StorageFactoryRestOptionsFactory{Options: *s, StorageFactory: factory}
// 认证
s.Authentication.ApplyTo()--> // clientcert, serviceaccount, bootstrap token,
authenticatorConfig.New()-->
newWebhookTokenAuthenticator(config) // webhook
// 鉴权
BuildAuthorizer(s, genericConfig.EgressSelector, versionedInformers)-->
authorizationConfig.New()-->
rbacAuthorizer := rbac.New()--> // if authorizer type is rbac
// 准入
buildServiceResolver(s.EnableAggregatorRouting, genericConfig.LoopbackClientConfig.Host, versionedInformers)
admissionConfig.New(proxyTransport, genericConfig.EgressSelector, serviceResolver)-->
admission.PluginInitializer{webhookPluginInitializer, kubePluginInitializer}
net.SplitHostPort(s.Etcd.StorageConfig.Transport.ServerList[0])
utilwait.PollImmediate(etcdRetryInterval, etcdRetryLimit*etcdRetryInterval, preflight.EtcdConnection{ServerList: s.Etcd.StorageConfig.Transport.ServerList}.CheckEtcdServers)
capabilities.Initialize() // allow privillage?
config := &controlplane.Config{}
createAPIExtensionsConfig()
createAPIExtensionsServer()-->
apiextensionsConfig.Complete().New(delegateAPIServer)-->
s.AddHealthChecks(delegateCheck)
// 注册通用handler
installAPI(s, c.Config) // register generic api handler e.g. index, profiling, metrics, flow control
CreateKubeAPIServer(kubeAPIServerConfig, apiExtensionsServer.GenericAPIServer)
kubeAPIServerConfig.Complete().New(delegateAPIServer)
m.InstallLegacyAPI(&c, c.GenericConfig.RESTOptionsGetter, legacyRESTStorageProvider)-->
m.GenericAPIServer.AddPostStartHookOrDie(controllerName, bootstrapController.PostStartHook)-->
controlplane.controller.Start()-->
async.NewRunner(c.RunKubernetesNamespaces, c.RunKubernetesService, repairClusterIPs.RunUntil, repairNodePorts.RunUntil)
m.GenericAPIServer.AddPreShutdownHookOrDie(controllerName, bootstrapController.PreShutdownHook)
// 注册core group API handler
m.GenericAPIServer.InstallLegacyAPIGroup() // register handler for /api
restStorageProviders := []RESTStorageProvider{appsrest.StorageProvider{}}
m.InstallAPIs(c.ExtraConfig.APIResourceConfigSource, c.GenericConfig.RESTOptionsGetter, restStorageProviders...)-->
// 初始化对应group中对象的watch cache
restStorageBuilder.NewRESTStorage(apiResourceConfigSource, restOptionsGetter)--> // trigger appsrest.StorageProvider
p.v1Storage(apiResourceConfigSource, restOptionsGetter)-->
daemonsetstore.NewREST(restOptionsGetter)-->
store.CompleteWithOptions(options)-->
opts, err := options.RESTOptions.GetRESTOptions(e.DefaultQualifiedResource)--> // etcd.go
ret.Decorator = genericregistry.StorageWithCacher()-->
cacherstorage.NewCacherFromConfig(cacherConfig)-->
watchCache := newWatchCache()-->
// 注册API handler
m.GenericAPIServer.InstallAPIGroups(apiGroupsInfo...)--> // register handler for /apis
s.installAPIResources(APIGroupPrefix, apiGroupInfo, openAPIModels)-->
apiGroupVersion.InstallREST(s.Handler.GoRestfulContainer)-->
discovery.NewAPIVersionHandler(g.Serializer, g.GroupVersion, staticLister{apiResources})
createAggregatorServer(aggregatorConfig, kubeAPIServer.GenericAPIServer, apiExtensionsServer.Informers)-->
apiServices := apiServicesToRegister(delegateAPIServer, autoRegistrationController)
server.PrepareRun()-->
s.GenericAPIServer.PrepareRun()-->
s.installHealthz()
s.installLivez()
s.installReadyz()
prepared.Run(stopCh)-->
s.runnable.Run(stopCh)--> // preparedGenericAPIServer.Run()
s.NonBlockingRun(delayedStopCh)-->
s.SecureServingInfo.Serve(s.Handler, s.ShutdownTimeout, internalStopCh)-->
RunServer(secureServer, s.Listener, shutdownTimeout, stopCh)Kubernetes 控制平面组件:调度器和控制器
调度
kube-scheduler
// Framework manages the set of plugins in use by the scheduling framework.
// Configured plugins are called at specified points in a scheduling context.
type Framework interface {
Handle
QueueSortFunc() LessFunc
RunPreFilterPlugins(ctx context.Context, state *CycleState, pod *v1.Pod) *Status
RunPostFilterPlugins(ctx context.Context, state *CycleState, pod *v1.Pod, filteredNodeStatusMap NodeToStatusMap) (*PostFilterResult, *Status)
RunPreBindPlugins(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string) *Status
RunPostBindPlugins(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string)
RunReservePluginsReserve(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string) *Status
RunReservePluginsUnreserve(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string)
RunPermitPlugins(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string) *Status
WaitOnPermit(ctx context.Context, pod *v1.Pod) *Status
RunBindPlugins(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string) *Status
HasFilterPlugins() bool
HasPostFilterPlugins() bool
HasScorePlugins() bool
ListPlugins() *config.Plugins
ProfileName() string
}
Schedule()-->
// filter
g.findNodesThatFitPod(ctx, extenders, fwk, state, pod)-->
// 1.filter预处理阶段:遍历pod的所有initcontainer和主container,计算pod的总资源需求
s := fwk.RunPreFilterPlugins(ctx, state, pod) // e.g. computePodResourceRequest
// 2. filter阶段,遍历所有节点,过滤掉不符合资源需求的节点
g.findNodesThatPassFilters(ctx, fwk, state, pod, diagnosis, allNodes)-->
fwk.RunFilterPluginsWithNominatedPods(ctx, state, pod, nodeInfo)-->
s, err := getPreFilterState(cycleState)
insufficientResources := fitsRequest(s, nodeInfo, f.ignoredResources, f.ignoredResourceGroups)
// 3. 处理扩展plugin
findNodesThatPassExtenders(extenders, pod, feasibleNodes, diagnosis.NodeToStatusMap)
// score
prioritizeNodes(ctx, extenders, fwk, state, pod, feasibleNodes)-->
// 4. score,比如处理弱亲和性,将preferredAffinity语法进行解析
fwk.RunPreScorePlugins(ctx, state, pod, nodes) // e.g. nodeAffinity
fwk.RunScorePlugins(ctx, state, pod, nodes)-->
// 5. 为节点打分
f.runScorePlugin(ctx, pl, state, pod, nodeName) // e.g. noderesource fit
// 6. 处理扩展plugin
extenders[extIndex].Prioritize(pod, nodes)
// 7.选择节点
g.selectHost(priorityList)
sched.assume(assumedPod, scheduleResult.SuggestedHost)-->
// 8.假定选中pod
sched.SchedulerCache.AssumePod(assumed)-->
fwk.RunReservePluginsReserve(schedulingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)-->
f.runReservePluginReserve(ctx, pl, state, pod, nodeName) // e.g. bindVolume。其实还没大用
runPermitStatus := fwk.RunPermitPlugins(schedulingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)-->
f.runPermitPlugin(ctx, pl, state, pod, nodeName) // empty hook
fwk.RunPreBindPlugins(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost) // 同 runReservePluginReserve
// bind
// 9.绑定pod
sched.bind(bindingCycleCtx, fwk, assumedPod, scheduleResult.SuggestedHost, state)-->
f.runBindPlugin(ctx, bp, state, pod, nodeName)-->
b.handle.ClientSet().CoreV1().Pods(binding.Namespace).Bind(ctx, binding, metav1.CreateOptions{})-->
return c.client.Post().Namespace(c.ns).Resource("pods").Name(binding.Name).VersionedParams(&opts, scheme.ParameterCodec).SubResource("binding").Body(binding).Do(ctx).Error()kube-scheduler 负责分配调度 Pod 到集群内的节点上,它监听 kube-apiserver,查询还未分配 Node 的 Pod,然后根据调度策略为这些 Pod 分配节点(更新 Pod 的NodeName 字段)。
调度器需要充分考虑诸多的因素:
- 公平调度
- 资源高效利用
- Qos
- affinity 和 anti-affinity
- 数据本地化(data locality)
- 内部负载干扰(inter-workload interfernece)
- deadlines
调度器
kube-scheduler 调度分为两个阶段:
- predicate:过滤不符合条件的节点
- priority:优先级排序,选择优先级最高的节点。
predicates 策略


predicates plugin 工作原理
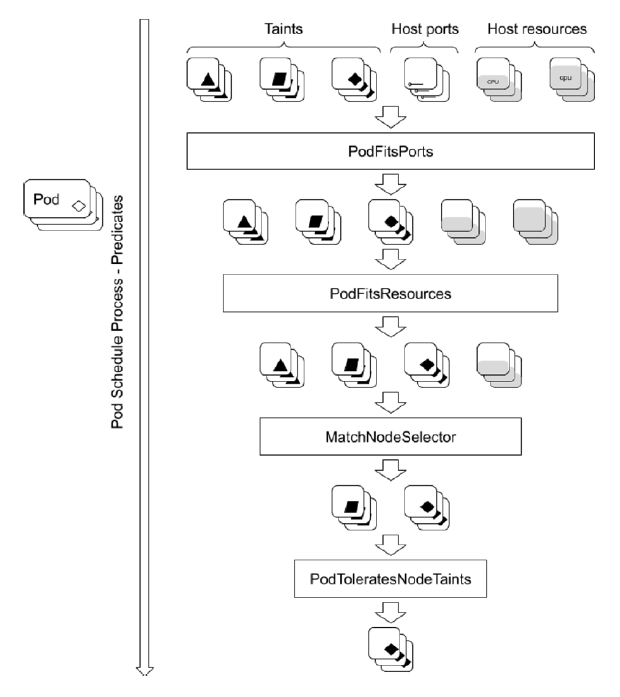
priorities 策略
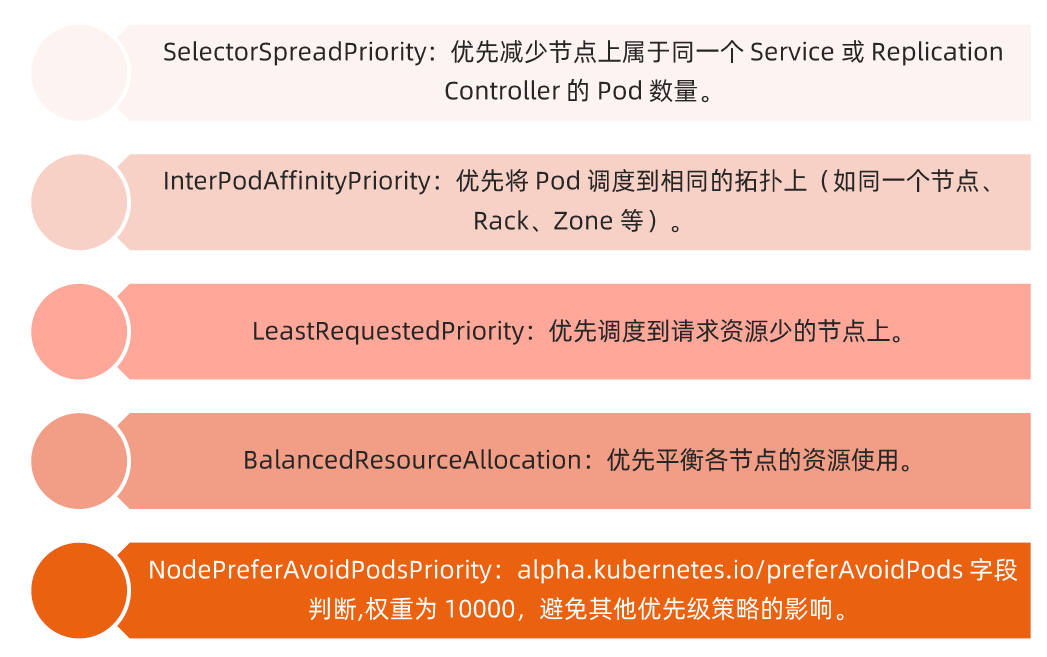

资源需求
- CPU
- requests
- Kubernetes 调度 Pod 时,会判断当前节点正在运行的 Pod 的 CPU Request 的总和,再加上当前调度 Pod 的 CPU Request,计算其是否超过节点的 CPU 的可分配资源
- limits
- 配置 cgroup 以限制资源上限
- requests
- 内存
- requests
- 判断节点的剩余内存是否满足 Pod 的内存请求量,以确定是否可以将 Pod 调度到该节点
- limits
- 配置 cgroup 以限制资源上限
- requests
调度时只看 request。
$ kubectl get node -oyaml
apiVersion: v1
items:
- apiVersion: v1
kind: Node
...
status:
allocatable:
cpu: "12"
ephemeral-storage: 1055762868Ki
hugepages-1Gi: "0"
hugepages-2Mi: "0"
memory: 65713368Ki
pods: "110"
capacity:
cpu: "12"
ephemeral-storage: 1055762868Ki
hugepages-1Gi: "0"
hugepages-2Mi: "0"
memory: 65713368Ki
pods: "110"
...
# 获取某个容器的 cgroup 信息
$ docker inspect 89bf4bbee272 -f "{{.HostConfig.CgroupParent}}"
/kubepods/burstable/pod8af0e85a28544808d52bb7c47ad824ed
$ find /sys/fs/cgroup -name "pod8af0e85a28544808d52bb7c47ad824ed"
/sys/fs/cgroup/systemd/system.slice/docker-2c68f760293681c1dcbffc164ad491d870ab0318521cbcfa9898d74132cee75b.scope/kubepods/burstable/pod8af0e85a28544808d52bb7c47ad824ed
/sys/fs/cgroup/misc/system.slice/docker-2c68f760293681c1dcbffc164ad491d870ab0318521cbcfa9898d74132cee75b.scope/kubepods/burstable/pod8af0e85a28544808d52bb7c47ad824ed
/sys/fs/cgroup/rdma/system.slice/docker-2c68f760293681c1dcbffc164ad491d870ab0318521cbcfa9898d74132cee75b.scope/kubepods/burstable/pod8af0e85a28544808d52bb7c47ad824ed
/sys/fs/cgroup/pids/system.slice/docker-2c68f760293681c1dcbffc164ad491d870ab0318521cbcfa9898d74132cee75b.scope/kubepods/burstable/pod8af0e85a28544808d52bb7c47ad824ed
/sys/fs/cgroup/hugetlb/system.slice/docker-2c68f760293681c1dcbffc164ad491d870ab0318521cbcfa9898d74132cee75b.scope/kubepods/burstable/pod8af0e85a28544808d52bb7c47ad824ed
/sys/fs/cgroup/net_prio/system.slice/docker-2c68f760293681c1dcbffc164ad491d870ab0318521cbcfa9898d74132cee75b.scope/kubepods/burstable/pod8af0e85a28544808d52bb7c47ad824ed
/sys/fs/cgroup/perf_event/system.slice/docker-2c68f760293681c1dcbffc164ad491d870ab0318521cbcfa9898d74132cee75b.scope/kubepods/burstable/pod8af0e85a28544808d52bb7c47ad824ed
/sys/fs/cgroup/net_cls/system.slice/docker-2c68f760293681c1dcbffc164ad491d870ab0318521cbcfa9898d74132cee75b.scope/kubepods/burstable/pod8af0e85a28544808d52bb7c47ad824ed
/sys/fs/cgroup/freezer/system.slice/docker-2c68f760293681c1dcbffc164ad491d870ab0318521cbcfa9898d74132cee75b.scope/kubepods/burstable/pod8af0e85a28544808d52bb7c47ad824ed
/sys/fs/cgroup/devices/system.slice/docker-2c68f760293681c1dcbffc164ad491d870ab0318521cbcfa9898d74132cee75b.scope/kubepods/burstable/pod8af0e85a28544808d52bb7c47ad824ed
/sys/fs/cgroup/memory/system.slice/docker-2c68f760293681c1dcbffc164ad491d870ab0318521cbcfa9898d74132cee75b.scope/kubepods/burstable/pod8af0e85a28544808d52bb7c47ad824ed
/sys/fs/cgroup/blkio/system.slice/docker-2c68f760293681c1dcbffc164ad491d870ab0318521cbcfa9898d74132cee75b.scope/kubepods/burstable/pod8af0e85a28544808d52bb7c47ad824ed
/sys/fs/cgroup/cpuacct/system.slice/docker-2c68f760293681c1dcbffc164ad491d870ab0318521cbcfa9898d74132cee75b.scope/kubepods/burstable/pod8af0e85a28544808d52bb7c47ad824ed
/sys/fs/cgroup/cpu/system.slice/docker-2c68f760293681c1dcbffc164ad491d870ab0318521cbcfa9898d74132cee75b.scope/kubepods/burstable/pod8af0e85a28544808d52bb7c47ad824ed
/sys/fs/cgroup/cpuset/system.slice/docker-2c68f760293681c1dcbffc164ad491d870ab0318521cbcfa9898d74132cee75b.scope/kubepods/burstable/pod8af0e85a28544808d52bb7c47ad824ed
/sys/fs/cgroup/unified/kubepods/burstable/pod8af0e85a28544808d52bb7c47ad824edapiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: 1Gi -> memory.limit_in_bytes = memory(1) * 1024 * 1024 * 1024
cpu: 1 -> cpu.cfs_quota_us(100000) = cpu.cfs_period_us(100000) * cpu(1)
requests:
memory: 256Mi
cpu: 100m -> cpu.shares = int(cpu(100m) / 1000m * 1024) = 102可以使用 LimitRange 来限制集群中资源的范围和设置默认的资源
https://github.com/kibaamor/101/blob/master/module7/scheduling/2.limit-range.yaml
https://kubernetes.io/docs/concepts/policy/limit-range/
apiVersion: v1
kind: LimitRange
metadata:
name: mem-limit-range
spec:
limits:
- default:
memory: 512Mi
defaultRequest:
memory: 256Mi
type: Container但是在真实的场景中不太用 LimitRange,因为 LimitRange 会对所有的容器生效,包括 init container。
磁盘资源需求
容器临时存储(ephemeral storage)包含日志和可写层数据,可以通过定义 Pod Spec 中的 limits.ephemeral-storage 和 requests.ephemeral-storage 来申请。
Pod 调度完成后,计算节点对临时存储的限制不是基于 CGroup 的,而是由 kubelet 定时获取容器的日志和容器可写层的磁盘使用情况,如果超过限制,则会对 Pod 进行驱逐。
Init Container 的资源需求
- 当 kube-scheduler 调度带有多个 init 容器的 Pod 时,只计算
cpu.request最多的 init 容器,而不是计算所有的 init 容器总和。 - 由于多个 init 容器按顺序执行,并且执行完成立即退出,所以申请最多的资源 init 容器中的所需资源,即可满足所有 init 容器需求。
- kube-scheduler 在计算该节点被占用的资源时,init 容器的资源依然会被纳入计算。因为 init 容器在特定情况下可能会被再次执行,比如由于更换镜像而引起 Sandbox 重建时。
把 Pod 调度到指定 Node 上
可以通过 nodeSelector、nodeAffinity、podAffinity 以及 Taints 和 tolerations 等来将 Pod 调度到需求的 Node 上。
也可以通过设置 nodeName 参数,将 Pod 调度到指定 node 节点上。
比如,使用 nodeSelector,首先给 Node 加上标签:kubectl label nodes <your-node-name> disktype=ssd
$ kubectl get node --show-labels
NAME STATUS ROLES AGE VERSION LABELS
minikube Ready control-plane 23h v1.27.4 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=minikube,kubernetes.io/os=linux,minikube.k8s.io/commit=fd7ecd9c4599bef9f04c0986c4a0187f98a4396e,minikube.k8s.io/name=minikube,minikube.k8s.io/primary=true,minikube.k8s.io/updated_at=2024_05_07T17_53_18_0700,minikube.k8s.io/version=v1.31.2,node-role.kubernetes.io/control-plane=,node.kubernetes.io/exclude-from-external-load-balancers=
$ kubectl label nodes minikube disktype=hdd
node/minikube labeled
$ kubectl get node --show-labels
NAME STATUS ROLES AGE VERSION LABELS
minikube Ready control-plane 23h v1.27.4 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,disktype=hdd,kubernetes.io/arch=amd64,kubernetes.io/hostname=minikube,kubernetes.io/os=linux,minikube.k8s.io/commit=fd7ecd9c4599bef9f04c0986c4a0187f98a4396e,minikube.k8s.io/name=minikube,minikube.k8s.io/primary=true,minikube.k8s.io/updated_at=2024_05_07T17_53_18_0700,minikube.k8s.io/version=v1.31.2,node-role.kubernetes.io/control-plane=,node.kubernetes.io/exclude-from-external-load-balancers=接着,指定该 Pod 只想运行在带有 disktype=ssd 标签的 Node 上。
https://github.com/kibaamor/101/blob/master/module7/scheduling/4.node-selector.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
nodeSelector:
disktype: ssdNodeAffinity
https://github.com/kibaamor/101/blob/master/module7/scheduling/5.readme.MD
NodeAffinity 目前支持两种:requiredDuringSchedulingIgnoredDuringExecution 和 preferredDuringSchedulingIgnoredDuringExecution,分别代表必须满足和优选条件。
可以用
NotIn等 operator 实现反亲和性。requiredDuringSchedulingIgnoredDuringExecution 在调度器的 predicate 阶段起作用,preferredDuringSchedulingIgnoredDuringExecution 在调度器的 priority 阶段起作用,所以 preferredDuringSchedulingIgnoredDuringExecution 中有 weight 参数。
比如下面的例子代表调度到包含标签 Kubernetes.io/e2e-az-name 并且值为 e2e-az1 或 e2e-az2 的 Node 上,并且优选还带有标签 another-node-label-key=another-node-label-value 的 Node 。
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExection:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/e2e-az-name
operator: In
values:
- e2e-az1
- e2e-az2
preferredDuringSchedulingIgnoredDuringExection:
- weight: 1
preference:
matchExpressions:
- key: another-node-label-key
operator: In
values:
- another-node-label-value
containers:
- name: with-node-affinity
image: gcr.io/google_containers/pause:2.0PodAffinity
https://github.com/kibaamor/101/blob/master/module7/scheduling/5.a.pod-anti-affinity.yaml
podAffinity 基于 Pod 的标签来选择 Node,仅调度到满足条件 Pod 所在的 Node 上,支持 PodAffinity 和 PodAntiAffinity。这个功能比较绕,以下面的例子为例:
如果一个 “Node 所在的 Zone 中包含至少一个带有 security=S1 标签且运行中的 Pod”,那么可以调度到该 Node,尽量不调度到 “包含至少一个带有 security=S2 标签且运行中 Pod” 的 Node 上。
apiVersion: v1
kind: Pod
metadata:
name: with-pod-affinity
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExection:
- labelSelector:
matchExpressons:
- key: security
operator: In
values:
- S1
topologyKey: failure-domain.beta.kubernetes.io/zone
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExection:
- weight: 100
podAffinityTerm:
- labelSelector:
matchExpressons:
- key: security
operator: In
values:
- S2
topologyKey: kubernetes.io/hostname
containers:
- name: with-pod-affinity
image: gcr.io/google_containers/pause:2.0Taints 和 Tolerations
https://github.com/kibaamor/101/blob/master/module7/scheduling/6.taint.MD
Taints 和 Tolerations 用于保证 Pod 不被调度到不合适的 Node 上,其中 Taint 应用于 Node 上,而 Toleration 则应用于 Pod 上。
目前支持的 Taint 类型:
- NoSchedule:新的 Pod 不调度到该 Node 上,不影响正在运行的 Pod
- PreferNoSchedule: soft 版的 NoSchedule,尽量不调度到该 Node 上
- NoExecute:新的 Pod 不调度到该 Node 上,并且删除(evict)已在运行的 Pod。 Pod 可以增加一个时间(tolerationSeconds)
然而,当 Pod 的 Tolerations 匹配 Node 的所有 Taints 的时候可以调度到该 Node 上;当 Pod 是已经运行的时候,也不会被删除(evicted)。另外对于 NoExecute,如果 Pod 增加一个 tolerationSeconds,则会在该时间之后才删除 Pod。
$ kubectl -n kube-system get po metrics-server-7746886d4f-l8gs7 -oyaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: "2024-05-07T09:53:31Z"
generateName: metrics-server-7746886d4f-
labels:
k8s-app: metrics-server
pod-template-hash: 7746886d4f
name: metrics-server-7746886d4f-l8gs7
namespace: kube-system
ownerReferences:
- apiVersion: apps/v1
blockOwnerDeletion: true
controller: true
kind: ReplicaSet
name: metrics-server-7746886d4f
uid: 394b2480-e048-4b10-977d-aaeabcf57ca0
resourceVersion: "586"
uid: 2a18e607-3bd2-4b66-959c-6a41de9f9e53
spec:
tolerations:
- effect: NoExecute
key: node.kubernetes.io/not-ready
operator: Exists
tolerationSeconds: 300
- effect: NoExecute
key: node.kubernetes.io/unreachable
operator: Exists
tolerationSeconds: 300
...如果一个 Node 上有一个 key 为 node.kubernetes.io/not-ready 或者 node.kubernetes.io/unreachable 的 taint ,那么这个 Node 上面的 Pod 允许存活 300 秒后再被驱逐。
上面的这两个 toleration 是创建 Pod 时 kubernetes 自动加上的。如果一个节点发生故障,这个节点上面的 Pod 会被自动驱逐。其背后的机制就是如果一个 node 变为 not-ready 或者 unreachable,kubernetes 会自动的给该 node 加上对应的 taint。这也是 kubernetes 能做故障转移的秘密。
pkg/controller/nodelifecycle/node_lifecycle_controller.go
NewNodeLifecycleController()-->
nc := &Controller{
kubeClient: kubeClient,
}
podInformer.Informer().AddEventHandler()
if nc.runTaintManager {
nodeInformer.Informer().AddEventHandler()
}
Run(stopCh <-chan struct{})-->
go nc.taintManager.Run(stopCh)-->
for i := 0; i < UpdateWorkerSize; i++ {
tc.nodeUpdateChannels = append(tc.nodeUpdateChannels, make(chan nodeUpdateItem, NodeUpdateChannelSize))
tc.podUpdateChannels = append(tc.podUpdateChannels, make(chan podUpdateItem, podUpdateChannelSize))
}
item, shutdown := tc.nodeUpdateQueue.Get()
hash := hash(nodeUpdate.nodeName, UpdateWorkerSize)
tc.nodeUpdateChannels[hash] <- nodeUpdate:
item, shutdown := tc.podUpdateQueue.Get() // that pods are processed by the same worker as nodes
hash := hash(podUpdate.nodeName, UpdateWorkerSize)
case tc.podUpdateChannels[hash] <- podUpdate:
go tc.worker(i, wg.Done, stopCh)-->
tc.handleNodeUpdate(nodeUpdate)-->
taints := getNoExecuteTaints(node.Spec.Taints)
tc.taintedNodes[node.Name] = taints
pods, err := tc.getPodsAssignedToNode(node.Name)
tc.processPodOnNode(podNamespacedName, node.Name, pod.Spec.Tolerations, taints, now)-->
allTolerated, usedTolerations := v1helper.GetMatchingTolerations(taints, tolerations)
// toleration 不匹配,立即驱逐
if !allTolerated {
tc.taintEvictionQueue.AddWork(NewWorkArgs(podNamespacedName.Name, podNamespacedName.Namespace), time.Now(), time.Now())
}
minTolerationTime := getMinTolerationTime(usedTolerations)
startTime := now
triggerTime := startTime.Add(minTolerationTime)
tc.taintEvictionQueue.AddWork(NewWorkArgs(podNamespacedName.Name, podNamespacedName.Namespace), startTime, triggerTime)
tc.handlePodUpdate(podUpdate)-->
tc.processPodOnNode(podNamespacedName, nodeName, pod.Spec.Tolerations, taints, time.Now())-->
tc.taintEvictionQueue.AddWork(NewWorkArgs(podNamespacedName.Name, podNamespacedName.Namespace), time.Now(), time.Now())-->
worker := createWorker(args, createdAt, fireAt, q.getWrappedWorkerFunc(key), q.clock)-->
delay := fireAt.Sub(createdAt)
if delay <= 0 {
go f(args)
return nil
}
timer := clock.AfterFunc(delay, func() { f(args) })
tm.taintEvictionQueue = CreateWorkerQueue(deletePodHandler(c, tm.emitPodDeletionEvent))-->
// delete pod多租户 Kubernetes 集群计算资源隔离
Kubernetes 集群一般是通用集群,可被所有用户共享,用户无需关心计算节点细节。
但往往某些自带计算资源的客户要求:
- 带着计算资源加入 Kubernetes 集群
- 要求资源隔离
实现方案:
- 将要隔离的计算节点打上 Taints
- 在用户创建 Pod 时,定义 Tolerations 来指定要调度到 node taints
该方案有漏洞吗?如何堵住?
- 其他用户如果可以 get nodes 或者 pods,可以看到 taints 信息,也可以用相同的 tolerations 占用资源
- 不让用户 get node detail?
- 不让用户 get 别人的 pod detail?
- 企业内部,也可以通过规范管理,通过统计数据看谁占用了哪些 node
- 数据平面上的隔离还需要其他方案配合
来自生产系统的经验
- 用户会忘记打 tolerance,导致 pod 无法调度,pending
- 新员工常犯的错误,通过聊天机器人的 Q&A 解决
- 其他用户会 get node detail,查到 taints,偷用资源
- 通过 dashboard,能看到哪些用户的什么应用跑在哪些节点上
- 对于违规用户,批评教育为主
优先级调度
从 v1.8 开始,kube-scheduler 支持定义 Pod 的优先级,从而保证高优先级的 Pod 优先调度。开启方法为:
- apiserver 配置
--feature-gates=PodPrioirity=true和--runtime-config=scheduling.k8s.io/v1alpha1=true - kube-scheduler 配置
--feature-gates=PodPriority=true
PriorityClass
在指定 Pod 的优先级之前需要先定义一个 PriorityClass(非 namespace 资源),如:
apiVersion: v1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false
description: "This priority class should be used for XYZ service pods only."为 pod 设置 Priority
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
priorityClassName: high-priority多调度器
如果默认的调度器不满足需求,还可以部署自定义的调度器。并且,在整个集群中还可以同时运行多个调度器实例,通过 podSpec.schedulerName 来选择使用哪一个调度器(默认使用内置的调度器)。
来从生产环境的一些经验
小集群
100 个 node,并发创建 8000 个 Pod 的最大调度耗时大概是 2 分钟左右,发生过 node 删除后,scheduler cache 还有信息的情况,导致 Pod 调度失败。
放大效应
当一个 node 出现问题所以 load 较小时,通常用户的 Pod 都会优先调度到该 Node 上,导致用户所有创建的新 Pod 都失败的情况。
应用炸弹
存在危险的用户 Pod(比如 fork bomb),在调度到某个 node 上后,会因为打开文件句柄过多导致 node down 机,Pod 会被 evict 到其他节点,再对其他节点造成伤害,依次循环会导致整个 cluster 所有节点不可用。
调度器可以说是运营过程中稳定性最好的组件之一,基本没有太大的维护 effort。
Controller Manager
控制器的工作流程
Informer 的内部机制
secretInformer := kubecoreinformers.NewSecretInformer()-->
NewFilteredSecretInformer()-->
NewSharedIndexInformer(&cache.ListWatch{}, &corev1.Secret{}, resyncPeriod, indexers)-->
sharedIndexInformer := &sharedIndexInformer{
processor: &sharedProcessor{clock: realClock},
indexer: NewIndexer(DeletionHandlingMetaNamespaceKeyFunc, indexers),
listerWatcher: lw,
objectType: exampleObject,
resyncCheckPeriod: defaultEventHandlerResyncPeriod,
defaultEventHandlerResyncPeriod: defaultEventHandlerResyncPeriod,
cacheMutationDetector: NewCacheMutationDetector(fmt.Sprintf("%T", exampleObject)),
clock: realClock,
}
secretInformer.AddEventHandler()-->
AddEventHandlerWithResyncPeriod()-->
listener := newProcessListener(handler, resyncPeriod, determineResyncPeriod(resyncPeriod, s.resyncCheckPeriod), s.clock.Now(), initialBufferSize)-->
ret := &processorListener{
nextCh: make(chan interface{}),
addCh: make(chan interface{}),
handler: handler,
pendingNotifications: *buffer.NewRingGrowing(bufferSize),
requestedResyncPeriod: requestedResyncPeriod,
resyncPeriod: resyncPeriod,
}
s.processor.addListener(listener)
listener.run()-->
for next := range p.nextCh {
p.handler.OnUpdate(notification.oldObj, notification.newObj)
p.handler.OnAdd(notification.newObj)
p.handler.OnDelete(notification.oldObj)
}
listener.pop()-->
for {
select {
case nextCh <- notification:
notification, ok = p.pendingNotifications.ReadOne()
case notificationToAdd, ok := <-p.addCh:
p.pendingNotifications.WriteOne(notificationToAdd)
}
for _, item := range s.indexer.List() {
listener.add(addNotification{newObj: item})-->
p.addCh <- notification
}
go secretInformer.Run(ctx.Stop)
fifo := NewDeltaFIFOWithOptions()
cfg := &Config{
Queue: fifo,
ListerWatcher: s.listerWatcher,
ObjectType: s.objectType,
FullResyncPeriod: s.resyncCheckPeriod,
RetryOnError: false,
ShouldResync: s.processor.shouldResync,
Process: s.HandleDeltas,
}
wg.StartWithChannel(processorStopCh, s.cacheMutationDetector.Run)
wg.StartWithChannel(processorStopCh, s.processor.run)
s.controller = New(cfg)
s.controller.Run(stopCh)-->
r := NewReflector(
c.config.ListerWatcher,
c.config.ObjectType,
c.config.Queue,
c.config.FullResyncPeriod,
)
wg.StartWithChannel(stopCh, r.Run)-->
r.ListAndWatch(stopCh)-->
list := pager.List(context.Background(), options) (1)
items, err := meta.ExtractList(list)
r.syncWith(items, resourceVersion)-->
r.store.Replace(found, resourceVersion) (2)
r.watchHandler(start, w, &resourceVersion, resyncerrc, stopCh)-->
r.store.Update(event.Object)
c.processLoop-->
c.config.Queue.Pop(PopProcessFunc(c.config.Process))//HandleDeltas
for _, d := range obj.(Deltas) {
s.processor.distribute(updateNotification)
s.processor.distribute(addNotification)
s.processor.distribute(deleteNotification)
}控制器的协同工作原理
通用 Controller
- Job Controller:处理 Job
- Pod AutoScaler:处理 Pod 的自动缩容/扩容
- ReplicaSet:依据 ReplicaSet Spec 创建 Pod
- Service Controller:为 LoadBalancer type 的 Service 创建 LB VIP
- ServiceAccount Controller:确保 ServiceAccount 在当前 Namepsace 存在
- StatefulSet Controller:处理 StatefulSet 中的 Pod
- Volume Controller:依据 PV spec 创建 Volume
- Resource Quota Controller:在用户使用资源之后,更新状态
- Namespace Controller:保证 Namespace 删除时,该 Namespace 下的所有资源都先被删除
- Replication Controller(后改名为 ReplicaSet):创建 RC 后,负责创建 Pod
- Node Controller(即 NodeLifeCycleController):维护 Node 状态,处理 evict 请求等
- Daemon Controller:依据 DaemonSet 创建 Pod
- Deployment Controller:依据 Deployment spec 创建 ReplicaSet
- Endpoint Controller:依据 Service spec 创建 Endpoint,依据 Pod ip 更新 Endpoint
- Garbage Collector:处理级联删除,比如删除 Deployment 的同时删除 ReplicaSet 以及 Pod。(根据对象中的 ownerReferences 可以算出对象的依赖关系,可以使用
kubectl delete daemonset nginx-ds --cascade=orphan来保留级联资源) - CronJob Controller:处理 CronJob
discoverResourcesFn := namespaceKubeClient.Discovery().ServerPreferredNamespacedResources--> // fetch all api resources
all, err := ServerPreferredResources(d)-->
serverGroupList, err := d.ServerGroups()
groupVersionResources, failedGroups := fetchGroupVersionResources(d, serverGroupList)
apiResourceList, ok := groupVersionResources[groupVersion]
NewNamespaceController()-->
namespaceController := &NamespaceController{
queue: workqueue.NewNamedRateLimitingQueue(nsControllerRateLimiter(), "namespace"),
namespacedResourcesDeleter: deletion.NewNamespacedResourcesDeleter(kubeClient.CoreV1().Namespaces(), metadataClient, kubeClient.CoreV1(), discoverResourcesFn, finalizerToken),
}
namespaceInformer.Informer().AddEventHandlerWithResyncPeriod()-->
AddFunc: func(obj interface{}) {
namespace := obj.(*v1.Namespace)
namespaceController.enqueueNamespace(namespace)
}
Run(workers int, stopCh <-chan struct{})-->
for i := 0; i < workers; i++ {
go wait.Until(nm.worker, time.Second, stopCh)-->
key, quit := nm.queue.Get()
err := nm.syncNamespaceFromKey(key.(string))
namespace, err := nm.lister.Get(key)
nm.namespacedResourcesDeleter.Delete(namespace.Name)-->
//func (d *namespacedResourcesDeleter) Delete(nsName string) error
namespace, err := d.nsClient.Get(context.TODO(), nsName, metav1.GetOptions{})
if namespace.DeletionTimestamp == nil {
return nil
}
d.deleteAllContent(namespace)-->
resources, err := d.discoverResourcesFn()
gvrDeletionMetadata, err := d.deleteAllContentForGroupVersionResource(gvr, namespace, namespaceDeletedAt)
deletableResources := discovery.FilteredBy(discovery.SupportsAllVerbs{Verbs: []string{"delete"}}, resources)
}StatefulSet
Stateful Set 需要配置一个 Headless Service 来一起使用。
https://github.com/kibaamor/101/blob/master/module7/controller-manager/statefulset.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: nginx-ss
spec:
serviceName: nginx-ss
replicas: 1
selector:
matchLabels:
app: nginx-ss
template:
metadata:
labels:
app: nginx-ss
spec:
containers:
- name: nginx-ss
image: nginx
---
apiVersion: v1
kind: Service
metadata:
name: nginx-ss
labels:
app: nginx-ss
spec:
ports:
- port: 80
clusterIP: None
selector:
app: nginx-ssStateful Set 的更新策略也与 Deployment 不同。
Deployment 的更新策略:
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdateStateful Set 的更新策略:
updateStrategy:
rollingUpdate:
partition: 0
type: RollingUpdateStateful Set 升级时会先升级编号小于等于 partition 的 Pod,等待人工确认后,并需要手动调整 partition 的值才会继续更新。
DaemonSet
每个 Node 一个 Pod
https://github.com/kibaamor/101/blob/master/module7/controller-manager/daemonset.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: nginx-ds
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginxDaemon Set 的更新策略用的是绝对值
updateStrategy:
rollingUpdate:
maxSurge: 0
maxUnavailable: 1
type: RollingUpdateDaemonSet 与 Deployment 控制过程也不同:
- Deployment 是 Deployment -> ReplicaSet -> Pod
- Daemon Set 是 Controller Revisions <- Daemon Set -> Pod
StatefulSet 和 DaemonSet 则是类似的。
另外 DaemonSet 创建出来的 Pod 和普通 Deployment 创建出来的 Pod 的 Toleration 也不同:
普通 Deployment 创建出来的 Pod 的 Toleration:
tolerations:
- effect: NoExecute
key: node.kubernetes.io/not-ready
operator: Exists
tolerationSeconds: 300
- effect: NoExecute
key: node.kubernetes.io/unreachable
operator: Exists
tolerationSeconds: 300而 DaemonSet 创建出来的 Pod 的 Toleration:
tolerations:
- effect: NoExecute
key: node.kubernetes.io/not-ready
operator: Exists
- effect: NoExecute
key: node.kubernetes.io/unreachable
operator: Exists
- effect: NoSchedule
key: node.kubernetes.io/disk-pressure
operator: Exists
- effect: NoSchedule
key: node.kubernetes.io/memory-pressure
operator: Exists
- effect: NoSchedule
key: node.kubernetes.io/pid-pressure
operator: Exists
- effect: NoSchedule
key: node.kubernetes.io/unschedulable
operator: ExistsCloud Controller Manager
什么时候需要 Cloud Controller Manager
Cloud Controller Manager 自 Kubernetes 1.6 开始,从 kube-controller-manager 中分离出来,主要是因为 Cloud Controller Manager 玩玩需要跟企业 Cloud 做深度集成,Release Cycle 跟 Kubernetes 相对独立。
与 Kubernetes 核心管理组件一起升级是一件费时费力的事。
通常 Cloud Controller Manager 需要:
- 认证授权:企业 Cloud 往往需要认证信息,Kubernetes 需要与 Cloud API 通信,需要获取 Cloud 系统里的 ServiceAccount。
- Cloud Controller Manager 本身作为一个用户态的 Component,需要在 Kubernetes 中有正确的 RBAC 设置,获得资源操作权限。
- 高可用:需要通过 Leader Election 来确保 Cloud Controller Manager 高可用。
Cloud Controller Manager 的配置
Cloud Controller Manager 是从老版本的 API Server 分离出来的。
kube-apiserver 和 kube-controller-manager 中一定不能指定 cloud-provider,否则会加载内置的 Cloud Controller Manager。
kubelet 要配置
--cloud-provider=external
Cloud Controller Manager 主要支持:
- Node Controller:访问 Cloud API,来更新 Node 状态;在 Cloud 删除该节点后,从 Kubernetes 删除 Node;
- Service Controller:负责为 LoadBalancer 类型的服务配置 LB VIP;
- Route Controller:在 Cloud 环境配置路由;
- 可以自定义任何需要的 Cloud Controller。
需要定制的 Cloud Controller Manager
- Ingress Controller
- Service Controller
- 自主研发的 Controller,比如之前提到的:
- RBAC Controller
- Account Controller
来自生产的经验
保护好 Controller Manager 的 kubeconfig:
- 此 kubeconfig 拥有所有资源的所有操作权限,防止普通用户通过
kubectl exec kube-controller-manager cat获取该文件 - 用户可能做任何你想象不到的操作,然后来找你 Support
Pod Evict 后 IP 发生变化,但 Endpoint 中的 Address 更新失败:
- 分析 Stacktrace 发现 Endpoint 在更新 LoadBalancer 时调用 gophercloud 连接 hang 住,导致 Endpoint Worker 线程全部卡死
确保 Scheduler 和 Controller 的高可用
Leaer Election
Kubernetes 提供基于 ConfigMap 和 Endpoint 的 Leader Election 类库
Kubernetes 采用 Leader Election 模式启动 Component 后,会创建对应 Endpoint,并把当前的 Leader 信息 annotate 到 Endpoint 上
apiVersion: v1
kind: Endpoints
metadata:
annotations:
control-plane.alpha.kubernetes.io/leader: '{"holderIdentity":"minikube","leaseDurationSeconds":15,"acquireTime":"2018-04-05T17:31:29Z","renewTime":"2018-04-05T17:31:29Z","leaderTransitions":0}'
creationTimestamp: 2018-04-05T17:31:29Z
name: kube-scheduler
namespace: kube-system
resourceVersion: "138930"
selfLink: /api/v1/namespaces/kube-system/endpoints/kube-scheduler
uid: 2d12578d-38f7-11e8-8df0-0800275259e5
subsets: null实际测试
$ kubectrl -n kube-system get ep k8s.io-minikube-hostpath -oyaml
apiVersion: v1
kind: Endpoints
metadata:
annotations:
control-plane.alpha.kubernetes.io/leader: '{"holderIdentity":"minikube_0989f3d2-ce87-471a-a6b6-def44e83738c","leaseDurationSeconds":15,"acquireTime":"2024-05-10T07:34:27Z","renewTime":"2024-05-10T08:07:48Z","leaderTransitions":1}'
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"v1","kind":"Endpoints","metadata":{"annotations":{},"labels":{"addonmanager.kubernetes.io/mode":"Reconcile"},"name":"k8s.io-minikube-hostpath","namespace":"kube-system"}}
creationTimestamp: "2024-05-07T09:54:02Z"
labels:
addonmanager.kubernetes.io/mode: Reconcile
name: k8s.io-minikube-hostpath
namespace: kube-system
resourceVersion: "221393"
uid: 2a2100dd-4038-4658-adf7-553bc1c0596c可以通过下面的命令来获取
$ kubectl -n kube-system get lease
NAME HOLDER AGE
apiserver-eqt674mfxb4j56mrjjkoe7b7ii apiserver-eqt674mfxb4j56mrjjkoe7b7ii_619ab684-7564-4019-ae1f-a44bd256bcce 19m
$ kubectl -n kube-system get lease apiserver-eqt674mfxb4j56mrjjkoe7b7ii -oyaml
apiVersion: coordination.k8s.io/v1
kind: Lease
metadata:
creationTimestamp: "2024-05-10T14:53:36Z"
labels:
apiserver.kubernetes.io/identity: kube-apiserver
kubernetes.io/hostname: minikube
name: apiserver-eqt674mfxb4j56mrjjkoe7b7ii
namespace: kube-system
resourceVersion: "61178"
uid: f1b44c05-136f-491e-94c9-5bef5da4329a
spec:
holderIdentity: apiserver-eqt674mfxb4j56mrjjkoe7b7ii_619ab684-7564-4019-ae1f-a44bd256bcce
leaseDurationSeconds: 3600
renewTime: "2024-05-10T15:13:28.775201Z"Leader Election
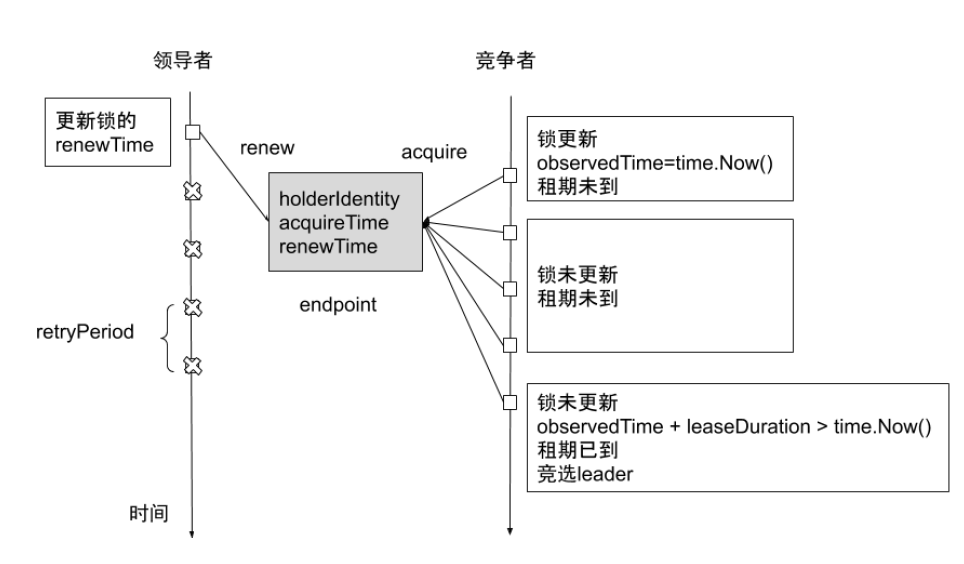
kubelet
server.go:NewKubeletCommand()-->>
kubeletDeps, err := UnsecuredDependencies(kubeletServer, utilfeature.DefaultFeatureGate)-->>
plugins, err := ProbeVolumePlugins(featureGate)
server.go:Run(kubeletServer, kubeletDeps, utilfeature.DefaultFeatureGate, stopCh)-->>
run(s, kubeDeps, featureGate, stopCh)-->>
kubeDeps.ContainerManager, err = cm.NewContainerManager() // init runtime service(CRI), -container-runtime=remote --runtime-request-timeout=15m --container-runtime-endpoint=unix:///var/containerd/containerd.sock
kubelet.PreInitRuntimeService()-->>
remote.NewRemoteRuntimeService(remoteRuntimeEndpoint, kubeCfg.RuntimeRequestTimeout.Duration)
RunKubelet(s, kubeDeps, s.RunOnce)-->>
createAndInitKubelet()-->>
kubelet.NewMainKubelet()-->>
makePodSourceConfig(kubeCfg, kubeDeps, nodeName, bootstrapCheckpointPath)-->>
updatechannel = cfg.Channel(kubetypes.ApiserverSource)
klet := &Kubelet{}
//*******init volume plugins
runtime, err := kuberuntime.NewKubeGenericRuntimeManager()
NewInitializedVolumePluginMgr()-->>
kvh.volumePluginMgr.InitPlugins(plugins, prober, kvh)-->>
startKubelet()-->>
k.Run(podCfg.Updates())-->>
//*******run volume manager, and reconcile function would attach volume for attachable plugin and mount volume
go kl.volumeManager.Run(kl.sourcesReady, wait.NeverStop)-->>
vm.desiredStateOfWorldPopulator.Run(sourcesReady, stopCh)-->>
populatorLoop-->>
dswp.findAndAddNewPods()-->>
dswp.processPodVolumes(pod, mountedVolumesForPod, processedVolumesForFSResize)-->>
mounts, devices := util.GetPodVolumeNames(pod)
dswp.createVolumeSpec(podVolume, pod.Name, pod.Namespace, mounts, devices)
dswp.desiredStateOfWorld.AddPodToVolume(uniquePodName, pod, volumeSpec, podVolume.Name, volumeGidValue)-->>
dsw.volumesToMount[volumeName] = volumeToMount{}
vm.reconciler.Run(stopCh)-->>
reconciliationLoopFunc() -->> // reconcile every 100 ms
mountAttachVolumes-->>
rc.desiredStateOfWorld.GetVolumesToMount()
rc.operationExecutor.AttachVolume()-->> // attachable plugin, e.g. CSI plugin
operationGenerator.GenerateAttachVolumeFunc(volumeToAttach, actualStateOfWorld).Run()
rc.operationExecutor.MountVolume()-->> // volume need to mount, like ceph, configmap, emptyDir
oe.operationGenerator.GenerateMapVolumeFunc().Run()-->>
volumePlugin, err := og.volumePluginMgr.FindPluginBySpec(volumeToMount.VolumeSpec)
volumePlugin.NewMounter()
volumeMounter.SetUp()
kl.syncLoop(updates, kl)-->>
kl.syncLoopIteration(updates, handler, syncTicker.C, housekeepingTicker.C, plegCh)-->>
//*******handle pod creation event
handler.HandlePodAdditions(u.Pods)-->>
kl.podManager.AddPod(pod)
kl.canAdmitPod(activePods, pod) // check admit, if admit check fail, it will error out
kl.dispatchWork(pod, kubetypes.SyncPodCreate, mirrorPod, start)-->>
kl.podWorkers.UpdatePod()-->>
p.managePodLoop(podUpdates)-->>
p.syncPodFn()-->>
kubelet.go:syncPod()-->>
runnable := kl.canRunPod(pod) // check soft admin, pod will be pending if check fails
kl.runtimeState.networkErrors() // check network plugin status
kl.containerManager.UpdateQOSCgroups()
kl.makePodDataDirs(pod)
kl.volumeManager.WaitForAttachAndMount(pod)
(kubeGenericRuntimeManager)kl.containerRuntime.SyncPod()-->>
m.computePodActions(pod, podStatus) // create sandbox container?
m.createPodSandbox(pod, podContainerChanges.Attempt)-->>
m.osInterface.MkdirAll(podSandboxConfig.LogDirectory, 0755)
//*******calling CRI
m.runtimeService.RunPodSandbox(podSandboxConfig, runtimeHandler)-->>// k8s.io/cri-api/pkg/apis/runtime/v1alpha2/api.pb.go
c.cc.Invoke(ctx, "/runtime.v1alpha2.RuntimeService/RunPodSandbox") // call remote runtime service which is served by containerd
start("init container", containerStartSpec(container))-->>
startContainer()
start("container", containerStartSpec(&pod.Spec.Containers[idx]))-->>
startContainer()-->>
m.imagePuller.EnsureImageExists(pod, container, pullSecrets, podSandboxConfig)-->>
c.cc.Invoke(ctx, "/runtime.v1alpha2.ImageService/PullImage"
m.runtimeService.CreateContainer(podSandboxID, containerConfig, podSandboxConfig)-->>
c.cc.Invoke(ctx, "/runtime.v1alpha2.RuntimeService/CreateContainer")
m.internalLifecycle.PreStartContainer(pod, container, containerID) // set cpu set
m.runtimeService.StartContainer(containerID)-->>
c.cc.Invoke(ctx, "/runtime.v1alpha2.RuntimeService/StartContainer")
containerd
server.go:service.Register(grpcServer)-->>
runtime.RegisterRuntimeServiceServer(s, instrumented)-->>
s.RegisterService(&_RuntimeService_serviceDesc, srv)-->>
Handler: _RuntimeService_RunPodSandbox_Handler, // api.pb.go
srv.(RuntimeServiceServer).RunPodSandbox(ctx, in)-->> //"/runtime.v1alpha2.RuntimeService/RunPodSandbox"
RunPodSandbox()-->> // pkg/server/sandbox_run.go
sandboxstore.NewSandbox()
c.ensureImageExists()
c.getSandboxRuntime(config, r.GetRuntimeHandler())
netns.NewNetNS()
c.setupPodNetwork(ctx, &sandbox)-->>
c.netPlugin.Setup(ctx, id, path, opts...)-->>
network.Attach(ctx, ns)-->>
n.cni.AddNetworkList(ctx, n.config, ns.config(n.ifName))-->>
c.addNetwork(ctx, list.Name, list.CNIVersion, net, result, rt)-->>// for each network plugin
c.exec.FindInPath(net.Network.Type, c.Path)
buildOneConfig(name, cniVersion, net, prevResult, rt)
invoke.ExecPluginWithResult(ctx, pluginPath, newConf.Bytes, c.args("ADD", rt), c.exec)
c.client.NewContainer(ctx, id, opts...)
c.os.MkdirAll(sandboxRootDir, 0755)
c.os.MkdirAll(volatileSandboxRootDir, 0755)
c.setupSandboxFiles(id, config)
container.NewTask(ctx, containerdio.NullIO, taskOpts...)
task.Start(ctx)-->>
c.client.TaskService().Create(ctx, request)-->>
s.local.Create(ctx, r)-->>
l.getRuntime(container.Runtime.Name)
rtime.Create(ctx, r.ContainerID, opts)-->>
b := shimBinary(ctx, bundle, opts.Runtime, m.containerdAddress, m.containerdTTRPCAddress, m.events, m.tasks)
b.Start()
shim.Create(ctx, opts)-->>
c.client.Call(ctx, "containerd.task.v2.Task", "Create", req, &resp)
runtime.RegisterImageServiceServer(s, instrumented)kubelet 架构

kubelet 管理 Pod 的核心流程
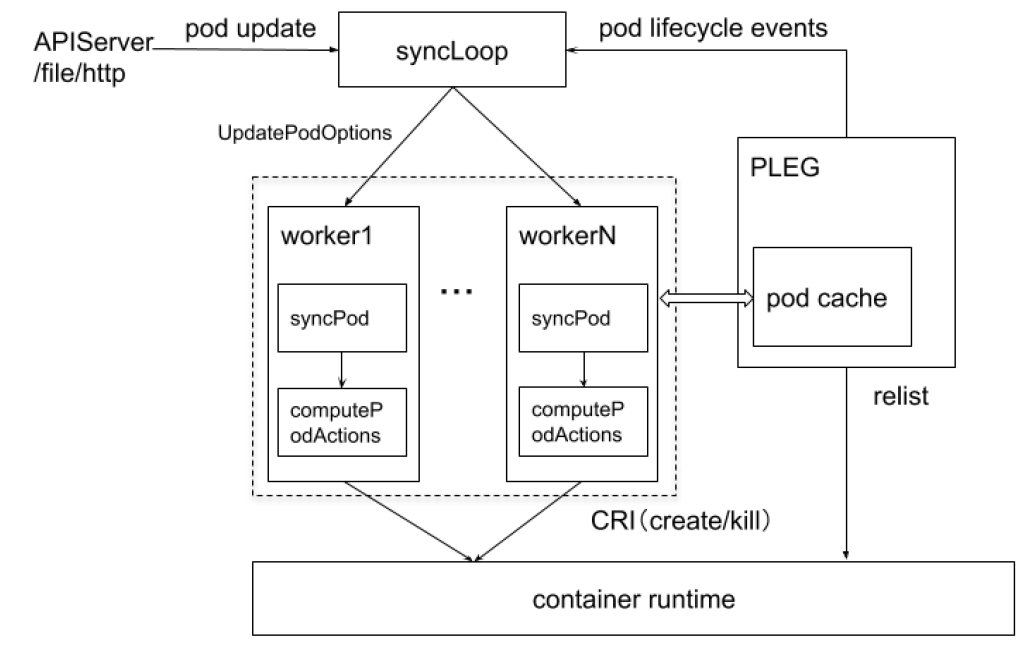
kubelet
每个节点上都运行一个 kubelet 服务进程,默认监听 10250 端口。
- 接收并执行 master 发来的指令
- 管理 Pod 及 Pod 中的容器
- 每个 kubelet 进程会在 API Server 上注册节点自身信息,定期向 master 节点汇报节点的资源使用情况,并通过 cAdvisor 监控节点和容器的资源
节点管理
节点管理主要是节点自注册和节点状态更新:
- kubelet 可以通过设置启动参数
--register-node来确定是否向 API Server 注册自己 - 如果 kubelet 没有选择自注册模式,则需要用户自己配置 Node 资源信息,同时需要告知 kubelet 集群上的 API Server 的位置
- kubelet 在启动时通过 API Server 注册节点信息,并定时向 API Server发送节点新消息,API Server 在接收到新消息后,将信息写入 etcd
Pod 管理
获取 Pod 清单:
- 文件:启动参数
--config指定的配置目录下的文件(默认/etc/kubernetes/manifests)。该文件每 20 秒重新检查一次(可配置) - HTTP endpoint(URL):启动参数
--manifest-url设置。每 20 秒检查一次这个端点(可配置) - API Server:通过 API Server 监听 etcd 目录,同步 Pod 清单
- HTTP Server:kubelet 侦听 HTTP 请求,并响应简单的 API 以提交新的 Pod 清单
Pod 启动流程
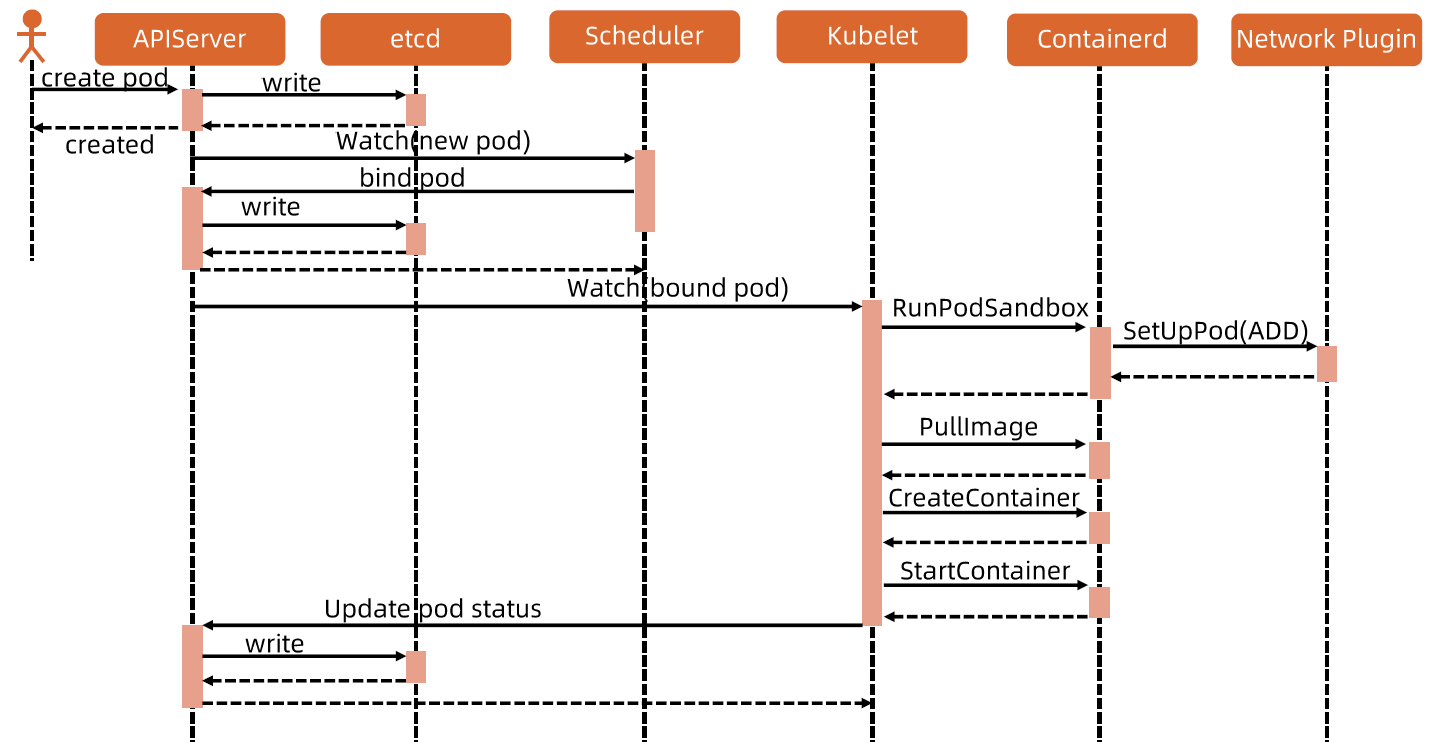
图中 RunPodSandbox 中 Sandbox 的意义:和 pause contain 有关。pod 不是直接启动的,而是先使用 pause 镜像启动 sandbox container 并设置好(共享 net、pid 等)后,再启动用户定义的 container。
kubelet 启动 Pod 的流程
CRI
容器运行时(Container Runtime),运行于 Kubernetes(k8s)集群的每个节点中,负责容器的整个生命周期。其中 Docker 是目前应用最广的。随着容器云的发展,越来越多的容器运行时涌现。为了解决这些容器运行时和 Kubernetes 的集成问题,在 Kubernetes 1.5 版本中,社区推出了 CRI(Container Runtime Interface,容器运行时接口)以支持更多的容器运行时。
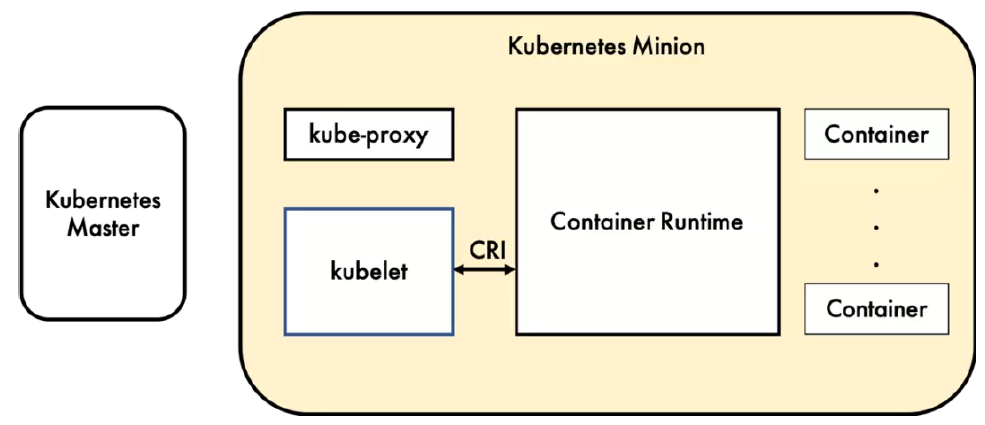
CRI 是 Kubernetes 定义的一组 gRPC 服务。kubelet 作为客户端,基于 gRPC 框架,通过 Socket 和容器运行时通信。它包括两类服务:镜像服务(Image Service)和运行时服务(Runtime Service)。镜像服务提供下载、检查和删除镜像的远程程序调用。运行时服务包括用于管理容器生命周期,以及与容器交互的调用(exec / attach / port-forward)的远程程序调用。
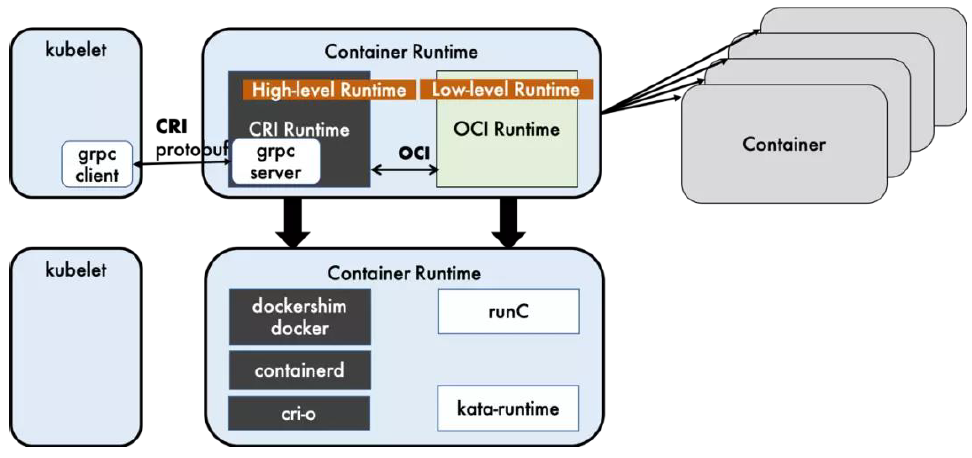
运行时的层级
Dockershim,containerd 和 CRI-O 都是遵循 CRI 的容器运行时,我们称他们为 高层级运行时(High-Level Runtime) 。
OCI(Open Container Initiative,开发容器计划)定义了创建容器的格式和运行时的开源行业标准,包括镜像规范(Image Specification)和运行时规范(Runtime Specification)。
镜像规范定义了 OCI 镜像的标准。高层级运行时将会下载一个 OCI 镜像,并把它解压成 OCI 运行时文件系统包(filesystem bundle)。
运行时规范则描述了如何从 OCI 运行时文件系统包运行容器,并定义它的配置、运行环境和生命周期。如何为新容器设置命名空间(namespaces)和控制组(cgroups),以及挂载根文件系统等等操作,都是在这里定义的。它的一个参考实现就 runC。我们称其为 低层级运行时(Low-Level Runtime)。除 runC 以外,也有以后很多其他的运行时遵循 OCI 标准,例如 kata-runtime。
CRI
容器运行时是真正起删和管理容器的组件。容器运行时可以分为高层和低层的运行时。高层运行时主要包括 Docker、containerd 和 CRI-O,低层的运行时,包含了 runC,kata 和 gVisor。低层运行时 kata 和 gVisor 都还处于小规模落地或者实验阶段,其生态成熟度和使用案例都比较欠缺,所以除非有特殊的需求,否则 runC 几乎是必然的选择。因此在对容器运行时的选择上,主要是聚焦于上层运行时的选择。
Docker 内部关于容器运行时功能的核心组件是 containerd,后来 containerd 也可以直接和 kubelet 通过 CRI 对接,独立在 Kubernetes 中使用。相对 Docker 而言,containerd 减少了 Docker 所需的处理模块 Dockerd 和 Docker-shim,并且对 Docker 支持的存储驱动进行了优化,因此在容器的创建启动停止和删除,以及对镜像的拉取上,都具有性能上的优势。架构的简化同时也带来了维护的便利。当然 Docker 也具有很多 containerd 不具有的功能,例如支持 zfs 存储驱动,支持对日志的大小和文件限制,在以 overlayfs2 做存储驱动的情况下,可以通过 xfs_quota 来对容器的可写层进行大小限制等。尽管如此,containerd 目前也基本上能够满足容器的众多管理需求,所以将它作为运行时的也越来越多。
kubelet 和运行时的关系:
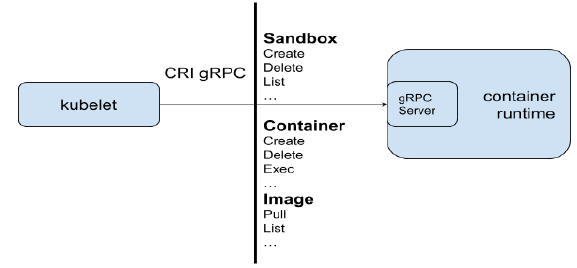
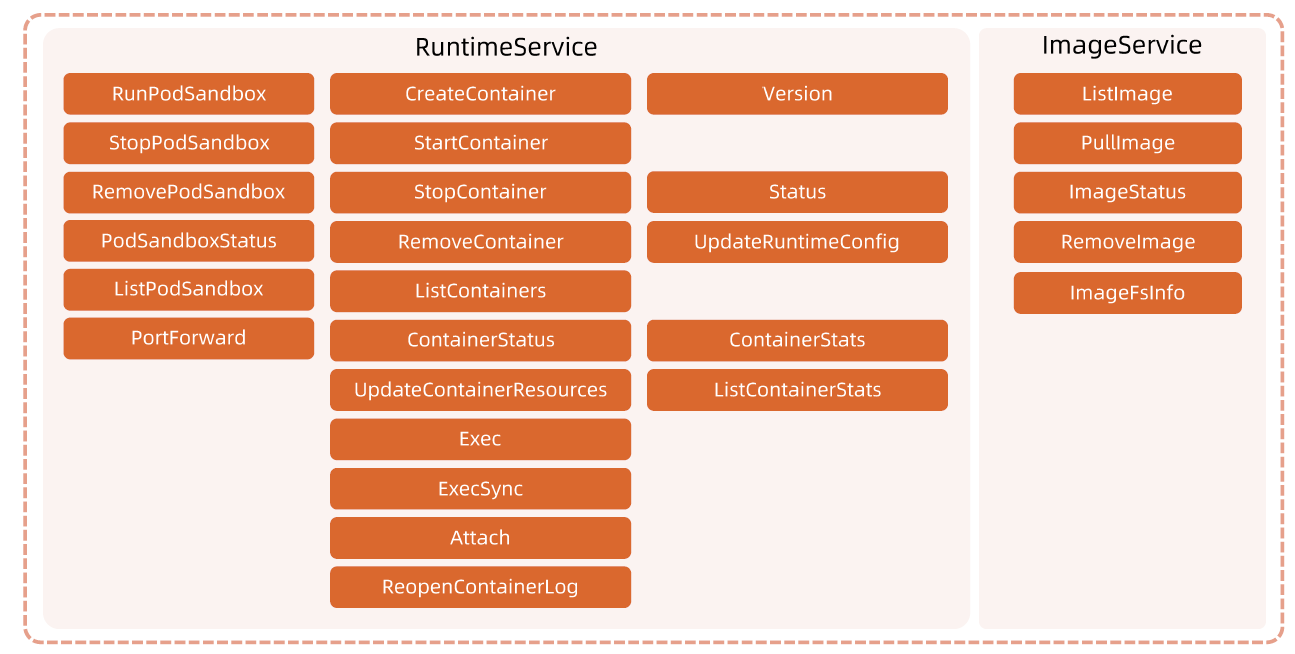
开源运行时的比较
Docker 的多层封装和调用,导致其在可维护性上略逊一筹,增加了线上问题的定位难度;几乎除了重启 Docker,我们就毫无他法了。
containerd 和 CRI-O 的方案比起 Docker 简洁很多。
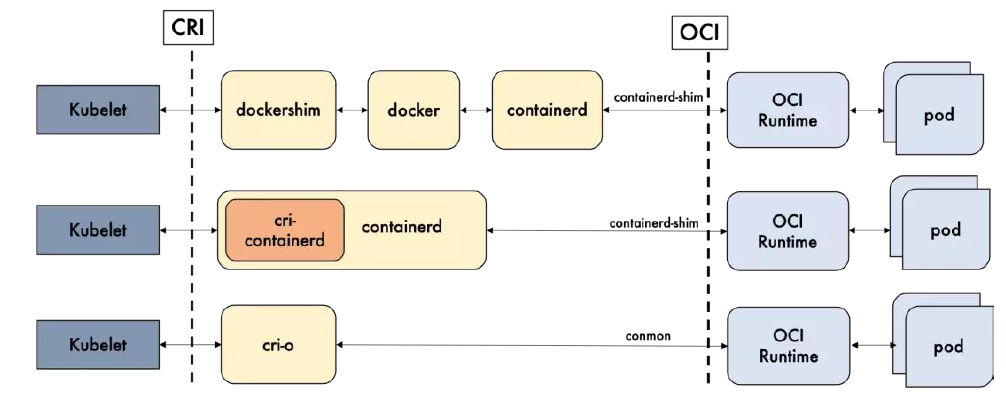
Docker 和 containerd 的差异细节
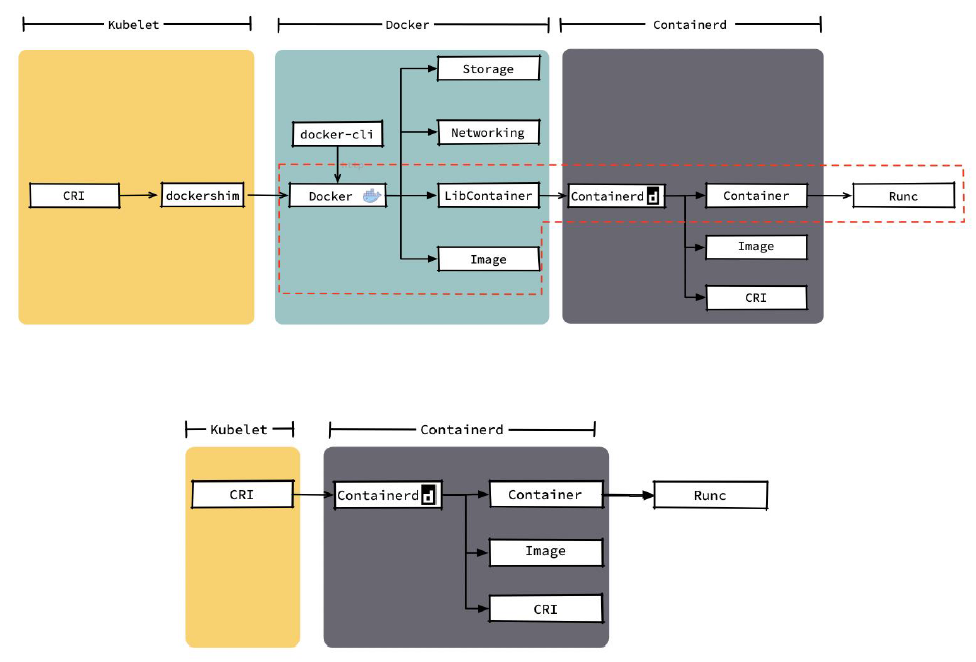
将 runtime 从 docker 切换到 containerd https://github.com/kibaamor/101/blob/master/module7/cri/docker2containerd.md
多种运行时性能比较
containerd 在各个方面都表现良好,除了启动容器这项。从总用时来看,containerd 的用时还是要比 CRI-O 要短的。
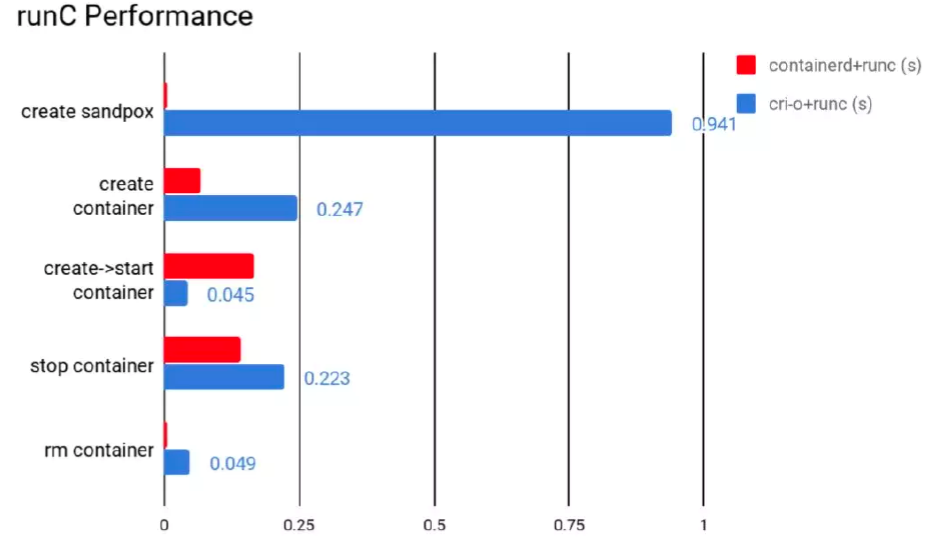
运行时优劣对比
- 功能性来讲,containerd 和 CRI-O 都符合 CRI 和 OCI 的标准
- 在稳定性上,containerd 略胜一筹
- 从性能上讲,containerd 胜出
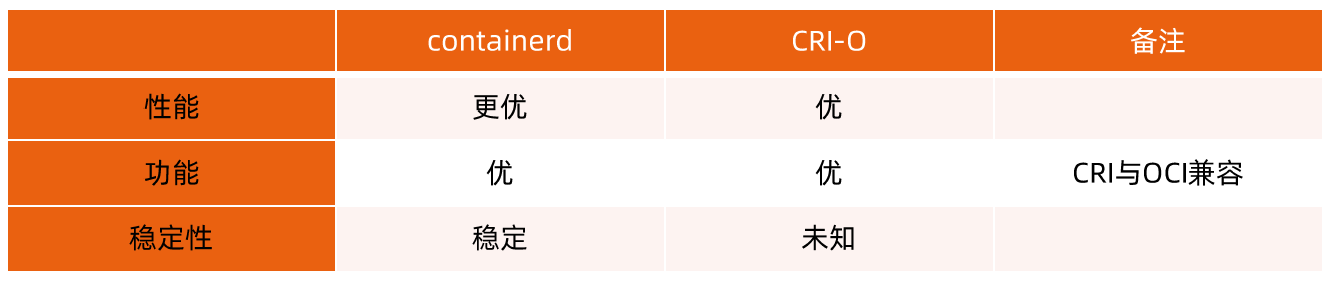
CNI
https://dramasamy.medium.com/life-of-a-packet-in-kubernetes-part-2-a07f5bf0ff14
Kubernetes 网络模型设计的基础原则是:
- 所有的 Pod 能够不通过 NAT 就能相互访问
- 所有的节点能够不通过 NAT 就能相互访问
- 容器内看见的 IP 地址和外部组件看到的容器 IP 是一样的
Kubernetes 的集群里,IP 地址是以 Pod 为单位进行分配的,每个 Pod 都拥有一个独立的 IP 地址。一个 Pod 内部的所有容器共享一个网络栈,即宿主机上的一个网络命名空间,包括它们的 IP 地址、网络设备、配置等都是共享的。也就是说,Pod 里面的所有容器都能通过 localhost:port 来连接对方。在 Kubernetes 中,提供一个轻量的通用容器网络接口 CNI(Container Network Interface),专门用于设置和删除容器的网络连通性。容器运行时通过 CNI 调用网络插件来完成容器的网络设置。
CNI 插件分类和常见插件
https://github.com/containernetworking/plugins
- IPAM(IP Allocation Manager):IP 地址分配
- 主插件:网卡设置
- bridge:创建一个网桥,并把主机端口和容器端口插入网桥
- ipvlan:为容器添加 ipvlan 网口
- loopback:设置 loopback 网口
- Meta:附加功能
- portmap:设置主机端口和容器端口映射
- bandwidth:利用 Linux Traffic Control 限流
- firewall:通过 iptables 或 firewalld 为容器设置防火墙规则
CNI 插件运行时机制
容器运行时在启动时会从 CNI 的配置目录中读取 Json 格式的配置文件,文件后缀为 “.conf”, “.conflist” 或 “.json”。如果配置目录中包含多个文件,一般情况下,会以名字排序选用第一个配置文件作为默认的网络配置,并加载获取其中指定的 CNI 插件名称和配置参数。
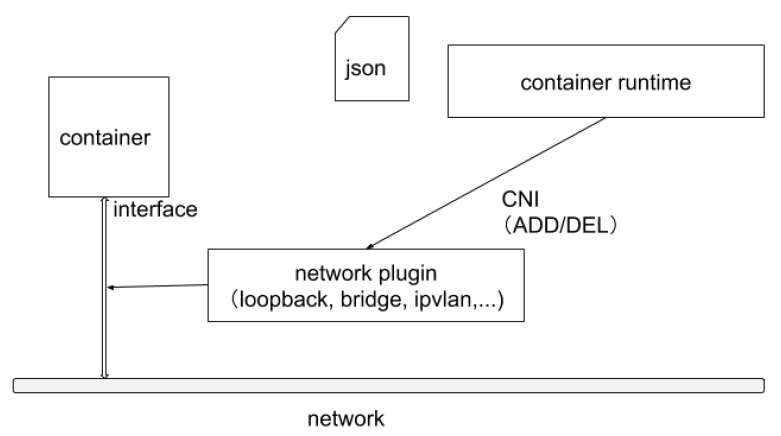
CNI 的运行机制
关于容器网络管理,容器运行时一般需要配置两个参数 --cni-bin-dir 和 --cni-conf-dir。有一种特殊情况,kubelet 内置的 Docker 作为容器运行时,是由 kubelet 来查找 CNI 插件的,运行插件来为容器设置网络,这两个参数应该配置在 kubelet 处:
cni-bin-dir:网络插件的可执行文件所在的目录。默认是/opt/cni/bin。cni-conf-dir:网络插件的配置文件所在目录。默认是/etc/cni/net.d。
CNI 插件设计考量


