开篇词
如何构建一个可靠的分布式系统?
作为一名架构师,在软件研发的过程中,最难的事儿,其实并不是如何解决具体某个缺陷、如何提升某段代码的性能,而是 如何才能让一系列来自不同开发者、不同厂商、不同版本、不同语言、质量也良莠不齐的软件模块,在不同的物理硬件和拓扑结构随时变动的网络环境中,依然能保证可靠的运行质量。
显然,这并不是一个研发过程的管理问题。一套”靠谱”的软件系统,尤其是大型的、分布式的软件系统,很难指望只依靠团队成员的个人能力水平,或者依靠质量管理流程来达成。
在我看来,这是一个系统性的、架构层面的问题,最终还是要在技术和架构中去解决。而这也正是我要在这门课中跟你一起探讨的主题: 如何构建一个可靠的分布式系统。
我是怎么规划课程的?
那么,为了能够讨论清楚这个话题,我把课程划分成了以下 5 个模块。
演进中的架构: 我会借着讨论历史之名,从全局性的视角,帮你梳理微服务发展历程中出现的大量技术名词、概念,让你了解这些技术的时代背景和探索过程,帮你在后续的课程讲解中,更容易去深入理解软件架构设计的本质。
分布式的基石:我会聚焦在分布式架构,和你探讨分布式带来的问题与应对策略。我会带你剖析分布式架构中出现的一系列问题,比如服务的注册发现、跟踪治理、负载均衡、故障隔离、认证授权、伸缩扩展、传输通讯、事务处理等,有哪些解决思路、方法和常见工具。
不可变基础设施:我会按照云原生时代”基础设施即代码”的新思路,带你深入理解基础设施不变性的目的、原理与实现途径,和你一起去体会用代码和用基础设施,来解决分布式问题的差异,让你能够理解不可变基础设施的内涵,便于在实际工作中做运维、程序升级和部署等工作。
探索与实践:我会带你一起开发不同架构的 Fenix”s Bookstore(”导读“这一讲会具体介绍这个项目),并看看在不同环境下都应该怎么部署。这个模块的定位是”实战”,为了保证学习效果,我特意没有安排音频,所以建议你一定要自己动手去实操。
因为我相信,如果你是一名驾驶初学者,最合理的学习路径应该是先把汽车发动,然后慢慢行驶起来,而不是马上从”引擎动力原理””变速箱构造”入手,去设法深刻地了解一台汽车。学习计算机技术也是同样的道理。所以在”探索与实践”模块,我会先带你从运行程序开始,看看效果,然后再搭建好开发、调试环境。
说到这里,我一定要和你说说怎么学习这门课,才能保证最好的效果。
你要怎么学习这门课?
如果你已经是一名系统架构师或者高级开发工程师了,那这门课程就非常适合你。通过跟随学习,你会知道,在软件设计、架构工作中,都需要考虑哪些因素、需要解决哪些问题、有哪些行业标准的解决方案。而如果你是个刚入行不久的程序员,那你可以把这门课程作为一个概念名词的速查手册。
很多内容对你来说可能是全新的,甚至会颠覆你过去的一些认知。而这门课程的好处就是,在不同的技术水平阶段,你都会找到不同的使用方法。具体怎么做呢?
- 第一步,先完整地跟着课程的节奏学习一遍。你可以先去串一下各种技术名词和架构理论概念,拓展一下视野,去看看大型的架构项目是怎么搭建的,涨涨见识,不一定要求自己深入地理解和记住每一讲的内容。
- 第二步,根据自己当前的情况,按图索骥寻找对应的章节深入学习并实践。
- 第三步,当你有了一定的实践经验之后,再来重新学习对应的章节,看看自己曾经的理解是否有遗漏或者有偏差,或者看看我的内容是否还有不完善的地方,真正将知识变成自己的认知。
写在最后
最后,我想说的是,我在极客时间上开设这门课程,既是为了分享与技术布道,也是为了借这个机会,系统性地整理自己的知识,查缺补漏,将它们都融入既有的知识框架之中。
我一直认为,技术人员的成长是有”捷径”的,做技术不仅要去看、去读、去想、去用,更要去写、去说。
把自己”认为掌握了的”知识给叙述出来,能够写得条理清晰,讲得理直气壮;能够让别人听得明白,释去心中疑惑;能够把自己的观点交给别人审视,乃至质疑。在这个过程之中,就会挖掘出很多潜藏在”已知”背后的”未知”。
什么是”The Fenix Project”?
软件架构探索
“Phoenix”的字面意思,就是”凤凰”,或者是”不死鸟”,这个词我们东方人不太常用,但它在西方的软件工程读物,尤其是关于 Agile、DevOps 话题的作品中经常会出现。
比如说,软件工程小说《The Phoenix Project》,就讲述了徘徊在死亡边缘的 Phoenix 项目,在精益方法下浴火重生的故事;马丁 · 福勒(Martin Fowler)对《Continuous Delivery》(持续交付)的诠释里,也多次提到过”Phoenix Server“(取其能够”涅槃重生”之意)与”Snowflake Server“(取其”世界上没有相同的两片雪花”之意)的优劣比对。

也许是东西方文化差异的原因,尽管我们东方人会说”失败是成功之母”,但骨子里还是更注重一次就能把事做对、做好,尽量别出乱子;而西方人则要”更看得开”一些,把出错看作是正常、甚至是必须的发展过程,只要出了问题能够兜底,能重回正轨就好。
其实在软件工程的世界里,任何产品的研发,只要时间尺度足够长,人就总会疏忽犯错,代码就总会带有缺陷,电脑就总会宕机崩溃,网络就总会堵塞中断……
所以如果一项工程需要大量的人员共同去研发,并保证它们分布在网络中的大量服务器节点能够同时运行,那么随着项目规模的增大、运作时间变长,它必然会受到墨菲定律的无情打击。
Murphy”s Law: Anything that can go wrong will go wrong.
墨菲定律:凡事只要有可能出错,那就一定会出错。
这样问题就来了:为了得到高质量的软件产品,我们是应该把精力更多地集中在提升每一个人员、过程、产出物的能力和质量上,还是放在整体流程和架构上?
这里我先给一个”和稀泥”式的回答:这两者都重要。前者重术,后者重道;前者更多与编码能力相关,后者更多与软件架构相关;前者主要由开发者个体水平决定,后者主要由技术决策者水平决定。
但是,我也必须要强调这个问题的另外一面:这两者的理解路径和抽象程度是不一样的。
如何学习一项具体的语言、框架、工具,比如 Java、Spring、Vue.js,等等,都是相对具象的,不论其蕴含的内容多少、复杂程度的高低,它们至少是能看得见、摸得着的。
而如何学习某一种风格的架构方法,比如单体、微服务、服务网格、无服务、云原生,等等,则是相对抽象的,谈论它们可能要面临着”一百个人眼中有一百个哈姆雷特”的困境。
所以,探讨这方面的话题,要想言之有物,就不能只是单纯的经验陈述了。
那么我就想,回到这些架构根本的出发点和问题上,带你一起真正去使用这些不同风格的架构方法,来实现某些需求、解决某些问题,然后在实践中观察它们的异同优劣,这会是一种很好的,也许是最好的学习方式。
可靠的系统
我们接着前面提出的”人与系统”的探讨,再来思考一个问题: 构建一个大规模但依然可靠的软件系统,是否可行?
看到这个问题,你的第一感觉可能会认为有点荒谬:废话。如果这个事情从理论上来说就根本不可能的话,那我们这些做软件开发的还在瞎忙活些什么呢?
但你再仔细想想,根据”墨菲定律”和在”大规模”这个前提下,在做软件开发时,你一定会遇到各种不靠谱的人员、代码、硬件、网络等因素。那你从中就能得出一个听起来很符合逻辑直觉的推论: 如果一项工作,要经过多个”不靠谱”的过程相互协作来完成,其中的误差应该会不断地累积叠加,导致最终结果必然不能收敛稳定才对。
这个问题,也并不是杞人忧天、庸人自扰式的瞎操心,计算机之父冯 · 诺依曼(John von Neumann)在 1940 年代末期,就曾经花了大约两年的时间,来研究这个问题,并且得出了一门理论《自复制自动机》(Theory of Self-Reproducing Automata),这个理论以机器应该如何从基本的部件中,构造出与自身相同的另一台机器引出。
他的目的并不是想单纯地模拟或者理解生物体的自我复制,也并不是简单地想制造自我复制的计算机,而就是想回答一个理论问题: 如何用一些不可靠的部件来构造出一个可靠的系统。

所以说,自复制机恰好就是一个最好的、用不可靠部件构造的可靠系统的例子。这里的”不可靠部件”,你可以理解为构成生命的大量细胞、甚至是分子。由于热力学扰动、生物复制差错等因素的干扰,这些分子本身并不可靠。
但是,生命系统之所以可靠的本质,恰恰是因为它可以使用不可靠的部件来完成遗传迭代。这其中的关键点,便是承认细胞、分子等这些零部件可能会出错,某个具体的零部件可能会崩溃消亡,但在存续生命的微生态系统中,一定会有其后代的出现,重新代替该零部件的作用,以维持系统的整体稳定。
因而,在这个微生态里,每一个部件都可以看作是一只不死鸟(Phoenix),它会老迈,而之后又能涅槃重生。
虽然几乎是在计算机诞生的同时,计算机科学家就开始研究如何构造可靠的软件系统,并且得到了”像 Phoenix 一样迭代的生态才是可靠的”明确的结论,但是软件架构却不是一蹴而就地直接照这个结论去设计。原因也很简单,因为软件架构有一个逐渐演进的过程。
架构的演进
软件架构风格从大型机(Mainframe),发展到了多层单体架构(Monolithic),到分布式(Distributed),到微服务(Microservices),到服务网格(Service Mesh),到无服务(Serverless)……你能发现,在技术架构上确实呈现出”从大到小”的发展趋势。
这几年微服务兴起后,出现了各类文章去总结、去赞美它的各种好处,比如简化了部署、逻辑拆分更清晰、便于技术异构、易于伸缩拓展应对更高的性能,等等。没错,这些都是微服务架构非常重要的优点,也是企业去搭建微服务的动力。
可是,如果不拘泥于特定系统或特定的某个问题,我们从更宏观的角度来看,前面所列举的这些好处,都只能算是”锦上添花”、是让系统”活得更好”的动因,肯定比不上系统如何”确保生存”的需求来得更关键、本质。
在我看来,架构演变最重要的驱动力,或者说产生这种”从大到小”趋势的最根本的驱动力,始终都是 为了方便某个服务能够顺利地”死去”与”重生”而设计 的。个体服务的生死更迭,是关系到整个系统能否可靠续存的关键因素。
我举个例子。假设某个企业中应用的是单体架构的 Java 系统,它的更新、升级都必须要有固定的停机计划,必须在特定的时间窗口内才能按时开始,而且必须按时结束。如果出现了非计划之中的宕机,那就是生产事故。
但是,软件的缺陷不会遵循领导定下的停机计划来”安排时间出错”,所以为了应对缺陷与变化,做到不停机地检修,Java 曾经搞出了 OSGi 和 JVMTI Instrumentation 等这样复杂的 HotSwap 方案,以实现给奔跑中的汽车更换轮胎这种匪夷所思却又无可奈何的需求。
而在微服务架构的视角下,所谓的系统检修,只不过是一次在线服务更新而已,先停掉 1/3 的机器,升级新的软件版本,再有条不紊地导流、测试、做金丝雀发布,一切都是显得如此理所当然;而在无服务架构的视角下,我们甚至都不可能去关心服务所运行的基础设施,甚至连机器是哪台都不用知道,停机升级什么的就根本无从谈起了。
流水不腐,有老朽、有消亡、有重生、有更迭,才是正常生态的运作合理规律。
那么你来设想一下,如果你的系统中,每个部件都符合”Phoenix”的特性,哪怕其中的某些部件采用了极不靠谱的程序代码,哪怕存在严重的内存泄漏问题,最多只能服务三分钟就一定会崩溃。而即便这样,只要在整体架构设计中,有恰当的、自动化的错误熔断、服务淘汰和重建的机制,那在系统外部来观察,它在整体上仍然有可能表现出稳定和健壮的服务能力。
铺垫到这里,我就可以给你解释清楚,到底什么是”The Fenix Project”了。
为什么叫做”The Fenix Project”?
你应该也知道,在企业软件开发的历史中,当发布一项新技术的时候,常常会有伴以该技术开发的”宠物店(PetStore)”作为演示的传统(如J2EE PetStore、.NET PetShop、Spring PetClinic等)。
所以,在课程里,我在带你做不同架构风格的演示时,也希望能遵循这个传统。不过无奈的是,我从来没养过宠物,于是就改行开了书店(Fenix”s Bookstore),里面出售了几本我写过的书,算是夹带了一点私货,这样也避免了在使用素材时可能产生的版权问题。
另外,尽管我相信没有人会误解,但我还是想多强调一句,Oracle、Microsoft、Pivotal 等公司设计宠物店的目的,绝不是为了日后能在网上贩卖小猫小狗,他们只是在纯粹地演示技术。
所以说,你也不要以”实现这种学生毕业设计复杂度的需求,却引入如此规模的架构或框架,纯属大炮打苍蝇,肯定是过度设计”的眼光,来看待这个”Fenix”s Bookstore”项目。
相反,如果可能的话,我会在有新的技术、框架发布出来的时候,持续更新,以恰当的形式添加到项目的不同版本中,让它的技术栈越来越复杂。我希望把这些新的、不断发展的知识,融合进已有的知识框架之中,让自己学习、理解、思考,然后将这些技术连同自己的观点看法,分享给你。
说到这儿,我和”Fenix”这个名字还有一段奇妙的缘分。在二十多年前,我就开始用”IcyFenix”这个网名了。这个名字来源于暴雪公司的即时战略游戏《星际争霸》,里面有一个 Protoss(普罗托斯)英雄叫Fenix(菲尼克斯)。就像这个名字所预示的那样,Fenix 曾经是 Zealot(狂热者),牺牲后以 Dragoon(龙骑兵)的形式重生,带领 Protoss 与刀锋女王 Kerrigan(凯瑞甘)继续抗争。
所以,既然我们要开始一段关于”Phoenix”的代码与故事,那便叫它”The Fenix Project”,如何?
演进中的架构
01 | 原始分布式时代:Unix设计哲学下的服务探索
架构并不是被”发明”出来的,而是持续进化的结果。所以在这一模块中,我会借着讨论历史之名,从全局性的视角,来带你一起梳理下微服务的发展历程中,出现的大量技术名词、概念。
我会和你一起去分析,它们都是什么、取代了什么,以及为什么能够在技术发展的斗争中取得成功,为什么会成为软件架构不可或缺的支撑;又或者它们为什么会失败,为什么会逐渐被我们遗忘。
了解了这些技术的时代背景和探索过程,在后续的课程中,我再去讲解它们的原理、它们是如何解决问题的时候,你就能与它们当初的设计思想产生共鸣,能更容易深入理解其本质了。
今天这一讲,让我们先把时间拨回到半个世纪之前,一起来探讨下计算机最开始进入公众视野的时候,在 Unix 设计哲学的指导下,分布式架构的第一次服务化探索的得与失。
Unix 的分布式设计哲学
Simplicity of both the interface and the implementation are more important than any other attributes of the system — including correctness, consistency, and completeness.
保持接口与实现的简单性,比系统的任何其他属性,包括准确性、一致性和完整性,都来得更加重要。
分布式架构的目标是使用多个独立的分布式服务,来共同构建一个更大型的系统。不过,可能跟绝大多数人心中的认知有点儿差异,分布式系统的设想和它实际的尝试,反而要比你今天所了解的大型单体系统出现的时间更早。
在 20 世纪 70 年代末到 80 年代初,计算机科学刚经历了从以大型机为主,到向以微型机为主的蜕变,计算机也逐渐从一种存在于研究机构、实验室当中的科研设备,转变为了存在于商业企业中的生产设备,甚至是面向家庭、个人用户的娱乐设备。
这个时候的微型计算机系统,通常具有 16 位寻址能力、不足 5MHz(兆赫)时钟频率的处理器和 128KB 左右的内存地址空间。比如说,著名的英特尔处理器的鼻祖,Intel 8086 处理器 就是在 1978 年研制成功,流行于 80 年代中期的,甚至一直到 90 年代初期还在生产销售。
不过,因为当时的计算机硬件的运算处理能力还相当薄弱,已经直接妨碍了单台计算机上信息系统软件能够达到的最大规模。所以,为了突破硬件算力的限制,各个高校、研究机构、软硬件厂商,都开始分头探索,想看看到底能不能使用多台计算机共同协作,来支撑同一套软件系统的运行。
这个阶段其实是对分布式架构最原始的探索与研究。你可能会觉得奇怪, 计算机科学这个技术发展一日千里的领域,半个世纪之前的研究对今天还能有什么指导意义? 那个时候探索的分布式如果是可行的,又怎么会拖到今时今日,软件系统才逐步进入微服务时代?
然而并非如此,从结果来看,历史局限决定了它不可能一蹴而就地解决分布式的难题,但仅从过程来看,这个阶段的探索可以称得上是硕果累累、成绩斐然。因为在这个时期提出的很多技术、概念,对 Unix 系统后续的发展,甚至是对今天计算机科学的很多领域,都产生了巨大而深远的影响,直接带动了后续的软件架构演化进程。
我们看一些比较熟悉的例子吧。
比如,惠普公司(及后来被惠普收购的 Apollo),在 80 年代初期提出的 网络运算架构(Network Computing Architecture,NCA) ,就可以说是未来远程服务调用的雏形。
再比如,卡内基 · 梅隆大学提出的 AFS 文件系统(Andrew File System) ,可以看作是分布式文件系统的最早实现(顺便一提,Andrew 的意思是纪念 Andrew Carnegie 和 Andrew Mellon)。
再比如,麻省理工学院提出的 Kerberos 协议) ,是服务认证和访问控制(ACL)的基础性协议,是分布式服务安全性的重要支撑,目前包括 Windows 和 macOS 在内的众多操作系统的登录、认证功能,等等,都会利用到这个协议。
而为了避免 Unix 系统的版本战争 在分布式领域中重演,负责制定 Unix 系统技术标准的 开放软件基金会(Open Software Foundation,OSF,也就是后来的”国际开放标准组织”) 就邀请了各个主要的研究厂商一起参与,共同制订了 “分布式运算环境”(Distributed Computing Environment,DCE) 的分布式技术体系。
DCE 包括了一整套完整的分布式服务组件的规范与实现。
比如,源自 NCA 的远程服务调用规范(Remote Procedure Call,RPC,在当时被称为是 DCE/RPC ),跟后来不局限于 Unix 系统的、基于通用 TCP/IP 协议的远程服务标准 ONC RPC ,一起被认为是现代 RPC 的共同鼻祖(这是 Sun 公司向互联网工程任务组提交的);源自 AFS 的分布式文件系统(Distributed File System,DFS)规范,在当时被称为 DCE/DFS ;源自 Kerberos 的服务认证规范;还有时间服务、命名与目录服务,就连现在程序中很常用的通用唯一识别符 UUID,也是在 DCE 中发明出来的。
因为 OSF 本身的背景(它是一个由 Unix 开发者组成的 Unix 标准化组织),所以在当时研究这些分布式技术,通常都会有一个预设的重要原则,也就是在实现分布式环境中的服务调用、资源访问、数据存储等操作的时候,要尽可能地透明化、简单化,让开发人员不用去过于关注他们访问的方法,或者是要知道其他资源是位于本地还是远程。
这样的主旨呢,确实非常符合 Unix 设计哲学 (有过几个版本的不同说法,这里我指的是 Common Lisp 作者 Richard P. Gabriel 提出的简单优先” Worse is Better “原则),但这个目标其实是过于理想化了,它存在一些在当时根本不可能完美解决的技术困难。
“调用远程方法”与”调用本地方法”尽管只是两字之差,但要是想能同时兼顾到简单、透明、性能、正确、鲁棒(Robust)、一致的目标的话,两者的复杂度就完全不能相提并论了。
我们先不说,远程方法是不可能做到像本地方法一样,能用内联等传统编译原理中的优化算法,来提升程序运行速度的,光是”远程”二字带来的网络环境下的新问题。
比如说,远程的服务在哪里(服务发现)、有多少个(负载均衡)、网络出现分区、超时或者服务出错了怎么办(熔断、隔离、降级)、方法的参数与返回结果如何表示(序列化协议)、如何传输(传输协议)、服务权限如何管理(认证、授权)、如何保证通信安全(网络安全层)、如何令调用不同机器的服务能返回相同的结果(分布式数据一致性)等一系列问题,就需要设计者耗费大量的心思。
那么,面对重重的困难与压力, DCE 不仅从零开始、从无到有地回答了其中大部分问题,构建出了大量的分布式基础组件与协议,而且它还真的尽力去做到了相对意义的”透明”。
比如说,你在 DFS 上访问文件,如果不考虑性能上的差异的话,就很难感受到,它与本地磁盘文件系统有什么不同。可是,一旦考虑性能上的差异,分布式和本地的鸿沟是无比深刻的,这是数量级上的差距,是不可调和的。
尤其是在那个年代,在机器硬件的限制下,开发者为了让程序在运行效率上可以接受,就只有在方法本身的运行时间很长,可以相对忽略远程调用成本时的情况下,才去考虑使用分布式。如果方法本身的运行时长不够,就要人为地用各种奇技淫巧来刻意构造出这样的场景,比如可能会将几个原本毫无关系的方法打包到一个方法内,一块进行远程调用。
一方面,刻意构造长时间运行的方法这本身就与使用分布式来突破硬件算力、提升性能的初衷相互矛盾,需要我们小心平衡;另一方面,此时的开发人员,实际上仍然必须无时无刻地都要意识到,自己是在编写分布式的程序,不能随随便便地踏过本地与远程的界限,让软件系统的设计向性能做出妥协,让 DCE”尽量简单透明”的努力几乎全部付诸东流。
因为本地与远程,无论是从编码、部署,还是从运行效率的角度上看,都有着天壤之别,所以在设计一个能运作良好的分布式应用的时候,就变得需要极高的编程技巧和各方面的知识来作为支撑,这个时候,反而是人员本身对软件规模的约束,超过机器算力上的约束了。
对 DCE 的研究呢,算得上是计算机科学中第一次有组织领导、有标准可循、有巨大投入的分布式计算的尝试。但无论是 DCE,还是稍后出现的 CORBA(Common ObjectRequest Broker Architecture,公共对象请求代理体系结构),我们从结果来看,都不能说它们取得了成功。
因为把一个系统直接拆分到不同的机器之中,这样做带来的服务的发现、跟踪、通讯、容错、隔离、配置、传输、数据一致性和编码复杂度等方面的问题,所付出的代价远远超过了分布式所取得的收益。
而亲身经历过那个年代的计算机科学家、IBM 院士凯尔 · 布朗(Kyle Brown),在事后曾经评价道,”这次尝试最大的收获就是对 RPC、DFS 等概念的开创,以及得到了一个价值千金的教训:某个功能能够进行分布式,并不意味着它就应该进行分布式,强行追求透明的分布式操作,只会自寻苦果”。
原始分布式时代的教训
Just because something can be distributed doesn’t mean it should be distributed. Trying to make a distributed call act like a local call always ends in tears.
某个功能能够进行分布式,并不意味着它就应该进行分布式,强行追求透明的分布式操作,只会自寻苦果。
—— Kyle Brown,IBM Fellow,Beyond buzzwords: A brief history of microservices patterns,2016
其实,从设计角度来看,以上的结论是有违 Unix 哲学的,但这也是在当时的现实情况下,不得不做出的让步。在当时计算机科学面前,有两条通往更大规模软件系统的道路, 一条路是尽快提升单机的处理能力,以避免分布式的种种问题;另一条路是找到更完美的解决方案,来应对如何构筑分布式系统的问题。
在 20 世纪 80 年代,正是 摩尔定律 开始稳定发挥作用的黄金时期,微型计算机的性能以每两年就增长一倍的惊人速度在提升,硬件算力束缚软件规模的链条,很快就松动了,我们用单台或者几台计算机,就可以作为服务器来支撑大型信息系统的运作了,信息系统进入了单体时代,而且在未来很长的一段时间内,单体系统都将是软件架构的主流。
不过尽管如此,对于另外一条路径,也就是对分布式计算、远程服务调用的探索,开发者们也从没有中断过。关于远程服务调用这个关键问题的历史、发展与现状,我还会在服务设计风格的”远程服务调用”部分(第 7~10 讲),以现代 RPC 和 RESTful 为主角,来进行更详细的讲述。而对于在原始分布式时代中遭遇到的其他问题,我也还会在软件架构演进的后面几个时代里,反复提起它们。
小结
今天,我给你介绍了计算机科学对分布式和服务化的第一次探索,着重分析了这次探索的主旨思想,也就是追求简单、符合 Unix 哲学的分布式系统,以及它当时所面临的困难,比如在捉襟见肘的运算能力、网络带宽下,设计不得不做出的妥协。
在这个过程中,我们接触到了 DCE、CORBA 等早期的分布式基础架构。其中许多的技术,比如远程服务调用、分布式文件系统、Kerberos 认证协议等。如果你对这些技术觉得还有点陌生、或者还有很多疑惑,没有关系,我还会在后面的课程中为你着重介绍。
原始分布式时代提出的构建”符合 Unix 的设计哲学的”,以及”如同本地调用一般简单透明的”分布式系统的这个目标,是软件开发者对分布式系统最初的美好愿景。不过迫于现实,它会在一定时期内被妥协、被舍弃,分布式将会经过一段越来越复杂的发展进程。
但是,到了三十多年以后的今天,随着微服务的逐渐成熟完善,成为大型软件的主流架构风格以后,这个美好的愿景终将还是会重新被开发者拾起。
一课一思
Richard P. Gabriel 提出的 Unix 设计哲学中写到:”保持接口与实现的简单性,比系统的任何其他属性,包括准确性、一致性和完整性,都来得更加重要。”
现在你来思考一下: 今天以微服务为代表的分布式系统,是如何看待”简单”的? 欢迎在留言区分享你的见解,我也将会在 第 5 讲”后微服务时代” 中,带你一起重新审视这个问题。
精选留言
Jxin
1.这个简单需要从两方面来看待,分别是业务和技术。
2.先说业务。现代的软件系统的业务复杂性越来越高。而分离关注点无疑是应对日益增长的业务复杂性的有效手段。但如果依旧是是一个大单体系统(所有业务单元都在一个容器下),那么跨业务单元的知识诉求便很难避免,并且开发迭代以及版本发布中彼此还会相互影响。而微服务的出现为其提供了设定物理边界的技术基础。使得多个特性团队对业务知识的诉求可以收敛在自身领域,降低单个特性团队所需了解的业务知识。
3.再说下技术。这里我认为主要提现在技术隔离上。就像rpc让你像调用本地方法一样调用远程方法,微服务技术组件的出现,大多是为了让开发人员可以基于意图去使用各种协调分布式系统的工具,而不用深入具体工具的实现细节去研究怎么解决的分布式难题。
4.同时就像 springboot 提到的生产就绪,微服务的生态已经不局限于开发的阶段。在部署和运行阶段都有健全组件支持。它可以让开发人员基于意图就可以简便的实现金丝雀发布,基于意图就能拿到所有系统运行期的数据。所有的这些便利都算是技术隔离带来的好处。
作者回复: 上述观点是比较深刻的。整个”演进中的架构”这部分,一条重要的逻辑线索就是软件工业对如何拆分业务、隔离技术复杂性的探索。从最初的不拆分,到通过越来越复杂的技术手段逐渐满足了业务的拆分与协作,再到追求隔离掉这些复杂技术手段,将它们掩埋于基础设施之中,到未来(有可能的)重新回到无需考虑算力、无需拆分的云端系统。
LYy
计算机技术一个关键命题是使用有限的”成本”尽可能”高效(性能)”的解决”复杂(度)”问题。
分布式的初期探索,其实就是在单机性能有限的情况下,期望通过”集群化”、”分离变化点”的架构手段来提升性能,但由于时代限制,这条路线的成本过高,同时随着摩尔定律+时间,性能问题在单机上得到了阶段性解决,所以才有了后面的单体时代。
但要解决的复杂度随着时代发展爆炸性增长,摩尔定律+时间这一法宝也日渐失灵,人们其实也不得不回到分布式这条路线上,于是有了后面微服务,云原生的故事。
02 | 单体系统时代:应用最广泛的架构风格
这一讲,我会带你去了解以单体架构构建的软件系统,都有哪些优势和缺点,还有哪些容易让人产生错误理解的误区。在探索的过程中,你可以同时思考一下,为什么单体架构能够在相当长的时间里成为软件架构的主流风格,然后再对比下我在这一讲最后给出答案。
大型单体系统
单体架构是绝大部分软件开发者都学习和实践过的一种软件架构,很多介绍微服务的图书和技术资料中,也常常会把这种架构形式的应用称作 “巨石系统”(Monolithic Application) 。
在整个软件架构演进的历史进程里,单体架构是出现时间最早、应用范围最广、使用人数最多、统治历史最长的一种架构风格。但”单体”这个名称,却是从微服务开始流行之后,才”事后追认”所形成的概念。在这之前,并没有多少人会把”单体”看成一种架构。
如果你去查找软件架构的开发资料,可以轻轻松松找到很多以微服务为主题的图书和文章,但却很难能找到专门教我们怎么开发单体系统的任何形式的材料。
这一方面体现了单体架构本身的简单性;另一方面也体现出,在相当长的时间里,我们都已经习惯了,软件架构就应该是单体这种样子的。
那在剖析单体架构之前呢,我们有必要 先搞清楚一个思维误区 ,那就是单体架构是落后的系统架构风格,最终会被微服务所取代。
因为在许多微服务的研究资料里,单体系统往往是以”反派角色”的身份登场的,比如著名的微服务入门书《 微服务架构设计模式 》,第一章的名字就是”逃离单体的地狱”。而这些材料所讲的单体系统,其实都有一个没有明说的隐含定语:”大型的单体系统”。
对于小型系统,也就是用单台机器就足以支撑其良好运行的系统来说,这样的单体不仅易于开发、易于测试、易于部署,而且因为各个功能、模块、方法的调用过程,都是在进程内调用的,不会发生 进程间通讯 ,所以程序的运行效率也要比分布式系统更高,完全不应该被贴上”反派角色”的标签。要我说的话,反倒是那些爱赶技术潮流,却不顾需求现状的微服务吹捧者更像是个反派。
进程间通讯:Inter-Process Communication,IPC。RPC 属于 IPC 的一种特例,但请注意,这里两个”PC”不是同个单词的缩写,关于 IPC 与 RPC 的知识,在”远程服务调用”这个小章节中我会详细讲解。
所以,当我们在讨论单体系统的缺陷的时候,必须基于软件的性能需求超过了单机,软件的开发人员规模明显超过了” 2 Pizza Teams “范畴的前提下,这样才有讨论的价值。那么,在咱们课程后续讨论中,我所说的单体,都应该是特指的”大型的单体系统”。
也正因如此,在这一讲的开篇中”单体是出现最早的架构风格”,跟我在上一讲介绍”原始分布式时代”时,在开篇中提到的”使用多个独立的分布式服务共同构建一个更大型系统的设想与实际尝试,反而要比今天你所了解的大型单体系统出现的时间更早”,这两句话实际上并没有矛盾的地方。
可拆分的单体系统
好了,回到主题,接下来我就带你来详细、深入地了解一下单体系统,看看”巨石系统”为何仍然是可以拆分的。
尽管”Monolithic”这个词语本身的意思”巨石”,确实是带有一些”不可拆分”的隐含意味,但我们也不能简单粗暴地把单体系统在维基百科上的定义”All in One Piece”,翻译成”铁板一块”,它其实更接近于自给自足(Self-Contained)的含义。
单体系统
Monolith means composed all in one piece. The Monolithic application describes a single-tiered software application in which different components combined into a single program from a single platform.
—— Monolithic Application,Wikipedia
当然了,这种”铁板一块”的译法也不全是段子。我相信肯定有一部分人说起单体架构、巨石系统的缺点,脑海中闪过的第一印象就是”不可拆分”,难以扩展,所以它才不能支撑起越来越大的软件规模。这种想法我觉得其实是有失偏颇的,至少不完整。
我为什么会这么判断呢?
因为从 纵向角度 来看,在现代信息系统中,我从来没有见到过实际的生产环境里,有哪个大型的系统是完全不分层的。
分层架构(Layered Architecture)已经是现在几乎所有的信息系统建设中,都普遍认可、普遍采用的软件设计方法了。无论是单体还是微服务,或者是其他架构风格,都会对代码进行纵向拆分,收到的外部请求会在各层之间,以不同形式的数据结构进行流转传递,在触及到最末端的数据库后依次返回响应。
那么,对于单体架构来说,在这个意义上的”可拆分”,单体其实完全不会展露出丝毫的弱势,反而还可能因为更容易开发、部署、测试而更加便捷。比如说,当前市面上所有主流的 IDE,如 Intellij IDEA、Eclipse 等,都对单体架构最为友好。IDE 提供的代码分析、重构能力,以及对编译结果的自动化部署和调试能力,都是主要面向单体架构而设计的。
.webp)
(上图来自 O’Reilly 的开放文档《 Software Architecture Patterns 》)
而在 横向角度 的”可拆分”上,单体架构也可以支持按照技术、功能、职责等角度,把软件拆分为各种模块,以便重用和团队管理。
实际上,单体系统并不意味着就只能有一个整体的程序封装形式,如果有需要,它完全可以由多个 JAR、WAR、DLL、Assembly 或者其他模块格式来构成。
即使是从 横向扩展(Scale Horizontally) 的角度来衡量,如果我们要在负载均衡器之后,同时部署若干个单体系统的副本,以达到分摊流量压力的效果,那么基于单体架构,也是轻而易举就可以实现的。
非独立的单体
不过,在”拆分”这方面, 单体系统的真正缺陷实际上并不在于要如何拆分,而在于拆分之后,它会存在隔离与自治能力上的欠缺。
在单体架构中,所有的代码都运行在同一个进程空间之内,所有模块、方法的调用也都不需要考虑网络分区、对象复制这些麻烦事儿,也不担心因为数据交换而造成性能的损失。
可是,在获得了进程内调用的简单、高效这些好处的同时,也就意味着,如果在单体架构中,有任何一部分的代码出现了缺陷,过度消耗进程空间内的公共资源,那所造成的影响就是全局性的、难以隔离的。
我们要怎么理解这个问题呢?
首先,一旦架构中出现了内存泄漏、线程爆炸、阻塞、死循环等问题,就都将会影响到整个程序的运行,而不仅仅是某一个功能、模块本身的正常运作;而如果消耗的是某些更高层次的公共资源,比如端口占用过多或者数据库连接池泄漏,还将会波及到整台机器,甚至是集群中其他单体副本的正常工作。
此外,同样是因为所有代码都共享着同一个进程空间,如果代码无法隔离,那也就意味着,我们无法做到单独停止、更新、升级某一部分代码,因为不可能有”停掉半个进程,重启 1/4 个进程”这样不合逻辑的操作。所以, 从动态可维护性的角度来说 ,单体系统也是有所不足的,对于程序升级、修改缺陷这样的工作,我们往往需要制定专门的停机更新计划,而且做灰度发布也相对会更加复杂。
补充:这里我说的”代码无法隔离,无法做到单独停止、更新……”,其实严谨来说还是有办法的,比如可以使用 OSGi 这种运行时模块化框架,只是会很别扭、很复杂。
这里就涉及到一个需要权衡的问题:如果说共享同一进程获得简单、高效这些优势的代价,是损失了各个功能模块的自治、隔离能力,那这两者孰轻孰重呢?这个问题很有代表性,我们还可以换个角度思考一下,它的潜台词其实是在比较微服务、单体架构哪种更好用、优秀?
在我看来,”好用和优秀”不一定是绝对的。我们看一个例子吧。
比如说,沃尔玛将超市分为仓储部、采购部、安保部、库存管理部、巡检部、质量管理部、市场营销部,等等,来划清职责,明确边界,让管理能力可以支持企业的成长规模;但如果你家楼下开的小卖部,爸、妈加儿子,再算上看家的中华田园犬小黄,一共也就只有四名员工,也去追求”先进管理”,来划分仓储部、采购部、库存管理部……的话,那纯粹是给自己找麻烦。
在单体架构下,哪怕是信息系统中两个毫无关联的子系统,我们也都必须部署到一起。当系统规模小的时候,这是个优势;但当系统规模扩大、程序需要修改的时候,相应的部署成本、技术升级时的迁移成本,都会变得非常高。
就拿沃尔玛例子来说,也就是当公司规模比较小的时候,让安保部和质检部两个不相干的部门在同一栋大楼中办公,算是节约资源。但当公司的人数增加了,办公室已经变得拥挤不堪的时候,我们也最多只能在楼顶加盖新楼层(相当于增强硬件性能),而不能让安保、质检分开地方办公,这才是缺陷所在。
另外,由于隔离能力的缺失,除了会带来难以阻断错误传播、不便于动态更新程序的问题,还会给带来难以 技术异构 等困难。
技术异构 :后面在介绍微服务时,我会提到马丁 · 福勒(Martin Fowler)提出的 9 个特征,技术异构就是其中之一。它的意思是说允许系统的每个模块,自由选择不一样的程序语言、不一样的编程框架等技术栈去实现。单体系统的技术栈异构不是一定做不到,比如 JNI 就可以让 Java 混用 C/C++,但是这也是很麻烦的事,是迫不得已下的选择。
不过,在我看来,我们提到的这些问题,还不是我们今天以微服务去代替单体系统的根本原因。我认为最根本的原因是:单体系统并不兼容” Phoenix “的特性。
单体这种架构风格,潜在的观念是希望系统的每一个部件,甚至每一处代码都尽量可靠,不出、少出错误,致力于构筑一个 7×24 小时不间断的可靠系统。
这种观念在小规模软件上能运作良好,但当系统越来越大的时候,交付一个可靠的单体系统就会变得越来越有挑战性。就像我在 导读《什么是”The Fenix Project”?》 中所说的,正是随着软件架构的不断演进,我们构建可靠系统的观念,开始从”追求尽量不出错”,转变为了正视”出错是必然”。实际上,这才是微服务架构能够挑战,并且能逐步开始代替运作了几十年的单体架构的根本驱动力。
不过,即使是为了允许程序出错,为了获得隔离、自治的能力,为了可以技术异构等目标,也并不意味着一定要依靠微服务架构。在新旧世纪之交,人们曾经探索过几种服务的拆分方法,把一个大的单体系统拆分为若干个更小的、不运行在同一个进程的独立服务,这些服务拆分的方法,后来导致了面向服务架构(Service-Oriented Architecture)的一段兴盛期,我们把它称作是” SOA 时代 “。
03 | SOA时代:成功理论与失败实践
SOA 架构是第一次被广泛使用过的、通过分布式服务来构建信息系统的工程实践。它有完善的理论和工具,可以说,它解决了分布式系统中,几乎所有主要的技术问题。
但遗憾的是,虽然 SOA 架构曾经被视为更大规模的软件发展的方向,但它最终还是没能成为一种普适的软件架构。
所以今天,我们就来探索一下 SOA 架构,一起来找找,它没能成为普适的软件架构的原因。通过这一讲,你能从中体会到 SOA 的设计思想与原则,理解它为什么不能成功。
三种代表性的服务拆分架构模式
在上一讲,我曾经提到过,为了对大型的单体系统进行拆分,让每一个子系统都能独立地部署、运行、更新,开发者们尝试了很多种方案。
所以,在介绍 SOA 架构模式之前,我还要先带你学习三种比较有代表性的服务拆分的架构模式。这些架构是 SOA 演化过程的中间产物,你也可以理解为,它们是 SOA 架构出现的必要前提。
烟囱式架构(Information Silo Architecture)
第一种架构模式是 烟囱式架构 。
信息烟囱也被叫做信息孤岛(Information Island),使用这种架构的系统呢,也被称为孤岛式信息系统或者烟囱式信息系统。这种信息系统,完全不会跟其他相关的信息系统之间进行互操作,或者是进行协调工作。
那你就会发现,这样的系统其实并没有什么”架构设计”可言。你还记不记得,我在上一讲中举的那个”企业与部门”的例子?如果两个部门真的完全不会发生任何交互,那我们就并没有什么理由,一定要强迫他们必须在一栋楼里办公。
所以,两个不发生交互的信息系统,让它们使用独立的数据库、服务器,就可以完成拆分了。
而唯一的问题,也是这个架构模式的致命问题,那就是: 企业中真的存在完全不发生交互的部门吗?
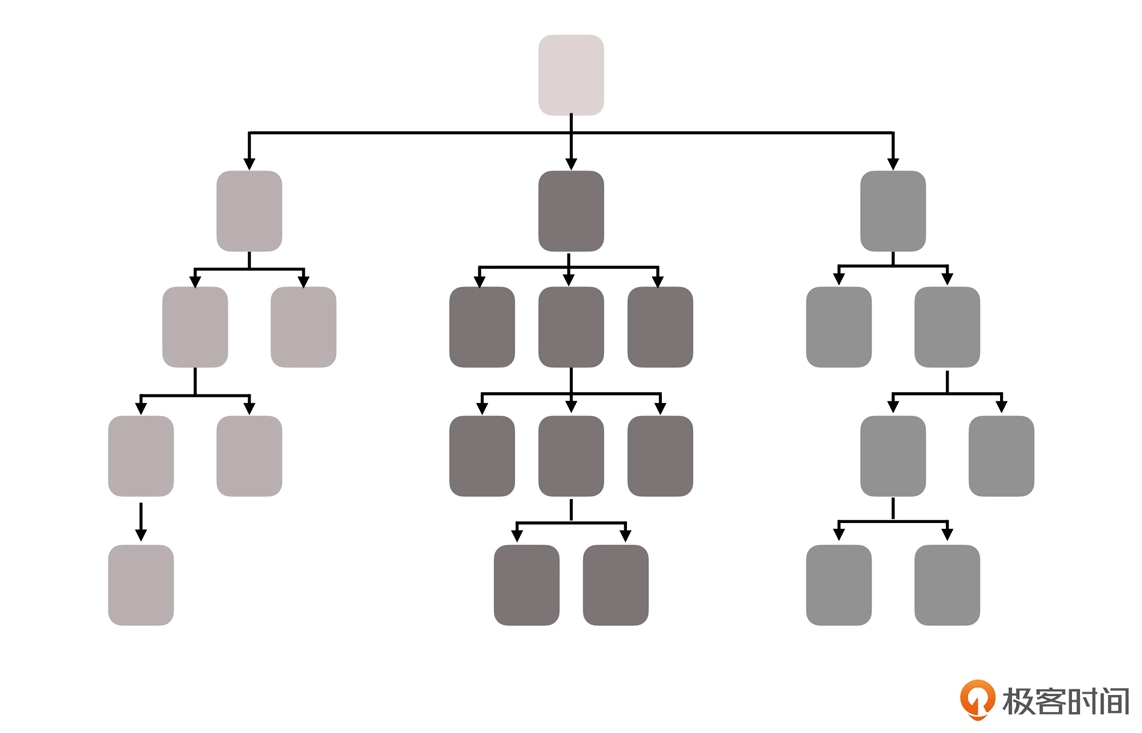
对于两个信息系统来说,哪怕真的毫无业务往来关系,但系统的人员、组织、权限等主数据,会是完全独立、没有任何重叠的吗?这样”独立拆分””老死不相往来”的系统,显然不可能是企业所希望见到的。
微内核架构(Microkernel Architecture)
第二种是 微内核架构 ,它也被称为插件式架构(Plug-in Architecture)。
既然在烟囱式架构中,我们说两个没有业务往来关系的系统,也可能需要共享人员、组织、权限等一些公共的主数据,那就不妨把这些主数据,连同其他可能被各个子系统使用到的公共服务、数据、资源,都集中到一块,成为一个被所有业务系统共同依赖的核心系统(Kernel,也称为 Core System)。
这样的话,具体的业务系统就能以 插件模块(Plug-in Modules) 的形式存在了,就可以为整个系统提供可扩展的、灵活的、天然隔离的功能特性。

(上图来自 O’Reilly 的开放文档《 Software Architecture Patterns 》)
以更高层次的抽象程度来看,任何计算机系统都是由各种架构的软件互相配合来实现各种功能的,这一讲我介绍的各种架构模式,一般都可以看作是整个系统的一种插件。对于产品型应用程序来说,如果我们想将新特性或者功能及时加入系统,微内核架构会是一个不错的选择。
微内核架构也可以嵌入到其它架构模式之中,通过插件的方式,来提供逐步演化的功能和增量开发。所以,如果你准备实现一个能够支持二次开发的软件系统,微内核就是一种良好的架构模式。
不过,微内核架构也有它的局限和使用前提,它会假设系统中各个插件模块之间是互不认识的(不可预知系统会安装哪些模块),这些插件会访问内核中一些公共的资源,但不会发生直接交互。
可是,无论是在企业信息系统还是在互联网,在许多场景中这一假设都不成立。比如说,你要建设一个购物网站,支付子系统和用户子系统是独立的,但当交易发生时,支付子系统可能需要从用户子系统中得到是否是 VIP、银行账号等信息,而用户子系统也可能要从支付子系统中获取交易金额等数据,来维护用户积分。
所以,我们必须找到一个办法,它既能拆分出独立的系统,也能让拆分后的子系统之间可以顺畅地互相调用通讯。
事件驱动架构(Event-Driven Architecture)
那么,为了能让子系统之间互相通讯, 事件驱动架构 就应运而生了。
这种架构模式的运作方案是,在子系统之间建立一套事件队列管道(Event Queues),来自系统外部的消息将以事件的形式发送到管道中,各个子系统可以从管道里获取自己感兴趣、可以处理的事件消息,也可以为事件新增或者是修改其中的附加信息,甚至还可以自己发布一些新的事件到管道队列中去。
这样一来,每一个消息的处理者都是独立的、高度解耦的,但它又能与其他处理者(如果存在该消息处理者的话)通过事件管道来进行互动。
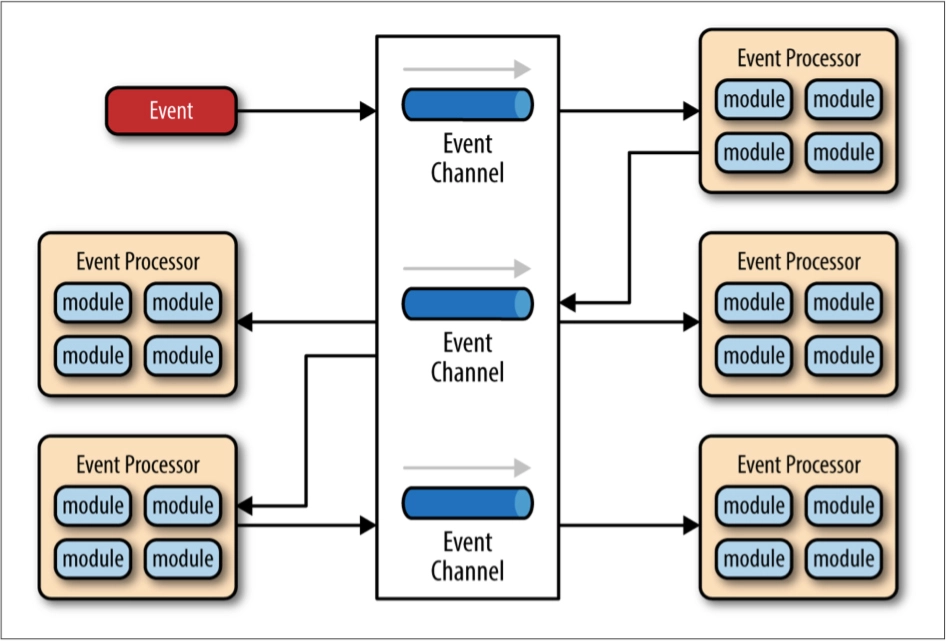
(上图来自 O’Reilly 的开放文档《 Software Architecture Patterns 》)
那么,当系统演化至事件驱动架构的时候,我在 原始分布式时代 这一讲的结尾中,提到的第二条通往大规模软件的路径,也就是仍然在并行发展的远程服务调用,就迎来了 SOAP 协议的诞生(我在后面第 7~10 讲分享远程服务调用的时候,还会给你详细介绍它,你到时可以再次印证一下这一讲的内容)。
此时”面向服务的架构”(Service Oriented Architecture,SOA),就已经有了登上软件架构舞台所需要的全部前置条件了。
SOA 架构时代的探索
SOA 的概念最早是由 Gartner 公司在 1994 年提出的。当时的 SOA 还不具备发展的条件,直到 2006 年情况才有所变化,IBM、Oracle、SAP 等公司,共同成立了 OSOA 联盟(Open Service Oriented Architecture),来联合制定和推进 SOA 相关行业标准。
到 2007 年,在 结构化资讯标准促进组织(Organization for the Advancement of Structured Information Standards,OASIS)) 的倡议与支持下,OSOA 就由一个软件厂商组成的松散联盟,转变为了一个制定行业标准的国际组织。它联合 OASIS 共同新成立了 Open CSA组织(Open Composite Services Architecture) ,也就是 SOA 的”官方管理机构”。
当软件架构发展至 SOA 时代的时候,其中的许多概念、思想都已经能在今天的微服务中,找到对应的身影了。比如说,服务之间的松散耦合、注册、发现、治理、隔离、编排等等,都是微服务架构中耳熟能详的概念了,也大多是在分布式服务刚被提出的时候,就已经可以预见到的困难。
所以,SOA 就针对这些问题,乃至于针对”软件开发”这件事儿本身,进行了更具体、更系统的探索。
更具体
“更具体”体现在,尽管 SOA 本身还是属于一种抽象概念,而不是特指某一种具体的技术,但它比单体架构和烟囱式架构、微内核架构、事件驱动架构,都要更具可操作性,细节也充实了很多。所以,我们已经不能简单地把 SOA 看作是一种架构风格了,而是可以称之为一套软件架构的基础平台了。
那,我们怎么理解”基础平台”这个概念呢?在我看来,主要是下面几个方面:
- SOA 拥有领导制定技术标准的组织 Open CSA;
- SOA 具有清晰的软件设计的指导原则,比如服务的封装性、自治、松耦合、可重用、可组合、无状态,等等;
- SOA 架构明确了采用 SOAP 作为远程调用的协议,依靠 SOAP 协议族(WSDL、UDDI 和一大票 WS-* 协议)来完成服务的发布、发现和治理;
- SOA 架构会利用一个被称为是 企业服务总线(Enterprise Service Bus,ESB) 的消息管道,来实现各个子系统之间的通讯交互,这就让各个服务间在 ESB 的调度下,不需要相互依赖就可以实- 现相互通讯,既带来了服务松耦合的好处,也为以后可以进一步实现 业务流程编排(Business Process Management,BPM) 提供了基础;
- SOA 架构使用了 服务数据对象(Service Data Object,SDO) 来访问和表示数据,使用 服务组件架构(Service Component Architecture,SCA) 来定义服务封装的形式和服务运行的容器;
- ……
在这一整套成体系、可以互相精密协作的技术组件的支持下,我们从技术可行性的角度来评判的话,SOA 实际上就可以算是成功地解决了分布式环境下,出现的诸如服务注册、发现、隔离、治理等主要技术问题了。
更系统
这里我说的”更系统”,指的是 SOA 的宏大理想。因为 SOA 最根本的目标,就是希望能够总结出一套自上而下的软件研发方法论,让企业只需要跟着它的思路,就能够一揽子解决掉软件开发过程中的全套问题。比如,如何挖掘需求、如何将需求分解为业务能力、如何编排已有服务、如何开发测试部署新的功能,等等。
如果这个目标真的能够达成,那么软件开发就有可能从此迈进工业化大生产的阶段。你可以试想一下,如果有一天,你在写符合客户需求的软件时,就像写八股文一样有迹可循、有法可依,那对你来说或许很无趣,但这肯定可以大幅提升整个社会实施信息化的效率。
SOA 在 21 世纪最初的十年里,曾经盛行一时,有 IBM 等一众巨头为其摇旗呐喊,吸引了不少软件开发商,尤其是企业级软件开发商的跟随,但最终却还是偃旗息鼓,沉寂了下去。
原因也很简单,开发信息系统毕竟不是写八股文,SOA 架构过于严谨精密的流程与理论,导致了软件开发的全过程,都需要有懂得复杂概念的专业人员才能够驾驭。从 SOA 诞生的那一天起,就已经注定了它只能是少数系统的阳春白雪式的精致奢侈品:它可以实现多个异构大型系统之间的复杂集成交互,却很难作为一种具有广泛普适性的软件架构风格来推广。
我在后面第 7~10 讲介绍远程服务调用时,我还会为你介绍 Web Service 的兴起与衰落。Web Service 之所以被逐渐边缘化,最本质的原因就是过于严格的规范定义,给架构带来了过度的复杂性。
而构建在 Web Service 基础之上的 ESB、BPM、SCA、SDO 等诸多的上层建筑,就进一步加剧了这种复杂性。
SOA 最终没有获得成功的致命伤,其实跟当年的 EJB(Enterprise JavaBean,企业级 JavaBean) 的失败如出一辙。
尽管在当时,EJB 有 Sun Microsystems(被甲骨文收购)和 IBM 等一众巨头在背后力挺,希望能把它发展成一套面向信息系统的编程范式,但它仍然被以 Spring、Hibernate 为代表的”草根框架”给打败了。可见,任何事物一旦脱离了人民群众,最终都会淹没在群众的海洋之中,就连信息技术也不曾例外过。
最后,当你读到这一段的时候,你不妨再重新思考下我们这一讲的开头提到的,”如何使用多个独立的分布式服务共同构建一个更大型系统”这个问题,再回顾下”原始分布式时代”这一讲中,Unix DCE 提出的分布式服务的主旨:”让开发人员不必关心服务是远程还是本地,都能够透明地调用服务或者访问资源”。
经过了三十年的技术发展,信息系统经历了巨石、烟囱、微内核、事件驱动、SOA 等架构模式,应用受架构复杂度的牵绊却是越来越大,距离”透明”二字已经越来越远了。这是否算不自觉间忘记了当年的初心呢?
接下来我们要探索的微服务时代,似乎正是带着这样自省式的问句而开启的。
小结
这一讲,我带你学习了解了 SOA 架构,重点了解了从原始分布式架构、单体架构演进到 SOA 架构这段过程中的一些中间产物,如烟囱式架构、微内核架构、事件驱动架构等。
另外,我之所以带你解构 SOA 架构,就是要帮助你弄清楚它成功的部分,比如它是如何提出了哪些技术、解决问题的方法论是什么,它是如何看待分布式、乃至是如何看待软件开发的;你也要弄清楚它失败的部分,要清楚为什么 SOA 在众多软件业巨头的推动下,仍然没能成为软件开发者所普遍接受的普适的软件开发方法。这是你了解和掌握推动架构时代演进原因的重要方式。
04 | 微服务时代:SOA的革命者
其实”微服务”这个词儿,Peter Rodgers 博士在 2005 年的云计算博览会(Web Services Edge 2005)上,就已经提出和使用了。当时的说法是”Micro-Web-Service”,指的是一种专注于单一职责的、与语言无关的、细粒度的 Web 服务(Granular Web Services)。
“微服务”这个词,并不是 Peter Rodgers 直接凭空创造出来的概念。最开始的微服务,可以说是在 SOA 发展的同时被催生出来的产物,就像是 EJB 在推广的过程中,催生出了 Spring 和 Hibernate 框架那样。这一阶段的微服务,是作为 SOA 的一种轻量化的补救方案而被提出来的。
到今天为止,在英文版的维基百科上,人们仍然是把微服务定义成了 SOA 的一个变种。所以,微服务在诞生和最初的发展阶段,跟 SOA、Web Service 这些概念有所牵扯,也是完全可以理解的。
What is microservices
Microservices is a software development technique — a variant of the service-oriented architecture (SOA) structural style.
—— Wikipedia,Microservices
但我们现在再来看,维基百科对微服务的定义,其实已经有些过时了。至于为什么这样说,就是我在这一讲中要和你解释的了。
在微服务的概念被提出后将近 10 年的时间里面,它都没有受到太多人的追捧。毕竟,如果只是对现有的 SOA 架构的修修补补,确实难以唤起广大技术人员的更多激情。
不过,也是在这 10 年的时间里,微服务本身其实一直在思考、蜕变。
2012 年,在波兰克拉科夫举行的”33rd Degree Conference”大会上,Thoughtworks 首席咨询师 James Lewis 做了题为《 Microservices - Java, the Unix Way 》的主题演讲。其中,他提到了单一服务职责、 康威定律 、自动扩展、领域驱动设计等原则,却只字未提 SOA,反而号召大家,应该重拾 Unix 的设计哲学(As Well Behaved Unix Services)。这一点跟我在上一讲中所说的”初心与自省”,可以说是一个意思。
微服务已经迫不及待地要脱离 SOA 的附庸,想要成为一种独立的架构风格,也许,它还将会是 SOA 的革命者,找到一条能被广大开发者普遍接受且愿意接受的、实现服务化系统的目标。
微服务真正崛起是在 2014 年。相信我们大多数程序员,也是从 Martin Fowler 和 James Lewis 合写的文章” Microservices: a definition of this new architectural term “里面,第一次了解到微服务的。这篇文章虽然不是最早提出”微服务”这个概念的,但却是真正丰富的、广为人知的和可操作的微服务指南。也就是说,这篇文章才是微服务的真正起源。
这篇文章定义了现代微服务的概念:微服务是一种通过多个小型服务的组合,来构建单个应用的架构风格,这些服务会围绕业务能力而非特定的技术标准来构建。各个服务可以采用不同的编程语言、不同的数据存储技术、运行在不同的进程之中。服务会采取轻量级的通讯机制和自动化的部署机制,来实现通讯与运维。
此外,在这篇论文中,作者还列举出了微服务的九个核心的业务与技术特征。接下来,我就一一解读为你解读下,希望你可以从中领悟到,微服务在团队、开发、运维等一系列研发过程中的核心思想。
第一,围绕业务能力构建(Organized around Business Capabilities)
这个核心技术特征,实际上再次强调了 康威定律 的重要性。它的意思是, 有怎样的结构、规模和能力的团队,就会产生出对应结构、规模、能力的产品。 这个结论不是某个团队、某个公司遇到的巧合,而是必然的演化结果。
如果本应该归属同一个产品内的功能,被划分在了不同的团队当中,那就必然会产生大量的跨团队沟通协作,而跨越团队边界,无论是在管理、沟通,还是在工作安排上,都会产生更高的成本。高效的团队,自然会针对这个情况进行改进,而当团队和产品磨合调节稳定了之后,就会拥有一致的结构。
第二,分散治理(Decentralized Governance)
这个技术特征,表达的是”谁家孩子谁来管”。微服务对应的开发团队,有着直接对服务运行质量负责的责任,也应该有着不受外界干预,掌控服务各个方面的权力,可以选择与其他服务异构的技术来实现自己的服务。
这一点在真正实践的时候,其实多少都会留点儿宽松的处理余地。因为大多数的公司都不会在某一个服务用 Java,另一个用 Python,下一个用 Golang,而是通常都会统一主流语言,甚至会有统一的技术栈或专有的技术平台。
微服务不提倡也并不反对这种”统一”,它只负责提供和维护基础技术栈的团队,有被各方依赖的觉悟,要有”经常被凌晨 3 点的闹钟吵醒”的心理准备就好。
微服务更加强调的是, 在确实有必要进行技术异构的时候,一个开发团队应该能有选择”不统一”的权利。 比如说,我们不应该强迫用 Node.js 去开发报表页面;要做人工智能计算的时候,也可以选择用 Python,等等。
第三,通过服务来实现独立自治的组件(Componentization via Services)
这里,Martin Fowler 与 James Lewis 之所以强调要通过”服务”(Service)而不是”类库”(Library)来构建组件,是因为类库是在编译期静态链接到程序中的,会通过本地调用来提供功能,而服务是进程外组件,它是通过远程调用来提供功能的。在 第 2 讲 中,我们已经分析过,尽管远程服务有更高昂的调用成本,但这是为组件带来隔离与自治能力的必要代价。
第四,产品化思维(Products not Projects)
产品化思维的意思就是,我们要 避免把软件研发看作是要去完成某种功能,而要把它当做是一种持续改进、提升的过程。 比如,我们不应该把运维看作就是运维团队的事,把开发看作就是开发团队的事。
开发团队应该为软件产品的整个生命周期负责。开发者不仅应该知道软件是如何开发的,还应该知道它会如何运作、用户如何反馈,乃至售后支持工作是怎样进行的。这里服务的用户,不一定是最终用户,也可能是消费这个服务的另外一个服务。
以前在单体的架构模式下,程序的规模决定了我们无法让全部的开发人员,都关注到一个完整的产品,在组织中会有开发、运维、支持等细致分工的成员,他们只关注于自己的一块工作。但在微服务下,我们可以让团队中的每一位成员,都具有产品化思维。因为在”2 Pizza Teams”的团队规模下,每一个人都了解全过程是完全有可能实现的。
第五,数据去中心化(Decentralized Data Management)
微服务这种架构模式也明确地提倡,数据应该按领域来分散管理、更新、维护和存储。
在单体服务中,通常一个系统的各个功能模块会使用同一个数据库,虽然这种中心化的存储确实天生就更容易避免一致性的问题,但是,同一个数据实体在不同服务的视角里,它的抽象形态往往也是不同的。
比如,Bookstore 应用中的书本,在销售领域中关注的是价格,在仓储领域中关注的是库存数量,在商品展示领域中关注的是书籍的介绍信息。如果是作为中心化的存储,那么这里所有的领域,都必须修改和映射到同一个实体之中,就会导致不同的服务之间,可能会互相产生影响,从而丧失了各自的独立性。
另外,尽管在分布式中,我们要想处理好一致性的问题也很困难,很多时候都没法使用传统的事务处理来保证不出现一致性问题。但是两害相权取其轻,一致性问题这些必要的代价是值得付出的。
第六,轻量级通讯机制(Smart Endpoints and Dumb Pipes)
这个弱管道(Dumb Pipes)机制,可以说几乎算是在直接指名道姓地反对 ESB、BPM 和 SOAP 等复杂的通讯机制。
ESB 可以处理消息的编码加工、业务规则转换等;BPM 可以集中编排企业的业务服务;SOAP 有几十个 WS-* 协议族在处理事务、一致性、认证授权等一系列工作。这些构筑在通讯管道上的功能,也许在某个系统中的确有一部分服务是需要的,但对于另外更多的服务来说是强加进来的负担。
如果服务需要上面的某一种功能或能力,那就应该在服务自己的 Endpoint(端点)上解决,而不是在通讯管道上一揽子处理。
微服务提倡的是类似于经典 Unix 过滤器那样,简单直接的通讯方式。比如说,RESTful 风格的通讯,在微服务中就是比较适合的。
第七,容错性设计(Design for Failure)
容错性设计,是指软件架构不再虚幻地追求服务永远稳定,而是接受服务总会出错的现实。
这个技术特征要求,在微服务的设计中,有自动的机制能够对其依赖的服务进行快速故障检测,在持续出错的时候进行隔离,在服务恢复的时候重新联通。所以 “断路器”这类设施,对实际生产环境的微服务来说,并不是可选的外围组件,而是一个必须的支撑点。 如果没有容错性的设计,系统很容易就会因为一两个服务的崩溃带来的雪崩效应而被淹没。
我想说的是,可靠系统完全可以由会出错的服务来组成,这是微服务最大的价值所在,也是咱们这门课的开篇导读标题中”The Fenix Project”的含义。
第八,演进式设计(Evolutionary Design)
容错性设计承认服务会出错,而演进式设计则是 承认服务会被报废淘汰。
一个良好设计的服务,应该是能够报废的,而不是期望得到长久的发展。如果一个系统中出现不可更改、无可替代的服务,这并不能说明这个服务有多么重要,反而是系统设计上脆弱的表现。微服务带来的独立、自治,也是在反对这种脆弱性。
第九,基础设施自动化(Infrastructure Automation)
基础设施自动化,如 CI/CD 的长足发展,大大降低了构建、发布、运维工作的复杂性。
由于微服务架构下,运维的服务数量比起单体架构来说,要有数量级的增长,所以使用微服务的团队,会更加依赖于基础设施的自动化。毕竟,人工是无法运维成百上千,乃至成千上万级别的服务的。
好,到这里,通过我的解读,你是不是已经大概理解了微服务核心的业务和技术特征了?
以上 9 个特征,是一个合理的微服务系统展示出来的内、外在表现,它能够指导你该如何应用微服务架构,却不必作为一种强加于系统中的束缚来看待。
“Microservices: a definition of this new architectural term” 一文中,对微服务特征的描写已经非常具体了,除定义了微服务是什么,还专门申明了微服务不是什么:微服务不是 SOA 的衍生品,应该明确地与 SOA 划清界线,不再贴上任何 SOA 的标签。
这样一来,微服务才算是一种真正丰满、独立、具体的架构风格,为它在未来的几年时间里,如同明星一般闪耀崛起于技术舞台奠定了坚实的基础。
Microservices and SOA
This common manifestation of SOA has led some microservice advocates to reject the SOA label entirely, although others consider microservices to be one form of SOA , perhaps service orientation done right. Either way, the fact that SOA means such different things means it”s valuable to have a term that more crisply defines this architectural style.
由于与 SOA 具有一致的表现形式,这让微服务的支持者更加迫切地拒绝再被打上 SOA 的标签。一些人坚持认为微服务就是 SOA 的一种变体,尽管仅从面向服务这个角度来考虑,这个观点可以说也是正确的。但无论如何,从整体上看 SOA 与微服务都是两种不同的东西。也因此,使用一个别的名称,来简明地定义这种架构风格就显得非常有必要了。
—— Martin Fowler / James Lewis,Microservices
从上面我对微服务的定义和特征的解读当中,你还可以明显地感觉到,微服务追求的是更加自由的架构风格,它摒弃了 SOA 中几乎所有可以抛弃的约束和规定,提倡以”实践标准”代替”规范标准”。
可是,如果没有了统一的规范和约束,以前 SOA 解决的那些分布式服务的问题,不又都重新出现了吗?
没错,的确如此。服务的注册发现、跟踪治理、负载均衡、故障隔离、认证授权、伸缩扩展、传输通讯、事务处理等问题,在微服务中,都不再会有统一的解决方案。
即使我们只讨论 Java 范围内会使用到的微服务,那么光一个服务间通讯的问题,可以列入候选清单的解决方案就有很多很多。比如,RMI(Sun/Oracle)、Thrift(Facebook)、Dubbo(阿里巴巴)、gRPC(Google)、Motan2(新浪)、Finagle(Twitter)、brpc(百度)、Arvo(Hadoop)、JSON-RPC、REST,等等。
再来举个例子,光一个服务发现问题,我们可以选择的解决方案就有:Eureka(Netflix)、Consul(HashiCorp)、Nacos(阿里巴巴)、ZooKeeper(Apache)、etcd(CoreOS)、CoreDNS(CNCF),等等。
其他领域的情况也很类似。总之,完全就是”八仙过海,各显神通”的局面。
所以说,微服务所带来的自由是一把双刃开锋的宝剑。当软件架构者拿起这把宝剑的时候,它的一刃指向的是 SOA 定下的复杂技术标准,而在将选择的权力夺回的同一时刻,另外一刃也正朝向着自己映出冷冷的寒光。
小结
在微服务时代中,软件研发本身的复杂度应该说是有所降低,一个简单服务,并不见得就会同时面临分布式中所有的问题,也就没有必要背上 SOA 那百宝袋般沉重的技术包袱。 微服务架构下,我们需要解决什么问题,就引入什么工具;团队熟悉什么技术,就使用什么框架。
此外,像 Spring Cloud 这样的胶水式的全家桶工具集,通过一致的接口、声明和配置,进一步屏蔽了源自于具体工具、框架的复杂性,降低了在不同工具、框架之间切换的成本。所以,作为一个普通的服务开发者,作为一个”螺丝钉”式的程序员,微服务架构对我们来说是很友善的。
可是,微服务对架构者来说却是满满的恶意,因为它对架构能力的要求可以说是史无前例。要知道, 技术架构者的第一职责就是做决策权衡 ,有利有弊才需要决策,有取有舍才需要权衡。如果架构者本身的知识面不足以覆盖所需要决策的内容,不清楚其中的利弊,也就不可避免地会陷入选择困难症的困境之中。
总而言之,微服务时代充满着自由的气息,也充斥着迷茫的选择。软件架构不会止步于自由,微服务仍然不可能是架构探索的终点。如果有下一个时代,我希望信息系统能同时拥有微服务的自由权利,围绕业务能力构建自己的服务而不受技术规范管束,但同时又不必承担自行解决分布式问题的代价。管他什么利弊权衡!小孩子才做选择题,成年人全部都要!
05 | 后微服务时代:跨越软件与硬件之间的界限
在开始探讨这一讲的主题之前呢,我想先跟你讨论一个问题。我们都知道,在微服务架构中,会面临一些必须解决的问题,比如注册发现、跟踪治理、负载均衡、传输通讯等。但这些问题,其实在 SOA 时代甚至可以说自原始分布式时代,就一直存在了。既然只要是分布式系统,就没办法完全避免这些问题,那我们就回过头来想一下:这些问题一定要由分布式系统自己来解决吗?
既然这样,那我们就先不去纠结到底是用微服务还是什么别的架构,直接看看面对这些问题,现在最常见的解决方法是怎样的:
- 如果某个系统需要 伸缩扩容 ,我们通常会购买新的服务器,多部署几套副本实例来分担压力;
- 如果某个系统需要解决 负载均衡 的问题,我们通常会布置负载均衡器,并选择恰当的均衡算法来分流;
- 如果需要解决 安全传输 的问题,我们通常会布置 TLS 传输链路,配置好 CA 证书,以保证通讯不被窃听篡改;
- 如果需要解决 服务发现 的问题,我们通常会设置 DNS 服务器,让服务访问依赖稳定的记录名而不是易变的 IP 地址,等等。
所以你会发现,计算机科学经过了这么多年的发展,这些问题已经大多都有了专职化的基础设施来帮助解决了。
那么,在微服务时代,我们之所以不得不在应用服务层面,而不是基础设施层面去解决这些分布式问题, 完全是因为由硬件构成的基础设施,跟不上由软件构成的应用服务的灵活性。 这其实是一种无奈之举。
软件可以做到只使用键盘就能拆分出不同的服务,只通过拷贝、启动就能够伸缩扩容服务。那么,硬件难道也可以通过敲键盘就变出相应的应用服务器、负载均衡器、DNS 服务器、网络链路等等的这些设施吗?嗯?好像也可以啊!
到这里,你是不是已经知道了,注册发现、跟踪治理等等问题的解决,依靠的就是 虚拟化 技术和 容器化 技术。我们也就明白了, 微服务时代所取得的成就,本身就离不开以 Docker 为代表的早期容器化技术的巨大贡献。
不知道你注意到没有,在这之前,我从来没有提起过”容器”二字。其实,这并不是我想刻意冷落它,而是因为早期的容器只是被简单地视为一种可快速启动的服务运行环境,使用它的目的是方便程序的分发部署。所以,早期阶段针对单个服务的容器,并没有真正参与到分布式问题的解决之中。
尽管 2014 年,微服务真正崛起的时候,Docker Swarm(2013 年)和 Apache Mesos(2012 年)就已经存在了,更早之前也出现过 软件定义网络(Software-Defined Networking,SDN) 、 软件定义存储(Software-Defined Storage,SDS) 等技术,但是,被业界广泛认可、普遍采用的通过虚拟化的基础设施,去解决分布式架构问题的方案,应该要从 2017 年 Kubernetes 赢得容器战争的胜利开始算起。
2017 年,可以说是容器生态发展历史中具有里程碑意义的一年。
在这一年,长期作为 Docker 竞争对手的 RKT 容器一派的领导者 CoreOS,宣布放弃了自己的容器管理系统 Fleet,未来将会把所有容器管理功能,转移到 Kubernetes 之上去实现。
在这一年,容器管理领域的独角兽 Rancher Labs,宣布放弃其内置了数年的容器管理系统 Cattle,提出了”All-in-Kubernetes”战略,从 2.0 版本开始,把 1.x 版本能够支持多种容器管理工具的 Rancher,”升级”为只支持 Kubernetes 一种的容器管理系统。
在这一年,Kubernetes 的主要竞争者 Apache Mesos,在 9 月正式宣布了” Kubernetes on Mesos “集成计划,开始由竞争关系,转为了对 Kubernetes 提供支持,使其能够与 Mesos 的其他一级框架(如 HDFS、Spark 和 Chros 等)进行集群资源动态共享、分配与隔离。
在这一年,Kubernetes 的最大竞争者,Docker Swarm 的母公司 Docker,终于在 10 月被迫宣布 Docker 要同时支持 Swarm 与 Kubernetes 两套容器管理系统,也就是承认了 Kubernetes 的统治地位。
至此,这场已经持续了三、四年时间,以 Docker Swarm、Apache Mesos 与 Kubernetes 为主要竞争者的”容器战争”,终于有了明确结果。可以说,Kubernetes 最后从众多的容器管理系统中脱颖而出、”登基加冕”,就代表了容器发展中一个时代的结束。而且我可以说,它带来的容器间网络、服务、负载均衡、配置等虚拟化基础设施,也将会是开启下一个软件架构发展新纪元的钥匙。
我为什么会这么肯定呢?
针对同一个分布式服务的问题,对比下 Spring Cloud 中提供的应用层面的解决方案,以及 Kubernetes 中提供的基础设施层面的解决方案,你就可以明白其中缘由了。
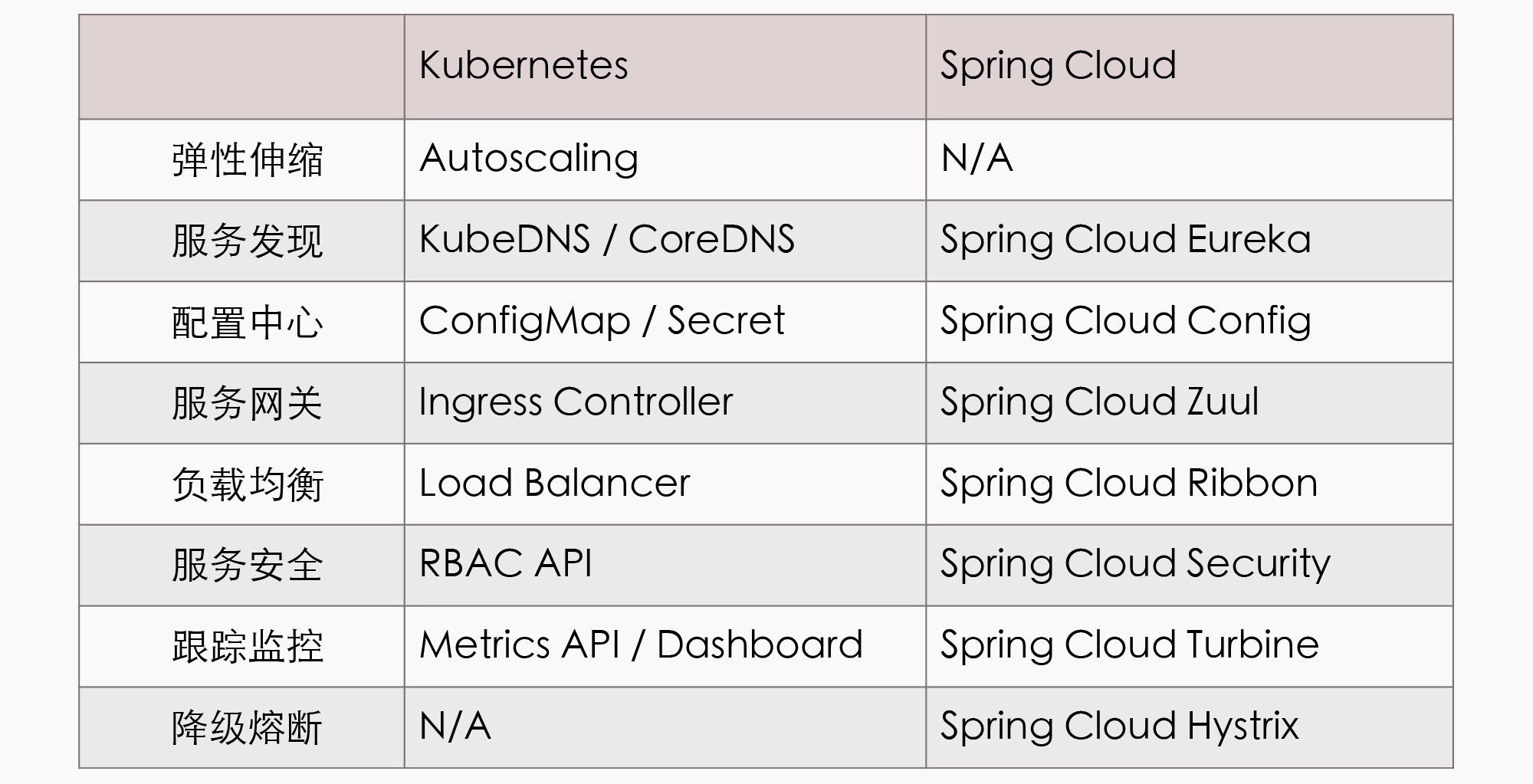
虽然 Spring Cloud 和 Kubernetes 的出发点不同,解决问题的方法和效果也不一样,但不容忽视的是,Kubernetes 的确提供了一条全新的、前途更加广阔的解题思路。
我说的”前途广阔”,不仅仅是一句恭维赞赏的客气话。当虚拟化的基础设施,开始从单个服务的容器发展到由多个容器构成的服务集群,以及集群所需的所有通讯、存储设施的时候,软件与硬件的界限就开始模糊了。
一旦硬件能够跟得上软件的灵活性,那么这些与业务无关的技术问题,便很可能从软件的层面剥离出来,在硬件的基础设施之内就被悄悄解决掉,让软件可以只专注于业务,真正”围绕业务能力构建”团队与产品。那么原来只能从软件层面解决的分布式架构问题,于是有了另外一种解法:应用代码与基础设施软硬一体,合力应对。
这样一来,在 DCE 中未能实现的”透明的分布式应用”就成为了可能,Martin Fowler 设想的” 凤凰服务器 “就成为了可能,Chad Fowler 提出的” 不可变基础设施 “也会成为可能。
没错,我们借此就来到了现在媒体文章中常说的”云原生”时代。这样理解下来,”云原生”这个概念,是不是没那么抽象了。
云原生时代追求的目标,跟此前微服务时代中追求的目标相比,并没有什么本质的改变,它们都是通过一系列小型服务去构建大型系统。在服务架构演进的历史进程中,我更愿意把”云原生时代”称为 “后微服务时代” 。
不过还有一点值得注意的是 ,前面我说,Kubernetes 成为了容器战争的胜利者,标志着后微服务时代的开端, 但 Kubernetes 其实并没有完美地解决全部的分布式问题。
这里所说的”不完美”的意思是,仅从功能灵活强大这点来看,Kubernetes 反而还不如之前的 Spring Cloud 方案。这是因为有一些问题处于应用系统与基础设施的边缘,我们很难能完全在基础设施的层面中,去精细化地解决掉它们。
给你举个例子,微服务 A 调用了微服务 B 中发布的两个服务,我们称之为 B1 和 B2,假设 B1 表现正常,但 B2 出现了持续的 500 错,那在达到一定的阈值之后,我们就应该对 B2 进行熔断,以避免产生 雪崩效应 。如果我们仅在基础设施的层面来做处理,这就会遇到一个两难问题,也就是切断 A 到 B 的网络通路,会影响到 B1 的正常调用,而不切断的话则会持续受到 B2 的错误影响。