打通主机层网络
CNI 插件外,Kubernetes 还需要标准的 CNI 插件 lo,最低版本为 0.2.0 版本。网络插件除支持设置和清理 Pod 网络接口外,该插件还需要支持 Iptables。如果 kube-proxy 工作在 Iptables 模式,网络插件需要确保容器流量能使用 Iptables 转发。例如,如果网络插件将容器连接到 Linux 网桥,必须将 net/bridge/bridge-nf-call-iptables 参数 sysctl 设置为 1,网桥上数据包将遍历 Iptables 规则。如果插件不使用 Linux 桥接器(而是类似 Open vSwitch 或其他某种机制的插件),则赢确保容器流量被正确设置了路由。
CNI Plugin
ContainerNetworking 组维护了一些 CNI 插件,包括网络接口创建的 bridge、ipvlan、loopback、macvlan、ptp、host-device 等,IP 地址分配的 DHCP、host-local 和 static,其他的 Flannel、tunning、portmap、firewall 等。
社区还有些第三方网络策略方面的插件,例如 Calico、Cilium 和 Weave 等。可用选项的多样性意味着大多数用户将能够找到适合当前需求和部署环境的 CNI 插件,并在情况变化时迅捷转换解决方案。
目前最有前景的是 https://github.com/cilium/cilium
Flannel
Flannel 是由 CoreOS 开发的项目,是 CNI 插件早起的入门产品,简单易用。
Flannel 使用 Kubernetes 集群的现有 etcd 集群来存储其状态信息,从而不必提供专用的数据存储,只需要在每个节点上运行 flanneld 来守护进程。
每个节点都被分配一个子网,为该节点上的 Pod 分配 IP 地址。
同一个主机内的 Pod 可以使用网桥进行通信,而不同主机上的 Pod 将通过 flanneld 将其流量封装在 UDP 数据包中,以路由到适当的目的地。
封装方式默认和推荐的方法是使用 VXLAN,因为它具有良好的性能,并且比其他选项要少些人为干预。虽然使用 VXLAN 之类的技术封装的解决方案效果很好,但缺点就是该过程使流量跟踪变得困难。
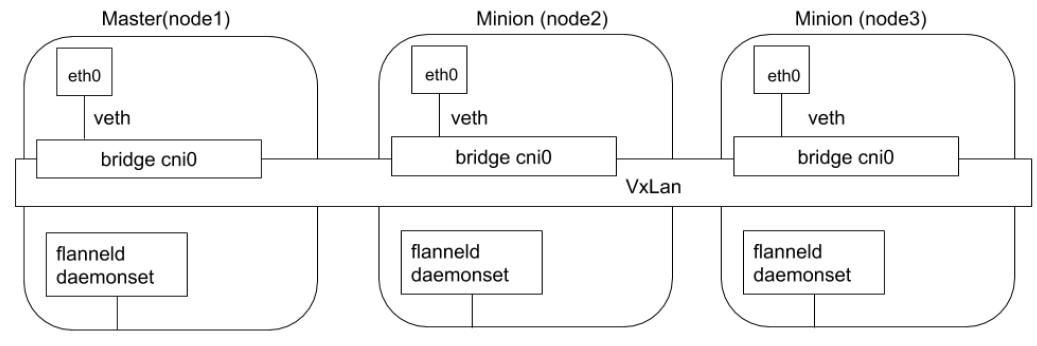
Calico
Calico 以其性能、灵活性和网络策略而闻名,不仅涉及在主机和 Pod 之间提供网络连接,而且还涉及网络安全性和策略管理。
对于同网段通信,基于第 3 层,Calico 使用 BGP 路由协议在主机之间路由数据包,使用 BGP 路由协议也意味着数据包在主机之间移动时不需要包装在额外的封装层中。
对于跨网段通信,基于 IPinIP 使用虚拟网卡设备 tunl0,用一个 IP 数据包封装另一个 IP 数据包,外层 IP 数据包头的源地址为隧道入口设置的 IP 地址,目标地址为隧道出口设备的 IP 地址。
网络策略是 Calico 最受欢迎的功能之一,使用 ACLs 协议和 kube-proxy 来创建 iptables 过滤规则,从而实现隔离容器网络的目的。
此外,Calico 还可以与服务网格 Istio 集成,在服务网格层和网络基础结构层上解释和实施集群中工作负载的策略。这意味着你可以配置功能强大的规则,以描述 Pod 应该如何发送和接收流量,提高安全性及加强网络环境的控制。
Calico 属于完全分布式的横向扩展结构,允许开发人员和管理员快速和平稳地扩展部署规模。对于性能和功能(如网络策略)要求高的环境,Calico 是一个不错的选择。
Calico 组件
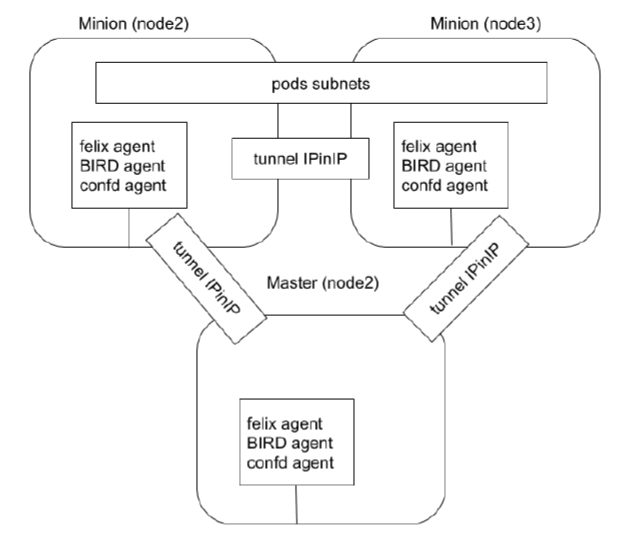
Calico 初始化
配置和 CNI 二进制文件由 initContainer 推送
- command:
- /opt/cni/bin/install
env:
- name: CNI_CONF_NAME
value: 10-calico.conflist
- name: SLEEP
value: "false"
- name: CNI_NET_DIR
value: /etc/cni/net.d
- name: CNI_NETWORK_CONFIG
valueFrom:
configMapKeyRef:
key: config
name: cni-config
- name: KUBERNETES_SERVICE_HOST
value: 10.96.0.1
- name: KUBERNETES_SERVICE_PORT
value: "443"
image: docker.io/calico/cni:v3.20.1
imagePullPolicy: IfNotPresent
name: install-cniCalico 配置一览
{
"name": "k8s-pod-network",
"cniVersion": "0.3.1",
"plugins": [
{
"type": "calico",
"datastore_type": "kubernetes",
"mtu": 0,
"nodename_file_optional": false,
"log_level": "Info",
"log_file_path": "/var/log/calico/cni/cni.log",
"ipam": {
"type": "calico-ipam",
"assign_ipv4": "true",
"asign_ipv6": "false"
},
"container_settings": {
"allow_ip_forwarding": false
},
"policy": {
"type": "k8s"
},
"kubernetes": {
"k8s_api_root": "https://10.96.0.1:443",
"kubeconfig": "/etc/cni/net.d/calico-kubeconfig"
}
},
{
"type": "bandwidth",
"capabilities": {
"bandwidth": true
}
},
{
"type": "portmap",
"snat": true,
"capabilities": {
"portMappings": true
}
}
]
}Calico VXLAN
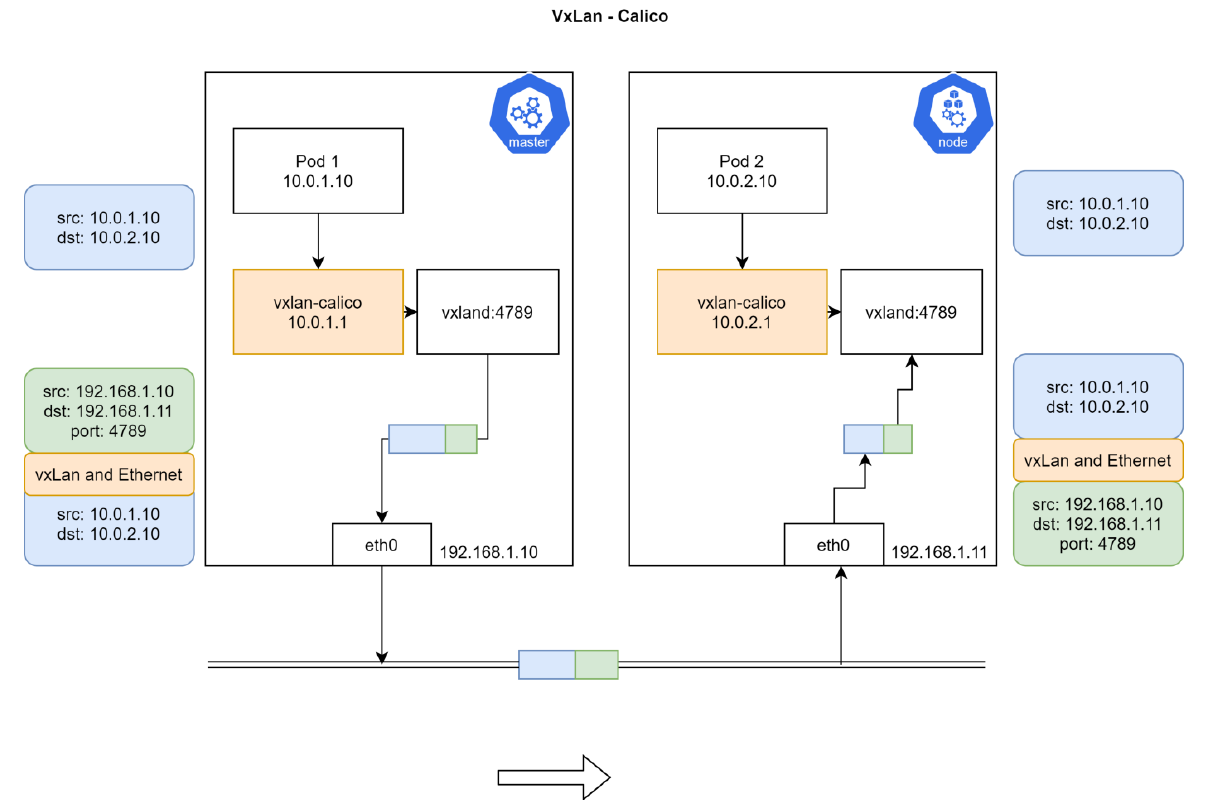
https://github.com/kibaamor/101/blob/master/module7/cni/data-path.MD
IPPool
IPPool 用来定义一个集群的预定义 IP 段
apiVersion: crd.projectcalico.org/v1
kind: IPPool
metadata:
name: default-ipv4-ippool
spec:
blockSize: 26 # 每个节点分多少个IP
cidr: 192.168.0.0/16
ipipMode: Never
natOutgoing: true
nodeSelector: all()
vxlanMode: CrossSubnetIPAMBlock
IPAMBlock 用来定义每个主机预分配的 IP 段
apiVersion: crd.projectcalico.org/v1
kind: IPAMBlock
metadata:
annotations:
name: 192-168-119-64-26 # 最后的 26 就是 IPPool 里的 blockSize
spec:
affinity: host:cadmin
allocations:
- null
- 0
- null
- 1
- 2
- 3
attributes:
- handle_id: vxlan-tunnel-addr-cadmin
secondary:
node: cadmin
type: vxlanTunnelAddress
- handle_id: k8s-pod-network.6680d3883d6150e75ffbd031f86c689a97a5be0f260c6442b2bb46b567c2ca40
secondary:
namespace: calico-apiserver
node: cadmin
pod: calico-apisever-77dffffcdf-g2tcx
timestamp: 2021-09-30 09:46:57.45651816 +0000 UTC
- handle_id: k8s-pod-network.b10d7702bf334fc55a5e399a731ab3201ea9990a1e3bc79894abddd712646699
secondary:
namespace: calico-system
node: cadmin
pod: calico-kube-controllers-bdd5f97c5-554z5
timestamp: 2021-09-30 09:46:57.502351346 +0000 UTCIPAMHandle
IPAMHandle 用来记录 IP 分配的具体细节(每个 Pod 一个)
apiVersion: crd.projectcalico.org/v1kind:IPAMHandle
metadata:
name:k8s-pod-network.8d756941d85c4998016b72c83f9c5a75512c82c052357daf0ec8e67365635d93
spec:
block:
192.168.119.64/26:1
deleted:false
handlelD:k8s-pod-network.8d75b941d85c4998016b72c83f9c5a75512c82c052357daf0ec8e67365635d93创建 Pod 并查看 IP 配置情况
容器 namespace
$ nsenter -t 720702 -n ip a
1: lo: <LOOPBACK,UP,LOWER UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid lft forever preferred lft forever
3: ethO@if27: <BROADCAST,MULTICAST,UP,LOWER UP> mtu 1450 gdisc noqueue state UP groupdefault
link/ether f2:86:d2:4f:1f:30 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet192.168.119.84/32 brd 192.168.119.84 scope global eth0
valid lft forever preferred lft forever
$ nsenter -t 720702-n ip r
default via 169.254.1.1 dev eth0
169.254.1.1 dev eth0 scope link
$ nsenter -t 720702 -n arp
Address HWtype HWaddress Flags Mask Iface
169.254.1.1 ether ee:ee:ee:ee:ee:ee C eth0
10.0.2.15 ether ee:ee:ee:ee:ee:ee C eth0主机 namespace
$ ip link
27: cali23a582ef038@if3:<BROADCAST,MULTICAST,UP,LOWER UP>mtu 1450 qdiscnoqueue state UP group default
link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netnsid 9
inet6 fe80::ecee:eeff:feee:eeee/64 scope link
valid lft forever preferred lft forever
$ ip route
192.168.119.84 dev cali23a582ef038scope linkCNI Plugin 的对比
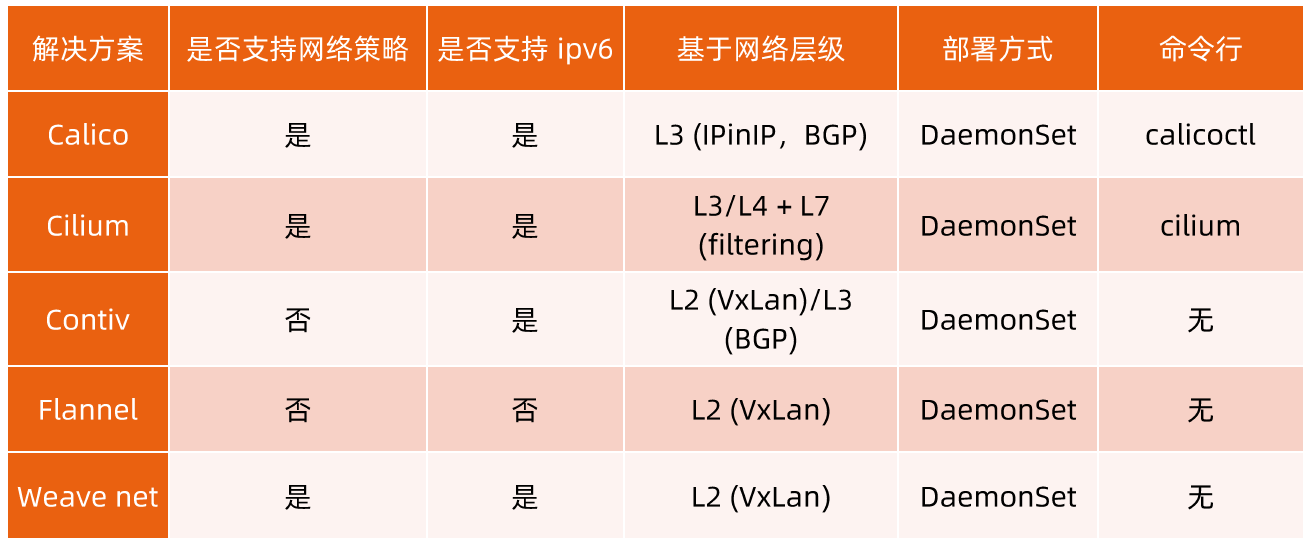
CSI
容器运行时存储
容器运行时存储不建议写数据,甚至不建议写日志,它基于 OverlayFS ,它的主要目的是挂载 rootfs 以启动容器,读写性能其实不高。需要写数据时应该外挂存储。
- 除外挂存储卷外,容器启动后,运行时所需文件系统性能直接影响容器性能
- 早起的 Docker 采用 Device Mapper 作为容器运行时存储驱动,因为 OverlayFS 尚未合并进 Kernel
- 目前 Docker 和 containerd 都默认以 OverlayFS 作为运行时存储驱动
- OverlayFS 目前已经有非常好的性能,与 DeviceMapper 相比优 20%,与操作主机文件性能几乎一致
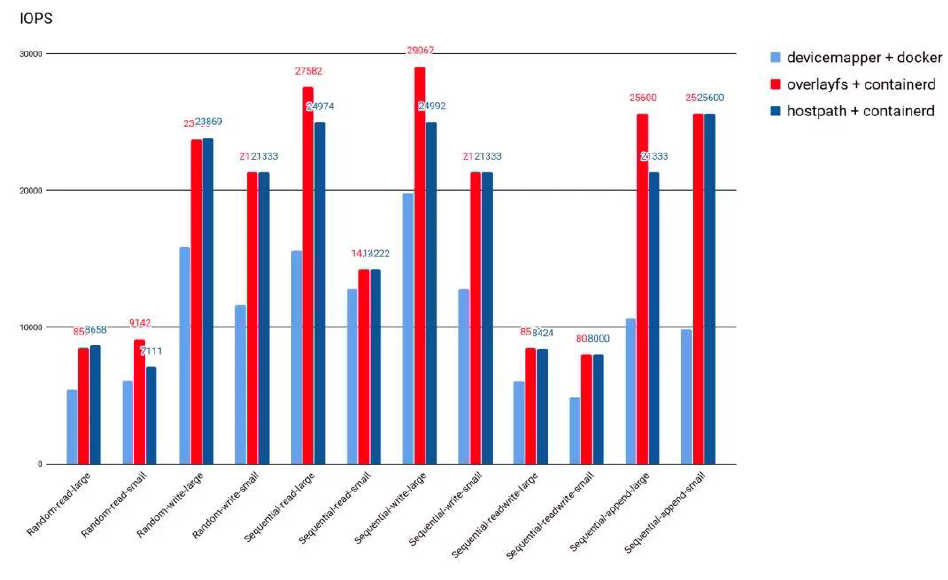
存储卷插件管理
Kubernetes 支持以插件的形式来实现对不同存储的支持和扩展,这些扩展基于如下三种方式:

out-of-tree CSI 插件
CSI 通过 RPC 与存储驱动进行交互
在设计 CSI 的时候,Kubernetes 对 CSI 存储驱动和打包和部署要求很少,主要定义了 Kubernetes 的两个相关模块:
- kube-controller-manager:
- kube-controller-manager 模块用于感知 CSI 驱动存在
- Kubernetes 的主控模块通过 Unix domain socket(而不是 CSI 驱动)或者其他方式进行直接地交互
- Kubernetes 的主控模块只与 Kubernetes 相关的 API 进行交互
- 因此 CSI 驱动若有依赖于 Kubernetes API 的操作,例如卷的创建、卷的 attach、卷的快照等,需要在 CSI 驱动里面通过 Kubernetes 的 API,来触发相关的 CSI 操作
- kubelet:
- kubelet 模块用于与 CSI 驱动进行交互
- kubelet 通过 Unix domain socket 向 CSI 驱动发起 CSI 调用(如 NodeStageVolume、NodePublishVolume 等),再发起 mount 卷和 umount 卷
- kubelet 通过插件注册机制发现 CSI 驱动及用于和 CSI 驱动交互的 Unix Domain Socket
- 所有部署在 Kubernetes 集群中的 CSI 驱动都要通过 kubelet 的插件注册机制来注册自己
CSI 驱动
CSI 的驱动一般包含 external-attacker、external-provisioner、external-resizer、external-snapshotter、node-driver-register、CSI driver 等模块,可以根据实际的存储类型和需求进行不同方式的部署。
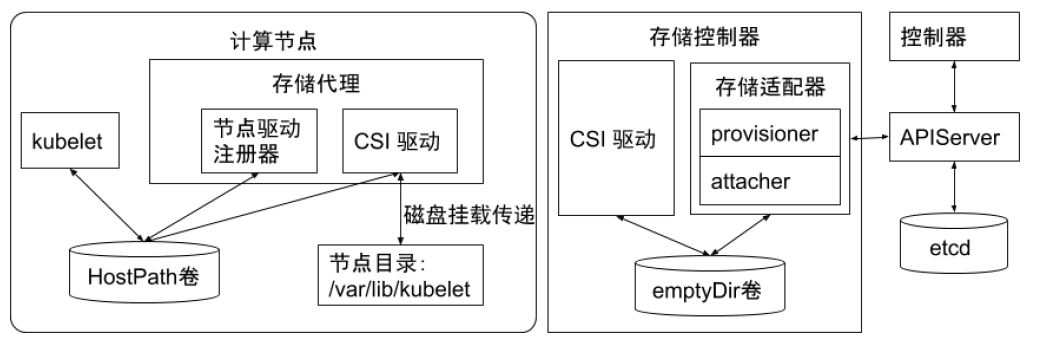
临时存储
https://github.com/kibaamor/101/blob/master/module7/csi/emptydir/emptydir.yaml
常见的临时存储主要就是 emptyDir 卷。
emptyDir 是一种经常被用户使用的卷类型,顾名思义,”卷”最初是空的。当 Pod 从节点上删除时,emptyDir 卷中的数据也会被永久删除。但当 Pod 的容器因为某些原因退出再重启时,emptyDir 卷内的数据并不会丢失。
默认情况下,emptyDir 卷存储在支持该节点所使用的存储介质上,可以是本地磁盘或者网络存储。
emptyDir 也可以通过将 emptyDir.medium 字段设置为 “Memory” 来通知 Kubernetes 为容器安装 tmpfs,此时数据被存储在内存中,速度相对于本地存储和网络存储快很多。但是在节点重启的时候,内存数据会被清楚;而如果存在磁盘上,则重启后数据依然存在。另外,使用 tmpfs 的内存也会计入容器的使用内存总量中,受系统的 cgroup 限制。
emptyDir 设计的初衷主要是给应用充当缓存空间,或者存储中间数据,用于快速恢复。然而,这并不是说满足以上需求的用户都被推荐使用 emptyDir,我们要根据用户业务的实际特点来判断是否使用 emptyDir。因为 emptyDir 的空间位于系统根盘,被所有容器共享,所以在磁盘的使用率较高时会触发 Pod 的 eviction 操作,从而影响业务的稳定。
半持久化存储
常见的半持久化存储主要是 hostPath 卷。hostPath 卷能将主机节点文件系统上的文件或目录挂载到指定 Pod 中。对普通用户而言一般不需要这样的卷,但是对很多需要获取节点系统信息的 Pod 而言,却是非常必要的。
例如,hostPath 的用法举例如下:
- 某个 Pod 需要获取节点上所有 Pod 的 log,可以通过 hostPath 访问所有 Pod 的 stdout 输出存储目录,例如 /var/log/pods 路径。
- 某个 Pod 需要统计系统相关的信息,可以通过 hostPath 访问系统的 /proc 目录。
使用 hostPath 的时候,除设置必需的 path 属性外,用户还可以有选择性地为 hostPath 卷指定类型支持类型包含目录、字符设备、块设备等。
hostPath 卷需要注意
https://github.com/kibaamor/101/blob/master/module7/csi/hostpath/readme.MD
使用同一个目录的 Pod 可能会由于调度到不同的节点,导致目录中的内容有所不同。
Kubernetes 在调度时无法顾及由 hostPath 使用的资源。
Pod被删除后,如果没有特别处理,那么hostPath上写的数据会遗留到节点上,占用磁盘空间。
持久化存储
支持持久化的存储是所有分布式系统所必备的特性。针对持久化存储,Kubernetes 引入了 StorageClass、Volume、PVC(Persistent Volume Claim)、PV(Persitent Volume)的概念,将存储独立于 Pod 的生命周期来进行管理。
Kuberntes 目前支持的持久化存储包含各种主流的块存储和文件存储,譬如 awsElasticBlockStore、azureDisk、cinder、NFS、cephfs、iscsi 等,在大类上可以将其分为网络存储和本地存储两种类型。
StorageClass
StorageClass 用于指示存储的类型,不同的存储类型可以通过不同的 StorageClass 来为用户提供服务。
StorageClass 主要包含存储插件 provisioner、卷的创建和 mount 参数等字段。
allowVolumeExpansion: true
apiVersion: storage.k8s.io/v1
kind: Storageclass
metadata:
annotations:
storageclass.kubernetes.io/is-default-class: "false"
name: rook-ceph-block
parameters:
clusterlD: rook-ceph
csi.storage.k8s.io/controller-expand-secret-name: rook-csi-rbd-provisioner
csi.storage.k8s.io/controller-expand-secret-namespace: rook-ceph
csi.storage.k8s.io/fstype: ext4
csi.storage.k8s.io/node-stage-secret-name: rook-csi-rbd-node
csi.storage.k8s.io/node-stage-secret-namespace: rook-ceph
csi.storage.k8s.io/provisioner-secret-name: rook-csi-rbd-provisioner
csi.storage.k8s.io/provisioner-secret-namespace: rook-ceph
imageFeatures: layering
imageFormat: "2"
pool: replicapool
provisioner: rook-ceph.rbd.csi.ceph.com
reclaimPolicy: Delete
volumeBindingMode: immediatePVC
由用户创建,代表用户对存储需求的声明,主要包含需要的存储大小、存储卷的访问模式、StroageClass 等类型,其中存储卷的访问模式必须与存储的类型一致
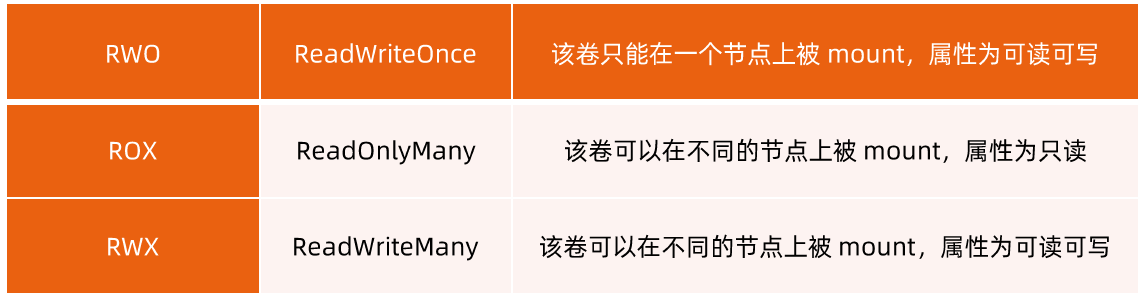
PV
由集群管理员提前创建,或者根据 PVC 的申请需求动态地创建,它代表系统后端的真实的存储空间,可以称之为卷空间。
存储对象关系
用户通过创建 PVC 来申请存储。控制器通过 PVC 的 StorageClass 和请求的大小声明来存储后端创建卷,进而创建 PV,Pod 通过指定 PVC 来引用存储。
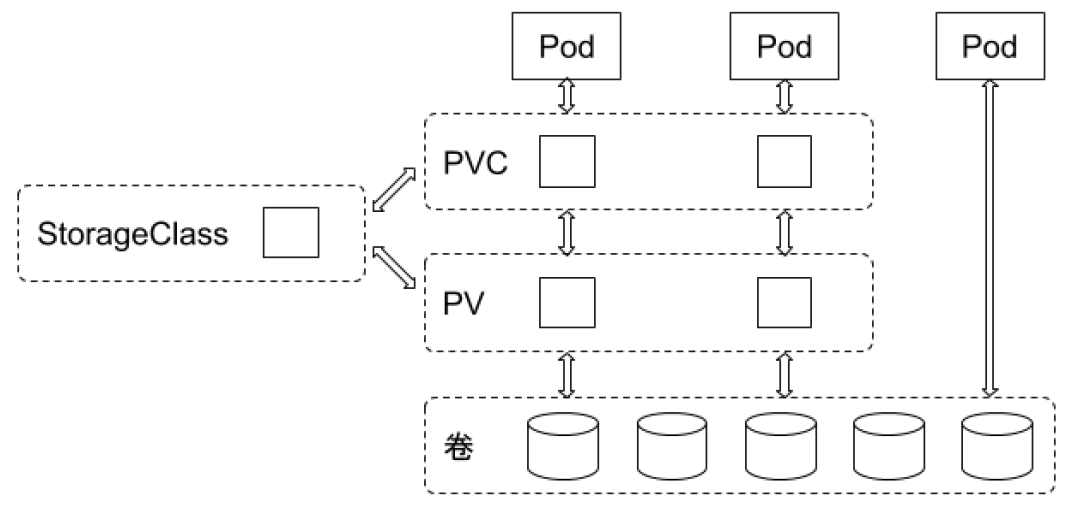
独占的 Local Volume
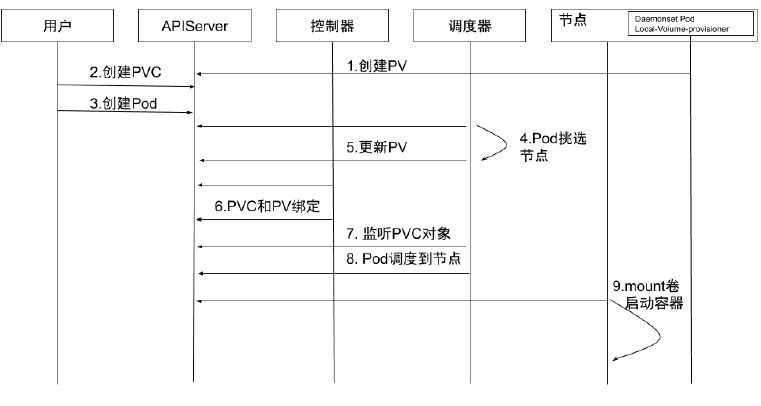
- 创建 PV:通过 local-volume-provisioner Daemonset 创建本地存储的 PV。
- 创建 PVC:用户创建 PVC,由于它处于 pending 状态,所以 kube-controller-manager 并不会对该 PVC 做任何操作。
- 创建 Pod:用户创建 Pod。
- Pod 挑选节点:kube-scheduler 开始调度 Pod,通过 PVC 的
resources.request.storage和volumeMode选择满足条件的 PV,并且为 Pod 选择一个合适的节点。 - 更新 PV:kube-scheduler 将 PV 的
pv.Spec.claimRef设置为对应的 PVC,并且设置 annotationpv.kubernetes.io/bound-by-controller的值为yes。 - PVC 和 PV 绑定:pv_controller 同步 PVC 和 PV 的状态,并将 PVC 和 PV 进行绑定。
- 监听 PVC 对象:kube-scheduler 等待 PVC 的状态变成 Bound 状态。
- Pod 调度到节点:如果 PVC 的状态变为 Bound 则说明调度成功,而如果 PVC一直处于 pending 状态,超时后会再次进行调度。
- Mount 卷启动容器:kubelet监听到有 Pod 已经调度到节点上,对本地存储进行 mount 操作,并启动容器。
Dynamic Local Volume
CSI 驱动需要汇报节点上相关存储的资源信息,以便用于调度但是机器的厂家不同,汇报方式也不同。
例如,有的厂家的机器节点上具有 NVMe、SSD、HDD 等多种存储介质,希望将这些存储介质分别进行汇报。
这种需求有别于其他存储类型的 CSI 驱动对接口的需求,因此如何汇报节点的存储信息,以及如何让节点的存储信息应用于调度,目前并没有形成统一的意见。
集群管理员可以基于节点存储的实际情况对开源 CSI 驱动和调度进行一些代码修改,再进行部署和使用。
Local Dynamic 的挂载流程
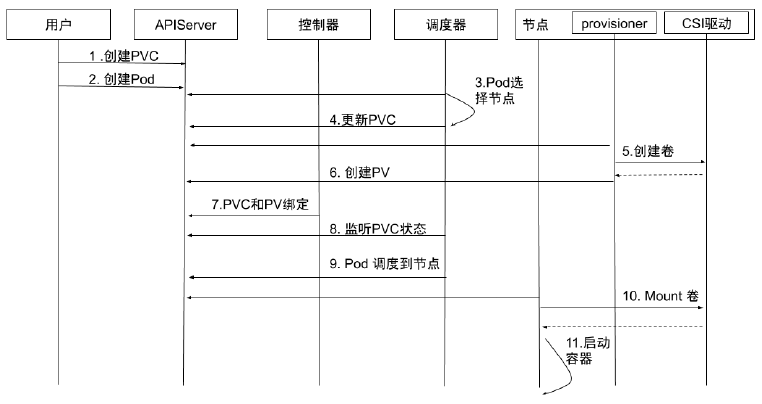
- 创建 PVC:用户创建 PVC,PVC 处于 pending 状态。
- 创建 Pod:用户创建 Pod。
- Pod 选择节点:kube-scheduler 开始调度 Pod,通过 PVC 的
pvc.spec.resources.request.storage等选择满足条件的节点。 - 更新 PVC:选择节点后,kube-scheduler 会给 PVC 添加包含节点信息的 annotation:
volume.kubernetes.io/selected-node:<节点名字>。 - 创建卷:运行在节点上的容器 external-provisioner 监听到 PVC 带有该节点相关的 annotation,向相应的 CSI 驱动申请分配卷。
- 创建 PV:PVC 申请到所需的存储空间后,external-provisione 创建 PV,该 PV 的
pv.Spec.claimRef设置为对应的 PVC。 - PVC 和 PV 绑定:kube-controller-manager 将 PVC 和 PV 进行绑定,状态修改为 Bound。
- 监听 PVC 状态:kube-scheduler 等待 PVC 变成 Bound 状态
- Pod 调度到节点:当 PVC 的状态为 Bound 时,Pod 才算真正调度成功了。如果 PVC一直处于 Pending状态,超时后会再次进行调度。
- Mount 卷:kubelet监听到有 Pod 已经调度到节点上,对本地存储进行 mount 操作。
- 启动容器:启动容器。
Local Dynamic 的挑战
如果将磁盘空间作为一个存储池(例如 LVM)来动态分配,那么在分配出来的逻辑卷空间的使用上,可能会受到其他逻辑卷的 I/O 干扰,因为底层的物理卷可能是同一个。
如果 PV 后端的磁盘空间是一块独立的物理磁盘,则 I/O 就不会受到干扰。
生产实践经验分享
不同介质类型的磁盘,需要设置不同的 StorageClass,以便让用户做区分。StorageClass 需要设置磁盘介质的类型,以便用户了解该类存储的属性。
在本地存储的 PV 静态部署模式下,每个物理磁盘都尽量只创建一个 PV,而不是划分为多个分区来提供多个本地存储 PV,避免在使用时分区之间的 I/O 干扰。
本地存储需要配合磁盘检测来使用。当集群部署规模化后,每个集群的本地存储 PV 可能会超过几万个,如磁盘损坏将是频发事件。此时,需要在检测到磁盘损坏、丢盘等问题后,对节点的磁盘和相应的本地存储 PV 进行特定的处理例如触发告警、自动 cordon 节点、自动通知用户等。
对于提供本地存储节点的磁盘管理,需要做到灵活管理和自动化。节点磁盘的信息可以归一、集中化管理。在 local-volume-provisioner 中增加部署逻辑,当容器运行起来时,拉取该节点需要提供本地存储的磁盘信息,例如磁盘的设备路径,以 Filesystem 或 Block 的模式提供本地存储,或者是否需要加入某个 LVM 的虚拟组(VG)等 local-volume-provisioner 根据获取的磁盘信息对磁盘进行格式化,或者加入到某个 VG,从而形成对本地存储支持的自动化闭环。
Rook
Rook 是一款云原生环境下的开源分布式存储编排系统,目前支持 Ceph、NFS、EdgeFS、Cassandra、CockroachDB 等存储系统。它实现了一个自动管理的、自动扩容的、自动修复的分布式存储服务。Rook 支持自动部署、启动、配置、分配、扩容/缩容、升级、迁移、灾难恢复、监控以及资源管理。
https://github.com/kibaamor/101/blob/master/module7/csi/rook/rook.md
Rook 架构
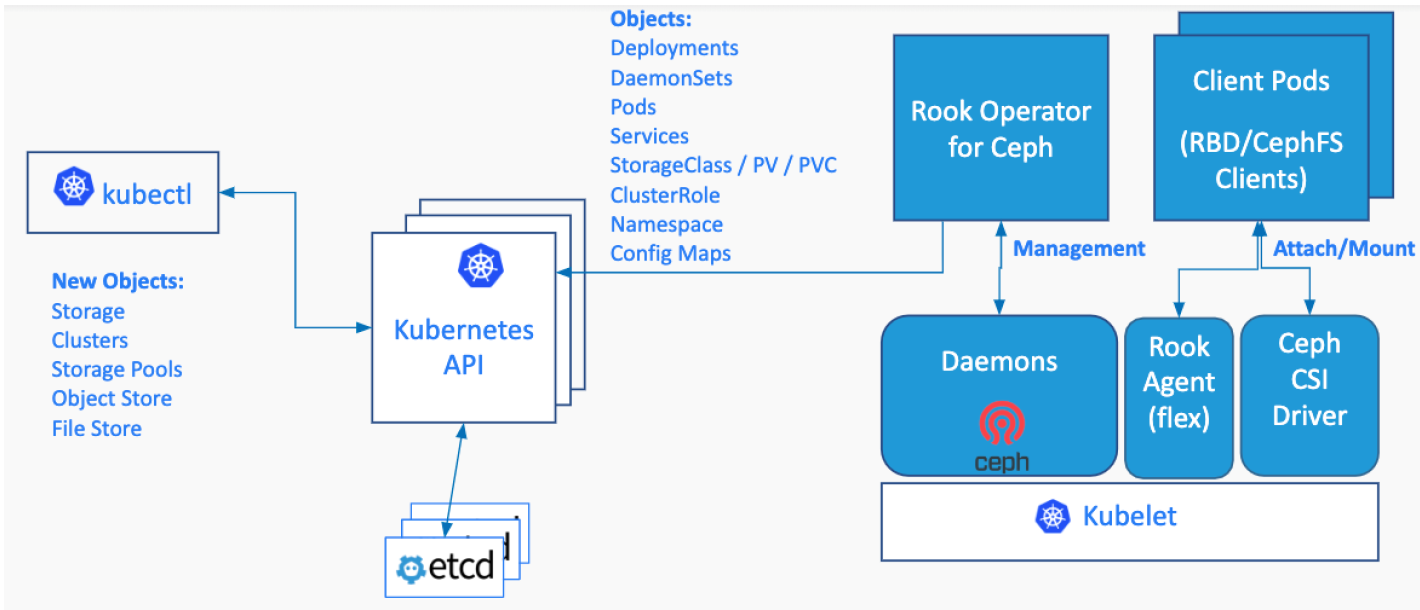
Rook Operator
RookOperater 是 Rook 的大脑,以deployment 形式存在。
其利用 Kubernetes 的 controller-runtime 框架实现了 CRD,并进而接受 Kubernetes 创建资源的请求并创建相关资源(集群,pool,块存储服务,文件存储服务等)。
RookOperater 监控存储守护进程,来确保存储集群的健康。
监听 Rook Discovers 收集到的存储磁盘设备,并创建相应服务(Ceph 的话就是 OSD 了)。
Rook Discover
Rook Discover 是以 DaemonSet 形式部署在所有的存储机上的,其检测挂接到存储节点上的存储设备。把符合要求的存储设备记录下来,这样 RookOperate 感知到以后就可以基于该存储设备创建相应服务了。
## discover device
lsblk --all --noheadings --list --output KNAME
lsblk /dev/vdd --bytes --nodeps --pairs --paths --0utput SIZE,ROTA,RO,TYPE,PKNAME,NAME,KNAME
udevadm info --query=property /dev/vdd$ lsblk --noheadings --pairs /dev/vdd
## discover ceph inventory
ceph-volume inventory--format json
if device has ceph inv,device.cephVolumeData=CvData
## put device info into configmap per nodeCSIDriver 发现
CSI 驱动发现:
如果一个 CSI 驱动创建 CSIDriver 对象,Kubernetes 用户可以通过 get CSIDriver 命令发现它们;
CSI 对象有如下特点:
- 自定义的 Kubernetes逻辑;
- Kubernetes 对存储卷有一些列操作,这些 CSIDriver 可以自定义支持哪些操作?
Provisioner
CSI external-provisioner 是一个监控 Kubernetes PVC 对象的 Sidecar 容器
当用户创建 PVC 后,Kubernetes 会监测 PVC 对应的 StorageClass,如果 StorageClass 中的 provisioner 与某插件匹配,该容器通过 CSI Endpoint(通常是 unixsocket)调用 CreateVolume 方法。
如果 CreateVolume 方法调用成功,则 Provisioner sidecar 创建 Kubernetes PV 对象。
CSI External Provisioner
containers:
- args:
- --csi-address=$(ADDRESS)
- --V=0
- --timeout=150s
- --retry-interval-start=500ms
env:
- name:ADDRESS
value:unix:///csi/csi-provisioner.sock
image: quay.io/k8scsi/csi-provisioner:v1.6.0
name: csi-provisioner
resources: {}
volumeMounts:
- mountPath: /csi
name: socket-dir
- mountPath: /var/run/secrets/kubernetes.io/serviceaccount
name: rook-csi-rbd-provisioner-sa-token-mxv84
readOnly: true
- args:
- --nodeid=$(NODE ID)
- --endpoint=$(CSI ENDPOINT)
- --V=0
- --type=rbd
- --controllerserver=true
- --drivername=rook-ceph.rbd.csi.ceph.com
env:
- name:CSI ENDPOINT
value: unix:///csi/csi-provisioner.sock
image: quay.io/cephcsi/cephcsi:v3.0.0
name: csi-rbdplugin
- emptyDir:
medium: Memory
name: socket-dirProvisioner 代码
controller/controller.go
syncClaim ->provisionClaimOperation->provisioner.Provision
pkg/operator/ceph/provisioner/provisioner.go
Provision->createVolume
ceph.Createlmage
pkg/daemon/ceph/client/image.go
rbd create poolName/name -size sizeMB
volumeStore.StoreVolume
controller/volume_store.go
doSaveVolume
client.CoreV1().PersistentVolumes().Create(volume)Provisioner log
10816 10:17:32.535207 1 connection.go:153] connecting to unix:///csi/csiprovisioner.sock
10816 10:17:54.361911 1 volume store.go:97] Starting save volume queue
10816 10:17:54.461930 1 controller.go:1284] provision "default/mysql-pv-claim" class
"rook-ceph-block": started
10816 10:17:54.462078 1 controller.go:848] Started provisioner controller rook-ceph.rbd.csi.ceph.com csi-rbdplugin-provisioner-677577c77c-vwkzz ca5971ab-2293-4e529bc9-c490f7f50b07!
1081610:17:54.465752 1event.go:281] Event(v1.0bjectReference{Kind:"PersistentVolumeClaim", Namespace:"default"Name:"mysal-pv-claim",UlD:"24449707-6738-425c-ac88-de3c470cf91a",APIVersion:"y1"ResourceVersion:"45668", FieldPath:""): type:'Normal' reason: 'Provisioning' Externalprovisioner is provisioning volume for claim "default/mysql-pv-claim"Rook Agent
RookAgent 是以 Daemonset 形式部署在所有的存储机上的,其处理所有的存储操作,例如挂卸载存储卷以及格式化文件系统等。
CSI 插件注册
spec:
hostNetwork: true
hostPID: true
- args:
- -V=0
- -csi-address=/csi/csi.sock
- -kubelet-registration-path=/var/lib/kubelet/plugins/rook-ceph.rbd.csi.ceph.com/csi.sock
image: quay.io/k8scsi/csi-node-driver-registrar:v1.2.0
name: driver-registrar
resources: {}
securitycontext:
privileged: true
volumeMounts:
- mountPath: /csi
name: plugin-dir
- mountPath: /registration
name: registration-dirCSI Driver
apiVersion:storage.k8s.io/v1
kind: CSlDriver
metadata:
name: rook-ceph.rbd.csi.ceph.com
spec:
attachRequired: true
podinfoOnMount: false
volumeLifecycleModes:
- Persistent$ ls /var/lib/kubelet/plugins/rook-ceph.rbd.csi.ceph.com
csi.sock- args:
- --nodeid=$(NODE ID)
- --endpoint=$(CSI ENDPOINT)
- --V=0
- --type=rbd
- --nodeserver=true
- --drivername=rook-ceph.rbd.csi.ceph.com
- --pidlimit=-1
- --metricsport=9090
- --metricspath=/metrics
- --enablegrpcmetrics=true
env:
- name: CSI ENDPOINT
value: unix:///csi/csi.sock
image: quay.io/cephcsi/cephcsi:v3.0.0
name: csi-rbdplugin
securityContext:
allowPrivilegeEscalation:true
capabilities:
add:
- SYS_ADMIN
privileged: true
- hostPath:
path:/var/lib/kubelet/plugins/rook-ceph.rbd.csi.ceph.com
type: DirectoryOrCreate
name: plugin-dirAgent
pkg/daemon/ceph/agent/agent.go
flexvolume.NewController(a.context, volumeAttachmentController, volumeManager)
rpc.Register(flexvolumeController)
flexvolumeServer.StartCluster
针对不同 ceph cluster,rook 启动一组管理组件,包括: mon, mgr, osd, mds, rgw。
apiVersion: ceph.rook.io/v1
kind: CephCluster
metadata:
name: rook-ceph
namespace: rook-ceph
spec:
cephVersion:
image: ceph/ceph:v14.2.10
dataDirHostPath: /var/lib/rook
mon:
count:3
allowMultiplePerNode: false
mgr:
modules:
- name: pg_autoscaler
enabled: true
dashboard:
enabled: true
storage:
useAllNodes: true
useAllDevices: truePool
-个 ceph cluster 可以有多个 pool 定义副本数量,故障域等多个属性。
apiVersion: ceph.rook.io/v1
kind: cephBlockPool
metadata:
name: replicapool
namespace: rook-ceph
spec:
compressionMode: ""
crushRoot: ""
deviceClass: ""
erasureCoded:
algorithm: ""
codingChunks: 0
dataChunks: 0
failureDomain: host
replicated:
requireSafeReplicaSize: false
size: 1
targetSizeRatio: 0
status:
phase: ReadyKubernetes 控制平面组件:生命周期管理和服务发现
深入理解 Pod 的生命周期
如何优雅的管理 Pod 的完整生命周期
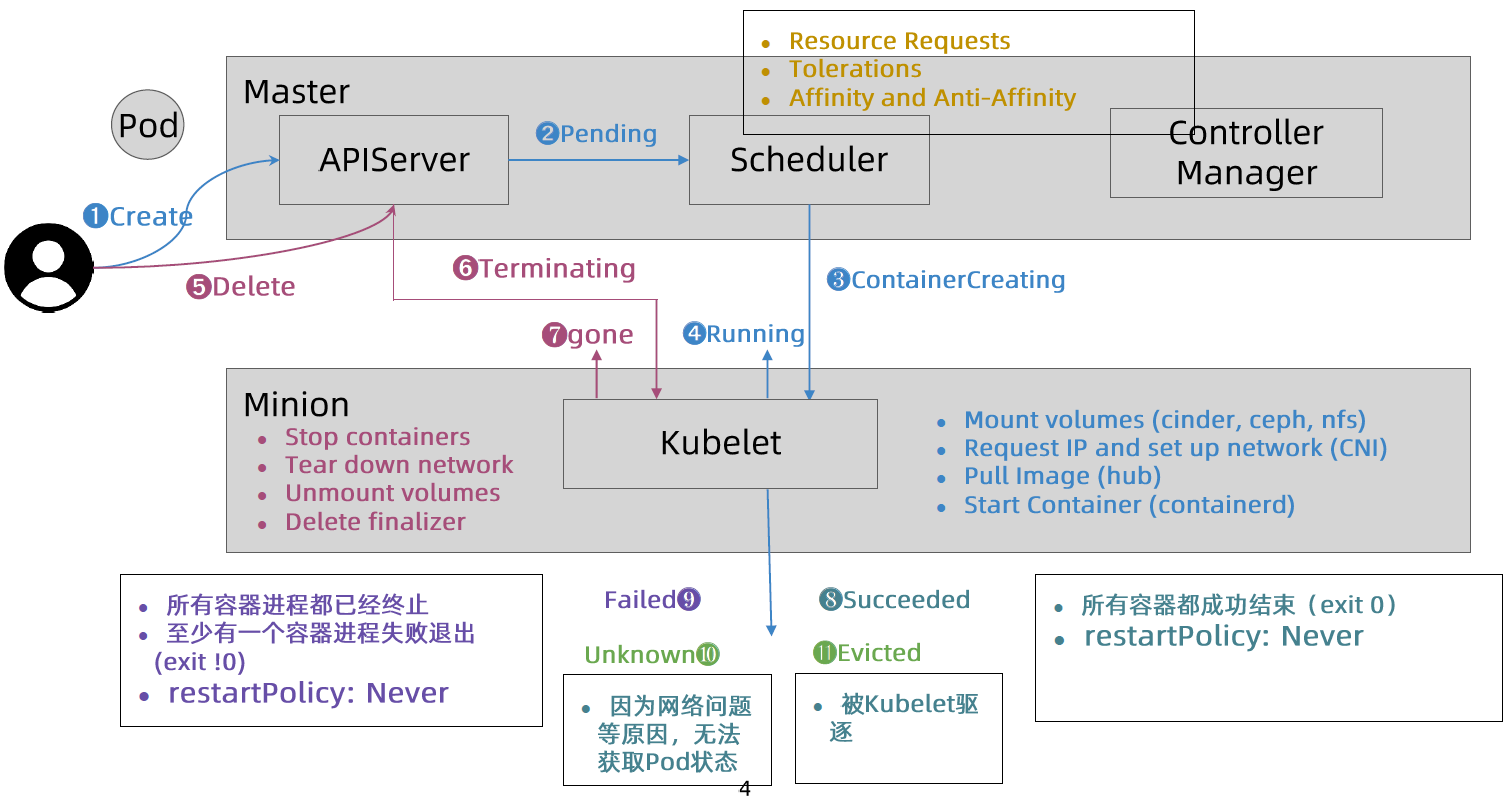
- Pending
Pod 创建成功,但是还未调度(即未与 Node 绑定) - ContainerCreating
Pod 成功被调度到某了 Node,等待 Node 创建对应的 Pod
Pod 状态机
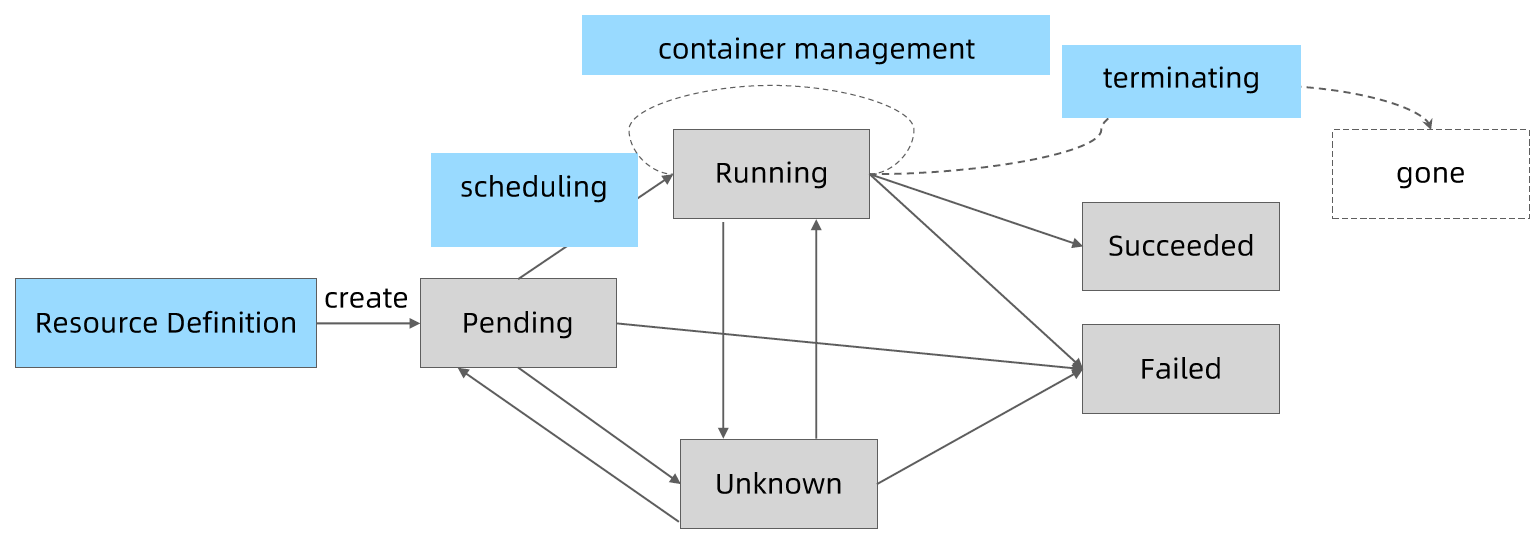
Pod Phase
Pod Phase
- Pending
- Running
- Succeeded
- Failed
- Unknown
kubectl get pod 显示的状态信息是由 podstatus 的 conditions 和 phase 计算出来的
- 查看 pod 细节
kubectl get pod $podname -oyaml - 查看 pod 相关事件
kubectl describe pod
Pod 状态计算细节
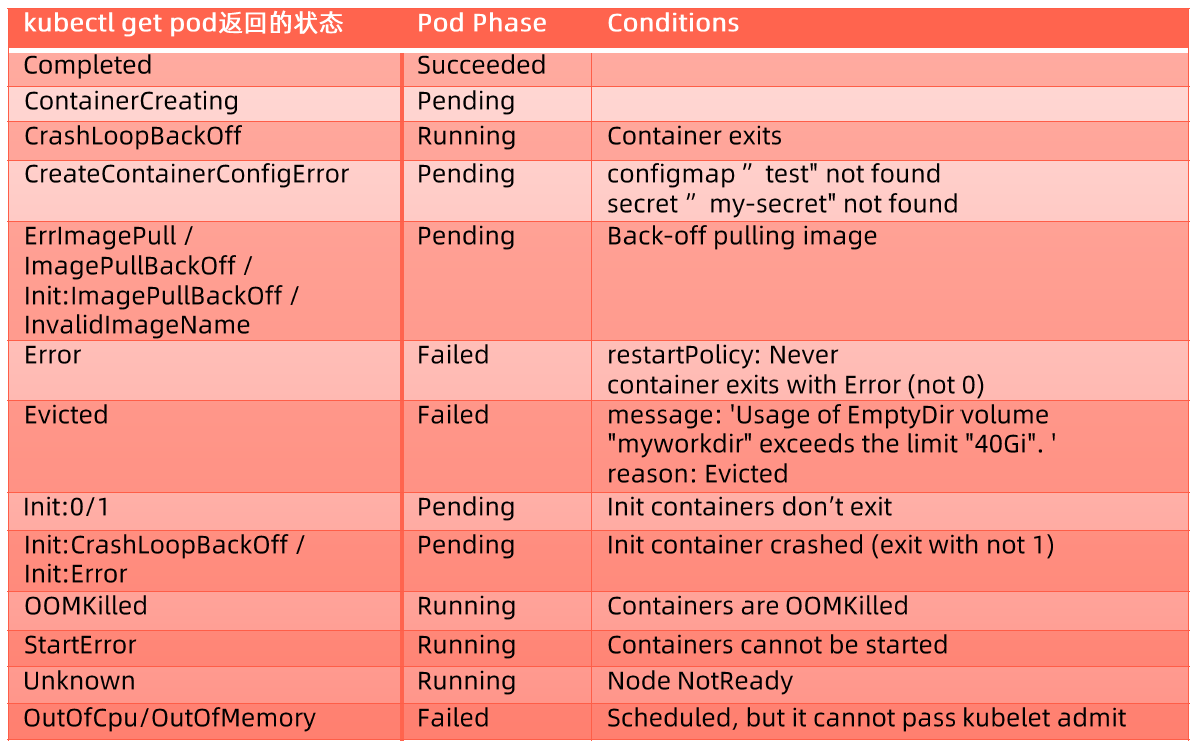
如何确保 Pod 的高可用
避免容器进程被终止避免 Pod 被驱逐
- 设置合理的 resources.memory limits 防止容器进程被 OOMKill
- 设置合理的 emptydir.sizeLimit 并且确保数据写入不超过 emptyDir 的限制,防止 Pod 被驱逐
Pod 的 QoS分类
- Guaranteed
- Pod 的每个容器都设置了资源 CPU 和内存需求
- Limits 和 requests 的值完全一致
- Burstable
- 至少一个容器指定了 CPU 或内存 request
- Pod 的资源需求不符合 Gauranteed Qos 的条件,也就是 request 和 limits 不一致
- BestEffort
- Pod 中的所有容器都未指定 CPU 或内存资源需要 request
仅配置 resources 中的 limits 的话,qos 会是 Guaranteed。
仅配置 resources 中的 requests 的话,qos 会是 Burstable。
当计算节点检测到内存压力时,Kubernetes 会按 BestEffort -> Burstable -> Guaranteed 的顺序依次驱逐 Pod
$ kubectl get pod xxx | grep qosClass
qosClass: Burstable定义 Guaranteed 类型的资源需求来保护你的重要 Pod。
认真考量 Pod 需要的真实需求并设置 limit 和 resource,这有利于将集群资源利用率控制在合理范围并减少 Pod 被驱逐的现象。
尽量避免将生产 Pod 设置为 BestEffort,但是对测试环境来讲,BestEffort Pod 能确保大多数应用不会因为资源不足而处于 Pending 状态。
Burstable 适用于大多数场景。思考:为什么?
PriorityClass 和 QosClass 之间的区别
Kubernetes Quality of Service (QoS) Class Vs Priority Class
PriorityClass 和 QosClass 属于两个不同的维度。
PriorityClass 是用来做资源调度时,判断谁的优先级高谁先抢占资源。
它的表现是,在所有的调度开始前,有一个 QueueSort 的步骤,把所有待调度的 Pod 按照优先级排序,高优先级的在前面,低优先级的排在后面。调度的时候,先调度高优先级的 Pod。
另外,PriorityClass 有一个是否抢占资源的属性,如果设置成”是”的话,当集群目前的资源不足时,调度器就会计算假如杀掉一些比当前待调度 Pod 优先级低的 Pod 后能否让待调度的 Pod 能成功运行,如果能的话,就会杀掉那些比当前待调度 Pod 优先级低的 Pod 以抢占它们的资源。
$ kubectl get priorityclasses system-node-critical -oyaml
apiVersion: scheduling.k8s.io/v1
description: Used for system critical pods that must not be moved from their current
node.
kind: PriorityClass
metadata:
creationTimestamp: "2024-05-11T10:12:53Z"
generation: 1
name: system-node-critical
resourceVersion: "74"
uid: bafc6e25-24ed-4d64-8115-16ad31aace29
preemptionPolicy: PreemptLowerPriority
value: 2000001000// PreemptionPolicy describes a policy for if/when to preempt a pod.
type PreemptionPolicy string
const (
// PreemptLowerPriority means that pod can preempt other pods with lower priority.
PreemptLowerPriority PreemptionPolicy = "PreemptLowerPriority"
// PreemptNever means that pod never preempts other pods with lower priority.
PreemptNever PreemptionPolicy = "Never"
)QosClass 根据资源需求来决定 Kubernetes 需要对 Pod 做什么样的质量保证。当 Node 出现资源紧张的情况下,Node 会根据 QosClass 的优先级从低到高进行驱逐,这个时候与 PriorityClass 是无关的。
PriorityClass 是 Pod 调度时抢资源用的,QosClass 是资源不足驱逐时用的。
“QosClass 是决定怎么死,PriorityClass 决定怎么生”
基于 Taint 的 Evictions
NotReady Node
taints:
- effect: NoSchedule
key: node.kubernetes.io/unreachable
timeAdded: "2020-07-09T11:25:10Z"
- effect: NoExecute
key: node.kubernetes.io/unreachable
timeAdded: "2020-07-09T11:25:21Z"
- effect: Noschedule
key: node.kubernetes.io/not-ready
timeAdded: "2020-07-09T11:24:28Z"
- effect: NoExecute
key: node.kubernetes.io/not-ready
timeAdded: "2020-07-09T11:24:32Z"K8s 为 Pod 自动增加的 Toleration
tolerations:
- effect: NoExecute
key: node.kubernetes.io/not-ready
operator: Exists
tolerationSeconds: 900
- effect: NoExecute
key: node.kubernetes.io/unreachable
operator: Existstoleration
seconds: 900节点临时不可达
- 网络分区
- kubelet, containerd 不工作
节点重启超过了 15 分钟
增大 tolerationSeconds 以避免被驱逐
- 特别是依赖于本地存储状态的有状态应用
健康检查探针
https://github.com/kibaamor/101/tree/master/module8/pods/graceful-start
健康探针类型分为
- livenessProbe
- 探活,当检查失败时,意味着该应用进程已经无法正常提供服务 kubelet 会终止该容器进程并按照 restartPolicy 决定是否重启
- livenessProbe 不会重建 Pod,只会重起 containerd
- livenessProbe 默认不配置时是成功的
- readinessProbe
- 就绪状态检查,当检查失败时,意味着应用进程正在运行,但因为某些原因不能提供服务,Pod 状态会被标记为 NotReady
- readinessProbe 默认不配置时是成功的,但如果配置了就不要成功后 service 才会转发流量给对应的 Pod
- readinessProbe 失败时并不会重启 Container 或者 Pod,只是会不 Ready
- startupProbe
- 在初始化阶段(Ready 之前)进行的健康检查,通常用来避免过于频繁的监测影响应用启动
- startupProbe 成功后,livenessProbe 和 readinessProbe 才会介入
探测方法包括
- ExecAction:在容器内部运行指定命令,当返回码为 0 时,探测结果为成功
- TCPSocketAction:由 kubelet 发起,通过 TCP 协议检查容器 IP 和端口,当端口可达时,探测结果为成功
- HTTPGetAction:由 kubelet 发起,对 Pod 的 IP 和指定端口以及路径进行 HTTPGet 操作,当返回码为 200-400 之间时,探测结果为成功
探针属性
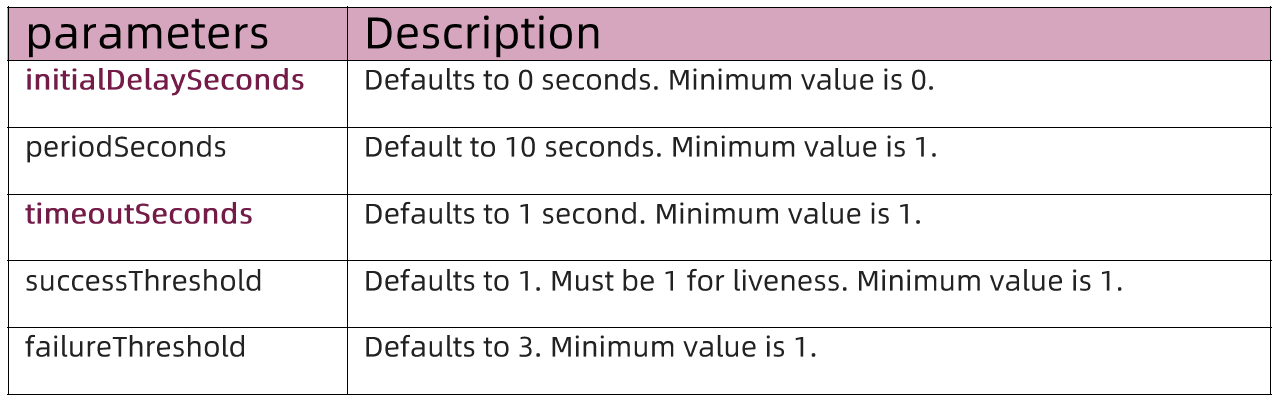
ReadinessGates
https://github.com/kibaamor/101/blob/master/module8/pods/graceful-start/readiness-gate.yaml
- Readiness 允许在 Kubernetes 自带的 Pod Conditions 之外引入自定义的就绪条件
- 新引入的 readinessGates condition 需要为 True 状态后,加上内置的 Conditions,Pod 才可以为就绪状态
- 该状态应该由某控制器修改
Post-start 和 Pre-Stop Hook
https://github.com/kibaamor/101/tree/master/module8/pods/graceful-stop
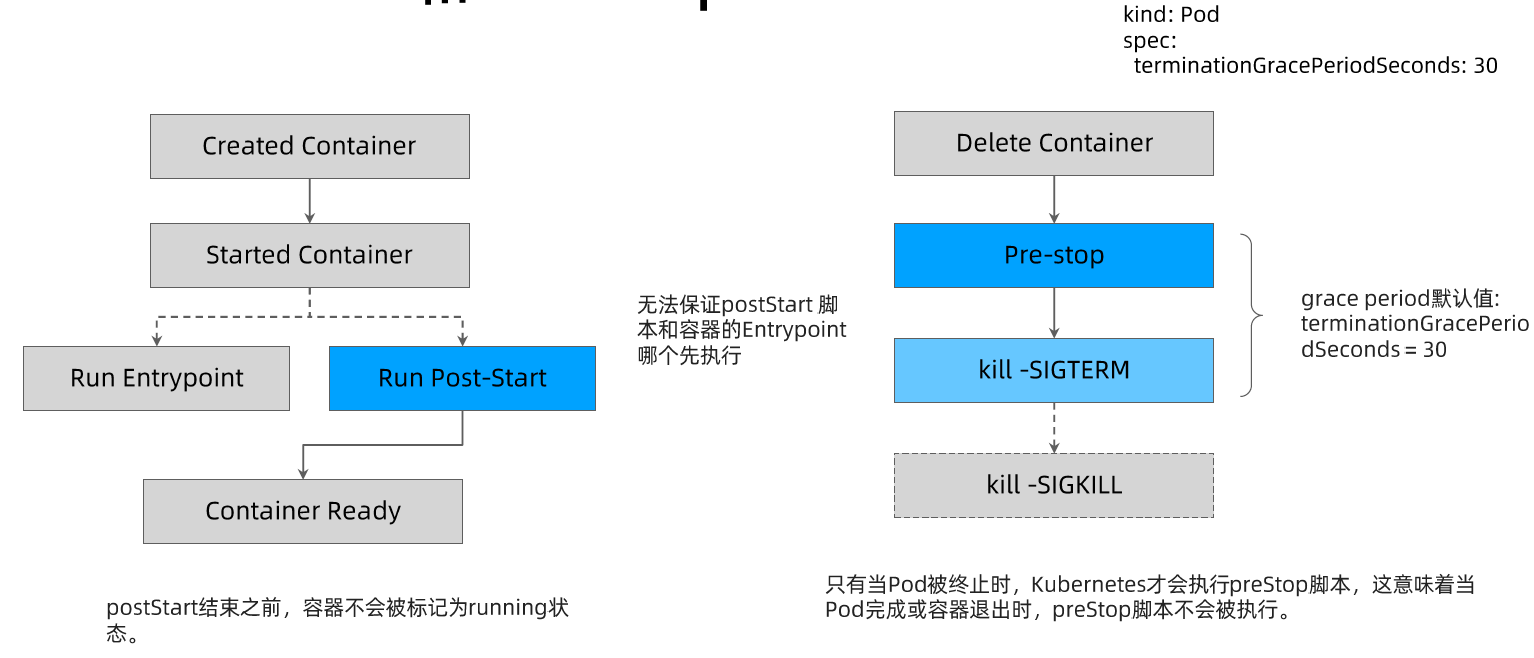
terminationGracePeriodSeconds 的分解

Terminating Pod 的误用
spec:
containers:
- image: netperf:0.1
command:
- /netperf-server.sh
imagePullPolicy: Always$ cat netperf-server.sh
#!/bin/bashnetserver -Dbash /sh 会忽略 SIGTERM 信号量,因此 kilL -SIGTERM 会永远超时,若应用使用 bash/sh 作为 Entrypoint,则应避免过长的 grace period

Terminating Pod 的经验分享
https://github.com/krallin/tini
terminationGracePeriodseconds 默认时长 30 秒
如果不关心 Pod 的终止时长,那么无需采取特殊措施
如果希望快速终止应用进程,那么可采取如下方案
- 在 preStop script 中主动退出进程
- 在主容器进程中使用特定的初始化进程
优雅的初始化进程应该
- 正确处理系统信号量,将信号量转发给子进程
- 在主进程退出之前,需要先等待并确保所有子进程退出
- 监控并清理孤儿子进程
在 Kubernetes 上部署应用的挑战
资源规划
- 每个实例需要多少计算资源
- CPU/GPU?
- Memory
- 超售需求
- 每个实例需要多少存储资源
- 大小
- 本地还是网盘
- 读写性能
- Disk IO
- 网络需求
- 整个应用总体 QPS 和带宽
存储带来的挑战
多容器之间共享存储,最简方案是 emptyDir
带来的挑战:
- emptyDir 需要控制 size limt,否则无限扩张的应用会撑爆主机磁盘导致主机不可用进而导致大规模集群故障
- emptyDir size limit 生效以后,kubelet 会定期对容器目录执行 du 操作,会导致些许的性能影响
- size limit达到以后,Pod 会被驱逐,原 Pod 的日志配置等信息会消失
应用配置
传入方式
- Environment Variables
- Volume Mount
数据来源
- ConfigMap
- Secret
- Downward AP
数据应该如何保存
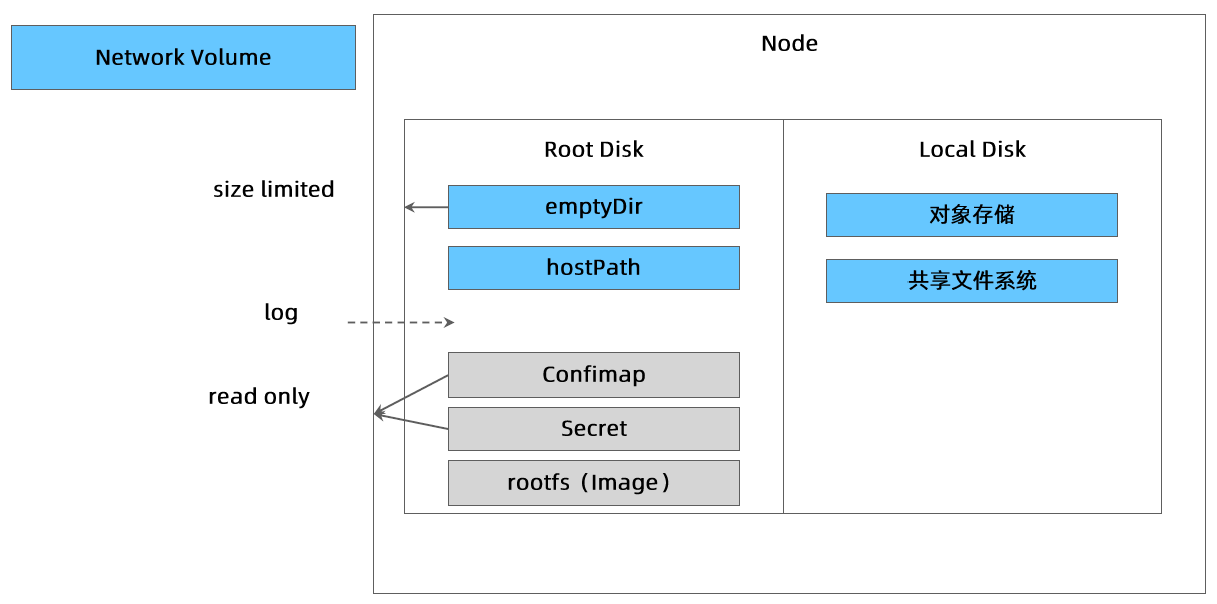
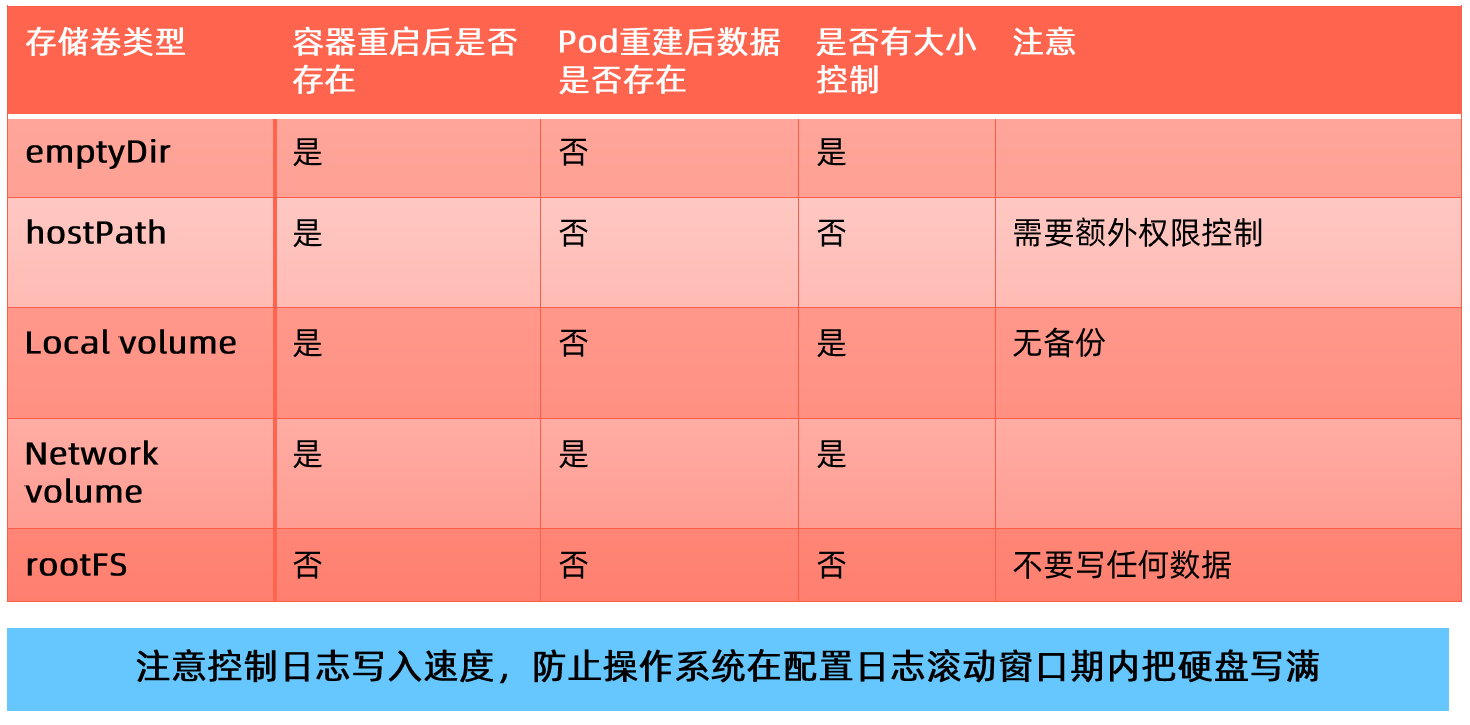
容器应用可能面临的进程中断

高可用部署方式
多少实例
更新策略
- maxsurge
- maxUnavailable(需要考虑 ResourceQuota 的限制)
深入理解 PodTemplateHash 导致的应用的易变性
课后作业(第一部分)
现在你对 Kubernetes 的控制面板的工作机制是否有了深入的了解呢?
是否对如何构建一个优雅的云上应用有了深刻的认识,那么接下来用最近学过的知识把你之前编写的 http 以优雅的方式部署起来吧,你可能需要审视之前代码是否能满足优雅上云的需求。
作业要求:编写 Kubernetes 部署脚本将 httpserver 部署到 kubernetes 集群,以下是你可以思考的维度
- 优雅启动
- 优雅终止
- 资源需求和 QoS 保证
- 探活
- 日常运维需求,日志等级
- 配置和代码分离
服务发现
服务发布
需要把服务发布至集群内部或者外部,服务的不同类型
- ClusterlP(Headless)
- NodePort
- LoadBalancer
- ExternalName
证书管理和七层负载均衡的需求
需要gRPC负载均衡如何做?
DNS需求
与上下游服务的关系
服务发布的挑战
kube-dns
- DNS TTL 问题
Service
- ClusterIP 只能对内
- kube-proxy 支持的 iptables/ipvs 规模有限
- IPVS 的性能和生产化问题 kube-proxy 的 drift 问题
- 频繁的 Pod 变动(specchange,failover,crashloop) 导致 LB 频繁变更
- 对外发布的 Service 需要与企业 ELB 集成
- 不支持 gRPC
- 不支持自定义 DNS 和高级路由功能
Ingress
- Spec 的成熟度?
其他可选方案?
跨地域部署
需要多少实例
如何控制失败域,部署在几个地区,AZ,集群?
如何进行精细的流量控制
如何做按地域的顺序更新
如何回滚
微服务架构下的高可用挑战
服务发现
微服务架构是由一系列职责单一的细粒度服务构成的分布式网状结构服务之间通过轻量机制进行通信,这时候必然引入一个服务注册发现问题,也就是说服务提供方要注册通告服务地址,服务的调用方要能发现目标服务。
同时服务提供方一般以集群方式提供服务,也就引入了负载均衡和健康检查问题。
互联网架构发展历程
理解网络包格式
集中式 LB 服务发现
- 在服务消费者和服务提供者之间有一个独立的 LB。
- LB 上有所有服务的地址映射表,通常由运维配置注册
- 当服务消费方调用某个目标服务时,它向 LB 发起请求,由 LB 以某种策略(比如 Round-Robin)做负载均衡后将请求转发到目标服务。
- LB 一般具备健康检查能力,能自动摘除不健康的服务实例。
- 服务消费方通过 DNS 发现 LB,运维人员为服务配置一个 DNS 域名,这个域名指向 LB。
- 集中式 LB 方案实现简单,在 LB 上也容易做集中式的访问控制,这一方案目前还是业界主流。
- 集中式 LB 的主要问题是单点问题,所有服务调用流量都经过 LB,当服务数量和调用量大的时候,LB 容易成为瓶颈,且一旦 LB 发生故障对整个系统的影响是灾难性的。
- LB 在服务消费方和服务提供方之间增加了一跳( hop ),有一定性能开销。
进程内 LB 服务发现
- 进程内 LB 方案将 LB 的功能以库的形式集成到服务消费方进程里头,该方案也被称为客户端负载方案。
- 服务注册表( Service Registry )配合支持服务自注册和自发现,服务提供方启动时,首先将服务地址注册到服务注册表(同时定期报心跳到服务注册表以表明服务的存活状态)
- 服务消费方要访问某个服务时,它通过内置的 LB 组件向服务注册表查询(同时缓存并定期刷新)目标服务地址列表,然后以某种负载均衡策略选择一个目标服务地址,最后向目标服务发起请求。
- 这一方案对服务注册表的可用性( Availability )要求很高,一般采用能满足高可用分布式一致的组件(例如 ZooKeeper,Consul,etcd 等)来实现。
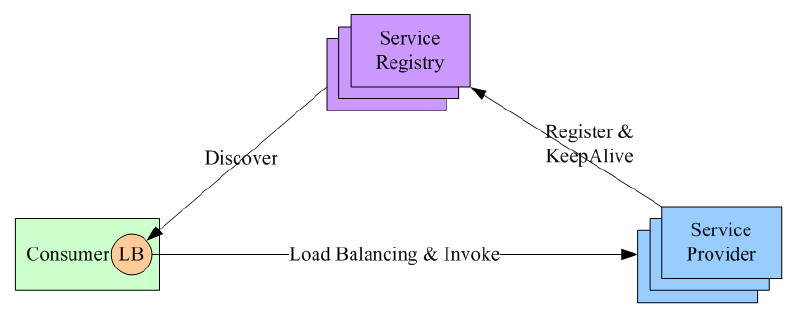
- 进程内 LB 是一种分布式模式,LB和服务发现能力被分散到每一个服务消费者的进程内部,同时服务消费方和服务提供方之间是直接调用,没有额外开销,性能比较好。该方案以客户库( Client Library )的方式集成到服务调用方进程里头,如果企业内有多种不同的语言栈,就要配合开发多种不同的客户端,有一定的研发和维护成本。
- 一旦客户端跟随服务调用方发布到生产环境中,后续如果要对客户库进行升级势必要求服务调用方修改代码并重新发布,所以该方案的升级推广有不小的阻力。
独立 LB 进程服务发现
- 针对进程内 LB 模式的不足而提出的一种折中方案,原理和第二种方案基本类似。
- 不同之处是,将 LB 和服务发现功能从进程内移出来,变成主机上的一个独立进程,主机上的一个或者多个服务要访问目标服务时,他们都通过同一主机上的独立 LB 进程做服务发现和负载均衡。
- LB 独立进程可以进一步与服务消费方进行解耦,以独立集群的形式提供高可用的负载均衡服务,
- 这种模式可以称之为真正的”软负载( Soft Load Balancing )”
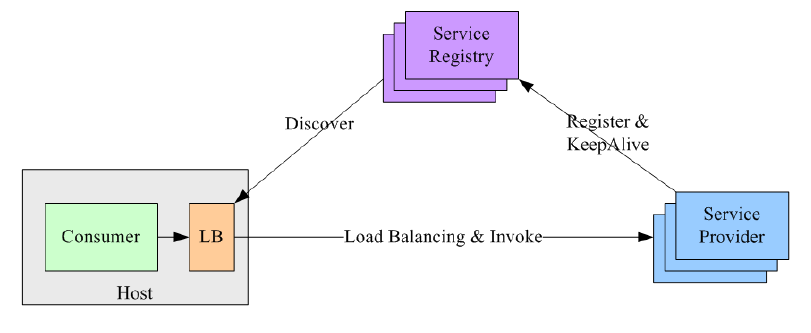
- 独立 LB 进程也是一种分布式方案,没有单点问题,一个 LB 进程挂了只影响该主机上的服务调用方。
- 服务调用方和 LB 之间是进程间调用,性能好
- 简化了服务调用方,不需要为不同语言开发客户库,LB 的升级不需要服务调用方改代码。
- 不足是部署较复杂,环节多,出错调试排查问题不方便。
负载均衡
系统的扩展可分为纵向(垂直)扩展和横向(水平)扩展
- 纵向扩展,是从单机的角度通过增加硬件处理能力,比如 CPU 处理能力,内存容量,磁盘等方面,实现服务器处理能力的提升,不能满足大型分布式系统(网站),大流量,高并发,海量数据的问题;
- 横向扩展,通过添加机器来满足大型网站服务的处理能力。比如:一台机器不能满足,则增加两台或者多台机器,共同承担访问压力,这就是典型的集群和负载均衡架构。
负载均衡的作用(解决的问题)
- 解决并发压力,提高应用处理性能,增加吞吐量,加强网络处理能力;
- 提供故障转移,实现高可用;
- 通过添加或减少服务器数量,提供网站伸缩性,扩展性;
- 安全防护,负载均衡设备上做一些过滤,黑白名单等处理。
DNS 负载均衡
最早的负载均衡技术,利用域名解析实现负载均衡,在 DNS 服务器,配置多个 A 记录,这些 A 记录对应的服务器构成集群。
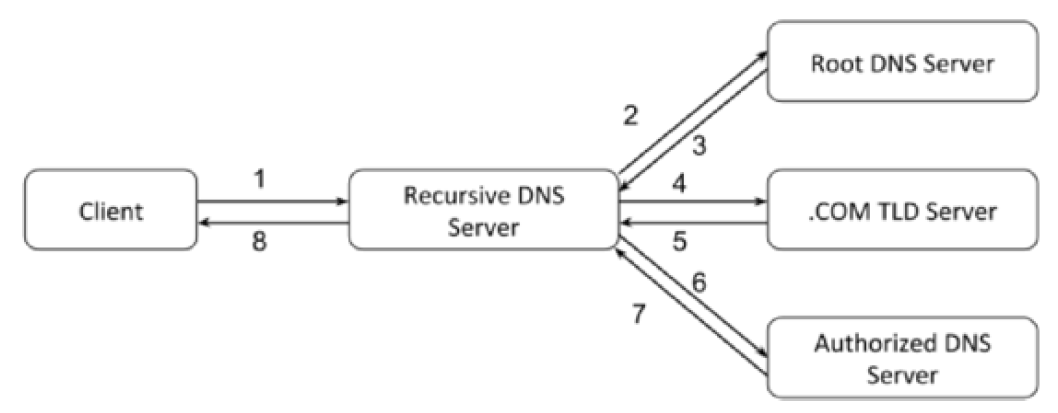

负载均衡技术概览
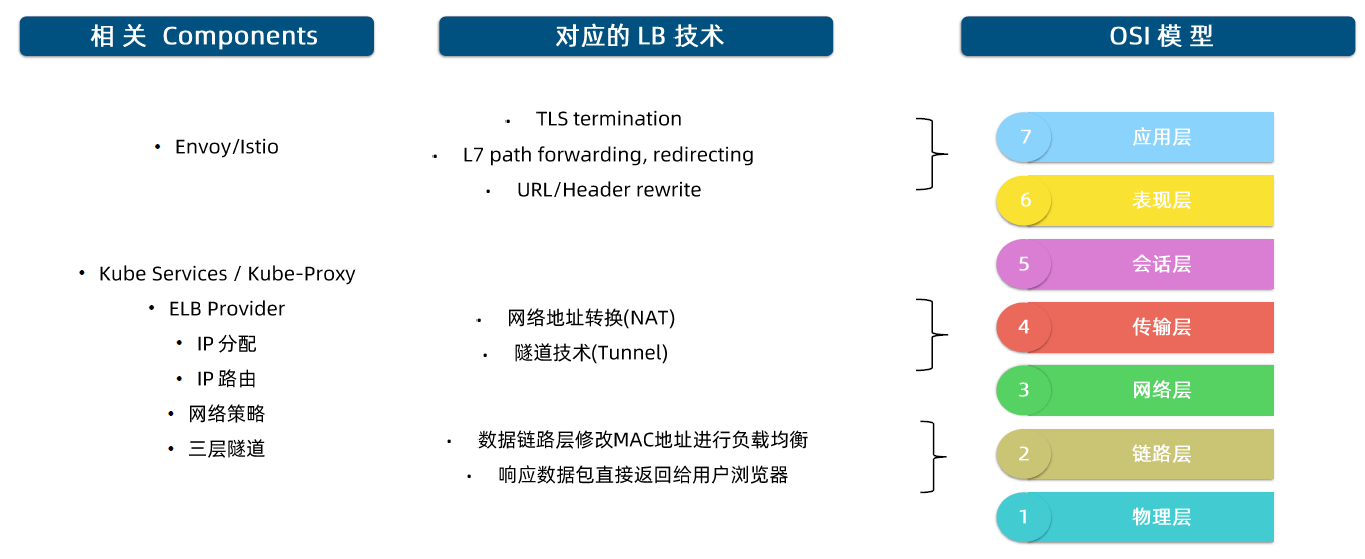
网络地址转换
网络地址转换( NetworkAddress Translation,NAT )通常通过修改数据包的源地址( Source NAT )或目标地址( Destination NAT )来控制数据包的转发行为
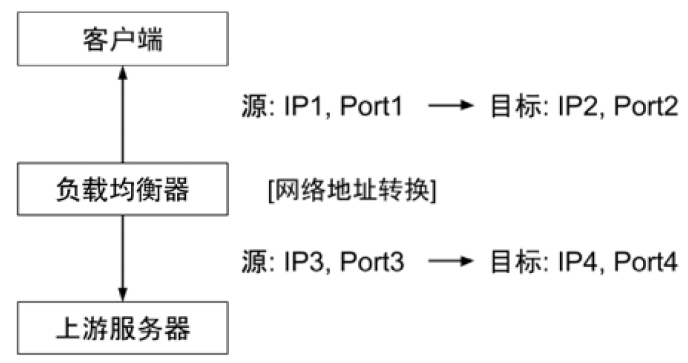
新建 TCP 连接
为记录原始客户端 IP 地址,负载均衡功能不仅需要进行数据包的源目标地址修改,同时要记录原始客户端 IP 地址,基于简单的 NAT 无法满足此需求,于是衍生出了基于传输层协议的负载均衡的
另一种方案—— TCP/UDPTermination 方案
Proxy protocol
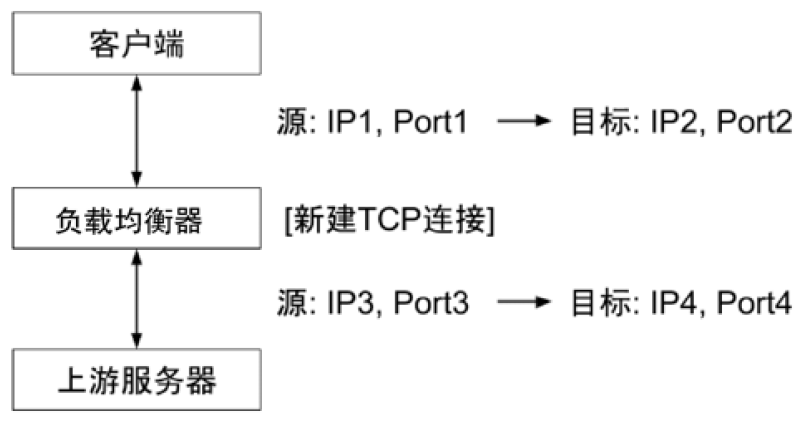
链路层负载均衡
在通信协议的数据链路层修改 MAC 地址进行负载均衡
数据分发时,不修改 IP 地址,只修改目标 MAC 地址,配置真实物理服务器集群所有机器虚拟 IP 和负载均衡服务器 IP 地址一致,达到不修改数据包的源地址和目标地址,进行数据分发的目的。
实际处理服务器 IP 和数据请求目的 IP 一致,不需要经过负载均衡服务器进行地址转换,可将响应数据包直接返回给用户浏览器,避免负载均衡服务器网卡带宽成为瓶颈。也称为直接路由模式( DR 模式)。
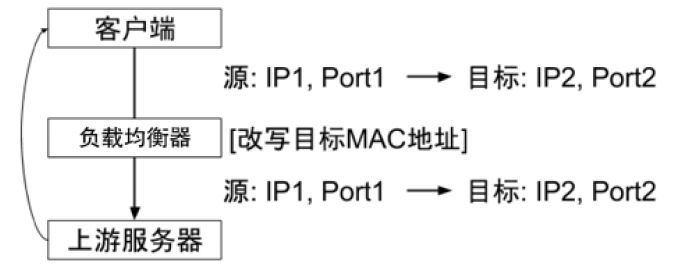
隧道技术
负载均衡中常用的隧道技术是 IP over IP,其原理是保持原始数据包 IP 头不变,在 IP 头外层增加额外的 IP 包头后转发给上游服务器。
上游服务器接收 IP 数据包,解开外层 IP 包头后,剩下的是原始数据包。
同样的,原始数据包中的目标 IP 地址要配置在上游服务器中,上游服务器处理完数据请求以后响应包通过网关直接返回给客户端。
Service 对象
https://github.com/kibaamor/101/tree/master/module8/service
Service对象
Service selector
- Kubernetes 允许将 Pod 对象通过标签( Label )进行标记,并通过 Service Selector 定义基于 Pod 标签的过滤规则以便选择服务的上游应用实例
Ports
- Ports 属性中定义了服务的端口、协议目标端口等信息
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
selector:
app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 80Endpoint 对象
Q:为什么需要 endpoint 对象?
A:为不同的 port 发布不同的服务器,处理多个 pod 对多个 service 的情况,endpont 就作为 pod 和 service 的中间表。
当 Service 的 selector 不为空时,Kubernetes EndpointController 会侦听服务创建事件,创建与 Service 同名的 Endpoint 对象
selector 能够选取的所有 PodIP 都会被配置到 addresses 属性中
- 如果此时 selector 所对应的 filter 查询不到对应的 Pod,则 addresses 列表为空
- 默认配置下,如果此时对应的 Pod 为 not ready 状态,则对应的 PodIP 只会出现在 subsets 的 notReadyAddresses 属性中,这意味着对应的 Pod 还没准备好提供服务,不能作为流量转发的目标。
- 如果设置了 PublishNotReadyAdddress 为 true,则无论 Pod 是否就绪都会被加入 readyAddress list
apiVersion: v1
kind: Endpoint
metadata:
name: nginx-service
subsets:
- addresses:
- ip: 10.1.1.21
nodeName: minikube
targetRef:
kind: Pod
name: nginx-deployment-5754944d6c-hnw27
namespace: default
resourceVersion: "722191"
uid: 8a3390ae-2f8e-47bf-b8dd-70fae7fb0d32Endpointslice 对象
当某个 Service 对应的 backend Pod 较多时 Endpoint 对象就会因保存的地址信息过多而变得异常庞大
Pod 状态的变更会引起 Endpoint 的变更 Endpoint 的变更会被推送至所有节点,从而导致持续占用大量网络带宽
EndpointSlice 对象,用于对 Pod 较多的 Endpoint 进行切片,切片大小可以自定义
apiVersion: discovery.k8s.io/vlbeta1
kind: Endpointslice
metadata:
name: example-abc
labels:
kubernetes.io/service-name: example
addressType: IPv4
ports:
name: http
protocol: TCP
port: 80
endpoints:
- addresses: "10.1.2.3"
conditions:
ready:true
hostname: pod-1
topology:
kubernetes.io/hostname: node-1
topology.kubernetes.io/zone: us-west2-a不定义 Selector 的 Service
用户创建了 Service 但不定义 Selector
- Endpoint Controller 不会为该 Service 自动创建 Endpoint
- 用户可以手动创建一个与 Service 同名的 Endpoint 对象,并设置任意 IP 地址到 Address 属性
- 访问该服务的请求会被转发至目标地址
通过该类型服务,可以为集群外的一组 Endpoint 创建服务
https://github.com/kibaamor/101/blob/master/module8/service/service-without-selector.yaml
apiVersion: v1
kind: Service
metadata:
name: service-without-selector
spec:
ports:
- port: 80
protocol: TCP
name: httphttps://github.com/kibaamor/101/blob/master/module8/service/endpoint-without-selector.yaml
apiVersion: v1
kind: Endpoints
metadata:
name: service-without-selector
subsets:
- addresses:
- ip: 220.181.38.148
ports:
- name: http
port: 80
protocol: TCPService、Endpoint 和 Pod 的对应关系
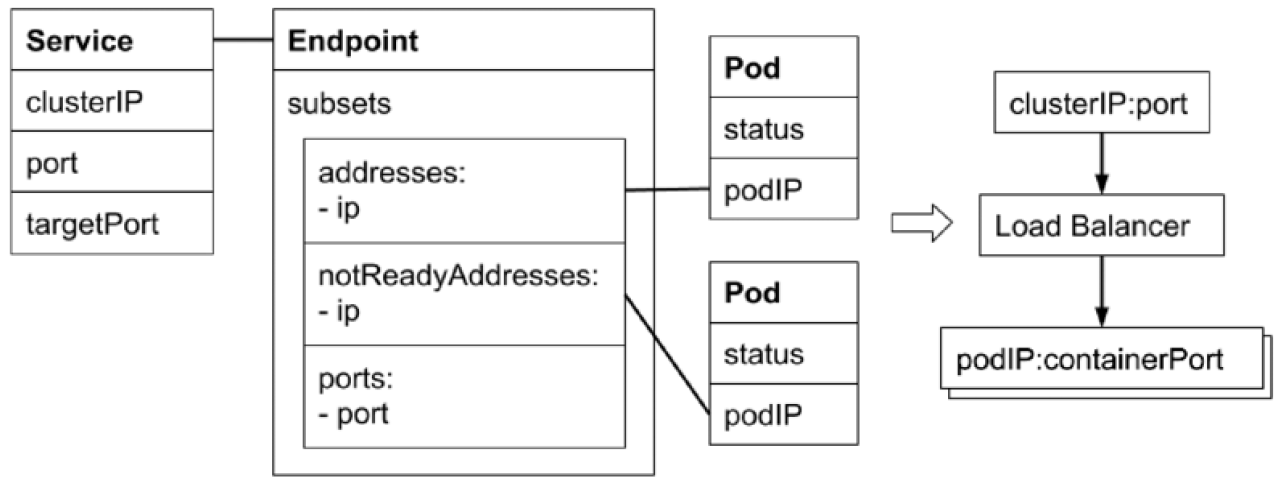
Service类型
clusterIP
- Service 的默认类型,服务被发布至仅集群内部可见的虚拟 IP 地址上。
- 在 API Server 启动时,需要通过
service-cluster-ip-range参数配置虚拟 IP 地址段, API Server 中有用于分配 IP 地址和端口的组件,当该组件捕获 Service 对象并创建事件时,会从配置的虚拟 IP 地址段中去一个有效的 IP 地址,分配给该 Service 对象。
nodePort
- 在 API Server 启动时,需要通过
node-port-range参数配置 nodePort 的范围,同样的,API Server 组件会捕获 Service 对象并创建事件,即从配置好的 nodePort 范围取一个有效端口,分配给该 Service。 - 每个节点的 kube-proxy 会尝试在服务分配的 nodePort 上建立侦听器接收请求,并转发给服务对应的后端 Pod 实例。
- 在 API Server 启动时,需要通过
LoadBalancer
- 企业数据中心一般会采购一些负载均衡器,作为外网请求进入数据中心内部的统一流量入口。
- 针对不同的基础架构云平台,Kubernertes Cloud Manager 提供支持不同供应商API的 Service Controller。如果需要在 Openstack 云平台上搭建 Kubernetes 集群,那么只需提供一份openstack.rc,Openstack Service Controller 即可通过调用 LBaaS API 完成负载均衡配置。
其他类型服务
Headless Service
https://github.com/kibaamor/101/blob/master/module8/service/headless-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: nginx-headless
spec:
ClusterIP: None
ports:
- port: 80
protocol: TCP
name: http
selector:
app: nginx- Headless 服务是用户将 clusterIP 显示定义为 None 的服务,
- 无头的服务意味着 Kubernetes 不会为该服务分配统一入口,包括 clusterIP,nodePort 等
ExternalName Service
https://github.com/kibaamor/101/blob/master/module8/service/service-external-name.yaml
apiVersion: v1
kind: Service
metadata:
name: my-service
namespace: prod
spec:
type: ExternalName
externalName: tencent.com- 为一个服务创建别名
Headless 和 externalName 服务的使用场景?我们随后讨论
Service Topology
一个网络调用的延迟受客户端和服务器所处位置的影响,两者是否在同一节点、同一机架、同-可用区、同一数据中心,都会影响参与数据传输的设备数量
在分布式系统中,为保证系统的高可用,往往需要控制应用的错误域( FailureDomain ),比如通过反亲和性配置,将一个应用的多个副本部署在不同机架,甚至不同的数据中心
Kubernetes 提供通用标签来标记节点所处的物理位置,如:
topology.kubernetes.io/zone: us-west2-a
failure-domain.beta.kubernetes.io/region: us-west
failure-domain.tess.io/network-device: us-west05-ra053
failure-domain.tess.io/rack: us_west02_02-314_19_12
kubernetes.io/hostname: node-1Service 引入了 topologyKeys 属性,可以通过如下设置来控制流量
- 当 topologyKeys 设置为 [“kubernetes.io/hostname”] 时,调用服务的客户端所在节点上如果有服务实例正在运行,则该实例处理请求,否则,调用失败。
- 当 topologyKeys 设置为 [“kubernetes.io/hostname”,”topology.kubernetes.io/zone”,”topology.kubernetes.io/region”] 时,若同一节点有对应的服务实例,则请求会优先转发至该实例。否则,顺序查找当前 zone 及当前 region 是否有服务实例,并将请求按顺序转发。
- 当 topologyKeys 设置为 [“topology.kubernetes.io/zone”,”*”] 时,请求会被优先转发至当前 zone 的服务实例。如果当前 zone 不存在服务实例,则请求会被转发至任意服务实例。
kube-proxy
kube-proxy
每台机器上都运行一个 kube-proxy 服务,它监听 API server 中 service 和 endpoint 的变化情况,并通过 iptables 等来为服务配置负载均衡(仅支持 TCP 和 UDP )。
kube-proxy 可以直接运行在物理机上,也可以以 static pod 或者 DaemonSet 的方式运行。
kube-proxy 当前支持一下几种实现
- userspace:最早的负载均衡方案,它在用户空间监听一个端口,所有服务通过 iptables 转发到这个端口,然后在其内部负载均衡到实际的 Pod。该方式最主要的问题是效率低,有明显的性能瓶颈
- iptables:目前推荐的方案,完全以 iptables 规则的方式来实现 service 负载均衡。该方式最主要的问题是在服务多的时候产生太多的 iptables 规则,非增量式更新会引入一定的时
延,大规模情况下有明显的性能问题 - ipvs:为解决 iptables 模式的性能问题,v1.8 新增了 ipvs 模式,采用增量式更新,并可以保证 service 更新期间连接保持不断开
- winuserspace:同 userspace,但仅工作在 windows 上
Linux内核处理数据包:Netfilter 框架
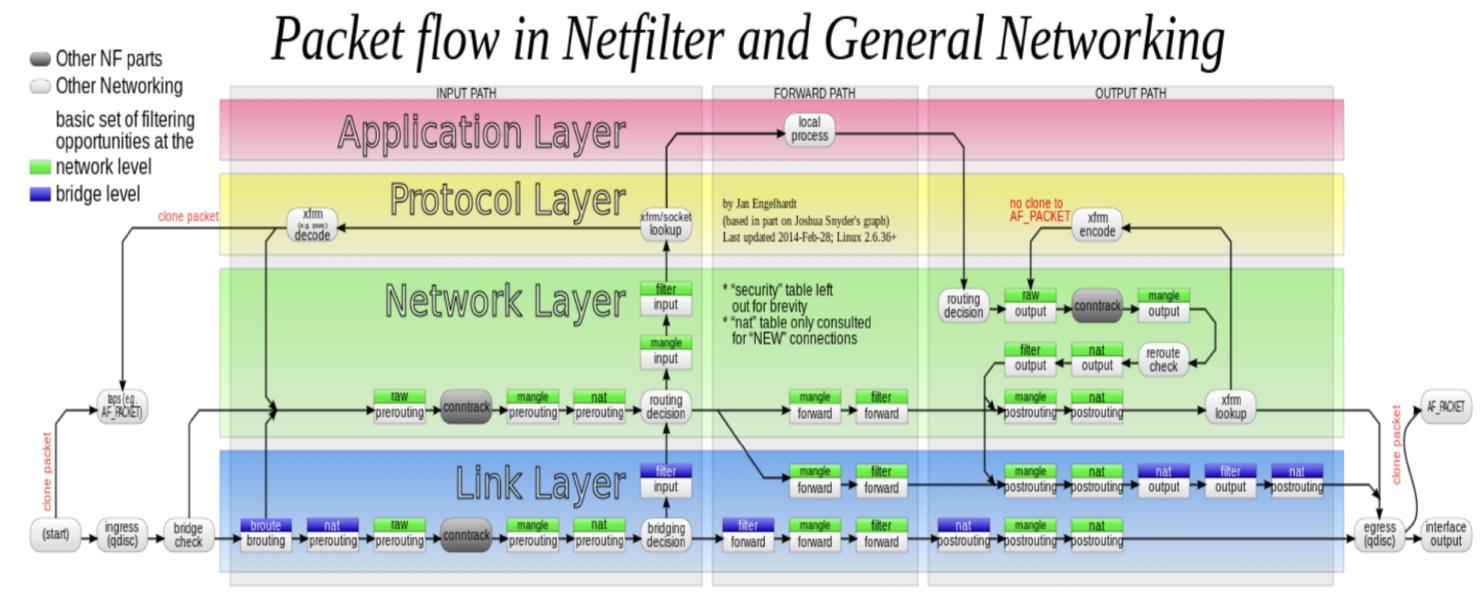
tcpdump 和 iptables(netfilter) 处理数据包的先后顺序
结论
- 进站的数据包先经过 tcpdump,再经过 iptables
- 出站的数据包先经过 iptables,再经过 tcpdump
原理分析
- 事实上tcpdump在链路层就已经捕获数据包 (从 tcpdump man page 得知)
- 而 iptables 工作在协议栈的网络层,原理上 tcpdump 就比 iptables 更接近网卡设备
Netfilter 和 iptables
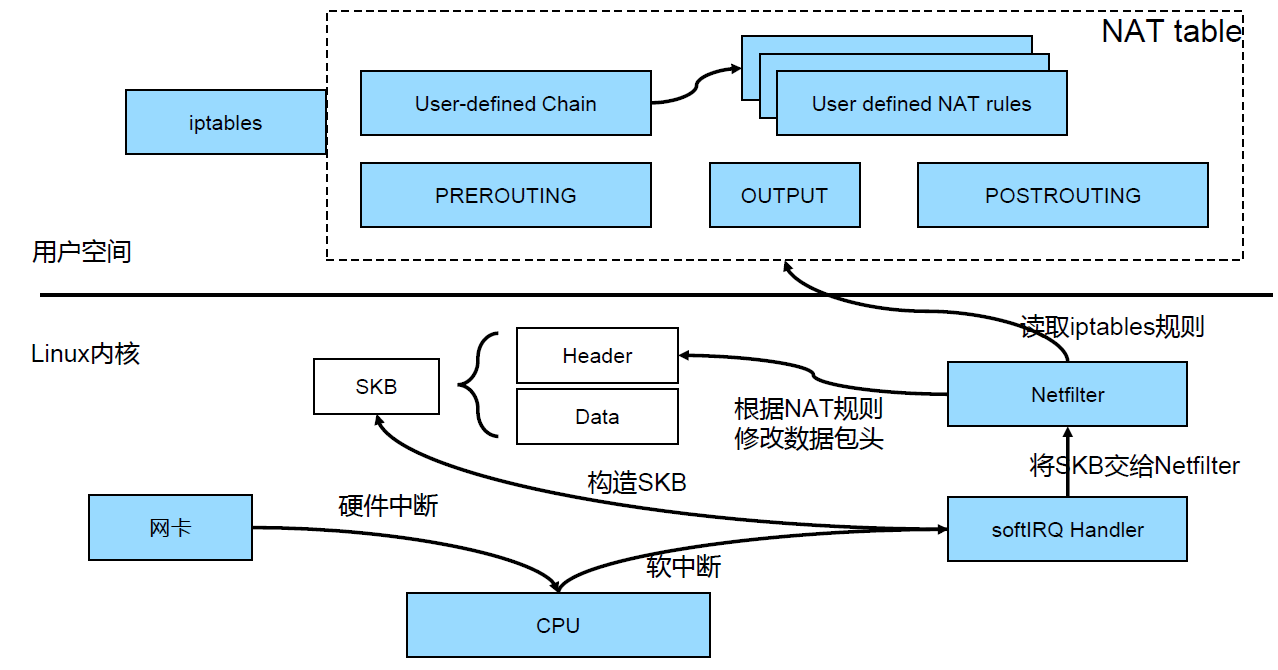
iptables
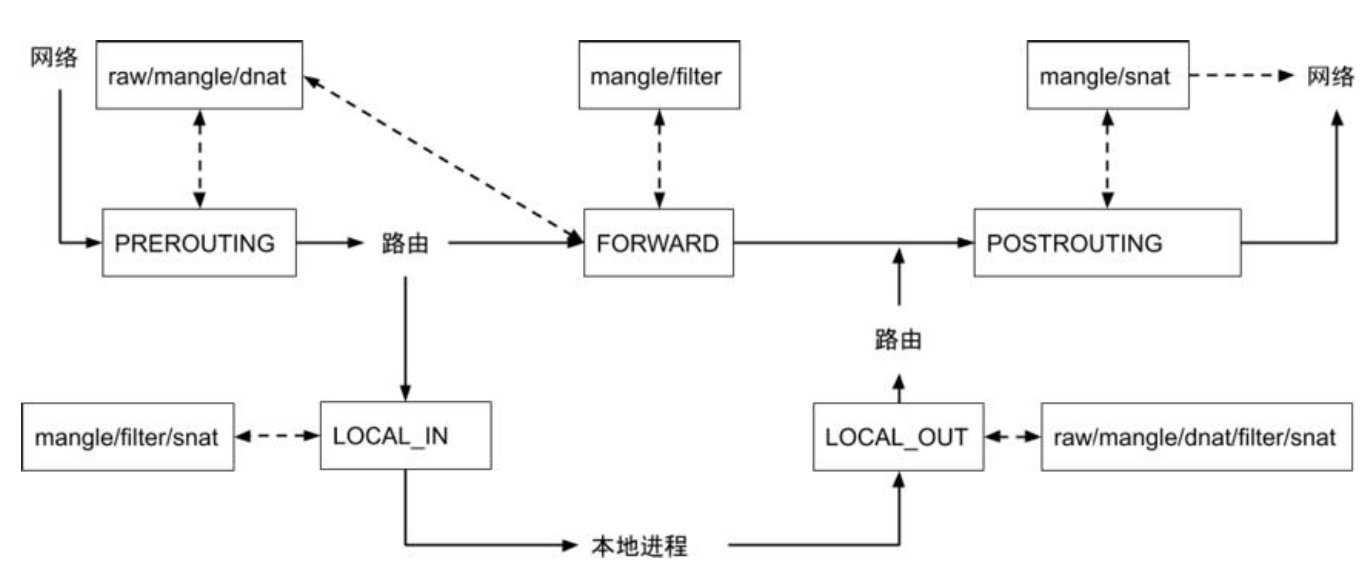
iptables 支持的锚点

kube-proxy 工作原理
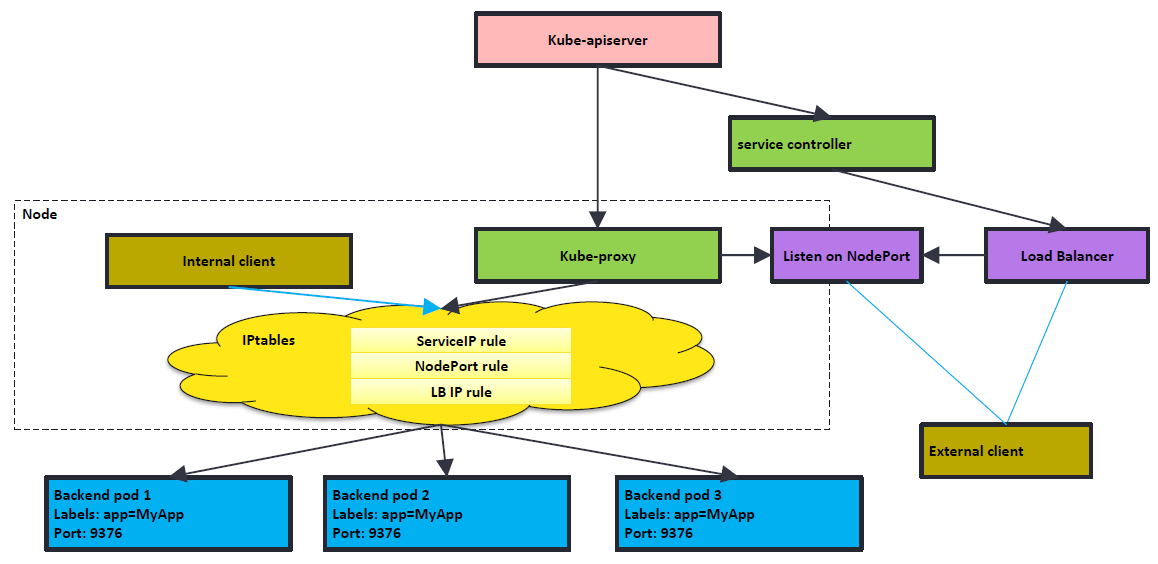
Kubernetes iptables 规则
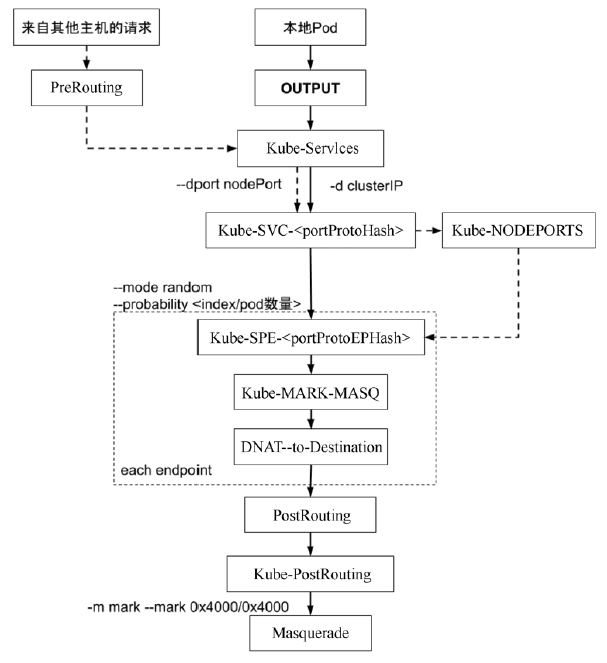
iptables 示例
ClusterIP 的 iptables 规则分析
$ kubectl get svc nginx-basic -owide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
nginx-basic ClusterIP 10.96.240.161 <none> 80/TCP 74m app=nginx
$ kubectl get pod -l app=nginx -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-77b4fdf86c-glrrd 1/1 Running 0 14s 10.244.0.52 minikube <none> <none>
nginx-deployment-77b4fdf86c-k7mf4 1/1 Running 0 14s 10.244.0.51 minikube <none> <none>
nginx-deployment-77b4fdf86c-wplrw 1/1 Running 0 14s 10.244.0.50 minikube <none> <none>-A PREROUTING -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
-A OUTPUT -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
-A KUBE-SERVICES -d 10.96.240.161/32 -p tcp -m comment --comment "default/nginx-basic:http cluster IP" -m tcp --dport 80 -j KUBE-SVC-WWRFY3PZ7W3FGMQW
-A KUBE-SVC-WWRFY3PZ7W3FGMQW ! -s 10.244.0.0/16 -d 10.96.240.161/32 -p tcp -m comment --comment "default/nginx-basic:http cluster IP" -m tcp --dport 80 -j KUBE-MARK-MASQ
-A KUBE-SVC-WWRFY3PZ7W3FGMQW -m comment --comment "default/nginx-basic:http -> 10.244.0.50:80" -m statistic --mode random --probability 0.33333333349 -j KUBE-SEP-GDFWTYWRXAR6P5IV
-A KUBE-SVC-WWRFY3PZ7W3FGMQW -m comment --comment "default/nginx-basic:http -> 10.244.0.51:80" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-KT26XBLI5UEBCGC6
-A KUBE-SVC-WWRFY3PZ7W3FGMQW -m comment --comment "default/nginx-basic:http -> 10.244.0.52:80" -j KUBE-SEP-LEDXNGZ5TZMIGQDD
-A KUBE-SEP-GDFWTYWRXAR6P5IV -s 10.244.0.50/32 -m comment --comment "default/nginx-basic:http" -j KUBE-MARK-MASQ
-A KUBE-SEP-GDFWTYWRXAR6P5IV -p tcp -m comment --comment "default/nginx-basic:http" -m tcp -j DNAT --to-destination 10.244.0.50:80
-A KUBE-SEP-KT26XBLI5UEBCGC6 -s 10.244.0.51/32 -m comment --comment "default/nginx-basic:http" -j KUBE-MARK-MASQ
-A KUBE-SEP-KT26XBLI5UEBCGC6 -p tcp -m comment --comment "default/nginx-basic:http" -m tcp -j DNAT --to-destination 10.244.0.51:80
-A KUBE-SEP-LEDXNGZ5TZMIGQDD -s 10.244.0.52/32 -m comment --comment "default/nginx-basic:http" -j KUBE-MARK-MASQ
-A KUBE-SEP-LEDXNGZ5TZMIGQDD -p tcp -m comment --comment "default/nginx-basic:http" -m tcp -j DNAT --to-destination 10.244.0.52:80
-A POSTROUTING -m comment --comment "kubernetes postrouting rules" -j KUBE-POSTROUTING
-A KUBE-MARK-MASQ -j MARK --set-xmark 0x4000/0x4000 # mark packet with 0x4000
-A KUBE-POSTROUTING -m mark ! --mark 0x4000/0x4000 -j RETURN
-A KUBE-POSTROUTING -j MARK --set-xmark 0x4000/0x0 # clear mark 0x4000
-A KUBE-POSTROUTING -m comment --comment "kubernetes service traffic requiring SNAT" -j MASQUERADE --random-fully
-A FORWARD -m comment --comment "kubernetes forwarding rules" -j KUBE-FORWARD
-A KUBE-FORWARD -m comment --comment "kubernetes forwarding rules" -m mark --mark 0x4000/0x4000 -j ACCEPTNodePort 的 iptables 分析
$ kubectl get svc nginx-service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx-service NodePort 10.97.2.223 <none> 80:30506/TCP 171m
$ kubectl get ep nginx-service
NAME ENDPOINTS AGE
nginx-service 10.244.0.10:80,10.244.0.11:80,10.244.0.9:80 171m
$ nft list chain ip nat KUBE-NODEPORTS
table ip nat {
chain KUBE-NODEPORTS {
meta l4proto tcp tcp dport 30506 counter packets 0 bytes 0 jump KUBE-EXT-6IM33IEVEEV7U3GP
meta l4proto tcp tcp dport 31235 counter packets 0 bytes 0 jump KUBE-EXT-CG5I4G2RS3ZVWGLK
meta l4proto tcp tcp dport 31687 counter packets 0 bytes 0 jump KUBE-EXT-EDNDUDH2C75GIR6O
}
}-A PREROUTING -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
-A KUBE-SERVICES -m comment --comment "kubernetes service nodeports; NOTE: this must be the last rule in this chain" -m addrtype --dst-type LOCAL -j KUBE-NODEPORTS
-A KUBE-NODEPORTS -p tcp -m comment --comment "default/nginx-service:http" -j KUBE-EXT-6IM33IEVEEV7U3GP
-A KUBE-EXT-6IM33IEVEEV7U3GP -m comment --comment "masquerade traffic for default/nginx-service:http external destinations" -j KUBE-MARK-MASQ
-A KUBE-EXT-6IM33IEVEEV7U3GP -j KUBE-SVC-6IM33IEVEEV7U3GP
-A KUBE-MARK-MASQ -j MARK --set-xmark 0x4000/0x4000
-A KUBE-SVC-6IM33IEVEEV7U3GP ! -s 10.244.0.0/16 -d 10.97.2.223/32 -p tcp -m comment --comment "default/nginx-service:http cluster IP" -j KUBE-MARK-MASQ
-A KUBE-SVC-6IM33IEVEEV7U3GP -m comment --comment "default/nginx-service:http -> 10.244.0.10:80" -m statistic --mode random --probability 0.33333333349 -j KUBE-SEP-UNA35ZJ3UYOAR4VQ
-A KUBE-SVC-6IM33IEVEEV7U3GP -m comment --comment "default/nginx-service:http -> 10.244.0.11:80" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-BSP7ITGKKKE54DZJ
-A KUBE-SVC-6IM33IEVEEV7U3GP -m comment --comment "default/nginx-service:http -> 10.244.0.9:80" -j KUBE-SEP-5AGZ67ZS4PKMABRU
-A KUBE-SEP-UNA35ZJ3UYOAR4VQ -s 10.244.0.10/32 -m comment --comment "default/nginx-service:http" -j KUBE-MARK-MASQ
-A KUBE-SEP-UNA35ZJ3UYOAR4VQ -p tcp -m comment --comment "default/nginx-service:http" -m tcp -j DNAT --to-destination 10.244.0.10:80
-A KUBE-SEP-BSP7ITGKKKE54DZJ -s 10.244.0.11/32 -m comment --comment "default/nginx-service:http" -j KUBE-MARK-MASQ
-A KUBE-SEP-BSP7ITGKKKE54DZJ -p tcp -m comment --comment "default/nginx-service:http" -m tcp -j DNAT --to-destination 10.244.0.11:80
-A KUBE-SEP-5AGZ67ZS4PKMABRU -s 10.244.0.9/32 -m comment --comment "default/nginx-service:http" -j KUBE-MARK-MASQ
-A KUBE-SEP-5AGZ67ZS4PKMABRU -p tcp -m comment --comment "default/nginx-service:http" -m tcp -j DNAT --to-destination 10.244.0.9:80IPVS
https://github.com/kubernetes/kubernetes/blob/master/pkg/proxy/ipvs/README.md
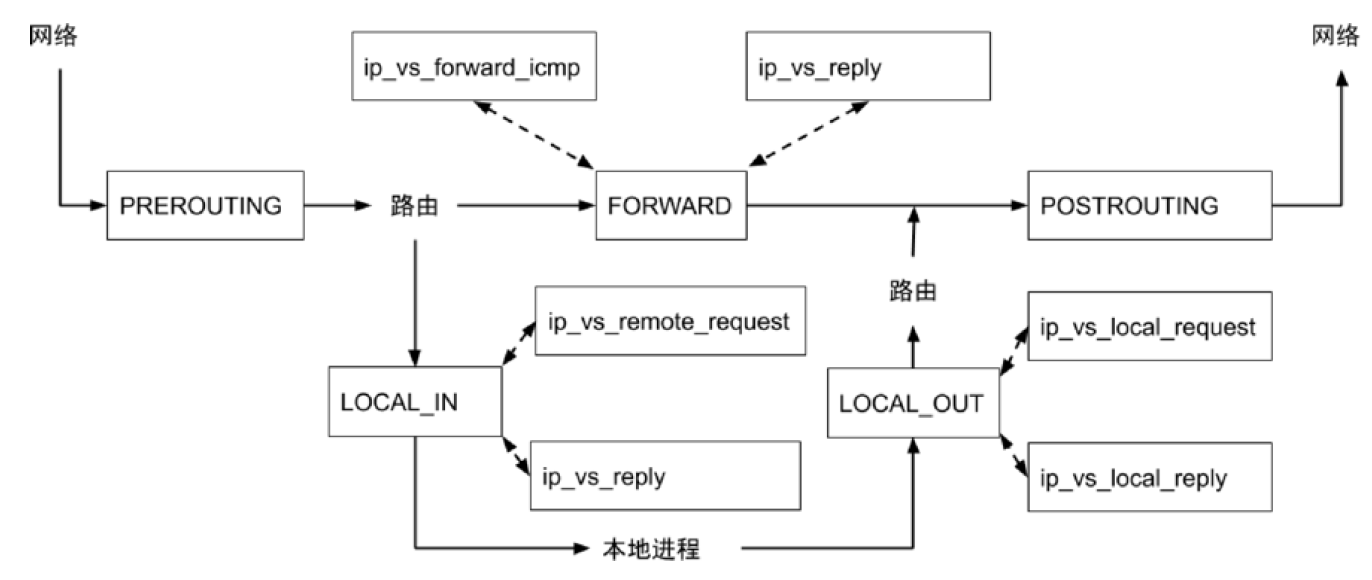
IPVS 支持的锚点和核心函数
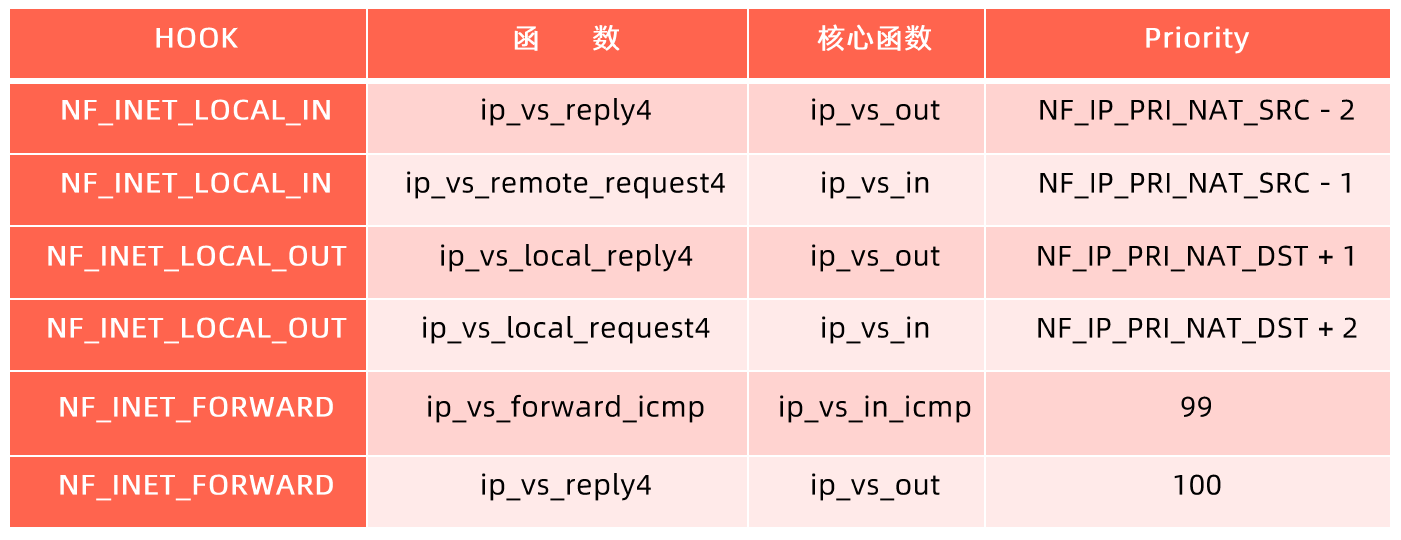
注意:PREROUTING 和 POSTROUTING 这个两个地方是没有 hook 的,所以 ipvs 不能像 iptables 那样在 PREROUTING 做 dnat 或者 在 POSTROUTING 做 dnat。
ipvs 的做法是在本机虚拟出一个新的网卡(一般叫 kube-ipvs0),然后把所有的 cluster ip 都绑定到这个网卡上,但是不接受 arp 的请求,所以依然不能 ping 通(ping 时会返回错误 Destination Port Unreachable)。随后当访问 cluster ip 时,kernel 就可以在 LOCAL_IN 做转发规则了。
因为 ipvs 在 POSTROUTING 是没有 hook 的,当需要做数据包转发 IP 伪装(IP 伪装指的是网络包从 pod 发出时,需要伪装成从 node 发出的,不然就可能收不到发回的数据包)时,即在数据包离开当前 Node 时需要进行处理,而由于 ipvs 在 POSTROUTING 是没有 hook 的,所以即使开启了 ipvs ,也需要通过配置一条 iptables 规则来完成 IP 伪装。
那么具体是如何用一条规则来完成 IP 伪装呢?通过使用 ipset 来完成。它会把那些一系列相同类型的 ip 归为一类来一起操作。
ipvs 的分析
$ kubectl get svc nginx-service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx-service ClusterIP 10.96.57.249 <none> 80/TCP 20m
$ kubectl get ep nginx-service
NAME ENDPOINTS AGE
nginx-service 10.244.0.6:80,10.244.0.7:80 56m
$ ipvsadm -L -n
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.96.57.249:80 rr
-> 10.244.0.6:53 Masq 1 0 0
-> 10.244.0.7:80 Masq 1 0 0
$ ip addr show dev kube-ipvs0
7: kube-ipvs0: <BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN group default
link/ether be:23:dc:d5:57:95 brd ff:ff:ff:ff:ff:ff
inet 10.96.0.1/32 scope global kube-ipvs0
valid_lft forever preferred_lft forever
inet 10.96.57.249/32 scope global kube-ipvs0
valid_lft forever preferred_lft forever
inet 10.96.0.10/32 scope global kube-ipvs0
valid_lft forever preferred_lft forever
$ sudo ipset -L
Name: KUBE-IPVS-IPS
Type: hash:ip
Revision: 5
Header: family inet hashsize 1024 maxelem 65536 bucketsize 12 initval 0x70d2a064
Size in memory: 320
References: 1
Number of entries: 3
Members:
10.96.0.1
10.96.57.249
10.96.0.10
Name: KUBE-CLUSTER-IP
Type: hash:ip,port
Revision: 6
Header: family inet hashsize 1024 maxelem 65536 bucketsize 12 initval 0x9d4edeef
Size in memory: 440
References: 3
Number of entries: 5
Members:
10.96.0.10,udp:53
10.96.0.10,tcp:53
10.96.57.249,tcp:80
10.96.0.1,tcp:443
10.96.0.10,tcp:9153
Name: KUBE-LOOP-BACK
Type: hash:ip,port,ip
Revision: 6
Header: family inet hashsize 1024 maxelem 65536 bucketsize 12 initval 0x7a7e1a5a
Size in memory: 488
References: 1
Number of entries: 5
Members:
10.244.0.5,tcp:9153,10.244.0.5
10.244.0.7,tcp:80,10.244.0.7
10.244.0.6,tcp:80,10.244.0.6
10.244.0.5,udp:53,10.244.0.5
10.244.0.5,tcp:53,10.244.0.5*filter
-A INPUT -m comment --comment "kubernetes ipvs access filter" -j KUBE-IPVS-FILTER
-A KUBE-IPVS-FILTER -m set --match-set KUBE-CLUSTER-IP dst,dst -j RETURN
-A KUBE-IPVS-FILTER -m conntrack --ctstate NEW -m set --match-set KUBE-IPVS-IPS dst -j REJECT --reject-with icmp-port-unreachable这也是为什么在 ipvs 模式下,ping cluster ip 会返回错误
icmp-port-unreachable。
*nat
-A PREROUTING -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
-A OUTPUT -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
-A POSTROUTING -m comment --comment "kubernetes postrouting rules" -j KUBE-POSTROUTING
-A KUBE-LOAD-BALANCER -j KUBE-MARK-MASQ
-A KUBE-MARK-MASQ -j MARK --set-xmark 0x4000/0x4000
-A KUBE-POSTROUTING -m comment --comment "Kubernetes endpoints dst ip:port, source ip for solving hairpin purpose" -m set --match-set KUBE-LOOP-BACK dst,dst,src -j MASQUERADE
-A KUBE-POSTROUTING -j RETURN
-A KUBE-POSTROUTING -j MARK --set-xmark 0x4000/0x0
-A KUBE-POSTROUTING -m comment --comment "kubernetes service traffic requiring SNAT" -j MASQUERADE --random-fully
-A KUBE-SERVICES -s 127.0.0.0/8 -j RETURN
-A KUBE-SERVICES ! -s 10.244.0.0/16 -m comment --comment "Kubernetes service cluster ip + port for masquerade purpose" -m set --match-set KUBE-CLUSTER-IP dst,dst -j KUBE-MARK-MASQ
-A KUBE-SERVICES -m addrtype --dst-type LOCAL -j KUBE-NODE-PORT
-A KUBE-SERVICES -m set --match-set KUBE-CLUSTER-IP dst,dst -j ACCEPT调整 kube-proxy 使用 ipvs
IPVS proxier will employ IPTABLES in doing packet filtering, SNAT or masquerade. Specifically, IPVS proxier will use ipset to store source or destination address of traffics that need DROP or do masquerade, to make sure the number of IPTABLES rules be constant, no matter how many services we have.
$ kubectl -n kube-system get configmap
NAME DATA AGE
coredns 1 13m
extension-apiserver-authentication 6 13m
kube-apiserver-legacy-service-account-token-tracking 1 13m
kube-proxy 2 13m
kube-root-ca.crt 1 12m
kubeadm-config 1 13m
kubelet-config 1 13m
$ kubectl -n kube-system edit configmap kube-proxy
# change mode from "" to "ipvs"
$ kubectl -n kube-system get configmap kube-proxy -oyaml | grep mode
mode: "ipvs"
$ kubectl -n kube-system get pods
NAME READY STATUS RESTARTS AGE
coredns-7db6d8ff4d-44mqh 1/1 Running 0 14m
etcd-minikube 1/1 Running 0 15m
kube-apiserver-minikube 1/1 Running 0 15m
kube-controller-manager-minikube 1/1 Running 0 15m
kube-proxy-6s7hr 1/1 Running 0 9m55s
kube-scheduler-minikube 1/1 Running 0 15m
storage-provisioner 1/1 Running 1 (14m ago) 15m
# delete kube-proxy pod to take effect
$ kubectl -n kube-system delete pod kube-proxy-6s7hr
pod "kube-proxy-6s7hr" deleted
$ minikube ssh
$ sudo ipvsadm -L -n
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.96.57.249:80 rr
-> 10.244.0.3:80 Masq 1 0 0
-> 10.244.0.4:80 Masq 1 0 0如果 kube-proxy 的模式配置的是使用 ipvs,但是一个节点并未安装 ipvs 模块,那么在这个节点会自动降级使用 iptables。
域名服务
Kubernetes Service 通过虚拟 IP 地址或者节点端口为用户应用提供访问入口
然而这些 IP 地址和端口是动态分配的,如果用户重建一个服务,其分配的 clusterIP 和 nodePort,以及 LoadBalancerIP 都是会变化的,我们无法把一个可变的入口发布出去供他人访问
Kubernetes 提供了内置的域名服务,用户定义的服务会自动获得域名,而无论服务重建多少次,只要服务名不改变,其对应的域名就不会改变
CoreDNS
CoreDNS 包含一个内存态 DNS,以及与其他 controller 类似的控制器
CoreDNS 的实现原理是,控制器监听 Service 和 Endpoint 的变化并配置 DNS,客户端 Pod 在进行域名解析时,从 CoreDNS 中查询服务对应的地址记录
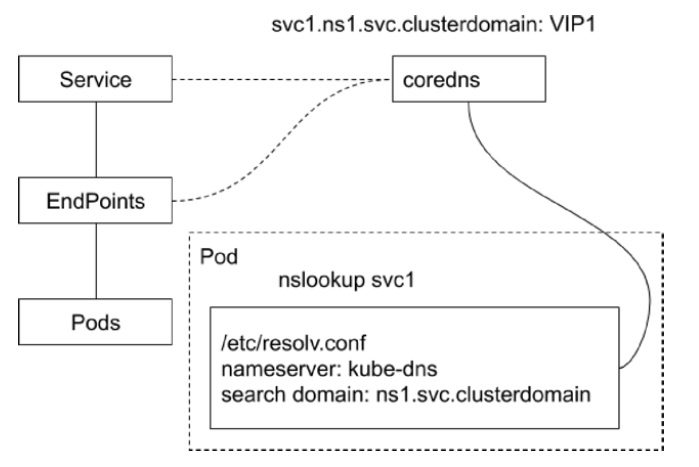
不同类型服务的 DNS 记录
- 普通 Service
- ClusterIP、nodePort、LoadBalancer 类型的 Service 都拥有 API Server 分配的 ClusterIP,CoreDNS 会为这些 Service 创建 FQDN 格式为
$svcname.$namespace.svc.$clusterdomain:clusterIP的 A 记录及 PTR 记录,并为端口创建 SRV 记录。
- ClusterIP、nodePort、LoadBalancer 类型的 Service 都拥有 API Server 分配的 ClusterIP,CoreDNS 会为这些 Service 创建 FQDN 格式为
- Headless Service
- 顾名思义,无头,是用户在 Spec 显式指定 ClusterIP 为 None 的 Service,对于这类 Service,API Server 不会为其分配 ClusterIP。CoreDNS 为此类 Service 创建多条 A 记录,并且目标为每个就绪的 PodIP。
- 另外,每个 Pod 会拥有一个 FQDN 格式为
$podname.$svcname.$namespace.svc.$clusterdomain的 A 记录指向 PodIP。
- ExternalName Service
- 此类 Service 用来引用一个已经存在的域名,CoreDNS 会为该 Service 创建一个 CName 记录指向目标域名。
从 ClusterIP 到 nodePort 到 LoadBalancer,后一个类型都包含前一个类型的内容。比如 NodePort 也会有一个 ClusterIP。
$ dig @10.96.0.10 nginx-headless-service.default.svc.cluster.local
; <<>> DiG 9.18.24-1-Debian <<>> @10.96.0.10 nginx-headless-service.default.svc.cluster.local
; (1 server found)
;; global options: +cmd
;; Got answer:
;; WARNING: .local is reserved for Multicast DNS
;; You are currently testing what happens when an mDNS query is leaked to DNS
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 20453
;; flags: qr aa rd; QUERY: 1, ANSWER: 3, AUTHORITY: 0, ADDITIONAL: 1
;; WARNING: recursion requested but not available
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 1232
; COOKIE: 6958770a033fcd30 (echoed)
;; QUESTION SECTION:
;nginx-headless-service.default.svc.cluster.local. IN A
;; ANSWER SECTION:
nginx-headless-service.default.svc.cluster.local. 30 IN A 10.244.0.13
nginx-headless-service.default.svc.cluster.local. 30 IN A 10.244.0.12
nginx-headless-service.default.svc.cluster.local. 30 IN A 10.244.0.14
;; Query time: 10 msec
;; SERVER: 10.96.0.10#53(10.96.0.10) (UDP)
;; WHEN: Thu May 16 10:29:47 UTC 2024
;; MSG SIZE rcvd: 281Kubernetes 中的域名解析
Kubernetes Pod 有一个与 DNS 策略相关的属性 DNSPolicy,默认值是 ClusterFirst。
Pod启动后的 /etc/resolv.conf 会被改写,所有的地址解析优先发送至 CoreDNS
$ cat /etc/resolv.conf
search ns1.svc.cluster.local svc.cluster.local cluster.local
nameserver 192.168.0.10
options ndots:4ndots 的意思是如果待查询的域名中点 “.” 的数量小于 ndots 的数量,那么解析这个域名时就是尝试将 search 后配置的域名按顺序添加到带解析的域名后,直到成功。
比如:解析域名 nginx-service 时,因为域名中的点 “.” 的个数为 0,小于配置的 ndots 数,就会依次尝试解析域名
nginx-service.ns1.svc.cluster.local,nginx-service.svc.cluster.local和nginx-service.cluster.local。
当 Pod 启动时,同一 Namespace 的所有 Service 都会以环境变量的形式设置到容器内(更准确的来说是能只用 service name 解析出同一 namespace 中的所有 service 的 IP)
影响?
自定义 DNSPolicy
apiVersion: v1
kind: Pod
metadata:
namespace: default
name: dns-example
spec:
containers:
- name: test
image: nginx
dnsPolicy: "None"
dnsConfig:
nameservers:
- 192.0.2.1 # this is an example
searches:
- ns1.svc.cluster-domain.example
- my.dns.search.suffix
options:
- name: ndots
value: "2"
- name: edns0CoreDNS 的配置
$ kubectl -n kube-system get configmap coredns -oyaml
apiVersion: v1
data:
Corefile: |
.:53 {
log
errors
health {
lameduck 5s
}
ready
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
fallthrough in-addr.arpa ip6.arpa
ttl 30
}
prometheus :9153
hosts {
192.168.49.1 host.minikube.internal
fallthrough
}
forward . /etc/resolv.conf {
max_concurrent 1000
}
cache 30
loop
reload
loadbalance
}
kind: ConfigMap
metadata:
creationTimestamp: "2024-05-16T09:16:06Z"
name: coredns
namespace: kube-system
resourceVersion: "253"
uid: aabafb2b-f121-4a2f-896b-89be5142d4d5关于 DNS 的落地实践
Kubernetes 作为企业基础架构的一部分,Kubernetes 服务也需要发布到企业 DNS,需要定制企业 DNS 控制器
- 对于 Kubernetes 中的服务,在企业 DNS 同样创建 A/PTR/SRV records (通常解析地址是 LoadBalancer VIP)
- 针对 headless service,在 PodIP 可全局路由的前提下,按需创建 DNS records
- Headless service 的 DNS 记录,应该按需创建,否则对企业 DNS 冲击过大
服务在集群内通过 CoreDNS 寻址,在集群外通过企业 DNS 寻址,服务在集群内外有统一标识。
Kubernetes 中的负载均衡技术
基于 L4 的服务
- 基于 iptables/ipvs 的分布式四层负载均衡技术
- 多种 Load Balancer Provider 提供与企业现有 ELB 的整合
- kube-proxy 基于 iptables rules 为 Kubernetes 形成全局统一的 distributed load balancer
- kube-proxy 是一种 mesh, InternalClient 无论通过 podip,nodeport 还是 LBVIP 都经由 kube-proxy 跳转至pod
- 属于 Kubernetes core
基于L7的 Ingress
- 基于七层应用层,提供更多功能
- TLS termination
- L7 path forwarding
- URL/http header rewrite
- 与采用 7 层软件紧密相关
Service 中的 Ingress 的对比
基于 L4 的服务
- 每个应用独占 ELB,浪费资源
- 为每个服务动态创建 DNS 记录,频繁的 DNS 更新
- 支持 TCP 和 UDP,业务部门需要启动 HTTPS 服务,自己管理证书
基于 L7 的 Ingress
- 多个应用共享 ELB,节省资源
- 多个应用共享一个 Domain,可采用静态 DNS 配置
- TLS termination 发生在 Ingress 层,可集中管理证书
- 更多复杂性,更多的网络 hop
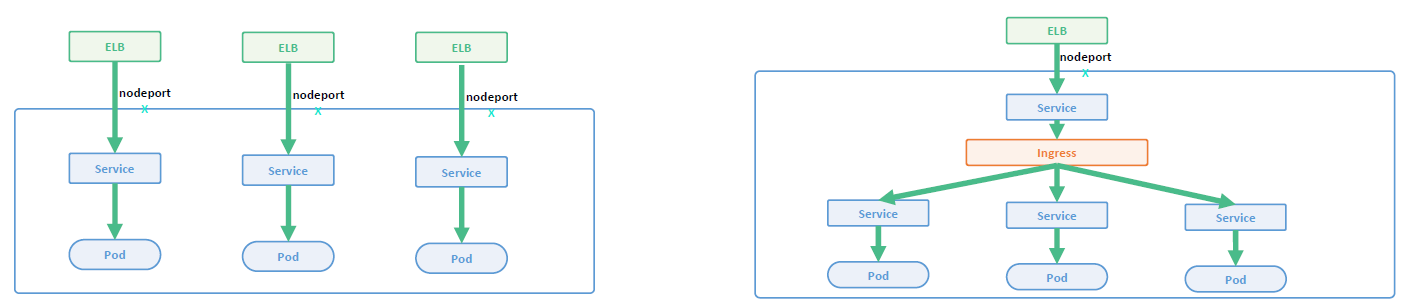
ingress
ingress
- Ingress 是一层代理
- 负责根据 hostname 和 path 将流量转发到不同的服务上,使得一个负载均衡器用于多个后台应用
- Kubernetes Ingress Spec 是转发规则的集合
ingress Controller
- 确保实际状态( Actual )与期望状态( Desired )一致的 ControlLoop
- Ingress Controller 确保
- 负载均衡配置
- 边缘路由配置
- DNS 配置
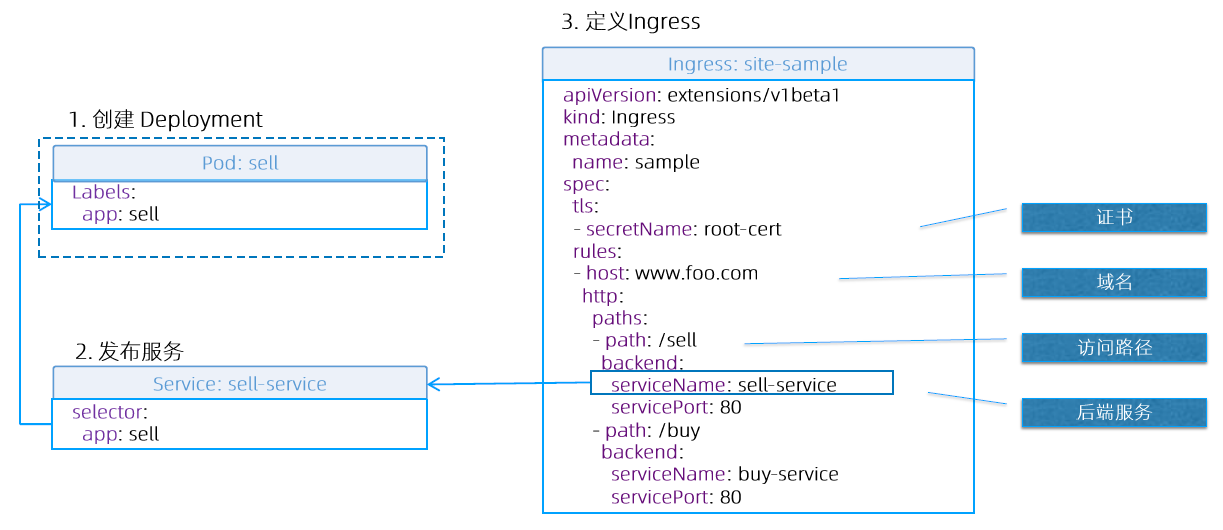
https://github.com/kibaamor/101/blob/master/module8/ingress/ingress.MD
https://cert-manager.io/docs/configuration/ca/
https://cert-manager.io/docs/configuration/selfsigned/
# 生成 key 和 cert
$ openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout tls.key -out tls.crt \
-subj '/CN=*/O=kiba' \
-addext 'subjectAltName = DNS:kiba.zen'
# OR
$ mkcert -key-file tls.key -cert-file tls.crt -- kiba.zen
# 创建 secret
$ kubectl create secret tls kiba-tls --cert=./tls.crt --key=./tls.key
secret/kiba-tls created# filename: nginx.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deploy
spec:
selector:
matchLabels:
app: nginx-pod
replicas: 3
template:
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx
---
apiVersion: v1
kind: Service
metadata:
name: nginx-svc
spec:
selector:
app: nginx-pod
ports:
- port: 80
targetPort: 80
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: nginx-ingress
spec:
ingressClassName: nginx
tls:
- hosts:
- kiba.zen
secretName: kiba-tls
rules:
- host: kiba.zen
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: nginx-svc
port:
number: 80# 创建 nginx
$ kubectl apply -f nginx.yaml
deployment.apps/nginx-deploy created
service/nginx-svc created
ingress.networking.k8s.io/nginx-ingress created
$ minikube ip
192.168.49.2
# 确保没有代理,https_proxy 和 HTTPS_PROXY 的值为空
$ https_proxy= HTTPS_PROXY= curl --resolve "kiba.zen:443:192.168.49.2" --cacert ./tls.crt https://kiba.zen
# OR
$ curl --noproxy '*' --resolve "kiba.zen:443:192.168.49.2" --cacert ./tls.crt https://kiba.zen
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>传统应用网络拓扑
三步构建 Ingress Controller
复用 Kubernetes LoadBalancer 接口
GetLoadBalancer(clusterName string, service *api.Service) (*api.LoadBalancerStatus, bool, error)
EnsureLoadBalancer(clusterName string, service *api.Senvice, members []string) (*api.LoadBalancerStatus, error)
UpdateLoadBalancer(clusterName string, service *api.Service, members []string) (*api.oadBalancerStatus, error)
EnsureLoadBalancerDeleted(clusterName string, service *api.Service) error定义 Informer,监控 ingress,secret,service,endpoint 的变化,加入相应的队列
lbc.ingLister.Store,lbc.ingController = framework.Newinformer(
&cache.Listwatch{
ListFunc: ingressListFunc(lbc.client, namespace),
WatchFunc: ingressWatchFunc(lbc.client, namespace),
},
&extensions.Ingress{}, resyncPeriod, framework.ResourceEventHandlerFuncs{
AddFunc: func(obi interface{}){
lbc.ingQueue.enqueueing(obj)
},
})启动 worker,遍历 ingress 队列
- 为 Ingress Domain 创建 LoadBalancer service 依 赖service controller 创建 ingress vip
- 为 Ingress Domain 创建 DNS A record 并指向 Ingress VIP
- 更新 Ingress 状态
为什么需要构建 SLB(Soft Load Balancer) 方案
成本
- 硬件 LB 价格昂贵
- 固定的 tech refresh 周期
配置管理
- LB 设备的 onboard/offboard 由不同 team 管理
- 不同设备 API 不一样,不支持 L7 API
- 基于传统的 ssh 接口,效率低下
- Flex up/down 以及 Migration 复杂
部署模式
- 1+1 模式
- 隔离性差
堪待解决的问题
负载均衡配置
- 7 层方案:Envoy vs. Nginx vs. Haproxy
- 4 层方案:抛弃传统 HLB(Hardware Load Balancer) 的支持,用 IPVS 取代
边缘路由配置
- Ingress VIP 通过 BGP 协议发布给 TOR (Top-of-rack)
DNS 配置
- Ingress VIP 通过 BGP 协议发布给 TOR (Top-of-rack)
需要解决问题:如何让 domain 用户自定义后台应用的访问地址,如何优化访问路径
L4 Provider
IPVS 插件
- 基于 IPAM 分配 VIP
- 将 VIP 绑定至 IPVS Directors
- 创建 IP tunnel
- 通过 BGP 发布 VIP 路由
L7 Provider
- 基于 Envoy 提供 L7 Path forwarding
- 可以提供 TLS Termination
- 基于 upstream 的 Istio 实现配置管理和热加载
- 基于 Istio 实现 Service Mesh
DNS Provider
- 创建 DNS 记录
- 为多个 Cluster 的 ingress VIP 生成相同的 DNS 记录实现 DNS 联邦
Ingress Controller
- 编排控制器
- 为 ingress 创建 service object,将 LB 配置委派给 service controller
- 创建 configmap 为每个 ingress 创建 envoy 配置
- 创建 L7 pod 的 deployment 加载 envoy 集群
- 生成 DNS 记录
L4 集群架构

L7 集群架构
数据流

跨大陆的互联网调用
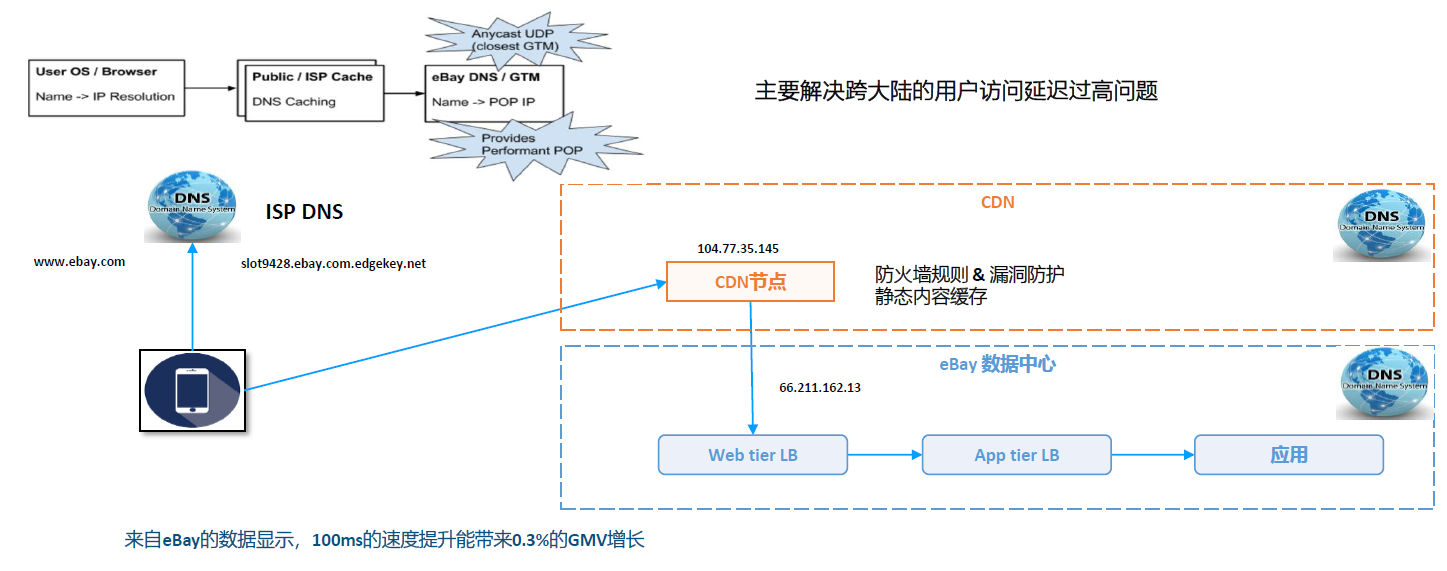
互联网路径的不确定性
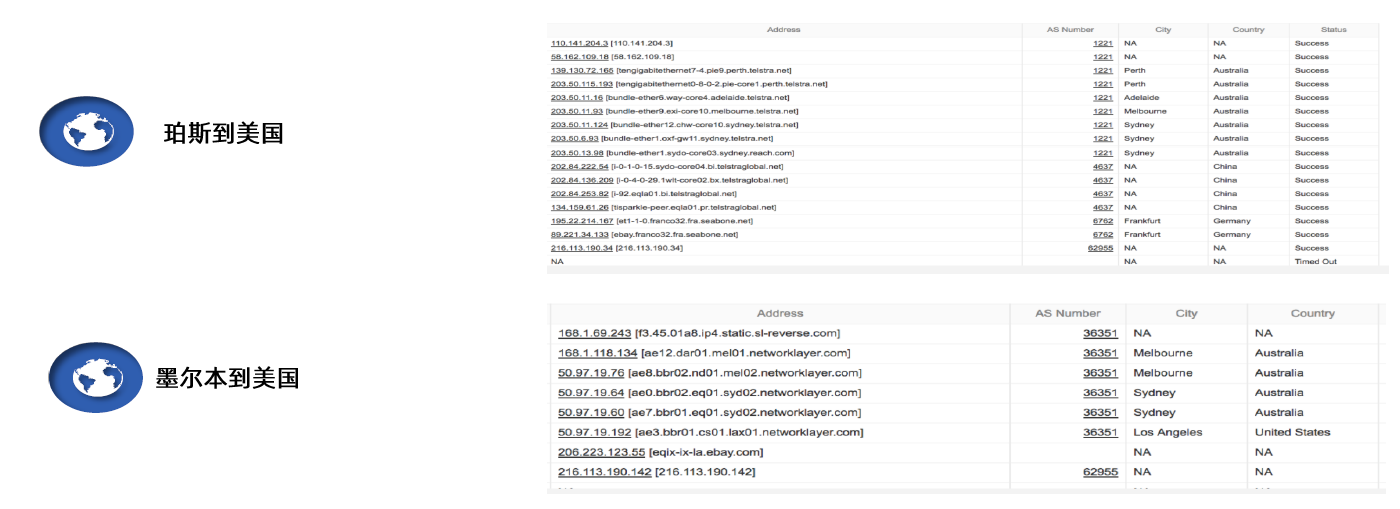
边缘加速方案综述

边缘加速组件
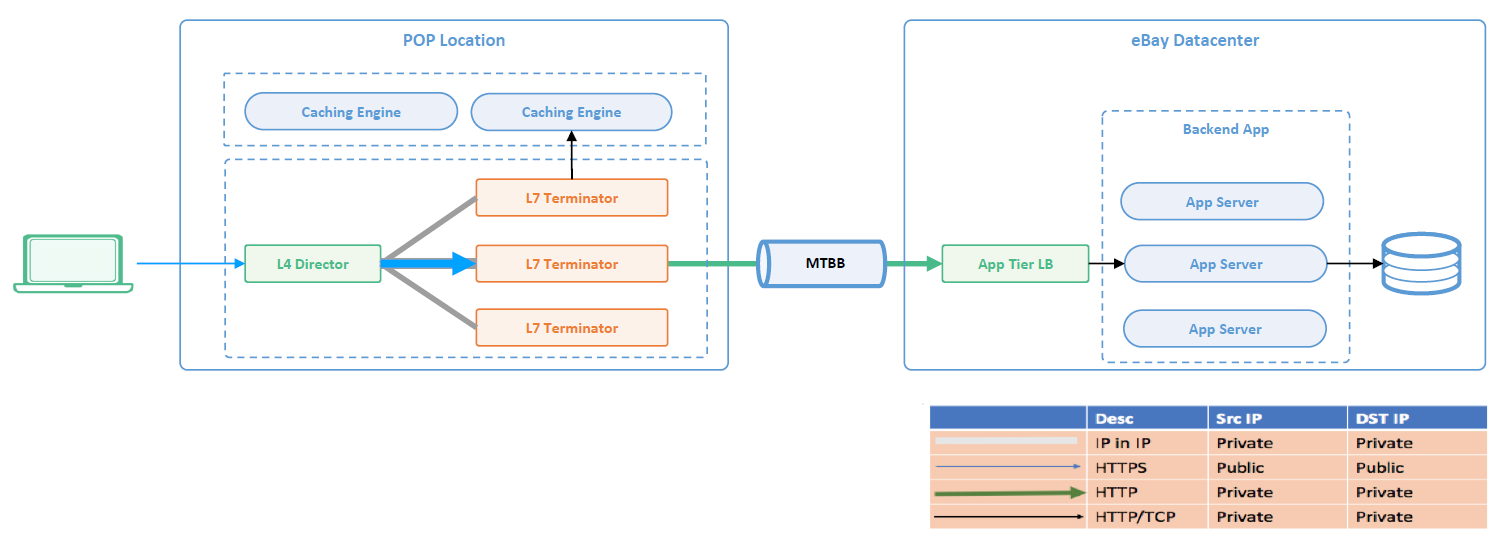
POP 指边缘的小的数据中心。
对网络路径的优化
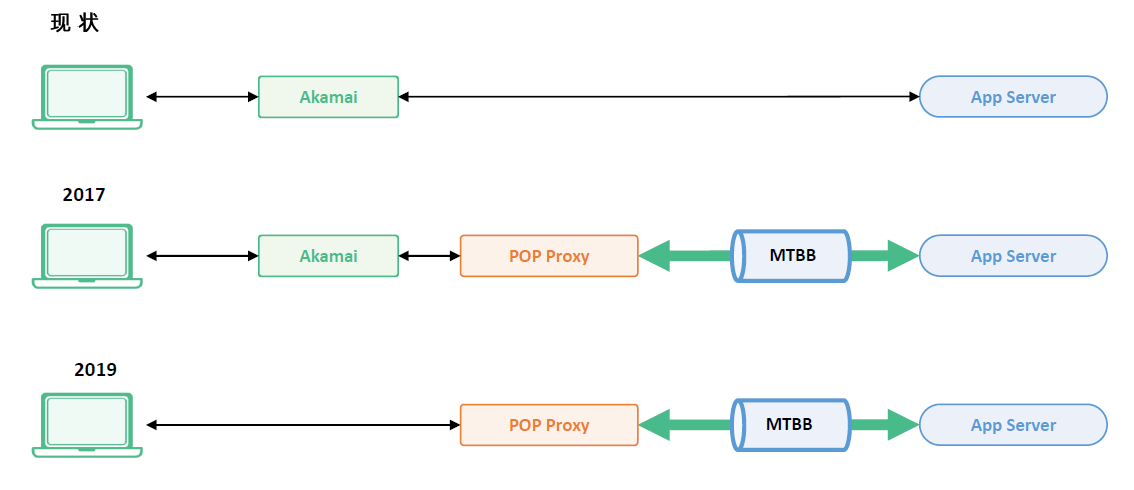
不同方案的响应时间对比
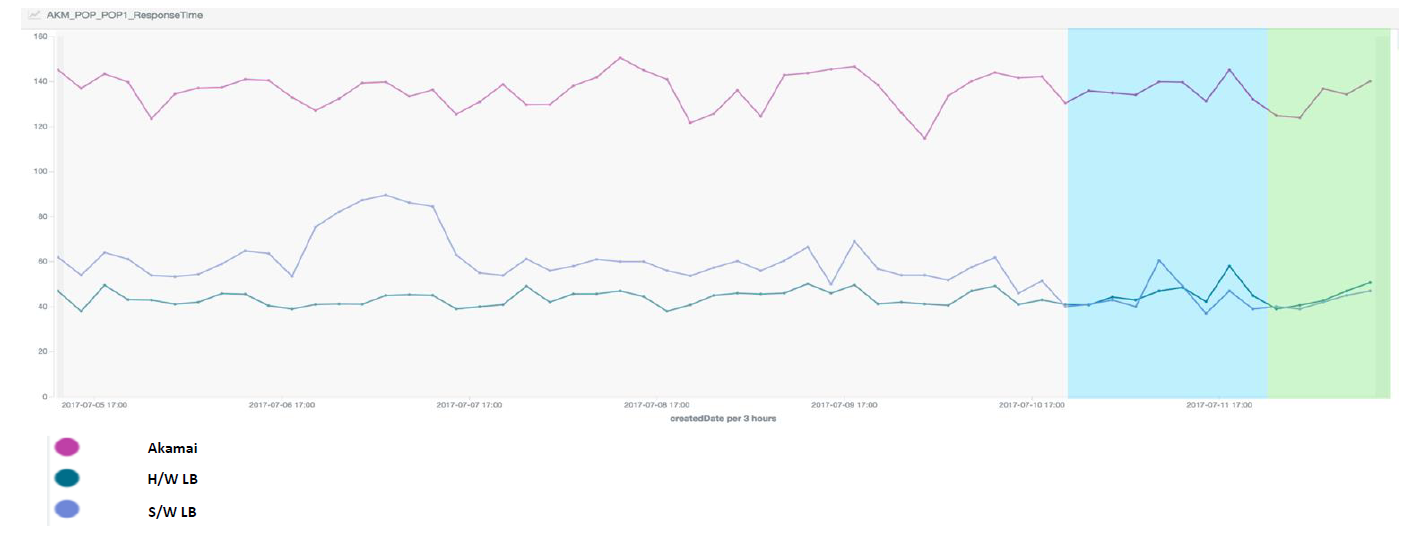
课后作业(第二部分)
除了将 httpServer 应用优雅的运行在 Kubernetes 之上,我们还应该考虑如何将服务发布给对内和对外的调用方。
来尝试用 Service,Ingress 将你的服务发布给集群外部的调用方吧
在第一部分的基础上提供更加完备的部署 spec,包括(不限于)
- Service
- Ingress
可以考虑的细节
- 如何确保整个应用的高可用
- 如何通过证书保证 httpServer 的通讯安全
生产化集群的管理
计算节点相关
生产化集群的考量
计算节点:
- 如何批量安装和升级计算节点的操作系统?
- 如何管理配置计算节点的网络信息?
- 如何管理不同 SKU(Stock Keeping Unit) 的计算节点?
- 如何快速下架故障的计算节点?
- 如何快速扩缩集群的规模?
控制平面:
- 如何在主节点上下载、安装和升级控制平面组件及其所需的配置文件?
- 如何确保集群所需的其他插件,例如 CoreDNS、监控系统等部署完成?
- 如何准备控制平面组件的各种安全证书?
- 如何快速升级或回滚控制平面组件的版本?
操作系统选择
操作系统的评估与选择
通用操作系统
- Ubuntu
- CentOs
- Fedora
专为容器优化的操作系统
- 最小化操作系统
- CoreOS
- RedHat Atomic
- Snappy Ubuntu core
- RancherOS
操作系统评估和选型的标准
- 是否有生态系统
- 成熟度
- 内核版本
- 对运行时的支持
- Init System
- 包管理和系统升级
- 安全
生态系统与成熟度
容器优化操作系统的优势
原子级升级和回退更高的安全性

云原生的原则
可变基础设施的风险
- 在灾难发生的时候,难以重新构建服务。持续过多的手工操作,缺乏记录,会导致很难由标准初始化后的服务器来重新构建起等效的服务。
- 在服务运行过程中,持续的修改服务器,就犹如程序中的可变变量的值发生变化而引入的状态不一致的并发风险。这些对于服务器的修改,同样会引入中间状态,从而导致不可预知的问题。
不可变基础设施 (immutable infrastructure)
- 不可变的容器镜像
- 不可变的主机操作系统
Atomic
由 Red Hat 支持的软件包安装系统
多种 Distro
- Fedora
- CentOS
- RHEL
优势
- 不可变操作系统,面向容器优化的基础设施
- 灵活和安全性较好
- 只有 /etc 和 /var 可以修改,其他目录均为只读
- 基于 rpm-ostree 管理系统包
- rpm-ostree 是一个开源项目,使得生产系统中构建镜像非常简单
- 支持操作系统升级和回滚的原子操作
最小化主机操作系统
原则:
- 最小化主机操作系统。
- 只安装必要的工具
- 必要:支持系统运行的最小工具集
- 任何调试工具,比如性能排查,网络排查工具,均可以后期以容器形式运行。
- 意义
- 性能
- 稳定性
- 安全保障
操作系统构建流程
ostree
提供一个共享库(libostree)和一些列命令行
提供与 git 命令行一致的体验,可以提交或者下载一个完整的可启动的文件系统树
提供将 ostree 部署进 bootloader 的机制
https://github.com/ostreedev/ostree/blob/main/src/boot/dracut/module-setup.sh
install() {
dracut_install /usr/lib/ostree/ostree-prepare-root
for r in /usr/lib /etc; do
if test -f "$r/ostree/prepare-root.conf"; then
inst_simple "$r/ostree/prepare-root.conf"
fi
done
if test -f "/etc/ostree/initramfs-root-binding.key"; then
inst_simple "/etc/ostree/initramfs-root-binding.key"
fi
inst_simple "${systemdsystemunitdir}/ostree-prepare-root.service"
mkdir -p "${initdir}${systemdsystemconfdir}/initrd-root-fs.target.wants"
ln_r "${systemdsystemunitdir}/ostree-prepare-root.service" \
"${systemdsystemconfdir}/initrd-root-fs.target.wants/ostree-prepare-root.service"
}构建 ostree

rpm-ostree
- 基于 treefile 将 rpm 包构建成为 ostree
- 管理 ostree 以及 bootloader 配置
treefile
- refer: 分支名(版本,cpu 架构)
- repo: rpm package repositories
- packages: 待安装组件
将 rpm 构建成 ostree
rpm-ostree compose tree --unified-core --cachedir=cache --repo=./build-repo/path/to/treefile.json
加载 ostree
初始化项目
ostree admin os-init centos-atomic-host
导入 ostree repo
ostree remote add atomic http://ostree.svr/ostree
拉取ostree
ostree pull atomic centos-atomic-host/8/x86 64/standard
部署 os
ostree admin deploy --os=centos-atomic-hostcentos-atomic-host/8/x86_64/standard --karg='root=/dev/atomicos/root
操作系统加载
物理机
- 物理机通常需要通过 foreman 启动,foreman 通过 pxe boot,并加载 kickstart
- kickstart 通过 ostree deploy 即可完成操作系统的部署
虚拟机
- 需要通过镜像工具将 ostree 构建成 qcow2 格式,vhd,raw 等模式
生产环境遭遇过的陷阱
cloud-init 0.7.7 bug
- 阻止 node 在初始化过程中的静态网络配置
Docker 1.9.1 bug
- 当 docker 实例日志快速输出时,会发生内存泄漏
Kernel panic in 4.4.6
- Cgroup 创建和销毁过程中,会产生kernel panic
rootfs 分区太小
- rootfs 无空间会导致 docker 无法启动
- 导致 rootfs 占满的情况
- CICD 中的 Maven build 会把下载的 lib 放在 /tmp
- 用户 Docker logs 日志过快,导致一个 log rotation 周期内日志文件撑爆硬盘
- 导致 rootfs 占满的情况
需要定制化的操作系统参数
- 比如 Elasticsearch 需要 max_map_count >= 262144,但操作系统默认值为 65535,我们需要在创建 Node 的时候就 apply 这个配置
节点资源管理
NUMA Node
Non-Uniform Memory Access是一种内存访问方式,是为多处理器计算机设计的内存架构。
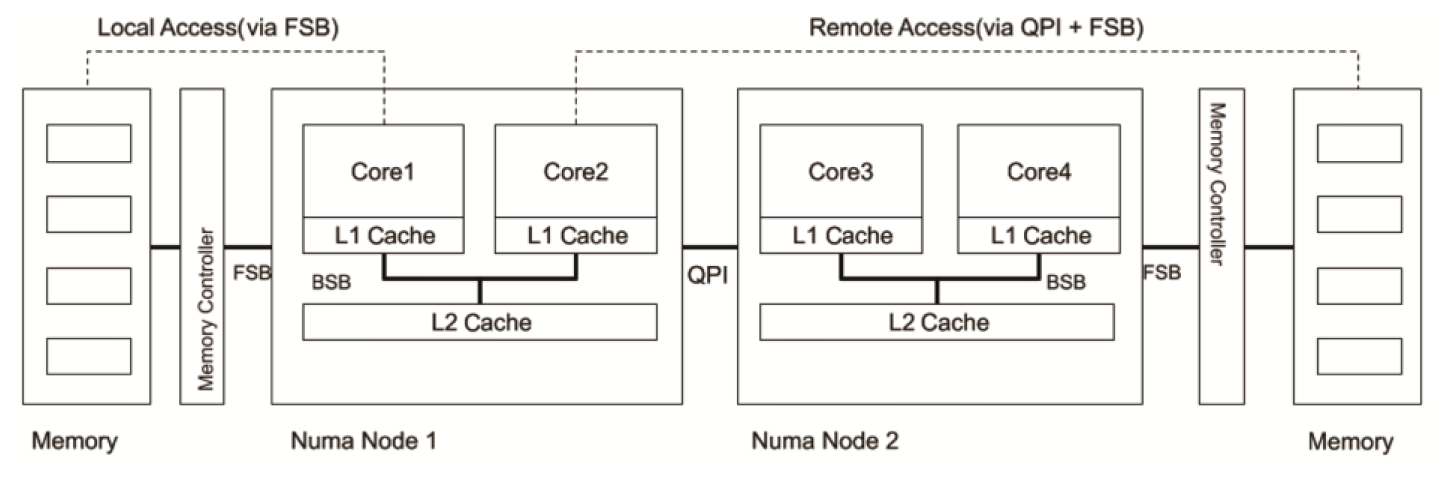
节点资源管理
状态汇报
资源预留
防止节点资源耗尽的防御机制驱逐
容器和系统资源的配置
状态上报
kubelet 周期性地向 APIServer 进行汇报,并更新节点的相关健康和资源使用信息
- 节点基础信息,包括 IP 地址、操作系统、内核、运行时、kubelet、kube-proxy版本信息。
- 节点资源信息包括 CPU、内存、HugePage、临时存储、GPU 等注册设备,以及这些资源中可以分配给容器使用的部分。
- 调度器在为 Pod 选择节点时会将机器的状态信息作为依据。

Lease
在早期版本 kubelet 的状态上报直接更新 node 对象,而上报的信息包含状态信息和资源信息,因此需要传输的数据包较大,给 APIServer 和 etcd 造成的压力较大。
后引入 Lease 对象用来保存健康信息,在默认 40s 的 nodeLeaseDurationSeconds 周期内,若 Lease 对象没有被更新,则对应节点可以被判定为不健康。
apiVersion: coordination.k8s.io/v1
kind: Lease
metadata:
creationTimestamp: "2021-08-19T02:50:09Z"
name: k8snode
namespace: kube-node-lease
ownerReferences:
- apiVersion:v1
kind: Node
name: k8snode
uid: 58679942-e2dd-4ead-aada-385f099d5f56
resourceVersion: "1293702"
uid: 1bf51951-b832-49da-8708-4b224b1ec3ed
spec:
holderIdentity: k8snode
leaseDurationSeconds: 40
renewTime: "2021-09-08T01:34:16.489589Z"资源预留
计算节点除用户容器外,还存在很多支撑系统运行的基础服务,譬如 systemd、journald、sshd、dockerd、Containerd、kubelet 等。
为了使服务进程能够正常运行,要确保它们在任何时候都可以获取足够的系统资源,所以我们要为这些系统进程预留资源。
kubelet 可以通过众多启动参数为系统预留 CPU、内存、PID 等资源,比如 SystemReserved、KubeReserved 等。
Capacity 和 Allocatable
容量资源 (Capacity) 是指 kubelet 获取的计算节点当前的资源信息。
- CPU 是从 /proc/cpuinfo 文件中获取的节点 CPU 核数;
- memory 是从 /proc/memoryinfo 中获取的节点内存大小;
- ephemeral-storage 是指节点根分区的大小。
资源可分配额 (Allocatable) 是用户 Pod 可用的资源,是资源容量减去分配给系统的资源的剩余部分。
allocatable:
cpu: "24"
ephemeral-storage: 205838Mi
memory: 177304536Ki
pods: "110"
capacity:
cpu: "24"
ephemeral-storage: 205838Mi
memory: 179504088Ki
pods: "110"
节点磁盘管理
https://github.com/kibaamor/101/blob/master/module9/node/readme.MD
https://kubernetes.io/docs/concepts/scheduling-eviction/node-pressure-eviction/#eviction-signals
系统分区 nodefs
- 工作目录和容器日志
- The node’s main filesystem, used for local disk volumes, emptyDir volumes not backed by memory, log storage, and more. For example, nodefs contains /var/lib/kubelet/.
容器运行时分区 imagefs
- 用户镜像和容器可写层
- 容器运行时分区是可选的,可以合并到系统分区中
- An optional filesystem that container runtimes use to store container images and container writable layers.
驱逐管理
kubelet 会在系统资源不够时中止一些容器进程,以空出系统资源,保证节点的稳定性。
但由 kubelet 发起的驱逐只停止 Pod 的所有容器进程,并不会直接删除Pod(便于查看原因)。
- Pod 的 status.phase 会被标记为 Failed
- status.reason 会被设置为 Evicted
- status.message 则会记录被驱逐的原因
资源可用额监控
kubelet 依赖内嵌的开源软件 cAdvisor,周期性检查节点资源使用情况
CPU 是可压缩资源,根据不同进程分配时间配额和权重,CPU 可被多个进程竞相使用
驱逐策略是基于磁盘和内存资源用量进行的,因为两者属于不可压缩的资源,当此类资源使用耗尽时将无法再申请
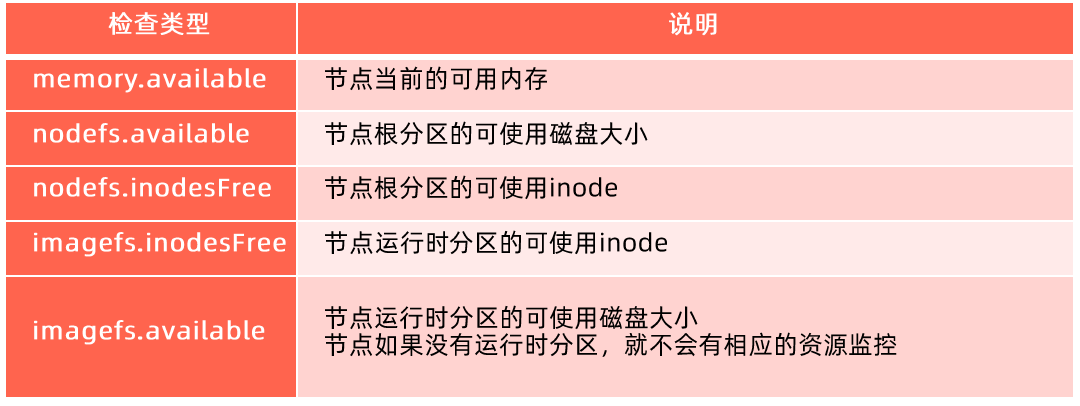
驱逐策略
kubelet 获得节点的可用额信息后,会结合节点的容量信息来判断当前节点运行的 Pod 是否满足驱逐条件。
驱逐条件可以是绝对值或百分比,当监资源的可使用额少于设定的数值或百分比时,kubelet 就会发起驱逐操作。
kubelet 参数 evictionMinimumReclaim 可以设置每次回收的资源的最小值,以防止小资源的多次回收。

基于内存压力的驱逐
memory.avaiable 表示当前系统的可用内存情况。
kubelet 默认设置了 memory.avaiable<100Mi 的硬驱逐条件
当 kubelet 检测到当前节点可用内存资源紧张并满足驱逐条件时,会将节点的 MemoryPressure 状态设置为 True,调度器会阻止 BestEffortPod 调度到内存承压的节点。
kubelet 启动对内存不足的驱逐操作时,会依照如下的顺序选取目标 Pod:
- 判断 Pod 所有容器的内存使用量总和是否超出了请求的内存量,超出请求资源的 Pod 会成为备选目标
- 查询 Pod 的调度优先级,低优先级的 Pod 被优先驱逐
- 计算 Pod 所有容器的内存使用量和 Pod 请求的内存量的差值,差值越小,越不容易被驱逐
基于磁盘压力的驱逐
以下任何一项满足驱逐条件时,它会将节点的 DiskPressure 状态设置为 True,调度器不会再调度任何 Pod 到该节点上
- nodefs.available
- nodefs.inodesFree
- imagefs.available
- imagefs.inodesFree
驱逐行为
- 有容器运行时分区
- nodefs 达到驱逐阈值,那么 kubelet 删除已经退出的容器
- imagefs 达到驱逐阈值,那么 kubelet 删除所有未使用的镜像
- 无容器运行时分区
- kubelet 同时删除未运行的容器和未使用的镜像
回收已经退出的容器和未使用的镜像后,如果节点依然满足驱逐条件,kubelet 就会开始驱逐正在运行的 Pod,进一步释放磁盘空间。
- 判断 Pod 的磁盘使用量是否超过请求的大小,超出请求资源的 Pod 会成为备选目标
- 查询Pod的调度优先级,低优先级的 Pod 优先驱逐
- 根据磁盘使用超过请求的数量进行排序,差值越小,越不容易被驱逐
容器和资源配置
CPU CGroup 配置
针对不同 QoS Class 的 Pod,Kubneretes 按如下 Hierarchy 组织 cgroup 中的 CPU 子系统
实际测试发现:burstable 容器的 cpu.cfs_quota_us 如果没配就是 -1,如果配置了就是实际的值。
内存 CGroup 配置
针对不同 QoS Class 的Pod,Kubneretes 按如下 Hierarchy 组织 cgroup 中的 Memory 子系统
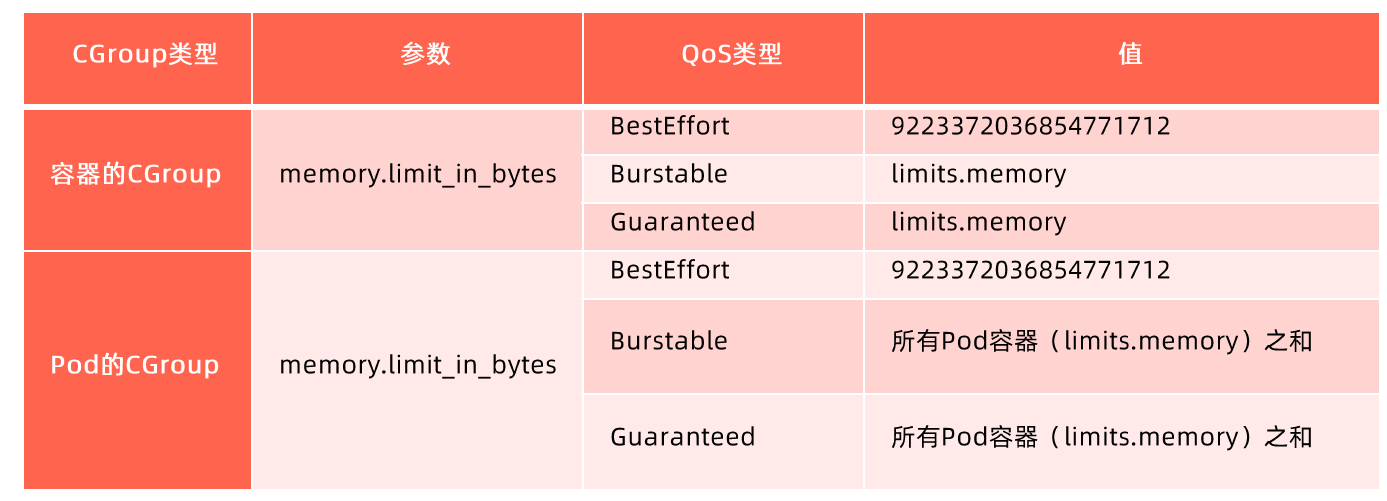
实际测试发现:burstable 容器的 memory.limit_in_bytes 如果没配就是 9223372036854771712(即未限制),如果配置了就是实际的值。。
OOM Killer 行为
https://github.com/kibaamor/101/blob/master/module9/oom_score/oom_score.md
系统的 OOM Killer 可能会采取 OOM 的方式来中止某些容器的进程,进行必要的内存回收操作
而系统根据进程的 oom_score 来进行优先级排序,选择待终止的进程,且进程的 oom_score 越高,越容易被终止
进程的 oom_score 是根据当前进程使用的内存占节点总内存的比例值乘以 10,再加上 oom_score_adj 综合得到的
而容器进程的 oom_score_adj 正是 kubelet 根据 memory.request 进行设置的

日志管理
节点上需要通过运行 logrotate 的定时任务对系统服务日志进行 rotate 清理,以防止系统服务日志占用大量的磁盘空间。
- logrotate 的执行周期不能过长,以防日志短时间内大量增长,
- 同时配置日志的 rotate 条件,在日志不占用太多空间的情况下,保证有足够的日志可供查看,
- Docker
- 除了基于系统 loarotate 管理日志,还可以依赖 Docker 自带的日志管理功能来设置容器日志的数量和每个日志文件的大小。
- Docker 写入数据之前会对日志大小进行检查和 rotate 操作,确保日志文件不会超过配置的数量和大小。
- Containerd
- 日志的管理是通过 kubelet 定期(默认为10s)执行
du命令,来检查容器日志的数量和文件的大小的。 - 每个容器日志的大小和可以保留的文件个数,可以通过 kubelet 的配置参数
container-log-max-size和container-log-max-files进行调整。
- 日志的管理是通过 kubelet 定期(默认为10s)执行
Docker卷管理
在构建容器镜像时,可以在 Dockerfile 中通过 VOLUME 指令声明一个存储卷,目前 Kubernetes 尚未将其纳入管控范围,不建议使用。
如果容器进程在可写层或 emptyDir 卷进行大量读写操作,就会导致磁盘 I/O 过高,从而影响其他容器进程甚至系统进程。
Docker 和 Containerd 运行时都基于 CGroupv1 。对于块设备,只支持对 Direct I/O 限速,而对于 Buffer I/O 还不具备有效的支持。因此,针对设备限速的问题,目前还没有完美的解决方案对于有特殊 I/O 需求的容器,建议使用独立的磁盘空间。
网络资源
由网络插件通过 LinuxTraffic control 为 Pod 限制带宽
可利用 CNI 社区提供的 bandwidth 插件
apiVersion: v1
kind: Pod
metadata:
annotations:
kubernetes.io/ingress-bandwidth: 10MB
kubernetes.io/egress-bandwidth: 10MB
...进程数
kubelet 默认不限制 Pod 可以创建的子进程数量,但可以通过启动参数 podPidsLimit 开启限制,还可以由 reserved 参数为系统进程预留进程数。
- kubelet 通过系统调用周期性地获取当前系统的 PID 的使用量,并读取
/proc/sys/kernel/pid_max获取系统支持的 PID 上限。 - 如果当前的可用进程数少于设定阈值,那么 kubelet 会将节点对象的 PIDPressure 标记为 True
- kube-scheduler 在进行调度时,会从备选节点中对处于 NodeUnderPIDPressure 状态的节点进行过滤。
节点异常检测
Kubernetes集群可能存在的问题
基础架构守护程序问题: NTP服务关闭;
硬件问题: CPU,内存或磁盘损坏;
内核问题: 内核死锁,文件系统损坏;
容器运行时问题: 运行时守护程序无响应
…
当 kubernetes 中节点发生上述问题,在整个集群中,k8s 服务组件并不会感知以上问题,就会导致 pod 仍会调度至问题节点。
node-problem-detector
为了解决这个问题,社区引入了守护进程 node-problem-detector,从各个守护进程收集节点问题,并使它们对上游层可见。
Kubernetes 节点诊断的工具,可以将节点的异常,例如
- Runtime 无响应
- Linux Kernel 无响应
- 网络异常
- 文件描述符异常
- 硬件问题如 CPU,内存或者磁盘故障
故障分类
问题汇报手段
node-problem-detector 通过设置 NodeCondition 或者创建 Event 对象来汇报问题
- NodeCondition: 针对永久性故障,会通过设置 Nodecondition 来改变节点状态
- Event: 临时故障通过 Event 来提醒相关对象,比如通知当前节点运行的所有 Pod
上手实践
代码 https://github.com/kubernetes/node-problem-detector
安装
helm repo add deliveryhero https://charts.deliveryhero.io
helm install deliveryhero/node-problem-detector使用插件 pod 启用 NPD
如果你使用的是自定义集群引导解决方案,不需要覆盖默认配置,可以利用插件 Pod 进一步自动化部署。
创建 node-strick-detector.yaml,并在控制平面节点上保存配置到插件 Pod 的目录 /etc/kubernetes/addons/node-problem-detector。
NPD 的异常处理行为
NPD 只负责获取异常事件,并修改 node condition,不会对节点状态和调度产生影响
lastHeartbeatTime: "2021-11-06T15:44:46Z"
lastTransitionTime: "2021-11-06T15:29:43Z"
message: 'kernel: INFO: task docker:20744 blocked for more than 120 seconds.'
reason: DockerHung
status: "True"
type: KernelDeadlock需要自定义控制器,监听 NPD 汇报的 condition,taint node,阻止 pod 调度到故障节点
问题修复后,重启 NPD Pod 来清理错误事件
常用节点问题排查手段
ssh 到内网节点
创建一个支持 ssh 的 pod
并通过负载均衡器转发 ssh 请求
https://github.com/kibaamor/101/blob/master/module9/node-problem-detector/ssh-pod.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: ssh
spec:
replicas: 1
selector:
matchLabels:
app: ssh
template:
metadata:
labels:
app: ssh
spec:
containers:
- name: alpine
image: alpine
stdin: true
tty: true
hostNetwork: true
nodeName: cadmin查看日志
针对使用 systemd 拉起的服务
journalctl -afu kubelet-S "2019-08-26 15:00:00"
# -u unit,对应的 systemd 拉起的组件,如 kubelet
# -f follow,跟踪最新日志
# -a show all,显示所有日志列
# -S since,从某一时间开始 -S "2019-08-26 15:00:00"对于标准的容器日志
kubectl logs -f -c <containername> <podname>
kubectl logs -f --all-containers <podname>
kubectl logs -f -c <podname> --previous如果容器日志被 shell 转储到文件,则需通过 exec kubectl exec -it xxx --tail -f /path/to/log
基于 extended resource 扩展节点资源
扩展资源
扩展资源是 kubernetes.io 域名之外的标准资源名称。它们使得集群管理员能够颁布非 Kubernetes 内置资源,而用户可以使用他们。
自定义扩展资源无法使用 kubernetes.io 作为资源域名
管理扩展资源
节点级扩展资源
- 节点级扩展资源绑定到节点
设备插件管理的资源
- 发布在各节点上由设备插件所管理的资源,如GPU,智能网卡等
为节点配置资源
集群操作员可以向 API 服务器提交 PATCH HTTP 请求,以在集群中节点的 status.capacity 中为其配置可用数量。
完成此操作后,节点的 status.capacity 字段中将包含新资源。
kubelet 会异步地对 status.allocatable 字段执行自动更新操作,使之包含新资源
调度器在评估 Pod 是否适合在某节点上执行时会使用节点的 status.allocatable 值,在更新节点容量使之包含新资源之后和请求该资源的第一个 Pod 被调度到该节点之间,可能会有短暂的延迟。
https://github.com/kibaamor/101/blob/master/module9/extended-resource/extended-resource.MD
curl --key admin.key --cert admin.crt --header "Content-Type: application/json-patch+json" \
--request PATCH -k \
--data '[{"op": "add", "path": "/status/capacity/cncamp.com~1reclaimed-cpu", "value": "2"}]' \
https://192.168.34.2:6443/api/v1/nodes/cadmin/status使用扩展资源
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
cncamp.com/reclaimed-cpu: 3
reguests:
cncamp.com/reclaimed-cpu: 3$ minikube cp ~/.minikube/profiles/minikube/client.key /home/docker/client.key
$ minikube cp ~/.minikube/profiles/minikube/client.crt /home/docker/client.crt
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 107m
$ minikube ssh
$ curl \
--key /home/docker/client.key \
--cert /home/docker/client.crt \
--header "Content-Type: application/json-patch+json" \
--request PATCH \
--data '[{"op": "add", "path": "/status/capacity/minikube~1reclaimed-cpu", "value": "2"}]' \
https://10.96.0.1:443/api/v1/nodes/minikube/status
$ kubectl get node minikube -oyaml
...
status:
allocatable:
cpu: "12"
ephemeral-storage: 1055762868Ki
hugepages-1Gi: "0"
hugepages-2Mi: "0"
memory: 65713372Ki
minikube/reclaimed-cpu: "2"
pods: "110"
capacity:
cpu: "12"
ephemeral-storage: 1055762868Ki
hugepages-1Gi: "0"
hugepages-2Mi: "0"
memory: 65713372Ki
minikube/reclaimed-cpu: "2"
pods: "110"
...集群层面的扩展资源
可选择由默认调度器管理资源,默认调度器像管理其他资源一样管理扩展资源
- Request 与 Limit 必须一致,因为 Kubernetes 无法确保扩展资源的超售
更常见的场景是,由调度器扩展程序 (SchedulerExtenders) 管理,这些程序处理资源消耗和资源配额
修改调度器策略配置 ignoredByScheduler 字段可配置调度器不要检查自定义资源
{
"kind": "Policy",
"apiVersion": "V1",
"extenders": [
{
"urlPrefix": "<extender-endpoint>",
"bindVerb": "bind",
"managedResources": [
{
"name": "example.com/foo",
"ignoredByScheduler": true
}
]
}
]
}扩展资源的一个应用:对于有波峰波谷的应用,在波谷时把闲置资源声明成扩展资源,这样就能让其他应用调度到节点上来使用闲置的资源。
构建和管理高可用集群
Kubernetes 高可用层级
高可用的数据中心
多地部署
每个数据中心需要划分成具有独立供电、制冷、网络设备的高可用区
每个高可用区管理独立的硬件资产,包括机架、计算节点、存储、负载均衡器、防火墙等硬件设备
Node 的生命周期管理
运营 Kubernetes 集群,不仅仅是集群搭建那么简单,运营需要对集群中所有节点的完整申明周期负责。
- 集群搭建
- 集群扩容/缩容
- 集群销毁(很少)
- 无论是集群搭建还是扩容,核心是 Node 的生命周期管理
- Onboard
- 物理资产上架
- 操作系统安装
- 网络配置
- Kubernetes 组件安装
- 创建 Node 对象
- 故障处理
- 临时故障?重启大法好
- 永久故障?机器下架
- Offboard
- 删除 Node 对象
- 物理资产下架,送修/报废
- Onboard
主机管理
选定哪个版本的系统内核、哪个发行版、安装哪些工具集、主机网络如何规划等。
日常的主机镜像升级更新也可能是造成服务不可用的因素之一。
- 主机镜像更新可以通过 A/B 系统 OTA(OverThe Air) 升级方式进行。
- 分别使用 A、B 两个存储空间,共享一份用户数据。在升级过程中,OTA 更新即往其中一个存储空间写入升级包,同时保证了另一个系统可以正常运行,而不会打断用户。如果 OTA 失败,那么设备会启动到 OTA 之前的磁盘分区,并且仍然可以使用。
生产化集群管理
如何设定单个集群规模
- 社区声明单一集群可支持 5000 节点,在如此规模的集群中,大规模部署应用是有诸多挑战的。应该更多还是更少?如何权衡?
如何根据地域划分集群
- 不同地域的计算节点划分到同一集群
- 将同一地域的节点划分到同一集群
如何规划集群的网络
- 企业办公环境、测试环境、预生产环境和生产环境应如何进行网络分离
- 不同租户之间应如何进行网络隔离
如何自动化搭建集群
- 如何自动化搭建和升级集群,包括自动化部署控制平面和数据平面的核心组件
- 如何与企业的公共服务集成
企业公共服务
需要与企业认证平台集成,这样企业用户就能通过统一认证平台接入 Kubernetes 集群,而无须重新设计和管理一套用户系统。
集成企业的域名服务、负载均衡服务,提供集群服务对企业外发布的访问入口
在与企业的公共服务集成时,需要考虑它们的服务是否可靠
对于不能异步调用的请求,采用同步调用需要设置合理的超时时间
过长的超时时间,会延迟结果等待时间,导致整体的链路调用时间延长,从而降低整体的 TPS
有些失败是短暂的、偶然的(比如网络抖动),进行重试即可。而有些失败是必然的,重试反而会造成调用请求量放大,加重对调用系统的负担
控制平面的高可用保证
针对大规模的集群,应该为控制平面组件划分单独节点,减少业务容器对控制平面容器或守护进程的干扰和资源抢占
控制平面所在的节点,应确保在不同机架上,以防止因为某些机架的交换机或电源出问题,造成所有的控制面节点都无法工作
保证控制平面的每个组件有足够的 CPU、内存和磁盘资源,过于严苛的资源限制会导致系统效率低下,降低集群可用性
应尽可能地减少或消除外部依赖。在 Kubneretes 初期版本中存在较多 Cloud Provider API 的调用,导致在运营过程中,当 Cloud Provider API 出现故障时,会使得 Kubernetes 集群也无法正常工作。
应尽可能地将控制平面和数据平面解耦,确保控制平面组件出现故障时,将业务影响降到最低。
Kubernetes 还有一些核心插件,是以普通的 Pod 形式加载运行的,可能会被调度到任意工作节点,与普通应用竞争资源。这些插件是否正常运行也决定了集群的可用性。
高可用集群
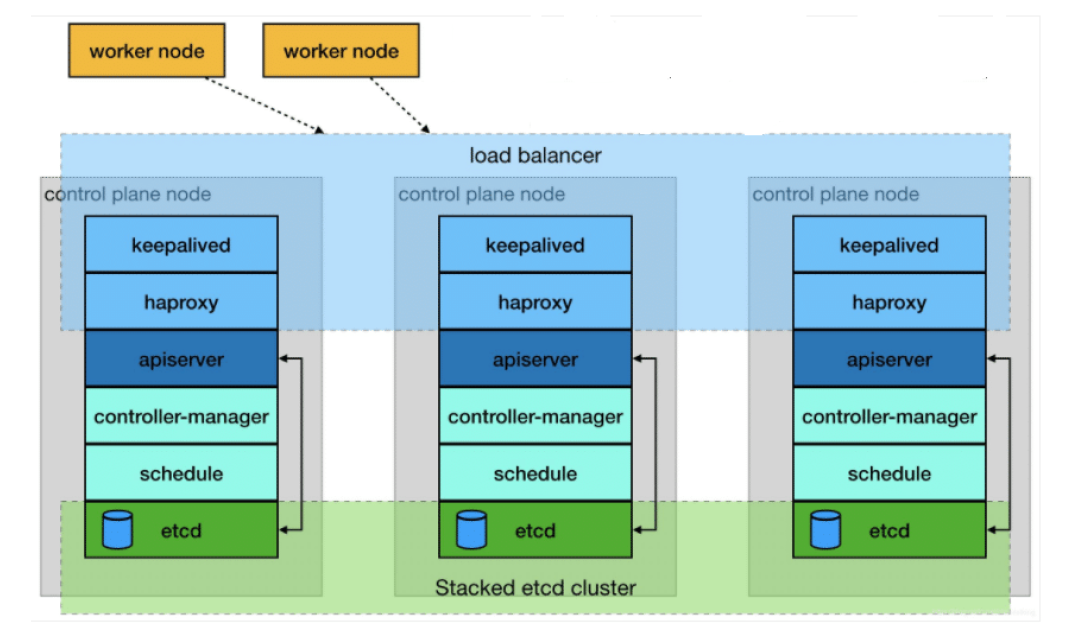
集群安装方法比较

用 Kubeadmin 搭建集群
Kubernetes Cluster Setup on Ubuntu 24.04 LTS Server
测试时使用了的是下面的这些电脑(Ubuntu 24.04 Server):
| Server Role | Host Name | Configuration | IP Address |
|---|---|---|---|
| Master | ubuntu2404-1 | 8GB Ram, 4vcpus | 172.31.203.100 |
| Worker | ubuntu2404-2 | 8GB Ram, 4vcpus | 172.31.203.101 |
| Worker | ubuntu2404-3 | 8GB Ram, 4vcpus | 172.31.203.102 |
计划使用的 POD CIDR 网段是 10.244.0.0/16。
安装容器运行时 containerd
https://docs.docker.com/engine/install/ubuntu/
# Add Docker's official GPG key:
sudo apt-get update
sudo apt-get install apt-transport-https ca-certificates curl gpg
sudo install -m 0755 -d /etc/apt/keyrings
sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
sudo chmod a+r /etc/apt/keyrings/docker.asc
# Add the repository to Apt sources:
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
sudo apt-get install containerd.io
sudo mkdir -p /etc/containerd
sudo containerd config default | sudo tee /etc/containerd/config.tomlhttps://kubernetes.io/docs/setup/production-environment/container-runtimes/#containerd-systemd
需要确认生成的配置文件 /etc/containerd/config.toml 中部分字段的内容如下:
[plugins."io.containerd.grpc.v1.cri".containerd]
snapshotter = "overlayfs"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
SystemdCgroup = true另外,可以通过修改配置文件中
sandbox_image字段的值来调整 pause 镜像的地址。
重启 contained
sudo systemctl restart containerd
sudo systemctl enable containerd
systemctl status containerd关闭交换分区
sudo swapoff -a然后编辑文件 /etc/fstab ,永久的关闭 Swap
-/swap.img none swap sw 0 0
+#/swap.img none swap sw 0 0确认每个节点的 MAC 地址和 product_uuid 都是唯一的以及端口 6443 未被使用
$ ip link show dev eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DEFAULT group default qlen 1000
link/ether 00:15:5d:a0:01:07 brd ff:ff:ff:ff:ff:ff
$ sudo cat /sys/class/dmi/id/product_uuid
1b653aa4-67b4-473b-8626-37b9cf1140ab
$ nc 127.0.0.1 6443 -v
nc: connect to 127.0.0.1 port 6443 (tcp) failed: Connection refused加载内核模块和配置 sysctl
加载内核模块
sudo modprobe overlay
sudo modprobe br_netfilter
sudo tee /etc/modules-load.d/k8s.conf <<EOF
overlay
br_netfilter
EOF配置 sysctl
sudo tee /etc/sysctl.d/kubernetes.conf<<EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF
sudo sysctl --system
sudo sh -c "echo 'net.ipv4.ip_forward = 1' >> /etc/sysctl.conf"
sudo sysctl -p确实配置生效
$ sudo lsmod | egrep '^(overlay|br_netfilter)'
br_netfilter 32768 0
overlay 212992 22
$ cat /proc/sys/net/ipv4/ip_forward
1安装Kubeadm、Kubectl和Kubelet
Installing kubeadm, kubelet and kubectl
sudo mkdir -p -m 755 /etc/apt/keyrings
curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.30/deb/Release.key | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
echo 'deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.30/deb/ /' | sudo tee /etc/apt/sources.list.d/kubernetes.list
sudo apt-get update
sudo apt-get install -y kubelet kubeadm kubectl
sudo apt-mark hold kubelet kubeadm kubectl
sudo systemctl enable --now kubelet网络设置
Kubernetes 使用与电脑默认网关关联的网络接口上的 IP。也就是使用命令 ip route show 输出中以 default via 开头的行包含的网口。
$ ip route show
default via 172.31.192.1 dev eth0 proto static
10.244.17.128/26 via 172.31.203.100 dev eth0 proto 80 onlink如果命令 ip route show 的输出像上面那样,则 Kubernetes 使用网口 eth0,即 IP 地址为 172.31.203.101。
$ ip address show dev eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:15:5d:a0:01:08 brd ff:ff:ff:ff:ff:ff
inet 172.31.203.101/20 brd 172.31.207.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::215:5dff:fea0:108/64 scope link
valid_lft forever preferred_lft forever初始化控制平面节点
本小节的内容仅在 Master 节点执行。
# 使用网段 10.244.0.0/16
$ sudo kubeadm init --pod-network-cidr=10.244.0.0/16 --cri-socket=/var/run/containerd/containerd.sock --v=5
...
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 172.31.203.100:6443 --token pl635t.48ykxo7y0xv7r5my \
--discovery-token-ca-cert-hash sha256:54259333f53f52e6304d0cabfe0ec3f4e85333295a9d48f8161752d4ff0c64c5配置 kubectl 命令
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config安装 Pod 使用的网络插件 calico
本小节的内容仅在 Master 节点执行。
https://docs.tigera.io/calico/latest/getting-started/kubernetes/quickstart
kubectl create -f https://raw.githubusercontent.com/projectcalico/calico/v3.28.0/manifests/tigera-operator.yaml
wget https://raw.githubusercontent.com/projectcalico/calico/v3.28.0/manifests/custom-resources.yaml因为之前安装 Kubernetes 集群是使用的 Pod CIDR 网段不是默认的 192.168.0.0/16,所以需要修改 custom-resources.yaml。
- cidr: 192.168.0.0/16
+ cidr: 10.244.0.0/16然后再继续安装
kubectl create -f ./custom-resources.yaml确认安装成功
$ kubectl get pods -n calico-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-67d57d8448-p9jcx 1/1 Running 0 10h
calico-node-2b2c2 1/1 Running 1 (10h ago) 10h
calico-node-lcmn6 1/1 Running 0 10h
calico-node-npzmt 1/1 Running 0 10h
calico-typha-7bc67d4678-fc2f6 1/1 Running 0 10h
calico-typha-7bc67d4678-ks8gm 1/1 Running 0 10h
csi-node-driver-rzw2b 2/2 Running 0 10h
csi-node-driver-tnst9 2/2 Running 0 10h
csi-node-driver-wcglz 2/2 Running 0 10h配置从节点加入集群
本小节的内容仅在 Worker 节点执行。
执行在安装 Master 节点时提示的加入集群的命令
$ kubeadm join 172.31.203.100:6443 --token pl635t.48ykxo7y0xv7r5my \
--discovery-token-ca-cert-hash sha256:54259333f53f52e6304d0cabfe0ec3f4e85333295a9d48f8161752d4ff0c64c5
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.确认集群状态
本小节的内容仅在 Master 节点执行。
$ kubectl cluster-info
Kubernetes control plane is running at https://172.31.203.100:6443
CoreDNS is running at https://172.31.203.100:6443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
$ kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
ubuntu2404-1 Ready control-plane 11h v1.30.1 172.31.203.100 <none> Ubuntu 24.04 LTS 6.8.0-31-generic containerd://1.6.32
ubuntu2404-2 Ready <none> 10h v1.30.1 172.31.203.101 <none> Ubuntu 24.04 LTS 6.8.0-31-generic containerd://1.6.32
ubuntu2404-3 Ready <none> 10h v1.30.1 172.31.203.102 <none> Ubuntu 24.04 LTS 6.8.0-31-generic containerd://1.6.32安装 Kubernetes Dashboard
本小节的内容仅在 Master 节点执行。
安装 Helm
https://helm.sh/docs/intro/install/
curl https://baltocdn.com/helm/signing.asc | gpg --dearmor | sudo tee /usr/share/keyrings/helm.gpg > /dev/null
sudo apt-get install apt-transport-https --yes
echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/helm.gpg] https://baltocdn.com/helm/stable/debian/ all main" | sudo tee /etc/apt/sources.list.d/helm-stable-debian.list
sudo apt-get update
sudo apt-get install helm安装 Dashboard
$ helm repo add kubernetes-dashboard https://kubernetes.github.io/dashboard/
$ helm upgrade --install kubernetes-dashboard kubernetes-dashboard/kubernetes-dashboard --create-namespace --namespace kubernetes-dashboard
Release "kubernetes-dashboard" does not exist. Installing it now.
NAME: kubernetes-dashboard
LAST DEPLOYED: Mon May 27 13:13:39 2024
NAMESPACE: kubernetes-dashboard
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
*************************************************************************************************
*** PLEASE BE PATIENT: Kubernetes Dashboard may need a few minutes to get up and become ready ***
*************************************************************************************************
Congratulations! You have just installed Kubernetes Dashboard in your cluster.
To access Dashboard run:
kubectl -n kubernetes-dashboard port-forward svc/kubernetes-dashboard-kong-proxy 8443:443
NOTE: In case port-forward command does not work, make sure that kong service name is correct.
Check the services in Kubernetes Dashboard namespace using:
kubectl -n kubernetes-dashboard get svc
Dashboard will be available at:
https://localhost:8443为 Kubernetes Dashboard 开启端口转发
nohup kubectl -n kubernetes-dashboard port-forward --address 0.0.0.0 svc/kubernetes-dashboard-kong-proxy 8443:443 2>&1 1>/dev/null &然后访问 Master 节点(172.31.203.100)的 8443 端口即可访问到 Kubernetes Dashboard。
创建一个用于访问 dashboard 的账号
本小节的内容仅在 Master 节点执行。
https://github.com/kubernetes/dashboard/blob/master/docs/user/access-control/creating-sample-user.md
创建 Service Account
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kubernetes-dashboard绑定用户到 cluster-admin
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kubernetes-dashboard获取一个用于临时访问 Kubernetes Dashboard 的 Bearer Token
$ kubectl -n kubernetes-dashboard create token admin-user
eyJhbGciOiJSUzI1NiIsImtpZCI6IjFsdnJlVk84Z1BOckwzQ2NyTHVxeUZWeUhpZjNHRUxDQjg3c3MxRUV1TmsifQ.eyJhdWQiOlsiaHR0cHM6Ly9rdWJlcm5ldGVzLmRlZmF1bHQuc3ZjLmNsdXN0ZXIubG9jYWwiXSwiZXhwIjoxNzE2ODI0ODY0LCJpYXQiOjE3MTY4MjEyNjQsImlzcyI6Imh0dHBzOi8va3ViZXJuZXRlcy5kZWZhdWx0LnN2Yy5jbHVzdGVyLmxvY2FsIiwianRpIjoiNzA1NGI0MWEtMWI3OC00NDlmLWJkZDQtNjAxODdhYzBkYmU5Iiwia3ViZXJuZXRlcy5pbyI6eyJuYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsInNlcnZpY2VhY2NvdW50Ijp7Im5hbWUiOiJhZG1pbi11c2VyIiwidWlkIjoiMWEwYWNmM2EtMzFiOC00ZTFlLTgxNzMtODg2NDY2MGE4NmM2In19LCJuYmYiOjE3MTY4MjEyNjQsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDprdWJlcm5ldGVzLWRhc2hib2FyZDphZG1pbi11c2VyIn0.IyoiZzuXQE-5P1OEPWwIWjI5dbHDe0BbdUjXaP1ML3137eTX-sOR__hs2cyv_1MwGLbUXipRl7NLDTY2qF359rcd4UZC5wjJKZE7WEVf8DQJgr1X4SiTYdmFeRp-JKb27oO7_jwWGlGJb1nY8t7exdvqSzbXWiuwDdc2Z52cXwP5n3sGErFXmchdZDV7Ims-1vF3_g_tKzxUBRe2bu0jfrQEqbUv_hLiEX7Ke1n6URGi1znEIs6tfSnhEOZ40JWvb5w0-bf1tx4qGFfhhVdzB16xMLGQNs4vrfekMvwXfzNNt5qTk2PX4olU9TG4OZofAWSCDAyJSLuYIXOtQUXn-g为 admin-user 创建一个长期有效的 Bearer Token
apiVersion: v1
kind: Secret
metadata:
name: admin-user
namespace: kubernetes-dashboard
annotations:
kubernetes.io/service-account.name: "admin-user"
type: kubernetes.io/service-account-token获取长期有效的 Token
需要使用临时 Token 访问过一次 Dashboard 后才能获取到长期有效的 Token。
$ kubectl get secret admin-user -n kubernetes-dashboard -o jsonpath={".data.token"} | base64 -d
eyJhbGciOiJSUzI1NiIsImtpZCI6IjFsdnJlVk84Z1BOckwzQ2NyTHVxeUZWeUhpZjNHRUxDQjg3c3MxRUV1TmsifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJhZG1pbi11c2VyIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQubmFtZSI6ImFkbWluLXVzZXIiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC51aWQiOiIxYTBhY2YzYS0zMWI4LTRlMWUtODE3My04ODY0NjYwYTg2YzYiLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZXJuZXRlcy1kYXNoYm9hcmQ6YWRtaW4tdXNlciJ9.dkfNd1OyFYq0SdzC_mdgA7BT7ODQDfpAeBFC4XXN-O0kRT9qywnIkHckXMCfpZvFU3veIO4HoXuEOattlf1Hg3NtchtiUReonIb2h90feVNxnUqp1b6iy1JohRhQi-VpE8-b5L80BRy1AP-ovMLAdg61g9F5FBQ9tQPJu8CRnc64CXBmFS-VL7Wi-7yXkhSRB1MDvmT7FQW12gkpQ1R2LrMoRjX65TcFkWw89SibvOfLLwsZ1XJRBK_CGhSi55mebiEWOrFkg-dAQibMoDMKFp_yCvV2oz4vX-r3Ni_mQS7nvDKECFqYgVXPMSdUbX5HdCZxKlgZdHuokzBEsjoOzw用 Kubespray 搭建高可用集群搭建
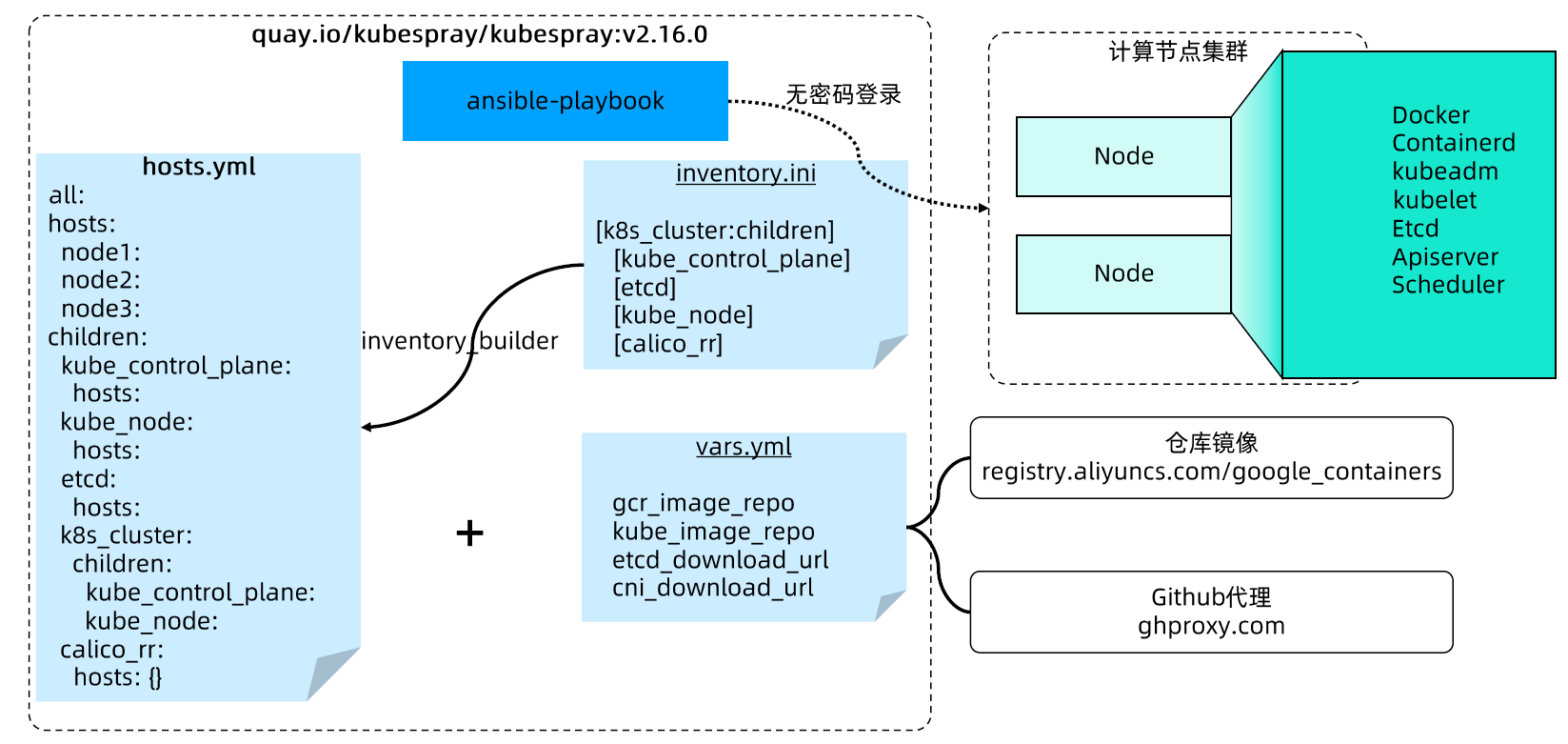
练习:使用 Kubespray 安装集群
https://cncamp.notion.site/Install-HA-cluster-using-kubespray-e398756229a649b8adc7338788df4672
基于声明式 API 管理集群
集群管理不仅仅包括集群搭建,还有更多功能需要支持
- 集群扩缩容
- 节点健康检查和自动修复
- Kubernetes 升级
- 操作系统升级
云原生场景中集群应该按照我们的期望的状态运行,这意味着我们应该将集群管理建立在声明式 API 的基础之上
Kubernetes Cluster API