这种问题在通过 Spring Cloud 这类应用代码实现的微服务中,其实并不难处理,反正是使用代码(或者配置)来解决问题,只要合乎逻辑,我们想做什么功能都是可以的,只是会受限于开发人员的想象力与技术能力。但基础设施是针对整个容器来做整体管理的,它的粒度就相对粗犷。
实际上,类似的情况不仅仅会在断路器上出现,服务的监控、认证、授权、安全、负载均衡等功能,都有细化管理的需求。比如,服务调用时的负载均衡,往往需要根据流量特征,调整负载均衡的层次、算法等,而 DNS 尽管能实现一定程度的负载均衡,但它通常并不能满足这些额外的需求。
所以,为了解决这一类问题,微服务基础设施很快就进行了第二次进化,引入在今天被我们叫做是 “服务网格”(Service Mesh) 的 “边车代理模式”(Sidecar Proxy) 。
所谓的”边车”,是指一种带挎斗的三轮摩托,我小时候还算常见,现在基本就只在抗日神剧中才会看到了。
.webp)
具体到咱们现在的语境里,”边车”的意思是,微服务基础设施会由系统自动地在服务的资源容器(指 Kubernetes 的 Pod)中注入一个通讯代理服务器(相当于那个挎斗),用类似网络安全里中间人攻击的方式进行流量劫持,在应用毫无感知的情况下,悄悄接管掉应用的所有对外通讯。
这个代理除了会实现正常的服务调用以外(称为数据平面通讯),同时还接受来自控制器的指令(称为控制平面通讯),根据控制平面中的配置,分析数据平面通讯的内容,以实现熔断、认证、度量、监控、负载均衡等各种附加功能。
这样,就实现了既不需要在应用层面附带额外的代码,也提供了几乎不亚于应用代码的精细管理能力的目的。
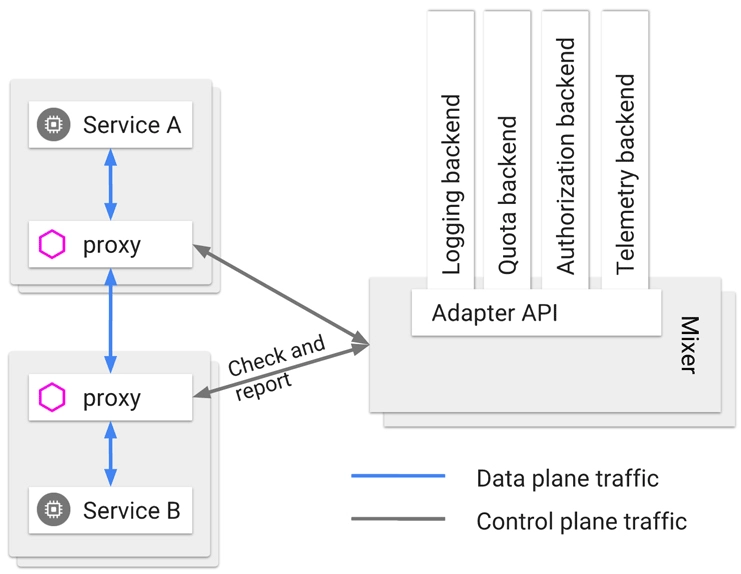
(来自 Istio 的 配置文档 ,图中的 Mixer 在 Istio 1.5 之后已经取消,这里仅作示意)
小结
今天,我带着你一起游览了后微服务时代,一起了解了容器化技术兴起对软件架构、软件开发的改变,并一起探讨了微服务如何通过虚拟化基础设施,来解决分布式问题的办法,即今天服务网格中的”边车代理模式”。
服务网格在 2018 年才火了起来,到今天它仍然是一个新潮的概念,Istio 和 Envoy 的发展时间还很短,仍然没有完全成熟,甚至连 Kubernetes 也还算是个新生事物(以它开源的日期来计算)。
但我相信,未来几年,Kubernetes 将会成为服务器端标准的运行环境,如同在此之前的 Linux 一样;服务网格将会成为微服务之间通讯交互的主流模式,它会把”选择什么通讯协议””如何做认证授权”之类的技术问题隔离于应用软件之外,取代今天的 Spring Cloud 全家桶中的大部分组件的功能。这是最理想的 Smart Endpoints 解决方案,微服务只需要考虑业务本身的逻辑就行了。
上帝的归上帝,凯撒的归凯撒,业务与技术完全分离,远程与本地完全透明,我想也许这就是分布式架构最好的时代吧。
06 | 无服务时代:”不分布式”云端系统的起点
今天是探索”演进中的架构”的最后一讲,我们来聊聊最近一两年才开始兴起的 “无服务架构” 。
我们都知道,分布式架构出现的最初目的,是要解决单台机器的性能成为整个软件系统的瓶颈的问题。后来随着技术的演进,容错能力、技术异构、职责划分等其他因素,也都成了分布式架构要考虑的问题。但不可否认的是,获得更好的性能,仍然在架构设计中占有非常大的比重。
在前面几讲我们也说,分布式架构也会引入一些新问题(比如服务的安全、容错,分布式事务的一致性),因此对软件开发这件事儿来说,不去做分布式无疑是最简单的。如果单台服务器的性能可以是无限的,那架构演进的结果,肯定会跟今天不一样。不管是分布式和容器化,还是微服务,恐怕都未必会出现了,最起码不会是今天的模样。
当然了,绝对意义上的无限性能肯定是不存在的,但相对意义上的无限性能其实已经实现了,云计算的成功落地就可以说明这一点。对基于云计算的软件系统来说,无论用户有多少、逻辑如何复杂,AWS、阿里云等云服务提供商都能在算力上满足系统对性能的需求,只要你能为这种无限的性能支付得起对应的代价。
在工业界,2012 年,iron.io 公司 率先提出了”无服务”(Serverless,应该翻译为”无服务器”才合适,但现在用”无服务”已形成习惯了)的概念;2014 年开始,AWS 发布了命名为 Lambda 的商业化无服务应用,并在后续的几年里逐步得到了开发者的认可,发展成目前世界上最大的无服务的运行平台;到了 2019 年,中国的阿里云、腾讯云等厂商,也发布了无服务的产品。”无服务”成了近期技术圈里的”新网红”之一。
我们再看看学术界对无服务的态度。在 2009 年云计算刚提出的时候,UC Berkeley 大学就发表了一篇论文 “Above the Clouds: A Berkeley View of Cloud Computing” ,文中预言的云计算的价值、演进和普及,在过去的十年(2009~2019 年)里一一得到了验证。十年之后的 2019 年,UC Berkeley 的第二篇命名风格相同的论文 “Cloud Programming Simplified: A Berkeley View on Serverless Computing” ,再次预言”无服务将会成为日后云计算的主流方式”。
由此可见,主流学术界也同样认可无服务是未来的一个发展方向。
虽然工业界和学术界在”无服务”这件事儿上都取得了些成果,但是到今天”无服务”也还没有一个特别权威的定义。不过这也不是什么问题,毕竟它没有我们前面讲到的微服务、SOA 等各种架构那么复杂, 它最大的卖点就是简单 ,只涉及了后端设施(Backend)和函数(Function)两块内容。
- 后端设施 是指数据库、消息队列、日志、存储等这一类用于支撑业务逻辑运行,但本身无业务含义的技术组件。这些后端设施都运行在云中,也就是无服务中的 “后端即服务”(Backend as a Service,BaaS) 。
- 函数 指的就是业务逻辑代码。这里函数的概念与粒度,都已经和程序编码角度的函数非常接近了,区别就在于,无服务中的函数运行在云端,不必考虑算力问题和容量规划(从技术角度可以不考虑,但从计费的角度来看,你还是要掂量一下自己的钱包够不够用),也就是无服务中的 “函数即服务”(Function as a Service,FaaS) 。
无服务的愿景是让开发者只需要纯粹地关注业务: 一是,不用考虑技术组件,因为后端的技术组件是现成的,可以直接取用,没有采购、版权和选型的烦恼;二是,不需要考虑如何部署,因为部署过程完全是托管到云端的,由云端自动完成;三是,不需要考虑算力,因为有整个数据中心的支撑,算力可以认为是无限的;四是,也不需要操心运维,维护系统持续地平稳运行是云服务商的责任,而不再是开发者的责任。
你看,这是不是就像从汇编语言发展到高级语言后,开发者不用再去关注寄存器、信号、中断等与机器底层相关的细节?没错儿,UC Berkeley 的论文 “Cloud Programming Simplified: A Berkeley View on Serverless Computing” 中,就是这样描述无服务给生产力带来的极大解放的。
不过,无服务架构的远期前景也许很美好,但我自己对无服务中短期内的发展,并没有那么乐观。为什么这么说呢?
与单体架构、微服务架构不同,无服务架构天生的一些特点,比如冷启动、 无状态、运行时间有限制等等,决定了它不是一种具有普适性的架构模式。 除非是有重大变革,否则它也很难具备普适性。
一方面,对一些适合的应用来说,使用无服务架构确实能够降低开发和运维环节的成本,比如不需要交互的离线大规模计算,又比如多数 Web 资讯类网站、小程序、公共 API 服务、移动应用服务端等,都跟无服务架构擅长的短链接、无状态、适合事件驱动的交互形式很契合。
但另一方面,对于那些信息管理系统、网络游戏等应用来说,又或者说对所有具有业务逻辑复杂、依赖服务端状态、响应速度要求较高、需要长连接等特征的应用来说,无服务架构至少在目前来看并不是最合适的。
这是因为,无服务天生”无限算力”的假设,就决定了它必须要按使用量(函数运算的时间和内存)来计费,以控制消耗算力的规模,所以函数不会一直以活动状态常驻服务器,只有请求到了才会开始运行。这导致了函数不便于依赖服务端状态,也导致了函数会有冷启动时间,响应的性能不可能会太好(目前,无服务的云函数冷启动过程大概是在百毫秒级别,对于 Java 这类启动性能差的应用,甚至能到秒级)。
但无论如何,云计算毕竟是大势所趋,今天信息系统建设的概念和观念,在较长尺度的”明天”都是会转变成适应云端的。我并不怀疑 Serverless+API 的这种设计方式,随着云计算的持续发展,将会成为一种主流的软件架构形式,无服务到时候也应该会有更广阔的应用空间。
如果说微服务架构是分布式系统这条路当前所能做到的极致,那无服务架构,也许就是”不分布式”的云端系统这条路的起点。
虽然在顺序上,我把”无服务”安排到了”微服务”和”云原生”时代之后,但它们并没有继承替代关系。我之所以要强调这一点,是为了避免你可能会从两者的名称和安排顺序的角度,产生”无服务比微服务更加先进”的错误想法。我相信,软件开发的未来,不会只存在某一种”最先进的”架构风格,而是会有多种具有针对性的架构风格并存。这才是软件产业更有生命力的形态。
我同样也相信,软件开发的未来,多种架构风格将会融合互补,”分布式”与”不分布式”的边界将会逐渐模糊,两条路线将会在云端的数据中心交汇。
今天,我们已经能初步看见一些使用无服务的云函数去实现微服务架构的苗头了,所以把无服务作为技术层面的架构,把微服务视为应用层面的架构,这样的组合使用也是完全合理可行的。比如,根据腾讯公开的资料,企业微信、QQ 小程序、腾讯新闻等产品,就是使用自己的无服务框架构成的微服务系统。以后,无论是通过物理机、虚拟机、容器,或者是无服务云函数,都会是微服务实现方案的一个候选项。
小结
今天是架构演进历史的最后一讲,如 第 1 讲 的开篇所说,我们谈历史重点不在考古,而是要借历史之名,来理解每种架构出现的意义以及被淘汰的原因。这样,我们才能更好地解决今天遇到的各种实际的问题,看清楚未来架构演进的发展道路。
对于架构演进的未来,2014 年的时候,Martin Fowler 和 James Lewis 在 《Microservices》 的结束语中分享的观点是,他们对于微服务日后能否被大范围地推广,最多只能持谨慎的乐观态度。无服务方兴未艾的今天,与那时微服务的情况十分相近,我对无服务日后的推广也是持有谨慎的乐观态度。软件开发的最大挑战就在于,只能在不完备的信息下决定当前要处理的问题。
时至今日,我们依然很难预想在架构演进之路的前方,微服务和无服务之后,还会出现什么形式的架构风格,这也正契合了图灵的那句名言:尽管目光所及之处,只是不远的前方,即使如此,依然可以看到那里有许多值得去完成的工作在等待我们。
We can only see a short distance ahead, but we can see plenty there that needs to be done.
尽管目光所及之处,只是不远的前方,即使如此,依然可以看到那里有许多值得去完成的工作在等待我们。
—— Alan Turing, Computing Machinery and Intelligence, 1950
架构师的视角
07 | 远程服务调用(上):从本地方法到远程方法的桥梁
“架构师”这个词,其实指向非常宽泛,你可以说做企业战略设计的是架构师,也可以说做业务流程分析的是架构师。而在这门课程中,我所针对的架构师视角,特指软件系统中技术模型的系统设计者。在这个模块当中,我会带你系统性地了解,在做架构设计的时候,架构师都应该思考哪些问题、可以选择哪些主流的解决方案和行业标准做法,以及这些主流方案都有什么优缺点、会给架构设计带来什么影响,等等。
理解了架构师的这些职责,你对”架构设计”这种听起来就很抽象的工作,是不是有个更具体的认识了?
从今天开始,我会花两讲的时间,和你一起学习 “远程服务调用(Remote Procedure Call,RPC)” 这个话题。我会尽可能地从根源到现状、从表现到本质,为你解释清楚 RPC 的一些常见的问题。
那今天,我们就先从”什么是 RPC”开始,一起去学习”远程服务”这个构建分布式系统的最基本的前置条件,看看它是如何出现、如何发展的,以及当前业界的主流实现手段。
其实,RPC 这个词儿在计算机科学中已经有超过 40 年的历史了,肯定不是一个新概念。但是直到今天,我们还是会在知乎等网站上,看到很多人提问”什么是 RPC?””如何评价某某 RPC 技术?””RPC 好还是 REST 好?”,仍然”每天”都有新的不同形状的 RPC 轮子被发明出来,仍然有层出不穷的文章,去比对 Google gRPC、Facebook Thrift 等各个厂家的 RPC 技术的优劣。
像计算机科学这种知识快速更迭的领域,一项 40 岁高龄的技术能有如此的关注度,可以说是相当稀罕的现象了。那为什么会出现这种现象呢?
我分析了其中的原因:一方面,可能是微服务风潮带来的热度;另一方面,也不得不承认,作为开发者,我们很多人对 RPC 本身可以解决什么问题、如何解决这些问题、为什么要这样解决,都或多或少存在些认知模糊的情况。
那接下来,我就给你详细解读一下,关于 RPC 的各种分歧和普遍的错误认知。
进程间通讯
尽管今天的大多数 RPC 技术已经不再追求”与本地方法调用一致”这个目标了,但不可否认的是,RPC 出现的最初目的,就是为了让计算机能够跟调用本地方法一样,去调用远程方法。所以,我们先来看一下在本地方法调用的时候,都会发生些什么。
我们先通过下面这段 Java 风格的伪代码,来定义几个概念:
// 调用者(Caller) : main()
// 被调用者(Callee) : println()
// 调用点(Call Site) : 发生方法调用的指令流位置
// 调用参数(Parameter) : 由Caller传递给Callee的数据,即"hello world"
// 返回值(Retval) : 由Callee传递给Caller的数据,如果方法正常完成,返回值是void,否则是对应的异常
public static void main(String[] args) {
System.out.println("hello world");
}通过这段伪代码,你可以发现,在完全不考虑编译器优化的前提下,程序运行至调用 println() 这一行的时候,计算机(物理机或者虚拟机)会做以下这些事情:
- 传递方法参数 :将字符串 hello world 的引用压栈。
- 确定方法版本 :根据 println() 方法的签名,确定它的执行版本其实并不是一个简单的过程,不管是编译时的静态解析也好,还是运行时的动态分派也好,程序都必须根据某些语言规范中明确定义的原则,找到明确的被调用者 Callee。这里的”明确”是指唯一的一个 Callee,或者有严格优先级的多个 Callee,比如不同的重载版本。我曾在 《深入理解 Java 虚拟机》 中用一整章介绍过这个过程。如果你感兴趣的话,可以去深入了解一下。
- 执行被调方法 :从栈中获得 Parameter,以此为输入,执行 Callee 内部的逻辑。
- 返回执行结果 :将 Callee 的执行结果压栈,并将指令流恢复到 Call Site 处,继续向下执行。
接下来,我们就需要考虑一下,当 println() 方法不在当前进程的内存地址空间中,会出现什么问题。不难想到,此时至少面临 两个直接的障碍 :
- 第一个障碍,前面的第一步和第四步所做的传递参数、传回结果都依赖于栈内存的帮助,如果 Caller 与 Callee 分属不同的进程,就不会拥有相同的栈内存,那么在 Caller 进程的内存中将参数压栈,对于 Callee 进程的执行毫无意义。
- 第二个障碍,第二步的方法版本选择依赖于语言规则的定义,而如果 Caller 与 Callee 不是同一种语言实现的程序,方法版本选择就将是一项模糊的不可知行为。
所以为了简化,我们暂时忽略第二个障碍,假设 Caller 与 Callee 是使用同一种语言实现的,先来解决两个进程之间如何交换数据的问题,这件事情在计算机科学中被称为”进程间通讯”(Inter-Process Communication,IPC)。那么我们可以考虑的解决办法就有以下几种:
第一,管道(Pipe)或具名管道(Named Pipe)
管道其实类似于两个进程间的桥梁,用于进程间传递少量的字符流或字节流。 普通管道 可用于 有亲缘关系进程间的通信(由一个进程启动的另外一个进程) ;而 具名管道 摆脱了普通管道没有名字的限制,除了具有普通管道所具有的功能以外,它还允许 无亲缘关系进程间的通信 。
管道典型的应用就是命令行中的” | “操作符,比如说,命令”ps -ef | grep java” ,就是管道操作符” | “将 ps 命令的标准输出通过管道,连接到 grep 命令的标准输入上。
第二,信号(Signal)
信号是用来通知目标进程有某种事件发生的。除了用于进程间通信外,信号还可以被进程发送给进程自身。信号的典型应用是 kill 命令,比如”kill -9 pid”,意思就是由 Shell 进程向指定 PID 的进程发送 SIGKILL 信号。
第三,信号量(Semaphore)
信号量是用于两个进程之间同步协作的手段,相当于操作系统提供的一个特殊变量。我们可以在信号量上,进行 wait() 和 notify() 操作。
第四,消息队列(Message Queue)
前面所说的这三种方式,只适合传递少量信息,而 POSIX 标准中,有定义”消息队列”用于进程间通讯的方法。也就是说,进程可以向队列中添加消息,而被赋予读权限的进程则可以从队列中消费消息。消息队列就克服了信号承载信息量少、管道只能用于无格式字节流,以及缓冲区大小受限等缺点 ,但实时性相对受限。
第五,共享内存(Shared Memory)
允许多个进程可以访问同一块内存空间,这是效率最高的进程间通讯形式。进程的内存地址空间是独立隔离的,但操作系统提供了让进程主动创建、映射、分离、控制某一块内存的接口。由于内存是多进程共享的,所以往往会与其它通信机制,如信号量等结合使用,来达到进程间的同步及互斥。
第六,本地套接字接口(IPC Socket)
消息队列和共享内存这两种方式,只适合单机多进程间的通讯。而 套接字接口,是更为普适的进程间通信机制,可用于不同机器之间的进程通信。
套接字(Socket)起初是由 Unix 系统的 BSD 分支开发出来的,但现在已经移植到所有的 Unix 和 Linux 系统上了。基于效率考虑,当仅限于本机进程间通讯的时候,套接字接口是被优化过的,不会经过网络协议栈,不需要打包拆包、计算校验和、维护序号和应答等操作,只是简单地将应用层数据从一个进程拷贝到另一个进程,这种进程间通讯方式有个专有的名称:Unix Domain Socket,又叫做 IPC Socket。
通信的成本
我之所以花这么多篇幅来介绍 IPC 的手段,是因为计算机科学家们最初的想法,就是将 RPC 作为 IPC 的一种特例来看待(其实现在分类上这么说也仍然合适,只是在具体操作手段上不会这么做了)。
这里,我们需要特别关注的是最后一种 基于套接字接口的通讯方式(IPC Socket) 。因为它不仅适用于本地相同机器的不同进程间通讯,而且因为 Socket 是网络栈的统一接口,它也理所当然地能支持基于网络的跨机器、跨进程的通讯。比如 Linux 系统的图形化界面中,X Window 服务器和 GUI 程序之间的交互,就是由这套机制来实现的。
此外,这样做还有一个看起来无比诱人的好处。因为 IPC Socket 是操作系统提供的标准接口,所以它完全有可能把远程方法调用的通讯细节,隐藏在操作系统底层,从应用层面上来看,可以做到远程调用与本地方法调用几乎完全一致。
事实上,在 原始分布式时代 的初期确实是奔着这个目标去做的, 但这种透明的调用形式反而让程序员们误以为通信是无成本的,从而被滥用,以至于显著降低了分布式系统的性能。
1987 年,当”透明的 RPC 调用”一度成为主流范式的时候,安德鲁 · 塔能鲍姆(Andrew Tanenbaum)教授曾发表了一篇论文 “A Critique of the Remote Procedure Call Paradigm” ,对这种透明的 RPC 范式提出了一系列质问:
- 两个进程通讯,谁作为服务端,谁作为客户端?
- 怎样进行异常处理?异常该如何让调用者获知?
- 服务端出现多线程竞争之后怎么办?
- 如何提高网络利用的效率,比如连接是否可被多个请求复用以减少开销?是否支持多播?
- 参数、返回值如何表示?应该有怎样的字节序?
- 如何保证网络的可靠性,比如调用期间某个链接忽然断开了怎么办?
- 服务端发送请求后,收不到回复该怎么办?
- ……
论文的中心观点 是:把本地调用与远程调用当作一样的来处理,是犯了方向性的错误,把系统间的调用做成透明的,反而会增加程序员工作的复杂度。
此后几年,关于 RPC 应该如何发展、如何实现的论文层出不穷,有支持的也有反对,有冷静分析的也有狂热唾骂的,但历史逐渐证明了 Andrew Tanenbaum 的预言是正确的。
最终,1994 年至 1997 年间,由 ACM 和 Sun 的院士 Peter Deutsch、套接字接口发明者 Bill Joy 、Java 之父 James Gosling 等众多在 Sun Microsystems 工作的大佬们,共同总结了 通过网络进行分布式运算的八宗罪(8 Fallacies of Distributed Computing) :
- 网络是可靠的(The network is reliable)
- 延迟是不存在的(Latency is zero )
- 带宽是无限的(Bandwidth is infinite)
- 网络是安全的(The network is secure)
- 拓扑结构是一成不变的(Topology doesn’t change)
- 总会有一个管理员(There is one administrator)
- 不考虑传输成本(Transport cost is zero)
- 网络是同质化的(The network is homogeneous)
这八宗罪,被认为是程序员在网络编程中经常忽略的八大问题,潜台词就是如果远程服务调用要弄透明化的话,就必须为这些罪过买单。这算是给 RPC 能否等同于 IPC 来实现,暂时定下了一个具有公信力的结论。
到这时为止,RPC 应该是一种高层次的,或者说语言层次的特征,而不是像 IPC 那样,是低层次的,或者说系统层次的特征,就成为了工业界、学术界的主流观点。
在 1980 年代初期,传奇的 施乐 Palo Alto 研究中心) ,发布了基于 Cedar 语言的 RPC 框架 Lupine,并实现了世界上第一个基于 RPC 的商业应用 Courier。这里施乐 PARC 定义的”远程服务调用”的概念,就是符合上面针对 RPC 的结论的。所以,尽管此前已经有用其他名词指代 RPC 的操作,我们也一般认为 RPC 的概念,最早是由施乐公司所提出的。
首次提出远程服务调用的定义
Remote procedure call is the synchronous language-level transfer of control between programs in address spaces whose primary communication is a narrow channel.
—— Bruce Jay Nelson, Remote Procedure Call ,Xerox PARC,1981
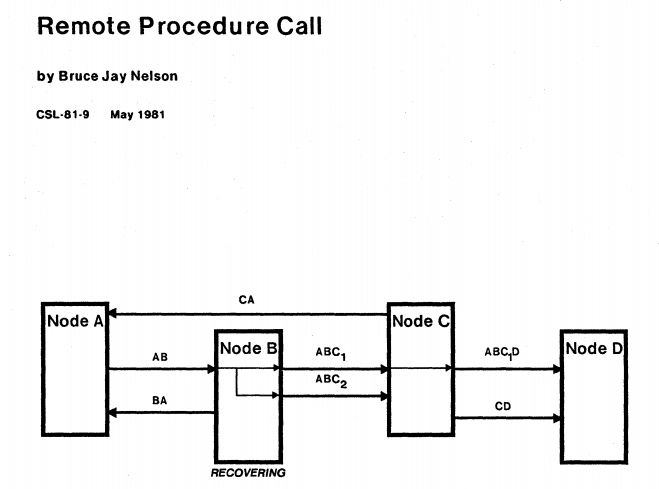
到这里,我们就可以得出 RPC 的定义了:RPC 是一种语言级别的通讯协议,它允许运行于一台计算机上的程序以某种管道作为通讯媒介(即某种传输协议的网络),去调用另外一个地址空间(通常为网络上的另外一台计算机)。
小结
这一讲,我们讨论了 RPC 的起源、概念,以及它发展上的一些分歧。以此为基础,我们才能更好地理解后面几讲要学习的内容,包括 RPC 本身要解决的三大问题、RPC 框架的现状与发展,以及它与 REST 的区别。
RPC 以模拟进程间方法调用为起点,许多思想和概念都借鉴的是 IPC,因此这一讲我也介绍了 IPC 中的一些关键概念和实现方法。但是,RPC 原本想照着 IPC 的发展思路,却在实现层面上遇到了很大的困难。RPC 作为一种跨网络的通讯手段,能否无视通讯的成本去迁就编程和设计的原则,这一点从几十年前的 DCE 开始,直到今天学术界、工业界都还有争议。
在下一讲,我会和你一起学习在 RPC 的定义提出之后,工业界中出现过的、著名的 RPC 协议,以及当今常用的各种 RPC 框架,学习它们的共性,也就是它们都必须解决哪几个问题,各自以什么为关注点,以及为何不会出现”完美的”RPC 框架。
08 | 远程服务调用(下):如何选择适合自己的RPC框架?
上一讲,我们主要是从学术的角度出发,一起学习了 RPC 概念的形成过程。今天这一讲,我会带你从技术的角度出发,去看看工业界在 RPC 这个领域曾经出现过的各种协议,以及时至今日还在层出不穷的各种框架。你会从中了解到 RPC 要解决什么问题,以及如何选择适合自己的 RPC 框架。
RPC 框架要解决的三个基本问题
在第 1 讲 “原始分布式时代” 中,我曾提到过,在 80 年代中后期,惠普和 Apollo 提出了 网络运算架构(Network Computing Architecture,NCA) 的设想,并随后在 DCE 项目 中,发展成了在 Unix 系统下的远程服务调用框架 DCE/RPC 。
这是历史上第一次对分布式有组织的探索尝试。因为 DCE 本身是基于 Unix 操作系统的,所以 DCE/RPC 也仅面向于 Unix 系统程序之间的通用。
补充:这句话其实不全对,微软 COM/DCOM 的前身 MS RPC,就是 DCE 的一种变体版本,而它就可以在 Windows 系统中使用。
在 1988 年,Sun Microsystems 起草并向互联网工程任务组(Internet Engineering Task Force,IETF)提交了RFC 1050规范,此规范中设计了一套面向广域网或混合网络环境的、基于 TCP/IP 网络的、支持 C 语言的 RPC 协议,后来也被称为是ONC RPC(Open Network Computing RPC/Sun RPC)。
这两个 RPC 协议,就可以算是如今各种 RPC 协议的鼻祖了。从它们开始,一直到接下来的这几十年,所有流行过的 RPC 协议,都不外乎通过各种手段来解决三个基本问题:
如何表示数据?
这里的数据包括了传递给方法的参数,以及方法的返回值。无论是将参数传递给另外一个进程,还是从另外一个进程中取回执行结果,都会涉及 应该如何表示 的问题。
针对进程内的方法调用,我们使用程序语言内置的和程序员自定义的数据类型,就很容易解决数据表示的问题了;而远程方法调用,则可能面临交互双方分属不同程序语言的情况。
所以,即使是只支持同一种语言的 RPC 协议,在不同硬件指令集、不同操作系统下,也完全可能有不一样的表现细节,比如数据宽度、字节序的差异等。
行之有效的做法,是 将交互双方涉及的数据,转换为某种事先约定好的中立数据流格式来传输,将数据流转换回不同语言中对应的数据类型来使用 。这个过程说起来比较拗口,但相信你一定很熟悉它,这其实就是序列化与反序列化。
每种 RPC 协议都应该有对应的序列化协议,比如:
- ONC RPC 的 External Data Representation (XDR)
- CORBA 的 Common Data Representation(CDR)
- Java RMI 的 Java Object Serialization Stream Protocol
- gRPC 的 Protocol Buffers
- Web Service 的 XML Serialization
- 众多轻量级 RPC 支持的 JSON Serialization
- ……
如何传递数据?
准确地说,如何传递数据是指如何通过网络,在两个服务 Endpoint 之间相互操作、交换数据。这里”传递数据”通常指的是应用层协议,实际传输一般是基于标准的 TCP、UDP 等传输层协议来完成的。
两个服务交互不是只扔个序列化数据流来表示参数和结果就行了,诸如异常、超时、安全、认证、授权、事务等信息,都可能存在双方交换信息的需求。在计算机科学中,专门有一个 “Wire Protocol” ,用来表示两个 Endpoint 之间交换这类数据的行为。常见的 Wire Protocol 有以下几种:
- Java RMI 的 Java Remote Message Protocol (JRMP,也支持 RMI-IIOP )
- CORBA 的 Internet Inter ORB Protocol (IIOP,是 GIOP 协议在 IP 协议上的实现版本)
- DDS 的 Real Time Publish Subscribe Protocol(RTPS)
- Web Service 的 Simple Object Access Protocol(SOAP)
- 如果要求足够简单,双方都是 HTTP Endpoint,直接使用 HTTP 也可以(如 JSON-RPC)
- ……
如何表示方法?
“如何表示方法”,这在本地方法调用中其实也不成问题,因为编译器或者解释器会根据语言规范,把调用的方法转换为进程地址空间中方法入口位置的指针。
不过一旦考虑到不同语言,这件事儿又麻烦起来了,因为每门语言的方法签名都可能有所差别,所以,针对”如何表示一个方法”和”如何找到这些方法”这两个问题,我们还是得有个统一的标准。
这个标准做起来其实可以很简单:只要给程序中的每个方法,都规定一个通用的又绝对不会重复的编号;在调用的时候,直接传这个编号就可以找到对应的方法。这种听起来无比寒碜的办法,还真的就是 DCE/RPC 最初准备的解决方案。虽然最后,DCE 还是弄出了一套跟语言无关的 接口描述语言(Interface Description Language,IDL) ,成为了此后许多 RPC 参考或依赖的基础(如 CORBA 的 OMG IDL),但那个唯一的”绝不重复”的编码方案 UUID ,却意外地流行了起来,已经被广泛应用到了程序开发的方方面面。
这类用于表示方法的协议还有:
- Android 的 Android Interface Definition Language(AIDL)
- CORBA 的 OMG Interface Definition Language(OMG IDL)
- Web Service 的 Web Service Description Language(WSDL)
- JSON-RPC 的 JSON Web Service Protocol(JSON-WSP)
- ……
你看,如何表示数据、如何传递数据、如何表示方法这三个 RPC 中的基本问题,都可以在本地方法调用中找到对应的操作。RPC 的思想始于本地方法调用,尽管它早就不再追求要跟本地方法调用的实现完全一样了,但 RPC 的发展仍然带有本地方法调用的深刻烙印。因此,我们在理解 PRC 的本质时,比较轻松的方式是,以它和本地调用的联系来对比着理解。
好,理解了 RPC 要解决的三个基本问题以后,我们接着来看一下,现代的 RPC 框架都为我们提供了哪些可选的解决方案,以及为什么今天会有这么多的 RPC 框架在并行发展。
统一的 RPC
DCE/RPC 与 ONC RPC 都有很浓厚的 Unix 痕迹,所以它们其实并没有真正地在 Unix 系统以外大规模流行过,而且它们还有一个”大问题”:只支持传递值而不支持传递对象(ONC RPC 的 XDR 的序列化器能用于序列化结构体,但结构体毕竟不是对象)。这两个 RPC 协议都是面向 C 语言设计的,根本就没有对象的概念。
而 90 年代,正好又是 面向对象编程(Object-Oriented Programming,OOP) 风头正盛的年代,所以在 1991 年, 对象管理组织(Object Management Group,OMG) 便发布了跨进程、面向异构语言的、支持面向对象的服务调用协议:CORBA 1.0(Common Object Request Broker Architecture)。
CORBA 1.0 和 1.1 版本只提供了对 C 和 C++ 的支持,而到了末代的 CORBA 3.0 版本,不仅支持了 C、C++、Java、Object Pascal、Python、Ruby 等多种主流编程语言,还支持了 Smalltalk、Lisp、Ada、COBOL 等已经”半截入土”的非主流语言,阵营不可谓不强大。
可以这么说,CORBA 是一套由国际标准组织牵头、由多个软件提供商共同参与的分布式规范。在当时,只有微软私有的 DCOM 的影响力可以稍微跟 CORBA 抗衡一下。但是,与 DCE 一样,DCOM 也受限于操作系统(不过比 DCE 厉害的是,DCOM 能跨语言哟)。所以,能够同时支持跨系统、跨语言的 CORBA,其实原本是最有机会统一 RPC 这个细分领域的竞争者。
但很无奈的是,CORBA 并没有抓住这个机会。一方面,CORBA 本身的设计实在是太过于啰嗦和繁琐了,甚至有些规定简直到了荒谬的程度。比如说,我们要写一个对象请求代理(ORB,这是 CORBA 中的关键概念)大概要 200 行代码,其中大概有 170 行是纯粹无用的废话(这句带有鞭尸性质的得罪人的评价不是我说的,是 CORBA 的首席科学家 Michi Henning 在文章《 The Rise and Fall of CORBA 》中自己说的)。
另一方面,为 CORBA 制定规范的专家逐渐脱离实际了,所以做出的 CORBA 规范非常晦涩难懂,导致各家语言的厂商都有自己的解读,结果弄出来的 CORBA 实现互不兼容,实在是对 CORBA 号称支持众多异构语言的莫大讽刺。这也间接造就了后来 W3C Web Service 的出现。
所以,Web Service 一出现,CORBA 就在这场竞争中,犹如十八路诸侯讨董卓,互乱阵脚、一触即溃,局面可以说是惨败无比。最终下场就是,CORBA 和 DCOM 一起被扫进了计算机历史的博物馆中,而 Web Service 获得了一统 RPC 的大好机会。
1998 年,XML 1.0 发布,并成为了 万维网联盟(World Wide Web Consortium,W3C) 的推荐标准。1999 年末,以 XML 为基础的 SOAP 1.0(Simple Object Access Protocol)规范的发布,代表着一种被称为”Web Service”的全新 RPC 协议的诞生。
Web Service 是由微软和 DevelopMentor 公司共同起草的远程服务协议,随后被提交给 W3C,并通过投票成为了国际标准。所以,Web Service 也被称为是 W3C Web Service。
Web Service 采用了 XML 作为远程过程调用的序列化、接口描述、服务发现等所有编码的载体,当时 XML 是计算机工业最新的银弹,只要是定义为 XML 的东西,几乎就都被认为是好的,风头一时无两,连微软自己都主动宣布放弃 DCOM,迅速转投 Web Service 的怀抱。
交给 W3C 管理后,Web Service 再没有天生属于哪家公司的烙印,商业运作非常成功,很受市场欢迎,大量的厂商都想分一杯羹。但从技术角度来看,它设计得也并不优秀,甚至同样可以说是有显著缺陷。
对于开发者而言, Web Service 的一大缺点,就是过于严格的数据和接口定义所带来的性能问题。
虽然 Web Service 吸取了 CORBA 的教训,不再需要程序员手工去编写对象的描述和服务代理了,但是 XML 作为一门描述性语言,本身的信息密度就很低(都不用与二进制协议比,与今天的 JSON 或 YAML 比一下就知道了)。同时,Web Service 是一个跨语言的 RPC 协议,这使得一个简单的字段,为了在不同语言中不会产生歧义,要以 XML 描述去清楚的话,往往比原本存储这个字段值的空间多出十几倍、几十倍乃至上百倍。
这个特点就导致了,要想使用 Web Service,就必须要有专门的客户端去调用和解析 SOAP 内容,也需要专门的服务去部署(如 Java 中的 Apache Axis/CXF);更关键的是,这导致了每一次数据交互都包含大量的冗余信息,性能非常差。
如果只是需要客户端、传输性能差也就算了, 又不是不能用 。既然选择了 XML 来获得自描述能力,也就代表着没打算把性能放到第一位。但是,Web Service 还有另外一点原罪:贪婪。
“贪婪”是指,它希望在一套协议上,一揽子解决分布式计算中可能遇到的所有问题。这导致 Web Service 生出了一整个家族的协议出来。
Web Service 协议家族中,除它本身包括了的 SOAP、WSDL、UDDI 协议之外,还有一堆以 WS-* 命名的子功能协议,来解决事务、一致性、事件、通知、业务描述、安全、防重放等问题。这些几乎数不清个数的家族协议,对开发者来说学习负担极其沉重。结果就是,得罪惨了开发者,谁爱用谁用去。
当程序员们对 Web Service 的热情迅速燃起,又逐渐冷却之后,也不禁开始反思:那些 面向透明的、简单的 RPC 协议 ,如 DCE/RPC、DCOM、Java RMI,要么依赖于操作系统,要么依赖于特定语言,总有一些先天约束;那些 面向通用的、普适的 RPC 协议 ,如 CORBA,就无法逃过使用复杂性的困扰;而那些 意图通过技术手段来屏蔽复杂性的 RPC 协议 ,如 Web Service,又不免受到性能问题的束缚。
简单、普适和高性能,似乎真的难以同时满足。
分裂的 RPC
由于一直没有一个能同时满足以上简单、普适和高性能的”完美 RPC 协议”,因此远程服务器调用这个小小的领域就逐渐进入了群雄混战、百家争鸣的”战国时代”,距离”统一”越来越远,并一直延续至今。
我们看看相继出现过的 RPC 协议 / 框架,就能明白了:RMI(Sun/Oracle)、Thrift(Facebook/Apache)、Dubbo(阿里巴巴 /Apache)、gRPC(Google)、Motan2(新浪)、Finagle(Twitter)、brpc(百度)、.NET Remoting(微软)、Arvo(Hadoop)、JSON-RPC 2.0(公开规范,JSON-RPC 工作组)……
这些 RPC 的功能、特点都不太一样,有的是某种语言私有,有的能支持跨越多门语言,有的运行在 HTTP 协议之上,有的能直接运行于 TCP/UDP 之上,但没有哪一款是”最完美的 RPC”。据此,我们也可以发现一个规律,任何一款具有生命力的 RPC 框架,都不再去追求大而全的”完美”,而是会找到一个独特的点作为主要的发展方向。
我们看几个典型的发展方向:
- 朝着面向对象发展。 这条线的缘由在于,在分布式系统中,开发者们不再满足于 RPC 带来的面向过程的编码方式,而是希望能够进行跨进程的面向对象编程。因此,这条线还有一个别名叫作 分布式对象(Distributed Object) ,它的代表有 RMI、.NET Remoting。当然了,之前的 CORBA 和 DCOM 也可以归入这一类。
- 朝着性能发展 ,代表为 gRPC 和 Thrift。决定 RPC 性能主要就两个因素:序列化效率和信息密度。序列化效率很好理解,序列化输出结果的容量越小,速度越快,效率自然越高;信息密度则取决于协议中,有效荷载(Payload)所占总传输数据的比例大小,使用传输协议的层次越高,信息密度就越低,SOAP 使用 XML 拙劣的性能表现就是前车之鉴。gRPC 和 Thrift 都有自己优秀的专有序列化器,而在传输协议方面,gRPC 是基于 HTTP/2 的,支持多路复用和 Header 压缩,Thrift 则直接基于传输层的 TCP 协议来实现,省去了额外的应用层协议的开销。
- 朝着简化发展 ,代表为 JSON-RPC。要是说选出功能最强、速度最快的 RPC 可能会有争议,但要选出哪个功能弱的、速度慢的,JSON-RPC 肯定会是候选人之一。它牺牲了功能和效率,换来的是协议的简单。也就是说,JSON-RPC 的接口与格式的通用性很好,尤其适合用在 Web 浏览器这类一般不会有额外协议、客户端支持的应用场合。
- ……
经历了 RPC 框架的”战国时代”,开发者们终于认可了,不同的 RPC 框架所提供的不同特性或多或少是互相矛盾的,很难有某一种框架说”我全部都要”。
要把面向对象那套全搬过来,就注定不会太简单(比如建 Stub、Skeleton 就很烦了,即使由 IDL 生成也很麻烦);功能多起来,协议就要弄得复杂,效率一般就会受影响;要简单易用,那很多事情就必须遵循约定而不是配置才行;要重视效率,那就需要采用二进制的序列化器和较底层的传输协议,支持的语言范围容易受限。
也正是因为每一种 RPC 框架都有不完美的地方,才会有新的 RPC 轮子不断出现。
而到了最近几年,RPC 框架有明显朝着更高层次(不仅仅负责调用远程服务,还管理远程服务)与插件化方向发展的趋势, 不再选择自己去解决表示数据、传递数据和表示方法这三个问题,而是将全部或者一部分问题设计为扩展点,实现核心能力的可配置 ,再辅以外围功能,如负载均衡、服务注册、可观察性等方面的支持。这一类框架的代表,有 Facebook 的 Thrift 和阿里的 Dubbo(现在两者都是 Apache 的)。
尤其是断更多年后重启的 Dubbo 表现得更为明显,它默认有自己的传输协议(Dubbo 协议),同时也支持其他协议,它默认采用 Hessian 2 作为序列化器,如果你有 JSON 的需求,可以替换为 Fastjson;如果你对性能有更高的需求,可以替换为 Kryo 、 FST 、Protocol Buffers 等;如果你不想依赖其他包,直接使用 JDK 自带的序列化器也可以。这种设计,就在一定程度上缓解了 RPC 框架必须取舍,难以完美的缺憾。
小结
今天,我们一起学习了 RPC 协议在工业界的发展,包括它要解决的三个基本问题,以及层出不穷的 RPC 协议 / 框架。
表示数据、传递数据和表示方法,是 RPC 必须解决的三大基本问题。要解决这些问题,可以有很多方案,这也是 RPC 协议 / 框架出现群雄混战局面的一个原因。
出现这种分裂局面的另一个原因,是简单的框架很难能达到功能强大的要求。
功能强大的框架往往要在传输中加入额外的负载和控制措施,导致传输性能降低,而如果既想要高性能,又想要强功能,这就必然要依赖大量的技巧去实现,进而也就导致了框架会变得过于复杂,这就决定了不可能有一个”完美”的框架同时满足简单、普适和高性能这三个要求。
认识到这一点后,一个 RPC 框架要想取得成功,就要选择一个发展方向,能够非常好地满足某一方面的需求。因此,我们也就有了朝着面向对象发展、朝着性能发展和朝着简化发展这三条线。
以上就是这一讲我要和你分享的 RPC 在工业界的发展成果了。这也是,你在日后工作中选择 RPC 实现方案的一个参考。
最后,我再和你分享一点我的心得。我在讲到 DCOM、CORBA、Web Service 的失败的时候,虽然说我的口吻多少有一些戏谑,但我们得明确一点:这些框架即使没有成功,但作为早期的探索先驱,并没有什么应该被讽刺的地方。而且其后续的发展,都称得上是知耻后勇,反而值得我们的掌声赞赏。
比如,说到 CORBA 的消亡,OMG 痛定思痛之后,提出了基于 RTPS 协议栈的” 数据分发服务 “商业标准(Data Distribution Service,DDS,”商业”就是要付费使用的意思)。这个标准现在主要用在物联网领域,能够做到微秒级延时,还能支持大规模并发通讯。
再比如,说到 DCOM 的失败和 Web Service 的衰落,微软在它们的基础上,推出了 .NET WCF(Windows Communication Foundation,Windows 通信基础) 。
.NET WCF 的优势主要有两点:一是,把 REST、TCP、SOAP 等不同形式的调用,自动封装为了完全一致的、如同本地方法调用一般的程序接口;二是,依靠自家的”地表最强 IDE”Visual Studio,把工作量减少到只需要指定一个远程服务地址,就可以获取服务描述、绑定各种特性(如安全传输)、自动生成客户端调用代码,甚至还能选择同步还是异步之类细节的程度。
虽然.NET WCF 只支持.NET 平台,而且也是采用 XML 语言描述,但使用体验真的是非常畅快,足够挽回 Web Service 得罪开发者丢掉的全部印象分。
09 | RESTful服务(上):从面向过程编程到面向资源编程
REST 与 RPC 的对比
很多人都会拿 REST 来跟 RPC 对比优劣,其实,无论是思想上、概念上,还是使用范围上,REST 与 RPC 都不完全一样,它们在本质上并不是同一个类型的东西,充其量只算是有一些相似,在应用中会有一部分功能重合的地方。
REST 与 RPC 在思想上存在差异的核心,是抽象的目标不一样,也就是面向资源的编程思想与面向过程的编程思想之间的区别。
面向过程编程和面向对象编程,想必你应该都听说过,但什么是面向资源编程呢?这个问题等我一会儿介绍完 REST 的特征之后,再回头细说。
那么,二者在概念上的不同,是指 REST 并不是一种远程服务调用协议,甚至我们可以把定语也去掉,它就不是一种协议。
因为协议都带有一定的规范性和强制性,最起码也该有个规约文档,比如 JSON-RPC,它哪怕再简单,也要有个《JSON-RPC Specification》来规定协议的格式细节、异常、响应码等信息。但是 REST 并没有定义这些内容,虽然它有一些指导原则,但实际上并不受任何强制的约束。
经常会有人批评说,某个系统接口”设计得不够 RESTful”,其实这句话本身就有些争议。因为 REST 只能说是一种风格,而不是规范、协议,并且能完全达到 REST 所有指导原则的系统,也是很少见的。这个问题我们会在下一讲中详细讨论。
至于使用范围上,REST 与 RPC 作为主流的两种远程调用方式,在使用上确实有重合之处,但重合的区域有多大就见仁见智了。
上一节课,我提到了当前的 RPC 协议框架各有侧重点,并且列举了 RPC 的一些典型发展方向,比如分布式对象、提升调用效率、简化调用复杂性等等。
其中的分布式对象这一条线的应用,对于 REST 就可以说是毫无关系;而能够重视远程服务调用效率的应用场景,就基本上已经排除了 REST 应用得最多的供浏览器端消费的远程服务。因为以浏览器作为前端,对于传输协议、序列化器这两点都没有什么选择权,哪怕想要更高效率也有心无力。
而在移动端、桌面端或者分布式服务端的节点之间通讯这一块,REST 虽然照样有宽阔的用武之地,只要支持 HTTP 就可以用于任何语言之间的交互,不过使用 REST 的前提是网络没有成为性能上的瓶颈。但是在需要追求传输效率的场景里,REST 提升传输效率的潜力有限,死磕 REST 又想要好的网络性能,一般不会有好的效果。
另外,对于追求简化调用的场景,我在前面提到的浏览器端就属于这一类的典型,在众多 RPC 里,也就 JSON-RPC 有机会与 REST 竞争,其他 RPC 协议与框架,哪怕是能够支持 HTTP 协议,哪怕提供了 JavaScript 版本的客户端(如 gRPC-Web),也只是具备前端使用的理论可行性,很少能看到有实际项目把它们真的用到浏览器上的。
可是,尽管有着种种不同,REST 跟 RPC 还是产生了很频繁的比较与争论,这两种分别面向资源和面向过程的远程调用方式,就像当年面向对象与面向过程的编程思想一样,非得分出个高低不可。
理解 REST
REST 概念的提出来自于罗伊·菲尔丁(Roy Fielding)在 2000 年发表的博士论文:《 Architectural Styles and the Design of Network-based Software Architectures 》(架构风格与网络的软件架构设计)。这篇文章的确是 REST 的源头,但我们也不能忽略 Fielding 的身份和他之前的工作背景,这对理解 REST 的设计思想也是非常重要的。
首先,Fielding 是一名很优秀的软件工程师,他是 Apache 服务器的核心开发者,后来成为了著名的 Apache 软件基金会 的联合创始人;同时,Fielding 也是 HTTP 1.0 协议(1996 年发布)的专家组成员,后来还成为了 HTTP 1.1 协议(1999 年发布)的负责人。
HTTP 1.1 协议设计得非常成功,以至于在发布后长达十年的时间里,都没有多少人认为有修订的必要。而用来指导设计 HTTP 1.1 协议的理论和思想,最初是以备忘录的形式,在专家组成员之间交流,这个备忘录其实就是 REST 的雏形。
那么从时间上看,当起草完 HTTP 1.1 协议之后,Fielding 就回到了加州大学欧文分校,继续攻读博士学位。然后到了第二年,也就是 2000 年,Fielding 更为系统、严谨地阐述了这套理论框架,并且以这套理论框架为基础,导出了一种新的编程风格,他把这种风格命名为了我们今天所熟知的 REST,即”表征状态转移”(Representational State Transfer)的缩写。
不过,哪怕是对编程和网络都很熟悉的同学,单从”表征状态转移”这个标题上看,也不太可能直接弄明白,什么叫”表征”、啥东西的”状态”、从哪”转移”到哪。虽然在论文当中,Fielding 有论述过这些概念,但他写得确实非常晦涩(不想读英文的话,你可以参考一下 中文翻译版本 )。
这里呢,我推荐你一种比较容易理解 REST 思想的方式,就是你 先去理解什么是 HTTP,再配合一些实际例子来进行类比 ,你就会发现”REST”实际上是”HTT”(Hyper Text Transfer,超文本传输)的进一步抽象,它们就像是接口与实现类之间的关系。
HTTP 中使用的”超文本”一词,是美国社会学家泰德·H·尼尔森(Theodor Holm Nelson)在 1967 年于《 Brief Words on the Hypertext 》一文里提出的,这里引用的是他本人在 1992 年修正后的定义:
Hypertext
By now the word “hypertext” has become generally accepted for branching and responding text, but the corresponding word “hypermedia”, meaning complexes of branching and responding graphics, movies and sound - as well as text - is much less used. Instead they use the strange term “interactive multimedia”: this is four syllables longer, and does not express the idea of extending hypertext.
—— Theodor Holm Nelson Literary Machines , 1992
可以看到,”超文本(或超媒体)”指的是一种”能够对操作进行判断和响应的文本(或声音、图像等)”,这个概念在上个世纪 60 年代提出的时候,应该还属于科幻的范畴,但是到了今天,我们已经完全接受了它,互联网中的一段文字可以点击、可以触发脚本执行、可以调用服务端,都已经非常平常,毫不稀奇了。
所以接下来,我们就尝试着从理解”超文本”的含义开始,根据一个具体的阅读文章的例子,来理解一下什么是”表征”,以及 REST 中的其他关键概念。
资源(Resource)
假设,你现在正在阅读一篇名为《REST 设计风格》的文章,这篇文章的内容本身(可以将其视作是某种信息、数据),我们称之为”资源”。无论你是在网上看的网页,还是打印出来看的文字稿,或者是在电脑屏幕上阅读、手机上浏览,尽管它呈现出来的样子都不一样,但其中的信息是不变的,你阅读的仍是同一个”资源”。
表征(Representation)
当你通过电脑浏览器阅读这篇文章的时候,浏览器会向服务端发出请求”我需要这个资源的 HTML 格式”,那么服务端向浏览器返回的这个 HTML,就被称之为”表征”,你通过其他方式拿到了文章的 PDF、Markdown、RSS 等其他形式的版本,它们也同样是一个资源的多种表征。可见, “表征”这个概念是指信息与用户交互时的表示形式 ,这跟应用分层中我们常说的”表示层”(Presentation Layer)的语义其实是一致的。
状态(State)
当你读完了这篇文章,想再接着看看下一篇文章的内容时,你向服务器发出请求”给我下一篇文章”。但是”下一篇”是个相对概念,必须依赖”当前你正在阅读的文章是哪一篇”,这样服务器才能正确回应,那么这类 在特定语境中才能产生的上下文信息就被称为”状态”。
这里我们要注意,有状态(Stateful)还是无状态(Stateless),都是只相对于服务端来说的,服务器要完成”取下一篇”的请求,要么是自己记住用户的状态(这个用户现在阅读的是哪一篇文章,这是有状态),要么是客户端来记住状态,在请求的时候明确告诉服务器(我正在阅读某某文章,现在要读下一篇,这是无状态)。
转移(Transfer)
要知道,无论状态是由服务端还是客户端来提供的,”取下一篇文章”这个行为逻辑必然只能由服务端来提供。 服务器通过某种方式,把”用户当前阅读的文章”转变成”下一篇文章”,这就被称为”表征状态转移”。
好,通过这个”阅读文章”的例子,对资源等概念进行通俗的解释,现在你应该就能理解 REST 所说的”表征状态转移”的含义了。
那么,借着这个例子的上下文,我再给你介绍几个现在不涉及,但在后面解读 REST 的 6 大核心特征时要用到的概念名词:
第一个,统一接口(Uniform Interface)。
在了解这个概念之前,我们先来思考一个问题,前面所说的”服务器通过某种方式”,让表征状态发生转移,具体指的是什么方式呢?
如果你现在正在使用 Web 端来学习这一讲的内容,你可以看到页面的左半部分有下一讲(或者是下面几讲)的 URI 超链接地址,这是服务端在渲染这讲内容时就预置好的,点击它让页面跳转到下一讲,就是所谓”某种方式”的其中一种方式(不过若下一讲还未更新出来时,你只能看到之前的课程内容,道理其实也差不多)。
现在,我们其实并不会对点击超链接网页出现跳转而感到奇怪,但你再细想一下,URI 的含义是统一资源标识符,是一个名词,那它如何能表达出”转移”这个动作的含义呢?
答案是 HTTP 协议中已经提前约定好了一套”统一接口”,它包括:GET、HEAD、POST、PUT、DELETE、TRACE、OPTIONS 七种基本操作,任何一个支持 HTTP 协议的服务器都会遵守这套规定,对特定的 URI 采取这些操作,服务器就会触发相应的表征状态转移。
第二个,超文本驱动(Hypertext Driven)。
尽管表征状态转移是由浏览器主动向服务器发出请求所引发的,该请求导致了”在浏览器屏幕上显示出了下一篇文章的内容”这个结果的出现。但是你我都清楚,这不可能真的是浏览器的主动意图,浏览器是根据用户输入的 URI 地址来找到服务器给予的首页超文本内容,通过超文本内部的链接,导航到了这篇文章,阅读结束时,也是通过超文本内部的链接再导航到下一篇。
浏览器作为所有网站的通用的客户端,任何网站的导航(状态转移)行为都不可能是预置于浏览器代码之中,而是由服务器发出的请求响应信息(超文本)来驱动的。这点与其他带有客户端的软件有十分本质的区别,在那些软件中,业务逻辑往往是预置于程序代码之中的,有专门的页面控制器(无论在服务端还是在客户端中)来驱动页面的状态转移。
第三个,自描述消息(Self-Descriptive Messages)。
前面我们知道了,资源的表征可能存在多种不同形态,因此在传输给浏览器的消息中应当有明确的信息,来告知客户端该消息的类型以及该如何处理这条消息。一种被广泛采用的自描述方法,是在名为”Content-Type”的 HTTP Header 中标识出 互联网媒体类型(MIME type) ,比如”Content-Type : application/json; charset=utf-8”,就说明了该资源会以 JSON 的格式返回,请使用 UTF-8 字符集进行处理。
好,除了以上列出的这些看名字不容易弄懂的概念外,在理解 REST 的时候,你还要注意一个常见的误区。Fielding 在提出 REST 时,所谈论的范围是”架构风格与网络的软件架构设计”(Architectural Styles and Design of Network-based Software Architectures),而不是现在被人们所狭义理解的一种”远程服务设计风格”。
这两者的范围差别,就好比这门课程所谈论的话题”软件架构”与这个小章节所谈论的话题”访问远程服务”的关系那样,前者是后者的一个很大的超集。尽管考虑到这节课的主题和多数人的关注点,我们确实是会以”远程服务设计风格”作为讨论的重点,但至少我们要知道它们在范围上的差别。
RESTful 风格的系统特征
OK,理解了前面解读的这些概念以后,现在我们就可以开始讨论面向资源的编程思想,以及 Fielding 所提出的具体的软件架构设计特征了。Fielding 认为,一套理想的、完全满足 REST 的系统应该满足以下六个特征。
服务端与客户端分离(Client-Server)
现在,有越来越多的开发者认可,分离开用户界面和数据存储所关注的逻辑,有助于提高用户界面跨平台的可移植性。
以前完全基于服务端控制和渲染(如 JSF 这类)框架的实际用户,现在已经很少见了。另外,在服务端进行界面控制(Controller),通过服务端或者客户端的模版渲染引擎,来进行界面渲染的框架(如 Struts、SpringMVC 这类)也受到了颇大的冲击。而推动这个局面发展的主要原因,实际上跟 REST 的关系并不大,随着前端技术(从 ES 规范,到语言实现,到前端框架等)近年来的高速发展,前端表达能力的大幅度加强才是真正的幕后推手。
此外,由于前端的日渐强势,现在还流行起由前端代码反过来驱动服务端进行渲染的 SSR(Server-Side Rendering)技术,在 Serverless、SEO 等场景中已经占领了一块领地。
无状态(Stateless)
这是 REST 的一条关键原则,部分开发者在做服务接口规划时,觉得 RESTful 风格的 API 怎么设计都别扭,一个很可能的原因就是服务端持有着比较重的状态。
REST 希望服务器能不负责维护状态,每一次从客户端发送的请求中,应该包括所有必要的上下文信息,会话信息也由客户端保存维护,服务器端依据客户端传递的状态信息来进行业务处理,并且驱动整个应用的状态变迁。
至于客户端承担状态维护职责后的认证、授权等各方面的可信问题,都会有针对性的解决方案(这部分内容,我会在后面讲解安全架构时展开介绍)。
但必须承认的现状是,目前大多数的系统是达不到这个要求的,越复杂、越大型的系统越是如此。服务端无状态可以在分布式环境中获得很高价值的好处,但大型系统的上下文状态数量,完全可能膨胀到,客户端在每次发送请求时,根本无法全部囊括系统里所有必要的上下文信息。在服务端的内存、会话、数据库或者缓存等地方,持有一定的状态是一种现实情况,而且会是长期存在、被广泛使用的主流方案。
可缓存(Cacheability)
前面我们提到的无状态服务,虽然提升了系统的可见性、可靠性和可伸缩性,但也降低了系统的网络性。这句话通俗的解释就是,某个功能使用有状态的架构只需要一次请求就能完成,而无状态的服务则可能会需要多个请求,或者在请求中带有冗余的信息。
所以,为了缓解这个矛盾,REST 希望软件系统能够像万维网一样,客户端和中间的通讯传递者(代理)可以将部分服务端的应答缓存起来。当然,应答中必须明确或者间接地表明本身是否可以进行缓存,以避免客户端在将来进行请求的时候得到过时的数据。
运作良好的缓存机制可以减少客户端、服务器之间的交互,甚至有些场景中可以完全避免交互,这就进一步提高了性能。
分层系统(Layered System)
这里所指的并不是表示层、服务层、持久层这种意义上的分层,而是指客户端一般不需要知道是否直接连接到了最终的服务器,或者是连接到路径上的中间服务器。中间服务器可以通过负载均衡和共享缓存的机制,提高系统的可扩展性,这样也便于缓存、伸缩和安全策略的部署。
统一接口(Uniform Interface)
REST 希望开发者面向资源编程,希望 软件系统设计的重点放在抽象系统该有哪些资源上 ,而不是抽象系统该有哪些行为(服务)上。
这个特征,你可以类比计算机中对文件管理的操作。我们知道,管理文件可能会进行创建、修改、删除、移动等操作,这些操作数量是可数的,而且对所有文件都是固定的、统一的。如果面向资源来设计系统,同样会具有类似的操作特征,由于 REST 并没有设计新的协议,所以这些操作都借用了 HTTP 协议中固有的操作命令来完成。
统一接口也是 REST 最容易陷入争论的地方,基于网络的软件系统,到底是面向资源更好,还是面向服务更合适,这件事情在很长的时间里恐怕都不会有个定论,也许永远都没有。但是,有一个已经基本清晰的结论是: 面向资源编程的抽象程度通常更高。
抽象程度高有好处但也有坏处。坏处是往往距离人类的思维方式更远,而好处是往往通用程度会更好。
不过这样来诠释 REST,大概本身就挺抽象的,你可能不太好理解,我还是举个例子来说明。
几乎每个系统都有登录和注销功能,如果你理解成登录对应于 login()、注销对应于 logout() 这样两个独立服务,这是”符合人类思维”的;如果你理解成登录是 PUT Session,注销是 DELETE Session,这样你只需要设计一种”Session 资源”即可满足需求,甚至以后对 Session 的其他需求,如查询登录用户的信息,就是 GET Session 而已,其他操作如修改用户信息等等,都可以被这同一套设计囊括在内,这便是”抽象程度更高”带来的好处。
而如果你想要在架构设计中合理恰当地利用统一接口,Fielding 给出了三个建议:第一,系统要能做到每次请求中都包含资源的 ID,所有操作均通过资源 ID 来进行;第二,每个资源都应该是自描述的消息;第三,通过超文本来驱动应用状态的转移。
按需代码( Code-On-Demand )
按需代码被 Fielding 列为了一条可选原则,原因其实并非是它特别难以达到,更多是出于必要性和性价比的实际考虑。按需代码是指任何按照客户端(如浏览器)的请求,将可执行的软件程序从服务器发送到客户端的技术。它赋予了客户端无需事先知道,所有来自服务端的信息应该如何处理、如何运行的宽容度。
举个具体例子,以前的 Java Applet 技术、今天的 WebAssembly 等都属于典型的按需代码,蕴含着具体执行逻辑的代码存放在了服务端,只有当客户端请求了某个 Java Applet 之后,代码才会被传输并在客户端机器中运行,结束后通常也会随即在客户端中被销毁掉。
到这里,REST 中的主要概念与思想原则就介绍完了,那么现在,我们再回过头来讨论一下这节课开篇中提出的 REST 与 RPC 在思想上的差异。
REST 与 RPC 在思想上的差异
我在前面提到, REST 的基本思想是面向资源来抽象问题,它与此前流行的面向过程的编程思想,在抽象主体上有本质的差别。
在 REST 提出以前,人们设计分布式系统服务的唯一方案就只有 RPC,RPC 是将本地的方法调用思路迁移到远程方法调用上,开发者是围绕着”远程方法”去设计两个系统间的交互的,比如 CORBA、RMI、DCOM,等等。
这样做的坏处,不仅是”如何在异构系统间表示一个方法””如何获得接口能够提供的方法清单”,都成了需要专门协议去解决的问题(RPC 的三大基本问题之一),更在于服务的每个方法都是不同的,服务使用者必须逐个学习才能正确地使用它们。Google 在《Google API Design Guide》中曾经写下这样一段话:
Traditionally, people design RPC APIs in terms of API interfaces and methods, such as CORBA and Windows COM. As time goes by, more and more interfaces and methods are introduced. The end result can be an overwhelming number of interfaces and methods, each of them different from the others. Developers have to learn each one carefully in order to use it correctly, which can be both time consuming and error prone.
以前,人们面向方法去设计 RPC API,比如 CORBA 和 DCOM,随着时间推移,接口与方法越来越多却又各不相同,开发人员必须了解每一个方法才能正确使用它们,这样既耗时又容易出错。
—— Google API Design Guide , 2017
而 REST 提出以资源为主体进行服务设计的风格,就为它带来了不少好处。我举几个典型例子。
第一,降低了服务接口的学习成本。
统一接口是 REST 的重要标志,它把对资源的标准操作都映射到了标准的 HTTP 方法上去,这些方法对每个资源的语义都是一致的,我们不需要刻意学习,更不会有什么 Interface Description Language 之类的协议存在。
第二,资源天然具有集合与层次结构。
以方法为中心抽象的接口,由于方法是动词,逻辑上决定了每个接口都是互相独立的;但以资源为中心抽象的接口,由于资源是名词,天然就可以产生集合与层次结构。
我举个例子。你可以想像一个商城用户中心的接口设计:用户资源会拥有多个不同的下级的资源,比如若干条短消息资源、一份用户资料资源、一部购物车资源,而购物车中又会有自己的下级资源,比如多本书籍资源。
这样,你就很容易在程序接口中构造出这些资源的集合关系与层次关系,而且能符合人们长期在单机或网络环境中管理数据的直觉。我相信,你并不需要专门去阅读接口说明书,也能轻易推断出获取用户 icyfenix 的购物车中,第 2 本书的 REST 接口应该表示为:
GET /users/icyfenix/cart/2。第三,REST 绑定于 HTTP 协议。
面向资源编程并不是必须构筑在 HTTP 之上,但对于 REST 来说,这是优点,也是缺点。
因为 HTTP 本来就是面向资源而设计的网络协议,纯粹只用 HTTP(而不是 SOAP over HTTP 那样在再构筑协议)带来的好处,是不需要再去考虑 RPC 中的 Wire Protocol 问题了,REST 可以复用 HTTP 协议中已经定义的语义和相关基础支持来解决。HTTP 协议已经有效运作了 30 年,与其相关的技术基础设施已是千锤百炼,无比成熟。而它的坏处自然就是,当你想去考虑那些 HTTP 不提供的特性时,就束手无策了。
小结
在这节课中,虽然我列举了一些面向资源的优点,但我并非要证明它比面向过程、面向对象更优秀。是否选用 REST 的 API 设计风格,需要权衡的是你的需求场景、你团队的设计,以及开发人员是否能够适应面向资源的思想来设计软件、来编写代码。
在互联网中,面向资源来进行网络传输,是这三十年来 HTTP 协议精心培养出来的用户习惯,如果开发者能够适应 REST 不太符合人类思维习惯的抽象方式,那 REST 通常能够更好地匹配在 HTTP 基础上构建的互联网,在效率与扩展性方面也会有可观的收益。
10 | RESTful服务(下):如何评价服务是否RESTful?
上一节课,我们一起学习了 REST 的思想、概念和指导原则等,今天我们把重心放在 REST 的实践上,把目光聚焦到具体如何设计 REST 服务接口上。这样我们也就能回答上节课提出的问题”如何评价服务是否 RESTful”了。
Richardson 成熟度模型
“ RESTful Web APIs “和” RESTful Web Services “的作者伦纳德 · 理查德森(Leonard Richardson),曾提出过一个衡量”服务有多么 REST”的 Richardson 成熟度模型( Richardson Maturity Model ,RMM)。这个模型的一个用处是,方便那些原本不使用 REST 的服务,能够逐步导入 REST。
Richardson 将服务接口按照”REST 的程度”,从低到高分为 0 至 3 共 4 级:
- The Swamp of Plain Old XML :完全不 REST。另外,关于 POX 这个说法,SOAP 表示感觉有被冒犯到。
- Resources:开始引入资源的概念。
- HTTP Verbs:引入统一接口,映射到 HTTP 协议的方法上。
- Hypermedia Controls:在咱们课程里面的说法是”超文本驱动”,在 Fielding 论文里的说法是 Hypertext as the Engine of Application State(HATEOAS),都说的是同一件事情。
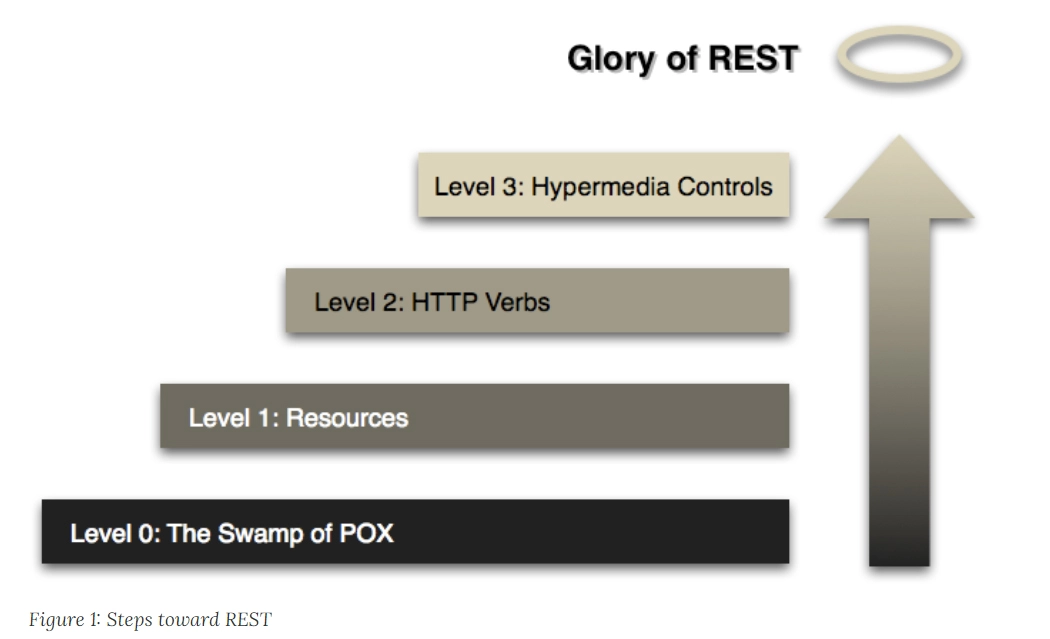
接下来,我们通过马丁 · 福勒(Martin Fowler)的关于 RMM 的 文章 中的实际例子(原文是 XML 写的,我简化了一下),来看看四种不同程度的 REST 反应到实际 API 是怎样的。
假设,你是一名软件工程师,接到需求(也被我尽量简化了)的用户故事是这样的:现在要开发一个医生预约系统,病人通过这个系统,可以知道自己熟悉的医生在指定日期是否有空闲时间,以方便预约就诊。
第 0 级成熟度:The Swamp of Plain Old XML
医院开放了一个 /appointmentService 的 Web API,传入日期、医生姓名作为参数,就可以得到该时间段、该医生的空闲时间。
这个 API 的一次 HTTP 调用如下所示:
POST /appointmentService?action=query HTTP/1.1 {date: "2020-03-04", doctor: "mjones"}在接收到请求之后,服务器会传回一个包含所需信息的结果:
HTTP/1.1 200 OK [ {start:"14:00", end: "14:50", doctor: "mjones"}, {start:"16:00", end: "16:50", doctor: "mjones"} ]得到了医生空闲的结果后,我觉得 14:00 的时间比较合适,于是预约确认,并提交了我的基本信息:
POST /appointmentService?action=comfirm HTTP/1.1 { appointment: {date: "2020-03-04", start:"14:00", doctor: "mjones"}, patient: {name: xx, age: 30, ……} }如果预约成功,那我能够收到一个预约成功的响应:
HTTP/1.1 200 OK { code: 0, message: "Successful confirmation of appointment" }如果发生了问题,比如有人在我前面抢先预约了,那么我会在响应中收到某种错误信息:
HTTP/1.1 200 OK { code: 1 message: "doctor not available" }到此,整个预约服务就完成了,可以说是直接明了。
在这个方案里,我们采用的是非常直观的基于 RPC 风格的服务设计,看似是很轻松地解决了所有问题,但真的是这样吗?
第 1 级成熟度:Resources
实际上你可以发现,第 0 级是 RPC 的风格,所以如果需求永远不会变化,也不会增加,那它完全可以良好地工作下去。但是,如果你不想为预约医生之外的其他操作、为获取空闲时间之外的其他信息去编写额外的方法,或者改动现有方法的接口,那就应该考虑一下如何使用 REST 来抽象资源。
通往 REST 的第一步是引入资源的概念,在 API 中最基本的体现,就是它会围绕着资源而不是过程来设计服务。说得直白一点,你可以理解为服务的 Endpoint 应该是一个名词而不是动词。此外,每次请求中都应包含资源 ID,所有操作均通过资源 ID 来进行。
POST /doctors/mjones HTTP/1.1 {date: "2020-03-04"}然后,服务器传回一个包含了 ID 的信息。注意,ID 是资源的唯一编号,有 ID 即代表”医生的档期”被视为一种资源:
HTTP/1.1 200 OK [ {id: 1234, start:"14:00", end: "14:50", doctor: "mjones"}, {id: 5678, start:"16:00", end: "16:50", doctor: "mjones"} ]我还是觉得 14:00 的时间比较合适,于是又预约确认,并提交了我的基本信息:
POST /schedules/1234 HTTP/1.1 {name: xx, age: 30, ……}后面预约成功或者失败的响应消息在这个级别里面与之前一致,就不重复了。
比起第 0 级,第 1 级的服务抽象程度有所提高,但至少还有三个问题并没有解决:
- 一是,只处理了查询和预约,如果我临时想换个时间要调整预约,或者我的病忽然好了想删除预约,这都需要提供新的服务接口。
- 二是,处理结果响应时,只能靠着结果中的 code、message 这些字段做分支判断,每一套服务都要设计可能发生错误的 code。而这很难考虑全面,而且也不利于对某些通用的错误做统一处理。
三是,并没有考虑认证授权等安全方面的内容。比如,要求只有登录过的用户才允许查询医生的档期;再比如,某些医生可能只对 VIP 开放,需要特定级别的病人才能预约等等。
这三个问题,其实都可以通过引入统一接口(Uniform Interface)来解决。接下来,我们就来到了第 2 级。
第 2 级成熟度:HTTP Verbs
前面说到,第 1 级中遗留的这三个问题,都可以靠引入统一接口来解决,而 HTTP 协议的标准方法便是最常接触到的统一接口。
HTTP 协议的标准方法是经过精心设计的,它几乎涵盖了资源可能遇到的所有操作场景(这其实更取决于架构师的抽象能力)。
那么,REST 的做法是:
- 针对 预约变更 的问题,把不同业务需求抽象为对资源的增加、修改、删除等操作来解决;
- 针对 响应代码 的问题,使用 HTTP 协议的 Status Code,可以涵盖大多数资源操作可能出现的异常(而且也是可以自定义扩展的);
针对 安全性 的问题,依靠 HTTP Header 中携带的额外认证、授权信息来解决(这个在实战中并没有体现,你可以去看看后面第 23~28 讲中关于安全架构的相关内容)。
按这个思路,我们在获取医生档期时,应该使用具有查询语义的 GET 操作来完成:
GET /doctors/mjones/schedule?date=2020-03-04&status=open HTTP/1.1然后,服务器会传回一个包含了所需信息的结果:
HTTP/1.1 200 OK [ {id: 1234, start:"14:00", end: "14:50", doctor: "mjones"}, {id: 5678, start:"16:00", end: "16:50", doctor: "mjones"} ]我还是觉得 14:00 的时间比较合适,于是就预约确认,并提交了我的基本信息用来创建预约。这是符合 POST 的语义的:
POST /schedules/1234 HTTP/1.1 {name: xx, age: 30, ……}如果预约成功,那我能够收到一个预约成功的响应:
HTTP/1.1 201 Created Successful confirmation of appointment否则,我会在响应中收到某种错误信息:
HTTP/1.1 409 Conflict doctor not available目前绝大多数的系统能够达到的 REST 级别,也就是第 2 级了。不过这种方案还不够完美,最主要的一个问题是:我们如何知道预约 mjones 医生的档期,需要访问”/schedules/1234”这个服务 Endpoint?
第 3 级成熟度:Hypermedia Controls
或许你第一眼看到这个问题会说,这当然是程序写的啊,我为什么会问这么奇怪的问题。但问题是,REST 并不认同这种已烙在程序员脑海中许久的想法。
RMM 中的第 3 级成熟度 Hypermedia Controls、Fielding 论文中的 HATEOAS 和现在提得比较多的超文本驱动,其实都是希望能达到这样一种效果: 除了第一个请求是由你在浏览器地址栏输入的信息所驱动的之外,其他的请求都应该能够自己描述清楚后续可能发生的状态转移,由超文本自身来驱动。
所以,当你输入了查询命令后:
GET /doctors/mjones/schedule?date=2020-03-04&status=open HTTP/1.1服务器传回的响应信息应该包括如何预约档期、如何了解医生信息等可能的后续操作:
HTTP/1.1 200 OK { schedules:[ { id: 1234, start:"14:00", end: "14:50", doctor: "mjones", links: [ {rel: "comfirm schedule", href: "/schedules/1234"} ] }, { id: 5678, start:"16:00", end: "16:50", doctor: "mjones", links: [ {rel: "comfirm schedule", href: "/schedules/5678"} ] } ], links: [ {rel: "doctor info", href: "/doctors/mjones/info"} ] }如果做到了第 3 级 REST,那么服务端的 API 和客户端就可以做到完全解耦了。这样一来,你再想要调整服务数量,或者同一个服务做 API 升级,将会变得非常简单。
至此,我们已经学完了 REST 的相关知识,了解了 REST 的一些优点,然而凡事总有两面,下面我们来看一看 REST 经常收到非议的方面。
REST 的不足与争议
第一个有争议的问题是:面向资源的编程思想只适合做 CRUD,只有面向过程、面向对象编程才能处理真正复杂的业务逻辑。
这是我们在实践 REST 时遇到的最多的一个问题。有这个争议的原因也很简单,HTTP 的 4 个最基础的命令 POST、GET、PUT 和 DELETE,很容易让人联想到 CRUD 操作,因此在脑海中就自然产生了直接的对应。
REST 涵盖的范围当然远不止于此。不过要说 POST、GET、PUT 和 DELETE 对应于 CRUD,其实也没什么不对,只是我们必须泛化地去理解这个 CRUD:它们涵盖了信息在客户端与服务端之间流动的几种主要方式(比如 POST、GET、PUT 等标准方法),所有基于网络的操作逻辑,都可以通过解决”信息在服务端与客户端之间如何流动”这个问题来理解,有的场景里比较直观,而另一些场景中可能比较抽象。
针对那些比较抽象的场景,如果确实不好把 HTTP 方法映射为资源的所需操作,REST 也并不会刻板地要求一定要做映射。这时,用户可以使用自定义方法,按 Google 推荐的 REST API 风格来拓展 HTTP 标准方法。
自定义方法 应该放在资源路径末尾,嵌入冒号加自定义动词的后缀。比如,我将删除操作映射到标准 DELETE 方法上,此外还要提供一个恢复删除的 API,那它可能会被设计为:
POST /user/user_id/cart/book_id:undelete要实现恢复删除,一个完全可行的设计是:设计一个回收站的资源,在那里保留还能被恢复的商品,我们把恢复删除看作是对这个资源的某个状态值的修改,映射到 PUT 或者 PATCH 方法上。
最后,我要再重复一遍,面向资源的编程思想与另外两种主流编程(面向过程和面向对象编程)思想,只是抽象问题时所处的立场不同,只有选择问题,没有高下之分:
- 面向过程编程时,为什么要以算法和处理过程为中心,输入数据,输出结果?当然是为了符合计算机世界中主流的交互方式。
- 面向对象编程时,为什么要将数据和行为统一起来、封装成对象?当然是为了符合现实世界的主流交互方式。
- 面向资源编程时,为什么要将数据(资源)作为抽象的主体,把行为看作是统一的接口?当然是为了符合网络世界的主流的交互方式。
第二个有争议的问题是:REST 与 HTTP 完全绑定,不适用于要求高性能传输的场景中。
其实,我在很大程度上赞同这个观点,但我并不认为这是 REST 的缺陷,因为锤子不能当扳手用,并不是锤子的质量有问题。
面向资源编程与协议无关,但是 REST(特指 Fielding 论文中所定义的 REST,而不是泛指面向资源的思想)的确依赖着 HTTP 协议的标准方法、状态码和协议头等各个方面。
我们也知道,HTTP 是应用层协议,而不是传输层协议,如果我们只是把 HTTP 用作传输是不恰当的(SOAP:再次感觉有被冒犯到)。因此,对于需要直接控制传输(如二进制细节 / 编码形式 / 报文格式 / 连接方式等)细节的场景,REST 确实不合适。这些场景往往存在于服务集群的内部节点之间,这也是我在上一讲提到的,虽然 REST 和 RPC 的应用场景的确有所重合,但重合的范围有多大就是见仁见智的事情了。
第三个有争议的问题是:REST 不利于事务支持。
其实,这个问题首先要看我们怎么去理解”事务(Transaction)”这个概念了。
- 如果”事务”指的是数据库那种狭义的刚性 ACID 事务,那分布式系统本身跟它之间就是有矛盾的(CAP 不可兼得)。这是分布式的问题,而不是 REST 的问题。
- 如果”事务”是指通过服务协议或架构,在分布式服务中,获得对多个数据同时提交的统一协调能力(2PC/3PC),比如 WS-AtomicTransaction 和 WS-Coordination 这样的功能性协议,那 REST 确实不支持。假如你已经理解了这样做的代价,仍决定要这样做的话,Web Service 是比较好的选择。
- 如果”事务”是指希望保证数据的最终一致性,说明你已经放弃刚性事务了。这才是分布式系统中的主流,使用 REST 肯定不会有什么阻碍,更谈不上”不利于”事务支持(当然,对于最终一致性的问题,REST 本身并没有提供什么帮助,而是完全取决于你系统的事务设计。我们在讲解事务处理的课程章节中,会再详细讨论)。
第四个有争议的问题是:REST 没有传输可靠性支持。
是的,REST 并没有提供对传输可靠性的支持。在 HTTP 中,你发送出去一个请求,通常会收到一个与之相对的响应,比如 HTTP/1.1 200 OK 或者 HTTP/1.1 404 Not Found 等。但是,如果你没有收到任何响应,那就无法确定消息到底是没有发送出去,还是没有从服务端返回回来。这其中的关键差别,是服务端到底是否被触发了某些处理?
应对传输可靠性最简单粗暴的做法,就是把消息再重发一遍。这种简单处理能够成立的前提,是服务具有 幂等性(Idempotency) ,也就是说服务被重复执行多次的效果与执行一次是相等的。
HTTP 协议要求 GET、PUT 和 DELETE 操作应该具有幂等性,我们把 REST 服务映射到这些方法时,也应该保证幂等性。
对于 POST 方法,曾经有过一些专门的提案(比如 POE 、POST Once Exactly),但并未得到 IETF 的通过。对于 POST 的重复提交,浏览器会出现相应警告,比如 Chrome 中会有”确认重新提交表单”的提示。而服务端就应该做预校验,如果发现可能重复,就返回 HTTP/1.1 425 Too Early。
另外,Web Service 中有 WS-ReliableMessaging 功能协议,用来支持消息可靠投递。类似的,REST 因为没有采用额外的 Wire Protocol,所以除了缺少对事务、可靠传输的支持外,一定还可以在 WS-* 协议中找到很多 REST 不支持的特性。
第五个有争议的问题是:REST 缺乏对资源进行”部分”和”批量”的处理能力。
这个观点我是认同的,而且我认为这很可能是未来面向资源的思想和 API 设计风格的发展方向。
REST 开创了面向资源的服务风格,却肯定不完美。以 HTTP 协议为基础,虽然给 REST 带来了极大的便捷(不需要额外协议,不需要重复解决一堆基础网络问题,等等),但也成了束缚 REST 的无形牢笼。
关于 HTTP 协议对 REST 的束缚,我会通过具体的例子和你解释。
第一种束缚,就是缺少对资源的”部分”操作的支持。 有些时候,我们只是想获得某个用户的姓名,RPC 风格中可以设计一个”getUsernameById”的服务,返回一个字符串。尽管这种服务的通用性实在称不上”设计”二字,但确实可以工作。而要是采用 REST 风格的话,你需要向服务端请求整个用户对象,然后丢弃掉返回结果中的其他属性,这就是一种请求冗余(Overfetching)。
REST 的应对手段是,通过位于中间节点或客户端缓存来缓解。但这治标不治本,因为这个问题的根源在于,HTTP 协议对请求资源完全没有结构化的描述能力(但有的是非结构化的部分内容获取能力,也就是今天多用于端点续传的 Range Header),所以返回资源的哪些内容、以什么数据类型返回等等,都不可能得到协议层面的支持。如果要实现这种能力,你就只能自己在 GET 方法的 Endpoint 上设计各种参数。
而与此相对的缺陷,也是 HTTP 协议对 REST 的第二种束缚,是对资源的”批量”操作的支持。 有时候,我们不得不为此而专门设计一些抽象的资源才能应对。
比如,我们要把某个用户的昵称增加一个”VIP”前缀,那提交一个 PUT 请求修改这个用户的昵称就可以了。但如果我们要给 1000 个用户的昵称加”VIP”前缀时,就不得不先创建一个(比如名为”VIP-Modify-Task”)任务资源,把 1000 个用户的 ID 交给这个任务,最后驱动任务进入执行状态(如果真去调用 1000 次 PUT,等浏览器回应我们 HTTP/1.1 429 Too Many Requests 的时候,老板就要发飙了)。
又比如,我们在网店买东西的时候,下单、冻结库存、支付、加积分、扣减库存这一系列步骤会涉及多个资源的变化,这时候我们就得创建一种”事务”的抽象资源,或者用某种具体的资源(比如”结算单”),贯穿网购这个过程的始终,每次操作其他资源时都带着事务或者结算单的 ID。对于 HTTP 协议来说,由于它的无状态性,相对来说不适用于(并非不能够)处理这类业务场景。
要解决批量操作这类问题,目前一种从理论上看还比较优秀的解决方案是 GraphQL(但实际使用人数并不多)。GraphQL 是由 Facebook 提出并开源的一种面向资源 API 的数据查询语言。它和 SQL 一样,挂了个”查询语言”的名字,但其实 CRUD 都能做。
相对于依赖 HTTP 无协议的 REST 来说,GraphQL 是另一种”有协议”地、更彻底地面向资源的服务方式。但是凡事都有两面,离开了 HTTP,GraphQL 又面临着几乎所有 RPC 框架都会遇到的如何推广交互接口的问题。
小结
介绍 REST 服务的两节课里面,我们学习了 REST 的思想内涵,讲解了 RESTful 系统的 6 个核心特征,以及如何衡量 RESTful 程度的 RMM 成熟度,同时也讨论了 REST 的争议与不足。
在软件行业发展的初期,程序编写都是以算法为核心的,程序员会把数据和过程分别作为独立的部分来考虑,数据代表问题空间中的客体,程序代码则用于处理这些数据。 这种直接站在计算机的角度去抽象问题和解决问题的思维方式,就是面向过程的编程思想。
与此类似, 后来出现的面向对象的编程思想,则是站在现实世界的角度去抽象和解决问题。 它把数据和行为都看作是对象的一部分,以方便程序员用符合现实世界的思维方式,来编写和组织程序。
我们今天再去看这两种编程思想,虽然它们出现的时间有先后,但在人类使用计算机语言来处理数据的工作中,无论用哪种思维来抽象问题都是合乎逻辑的。
经过了 20 世纪 90 年代末到 21 世纪初期面向对象编程的火热,如今,站在网络角度考虑如何对内封装逻辑、对外重用服务的新思想,也就是面向资源的编程思想,又成为了新的受追捧的对象。
面向资源编程这种思想,是把问题空间中的数据对象作为抽象的主体,把解决问题时从输入数据到输出结果的处理过程,看作是一个(组)数据资源的状态不断发生变换而导致的结果。 这符合目前网络主流的交互方式,也因此 REST 常常被看作是为基于网络的分布式系统量身定做的交互方式。
11 | 本地事务如何实现原子性和持久性?
事务处理几乎是每一个信息系统中都会涉及到的问题,它存在的意义就是保证系统中的数据是正确的,不同数据间不会产生矛盾,也就是保证数据状态的一致性(Consistency)。
关于一致性,我这里先做个说明。”一致性”在数据科学中有严肃定义,并且有多种细分类型的概念。这里我们重点关注的是数据库状态的一致性,它跟课程后面第三个模块”分布式的基石”当中,即将要讨论的分布式共识算法时所说的一致性,是不一样的,具体的差别我们会在第三个模块中探讨。
说回数据库状态的一致性,理论上,要达成这个目标需要三方面的共同努力:
- 原子性(Atomic):在同一项业务处理过程中,事务保证了多个对数据的修改,要么同时成功,要么一起被撤销。
- 隔离性(Isolation):在不同的业务处理过程中,事务保证了各自业务正在读、写的数据互相独立,不会彼此影响。
- 持久性(Durability):事务应当保证所有被成功提交的数据修改都能够正确地被持久化,不丢失数据。
以上就是事务的”ACID”的概念提法。我自己对这种已经形成习惯的”ACID”的提法是不太认同的,因为这四种特性并不正交,A、I、D 是手段,C 是目的,完全是为了拼凑个单词缩写才弄到一块去,误导的弊端已经超过了易于传播的好处。所以明确了这一点,也就明确了我们今天的讨论,就是要聚焦在事务处理的 A、I、D 上。
那接下来,我们先来看看事务处理的场景。
事务场景
事务的概念最初是源于数据库,但今天的信息系统中,所有需要保证数据正确性(一致性)的场景下,包括但不限于数据库、缓存、 事务内存 、消息、队列、对象文件存储等等,都有可能会涉及到事务处理。
当一个服务只操作一个数据源的时候,通过 A、I、D 来获得一致性是相对容易的,但当一个服务涉及到多个不同的数据源,甚至多个不同服务同时涉及到多个不同的数据源时,这件事情就变得很困难,有时需要付出很大、甚至是不切实际的代价,因此业界探索过许多其他方案,在确保可操作的前提下获得尽可能高的一致性保障。 由此,事务处理才从一个具体操作上的”编程问题”上升成一个需要仔细权衡的”架构问题”。
人们在探索这些事务方案的过程中,产生了许多新的思路和概念,有一些概念看上去并不那么直观,因此,在接下来的这几节课中,我会带着你,一起探索 同一个事例在不同的事务方案中的不同处理 ,以此来贯穿、理顺这些概念。
场景事例
我先来给你介绍下具体的事例。
Fenix’s Bookstore 是一个在线书店。一份商品成功售出,需要确保以下三件事情被正确地处理:
- 用户的账号扣减相应的商品款项;
- 商品仓库中扣减库存,将商品标识为待配送状态;
- 商家的账号增加相应的商品款项。
接下来,我将逐一介绍在”单个服务使用单个数据源””单个服务使用多个数据源””多个服务使用单个数据源”以及”多个服务使用多个数据源”的不同场景下,我们可以采用哪些手段来保证以上场景实例的正确性。
今天这一讲,我们先来看”单个服务使用单个数据源”,也就是本地事务场景。
本地事务
本地事务(Local Transactions)其实应该翻译成”局部事务”,才好与 第 13 讲 中要讲解的”全局事务”对应起来。不过,现在”本地事务”的译法似乎已经成为主流,我们就不去纠结名称了。
本地事务是指仅操作特定单一事务资源的、不需要”全局事务管理器”进行协调的事务。 如果这个定义你现在不能理解的话,不妨暂且先放下,等学完”全局事务”这个小章节后再回过头来想想。
本地事务是最基础的一种事务处理方案,通常只适用于单个服务使用单个数据源的场景,它是直接依赖于数据源(通常是数据库系统)本身的事务能力来工作的。在程序代码层面,我们最多只能对事务接口做一层标准化的包装(如 JDBC 接口),并不能深入参与到事务的运作过程当中。
事务的开启、终止、提交、回滚、嵌套、设置隔离级别、乃至与应用代码贴近的传播方式,全部都要依赖底层数据库的支持,这一点与后面的 14、15 两讲中要介绍的 XA、TCC、SAGA 等主要靠应用程序代码来实现的事务,有着十分明显的区别(到时你可以跟今天所讲的内容相互对照下)。
我举个具体的例子,假设你的代码调用了 JDBC 中的 Transaction::rollback() 方法,方法的成功执行并不代表事务就已经被成功回滚,如果数据表采用引擎的是 MyISAM ,那 rollback() 方法便是一项没有意义的空操作。因此, 我们要想深入地讨论本地事务,便不得不越过应用代码的层次,去了解一些数据库本身的事务实现原理,弄明白传统数据库管理系统是如何实现 ACID 的。
ARIES 理论
如今研究事务的实现原理,必定会追溯到 ARIES理论(Algorithms for Recovery and Isolation Exploiting Semantics,基于语义的恢复与隔离算法) 。起这拗口的名字应该多少也有些拼凑”ARIES”这个单词的目的(跟 ACID 一样的恶趣味)。
虽然,我们不能说所有的数据库都实现了 ARIES 理论,但现代的主流关系型数据库(Oracle、Microsoft SQLServer、MySQL-InnoDB、IBM DB2、PostgreSQL,等等)在事务实现上都深受该理论的影响。
上世纪 90 年代, IBM Almaden 研究院 总结了研发原型数据库系统”IBM System R”的经验,发表了 ARIES 理论中最主要的三篇论文,这里先给你介绍两篇。《 ARIES: A Transaction Recovery Method Supporting Fine-Granularity Locking and Partial Rollbacks Using Write-Ahead Logging 》着重解决了事务的 ACID 三个属性中,原子性(A)和持久性(D)在算法层面上应当如何实现;而另一篇《 ARIES/KVL: A Key-Value Locking Method for Concurrency Control of Multiaction Transactions Operating on B-Tree Indexes 》则是现代数据库隔离性(I)奠基式的文章。
我们先从原子性和持久性说起。至于隔离性,在下一节课中我们再接着展开介绍。
实现原子性和持久性
原子性和持久性在事务里是密切相关的两个属性,原子性保证了事务的多个操作要么都生效要么都不生效,不会存在中间状态;持久性保证了一旦事务生效,就不会再因为任何原因而导致其修改的内容被撤销或丢失。
显而易见,数据必须要成功写入磁盘、磁带等持久化存储器后才能拥有持久性,只存储在内存中的数据,一旦遇到程序忽然崩溃、数据库崩溃、操作系统崩溃,机器突然断电宕机(后面我们都统称为崩溃,Crash)等情况就会丢失。 实现原子性和持久性所面临的困难是,”写入磁盘”这个操作不会是原子的 ,不仅有”写入”与”未写入”,还客观地存在着”正在写”的中间状态。
按照上面我们列出的示例场景,从 Fenix’s Bookstore 购买一本书需要修改三个数据:在用户账户中减去货款、在商家账户中增加货款、在商品仓库中标记一本书为配送状态,由于写入存在中间状态,可能发生以下情形:
- 未提交事务 :程序还没修改完三个数据,数据库已经将其中一个或两个数据的变动写入了磁盘,此时出现崩溃,一旦重启之后,数据库必须要有办法得知崩溃前发生过一次不完整的购物操作,将已经修改过的数据从磁盘中恢复成没有改过的样子,以保证原子性。
- 已提交事务 :程序已经修改完三个数据,数据库还未将全部三个数据的变动都写入到磁盘,此时出现崩溃,一旦重启之后,数据库必须要有办法得知崩溃前发生过一次完整的购物操作,将还没来得及写入磁盘的那部分数据重新写入,以保证持久性。
这种数据恢复操作被称为 崩溃恢复 (Crash Recovery,也有称作 Failure Recovery 或 Transaction Recovery)。为了能够顺利地完成崩溃恢复,在磁盘中写数据就不能像程序修改内存中变量值那样,直接改变某表某行某列的某个值,必须将修改数据这个操作所需的全部信息(比如修改什么数据、数据物理上位于哪个内存页和磁盘块中、从什么值改成什么值等等),以日志的形式(日志特指仅进行顺序追加的文件写入方式,这是最高效的写入方式)先记录到磁盘中。
只有在日志记录全部都安全落盘,见到代表事务成功提交的”Commit Record”后,数据库才会根据日志上的信息对真正的数据进行修改,修改完成后,在日志中加入一条”End Record”表示事务已完成持久化,这种事务实现方法被称为”Commit Logging”。
额外知识:Shadow Paging
通过日志实现事务的原子性和持久性是当今的主流方案,但并非唯一的选择。除日志外,还有另外一种称为” Shadow Paging “(有中文资料翻译为”影子分页”)的事务实现机制,常用的轻量级数据库 SQLite Version 3 采用的就是 Shadow Paging。
Shadow Paging 的大体思路是对数据的变动会写到硬盘的数据中,但并不是直接就地修改原先的数据,而是先将数据复制一份副本,保留原数据,修改副本数据。在事务过程中,被修改的数据会同时存在两份,一份修改前的数据,一份是修改后的数据,这也是”影子”(Shadow)这个名字的由来。
当事务成功提交,所有数据的修改都成功持久化之后,最后一步要修改数据的引用指针,将引用从原数据改为新复制出来修改后的副本,最后的”修改指针”这个操作将被认为是原子操作,所以 Shadow Paging 也可以保证原子性和持久性。
Shadow Paging 相对简单,但涉及到隔离性与锁时,Shadow Paging 实现的事务并发能力相对有限,因此在高性能的数据库中应用不多。
Commit Logging 保障数据持久性、原子性的原理并不难想明白。
首先,日志一旦成功写入 Commit Record,那整个事务就是成功的,即使修改数据时崩溃了,重启后根据已经写入磁盘的日志信息恢复现场、继续修改数据即可,这保证了持久性。
其次,如果日志没有写入成功就发生崩溃,系统重启后会看到一部分没有 Commit Record 的日志,那将这部分日志标记为回滚状态即可,整个事务就像完全没有发生过一样,这保证了原子性。
Commit Logging 实现事务简单清晰,也有一些数据库就是采用 Commit Logging 机制来实现事务的(较具代表性的是阿里的 OceanBase)。但是, Commit Logging 存在一个巨大的缺陷 :所有对数据的真实修改都必须发生在事务提交、日志写入了 Commit Record 之后,即使事务提交前磁盘 I/O 有足够空闲、即使某个事务修改的数据量非常庞大,占用大量的内存缓冲,无论何种理由,都决不允许在事务提交之前就开始修改磁盘上的数据,这一点对提升数据库的性能是很不利的。
为了解决这个缺陷,前面提到的 ARIES 理论终于可以登场了。 ARIES 提出了”Write-Ahead Logging”的日志改进方案,其名字里所谓的”提前写入”(Write-Ahead),就是允许在事务提交之前,提前写入变动数据的意思。
Write-Ahead Logging 先将何时写入变动数据,按照事务提交时点为界,分为了 FORCE 和 STEAL 两类:
- FORCE :当事务提交后,要求变动数据必须同时完成写入则称为 FORCE,如果不强制变动数据必须同时完成写入则称为 NO-FORCE。现实中绝大多数数据库采用的都是 NO-FORCE 策略,只要有了日志,变动数据随时可以持久化,从优化磁盘 I/O 性能考虑,没有必要强制数据写入立即进行。
- STEAL :在事务提交前,允许变动数据提前写入则称为 STEAL,不允许则称为 NO-STEAL。从优化磁盘 I/O 性能考虑,允许数据提前写入,有利于利用空闲 I/O 资源,也有利于节省数据库缓存区的内存。
Commit Logging 允许 NO-FORCE,但不允许 STEAL。因为假如事务提交前就有部分变动数据写入磁盘,那一旦事务要回滚,或者发生了崩溃,这些提前写入的变动数据就都成了错误。
Write-Ahead Logging 允许 NO-FORCE,也允许 STEAL,它给出的解决办法是增加了另一种称为 Undo Log 的日志。当变动数据写入磁盘前,必须先记录 Undo Log,写明修改哪个位置的数据、从什么值改成什么值,以便在事务回滚或者崩溃恢复时,根据 Undo Log 对提前写入的数据变动进行擦除。
Undo Log 现在一般被翻译为”回滚日志”,此前记录的用于崩溃恢复时重演数据变动的日志,就相应被命名为 Redo Log,一般翻译为”重做日志”。
由于 Undo Log 的加入,Write-Ahead Logging 在崩溃恢复时,会以此经历以下三个阶段:
- 分析阶段(Analysis) :该阶段从最后一次检查点(Checkpoint,可理解为在这个点之前所有应该持久化的变动都已安全落盘)开始扫描日志,找出所有没有 End Record 的事务,组成待恢复的事务集合(一般包括 Transaction Table 和 Dirty Page Table)。
- 重做阶段(Redo) :该阶段依据分析阶段中,产生的待恢复的事务集合来重演历史(Repeat History),找出所有包含 Commit Record 的日志,将它们写入磁盘,写入完成后增加一条 End Record,然后移除出待恢复事务集合。
- 回滚阶段(Undo) :该阶段处理经过分析、重做阶段后剩余的恢复事务集合,此时剩下的都是需要回滚的事务(被称为 Loser),根据 Undo Log 中的信息回滚这些事务。
重做阶段和回滚阶段的操作都应该设计为幂等的。而为了追求高性能,以上三个阶段都无可避免地会涉及到非常繁琐的概念和细节(如 Redo Log、Undo Log 的具体数据结构等),这里我们就不展开讲了,如果想要继续学习,前面讲到的那两篇论文就是学习的最佳途径。
Write-Ahead Logging 是 ARIES 理论的一部分,整套 ARIES 拥有严谨、高性能等很多的优点,但这些也是以复杂性为代价的。
数据库按照”是否允许 FORCE 和 STEAL”可以产生四种组合,从优化磁盘 I/O 的角度看,NO-FORCE 加 STEAL 组合的性能无疑是最高的;从算法实现与日志的角度看,NO-FORCE 加 STEAL 组合的复杂度无疑是最高的。
这四种组合与 Undo Log、Redo Log 之间的具体关系如下图所示:
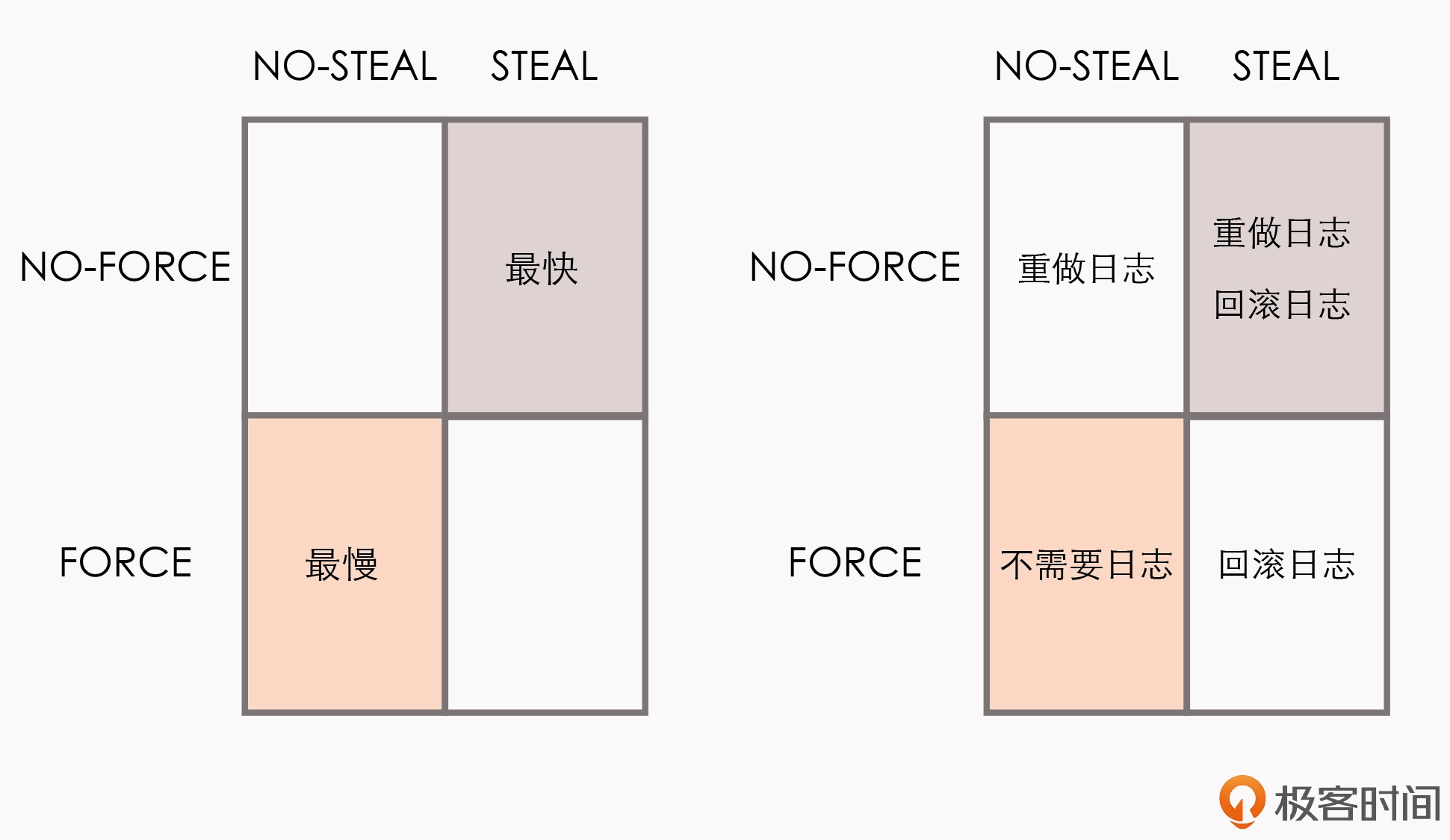
小结
今天这节课,我们学习了经典 ARIES 理论下实现本地事务中原子性与持久性的方法。通过写入日志来保证原子性和持久性是业界的主流做法,这个做法最困难的一点,就是如何处理日志”写入中”的中间状态,才能既保证严谨,也能够高效。
ARIES 理论提出了 Write-Ahead Logging 式的日志写入方法,通过分析、重做、回滚三个阶段实现了 STEAL、NO-FORCE,从而实现了既高效又严谨的日志记录与故障恢复。
12 | 本地事务如何实现隔离性?
隔离性保证了每个事务各自读、写的数据互相独立,不会彼此影响。只从定义上,我们就能感觉到隔离性肯定与并发密切相关。如果没有并发,所有事务全都是串行的,那就不需要任何隔离,或者说这样的访问具备了天然的隔离性。
但在现实情况中不可能没有并发,要在并发下实现串行的数据访问,该怎样做?几乎所有程序员都会回答到:加锁同步呀!现代数据库都提供了以下三种锁:
- 写锁 (Write Lock,也叫做排他锁 eXclusive Lock,简写为 X-Lock):只有持有写锁的事务才能对数据进行写入操作,数据加持着写锁时,其他事务不能写入数据,也不能施加读锁。
- 读锁 (Read Lock,也叫做共享锁 Shared Lock,简写为 S-Lock):多个事务可以对同一个数据添加多个读锁,数据被加上读锁后就不能再被加上写锁,所以其他事务不能对该数据进行写入,但仍然可以读取。对于持有读锁的事务,如果该数据只有一个事务加了读锁,那可以直接将其升级为写锁,然后写入数据。
范围锁 (Range Lock):对于某个范围直接加排他锁,在这个范围内的数据不能被读取,也不能被写入。如下语句是典型的加范围锁的例子:
SELECT * FROM books WHERE price < 100 FOR UPDATE;请注意”范围不能写入”与”一批数据不能写入”的差别,也就是我们不要把范围锁理解成一组排他锁的集合。加了范围锁后,不仅无法修改该范围内已有的数据,也不能在该范围内新增或删除任何数据,这是一组排他锁的集合无法做到的。
本地事务的四种隔离级别
可串行化
串行化访问提供了强度最高的隔离性,ANSI/ISO SQL-92 中定义的最高等级的隔离级别便是可串行化(Serializable)。
可串行化比较符合普通程序员对数据竞争加锁的理解,如果不考虑性能优化的话,对事务所有读、写的数据全都加上读锁、写锁和范围锁即可(这种可串行化的实现方案称为 Two-Phase Lock)。
但数据库不考虑性能肯定是不行的,并发控制理论(Concurrency Control)决定了隔离程度与并发能力是相互抵触的,隔离程度越高,并发访问时的吞吐量就越低。现代数据库一定会提供除可串行化以外的其他隔离级别供用户使用,让用户调节隔离级别的选项,这样做的根本目的是让用户可以调节数据库的加锁方式,取得隔离性与吞吐量之间的平衡。
可重复读
可串行化的下一个隔离级别是可重复读(Repeatable Read)。可重复读的意思就是对事务所涉及到的数据加读锁和写锁,并且一直持续到事务结束,但不再加范围锁。
可重复读比可串行化弱化的地方在于 幻读问题(Phantom Reads)#Phantom_reads) ,它是指在事务执行的过程中,两个完全相同的范围查询得到了不同的结果集。比如我现在准备统计一下 Fenix’s Bookstore 中售价小于 100 元的书有多少本,就可以执行以下第一条 SQL 语句:
SELECT count(1) FROM books WHERE price < 100 /* 时间顺序:1,事务: T1 */ INSERT INTO books(name,price) VALUES ('深入理解Java虚拟机',90) /* 时间顺序:2,事务: T2 */ SELECT count(1) FROM books WHERE price < 100 /* 时间顺序:3,事务: T1 */那么,根据前面对范围锁、读锁和写锁的定义,我们可以知道,假如这条 SQL 语句在同一个事务中重复执行了两次,并且这两次执行之间,恰好有另外一个事务在数据库中插入了一本小于 100 元的书籍(这是当前隔离级别允许的操作),那这两次相同的查询就会得到不一样的结果。原因就是,可重复读没有范围锁来禁止在该范围内插入新的数据。
这就是一个事务遭到其他事务影响,隔离性被破坏的表现。
这里我要提醒你注意一个地方,我这里的介绍实际上是以 ARIES 理论作为讨论目标的,而具体的数据库并不一定要完全遵照着这个理论去实现。
我给你举个例子。MySQL/InnoDB 的默认隔离级别是可重复读,但它在只读事务中就可以完全避免幻读问题。
比如在前面这个例子中,事务 T1 只有查询语句,它是一个只读事务,所以这个例子里出现的幻读问题在 MySQL 中并不会出现。但在读写事务中,MySQL 仍然会出现幻读问题,比如例子中的事务 T1,如果在其他事务插入新书后,不是重新查询一次数量,而是要把所有小于 100 元的书全部改名,那就依然会受到新插入书籍的影响。
读已提交
可重复读的下一个隔离级别是读已提交(Read Committed)。读已提交对事务涉及到的数据加的写锁,会一直持续到事务结束,但加的读锁在查询操作完成后就马上会释放。
读已提交比可重复读弱化的地方在于 不可重复读问题(Non-Repeatable Reads)#Non-repeatable_reads) ,它是指在事务执行过程中,对同一行数据的两次查询得到了不同的结果。
比如说,现在我要获取 Fenix’s Bookstore 中《深入理解 Java 虚拟机》这本书的售价,同样让程序执行了两条 SQL 语句。而在这两条语句执行之间,恰好有另外一个事务修改了这本书的价格,从 90 元调整到了 110 元,如下所示:
SELECT * FROM books WHERE id = 1; /* 时间顺序:1,事务: T1 */ UPDATE books SET price = 110 WHERE ID = 1; COMMIT; /* 时间顺序:2,事务: T2 */ SELECT * FROM books WHERE id = 1; COMMIT; /* 时间顺序:3,事务: T1 */所以到这里,你其实也会发现,如果隔离级别是读已提交,那么这两次重复执行的查询结果也会不一样。原因是读已提交的隔离级别缺乏贯穿整个事务周期的读锁,无法禁止读取过的数据发生变化。而此时,事务 T2 中的更新语句可以马上提供成功,这也是一个事务遭到其他事务影响,隔离性被破坏的表现。
不过,假如隔离级别是可重复读的话,由于数据已被事务 T1 施加了读锁,并且读取后不会马上释放,所以事务 T2 无法获取到写锁,更新就会被阻塞,直至事务 T1 被提交或回滚后才能提交。
读未提交
读已提交的下一个级别是读未提交(Read Uncommitted)。读未提交对事务涉及到的数据只加写锁,这会一直持续到事务结束,但完全不加读锁。
读未提交比读已提交弱化的地方在于 脏读问题(Dirty Reads)#Dirty_reads) ,它是指在事务执行的过程中,一个事务读取到了另一个事务未提交的数据。
比如说,我觉得《深入理解 Java 虚拟机》从 90 元涨价到 110 元是损害消费者利益的行为,又执行了一条更新语句,把价格改回了 90 元。而在我提交事务之前,同事过来告诉我,这并不是随便涨价的,而是印刷成本上升导致的,按 90 元卖要亏本,于是我随即回滚了事务。那么在这个场景下,程序执行的 SQL 语句是这样的:
SELECT * FROM books WHERE id = 1; /* 时间顺序:1,事务: T1 */ /* 注意没有COMMIT */ UPDATE books SET price = 90 WHERE ID = 1; /* 时间顺序:2,事务: T2 */ /* 这条SELECT模拟购书的操作的逻辑 */ SELECT * FROM books WHERE id = 1; /* 时间顺序:3,事务: T1 */ ROLLBACK; /* 时间顺序:4,事务: T2 */不过,在我修改完价格之后,事务 T1 已经按 90 元的价格卖出了几本。出现这个问题的原因就在于,读未提交在数据上完全不加读锁,这反而令它能读到其他事务加了写锁的数据,也就是我前面所说的,事务 T1 中两条查询语句得到的结果并不相同。
这里,你可能会有点疑问,”为什么完全不加读锁,反而令它能读到其他事务加了写锁的数据”,这句话中的”反而”代表的是什么意思呢?不理解也没关系,我们再来重新读一遍写锁的定义:写锁禁止其他事务施加读锁,而不是禁止事务读取数据。
所以说,如果事务 T1 读取数据时,根本就不用去加读锁的话,就会导致事务 T2 未提交的数据也能马上就被事务 T1 所读到。这同样是一个事务遭到其他事务影响,隔离性被破坏的表现。
那么,这里我们假设隔离级别是读已提交的话,由于事务 T2 持有数据的写锁,所以事务 T1 的第二次查询就无法获得读锁。而读已提交级别是要求先加读锁后读数据的,所以 T1 中的查询就会被阻塞,直到事务 T2 被提交或者回滚后才能得到结果。
理论上还有更低的隔离级别,就是”完全不隔离”,即读、写锁都不加。 读未提交会有脏读问题,但不会有脏写问题(Dirty Write,即一个事务没提交之前的修改可以被另外一个事务的修改覆盖掉),脏写已经不单纯是隔离性上的问题了,它会导致事务的原子性都无法实现,所以一般隔离级别不会包括它,会把读未提交看作是最低级的隔离级别。
这四种隔离级别属于数据库的基础知识,多数大学的计算机课程应该都会讲到,但不少教材、资料都把它们当作数据库的某种固有设定来进行讲解,导致很多人只能对这些现象死记硬背。 其实,不同隔离级别以及幻读、脏读等问题都只是表面现象,它们是各种锁在不同加锁时间上组合应用所产生的结果,锁才是根本的原因。
除了锁之外,以上对四种隔离级别的介绍还有一个共同特点,就是一个事务在读数据过程中,受另外一个写数据的事务影响而破坏了隔离性。针对这种”一个事务读 + 另一个事务写”的隔离问题,有一种名为” 多版本并发控制 “(Multi-Version Concurrency Control,MVCC)的无锁优化方案被主流的商业数据库广泛采用。
接下来我们就一起讨论下 MVCC。
MVCC 的基础原理
MVCC 是一种读取优化策略,它的”无锁”是特指读取时不需要加锁。 MVCC 的基本思路是对数据库的任何修改都不会直接覆盖之前的数据,而是产生一个新版副本与老版本共存,以此达到读取时可以完全不加锁的目的。
这句话里的”版本”是个关键词,你不妨将其理解为数据库中每一行记录都存在两个看不见的字段:CREATE_VERSION 和 DELETE_VERSION,这两个字段记录的值都是事务 ID(事务 ID 是一个全局严格递增的数值),然后:
- 数据被插入时:CREATE_VERSION 记录插入数据的事务 ID,DELETE_VERSION 为空。
- 数据被删除时:DELETE_VERSION 记录删除数据的事务 ID,CREATE_VERSION 为空。
- 数据被修改时:将修改视为”删除旧数据,插入新数据”,即先将原有数据复制一份,原有数据的 DELETE_VERSION 记录修改数据的事务 ID,CREATE_VERSION 为空。复制出来的新数据的 CREATE_VERSION 记录修改数据的事务 ID,DELETE_VERSION 为空。
此时,当有另外一个事务要读取这些发生了变化的数据时,会根据隔离级别来决定到底应该读取哪个版本的数据:
- 隔离级别是可重复读 :总是读取 CREATE_VERSION 小于或等于当前事务 ID 的记录,在这个前提下,如果数据仍有多个版本,则取最新(事务 ID 最大)的。
- 隔离级别是读已提交 :总是取最新的版本即可,即最近被 Commit 的那个版本的数据记录。
另外,两个隔离级别都没有必要用到 MVCC,读未提交直接修改原始数据即可,其他事务查看数据的时候立刻可以查看到,根本无需版本字段。可串行化本来的语义就是要阻塞其他事务的读取操作,而 MVCC 是做读取时无锁优化的,自然就不会放到一起用。
MVCC 是只针对”读 + 写”场景的优化,如果是两个事务同时修改数据,即”写 + 写”的情况,那就没有多少优化的空间了,加锁几乎是唯一可行的解决方案。
稍微有点讨论余地的是” 乐观加锁 “(Optimistic Locking)或” 悲观加锁 “(Pessimistic Locking),对此我们还可以根据实际情况去商量一下。
前面我介绍的加锁都属于悲观加锁策略,也就是数据库认为如果不先做加锁再访问数据,就肯定会出现问题。与之相对的,乐观加锁策略认为,事务之间数据存在竞争是偶然情况,没有竞争才是普遍情况,这样就不应该一开始就加锁,而是应当出现竞争时再找补救措施。这种思路被称为” 乐观并发控制 “(Optimistic Concurrency Control,OCC),这一点我就不再展开了。不过提醒一句, 不要迷信什么乐观锁要比悲观锁更快的说法,这纯粹看竞争的剧烈程度,如果竞争剧烈的话,乐观锁反而会更慢。
评论
RED UNCOMMITTED(未提交读)
在RED UNCOMMITTED级别,事务中的修改,即使没提交,对其他事务也是可见的。事务可以读取未提交的数据,这被称为”脏读”(Dirty Read),因为读取的很可能是中间过程的脏数据,而不是最终数据。
RED COMMITTED(提交读)
大多数数据库系统默认的隔离级别都是RED COMMITTED,但是MYSQL不是。RED COMMITTED说的是,一个事务只能读到其他事务已经提交的数据,所以叫提交读。这个事务级别也叫做不可重复读(nonrepeatableread),因为两次同样的查询,可能会得到不同的结果。
REPEATABLE READ(可重复读)
REPEATABLE READ解决了脏读的问题。该级别保证了在同一事务中多次读取同样的记录结果是一致的。但是无法解决幻读的问题,所谓幻读,指的是当某个事务再读取某个范围内的记录时,另外一个事务又在该范围内插入了新的记录,当之前的事务再次读取该范围内的记录时,发现多了一行,会产生幻行。
SERIALIZABLE(可串行化)
SERIALIZABLE是最高级别的隔离。它通过强制事务串行执行,避免了前面说的幻读的问题。简单来说,SERIALIZABLE会在读取的每一行数据上都加锁,所以可能导致大量的超时和锁争用的问题。
MVCC是一种读取优化策略,它在读取时不需要加锁的情况下,实现了提交读和可重复读的隔离级别。
可重复读:总是读在事务启动前就已经提交完成的数据。
提交读:总是读已经提交完成的数据。
13 | 全局事务和共享事务是如何实现的?
今天,我们一起来学习全局事务(Global Transactions)和共享事务(Share Transactions)的原理与实现。
其实,相对于我们前两节课学习的本地事务,全局事务和共享事务的使用频率已经很低了。但这两种事务类型,是分布式事务(下一讲要学习)的中间形式,起到的是承上启下的作用。
所以,我们还是有必要去理解它们的实现方式,这样才能更透彻地理解事务处理这个话题。
接下来,我们就从全局事务学起吧。
全局事务
与本地事务相对的是全局事务,一些资料中也会称之为外部事务(External Transactions)。在今天这一讲,我会给全局事务做个限定:一种适用于单个服务使用多个数据源场景的事务解决方案。
需要注意的是,理论上,真正的全局事务是没有”单个服务”这个约束的,它本来就是 DTP( Distributed Transaction Processing )模型中的概念。那我为什么要在这一讲给它做个限定呢?
这是因为,我们今天要学习的内容,也就是一种在分布式环境中仍追求强一致性的事务处理方案,在多节点互相调用彼此服务的场景(比如现在的微服务)中是非常不合适的。从目前的情况来看,这种方案几乎只实际应用在了单服务多数据源的场景中。
为了避免与我们下一讲要学习的放弃了 ACID 的弱一致性事务处理方式混淆,所以我在这一讲缩减了全局事务所指的范围;对于涉及多服务多数据源的事务,我将其称为”分布式事务”。
XA 协议
为了解决分布式事务的一致性问题,1991 年的时候 X/Open 组织(后来并入了 The Open Group )提出了一套叫做 X/Open XA(XA 是 eXtended Architecture 的缩写)的事务处理框架。这个框架的核心内容是,定义了全局的事务管理器(Transaction Manager,用于协调全局事务)和局部的资源管理器(Resource Manager,用于驱动本地事务)之间的通讯接口。
XA 接口是双向的,是一个事务管理器和多个资源管理器之间通信的桥梁,通过协调多个数据源的动作保持一致,来实现全局事务的统一提交或者统一回滚。现在,我们在 Java 代码中还偶尔能看见的 XADataSource、XAResource 等名字,其实都是源于 XA 接口。
这里你要注意的是,XA 并不是 Java 规范(因为当时还没有 Java),而是一套通用的技术规范。Java 后来专门定义了一套全局事务处理标准,也就是我们熟知的 JTA( JSR 907 Java Transaction API )接口。它有两个最主要的接口:
- 事务管理器的接口:javax.transaction.TransactionManager,这套接口是给 Java EE 服务器提供容器事务(由容器自动负责事务管理)使用的。另外它还提供了另外一套 javax.transaction.UserTransaction 接口,用于给程序员通过程序代码手动开启、提交和回滚事务。
- 满足 XA 规范的资源定义接口:javax.transaction.xa.XAResource。任何资源(JDBC、JMS 等)如果需要支持 JTA,只要实现 XAResource 接口中的方法就可以了。
JTA 原本是 Java EE 中的技术,一般情况下应该由 JBoss、WebSphere、WebLogic 这些 Java EE 容器来提供支持,但现在 Bittronix 、 Atomikos 和 JBossTM (以前叫 Arjuna)都以 JAR 包的形式实现了 JTA 的接口,也就是 JOTM(Java Open Transaction Manager)。有了 JOTM 的支持,我们就可以在 Tomcat、Jetty 这样的 Java SE 环境下使用 JTA 了。
我们在 第 11 讲 讲解本地事务的时候,设计了一个 Fenix’s Bookstore 在线书店场景。一份商品成功售出,需要确保以下三件事情被正确地处理:
- 用户的账号扣减相应的商品款项;
- 商品仓库中扣减库存,将商品标识为待配送状态;
- 商家的账号增加相应的商品款项。
现在,我们对这个示例场景做另外一种假设:如果书店的用户、商家、仓库分别处于不同的数据库中,其他条件不变,那会发生什么变化呢?
如果我们以声明式事务来编码的话,那与本地事务看起来可能没什么区别,都是标个 @Transactional 注解而已,但如果是以编程式事务来实现的话,在写法上就有差异了。我们具体看看:
public void buyBook(PaymentBill bill) {
userTransaction.begin();
warehouseTransaction.begin();
businessTransaction.begin();
try {
userAccountService.pay(bill.getMoney());
warehouseService.deliver(bill.getItems());
businessAccountService.receipt(bill.getMoney());
userTransaction.commit();
warehouseTransaction.commit();
businessTransaction.commit();
} catch(Exception e) {
userTransaction.rollback();
warehouseTransaction.rollback();
businessTransaction.rollback();
}
}两段式提交
代码上能看出程序的目的是要做三次事务提交,但实际代码并不能这样写。为什么呢?
我们可以试想一下:如果程序运行到 businessTransaction.commit() 中出现错误,会跳转到 catch 块中继续执行,这时候 userTransaction 和 warehouseTransaction 已经提交了,再去调用 rollback() 方法已经无济于事。因为这会导致一部分数据被提交,另一部分被回滚,无法保证整个事务的一致性。
为了解决这个问题,XA 将事务提交拆分成了两阶段过程,也就是准备阶段和提交阶段。
准备阶段 ,又叫做投票阶段。在这一阶段,协调者询问事务的所有参与者是否准备好提交,如果已经准备好提交回复 Prepared,否则回复 Non-Prepared。
这里的”准备”操作,其实和我们通常理解的”准备”不太一样:对于数据库来说,准备操作是在重做日志中记录全部事务提交操作所要做的内容,它与本地事务中真正提交的区别只是暂不写入最后一条 Commit Record。这意味着在做完数据持久化后并不会立即释放隔离性,也就是仍继续持有锁,维持数据对其他非事务内观察者的隔离状态。
提交阶段 ,又叫做执行阶段,协调者如果在准备阶段收到所有事务参与者回复的 Prepared 消息,就会首先在本地持久化事务状态为 Commit,然后向所有参与者发送 Commit 指令,所有参与者立即执行提交操作;否则,任意一个参与者回复了 Non-Prepared 消息,或任意一个参与者超时未回复,协调者都会将自己的事务状态持久化为”Abort”之后,向所有参与者发送 Abort 指令,参与者立即执行回滚操作。
对于数据库来说,提交阶段的提交操作是相对轻量的,仅仅是持久化一条 Commit Record 而已,通常能够快速完成。回滚阶段则相对耗时,收到 Abort 指令时,需要根据回滚日志清理已提交的数据,这可能是相对重负载操作。
“准备”和”提交”这两个过程,被称为” 两段式提交 “(2 Phase Commit,2PC)协议。那么,使用了两阶段提交协议,就一定可以成功保证一致性吗?也不是的,它还需要 两个前提条件 。
第一,必须假设网络在提交阶段这个短时间内是可靠的,即提交阶段不会丢失消息。同时也假设网络通讯在全过程都不会出现误差,即可以丢失后消息,但不会传递错误的消息,XA 的设计目标并不是解决诸如 拜占庭将军 一类的问题。
两段式提交中投票阶段失败了可以补救(回滚),而提交阶段失败了无法补救(不再改变提交或回滚的结果,只能等崩溃的节点重新恢复),因而提交阶段的耗时应尽可能短,这也是为了尽量控制网络风险的考虑。
第二,必须假设因为网络分区、机器崩溃或者其他原因而导致失联的节点最终能够恢复,不会永久性地处于失联状态。由于在准备阶段已经写入了完整的重做日志,所以当失联机器一旦恢复,就能够从日志中找出已准备妥当但并未提交的事务数据,再向协调者查询该事务的状态,确定下一步应该进行提交还是回滚操作。
到这里,我还要给你澄清一个概念。我们前面提到的协调者和参与者,通常都是由数据库自己来扮演的,不需要应用程序介入,应用程序相对于数据库来说只扮演客户端的角色。
两段式提交的原理很简单,也不难实现,但有三个非常明显的缺点。
单点问题 :协调者在两段提交中具有举足轻重的作用,协调者等待参与者回复时可以有超时机制,允许参与者宕机,但参与者等待协调者指令时无法做超时处理。一旦协调者宕机,所有参与者都会受到影响。如果协调者一直没有恢复,没有正常发送 Commit 或者 Rollback 的指令,那所有参与者都必须一直等待。
性能问题 :两段提交过程中,所有参与者相当于被绑定成为一个统一调度的整体,期间要经过两次远程服务调用、三次数据持久化(准备阶段写重做日志,协调者做状态持久化,提交阶段在日志写入 Commit Record),整个过程将持续到参与者集群中最慢的那一个处理操作结束为止。这就决定了两段式提交的性能通常都比较差。
一致性风险 :当网络稳定性和宕机恢复能力的假设不成立时,两段式提交可能会出现一致性问题。
宕机恢复能力这一点无需多说。1985 年 Fischer、Lynch、Paterson 用定理(被称为 FLP 不可能原理#Solvability_results_for_some_agreement_problems) ,在分布式中与 CAP 定理齐名)证明了 如果宕机最后不能恢复,那就不存在任何一种分布式协议可以正确地达成一致性结果。
我们重点看看网络稳定性带来的一致性风险。尽管提交阶段时间很短,但仍是明确存在的危险期。如果协调者在发出准备指令后,根据各个参与者发回的信息确定事务状态是可以提交的,协调者就会先持久化事务状态,并提交自己的事务。如果这时候网络忽然断开了,无法再通过网络向所有参与者发出 Commit 指令的话,就会导致部分数据(协调者的)已提交,但部分数据(参与者的)既未提交也没办法回滚,导致数据不一致。
三段式提交
为了解决两段式提交的单点问题、性能问题和数据一致性问题,” 三段式提交 “(3 Phase Commit,3PC)协议出现了。但是三段式提交,也并没有解决一致性问题。
这是为什么呢?别着急,接下来我就具体和你分析下其中的缘由,以及了解三段式提交是否真正解决了单点问题和性能问题。
三段式提交把原本的两段式提交的准备阶段再细分为两个阶段,分别称为 CanCommit、PreCommit,把提交阶段改为 DoCommit 阶段。其中,新增的 CanCommit 是一个询问阶段,协调者让每个参与的数据库根据自身状态,评估该事务是否有可能顺利完成。
将准备阶段一分为二的理由是,这个阶段是重负载的操作,一旦协调者发出开始准备的消息,每个参与者都将马上开始写重做日志,这时候涉及的数据资源都会被锁住。如果此时某一个参与者无法完成提交,相当于所有的参与者都做了一轮无用功。
所以,增加一轮询问阶段,如果都得到了正面的响应,那事务能够成功提交的把握就比较大了,也意味着因某个参与者提交时发生崩溃而导致全部回滚的风险相对变小了。
因此, 在事务需要回滚的场景中,三段式的性能通常要比两段式好很多,但在事务能够正常提交的场景中,两段式和三段式提交的性能都很差,三段式因为多了一次询问,性能还要更差一些。
同样地,也是因为询问阶段使得事务失败回滚的概率变小了,所以在三段式提交中,如果协调者在 PreCommit 阶段开始之后发生了宕机,参与者没有能等到 DoCommit 的消息的话,默认的操作策略将是提交事务而不是回滚事务或者持续等待。你看,这就相当于避免了协调者的单点问题。
三段式提交的操作时序如下图所示。
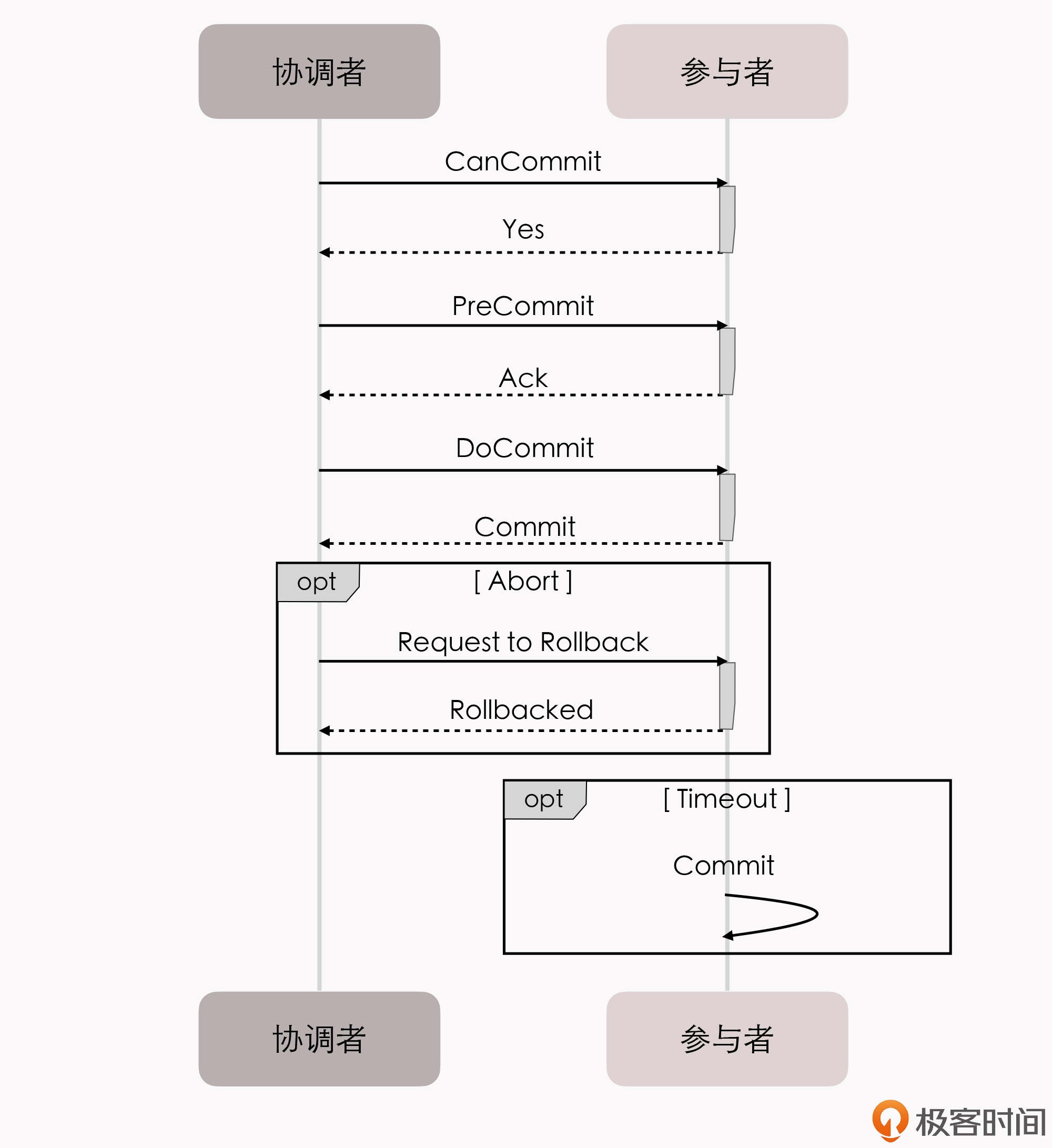
可以看出, 三段式提交对单点问题和回滚时的性能问题有所改善,但是对一致性风险问题并未有任何改进 ,甚至是增加了面临的一致性风险。为什么这么说呢?
我们看一个例子。比如,进入 PreCommit 阶段之后,协调者发出的指令不是 Ack 而是 Abort,而此时因为网络问题,有部分参与者直至超时都没能收到协调者的 Abort 指令的话,这些参与者将会错误地提交事务,这就产生了不同参与者之间数据不一致的问题。
共享事务
与全局事务的单个服务使用多个数据源正好相反,共享事务是指多个服务共用同一个数据源。
这里,我要再强调一次”数据源”与”数据库”的区别:数据源是指提供数据的逻辑设备,不必与物理设备一一对应。
在部署应用集群时最常采用的模式是,将同一套程序部署到多个中间件服务器上,构成多个副本实例来分担流量压力。它们虽然连接了同一个数据库,但每个节点配有自己的专属数据源,通常是中间件以 JNDI 的形式开放给程序代码使用。
这种情况下,所有副本实例的数据访问都是完全独立的,并没有任何交集,每个节点使用的仍是最简单的本地事务。但是有些场景下,多个服务之间是有业务交集的,它们可能会共用一个数据源,共享事务也有可能成为专门针对这种业务场景的一种解决方案。
举个例子。在 Fenix’s Bookstore 的场景事例中,假设用户账户、商家账户和商品仓库都存储在同一个数据库里面,但用户、商户和仓库每个领域部署了独立的微服务。此时,一次购书的业务操作将贯穿三个微服务,而且都要在数据库中修改数据。
如果我们直接将不同数据源视为不同的数据库,那我们完全可以用全局事务或者下一讲要学习的分布式事务来实现。不过,针对每个数据源连接的都是同一个物理数据库的特例,共享事务可能是另一条可以提高性能、降低复杂度的途径,当然这也很有可能是一个伪需求。
一种理论可行的方案 是,直接让各个服务共享数据库连接。同一个应用进程中的不同持久化工具(JDBC、ORM、JMS 等)共享数据库连接并不困难,一些中间件服务器(比如 WebSphere),就内置了” 可共享连接 “功能来专门支持共享数据库的连接。
但这种”共享”的前提是,数据源的使用者都在同一个进程内。由于数据库连接的基础是网络连接,它是与 IP 地址和端口号绑定的,字面意义上的”不同服务节点共享数据库连接”很难做到。所以,为了实现共享事务,就必须新增一个中间角色,也就是交易服务器。无论是用户服务、商家服务还是仓库服务,它们都要通过同一台交易服务器来与数据库打交道。
如果将交易服务器的对外接口实现为满足 JDBC 规范,那它完全可以看作一个独立于各个服务的远程数据库连接池,或者直接作为数据库代理来看待。此时,三个服务所发出的交易请求就有可能做到,由交易服务器上的同一个数据库连接,通过本地事务的方式完成。
比如,交易服务器根据不同服务节点传来的同一个事务 ID,使用同一个数据库连接来处理跨越多个服务的交易事务。
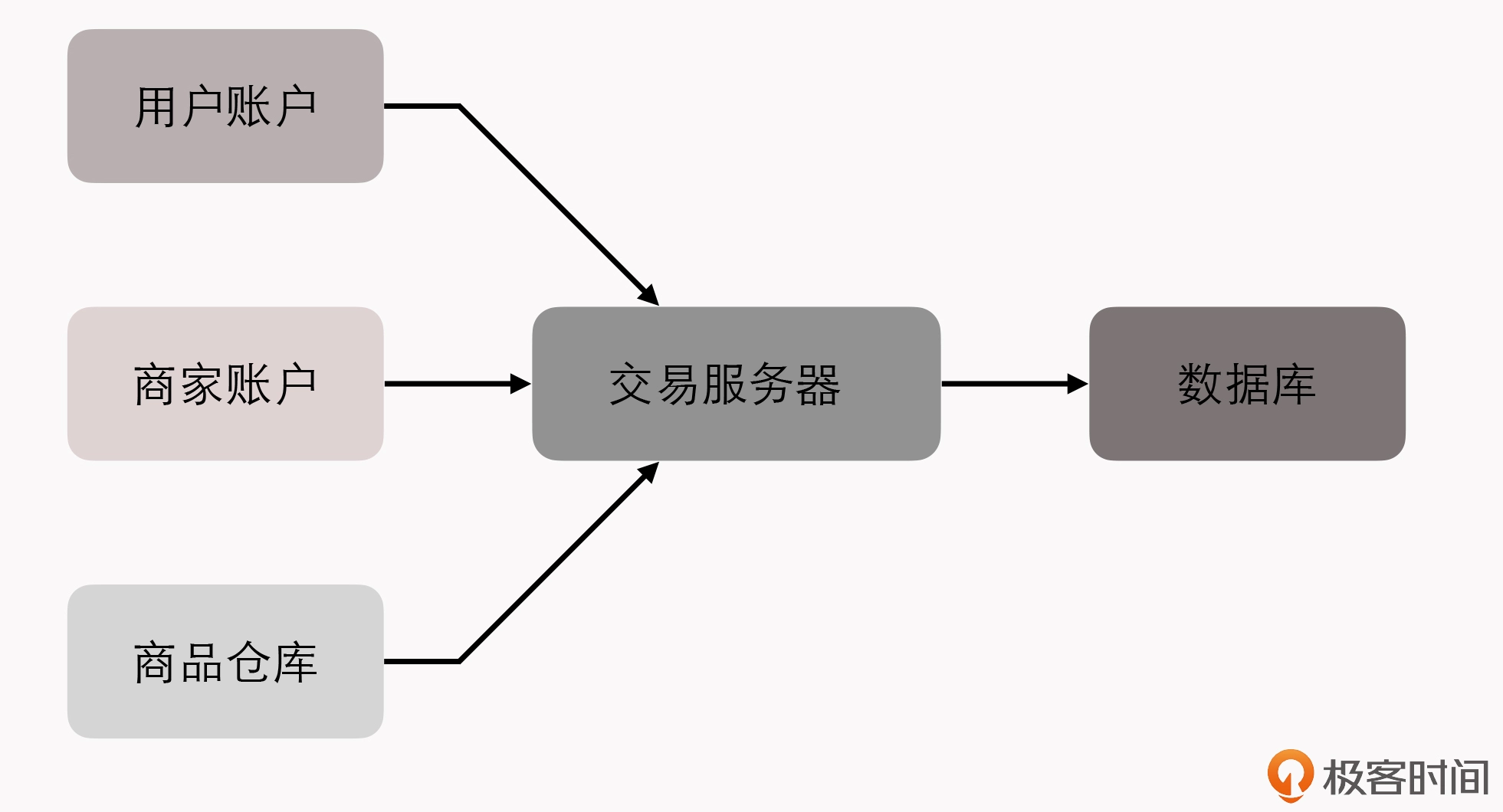
之所以强调理论可行 ,是因为这个方案,其实是与实际生产系统中的压力方向相悖的。一个服务集群里,数据库才是压力最大、最不容易伸缩拓展的重灾区。
所以,现实中只有类似 ProxySQL 和 MaxScale 这样用于对多个数据库实例做负载均衡的数据库代理,而几乎没有反过来代理一个数据库为多个应用提供事务协调的交易服务代理。
这也是为什么说它更有可能是个伪需求的原因。如果你有充足理由让多个微服务去共享数据库,那就必须找到更加站得住脚的理由,来向团队解释拆分微服务的目的是什么。
让多个微服务去共享一个数据库这个方案,其实还有另一种应用形式:使用消息队列服务器来代替交易服务器,用户、商家、仓库的服务操作业务时,通过消息将所有对数据库的改动传送到消息队列服务器,然后通过消息的消费者来统一处理,实现由本地事务保障的持久化操作。这就是” 单个数据库的消息驱动更新 “(Message-Driven Update of a Single Database)。
“共享事务”这种叫法,以及我们刚刚讲到的通过交易服务器或者通过消息驱动来更新单个数据库这两种处理方式,在实际应用中并不常见,也几乎没有相应的成功案例,能够查到的资料几乎都来源于十多年前 Spring 的核心开发者 Dave Syer 的文章” Distributed Transactions in Spring, with and without XA “。
正如我在这一讲的开头所说,我把共享事务和本地事务、全局事务、分布式事务并列成为四大事务类型,更多的考虑到事务演进过程的完备性,也是为了方便你理解这三种事务类型。同时,拆分微服务后仍然共享数据库的案例,我们经常会在实践中看到,但我个人仍旧不赞同将共享事务看作是一种常规的解决方案。
小结
这节课我们学习了全局事务和共享事务的实现方式。目前,共享事务确实已经很少见了,但是全局事务中的两段式提交和三段式提交模式仍然会在一些多数据源的场景中用到,Java 的 JTA 事务也仍然有一定规模的用户群体。
两段式提交和三段式提交仍然追求 ACID 的强一致性,这个目标不仅给它带来了很高的复杂度,而且吞吐量和使用效果上也不佳。因此,现在系统设计的主流,已经变成了不追求 ACID 而是强调 BASE 的弱一致性事务,这就是我们要在下一讲学习的分布式事务了。
14 | 分布式事务之可靠消息队列
前面几节课,我们谈论了事务处理中的本地事务(单个服务、单个数据源)、全局事务(单个服务、多个数据源)和共享事务(多个服务、单个数据源),这一讲我们将聚焦于事务处理中最复杂的分布式事务(多个服务、多个数据源)。
在开始展开介绍之前,我想先给你强调一下,这里所说的分布式事务(Distributed Transactions),跟 DTP 模型 中所指的”分布式事务”的含义是不一样的:DTP 模型所指的”分布式”是相对于数据源而言的,并不涉及服务,这部分内容我们在上节课已经讨论过了;而这里的”分布式”是相对于服务而言的,它特指的是多个服务同时访问多个数据源的事务处理机制,严谨地说,它更应该被称为”在分布式服务环境下的事务处理机制”。
其实在上一讲我们就提到过,为了解决分布式事务的一致性问题,1991 年 X/Open 组织提出了一套 XA 的事务处理架构。在 2000 年以前,人们还寄希望于这套事务处理架构能良好地应用在分布式环境中。不过很遗憾,这个美好的愿望今天已经被 CAP 理论彻底地击碎了。
那么,为什么会出现这种局面呢?就让我们从 CAP 与 ACID 的矛盾开始说起吧。
CAP 与 ACID 之间的矛盾
CAP 理论又叫 Brewer 理论,这是加州大学伯克利分校的埃里克 · 布鲁尔(Eric Brewer)教授,在 2000 年 7 月”ACM 分布式计算原理研讨会(PODC)”上提出的一个猜想。

然后到了 2002 年,麻省理工学院的赛斯 · 吉尔伯特(Seth Gilbert)和南希 · 林奇(Nancy Lynch)就以严谨的数学推理证明了这个 CAP 猜想。在这之后,CAP 理论就正式成为了分布式计算领域公认的著名定理。
这个定理里,描述了一个分布式的系统中,当涉及到共享数据问题时,以下三个特性最多只能满足其中两个:
- 一致性(Consistency) :代表在任何时刻、任何分布式节点中,我们所看到的数据都是没有矛盾的。这与 第 11 讲 所提到的 ACID 中的 C 是相同的单词,但它们又有不同的定义(分别指 Replication 的一致性和数据库状态的一致性)。在分布式事务中,ACID 的 C 要以满足 CAP 中的 C 为前提。
- 可用性(Availability) :代表系统不间断地提供服务的能力。
- 分区容忍性(Partition Tolerance) :代表分布式环境中,当部分节点因网络原因而彼此失联(即与其他节点形成”网络分区”)时,系统仍能正确地提供服务的能力。
当然,单纯只看这个概念的话,CAP 是比较抽象的,我还是以第 11 讲开头所列的事例场景来说明一下,这三种特性对分布式系统来说都意味着什么。
事例场景:Fenix’s Bookstore 是一个在线书店。一份商品成功售出,需要确保以下三件事情被正确地处理:
用户的账号扣减相应的商品款项;
商品仓库中扣减库存,将商品标识为待配送状态;
商家的账号增加相应的商品款项。
假设,Fenix’s Bookstore 的服务拓扑如下图所示,一个来自最终用户的交易请求,将交由账号、商家和仓库服务集群中的某一个节点来完成响应:
你可以看到,在这套系统中,每一个单独的服务节点都有着自己的数据库。
假设某次交易请求分别由”账号节点 1””商家节点 2””仓库节点 N”来进行响应,当用户购买一件价值 100 元的商品后,账号节点 1 首先应该给用户账号扣减 100 元货款。
账号节点 1 在自己的数据库扣减 100 元是很容易的,但它还要把这次交易变动告知账号节点 2 到 N,以及确保能正确变更商家和仓库集群其他账号节点中的关联数据。那么此时,我们可能会面临以下几种情况:
- 如果该变动信息没有及时同步给其他账号节点,那么当用户购买其他商品时,会被分配给另一个节点处理,因为没有及时同步,此时系统会看到用户账户上有不正确的余额,从而错误地发生了原本无法进行的交易。 此为一致性问题。
- 如果因为要把该变动信息同步给其他账号节点,就必须暂停对该用户的交易服务,直到数据同步一致后再重新恢复,那么当用户在下一次购买商品时,可能会因为系统暂时无法提供服务而被拒绝交易。 此为可用性问题。
- 如果由于账号服务集群中某一部分节点,因出现网络问题,无法正常与另一部分节点交换账号变动信息,那么此时的服务集群中,无论哪一部分节点对外提供的服务,都可能是不正确的,我们需要考虑能否接受由于部分节点之间的连接中断,而影响整个集群的正确性的情况。 此为分区容忍性问题。
以上还只是涉及到了账号服务集群自身的 CAP 问题,而对于整个 Bookstore 站点来说,它更是面临着来自于账号、商家和仓库服务集群带来的 CAP 问题。
比如,用户账号扣款后,由于没有及时通知仓库服务,导致另一次交易中看到仓库中有不正确的库存数据而发生了超售。再比如,因为仓库中某个商品的交易正在进行当中,为了同步用户、商家和仓库此时的交易变动,而暂时锁定了该商品的交易服务,导致了可用性问题,等等。
不过既然 CAP 理论已经有了数学证明,也成为了业界公认的计算定理,我们就不去讨论为何 CAP 特性会存在不可兼得的问题了,直接来分析下在实际的应用场景中,我们要如何权衡取舍 CAP,然后看看这些不同取舍都会带来哪些问题。
如果放弃分区容错性(CA without P)
这意味着,我们将假设节点之间的通讯永远是可靠的。可是永远可靠的通讯在分布式系统中必定是不成立的,这不是你想不想的问题,而是网络分区现象始终会存在。
在现实场景中,主流的 RDBMS(关系数据库管理系统)集群通常就是采用放弃分区容错性的工作模式。以 Oracle 的 RAC 集群为例,它的每一个节点都有自己的 SGA(系统全局区)、重做日志、回滚日志等,但各个节点是共享磁盘中的同一份数据文件和控制文件的,也就是说,RAC 集群是通过共享磁盘的方式来避免网络分区的出现。
如果放弃可用性(CP without A)
这意味着,我们将假设一旦发生分区,节点之间的信息同步时间可以无限制地延长,那么这个问题就相当于退化到了上一讲所讨论的全局事务的场景之中,即一个系统可以使用多个数据源。我们可以通过 2PC/3PC 等手段,同时获得分区容错性和一致性。
在现实中,除了 DTP 模型的分布式数据库事务外,著名的 HBase 也是属于 CP 系统。以它的集群为例,假如某个 RegionServer 宕机了,这个 RegionServer 持有的所有键值范围都将离线,直到数据恢复过程完成为止,这个时间通常会是很长的。
如果放弃一致性(AP without C)
这意味着,我们将假设一旦发生分区,节点之间所提供的数据可能不一致。
AP 系统目前是分布式系统设计的主流选择,大多数的 NoSQL 库和支持分布式的缓存都是 AP 系统。因为 P 是分布式网络的天然属性,你不想要也无法丢弃;而 A 通常是建设分布式的目的,如果可用性随着节点数量增加反而降低的话,很多分布式系统可能就没有存在的价值了(除非银行这些涉及到金钱交易的服务,宁可中断也不能出错)。
以 Redis 集群为例,如果某个 Redis 节点出现网络分区,那也不妨碍每个节点仍然会以自己本地的数据对外提供服务。但这时有可能出现这种情况,即请求分配到不同节点时,返回给客户端的是不同的数据。
那么看到这里,你是否感受到了一丝无奈?这个小章节所讨论的话题”事务”,原本的目的就是要获得”一致性”。而在分布式环境中,”一致性”却不得不成为了通常被牺牲、被放弃的那一项属性。
但无论如何,我们建设信息系统,终究还是要保证操作结果(在最终被交付的时候)是正确的。为此,人们又重新给一致性下了定义,把前面我们在 CAP、ACID 中讨论的一致性称为” 强一致性 “(Strong Consistency),有时也称为” 线性一致性 “(Linearizability),而把牺牲了 C 的 AP 系统,又要尽可能获得正确的结果的行为,称为追求” 弱一致性 “。
不过,如果单纯只说”弱一致性”,那其实就是”不保证一致性”的意思……人类语言这东西真是博大精深。
所以,在弱一致性中,人们又总结出了一种特例,叫做” 最终一致性 “(Eventual Consistency)。它是指,如果数据在一段时间内没有被另外的操作所更改,那它最终将会达到与强一致性过程相同的结果,有时候面向最终一致性的算法,也被称为”乐观复制算法”。
那么,在”分布式事务”中,我们的设计目标同样也不得不从获得强一致性,降低为获得”最终一致性”,在这个意义上,其实”事务”一词的含义也已经被拓宽了。
除了本地事务、全局事务和分布式事务以外,还有一种对于不同事务的叫法,那就是针对追求 ACID 的事务,我们称之为”刚性事务”。而在接下来和下一讲中,我将要介绍的几种分布式事务的常见做法,会统称为”柔性事务”。
这一讲我们先来讨论下,可靠消息队列这种分布式事务的实现方式。
可靠事件队列
前面提到的最终一致性的概念,是由 eBay 的系统架构师丹 · 普利切特(Dan Pritchett)在 2008 年发表于 ACM 的论文” Base: An Acid Alternative “中提出的。
这篇文章中,总结了一种独立于 ACID 获得的强一致性之外的途径,即通过 BASE 来达成一致性目的,最终一致性就是其中的”E”。
BASE 这个提法,比 ACID 凑缩写的痕迹更重,不过因为有 ACID vs BASE(酸 vs 碱)这个朗朗上口的梗,这篇文章传播得足够快。在这里我就不多谈 BASE 中的概念了,但这篇论文本身作为最终一致性的概念起源,并系统性地总结了一种在分布式事务的技术手段,还是非常有价值的。
下面,我们继续以 Fenix’s Bookstore 的事例场景,来解释下丹 · 普利切特提出的”可靠事件队列”的具体做法,下图为操作时序:
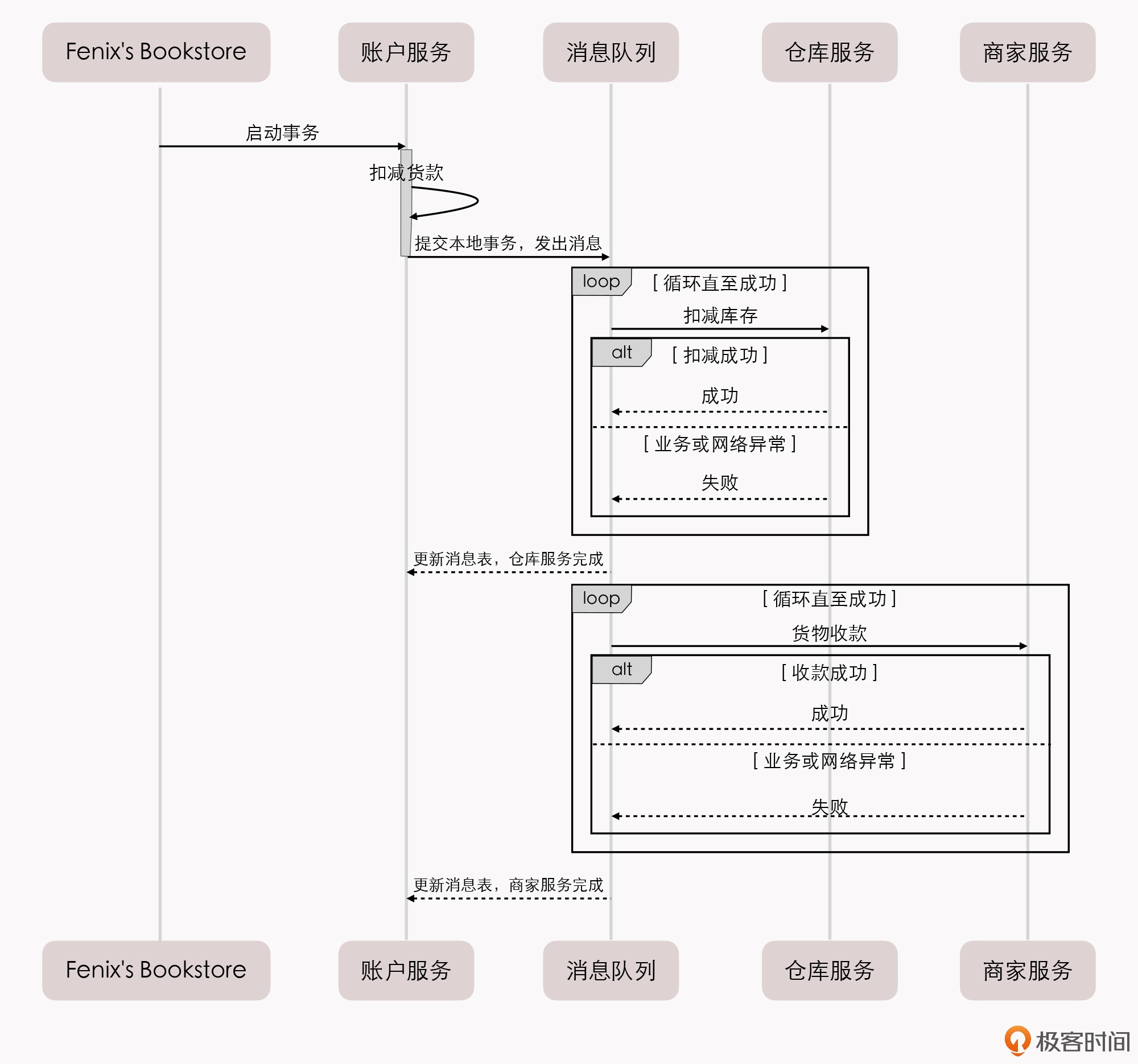
我们按照顺序,一步步来解读一下。
第一步,最终用户向 Fenix’s Bookstore 发送交易请求:购买一本价值 100 元的《深入理解 Java 虚拟机》。
第二步,Fenix’s Bookstore 应该对用户账户扣款、商家账户收款、库存商品出库这三个操作有一个出错概率的先验评估,根据出错概率的大小来安排它们的操作顺序(这个一般体现在程序代码中,有一些大型系统也可能动态排序)。比如,最有可能出错的地方,是用户购买了,但是系统不同意扣款,或者是账户余额不足;其次是商品库存不足;最后是商家收款,一般收款不会遇到什么意外。那么这个顺序就应该是最容易出错的最先进行,即:账户扣款 → 仓库出库 → 商家收款。
第三步,账户服务进行扣款业务,如果扣款成功,就在自己的数据库建立一张消息表,里面存入一条消息:”事务 ID:UUID;扣款:100 元(状态:已完成);仓库出库《深入理解 Java 虚拟机》:1 本(状态:进行中);某商家收款:100 元(状态:进行中)”。注意,这个步骤中”扣款业务”和”写入消息”是依靠同一个本地事务写入自身数据库的。
第四步,系统建立一个消息服务,定时轮询消息表,将状态是”进行中”的消息同时发送到库存和商家服务节点中去。
这时候可能会产生以下几种情况:
商家和仓库服务成功完成了收款和出库工作,向用户账户服务器返回执行结果,用户账户服务把消息状态从”进行中”更新为”已完成”。整个事务宣告顺利结束,达到最终一致性的状态。
商家或仓库服务有某些或全部因网络原因,未能收到来自用户账户服务的消息。此时,由于用户账户服务器中存储的消息状态,一直处于”进行中”,所以消息服务器将在每次轮询的时候,持续地向对应的服务重复发送消息。这个步骤的可重复性,就决定了所有被消息服务器发送的消息都必须具备幂等性。通常我们的设计是让消息带上一个唯一的事务 ID,以保证一个事务中的出库、收款动作只会被处理一次。
商家或仓库服务有某个或全部无法完成工作。比如仓库发现《深入理解 Java 虚拟机》没有库存了,此时,仍然是持续自动重发消息,直至操作成功(比如补充了库存),或者被人工介入为止。
商家和仓库服务成功完成了收款和出库工作,但回复的应答消息因网络原因丢失。此时,用户账户服务仍会重新发出下一条消息,但因消息幂等,所以不会导致重复出库和收款,只会导致商家、仓库服务器重新发送一条应答消息。此过程会一直重复,直至双方网络恢复。
也有一些支持分布式事务的消息框架,如 RocketMQ,原生就支持分布式事务操作,这时候前面提到的情况 2、4 也可以交给消息框架来保障。
前面这种靠着持续重试来保证可靠性的操作,在计算机中就非常常见,它有个专门的名字,叫做” 最大努力交付 “(Best-Effort Delivery),比如 TCP 协议中的可靠性保障,就属于最大努力交付。
而”可靠事件队列”有一种更普通的形式,被称为”最大努力一次提交”(Best-Effort 1PC),意思就是系统会把最有可能出错的业务,以本地事务的方式完成后,通过不断重试的方式(不限于消息系统)来促使同个事务的其他关联业务完成。
小结
这节课,我第一次引入了 CAP 定理,希望你能通过事务处理的上下文场景去理解它。这套理论不仅是在事务处理中,而且在一致性、共识,乃至整个分布式所有涉及到数据的知识点中,都有重要的应用,后面讲到分布式共识算法、微服务中多种基础设施等内容的时候,我们还会多次涉及到它。
除了可靠事件队列之外,下一讲我还会给你介绍 TCC 和 SAGA 这两种主流的实现方式,它们都有各自的优缺点和应用场景。分布式系统中不存在放之四海皆准的万能事务解决方案,针对具体场景,选择合适的解决方案,达到一致性与可用性之间的最佳平衡,是我们作为一名设计者必须具备的技能。
15 | 分布式事务之TCC与SAGA
今天,我们接着上一节课的话题,继续讨论另外两种主流的分布式事务实现方式:TCC 和 SAGA。
TCC 事务的实现过程
TCC(Try-Confirm-Cancel)是除可靠消息队列以外的另一种常见的分布式事务机制,它是由数据库专家帕特 · 赫兰德(Pat Helland)在 2007 年撰写的论文《 Life beyond Distributed Transactions: An Apostate’s Opinion 》中提出的。
在上一讲,我给你介绍了可靠消息队列的实现原理,虽然它也能保证最终的结果是相对可靠的,过程也足够简单(相对于 TCC 来说),但现在你已经知道,可靠消息队列的整个实现过程完全没有任何隔离性可言。
虽然在有些业务中,有没有隔离性不是很重要,比如说搜索系统。但在有些业务中,一旦缺乏了隔离性,就会带来许多麻烦。比如说前几讲,我一直引用的 Fenix’s Bookstore 在线书店的场景事例中,如果缺乏了隔离性,就会带来一个显而易见的问题:超售。
事例场景:Fenix’s Bookstore 是一个在线书店。一份商品成功售出,需要确保以下三件事情被正确地处理:
用户的账号扣减相应的商品款项;
商品仓库中扣减库存,将商品标识为待配送状态;
商家的账号增加相应的商品款项。
也就是说,在书店的业务场景下,很有可能会出现这样的情况:两个客户在短时间内都成功购买了同一件商品,而且他们各自购买的数量都不超过目前的库存,但他们购买的数量之和,却超过了库存。
如果这件事情是发生在刚性事务且隔离级别足够的情况下,其实是可以完全避免的。比如,我前面提到的”超售”场景,就需要”可重复读”(Repeatable Read)的隔离级别,以保证后面提交的事务会因为无法获得锁而导致失败。但用可靠消息队列就无法保证这一点了。我在 第 12 讲 中已经给你介绍过数据库本地事务的相关知识,你可以再去回顾复习下。
所以,如果业务需要隔离,我们通常就应该重点考虑 TCC 方案,它天生适合用于需要强隔离性的分布式事务中。
在具体实现上,TCC 的操作其实有点儿麻烦和复杂, 它是一种业务侵入性较强的事务方案,要求业务处理过程必须拆分为”预留业务资源”和”确认 / 释放消费资源”两个子过程。 另外,你看名字也能看出来,TCC 的实现过程分为了三个阶段:
- Try:尝试执行阶段,完成所有业务可执行性的检查(保障一致性),并且预留好事务需要用到的所有业务资源(保障隔离性)。
- Confirm:确认执行阶段,不进行任何业务检查,直接使用 Try 阶段准备的资源来完成业务处理。注意,Confirm 阶段可能会重复执行,因此需要满足幂等性。
- Cancel:取消执行阶段,释放 Try 阶段预留的业务资源。注意,Cancel 阶段也可能会重复执行,因此也需要满足幂等性。
那么,根据 Fenix’s Bookstore 在线书店的场景事例,TCC 的执行过程应该是这样的:
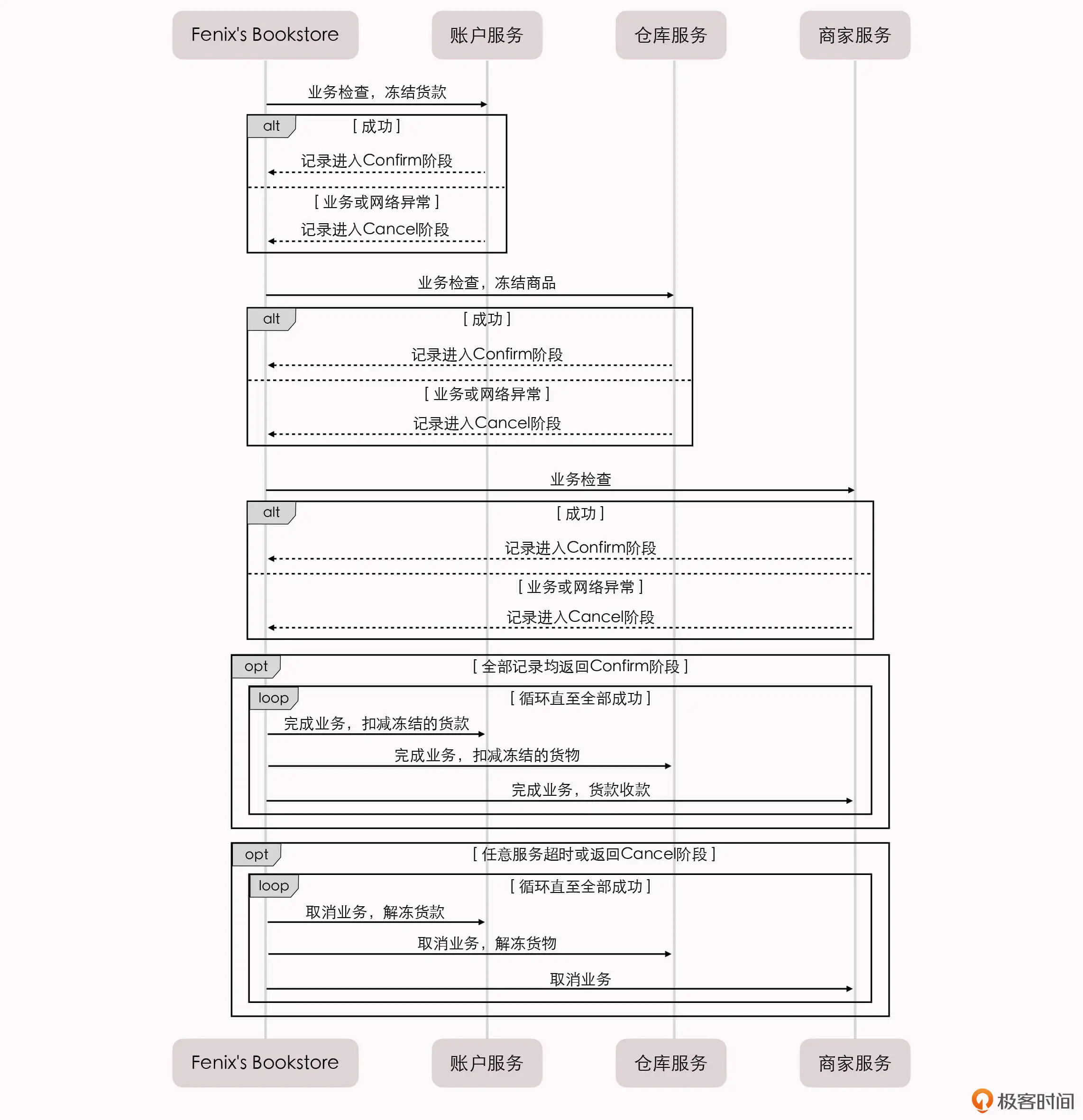
第一步,最终用户向 Fenix’s Bookstore 发送交易请求:购买一本价值 100 元的《深入理解 Java 虚拟机》。
第二步,创建事务,生成事务 ID,记录在活动日志中,进入 Try 阶段:
- 用户服务:检查业务可行性,可行的话,把该用户的 100 元设置为”冻结”状态,通知下一步进入 Confirm 阶段;不可行的话,通知下一步进入 Cancel 阶段。
- 仓库服务:检查业务可行性,可行的话,将该仓库的 1 本《深入理解 Java 虚拟机》设置为”冻结”状态,通知下一步进入 Confirm 阶段;不可行的话,通知下一步进入 Cancel 阶段。
- 商家服务:检查业务可行性,不需要冻结资源。
第三步,如果第二步中所有业务都反馈业务可行,就将活动日志中的状态记录为 Confirm,进入 Confirm 阶段:
- 用户服务:完成业务操作(扣减被冻结的 100 元)。
- 仓库服务:完成业务操作(标记那 1 本冻结的书为出库状态,扣减相应库存)。
-商家服务:完成业务操作(收款 100 元)。
第四步,如果第三步的操作全部完成了,事务就会宣告正常结束。而如果第三步中的任何一方出现了异常,不论是业务异常还是网络异常,都将会根据活动日志中的记录,来重复执行该服务的 Confirm 操作,即进行”最大努力交付”。
第五步,如果是在第二步,有任意一方反馈业务不可行,或是任意一方出现了超时,就将活动日志的状态记录为 Cancel,进入 Cancel 阶段:
- 用户服务:取消业务操作(释放被冻结的 100 元)。
- 仓库服务:取消业务操作(释放被冻结的 1 本书)。
- 商家服务:取消业务操作(大哭一场后安慰商家谋生不易)。
第六步,如果第五步全部完成了, 事务就会宣告以失败回滚结束。 而如果第五步中的任何一方出现了异常,不论是业务异常还是网络异常,也都将会根据活动日志中的记录,来重复执行该服务的 Cancel 操作,即进行”最大努力交付”。
那么,你从上述的操作执行过程中可以发现,TCC 其实有点类似于 2PC 的准备阶段和提交阶段,但 TCC 是位于用户代码层面,而不是在基础设施层面,这就为它的实现带来了较高的灵活性,我们可以根据需要设计资源锁定的粒度。
另外,TCC 在业务执行的时候,只操作预留资源,几乎不会涉及到锁和资源的争用,所以它 具有很高的性能潜力。
但是,由于 TCC 的业务侵入性比较高,需要开发编码配合,在一定程度上增加了不少工作量,也就给我们带来了一些使用上的弊端,那就是我们需要投入更高的开发成本和更换事务实现方案的替换成本。
所以,通常我们并不会完全靠裸编码来实现 TCC,而是会基于某些分布式事务中间件(如阿里开源的 Seata )来完成,以尽量减轻一些编码工作量。
好,现在你就已经知道了,TCC 事务具有较强的隔离性,能够有效避免”超售”的问题,而且它的性能可以说是包括可靠消息队列在内的几种柔性事务模式中最高的。但是,TCC 仍然不能满足所有的业务场景。
我在前面也提到了,TCC 最主要的限制是它的业务侵入性很强,但并不是指由此给开发编码带来的工作量,而是指它所要求的技术可控性上的约束。
比如说,我们把这个书店的场景事例修改一下:由于中国网络支付日益盛行,在书店系统中,现在用户和商家可以选择不再开设充值账号,至少不会强求一定要先从银行充值到系统中才能进行消费,而是允许在购物时,直接通过 U 盾或扫码支付,在银行账户中划转货款。
这个需求完全符合我们现在支付的习惯,但这也给系统的事务设计增加了额外的限制:如果用户、商家的账户余额由银行管理的话,其操作权限和数据结构就不可能再随心所欲地自行定义了,通常也就无法完成冻结款项、解冻、扣减这样的操作,因为银行一般不会配合你的操作。所以,在 TCC 的执行过程中,第一步 Try 阶段往往就已经无法施行了。
那么,我们就只能考虑采用另外一种柔性事务方案:SAGA 事务。
SAGA 事务基于数据补偿代替回滚的解决思路
SAGA 事务模式的历史十分悠久,比分布式事务的概念提出还要更早。SAGA 的意思是”长篇故事、长篇记叙、一长串事件”,它起源于 1987 年普林斯顿大学的赫克托 · 加西亚 · 莫利纳(Hector Garcia Molina)和肯尼斯 · 麦克米伦(Kenneth Salem)在 ACM 发表的一篇论文《 SAGAS 》(这就是论文的全名)。
文中提出了一种如何提升”长时间事务”(Long Lived Transaction)运作效率的方法,大致思路是把一个大事务分解为可以交错运行的一系列子事务的集合。原本提出 SAGA 的目的,是为了避免大事务长时间锁定数据库的资源,后来才逐渐发展成将一个分布式环境中的大事务,分解为一系列本地事务的设计模式。
SAGA 由两部分操作组成。
一部分是把大事务拆分成若干个小事务,将整个分布式事务 T 分解为 n 个子事务,我们命名为 T1,T2,…,Ti,…,Tn。每个子事务都应该、或者能被看作是原子行为。如果分布式事务 T 能够正常提交,那么它对数据的影响(最终一致性)就应该与连续按顺序成功提交子事务 Ti 等价。
另一部分是为每一个子事务设计对应的补偿动作,我们命名为 C1,C2,…,Ci,…,Cn。Ti 与 Ci 必须满足以下条件:
- Ti 与 Ci 都具备幂等性;
- Ti 与 Ci 满足交换律(Commutative),即不管是先执行 Ti 还是先执行 Ci,效果都是一样的;
- Ci 必须能成功提交,即不考虑 Ci 本身提交失败被回滚的情况,如果出现就必须持续重试直至成功,或者要人工介入。
如果 T1 到 Tn 均成功提交,那么事务就可以顺利完成。否则,我们就要采取以下两种恢复策略之一:
- 正向恢复(Forward Recovery) :如果 Ti 事务提交失败,则一直对 Ti 进行重试,直至成功为止(最大努力交付)。这种恢复方式不需要补偿,适用于事务最终都要成功的场景,比如在别人的银行账号中扣了款,就一定要给别人发货。正向恢复的执行模式为:T1,T2,…,Ti(失败),Ti(重试)…,Ti+1,…,Tn。
- 反向恢复(Backward Recovery) :如果 Ti 事务提交失败,则一直执行 Ci 对 Ti 进行补偿,直至成功为止(最大努力交付)。这里要求 Ci 必须(在持续重试后)执行成功。反向恢复的执行模式为:T1,T2,…,Ti(失败),Ci(补偿),…,C2,C1。
所以你能发现,与 TCC 相比,SAGA 不需要为资源设计冻结状态和撤销冻结的操作,补偿操作往往要比冻结操作容易实现得多。
我给你举个例子。我在前面提到的账户余额直接在银行维护的场景,从银行划转货款到 Fenix’s Bookstore 系统中,这步是经由用户支付操作(扫码或 U 盾)来促使银行提供服务;如果后续业务操作失败,尽管我们无法要求银行撤销掉之前的用户转账操作,但是作为补偿措施,我们让 Fenix’s Bookstore 系统将货款转回到用户账上,却是完全可行的。
SAGA 必须保证所有子事务都能够提交或者补偿,但 SAGA 系统本身也有可能会崩溃,所以它必须设计成与数据库类似的日志机制(被称为 SAGA Log),以保证系统恢复后可以追踪到子事务的执行情况,比如执行都到哪一步或者补偿到哪一步了。
另外你还要注意,尽管补偿操作通常比冻结 / 撤销更容易实现,但要保证正向、反向恢复过程能严谨地进行,也需要你花费不少的工夫。比如,你可能需要通过服务编排、可靠事件队列等方式来完成。所以, SAGA 事务通常也不会直接靠裸编码来实现,一般也是在事务中间件的基础上完成。我前面提到的 Seata 就同样支持 SAGA 事务模式。
还有,SAGA 基于数据补偿来代替回滚的思路,也可以应用在其他事务方案上。举个例子,阿里的 GTS(Global Transaction Service,Seata 由 GTS 开源而来)所提出的” AT 事务模式 “就是这样的一种应用。
另一种应用模式:AT 事务
从整体上看,AT 事务是参照了 XA 两段提交协议来实现的,但针对 XA 2PC 的缺陷,即在准备阶段,必须等待所有数据源都返回成功后,协调者才能统一发出 Commit 命令而导致的 木桶效应 (所有涉及到的锁和资源,都需要等到最慢的事务完成后才能统一释放),AT 事务也设计了针对性的解决方案。
它大致的做法是在业务数据提交时,自动拦截所有 SQL,分别保存 SQL 对数据修改前后结果的快照,生成行锁,通过本地事务一起提交到操作的数据源中,这就相当于自动记录了重做和回滚日志。
如果分布式事务成功提交了,那么我们后续只需清理每个数据源中对应的日志数据即可;而如果分布式事务需要回滚,就要根据日志数据自动产生用于补偿的”逆向 SQL”。
所以,基于这种补偿方式,分布式事务中所涉及的每一个数据源都可以单独提交,然后立刻释放锁和资源。AT 事务这种异步提交的模式,相比 2PC 极大地提升了系统的吞吐量水平。 而使用的代价就是大幅度地牺牲了隔离性,甚至直接影响到了原子性。 因为在缺乏隔离性的前提下,以补偿代替回滚不一定总能成功。
比如,当在本地事务提交之后、分布式事务完成之前,该数据被补偿之前又被其他操作修改过,即出现了 脏写(Dirty Write) ,而这个时候一旦出现分布式事务需要回滚,就不可能再通过自动的逆向 SQL 来实现补偿,只能由人工介入处理了。
一般来说,对于脏写我们是一定要避免的,所有传统关系数据库在最低的隔离级别上,都仍然要加锁以避免脏写。因为脏写情况一旦发生,人工其实也很难进行有效处理。
所以,GTS 增加了一个” 全局锁 “(Global Lock)的机制来实现 写隔离 ,要求本地事务提交之前,一定要先拿到针对修改记录的全局锁后才允许提交,而在没有获得全局锁之前就必须一直等待。
这种设计以牺牲一定性能为代价,避免了在两个分布式事务中,数据被同一个本地事务改写的情况,从而避免了脏写。
另外,在 读隔离 方面,AT 事务默认的隔离级别是 读未提交(Read Uncommitted) ,这意味着可能会产生 脏读(Dirty Read) 。读隔离也可以采用全局锁的方案来解决,但直接阻塞读取的话,我们要付出的代价就非常大了,一般并不会这样做。
所以到这里,你其实能发现,分布式事务中并没有能一揽子包治百病的解决办法,你只有因地制宜地选用合适的事务处理方案,才是唯一有效的做法。
小结
通过上一讲和今天这节课的学习,我们已经知道,CAP 定理决定了 C 与 A 不可兼得,传统的 ACID 强一致性在分布式环境中,要想能保证一致性(C),就不得不牺牲可用性(A)。那么这个时候,随着分布式系统中节点数量的增加,整个系统发生服务中断的概率和时间都会随之增长。
所以,我们只能退而求其次,把”最终一致性”作为分布式架构下事务处理的目标。在这两节课中,我给你介绍的可靠事件队列、TCC 和 SAGA,都是实现最终一致性的三种主流模式。
16 | 域名解析系统,优化HTTP性能的第一步
从今天这节课开始,我们一起来学习下,如何引导流量分配到最合适的系统部件中进行响应。
那么在正式开始学习之前,我们先来了解下所谓的透明多级分流系统的定义。
理解透明多级分流系统的设计原则
我们都知道,用户在使用信息系统的过程中,请求首先是从浏览器出发,在 DNS 的指引下找到系统的入口,然后经过了网关、负载均衡器、缓存、服务集群等一系列设施,最后接触到了系统末端存储于数据库服务器中的信息,然后再逐级返回到用户的浏览器之中。
这个过程需要经过许许多多的技术部件。那么作为系统的设计者,我们应该意识到不同的设施、部件在系统中,都具有各自不同的价值:
- 有一些部件位于客户端或网络的边缘,能够迅速响应用户的请求,避免给后方的 I/O 与 CPU 带来压力,典型的如 本地缓存、内容分发网络、反向代理 等。
- 有一些部件的处理能力能够线性拓展,易于伸缩,可以通过使用较小的代价堆叠机器,来获得与用户数量相匹配的并发性能,并且应尽量作为业务逻辑的主要载体,典型的如 集群中能够自动扩缩的服务节点。
- 有一些部件的稳定服务,对系统运行具有全局性的影响,要时刻保持着容错备份,维护着高可用性,典型的如 服务注册中心、配置中心。
- 有一些设施是天生的单点部件,只能依靠升级机器本身的网络、存储和运算性能来提升处理能力,比如位于 系统入口的路由、网关或者负载均衡器 (它们都可以做集群,但一次网络请求中无可避免至少有一个是单点的部件)、 位于请求调用链末端的传统关系数据库 等,都是典型的容易形成单点部件。
所以,在对系统进行流量规划时,我们需要充分理解这些部件的价值差异。这里,我认为有两个简单、普适的原则,能指导我们进行设计。
第一个原则是尽可能减少单点部件,如果某些单点是无可避免的,则应尽最大限度减少到达单点部件的流量。
用户的请求在系统中往往会有多个部件都能够处理响应,比如要获取一张存储在数据库的用户头像图片,浏览器缓存、内容分发网络、反向代理、Web 服务器、文件服务器、数据库等,都可能会提供这张图片。
所以,恰如其分地引导请求分流至最合适的组件中,避免绝大多数流量汇集到单点部件(如数据库),同时依然能够、或者在绝大多数时候能够保证处理结果的准确性,在单点系统出现故障时,仍能自动而迅速地实施补救措施,这便是系统架构中多级分流的意义。
那么,缓存、节流、主备、负载均衡等措施,就都是为了达成该目标所采用的工具与手段,而高可用架构、高并发架构,则是通过该原则所获得的价值。
许多介绍架构设计的资料呢,都会以”高可用、高并发架构”为主题,主要聚焦于流量到达服务端后,如何构建强大的服务端集群来应对。
而在这个小章节中,我们是以”透明多级分流系统”为主题,聚焦于流量从客户端发出,到达服务端处理节点前的过程,并会去了解在这个过程中对流量削峰填谷的基础设施与通用组件。
第二个原则是奥卡姆剃刀原则,它更为关键。
奥卡姆剃刀原则
Entities should not be multiplied without necessity.
如无必要,勿增实体。
作为一个架构设计者,你应该对前面提到的多级分流的手段,有一个全面的理解与充分的准备。同时你也要清晰地意识到,这些设施并不是越多越好,在实际构建系统的时候,你要在有明确需求、真正有必要的时候,再去考虑部署它们。
因为并不是每一个系统都要追求高并发、高可用的,从系统的用户量、峰值流量和团队本身的技术与运维能力出发,来考虑如何布置这些设施,才是最合理的做法。
在能满足需求的前提下,最简单的系统就是最好的系统。
所以,在这个章节的第一节课当中,我们就先来学习一个相对简单,但又是全世界最大规模的查询系统,即 DNS 域名解析查询系统,我们一起来看看它是如何实现多级分流的。
DNS 的工作原理
我们都知道, DNS 的作用是把便于人类理解的域名地址,转换为便于计算机处理的 IP 地址。
说到 DNS,我想到了一件事,你可能会觉得有点儿好笑:我在刚接触计算机网络有一小段时间以后,一直都把 DNS 想像成是一个部署在世界上某个神秘机房里的大型电话本式的翻译服务。直到后来,当我第一次了解到 DNS 的工作原理,也知道了世界根域名服务器的 ZONE 文件只有 2MB 大小,甚至可以打印出来物理备份的时候,我就对 DNS 系统的设计惊叹得不得了。
域名解析对于大多数信息系统,尤其是基于互联网的系统来说是必不可少的组件,可是现在想想,它在我们的开发工作里其实根本没有特别高的存在感,通常它都是不会受到重点关注的设施。这就导致了很多程序员还不太了解 DNS 本身的工作过程,以及它对系统流量能够施加的影响;而且,DNS 本身就堪称是示范性的透明多级分流系统,非常符合我们这个章节的主题,也很值得我们去借鉴。
无论是使用浏览器,还是在程序代码中访问某个网址域名,如果没有缓存的话,都会先经过 DNS 服务器的解析翻译,找到域名对应的 IP 地址,才能开始通讯。
后面我就以 www.icyfenix.com.cn 为例吧。这项操作是操作系统自动完成的,一般不需要用户程序的介入。
不过,DNS 服务器并不是一次性地把 www.icyfenix.com.cn 直接解析成 IP 地址的,这个解析需要经历一个递归的过程。
首先,DNS 会把域名还原为”www.icyfenix.com.cn.”。注意这里最后多了一个点”.”,它是”.root”的意思。早期的域名都必须得带这个点,DNS 才能正确解析,不过现在几乎所有的操作系统、DNS 服务器都可以自动补上结尾的点号了。
然后,DNS 就开始进行解析了。它的解析步骤是这样的:
第一步,客户端先检查本地的 DNS 缓存,查看是否存在并且是存活着的该域名的地址记录。
DNS 是以 存活时间 (Time to Live,TTL)来衡量缓存的有效情况的,因此如果某个域名改变了 IP 地址,它也无法去通知缓存了该地址的机器来更新或失效掉缓存,只能依靠 TTL 超期后重新获取来保证一致性。后续每一级 DNS 查询的过程,都会有类似的缓存查询操作,所以我就不重复说了。
第二步,客户端将地址发送给本机操作系统中配置的本地 DNS(Local DNS)。这个本地 DNS 服务器可以由用户手工设置,也可以在 DHCP 分配时或者在拨号时,从 PPP 服务器中自动获取。
第三步,本地 DNS 收到查询请求后,会按照”是否有 www.icyfenix.com.cn 的权威服务器”→”是否有 icyfenix.com.cn 的权威服务器”→”是否有 com.cn 的权威服务器”→”是否有 cn 的权威服务器”的顺序,依次查询自己的地址记录。如果都没有查询到,本地 DNS 就会一直找到最后点号代表的根域名服务器为止。
这个步骤里涉及了两个重要名词,你需要好好掌握:
权威域名服务器(Authoritative DNS) :是指负责翻译特定域名的 DNS 服务器,”权威”的意思就是说,服务器决定了这个域名应该翻译出怎样的结果。DNS 翻译域名的时候,不需要像查电话本一样刻板地一对一翻译,它可以根据来访机器、网络链路、服务内容等各种信息,玩出很多花样。权威 DNS 的灵活应用,在后面的内容分发网络、服务发现等课程内容中都还会涉及到。
根域名服务器(Root DNS) :是指固定的、无需查询的 顶级域名 (Top-Level Domain)服务器,可以默认为它们已内置在操作系统代码之中。全世界一共有 13 组根域名服务器(注意并不是 13 台,每一组根域名都通过 任播 的方式建立了一大群镜像,根据维基百科的数据,迄今已经超过 1000 台根域名服务器的镜像了),之所以有 13 这个数字的限制是因为,DNS 主要是采用 UDP 传输协议(在需要稳定性保证的时候也可以采用 TCP)来进行数据交换的,未分片的 UDP 数据包在 IPv4 下最大有效值为 512 字节,最多可以存放 13 组地址记录。
第四步,现在假设本地 DNS 是全新的,上面不存在任何域名的权威服务器记录,所以当 DNS 查询请求按步骤 3 的顺序,一直查到根域名服务器之后,它将会得到”cn 的权威服务器”的地址记录,然后通过”cn 的权威服务器”,得到”com.cn 的权威服务器”的地址记录,以此类推,最后找到能够解释 www.icyfenix.com.cn 的权威服务器地址。
第五步,通过”www.icyfenix.com.cn 的权威服务器”,查询 www.icyfenix.com.cn 的地址记录。这里的地址记录并不一定就是指 IP 地址,在 RFC 规范中,有定义的地址记录类型已经 多达几十种 ,比如 IPv4 下的 IP 地址为 A 记录,IPv6 下的 AAAA 记录、主机别名 CNAME 记录,等等。
我给你举一个例子。假设一个域名下配置了多条不同的 A 记录,此时权威服务器就可以根据自己的策略来进行选择,典型的应用是智能线路:根据访问者所处的不同地区(如华北、华南、东北)、不同服务商(如电信、联通、移动)等因素,来确定返回最合适的 A 记录,将访问者路由到最合适的数据中心,达到智能加速的目的。
可见,DNS 系统多级分流的设计,就让 DNS 系统能够经受住全球网络流量不间断的冲击,但它也并不是没有缺点。
典型的问题就是 响应速度会受影响 。在极端情况(如各级服务器均无缓存)下,域名解析可能会导致每个域名都必须递归多次才能查询到结果,显著影响传输的响应速度。
如下图所示,你可以看到其高达 310 毫秒的 DNS 查询速度:
所以,为了避免产生这种问题,专门就有一种前端优化手段,叫做 DNS 预取 (DNS Prefetching):如果网站后续要使用来自于其他域的资源,那就在网页加载时便生成一个 link 请求,促使浏览器提前对该域名进行预解释,如下所示:
<link rel="dns-prefetch" href="//domain.not-icyfenx.cn">而另一种可能更严重的缺陷,就是 DNS 的分级查询意味着每一级都有可能受到中间人攻击的威胁,产生被劫持的风险。
我们应该都知道,要攻陷位于递归链条顶层的(如根域名服务器,cn 权威服务器)服务器和链路是非常困难的,它们都有很专业的安全防护措施。但很多位于递归链底层的、或者来自本地运营商的 Local DNS 服务器,安全防护就相对松懈,甚至不少地区的运行商自己就会主动进行劫持,专门返回一个错的 IP,通过在这个 IP 上代理用户请求,以便给特定类型的资源(主要是 HTML)注入广告,进行牟利。
所以针对这种情况,最近几年出现了一种新的 DNS 工作模式: HTTPDNS (也称为 DNS over HTTPS,DoH)。它把原本的 DNS 解析服务开放为一个基于 HTTPS 协议的查询服务,替代基于 UDP 传输协议的 DNS 域名解析,通过程序代替操作系统直接从权威 DNS,或者可靠 Local DNS 获取解析数据,从而绕过传统 Local DNS。
这种做法的好处是完全免去了”中间商赚差价”的环节,不再惧怕底层的域名劫持,能有效避免 Local DNS 不可靠导致的域名生效缓慢、来源 IP 不准确、产生的智能线路切换错误等问题。
小结
这节课作为”透明多级分流系统”的第一讲,我给你介绍了这个名字的意义与来由。在开发过程中没有太多存在感的 DNS 系统,其实就很符合透明和多级分流的特点。所以我也以此为例,给你简要介绍了它的工作原理。
根据请求从浏览器发出到最终查询或修改数据库的信息,除了 DNS 以外,还会有客户端浏览器、网络传输链路、内容分发网络、负载均衡器和缓存中间件这些位于服务器、数据库之外的组件,可以帮助分担流量,便于我们构建出更加高并发、高可用的系统。在后面的几节课中,我们就会逐一来探讨它们的工作原理。
17 | 客户端缓存是如何帮助服务器分担流量的?
这节课,我们继续来讨论透明多级分流系统中,最靠近用户一侧的分流部件:浏览器的客户端缓存。
当万维网刚刚出现的时候,浏览器的缓存机制差不多就已经存在了。在 HTTP 协议设计之初,人们便确定了服务端与客户端之间”无状态”(Stateless)的交互原则,即要求客户端的每次请求是独立的,每次请求无法感知、也不能依赖另一个请求的存在,这既简化了 HTTP 服务器的设计,也为它的水平扩展能力留下了广阔的空间。
但无状态并不是只有好的一面。因为客户端的每次请求都是独立的,服务端不会保存之前请求的状态和资源,所以也不可避免地导致它会携带重复的数据,造成网络性能的降低。
那么,HTTP 协议针对这个问题的解决方案,就是客户端缓存。从 HTTP/1.0 到 1.1、再到 2.0 版本的演进中,逐步形成了现在被称为”状态缓存”、”强制缓存”(或简称为”强缓存”)和”协商缓存”这三种 HTTP 缓存机制。
这其中的状态缓存,是指不经过服务器,客户端直接根据缓存信息来判断目标网站的状态。以前只有 301/Moved Permanently(永久重定向)这一种;后来在 RFC6797 中增加了 HSTS (HTTP Strict Transport Security)机制,用来避免依赖 301/302 跳转 HTTPS 时,可能产生的降级中间人劫持问题(在第 28、29 讲中,我还会展开讲解这个问题),这也属于另一种状态缓存。
因为状态缓存涉及的内容只有这么一点,所以后面,我们就只聚焦在强制缓存与协商缓存这两种机制的探讨上。
下面我们就先来看看强制缓存的实现机制吧。
实现强制缓存机制的两类 Headers
就像”强制缓存”这个名字一样,它对一致性问题的处理策略十分直接:假设在某个时间点内,比如服务器收到响应后的 10 分钟内,资源的内容和状态一定不会被改变,因此客户端可以不需要经过任何请求,在该时间点到来之前一直持有和使用该资源的本地缓存副本。
根据约定,在浏览器的地址输入、页面链接跳转、新开窗口、前进和后退中,强制缓存都可以生效,但在用户主动刷新页面时应当自动失效。
在 HTTP 协议中,设置了两类可以实现强制缓存的 Headers(标头):Expires 和 Cache-Control。
第一类:Expires
Expires 是 HTTP/1.0 协议中开始提供的 Header,后面跟随了一个截止时间参数。当服务器返回某个资源时,如果带有该 Header 的话,就意味着服务器承诺在截止时间之前,资源不会发生变动,浏览器可直接缓存该数据,不再重新发请求。我们直接来看一个 Expires 头的示例程序:
HTTP/1.1 200 OK
Expires: Wed, 8 Apr 2020 07:28:00 GMT那么,你能看到,Expires 设计得非常直观易懂,但它考虑得其实并不周全。我给你简单举几个例子。
受限于客户端的本地时间
比如,在收到响应后,客户端修改了本地时间,将时间点前后调整了几分钟,这就可能会造成缓存提前失效或超期持有。
无法处理涉及到用户身份的私有资源
比如,合理的做法是,某些资源被登录用户缓存在了自己的浏览器上。但如果被代理服务器或者内容分发网络(CDN)缓存起来,就可能会被其他未认证的用户获取。
无法描述”不缓存”的语义
比如,一般浏览器为了提高性能,往往会自动在当次会话中缓存某些 MINE 类型的资源,这会造成设计者不希望缓存的资源无法被及时更新。而在 HTTP/1.0 的设计中,Expires 并没有考虑这方面的需求,导致无法强制浏览器不允许缓存某个资源。
所以,以前为了实现这类功能,我们通常不得不使用脚本,或者手工在资源后面增加时间戳(如”xx.js?t=1586359920””xx.jpg?t=1586359350”)来保证每次资源都会重新获取。
不过,关于”不缓存”的语义,在 HTTP/1.0 中其实是预留了”Pragma: no-cache”来表达的,但在 HTTP/1.0 中,并没有确切地描述 Pragma 参数的具体行为,随后它就被 HTTP/1.1 中出现过的 Cache-Control 给替代了。
现在,尽管主流的浏览器也通常都会支持 Pragma,但它的行为仍然是不确定的,实际上并没有什么使用价值。而 Cache-Control 的出现,进一步压缩了 Pragma 的生存空间。所以接下来,我们就一起来看看,它是如何支持强制缓存机制的实现的。
第二类:Cache-Control
Cache-Control 是 HTTP/1.1 协议中定义的强制缓存 Header,它的语义比起 Expires 来说就丰富了很多。而如果 Cache-Control 和 Expires 同时存在,并且语义存在冲突(比如 Expires 与 max-age / s-maxage 冲突)的话,IETF 规定必须以 Cache-Control 为准。
同样这里,我们也看看 Cache-Control 的使用示例:
200 OKCache-Control: max-age=600
那么,你能看到,这里的示例中使用的参数是 max-age。实际上,在客户端的请求 Header 或服务器的响应 Header 中,Cache-Control 都可以存在,它定义了一系列的参数,并且允许自行扩展(即不在标准 RFC 协议中,由浏览器自行支持的参数)。Cache-Control 标准的参数主要包括 6 种,下面我就带你一一了解下。
max-age 和 s-maxage
在前面的示例中,你会发现 max-age 后面跟随了一个数字,它是以秒为单位的,表明相对于请求时间(在 Date Header 中会注明请求时间)多少秒以内,缓存是有效的,资源不需要重新从服务器中获取。这个相对时间,就避免了 Expires 中,采用的绝对时间可能受客户端时钟影响的问题。
另一个类似的参数是 s-maxage,其中的”s”是”Share”的缩写,意味着”共享缓存”的有效时间,即允许被 CDN、代理等持有的缓存有效时间,这个参数主要是用来提示 CDN 这类服务器如何对缓存进行失效。
public 和 private
这一类参数表明了是否涉及到用户身份的私有资源。如果是 public,就意味着资源可以被代理、CDN 等缓存;如果是 private,就意味着只能由用户的客户端进行私有缓存。
no-cache 和 no-store
no-cache 表明该资源不应该被缓存,哪怕是同一个会话中对同一个 URL 地址的请求,也必须从服务端获取,从而令强制缓存完全失效(但此时的协商缓存机制依然是生效的);no-store 不强制会话中是否重复获取相同的 URL 资源,但它禁止浏览器、CDN 等以任何形式保存该资源。
no-transform
no-transform 禁止资源以任何形式被修改。比如,某些 CDN、透明代理支持自动 GZip 压缩图片或文本,以提升网络性能,而 no-transform 就禁止了这样的行为,它要求 Content-Encoding、Content-Range、Content-Type 均不允许进行任何形式的修改。
min-fresh 和 only-if-cached
这两个参数是仅用于客户端的请求 Header。min-fresh 后续跟随了一个以秒为单位的数字,用于建议服务器能返回一个不少于该时间的缓存资源(即包含 max-age 且不少于 min-fresh 的数字);only-if-cached 表示服务器希望客户端不要发送请求,只使用缓存来进行响应,若缓存不能命中,就直接返回 503/Service Unavailable 错误。
must-revalidate 和 proxy-revalidate
must-revalidate 表示在资源过期后,一定要从服务器中进行获取,即超过了 max-age 的时间后,就等同于 no-cache 的行为;proxy-revalidate 用于提示代理、CDN 等设备资源过期后的缓存行为,除对象不同外,语义与 must-revalidate 完全一致。
好了,现在你应该就已经理解了强制缓存的实现机制了。但是,强制缓存是基于时效性的,无论是人还是服务器,在大多数情况下,其实都没有什么把握去承诺某项资源多久不会发生变化。
所以,接下来我就要给你介绍另一种基于变化检测的缓存机制,也就是协商缓存。它在处理一致性问题上,比强制缓存会有更好的表现。不过它需要一次变化检测的交互开销,在性能上就会略差一些。
协商缓存的两种变动检查机制
那么,在开始了解协商缓存的实现机制之前,你要先注意一个地方,就是在 HTTP 中,协商缓存与强制缓存并没有互斥性,这两套机制是并行工作的。
比如说,当强制缓存存在时,客户端可以直接从强制缓存中返回资源,无需进行变动检查;而当强制缓存超过时效,或者被禁止(no-cache / must-revalidate),协商缓存也仍然可以正常工作。
协商缓存有两种变动检查机制, 一种是根据资源的修改时间进行检查,另一种是根据资源唯一标识是否发生变化来进行检查。 它们都是靠一组成对出现的请求、响应 Header 来实现的。
根据资源的修改时间进行检查
我们先来看看根据资源的修改时间进行检查的协商缓存机制。它的语义中包含了两种标准参数:Last-Modified 和 If-Modified-Since 。
Last-Modified 是服务器的响应 Header,用来告诉客户端这个资源的最后修改时间。
而对于带有这个 Header 的资源,当客户端需要再次请求时,会通过 If-Modified-Since,把之前收到的资源最后修改时间发送回服务端。
如果此时,服务端发现资源在该时间后没有被修改过,就只要返回一个 304/Not Modified 的响应即可,无需附带消息体,从而达到了节省流量的目的:
HTTP/1.1 304 Not Modified
Cache-Control: public, max-age=600
Last-Modified: Wed, 8 Apr 2020 15:31:30 GMT而如果此时,服务端发现资源在该时间之后有变动,就会返回 200/OK 的完整响应,在消息体中包含最新的资源。
HTTP/1.1 200 OK
Cache-Control: public, max-age=600
Last-Modified: Wed, 8 Apr 2020 15:31:30 GMT
Content根据资源唯一标识是否发生变化来进行检查
好,我们再来看看”根据资源唯一标识是否发生变化来进行检查”的协商缓存机制。它的语义中也包含了两种标准参数: Etag 和 If-None-Match 。
Etag 是服务器的响应 Header,用于告诉客户端这个资源的唯一标识。HTTP 服务器可以根据自己的意愿,来选择如何生成这个标识,比如 Apache 服务器的 Etag 值,就默认是对文件的索引节点(INode)、大小和最后修改时间进行哈希计算后而得到的。
然后,对于带有这个 Header 的资源,当客户端需要再次请求时,就会通过 If-None-Match,把之前收到的资源唯一标识发送回服务端。
如果此时,服务端计算后发现资源的唯一标识与上传回来的一致,就说明资源没有被修改过,同样也只需要返回一个 304/Not Modified 的响应即可,无需附带消息体,达到节省流量的目的:
HTTP/1.1 304 Not Modified
Cache-Control: public, max-age=600
ETag: "28c3f612-ceb0-4ddc-ae35-791ca840c5fa"而如果此时,服务端发现资源的唯一标识有变动,也一样会返回 200/OK 的完整响应,在消息体中包含最新的资源。
HTTP/1.1 200 OK
Cache-Control: public, max-age=600
ETag: "28c3f612-ceb0-4ddc-ae35-791ca840c5fa"
Content另外,我还想强调的是, Etag 是 HTTP 中一致性最强的缓存机制。
为什么会这么说呢?我直接给你举个例子。
前面我提到的 Last-Modified 参数,它标注的最后修改只能精确到秒级,而如果某些文件在一秒钟以内被修改多次的话,它就不能准确标注文件的修改时间了;又或者,如果某些文件会被定期生成,可能内容上并没有任何变化,但 Last-Modified 却改变了,导致文件无法有效使用缓存。而这些情况,Last-Modified 都有可能产生资源一致性的问题,只能使用 Etag 解决。
但是,Etag 又是 HTTP 中性能最差的缓存机制。 这个”最差”体现在每次请求时,服务端都必须对资源进行哈希计算,这比起简单获取一下修改时间,开销要大了很多。
所以,Etag 和 Last-Modified 是允许一起使用的,服务器会优先验证 Etag,在 Etag 一致的情况下,再去对比 Last-Modified,这是为了防止有一些 HTTP 服务器没有把文件修改日期纳入哈希范围内。
HTTP 的内容协商机制
那到这里为止,HTTP 的协商缓存机制,就已经能很好地处理通过 URL 获取单个资源的场景了。不过你可能要问了: 为什么要强调”单个资源”呢?
我们知道,在 HTTP 协议的设计中,一个 URL 地址是有可能提供多份不同版本的资源的,比如说,一段文字的不同语言版本,一个文件的不同编码格式版本,一份数据的不同压缩方式版本,等等。因此针对请求的缓存机制,也必须能够提供对应的支持。
所以,针对这种情况,HTTP 协议设计了以 Accept* (Accept、Accept-Language、Accept-Charset、Accept-Encoding)开头的一套请求 Header,以及对应的以 Content-* (Content-Language、Content-Type、Content-Encoding)开头的响应 Header。 这些 Headers 被称为 HTTP 的内容协商机制。
那么,与之对应的,对于一个 URL 能够获取多个资源的场景中,缓存同样也需要有明确的标识来获知,它要根据什么内容来对同一个 URL 返回给用户正确的资源。这个就是 Vary Header 的作用,Vary 后面应该跟随一组其他 Header 的名字,比如说:
HTTP/1.1 200 OK
Vary: Accept, User-Agent这里你要知道,这个响应的含义是应该根据 MINE 类型和浏览器类型来缓存资源,另外服务端在获取资源时,也需要根据请求 Header 中对应的字段,来筛选出适合的资源版本。
根据约定,协商缓存不仅可以在浏览器的地址输入、页面链接跳转、新开窗口、前进、后退中生效,而且在用户主动刷新页面(F5)时也同样是生效的。只有用户强制刷新(Ctrl+F5)或者明确禁用缓存(比如在 DevTools 中设定)时才会失效,此时客户端向服务端发出的请求会自动带有”Cache-Control: no-cache”。
小结
HTTP 协议以”无状态”作为基本的交互原则,那么由此而来的资源重复访问问题,就需要通过网络链路中的缓存来解决了。现在你也已经知道,客户端缓存具体包括了”状态缓存”、”强制缓存”和”协商缓存”三类。
这节课,我们详细分析了强制缓存和协商缓存的工作原理。利用好客户端的缓存,能够节省大量网络流量,这是为后端系统分流,以实现更高并发的第一步。
18 | 传输链路,优化HTTP传输速度的小技巧
在经过了客户端缓存的节流和 DNS 服务的解析指引以后,程序发出的请求流量就正式离开了客户端,踏上以服务器为目的地的旅途了。而这个过程就是我们今天这节课要讨论的主角: 传输链路。
以优化链路传输为目的的前端设计原则未来或许不再适用
可能不少人的第一直觉都会认为,传输链路是完全不受开发者控制的因素,觉得网络路由跳点的数量、运营商铺设线路的质量,已经决定了线路带宽的大小、速率的高低。不过事实并非如此,程序发出的请求能否与应用层、传输层协议提倡的方式相匹配,对传输的效率也会有非常大的影响。
最容易体现出这点的,就是那些前端网页的优化技巧。我们只要简单搜索一下,就能找到很多以优化链路传输为目的的前端设计原则,比如经典的 雅虎 YSlow-23 条规则 中,就涵盖了很多与传输相关的内容。
下面我来给你简单举几个例子。
Minimize HTTP Requests
即减少请求数量:对于客户端发出的请求,服务器每次都需要建立通信链路进行数据传输,这些开销很昂贵,所以减少请求的数量,就可以有效地提高访问性能。如果你是做前端开发的,那你可能就听说过下面这几种减少请求数量的手段:
a. 雪碧图( CSS Sprites )
b. CSS、JS 文件合并 / 内联(Concatenation / Inline)
c. 分段文档( Multipart Document )
d. 媒体(图片、音频)内联( Data Base64 URI )
e. 合并 Ajax 请求(Batch Ajax Request)
f. ……
Split Components Across Domains
即扩大并发请求数:现代浏览器(Chrome、Firefox)一般可以为每个域名支持 6 个(IE 为 8-13 个)并发请求。如果你希望更快地加载大量图片或其他资源,就需要进行域名分片(Domain Sharding),将图片同步到不同主机或者同一个主机的不同域名上。
GZip Components
即启用压缩传输:启用压缩能够大幅度减少需要在网络上传输内容的大小,节省网络流量。
Avoid Redirects
即避免页面重定向:当页面发生了重定向,就会延迟整个文档的传输。在 HTML 文档到达之前,页面中不会呈现任何东西,会降低用户的体验。
Put Stylesheets at the Top,Put Scripts at the Bottom
即按重要性调节资源优先级:将重要的、马上就要使用的、对客户端展示影响大的资源,放在 HTML 的头部,以便优先下载。
……
这些原则在今天暂且仍算得上是有一定价值,但如果在若干年后的未来再回头看它们,大概率其中的多数原则已经成了奇技淫巧,有些甚至成了反模式。
我为什么这么说呢?这是因为 HTTP 协议还在持续发展,从上世纪 90 年代的 HTTP/1.0 和 HTTP/1.1,到 2015 年发布的 HTTP/2,再到 2019 年的 HTTP/3,由于 HTTP 协议本身的变化,造成了”适合 HTTP 传输的请求”的特征也在不断变化。
那么接下来,我们就来看看这里所说的特征变化指的都是什么。
连接数优化
我们知道,HTTP(特指 HTTP/3 以前)是以 TCP 为传输层的应用层协议, 但 HTTP over TCP 这种搭配,只能说是 TCP 目前在互联网中的统治性地位所造就的结果,而不能说它们两者配合工作就是合适的。
为啥呢?一方面,你可以回想一下,平常你在上网的时候,平均每个页面停留的时间都有多长?然后你也可以大概估算一下每个页面中包含的资源(HTML、JS、CSS、图片等)数量,由此你其实就可以大致总结出 HTTP 传输对象的主要特征了,那就是数量多、时间短、资源小、切换快。
另一方面,TCP 协议要求必须在 三次握手 完成之后才能开始数据传输,这是一个可能高达”百毫秒”为计时尺度的事件;另外,TCP 还有 慢启动 的特性,这就会导致通信双方在刚刚建立连接时的传输速度是最低的,后面再逐步加速直至稳定。
由于 TCP 协议本身是面向长时间、大数据传输来设计的,所以只有在一段较长的时间尺度内,TCP 协议才能展现出稳定性和可靠性的优势,不会因为建立连接的成本太高,成为了使用瓶颈。
所以我才说,HTTP over TCP 这种搭配在目标特征上确实是有矛盾的,以至于 HTTP/1.x 时代,大量短而小的 TCP 连接导致了网络性能的瓶颈。
开发 Tricks 的使用困境
那么,为了缓解 HTTP 与 TCP 之间的矛盾,聪明的程序员们一面致力于减少发出的请求数量,另一面也在致力于增加客户端到服务端的连接数量。这就是我在前面提到的 Yslow 规则中,”Minimize HTTP Requests”与”Split Components Across Domains”两条优化措施的根本依据所在。
由此可见,通过前端开发者的各种 Tricks,确实能够减少 TCP 连接数量的消耗,这是有数据统计作为支撑的。
HTTP Archive 就对最近 5 年来数百万个 URL 地址进行了采样,并得出了一个结论:页面平均请求没有改变的情况下(桌面端下降 3.8%,移动端上升 1.4%),TCP 连接正在持续且幅度较大地下降(桌面端下降 36.4%,移动端下降 28.6%)。我们一起来具体看看这个变化:
但是,这些开发 Tricks 除了可以节省 TCP 连接以外,其实也给我们带来了不少的副作用,比如说:
- 如果你用 CSS Sprites 合并了多张图片,就意味着在任何场景下,哪怕你只用到了其中一张小图,也必须要完整地加载整个大图片;或者哪怕只有一张小图需要修改,也都会导致整个大图的缓存失效。类似的,样式、脚本等其他文件的合并,也会造成同样的问题。
- 如果你使用了媒体内嵌,除了要承受 Base64 编码导致传输容量膨胀 1/3 的代价以外(Base64 以 8 bit 表示 6 bit 数据),也会无法有效利用缓存。
- 如果你合并了异步请求,就会导致所有请求的返回时间,都要受最慢的那个请求拖累,页面整体的响应速度会下降。
- 如果你把图片放到了不同子域下面,将会导致更大的 DNS 解析负担,而且浏览器对两个不同子域下的同一图片必须持有两份缓存,这也使得缓存效率下降。
- ……
所以我们也不难看出,一旦需要使用者通过各种 Tricks,来解决基于技术根基而出现的各种问题时,就会导致 TA 再也没办法摆脱”两害相权取其轻”的困境。否则,这就不是 Tricks,而是会成为一种标准的设计模式了。
连接复用技术的优势和缺陷
实际上,HTTP 的设计者们也不是没有尝试过在 协议层面 去解决连接成本过高的问题,即使是 HTTP 协议的最初版本(指 HTTP/1.0,忽略非正式的 HTTP/0.9 版本),就已经支持(HTTP/1.0 中不是默认开启的,HTTP/1.1 中变为默认)连接复用技术了,也就是今天我们所熟知的 持久连接 (Persistent Connection),或者叫连接 Keep-Alive 机制。
它的原理是,让客户端对同一个域名长期持有一个或多个不会用完即断的 TCP 连接。典型做法是在客户端维护一个 FIFO 队列,每次取完数据之后的一段时间内,不自动断开连接,以便获取下一个资源时可以直接复用,避免创建 TCP 连接的成本。
但是,连接复用技术依然是不完美的,最明显的副作用就是” 队首阻塞 “(Head-of-Line Blocking)问题。
我们来设想一下这样的场景:浏览器有 10 个资源需要从服务器中获取,这个时候它把 10 个资源放入队列,入列顺序只能是按照浏览器预见这些资源的先后顺序来决定。但是,如果这 10 个资源中的第 1 个就让服务器陷入了长时间运算状态,会发生怎样的状况呢?
答案是,当它的请求被发送到服务端之后,服务端就会开始计算,而在运算结果出来之前,TCP 连接中并没有任何数据返回,此时后面的 9 个资源都必须阻塞等待。
虽然说服务端可以并行处理另外 9 个请求,比如第 1 个是复杂运算请求,消耗 CPU 资源;第 2 个是数据库访问,消耗数据库资源;第 3 个是访问某张图片,消耗磁盘 I/O 资源,等等,这就很适合并行。
但问题是,这些请求的处理结果无法及时发回给客户端,服务端也不能哪个请求先完成就返回哪个,更不可能把所有要返回的资源混杂到一起交叉传输。这是因为,只使用一个 TCP 连接来传输多个资源的话,一旦顺序乱了,客户端就很难区分清楚哪个数据包归属哪个资源了。
因此,在 2014 年 IETF 发布的 RFC 7230 中,提出了名为”HTTP 管道”(HTTP Pipelining)复用技术,试图在 HTTP 服务器中也建立类似客户端的 FIFO 队列,让客户端一次性将所有要请求的资源名单全部发给服务端,由服务端来安排返回顺序,管理传输队列。
不过,无论队列维护是在服务端还是在客户端,其实都无法完全避免队首阻塞的问题。这是因为很难在真正传输之前,完全精确地评估出传输队列中每一项的时间成本,但由于服务端能够较为准确地评估资源消耗情况,这样确实能更紧凑地安排资源传输,保证队列中两项工作之间尽量减少空隙,甚至可能做到并行化传输,从而提升链路传输的效率。
可是,因为 HTTP 管道需要多方共同支持,协调起来相当复杂,因此推广得并不算成功。
后来,队首阻塞问题一直持续到 HTTP/2 发布后,才算是被比较完美地解决了。
解决方案:HTTP/2 的多路复用技术
在 HTTP/1.x 中,HTTP 请求就是传输过程中最小粒度的信息单位了,所以如果将多个请求切碎,再混杂在一块传输,客户端势必难以分辨重组出有效信息。
而在 HTTP/2 中,帧(Frame)才是最小粒度的信息单位 ,它可以用来描述各种数据,比如请求的 Headers、Body,或者是用来做控制标识,如打开流、关闭流。
这里我说的 流(Stream) ,是一个逻辑上的数据通道概念,每个帧都附带有一个流 ID,以标识这个帧属于哪个流。这样,在同一个 TCP 连接中,传输的多个数据帧就可以根据流 ID 轻易区分出来,在客户端就能毫不费力地将不同流中的数据,重组出不同 HTTP 请求和响应报文来。
这项设计是 HTTP/2 的最重要的技术特征之一,被称为 HTTP/2 多路复用 (HTTP/2 Multiplexing)技术。
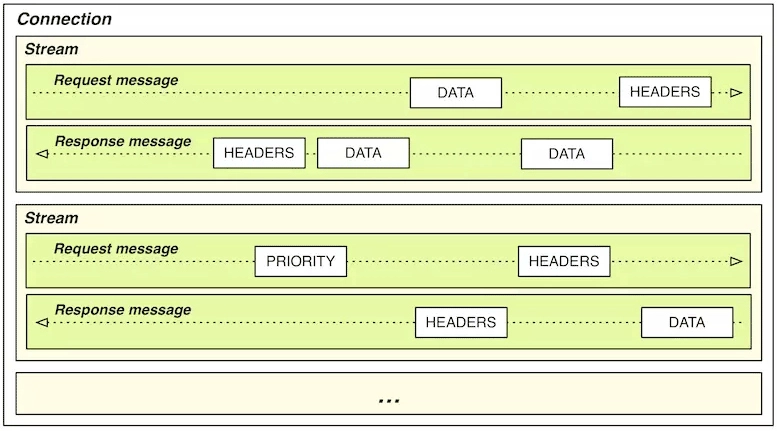
这样,有了多路复用的支持,HTTP/2 就可以对每个域名只维持一个 TCP 连接(One Connection Per Origin),来以任意顺序传输任意数量的资源。这样就既减轻了服务器的连接压力,开发者也不用去考虑域名分片这种事情,来突破浏览器对每个域名最多 6 个连接数的限制了。
而更重要的是,没有了 TCP 连接数的压力,客户端就不需要再刻意压缩 HTTP 请求了,所有通过合并、内联文件(无论是图片、样式、脚本)以减少请求数的需求都不再成立,甚至反而是徒增副作用的反模式。
当然,我说这是反模式,可能还会有一些前端开发者不同意,觉得 HTTP 请求少一些总是好的。减少请求数量,最起码还减少了传输中耗费的 Headers。
这里我们必须要先承认一个事实,在 HTTP 传输中,Headers 占传输成本的比重是相当地大,对于许多小资源,甚至可能出现 Headers 的容量比 Body 的还要大,以至于在 HTTP/2 中必须专门考虑如何进行 Header 压缩的问题。
但实际上,有这样几个因素,就决定了即使是通过合并资源文件来减少请求数,对节省 Headers 成本来说,也并没有太大的帮助:
- Header 的传输成本在 Ajax(尤其是只返回少量数据的请求)请求中可能是比重很大的开销,但在图片、样式、脚本这些 静态资源的请求中,一般并不占主要比重。
- 在 HTTP/2 中,Header 压缩的原理是基于字典编码的信息复用,简而言之是同一个连接上产生的请求和响应越多,动态字典积累得越全,头部压缩效果也就越好。所以, HTTP/2 是单域名单连接的机制 ,合并资源和域名分片反而对性能提升不利。
- 与 HTTP/1.x 相反,HTTP/2 本身反而变得 更适合传输小资源 了,比如传输 1000 张 10K 的小图,HTTP/2 要比 HTTP/1.x 快,但传输 10 张 1000K 的大图,则应该 HTTP/1.x 会更快。这其中有 TCP 连接数量(相当于多点下载)的影响,更多的是由于 TCP 协议 可靠传输机制 导致的,一个错误的 TCP 包会导致所有的流都必须等待这个包重传成功,而这个问题就是 HTTP/3.0 要解决的目标了。因此,把小文件合并成大文件,在 HTTP/2 下是毫无好处的。
传输压缩
好,了解了 TCP 连接数的各种优化机制之后,我们再来讨论下,在链路优化中除缓存、连接之外的另一个重要话题: 压缩 。同时,这也可以解决我们之前遗留的一个问题: 如何不以断开 TCP 连接为标志,来判断资源已传输完毕?
HTTP 很早就支持了 GZip 压缩,因为 HTTP 传输的主要内容,比如 HTML、CSS、Script 等,主要是文本数据,因此对于文本数据启用压缩的收益是非常高的,传输数据量一般会降至原有的 20% 左右。而对于那些不适合压缩的资源,Web 服务器则能根据 MIME 类型,来自动判断是否对响应进行压缩。这样,对于已经采用过压缩算法存储的资源,比如 JPEG、PNG 图片,就不会被二次压缩,空耗性能了。
不过,大概没有多少人想过, 压缩其实跟我们前面提到的,用于节约 TCP 的持久连接机制是存在冲突的。
在网络时代的早期,服务器的处理能力还很薄弱,为了启用压缩,会把静态资源预先压缩为.gz 文件的形式给存放起来。当客户端可以接受压缩版本的资源时(请求的 Header 中包含 Accept-Encoding: gzip),就返回压缩后的版本(响应的 Header 中包含 Content-Encoding: gzip),否则就返回未压缩的原版。这种方式被称为” 静态预压缩 “(Static Precompression)。
而现代的 Web 服务器处理能力有了大幅提升,已经没有人再采用这种麻烦的预压缩方式了,都是由服务器对符合条件的请求,在即将输出时进行” 即时压缩 “(On-The-Fly Compression),整个压缩过程全部在内存的数据流中完成,不必等资源压缩完成再返回响应,这样可以显著提高” 首字节时间 “(Time To First Byte,TTFB),改善 Web 性能体验。
而这个过程中唯一不好的地方,就是 服务器再也没有办法给出 Content-Length 这个响应 Header 了。因为输出 Header 时,服务器还不知道压缩后资源的确切大小。
那看到这里,你想明白即时压缩与持久连接的冲突在哪了吗?
实际上,持久连接机制不再依靠 TCP 连接是否关闭,来判断资源请求是否结束了。它会重用同一个连接,以便向同一个域名请求多个资源。这样,客户端就必须要有除了关闭连接之外的其他机制,来判断一个资源什么时候才算是传递完毕。
这个机制最初(在 HTTP/1.0 时)就只有 Content-Length,即靠着请求 Header 中明确给出资源的长度,传输到达该长度即宣告一个资源的传输已经结束。不过,由于启用即时压缩后就无法给出 Content-Length 了,如果是 HTTP/1.0 的话,持久连接和即时压缩只能二选其一。事实上,在 HTTP/1.0 中这两者都支持,却默认都是不启用的。
另外,依靠 Content-Length 来判断传输结束的缺陷,不仅只有即时压缩这一种场景,对于动态内容(Ajax、PHP、JSP 等输出)等应用场景,服务器也同样无法事先得知 Content-Length。
不过,HTTP/1.1 版本中已经修复了这个缺陷,并 增加了另一种” 分块传输编码 “(Chunked Transfer Encoding)的资源结束判断机制 ,彻底解决了 Content-Length 与持久连接的冲突问题。
分块编码的工作原理相当简单:在响应 Header 中加入”Transfer-Encoding: chunked”之后,就代表这个响应报文将采用分块编码。此时,报文中的 Body 需要改为用一系列”分块”来传输。每个分块包含十六进制的长度值和对应长度的数据内容,长度值独占一行,数据从下一行开始。最后以一个长度值为 0 的分块,来表示资源结束。
给你举个具体的例子(例子来自于 维基百科 ,为便于观察,只分块,未压缩):
HTTP/1.1 200 OK
Date: Sat, 11 Apr 2020 04:44:00 GMT
Transfer-Encoding: chunked
Connection: keep-alive
25
This is the data in the first chunk
1C
and this is the second one
3
con
8
sequence
0根据分块长度就可以知道,前两个分块包含显式的回车换行符(CRLF,即\r\n 字符)
"This is the data in the first chunk\r\n" (37 字符 => 十六进制: 0x25)
"and this is the second one\r\n" (28 字符 => 十六进制: 0x1C)
"con" (3 字符 => 十六进制: 0x03)
"sequence" (8 字符 => 十六进制: 0x08)所以解码后的内容为:
This is the data in the first chunk
and this is the second one
consequence另外,这里你要知道的是,一般来说,Web 服务器给出的数据分块大小应该(但并不强制)是一致的,而不是像这个例子一样随意。
HTTP/1.1 通过分块传输解决了即时压缩与持久连接并存的问题,到了 HTTP/2,由于多路复用和单域名单连接的设计,已经不需要再刻意去强调持久连接机制了,但数据压缩仍然有节约传输带宽的重要价值。
快速 UDP 网络连接
OK,那么到这里,我们还需要明确一件事情,就是 HTTP 是应用层协议,而不是传输层协议,它的设计原本并不应该过多地考虑底层的传输细节。从职责上来讲,持久连接、多路复用、分块编码这些能力,已经或多或少超过了应用层的范畴。
所以说,要想从根本上改进 HTTP,就必须直接替换掉 HTTP over TCP 的根基,即 TCP 传输协议,这便是最新一代 HTTP/3 协议的设计重点。
推动替换 TCP 协议的先驱者并不是 IETF,而是 Google 公司。目前,世界上只有 Google 公司具有这样的能力,这并不是因为 Google 的技术实力雄厚,而是由于它同时持有着占浏览器市场 70% 份额的 Chrome 浏览器,与占移动领域半壁江山的 Android 操作系统。
2013 年,Google 在它的服务器(如 Google.com、YouTube.com 等)及 Chrome 浏览器上,同时启用了名为” 快速 UDP 网络连接 “(Quick UDP Internet Connections,QUIC)的全新传输协议。
在 2015 年,Google 将 QUIC 提交给了 IETF,并在 IETF 的推动下,对 QUIC 进行重新规范化(为以示区别,业界习惯将此前的版本称为 gQUIC,规范化后的版本称为 iQUIC),使其不仅能满足 HTTP 传输协议,日后还能支持 SMTP、DNS、SSH、Telnet、NTP 等多种其他上层协议。
2018 年末,IETF 正式批准了 HTTP over QUIC 使用 HTTP/3 的版本号,将其确立为最新一代的互联网标准。
那么,你从 QUIC 的名字上就能看出,它会以 UDP 协议作为基础。UDP 协议没有丢包自动重传的特性,因此 QUIC 的可靠传输能力并不是由底层协议提供的,而是完全由自己来实现。 由 QUIC 自己实现的好处是能对每个流能做单独的控制 ,如果在一个流中发生错误,协议栈仍然可以独立地继续为其他流提供服务。
这个特性对提高易出错链路的性能方面非常有用。因为在大多数情况下,TCP 协议接到数据包丢失或损坏通知之前,可能已经收到了大量的正确数据,但是在纠正错误之前,其他的正常请求都会等待甚至被重发。这也是前面我在讲连接数优化的时候,提到 HTTP/2 没能解决传输大文件慢的根本原因。
此外,QUIC 的另一个设计目标是 面向移动设备的专门支持。
以前 TCP、UDP 传输协议在设计的时候,根本不可能设想到今天移动设备盛行的场景,因此肯定不会有任何专门的支持。 而 QUIC 在移动设备上的优势就体现在网络切换时的响应速度上 ,比如当移动设备在不同 WiFi 热点之间切换,或者从 WiFi 切换到移动网络时,如果使用 TCP 协议,现存的所有连接都必定会超时、中断,然后根据需要重新创建。这个过程会带来很高的延迟,因为超时和重新握手都需要大量的时间。
为此,QUIC 提出了 连接标识符 的概念,该标识符可以唯一地标识客户端与服务器之间的连接,而无需依靠 IP 地址。这样,在切换网络后,只需向服务端发送一个包含此标识符的数据包,就可以重用既有的连接。因为即使用户的 IP 地址发生了变化,原始连接标识符依然是有效的。
到现在,无论是 TCP 协议还是 HTTP 协议,都已经存在了数十年的时间。它们积累了大量用户的同时,也承载了很重的技术惯性。就算是 Google 和 IETF,要是想把 HTTP 从 TCP 迁移出去,也不是件容易的事儿。最主要的一个问题就是,互联网基础设施中的许多中间设备,都只面向 TCP 协议去建造,也只对 UDP 做很基础的支持,有的甚至会完全阻止 UDP 的流量。
所以,Google 在 Chromium 的网络协议栈中,同时启用了 QUIC 和传统 TCP 连接,并在 QUIC 连接失败时,能以零延迟回退到 TCP 连接,尽可能让用户无感知地、逐步地扩大 QUIC 的使用面。
根据 W3Techs 的数据,截至 2020 年 10 月,全球已经有 48.9% 的网站支持了 HTTP/2 协议,按照维基百科中的记录,这个数字在 2019 年 6 月份的时候,还只是 36.5%。另外在 HTTP/3 方面,今天也已经有了 7.2% 的使用比例。
由此我们可以肯定地说,目前网络链路传输这个领域正处于新旧交替的时代,许多既有的设备、程序、知识,都会在未来几年的时间里出现重大更新。
小结
这节课,我们一起了解了 HTTP 传输的优化技巧。HTTP 的意思就是超文本传输协议,但它并不是只将内容顺利传输到客户端就算完成任务了,其中,如何做到高效、无状态也是很重要的目标。
另外你还要记住的是,在 HTTP/2 之前,要想在应用一侧优化传输,就必须要同时在其他方面付出相应的成本,而 HTTP/2 中的多路复用、头压缩等改进项,就从根本上给出了传输优化的解决方案。
留言
QUIC相对于TCP补充:
1.自定义重传机制:TCP是通过采样往返时间 RTT 不断调整的,但这个采样存在不准的问题。第一次发送包A超时未返回,第二次重发包A,这时收到了包A的响应,但TCP并不能识别当前包A的响应是第一次发送还是第二次重发返回的,这时不管怎么减都可能出现计时偏长或过偏短的问题。而QUIC为每次发送包都打了版本号(包括重发),所以可以很好的识别返回的包是那次发送包的。进而计算就相对准确。
2.自定义流量控制:TCP 的流量控制是通过滑动窗口协议,是在连接上控制的窗口。QUIC也玩滑动窗口,但是力度是可以细分到具体的stream的。
其实应用层的协议多种多样,直播的RTMP,物联网终端的MQTT等等,但感觉都是两害取其轻的专项优化对症下药。只有QUIC,直面TCP的问题,通过应用层的编码实现,系统的提供更好的”TCP连接”。
19 | 如何利用内容分发网络来提高网络性能?
前面几讲中,我给你介绍了客户端缓存、域名解析、链路优化这三种与客户端关系较密切的传输优化机制。这节课,我们来讨论一个针对这三种机制的经典综合运用案例: 内容分发网络 (CDN,Content Distribution Network 或 Content Delivery Network)。
内容分发网络是一种十分古老的应用,你应该也听说过它的名字,多少知道它是用来做什么的。简单理解的话,CDN 其实就是做”内容分销”工作的。
我给你举个例子吧。假设,我们把某个互联网系统比喻为一家开门营业的企业,那内容分发网络就是它遍布世界各地的分支销售机构。如果一位客户要买一块 CPU,我们要是订机票飞到美国 Intel 总部去采购,那肯定是不合适的,到本地电脑城找个装机铺才是正常人的做法。所以在这个场景里,内容分发网络就相当于电脑城那吆喝着 CPU 三十块钱一斤的本地经销商。
然后,内容分发网络又是一种十分透明的应用,一般不需要我们参与它的工作过程。所以我想,如果你没有自己亲身使用和专门研究过,那可能就不太清楚它是如何为互联网站点分流的,也不太会注意到它的工作原理是什么。
实际上,内容分发网络的工作过程,主要涉及到路由解析、内容分发、负载均衡和它所能支持的应用内容四个方面。今天这节课,我们先来了解内容分发网络可以解决哪些网络传输问题,也就是先着重探讨除负载均衡以外的其他三个方面的工作。在下一讲中,我会专门跟你讨论负载均衡的内容。
好,如果忽略其他影响服务质量的因素,仅从网络传输的角度来看,一个互联网系统的速度快慢,主要取决于以下四点因素:
- 网站服务器接入网络运营商的链路所能提供的出口带宽。
- 用户客户端接入网络运营商的链路所能提供的入口带宽。
- 从网站到用户之间,经过的不同运营商之间互联节点的带宽。一般来说,两个运营商之间只有固定的若干个点是互通的,所有跨运营商之间的交互都要经过这些点。
- 从网站到用户之间的物理链路传输时延。你要是爱打游戏的话,应该就很清楚了,延迟(Ping 值)通常比带宽更重要。
以上四个网络问题,除了第二个只能由用户掏腰包,装个更好的宽带才能够解决之外,其余三个都能通过内容分发网络来改善。
所以说,一个运作良好的内容分发网络,能为互联网系统解决跨运营商、跨地域物理距离所导致的时延问题,也能给网站流量带宽起到分流、减负的作用。
举个例子,如果没有遍布全国乃至全世界的阿里云 CDN 网络支持,哪怕把整个杭州所有网民的上网权利都剥夺了,把带宽全部让给淘宝的机房,恐怕也撑不住双十一全国甚至是全球用户的疯狂围殴。
那么接下来,我们就从 CDN 工作流程的第一步”路由解析”开始,来全面了解下,CDN 是如何进行网络加速的。
路由解析
在 第 16 讲 我给你介绍 DNS 域名解析的时候,提到过翻译域名不需要像查电话本一样,刻板地一对一翻译,DNS 可以根据来访机器、网络链路、服务内容等各种信息,玩出很多花样。
而内容分发网络将用户请求路由到它的资源服务器上,其实就是依靠 DNS 服务器来实现的。
那么,根据我们现在对 DNS 域名解析的了解,一次没有内容分发网络参与的用户访问,它的解析过程应该是这样的:
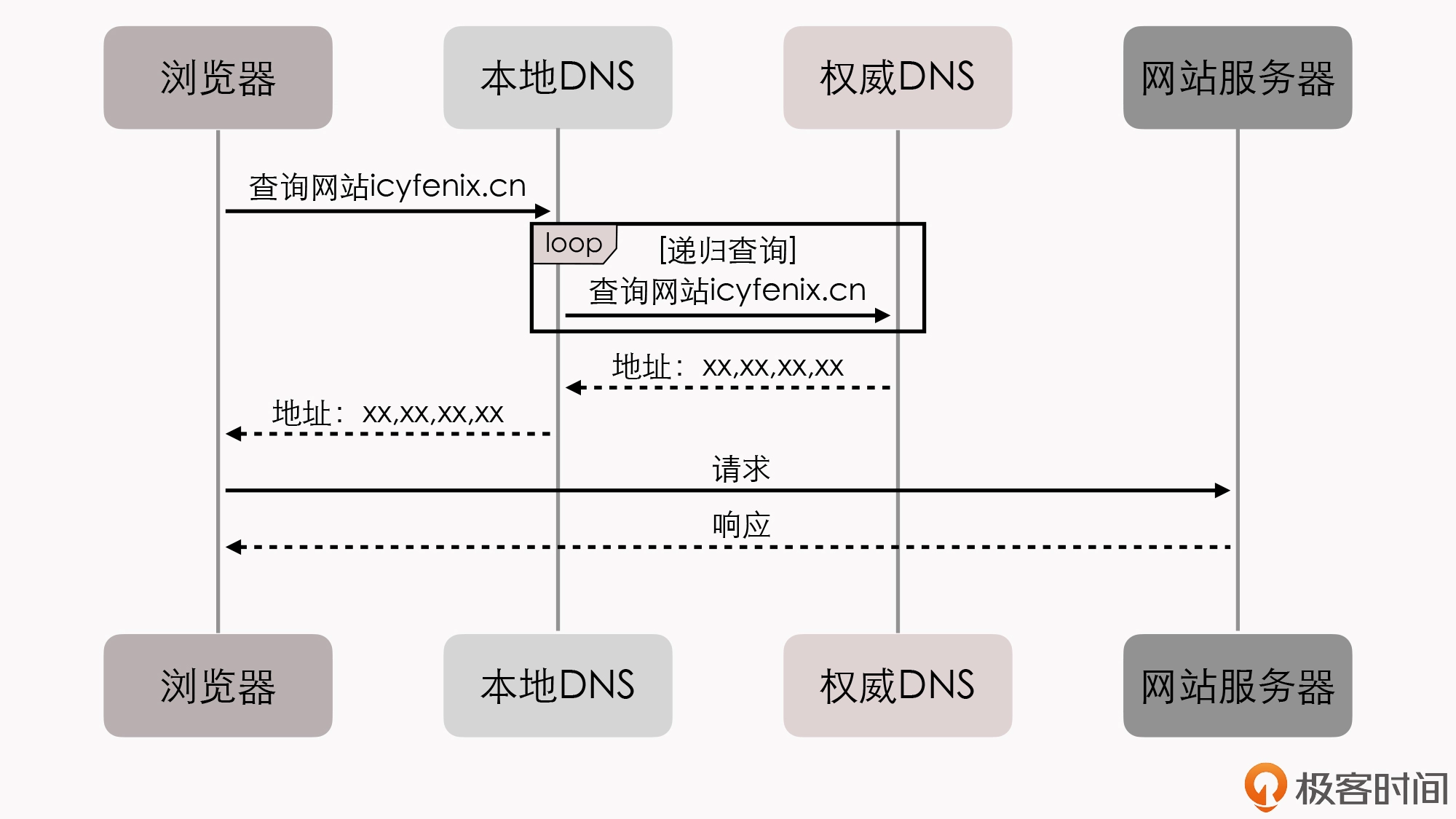
即查询 icyfenix.cn 的请求,发送至本地 DNS 后,会递归查询,直至找到能够解析 icyfenix.cn 地址的权威 DNS 服务器,最终把解析结果返回给浏览器。
而有了内容分发网络的介入,这个解析过程会发生什么变化呢?
我们不妨先来看一段对网站”icyfenix.cn”进行 DNS 查询的真实应答记录,这个网站就是通过国内的内容分发网络,来给位于 GitHub Pages 上的静态页面加速的。
通过 dig 或者 host 命令,我们就能很方便地得到 DNS 服务器的返回结果(结果中头 4 个 IP 的城市地址是我手工加入的,后面的其他记录就不一个一个查了),如下所示:
$ dig icyfenix.cn
; <<>> DiG 9.11.3-1ubuntu1.8-Ubuntu <<>> icyfenix.cn
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 60630
;; flags: qr rd ra; QUERY: 1, ANSWER: 17, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 65494
;; QUESTION SECTION:
;icyfenix.cn. IN A
;; ANSWER SECTION:
icyfenix.cn. 600 IN CNAME icyfenix.cn.cdn.dnsv1.com.
icyfenix.cn.cdn.dnsv1.com. 599 IN CNAME 4yi4q4z6.dispatch.spcdntip.com.
4yi4q4z6.dispatch.spcdntip.com. 60 IN A 101.71.72.192 #浙江宁波市
4yi4q4z6.dispatch.spcdntip.com. 60 IN A 113.200.16.234 #陕西省榆林市
4yi4q4z6.dispatch.spcdntip.com. 60 IN A 116.95.25.196 #内蒙古自治区呼和浩特市
4yi4q4z6.dispatch.spcdntip.com. 60 IN A 116.178.66.65 #新疆维吾尔自治区乌鲁木齐市
4yi4q4z6.dispatch.spcdntip.com. 60 IN A 118.212.234.144
4yi4q4z6.dispatch.spcdntip.com. 60 IN A 211.91.160.228
4yi4q4z6.dispatch.spcdntip.com. 60 IN A 211.97.73.224
4yi4q4z6.dispatch.spcdntip.com. 60 IN A 218.11.8.232
4yi4q4z6.dispatch.spcdntip.com. 60 IN A 221.204.166.70
4yi4q4z6.dispatch.spcdntip.com. 60 IN A 14.204.74.140
4yi4q4z6.dispatch.spcdntip.com. 60 IN A 43.242.166.88
4yi4q4z6.dispatch.spcdntip.com. 60 IN A 59.80.39.110
4yi4q4z6.dispatch.spcdntip.com. 60 IN A 59.83.204.12
4yi4q4z6.dispatch.spcdntip.com. 60 IN A 59.83.204.14
4yi4q4z6.dispatch.spcdntip.com. 60 IN A 59.83.218.235
;; Query time: 74 msec
;; SERVER: 127.0.0.53#53(127.0.0.53)
;; WHEN: Sat Apr 11 22:33:56 CST 2020
;; MSG SIZE rcvd: 152那么,根据这个解析信息,我们可以知道,DNS 服务为”icyfenix.cn”的查询结果先返回了一个 CNAME 记录 “icyfenxi.cn.cdn.dnsv1.com”,服务器在递归查询该 CNAME 时候,返回了另一个看起来更奇怪的 CNAME”4yi4q4z6.dispatch.spcdntip.com”。继续查询后,这个 CNAME 返回了十几个位于全国不同地区的 A 记录。
很明显,这些 A 记录就是分布在全国各地、存有本站缓存的 CDN 节点。由此,我们就能清晰地了解到 CDN 路由解析的具体工作过程了:
- 架设好”icyfenix.cn”的服务器后,将服务器的 IP 地址在你的 CDN 服务商上注册为”源站”,注册后你会得到一个 CNAME,也就是这个例子当中的”icyfenxi.cn.cdn.dnsv1.com”。
- 接着,将得到的 CNAME 在你购买域名的 DNS 服务商上,注册为一条 CNAME 记录。
- 当第一位用户来访问你的站点时,会首先发生一次未命中缓存的 DNS 查询,域名服务商解析出 CNAME 后,会返回给本地 DNS。到这里,后续的链路解析的主导权就开始由内容分发网络的调度服务接管了。
- 本地 DNS 查询 CNAME 时,由于能解析该 CNAME 的权威服务器,只有 CDN 服务商所架设的权威 DNS,这个 DNS 服务会根据一定的均衡策略和参数,比如拓扑结构、容量、时延等等,在全国各地能提供服务的 CDN 缓存节点中挑选一个最适合的,把它的 IP 替换成源站的 IP 地址,然后返回给本地 DNS。
- 浏览器从本地 DNS 拿到了 IP 地址后,就会把该 IP 当作源站服务器来进行访问,此时该 IP 的 CDN 节点上可能有,也可能没有缓存过源站的资源(这一点我们马上会在讲”内容分发”的部分展开讨论)。
- 最后,经过内容分发后的 CDN 节点,就有能力代替源站向用户提供所请求的资源了。
那么,把前面解析的这个步骤反映在时序图上,会是什么样子的呢?你可以参考我在这里给出的图例,然后对比一下我在前面所给出的没有 CDN 参与的时序图,看看它们都有什么不同之处:
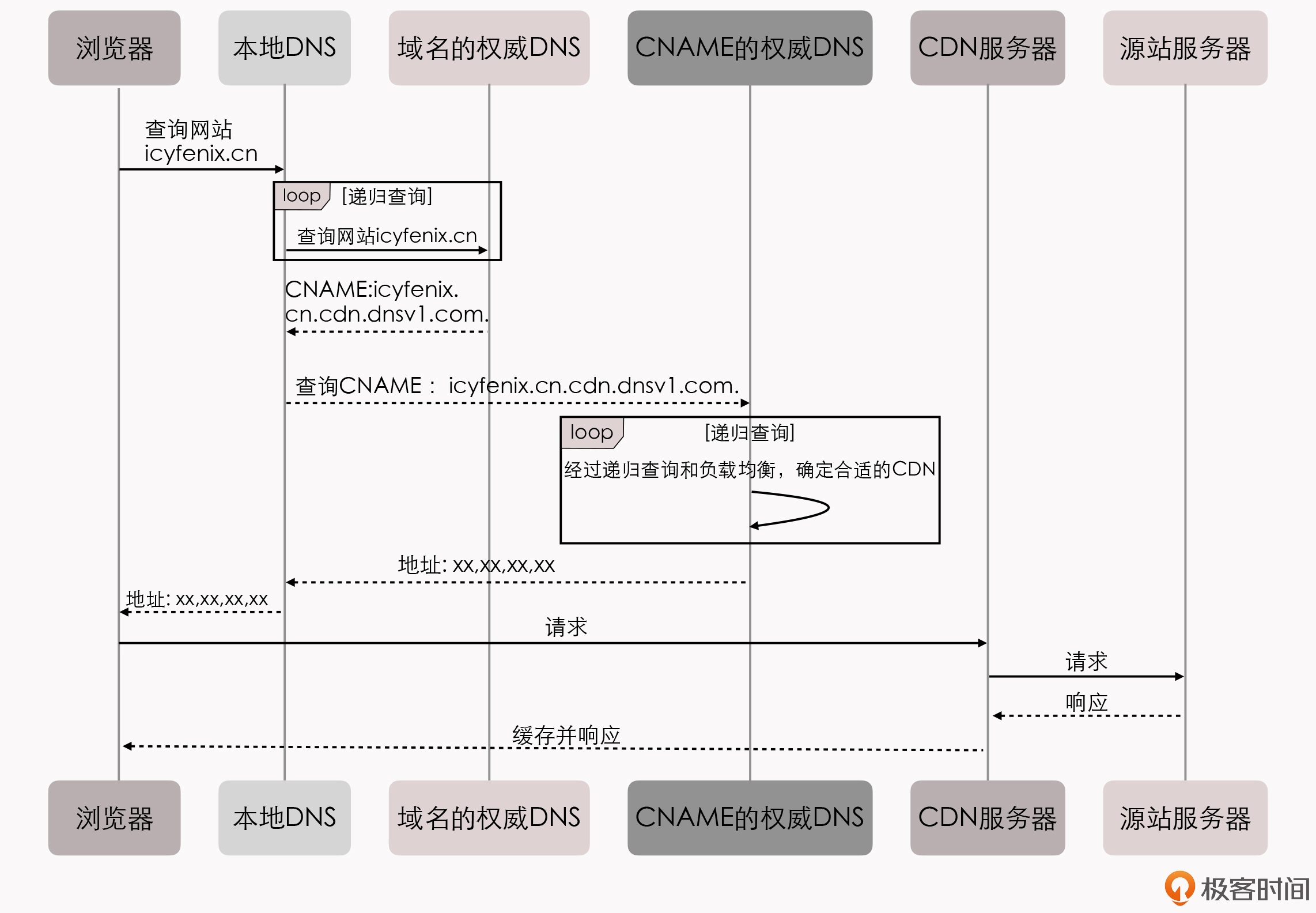
好了,现在我们就已经了解了 CDN 中路由解析的工作流程了。下面我们一起来看看 CDN 加速的核心:内容分发。
内容分发
我们已经知道,在 DNS 服务器的协助下,无论是对用户还是服务器,内容分发网络都可以是完全透明的,在两者都不知情的情况下,由 CDN 的缓存节点接管用户向服务器发出的资源请求。
但随之而来的问题,就是缓存节点中必须要有用户想要请求的资源副本,才可能代替源站来响应用户请求。而这里面又 包括了两个子问题:”如何获取源站资源”和”如何管理(更新)资源”。
所以,CDN 是如何解决这两个问题的呢?
首先,对于” 如何获取源站资源 “这个问题,CDN 获取源站资源的过程被称为”内容分发”,”内容分发网络”的名字也正是由此而来的,可见这是 CDN 的核心价值。
那么,在内容分发的过程中,我们可以采取两种主流的内容分发方式:
第一种:主动分发(Push)
顾名思义,主动分发就是由源站主动发起,将内容从源站或者其他资源库推送到用户边缘的各个 CDN 缓存节点上。这个推送的操作没有什么业界标准可循,我们可以采用任何传输方式(如 HTTP、FTP、P2P 等)、任何推送策略(如满足特定条件、定时、人工等)、任何推送时间,只要与我后面要说的更新策略相匹配即可。
不过你要注意,由于主动分发通常需要源站、CDN 服务双方提供的程序 API 接口层面的配合,所以它对源站并不是透明的,只对用户一侧单向透明。
另外,主动分发的方式一般是用于网站要预载大量资源的场景。比如双十一之前的一段时间内,淘宝、京东等各个网络商城,就会开始把未来活动中需要用到的资源推送到 CDN 缓存节点中,特别常用的资源甚至会直接缓存到你的手机 App 的存储空间,或者浏览器的localStorage上。
第二种:被动回源(Pull)
被动回源就是指由用户访问所触发的全自动、双向透明的资源缓存过程。当某个资源首次被用户请求的时候,CDN 缓存节点如果发现自己没有该资源,就会实时从源站中获取。这时资源的响应时间可粗略认为是资源从源站到 CDN 缓存节点的时间,再加上资源从 CDN 发送到用户的时间之和。
所以,被动回源的首次访问通常是比较慢的(但由于 CDN 的网络条件一般远高于普通用户,并不一定就会比用户直接访问源站更慢),不适合应用于数据量较大的资源。
但是被动回源也有优点,就是它可以做到完全的双向透明,不需要源站在程序上做任何的配合,使用起来非常方便。
这种分发方式是小型站点使用 CDN 服务的主流选择,如果你不是自建 CDN,而是购买阿里云、腾讯云的 CDN 服务的站点,它们多数采用的就是这种方式。
其次,对于” CDN 如何管理(更新)资源 “这个问题,同样也没有统一的标准可言。尽管在 HTTP 协议中,关于缓存的 Header 定义中确实是有对 CDN 这类共享缓存的一些指引性参数,比如 Cache-Control 的 s-maxage,但是否要遵循,完全取决于 CDN 本身的实现策略。
而且,更令人感到无奈的是,由于大多数网站的开发和运维人员并不十分了解 HTTP 缓存机制,所以就导致了,如果 CDN 完全照着 HTTP Headers 来控制缓存失效和更新,效果反而会更差,而且还可能会引发其他的问题。所以,CDN 缓存的管理没有通用的准则。
现在,最常见的管理(更新)资源的做法是 超时被动失效与手工主动失效相结合。
超时失效是指给予缓存资源一定的生存期,超过了生存期就在下次请求时重新被动回源一次。而手工失效是指,CDN 服务商一般会给程序调用提供失效缓存的接口,在网站更新时,由持续集成的流水线自动调用该接口来实现缓存更新,比如”icyfenix.cn”就是依靠 Travis-CI 的持续集成服务,来触发 CDN 失效和重新预热的。
CDN 应用
内容分发网络最初是为了快速分发静态资源而设计的,但今天的 CDN 能做到的事情,已经远远超越了开始建设时的目标。所以下面,我想带你来了解一下现在的 CDN 都可以做到什么,它都有哪些应用。这里我先说明一下,我不会把 CDN 的各种应用全部展开细说,而是只做个简要地列举说明,我的目的是想帮你建立一个总体的关于 CDN 的认知,只要理解和掌握了 CDN 的原理,相信你也能发掘出许多这里没有列举的应用。
加速静态资源
这是 CDN 本职工作。
安全防御
在广义上,你可以把 CDN 看作是你网站的堡垒机,源站只对 CDN 提供服务,然后由 CDN 来服务外界的其他用户,这样恶意攻击者就不容易直接威胁源站。CDN 对防御某些攻击手段,如 DDoS 攻击 等尤其有效。
但你也需要注意的是,把安全性都寄托在 CDN 上本身其实是不安全的,一旦源站的真实 IP 被泄露,就会面临很高的风险。
协议升级
不少 CDN 提供商都同时对接(代售 CA 的)SSL 证书服务,这样就可以实现源站是 HTTP 协议的,而对外开放的网站是基于 HTTPS 的。
同理,这样的做法也可以实现源站到 CDN 是 HTTP/1.x 协议,而 CDN 提供的外部服务是 HTTP/2 或 HTTP/3 协议;或者是实现源站是基于 IPv4 网络的,CDN 提供的外部服务支持 IPv6 网络,等等。
状态缓存
在 第 17 讲 我介绍客户端缓存的时候,简要提到了状态缓存的实现机制,即不经过服务器,客户端直接根据缓存信息来判断目标网站的状态。而 CDN 不仅可以缓存源站的资源,还可以缓存源站的状态,比如源站的 301/302 转向就可以缓存起来,让客户端直接跳转;还可以通过 CDN 开启 HSTS 、通过 CDN 进行 OCSP 装订 ,来加速 SSL 证书访问,等等。
另外,有一些情况下,我们甚至可以配置 CDN 对任意状态码(如 404)进行一定时间的缓存,以减轻源站压力。但这个操作你要慎重,注意要在网站状态发生改变时去及时刷新缓存。
修改资源
CDN 可以在给用户返回资源的时候,修改它的任何内容,以实现不同的目的。比如说,可以对源站未压缩的资源自动压缩,并修改 Content-Encoding,以节省用户的网络带宽消耗;可以针对源站未启用客户端缓存的内容,加上缓存 Header,来自动启用客户端缓存;可以修改 CORS 的相关 Header,给源站不支持跨域的资源提供跨域能力,等等。
访问控制
CDN 可以实现 IP 黑 / 白名单功能。比如,根据不同的来访 IP 提供不同的响应结果、根据 IP 的访问流量来实现 QoS 控制、根据 HTTP 的 Referer 来实现防盗链,等等。
注入功能
CDN 可以在不修改源站代码的前提下,为源站注入各种功能。举个例子,下图是国际 CDN 巨头 CloudFlare 提供的 Google Analytics、PACE、Hardenize 等第三方应用,这些原本需要在源站中注入代码的应用,在 CDN 下都可以做到无需修改源站任何代码即可使用。
小结
CDN 是一种已经存在了很长时间,也被人们广泛应用的分流系统。它能为互联网系统提供性能上的加速,也能帮助增强许多功能,比如说我今天所讲的安全防御、资源修改、功能注入,等等。
而且,这一切又实现得极为透明,可以完全不需要我们这样的开发者来配合,甚至可以在我们不知情的情况下完成,以至于 CDN 没什么存在感,虽然我们可能都说听过它,但却没有真正了解过它。所以学完了这一讲,你应该就对 CDN 有更全面的理解了。
另外,CDN 本身就是透明多级分流系统的一个优秀范例,我希望你不仅可以学会 CDN 本身的功能与运作原理,而且可以在实际的工作中,将这种透明多级分流的思路应用于不同的场景,构建出更加健壮、能应对更大流量的系统。
20 | 常见的四层负载均衡的工作模式是怎样的?
在上节课,我们学习了利用 CDN 来加速网络性能的工作内容,包括路由解析、内容分发、负载均衡和它所支持的应用。其中,负载均衡是相对独立的内容,它不仅在 CDN 方面有应用,在大量软件系统的生产部署中,也都离不开负载均衡器的支持。所以今天这节课,我们就一起来了解下负载均衡器的作用与原理。
在互联网时代的早期,网站流量还比较小,业务也比较简单,使用单台服务器基本就可以满足访问的需要了。但时至今日,互联网也好,企业级也好,一般实际用于生产的系统,几乎都离不开集群部署了。
一方面,不管是采用单体架构多副本部署还是微服务架构,也不管是为了实现高可用还是为了获得高性能,信息系统都需要利用多台机器来扩展服务能力,希望用户的请求不管连接到哪台机器上,都能得到相同的处理。
另一方面,如何构建和调度服务集群这件事情,又必须对用户一侧保持足够的透明,即使请求背后是由一千台、一万台机器来共同响应的,这也都不是用户会关心的事情,用户需要记住的只有一个域名地址而已。
那么,这里承担了调度后方的多台机器,以统一的接口对外提供服务的技术组件,就是”负载均衡器”(Load Balancer)了。
真正的大型系统的负载均衡过程往往是多级的。比如,在各地建有多个机房,或者是机房有不同网络链路入口的大型互联网站,然后它们会从 DNS 解析开始,通过”域名” → “CNAME” → “负载调度服务” → “就近的数据中心入口”的路径,先根据 IP 地址(或者其他条件)将来访地用户分配到一个合适的数据中心当中,然后才到了我们马上要讨论的各式负载均衡。
这里我先跟你说明一下:在 DNS 层面的负载均衡的工作模式,与我在前几讲中介绍的 DNS 智能线路、内容分发网络等的工作原理是类似的,它们之间的差别只是数据中心能提供的不仅是缓存,而是全方位的服务能力。所以这种负载均衡的工作模式我就不再重复介绍了,后面我们主要聚焦在讨论网络请求进入数据中心入口之后的其他级次的负载均衡。
好,那么接下来,我们就先从负载均衡的实现形式开始了解吧。
负载均衡的两种形式
实际上,无论我们在网关内部建立了多少级的负载均衡,从形式上来说都可以分为两种:四层负载均衡和七层负载均衡。
那么,在详细介绍它们是什么、如何工作之前,我们先来建立两个总体的、概念性的印象:
- 四层负载均衡的优势是性能高,七层负载均衡的优势是功能强。
- 做多级混合负载均衡,通常应该是低层的负载均衡在前,高层的负载均衡在后(你可以先想一想为什么?)。
这里,我们所说的”四层””七层”,一般指的是经典的 OSI 七层模型 中,第四层传输层和第七层应用层。你可以参考下面表格中给出的维基百科上对 OSI 七层模型的介绍,我们在后面还会多次使用它。
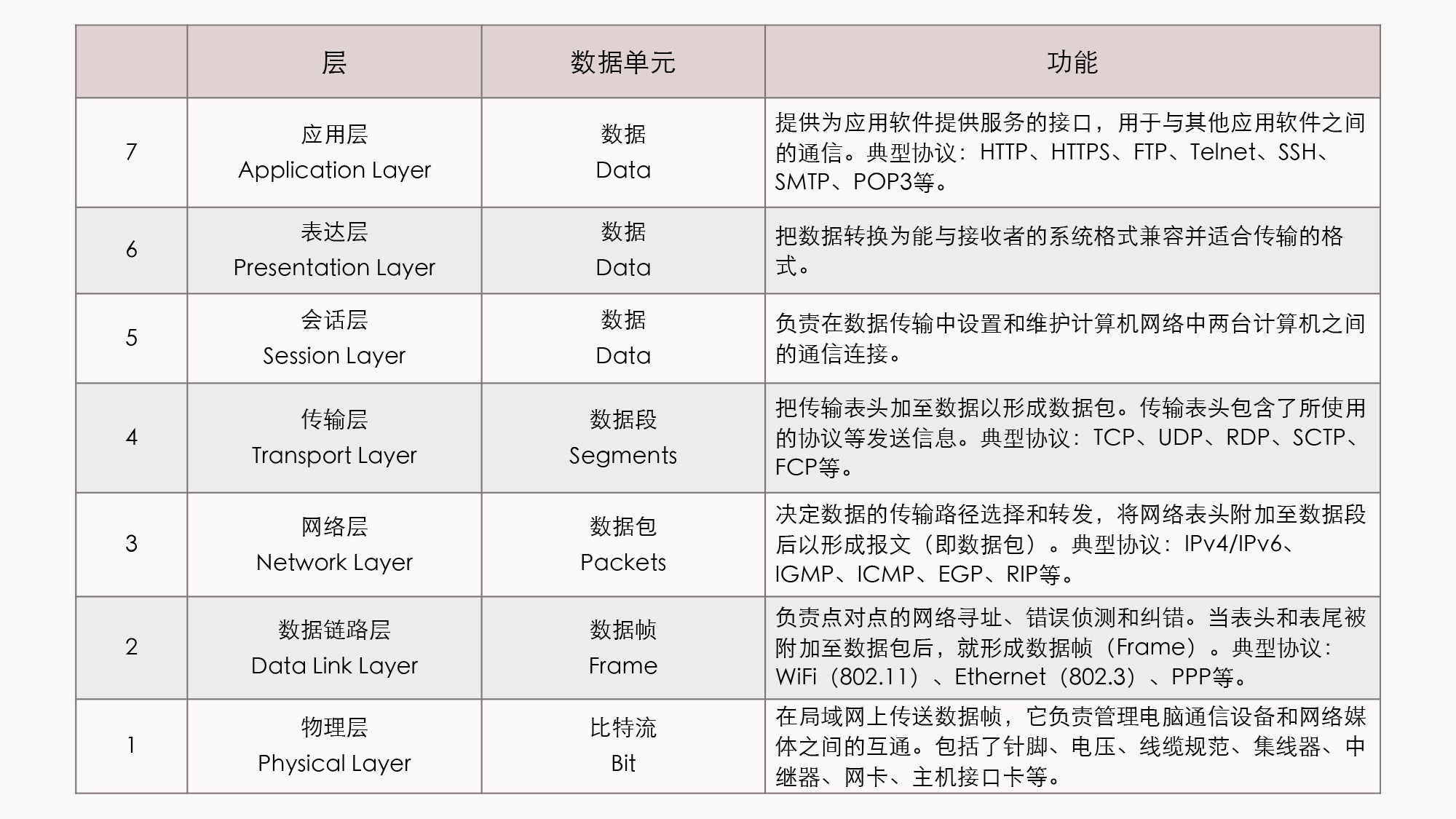
另外我还想说明一点,就是现在人们所说的”四层负载均衡”,其实是多种均衡器工作模式的统称。 “四层”的意思是说,这些工作模式的共同特点是都维持着同一个 TCP 连接,而不是说它就只工作在第四层。
事实上,这些模式主要都是工作在二层(数据链路层,可以改写 MAC 地址)和三层上(网络层,可以改写 IP 地址),单纯只处理第四层(传输层,可以改写 TCP、UDP 等协议的内容和端口)的数据无法做到负载均衡的转发,因为 OSI 的下面三层是媒体层(Media Layers),上面四层是主机层(Host Layers)。所以,既然流量都已经到达目标主机上了,也就谈不上什么流量转发,最多只能做代理了。
但出于习惯和方便,现在几乎所有的资料都把它们统称为四层负载均衡,这里我也就遵循习惯,同样称呼它为四层负载均衡。而如果你在某些资料上,看见”二层负载均衡””三层负载均衡”的表述,这就真的是在描述它们工作的层次了,和我这里讲的”四层负载均衡”并不是同一类意思。
常见的四层负载均衡的工作模式
好,回到我们这一讲的重点上来,我们一起来看看几种常见的四层负载均衡的工作模式都是怎样的。
数据链路层负载均衡
这里你可以参考前面的 OSI 模型表格,数据链路层传输的内容是数据帧(Frame),比如我们常见的以太网帧、ADSL 宽带的 PPP 帧等。当然了,在我们所讨论的具体上下文里,探究的目标必定就是以太网帧了。按照 IEEE 802.3 标准,最典型的 1500 Bytes MTU 的以太网帧结构如下表所示:
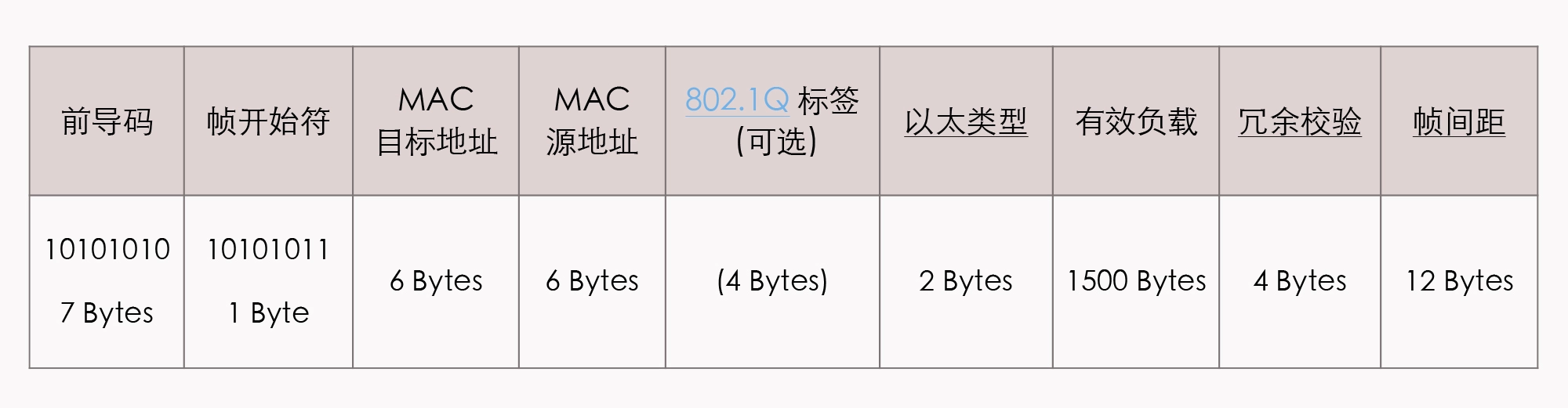
阅读链接补充:
802.1Q 标签
在这个帧结构中,其他数据项的含义你可以暂时不去理会,只需要注意到”MAC 目标地址”和”MAC 源地址”两项即可。
我们知道,每一块网卡都有独立的 MAC 地址,而以太帧上的这两个地址告诉了交换机,此帧应该是从连接在交换机上的哪个端口的网卡发出,送至哪块网卡的。
数据链路层负载均衡所做的工作,是修改请求的数据帧中的 MAC 目标地址,让用户原本是发送给负载均衡器的请求的数据帧,被二层交换机根据新的 MAC 目标地址,转发到服务器集群中,对应的服务器(后面都叫做”真实服务器”,Real Server)的网卡上,这样真实服务器就获得了一个原本目标并不是发送给它的数据帧。
由于二层负载均衡器在转发请求过程中,只修改了帧的 MAC 目标地址,不涉及更上层协议(没有修改 Payload 的数据),所以在更上层(第三层)看来,所有数据都是没有被改变过的。
这是因为第三层的数据包,也就是 IP 数据包中,包含了源(客户端)和目标(均衡器)的 IP 地址,只有真实服务器保证自己的 IP 地址与数据包中的目标 IP 地址一致,这个数据包才能被正确处理。
所以,我们在使用这种负载均衡模式的时候,需要把真实物理服务器集群所有机器的 虚拟 IP 地址 (Virtual IP Address,VIP),配置成跟负载均衡器的虚拟 IP 一样,这样经均衡器转发后的数据包,就能在真实服务器中顺利地使用。
另外,也正是因为实际处理请求的真实物理服务器 IP 和数据请求中的目的 IP 是一致的,所以 响应结果就不再需要通过负载均衡服务器进行地址交换 ,我们可以把响应结果的数据包直接从真实服务器返回给用户的客户端,避免负载均衡器网卡带宽成为瓶颈, 所以数据链路层的负载均衡效率是相当高的。
整个请求到响应的过程如下图所示:
那么这里你就可以发现,数据链路层负载均衡的工作模式是,只有请求会经过负载均衡器,而服务的响应不需要从负载均衡器原路返回,整个请求、转发、响应的链路形成了一个”三角关系”。所以,这种负载均衡模式也被很形象地称为”三角传输模式”(Direct Server Return,DSR),也有人叫它是”单臂模式”(Single Legged Mode)或者”直接路由”(Direct Routing)。
不过,虽然数据链路层负载均衡的效率很高,但它并不适用于所有的场合。除了那些需要感知应用层协议信息的负载均衡场景它无法胜任外(所有的四层负载均衡器都无法胜任,这个我后面介绍七层负载均衡器时会一并解释),在网络一侧受到的约束也很大。
原因是,二层负载均衡器直接改写目标 MAC 地址的工作原理,决定了它与真实服务器的通讯必须是二层可达的。通俗地说,就是它们必须位于同一个子网当中,无法跨 VLAN。
所以,这个优势(效率高)和劣势(不能跨子网)就共同决定了, 数据链路层负载均衡最适合用来做数据中心的第一级均衡设备,用来连接其他的下级负载均衡器。
好,我们再来看看第二种常见的四层负载均衡工作模式:网络层负载均衡。
网络层负载均衡
根据 OSI 七层模型我们可以知道,在第三层网络层传输的单位是分组数据包(Packets),这是一种在 分组交换网络 (Packet Switching Network,PSN)中传输的结构化数据单位。
我拿 IP 协议来给你举个例子吧。一个 IP 数据包由 Headers 和 Payload 两部分组成,Headers 长度最大为 60 Bytes,它是由 20 Bytes 的固定数据和最长不超过 40 Bytes 的可选数据组成的。按照 IPv4 标准,一个典型的分组数据包的 Headers 部分的结构是这样的:
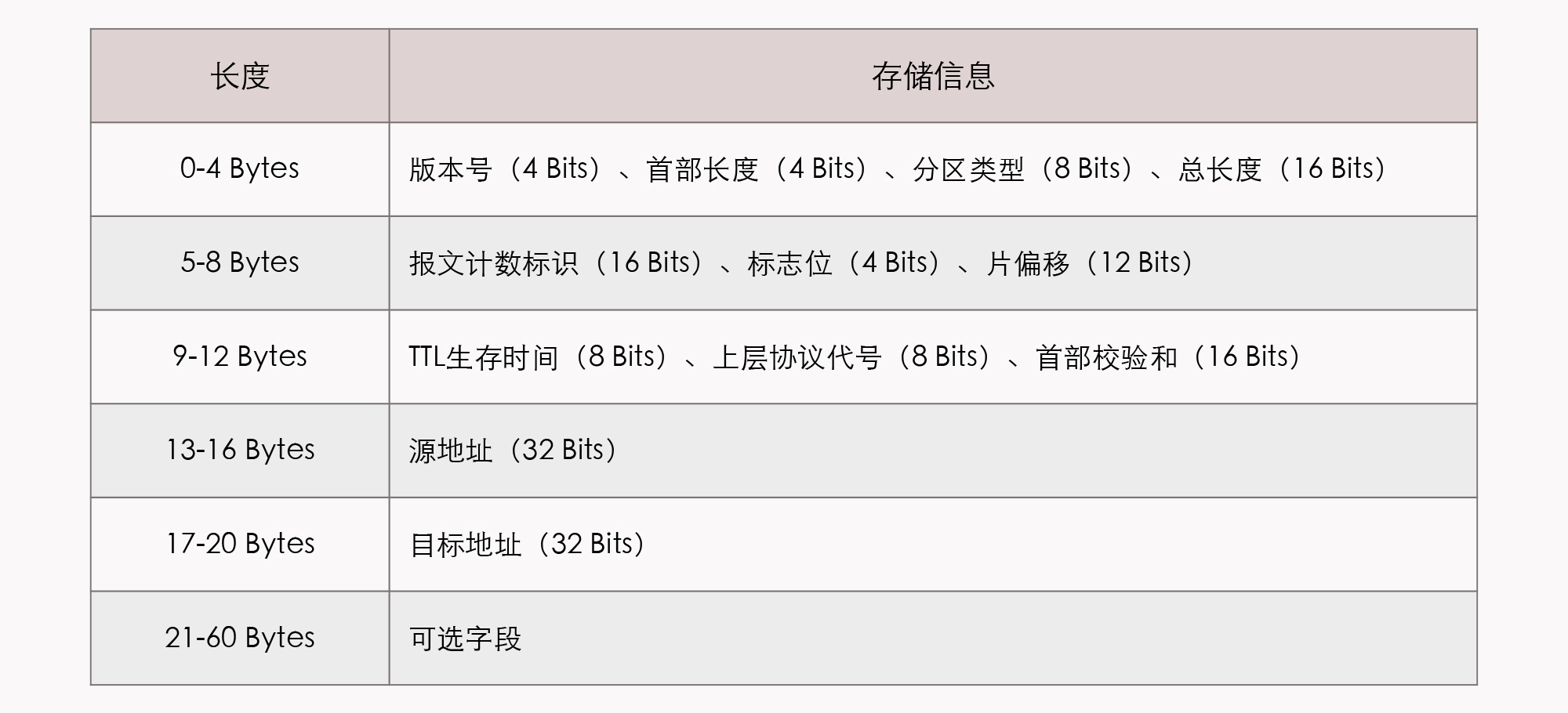
同样,我们也不需要过多关注表中的其他信息,只要知道在 IP 分组数据包的 Headers 带有源和目标的 IP 地址即可。
源和目标 IP 地址代表了”数据是从分组交换网络中的哪台机器发送到哪台机器的”,所以我们就可以沿用与二层改写 MAC 地址相似的思路,通过改变这里面的 IP 地址,来实现数据包的转发。
具体有两种常见的修改方式:
第一种是保持原来的数据包不变,新创建一个数据包,把原来数据包的 Headers 和 Payload 整体作为另一个新的数据包的 Payload,在这个新数据包的 Headers 中,写入真实服务器的 IP 作为目标地址,然后把它发送出去。
如此经过三层交换机的转发,当真实服务器收到数据包后,就必须在接收入口处,设计一个针对性的拆包机制,把由负载均衡器自动添加的那层 Headers 扔掉,还原出原来的数据包来进行使用。
这样,真实服务器就同样拿到了一个原本不是发给它(目标 IP 不是它)的数据包,从而达到了流量转发的目的。
在那个时候,还没有流行起”禁止套娃”的梗,所以设计者给这种”套娃式”的传输起名为” IP 隧道 “(IP Tunnel)传输,也是相当的形象了。
当然,尽管因为要封装新的数据包,IP 隧道的转发模式比起直接路由的模式,效率会有所下降,但 因为它并没有修改原有数据包中的任何信息,所以 IP 隧道的转发模式仍然具备三角传输的特性 ,即负载均衡器转发来的请求,可以由真实服务器去直接应答,无需再经过均衡器原路返回。
而且因为 IP 隧道工作在网络层,所以 可以跨越 VLAN ,也就摆脱了我前面所讲的直接路由模式中网络侧的约束。现在,我们来看看这种转发模式从请求到响应的具体过程:
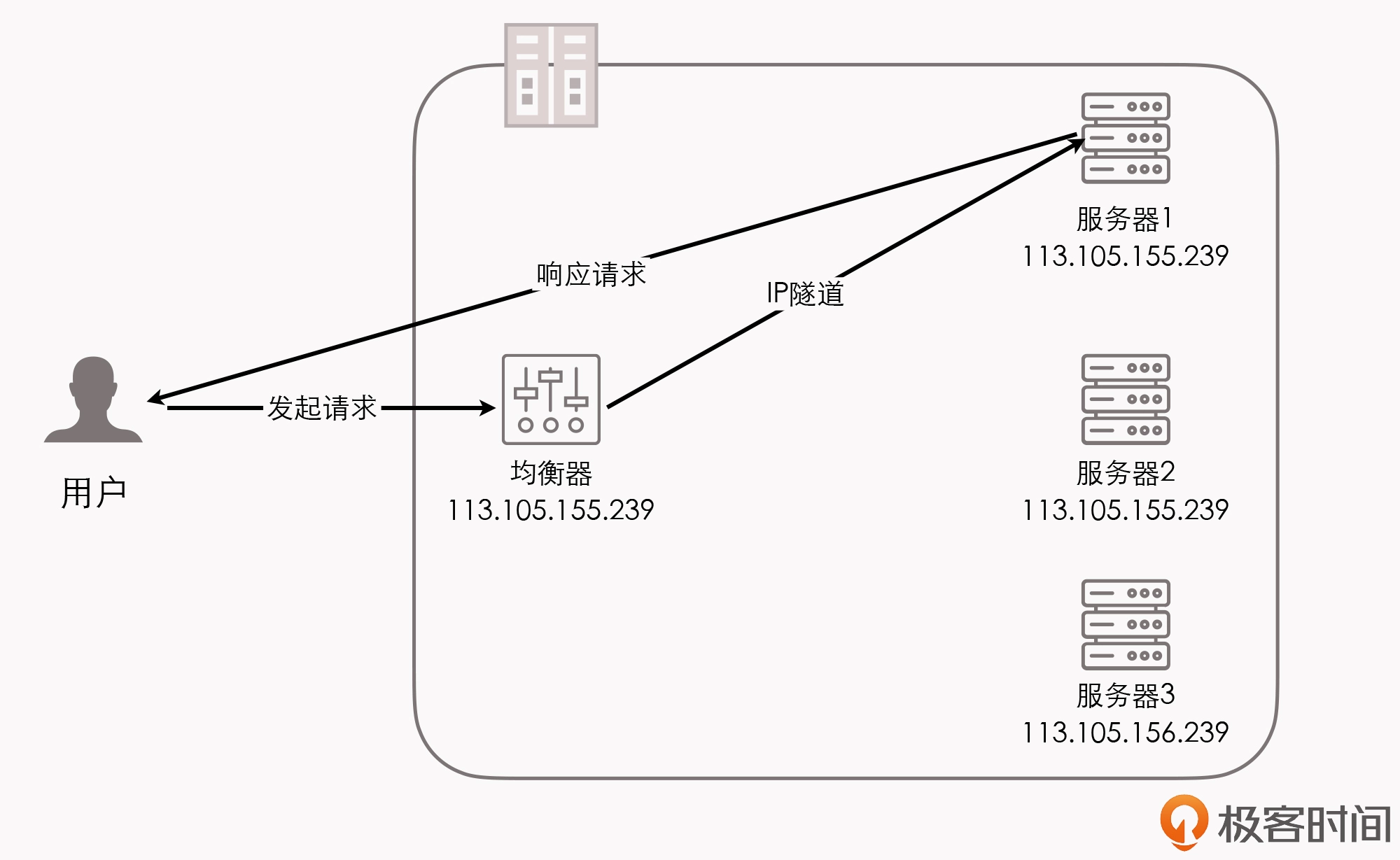
不过, 这种转发模式也有缺点 ,就是它要求真实服务器必须得支持” IP 隧道协议) “(IP Encapsulation),也就是它得学会自己拆包扔掉一层 Headers。当然这个其实并不是什么大问题,现在几乎所有的 Linux 系统都支持 IP 隧道协议。
可另一个问题是,这种模式仍然必须通过专门的配置,必须保证所有的真实服务器与均衡器有着相同的虚拟 IP 地址。因为真实服务器器在回复该数据包的时候,需要使用这个虚拟 IP 作为响应数据包的源地址,这样客户端在收到这个数据包的时候才能正确解析。
这个限制就相对麻烦了一些,它跟”透明”的原则冲突了,需由系统管理员去专门介入。而且,并不是在任何情况下,我们都可以对服务器进行虚拟 IP 的配置的,尤其是当有好几个服务共用一台物理服务器的时候。
那么在这种情况下,我们就必须考虑 第二种改变目标数据包的方式:直接把数据包 Headers 中的目标地址改掉,修改后原本由用户发给均衡器的数据包,也会被三层交换机转发送到真实服务器的网卡上,而且因为没有经过 IP 隧道的额外包装,也就无需再拆包了。
但问题是,这种模式是修改了目标 IP 地址才到达真实服务器的,而如果真实服务器直接把应答包发回给客户端的话,这个应答数据包的源 IP 是真实服务器的 IP,也就是均衡器修改以后的 IP 地址,那么客户端就不可能认识该 IP,自然也就无法再正常处理这个应答了。
因此,我们只能让应答流量继续回到负载均衡,负载均衡把应答包的源 IP 改回自己的 IP,然后再发给客户端,这样才能保证客户端与真实服务器之间正常通信。
如果你对网络知识有些了解的话,肯定会觉得这种处理似曾相识:这不就是在家里、公司、学校上网的时候,由一台路由器带着一群内网机器上网的” 网络地址转换 “(Network Address Translation,NAT)操作吗?
这种负载均衡的模式的确就被称为 NAT 模式 。此时,负载均衡器就是充当了家里、公司、学校的上网路由器的作用。
NAT 模式的负载均衡器运维起来也十分简单,只要机器把自己的网关地址设置为均衡器地址,就不需要再进行任何额外设置了。
我们来看看这种工作模式从请求到响应的过程:
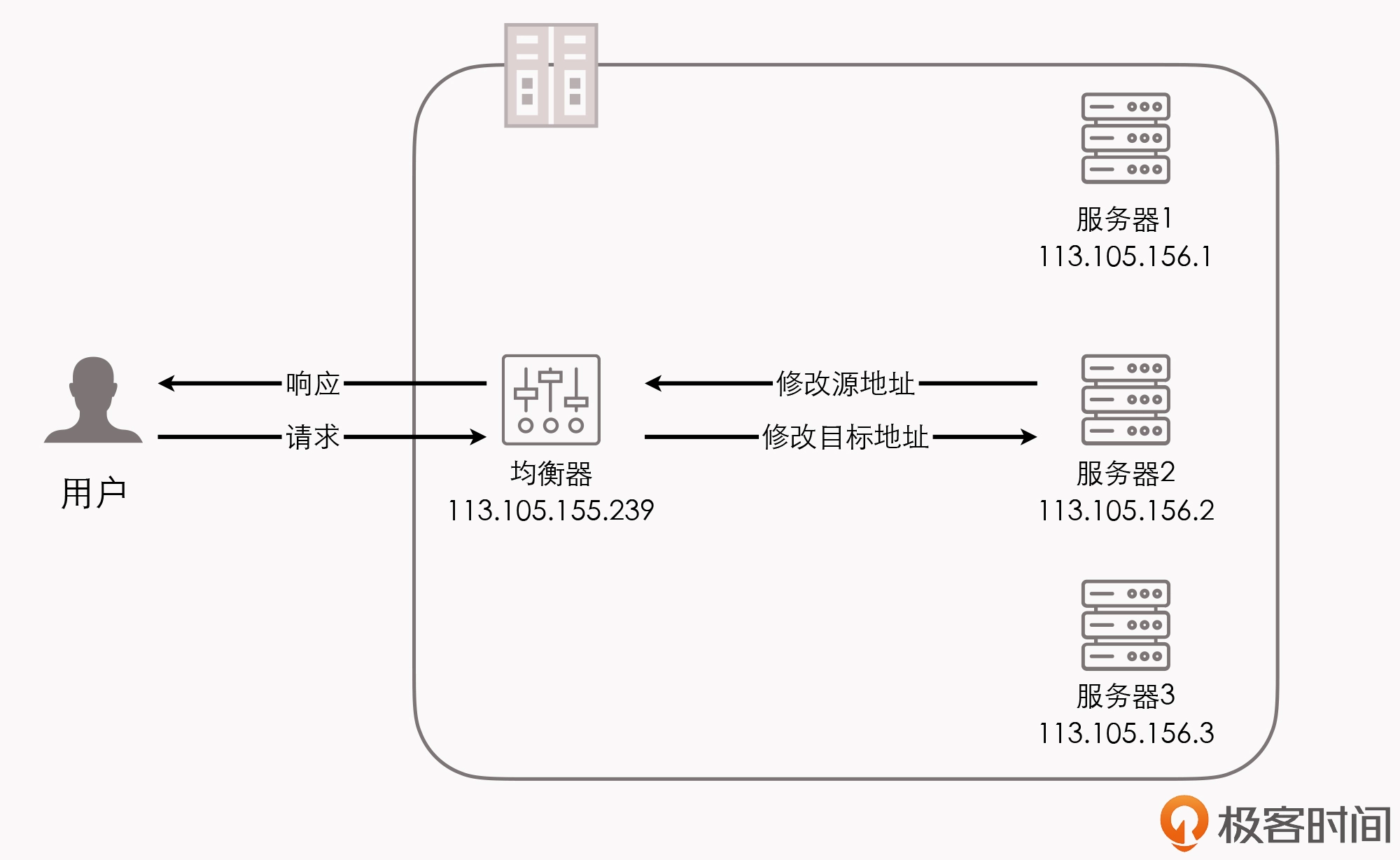
不过这里,你还要知道的是, 在流量压力比较大的时候,NAT 模式的负载均衡会带来较大的性能损失,比起直接路由和 IP 隧道模式,甚至会出现数量级上的下降。
这个问题也是显而易见的,因为由负载均衡器代表整个服务集群来进行应答,各个服务器的响应数据都会互相争抢均衡器的出口带宽。这就好比在家里用 NAT 上网的话,如果有人在下载,你打游戏可能就会觉得卡顿是一个道理,此时整个系统的瓶颈很容易就出现在负载均衡器上。
不过还有一种更加彻底的 NAT 模式,就是均衡器在转发时,不仅修改目标 IP 地址,连源 IP 地址也一起改了,这样源地址就改成了均衡器自己的 IP。这种方式被叫做 Source NAT(SNAT)。
这样做的好处是真实服务器连网关都不需要配置了,它能让应答流量经过正常的三层路由,回到负载均衡器上,做到了彻底的透明。
但它的缺点是由于做了 SNAT,真实服务器处理请求时就无法拿到客户端的 IP 地址了,在真实服务器的视角看来,所有的流量都来自于负载均衡器,这样有一些需要根据目标 IP 进行控制的业务逻辑就无法进行了。
应用层负载均衡
前面我介绍的两种四层负载均衡的工作模式都属于”转发”,即直接将承载着 TCP 报文的底层数据格式(IP 数据包或以太网帧),转发到真实服务器上,此时客户端到响应请求的真实服务器维持着同一条 TCP 通道。
但工作在四层之后的负载均衡模式就无法再进行转发了,只能进行代理。此时正式服务器、负载均衡器、客户端三者之间,是由两条独立的 TCP 通道来维持通讯的。
那么,转发与代理之间的具体区别是怎样的呢?我们来看一个图例:
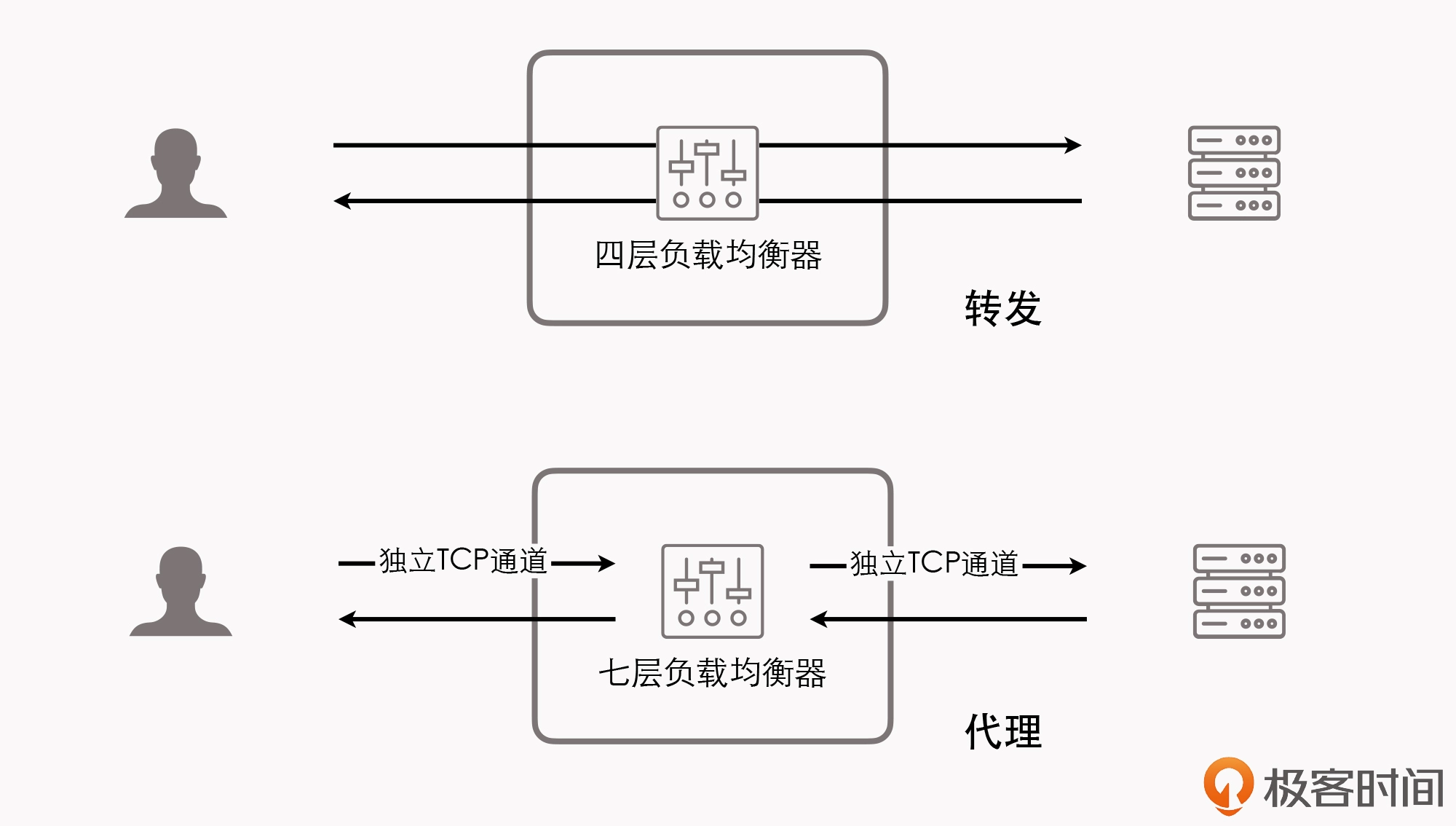
首先,”代理”这个词,根据”哪一方能感知到”的原则,可以分为”正向代理””反向代理”和”透明代理”三类。
- 正向代理 就是我们通常简称的代理,意思就是在客户端设置的、代表客户端与服务器通讯的代理服务。它是客户端可知,而对服务器是透明的。
- 反向代理 是指设置在服务器这一侧,代表真实服务器来与客户端通讯的代理服务。此时它对客户端来说是透明的。
- 透明代理 是指对双方都透明的,配置在网络中间设备上的代理服务。比如,架设在路由器上的透明翻墙代理。
那么根据这个定义,很显然,七层负载均衡器就属于反向代理中的一种,如果只论网络性能,七层负载均衡器肯定是无论如何比不过四层负载均衡器的。毕竟它比四层负载均衡器至少要多一轮 TCP 握手,还有着跟 NAT 转发模式一样的带宽问题,而且通常要耗费更多的 CPU,因为可用的解析规则远比四层丰富。
所以说,如果你要用七层负载均衡器去做下载站、视频站这种流量应用,一定是不合适的,起码它不能作为第一级均衡器。
但是,如果网站的性能瓶颈并不在于网络性能,而是要论整个服务集群对外所体现出来的服务性能,七层负载均衡器就有它的用武之地了。这里,七层负载均衡器的底气就来源于, 它是工作在应用层的,可以感知应用层通讯的具体内容,往往能够做出更明智的决策,玩出更多的花样来。
我举个生活中的例子。
四层负载均衡器就像是银行的自助排号机,转发效率高且不知疲倦,每一个达到银行的客户都可以根据排号机的顺序,选择对应的窗口接受服务;而七层负载均衡器就像银行的大堂经理,他会先确认客户需要办理的业务,再安排排号。这样,办理理财、存取款等业务的客户,可以根据银行内部资源得到统一的协调处理,加快客户业务办理流程;而有些无需柜台办理的业务,由大堂经理直接就可以解决了。
比如说,反向代理的工作模式就能够实现静态资源缓存,对于静态资源的请求就可以在反向代理上直接返回,无需转发到真实服务器。
这里关于代理的工作模式,相信你应该是比较熟悉的,所以这里关于七层负载均衡器的具体工作过程我就不详细展开了。下面我来列举一些七层代理可以实现的功能,让你能对它”功能强大”有个直观的感受:
- 在上一讲我介绍 CDN 应用的时候就提到过,所有 CDN 可以做的 缓存方面的工作 (就是除去 CDN 根据物理位置就近返回这种优化链路的工作外),七层负载均衡器全都可以实现,比如静态资源缓存、协议升级、安全防护、访问控制,等等。
- 七层负载均衡器可以实现 更智能化的路由 。比如,根据 Session 路由,以实现亲和性的集群;根据 URL 路由,实现专职化服务(此时就相当于网关的职责);甚至根据用户身份路由,实现对部分用户的特殊服务(如某些站点的贵宾服务器),等等。
- 某些安全攻击可以由七层负载均衡器来抵御。 比如,一种常见的 DDoS 手段是 SYN Flood 攻击,即攻击者控制众多客户端,使用虚假 IP 地址对同一目标大量发送 SYN 报文。从技术原理上看,因为四层负载均衡器无法感知上层协议的内容,这些 SYN 攻击都会被转发到后端的真实服务器上;而在七层负载均衡器下,这些 SYN 攻击自然就会在负载均衡设备上被过滤掉,不会影响到后面服务器的正常运行。类似地,我们也可以在七层负载均衡器上设定多种策略,比如过滤特定报文,以防御如 SQL 注入等应用层面的特定攻击手段。
- 很多微服务架构的系统中,链路治理措施 都需要在七层中进行,比如服务降级、熔断、异常注入,等等。我举个例子,一台服务器只有出现物理层面或者系统层面的故障,导致无法应答 TCP 请求,才能被四层负载均衡器感知到,进而剔除出服务集群,而如果一台服务器能够应答,只是一直在报 500 错,那四层负载均衡器对此是完全无能为力的,只能由七层负载均衡器来解决。
均衡策略与实现
好,现在你应该也能知道,负载均衡的两大职责是”选择谁来处理用户请求”和”将用户请求转发过去”。那么到这里为止,我们只介绍了后者,即请求的转发或代理过程。
而”选择谁来处理用户请求”是指均衡器所采取的均衡策略,这一块因为涉及的均衡算法太多,我就不一一展开介绍了。所以接下来,我想从功能和应用的角度,来给你介绍一些常见的均衡策略,你可以在自己的实践当中根据实际需求去配置选择。
轮循均衡(Round Robin)
即每一次来自网络的请求,会轮流分配给内部中的服务器,从 1 到 N 然后重新开始。这种均衡算法适用于服务器组中的所有服务器都有相同的软硬件配置,并且平均服务请求相对均衡的情况。
权重轮循均衡(Weighted Round Robin)
即根据服务器的不同处理能力,给每个服务器分配不同的权值,使其能够接受相应权值数的服务请求。比如,服务器 A 的权值被设计成 1,B 的权值是 3,C 的权值是 6,则服务器 A、B、C 将分别接收到 10%、30%、60%的服务请求。这种均衡算法能确保高性能的服务器得到更多的使用率,避免低性能的服务器负载过重。
随机均衡(Random)
即把来自客户端的请求随机分配给内部中的多个服务器。这种均衡算法在数据足够大的场景下,能达到相对均衡的分布。
权重随机均衡(Weighted Random)
这种均衡算法类似于权重轮循算法,不过在处理请求分担的时候,它是个随机选择的过程。
一致性哈希均衡(Consistency Hash)
即根据请求中的某些数据(可以是 MAC、IP 地址,也可以是更上层协议中的某些参数信息)作为特征值,来计算需要落在哪些节点上,算法一般会保证同一个特征值,每次都一定落在相同的服务器上。这里一致性的意思就是,保证当服务集群的某个真实服务器出现故障的时候,只影响该服务器的哈希,而不会导致整个服务集群的哈希键值重新分布。
响应速度均衡(Response Time)
即负载均衡设备对内部各服务器发出一个探测请求(如 Ping),然后根据内部中各服务器对探测请求的最快响应时间,来决定哪一台服务器来响应客户端的服务请求。这种均衡算法能比较好地反映服务器的当前运行状态,但要注意,这里的最快响应时间,仅仅指的是负载均衡设备与服务器间的最快响应时间,而不是客户端与服务器间的最快响应时间。
最少连接数均衡(Least Connection)
客户端的每一次请求服务,在服务器停留的时间可能会有比较大的差异。那么随着工作时间加长,如果采用简单的轮循或者随机均衡算法,每一台服务器上的连接进程可能会产生极大的不平衡,并没有达到真正的负载均衡。所以,最少连接数均衡算法就会对内部中需要负载的每一台服务器,都有一个数据记录,也就是记录当前该服务器正在处理的连接数量,当有新的服务连接请求时,就把当前请求分配给连接数最少的服务器,使均衡更加符合实际情况,负载也能更加均衡。这种均衡算法适合长时间处理的请求服务,比如 FTP 传输。
…………
另外,从实现角度来看,负载均衡器的实现有”软件均衡器”和”硬件均衡器”两类。
在软件均衡器方面,又分为直接建设在操作系统内核的均衡器和应用程序形式的均衡器两种。前者的代表是 LVS(Linux Virtual Server),后者的代表有 Nginx、HAProxy、KeepAlived,等等;前者的性能会更好,因为它不需要在内核空间和应用空间中来回复制数据包;而后者的优势是选择广泛,使用方便,功能不受限于内核版本。
在硬件均衡器方面,往往会直接采用 应用专用集成电路 (Application Specific Integrated Circuit,ASIC)来实现。因为它有专用处理芯片的支持,可以避免操作系统层面的损耗,从而能够达到最高的性能。这类的代表就是著名的 F5 和 A10 公司的负载均衡产品。
小结
这节课,我给你介绍了数据链路层负载均衡和网络层负载均衡的基本原理。对于一个普通的开发人员来说,可能平常不太接触这些偏向底层网络的知识,但如果你要对软件系统工作有全局的把握,进阶成为一名架构人员,那么即使不会去实际参与网络拓扑设计与运维,至少也必须理解它们的工作原理,这是系统做流量和容量规划的必要基础。
21 | 服务端缓存的三种属性
在透明多级分流系统这个小章节中,我们的研究思路是以流量从客户端中发出开始,以流量到达服务器集群中真正处理业务的节点作为结束,一起探索了在这个过程中与业务无关的一些通用组件,包括 DNS、CDN、客户端缓存,等等。
实际上,服务端缓存也是一种通用的技术组件,它主要用于减少多个客户端相同的资源请求,缓解或降低服务器的负载压力。所以,说它是一种分流手段也是很合理的。
另外,我们其实很难界定服务端缓存到底算不算与业务逻辑无关,因为服务端缓存通常是在代码中被显式调用的,这就很难说它是”透明分流”了。但是,服务端缓存作为流量到达服务端实际处理逻辑之前的最后一道防御线,把它作为这个小章节的最后一讲,倒也是合适的。
所以这节课,我就带你来了解下服务端缓存的相关知识点,你可以从中理解和掌握缓存的三种常见属性,然后灵活运用在自己的软件开发当中。
好,接下来,我们就从引入缓存的价值开始学起吧。
为系统引入缓存的理由
关于服务端缓存,首先你需要明确的问题是,在为你的系统引入缓存之前,它是否真的需要缓存呢?
我们很多人可能都会有意无意地,把硬件里那种常用于区分不同产品档次、”多多益善”的缓存(如 CPU L1/2/3 缓存、磁盘缓存,等等)代入到软件开发中去。但实际上,这两者的差别是很大的。毕竟,服务端缓存是程序的一部分,而硬件缓存是一种硬件对软件运行效率的优化手段。
在软件开发中,引入缓存的负面作用要明显大于硬件的缓存。主要有这样几个原因:
- 从开发角度来说 ,引入缓存会提高系统的复杂度,因为你要考虑缓存的失效、更新、一致性等问题(硬件缓存也有这些问题,只是不需要由你来考虑,主流的 ISA 也都没有提供任何直接操作缓存的指令);
- 从运维角度来说 ,缓存会掩盖掉一些缺陷,让问题在更久的时间以后,出现在距离发生现场更远的位置上;
- 从安全角度来说 ,缓存可能泄漏某些保密数据,这也是容易受到攻击的薄弱点。
那么,冒着前面提到的这种种风险,你还是想要给系统引入缓存,是为了什么呢?其实无外乎有两种理由。
第一种,为了缓解 CPU 压力而做缓存。
比如说,把方法运行结果存储起来、把原本要实时计算的内容提前算好、把一些公用的数据进行复用,等等,这些引入缓存的做法,都可以节省 CPU 算力,顺带提升响应性能。
第二种,为了缓解 I/O 压力而做缓存。
比如说,通过引入缓存,把原本对网络、磁盘等较慢介质的读写访问,变为对内存等较快介质的访问;把原本对单点部件(如数据库)的读写访问,变为对可扩缩部件(如缓存中间件)的访问,等等,也顺带提升了响应性能。
这里请你注意,缓存虽然是典型的以空间换时间来提升性能的手段,但它的出发点是缓解 CPU 和 I/O 资源在峰值流量下的压力,”顺带”而非”专门”地提升响应性能。
所以我的言外之意就是,如果你可以通过增强 CPU、I/O 本身的性能(比如扩展服务器的数量)来满足需要的话,那 升级硬件往往是更好的解决方案 。即使需要你掏腰包多花一点儿钱,那通常也比引入缓存带来的风险更低。
这样,当你有了使用服务端缓存的明确目的后,下一步就是要如何选择缓存了。所以接下来,我们就一起讨论一下,设计或者选择缓存时要考虑哪些方面的属性。
缓存属性
其实,不少软件系统最初的缓存功能,都是以 HashMap 或者 ConcurrentHashMap 为起点开始的演进的。当我们在开发中发现,系统中某些资源的构建成本比较高,而这些资源又有被重复使用的可能性,那很自然就会产生”循环再利用”的想法,把它们放到 Map 容器中,下次需要时取出重用,避免重新构建。这种原始朴素的复用就是最基本的缓存了。
不过,一旦我们专门把”缓存”看作是一项技术基础设施,一旦它有了通用、高效、可统计、可管理等方面的需求,那么我们需要考虑的因素就会变得复杂起来了。通常我们在设计或者选择缓存时,至少需要考虑以下四个维度的属性:
- 吞吐量 :缓存的吞吐量使用 OPS 值(每秒操作数,Operations per Second,ops/s)来衡量,它反映了对缓存进行并发读、写操作的效率,即缓存本身的工作效率高低。
- 命中率 :缓存的命中率即成功从缓存中返回结果次数与总请求次数的比值,它反映了引入缓存的价值高低,命中率越低,引入缓存的收益越小,价值越低。
- 扩展功能 :缓存除了基本读写功能外,还提供了一些额外的管理功能,比如最大容量、失效时间、失效事件、命中率统计,等等。
- 分布式支持 :缓存可以分为”进程内缓存”和”分布式缓存”两大类,前者只为节点本身提供服务,无网络访问操作,速度快但缓存的数据不能在各个服务节点中共享。后者则相反。
在今天这节课,我们就先来探讨下前三个属性(下一讲我们会重点讨论分布式缓存)。
吞吐量
首先你要知道,缓存的吞吐量只在并发场景中才有统计的意义,因为不考虑并发的话,即使是最原始的、以 HashMap 实现的缓存,访问效率也已经是 常量时间复杂度 ,即 O(1)。其中主要涉及到碰撞、扩容等场景的处理,这些都是属于数据结构基础知识,我就不展开讲了。
但 HashMap 并不是线程安全的容器,如果要让它在多线程并发下能正确地工作,就要用 Collections.synchronizedMap 进行包装,这相当于给 Map 接口的所有访问方法都自动加上了全局锁;或者,我们也可以改用 ConcurrentHashMap 来实现,这相当于给 Map 的访问分段加锁(从 JDK 8 起已取消分段加锁,改为 CAS+Synchronized 锁单个元素)。
而无论采用怎样的实现方法,线程安全措施都会带来一定的吞吐量损失。
所以进一步说,如果我们只比较吞吐量,完全不去考虑命中率、淘汰策略、缓存统计、过期失效等功能该如何实现,那也不必去选择哪种缓存容器更好了,JDK 8 改进之后的 ConcurrentHashMap,基本上就是你能找到的吞吐量最高的缓存容器了。
可是,在很多场景里,前面提到的这些功能至少有一两项是必须的,我们不可能完全不考虑。所以,这就涉及到了 不同缓存方案的权衡问题。
根据 Caffeine 给出的一组目前业界主流进程内缓存的实现方案,其中包括了 Caffeine、ConcurrentLinkedHashMap、LinkedHashMap、Guava Cache、Ehcache 和 Infinispan Embedded 等缓存组件库的对比。从它们在 8 线程、75% 读操作、25% 写操作下的吞吐量表现 Benchmarks 来看,各种缓存组件库的性能差异还是十分明显的,最高与最低相差了足有一个数量级,你可以参考下图:
其中你可以发现,在这种 并发读写的场景中,吞吐量会受多方面因素的共同影响。 比如说,怎样设计数据结构以尽可能避免数据竞争、存在竞争风险时怎样处理同步(主要有使用锁实现的悲观同步和使用 CAS 实现的乐观同步)、如何避免 伪共享现象 (False Sharing,这也算是典型的用缓存提升开发复杂度的例子)发生,等等。
其中的第一点, “尽可能避免数据竞争”是最关键的。因为无论我们如何实现同步,都不会比直接不需要同步更快。
那么下面,我就以 Caffeine 为例,来给你介绍一些缓存如何避免竞争、提高吞吐量的设计方法。
我们知道,缓存中最主要的数据竞争来源于读取数据的同时,也会伴随着对数据状态的写入操作,而写入数据的同时,也会伴随着数据状态的读取操作。
比如说,读取数据时,服务器要同时更新数据的最近访问时间和访问计数器的状态(后面讲命中率时会提到,为了追求高效,程序可能不会记录时间和次数,比如通过调整链表顺序来表达时间先后、通过 Sketch 结构来表达热度高低),以实现缓存的淘汰策略;又或者,在读取时,服务器要同时判断数据的超期时间等信息,以实现失效重加载等其他扩展功能。
那么,针对前面所讲的伴随读写操作而来的状态维护,我们可以选择两种处理思路。
一种是以 Guava Cache 为代表的同步处理机制。 即在访问数据时一并完成缓存淘汰、统计、失效等状态变更操作,通过分段加锁等优化手段来尽量减少数据竞争。
另一种是以 Caffeine 为代表的异步日志提交机制。 这种机制参考了经典的数据库设计理论,它把对数据的读、写过程看作是日志(即对数据的操作指令)的提交过程。
尽管日志也涉及到了写入操作,而有并发的数据变更就必然面临着锁竞争。但是异步提交的日志,已经将原本在 Map 内的锁转移到了日志的追加写操作上,日志里腾挪优化的余地就比在 Map 中要大得多。
另外,在 Caffeine 的实现中,还设有专门的 环形缓存区 (Ring Buffer,也常称作 Circular Buffer),来记录由于数据读取而产生的状态变动日志。而且为了进一步减少数据竞争,Caffeine 给每条线程(对线程取 Hash,哈希值相同的使用同一个缓冲区)都设置了一个专用的环形缓冲。
额外知识:环形缓冲
所谓环形缓冲,并不是 Caffeine 的专有概念,它是一种拥有读、写两个指针的数据复用结构,在计算机科学中有非常广泛的应用。
我给你举个具体例子。比如说,一台计算机通过键盘输入,并通过 CPU 读取”HELLO WIKIPEDIA”这个长 14 字节的单词,那么通常就需要一个至少 14 字节以上的缓冲区才行。
但如果是环形缓冲结构,读取和写入就应当一起进行,在读取指针之前的位置都可以重复使用。理想情况下,只要读取指针不落后于写入指针一整圈,这个缓冲区就可以持续工作下去,就能容纳无限多个新字符。否则,就必须阻塞写入操作,去等待读取清空缓冲区。
然后,从 Caffeine 读取数据时,数据本身会在其内部的 ConcurrentHashMap 中直接返回,而数据的状态信息变更,就存入了环形缓冲中,由后台线程异步处理。
而如果异步处理的速度跟不上状态变更的速度,导致缓冲区满了,那此后接收的状态的变更信息就会直接被丢弃掉,直到缓冲区重新有了富余。
所以,通过环形缓冲和容忍有损失的状态变更,Caffeine 大幅降低了由于数据读取而导致的垃圾收集和锁竞争,因而 Caffeine 的读取性能几乎能与 ConcurrentHashMap 的读取性能相同。
另外你要知道,在向 Caffeine 写入数据时,还要求要使用传统的有界队列(ArrayQueue)来存放状态变更信息,写入带来的状态变更是无损的,不允许丢失任何状态。这是考虑到许多状态的默认值必须通过写入操作来完成初始化,因此写入会有一定的性能损失。根据 Caffeine 官方给出的数据,相比 ConcurrentHashMap,Caffeine 在写入时大约会慢 10% 左右。