参与角色
管理集群
- 管理 workload 集群的集群,用来存放 Cluster API 对象的地方
Workload 集群
- 真正开放给用户用来运行应用的集群,由管理集群管理
Infrastructure provider
- 提供不同云的基础架构管理,包括计算节点,网络等。目前流行的公有云多与 Cluster API 集成了。
Bootstrap provider
- 证书生成
- 控制面组件安装和初始化,监控节点的创建
- 将主节点和计算节点加入集群
Control plane
- Kubernetes 控制平面组件
涉及模型
Machine
- 计算节点,用来描述可以运行 Kubernetes 组件的机器对象(注意与 Kubernetes Node )的差异
- 一个新 Machine 被创建以后,对应的控制器会创建一个计算节点,安装好操作系统并更新 Machine 的状态
- 当一个 Machine 被删除后,对应的控制器会删除掉该节点并回收计算资源。
- 当 Machine 属性被更新以后(比如 Kubernetes 版本更新),对应的控制器会删除旧节点并创建新书点
Machine Immutability(In-place Upgrade vs. Replace)
- 不可变基础架构
MachineDeployment
- 提供针对 Machine 和 MachineSet 的声明式更新,类似于 Kubernetes Deployment
MachineSet
- 维护一个稳定的机器集合,类似 Kubernetes ReplicaSet
MachineHealthcheck
- 定义节点应该被标记为不可用的条件
用 cluster api 管理集群
### create host cluster
./create cluster.sh
### generate cluster specs
cd cluster-api
./generate_workload_cluster.sh
### replace image repository
vi capi-quickstart.yaml
replace KubeadmConfigTemplate
### apply cluster spec
kubectl apply-f capi-quickstart.yamlapiVersion: bootstrap.cluster.x-k8s.io/v1alpha4
kind: KubeadmConfigTemplate
metadata:
name: capi-quickstart-md-0
namespace: default
spec:
template:
spec:
joinConfiguration:
nodeRegistration:
kubeletExtraArgs:
cgroup-driver: cgroupfs
eviction-hard: nodefs.available<0%,nodefs.inodesFree<0%,imagefs.available<0%
clusterconfiguration:
imageRepository: registry.aliyuncs.com/google containers用 kind 和 cluster API 搭建集群
https://github.com/kibaamor/101/blob/master/module9/kind/readme.MD
https://medium.com/@dipendra.chaudhary/kubernetes-74a5d6bd4bdb
https://cluster-api.sigs.k8s.io/user/quick-start.html#install-andor-configure-a-kubernetes-cluster
创建管理集群
$ cat > cluster-mgmt.yaml <<EOF
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
networking:
ipFamily: dual
nodes:
- role: control-plane
extraMounts:
- hostPath: /var/run/docker.sock
containerPath: /var/run/docker.sock
EOF
$ kind create cluster --config cluster-mgmt.yaml --name mgmt
Creating cluster "mgmt" ...
✓ Ensuring node image (kindest/node:v1.30.0) 🖼
✓ Preparing nodes 📦
✓ Writing configuration 📜
✓ Starting control-plane 🕹️
✓ Installing CNI 🔌
✓ Installing StorageClass 💾
Set kubectl context to "kind-mgmt"
You can now use your cluster with:
kubectl cluster-info --context kind-mgmt
Have a question, bug, or feature request? Let us know! https://kind.sigs.k8s.io/#community 🙂创建工作集群
$ export CLUSTER_TOPOLOGY=true
$ clusterctl init --infrastructure docker --target-namespace capi-docker
Fetching providers
Installing cert-manager Version="v1.14.5"
Waiting for cert-manager to be available...
Installing Provider="cluster-api" Version="v1.7.2" TargetNamespace="capi-system"
Installing Provider="bootstrap-kubeadm" Version="v1.7.2" TargetNamespace="capi-kubeadm-bootstrap-system"
Installing Provider="control-plane-kubeadm" Version="v1.7.2" TargetNamespace="capi-kubeadm-control-plane-system"
Installing Provider="infrastructure-docker" Version="v1.7.2" TargetNamespace="capd-system"
Your management cluster has been initialized successfully!
You can now create your first workload cluster by running the following:
clusterctl generate cluster [name] --kubernetes-version [version] | kubectl apply -f -
# 确定所有的资源都ready
$ kubectl -n capi-docker get all -owide
# 建议 kubernetes-version 使用的版本与 kind create cluster 时输出的 kindest/node 版本相同
$ clusterctl generate cluster capi-quickstart --flavor development \
--kubernetes-version v1.30.0 \
--control-plane-machine-count=1 \
--worker-machine-count=1 \
--target-namespace capi-docker \
> capi-quickstart.yaml
$ kubectl apply -f capi-quickstart.yaml
clusterclass.cluster.x-k8s.io/quick-start created
dockerclustertemplate.infrastructure.cluster.x-k8s.io/quick-start-cluster created
kubeadmcontrolplanetemplate.controlplane.cluster.x-k8s.io/quick-start-control-plane created
dockermachinetemplate.infrastructure.cluster.x-k8s.io/quick-start-control-plane created
dockermachinetemplate.infrastructure.cluster.x-k8s.io/quick-start-default-worker-machinetemplate created
dockermachinepooltemplate.infrastructure.cluster.x-k8s.io/quick-start-default-worker-machinepooltemplate created
kubeadmconfigtemplate.bootstrap.cluster.x-k8s.io/quick-start-default-worker-bootstraptemplate created
$ kubectl get cluster
NAME CLUSTERCLASS PHASE AGE VERSION
capi-quickstart quick-start Provisioned 25s v1.30.0
# controlplane 还未 ready 是因为还未安装 CNI 插件
$ kubectl get kubeadmcontrolplane
NAME CLUSTER INITIALIZED API SERVER AVAILABLE REPLICAS READY UPDATED UNAVAILABLE AGE VERSION
capi-quickstart-xrg9s capi-quickstart true 1 1 1 99s v1.30.0
# 获取 workload 集群的kubeconfig
$ clusterctl get kubeconfig capi-quickstart > capi-quickstart.kubeconfig
# 确认没有代理
$ https_proxy= HTTPS_PROXY= kubectl --kubeconfig ./capi-quickstart.kubeconfig get nodes
NAME STATUS ROLES AGE VERSION
capi-quickstart-md-0-6c9b6-wcx8l-8qsql NotReady <none> 93m v1.30.0
capi-quickstart-worker-6g0j6q NotReady <none> 93m v1.30.0
capi-quickstart-xrg9s-4xcdb NotReady control-plane 93m v1.30.0安装 CNI 插件
$ https_proxy= HTTPS_PROXY= kubectl --kubeconfig=./capi-quickstart.kubeconfig create -f https://raw.githubusercontent.com/projectcalico/calico/v3.28.0/manifests/tigera-operator.yaml
deployment.apps/tigera-operator created
$ https_proxy= HTTPS_PROXY= kubectl --kubeconfig=./capi-quickstart.kubeconfig create -f https://raw.githubusercontent.com/projectcalico/calico/v3.28.0/manifests/custom-resources.yaml
installation.operator.tigera.io/default created
apiserver.operator.tigera.io/default created
$ https_proxy= HTTPS_PROXY= kubectl --kubeconfig=./capi-quickstart.kubeconfig get nodes
NAME STATUS ROLES AGE VERSION
capi-quickstart-md-0-6c9b6-wcx8l-8qsql Ready <none> 97m v1.30.0
capi-quickstart-worker-6g0j6q Ready <none> 97m v1.30.0
capi-quickstart-xrg9s-4xcdb Ready control-plane 97m v1.30.0KubeadmControlPlane
apiVersion: controlplane.cluster.x-k8s.io/v1alpha4
kind: KubeadmControlPlane
metadata:
name: capi-quickstart-control-plane
spec:
kubeadmConfigspec:
clusterConfiguration:
apiserver:
certSANs:
- localhost
- 127.0.0.1
controllerManager:
extraArgs:
enable-hostpath-provisioner: "true"
dns: {}
etcd: {}
networking: {}
scheduler: {}
joinConfiguration:
discovery: {}
nodeRegistration:
criSocket: /var/run/containerd/containerd.sock
kubeletExtraArgs:
cgroup-driver: cgroupfs
eviction-hard: nodefs.available<0%,nodefs.inodesFree<0%,imagefs.available<0%
initConfiguration:
localAPlEndpoint: {}
nodeRegistration:
criSocket: /var/run/containerd/containerd.sock
kubeletExtraArgs:
cgroup-driver: cgroupfs
eviction-hard: nodefs.available<0%,nodefs.inodesFree<0%,imagefs.available<0%
machineTemplate:
infrastructureRef:
apiVersion: infrastructure.cluster.x-k8s.io/v1alpha4
kind: DockerMachineTemplate
name: capi-quickstart-control-plane
namespace: default
metadata:{}
replicas: 1
rolloutStrategy:
rollingUpdate:
maxSurge: 1
type: RollingUpdate
version: v1.22.0MachineDeployment
apiVersion: cluster.x-k8s.io/v1alpha4
kind: MachineDeployment
metadata:
name:capi-quickstart-md-0
spec:
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
type: Rollingupdate
template:
metadata:
labels:
cluster.x-k8s.io/cluster-name: capi-quickstart
cluster.x-k8s.io/deployment-name: capi-quickstart-md-0
spec:
bootstrap:
configRef:
apiVersion: bootstrap.cluster.x-k8s.io/v1alpha4
kind: KubeadmconfigTemplate
name: capi-quickstart-md-0
namespace: default
clusterName: capi-quickstart
infrastructureRef:
apiVersion: infrastructure.cluster.x-k8s.io/v1alpha4
kind: DockerMachineTemplate
name: capi-quickstart-md-0
namespace: default
version: v1.22.0MachineHealthCheck
apiVersion: cluster.x-k8s.io/v1alpha3
kind: MachineHealthCheck
metadata:
name: capi-quickstart-node-unhealthy-5m
spec:
clusterName: capi-quickstart
maxUnhealthy: 40% # 自动修复节点数的上限,默认行为是替换该节点,云提供商可自定义
nodeStartupTimeout: 10m
selector:
matchLabels: # 健康检查的目标节点
nodepool: nodepool-0
unhealthyConditions: # 认定节点不健康的条件
- type: Ready
status: Unknown
timeout: 300s
- type: Ready
status: "False"
timeout: 300s日常运营中的节点问题归类
可自动修复的问题
- 计算节点 down
- Ping不通
- TCP probe 失败
- 节点上的所有应用都不可达
不可自动修复的问题
- 文件系统坏
- 磁盘阵列故障
- 网盘挂载问题
- 其他硬件故障
- Kernel出错,core dumps
其他问题
- 软件Bug
- 进程锁死,或者 memory/CPU 竞争问题
- Kubernetes 组件出问题
- Kubelet/Kube-proxy/Docker/Salt
故障监测和自动恢复
当创建 Compute 节点时,允许定义 LivenessProbe
- 当 livenessProbe 失败时,ComputeNode 的 ProbePassed 设置为 false
在 Prometheus 中,已经有 Node level 的 alert,抓取 Prometheus 中的 alert
设定自动恢复规则
- 大多数情况下,重启大法好(人人都是 Restartoperator)
- 如果重启不行就重装。(reprovision)
- 重装不行就重修。(breakfix)
Cluster Autoscaler
工作机制
扩容
- 由于资源不足,pod 调度失败,即有 pod 一直处于 Pending 状态
缩容
- node 的资源利用率较低时,持续 10 分钟低于 50%
- 此 node 上存在的 pod 都能被重新调度到其他 node 上运行
Cluster Autoscaler 架构
Autoscaler: 核心模块,负责整体扩缩容功能
Estimator: 负责评估计算扩容节点
Simulator: 负责模拟调度,计算缩容节点
Cloud-Provider: 与云交互进行节点的增删操作,每个支持 CA 的主流厂商都实现自己的 plugin 实现动态缩放
ClusterAutoscaler 架构
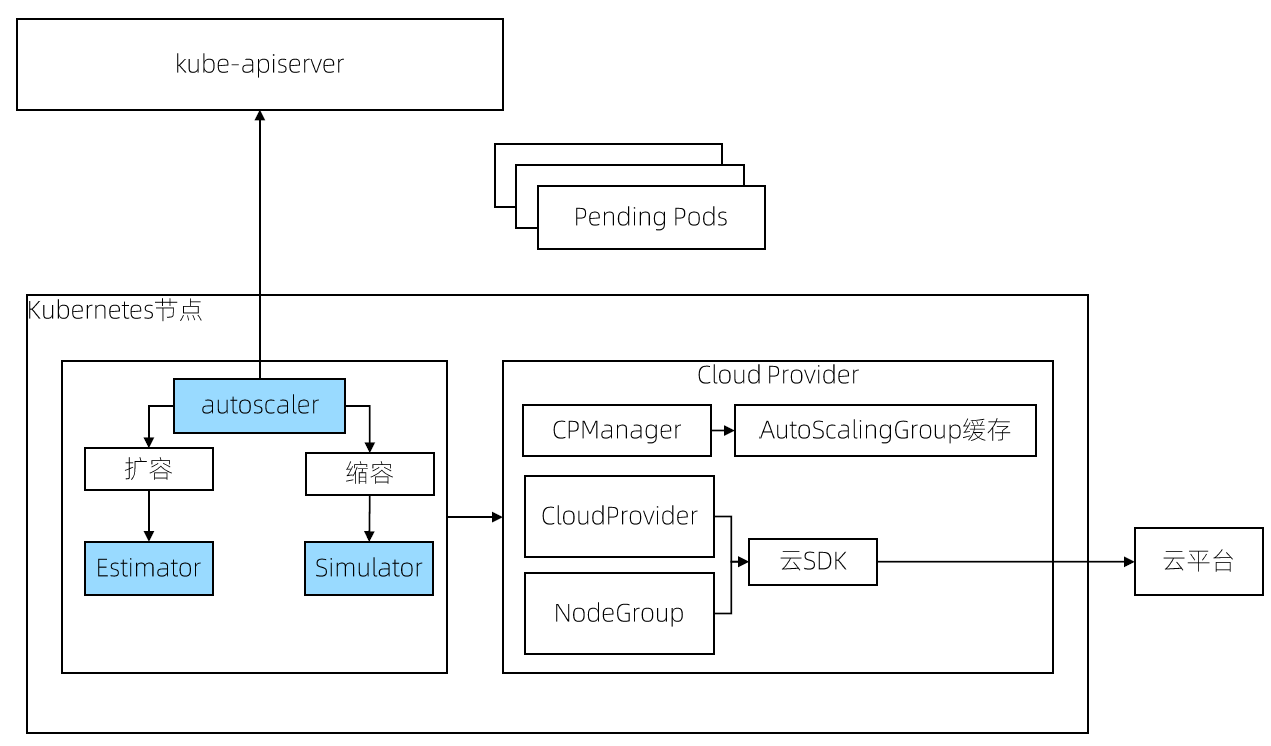
ClusterAutoscaler 的扩展机制
为了自动创建和初始化 Node,Cluster Autoscaler 要求 Node 必须属于某个 Node Group,比如
- GCE/GKE 中的 Managed instance groups(MIG)
- AWS 中的 Autoscaling Groups
- Cluster API Node
当集群中有多个 Node Group 时,可以通过 --expander=<option> 选项配置选择 Node Group 的策略,支持如下四种方式
- random: 随机选择
- most-pods: 选择容量最大(可以创建最多 Pod)的 Node Group
- least-waste: 以最小浪费原则选择,即选择有最少可用资源的 Node Group
- price: 选择最便宜的 Node Group
附加资料
代码走读 https://cncamp.notion.site/CA-204f3767ba8d4ed0a464d2ea6ac2abca
buildAutoscaler()-->
core.NewAutoscaler(opts)
autoscaler.Start()-->
a.clusterStateRegistry.Start()-->
csr.cloudProviderNodeInstancesCache.Start(csr.interrupt)-->
cache.cloudProvider.NodeGroups() // load provider specified group
nodeGroupInstances, err := nodeGroup.Nodes()-->
cache.updateCacheEntryLocked(nodeGroup, &cloudProviderNodeInstancesCacheEntry{nodeGroupInstances, time.Now()})
for { // interval 10s
autoscaler.RunOnce(loopStart)-->
unschedulablePodLister := a.UnschedulablePodLister() // phase != succeeded and != failed
scheduledPodLister := a.ScheduledPodLister()
pdbLister := a.PodDisruptionBudgetLister()
allNodes, readyNodes, typedErr := a.obtainNodeLists() // Get nodes and pods currently living on cluster
// Update cluster resource usage metrics
coresTotal, memoryTotal := calculateCoresMemoryTotal(allNodes, currentTime)
daemonsets, err := a.ListerRegistry.DaemonSetLister().List(labels.Everything())
err = a.AutoscalingContext.CloudProvider.Refresh()
cache.cloudProvider.NodeGroups() // load provider specified group
nodeGroupInstances, err := nodeGroup.Nodes()
a.initializeClusterSnapshot(allNodes, nonExpendableScheduledPods) // exclude low priority pods
a.processors.TemplateNodeInfoProvider.Process()-->
processNode(node)-->
simulator.BuildNodeInfoForNode(node, podsForNodes) // simulate scheduled pods right after node is created
sanitizedNodeInfo, err := utils.SanitizeNodeInfo(nodeInfo, id, ignoredTaints) // modify node name
a.updateClusterState(allNodes, nodeInfosForGroups, currentTime)
a.updateClusterState(allNodes, nodeInfosForGroups, currentTime)
ScaleUp(autoscalingContext, a.processors, a.clusterStateRegistry, unschedulablePodsToHelp, readyNodes, daemonsets, nodeInfosForGroups, a.ignoredTaints)-->
// filter out virtual kubelet
nodesFromNotAutoscaledGroups, err := utils.FilterOutNodesFromNotAutoscaledGroups(nodes, context.CloudProvider)
computeScaleUpResourcesLeftLimits(context, processors, nodeGroups, nodeInfos, nodesFromNotAutoscaledGroups, resourceLimiter)-->
calculateScaleUpCoresMemoryTotal(nodeGroups, nodeInfos, nodesFromNotAutoscaledGroups) // sum totoal cpu and mem resource of the node group
calculateScaleUpCustomResourcesTotal() // sum allocable gpu of the node group
clusterStateRegistry.GetUpcomingNodes()-->
newNodes := ar.CurrentTarget - (readiness.Ready + readiness.Unready + readiness.LongUnregistered)
upcomingNodes = append(upcomingNodes, nodeTemplate) // build node template for each node group
computeScaleUpResourcesDelta(context, processors, nodeInfo, nodeGroup, resourceLimiter)
context.ExpanderStrategy.BestOption(options, nodeInfos) // different strategy, e.g.leastwaste, mostpods, priceBased
processors.NodeGroupManager.CreateNodeGroup(context, bestOption.NodeGroup)
// calculate node numbers
newNodes, err = applyScaleUpResourcesLimits(context, processors, newNodes, scaleUpResourcesLeft, nodeInfo, bestOption.NodeGroup, resourceLimiter)
// find similar group
processors.NodeGroupSetProcessor.FindSimilarNodeGroups(context, bestOption.NodeGroup, nodeInfos)
processors.NodeGroupSetProcessor.BalanceScaleUpBetweenGroups()
executeScaleUp(context, clusterStateRegistry, info, gpu.GetGpuTypeForMetrics(gpuLabel, availableGPUTypes, nodeInfo.Node(), nil), now)-->
info.Group.IncreaseSize(increase)
}ClusterAPI 与 ClusterAutoscaler 的整合
https://cluster-api.sigs.k8s.io/tasks/cluster-autoscaler.html
集群管理实践案例分享
集群管理实践案例分享

声明式集群配置
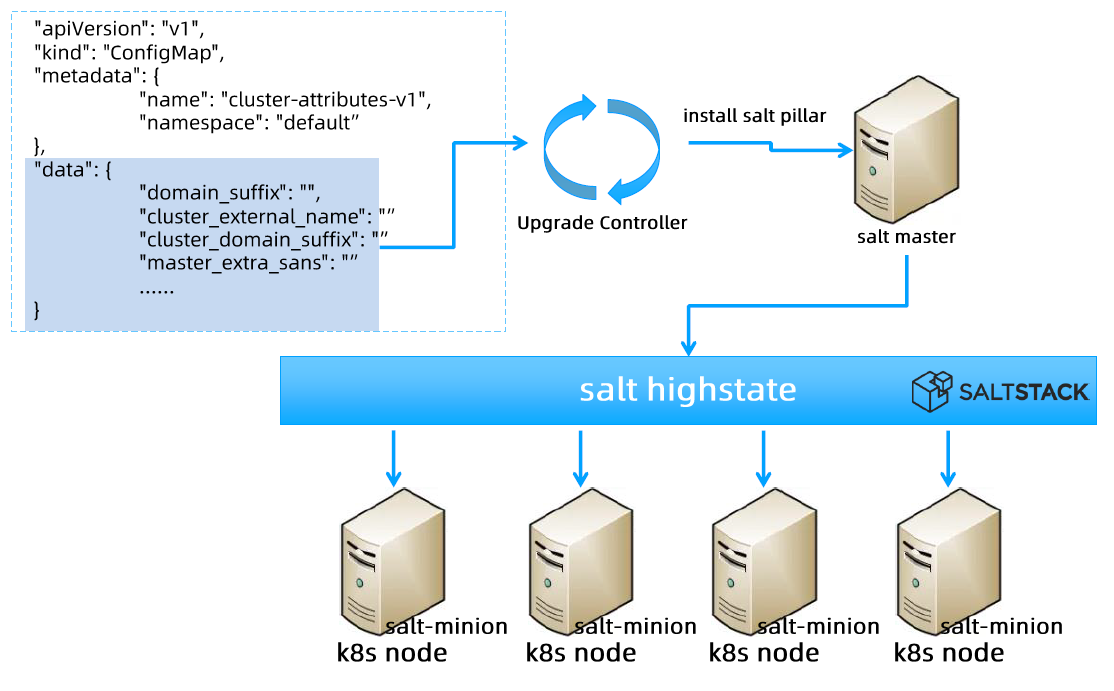
声明式扩容
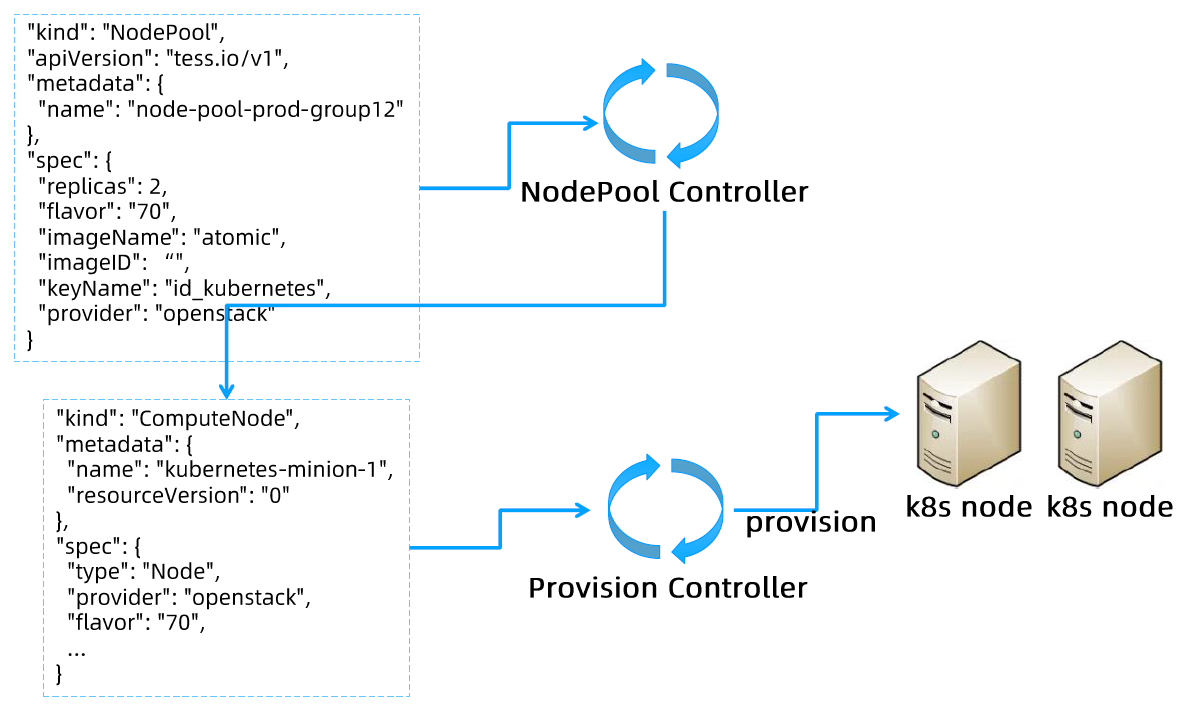
声明式持续发布
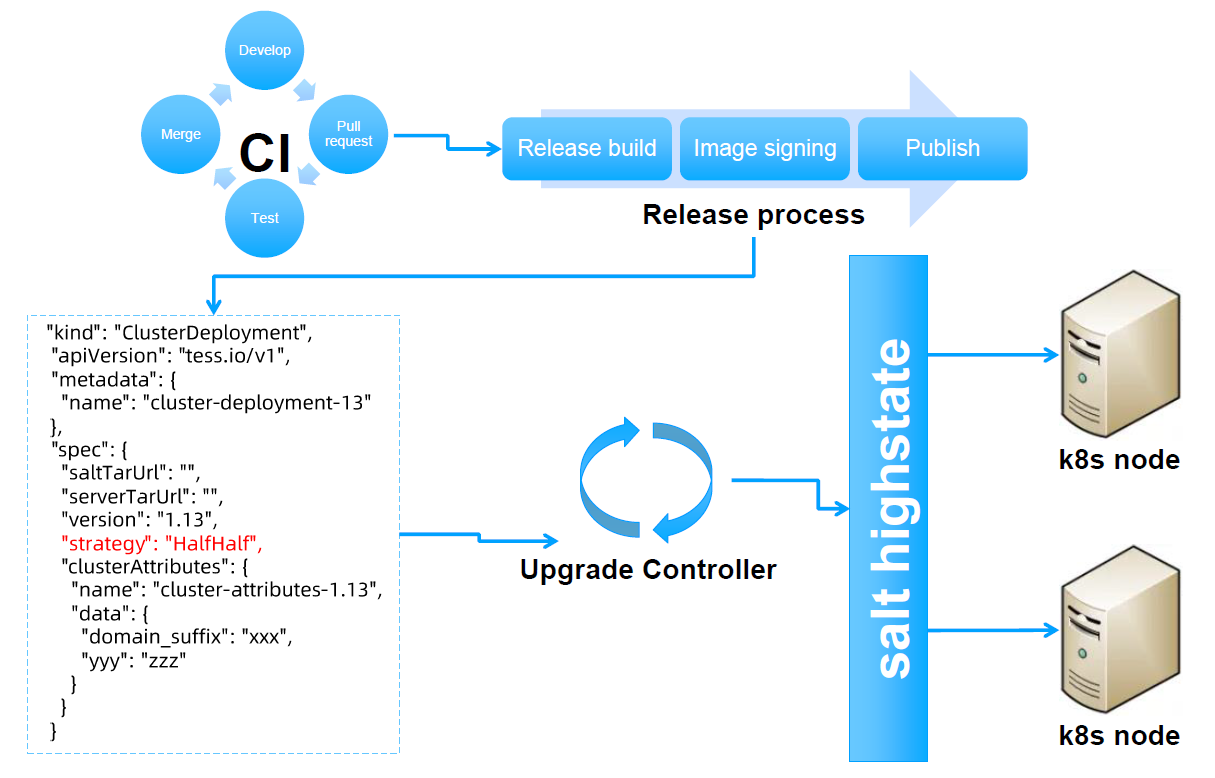
自定义插件 - 声明式集群管理对象
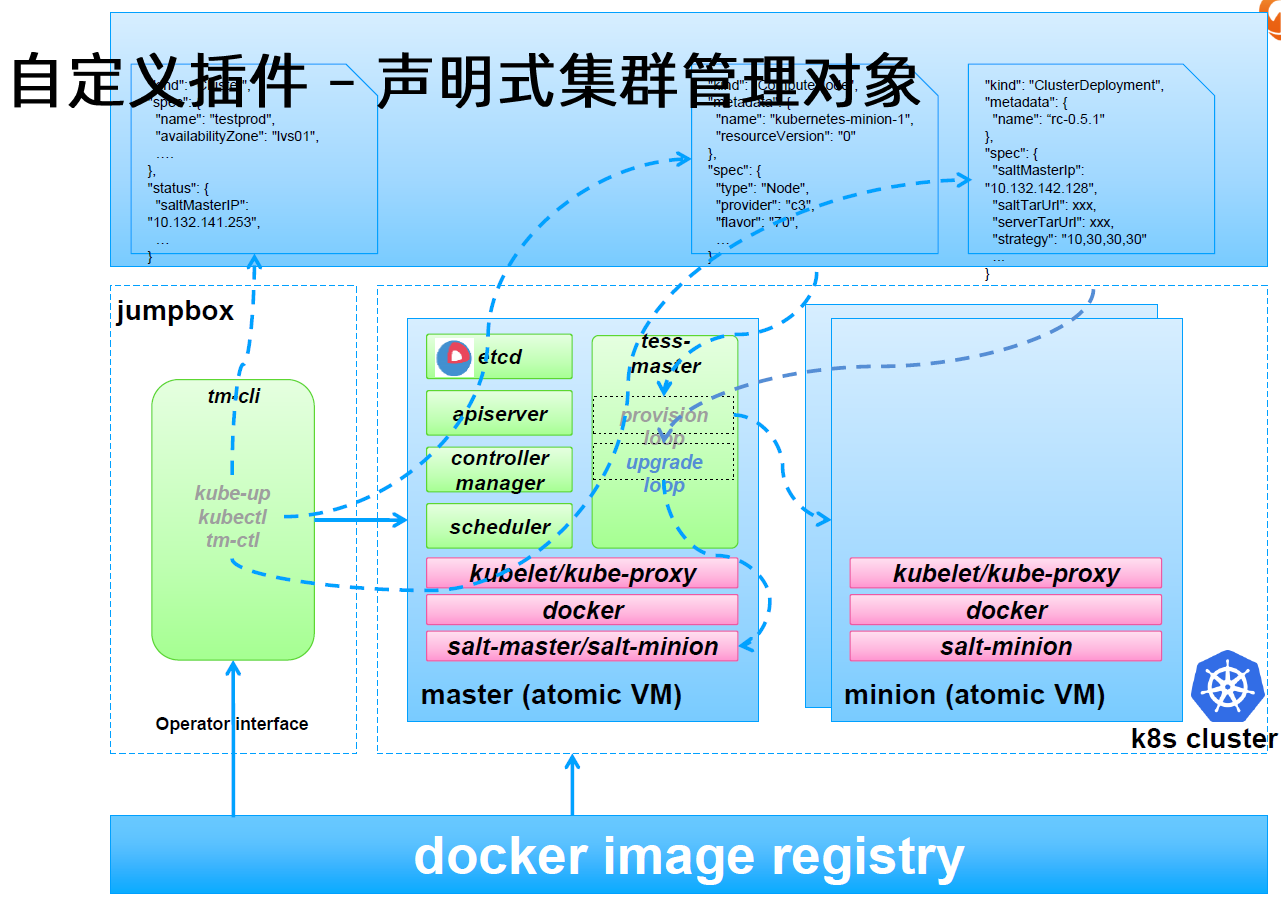
多租户集群管理
租户
租户是指一组拥有访问特定软件资源权限的用户集合,在多租户环境中,它还包括共享的应用服务、数据和各项配置等
多租户集群必须将租户彼此隔离,以最大限度地减少租户与租户、租户与集群之间的影响
集群须在租户之间公平地分配集群资源。通过多租户共享集群资源,可以有效地降低集群管理成本,提高整体集群的资源利用率
认证 - 实现多租户的基础
租户管理首先需要识别访问的用户是谁,因此用户身份认证是多租户的基础
权限控制,如允许合法登录的用户访问、拒绝非法登录的用户访问或提供有限的匿名访问
Kubernetes 可管理两类用户
- 用来标识和管理系统组件的 ServiceAccount
- 外部用户的认证,需要通过 Kubernetes 的认证扩展来对接企业、供应商的认证服务,为用户验证、操作授权、资源隔离等提供基础
隔离
除认证、授权这些基础条件外,还要能够保证用户的工作负载彼此之间有尽可能安全的隔离,减少用户工作负载之间的影响。通常从权限、网络、数据三个方面对不同用户进行隔离
- 权限隔离
- 普通用户的容器默认不具有 priviledqed、sys admin、net admin 等高级管理权限,以阻止对宿主机及其他用户的容器进行读取、写入等操作。
- 网络隔离
- 不同的 Pod,运行在不同的 Network Namespace 中,拥有独立的网络协议。Pod 之间只能通过容器开放的端口进行通信,不能通过其他方式进行访问。
- 数据隔离
- 容器之间利用 Namespace 进行隔离,在第 2 章中我们已经对不同的 Namespace 进行了详细描述。不同 Pod 的容器,运行在不同的 MNT、UTS、PID、IPC Namespace 上,相互之间无法访问对方的文件系统、进程、IPC等信息;同一个Pod的容器,其 mnt、PID Namespace 也不共享。
租户隔离手段
Namespace: Namespace 属于且仅属于一个租户
权限定义: 定义内容包括命名空间中的 Role 与 RoleBinding 。这些资源表示目前租户在归属于自己的命名空间中定义了什么权限授权给了哪些租户的成员。
Pod 安全策略: 特殊权限指集群级的特定资源定义 —— PodSecurityPolicy。它定义了一系列工作负载与基础设施之间,工作负载与工作负载之间的关联关系,并通过命名空间的 RoleBinding 完成授权。
网络策略: 基础设施层面为保障租户网络的隔离机制提供了一系列默认策略,以及租户自己定制的用于租户应用彼此访问的策略。
Pod、Service、PersistentVolumeClaim 等命名空间资源: 这些定义表示租户的应用落地到 Kubernetes 中的实体。
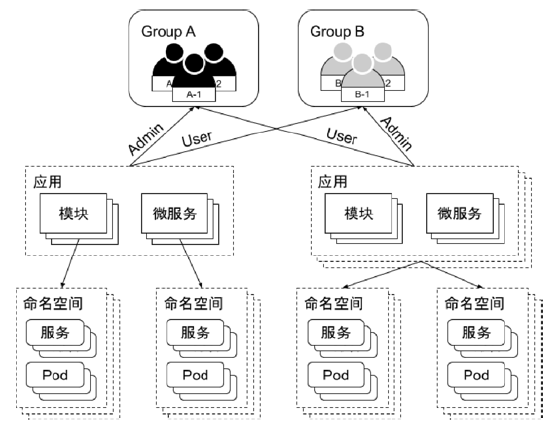
权限隔离
基于 Namespace 的权限隔离
- 创建一个 namespace-admin ClusterRole,拥有所有对象的所有权限
- 为用户开辟新 namespace,并在该 namespace 创建 rolebinding 绑定 namespace-admin ClusterRole,用户即可拥有当前 namespace 所有对象操作权限
自动化解决方案
- 当 Namespace 创建时,通过 mutatingwebhook 将 namespace 变形,将用户信息记录至 namespace annotation
- 创建一个控制器,监控 namespace,创建 rolebinding 为该用户绑定 namespace-admin 的权限

Quota 管理
开启 ResourceQuota 准入插件。
在用户 namespace 创建 ResourceQuota 对象进行限额配置。
apiVersion: v1
kind: ResourceQuota
metadata:
name: high-gos-limit-requests
spec:
hard:
limits.cpu: 8
limits.memory: 24Gi
pods: 10
requests.cpu: 4
requests.memory: 12Gi
scopes:
- NotBestEffort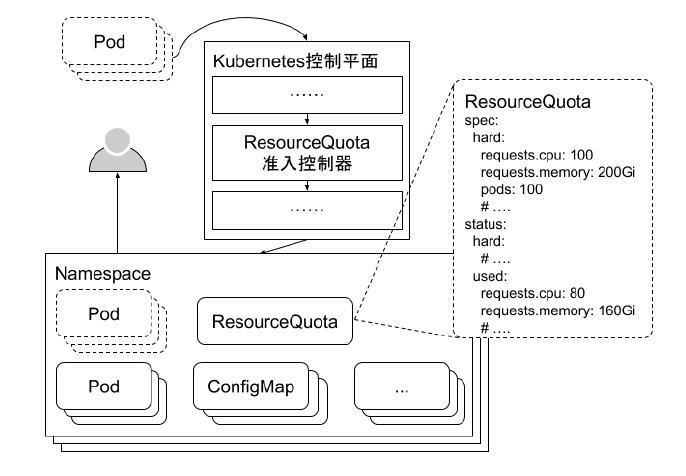
节点资源隔离
通过为节点设置不同 taint 来识别不同租户的计算资源。
不同租户在创建 Pod 时,增加 Toleration 关键字,确保其能调度至某个 taint 的节点。
练习:基于 Cluster API 搭建一个集群
Kubernetes 的生产化运维
镜像仓库
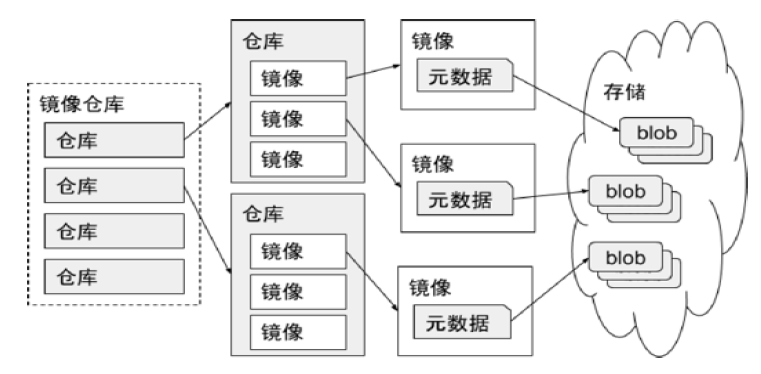
镜像仓库(Docker Registry)负责存储、管理和分发镜像。
镜像仓库管理多个 Repository,Repository 通过命名来区分。 每个 Repository 包含一个或多个镜像,镜像通过镜像名称和标签( Tag )来区分。
客户端拉取镜像时,要指定三要素:
- 镜像仓库:要从哪一个镜像仓库拉取镜像,通常通过 DNS 或 IP 地址来确定一个镜像仓库,如
- Repository:组织名,如 cncamp
- 镜像名称+标签:如 nginx:latest
镜像仓库遵循 OCI 的 Distribution Spec
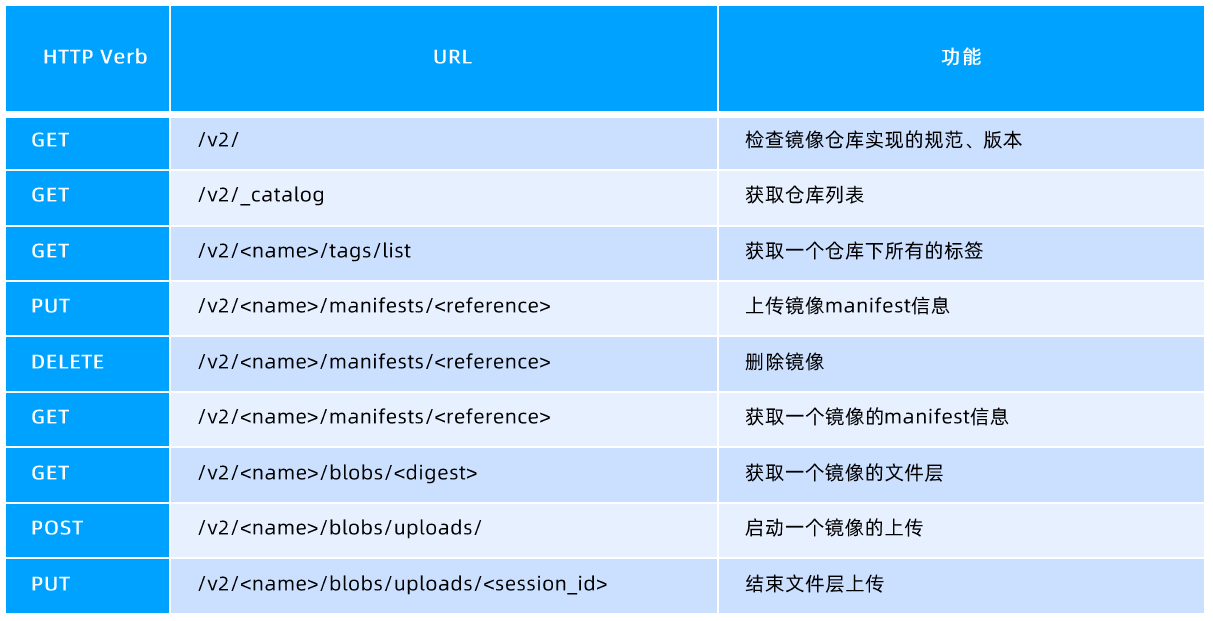
数据和块文件
镜像由元数据和块文件两部分组成,镜像仓库的核心职能就是管理这两项数据。
元数据:
- 元数据用于描述一个镜像的核心信息,包含镜像的镜像仓库、仓库、标签、校验码、文件层镜像构建描述等信息。
- 通过这些信息,可以从抽象层面完整地描述一个镜像:它是如何构建出来的、运行过什么构建命令、构建的每一个文件层的校验码、打的标签、镜像的校验码等。
块文件(blob)
- 块文件是组成镜像的联合文件层的实体,每一个块文件是一个文件层,内部包含对应文件层的变更。
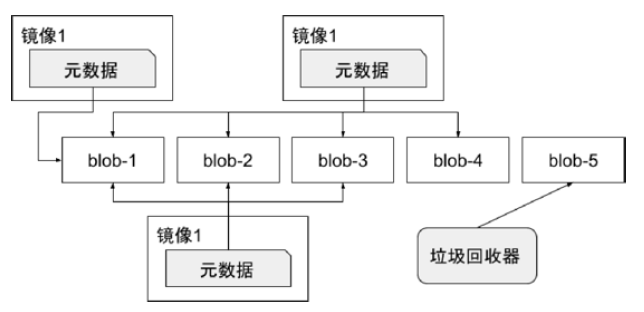
镜像仓库
公有镜像仓库优势
- 开放:任何开发者都可以上传、分享镜像到公有镜像仓库中。
- 便捷:开发者可以非常方便地搜索、拉取其他开发者的镜像,避免重复造轮子。
- 免运维:开发者只需要关注应用开发,不必关心镜像仓库的更新、升级、维护等。
- 成本低:企业或开发者不需要购买硬件、解决方案来搭建镜像仓库,也不需要团队来维护。
私有镜像仓库优势
- 隐私性:企业的代码和数据是企业的私有资产,不允许随意共享到公共平台。
- 敏感性:企业的镜像会包含一些敏感信息,如密钥信息、令牌信息等。这些敏感信息严禁暴露到企业外部,网络连通性:企业的网络结构多种多样,并非所有环境都可以访问互联网,
- 安全性:而在企业环境中,若使用一些含有漏洞的依赖包,则会引入安全隐患。
Harbor
Harbor是VMware开源的企业级镜像仓库,目前已是CNCF的毕业项目。它拥有完整的仓库管理镜像管理、基于角色的权限控制、镜像安全扫描集成、镜像签名等。
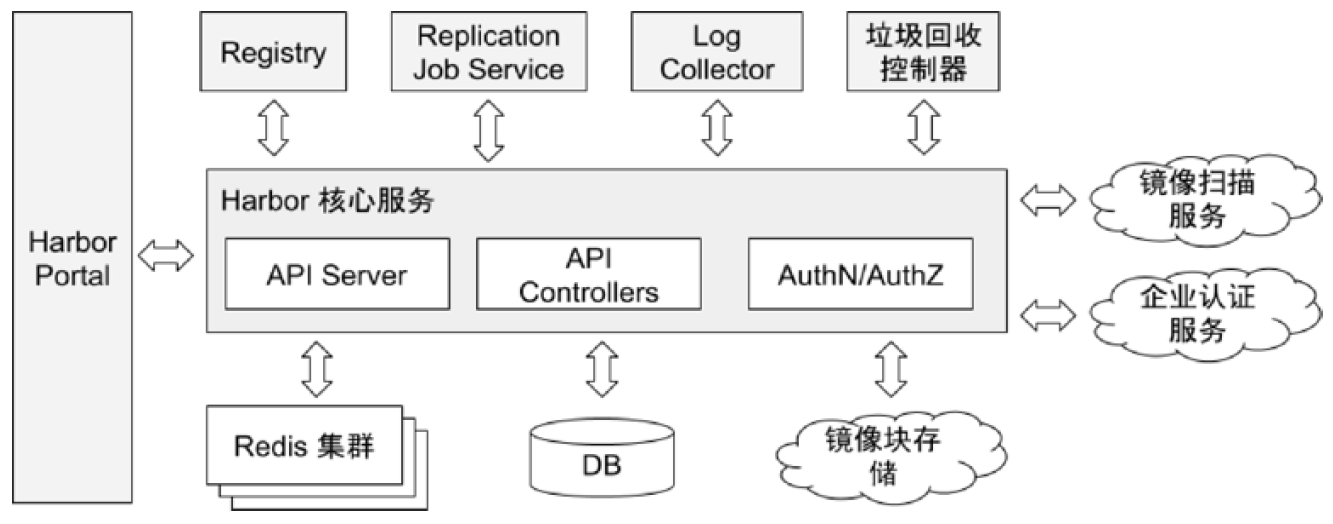
Harbor 提供的服务
Harbor 核心服务: 提供 Harbor 的核心管理服务 API,包括仓库管理、认证管理、授权管理配置管理、项目管理、配额管理、签名管理、副本管理等。
Harbor Portal: Harbor 的 Web 界面。
Reqistry: Registry 负责接收客户端的 pull/push 请求,其核心为 docker/Distribution。
副本控制器: Harbor 可以以主从模式来部署镜像仓库,副本控制器将镜像从主镜像服务分发到从镜像服务。
日志收集器:收集各模块的日志。
垃圾回收控制器:回收日常操作中删除镜像记录后遗留在块存储中的孤立块文件。
Harbor 架构

Harbor 安装
helm repo add harbor https://helm.goharbor.io
helm fetch harbor/harbor --untar
k create ns harbor
helm install-n harbor harborHarbor Demo Server
Demo Server
- 2 天清理一次数据
- 不能 push 超过 100Mb 的镜像
- 不能使用管理功能
Portal
https://demo.goharbor.io/harbor/projects
镜像使用
docker login demo.goharbor.io
docker build -t demo.goharbor.io/your-project/test-image
docker push demo.goharbor.io/your-project/test-imageHarbor 高可用架构
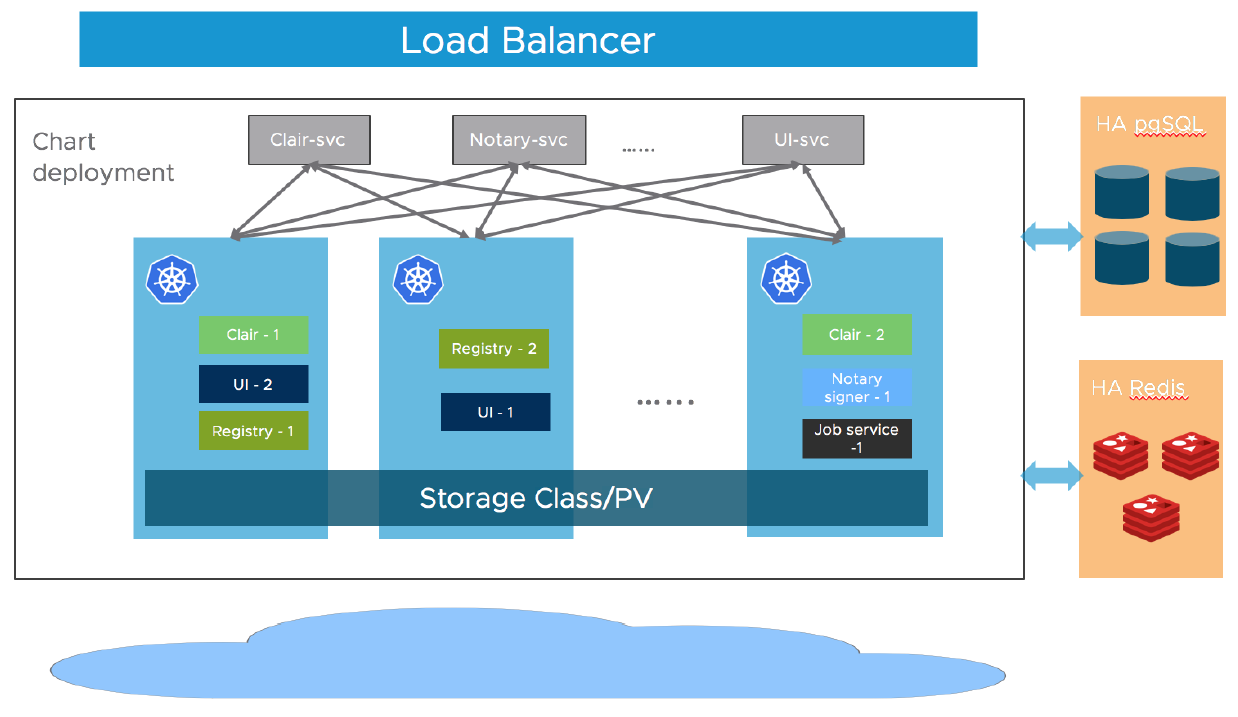
Harbor 的用户管理
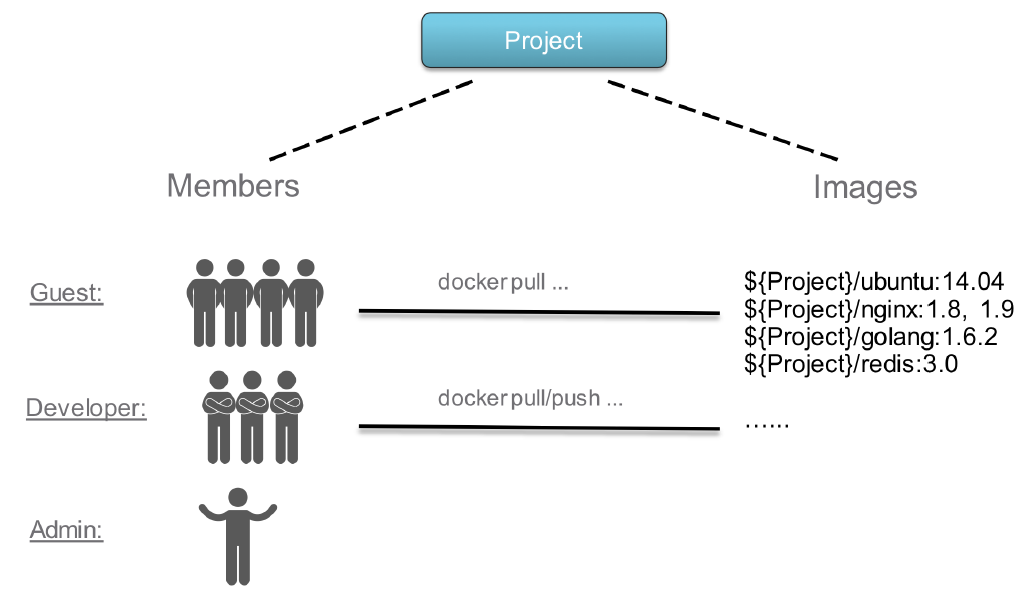
垃圾回收
镜像删除时,blob 文件不会被删除。(你能想起来为什么吗)
需要通过垃圾回收机制来删除不用的 blob,进而回收存储空间。
本地镜像加速 Dragonfly
Dragonfly 是一款基于 P2P 的智能镜像和文件分发工具
它旨在提高文件传输的效率和速率,最大限度地利用网络带宽,尤其是在分发大量数据时
- 应用分发
- 缓存分发
- 日志分发
- 镜像分发
优势
- 基于 P2P 的文件分发
- 非侵入式支持所有类型的容器技术
- 机器级别的限速
- 被动式 CDN
- 高度一致性磁盘保护和高效 IO
- 高性能
- 自动隔离异常
- 对文件源无压力
- 支持标准 HTTP 头文件
- 有效的 Registry 鉴权并发控制
- 简单易用
镜像下载流程
dfget proxy 也称为 dfdaemon,会拦截来自 docker pull或 docker push 的 HTTP 请求,然后使用 dfget 来处理那些跟镜像分层相关的请求。
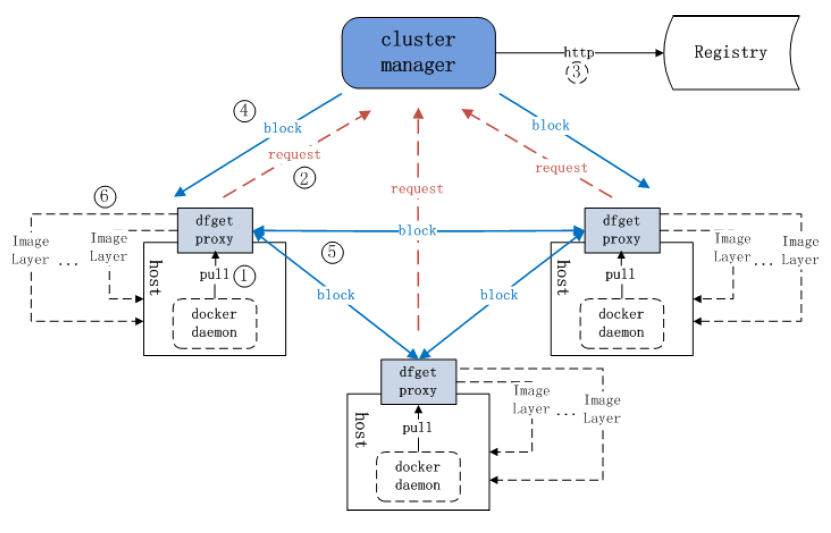
每个文件会被分成多个分块,并在对等节点之间传输
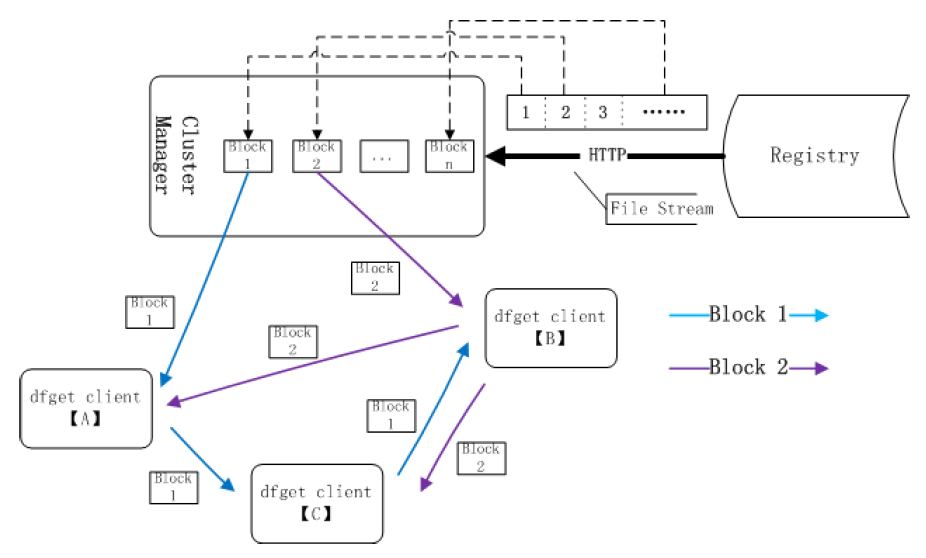
镜像安全
镜像安全的最佳实践
构建指令问题
- 避免在构建竟像时添加密钥,Token 等敏感信息(配置与代码应分离)
应用依赖问题
- 应尽量避免安装不必要的依赖
- 确保依赖无安全风险,,一些长时间不更新的基础镜像的可能面临安全风险,比如基于 openssl1.0,只支持 tls1.0 等
文件问题
- 在构建镜像时,除应用本身外,还会添加应用需要的配置文件、模板等,在添加这些文件时,会无意间添加一些包含敏感信息或不符合安全策略的文件到镜像中。
- 当镜像中存在文件问题时,需要通过引入该文件的构建指令行进行修复,而不是通过追加一条删除指令来修复
镜像扫描(Vulnerability Scanning)
镜像扫描通过扫描工具或扫描服务对镜像进行扫描,来确定镜像是否安全
- 分析构建指令、应用、文件、依赖包
- 查询CVE库、安全策略
- 检测镜像是否安全,是否符合企业的安全标准
镜像策略准入控制
镜像准入控制是在部署 Pod、更新 Pod 时,对 Pod 中的所有镜像进行安全验证以放行或拦截对Pod的操作:
- 放行: Pod 中所有的镜像都安全,允许此次的操作,Pod 成功被创建或更新。
- 拦截: Pod 中的镜像未扫描,或已经扫描但存在安全漏洞,或不符合安全策略,Pod 无法被创建或更新。
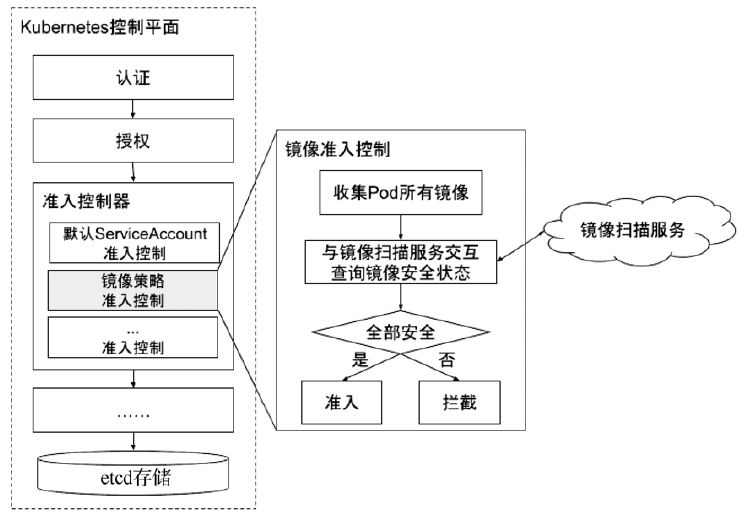
扫描镜像
- 镜像扫描服务从镜像仓库拉取镜像。
- 解析镜像的元数据。
- 解压镜像的每一个文件层。
- 提取每一层所包含的依赖包、可运行程序、文件列表、文件内容扫描
- 将扫描结果与 CVE 字典、安全策略字典进行匹配,以确认最终镜像是否安全
镜像扫描服务
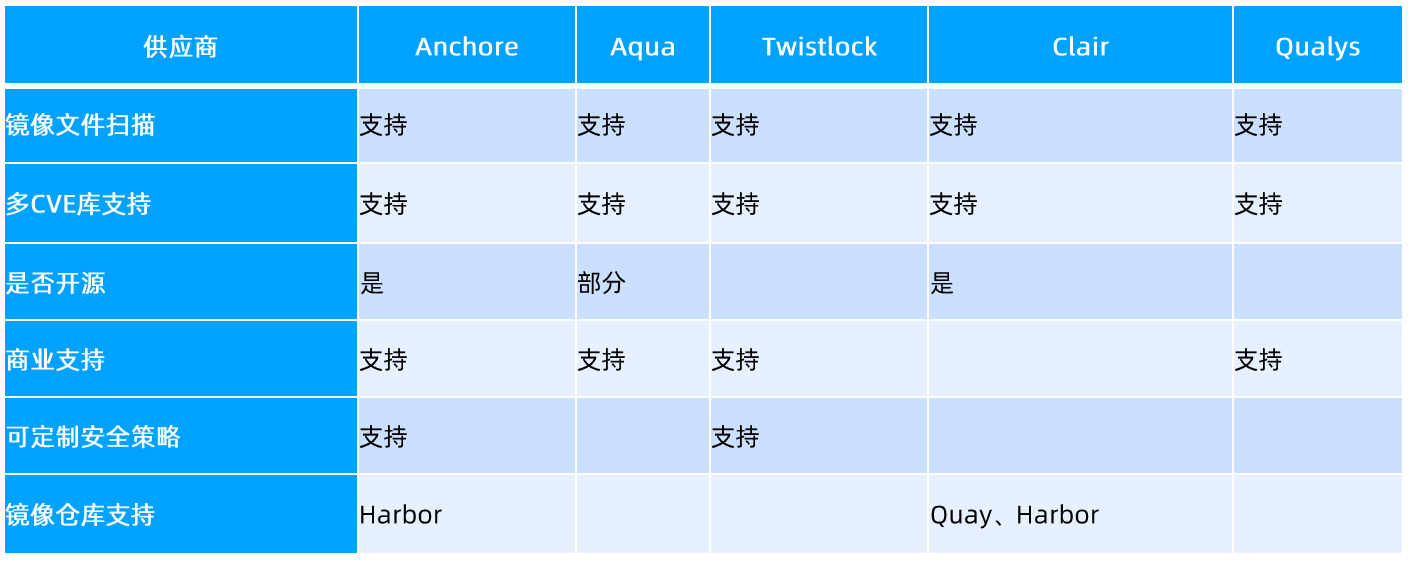
Clair 架构
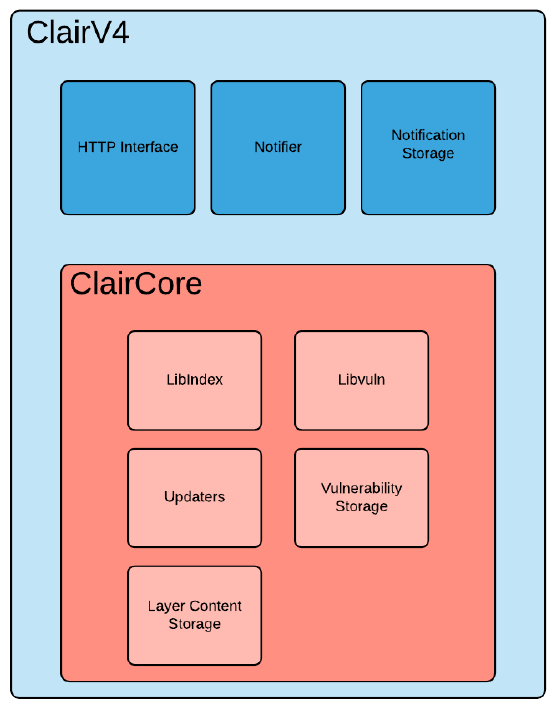
课后练习
将 Nginx 容器镜像上传至 Harbor Demo server 并运行在测试环境中。
基于 Kubernetes 的 DevOps
传统运维模式
- 缺乏一致性环境
- 平台与应用部署相互割裂
- 缺乏工具链支持
- 缺乏统一的灰度发布管理
- 缺乏统一监控能力和持续运维能力
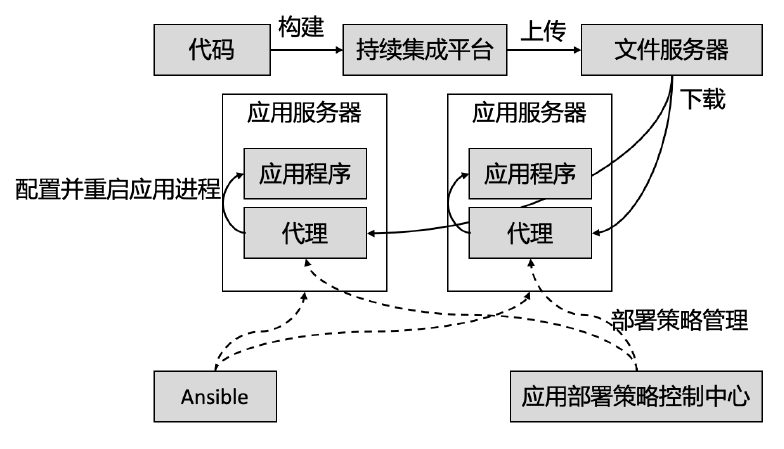
建立持续交付的服务体系
传统的开发运维模式下,存在的问题:
- 从需求到版本上线中间是个黑箱子,风险不可控;
- 开发设计时未过多考虑运维,导致后续部署及维护的困难:
- 开发各自为政,烟囱式开发,未考虑共享重用、联调,开发的资产积累不能快速交移到运维手中;
应对这样的问题,我们通常倡导的解决之道是:运维前移,统一运维,建立持续交付服务体系。
基于 Docker 的开发模式驱动持续集成
DevOps 流程定义
Dev 和 ops 的边界定义
Programming vs.Engineering
- Programming 更多的是系统设计和编码实现
- Engineering 包含更大范围概念,除了功能层面的实现,还需为运维服务
定义production readiness
Function ready vs. production ready
- Function Ready 只是交付的软件产品从功能层面满足需求定义
- ProductionReady 除了功能就绪还包含
- LnP 测试通过,满足性能需求
- 用户手册完成,用户可按照用户手册使用既定功能
- 管理手册完成,运维人员可以依照管理手册部署,升级产品并解决现网问题
- 监控,包括
- 组件健康状态检查(UP)
- 性能指标(Metrics)
- 基于性能指标,定义 alertrule,在系统故障或缓慢时,发送告警信息给运维人员 Assertion,定期测试某功能并检查结果,比如每小时创建 service,测试 vip 连通性
单体架构下的人员配置
微服务架构下的人员配置
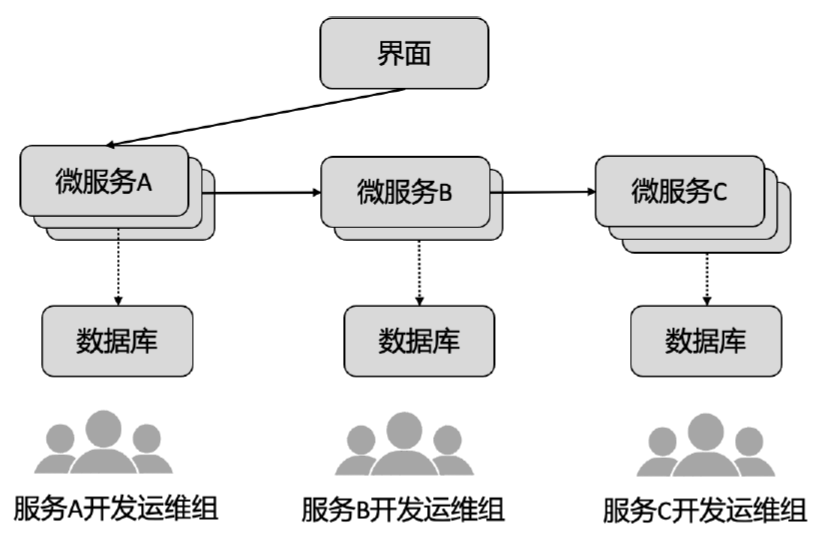
Devops 下的人员划分
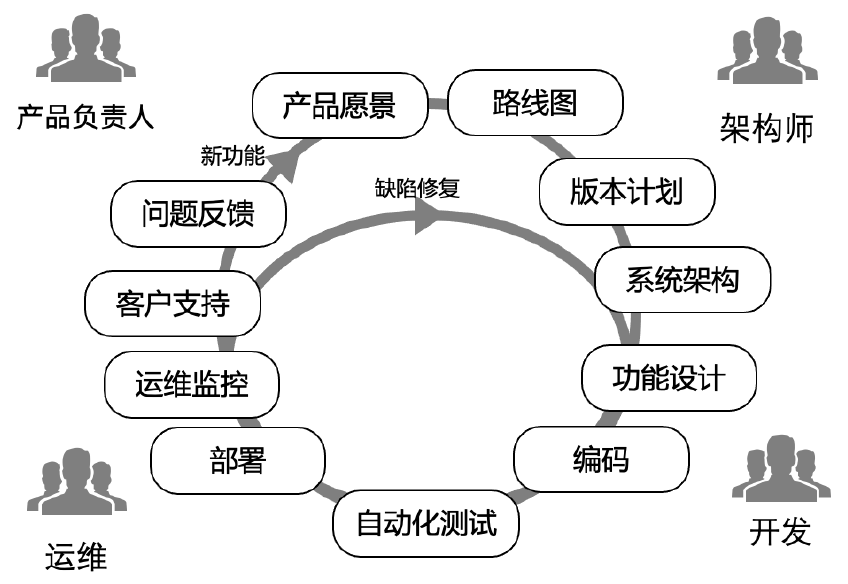
此组织结构的优缺点
优势
- 一个架构师负责整个产品的规划,使得产品更规范,产品进化不同的 Program 由不同 PO 负责端到端,从需求到生产系统部署,保证 solution 质量研发和运营统一,一个最大的作用是研发可以深刻理解现网痛苦,对功能需求的设计,和优先级定义有极大帮助。
- Function ready vs. production ready
- Programming vs.Engineering
- 更具连续性
问题
- 传统运营和开发的冲突并非消失,而是转变为了运营经理和架构以及 PO(Project Owner) 之间的冲突。
- 运营轮值导致生产系统权责不明确
- 轮值期间期待不出故障
- 对于出现的故障缺少端对端的跟踪,可能问题还没处理结束,已经要交接给下一个人了
- 对于生产系统的积累问题,如故障节点,无人专职处理,导致比较多的故障节点堆积
- 对于生产系统的配置,无统一规划,每个人可能用不同的配置达到相同的目的
- Dev 自主权过高导致 Dev 可以偷偷加功能并部署到生产
我眼中理想的 DevOps
Dev 和 Ops 需要责权划分,可以有 overlap,同时做部署,同时做计划,但 Dev 应侧重功能开发,Ops 偏重生产系统运维
Ops 参与到版本规划流程中,并为一个功能能不能 release 和 deploy 把关
Dev
- Plan
- Code
- Build
- Test
- Release
- Deploy
Ops
- Deploy
- Operate
- Monitor
Plan
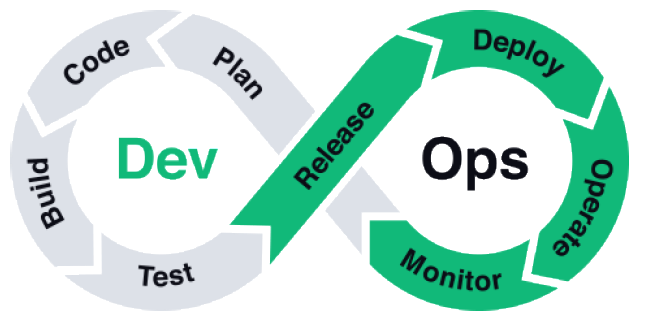
产品愿景
产品愿景的定义有多个目的:
- 统一团队思想,让团队成员知道我们要往哪里去,这有助于让团队专注于交付产品价值。
- 长期愿景往往是有野心的,能对团队成员起到激励作用,比如”业界尖端技术”往往能刺激团队成员努力自我提升。
- 该愿景应该是团队成员的共识,是所有人的共同理想,
- 愿景要产生真正的价值,是真正建立在对当前业务痛点的充分理解基础之上的,
例如:
- 长期愿景:基于业界尖端技术打造下一代流量管理平台
- 产品价值:
- 节省时间成本,负载均衡上架时间从数月降低到分钟级
- 移除供应商依赖问题,出现生产系统故障不再依赖供应商上门调试
- 构建一套统一模型管理所有业务场景,降低系统集成成本
- 全自动化,减少手工操作,降低维护人力成本
- 故障检测和根因分析能力,快速定位故障,提升可用性
产品路线图定义
而项目执行需要有明确时间线的近期目标,因此需要将产品价值转化成可控的产品需求。产品需求的输入包括新功能和当前产品的功能缺陷等,产品经理需要与核心团队一道定义近期(比如2-3个季度)的产品核心功能,并定义近期产品版本需要包含的功能。

敏捷开发
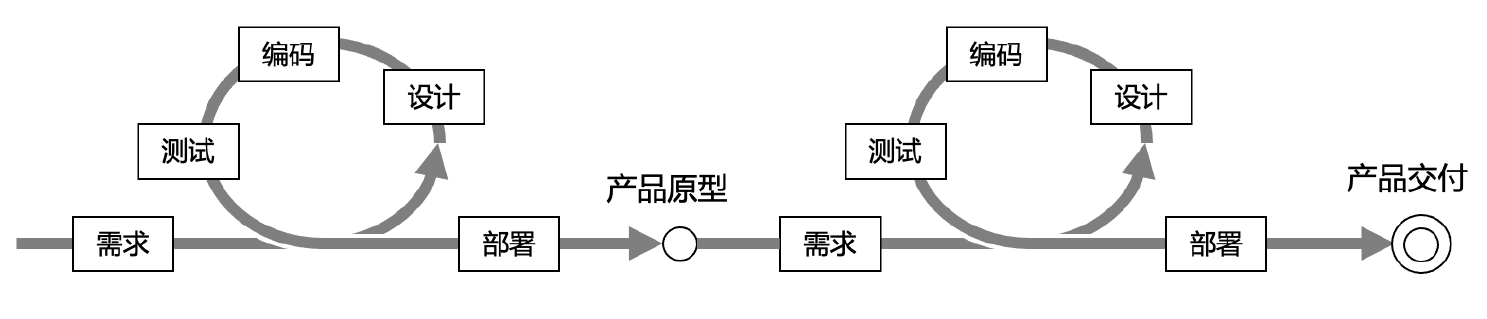
Devops 流程概览
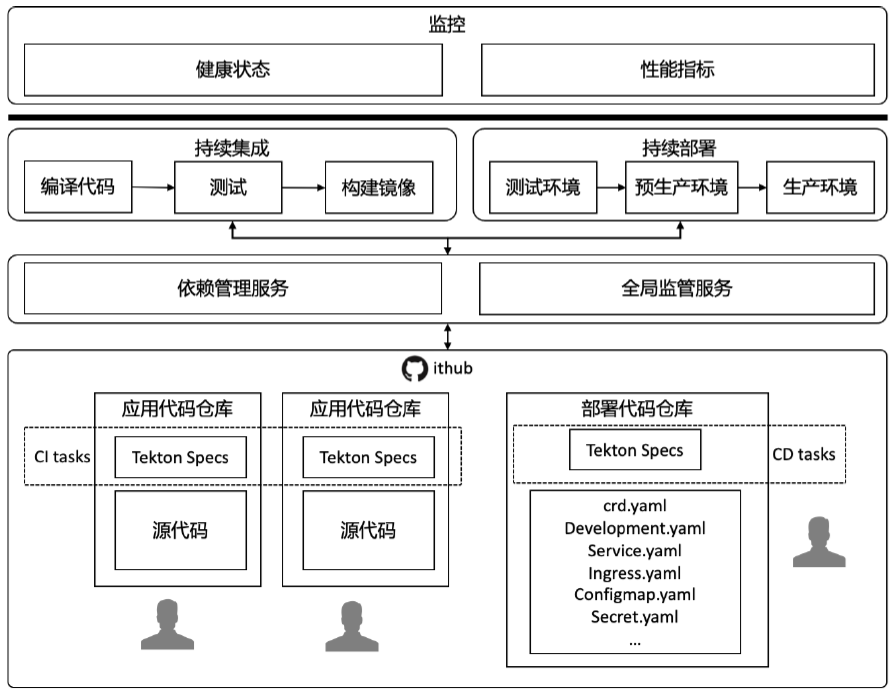
代码分支管理
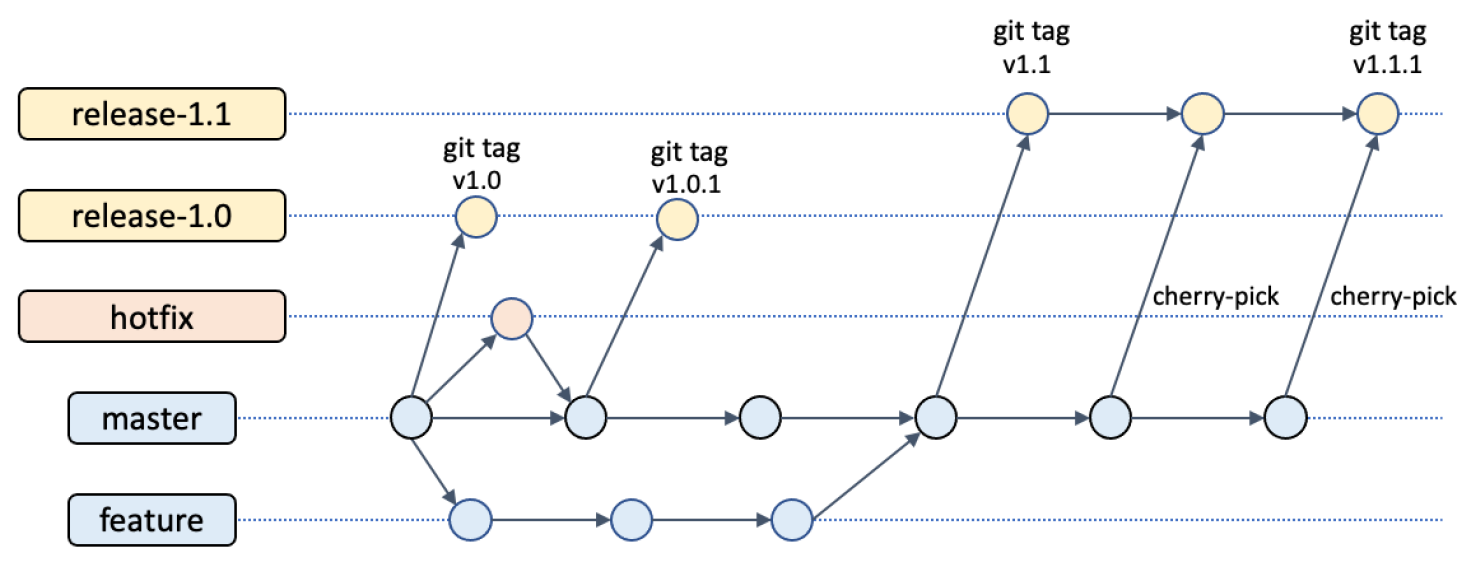
持续集成
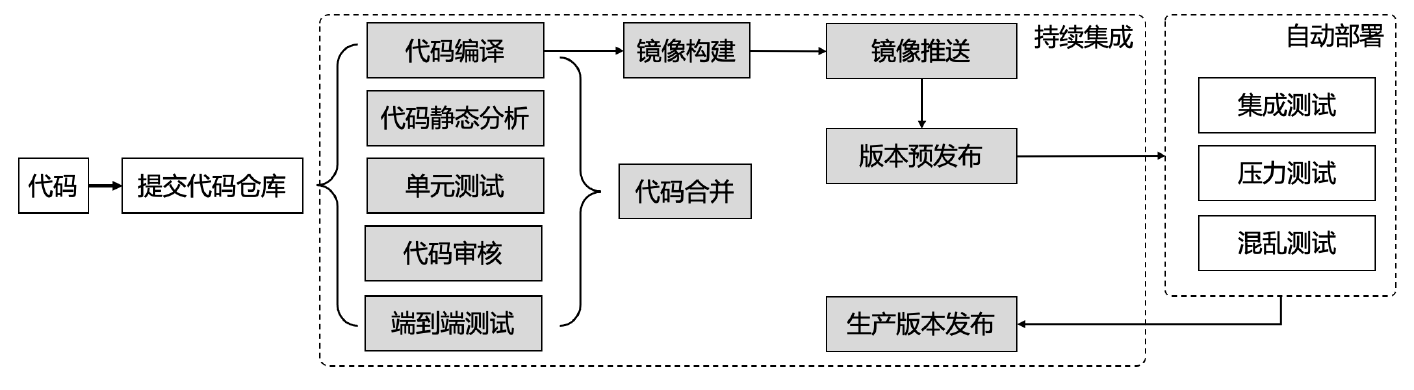
持续部署
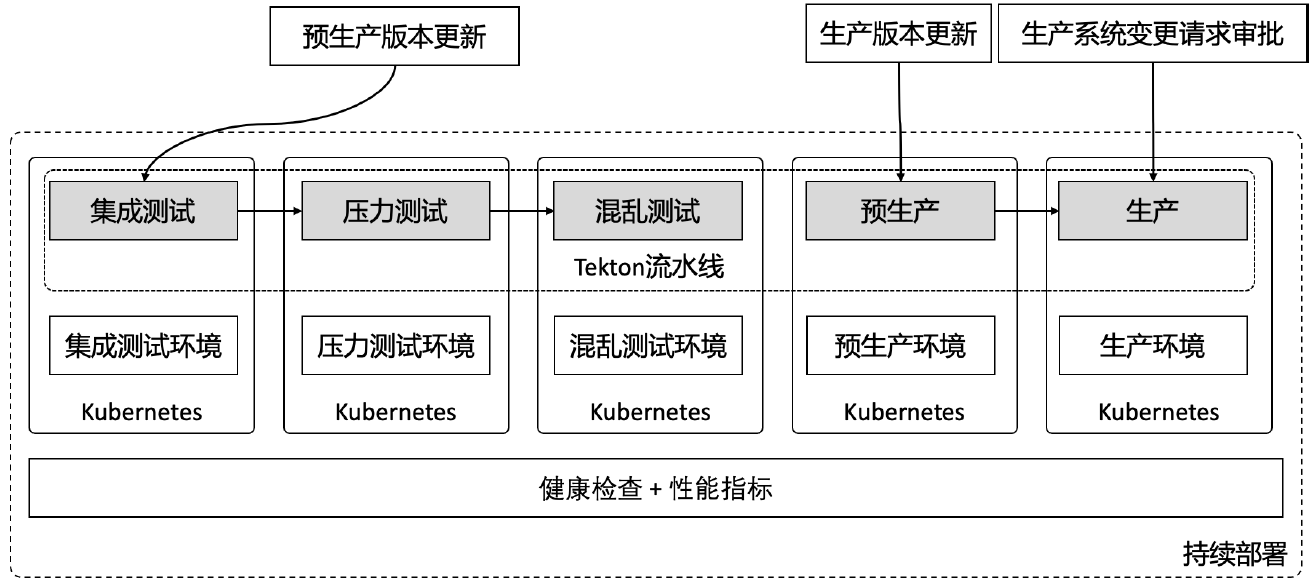
GitOps
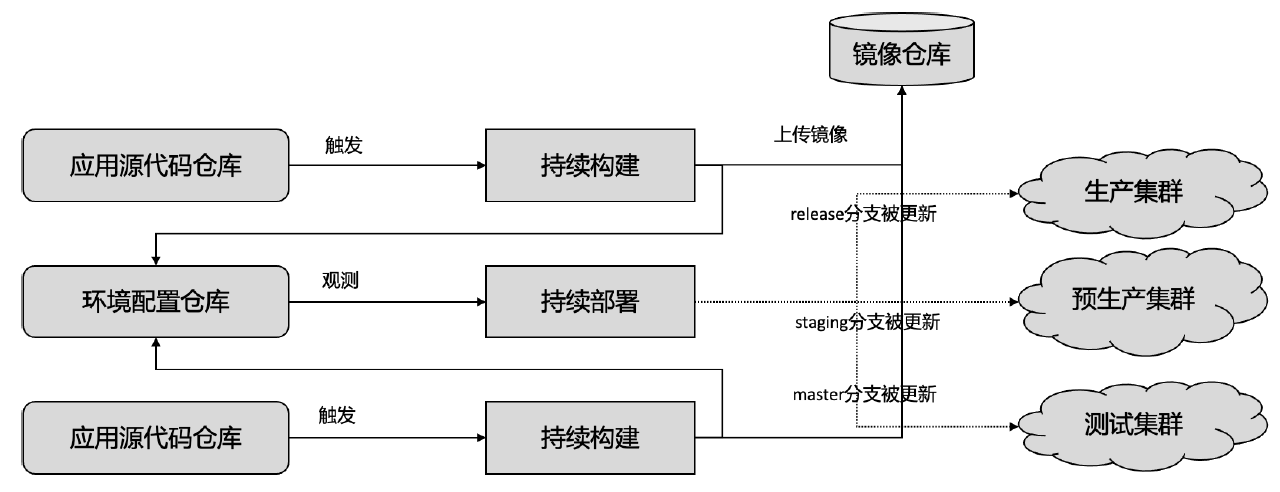
基于 GitHub Action 的自动化流水线
基于公共 GitHub 的 action 构建流水线
低成本
- GitHub 目前为项目提供免费构建流水线,可满足日常构建需求
免运维
- 无需自己构建流水线,GitHub 提供小量构建请求
易构建
- GitHub action 非常容易构建,只需点击几次按钮,即可完成
- GitHub 提供了一系列内建 action,社区有大量可复用的 action
易集成
- 无需配置 GitHub Webhook 即可完成与 PR 的联动
Action 的创建
Action 细节
https://github.com/cncamp/golang/blob/master/.github/workflows/go.yml
on:
pull_request:
branches: [ master ]
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Set up Go
uses: actions/setup-go@v2
with:
go-version: 1.17
- name: Build
run: go build -v ./...
- name: Test
run: go test -v ./...基于 Jenkins 的自动化流水线

Kubernetes CI&CD 完整流程

持续集成容器化
最主要解决的问题是保证CI构建环境和开发构建环境的统一。
使用容器作为标准的构建环境,将代码库作为 Volume 挂载进构建容器。
由于构建结果是 Docker 镜像,所以要在构建容器中执行”docker build”命令,需要注意 DIND(docker in docker) 的问题,
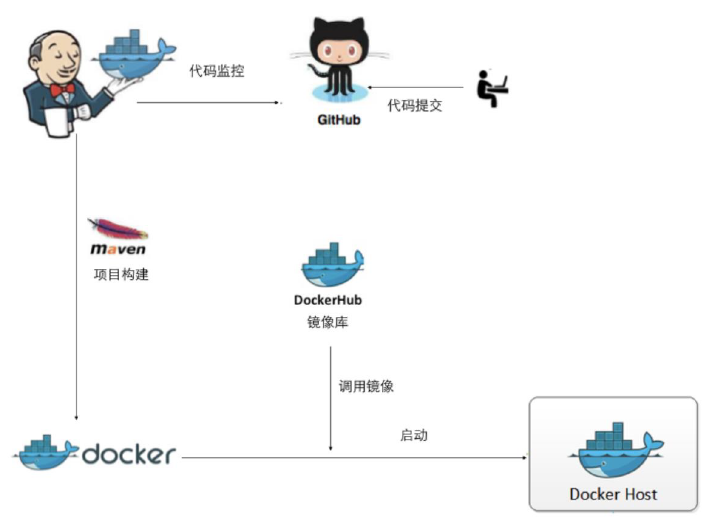
基于 Kubernetes 的持续集成
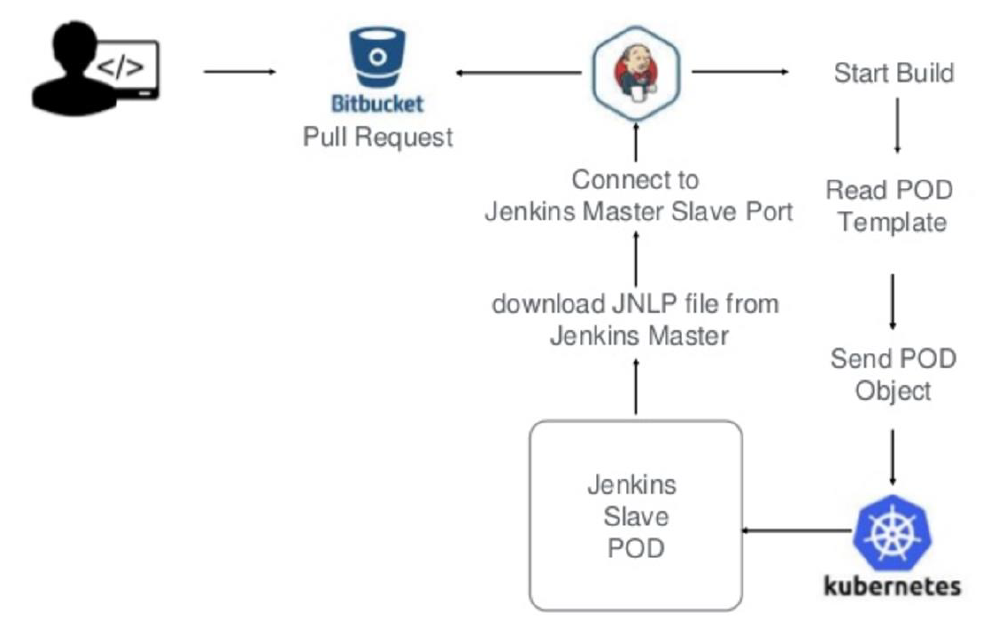
Docker in Docker 问题展开
方法1
docker in docker
早期尝试
https://github.com/jpetazzo/dind
官方支持
https://hub.docker.com/_/docker/
docker run --privileged -d docker:dind可能引入的问题: https://ipetazzo.github.io/2015/09/03/do-not-use-docker-in-docker-for-ci/
if your use case really absolutely mandates Docker-in-Docker, have a look at sysbox, it might be what you need.
方法2
mount host docker.socket
docker run -v /var/run/docker.sock:/var/run/docker.sock ...思考:可能引入的问题?
方法3
Kaniko
https://github.com/GoogleContainerTools/kaniko
echo -e 'FROM alpine \nRUN echo "created from standard input"' > Dockerfile | tar -cf - Dockerfile | gzip -9 | docker run \
--interactive -v $(pwd):/workspace gcr.io/kaniko-project/executor:latest \
--context tar://stdin \
--destination=cncamp/echoimage构建基于 Kubernetes 的 Jenkins Pipeline
Image准备: 基于Jenkins官方Image安装自定义插件
- https://github.com/ienkinsci/kubernetes-plugin
默认安装kubernete plugin - https://github.com/ienkinsci/docker-inlp-slave
如果需要做 docker build,则需要自定义 Dockerfile,安装 docker binary,并且把 host 的 docker.socket mount 进 container
- https://github.com/ienkinsci/kubernetes-plugin
Jenkins 配置的保存
- 需要创建 PVC,以便保证在 jenkins master pod 出错时,新的 kubernetes pod 可以 mount 同样的工作目录保证配置不丢失
- 可以通过 jenkins scm plugin 把 jenkins 配置保存至GitHub
创建 Kubernetes spec
jenkins 的配置
Cloud provider 配置
- 在 jenkins System config 选择点击 Cloud,并选择 kubernetes
- 创建 Kubernetes ServiceAccount,并在 kubernetes 对应的 namespace 授予 namespace admin 权限
- 指定 Jenkins slave 的 image
- 按需指定 volume mount,如需在 slave container 内部执行 docker 命令,则需要 mount/var/run/docker.sock
创建 jenkins Job
Git integration
- Jenkins webhook on Github
- Git review/merge Bot
Build job
- Git clone code
- Build binary
- Build Docker image
- Push Docker image to hub
Testing
- UT/UT Coverage
- E2E
- Conformance
- Conformance Slow
- LnP
Jenkins 练习
创建 Jenkins Master
kubectlapply-fjenkins.yaml
kubectl apply -f sa.yaml等待 Jenkins-0 pod 运行,查看日志查找 root 密码
kubectllogs -f jenkins-0查看 Jenkins Service 的 NodePort,登录 Jenkins console
http://192.168.34.2:<nodePort>
输入 root 密码并创建管理员用户,登录
安装Kubernetes插件
- 菜单 ManageJenkins->Manage Plugins->Available
- 查找并安装 Kubernetes
- 选择 Kubernetes,点击 install without restart
- 等待安装完成
配置 Cloud Provider
- 菜单 Managejenkins->Manage Node and Cloud->Configure Cloud
- Add a new cloud:Kubernetes
- Kubernetes URL: https://kubernetes.default
- Kubernetes Namespace: default
- Credentials: Add->Jenkins->Kind: Kubernetes Service Account
- Test connection
- Jenkins URL: http://Jenkins
- PodTemplate
- Labels: inlp-slave
- Add Container // 新版本 Jenkins 会默认用社区镜像启动 jnlp slave,可以通过定义同名容器覆盖
- Name: jnlp
- Image: cncamp/inbound-agent2
- command: “”
- Arguments to pass to the command:
${computer.jnlpmac} ${computer.name}
- save
create a job and tes
- Dashboard->Create a job->Freestyle project
- Restrict where this project can be run
- LabelExpression: inlp-slave
- Build->Add build step->Execute shell
- echo hello world
- Build Now
- 查看 jenkins slave pod:
kubectl get pod - 查看job log
Tekton
Jenkins 的不足
基于脚本的 Job 配置复用率不足。
- Jenkins 等工具的流水线作业通常基于大量不可复用的脚本语言,如何提高代码复用率
代码调试困难
- 如何让流水线作业的配置更好地适应云原生场景的需求越来越急迫
基于声明式 API 的流水线-Tekton
自定义: Tekton 对象是高度自定义的,可扩展性极强。平台工程师可预定义可重用模块以详细的模块目录提供,开发人员可在其他项目中直接引用。
可重用: Tekton 对象的可重用性强,组件只需一次定义,即可被组织内的任何人在任何流水线都可重用。使得开发人员无需重复造轮子即可构建复杂流水线。
可扩展性: Tekton 组件目录(TektonCatalog)是一个社区驱动的 Tekton 组件的存储仓库,任何用户可以直接从社区获取成熟的组件并在此之上构建复杂流水线,也就是当你要构建一个流水线时,很可能你需要的所有代码和配置都可以从 Tekton Catalog 直接拿下来复用,而无需重复开发
标准化: Tekton 作为 Kubernetes 集群的扩展安装和运行,并使用业界公认的 Kubernetes 资源模型 Tekton 作业以 Kubernetes 容器形态执行。
规模化支持: 只需增加 Kubernetes 节点,即可增加作业处理能力。Tekton 的能力可依照集群规模随意扩充,无需重新定义资源分配需求或者重新定义流水线。
Tekton 核心组件
Pipeline: 对象定义了一个流水线作业,一个 Pipeline 对象由一个或数个 Task 对象组成。
Task: 一个可独立运行的任务,如获取代码,编译,或者推送镜像等等,当流水线被运行时,Kubernetes 会为每个 Task 创建一个 Pod。一个 Task 由多个 Step 组成,每个 Step 体现为这个 Pod 中的一个容器。
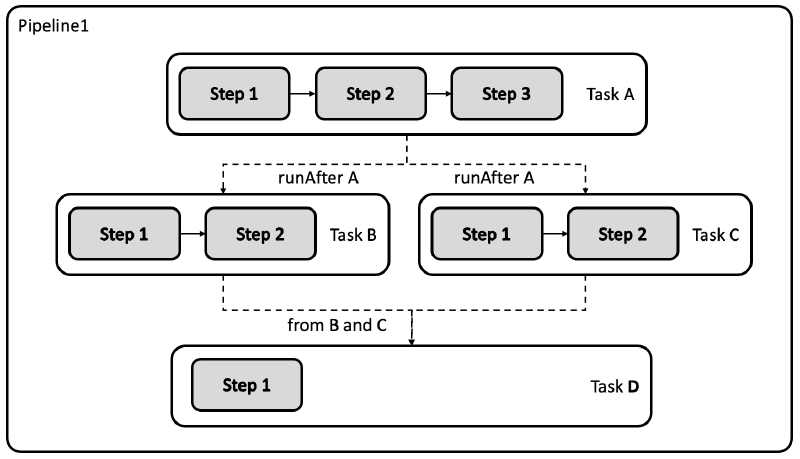
输入输出资源
Pipeline 和 Task 对象可以接收 git reposity,pull request 等资源作为输入,可以将 Image, Kubernetes Cluster,Storage,CloudEvent 等对象作为输出

事件触发的自动化流水线
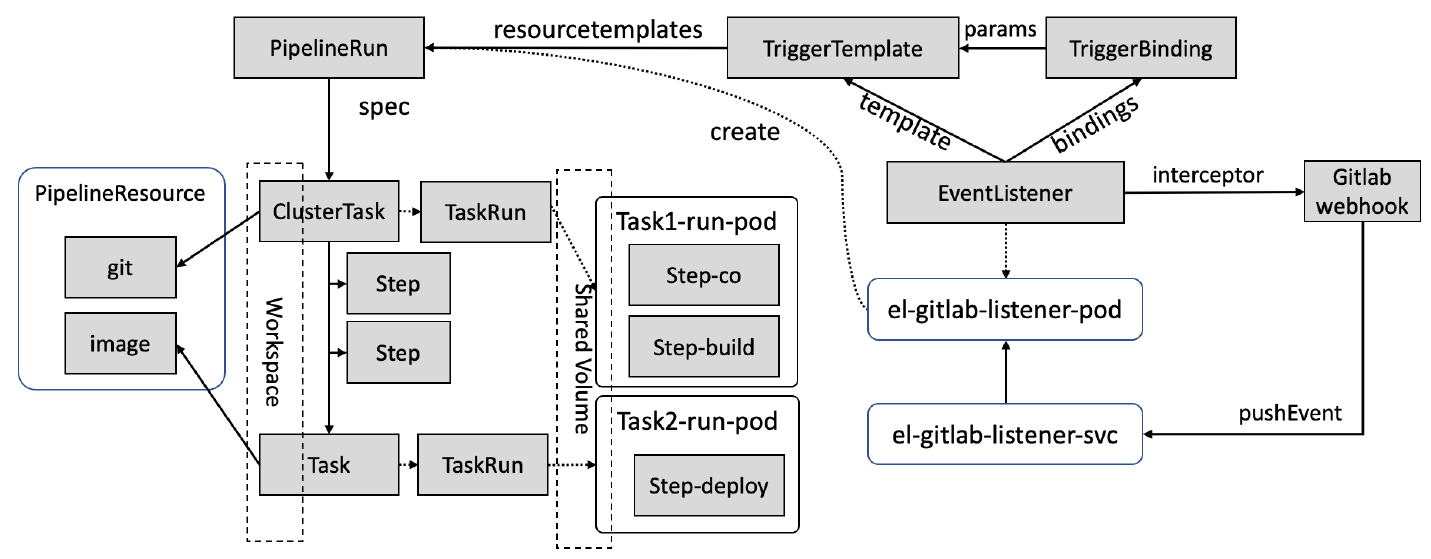
EventListener
事件监听器,该对象核心属性是 interceptors 拦截器,该拦截器可监听多种类型的事件,比如监听来自 GitLab 的 Push 事件。
当该 EventListener 对象被创建以后,Tekton 控制器会为该 EventListener 创建 Kubernetes Pod 和 Service,并启动一个 HTTP 服务以监听 Push 事件。
当用户在 GitLab 项目中设置 webhook 并填写该 EventListener 的服务地址以后,任何人针对被管理项目发起的 Push 操作,都会被 EventListener 捕获。
apiVersion: triggers.tekton.dev/v1alpha1
kind: EventListener
metadata:
name: gitlab-listener
spec:
serviceAccountName:cncampgitlab-sa
triggers:
- name: gitlab-push-events-trigger
interceptors:
- ref:
name: gitlab
params:
- name: secretRef
value:
secretName: cncamp-gitlab-secret
secretKey: secretToken
- name:eventTypes
value:
- Push Hook
bindings:
- ref: gitlab-binding
template:
ref: gitlab-triggertemplateTriggerTemplate
apiVersion: triggers.tekton.dev/v1alpha1
kind: TriggerTemplate
metadata:
name: gitlab-triggertemplate
spec:
params:
- name: gitrevision
- name: gitrepositoryurl
resourcetemplates:
- kind: PipelineRun
apiVersion: tekton.dev/v1beta1
metadata:
generateName: gitlab-pipeline-run-
spec:
serviceAccountName: cncamp-gitlab-sa
pipelinespec:
tasks:
- name: checkout
taskRef:
name: gitlab-checkout
resources:
inputs:
- name: source
resource: source
resources:
- name: source
type: git
resources:
- name: source
resourceSpec:
type: git
params:
- name: revision
value: $(tt.params.gitrevision)
- name: url
value: $(tt.params.gitrepositoryurl)GitLab webhook
只需在 GitLab 中的被管理项目中设置一个 Webhook,以确保该项目中的事件通知会发送至 EventListener 的服务地址即可。
Argocd
ArgoCD 是用于 Kubernetes 的声明性 GitOps 连续交付工具。
为什么选择 Argo CD?
应用程序定义,配置和环境应为声明性的,并受版本控制。
应用程序部署和生命周期管理应该是自动化的,可审核的且易于理解的。
argo cd 架构
Argo CD 被实现为 kubernetes 控制器,该控制器连续监视正在运行的应用程序,并将当前的活动状态与所需的目标状态(在Git存储库中指定)进行比较。
其活动状态偏离目标状态的已部署应用程序被标记为 OutOfSync。
Argo CD 报告并可视化差异,同时提供了自动或手动将实时状态同步回所需目标状态的功能。
在 Git 存储库中对所需目标状态所做的任何修改都可以自动应用并反映在指定的目标环境中。
安装 argocd
kubectl create namespace argocd
kubectl apply -n argocd -f https://raw.githubusercontent.com/argoproj/argo-cd/stable/manifests/install.yaml确保 argocd-serverservice 类型为 NodePort
访问 argocd 控制台
- 用户名: admin
- 密码:
kget secret -n argocd argocd-initial-admin-secret -oyaml
argocd 的适用场景
- 低成本的 Gitops 利器
- 多集群管理
- 不同目的集群: 测试,集成,预生产,生产
- 多生产集群管理
监控和日志
数据系统构建
日志收集与分析
监控系统构建
日志系统的价值
分布式系统的日志查看比较复杂,因为多对节点的系统,要先找到正确的节点,才能看到想看的日志。日志系统把整个集群的日志汇总在一起,方便查看
因为节点上的日志滚动机制,如果有应用打印太多日志,如果没有日志系统,会导致关键日志丢失。
日志系统的重要意义在于解决,节点出错导致不可访问,进而丢失日志的情况,
常用数据系统构建模式
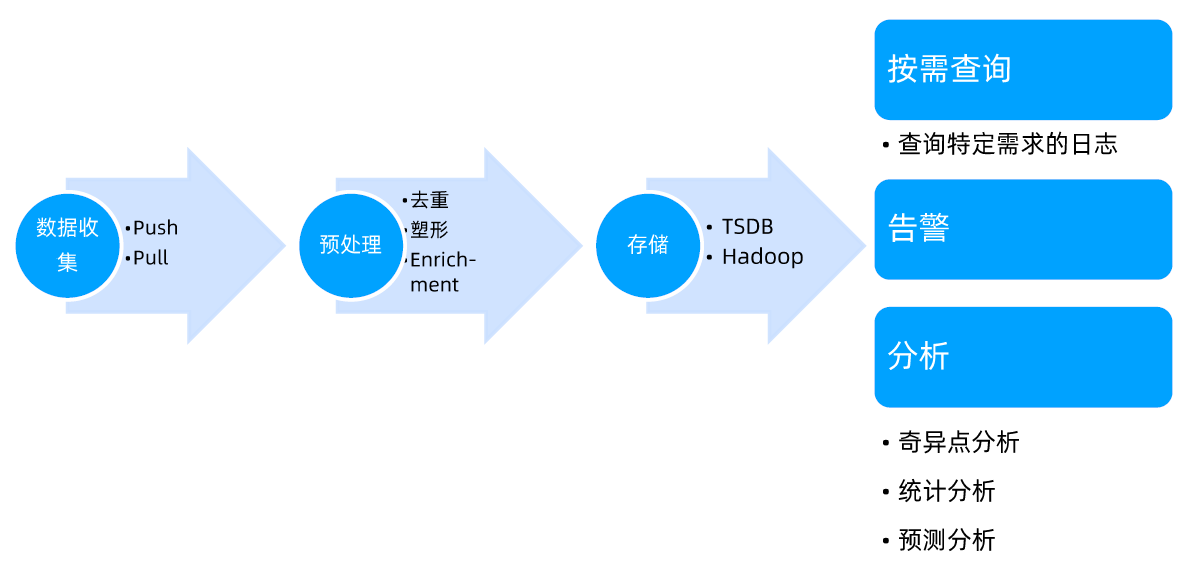
日志收集系统 Loki
Grafana Loki 是可以组成功能齐全的日志记录堆栈的一组组件,
- 与其他日志记录系统不同,Loki 是基于仅索引有关日志的元数据的想法而构建的:标签。
- 日志数据本身被压缩并存储在对象存储(例如 S3 或 GCS )中的块中,甚至存储在文件系统本地。
- 小索引和高度压缩的块简化了操作,并大大降低了 Loki 的成本。
基于 Loki 的日志收集系统
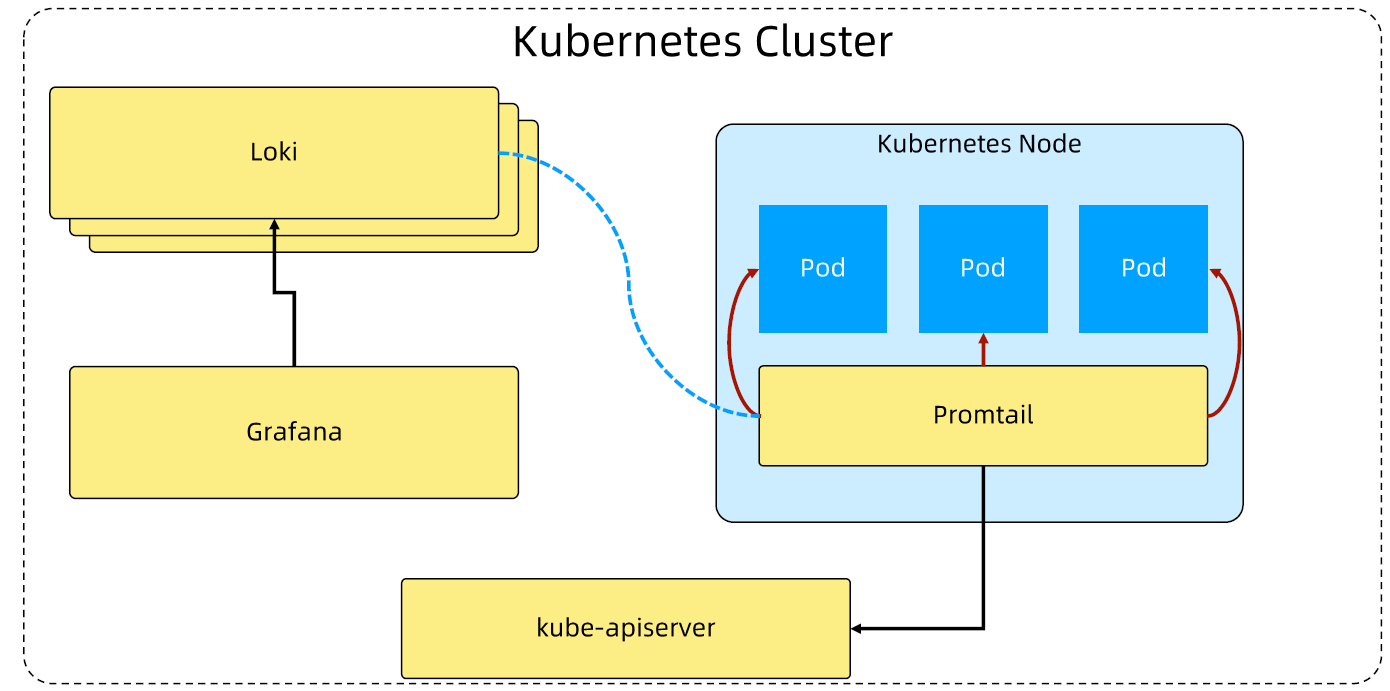
Loki-stack 子系统
Promtail
- 将容器日志发送到 Loki 或者 Grafana 服务上的日志收集工具
- 发现采集目标以及给日志流添加上 Label,然后发送给 Loki
- Promtail 的服务发现是基于 Prometheus 的服务发现机制实现的,可以查看configmap lokipromtail了解细节
Loki
- Loki 是可以水平扩展、高可用以及支持多租户的日志聚合系统
- 使用和 Prometheus 相同的服务发现机制,将标签添加到日志流中而不是构建全文索引
- Promtail 接收到的日志和应用的 metrics 指标就具有相同的标签集
Grafana
- Grafana 是一个用于监控和可视化观测的开源平台,支持非常丰富的数据源
- 在 Loki 技术栈中它专门用来展示来自 Prometheus 和 Loki 等数据源的时间序列数据
- 允许进行查询、可视化、报警等操作,可以用于创建、探索和共享数据 Dashboard
Loki 架构
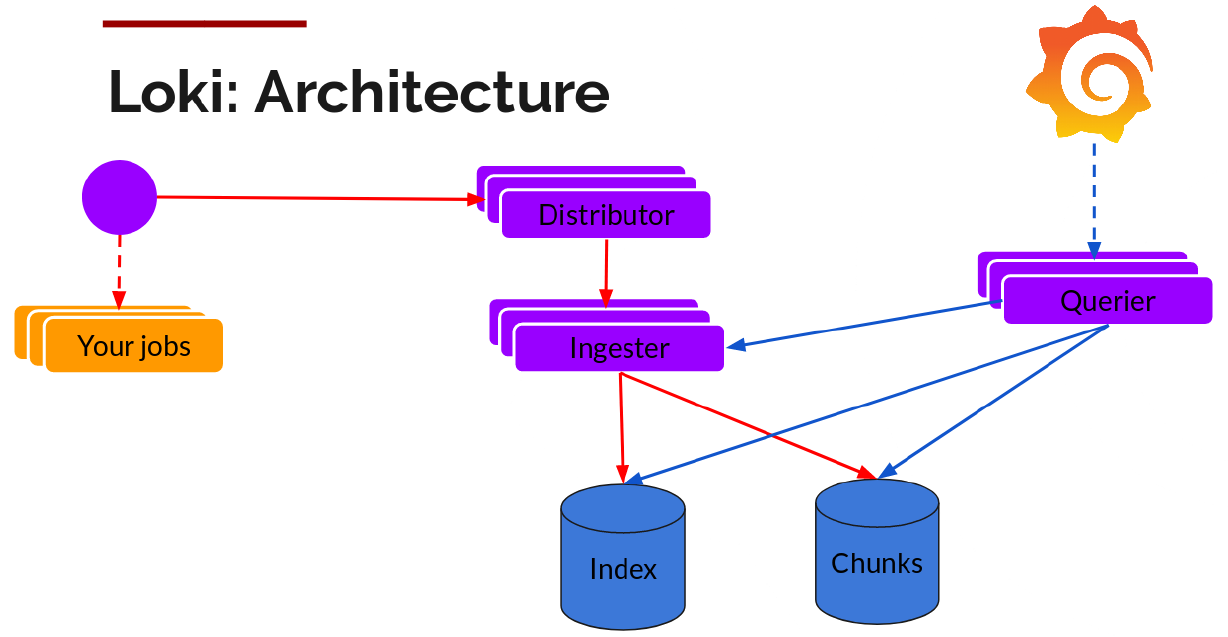
Loki 组件
Distributor(分配器)
- 分配器服务负责处理客户端写入的日志。
- 一旦分配器接收到日志数据,它就会把它们分成若干批次,并将它们并行地发送到多个采集器去。
- 分配器通过 RPC 和采集器进行通信。
- 它们是无状态的,基于一致性哈希,我们可以根据实际需要对他们进行扩缩容。
Ingester(采集器)
- 采集器服务负责将日志数据写入长期存储的后端(DvnamoDB、S3、Cassandra 等等)
- 采集器会校验采集的日志是否乱序。
- 采集器验证接收到的日志行是按照时间戳递增的顺序接收的,否则日志行将被拒绝并返回错误。
Querier(查询器)
- 查询器服务负责处理 LogQL 查询语句来评估存储在长期存储中的日志数据
安装 Loki stack
https://github.com/kibaamor/101/blob/master/module10/loki-stack/readme.MD
https://github.com/grafana/helm-charts/blob/main/charts/loki-stack/README.md
helm repo add grafana https://grafana.github.io/helm-charts
helm repo update
kubectl create namespace loki-stack
helm upgrade --install --namespace=loki-stack --set grafana.enabled=true,prometheus.enabled=true,prometheus.alertmanager.persistentVolume.enabled=false,prometheus.server.persistentVolume.enabled=false loki grafana/loki-stack
kubectl get secret --namespace loki-stack loki-grafana -o jsonpath="{.data.admin-password}" | base64 --decode ; echo
kubectl port-forward --namespace loki-stack service/loki-grafana 3000:80
# username: admin在 Kubernetes 集群中的日志系统
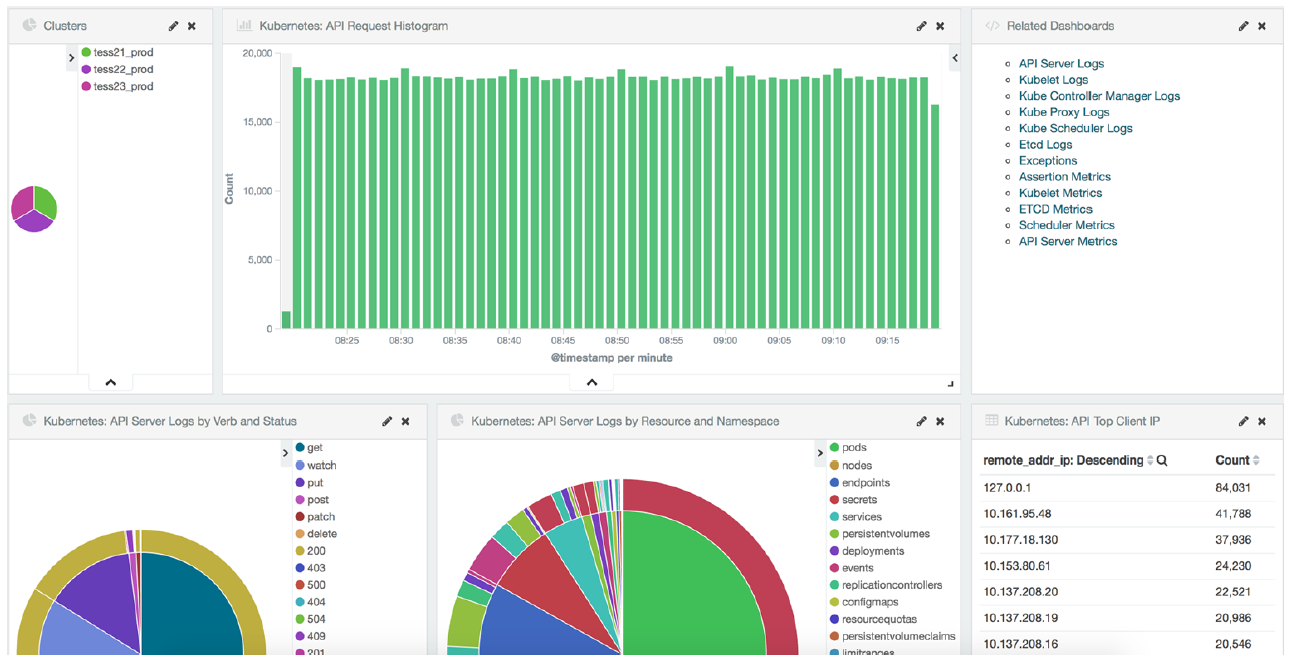
在生产中的问题
利用率低
- 日志大多数目的是给管理员做问题分析用的,但管理员更多的是登陆到节点或者 pod 里做分析,因为日志分析只是整个分析过程中的一部分,所以很多时候顺手就把日志看了
Beats 出现过锁住文件系统,docker container 无法删除的情况
与监控系统相比,日志系统的重要度稍低
出现过多次因为日志滚动太快而使得日志收集占用太大网络带宽的情况
监控系统
为什么监控,监控什么内容?
- 对自己系统的运行状态了如指掌,有问题及时发现,而不让用户先发现我们系统不能使用。
- 我们也需要知道我们的服务运行情况。例如,slowsql 处于什么水平,平均响应时间超过 200ms 的占比有百分之多少?
我们为什么需要监控我们的服务?
- 需要监控工具来提醒我服务出现了故障,比如通过监控服务的负载来决定扩容或缩容。如果机器普遍负载不高,则可以考虑是否缩减一下机器规模,如果数据库经常维持在一个高位水平,则可以考虑一下是否可以进行拆库处理,优化一下架构。
- 监控还可以帮助进行内部统制,尤其是对安全比较敏感的行业比如证券银行等。比如服务器受到攻击时我们需要分析事件,找到根本原因,识别类似攻击,发现没有发现的被攻的系统,甚完成取证等工作
监控目的
- 减少宕机时间
- 扩展和性能管理
- 资源计划
- 识别异常事件
- 故障排除、分析
在 Kubernetes 集群中的监控系统
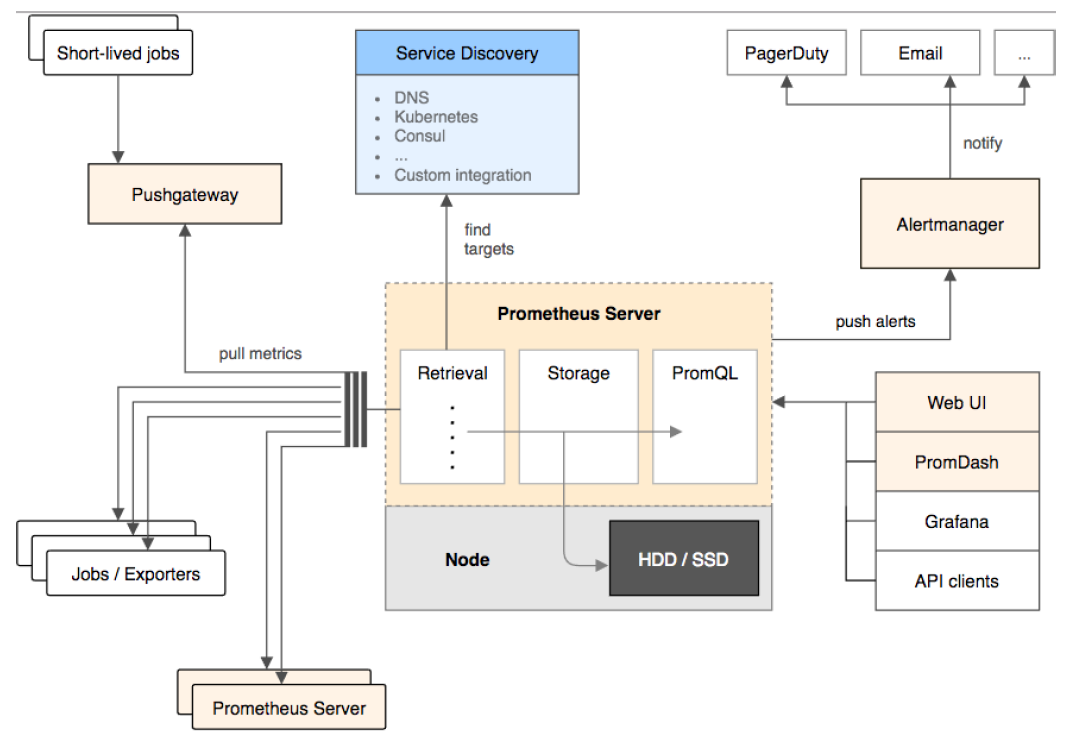
每个节点的 kubelet(集成了 cAdvisor)会收集当前节点 host 上所有信息,包括 cpu、内存、磁盘等。Prometheus 会 pull 这些信息,给每个节点打上标签来区分不同的节点。
HELP container cpu system seconds total Cumulative system cpu time consumed in seconds.
# TYPE container cpu system seconds total counter
container_cpu_system_seconds_total{id="/"} 735292
container_cpu_system_seconds_total{id="/system.slice"} 710067.82
container_cpu_system_seconds_total{id="/system.slice/atd.service"} 0.04
container_cpu_system_seconds_total{id="/system.slice/auditd.service"} 652.29
container_cpu_system_seconds_total{id="/system.slice/cloud-config.seryice"} 0
container_cpu_system_seconds_total{id=""/system.slice/cloud-final.service"} 0
container_cpu_system_seconds_total{id="/system.slice/cloud-init-local.service"} 0
container_cpu_system_seconds_totalfid="/system,slice/cloud-init.seryice"} 0
container_cpu_system_seconds_total{id="/system.slice/crond.service"} 4267.6
container_cpu_system_seconds_totallid="/system.slice/dbus.service"} 3.44
container_cpu_system_seconds_total{id="/system,slice/dm-event.service"} 428.39
container_cpu_system_seconds_total{id="/system.slice/docker.seryice"} 55096.24
container_cpu_svstem_seconds_totallid="/system,slice/dracut-shutdown,service"} 0
container_cpu_system_seconds_total{id="/system,slice/fedora-autorelabel-mark.service"} 0
container_cpu_system_seconds_total{id="/system,slice/fedora-import-state.service"} 0
container_cpu_svstem_seconds_totallid"/svstem,slice/fedora-readonly.seryice"} 0
container_cpu_system_seconds_totalfid="/system,slice/assproxy,seryice"} 27.07
container_cpu_system_seconds_total{id="/system.slice/iscsi-shutdown.service"} 0在 Kubernetes 中汇报指标
应用 Pod 需要声明上报指标端口和地址
apiVersion: v1
kind: Pod
metadata:
annotations:
prometheus.io/port: http-metrics
prometheus.io/scrape:"true
name: loki-0
namespace: default
spec:
ports:
- containerPort: 3100
name: http-metrics
protocol: TCP应用启动时,需要注册 metrics
http.Handle("/metrics",promhttp.Handler())
http.ListenAndServe(sever.MetricsBindAddress,nil)注册指标
func RegisterMetrics(){
registerMetricOnce.Do(func(){
prometheus.MustRegister(APiServerRequests)
prometheus.MustRegister(WorkQueueSize)
})
}代码中输出指标
metrics.AddAPServerRequest(controllerName, constants.CoreAPlGroup, constants.SecretResourceconstants.Get, cn.Namespace)Kubernetes 集群中的监控系统
Kubernetes 的 controlpanel,包括各种 controller 都原生的暴露 Prometheus 格式的 metrics。
Prometheus 中的指标类型
Counter 计数器
- Counter 类型代表一种样本数据单调递增的指标,即只增不减,除非监控系统发生了重置。
Gauge 仪表盘
- Guage 类型代表一种样本数据可以任意变化的指标,即可增可减。
Histogram 直方图
- Histogram 在一段时间范围内对数据进行采样(通常是请求持续时间或响应大小等),并将其计入可配置的存储桶 bucket 中,后续可通过指定区间筛选样本,也可以统计样本总数,最后一般将数据展示为直方图
- 样本的值分布在 bucket 中的数量,命名为
<basename>_bucket{le="<上边界>"} - 所有样本值的大小总和,命名为
<basename>_sum - 样本总数,命名为
<basename>_count。值和<basename>_bucket{le="+inf"}相同
Summary 摘要
- 与 Histogram 类型类似,用于表示一段时间内的数据采样结果(通常是请求持续时间或响应大小等),但它直接存储了分位数(通过客户端计算,然后展示出来),而不是通过区间来计算
- 它们都包含了
basename>_sum和<basename>_count指标 - Histogram 需要通过
<basename>_bucket来计算分位数,而 Summary 则直接存储了分位数的值。
Prometheus QueryLanguage
histogram_quantile(0.95, sum(httpserver_execution_latency_seconds_bucket[5m])) by (le))
- Histogram 是直方图,
httpserver_execution_latency_seconds_bucket是直方图指标 ,是将 httpserver 处理请求的时间放入不同的桶内,其表达的是落在不同时长区间的响应次数 by (le)是将采集的数据按桶的上边界分组rate(httpserver_execution_latency_seconds_bucket[5m]),计算的是五分钟内的变化率Sum()是将所有指标的变化率总计0.95是取 95 分位
综上:上述表达式计算的是 httpserver 处理请求时,95% 的请求在五分钟内,在不同响应时间区间的处理的数量的变化情况
Grafana Dashboard
开启告警
修改 Prometheus 配置文件 prometheus.yml,添加以下配置:
rule files:
- /etc/prometheus/rules/*.rules在目录 /etc/prometheus/rules/ 下创建告警文件 hoststats-alert.rules 内容如下:
groups:
- name: hostStatsAlert
rules:
- alert: hostCpuUsageAlert
expr: sum(avg without (cpu)(irate(node_cpu{mode!='idle'}[5m]))) by (instance) > 0.85
for: 1m
labels:
severity: High
annotations:
summary: "Instance {{$labels.instance}} CPU usgae high"
description: "{{ $labels.instance }} CPU usage above 85% (current value: {{ $value }})"构建支撑生产的监控系统
Metrics
- 收集数据
Alert
- 创建告警规则,如果告警规则被触发,则按不同眼中程度来告警
Assertion
- 以一定时间间隔,模拟客户行为,操作 kubernetes 对象,并断言成功,如果不成功则按眼中程度告警
来自生产系统的经验分享
Prometheus 需要大内存和存储
- 最初 prometheus 经常发生 OOM kill
- 在提高指定的资源以后,如果发生 crash 或者重启,prometheus 需要 30 分钟以上的时间来读取数据进行初始化
Prometheus 是运营生产系统过程中最重要的模块
- 如果 prometheus down 机,则没有任何数据和告警,管理员两眼一黑,什么都不知道了
课后练习
- 为 HTTPServer 添加 0-2 秒的随机延时
- 为 HTTPServer 项目添加延时 Metric
- 将 HTTPServer 部署至测试集群,并完成 Prometheus 配置
- 从 Promethus 界面中查询延时指标数据
- (可选)创建一个 Grafana Dashboard 展现延时分配情况
将应用迁移至 Kubernetes 平台
应用接入最佳实践
应用容器化
目标
稳定性、可用性、性能、安全
从多维度思考高可用的问题
单个实例视角
- 资源需求
- 配置管理
- 数据保存
- 日志和指标收集
应用视角
- 冗余部署
- 部署多少个实例
- 负载均衡
- 健康检查
- 服务发现
- 监控
- 故障转移
- 扩缩容
安全视角
- 镜像安全
- 应用安全
- 数据安全
- 通讯安全
应用容器化的思考
应用本身
- 启动速度
- 健康检查
- 启动参数
Dockerfile
用什么基础镜像
- 基础镜像越小越好
需要装什么 Utility
- lib 越少越好?
多少个进程
- 主次要分清楚,哪个是决定状态的主程序
- Fork bomb 的危害
代码(应用程序)和配置分离
配置如何管理
- 环境变量
- 配置文件
分层的控制
Entrypoint
思考:GOMAXPROCS 会如何设置?
容器额外开销和风险
Log driver
- Blocking mode
- Non blocking mode
共用 kernel 所以
- 系统参数配置共享
- 进程数共享 - Fork bomb
- fd 数共享
- 主机磁盘共享
容器化应用的资源监控
容器中看到的资源是主机资源
- Top
- Java
runtime.GetAvailableProcesses() cat /proc/cpuinfocat /proc/meminfodf -k
解决方案
查询
/proc/1/cgroup是否包含kubepods关键字(docker 关键字不可靠)。11:cpu,cpuacct:/kubepods.slice/kubepods-besteffort.slice/kubepods-besteffort-pod521722c3 85a8 11e9 87fc 3cfdfe57c998.slice/9568cc0d8ae182395e1ce172e2cac723c4781a999e89e0f9f10d33af079a56e9
包含此关键字,则表明是运行在 Kubernetes 之上。
内存开销
# 配额
$ cat /sys/fs/cgroup/memory/memory.limit_in_bytes
36854771712
# 用量
$ cat /sys/fs/cgroup/memory/memory.usage_in_bytes
448450560CPU
# 配额,分配的CPU个数 = quota/period,quota = -1 代表 besteffort
$ cat /sys/fs/cgroup/cpu/cpu.cfs_quota_us
-1
$ cat /sys/fs/cgroup/cpu/cpu.cfs_period_us
100000
# 用量 (按CPU区分)
$ cat /sys/fs/cgroup/cpuacct/cpuacct.usage_percpu
8081106980 4323359623 4636995549 3325343025 4953653066 3540876400 5181477709 4144887674 10399151669 2410161200 8233879500 3909704000 6805757900 2647133700 7813652536 2739789424
$ cat /sys/fs/cgroup/cpuacct/cpuacct.usage
83905685155其他方案
lxcfs
- 通过 so 挂载的方式,使容器获得正确的资源信息
Kata
- VM 中跑 container
Virtlet
- 直接启动 VM
对应用造成的影响
Java
- Concurrent GC Thread;
- Heap Size;
- 线程数不可控。
Node.js
- 多线程模式启动的 Thread 数量过多,导致 OOM Kill。
将应用迁移至 Kubernetes
Pod spec
初始化需求(init container)
需要几个主 container
权限?Privilege 和 Securitycontext(PSP)
共享哪些 Namespace(PID,IPC, NET, UTS, MNT)
配置管理
优雅终止
健康检查
- Liveness Probe
- Readiness Probe
DNS 策略以及对 resolv.conf 的影响imagePullPolicylmage 拉取策略
Probe 误用会造成严重后果
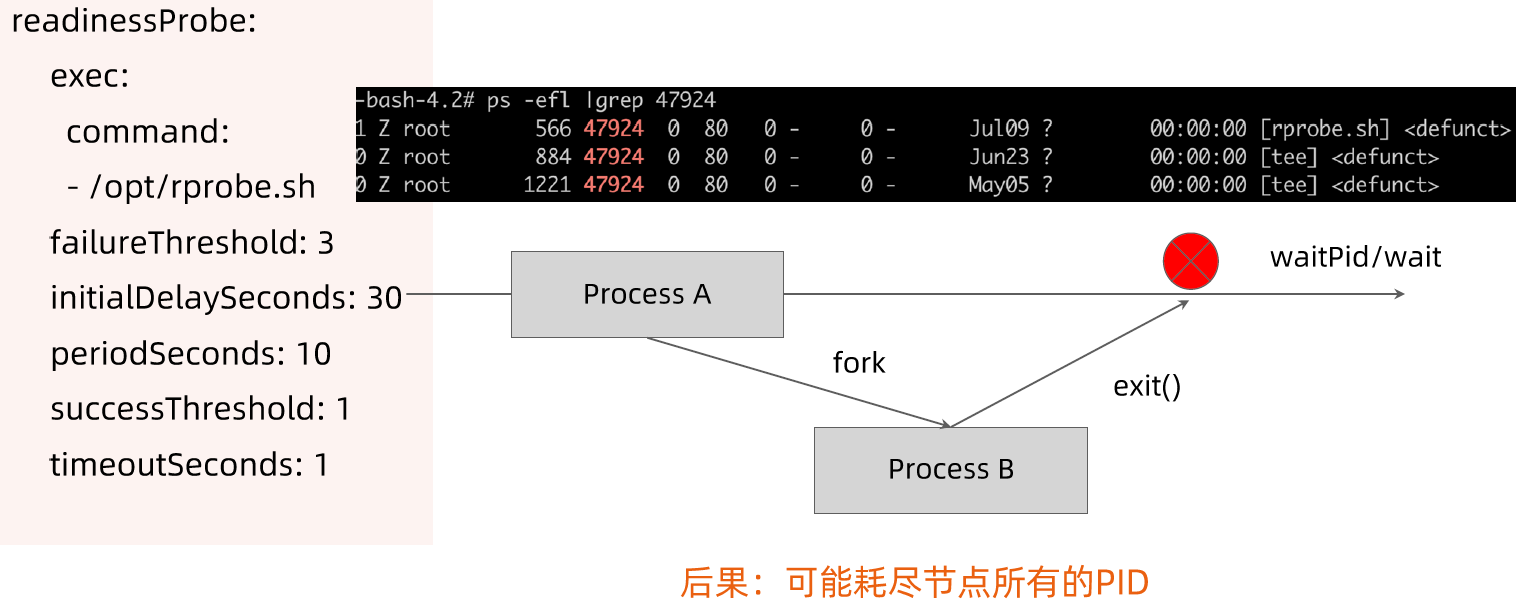
probe 其实就是通过 entrypoint fork 一个进程来执行的,probe 脚本的父进程是 entrypoint。脚本超时后 kubernetes 就会把进程强制杀死,被杀死的进程需要等待父进程(即 entrypoint)清理(waitpid/wait)后才会释放资源。如果entrypoint 不具备清理子进程的能力就会出现僵尸进程。
如何防止 PID 泄露
单进程容器
合理的处理多进程容器
- 容器的初始化进程必须负责清理 fork 出来的所有子进程
开源方案
- Tini https://github.com/krallin/tini
- 采用 Tini 作为容器的初始化进程 (PID=1) 容器中僵尸进程的父进程会被置为 1
如果不采用特殊初始化进程
- 建议采用 HTTPCheck 作为 Probe
- 为 exec Probe 设置合理的超时时间
在 Kubernetes 上部署应用的挑战
资源规划
每个实例需要多少计算资源
- CPU/GPU?
- Memory
超售需求
每个实例需要多少存储资源
- 大小
- 本地还是网盘
- 读写性能
- DiskIO
网络需求
- 整个应用总体 OPS 和带宽
Pod 的数据管理
- local-ssd:独占的本地磁盘,独占IO,固定大小,读写性能高。
- Local-dynamic:基于LVM,动态分配空间,效率低。
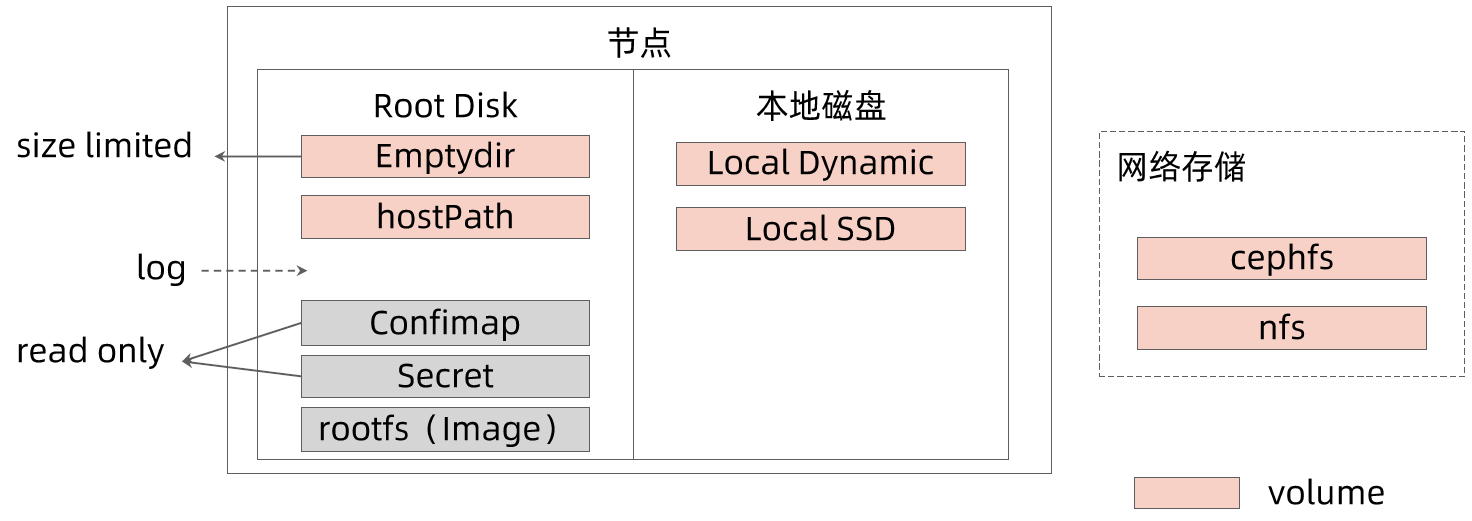
我的数据应该保存在哪里
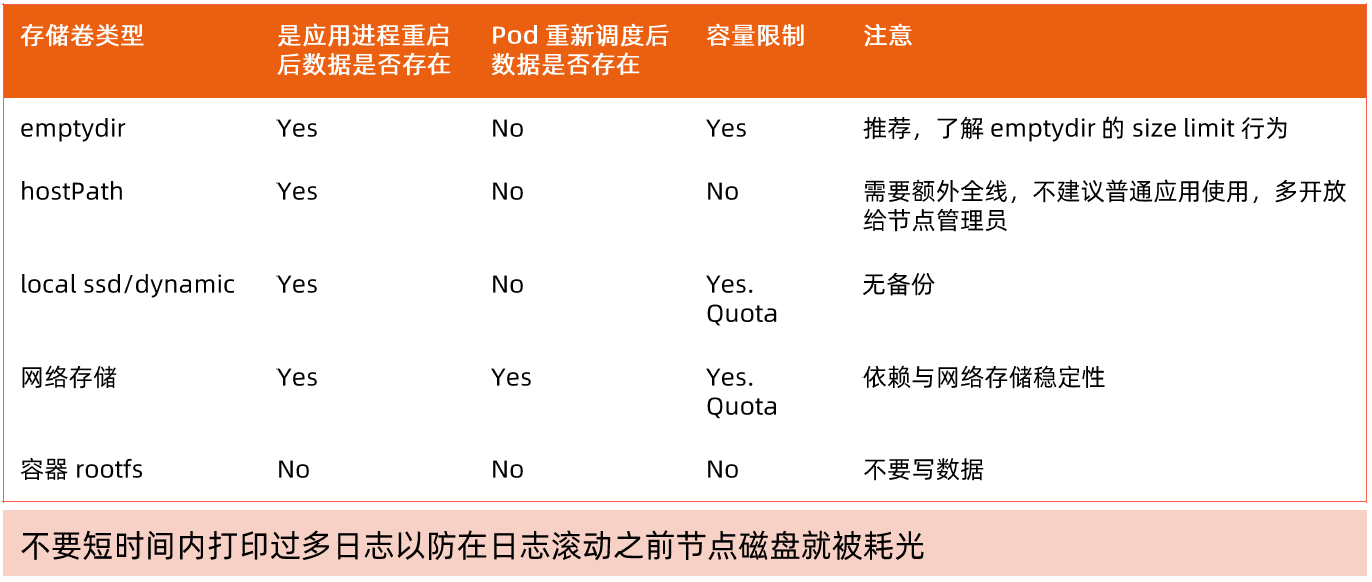
应用配置
传入方式
- Environment Variables
- Volume Mount
数据来源
- Configmap
- Secret
- Downward API
高可用部署
需要多少实例?
如何控制失败域,部署在几个地区,AZ,集群?
如何进行精细的流量控制?
如何做按地域的顺序更新?
如何回滚?
如何应对基础架构的影响
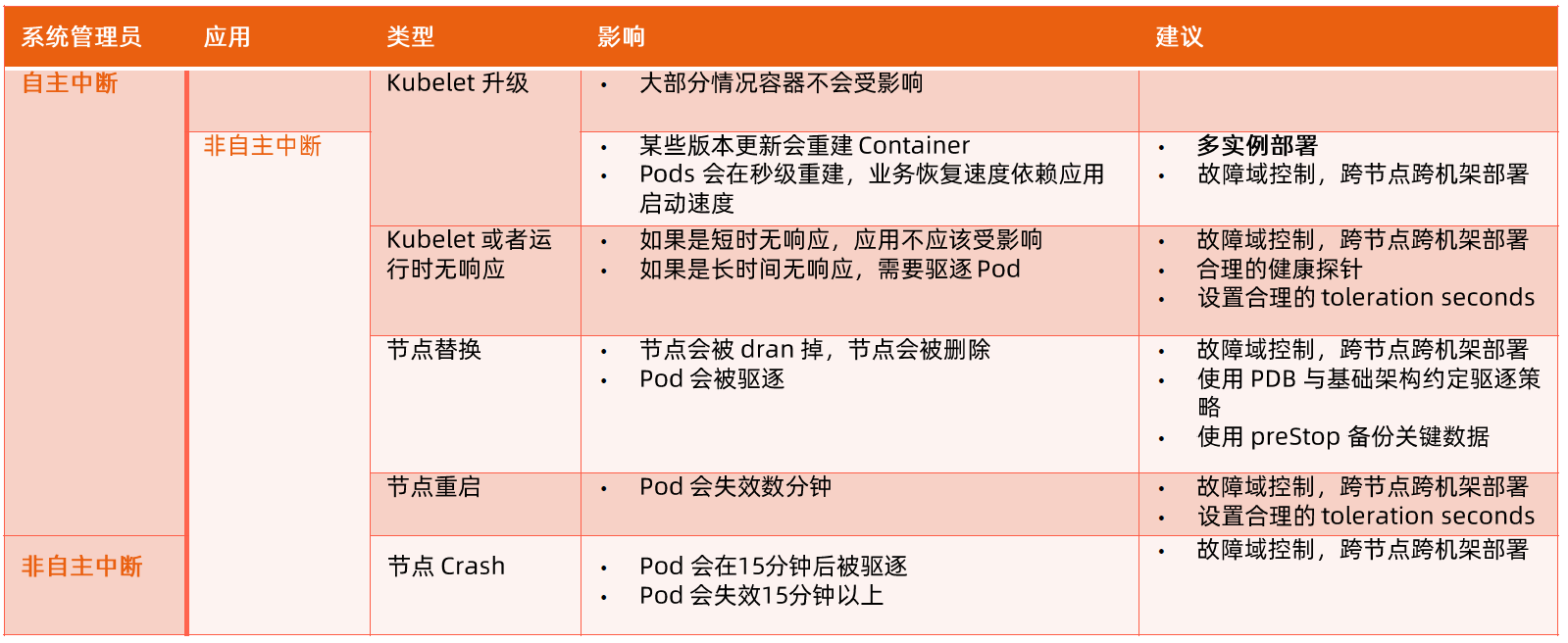
PodDisruptionBudget
PDB 是为了自主中断时保障应用的高可用。
在使用 PDB 时,你需要弄清楚你的应用类型以及你想要的应对措施:
无状态应用:
- 目标:至少有60%的副本 Available。
- 方案:创建 PDB Object,指定 minAvailable为 60%,或者 maxUnavailable 为 40%。
单实例的有状态应用:
- 目标:终止这个实例之前必须提前通知客户并取得同意。
- 方案:创建 PDB Object,并设置 maxUnavailable 为 0。
多实例的有状态应用:
- 目标最少可用的实例数不能少于某个数 N,例如 etcd。
- 方案:设置 maxUnavailable=1或者 minAvailable=N,分别允许每次只删除一个实例和每次删除 expected_replicas - minAvailable 个实例。
PDB 仅在主动驱逐时有效,当 node 出现 memory_presure 等时是无效的。
基础架构与应用团队的约束
基础架构团队在移除一个节点时,应遵循如下流程:
将node置为不可调度kubectl cordon` - 执行 node drain 排空节点,将其上运行的Pod平滑迁移至其他节点
kubectl drain <node name>
应用开发人员针对敏感应用,可定义 PDB 来确保应用不会被意外中断
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: zk-pdb
spec:
minAvailable: 2
selector:
matchLabels:
app: zookeeper测试 PodDisruptionBudget
https://github.com/kibaamor/101/blob/master/module11/drain-node/drain.MD
https://kubernetes.io/docs/concepts/scheduling-eviction/api-eviction/
部署文件
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
---
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: nginx-pdb
spec:
minAvailable: 1
selector:
matchLabels:
app: nginx测试过程
$ kubectl apply -f .
deployment.apps/nginx-deployment created
poddisruptionbudget.policy/nginx-pdb created
$ kubectl get pdb
NAME MIN AVAILABLE MAX UNAVAILABLE ALLOWED DISRUPTIONS AGE
nginx-pdb 1 N/A 1 102s
$ kubectl scale deployment nginx-deployment --replicas 1
deployment.apps/nginx-deployment scaled
$ kubectl get pdb
NAME MIN AVAILABLE MAX UNAVAILABLE ALLOWED DISRUPTIONS AGE
nginx-pdb 1 N/A 0 4m11s
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deployment-bf5d5cf98-54d9q 1/1 Running 0 16m
$ cat eviction.json
{
"apiVersion": "policy/v1",
"kind": "Eviction",
"metadata": {
"name": "nginx-deployment-bf5d5cf98-54d9q",
"namespace": "default"
}
}
$ curl -H 'Content-type: application/json' \
--cacert ~/.minikube/ca.crt \
--key ~/.minikube/profiles/minikube/client.key \
--cert ~/.minikube/profiles/minikube/client.crt \
https://127.0.0.1:32779/api/v1/namespaces/default/pods/nginx-deployment-bf5d5cf98-54d9q/eviction \
-d @eviction.json
{
"kind": "Status",
"apiVersion": "v1",
"metadata": {},
"status": "Failure",
"message": "Cannot evict pod as it would violate the pod's disruption budget.",
"reason": "TooManyRequests",
"details": {
"causes": [
{
"reason": "DisruptionBudget",
"message": "The disruption budget nginx-pdb needs 1 healthy pods and has 1 currently"
}
]
},
"code": 429
}
$ kubectl scale deployment nginx-deployment --replicas 2
deployment.apps/nginx-deployment scaled
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deployment-bf5d5cf98-54d9q 1/1 Running 0 20m
nginx-deployment-bf5d5cf98-v4p9b 1/1 Running 0 104s
$ curl -H 'Content-type: application/json' \
--cacert ~/.minikube/ca.crt \
--key ~/.minikube/profiles/minikube/client.key \
--cert ~/.minikube/profiles/minikube/client.crt \
https://127.0.0.1:32779/api/v1/namespaces/default/pods/nginx-deployment-bf5d5cf98-54d9q/eviction \
-d @eviction.json
{
"kind": "Status",
"apiVersion": "v1",
"metadata": {},
"status": "Success",
"code": 201
}部署方式
多少实例
更新策略
- Maxsurge
- MaxUnavailable(需要考虑 ResourceQuota 的限制)
深入理解 PodTemplateHash 导致的应用的易变性
服务发布
需要把服务发布至集群内部或者外部,服务的不同类型:
- Clusterlp(Headless)
- NodePort
- LoadBalancer
- ExternalName
证书管理和七层负载均衡的需求
需要 RPC 负载均衡如何做?
DNS 需求
与上下游服务的关系
服务发布的挑战
kube-dns
- DNS TTL 问题
Service
- ClusterlP 只能对内.
- Kube-proxy 支持的 iptables/ipvs 规模有限.
- IPVS 的性能和生产化问题。
- kube-proxy 的 drift 问题
- 频繁的 Pod 变动(specchange,failover,crashLoop)导致LB 频繁变更
- 对外发布的 Service 需要与企业 ELB 即成。.
- 不支持 gRPC
- 不支持自定义 DNS 和高级路由功能
Ingress
- Spec 要 deprecate
其他可选方案?
无状态应用管理
Replicaset 副本集
- 用什么 Pod 模版创建多少个实例。
replicas:2
Deployment
描述的是部署过程
版本管理
annotations.
deployment.kubernetes.io/revision:"1"
spec:
revisionHistoryLimit:10滚动升级策略
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 1
type: RollingUpdate有状态应用管理
Statefulset
与 deployment相比,多了
serviceName: nginx-ssVolume claim template
volumeClaimTemplates:
- metadata:
creationTimestamp: null
name: www
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
volumeMode: Filesystem有状态应用 Operator
Operator = CRD + Controller
创建 Operator 的关键是 CRD (自定义资源)的设计
Kubernetes 对象是可扩展的,扩展的方式有
基于原生对象
- 生成 types 对象,并通过 client-go 生成相应的 clientset, lister, informer。
- 实现对象的 registery backend,即定义对象任何存储进 etcd。
- 注册对象的 scheme 至 apiserver。
创建该对象的 apiservice 生命,注册该对象所对应的 api handler。
基于原生对象往往需要通过 aggregation apiserver把不同对象组合起来,
基于 CRD
- 在不同应用业务环境下,对于平台可能有一些特殊的需求,这些需求可以抽象为 Kubernetes 的扩展资源,而 Kubernetes 的 CRD(CustomResourceDefinition) 为这样的需求提供了轻量级的机制,保证新的资源的快速注册和使用。
- 在更老的版本中,TPR(ThirdPartyResource)是与CRD类似的概念,但是在1.9以上的版本中被弃用而 CRD 则进入的 beta 状态。
如何使用 CRD
用户向 Kubernetes API 服务注册一个带特定 schema 的资源,并定义相关 API
- 注册一系列该资源的实例
- 在 Kubernetes 的其它资源对象中引用这个新注册资源的对象实例
- 用户自定义的 controller 例程需要对这个引用进行释义和实施,让新的资源对象达到预期的状态
基于 CRD 的开发过程
借助 Kubernetes RBAC和 authentication 机制来保证该扩展资源的 security、access control、authentication 和multitenancy.
将扩展资源的数据存储到 Kubernetes 的 etcd 集群。
借助 Kubernetes 提供的 controller 模式开发框架,实现新的 controller,并借助 APIServer 监听etcd 集群关于该资源的状态并定义状态变化的处理逻辑。
该功能可以让开发人员扩展添加新功能,更新现有的功能,并且可以自动执行一些管理任务,这些自定义的控制器就像 Kubernetes 原生的组件一样,Operator 直接使用 Kubernetes API 进行开发,也就是说他们可以根据这些控制器内部编写的自定义规则来监控集群、更改 Pods/Services、对正在运行的应用进行扩缩容。
控制器模式
控制器代码示例
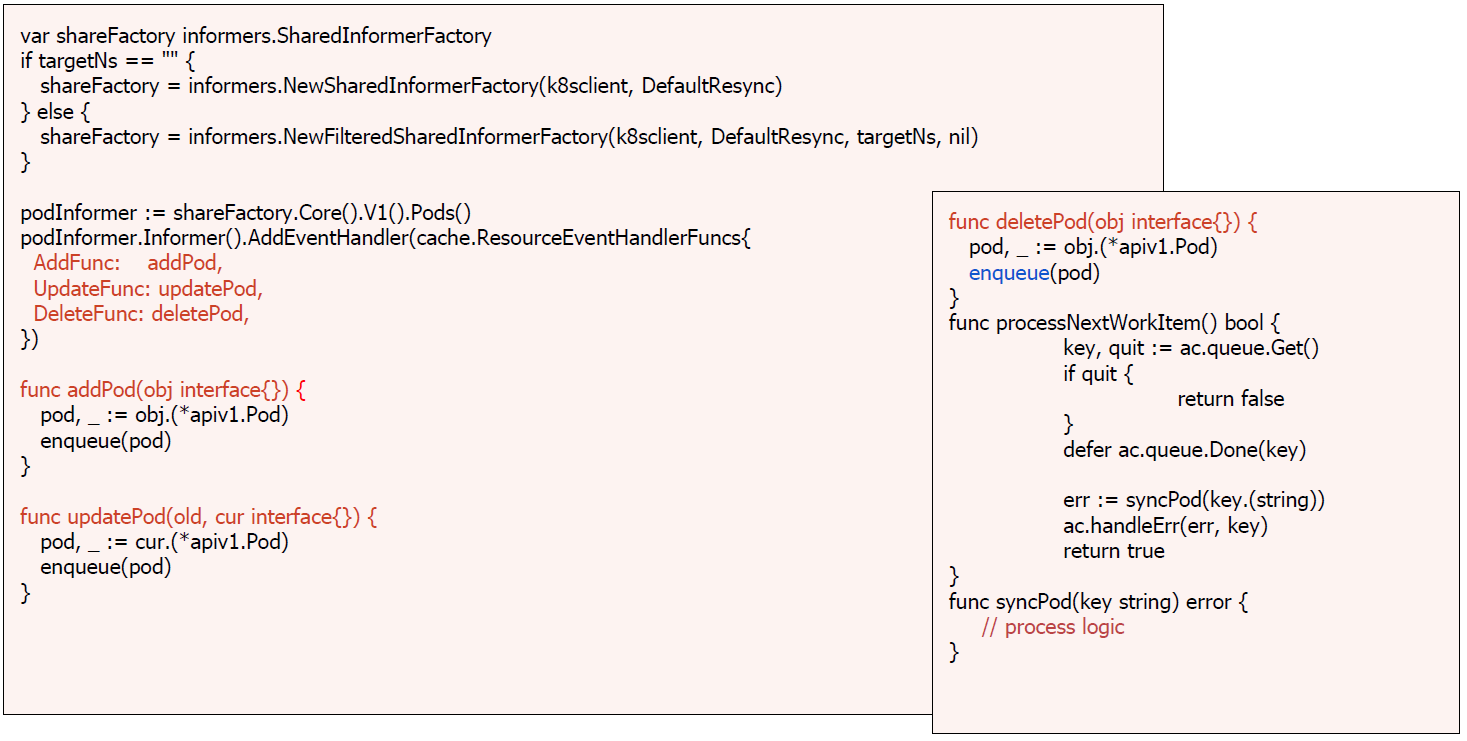
安装 kubebuilder
下载至本地
参考链接: https://github.com/kubernetes-sigs/kubebuilder/releases
mv <your download binary> /usr/local/bin/kubebuilderKubebuilder
辅助生成 CRD
kubebuilder init --domain example.comkubebuilder create api --group infra --version v1 --kind WebService
修改 Spec
Make install 更新 CRD 定义
创建项目
运行下面的命令创建项目
kubebuilderinit--domain myapps.cncamp.io
该命令生成如下文件
go.mod: 依赖管理Makefile: 编译文件PROJECT: Kubebuilder 为生成新组建的元数据配置
为项目添加新 API

更新 CRD

修改控制器代码并运行
参考链接 https://github.com/cncamp/httpclient
make run
创建 httpclient 对象
kubebuilder 练习
https://github.com/kibaamor/operator-demo
有状态应用的复杂性讨论
有状态应用部署示例-mysal
高可用部署
构建 Galara cluster,提供多活高可用 mysql集群。
多实例跨集群/跨机架/跨主机
持久化存储
需要为每个 Pod 创建 PVC 并 mount。
读写性能保证
localdynamic 作为数据盘,cephfs 作为备份盘
有状态应用的复杂配置
与无状态应用不一样,mysql 需要复杂配置以完成 galara 集群的构建
/etc/mysql/conf.d/galera.cnf
配置细节
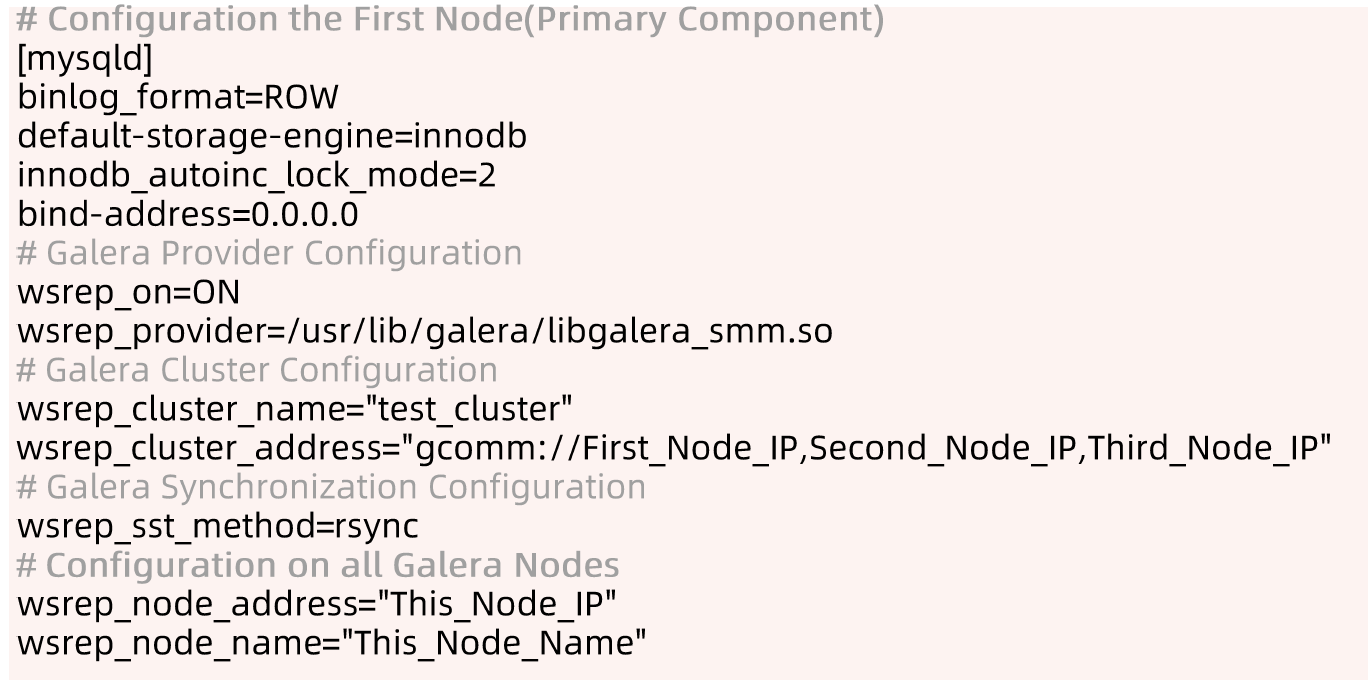
启动顺序
在 Primary Component 节点上运行
- mysqld bootstrap
在其他节点上运行
- systemctl start mysgl
发生了什么?
- 当节点第一次启动时,会自动生成 UUID 以代表当前节点身份
- 启动后,garala 会在数据目录生成 gvwstate.dat 文件,该文件内容记录 Primary component 的 UUID 以及连接到当前Primary component 的节点的 UUID
- 如果 Primary component 出现故障,则剩余节点会重新选择新的 Primary component
- 若该文件已经存在,则无需额外执行 bootstrap 命令启动 Primarycompont,可依此规则编写 Operator 在多个节点构建此文件
健康检查
mysql 提供健康检查 API
- 检查集群成员是否能接受查询请求
SHOW GLOBAL STATUS LIKE 'wsrep_ready'; - 检查节点是否与其他节点网络互通
SHOW GLOBAL STATUS LIKE 'wsrep_connected'; - 检查节点自场次查询结束后接收到的查询请求数量,如果结果为非0,意味着写请求不能立即处理
SHOW STATUS LIKE 'wsrep_local_recv_queue_avg';
健康检査应该影响 Pod 的 readiness probe,在进行版本升级时,确保大多数集群节点状态一致。
数据备份
推荐为 mysql 创建不同类型的 volume
- Localvolume 用来做数据盘
- Networkvolume 用来做数据备份
创建 cronjob,每天将数据备份至 backup 目录
- 备份文件为
一键恢复能力
- 导入备份目录的 sql file
版本发布和故障转移
针对配置了 Local disk 的 Pod,当发生因版本变更而引发的 Pod 重建时 ,新 Pod 在进行调度时调度器会査询 Pod 挂载的 volume 所在节点,并将新 Pod 优先调度至该节点,此场景不涉及到数据恢复。
其开销与 mysql进程重启相差不大。
如果节点出现故障,如硬件故障,Kubernetes 的 Evict Manager 会将该 Pod 从故障节点驱逐Operator 应确保新 Pod 会被重新构建。 而新 Pod 会被调度至新节点,此场景等价于替换 mysql 中的少数节点。
- galara 集群中的少数 mysql 节点替换,不涉及到数据迁移,qalara 会确保新节点的数据同步
若整个 mysql集群需要做数据恢复,则应该从 backup 目录对应的网络 volume 恢复数据。此时可选择:
- 只恢复单一节点数据: 配置简单
- 恢复所有节点数据: 恢复速度快
与基础架构的 Contract
- PodDisruptionBudget
业界高可用数据库方案分享
参考链接: https://cncamp.notion.site/mysql-on-kubernetes-eb043ee841dc41618ce4798bca187bbf
Spec 管理神器 - Helm
什么是 Helm
Helm 特性
- Helm chart 是创建一个应用实例的必要的配置组,也就是一堆 Spec。
- 配置信息被归类为模版(Template)和值(Value),这些信息经过渲染生成最终的对象。
= 所有配置可以被打包进一个可以发布的对象中。 - -个 release 就是一个有特定配置的 chart 的实例。
Helm 的组件
Helm client
- 本地 chart 开发
- 管理 repository
- 管理 release
与 helm library 交互
- 发送需要安装的 chart
- 请求升级或着卸载存在的 release.
Helm library
- 负责与 APIserver 交互,并提供以下功能
- 基于 chart 和 confiquration 创建-个release
- 把 chart 安装进 kubernetes,并提供相应的 release 对象。
- 升级和卸载
- Helm 采用 Kubernetes 存储所有配置信息,无需自己的数据库
Kubernetes Helm 架构
Helm 的目标
从头创建 chart
把 chart 打包成压缩文件(tgz)
与 chart 的存储仓库交互(chart repositry)
Kubernetes 集群中的 chart 安装与卸载
管理用 Helm 安装的 release 的生命周期
Helm 的安装
下载
参考链接: https://github.com/helm/helm/releases
安装
- 解压
mv <your downloaded binary> /usr/local/bin/helm
Helm chart 的基本使用
创建一个 chart helm create myapp
myapp/
- Chart.yaml # 包含了 chart 信息的 YAML 文件
- values.yaml # chart 默认的配置值
- charts/ # 包含 chart 依赖的其他 chart
- templates/ # 模板目录,当和 values 结合时,可生成有效的 Kubernetes manifest 文件
复用已存在的成熟 Helm release
针对 Helm release repo 的操作
helm repo add grafana https://grafana.github.io/helm-charts
helm repo update
helm repo list
helm search repo grafana从 remote repo 安装 Helm chart
helm upgrade --install loki grafana/loki-stack下载并从本地安装 helm chart
helm pull grafana/loki-stack
helm upgrade --install loki ./lock-stackmetrics-server
Aggregated APIServer
Metrics-Server
metrics-server 是 Kubernetes 监控体系中的核心组件之一,它负责从 kubelet 收集资源指标然后对这些指标监控数据进行聚合(依赖kube-aggregator),并在 Kubernetes Apiserver 中通过 Metrics API (/apis/metrics.k8s.io/) 公开暴露它们,但是 metrics-server 只存储最新的指标数据(CPU/Memory) 。
你的 kube-apiserver 要能访问到 metrics-server;
需要 kube-apiserver 启用聚合层;
组件要有认证配置并且绑定到 metrics-server;
Pod/Node 指标需要由 Summary API 通过 kubelet 公开。
metrics-server 的本质
将指标数据转换成 metrics.k8s.io 的 api 调用返回值
$ kubectl get --raw "/api/v1/nodes/node1/proxy/metrics/resource"
$ kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
node1 294m 7% 3003Mi 25%
$ kubectl top pod
NAME CPU(cores) MEMORY(bytes)
centos-5fdd4bb694-bl62g 3m 3Mi
httpserver-deployments-7df744646-jclhz 1m 5Mi
nginx-deployment-6799fc88d8-6pmrt 0m 5Mi
nginx-deployment-6799fc88d8-gv5f4 0m 5Mi
nginx-deployment-6799fc88d8-zkf9d 0m 5Mi自动扩容缩容-HPA
横向伸缩和纵向伸缩
应用扩容是指在应用接收到的并发请求已经处于其处理请求极限边界的情形下,扩展处理能力而确保应用高可用的技术手段
Horizontal Scaling
- 所谓横向伸缩是指通过增加应用实例数量分担负载的方式来提升应用整体处理能力的方式
Vertical Scaling
- 所谓纵向伸缩是指通过增加单个应用实例资源以提升单个实例处理能力,进而提升应用整体处理能力的方式
理解云原生的弹性能力
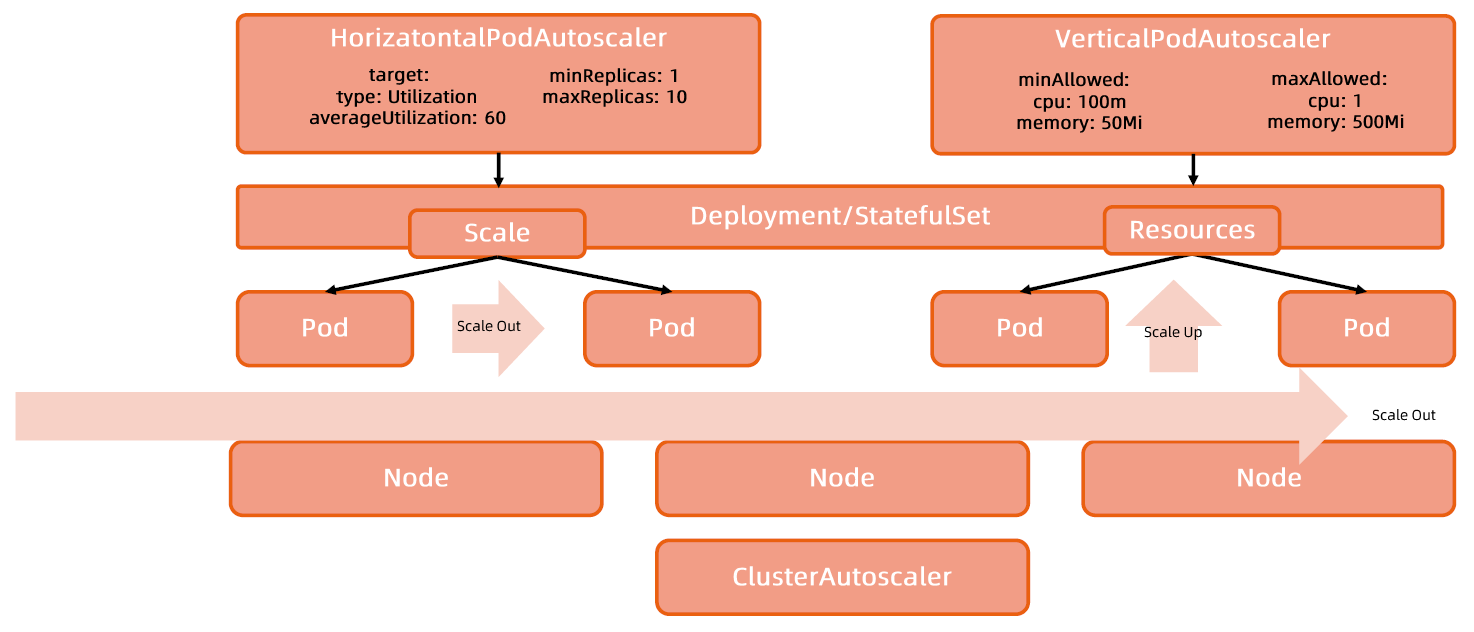
HPA
HPA(HorizontalPod Autoscaler) 是 Kubernetes 的一种资源对象,能够根据某些指标对在 statefulSet、replicaSet、deployment 等集合中的 Pod 数量进行横向动态伸缩,使运行在上面的服务对指标的变化有一定的自适应能力。
因节点计算资源固定,当 Pod 调度完成并运行以后,动态调整计算资源变得较为困难,因为横向扩展具有更大优势,HPA是扩展应用能力的第一选择,
多个冲突的 HPA 同时创建到同一个应用的时候会有无法预期的行为,因此需要小心维护 HPA 规则。
HPA 依赖于 Metrics-Server.
HPA Spec
https://github.com/kibaamor/101/tree/master/module11/hpa
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: mynginx
spec:
# HPA 的伸缩对象描述,HPA会动态修改该对象的 Pod 数量
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: mynginx
# HPA 的最小 Pod 数量和最大 Pod 数量
minReplicas: 1
maxReplicas: 3
# 监控的指标数组,支持多种类型的指标共存
metrics:HPA 支持的指标类型
对于按 Pod 统计的资源指标(如 CPU),控制器从资源指标API中获取每一个 HorizontalPodAutoscaler 指定的 Pod 的度量值,如果设置了目标使用率,控制器获取每个 Pod 中的容器资源使用情况,并计算资源使用率。如果设置了target值,将直接使用原始数据(不再计算百分比)。
如果 Pod 使用自定义指示,控制器机制与资源指标类似,区别在于自定义指标只使用原始值,而不是使用率。
如果 Pod 使用对象指标和外部指标(每个指标描述一个对象信息)。这个指标将直接根据目标设定值相比较,并生成一个上面提到的扩缩比例。 在 autoscaling/v2beta2 版本 API中,这个指标也可以根据 Pod 数量平分后再计算。
HPA 指标
Resource 类型的指标(k8s自己支持的指标)
- type: Resource
resource:
name: cpu
# Utilization 类型的目标值,Resource 类型的指标只支持 Utilization 和 AverageValue 类型的目标值
target:
type: Utilization
averageUtilization: 50Pods 类型的指标
- type: Pods
pods:
metric:
name: packets-per-second
# AverageValue 类型的目标值,Pods 指标类型下只支持 AverageValue 类型的目标值
target:
type: AverageValue
averageValue: 1k算法细节
HPA 算法非常简单
期望副本数 = ceil[当前副本数 * (当前指标 / 期望指标)]当前度量值为 200m,目标设定值为 100m,那么由于 200.0/100.0-2.0,副本数量将会翻倍如果当前指标为 50m,副本数量将会减半,因为50.0/100.0=-0.5。如果计算出的扩缩比例接近1.0(根据 --horizontal-pod-autoscaler-tolerance 参数全局配置的容忍值,默认为 0.1)将会放弃本次扩缩。
滚动升级时扩缩
当你为一个 Deployment 配置自动扩缩时,你要为每个Deployment绑定一个 HorizontalPodAutoscaler.
HorizontalPodAutoscaler管理 Deployment 的 replicas 字段。Deployment Controller负责设置下层ReplicaSet的replicas 字段,以便确保在上线及后续过程副本个数合适。
想一想:为什么 deploymentspec 中的 replicas 字段的类型为 *int,而不是 int?
冷却/延迟支持
当使用 HorizontalPod Autoscaler 管理一组副本扩缩时,有可能因为指标动态的变化造成副本数量频繁的变化,有时这被称为 抖动(Thrashing)。
--horizontal-pod-autoscaler-downscale-stabilization:设置缩容冷却时间窗口长度。
水平 Pod 扩缩器能够记住过去建议的负载规模,并仅对此时间窗口内的最大规模执行操作。默认值是5分钟(5m0s)
扩缩策略
在 Spec 字段的 behavior 部分可以指定一个或多个扩缩策略。当指定多个策略时,默认选择允许更改最多的策略。下面的例子展示了缩容时的行为:
behavior:
scaleDown:
policies:
- type: Pods
value: 4
periodseconds: 60
- type: Percent
value: 10
periodseconds: 60HPA 练习
安装 metrics-server(本质上是一个 aggregated Server)
$ cd 101/appsonk8s/hpa/metrics-server
$ kubectlapply-f components.yaml
$ kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
k8snode 325m 5% 2148Mi 18%启动应用
创建 php server
cd 101/appsonk8s/hpa
kubectl apply -f php-apache.yaml设置 HPA 规则
kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=3查看 HPASpec
spec:
maxReplicas: 3
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
targetCPUUtilizationPercentage: 50测试 HPA
为服务器加压
kubectl run -i --tty load-generator --rm --image=busybox --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -g -0- http://php-apache; done"观测 top pod,可以发现当 pod cpu 利用率大于 500m 的时候,会创建更多 pod 出来分担压力停止 load-generator 以后,等待一段时间,pod 数量会降为一个
watch kubectl top pod
NAME CPU(cores) MEMORY(bytes)
load-generator 12m 1Mi
php-apache-6cd4b65f7b-4rwsq 240m 2Mi
php-apache-6cd4b65f7b-p878h 488m1 2Mi HPA 存在的问题
基于指标的弹性有滞后效应,因为弹性控制器操作的链路过长。
从应用负载超出阈值到 HPA 完成扩容之间的时间差包括:
- 应用指标数据已经超出阈值;
- HPA定期执行指标收集滞后效应;
- HPA 控制 Deployment 进行扩容的时间
- Pod 调度,运行时启动挂载存储和网络的时间;
- 应用启动到服务就绪的时间。
很可能在突发流量出现时,还没完成弹性扩容,既有的服务实例已经被流量击垮
自动扩容缩容-VPA
VPA
VPA 全称 Vertical Pod Autoscaler,即垂直 Pod 自动扩缩容 ,它根据容器资源使用率自动设置 CPU 和内存的 requests,从而允许在节点上进行适当的调度以便为每个 Pod 提供适当的资源,它既可以缩小过度请求资源的容器,也可以根据其使用情况随时提升资源不足的容量。
使用 VPA 的意义:
- Pod 资源用其所需,提升集群节点使用效率;
- 不必运行基准测试任务来确定 CPU 和内存请求的合适值;
- VPA 可以随时调整 CPU 和内存请求,无需人为操作,因此可以减少维护时间,
注意:VPA 目前还没有生产就绪,在使用之前需要了解资源调节对应用的影响。
VPA 架构图
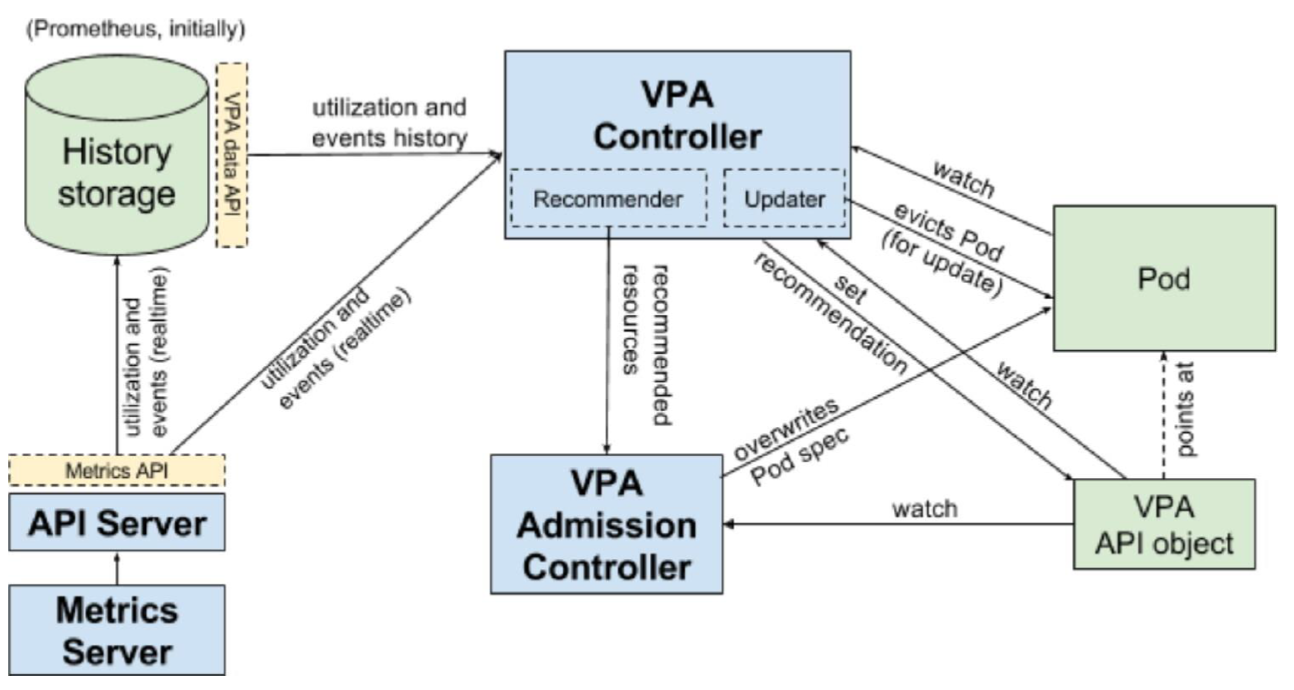
VPA 组件
VPA 引入了一种新型的 AP|资源: VerticalPodAutoscaler。
VPA Recommender 监视所有 Pod,不断为它们计算新的推荐资源,并将推荐值存储在 VPA对象中。它使用来自 Metrics-Server的集群中所有 Pod 的利用率和 OOM 事件。
所有 Pod 创建请求都通过 VPA Admission Controller。
VPA Updater 是负责 Pod 实时更新的组件。如果 Pod 在 “Auto” 模式下使用 VPA,则 Updater 可以决定使用推荐器资源对其进行更新。
History Storage 是一个存储组件(如Prometheus),它使用来自 APIServer 的利用率信息和 OOM(与推荐器相同的数据)并将其持久存储。
VPA 更新模式:
- Off
- Auto
VPA 工作原理
Recommender 设计理念
推荐模型(MVP)假设内存和 CPU 利用率是独立的随机变量,其分布等于过去 N 天观察到的变量(推荐值为 N=8 以捕获每周峰值)。
对于 CPU,目标是将容器使用率超过请求的高百分比(例如95%)时的时间部分保持在某个阈值(例如 1% 的时间)以下。在此模型中,”CPU 使用率” 被定义为在短时间间隔内测量的平均使用率。测量间隔越短,针对尖峰、延迟敏感的工作负载的建议质量就越高。最小合理分辨率为 1/min,推荐为 1/sec。
对于内存,目标是将特定时间窗口内容器使用率超过请求的概率保持在某个值以下(例如24 小时内低于 1%)。窗口必须很长(>24 小时)以确保由 OOM 引起的驱逐不会明显影响(a)服务应用程序的可用性(b)批处理计算的进度(更高级的模型可以允许用户指定SLO来控制它)。
主要流程
滑动窗口与半衰指数直方图
Recommender 的资源推荐算法主要受 Google AutoPilot moving window 推荐器的启发,假设 CPU 和 Memory 消耗是独立的随机变量,其分布等于过去 N 天观察到的变量分布(推荐值为 N=8 以捕获每周业务容器峰值)。
Recommender 组件获取资源消耗实时数据,存到相应资源对象 CheckPoint 中。CheckPoint CRD 资源本质上是一个直方图
直方图统一对外提供的接口
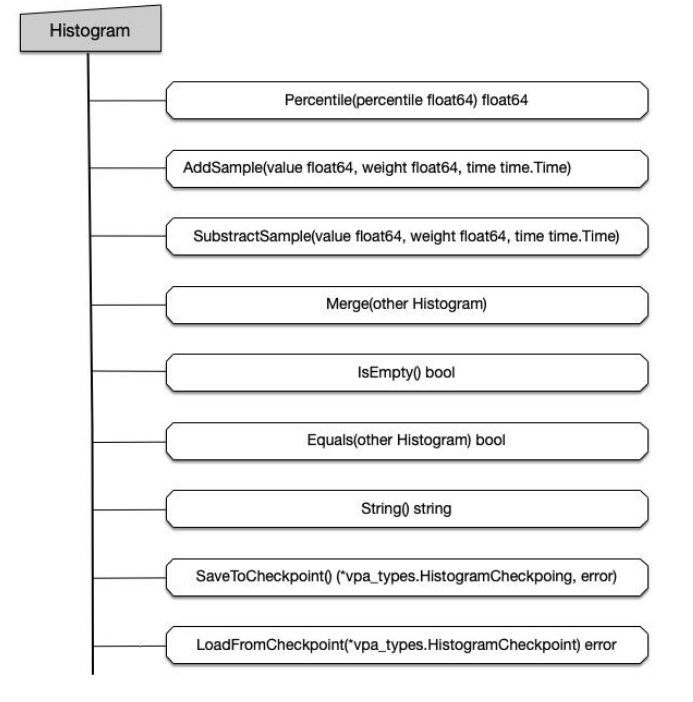
直方图数据范围
半衰期和权重系数
为每个样本数据权重乘上 指数2^((sampleTime-referenceTimestamp)/halfLife),以保证较新的样本被赋予更高的权重,而较老的样本随时间推移权重逐步衰减
默认情况下,每 24h 为一个半衰期,即每经过 24h,直方图中所有样本的权重(重要性)衰减为原来的一半。
当指数过大时,referenceTimestamp 就需要向前调整,以避免浮点乘法计算时向上溢出,
- CPU 使用量样本对应的权重是基于容器 CPUrequest 值确定的。当 CPUrequest 增加时对应的权重也随之增加。
- 而 Memory 使用量样本对应的权重固定为 1.0。
https://github.com/kibaamor/101/blob/master/module11/vpa/readme.MD
VPA
VPA 的成熟度还不足
- 更新正在运行的 Pod 资源配置是 VPA的一项试验性功能,会导致 Pod 的重建和重启,而且有可能被调度到其他的节点上。
- VPA 不会驱逐没有在副本控制器管理下的 Pod。目前对于这类 Pod,Auto 模式等同于 Initial 模式。
- 目前 VPA 不能和监控 CPU 和内存度量的 Horizontal Pod Autoscaler(HPA) 同时运行除非 HPA 只监控其他定制化的或者外部的资源度量。
- VPA 使用 admission webhook 作为其准入控制器。如果集群中有其他的 admissionwebhook,需要确保它们不会与VPA发生冲突。准入控制器的执行顺序定义在 APIServer的配置参数中。
- VPA 会处理出现的绝大多数 OOM(Out Of Memory)的事件,但不保证所有的场景下都有效。
- VPA的性能还没有在大型集群中测试过。
- VPA 对 Pod 资源 requests 的修改值可能超过实际的资源上限,例如节点资源上限、空闲资源或资源配额,从而造成 Pod 处于 Pending 状态无法被调度。同时使用集群自动伸缩(ClusterAutoscaler)可以一定程度上解决这个问题。
- 多个 VPA 同时匹配同一个 Pod 会造成未定义的行为。
如何解决社区基础弹性能力不足的问题
弹性的意义