好,说完了吞吐量,我们接着来看看缓存的第二个属性:命中率。
命中率与淘汰策略
有限的物理存储,决定了任何缓存的容量都不可能是无限的,所以缓存需要在消耗空间与节约时间之间取得平衡,这就要求缓存必须能够自动、或者由人工淘汰掉缓存中的低价值数据。不过,由人工管理的缓存淘汰主要取决于开发者如何编码,不能一概而论,所以这里我们就只讨论由缓存自动进行淘汰的情况。
这里我所说的”缓存如何自动地实现淘汰低价值目标”,现在也被称之为缓存的淘汰策略,或者是替换策略、清理策略。
那么,在缓存实现自动淘汰低价值数据的容器之前,我们首先要定义,怎样的数据才算是”低价值”的数据。
由于缓存的通用性,这个问题的答案必须是与具体业务逻辑无关的,所以我们只能从缓存工作过程中收集到的统计结果,来确定数据是否有价值。这个通用的统计结果包括但不限于数据何时进入缓存、被使用过多少次、最近什么时候被使用,等等。
这就由此决定了,一旦确定了选择何种统计数据,以及如何通用地、自动地判定缓存中每个数据价值高低,也就相当于决定了缓存的淘汰策略是如何实现的。
那么目前,最基础的淘汰策略实现方案主要有三种,我来一一给你介绍下。
第一种:FIFO(First In First Out)
即优先淘汰 最早进入被缓存的数据 。FIFO 的实现十分简单,但一般来说,它并不是优秀的淘汰策略,因为越是频繁被用到的数据,往往越会早早地被存入缓存之中。所以如果采用这种淘汰策略,很可能会大幅降低缓存的命中率。
第二种:LRU(Least Recent Used)
即优先淘汰 最久未被使用访问过的数据 。LRU 通常会采用 HashMap 加 LinkedList 的双重结构(如 LinkedHashMap)来实现。也就是,它以 HashMap 来提供访问接口,保证常量时间复杂度的读取性能;以 LinkedList 的链表元素顺序来表示数据的时间顺序,在每次缓存命中时,把返回对象调整到 LinkedList 开头,每次缓存淘汰时从链表末端开始清理数据。
所以你也能发现,对大多数的缓存场景来说,LRU 都明显要比 FIFO 策略合理,尤其适合用来处理短时间内频繁访问的热点对象。但相反它的问题是,如果一些热点数据在系统中经常被频繁访问,但最近一段时间因为某种原因未被访问过,那么这时,这些热点数据依然要面临淘汰的命运,LRU 依然可能错误淘汰掉价值更高的数据。
第三种:LFU(Least Frequently Used)
即优先淘汰 最不经常使用的数据。LFU 会给每个数据添加一个访问计数器,每访问一次就加 1,当需要淘汰数据的时候,就清理计数器数值最小的那批数据。
LFU 可以解决前面 LRU 中,热点数据间隔一段时间不访问就被淘汰的问题,但同时它又引入了两个新的问题。
- 第一个问题是需要对每个缓存的数据专门去维护一个计数器,每次访问都要更新,在前面讲”吞吐量”的时候,我也解释了这样做会带来高昂的维护开销;
第二个问题是不便于处理随时间变化的热度变化,比如某个曾经频繁访问的数据现在不需要了,它也很难自动被清理出缓存。
可见,缓存淘汰策略会直接影响缓存的命中率,没有一种策略是完美的、能够满足全部系统所需的。
不过,随着淘汰算法的发展,近几年的确出现了许多相对性能要更好、也更为复杂的新算法。下面我就以 LFU 分支为例,针对它存在的这两个问题,给你讲讲近年来提出的 TinyLFU 和 W-TinyLFU 算法,都分别带来了什么样的优化效果。
TinyLFU(Tiny Least Frequently Used)
TinyLFU 是 LFU 的改进版本。为了缓解 LFU 每次访问都要修改计数器所带来的性能负担,TinyLFU 首先采用 Sketch 结构,来分析访问数据。
所谓的 Sketch,它实际上是统计学中的概念,即指用少量的样本数据来估计全体数据的特征。这种做法显然牺牲了一定程度的准确性,但是只要样本数据与全体数据具有相同的概率分布,Sketch 得出的结论仍不失为一种在高效与准确之间做好权衡的有效结论。
所以,借助 Count-Min Sketch 算法(可以看作是 布隆过滤器 的一种等价变种结构),TinyLFU 可以用相对小得多的记录频率和空间,来近似地找出缓存中的低价值数据。
另外,为了解决 LFU 不便于处理随时间变化的热度变化问题,TinyLFU 采用了基于”滑动时间窗”(在第 38 讲中我们会更详细地分析这种算法)的热度衰减算法。简单理解就是每隔一段时间,便会把计数器的数值减半,以此解决”旧热点”数据难以清除的问题。
W-TinyLFU(Windows-TinyLFU)
W-TinyLFU 又是 TinyLFU 的改进版本。TinyLFU 在实现减少计数器维护频率的同时,也带来了无法很好地应对稀疏突发访问的问题。
所谓的稀疏突发访问,是指有一些绝对频率较小,但突发访问频率很高的数据,比如某些运维性质的任务,也许一天、一周只会在特定时间运行一次,其余时间都不会用到,那么此时 TinyLFU 就很难让这类元素通过 Sketch 的过滤,因为它们无法在运行期间积累到足够高的频率。
而应对短时间的突发访问是 LRU 的强项,因此 W-TinyLFU 就结合了 LRU 和 LFU 两者的优点。 从整体上看,它是 LFU 策略,从局部实现上看,它又是 LRU 策略。
怎么理解这个”整体”和”局部”呢?
W-TinyLFU 的具体做法是,把新记录暂时放入一个名为 Window Cache 的前端 LRU 缓存里面,让这些对象可以在 Window Cache 中累积热度,如果能通过 TinyLFU 的过滤器,再进入名为 Main Cache 的主缓存中存储。
主缓存根据数据的访问频繁程度,分为了不同的段(LFU 策略,实际上 W-TinyLFU 只分了两段),但单独某一段从局部来看,又是基于 LRU 策略去实现的(称为 Segmented LRU) 。每当前一段缓存满了之后,就会将低价值数据淘汰到后一段中去存储,直至最后一段也满了之后,该数据就彻底清理出缓存。
当然,只靠这种简单的、有限的介绍,你不一定能完全理解 TinyLFU 和 W-TinyLFU 的工作原理,但是你肯定能看出来,这些改进算法比起原来基础版本的 LFU 要复杂许多。
有时候,为了取得理想的效果,采用较为复杂的淘汰策略只是不得已的选择。
除了 W-TinyLFU 之外,Caffeine 官方还制定了另外两种高级淘汰策略, ARC (Adaptive Replacement Cache)和 LIRS (Low Inter-Reference Recency Set)。这里你可以看看这三种新的淘汰策略与基础的 LFU 策略之间的命中率对比:
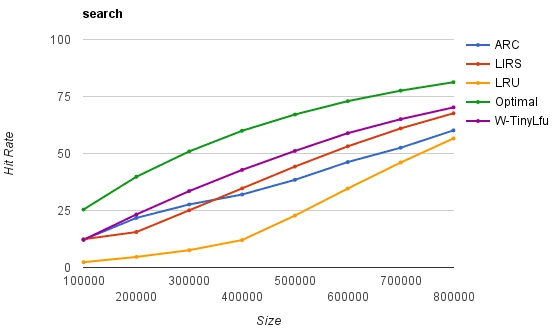
在搜索场景中,三种高级策略的命中率比较为接近于理想曲线(Optimal),而 LRU 则差距最远。另外,在 Caffeine 官方给出的 数据库、网站、分析类等应用场景中,这几种策略之间的绝对差距也不完全一样,但相对排名基本上没有改变,最基础的淘汰策略的命中率是最低的。如果你对其他缓存淘汰策略感兴趣的话,可以参考维基百科中对 Cache Replacement Policies 的介绍。
好,最后我们再来看看服务端缓存的第三种属性,也就是它提供的一些额外的管理功能。
扩展功能
一般来说,一套标准的 Map 接口(或者是来自 JSR 107 的 javax.cache.Cache 接口)就可以满足缓存访问的基本需要,不过在”访问”之外,专业的缓存往往还会提供很多额外的功能。
加载器
许多缓存都有”CacheLoader”之类的设计,加载器可以让缓存从只能被动存储外部放入的数据,变为能够主动通过加载器去加载指定 Key 值的数据,加载器也是实现自动刷新功能的基础前提。
淘汰策略
有的缓存淘汰策略是固定的,也有一些缓存可以支持用户根据自己的需要,来选择不同的淘汰策略。
失效策略
失效策略就是要求缓存的数据在一定时间后自动失效(移除出缓存)或者自动刷新(使用加载器重新加载)。
事件通知
缓存可能会提供一些事件监听器,让你在数据状态变动(如失效、刷新、移除)时进行一些额外操作。有的缓存还提供了对缓存数据本身的监视能力(Watch 功能)。
并发级别
对于通过分段加锁来实现的缓存(以 Guava Cache 为代表),往往会提供并发级别的设置。
这里你可以简单地理解为,缓存内部是使用多个 Map 来分段存储数据的,并发级别就用于计算出使用 Map 的数量。如果这个参数设置过大,会引入更多的 Map,你需要额外维护这些 Map 而导致更大的时间和空间上的开销;而如果设置过小,又会导致在访问时产生线程阻塞,因为多个线程更新同一个 ConcurrentMap 的同一个值时会产生锁竞争。
容量控制
缓存通常都支持指定初始容量和最大容量。设定初始容量的目的是减少扩容频率,这与 Map 接口本身的初始容量含义是一致的;而最大容量类似于控制 Java 堆的 -Xmx 参数,当缓存接近最大容量时,会自动清理掉低价值的数据。
引用方式
Java 语言支持将数据设置为软引用或者弱引用,而提供引用方式的设置,就是为了将缓存与 Java 虚拟机的垃圾收集机制联系起来。
统计信息
缓存框架会提供诸如缓存命中率、平均加载时间、自动回收计数等统计信息。
持久化
也就是支持将缓存的内容存储到数据库或者磁盘中。进程内缓存提供持久化功能的作用不是太大,但分布式缓存大多都会考虑提供持久化功能。
小结
今天这节课,我给你介绍了缓存的三项属性:吞吐量、命中率和扩展功能。为了便于你回顾知识点,我把目前几款主流的进程内缓存方案整理成了一个表格,供你参考。
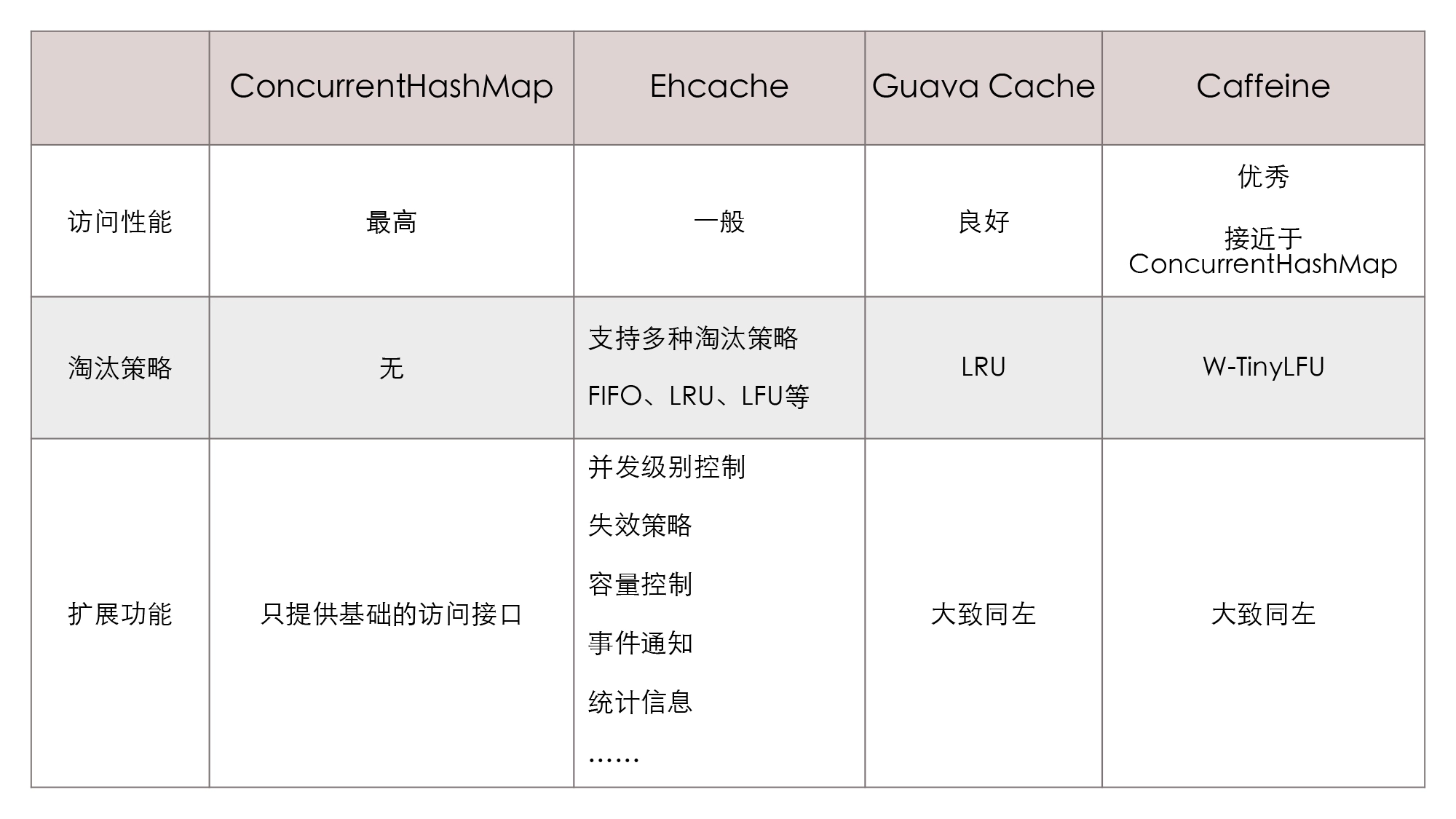
那么总的来说,表格里的四类就基本囊括了目前主流的进程内缓存方案。希望通过这节课的学习,你能够掌握服务端缓存的原理,能够独立分析各种缓存框架所提供的功能属性,明白它们有什么影响,有什么收益和代价。
22 | 分布式缓存如何与本地缓存配合,提高系统性能?
今天,我们接着上节课服务端缓存的话题,继续来学习下分布式缓存的实现形式、与本地缓存搭配使用的方法,以及一起来了解下,在实际使用缓存的过程中,可能会存在的各种风险和应对手段。
分布式缓存
首先通过上节课的学习,现在我们已经知道了,服务端缓存可以分为”进程内缓存”和”分布式缓存”两大类。相比缓存数据在进程内存中读写的速度,一旦涉及到了网络访问,那么由网络传输、数据复制、序列化和反序列化等操作所导致的延迟,就要比内存访问高得多。
所以,对于分布式缓存来说,处理与网络有关的操作是影响吞吐量的主要因素,这也是比淘汰策略、扩展功能更重要的关注点。
而这就决定了,尽管也有 Ehcache、Infinispan 这类能同时支持分布式部署和进程内嵌部署的缓存方案,但在通常情况下,进程内缓存和分布式缓存在选型时,会有完全不同的候选对象和考察点。
所以说,我们在决定使用哪种分布式缓存之前,必须先确认好自己的需求是什么。
那么接下来,我们就从两个不同的需求场景出发,看看都可以选择哪些分布式缓存方案。我们先从数据访问的需求场景开始了解吧。
复制式缓存与集中式缓存
从访问的角度来说, 如果是频繁更新但很少读取的数据,正常是不会有人把它拿去做缓存的,因为这样做没有收益。
然后,对于很少更新但频繁读取的数据,理论上更适合做复制式缓存;而对于更新和读取都较为频繁的数据,理论上就更适合做集中式缓存。
所以在这里,我就针对这两种比较通用的缓存形式,给你介绍一下二者之间的差别,以及各自具有代表性的产品。
复制式缓存
对于复制式缓存,你可以看作是” 能够支持分布式的进程内缓存 “,它的工作原理与 Session 复制类似:缓存中的所有数据,在分布式集群的每个节点里面都存有一份副本,当读取数据时,无需网络访问,直接从当前节点的进程内存中返回,因此理论上可以做到与进程内缓存一样高的读取性能;而当数据发生变化的时候,就必须遵循复制协议,将变更同步到集群的每个节点中,这时,复制性能会随着节点的增加呈现平方级下降,变更数据的代价就会变得十分高昂。
复制式缓存的代表是 JBossCache ,这是 JBoss 针对企业级集群设计的缓存方案,它可以支持 JTA 事务,依靠 JGroup 进行集群节点间数据同步。
以 JBossCache 为典型的复制式缓存,曾经有过一段短暂的兴盛期,但是在今天,我们基本上已经很难再见到使用这种缓存形式的大型信息系统了。
为什么今天 JBossCache 会被淘汰掉呢?
主要是因为 JBossCache 的写入性能实在是差到了不堪入目的程度,它在小规模集群中同步数据还算是差强人意,但在大规模集群下,动辄就会因为网络同步的速度跟不上写入速度,进而导致在内存中累计大量待重发对象,最终引发 OutOfMemory 崩溃。如果我们对 JBossCache 没有足够了解的话,稍有不慎就会被埋进坑里。
后来,为了缓解复制式同步的写入效率问题,JBossCache 的继任者 Infinispan 提供了另一种分布式同步模式。它允许用户配置数据需要复制的副本数量,比如集群中有八个节点,我们可以要求每个数据只保存四份副本,这样就降低了复制数据时的网络负担。
此时,缓存的总容量就相当于是传统复制模式的一倍,如果要访问的数据在本地缓存中没有存储,Infinispan 完全有能力感知网络的拓扑结构,知道应该到哪些节点中寻找数据。
集中式缓存
集中式缓存是目前分布式缓存的 主流形式 。集中式缓存的读、写都需要网络访问,它的好处是不会随着集群节点数量的增加而产生额外的负担,而坏处自然是读、写都不可能再达到进程内缓存那样的高性能。
集中式缓存还有一个必须提到的关键特点,那就是它与使用缓存的应用分处在独立的进程空间中。
这样做的 好处 是它能够为异构语言提供服务,比如用 C 语言编写的 Memcached 完全可以毫无障碍地为 Java 语言编写的应用提供缓存服务;但 坏处 是如果要缓存像对象这种复杂类型的话,基本上就只能靠序列化来支撑具体语言的类型系统了(支持 Hash 类型的缓存,可以部分模拟对象类型)。这样就不仅产生了序列化的成本,还很容易导致传输成本的大幅增加。
我举个例子,假设某个有 100 个字段的大对象变更了其中 1 个字段的值,通常缓存也不得不把整个对象的所有内容重新序列化传输出去,才能实现更新。所以,一般集中式缓存更提倡直接缓存原始数据类型,而不是对象。
相比之下,JBossCache 则通过它的 字节码自审 (Introspection)功能和 树状存储结构 (TreeCache),做到了自动跟踪、处理对象的部分变动。如果用户修改了对象中某些字段的数据,缓存就只会同步对象中真正变更的那部分数据。
不过现在,因为 Redis 在集中式缓存中处于统治地位,已经打败了 Memcached 和其他集中式缓存框架,成为了集中式缓存的首选,甚至可以说成为了分布式缓存的首选,几乎到了不用管读取、写入哪种操作更频繁,都可以无脑上 Redis 的程度。
也正是因为如此,前面我在说到哪些数据适合用复制式缓存、哪些数据适合用集中式缓存的时候,我都加了个拗口的”理论上”。尽管 Redis 最初设计的本意是 NoSQL 数据库,而不是专门用来做缓存的,可今天它确实已经成为许多分布式系统中不可或缺的基础设施,被广泛用作缓存的实现方案。
而另一方面,访问缓存不仅仅要考虑如何快速取到数据,还需要考虑取到的是否是正确的数据,缓存的数据质量是另一个重要的考量因素。
从数据一致性的角度来说, 缓存本身也有集群部署的需求。所以在理论上,我们需要好好考虑一下,如果不同的节点取到的缓存数据不一样,我们是否可以接受。比如说,我们刚刚放入缓存中的数据,另外一个节点马上访问发现未能读到;或者刚刚更新缓存中的数据,另外一个节点访问时,在短时间内读取到的仍是旧的数据,等等。
那么,根据分布式缓存集群是否能保证数据一致性,我们可以将它分为 AP 和 CP 两种类型(在” 分布式事务 “中已经介绍过 CAP 各自的含义)。
你可以发现,这里我又说的是”理论上”,这是因为我们在实际开发中,通常不太会使用缓存来处理追求强一致性的数据。当然我们是可以这样做,但其实没必要(可类比 MESI 等缓存一致性协议)。
给你举个例子。Redis 集群就是典型的 AP 式,它具有高性能、高可用等特点,但它却并不保证强一致性。而能够保证强一致性的 ZooKeeper、Doozerd、Etcd 等分布式协调框架,我们可通常不会把它们当作”缓存框架”来使用,这些分布式协调框架的吞吐量相对 Redis 来说,是非常有限的。不过,ZooKeeper、Doozerd、Etcd 倒是常跟 Redis 和其他分布式缓存搭配工作,用来实现其中的通知、协调、队列、分布式锁等功能。
透明多级缓存
那到这里,你也能发现,分布式缓存与进程内缓存各有所长,也有各有局限,它们是互补的,而不是竞争的关系。所以如果你有需要,完全可以同时互相搭配进程内缓存和分布式缓存,来构成 透明多级缓存 (Transparent Multilevel Cache,TMC)。
这里,我们先不去考虑”透明”这个词的定义是啥,单看”多级缓存”的话,倒还很好理解。
它的意思就是,使用进程内缓存做一级缓存,分布式缓存做二级缓存,如果能在一级缓存中查询到结果就直接返回,否则就到二级缓存中去查询;再将二级缓存中的结果回填到一级缓存,以后再访问该数据就没有网络请求了。
而如果二级缓存也查询不到,就发起对最终数据源的查询,将结果回填到一、二级缓存中去。
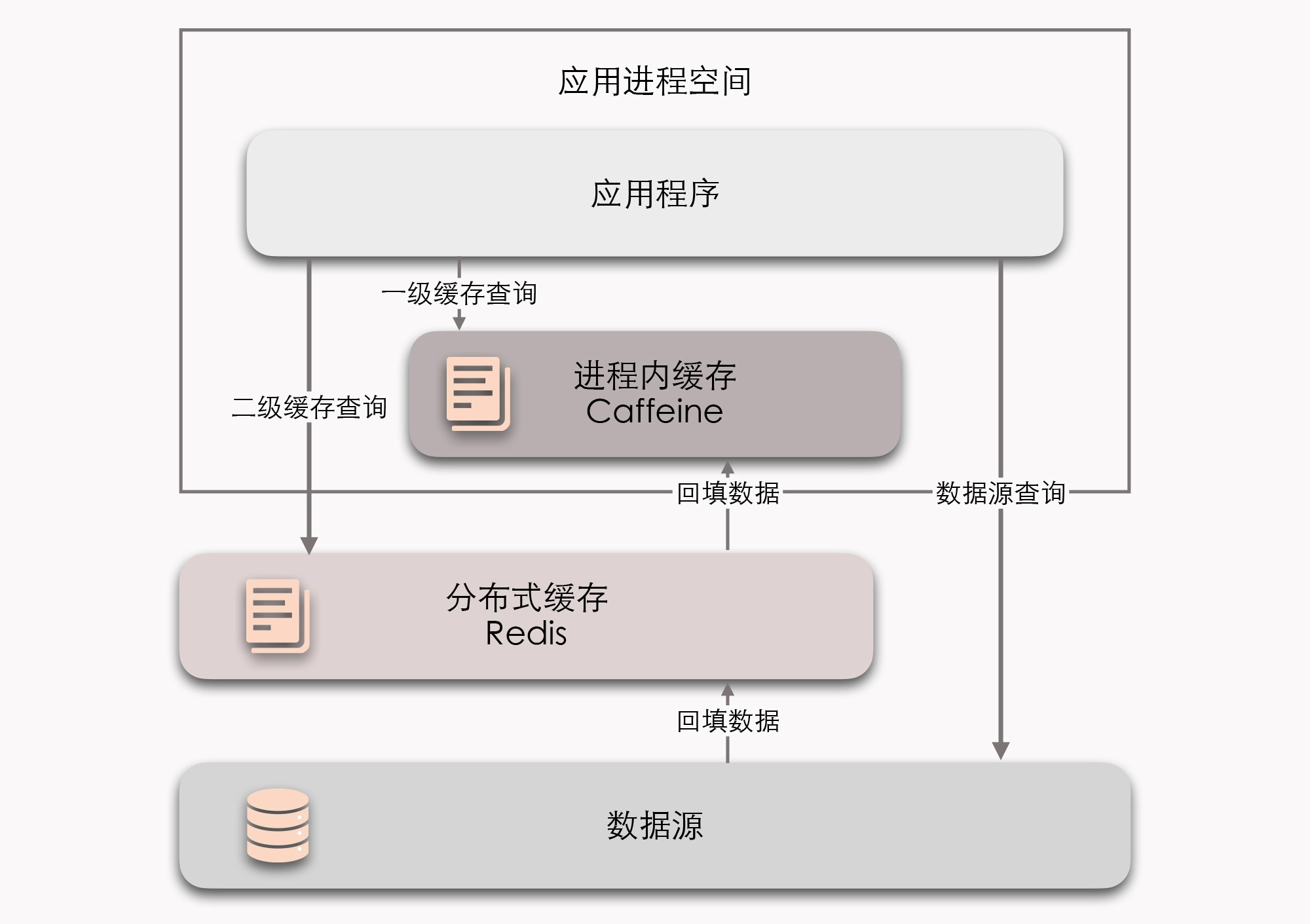
不过,尽管多级缓存结合了进程内缓存和分布式缓存的优点,但它的代码侵入性较大,需要由开发者承担多次查询、多次回填的工作,也不便于管理,像是超时、刷新等策略,都要设置多遍,数据更新更是麻烦,很容易会出现各个节点的一级缓存、二级缓存里的数据互相不一致的问题。
所以,我们必须” 透明 “地解决这些问题,多级缓存才具有实用的价值。
一种常见的设计原则,就是 变更以分布式缓存中的数据为准,访问以进程内缓存的数据优先。
大致做法是当数据发生变动时,在集群内发送推送通知(简单点的话可以采用 Redis 的 PUB/SUB,求严谨的话可以引入 ZooKeeper 或 Etcd 来处理),让各个节点的一级缓存自动失效掉相应数据。
然后,当访问缓存时,缓存框架提供统一封装好的一、二级缓存联合查询接口,接口外部只查询一次,接口内部自动实现优先查询一级缓存。如果没有获取到数据,就再自动查询二级缓存。
缓存风险
OK,现在,你也对不同需求场景下的不同分布式缓存实现方案有大概的了解了。而在上一节课开头,我提到过缓存并不是多多益善,它有利也有弊,是要真正到必要的时候才去考虑的解决方案。因此接下来,我就带你详细了解一下使用缓存的各种常见风险和注意事项,以及应对风险的方法。
缓存穿透
我们知道,引入缓存的目的是为了缓解 CPU 或者 I/O 的压力,比如对数据库做缓存,大部分流量都从缓存中直接返回,只有缓存未能命中的数据请求才会流到数据库中,数据库压力自然就减小了。
但是如果查询的数据在数据库中根本不存在的话,缓存里自然也不会有。这样,这类请求的流量每次都不会命中,每次都会触及到末端的数据库,缓存自然也就起不到缓解压力的作用了。那么,这种查询不存在数据的现象,就被称为 缓存穿透 。
缓存穿透有可能是业务逻辑本身就存在的固有问题,也有可能是被恶意攻击的所导致的。所以,为了解决缓存穿透,我们一般会采取下面两种办法:
对于业务逻辑本身就不能避免的缓存穿透
我们可以约定在一定时间内,对返回为空的 Key 值依然进行缓存(注意是正常返回但是结果为空,不要把抛异常的也当作空值来缓存了),这样在一段时间内,缓存就最多被穿透一次。
如果后续业务在数据库中对该 Key 值插入了新记录,那我们就应当在插入之后主动清理掉缓存的 Key 值。如果业务时效性允许的话,也可以设置一个较短的超时时间来自动处理缓存。
对于恶意攻击导致的缓存穿透
针对这种原因,我们通常会在缓存之前设置一个布隆过滤器来解决。所谓的恶意攻击是指,请求者刻意构造数据库中肯定不存在的 Key 值,然后发送大量请求进行查询。而布隆过滤器是用最小的代价,来判断某个元素是否存在于某个集合的办法。
如果布隆过滤器给出的判定结果是请求的数据不存在,那就直接返回即可,连缓存都不必去查。虽然维护布隆过滤器本身需要一定的成本,但比起攻击造成的资源损耗,还是比较值得的。
缓存击穿
我们都知道,缓存的基本工作原理是首次从真实数据源加载数据,完成加载后回填入缓存,以后其他相同的请求就从缓存中获取数据,缓解数据源的压力。
但是,如果缓存中的某些热点数据忽然因为某种原因失效了,比如典型地由于超期而失效,而此时又有多个针对该数据的请求同时发送过来,那么这些请求就会全部未能命中缓存,都到达真实数据源中去,导致其压力剧增。这种现象,就被称为缓存击穿。
所以,要如何避免缓存击穿问题呢?我们通常可以采取这样两种办法:
加锁同步 。以请求该数据的 Key 值为锁,这样就只有第一个请求可以流入到真实的数据源中,其他线程采取阻塞或重试策略。如果是进程内缓存出现了问题,施加普通互斥锁就可以了;如果是分布式缓存中出现的问题,就施加分布式锁,这样数据源就不会同时收到大量针对同一个数据的请求了。
热点数据由代码来手动管理 。缓存击穿是只针对热点数据被自动失效才引发的问题,所以对于这类数据,我们可以直接通过代码来有计划地完成更新、失效,避免由缓存的策略自动管理。
缓存雪崩
现在我们了解了,缓存击穿是针对单个热点数据失效,由大量请求击穿缓存而给真实数据源带来了压力。
而另一种可能更普遍的情况,是不需要针对单个热点数据的大量请求,而是由于大批不同的数据在短时间内一起失效,导致了这些数据的请求都击穿了缓存,到达数据源,这同样也会令数据源在短时间内压力剧增。
那么,之所以会出现这种情况,往往是因为系统有专门的缓存预热功能,也可能是因为,大量的公共数据都是由某一次冷操作加载的,这样都可能会出现由此载入缓存的大批数据具有相同的过期时间,在同一时刻一起失效。
还有一种情况是缓存服务由于某些原因崩溃后重启,此时也会造成大量数据同时失效。那么以上出现的这种现象,就被称为缓存雪崩。
而要避免缓存雪崩的问题,我们通常可以采取这三种办法:
- 提升缓存系统可用性,建设分布式缓存的集群。
- 启用透明多级缓存,各个服务节点的一级缓存中的数据,通常会具有不一样的加载时间,这样做也就分散了它们的过期时间。
- 将缓存的生存期从固定时间改为一个时间段内的随机时间,比如原本是一个小时过期,那可以在缓存不同数据时,设置生存期为 55 分钟到 65 分钟之间的某个随机时间。
缓存污染
所谓的缓存污染是指,缓存中的数据与真实数据源中的数据不一致的现象。尽管我在前面有说过,缓存通常不追求强一致性,但这显然不能等同于,缓存和数据源间连最终的一致性都可以不要求了。
缓存污染多数是因为开发者更新缓存不规范造成的。 比如说,你从缓存中获得了某个对象,更新了对象的属性,但最后因为某些原因,比如后续业务发生异常回滚了,最终没有成功写入到数据库,此时缓存的数据是新的,而数据库中的数据是旧的。
所以,为了尽可能地提高使用缓存时的一致性,人们已经总结了不少更新缓存时可以遵循的设计模式,比如 Cache Aside、Read/Write Through、Write Behind Caching,等等。
这里,我想给你介绍下 Cache Aside 模式,因为这种设计模式最简单,成本也最低。它的主要内容只有两条:
- 读数据时,先读缓存,缓存没有的话,再读数据源,然后将数据放入缓存,再响应请求。
- 写数据时,先写数据源,然后失效(而不是更新)掉缓存。
在读数据方面,一般不会有什么出错的余地。但是写数据时,我有必要专门给你强调两点。
一个是先后顺序一定要先数据源后缓存。 你试想一下,如果采用先失效缓存后写数据源的顺序,那一定会存在一段时间内缓存已经删除完毕,但数据源还未修改完成的情况。此时新的查询请求到来,缓存未能命中,就会直接流到真实数据源中。
这样,请求读到的数据依然是旧数据,随后又重新回填到缓存中。而当数据源修改完成后,结果就成了数据在数据源中是新的,在缓存中是老的,两者就会有不一致的情况。
二个是应当失效缓存,而不是尝试去更新缓存。 这很容易理解,如果去更新缓存,更新过程中数据源又被其他请求再次修改的话,缓存又要面临处理多次赋值的复杂时序问题。所以直接失效缓存,等下次用到该数据时自动回填,期间数据源中的值无论被改了多少次,都不会造成任何影响。
不过,Cache Aside 模式依然也不能保证在一致性上绝对不出问题,否则我们就不需要设计出 Paxos 这样复杂的共识算法了。采用 Cache Aside 模式典型的出错场景,就是如果某个数据是从未被缓存过的,请求会直接流到真实数据源中,如果数据源中的写操作发生在查询请求之后,结果回填到缓存之前,也会出现缓存中回填的内容与数据库的实际数据不一致的情况。
但是,出现这种情况的概率实际上是很低的,Cache Aside 模式仍然是以低成本更新缓存,并且获得相对可靠结果的解决方案。
小结
今天这一讲,我着重给你介绍了两种主要的分布式缓存形式,分别是复制式缓存和集中式缓存。其中我强调了,在选择使用不同缓存方案的时候,你需要注意对读效率和写效率,以及对访问效率和数据质量之间的权衡。而在实际的应用场景中,你其实可以考虑选择将两种缓存结合使用,构成透明多级缓存,以此达到各取所长的目的。
最后,在为系统引入缓存的时候,你还要特别注意可能会出现的风险问题,比如说缓存穿透、缓存击穿、缓存雪崩、缓存污染,等等。如果你对这些可能出现的风险问题有了一定的准备和应对方案,那么可以说,你基本上算是对服务端缓存建立了基本的整体认知了。
23 | 认证:系统如何正确分辨操作用户的真实身份?
我们应该都很清楚,对于软件研发来说,即使只限定在”软件架构设计”这个语境下,系统安全仍然是一个很大的话题。它不仅包括”防御系统被黑客攻击”这样狭隘的安全,还包括一些与管理、运维、审计等领域主导的相关安全性问题,比如说安全备份与恢复、安全审计、防治病毒,等等。
不过在这门课程里,我们的关注重点并不会放在以上这些内容上,我们所谈论的软件架构安全,主要包括(但不限于)以下这些问题的具体解决方案:
- 认证(Authentication):系统如何正确分辨出操作用户的真实身份?
- 授权( Authorization):系统如何控制一个用户该看到哪些数据、能操作哪些功能?
- 凭证(Credentials):系统如何保证它与用户之间的承诺是双方当时真实意图的体现,是准确、完整且不可抵赖的?
- 保密(Confidentiality):系统如何保证敏感数据无法被包括系统管理员在内的内外部人员所窃取、滥用?
- 传输(Transport Security):系统如何保证通过网络传输的信息无法被第三方窃听、篡改和冒充?
- 验证(Verification):系统如何确保提交到每项服务中的数据是合乎规则的,不会对系统稳定性、数据一致性、正确性产生风险?
由于跟安全相关的问题,一般都不会给架构设计直接创造价值,而且解决起来又很繁琐复杂、费时费力,所以可能会经常性地被一部分开发人员给有意无意地忽略掉。
不过庆幸的是,这些问题基本上也都是与具体系统、具体业务无关的通用性问题,这就意味着它们往往会存在一些业界通行的、已经被验证过是行之有效的解决方案,乃至已经形成了行业标准,不需要我们再从头去构思如何解决。
所以,在”安全架构”这个小章节里,我会花六讲的时间,围绕系统安全的标准方案,带你逐一探讨以上这些问题的处理办法,并会以 Fenix’s Bookstore 作为案例实践。而出于方便你进行动手实操的目的,我不会在课程中直接贴出大段的项目代码(当然必要的代码示例还是会有的),所以我建议你要结合着从 Fenix’s Bookstore 的 GitHub 仓库 中获取的示例代码来进行学习。
好,那么今天这节课,我们就从”认证”这个话题开始,一起来解决”系统如何正确分辨操作用户的真实身份”这个问题。
什么是认证?
认证(Authentication)、授权(Authorization)和凭证(Credentials)这三项可以说是一个系统中最基础的安全设计了,哪怕是再简陋的信息系统,大概也不可能忽略掉”用户登录”这个功能。
信息系统在为用户提供服务之前,总是希望先弄清楚”你是谁?”(认证)、”你能干什么?”(授权)以及”你如何证明?”(凭证)这三个基本问题的答案。然而,认证、授权与凭证这三个基本问题,又并不像部分开发者认为的那样,只是一个”系统登录”功能而已,仅仅是校验一下用户名、密码是否正确这么简单。
账户和权限信息作为一种必须最大限度保障安全和隐私,同时又要兼顾各个系统模块、甚至是系统间共享访问的基础主数据,它的存储、管理与使用都面临一系列复杂的问题。
因此,对于某些大规模的信息系统,账户和权限的管理往往要由专门的基础设施来负责,比如微软的 活动目录 (Active Directory,AD)或者 轻量目录访问协议 (Lightweight Directory Access Protocol,LDAP),跨系统的共享使用问题甚至还会用到区块链技术来解决。
另外,还有一个不少人会先入为主的 认知偏差 :尽管”认证”是解决”你是谁?”的问题,但这里的”你”并不一定是个人(真不是在骂你),也 很有可能是指外部的代码 ,即第三方的类库或者服务。
因为最初在计算机软件当中,对代码认证的重要程度甚至要高于对最终用户的认证,比如早期的 Java 系统里,安全中的认证默认是特指”代码级安全”,即 你是否信任要在你的电脑中运行的代码。
这是由 Java 当时的主要应用形式 Java Applets 所决定的:类加载器从远端下载一段字节码,以 Applets 的形式在用户的浏览器中运行,由于 Java 的语言操控计算机资源的能力要远远强于 JavaScript,所以系统必须要先确保这些代码不会损害用户的计算机,否则就谁都不敢去用。
这一阶段的安全观念,就催生了现在仍然存在于 Java 技术体系中的”安全管理器”(java.lang.SecurityManager)、”代码权限许可”(java.lang.RuntimePermission)等概念。到了现在,系统对外部类库和服务的认证需求依然很普遍,但相比起五花八门的最终用户认证来说,代码认证的研究发展方向已经很固定了,基本上都是统一到证书签名上。
不过在咱们这节课里,对认证的探究范围只限于对最终用户的认证。关于对代码的认证,我会安排在”分布式的基石”模块中的第 40 讲”服务安全”来讲解。
好,那么在理解了什么是认证、界定了认证的范围之后,我们接下来看一下软件工业界是如何进行认证的。
认证的标准
在世纪之交,Java 迎来了 Web 时代的辉煌,互联网的迅速兴起促使 Java 进入了快速发展时期。这时候,基于 HTML 和 JavaScript 的超文本 Web 应用,就迅速超过了”Java 2 时代”之前的 Java Applets 应用,B/S 系统对最终用户认证的需求,使得”安全认证”的重点逐渐从”代码级安全”转为了”用户级安全”, 即你是否信任正在操作的用户。
在 1999 年,随 J2EE 1.2(它是 J2EE 的首个版本,为了与 J2SE 同步,初始版本号直接就是 1.2)一起发布的 Servlet 2.2 中,添加了一系列用于认证的 API,主要包括了两部分内容:
- 标准方面 ,添加了四种内置的、不可扩展的认证方案,即 Client-Cert、Basic、Digest 和 Form。
- 实现方面 ,添加了与认证和授权相关的一套程序接口,比如 HttpServletRequest::isUserInRole()、HttpServletRequest::getUserPrincipal() 等方法。
到这儿你可能会觉得,这都是一项发布超过 20 年的老旧技术了,为啥还要专门提一嘴呢?这是因为,我希望从它包含的两部分内容中,引出一个 架构安全性的经验原则:以标准规范为指导、以标准接口去实现。
因为安全涉及的问题很麻烦,但它的解决方案也相当的成熟。 对于 99% 的系统来说,在安全上不去做轮子,不去想发明创造,严格遵循标准就是最恰当的安全设计。
然后,我之所以引用 J2EE 1.2 对安全的改进,还有一个原因,就是它内置支持的 Basic、Digest、Form 和 Client-Cert 四种认证方案都很有代表性,刚好分别覆盖了通讯信道、协议和内容层面的认证,这三种层面的认证又涵盖了主流的三种认证方式,下面我们分别来看看它们各自的含义和应用场景:
- 通讯信道上的认证 :你和我建立通讯连接之前,要先证明你是谁。在网络传输(Network)场景中的典型是基于 SSL/TLS 传输安全层的认证。
- 通讯协议上的认证 :你请求获取我的资源之前,要先证明你是谁。在互联网(Internet)场景中的典型是基于 HTTP 协议的认证。
- 通讯内容上的认证 :你使用我提供的服务之前,要先证明你是谁。在万维网(World Wide Web)场景中的典型是基于 Web 内容的认证。
关于第一点”信道上的认证”,由于它涉及的内容较多,又与后面第 28、29 讲要介绍的微服务安全方面的话题关系密切,所以这节课我就不展开讲了(而且 J2EE 中的 Client-Cert 其实并不是用于 TLS 的,以它引出 TLS 并不合适)。
那么接下来,我们就针对后两种认证方式,来看看它们各自都有什么样的实现特点和工作流程。
基于通讯协议:HTTP 认证
前面我在介绍 J2EE 1.2 这项老技术的时候,已经提前用到了一个技术名词,”认证方案”(Authentication Schemes)。它是指生成用户身份凭证的某种方法,这个概念最初是来源于 HTTP 协议的认证框架(Authentication Framework)。
IETF 在 RFC 7235 中定义了 HTTP 协议的通用认证框架,要求所有支持 HTTP 协议的服务器,当未授权的用户意图访问服务端保护区域的资源时,应返回 401 Unauthorized 的状态码,同时要在响应报文头里,附带以下两个分别代表网页认证和代理认证的 Header 之一,告知客户端应该采取哪种方式,产生能代表访问者身份的凭证信息:
WWW-Authenticate: <认证方案> realm=<保护区域的描述信息>
Proxy-Authenticate: <认证方案> realm=<保护区域的描述信息>而在接收到该响应后,客户端必须遵循服务端指定的认证方案,在请求资源的报文头中加入身份凭证信息,服务端核实通过后才会允许该请求正常返回,否则将返回 403 Forbidden。其中,请求报文头要包含以下 Header 项之一:
Authorization: <认证方案> <凭证内容>
Proxy-Authorization: <认证方案> <凭证内容>由此我们其实可以发现, HTTP 认证框架提出的认证方案,是希望能把认证”要产生身份凭证”的目的,与”具体如何产生凭证”的实现给分开来。 无论客户端是通过生物信息(指纹、人脸)、用户密码、数字证书,还是其他方式来生成凭证,都是属于如何生成凭证的具体实现,都可以包容在 HTTP 协议预设的框架之内。
HTTP 认证框架的工作流程如下面的时序图所示:
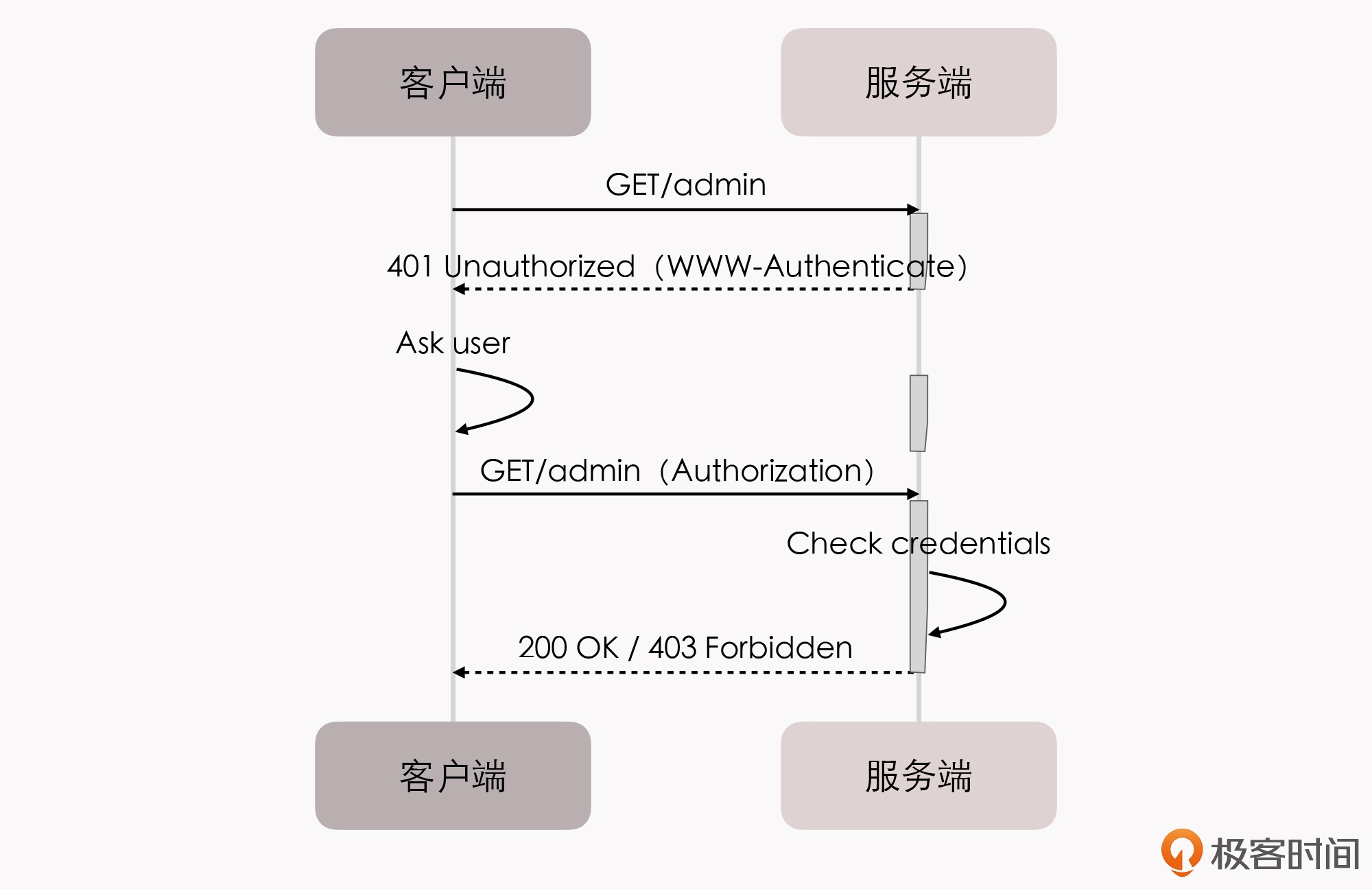
不过,只有这种概念性的介绍,你可能还是会觉得有点儿枯燥和抽象,接下来我就以最基础的认证方案 HTTP Basic Authentication 为例,来给你解释下认证具体是如何工作的。
HTTP Basic 认证是一种 以演示为目的 的认证方案,在一些不要求安全性的场合也有实际应用,比如你家里的路由器登录,有可能就是这种认证方式。
Basic 认证产生用户身份凭证的方法是让用户输入用户名和密码,经过 Base64 编码”加密”后作为身份凭证。比如请求资源”GET/admin”后,浏览器会收到服务端如下响应:
HTTP/1.1 401 Unauthorized
Date: Mon, 24 Feb 2020 16:50:53 GMT
WWW-Authenticate: Basic realm="example from icyfenix.cn"此时,浏览器必须询问最终用户,要求提供用户名和密码,并会弹出类似下图所示的 HTTP Basic 认证窗口:
然后,用户在对话框中输入密码信息,比如输入用户名”icyfenix”,密码 123456,浏览器会将字符串”icyfenix:123456”编码为”aWN5ZmVuaXg6MTIzNDU2”,然后发送给服务端,HTTP 请求如下所示:
GET /admin HTTP/1.1
Authorization: Basic aWN5ZmVuaXg6MTIzNDU2服务端接收到请求,解码后检查用户名和密码是否合法,如果合法就允许返回 /admin 的资源,否则就返回 403 Forbidden 禁止下一步操作。
这里要注意一点,Base64 只是一种编码方式,而并不是任何形式的加密,所以 Basic 认证的风险是显而易见的, 它只能是一种以演示为主要目的的认证方案。
那么,除 Basic 认证外,IETF 还定义了很多种可用于实际生产环境的认证方案,比如:
- Digest : RFC 7616 ,HTTP 摘要认证,你可以把它看作是 Basic 认证的改良版本,针对 Base64 明文发送的风险,Digest 认证把用户名和密码加盐(一个被称为 Nonce 的变化值作为盐值)后,再通过 MD5/SHA 等哈希算法取摘要发送出去。 这种认证方式依然是不安全的 ,无论客户端使用何种加密算法加密,无论是否采用了 Nonce 这样的动态盐值去抵御重放和冒认,当遇到中间人攻击时,依然存在显著的安全风险。在第 27”保密”一讲中,我还会跟你具体讨论加解密方面的问题。
Bearer : RFC 6750 ,基于 OAuth 2.0 规范来完成认证,OAuth 2.0 是一个同时涉及到认证与授权的协议。在下节课讲解”授权”的时候,我会详细介绍 OAuth 2.0。
HOBA : RFC 7486 ,HOBA 是 HTTP Origin-Bound Authentication 的缩写,这是一种基于自签名证书的认证方案。基于数字证书的信任关系主要有两类模型,一类是采用 CA(Certification Authority)层次结构的模型,由 CA 中心签发证书;另一种是以 IETF 的 Token Binding 协议为基础的 OBC(Origin Bound Certificates)自签名证书模型。同样在后面讲”传输”的时候,我会给你详细介绍数字证书。
还有,在 HTTP 认证框架中,认证方案是允许自行扩展的,也并不要求一定要由 RFC 规范来定义,只要用户代理(User Agent,通常是浏览器,泛指任何使用 HTTP 协议的程序)能够识别这种私有的认证方案即可。
因此,很多厂商也扩展了自己的认证方案,比如:
- AWS4-HMAC-SHA256:相当简单粗暴的名字,就是亚马逊 AWS 基于 HMAC-SHA256 哈希算法的认证。
- NTLM / Negotiate:这是微软公司 NT LAN Manager(NTLM)用到的两种认证方式。
- Windows Live ID:这个顾名思义即可。
- Twitter Basic:一个不存在的网站所改良的 HTTP 基础认证。
- ……
好,说完了基于通讯协议的认证方案,我们再来看看基于通讯内容的 Web 认证是如何实现的。
基于通讯内容:Web 认证
IETF 为 HTTP 认证框架设计了可插拔(Pluggable)的认证方案,原本是希望能涌现出各式各样的认证方案,去支持不同的应用场景。尽管前面我也列举了一些还算常用的认证方案,但目前的信息系统,尤其是在系统对终端用户的认证场景中,直接采用 HTTP 认证框架的比例其实是非常低的。
这也不难理解,HTTP 是”超文本传输协议”,传输协议的根本职责是把资源从服务端传输到客户端,至于资源具体是什么内容,只能由客户端自行解析驱动。所以说, 以 HTTP 协议为基础的认证框架,也只能面向传输协议而不是具体传输内容来设计。
如果用户想要从服务器中下载文件,弹出一个 HTTP 服务器的对话框让用户登录,是可以接受的;但如果用户访问信息系统中的具体服务,身份认证肯定希望是由系统本身的功能去完成的,而不是由 HTTP 服务器来负责认证。
那么, 这种依靠内容而不是传输协议来实现的认证方式,在万维网里就被称为”Web 认证” ,由于在实现形式上,登录表单占了绝对的主流,因此它通常也被称为” 表单认证 “(Form Authentication)。
实际上,直到 2019 年之前,表单认证都没有什么行业标准可循,表单长什么样子、其中的用户字段、密码字段、验证码字段、是否要在客户端加密、采用何种方式加密、接受表单的服务地址是什么等等,都完全由服务端与客户端的开发者自行协商决定。
可”没有标准的约束”,反倒成了表单认证的一大优点,表单认证允许我们做出五花八门的页面,各种程序语言、框架或开发者本身,都可以自行决定认证的全套交互细节。
到这里你可能要说了,在前面讲认证标准的时候,我说”遵循规范、别造轮子就是最恰当的安全”,这里我又把表单认证的高自由度说成是一大优点,好话都让我给说全了。
其实啊,我提倡用标准规范去解决安全领域的共性问题,这条原则完全没有必要与界面是否美观合理、操作流程是否灵活便捷这些应用需求对立起来。
比如,想要支持密码或扫码等多种登录方式、想要支持图形验证码来驱逐爬虫与机器人、想要支持在登录表单提交之前进行必要的表单校验,等等,这些需求都很具体,不具备写入标准规范的通用性,但它们都具备足够的合理性,应当在实现层面去满足。
同时,如何控制权限保证不产生越权操作、如何传输信息保证内容不被窃听篡改、如何加密敏感内容保证即使泄漏也不被逆推出明文,等等,这些问题也已经有了通行的解决方案,明确定义在规范之中,因此也应当在架构层面去遵循。
所以说, 表单认证与 HTTP 认证不见得是完全对立的,它们分别有不同的关注点,可以结合使用。 就以 Fenix’s Bootstore 的登录功能为例,这个项目的页面表单是一个自行设计的 Vue.js 页面,但认证的整个交互过程,就遵循了 OAuth 2.0 规范的密码模式来完成。
2019 年 3 月,万维网联盟批准了由 FIDO (Fast IDentity Online,一个安全、开放、防钓鱼、无密码认证标准的联盟)领导起草的世界首份 Web 内容认证的标准” WebAuthn “(在这节课里,我们只讨论 WebAuthn,不会涉及 CTAP、U2F 和 UAF)。如果你的思维很严谨的话,可能又会觉得奇怪和矛盾了:不是才说了 Web 表单长什么样、要不要验证码、登录表单是否在客户端校验等等,是十分具体的需求,不太可能定义在规范上的吗?
确实如此,所以 WebAuthn 彻底抛弃了传统的密码登录方式 ,改为直接采用生物识别(指纹、人脸、虹膜、声纹)或者实体密钥(以 USB、蓝牙、NFC 连接的物理密钥容器)来作为身份凭证,从根本上消灭了用户输入错误产生的校验需求,以及防止机器人模拟产生的验证码需求等问题,甚至连表单界面都可能省略掉,所以这个规范不关注界面该是什么样子、要不要验证码、是否要前端校验等这些问题。
不过,由于 WebAuthn 相对比较复杂,在学习后面的内容之前,我建议如果你的设备和环境允许的话,可以先在 GitHub 网站的 2FA 认证功能 中,实际体验一下通过 WebAuthn 完成的两段式登录。
在硬件方面,需要你用带有 TouchBar 的 MacBook,或者其他支持指纹、FaceID 验证的手机均可,现在应该在售的移动设备基本都带有生物识别的装置了。在软件方面,直至 iOS13.6,iPhone 和 iPad 都不支持 WebAuthn,但 Android 和 macOS 系统中的 Chrome,以及 Windows 的 Edge 浏览器,都已经可以正常使用 WebAuthn 了。

WebAuthn 规范涵盖了”注册”与”认证”两大流程,我先来介绍下注册流程的大致步骤:
- 用户进入系统的注册页面,这个页面的格式、内容和用户注册时需要填写的信息,都不包含在 WebAuthn 标准的定义范围内。
- 当用户填写完信息,点击”提交注册信息”的按钮后,服务端先暂存用户提交的数据,生成一个随机字符串(规范中称为 Challenge)和用户的 UserID(在规范中称作凭证 ID),返回给客户端。
- 客户端的 WebAuthn API 接收到 Challenge 和 UserID,把这些信息发送给验证器(Authenticator),这个验证器你可以理解为用户设备上 TouchBar、FaceID、实体密钥等认证设备的统一接口。
- 验证器提示用户进行验证,如果你的机器支持多种认证设备,还会提示用户选择一个想要使用的设备。验证的结果是生成一个密钥对(公钥和私钥),验证器自己存储好私钥、用户信息以及当前的域名。然后使用私钥对 Challenge 进行签名,并将签名结果、UserID 和公钥一起返回给客户端。
- 浏览器将验证器返回的结果转发给服务器。
- 服务器核验信息,检查 UserID 与之前发送的是否一致,并对比用公钥解密后得到的结果与之前发送的 Challenge 是否一致,一致即表明注册通过,服务端存储该 UserID 对应的公钥。
你可以参考一下这个注册步骤的时序图:

登录流程其实跟注册流程差不多,如果你理解了注册流程,登录就比较简单了,大致可以分为这样几个步骤:
- 用户访问登录页面,填入用户名后即可点击登录按钮。
- 服务器返回随机字符串 Challenge、用户 UserID。
- 浏览器将 Challenge 和 UserID 转发给验证器。
- 验证器提示用户进行认证操作。由于在注册阶段,验证器已经存储了该域名的私钥和用户信息,所以如果域名和用户都相同的话,就不需要生成密钥对了,直接以存储的私钥加密 Challenge,然后返回给浏览器。
- 服务端接收到浏览器转发来的被私钥加密的 Challenge,以此前注册时存储的公钥进行解密,如果解密成功则宣告登录成功。
WebAuthn 采用非对称加密的公钥、私钥替代传统的密码,这是非常理想的认证方案。 私钥是保密的,只有验证器需要知道它,连用户本人都不需要知道,也就没有人为泄漏的可能;公钥是公开的,可以被任何人看到或存储。
另外,公钥可用于验证私钥生成的签名,但不能用来签名,除了得知私钥外,没有其他途径能够生成可被公钥验证为有效的签名,这样服务器就可以通过公钥是否能够解密,来判断最终用户的身份是否合法。
而且,WebAuthn 还一揽子地解决了传统密码在网络传输上的风险,在”保密”一节课中,我们还会讲到无论密码是否在客户端进行加密、如何加密,对防御中间人攻击来说都是没有意义的。
更值得夸赞的是,WebAuthn 还为登录过程带来了极大的便捷性,不仅注册和验证的用户体验十分优秀,而且彻底避免了用户在一个网站上泄漏密码,所有使用相同密码的网站都受到攻击的问题,这个优点可以让用户不需要再为每个网站想不同的密码。
当然,现在的 WebAuthn 还很年轻,普及率暂时还很有限,但我相信,几年之内它必定会发展成 Web 认证的主流方式,被大多数网站和系统所支持。
认证的实现
OK,在了解了业界标准的认证规范以后,我们再来看看在 Java 技术体系内,通常都是如何实现安全认证的。
Java 其实也有自己的认证规范,第一个系统性的 Java 认证规范发布于 Java 1.3 时代,Sun 公司提出了同时 面向代码级安全和用户级安全的认证授权服务 JAAS (Java Authentication and Authorization Service,1.3 处于扩展包中,1.4 纳入标准包)。不过,尽管 JAAS 已经开始照顾了最终用户的认证,但相对而言,该规范中代码级安全仍然占更主要的地位。
可能今天用过、甚至是听过 JAAS 的 Java 程序员都已经不多了,但是这个规范提出了很多在今天仍然活跃于主流 Java 安全框架中的概念。比如说,一般把用户存放在”Principal”之中、密码存在”Credentials”之中、登录后从安全上下文”Context”中获取状态等常见的安全概念,都可以追溯到这一时期所定下的 API:
- LoginModule (javax.security.auth.spi.LoginModule)
- LoginContext (javax.security.auth.login.LoginContext)
- Subject (javax.security.auth.Subject)
- Principal (java.security.Principal)
- Credentials(javax.security.auth.Destroyable、javax.security.auth.Refreshable)
可是,虽然 JAAS 开创了这些沿用至今的安全概念,但其规范本身,实质上并没有得到广泛的应用。我认为主要有两大原因。
一方面是由于,JAAS 同时面向代码级和用户级的安全机制,使得它过度复杂化,难以推广。在这个问题上,Java 社区一直有做持续的增强和补救,比如 Java EE 6 中的 JASPIC、Java EE 8 中的 EE Security:
- JSR 115: Java Authorization Contract for Containers (JACC)
- JSR 196: Java Authentication Service Provider Interface for Containers (JASPIC)
- JSR 375: Java EE Security API (EE Security)
而另一方面,也可能是更重要的一个原因,就是在 21 世纪的第一个十年里,以”With EJB”为口号、以 WebSphere、Jboss 等为代表 J2EE 容器环境 ,与以”Without EJB”为口号、以 Spring、Hibernate 等为代表的 轻量化开发框架 ,产生了激烈的竞争,结果是后者获得了全面胜利。
这个结果就导致了依赖于容器安全的 JAAS 无法得到大多数人的认可。在今时今日,实际活跃于 Java 安全领域的,是两个 私有的 (私有的意思是不由 JSR 所规范的,即没有 java/javax.* 作为包名的)的安全框架: Apache Shiro 和 Spring Security 。
那么,相较而言,Shiro 更加便捷易用,而 Spring Security 的功能则要复杂强大一些。因此在后面课程中要介绍的 Fenix’s Bookstore 项目中,无论是单体架构、还是微服务架构,我都选择了 Spring Security 作为安全框架,这个选择与功能、性能之类的考量没什么关系,就只是因为 Spring Boot、Spring Cloud 全家桶的缘故(这里我不打算罗列代码来介绍 Shiro 与 Spring Security 的具体使用,如果你感兴趣可以参考 Fenix’s Bookstore 的源码仓库 )。
只从目标上来看,两个安全框架提供的功能都很类似,大致包括以下四类:
- 认证功能:以 HTTP 协议中定义的各种认证、表单等认证方式确认用户身份,这也是这节课所探讨的主要话题。
- 安全上下文:用户获得认证之后,要开放一些接口,让应用可以得知该用户的基本资料、用户拥有的权限、角色,等等。
- 授权功能:判断并控制认证后的用户对什么资源拥有哪些操作许可,这部分内容我会在下一节课讲”授权”时介绍。
- 密码的存储与验证:密码是烫手的山芋,不管是存储、传输还是验证,都应该谨慎处理,这部分内容我会放到”保密”一讲去具体讨论。
小结
这节课,我们了解了信道、协议和内容这三种主要标准化认证类型的其中两种,分别是 HTTP 认证(协议)和 Web 认证(内容)。现在你应该就很清楚 HTTP 认证和 Web 认证的特点了,那就是认证的载体不一样,决定了认证的形式和功能范围都有不同。
另外我还给你介绍了它们各自的工作流程,其中你要关注的重点是认证框架的整体的运作,不必一下子陷入到具体的认证方案上去。
除此之外,我还介绍了认证标准在 Java 中的落地实现。在 Java 技术体系中,原本也有自己的认证标准与实现,那就是依赖于 JAAS 的面向代码级和用户级的安全机制,不过目前应用更广泛的反而是两个私有的安全框架,这又是一个官方标准被民间草根框架击败的例子,可见软件中设计必须贴近实际用户,才能达到实用的效果。
24 | 授权(上):系统如何确保授权的过程可靠?
在上节课,我们探讨了信息系统中关于安全认证的相关话题,它主要解决的是”你是谁”的问题。那么今天我们要探讨的授权话题,是要解决”你能干什么”的问题。
“授权”这个概念通常伴随着”认证””审计””账号”一同出现,被合称为 AAAA(Authentication、Authorization、Audit、Account)。授权行为在程序中的应用也是非常广泛的,我们给某个类或某个方法设置范围控制符(如 public、protected、private、),本质上也是一种授权(访问控制)行为。
而在安全领域中,我们所谈论的授权就更要具体一些,它通常涉及到以下两个相对独立的问题:
确保授权的过程可靠
对于单一系统来说,授权的过程是比较容易做到可控的,以前在很多语境上提到授权,实质上讲的都是访问控制,理论上两者是应该分开的。
而在涉及多方的系统中,授权过程则是一个比较困难,但必须要严肃对待的问题:如何既让第三方系统能够访问到所需的资源,又能保证其不泄露用户的敏感数据?现在,常用的多方授权协议主要有 OAuth 2.0 和 SAML 2.0(两个协议涵盖的功能并不是直接对等的)。
确保授权的结果可控
授权的结果是用于对程序功能或者资源的 访问控制 (Access Control)。现在,已形成理论体系的权限控制模型有很多,比如 自主访问控制 (Discretionary Access Control,DAC)、 强制访问控制 (Mandatory Access Control,MAC)、 基于属性的访问控制 (Attribute-Based Access Control,ABAC),还有最为常用的 基于角色的访问控制 (Role-Based Access Control,RBAC)。
所以,在接下来的两节课中,我们将会围绕前面这两个问题,分别以 Fenix’s Bookstore 中用到的 OAuth 2.0 和 RBAC 为例,去探讨软件业界中授权的标准协议与实现。
好,下面我们就先来看看,OAuth 2.0 的具体工作流程是什么样的吧。
OAuth 2.0 解决的是第三方服务中涉及的安全授权问题
OAuth 2.0 是一种相对复杂繁琐的认证授权协议。它是在 RFC 6749 中定义的国际标准,RFC 6749 正文的第一句就阐明了 OAuth 2.0 是面向于解决第三方应用(Third-Party Application)的认证授权协议。
如果你的系统并不涉及到第三方,比如单体架构的 Fenix’s Bookstore 中,就既不为第三方提供服务,也不使用第三方的服务,那引入 OAuth 2.0 其实就没必要。
这里我为什么要强调第三方呢? 在多方系统授权的过程中,具体会有什么问题,需要专门制定一个标准协议来解决呢?
我举个现实的例子来给你解释一下。”The Fenix Project”这部文档的 官方网站 ,它的建设和更新的大致流程是:我以 Markdown 形式写好了某篇文章,上传到由 GitHub 提供的代码仓库 ,接着由 Travis-CI 提供的持续集成服务会检测到该仓库发生了变化,触发一次 Vuepress 编译活动,生成目录和静态的 HTML 页面,然后推送回 GitHub Pages,再触发国内的 CDN 缓存刷新。
如果要想保证这个过程能顺利进行,就存在一系列必须要解决的授权问题,Travis-CI 只有得到了我的明确授权,GitHub 才能同意它读取我代码仓库中的内容。问题是,它该如何获得我的授权呢?
一种最简单粗暴的方案是把我的用户账号和密码都告诉 Travis-CI,但这显然会导致下面这些问题:
- 密码泄漏 :如果 Travis-CI 被黑客攻破,将导致我的 GitHub 的密码也同时被泄漏。
- 访问范围 :Travis-CI 将有能力读取、修改、删除、更新我放在 GitHub 上的所有代码仓库,而我并不希望它能够修改删除文件。
- 授权回收 :只有修改密码才能回收我授予给 Travis-CI 的权限,可是我在 GitHub 的密码只有一个,授权的应用除了 Travis-CI 之外却还有许多,修改了就意味着所有别的第三方的应用程序会全部失效。
那么,前面列举的这些问题,也正是 OAuth 2.0 所要解决的问题,尤其是要求第三方系统在没有支持 HTTPS 传输安全的环境下,依然能够解决这些问题,这可不是件容易的事情。
因此,OAuth 2.0 给出了很多种解决办法,这些办法的共同特征是以令牌(Token)代替用户密码作为授权的凭证。有了令牌之后,哪怕令牌被泄漏,也不会导致密码的泄漏;令牌上可以设定访问资源的范围以及时效性;每个应用都持有独立的令牌,哪个失效都不会波及其他。
这样一下子前面提出的三个问题就都解决了,有了一层令牌之后,整个授权的流程如下图所示:
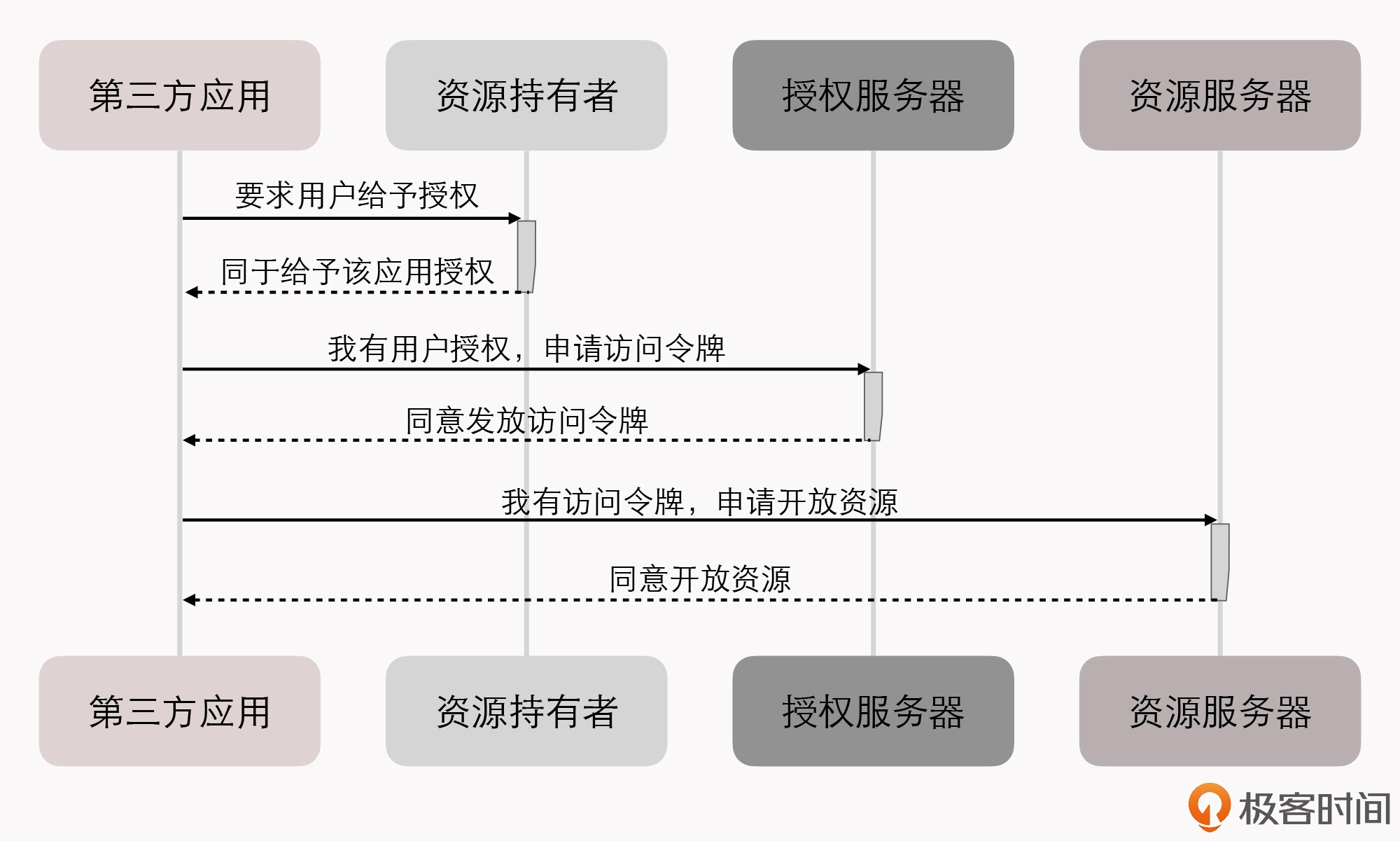
这个时序图里涉及到了 OAuth 2.0 中的几个关键术语,我们根据前面的例子,一起来解读下它们的含义,这对理解后面要介绍的几种授权模式非常重要:
- 第三方应用(Third-Party Application):需要得到授权访问我资源的那个应用,即此场景中的”Travis-CI”。
- 授权服务器(Authorization Server):能够根据我的意愿提供授权(授权之前肯定已经进行了必要的认证过程,但它与授权可以没有直接关系)的服务器,即此场景中的”GitHub”。
- 资源服务器(Resource Server):能够提供第三方应用所需资源的服务器,它与认证服务可以是相同的服务器,也可以是不同的服务器,即此场景中的”我的代码仓库”。
- 资源所有者(Resource Owner): 拥有授权权限的人,即此场景中的”我”。
- 操作代理(User Agent):指用户用来访问服务器的工具,对于人类用户来说,这个通常是指浏览器。但在微服务中,一个服务经常会作为另一个服务的用户,此时指的可能就是 HttpClient、RPCClient 或者其他访问途径。
OAuth 2.0 的认证流程
当然,”用令牌代替密码”确实是解决问题的好方法,但这充其量只能算个思路,距离可实施的步骤还是不够具体。所以,时序图中的 “要求 / 同意授权””要求 / 同意发放令牌””要求 / 同意开放资源” 这几个服务请求、响应要如何设计,就是执行步骤的关键了。
对此,OAuth 2.0 一共提出了四种不同的授权方式(这是我为什么说 OAuth 2.0 较为复杂繁琐的其中一个原因),分别为:
- 授权码模式(Authorization Code)
- 简化模式(Implicit)
- 密码模式(Resource Owner Password Credentials)
- 客户端模式(Client Credentials)
接下来,我们就一一来解读下这四种授权方式的具体流程,以此理解 OAuth 2.0 是如何实现多方系统中相对安全、相对可控的授权的。
授权码模式
授权码模式是四种模式中最严(luō)谨(suō)的,它考虑到了几乎所有敏感信息泄露的预防和后果。我们来看看这种模式的具体步骤:
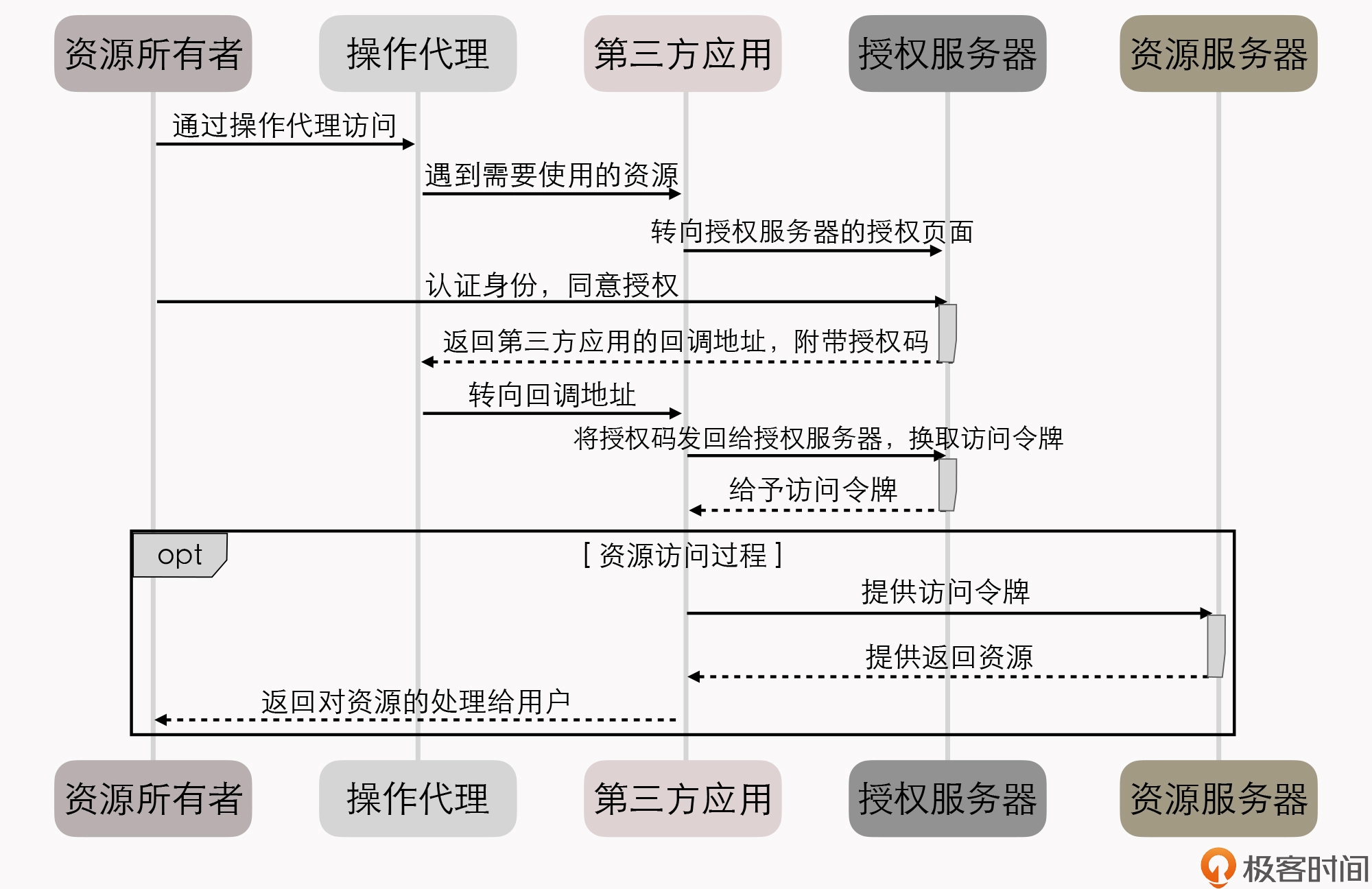
这里你要注意,在开始进行授权过程之前,第三方应用要先到授权服务器上进行注册。所谓的注册,是指第三方应用向认证服务器提供一个域名地址,然后从授权服务器中获取 ClientID 和 ClientSecret,以便能够顺利完成如下的授权过程:
- 第三方应用将资源所有者(用户)导向授权服务器的授权页面,并向授权服务器提供 ClientID 及用户同意授权后的回调 URI,这是第一次客户端页面转向。
- 授权服务器根据 ClientID 确认第三方应用的身份,用户在授权服务器中决定是否同意向该身份的应用进行授权。注意,用户认证的过程未定义在此步骤中,在此之前就应该已经完成。
- 如果用户同意授权,授权服务器将转向第三方应用在第 1 步调用中提供的回调 URI,并附带上一个授权码和获取令牌的地址作为参数,这是第二次客户端页面转向。
- 第三方应用通过回调地址收到授权码,然后将授权码与自己的 ClientSecret 一起作为参数,通过服务器向授权服务器提供的获取令牌的服务地址发起请求,换取令牌。该服务器的地址应该与注册时提供的域名处于同一个域中。
- 授权服务器核对授权码和 ClientSecret,确认无误后,向第三方应用授予令牌。令牌可以是一个或者两个,其中必定要有的是访问令牌(Access Token),可选的是刷新令牌(Refresh Token)。访问令牌用于到资源服务器获取资源,有效期较短,刷新令牌用于在访问令牌失效后重新获取,有效期较长。
- 资源服务器根据访问令牌所允许的权限,向第三方应用提供资源。
由此你也能看到,这个过程设计已经考虑到了几乎所有合理的意外情况。这里我再给你举几个容易遇到的意外情况的例子,以便你能够更好地理解为何 OAuth 2.0 要这样设计:
会不会有其他应用冒充第三方应用骗取授权?
ClientID 代表一个第三方应用的”用户名”,这项信息是可以完全公开的。但 ClientSecret 应当只有应用自己才知道,这个代表了第三方应用的”密码”。在第 5 步发放令牌时,调用者必须能够提供 ClientSecret 才能成功完成。只要第三方应用妥善保管好 ClientSecret,就没有人能够冒充它。
为什么要先发放授权码,再用授权码换令牌?
这是因为客户端转向(通常就是一次 HTTP 302 重定向)对于用户是可见的。换言之,授权码可能会暴露给用户以及用户机器上的其他程序,但由于用户并没有 ClientSecret,光有授权码也无法换取到令牌,所以就避免了令牌在传输转向过程中被泄漏的风险。
为什么要设计一个时限较长的刷新令牌和时限较短的访问令牌?不能直接把访问令牌的时间调长吗?
这是为了缓解 OAuth 2.0 在实际应用中的一个主要缺陷。因为通常情况下,访问令牌一旦发放,除非超过了令牌中的有效期,否则很难有其他方式让它失效。所以访问令牌的时效性一般会设计得比较短,比如几个小时,如果还需要继续用,那就定期用刷新令牌去更新,授权服务器可以在更新过程中决定是否还要继续给予授权。至于为什么说很难让它失效,我们将放到下一讲”凭证”中去解释。
不过,尽管授权码模式是很严谨的,但它并不够好用,这不仅仅体现在它那繁复的调用过程上,还体现在它对第三方应用提出了一个”貌似不难”的要求:第三方应用必须有应用服务器,因为第 4 步要发起服务端转向,而且要求服务端的地址必须与注册时提供的地址在同一个域内。
你不要觉得,要求一个系统要有应用服务器是天经地义理所当然的事情,”The Fenix Project”这部文档的 官方网站 就没有任何应用服务器的支持,里面使用到了 Gittalk 作为每篇文章的留言板,它对 GitHub 来说照样是第三方应用,需要 OAuth 2.0 授权来解决。
除了基于浏览器的应用外,现在越来越普遍的是移动或桌面端的客户端 Web 应用(Client-Side Web Applications),比如现在大量的基于 Cordova、Electron、Node-Webkit.js 的 PWA 应用 ,它们都不会有应用服务器的支持。
正是因为有这样的实际需求,就引出了 OAuth 2.0 的第二种授权模式: 隐式授权。
隐式授权
隐式授权省略掉了通过授权码换取令牌的步骤,整个授权过程都不需要服务端的支持,一步到位。而使用的代价是在隐式授权中,授权服务器 不会再去验证第三方应用的身份 ,因为已经没有应用服务器了,ClientSecret 没有人保管,就没有存在的意义了。
但隐式授权中的授权服务器,还是会限制第三方应用的回调 URI 地址必须与注册时提供的域名一致,虽然有可能会被 DNS 污染之类的攻击所攻破,但这也算是它尽可能地努力了一下吧。同样的原因,隐式授权也不能避免令牌暴露给资源所有者,不能避免用户机器上可能意图不轨的其他程序、HTTP 的中间人攻击等风险。
隐式授权的调用时序图如下图所示(后面展示的几种授权模式,时序图中我就不再画出资源访问部分的内容了,就是前面授权码图例中 opt 框里的那一部分,以便更聚焦重点):
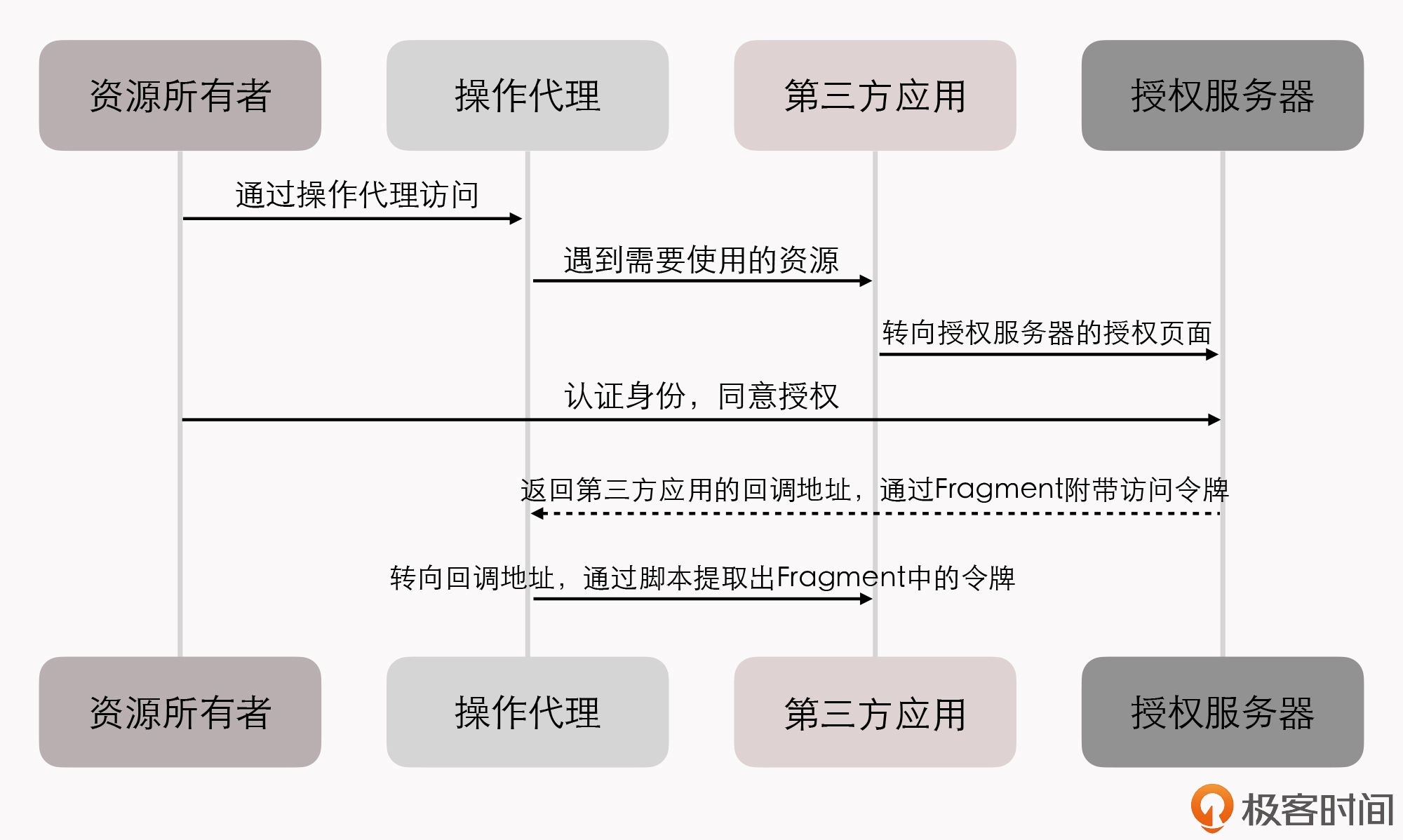
你可以发现,在这个交互过程里, 隐式模式与授权码模式的显著区别是授权服务器在得到用户授权后,直接返回了访问令牌 ,这很明显会降低授权的安全性。
但 OAuth 2.0 仍然在尽可能地努力做到相对安全,比如前面我提到在隐式授权中,尽管不需要用到服务端,但仍然需要在注册时提供回调域名,此时会要求该域名与接受令牌的服务处于同一个域内。此外,同样基于安全考虑,在隐式模式中也明确禁止发放刷新令牌。
还有一点,在 RFC 6749 对隐式授权的描述中,特别强调了令牌必须是”通过 Fragment 带回”的。如果你对超文本协议没有多少了解的话,可能还不知道 Fragment 是个什么东西,我们来看一下它的英文释义。
Fragment
In computer hypertext, a fragment identifier is a string of characters that refers to a resource that is subordinate to another, primary resource. The primary resource is identified by a Uniform Resource Identifier (URI), and the fragment identifier points to the subordinate resource.
——URI Fragment,Wikipedia
要是你看完后,还是觉得概念不好理解的话,我就简单告诉你,Fragment 就是地址中”#”号后面的部分,比如这个地址:
http://bookstore.icyfenix.cn/#/detail/1后面的 /detail/1 便是 Fragment,这个语法是在 RFC 3986 中定义的。该规范中解释了这是用于客户端定位的 URI 从属资源,比如在 HTML 中,就可以使用 Fragment 来做文档内的跳转而不会发起服务端请求。
此外,RFC 3986 还规定了,如果浏览器对一个带有 Fragment 的地址发出 Ajax 请求,那 Fragment 是不会跟随请求被发送到服务端的,只能在客户端通过 Script 脚本来读取。
所以,隐式授权巧妙地利用这个特性,尽最大努力地 避免了令牌从操作代理到第三方服务之间的链路,存在被攻击而泄露出去的可能性。
至于认证服务器到操作代理之间的这一段链路的安全,则只能通过 TLS(即 HTTPS)来保证不会受到中间人攻击了,我们可以要求认证服务器必须都是启用 HTTPS 的,但无法要求第三方应用同样都支持 HTTPS。
密码模式
前面所说的授权码模式和隐式模式都属于纯粹的授权模式,它们与认证没有直接的联系,如何认证用户的真实身份,跟如何进行授权是两个互相独立的过程。但在密码模式里,认证和授权就被整合成了同一个过程。
密码模式原本的设计意图是,仅限于在用户对第三方应用是高度可信任的场景中使用,因为用户需要把密码明文提供给第三方应用,第三方以此向授权服务器获取令牌。
这种高度可信的第三方是非常罕见的,尽管在介绍 OAuth 2.0 的材料中,经常举的例子是”操作系统作为第三方应用向授权服务器申请资源”,但真实应用中极少遇到这样的情况,合理性依然十分有限。
我认为,如果要采用密码模式,那”第三方”属性就必须弱化 ,把”第三方”看作是系统中与授权服务器相对独立的子模块,在物理上独立于授权服务器部署,但是在逻辑上与授权服务器仍同属一个系统。这样把认证和授权一并完成的密码模式,才会有合理的应用场景。
比如说,Fenix’s Bookstore 就直接采用了密码模式,将认证和授权统一到一个过程中完成,尽管 Fenix’s Bookstore 中的 Frontend 工程和 Account 工程,都能直接接触到用户名和密码,但它们事实上都是整个系统的一部分,在这个前提下密码模式才具有可用性(关于分布式系统各个服务之间的信任关系,我会在”零信任网络”与”服务安全”两讲中和你作进一步讨论)。
这样,理解了密码模式的用途,你再去看它的调用过程就很简单了,也就是第三方应用拿着用户名和密码向授权服务器换令牌而已。具体的时序如下图所示:
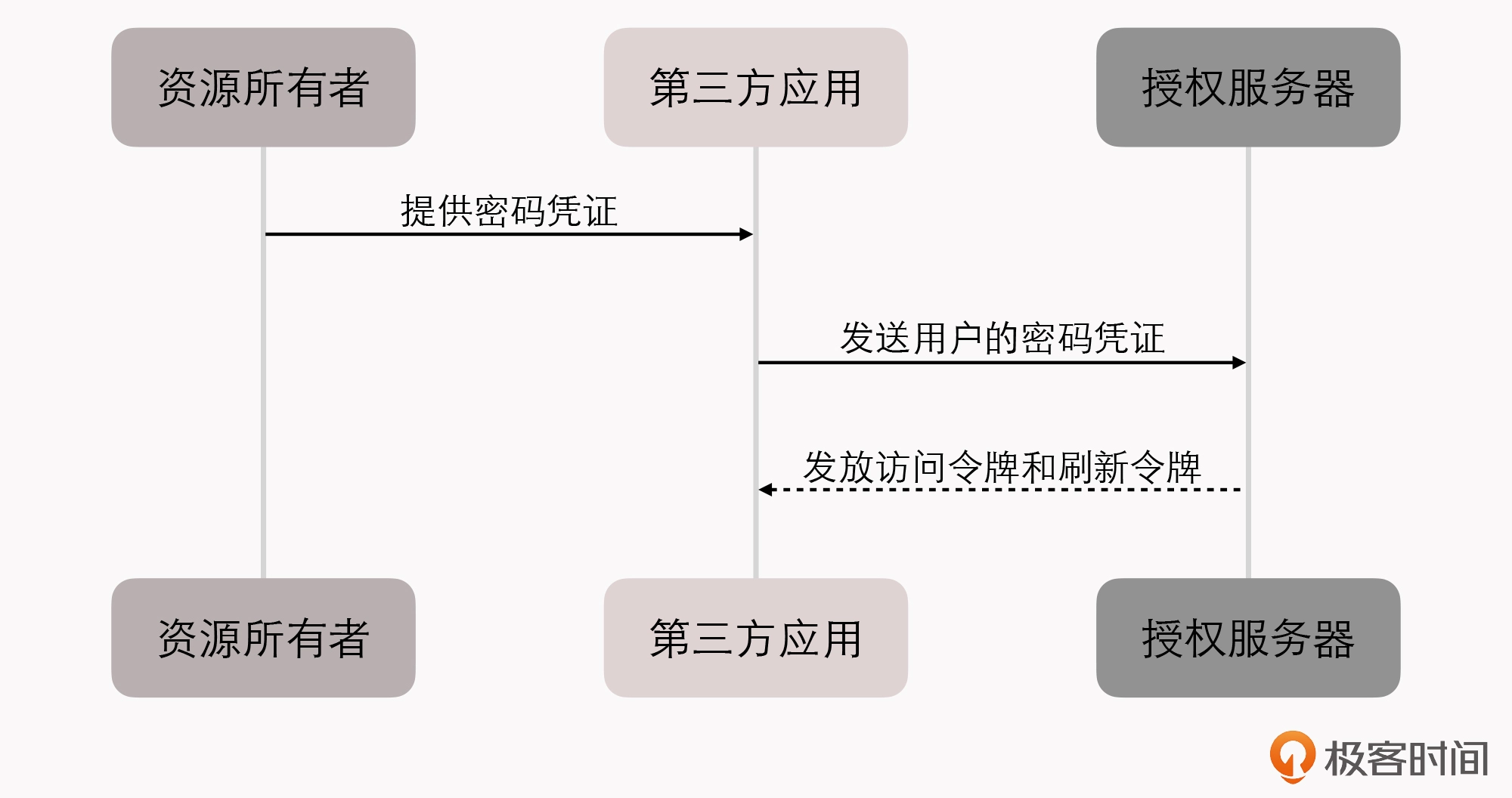
此外你还要明确一件事,在密码模式下,”如何保障安全”的职责无法由 OAuth 2.0 来承担,只能由用户和第三方应用来自行保障,尽管 OAuth 2.0 在规范中强调到”此模式下,第三方应用不得保存用户的密码”,但这并没有任何技术上的约束力。
OK,我们再来看看 OAuth 2.0 的最后一种授权模式:客户端模式。
客户端模式
客户端模式是四种模式中 最简单 的,它只涉及到两个主体: 第三方应用和授权服务器 。如果我们严谨一点,现在叫”第三方应用”其实已经不合适了,因为已经没有了”第二方”的存在,资源所有者、操作代理在客户端模式中都是不必出现的。甚至严格来说,叫”授权”都已经不太恰当,毕竟资源所有者都没有了,也就不会有谁授予谁权限的过程。
那么,客户端模式就是指第三方应用(考虑到前后统一,我们还是继续沿用这个称呼)以自己的名义,向授权服务器申请资源许可。 这种模式通常用于管理操作或者自动处理类型的场景中。
举个具体例子。比如我开了一家叫 Fenix’s Bookstore 的书店,因为小本经营,不像京东那样全国多个仓库可以调货,因此我必须保证只要客户成功购买,书店就必须有货可发,不允许超卖。但问题是,经常有顾客下了订单又拖着不付款,导致部分货物处于冻结状态。
所以,Fenix’s Bookstore 中有一个订单清理的定时服务,自动清理超过两分钟还未付款的订单。在这个场景里,订单肯定是属于下单用户自己的资源,如果把订单清理服务看作是一个独立的第三方应用的话,它是不可能向下单用户去申请授权来删掉订单的,而是应该直接以自己的名义,向授权服务器申请一个能清理所有用户订单的授权。那么这个客户端模式的时序就会是这样的:
在微服务架构中,其实并不提倡同一个系统的各服务间有默认的信任关系,所以服务之间的调用也需要先进行认证授权,然后才能通讯。
那么此时,客户端模式便是一种常用的服务间认证授权的解决方案。Spring Cloud 版本的 Fenix’s Bookstore 就是采用这种方案,来保证微服务之间的合法调用的;而 Istio 版本的 Fenix’s Bookstore 则启用了双向 mTLS 通讯,使用客户端证书来保障安全。它们可作为上一节课我介绍认证时,提到的”通讯信道认证”和”通讯内容认证”的例子,你要是感兴趣可以对比一下这两种方式的差异优劣。
此外,在 OAuth 2.0 中呢,还有一种与客户端模式类似的授权模式,在 RFC 8628 中定义为” 设备码模式 “(Device Code),这里我顺带提一下。
设备码模式用于在无输入的情况下区分设备是否被许可使用,典型的应用就是手机锁网解锁(锁网在国内较少,但在国外很常见)或者设备激活(比如某游戏机注册到某个游戏平台)的过程。它的时序如下图所示:
这里你可以记着,采用设备码模式在进行验证时,设备需要从授权服务器获取一个 URI 地址和一个用户码,然后需要用户手动或设备自动地到验证 URI 中输入用户码。在这个过程中,设备会一直循环,尝试去获取令牌,直到拿到令牌或者用户码过期为止。
设备码设计的目的是让设备投入工作前,必须获得用户的授权。
假设所有设备都有键盘、屏幕这样的用户交互能力,最佳的方式确实如你所说,让设备直接与授权服务器交互就行了。
但你设想一下,如果你买的是一台输入受限的设备,譬如打印机、电视,甚至是冰箱、热水器这些智能家电,这时候就需要有一个间接层的存在,引导用户能够使用其他能够进行输入的设备(譬如手机)去授权。
25 | 授权(下):系统如何确保授权的结果可控?
你好,我是周志明。今天,我们接着上一讲的话题,继续来探究关于授权的第二个核心问题:系统如何确保授权的结果可控?
在上节课的开篇,我提到了授权的结果是用于对程序功能或者资源的 访问控制 (Access Control),并且也给你介绍了一种最为常用的权限控制模型 RBAC( 基于角色的访问控制 ,Role-Based Access Control)。
那么这节课,我就来和你聊聊这种访问控制模型的概念、原理和一些要注意的问题。希望你能在理解了 RBAC 是如何运作的之后,将其灵活运用在自己实际工作中关于功能、数据权限的管理上,而且这也是为后面学习 Kubernetes 的权限控制、服务安全等内容提前做的铺垫工作。
好,接下来,我们就从 RBAC 的几个基础概念开始学起吧。
RBAC 的基础概念
首先,我们要明确,所有的访问控制模型,实质上都是在解决同一个问题: 谁(User)拥有什么权限(Authority)去操作(Operation)哪些资源(Resource)。
这个问题初看起来并不太难,一种直观的解决方案就是在用户对象上设定一些权限,当用户使用资源时,检查是否有对应的操作权限即可。很多著名的安全框架,比如 Spring Security 的访问控制,本质上就是支持这么做的。
不过,这种把权限直接关联在用户身上的简单设计,在复杂系统上确实会导致一些比较繁琐的问题。
你可以试想一下, 如果某个系统涉及到成百上千的资源,又有成千上万的用户,一旦两者搅合到一起,要为每个用户访问每个资源都分配合适的权限,就必定会导致巨大的操作量和极高的出错概率。
而这也正是 RBAC 所关注的核心问题。
RBAC 模型在业界有很多种说法,其中,最具系统性且得到了普遍认可的说法,是美国乔治梅森(George Mason)大学信息安全技术实验室提出的 RBAC96 模型 。
为了避免对每一个用户设定权限,RBAC 将权限从用户身上剥离,改为绑定到”角色”(Role)上,”权限控制”这项工作,就可以具体化成针对”角色拥有操作哪些资源的许可”这个逻辑表达式的值是否为真的求解过程。
这个逻辑表达式中涉及的关键概念有用户、角色、资源等,我画了张图,你可以参考图中展示的 RBAC 主要元素之间的关系:

其中,你可能发现了,除了前面提到的用户、角色和资源以外,图上还出现了一个新的名词”许可”(Permission)。
许可其实是抽象权限的具象化体现。 权限在 RBAC 系统中的含义是”允许何种操作作用于哪些资源之上”,这句话的具体实例即为”许可”。
提出许可这个概念的目的,其实跟提出角色的目的是完全一致的,只是许可会更抽象。角色为的是解耦用户与权限之间的多对多关系,而许可为的是解耦操作与资源之间的多对多关系。比如说,不同的数据都能够有增、删、改等操作,而如果把操作与数据搅和在一起,也会面临前面我提到的权限配置膨胀的问题。
不过现在,你可能快被这些概念、逻辑给绕晕了。没事儿,我再给你举个更具体的例子,帮你理清这一堆名词之间的关系。
想像一下,某个论文管理系统的 UserStory 中,与访问控制相关的 Backlog 可能会是这样描述的:
Backlog:周同学(User)是某 SCI 杂志的审稿人(Role),职责之一是在系统中审核论文(Authority)。在审稿过程(Session)中,当他认为某篇论文(Resource)达到了可以公开发表的标准时,就会在后台点击”通过”按钮(Operation)来完成审核。
所以,在这个 Backlog 中,”给论文点击通过按钮”就是一种许可,它是”审核论文”这项权限的具象化体现。现在你是不是就清楚一些了?
另外我还想强调的是,采用 RBAC 的角色、资源等概念不仅是为了简化配置操作,通过设定这些概念之间的关系与约束,还是很多关键的安全原则和设计原则的实现基础。下面,我们就从计算机安全中的” 最小特权原则 “(Least Privilege)开始来了解一下吧。
RBAC 的概念间关系
在 RBAC 模型中,角色拥有许可的数量,是根据完成该角色工作职责所需的最小权限所赋予的。
最典型的例子是 操作系统权限管理中的用户组 。即根据对不同角色的职责分工,如管理员(Administrator)、系统用户(System)、验证用户(Authenticated Users)、普通用户(Users)、来宾用户(Guests)等,分配其各自的权限。这样就既保证了用户能够正常工作,也避免了用户出现越权操作的风险。
而当用户的职责发生变化时,在系统中就体现为它所隶属的角色被改变,比如将”普通用户角色”改变为”管理员角色”,就可以迅速让该用户具备管理员的多个细分权限,降低权限分配错误的风险。
另外,RBAC 还允许定义不同角色之间的关联与约束关系,以此进一步强化它的抽象描述能力。
比如说,不同的角色之间可以有继承性,典型的就是 RBAC-1 模型的角色权限继承关系。
我举个例子。如果要描述开发经理应该和开发人员一样具有代码提交的权限,描述开发人员应该和任何公司的员工一样具有食堂就餐的权限,那么我们就可以直接把食堂就餐的权限赋予到公司员工的角色上,把代码提交的权限赋予到开发人员的角色上,再让开发人员的角色从公司员工派生,开发经理的角色从开发人员中派生即可。
另外,不同的角色之间也可以具有互斥性,典型的就是 RBAC-2 模型的角色职责分离关系。 互斥性要求,当权限被赋予角色时、或角色被赋予用户时应该遵循的强制性职责分离规定。
我举个例子。角色的互斥约束可以限制同一用户,只能分配到一组互斥角色集合中至多一个角色,比如不能让同一名员工既当会计,也当出纳,否则资金安全无法保证。而角色的基数约束可以限制某一个用户拥有的最大角色数目,比如不能让同一名员工全部包揽产品、设计、开发、测试等工作,否则产品质量无法保证。
OK,现在我们就了解了通过 RBAC 建立的用户、角色等概念,并且也定义了它们之间的关联与约束关系,其实这些都属于 RBAC 中”Role Based”范畴的内容,而 RB 只是手段,是为了 AC 这个目的服务的。
所以接下来,我们就一起来看看”Access Control”范畴的内容,也就是 RBAC 的访问控制。
RBAC 的访问控制
建立访问控制模型的基本目的就是为了管理垂直权限和水平权限。垂直权限即功能权限,比如前面提到的审稿编辑有通过审核的权限、开发经理有代码提交的权限、出纳有从账户提取资金的权限,这一类某个角色完成某项操作的许可,都可以直接翻译为 功能权限 。
由于实际应用与权限模型具有高度对应的关系,因此把权限从具体的应用中抽离出来,放到通用的模型中是相对容易的,Spring Security、Apache Shiro 等权限框架就是这样的抽象产物,大多数系统都能采用这些权限框架来管理功能权限。
那么与此相对,要管理水平权限,也就是 数据权限 的话,则要困难得多。比如用户 A、B 都属于同一个角色,但它们各自在系统中产生的数据完全有可能是私有的,A 访问或删除了 B 的数据也照样属于越权。
一般来说,数据权限是很难抽象与通用的,仅在角色层面进行控制并不能满足全部业务的需要。很多时候,数据权限必须具体到用户,甚至具体管理到发生数据的某一行、某一列之上,因此数据权限基本上只能由信息系统自主来完成,并不存在能放之四海皆准的通用数据权限框架。
Spring Security 的 RBAC 实现
在课程后面要介绍的”不可变基础设施”的模块里,其中要讲解的一个”重要角色”Kubernetes,也是完全遵循 RBAC 模型来进行服务访问控制的。Fenix’s Bookstore 所使用的 Spring Security 也参考了(但并没有完全遵循)RBAC 来设计它的访问控制功能,所以这里我就以 Spring Security 为例,给你简要介绍一下 RBAC 的实现。
在 Spring Security 的设计里,用户和角色都可以拥有权限,比如在它的 HttpSecurity 接口就同时有着 hasRole() 和 hasAuthority() 方法,如果你是刚接触 Spring Security 的设计的话,可能会混淆它们之间的关系。那么下面我们就直接来看看,Spring Security 的访问控制模型是长什么样子的,你也可以去对比一下前面的 RBAC 的关系图:
从 实现角度 来看,Spring Security 中 Role 和 Authority 的差异很小,它们完全共享同一套存储结构,唯一的差别就只是 Role 会在存储时,自动带上”ROLE_”前缀罢了。
但从 使用角度 来看,Role 和 Authority 的差异可以很大,用户可以自行决定系统中到底 Permission 只能对应到角色身上,还是可以让用户也拥有某些角色中没有的权限。
你应该会觉得,这一点好像不符合 RBAC 的思想,但我个人认为这是一种创新而非破坏,在 Spring Security 的文档上也说的很清楚: 这取决于你自己如何使用。
The core difference between these two(注:指 Role 和 Authority) is the semantics we attach to how we use the feature. For the framework, the difference is minimal - and it basically deals with these in exactly the same way.
这样,我们通过 RBAC,就很容易控制最终用户在广义和精细级别上能够做什么,我们可以指定用户是管理员、专家用户或者只是普通用户,并使角色和访问权限与组织中员工的身份职位保持一致,仅根据需要为员工完成工作的最低限度来分配权限。
这些都是人们通过设计大量的软件系统、长时间积累下来的实践经验,将这些经验运用在软件产品上,绝大多数情况下都要比自己发明创造一个新的轮子更加安全。
小结
针对如何确保授权的结果可控的问题,这节课我们学习了一种最常用的解决方案:基于角色的访问控制(RBAC)。
其中,在 Role-Based 部分,我通过一些例子,给你介绍了以角色为中心的一系列概念,以及这些概念之间的关系与约束;在 Access Control 部分,我还介绍了垂直和水平权限的控制的差异,也以 Spring Security 为例,带你了解了它的大致运作过程。你需要记住以下几个核心要点:
- 所有的访问控制模型,实质上都是在解决同一个问题:谁(User)拥有什么权限(Authority)去操作(Operation)哪些资源(Resource)。
- 为避免对每一个用户设定权限,RBAC 提出了角色和许可等概念,角色为的是解耦用户与权限之间的多对多关系,而许可为的是解耦操作与资源之间的多对多关系。
- 建立访问控制模型的基本目的就是为了管理垂直权限和水平权限。垂直权限即功能权限,水平权限则是数据权限,它很难抽象与通用。
26 | 凭证:系统如何保证与用户之间的承诺是准确完整且不可抵赖的?
在 第 24 讲 我给你介绍 OAuth 2.0 协议的时候,提到过每一种授权模式的最终目标都是拿到访问令牌,但我并没有讲拿回来的令牌应该长什么样子,反而还挖了一些坑没有填,即为什么说 OAuth 2.0 的一个主要缺陷是令牌难以主动失效。
所以,这节课我们要讨论的主角就是令牌了。我会带你了解令牌的结构、原理与实现,让你明确系统是如何保证它和用户之间的承诺是双方当时意图的体现、是准确完整且不可抵赖的;另外我还会跟你一起看看,如果不使用 OAuth 2.0 的话,通过最传统的状态管理机制的方式,系统要如何完成认证和授权。
好,那接下来,我们就先来看看 HTTP 协议中最传统的状态管理机制,Cookie-Session 是如何运作的吧。
Cookie-Session:HTTP 的状态管理机制
我们应该都知道,HTTP 协议是一种无状态的传输协议,也就是协议对事务处理没有上下文的记忆能力,每一个请求都是完全独立的。但是我想,肯定很多人都没有意识到 HTTP 协议无状态的重要性。
为什么这么说呢?假如你做了一个简单的网页,其中包含了 1 个 HTML、2 个 Script 脚本、3 个 CSS,还有 10 张图片,那么这个网页要想成功地展示在用户屏幕前,就需要完成 16 次与服务器的交互来获取这些资源。
但是,因为网络传输等各种因素的影响,服务器发送的顺序与客户端请求的先后并没有必然的联系,所以按照可能出现的响应顺序,理论上最多会有 P(16,16) = 20,922,789,888,000 种可能性。
所以我们可以试想一下,如果 HTTP 协议不是设计成无状态的,这 16 次请求每一个都有依赖关联,先调用哪一个、先返回哪一个,都会对结果产生影响的话,那么服务器与客户端交互的协调工作会有多么复杂。
可是,HTTP 协议的无状态特性,又有悖于我们最常见的网络应用场景,典型的就是认证授权,毕竟系统总得要获知用户身份才能提供合适的服务。因此,我们也希望 HTTP 能有一种手段,让服务器至少有办法区分出发送请求的用户是谁。
所以,为了实现这个目的, RFC 6265 规范就定义了 HTTP 的状态管理机制,在 HTTP 协议中增加了 Set-Cookie 指令。
这个指令的含义是以键值对的方式向客户端发送一组信息,在此后一段时间内的每次 HTTP 请求中,这组信息会附带着名为 Cookie 的 Header 重新发回给服务端,以便服务器区分来自不同客户端的请求。
我们直接来看一个典型的 Set-Cookie 指令具体是怎么做的:
Set-Cookie: id=icyfenix; Expires=Wed, 21 Feb 2020 07:28:00 GMT; Secure; HttpOnly服务器在收到该指令以后,客户端再对同一个域的请求中,就会自动附带有键值对信息”id=icyfenix”,比如说:
GET /index.html HTTP/2.0
Host: icyfenix.cn
Cookie: id=icyfenix那么,根据每次请求传到服务端的 Cookie,服务器就能分辨出请求来自于哪一个用户。由于 Cookie 是放在请求头上的,属于额外的传输负担,不应该携带过多的内容,而且放在 Cookie 中传输也并不安全,容易被中间人窃取或篡改,所以在实际情况中,通常是不会像这个例子一样,设置”id=icyfenix”这样的明文信息的。
一般来说,系统会把状态信息保存在服务端,而在 Cookie 里只传输一个无字面意义的、不重复的字符串,通常习惯上是以 sessionid 或者 jsessionid 为名。然后,服务器拿这个字符串为 Key,在内存中开辟一块空间,以 Key/Entity 的结构,来存储每一个在线用户的上下文状态,再辅以一些超时自动清理之类的管理措施。
这种服务端的状态管理机制,就是今天我们非常熟悉的 Session。 Cookie-Session 也就是最传统的,但在今天依然广泛应用于大量系统中的、由服务端与客户端联动来完成的状态管理机制。
Cookie-Session 的方案在安全架构的系统当中,其实是占有一定天生优势的:因为状态信息都存储于服务器,只要依靠客户端的 同源策略 和 HTTPS 的传输层安全,保证 Cookie 中的键值不被窃取而出现被冒认身份的情况,就能完全规避掉信息在传输过程中被泄露和篡改的风险。
Cookie-Session 方案另一大优点是服务端有主动的状态管理能力,可以根据自己的意愿随时修改、清除任意的上下文信息,比如很轻易就能实现强制某用户下线这样的功能。
不过,Cookie-Session 在单节点的单体服务环境中确实是最合适的方案,但当服务器需要具备水平扩展服务能力,要部署集群时就有点儿麻烦了。
因为 Session 存储在服务器的内存中,那么当服务器水平拓展成多节点时,我们在设计时就必须在以下三种方案中选择其一:
- 要么就牺牲集群的一致性(Consistency) ,让均衡器采用亲和式的负载均衡算法。比如根据用户 IP 或者 Session 来分配节点,每一个特定用户发出的所有请求,都一直被分配到其中某一个节点来提供服务,每个节点都不重复地保存着一部分用户的状态,如果这个节点崩溃了,里面的用户状态便完全丢失。
- 要么就牺牲集群的可用性(Availability) ,让各个节点之间采用复制式的 Session,每一个节点中的 Session 变动,都会发送到组播地址的其他服务器上,这样即使某个节点崩溃了,也不会中断某个用户的服务。但 Session 之间组播复制的同步代价比较高昂,节点越多时,同步成本就越高。
- 要么就牺牲集群的分区容错性(Partition Tolerance) ,让普通的服务节点中不再保留状态,将上下文集中放在一个所有服务节点都能访问到的数据节点中进行存储。此时的矛盾是数据节点就成为了单点,一旦数据节点损坏或出现网络分区,整个集群都不能再提供服务。
通过 第 14 讲 内容的学习,现在我们已经知道了,只要在分布式系统中共享信息,CAP 就不可兼得,所以分布式环境中的状态管理一定会受到 CAP 的局限,无论怎样都不可能完美。
但如果,我们只是解决分布式下的认证授权问题,并顺带解决少量状态的问题,就不一定只能依靠共享信息去实现了。
我说这句话的言外之意是想先提醒一下你,接下来我要给你介绍的 JWT 令牌,跟 Cookie-Session 并不是完全对等的解决方案,它只用来处理认证授权问题,是 Cookie-Session 在认证授权问题上的替代品,充其量能携带少量非敏感的信息。而我们不能说,JWT 要比 Cookie-Session 更加先进,它也更不可能全面取代 Cookie-Session 机制。
JWT:解决认证授权问题的无状态方案
好,现在我们知道了,Cookie-Session 机制在分布式环境下会遇到 CAP 不可兼得的问题,而在多方系统中,也就更不可能谈什么 Session 层面的数据共享了,哪怕服务端之间能共享数据,客户端的 Cookie 也没法跨域。
所以,我们不得不重新捡起最初被抛弃的思路: 当服务器存在多个,客户端只有一个时,那就把状态信息存储在客户端,每次随着请求发回服务器中去。 可是奇怪了,前面我才说过,这样做的缺点是无法携带大量信息,而且有泄露和篡改的安全风险。
其实啊,信息量受限的问题目前并没有太好的解决办法,但是要确保信息不被中间人篡改,还是可以实现的,JWT 便是这个问题的标准答案。
JWT(JSON Web Token)定义于 RFC 7519 标准之中,是目前广泛使用的一种令牌格式,尤其经常与 OAuth 2.0 配合应用于分布式的、涉及多方的应用系统中。
那么,在介绍 JWT 的具体构成之前,我们先来直观地看一下它是什么样子的:
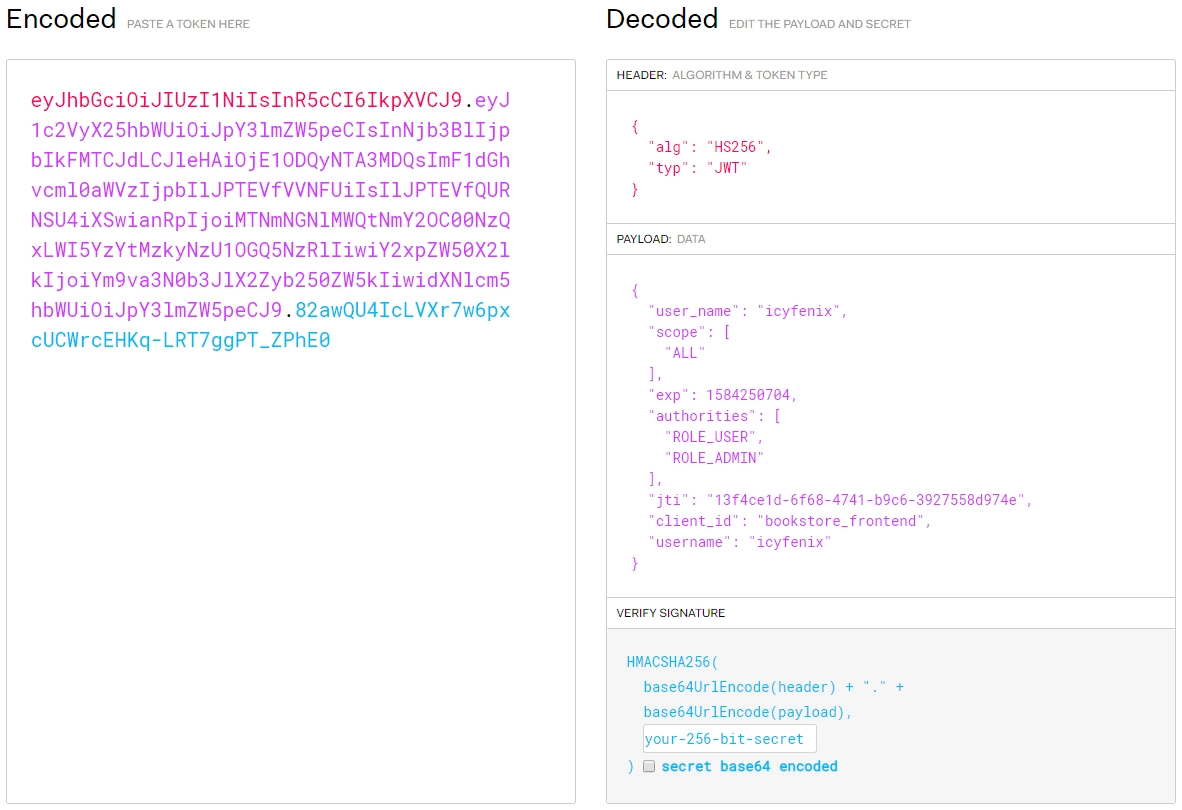
这个示意图来源于 JWT 官网 ,数据则是我随意编的。图上右边的 JSON 结构,是 JWT 令牌中携带的信息,左边的字符串呈现了 JWT 令牌的本体。它最常见的使用方式是附在名为 Authorization 的 Header 发送给服务端,其前缀在 RFC 6750 中被规定为 Bearer。
如果你没有忘记 第 23 讲 “认证方案”与 第 24 讲 “OAuth 2.0”的知识内容,那么当你在看到 Authorization 这个 Header 与 Bearer 这个前缀的时候,就应该能意识到,它是 HTTP 认证框架中的 OAuth 2.0 认证方案。下面的示例代码就展示了一次采用 JWT 令牌的 HTTP 实际请求:
GET /restful/products/1 HTTP/1.1
Host: icyfenix.cn
Connection: keep-alive
Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VyX25hbWUiOiJpY3lmZW5peCIsInNjb3BlIjpbIkFMTCJdLCJleHAiOjE1ODQ5NDg5NDcsImF1dGhvcml0aWVzIjpbIlJPTEVfVVNFUiIsIlJPTEVfQURNSU4iXSwianRpIjoiOWQ3NzU4NmEtM2Y0Zi00Y2JiLTk5MjQtZmUyZjc3ZGZhMzNkIiwiY2xpZW50X2lkIjoiYm9va3N0b3JlX2Zyb250ZW5kIiwidXNlcm5hbWUiOiJpY3lmZW5peCJ9.539WMzbjv63wBtx4ytYYw_Fo1ECG_9vsgAn8bheflL8另外我还要跟你强调的是,在前面的令牌结构示意图中,右边的状态信息是对令牌使用 Base64URL 转码后得到的明文, 请你特别注意它是明文。
毕竟 JWT 只解决防篡改的问题,并不解决防泄露的问题,所以令牌默认是不加密的。尽管你自己要加密的话也并不难做到,接收时自行解密即可,但这样做其实没有太大的意义,具体原因我这里先卖个关子,下一节课我讲”保密”的时候再给你详细解释。
JWT 令牌的三部分结构
那么,从前面给出的明文中你已经知道,JWT 令牌是以 JSON 结构(毕竟名字就叫 JSON Web Token)存储的,其结构总体上可以划分为三个部分,每个部分用点号” . “分隔开。
令牌的第一部分是令牌头(Header) ,其内容如下所示:
{
"alg": "HS256",
"typ": "JWT"
}这里你可以看到,它描述了令牌的类型(统一为 typ:JWT)以及令牌签名的算法,示例中 HS256 为 HMAC SHA256 算法的缩写,其他各种系统支持的签名算法你可以参考 JWT 官网 。
额外知识:散列消息认证码
在这一讲及后面其他关于安全的课程内容中,你会经常看到在某种哈希算法前出现”HMAC”的前缀,这是指散列消息认证码(Hash-based Message Authentication Code,HMAC)。你可以简单将它理解为一种带有密钥的哈希摘要算法,实现形式上通常是把密钥以加盐方式混入,与内容一起做哈希摘要。
HMAC 哈希与普通哈希算法的差别是,普通的哈希算法通过 Hash 函数结果易变性,保证了原有内容未被篡改,而 HMAC 不仅保证了内容未被篡改过,还保证了该哈希确实是由密钥的持有人所生成的。
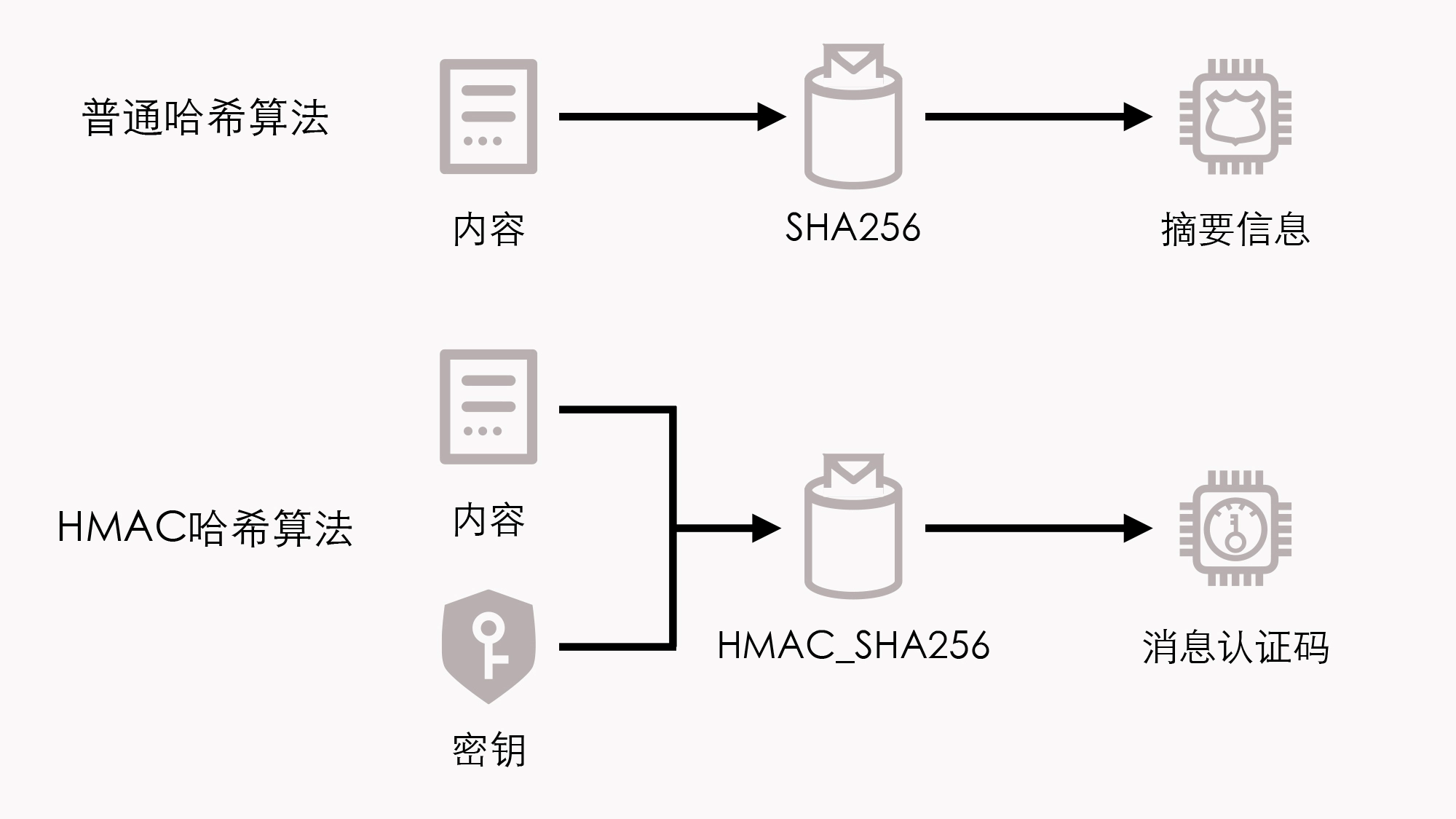
令牌的第二部分是负载(Payload) ,这是令牌真正需要向服务端传递的信息。针对认证问题,负载至少应该包含能够告知服务端”这个用户是谁”的信息;针对授权问题,令牌至少应该包含能够告知服务端”这个用户拥有什么角色 / 权限”的信息。
JWT 的负载部分是可以完全自定义的,我们可以根据具体要解决的问题,设计自己所需要的信息,只是总容量不能太大,毕竟它受 HTTP Header 大小的限制。下面我们来看一个 JWT 负载的例子:
{
"username": "icyfenix",
"authorities": [
"ROLE_USER",
"ROLE_ADMIN"
],
"scope": [
"ALL"
],
"exp": 1584948947,
"jti": "9d77586a-3f4f-4cbb-9924-fe2f77dfa33d",
"client_id": "bookstore_frontend"
}另外,JWT 在 RFC 7519 标准中,推荐(非强制约束)了七项声明名称(Claim Name),如果你在设计令牌时需要用到这些内容,我建议其字段名要与官方的保持一致:
- iss(Issuer):签发人。
- exp(Expiration Time):令牌过期时间。
- sub(Subject):主题。
- aud (Audience):令牌受众。
- nbf (Not Before):令牌生效时间。
- iat (Issued At):令牌签发时间。
- jti (JWT ID):令牌编号。
补充:除此之外,在 RFC 8225、RFC 8417、RFC 8485 等规范文档,以及 OpenID 等协议当中,都定义有约定好公有含义的名称,内容比较多,我就不贴出来了,你可以参考IANA JSON Web Token Registry。
令牌的第三部分是签名(Signature) 。签名的意思是:使用在对象头中公开的特定签名算法,通过特定的密钥(Secret,由服务器进行保密,不能公开)对前面两部分内容进行加密计算,产生签名值。
这里我们继续以前面例子里使用的 JWT 默认的 HMAC SHA256 算法为例,它会通过以下公式产生签名值:
HMACSHA256(base64UrlEncode(header) + "." + base64UrlEncode(payload) , secret)签名的意义在于,它可以确保负载中的信息是可信的、没有被篡改的,也没有在传输过程中丢失任何信息。因为被签名的内容哪怕是发生了一个字节的变动,也会导致整个签名发生显著变化。
此外,由于签名这件事情,只能由认证授权服务器完成(只有它知道 Secret),任何人都无法在篡改后重新计算出合法的签名值,所以服务端才能够完全信任客户端传上来的 JWT 中的负载信息。
JWT 默认的签名算法 HMAC SHA256 是一种带密钥的哈希摘要算法,加密与验证过程都只能由中心化的授权服务来提供,所以 这种方式一般只适合于授权服务与应用服务处于同一个进程中的单体应用。
另外,在多方系统,或者是授权服务与资源服务分离的分布式应用当中,通常会采用非对称加密算法来进行签名。这时候,除了授权服务端持有的可以用于签名的私钥以外,还会对其他服务器公开一个公钥,公开方式一般遵循 JSON Web Key 规范 。
不过,这个公钥不能用来签名,但它能被其他服务用于验证签名是否由私钥所签发的。这样,其他服务器就也能不依赖授权服务器、无需远程通讯,即可独立判断 JWT 令牌中的信息的真伪了。
在后面课程会展示的 Fenix’s Bookstore 的单体服务版本中,我们采用了默认的 HMAC SHA256 算法来加密签名,而在 Istio 服务网格版本里,终端用户认证会由服务网格的基础设施来完成,此时就改用了非对称加密的 RSA SHA256 算法来进行签名。如果你还想更深入地了解凭证安全,到时不妨对比一下这两部分的代码。更多关于哈希摘要、对称和非对称加密的讨论,我将会在”传输”这个小章节中继续展开介绍。
JWT 令牌的缺陷
现在我们知道,JWT 令牌是多方系统中的一种优秀的凭证载体,它不需要任何一个服务节点保留任何一点状态信息,就能够保障认证服务与用户之间的承诺是双方当时真实意图的体现,是准确、完整、不可篡改且不可抵赖的。
同时,由于 JWT 本身可以携带少量信息,这十分有利于 RESTful API 的设计,比较容易地做成无状态服务,我们在做水平扩展时就不需要像前面 Cookie-Session 方案那样,考虑如何部署的问题了。在现实应用中,也确实有一些项目直接采用 JWT 来承载上下文信息,以此实现完全无状态的服务端,这样就可以获得任意加入或移除服务节点的巨大便利,天然具有完美的水平扩缩能力。
比如,在调试 Fenix’s Bookstore 的代码 时,你随时都可以重启服务,在重启后,客户端仍然能毫无感知地继续操作流程;而对于有状态的系统,就必须通过重新登录、进行前置业务操作,来为服务端重建状态。尽管在大型系统中,只使用 JWT 来维护上下文状态,服务端完全不持有状态是不太现实的,不过将热点的服务单独抽离出来做成无状态,仍然是一种有效提升系统吞吐能力的架构技巧。
但是,JWT 也并不是一种完美的解决方案,它存在着以下几个经常被提及的缺点:
令牌难以主动失效
JWT 令牌一旦签发,理论上就和认证服务器没有什么瓜葛了,在到期之前就会始终有效,除非我们在服务器部署额外的逻辑去处理失效问题,而这对某些管理功能的实现是很不利的。比如说,一种十分常见的需求是:要求一个用户只能在一台设备上登录,在 B 设备登录后,之前已经登录过的 A 设备就应该自动退出。
如果我们采用 JWT,就必须设计一个”黑名单”的额外逻辑,把要主动失效的令牌集中存储起来,而无论这个黑名单是实现在 Session、Redis 还是数据库当中,都会让服务退化成有状态服务,这就降低了 JWT 本身的价值。但在使用 JWT 时,设置黑名单依然是很常见的做法,需要维护的黑名单一般是很小的状态量,因此在许多场景中还是有存在价值的。
相对更容易遭受重放攻击
这里首先我要说明,Cookie-Session 也是有重放攻击问题的,只是因为 Session 中的数据控制在服务端手上,应对重放攻击会相对主动一些。
但是,要在 JWT 层面解决重放攻击,就需要付出比较大的代价了,因为无论是加入全局序列号(HTTPS 协议的思路)、Nonce 字符串(HTTP Digest 验证的思路)、挑战应答码(当下网银动态令牌的思路)、还是缩短令牌有效期强制频繁刷新令牌,在真正应用起来时都很麻烦。
而真要处理重放攻击的话,我建议的解决方案是在信道层次(比如启用 HTTPS)上解决,而不提倡在服务层次(比如在令牌或接口其他参数上增加额外逻辑)上解决。
只能携带相当有限的数据
HTTP 协议并没有强制约束 Header 的最大长度,但是,各种服务器、浏览器都会有自己的约束,比如 Tomcat 就要求 Header 最大不超过 8KB,而在 Nginx 中则默认为 4KB。所以在令牌中存储过多的数据,不仅耗费传输带宽,还有额外的出错风险。
必须考虑令牌在客户端如何存储
严谨地说,这个并不是 JWT 的问题,而是系统设计的问题。如果在授权之后,操作完关掉浏览器就结束了,那把令牌放到内存里面,压根不考虑持久化,其实才是最理想的方案。
但并不是谁都能忍受一个网站关闭之后,下次就一定强制要重新登录的。这样的话,你想想客户端该把令牌存放到哪里呢?Cookie?localStorage?还是 Indexed DB?它们都有泄露的可能,而令牌一旦泄露,别人就可以冒充用户的身份做任何事情。
无状态也不总是好的
这个其实不也是 JWT 的问题。如果不能想像无状态会有什么不好的话,我给你提个需求:请基于无状态 JWT 的方案,做一个在线用户实时统计功能。兄弟,难搞哦。
小结
Cookie-Session 机制是为 HTTP 量身定做的经典凭证实现方案,它曾经为信息系统解决过无数问题。不过,随着微服务的流行,分布式系统变得越来越主流,因此由于分布式下共享数据的 CAP 矛盾,就导致了 Cookie-Session 在一些场景中遇到了 C 与 A 难以取舍的情况。
而无状态的 JWT 方案在合适的场景下,确实可以带来实实在在的好处,它可以让服务端水平扩容变得异常容易,不用担心 Session 复制的效率问题,也不用担心 Session 挂掉后,整个集群全部无法正常工作的问题。
然而,场景二字仍然是关键词,脱离了具体场景,我们就很难说哪种凭证方案更好或者更坏,在这节课中,我也特别强调了 JWT 的几个缺点。你要记住,权衡才是架构设计中最关键的地方。
27 | 保密:系统如何保证敏感数据无法被内外部人员窃取滥用?
你好,我是周志明。这节课,我们来讨论在信息系统中,一个一直非常受人关注的安全性议题:保密。
保密是加密和解密的统称,意思就是以某种特殊的算法改变原有的信息数据,使得未授权的用户即使获得了已加密的信息,但因为不知道解密的方法,或者就算知晓解密的算法、但缺少解密所需的必要信息,所以仍然无法了解数据的真实内容。
那么,根据需要保密信息所处的不同环节,我们可以将其划分为”信息在客户端时的保密””信息在传输时的保密”和”信息在服务端时的保密”三类,或者也可以进一步概括为”端的保密”和”链路的保密”两类。
这里,我们先把最复杂、最有效,但是又最早就有了标准解决方案的”传输”环节单独拿出来,放到后面两讲中展开探讨。在今天的这节课当中,我们只讨论两个端的环节,即在客户端和服务端中的信息保密问题。
保密的强度
好,首先我们要知道,保密是有成本的,追求越高的安全等级,我们就要付出越多的工作量与算力消耗。就连国家保密法都会把秘密信息划分为秘密、机密、绝密三级来区别对待,可见即使是信息安全,也应该有所取舍。
那么接下来,我就以用户登录为例,给你列举几种不同强度的保密手段,看看它们的防御关注点与弱点分别都是什么。这里你需要注意的是,以下提及到的不同保密手段,并不一定就是正确的做法,只是为了强调保密手段是有成本、有不同的强度的。
以摘要代替明文
如果密码本身比较复杂,那么一次简单的哈希摘要就至少可以保证,即使在传输过程中有信息泄露,也不会被逆推出原信息;即使密码在一个系统中泄露了,也不至于威胁到其他系统的使用。但这种处理不能防止弱密码被 彩虹表攻击 所破解。
先加 盐值) 再做哈希是应对弱密码的常用方法
盐值可以替弱密码建立一道防御屏障,在一定程度上可以防御已有的彩虹表攻击。但它并不能阻止加密结果被监听、窃取后,攻击者直接发送加密结果给服务端进行冒认。
将盐值变为动态值能有效防止冒认
如果每次向服务端传输时,密码都掺入了动态的盐值,让每次加密的结果都不一样,那么即使传输给服务端的加密结果被窃取了,攻击者也不能冒用来进行另一次调用。不过,尽管在双方通讯均可能泄露的前提下,协商出只有通讯双方才知道的保密信息是完全可行的(后面两讲介绍”传输安全层”时会提到),但这样协商出盐值的过程将变得极为复杂,而且每次协商只能保护一次操作,因而也很难阻止攻击者对其他服务的 重放攻击 。
加入动态令牌防止重放攻击
我们可以给服务加入动态令牌,这样在网关或其他流量公共位置建立校验逻辑,服务端愿意付出在集群中分发令牌信息等代价的前提下,就可以做到防止重放攻击。但这种手段的弱点是,依然不能抵御传输过程中被嗅探而泄露信息的问题。
启用 HTTPS 来应对因嗅探而导致的信息泄露问题
启用 HTTPS 可以防御链路上的恶意嗅探,也能在通讯层面解决重放攻击的问题。但是它依然有因客户端被攻破而产生伪造根证书的风险、因服务端被攻破产生证书泄露被中间人冒认的风险、因 CRL 更新不及时或者 OCSP Soft-fail 产生吊销证书被冒用的风险,以及因 TLS 的版本过低或密码学套件选用不当产生加密强度不足的风险。
进一步提升保密强度的不同手段
为了抵御前面提到的这种种风险,我们还要进一步提升保密强度。比如说,银行会使用独立于客户端的存储证书的物理设备(俗称的 U 盾),来避免根证书被客户端中的恶意程序窃取伪造;当大型网站涉及到账号、金钱等操作时,会使用双重验证开辟出一条独立于网络的信息通道(如手机验证码、电子邮件),来显著提高冒认的难度;甚至一些关键企业(如国家电网)或机构(如军事机构),会专门建设遍布全国各地的、与公网物理隔离的专用内部网络,来保障通讯安全。
现在,通过了解以上这些逐步升级的保密措施,你应该能对”更高的安全强度同时也意味着要付出更多的代价”,有更加具体的理解了,并不是任何一个网站、系统、服务都需要无限拔高的安全性。
也许这个时候,你还会好奇另一个问题: 安全的强度有尽头吗?存不存在某种绝对安全的保密方式?
答案可能会出乎你的意料,确实是有的。信息论之父香农就严格证明了 一次性密码(One Time Password)的绝对安全性。
但是使用一次性密码必须有个前提,就是我们已经提前安全地把密码或密码列表传达给了对方。比如说,你给朋友人肉送去一本存储了完全随机密码的密码本,然后每次使用其中一条密码来进行加密通讯,用完一条丢弃一条。这样理论上可以做到绝对的安全,但显然这种绝对安全对于互联网来说没有任何的可行性。
所以下面,我们就来看一下在互联网中,信息在客户端的加密是否有必要和有价值。
客户端加密的意义
其实,客户端在用户登录、注册一类场景里是否需要对密码进行加密,这个问题一直存有争议。而 我的观点很明确:为了保证信息不被黑客窃取而去做客户端加密,其实没有太大意义,对绝大多数的信息系统来说,启用 HTTPS 可以说是唯一的实际可行的方案。但是!为了保证密码不在服务端被滥用,而在客户端就开始加密的做法,还是很有意义的。
现在,大网站被拖库的事情层出不穷,密码明文被写入数据库、被输出到日志中之类的事情也屡见不鲜。所以在做系统设计的时候,我们就应该把明文密码这种东西当成是最烫手的山芋来看待,越早消灭掉越好。毕竟把一个潜在的炸弹从客户端运到服务端,对绝大多数系统来说都没有必要。
那我为什么会说,客户端加密对防御泄密没有意义呢? 原因是网络通讯并不是由发送方和接收方点对点进行的,客户端无法决定用户送出的信息能不能到达服务端,或者会经过怎样的路径到达服务端,所以在传输链路必定是不安全的前提下,无论客户端做什么防御措施,最终都会沦为”马其诺防线”。
此外,前面我还多次提到过中间人攻击(即攻击者),它是指通过劫持掉客户端到服务端之间的某个节点,包括但不限于代理(通过 HTTP 代理返回赝品)、路由器(通过路由导向赝品)、DNS 服务(直接将机器的 DNS 查询结果替换为赝品地址)等,来给你访问的页面或服务注入恶意的代码。极端情况下,甚至可能把你要访问的服务或页面整个给取代掉,此时不管你在页面上设计了多么精巧严密的加密措施,也都不会有保护作用。而攻击者只需劫持路由器,或者是在局域网内的其他机器上释放 ARP 病毒 ,便有可能做到这一点。
额外知识:中间人攻击(Man-in-the-Middle Attack,MitM)
在消息发出方和接收方之间拦截双方通讯。我们用写信来做个类比:你给朋友写了一封信,而邮递员可以拆开看你寄出去的信,甚至把信的内容改掉,然后重新封起来,再寄出去给你的朋友。朋友收到信之后给你回信,邮递员又可以拆开看,看完随便改,改完封好再送到你手上。你全程都不知道自己寄出去的信和收到的信都经过邮递员这个”中间人”转手和处理。换句话说,对于你和你朋友来讲,邮递员这个”中间人”角色是不可见的。
当然了, 对于”不应把明文传递到服务端”的这个观点 ,很多人也会有一些不同的意见。比如其中一种保存明文密码的理由是为了便于客户端做动态加盐,因为这样需要服务端先存储明文,或者是存储某种盐值 / 密钥固定的加密结果,才能每次用新的盐值重新加密,然后与客户端传上来的加密结果进行比对。
而对此 我的看法 是,这种每次从服务端请求动态盐值,在客户端加盐传输的做法通常都得不偿失,因为客户端无论是否动态加盐,都不可能代替 HTTPS。真正防御性的密码加密存储确实应该在服务端中进行,但这是为了防御服务端被攻破而批量泄露密码的风险,并不是为了增强传输过程的安全性。
那么,在服务端是如何处理信息的保密问题的呢?
密码的存储和验证
接下来,我就以 Fenix’s Bookstore 中的真实代码为例,给你介绍一下针对一个普通安全强度的信息系统,密码要如何从客户端传输到服务端,然后存储进数据库。
这里的”普通安全强度”的意思是,在具有一定保密安全性的同时,避免消耗过多的运算资源,这样验证起来也相对便捷。毕竟对多数信息系统来说,只要配合一定的密码规则约束,比如密码要求长度、特殊字符等等,再配合 HTTPS 传输,就已经足够防御大多数风险了。即使是用户采用了弱密码、客户端通讯被监听、服务端被拖库、泄露了存储的密文和盐值等问题同时发生,也能够最大限度地避免用户明文密码被逆推出来。
好,下面我们就先来看看,在 Fenix’s Bookstore 中密码是如何创建出来的。
首先,用户在客户端注册,输入明文密码:123456。
password = 123456然后,客户端对用户密码进行简单哈希摘要,我们可选的算法有 MD2/4/5、SHA1/256/512、BCrypt、PBKDF1/2,等等。这里为了突出”简单”的哈希摘要,我故意没有排除掉 MD 系这些已经有了高效碰撞手段的算法。
client_hash = MD5(password) // e10adc3949ba59abbe56e057f20f883e接着,为了防御彩虹表攻击,我们应进行加盐处理,客户端加盐只需要取固定的字符串即可,如果实在不安心,可以使用伪动态的盐值(”伪动态”是指服务端不需要额外通讯就可以得到的信息,比如由日期或用户名等自然变化的内容,加上固定字符串构成)。
client_hash = MD5(MD5(password) + salt) // SALT = $2a$10$o5L.dWYEjZjaejOmN3x4Qu现在,我们假设攻击者截获了客户端发出的信息,得到了摘要结果和采用的盐值,那攻击者就可以枚举遍历所有 8 位字符以内(”8 位”只是举个例子,反正就是指弱密码,你如果拿 1024 位随机字符当密码用,加不加盐,彩虹表都跟你没什么关系)的弱密码,然后对每个密码再加盐计算,就得到了一个针对固定盐值的对照彩虹表。
所以为了应对这种暴力破解,我并不提倡在盐值上做动态化,更理想的方式是引入 慢哈希函数 来解决。
慢哈希函数是指这个函数的执行时间是可以调节的哈希函数,它通常是以控制调用次数来实现的。BCrypt 算法就是一种典型的慢哈希函数,它在做哈希计算时,接受盐值 Salt 和执行成本 Cost 两个参数(代码层面 Cost 一般是混入在 Salt 中,比如上面例子中的 Salt 就是混入了 10 轮运算的盐值,10 轮的意思是 2 的 10 次方哈希,Cost 参数是放在指数上的,最大取值就 31)。
那么,如果我们控制 BCrypt 的执行时间,大概是 0.1 秒完成一次哈希计算的话,按照 1 秒生成 10 个哈希值的速度,要算完所有的 10 位大小写字母和数字组成的弱密码,就大概需要 P(62,10)/(360024365)/0.1=1,237,204,169 年的时间。
client_hash = BCrypt(MD5(password) + salt) // MFfTW3uNI4eqhwDkG7HP9p2mzEUu/r2好,接下来,我们要做的就只是防御服务端被拖库后,针对固定盐值的批量彩虹表攻击。具体做法是为每一个密码(指客户端传来的哈希值)产生一个随机的盐值。我建议采用” 密码学安全伪随机数生成器 “(Cryptographically Secure Pseudo-Random Number Generator,CSPRNG),来生成一个长度与哈希值相等的随机字符串。
对于 Java 语言来说,从 Java SE 7 开始,就提供了 java.security.SecureRandom 类,用于支持 CSPRNG 字符串生成。
SecureRandom random = new SecureRandom();
byte server_salt[] = new byte[36];
random.nextBytes(server_salt); // tq2pdxrblkbgp8vt8kbdpmzdh1w8bex好,我们继续进行这个密码的创建过程。我们把动态盐值混入客户端传来的哈希值,再做一次哈希,产生出最终的密文,并和上一步随机生成的盐值一起写入到同一条数据库记录中(由于慢哈希算法会占用大量的处理器资源,所以我并不推荐在服务端中采用)。
不过,如果你在学习课程后面的实战模块时,阅读了 Fenix’s Bookstore 的源码 ,就会发现这步依然采用了 Spring Security 5 中的 BcryptPasswordEncoder。但是请注意,它默认构造函数中的 Cost 参数值为 -1,经转换后实际只进行了 2 的 10 次方 =1024 次计算,所以不会对服务端造成额外的压力。
另外你还可以看到,代码中并没有显式地传入 CSPRNG 生成的盐值,这是因为 BCryptPasswordEncoder 本身就会自动调用 CSPRNG 产生盐值,并将该盐值输出在结果的前 32 位之中,所以也不需要专门在数据库中设计存储盐值字段。
这个过程我们用伪代码来表示一下:
server_hash = SHA256(client_hash + server_salt); // 55b4b5815c216cf80599990e781cd8974a1e384d49fbde7776d096e1dd436f67
DB.save(server_hash, server_salt);到这里,你会发现这个加密存储的过程其实相对比较复杂,但是运算压力最大的过程(慢哈希)是在客户端完成的,对服务端的压力很小,也不用怕因网络通讯被截获而导致明文密码泄露的问题。
OK,等密码存储完之后,后面验证的过程就跟加密的操作是类似的,我们简单了解下这个步骤就可以了:
首先,在客户端,用户在登录页面中输入密码明文:123456,经过与注册相同的加密过程,向服务端传输加密后的结果。
authentication_hash = MFfTW3uNI4eqhwDkG7HP9p2mzEUu/r2然后,在服务端,接收到客户端传输上来的哈希值,从数据库中取出登录用户对应的密文和盐值,采用相同的哈希算法,针对客户端传来的哈希值、服务端存储的盐值计算摘要结果。
result = SHA256(authentication_hash + server_salt); // 55b4b5815c216cf80599990e781cd8974a1e384d49fbde7776d096e1dd436f67最后,比较上一步的结果和数据库储存的哈希值是否相同,如果相同就说明密码正确,反之密码错误。
authentication = compare(result, server_hash) // yes小结
这节课我们其实讨论了两个观点:
- 第一个观点是,安全并不是一个非此即彼的二元选项,它是连续值,而不是安全与不安全的问题。
- 第二个观点是,你要明确在信息系统里,客户端加密、服务端解密两项操作的意义是什么。
另外,针对”如何取得相对安全与良好性能之间平衡”这个问题,也是你在进行架构设计时必须权衡取舍的。
28 | 传输(上):传输安全的基础,摘要、加密与签名
其实在前面几讲中,我已经为传输安全层挖下了不少坑,比如说:
- 基于信道的认证是怎样实现的?
- 为什么说,HTTPS 是绝大部分信息系统防御通讯被窃听和篡改的唯一可行手段?
- 传输安全层难道不也是一种自动化的加密吗?
- 为什么说客户端如何加密都不能代替 HTTPS 呢?
所以接下来,我会花两讲的时间,通过”假设链路上的安全得不到保障,攻击者要如何摧毁之前在认证、授权、凭证、保密中所提到的种种安全机制”这个场景,来给你讲解传输层安全所要解决的问题,同时这也能给你解答前面提到的这些问题。
另外,在上节课的开篇里我也提到过,安全架构中的传输环节是最复杂、最有效,但又是最早就有了标准解决方案的,它包含了许多今天在开发中经常听说,但却不为多数开发人员所知的细节,比如传输安全中的摘要、加密与签名,以及数字证书与传输安全层,等等。那么今天这一讲,我们就先来理清系统安全中,摘要、加密与签名这三种行为的异同之处。
哈希摘要的特点和作用
现在,让我们先从 JWT 令牌的一小段”题外话”,来引出这一讲要讨论的话题吧。
你应该已经知道,JWT 令牌携带信息的可信度源于它是被签名过的信息,所以是不可篡改的,是令牌签发者真实意图的体现。然而,你是否了解过签名具体做了什么呢?为什么有签名就能够让负载中的信息变得不可篡改和不可抵赖呢?
要解释 数字签名 (Digital Signature)的话,就必须先从密码学算法的另外两种基础应用”摘要”和”加密”说起。
摘要 也被叫做是数字摘要(Digital Digest)或数字指纹(Digital Fingerprint)。在 JWT 令牌中,默认的签名信息就是通过令牌头中指定的哈希算法(HMAC SHA256),针对令牌头、负载和密钥所计算出来的摘要值。
我们来看一个例子:
signature = SHA256(base64UrlEncode(header) + "." + base64UrlEncode(payload) , secret)理想的哈希算法都具备这样两个特性:
一是易变性 。这是指算法的输入端发生了任何一点细微变动,都会引发 雪崩效应 (Avalanche Effect),导致输出端的结果产生极大的变化。
这个特性经常被用来做校验,以此保护信息在传输的过程中不会被篡改。比如在互联网下载大文件,通常都会附有一个哈希校验码,用来确保下载下来的文件没有因网络或其他原因,与原文件产生任何偏差。
二是不可逆性 。要知道,摘要的过程是单向的,我们不可能从摘要的结果中,逆向还原出输入值来。
其实这点只要你具备初中数学知识就能想明白,世间的信息有无穷多种,而不管摘要结果的位数是 32、128 还是 512 Bit,即使它再大也总归是个有限的数字,所以输入数据与输出的摘要结果必然不是一一对应的关系。
可以想想看,如果我把一部电影进行了摘要,形成 256 Bit 的哈希值,应该不会有人指望能从这个哈希值中还原出一部电影的。
实际上,现在我们偶尔还能听到 MD5、SHA1 或其他哈希算法被破解了的新闻,这里的”破解”并不是”解密”的意思,而是指找到了该算法的高效率碰撞方法,它能够在合理的时间内,生成一个摘要结果为指定内容的输入比特流,但它并不能代表这个碰撞产生的比特流就会是原来的输入源。
所以通过这两个特性,我们能发现, 摘要的意义就是在源信息不泄露的前提下辨别其真伪。 易变性保证了,从公开的特征上就可以甄别出摘要结果是否来自于源信息;而不可逆性保证了,从公开的特征并不会暴露出源信息。这跟我们今天用来做身份识别的指纹、面容和虹膜的生物特征是具有高度可比性的。
摘要与加密和签名的本质区别
另外,在一些场合中,摘要也会被借用来做加密(如上节课”保密”中介绍的慢哈希 Bcrypt 算法)和签名(如第 26 讲中提到 JWT 签名中的 HMAC SHA256 算法)。但从严格意义上看,摘要与这两者是有本质的区别的。
加密与摘要的本质区别就在于,摘要是不可逆的,而加密是可逆的,逆过程就是解密。
在经典密码学时代,加密的安全主要是依靠机密性来保证的,也就是依靠保护加密算法或算法的执行参数不被泄露,来保障信息的安全。
而现代密码学并不依靠机密性,加解密算法都是完全公开的,信息的安全是建立在特定问题的计算复杂度之上。具体来说,就是算法根据输入端计算输出结果,这里耗费的算力资源很小;但根据输出端的结果反过来推算原本的输入,耗费的算力就极其庞大。
一个经常被用来说明计算复杂度的例子,就是大数的 质因数分解 ,我们可以轻而易举地( 以 O(nlogn) 的复杂度 )计算出两个大素数的乘积:
97667323933 * 128764321253 = 12576066674829627448049我们知道,根据 算术基本定理 ,质因数的分解形式是唯一的,而且示例前面的计算条件中,给出的运算因子已经是质数了,所以 12,576,066,674,829,627,448,049 的分解形式,就只有一种,即上面给出的唯一答案。
然而,如何对大数进行质因数分解,其实到今天都还没有找到多项式时间的算法,甚至我们都无法确切地知道,这个问题属于哪个 复杂度类 (Complexity Class)。
所以说,尽管这个加密过程理论上一定是可逆的,但实际上的算力差异决定了其逆过程根本无法实现。
注:24 位十进制数的因数分解完全在现代计算机的暴力处理能力范围内,这里只是举例。但目前很多计算机科学家都相信,大数分解问题就是一种 P!=NP 的证例,尽管也并没有人能证明它一定不存在多项式时间的解法。除了质因数分解外,离散对数和椭圆曲线也是具备实用性的复杂问题。
那既然我们提到了密码学,下面我们就来了解下密码学中最重要的应用,信息加密算法,一起来学习、理解下加密是如何保护信息不被泄露的。
加密算法的两大类型:对称与非对称
在现代密码学算法中,根据加密与解密是否采用了同一个密钥,将算法分为了对称加密和非对称加密两大类型。这两类算法各有明确的优劣势与应用场景。
首先我们来看看 对称加密算法 。
对称加密的缺点显而易见:因为加密和解密都使用相同的密钥,那么当通讯的成员数量增加时,为了保证两两通讯都能采用独立的密钥,密钥数量就要与成员数量的平方成正比,这必然就会面临密钥管理的难题。
而更尴尬的难题是,当通讯双方原本就不存在安全的信道时,如何才能把一个只能让通讯双方才能知道的密钥传输给对方?而如果有通道可以安全地传输密钥,那为何不使用现有的通道传输信息呢?这个” 蛋鸡悖论 “曾经在很长的时间里,严重阻碍了密码学在真实世界中的推广应用。
因此,在 1970 年代中后期出现的非对称加密算法,就从根本上解决了密钥分发的难题。
非对称加密算法把密钥分成了公钥和私钥,公钥可以完全公开,无需安全传输的保证。私钥由用户自行保管,不参与任何通讯传输。这两个密钥谁加密、谁解密,就构成了两种不同的用途:
- 公钥加密,私钥解密,这种就是加密 ,用于向私钥所有者发送信息,这个信息可能被他人篡改,但是无法被他人得知。举个例子,如果甲想给乙发一个安全保密的数据,那么应该甲乙各自有一个私钥,甲先用乙的公钥加密这段数据,再用自己的私钥加密这段加密后的数据,最后再发给乙。这样确保了内容既不会被读取,也不能被篡改。
- 私钥加密,公钥解密,这种就是签名 ,用于让所有公钥所有者验证私钥所有者的身份,并能用来防止私钥所有者发布的内容被篡改。但是它不用来保证内容不被他人获得。
这两种用途理论上肯定是成立的,但在现实中一般却不成立,因为单靠非对称加密算法,既做不了加密也做不了签名。原因是, 不管加密还是解密,非对称加密算法的计算复杂度都相当高,性能比对称加密要差上好几个数量级 (不是好几倍)。
要知道,加解密的性能不仅影响运行速度,还导致了现行的非对称加密算法都没有支持分组加密模式。分组的意思就是,由于明文长度与密钥长度在安全上具有相关性,通俗地说就是多长的密钥决定了它能加密多长的明文,如果明文太短就需要进行填充,太长就需要进行分组。
这也就是说,因为非对称加密本身的效率所限,难以支持分组,所以主流的非对称加密算法都只能加密不超过密钥长度的数据,这就决定了非对称加密不能直接用于大量数据的加密。
所以 在加密方面,现在一般会结合对称与非对称加密的优点,通过混合加密来保护信道传输的安全。 具体是怎么做的呢?
通常我们的做法是,用非对称加密来安全地传递少量数据给通讯的另一方,然后再以这些数据为密钥,采用对称加密来安全高效地大量加密传输数据。这种由多种加密算法组合的应用形式,就被称为” 密码学套件 “,非对称加密在这个场景中发挥的作用被称为” 密钥协商 “。
然后, 在签名方面,现在一般会结合摘要与非对称加密的优点,通过对摘要结果做加密的形式来保证签名的适用性。 由于对任何长度的输入源做摘要之后,都能得到固定长度的结果,所以只要对摘要的结果进行签名,就相当于对整个输入源进行了背书,这样就能保证一旦内容遭到了篡改,摘要结果就会变化,签名也就马上失效了。
这里,我也汇总了前面提到的这三种与密码学相关的应用,你可以参考下表格,去深入理解它们的主要特征、用途和局限性:
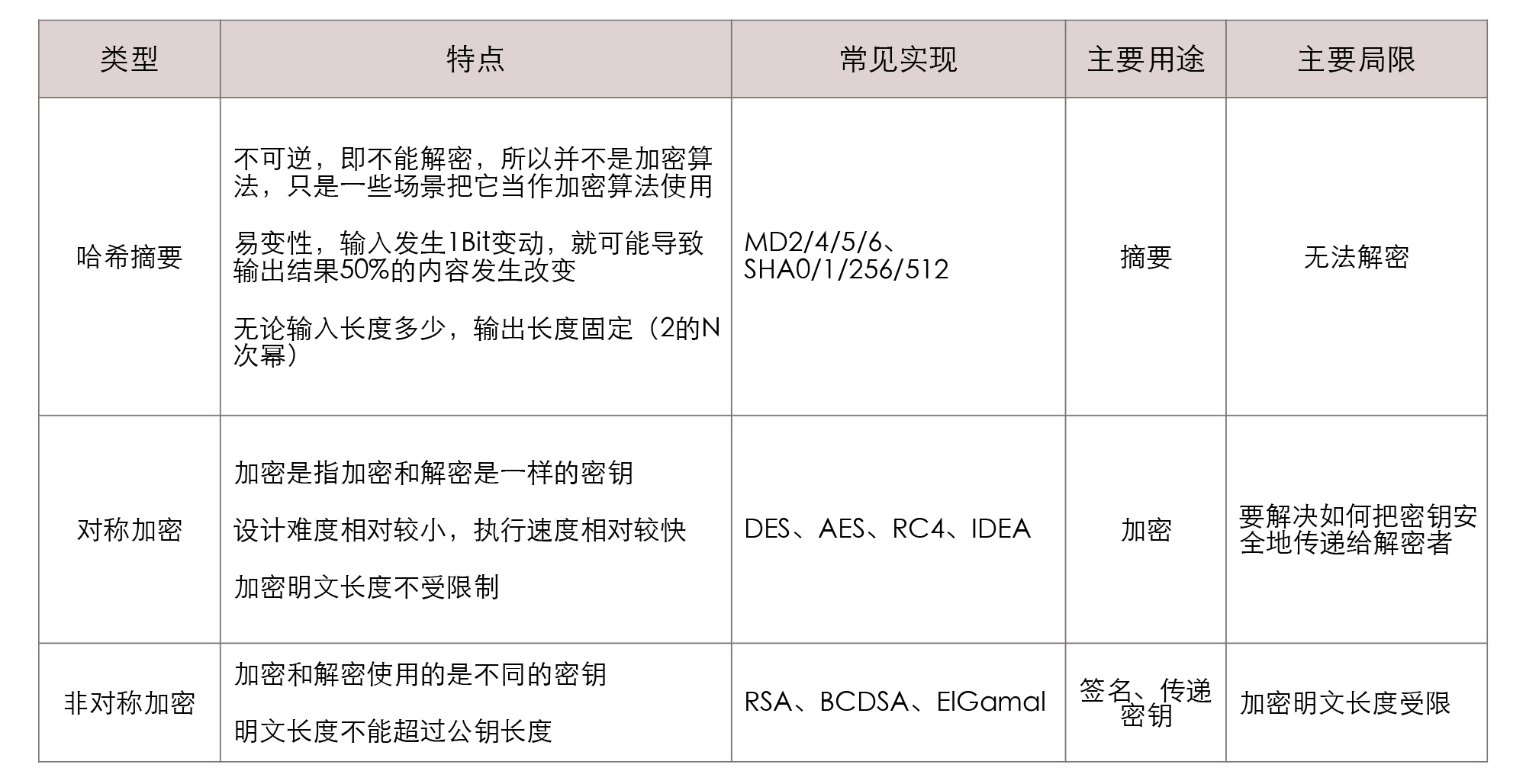
那么现在,让我们再回到开篇中提到的关于 JWT 令牌的几个问题上来: 有了哈希摘要、对称和非对称加密,JWT 令牌的签名就能保证负载中的信息不可篡改、不可抵赖吗?
其实还是不行的,在这个场景里,数字签名的安全性仍然存在一个致命的漏洞:公钥虽然是公开的,但在网络世界里,”公开”具体是一种什么操作?如何保证每一个获取公钥的服务,拿到的公钥就是授权服务器所希望它拿到的?
在网络传输是不可信任的前提下,公钥在网络传输的过程中可能已经被篡改了,所以如果获取公钥的网络请求被攻击者截获并篡改,返回了攻击者自己的公钥,那以后攻击者就可以用自己的私钥来签名,让资源服务器无条件信任它的所有行为了。
也就是说,如果是在现实世界中公开公钥,我们可以通过打电话、发邮件、发短信、登报纸、同时发布在多个网站上等多种网络通讯之外的途径来达成。但在程序与网络的世界中,就必须找到一种可信任的公开方法,而且这种方法不能依赖加密来实现,否则又会陷入到蛋鸡的问题之中。
小结
今天,我们从哈希摘要、对称加密和非对称加密这三种安全架构中常见的保密操作说起,一起学习了摘要、加密、签名这三种现代密码学算法基础应用的主要用途和区别差异。
首先我们要明确的是,哈希是不可逆的,它不能解密,并不是加密算法,只是一些场景把它当作加密算法使用。哈希的特点是易变性,输入发生 1Bit 变动,就可能导致输出结果 50% 的内容发生改变;无论输入长度多少,都有长度固定的输出(2 的 N 次幂)。所以这些特点决定了哈希的主要应用是做摘要,用来保证原文未被修改。
而加密是现代密码学算法的关键应用,对称加密的设计难度比较小,执行速度快,加密明文长度不受限制,这些特点就决定了对于大量数据的加密传输,目前都是靠对称加密来完成的。但是对称加密难以解决如何把密钥传递给对方的问题,因而出现了非对称加密,它的特点是加密和解密使用的是不同的密钥,但是性能和加密明文的长度都受限。
29 | 传输(下):数字证书与传输安全层
上节课,我们花了很多时间来学习传输安全层中的摘要、加密和签名的主要用途和差别,在最后,我给你留了一个问题:数字签名需要分发公钥,但在网络世界里,”公开”具体是一种什么操作?如何保证每一个获取公钥的服务,拿到的公钥就是授权服务器所希望它拿到的呢?在网络中一切皆不可信任的假设前提下,任何传输都有可能被篡改,那这个问题能够解决吗?
答案其实是可以的,这就是数字证书要解决的问题。
所以接下来,我们就先从数字证书如何达成共同信任开始说起,一起来了解下在传输安全的过程中,数字证书与传输安全层的相关实现细节。
如何通过数字证书达成共同信任?
有了哈希摘要、对称和非对称加密之后,签名还是无法保证负载中的信息不可篡改、不可抵赖。所以,当我们无法以”签名”的手段来达成信任时,就只能求助于其他途径。
现在,你不妨想想真实的世界中,我们是如何达成信任的。其实不外乎以下这两种:
基于共同私密信息的信任
比如某个陌生号码找你,说是你的老同学,生病了要找你借钱。你能够信任他的方式是向对方询问一些你们两个应该知道,而且只有你们两个知道的私密信息,如果对方能够回答上来,他有可能真的是你的老同学,否则他十有八九就是个诈骗犯。
基于权威公证人的信任
如果有个陌生人找你,说他是警察,让你把存款转到他们的安全账号上。你能够信任他的方式是去一趟公安局,如果公安局担保他确实是个警察,那他有可能真的是警察,否则他也十有八九就是个诈骗犯。
那回到网络世界中,我们其实并不能假设授权服务器和资源服务器是互相认识的,所以通常不太会采用第一种方式。而第二种就是目前保证公钥可信分发的标准,这个标准有一个名字: 公开密钥基础设施 (Public Key Infrastructure,PKI)。
额外知识:公开密钥基础设施(Public Key Infrastructure,PKI)
又称公开密钥基础架构、公钥基础建设、公钥基础设施、公开密码匙基础建设或公钥基础架构,是一组由硬件、软件、参与者、管理政策与流程组成的基础架构,其目的在于创造、管理、分配、使用、存储以及撤销数字证书。
密码学上,公开密钥基础建设借着数字证书认证中心(Certificate Authority,CA)将用户的个人身份跟公开密钥链接在一起。对每个证书中心用户的身份必须是唯一的。链接关系通过注册和发布过程创建,取决于担保级别,链接关系可能由 CA 的各种软件或在人为监督下完成。PKI 的确定链接关系的这一角色称为注册管理中心(Registration Authority,RA)。RA 确保公开密钥和个人身份链接,可以防抵赖。
咱们不必纠缠于 PKI 概念上的内容,只要知道里面定义的”数字证书认证中心”,就相当于前面例子中”权威公证人”的角色,它是负责发放和管理数字证书的权威机构。
当然,任何人包括你我,也都可以签发证书,只是不权威罢了,而 CA 作为受信任的第三方,就承担了公钥体系中公钥的合法性检验的责任。
可是,这里和现实世界仍然有一些区别。在现实世界里,你去找的公安局大楼不太可能是剧场布景冒认的;而网络世界里,在假设所有网络传输都有可能被截获冒认的前提下,”去 CA 中心进行认证”本身也是一种网络操作。那你就要问了, 这跟之前的”去获取公钥”的操作,在本质上不是没什么差别吗?
其实还是有差别的,世界上的公钥成千上万、不可枚举,而权威的 CA 中心则应该是可数的。”可数的”就意味着可以不通过网络,而是在浏览器与操作系统出厂时就预置好,或者是提前就安装好(如银行的证书)。比如说,下图就是我机器上现存的根证书:
那到这里,其实就出现了我们这节课要探讨的主角之一: 证书(Certificate) 。
证书是权威 CA 中心对特定公钥信息的一种公证载体,你也可以理解为是权威 CA 对特定公钥未被篡改的签名背书。由于客户的机器上已经预置了这些权威 CA 中心本身的证书(可以叫做 CA 证书或者根证书),这样就让我们在不依靠网络的前提下,使用根证书里面的公钥信息,对其所签发的证书中的签名进行确认。
所以到这里,我们就终于打破了鸡生蛋、蛋生鸡的循环,使得整套数字签名体系有了坚实的逻辑基础。
PKI 中采用的证书格式是 X.509 标准格式 ,它定义了证书中应该包含哪些信息,并描述了这些信息是如何编码的。 其中最关键的,就是认证机构的数字签名和公钥信息两项内容。
那么下面,我们就通过一个标准 X.509 格式的 CA 证书的例子,来看看一个数字证书具体都包含了哪些内容。
第一是 版本号(Version) :它会指出该证书使用了哪种版本的 X.509 标准(版本 1、版本 2 或是版本 3)。版本号会影响证书中的一些特定信息,在这个例子当中,目前的版本为 3。
Version: 3 (0x2)第二是 序列号(Serial Number) :这是由证书颁发者分配的本证书的唯一标识符。
Serial Number: 04:00:00:00:00:01:15:4b:5a:c3:94第三是 签名算法标识符(Signature Algorithm ID) :它是签证书的算法标识,由对象标识符加上相关的参数组成,用于说明本证书所用的数字签名算法。比如,SHA1 和 RSA 的对象标识符就用来说明,该数字签名是利用 RSA 对 SHA1 的摘要结果进行加密。
Signature Algorithm: sha1WithRSAEncryption第四是 认证机构的数字签名(Certificate Signature) :这是使用证书发布者私钥生成的签名,以确保这个证书在发放之后没有被篡改过。
第五是 认证机构(Issuer Name) : 即证书颁发者的可识别名。
Issuer: C=BE, O=GlobalSign nv-sa, CN=GlobalSign Organization Validation CA - SHA256 - G2第六是 有效期限(Validity Period) : 即证书起始日期和时间以及终止日期和时间,意为指明证书在这两个时间内有效。
Validity Not Before: Nov 21 08:00:00 2020 GMT Not After : Nov 22 07:59:59 2021 GMT第七是 主题信息(Subject) :证书持有人唯一的标识符(Distinguished Name),这个名字在整个互联网上应该是唯一的,通常使用的是网站的域名。
Subject: C=CN, ST=GuangDong, L=Zhuhai, O=Awesome-Fenix, CN=*.icyfenix.cn第八是公钥信息(Public-Key): 它包括了证书持有人的公钥、算法 (指明密钥属于哪种密码系统) 的标识符和其他相关的密钥参数。
那么,到此为止,数字签名的安全性其实已经可以完全自洽了,但相信你大概也已经感受到了这条信任链的复杂与繁琐:如果从确定加密算法,到生成密钥、公钥分发、CA 认证、核验公钥、签名、验证,每一个步骤都要由最终用户来完成的话,这种意义的”安全”估计只能一直是存于实验室中的阳春白雪。
所以,如何把这套繁琐的技术体系,自动化地应用于无处不在的网络通讯之中,就是接下来我们要讨论的主题了。
传输安全层是如何隐藏繁琐的安全过程的?
在计算机科学里, 隔离复杂性的最有效手段(没有之一)就是分层 ,如果一层不够就再加一层,这点在网络中更是体现得淋漓尽致。
OSI 模型、TCP/IP 模型从物理特性(比特流)开始,将网络逐层封装隔离,到了 HTTP 协议这种面向应用的协议里,使用者就已经不会去关心网卡 / 交换机是如何处理数据帧、MAC 地址的了;也不会去关心 ARP 如何做地址转换;不会去关心 IP 寻址、TCP 传输控制等细节。
那么,想要在网络世界中, 让用户无感知地实现安全通讯,最合理的做法就是在传输层之上、应用层之下加入专门的安全层来实现。 这样对上层原本是基于 HTTP 的 Web 应用来说,甚至都察觉不到有什么影响。
而且,构建传输安全层这个想法,几乎可以说是和万维网的历史一样长,早在 1994 年,就已经有公司开始着手去实践了:
- 1994 年,网景(Netscape)公司开发了 SSL 协议(Secure Sockets Layer)的 1.0 版,这是构建传输安全层的起源,但是 SSL 1.0 从未正式对外发布过。
- 1995 年,Netscape 把 SSL 升级到 2.0 版,正式对外发布,但是刚刚发布不久,就被发现有严重漏洞,所以并未大规模使用。
- 1996 年,修补好漏洞的 SSL 3.0 对外发布,这个版本得到了广泛的应用,很快成为 Web 网络安全层的事实标准。
- 1999 年,互联网标准化组织接替网景公司,将 SSL 改名为 TLS(Transport Layer Security),随即就形成了传输安全层的国际标准。第一个正式的版本是 RFC 2246 定义的 TLS 1.0,该版 TLS 的生命周期极长,直到 2020 年 3 月,主流浏览器(Chrome、Firefox、IE、Safari)才刚刚宣布同时停止 TLS 1.0/1.1 的支持。而讽刺的是,由于停止后许多政府网站被无法被浏览,此时又正值新冠病毒的爆发期,Firefox 紧急 发布公告 宣布撤回该改动,因此目前 TLS 1.0 的生命还在顽强延续。
- 2006 年,TLS 的第一个升级版 1.1 发布( RFC 4346 ),但它除了增加对 CBC 攻击的保护外,几乎没有任何改变,沦为了被遗忘的孩子,当时也很少有人会使用 TLS 1.1,甚至 TLS 1.1 根本都没有被提出过有啥已知的协议漏洞。
- 2008 年,TLS 1.1 发布 2 年之后,TLS 1.2 标准发布( RFC 5246 ),迄今超过 90% 的互联网 HTTPS 流量都是由 TLS 1.2 所支持的,现在我们仍在使用的浏览器几乎都完美支持了该协议。
- 2018 年,最新的 TLS 1.3( RFC 8446 )发布,比起前面版本相对温和的升级,TLS 1.3 做出了一些激烈的改动,修改了从 1.0 起一直没有大变化的两轮四次(2-RTT)握手,首次连接仅需一轮(1-RTT)握手即可完成;在有连接复用支持的时候,甚至可以把 TLS 1.2 原本的 1-RTT 下降到 0-RTT,显著提升了访问速度。
那么接下来,我就以现在被广泛使用的 TLS 1.2 为例,给你介绍一下传输安全层是如何保障所有信息都是第三方无法窃听(加密传输)、无法篡改(一旦篡改通讯算法会立刻发现)、无法冒充(证书验证身份)的。
TLS 1.2 在传输之前的握手过程中,一共需要进行上下两轮、共计四次的通讯。我们来看一下这个握手过程的时序图:
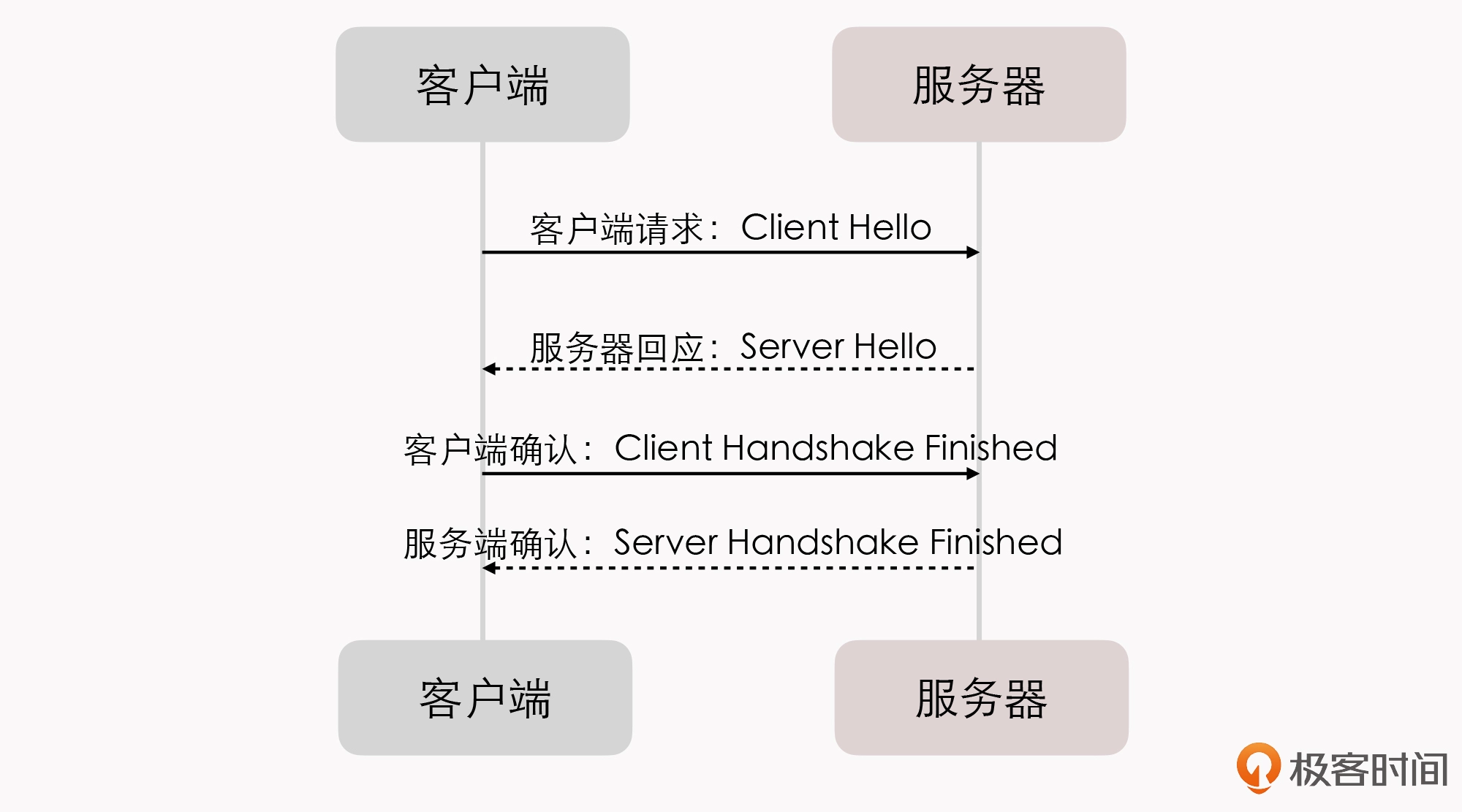
下面,我们就一一来详细解读一下这个过程。
第一步,客户端请求:Client Hello
客户端向服务器请求进行加密通讯,在这个请求里面,它会以明文的形式,向服务端提供以下信息:
- 支持的协议版本,比如 TLS 1.2。但是你要注意,1.0 至 3.0 分别代表了 SSL1.0 至 3.0,而 TLS1.0 则是 3.1,一直到 TLS1.3 的 3.4。
- 一个客户端生成的 32 Bytes 随机数。这个随机数将稍后用于产生加密的密钥。
- 一个可选的 SessionID。注意,你不要和前面的 Cookie-Session 机制混淆了,这个 SessionID 是指传输安全层的 Session,它是为了 TLS 的连接复用而设计的。
- 一系列支持的 密码学算法套件 。比如 TLS_RSA_WITH_AES_128_GCM_SHA256,代表着密钥交换算法是 RSA,加密算法是 AES128-GCM,消息认证码算法是 SHA256。
- 一系列支持的数据压缩算法。
- 其他可扩展的信息。为了保证协议的稳定,后续对协议的功能扩展大多都是添加到这个变长结构中。比如 TLS 1.0 中,由于发送的数据并不包含服务器的域名地址,导致了一台服务器只能安装一张数字证书,这对虚拟主机来说就很不方便,所以从 TLS 1.1 起,就增加了名为”Server Name”的扩展信息,以便一台服务器给不同的站点安装不同的证书。
第二步,服务器回应:Server Hello
服务器接收到客户端的通讯请求后,如果客户端声明支持的协议版本和加密算法组合,与服务端相匹配的话,就向客户端发出回应。如果不匹配,将会返回一个握手失败的警告提示。这次回应同样是以明文发送的,主要包括以下信息:
- 服务端确认使用的 TLS 协议版本。
- 第二个 32 Bytes 的随机数,稍后用于产生加密的密钥。
- 一个 SessionID,以后可通过连接复用减少一轮握手。
- 服务端在列表中选定的密码学算法套件。
- 服务端在列表中选定的数据压缩方法。
- 其他可扩展的信息。
- 如果协商出的加密算法组合是依赖证书认证的,服务端还要发送出自己的 X.509 证书,而证书中的公钥是什么,也必须根据协商的加密算法组合来决定。
- 密钥协商消息,这部分内容对于不同的密码学套件有着不同的价值。比如对于 ECDH + anon 这样的密钥协商算法组合来说(基于椭圆曲线的 ECDH 算法 可以在双方通讯都公开的情况下,协商出一组只有通讯双方知道的密钥),就不需要依赖证书中的公钥,而是通过 Server Key Exchange 消息协商出密钥。
第三步,客户端确认:Client Handshake Finished
由于密码学套件的组合复杂多样,这里我就只用 RSA 算法作为密钥交换算法来给你举个例子,介绍下客户端确认的后续过程。
首先,客户端在收到服务器应答后,要先验证服务器的证书合法性。然后,如果证书不是可信机构颁布的,或者是证书中的信息存在问题,比如域名与实际域名不一致、或证书已经过期、或通过在线证书状态协议得知证书已被吊销,等等,这都会向访问者显示一个”证书不可信任”的警告,由用户自行选择是否还要继续通信。
而如果证书没有问题,客户端就会从证书中取出服务器的公钥,并向服务器发送以下信息:
- 客户端证书(可选)。部分服务端并不是面向全公众的,而是只对特定的客户端提供服务,此时客户端就需要发送它自身的证书来证明身份。如果不发送,或者验证不通过,服务端可自行决定是否要继续握手,或者返回一个握手失败的信息。 客户端需要证书的 TLS 通讯,也被称为”双向 TLS” (Mutual TLS,常简写为 mTLS),这是云原生基础设施的主要认证方法,也是基于信道认证的最主流形式。
- 第三个 32 Bytes 的随机数,这个随机数不再是明文发送,而是以服务端传过来的公钥加密的,它被称为 PreMasterSecret,将与前两次发送的随机数一起,根据 特定算法 计算出 48 Bytes 的 MasterSecret,这个 MasterSecret 也就是为后续内容传输时的对称加密算法所采用的私钥。
- 编码改变通知,表示随后的信息都将用双方商定的加密方法和密钥发送。
- 客户端握手结束通知,表示客户端的握手阶段已经结束。这一项同时也是前面发送的所有内容的哈希值,以供服务器校验。
第四步,服务端确认:Server Handshake Finished
服务端向客户端回应最后的确认通知,包括以下信息:
- 编码改变通知,表示随后的信息都将用双方商定的加密方法和密钥发送。
- 服务器握手结束通知,表示服务器的握手阶段已经结束。这一项同时也是前面发送的所有内容的哈希值,以供客户端校验。
那么到这里,整个 TLS 握手阶段就宣告完成,一个安全的连接就成功建立了。你要知道,每一个连接建立的时候,客户端和服务端都会通过上面的握手过程协商出许多信息,比如一个只有双方才知道的随机产生的密钥、传输过程中要采用的对称加密算法(例子中的 AES128)、压缩算法等,此后该连接的通讯将使用此密钥和加密算法进行加密、解密和压缩。
这种处理方式对上层协议的功能上完全透明的,在传输性能上会有下降,但在功能上完全不会感知到有 TLS 的存在。建立在这层安全传输层之上的 HTTP 协议,就被称为”HTTP Over SSL/TLS”,也即是我们所熟知的 HTTPS。
另外,从上面握手协商的过程中我们还可以得知,HTTPS 并非不是只有”启用了 HTTPS”和”未启用 HTTPS”的差别,采用不同的协议版本、不同的密码学套件、证书是否有效、服务端 / 客户端对面对无效证书时的处理策略如何,都会导致不同 HTTPS 站点的安全强度的不同。因此并不能说只要启用了 HTTPS,就必定能够安枕无忧。
小结
今天,我们通过在网络中如何安全分发公钥这个问题,引出了如何通过数字证书达成共同信任、如何通过 PKI 体系来签发数字证书。在了解了数字证书的工作原理后,你还要了解的重点是如何通过传输安全层,把繁琐的安全过程隐藏起来,让开发者不需要时刻注意到那些麻烦而又琐碎的安全细节。
留言
关于数字证书,有一篇我觉得非常经典的文章: http://www.youdzone.com/signature.html
30 | 验证:系统如何确保提交给服务的数据是安全的?
你好,我是周志明。今天是安全架构这个小章节的最后一讲,我们来讨论下”验证”这个话题,一起来看看,关于”系统如何确保提交到每项服务中的数据是合乎规则的,不会对系统稳定性、数据一致性、正确性产生风险”这个问题的具体解决方案。
数据验证也很重要
数据验证与程序如何编码是密切相关的,你在做开发的时候可能都不会把它归入安全的范畴之中。但你细想一下,如果说关注”你是谁”(认证)、”你能做什么”(授权)等问题是很合理的安全,那么关注”你做的对不对”(验证)不也同样合理吗?
首先,从数量上来讲,因为数据验证不严谨而导致的安全问题,要比其他安全攻击所导致的问题多得多;其次,从风险上来讲,由于数据质量而导致的安全问题,要承受的风险可能有高有低,可当我们真的遇到了高风险的数据问题,面临的损失不一定就比被黑客拖库来得小。
当然不可否认的是,相比其他富有挑战性的安全措施,比如说,防御与攻击之间精彩的缠斗需要人们综合运用数学、心理、社会工程和计算机等跨学科知识,数据验证这项常规工作确实有点儿无聊。在日常的开发工作当中,它会贯穿于代码的各个层次,我们每个人肯定都写过。
但是,这种常见的代码反而是迫切需要被架构约束的。
这里我们要先明确一个要点: 缺失的校验会影响数据质量,而过度的校验也不会让系统更加健壮,反而在某种意义上会制造垃圾代码,甚至还会有副作用。
我们来看看下面这个实际的段子:
前 端: 提交一份用户数据(姓名:某, 性别:男, 爱好:女, 签名:xxx, 手机:xxx, 邮箱:null)
控制器: 发现邮箱是空的,抛ValidationException("邮箱没填")
前 端: 已修改,重新提交
安 全: 发送验证码时发现手机号少一位,抛RemoteInvokeException("无法发送验证码")
前 端: 已修改,重新提交
服务层: 邮箱怎么有重复啊,抛BusinessRuntimeException("不允许开小号")
前 端: 已修改,重新提交
持久层: 签名字段超长了插不进去,抛SQLException("插入数据库失败,SQL:xxx")
…… ……
前 端: 你们这些坑管挖不管埋的后端,各种异常都往前抛!
用 户: 这系统牙膏厂生产的?你应该也知道,最基础的数据问题可以在前端做表单校验来处理,但服务端验证肯定也是要做的。那么在看完了前面这个段子以后,你可以想一想, 服务端应该在哪一层去做校验呢? 我想你可能会得出这样的答案:
- 在 Controller 层做,在 Service 层不做。 理由是从 Service 开始会有同级重用,当出现 ServiceA.foo(params) 调用 ServiceB.bar(params) 的时候,就会对 params 重复校验两次。
- 在 Service 层做,在 Controller 层不做。 理由是无业务含义的格式校验,已经在前端表单验证处理过了;而有业务含义的校验,不应该放在 Controller 中,毕竟页面控制器的职责是管理页面流,不该承载业务。
- 在 Controller、Service 层各做各的。 Controller 做格式校验,Service 层做业务校验,听起来很合理,但这其实就是前面段子中被嘲笑的行为。
- 还有其他一些意见,比如说在持久层做校验,理由是这是最终入口,把守好写入数据库的质量最重要。
这样的讨论大概是不会有一个统一、正确的结论的,但是在 Java 里确实是有验证的标准做法,即 Java Bean Validation。这也是我比较提倡的做法,那就是 把校验行为从分层中剥离出来,不是在哪一层做,而是在 Bean 上做。
Java Bean Validation
从 2009 年 JSR 303 的 1.0,到 2013 年 JSR 349 更新的 1.1,到目前最新的 2017 年发布的 JSR 380 ,Java 定义了 Bean 验证的全套规范。这种单独将验证提取、封装的做法,可以让我们获得不少好处:
- 对于无业务含义的格式验证,可以做到预置。
- 对于有业务含义的业务验证,可以做到重用。一个 Bean 作为参数或返回值,被用于多个方法的情况是很常见的,因此针对 Bean 做校验,就比针对方法做校验更有价值,这样利于我们集中管理,比如统一认证的异常体系、统一做国际化、统一给客户端的返回格式,等等。
避免对输入数据的防御污染到业务代码。如果你的代码里面有很多像是下面这样的条件判断,就应该考虑重构了:
// 一些已执行的逻辑 if (someParam == null) { throw new RuntimeException("客官不可以!") }- 利于多个校验器统一执行,统一返回校验结果,避免用户踩地雷、挤牙膏式的试错体验。
据我所知,国内的项目使用 Bean Validation 的并不少见,但大多数程序员都只使用到它的 Built-In Constraint,来做一些与业务逻辑无关的通用校验,也就是下面展示的这堆注解,看类名我们基本上就能明白它们的含义了:
@Null、@NotNull、@AssertTrue、@AssertFalse、@Min、@Max、@DecimalMin、@DecimalMax、@Negative、@NegativeOrZero、@Positive、@PositiveOrZero、@Size、@Digits、@Pass、@PassOrPresent、@Future、@FutureOrPresent、@Pattern、@NotEmpty、@NotBlank、@Email不过我们要知道,与业务相关的校验往往才是最复杂的校验。而把简单的校验交给 Bean Validation,把复杂的校验留给自己,这简直是买椟还珠故事的程序员版本。其实,以 Bean Validation 的标准方式来做业务校验是非常优雅的。
接下来,我就用 Fenix’s Bookstore 项目在用户资源上的两个方法:”创建新用户”和”更新用户信息”,来给你举个例子:
/**
* 创建新的用户
*/
@POST
public Response createUser(@Valid @UniqueAccount Account user) {
return CommonResponse.op(() -> service.createAccount(user));
}
/**
* 更新用户信息
*/
@PUT
@CacheEvict(key = "#user.username")
public Response updateUser(@Valid @AuthenticatedAccount @NotConflictAccount Account user) {
return CommonResponse.op(() -> service.updateAccount(user));
}这里你要注意其中的三个自定义校验注解,它们的含义分别是:
- @UniqueAccount :传入的用户对象必须是唯一的,不与数据库中任何已有用户的名称、手机、邮箱产生重复。
- @AuthenticatedAccount :传入的用户对象必须与当前登录的用户一致。
- @NotConflictAccount :传入的用户对象中的信息与其他用户是无冲突的,比如将一个注册用户的邮箱,修改成与另外一个已存在的注册用户一致的值,这便是冲突。
这里的需求我们其实很容易就能想明白:当注册新用户时,要约束其不与任何已有用户的关键信息重复;而当用户修改自己的信息时,只能与自己的信息重复,而且只能修改当前登录用户的信息。
这些约束规则不仅仅是为这两个方法服务,它们还可能会在用户资源中的其他入口被使用到,乃至在其他分层的代码中被使用到。而在 Bean 上做校验,我们就能一揽子地覆盖前面提到的这些使用场景。
现在我们来看前面代码中用到的三个自定义注解对应校验器的实现类:
public static class AuthenticatedAccountValidator extends AccountValidation<AuthenticatedAccount> {
public void initialize(AuthenticatedAccount constraintAnnotation) {
predicate = c -> {
AuthenticAccount loginUser = (AuthenticAccount) SecurityContextHolder.getContext().getAuthentication().getPrincipal();
return c.getId().equals(loginUser.getId());
};
}
}
public static class UniqueAccountValidator extends AccountValidation<UniqueAccount> {
public void initialize(UniqueAccount constraintAnnotation) {
predicate = c -> !repository.existsByUsernameOrEmailOrTelephone(c.getUsername(), c.getEmail(), c.getTelephone());
}
}
public static class NotConflictAccountValidator extends AccountValidation<NotConflictAccount> {
public void initialize(NotConflictAccount constraintAnnotation) {
predicate = c -> {
Collection<Account> collection = repository.findByUsernameOrEmailOrTelephone(c.getUsername(), c.getEmail(), c.getTelephone());
// 将用户名、邮件、电话改成与现有完全不重复的,或者只与自己重复的,就不算冲突
return collection.isEmpty() || (collection.size() == 1 && collection.iterator().next().getId().equals(c.getId()));
};
}
}这样,业务校验就可以和业务逻辑完全分离开,在需要校验时,你可以用 @Valid 注解自动触发,或者通过代码手动触发执行。你可以根据自己项目的要求,把这些注解应用于控制器、服务层、持久层等任何层次的代码之中。
而且,采用 Bean Validation 也便于我们统一处理校验结果不满足时的提示信息。比如提供默认值、提供国际化支持(这里没做)、提供统一的客户端返回格式(创建一个用于 ConstraintViolationException 的异常处理器来实现),以及批量执行全部校验,避免出现开篇那个段子中挤牙膏的尴尬情况。
除此之外,对于 Bean 与 Bean 校验器,我还想给你两条关于编码的建议。
第一条建议是,要对校验项预置好默认的提示信息,这样当校验不通过时,用户能获得明确的修正提示。这里你可以参考下面的代码示例:
/** * 表示一个用户的信息是无冲突的 * * "无冲突"是指该用户的敏感信息与其他用户不重合,比如将一个注册用户的邮箱,修改成与另外一个已存在的注册用户一致的值,这便是冲突 **/ @Documented @Retention(RUNTIME) @Target({FIELD, METHOD, PARAMETER, TYPE}) @Constraint(validatedBy = AccountValidation.NotConflictAccountValidator.class) public @interface NotConflictAccount { String message() default "用户名称、邮箱、手机号码与现存用户产生重复"; Class<?>[] groups() default {}; Class<? extends Payload>[] payload() default {}; }第二条建议是,要把不带业务含义的格式校验注解放到 Bean 的类定义之上,把带业务逻辑的校验放到 Bean 的类定义的外面。
这两者的区别是,放在类定义中的注解能够自动运行,而放到类外面的业务校验需要像前面的示例代码那样,明确标出注解时才会运行。比如用户账号实体中的部分代码为:
public class Account extends BaseEntity { @NotEmpty(message = "用户不允许为空") private String username; @NotEmpty(message = "用户姓名不允许为空") private String name; private String avatar; @Pattern(regexp = "1\\d{10}", message = "手机号格式不正确") private String telephone; @Email(message = "邮箱格式不正确") private String email }你可以发现,这些校验注解都直接放在了类定义中,每次执行校验的时候它们都会被运行。因为 Bean Validation 是 Java 的标准规范,它执行的频率可能比编写代码的程序所预想的更高,比如使用 Hibernate 来做持久化时,便会自动执行 Data Object 上的校验注解。
对于那些不带业务含义的注解,在运行时是不需要其他外部资源的参与的,它们不会调用远程服务、访问数据库,这种校验重复执行实际上并没有什么成本。
但带业务逻辑的校验,通常就需要外部资源参与执行,这不仅仅是多消耗一点时间和运算资源的问题,因为我们很难保证依赖的每个服务都是幂等的,重复执行校验很可能会带来额外的副作用。因此应该放到外面,让使用者自行判断是否要触发。
另外,还有一些”需要触发一部分校验”的非典型情况,比如”新增”操作 A 需要执行全部校验规则,”修改”操作 B 中希望不校验某个字段,”删除”操作 C 中希望改变某一条校验规则,这个时候,我们就要启用分组校验来处理,设计一套”新增””修改””删除”这样的标识类,置入到校验注解的 groups 参数中去实现。
小结
这节课算是 JSR 380 Bean Validation 的小科普,Bean 验证器在 Java 中存在的时间已经超过了十年,应用范围也非常广泛,但现在还是有很多的信息系统选择自己制造轮子,去解决数据验证的问题,而且做的也并没有 Bean 验证器好。
所以在这节课里,我给你总结了正确使用 Bean 验证器的一些最佳实践,涉及到不少具体的代码,建议你好好结合着代码进行学习和实践。在课程后面的实战模块中,我还会给你具体展示 Fenix’s Bookstore 的工程代码,到时你也可以结合着该模块一起学习,印证或增强实战学习的效果。
春节特别放送
春节特别放送(上)| 有的放矢,事半功倍
“演进中的架构”模块内容复盘
这个模块里,我们一起了解了微服务发展历程中出现的大量技术名词、概念,以及了解了这些技术的时代背景和探索过程,同时也在此过程中,更深入地理解了 Unix 设计哲学的思想。
原始分布式时代。 这是计算机科学对分布式和服务化的第一次探索,DCE、CORBA 等都是早期的分布式基础架构,原始分布式架构设计的主要目的,就是为了追求简单、符合 Unix 哲学的分布式系统,这也是软件开发者对分布式系统最初的美好愿景。
单体系统时代。 单体作为迄今为止使用人数最多的一种软件架构风格,具有易于分层、易于开发、易于部署测试、进程内的高效交互等优势。它也存在一些关键性的问题,比如存在隔离与自治能力上的欠缺、不兼容”Phoenix”的特性等。但这并不意味着单体最终会被微服务所取代,未来它仍然会长期存在。
SOA 时代。 虽然 SOA 架构具有完善的理论和工具,可以解决分布式系统中几乎所有主要的技术问题,曾经也被视为更大规模的软件发展的方向,但它最终还是没能成为一种普适的软件架构。为什么呢?实际上这正是由于 SOA 架构过于严谨精密的流程与理论,使得它脱离了人民群众,从而走上了被架构者抛弃的不归路。
微服务时代。 早期的微服务架构作为 SOA 的一种轻量化的补救方案,是在 SOA 发展的同时被催生出来的产物。但发展到现在,可以说微服务已然成为了一种独立的架构风格。在该架构模式下,我们需要解决什么问题,就引入什么工具;团队熟悉什么技术,就使用什么框架,对开发者来说十分友善。不过我们也同样需要警惕,因为在微服务中,对于那些分布式服务的问题不再有统一的解决方案,因此可以说微服务所带来的自由是一把双刃剑。
后微服务时代。 现在人们常说的”云原生”时代,就是课程中所讲的后微服务时代,因为它跟前面的微服务时代中追求的目标相比,并没有什么本质的改变,都是通过一系列小型服务去构建大型系统。可以说,容器化技术、虚拟化技术的发展和兴起,对软件架构、软件开发产生了很大改变,软件和硬件的界限开始变得模糊,业务与技术能够完全分离,远程与本地完全透明,如同老师所说,也许这就是分布式架构最好的时代。
无服务时代。 无服务是近几年出现的新概念,它最大的卖点就是简单,只涉及了后端设施和函数两块内容,其设计目标是为了让开发者能够更纯粹地关注业务。不过我们要注意,与单体架构、微服务架构不同,无服务架构天生的一些特点,比如冷启动、无状态、运行时间有限制等等,决定了它不是一种具有普适性的架构模式,我们也不要误会它比微服务更先进。
模块留言精选
第 1 讲
来自 @Jxin
我认为,可以从两个方面来看待”简单”,分别是业务和技术。
先说业务。现代软件系统的业务复杂性越来越高,而分离关注点,无疑是应对日益增长的业务复杂性的有效手段。但如果依旧是一个大型单体系统(所有业务单元都在一个容器下),那么跨业务单元的知识诉求便很难避免了,并且在开发迭代以及版本发布中,彼此还会相互影响。而微服务的出现,就为其提供了设定物理边界的技术基础,这就使得多个特性团队对业务知识的诉求可以收敛在自身领域内,降低了单个特性团队所需了解的业务知识。
再来说下技术。这里我认为主要体现在技术隔离上。就如同 RPC 可以让你像调用本地方法一样调用远程方法,微服务技术组件的出现,大多是为了让开发人员可以基于意图,去使用各种协调分布式系统的工具,而不用深入具体工具的实现细节,去研究怎么解决的分布式难题。
另外,就像 SpringBoot 提到的生产就绪,微服务的生态已经不局限于开发的阶段。在部署和运行阶段都有健全组件的支持。它可以让开发人员基于意图就可以简便地实现金丝雀发布,基于意图就能拿到所有系统运行期的数据。而所有的这些便利,都算是技术隔离带来的好处。
来自 @J.Spring
目前我们团队在做从传统 HTTP 直接调用、向 SOA 服务化架构的改造,这个过程让我对 SpringCloud 这种面向 HTTP 的服务,以及 Dubbo-RPC 服务产生了疑问。
因为单论简单,SpringCloud 看起来更简单,但它缺乏完善且强大的服务治理能力。而 Dubbo 框架看似沉重,却拥有很强大的服务治理功能。
所以我认为,简单的东西可能后期会变得复杂。而一开始的复杂,可能后期会变得简单。
第 2 讲
来自 @STOREFEE
如果可以很明显地预估到项目的开发规模不会很大,但是对性能要求很高,局部范围需要经常迭代,而且需要多点部署的场景,那就非常适合单体架构。
不过我观察到,凡是和互联网沾边的流行的软件项目,基本其规模都在不断膨胀,趋向于包罗万象。因为现在很多用户会觉得软件越来越多,去切换不同的东西太麻烦了,有的还得申请账号、填写资料等,比较繁琐。最明显的例子就是石墨和飞书,前几年感觉石墨文档很贴近 Word,挺不错的。另外,现在飞书、企业微信等工具,都整合了企业聊天、会议、文档、存储、绘图等一系列的东西。
所以说像这种一站式服务,绝对会采用非单体架构。
来自 @小高
单体架构并不是一无是处的。在公司的初始阶段,为了让业务快速上线,就必须得采用单体架构。然后随着业务的增长,架构才得以演进。
还是那句话,架构不是一成不变的,而是持续演进的。或许,微服务也不是终点。
第 3 讲
来自 @Wacky 小恺
在目前的信息技术行业中,如果按照严谨的 SOA 架构去设计系统,那么不仅为开发人员带来了负担,也加重了用户的学习成本,使得在快速迭代中,需求会被架构所限制。
我认为软件的设计应当为简洁的、无门槛使用的,比如国民产品微信,不需要过多的学习成本即可使用。而 SOA 的风格是自上向下的工业标准,自然不符合时代的潮流,”不接地气”,因而就会被时代所抛弃。
来自 @Frank
我之前也使用过 SOAP 协议来开发服务,那时候,我们公司自己搞了一个 ESB,但是好景不长。一开始是所有服务调用均走 ESB,不过后来由于某些原因,直接绕过了 ESB,当时我其实并不理解为什么要这么做。后面随着不断学习才慢慢明白,之前搞得 ESB,服务之间的协议等等的 “太重”了,实施维护成本很高,不适合自身业务的发展。
第 4 讲
来自 @陈珙
我做.Net 实施微服务的时候,当时业界还没有特别成熟的选型与方案,所以自己在组件、方案之间选型对比、整合花了不少的功夫。
老师说架构师是做平衡与取舍,而开发工程师是实施。我也这么认为。微服务的分而治之、化繁为简的思想是减少了业务开发复杂度,但同时引入了很多组件支撑服务,因此加大了技术复杂度。
我自己是有几条设计原则的,如下:
- 技术服务于架构,架构服务于业务;
- 康威定律;
架构的实施是需要对应开发模式支撑的。
那总结起来就是,业务规模与团队规模决定了架构的规模,一个增删查改的系统并不需要用微服务架构;使用了前后端分离,那么团队里多数是有前端工程师;由微服务架构拆分引起的量变导致质变,结合 DevOps 能更好地支持运作。
来自 @Mr.Chen
其实用不用微服务架构,主要取决于业务,撇开业务谈架构都是在耍流氓!
我们公司面向企业私有化的项目就没有用微服务,主要是用户的并发量小,考虑到部署和运维的简单,直接上单体架构。
第 5 讲
来自 @zhanyd
软件架构的发展方向,是慢慢地把与业务无关的技术问题,从软件的层面剥离出来,在硬件的基础设施之内就被悄悄解决掉,让开发人员只专注于业务,真正”围绕业务能力构建”团队与产品。
把复杂的问题交给计算机硬件解决,使得开发人员只需要关注业务,让开发越来越简单,同时能够调用的计算机资源也会越来越强大。
这也符合奥卡姆剃刀原则:”如无必要,勿增实体”。如果问题能让计算机自动解决,就不要麻烦人类。
来自 @Jxin
分布式架构发展到服务网格后,真的是到达”最好的时代”了吗?我的回答是:没有最好,只有更好。
云原生下,SLS 的 FaaS 和服务网格的纯应用包,这两个各自的需求差异还是挺大的。前者算是技术架构上对效率和成本的创新,后者算是业务架构上对技术分离的追求。这是两个发展分支,但是也不知道会不会产生新的问题。
不过,业务知识的易传递性、代码的开发、软件发布的效率、高可用和高性能的诉求,等等,这些在可见的未来,应该还会是需要持续解决的问题。
第 6 讲
来自 @大 D
2011 年我刚毕业进公司,开始使用 Mule、ESB 做集成,当时我也是初次接触 WebService 这一套东西,SOAP、WSDL 等等用了一年也没搞明白都是干啥用的,感觉就是俩字”复杂”。再后来,公司的产品采用 OSGI 的方式,自己通过订制 Eclipse 插件的方式开发了一套 IDE,每次打包要勾选一堆的依赖,解决依赖冲突、查找依赖,苦不堪言。这些东西本身就有很多技术壁垒和学习成本。
再后来,Maven 流行,开始各种分模块,后面公司用 MQ 实现了一套总线,现在看来它就类似于老师讲的事件驱动架构,这个架构还是要自己解决很多负载、补偿、事务等问题,不过总体来说比之前有进步。
然后直到微服务的出现,感觉轻松了很多,框架层面的东西已经有了很多的解决方案,选择一个合适的就行,其他的专注于业务开发即可。
现在的年轻人确实赶上了一个好时代,不用理解那么多的复杂实现,可以更多地磨练自身编码能力。但我觉得经历过的都是财富,不然也不会对老师的课程产生强烈的共鸣。
来自 @walkingonair
我正在腾讯云上摸索无服务的架构模式,完全赞同老师的说法。选择无服务的初始原因是由于微信小程序生态的强大,在腾讯云上进行产品的开发,能大大降低人力成本、运维成本,提高产品的开发速度,帮助创业小公司度过艰难的初期。
同时,无服务的架构模式,也能在业务量快速上升时,只需要简单增加成本投入,即可快速提高整个架构的业务承载能力,满足未来更大的业务增长。
但这种架构模式的不足也是十分明显的:
我虽然是一个全栈开发工程师,但是平常使用最多的还是 Java 语言,而 Java 的运行离不开 Java 虚拟机,那么在这种架构下使用 Java 开发的云函数,性能上能得到保证吗?这个问题我保持怀疑态度,这也导致我在语言方面选择的是 Node,而且它也更适合小程序开发者。
虽然无服务与编程语言无关,但是工程师的开发能力与语言有关,代码的规范、设计、管理方面与语言有关。就像老师所说的,做到普适性还有很长的路要走。
由于无服务架构对非业务层(云函数)的封装,一些特殊需求变得难以实现。例如云数据库的封装和限制,使基于云函数的开发、批量数据变得难以处理,函数运行的超时时间限制和数据库对大批量获取的限制等等,都是瓶颈。
无服务架构虽然屏蔽了除业务开发外的实现,但是也对开发人员提出了更高的要求。云函数的实现,需要满足无状态、幂等的要求,否则或许会出现”匪夷所思”的 Bug。
当前云开发的各项功能还不完善,开发人员权限的管理、各种资源的授权分配、云函数和云数据库等产品的管理在大型企业的模式下难以适用。
总而言之,云开发有着诱人的优点,但也有一些致命的不足。从架构演化的角度来说,无服务架构未来值得期待,这也是我选择无服务架构的最大原因。
春节特别放送(下)| 积累沉淀,知行合一
“架构师的视角”模块内容复盘
在这个模块里,我们系统性地了解了在做架构设计时,架构师都应该思考哪些问题、可以选择哪些主流的解决方案和行业标准做法,以及这些主流方案都有什么优缺点、会给架构设计带来什么影响,等等,以此对架构设计这种抽象的工作有了更具体、更具象的认知。
服务风格设计
- 远程服务调用: RPC 以模拟进程间方法调用为起点,表示数据、传递数据和表示方法,是 RPC 必须解决的三大基本问题。解决这些问题可以有很多方案,这也是 RPC 协议 / 框架出现群雄混战局面的一个原因,而另一个原因是简单的框架很难能达到功能强大的要求。一个 RPC 框架要想取得成功,就要选择一个发展方向,因此我们也就有了朝着面向对象发展、朝着性能发展和朝着简化发展这三条线。
- RESTful 服务: 面向过程和面向对象两种编程思想虽然出现的时间有先后,但在人类使用计算机语言来处理数据的工作中,无论用哪种思维来抽象问题都是合乎逻辑的。而面向资源编程这种思想,是把问题空间中的数据对象作为抽象的主体,把解决问题时从输入数据到输出结果的处理过程,看作是一个(组)数据资源的状态不断发生变换而导致的结果。这符合目前网络主流的交互方式,所以 REST 常常被看作是为基于网络的分布式系统量身定做的交互方式。
事务处理
- 本地事务: 本地事务是指仅操作特定单一事务资源的、不需要”全局事务管理器”进行协调的事务。ARIES 理论提出了 Write-Ahead Logging 式的日志写入方法,通过分析、重做、回滚三个阶段实现了 STEAL、NO-FORCE,从而实现了既高效又严谨的日志记录与故障恢复。此外在实现隔离性这方面,我们要知道不同隔离级别以及幻读、脏读等问题,都只是表面现象,它们是各种锁在不同加锁时间上组合应用所产生的结果,锁才是根本的原因。
- 全局事务: 全局事务可以理解为是一种适用于单个服务使用多个数据源场景的事务解决方案,其中的两段式提交和三段式提交模式还会在一些多数据源的场景中用到,它们追求 ACID 的强一致性,这个目标不仅给它带来了很高的复杂度,而且吞吐量和使用效果上也不够好。
- 共享事务: 共享事务是指多个服务共用同一个数据源,虽然目前共享事务确实已经很少见,不过通过了解事务演进的过程,也更便于我们理解其他三种事务类型。
- 分布式事务: 现在系统设计的主流,已经变成了不追求 ACID 而是强调 BASE 的弱一致性事务,也就是分布式事务,它是指多个服务同时访问多个数据源的事务处理机制。我们要知道,分布式系统中不存在放之四海皆准的万能事务解决方案,针对具体场景,选择合适的解决方案,达到一致性与可用性之间的最佳平衡,是我们作为一名设计者必须具备的技能。
透明多级分流系统
- 客户端缓存: 客户端缓存具体包括”状态缓存”、”强制缓存”和”协商缓存”三类,利用好客户端的缓存能够节省大量网络流量,这是为后端系统分流,以实现更高并发的第一步。
- 域名解析: 域名解析对于大多数信息系统,尤其是基于互联网的系统来说是必不可少的组件,它的主要作用就是把便于人类理解的域名地址,转换为便于计算机处理的 IP 地址。
- 传输链路: 这也是一种与客户端关系较为密切的传输优化机制。这里我们要明确一点,即 HTTP 并不是只将内容顺利传输到客户端就算完成任务了,如何做到高效、无状态也是很重要的目标。另外在 HTTP/2 之前,要想在应用一侧优化传输,就必须要同时在其他方面付出相应的成本,而 HTTP/2 中的多路复用、头压缩等改进项,就从根本上给出了传输优化的解决方案。
- 内容分发网络: 内容分发网络(CDN)是一种已经存在了很长时间,也被人们广泛应用的分流系统,其工作过程主要涉及到路由解析、内容分发、负载均衡和它所能支持的应用内容四个方面。CDN 能为互联网系统提供性能上的加速,也能帮助增强许多功能,比如说安全防御、资源修改、功能注入等。而且这一切又实现得极为透明,可以完全不需要开发者来配合。
- 负载均衡: 负载均衡的两大职责就是”选择谁来处理用户请求”和”将用户请求转发过去”。如今一般实际用于生产的系统几乎都离不开集群部署,而在其中用于承担调度后方的多台机器,以统一的接口对外提供服务的技术组件,就是负载均衡器了。理解其工作原理,对于我们做系统的流量和容量规划工作是很有必要的。
- 服务端缓存: 服务端缓存也是一种通用的技术组件,它主要用于减少多个客户端相同的资源请求,缓解或降低服务器的负载压力,因此可以作为一种分流手段。
安全架构
- 认证: 认证解决的是”你是谁?”的问题,即如何正确分辨出操作用户的真实身份。在课程中我们了解了三种主流的认证方式,分别为通讯信道上的认证、通讯协议上的认证、通讯内容上的认证。
- 授权: 授权解决的是”你能干什么?”的问题,即如何控制一个用户该看到哪些数据、能操作哪些功能。我们可以使用 OAuth 2.0 来解决涉及到多方系统调用时可靠授权的问题,而针对如何确保授权的结果可控的问题,可以通过基于角色的访问控制(RBAC)来解决。
- 凭证: 凭证解决的是”你要如何证明?”的问题,即如何保证它与用户之间的承诺是准确、完整且不可抵赖的。对此我们也了解了 Cookie-Session 机制和无状态的 JWT 两种凭证实现方案,它们分别适用于不同的场景,因此我们在做架构设计时要做好权衡。
- 保密: 即解决如何保证敏感数据无法被内外部人员所窃取、滥用的问题。这里我们要知道,保密是有成本的,追求越高的安全等级,我们就要付出越多的工作量与算力消耗。
- 传输: 即解决如何保证通过网络传输的信息无法被第三方窃听、篡改和冒充的问题。传输环节是最复杂、最有效,但又是最早就有了标准解决方案的,不管是哈希摘要、对称加密和非对称加密这三种安全架构中常见的保密操作,还是通过数字证书达成共同信任、通过传输安全层隐藏繁琐的安全过程。
- 验证: 验证解决的是”你做的对不对?”的问题,即如何确保提交的信息不会对系统稳定性、数据一致性、正确性产生风险。虽然貌似数据验证并不属于安全的范畴,但其实它与程序如何编码是密切相关的。这里我们需要明确一点,就是缺失的校验会影响数据质量,而过度的校验也不会让系统更加健壮,反而在某种意义上会制造垃圾代码,甚至还会有副作用。
模块留言精选
第 7 讲
来自 @zhanyd
让计算机能够跟调用本地方法一样,去调用远程方法,应该是 RPC 的终极目标。但是目前的技术水平无法实现这一终极目标,所以就有了其他更可行的折中方案。
事物是慢慢演化发展的,目标可以远大,但是做事还是要根据实际情况,实事求是。
第 8 讲
来自 @Mr.Chen
RPC 只是服务(进程)之间简化调用的一种方式,它可以让开发者聚焦于业务本身。而对于服务间通信的各种细节交给框架处理这个维度来说,如果撇开这一层面,分布式系统的服务调用可以采用任何一种通信方式,比如 HTTP、Socket 等。
第 9 讲
来自 @tt
对于 REST,我的第一印象就是服务端无状态,有利于水平扩展,但更多的是停留于具体的技术层面。
过程如果有意义的话,一定会产生一个结果,这个结果就是资源的状态发生了转移(幂等前提下的重试不算),但是过程的细节更多,所以抽象程度无法做到向面向资源看齐。在一个过程中,我们可以对有关联关系的不同层次与结构的资源同时进行处理,但是面向资源却不容易做到。
我能想到的例子是转账操作,同时操作两个资源(即账户),而且要保证事务的 ACID。在转账的过程中要处理很多异常情况,尤其是涉及到多方交易的时候,所以写这样的交易就非常复杂,容易出错。
如果用面向资源的角度去考察,可以看成是对三个资源的操作:转出账户、转入账户以及事务。这里把事务列为单独的资源,是为了呼应上面提到的一个资源状态变化引起的关联资源的变化。
如果转账操作利用 TCC(Try-Confirm-Cancel)的方法,我觉得就是一种更偏向于面向资源的做法,每次只改变一个资源的状态。如果某个关联资源的状态改变失败,就对它发起一个逆操作(比如冲正)。这样可以做到很高的并发,在做到保序性的前提下,做差错处理也很简单。相当于把一个复杂操作分解成了多个简单操作,这样开发起来也很快,很容易复用。有点类似 CISC 和 RISC 指令集的关系。
第 10 讲
来自 @陈珙
谢谢老师的分享,我也谈谈自己实践 REST 和 RPC 后的感想,主要在第一、第二的争议点,感触非常深。
争议一:面向资源的编程思想只适合做 CRUD,只有面向过程、面向对象编程才能处理真正复杂的业务逻辑。
争议二:REST 与 HTTP 完全绑定,不适用于要求高性能传输的场景中。
之前我们用 REST 到了第 2 成熟度,关于第一点争议,包括我现在的想法,也是认为面向资源更加适合做数据读写接口的场景,例如某 NoSQL 的应用服务 API 封装,或者提供某内部使用 API 的微服务更加适合。
原因主要有两个。首先,如果是作为提供给前端使用,处理起复杂业务的时候不好抽象;其次,原本一个接口可以处理的复杂逻辑,但是因为 REST 原因,导致接口粒度要细到 N 个,假如由前端人员对接,那么就会增大他们的业务组合难度(我更加倾向大部分的业务逻辑由后端解决,前端尽量关注数据展示与动画交互,数据离后端人员最近)。
那么当粒度细化了以后,就会引申出第二个争议所说的性能问题。这里也有两方面原因:首先是因为要做接口的编排组合;其次也是因为 REST 被 HTTP 绑得死死的,那么开发人员就不得不去关注那些细节了。
举个例子,HTTP Status Code 的参数,除了是 body 外可能还会是 header,也有可能是 URI 参数,对于实际开发的便捷度来说并不够友好。
另外课程中老师还提到了 GraphQL。该技术的确能缓解 Query 的部分问题,但是我认为它同时也存在不可避免的问题,就是如何让使用端可以很好地了解并对接数据源及其属性?
对于这种存在争议性的东西,我的建议是尽可能地少引入团队。毕竟争议性越大,就意味着大家对它的理解越少,无论是引入推广还是实施的具体效果,都会存在很长周期的磨合与统一。
不过它也不是一文不值的。我们团队做的是解决方案,解决的是针对性的问题场景,对于一些比较清晰、比较接近数据的场景,如 NoSQL 的 API,或者简单的、方便抽象的、相对需求稳定的业务场景,如某内部微服务的 API,我认为是可以尝试使用的。
第 11 讲
来自 @zhanyd
FORCE 策略要求事务提交后,变动的数据马上写入磁盘,没有日志保护,但是这样不能保证事务的原子性。比如用户的账号扣了钱、写入了数据库,这时候系统崩溃了,商品库存的变更信息和商家账号的变更信息都还没来得及写入数据库,这样数据就不一致了。
因此为了实现原子性,保证能够恢复崩溃,绝大多数的数据库都采用 NO-FORCE 策略。而为了实现 NO-FORCE 策略,就需要引入 Redo Log(重做日志)来实现,即使修改数据时系统崩溃了,重启后根据 Redo Log,就可以选择恢复现场,继续修改数据,或者直接回滚整个事务。
换句话说就是,我先把我要改的东西记录在日志里,再根据日志统一写到磁盘中。万一我在写入磁盘的过程中晕倒了,等我醒来的时候,我照着日志重新做一遍,也能成功。
Commit Logging 方式实行了 NO-FORCE 策略,照理说这样已经实现了事务的功能,已经很牛了,但是当一个事务中的数据量特别大的时候,等全部变更写入 Redo Log 然后再统一写入磁盘,这样性能就不是很好,就会很慢,老板就会不开心。
那能不能在事务提交之前,偷偷地先写一点数据到磁盘呢(偷跑)?
答案是可以的,这就是 STEAL 策略。但是问题来了,你偷摸地写了数据,万一事务要回滚,或者系统崩溃了,这些提前写入的数据就变成了脏数据,必须想办法把它恢复才行。
这就需要引入 Undo Log(回滚日志),在偷摸写入数据之前,必须先在 Undo Log 中记录都写入了什么数据、改了什么地方,到时候事务回滚了,就按照 Undo Log 日志,一条条恢复到原来的样子,就像没有改过一样。
这种能够偷摸先写数据的方式,就叫做 Write-Ahead Logging。性能提高了,同时也更复杂了。不过虽然它复杂了点,但是效果很好啊,MySQL、SQLite、PostgreSQL、SQL Server 等数据库都实现了 WAL 机制呢。
第 12 讲
来自 @Wacky 小恺
在软件开发的发展历程中,”提供简洁的 API”始终贯穿至今,因此这一讲中提到的透明事务,在我看来对普通开发人员的使用层面来说,是完全有必要的。
但是作为开发人员,一定要有精益求精的品质,也许我们在日常使用中已经习惯了使用简洁的 API 来实现强大的功能。但如果遇到棘手的问题,或者需要自己思考解决方案的场景,那么”内功”就能显露出它的威力。
第 13 讲
来自 @zhanyd
学校组织知识竞赛,学生们(参与者)以一组为单位参加比赛,由一个监考老师(协调者)负责监考。考试分为考卷和答题卡,学生必须先在十分钟内把答案写在考卷上(记录日志),然后在三分钟内把答案涂到答题卡上(提交事务)。
两段式提交
- 准备阶段: 老师宣布:”开始填写考卷,时间十分钟”。十分钟内,写好考卷的学生就回答:Prepared。十分钟一到,动作慢还没写好的学生,就回答:Non-Prepared。如果有学生回答 Non-Prepared,该小组被淘汰。
提交阶段: 如果所有的学生都回答了 Prepared,老师就会在笔记本上记下,”开始填答题卡”(Commit),然后对所有的学生说:”开始填答题卡”(发送 Commit 指令)。学生听到指令后,就开始根据考卷去涂答题卡。
如果学生在涂答题卡的时候,过于紧张把答题卡涂错了,还可以根据考卷重新涂;如果所有的学生在规定时间内都填好了答题卡,老师宣布该小组考试通过。
三段式提交
- CanCommit 阶段: 老师先给学生看一下考卷,问问学生能不能在十分钟内做完。如果有学生说没信心做完,该小组直接淘汰。
- PreCommit 阶段: 如果学生都说能做完,老师就宣布:”开始填写考卷,时间十分钟”,和两段式提交的准备阶段一样。
- DoCommit 阶段: 和两段式提交的提交阶段一样。
第 14 讲
来自 @Goku
XA 事务成立的前提是所有的服务都可用,在分布式环境下使用的代价是如果有一个服务不可用,那么整个系统就不可用了。另外,XA 事务可能会对业务有侵入,而依靠可靠消息队列和重试机制则不需要侵入业务。
第 15 讲
来自 @tt
我觉得可靠事件队列最适用的场景就是在内部系统中做高可靠。
TCC 的范围扩大了一些,适合于新设计的系统;SAGA 的适用性最广,因为对服务提供的接口没有要求,可以有落地人工处理做保证。我们现在涉及三方互联的老系统,都可以看作是 SAGA 的一种形式。
第 16 讲
来自 @zhanyd
一个不起眼的 DNS 竟然暗藏了这么多精妙的设计,计算机技术发展的每个阶段成果,都是人类智慧的结晶。
关于奥卡姆剃刀原则,我也想做点补充。奥卡姆剃刀原则,又被称为”简约之原则”,它是由 14 世纪圣方济各会修道士奥卡姆(英格兰的一个地方)的威廉(William of Occam)提出来的,他说过这样一段话:
切勿浪费较多东西,去做”用较少的东西,同样可以做好的事情”。
更有名的一句话是:如无必要,勿增实体。
在历史上各个时代,最高深的物理学理论,从形式上讲都不复杂,从牛顿力学,到爱因斯坦的相对论,到今天物理学的标准模型。例如,质能方程 E=mc^2 ,欧拉恒等式 e^(iπ) + 1 = 0,都以极简的方式描述了极其复杂的规律。
关于计算机系统,在能满足需求的前提下,最简单的系统就是最好的系统。很多人为了显示自己的技术水平,明明是很简单的需求,却上了一堆高大上的技术,为了技术而技术,忘了技术的本质是为业务服务的,这显然违背了奥卡姆剃刀原则。
第 17 讲
来自 @追忆似水年华
我在做前端开发的时候,遇到了微信会自动缓存页面静态资源的问题,必须要手动刷新页面才行,有时候还得刷新好几遍才可以,有些极端情况则是短时间内连续刷新依然显示旧页面,这个问题在公司内一些同事的手机上均出现过。学习了周老师的这节课,对缓存有了基本的了解,明天就用 Charles 抓包,看看微信内对网页的客户端缓存策略是什么。
第 18 讲
来自 @Jxin
这里想补充一下 QUIC 相对于 TCP 的两点内容:自定义重传机制: TCP 是通过采样往返时间 RTT 不断调整的,但这个采样存在不准的问题。第一次发送包 A 超时未返回,第二次重发包 A,这时收到了包 A 的响应,但 TCP 并不能识别当前包 A 的响应是第一次发送,还是第二次重发返回的,这时不管怎么减,都可能出现计时偏长或过偏短的问题。而 QUIC 为每次发送包都打了版本号(包括重发),所以可以很好地识别返回的包是哪次发送包的,进而计算也就相对准确。
自定义流量控制: TCP 的流量控制是通过滑动窗口协议,是在连接上控制的窗口。QUIC 也玩滑动窗口,但是力度是可以细分到具体的 Stream。
其实应用层的协议多种多样,比如直播的 RTMP、物联网终端的 MQTT 等,但感觉都是两害取其轻的专项优化、对症下药的方案。只有 QUIC 直面了 TCP 的问题,通过应用层的编码实现,系统地提供更好的”TCP 连接”。
第 19 讲
来自 @zhanyd
在网上看到华为云 CDN 主要的应用场景,希望借此可以帮助我们更好地理解内容:
- 网站加速:CDN 网络能够对加速域名下的静态内容提供良好的加速服务。支持自定义缓存规则,用户可以根据数据需求设置缓存过期时间,缓存格式包括但不限于 zip、exe、wmv、gif、png、bmp、wma、rar、jpeg、jpg 等。
- 文件下载加速:适用于使用 http/https 文件下载业务的网站、下载工具、游戏客户端、App 商店等。
- 点播加速:适用于提供音视频点播服务的客户。通过分布在各个区域的 CDN 节点,将音视频内容扩展到距离用户较近的地方,随时随地为用户提供高品质的访问体验。
-全站加速:适用于各行业动静态内容混合,含较多动态资源请求(如 asp、jsp、php 等格式的文件)的网站。
第 20 讲
来自 @zhanyd
为什么负载均衡不能只在某一个网络层次中完成,而是要进行多级混合的负载均衡?
因为每一个网络层的功能是不一样的,这样就决定了每一层都有自己独有的数据,在不同的网络层做负载均衡能达到不同的效果。比如要修改 MAC 地址,在数据链路层修改最方便,要修改 IP 地址最好在网络层修改。
关于网络分层,我这里也打个比方。小帅在网上下单买东西,卖家需要寄快递,把要寄的商品(物理层)打包到包装盒里(数据链路层),然后把包装盒放到快递盒子里(网络层),在快递单上写上寄件地址和收件地址(Headers)。
然后快递员打电话给小帅拿快递(传输层),这里出现了 TCP 三次握手连接:
- 快递员:”喂,这里有你的快递,麻烦到门口拿一下”。
- 小帅:”好的,我这就过来”。
快递员:”那我在门口等你”。
小帅拿到快递后,在网上点击确认收货按钮,确认收货(返回 http Status Code 200,应用层)。
第 22 讲
来自 @zhanyd
“能满足需求的前提下,最简单的系统就是最好的系统”。这句话的隐藏前提是,我们的选择空间要足够大。不管是 CDN、负载均衡、客户端缓存、服务端缓存,还是分布式缓存,都给我们提供了大量的选择余地,可以根据自己系统的实际情况,灵活地选择最适合的方案。
这句话的另一种理解是:没有最好的方案,只有最合适的方案。
第 25 讲
来自 @zhanyd
角色是为了解耦用户和权限之间的多对多关系。比如有 100 个用户,他们的权限都是一样的,如果给每个用户都设一遍权限,这就太麻烦了,而且还很容易出错。这时候设置一个角色,把对应的权限配置到角色上,然后这 100 个用户加到这个角色中就行了。
角色还有一个好处,如果角色的权限变了,所有角色中用户的权限也会同时变更,不用一个个用户去设置了。
许可是为了解耦操作与资源之间的多对多关系,比如有新增用户、编辑用户、删除用户的三种操作,通常这些都是一起的,要么都能操作,要么都不能操作。这时候就可以把这三种操作打包成一个用户维护许可,用许可和角色关联更简洁。
关于 Spring Security 中的 Role 和 Authority 我是这么理解的:Role 就是普通的角色,拥有一组许可,这个角色下的所有用户的权限都是一样的。
但是如果一个角色中的一些用户有个性化的需求,比如销售助理角色,本来没有查看客户的权限,但是某个销售助理比较特殊,需要查看客户的信息,这时如果是单角色的系统,就需要新增一个”销售助理可查看客户角色”,这样很容易导致角色数量爆炸。
而有了 Authority,就可以满足这种个性化需求,只要把查看客户的权限加到 Authority 中赋予用户就行了。
第 26 讲
- 来自 @zhanyd
Cookie-Session 就相当于是坐飞机托运了行李,只要带着登机牌就行了。但是一旦托运了行李,行李就和飞机绑定了,你就不能随意换航班了。
JWT 就相当于是坐飞机拎着行李到处跑,每次过安检还要打开行李箱检查,而且箱子太小也带不了多少东西。但它的优点是可以随意换航班,行李都在自己身边。
用户故事 | 詹应达:持续成长,不惧未来
你好,我是詹应达(zhanyd),一名工作十多年的程序员,目前在温州做制造业信息化相关的工作,很高兴能和你分享我学习这门课程的心得。
为什么要学这门课?
首先我想和你聊聊我为什么想要学习这门课。
作为一个三线城市的程序员,CRUD BOY,想在工作中不断学习、突破瓶颈,有质的飞跃?说实话,我觉得真的很难。
就拿我自己来说吧,我们公司搞开发的就那么几个人,大家的水平都差不多,都是”面向百度编程”,而且业务上只有简单的 CRUD 和复杂的 CRUD,高并发?分布式?不存在的。要想提升技术能力的话,就只能靠自己的悟性了。
可是高并发和分布式系统在程序员的能力进阶之路上,都是绕不开的高墙。所以就算是工作中没需求,我也想要学,不然像我这种”高龄”程序员,再不往上提升的话,迟早会被市场淘汰。
然而,分布式系统是出了名的难搞,我想学,但是无从下手,在网上东看篇文章,西学点概念,都是很零碎的知识,不成体系,又没深度。再这样下去,我迟早会知难而退,对分布式系统敬而远之。
不过幸运的是,后来我在极客时间找到了周老师的课程,看了课程的目录,真是如获至宝。现在也跟着课程更新学完了一半的内容,收获颇多,老师对不同架构风格的阐释,让我可以从全局性的视角来理解分布式架构的发展历史、来龙去脉,了解各种架构技术的时代背景和探索过程,从而让我能去深入理解架构设计的本质。
而且除此之外,课程里的很多内容都有既高屋建瓴、又深入浅出的特点,就算是对架构知识的积累不够多的人,都可以做到不紧不慢地跟上老师的脚步。所以,我也想来谈谈这门课程最吸引我的三个原因。
自成体系
分布式架构内容太多、太复杂,让人望而生畏,无从下手?不要怕,这门课程的知识内容真的非常全面,它并没有像现在市面上的一些介绍分布式的书籍资料,只是着眼于一个很小的分支,而是涵盖了分布式系统的方方面面,且自成体系,既有广度,又有深度。
在课程中,周老师已经给我们画好了学习地图,按照这个地图去探索分布式架构,就一定不会迷路,而且这个地图还能让我们对分布式架构的演化历程、如何解决分布式系统难题的高手思路,以及不同的技术方案都有什么优缺点、如果对各种技术做好取舍等,都有具体化、具象化的感知,我们能够清楚地知道自己所掌握的知识程度,也能以此查漏补缺,弥补认知上的不足。
授之以渔
周老师不仅在课程中表达了自己的观点,用自己的话把架构技术知识讲解得很透彻,而且在课程里针对很多理论概念都给出了超链接,把参考资料以及思考的过程展示给我们看。
其中包括很多专业的论文,老师会找到原始的出处,带我们去看第一手资料,从技术的诞生开始,把技术的来龙去脉讲得清清楚楚,有理有据。
我平时在网上看惯了二手、三手的资料,很多内容都是互相搬运,甚至可能是错的。而老师提供的原始论文以及高质量的文章,最能接近技术的本质,信息量极大,不仅教会了我们知识,还教会了我们学习的方法,既授之以鱼,又授之以渔。
独到见解
在学习课程的过程中,我常常惊叹于老师的知识面之广、对技术的理解之深。这么多的知识点,老师都能讲得驾轻就熟,把复杂的知识概念解释得通俗易懂。
有些内容我以前找了好多资料,还是搞不懂其中的概念,而老师一两节课就讲明白了,对新人非常友好。举个简单的例子,像是 CAP 定理、TCC、SAGA 等概念,我一直都处于懵懵懂懂的状态,而且时间一长就会觉得这都是些高深难懂的理论,大厂专用,不是我等能学会的,严重打击了我的自信心。结果老师在讲” 分布式事务 “这两节课的时候,就从原理上解释得清清楚楚,我一看就懂了。
还有,老师很多时候并不会囿于”术”的层面去讲解知识点,还会从”道”的层面帮我们拓展技术视野。比如我们很熟悉的奥卡姆剃刀原则:如无必要,勿增实体。这不仅体现在架构设计上,对于我们的生活来说,也是一样的道理,只有适合自己的才是最好的。可以说,周老师的课程真正做到了”道”与”术”的平衡,为我们揭开了软件架构设计的神秘面纱。
总而言之,在这门课程中,我找到了学习分布式系统的绝好资料和学习路径,手拿老师的课程地图,和同学们一起脚踏实地地学习,做到心中有数,不会迷路、不孤单。
我对于学习方法的思考
我猜,一直跟随学习课程的同学,应该对我比较眼熟,因为几乎每节课学完后,我都会来留言,不管是说说对这节课的思考也好,还是只简单地刷一下存在感也好,我都一直在坚持做这件事。
其实我这么做是有原因的。
不知道你有没有类似的感受,以前在学习其他专栏课程的时候,明明学得很认真、很仔细,每节课的知识点我都觉得理解了、学明白了,但总是过几天就会忘掉,再久一点儿就只剩一个很模糊的印象了。
后来我发现这里存在一个问题,就是从学校到职场,我们一直都在学习各种新知识、新技术,但貌似具体的学习方法却从没有系统地学习过。
而直到我接触了学习金字塔,才终于知道这是怎么回事了。
原来,人的学习分为了被动学习和主动学习两个层次。
在单纯地听讲时,人们只能记住 5% 的内容,阅读只能记住 10% 的内容,这些都是在低效地、被动地学习,所以怪不得我听过看过的内容忘得这么快。而主动地、高效地学习,是要去思考、总结和归纳,并且要找人讨论、实践,然后以教为学。
所以也就是说, 我们一定要有输出,用输出来倒逼输入。 这正如同周老师在开篇词里所说的:把自己”认为掌握了的”知识给叙述出来,能够写得条理清晰,讲得理直气壮;能够让别人听得明白,释去心中疑惑;能够把自己的观点交给别人审视,乃至质疑。在这个过程之中,就会挖掘出很多潜藏在”已知”背后的”未知”。
那么具体我们要如何学会主动学习呢?这里我想啰嗦一下非常著名的费曼学习法。简单来说分为四步:
- 选择一个你要了解的概念或知识点;
- 试着把它讲给 10 岁的小孩子听;
- 如果卡壳了,或者说不明白,就重新去查资料学习;
- 确认自己理解清楚了,再用最简洁的语言或者比喻重新讲一遍。
因此按照费曼学习法,我在开始学习课程之前就立了个 Flag:每篇文章下面都要写留言,而且最好能用通俗的语言或比喻表达出来。
不得不说,写留言真的很有效果,一些看似已经明白的概念,如果用自己的话再说一次,就会发现其中的很多细节我其实根本没搞懂,我要不停地查资料,把不懂的地方搞明白,然后再试着联系生活场景来打比方,用自己的话讲出来。有时候一条一两百字的留言,我甚至要写好几个小时。
第 26 讲 中关于我对 Cookie-Session 和 JWT 两种凭证实现方案的理解:
Cookie-Session 相当于坐飞机托运了行李,只要带着登机牌就行了,但是一旦托运了行李,行李就和飞机绑定了,你就不能随意换航班了;JWT 相当于坐飞机拎着行李到处跑,每次过安检还要打开行李箱检查,而且箱子太小也带不了多少东西,但优点是可以随意换航班,行李都在自己身边。
而且留言还有一个好处,就是我可以通过其他同学的提问,以及与同学们的交流讨论,再次巩固学到的知识点,让不同的思想碰撞,从而更接近学习的本质;更重要的也是能通过周老师的回复和指点,可以进一步拓展认知,收获应用、实践的经验。
周老师这样的大神,我在平时是绝无可能碰到的,能和老师近距离地交流,是非常难得的机会,要好好珍惜。
写在最后
说起来,我也算是周老师的老读者了,《深入理解 Java 虚拟机》读完之后收获非常大,对 Java 虚拟机有了全面的认识,老师总能抓住事物的本质,把问题说得明明白白,这门课程也保持了老师一贯的高品质。
周老师在课程里提到过技术人的成长捷径,就是”做技术不仅要去看、去读、去想、去用,更要去写、去说”,这让我印象非常深刻。
所以在最后,我还想说的是,我们一定要保持成长型的思维模式,也就是相信自己只要努力就可以做得更好。我一直认为,成功主要来源于尽自己最大的努力做事情,来源于主动学习和自我提高,不管我们的起点有多低,受到过多少挫折,只要我们有成长型思维,努力奋斗、不怕失败,保持终身学习、不断成长,就能在如今技术日新月异的时代,不被淘汰、不惧未来。
我都可以做到,相信你一定能行!
分布式的基石
31 | 分布式共识(上):想用好分布式框架,先学会Paxos算法吧
可靠与可用、共识与一致
在正式开始探讨分布式环境面临的各种技术问题和解决方案之前,我们先把目光从工业界转到学术界,学习两三种具有代表性的分布式共识算法,为后续分布式环境中操作共享数据打好理论基础。
我们先从一个最简单、最常见的场景开始: 如果你有一份很重要的数据,要确保它长期存储在电脑上不会丢失,你会怎么做?
这不是什么脑筋急转弯的古怪问题,答案就是去买几块磁盘,把数据在不同磁盘上多备份几个副本。
假设一块磁盘每年损坏的概率是 5%,那把文件复制到另一块磁盘上备份后,数据丢失的概率就变成了 0.25%(两块磁盘同时损坏才会导致数据丢失)。以此类推,使用三块磁盘存储数据丢失的概率就是 0.00125%,使用四块则是 0.0000625%。换句话说,使用四块磁盘来保存同一份数据,就已经保证了这份数据在一年内有超过 99.9999% 的概率是安全可靠的。
那 对应到软件系统里,保障系统可靠性的方法,与拿几个磁盘备份并没有什么本质区别。
单个节点的系统宕机导致无法访问数据的原因可能有很多,比如程序运行出错、硬件损坏、网络分区、电源故障,等等,一年中出现系统宕机的概率也许比 5% 还要大。这就决定了软件系统也必须有多台机器能够拥有一致的数据副本,才有可能对外提供可靠的服务。
但是, 在软件系统里,要保障系统的可用性,面临的困难与磁盘备份却又有着本质的区别。
其中的原因也很好理解:磁盘之间是孤立的不需要互相通讯,备份数据是静态的,初始化后状态就不会发生改变,由人工进行的文件复制操作,很容易就能保证数据在各个备份盘中是一致的。但是,到了分布式系统里面,我们就必须考虑动态的数据如何在不可靠的网络通讯条件下,依然能在各个节点之间正确复制的问题。
现在,我们来修改下要讨论的场景: 如果你有一份会随时变动的数据,要确保它能正确地存储在网络中几台不同的机器上,你会怎么做?
这时,你最容易想到的答案一定是”数据同步”:每当数据有变化,就把变化情况在各个节点间的复制看成是一种事务性的操作,只有系统里的每一台机器都反馈成功地完成磁盘写入后,数据的变化才能宣布成功。
我们在 第 13 讲 学过的 2PC、3PC,就可以实现这种同步操作。同步的一种真实应用场景是,数据库的主从全同步复制(Fully Synchronous Replication)。比如,MySQL Cluster 进行全同步复制时,所有 Slave 节点的 Binlog 都完成写入后,Master 的事务才会进行提交。
不过,这里有一个显而易见的缺陷,尽管可以确保 Master 和 Slave 中的数据是绝对一致的,但任何一个 Slave 节点、因为任何原因未响应都会阻塞整个事务。也就是说,每增加一个 Slave 节点,整个系统的可用性风险都会增加一分。
以同步为代表的数据复制方法,叫做 状态转移(State Transfer) 。这类方法属于比较符合人类思维的可靠性保障手段,但通常要以牺牲可用性为代价。
但是,我们在建设分布式系统的时候,往往不能承受这样的代价。对于一些关键系统来说,在必须保障数据正确可靠的前提下,对可用性的要求也非常苛刻。比如,系统要保证数据要达到 99.999999% 可靠性,同时也要达到 99.999% 可用的程度。
这就引出了第三个问题: 如果你有一份会随时变动的数据,要确保它正确地存储于网络中的几台不同机器之上,并且要尽可能保证数据是随时可用的,你会怎么做?
系统高可用和高可靠之间的矛盾,是由于增加机器数量反而降低了可用性带来的。为缓解这个矛盾,在分布式系统里主流的数据复制方法,是以操作转移(Operation Transfer)为基础的。我们想要改变数据的状态,除了直接将目标状态赋予它之外,还有另一种常用的方法,就是通过某种操作,把源状态转换为目标状态。
能够使用确定的操作,促使状态间产生确定的转移结果的计算模型,在计算机科学中被称为 状态机(State Machine) 。
状态机有一个特性:任何初始状态一样的状态机,如果执行的命令序列一样,那么最终达到的状态也一样。在这里我们可以这么理解这个特性,要让多台机器的最终状态一致,只要确保它们的初始状态和接收到的操作指令都是完全一致的就可以。
无论这个操作指令是新增、修改、删除或者其他任何可能的程序行为,都可以理解为要将一连串的操作日志正确地广播给各个分布式节点。
广播指令与指令执行期间,允许系统内部状态存在不一致的情况,也就是不要求所有节点的每一条指令都是同时开始、同步完成的,只要求在此期间的内部状态不能被外部观察到,且当操作指令序列执行完成的时候,所有节点的最终的状态是一致的。这种模型,就是状态机复制(State Machine Replication)。
在分布式环境下,考虑到网络分区现象是不可能消除的,而且可以不必去追求系统内所有节点在任何情况下的数据状态都一致,所以采用的是”少数服从多数”的原则。
也就是说,一旦系统中超过半数的节点完成了状态的转换,就可以认为数据的变化已经被正确地存储在了系统当中。这样就可以容忍少数(通常是不超过半数)的节点失联,使得增加机器数量可以用来提升系统整体的可用性。在分布式中,这种思想被叫做 Quorum 机制) 。
根据这些讨论,我们需要设计出一种算法,能够让分布式系统内部可以暂时容忍存在不同的状态,但最终能够保证大多数节点的状态能够达成一致;同时,能够让分布式系统在外部看来,始终表现出整体一致的结果。
这个让系统各节点不受局部的网络分区、机器崩溃、执行性能或者其他因素影响,能最终表现出整体一致的过程,就是各个节点的协商共识(Consensus)。
这里需要注意的是,共识(Consensus)与一致性(Consistency)是有区别的:一致性指的是数据不同副本之间的差异,而共识是指达成一致性的方法与过程。
由于翻译的关系,很多中文资料把 Consensus 同样翻译为一致性,导致网络上大量的”二手中文资料”都混淆了这两个概念。以后你再看到”分布式一致性算法”的时候,应该就知道它指的其实是”Distributed Consensus Algorithm”了。
好了,我们继续来学习分布式中的共识算法。说到这里,我们就不得不提 Paxos 算法了。
Paxos 算法
Paxos 算法,是由 Leslie Lamport (就是大名鼎鼎的 LaTeX 中的”La”)提出的一种基于消息传递的协商共识算法。现在,Paxos 算法已经成了分布式系统最重要的理论基础,几乎就是”共识”这两字的代名词了。
这个极高的评价来自提出 Raft 算法的论文” In Search of an Understandable Consensus Algorithm “,更是显得分量十足。
关于 Paxos 在分布式共识算法中的地位,还有这么一种说法:
There is only one consensus protocol, and that’s “Paxos” — all other approaches are just broken versions of Paxos.
世界上只有一种共识协议,就是 Paxos,其他所有共识算法都是 Paxos 的退化版本。
—— Mike Burrows ,Inventor of Google Chubby
虽然我认为”世界上只有 Paxos 一种分布式共识算法”的说法有些夸张,但是如果没有 Paxos,那后续的 Raft、ZAB 等算法,ZooKeeper、etcd 这些分布式协调框架,Hadoop、Consul 这些在此基础上的各类分布式应用,都很可能会延后好几年面世。
但 Paxos 算法从被第一次提出,到成为分布式系统最重要的理论基础,可谓是经历了一番波折。我们来具体看看。
Paxos 算法的诞生之路
为了解释清楚 Paxos 算法,Lamport 虚构了一个叫做”Paxos”的希腊城邦,这个城邦按照民主制度制定法律,却又不存在一个中心化的专职立法机构,而是靠着”兼职议会”(Part-Time Parliament)来完成立法。这就无法保证所有城邦居民都能够及时地了解新的法律提案,也无法保证居民会及时为提案投票。
Paxos 算法的目标,就是让城邦能够在每一位居民都不承诺一定会及时参与的情况下,依然可以按照少数服从多数的原则,最终达成一致意见。但是,Paxos 算法并不考虑 拜占庭将军 问题,也就是假设信息可能丢失也可能延迟,但不会被错误传递。
Lamport 在 1990 年首次发表了 Paxos 算法,选的论文题目就是” The Part-Time Parliament “。由于这个算法本身非常复杂,希腊城邦的比喻使得描述更为晦涩难懂。所以,这篇论文的三个审稿人,一致要求 Lamport 删掉希腊城邦的故事。这就让 Lamport 非常不爽,然后干脆就撤稿不发了,所以 Paxos 刚刚被提出的时候并没有引起什么反响。
到了八年之后,也就是 1998 年,Lamport 把这篇论文重新整理后投到了” ACM Transactions on Computer Systems “。这次论文成功发表,Lamport 的名气也确实吸引了一些人去研究,但是并没有多少人能看懂他到底在说什么。
时间又过去了三年,来到了 2001 年,Lamport 认为前两次没有引起什么反响,是因为同行们无法理解他以”希腊城邦”来讲故事的幽默感。所以,他第三次以” Paxos Made Simple “为题,在” SIGACT News “杂志上发表这篇论文的时候,终于放弃了”希腊城邦”的比喻,尽可能用(他认为)简单直接、可读性较强的方式去介绍 Paxos 算法。这次的情况虽然比前两次要好一些,但以 Paxos 本应获得的重视程度来说,依然只能算是应者寥寥。
这一段听起来跟网络段子一般的经历,被 Lamport 以自嘲的形式放到了他的 个人网站 上。尽管我们作为后辈应该尊重 Lamport 老爷子,但是当我翻开” Paxos Made Simple “这篇论文,见到只有”The Paxos algorithm, when presented in plain English, is very simple.”这一句话的”摘要”时,还是忍不住在心里怀疑,Lamport 这样写论文是不是在恶搞审稿人和读者,在嘲讽”你们这些愚蠢的人类!”。
虽然 Lamport 本人连发三篇文章都没能让大多数同行理解 Paxos,但当时间来到了 2006 年,Google 的 Chubby、Megastore 和 Spanner 等分布式系统,都使用 Paxos 解决了分布式共识的问题,并将其整理成正式的论文发表。
之后,得益于 Google 的行业影响力,再加上 Chubby 的作者 Mike Burrows 那略显夸张但足够吸引眼球的评价推波助澜,Paxos 算法一夜间成为计算机科学分布式这条分支中,最炙手可热网红概念,开始被学术界众人争相研究。
2013 年,因为对分布式系统的杰出理论贡献,Lamport 获得了 2013 年的图灵奖。随后,才有了 Paxos 在区块链、分布式系统、云计算等多个领域大放异彩的故事。其实这样充分说明了,在技术圈里即使再有本事,也还是需要好好包装一下。
讲完段子吃过西瓜,希望你没有被这些对 Paxos 的”困难”做的铺垫所吓倒,反正又不让你马上去实现它。
其实说难不难,如果放弃些许严谨性,并简化掉最繁琐的分支细节和特殊情况的话,Paxos 是完全可以去通俗地理解的。毕竟,Lamport 在 论文中 只用两段话就描述”清楚”了 Paxos 的工作流程。
下面,我们来正式学习 Paxos 算法(在本小节中 Paxos 指的都是最早的 Basic Paxos 算法)。
Paxos 算法的工作流程
Paxos 算法将分布式系统中的节点分为提案节点、决策节点和记录节点三类。
提案节点:称为 Proposer ,提出对某个值进行设置操作的节点,设置值这个行为就是提案(Proposal)。值一旦设置成功,就是不会丢失也不可变的。
需要注意的是,Paxos 是典型的基于操作转移模型而非状态转移模型来设计的算法,所以这里的”设置值”不要类比成程序中变量的赋值操作,而应该类比成日志记录操作。因此,我在后面介绍 Raft 算法时,就索性直接把”提案”叫做”日志”了。
决策节点:称为 Acceptor ,是应答提案的节点,决定该提案是否可被投票、是否可被接受。提案一旦得到过半数决策节点的接受,就意味着这个提案被批准(Accept)。提案被批准,就意味着该值不能再被更改,也不会丢失,且最终所有节点都会接受它。
记录节点:被称为 Learner ,不参与提案,也不参与决策,只是单纯地从提案、决策节点中学习已经达成共识的提案。比如,少数派节点从网络分区中恢复时,将会进入这种状态。
在使用 Paxos 算法的分布式系统里,所有的节点都是平等的,它们都可以承担以上某一种或者多种角色。
不过,为了便于确保有明确的多数派,决策节点的数量应该被设定为奇数个,且在系统初始化时,网络中每个节点都知道整个网络所有决策节点的数量、地址等信息。另外,在分布式环境下,如果说各个节点”就某个值(提案)达成一致”,代表的意思就是”不存在某个时刻有一个值为 A,另一个时刻这个值又为 B 的情景”。
而如果要解决这个问题的复杂度,主要会受到下面两个因素的共同影响:
- 系统内部各个节点间的通讯是不可靠的。不论对于系统中企图设置数据的提案节点,抑或决定是否批准设置操作的决策节点来说,它们发出、收到的信息可能延迟送达、也可能会丢失,但不去考虑消息有传递错误的情况。
- 系统外部各个用户访问是可并发的。如果系统只会有一个用户,或者每次只对系统进行串行访问,那单纯地应用 Quorum 机制,少数节点服从多数节点,就已经足以保证值被正确地读写了。
第一点”系统内部各个节点间的通讯是不可靠的”,是网络通讯中客观存在的现象,也是所有共识算法都要重点解决的问题。所以我们重点看下第二点”系统外部各个用户访问是可并发的”,即”分布式环境下并发操作的共享数据”问题。
为了方便理解,我们可以先不考虑是不是在分布式的环境下,只考虑并发操作。
假设有一个变量 i 当前在系统中存储的数值为 2,同时有外部请求 A、B 分别对系统发送操作指令,”把 i 的值加 1”和”把 i 的值乘 3”。如果不加任何并发控制的话,将可能得到”(2+1)×3=9”和”2×3+1=7”这两种结果。因此,对同一个变量的并发修改,必须先加锁后操作,不能让 A、B 的请求被交替处理。这,可以说是程序设计的基本常识了。
但是,在分布式的环境下,还要同时考虑到分布式系统内,可能在任何时刻出现的通讯故障。如果一个节点在取得锁之后、在释放锁之前发生崩溃失联,就会导致整个操作被无限期的等待所阻塞。因此,算法中的加锁,就不完全等同于并发控制中以互斥量来实现的加锁,还必须提供一个其他节点能抢占锁的机制,以避免因通讯问题而出现死锁的问题。
我们继续看 Paxos 算法是怎么解决并发操作带来的竞争的。
Paxos 算法包括”准备(Prepare)”和”批准(Accept)”两个阶段。
第一阶段”准备”(Prepare)就相当于抢占锁的过程。如果某个提案节点准备发起提案,必须先向所有的决策节点广播一个许可申请(称为 Prepare 请求)。提案节点的 Prepare 请求中会附带一个全局唯一的数字 n 作为提案 ID,决策节点收到后,会给提案节点两个承诺和一个应答。
其中,两个承诺是指:承诺不会再接受提案 ID 小于或等于 n 的 Prepare 请求;承诺不会再接受提案 ID 小于 n 的 Accept 请求。
一个应答是指:在不违背以前作出的承诺的前提下,回复已经批准过的提案中 ID 最大的那个提案所设定的值和提案 ID,如果该值从来没有被任何提案设定过,则返回空值。如果违反此前做出的承诺,也就是说收到的提案 ID 并不是决策节点收到过的最大的,那就可以直接不理会这个 Prepare 请求。
- 当提案节点收到了多数派决策节点的应答(称为 Promise 应答)后,可以开始第二阶段”批准”(Accept)过程。这时有两种可能的结果:
- 如果提案节点发现所有响应的决策节点此前都没有批准过这个值(即为空),就说明它是第一个设置值的节点,可以随意地决定要设定的值;并将自己选定的值与提案 ID,构成一个二元组 (id, value),再次广播给全部的决策节点(称为 Accept 请求)。
如果提案节点发现响应的决策节点中,已经有至少一个节点的应答中包含有值了,那它就不能够随意取值了,必须无条件地从应答中找出提案 ID 最大的那个值并接受,构成一个二元组 (id, maxAcceptValue),然后再次广播给全部的决策节点(称为 Accept 请求)。
当每一个决策节点收到 Accept 请求时,都会在不违背以前作出的承诺的前提下,接收并持久化当前提案 ID 和提案附带的值。如果违反此前做出的承诺,即收到的提案 ID 并不是决策节点收到过的最大的,那允许直接对此 Accept 请求不予理会。
当提案节点收到了多数派决策节点的应答(称为 Accepted 应答)后,协商结束,共识决议形成,将形成的决议发送给所有记录节点进行学习。整个过程的时序图如下所示:

到这里,整个 Paxos 算法的工作流程就结束了。
如果你之前没有专门学习过分布式的知识,那学到这里,你的感受很可能是:操作过程中的每一步都能看懂,但还是不能对 Paxos 算法究竟是如何解决协商共识这个问题,形成具体的认知。
所以接下来,我就不局限于抽象的算法步骤,以一个更具体例子来讲解 Paxos。这个例子以及其中使用的图片,都来源于” Implementing Replicated Logs with Paxos “。
借助一个例子来理解 Paxos 算法
在这个例子中,我们只讨论正常通讯的场景,不会涉及网络分区。
假设一个分布式系统有五个节点,分别是 S1、S2、S3、S4 和 S5;全部节点都同时扮演着提案节点和决策节点的角色。此时,有两个并发的请求希望将同一个值分别设定为 X(由 S1 作为提案节点提出)和 Y(由 S5 作为提案节点提出);我们用 P 代表准备阶段、用 A 代表批准阶段,这时候可能发生下面四种情况。
情况一:比如,S1 选定的提案 ID 是 3.1(全局唯一 ID 加上节点编号),先取得了多数派决策节点的 Promise 和 Accepted 应答;此时 S5 选定的提案 ID 是 4.5,发起 Prepare 请求,收到的多数派应答中至少会包含 1 个此前应答过 S1 的决策节点,假设是 S3。
那么,S3 提供的 Promise 中,必将包含 S1 已设定好的值 X,S5 就必须无条件地用 X 代替 Y 作为自己提案的值。由此,整个系统对”取值为 X”这个事实达成了一致。如下图所示:
情况二:事实上,对于情况一,X 被选定为最终值是必然结果。但从图中可以看出,X 被选定为最终值并不是一定要多数派的共同批准,而只取决于 S5 提案时 Promise 应答中是否已经包含了批准过 X 的决策节点。
比如下图所示,S5 发起提案的 Prepare 请求时,X 并未获得多数派批准,但由于 S3 已经批准的关系,最终共识的结果仍然是 X。
情况三:当然,另外一种可能的结果是,S5 提案时 Promise 应答中并未包含批准过 X 的决策节点。
比如,应答 S5 提案时,节点 S1 已经批准了 X,节点 S2、S3 未批准但返回了 Promise 应答,此时 S5 以更大的提案 ID 获得了 S3、S4 和 S5 的 Promise。这三个节点均未批准过任何值,那么 S3 将不会再接受来自 S1 的 Accept 请求,因为它的提案 ID 已经不是最大的了。所以,这三个节点将批准 Y 的取值,整个系统最终会对”取值为 Y”达成一致。
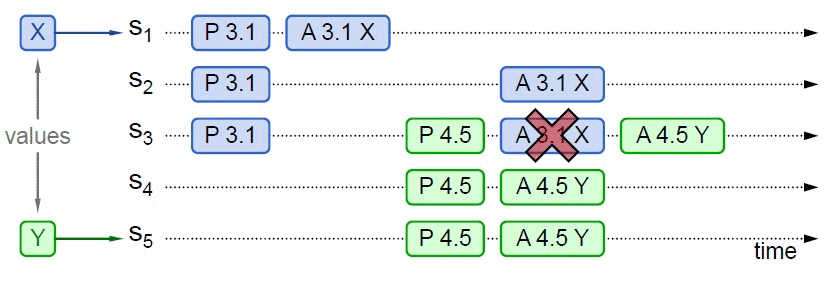
情况四:从情况三可以推导出另一种极端的情况,如果两个提案节点交替使用更大的提案 ID 使得准备阶段成功,但是批准阶段失败的话,这个过程理论上可以无限持续下去,形成活锁(Live Lock)。在算法实现中,会引入随机超时时间来避免活锁的产生。
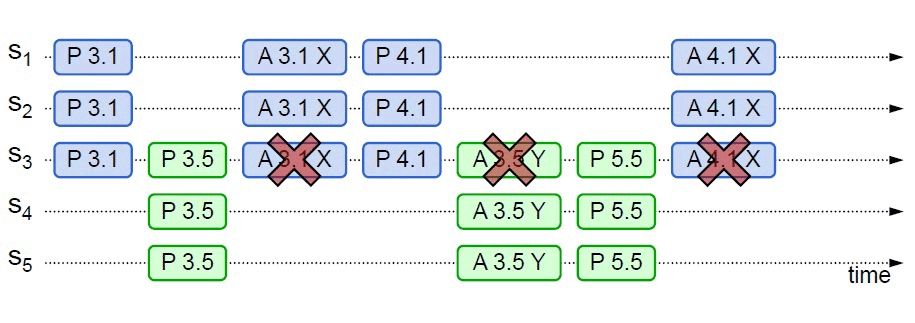
到这里,我们就又通过一个例子,算是通俗地学习了一遍 Paxos 算法。
虽然 Paxos 是以复杂著称的算法,但我们上面学习的是基于 Basic Paxos、以正常流程(未出现网络分区等异常)、以通俗的方式讲解的 Paxos 算法,并没有涉及到严谨的逻辑和数学原理,也没有讨论 Paxos 的推导证明过程。所以,这对于大多数不从事算法研究的技术人员来说,理解起来应该也不会太过困难。
Basic Paxos 的价值在于开拓了分布式共识算法的发展思路,但因为它有如下缺陷,一般不会直接用于实践:Basic Paxos 只能对单个值形成决议,并且决议的形成至少需要两次网络请求和应答(准备和批准阶段各一次),高并发情况下将产生较大的网络开销,极端情况下甚至可能形成活锁。
总之,Basic Paxos 是一种很学术化、对工业化并不友好的算法,现在几乎只用来做理论研究。实际的应用都是基于 Multi Paxos 和 Fast Paxos 算法的,在下一讲我们就会了解 Multi Paxos 以及和它理论等价的几个算法,比如 Raft、ZAB 等算法。
小结
今天这节课,我们从分布式系统的高可靠与高可用的矛盾开始,首先学习了分布式共识算法的含义,以及为什么需要这种算法。我们也明确了”共识”这个词,在这个上下文中所指含义,就是”各个分布式节点针对于某个取值达成一致”。
其次,我们了解了 Basic Paxos 算法发表的一些背景历史,以及这种算法的主要工作流程。尽管我们很少有机会去研究或者实现分布式共识算法,但理解它的基本原理,是我们日后理解和使用 etcd、ZooKeeper 等分布式框架的重要基础。
32 | 分布式共识(下):Multi Paxos、Raft与Gossip,分布式领域的基石
在上节课的最后,我通过一个批准阶段重复失败例子,和你介绍了 Basic Paxos 的活锁问题,两个提案节点互不相让地提出自己的提案,抢占同一个值的修改权限,导致整个系统在持续性地”反复横跳”,从外部看就像是被锁住了。
同时,我还讲过一个观点,分布式共识的复杂性,主要来源于网络的不可靠、请求的可并发,这两大因素。活锁问题和许多 Basic Paxos 异常场景中所遭遇的麻烦,都可以看作是源于任何一个提案节点都能够完全平等地、与其他节点并发地提出提案而带来的复杂问题。
为此,Lamport 专门设计(”专门设计”的意思是,在 Paxos 的论文中 Lamport 随意提了几句可以这么做)了一种 Paxos 的改进版本”Multi Paxos”算法,希望能够找到一种两全其美的办法:既不破坏 Paxos 中”众节点平等”的原则,又能在提案节点中实现主次之分,限制每个节点都有不受控的提案权利。
这两个目标听起来似乎是矛盾的,但现实世界中的选举,就很符合这种在平等节点中挑选意见领袖的情景。
Multi Paxos
Multi Paxos 对 Basic Paxos 的核心改进是,增加了”选主”的过程:
- 提案节点会通过定时轮询(心跳),确定当前网络中的所有节点里是否存在一个主提案节点;
- 一旦没有发现主节点存在,节点就会在心跳超时后使用 Basic Paxos 中定义的准备、批准的两轮网络交互过程,向所有其他节点广播自己希望竞选主节点的请求,希望整个分布式系统对”由我作为主节点”这件事情协商达成一致共识;
- 如果得到了决策节点中多数派的批准,便宣告竞选成功。
当选主完成之后,除非主节点失联会发起重新竞选,否则就只有主节点本身才能够提出提案。此时,无论哪个提案节点接收到客户端的操作请求,都会将请求转发给主节点来完成提案,而主节点提案的时候,也就无需再次经过准备过程,因为可以视作是经过选举时的那一次准备之后,后续的提案都是对相同提案 ID 的一连串的批准过程。
我们也可以通俗地理解为:选主过后,就不会再有其他节点与它竞争,相当于是处于无并发的环境当中进行的有序操作,所以此时系统中要对某个值达成一致,只需要进行一次批准的交互即可。具体如下序列所示:
你可能会注意到,二元组 (id, value) 已经变成了三元组 (id, i, value),这是因为需要给主节点增加一个”任期编号”,这个编号必须是严格单调递增的,以应付主节点陷入网络分区后重新恢复,但另外一部分节点仍然有多数派,且已经完成了重新选主的情况,此时必须以任期编号大的主节点为准。
从整体来看,当节点有了选主机制的支持后,就可以进一步简化节点角色,不必区分提案节点、决策节点和记录节点了,可以统称为”节点”,节点只有主(Leader)和从(Follower)的区别。此时的协商共识的时序图如下:
在这个理解的基础上,我们换一个角度来重新思考”分布式系统中如何对某个值达成一致”这个问题,可以把它分为下面三个子问题来考虑:
- 如何选主(Leader Election)
- 如何把数据复制到各个节点上(Entity Replication)
- 如何保证过程是安全的(Safety)
可以证明(具体证明就不列在这里了,感兴趣的读者可参考结尾给出的论文),当这三个问题同时被解决时,就等价于达成共识。
接下来,我们分别看下这三个子问题如何解决。
关于” 如何选主 “,虽然选主问题会涉及到许多工程上的细节,比如心跳、随机超时、并行竞选等,但从原理上来说,只要你能够理解 Paxos 算法的操作步骤,就不会有啥问题了。因为,选主问题的本质,仅仅是分布式系统对”谁来当主节点”这件事情的达成的共识而已。我们上节课,其实就已经解决了”分布式系统该如何对一件事情达成共识”这个问题。
我们继续来解决 数据(Paxos 中的提案、Raft 中的日志)在网络各节点间的复制问题。
在正常情况下,当客户端向主节点发起一个操作请求后,比如提出”将某个值设置为 X”,数据复制的过程为:
- 主节点将 X 写入自己的变更日志,但先不提交,接着把变更 X 的信息在下一次心跳包中广播给所有的从节点,并要求从节点回复”确认收到”的消息;
- 从节点收到信息后,将操作写入自己的变更日志,然后给主节点发送”确认签收”的消息;
- 主节点收到过半数的签收消息后,提交自己的变更、应答客户端并且给从节点广播”可以提交”的消息;
从节点收到提交消息后提交自己的变更,数据在节点间的复制宣告完成。
那异常情况下的数据复制问题怎么解决呢?
网络出现了分区,部分节点失联,但只要仍能正常工作的节点数量能够满足多数派(过半数)的要求,分布式系统就仍然可以正常工作。假设有 S1、S2、S3、S4 和 S5 共 5 个节点,我们来看下数据复制过程。
假设由于网络故障,形成了 S1、S2 和 S3、S4、S5 两个分区。
- 一段时间后,S3、S4、S5 三个节点中的某一个节点比如 S3,最先达到心跳超时的阈值,获知当前分区中已经不存在主节点了;于是,S3 向所有节点发出自己要竞选的广播,并收到了 S4、S5 节点的批准响应,加上自己一共三票,竞选成功。此时,系统中同时存在 S1 和 S3 两个主节点,但由于网络分区,它们都不知道对方的存在。
这种情况下,客户端发起操作请求的话,可能出现这么两种情况:
- 第一种,如果客户端连接到了 S1、S2 中的一个,都将由 S1 处理,但由于操作只能获得最多两个节点的响应,无法构成多数派的批准,所以任何变更都无法成功提交。
第二种,如果客户端连接到了 S3、S4、S5 中的一个,都将由 S3 处理,此时操作可以获得最多三个节点的响应,构成多数派的批准,变更就是有效的可以被提交,也就是说系统可以继续提供服务。
事实上,这两种”如果”的场景同时出现的机会非常少。为什么呢?网络分区是由软、硬件或者网络故障引起的,内部网络出现了分区,但两个分区都能和外部网络的客户端正常通讯的情况,极为少见。更多的场景是,算法能容忍网络里下线了一部分节点,针对咱们这个例子来说,如果下线了两个节点系统可以正常工作,但下线了三个节点的话,剩余的两个节点也不可能继续提供服务了。
假设现在故障恢复,分区解除,五个节点可以重新通讯了:
- S1 和 S3 都向所有节点发送心跳包,从它们的心跳中可以得知 S3 的任期编号更大、是最新的,所以五个节点均只承认 S3 是唯一的主节点。
- S1、S2 回滚它们所有未被提交的变更。
- S1、S2 从主节点发送的心跳包中获得它们失联期间发生的所有变更,将变更提交写入本地磁盘。
- 此时分布式系统各节点的状态达成最终一致。
到这里,第二个问题”数据在网络节点间的复制问题”也就解决了。
我们继续看第三个问题, 如何保证过程是安全的 。
你可能要说了,选主和数据复制这两个问题都是很具体的行为,但”安全”这个表述很模糊啊,怎么判断什么是安全或者不安全呢?
要想搞明白这个问题,我们需要先看下 Safety 和 Liveness 这两个术语。
在专业资料中,Safety 和 Liveness 通常会被翻译为”协定性”和”终止性”。它们也是由 Lamport 最先提出的,定义是:
- 协定性(Safety):所有的坏事都不会发生(Something “bad” will never happen)。
终止性(Liveness):所有的好事都终将发生,但不知道是啥时候(Something “good” will must happen, but we don’t know when)。
这种就算解释了你也看不明白的定义,是不是很符合 Lamport 老爷子一贯的写作风格?(我也是无奈地摊手苦笑)。不过没关系,我们不用去纠结严谨的定义,可以通过例子来理解它们的具体含义。
还是以选主问题为例,Safety 保证了选主的结果一定是有且只有唯一的一个主节点,不可能同时出现两个主节点;而 Liveness 则要保证选主过程是一定可以在某个时刻能够结束的。
我们再回想一下活锁的内容的话,可以发现,在 Liveness 这个属性上,选主问题是存在理论上的瑕疵的,可能会由于活锁而导致一直无法选出明确的主节点。所以,Raft 论文中只写了对 Safety 的保证,但由于工程实现上的处理,现实中是几乎不可能会出现终止性的问题。
最后,以上这种把共识问题分解为”Leader Election”、”Entity Replication”和”Safety”三个问题来思考、解决的解题思路,就是咱们这一节标题中的”Raft 算法”。
《 一种可以让人理解的共识算法 》(In Search of an Understandable Consensus Algorithm)这篇论文提出了 Raft 算法,并获得了 USENIX ATC 2014 大会的 Best Paper,更是成为了日后 etcd、LogCabin、Consul 等重要分布式程序的实现基础。ZooKeeper 的 ZAB 算法和 Raft 的思路也非常类似,这些算法都被认为是与 Multi Paxos 的等价派生实现。
Gossip 协议
Paxos、Raft、ZAB 等分布式算法经常会被称作是”强一致性”的分布式共识协议,其实这样的描述扣细节概念的话是很别扭的,会有语病嫌疑,但我们都明白它的意思其实是在说”尽管系统内部节点可以存在不一致的状态,但从系统外部看来,不一致的情况并不会被观察到,所以整体上看系统是强一致性的”。
与它们相对的,还有另一类被冠以”最终一致性”的分布式共识协议,这表明系统中不一致的状态有可能会在一定时间内被外部直接观察到。
一种典型而且非常常见的最终一致的分布式系统,就是 DNS 系统 ,在各节点缓存的 TTL 到期之前,都有可能与真实的域名翻译结果存在不一致。
还有一种很有代表性的”最终一致性”的分布式共识协议,那就是 Gossip 协议。Gossip 协议,主要应用在比特币网络和许多重要的分布式框架(比如 Consul 的跨数据中心同步)中。
Gossip 最早是由 施乐公司 Palo Alto 研究中心在论文” Epidemic Algorithms for Replicated Database Maintenance “中提出的,是一种用于分布式数据库在多节点间复制同步数据的算法。
扩展:施乐公司(Xerox),现在可能很多人不了解施乐了,或只把施乐当一家复印产品公司看待。其实,施乐是计算机许多关键技术的鼻祖,是图形界面的发明者、以太网的发明者、激光打印机的发明者、MVC 架构的提出者、RPC 的提出者、BMP 格式的提出者……
从论文题目中可以看出,最初它是被称作”流行病算法”(Epidemic Algorithm)的,但因为不太雅观,Gossip 这个名字会更普遍。另外,你可能还会听到有人把它叫做”流言算法””八卦算法””瘟疫算法”等。其实,这些名字都是很形象化的描述,反映了 Gossip 的特点:要同步的信息如同流言一般传播、病毒一般扩散。
按照习惯,我也会把 Gossip 叫做”共识协议”,但首先必须强调它所解决的问题并不是直接与 Paxos、Raft 这些共识算法等价的,只是基于 Gossip 之上可以通过某些方法去实现与 Paxos、Raft 相类似的目标而已。
一个最典型的例子是,比特币网络中使用到了 Gossip 协议,用来在各个分布式节点中互相同步区块头和区块体的信息。这是整个网络能够正常交换信息的基础,但并不能称作共识。比特币使用 工作量证明 (Proof of Work,PoW),来对”这个区块由谁来记账”这一件事儿在全网达成共识。这个目标才可以认为与 Paxos、Raft 的目标是一致的。
接下来,我们一起学习下 Gossip 的具体工作过程。其实,和 Paxos、Raft 等算法相比,Gossip 的过程可以说是十分简单了,可以看作是两个步骤的简单循环:
- 如果有某一项信息需要在整个网络中的所有节点中传播,那从信息源开始,选择一个固定的传播周期(比如 1 秒),随机选择与它相连接的 k 个节点(称为 Fan-Out)来传播消息。
- 如果一个节点收到消息后发现这条消息之前没有收到过,就会在下一个周期内,把这条消息发送给除了给它发消息的那个节点之外的相邻的 k 个节点,直到网络中所有节点都收到了这条消息。尽管这个过程需要一定的时间,但理论上网络的所有节点最终都会拥有相同的消息。
Gossip 传播过程的示意图如下所示:

根据示意图和 Gossip 的过程描述,我们很容易发现,Gossip 对网络节点的连通性和稳定性几乎没有任何要求,表现在两个方面:
- 它一开始就将某些节点只能与一部分节点 部分连通 (Partially Connected Network)而不是 全连通网络 (Fully Connected Network)作为前提;
- 能够容忍网络上节点的随意地增加或者减少、随意地宕机或者重启,新增加或者重启的节点的状态,最终会与其他节点同步达成一致。
也就是说,Gossip 把网络上所有节点都视为平等而普通的一员,没有中心化节点或者主节点的概念。这些特点使得 Gossip 具有极强的鲁棒性,而且非常适合在公众互联网(WAN)中应用。
同时,我们也很容易发现 Gossip 协议有两个缺点。
第一个缺点是,消息是通过多个轮次的散播而到达全网的,因此必然会存在各节点状态不一致的情况。而且,因为是随机选取的发送消息的节点,所以尽管可以在整体上测算出统计学意义上的传播速率,但我们还是没办法准确估计出单条消息的传播,需要多久才能达成全网一致。
第二个缺点是消息的冗余。这也是因为随机选取发送消息的节点,会不可避免地存在消息重复发送给同一节点的情况。这种冗余会增加网络的传输压力,也会给消息节点带来额外的处理负载。
达到一致性耗费的时间与网络传播中消息冗余量这两个缺点存在一定的对立关系,如果要改善其中一个,就会恶化另外一个。由此,Gossip 传播消息时,有两种可能的方式:反熵(Anti-Entropy)和传谣(Rumor-Mongering)。这两个名字听起来都挺文艺的,我们具体分析下。
熵(Entropy)这个概念,在生活中很少见,但在科学中却很常用,它代表的是事物的混乱程度。反熵就是反混乱的意思,它把提升网络各个节点之间的相似度作为目标。
所以,在反熵模式下,为了达成全网各节点的完全一致的目标,会 同步节点的全部数据 ,来消除各节点之间的差异。但是,在节点本身就会发生变动的前提下,这个目标将使得整个网络中消息的数量非常庞大,给网络带来巨大的传输开销。
而传谣模式是以传播消息为目标,仅仅发送新到达节点的数据,即 只对外发送变更信息 ,这样消息数据量将显著缩减,网络开销也相对较小。
小结
对于普通开发者来说,分布式共识算法这两讲的内容理解起来还是有些困难的,因为算法更接近研究而不是研发的范畴。
但是,理解 Paxos 算法对深入理解许多分布式工具,比如 HDFS、ZooKeeper、etcd、Consul 等的工作原理,是无可回避的基础。虽然 Paxos 不直接应用于工业界,但它的变体算法,比如我们今天学习的 Multi Paxos、Raft 算法,以及今天我们没有提到的 ZAB 等算法,都是分布式领域中的基石。
33 | 服务发现如何做到持续维护服务地址在动态运维中的时效性?
前面的两节课,我们已经学习了与分布式相关的算法和理论,掌握了一致性、共识、Paxos 等共识算法,为了解分布式环境中的操作共享数据打好了理论基础。那么从这一讲开始,我们就来一起了解下,在使用分布式服务构造大型系统的过程中,都可能会遇到哪些问题,以及针对这些问题,都可以选择哪些解决方案。
好,那在正式开始学习之前呢,让我们先来思考一个问题:为什么在微服务应用中,需要引入服务发现呢?它的意义是什么?
服务发现解耦对位置的依赖
事实上,服务发现的意义是解耦程序对服务具体位置的依赖,对于分布式应用来说,服务发现不是可选项,而是必须的。
要理解分布式中的服务发现,那不妨先以单机程序中的类库来类比,因为类库概念的普及,让计算机实现了通过位于不同模块的方法调用,来组装复用指令序列的目的,打开了软件达到更大规模的一扇大门。无论是编译期链接的 C/CPP,还是运行期链接的 Java,都要通过 链接器) (Linker),把代码里的 符号引用 转换为模块入口或进程内存地址的直接引用。
而服务概念的普及,让计算机可以通过分布于网络中的不同机器互相协作来复用功能,这是软件发展规模的第二次飞跃。此时, 如何确定目标方法的确切位置,便是与编译链接有着等同意义的问题,解决该问题的过程,就被叫做” 服务发现 “(Service Discovery) 。
通过服务来实现组件
Microservice architectures will use libraries, but their primary way of componentizing their own software is by breaking down into services.
微服务架构也会使用到类库,但构成软件系统组件的主要方式是将其拆分为一个个服务。
—— Martin Fowler / James Lewis, Microservices , 2014
所有的远程服务调用都是使用” 全限定名 (Fully Qualified Domain Name,FQDN)、端口号、服务标识”构成的三元组,来确定一个远程服务的精确坐标的。全限定名代表了网络中某台主机的精确位置,端口代表了主机上某一个提供服务的程序,服务标识则代表了该程序所提供的一个方法接口。
其中,”全限定名、端口号”的含义在各种远程服务中都一致,而”服务标识”则与具体的应用层协议相关,它可以是多样的,比如 HTTP 的远程服务,标识是 URL 地址;RMI 的远程服务,标识是 Stub 类中的方法;SOAP 的远程服务,标识是 WSDL 中的定义,等等。
也正是因为远程服务的多样性,导致了”服务发现”也会有两种不同的理解。
一种是以 UDDI 为代表的”百科全书式”的服务发现。 上到提供服务的企业信息(企业实体、联系地址、分类目录等),下到服务的程序接口细节(方法名称、参数、返回值、技术规范等),它们都在服务发现的管辖范围之内。
另一种是类似于 DNS 这样的”门牌号码式”的服务发现。 这种服务发现只满足从某个代表服务提供者的全限定名,到服务实际主机 IP 地址的翻译转换。它并不关心服务具体是哪个厂家提供的,也不关心服务有几个方法,各自都由什么参数所构成,它默认这些细节信息服务消费者本身就是了解的。此时,服务坐标就可以退化为简单的”全限定名 + 端口号”。
现如今,主要是后一种服务发现占主流地位,所以咱们这节课要探讨的服务发现,如无说明,都是指的后者。
在前面讲”透明多级分流系统”这个小章节的时候,我提到过,原本程序只依赖 DNS 把一个全限定名翻译为一个或者多个 IP 地址(或者 SRV 等其他记录),就可以实现服务发现了,后来的负载均衡器实质上也承担了一部分服务发现的职责(指外部 IP 地址到各个服务内部实际 IP 的转换)。我们也已经详细解析过,这种方式在软件追求不间断长时间运行的时代是很合适的。
但随着微服务的逐渐流行,服务的非正常宕机重启和正常的上下线操作变得更加频繁,仅靠着 DNS 服务器和负载均衡器等基础设施,就显得逐渐有些疲于应对,无法跟上服务变动的步伐了。
因此,人们开始尝试使用 ZooKeeper 这样的分布式 K/V 框架,通过软件自身来完成服务注册与发现。ZooKeeper 曾短暂统治过远程服务发现,是微服务早期对服务发现的主流选择,但毕竟 ZooKeeper 是很底层的分布式工具,用户自己还需要做相当多的工作,才能满足服务发现的需求。
那到了 2014 年,在 Netflix 内部经受过长时间实际考验的、专门用于服务发现的 Eureka,宣布了开源,并很快被纳入 Spring Cloud,成为 Spring 默认的远程服务发现的解决方案。从此,Java 程序员就无需再在服务注册这件事情上花费太多的力气。
然后到 2018 年,Spring Cloud Eureka 进入维护模式以后,HashiCorp 的 Consul 和阿里巴巴的 Nacos 就很快从 Eureka 手上接过传承的衣钵。此时的服务发现框架已经发展得相当成熟,考虑到了几乎方方面面的问题,比如可以支持通过 DNS 或者 HTTP 请求,进行符号与实际地址的转换,支持各种各样的服务健康检查方式,支持集中配置、K/V 存储、跨数据中心的数据交换等多种功能,可以说是以应用自身去解决服务发现的一个顶峰。
而如今,云原生时代来临,基础设施的灵活性得到了大幅度地增强,最初使用基础设施来透明化地做服务发现的方式,又重新被人们所重视了,如何在基础设施和网络协议层面,对应用尽可能无感知、尽可能方便地实现服务发现,便是目前一个主要的发展方向。
接下来,我们就具体来看看服务发现的三个关键的子问题,并一起探讨、对比下最常见的用作服务发现的几种形式,以此让你了解服务发现中,可用性与可靠性之间的关系和权衡。
服务发现要解决注册、维护和发现三大功能问题
那么,第一个问题就是,”服务发现”具体是指进行过什么操作呢?我认为,这里面其实包含了三个必须的过程:
服务的注册(Service Registration)
当服务启动的时候,它应该通过某些形式(比如调用 API、产生事件消息、在 ZooKeeper/Etcd 的指定位置记录、存入数据库,等等)把自己的坐标信息通知给服务注册中心,这个过程可能由应用程序来完成(比如 Spring Cloud 的 @EnableDiscoveryClient 注解),也可能是由容器框架(比如 Kubernetes)来完成。
服务的维护(Service Maintaining)
尽管服务发现框架通常都有提供下线机制,但并没有什么办法保证每次服务都能 优雅地下线 (Graceful Shutdown),而不是由于宕机、断网等原因突然失联。所以,服务发现框架就必须要自己去保证所维护的服务列表的正确性,以避免告知消费者服务的坐标后,得到的服务却不能使用的尴尬情况。
现在的服务发现框架,一般都可以支持多种协议(HTTP、TCP 等)、多种方式(长连接、心跳、探针、进程状态等)来监控服务是否健康存活,然后把不健康的服务自动下线。
服务的发现(Service Discovery)
这里所说的发现是狭义的,它特指消费者从服务发现框架中,把一个符号(比如 Eureka 中的 ServiceID、Nacos 中的服务名、或者通用的 FQDN )转换为服务实际坐标的过程,这个过程现在一般是通过 HTTP API 请求,或者是通过 DNS Lookup 操作来完成的(还有一些相对少用的方式,如 Kubernetes 也支持注入环境变量)。
当然,我提到的这三点只是列举了服务发现中必须要进行的过程,除此之外它还是会有一些可选的功能的,比如在服务发现时,进行的负载均衡、流量管控、K/V 存储、元数据管理、业务分组,等等,这些功能都属于具体服务发现框架的功能细节,这里就不再展开了。
下面我们来讨论另一个很常见的问题。
不知道你有没有观察过,很多谈论服务发现的文章,总是无可避免地会先扯到”CP”还是”AP”的问题上。那么, 为什么服务发现对 CAP 如此关注、如此敏感呢?
其实,我们可以从服务发现在整个系统中所处的角色,来着手分析这个问题。
在概念模型中,服务中心所处的地位是这样的:提供者在服务发现中注册、续约和下线自己的真实坐标,消费者根据某种符号从服务发现中获取到真实坐标,它们都可以看作是系统中平等的微服务。我们来看看这个概念模型示意图:
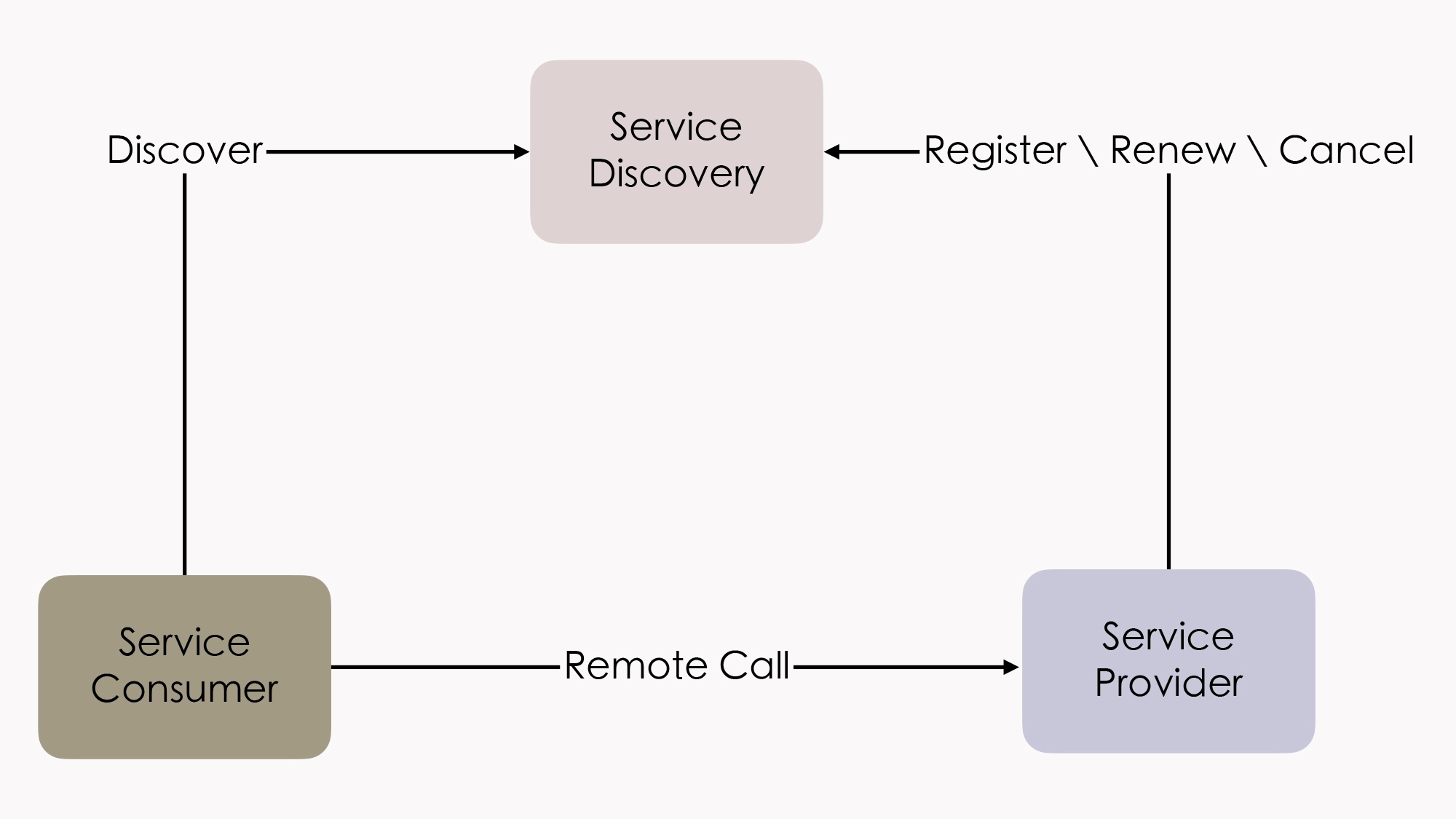
不过,在真实的系统中,服务发现的地位还是有一些特殊,我们还不能把它完全看作是一个普通的服务。为啥呢?
这是因为, 服务发现是整个系统中,其他所有服务都直接依赖的最基础的服务 (类似相同待遇的大概就数配置中心了,现在服务发现框架也开始同时提供配置中心的功能,以避免配置中心又去专门搞出一集群的节点来), 几乎没有办法在业务层面进行容错处理 。而服务注册中心一旦崩溃,整个系统都会受到波及和影响,因此我们必须尽最大可能,在技术层面上保证系统的可用性。
所以,在分布式系统中,服务注册中心一般会 以内部小集群的方式进行部署 ,提供三个或者五个节点(通常最多七个,一般也不会更多了,否则日志复制的开销太高)来保证高可用性。你可以看看下面给出的这个例子:
另外,这里你还要注意一点,就是这个图例中各服务发现节点之间的”Replicate”字样。
作为用户,我们当然希望服务注册一直可用、永远健康的同时,也能够在访问每一个节点中都取到一致的数据,而这两个需求就构成了 CAP 矛盾。
我拿前面提到的最有代表性的 Eureka 和 Consul 来举个例子。
这里,我以 AP、CP 两种取舍作为选择维度,Consul 采用的是 Raft 协议 ,要求多数派节点写入成功后,服务的注册或变动才算完成,这就严格地保证了在集群外部读取到的服务发现结果一定是一致的;Eureka 的各个节点间采用异步复制来交换服务注册信息,服务注册或变动时,并不需要等待信息在其他节点复制完成,而是马上在该服务发现节点就宣告可见(但其他节点是否可见并不保证)。
实际上,这两点差异带来的影响并不在于服务注册的快慢(当然,快慢确实是有差别),而在于你如何看待以下这件事情:
假设系统形成了 A、B 两个网络分区后,A 区的服务只能从区域内的服务发现节点获取到 A 区的服务坐标,B 区的服务只能取到在 B 区的服务坐标,这对你的系统会有什么影响?
如果这件事情对你并没有什么影响,甚至有可能还是有益的,那你就应该倾向于选择 AP 的服务发现。比如假设 A、B 就是不同的机房,是机房间的网络交换机导致服务发现集群出现的分区问题,但每个分区中的服务仍然能独立提供完整且正确的服务能力,此时尽管不是有意而为,但网络分区在事实上避免了跨机房的服务请求,反而还带来了服务调用链路优化的效果。
如果这件事情可能对你影响非常大,甚至可能带来比整个系统宕机更坏的结果,那你就应该倾向于选择 CP 的服务发现。比如系统中大量依赖了集中式缓存、消息总线、或者其他有状态的服务,一旦这些服务全部或者部分被分隔到某一个分区中,会对整个系统的操作正确性产生直接影响的话,那与其搞出一堆数据错误,还不如停机来得痛快。
除此之外,在服务发现的过程中,对系统的可用性和可靠性的取舍不同,对服务发现框架的具体实现也有着决定性的影响。接下来,我们就具体来了解下几类不同的服务发现的实现形式。
服务发现需要有效权衡一致性与可用性的矛盾
数据一致性与服务可用性之间的矛盾是分布式系统永恒的话题。而在服务发现这个场景里,权衡的主要关注点是一旦出现分区所带来的后果,其他在系统正常运行过程中,出现的速度问题都是次要的。
所以最后,我们再来讨论一个很”务实”的话题:现在那么多的服务发现框架,哪一款最好呢?或者说我们应该如何挑选最适合的呢?
实际上,现在直接以服务发现、服务注册中心为目标,或者间接用来实现这个目标的方式主要有以下三类:
第一类:在分布式 K/V 存储框架上自己实现的服务发现
这类的代表是 ZooKeeper、Doozerd、Etcd。这些 K/V 框架提供了分布式环境下 读写操作的共识保证 ,Etcd 采用的是我们学习过的 Raft 算法,ZooKeeper 采用的是 ZAB 算法(一种 Multi Paxos 的派生算法),所以采用这种方案,就不必纠结 CP 还是 AP 的问题了,它们都是 CP 的。
这类框架的宣传语中往往会主动提及”高可用性”,它们的潜台词其实是”在保证一致性和分区容错性的前提下,尽最大努力实现最高的可用性”,比如 Etcd 的宣传语就是”高可用的集中配置和服务发现”(Highly-Available Key Value Store for Shared Configuration and Service Discovery)。
这些 K/V 框架的另一个共同特点是在整体较高复杂度的架构和算法的外部, 维持着极为简单的应用接口 ,只有基本的 CRUD 和 Watch 等少量 API,所以我们如果要在上面完成功能齐全的服务发现,有很多基础的能力,比如服务如何注册、如何做健康检查等等,都必须自己实现,因此现在一般也只有”大厂”才会直接基于这些框架去做服务发现了。
第二类:以基础设施(主要是指 DNS 服务器)来实现服务发现
这类的代表是 SkyDNS、CoreDNS。在 Kubernetes 1.3 之前的版本,是使用 SkyDNS 作为默认的 DNS 服务,它的工作原理是从 API Server 中监听集群服务的变化,然后根据服务生成 NS、SRV 等 DNS 记录存放到 Etcd 中,kubelet 会在每个 Pod 内部设置 DNS 服务的地址,作为 SkyDNS 的地址,在需要调用服务时,只需查询 DNS,把域名转换成 IP 列表便可实现分布式的服务发现。
而在 Kubernetes 1.3 之后,SkyDNS 不再是默认的 DNS 服务器,也不再使用 Etcd 存储记录,而是只将 DNS 记录存储在内存中的 KubeDNS 代替;到了 1.11 版,就更推荐采用扩展性很强的 CoreDNS,此时我们可以通过各种插件来决定是否要采用 Etcd 存储、重定向、定制 DNS 记录、记录日志,等等。
那么采用这种方案的话,是 CP 还是 AP 就取决于后端采用何种存储,如果是基于 Etcd 实现的,那自然是 CP 的;如果是基于内存异步复制的方案实现的,那就是 AP 的。
也就是说,以基础设施来做服务发现, 好处是对应用透明 ,任何语言、框架、工具都肯定是支持 HTTP、DNS 的,所以完全不受程序技术选型的约束。但它的 坏处是透明的并不一定简单 ,你必须自己考虑如何去做客户端负载均衡、如何调用远程方法等这些问题,而且必须遵循或者说受限于这些基础设施本身所采用的实现机制。
比如在服务健康检查里,服务的缓存期限就必须采用 TTL(Time to Live)来决定,这是 DNS 协议所规定的,如果想改用 KeepAlive 长连接来实时判断服务是否存活就很麻烦。
第三类:专门用于服务发现的框架和工具
这类的代表是 Eureka、Consul 和 Nacos。
这一类框架中,你可以自己决定是 CP 还是 AP 的问题,比如 CP 的 Consul、AP 的 Eureka,还有同时支持 CP 和 AP 的 Nacos(Nacos 采用类 Raft 协议做的 CP,采用自研的 Distro 协议做的 AP,注意这里的”同时”是”都支持”的意思,它们必须二取其一,不是说 CAP 全能满足)。
另外,还有很重要一点是,它们对应用并不是透明的。 尽管 Consul、Nacos 也支持基于 DNS 的服务发现,尽管这些框架都基本上做到了以声明代替编码(比如在 Spring Cloud 中只改动 pom.xml、配置文件和注解即可实现),但它们依然是应用程序有感知的。所以或多或少还需要考虑你所用的程序语言、技术框架的集成问题。
但这一点其实并不见得就是坏处,比如采用 Eureka 做服务注册,那在远程调用服务时,你就可以用 OpenFeign 做客户端,写个声明式接口就能跑,相当能偷懒;在做负载均衡时,你就可以采用 Ribbon 做客户端,要想换均衡算法的话,改个配置就成,这些”不透明”实际上都为编码开发带来了一定的便捷,而前提是你选用的语言和框架要支持。如果你的老板提出要在 Rust 上用 Eureka,那你就只能无奈叹息了(原本这里我写的是 Node、Go、Python 等,查了一下这些居然都有非官方的 Eureka 客户端,用的人多就是有好处啊)。
小结
微服务架构中的一个重要设计原则是”通过服务来实现独立自治的组件”(Componentization via Services),微服务强调通过”服务”(Service)而不是”类库”(Library)来构建组件,这是因为两者具有很大的差别:类库是在编译期静态链接到程序中的,通过本地调用来提供功能;而服务是进程外组件,通过远程调用来提供功能。
在这节课中,我们共同了解了服务发现在微服务架构中的意义,它是将固定的代表服务的标识符转化为动态的真实服务地址,并持续维护这些地址在动态运维过程中的时效性。因此,为了完成这个目标,服务发现需要解决注册、维护和发现三大功能问题,并且需要妥善权衡分布式环境下一致性与可用性之间的矛盾,由此便派生出了以 DNS、专有服务等不同形式,AP 和 CP 两种不同权衡取向的实现方案。
而且,基于服务来构建程序,这也迫使微服务在复杂性与执行性能方面作出了极大的让步,而换来的收益就是软件系统”整体”与”部分”的物理层面的真正的隔离。
34 | 路由凭什么作为微服务网关的基础职能?
网关(Gateway)这个词我们应该都很熟悉了,它在计算机科学中,尤其是计算机网络中十分常见,主要是用来表示位于内部区域边缘,与外界进行交互的某个物理或逻辑设备,比如你家里的路由器就属于家庭内网与互联网之间的网关。
在单体架构下,我们一般不太强调”网关”这个概念,因为给各个单体系统的副本分发流量的负载均衡器,实质上就承担着内部服务与外部调用之间的网关角色。
不过在微服务环境中,网关的存在感就极大地增强了,甚至成为微服务集群中必不可少的设施之一。
其中原因并不难理解。你可以想想看,在微服务架构下,每个服务节点都由不同的团队负责,它们有自己独立的、各不相同的能力,所以如果服务集群没有一个统一对外交互的代理人角色,那外部的服务消费者就必须知道所有微服务在集群中的精确坐标(上一讲我介绍过”坐标”的概念)。
这样,消费者不仅会受到服务集群的网络限制(不能确保集群中每个节点都有外网连接)、安全限制(不仅是服务节点的安全,外部自身也会受到如浏览器 同源策略 的约束)、依赖限制(服务坐标这类信息不属于对外接口承诺的内容,随时可能变动,不应该依赖它),就算是我们自己也不可能愿意记住每一个服务的坐标位置来编写代码。
所以,微服务中网关的首要职责,就是 以统一的地址对外提供服务,将外部访问这个地址的流量,根据适当的规则路由到内部集群中正确的服务节点之上。 也正是因为这样,微服务中的网关,也常被称为”服务网关”或者”API 网关”。
可见, 微服务的网关首先应该是个路由器 ,在满足此前提的基础上,网关还可以根据需要作为流量过滤器来使用,以提供某些额外的可选的功能。比如安全、认证、授权、限流、监控、缓存,等等。
简而言之:
网关 = 路由器(基础职能) + 过滤器(可选职能)
在”路由”这个基础职能里,服务网关主要考虑的是能够支持路由的”网络层次与协议”和”性能与可用性”两方面的因素。那么接下来,我们就围绕这两方面因素来讲解路由的原理与知识点。
网络层次与协议
在 第 20 讲”负载均衡器” 中,我曾给你介绍过四层流量转发与七层流量代理,这里所说的”层次”就是指 OSI 七层协议中的层次,更具体的话,其实就是”四层”和”七层”的意思。
仅从 技术实现 的角度来看,对于路由流量这项工作,负载均衡器与服务网关的实现是没有什么差别的,很多服务网关本身就是基于老牌的负载均衡器来实现的,比如 Nginx、HAProxy 对应的 Ingress Controller,等等;而从路由目的这个角度来看,负载均衡器与服务网关的区别在于,前者是为了根据均衡算法对流量进行平均地路由,后者是为了根据流量中的某种特征进行正确地路由。
也就是说,网关必须能够识别流量中的特征,这意味着网关能够支持的网络层次、通讯协议的数量,将会直接限制后端服务节点能够选择的服务通讯方式:
- 如果服务集群只提供如 Etcd 这类直接基于 TCP 访问的服务,那就可以只部署四层网关,以 TCP 报文中的源地址、目标地址为特征进行路由;
- 如果服务集群要提供 HTTP 服务的话,就必须部署一个七层网关,根据 HTTP 的 URL、Header 等信息为特征进行路由;
- 如果服务集群要提供更上层的 WebSocket、SOAP 等服务,那就必须要求网关同样能够支持这些上层协议,才能从中提取到特征。
我们直接来看一个例子吧。
这里是一段基于 SpringCloud 实现的 Fenix’s Bootstore 中,用到的 Netflix Zuul 网关的配置。Zuul 是 HTTP 网关, /restful/accounts/** 和 /restful/pay/** 是 HTTP 中 URL 的特征,而配置中的”serviceId”就是路由的目标服务。
routes:
account:
path: /restful/accounts/**
serviceId: account
stripPrefix: false
sensitiveHeaders: "*"
payment:
path: /restful/pay/**
serviceId: payment
stripPrefix: false
sensitiveHeaders: "*"最后呢,我还想给你一个提醒:现在,围绕微服务的各种技术都处于快速发展期,我其实并不提倡你针对每一种框架本身,去记忆配置的细节,也就是你并不需要去纠结前面给出的这些配置的确切写法、每个指令的含义。因为如果你从根本上理解了网关的原理,那你参考一下技术手册,很容易就能够将前面给出的这些信息改写成 Kubernetes Ingress Controller、Istio VirtualServer 或者是其他服务网关所需的配置形式。
OK, 我们再来了解下服务网关的另一个能够支持路由的重要因素:性能与可用性。
性能与可用性
性能与可用性是网关的一大关注点。因为网关是所有服务对外的总出口,是流量必经之地,所以网关的路由性能是全局的、系统性的,如果某个服务经过网关路由会有 10 毫秒的性能损失,就意味着整个系统所有服务的性能都会降低 10 毫秒。
网关的性能与它的工作模式和自身实现都有关系,但毫无疑问,工作模式是最主要的。如果网关能够采用三角传输模式(DSR,即数据链路层负载均衡模式),原理上就决定了性能一定会比代理模式来的强(DSR、代理等都是 负载均衡 的基础知识,你可以去回顾复习一下)。
不过,因为今天 REST 和 JSON-RPC 等基于 HTTP 协议的接口形式,在对外部提供的服务中占绝对主流的地位,所以我们这里所讨论的服务网关默认都必须支持七层路由,这样通常就默认无法转发,只能采用代理模式。
那么在这个前提约束下,网关的性能就主要取决于它们是如何代理网络请求的,也就是它们的网络 I/O 模型了。既然如此,下面我们就一起来了解下网络 I/O 的基础知识,剖析下网络 I/O 模型的工作原理,借此也掌握不同网关的特点与性能差异。
网络 I/O 的基础知识
在套接字接口的抽象下,网络 I/O 的本质其实是 Socket 的读取 ,Socket 在操作系统接口中被抽象为了数据流,而网络 I/O 就可以理解为是 对流的操作 。
对于每一次网络访问,从远程主机返回的数据会先存放到操作系统内核的缓冲区中,然后再从内核的缓冲区,复制到应用程序的地址空间,所以当一次网络请求发生后,就会按顺序经历”等待数据从远程主机到达缓冲区”和”将数据从缓冲区拷贝到应用程序地址空间”两个阶段。
那么,根据完成这两个阶段的不同方法,我们可以把网络 I/O 模型总结为两类、五种模型。两类是指 同步 I/O 与异步 I/O ;五种是指在同步 I/O 中又划分出了 阻塞 I/O、非阻塞 I/O、多路复用 I/O 和信号驱动 I/O 四种细分模型。
同步就是指调用端发出请求之后,在得到结果之前必须一直等待,与之相对的就是异步,在发出调用请求之后将立即返回,不会马上得到处理结果,这个结果将通过状态变化和回调来通知给调用者。而阻塞和非阻塞 I/O 针对请求处理的过程,就是指在收到调用请求、返回结果之前,当前处理线程是否会被挂起。
当然,这种概念上的讲述估计你也不好理解,所以下面我就以”你如何领到盒饭”这个情景,来给你类比解释一下:
异步 I/O(Asynchronous I/O)
这就好比你在某团外卖订了个盒饭,付款之后你自己该干嘛还干嘛去,饭做好了骑手自然会到门口打电话通知你。所以说,异步 I/O 中,数据到达缓冲区后,不需要由调用进程主动进行从缓冲区复制数据的操作,而是在复制完成后,由操作系统向线程发送信号,所以它一定是 非阻塞的 。
同步 I/O(Synchronous I/O)
这就好比你自己去饭堂打饭,这时可能有以下几种情形发生:
阻塞 I/O(Blocking I/O)
你去到饭堂,发现饭还没做好,你也干不了别的,只能打个瞌睡(线程休眠),直到饭做好。阻塞 I/O 是最直观的 I/O 模型,逻辑清晰,也比较节省 CPU 资源,但 缺点就是线程休眠所带来的上下文切换 ,这是一种需要切换到内核态的重负载操作,不应当频繁进行。
非阻塞 I/O(Non-Blocking I/O)
你去到饭堂,发现饭还没做好,你就回去了,然后每隔 3 分钟来一次饭堂看饭做好了没,直到饭做好。非阻塞 I/O 能够避免线程休眠,对于一些很快就能返回结果的请求,非阻塞 I/O 可以节省上下文切换的消耗,但是对于较长时间才能返回的请求,非阻塞 I/O 反而白白浪费了 CPU 资源,所以 目前并不常用 。
多路复用 I/O(Multiplexing I/O)
多路复用 I/O 本质上是阻塞 I/O 的一种,但是它的 好处是可以在同一条阻塞线程上处理多个不同端口的监听 。可以类比这样一个情景:你是活雷锋,代表整个宿舍去饭堂打饭,去到饭堂,发现饭还没做好,还是继续打瞌睡,不过哪个舍友的饭好了,你就马上把那份饭送回去,然后继续打着瞌睡哼着歌等待其他的饭做好。多路复用 I/O 是目前的 高并发网络应用的主流 ,它下面还可以细分 select、epoll、kqueue 等不同实现。
信号驱动 I/O(Signal-Driven I/O)
你去到饭堂,发现饭还没做好,但你跟厨师熟,跟他说饭做好了叫你,然后回去该干嘛干嘛,等收到厨师通知后,你把饭从饭堂拿回宿舍。这里厨师的通知就是那个”信号”, 信号驱动 I/O 与异步 I/O 的区别是”从缓冲区获取数据”这个步骤的处理 ,前者收到的通知是可以开始进行复制操作了,也就是你要自己把饭从饭堂拿回宿舍,在复制完成之前线程处于阻塞状态,所以它仍属于同步 I/O 操作;而后者收到的通知是复制操作已经完成,即外卖小哥已经把饭送到了。
那么显而易见,异步 I/O 模型是最方便的,毕竟能叫外卖谁愿意跑饭堂啊,但前提是你学校里得让送美团外卖。所以,异步 I/O 受限于操作系统,Windows NT 内核早在 3.5 以后,就通过 IOCP 实现了真正的异步 I/O 模型。而 Linux 系统下,是在 Linux Kernel 2.6 才首次引入,目前也还并不完善,因此在 Linux 下实现高并发网络编程时,仍然是以多路复用 I/O 模型模式为主。
网关的性能考量
好,回到服务网关的话题上,现在我们掌握了网络 I/O 模型的知识,就可以在理论上定性分析不同网关的性能差异了。
服务网关处理一次请求代理时,包含了两组网络操作 ,分别是”作为服务端对外部请求的应答”和”作为客户端对内部服务的调用”。理论上这两组网络操作可以采用不同的网络 I/O 模型去完成,但一般来说并没有必要这样做。
为什么呢?我以 Zuul 网关来给你举个例子。
在 Zuul 1.0 时,它采用的是阻塞 I/O 模型,来进行最经典的”一条线程对应一个连接”(Thread-per-Connection)的方式来代理流量,而采用阻塞 I/O 就意味着它会有线程休眠,就有上下文切换的成本。
所以如果 后端服务普遍属于计算密集型 (CPU Bound,可以通俗理解为服务耗时比较长,主要消耗在 CPU 上)时,这种模式能够 节省网关的 CPU 资源 ,但如果后端服务普遍都是 I/O 密集型 (I/O Bound,可以理解服务都很快返回,主要消耗在 I/O 上),它就会由于频繁的上下文切换而 降低性能 。
那么到了 Zuul 的 2.0 版本,最大的改进就是 基于 Netty Server 实现了异步 I/O 模型来处理请求 ,大幅度减少了线程数,获得了更高的性能和更低的延迟。根据 Netflix 官方自己给出的数据,Zuul 2.0 大约要比 Zuul 1.0 快 20% 左右。当然还有一些网关,我们也可以自行配置,或者根据环境选择不同的网络 I/O 模型,典型的就是 Nginx,可以支持在配置文件中指定 select、poll、epoll、kqueue 等并发模型。
不过,网关的性能高低一般 只能去定性分析 ,要想定量地说哪一种网关性能最高、高多少,是很难的,就像我们都认可 Chrome 要比 IE 快,但具体要快上多少,我们很难说得清楚。
所以尽管我上面引用了 Netflix 官方对 Zuul 两个版本的量化对比,网络上也有不少关于各种网关的性能对比数据,但要是脱离具体应用场景去定量地比较不同网关的性能差异,还是难以令人信服,毕竟不同的测试环境、后端服务都会直接影响结果。
网关的可用性考量
OK,我们还有一点要关注的就是网关的可用性问题。任何系统的网络调用过程中都至少会有一个单点存在,这是由用户只通过唯一的一个地址去访问系统决定的。即使是淘宝、亚马逊这样全球多数据中心部署的大型系统,给多数据中心翻译地址的权威 DNS 服务器,也可以认为是它的单点。
而对于更普遍的小型系统(小型是相对淘宝这些而言)来说, 作为后端对外服务代理人角色的网关,经常被看作是系统的入口,往往很容易成为网络访问中的单点。这时候,它的可用性就尤为重要。
另外,由于网关具有唯一性,它不像之前讲服务发现时的那些注册中心一样,可以直接做个集群,随便访问哪一台都可以解决问题。所以针对这个情况,在网关的可用性方面,我们应该考虑到以下几点:
- 网关应 尽可能轻量 。尽管网关作为服务集群统一的出入口,可以很方便地做安全、认证、授权、限流、监控等功能,但在给网关附加这些能力时,我们还是要仔细权衡,取得功能性与可用性之间的平衡,不然过度增加网关的职责是很危险的。
- 网关选型时,应该尽可能 选择较成熟的产品实现 。比如 Nginx Ingress Controller、KONG、Zuul 等等这些经受过长期考验的产品,我们不能一味只考虑性能,选择最新的产品,毕竟性能与可用性之间的平衡也需要做好权衡。
- 在需要高可用的生产环境中,应当考虑 在网关之前部署负载均衡器或者 等价路由器 (ECMP) ,让那些更成熟健壮的(往往是硬件物理设备)的设施去充当整个系统的入口地址,这样网关就可以很方便地设置多路扩展了。
这里我提到了网关的唯一性、高可用与扩展,所以我顺带也说一下近年来随着微服务一起火起来的概念”BFF”(Backends for Frontends)。
这个概念目前还没有权威的中文翻译,不过在我们讨论的上下文里,它的意思可以理解为,网关不必为所有的前端提供无差别的服务,而是应该针对不同的前端,聚合不同的服务,提供不同的接口和网络访问协议支持。
比如,运行于浏览器的 Web 程序,由于浏览器一般只支持 HTTP 协议,服务网关就应该提供 REST 等基于 HTTP 协议的服务,但同时我们也可以针对运行于桌面系统的程序,部署另外一套网关,它能与 Web 网关有完全不同的技术选型,能提供基于更高性能协议(如 gRPC)的接口,来获得更好的体验。
所以这个概念要表达的就是,在网关这种边缘节点上,针对同样的后端集群,裁剪、适配、聚合出适应不一样的前端服务,有助于后端的稳定,也有助于前端的赋能。
小结
这节课我们主要探讨的话题是网关,但我只给你介绍了网关的路由职能,其他可以在网关上实现的限流、容错、安全、认证等等的过滤职能,在课程中都有专门的讲解,所以这里我们就不展开了。
那么在路由方面,因为现在我们所讨论的服务网关默认都必须支持七层路由,通常就默认无法转发,只能采用代理模式。因此你要掌握这样一个核心知识点:在必须支持七层路由的前提下,网关的性能主要取决于它们是如何代理网络请求的,也就是说,你要了解它们的网络 I/O 模型。现在,在学习了典型的网络 I/O 模型的工作原理之后,希望你在后面的学习或者实践过程当中,看到网关的 I/O 模型,你就能够对它的特点与性能有个大致的判断。
35 | 如何在客户端实现服务的负载均衡?
在正式开始讨论之前,我们先来区分清楚几个容易混淆的概念,分别是前面两讲中我介绍过的 服务发现、网关路由 ,以及这节课要探讨的 负载均衡 ,还有在下一讲中将会介绍的 调用容错 。这几个技术名词都带有”从服务集群中寻找到一个合适的服务来调用”的含义,那么它们之间的差别都体现在哪呢?下面我就通过一个具体的案例场景来给你说明一下。
理解服务发现、网关路由、负载均衡、调用容错的具体区别
假设,你目前身处广东,要上 Fenix’s Bookstore 购买一本书。在程序业务逻辑里,购书的其中一个关键步骤是调用商品出库服务来完成货物准备,在代码中该服务的调用请求为:
PATCH https://warehouse:8080/restful/stockpile/3
{amount: -1}假设 Fenix’s Bookstore 是个大书店,在北京、武汉、广州的机房均部署有服务集群,那么此时按顺序会发生以下事件:
首先是将 warehouse 这个服务名称转换为了恰当的服务地址。
注意,这里的”恰当”是个宽泛的描述,一种典型的”恰当”就是因为调用请求来自于广东,DNS 层面的负载均衡就会优先分配给传输距离最短的广州机房来应答。
其实按常理来说,这次出库服务的调用应该是集群内的流量,而不是用户浏览器直接发出的请求。所以尽管结果都一样,但更接近实际的情况应该是用户访问首页时,已经被 DNS 服务器分配到了广州机房,请求出库服务时,应优先选择同机房的服务进行调用,此时该服务的调用请求就变为:
PATCH https://guangzhou-ip-wan:8080/restful/stockpile/3然后,广州机房的服务网关将该请求与配置中的特征进行比对,由 URL 中的”/restful/stockpile/**”得知该请求访问的是商品出库服务。因此,将请求的 IP 地址转换为内网中 warehouse 服务集群的入口地址:
PATCH https://warehouse-gz-lan:8080/restful/stockpile/3由于集群中部署有多个 warehouse 服务,所以在收到调用请求后,负载均衡器要在多个服务中根据某种标准或均衡策略(可能是随机挑选,也可能是按顺序轮询,或者是选择此前调用次数最少那个,等等),找出要响应本次调用的服务,我们称其为 warehouse-gz-lan-node1。
PATCH https://warehouse-gz-lan-node1:8080/restful/stockpile/3接着,访问 warehouse-gz-lan-node1 服务,没有返回需要的结果,而是抛出了 500 错。
HTTP/1.1 500 Internal Server Error那么根据预置的 故障转移 (Failover)策略,负载均衡器会进行重试,把调用分配给能够提供该服务的其他节点,我们称其为 warehouse-gz-lan-node2。
PATCH https://warehouse-gz-lan-node2:8080/restful/stockpile/3最后,warehouse-gz-lan-node2 服务返回商品出库成功。
HTTP/1.1 200 OK所以,从整体上看,前面步骤中的 1、2、3、5,就分别对应了服务发现、网关路由、负载均衡和调用容错;而从细节上看,其中的部分职责又是有交叉的,并不是注册中心就只关心服务发现,网关只关心路由,均衡器只关心负载均衡。
比如,步骤 1 服务发现的过程中,”根据请求来源的物理位置来分配机房”这个操作,本质上是根据请求中的特征(地理位置)来进行流量分发,这其实是一种路由行为。在实际的系统中,DNS 服务器(DNS 智能线路)、服务注册中心(如 Eureka 等框架中的 Region、Zone 概念)或者负载均衡器(可用区负载均衡,如 AWS 的 NLB,或 Envoy 的 Region、Zone、Sub-zone)里都有可能实现路由功能。
而且除此之外,你有没有感觉到这个网络调用的过程好像过于繁琐了,一个从广州机房内网发出的服务请求,绕到了网络边缘的网关、负载均衡器这些设施上,然后再被分配回内网中另外一个服务去响应。这不仅消耗了带宽,降低了性能,也增加了链路上的风险和运维的复杂度。
可是,如果流量不经过这些设施,它们相应的职责就无法发挥作用了:如果不经过负载均衡器的话,甚至连请求应该具体交给哪一个服务去处理都无法确定。
所以既然如此,我们有什么办法可以简化这个调用过程吗?这就需要用到客户端负载均衡器了。
客户端负载均衡器的工作原理
我们知道,对于任何一个大型系统来说,负载均衡器都是必不可少的设施。以前,负载均衡器大多只部署在整个服务集群的前端,将用户的请求分流到各个服务进行处理,这种经典的部署形式现在被称为 集中式的负载均衡 (在 第 20 讲 中,我已经给你介绍过这种经典的负载均衡的工作原理,你可以去复习一下)。
而随着微服务的日渐流行,服务集群收到的请求来源就不再局限于外部了,越来越多的访问请求是由集群内部的某个服务发起,由集群内部的另一个服务进行响应的。对于这类流量的负载均衡,既有的方案依然是可行的,但针对内部流量的特点,直接在服务集群内部消化掉,肯定是更合理、更受开发者青睐的办法。
由此,一种全新的、独立位于每个服务前端的、分散式的负载均衡方式正逐渐变得流行起来,这就是本节课我们要讨论的主角: 客户端负载均衡器(Client-Side Load Balancer) 。
客户端负载均衡器的理念提出以后,此前的集中式负载均衡器也有了一个方便与它对比的名字,”服务端负载均衡器”(Server-Side Load Balancer)。
从上图中,你其实能够清晰地看到这两种均衡器的关键差别所在:服务端负载均衡器是集中式的,同时为多个节点提供服务,而客户端负载均衡器是和服务实例一一对应的,而且与服务实例并存于同一个进程之内。 这能为它带来很多好处 ,比如说:
- 均衡器与服务之间的信息交换是进程内的方法调用,不存在任何额外的网络开销。
- 客户端均衡器不依赖集群边缘的设施,所有内部流量都仅在服务集群的内部循环,避免出现前面提到的,集群内部流量要”绕场一周”的尴尬局面。
- 分散式的均衡器意味着它天然避免了集中式的单点问题,它的带宽资源将不会像集中式均衡器那样敏感,这在以七层均衡器为绝对主流、不能通过 IP 隧道和三角传输这样的方式来节省带宽的微服务环境中,显得更具优势。
- 客户端均衡器要更加灵活,能够针对每一个服务实例单独设置均衡策略等参数。比如访问某个服务是否需要具备亲和性,选择服务的策略是随机、轮询、加权还是最小连接,等等,都可以单独设置而不影响其他服务。
- ……
但是你也要清楚, 客户端均衡器并不是银弹,它的缺点同样是不少的:
- 它与服务运行于同一个进程之内,就意味着它的选型要受到服务所使用的编程语言的限制。比如,用 Golang 开发的微服务,就不太可能搭配 Spring Cloud Load Balancer 来一起使用,因为要为每种语言都实现对应的能够支持复杂网络情况的均衡器是非常难的。客户端均衡器的这个缺陷其实有违于微服务中,技术异构不应受到限制的原则。
- 从个体服务来看,由于客户端均衡器与服务实例是共用一个进程,均衡器的稳定性会直接影响整个服务进程的稳定性,而消耗的 CPU、内存等资源也同样会影响到服务的可用资源。从集群整体来看,在服务数量达到成千乃至上万的规模时,客户端均衡器消耗的资源总量是相当可观的。
- 由于请求的来源可能是来自集群中任意一个服务节点,而不再是统一来自集中式均衡器,这就会导致内部网络安全和信任关系变得复杂,当入侵者攻破任何一个服务时,都会更容易通过该服务突破集群中的其他部分。
- 我们知道,服务集群的拓扑关系是动态的,每一个客户端均衡器必须持续跟踪其他服务的健康状况,以实现上线新服务、下线旧服务、自动剔除失败的服务、自动重连恢复的服务等均衡器必须具备的功能。由于这些操作都需要通过访问服务注册中心来完成,因此数量庞大的客户端均衡器需要一直持续轮询服务注册中心,这也会为它带来不小的负担。
- ……
代理客户端负载均衡器
在 Java 领域,客户端负载均衡器中最具代表性的产品,就是 Netflix Ribbon 和 Spring Cloud Load Balancer 了,随着微服务的流行,它们在 Java 微服务中已经积聚了相当可观的使用者。
而到了最近两三年,服务网格(Service Mesh)开始盛行,另一种被称为” 代理客户端负载均衡器 “(Proxy Client-Side Load Balancer,后面就简称”代理均衡器”)的客户端均衡器变体形式,开始引起不同编程语言的微服务开发者的共同关注,因为它解决了此前客户端均衡器的大部分缺陷。
代理均衡器对此前的客户端负载均衡器的改进,其实就是将原本嵌入在服务进程中的均衡器提取出来,放到 边车代理 中去实现 ,它的流量关系如下图所示:
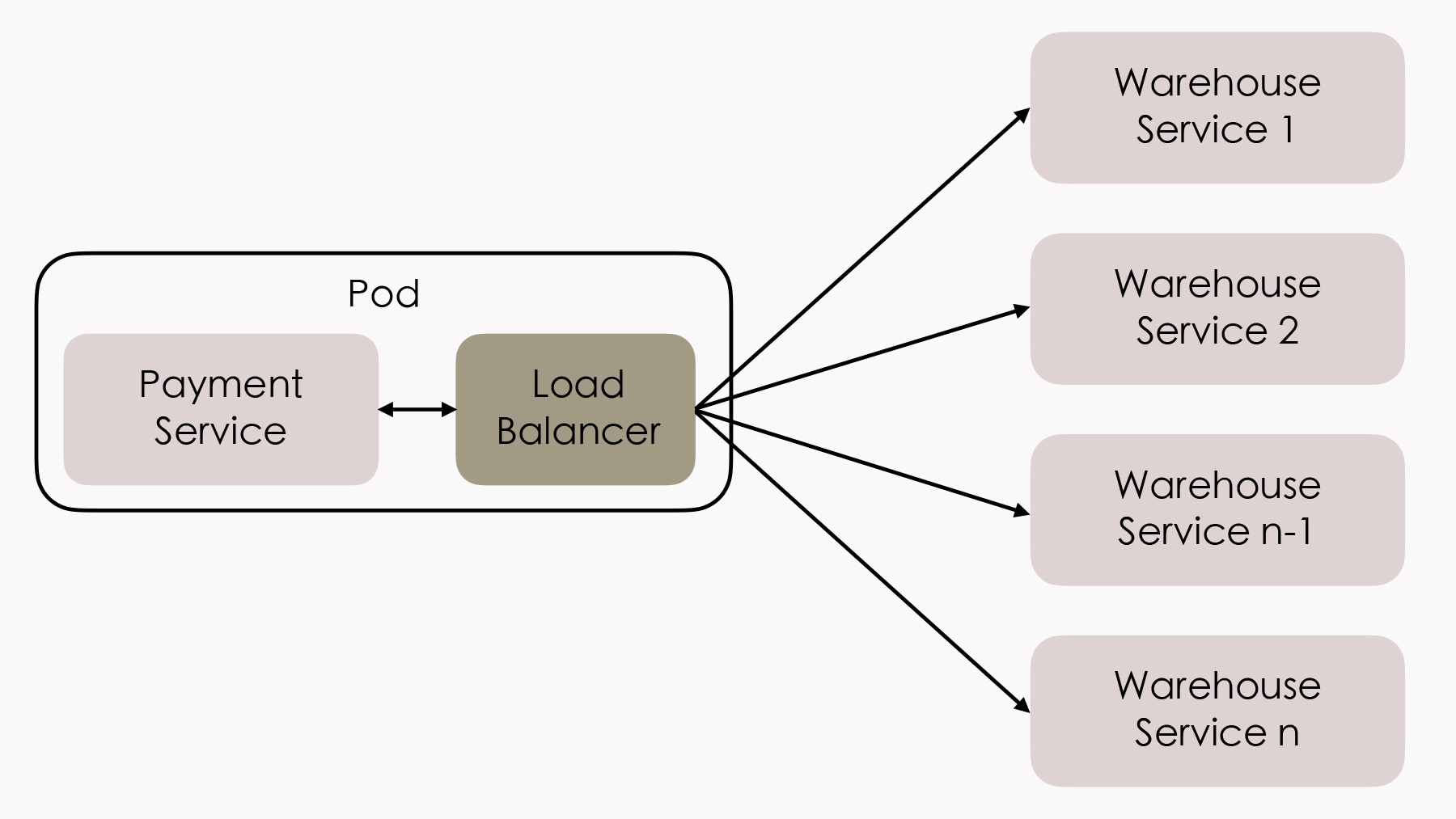
这里你可以发现,虽然代理均衡器与服务实例不再是进程内通讯,而是通过虚拟化网络进行数据交换的,数据要经过操作系统的协议栈,要进行打包拆包、计算校验和、维护序列号等网络数据的收发等步骤(Envoy 中支持使用 Unix Domain Socket 来进一步避免这种消耗),流量比起之前的客户端均衡器确实多经历了一次代理过程。
不过,Kubernetes 严格保证了同一个 Pod 中的容器不会跨越不同的节点,相同 Pod 中的容器共享同一个网络和 Linux UTS 名称空间 ,因此代理均衡器与服务实例的交互,仍然要比真正的网络交互高效且稳定得多,代价很小。但它从服务进程中分离出来的收益则是非常明显的:
- 代理均衡器不再受编程语言的限制。 比如说,要发展一个支持 Java、Golang、Python 等所有微服务应用的通用代理均衡器,就具有很高的性价比。集中不同编程语言的使用者的力量,也更容易打造出能面对复杂网络情况的、高效健壮的均衡器。即使退一步说,独立于服务进程的均衡器,也不会因为自身的稳定性而影响到服务进程的稳定。
- 在服务拓扑感知方面,代理均衡器也要更有优势。 由于边车代理接受控制平面的统一管理,当服务节点拓扑关系发生变化时,控制平面就会主动向边车代理发送更新服务清单的控制指令,这避免了此前客户端均衡器必须长期主动轮询服务注册中心所造成的浪费。
- 在安全性、可观测性上,由于边车代理都是一致的实现,有利于在服务间建立双向 TLS 通讯,也有利于对整个调用链路给出更详细的统计信息。
- ……
所以总体而言,边车代理这种通过同一个 Pod 的独立容器实现的负载均衡器,就是目前处理微服务集群内部流量最理想的方式。只是服务网格本身仍然是初生事物,它还不够成熟,对程序员的操作系统、网络和运维方面的知识要求也比较高,但我们有理由相信,随着时间的推移,未来服务网格将会是微服务的主流通讯方式。
地域与区域
OK,最后,我想再和你探讨一个与负载均衡相关,但又不仅仅只涉及到负载均衡的概念:地域与区域。
不知道你有没有注意到,在与微服务相关的许多设施中,都带有 Region、Zone 参数,比如前面我提到过的服务注册中心 Eureka 的 Region、Zone,边车代理 Envoy 中的 Region、Zone、Sub-zone,等等。如果你有云计算 IaaS 的使用经历,你也会发现几乎所有的云计算设备都有类似的概念。
实际上,Region 和 Zone 是公有云计算先驱亚马逊 AWS 提出的概念 ,我们分别来看看它们的含义。
Region 是地域的意思 ,比如华北、东北、华东、华南,这些都是地域范围。
面向全球或全国的大型系统的服务集群,往往都会部署在多个不同的地域,就像是这节课开篇我设计的那个案例场景一样,它就是通过不同地域的机房,来缩短用户与服务器之间的物理距离,提升响应速度的;而对于小型系统来说,地域一般就只在异地容灾时才会涉及到。
这里你需要注意的是,不同的地域之间是没有内网连接的,所有流量都只能经过公众互联网相连,如果微服务的流量跨越了地域,实际上就跟调用外部服务商提供的互联网服务没有任何差别了。所以,集群内部流量是不会跨地域的,服务发现、负载均衡器也默认是不会支持跨地域的服务发现和负载均衡。
Zone 是区域的意思 ,它是可用区域(Availability Zones)的简称。区域的意思是在地理上位于同一地域内,但电力和网络是互相独立的物理区域,比如在华东的上海、杭州、苏州的不同机房,就是同一个地域的几个可用区域。
同一个地域的区域之间具有内网连接,流量不占用公网带宽,因此区域是微服务集群内,流量能够触及的最大范围。但是,你的应用是只部署在同一区域内,还是部署到几个可用区域中,主要取决于你是否有做异地双活的需求,以及对网络延时的容忍程度。
- 如果你追求高可用 ,比如希望系统即使在某个地区发生电力或者骨干网络中断时,仍然可用,那你可以考虑将系统部署在多个区域中。 这里你要注意异地容灾和异地双活的差别 :容灾是非实时的同步,而双活是实时或者准实时的,跨地域或者跨区域做容灾都可以,但只能一般只能跨区域做双活,当然你也可以将它们结合起来同时使用,即”两地三中心”模式。
- 如果你追求低延迟 ,比如对时间有高要求的 SLA 应用 ,或者网络游戏服务器等,那就应该考虑将系统部署在同一个区域中。因为尽管内网连接不受限于公网带宽,但毕竟机房之间的专线容量也是有限的,难以跟机房内部的交换机相比,延时也会受物理距离、 网络跃点) 等因素的影响。
当然,可用区域对应于城市级别的区域范围,在一些场景中仍然是过大了一些,即使是同一个区域中的机房,也可能存在不同的具有差异的子网络,所以部分的微服务框架也提供了 Group、Sub-zone 等做进一步的细分控制。这些参数的意思通常是加权或优先访问同一个子区域的服务,但如果子区域中没有合适的,还是会访问到可用区域中的其他服务。
另外,地域和区域原本是云计算中的概念,对于一些中小型的微服务系统,尤其是非互联网的企业信息系统来说,很多仍然没有使用云计算设施,只部署在某个专有机房内部,只为特定人群提供服务,这就不需要涉及地理上的地域、区域的概念了。这时你完全可以自己灵活延伸拓展 Region、Zone 参数的含义,达到优化虚拟化基础设施流量的目的。
比如说,将框架的这类设置与 Kubernetes 的标签、选择器相配合,实现内部服务请求其他服务时,优先使用同一个 Node 中提供的服务进行应答,以降低真实的网络消耗。
小结
这节课,我们从”如何将流量转发到最恰当的服务”开始,讨论了客户端负载均衡器出现的背景、它与服务端负载均衡器之间的差异,以及通过代理来实现客户端负载均衡器的差别。
最后,借助本节课建立的上下文场景,我还给你介绍了地域与可用区域的概念。这些概念不仅在购买、使用云计算服务时会用到,还直接影响到了应用程序中路由、负载均衡的请求分发形式。
36 | 面对程序故障,我们该做些什么?
“容错性设计”(Design for Failure)是微服务的另一个 核心原则 ,也是我在这门课中反复强调的开发观念的转变。
不过,虽然已经有了一定的心理准备,但在首次将微服务架构引入实际生产系统时,在 服务发现 、 网关路由 等支持下,踏出了服务化的第一步以后,我们还是很可能会经历一段阵痛期。随着拆分出的服务越来越多,随之而来的,我们也会面临以下两个问题的困扰:
- 某一个服务的崩溃,会导致所有用到这个服务的其他服务都无法正常工作,一个点的错误经过层层传递,最终波及到调用链上与此有关的所有服务,这便是 雪崩效应 。如何防止雪崩效应,便是微服务架构容错性设计原则的具体实践,否则服务化程度越高,整个系统反而越不稳定。
- 服务虽然没有崩溃,但由于处理能力有限,面临超过预期的突发请求时,大部分请求直至超时都无法完成处理。这种现象产生的后果跟交通堵塞是类似的,如果一开始没有得到及时地治理,后面就会需要很长时间才能使全部服务都恢复正常。
这两个问题,就是”流量治理”这个话题要解决的了。在这个小章节,我们将围绕着如何解决这两个问题,提出服务容错、流量控制、服务质量管理等一系列解决方案。
当然了,这些措施并不是孤立的,它们相互之间存在很多联系,其中的许多功能还必须与咱们之前学习过的服务注册中心、服务网关、负载均衡器配合才能实现。理清楚了这些技术措施背后的逻辑链条,我们就找到了理解它们工作原理的捷径。
接下来,我们就从服务容错这个解决方案学起吧。
服务容错
Martin Fowler 与 James Lewis 提出的” 微服务的九个核心特征 “是构建微服务系统的指导性原则,但不是技术规范,并没有严格的约束力。在实际构建系统时候,其中多数特征可能会有或多或少的妥协,比如分散治理、数据去中心化、轻量级通讯机制、演进式设计,等等。但也有一些特征是无法做出妥协的,其中典型的就是今天我们讨论的主题:容错性设计。
容错性设计不能妥协的原因在于,分布式系统的本质是不可靠的,一个大的服务集群中,程序可能崩溃、节点可能宕机、网络可能中断,这些”意外情况”其实全部都在”意料之中”。原本信息系统设计成分布式架构的主要动力之一,就是提升系统的可用性,最低限度也必须保证将原有系统重构为分布式架构之后,可用性不出现倒退才行。
如果说,服务集群中出现任何一点差错都能让系统面临”千里之堤溃于蚁穴”的风险,那么分布式恐怕就根本没有机会成为一种可用的系统架构形式了。
容错策略
那在实践中怎么落实容错性设计这条原则呢?除了思想观念上转变过来,正视程序必然是会出错的,对它进行有计划的防御之外,我们还必须了解一些常用的容错策略和容错设计模式,来指导具体的设计与编码实践。
那怎么理解容错策略和容错设计模式呢?其实, 容错策略,指的是”面对故障,我们该做些什么”;而容错设计模式,指的是”要实现某种容错策略,我们该如何去做”。
所以,接下来我们先一起学习 7 种常见的容错策略,包括故障转移、快速失败、安全失败、沉默失败、故障恢复、并行调用和广播调用,然后下一讲我们再学习几种被实践证明有效的服务容错设计模式。
第一种容错策略,是故障转移(Failover)。
高可用的服务集群中,多数的服务,尤其是那些经常被其他服务依赖的关键路径上的服务,都会部署多个副本。这些副本可能部署在不同的节点(避免节点宕机)、不同的网络交换机(避免网络分区),甚至是不同的可用区(避免整个地区发生灾害或电力、骨干网故障)中。
故障转移是指,如果调用的服务器出现故障,系统不会立即向调用者返回失败结果,而是自动切换到其他服务副本,尝试其他副本能否返回成功调用的结果,从而保证了整体的高可用性。
故障转移的容错策略应该有一定的调用次数限制,比如允许最多重试三个服务,如果都发生报错,那还是会返回调用失败。引入调用次数的限制,不仅是因为重试有执行成本,更是因为过度的重试反而可能让系统处于更加不利的状况。
我们看一个例子。现在有 Service A → Service B → Service C 这么一条调用链。假设 A 的超时阈值为 100 毫秒,而 B 调用 C 需要 60 毫秒,然后不幸失败了,这时候做故障转移其实已经没有太大意义了。因为即使下一次调用能够返回正确结果,也很可能同样需要耗费 60 毫秒的时间,时间总和就已经超过了 Service A 的超时阈值。所以,在这种情况下故障转移反而对系统是不利的。
第二种容错策略,是快速失败(Failfast)。
有一些业务场景是不允许做故障转移的,因为故障转移策略能够实施的前提,是服务具有幂等性。那对于非幂等的服务,重复调用就可能产生脏数据,引起的麻烦远大于单纯的某次服务调用失败。这时候,就应该把快速失败作为首选的容错策略。
比如,在支付场景中,需要调用银行的扣款接口,如果该接口返回的结果是网络异常,那程序很难判断到底是扣款指令发送给银行时出现的网络异常,还是银行扣款后给服务返回结果时出现的网络异常。为了避免重复扣款,此时最恰当的方案就是尽快让服务报错并抛出异常,坚决避免重试,由调用者自行处理。
第三种容错策略,是安全失败(Failsafe)。
在一个调用链路中的服务,通常也有主路和旁路之分,并不见得每个服务都是不可或缺的,属于旁路逻辑的一个显著特点是,服务失败了也不影响核心业务的正确性。比如,开发基于 Spring 管理的应用程序时,通过扩展点、事件或者 AOP 注入的逻辑往往就属于旁路逻辑,典型的有审计、日志、调试信息,等等。
属于旁路逻辑的另一个显著特征是,后续处理不会依赖其返回值,或者它的返回值是什么都不会影响后续处理的结果。比如只是将返回值记录到数据库,并不使用它参与最终结果的运算。
对这类逻辑,一种理想的容错策略是,即使旁路逻辑调用失败了,也当作正确来返回,如果需要返回值的话,系统就自动返回一个符合要求的数据类型的对应零值,然后自动记录一条服务调用出错的日志备查即可。这种容错策略,被称为安全失败。
第四种容错策略,是沉默失败(Failsilent)。
如果大量的请求需要等到超时(或者长时间处理后)才宣告失败,很容易因为某个远程服务的请求堆积而消耗大量的线程、内存、网络等资源,进而影响到整个系统的稳定性。
面对这种情况,一种合理的失败策略是当请求失败后,就默认服务提供者一定时间内无法再对外提供服务,不再向它分配请求流量,并将错误隔离开来,避免对系统其他部分产生影响。这种容错策略,就被称为沉默失败。
第五种容错策略,是故障恢复(Failback)。
故障恢复一般不单独存在,而是作为其他容错策略的补充措施。在微服务管理框架中,如果设置容错策略为故障恢复的话,通常默认会采用快速失败加上故障恢复的策略组合。
故障恢复是指,当服务调用出错了以后,将该次调用失败的信息存入一个消息队列中,然后由系统自动开始异步重试调用。
从这个定义中也可以看出,故障恢复策略,一方面是尽力促使失败的调用最终能够被正常执行,另一方面也可以为服务注册中心和负载均衡器及时提供服务恢复的通知信息。很显然,故障恢复也要求服务必须具备幂等性,由于它的重试是后台异步进行,即使最后调用成功了,原来的请求也早已经响应完毕。所以,故障恢复策略一般用于对实时性要求不高的主路逻辑,也适合处理那些不需要返回值的旁路逻辑。
为了避免在内存中的异步调用任务堆积,故障恢复与故障转移一样,也应该有最大重试次数的限制。
故障转移、快速失败、安全失败、沉默失败和故障恢复这 5 种容错策略的英文,都是以”Fail”开头的,它们有一个共同点,都是针对调用失败时如何进行弥补的。接下来,咱们要学习的并行调用和广播调用这两种策略,则是在调用之前就开始考虑如何获得最大的成功概率。
第六种容错策略,是并行调用(Forking)。
并行调用策略,是指一开始就同时向多个服务副本发起调用,只要有其中任何一个返回成功,那调用便宣告成功。这种策略是在一些关键场景中,使用更高的执行成本换取执行时间和成功概率的策略。
这种处理思路,其实对应的就是,咱们在日常生活中,对一些重要环节采取的”双重保险”或者”多重保险”的处理思路。
第七种容错策略,是广播调用(Broadcast)。
广播调用与并行调用是相对应的,都是同时发起多个调用,但并行调用是任何一个调用结果返回成功便宣告成功,而广播调用则是要求所有的请求全部都成功,才算是成功。
也就是说,对于广播调用来说,任何一个服务提供者出现异常都算调用失败。因此,广播调用通常被用于实现”刷新分布式缓存”这类的操作。
小结
今天这一讲,我们学习了故障转移、快速失败、安全失败、沉默失败、故障恢复、并行调用和广播调用,一共 7 种容错策略。
其实,容错策略并不是计算机领域独有的,在交通、能源、航天等非常多的领域都有容错性设计,也会使用到上面这些策略,并在自己的行业领域中进行解读与延伸。
这里,我把今天讲到的 7 种容错策略进行了一次对比梳理,你可以在下面的表格中看到它们的优缺点和应用场景。
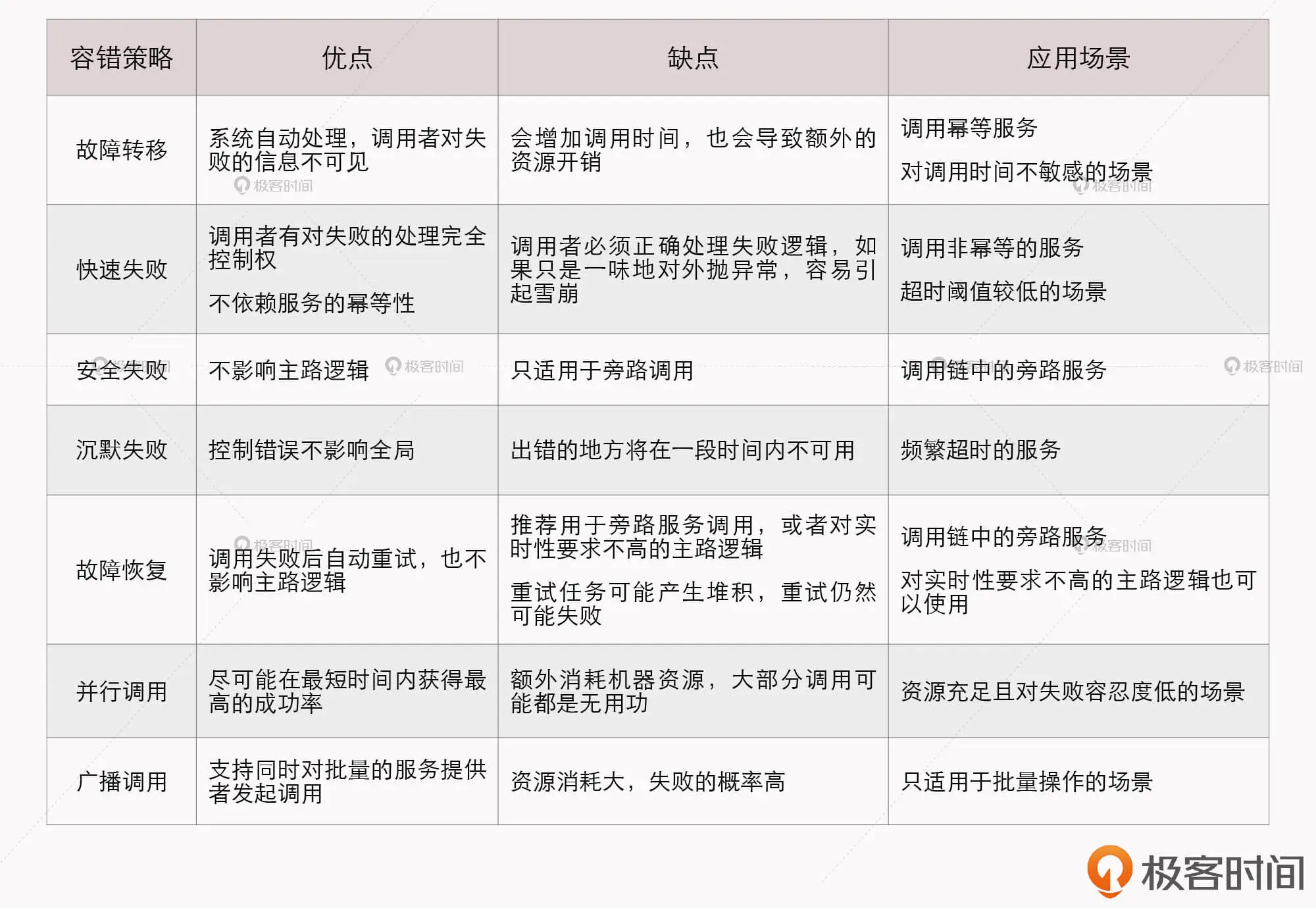
37 | 要实现某种容错策略,我们该怎么做?
在上一讲,我们首先界定了容错策略和容错设计模式这两个概念: 容错策略,指的是”面对故障,我们该做些什么”;而容错设计模式,指的是”要实现某种容错策略,我们该如何去做”。
然后,我们讲了 7 种常见的容错策略 ,包括故障转移、快速失败、安全失败、沉默失败、故障恢复、并行调用和广播调用。
那么为了实现各种各样的容错策略,开发人员总结出了一些被实践证明有效的服务容错设计模式。这些设计模式,包括了这一讲我们要学习的,微服务中常见的断路器模式、舱壁隔离模式和超时重试模式等,以及我们下一讲要学习的流量控制模式,比如滑动时间窗模式、漏桶模式、令牌桶模式,等等。
我们先来学习断路器模式。
断路器模式
断路器模式是微服务架构中最基础的容错设计模式,以至于像 Hystrix 这种服务治理工具,我们往往会忽略了它的服务隔离、请求合并、请求缓存等其他服务治理职能,直接把它叫做微服务断路器或者熔断器。这下你明白断路器模式为啥是”最基础”的容错设计模式了吧,也明白为啥我们要首先学习这种模式了吧。
断路器模式最开始是由迈克尔 · 尼加德(Michael Nygard)在” Release It! “这本书中提出来的,后来又因为马丁 · 福勒(Martin Fowler)的文章” Circuit Breaker “而广为人知。
其实, 断路器的思路很简单 ,就是通过代理(断路器对象)来一对一(一个远程服务对应一个断路器对象)地接管服务调用者的远程请求。那怎么实现的呢?
断路器会持续监控并统计服务返回的成功、失败、超时、拒绝等各种结果,当出现故障(失败、超时、拒绝)的次数达到断路器的阈值时,它的状态就自动变为”OPEN”。之后这个断路器代理的远程访问都将直接返回调用失败,而不会发出真正的远程服务请求。
通过断路器对远程服务进行熔断,就可以避免因为持续的失败或拒绝而消耗资源,因为持续的超时而堆积请求,最终可以避免雪崩效应的出现。由此可见, 断路器本质上是快速失败策略的一种实现方式。
断路器模式的工作过程,可以用下面的序列图来表示:
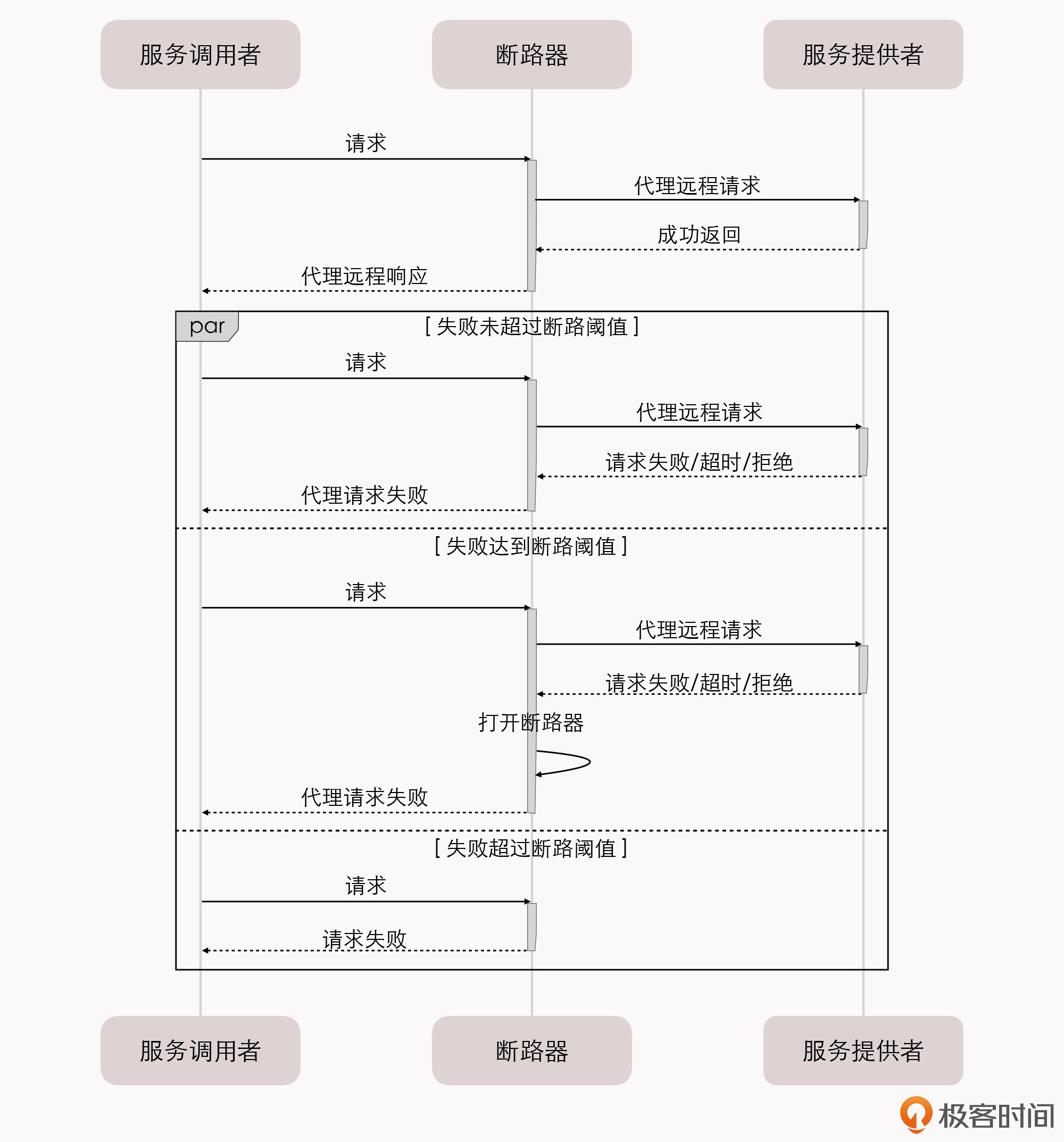
从调用序列来看,断路器就是一种有限状态机,断路器模式就是根据自身的状态变化,自动调整代理请求策略的过程。
断路器一般可以设置为 CLOSED、OPEN 和 HALF OPEN 三种状态。
- CLOSED:表示断路器关闭,此时的远程请求会真正发送给服务提供者。断路器刚刚建立时默认处于这种状态,此后将持续监视远程请求的数量和执行结果,决定是否要进入 OPEN 状态。
- OPEN:表示断路器开启,此时不会进行远程请求,直接给服务调用者返回调用失败的信息,以实现快速失败策略。
- HALF OPEN:是一种中间状态。断路器必须带有自动的故障恢复能力,当进入 OPEN 状态一段时间以后,将”自动”(一般是由下一次请求而不是计时器触发的,所以这里的自动是带引号的)切换到 HALF OPEN 状态。在中间状态下,会放行一次远程调用,然后根据这次调用的结果成功与否,转换为 CLOSED 或者 OPEN 状态,来实现断路器的弹性恢复。
CLOSED、OPEN 和 HALF OPEN 这三种状态的转换逻辑和条件,如下图所示:
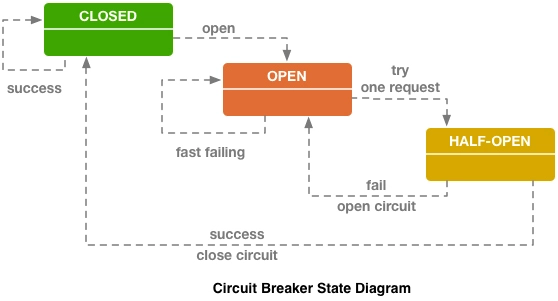
图片引自” Application Resiliency Using Netflix Hystrix“
OPEN 和 CLOSED 状态的含义是十分清晰的,和我们日常生活中电路的断路器并没有什么差别,值得讨论的是这两种状态的转换条件是什么?
最简单直接的方案是,只要遇到一次调用失败,那就默认以后所有的调用都会接着失败,断路器直接进入 OPEN 状态。但这样做的效果非常差,虽然避免了故障扩散和请求堆积,却使得在外部看来系统表现的极其不稳定。
那怎么解决这个问题呢?一个可行的办法是,当一次调用失败后,如果还同时满足下面两个条件,断路器的状态就变为 OPEN:
- 一段时间(比如 10 秒以内)内,请求数量达到一定阈值(比如 20 个请求)。这个条件的意思是,如果请求本身就很少,那就用不着断路器介入。
- 一段时间(比如 10 秒以内)内,请求的故障率(发生失败、超时、拒绝的统计比例)到达一定阈值(比如 50%)。这个条件的意思是,如果请求本身都能正确返回,也用不着断路器介入。
括号中举例的数值,10 秒、20 个请求、50%,是 Netflix Hystrix 的默认值。其他服务治理的工具,比如 Resilience4j、Envoy 等也有类似的设置,你可以在它们的帮助文档中找到对应的默认值。
借着断路器的上下文,我再顺带讲一下服务治理中两个常见的易混淆概念:服务熔断和服务降级之间的联系与差别。
断路器做的事情是自动进行服务熔断,属于一种快速失败的容错策略的实现方法。在快速失败策略明确反馈了故障信息给上游服务以后,上游服务必须能够主动处理调用失败的后果,而不是坐视故障扩散。这里的”处理”,指的就是一种典型的服务降级逻辑,降级逻辑可以是,但不应该只是,把异常信息抛到用户界面去,而应该尽力想办法通过其他路径解决问题,比如把原本要处理的业务记录下来,留待以后重新处理是最低限度的通用降级逻辑。
举个例子:你女朋友有事儿想召唤你,打你手机没人接,响了几声气冲冲地挂断后(快速失败),又打了你另外三个不同朋友的手机号(故障转移),都还是没能找到你(重试超过阈值)。这时候她生气地在微信上给你留言”三分钟不回电话就分手”,以此来与你取得联系。在这个不是太吉利的故事里,女朋友给你留言这个行为便是服务降级逻辑。
服务降级不一定是在出现错误后才被动执行的,我们在很多场景中谈论的降级更可能是指,需要主动迫使服务进入降级逻辑的情况。比如,出于应对可预见的峰值流量,或者是系统检修等原因,要关闭系统部分功能或关闭部分旁路服务,这时候就有可能会主动迫使这些服务降级。当然,此时服务降级就不一定是出于服务容错的目的了,更可能是属于下一讲我们要学习的流量控制的范畴。
舱壁隔离模式
了解了服务熔断和服务降级以后,我们再来看看微服务治理中常听见的另一概念:服务隔离。
舱壁隔离模式,是常用的实现服务隔离的设计模式。”舱壁”这个词来自造船业,它原本的意思是设计舰船时,要在每个区域设计独立的水密舱室,一旦某个舱室进水,也只会影响到这个舱室中的货物,而不至于让整艘舰艇沉没。
那对应到分布式系统中,服务隔离,就是避免某一个远程服务的局部失败影响到全局,而设置的一种止损方案。这种思想,对应的就是容错策略中的失败静默策略。那为什么会有一个服务失败会影响全局的事情发生呢?
咱们在刚刚学习断路器模式时,把调用外部服务的故障分为了失败、拒绝和超时三大类。
其中,”超时”引起的故障,尤其容易给调用者带来全局性的风险。这是因为,目前主流的网络访问大多是基于 TPR 并发模型(Thread per Request)来实现的,只要请求一直不结束(无论是以成功结束还是以失败结束),就要一直占用着某个线程不能释放。而线程是典型的整个系统的全局性资源,尤其是在 Java 这类将线程映射为操作系统内核线程来实现的语言环境中。
我们来看一个更具体的场景。
当分布式系统依赖的某个服务,比如”服务 I”发生了超时,那在高流量的访问下,或者更具体点,假设平均 1 秒钟内会调用这个服务 50 次,就意味着该服务如果长时间不结束的话,每秒会有 50 条用户线程被阻塞。
如果这样的访问量一直持续,按照 Tomcat 默认的 HTTP 超时时间 20 秒来计算的话,20 秒内将会阻塞掉 1000 条用户线程。此后才陆续会有用户线程因超时被释放出来,回归 Tomcat 的全局线程池中。
通常情况下,Java 应用的线程池最大只会设置为 200~400,这就意味着从外部来看,此时系统的所有服务已经全面瘫痪,而不仅仅是只有涉及到”服务 I”的功能不可用。因为 Tomcat 已经没有任何空余的线程来为其他请求提供服务了。
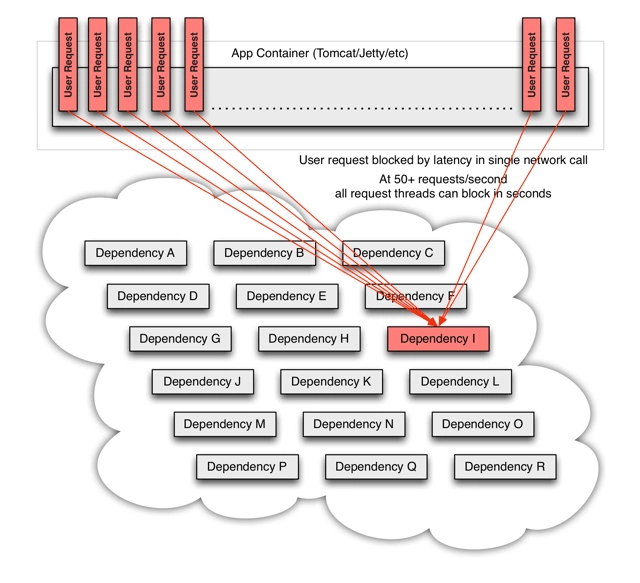
图片来自 Hystrix 使用文档
要解决这类问题,本质上就是要控制单个服务的最大连接数。一种可行的解决办法是 为每个服务单独设立线程池 ,这些线程池默认不预置活动线程,只用来控制单个服务的最大连接数。
比如,对出问题的”服务 I”设置了一个最大线程数为 5 的线程池,这时候它的超时故障就只会最多阻塞 5 条用户线程,而不至于影响全局。此时,其他不依赖”服务 I”的用户线程,依然能够正常对外提供服务,如下图所示。
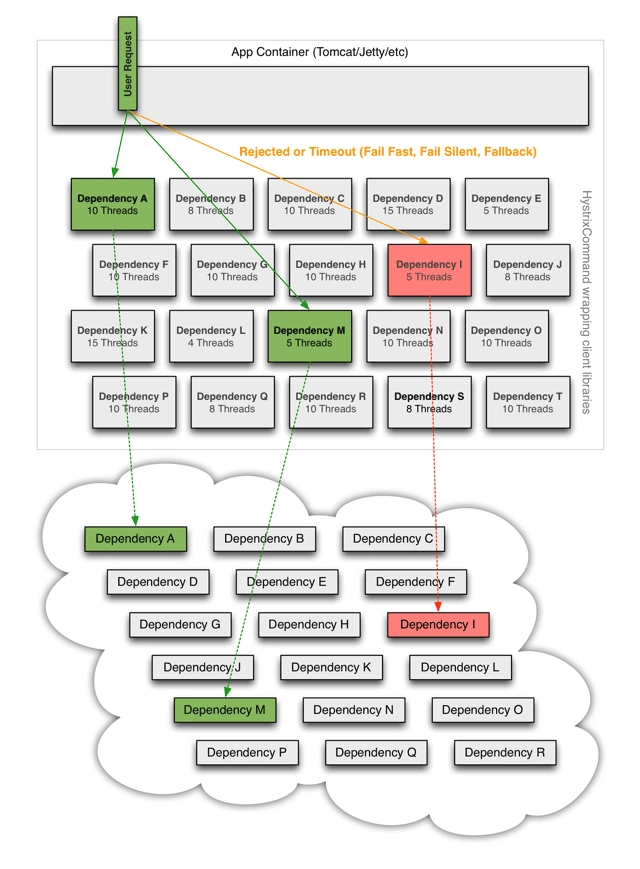
图片来自 Hystrix 使用文档
使用局部的线程池来控制服务的最大连接数,有很多好处,比如当服务出问题时能够隔离影响,当服务恢复后,还可以通过清理掉局部线程池,瞬间恢复该服务的调用。而如果是 Tomcat 的全局线程池被占满,再恢复就会非常麻烦。
但是,局部线程池有一个显著的弱点,那就是它额外增加了 CPU 的开销,每个独立的线程池都要进行排队、调度和下文切换工作。根据 Netflix 官方给出的数据,一旦启用 Hystrix 线程池来进行服务隔离,每次服务调用大概会增加 3~10 毫秒的延时。如果调用链中有 20 次远程服务调用的话,那每次请求就要多付出 60 毫秒至 200 毫秒的代价,来换取服务隔离的安全保障。
为应对这种情况,还有一种更轻量的控制服务最大连接数的办法,那就是信号量机制(Semaphore)。
如果不考虑清理线程池、客户端主动中断线程这些额外的功能,仅仅是为了控制单个服务并发调用的最大次数的话,我们可以只为每个远程服务维护一个线程安全的计数器,并不需要建立局部线程池。
具体做法是,当服务开始调用时计数器加 1,服务返回结果后计数器减 1;一旦计数器的值超过设置的阈值就立即开始限流,在回落到阈值范围之前都不再允许请求了。因为不需要承担线程的排队、调度和切换工作,所以单纯维护一个作为计数器的信号量的性能损耗,相对于局部线程池来说,几乎可以忽略不计。
以上介绍的是从微观的、服务调用的角度应用舱壁隔离设计模式,实际上舱壁隔离模式还可以在更高层、更宏观的场景中使用,不按调用线程,而是按功能、按子系统、按用户类型等条件来隔离资源都是可以的。比如,根据用户等级、用户是否是 VIP、用户来访的地域等各种因素,将请求分流到独立的服务实例去,这样即使某一个实例完全崩溃了,也只是影响到其中某一部分的用户,把波及范围尽可能控制住。
一般来说,我们会选择将服务层面的隔离实现在服务调用端或者边车代理上,将系统层面的隔离实现在 DNS 或者网关处。
到这里,我们回顾下已经学习了哪几种安全策略的实现方式:
- 使用断路器模式实现快速失败策略;
- 使用舱壁隔离模式实现静默失败策略;
- 在断路器中的案例中提到的主动对非关键的旁路服务进行降级,也可以算作是安全失败策略的一种体现。
再对照着我们上一讲学习的 7 种常见安全策略来说,我们还剩下故障转移和故障恢复两种策略的实现没有学习。接下来,我就以重试模式和你介绍这两种容错策略的主流实现方案。
重试模式
故障转移和故障恢复这两种策略都需要对服务进行重复调用,差别就在于这些重复调用有可能是同步的,也可能是后台异步进行;有可能会重复调用同一个服务,也可能会调用服务的其他副本。但是,无论具体是通过怎样的方式调用、调用的服务实例是否相同,都可以归结为重试设计模式的应用范畴。
重试模式适合解决系统中的瞬时故障,简单地说就是有可能自己恢复(Resilient,称为自愈,也叫做回弹性)的临时性失灵,比如网络抖动、服务的临时过载(比如返回了 503 Bad Gateway 错误)这些都属于瞬时故障。
重试模式实现起来并不难,即使完全不考虑框架的支持,程序员自己编写十几行代码也能完成。也正因为实现起来简单,使用重试模式面临的最大风险就是滥用。那怎么避免滥用呢?在实践中, 我们判断是否应该且是否能够对一个服务进行重试时,要看是否同时满足下面 4 个条件。
第一,仅在主路逻辑的关键服务上进行同步的重试。也就是说,如果不是关键的服务,一般不要把重试作为首选的容错方案,尤其不应该进行同步重试。
第二,仅对由瞬时故障导致的失败进行重试。尽管要做到精确判定一个故障是否属于可自愈的瞬时故障并不容易,但我们至少可以从 HTTP 的状态码上获得一些初步的结论。比如,当发出的请求收到了 401 Unauthorized 响应时,说明服务本身是可用的,只是你没有权限调用,这时候再去重试就没有什么意义。
功能完善的服务治理工具会提供具体的重试策略配置(如 Envoy 的 Retry Policy ),可以根据包括 HTTP 响应码在内的各种具体条件来设置不同的重试参数。
第三,仅对具备幂等性的服务进行重试。你可能会说了,如果服务调用者和提供者不属于同一个团队,那服务是否幂等,其实也是一个难以精确判断的问题。这个问题确实存在,但我们还是可以找到一些总体上通用的原则来帮助我们做判断。
比如,RESTful 服务中的 POST 请求是非幂等的;GET、HEAD、OPTIONS、TRACE 请求应该被设计成幂等的,因为它们不会改变资源状态;PUT 请求一般也是幂等的,因为 n 个 PUT 请求会覆盖相同的资源 n-1 次;DELETE 请求也可看作是幂等的,同一个资源首次删除会得到 200 OK 响应,此后应该得到 204 No Content 响应。
这些都是 HTTP 协议中定义的通用的指导原则,虽然对于具体服务如何实现并无强制约束力,但建设系统时遵循业界惯例本身就是一种良好的习惯。
第四,重试必须有明确的终止条件,常用的终止条件有超时终止和次数终止两种。
- 超时终止。其实,超时机制并不限于重试策略,所有涉及远程调用的服务都应该有超时机制来避免无限期的等待。这里我只是强调重试模式更应该配合超时机制来使用,否则重试对系统很可能是有害的。在介绍故障转移策略时,我已经举过类似的例子,你可以再去看一下。
- 次数终止。重试必须要有一定限度,不能无限制地做下去,通常是重试 2~5 次。因为重试不仅会给调用者带来负担,对服务提供者来说也同样是负担,所以我们要避免把重试次数设得太大。此外,如果服务提供者返回的响应头中带有 Retry-After 的话,尽管它没有强制约束力,我们也应该充分尊重服务端的要求,做个”有礼貌”的调用者。
另外,由于重试模式可以在网络链路的多个环节中去实现,比如在客户端发起调用时自动重试、网关中自动重试、负载均衡器中自动重试,等等,而且现在的微服务框架都足够便捷,只需设置一两个开关参数,就可以开启对某个服务、甚至是全部服务的重试机制了。
所以,如果你没有太多经验的话,可能根本就意识不到其中会带来多大的负担。
这里我给你举个具体的例子:一套基于 Netflix OSS 建设的微服务系统,如果同时在 Zuul、Feign 和 Ribbon 上都打开了重试功能,且不考虑重试被超时终止的话,那总重试次数就相当于它们的重试次数的乘积。假设按它们都重试 4 次,且 Ribbon 可以转移 4 个服务副本来计算的话,理论上最多会产生高达 4×4×4×4=256 次调用请求。
小结
熔断、隔离、重试、降级、超时等概念,都是建立具有韧性的微服务系统的必须的保障措施。那么就目前来说,这些措施的正确运作,主要还是依靠开发人员对服务逻辑的了解,以及根据运维人员的经验去静态地调整、配置参数和阈值。
但是,面对能够自动扩缩(Auto Scale)的大型分布式系统,静态的配置越来越难以起到良好的效果。
所以这就要求,系统不仅要有能力可以自动地根据服务负载来调整服务器的数量规模,同时还要有能力根据服务调用的统计结果,或者 启发式搜索) 的结果来自动变更容错策略和参数。当然,目前这方面的研究,还处于各大厂商在内部分头摸索的初级阶段,不过这正是服务治理未来的重要发展方向之一。
这节课我给你介绍的容错策略和容错设计模式,最终目的都是为了避免服务集群中,某个节点的故障导致整个系统发生雪崩效应。
但我们要知道,仅仅做到容错,只让故障不扩散是远远不够的,我们还希望系统或者至少系统的核心功能能够表现出最佳的响应的能力,不受或少受硬件资源、网络带宽和系统中一两个缓慢服务的拖累。在下一节课,我们还将会面向如何解决集群中的短板效应,去讨论服务质量、流量管控等话题。
38 | 限流的目标与模式
在前面两讲中,我们了解了分布式服务中的容错机制,这是分布式服务调用中必须考虑的因素。今天这节课,我们接着来学习分布式服务中另一个常见的机制:限流。
任何一个系统的运算、存储、网络资源都不是无限的,当系统资源不足以支撑外部超过预期的突发流量时,就应该要有取舍,建立面对超额流量自我保护的机制,而这个机制就是微服务中常说的”限流”。
限流的目标
在介绍限流具体的实现细节之前,我们先来做一道小学三年级难度的四则运算场景应用题:
已知条件:
系统中一个业务操作需要调用 10 个服务协作来完成,该业务操作的总超时时间是 10 秒,每个服务的处理时间平均是 0.5 秒,集群中每个服务均部署了 20 个实例副本。
求解以下问题:
(1) 单个用户访问,完成一次业务操作,需要耗费系统多少处理器时间?
答:0.5 × 10 = 5 Sec CPU Time
(2) 集群中每个服务每秒最大能处理多少个请求?
答:(1 ÷ 0.5) × 20 = 40 QPS
(3) 假设不考虑顺序且请求分发是均衡的,在保证不超时的前提下,整个集群能持续承受最多每秒多少笔业务操作?
答:40 × 10 ÷ 5 = 80 TPS
(4) 如果集群在一段时间内持续收到 100 TPS 的业务请求,会出现什么情况?
答:这就超纲了小学水平,得看你们家架构师的本事了。
前三个问题都很基础我就不说了,对于最后一个问题,如果仍然按照小学生的解题思路,最大处理能力为 80 TPS 的系统遇到 100 TPS 的请求,应该能完成其中的 80 TPS,也就是只有 20 TPS 的请求失败或被拒绝才对。然而这其实是最理想的情况,也是我们追求的目标。
事实上,如果不做任何处理的话,更可能出现的结果是,这 100 个请求中的每一个都开始了处理,但是大部分请求都只完成了 10 次服务调用中的 8 次或者 9 次,然后就是超时没有然后了。
其实在很多的微服务应用中,多数服务调用都是白白浪费掉的,没有几个请求能够走完整笔业务操作。比如早期的 12306 系统就明显存在这样的问题,全国人民都上去抢票的结果,就是全国人民谁都买不上票。
那么,为了避免这种状况出现,一个健壮的系统就需要做到恰当的流量控制,更具体地说,需要妥善解决以下三个问题:
依据什么限流?
要不要控制流量、要控制哪些流量、控制力度要有多大,等等,这些操作都没法在系统设计阶段静态地给出确定的结论,必须根据系统此前一段时间的运行状况,甚至未来一段时间的预测情况来动态决定。
具体如何限流?
要想解决系统具体是如何做到允许一部分请求能够通行,而另外一部分流量实行受控制的失败降级的问题,就必须要了解和掌握常用的服务限流算法和设计模式。
超额流量如何处理?
超额流量可以有不同的处理策略,也许会直接返回失败(如 429 Too Many Requests),或者被迫使它们进入降级逻辑,这种策略被称为 否决式限流 ;也可能是让请求排队等待,暂时阻塞一段时间后继续处理,这种则被称为阻塞式限流。
流量统计指标
那么,要做好流量控制,首先就要弄清楚到底哪些指标能反映系统的流量压力大小。
相比较而言,容错的统计指标是明确的,容错的触发条件基本上只取决于请求的故障率,发生失败、拒绝与超时都算作故障。但限流的统计指标就不那么明确了,所以这里我们要先搞明白一个问题: 限流中的”流”到底指什么呢?
要解答这个问题,我们得先梳理清楚经常用于衡量服务流量压力,但又比较容易混淆的三个指标的定义:
每秒事务数(Transactions per Second,TPS)
TPS 是衡量信息系统吞吐量的最终标准。”事务”可以理解为一个逻辑上具备原子性的业务操作。比如你在 Fenix’s Bookstore 买了一本书要进行支付,这个”支付”就是一笔业务操作,无论支付成功还是不成功,这个操作在逻辑上就是原子的,即逻辑上不可能让你买本书可以成功支付前面 200 页,但失败了后面 300 页。
每秒请求数(Hits per Second,HPS)
HPS 是指每秒从客户端发向服务端的请求数(这里你要把 Hits 理解为 Requests 而不是 Clicks,国内某些翻译把它理解为”每秒点击数”多少有点望文生义的嫌疑)。如果只要一个请求就能完成一笔业务,那 HPS 与 TPS 是等价的,但在一些场景里(尤其常见于网页中),一笔业务可能需要多次请求才能完成。
比如你在 Fenix’s Bookstore 买了一本书要进行支付,尽管在操作逻辑上它是原子的,但在技术实现上,除非你是直接在银行开的商城中购物能够直接扣款,否则这个操作就很难在一次请求里完成,总要经过显示支付二维码、扫码付款、校验支付是否成功等过程,中间不可避免地会发生多次请求。
每秒查询数(Queries per Second,QPS)
QPS 是指一台服务器能够响应的查询次数。如果只有一台服务器来应答请求,那 QPS 和 HPS 是等价的,但在分布式系统中,一个请求的响应,往往要由后台多个服务节点共同协作来完成。
比如你在 Fenix’s Bookstore 买了一本书要进行支付,在扫描支付二维码时,尽管客户端只发送了一个请求,但在这背后,服务端很可能需要向仓储服务确认库存信息避免超卖、向支付服务发送指令划转货款、向用户服务修改用户的购物积分,等等,这里面每次的内部访问,都要消耗掉一次或多次查询数。
总体来说,以上这三点都是基于调用计数的指标,而在整体目标上,我们当然 最希望能够基于 TPS 来限流 ,因为信息系统最终是为人类用户提供服务的,用户并不关心业务到底是由多少个请求、多少个后台查询共同协作来实现的。
但是,系统的业务五花八门,不同的业务操作对系统的压力往往差异巨大,不具备可比性;而更关键的是,流量控制是针对用户实际操作场景来限流的,这不同于压力测试场景中无间隙(最多有些集合点)的全自动化操作,真实业务操作的耗时会无可避免地受限于用户交互带来的不确定性。比如前面例子中的”扫描支付二维码”这个步骤,如果用户在掏出手机扫描二维码前,先顺便回了两条短信,那整个付款操作就要持续更长时间。
那么此时,如果按照业务开始时计数器加 1,业务结束时计数器减 1,通过限制最大 TPS 来限流的话,就不能准确地反映出系统所承受的压力了。所以直接针对 TPS 来限流,实际上是很难操作的。
目前来说, 主流系统大多倾向于使用 HPS 作为首选的限流指标,因为它相对容易观察统计,而且能够在一定程度上反映系统当前以及接下来一段时间的压力。
但你要知道的是,限流指标并不存在任何必须遵循的权威法则,根据系统的实际需要,哪怕完全不选择基于调用计数的指标都是有可能的。我举个简单的例子,下载、视频、直播等 I/O 密集型系统,往往会把每次请求和响应报文的大小作为限流指标,而不是调用次数。
比如说,只允许单位时间通过 100MB 的流量;再比如网络游戏等基于长连接的应用,可能会把登录用户数作为限流指标,热门的网游往往超过一定用户数就会让你在登录前排队等候。
限流设计模式
与容错模式类似,对于具体如何进行限流,业界内也有一些常见、常用、被实践证明有效的设计模式可以参考使用,包括流量计数器、滑动时间窗、漏桶和令牌桶这四种,下面我们一起来看看。
流量计数器模式
我们最容易想到的一种做限流的方法,就是设置一个计算器,根据当前时刻的流量计数结果是否超过阈值来决定是否限流。比如在前面的小学场景应用题中,我们计算得出了该系统能承受的最大持续流量是 80 TPS,那我们就可以控制任何一秒内,发现超过 80 次的业务请求就直接拒绝掉超额部分。
这种做法很直观,而且有些简单的限流就是这么实现的,但它并不严谨,比如说以下两个结论,就很可能出乎你对限流算法的意料之外:
即使每一秒的统计流量都没有超过 80 TPS,也不能说明系统没有遇到过大于 80 TPS 的流量压力。
你可以想像这样一个场景:如果系统连续两秒都收到了 60 TPS 的访问请求,但这两个 60 TPS 请求分别是前 1 秒里的后 0.5 秒,以及后 1 秒中的前 0.5 秒所发生的。这样虽然每个周期的流量都不超过 80 TPS 请求的阈值,但是系统确实是曾经在 1 秒内发生了超过阈值的 120 TPS 请求。
即使连续若干秒的统计流量都超过了 80 TPS,也不能说明流量压力就一定超过了系统的承受能力。
你同样可以想像这样一个场景:如果 10 秒的时间片段中,前 3 秒的 TPS 平均值到了 100,而后 7 秒的平均值是 30 左右,此时系统是否能够处理完这些请求而不产生超时失败?
答案是可以的,因为条件中给出的超时时间是 10 秒,而最慢的请求也能在 8 秒左右处理完毕。如果只基于固定时间周期来控制请求阈值为 80 TPS,反而会误杀一部分请求,造成部分请求出现原本不必要的失败。
由此可见,流量计数器模式缺陷的根源在于,它只是针对时间点进行离散的统计。因此为了弥补该缺陷,一种名为”滑动时间窗”的限流模式就被设计了出来,它可以实现平滑的基于时间片段的统计。
滑动时间窗模式
滑动窗口算法 (Sliding Window Algorithm)在计算机科学的很多领域中都有成功的应用,比如编译原理中的 窥孔优化 (Peephole Optimization)、TCP 协议的 阻塞控制 (Congestion Control)等都使用到了滑动窗口算法。而对分布式系统来说,无论是服务容错中对服务响应结果的统计,还是流量控制中对服务请求数量的统计,也都经常要用到滑动窗口算法。
关于这个算法的运作过程,现在你可以充分发挥下想象力,在脑海中构造这样一个场景:在不断向前流淌的时间轴上,漂浮着一个固定大小的窗口,窗口与时间一起平滑地向前滚动。在任何时刻,我们静态地通过窗口内观察到的信息,都等价于一段长度与窗口大小相等、动态流动中的时间片段的信息。由于窗口观察的目标都是时间轴,所以它就被称为形象地称为”滑动时间窗模式”。
我再举个更具体的例子,假如我们准备观察的时间片段为 10 秒,并以 1 秒作为统计精度的话,那可以设定一个长度为 10 的数组(实际设计中通常是以双头队列来实现的,这里简化一下)和一个每秒触发 1 次的定时器。
现在,假设我们准备通过统计结果进行限流和容错,并定下限流阈值是最近 10 秒内收到的外部请求不要超过 500 个,服务熔断的阈值是最近 10 秒内的故障率不超过 50%,那么在每个数组元素中(下图中称为 Buckets),就应该存储请求的总数(实际是通过明细相加得到的)和其中成功、失败、超时、拒绝的明细数,具体如下图所示:

图片来自 Hystrix 使用文档
补充:这里虽然引用了 Hystrix 文档的图片,但 Hystrix 实际上是基于 RxJava 实现的,RxJava 的响应式编程思路与我下面描述的步骤差异比较大。我的本意并不是去讨论某一款流量治理工具的具体实现细节,因此这里你可以将以下描述的步骤作为原理来理解。
这样,当频率固定为每秒 1 次的定时器被唤醒时,它应该完成以下几项工作,这也就是滑动时间窗的工作过程:
- 将数组最后一位的元素丢弃掉,并把所有元素都后移一位,然后在数组第一个插入一个新的空元素。这个步骤即为”滑动窗口”。
- 将计数器中所有统计信息写入到第一位的空元素中。
- 对数组中所有元素进行统计,并复位清空计数器数据供下一个统计周期使用。
所以简而言之,滑动时间窗口模式的限流完全解决了流量计数器的缺陷,它可以保证在任意时间片段内,只需经过简单的调用计数比较,就能控制住请求次数一定不会超过限流的阈值,在单机限流或者分布式服务单点网关中的限流中很常用。
不过,这种限流模式也有一些缺点, 它通常只适用于否决式限流 ,对于超过阈值的流量就必须强制失败或降级,很难进行阻塞等待处理,也就很难在细粒度上对流量曲线进行整形,起不到削峰填谷的作用。而接下来我要介绍的这两种限流模式,就适用于阻塞式限流的处理策略。
我们先来看看漏桶模式。
漏桶模式
在计算机网络中,专门有一个术语” 流量整形 “(Traffic Shaping),用来描述如何限制网络设备的流量突变,使得网络报文以比较均匀的速度向外发送。流量整形通常都需要用到缓冲区来实现,当报文的发送速度过快时,首先在缓冲区中暂存,然后在控制算法的调节下,均匀地发送这些被缓冲的报文。
可以发现这里我提到了控制算法,常用的控制算法有 漏桶算法 (Leaky Bucket Algorithm)和 令牌桶算法 (Token Bucket Algorithm)两种,这两种算法的思路截然相反,但达到的效果又是相似的。
所谓漏桶,可以理解为就是你在小学做应用题时,一定遇到过的那个奇怪的水池:”一个水池,每秒以 X 升速度注水,同时又以 Y 升速度出水,问水池啥时候装满”。
那么针对限流模式的话,你可以把”请求”想像成是”水”,水来了都先放进池子里,水池同时又以额定的速度出水,让请求进入系统中。这样,如果一段时间内注水过快的话,水池还能充当缓冲区,让出水口的速度不至于过快。
不过,由于请求总是有超时时间的,所以缓冲区的大小也必须是有限度的,当注水速度持续超过出水速度一段时间以后,水池终究会被灌满。 此时,从网络的流量整形的角度看,就体现为部分数据包被丢弃;而从信息系统的角度看,就体现为有部分请求会遭遇失败和降级。
另外漏桶在代码实现上也非常简单,它其实就是一个以请求对象作为元素的先入先出队列(FIFO Queue),队列长度就相当于漏桶的大小,当队列已满时就拒绝新的请求进入。漏桶实现起来很容易,比较困难的地方只在于如何确定漏桶的两个参数:桶的大小和水的流出速率。
首先是桶的大小。如果桶设置得太大,那服务依然可能遭遇流量过大的冲击,不能完全发挥限流的作用;如果设置得太小,那很可能就会误杀掉一部分正常的请求,这种情况与流量计数器模式中举过的例子是一样的。
而流出速率在漏桶算法中一般是个固定值,这对于开篇我提到的那个场景应用题中,固定拓扑结构的服务是很合适的;但同时你也应该明白,那是经过最大限度简化的场景,现实世界里系统的处理速度,往往会受到其内部拓扑结构变化和动态伸缩的影响。所以,能够支持变动请求处理速率的令牌桶算法,可能往往会是更受我们青睐的选择。
令牌桶模式
如果说漏桶是小学应用题中的奇怪水池,那令牌桶就是你去银行办事时摆在门口的那台排队取号机。它与漏桶一样都是基于缓冲区的限流算法,只是方向刚好相反: 漏桶是从水池里往系统出水,令牌桶则是系统往排队机中放入令牌。
令牌桶模式具体是如何实现的呢?我来举个例子。
假设我们要限制系统在 X 秒内的最大请求次数不超过 Y,那我们可以每间隔 X/Y 时间,就往桶中放一个令牌,当有请求进来时,首先要从桶中取得一个准入的令牌,然后才能进入系统处理。任何时候,一旦请求进入桶中发现没有令牌可取了,就应该马上失败或进入服务降级逻辑。
与漏桶类似,令牌桶同样有最大容量,这意味着当系统比较空闲的时候,桶中的令牌累积到一定程度就不再无限增加,而预存在桶中的令牌便是请求最大缓冲的余量。
这里可能说得有些抽象,你可以转化为以下步骤来指导程序编码:
- 让系统以一个由限流目标决定的速率向桶中注入令牌,比如要控制系统的访问不超过 100 次,速率即设定为 1/100=10 毫秒。
- 桶中最多可以存放 N 个令牌,N 的具体数量是由超时时间和服务处理能力共同决定的。如果桶已满,第 N+1 个进入的令牌就会被丢弃掉。
- 请求到时会先从桶中取走 1 个令牌,如果桶已空就进入降级逻辑。
总体来说,令牌桶模式的实现看似可能比较复杂,每间隔固定时间,我们就要把新的令牌放到桶中,但其实我们并不需要真的用一个专用线程或者定时器来做这件事情,只要在令牌中增加一个时间戳记录,每次获取令牌前,比较一下时间戳与当前时间,就可以轻易计算出这段时间需要放多少令牌进去,然后一次性放完全部令牌即可,所以真正编码时并不会显得很复杂。
分布式限流
那么,在理解了实践可用的几种限流模式之后,我们接着再向实际的信息系统前进一步,一起来讨论下分布式系统中的限流问题。
此前,我们讨论的种种限流算法和模式全部是针对整个系统的限流,总是有意无意地假设或默认系统只提供一种业务操作,或者所有业务操作的消耗都是等价的,并不涉及不同业务请求进入系统的服务集群后,分别会调用哪些服务、每个服务节点处理能力有何差别等问题。
另外,这些限流算法直接使用在单体架构的集群上确实是完全可行的,但到了微服务架构下,它们就最多只能应用于集群最入口处的网关上,对整个服务集群进行流量控制,而无法细粒度地管理流量在内部微服务节点中的流转情况。
所以,我们把前面介绍的限流模式都统称为单机限流,把能够精细控制分布式集群中每个服务消耗量的限流算法称为分布式限流。
你可能要问,这两种限流算法在实现上的核心差别是什么呢?
答案是,要看二者是 如何管理限流的统计指标的。
单机限流很好办,指标都是存储在服务的内存当中;而分布式限流的目的是要让各个服务节点的协同限流。无论是将限流功能封装为专门的远程服务,还是在系统采用的分布式框架中有专门的限流支持,都需要把每个服务节点的内存中的统计数据给开放出来,让全局的限流服务可以访问到才行。
一种常见的简单分布式限流方法,是将所有服务的统计结果都存入集中式缓存 (如 Redis)中,以实现在集群内的共享,并通过分布式锁、信号量等机制,解决这些数据在读写访问时的并发控制问题。
那么由此我们也能得出一个结论,在可以共享统计数据的前提下,原本用于单机的限流模式,理论上也是可以应用于分布式环境中的,可是它的代价也显而易见:每次服务调用都必须要额外增加一次网络开销,所以这种方法的效率肯定是不高的,当流量压力大的时候,限流本身反倒会显著降低系统的处理能力。
这也就是说,只要集中式存储统计信息,就不可避免地会产生网络开销。因此为了缓解这里产生的性能损耗,一种可以考虑的办法是 在令牌桶限流模式的基础上,进行”货币化改造”改造。 即不把令牌看作是只有准入和不准入的”通行证”,而把它看作是数值形式的”货币额度”。
具体是什么意思呢?也就是当请求进入集群时,首先在 API 网关处领取到一定数额的”货币”,为了体现不同等级用户重要性的差别,他们的额度可以有所差异,比如让 VIP 用户的额度更高甚至是无限的。
这里我们将用户 A 的额度表示为 QuanityA。由于任何一个服务在响应请求时,都需要消耗集群中一定量的处理资源,所以在访问每个服务时都要求消耗一定量的”货币”。
假设服务 X 要消耗的额度表示为 CostX,那当用户 A 访问了 N 个服务以后,他剩余的额度 LimitN 就会表示为:
LimitN = QuanityA - ∑NCostX
此时,我们可以把剩余额度 LimitN 作为内部限流的指标,规定在任何时候,只要剩余额度 LimitN 小于等于 0 时,就不再允许访问其他服务了。另外,这时还必须先发生一次网络请求,重新向令牌桶申请一次额度,成功后才能继续访问,不成功则进入降级逻辑。除此之外的任何时刻,即 LimitN 不为 0 时,都无需额外的网络访问,因为计算 LimitN 是完全可以在本地完成的。
这种基于额度的限流方案,对限流的精确度会有一定的影响,比如可能存在业务操作已经进行了一部分服务调用,却无法从令牌桶中再获取到新额度,因”资金链断裂”而导致业务操作失败的情况。这种失败的代价是比较高昂的,它白白浪费了部分已经完成了的服务资源,但总体来说,它仍然是一种在并发性能和限流效果上,都相对折衷可行的分布式限流方案。
小结
这节课,我带你学习了限流的目标与指标这两项概念性的内容,现在你可以根据系统的服务和流量特征,来事先做好系统开发设计中针对流量的规划问题了。
另外,我还带你重点学习了单机限流的流量计数器、滑动时间窗、漏桶和令牌桶这四种实现模式,也了解了如何将单机限流升级为分布式限流的实现方案。你要注意的地方是,对于分布式系统容错的设计,是必须要有且无法妥协的措施。但限流与容错不一样,做分布式限流从不追求”越彻底越好”,我们往往需要权衡方案的代价与收益。
39 | 如何构建零信任网络安全?
在学完 第 4 讲 的课程之后,现在我们知道了微服务的核心技术特征之一是 分散治理 (Decentralized Governance),这表明了微服务并不追求统一的技术平台,而是提倡让团队有自由选择的权利,不受制于语言和技术框架。
在开发阶段构建服务时,分散治理打破了由技术栈带来的约束,它带来的好处是不言自明的。但在运维阶段部署服务时,尤其是在考量起安全问题时,由 Java、Golang、Python、Node.js 等多种语言和框架共同组成的微服务系统,出现安全漏洞的概率肯定要比只采用其中某种语言、某种框架所构建的单体系统更高。
于是,为了避免由于单个服务节点出现漏洞被攻击者突破,进而导致整个系统和内网都遭到入侵,我们就必须打破一些传统的安全观念,以此来构筑更加可靠的服务间通讯机制。
基于边界的安全模型
长期以来,主流的网络安全观念都比较提倡根据某类与宿主机相关的特征,比如机器所处的位置,或者机器的 IP 地址、子网等等,把网络划分为不同的区域,不同的区域对应不同的风险级别和允许访问的网络资源权限,把安全防护措施集中部署在各个区域的边界之上,重点关注跨区域的网络流量。
现在我们所熟知的 VPN、DMZ、防火墙、内网、外网等概念,可以说都是因此而生的,这种安全模型今天也被叫做是 基于边界的安全模型 (Perimeter-Based Security Model,简称”边界安全”)。
边界安全是完全合情合理的做法,在”安全架构”这个小章节中,我就强调过 安全不可能是绝对的 ,我们必须在可用性和安全性之间做好权衡和取舍。不然我们想想,把一台”服务器”的网线拔掉、电源关掉,不让它对外提供服务,那它肯定是最安全的。
另外,边界安全着重检查的是经过网络区域边界的流量,而对可信任区域(内网)内部机器之间的流量,会给予直接信任、或者至少是较为宽松的处理策略,这样就减小了安全设施对整个应用系统复杂度的影响,以及网络传输性能的额外损耗,所以它当然是很合理的。
可是,今天单纯的边界安全,已经不能满足大规模微服务系统技术异构和节点膨胀的发展需要了。
这是因为 边界安全的核心问题在于 ,边界上的防御措施即使自身能做到永远滴水不漏、牢不可破,也很难保证内网中它所尽力保护的某一台服务器不会成为”猪队友”,一旦”可信的”网络区域中的某台服务器被攻陷,那边界安全措施就成了马其诺防线,攻击者很快就能以一台机器为跳板,侵入到整个内网。
实际上,这是边界安全的基因所决定的固有缺陷,从边界安全被提出的第一天起,这就已经是可以预料到的问题了。不过在微服务时代,我们已经转变了开发观念,承认服务了总是会出错的,那么现在我们也必须转变安全观念,承认一定会有被攻陷的服务。
为此,我们就需要寻找到与之匹配的新的网络安全模型。
零信任安全模型
2010 年, Forrester Research 的首席分析师约翰 · 金德维格(John Kindervag)提出了零信任安全模型的概念(Zero-Trust Security Model,后面简称”零信任安全”),最初提出时它是叫”零信任架构”(Zero-Trust Architecture),这个概念在当时并没有引发太大的关注,但随着微服务架构的日渐兴盛,越来越多的开发和运维人员注意到零信任安全模型与微服务所追求的安全目标是高度吻合的。
零信任安全的中心思想是 不应当以某种固有特征来自动信任任何流量 ,除非明确得到了能代表请求来源(不一定是人,更可能是另一台服务)的身份凭证,否则一律不会有默认的信任关系。
在 2019 年,Google 发表了一篇在安全与研发领域里都备受关注的论文《 BeyondProd: A New Approach to Cloud-Native Security 》(BeyondCorp 和 BeyondProd 是谷歌最新一代安全框架的名字),其中详细列举了传统的基于边界的网络安全模型,与云原生时代下基于零信任网络的安全模型之间的差异,并描述了要完成边界安全模型到零信任安全模型的迁移所要实现的具体需求点,这里我把它翻译、整理了出来,你可以参考下:
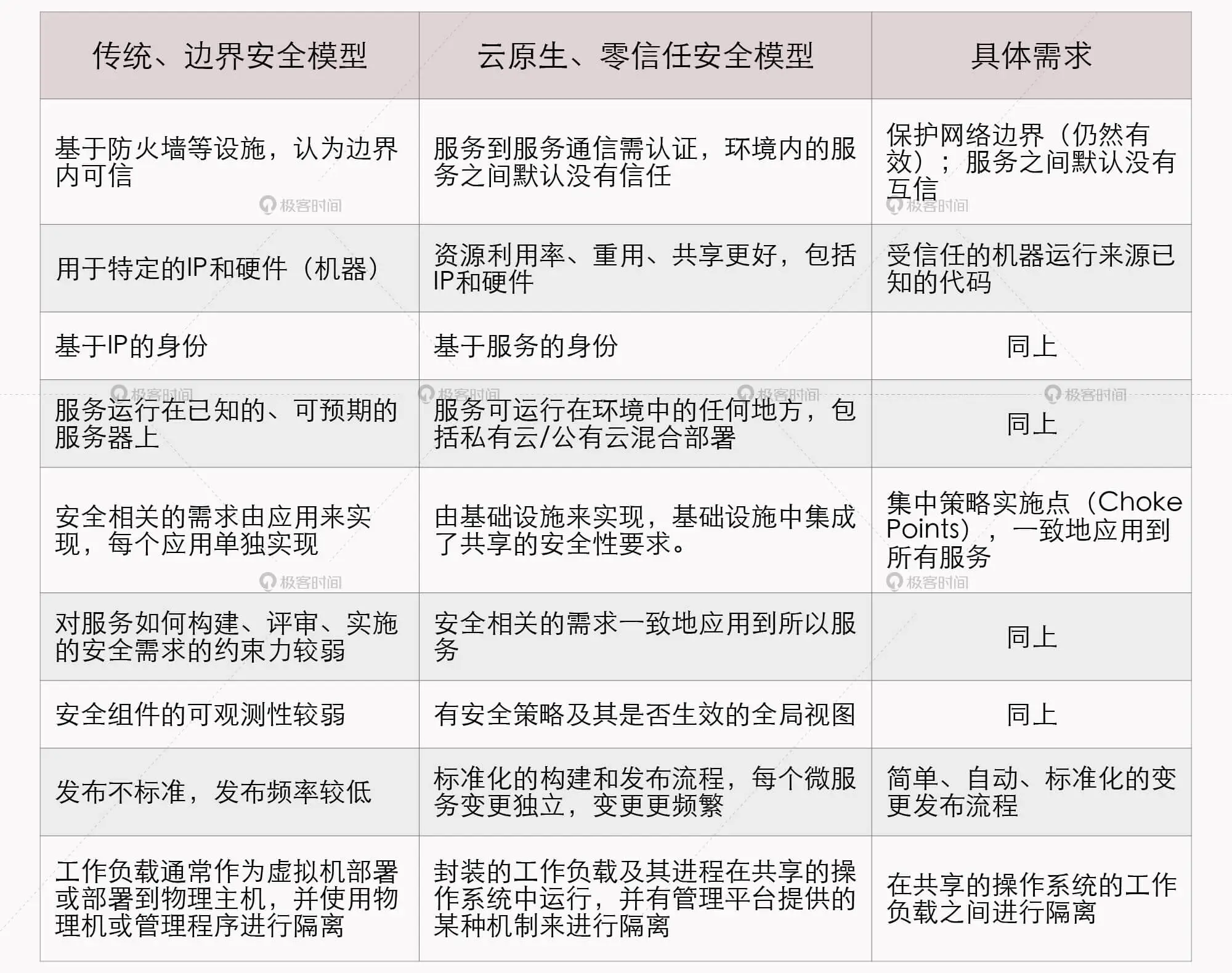
这个表格已经系统地阐述了零信任安全在微服务、云原生环境中的具体落地过程了,后续的整篇论文(除了介绍 Google 自己的实现框架外)就是以此为主线来展开论述的,但是这个表格还是过于简单,论文原文也写得比较分散晦涩,所以这里我就根据自己的理解,给你展开介绍一下其中的主要观点,以此让你进一步理解零信任安全的含义。
零信任网络不等同于放弃在边界上的保护设施
虽然像防火墙这样的位于网络边界的设施,是属于边界安全而不是零信任安全的概念,但它仍然是一种提升安全性的有效且必要的做法。在微服务集群的前端部署防火墙,把内部服务节点间的流量与来自互联网的流量隔离开,这种做法无论何时都是值得提倡的,因为这样至少能够让内部服务避开来自互联网未经授权流量的饱和攻击,比如最典型的 DDoS 拒绝服务攻击 。
身份只来源于服务
我们知道,传统应用一般是部署在特定的服务器上的,这些机器的 IP、MAC 地址很少会发生变化,此时系统的拓扑状态是相对静态的。基于这个前提,安全策略才会使用 IP 地址、主机名等作为身份标识符(Identifiers),无条件信任具有特性身份表示的服务。
而如今的微服务系统,尤其是云原生环境中的微服务系统,其虚拟化基础设施已经得到了大范围的应用,这就会导致服务所部署的 IP 地址、服务实例的数量随时都可能发生变化。因此,身份只能来源于服务本身所能够出示的身份凭证(通常是数字证书),而不再是服务所在的 IP 地址、主机名或者其他特征。
服务之间也没有固有的信任关系
这点决定了只有已知的、明确授权的调用者才能访问服务,从而阻止攻击者通过某个服务节点中的代码漏洞来越权调用到其他服务。
另外,如果某个服务节点被成功入侵,这个原则也能阻止攻击者扩大其入侵范围。这个其实比较类似于微服务设计模式中,使用断路器、舱壁隔离实现容错来避免雪崩效应,在安全方面,我们也应当采用这种”互不信任”的模式来隔离入侵危害的影响范围。
集中、共享的安全策略实施点
这点与微服务的”分散治理”刚好相反,微服务提倡每个服务独立地负责自身所有的功能性与非功能性需求。而 Google 这个观点相当于为分散治理原则做了一个补充:分散治理,但涉及安全的非功能性需求(如身份管理、安全传输层、数据安全层)最好除外。
一方面,要写出高度安全的代码非常不容易,为此付出的精力甚至可能远高于业务逻辑本身。如果你有兴趣阅读 基于 Spring Cloud 的 Fenix’s Bookstore 的源码 ,很容易就会发现在 Security 工程中的代码量是该项目中,所有微服务中最多的。
更重要的是另一方面,也就是如果让服务各自处理安全问题,很容易会出现实现不一致、或者出现漏洞时要反复修改多处地方的情况,而且还有一些安全问题,如果不立足于全局是很难彻底解决的(在下节课面向具体操作实践的”服务安全”中我还会详细讲述)。
所以,Google 明确提出应该有集中式的”安全策略实施点”(原文中称为 Choke Points),安全需求应该从微服务的应用代码下沉至云原生的基础设施里,这也就契合了论文的标题”Cloud-Native Security”。
受信的机器运行来源已知的代码
这条原则就限制了服务只能使用认证过的代码和配置,并且只能运行在认证过的环境中。
分布式软件系统除了促使软件架构发生了重大变化之外,对软件的发布流程也有很大的改变,使其严重依赖 持续集成与持续部署 (Continuous Integration / Continuous Delivery,CI/CD)。从开发人员编写代码,到自动化测试,到自动集成,再到漏洞扫描,最后发布上线,这整套 CI/CD 流程被称作”软件供应链”(Software Supply Chain)。
可是安全问题并不仅仅局限于软件运行阶段。我举个例子,之前造成过很大影响的 XCodeGhost 风波 ,就是针对软件供应链的攻击事件,它是在编译阶段把恶意代码嵌入到软件当中,只要安装了此软件的用户就可能触发恶意代码。
因此也是为了避免这样的事件再发生,零信任安全针对软件供应链的每一步,都加入了安全控制策略。
自动化、标准化的变更管理
这点也是提倡要通过基础设施,而不是应用代码去实现安全功能的另一个重要理由。如果将安全放在应用上,由于应用本身的分散治理,这决定了安全也必然是难以统一和标准化的,而做不到标准化就意味着做不到自动化。
相反,一套独立于应用的安全基础设施,就可以让运维人员轻松地了解基础设施变更对安全性的影响,并且可以在几乎不影响生产环境的情况下,发布安全补丁程序。
强隔离性的工作负载
“工作负载”的概念贯穿了 Google 内部的 Borg 系统与后来的 Kubernetes 系统,它是指在虚拟化技术支持下,运行的一组能够协同提供服务的镜像。下个模块我介绍云原生基础设施的时候,会详细介绍容器化,这里我先给你说明一个要点,就是容器化仅仅是虚拟化的一个子集。
实际上,容器比起传统虚拟机的隔离能力是有所降低的,这种设计对性能非常有利,却对安全相对不利,因此在强调安全性的应用里,会有专门关注强隔离性的容器运行工具出现。
Google 的零信任安全实践
Google 认为,零信任安全模型的最终目标是实现整个基础设施之上的自动化安全控制,服务所需的安全能力可以与服务自身一起,以相同方式自动进行伸缩扩展。
对于程序来说,做到安全是日常,风险是例外(Secure by Default and Insecure by Exception);对于人类来说,做到袖手旁观是日常,主动干预是例外(Human Actions Should Be by Exception, Not Routine)。
这的确是很美好的愿景,只是这种”喊口号”式的目标,在软件发展史上也提出过很多次,却一直难以真正达成,其中的原因我在开篇其实就提到过, 安全不可能是绝对的,而是有成本的。
那么你其实也能很明显地发现,之所以在今天这节课,我们才真正严肃地讨论零信任网络模型,并不是因为它本身有多么巧妙、有什么此前没有想到的好办法,而是因为它受制于前面我提到的边界安全模型的”合理之处”,即”安全设施对整个应用系统复杂度的影响,以及网络传输性能的额外损耗”。
那到底零信任安全要实现这个目标的代价是什么呢?会有多大? 这里我根据 Google 论文的观点来回答下这个问题:为了保护服务集群内的代码与基础设施,Google 设计了一系列的内部工具,才最终得以实现前面所说的那些安全原则:
- 为了在网络边界上保护内部服务免受 DDoS 攻击 ,设计了名为 Google Front End(名字意为”最终用户访问请求的终点”)的边缘代理,负责保证此后所有流量都在 TLS 之上传输,并自动将流量路由到适合的可用区域之中。
- 为了强制身份只来源于服务 ,设计了名为 Application Layer Transport Security(应用层传输安全)的服务认证机制,这是一个用于双向认证和传输加密的系统,它可以自动把服务与它的身份标识符绑定,使得所有服务间流量都不必再使用服务名称、主机 IP 来判断对方的身份。
- 为了确保服务间不再有默认的信任关系 ,设计了 Service Access Policy(服务访问策略),来管理一个服务向另一个服务发起请求时需要提供的认证、鉴权和审计策略,并支持全局视角的访问控制与分析,以达成”集中、共享的安全策略实施点”这条原则。
- 为了实现仅以受信的机器运行来源已知的代码 ,设计了名为 Binary Authorization(二进制授权)的部署时检查机制,确保在软件供应链的每一个阶段,都符合内部安全检查策略,并对此进行授权与鉴权。同时谷歌设计了名为 Host Integrity(宿主机完整性)的机器安全启动程序,在创建宿主机时,自动验证包括 BIOS、BMC、Bootloader 和操作系统内核的数字签名。
- 为了工作负载能够具有强隔离性 ,设计了名为 gVisor 的轻量级虚拟化方案。这个方案与此前由 Intel 发起的 Kata Containers 的思路异曲同工,目的都是解决容器共享操作系统内核而导致隔离性不足的安全缺陷,它们的做法也都是为每个容器提供了一个独立的虚拟 Linux 内核。比如,gVisor 是用 Golang 实现了一个名为 Sentry 的、能够提供传统操作系统内核能力的进程。严格来说,无论是 gVisor 还是 Kata Containers,尽管都披着容器运行时的外衣,但它们在本质上都是轻量级虚拟机。
到这里,作为一名普通的软件开发者,你在看完 Google 关于零信任安全的论文,或者学习完我这些简要的转述,了解到即使是 Google 也必须要花费如此庞大的精力,才能做到零信任安全,那你最有可能的感受,大概不是对零信任安全心生向往,而是准备对它挥手告别了。
其实哪怕不需要开发、不需要购买,免费把前面 Google 开发的安全组件赠送给我们,大多数的开发团队恐怕也没有足够的运维能力。
小结
在微服务时代以前,传统的软件系统与研发模式的确是很难承受零信任安全模型的代价的,只有到了云原生时代,虚拟化的基础设施长足发展,能将复杂性隐藏于基础设施之内,开发者不需要为了达成每一条安全原则,而专门开发或引入可感知的安全设施;只有容器与虚拟化网络的性能足够高,在可以弥补安全隔离与安全通讯的额外损耗的前提下,零信任网络的安全模型才有它生根发芽的土壤。
另外,零信任安全引入了比边界安全更细致、更复杂的安全措施的同时,也强调自动与透明的重要性。这既要保证系统各个微服务之间能安全通讯,同时也不削弱微服务架构本身的设计原则,比如集中式的安全并不抵触于分散治理原则,安全机制并不影响服务的自动伸缩和有效的封装,等等。
总而言之,只有零信任安全的成本在开发与运维上都是可接受的,它才不会变成仅仅具备理论可行性的”大饼”,不会给软件带来额外的负担。
当然,如何构建零信任网络安全是一个非常大而且比较前沿的话题,在下一节课,我会从实践的角度出发,更具体、更量化地给你展示零信任安全模型的价值与权衡。
40 | 如何实现零信任网络下安全的服务访问?
在上节课”零信任网络安全”当中,我们探讨了与微服务运作特点相适应的零信任安全模型。今天这节课,我们会从实践和编码的角度出发,一起来了解在前微服务时代( 以 Spring Cloud 为例 )和云原生时代( 以 Kubernetes with Istio 为例 ),零信任网络分别是如何实现安全传输、认证和授权的。
这里我要说明的是,由于这节课是面向实践的,必然会涉及到具体代码,为了便于讲解,在课程中我只贴出了少量的核心代码片段,所以我建议你在开始学习这节课之前,先去浏览一下这两个样例工程的代码,以便获得更好的学习效果。
建立信任
首先我们要知道,零信任网络里不存在默认的信任关系,一切服务调用、资源访问成功与否,都需要以调用者与提供者间已建立的信任关系为前提。
之前我们在 第 23 讲 也讨论过,真实世界里,能够达成信任的基本途径不外乎基于共同私密信息的信任和基于权威公证人的信任两种;而在网络世界里,因为客户端和服务端之间一般没有什么共同私密信息,所以真正能采用的就只能是基于权威公证人的信任,它有个标准的名字: 公开密钥基础设施 (Public Key Infrastructure,PKI)。
这里你可以先记住一个要点,PKI 是构建 传输安全层 (Transport Layer Security,TLS)的必要基础。
在任何网络设施都不可信任的假设前提下,无论是 DNS 服务器、代理服务器、负载均衡器还是路由器,传输路径上的每一个节点都有可能监听或者篡改通讯双方传输的信息。那么要保证通讯过程不受到中间人攻击的威胁, 唯一具备可行性的方案是启用 TLS 对传输通道本身进行加密,让发送者发出的内容只有接受者可以解密。
建立 TLS 传输,说起来好像并不复杂,只要在部署服务器时预置好 CA 根证书 ,以后用该 CA 为部署的服务签发 TLS 证书就行了。
但落到实际操作上,这个事情就属于典型的”必须集中在基础设施中自动进行的安全策略实施点”,毕竟面对数量庞大且能够自动扩缩的服务节点,依赖运维人员手工去部署和轮换根证书,肯定是很难持续做好的。
而除了随服务节点动态扩缩而来的运维压力外,微服务中 TLS 认证的频次 也很明显地高于传统的应用。比起公众互联网中主流单向的 TLS 认证,在零信任网络中,往往要启用 双向 TLS 认证 (Mutual TLS Authentication,常简写为 mTLS),也就是不仅要确认服务端的身份,还需要确认调用者的身份。
- 单向 TLS 认证 :只需要服务端提供证书,客户端通过服务端证书验证服务器的身份,但服务器并不验证客户端的身份。 单向 TLS 用于公开的服务 ,即任何客户端都被允许连接到服务进行访问,它保护的重点是客户端免遭冒牌服务器的欺骗。
- 双向 TLS 认证 :客户端、服务端双方都要提供证书,双方各自通过对方提供的证书来验证对方的身份。 双向 TLS 用于私密的服务 ,即服务只允许特定身份的客户端访问,它除了保护客户端不连接到冒牌服务器外,也保护服务端不遭到非法用户的越权访问。
另外,对于前面提到的围绕 TLS 而展开的密钥生成、证书分发、 签名请求 (Certificate Signing Request,CSR)、更新轮换,等等,这其实是一套操作起来非常繁琐的流程,稍有疏忽就会产生安全漏洞。所以尽管它在理论上可行,但实践中如果没有自动化的基础设施的支持,仅靠应用程序和运维人员的努力,是很难成功实施零信任安全模型的。
那么接下来,我们就结合 Fenix’s Bookstore 的代码,聚焦于”认证”和”授权”这两个最基本的安全需求,来看看它们在微服务架构下,有或者没有基础设施支持的时候,各自都是如何实现的。
我们先来看看认证。
认证
根据认证的目标对象,我们可以把认证分为两种类型,
- 一种是以机器作为认证对象 ,即访问服务的流量来源是另外一个服务,这被叫做服务认证(Peer Authentication,直译过来是”节点认证”);
- 另一种是以人类作为认证对象 ,即访问服务的流量来自于最终用户,这被叫做请求认证(Request Authentication)。
当然,无论是哪一种认证,无论有没有基础设施的支持,它们都要有可行的方案来确定服务调用者的身份,只有建立起信任关系才能调用服务。
好,下面我们来了解下服务认证的相关实现机制。
服务认证
Istio 版本的 Fenix’s Bookstore 采用了双向 TLS 认证,作为服务调用双方的身份认证手段。得益于 Istio 提供的基础设施的支持,我们不需要 Google Front End、Application Layer Transport Security 这些安全组件,也不需要部署 PKI 和 CA,甚至无需改动任何代码,就可以启用 mTLS 认证。
不过,Istio 毕竟是新生事物,如果你要在自己的生产系统中准备启用 mTLS,还是要先想一下,是否整个服务集群的全部节点都受 Istio 管理?如果每一个服务提供者、调用者都会受到 Istio 的管理,那 mTLS 就是最理想的认证方案。你只需要参考以下简单的 PeerAuthentication CRD 配置,就可以对某个 Kubernetes 名称空间 范围内的所有流量启用 mTLS:
apiVersion: security.istio.io/v1beta1
kind: PeerAuthentication
metadata:
name: authentication-mtls
namespace: bookstore-servicemesh
spec:
mtls:
mode: STRICT不过,如果你的分布式系统还没有达到完全云原生的程度,其中还存在部分不受 Istio 管理(即未注入 Sidecar)的服务端或者客户端(这是很常见的),你也可以将 mTLS 传输声明为” 宽容模式 “(Permissive Mode)。
宽容模式的含义是 受 Istio 管理的服务,会允许同时接受纯文本和 mTLS 两种流量 。纯文本流量只用来和那些不受 Istio 管理的节点进行交互,你需要自行想办法解决纯文本流量的认证问题;而对于服务网格内部的流量,就可以使用 mTLS 认证。
这里你要知道的是,宽容模式为普通微服务向服务网格迁移提供了良好的灵活性,让运维人员能够逐个给服务进行 mTLS 升级。甚至在原本没有启用 mTLS 的服务中启用 mTLS 时,可以不中断现存已经建立的纯文本传输连接,完全不会被最终用户感知到。
这样,一旦所有服务都完成迁移,就可以把整个系统设置为严格 TLS 模式,即前面代码中的 mode: STRICT。
在 Spring Cloud 版本的 Fenix’s Bookstore 里,因为没有基础设施的支持,一切认证工作就不得不在应用层面去实现。我选择的方案是借用 OAuth 2.0 协议 的客户端模式来进行认证的,其大体思路有如下两步。
第一步,每一个要调用服务的客户端,都与认证服务器约定好一组只有自己知道的密钥(Client Secret),这个约定过程应该是由运维人员在线下自行完成,通过参数传给服务,而不是由开发人员在源码或配置文件中直接设定。我在演示工程的代码注释中,也专门强调了这点,以免你被示例代码中包含密钥的做法所误导。
这个密钥其实就是客户端的身份证明,客户端在调用服务时,会先使用该密钥向认证服务器申请到 JWT 令牌,然后通过令牌证明自己的身份,最后访问服务。
你可以看看下面给出的代码示例,它定义了五个客户端,其中四个是集群内部的微服务,均使用客户端模式,并且注明了授权范围是 SERVICE(授权范围在下面介绍授权中会用到),示例中的第一个是前端代码的微服务,它使用密码模式,授权范围是 BROWSER。
/** * 客户端列表 */ private static final List<Client> clients = Arrays.asList( new Client("bookstore_frontend", "bookstore_secret", new String[]{GrantType.PASSWORD, GrantType.REFRESH_TOKEN}, new String[]{Scope.BROWSER}), // 微服务一共有Security微服务、Account微服务、Warehouse微服务、Payment微服务四个客户端 // 如果正式使用,这部分信息应该做成可以配置的,以便快速增加微服务的类型。clientSecret也不应该出现在源码中,应由外部配置传入 new Client("account", "account_secret", new String[]{GrantType.CLIENT_CREDENTIALS}, new String[]{Scope.SERVICE}), new Client("warehouse", "warehouse_secret", new String[]{GrantType.CLIENT_CREDENTIALS}, new String[]{Scope.SERVICE}), new Client("payment", "payment_secret", new String[]{GrantType.CLIENT_CREDENTIALS}, new String[]{Scope.SERVICE}), new Client("security", "security_secret", new String[]{GrantType.CLIENT_CREDENTIALS}, new String[]{Scope.SERVICE}) );第二步 ,每一个对外提供服务的服务端,都扮演着 OAuth 2.0 中的资源服务器的角色,它们都声明为要求提供客户端模式的凭证,如以下代码所示。客户端要调用受保护的服务,就必须先出示能证明调用者身份的 JWT 令牌,否则就会遭到拒绝。这个操作本质上是授权的过程,但它在授权过程中其实已经实现了服务的身份认证。
public ClientCredentialsResourceDetails clientCredentialsResourceDetails() { return new ClientCredentialsResourceDetails(); }而且,由于每一个微服务都同时具有服务端和客户端两种身份,它们既消费其他服务,也提供服务供别人消费,所以在每个微服务中,都应该要包含以上这些代码(放在公共 infrastructure 工程里)。
另外,Spring Security 提供的过滤器会自动拦截请求,驱动认证、授权检查的执行,以及申请和验证 JWT 令牌等操作,无论是在开发期对程序员,还是在运行期对用户,都能做到相对透明。
不过尽管如此,这样的做法仍然是一种应用层面的、不加密传输的解决方案。为什么呢?
前面我提到,在零信任网络中面对可能的中间人攻击,TLS 是唯一可行的办法。其实我的言下之意是,即使应用层的认证能在一定程度上,保护服务不被身份不明的客户端越权调用,但是如果内容在传输途中被监听、篡改,或者被攻击者拿到了 JWT 令牌之后,冒认调用者的身份去调用其他服务,应用层的认证就无法防御了。
所以简而言之,这种方案并不适用于零信任安全模型,只有在默认内网节点间具备信任关系的边界安全模型上,才能良好工作。
好,我们再来说说请求认证。
请求认证
对于来自最终用户的请求认证,Istio 版本的 Fenix’s Bookstore 仍然能做到单纯依靠基础设施解决问题,整个认证过程不需要应用程序参与(JWT 令牌还是在应用中生成的,因为 Fenix’s Bookstore 并没有使用独立的用户认证服务器,只有应用本身才拥有用户信息)。
当来自最终用户的请求进入服务网格时,Istio 会自动根据配置中的 JWKS (JSON Web Key Set)来验证令牌的合法性,如果令牌没有被篡改过且在有效期内,就信任 Payload 中的用户身份,并从令牌的 Iss 字段中获得 Principal。关于 Iss、Principals 等概念,我在安全架构这个小章节中都介绍过了,你可以去回顾复习一下第 23 到 30 讲。而 JWKS 倒是之前从没有提到过,它代表了一个 密钥仓库 。
我们知道在分布式系统中,JWT 要采用非对称的签名算法(RSA SHA256、ECDSA SHA256 等,默认的 HMAC SHA256 属于对称加密),认证服务器使用私钥对 Payload 进行签名,资源服务器使用公钥对签名进行验证。
而常与 JWT 配合使用的 JWK(JSON Web Key)就是一种存储密钥的纯文本格式,在功能上,它和 JKS (Java Key Storage)、 P12 (Predecessor of PKCS#12)、 PEM (Privacy Enhanced Mail)这些常见的密钥格式并没有什么本质上的差别。
所以顾名思义,JWKS 就是一组 JWK 的集合。支持 JWKS 的系统,能通过 JWT 令牌 Header 中的 KID(Key ID)自动匹配出应该使用哪个 JWK 来验证签名。
以下是 Istio 版本的 Fenix’s Bookstore 中的用户认证配置。其中,jwks 字段配的就是 JWKS 全文(实际生产中并不推荐这样做,应该使用 jwkUri 来配置一个 JWKS 地址,以方便密钥轮换),根据这里配置的密钥信息,Istio 就能够验证请求中附带的 JWT 是否合法。
apiVersion: security.istio.io/v1beta1
kind: RequestAuthentication
metadata:
name: authentication-jwt-token
namespace: bookstore-servicemesh
spec:
jwtRules:
- issuer: "icyfenix@gmail.com"
# Envoy默认只认"Bearer"作为JWT前缀,之前其他地方用的都是小写,这里专门兼容一下
fromHeaders:
- name: Authorization
prefix: "bearer "
# 在rsa-key目录下放了用来生成这个JWKS的证书,最初是用java keytool生成的jks格式,一般转jwks都是用pkcs12或者pem格式,为方便使用也一起附带了
jwks: |
{
"keys": [
{
"e": "AQAB",
"kid": "bookstore-jwt-kid",
"kty": "RSA",
"n": "i-htQPOTvNMccJjOkCAzd3YlqBElURzkaeRLDoJYskyU59JdGO-p_q4JEH0DZOM2BbonGI4lIHFkiZLO4IBBZ5j2P7U6QYURt6-AyjS6RGw9v_wFdIRlyBI9D3EO7u8rCA4RktBLPavfEc5BwYX2Vb9wX6N63tV48cP1CoGU0GtIq9HTqbEQs5KVmme5n4XOuzxQ6B2AGaPBJgdq_K0ZWDkXiqPz6921X3oiNYPCQ22bvFxb4yFX8ZfbxeYc-1rN7PaUsK009qOx-qRenHpWgPVfagMbNYkm0TOHNOWXqukxE-soCDI_Nc--1khWCmQ9E2B82ap7IXsVBAnBIaV9WQ"
}
]
}
forwardOriginalToken: true而 Spring Cloud 版本的 Fenix’s Bookstore 就要稍微麻烦一些,它依然是采用 JWT 令牌作为用户身份凭证的载体,认证过程依然在 Spring Security 的过滤器里中自动完成。不过因为这节课我们讨论的重点不在 Spring Security 的过滤器工作原理,所以它的详细过程就不展开了,只简单说说其主要路径:过滤器→令牌服务→令牌实现。
既然如此,Spring Security 已经做好了认证所需的绝大部分工作,那么真正要开发者去编写的代码就是令牌的具体实现,即代码中名为”RSA256PublicJWTAccessToken”的实现类。
它的作用是加载 Resource 目录下的公钥证书 public.cert(实在是怕”抄作业不改名字”的行为,我再一次强调不要将密码、密钥、证书这类敏感信息打包到程序中,示例代码只是为了演示,实际生产应该由运维人员管理密钥),验证请求中的 JWT 令牌是否合法。
@Named
public class RSA256PublicJWTAccessToken extends JWTAccessToken {
RSA256PublicJWTAccessToken(UserDetailsService userDetailsService) throws IOException {
super(userDetailsService);
Resource resource = new ClassPathResource("public.cert");
String publicKey = new String(FileCopyUtils.copyToByteArray(resource.getInputStream()));
setVerifierKey(publicKey);
}
}如果 JWT 令牌合法,Spring Security 的过滤器就会放行调用请求,并从令牌中提取出 Principals,放到自己的安全上下文中(即”SecurityContextHolder.getContext()”)。
在开发实际项目的时候,你可以根据需要自行决定 Principals 的具体形式,比如既可以像 Istio 中那样,直接从令牌中取出来,以字符串的形式原样存放,节省一些数据库或者缓存的查询开销;也可以统一做些额外的转换处理,以方便后续业务使用,比如将 Principals 转换为系统中的用户对象。
Fenix’s Bookstore 的转换操作是在 JWT 令牌的父类 JWTAccessToken 中完成的。所以可见,尽管由应用自己来做请求验证,会有一定的代码量和侵入性,但同时自由度确实也会更高一些。
这里为了方便不同版本实现之间的对比,在 Istio 版本中,我保留了 Spring Security 自动从令牌转换 Principals 为用户对象的逻辑,因此就必须在 YAML 中包含 forwardOriginalToken: true 的配置,告诉 Istio 验证完 JWT 令牌后,不要丢弃掉请求中的 Authorization Header,而是要原样转发给后面的服务处理。
授权
那么,经过认证之后,合法的调用者就有了可信任的身份,此时就不再需要区分调用者到底是机器(服务)还是人类(最终用户)了,只需要根据其身份角色来进行权限访问控制就行,即我们常说的 RBAC。
不过为了更便于理解,Fenix’s Bookstore 提供的示例代码仍然沿用此前的思路,分别针对来自”服务”和”用户”的流量来控制权限和访问范围。
举个具体例子。如果我们准备把一部分微服务看作是私有服务,限制它只接受来自集群内部其他服务的请求,把另外一部分微服务看作是公共服务,允许它可以接受来自集群外部的最终用户发出的请求;又或者,我们想要控制一部分服务只允许移动应用调用,另外一部分服务只允许浏览器调用。
那么,一种可行的方案就是 为不同的调用场景设立角色,进行授权控制 (另一种常用的方案是做 BFF 网关)。
我们还是以 Istio 和 Spring Cloud 版本的 Fenix’s Bookstore 为例。
在 Istio 版本的 Fenix’s Bookstore 中 ,通过以下文稿这里给出的配置,就限制了来自 bookstore-servicemesh 名空间的内部流量,只允许访问 accounts、products、pay 和 settlements 四个端点的 GET、POST、PUT、PATCH 方法,而对于来自 istio-system 名空间(Istio Ingress Gateway 所在的名空间)的外部流量就不作限制,直接放行。
apiVersion: security.istio.io/v1beta1 kind: AuthorizationPolicy metadata: name: authorization-peer namespace: bookstore-servicemesh spec: action: ALLOW rules: - from: - source: namespaces: ["bookstore-servicemesh"] to: - operation: paths: - /restful/accounts/* - /restful/products* - /restful/pay/* - /restful/settlements* methods: ["GET","POST","PUT","PATCH"] - from: - source: namespaces: ["istio-system"]但针对外部的请求(不来自 bookstore-servicemesh 名空间的流量),又进行了另外一层控制,如果请求中没有包含有效的登录信息,就限制不允许访问 accounts、pay 和 settlements 三个端点,如以下配置所示:
apiVersion: security.istio.io/v1beta1 kind: AuthorizationPolicy metadata: name: authorization-request namespace: bookstore-servicemesh spec: action: DENY rules: - from: - source: notRequestPrincipals: ["*"] notNamespaces: ["bookstore-servicemesh"] to: - operation: paths: - /restful/accounts/* - /restful/pay/* - /restful/settlements*由此可见,Istio 已经提供了比较完善的目标匹配工具,比如前面配置中用到的源 from、目标 to,以及没有用到的条件匹配 when,还有其他像是通配符、IP、端口、名空间、JWT 字段,等等。
当然了,要说灵活和功能强大,它肯定还是不可能跟在应用中由代码实现的授权相媲美,但对绝大多数场景来说已经够用了。在便捷性、安全性、无侵入、统一管理等方面,Istio 这种在基础设施上实现授权的方案,显然要更具优势。
而在 Spring Cloud 版本的 Fenix’s Bookstore 中 ,授权控制自然还是使用 Spring Security、通过应用程序代码来实现的。
常见的 Spring Security 授权方法有两种。
第一种是使用它的 ExpressionUrlAuthorizationConfigurer,也就是类似下面编码所示的写法来进行集中配置。这个写法跟前面在 Istio 的 AuthorizationPolicy CRD 中的写法,在体验上是比较相似的,也是几乎所有 Spring Security 资料中都会介绍的最主流的方式,比较适合对批量端点进行控制,不过在 Fenix’s Bookstore 的示例代码中并没有采用(没有什么特别理由,就是我的个人习惯而已)。
http.authorizeRequests() .antMatchers("/restful/accounts/**").hasScope(Scope.BROWSER) .antMatchers("/restful/pay/**").hasScope(Scope.SERVICE)第二种写法就是下面的示例代码中采用的方法了。它是通过 Spring 的 全局方法级安全 (Global Method Security)以及 JSR 250 的 @RolesAllowed 注解来做授权控制。
这种写法对代码的侵入性更强,需要以注解的形式分散写到每个服务甚至是每个方法中,但好处是能以更方便的形式做出更加精细的控制效果。比如,要控制服务中某个方法,只允许来自服务或者来自浏览器的调用,那直接在该方法上标注 @PreAuthorize 注解即可,而且它还支持 SpEL 表达式 来做条件。
表达式中用到的 SERVICE、BROWSER 代表的是授权范围,就是在声明客户端列表时传入的,具体你可以参考这节课开头声明客户端列表的代码清单。
/** * 根据用户名称获取用户详情 */ @GET @Path("/{username}") @Cacheable(key = "#username") @PreAuthorize("#oauth2.hasAnyScope('SERVICE','BROWSER')") public Account getUser(@PathParam("username") String username) { return service.findAccountByUsername(username); } /** * 创建新的用户 */ @POST @CacheEvict(key = "#user.username") @PreAuthorize("#oauth2.hasAnyScope('BROWSER')") public Response createUser(@Valid @UniqueAccount Account user) { return CommonResponse.op(() -> service.createAccount(user)); }
小结
这节课里,我们尝试以 程序代码和基础设施 两种方式,去实现功能类似的认证与授权,通过这两者的对比,探讨了在微服务架构下,应该如何把业界的安全技术标准引入并实际落地,实现零信任网络下安全的服务访问。
由此我们也得出了一个基本的结论:在以应用代码为主,去实现安全需求的微服务系统中,是很难真正落地零信任安全的,这不仅仅是由于安全需求所带来的庞大开发、管理(如密钥轮换)和建设(如 PKI、CA)的工作量,更是因为这种方式很难符合上节课所提到的零信任安全中”集中、共享的安全策略实施点””自动化、标准化的变更管理”等基本特征。
但另一方面,我们也必须看到,现在以代码去解决微服务非功能性需求的方案是很主流的,像 Spring Cloud 这些方案,在未来的很长一段时间里,都会是信息系统重点考虑的微服务框架。因此,去学习、了解如何通过代码,尽最大可能地去保证服务之间的安全通讯,仍然非常有必要。
41 | 分布式架构中的可观测到底说的是什么?
从这节课开始,我们将会花四节课的时间去学习”可观测性”方面的知识。
在以前,可观测性并不是软件设计中要重点考虑的问题,甚至很长时间里,人们也并没有把这种属性与可并发性、可用性、安全性等并列,作为系统的非功能属性之一,直到微服务与云原生时代的来临。
对于单体系统来说,可观测性可能确实是附属的边缘属性,但对于分布式系统来说,可观测性就是不可或缺的了。为什么呢?别着急,接下来我就跟你详细说道说道。
可观测性的概念
好,首先呢,我们来了解下可观测性的含义和特点。
随着分布式架构逐渐成为了架构设计的主流, 可观测性 (Observability)一词也日益被人频繁地提起。
最初,它是与 可控制性 (Controllability)一起,由匈牙利数学家鲁道夫 · 卡尔曼(Rudolf E. Kálmán)针对线性动态控制系统提出的一组对偶属性。可观测性原本的含义是”可以由系统的外部输出推断其内部状态的程度”。
在学术界,”可观测性”这个名词其实是最近几年才从控制理论中借用的舶来概念,不过实际上,计算机科学中关于可观测性的研究内容已经有了很多年的实践积累。通常,人们会把可观测性分解为三个更具体的方向进行研究,分别是: 日志收集、链路追踪和聚合度量。
这三个方向各有侧重,但又不是完全独立的,因为它们天然就有重合或者可以结合的地方。
在 2017 年的分布式追踪峰会(2017 Distributed Tracing Summit)结束后,彼得 · 波本(Peter Bourgon)撰写了总结文章《 Metrics, Tracing, and Logging 》,就系统地阐述了这三者的定义、特征,以及它们之间的关系与差异,受到了业界的广泛认可。
假如你平时只开发单体系统,从来没有接触过分布式系统的观测工作,那你可能就只熟悉日志这一项工作,对追踪和度量会相对比较陌生。
然而按照彼得 · 波本(Peter Bourgon)给出的定义来看,尽管在分布式系统中,追踪和度量的必要性和复杂程度确实比单体系统时要更高,但是在单体时代,你肯定已经接触过这三项工作了,只是并没有意识到而已。
你可能会想进一步了解这三项工作的具体含义,想知道为什么要这样划分,下面我来给你简单介绍一下它们各自的特征,你就能明白其中的原因了:
日志(Logging)
我们都知道, 日志的职责是记录离散事件,通过这些记录事后分析出程序的行为 ,比如曾经调用过什么方法、曾经操作过哪些数据,等等。通常,打印日志被认为是程序中最简单的工作之一,你在调试问题的时候,可能也经历过这样的情景”当初这里记得打点日志就好了”,可见这就是一项举手之劳的任务。
当然,输出日志的确很容易,但收集和分析日志却可能会很复杂,面对成千上万的集群节点、面对迅速滚动的事件信息、面对数以 TB 计算的文本,传输与归集都并不简单。对大多数程序员来说,分析日志也许就是最常遇见、也最有实践可行性的”大数据系统”了。
追踪(Tracing)
在单体系统时代,追踪的范畴基本只局限于 栈追踪 (Stack Tracing)。比如说,你在调试程序的时候,在 IDE 打个断点,看到的 Call Stack 视图上的内容便是跟踪;在编写代码时,处理异常调用了 Exception::printStackTrace() 方法,它输出的堆栈信息也是追踪。
而在微服务时代,追踪就不只局限于调用栈了,一个外部请求需要内部若干服务的联动响应,这时候完整的调用轨迹就会跨越多个服务,会同时包括服务间的网络传输信息与各个服务内部的调用堆栈信息。因此,分布式系统中的追踪在国内通常被称为” 全链路追踪 “(后面我就直接称”链路追踪”了),许多资料中也把它叫做是” 分布式追踪 “(Distributed Tracing)。
追踪的主要目的是排查故障 ,比如分析调用链的哪一部分、哪个方法出现错误或阻塞,输入输出是否符合预期,等等。
度量(Metrics)
度量是指对系统中某一类信息的统计聚合。比如,证券市场的每一只股票都会定期公布财务报表,通过财报上的营收、净利、毛利、资产、负载等等一系列数据,来体现过去一个财务周期中公司的经营状况,这就是一种信息聚合。
Java 天生自带有一种基本的度量,就是由虚拟机直接提供的 JMX(Java Management eXtensions)度量,像是内存大小、各分代的用量、峰值的线程数、垃圾收集的吞吐量、频率,等等,这些数据信息都可以从 JMX 中获得。
度量的主要目的是监控(Monitoring)和预警(Alert) ,比如说,当某些度量指标达到了风险阈值时就触发事件,以便自动处理或者提醒管理员介入。
那到这里,你应该也就知道为什么在单体系统中,除了接触过日志之外,其实也同样接触过其他两项工作了,因为追踪和度量本来就是我们调试和监控程序时的常用手段。
好,说完了学术界对于可观测性的定义和研究,下面我们来看看对于工业界,在云原生时代下,这三个方向都有哪些新的发展。
工业界的遥测产品
在工业界,目前针对可观测性的产品已经是一片红海,经过多年的角逐,日志、度量两个领域的胜利者算是基本尘埃落定了。
一方面,在日志领域,日志收集和分析大多被统一到了 Elastic Stack(ELK)技术栈上,如果说未来还能出现什么变化的话,也就是其中的 Logstash 能看到有被 Fluentd 取代的趋势,让 ELK 变成 EFK,但整套 Elastic Stack 技术栈的地位已经是相当稳固了。
而在度量方面,跟随着 Kubernetes 统一容器编排的步伐,Prometheus 也击败了度量领域里以 Zabbix 为代表的众多前辈,即将成为云原生时代度量监控的事实标准。虽然从市场角度来说,Prometheus 还没有达到 Kubernetes 那种”拔剑四顾,举世无敌”的程度,但是从社区活跃度上看,Prometheus 已经占有了绝对的优势,在 Google 和 CNCF 的推动下,未来前途可期。
额外知识:Kubernetes 与 Prometheus 的关系
Kubernetes 是 CNCF 第一个孵化成功的项目,Prometheus 是 CNCF 第二个孵化成功的项目。
Kubernetes 起源于 Google 的编排系统 Borg,Prometheus 起源于 Google 为 Borg 做的度量监控系统 BorgMon。
不过,追踪方面的情况与日志、度量有所不同,追踪是与具体网络协议、程序语言密切相关的。
我们在收集日志时,不必关心这段日志是由 Java 程序输出的,还是由 Golang 程序输出的,对程序来说它们就只是一段非结构化文本而已;同理,度量对程序来说,也只是一个个聚合的数据指标而已。
但链路追踪就不一样了,各个服务之间是使用 HTTP 还是 gRPC 来进行通信,会直接影响到追踪的实现,各个服务是使用 Java、Golang 还是 Node.js 来编写,也会直接影响到进程内调用栈的追踪方式。
所以,这就决定了追踪工具本身有较强的侵入性,通常是以插件式的探针来实现的;这也决定了在追踪领域很难出现一家独大的情况,通常要有多种产品来针对不同的语言和网络。
最近几年,各种链路追踪产品层出不穷,市面上主流的工具,既有像 Datadog 这样的一揽子商业方案,也有像 AWS X-Ray 和 Google Stackdriver Trace 这样的云计算厂商产品,还有像 SkyWalking、Zipkin、Jaeger 这样来自开源社区的优秀产品。
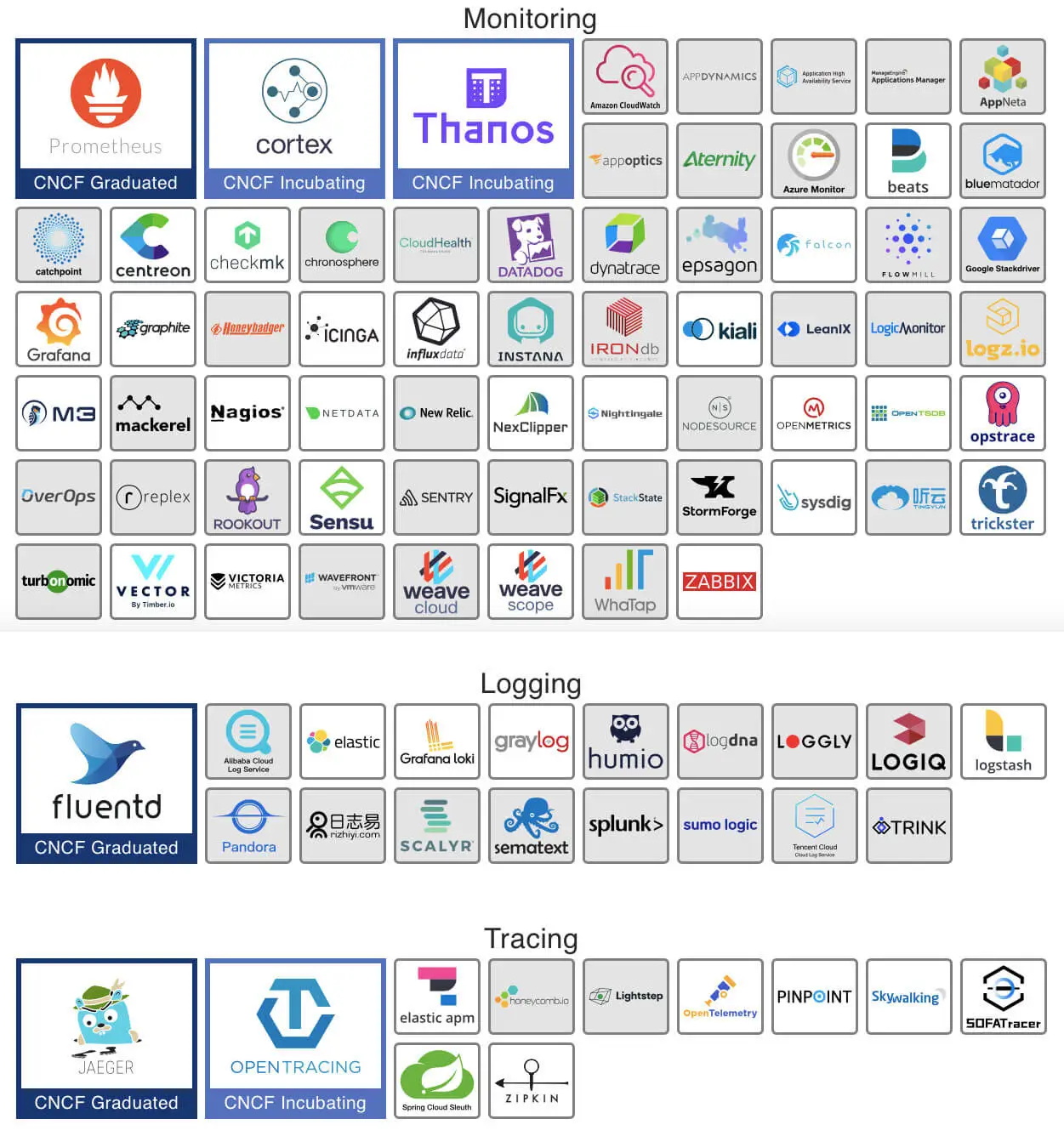
这里我给出的示意图是 CNCF Interactive Landscape 中列出的日志、追踪、度量领域的著名产品。其实这里很多不同领域的产品是跨界的,比如,ELK 可以通过 Metricbeat 来实现度量的功能;Apache SkyWalking 的探针就可以同时支持度量和追踪两方面的数据来源;由 OpenTracing 进化而来 OpenTelemetry ,更是融合了日志、追踪、度量三者所长,有望成为三者兼备的统一可观测性的解决方案。在后面关于可观测性的三节课里,我也会紧扣每个领域中最具统治性的产品,给你做一个详细的介绍。
小结
这节课,我们了解了可观测性的概念、特征与现状,并明确了在今天,可观测性一般会被分成事件日志、链路追踪和聚合度量三个主题方向进行探讨和研究。你可以记住以下几个核心要点:
- 事件日志的职责是记录离散事件,通过这些记录事后分析出程序的行为;
- 追踪的主要目的是排查故障,比如分析调用链的哪一部分、哪个方法出现错误或阻塞,输入输出是否符合预期;
- 度量是指对系统中某一类信息的统计聚合,主要目的是监控和预警,当某些度量指标达到风险阈值时就触发事件,以便自动处理或者提醒管理员介入。
另外,事件日志、链路追踪和聚合度量这三个主题也是未来三节课我们要学习的主角,到时你也可以与这节课的学习内容相互印证。
42 | 分析日志真的没那么简单
在上节课明确了可观测性的概念、特征与现状之后,我们知道了可观测性一般会被分成三种具体的表现形式,分别是日志、追踪和度量。那么这节课,我们就来讨论其中最普遍的形式:事件日志。
日志主要是用来记录系统运行期间发生过的离散事件。我想应该没有哪一个生产系统会缺少日志功能,不过我也相信,没有多少人会把日志看作是多关键的功能。它就像是阳光与空气,不可或缺但又不太被人重视。
除此之外,我想在座的很多人也都会说日志很简单,其实这是在说”打印日志”这个操作简单。打印日志的目的是为了日后能从中得到有价值的信息,而今天只要是稍微复杂点的系统,尤其是复杂的分布式系统,就很难只依靠 tail、grep、awk 来从日志中挖掘信息了,往往还要有专门的全局查询和可视化功能。
此时,从打印日志到分析查询之间,还隔着收集、缓冲、聚合、加工、索引、存储等若干个步骤,如下图所示:

而这一整个链条中,会涉及到大量需要我们注意的细节,其复杂性并不亚于任何一项技术或业务功能的实现。所以接下来,我就以这个日志的处理过程为主线,以最成熟的 Elastic Stack 技术栈为例子,给你介绍该链条每个步骤的目的与方法。
好,下面我们就先来了解下日志处理中的输出工作。
输出
要是说好的日志能像文章一样,让人读起来身心舒畅,这话肯定有夸大的成分,不过好的日志应该能做到像”流水账”一样,可以毫无遗漏地记录信息,格式统一,内容恰当。其中, “恰当”是一个难点,它要求日志不应该过多,也不应该过少。
这里的”多与少”一般不针对输出的日志行数。尽管我听说过最夸张的系统,有单节点 INFO 级别下,每天的日志都能以 TB 计算(这样的是代码有问题的),给网络与磁盘 I/O 带来了不小的压力,但我通常不会用数量来衡量日志是否恰当。
我所说的”恰当”,是指 日志中不该出现的内容不要有,而该有的不要少 。具体是什么意思呢?下面我就分别给你举几个例子。
不该出现的内容不要有
首先,我们来看看有哪些常见的”不应该有”的日志内容:
避免打印敏感信息
不用专门去提醒,我们肯定都知道不该把密码、银行账号、身份证件等这些敏感信息打到日志里,但我就见过不止一个系统的日志中,能直接找到这些信息。一旦这些敏感信息随日志流到了后续的索引、存储、归档等步骤后,清理起来就会非常麻烦。
不过,日志中应该要包含必要的非敏感信息,比如当前用户的 ID(最好是内部 ID,避免登录名或者用户名称),有些系统就直接用 MDC (Mapped Diagnostic Context)把用户 ID 自动打印在 Pattern Layout 上。
避免引用慢操作
要知道,日志中打印的信息应该是在上下文中可以直接取到的,而如果当前的上下文中根本没有这项数据,需要专门调用远程服务或者从数据库中获取,又或者要通过大量计算才能取到的话,那我们就应该先考虑下,这项信息放到日志中是不是必要且恰当的。
避免打印追踪诊断信息
即日志中不要打印方法输入参数、输出结果、方法执行时长之类的调试信息。
这个观点其实是反直觉的,不少公司甚至会提倡把这一点作为最佳实践,但是我仍然坚持把它归入反模式中。这是因为日志的职责是记录事件,而追踪诊断应该由追踪系统去处理,哪怕贵公司完全没有开发追踪诊断方面功能的打算,我也建议使用 BTrace 或者 Arthas 这类”On-The-Fly”的工具来解决。
还有,我之所以将其归为反模式,也是因为前面所说的敏感信息、慢操作等主要源头,就是这些原本想用于调试的日志。
比如,当前方法入口参数有个 User 对象,如果要输出这个对象的话,常见的做法是将它序列化成 JSON 字符串,然后打到日志里。那么这个时候,User 里面的 Password 字段、BankCard 字段就很容易被暴露出来。
再比如,当前方法的返回值是个 Map,我们在开发期的调试数据只做了三五个 Entity,然后觉得遍历一下把具体内容打到日志里面没什么问题。而到了生产期,这个 Map 里面有可能存放了成千上万个 Entity,那么这时候打印日志就相当于引用慢操作了。
避免误导他人
你可能也知道,在日志中给以后调试除错的人挖坑是十分恶劣却又常见的行为。不过我觉得大部分人并不是专门要去误导别人,很可能只是无意识地这样做了。
比如,明明已经在逻辑中妥善处理好了某个异常,只是偏习惯性地调用 printStackTrace() 方法,把堆栈打到日志中,那么一旦这个方法附近出现问题,由其他人来除错的话,就很容易会盯着这段堆栈去找线索,从而浪费大量时间。
……
该出现的内容不要少
然后,日志中不该缺少的内容也”不应该少”,这里我同样给你举几个建议应该输出到日志中的内容的例子:
处理请求时的 TraceID
当服务收到请求时,如果该请求没有附带 TraceID,就应该自动生成唯一的 TraceID 来对请求进行标记,并使用 MDC 自动输出到日志。TraceID 会贯穿整条调用链,目的是通过它把请求在分布式系统各个服务中的执行过程给串联起来。TraceID 通常也会随着请求的响应返回到客户端,如果响应内容出现了异常,用户就能通过此 ID 快速找到与问题相关的日志。
这个 TraceID 其实是链路追踪里的概念,类似的还有用于标识进程内调用状况的 SpanID,在 Java 程序中,这些都可以用 Spring Cloud Sleuth 来自动生成(下一讲我还会提到)。
另外,尽管 TraceID 在分布式追踪系统中会发挥最大的作用,但对单体系统来说,将 TraceID 记录到日志并返回给最终用户,对快速定位错误也仍然十分有价值。
系统运行过程中的关键事件
我们都知道,日志的职责就是记录事件,包括系统进行了哪些操作、发生了哪些与预期不符的情况、在运行期间出现了哪些未能处理的异常或警告、定期自动执行的各种任务,等等,这些都应该在日志中完整地记录下来。
那么原则上,程序中发生的事件只要有价值,就应该去记录,但我们还是要判断清楚事件的重要程度,选定相匹配的日志的级别。至于如何快速处理大量日志,这是后面的步骤需要考虑的问题,如果输出日志实在太频繁,以至于影响到了性能,就应该由运维人员去调整全局或单个类的日志级别来解决。
启动时输出配置信息
与避免输出诊断信息不同,对于系统启动时或者检测到配置中心变化时更新的配置,就应该把非敏感的配置信息输出到日志中,比如连接的数据库、临时目录的路径等等,因为初始化配置的逻辑一般只会执行一次,不便于诊断时复现,所以应该输出到日志中。
……
总而言之,日志输出是程序中非常普遍的行为,我们要把握好”不应该有”和”不应该少”这两个关键点。接下来,我们继续学习日志处理分析链路中,关于收集和缓冲这两个步骤。
收集与缓冲
我们知道,写日志是在服务节点中进行的,但我们不可能在每个节点都单独建设日志查询功能。这不是资源或工作量的问题,而是分布式系统处理一个请求要跨越多个服务节点,因此为了能看到跨节点的全部日志,就要有 能覆盖整个链路的全局日志系统。
那么这个需求就决定了, 当每个节点输出日志到文件后,就必须要把日志文件统一收集起来,集中存储、索引(这一步由 Elasticsearch 来负责) ,由此便催生出了专门的日志收集器。
最初,ELK(Elastic Stack)中的日志收集与下面要讲的加工聚合的职责,都是由 Logstash 来承担的。Logstash 既部署在各个节点中作为收集的客户端(Shipper),也同时有独立部署的节点,扮演归集转换日志的服务端(Master)。毕竟 Logstash 有良好的插件化设计,而收集、转换、输出都支持插件化定制,所以它应对多重角色本身并没有什么困难。
但问题是,Logstash 与它的插件是基于 JRuby 编写的,要跑在单独的 Java 虚拟机进程上,而且 Logstash 默认的堆大小就到了 1GB。对于归集部分(Master)来说,这种消耗当然不算什么问题,但作为每个节点都要部署的日志收集器,这样的消耗就显得太过负重了。
所以后来,Elastic.co 公司就把 所有需要在服务节点中处理的工作,整理成了以 Libbeat 为核心的 Beats 框架 ,并使用 Golang 重写了一个功能较少,却更轻量高效的日志收集器,这就是今天流行的 Filebeat 。
现在的 Beats 已经是一个很大的家族了,除了 Filebeat 外,Elastic.co 还提供用于收集 Linux 审计数据的 Auditbeat 、用于无服务计算架构的 Functionbeat 、用于心跳检测的 Heartbeat 、用于聚合度量的 Metricbeat 、用于收集 Linux Systemd Journald 日志的 Journalbeat 、用于收集 Windows 事件日志的 Winlogbeat ,用于网络包嗅探的 Packetbeat ,等等。
而如果再算上大量由社区维护的 Community Beats ,那几乎是你能想象到的数据都可以被收集到,以至于 ELK 在一定程度上也可以代替度量和追踪系统,实现它们的部分职能。
这对于中小型分布式系统来说是很便利的,但对于大型系统,我建议还是 让专业的工具去做专业的事情。
还有一点你要知道, 日志收集器不仅要保证能覆盖全部数据来源,还要尽力保证日志数据的连续性, 这其实是不太容易做到的。为啥呢?
我给你举个例子。像淘宝这类大型的互联网系统,每天的日志量超过了 10,000TB(10PB)量级,日志收集器的部署实例数能达到 百万量级 ,那么此时归集到系统中的日志,要想与实际产生的日志保持绝对的一致性,是非常困难的,我们也不应该为此付出过高的成本。
所以换言之,日志的处理分析其实并不追求绝对的完整精确,只追求在代价可承受的范围内,尽可能地保证较高的数据质量。
一种最常用的缓解压力的做法,是将日志接收者从 Logstash 和 Elasticsearch 转移至抗压能力更强的队列缓存。 比如在 Logstash 之前,架设一个 Kafka 或者 Redis 作为缓冲层,当面对突发流量,Logstash 或 Elasticsearch 的处理能力出现瓶颈时,就自动削峰填谷,这样甚至当它们短时间停顿,也不会丢失日志数据。
加工与聚合
那么,在将日志集中收集之后,以及存入 Elasticsearch 之前,我们一般还要对它们进行加工转换和聚合处理,这一步通常就要使用到前面我提过的 Logstash。
这是因为日志是非结构化数据,一行日志中通常会包含多项信息,如果不做处理,那在 Elasticsearch 就只能以全文检索的原始方式去使用日志,这样既不利于统计对比,也不利于条件过滤。
举个具体例子,下面是一行 Nginx 服务器的 Access Log,代表了一次页面访问操作:
14.123.255.234 - - [19/Feb/2020:00:12:11 +0800] “GET /index.html HTTP/1.1” 200 1314 “https://icyfenix.cn“ “Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36”
在这一行日志里面,包含了下表所列的 10 项独立数据项:
14.123.255.234 - - [19/Feb/2020:00:12:11 +0800] "GET /index.html HTTP/1.1" 200 1314 "https://icyfenix.cn" "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36"在这一行日志里面,包含了下表所列的 10 项独立数据项:
所以也就是说, Logstash 的基本职能 是把日志行中的非结构化数据,通过 Grok 表达式语法转换为表格那样的结构化数据。而在进行结构化的同时,它还可能会根据需要,调用其他插件来完成时间处理(统一时间格式)、类型转换(如字符串、数值的转换)、查询归类(比如将 IP 地址根据地理信息库按省市归类)等各种额外处理的工作,然后以 JSON 格式输出到 Elasticsearch 中(这是最普遍的输出形式,Logstash 输出也有很多插件可以具体定制不同的格式)。
如此一来,有了这些经过 Logstash 转换,已经结构化了的日志,Elasticsearch 便可针对不同的数据项来建立索引,进行条件查询、统计、聚合等操作了。
而提到聚合,这也是 Logstash 的另一个常见职能。
我们已经知道,日志中存储的是离散事件,离散的意思就是每个事件都是相互独立的,比如有 10 个用户访问服务,他们操作所产生的事件都会在日志中分别记录。
那么,如果想从离散的日志中获得统计信息,比如想知道这些用户中正常返回(200 OK)的有多少、出现异常的(500 Internal Server Error)的有多少,再生成个可视化统计图表, 一种解决方案是通过 Elasticsearch 本身的处理能力做实时的聚合统计。 这是一种很便捷的方式,不过要消耗 Elasticsearch 服务器的运算资源。
另一种解决方案是在收集日志后自动生成某些常用的、固定的聚合指标,这种聚合就会在 Logstash 中通过聚合插件来完成。
这两种聚合方式都有不少的实际应用,前者一般用于应对即席查询,后者更多是用于应对固定查询。
存储与查询
OK,经过了前面收集、缓冲、加工、聚合之后的日志数据,现在就终于可以放入 Elasticsearch 中索引存储了。
可以说,Elasticsearch 是整个 Elastic Stack 技术栈的核心。其他步骤的工具,比如 Filebeat、Logstash、Kibana 等都有替代品,有自由选择的余地,唯独 Elasticsearch 在日志分析这方面,完全没有什么值得一提的竞争者,几乎就是解决这个问题的唯一答案。
这样的结果肯定与 Elasticsearch 本身就是一款优秀的产品有关,然而更关键的是,Elasticsearch 的优势正好与日志分析的需求完美契合,我们可以根据以下三个角度进行观察:
从数据特征的角度看
日志是典型的基于时间的数据流,但它与其他时间数据流,比如你的新浪微博、微信朋友圈这种社交网络数据又稍微有点儿区别:日志虽然增长速度很快,但已经写入的数据几乎没有再发生变动的可能。
由此可见,日志的数据特征就决定了所有用于日志分析的 Elasticsearch,都会使用时间范围作为索引,比如根据实际数据量的大小,可能是按月、按周或者按日、按时。
这里我以按日索引为例,因为你能准确地预知明天、后天的日期,所以全部索引都可以预先创建,这就免去了动态创建时的寻找节点、创建分片、在集群中广播变动信息等开销。而又因为所有新的日志都是”今天”的日志,所以你只要建立”logs_current”这样的索引别名,来指向当前索引,就能避免代码因日期而变动。
从数据价值的角度看
日志基本上只会以最近的数据为检索目标,随着时间推移,早期的数据会逐渐失去价值。这点就决定了我们可以很容易地区出分冷数据和热数据,进而对不同数据采用不一样的硬件策略。
比如说,为热数据配备 SSD 磁盘和更好的处理器,为冷数据配备 HDD 磁盘和较弱的处理器,甚至可以放到更为廉价的 对象存储 (如阿里云的 OSS、腾讯云的 COS、AWS 的 S3)中归档。
不过这里我也想给你提个醒儿,咱们课程这部分的主题是日志在可观测性方面的作用,而还有一些基于日志的其他类型的应用,比如从日志记录的事件中去挖掘业务热点、分析用户习惯等等,这就属于大数据挖掘的范畴了,并不在我们讨论”价值”的范围之内,事实上它们更可能采用的技术栈是 HBase 与 Spark 的组合,而不是 Elastic Stack。
从数据使用的角度看
要知道,分析日志很依赖全文检索和即席查询,这对实时性的要求就是处于实时与离线两者之间的”近实时”,也就是并不强求日志产生后立刻能查到,但我们也不能接受日志产生之后按小时甚至按天的频率来更新,而这些检索能力和近实时性,也正好都是 Elasticsearch 的强项。
Elasticsearch 只提供了 API 层面的查询能力,它通常搭配同样出自 Elastic.co 公司的 Kibana 一起使用,我们可以把 Kibana 看作是 Elastic Stack 的 GUI 部分。
不过,尽管 Kibana 只负责图形界面和展示,但它提供的能力,远不止让你能在界面上执行 Elasticsearch 的查询那么简单。
Kibana 宣传的核心能力是” 探索数据并可视化 “,也就是把存储在 Elasticsearch 中的,被检索、聚合、统计后的数据,定制形成各种图形、表格、指标、统计,以此观察系统的运行状态,找出日志事件中潜藏的规律和隐患。按 Kibana 官方的宣传语来说,就是”一张图片胜过千万行日志”。
小结
这节课,我们学习了日志从输出、收集、缓冲、加工、聚合、存储、查询等这些步骤的职责与常见的解决方案。
由于日志是程序中最基础的功能之一,我们每个人一定都做过,所以我只花了一节课的时间去讲解,而我的重点并不在于介绍具体的步骤该如何操作,而在于向你呈现每个步骤需要注意的事项。你可以记住以下几个核心要点:
- 好的日志要能够毫无遗漏地记录信息、格式统一、内容恰当,而”恰当”的真正含义是指日志中不该出现的内容不要有,而该有的不要少。
- 分布式系统处理一个请求要跨越多个服务节点,因此当每个节点输出日志到文件后,就必须要把日志文件统一收集起来,集中存储、索引,而这正是日志收集器需要做的工作。此外,日志收集器还要尽力保证日志数据的连续性。
- 由于日志是非结构化数据,因此我们需要进行加工,把日志行中的非结构化数据转换为结构化数据,以便针对不同的数据项来建立索引,进行条件查询、统计、聚合等操作。
43 | 一个完整的分布式追踪系统是什么样子的?
虽然在 2010 年之前,就已经有了 X-Trace、Magpie 等跨服务的追踪系统了,但现代分布式链路追踪公认的起源,是 Google 在 2010 年发表的论文《 Dapper : a Large-Scale Distributed Systems Tracing Infrastructure 》,这篇论文介绍了 Google 从 2004 年开始使用的分布式追踪系统 Dapper 的实现原理。
此后,所有业界有名的追踪系统,无论是国外 Twitter 的 Zipkin 、Naver 的 Pinpoint (Naver 是 Line 的母公司,Pinpoint 的出现其实早于 Dapper 论文的发表,在 Dapper 论文中还提到了 Pinpoint),还是国内阿里的鹰眼、大众点评的 CAT 、个人开源的 SkyWalking (后来进入 Apache 基金会孵化毕业),都受到了 Dapper 论文的直接影响。
那么, 从广义上讲 ,一个完整的分布式追踪系统,应该由数据收集、数据存储和数据展示三个相对独立的子系统构成;而 从狭义上讲 ,则就只是特指链路追踪数据的收集部分。比如 Spring Cloud Sleuth 就属于狭义的追踪系统,通常会搭配 Zipkin 作为数据展示,搭配 Elasticsearch 作为数据存储来组合使用。
而前面提到的那些 Dapper 的徒子徒孙们,就大多都属于广义的追踪系统,它们通常也被称为”APM 系统”(Application Performance Management,应用性能管理)。
追踪与跨度
为了有效地进行分布式追踪,Dapper 提出了”追踪”与”跨度”两个概念。
从客户端发起请求抵达系统的边界开始,记录请求流经的每一个服务,直到向客户端返回响应为止,这整个过程就叫做一次” 追踪 “(Trace,为了不产生混淆,我后面就直接使用英文 Trace 来指代了)。
由于每次 Trace 都可能会调用数量不定、坐标不定的多个服务,那么为了能够记录具体调用了哪些服务,以及调用的顺序、开始时点、执行时长等信息,每次开始调用服务前,系统都要先埋入一个调用记录,这个记录就叫做一个” 跨度 “(Span)。
Span 的数据结构应该足够简单,以便于能放在日志或者网络协议的报文头里;也应该足够完备,起码要含有时间戳、起止时间、Trace 的 ID、当前 Span 的 ID、父 Span 的 ID 等能够满足追踪需要的信息。
事实上,每一次 Trace 都是由若干个有顺序、有层级关系的 Span 所组成一颗”追踪树”(Trace Tree),如下图所示:
图片来源于 Dapper 论文
那么这样来看,我们就可以从下面两个角度来观察分布式追踪的特征:
从目标来看 ,链路追踪的目的是为排查故障和分析性能提供数据支持,系统在对外提供服务的过程中,持续地接受请求并处理响应,同时持续地生成 Trace,按次序整理好 Trace 中每一个 Span 所记录的调用关系,就能绘制出一幅系统的服务调用拓扑图了。
这样,根据拓扑图中 Span 记录的时间信息和响应结果(正常或异常返回),我们就可以定位到缓慢或者出错的服务;然后,将 Trace 与历史记录进行对比统计,就可以从系统整体层面分析服务性能,定位性能优化的目标。
从实现来看 ,为每次服务调用记录 Trace 和 Span,并以此构成追踪树结构,看起来好像也不是很复杂。然而考虑到实际情况,追踪系统在功能性和非功能性上都有不小的挑战。
功能上的挑战来源于服务的异构性,各个服务可能会采用不同的程序语言,服务间的交互也可能会采用不同的网络协议,每兼容一种场景,都会增加功能实现方面的工作量。
而非功能性的挑战,具体就来源于以下这四个方面:
- 低性能损耗:分布式追踪不能对服务本身产生明显的性能负担。追踪的主要目的之一就是为了寻找性能缺陷,越慢的服务就越是需要追踪,所以工作场景都是性能敏感的地方。
- 对应用透明:追踪系统通常是运维期才事后加入的系统,所以应该尽量以非侵入或者少侵入的方式来实现追踪,对开发人员做到透明化。
- 随应用扩缩:现代的分布式服务集群都有根据流量压力自动扩缩的能力,这就要求当业务系统扩缩时,追踪系统也能自动跟随,不需要运维人员人工参与。
- 持续的监控:即要求追踪系统必须能够 7x24 小时工作,否则就难以定位到系统偶尔抖动的行为。
所以总而言之,分布式追踪的主要需求是如何围绕着一个服务调用过程中的 Trace 和 Span,来低损耗、高透明度地收集信息,不管是狭义还是广义的链路追踪系统,都要包含数据收集的工作,这是可以说是追踪系统的核心。那么接下来,我们就来了解下三种主流的数据收集方式。
数据收集的三种主流实现方式
目前,追踪系统根据数据收集方式的差异,可以分为三种主流的实现方式,分别是基于日志的追踪(Log-Based Tracing),基于服务的追踪(Service-Based Tracing)和基于边车代理的追踪(Sidecar-Based Tracing)。
基于日志的追踪
基于日志的追踪思路是将 Trace、Span 等信息直接输出到应用日志中,然后随着所有节点的日志归集过程汇聚到一起,再从全局日志信息中反推出完整的调用链拓扑关系。 日志追踪对网络消息完全没有侵入性,对应用程序只有很少量的侵入性,对性能的影响也非常低。
但这种实现方式的缺点是直接依赖于日志归集过程,日志本身不追求绝对的连续与一致,这就导致了基于日志的追踪,往往不如其他两种追踪实现来的精准。
还有一个问题是,由于业务服务的调用与日志的归集并不是同时完成的,也通常不由同一个进程完成,有可能发生业务调用已经顺利结束了,但由于日志归集不及时或者精度丢失,导致日志出现延迟或缺失记录,进而产生 追踪失真 的情况。这也正是我在上节课介绍 Elastic Stack 时提到的观点,ELK 在日志、追踪和度量方面都可以发挥作用,这对中小型应用确实能起到一定的便利作用,但对于大型系统来说,最好还是由专业的工具来做专业的事。
日志追踪的代表产品是 Spring Cloud Sleuth,下面是一段由 Sleuth 在调用时自动生成的日志记录,你可以从中观察到 TraceID、SpanID、父 SpanID 等追踪信息。
# 以下为调用端的日志输出:
Created new Feign span [Trace: cbe97e67ce162943, Span: bb1798f7a7c9c142, Parent: cbe97e67ce162943, exportable:false]
2019-06-30 09:43:24.022 [http-nio-9010-exec-8] DEBUG o.s.c.s.i.web.client.feign.TraceFeignClient - The modified request equals GET http://localhost:9001/product/findAll HTTP/1.1
X-B3-ParentSpanId: cbe97e67ce162943
X-B3-Sampled: 0
X-B3-TraceId: cbe97e67ce162943
X-Span-Name: http:/product/findAll
X-B3-SpanId: bb1798f7a7c9c142
# 以下为服务端的日志输出:
[findAll] to a span [Trace: cbe97e67ce162943, Span: bb1798f7a7c9c142, Parent: cbe97e67ce162943, exportable:false]
Adding a class tag with value [ProductController] to a span [Trace: cbe97e67ce162943, Span: bb1798f7a7c9c142, Parent: cbe97e67ce162943, exportable:false]基于服务的追踪
基于服务的追踪是 目前最为常见的追踪实现方式 ,被 Zipkin、SkyWalking、Pinpoint 等主流追踪系统广泛采用。服务追踪的实现思路是 通过某些手段给目标应用注入追踪探针(Probe) ,比如针对 Java 应用,一般就是通过 Java Agent 注入的。
探针在结构上可以看作是一个寄生在目标服务身上的小型微服务系统,它一般会有自己专用的服务注册、心跳检测等功能,有专门的数据收集协议,可以把从目标系统中监控得到的服务调用信息,通过另一次独立的 HTTP 或者 RPC 请求,发送给追踪系统。
因此,基于服务的追踪会比基于日志的追踪消耗更多的资源,也具有更强的侵入性,而换来的收益就是 追踪的精确性与稳定性都有所保证,不必再依靠日志归集来传输追踪数据。
这里我放了一张 Pinpoint 的追踪效果截图,从图中可以看到参数、变量等相当详细的方法级调用信息。不知道你还记不记得,在上节课”日志分析”里,我把”打印追踪诊断信息”列为了反模式,并提到,如果需要诊断方法参数、返回值、上下文信息,或者方法调用耗时这类数据,通过追踪系统来实现,会是比通过日志系统实现更加恰当的解决方案。
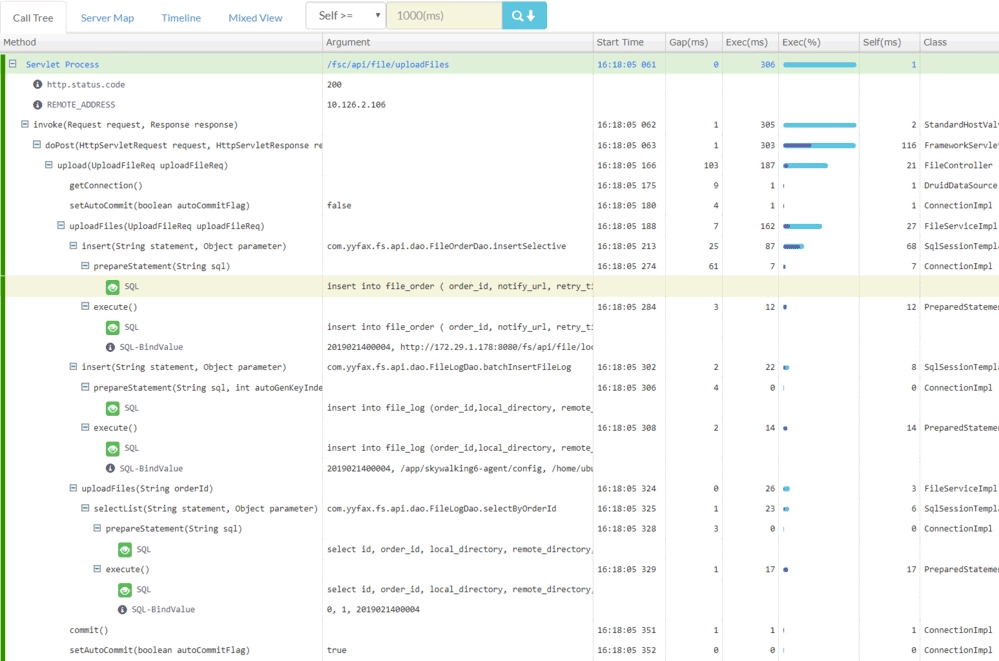
另外,我也必须给你说明清楚,像图例中的 Pinpoint 这种详细程度的追踪,对应用系统的性能压力是相当大的,一般仅在除错时开启,而且 Pinpoint 本身就是比较重负载的系统(运行它必须先维护一套 HBase),这其实就严重制约了它的适用范围。目前服务追踪的其中一个发展趋势是轻量化,国产的 SkyWalking 正是这方面的佼佼者。
基于边车代理的追踪
基于边车代理的追踪是 服务网格的专属方案,也是最理想的分布式追踪模型 ,它对应用完全透明,无论是日志还是服务本身,都不会有任何变化;它与程序语言无关,无论应用是采用什么编程语言来实现的,只要它还是通过网络(HTTP 或者 gRPC)来访问服务,就可以被追踪到;它也有自己独立的数据通道,追踪数据通过控制平面进行上报,避免了追踪对程序通信或者日志归集的依赖和干扰,保证了最佳的精确性。
而如果要说这种追踪实现方式还有什么缺点的话,那就是 服务网格现在还不够普及 。当然未来随着云原生的发展,相信它会成为追踪系统的主流实现方式之一。
还有一点就是,边车代理本身对应用透明的工作原理,决定了它 只能实现服务调用层面的追踪 ,像前面 Pinpoint 截图那样的本地方法调用级别的追踪诊断,边车代理是做不到的。
现在,市场占有率最高的边车代理 Envoy 就提供了相对完善的追踪功能,但没有提供自己的界面端和存储端,所以 Envoy 和 Sleuth 一样,都属于狭义的追踪系统,需要配合专门的 UI 与存储来使用。SkyWalking、Zipkin、 Jaeger 、 LightStep Tracing 等系统,现在都可以接受来自于 Envoy 的追踪数据,充当它的界面端。
不过,虽然链路追踪在数据的收集这方面,已经有了几种主流的实现方式,但各种追踪产品通常并不互通。接下来我们就具体看看追踪在行业标准与规范方面存在的问题。
追踪规范化
要知道,比起日志与度量,追踪这个领域的产品竞争要相对激烈得多。
一方面,在这个领域内目前还没有像日志、度量那样出现具有明显统治力的产品,仍处于群雄混战的状态。另一方面,现在几乎市面上所有的追踪系统,都是以 Dapper 的论文为原型发展出来的,基本都算是同门师兄弟,在功能上并没有太本质的差距,却又受制于实现细节,彼此互斥,很难搭配工作。
之所以出现这种局面,我觉得只能怪当初 Google 发表的 Dapper 只是论文,而不是有约束力的规范标准,它只提供了思路,并没有规定细节。比如该怎样进行埋点、Span 上下文具体该有什么数据结构、怎样设计追踪系统与探针或者界面端的 API 接口,等等,这些都没有权威的规定。
因此,为了推进追踪领域的产品标准化,2016 年 11 月,CNCF 技术委员会接受了 OpenTracing 作为基金会的第三个项目。OpenTracing 是一套与平台无关、与厂商无关、与语言无关的追踪协议规范,只要遵循 OpenTracing 规范,任何公司的追踪探针、存储、界面都可以随时切换,也可以相互搭配使用。
在操作层面,OpenTracing 只是制定了一个很薄的标准化层,位于应用程序与追踪系统之间,这样,探针与追踪系统只要都支持 OpenTracing 协议,就算它们不是同一个厂商的产品,那也可以互相通讯。此外,OpenTracing 还规定了微服务之间在发生调用时,应该如何传递 Span 信息(OpenTracing Payload)。
关于这几点,我们具体可以参考下图例中的绿色部分:
如此一来,在 OpenTracing 规范公布后,几乎所有业界有名的追踪系统,比如 Zipkin、Jaeger、SkyWalking 等,都很快宣布支持 OpenTracing。
但谁也没想到的是,Google 自己却在这个时候出来表示反对,并提出了与 OpenTracing 目标类似的 OpenCensus 规范 ,随后又得到了巨头 Microsoft 的支持和参与。
OpenCensus 不仅涉及到追踪,还把指标度量也纳入了进来;而在内容上,它不仅涉及到规范制定,还把数据采集的探针和收集器都一起以 SDK(目前支持五种语言)的形式提供出来了。
这样,OpenTracing 和 OpenCensus 就迅速形成了可观测性的两大阵营,一边是在这方面深耕多年的众多老牌 APM 系统厂商,另一边是分布式追踪概念的提出者 Google,以及与 Google 同样庞大的 Microsoft。
所以,对追踪系统的规范化工作,也并没有平息厂商竞争的混乱,反倒是把水搅得更浑了。
不过,正当群众们买好西瓜搬好板凳的时候,2019 年,OpenTracing 和 OpenCensus 又忽然宣布握手言和,它们共同发布了可观测性的终极解决方案 OpenTelemetry ,并宣布会各自冻结 OpenTracing 和 OpenCensus 的发展。
OpenTelemetry 的野心很大,它不仅包括了追踪规范,还包括了日志和度量方面的规范、各种语言的 SDK,以及采集系统的参考实现。距离一个完整的追踪与度量系统,只是差了一个界面端和指标预警这些会与用户直接接触的后端功能,OpenTelemetry”大度”地把它们留给具体产品去实现,勉强算是没有对一众 APM 厂商赶尽杀绝,留了一条活路。
可以说,OpenTelemetry 一诞生就带着无比炫目的光环,直接进入 CNCF 的孵化项目,它的目标是统一追踪、度量和日志三大领域(目前主要关注的是追踪和度量,在日志方面,官方表示将放到下一阶段再去处理)。不过,OpenTelemetry 毕竟是 2019 年才出现的新生事物,尽管背景渊源深厚,前途光明,但未来究竟如何发展,能否打败现在已有的众多成熟系统,目前仍然言之尚早。
小结
这节课,我给你介绍了分布式追踪里”追踪”与”跨度”两个概念,要知道目前几乎所有的追踪工具都是围绕这两个 Dapper 提出的概念所设计的,因此理解它们的含义,对你使用任何一款追踪工具都会有帮助。
而在理论之外,我还讲解了三种追踪数据收集的实现方式,分别是基于日志、基于服务、基于边车代理的追踪,你可以重点关注下这几种方式各自的优势和缺点,以此在工作实践中选择合适的追踪方式。
44 | 聚合度量能给我们解决什么问题?
度量(Metrics)的目的是揭示系统的总体运行状态。 相信你可能在一些电影里见过这样的场景:舰船的驾驶舱或者卫星发射中心的控制室,处在整个房间最显眼的位置,布满整面墙壁的巨型屏幕里显示着一个个指示器、仪表板与统计图表,沉稳端坐中央的指挥官看着屏幕上闪烁变化的指标,果断决策,下达命令……
而如果以上场景被改成指挥官双手在键盘上飞舞,双眼紧盯着日志或者追踪系统,试图判断出系统工作是否正常。这光想像一下,你都能感觉到一股身份与行为不一致的违和气息,由此可见度量与日志、追踪的差别。
简单来说, 度量就是用经过聚合统计后的高维度信息,以最简单直观的形式来总结复杂的过程,为监控、预警提供决策支持。
我们大多数人的人生经历可能都会比较平淡,没有驾驶航母的经验,甚至连一颗卫星或者导弹都没有发射过,那就只好打开电脑,按 CTRL+ALT+DEL 呼出任务管理器,看看下面这个熟悉的界面,它也是一个非常具有代表性的度量系统。
在总体上,度量可以分为 客户端的指标收集、服务端的存储查询以及终端的监控预警 三个相对独立的过程,每个过程在系统中一般也会设置对应的组件来实现。
那么现在呢,你不妨先来看一下我在后面举例时会用到的 Prometheus 组件流程图,图中 Prometheus Server 左边的部分都属于客户端过程,而右边的部分就属于终端过程。
虽然说Prometheus在度量领域的统治力,暂时还不如日志领域中 Elastic Stack 的统治地位那么稳固,但在云原生时代里,它基本已经算得上是事实标准了。所以接下来,我就主要以 Prometheus 为例,给你介绍这三部分组件的总体思路、大致内容与理论标准。
指标收集
我们先来了解下客户端指标收集部分的核心思想。这一部分主要是解决两个问题:”如何定义指标”以及”如何将这些指标告诉服务端”。
如何定义指标?
首先我们来聊聊” 如何定义指标 “这个问题。乍一看你可能会觉得它应该是与目标系统密切相关的,必须根据实际情况才能讨论,但其实并不绝对。
要知道,无论目标是何种系统,它都具备了一些共性特征,虽然在确定目标系统前,我们无法决定要收集什么指标,但指标的 数据类型 (Metrics Types)是可数的,所有通用的度量系统都是面向指标的数据类型来设计的,现在我就来一一给你解读下:
- 计数度量器(Counter) :这是最好理解也是最常用的指标形式,计数器就是对有相同量纲、可加减数值的合计量。比如业务指标像销售额、货物库存量、职工人数等;技术指标像服务调用次数、网站访问人数等,它们都属于计数器指标。
- 瞬态度量器(Gauge) :瞬态度量器比计数器更简单,它就表示某个指标在某个时点的数值,连加减统计都不需要。比如当前 Java 虚拟机堆内存的使用量,这就是一个瞬态度量器;再比如,网站访问人数是计数器,而网站在线人数则是瞬态度量器。
- 吞吐率度量器(Meter) :顾名思义,它是用于统计单位时间的吞吐量,即单位时间内某个事件的发生次数。比如在交易系统中,常以 TPS 衡量事务吞吐率,即每秒发生了多少笔事务交易;再比如,港口的货运吞吐率常以”吨 / 每天”为单位计算,10 万吨 / 天的港口通常要比 1 万吨 / 天的港口的货运规模更大。
- 直方图度量器(Histogram) :直方图就是指常见的二维统计图,它的两个坐标分别是统计样本和该样本对应的某个属性的度量,以长条图的形式记录具体数值。比如经济报告中,要衡量某个地区历年的 GDP 变化情况,常会以 GDP 为纵坐标、时间为横坐标构成直方图来呈现。
- 采样点分位图度量器(Quantile Summary) :分位图是统计学中通过比较各分位数的分布情况的工具,主要用来验证实际值与理论值的差距,评估理论值与实际值之间的拟合度。比如,我们说”高考成绩一般符合正态分布”,这句话的意思就是:高考成绩高低分的人数都比较少,中等成绩的比较多,按不同分数段来统计人数,得出的统计结果一般能够与正态分布的曲线较好地拟合。
- 除了以上常见的度量器之外,还有 Timer、Set、Fast Compass、Cluster Histogram 等其他各种度量器,采用不同的度量系统,支持度量器类型的范围肯定会有所差别,比如 Prometheus 就支持了上面提到的五种度量器中的 Counter、Gauge、Histogram 和 Summary 四种。
如何将这些指标告诉服务端?
然后是针对” 如何将这些指标告诉服务端 “这个问题,它通常有两种解决方案:拉取式采集(Pull-Based Metrics Collection)和推送式采集(Push-Based Metrics Collection)。
所谓 Pull 是指度量系统主动从目标系统中拉取指标;相对地,Push 就是由目标系统主动向度量系统推送指标。
这两种方式实际上并没有绝对的好坏优劣,以前很多老牌的度量系统,比如 Ganglia) 、 Graphite 、 StatsD 等是基于 Push 的,而以 Prometheus、 Datadog 、 Collectd 为代表的另一派度量系统则青睐 Pull 式采集(Prometheus 官方解释 选择 Pull 的原因 )。另外你也要知道,对于是要选择 Push 还是 Pull,不仅是在度量中才有,所有涉及到客户端和服务端通讯的场景,都会涉及到该谁主动的问题,上一节课讲的追踪系统也是如此。
不过一般来说, 度量系统只会支持其中一种指标采集方式 ,这是因为度量系统的网络连接数量,以及对应的线程或者协程数可能非常庞大,如何采集指标将直接影响到整个度量系统的架构设计。
然而,Prometheus 在基于 Pull 架构的同时,还能够有限度地兼容 Push 式采集,这是为啥呢?原因是它有 Push Gateway 的存在。
如下图所示,这是一个位于 Prometheus Server 外部的相对独立的中介模块,它会把外部推送来的指标放到 Push Gateway 中暂存,然后再等候 Prometheus Server 从 Push Gateway 中去拉取。
Prometheus 设计 Push Gateway 的本意是为了解决 Pull 的一些固有缺陷,比如目标系统位于内网,需要通过 NAT 访问外网,而外网的 Prometheus 是无法主动连接目标系统的,这就只能由目标系统主动推送数据;又比如某些小型短生命周期服务,可能还等不及 Prometheus 来拉取,服务就已经结束运行了,因此也只能由服务自己 Push 来保证度量的及时和准确。
而在由 Push 和 Pull 决定完该谁主动以后,另一个问题就是:指标应该通过怎样的网络访问协议、取数接口、数据结构来获取呢?
跟计算机科学中其他类似的问题一样,人们一贯的解决方向是”定义规范”,应该由行业组织和主流厂商一起协商出专门用于度量的协议,目标系统按照协议与度量系统交互。比如说,网络管理中的 SNMP 、Windows 硬件的 WMI ,以及 第 41 讲 中提到的 Java 的 JMX 都属于这种思路的产物。
但是,定义标准这个办法在度量领域中其实没有那么有效,前面列举的这些度量协议,只是在特定的一小块领域里流行过。
要究其原因的话,一方面是因为业务系统要使用这些协议并不容易,你可以想像一下,让订单金额存到 SNMP 中,让 Golang 的系统把指标放到 JMX Bean 里,即便技术上可行,这也不像是正常程序员会干的事;而另一方面,度量系统又不会甘心局限于某个领域,成为某项业务的附属品。
另外我们也要明确一个事实,度量面向的是广义上的信息系统,它横跨存储(日志、文件、数据库)、通讯(消息、网络)、中间件(HTTP 服务、API 服务),直到系统本身的业务指标,甚至还会包括度量系统本身(部署两个独立的 Prometheus 互相监控是很常见的)。
所以,这些度量协议其实都没有成为最正确答案的希望。
如此一来,既然没有了标准,有一些度量系统,比如老牌的 Zabbix 就选择同时支持了 SNMP、JMX、IPMI 等多种不同的度量协议。而另一些以 Prometheus 为代表的度量系统就相对强硬,它们不支持任何一种协议,只允许通过 HTTP 访问度量端点这一种访问方式。如果目标提供了 HTTP 的度量端点(如 Kubernetes、Etcd 等本身就带有 Prometheus 的 Client Library)就直接访问,否则就需要一个专门的 Exporter 来充当媒介。
这里的 Exporter 是 Prometheus 提出的概念,它是目标应用的代表,它既可以独立运行,也可以与应用运行在同一个进程中,只要集成 Prometheus 的 Client Library 就可以了。
Exporter 的作用就是以 HTTP 协议(Prometheus 在 2.0 版本之前支持过 Protocol Buffer,目前已不再支持)返回符合 Prometheus 格式要求的文本数据给 Prometheus 服务器。得益于 Prometheus 的良好社区生态,现在已经有大量、各种用途的 Exporter,让 Prometheus 的监控范围几乎能涵盖到所有用户关心的目标,绝大多数用户都只需要针对自己系统业务方面的度量指标编写 Exporter 即可。你可以参考下这里给出的表格:
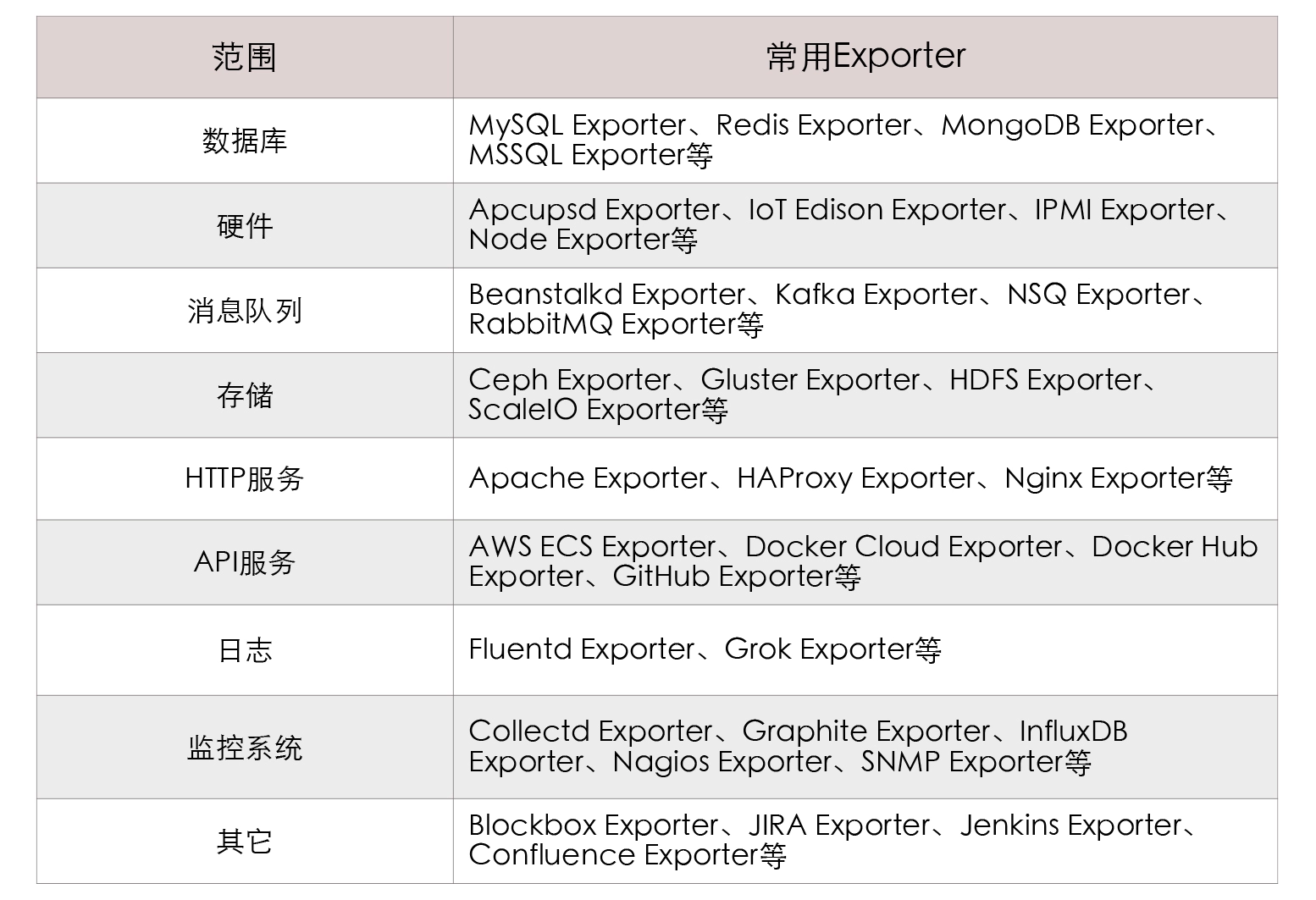
另外顺便一提,在前面我提到了一堆没有希望成为最终答案的协议,比如 SNMP、WMI 等等。不过现在一种名为 OpenMetrics 的度量规范正逐渐从 Prometheus 的数据格式中分离出来,有望成为监控数据格式的国际标准,最终结果究竟如何,要看 Prometheus 本身的发展情况,还有 OpenTelemetry 与 OpenMetrics 的关系如何协调。
存储查询
好,那么当指标从目标系统采集过来了之后,就应该存储在度量系统中,以便被后续的分析界面、监控预警所使用。
存储数据对于计算机软件来说其实是司空见惯的操作,但如果用传统关系数据库的思路来解决度量系统的存储,效果可能不会太理想。
我举个例子,假设你要建设一个中等规模、有着 200 个节点的微服务系统,每个节点要采集的存储、网络、中间件和业务等各种指标加一起,也按 200 个来计算,监控的频率如果按秒为单位的话,一天时间内就会产生超过 34 亿条记录,而对于这个结果你可能会感到非常意外:
200(节点)× 200(指标)× 86400(秒)= 3,456,000,000(记录)
因为在实际情况中,大多数这种 200 节点规模的系统,本身一天的生产数据都远到不了 34 亿条,那么建设度量系统,肯定不能让度量反倒成了业务系统的负担。可见,度量的存储是需要专门研究解决的问题。至于具体要如何解决,让我们先来观察一段 Prometheus 的真实度量数据吧:
{
// 时间戳
"timestamp": 1599117392,
// 指标名称
"metric": "total_website_visitors",
// 标签组
"tags": {
"host": "icyfenix.cn",
"job": "prometheus"
},
// 指标值
"value": 10086
}通过观察,我们可以发现这段度量数据的特征:每一个度量指标由时间戳、名称、值和一组标签构成,除了时间之外,指标不与任何其他因素相关。
当然,指标的数据总量固然是不小的,但它没有嵌套、没有关联、没有主外键,不必关心范式和事务,这些就都是可以针对性优化的地方。事实上,业界也早就有了专门针对该类型数据的数据库,即”时序数据库”(Time Series Database)。
额外知识:时序数据库
时序数据库是用于存储跟随时间而变化的数据,并且以时间(时间点或者时间区间)来建立索引的数据库。
时序数据库最早是应用于工业(电力行业、化工行业)应用的各类型实时监测、检查与分析设备所采集、产生的数据,这些工业数据的典型特点是产生频率快(每一个监测点一秒钟内可产生多条数据)、严重依赖于采集时间(每一条数据均要求对应唯一的时间)、测点多信息量大(常规的实时监测系统均可达到成千上万的监测点,监测点每秒钟都在产生数据)。
时间序列数据是历史烙印,它具有不变性、唯一性、有序性。时序数据库同时具有数据结构简单、数据量大的特点。
我们应该注意到,存储数据库在写操作时,时序数据通常只是追加,很少删改或者根本不允许删改。因此, 针对数据热点只集中在近期数据、多写少读、几乎不删改、数据只顺序追加等特点,时序数据库被允许可以做出很激进的存储、访问和保留策略(Retention Policies):
- 以 日志结构的合并树 (Log Structured Merge Tree,LSM-Tree)代替传统关系型数据库中的 B+Tree 作为存储结构,LSM 适合的应用场景就是写多读少,且几乎不删改的数据。
- 设置激进的数据保留策略,比如根据过期时间(TTL),自动删除相关数据以节省存储空间,同时提高查询性能。对于普通的数据库来说,数据会存储一段时间后被自动删除的这个做法,可以说是不可想象的。
- 对数据进行再采样(Resampling)以节省空间,比如最近几天的数据可能需要精确到秒,而查询一个月前的数据只需要精确到天,查询一年前的数据只要精确到周就够了,这样将数据重新采样汇总,就极大地节省了存储空间。
而除此之外,时序数据库中甚至还有一种并不罕见却更加极端的形式,叫做 轮替型数据库 (Round Robin Database,RRD),它是以环形缓冲(在” 服务端缓存 “一节介绍过)的思路实现,只能存储固定数量的最新数据,超期或超过容量的数据就会被轮替覆盖,因此它也有着固定的数据库容量,却能接受无限量的数据输入。
所以,Prometheus 服务端自己就内置了一个强大的时序数据库实现,我说它”强大”并不是客气,在 DB-Engines 中近几年它的排名就在不断提升,目前已经跃居时序数据库排行榜的前三。
这个时序数据库提供了一个名为 PromQL 的数据查询语言 ,能对时序数据进行丰富的查询、聚合以及逻辑运算。当然了,某些时序库(如排名第一的 InfluxDB )也会提供类 SQL 风格的查询,但 PromQL 不是,它是一套完全由 Prometheus 自己定制的数据查询 DSL ,写起来的风格有点像带运算与函数支持的 CSS 选择器。比如,我要查找网站 icyfenix.cn 的访问人数的话,会是如下写法:
// 查询命令:
total_website_visitors{host="icyfenix.cn"}
// 返回结果:
total_website_visitors{host="icyfenix.cn",job="prometheus"}=(10086)这样,通过 PromQL 就可以轻易实现指标之间的运算、聚合、统计等操作,在查询界面中也往往需要通过 PromQL 计算多种指标的统计结果,才能满足监控的需要,语法方面的细节我就不详细展开了,具体你可以参考 Prometheus 的文档手册 。
最后我还想补充说明一下,时序数据库对度量系统来说确实是很合适的选择,但并不是说绝对只有用时序数据库才能解决度量指标的存储问题,Prometheus 流行之前最老牌的度量系统 Zabbix,用的就是传统关系数据库来存储指标。
好,接下来我们继续探讨聚合度量的第三个过程:终端的监控预警。
监控预警
首先要知道,指标度量是手段,而最终目的是要做分析和预警。
界面分析和监控预警是与用户更加贴近的功能模块,但对度量系统本身而言,它们都属于相对外围的功能。与追踪系统的情况类似, 广义上的度量系统 由面向目标系统进行指标采集的客户端(Client,与目标系统进程在一起的 Agent,或者代表目标系统的 Exporter 等都可归为客户端),负责调度、存储和提供查询能力的服务端(Server,Prometheus 的服务端是带存储的,但也有很多度量服务端需要配合独立的存储来使用),以及面向最终用户的终端(Backend,UI 界面、监控预警功能等都归为终端)组成;而 狭义上的度量系统 就只包括客户端和服务端,不包含终端。
那么按照定义,Prometheus 应该算是处于狭义和广义的度量系统之间,尽管它确实内置了一个界面解决方案”Console Template”,以模版和 JavaScript 接口的形式提供了一系列预设的组件(菜单、图表等),让用户编写一段简单的脚本就可以实现可用的监控功能。不过这种可用程度,往往不足以支撑正规的生产部署,只能说是为把度量功能嵌入到系统的某个子系统中,提供了一定的便利。
因而在生产环境下,大多是 Prometheus 配合 Grafana 来进行展示的,这是 Prometheus 官方推荐的组合方案。但该组合也并非唯一的选择,如果你要搭配 Klbana 甚至 SkyWalking(8.x 版之后的 SkyWalking 支持从 Prometheus 获取度量数据)来使用,也都是完全可行的。
另外, 良好的可视化能力对于提升度量系统的产品力也非常重要 ,长期趋势分析(比如根据对磁盘增长趋势的观察,判断什么时候需要扩容)、对照分析(比如版本升级后对比新旧版本的性能、资源消耗等方面的差异)、故障分析(不仅从日志、追踪自底向上可以分析故障,高维度的度量指标也可能自顶向下寻找到问题的端倪)等分析工作,既需要度量指标的持续收集、统计,往往还需要对数据进行可视化,这样才能让人更容易地从数据中挖掘规律,毕竟数据最终还是要为人类服务的。
而除了为分析、决策、故障定位等提供支持的用户界面外,度量信息的另一种主要的消费途径就是用来做 预警 。比如你希望当磁盘消耗超过 90% 时,给你发送一封邮件或者是一条微信消息,通知管理员过来处理,这就是一种预警。
Prometheus 提供了专门用于预警的 Alert Manager,我们将 Alert Manager 与 Prometheus 关联后,可以设置某个指标在多长时间内、达到何种条件就会触发预警状态,在触发预警后,Alert Manager 就会根据路由中配置的接收器,比如邮件接收器、Slack 接收器、微信接收器,或者更通用的 WebHook 接收器等来自动通知我们。
小结
今天是”可观测性”章节的最后一节课,可观测性作为控制理论中的一个概念,从 1960 年代起就已经存在了,虽然它针对信息系统和分布式服务的适用性,是最近若干年中新发现的,但在某种程度上,这也算是过去 20 年对这些系统的监控方式的演变产物。
那么学完了今天这节课,你需要记住一个要点,即传统监控和可观测性之间的关键区别在于:可观测性是系统或服务内在的固有属性,而不是在系统之外对系统所做出的额外增强,后者是传统监控的处理思路。
除此之外,构建具有可观测性的服务,也是构建健壮服务不可缺少的属性,这是分布式系统架构师的职责。那么作为服务开发者和设计者,我们应该在其建设期间,就要设想控制系统会发出哪些信号、如何接收和存储这些信号,以及如何使用它们,以确保在用户能在受到影响之前了解问题、能使用度量数据来更好地了解系统的健康状况和状态。
不可变基础设施
45 | 模块导学:从微服务到云原生
上一个模块,我们以”分布式的基石”为主题,了解并学习了微服务中的关键技术问题与解决方案。实际上,解决这些技术问题,原本就是我们架构师和程序员的本职工作。
而从今天开始,我们就进入了一个全新的模块,从微服务走到了云原生。在这个模块里,我会围绕”不可变基础设施”的相关话题,以容器、编排系统和服务网格的发展为主线,给你介绍虚拟化容器与服务网格是如何模糊掉软件与硬件之间的界限,如何在基础设施与通讯层面上帮助微服务隐藏复杂性,以此解决原本只能由程序员通过软件编程来解决的分布式问题。
什么是不可变基础设施?
“不可变基础设施”这个概念由来已久。2012 年,马丁 · 福勒(Martin Fowler)设想的” 凤凰服务器 “与 2013 年查德 · 福勒(Chad Fowler)正式提出的” 不可变基础设施 “,都阐明了基础设施不变性给我们带来的好处。
而在 云原生基金会 定义的”云原生”概念中,”不可变基础设施”提升到了与微服务平级的重要程度。此时,它的内涵已经不再局限于只是方便运维、程序升级和部署的手段,而是升华为了向应用代码隐藏分布式架构复杂度、让分布式架构得以成为一种能够普遍推广的普适架构风格的必要前提。
云原生定义(Cloud Native Definition)
Cloud native technologies empower organizations to build and run scalable applications in modern, dynamic environments such as public, private, and hybrid clouds. Containers, service meshes, microservices, immutable infrastructure, and declarative APIs exemplify this approach.
These techniques enable loosely coupled systems that are resilient, manageable, and observable. Combined with robust automation, they allow engineers to make high-impact changes frequently and predictably with minimal toil.
云原生技术有利于各组织在公有云、私有云和混合云等新型动态环境中,构建和运行可弹性扩展的应用。云原生的代表技术包括容器、服务网格、微服务、不可变基础设施和声明式 API。
这些技术能够构建容错性好、易于管理和便于观察的松耦合系统。结合可靠的自动化手段,云原生技术使工程师能够轻松地对系统作出频繁和可预测的重大变更。
—— Cloud Native Definition , CNCF ,2018
不过,不可变基础设施是一种抽象的概念,不太容易直接对它分解描述,所以为了能把云原生这个本来就比较抽象的架构思想落到实处,我选择从我们都比较熟悉的,至少是能看得见、摸得着的容器化技术开始讲起。
虚拟化的目标与类型
容器是云计算、微服务等诸多软件业界核心技术的共同基石。 容器的首要目标 是让软件分发部署的过程,从传统的发布安装包、靠人工部署,转变为直接发布已经部署好的、包含整套运行环境的虚拟化镜像。
在容器技术成熟之前,主流的软件部署过程是由系统管理员编译或下载好二进制安装包,根据软件的部署说明文档,准备好正确的操作系统、第三方库、配置文件、资源权限等各种前置依赖以后,才能将程序正确地运行起来。
这样做当然是非常麻烦的, Chad Fowler 在提出”不可变基础设施”这个概念的文章《 Trash Your Servers and Burn Your Code 》里,开篇就直接吐槽:要把一个不知道打过多少个升级补丁,不知道经历了多少任管理员的系统迁移到其他机器上,毫无疑问会是一场灾难。
另外我们也知道,让软件能够在任何环境、任何物理机器上达到”一次编译,到处运行”,曾经是 Java 早年的宣传口号,不过这并不是一个简单的目标,不设前提的”到处运行”,仅靠 Java 语言和 Java 虚拟机是不可能达成的。因为一个计算机软件要能够正确运行,需要通过以下三方面的兼容性来共同保障(这里仅讨论软件兼容性,不去涉及”如果没有摄像头就无法运行照相程序”这类问题):
- ISA 兼容 :目标机器指令集兼容性,比如 ARM 架构的计算机无法直接运行面向 x86 架构编译的程序。
- ABI 兼容 :目标系统或者依赖库的二进制兼容性,比如 Windows 系统环境中无法直接运行 Linux 的程序,又比如 DirectX 12 的游戏无法运行在 DirectX 9 之上。
- 环境兼容 :目标环境的兼容性,比如没有正确设置的配置文件、环境变量、注册中心、数据库地址、文件系统的权限等等,当任何一个环境因素出现错误,都会让你的程序无法正常运行。
额外知识:ISA 与 ABI
指令集架构 (Instruction Set Architecture,ISA)是计算机体系结构中与程序设计有关的部分,包含了基本数据类型、指令集、寄存器、寻址模式、存储体系、中断、异常处理以及外部 I/O。指令集架构包含一系列的 Opcode 操作码(即通常所说的机器语言),以及由特定处理器执行的基本命令。
应用二进制接口 (Application Binary Interface,ABI)是应用程序与操作系统之间或其他依赖库之间的低级接口。ABI 涵盖了各种底层细节,如数据类型的宽度大小、对象的布局、接口调用约定等等。ABI 不同于 应用程序接口 (Application Programming Interface,API),API 定义的是源代码和库之间的接口,因此同样的代码可以在支持这个 API 的任何系统中编译,而 ABI 允许编译好的目标代码在使用兼容 ABI 的系统中无需改动就能直接运行。
这里,我把使用仿真(Emulation)以及虚拟化(Virtualization)技术来解决以上三项兼容性问题的方法,都统称为虚拟化技术。那么,根据抽象目标与兼容性高低的不同,虚拟化技术又分为了五类,下面我们就分别来看看:
指令集虚拟化(ISA Level Virtualization)
即通过软件来模拟不同 ISA 架构的处理器工作过程,它会把虚拟机发出的指令转换为符合本机 ISA 的指令,代表为 QEMU 和 Bochs 。
指令集虚拟化就是仿真 ,它提供了几乎完全不受局限的兼容性,甚至能做到直接在 Web 浏览器上运行完整操作系统这种令人惊讶的效果。但是,由于每条指令都要由软件来转换和模拟,它也是性能损失最大的虚拟化技术。
硬件抽象层虚拟化(Hardware Abstraction Level Virtualization)
即以软件或者直接通过硬件来模拟处理器、芯片组、内存、磁盘控制器、显卡等设备的工作过程。
硬件抽象层虚拟化既可以使用纯软件的二进制翻译来模拟虚拟设备,也可以由硬件的 Intel VT-d 、 AMD-Vi) 这类虚拟化技术,将某个物理设备直通(Passthrough)到虚拟机中使用,代表为 VMware ESXi 和 Hyper-V 。这里你可以知道的是,如果没有预设语境,一般人们所说的”虚拟机”就是指这一类虚拟化技术。
操作系统层虚拟化(OS Level Virtualization)
无论是指令集虚拟化还是硬件抽象层虚拟化,都会运行一套完全真实的操作系统,来解决 ABI 兼容性和环境兼容性的问题,虽然 ISA 兼容性是虚拟出来的,但 ABI 兼容性和环境兼容性却是真实存在的。
而操作系统层虚拟化则不会提供真实的操作系统,而是会采用隔离手段,使得不同进程拥有独立的系统资源和资源配额,这样看起来它好像是独享了整个操作系统一般,但其实系统的内核仍然是被不同进程所共享的。
操作系统层虚拟化的另一个名字,就是这个模块的主角”容器化”(Containerization) 。所以由此可见,容器化仅仅是虚拟化的一个子集,它只能提供操作系统内核以上的部分 ABI 兼容性与完整的环境兼容性。
而这就意味着,如果没有其他虚拟化手段的辅助,在 Windows 系统上是不可能运行 Linux 的 Docker 镜像的(现在可以,是因为有其他虚拟机或者 WSL2 的支持),反之亦然。另外,这也同样决定了,如果 Docker 宿主机的内核版本是 Linux Kernel 5.6,那无论上面运行的镜像是 Ubuntu、RHEL、Fedora、Mint,或者是其他任何发行版的镜像,看到的内核一定都是相同的 Linux Kernel 5.6。
容器化牺牲了一定的隔离性与兼容性,换来的是比前两种虚拟化更高的启动速度、运行性能和更低的执行负担。
运行库虚拟化(Library Level Virtualization)
与操作系统虚拟化采用隔离手段来模拟系统不同,运行库虚拟化选择使用软件翻译的方法来模拟系统,它是以一个独立进程来代替操作系统内核,来提供目标软件运行所需的全部能力。
那么,这种虚拟化方法获得的 ABI 兼容性高低,就取决于软件能不能足够准确和全面地完成翻译工作,它的代表为 WINE (Wine Is Not an Emulator 的缩写,一款在 Linux 下运行 Windows 程序的软件)和 WSL (特指 Windows Subsystem for Linux Version 1)。
语言层虚拟化(Programming Language Level Virtualization)
即由虚拟机将高级语言生成的中间代码,转换为目标机器可以直接执行的指令,代表为 Java 的 JVM 和.NET 的 CLR。
不过,虽然各大厂商肯定都会提供在不同系统下接口都相同的标准库,但本质上,这种虚拟化技术并不是直接去解决任何 ABI 兼容性和环境兼容性的问题,而是将不同环境的差异抽象封装成统一的编程接口,供程序员使用。
小结
作为整个模块的开篇,我们这节课的学习目的是要明确软件运行的”兼容性”指的是什么,以及要能理解我们经常能听到的”虚拟化”概念指的是什么。只有理清了这些概念、统一了语境,在后续的课程学习中,我们关于容器、编排、云原生等的讨论,才不会产生太多的歧义。
46 | 容器的崛起(上):文件、访问、资源的隔离
今天,我们就先来学习下 Linux 系统中隔离技术的发展历程,以此为下节课理解”以容器封装应用”的思想打好前置基础。
隔离文件:chroot
首先要知道,人们使用容器的最初目的,并不是为了部署软件,而是为了隔离计算机中的各类资源,以便降低软件开发、测试阶段可能产生的误操作风险,或者是专门充当 蜜罐) ,吸引黑客的攻击,以便监视黑客的行为。
容器的起点呢,可以追溯到 1979 年 Version 7 UNIX 系统中提供的 chroot 命令 ,这个命令是英文单词”Change Root”的缩写,它所具备的功能是当某个进程经过 chroot 操作之后,它的根目录就会被锁定在命令参数所指定的位置,以后它或者它的子进程就不能再访问和操作该目录之外的其他文件。
1991 年,世界上第一个监控黑客行动的蜜罐程序就是使用 chroot 来实现的,那个参数指定的根目录当时被作者被戏称为”Chroot 监狱”(Chroot Jail),而黑客突破 chroot 限制的方法就叫做 Jailbreak。后来,FreeBSD 4.0 系统重新实现了 chroot 命令,把它作为系统中进程沙箱隔离的基础,并将其命名为 FreeBSD jail 。
再后来,苹果公司又以 FreeBSD 为基础研发出了举世闻名的 iOS 操作系统,此时,黑客们就把绕过 iOS 沙箱机制,以 root 权限任意安装程序的方法称为” 越狱 “(Jailbreak),当然这些故事都是题外话了。
到了 2000 年,Linux Kernel 2.3.41 版内核引入了 pivot_root 技术来实现文件隔离,pivot_root 直接切换了 根文件系统 (rootfs),有效地避免了 chroot 命令可能出现的安全性漏洞。咱们课程后面要提到的容器技术,比如 LXC、Docker 等等,也都是优先使用 pivot_root 来实现根文件系统切换的。
不过时至今日,chroot 命令依然活跃在 Unix 系统,以及几乎所有主流的 Linux 发行版中,同时也以命令行工具( chroot(8) )或者系统调用( chroot(2) )的形式存在着,但无论是 chroot 命令还是 pivot_root,它们都不能提供完美的隔离性。
其实原本按照 Unix 的设计哲学, 一切资源都可以视为文件 (In UNIX,Everything is a File),一切处理都可以视为对文件的操作,在理论上应该是隔离了文件系统就可以安枕无忧才对。
可是,哲学归哲学,现实归现实,从硬件层面暴露的低层次资源,比如磁盘、网络、内存、处理器,再到经操作系统层面封装的高层次资源,比如 UNIX 分时(UNIX Time-Sharing,UTS)、进程 ID(Process ID,PID)、用户 ID(User ID,UID)、进程间通信(Inter-Process Communication,IPC)等等,都存在着大量以非文件形式暴露的操作入口。
所以我才会说,以 chroot 为代表的文件隔离,仅仅是容器崛起之路的起点而已。
隔离访问:namespaces
那么到了 2002 年,Linux Kernel 2.4.19 版内核引入了一种全新的隔离机制: Linux 名称空间 (Linux Namespaces)。
名称空间的概念在很多现代的高级程序语言中都存在,它主要的作用是 避免不同开发者提供的 API 相互冲突 ,相信作为一名开发人员的你肯定不陌生。
Linux 的名称空间是一种 由内核直接提供的全局资源封装,它是内核针对进程设计的访问隔离机制 。进程在一个独立的 Linux 名称空间中朝系统看去,会觉得自己仿佛就是这方天地的主人,拥有这台 Linux 主机上的一切资源,不仅文件系统是独立的,还有着独立的 PID 编号(比如拥有自己的 0 号进程,即系统初始化的进程)、UID/GID 编号(比如拥有自己独立的 root 用户)、网络(比如完全独立的 IP 地址、网络栈、防火墙等设置),等等,此时进程的心情简直不能再好了。
事实上,Linux 的名称空间是受” 贝尔实验室九号项目 “(一个分布式操作系统,”九号”项目并非代号,操作系统的名字就叫”Plan 9 from Bell Labs”,充满了赛博朋克风格)的启发而设计的,最初的目的依然只是为了隔离文件系统,而不是为了什么容器化的实现。这点我们从 2002 年发布时,Linux 只提供了 Mount 名称空间,并且其构造参数为”CLONE_NEWNS”(即 Clone New Namespace 的缩写)而非”CLONE_NEWMOUNT”,就能看出一些端倪。
到了后来,要求系统隔离其他访问操作的呼声就愈发强烈,从 2006 年起,内核陆续添加了 UTS、IPC 等名称空间隔离,直到目前最新的 Linux Kernel 5.6 版内核为止,Linux 名称空间支持了以下八种资源的隔离(内核的官网 Kernel.org 上仍然只列出了 前六种 ,从 Linux 的 Man 命令能查到 全部八种 ):

阅读链接补充:
如今,对文件、进程、用户、网络等各类信息的访问,都被囊括在 Linux 的名称空间中,即使一些今天仍有没被隔离的访问(比如 syslog 就还没被隔离,容器内可以看到容器外其他进程产生的内核 syslog),在以后也可以跟随内核版本的更新纳入到这套框架之内。
现在,距离完美的隔离性就只差最后一步了:资源的隔离。
隔离资源:cgroups
如果要让一台物理计算机中的各个进程看起来像独享整台虚拟计算机的话,不仅要隔离各自进程的访问操作,还必须能独立控制分配给各个进程的资源使用配额。不然的话,一个进程发生了内存溢出或者占满了处理器,其他进程就莫名其妙地被牵连挂起,这样肯定算不上是完美的隔离。
而 Linux 系统解决以上问题的方案就是 控制群组 (Control Groups,目前常用的简写为 cgroups),它与名称空间一样,都是 直接由内核提供的功能,用于隔离或者说分配并限制某个进程组能够使用的资源配额 。这里的资源配额包括了处理器时间、内存大小、磁盘 I/O 速度,等等,具体你可以参考下这里给出的表格:
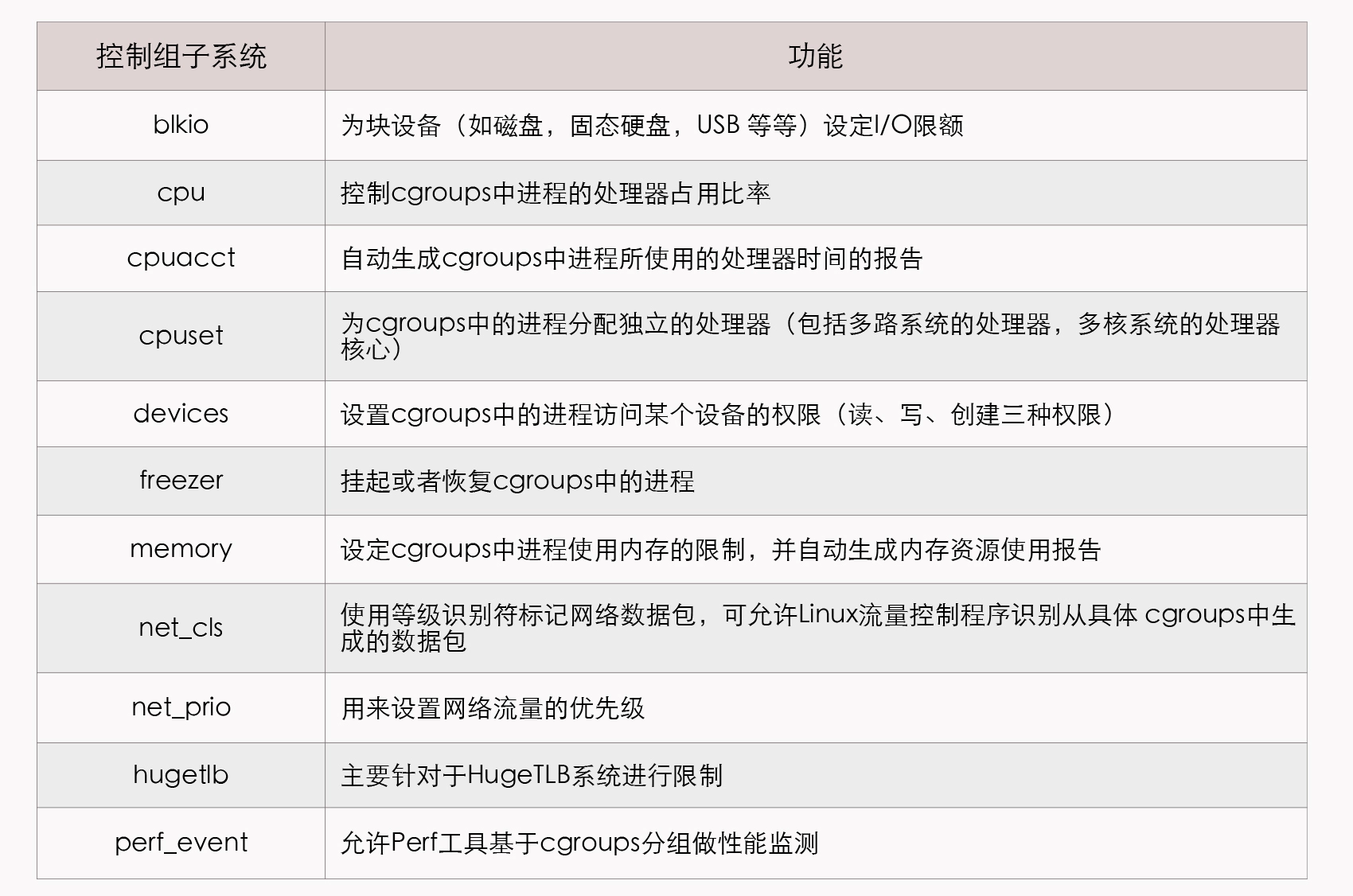
cgroups 项目最早是由 Google 的工程师(主要是 Paul Menage 和 Rohit Seth)在 2006 年发起的,当时取的名字就叫做”进程容器”(Process Containers),不过”容器”(Container)这个名词的定义在那时候还没有今天那么清晰,不同场景中常有不同的指向。
所以,为了避免混乱,到 2007 年这个项目才被重新命名为 cgroups,在 2008 年合并到了 2.6.24 版的内核后正式对外发布,这一阶段的 cgroups 就被称为”第一代 cgroups”。
后来,在 2016 年 3 月发布的 Linux Kernel 4.5 中,搭载了由 Facebook 工程师(主要是 Tejun Heo)重新编写的”第二代 cgroups”,其关键改进是支持 Unified Hierarchy ,这个功能可以让管理员更加清晰、精确地控制资源的层级关系。目前这两个版本的 cgroups 在 Linux 内核代码中是并存的,不过在下节课我会给你介绍的封装应用 Docker,就暂时仅支持第一代的 cgroups。
小结
这节课,我给你介绍了容器技术和思想的起源:chroot 命令,这是计算机操作系统中最早的成规模的隔离技术。
此外,你现在也了解到了 namespaces 和 cgroups 对资源访问与资源配额的隔离,它们不仅是容器化技术的基础,在现代 Linux 操作系统中也已经成为了无可或缺的基石。理解了这些基础性的知识,是学习和掌握下节课中讲解的容器应用,即不同封装对象、封装思想的必要前提。
47 | 容器的崛起(下):系统、应用、集群的封装
在理解了从隔离角度出发的容器化技术的发展之后,这节课我们接着从封装的角度来学习容器应用的发展。
封装系统:LXC
当文件系统、访问、资源都可以被隔离后,容器就已经具备它降生所需要的全部前置支撑条件了,并且 Linux 的开发者们也已经明确地看到了这一点。
因此,为了降低普通用户综合使用 namespaces、cgroups 这些低级特性的门槛,2008 年 Linux Kernel 2.6.24 内核在刚刚开始提供 cgroups 的同一时间,就马上发布了名为 Linux 容器 (LinuX Containers,LXC)的系统级虚拟化功能。
当然在这之前,在 Linux 上并不是没有系统级虚拟化的解决方案,比如传统的 OpenVZ 和 Linux-VServer 都能够实现容器隔离,并且只会有很低的性能损失(按 OpenVZ 提供的数据,只会有 1~3% 的损失), 但它们都是非官方的技术,使用它们最大的阻碍是系统级虚拟化必须要有内核的支持。 为此,它们就只能通过非官方内核补丁的方式来修改标准内核,才能获得那些原本在内核中不存在的能力。
如此一来,LXC 就带着令人瞩目的光环登场,它的出现促使”容器”从一个阳春白雪的、只流传于开发人员口中的技术词汇,逐渐向整个软件业的公共概念、共同语言发展,就如同今天的”服务器””客户端”和”互联网”一样。
不过,相信你现在肯定会好奇:为什么如今一提到容器,大家首先联想到的是 Docker 而不是 LXC?为什么去问 10 个开发人员,至少有 9 个听过 Docker,但如果问 LXC,可能只有 1 个人听说过?
那么,我们首先可以知道的是,LXC 的出现肯定是受到了 OpenVZ 和 Linux-VServer 的启发,摸着巨人的肩膀过河当然没有什么不对。但可惜的是,LXC 在设定自己的发展目标时,也被前辈们的影响所局限了。
其实,LXC 眼中的容器的定义与 OpenVZ 和 Linux-VServer 并没有什么差别,它们都是 一种封装系统的轻量级虚拟机 ,而 Docker 眼中的容器的定义则是一种封装应用的技术手段。这两种封装理念在技术层面并没有什么本质区别,但在应用效果上差异可就相当大了。
我举个具体的例子,如果你要建设一个 LAMP) (Linux、Apache、MySQL、PHP)应用,按照 LXC 的思路,你应该先编写或者寻找到 LAMP 的 template (可以暂且不准确地类比为 LXC 版本的 Dockerfile 吧),以此构造出一个安装了 LAMP 的虚拟系统。
如果按部署虚拟机的角度来看,这还算挺方便的,作为那个时代(距今也就十年)的系统管理员,所有软件、补丁、配置都是要自己搞定的,部署一台新虚拟机要花费一两天时间都很正常,而有了 LXC 的 template,一下子帮你把 LAMP 都安装好了,还想要啥自行车?
但是,作为一名现代的系统管理员,这里的问题就相当大了:如果我想把 LAMP 改为 LNMP(Linux、Nginx、MySQL、PHP)该怎么办?如果我想把 LAMP 里的 MySQL 5 调整为 MySQL 8 该怎么办?这些都得通过找到或者自己编写新的 template 来解决。
或者好吧,那这台机的软件、版本都配置对了,下一台机我要构建 LYME) 或者 MEAN) ,又该怎么办呢?以封装系统为出发点,如果仍然是按照先装系统再装软件的思路,就永远无法做到一两分钟甚至十几秒钟就构造出一个合乎要求的软件运行环境,这也就决定了 LXC 不可能形成今天的容器生态。
所以,接下来舞台的聚光灯终于落到了 Docker 身上。
封装应用:Docker
在 2013 年宣布开源的 Docker,毫无疑问是容器发展历史上里程碑式的发明,然而 Docker 的成功似乎没有太多技术驱动的成分。至少对于开源早期的 Docker 而言,确实没有什么能构成壁垒的技术。
事实上,它的容器化能力直接来源于 LXC,它的镜像分层组合的文件系统直接来源于 AUFS ,在 Docker 开源后不久,就有人仅用了一百多行的 Shell 脚本,便实现了 Docker 的核心功能(名为 Bocker ,提供了 docker bulid/pull/images/ps/run/exec/logs/commit/rm/rmi 等功能)。
那你可能就要问了: 为何历史选择了 Docker,而不是 LXC 或者其他容器技术呢? 对于这个问题,我想引用下(转述非直译,有所精简)DotCloud 公司(当年创造 Docker 的公司,已于 2016 年倒闭)创始人所罗门 · 海克斯(Solomon Hykes) 在Stackoverflow 上的一段问答:
为什么要用 Docker 而不是 LXC?(Why would I use Docker over plain LXC?)
Docker 除了包装来自 Linux 内核的特性之外,它的价值还在于:
- 跨机器的绿色部署 :Docker 定义了一种将应用及其所有的环境依赖都打包到一起的格式,仿佛它原本就是绿色软件一样。而 LXC 并没有提供这样的能力,使用 LXC 部署的新机器很多细节都要依赖人的介入,虚拟机的环境基本上肯定会跟你原本部署程序的机器有所差别。
- 以应用为中心的封装 :Docker 封装应用而非封装机器的理念贯穿了它的设计、API、界面、文档等多个方面。相比之下,LXC 将容器视为对系统的封装,这局限了容器的发展。
- 自动构建 :Docker 提供了开发人员从在容器中构建产品的全部支持,开发人员无需关注目标机器的具体配置,就可以使用任意的构建工具链,在容器中自动构建出最终产品。
- 多版本支持 :Docker 支持像 Git 一样管理容器的连续版本,进行检查版本间差异、提交或者回滚等操作。从历史记录中,你可以查看到该容器是如何一步一步构建成的,并且只增量上传或下载新版本中变更的部分。
- 组件重用 :Docker 允许将任何现有容器作为基础镜像来使用,以此构建出更加专业的镜像。
- 共享 :Docker 拥有公共的镜像仓库,成千上万的 Docker 用户在上面上传了自己的镜像,同时也使用他人上传的镜像。
- 工具生态 :Docker 开放了一套可自动化和自行扩展的接口,在此之上用户可以实现很多工具来扩展其功能,比如容器编排、管理界面、持续集成,等等。
—— Solomon Hykes,Stackoverflow ,2013
这段回答也被收录到了 Docker 官网的 FAQ 上,从 Docker 开源到今天从没有改变过。
其实,促使 Docker 一问世就惊艳世间的,并不是什么黑科技式的秘密武器,而是它符合历史潮流的创意与设计理念,还有充分开放的生态运营。由此可见,在正确的时候,正确的人手上有一个优秀的点子,确实有机会引爆一个时代。
这里我还想让你看一张图片,它是 Docker 开源一年后(截至 2014 年 12 月)获得的成绩。
我们可以发现,从开源到现在,只过了短短数年时间,Docker 就已经成为了软件开发、测试、分发、部署等各个环节都难以或缺的基础支撑,而它自身的架构也发生了相当大的改变:Docker 被分解为了几个子系统,包括 Docker Client、Docker Daemon、Docker Registry、Docker Container 等等,以及 Graph、Driver、libcontainer 等各司其职的模块。
所以此时,我们再说一百多行脚本就能实现 Docker 的核心功能,再说 Docker 没有太高的技术含量,就不太合适了。
2014 年,Docker 开源了自己用 Golang 开发的 libcontainer ,这是一个越过 LXC 直接操作 namespaces 和 cgroups 的核心模块,有了 libcontainer 以后,Docker 就能直接与系统内核打交道,不必依赖 LXC 来提供容器化隔离能力了。
到了 2015 年,在 Docker 的主导和倡议下,多家公司联合制定了” 开放容器交互标准 “(Open Container Initiative,OCI),这是一个关于容器格式和运行时的规范文件,其中包含了运行时标准( runtime-spec )、容器镜像标准( image-spec )和镜像分发标准( distribution-spec ,分发标准还未正式发布)。
- 运行时标准定义了应该如何运行一个容器、如何管理容器的状态和生命周期、如何使用操作系统的底层特性(namespaces、cgroup、pivot_root 等);
- 容器镜像标准规定了容器镜像的格式、配置、元数据的格式,你可以理解为对镜像的静态描述;
- 镜像分发标准则规定了镜像推送和拉取的网络交互过程。
由此,为了符合 OCI 标准,Docker 推动自身的架构继续向前演进。
首先,它是将 libcontainer 独立出来,封装重构成 runC 项目 ,并捐献给了 Linux 基金会管理。runC 是 OCI Runtime 的首个参考实现,它提出了”让标准容器无所不在”(Make Standard Containers Available Everywhere)的口号。
而为了能够兼容所有符合标准的 OCI Runtime 实现,Docker 进一步重构了 Docker Daemon 子系统,把其中与运行时交互的部分抽象为了 containerd 项目 。
这是一个负责管理容器执行、分发、监控、网络、构建、日志等功能的核心模块,其内部会为每个容器运行时创建一个 containerd-shim 适配进程,默认与 runC 搭配工作,但也可以切换到其他 OCI Runtime 实现上(然而实际并没做到,最后 containerd 仍是紧密绑定于 runC)。
后来到了 2016 年,Docker 把 containerd 捐献给了 CNCF 管理。
可以说,runC 与 containerd 两个项目的捐赠托管,既带有 Docker 对开源信念的追求,也带有 Docker 在众多云计算大厂夹击下自救的无奈,这两个项目也将会成为未来 Docker 消亡和存续的伏笔(到这节课的末尾你就能理解这句矛盾的话了)。
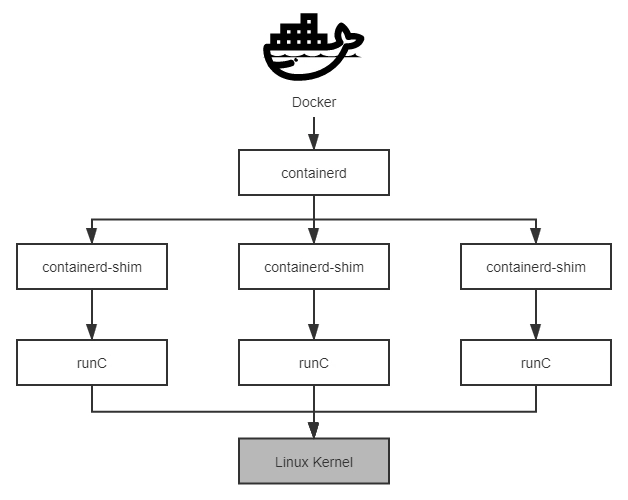
以上我列举的这些 Docker 推动的开源与标准化工作,既是对 Docker 为开源乃至整个软件业做出贡献的赞赏,也是为后面给你介绍容器编排时,讲解当前容器引擎的混乱关系做的前置铺垫。
我们当然很清楚的一个事实就是,Docker 目前无疑在容器领域具有统治地位,但其统治的稳固程度不仅没到高枕无忧,说是危机四伏都不为过。
我之所以这么说的原因,是因为现在已经能隐隐看出足以威胁动摇 Docker 地位的潜在可能性,而引出这个风险的,就是 Docker 虽然赢得了容器战争的胜利,但 Docker Swarm 却输掉了容器编排战争。
实际上,从结果回望当初,Docker 能赢得容器战争是存在了一些偶然性的,而能确定的是 Docker Swarm 输掉编排战争是必然的。为什么这么说呢?下面我就来揭晓答案。
封装集群:Kubernetes
如果说 以 Docker 为代表的容器引擎 ,是把软件的发布流程从分发二进制安装包,转变为了直接分发虚拟化后的整个运行环境,让应用得以实现跨机器的绿色部署;那 以 Kubernetes 为代表的容器编排框架 ,就是把大型软件系统运行所依赖的集群环境也进行了虚拟化,让集群得以实现跨数据中心的绿色部署,并能够根据实际情况自动扩缩。
我们从上节课的容器崛起之路,讲到现在 Docker 和 Kubernetes 这个阶段,已经不再是介绍历史了,从这里开始发生的变化,都是近几年软件业界中的热点事件,也是”容器的崛起”这个小章节我们要讨论的主要话题。不过现在,我暂时不打算介绍 Kubernetes 的技术细节,在”容器间网络””容器持久化存储”及”资源调度”这几个章节中,我还会进行更详细的解析。
在今天这节课里,我们就先从 宏观层面 去理解 Kubernetes 的诞生与演变的驱动力,这对正确理解未来云原生的发展方向是至关重要的。
从 Docker 到 Kubernetes
众所周知,Kubernetes 可谓是出身名门,它的前身是 Google 内部已经运行多年的集群管理系统 Borg,在 2014 年 6 月使用 Golang 完全重写后开源。自它诞生之日起,只要能与云计算稍微扯上关系的业界巨头,都对 Kubernetes 争相追捧,IBM、RedHat、Microsoft、VMware 和华为都是它最早期的代码贡献者。
此时,距离云计算从实验室到工业化应用已经有十个年头,不过大量应用使用云计算的方式,还是停滞在了传统的 IDC(Internet Data Center)时代,它们仅仅是用云端的虚拟机代替了传统的物理机而已。
尽管早在 2013 年,Pivotal(持有着 Spring Framework 和 Cloud Foundry 的公司)就提出了”云原生”的概念,但是要实现服务化、具备韧性(Resilience)、弹性(Elasticity)、可观测性(Observability)的软件系统依旧十分困难,在当时基本只能依靠架构师和程序员高超的个人能力,云计算本身还帮不上什么忙。
而在云的时代,不能充分利用云的强大能力,这让云计算厂商无比遗憾,也无比焦虑。
所以可以说,直到 Kubernetes 横空出世,大家才终于等到了破局的希望,认准了这就是云原生时代的操作系统,是让复杂软件在云计算下获得韧性、弹性、可观测性的最佳路径,也是为厂商们推动云计算时代加速到来的关键引擎之一。
2015 年 7 月,Kubernetes 发布了第一个正式版本 1.0 版,更重要的事件是 Google 宣布与 Linux 基金会共同筹建 云原生基金会 (Cloud Native Computing Foundation,CNCF),并且把 Kubernetes 托管到 CNCF,成为其第一个项目。随后,Kubernetes 就以摧枯拉朽之势消灭了容器编排领域的其他竞争对手,哪怕 Docker Swarm 有着 Docker 在容器引擎方面的先天优势,DotCloud 后来甚至把 Swarm 直接内置入 Docker 之中,都不能稍稍阻挡 Kubernetes 前进的步伐。
但是我们也要清楚, Kubernetes 的成功与 Docker 的成功并不一样。
Docker 靠的是优秀的理念,它是以一个”好点子”引爆了一个时代。我相信就算没有 Docker,也会有 Cocker 或者 Eocker 的出现,但由成立仅三年的 DotCloud 公司(三年后又倒闭)做成了这样的产品,确实有一定的偶然性。
而 Kubernetes 的成功,不仅有 Google 深厚的技术功底作支撑、有领先时代的设计理念,更加关键的是 Kubernetes 的出现,符合所有云计算大厂的切身利益,有着业界巨头不遗余力地广泛支持,所以它的成功便是一种必然。
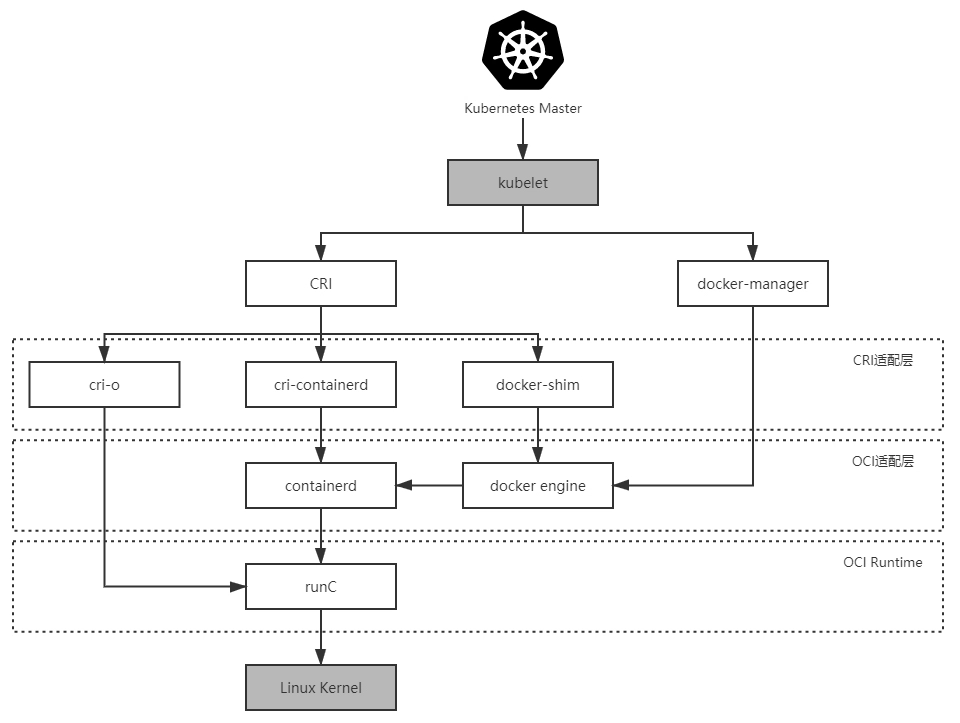
Kubernetes 与 Docker 两者的关系十分微妙,因此我们 把握住两者关系的变化过程,是理解 Kubernetes 架构演变与 CRI、OCI 规范的良好线索。
Kubernetes 是如何一步步与 Docker 解耦的?
在 Kubernetes 开源的早期,它是完全依赖且绑定 Docker 的,并没有过多地考虑日后有使用其他容器引擎的可能性。直到 Kubernetes 1.5 之前,Kubernetes 管理容器的方式都是通过内部的 DockerManager,向 Docker Engine 以 HTTP 方式发送指令,通过 Docker 来操作镜像的增删改查的,如上图最右边线路的箭头所示(图中的 kubelet 是集群节点中的代理程序,负责与管理集群的 Master 通信,其他节点的含义在下面介绍时都会有解释)。
现在,我们可以把这个阶段的 Kubernetes 与容器引擎的调用关系捋直,并结合前面提到的 Docker 捐献 containerd 与 runC 后重构的调用,一起来梳理下这个完整的调用链条:
Kubernetes Master → kubelet → DockerManager → Docker Engine → containerd → runC
然后到了 2016 年,Kubernetes 1.5 版本开始引入” 容器运行时接口 “(Container Runtime Interface,CRI),这是一个定义容器运行时应该如何接入到 kubelet 的规范标准,从此 Kubernetes 内部的 DockerManager,就被更为通用的 KubeGenericRuntimeManager 所替代了(实际上在 1.6.6 之前都仍然可以看到 DockerManager),kubelet 与 KubeGenericRuntimeManager 之间通过 gRPC 协议通信。
不过,由于 CRI 是在 Docker 之后才发布的规范,Docker 是肯定不支持 CRI 的,所以 Kubernetes 又提供了 DockerShim 服务作为 Docker 与 CRI 的适配层,由它与 Docker Engine 以 HTTP 形式通信,从而实现了原来 DockerManager 的全部功能。
此时,Docker 对 Kubernetes 来说就只是一项默认依赖,而非之前的不可或缺了,现在它们的调用链为:
Kubernetes Master → kubelet → KubeGenericRuntimeManager → DockerShim → Docker Engine → containerd → runC
接着再到 2017 年,由 Google、RedHat、Intel、SUSE、IBM 联合发起的 CRI-O (Container Runtime Interface Orchestrator)项目发布了首个正式版本。
一方面,我们从名字上就可以看出来,它肯定是完全遵循 CRI 规范来实现的;另一方面,它可以支持所有符合 OCI 运行时标准的容器引擎,默认仍然是与 runC 搭配工作的,如果要换成 Clear Containers 、 Kata Containers 等其他 OCI 运行时,也完全没有问题。
不过到这里,开源版的 Kubernetes 虽然完全支持用户去自由选择(根据用户宿主机的环境选择)是使用 CRI-O、cri-containerd,还是 DockerShim 来作为 CRI 实现,但在 RedHat 自己扩展定制的 Kubernetes 企业版,即 OpenShift 4 中,调用链已经没有了 Docker Engine 的身影:
Kubernetes Master → kubelet → KubeGenericRuntimeManager → CRI-O→ runC
当然,因为此时 Docker 在容器引擎中的市场份额仍然占有绝对优势,对于普通用户来说,如果没有明确的收益,也并没有什么动力要把 Docker 换成别的引擎。所以 CRI-O 即使摆出了直接挖掉 Docker 根基的凶悍姿势,实际上也并没有给 Docker 带来太多即时可见的影响。不过,我们能够想像此时 Docker 心中肯定充斥了难以言喻的危机感。
时间继续来到了 2018 年,由 Docker 捐献给 CNCF 的 containerd,在 CNCF 的精心孵化下发布了 1.1 版,1.1 版与 1.0 版的最大区别是此时它已经完美地支持了 CRI 标准,这意味着原本用作 CRI 适配器的 cri-containerd 从此不再被需要。
此时,我们再观察 Kubernetes 到容器运行时的调用链,就会发现调用步骤会比通过 DockerShim、Docker Engine 与 containerd 交互的步骤要减少两步,这又意味着用户只要愿意抛弃掉 Docker 情怀的话,在容器编排上就可以至少省略一次 HTTP 调用,获得性能上的收益。而且根据 Kubernetes 官方给出的 测试数据 ,这些免费的收益还相当地可观。
如此,Kubernetes 从 1.10 版本宣布开始支持 containerd 1.1,在调用链中就已经能够完全抹去 Docker Engine 的存在了:
Kubernetes Master → kubelet → KubeGenericRuntimeManager → containerd → runC
而到了今天,要使用哪一种容器运行时,就取决于你安装 Kubernetes 时宿主机上的容器运行时环境,但对于云计算厂商来说,比如国内的 阿里云 ACK 、 腾讯云 TKE 等直接提供的 Kubernetes 容器环境,采用的容器运行时普遍都已经是 containerd 了,毕竟运行性能对它们来说就是核心生产力和竞争力。
小结
学完这节课,我们可以试着来做一个判断:在未来,随着 Kubernetes 的持续发展壮大,Docker Engine 经历从不可或缺、默认依赖、可选择、直到淘汰,会是大概率的事件。从表面上看,这件事情是 Google、RedHat 等云计算大厂联手所为,可实际淘汰它的还是技术发展的潮流趋势。这就如同 Docker 诞生时依赖 LXC,到最后用 libcontainer 取代掉 LXC 一样。
同时,我们也该看到事情的另一面:现在连 LXC 都还没有挂掉,反倒还发展出了更加专注于跟 OpenVZ 等系统级虚拟化竞争的 LXD ,就可以相信 Docker 本身也是很难彻底消亡的,已经养成习惯的 CLI 界面,已经形成成熟生态的镜像仓库等,都应该会长期存在,只是在容器编排领域,未来的 Docker 很可能只会以 runC 和 containerd 的形式存续下去,毕竟它们最初都源于 Docker 的血脉。
48 | 以容器构建系统(上):隔离与协作
从这节课开始,我们讨论的焦点会从容器本身,过渡到容器编排上。
我们知道,自从 Docker 提出”以封装应用为中心”的容器发展理念,成功取代了”以封装系统为中心”的 LXC 以后,一个容器封装一个单进程应用,已经成为了被广泛认可的最佳实践。
然而当单体时代过去之后,分布式系统里对于应用的概念已经不再等同于进程了,此时的应用需要多个进程共同协作,通过集群的形式对外提供服务,那么以虚拟化方法实现这个目标的过程,就被称为 容器编排(Container Orchestration) 。
而到今天,Kubernetes 已经成为了容器编排的代名词。不过在课程中,我并不打算过多介绍 Kubernetes 具体有哪些功能,也不会为你说明它由 Pod、Node、Deployment、ReplicaSet 等各种类型的资源组成可用的服务、集群管理平面与节点之间是如何工作的、每种资源该如何配置使用,等等,如果你想了解这方面信息,可以去查看 Kubernetes 官网的文档库或任何一本以 Kubernetes 为主题的使用手册。
在课程中,我真正希望能帮你搞清楚的问题是 “为什么 Kubernetes 会设计成现在这个样子?””为什么以容器构建系统应该这样做?”
而要寻找这些问题的答案,最好是从它们 设计的实现意图 出发。所以在接下来的两节课中,我虚构了一系列从简单到复杂的场景,带你来理解并解决这些场景中的问题。
这里我还想说明一点,学习这两节课的内容并不要求你对 Kubernetes 有过多深入的了解,但需要你至少使用过 Kubernetes 和 Docker,基本了解它的核心功能与命令;另外,课程中还会涉及到一点儿 Linux 系统内核资源隔离的基础知识,别担心,只要你仔细学习了”容器的崛起”这个小章节,就已经完全够用了。
构建容器编排系统时都会遇到什么问题?
好,现在我们来设想一下,如果让你来设计一套容器编排系统,协调各种容器来共同来完成一项工作,你可能会遇到什么问题?会如何着手解决呢?
我们先从最简单的场景开始吧:
场景一:假设你现在有两个应用,其中一个是 Nginx,另一个是为该 Nginx 收集日志的 Filebeat,你希望将它们封装为容器镜像,以方便日后分发。
最直接的方案就将 Nginx 和 Filebeat 直接编译成同一个容器镜像,这是可以做到的,而且并不复杂。不过这样做其实会埋下很大的隐患: 它违背了 Docker 提倡的单个容器封装单进程应用的最佳实践。
Docker 设计的 Dockerfile 只允许有一个 ENTRYPOINT,这并不是什么随便添加的人为限制,而是因为 Docker 只能通过监视 PID 为 1 的进程(即由 ENTRYPOINT 启动的进程)的运行状态,来判断容器的工作状态是否正常,像是容器退出执行清理、容器崩溃自动重启等操作,Docker 都必须先判断状态。
那么我们可以设想一下,即使我们使用了 supervisord 之类的进程控制器,来解决同时启动 Nginx 和 Filebeat 进程的问题,如果因为某种原因它们不停发生崩溃、重启,那 Docker 也无法察觉到,它只能观察到 supervisord 的运行状态。所以,场景一关于封装为容器镜像的需求会理所当然地演化成场景二。
场景二:假设你现在有两个 Docker 镜像,其中一个封装了 HTTP 服务,为便于称呼,叫它 Nginx 容器,另一个封装了日志收集服务,叫它 Filebeat 容器。现在你要求 Filebeat 容器能收集 Nginx 容器产生的日志信息。
其实,场景二的需求依然不难解决,只要在 Nginx 容器和 Filebeat 容器启动时,分别把它们的日志目录和收集目录挂载为宿主机同一个磁盘位置的 Volume 即可,在 Docker 中,这种操作是十分常用的容器间信息交换手段。
不过,容器间信息交换不仅仅是文件系统。
假如此时我又引入了一个新的工具 confd ,它是 Linux 下的一种配置管理工具,作用是根据配置中心(Etcd、ZooKeeper、Consul)的变化,自动更新 Nginx 的配置。那么这样的话,就又会遇到新的问题。
这是因为,confd 需要向 Nginx 发送 HUP 信号,才便于 通知 Nginx 配置已经发生了变更,而发送 HUP 信号自然就要求 confd 与 Nginx 能够进行 IPC 通信才行。
当然,尽管共享 IPC 名称空间不如共享 Volume 常见,但 Docker 同样支持了这个功能,也就是通过 docker run 命令提供了 —ipc 参数,用来把多个容器挂载到同一个父容器的 IPC 名称空间之下,以实现容器间共享 IPC 名称空间的需求。类似地,如果要共享 UTS 名称空间,可以使用 —uts 参数;要共享网络名称空间的话,就使用 —net 参数。
这就是 Docker 针对场景二这种不跨机器的多容器协作,所给出的解决方案了。
实际上, 自动地为多个容器设置好共享名称空间,就是Docker Compose提供的核心能力。
不过,这种针对具体应用需求来共享名称空间的方案,确实可以工作,但并不够优雅,也谈不上有什么扩展性。要知道,容器的本质是对 cgroups 和 namespaces 所提供的隔离能力的一种封装,在 Docker 提倡的单进程封装的理念影响下,容器蕴含的隔离性也多了仅针对于单个进程的额外局限。
然而 Linux 的 cgroups 和 namespaces,原本都是针对进程组而不只是单个进程来设计的,同一个进程组中的多个进程,天然就可以共享相同的访问权限与资源配额。
所以,如果现在我们把容器与进程在概念上对应起来,那 容器编排的第一个扩展点,就是要找到容器领域中与”进程组”相对应的概念,这是实现容器从隔离到协作的第一步。在 Kubernetes 的设计里,这个对应物叫做Pod。
额外知识:Pod 名字的由来与含义
在容器正式出现之前的 Borg 系统中,Pod 的概念就已经存在了,从 Google 的发表的《 Large-Scale Cluster Management at Google with Borg 》里可以看出,Kubernetes 时代的 Pod 整合了 Borg 时代的”Prod”(Production Task 的缩写)与”Non-Prod”的职能。由于 Pod 一直没有权威的中文翻译,我在后面课程中会尽量用英文指代,偶尔需要中文的场合就使用 Borg 中 Prod 的译法,即”生产任务”来指代。
这样,有了”容器组”的概念,只需要把多个容器放到同一个 Pod 中,场景二的问题就可以解决了。
Pod 的含义与职责
事实上, 扮演容器组的角色,满足容器共享名称空间的需求,是 Pod 两大最基本的职责之一 ,同处于一个 Pod 内的多个容器,相互之间会以超亲密的方式协作。请注意,”超亲密”在这里的用法不是什么某种带强烈感情色彩的形容词,而是代表了一种有具体定义的协作程度。
具体是什么意思呢?
对于普通非亲密的容器来说,它们一般以网络交互方式(其他的如共享分布式存储来交换信息,也算跨网络)协作;对于亲密协作的容器来说,是指它们被调度到同一个集群节点上,可以通过共享本地磁盘等方式协作;而超亲密的协作,是特指多个容器位于同一个 Pod 这种特殊关系,它们将默认共享以下名称空间:
- UTS 名称空间 :所有容器都有相同的主机名和域名。
- 网络名称空间 :所有容器都共享一样的网卡、网络栈、IP 地址,等等。因此,同一个 Pod 中不同容器占用的端口不能冲突。
- IPC 名称空间 :所有容器都可以通过信号量或者 POSIX 共享内存等方式通信。
- 时间名称空间 :所有容器都共享相同的系统时间。
也就是说,同一个 Pod 的容器,只有 PID 名称空间 和 文件名称空间 默认是隔离的。
PID 的隔离让开发者的每个容器都有独立的进程 ID 编号,它们封装的应用进程就是 PID 为 1 的进程,开发人员可以通过 Pod 元数据定义中的 spec.shareProcessNamespace,来改变这点。而一旦要求共享 PID 名称空间,容器封装的应用进程就不再具有 PID 为 1 的特征了,这就有可能导致部分依赖该特征的应用出现异常。
而在文件名称空间方面,容器要求文件名称空间的隔离是很理所应当的需求,因为容器需要相互独立的文件系统以避免冲突。但容器间可以 共享存储卷 ,这是通过 Kubernetes 的 Volume 来实现的。
额外知识:Kubernetes 中 Pod 名称空间共享的实现细节
Pod 内部多个容器共享 UTS、IPC、网络等名称空间,是通过一个名为 Infra Container 的容器来实现的,这个容器是整个 Pod 中第一个启动的容器,只有几百 KB 大小(代码只有很短的几十行,见 这里 ),Pod 中的其他容器都会以 Infra Container 作为父容器,UTS、IPC、网络等名称空间,实质上都是来自 Infra Container 容器。
如果容器设置为共享 PID 名称空间的话,Infra Container 中的进程将作为 PID 1 进程,其他容器的进程将以它的子进程的方式存在,此时就会由 Infra Container 来负责进程管理(比如清理 僵尸进程 )、感知状态和传递状态。
由于 Infra Container 的代码除了注册 SIGINT、SIGTERM、SIGCHLD 等信号的处理器外,就只是一个以 pause() 方法为循环体的无限循环,永远处于 Pause 状态,所以它也常被称为”Pause Container”。
好,除此之外,Pod 的另一个基本职责是 实现原子性调度 。这里我们可以先明确一点,就是如果容器编排不跨越集群节点,那是否具有原子性其实都不影响大局。
但是在集群环境中,容器可能会跨机器调度时,这个特性就变得非常重要了。
如果以容器为单位来调度的话,不同容器就有可能被分配到不同机器上。而两台机器之间本来就是物理隔离,依靠网络连接的,所以这时候谈什么名称空间共享、cgroups 配额共享都没有意义了,由此我们就从场景二又演化出了场景三。
场景三:假设你现在有 Filebeat、Nginx 两个 Docker 镜像,在一个具有多个节点的集群环境下,要求每次调度都必须让 Filebeat 和 Nginx 容器运行于同一个节点上。
其实,两个关联的协作任务必须一起调度的需求,在容器出现之前很久就有了。
我举个简单的例子。在传统的多线程(或多进程) 并发调度) 中,如果两个线程(或进程)的工作是强依赖的,单独给谁分配处理时间而让另一个被挂起,都会导致某一个线程无法工作,所以也就有了 协同调度 (Coscheduling)的概念,它主要用来保证一组紧密联系的任务能够被同时分配资源。
这样来看的话,如果我们在容器编排中,仍然坚持 把容器看作是调度的最小粒度,那针对容器运行所需资源的需求声明,就只能设定在容器上。 如此一来,集群每个节点的剩余资源越紧张,单个节点无法容纳全部协同容器的概率就越大,协同的容器被分配到不同节点的可能性就越高。
说实话,协同调度是很麻烦的,实现起来要么很低效,比如 Apache Mesos 的 Resource Hoarding 调度策略,就要等所有需要调度的任务都完备后,才会开始分配资源;要么就是很复杂,比如 Google 就曾针对 Borg 的下一代 Omega 系统,发表过论文《 Omega: Flexible, Scalable Schedulers for Large Compute Clusters 》,其中介绍了它是如何通过乐观并发(Optimistic Concurrency)、冲突回滚的方式,做到高效率且高度复杂的协同调度。
而 如果我们将运行资源的需求声明定义在 Pod 上 ,直接以 Pod 为最小的原子单位来实现调度的话,由于多个 Pod 之间一定不存在超亲密的协同关系,只会通过网络非亲密地协作,那就根本 没有协同 的说法,自然也不需要考虑复杂的调度了(关于 Kubernetes 的具体调度实现,我会在”资源与调度”这个小章节中展开讲解)。
Pod 是隔离与调度的基本单位,也是我们接触的第一种 Kubernetes 资源。 Kubernetes 把一切都看作是资源,不同资源之间依靠层级关系相互组合协作,这个思想是贯穿 Kubernetes 整个系统的两大核心设计理念之一,不仅在容器、Pod、主机、集群等计算资源上是这样,在工作负载、持久存储、网络策略、身份权限等其他领域中,也都有着一致的体现。
另外我想说的是,因为 Pod 是 Kubernetes 中最重要的资源,又是资源模型中一种仅在逻辑上存在、没有物理对应的概念(因为对应的”进程组”也只是个逻辑概念),也是其他编排系统没有的概念,所以我这节课专门给你介绍了下它的设计意图,而不是像帮助手册那样直接给出它的作用和特性。
对于 Kubernetes 中的其他计算资源,像 Node、Cluster 等都有切实的物理对应物,很容易就能形成共同的认知,我就不一一介绍了,这里你只需要了解下它们的设计意图就行:
- 容器(Container) :延续了自 Docker 以来一个容器封装一个应用进程的理念,是镜像管理的最小单位。
- 生产任务(Pod) :补充了容器化后缺失的与进程组对应的”容器组”的概念,Pod 中的容器共享 UTS、IPC、网络等名称空间,是资源调度的最小单位。
- 节点(Node) :对应于集群中的单台机器,这里的机器既可以是生产环境中的物理机,也可以是云计算环境中的虚拟节点,节点是处理器和内存等资源的资源池,是硬件单元的最小单位。
- 集群(Cluster):对应于整个集群,Kubernetes 提倡的理念是面向集群来管理应用。当你要部署应用的时候,只需要通过声明式 API 将你的意图写成一份元数据(Manifests),把它提交给集群即可,而无需关心它具体分配到哪个节点(尽管通过标签选择器完全可以控制它分配到哪个节点,但一般不需要这样做)、如何实现 Pod 间通信、如何保证韧性与弹性,等等,所以集群是处理元数据的最小单位。
- 集群联邦(Federation) :对应于多个集群,通过联邦可以统一管理多个 Kubernetes 集群,联邦的一种常见应用是支持跨可用区域多活、跨地域容灾的需求。
小结
学完了这节课,我们要知道,容器之间顺畅地交互通信是协作的核心需求,但容器协作并不只是通过高速网络来互相连接容器而已。如何调度容器,如何分配资源,如何扩缩规模,如何最大限度地接管系统中的非功能特性,让业务系统尽可能地免受分布式复杂性的困扰,都是容器编排框架必须考虑的问题,只有恰当解决了这一系列问题,云原生应用才有可能获得比传统应用更高的生产力。
49 | 以容器构建系统(下):韧性与弹性
今天,我们接着上节课”隔离与协作”的话题,继续来讨论容器编排的另一个目标:韧性与弹性。
我曾经看过一部电影,叫做《 Bubble Boy 》,主要讲了一个体内没有任何免疫系统的小男孩,每天只能生活在无菌的圆形气球里,对常人来说不值一提的细菌,都会直接威胁到他的性命。小男孩尽管能够降生于世,但并不能真正地与世界交流,这种生命是极度脆弱的。
真实世界的软件系统,跟电影世界中的小男孩所面临的处境其实差不多。
要知道,让容器能够相互连通、相互协作,仅仅是以容器构建系统的第一步,我们不仅希望得到一个能够运行起来的系统,而且还希望得到一个能够健壮运行的系统、能够抵御意外与风险的系统。
当然,在 Kubernetes 的支持下,你确实可以直接创建 Pod 将应用运行起来,但这样的应用就像是电影中只能存活在气球中的小男孩一样脆弱,无论是软件缺陷、意外操作或者硬件故障,都可能导致在复杂协作的过程中某个容器出现异常,进而出现系统性的崩溃。
为了解决这个问题,架构师专门设计了服务容错的策略和模式(你可以回顾复习第 36 、 37 讲)。而 Kubernetes 作为云原生时代的基础设施,也尽力帮助我们以最小的代价来实现容错,为系统健壮运行提供底层支持。
那么,Kubernetes 所提供的帮助,就是指除资源模型之外的另一个核心设计理念:控制器设计模式。它的其中一种重要应用,就是这节课我们要探讨的主题,实现具有韧性与弹性的系统。
接下来,我们就从如何解决场景四的问题开始,一起来探讨下为什么 Kubernetes 要设计这些控制器,以及为什么这些控制器会被设计成现在这种样子。
编排系统如何快速调整出错的服务?
我们先来看看场景四的问题:
场景四:假设有个由数十个 Node、数百个 Pod、近千个 Container 所组成的分布式系统,作为管理员,你想要避免该系统因为外部流量压力、代码缺陷、软件更新、硬件升级、资源分配等各种原因而出现中断的状况,那么你希望编排系统能为你提供何种支持?
作为用户,我们当然最希望容器编排系统能自动地把所有意外因素都消灭掉,让每一个服务都永远健康,永不出错。但 永不出错的服务是不切实际的 ,只有凑齐七颗龙珠才可能办得到。
所以我们就只能退而求其次,让编排系统在这些服务出现问题、运行状态不正确的时候,能自动将它们调整成正确的状态。
这种需求听起来其实也挺贪心的,但已经具备足够的可行性了。而且我们可以采取的应对办法在 工业控制系统 里,已经有了非常成熟的应用,它叫做 控制回路 (Control Loop)。
关于控制回路的一般工作过程,在 Kubernetes 官方文档 中,是以”房间里空调自动调节温度”为例来具体介绍的:当你设置好了温度,就是告诉空调你对温度的”期望状态”(Desired State),而传感器测量出的房间实际温度是”当前状态”(Current State)。
那么,根据当前状态与期望状态的差距,控制器对空调制冷的开关进行调节控制,就能让其当前状态逐渐接近期望状态。