成本优化的关键路径

开启降本之路
统一思想 - FinOps
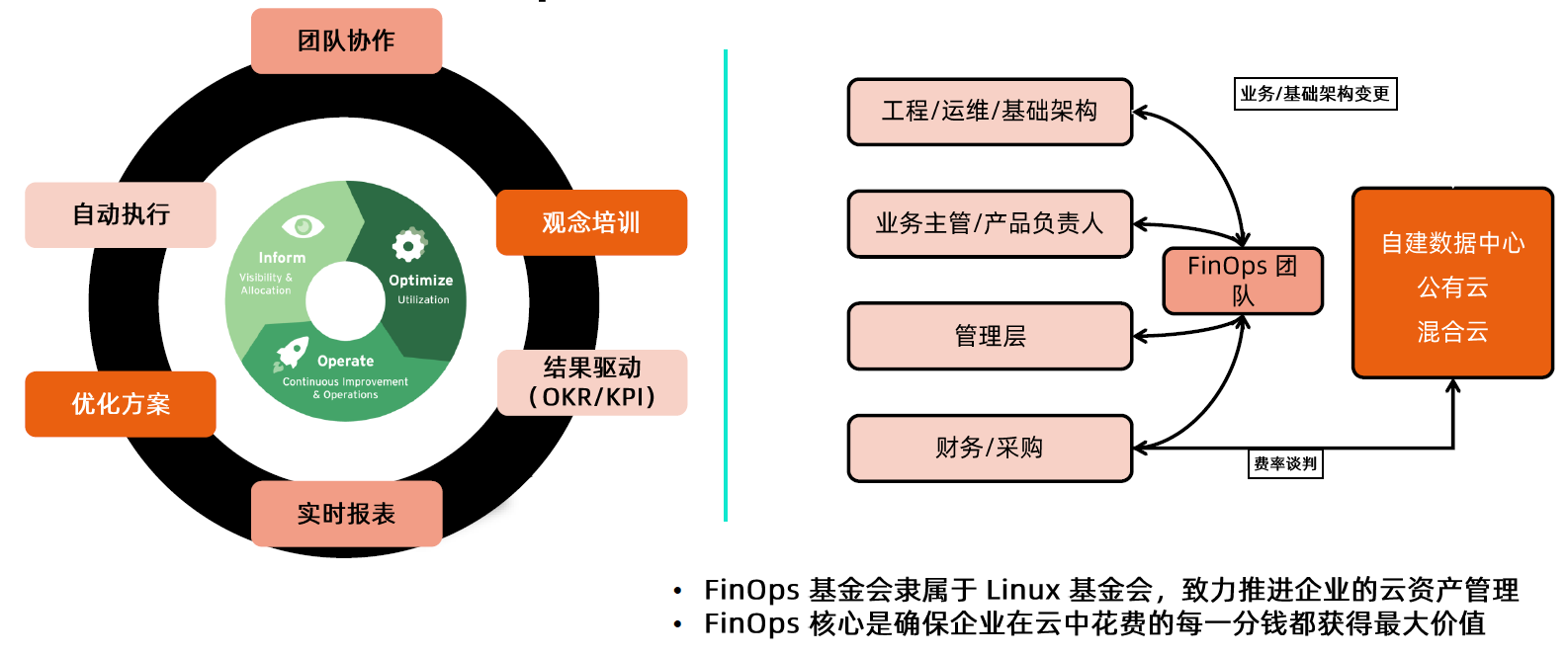
流程建设-云原生成熟度模型
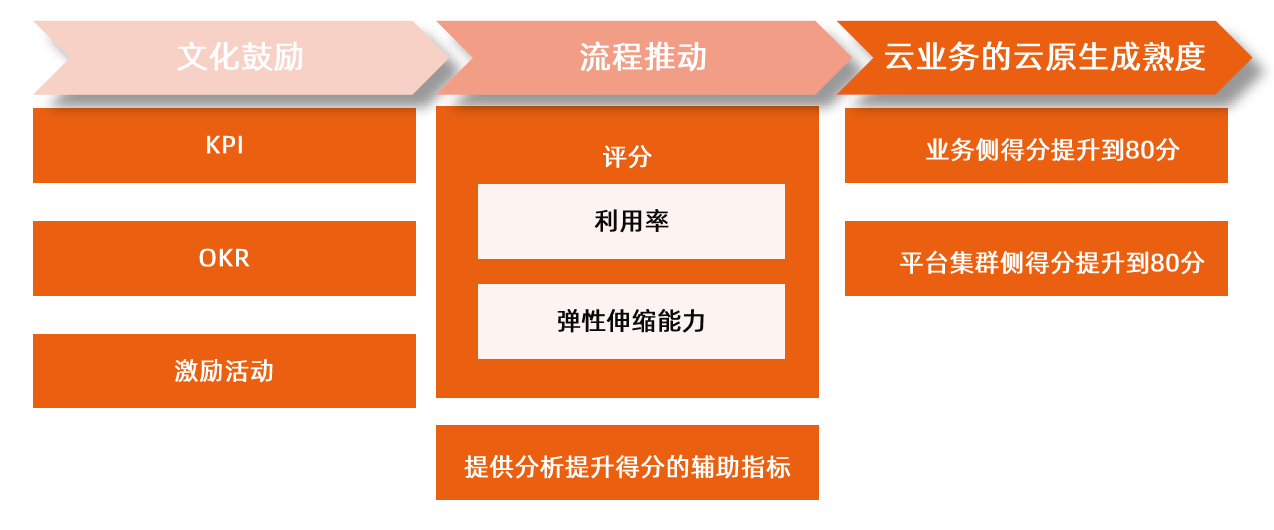
业务侧 Workload 评分
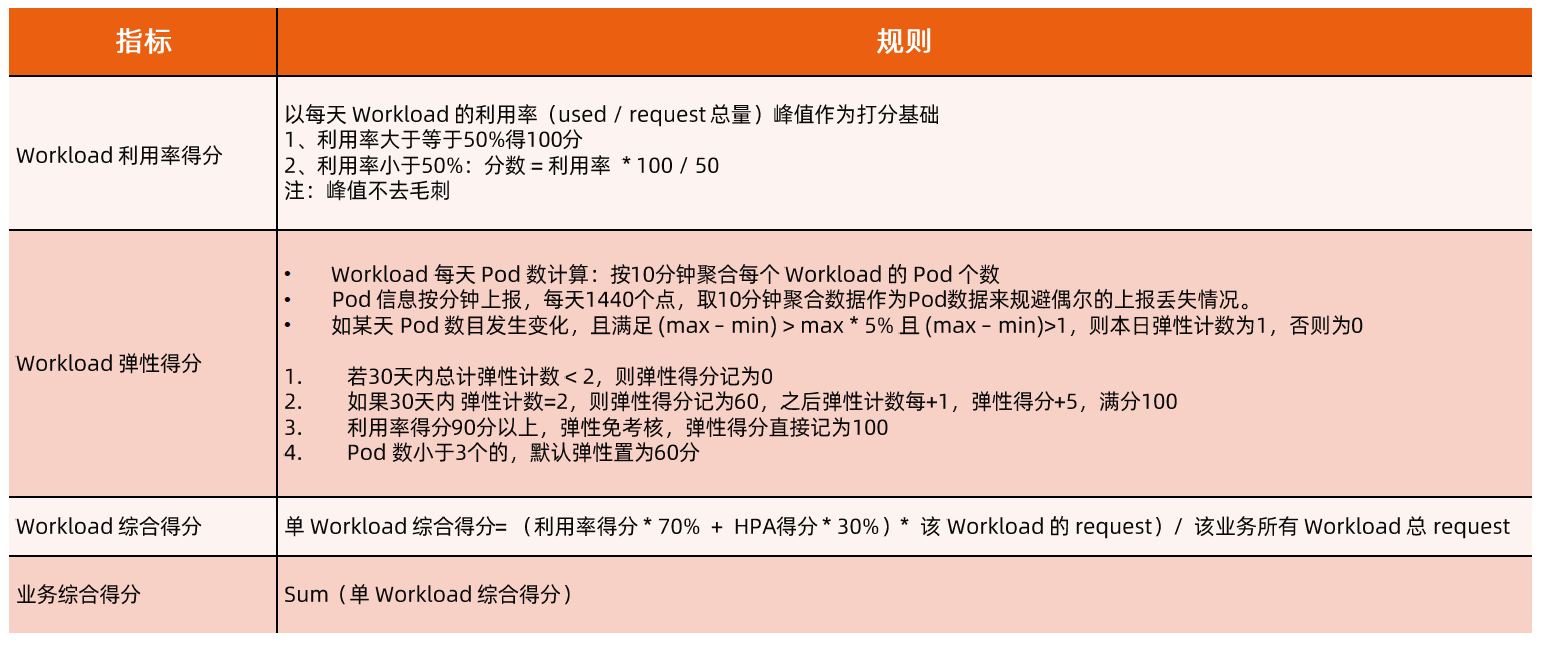
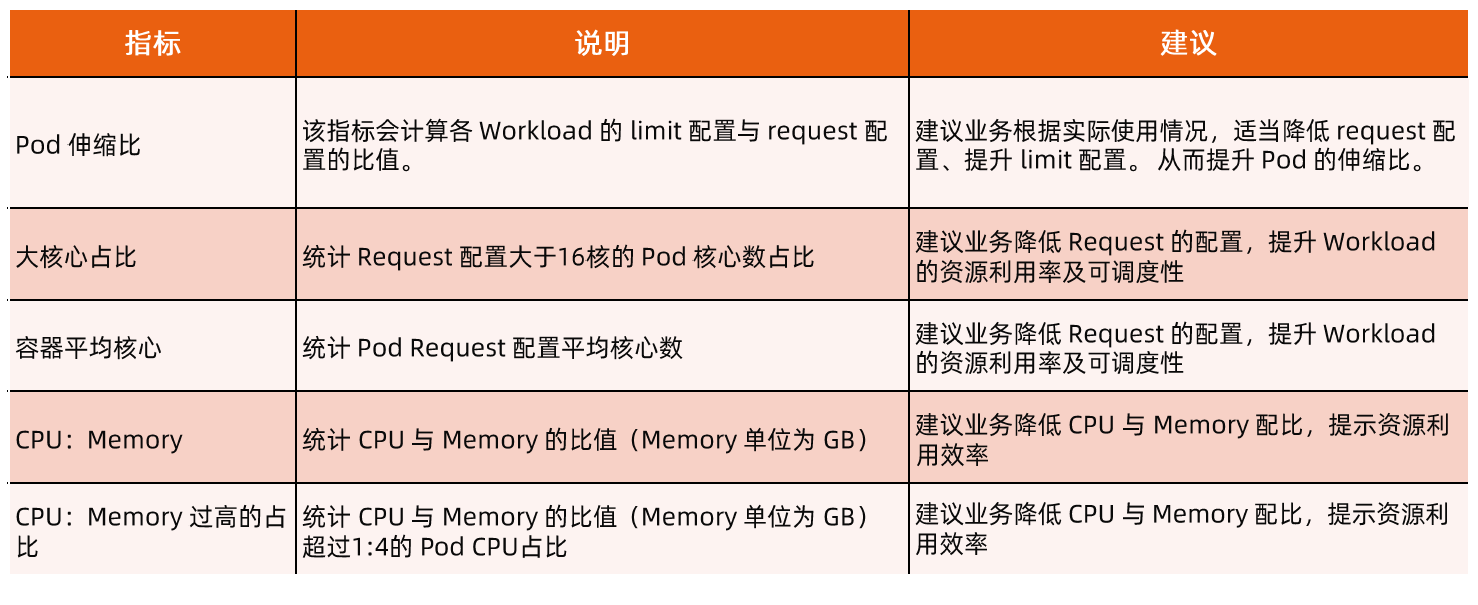
平台集群评分


成熟度指标计算公式
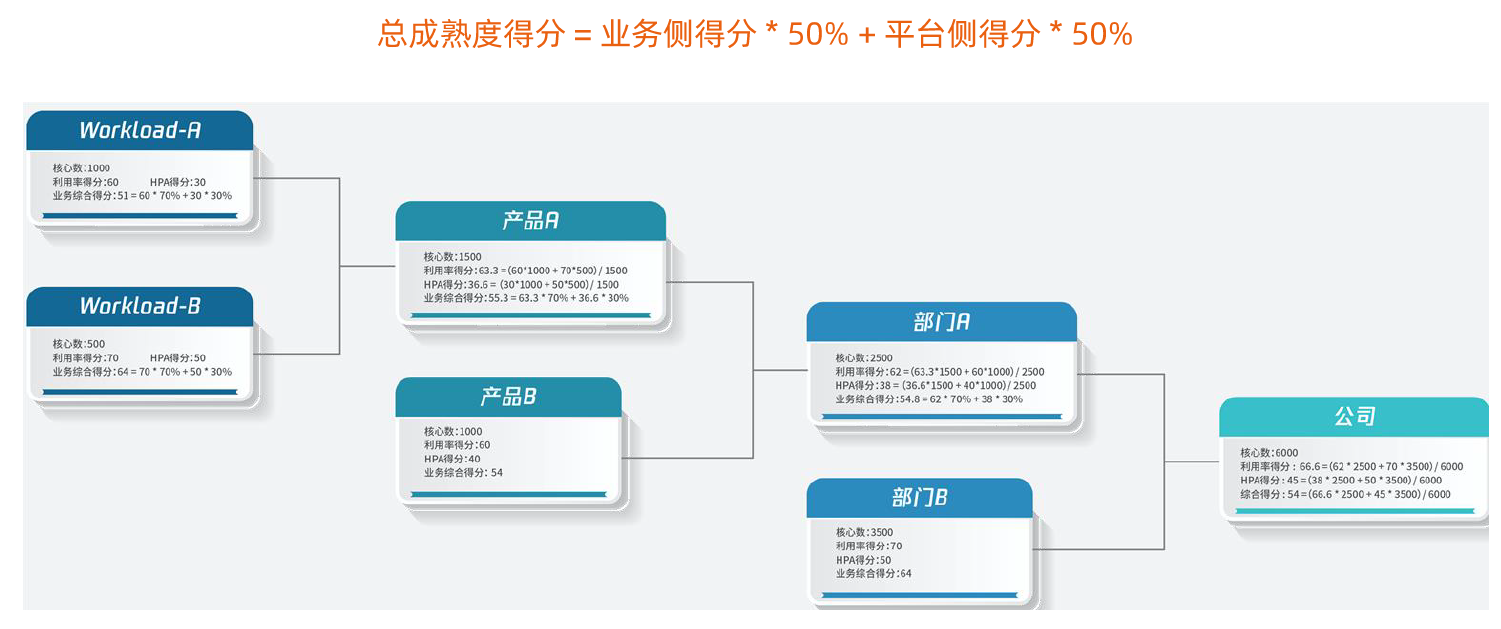
驱动力

云成熟度模型成效
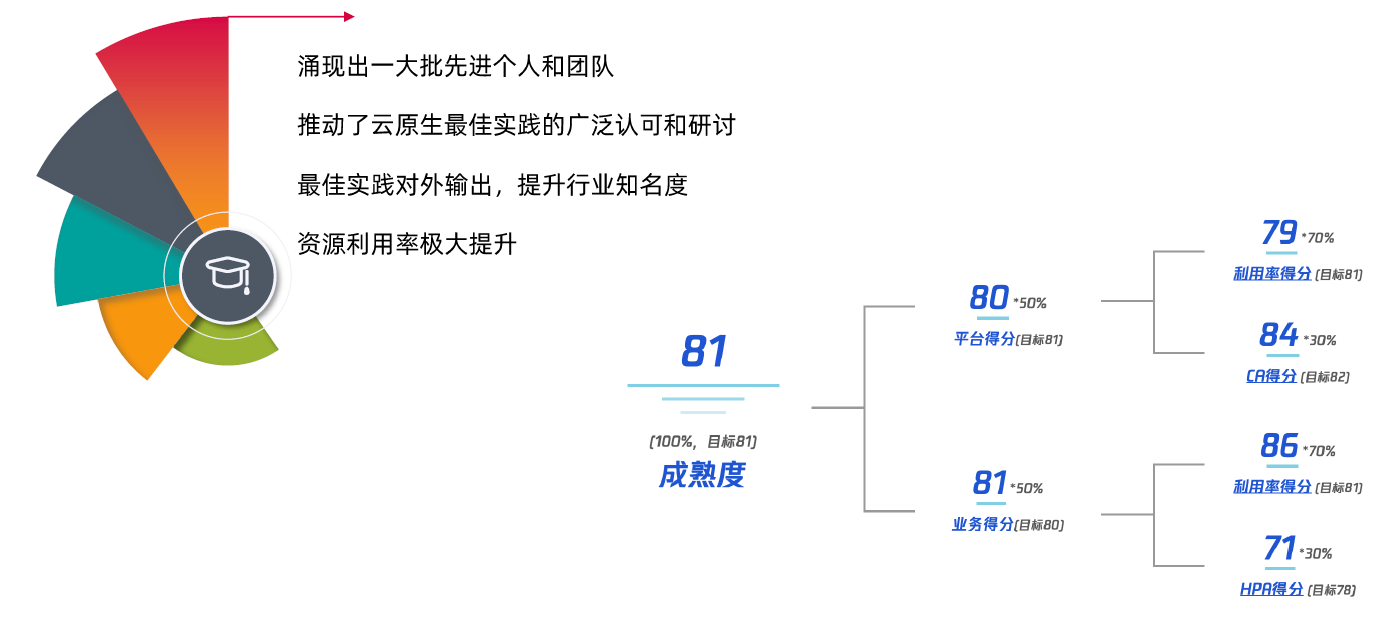
Crane-工具链打通

Crane 高层架构
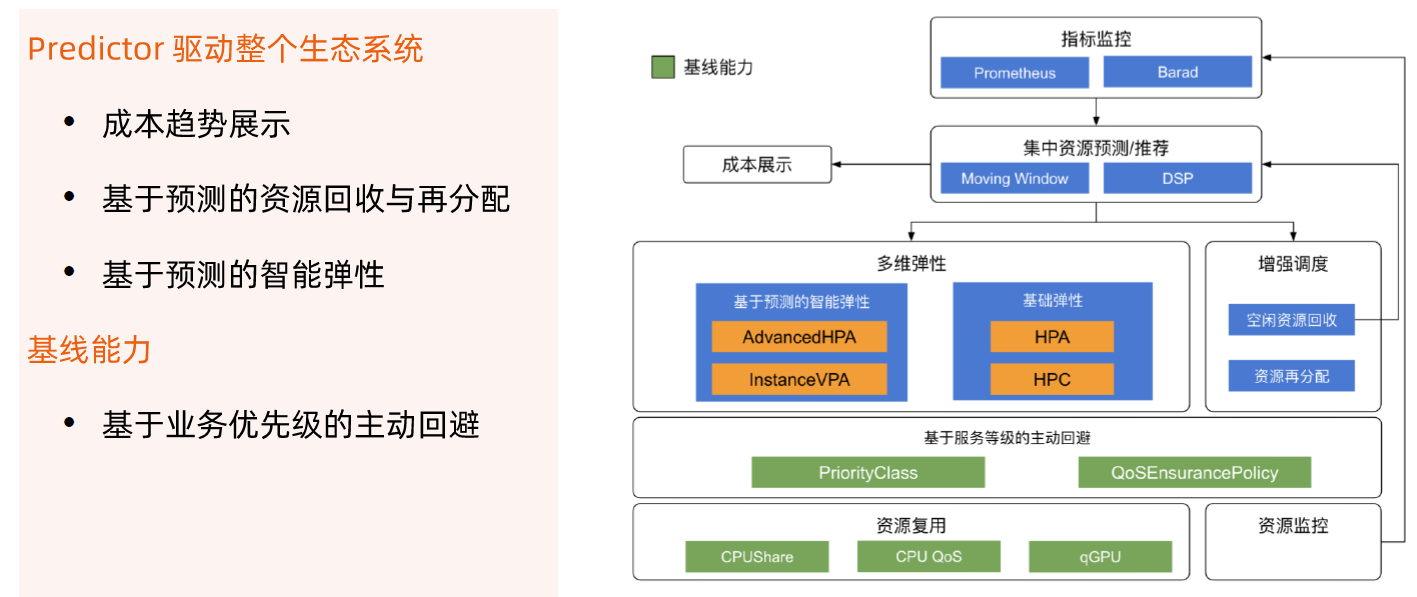
资源预测
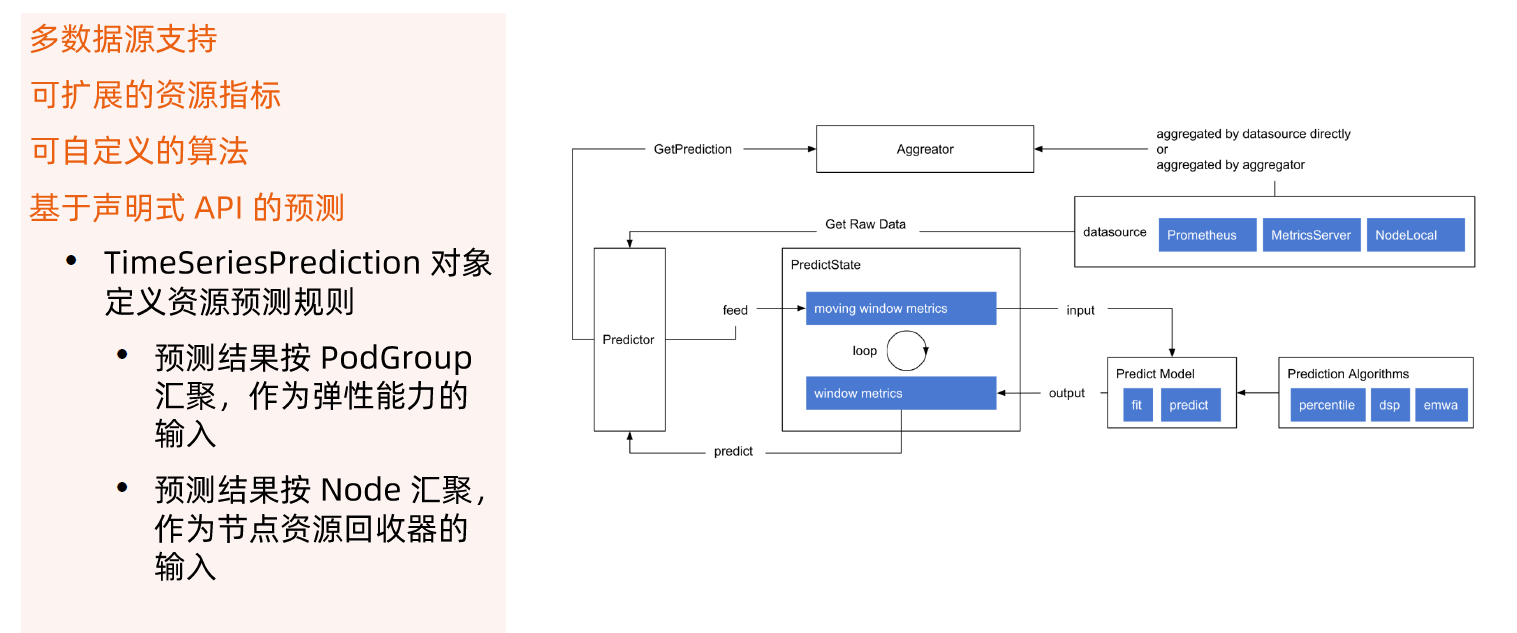
多维的成本展示
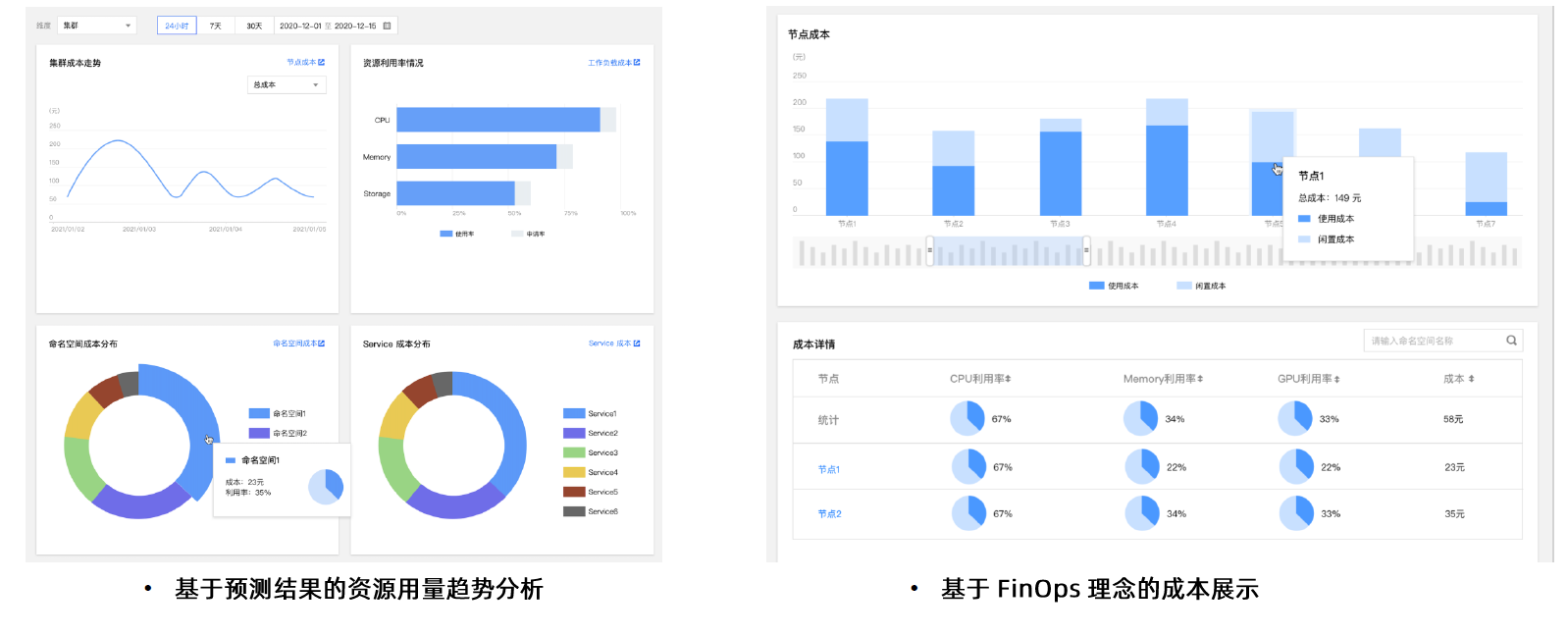
精准的浪费识别
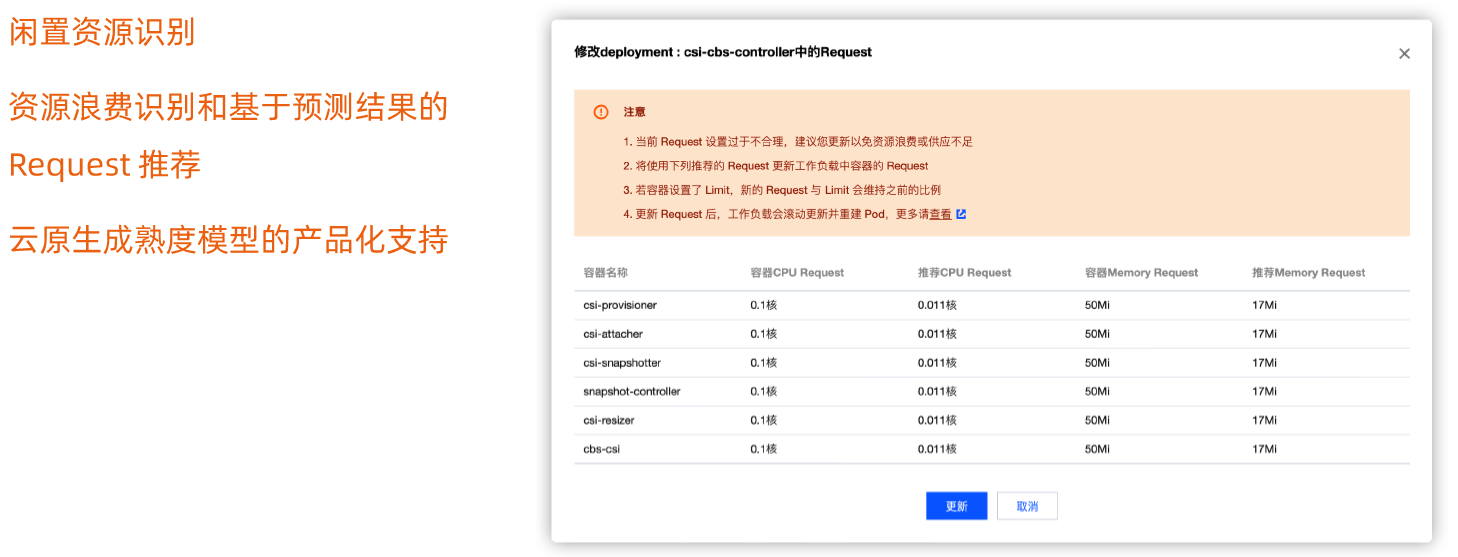
常规优化手段
弹性
按作业负载动态调节实例副本数或单实例的资源上
- 负载高峰扩容以保证业务服务等级
- 负载低谷缩容以回收资源减少浪费
混部
在负载低谷运行离线作业以提升总体资源利用率
TKE-Scheduler 专为离线场景优化:gang-scheduling、all-or-nothing,10X性能提升
社区原生弹性能力的不足
HPA
- 业务指标驱动,指标的滞后导致业务突发流量时来不及弹。
VPA
- 资源需求是 Pod 对象中的不可变属性,VPA纵向调整资源后,Pod 需要重建,而现实场景中,Pod 重建是大量业务不可接受的。
CA
- 当集群资源不足时,CA 可按照既定规则扩容集群节点,但这对基础架构层面的空闲资源和可靠性都有极高的要求。
AHPA-基于预测的横向伸缩
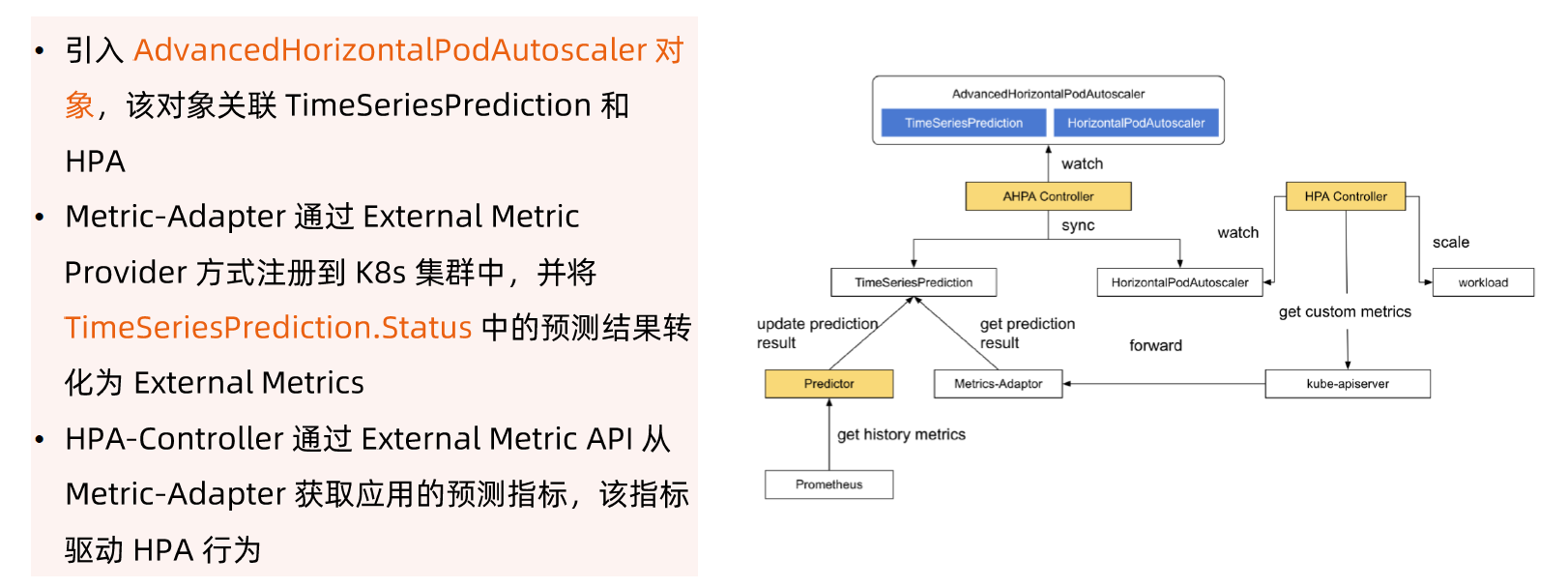
IVPA-基于扩展资源回收的实时纵向仲缩
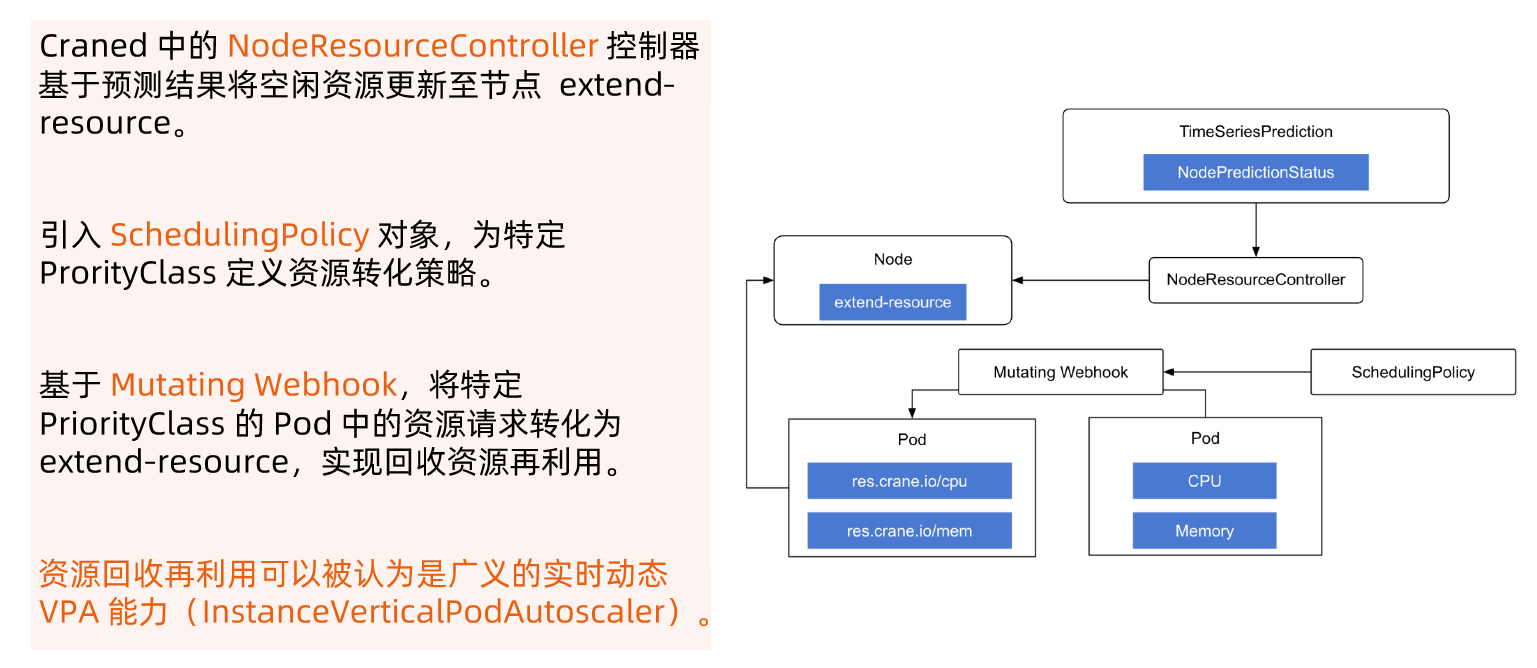
基于分布式云虚拟节点技术的集群弹性
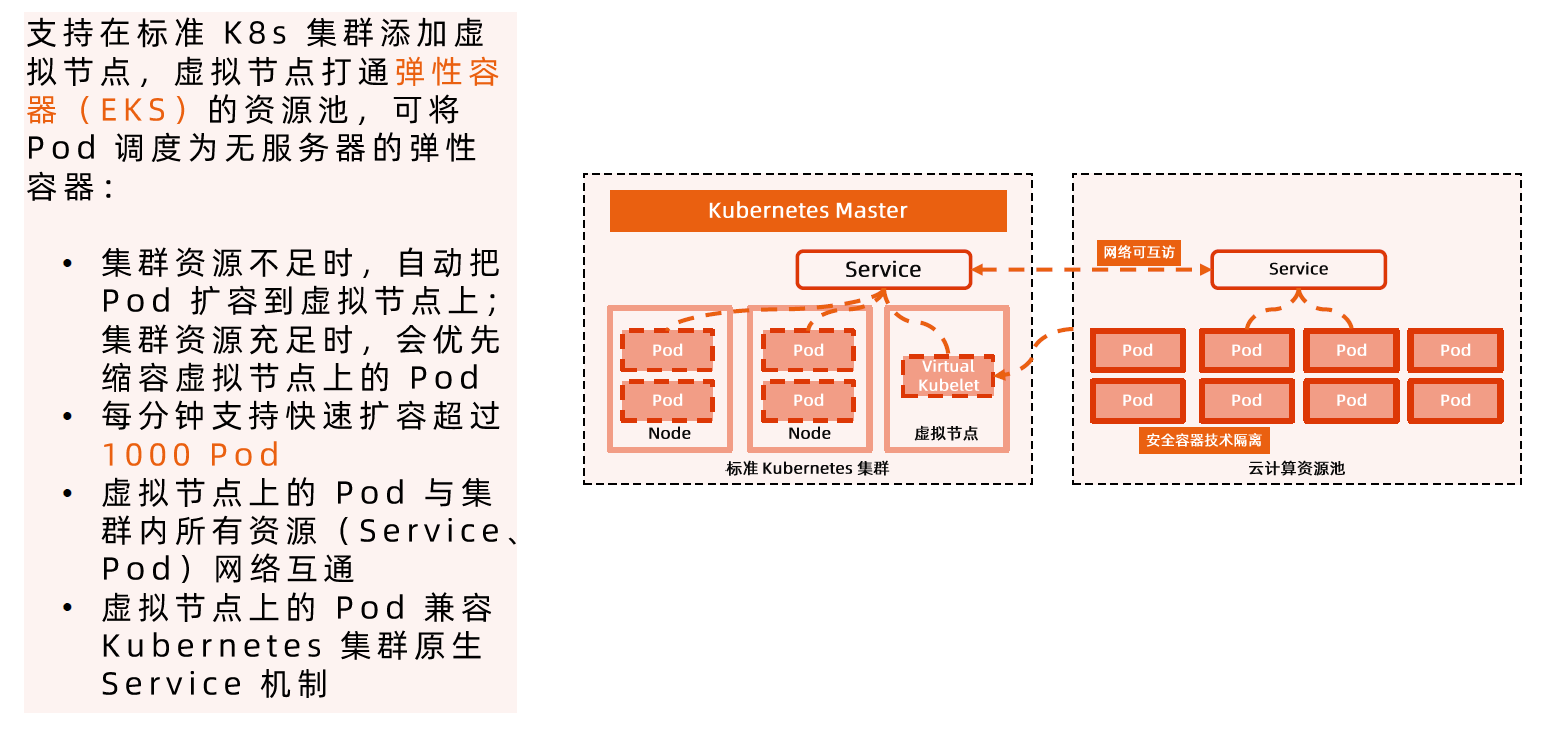
服务质量保证-安心拉升资源利用率的秘密

资源隔离-OS 隔离-ROSM 框架

基于 Istio 的高级流量管理
微服务架构的演变
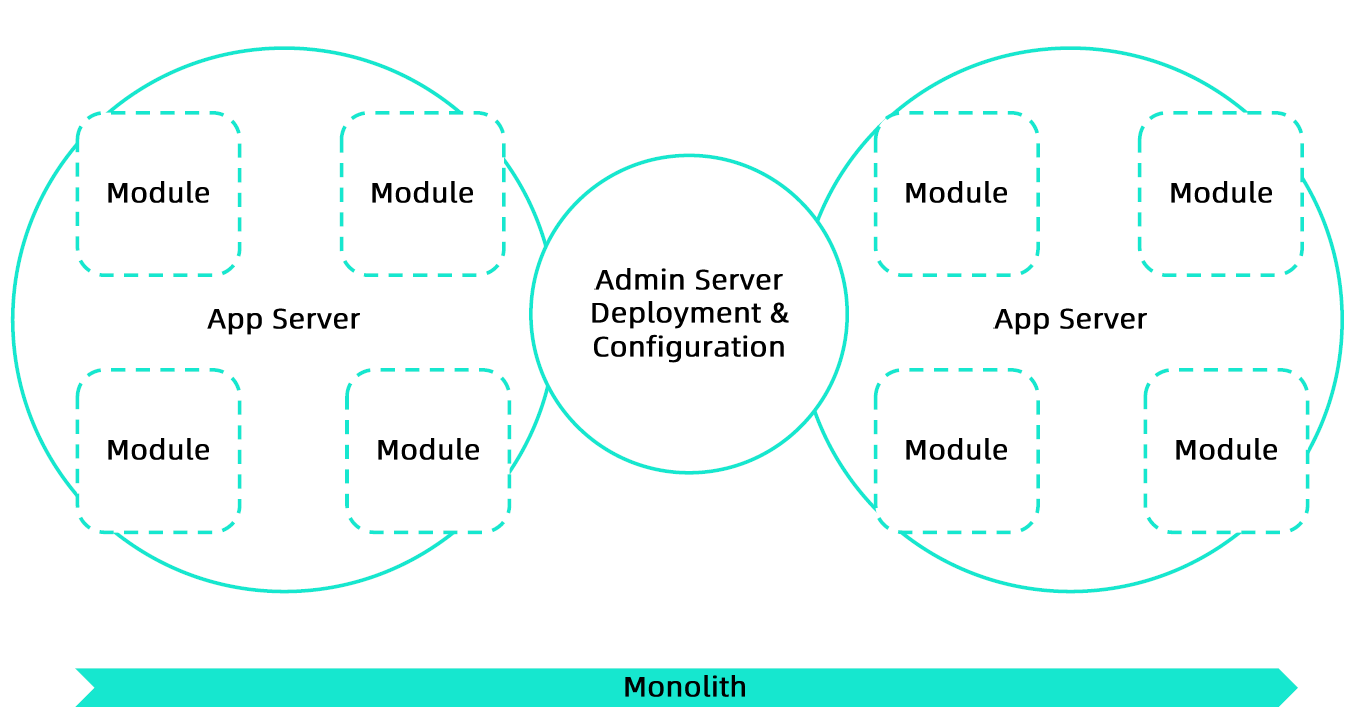
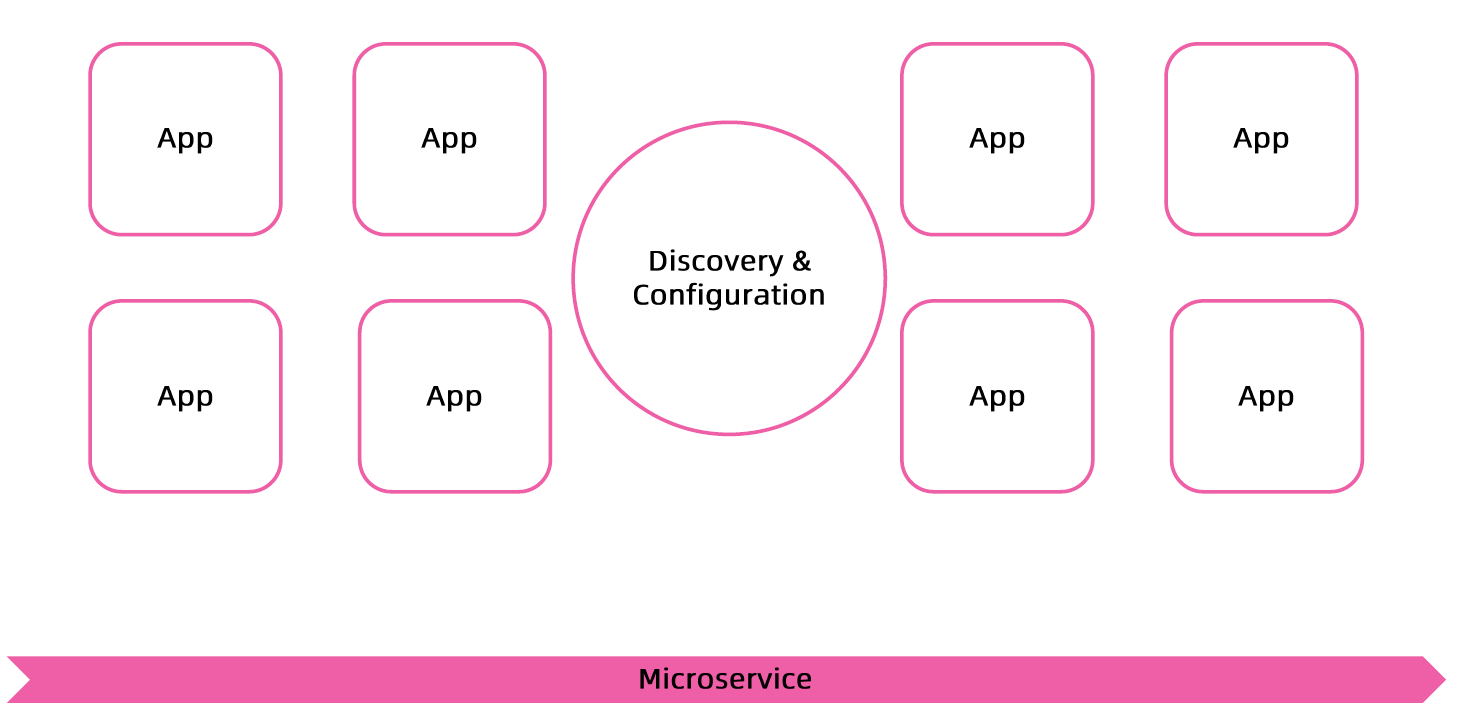
从单体系统到微服务系统的演进
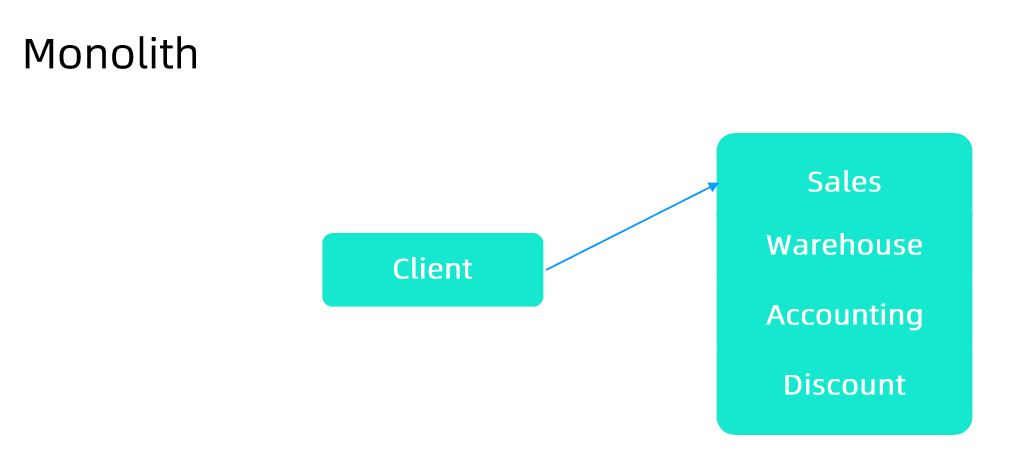
微服务架构的演进
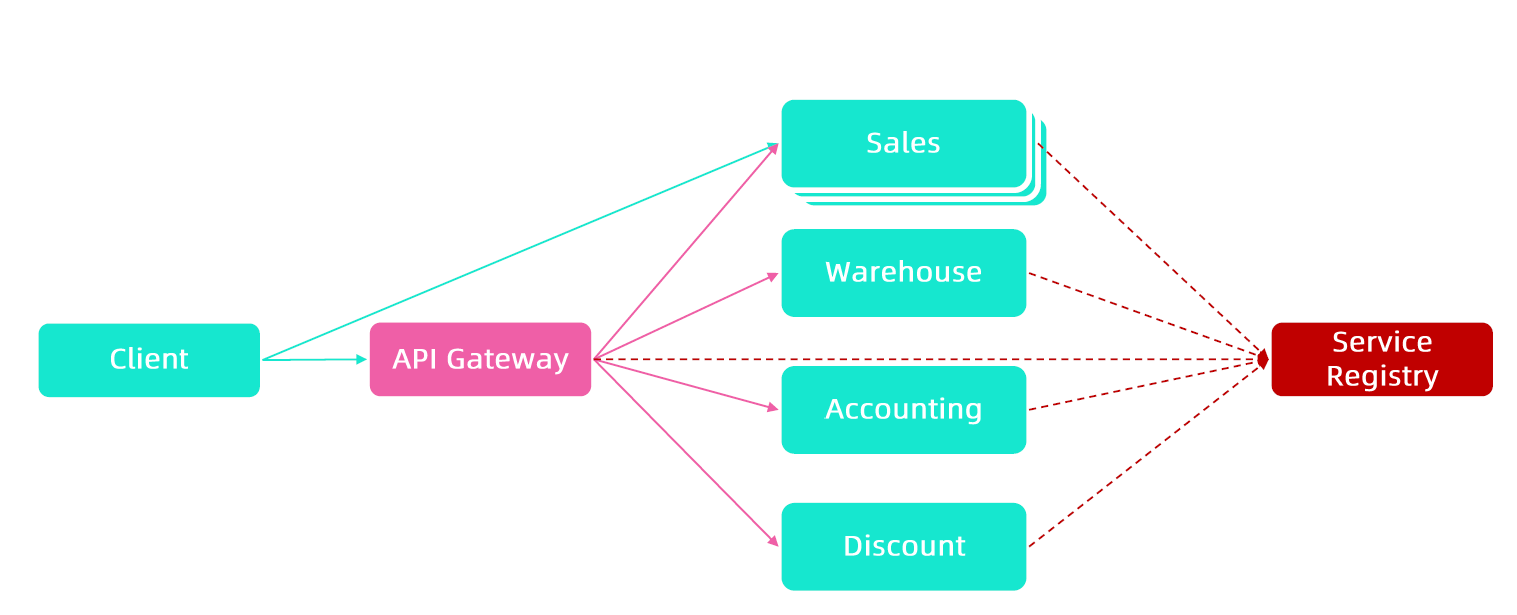
典型的微服务业务场景
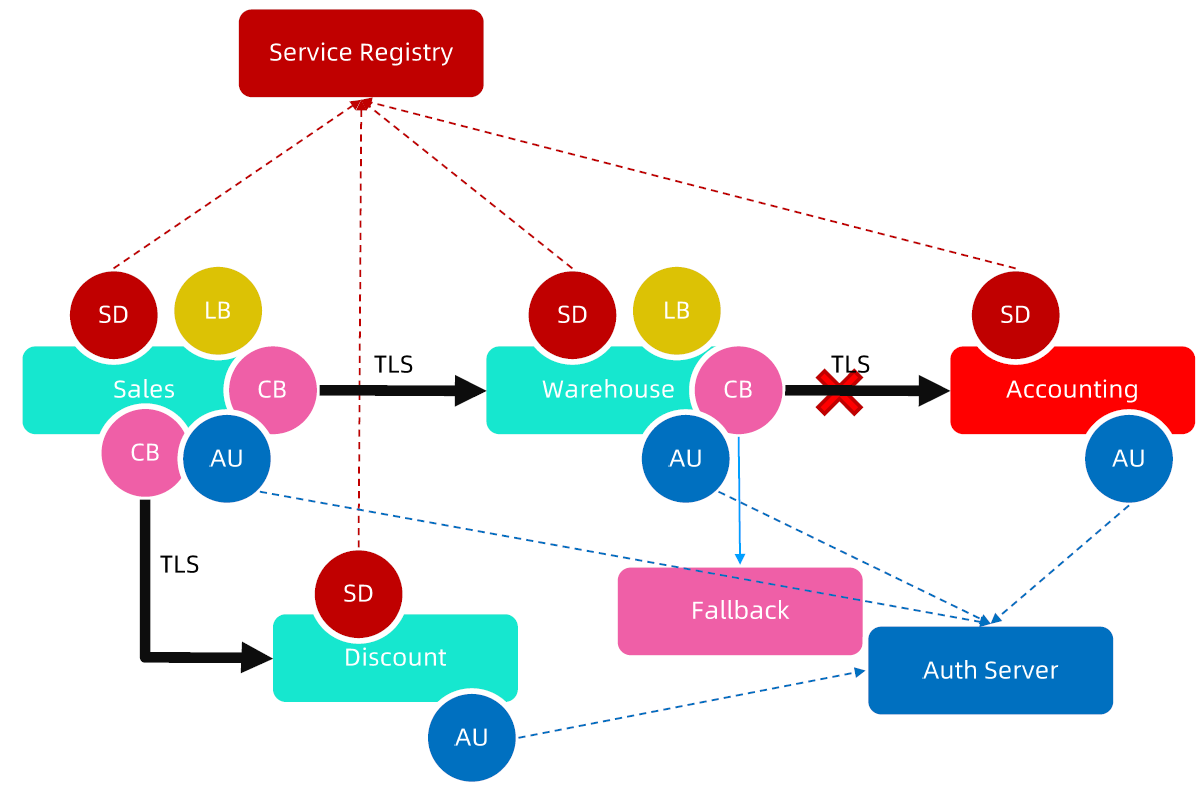
CB: circuit breaker,熔断器。CB 一般在客户端做。
SD: Service Discovery,服务发现。
LD: Load balance,负载均衡。
AU:Authentication,认证。
更完整的微服务架构

系统边界
让业务只关心业务,CB、SD、LD、AU 交给平台。
微服务到服务网格还缺什么?
Sidecar 的工作原理
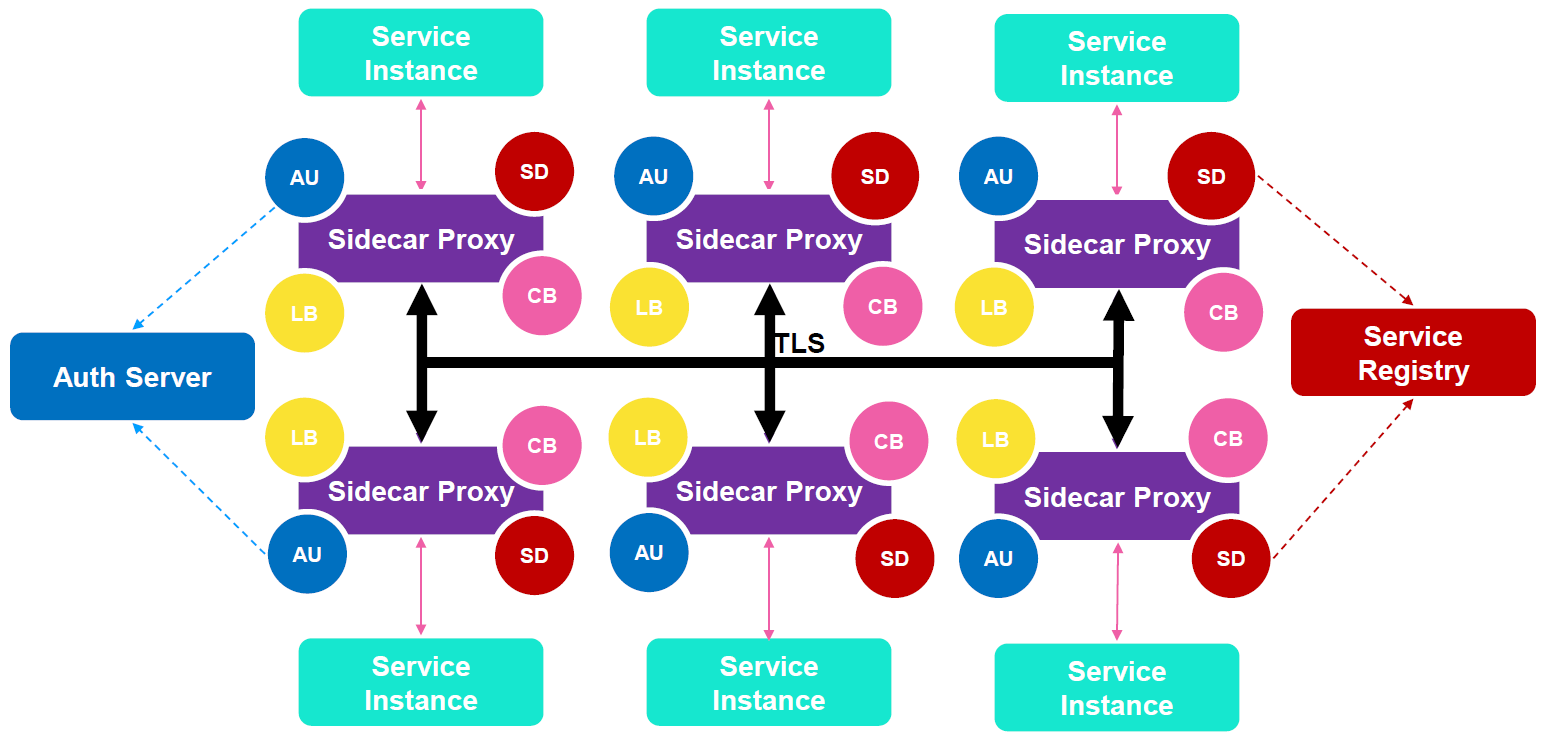
Service Mesh
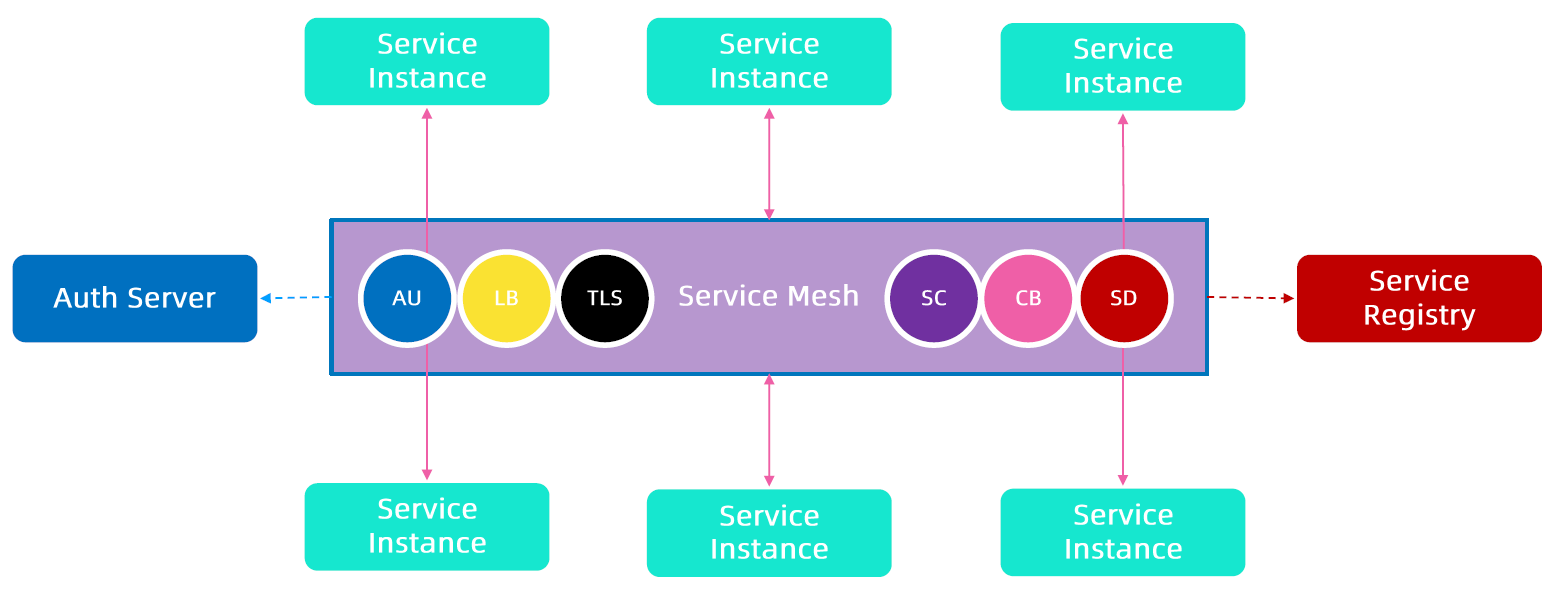
适应性
- 熔断
- 重试
- 超时处理失败处理负载均衡
- Failover
服务发现
- 路由
安全和访问控制
- TLS 和证书管理
可观察性
- Metrics
- 监控
- 分布式日志
- 分布式 tracing
部署
- 容器
通讯
- HTTP
- WS
- gRPC
- TCP
微服务的优劣
优势
将基础架构逻辑从业务代码中剥离出来
- 分布式 tracing
- 日志
自由选择技术栈
帮助业务开发部门只关注业务逻辑
劣势
复杂
- 更多的运行实例
可能带来额外的网络跳转
- 每个服务调用都要经过 Sidecar
解决了一部分问题,同时要付出代价
依然要处理复杂路由,类型映射,与外部系统整合等方面问题
不解决业务逻辑或服务整合,服务组合等问题
服务网格可选方案
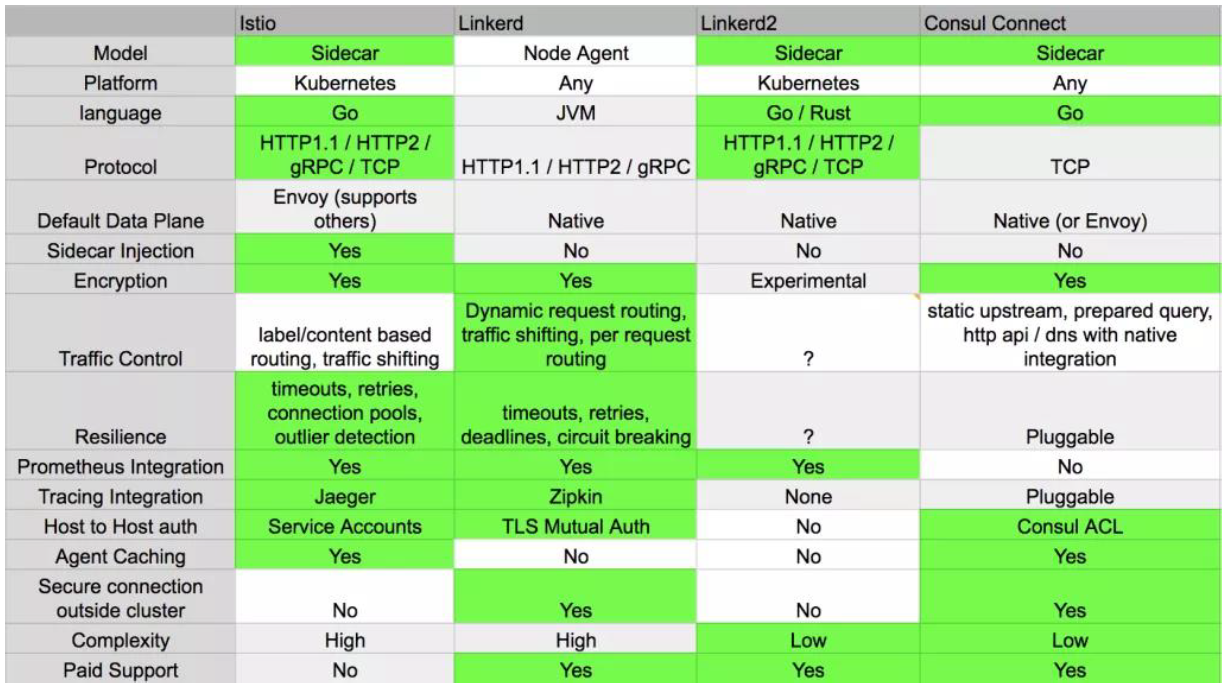
什么是服务网格
服务网格(Service Mesh)这个术语通常用于描述构成这些应用程序的微服务网络以及应用之间的交互。 随着规模和复杂性的增长,服务网格越来越难以理解和管理。
它的需求包括服务发现、负载均衡、故障恢复、指标收集和监控以及通常更加复杂的运维需求例如 A/B 测试、金丝雀发布、限流、访问控制和端到端认证等。
为什么要使用 Istio
HTTP、gRPC、WebSocket 和 TCP 流量的自动负载均衡。
通过丰富的路由规则、重试、故障转移和故障注入,可以对流量行为进行细粒度控制。
可插入的策略层和配置 API,支持访问控制、速率限制和配额。
对出入集群入口和出口中所有流量的自动度量指标、日志记录和跟踪。
通过强大的基于身份的验证和授权,在集群中实现安全的服务间通信。
Istio 功能概览
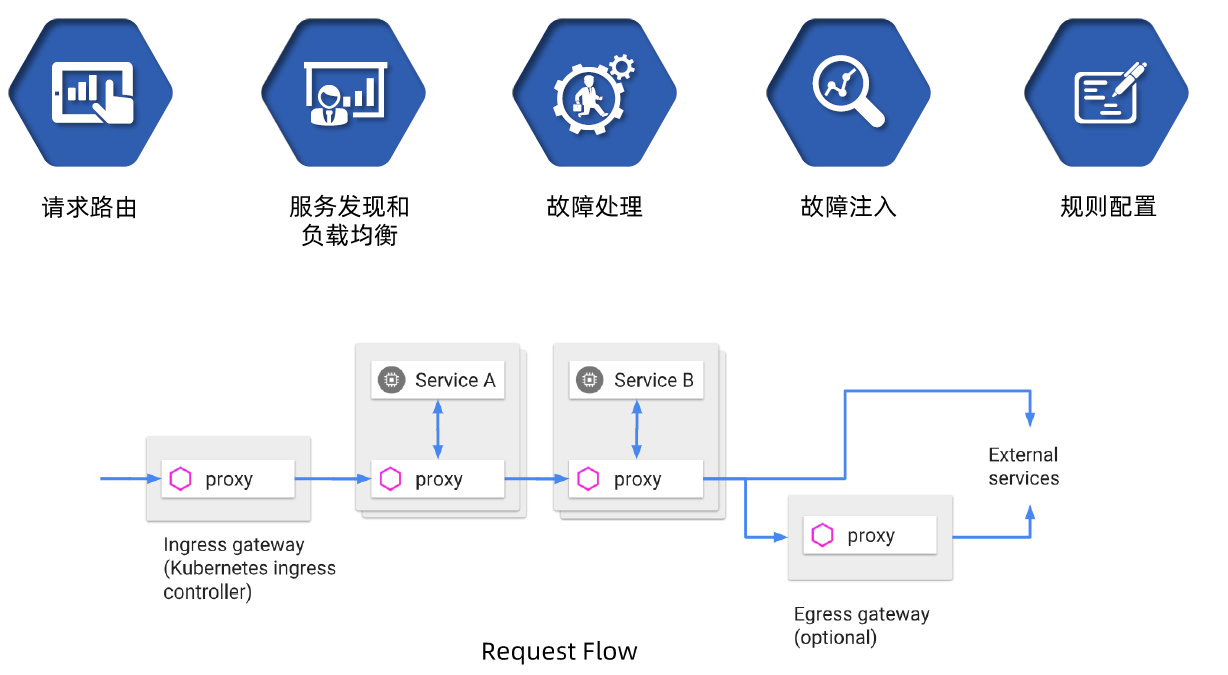
流量管理
连接
- 通过简单的规则配置和流量路由,可以控制服务之间的流量和 API调用。lstio 简化了断路器超时和重试等服务级别属性的配置,并且可以轻松设置 A/B 测试、金丝雀部署和基于百分比的流量分割的分阶段部署等重要任务。
控制
- 通过更好地了解流量和开箱即用的故障恢复功能,可以在问题出现之前先发现问题,使调用更可靠,并且使您的网络更加强大—无论您面临什么条件。
安全
使开发人员可以专注于应用程序级别的安全性。 Istio 提供底层安全通信信道,并大规管理服务通信的认证、授权和加密。使用Istio,服务通信在默认情况下是安全的,它允许跨多种协议和运行时一致地实施策略——所有这些都很少或根本不需要应用程序更改。
虽然 Istio 与平台无关,但将其与 Kubernetes(或基础架构)网络策略结合使用,其优势会更大,包括在网络和应用层保护 Pod 间或服务间通信的能力。
可观察性
Istio 生成以下类型的遥测数据,以提供对整个服务网格的可观察性:
- 指标: Istio 基于4个监控的黄金标识(延迟、流量、错误、饱和)生成了一系列服务指标。Istio 还为网格控制平面提供了更详细的指标。除此以外还提供了一组默认的基于这些指标的网格监控仪表板。
- 分布式追踪: Istio 为每个服务生成分布式追踪span,运维人员可以理解网格内服务的依赖和调用流程。
- 访问日志: 当流量流入网格中的服务时,Istio 可以生成每个请求的完整记录,包括源和目标的元数据。此信息使运维人员能够将服务行为的审查控制到单个工作负载实例的级别。
所有这些功能可以更有效地设置、监控和实施服务上的 SLO,快速有效地检测和修复问题
Istio 架构演进
数据平面
- 由一组以 Sidecar 方式部署的智能代理(Envoy)组成。这些代理可以调节和控制微服务及 Mixer 之间所有的网络通信。
控制平面
负责管理和配置代理来路由流量。此外控制平面配置 Mixer 以实施策略和收集遥测数据。
架构演进
- 从微服务回归单体。
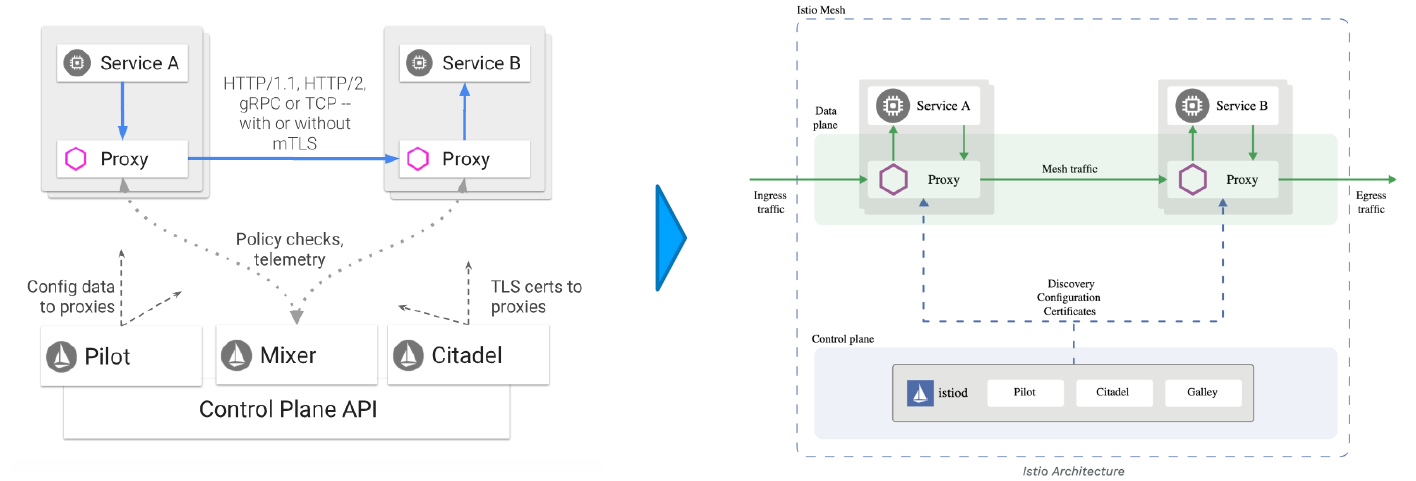
设计目标
最大化透明度
- Istio 将自身自动注入到服务间所有的网络路径中,运维和开发人员只需付出很少的代价就可以从中受益
- Istio 使用 Sidecar 代理来捕获流量,并且在尽可能的地方自动编程网络层,以路由流量通过这些代理而无需对已部署的应用程序代码进行任何改动。
- 在 Kubernetes 中,代理被注入到 Pod 中,通过编写 iptables 规则来捕获流量。注入 Sidecar 代理到Pod 中并且修改路由规则后,Istio 就能够调解所有流量。
- 所有组件和 API 在设计时都必须考虑性能和规模。
增量
- 预计最大的需求是扩展策略系统,集成其他策略和控制来源,并将网格行为信号传播到其他系统进行分析策略运行时支持标准扩展机制以便插入到其他服务中。
可移植性
- 将基于 Istio 的服务移植到新环境应该是轻而易举的,而使用 Istio 将一个服务同时部署到多个环境中也是可行的(例如,在多个云上进行几余部署)。
策略一致性
- 在服务间的 API 调用中,策略的应用使得可以对网格间行为进行全面的控制,但对于无需在 API 级别表达的资源来说,对资源应用策略也同样重要,
- 因此,策略系统作为独特的服务来维护,具有自己的 API,而不是将其放到代理 /sidecar 中,这容许服务根据需要直接与其集成。
深入理解数据平面 Envoy
主流七层代理的比较

Connection draining:进程重启时,容许一定的时间等待正在的处理的网络链接请求被处理完成后再退出进程。
Envoy 的优势
性能:
- 在具备大量特性的同时,Envoy 提供极高的吞吐量和低尾部延迟差异,而 CPU 和 RAM 消耗却相对较少。
可扩展性:
- Envoy 在 L4 和 L7 都提供了丰富的可插拔过滤器能力,使用户可以轻松添加 开源版本中没有的功能。
API 可配置性:
- Envoy提供了一组可以通过控制平面服务实现的管理 API。如果控制平面实现所有的 API,则可以使用通用引导配置在整个基础架构上运行 Envoy。所有进一步的配置更改通过管理服务器以无缝方式动态传送,因此 Envoy 从不需要重新启动。这使得 Envoy 成为通用数据平面当它与一个足够复杂的控制平面相结合时,会极大的降低整体运维的复杂性。
Envoy 线程模式
Envoy 采用单进程多线程模式:
- 主线程负责协调;
- 子线程负责监听过滤和转发
当某连接被监听器接受,那么该连接的全部生命周期会与某线程绑定。
Envoy基于非阻塞模式(Epoll)。
建议 Envoy 配置的 worker 数量与 Envoy 所在的硬件线程数一致。
Envoy 架构
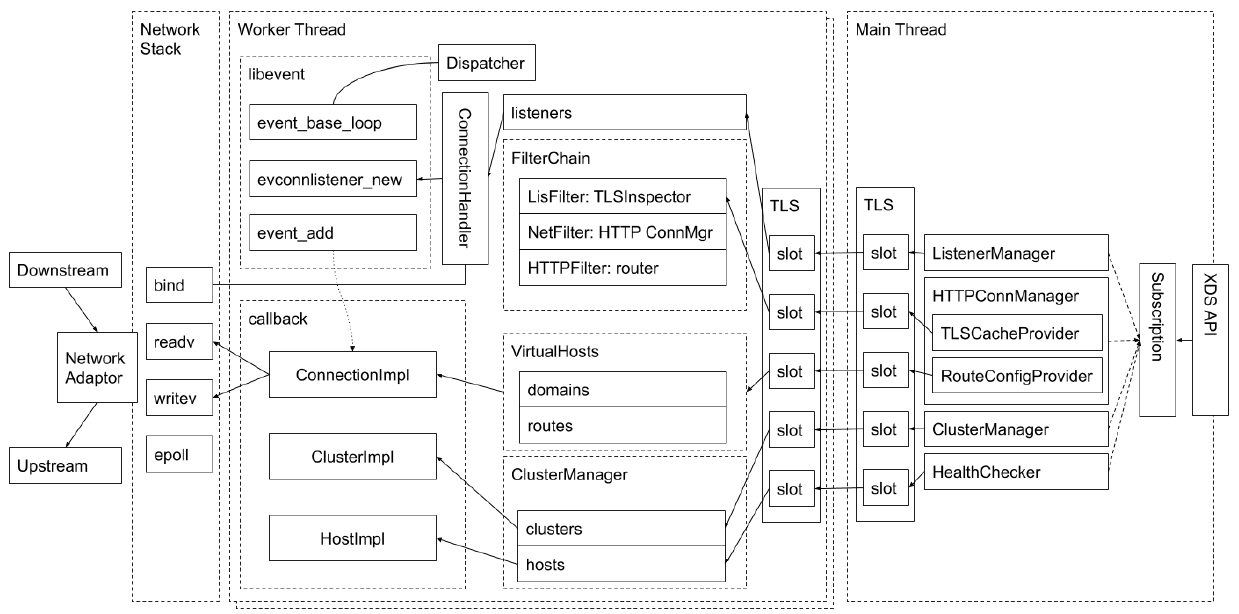
V1 API 的缺点和 v2 的引入
V1 API 仅使用 JSON/REST,本质上是轮询。 这有几个缺点:
- 尽管 Envoy 在内部使用的是 JSON 模式,但 API 本身并不是强类型,而且安全实现它们的通用服务器也很难。
- 虽然轮询工作在实践中是很正常的用法,但更强大的控制平面更喜欢 streaming API,当其就绪后,可以将更新推送给每个 Envoy。这可以将更新传播时间从 30-60 秒降低到 250-500 毫秒,即使在极其庞大的部署中也是如此。
v2 API 具有以下属性:
- 新的 API 模式使用 proto3 指定,并同时以 gRPC 和 REST+JSON/YAML 端点实现。
- 它们被定义在一个名为 envoy-api 的新的专用源代码仓库中。proto3 的使用意味着这些 API 是强类型的,同时仍然通过 proto3 的 JSON/YAML 表示来支持 JSON/YAML 变体。
- 专用存储仓库的使用意味着项目可以更容易的使用 API 并用 gRPC 支持的所有语言生成存根 (实际上,对于希望使用它的用户,我们将继续支持基于 REST 的 JSON/YAML 变体) 。
xDS-Envoy 的发现机制
Endpoint Discovery Service (EDS):
- 这是V1 SDS API的替代品。此外,gRPC的双向流性质将允许将负载/健康信息报告回管理服务器,为将来的全局负载均衡功能开启大门。
Cluster Discovery Service (CDS):
- 和 v1 没有实质性变化。
Route Discovery Service (RDS):
- 和 v1 没有实质性变化。
Listener Discovery Service (LDS):
- 和 v1 的唯一主要变化是: 现在允许监听器定义多个并发过滤栈,这些过滤栈可以基于一组监听器路由规则(例如,SNI,源/目的地 IP 匹配等)来选择。这是处理”原始目的地”策略路由的更简洁的方式,这种路由是透明数据平面解决方案(如Istio)所需要的。
Secret Discovery Service (SDS):
- 一个专用的 API 来传递 TLS 密钥材料。这将解耦通过 LDS/CDS 发送主要监听器、集群配置和通过专用密钥管理系统发送秘钥素材。
Health Discovery Service (HDS):
- 该 API 将允许 Envoy 成为分布式健康检查网络的成员。中央健康检查服务可以使用一组 Envoy 作为健康检查终点并将状态报告回来,从而缓解 N^2 健康检查问题,这个问题指的是其间的每个 Envoy都可能需要对每个其他 Envoy 进行健康检查。
Aggregated Discovery Service(ADS):
- 总的来说,Envoy 的设计是最终一致的。这意味着默认情况下,每个管理 API 都并发运行并且不会相互交互。在某些情况下,一次一个管理服务器处理单个 Envoy 的所有更新是有益的(例如,如果需要对更新进行排序以避免流量下降)。此API允许通过单个管理服务器的单个 gRPC 双向流对所有其他 API 进行编组,从而实现确定性排序。
Envoy 的过滤器模式
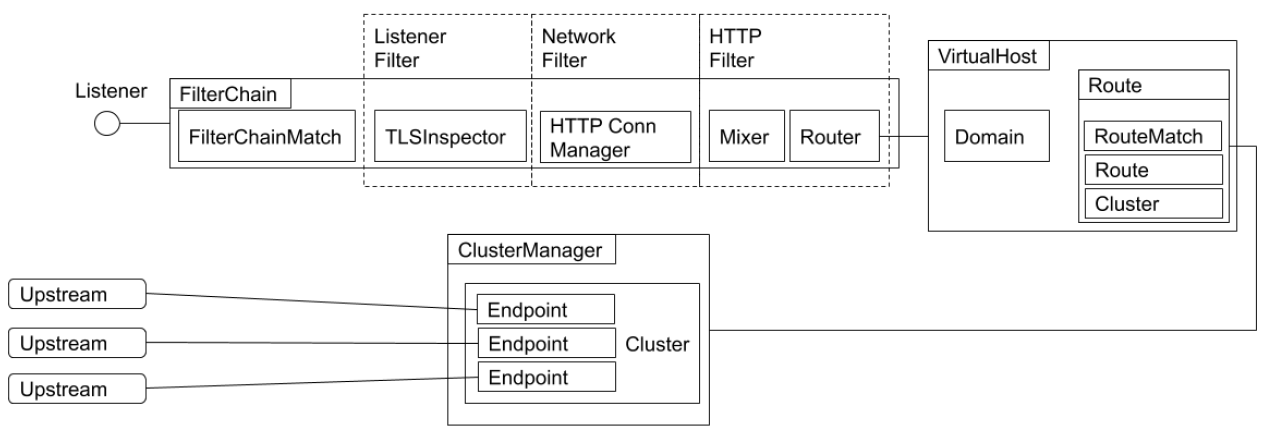
Envoy 实验
# simple 的配置
$ cat simple.yaml -p
apiVersion: apps/v1
kind: Deployment
metadata:
name: simple
spec:
replicas: 1
selector:
matchLabels:
app: simple
template:
metadata:
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "80"
labels:
app: simple
spec:
containers:
- name: simple
imagePullPolicy: Always
image: cncamp/httpserver:v1.0-metrics
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: simple
spec:
ports:
- name: http
port: 80
protocol: TCP
targetPort: 80
selector:
app: simple
# 创建 simple
$ kubectl apply -f ./simple.yaml
deployment.apps/simple created
service/simple created
$ kubectl get svc simple
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
simple ClusterIP 10.108.197.81 <none> 80/TCP 15m
$ curl 10.108.197.81/hello
hello [stranger]
===================Details of the http request header:============
User-Agent=[curl/7.81.0]
Accept=[*/*]
# envoy的配置
$ cat envoy.yaml
admin:
address:
socket_address: { address: 127.0.0.1, port_value: 9901 }
static_resources:
listeners:
- name: listener_0
address:
socket_address: { address: 0.0.0.0, port_value: 10000 }
filter_chains:
- filters:
- name: envoy.filters.network.http_connection_manager
typed_config:
"@type": type.googleapis.com/envoy.extensions.filters.network.http_connection_manager.v3.HttpConnectionManager
stat_prefix: ingress_http
codec_type: AUTO
route_config:
name: local_route
virtual_hosts:
- name: local_service
domains: ["*"]
routes:
- match: { prefix: "/" }
route: { cluster: some_service }
http_filters:
- name: envoy.filters.http.router
typed_config:
"@type": type.googleapis.com/envoy.extensions.filters.http.router.v3.Router
clusters:
- name: some_service
connect_timeout: 0.25s
type: LOGICAL_DNS
lb_policy: ROUND_ROBIN
load_assignment:
cluster_name: some_service
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address:
address: simple
port_value: 80
$ kubectl create configmap envoy-config --from-file envoy.yaml
configmap/envoy-config created
$ cat envoy-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
run: envoy
name: envoy
spec:
replicas: 1
selector:
matchLabels:
run: envoy
template:
metadata:
labels:
run: envoy
spec:
containers:
- image: envoyproxy/envoy-dev
name: envoy
volumeMounts:
- name: envoy-config
mountPath: "/etc/envoy"
readOnly: true
volumes:
- name: envoy-config
configMap:
name: envoy-config
$ kubectl apply -f ./envoy-deploy.yaml
deployment.apps/envoy created
$ kubectl get pods -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
envoy-7c8f878d77-f8mg7 1/1 Running 0 13m 10.244.1.4 minikube-m02 <none> <none>
simple-7b4d48d56b-lp8dq 1/1 Running 0 20m 10.244.1.2 minikube-m02 <none> <none>
$ curl 10.244.1.4:10000/hello
hello [stranger]
===================Details of the http request header:============
X-Envoy-Expected-Rq-Timeout-Ms=[15000]
User-Agent=[curl/7.81.0]
Accept=[*/*]
X-Forwarded-Proto=[http]
X-Request-Id=[4048f3e2-2e03-4900-a3fa-76eee47a6fc4]Isito 流量管理
可以使用命令 istioctl analyze -n <namespace> 来分析某个命名空间的istio配置是否正确。
流量劫持实验
准备环境
# 创建集群
$ minikube start --cpus=4 --memory=16384
# 安装 istio
$ istioctl install --set profile=demo -y
# 下载教程相关资源
$ git clone git@github.com:kibaamor/101.git
$ cd 101/module12/istio/4.sidecar
# 创建 sidecar 空间以及其他资源
$ kubectl create ns sidecar
$ kubectl label ns sidecar istio-injection=enabled
$ kubectl apply -f nginx.yaml -n sidecar
$ kubectl apply -f toolbox.yaml -n sidecar
# 确认部署成功
$ kubectl -n sidecar exec deploy/toolbox -- curl nginx
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>分析出站流量
查看 toolbox 容器 iptables 规则
# 进入minikube所在的docker
$ minikube ssh
# 查看toolbox容器的Id
$ docker ps | grep -i toolbox
8d3e31b6693e e748609498a4 "/usr/local/bin/pilo…" 6 minutes ago Up 6 minutes k8s_istio-proxy_toolbox-65fdb8f7b8-d5b22_sidecar_44e06cc3-77b8-4004-86bc-cc6e3bd9da3d_0
96098aeea9e8 centos "tail -f /dev/null" 6 minutes ago Up 6 minutes k8s_toolbox_toolbox-65fdb8f7b8-d5b22_sidecar_44e06cc3-77b8-4004-86bc-cc6e3bd9da3d_0
d452cae17d8d registry.k8s.io/pause:3.9 "/pause" 7 minutes ago Up 7 minutes k8s_POD_toolbox-65fdb8f7b8-d5b22_sidecar_44e06cc3-77b8-4004-86bc-cc6e3bd9da3d_0
# 查看toolbox容器的Pid
$ docker inspect 96098aeea9e8 | grep -i pid
"Pid": 4938,
"PidMode": "",
"PidsLimit": null,
# 查看toolbox容器的iptables规则
$ sudo nsenter -t 4938 -n iptables-legacy-save
# Generated by iptables-save v1.8.7 on Tue Jul 9 11:14:24 2024
*nat
:PREROUTING ACCEPT [40:2400]
:INPUT ACCEPT [40:2400]
:OUTPUT ACCEPT [27:2185]
:POSTROUTING ACCEPT [30:2365]
:ISTIO_INBOUND - [0:0]
:ISTIO_IN_REDIRECT - [0:0]
:ISTIO_OUTPUT - [0:0]
:ISTIO_REDIRECT - [0:0]
-A PREROUTING -p tcp -j ISTIO_INBOUND
-A OUTPUT -p tcp -j ISTIO_OUTPUT
-A ISTIO_INBOUND -p tcp -m tcp --dport 15008 -j RETURN
-A ISTIO_INBOUND -p tcp -m tcp --dport 15090 -j RETURN
-A ISTIO_INBOUND -p tcp -m tcp --dport 15021 -j RETURN
-A ISTIO_INBOUND -p tcp -m tcp --dport 15020 -j RETURN
-A ISTIO_INBOUND -p tcp -j ISTIO_IN_REDIRECT
-A ISTIO_IN_REDIRECT -p tcp -j REDIRECT --to-ports 15006
-A ISTIO_OUTPUT -s 127.0.0.6/32 -o lo -j RETURN
-A ISTIO_OUTPUT ! -d 127.0.0.1/32 -o lo -p tcp -m tcp ! --dport 15008 -m owner --uid-owner 1337 -j ISTIO_IN_REDIRECT
-A ISTIO_OUTPUT -o lo -m owner ! --uid-owner 1337 -j RETURN
-A ISTIO_OUTPUT -m owner --uid-owner 1337 -j RETURN
-A ISTIO_OUTPUT ! -d 127.0.0.1/32 -o lo -p tcp -m tcp ! --dport 15008 -m owner --gid-owner 1337 -j ISTIO_IN_REDIRECT
-A ISTIO_OUTPUT -o lo -m owner ! --gid-owner 1337 -j RETURN
-A ISTIO_OUTPUT -m owner --gid-owner 1337 -j RETURN
-A ISTIO_OUTPUT -d 127.0.0.1/32 -j RETURN
-A ISTIO_OUTPUT -j ISTIO_REDIRECT
-A ISTIO_REDIRECT -p tcp -j REDIRECT --to-ports 15001
COMMIT
# Completed on Tue Jul 9 11:14:24 2024从上面的 iptables 规则可以看出,toolbox 容器访问 nginx pod 的流量会被重定向到本地的 15001 端口。
我们可以先看看 istio 规则的同步状态(命令 ps 是命令 proxy-status 的简写)。
$ istioctl ps -n sidecar
NAME CLUSTER CDS LDS EDS RDS ECDS ISTIOD VERSION
nginx-deployment-bf5d5cf98-k5tlz.sidecar Kubernetes SYNCED SYNCED SYNCED SYNCED NOT SENT istiod-869cfc56b5-ffktv 1.22.2
toolbox-65fdb8f7b8-d5b22.sidecar Kubernetes SYNCED SYNCED SYNCED SYNCED NOT SENT istiod-869cfc56b5-ffktv 1.22.2查看容器中 istio 的代理配置情况(命令 pc 是命令 proxy-config 的简写)。
$ kubectl get pods -n sidecar
NAME READY STATUS RESTARTS AGE
nginx-deployment-bf5d5cf98-k5tlz 2/2 Running 0 16m
toolbox-65fdb8f7b8-d5b22 2/2 Running 0 16m
$ istioctl pc listeners toolbox-65fdb8f7b8-d5b22 -n sidecar
ADDRESSES PORT MATCH DESTINATION
10.96.0.10 53 ALL Cluster: outbound|53||kube-dns.kube-system.svc.cluster.local
0.0.0.0 80 Trans: raw_buffer; App: http/1.1,h2c Route: 80
0.0.0.0 80 ALL PassthroughCluster
10.105.7.120 443 ALL Cluster: outbound|443||istio-egressgateway.istio-system.svc.cluster.local
10.111.188.103 443 ALL Cluster: outbound|443||istiod.istio-system.svc.cluster.local
10.111.255.7 443 ALL Cluster: outbound|443||istio-ingressgateway.istio-system.svc.cluster.local
10.96.0.1 443 ALL Cluster: outbound|443||kubernetes.default.svc.cluster.local
10.96.0.10 9153 Trans: raw_buffer; App: http/1.1,h2c Route: kube-dns.kube-system.svc.cluster.local:9153
10.96.0.10 9153 ALL Cluster: outbound|9153||kube-dns.kube-system.svc.cluster.local
0.0.0.0 15001 ALL PassthroughCluster
0.0.0.0 15001 Addr: *:15001 Non-HTTP/Non-TCP
0.0.0.0 15006 Addr: *:15006 Non-HTTP/Non-TCP
0.0.0.0 15006 Trans: tls; App: istio-http/1.0,istio-http/1.1,istio-h2; Addr: 0.0.0.0/0 InboundPassthroughClusterIpv4
0.0.0.0 15006 Trans: raw_buffer; App: http/1.1,h2c; Addr: 0.0.0.0/0 InboundPassthroughClusterIpv4
0.0.0.0 15006 Trans: tls; App: TCP TLS; Addr: 0.0.0.0/0 InboundPassthroughClusterIpv4
0.0.0.0 15006 Trans: raw_buffer; Addr: 0.0.0.0/0 InboundPassthroughClusterIpv4
0.0.0.0 15006 Trans: tls; Addr: 0.0.0.0/0 InboundPassthroughClusterIpv4
0.0.0.0 15010 Trans: raw_buffer; App: http/1.1,h2c Route: 15010
0.0.0.0 15010 ALL PassthroughCluster
10.111.188.103 15012 ALL Cluster: outbound|15012||istiod.istio-system.svc.cluster.local
0.0.0.0 15014 Trans: raw_buffer; App: http/1.1,h2c Route: 15014
0.0.0.0 15014 ALL PassthroughCluster
0.0.0.0 15021 ALL Inline Route: /healthz/ready*
10.111.255.7 15021 Trans: raw_buffer; App: http/1.1,h2c Route: istio-ingressgateway.istio-system.svc.cluster.local:15021
10.111.255.7 15021 ALL Cluster: outbound|15021||istio-ingressgateway.istio-system.svc.cluster.local
0.0.0.0 15090 ALL Inline Route: /stats/prometheus*
10.111.255.7 15443 ALL Cluster: outbound|15443||istio-ingressgateway.istio-system.svc.cluster.local
10.111.255.7 31400 ALL Cluster: outbound|31400||istio-ingressgateway.istio-system.svc.cluster.local查看 15001 端口的具体配置
$ istioctl pc listeners toolbox-65fdb8f7b8-d5b22 -n sidecar --port 15001 -oyaml
- accessLog: # 端口访问日志
- filter:
responseFlagFilter:
flags:
- NR
name: envoy.access_loggers.file
typedConfig:
'@type': type.googleapis.com/envoy.extensions.access_loggers.file.v3.FileAccessLog
logFormat:
textFormatSource:
inlineString: |
[%START_TIME%] "%REQ(:METHOD)% %REQ(X-ENVOY-ORIGINAL-PATH?:PATH)% %PROTOCOL%" %RESPONSE_CODE% %RESPONSE_FLAGS% %RESPONSE_CODE_DETAILS% %CONNECTION_TERMINATION_DETAILS% "%UPSTREAM_TRANSPORT_FAILURE_REASON%" %BYTES_RECEIVED% %BYTES_SENT% %DURATION% %RESP(X-ENVOY-UPSTREAM-SERVICE-TIME)% "%REQ(X-FORWARDED-FOR)%" "%REQ(USER-AGENT)%" "%REQ(X-REQUEST-ID)%" "%REQ(:AUTHORITY)%" "%UPSTREAM_HOST%" %UPSTREAM_CLUSTER% %UPSTREAM_LOCAL_ADDRESS% %DOWNSTREAM_LOCAL_ADDRESS% %DOWNSTREAM_REMOTE_ADDRESS% %REQUESTED_SERVER_NAME% %ROUTE_NAME%
path: /dev/stdout
address: # 端口监听配置
socketAddress:
address: 0.0.0.0
portValue: 15001
filterChains: # 处理链(顺序很重要)
- filterChainMatch: # 第一个处理
destinationPort: 15001 # 如果转发后的请求的目的地是15001端口,即本来就是发给15001端口的流量
filters:
- name: istio.stats
typedConfig:
'@type': type.googleapis.com/stats.PluginConfig
- name: envoy.filters.network.tcp_proxy
typedConfig:
'@type': type.googleapis.com/envoy.extensions.filters.network.tcp_proxy.v3.TcpProxy
cluster: BlackHoleCluster # 则把请求转发到 BlackHoleCluster 集群
statPrefix: BlackHoleCluster
name: virtualOutbound-blackhole
- filters: # 第二个处理,没有filterChainMatch,表示会处理剩下的所有请求,即通过 iptable 拦截而来的流量
- name: istio.stats
typedConfig:
'@type': type.googleapis.com/stats.PluginConfig
- name: envoy.filters.network.tcp_proxy
typedConfig:
'@type': type.googleapis.com/envoy.extensions.filters.network.tcp_proxy.v3.TcpProxy
accessLog:
- name: envoy.access_loggers.file
typedConfig:
'@type': type.googleapis.com/envoy.extensions.access_loggers.file.v3.FileAccessLog
logFormat:
textFormatSource:
inlineString: |
[%START_TIME%] "%REQ(:METHOD)% %REQ(X-ENVOY-ORIGINAL-PATH?:PATH)% %PROTOCOL%" %RESPONSE_CODE% %RESPONSE_FLAGS% %RESPONSE_CODE_DETAILS% %CONNECTION_TERMINATION_DETAILS% "%UPSTREAM_TRANSPORT_FAILURE_REASON%" %BYTES_RECEIVED% %BYTES_SENT% %DURATION% %RESP(X-ENVOY-UPSTREAM-SERVICE-TIME)% "%REQ(X-FORWARDED-FOR)%" "%REQ(USER-AGENT)%" "%REQ(X-REQUEST-ID)%" "%REQ(:AUTHORITY)%" "%UPSTREAM_HOST%" %UPSTREAM_CLUSTER% %UPSTREAM_LOCAL_ADDRESS% %DOWNSTREAM_LOCAL_ADDRESS% %DOWNSTREAM_REMOTE_ADDRESS% %REQUESTED_SERVER_NAME% %ROUTE_NAME%
path: /dev/stdout
cluster: PassthroughCluster # 把剩下的请求转发到 PassthroughCluster 集群
statPrefix: PassthroughCluster
name: virtualOutbound-catchall-tcp
name: virtualOutbound
trafficDirection: OUTBOUND
useOriginalDst: true # 表示会把请求向原始的地址转发根据上面的配置可以看出,发送给 15001 端口的流量会被转发给原始的目标地址。如果原始目标地址就是 15001 端口,流量会被转发到 BlackHoleCluster 集群,其他流量则会被转发到 PassthroughCluster 集群。
BlackHoleCluster 和 PassthroughCluster
查看 BlackHoleCluster 的配置
$ istioctl pc cluster toolbox-65fdb8f7b8-d5b22 -n sidecar -o yaml --fqdn BlackHoleCluster
- connectTimeout: 10s
name: BlackHoleCluster
type: STATIC
$ istioctl pc endpoint toolbox-65fdb8f7b8-d5b22 -n sidecar --cluster BlackHoleCluster -o yaml
[]可以看到 BlackHoleCluster 集群的类型是静态类型,但是却没有任何的 endpoint,所以所有发给 BlackHoleCluster 集群的流量都会被丢掉。
查看 PassthroughCluster 的配置
$ istioctl pc cluster toolbox-65fdb8f7b8-d5b22 -n sidecar -o yaml --fqdn PassthroughCluster
- circuitBreakers:
thresholds:
- maxConnections: 4294967295
maxPendingRequests: 4294967295
maxRequests: 4294967295
maxRetries: 4294967295
trackRemaining: true
connectTimeout: 10s
filters:
- name: istio.metadata_exchange
typedConfig:
'@type': type.googleapis.com/udpa.type.v1.TypedStruct
typeUrl: type.googleapis.com/envoy.tcp.metadataexchange.config.MetadataExchange
value:
enable_discovery: true
protocol: istio-peer-exchange
lbPolicy: CLUSTER_PROVIDED
name: PassthroughCluster
type: ORIGINAL_DST
typedExtensionProtocolOptions:
envoy.extensions.upstreams.http.v3.HttpProtocolOptions:
'@type': type.googleapis.com/envoy.extensions.upstreams.http.v3.HttpProtocolOptions
commonHttpProtocolOptions:
idleTimeout: 300s
useDownstreamProtocolConfig:
http2ProtocolOptions: {}
httpProtocolOptions: {}可以看到 PassthroughCluster 集群的类型是 ORIGINAL_DST ,表面这个集群使用了 original destination load balancing 策略,也就是会将流量转发给其原始的目标地址。
综上,可以看出,本来就是发给15001端口的流量会被丢弃,而被 iptable 拦截并转发到 15001 端口的流量,会再发送给流量原来的地址。
查看 80 端口的配置
$ istioctl pc listeners toolbox-65fdb8f7b8-d5b22 -n sidecar --port 80
ADDRESSES PORT MATCH DESTINATION
0.0.0.0 80 Trans: raw_buffer; App: http/1.1,h2c Route: 80
0.0.0.0 80 ALL PassthroughCluster可以看出,当 toolbox 容器访问 nginx service 的 80 端口时,使用 http/1.1或h2c协议时,会使用名为 80 的路由规则。
$ istioctl pc route toolbox-65fdb8f7b8-d5b22 -n sidecar --name 80 -o yaml
- ignorePortInHostMatching: true
maxDirectResponseBodySizeBytes: 1048576
name: "80"
validateClusters: false
virtualHosts:
- domains:
- istio-egressgateway.istio-system.svc.cluster.local
- istio-egressgateway.istio-system
- istio-egressgateway.istio-system.svc
- 10.105.7.120
includeRequestAttemptCount: true
name: istio-egressgateway.istio-system.svc.cluster.local:80
routes:
- decorator:
operation: istio-egressgateway.istio-system.svc.cluster.local:80/*
match:
prefix: /
name: default
route:
cluster: outbound|80||istio-egressgateway.istio-system.svc.cluster.local
maxGrpcTimeout: 0s
retryPolicy:
hostSelectionRetryMaxAttempts: "5"
numRetries: 2
retriableStatusCodes:
- 503
retryHostPredicate:
- name: envoy.retry_host_predicates.previous_hosts
typedConfig:
'@type': type.googleapis.com/envoy.extensions.retry.host.previous_hosts.v3.PreviousHostsPredicate
retryOn: connect-failure,refused-stream,unavailable,cancelled,retriable-status-codes
timeout: 0s
- domains:
- istio-ingressgateway.istio-system.svc.cluster.local
- istio-ingressgateway.istio-system
- istio-ingressgateway.istio-system.svc
- 10.111.255.7
includeRequestAttemptCount: true
name: istio-ingressgateway.istio-system.svc.cluster.local:80
routes:
- decorator:
operation: istio-ingressgateway.istio-system.svc.cluster.local:80/*
match:
prefix: /
name: default
route:
cluster: outbound|80||istio-ingressgateway.istio-system.svc.cluster.local
maxGrpcTimeout: 0s
retryPolicy:
hostSelectionRetryMaxAttempts: "5"
numRetries: 2
retriableStatusCodes:
- 503
retryHostPredicate:
- name: envoy.retry_host_predicates.previous_hosts
typedConfig:
'@type': type.googleapis.com/envoy.extensions.retry.host.previous_hosts.v3.PreviousHostsPredicate
retryOn: connect-failure,refused-stream,unavailable,cancelled,retriable-status-codes
timeout: 0s
- domains:
- nginx.sidecar.svc.cluster.local
- nginx
- nginx.sidecar.svc
- nginx.sidecar
- 10.97.154.185
includeRequestAttemptCount: true
name: nginx.sidecar.svc.cluster.local:80
routes:
- decorator:
operation: nginx.sidecar.svc.cluster.local:80/*
match:
prefix: /
name: default
route:
cluster: outbound|80||nginx.sidecar.svc.cluster.local
maxGrpcTimeout: 0s
retryPolicy:
hostSelectionRetryMaxAttempts: "5"
numRetries: 2
retriableStatusCodes:
- 503
retryHostPredicate:
- name: envoy.retry_host_predicates.previous_hosts
typedConfig:
'@type': type.googleapis.com/envoy.extensions.retry.host.previous_hosts.v3.PreviousHostsPredicate
retryOn: connect-failure,refused-stream,unavailable,cancelled,retriable-status-codes
timeout: 0s
- domains:
- '*'
includeRequestAttemptCount: true
name: allow_any
routes:
- match:
prefix: /
name: allow_any
route:
cluster: PassthroughCluster
maxGrpcTimeout: 0s
timeout: 0s可以看到,但访问的域名是 nginx 是时,流量会被路由到 outbound|80||nginx.sidecar.svc.cluster.local 集群。
$ istioctl pc cluster toolbox-65fdb8f7b8-d5b22 -n sidecar --fqdn 'outbound|80||nginx.sidecar.svc.cluster.local'
SERVICE FQDN PORT SUBSET DIRECTION TYPE DESTINATION RULE
nginx.sidecar.svc.cluster.local 80 - outbound EDS
$ istioctl pc endpoint toolbox-65fdb8f7b8-d5b22 -n sidecar --cluster 'outbound|80||nginx.sidecar.svc.cluster.local'
ENDPOINT STATUS OUTLIER CHECK CLUSTER
10.244.0.6:80 HEALTHY OK outbound|80||nginx.sidecar.svc.cluster.local
$ kubectl get pods -n sidecar -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-bf5d5cf98-k5tlz 2/2 Running 0 4h23m 10.244.0.6 minikube <none> <none>
toolbox-65fdb8f7b8-d5b22 2/2 Running 0 4h23m 10.244.0.7 minikube <none> <none>可以看到,流量最终会被路由到 nginx pod 中。
当 nginx deploy 扩容后
$ kubectl scale deployment nginx-deployment --replicas 3 -n sidecar
deployment.apps/nginx-deployment scaled
$ istioctl pc endpoint toolbox-65fdb8f7b8-d5b22 -n sidecar --cluster 'outbound|80||nginx.sidecar.svc.cluster.local'
ENDPOINT STATUS OUTLIER CHECK CLUSTER
10.244.0.6:80 HEALTHY OK outbound|80||nginx.sidecar.svc.cluster.local
10.244.0.8:80 HEALTHY OK outbound|80||nginx.sidecar.svc.cluster.local
10.244.0.9:80 HEALTHY OK outbound|80||nginx.sidecar.svc.cluster.local
$ kubectl get pods -n sidecar -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-bf5d5cf98-5455w 2/2 Running 0 104s 10.244.0.8 minikube <none> <none>
nginx-deployment-bf5d5cf98-8kb84 2/2 Running 0 104s 10.244.0.9 minikube <none> <none>
nginx-deployment-bf5d5cf98-k5tlz 2/2 Running 0 4h27m 10.244.0.6 minikube <none> <none>
toolbox-65fdb8f7b8-d5b22 2/2 Running 0 4h27m 10.244.0.7 minikube <none> <none>
# 还原配置
$ kubectl scale deployment nginx-deployment --replicas 1 -n sidecar分析入站流量
查看 nginx 容器 iptables 规则
$ minikube ssh
$ crictl ps -r --image nginx
CONTAINER IMAGE CREATED STATE NAME ATTEMPT POD ID POD
696d66a2cc3a6 nginx:latest 22 hours ago Running nginx 0 dcb43bcd3d41e nginx-deployment-bf5d5cf98-k5tlz
$ crictl inspect dcb43bcd3d41e | grep pid
"pid": 4308
$ sudo nsenter -t 4308 -n iptables-legacy-save
# Generated by iptables-save v1.8.7 on Wed Jul 10 09:22:26 2024
*nat
:PREROUTING ACCEPT [5353:321180]
:INPUT ACCEPT [5355:321300]
:OUTPUT ACCEPT [339:31474]
:POSTROUTING ACCEPT [339:31474]
:ISTIO_INBOUND - [0:0]
:ISTIO_IN_REDIRECT - [0:0]
:ISTIO_OUTPUT - [0:0]
:ISTIO_REDIRECT - [0:0]
-A PREROUTING -p tcp -j ISTIO_INBOUND
-A OUTPUT -p tcp -j ISTIO_OUTPUT
-A ISTIO_INBOUND -p tcp -m tcp --dport 15008 -j RETURN
-A ISTIO_INBOUND -p tcp -m tcp --dport 15090 -j RETURN
-A ISTIO_INBOUND -p tcp -m tcp --dport 15021 -j RETURN
-A ISTIO_INBOUND -p tcp -m tcp --dport 15020 -j RETURN
-A ISTIO_INBOUND -p tcp -j ISTIO_IN_REDIRECT
-A ISTIO_IN_REDIRECT -p tcp -j REDIRECT --to-ports 15006
-A ISTIO_OUTPUT -s 127.0.0.6/32 -o lo -j RETURN
-A ISTIO_OUTPUT ! -d 127.0.0.1/32 -o lo -p tcp -m tcp ! --dport 15008 -m owner --uid-owner 1337 -j ISTIO_IN_REDIRECT
-A ISTIO_OUTPUT -o lo -m owner ! --uid-owner 1337 -j RETURN
-A ISTIO_OUTPUT -m owner --uid-owner 1337 -j RETURN
-A ISTIO_OUTPUT ! -d 127.0.0.1/32 -o lo -p tcp -m tcp ! --dport 15008 -m owner --gid-owner 1337 -j ISTIO_IN_REDIRECT
-A ISTIO_OUTPUT -o lo -m owner ! --gid-owner 1337 -j RETURN
-A ISTIO_OUTPUT -m owner --gid-owner 1337 -j RETURN
-A ISTIO_OUTPUT -d 127.0.0.1/32 -j RETURN
-A ISTIO_OUTPUT -j ISTIO_REDIRECT
-A ISTIO_REDIRECT -p tcp -j REDIRECT --to-ports 15001
COMMIT
# Completed on Wed Jul 10 09:22:26 2024从上面的 iptables 规则可以看出,访问 nginx pod 的流量,如果目的端口不是 15008, 15090, 15021, 15020,就会被重定向到本地的 15006 端口。
查看 15006 端口的具体配置
$ kubectl get pods -n sidecar -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-bf5d5cf98-k5tlz 2/2 Running 0 22h 10.244.0.6 minikube <none> <none>
toolbox-65fdb8f7b8-d5b22 2/2 Running 0 22h 10.244.0.7 minikube <none> <none>
$ istioctl pc listener nginx-deployment-bf5d5cf98-k5tlz -n sidecar --port 15006
ADDRESSES PORT MATCH DESTINATION
0.0.0.0 15006 Addr: *:15006 Non-HTTP/Non-TCP
0.0.0.0 15006 Trans: tls; App: istio-http/1.0,istio-http/1.1,istio-h2; Addr: 0.0.0.0/0 InboundPassthroughClusterIpv4
0.0.0.0 15006 Trans: raw_buffer; App: http/1.1,h2c; Addr: 0.0.0.0/0 InboundPassthroughClusterIpv4
0.0.0.0 15006 Trans: tls; App: TCP TLS; Addr: 0.0.0.0/0 InboundPassthroughClusterIpv4
0.0.0.0 15006 Trans: raw_buffer; Addr: 0.0.0.0/0 InboundPassthroughClusterIpv4
0.0.0.0 15006 Trans: tls; Addr: 0.0.0.0/0 InboundPassthroughClusterIpv4
0.0.0.0 15006 Trans: tls; App: istio,istio-peer-exchange,istio-http/1.0,istio-http/1.1,istio-h2; Addr: *:80 Cluster: inbound|80||
0.0.0.0 15006 Trans: raw_buffer; Addr: *:80 Cluster: inbound|80||根据上面的配置可以看出,toolbox 访问 nginx 80 端口的流量会被路由到 InboundPassthroughClusterIpv4 集群。
InboundPassthroughClusterIpv4
$ istioctl pc clusters nginx-deployment-bf5d5cf98-k5tlz -n sidecar --fqdn InboundPassthroughClusterIpv4 -oyaml
- circuitBreakers:
thresholds:
- maxConnections: 4294967295
maxPendingRequests: 4294967295
maxRequests: 4294967295
maxRetries: 4294967295
trackRemaining: true
connectTimeout: 10s
lbPolicy: CLUSTER_PROVIDED
name: InboundPassthroughClusterIpv4
type: ORIGINAL_DST
typedExtensionProtocolOptions:
envoy.extensions.upstreams.http.v3.HttpProtocolOptions:
'@type': type.googleapis.com/envoy.extensions.upstreams.http.v3.HttpProtocolOptions
commonHttpProtocolOptions:
idleTimeout: 300s
useDownstreamProtocolConfig:
http2ProtocolOptions: {}
httpProtocolOptions: {}
upstreamBindConfig:
sourceAddress:
address: 127.0.0.6
portValue: 0可以看到 InboundPassthroughClusterIpv4 集群的类型与 PassthroughCluster 集群的类型一样,也是 ORIGINAL_DST,也就是会将流量转发给其原始的目标地址。
查看 80 端口的配置
$ istioctl pc listener nginx-deployment-bf5d5cf98-k5tlz -n sidecar --port 80
ADDRESSES PORT MATCH DESTINATION
0.0.0.0 80 Trans: raw_buffer; App: http/1.1,h2c Route: 80
0.0.0.0 80 ALL PassthroughCluster即访问 nginx 80 端口时会使用名为 80 的路由规则。
后面的流程就与 toolbox中一样了。
$ istioctl pc route nginx-deployment-bf5d5cf98-k5tlz -n sidecar --name 80 -oyaml
- ignorePortInHostMatching: true
maxDirectResponseBodySizeBytes: 1048576
name: "80"
validateClusters: false
virtualHosts:
- ...
- domains:
- nginx.sidecar.svc.cluster.local
- nginx
- nginx.sidecar.svc
- nginx.sidecar
- 10.97.154.185
includeRequestAttemptCount: true
name: nginx.sidecar.svc.cluster.local:80
routes:
- decorator:
operation: nginx.sidecar.svc.cluster.local:80/*
match:
prefix: /
name: default
route:
cluster: outbound|80||nginx.sidecar.svc.cluster.local
...
- ...
$ istioctl pc cluster nginx-deployment-bf5d5cf98-k5tlz -n sidecar --fqdn 'outbound|80||nginx.sidecar.svc.cluster.local'
SERVICE FQDN PORT SUBSET DIRECTION TYPE DESTINATION RULE
nginx.sidecar.svc.cluster.local 80 - outbound EDS
$ istioctl pc endpoint nginx-deployment-bf5d5cf98-k5tlz -n sidecar --cluster 'outbound|80||nginx.sidecar.svc.cluster.local'
ENDPOINT STATUS OUTLIER CHECK CLUSTER
10.244.0.6:80 HEALTHY OK outbound|80||nginx.sidecar.svc.cluster.local
$ kubectl get pods -n sidecar -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-bf5d5cf98-k5tlz 2/2 Running 0 22h 10.244.0.6 minikube <none> <none>
toolbox-65fdb8f7b8-d5b22 2/2 Running 0 22h 10.244.0.7 minikube <none> <none>查看pod中envoy的配置
$ kubectl exec deploy/toolbox -n sidecar -- curl localhost:15000/help
/: Admin home page
/certs: print certs on machine
/clusters: upstream cluster status
/config_dump: dump current Envoy configs (experimental)
resource: The resource to dump
mask: The mask to apply. When both resource and mask are specified, the mask is applied to every element in the desired repeated field so that only a subset of fields are returned. The mask is parsed as a ProtobufWkt::FieldMask
name_regex: Dump only the currently loaded configurations whose names match the specified regex. Can be used with both resource and mask query parameters.
include_eds: Dump currently loaded configuration including EDS. See the response definition for more information
/contention: dump current Envoy mutex contention stats (if enabled)
/cpuprofiler (POST): enable/disable the CPU profiler
enable: enables the CPU profiler; One of (y, n)
/drain_listeners (POST): drain listeners
graceful: When draining listeners, enter a graceful drain period prior to closing listeners. This behaviour and duration is configurable via server options or CLI
skip_exit: When draining listeners, do not exit after the drain period. This must be used with graceful
inboundonly: Drains all inbound listeners. traffic_direction field in envoy_v3_api_msg_config.listener.v3.Listener is used to determine whether a listener is inbound or outbound.
/healthcheck/fail (POST): cause the server to fail health checks
/healthcheck/ok (POST): cause the server to pass health checks
/heap_dump: dump current Envoy heap (if supported)
/heapprofiler (POST): enable/disable the heap profiler
enable: enable/disable the heap profiler; One of (y, n)
/help: print out list of admin commands
/hot_restart_version: print the hot restart compatibility version
/init_dump: dump current Envoy init manager information (experimental)
mask: The desired component to dump unready targets. The mask is parsed as a ProtobufWkt::FieldMask. For example, get the unready targets of all listeners with /init_dump?mask=listener`
/listeners: print listener info
format: File format to use; One of (text, json)
/logging (POST): query/change logging levels
paths: Change multiple logging levels by setting to <logger_name1>:<desired_level1>,<logger_name2>:<desired_level2>.
level: desired logging level; One of (, trace, debug, info, warning, error, critical, off)
/memory: print current allocation/heap usage
/quitquitquit (POST): exit the server
/ready: print server state, return 200 if LIVE, otherwise return 503
/reopen_logs (POST): reopen access logs
/reset_counters (POST): reset all counters to zero
/runtime: print runtime values
/runtime_modify (POST): Adds or modifies runtime values as passed in query parameters. To delete a previously added key, use an empty string as the value. Note that deletion only applies to overrides added via this endpoint; values loaded from disk can be modified via override but not deleted. E.g. ?key1=value1&key2=value2...
/server_info: print server version/status information
/stats: print server stats
usedonly: Only include stats that have been written by system since restart
filter: Regular expression (Google re2) for filtering stats
format: Format to use; One of (html, active-html, text, json)
type: Stat types to include.; One of (All, Counters, Histograms, Gauges, TextReadouts)
histogram_buckets: Histogram bucket display mode; One of (cumulative, disjoint, detailed, summary)
/stats/prometheus: print server stats in prometheus format
usedonly: Only include stats that have been written by system since restart
text_readouts: Render text_readouts as new gaugues with value 0 (increases Prometheus data size)
filter: Regular expression (Google re2) for filtering stats
histogram_buckets: Histogram bucket display mode; One of (cumulative, summary)
/stats/recentlookups: Show recent stat-name lookups
/stats/recentlookups/clear (POST): clear list of stat-name lookups and counter
/stats/recentlookups/disable (POST): disable recording of reset stat-name lookup names
/stats/recentlookups/enable (POST): enable recording of reset stat-name lookup names
$ kubectl exec deploy/toolbox -n sidecar -- curl localhost:15000/config_dump流量管理
Gateway
Virtualservice
DestinationRule
ServieEntry
WorkloadEntry
Sidecar
Istio 的流量劫持机制
为用户应用注入 Sidecar
- 自动注入
手动注入
istioctl kube-inject -fyaml/istio-bookinfo/bookinfo.yaml
注入后的结果
注入了init-container istio-init。
istio-iptables -p 15001 -z 15006 -u 1337 -m REDIRECT -i * -x -b 9080 -d 15090,15021,15020- 命令行参数
-p 15001表示出向流量被 iptable 重定向到 Envoy 的 15001端口 - 命令行参数
-z 15006表示入向流量被 iptable 重定向到 Envoy 的 15006端口 - 命令行参数
-u 1337参数用于排除用户 ID 为 1337,即 Envoy 自身的流量,以避免 Iptable 把 Envoy 发出的数据又重定向到 Envoy,形成死循环。在 istio-proxy 容器中执行命令id可以看到结果是uid=1337(istio-proxy) gid=1337(istio-proxy) groups=1337(istio-proxy。
注入了 sidecar container istio-proxy
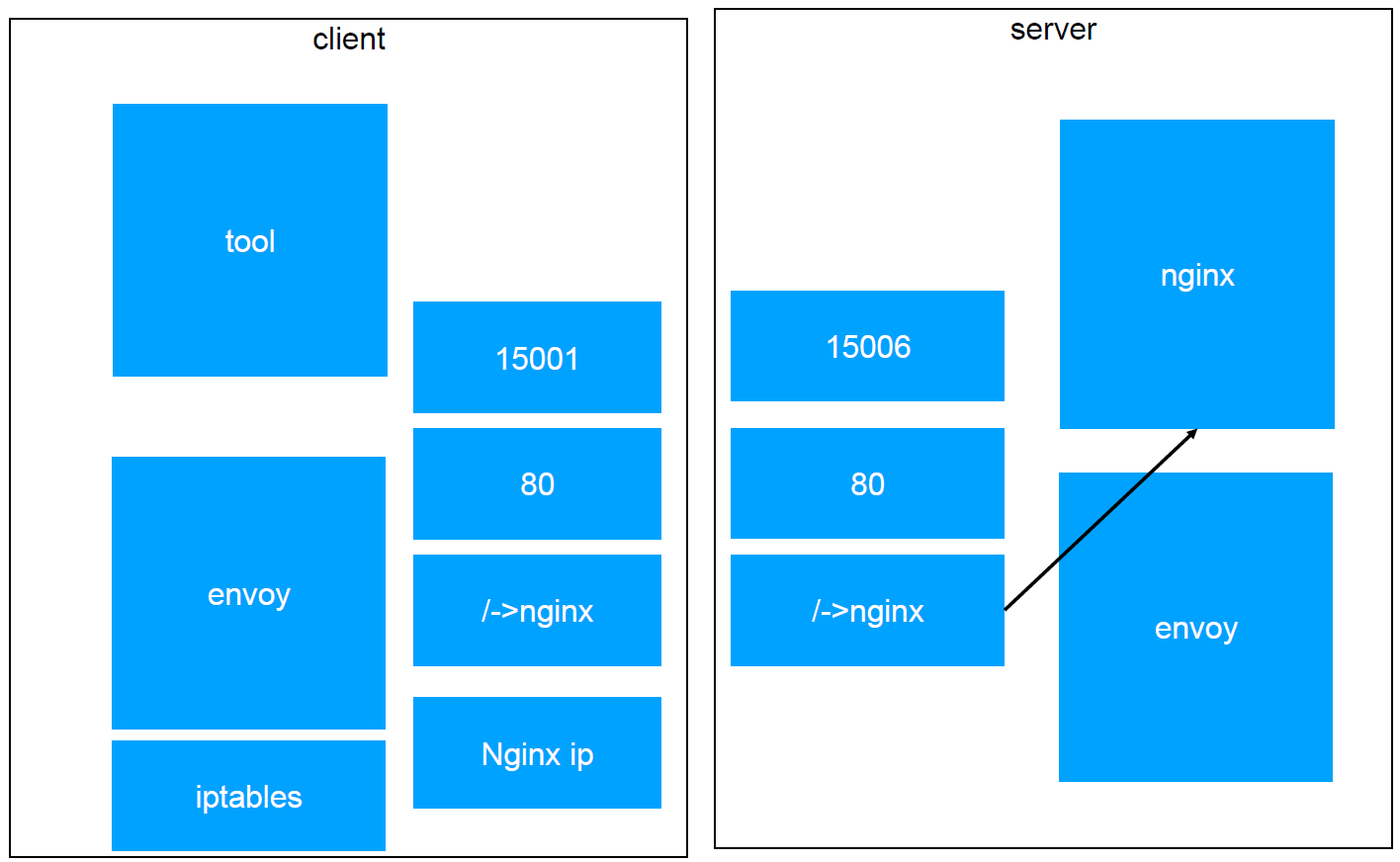
Init container
将应用容器的所有流量都转发到 Envoy 的 15001 端口。
使用 istio-proxy 用户身份运行,UID 为 1337 即 Envoy 所处的用户空间,这也是 istio-proxy 容器默认使用的用户,见 YAML 配置中的 runAsUser 字段。
使用默认的 REDIRECT 模式来重定向流量。
将所有出站流量都重定向到 Envoy 代理。
将所有访问 9080 端口(即应用容器 productpage 的端口)的流量重定向到 Envoy 代理。
//所有入站TCP流量走ISTIO_INBOUND
-A PREROUTING -p tcp -j ISTIO_INBOUND
//所有出站TCP流量走ISTIO_OUTPUT
-A OUTPUT -p tcp -j ISTIO_OUTPUT
//忽路ssh,health check等端口
-A ISTIO_INBOUND -p tcp -m tcp --dport 22 -j RETURN
-A ISTIO_INBOUND -p tcp -m tcp --dport 15090 -j RETURN
-A ISTIO_INBOUND -p tcp -m tcp --dport 15021 -j RETURN
-A ISTIO_INBOUND -p tcp -m tcp --dport 15020 -j RETURN
//所有入站TCP流量走ISTIO_IN_REDIRECT
-A ISTIO_INBOUND -p tcp -j ISTIO_IN_REDIRECT
// TCP流量转发至 15006 端口
-A ISTIO_IN_REDIRECT -p tcp -j REDIRECT --to-ports 15006
//loopback passthrough
-A ISTIO_OUTPUT -s 127.0.0.6/32 -o lo -j RETURN
//从loopback口出来,目标非本机地址,owner是envoy,交由ISTIO_IN_REDIRECT处理
-A ISTIO_OUTPUT ! -d 127.0.0.1/32 -o lo -m owner --uid-owner 1337 -j ISTIO_IN_REDIRECT
//从lo口出来,owner非envoy,return
-A ISTIO_OUTPUT -o lo -m owner ! --uid-owner 1337 -j RETURN
//owner是envoy,return
-A ISTIO_OUTPUT -m owner --uid-owner 1337 -j RETURN
-A ISTIO_OUTPUT ! -d 127.0.0.1/32 -o lo -m owner --gid-owner 1337 -j ISTIO_IN_REDIRECT
-A ISTIO_OUTPUT -o lo -m owner ! --gid-owner 1337 -j RETURN
-A ISTIO_OUTPUT -m owner --gid-owner 1337 -j RETURN
-A ISTIO OUTPUT -d 127.0.0.1/32 -j RETURN
//如以上规则都不匹配,则交给ISTIO_REDIRECT处理
-A ISTIO_OUTPUT -j ISTIO_REDIRECT
-A ISTIO_REDIRECT -p tcp -j REDIRECT --to-ports 15001Sidecar container
Istio 会生成以下监听器
- 0.0.0.0:15001 上的监听器接收进出 Pod 的所有流量,然后将请求移交给虚拟监听器。
- 每个 service IP 一个虚拟监听器,每个出站TCP/HTTPS 流量一个非 HTTP 监听器。
- 每个 Pod 入站流量暴露的端口一个虚拟监听器
- 每个 出站 HTTP 流量的 HTTP 0.0.0.0 端口一个虚拟监听器。
istioctl proxy-config listeners productpage-v1-8b96c8794-bttdd-n bookinfo --port 15001 -ojson{
"name": "virtual",
"address": {
"socketAddress": {
"address": "0.0.0.0",
"portValue": 15001
}
},
"filterChains": [
{
"filters": {
"name": "envoy.tcp_proxy",
"config": {
"cluster": "BlackHoleCluster",
"stat_prefix": "BlackHoleCluster"
}
}
}
],
"useOriginalDst": true
}我们的请求是到 9080 端口的 HTTP 出站请求,这意味着它被切换到0.0.0.0:9080 虚拟监听器。然后,此监听器在其配置的 RDS 中查找路由配置。在这种情况下,它将查找由 Pilot 配置的 RDS 中的路由 9080(通过 ADS)。
istioctl proxy-config listeners productpage-v1-8b96c8794-bttdd -n bookinfo --port 9080 --address 0.0.0.0-ojsonnetstat -na | grep LISTEN
tcp 0 0 127.0.0.1:15000 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:15001 0.0.0.0:* LISTEN
tcp6 0 0 :::9080 :::* LISTEN{
"rds": {
"config_source": {
"ads": {}
},
"route_config_name": "9080"
}
}9080 路由配置仅为每个服务提供虚拟主机。 我们的请求正在前往 reviews 服务,因此 Envoy 将选择我们的请求与域匹配的虚拟主机。一旦在域上匹配,Envoy 会查找与请求匹配的第一条路径。在这种情况下,我们没有任何高级路由,因此只有一条路由匹配所有内容。
这条路由告诉 Envoy 将请求发送到 outbound|9080||reviews.default.svc.cluster.local集群。
istioctl proxy-config routes productpage-v1-8b96c8794-bttdd --name 9080 -ojson -nbookinfo{
"name": "9080",
"virtualHosts": [
{
"name": "reviews.bookinfo.svc.cluster.local:9080",
"domains": [
"reviews.bookinfo.svc.cluster.local",
"reviews.bookinfo.svc.cluster.local:9080",
"reviews",
"reviews:9080",
"reviews.bookinfo.svc.cluster",
"reviews.bookinfo.svc.cluster:9080",
"reviews.bookinfo.svc",
"reviews.bookinfo.svc:9080",
"reviews.bookinfo",
"reviews.bookinfo:9080",
"192.168.143.232",
"192.168.143.232:9080"
],
"routes": [
{
"match": {
"prefix": "/"
},
"route": {
"cluster": "outbound|9080||reviews.bookinfo.svc.cluster.local",
"timeout": "0.000s",
"maxGrpcTimeout": "0.000s"
}
}
]
}
]
}此集群配置为从 Pilot(通过 ADS)检索关联的端点。 因此,Envoy 将使用 serviceName 字段作为密钥来查找端点列表并将请求代理到其中一个端点。
istioctl proxy-config clusters productpage-v1-8b96c8794-bttdd --fqdn reviews.bookinfo.svc.cluster.local -n bookinfo -ojson{
"name": "outbound|9080||reviews.bookinfo.svc.cluster.local",
"type": "EDS",
"edsClusterconfig": {
"edsConfig": {
"ads": {}
},
"serviceName": "outbound|9080||reviews.bookinfo.svc.cluster.local"
},
"connectTimeout": "1.000s",
"circuitBreakers": {
"thresholds": [
{}
]
}
}流量管理
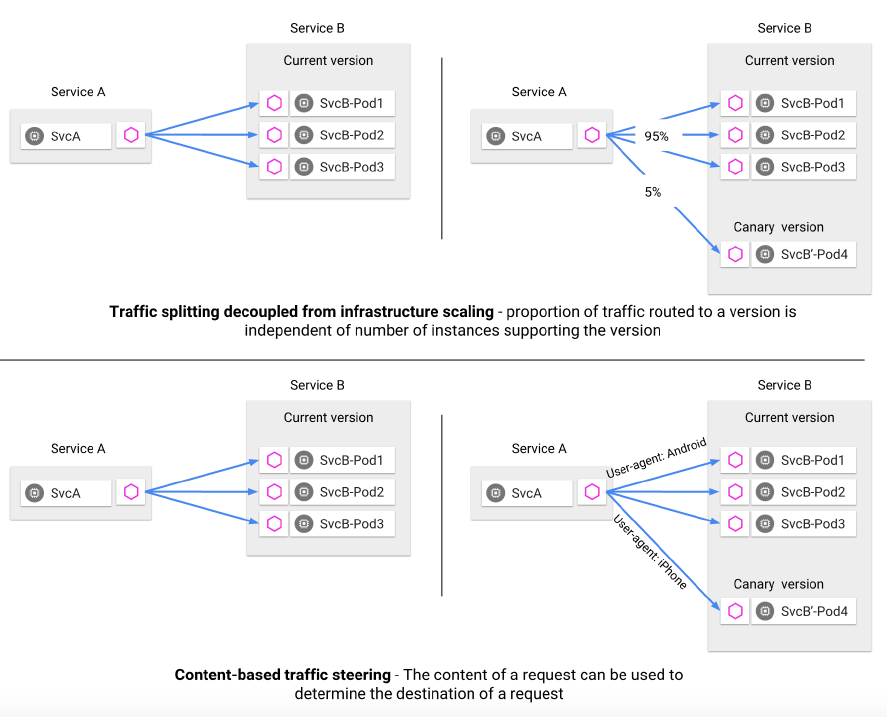
请求路由
特定网格中服务的规范表示由 Pilot 维护。 服务的 Istio 模型和在底层平台(Kubernetes、Mesos以及 Cloud Foundry等)中的表达无关。特定平台的适配器负责从各自平台中获取元数据的各种字段,然后对服务模型进行填充。
Istio 引入了服务版本的概念,可以通过版本(v1、v2)或环境(staging、prod)对服务进行进一步的细分。这些版本不一定是不同的 API版本:它们可能是部署在不同环境(prod、staging或者 dev 等)中的同一服务的不同迭代。使用这种方式的常见场景包括 A/B 测试或金丝雀部署
Istio 的流量路由规则可以根据服务版本来对服务之间流量进行附加控制。
服务之间的通讯
服务的客户端不知道服务不同版本间的差异。它们可以使用服务的主机名或者 IP 地址继续访问服务。Envoy sidecar/ 代理拦截并转发客户端和服务器之间的所有请求和响应。
Istio 还为同一服务版本的多个实例提供流量负载均衡。可以在服务发现和负载均衡中找到更多信息。
Istio 不提供 DNS。应用程序可以尝试使用底层平台(kube-dns、mesos-dns等)中存在的DNS 服务来解析 FODN。
Ingress 和 Egress
Istio 假定进入和离开服务网络的所有流量都会通过 Envoy 代理进行传输
通过将 Envoy 代理部署在服务之前,运维人员可以针对面向用户的服务进行 A/B 测试、部署金丝雀服务等
类似地,通过使用 Envoy将流量路由到外部 Web 服务(例如,访问 Maps API 或视频服务 API)的方式,运维人员可以为这些服务添加超时控制、重试、断路器等功能,同时还能从服务连接中获取各种细节指标。
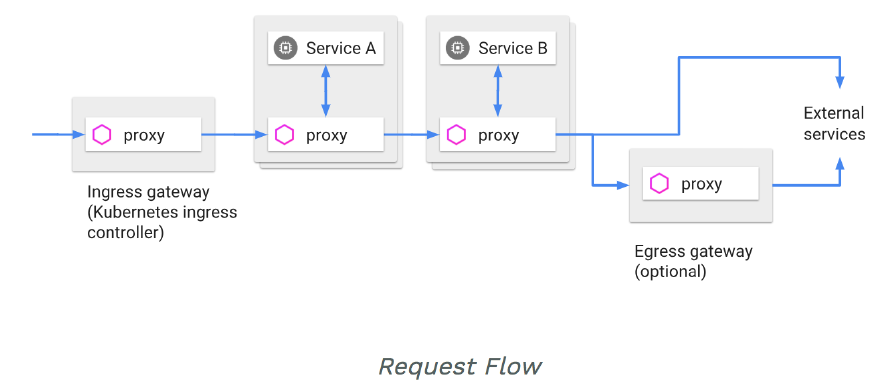
服务发现和负载均衡
Istio 负载均衡服务网格中实例之间的通信
Istio 假定存在服务注册表,以跟踪应用程序中服务的 pod/VM。它还假设服务的新实例自动注册到服务注册表,并且不健康的实例将被自动删除。诸如 Kubernetes、Mesos 等平台已经为基于容器的应用程序提供了这样的功能。为基于虚拟机的应用程序提供的解决方案就更多了。
Pilot 使用来自服务注册的信息,并提供与平台无关的服务发现接口。网格中的 Envoy 实例执行服务发现,并相应地动态更新其负载均衡池。
网格中的服务使用其 DNS 名称访问彼此。服务的所有 HTTP 流量都会通过 Envoy 自动重新路由。Envoy 在负载均衡池中的实例之间分发流量。虽然 Envoy 支持多种复杂的负载均衡算法,但Istio 目前仅允许三种负载均衡模式:轮循、随机和带权重的最少请求。
除了负载均衡外,Envoy还会定期检查池中每个实例的运行状况。 Envoy 遵循熔断器风格模式根据健康检查 API调用的失败率将实例分类为不健康和健康两种。当给定实例的健康检查失败次数超过预定阈值时,将会被从负载均衡池中弹出。类似地,当通过的健康检查数超过预定阈值时该实例将被添加回负载均衡池。您可以在处理故障中了解更多有关 Envoy的故障处理功能
服务可以通过使用 HTTP 503 响应健康检查来主动减轻负担。在这种情况下,服务实例将立即从调用者的负载均衡池中删除。
故障处理
超时处理
基于超时预算的重试机制
基于并发连接和请求的流量控制
对负载均衡器成员的健康检查
细粒度的熔断机制,可以针对Load Balancing Pool中的每个成员设置规则
微调
Istio 的流量管理规则允许运维人员为每个服务/版本设置故障恢复的全局默认值。 然而,服务的消费者也可以通过特殊的 HTTP 头提供的请求级别值覆盖超时和重试的默认值。在 Envoy 代理的实现中,对应的 Header 分别是x-envoy-upstream-rq-timeout-ms 和 x-envoy-max-retries。
故障注入
为什么需要错误注入:
- 微服务架构下,需要测试端到端的故障恢复能力,
Istio 允许在网络层面按协议注入错误来模拟错误,无需通过应用层面删除 Pod,或者人为在 TCP层造成网络故障来模拟。
注入的错误可以基于特定的条件,可以设置出现错误的比例:
- Delay - 提高网络延时:
- Aborts - 直接返回特定的错误码,
规则配置
VirtualService 在 Istio 服务网格中定义路由规则,控制路由如何路由到服务上。
DestinationRule 是 Virtualservice 路由生效后,配置应用与请求的策略集
ServiceEntry 是通常用于在 Istio 服务网格之外启用对服务的请求。
Gateway 为 HTTP/TCP 流量配置负载均衡器,最常见的是在网格的边缘的操作,以启用应用程序的入口流量。
简单测试 Gateway 和 VirtualService
测试过程
$ git clone git@github.com:kibaamor/101.git
$ cd module12/istio/1.http-gw
$ kubectl create ns simple
$ kubectl create -f simple.yaml -n simple
$ kubectl create -f istio-specs.yaml -n simple
$ kubectl -n istio-system get svc -l istio=ingressgateway
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
istio-ingressgateway LoadBalancer 10.111.255.7 <pending> 15021:30940/TCP,80:30265/TCP,443:32345/TCP,31400:31186/TCP,15443:30180/TCP 23h
$ curl 10.111.255.7/hello -v
* Trying 10.111.255.7:80...
* Connected to 10.111.255.7 (10.111.255.7) port 80 (#0)
> GET /hello HTTP/1.1
> Host: 10.111.255.7
> User-Agent: curl/7.81.0
> Accept: */*
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 404 Not Found
< date: Wed, 10 Jul 2024 11:01:54 GMT
< server: istio-envoy
< content-length: 0
<
* Connection #0 to host 10.111.255.7 left intact
$ curl -H "Host: simple.cncamp.io" 10.111.255.7/hello
hello [stranger]
===================Details of the http request header:============
X-Envoy-Internal=[true]
X-Envoy-Decorator-Operation=[simple.simple.svc.cluster.local:80/*]
X-Envoy-Peer-Metadata=[ChoKCkNMVVNURVJfSUQSDBoKS3ViZXJuZXRlcwocCgxJTlNUQU5DRV9JUFMSDBoKMTAuMjQ0LjAuNAoZCg1JU1RJT19WRVJTSU9OEggaBjEuMjIuMgqcAwoGTEFCRUxTEpEDKo4DCh0KA2FwcBIWGhRpc3Rpby1pbmdyZXNzZ2F0ZXdheQoTCgVjaGFydBIKGghnYXRld2F5cwoUCghoZXJpdGFnZRIIGgZUaWxsZXIKNgopaW5zdGFsbC5vcGVyYXRvci5pc3Rpby5pby9vd25pbmctcmVzb3VyY2USCRoHdW5rbm93bgoZCgVpc3RpbxIQGg5pbmdyZXNzZ2F0ZXdheQoZCgxpc3Rpby5pby9yZXYSCRoHZGVmYXVsdAowChtvcGVyYXRvci5pc3Rpby5pby9jb21wb25lbnQSERoPSW5ncmVzc0dhdGV3YXlzChIKB3JlbGVhc2USBxoFaXN0aW8KOQofc2VydmljZS5pc3Rpby5pby9jYW5vbmljYWwtbmFtZRIWGhRpc3Rpby1pbmdyZXNzZ2F0ZXdheQovCiNzZXJ2aWNlLmlzdGlvLmlvL2Nhbm9uaWNhbC1yZXZpc2lvbhIIGgZsYXRlc3QKIgoXc2lkZWNhci5pc3Rpby5pby9pbmplY3QSBxoFZmFsc2UKGgoHTUVTSF9JRBIPGg1jbHVzdGVyLmxvY2FsCi4KBE5BTUUSJhokaXN0aW8taW5ncmVzc2dhdGV3YXktNWM1ODk5NTY3LTQ5MnJ6ChsKCU5BTUVTUEFDRRIOGgxpc3Rpby1zeXN0ZW0KXQoFT1dORVISVBpSa3ViZXJuZXRlczovL2FwaXMvYXBwcy92MS9uYW1lc3BhY2VzL2lzdGlvLXN5c3RlbS9kZXBsb3ltZW50cy9pc3Rpby1pbmdyZXNzZ2F0ZXdheQonCg1XT1JLTE9BRF9OQU1FEhYaFGlzdGlvLWluZ3Jlc3NnYXRld2F5]
X-Envoy-Attempt-Count=[1]
X-Forwarded-Proto=[http]
X-Forwarded-For=[10.244.0.1]
X-Request-Id=[8ab668b4-4da9-9ae2-9ffc-6e2580b0c5a1]
X-Envoy-Peer-Metadata-Id=[router~10.244.0.4~istio-ingressgateway-5c5899567-492rz.istio-system~istio-system.svc.cluster.local]
User-Agent=[curl/7.81.0]
Accept=[*/*]simple.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: simple
spec:
replicas: 1
selector:
matchLabels:
app: simple
template:
metadata:
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "80"
labels:
app: simple
spec:
containers:
- name: simple
imagePullPolicy: Always
image: cncamp/httpserver:v1.0-metrics
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: simple
spec:
ports:
- name: http
port: 80
protocol: TCP
targetPort: 80
selector:
app: simpleistio-specs.yaml
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: simple
spec:
gateways:
- simple
hosts:
- simple.cncamp.io
http:
- match:
- port: 80
route:
- destination:
host: simple.simple.svc.cluster.local
port:
number: 80
---
apiVersion: networking.istio.io/v1beta1
kind: Gateway
metadata:
name: simple
spec:
selector:
istio: ingressgateway
servers:
- hosts:
- simple.cncamp.io
port:
name: http-simple
number: 80
protocol: HTTP在文件 istio-specs.yaml 中,Gateway 对应 Envoy 中 listener 的配置。
Gateway 的 spec 中的 selector 表示将使用什么 selector 选择 istio-system 命名空间中的 pod。
$ kubectl -n istio-system get deploy --show-labels
NAME READY UP-TO-DATE AVAILABLE AGE LABELS
istio-egressgateway 1/1 1 1 28h app=istio-egressgateway,install.operator.istio.io/owning-resource-namespace=istio-system,install.operator.istio.io/owning-resource=installed-state,istio.io/rev=default,istio=egressgateway,operator.istio.io/component=EgressGateways,operator.istio.io/managed=Reconcile,operator.istio.io/version=1.22.2,release=istio
istio-ingressgateway 1/1 1 1 28h app=istio-ingressgateway,install.operator.istio.io/owning-resource-namespace=istio-system,install.operator.istio.io/owning-resource=installed-state,istio.io/rev=default,istio=ingressgateway,operator.istio.io/component=IngressGateways,operator.istio.io/managed=Reconcile,operator.istio.io/version=1.22.2,release=istio
istiod 1/1 1 1 28h app=istiod,install.operator.istio.io/owning-resource-namespace=istio-system,install.operator.istio.io/owning-resource=installed-state,istio.io/rev=default,istio=pilot,operator.istio.io/component=Pilot,operator.istio.io/managed=Reconcile,operator.istio.io/version=1.22.2,release=istio可以看到,label istio=ingressgateway 将会选中 pod istio-ingressgateway-5c5899567-492rz 。即 Gateway 中的配置将会添加到 deploy istio-ingressgateway 的所有 pod 中。
servers:
- hosts:
- simple.cncamp.io
port:
name: http-simple
number: 80
protocol: HTTP则表示对 istio-ingressgateway 中的 envoy 添加一个处理监听在 80 端口,域名为 simple.cncamp.io 的 listener 配置。
而监听成功后,具体的配置则由 VirtualService 来指定。 Gateway 和 VirtualService 之间的关联是通过 VirtualService 中 spec 中 gateways 字段来指定的。
hosts:
- simple.cncamp.io
http:
- match:
- port: 80
route:
- destination:
host: simple.simple.svc.cluster.local
port:
number: 80上面配置作用就是在设置在访问 host 是 simple.cncamp.io,端口是 80 时,将流量转发给 simple.simple.svc.cluster.local (即 simple namespace 中的 simple service) 的 80 端口。
分析流量转发过程
测试时,我们访问的是 istio-ingressgateway 的 clusterip 的 80 端口。
$ kubectl -n istio-system get svc istio-ingressgateway -o yaml
apiVersion: v1
kind: Service
metadata:
name: istio-ingressgateway
namespace: istio-system
...
spec:
allocateLoadBalancerNodePorts: true
clusterIP: 10.111.255.7
clusterIPs:
- 10.111.255.7
externalTrafficPolicy: Cluster
internalTrafficPolicy: Cluster
ipFamilies:
- IPv4
ipFamilyPolicy: SingleStack
ports:
- name: http2
nodePort: 30265
port: 80
protocol: TCP
targetPort: 8080
- ...
selector:
app: istio-ingressgateway
istio: ingressgateway
sessionAffinity: None
type: LoadBalancer
status:
loadBalancer: {}可以看到访问 cluster ip 的 80 端口,实际会转发到 pod 中的 8080 端口。
再来看看 pod 中 8080 端口的配置。
$ kubectl -n istio-system get pod -l istio=ingressgateway
NAME READY STATUS RESTARTS AGE
istio-ingressgateway-5c5899567-492rz 1/1 Running 0 28h
$ kubectl -n istio-system exec pod/istio-ingressgateway-5c5899567-492rz -- ss -antp | grep 8080
LISTEN 0 4096 0.0.0.0:8080 0.0.0.0:* users:(("envoy",pid=23,fd=37))
LISTEN 0 4096 0.0.0.0:8080 0.0.0.0:* users:(("envoy",pid=23,fd=35))
$ istioctl pc listener pod/istio-ingressgateway-5c5899567-492rz -n istio-system
ADDRESSES PORT MATCH DESTINATION
0.0.0.0 8080 ALL Route: http.8080
0.0.0.0 15021 ALL Inline Route: /healthz/ready*
0.0.0.0 15090 ALL Inline Route: /stats/prometheus*可以看到,pod 中 8080 端口由进程 envoy 监听,而 envoy 在 8080 端口的流量会根据路由 http.8080 来确定。
$ istioctl pc route pod/istio-ingressgateway-5c5899567-492rz -n istio-system
NAME VHOST NAME DOMAINS MATCH VIRTUAL SERVICE
http.8080 simple.cncamp.io:80 simple.cncamp.io /* simple.simple
backend * /stats/prometheus*
backend * /healthz/ready*查看路由规则就会发现,当访问目标是 simple.cncamp.io:80 时,流量就会被路由到 service simple.simple。这和yaml配置中一样。
VirtualService
是在 Istio 服务网格内对服务的请求如何进行路由控制。
规则的目标描述
路由规则对应着一或多个用 Virtualservice 配置指定的请求目的主机。这些主机可以是也可以不是实际的目标负载,甚至可以不是同一网格内可路由的服务。例如要给到 reviews 服务的请求定义路由规则,可以使用内部的名称 reviews,也可以用域名 bookinfo.com,VirtualService 可以定义这样的 host 字段:
host 字段用显示或者隐式的方式定义了一或多个完全限定名(FQDN)。上面的 reviews,会隐式的扩展成为特定的 FODN,例如在 Kubernetes 环境中,全名会从 VirtualService 所在的集群和命名空间中继承而来(比如说reviews.default.svc.cluster.local)。
hosts:
- reviews
- bookinfo.com在服务之间分拆流量
例如下面的规则会把 25%的 reviews 服务流量分配给 v2 标签;其余的 75% 流量分配给 1。
apiVersion: networking.istio.io/v1alpha3
kind: Virtualservice
metadata:
name: reviews
spec:
hosts:
- reviews
http:
- route:
- destination:
host: reviews
subset: v1
weight: 75
- destination:
host: reviews
subset: v2
weight: 25超时和重试
apiVersion: networking.istio.io/vlalpha3
kind: VirtualService
metadata:
name: ratings
spec:
hosts:
- ratings
http:
- route:
- destination:
host: ratings
subset: v1
timeout: 10s
---
apiVersion: networking.istio.io/vlalpha3
kind: VirtualService
metadata:
name: ratings
spec:
hosts:
- ratings
http:
- route:
- destination:
host: ratings
subset: v1
reties:
attempts: 3
perTryTimeout: 2s错误注入
apiVersion: networking.istio.io/vlalpha3
kind: VirtualService
metadata:
name: ratings
spec:
hosts:
- ratings
http:
- fault:
delay:
percent: 10
fixedDelay: 5s
route:
- destination:
host: ratings
subset: v1
---
apiVersion: networking.istio.io/vlalpha3
kind: VirtualService
metadata:
name: ratings
spec:
hosts:
- ratings
http:
- fault:
abort:
percent: 10
httpStatus: 400
route:
- destination:
host: ratings
subset: v1条件规则
apiVersion: networking.istio.io/vlalpha3
kind: VirtualService
metadata:
name: productpage
spec:
hosts:
- productpage
http:
- match:
- uri:
prefix: /api/v1
...
---
apiVersion: networking.istio.io/vlalpha3
kind: VirtualService
metadata:
name: reviews
spec:
hosts:
- reviews
http:
- match:
- headers:
end-user:
exact: jason
...
---
apiVersion: networking.istio.io/vlalpha3
kind: VirtualService
metadata:
name: ratings
spec:
hosts:
- ratings
http:
- match:
sourceLabels:
app: reviews流量镜像
mirror 规则可以使 Envoy 截取所有 request 并在转发请求的同时,将request 转发至 Mirror 版本同时在 Header 的 Host/Authority 加上 -shadow。
这些 mirror 请求会工作在 fire and forget 模式所有的 response 都会被废弃
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: httpbin
spec:
hosts:
- httpbin
http:
- route:
- destination:
host: httpbin
subset: v1
weight: 100
mirror:
host: httpbin
subset: v2规则委托
apiVersion: networking.istio.io/v1alpha3
kind: Virtualservice
metadata:
name: bookinfo
spec:
hosts:
- "bookinfo.com"
gateways:
- mygateway
http:
- match:
- uri:
prefix: "/productpage"
delegate:
name: productpage
namespace: nsA
- match:
- uri:
prefix: "/reviews"
delegate:
name: reviews
namespace: nsB
---
apiVersion: networking.istio.io/vlalpha3
kind: Virtualservicemetadata:
name: productpage
namespace: nsA
spec:
http:
- match:
- uri:
prefix: "/productpage/v1/"
route:
- destination:
host: productpage-v1.nsA.svc.cluster.local
- route:
- destination:
host: productpage.nsA.svc.cluster.local优先级
当对同一目标有多个规则时,会按照在 Virtualservice 中的顺序进行应用,换句话说,列表中的第一条规则具有最高优先级。
当对某个服务的路由是完全基于权重的时候,就可以在单一规则中完成。另一方面,如果有多重条件(例如来自特定用户的请求)用来进行路由,就会需要不止一条规则。这样就出现了优先级问题,需要通过优先级来保证根据正确的顺序来执行规则。
常见的路由模式是提供一或多个高优先级规则,这些优先规则使用源服务以及 Header 来进行路由判断,然后才提供一条单独的基于权重的规则,这些低优先级规则不设置匹配规则,仅根据权重对所有剩余流量进行分流。
目标规则
在请求被 Virtualservice 路由之后 DestinationRule 配置的一系列策略就生效了, 这些策略由服务属主编写,包含断路器、负载均衡以及 TLS 等的配置内容。
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: reviews
spec:
host: reviews
trafficPolicy:
loadBalancer:
simple: RANDOM
subsets:
- name: v1
labels:
version: v1
- name: v2
labels:
version: v2
trafficPolicy:
loadBalancer:
simple: ROUND_ROBIN
- name: v3
labels:
version: v3断路器
可以用一系列的标准,例如连接数和请求数限制来定义简单的断路器。
可以通过定义 outlierDetection 自定义健康检查模式。
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: httpbin
spec:
host: httpbin
trafficPolicy:
connectionPool:
tcp:
maxconnections: 1
http:
http1MaxPendingRequests: 1
maxRequestsPerconnection: 1
outlierDetection:
consecutiveErrors: 1
interval: 1s
baseEjectionTime: 3m
maxEjectionPercent: 100ServiceEntry
Istio 内部会维护一个服务注册表,可以用 ServiceEntry 向其中加入额外的条目。通常这个对象用来启用对 Istio 服务网格之外的服务发出请求。
ServiceEntry 中使用 hosts 字段来指定目标,字段值可以是一个完全限定名,也可以是个通配符域名。其中包含的白名单,包含一或多个允许网格中服务访问的服务。
只要 ServiceEntry 涉及到了匹配 host 的服务,就可以和 Virtualservice 以及 DestinationRule 配合工作。
apiVersion: networking.istio.io/v1alpha3
kind: serviceEntry
metadata:
name: foo-ext-SVc
spec:
hosts:
- *.fo0.com
ports:
- number: 80
name: http
protocol: HTTP
- number: 443
name: https
protocol: HTTPSWorkloadEntry
apiVersion: networking.istio.io/v1beta1
kind: serviceEntry
metadata:
name: details-svc
spec:
hosts:
- details.bookinfo.com
location: MESH_INTERNAL
ports:
- number: 80
name: http
protocol: HTTP
resolution: STATIC
workloadselector:
labels:
app: details-legacy
---
apiVersion: networking.istio.io/v1beta1
kind: WorkloadEntry
metadata:
name: details-svc
spec:
serviceAccount: details-legacy
address: 2.2.2.2
labels:
app: details-legacy
instance-id: vm1Gateway
Gateway 为 HTTP/TCP 流量配置了一个负载均衡,多数情况下在网格边缘进行操作,用于启用一个服务的入口(ingress)流量。
和 Kubernetes Ingress 不同,lstio Gateway 只配置四层到六层的功能(例如开放端口或者 TLS 配置)。绑定一个 VirtualService 到 Gateway上,用户就可以使用标准的 Istio 规则来控制进入的 HTTP 和 TCP 流量。
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
name: bookinfo-gateway
spec:
servers:
- port:
number: 443
name: https
protocol: HTTPS
hosts:
- bookinfo.com
tls:
mode: SIMPLE
serverCertificate: /tmp/tls.crt
privateKey: /tmp/tls.key
---
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: bookinfo
spec:
hosts:
- bookinfo.com
gateways:
- bookinfo-gateway
http:
- match:
- uri:
prefix: /reviews
route:
...开启网关安全加固
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
name: bookinfo-gateway
spec:
servers:
- port:
number: 443
name: https
protocol: HTTPS
hosts:
- bookinfo.com
tls:
mode: SIMPLE
serverCertificate: /tmp/tls.crt
privateKey: /tmp/tls.key
---
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
name: bookinfo-gateway
spec:
servers:
- port:
number: 443
name: https
protocol: HTTPS
hosts:
- bookinfo.com
tls:
mode: SIMPLE
credentialName: foo遥测(Telemetry V2)
基本 Metrics
针对 HTTP,HTTP/2 和 GRPC 协议,Istio 收集以下指标:
- Request count (istio_requests_total) 请总数
- Request Duration(istio_request_duration_milliseconds) 请求处理时长
- Request Size (istio_request_bytes) 请求包大小
- Response Size(istio_response_bytes) 响应包大小
针对 TCP 协议, Istio 收集以下指标:
- Tcp Byte Sent(istio_tcp_sent_bytes_total) 发送的数据响应包的总大小
- Tcp Byte Received (istio_tcp_received_bytes_total) 接收到的数据包大小
- Tcp Connections Opened(istio_tcp_connections_opened_total) TCP 连接数
- Tcp Connections Closed(istio_tcp_connections_closed_total) 关闭的 TCP 连接数
- 同时支持 WASM(Web Assembly) plugin 收集数据, 但启用 WASM 后资源开销显著上升
多集群网格扩展
基于Gateway
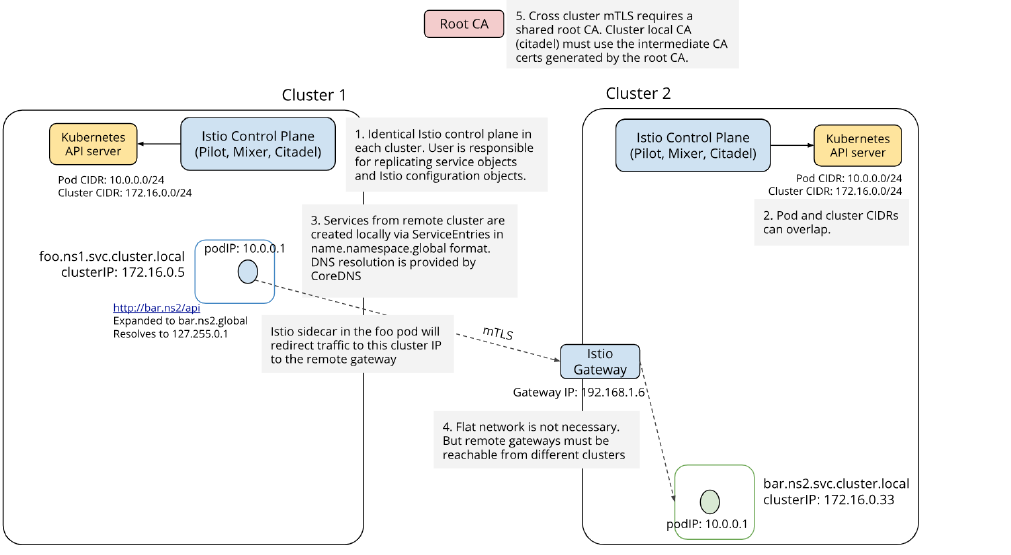
基于 VPN 或可互通的集群
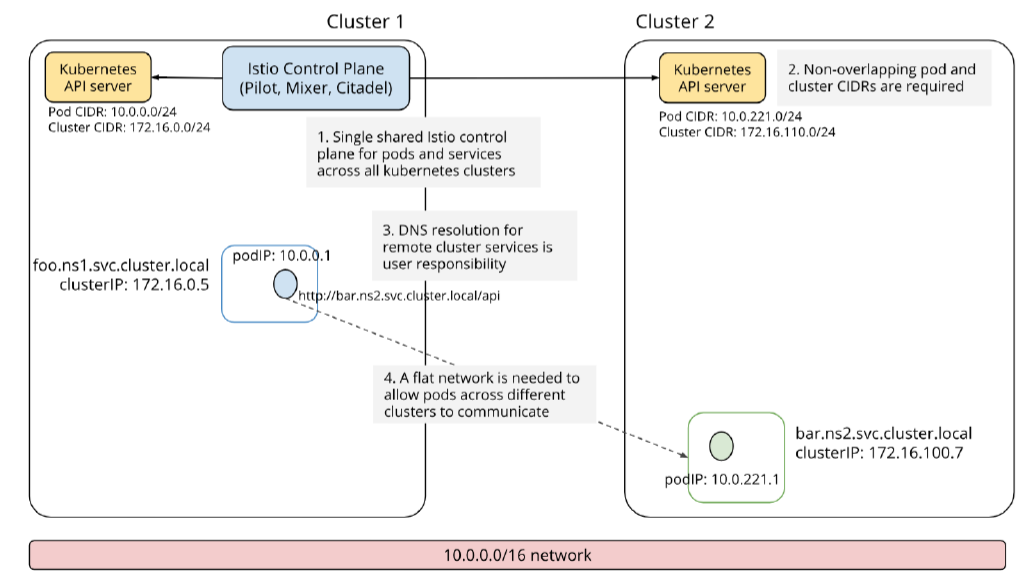
跟踪采样
跟踪采样配置
Istio 默认捕获所有请求的跟踪。例如,何时每次访问时都使用上面的 Bookinfo 示例应用程序/productpage 你在Jaeger 看到了相应的痕迹仪表板。此采样率适用于测试或低流量目。
- 在运行的网格中,编辑 istio-pilot 部署并使用以下步骤更改环境变量:
istioctl upgrade --set values.global.tracer.zipkin.address=jaeger-collector:9411应用程序埋点
虽然 Istio 代理能够自动发送 Span 信息,但还是需要一些辅助手段来把整个跟踪过程统一起来。 应用程序应该自行传播跟踪相关的 HTTP Header,这样在代理发送 Span 信息的时候,才能正确的把同一个跟踪过程统一起来。
为了完成跟踪的传播过程,应用应该从请求源头中收集下列的 HTTP Header,并传播给外发请求:
- x-request-id
- x-b3-traceid
- x-b3-spanid
- x-b3-parentspanid
- x-b3-sampled
- x-b3-flags
- x-ot-span-context
分布式跟踪
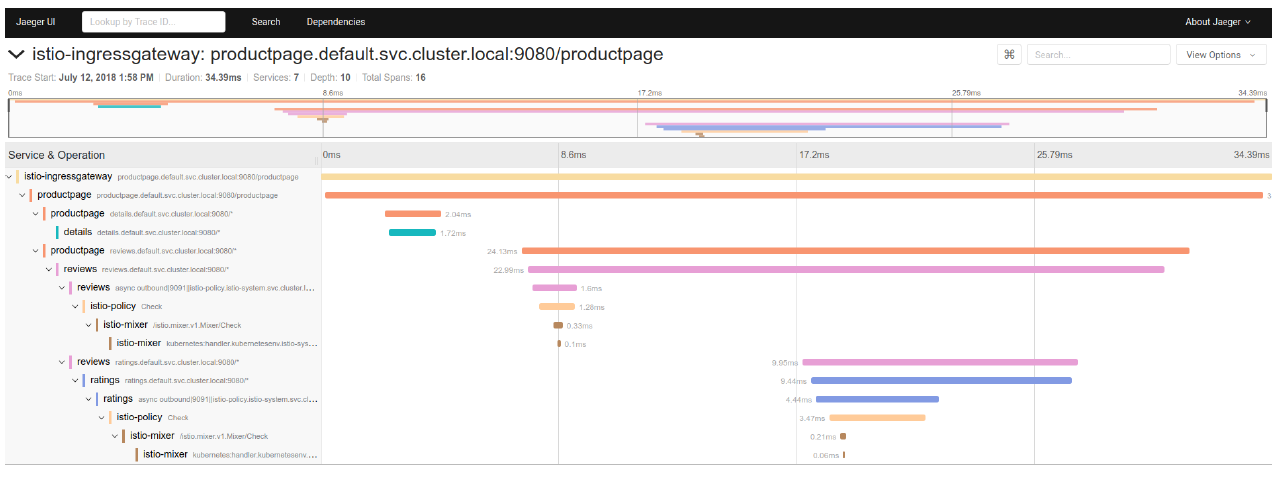
Service Mesh 涉及的网络栈
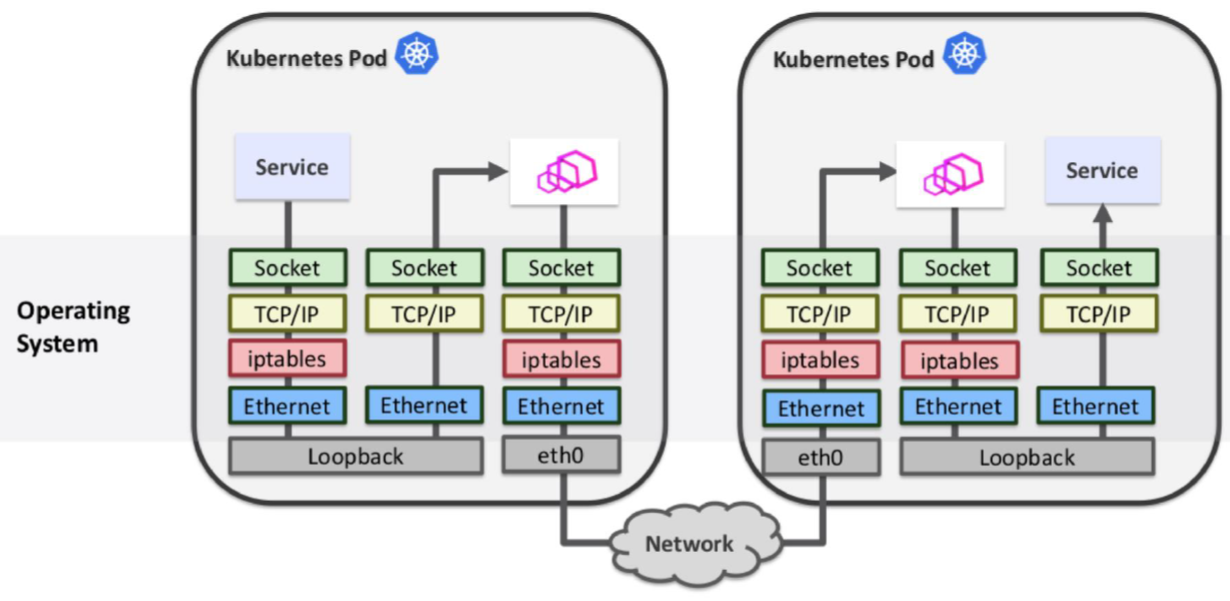
Cilium 数据平面加速
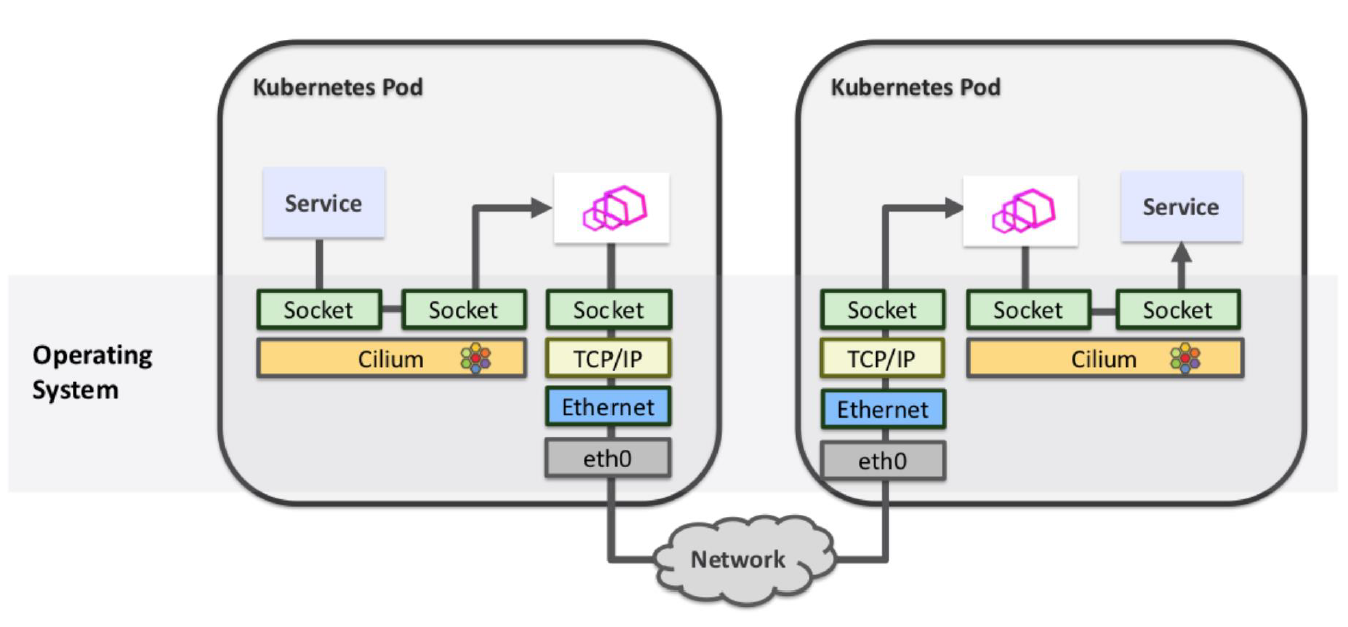
小结
微服务架构是当前业界普遍认可的架构模式,容器的封装性,隔离性为微服务架构的兴盛提供了有力的保障。
Kubernetes 作为声明式集群管理系统,代表了分布式系统架构的大方向:
- kube-proxy本身提供了基于iptables/ipvs 的四层 Service Mesh 方案;
- Istio/linkerd 作为基于 Kubernetes 的七层 Service Mesh 方案,近期会有比较多的生产部署案例。
生产系统需要考虑的,除了 Service Mesh 架构带来的便利性,还需要考虑:
- 配置一致性检查;
- endpoint健康检查,
- 海量转发规则情况下的 scalability。
作业
把我们的 httpserver 服务以 Istio Ingress Gateway 的形式发布出来。以下是你需要考虑的几点:
- 如何实现安全保证;
- 七层路由规则;
- 考虑 open tracing 的接入。
Kubernetes 集群联邦和 Istio 多集群管理
分布式云是未来
- 成本优化(Cost Effective)
- 更好的弹性及灵活性(Elasticity& Flexibility)
- 避免厂商锁定(Avoid Vendor Lock-in)
- 第一时间获取云上的新功能(Innovation)
- 容灾(Resilience&Recovery)
- 数据保护及风险管理(Data Protection&Risk Management)
- 提升响应速度(NetworkPerformancelmprovements)
分布式云的挑战
- Kubernetes 单集群承载能力有限
- 异构的基础设施
- 存量资源接入
- 配置变更及下发
- 跨地域、跨机房应用部署及管理
- 容灾与隔离性,异地多活
- 弹性调度及自动伸缩
- 监控告警
如何应对
- 通过 Kubernetes 屏蔽底层基础设施,提供统一的接入层
- 多云架构
- 多集群 ≠ 多云。
- 多集群管控
- 统一的管控面
- 方便接入,降低使用门槛
跨地域的集群管理
apiVersion: v1
kind: Pod
metadata:
name: with-pod-affinity
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: region
operator: In
values:
- beijing
topologyKey: topology.kubernetes.io/zone
---
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: my-app
ports:
- protocol: TCP
port: 80
targetPort: 9376
topologyKeys:
- topology.kubernetes.io/zone
- topology.kubernetes.io/region集群联邦
集群联邦的必要性
单一集群的管理规模有上限
数据库存储
- etcd 作为 Kubernetes 集群的后端存储数据库,对空间大小的要求比较苛刻,这限制了集群能存储的对象数量和大小。
内存占用
- 为提高系统效率,Kubernetes 的 APIServer 作为 API 网关,会对该集群的所有对象做缓存。集群越大,缓存需要的内存空间就越大。
- 其他 Kubernetes 控制器也需要对侦听的对象构建客户端缓存,这些都需要占用系统内存。这些内存需求都要求对系统的规模有所限制。
控制器复杂度
- Kubernetes 的一个业务流程是由多个对象和控制器联动完成的,即使控制器遵循了设计原则,随着对象数量的增长,控制器的处理耗时也会越来越长,
单个计算节点资源上限
- 单个计算节点的资源,不仅仅是 CPU、内存等可量化资源,
- 还有端口、进程数量等不可量化资源。比如 Linux 支持的TCP 端口上限是 65535,去除常用端口和程序源端口后,留给 Service nodePort 的端口数量是有限的,这限制了集群支持的 Service 的数量。
故障域控制
- 集群规模越大,控制平面组件出现故障时的影响范围就越大。为了更好地控制故障域(FaultDomain),需要将大规模的数据中心切分成多个规模相对较小的集群,每个集群控制在一定规模。
应用高可用部署
- 生产应用通常需要多数据中心部署来保障跨地域高可用,以确保当其中一个数据中心出现故障,或者集群做技术迭代更新时,其他数据中心可以继续提供服务。
混合云
- 私有云加公有云的混合云模式逐渐成为企业的主流架构。
集群联邦的职责
跨集群同步资源
- 联邦可以将资源同步到多个集群并协调资源的分配。例如,联邦可以保证一个应用的Deployment 被部署到多个集群中,同时能够满足全局的调度策略。
跨集群服务发现
- 联邦汇总各个集群的服务和 Ingress,并暴露到全局 DNS 服务中。
高可用
- 联邦可以动态地调整每个集群的应用实例,且隐藏了具体的集群信息。
避免厂商锁定
- 每个集群都是部署在真实的硬件或云供应商提供的硬件(或虚拟硬件)之上的,若要更换供应商,只需在新供应商提供的硬件上部署新的集群,并加入联邦。联邦可以几乎透明地将应用从原集群迁移到新集群而无须对应用做更改。
混合云
混合云是指将公有云和私有云整合在一起的统一云平台。
用户业务可灵活部署或扩容在不同云中。
混合云避免厂商锁定。
混合云可支持更多复杂业务场景:
- Cloud Burst.
- 如 12306,低流量时运行在本地数据中心,当请求量突然爆发的时候,可以直接在公有云扩容,节省数据中心成本。
- 可将业务分为包含敏感数据和不包含敏感数据的业务,将敏感数据业务运行在私有云,将非敏感数据业务运行在公有云,
- 可重复利用公有云提供商数据中心靠近边缘的能力。
集群联邦
集群联邦(Federation)是将多个Kubernetes 集群注册到统一控制平面为用户提供统一 API 入口的多集群解决方案。
集群联邦设计的核心是提供在全局层面对应用的描述能力,并将联邦对象实例化为 Kubernetes 对象,分发到联邦下辖的各个成员集群中。
基于集群联邦的高可用应用部署
集群联邦核心架构
etcd 作为分布式存储后端存储所有对象
APIServer作为 API网关,接收所有来自用户及控制平面组件的请求
不同的控制器对联邦层面的对象进行管理协调等
调度控制器在联邦层面对应用进行调度分配。
集群联邦支持灵活的对象扩展,允许将基本 Kubernetes 对象扩展为集群联邦对象并通过统一的联邦控制器推送和收集状态
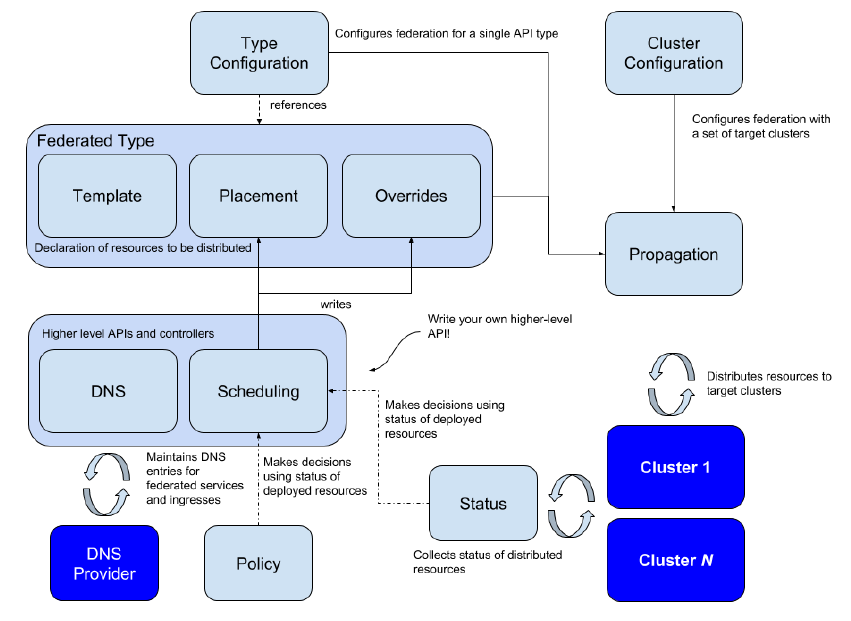
集群联邦管理的对象
成员集群是联邦的基本管理单元,所有待管理集群均须注册到集群联邦。
集群联邦 V2 提供了统一的工具集(Kubefedctl),允许用户对单个对象动态地创建联邦对象。
动态对象的生成基于 CRD。

集群注册中心
集群注册中心(ClusterRegistry)提供了所有联邦下辖的集群清单,以及每个集群的认证信息状态信息等。
集群联邦本身不提供算力,它只承担多集群的协调工作,所有被管理的集群都应注册到集群联邦中。
集群联邦使用了单独的 KubeFedCluster 对象(同样适用 CRD 来定义)来管理集群注册信息:
- 在该对象的定义中,不仅包含集群的注册信息,还包含集群的认证信息的引用,以明确每个集群使用的认证信息;
- 该对象还包含各个集群的健康状态、域名等,
- 当控制器行为出现异常时,直接通过集群状态信息即可获知控制器异常的原因。
安装
https://github.com/kibaamor/101/blob/master/module13/federation/readme.MD
下载 federation 代码
git clone https://github.com/kubernetes-sigs/kubefed.git选择 HostCluster,确认 kubeconfig 符合federation 命名规范,用 vi 编辑 kubeconfig,确保 context属性没用 @ 字符;
vi ~/.kube/config
contexts:
- context:
cluster: kubernetes
user: kubernetes-admin
name: cluster1
current-context: cluster1安装
cd kubefed/
./scripts/deploy-kubefed-latest.sh安装完成后,相关资源均可在 kube-federation-system 查看。
集群类型
Host:
- 用于提供 KubeFed AP|与控制平面的集群,本质上就是 Federation 控制面。
Member:
- 通过 KubeFed API注册的集群,并提供相关身份凭证来让 KubeFed controler 能够存取集群,Host集群也可以作为 Member被加入。
注册集群 KubeFedCluster
用来定义哪些 Kubernetes 集群要被联邦。
可透过 kubefedctl join/unjoin 来加入/删除集群当成功加入时,会建立一个 KubeFedCluster 组件来储存集群相关信息,如 APIEndpoint、CA Bundle 等,
这些信息会被用在 KubeFedController 存取不同 Kubernetes 集群上,以确保能够建立 Kubernetes API资源。

KubeFedCluster
apiVersion: core.kubefed.io/v1beta1
kind: KubeFedCluster
metadata:
name: "cluster1"
spec:
apiEndpoint: https://APServer.cluster1.example.com
caBundle:LSOtLS****LSOK
disabledTLsValidations:
- '*'
secretRef:
name: cluster1-vhvfw
status:
conditions:
- reason:ClusterReady
type: Ready
region: China
zones:
- Shanghai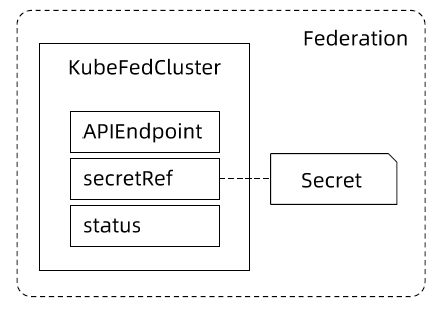
Federation 支持的核心对象
Type Configuration
定义了哪些 Kubernetes API 资源要被用于联邦管理。
若想新增 Federated API 的话,可通过 kubefedctl enable <res> 指令来建立
比如说想将 ConfigMap 资源通过联邦机制建立在不同集群上时,就必须先在 Federation Host 集群中,通过 CRD 建立新资源 FederatedconfigMap,接着再建立名称为configmaps 的Type configuration(FederatedTypeConfig)资源,然后描述 ConfigMap 要被 FederatedconfigMap 所管理
这样 KubeFed controllers 才能知道如何建立 Federated 资源。
FederatedConfigMap
k get crd federatedconfigmaps.types.kubefed.io
NAME CREATED AT
federatedconfigmaps.types.kubefed.io 2021-09-13T10:10:03ZapiVersion: core.kubefed.io/v1beta1
kind: FederatedTypeConfig
metadata:
name: configmaps
spec:
federatedType:
group: types.kubefed.io
kind: FederatedConfigMap
pluralName: federatedconfigmaps
scope: Namespaced
version: vlbeta1
propagation: Enabled
targetType:
kind: ConfigMap
pluralName: configmaps
scope: Namespaced
version: v1联邦对象组成
Template: 定义 Kubernetes 对象的模板
Placement: 定义联邦对象需要被同步的目标集群。
Overrides: 不同目标集群中,对 Kubernetes 对象模板的本地化属性
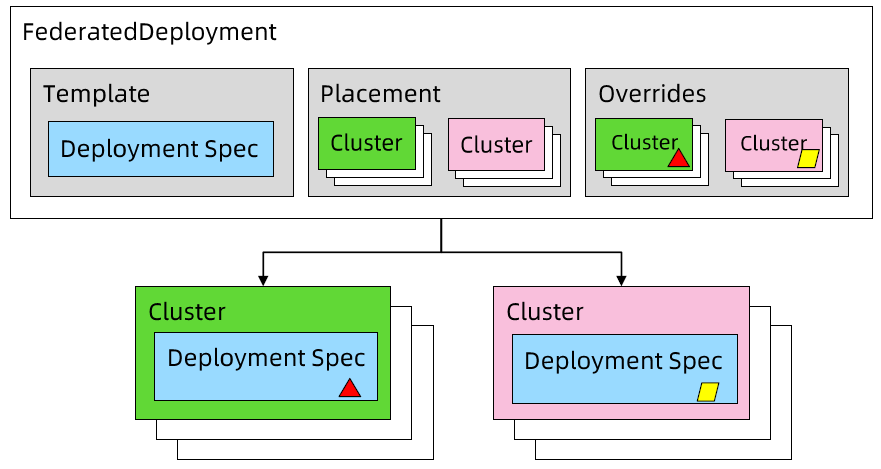
Template
Template 是联邦对象中定义 Kubernetes集群对象的模板部分,它的内容为完整的Kubernetes 对象。
apiVersion: types.federation.k8s.io/vlalpha1
kind: FederatedDeployment
metadata:
name: sample-federated-deployment
spec:
template:
metadata:
spec:
replicas: 2
template:
spec:
containers:
- image: nginx
name: nginx
placement:
#...
overrides:
#...Placement
Placement用来配置联邦对象的目标集群,其值可以是具体的集群名单,也可以是 clusterseletor 选择对应标签(label)的集群。
当两者同时存在时,明确定义的集群名单具有较高优先级
联邦根据优先级来定义要同步对象的目标集群,如果提供了集群名单(哪怕是一个空 List),则无论 clusterselector提供什么内容,都会被忽略。
apiVersion: types.federation.k8s.io/vlalpha1
kind: FederatedDeployment
metadata:
name: sample
namespace: sample
spec:
template:
#...
placement:
clusters:
- name: cluster1
- name: cluster2
clusterSelector:
matchLabels:
region: china
zone: shanghai
overrides:
#...Overrides
Overrides 用于针对每个集群进行本地化定制。
在实际部署应用时,通常会通过调整不同集群中的配置模板,部署符合特定集群需求的应用,以更好地发挥网络、计算资源、存储等的优势。
目前 Overrides 不支持 List(Array)。比如说无法修改 spec.template.spec.containers0].image
Q: 思考一下为什么?
A: 数值可能会变。比如顺序变了、大小变了等。
apiVersion: types.federation.k8s.io/v1alpha1
kind: FederatedDeployment
metadata:
spec:
template:
spec:
replicas: 2
template:
#...
placement:
clusters:
- name: cluster1
- name: cluster2
overrides:
- clusterName: cluster2
clusterOverrides:
- path: /spec/replicas
value: 3使用 Federated 对象
将 Namespace 设置为联邦对象
kubefedctl federate ns default联邦调度
KubeFed 提供了一种自动化机制来将工作负载实例分散到不同的集群中,这能够基于总副本数与集群的定义策略来将Deployment或 Replicaset 资源进行编排。
编排策略是通过建立ReplicaSchedulingPreference(RSP)文件,再由 KubeFed RSP Controller监听与撷取 RSP 内容来将工作负载实例建立到指定的集群上。
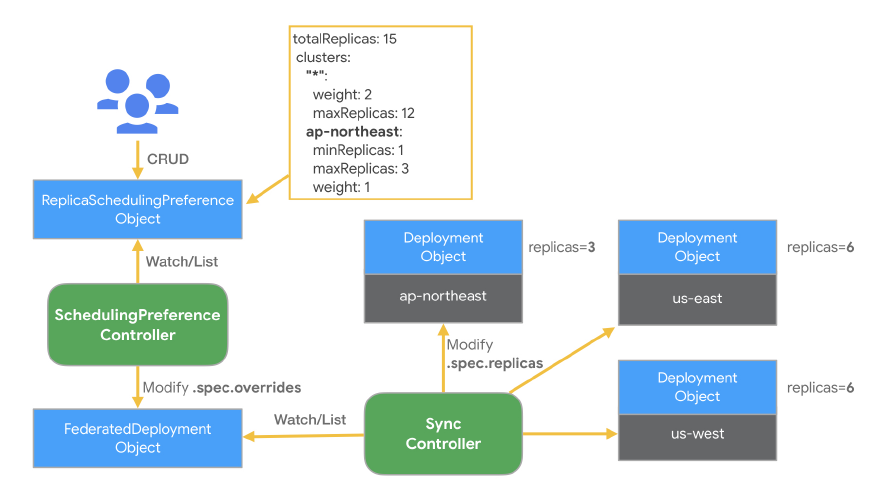
多集群 DNS
KubeFed 提供了一组 API 资源,以及 Controllers 来实现跨集群 Service/ingress 的 DNSrecords 自动产生机制。
需要结合 ExternalDNS 来同步更新至 DNS 服务供应商
在 2020 年被移出,这里提供一个 DNS 接入的思路。
Kubefed v2 should be only focused on the federation of resources across kubefedclusters. In the Kubernetes ecosystem there are other third party tools (such as servicemeshes) that already provide support to the DNs based federated ingress.
ServiceDNSRecord 原理
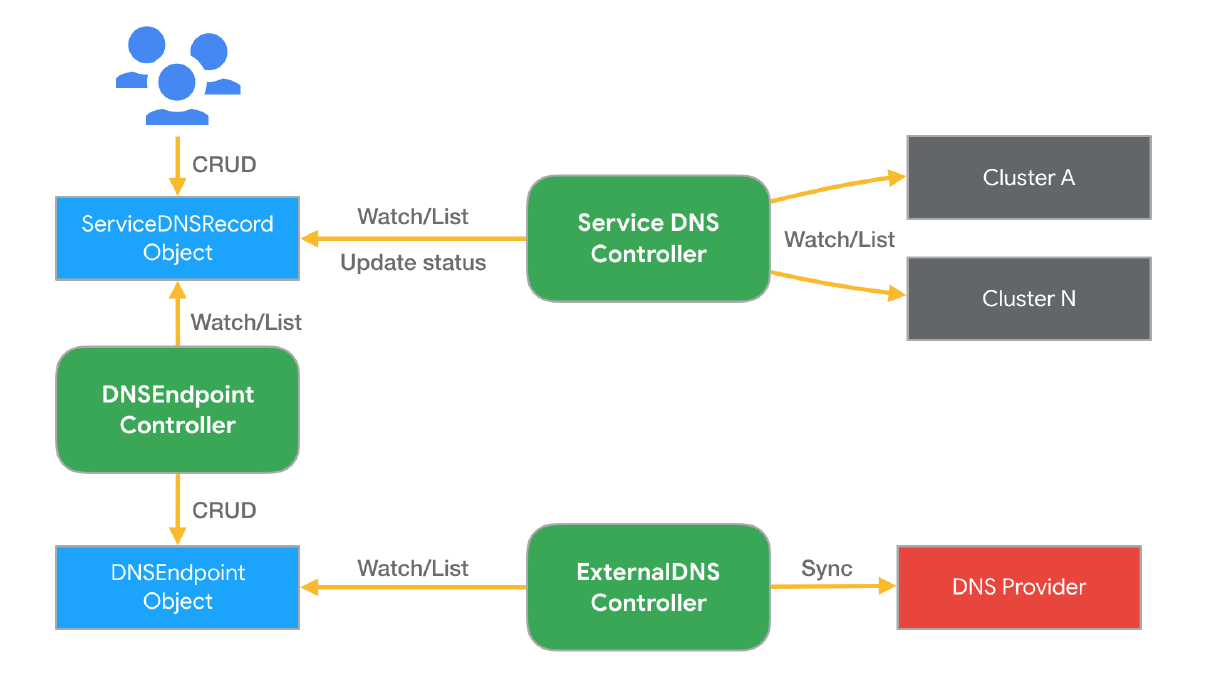
Clusternet
Clusternet简介
Clusternet(Cluster Internet)是一个兼具多集群管理和跨集群应用编排的开源云原生管控平台打通了跨 VPC、跨地域、跨云的集群管理。
Clusternet 面向未来混合云、分布式云和边缘计算场景设计,支持海量集群的接入和管理。Clusternet 在保证无侵入且轻量化的基础上,创建了一张集群网络,对子集群进行纳管,并支持多集群的应用编排与治理。
开源项目地址: https://github.com/clusternet/clusternet
- 最新版本 v0.6.0
- 多平台支持: linux/amd64,linux/arm64, linux/ppc64le,linux/s390x,linux/386linux/arm
Clusternet 能力一览
- 统一管控各类 Kubernetes 集群;
- 集群管理 Pull/ Push 模式;
- 轻量化,开箱即用,易于部署和维护;
- 跨集群的服务发现及服务互访,
- Kubernetes 原生,没有额外的学习成本
- 完善的 RBAC 能力,访问任一子集群;
- 完善的接入能力: kubectl plugin/client-go;
- 支持分发各类原生应用/CRD/Helmchart。
多集群管理的挑战
- 集群无处不在
- 公有云、私有云、混合云、边缘、裸金属
- 提供一致的纳管能力
- 集群一键注册能力
- 一致性的集群访问体验,比如 exec,logs
- 权限管控 RBAC
- 架构要足够轻量化,方便一键接入
Clusternet 架构
- 最轻量化的架构
- 一站式连接各类集群
- 支持 Pull 和 Push 模式
- 跨集群路由访问
- 支持子集群 RBAC 访问
- 提供一致的集群访问体验,比如 exec,logs
- 原生 Kubernetes API
- 接入成本低,kubectl plugin/client-go
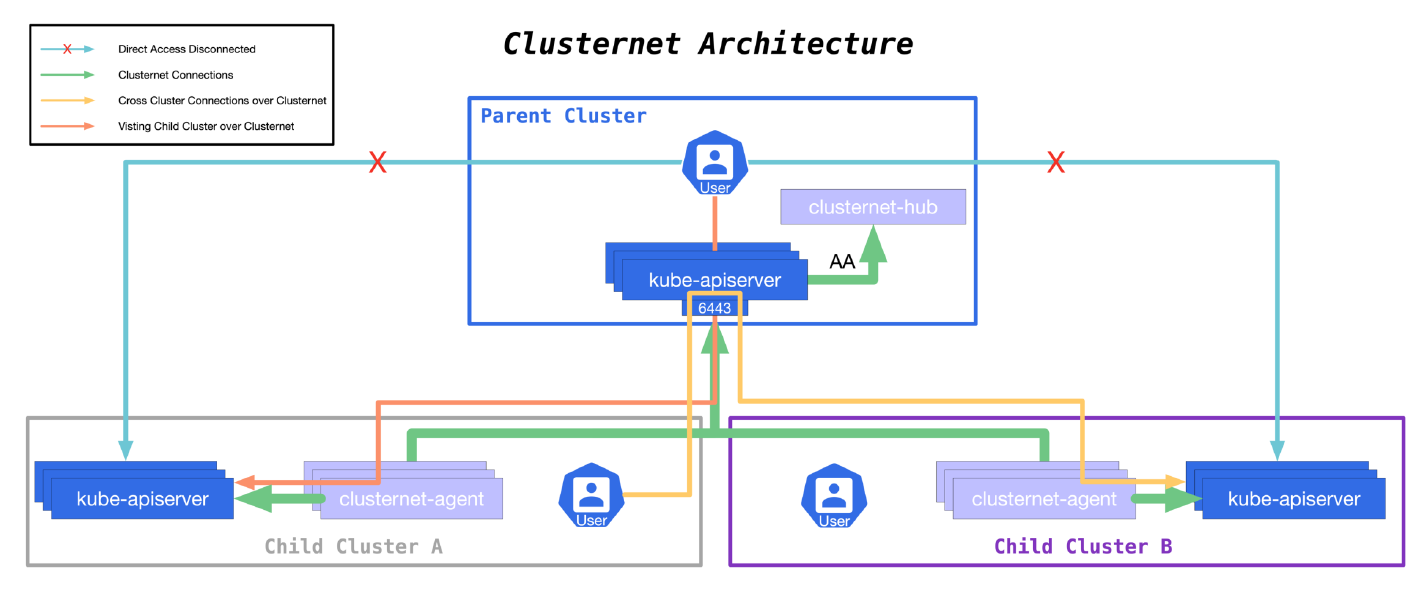
如何通过 Clusternet 访问任一子集群
Clusternet支持通过 Bootstrap Token,Service Token,TLS 证书等 RBAC的方式访问子集群;
子集群的 credential 信息不需要存在父集群中
也支持通过 kubectl命令行的方式对子集群进行 create/get/list/watch/patch/exec 等操作。
更详细步骤及功能可以参照 https://github.com/clusternet/clusternet/blob/main/docs/tutorials/visiting-child-clusters-with-rbac.md
- 使用 curl 进行访问
- 通过 kubectl 进行访问
Clusternet应用分发设计
- 完全兼容 Kubernetes 的内置 API
- 支持 Helm Charts
- 支持 CRD
- 丰富灵活的分发策略配置、差异化策略
应用分发的差异化痛点
- 在分发的资源上全部打上统一的标签,比如 apps.my.company/deployed-by: myplatform;
- 在分发到子集群的资源上标记集群的信息,比如 apps.my.company/running-in:cluster-01’
- 调整应用在每个集群中的副本数目、镜像名称等;
- 在分发到某集群前,调整应用在该集群中的一些配置,比如注入一个Sidecar 容器等,
- 灰度升级,变更可控,方便回滚;
- 重复定义怎么办?冲突吗?
- …
Clusternet 应用分发模型
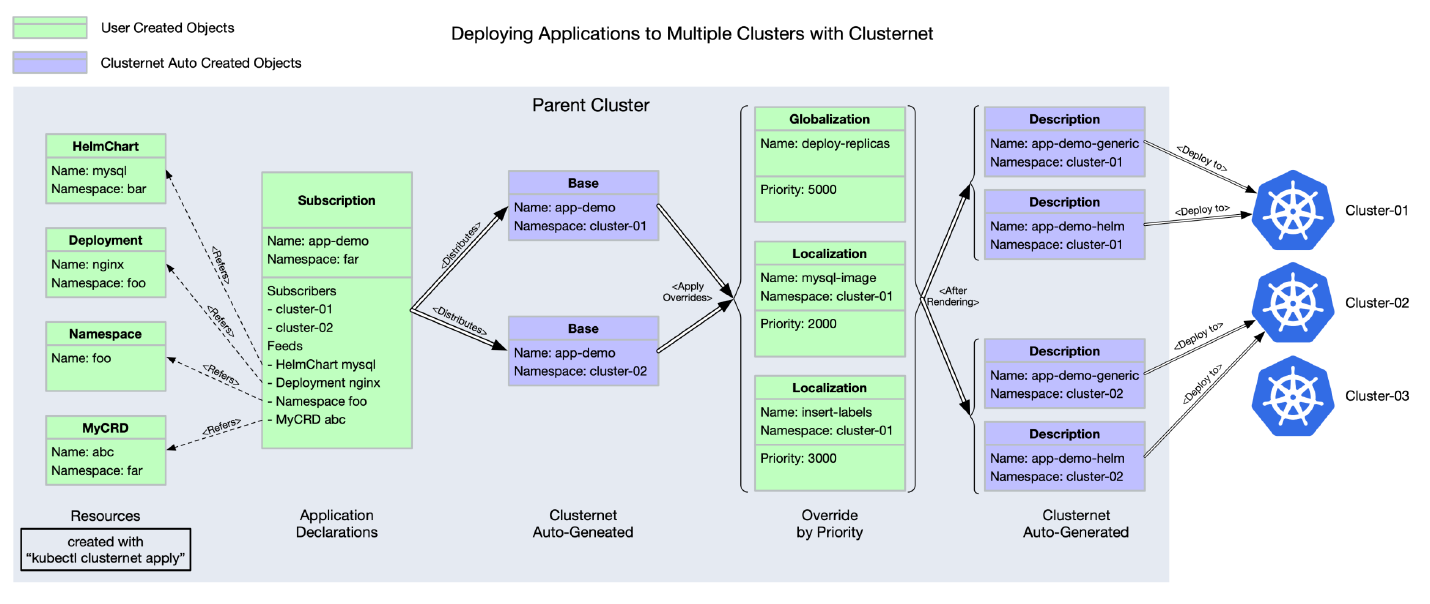
如何创建一个资源
kubectl 插件 kubectl-clusternet
$ kubectl krew update
$ kubectl krew install clusternet
# check plugin version
$ kubectl clusternet version通过 client-go wrapper
- 一键接入,无需改造
- 兼容 client-go 各个版本
- 示例: https://github,com/clusternet/clusternet/blob/main/examples/clientgO/READEME.md
示例:声明多集群应用 Subscription
apiVersion: apps.clusternet.io/v1alpha1
kind: Subscription
metadata:
name: app-demo
namespace: default
spec:
subscribers: #defines the clusters to be distributed to
- clusterAffinity:
matchLabels:
clusters.clusternet,io/cluster-id: dc91021d-2361-4f6d-a404-7c33b9e01118
feeds: # defines all the resources to be deployed with
- apiVersion: apps.clusternet.io/v1alpha1
kind: HelmChart
name: mysql
namespace: default
- apiVersion: v1
kind: Namespace
name: foo
- apiVersion: apps/v1
kind: Service
name: my-nginx-svc
namespace: foo
- apiVersion: apps/v1
kind: Deployment
name: my-nginx
namespace: fo0示例:差异化策略Localization/Globalization
apiVersion: apps.clusternet.io/vlalpha1
kind: Localization
metadata:
name: nginx-local-overrides-demo-lower-priority
namespace: clusternet-51821 # PLEASE UPDATE THIS TO YOUR Managedcluster NAMESPACE!! !
spec:
# Priority is an integer defining the relative importance of this Localization compared to others
# Lower numbers are considered lower priority.
# Override values in lower Localization will be overridden by those in higher Localization.
#(0ptional)Default priority is 500.
priority: 300
feed:
apiVersion: apps/v1
kind: Deployment
name: my-nginx
namespace: foo
overrides: # defines all the overrides to be processed with
- name: add-update-labels
type: MergePatch
# Value is a YAML/JSON format patch that provides MergePatch to current resource defined by feed.
# This override adds or updates some labels.
value: '{"metadata": {"labels": {"deployed-in-cluster":"clusternet-5l82l"}}}'
- name: scale-replicas
type: JSONPatch
# Value is a YAML/JSON format patch that provides JSONPatch to current resource defined by feed
# This patch sets replicas to 1.
# But due to lower priority, this value will be overridden by above "nginx-local-overrides-demo-higher-priority" eventually
value: |-
[
{
"path": "/spec/replicas",
"value":1
"op": "replace"
}
]更多示例
注册一个集群 https://github.com/clusternet/clusternet/blob/main/docs/tutorials/installing.clusternet-with-helm.md
部署一个完整的多集群应用 https://github.com/clusternet/clusternet/blob/main/docs/tutorials/deploying-applications-to-multiple-clusters.md
如何使用 client-go 创建多集群应用 https://github.com/clusternet/clusternet/blob/main/examples/clientgo/READEMEmd
Istio 多集群
跨地域流量管理的挑战
采用多活数据中心的网络拓扑,任何生产应用都需要完成跨三个数据中心的部署。
为满足单集群的高可用,针对每个数据中心,任何应用都需进行多副本部署,并配置负载均衡。
以实现全站微服务化,但为保证高可用服务之间的调用仍以南北流量为主。
针对核心应用,除集群本地负载均衡配置以外,还需配置跨数据中心负载均衡并通过权重控制将 99% 的请求转入本地数据中心,将1%的流量转向跨地域的数据中心。
规模化带来的挑战
3 主数据中心,20 边缘数据中心,100+Kubernetes 集群
规模化运营 Kubernetes 集群
- 总计 100,000 物理节点
- 单集群物理机节点规模高达5,000
业务服务全面容器化,单集群
- Pod 实例可达 100,000
- 发布服务 5,000-10000
单集群多环境支持
- 功能测试、集成测试、压力测试共用单集群
- 不同环境需要彼此隔离
异构应用
- 云业务,大数据,搜索服务
- 多种应用协议
- 灰度发布
日益增长的安全需求
- 全链路 TLS
可见性需求
- 访问日志
- Tracing
多集群部署
Kubernetes 集群联邦
- 集群联邦 APIServer作为用户访问 Kubernetes 集群入口
- 所有 Kubernetes 集群注册至集群联邦
可用区
- 数据中心中具有独立供电制冷设备的故障域
- 同一可用区有较小网络延迟
- 同一可用区部署了多个 Kubernetes 集群
多集群部署
- 同一可用区设定一个网关集群
- 网关集群中部署 lstio Primary
- 同一可用区的其他集群中部署 lstio Remote
- 所有集群采用相同 RootCA
- 相同环境 TrustDomain 相同
东西南北流量统一管控
- 同一可用区的服务调用基于 Sidecar
- 跨可用区的服务调用基于Istio Gateway
入站流量架构 L4+L7
为不同应用配置独立的网关服务以方便网络隔离。
基于IPVS/xDP 的 Service controller:
- 四层网关调度;
- 虚拟 IP 地址分配;
- 基于 IPIP 协议的转发规则配置,
- 基于 BGP 的 IP 路由宣告,
- 在 Ingress Pod 中配置 Tunnel 设备并绑定虚拟 IP 地址以卸载 IPIP 包。
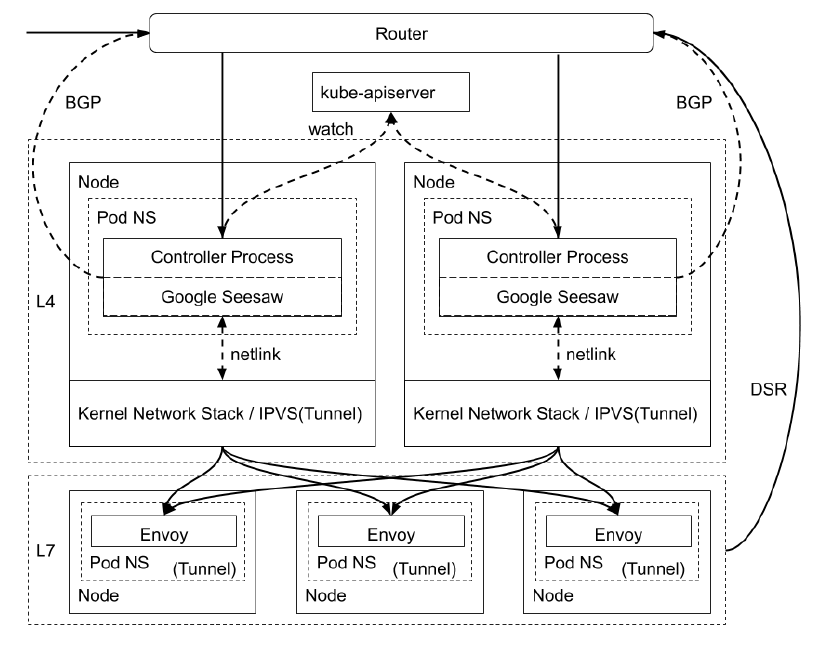
单网关集群多环境支持
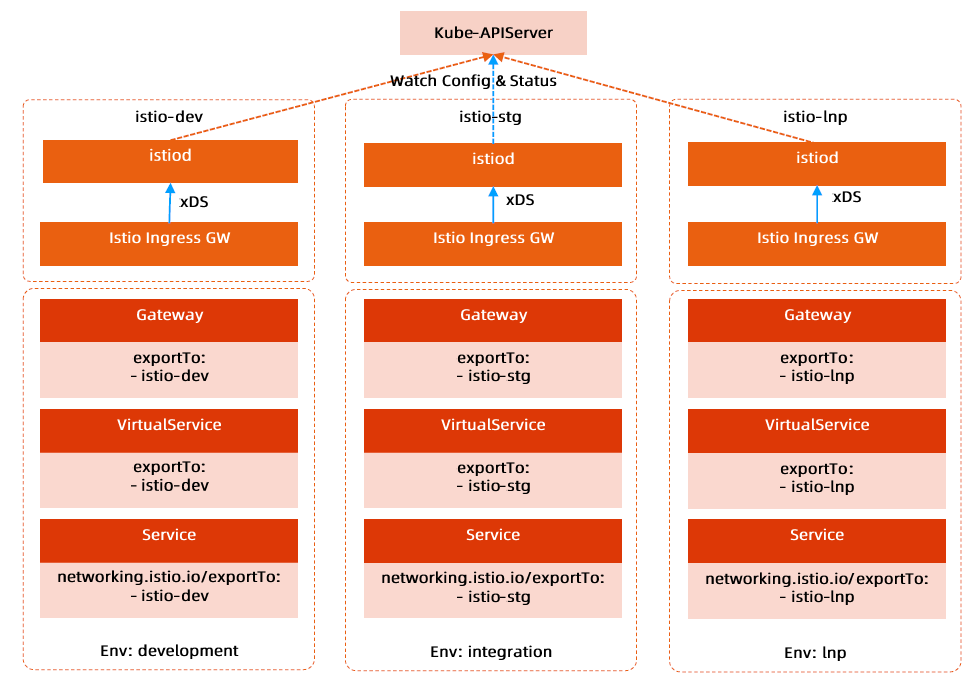
应用高可用接入方案
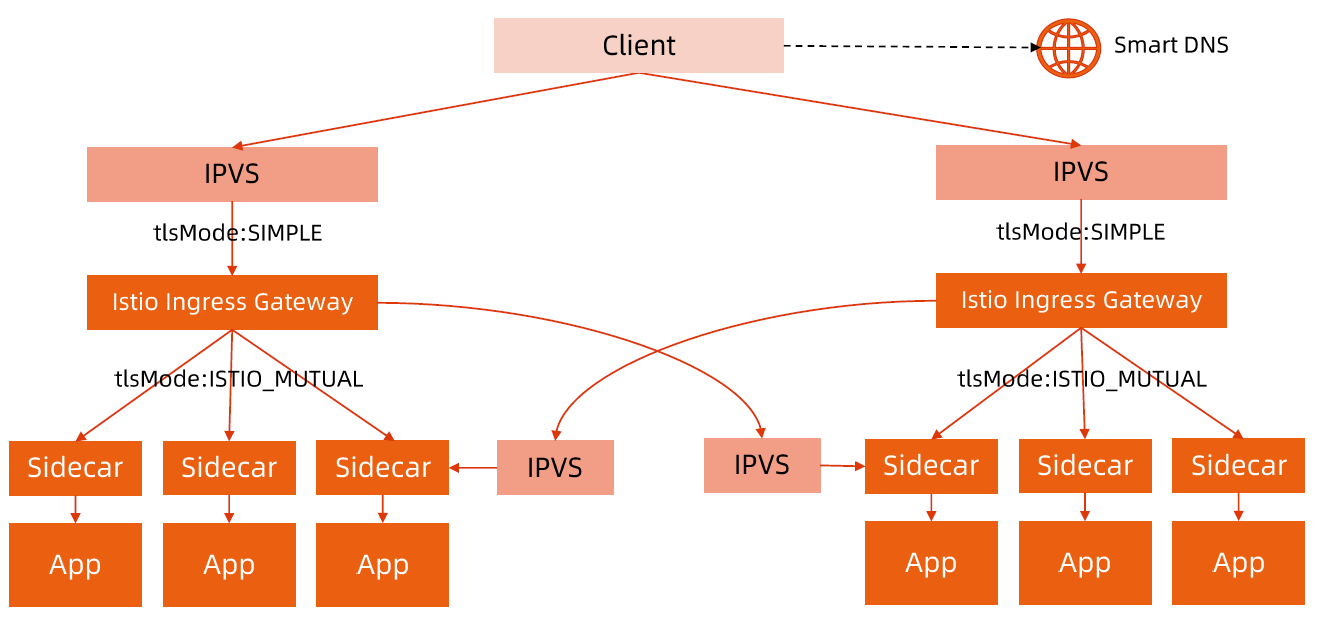
为应用发布服务
定义 LoadBalancer Type Service,提供集群外可访问的 LoadBalancerIP.
其他集群可通过定义 WorkloadEntry 指向该 LoadBalancerlP,以实现故障转移目的。
创建 WorkloadEntry
创建 WorkloadEntry 指向其他数据中心 LoadBalancerIP
apiVersion: networking.istio.io/v1beta1
kind: WorkloadEntry
metadata:
name: foo
spec:
address: foo.bar.svc.cluster2
labels:
run: foo
locality: region1/zone1定义 ServiceEntry
同时选择 WorkloadEntry 和本地 Pod。
ServiceEntry 对象可以将本地 Pod 和具有相同 Label的 WorkloadEntry定义成相同的Envoy Cluster。
apiVersion: networking.istio.io/v1beta1
kind: ServiceEntry
metadata:
name: foo
spec:
hosts:
- foo.com
ports:
- name: http-default
number: 80
protocol: HTTP
targetPort: 80
resolution: STATIC
workloadselector:
labels:
run: foo在 VirtualService 中引用 ServiceEntry
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: foo
spec:
gateways:
- foo
hosts:
- foo.com
http:
- match:
- port: 80
route:
- destination:
host: foo.com
port:
number: 80
---
apiVersion: networking.istio.io/v1beta1
kind: Gateway
metadata:
name: foo
spec:
selector:
istio: ingressgateway
servers:
- hosts:
- foo.com
port:
name: http-default
number: 80
protocol: HTTP为 workload 添加 Locality 信息
Istio 从如下配置中读取,基于这些配置,我们可以为lstio 中运行的所有 workload 添加地域属性。
Kubernetes Node 对象中的地域信息,所有 Pod 自动继承该 Locality 信息
- region: topology.kubernetes.io/region
- zone: topology.kubernetes.io/zone
- subzone: topology.istio.io/subzone
Kubernetes Pod 的 istio-locality 标签,可覆盖节点 Locality 信息
- istio-locality:”region/zone/subzone”
WorkloadEntry 的 Locality 属性
- locality:region/zone/subzone
定义基于 Locality 的流量转发规则
Distribute
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: foo
spec:
host: foo.com
trafficPolicy:
loadBalancer:
localityLbsetting:
distribute:
- from: "*/*"
to:
region1/zone1/*: 99
region2/zone2/*: 1
enabled: true
outlierDetection:
baseEjectionTime: 10s
consecutive5xxErrors: 100
interval: 10s
tls:
mode: ISTIO_MUTUALFailover
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: foo
spec:
host: foo.com
trafficPolicy:
loadBalancer:
localityLbsetting:
enabled: true
failover:
- from: region1/zone1
to: region2/zone2
outlierDetection:
baseEjectionTime: 10m
consecutive5xxErrors: 1
interval: 2s
tls:
mode:ISTIO_MUTUAL应对规模化集群挑战
Istio xDs 默认发现集群中所有的配置和服务状态,在超大规模集群中,lstiod 或者 Envoy 都承受比较大的压力。
- 集群中的有 10000 Service,每个Service 开放 80 和 443 两个端口,lstio 的 CDS 会 discover出 20000 个 Envoy Cluster。
- 如果开启多集群,Istio 还会为每个 cluster 创建符合域名规范的集群。
- Istio 还需要发现 remote cluster 中的 Service,Endpoint和 Pod 信息,而这些信息的频繁变更,会导致网络带宽占用和控制面板的压力都很大。
meshconfig 中控制可见性:
defaultServiceExportTo:
- "."
defaultVirtualServiceExportTo:
- "."
defaultDestinationRuleExportTo:
- "."通过 Istio 对象中的 exportTo 属性覆盖默认配置。
Istiod 自身的规模控制
社区新增加了 discoverySelector 的支持,允许 Istiod 只发现添加了特定 label的 namespaces下的 lstio 以及 Kubernetes 对象
但因为 Kubernetes 框架的限制,改功能依然要让 lstiod 接收所有配置和状态变更新细,并且在Istiod 中进行对象过滤。在超大集群规模中,并未降低网络带宽占用和 lstiod 的处理压力。
需要继续寻求从 Kubernetes Server端过滤的解决方案。
基于联邦的统一流量模型
Spec
- Scope
TrafficTemplate
- Istio models
- Kubernetes Services
Override
- 可为不同目标集群修改模板属性值
- 支持多种 override 方法
- jsonPatch
- mergePatch
Policy
- PlacementPolicy
- RolloutPolicy
- RuntimePolicy
Status
Conditions
- 四层网关状态
- 七层网关配置完成度
- 证书版本
- 网关服务 IP 和 FODN
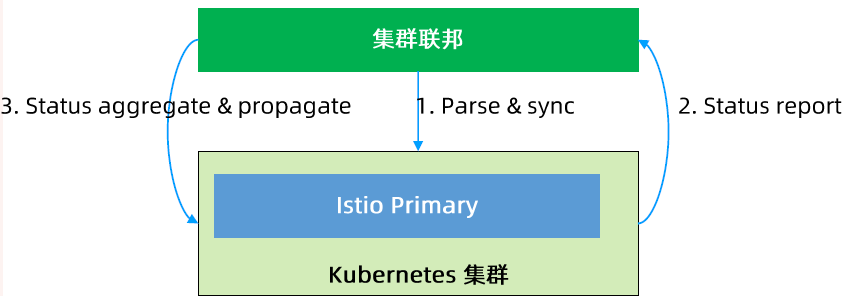
统一流量模型 - Nameservice
Spec
- GlobalName FODN
- TTL
DNSPolicy
- RoundRobin
- Locality
- Ratio
HeathCheck Port
Target
- Target Service FQDN
- Ratio
Status
Conditions
- 域名配置结果
配置错误信息
AccessPoint 控制器
PlacementPolicy控制,用户可以选择目标集群来完成流量配置,甚至可以选择关联的FederatedDeployment 对象,使得 AccessPoint 自动发现目标集群并完成配置。
完成了状态上报,包括网关虚拟IP地址,网关 FQDN,证书安装状态以及版本信息,路由策略是否配置完成等。这补齐了 Istio 自身的短板,使得任何部署在 lstio 的应用的网络配置状态一目了然。
发布策略控制,针对多集群的配置,可实现单集群的灰度发布,并且能够自动暂停发布,管理员验证单个集群的变更正确以后,再继续发布。通过此机制,避免因为全局流量变更产生的故障。
不同域名的 AccessPoint 可拥有不同的四层网关虚拟IP 地址,以实现基于 IP 地址的四层网络隔离。
控制器可以基于 AccessPoint 自动创建 WorkloadEntry,并设置 Locality 信息。
未来展望
全面构建基于 Mesh 的流量管理
在用户无感知的前提下将南北流量转成东西流量
数据平面加速 Cilium
基于Kubernetes和Istio的安全保证
云原生语境下的安全保证
- 安全保证是贯穿软件整个生命周期的重要部分。
- 安全与效率有时候是相违背的。
- 如何将二者统一起来,提升整体效率是关键
- 这需要我们将安全思想贯穿到软件开发运维的所有环节
云原生层次模型
软件的生命周期: 开发->分发->部署->运行
开发环节的安全保证
SaaS 应用的 12-factor 设计原则的一些理念与云原生安全不谋而合。
传统的安全三元素 CIA(Confidentiality,Integrity和 Availability),在云原生安全中被充分应用,如对工作负载的完整性保护,与I(Integrity)完整性保护相对应
- 机密性(Confidentiality)指只有授权用户可以获取信息。
- 完整性(integrity)指信息在输入和传输的过程中,不被非法授权修改和破坏,保证数据的一致性。
- 可用性(Availability)指保证合法用户对信息和资源的使用不会被不正当地拒绝。
基础设施即代码(Infrastructure as code,简称 laC)也与云原生的实践紧密相关
这些方法和原则,都强调通过早期集成安全检测,以确保对过程的控制,使其按预期运行
通过早期检测的预防性成本,降低后续的修复成本,提升了安全的价值,
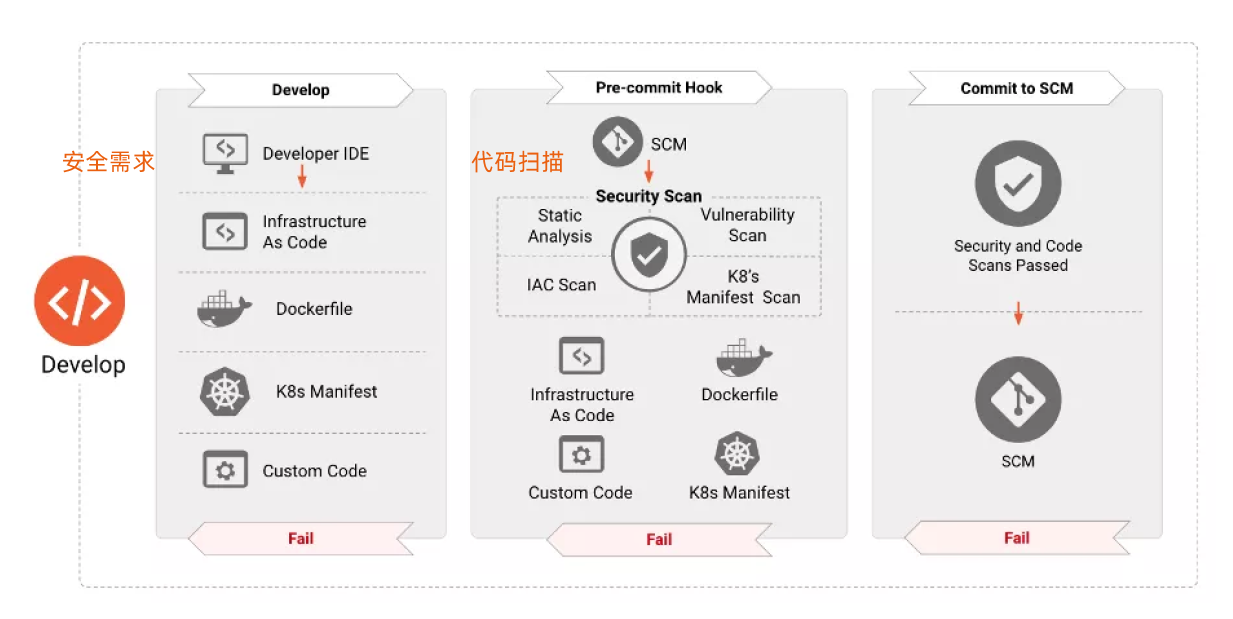
分发环节的安全保证
云原生应用生命周期中的分发阶段不仅需要包括验证工作负载本身的完整性的方法,还需要包括创建工作负载的过程和操作手段。
对于软件生产周期流水线中产生的工件(如容器镜像),需要进行持续的自动扫描和更新来确保安全,防止漏洞、恶意软件、不安全的编码和其他不安全的行为。
在完成这些检查后,更重要的是对产品进行加密签名,以确保产品的完整性及不可抵赖性
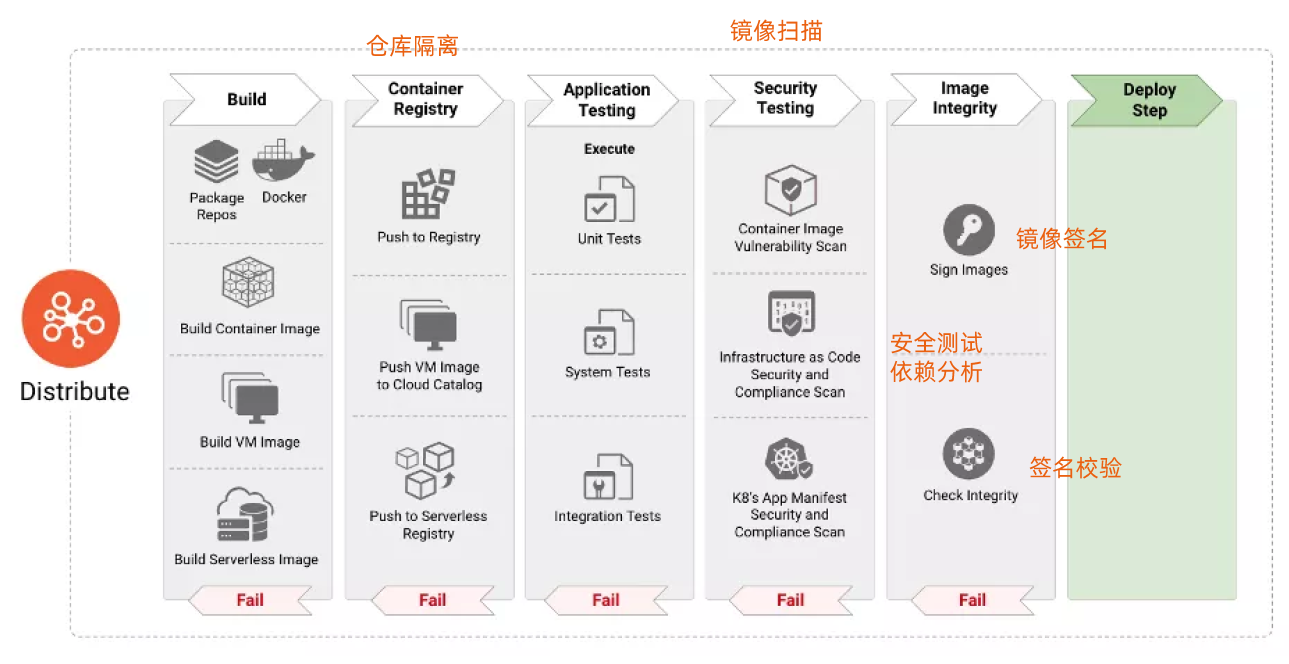
部署环节的安全保证
在整个开发和集成发布阶段,应对候选工作负载的安全性进行实时和持续的验证,如,对签名的工件进行校验,确保容器镜像安全和运行时安全,并可验证主机的适用性。
安全工作负载的监控能力,应以可信的方式监控日志和可用指标,与工作负载一同部署来完善整体的安全性。
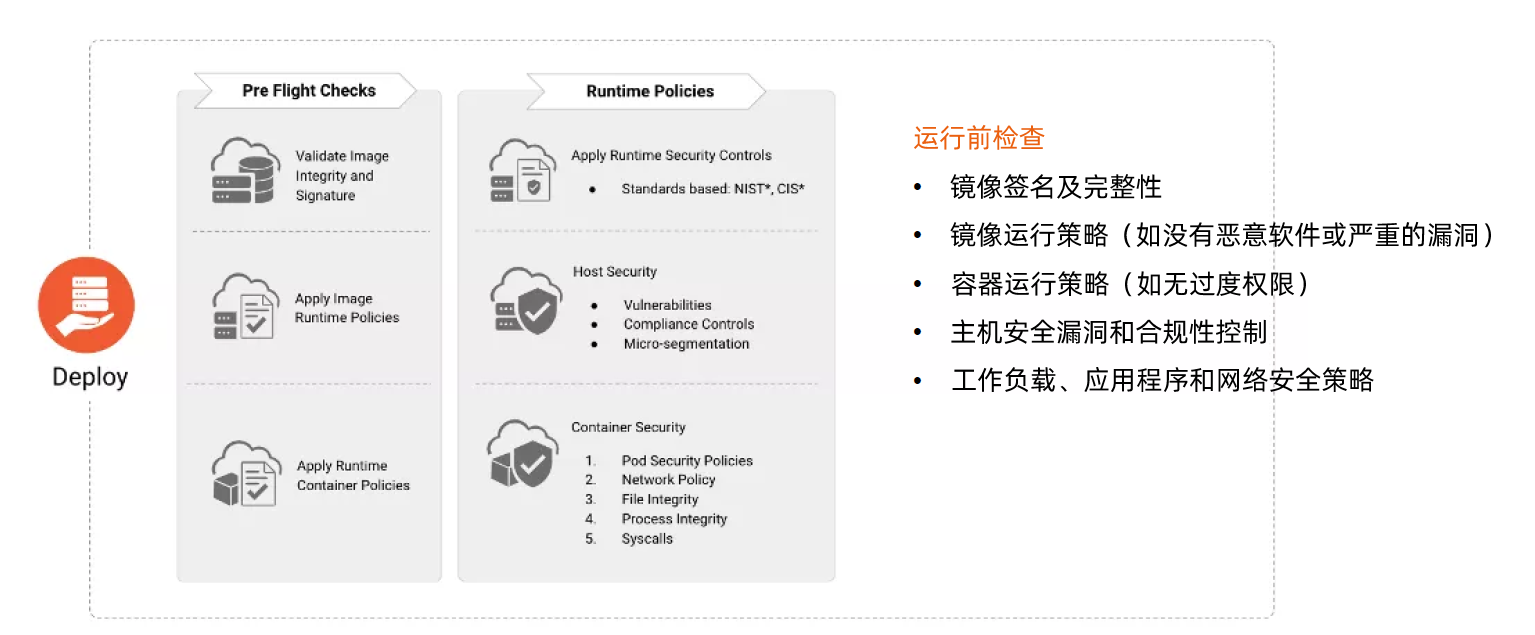
运行时环节的安全保证
应用程序通常由多个独立和单一职责的微服务组成,容器编排层使得这些微服务通过服务层抽象进行相互通信。
确保这种相互关联的组件架构安全的最佳实践,包括以下几点:
- 只有经过批准的进程能在容器命名空间内运行;
- 禁止并报告未经授权的资源访问;
- 监控网络流量以检测恶意的活动;
- 服务网格是另一种常见的服务层抽象,它为已经编排的服务提供了整合和补充功能,而不会改变工作负载软件本身(例如,API流量的日志记录、传输加密、可观察性标记、认证和授权)。
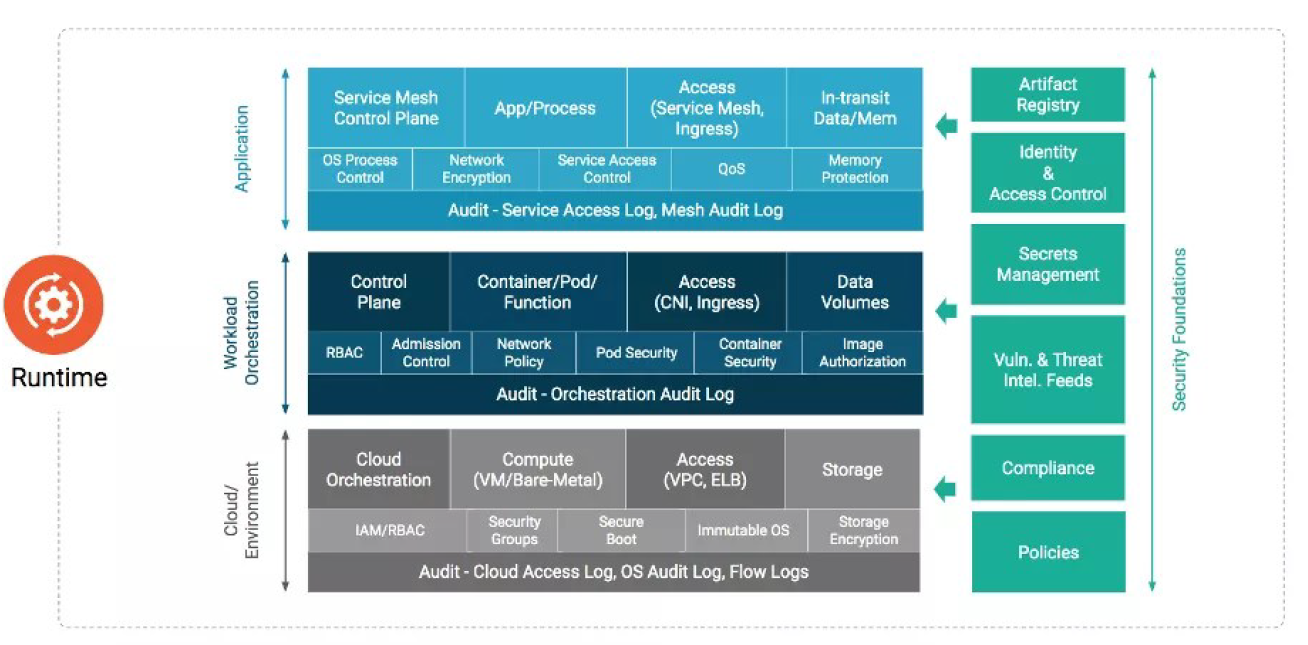
容器运行时的安全保证
以 Non-root 身份运行容器
在 Dockerfile 中通过 USER 命令切换成非 root 用户
原因分析:
防止某些坏的镜像窃取主机的 root 权限并造成危害。
有些运行时容器内部的 root用户与主机的root 用户是同一个用户,如不进行用户切换很可能因为权限过大引发严重的问题,比如一个最简单的case,主机上的重要文件夹被 mount 到容器内部,并被容器修改配置。
即使在容器内部也应该进行权限隔离,比如当我们希望构建不可变配置的容器镜像时,应该将运行容器的用户切换为非 root用户,并且限制其读写权限和读写目录。
FROM ubuntu
RUN user add patrick
USER patrickUser Namespace 和 rootless container
User Namespace.
- 依赖于 User namespace,任何容器内部的用户都会映射成主机的非root 用户
- 但该功能未被默认 enable,因其引入配置复杂性,比如系统不知道主机用户和容器用户的映射关系,在 mount 文件的时候无法设置适当的权限。
Rootless container:
- rootless container 是指容器运行时以非 root 身份启动。
- 在该配置下,即使容器被突破,在主机层面获得的用户权限也是非 root 身份的用户,这确保了安全。
- Docker 和其他运行时本身的后台 Daemon(如Docker Daemon)需要 root身份运行,然后其他用户的容器才能以 rootless 身份运行。
- 一些运行时,比如 Podman,无需 Daemon 进程,因为可以完全不需要root 身份。
集群的安全性保证
保证容器与容器之间、容器与主机之间隔离,限制容器对其他容器和主机的消极影响。
保证组件、用户及容器应用程序都是最小权限,限制它们的权限范围。
保证集群的敏感数据的传输和存储安全。
常用手段
- Pod安全上下文(Pod Security Context)
- APIServer的认证、授权、审计和准入控制
- 数据的加密机制等
Kubernetes 的安全保证
集群的安全通信
Kubernetes期望集群中所有的 API通信在默认情况下都使用 TLS 加密,大多数安装方法也允许创建所需的证书并且分发到集群组件中。
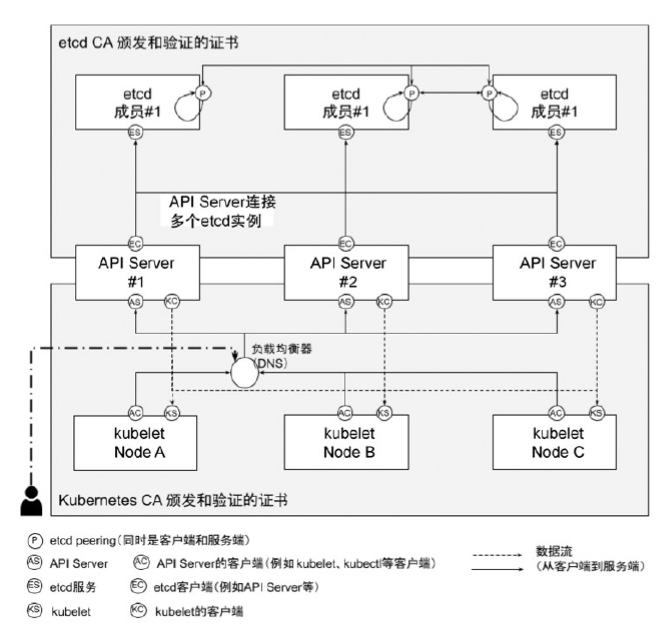
控制面安全保证
认证
- 小型的单用户集群可能希望使用简单的证书或静态承载令牌方法。
- 更大的集群则可能希望整合现有的、OIDC、LDAP 等允许用户分组的服务器。
- 所有 API客户端都必须经过身份验证,即使它是基础设施的一部分,比如节点、代理、调度程序和卷插件。这些客户端通常使用服务帐户或 X509 客户端证书,并在集群启动时自动创建或是作为集群安装的一部分进行设置。
授权
- 与身份验证一样,简单而广泛的角色可能适合于较小的集群,但是随着更多的用户与集群交互,可能.需要将团队划分成有更多角色限制的单独的命名空间。
配额
- 资源配额限制了授予命名空间的资源的数量或容量。这通常用于限制命名空间可以分配的 CPU、内存或持久磁盘的数量,但也可以控制每个命名空间中有多少个 Pod、服务或卷的存在。
NodeRestriction
准入控制器限制了 kubelet 可以修改的 Node 和 Pod 对象,kubelet 只可修改自己的 Node API对象,只能修改绑定到节点本身的 Pod 对象。
NodeRestriction 准入插件可防止 kubelet 删除 Node API 对象。
防止 kubelet 添加/删除/更新带有 node-restriction.kubernetes.io/ 前缀的标签将来的版本可能会增加其他限制,以确保 kubelet具有正常运行所需的最小权限集。
思考为什么?
降低获得 kubelet kubeconfig 的人能做成的破坏。
存储加密
apiVersion: APIServer.config.k8s.io/v1
kind: EncryptionConfiguration
resources:
- resources:
- secrets
providers:
- identity:
- aesgcm:
keys:
- name: key1
secret: c2VjcmVOlGlzIHNIY3VyZQ=
- name: key2
secret: dGhpcyBpcyBWYXNzd29yZA=
- aescbc:
keys:
- name: key1
secret: c2VjcmV0lGlzIHNlY3VyZO==
- secretbox:
keys:
- name: key1
secret: YW]jZGVmZ2hpamtsbW5vcHFyc3R1dnd4eXoxMjM0NTY
- kms:
name: myKmsPlugin
endpoint: unix:///tmp/socketfile.sock
cachesize: 100runAsUser
- SecurityContext
- PodsecurityPolicy
- MustRunAs
- MustRunAsNonRoot
Security Context
Pod 定义包含了一个安全上下文,用于描述允许它请求访问某个节点上的特定 Linux 用户(如root)、获得特权或访问主机网络,以及允许它在主机节点上不受约束地运行的其它控件。
Pod 安全策略可以限制哪些用户或服务帐户可以提供危险的安全上下文设置。例如:Pod 的安全策略可以限制卷挂载,尤其是 hostpath,这些都是 Pod 应该控制的一些方面。
一般来说,大多数应用程序需要限制对主机资源的访问,他们可以在不能访问主机信息的情况下成功以根进程(UID0)运行。但是,考虑到与root用户相关的特权,在编写应用程序容器时,你应该使用非 root用户运行。\
类似地,希望阻止客户端应用程序逃避其容器的管理员,应该使用限制性的 Pod 安全策略。
Kubernetes 提供了三种配置 Security context 的方法:
- Container-levelSecurity Context: 仅应用到指定的容器。
- Pod-levelSecurity Context: 应用到 Pod 内所有容器以及 Volume。
- Pod Security Policies(PSP): 应用到集群内部所有 Pod 以及 Volume。
Container-level Security Context
Container-level Security Context 仅应用到指定的容器上,并且不会影响Volume。比如设置容器运行在特权模式:
apiVersion: v1
kind: Pod
metadata:
name: hello-world
spec:
containers:
- name: hello-world-container
# The container definition
# ...
securityContext:
privileged: truePod-level Security Context
Pod-level Security Context 应用到 Pod内所有容器,并且还会影响 Volume(包括fsGroup 和 selinuxOptions)
apiVersion: v1
kind: Pod
metadata:
name: hello-world
spec:
containers:
# specification of the pod's containers
# ...
securityContext:
fsGroup: 1234
supplementalGroups: [ 5678 ]
seLinuxOptions:
level: "s0:c123,c456"Pod Security Policies(PSP)
Pod Security Policies(PSP)是集群级的 Pod 安全策略,自动为集群内的 Pod 和 Volume 设置Security Context.
PSP 示例
限制容器的 host 端口范围为 8000-8080:
apiVersion: extensions/v1beta1
kind: PodSecurityPolicy
metadata:
name: permissive
spec:
seLinux:
rule: RunAsAny
supplementalGroups:
rule: RunAsAny
runAsUser:
rule: RunAsAny
fsGroup:
rule: RunAsAny
hostPorts:
- min: 8000
max: 8080
volumes:
- '*'Taint
为节点增加 taint
使用命令 kubectl taint 给节点增加一个 Taint:
kubectltaint nodes node1 key=value:Noschedule运行如下命令删除 Taint:
kubectltaint nodes nodel key:NoSchedule-在 Podspec 中为容器设定容忍标签
tolerations:
- key: "key"
operator: "Equal"
value: "value"
effect: "Noschedule"
---
tolerations:
- key: "key"
operator: "Exists"
effect: "Noschedule"Taint
可以以租户为粒度,为不同租户的节点增加 Taint,使得节点彼此隔离。
Taint 的作用是让租户独占节点,无对应 Toleration 的 Pod 无法被调度到 Taint 节点上,实现了应用部署的隔离。
NetworkPolicy
NetworkPolicy
如果你希望在 IP 地址或端口层面(OSl第3层或第4层)控制网络流量,则你可以考虑为集群中特定应用使用 Kubernetes网络策略(NetworkPolicy)
Pod 可以通信的 Pod 是通过如下三个标识符的组合来辩识的:
- 其他被允许的 Pods;
- 被允许的名字空间;
- IP 组块。
网络策略通过网络插件来实现。要使用网络策略,你必须使用支持NetworkPolicv的网络解决方案。创建一个 NetworkPolicy资源对象而没有控制器来使它生效的话,是没有任何作用的。
隔离和非隔离的 Pod
默认情况下,Pod 是非隔离的,它们接受任何来源的流量。
Pod 在被某 NetworkPolicy选中时进入被隔离状态。
一旦名字空间中有 NetworkPolicy选择了特定的 Pod,该 Pod 会拒绝该 NetworkPolicy 所不允许的连接
网络策略不会冲突,它们是累积的。如果任何一个或多个策略选择了一个Pod,则该 Pod 受限于这些策略的入站(Ingress)/出站(Egress)规则的并集。因此评估的顺序并不会影响策略的结果。
为了允许两个 Pods 之间的网络数据流,源端 Pod 上的出站(Egress)规则和目标端 Pod 上的入站(Ingress)规则都需要允许该流量。如果源端的出站(Egress)规则或目标端的入站(ingress)规则拒绝该流量,则流量将被拒绝。
安全策略属性
spec:
- NetworkPolicy规约中包含了在一个名字空间中定义特定网络策略所需的所有信息。
podSelector:
- 每个 NetworkPolicy都包括一个 podSelector,它对该策略所适用的一组 Pod 进行选择。
- 空的 podSelector 选择名字空间下的所有 Pod。
policyTypes:
- 每个 NetworkPolicy都包含一个 policyTypes 列表,其中包含 Ingress 或 Egress 或两者兼具
- 如果 NetworkPolicy 未指定 policyTypes 则默认情况下始终设置 Ingress;
- 如果 NetworkPolicy 有任何出口规则的话则设置 Egress。
Ingress:
- 每个 NetworkPolicy 可包含一个Ingress 规则的白名单列表。
- 每个规则都允许同时匹配 from 和 ports 部分的流量。
Egress:
- 每个 NetworkPolicy 可包含一个 Egress 规则的白名单列表。
- 每个规则都允许匹配 to 和 port 部分的流量。
NetworkPolicy
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: test-network-policy
namespace: default
spec:
podSelector:
matchLabels:
role: db # 隔离"default"名字空间下"role=db"的 Pod
policyTypes:
- Ingress
- Egress
ingress:
# "default"名字空间下带有"role=frontend"标签的所有 Pod
# 带有"project=myproject"标签的所有名字空间中的 Pod
# IP 地址范围为 172.17.0.0-172.17.0.255 和172.17.2.0-172.17.255.255
- from:
- ipBlock:
cidr: 172.17.0.0/16
except:
- 172.17.1.0/24
- namespaceSelector:
matchLabels:
project: myproject
- podSelector:
matchLabels:
role: frontend
ports:
- protocol: TCP
port: 6379
egress:
# 允许从带有"role=db"标签的名字空间下的任何 Poc到 CIDR 10.0.0.0/24下5978 TCP 端口
- to:
- ipBlock:
cidr: 10.0.0.0/24
ports:
- protocol: TCP
port: 5978默认策略
默认拒绝所有入站流量
即使是同一个 POD 的流量也会拒绝。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-ingress
spec:
podSelector: {}
policyTypes:
- Ingress默认允许所有入站流量
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-all-ingress
spec:
podSelector: {}
ingress:
- {}
policyTypes:
- Ingress默认允许所有出站流量
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-all-egress
spec:
podSelector: {}
egress:
- {}
policyTypes:
- Egress默认拒绝所有入口和所有出站流量
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-all
spec:
podselector: {}
policyTypes:
- Ingress
- Egress依托于 Calico 的 NetworkPolicy
NetworkPolicy
NetworkPolicy是命名空间级别资源。规则应用于与标签选择器匹配的endpoint 的集合
apiVersion: projectcalico.org/v3
kind: NetworkPolicy
metadata:
name: allow-tcp-90
spec:
selector: app =='envoy' # 应用此策略的endpoint
types: # 应用策略的流量方向
- Ingress
- Egress
ingress: # 入口的流量规则
- action: Allow #流量的行为
protocol: ICMP #流量的协议
notProtocol: TCP # 匹配流量协议不为值的流量
source: # 流量的来源 src与 dst 的匹配关系为与,所有的都生效即生效
nets: # 有效的来源IP
selector: #标签选择器
namespaceSelector: # 名称空间选择器
ports: #端口
- 80 # 单独端口
- 6040:6050 # 端口范围
destination: # 流量的目标
egress: # 出口的流量规则
- action: Allow
serviceAccountselector: #使用与此规则的serviceAccountGlobalNetworkPolicy
GlobalNetworkPolicy与 NetworkPolicy功能一样,是整个集群级别的资源。
GlobalNetworkPolicy会在集群中所有 Namespace 生效,并且能限制主机(HostEndpoint)。
创建 NetworkPolicy 并查看结果
创建 networkpolicy kubectl apply -f module14/networkpolicy.yaml
查看创建结果 kubectl get po -nns-calico-01
登陆toolbox 容器 kubectlexec -it toolbox-68f79dd5f8-4664n bash
测试网络
$ ping 192.168.119.84
PING 192.168.119.84(192.168.119.84)
56(84) bytes of data.
^C
--- 192.168.119.84 ping statistics ---理解 Calico 的防火墙规则

创建 NetworkPolicy 并查看结果

创建规则允许ICMP
创建规则允许ICMP 协议 kubectl apply -f module14/allow-icmp-incluster.yaml
查看结果
nsenter -t 5989 -n ping 192.168.119.84
PING 192.168.119.84(192.168.119.84)56(84) bytesof data.
64 bytes from 192.168.119.84:icmp seg=1 ttl=63 time=0.061 ms
64 bytes from 192.168.119.84:icmp seg=2 ttl=63 time=0.071 ms查看规则变化
零信任架构(ZTA)
传统安全模型
DMZ 模式
传统的网络安全架构理念是基于边界的安全架构,企业构建网络安全体系时,首先寻找安全边界,把网络划分为外网、内网、DMZ(DeMilitarized Zone)区等不同的区域然后在边界上部署防火墙、入侵检测、WAF 等产品。
这种网络安全架构假设或默认了内网比外网更安全,在某种程度上预设了对内网中的人、设备和系统的信任,忽视加强内网安全措施。
不法分子一旦突破企业的边界安全防护进入内网,会像进入无人之境,将带来严重的后果。
传统的认证,即信任、边界防护、静态访问控制、以网络为中心。
零信任架构(Zero Trust Architecture,ZTA)
随着云计算、大数据、物联网、移动办公等新技术与业务的深度融合,网络安全边界也逐渐变得更加模糊,传统边界安全防护理念面临巨大挑战。
零信任核心原则: 从不信任,始终验证
动态安全架构:
- 以身份为中心
- 以识别、持续认证、动态访问控制、授权、审计以及监测为链条
- 以最小化实时授权为核心
- 以多维信任算法为基础
- 认证达末端
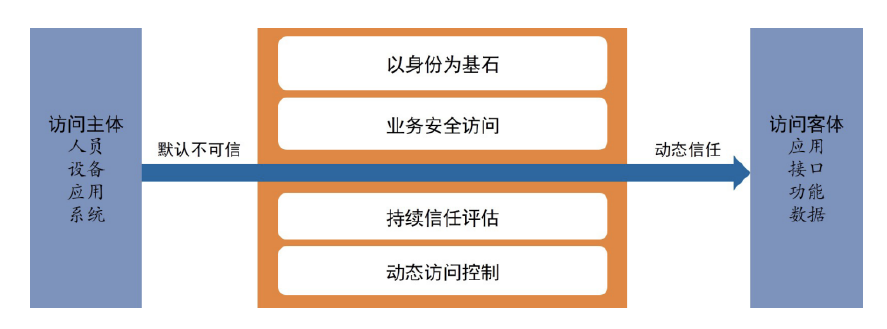
与边界模型的”信任但验证”不同,零信任的核心原则是”从不信任、始终验证”
根据 Evan Gilman《Zero Trust Networks》书中所述,零信任网络建立在五个假设前提之下:
- 应该始终假设网络充满威胁;
- 外部和内部威胁每时每刻都充斥着网络;
- 不能仅仅依靠网络位置来确认信任关系;
- 所有设备、用户、网络流量都应该被认证和授权,
- 访问控制策略应该动态地基于尽量多的数据源进行计算和评估
ZTA 安全模型
- 零信任数据
- 零信任人员
- 零信任网络
- 零信任工作负载
- 零信任设备
- 可视化和分析
- 自动化和编排
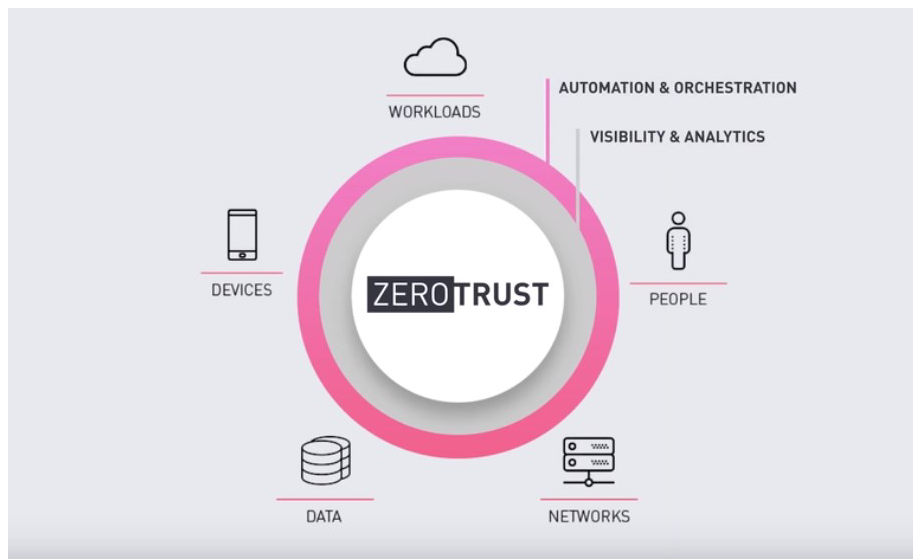
零信任架构的三大技术 “SIM”
零信任架构的三大技术”SIM”,即
- 软件定义边界(SDP,Software Defined Perimeter)
- 身份识别与访问管理(IAM,Identityand Access Management)
- 微隔离(MSG,Micro Segmentation)
软件定义边界(SDP)
SDP 旨在使应用程序所有者能在需要时部署安全边界,以便将服务与不安全的网络隔离开
SDP 将物理设备替换为在应用程序所有者控制下运行的逻辑组件,仅在设备验证和身份验证后才允许访问企业应用基础架构。
基于 SDP 的系统通常会实施控制层与数据层的分离:
- 控制流阶段,用户及其设备进行预认证来获取丰富的属性凭据作为身份主体,以此结合基于属性的预授权策略,映射得到仅供目标访问的特定设备和服务;
- 数据传输阶段直接建立相应安全连接并传输数据。
身份识别与访问管理(IAM)
零信任强调基于身份的信任链条,即该身份在可信终端,该身份拥有权限才可对资源进行请求
传统的 IAM 系统可以协助解决身份唯一标识、身份属性、身份全生命周期管理的功能问题
通过 IAM 将身份信息(身份吊销离职、身份过期、身份异常等)传递给零信任系统后,零信任系统可以通过 IAM 系统的身份信息来分配相应权限
通过 IAM 系统对身份的唯一标识,可有利于零信任系统确认用户可信,通过唯一标识对用户身份建立起终端、资源的信任关系,并在发现风险时实施针对关键用户相关的访问连接进行阻断等控制。
微隔离(MSG)
微隔离本质上是一种网络安全隔离技术
- 能够在逻辑上将数据中心划分为不同的安全段,一直到各个工作负载级别;。
- 为每个独立的安全段定义访问控制策略。
它主要聚焦在云平台东西向流量的隔离
- 一是区别传统物理防火墙的隔离作用;
- 二是更加贴近云计算环境中的真实需求
微隔离将网络边界安全理念发挥到极致,将网络边界分割到尽可能的小,能够很好的缓解传统边界安全理念下的边界过度信任带来的安全风险。
基于 Istio 的安全保证
微服务架构下的安全挑战
为了抵御中间人攻击,需要流量加密
为了提供灵活的服务访问控制,需要双向 TLS 和细粒度的访问策略
要确定谁在什么时候做了什么,需要审计工具。
Istio 的安全保证
Istio 安全功能提供
- 身份识别;
- 灵活策略
- 透明的 TLS 加密;
- 认证,授权和审计(AAA)工具来保护你的服务和数据。
Istio 安全的目标是
- 默认安全:应用程序代码和基础设施无需更改。
- 深度防御:与现有安全系统集成以提供多层防御
- 零信任网络:在不受信任的网络上构建安全解决方案,
高层架构
用于密钥和证书管理的证书颁发机构(CA)。
配置 API服务器分发给代理:
- 认证策略
- 授权策略
安全命名信息
Sidecar和边缘代理作为 Policy Enforcement Points(PEPS)以保护客户端和服务器之间的通信安全。
一组 Envoy 代理扩展,用于管理遥测和审计。
Istio 安全架构
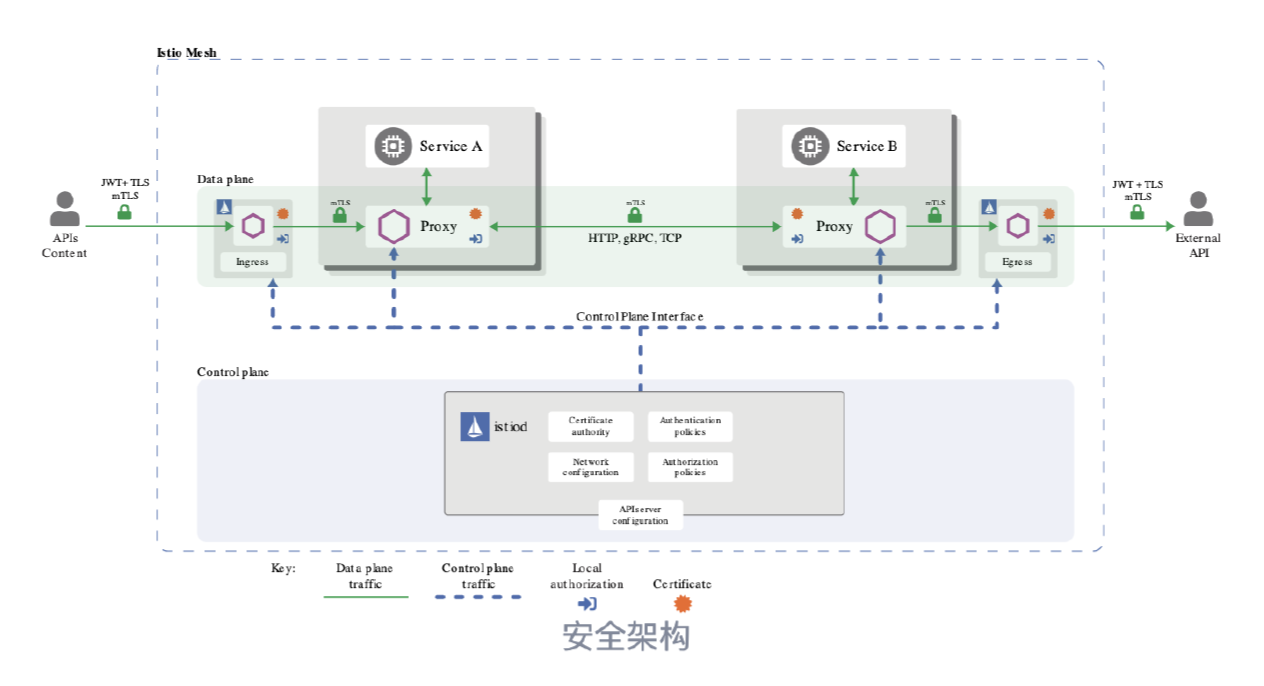
Istio 身份
身份是任何安全基础架构的基本概念
在工作负载间通信开始时,双方必须交换包含身份信息的凭证以进行双向验证。
在客户端,根据安全命名信息检查服务器的标识,以查看它是否是该服务的授权运行程序
在服务器端,服务器可以根据授权策略确定客户端可以访问哪些信息,审计谁在什么时间访问了什么,根据他们使用的工作负载向客户收费,并拒绝任何未能支付账单的客户访问工作负载
Istio 身份模型使用 service identity(服务身份)来确定一个请求源端的身份。
- Kubernetes: Kubernetes服务帐户
- GKE/GCE: 可以使用 GCP 服务帐户
- GCP: GCP 服务帐户
- AWS: AWS IAM 用户/角色 帐户
- On-premises(非 Kubernetes): 用户帐户、自定义服务帐户、服务名称、Istio 服务帐户或 GCP 服务帐户。
Istio 安全与 SPIFFE:
- Istio 和 SPIFFE共享相同的身份文件:SVID(SPIFFE 可验证身份证件)。例如:在 Kubernetes 中X.509 证书的 URI 字段格式为
spiffe://<domain>/ns/<namespace>/sa/<serviceaccount>。这使 Istio 服务能够建立和接受与其他 SPIFFE 兼容系统的连接。
SDS
Istio 供应身份是通过 secret discovery service(SDs)来实现的:
- istiod 提供 gRPC服务以接受证书签名请求(CSRS)
- 当工作负载启动时,Envoy通过秘密发现服务(SDS)API向同容器内的 istio-agent 发送证书和密钥请求。
- 在收到 SDS 请求后,,istio-agent创建私钥和CSR然后将 CSR 及其凭据发送到 istiod CA 进行签名。
- istiod CA 验证 CSR 中携带的凭据,成功验证后签署CSR 以生成证书。
- istio-agent 通过 Envoy SDS API将私钥和从 lstio CA收到的证书发送给 Envoy。
- istio-agent 会监工作负载证书的有效期。上述 CSR过程会周期性地重复,以处理证书和密钥轮换。
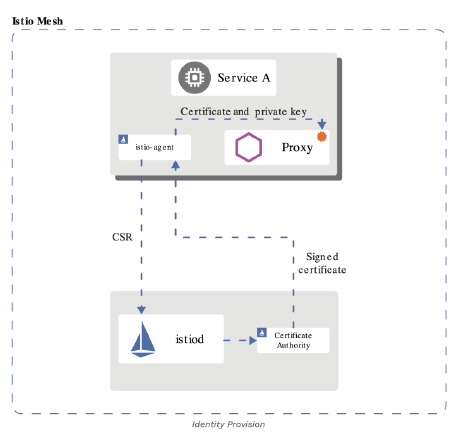
认证
基于 Istio 的认证
Istio 通过客户端和服务器端 Policy Enforcement Points(PEPS)建立服务到服务的通信通道
PEPS 在 Istio 架构中的实现是 Envoy。
Peer authentication:
- 用于服务到服务的认证,以验证进行连接的客户端,
Istio 提供双向 TLS 作为传输认证的全栈解决方案,无需更改服务代码就可以启用它。这个解决方案为:
- 为每个服务提供强大的身份,表示其角色,以实现跨群集和云的互操作性。
- 保护服务到服务的通信。
- 提供密钥管理系统,以自动进行密钥和证书的生成,分发和轮换,
Request authentication
- 用于最终用户认证,以验证附加到请求的凭据
- Istio 使用 ISON Web Token(WT)验证启用请求级认证,并使用自定义认证实现或任何OpenID Connect的认证实现(例如下面列举的)来简化的开发人员体验。
Istio 认证架构
未设置模式的网格范围的 peer认证策略默认使用 PERMISSIVE 模式。
发送请求的客户端服务负责遵循必要的认证机制。
RequestAuthentication
- 应用程序负责获取JWT 凭证并将其附加到请求,
PeerAuthentication
- Istio 会自动将两个 PEPS 之间的所有流量升级为双向 TLS。
- 如果认证策略禁用了双向 TLS 模式,则lstio 将继续在 PEPS 之间使用纯文本。
- 要覆盖此行为,destination rules 显式禁用双向TLS 模式。
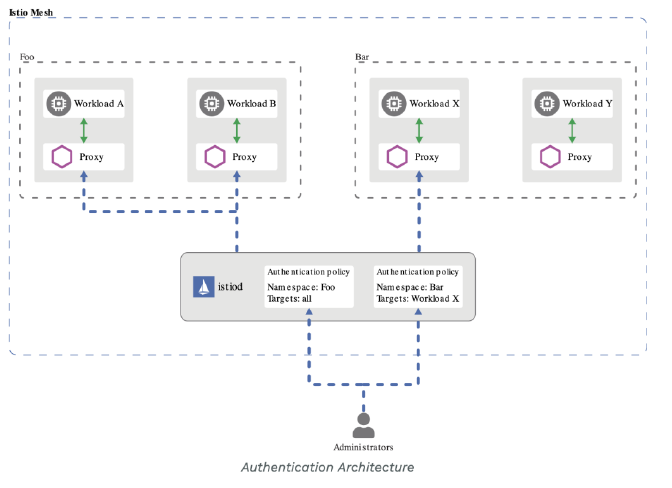
双向 TLS 认证
当一个工作负载使用双向 TLS 认证向另一个工作负载发送请求时,该请求的处理方式如下:
- Istio 将出站流量从客户端重新路由到客户端的本地 sidecar Envoy。
- 客户端 Envoy 与服务器端 Envoy 开始双向 TLS 握手。在握手期间,客户端 Envoy 还做了安全命名检查,以验证服务器证书中显示的服务帐户是否被授权运行目标服务。
- 客户端 Envoy 和服务器端 Envoy 建立了一个双向的 TLS 连接,lstio 将流量从客户端 Envoy转发到服务器端 Envoy。
- 授权后,服务器端 Envoy通过本地 TCP 连接将流量转发到服务器服务,
宽容模式(permissive mode)
允许服务同时接受纯文本流量和双向 TLS 流量
这个功能极大地提升了双向 TLS 的入门体验
在运维人员希望将服务移植到启用了双向 TLS 的Istio 上时,许多非Istio 客户端和非 Istio 服务端通信时会产生问题。
通常情况下,运维人员无法同时为所有客户端安装 Istio sidecar,甚至没有这样做的权限。即使在服务端上安装了 Istio sidecar,运维人员也无法在不中断现有连接的情况下启用双向 TLS。
安全命名
服务器身份(serveridentities)被编码在证书里,但服务名称(service names)通过服务发现或 DNS 被检索
安全命名信息将服务器身份映射到服务名称。
身份 A到服务名称 B的映射表示 “授权 A运行服务 B”
控制平面监视 apiserver,生成安全命名映射,并将其安全地分发到 PEPS。以下示例说明了为什么安全命名对身份验证至关重要。
认证策略
认证策略是对服务收到的请求生效的,要在双向 TLS 中指定客户端认证策略,需要在 DetinationRule 中设置 TLSSettings。
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: db-mtls
spec:
host: mydbserver.prod.svc.cluster.local
trafficPolicy:
tls:
mode: MUTUAL
clientCertificate: /etc/certs/myclientcert.pem
privateKey: /etc/certs/client private key.pem
caCertificates: /etc/certs/rootcacerts.pem
---
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: tls-foo
spec:
host: "*.foo.com"
trafficPolicy:
tls:
mode: SIMPLE
---
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: ratings-istio-mtls
spec:
host: ratings.prod.svc.cluster.local
trafficPolicy:
tls:
mode: ISTIO MUTUAL认证策略
相应的需要通过 PeerAuthentication配置服务端接受何种认证方式
apiVersion: "security.istio.io/v1beta1"
kind: "PeerAuthentication"
metadata:
name: "example-peer-policy"
namespace: "foo"
spec:
selector:
matchLabels:
app: reviews
mtls:
mode: STRICT
---
apiVersion: "security.istio.io/v1beta1"
kind: "PeerAuthentication"
metadata:
name: "example-workload-policy"
namespace: "foo"
spec:
selector:
matchLabels:
app: example-app
portLevelMtls:
80:
mode: DISABLEReouestAuthentication
Request 认证策略指定验证JSON Web Token(JWT)所需的值。这些值包括
- token 在请求中的位置
- 请求的 issuer
- 公共JSON Web Key Set(JWKS)
Istio 会根据 request认证策略中的规则检查提供的令牌(如果已提供),并拒绝令牌无效的请求当请求不带有令牌时,默认情况下将接受它们。
apiVersion: security.istio.io/vibeta
kind: RequestAuthentication
metadata:
name: "default"
namespace: istio-system
spec:
selector:
matchLabels:
istio: ingressgateway
iwtRules:
- issuer: "testing@secure.istio.io"
jwksUri: "https://raw.githubusercontent.com/istio/istio/release.1.12/security/tools/iwt/samples/iwks.json"鉴权
授权架构
每个 Envoy 代理都运行一个授权引擎该引擎在运行时授权请求。
- 当请求到达代理时,授权引擎根据当前授权策略评估请求上下文,并返回授权结果 ALLOW 或 DENY.
- 授权策略支持 ALLOW 和 DENY 动作拒绝策略优先于允许策略。
- 如果将任何允许策略应用于工作负载则默认情况下,不符合该策略的访问都将被禁止。
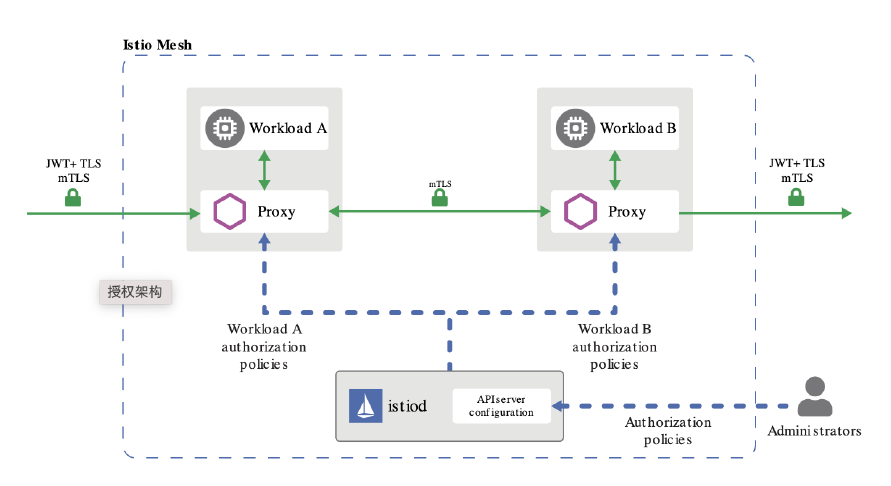
授权策略(AuthorizationPolicy)
selector 字段指定策略的目标
action 字段指定允许还是拒绝请求
rules 指定何时触发动作
- rules 下的 from 字段指定请求的来源
- rules 下的 to 字段指定请求的操作
- rules 下的 when 字段指定应用规则所需的条件
apiVersion: security.istio.io/v1beta1
kind: AuthorizationPolicy
metadata:
name: httpbin-deny
namespace: foo
spec:
selector:
matchLabels:
app: httpbin
version: v1
action: DENY
rules:
# 若非来自 foo,则拒绝
- from:
- source:
notNamespaces: ["foo"]
---
apiVersion: security.istio.io/v1beta1
kind: AuthorizationPolicy
metadata:
name: httpbin
namespace: foo
spec:
selector:
matchLabels:
app: httpbin
version: v1
action: ALLOW
rules:
# 若来自 default/sleep 或 dev,则允许
- from:
- source:
principals: ["cluster.local/ns/default/sa/sleep"]
- source:
namespaces: ["dev"] # OR 关系
to:
- operation:
methods: ["GET"]
when:
- key: request.auth.claims[iss]
values: ["https://accounts.google.com"]策略目标
可以通过 metadata/namespace 字段和可选的 selector字段来指定策略的范围或目标。
metadata/namespace 告诉该策略适用于哪个命名空间。如果将其值设置为根名称空间,则该策略将应用于网格中的所有名称空间。
根命名空间的值是可配置的,默认值为istio-system。
您可以使用 selector 字段来进一步限制策略以应用于特定工作负载。
如果未设置,则授权策略将应用于与授权策略相同的命名空间中的所有工作负载。
apiVersion: security.istio.io/v1beta1
kind: AuthorizationPolicy
metadata:
name: allow-read
namespace: default
spec:
selector:
matchLabels:
app: products
action: ALLOW
rules:
- to:
- operation:
methods: ["GET","HEAD"]值匹配
授权策略中的大多数字段都支持以下所有匹配模式
- 完全匹配: 即完整的字符串匹配,
- 前缀匹配:
*结尾的字符串。例如test.abc.*匹配 “test.abc.com”、”test.abc.com.cn”、”test.abc.org” 等等。 - 后缀匹配:
*开头的字符串。例如*.abc.com匹配 “eng.abc.com”、”test.eng.abc.com” 等等。 - 存在匹配:
*用于指定非空的任意内容。您可以使用格式fieldname:"*"指定必须存在的字段。这意味着该字段可以匹配任意内容,但是不能为空。
apiVersion: security.istio.io/v1beta1
kind: AuthorizationPolicy
metadata:
name: tester
namespace: default
spec:
selector:
matchLabels:
app: products
action: ALLOW
rules:
- to:
- operation:
paths: ["/test/*", "*/info"]全部允许和默认全部拒绝授权策略
允许完全访问 default 命名空间中的所有工作负载
apiVersion: security.istio.io/v1beta1
kind: AuthorizationPolicy
metadata:
name: allow-all
namespace: default
spec:
action: ALLOW
rules:
- {}不允许任何对 admin 命名空间工作负载的访问
apiVersion: security.istio.io/v1beta1
kind: AuthorizationPolicy
metadata:
name: deny-all
namespace: admin
spec:
{}自定义条件
apiVersion: security.istio.io/v1beta1
kind: AuthorizationPolicy
metadata:
name: httpbin
namespace: foo
spec:
selector:
matchLabels:
app: httpbin
version:v1
action: ALLOW
rules:
- from:
- source:
principals: ["cluster.local/ns/default/sa/sleep"]
to:
- operation:
methods: ["GET"]
when:
- key: request.headers[version]
values: ["v1", "v2"]认证与未认证身份
如果要使工作负载可公开访问,则需要将 source 部分留空
apiVersion: security.istio.io/v1beta1
kind: AuthorizationPolicy
metadata:
name: httpbin
namespace: foo
spec:
selector:
matchLabels:
app: httpbin
version:v1
action: ALLOW
rules:
- to:
operation:
methods: ["GET","POST"]将 principal 设置为 * 代表仅允许经过认证的用户
apiVersion: security.istio.io/v1beta1
kind: AuthorizationPolicy
metadata:
name: httpbin
spec:
selector:
matchLabels:
app: httpbin
version:v1
action: ALLOW
rules:
- from:
- source:
principals: ["*"]
to:
- operation:
methods: ["GET", "POST"]在普通 TCP 协议上使用 Istio 授权
如果您授权策略中对 TCP 工作负载使用了任何只适用于 HTTP 的字段,lstio 将会忽略它们。
apiVersion: "security.istio.io/v1beta1"
kind: AuthorizationPolicy
metadata:
name: mongodb-policy
namespace: default
spec:
selector:
matchLabels:
app: mongodb
action: ALLOW
rules:
- from:
- source:
principals: ["cluster.local/ns/default/sa/bookinfo-ratings-v2"]
to:
- operation:
ports: ["27017"]微服务项目的开发和部署案例
应用管理的实践分享
多租户系统
- 基于 Kubernetes 构建多租户平台
- 基于 Account 的租户治理
- 基于 Application 的应用治理
ApplicationInstance
Applicationlnstance 描述应用实例,每一组有特定业务目的独立的部署(deploymentstatefulset, daemonset)可定义为一个ApplicationInstance。
Application
Application 是对应用的抽象
ApplicationInstance 是应用的部署实例
Application 是一个或多个具有相同业务目的的应用实例的抽象。
包含应用配置,应用代码定义,责任人,联系方式等等,
Application 被 Account 管理
Application 定义如下属性:
- Application type:web,bigdata等是
- 否要加密Data classification:数据安全需求,
- Owner:责任人
- Admin Account:管理账号
- IssueTracker:问题跟踪地址
- GitHub:源代码地址
- …
Account
Account是管理应用的账号
Account 也是集群费用分摊实体
Account 是多租户集群中的租户
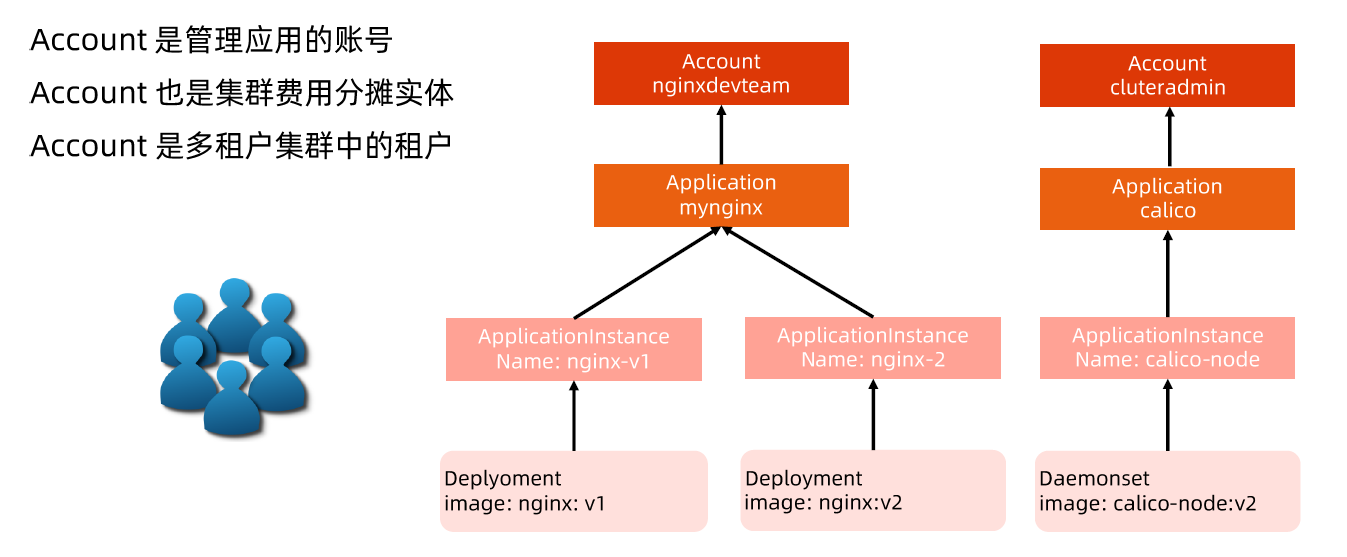
Group
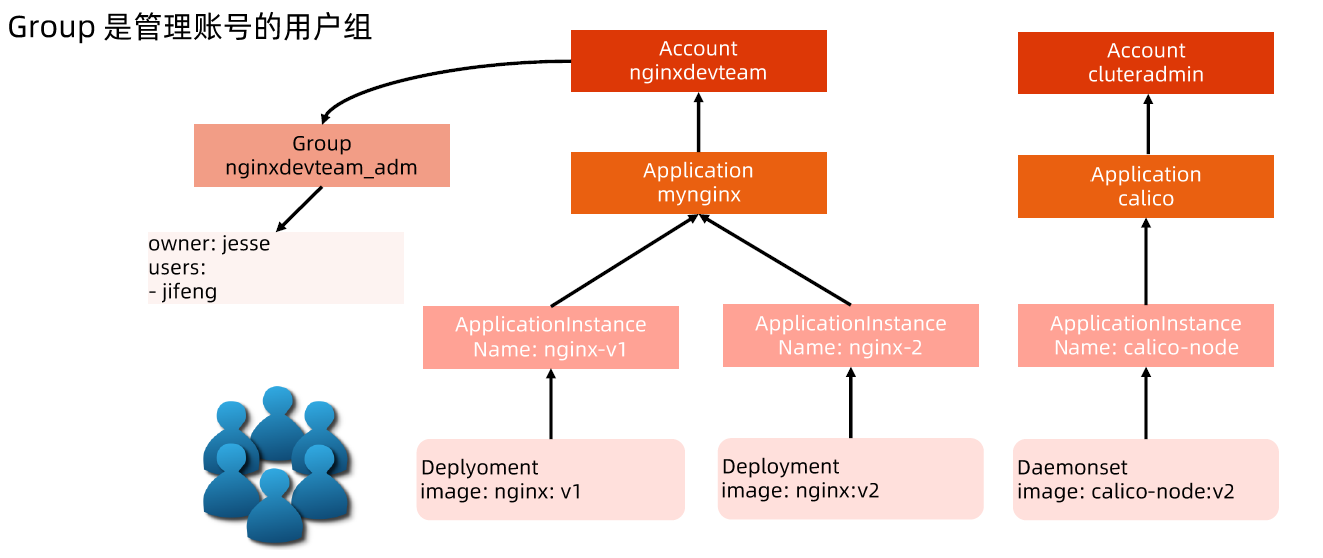
Account 树状分级
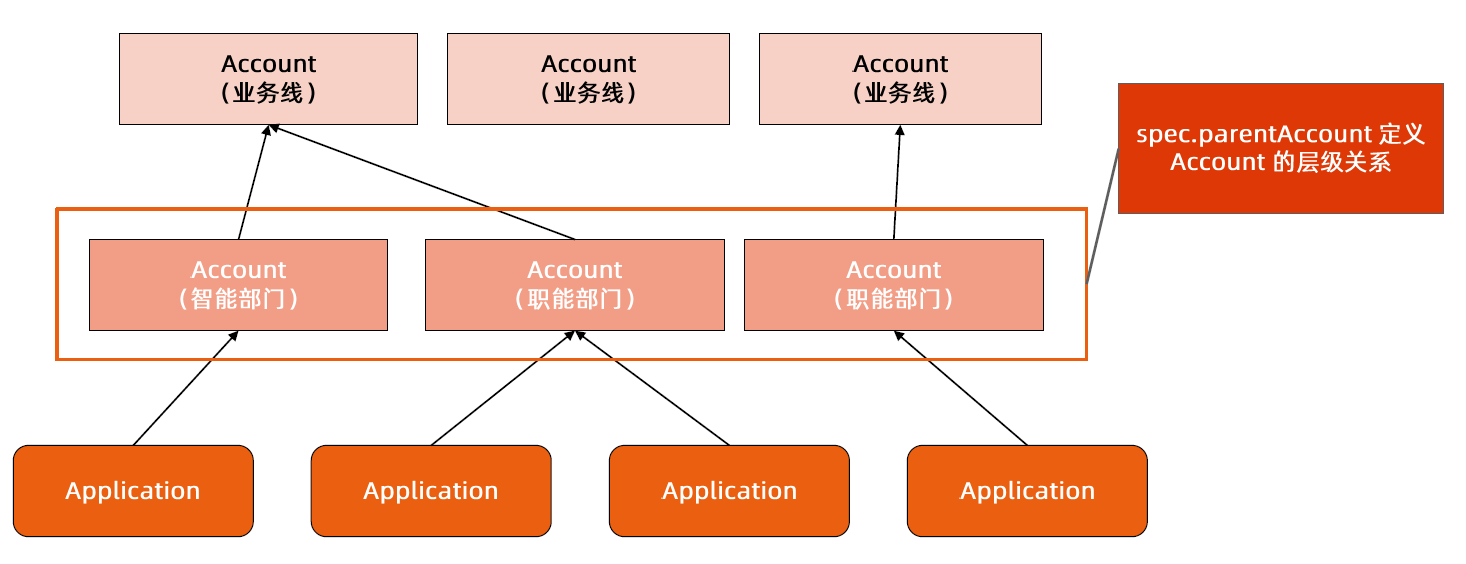
基于 Account 管理的企业组织架构
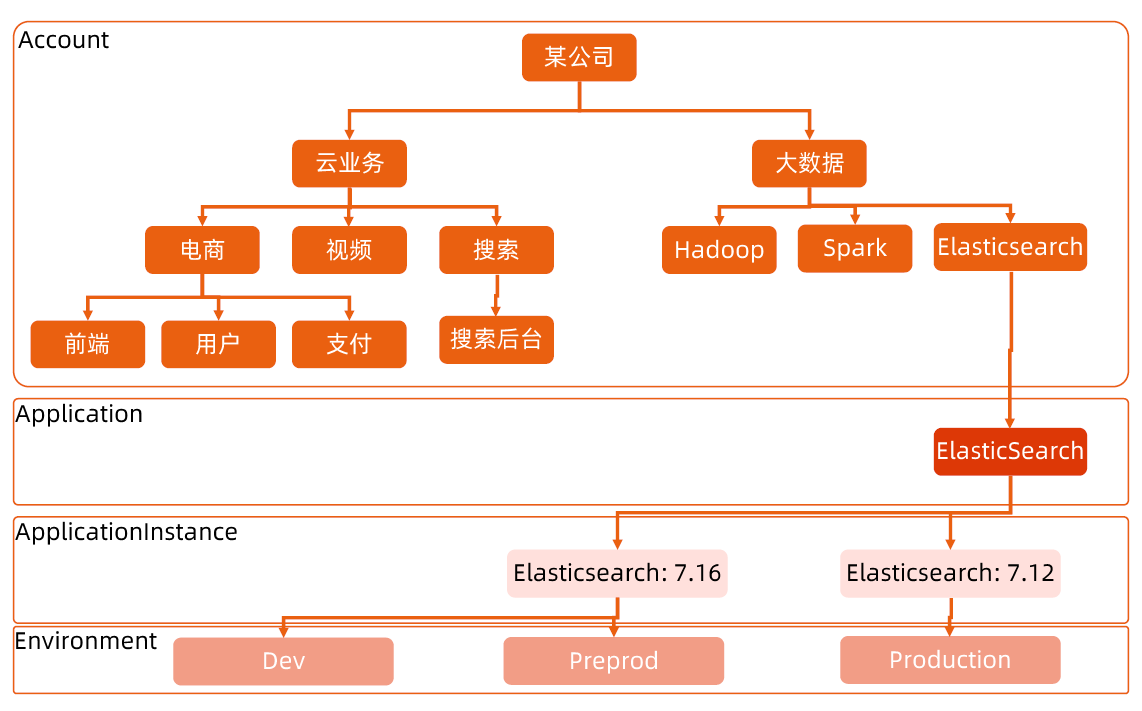
新模型与 Kubernetes 原生对象的关联
将 Namespace 定义为应用运行的隔离环境
apiVersion: v1
kind: Namespace
metadata:
annotations:
application.k8s.io/name: mynginx # 该 Namespace 的默认 application
account.l8s.io/name: jesse
name:mynginx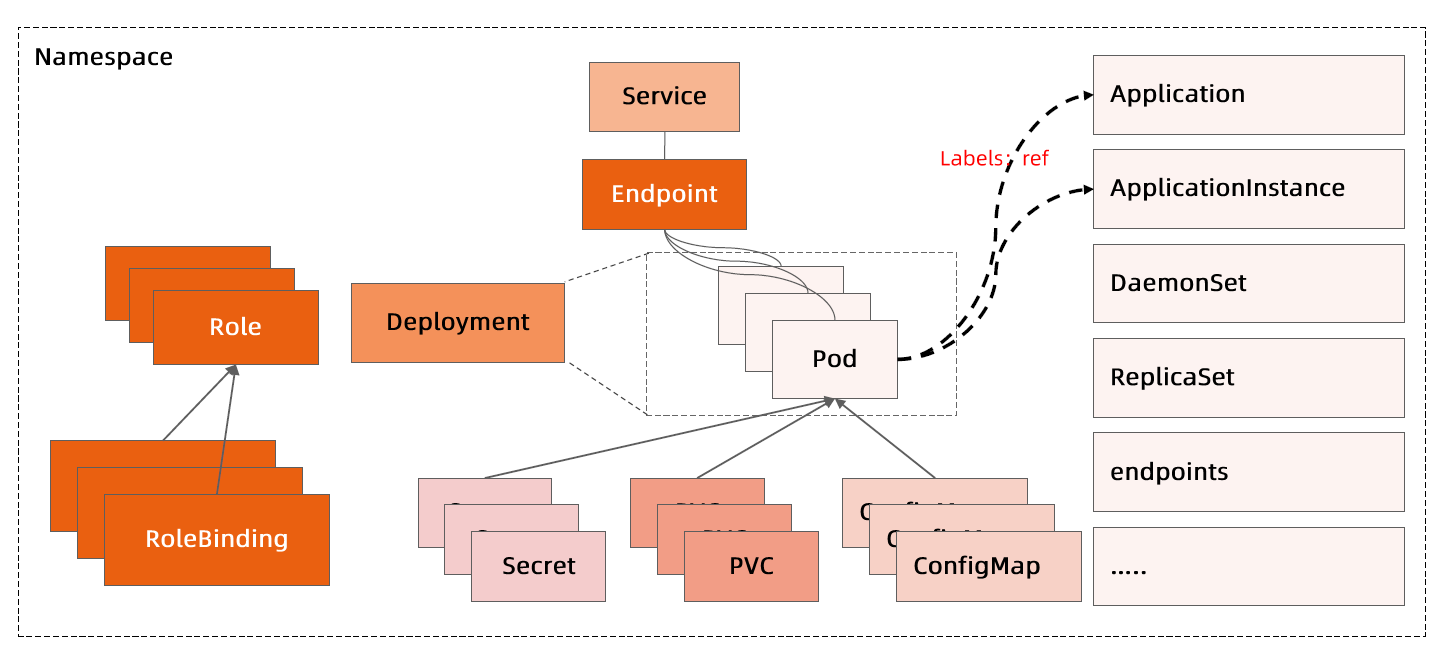
Kubernetes 应用实战回顾

基于 Bookinfo 的服务治理
Bookinfo 简介
Bookinfo 应用分为四个单独的微服务
- productpage 会调用 details和reviews 两个微服务,用来生成页面。
- details 中包含了书籍的信息。
- reviews 中包含了书籍相关的评论。它还会调用ratings 微服务
- ratings 中包含了由书籍评价组成的评级信息。
reviews 微服务有3个版本,可用来展示各服务之间的不同的调用链路
- v1 版本不会调用 ratings 服务
- v2 版本会调用 ratings 服务,并使用1到5个黑色星形图标来显示评分信息
- v3 版本会调用 ratings 服务,并使用1到5个红色星形图标来显示评分信息
Bookinfo 应用架构
安装
# 下载
curl-L https://istio.io/downloadlstiosh
# 安装应用
cd /root/istio-1.12.0
kubectl label namespace default istio-injection=enabled
kubectl apply -f<(istioctl kube-inject -fsamples/bookinfo/platform/kube/bookinfo.yaml)第一步:将应用发布至istio ingress 网关
# 创建 Istio 配置对象
$ kubectl apply -f samples/bookinfo/networking/bookinfo-gateway.yaml
# 查看 Istio 网关入口
$ kubectlget svc -n istio-system
istio-ingressgateway LoadBalancer 10.109.127.136 <pending> 15021:30784/TCP,80:31783/TCP,443:31106/TCP,31400:31463/TCP,15443:31663/TCP 13d
# 通过 istio ingress 网关访问 Bookinfo
http://192.168.34.2:31783/productpage第二步:安全保证
# 将 http 网关转换为 https 网关
opensslreq -x509-sha256 -nodes -days 365 -newkeyrsa:2048 -subj '/0=cncampInc./CN=192.168.34.2' -keyout bookinfo.key -out bookinfo.crt
kubectl create -n istio-system secret tls bookinfo-credential --key=bookinfo.key -cert=bookinfo.crt
kubectlapply -f https-gateway.yaml
# 通过 https 端口访问 Bookinfo
https://192.168.34.2:31106/productpage第三步:开启全链路 mTLS
# 在开启全链路 mTLS 之前,直接访问 productpage 返回成功;
# 创建全局默认 PeerAuthentication
$ kubectl apply -f mtls.yaml -n istio-system
# 在开启全链路 mTLS 之后,直接访问 productpage 返回不成功第四步:开启服务认证授权
# 创建 RequestAuthentication,解密JWT token,
kubectl apply -f requestauthentication.yaml
# 创建 AuthorizationPolicy,开启 details 服务基于 JWT 授权;
kubectl apply -f authorizationpolicy.yaml
# 访问 productpage 页面,会看到 details 已经无法显示,
# Sorry, product details are currently unavailable for this book.
# 改造 productpage 应用;
# cat productpage-v2/productpage.py
# 部署 productpage v2.
kubectl apply -f productpage-v2/productpage.yaml
# scale down productpage v1第五步:开启 http 到 https 的跳转
# 更新 gateway,增加 80 端口并设置 TLS 转发规则;
kubectl apply -f https-gateway.yaml
# 访问 gateway(基于浏览器的跳转不工作,因为 http redirect 跳转至默认端口)
curl 10.109.127.136/productpage -v -L -k第六步:开启 Kiali
# 安装 Prometheus;
kubectl apply -f prometheus.yaml
# 安装 Kiali;
kubectl apply -f samples/addons/kiali.yaml
# 更新 Kiali service 为 NodePort 类型;
k edit svc kiali -n istio-system
# 登录 Kialia,进入 Graph 页面查看调用视图
# http://192.168.34.2:31816/第七步:灰度发布
灰度,就是存在于黑与白之间的一个平滑过渡的区域。 对于互联网产品来说,上线和未上线就是黑与白之分,而实现未上线功能平稳过渡的一种方式就叫做灰度发布。
按流量百分比
先到先得的方式,比如: 限制10% 的用户体验的是新版本,90%的用户体验的是老版本。先访问网站的用户就优先命中新版本,直到流量用完为止。
按人群划分
按用户 ID、用户 IP、设备类型划分,比如:可通过平时的埋点上报数据得知用户的 PV、UV、页面平均访问时长等数据,根据用户活跃度来让用户优先体验新版本,进而快速观察使用效果。
按地域、性别、年龄等用户画像划分,比如:可通过用户的性别、年龄等做下新老版本的对比效果来看看目标用户在新版本的使用年龄段,性别范围是多少。
# 为每个服务创建 destinationrule,该步骤将所有服务按版本切分为不同子集;
kubectl apply -f samples/bookinfo/networking/destination-rule-all.yaml
# 将所有流量转发至v1;
kubectl apply -f samples/bookinfo/networking/virtual-service-all-v1.yaml
# 访问 Bookinfo,可看到 ratings 从三个版本轮番切换变成了不显示,因为reviews v1 版本不调用ratings;
# 定义灰度流量规则,将jason用户切换至reviews v2;
kubectl apply -f samples/bookinfo/networking/virtual-service-reviews-test-v2.yaml
# 访问 Bookinfo,课看到 ratings 变为固定版本。第八步:故障注入
故障注入通常用于混乱测试场景,确保单个服务出现故障不会引起联动效应,导致局部错误引起全局系统性故障;
# 为 ratings 服务 v2 添加固定延迟时间:
kubectl apply-fsamples/bookinfo/networking/virtual-service-ratings-test-delay.yaml
# 更新后,延迟超出了客户端的等待时间,当登录用户为jason时,productpage页面出错,其他用户
# Sorry, product reviews are currently unavailable for this book.
# 为 ratings 服务添加错误返回值;
kubectl apply -f samples/bookinfo/networking/virtual-service-ratings-test-abort.yaml
# 更新后 ratings 服务不可用。第九步:最佳实践
记得为客户端添加超时时间
http:
- route:
- destination:
host: reviews
subset: v2
timeout: 0.5s记得加断路器规则
trafficPolicy:
connectionPool:
tcp:
maxConnections: 1
http:
http1MaxPendingRequests: 1
maxRequestsPerconnection: 1
outlierDetection:
consecutive5xxErrors: 1
interval: 1s
baseEjectionTime: 3m
maxEjectionPercent: 100全课总结
回顾一下内容
Go语言
- 核心知识点和原理
容器技术
- Namespace
- Cgroup
- OverlayFS
- Network
- 最佳实践
Kubernetes
- 架构基础
- 核心组件
- 生产集群管理
- 集群运维
- 应用上云
服务网格
- 流量管理
- 安全