由此,我们把这种控制回路的思想迁移应用到容器编排上,自然会为 Kubernetes 中的资源附加上了期望状态与实际状态两项属性。
不管是已经出现在上节课的资源模型中,用于抽象容器运行环境的计算资源,还是没有登场的对应于安全、服务、令牌、网络等功能的资源( 第 40 讲 中曾提及过),如果用户想使用这些资源来实现某种需求,并不能像平常编程那样,去调用某个或某一组方法来达成目的。而是要通过描述清楚这些资源的期望状态,由 Kubernetes 中对应监视这些资源的控制器,来驱动资源的实际状态逐渐向期望状态靠拢,才能够达成自己的目的。
而这种交互风格就被叫做 Kubernetes 的声明式 API ,如果你之前有过实际操作 Kubernetes 的经验,那你日常在元数据文件中的 spec 字段所描述的就是资源的期望状态。
额外知识:Kubernates 的资源对象与控制器
目前,Kubernetes 已内置支持相当多的资源对象,并且还可以使用CRD(Custom Resource Definition)来自定义扩充,你可以使用 kubectl api-resources 来查看它们。下面我根据用途分类,给你列举了一些常见的资源:
- 用于描述如何创建、销毁、更新、扩缩 Pod,包括:Autoscaling(HPA)、CronJob、DaemonSet、Deployment、Job、Pod、ReplicaSet、StatefulSet
- 用于配置信息的设置与更新,包括:ConfigMap、Secret
- 用于持久性地存储文件或者 Pod 之间的文件共享,包括:Volume、LocalVolume、PersistentVolume、PersistentVolumeClaim、StorageClass
- 用于维护网络通信和服务访问的安全,包括:SecurityContext、ServiceAccount、Endpoint、NetworkPolicy
- 用于定义服务与访问,包括:Ingress、Service、EndpointSlice
- 用于划分虚拟集群、节点和资源配额,包括:Namespace、Node、ResourceQuota
这些资源在控制器管理框架中,一般都会有相应的控制器来管理,这里我也列举了一些常见的控制器,按照它们的启动情况进行了分类,如下:
必须启用的控制器:EndpointController、ReplicationController、PodGCController、ResourceQuotaController、NamespaceController、ServiceAccountController、GarbageCollectorController、DaemonSetController、JobController、DeploymentController、ReplicaSetController、HPAController、DisruptionController、StatefulSetController、CronJobController、CSRSigningController、CSRApprovingController、TTLController
默认启用的可选控制器,可通过选项禁止:TokenController、NodeController、ServiceController、RouteController、PVBinderController、AttachDetachController
默认禁止的可选控制器,可通过选项启用:BootstrapSignerController、TokenCleanerController
那么,与资源相对应的,只要是实际状态有可能发生变化的资源对象,就通常都会 由对应的控制器进行追踪,每个控制器至少会追踪一种类型的资源。
因此,为了管理众多资源控制器,Kubernetes 设计了 统一的控制器管理框架( kube-controller-manager ) 来维护这些控制器的正常运作,并设计了 统一的指标监视器( kube-apiserver ) ,用于在控制器工作时,为它提供追踪资源的度量数据。
Kubernetes 控制器模式的工作原理
那么 Kubernetes 具体是怎么做的呢?在回答之前,我想先解释下,毕竟我们不是在写 Kubernetes 的操作手册,没办法展开和详解每个控制器,所以下面我就以两三种资源和控制器为代表,来举例说明一下。
OK,回到问题上。这里我们只要把场景四进一步具体化,转换成下面的场景五,就可以得到一个很好的例子了。
比如说,我们就以部署控制器(Deployment Controller)、副本集控制器(ReplicaSet Controller)和自动扩缩控制器(HPA Controller)为例,来看看 Kubernetes 控制器模式的工作原理。
场景五:通过服务编排,我们让任何分布式系统自动实现以下三种通用的能力:
- Pod 出现故障时,能够自动恢复,不中断服务;
- Pod 更新程序时,能够滚动更新,不中断服务;
- Pod 遇到压力时,能够水平扩展,不中断服务。
在这节课的一开始我提到过,虽然 Pod 本身也是资源,完全可以直接创建,但由 Pod 直接构成的系统是十分脆弱的,就像是那个气球中的小男孩,所以在实际生产中并不提倡。
正确的做法是 通过副本集(ReplicaSet)来创建 Pod。
ReplicaSet 也是一种资源,它是属于工作负荷一类的资源,代表了一个或多个 Pod 副本的集合,你可以在 ReplicaSet 资源的元数据中,描述你期望 Pod 副本的数量(即 spec.replicas 的值)。
当 ReplicaSet 成功创建之后,副本集控制器就会持续跟踪该资源,一旦有 Pod 发生崩溃退出,或者状态异常(默认是靠进程返回值,你还可以在 Pod 中设置探针,以自定义的方式告诉 Kubernetes 出现何种情况 Pod 才算状态异常),ReplicaSet 都会自动创建新的 Pod 来替代异常的 Pod;如果因异常情况出现了额外数量的 Pod,也会被 ReplicaSet 自动回收掉。
总之就是确保在任何时候,集群中这个 Pod 副本的数量都会向期望状态靠拢。
另外,我们还要清楚一点,就是 ReplicaSet 本身就能满足场景五中的第一项能力,可以保证 Pod 出现故障时自动恢复。但是在升级程序版本时,ReplicaSet 就不得不主动中断旧 Pod 的运行,重新创建新版的 Pod 了,而这会 造成服务中断。
因此,对于那些不允许中断的业务,以前的 Kubernetes 曾经提供过 kubectl rolling-update 命令,来辅助实现滚动更新。
所谓的 滚动更新 (Rolling Updates),是指先停止少量旧副本,维持大量旧副本继续提供服务,当停止的旧副本更新成功,新副本可以提供服务以后,再重复以上操作,直至所有的副本都更新成功。我们把这个过程放到 ReplicaSet 上,就是先创建新版本的 ReplicaSet,然后一边让新 ReplicaSet 逐步创建新版 Pod 的副本,一边让旧的 ReplicaSet 逐渐减少旧版 Pod 的副本。
而到了现在,之所以 kubectl rolling-update 命令会被淘汰,其实是因为这样的命令式交互,完全不符合 Kubernetes 的设计理念(这是台面上的说法,我觉得淘汰的根本原因主要是因为它不够好用)。如果你希望改变某个资源的某种状态,就应该将期望状态告诉 Kubernetes,而不是去教 Kubernetes 具体该如何操作。
所以,现在新的部署资源(Deployment)与部署控制器就被设计出来了。具体的实现步骤是这样的:我们可以由 Deployment 来创建 ReplicaSet,再由 ReplicaSet 来创建 Pod,当我们更新了 Deployment 中的信息以后(比如更新了镜像的版本),部署控制器就会跟踪到新的期望状态,自动地创建新 ReplicaSet,并逐渐缩减旧的 ReplicaSet 的副本数,直到升级完成后,彻底删除掉旧 ReplicaSet。这个工作过程如下图所示:
好,我们再来看看场景五中的最后一种情况。
你可能会知道,在遇到流量压力时,管理员完全可以手动修改 Deployment 中的副本数量,或者通过 kubectl scale 命令指定副本数量,促使 Kubernetes 部署更多的 Pod 副本来应对压力。然而这种扩容方式不仅需要人工参与,而且只靠人类经验来判断需要扩容的副本数量,也不容易做到精确与及时。
为此,Kubernetes 又提供了 Autoscaling 资源和自动扩缩控制器,它们能够自动地根据度量指标,如处理器、内存占用率、用户自定义的度量值等,来设置 Deployment(或者 ReplicaSet)的期望状态,实现当度量指标出现变化时,系统自动按照”Autoscaling→Deployment→ReplicaSet→Pod”这样的顺序层层变更,最终实现根据度量指标自动扩容缩容。
小结
故障恢复、滚动更新、自动扩缩这些特性,在云原生时代中常常被概括成服务的弹性(Elasticity)与韧性(Resilience),ReplicaSet、Deployment、Autoscaling 的用法,也是所有 Kubernetes 教材资料中都会讲到的”基础必修课”。
学完了这两节课,我还想再说明一点:如果你准备学习 Kubernetes 或者其他云原生的相关技术,我建议你最好不要死记硬背地学习每个资源的元数据文件该如何编写、有哪些指令、有哪些功能,更好的方式是站在解决问题的角度,去理解为什么 Kubernetes 要设计这些资源和控制器,理解为什么这些资源和控制器会被设计成现在这种样子。
50 | 应用为中心的封装(上):Kustomize与Helm
在理解了前面几节课所讲的容器技术发展的历程之后,不知你会不会有种”套娃式”的迷惑感?
- 现在你已经知道,容器的崛起缘于 chroot、namespaces、cgroups 等内核提供的隔离能力,而系统级的虚拟化技术,使得同一台机器上互不干扰地运行多个服务成为了可能;
- 为了降低用户使用内核隔离能力的门槛,随后出现了 LXC,它是 namespaces、cgroups 特性的上层封装,这就让”容器”一词真正走出了实验室,开始走入工业界进行实际应用;
- 然后,为了实现跨机器的软件绿色部署,出现了 Docker,它(最初)是 LXC 的上层封装,彻底改变了软件打包分发的方式,迅速被大量企业广泛采用;
- 而为了满足大型系统对服务集群化的需要,又出现了 Kubernetes,它(最初)是 Docker 的上层封装,从而使得以多个容器共同协作构建出健壮的分布式系统,成为了今天云原生时代的技术基础设施。
那这样你的疑惑可能也就出现了:Kubernetes 会是容器化崛起之路的终点线吗?它达到了人们对云原生时代技术基础设施的期望了吗?
首先, 从能力角度来看 ,可以说是的。Kubernetes 被誉为云原生时代的操作系统,自诞生之日起它就因为出色的管理能力、扩展性和以声明代替命令的交互理念,收获了无数喝彩声。
但是, 从易用角度来看 ,坦白说差距还非常大。云原生基础设施的其中一个重要目标,是接管掉业务系统复杂的非功能特性,这会让业务研发与运维工作变得足够简单,不受分布式的牵绊。然而,Kubernetes 被诟病得最多的就是复杂,它从诞生之日起,就因为陡峭的学习曲线而出名。
我举个具体例子吧。如果要用 Kubernetes 部署一套 Spring Cloud 版的 Fenix’s Bookstore ,你需要分别部署一个到多个的配置中心、注册中心、服务网关、安全认证、用户服务、商品服务、交易服务,然后要对每个微服务都配置好相应的 Kubernetes 工作负载与服务访问,为每一个微服务的 Deployment、ConfigMap、StatefulSet、HPA、Service、ServiceAccount、Ingress 等资源都编写好元数据配置。
这个过程最难的地方不仅在于繁琐,还在于要想写出合适的元数据描述文件,你既需要懂开发(网关中服务调用关系、使用容器的镜像版本、运行依赖的环境变量等等这些参数,只有开发最清楚),又需要懂运维(要部署多少个服务、配置何种扩容缩容策略、数据库的密钥文件地址等等,只有运维最清楚),有时候还需要懂平台(需要什么样的调度策略、如何管理集群资源,通常只有平台组、中间件组或者核心系统组的同学才会关心),一般企业根本找不到合适的角色来为它管理、部署和维护应用。
这个事儿 Kubernetes 心里其实也挺委屈,因为以上提到的复杂性不能说是 Kubernetes 带来的,而是 分布式架构本身的原罪 。
对于大规模的分布式集群来说,无论是最终用户部署应用,还是软件公司管理应用,都存在着像前面提到的这诸多痛点。这些困难的实质是源于 Docker 容器镜像封装了单个服务,而 Kubernetes 通过资源封装了服务集群,却没有一个载体真正封装整个应用,这就使得它会把原本属于应用内部的技术细节给圈禁起来,不暴露给最终用户、系统管理员和平台维护者,而让使用者去埋单。
那么如此所造成的应用难以管理的矛盾,就在于 封装应用的方法没能将开发、运维、平台等各种角色的关注点恰当地分离。
但是,既然在微服务时代,应用的形式已经不再局限于单个进程,那就也该到了重新定义”以应用为中心的封装”这句话的时候了。至于具体怎样的封装才算是正确的,其实到今天也还没有特别权威的结论,不过经过人们的尝试探索,已经能够窥见未来容器应用的一些雏形了。
所以接下来,我会花两节课的时间,给你介绍一下最近几年容器封装的两种主流思路,你可以从中理解容器”以应用为中心的封装”这个理念在不同阶段的内涵变化,这也是对”应用”这个概念的不断扩展升华的过程。
今天这节课呢,我们就先来了解下 Kustomize 和 Helm,它们是封装”无状态应用”的典型代表。
额外知识:无状态应用与有状态应用的区别
无状态应用(Stateless Application)与有状态应用(Stateful Application)说的是应用程序是否要自己持有其运行所需的数据,如果程序每次运行都跟首次运行一样,不依赖之前任何操作所遗留下来的痕迹,那它就是无状态的;反之,如果程序推倒重来之后,用户能察觉到该应用已经发生变化,那它就是有状态的。
下一讲要介绍的 Operator 与 OAM 就是支持有状态应用的封装方式,这里你可以先了解一下。
Kustomize
最初,由 Kubernetes 官方给出的”如何封装应用”的解决方案是” 用配置文件来配置文件 “,这不是绕口令,你可以把它理解为是一种针对 YAML 的模版引擎的变体。
Kubernetes 官方认为,应用就是一组具有相同目标的 Kubernetes 资源的集合,如果逐一管理、部署每项资源元数据太麻烦啰嗦的话,那就提供一种便捷的方式,把应用中不变的信息与易变的信息分离开,以此解决管理问题;把应用所有涉及的资源自动生成一个多合一(All-in-One)的整合包,以此解决部署问题。
而完成这项工作的工具就叫做 Kustomize ,它原本只是一个独立的小程序,从 Kubernetes 1.14 起,被纳入了 kubectl 命令之中,成为随着 Kubernetes 提供的内置功能。Kustomize 使用 Kustomization 文件 来组织与应用相关的所有资源,Kustomization 本身也是一个以 YAML 格式编写的配置文件,里面定义了构成应用的全部资源,以及资源中需根据情况被覆盖的变量值。
Kustomize 的主要价值是根据环境来生成不同的部署配置。只要建立多个 Kustomization 文件,开发人员就能 以基于基准进行派生 (Base and Overlay)的方式,对不同的模式(比如生产模式、调试模式)、不同的项目(同一个产品对不同客户的客制化)定制出不同的资源整合包。
在配置文件里,无论是开发关心的信息,还是运维关心的信息,只要是在元数据中有描述的内容,最初都是由开发人员来编写的,然后在编译期间由负责 CI/CD 的产品人员针对项目进行定制。最后在部署期间,由运维人员通过 kubectl 的补丁(Patch)机制更改其中需要运维去关注的属性,比如构造一个补丁来增加 Deployment 的副本个数,构造另外一个补丁来设置 Pod 的内存限制,等等。
k8s
├── base
│ ├── deployment.yaml
│ ├── kustomization.yaml
│ └── service.yaml
└── overlays
└── prod
│ ├── load-loadbalancer-service.yaml
│ └── kustomization.yaml
└── debug
└── kustomization.yaml从上面这段目录结构中,我们可以观察到一个由 kustomize 管理的应用结构,它主要由 base 和 overlays 组成。Kustomize 使用 Base、Overlay 和 Patch 生成最终配置文件的思路,与 Docker 中分层镜像的思路有些相似,这样的方式既规避了以”字符替换”对资源元数据文件的入侵,也不需要用户学习额外的 DSL 语法(比如 Lua)。
从效果来看,使用由 Kustomize 编译生成的 All-in-One 整合包来部署应用是相当方便的,只要一行命令就能够把应用涉及的所有服务一次安装好,在”探索与实践”小章节中会介绍的Kubernetes 版本和Istio 版本的 Fenix’s Booktstore,都使用了这种方式来发布应用,你也不妨实际体验一下。
但是,毕竟 Kustomize 只是一个”小工具”性质的辅助功能,对于开发人员来说,Kustomize 只能简化产品针对不同情况的重复配置,它其实并没有真正解决应用管理复杂的问题,要做的事、要写的配置,最终都没有减少,只是不用反复去写罢了;而对于运维人员来说,应用维护不仅仅只是部署那一下,应用的整个生命周期,除了安装外还有更新、回滚、卸载、多版本、多实例、依赖项维护等诸多问题,都很麻烦。
所以说,要想真正解决这些问题,还需要更加强大的管理工具,比如下面我要介绍的主角 Helm。不过 Kustomize 能够以极小的成本,在一定程度上分离了开发和运维的工作,不用像 Helm 那样需要一套独立的体系来管理应用,这种轻量便捷,本身也是一种可贵的价值。
OK,下面我们就来具体讲讲 Helm。
Helm 与 Chart
Helm 是由 Deis 公司 开发的一种更具系统性的管理和封装应用的解决方案,它参考了各大 Linux 发行版管理应用的思路,应用格式是 Chart。
Helm 一开始的目标就很明确: 如果说 Kubernetes 是云原生操作系统的话,那 Helm 就要成为这个操作系统上面的应用商店与包管理工具。
我相信,Linux 下的包管理工具和封装格式,如 Debian 系的 apt-get 命令与 dpkg 格式、RHEL 系的 yum 命令与 rpm 格式,你肯定不会陌生。有了包管理工具,你只要知道应用的名称,就可以很方便地从应用仓库中下载、安装、升级、部署、卸载、回滚程序,而且包管理工具掌握着应用的依赖信息和版本变更情况,具备完整的自管理能力,每个应用需要依赖哪些前置的第三方库,在安装的时候都会一并处理好。
Helm 模拟的就是这种做法,它提出了与 Linux 包管理直接对应的 Chart 格式和 Repository 应用仓库,另外针对 Kubernetes 中特有的一个应用经常要部署多个版本的特点,也提出了 Release 的专有概念。
Chart 用于封装 Kubernetes 应用涉及到的所有资源,通常是以目录内的文件集合的形式存在的。目录名称就是 Chart 的名称(没有版本信息),比如官方仓库中 WordPress Chart 的目录结构是这样的:
WordPress
├── templates
│ ├── NOTES.txt
│ ├── deployment.yaml
│ ├── externaldb-secrets.yaml
│ └── 版面原因省略其他资源文件
│ └── ingress.yaml
└── Chart.yaml
└── requirements.yaml
└── values.yaml其中有几个固定的配置文件:Chart.yaml 给出了应用自身的详细信息(名称、版本、许可证、自述、说明、图标,等等),requirements.yaml 给出了应用的依赖关系,依赖项指向的是另一个应用的坐标(名称、版本、Repository 地址),values.yaml 给出了所有可配置项目的预定义值。
可配置项就是指需要部署期间由运维人员调整的那些参数,它们以花括号包裹在 templates 目录下的资源文件中。当部署应用时,Helm 会先将管理员设置的值覆盖到 values.yaml 的默认值上,然后以字符串替换的形式,传递给 templates 目录的资源模版,最后生成要部署到 Kubernetes 的资源文件。
由于 Chart 封装了足够丰富的信息,所以 Helm 除了支持命令行操作外,也能很容易地根据这些信息自动生成图形化的应用安装、参数设置界面。
我们再来说说 Repository 仓库。它主要是用于实现 Chart 的搜索与下载服务,Helm 社区维护了公开的 Stable 和 Incubator 的中央仓库(界面如下图所示),也支持其他人或组织搭建私有仓库和公共仓库,并能够通过 Hub 服务,把不同个人或组织搭建的公共仓库聚合起来,形成更大型的分布式应用仓库,这也有利于 Chart 的查找与共享。
所以整体来说,Helm 提供了应用全生命周期、版本、依赖项的管理能力,同时,Helm 还支持额外的扩展插件,能够加入 CI/CD 或者其他方面的辅助功能。
如此一来,它的定位就已经从单纯的工具升级到应用管理平台了,强大的功能让 Helm 收到了不少支持,有很多应用主动入驻到官方的仓库中。而从 2018 年起,Helm 项目被托管到 CNFC,成为其中的一个孵化项目。
总而言之,Helm 通过模仿 Linux 包管理器的思路去管理 Kubernetes 应用,在一定程度上确实是可行的。不过,在 Linux 与 Kubernetes 中部署应用还是存在一些差别,最重要的一点是在 Linux 中 99% 的应用都只会安装一份,而 Kubernetes 里为了保证可用性,同一个应用部署多份副本才是常规操作。
所以,Helm 为了支持对同一个 Chart 包进行多次部署,每次安装应用都会产生一个 Release,Release 就相当于该 Chart 的安装实例。对于无状态的服务来说,靠着不同的 Release 就已经足够支持多个服务并行工作了,但对于有状态的服务来说,服务会与特定资源或者服务产生依赖关系,比如要部署数据库,通常要依赖特定的存储来保存持久化数据,这样事情就变得复杂起来了。
既然 Helm 无法很好地管理这种有状态的依赖关系,那么这一类问题就是 Operator 要解决的痛点了。这也是我在下一节课要给你重点介绍的工具。
小结
今天,我给你介绍了两种比较常用,也较为具体的应用封装方式,分别是 Kubernetes 官方推出的 Kustomize,以及目前在 Kubernetes 上较为主流的”应用商店”格式 Helm 与 Chart。这样的封装对于无状态应用已经足够了,但对于有状态应用来说,仍然不能满足需要。
在下节课,我们将继续应用封装这个话题,一起来探讨如何为有状态应用提供支持。
51 | 应用为中心的封装(下):Operator与OAM
你好,我是周志明。上节课我们了解了无状态应用的两种主流封装方式,分别是 Kustomize 和 Helm。那么今天这节课,我们继续来学习有状态应用的两种封装方法,包括 Operator 和开放应用模型。
Operator
与 Kustomize 和 Helm 不同的是, Operator 不应当被称作是一种工具或者系统,它应该算是一种封装、部署和管理 Kubernetes 应用的方法,尤其是针对最复杂的有状态应用去封装运维能力的解决方案,最早是由 CoreOS 公司(于 2018 年被 RedHat 收购)的华人程序员邓洪超提出的。
简单来说,Operator 是通过 Kubernetes 1.7 开始支持的自定义资源(Custom Resource Definitions,CRD,此前曾经以 TPR,即 Third Party Resource 的形式提供过类似的能力),把应用封装为另一种更高层次的资源,再把 Kubernetes 的控制器模式从面向内置资源,扩展到了面向所有自定义资源,以此来完成对复杂应用的管理。
具体怎么理解呢?我们来看一下 RedHat 官方对 Operator 设计理念的阐述:
Operator 设计理念
Operator 是使用自定义资源(CR,本人注:CR 即 Custom Resource,是 CRD 的实例)管理应用及其组件的自定义 Kubernetes 控制器。高级配置和设置由用户在 CR 中提供。Kubernetes Operator 基于嵌入在 Operator 逻辑中的最佳实践,将高级指令转换为低级操作。Kubernetes Operator 监视 CR 类型并采取特定于应用的操作,确保当前状态与该资源的理想状态相符。
—— 什么是 Kubernetes Operator ,RedHat
这段文字是直接由 RedHat 官方撰写并翻译成中文的,准确严谨,但比较拗口,对于没接触过 Operator 的人来说并不友好,比如,你可能就会问,什么叫做”高级指令”?什么叫做”低级操作”?它们之间具体如何转换呢?等等。
其实要理解这些问题,你必须先弄清楚有状态和无状态应用的含义及影响,然后再来理解 Operator 所做的工作。在上节课,我给你补充了一个”额外知识”,已经介绍过了二者之间的区别,现在我们再来看看:
有状态应用(Stateful Application)与无状态应用(Stateless Application)说的是应用程序是否要自己持有其运行所需的数据,如果程序每次运行都跟首次运行一样,不依赖之前任何操作所遗留下来的痕迹,那它就是无状态的;反之,如果程序推倒重来之后,用户能察觉到该应用已经发生变化,那它就是有状态的。
无状态应用在分布式系统中具有非常巨大的价值,我们都知道分布式中的 CAP 不兼容原理,如果无状态,那就不必考虑状态一致性,没有了 C,那 A 和 P 就可以兼得。换句话说,只要资源足够,无状态应用天生就是高可用的。但不幸的是,现在的分布式系统中,多数关键的基础服务都是有状态的,比如缓存、数据库、对象存储、消息队列,等等,只有 Web 服务器这类服务属于无状态。
站在 Kubernetes 的角度看,是否有状态的本质差异在于, 有状态应用会对某些外部资源有绑定性的直接依赖 ,比如说,Elasticsearch 在建立实例时,必须依赖特定的存储位置,只有重启后仍然指向同一个数据文件的实例,才能被认为是相同的实例。另外,有状态应用的多个应用实例之间,往往有着特定的拓扑关系与顺序关系,比如 etcd 的节点间选主和投票,节点们都需要得知彼此的存在,明确每一个节点的网络地址和网络拓扑关系。
为了管理好那些与应用实例密切相关的状态信息,Kubernetes 从 1.9 版本开始正式发布了 StatefulSet 及对应的 StatefulSetController。与普通 ReplicaSet 中的 Pod 相比,由 StatefulSet 管理的 Pod 具备几项额外特性。
- Pod 会按顺序创建和按顺序销毁 :StatefulSet 中的各个 Pod 会按顺序地创建出来,而且,再创建后面的 Pod 之前,必须要保证前面的 Pod 已经转入就绪状态。如果要销毁 StatefulSet 中的 Pod,就会按照与创建顺序的逆序来执行。
- Pod 具有稳定的网络名称 :Kubernetes 中的 Pod 都具有唯一的名称,在普通的副本集中,这是靠随机字符产生的,而在 StatefulSet 中管理的 Pod,会以带有顺序的编号作为名称,而且能够在重启后依然保持不变。
- Pod 具有稳定的持久存储 :StatefulSet 中的每个 Pod 都可以拥有自己独立的 PersistentVolumeClaim 资源。即使 Pod 被重新调度到其他节点上,它所拥有的持久磁盘也依然会被挂载到该 Pod,这点会在”容器持久化”这个小章节中进一步介绍。
看到这些特性以后,你可能还会说,我还是不太理解 StatefulSet 的设计意图呀。没关系,我来举个例子,你一看就理解了。
如果把 ReplicaSet 中的 Pod 比喻为养殖场中的”肉猪”,那 StatefulSet 就是被当作宠物圈养的”荷兰猪”,不同的肉猪在食用功能上并没有什么区别,但每只宠物猪都是独一无二的,有专属于自己的名字、习性与记忆。事实上,早期的 StatefulSet 就曾经使用过 PetSet 这个名字。
StatefulSet 出现以后,Kubernetes 就能满足 Pod 重新创建后,仍然保留上一次运行状态的需求了。不过,有状态应用的维护并不仅限于此。比如说,对于一套 Elasticsearch 集群来说,通过 StatefulSet,最多只能做到创建集群、删除集群、扩容缩容等最基本的操作,并不支持常见的运维操作,比如备份和恢复数据、创建和删除索引、调整平衡策略,等等。
我再举个实际例子,来说明一下,Operator 是如何解决那些 StatefulSet 覆盖不到的有状态服务管理需求的。
假设我们要部署一套 Elasticsearch 集群,通常要在 StatefulSet 中定义相当多的细节,比如服务的端口、Elasticsearch 的配置、更新策略、内存大小、虚拟机参数、环境变量、数据文件位置,等等。
这里我直接把满足这个需求的 YAML 全部贴出来,让你对咱们前面反复提到的 Kubernetes 的复杂性有更加直观的理解。
apiVersion: v1
kind: Service
metadata:
name: elasticsearch-cluster
spec:
clusterIP: None
selector:
app: es-cluster
ports:
- name: transport
port: 9300
---
apiVersion: v1
kind: Service
metadata:
name: elasticsearch-loadbalancer
spec:
selector:
app: es-cluster
ports:
- name: http
port: 80
targetPort: 9200
type: LoadBalancer
---
apiVersion: v1
kind: ConfigMap
metadata:
name: es-config
data:
elasticsearch.yml: |
cluster.name: my-elastic-cluster
network.host: "0.0.0.0"
bootstrap.memory_lock: false
discovery.zen.ping.unicast.hosts: elasticsearch-cluster
discovery.zen.minimum_master_nodes: 1
xpack.security.enabled: false
xpack.monitoring.enabled: false
ES_JAVA_OPTS: -Xms512m -Xmx512m
---
apiVersion: apps/v1beta1
kind: StatefulSet
metadata:
name: esnode
spec:
serviceName: elasticsearch
replicas: 3
updateStrategy:
type: RollingUpdate
template:
metadata:
labels:
app: es-cluster
spec:
securityContext:
fsGroup: 1000
initContainers:
- name: init-sysctl
image: busybox
imagePullPolicy: IfNotPresent
securityContext:
privileged: true
command: ["sysctl", "-w", "vm.max_map_count=262144"]
containers:
- name: elasticsearch
resources:
requests:
memory: 1Gi
securityContext:
privileged: true
runAsUser: 1000
capabilities:
add:
- IPC_LOCK
- SYS_RESOURCE
image: docker.elastic.co/elasticsearch/elasticsearch:7.9.1
env:
- name: ES_JAVA_OPTS
valueFrom:
configMapKeyRef:
name: es-config
key: ES_JAVA_OPTS
readinessProbe:
httpGet:
scheme: HTTP
path: /_cluster/health?local=true
port: 9200
initialDelaySeconds: 5
ports:
- containerPort: 9200
name: es-http
- containerPort: 9300
name: es-transport
volumeMounts:
- name: es-data
mountPath: /usr/share/elasticsearch/data
- name: elasticsearch-config
mountPath: /usr/share/elasticsearch/config/elasticsearch.yml
subPath: elasticsearch.yml
volumes:
- name: elasticsearch-config
configMap:
name: es-config
items:
- key: elasticsearch.yml
path: elasticsearch.yml
volumeClaimTemplates:
- metadata:
name: es-data
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 5Gi可以看到,这里面的细节配置非常多。其实,之所以会这样,根本原因在于 Kubernetes 完全不知道 Elasticsearch 是个什么东西。所有 Kubernetes 不知道的信息、不能 启发式推断) 出来的信息,都必须由用户在资源的元数据定义中明确列出,必须一步一步手把手地”教会”Kubernetes 部署 Elasticsearch,这种形式就属于咱们刚刚提到的”低级操作”。
如果我们使用 Elastic.co 官方提供的 Operator ,那就会简单多了。Elasticsearch Operator 提供了一种kind: Elasticsearch的自定义资源,在它的帮助下,只需要十行代码,将用户的意图是”部署三个版本为 7.9.1 的 ES 集群节点”说清楚,就能实现跟前面 StatefulSet 那一大堆配置相同甚至是更强大的效果,如下面代码所示:
apiVersion: elasticsearch.k8s.elastic.co/v1
kind: Elasticsearch
metadata:
name: elasticsearch-cluster
spec:
version: 7.9.1
nodeSets:
- name: default
count: 3
config:
node.master: true
node.data: true
node.ingest: true
node.store.allow_mmap: false有了 Elasticsearch Operator 的自定义资源,就相当于 Kubernetes 已经学会怎样操作 Elasticsearch 了。知道了所有它相关的参数含义与默认值,就不需要用户再手把手地教了,这种就是所谓的”高级指令”。
Operator 将简洁的高级指令转化为 Kubernetes 中具体操作的方法,跟 Helm 或 Kustomize 的思路并不一样:
- Helm 和 Kustomize 最终仍然是依靠 Kubernetes 的内置资源,来跟 Kubernetes 打交道的;
- Operator 则是要求开发者自己实现一个专门针对该自定义资源的控制器,在控制器中维护自定义资源的期望状态。
通过程序编码来扩展 Kubernetes,比只通过内置资源来与 Kubernetes 打交道要灵活得多。比如,在需要更新集群中某个 Pod 对象的时候,由 Operator 开发者自己编码实现的控制器,完全可以在原地对 Pod 进行重启,不需要像 Deployment 那样,必须先删除旧 Pod,然后再创建新 Pod。
使用 CRD 定义高层次资源、使用配套的控制器来维护期望状态,带来的好处不仅仅是”高级指令”的便捷,更重要的是,可以在遵循 Kubernetes 的一贯基于资源与控制器的设计原则的同时,又不必受制于 Kubernetes 内置资源的表达能力。只要 Operator 的开发者愿意编写代码,前面提到的那些 StatfulSet 不能支持的能力,如备份恢复数据、创建删除索引、调整平衡策略等操作,都完全可以实现出来。
把运维的操作封装在程序代码上,从表面上看,最大的受益者是运维人员,开发人员要为此付出更多劳动。然而,Operator 并没有被开发者抵制,相反,因为用代码来描述复杂状态往往反而比配置文件更加容易,开发与运维之间的协作成本降低了,还受到了开发者的一致好评。
因为 Operator 的各种优势,它变成了近两、三年容器封装应用的一股新潮流,现在很多复杂分布式系统都有了官方或者第三方提供的 Operator( 这里收集了一部分 )。RedHat 公司也持续在 Operator 上面进行了大量投入,推出了简化开发人员编写 Operator 的 Operator Framework/SDK 。
目前看来,应对有状态应用的封装运维,Operator 也许是最有可行性的方案,但这依然不是一项轻松的工作。以 etcd 的 Operator 为例,etcd 本身不算什么特别复杂的应用,Operator 实现的功能看起来也相当基础,主要有创建集群、删除集群、扩容缩容、故障转移、滚动更新、备份恢复等功能,但是代码就已经超过一万行了。
现在,开发 Operator 的确还是有着相对较高的门槛,通常由专业的平台开发者而非业务开发或者运维人员去完成。但是,Operator 非常符合技术潮流,顺应了软件业界所提倡的 DevOps 一体化理念,等 Operator 的支持和生态进一步成熟之后,开发和运维都能从中受益,未来应该能成长为一种应用封装的主流形式。
OAM
我要给你介绍的最后一种应用封装的方案,是阿里云和微软在 2019 年 10 月上海 QCon 大会上联合发布的 开放应用模型 (Open Application Model,OAM),它不仅是中国云计算企业参与制定,甚至是主导发起的国际技术规范,也是业界首个云原生应用标准定义与架构模型。
OAM 思想的核心是将开发人员、运维人员与平台人员的关注点分离,开发人员关注业务逻辑的实现,运维人员关注程序的平稳运行,平台人员关注基础设施的能力与稳定性。毕竟,长期让几个角色厮混在同一个 All-in-One 资源文件里,并不能擦出什么火花,反而会将配置工作弄得越来越复杂,把” YAML Engineer “弄成容器界的嘲讽梗。
OAM 对云原生应用的定义是:”由一组相互关联但又离散独立的组件构成,这些组件实例化在合适的运行时上,由配置来控制行为并共同协作提供统一的功能”。你可能看不懂是啥意思,没有关系,为了方便跟后面的概念对应,我先把这句话拆解一下:
OAM 定义的应用
一个Application由一组Components构成,每个Component的运行状态由Workload描述,每个Component可以施加Traits来获取额外的运维能力,同时,我们可以使用Application Scopes将Components划分到一或者多个应用边界中,便于统一做配置、限制、管理。把Components、Traits和Scopes组合在一起实例化部署,形成具体的Application Configuration,以便解决应用的多实例部署与升级。
然后,我来具体解释一下上面列出来的核心概念,来帮助你理解 OAM 对应用的定义。在这句话里面,每一个用英文标注出来的技术名词,都是 OAM 在 Kubernetes 的基础上扩展而来的概念,每一个名词都有相对应的自定义资源。换句话说,它们并不是单纯的抽象概念,而是可以被实际使用的自定义资源。
我们来看一下这些概念的具体含义。
Components (服务组件):自 SOA 时代以来,由 Component 构成应用的思想就屡见不鲜,然而,OAM 的 Component 不仅仅是特指构成应用”整体”的一个”部分”,它还有一个重要的职责,那就是抽象出那些应该由开发人员去关注的元素。比如应用的名字、自述、容器镜像、运行所需的参数,等等。
Workload (工作负荷):Workload 决定了应用的运行模式,每个 Component 都要设定自己的 Workload 类型,OAM 按照”是否可访问、是否可复制、是否长期运行”预定义了六种 Workload 类型,如下表所示。如果有必要,使用者还可以通过 CRD 与 Operator 去扩展。
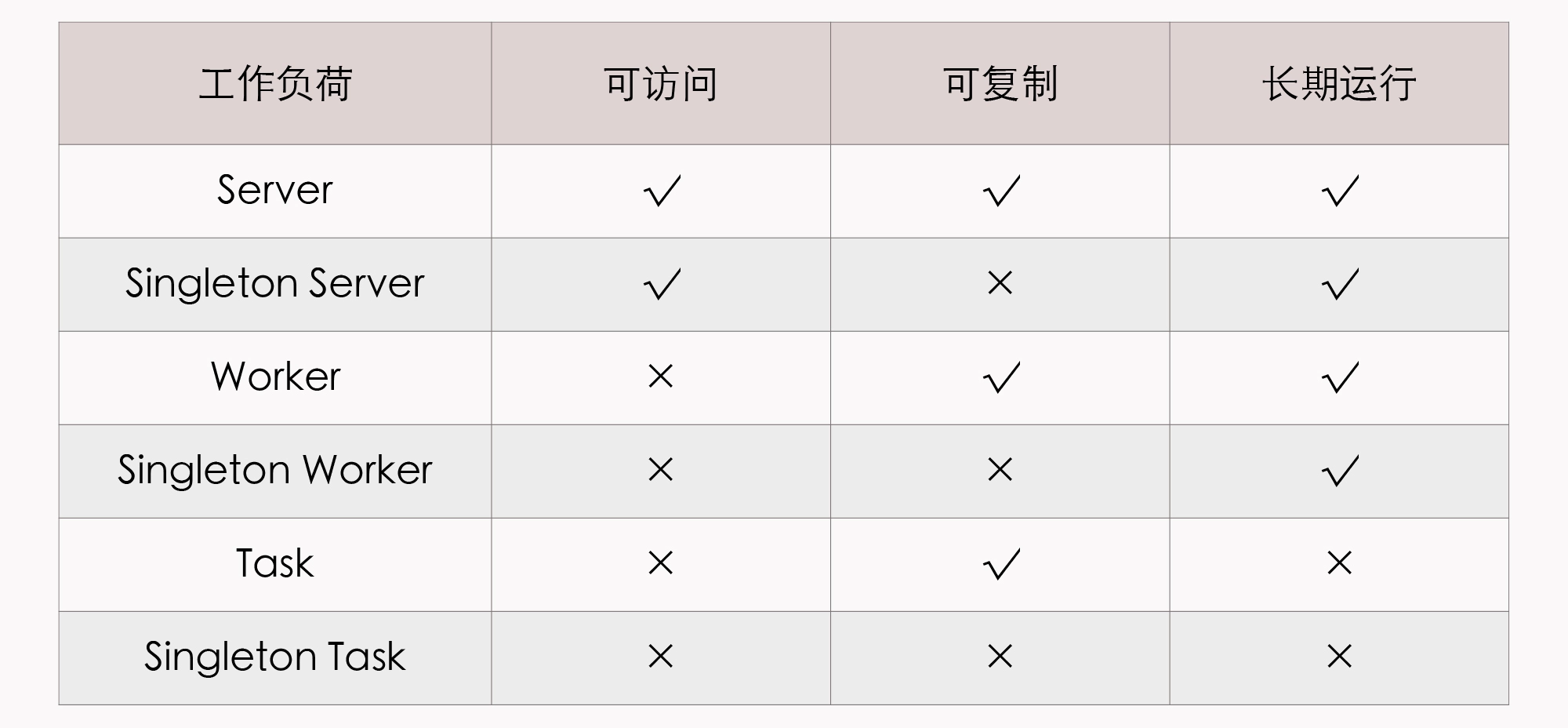
Traits (运维特征):开发活动有大量复用功能的技巧,但运维活动却很缺少这样的技巧,平时能为运维写个 Shell 脚本或简单工具,就已经算是个高级的运维人员了。Traits 就可以用来封装模块化后的运维能力,它可以针对运维中的可重复操作预先设定好一些具体的 Traits,比如日志收集 Trait、负载均衡 Trait、水平扩缩容 Trait,等等。这些预定义的 Traits 定义里,会注明它们可以作用于哪种类型的工作负荷,还包括能填哪些参数、哪些必填选填项、参数的作用描述是什么,等等。
- Application Scopes (应用边界):多个 Component 共同组成一个 Scope,你可以根据 Component 的特性或作用域来划分 Scope。比如,具有相同网络策略的 Component 放在同一个 Scope 中,具有相同健康度量策略的 Component 放到另一个 Scope 中。同时,一个 Component 也可能属于多个 Scope,比如,一个 Component 完全可能既需要配置网络策略,也需要配置健康度量策略。
- Application Configuration (应用配置):将 Component(必须)、Trait(必须)、Scope(非必须)组合到一起进行实例化,就形成了一个完整的应用配置。
OAM 使用咱们刚刚所说的这些自定义资源,对原先 All-in-One 的复杂配置做了一定层次的解耦:
- 开发人员负责管理 Component;
- 运维人员将 Component 组合并绑定 Trait,把它变成 Application Configuration;
- 平台人员或基础设施提供方负责提供 OAM 的解释能力,将这些自定义资源映射到实际的基础设施。
这样,不同角色分工协作,就整体简化了单个角色关注的内容,让不同角色可以更聚焦、更专业地做好本角色的工作,整个过程如下图所示:
图片来自 OAM 规范 GitHub
事实上,OAM 未来能否成功,很大程度上取决于云计算厂商的支持力度,因为 OAM 的自定义资源一般是由云计算基础设施负责解释和驱动的,比如阿里云的 EDAS 就已内置了 OAM 的支持。
如果你希望能够应用在私有 Kubernetes 环境中,目前,OAM 的主要参考实现是 Rudr (已声明废弃)和 Crossplane 。Crossplane 是一个仅发起一年多的 CNCF 沙箱项目,主要参与者包括阿里云、微软、Google、RedHat 等工程师。Crossplane 提供了 OAM 中全部的自定义资源和控制器,安装以后,就可以用 OAM 定义的资源来描述应用了。
小结
今天,容器圈的发展是一日千里,各种新规范、新技术层出不穷。在这两节课里,我特意挑选了非常流行,而且有代表性的四种,分别是”无状态应用”的典型代表 Kustomize 和 Helm,和”有状态应用”的典型代表 Operator 和 OAM。
其他我没有提到的应用封装技术,还有 CNAB 、 Armada 、 Pulumi ,等等。这些封装技术会有一定的重叠之处,但并非都是重复的轮子,在实际应用的时候,往往会联合其中多个工具一起使用。而至于怎么封装应用才是最佳的实践,目前也还没有定论,但可以肯定的是,以应用为中心的理念已经成为了明确的共识。
52 | Linux网络虚拟化(上):信息是如何通过网络传输被另一个程序接收到的?
从这节课开始,我会用两讲的时间带你学习 虚拟化网络 方面的知识点。
如果不加任何限定,”虚拟化网络”其实是一项内容十分丰富,研究历史十分悠久的计算机技术,它完全不依附于虚拟化容器,而是作为计算机科学中一门独立的分支。像是网络运营商经常提起的” 网络功能虚拟化 “(Network Function Virtualization,NFV),还有网络设备商和网络管理软件提供商经常提起的” 软件定义网络 “(Software Defined Networking,SDN)等等,这些都属于虚拟化网络的范畴。
不过,对于我们这样普通的软件开发者来说,一般没有什么必要去完全理解和掌握虚拟化网络,因为这需要储备大量开发中不常用到的专业知识,而且还会消耗大量的时间成本。
所以在课程里,我们讨论的虚拟化网络是狭义的,它特指”如何基于 Linux 系统的网络虚拟化技术来实现的容器间网络通信”,更通俗一点说,就是只关注那些为了相互隔离的 Linux 网络名称空间可以相互通信,而设计出来的虚拟化网络设施。
另外我还要说明的是,在这个语境中的”虚拟化网络”就是直接为容器服务的,说它是依附于容器而存在的也完全可行。所以为了避免混淆,我在课程中会尽量回避”虚拟化网络”这个范畴过大的概念,而是会以”容器间网络”和”Linux 网络虚拟化”为题来展开讲解。
好了,下面我们就从 Linux 下网络通信的协议栈模型,以及程序如何干涉在协议栈中流动的信息来开始了解吧。
Linux 系统下的网络通信模型
如果抛开虚拟化,只谈网络的话,那我认为首先应该了解的知识,就是 Linux 系统的网络通信模型,即 信息是如何从程序中发出,通过网络传输,再被另一个程序接收到的。
从整体上看,Linux 系统的通信过程无论是按理论上的 OSI 七层模型,还是以实际上的 TCP/IP 四层模型来解构,都明显地呈现出”逐层调用,逐层封装”的特点,这种逐层处理的方式与栈结构,比如程序执行时的方法栈很类似,所以它通常被称为” Linux 网络协议栈 “,简称”网络栈”,有时也称”协议栈”。
下图就体现了 Linux 网络通信过程与 OSI 或者 TCP/IP 模型的对应关系,也展示了网络栈中的数据流动的路径,你可以看一下:
在图中传输模型的左侧,我特别标示出了网络栈在用户与内核空间的部分,也就是说几乎整个网络栈(应用层以下)都位于系统内核空间之中,而 Linux 系统之所以采用这种设计,主要是从数据安全隔离的角度出发来考虑的。
由内核去处理网络报文的收发,无疑会有更高的执行开销,比如数据在内核态和用户态之间来回拷贝的额外成本,所以就会损失一些性能,但是这样能够保证应用程序无法窃听到或者去伪造另一个应用程序的通信内容。当然,针对特别关注收发性能的应用场景,也有直接在用户空间中实现全套协议栈的旁路方案,比如开源的 Netmap 以及 Intel 的 DPDK ,都能做到零拷贝收发网络数据包。
另外,图中传输模型的箭头展示的是数据流动的方向,它体现了信息从程序中发出以后,到被另一个程序接收到之前经历的几个阶段,下面我来给你一一分析下。
Socket
应用层的程序是通过 Socket 编程接口,来和内核空间的网络协议栈通信的。Linux Socket 是从 BSD Socket 发展而来的,现在的 Socket 已经不局限于作为某个操作系统的专属功能,而是成为了各大主流操作系统共同支持的通用网络编程接口,是网络应用程序实际上的交互基础。
在这里,应用程序通过读写收、发缓冲区(Receive/Send Buffer)来与 Socket 进行交互,在 Unix 和 Linux 系统中,出于”一切皆是文件”的设计哲学,对 Socket 的操作被实现为了对文件系统(socketfs)的读写访问操作,通过文件描述符(File Descriptor)来进行。
TCP/UDP
传输层协议族里,最重要的协议无疑就是 传输控制协议 (Transmission Control Protocol,TCP)和 用户数据报协议 (User Datagram Protocol,UDP)两种,它们也是在 Linux 内核中被直接支持的协议。此外还有 流控制传输协议 (Stream Control Transmission Protocol,SCTP)、 数据报拥塞控制协议 (Datagram Congestion Control Protocol,DCCP),等等。当然了,不同的协议处理流程大致都是一样的,只是封装的报文和头、尾部信息会有些不一样。
这里我以 TCP 协议为例,内核发现 Socket 的发送缓冲区中,有新的数据被拷贝进来后,会把数据封装为 TCP Segment 报文,常见的网络协议的报文基本上都是由报文头(Header)和报文体(Body,也叫荷载”Payload”)两部分组成。
接着,系统内核将缓冲区中用户要发送出去的数据作为报文体,然后把传输层中的必要控制信息,比如代表哪个程序发、由哪个程序收的源、目标端口号,用于保证可靠通信(重发与控制顺序)的序列号、用于校验信息是否在传输中出现损失的校验和(Check Sum)等信息,封装入报文头中。
IP
网络层协议最主要的就是 网际协议 (Internet Protocol,IP),其他的还会有 因特网组管理协议 (Internet Group Management Protocol,IGMP)、大量的路由协议(EGP、NHRP、OSPF、IGRP、……),等等。
这里我就以 IP 协议为例,它会把来自上一层(即前面例子中的 TCP 报文)的数据包作为报文体,然后再次加入到自己的报文头中,比如指明数据应该发到哪里的路由地址、数据包的长度、协议的版本号,等等,这样封装成 IP 数据包后再发往下一层。关于 TCP 和 IP 协议报文的内容,我曾在” 负载均衡 “这节课中详细讲解过,你可以去回顾复习下。
Device
Device 即网络设备,它是网络访问层中面向系统一侧的接口。不过这里所说的设备,跟物理硬件设备并不是同一个概念,Device 只是一种向操作系统端开放的接口,它的背后既可能代表着真实的物理硬件,也可能是某段具有特定功能的程序代码,比如即使不存在物理网卡,也依然可以存在回环设备(Loopback Device)。
许多网络抓包工具,比如 tcpdump 、 Wirshark 就是在此处工作的,我在前面 第 38 讲 介绍微服务流量控制的时候,曾提到过的网络流量整形,通常也是在这里完成的。
Device 主要的作用是抽象出统一的界面,让程序代码去选择或影响收发包出入口,比如决定数据应该从哪块网卡设备发送出去;还有就是准备好网卡驱动工作所需的数据,比如来自上一层的 IP 数据包、 下一跳) (Next Hop)的 MAC 地址(这个地址是通过 ARP Request 得到的),等等。
Driver
网卡驱动程序(Driver)是网络访问层中面向硬件一侧的接口,网卡驱动程序会通过 DMA 把主存中的待发送的数据包,复制到驱动内部的缓冲区之中。数据被复制的同时,也会把上层提供的 IP 数据包、下一跳的 MAC 地址这些信息,加上网卡的 MAC 地址、VLAN Tag 等信息,一并封装成为 以太帧 (Ethernet Frame),并自动计算校验和。而对于需要确认重发的信息,如果没有收到接收者的确认(ACK)响应,那重发的处理也是在这里自动完成的。
好了,上面这些阶段就是信息从程序中对外发出时,经过协议栈的过程了,而接收过程则是从相反方向进行的逆操作。
这里你需要记住, 程序发送数据做的是层层封包,加入协议头,传给下一层;而接受数据则是层层解包,提取协议体,传给上一层。 你可以通过类比来理解数据包的接收过程,我就不再啰嗦一遍数据接收的步骤了。
干预网络通信的 Netfilter 框架
到这里,我们似乎可以发现,网络协议栈的处理是一套相对固定和封闭的流程,在整套处理过程中,除了在网络设备这层,我们能看到一点点程序以设备的形式介入处理的空间以外,其他过程似乎就没有什么可供程序插手的余地了。
然而事实并非如此, 从 Linux Kernel 2.4 版开始,内核开放了一套通用的、可供代码干预数据在协议栈中流转的过滤器框架,这就是 Netfilter 框架。
Netfilter 框架是 Linux 防火墙和网络的主要维护者罗斯迪·鲁塞尔(Rusty Russell)提出并主导设计的,它围绕网络层(IP 协议)的周围,埋下了五个 钩子 (Hooks),每当有数据包流到网络层,经过这些钩子时,就会自动触发由内核模块注册在这里的回调函数,程序代码就能够通过回调来干预 Linux 的网络通信。
下面我给你介绍一下这五个钩子分别都是什么:
- PREROUTING :来自设备的数据包进入协议栈后,就会立即触发这个钩子。注意,如果 PREROUTING 钩子在进入 IP 路由之前触发了,就意味着只要接收到的数据包,无论是否真的发往本机,也都会触发这个钩子。它一般是用于目标网络地址转换(Destination NAT,DNAT)。
- INPUT :报文经过 IP 路由后,如果确定是发往本机的,将会触发这个钩子,它一般用于加工发往本地进程的数据包。
- FORWARD :报文经过 IP 路由后,如果确定不是发往本机的,将会触发这个钩子,它一般用于处理转发到其他机器的数据包。
- OUTPUT :从本机程序发出的数据包,在经过 IP 路由前,将会触发这个钩子,它一般用于加工本地进程的输出数据包。
- POSTROUTING :从本机网卡出去的数据包,无论是本机的程序所发出的,还是由本机转发给其他机器的,都会触发这个钩子,它一般是用于源网络地址转换(Source NAT,SNAT)。
Netfilter 允许在同一个钩子处注册多个回调函数,所以数据包在向钩子注册回调函数时,必须提供明确的优先级,以便触发时能按照优先级从高到低进行激活。而因为回调函数会有很多个,看起来就像是挂在同一个钩子上的一串链条,所以钩子触发的回调函数集合,就被称为”回调链”(Chained Callbacks),这个名字也导致了后续基于 Netfilter 设计的 Xtables 系工具,比如下面我要介绍的 iptables,都使用到了”链”(Chain)的概念。
那么,虽然现在看来,Netfilter 只是一些简单的事件回调机制而已,但这样一套简单的设计,却 成为了整座 Linux 网络大厦的核心基石 ,Linux 系统提供的许多网络能力,比如数据包过滤、封包处理(设置标志位、修改 TTL 等)、地址伪装、网络地址转换、透明代理、访问控制、基于协议类型的连接跟踪、带宽限速,等等,它们都是在 Netfilter 的基础之上实现的。
而且,以 Netfilter 为基础的应用也有很多,其中使用最广泛的毫无疑问要数 Xtables 系列工具,比如 iptables 、ebtables、arptables、ip6tables,等等。如果你用过 Linux 系统来做过开发的话,那我估计至少这里面的 iptables 工具,你会或多或少地使用过,它常被称为是 Linux 系统”自带的防火墙”。
但其实,iptables 实际能做的事情已经远远超出了防火墙的范畴,严谨地讲,iptables 比较贴切的定位应该是能够代替 Netfilter 多数常规功能的 IP 包过滤工具。
要知道,iptables 的设计意图是因为 Netfilter 的钩子回调虽然很强大,但毕竟要通过程序编码才够能使用,并不适合系统管理员用来日常运维,而它的价值就是 以配置去实现原本用 Netfilter 编码才能做到的事情。
一般来说,iptables 会先把用户常用的管理意图总结成具体的行为,预先准备好,然后就会在满足条件的时候自动激活行为,比如以下几种常见的 iptables 预置的行为:
- DROP:直接将数据包丢弃。
- REJECT:给客户端返回 Connection Refused 或 Destination Unreachable 报文。
- QUEUE:将数据包放入用户空间的队列,供用户空间的程序处理。
- RETURN:跳出当前链,该链里后续的规则不再执行。
- ACCEPT:同意数据包通过,继续执行后续的规则。
- JUMP:跳转到其他用户自定义的链继续执行。
- REDIRECT:在本机做端口映射。
- MASQUERADE:地址伪装,自动用修改源或目标的 IP 地址来做 NAT
- LOG:在 /var/log/messages 文件中记录日志信息。
- ……
当然,这些行为本来能够被挂载到 Netfilter 钩子的回调链上,但 iptables 又进行了一层额外抽象,它不是把行为与链直接挂钩,而是会根据这些底层操作的目的,先总结为更高层次的规则。
我举个例子,假设你挂载规则的目的是为了实现网络地址转换(NAT),那就应该对符合某种特征的流量(比如来源于某个网段、从某张网卡发送出去)、在某个钩子上(比如做 SNAT 通常在 POSTROUTING,做 DNAT 通常在 PREROUTING)进行 MASQUERADE 行为,这样具有相同目的的规则,就应该放到一起才便于管理,所以也就形成了”规则表”的概念。
iptables 内置了五张不可扩展的规则表(其中的 security 表并不常用,很多资料只计算了前四张表),我们来看看:
- raw 表 :用于去除数据包上的 连接追踪机制 (Connection Tracking)。
- mangle 表 :用于修改数据包的报文头信息,比如服务类型(Type Of Service,ToS)、生存周期(Time to Live,TTL),以及为数据包设置 Mark 标记,典型的应用是链路的服务质量管理(Quality Of Service,QoS)。
- nat 表 :用于修改数据包的源或者目的地址等信息,典型的应用是网络地址转换(Network Address Translation)。
- filter 表 :用于对数据包进行过滤,控制到达某条链上的数据包是继续放行、直接丢弃或拒绝(ACCEPT、DROP、REJECT),典型的应用是防火墙。
- security 表 :用于在数据包上应用 SELinux ,这张表并不常用。
这五张规则表是有优先级的:raw→mangle→nat→filter→security,也就是前面我列举出的顺序。这里你要注意,在 iptables 中新增规则时,需要按照规则的意图指定要存入到哪张表中,如果没有指定,就默认会存入 filter 表。此外,每张表能够使用到的链也有所不同,具体表与链的对应关系如下所示:
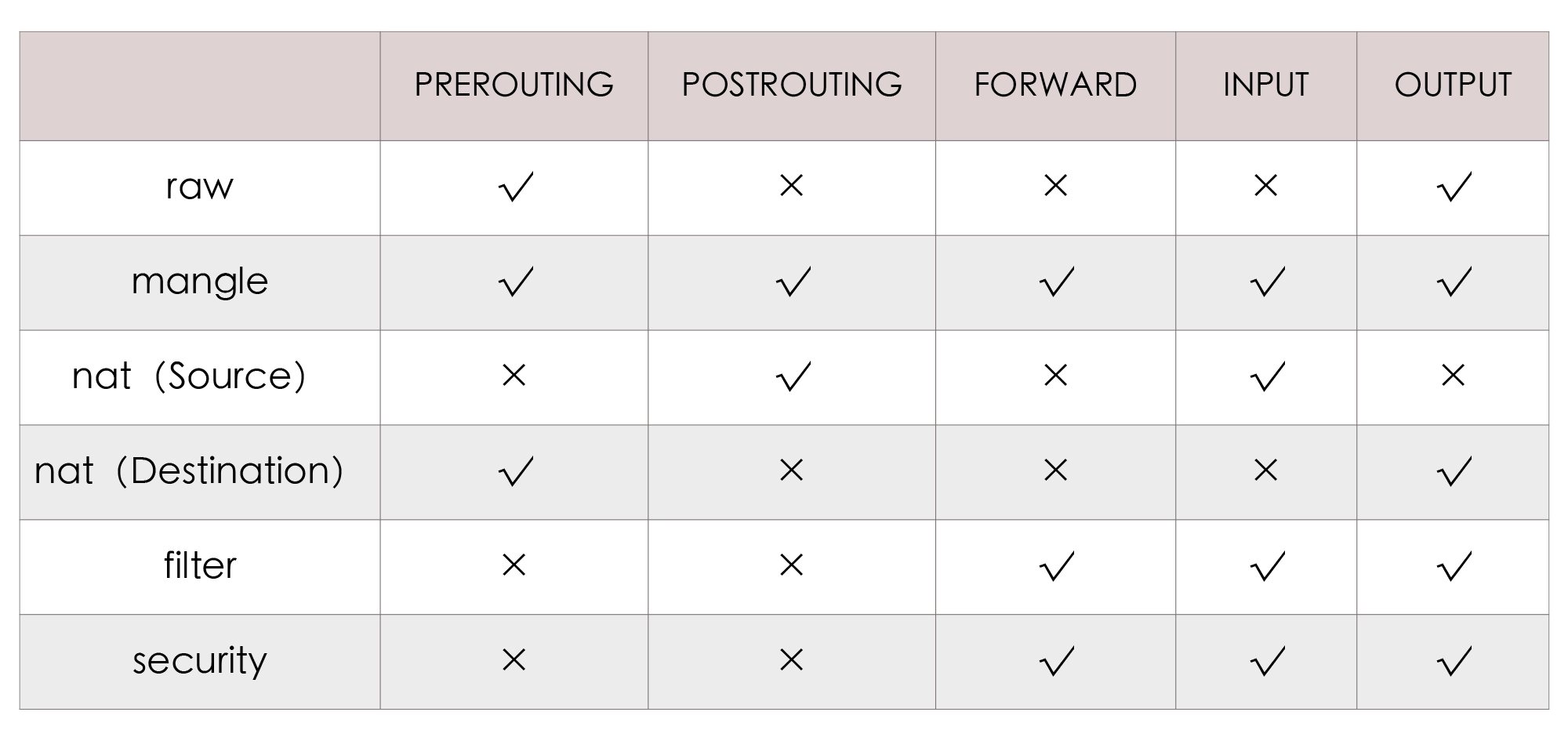
那么,你从名字上其实就能看出,预置的五条链是直接源自于 Netfilter 的钩子,它们与五张规则表的对应关系是固定的,用户不能增加自定义的表,或者修改已有表与链的关系,但可以增加自定义的链。
新增的自定义链与 Netfilter 的钩子没有天然的对应关系,换句话说就是不会被自动触发,只有显式地使用 JUMP 行为,从默认的五条链中跳转过去,才能被执行。
可以说,iptables 不仅仅是 Linux 系统自带的一个网络工具,它在容器间通信中也扮演着相当重要的角色。比如,Kubernetes 用来管理 Sevice 的 Endpoints 的核心组件 kube-proxy,就依赖 iptables 来完成 ClusterIP 到 Pod 的通信(也可以采用 IPVS,IPVS 同样是基于 Netfilter 的),这种通信的本质就是一种 NAT 访问。
当然,对于 Linux 用户来说,前面提到的内容可能都是相当基础的网络常识,但如果你平常比较少在 Linux 系统下工作,就可能需要一些用 iptables 充当防火墙过滤数据、充当作路由器转发数据、充当作网关做 NAT 转换的实际例子,来帮助理解了,这些操作在网上也很容易就能找到,这里我就不专门去举例说明了。
小结
Linux 目前提供的八种名称空间里,网络名称空间无疑是隔离内容最多的一种,它为名称空间内的所有进程提供了全套的网络设施,包括独立的设备界面、路由表、ARP 表,IP 地址表、iptables/ebtables 规则、协议栈,等等。
虚拟化容器是以 Linux 名称空间的隔离性为基础来实现的,那解决隔离的容器之间、容器与宿主机之间,乃至跨物理网络的不同容器间通信问题的责任,就很自然地落在了 Linux 网络虚拟化技术的肩上。这节课里,我们暂时放下了容器编排、云原生、微服务等等这些上层概念,走进 Linux 网络的底层世界,去学习了一些与设备、协议、通信相关的基础网络知识。
最后我想说的是,到目前为止,我给你介绍的 Linux 下网络通信的协议栈模型,以及程序如何干涉在协议栈中流动的信息,它们与虚拟化都没有产生什么直接联系,而是整个 Linux 网络通信的必要基础。在下节课,我们就要开始专注于跟网络虚拟化密切相关的内容了。
53 | Linux网络虚拟化(下):Docker所提供的容器通讯方案有哪些?
今天我们接着上节课介绍的 Linux 网络知识,继续来学习它们在虚拟化网络方面的应用,从而为后续学习容器编排系统、理解各个容器是如何通过虚拟化网络来协同工作打好基础。
虚拟化网络设备
首先我们要知道,虚拟化网络并不需要完全遵照物理网络的样子来设计。不过,由于现在大量现成的代码,原来就是面向于物理存在的网络设备来编码实现的,另外也有出于方便理解和知识继承方面的考虑,因此虚拟化网络与物理网络中的设备还是具有相当高的相似性。
所以接下来,我就会从网络中那些与网卡、交换机、路由器等对应的虚拟设施,以及如何使用这些虚拟设施来组成网络入手,给你介绍容器间网络的通信基础设施。
好了,我们开始吧。
网卡:tun/tap、veth
首先是虚拟网卡设备。
目前主流的虚拟网卡方案有 tun/tap 和 veth 两种,其中 tun/tap 出现得时间更早,它是一组通用的虚拟驱动程序包,里面包含了两个设备,分别是用于网络数据包处理的虚拟网卡驱动,以及用于内核空间与用户空间交互的 字符设备 (Character Devices,这里具体指/dev/net/tun)驱动。
大概在 2000 年左右,Solaris 系统为了实现 隧道协议 (Tunneling Protocol)开发了这套驱动,从 Linux Kernel 2.1 版开始,tun/tap 移植到了 Linux 内核中,当时它是作为源码中的可选模块,而在 2.4 版之后发布的内核,都会默认编译 tun/tap 的驱动。tun 和 tap 是两个相对独立的虚拟网络设备,其中 tap 模拟了以太网设备,操作二层数据包(以太帧),tun 则是模拟了网络层设备,操作三层数据包(IP 报文)。
那么,使用 tun/tap 设备的目的,其实是为了把来自协议栈的数据包,先交给某个打开了/dev/net/tun字符设备的用户进程处理后,再把数据包重新发回到链路中。这里你可以通俗地理解为,这块虚拟化网卡驱动一端连接着网络协议栈,另一端连接着用户态程序,而普通的网卡驱动则是一端连接着网络协议栈,另一端连接着物理网卡。
如此一来,只要协议栈中的数据包能被用户态程序截获并加工处理,程序员就有足够的舞台空间去玩出各种花样,比如数据压缩、流量加密、透明代理等功能,都能够在此基础上实现。
这里我就以最典型的 VPN 应用程序为例,程序发送给 tun 设备的数据包,会经过如下所示的顺序流进 VPN 程序:
应用程序通过 tun 设备对外发送数据包后,tun 设备如果发现另一端的字符设备已经被 VPN 程序打开(这就是一端连接着网络协议栈,另一端连接着用户态程序),就会把数据包通过字符设备发送给 VPN 程序,VPN 收到数据包,会修改后再重新封装成新报文,比如数据包原本是发送给 A 地址的,VPN 把整个包进行加密,然后作为报文体,封装到另一个发送给 B 地址的新数据包当中。
这种把一个数据包套进另一个数据包中的处理方式,就被形象地形容为”隧道”(Tunneling),隧道技术是在物理网络中构筑逻辑网络的经典做法。而其中提到的加密,实际上也有标准的协议可以遵循,比如 IPSec 协议。
不过,使用 tun/tap 设备来传输数据需要经过两次协议栈,所以会不可避免地产生一定的性能损耗,因而如果条件允许, 容器对容器的直接通信并不会把 tun/tap 作为首选方案,而是一般基于 veth 来实现的。
但 tun/tap 并没有像 veth 那样,有要求设备成对出现、数据要原样传输的限制,数据包到了用户态程序后,我们就有完全掌控的权力,要进行哪些修改、要发送到什么地方,都可以通过编写代码去实现,所以 tun/tap 方案比起 veth 方案有更广泛的适用范围。
那么这里我提到的 veth,就是另一种主流的虚拟网卡方案了,在 Linux Kernel 2.6 版本,Linux 开始支持网络名空间隔离的同时,也提供了专门的虚拟以太网(Virtual Ethernet,习惯简写为 veth),让两个隔离的网络名称空间之间可以互相通信。
其实,直接把 veth 比喻成虚拟网卡并不是很准确,如果要和物理设备类比,它应该相当于由 交叉网线 连接的一对物理网卡。
额外知识:直连线序、交叉线序
交叉网线是指一头是 T568A 标准,另外一头是 T568B 标准的网线。直连网线则是两头采用同一种标准的网线。
网卡对网卡这样的同类设备,需要使用交叉线序的网线来连接,网卡到交换机、路由器就采用直连线序的网线,不过现在的网卡大多带有线序翻转功能,直连线也可以网卡对网卡地连通了。
veth 实际上也不是一个设备,而是一对设备,因而它也常被称作 veth pair。我们要使用 veth,就必须在两个独立的网络名称空间中进行才有意义,因为 veth pair 是一端连着协议栈,另一端彼此相连的,在 veth 设备的其中一端输入数据,这些数据就会从设备的另一端原样不动地流出,它在工作时的数据流动如下图所示:
由于两个容器之间采用 veth 通信,不需要反复多次经过网络协议栈,这就让 veth 比起 tap/tun 来说,具备了更好的性能,也让 veth pair 的实现变得十分简单,内核中只用几十行代码实现一个数据复制函数,就可以完成 veth 的主体功能。
不过 veth 其实也存在局限性。
虽然 veth 以模拟网卡直连的方式,很好地解决了两个容器之间的通信问题,然而对多个容器间通信,如果仍然单纯只用 veth pair 的话,事情就会变得非常麻烦,毕竟,让每个容器都为与它通信的其他容器建立一对专用的 veth pair,根本就不实际,真正做起来成本会很高。
因此这时,就迫切需要有一台虚拟化的交换机,来解决多容器之间的通信问题了。
交换机:Linux Bridge
既然有了虚拟网卡,我们很自然就会联想到让网卡接入到交换机里,来实现多个容器间的相互连接。而 Linux Bridge 就是 Linux 系统下的虚拟化交换机,虽然它是以”网桥”(Bridge)而不是”交换机”(Switch)为名,但在使用过程中,你会发现 Linux Bridge 看起来像交换机,功能使用起来像交换机、程序实现起来也像交换机,所以它实际就是一台虚拟交换机。
Linux Bridge 是在 Linux Kernel 2.2 版本开始提供的二层转发工具,由brctl命令创建和管理。Linux Bridge 创建以后,就能够接入任何位于二层的网络设备,无论是真实的物理设备(比如 eth0),还是虚拟的设备(比如 veth 或者 tap),都能与 Linux Bridge 配合工作。当有二层数据包(以太帧)从网卡进入 Linux Bridge,它就会根据数据包的类型和目标 MAC 地址,按照如下规则转发处理:
- 如果数据包是广播帧,转发给所有接入网桥的设备。
- 如果数据包是单播帧,且 MAC 地址在地址转发表中不存在,则 洪泛) (Flooding)给所有接入网桥的设备,并把响应设备的接口与 MAC 地址学习(MAC Learning)到自己的 MAC 地址转发表中。
- 如果数据包是单播帧,且 MAC 地址在地址转发表中已存在,则直接转发到地址表中指定的设备。
- 如果数据包是此前转发过的,又重新发回到此 Bridge,说明冗余链路产生了环路。由于以太帧不像 IP 报文那样有 TTL 来约束,所以一旦出现环路,如果没有额外措施来处理的话,就会永不停歇地转发下去。那么对于这种数据包,就需要交换机实现 生成树协议 (Spanning Tree Protocol,STP)来交换拓扑信息,生成唯一拓扑链路以切断环路。
刚刚提到的这些名词,比如二层转发、泛洪、STP、MAC 学习、地址转发表,等等,都是物理交换机中已经非常成熟的概念了,它们在 Linux Bridge 中都有对应的实现,所以我才说,Linux Bridge 不仅用起来像交换机,实现起来也像交换机。
不过,它与普通的物理交换机也还是有一点差别的,普通交换机只会单纯地做二层转发, Linux Bridge 却还支持把发给它自身的数据包,接入到主机的三层协议栈中。
对于通过brctl命令显式接入网桥的设备,Linux Bridge 与物理交换机的转发行为是完全一致的,它也不允许给接入的设备设置 IP 地址,因为网桥是根据 MAC 地址做二层转发的,就算设置了三层的 IP 地址也没有意义。
然而,Linux Bridge 与普通交换机的区别是,除了显式接入的设备外,它自己也无可分割地连接着一台有着完整网络协议栈的 Linux 主机,因为 Linux Bridge 本身肯定是在某台 Linux 主机上创建的,我们可以看作是 Linux Bridge 有一个与自己名字相同的隐藏端口,隐式地连接了创建它的那台 Linux 主机。
因此,Linux Bridge 允许给自己设置 IP 地址,这样就比普通交换机多出了一种特殊的转发情况:如果数据包的目的 MAC 地址为网桥本身,并且网桥设置了 IP 地址的话,那该数据包就会被认为是收到发往创建网桥那台主机的数据包,这个数据包将不会转发到任何设备,而是直接交给上层(三层)协议栈去处理。
这时,网桥就取代了物理网卡 eth0 设备来对接协议栈,进行三层协议的处理。
那么设置这条特殊转发规则的好处是什么呢?就是 只要通过简单的 NAT 转换,就可以实现一个最原始的单 IP 容器网络。这种组网是最基本的容器间通信形式, 下面我举个具体例子来帮助你理解。
假设现在有以下几个设备,它们的连接情况如图所示,具体配置是这样的:
- 网桥 br0:分配 IP 地址 192.168.31.1。
容器:三个网络名称空间(容器),分别编号为 1、2、3,均使用 veth pair 接入网桥,且有如下配置:
- 在容器一端的网卡名为 veth0,在网桥一端网卡名为 veth1、veth2、veth3;
- 三个容器中的 veth0 网卡分配 IP 地址:192.168.1.10、192.168.1.11、192.168.1.12;
- 三个容器中的 veth0 网卡设置网关为网桥,即 192.168.31.1;
- 网桥中的 veth1、veth2、veth3 无 IP 地址。
物理网卡 eth0:分配的 IP 地址 14.123.254.86。
- 外部网络:外部网络中有一台服务器,地址为 122.246.6.183。
这样一来,如果名称空间 1 中的应用程序想访问外网地址为 122.246.6.183 的服务器,由于容器没有自己的公网 IP 地址,程序发出的数据包必须经过处理之后,才能最终到达外网服务器。
我们来具体分析下这个处理步骤:
应用程序调用 Socket API 发送数据,此时生成的原始数据包为:
- 源 MAC:veth0 的 MAC
- 目标 MAC:网关的 MAC(即网桥的 MAC)
- 源 IP:veth0 的 IP,即 192.168.31.1
- 目标 IP:外网的 IP,即 122.246.6.183
从 veth0 发送的数据,会在 veth1 中原样出来,网桥将会从 veth1 中接收到一个目标 MAC 为自己的数据包,并且网桥有配置 IP 地址,这样就触发了 Linux Bridge 的特殊转发规则。这个数据包也就不会转发给任何设备,而是转交给主机的协议栈处理。
注意,从这步以后就是三层路由了,已经不在网桥的工作范围之内,而是由 Linux 主机依靠 Netfilter 进行 IP 转发(IP Forward)去实现的。
数据包经过主机协议栈,Netfilter 的钩子被激活,预置好的 iptables NAT 规则会修改数据包的源 IP 地址,把它改为物理网卡 eth0 的 IP 地址,并在映射表中记录设备端口和两个 IP 地址之间的对应关系,经过 SNAT 之后的数据包,最终会从 eth0 出去,此时报文头中的地址为:
- 源 MAC:eth0 的 MAC
- 目标 MAC:下一跳(Hop)的 MAC
- 源 IP:eth0 的 IP,即 14.123.254.86
- 目标 IP:外网的 IP,即 122.246.6.183
可见,经过主机协议栈后,数据包的源和目标 IP 地址均为公网的 IP,这个数据包在外部网络中,可以根据 IP 正确路由到目标服务器手上。这样,当目标服务器处理完毕,对该请求发出响应后,返回数据包的目标地址也是公网 IP。当返回的数据包经过链路上所有跳点,由 eth0 达到网桥时,报文头中的地址为:
- 源 MAC:eth0 的 MAC
- 目标 MAC:网桥的 MAC
- 源 IP:外网的 IP,即 122.246.6.183
- 目标 IP:eth0 的 IP,即 14.123.254.86
可见,这同样是一个以网桥 MAC 地址为目标的数据包,同样会触发特殊转发规则,然后交给协议栈处理。这时,Linux 会根据映射表中的转换关系做 DNAT 转换,把目标 IP 地址从 eth0 替换回 veth0 的 IP,最终 veth0 收到的响应数据包为:
- 源 MAC:网桥的 MAC
- 目标 MAC:veth0 的 MAC
- 源 IP:外网的 IP,即 122.246.6.183
- 目标 IP:veth0 的 IP,即 192.168.31.1
好了,这就是程序发出的数据包到达外网服务器之前的所有处理步骤。
在这个处理过程中,Linux 主机独立承担了三层路由的职责,一定程度上扮演了路由器的角色。而且由于有 Netfilter 的存在,对网络层的路由转发,就不需要像 Linux Bridge 一样,专门提供brctl这样的命令去创建一个虚拟设备了。
通过 Netfilter,很容易就能在 Linux 内核完成根据 IP 地址进行路由的功能。你也可以把 Linux Bridge 理解为是一个人工创建的虚拟交换机,而 Linux 内核是一个天然的虚拟路由器。
当然,除了我介绍的 Linux Bridge 这一种虚拟交换机的方案,还有 OVS(Open vSwitch)等同样常见,而且更强大、更复杂的方案,这里我就不讨论了,感兴趣的话你可以去参考 这个链接 。
网络:VXLAN
那么,有了虚拟化网络设备后,下一步就是要使用这些设备组成网络了。
我们知道,容器分布在不同的物理主机上,每一台物理主机都有物理网络相互联通,然而这种网络的物理拓扑结构是相对固定的,很难跟上云原生时代下,分布式系统的逻辑拓扑结构变动频率,比如服务的扩缩、断路、限流,等等,都可能要求网络跟随做出相应的变化。
也正因为如此,软件定义网络(Software Defined Network,SDN)的需求在云计算和分布式时代,就变得前所未有地迫切。 SDN 的核心思路是在物理的网络之上,再构造一层虚拟化的网络,把控制平面和数据平面分离开来,实现流量的灵活控制,为核心网络及应用的创新提供良好的平台。
SDN 里,位于下层的物理网络被称为 Underlay,它着重解决网络的连通性与可管理性;位于上层的逻辑网络被称为 Overlay,它着重为应用提供与软件需求相符的传输服务和网络拓扑。
事实上,SDN 已经发展了十几年的时间,比云原生、微服务这些概念出现得要早得多。网络设备商基于硬件设备开发出了 EVI(Ethernet Virtualization Interconnect)、TRILL(Transparent Interconnection of Lots of Links)、SPB(Shortest Path Bridging)等大二层网络技术;软件厂商也提出了 VXLAN(Virtual eXtensible LAN)、NVGRE(Network Virtualization Using Generic Routing Encapsulation)、STT(A Stateless Transport Tunneling Protocol for Network Virtualization)等一系列基于虚拟交换机实现的 Overlay 网络。
不过,由于跨主机的容器间通信用的大多是 Overlay 网络,所以接下来,我会以 VXLAN 为例,给你介绍 Overlay 网络的原理。
VXLAN 你可能没怎么听说过,但 VLAN 相信只要从事计算机专业的人都会有所了解。VLAN 的全称是”虚拟局域网”(Virtual Local Area Network),从名称来看,它也算是网络虚拟化技术的早期成果之一了。
由于二层网络本身的工作特性,决定了 VLAN 非常依赖于广播,无论是广播帧(如 ARP 请求、DHCP、RIP 都会产生广播帧),还是泛洪路由,它的执行成本会随着接入二层网络设备数量的增长而等比例地增加,当设备太多,广播又频繁的时候,很容易就会形成 广播风暴 (Broadcast Radiation)。
因此, VLAN 的首要职责就是划分广播域 ,把连接在同一个物理网络上的设备区分开来。
划分的具体方法是在以太帧的报文头中加入 VLAN Tag,让所有广播只针对具有相同 VLAN Tag 的设备生效。这样既缩小了广播域,也附带提高了安全性和可管理性,因为 两个 VLAN 之间不能直接通信 。如果确实有通信的需要,就必须通过三层设备来进行,比如使用 单臂路由 (Router on a Stick)或者三层交换机。
可是,VLAN 有两个明显的缺陷, 第一个缺陷在于 VLAN Tag 的设计 。定义 VLAN 的 802.1Q 规范 是在 1998 年提出的,当时的网络工程师完全不可能预料到在未来云计算会如此地普及,因而就只给 VLAN Tag 预留了 32 Bits 的存储空间,其中还要分出 16 Bits 存储标签协议识别符(Tag Protocol Identifier)、3 Bits 存储优先权代码点(Priority Code Point)、1 Bits 存储标准格式指示(Canonical Format Indicator),剩下的 12 Bits 才能用来存储 VLAN ID(Virtualization Network Identifier,VNI)。
所以换句话说,VLAN ID 最多只能有 2**12=4096 种取值。当云计算数据中心出现后,即使不考虑虚拟化的需求,单是需要分配 IP 的物理设备,都有可能数以万计、甚至数以十万计,这样的话,4096 个 VLAN 肯定是不够用的。
后来,IEEE 的工程师们又提出 802.1AQ 规范 力图补救这个缺陷,大致思路是给以太帧连续打上两个 VLAN Tag,每个 Tag 里仍然只有 12 Bits 的 VLAN ID,但两个加起来就可以存储 2**24=16,777,216 个不同的 VLAN ID 了,由于两个 VLAN Tag 并排放在报文头上,802.1AQ 规范还有了个 QinQ(802.1Q in 802.1Q)的昵称别名。
QinQ 是 2011 年推出的规范,但是直到现在其实都没有特别普及,这是因为除了需要设备支持外,它还解决不了 VLAN 的第二个缺陷:跨数据中心传递。
VLAN 本身是为二层网络所设计的,但是在两个独立数据中心之间,信息只能跨三层传递。而由于云计算的灵活性,大型分布式系统完全有跨数据中心运作的可能性,所以此时如何让 VLAN Tag 在两个数据中心间传递,又成了不得不考虑的麻烦事。
由此,为了统一解决以上两个问题,IETF 定义了 VXLAN 规范 ,这是 三层虚拟化网络 (Network Virtualization over Layer 3,NVO3)的标准技术规范之一, 是一种典型的 Overlay 网络。
VXLAN 采用 L2 over L4 (MAC in UDP)的报文封装模式,把原本在二层传输的以太帧,放到了四层 UDP 协议的报文体内,同时加入了自己定义的 VXLAN Header。在 VXLAN Header 里直接就有 24 Bits 的 VLAN ID,同样可以存储 1677 万个不同的取值。
如此一来,VXLAN 就可以让二层网络在三层范围内进行扩展,不再受数据中心间传输的限制了。VXLAN 的整个报文结构如下图所示:
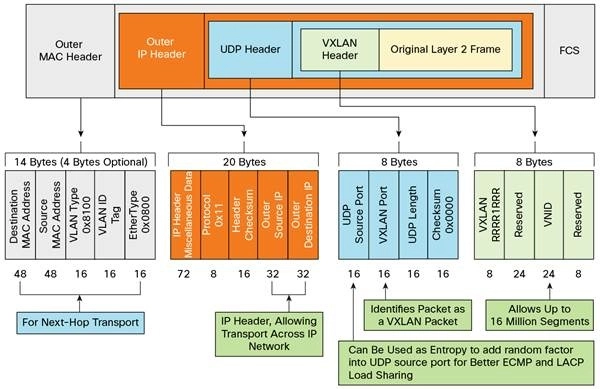
(图片来源: Orchestrating EVPN VXLAN Services with Cisco NSO )
VXLAN 对网络基础设施的要求很低,不需要专门的硬件提供特别支持,只要三层可达的网络就能部署 VXLAN。
VXLAN 网络的每个边缘入口上,布置有一个 VTEP(VXLAN Tunnel Endpoints)设备,它既可以是物理设备,也可以是虚拟化设备,主要负责 VXLAN 协议报文的封包和解包。 互联网号码分配局 (Internet Assigned Numbers Authority,IANA)也专门分配了 4789 作为 VTEP 设备的 UDP 端口(以前 Linux VXLAN 用的默认端口是 8472,目前这两个端口在许多场景中仍有并存的情况)。
从 Linux Kernel 3.7 版本起,Linux 系统就开始支持 VXLAN。到了 3.12 版本,Linux 对 VXLAN 的支持已经达到了完全完备的程度,能够处理单播和组播,能够运行于 IPv4 和 IPv6 之上,一台 Linux 主机经过简单配置之后,就可以把 Linux Bridge 作为 VTEP 设备来使用。
VXLAN 带来了很高的灵活性、扩展性和可管理性 ,同一套物理网络中可以任意创建多个 VXLAN 网络,每个 VXLAN 中接入的设备,都像是在一个完全独立的二层局域网中一样,不会受到外部广播的干扰,也很难遭受外部的攻击,这就让 VXLAN 能够良好地匹配分布式系统的弹性需求。
不过,VXLAN 也带来了额外的复杂度和性能开销 ,具体表现为以下两点:
- 传输效率的下降 ,如果你仔细数过前面 VXLAN 报文结构中 UDP、IP、以太帧报文头的字节数,你就会发现经过 VXLAN 封装后的报文,新增加的报文头部分就整整占了 50 Bytes(VXLAN 报文头占 8 Bytes,UDP 报文头占 8 Bytes,IP 报文头占 20 Bytes,以太帧的 MAC 头占 14 Bytes),而原本只需要 14 Bytes 而已,而且现在这 14 Bytes 的消耗也还在,只是被封到了最里面的以太帧中。以太网的 MTU 是 1500 Bytes,如果是传输大量数据,额外损耗 50 Bytes 并不算很高的成本,但如果传输的数据本来就只有几个 Bytes 的话,那传输消耗在报文头上的成本就很高昂了。
- 传输性能的下降 ,每个 VXLAN 报文的封包和解包操作都属于额外的处理过程,尤其是用软件来实现的 VTEP,要知道额外的运算资源消耗,有时候会成为不可忽略的性能影响因素。
副本网卡:MACVLAN
现在,理解了 VLAN 和 VXLAN 的原理后,我们就有足够的前置知识,去了解 MACVLAN 这最后一种网络设备虚拟化的方式了。
前面我提到,两个 VLAN 之间位于独立的广播域,是完全二层隔离的,要通信就只能通过三层设备。而最简单的三层通信就是靠 单臂路由 了。
接下来,我就以这里的示意图中给出的网络拓扑结构为例,来给你介绍下单臂路由是如何工作的。
假设位于 VLAN-A 中的主机 A1,希望把数据包发送给 VLAN-B 中的主机 B2,由于 A、B 两个 VLAN 之间二层链路不通,因此引入了单臂路由。单臂路由不属于任何 VLAN,它与交换机之间的链路允许任何 VLAN ID 的数据包通过,这种接口被称为 TRUNK 。
这样,A1 要和 B2 通信,A1 就把数据包先发送给路由(只需把路由设置为网关即可做到),然后路由根据数据包上的 IP 地址得知 B2 的位置,去掉 VLAN-A 的 VLAN Tag,改用 VLAN-B 的 VLAN Tag 重新封装数据包后,发回给交换机,交换机收到后就可以顺利转发给 B2 了。
这个过程并没什么复杂的地方,但不知道你有没有注意到一个问题: 路由器应该设置怎样的 IP 地址呢?
由于 A1、B2 各自处于独立的网段上,它们又各自要把同一个路由作为网关使用,这就要求路由器必须同时具备 192.168.1.0/24 和 192.168.2.0/24 的 IP 地址。当然,如果真的就只有 VLAN-A、VLAN-B 两个 VLAN,那把路由器上的两个接口分别设置不同的 IP 地址,然后用两条网线分别连接到交换机上,也勉强算是一个解决办法。
但要知道,VLAN 最多可以支持 4096 个 VLAN,那如果要接四千多条网线就太离谱了。因此为了解决这个问题,802.1Q 规范中专门定义了子接口(Sub-Interface)的概念,它的作用是允许在同一张物理网卡上,针对不同的 VLAN 绑定不同的 IP 地址。
所以,MACVLAN 就借用了 VLAN 子接口的思路,并且在这个基础上更进一步, 不仅允许对同一个网卡设置多个 IP 地址,还允许对同一张网卡上设置多个 MAC 地址 ,这也是 MACVLAN 名字的由来。
原本 MAC 地址是网卡接口的”身份证”,应该是严格的一对一关系,而 MACVLAN 打破了这层关系。方法就是在物理设备之上、网络栈之下生成多个虚拟的 Device,每个 Device 都有一个 MAC 地址,新增 Device 的操作本质上相当于在系统内核中,注册了一个收发特定数据包的回调函数,每个回调函数都能对一个 MAC 地址的数据包进行响应,当物理设备收到数据包时,会先根据 MAC 地址进行一次判断,确定交给哪个 Device 来处理,如下图所示。
这样,我们以交换机一侧的视角来看,这个端口后面就像是另一台已经连接了多个设备的交换机一样。
用 MACVLAN 技术虚拟出来的副本网卡,在功能上和真实的网卡是完全对等的,此时真正的物理网卡实际上也确实承担着类似交换机的职责。
在收到数据包后,物理网卡会根据目标 MAC 地址,判断这个包应该转发给哪块副本网卡处理,由同一块物理网卡虚拟出来的副本网卡,天然处于同一个 VLAN 之中,因此可以直接二层通信,不需要将流量转发到外部网络。
那么,与 Linux Bridge 相比,这种以网卡模拟交换机的方法在目标上其实没有什么本质上的不同,但 MACVLAN 在内部实现上,则要比 Linux Bridge 轻量得多。
从数据流来看,副本网卡的通信只比物理网卡多了一次判断而已,就能获得很高的网络通信性能;从操作步骤来看,由于 MAC 地址是静态的,所以 MACVLAN 不需要像 Linux Bridge 那样,要考虑 MAC 地址学习、STP 协议等复杂的算法,这也进一步突出了 MACVLAN 的性能优势。
而除了模拟交换机的 Bridge 模式外,MACVLAN 还支持虚拟以太网端口聚合模式(Virtual Ethernet Port Aggregator,VEPA)、Private 模式、Passthru 模式、Source 模式等另外几种工作模式,有兴趣的话你可以去参考下相关资料,我就不再逐一介绍了。
容器间通信
好了,前面我们通过对虚拟化网络基础知识的一番铺垫后,现在,我们就可以尝试使用这些知识去解构容器间的通信原理了,毕竟运用知识去解决问题,才是学习网络虚拟化的根本目的。
在这节课里,我们先以 Docker 为目标,谈一谈 Docker 所提供的容器通信方案 。当下节课介绍过 CNI 下的 Kubernetes 网络插件生态后,你也许会觉得 Docker 的网络通信相对简单,对于某些分布式系统的需求来说,甚至是过于简陋了。不过,虽然容器间的网络方案多种多样,但通信主体都是固定的,不外乎没有物理设备的虚拟主体(容器、Pod、Service、Endpoints 等等)、不需要跨网络的本地主机、以及通过网络连接的外部主机三种层次。
所有的容器网络通信问题,其实都可以归结为本地主机内部的多个容器之间、本地主机与内部容器之间,以及跨越不同主机的多个容器之间的通信问题,其中的许多原理都是相通的,所以我认为 Docker 网络的简单,在作为检验前面网络知识有没有理解到位时,倒不失为一种优势。
好,下面我们就具体来看看吧。
Docker 的网络方案在操作层面上,是指能够直接通过docker run —network参数指定的网络,或者是先被docker network create创建后再被容器使用的网络。安装 Docker 的过程中,会自动在宿主机上创建一个名为 docker0 的网桥,以及三种不同的 Docker 网络,分别是 bridge、host 和 none,你可以通过docker network ls命令查看到这三种网络,具体如下所示:
$ docker network ls
NETWORK ID NAME DRIVER SCOPE
2a25170d4064 bridge bridge local
a6867d58bd14 host host local
aeb4f8df39b1 none null local事实上,这三种网络,对应着 Docker 提供的三种开箱即用的网络方案,它们分别为:
- 桥接模式 ,使用—network=bridge指定,这种也是未指定网络参数时的默认网络。桥接模式下,Docker 会为新容器分配独立的网络名称空间,创建好 veth pair,一端接入容器,另一端接入到 docker0 网桥上。Docker 会为每个容器自动分配好 IP 地址,默认配置下的地址范围是 172.17.0.0/24,docker0 的地址默认是 172.17.0.1,并且会设置所有容器的网关均为 docker0,这样所有接入同一个网桥内的容器,可以直接依靠二层网络来通信,在此范围之外的容器、主机就必须通过网关来访问(具体过程我在前面介绍 Linux Bridge 时已经举例讲解过了,这里不再啰嗦)。
- 主机模式 ,使用—network=host指定。主机模式下,Docker 不会为新容器创建独立的网络名称空间,这样容器一切的网络设施,比如网卡、网络栈等,都会直接使用宿主机上的,容器也就不会拥有自己独立的 IP 地址。在这个模式下与外界通信,也不需要进行 NAT 转换,没有性能损耗,但它的缺点也十分明显,因为没有隔离,就无法避免网络资源的冲突,比如端口号就不允许重复。
- 空置模式 ,使用—network=none指定。空置模式下,Docker 会给新容器创建独立的网络名称空间,但是不会创建任何虚拟的网络设备,此时容器能看到的只有一个回环设备(Loopback Device)而已。提供这种方式是为了方便用户去做自定义的网络配置,比如自己增加网络设备、自己管理 IP 地址,等等。
而除了前面三种开箱即用的网络方案以外,Docker 还支持由用户自行创建的网络,比如说:
- 容器模式 ,创建容器后使用—network=container:容器名称指定。容器模式下,新创建的容器将会加入指定的容器的网络名称空间,共享一切的网络资源,但其他资源,比如文件、PID 等默认仍然是隔离的。两个容器间可以直接使用回环地址(localhost)通信,端口号等网络资源不能有冲突。
- MACVLAN 模式 ,使用docker network create -d macvlan创建。这种网络模式允许为容器指定一个副本网卡,容器通过副本网卡的 MAC 地址来使用宿主机上的物理设备,所以在追求通信性能的场合,这种网络是最好的选择。这里要注意,Docker 的 MACVLAN 只支持 Bridge 通信模式,所以在功能表现上跟桥接模式是类似的。
- Overlay 模式 ,使用docker network create -d overlay创建。Docker 说的 Overlay 网络,实际上就是特指 VXLAN,这种网络模式主要用于 Docker Swarm 服务之间进行通信。然而由于 Docker Swarm 败给了 Kubernetes,并没有成为主流,所以这种网络模式实际上很少被人使用。
小结
这节课我从模拟网卡、交换机这些网络设备开始,给你介绍了如何在 Linux 网络名称空间的支持下,模拟出一个物理上实际并不存在,但可以像物理网络一样,让程序可以进行通讯的虚拟化网路。
虚拟化网络是容器编排必不可少的功能,网络的功能和性能,对应用程序各个服务间通讯都有非常密切的关联,这一点你要重点关注。在实际生产中,容器编排系统就是由一批容器通过网络交互来共同对外提供服务的,其中的开发、除错、效率优化等工作,都离不开这些基础的网络知识。
54 | 容器网络与生态:与CNM竞争过后的CNI下的网络插件生态
前面的两节课,我们学习了 Linux 系统本身的网络虚拟化知识,今天这节课,我们就来看看这些理论知识实际是如何应用于容器间网络的。
容器网络的第一个业界标准,是源于 Docker 在 2015 年发布的 libnetwork 项目。如果你还记得在” 容器的崛起 “这个小章节中我提到的关于 libcontainer 的故事,那从名字上,你就能很容易地推断出 libnetwork 项目的目的与意义。libnetwork 项目是 Docker 用 Golang 编写的、专门用来抽象容器间网络通信的一个独立模块。
类似于 libcontainer 是作为 OCI 的标准来实现的,libnetwork 是作为 Docker 提出的 CNM 规范(Container Network Model)的标准实现而设计的。不过,跟 ibcontainer 因为孵化出 runC 项目,到今天都仍然广为人知的结局不一样,libnetwork 随着 Docker Swarm 的失败,已经基本上失去了实用的价值,只具备历史与学术研究方面的价值了。
接下来,我就会从 CNM 规范的出现以及它与 CNI 的竞争开始说起,带你了解容器间网络所解决的问题。
CNM 与 CNI
首先,可以说,现在的容器网络的事实标准 CNI (Container Networking Interface)与 CNM 在目标上几乎是完全重叠的,这就决定了 CNI 与 CNM 之间,只能是你死我活的竞争关系 ,而这与容器运行时提到的 CRI 和 OCI 的关系明显不一样。CRI 与 OCI 的目标并不相同,所以两者有足够的空间可以和平共处。
不过,尽管 CNM 规范已是明日黄花,但它作为容器网络的先行者,对后续的容器网络标准的制定仍然有直接的指导意义。
要知道, 提出容器网络标准的目的 ,就是为了把网络功能从容器运行时引擎、或者容器编排系统中剥离出去,毕竟网络的专业性和针对性极强,如果不把它变成外部可扩展的功能,而都由自己来做的话,不仅费时费力,还不讨好。这个特点从下图所列的一大堆容器网络提供商就可见一斑。

另外,网络的专业性与针对性也决定了 CNM 和 CNI 都采用了插件式的设计,这样需要接入什么样的网络,就设计一个对应的网络插件即可。所谓的插件,在形式上也就是一个可执行文件,再配上相应的 Manifests 描述。
为了方便插件编写,CNM 把协议栈、网络接口(对应于 veth、tap/tun 等)和网络(对应于 Bridge、VXLAN、MACVLAN 等)分别抽象为 Sandbox、Endpoint 和 Network,并在接口的 API 中提供了这些抽象资源的读写操作。
而 CNI 中尽管也有 Sandbox、Network 的概念,其含义也跟 CNM 的大致相同,不过在 Kubernetes 资源模型的支持下,它就不需要刻意去强调某一种网络资源应该如何描述、如何访问了,所以在结构上就显得更加轻便。
那么从程序功能上看,CNM 和 CNI 的网络插件提供的能力,都可以划分为网络的管理与 IP 地址的管理两类,而插件可以选择只实现其中的某一个,也可以全部都实现。下面我们就具体来了解一下。
管理网络创建与删除
顾名思义,这项能力解决的是如何创建网络、如何将容器接入到网络,以及容器如何退出和删除网络的问题。这个过程实际上是对容器网络的生命周期管理,如果你更熟悉 Docker 命令,可以把它类比理解成基本上等同于docker network命令所做的事情。
CNM 规范中定义了创建网络、删除网络、容器接入网络、容器退出网络、查询网络信息、创建通信 Endpoint、删除通信 Endpoint 等十个编程接口,而 CNI 中就更加简单了,只要实现对网络的增加与删除两项操作即可。你甚至不需要学过 Golang 语言,只从名称上都能轻松看明白以下接口中,每个方法的含义是什么。
type CNI interface { AddNetworkList (net *NetworkConfigList, rt *RuntimeConf) (types.Result, error) DelNetworkList (net *NetworkConfigList, rt *RuntimeConf) error AddNetwork (net *NetworkConfig, rt *RuntimeConf) (types.Result, error) DelNetwork (net *NetworkConfig, rt *RuntimeConf) error }管理 IP 地址分配与回收
这项能力解决的是如何为三层网络分配唯一的 IP 地址的问题。我们知道,二层网络的 MAC 地址天然就具有唯一性,不需要刻意考虑如何分配的问题。但是三层网络的 IP 地址只有通过精心规划,才能保证在全局网络中都是唯一的。否则,如果两个容器之间可能存在相同地址,那它们就最多只能做 NAT,而不可能做到直接通信。
相比起基于 UUID 或者数字序列实现的全局唯一 ID 产生器,IP 地址的全局分配工作要更加困难一些。
首先是要符合 IPv4 的网段规则 ,而且得保证不重复,这在分布式环境里就只能依赖 etcd、ZooKeeper 等协调工具来实现,Docker 自己也提供了类似的 libkv 来完成这项工作; 其次是必须考虑到回收的问题 ,否则一旦 Pod 发生持续重启,就有可能耗尽某个网段中的所有地址; 最后还必须要关注时效性 ,原本 IP 地址的获取采用标准的 DHCP 协议(Dynamic Host Configuration Protocol)就可以了,但 DHCP 有可能产生长达数秒的延迟,对于某些生存周期很短的 Pod,这就已经超出了它的忍受限度,所以在容器网络中,往往 Host-Local 的 IP 分配方式会比 DHCP 更加实用。
总而言之,虽然现在时过境迁,舞台的聚光灯已然落到了 CNI 身上,但 CNM 规范作为容器间网络的首个技术规范,依然起到了为继任者指明方向的作用。
CNM 到 CNI
容器网络标准能够提供一致的网络操作界面,不管是什么网络插件都使用一致的 API,这就提高了网络配置的自动化程度和在不同网络间迁移的体验,对最终用户、容器提供商、网络提供商来说,都是三方共赢的事情。
从 CNM 规范发布以后,借助 Docker 在容器领域的强大号召力,很快就得到了网络提供商与开源组织的支持,不说专门为 Docker 设计针对容器互联的网络,最起码也会让现有的网络方案兼容于 CNM 规范,以便能在容器圈中多分一杯羹,比如 Cisco 的 Contiv 、OpenStack 的 Kuryr 、Open vSwitch 的 OVN (Open Virtual Networking),以及来自开源项目的 Calico 和 Weave 等都是 CNM 阵营中的成员。
而唯一对 CNM 持有不同意见的,是那些和 Docker 存在直接竞争关系的产品,比如 Docker 的最大竞争对手,来自 CoreOS 公司的 RKT 容器引擎。
其实凭良心说,并不是其他容器引擎想刻意去抵制 CNM,而是 Docker 制定 CNM 规范时,完全是基于 Docker 本身来设计的,并没有考虑 CNM 用于其他容器引擎的可能性。因而,为了平衡 CNM 规范的影响力,也是为了在 Docker 的垄断背景下寻找一条出路,RKT 提出了与 CNM 目标类似的” RKT 网络提案 “(RKT Networking Proposal)。
事实上,一个业界标准成功与否,很大程度上取决于它的支持者阵营的规模,对于容器网络这种插件式的规范就更是如此了。Docker 力推的 CNM,毫无疑问是当时统一容器网络标准的最有力的竞争者,如果没有外力的介入,有很大的可能会成为最后的胜利者。
然而,影响容器网络发展的外力还是出现了,即使我之前没有提过 CNI,你也应该很容易猜到,在容器圈里能够掀翻 Docker 的”外力”,也就只有 Kubernetes 一家而已。
Kubernetes 开源的初期(Kubernetes 1.5 提出 CRI 规范之前),在容器引擎上是选择彻底绑定于 Docker 的,但是 在容器网络的选择上,Kubernetes 一直都坚持独立于 Docker ,自己来维护网络。
在 CNM 和 CNI 提出以前的早期版本里,Kubernetes 会使用 Docker 的空置网络模式(—network=none)来创建 Pause 容器,然后通过内部的 kubenet 来创建网络设施,再让 Pod 中的其他容器加入到 Pause 容器的名称空间中,共享这些网络设施。
额外知识:kubenet
kubenet 是 kubelet 内置的一个非常简单的网络,它是采用网桥来解决 Pod 间通信。kubenet 会自动创建一个名为 cbr0 的网桥,当有新的 Pod 启动时,会由 kubenet 自动将其接入 cbr0 网桥中,再将控制权交还给 kubelet,完成后续的 Pod 创建流程。kubenet 采用 Host-Local 的 IP 地址管理方式,具体来说是根据当前服务器对应的 Node 资源上的PodCIDR字段所设的网段,来分配 IP 地址。当有新的 Pod 启动时,会由本地节点的 IP 段中分配一个空闲的 IP 给 Pod 使用。
其实,在 CNM 规范还没有提出之前,Kubernetes 自己来维护网络是必然的结果,因为 Docker 自带的网络基本上只聚焦于如何解决本地通信,完全无法满足 Kubernetes 跨集群节点的容器编排的需要。而当 CNM 规范提出之后,原本 Kubernetes 应该是除 Docker 外的最大受益者才对,毕竟 CNM 的价值就是能很方便地引入其他网络插件,来替代掉 Docker 自带的网络。
但 Kubernetes 却对 Docker 的 CNM 规范表现得很是犹豫,经过一番评估考量,Kubernetes 最终决定,转为支持当时极不成熟的 RKT 的网络提案,他们与 CoreOS 合作,以 RKT 网络提案为基础发展出了 CNI 规范。
Kubernetes Network SIG 的 Leader、Google 的工程师蒂姆·霍金(Tim Hockin)也曾专门撰写过一篇文章《 Why Kubernetes doesn’t use libnetwork 》,来解释为什么 Kubernetes 要拒绝 CNM 与 libnetwork。
当时,容器编排战争还处于三国争霸(Kubernetes、Apache Mesos、Docker Swarm)的拉锯阶段,即使强势如 Kubernetes,拒绝 CNM 其实也要冒不小的风险,付出很大的代价,因为这个决定不可避免地会引发一系列技术和非技术的问题,比如网络提供商要为 Kubernetes 专门编写不同的网络插件、由docker run启动的独立容器将会无法与 Kubernetes 启动的容器直接相互通信,等等。
而促使 Kubernetes 拒绝 CNM 的理由,也同样有来自于技术和非技术方面的。
首先在技术方面, Docker 的网络模型做出了许多对 Kubernetes 无效的假设 :Docker 的网络有本地网络(不带任何跨节点协调能力,比如 Bridge 模式就没有全局统一的 IP 分配)和全局网络(跨主机的容器通信,例如 Overlay 模式)的区别,本地网络对 Kubernetes 来说毫无意义,而全局网络又默认依赖 libkv,来实现全局 IP 地址管理等跨机器的协调工作。
这里的 libkv,是指 Docker 建立的 lib* 家族中的另一位成员,它主要是用来对标 etcd、ZooKeeper 等分布式 K/V 存储,而这对于已经拥有了 etcd 的 Kubernetes 来说就如同鸡肋。
然后在非技术方面,Kubernetes 决定放弃 CNM 的原因,很大程度上还是由于他们与 Docker 在发展理念上的冲突,Kubernetes 当时已经开始推进 Docker 从必备依赖变为可选引擎的重构工作了,而 Docker 则坚持 CNM 只能基于 Docker 来设计。
蒂姆·霍金在他的文章中举了一个例子:CNM 的网络驱动没有向外部暴露网络所连接容器的具体名称,只使用了一个内部分配的 ID 来代替,这就让外部(包括网络插件和容器编排系统)很难将网络连接的容器与自己管理的容器对应关联起来,而当他们向 Docker 开发人员反馈这个问题时,却以”工作符合预期结果”(Working as Intended)为理由,被直接关闭掉了这个问题。
蒂姆·霍金还专门列出了这些问题的详细清单,比如 libnetwork #139 、 libnetwork #486 、 libnetwork #514 、 libnetwork #865 、 docker #18864 。这种设计,被 Kubernetes 认为是在人为地给非 Docker 的第三方容器引擎使用 CNM 设置障碍。而在整个沟通过程中,Docker 表现得也很强硬,明确表示他们对偏离当前路线或委托控制的想法都不太欢迎。
其实,刚刚提到的这些”非技术”的问题,即使没有 Docker 的支持,Kubernetes 自己也不是不能从”技术上”去解决,但 Docker 的理念会让 Kubernetes 感到忧虑,因为 Kubernetes 在 Docker 之上扩展了很多功能,而 Kubernetes 却并不想这些功能永远绑定在 Docker 之上。
CNM 与 libnetwork 是 2015 年 5 月 1 日发布的,CNI 则是在 2015 年 7 月发布,两者的正式诞生只相差不到两个月时间,可见这显然是竞争的需要,而不是什么单纯的巧合。
当然,在五年之后的今天,这场容器网络的话语权之争已经尘埃落定,CNI 获得了全面的胜利,除了 Kubernetes 和 RKT 之外,Amazon ECS、RedHat OpenShift、Apache Mesos、Cloud Foundry 等容器编排圈子中,除了 Docker 之外,其他具有影响力的参与者都已经宣布支持 CNI 规范,而原本已经加入了 CNM 阵营的 Contiv、Calico、Weave 网络提供商,也纷纷推出了自己的 CNI 插件。
那么下面,我就带你具体了解下当前的网络插件生态,看看目前业界常用的容器间网络大体上是如何实现的。
网络插件生态
首先要说明的是,到今天为止,支持 CNI 的网络插件已经多达数十种,我不太可能逐一细说。不过,跨主机通信的网络实现方式,来去也就 Overlay 模式、路由模式、Underlay 模式这三种,所以接下来,我就不妨以网络实现模式为主线,每种模式给你介绍一个具有代表性的插件,以达到对网络插件生态窥斑见豹的效果。
Overlay 模式
我们已经学习过 Overlay 网络,知道这是一种虚拟化的上层逻辑网络,好处在于它不受底层物理网络结构的约束,有更大的自由度,更好的易用性;坏处是由于额外的包头封装,导致信息密度降低,额外的隧道封包解包会导致传输性能下降。
而在虚拟化环境(如 OpenStack)中,网络限制往往比较多,比如不允许机器之间直接进行二层通信,只能通过三层转发。那么, 在这类被限制网络的环境里,基本上就只能选择 Overlay 网络插件。
常见的 Overlay 网络插件有 Flannel(VXLAN 模式)、Calico(IPIP 模式)、Weave,等等。这里我就以 Flannel-VXLAN 为例来给你介绍一下。
由 CoreOS 开发的 Flannel,可以说是最早的跨节点容器通信解决方案,在很多其他网络插件的设计中,都能找到 Flannel 的影子。
早在 2014 年,VXLAN 还没有进入 Linux 内核的时候,Flannel 就已经开始流行了。当时的 Flannel 只能采用自定义的 UDP 封包,实现自己私有协议的 Overlay 网络,由于封包、解包的操作只能在用户态中进行,而数据包在内核态的协议栈中流转,这就导致数据要反复在用户态、内核态之间拷贝,因此性能堪忧,从此 Flannel 就给人留下了速度慢的坏印象。
而当 VXLAN 进入了 Linux 内核以后,这种内核态用户态的转换消耗已经完全消失了,Flannel-VXLAN 的效率比起 Flannel-UDP 有了很大提升,所以目前已经成为最常用的容器网络插件之一。
路由模式
路由模式其实是属于 Underlay 模式的一种特例,这里我把它单独作为一种网络实现模式来给你介绍一下。
相比起 Overlay 网络,路由模式的主要区别在于, 它的跨主机通信是直接通过路由转发来实现的,因而不需要在不同主机之间进行隧道封包。 这种模式的好处是性能相比 Overlay 网络有明显提升,而坏处是路由转发要依赖于底层网络环境的支持,并不是你想做就能做到的。
路由网络要求要么所有主机都位于同一个子网之内,都是二层连通的;要么不同二层子网之间由支持 边界网关协议 (Border Gateway Protocol,BGP)的路由相连,并且网络插件也同样支持 BGP 协议去修改路由表。
在上节课我介绍 Linux 网络基础知识的时候,提到过 Linux 下不需要专门的虚拟路由,因为 Linux 本身就具备路由的功能。而路由模式就是依赖 Linux 内置在系统之中的路由协议,把路由表分发到子网的每一台物理主机的。这样,当跨主机访问容器时,Linux 主机可以根据自己的路由表得知,该容器具体位于哪台物理主机之中,从而直接将数据包转发过去,避免了 VXLAN 的封包解包而导致的性能降低。
常见的路由网络有 Flannel(HostGateway 模式)、Calico(BGP 模式)等等。这里我就以 Flannel-HostGateway 为例,Flannel 通过在各个节点上运行的 Flannel Agent(Flanneld),把容器网络的路由信息设置到主机的路由表上,这样一来,所有的物理主机都拥有整个容器网络的路由数据,容器间的数据包可以被 Linux 主机直接转发,通信效率与裸机直连都相差无几。
不过,因为 Flannel Agent 只能修改它运行主机上的路由表,一旦主机之间隔了其他路由设备,比如路由器或者三层交换机,这个包就会在路由设备上被丢掉,而要解决这种问题,就必须依靠 BGP 路由和 Calico-BGP 这类支持标准 BGP 协议,修改路由表的网络插件共同协作才行。
Underlay 模式
这里的 Underlay 模式特指让容器和宿主机处于同一网络,两者拥有相同的地位的网络方案。Underlay 网络要求容器的网络接口能够直接与底层网络进行通信,因此 这个模式是直接依赖于虚拟化设备与底层网络能力的 。常见的 Underlay 网络插件,有 MACVLAN、 SR-IOV (Single Root I/O Virtualization)等。
实际上,对于真正的大型数据中心、大型系统来说,Underlay 模式才是最有发展潜力的网络模式。 这种方案能够最大限度地利用硬件的能力,往往有着最优秀的性能表现。但也是由于它直接依赖于硬件与底层网络环境,必须根据软、硬件情况来进行部署,所以很难能做到 Overlay 网络那样的开箱即用的灵活性。
这里我以 SR-IOV 为例来给你介绍下。SR-IOV 不是某种专门的网络名字,而是一种将 PCIe 设备共享给虚拟机使用的硬件虚拟化标准,目前用在网络设备上的应用比较多,理论上也可以支持其他的 PCIe 硬件。通过 SR-IOV,程序员能够让硬件在虚拟机上实现独立的内存地址、中断和 DMA 流,而不需要虚拟机管理系统的介入。
对于容器系统来说,SR-IOV 的价值是可以直接在硬件层面虚拟多张网卡,并且以硬件直通(Passthrough)的形式,交付给容器使用。但 SR-IOV 直通部署起来一般都很繁琐,现在容器用的 SR-IOV 方案,不少是使用 MACVTAP 来对 SR-IOV 网卡进行转接的。
不过,虽然 MACVTAP 提升了 SR-IOV 的易用性,但是这种转接又会带来额外的性能损失,并不一定会比其他网络方案有更好的表现。
好了,在了解过 CNI 插件的大致实现原理与分类后,相信你的下一个问题,就是哪种 CNI 网络最好?如何选择合适的 CNI 插件?
其实, 选择 CNI 网络插件主要有两方面的考量因素。
首先就必须是 你系统所处的环境是支持的 ,这点我在前面已经有针对性地介绍过。然后在环境可以支持的前提下,另一个因素就是 性能与功能方面是否合乎你的要求。
关于性能方面,这里我引用一组测试数据来供你参考。这些数据来自于 2020 年 8 月刊登在 IETF 的论文《 Considerations for Benchmarking Network Performance in Containerized Infrastructures 》,其中测试了不同 CNI 插件在 裸金属服务器 之间(BMP to BMP,Bare Metal Pod)、虚拟机之间(VMP to VMP,Virtual Machine Pod),以及裸金属服务器与虚拟机之间(BMP to VMP)的本地网络和跨主机网络的通信表现。
其中,最具代表性的是裸金属服务器之间的跨主机通信,这里我把它的结果列了出来,你可以去看看:
.webp)
.webp)
那么,从测试结果来看,MACVLAN 和 SR-IOV 这样的 Underlay 网络插件的吞吐量最高、延迟最低,所以只从网络性能上看,它们肯定是最优秀的。而相对来说 Flannel-VXLAN 这样的 Overlay 网络插件,它的吞吐量只有 MACVLAN 和 SR-IOV 的 70% 左右,延迟更是高了两至三倍之多。
所以说,Overlay 为了易用性、灵活性所付出的代价还是不可忽视的,但是对于那些不以网络 I/O 为性能瓶颈的系统来说,这样的代价并不是一定不能接受,就看你心中对通用性与性能是如何权衡取舍的了。
而在功能方面的问题就比较简单了,这完全取决于你的需求是否能够满足。
对于容器编排系统来说,网络并不是孤立的功能模块,只提供网络通信就可以的,比如 Kubernetes 的 NetworkPolicy 资源是用于描述”两个 Pod 之间是否可以访问”这类 ACL 策略。但它不属于 CNI 的范畴,所以不是每个 CNI 插件都会支持 NetworkPolicy 的声明。
如果你有这方面的需求,就应该放弃 Flannel,去选择 Calico、Weave 等插件。类似的其他功能上的选择的例子还有很多,这里我就不一一列举了。
小结
如何保证信息安全准确快速地出传输、如何更好地连接不同的集群节点、如何连接异构的容器云平台,这些都是我们需要考虑的一系列的网络问题。
当然,容器网络技术也在持续地演进之中。我们要知道,容器间网络是把应用从单机扩展到集群的关键钥匙,但它也把虚拟化容器推入到了更复杂的境地,网络要去适应这种变化,要去适配容器的各种需求,所以才出现了百花齐放的容器网络方案。
55 | 谈谈Kubernetes的存储设计理念
从这节课起,我会用三讲带你学习容器编排系统存储方面的知识点。今天这节课,我们先来探讨下 Kubernetes 的存储设计理念。
Kubernetes 的存储设计考量
在开始之前,我想先表明一下我对 Kubernetes 存储能力的态度。Kubernetes 在规划持久化存储能力的时候,依然遵循着它的一贯设计哲学,用户负责以资源和声明式 API 来描述自己的意图,Kubernetes 负责根据用户意图来完成具体的操作。不过我认为,就算只是描述清楚用户的存储意图,也不是一件容易的事情,相比 Kubernetes 提供的其他能力的资源,它内置的存储资源其实格外地复杂,甚至可以说是有些繁琐的。
如果你是 Kubernetes 的拥趸,不能认同我对 Kubernetes 的批评,那不妨来看一看下列围绕着”Volume”所衍生出的概念,它们仅仅是与 Kubernetes 存储相关概念的一个子集而已,你在看的时候也可以来思考一下,这些概念是否全都是必须的、是否还有整合的空间、是否有化繁为简的可能性:
概念: Volume 、 PersistentVolume 、 PersistentVolumeClaim 、 Provisioner 、 StorageClass 、 Volume Snapshot 、 Volume Snapshot Class 、 Ephemeral Volumes 、 FlexVolume Driver 、 Container Storage Interface 、 CSI Volume Cloning 、 Volume Limits 、 Volume Mode 、 Access Modes 、 Storage Capacity ……
操作: Mount 、 Bind 、 Use 、 Provision 、 Claim 、 Reclaim 、 Reserve 、 Expand 、 Clone 、 Schedule 、 Reschedule ……
其实啊,Kubernetes 之所以有如此多关于存储的术语概念,最重要的原因是存储技术本来就有很多种类,为了尽可能多地兼容各种存储,Kubernetes 不得不预置了很多 In-Tree(意思是在 Kubernetes 的代码树里)插件来对接,让用户根据自己的业务按需选择。
同时,为了兼容那些不在预置范围内的需求场景,Kubernetes 也支持用户使用 FlexVolume 或者 CSI 来定制 Out-of-Tree(意思是在 Kubernetes 的代码树之外)的插件,实现更加丰富多样的存储能力。下表中列出了 Kubernetes 目前提供的一部分存储与扩展的插件:
事实上,迫使 Kubernetes 存储设计得如此复杂的原因,除了是要扩大兼容范畴之外,还有一个非技术层面的因素,就是 Kubernetes 是一个工业级的、面向生产应用的容器编排系统。
而这就意味着,即使 Kubernetes 发现了某些已存在的功能有更好的实现方式,但直到旧版本被淘汰出生产环境以前,原本已支持的功能都不允许突然间被移除或者替换掉。否则,当生产系统更新版本时,已有的功能就会出现异常,那就会极大威胁到产品的信誉。
当然,在一定程度上,我们可以原谅 Kubernetes 为了实现兼容而导致的繁琐,但这样的设计确实会让 Kubernetes 的学习曲线变得更加陡峭。
Kubernetes 提供的官方文档的主要作用是为实际开发提供参考,它并不会告诉你 Kubernetes 中各种概念的演化历程、版本发布新功能的时间线、改动的缘由与背景等信息,只会以”平坦”的方式来陈述所有目前可用的功能,这可能有利于熟练的管理员快速查询到关键信息,却不利于初学者去理解 Kubernetes 的设计思想。
如此一来,因为很难理解那些概念和操作的本意,初学者往往就只能死记硬背,很难分辨出它们应该如何被”更正确”地使用。而介绍 Kubernetes 设计理念的职责,只能由 Kubernetes 官方的 Blog 这类信息渠道,或者其他非官方资料去完成。
所以接下来,我会从 Volume 的概念开始,以操作系统到 Docker,再到 Kubernetes 的演进历程为主线,带你去梳理前面提到的那些概念与操作,以此帮你更好地理解 Kubernetes 的存储设计。
首先,我们来看看 Mount 和 Volume 这两个概念。
Mount 和 Volume
Mount 和 Volume 都是来源于操作系统的常用术语,Mount 是动词,表示将某个外部存储挂载到系统中;Volume 是名词,表示物理存储的逻辑抽象,目的是为物理存储提供有弹性的分割方式。
而我们知道,容器是源于对操作系统层的虚拟化,为了满足容器内生成数据的外部存储需求,我们也很自然地会把 Mount 和 Volume 的概念延至容器中。因此,要想了解容器存储的发展,我们不妨就以 Docker 的 Mount 操作为起始点。
目前,Docker 内建支持了三种挂载类型,分别是 Bind(—mount type=bind)、Volume(—mount type=volume)和 tmpfs(—mount type=tmpfs),如下图所示。其中,tmpfs 主要用于在内存中读写临时数据,跟我们这个小章节要讨论的对象”持久化存储”并不相符,所以后面我们只着重关注 Bind 和 Volume 两种挂载类型就可以了。

(图片来自 Docker 官网文档 )
我们先来聊聊 Bind。
Bind Mount 是 Docker 最早提供的(发布时就支持)挂载类型,作用是把宿主机的某个目录(或文件)挂载到容器的指定目录(或文件)下,比如下面命令中,参数-v表达的意思就是把外部的 HTML 文档,挂到 Nginx 容器的默认网站根目录下:
docker run -v /icyfenix/html:/usr/share/nginx/html nginx:latest请注意,虽然命令中-v参数是—volume的缩写,但-v最初只是用来创建 Bind Mount,而不是创建 Volume Mount 的。
这种迷惑的行为其实也并不是 Docker 的本意,只是因为 Docker 刚发布的时候考虑得不够周全,随随便便就在参数中占用了”Volume”这个词,到后来真的需要扩展 Volume 的概念来支持 Volume Mount 的时候,前面的-v已经被用户广泛使用了,所以也就只能如此将就着继续用。
从 Docker 17.06 版本开始,Bind 就在 Docker Swarm 中借用了—mount参数过来,这个参数默认创建的是 Volume Mount,用户可以通过明确的 type 子参数来指定另外两种挂载类型。比如说,前面给到的命令,就可以等价于下面所示的—mount版本:
docker run --mount type=bind,source=/icyfenix/html,destination=/usr/share/nginx/html nginx:latest从 Bind Mount 到 Volume Mount,实质上是容器发展过程中对存储抽象能力提升的外在表现。 我们根据”Bind”这个名字,以及 Bind Mount 的实际功能,其实可以合理地推测,Docker 最初认为”Volume”就只是一种”外部宿主机的磁盘存储到内部容器存储的映射关系”,但后来它眉头一皱,发现事情并没有那么简单: 存储的位置并不局限只在外部宿主机,存储的介质并不局限只是物理磁盘,存储的管理也并不局限只有映射关系。
我给你举几个例子。
比如,Bind Mount 只能让容器与本地宿主机之间建立某个目录的映射,那么如果想要在不同宿主机上的容器共享同一份存储,就必须先把共享存储挂载到每一台宿主机操作系统的某个目录下,然后才能逐个挂载到容器内使用,这种跨宿主机共享存储的场景如下图所示:
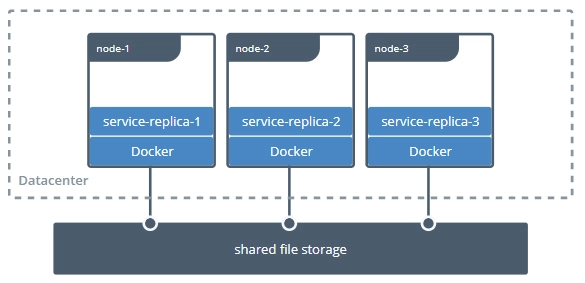
(图片来自 Docker 官网文档 )
这种存储范围超越了宿主机的共享存储,配置过程却要涉及到大量与宿主机环境相关的操作,只能由管理员人工地去完成,不仅繁琐,而且由于每台宿主机环境的差异,还会导致主机很难实现自动化。
再比如,即使只考虑单台宿主机的情况,基于可管理性的需求,Docker 也完全有支持 Volume Mount 的必要。为什么这么说呢?
实际上,在 Bind Mount 的设计里,Docker 只有容器的控制权,存放容器生产数据的主机目录是完全独立的,与 Docker 没有任何关系,它既不受 Docker 保护,也不受 Docker 管理。所以这就使得数据很容易被其他进程访问到,甚至是被修改和删除。如果用户想对挂载的目录进行备份、迁移等管理运维操作,也只能在 Docker 之外靠管理员人工进行,而这些都增加了数据安全与操作意外的风险。
因此,Docker 希望能有一种抽象的资源,来代表在宿主机或网络中存储的区域,以便让 Docker 能管理这些资源,这样就很自然地联想到了操作系统里的 Volume。
提出 Volume 最核心的一个目的 ,是为了提升 Docker 对不同存储介质的支撑能力,这同时也是为了减轻 Docker 本身的工作量。
要知道,存储并不是只有挂载在宿主机上的物理存储这一种介质。在云计算时代,网络存储逐渐成为了数据中心的主流选择,不同的网络存储都有各自的协议和交互接口。而且,并不是所有的存储系统都适合先挂载到操作系统,然后再挂载到容器的,如果 Docker 想要越过操作系统去支持挂载某种存储系统,首先必须要知道该如何访问它,然后才能把容器中的读写操作自动转移到该位置。
Docker 把解决如何访问存储的功能模块叫做存储驱动(Storage Driver)。通过docker info命令,你能查看到当前 Docker 所支持的存储驱动。虽然 Docker 已经内置了市面上主流的 OverlayFS 驱动,比如 Overlay、Overlay2、AUFS、BTRFS、ZFS 等等,但面对云计算的快速迭代,只靠 Docker 自己来支持全部云计算厂商的存储系统是完全不现实的。
为此,Docker 就提出了与 Storage Driver 相对应的 Volume Driver(卷驱动)的概念。
我们可以通过docker plugin install命令安装 外部的卷驱动 ,并在创建 Volume 时,指定一个与其存储系统相匹配的卷驱动。比如,我们希望数据存储在 AWS Elastic Block Store 上,就找一个 AWS EBS 的驱动;如果想存储在 Azure File Storage 上,也是找一个对应的 Azure File Storage 驱动即可。
而如果在创建 Volume 时,不指定卷驱动,那默认就是 local 类型,在 Volume 中存放的数据就会存储在宿主机的/var/lib/docker/volumes/目录之中。
Static Provisioning
好了,了解了 Mount 和 Volume 的概念含义之后,现在我们把讨论主角转回容器编排系统上。
这里,我们会从存储如何分配、持久存储与非持久存储的差异出发,来具体学习下 Static Provisioning 的设计。
首先我们可以明确一件事,即 Kubernetes 同样是把操作系统和 Docker 的 Volume 概念延续了下来,并对其进行了进一步的细化。
Kubernetes 把 Volume 分为了 持久化的 PersistentVolume 和非持久化的普通 Volume 两类,这里为了不跟我前面定义的 Volume 这个概念产生混淆,后面课程我提到的 Kubernetes 中非持久化的 Volume 时,都会带着”普通”这个前缀。
普通 Volume 的设计目标并不是为了持久地保存数据,而是为同一个 Pod 中多个容器提供可共享的存储资源,所以普通 Volume 的生命周期非常明确,也就是与挂载它的 Pod 有着相同的生命周期。
这样,就意味着尽管普通 Volume 不具备持久化的存储能力,但至少比 Pod 中运行的任何容器的存活期都更长,Pod 中不同的容器能共享相同的普通 Volume,当容器重新启动时,普通 Volume 中的数据也能够得到保留。
当然,一旦整个 Pod 被销毁,普通 Volume 也就不复存在了,数据在逻辑上也会被销毁掉。至于实际中是否会真正删除数据,就取决于存储驱动具体是如何实现 Unmount、Detach、Delete 接口的(这个小章节的主题是”持久化存储”,所以关于无持久化能力的普通 Volume,我就不再展开了)。
如此一来,从操作系统里传承下来的 Volume 概念,就在 Docker 和 Kubernetes 中继续按照一致的逻辑延伸拓展了,只不过 Kubernetes 为了把它跟普通 Volume 区别开来,专门取了 PersistentVolume 这个名字。你可以从下图中直观地看出普通 Volume、PersistentVolume 和 Pod 之间的关系差异:
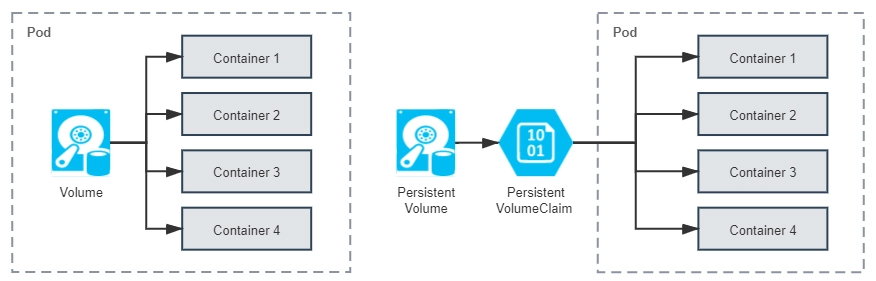
其实,我们从 Persistent 这个单词的意思,就能大致了解 PersistentVolume 的含义,它是指 能够将数据进行持久化存储的一种资源对象。
PersistentVolume 可以独立于 Pod 存在,生命周期与 Pod 无关,所以也就决定了 PersistentVolume 不应该依附于任何一个宿主机节点,否则必然会对 Pod 调度产生干扰限制。我们在前面”Docker 的三种挂载类型”图例中,可以看到”Persistent”一列里都是网络存储,这便是很好的印证。
额外知识:Local PersistentVolume
对于部署在云端数据中心的系统,通过网络访问同一个可用区中的远程存储,速度是完全可以接受的。但对于私有部署的系统来说,基于性能考虑,使用本地存储往往会更加常见。
因此,考虑到这样的实际需求,从 1.10 版起,Kubernetes 开始支持 Local PersistentVolume ,这是一种将一整块本地磁盘作为 PersistentVolume 供容器使用的专用方案。
所谓的”专用方案”就是字面意思,它并不适用于全部应用,Local PersistentVolume 只是针对以磁盘 I/O 为瓶颈的特定场景的解决方案,因而它的副作用就很明显:由于不能保证这种本地磁盘在每个节点中都一定存在,所以 Kubernetes 在调度时就必须考虑到 PersistentVolume 分布情况,只能把使用了 Local PersistentVolume 的 Pod 调度到有这种 PersistentVolume 的节点上。
尽管调度器中专门有个 Volume Binding Mode 模式来支持这项处理,但是一旦使用了 Local PersistentVolume,还是会限制 Pod 的可调度范围。
那么,在把 PersistentVolume 与 Pod 分离后,就需要专门考虑 PersistentVolume 该如何被 Pod 所引用的问题了。
实际上,原本在 Pod 中引用其他资源是常有的事,要么是通过资源名称直接引用,要么是通过 标签选择器 (Selectors)间接引用。但是类似的方法在这里却都不太妥当,至于原因,你可以先思考一下:”Pod 该使用何种存储”这件事情,应该是系统管理员(运维人员)说的算,还是由用户(开发人员)说的算?
要我看,最合理的答案是他们一起说的才算,因为只有开发能准确评估 Pod 运行需要消耗多大的存储空间,只有运维能清楚地知道当前系统可以使用的存储设备状况。
所以,为了让这二者能够各自提供自己擅长的信息,Kubernetes 又额外设计出了 PersistentVolumeClaim 资源。
其实在 Kubernetes 官方给出的概念定义中,也特别强调了 PersistentVolume 是由管理员(运维人员)负责维护的,用户(开发人员)通过 PersistentVolumeClaim,来匹配到合乎需求的 PersistentVolume。
PersistentVolume & PersistentVolumeClaim
A PersistentVolume (PV) is a piece of storage in the cluster that has been provisioned by an administrator.
A PersistentVolumeClaim (PVC) is a request for storage by a user.
PersistentVolume 是由管理员负责提供的集群存储。
PersistentVolumeClaim 是由用户负责提供的存储请求。
—— Kubernetes Reference Documentation, Persistent Volumes
PersistentVolume 是 Volume 这个抽象概念的具象化表现,通俗点儿说,即它是已经被管理员分配好的具体的存储。
这里的”具体”是指有明确的存储系统地址,有明确的容量、访问模式、存储位置等信息;而 PersistentVolumeClaim 是 Pod 对其所需存储能力的声明,通俗地说就是”如果要满足这个 Pod 正常运行,需要满足怎样的条件”,比如要消耗多大的存储空间、要支持怎样的访问方式。
所以,实际上管理员和用户并不是谁引用谁的固定关系,而是根据实际情况动态匹配的。
下面我们就来看看这两者配合工作的具体过程:
管理员准备好要使用的存储系统,它应该是某种网络文件系统(NFS)或者云储存系统,一般来说应该具备跨主机共享的能力。
管理员会根据存储系统的实际情况,手工预先分配好若干个 PersistentVolume,并定义好每个 PersistentVolume 可以提供的具体能力。如下面例子所示:
apiVersion: v1 kind: PersistentVolume metadata: name: nginx-html spec: capacity: storage: 5Gi # 最大容量为5GB accessModes: - ReadWriteOnce # 访问模式为RXO persistentVolumeReclaimPolicy: Retain # 回收策略是Retain nfs: # 存储驱动是NFS path: /html server: 172.17.0.2这里我们来简单分析下以上 YAML 中定义的存储能力:
- 存储的最大容量是 5GB。
- 存储的访问模式是”只能被一个节点读写挂载”(ReadWriteOnce,RWO),另外两种可选的访问模式是”可以被多个节点以只读方式挂载”(ReadOnlyMany,ROX)和”可以被多个节点读写挂载”(ReadWriteMany,RWX)。
存储的回收策略是 Retain,即在 Pod 被销毁时并不会删除数据。另外两种可选的回收策略分别是 Recycle ,即在 Pod 被销毁时,由 Kubernetes 自动执行rm -rf /volume/*这样的命令来自动删除资料;以及 Delete,它让 Kubernetes 自动调用 AWS EBS、GCE PersistentDisk、OpenStack Cinder 这些云存储的删除指令。
存储驱动是 NFS,其他常见的存储驱动还有 AWS EBS、GCE PD、iSCSI、RBD(Ceph Block Device)、GlusterFS、HostPath,等等。
用户根据业务系统的实际情况,创建 PersistentVolumeClaim,声明 Pod 运行所需的存储能力。如下面例子所示:
kind: PersistentVolumeClaim apiVersion: v1 metadata: name: nginx-html-claim spec: accessModes: - ReadWriteOnce # 支持RXO访问模式 resources: requests: storage: 5Gi # 最小容量5GB可以看到,在以上 YAML 中,声明了要求容量不得小于 5GB,必须支持 RWO 的访问模式。
Kubernetes 在创建 Pod 的过程中,会根据系统中 PersistentVolume 与 PersistentVolumeClaim 的供需关系,对两者进行撮合,如果系统中存在满足 PersistentVolumeClaim 声明中要求能力的 PersistentVolume,就表示撮合成功,它们将会被绑定。而如果撮合不成功,Pod 就不会被继续创建,直到系统中出现新的、或让出空闲的 PersistentVolume 资源。
以上几步都顺利完成的话,意味着 Pod 的存储需求得到满足,进而继续 Pod 的创建过程。
以上的整个运作过程如下图所示:
(图片来自《 Kubernetes in Action 》)
Kubernetes 对 PersistentVolumeClaim 与 PersistentVolume 撮合的结果是产生一对一的绑定关系,”一对一”的意思是 PersistentVolume 一旦绑定在某个 PersistentVolumeClaim 上,直到释放以前都会被这个 PersistentVolumeClaim 所独占,不能再与其他 PersistentVolumeClaim 进行绑定。
这意味着即使 PersistentVolumeClaim 申请的存储空间比 PersistentVolume 能够提供的要少,依然要求整个存储空间都为该 PersistentVolumeClaim 所用,这有可能会造成资源的浪费。
比如,某个 PersistentVolumeClaim 要求 3GB 的存储容量,当前 Kubernetes 手上只剩下一个 5GB 的 PersistentVolume 了,此时 Kubernetes 只好将这个 PersistentVolume 与申请资源的 PersistentVolumeClaim 进行绑定,平白浪费了 2GB 空间。
假设后续有另一个 PersistentVolumeClaim 申请 2GB 的存储空间,那它也只能等待管理员分配新的 PersistentVolume,或者有其他 PersistentVolume 被回收之后,才被能成功分配。
Dynamic Provisioning
对于中小规模的 Kubernetes 集群,PersistentVolume 已经能够满足有状态应用的存储需求。PersistentVolume 依靠人工介入来分配空间的设计虽然简单直观,却算不上是先进,一旦应用规模增大,PersistentVolume 很难被自动化的问题就会凸显出来。
这是由于 Pod 创建过程中需要去挂载某个 Volume 时,都要求该 Volume 必须是真实存在的,否则 Pod 启动可能依赖的数据(如一些配置、数据、外部资源等)都将无从读取。Kubernetes 虽然有能力随着流量压力和硬件资源状况,自动扩缩 Pod 的数量,但是当 Kubernetes 自动扩展出一个新的 Pod 后,并没有办法让 Pod 去自动挂载一个还未被分配资源的 PersistentVolume。
想解决这个问题,要么允许多个不同的 Pod 都共用相同的 PersistentVolumeClaim,这种方案确实只靠 PersistentVolume 就能解决,却损失了隔离性,难以通用;要么就要求每个 Pod 用到的 PersistentVolume 都是已经被预先建立并分配好的,这种方案靠管理员提前手工分配好大量的存储也可以实现,却损失了自动化能力。
无论哪种情况,都难以符合 Kubernetes 工业级编排系统的产品定位,对于大型集群,面对成百上千,来自成千上万的 Pod,靠管理员手工分配存储肯定是无法完成的。在 2017 年 Kubernetes 发布 1.6 版本后,终于提供了今天被称为 Dynamic Provisioning 的动态存储解决方案,让系统管理员摆脱了人工分配的 PersistentVolume 的窘境,并把此前的分配方式称为 Static Provisioning。
那 Dynamic Provisioning 方案是如何解放系统管理员的呢?我们先来看概念,Dynamic Provisioning 方案是指在用户声明存储能力的需求时,不是期望通过 Kubernetes 撮合来获得一个管理员人工预置的 PersistentVolume,而是由特定的资源分配器(Provisioner)自动地在存储资源池或者云存储系统中分配符合用户存储需要的 PersistentVolume,然后挂载到 Pod 中使用,完成这项工作的资源被命名为 StorageClass,它的具体工作过程如下:
管理员根据储系统的实际情况,先准备好对应的 Provisioner。Kubernetes 官方已经提供了一系列预置的 In-Tree Provisioner ,放置在kubernetes.io的 API 组之下。其中部分 Provisioner 已经有了官方的 CSI 驱动,如 vSphere 的 Kubernetes 自带驱动为kubernetes.io/vsphere-volume,VMware 的官方驱动为csi.vsphere.vmware.com。
管理员不再是手工去分配 PersistentVolume,而是根据存储去配置 StorageClass。Pod 是可以动态扩缩的,而存储则是相对固定的,哪怕使用的是具有扩展能力的云存储,也会将它们视为存储容量、IOPS 等参数可变的固定存储来看待,比如你可以将来自不同云存储提供商、不同性能、支持不同访问模式的存储配置为各种类型的 StorageClass,这也是它名字中”Class”(类型)的由来,如下面这个例子:
apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: standard provisioner: kubernetes.io/aws-ebs #AWS EBS的Provisioner parameters: type: gp2 reclaimPolicy: Retain用户依然通过 PersistentVolumeClaim 来声明所需的存储,但是应在声明中明确指出该由哪个 StorageClass 来代替 Kubernetes 处理该 PersistentVolumeClaim 的请求,如下面这个例子:
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: standard-claim spec: accessModes: - ReadWriteOnce storageClassName: standard #明确指出该由哪个StorageClass来处理该PersistentVolumeClaim的请求 resource: requests: storage: 5Gi如果 PersistentVolumeClaim 中要求的 StorageClass 及它用到的 Provisioner 均是可用的话,那这个 StorageClass 就会接管掉原本由 Kubernetes 撮合的 PersistentVolume 和 PersistentVolumeClaim 的操作,按照 PersistentVolumeClaim 中声明的存储需求,自动产生出满足该需求的 PersistentVolume 描述信息,并发送给 Provisioner 处理。
Provisioner 接收到 StorageClass 发来的创建 PersistentVolume 请求后,会操作其背后存储系统去分配空间,如果分配成功,就生成并返回符合要求的 PersistentVolume 给 Pod 使用。
前面这几步都顺利完成的话,就意味着 Pod 的存储需求得到了满足,会继续 Pod 的创建过程,整个过程如下图所示。
(图片来自《 Kubernetes in Action 》)
好了,通过刚刚的讲述,相信你可以看出 Dynamic Provisioning 与 Static Provisioning 并不是各有用途的互补设计,而是对同一个问题先后出现的两种解决方案。你完全可以只用 Dynamic Provisioning 来实现所有的 Static Provisioning 能够实现的存储需求,包括那些不需要动态分配的场景,甚至之前例子里使用 HostPath 在本地静态分配存储,都可以指定no-provisioner作为 Provisioner 的 StorageClass,以 Local Persistent Volume 来代替,比如下面这个例子:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: local-storage
provisioner: kubernetes.io/no-provisioner
volumeBindingMode: WaitForFirstConsumer所以说,相较于 Static Provisioning,使用 Dynamic Provisioning 来分配存储无疑是更合理的设计,不仅省去了管理员的人工操作的中间层,也不再需要将 PersistentVolume 这样的概念暴露给最终用户,因为 Dynamic Provisioning 里的 PersistentVolume 只是处理过程的中间产物,用户不再需要接触和理解它,只需要知道由 PersistentVolumeClaim 去描述存储需求,由 StorageClass 去满足存储需求即可。只描述意图而不关心中间具体的处理过程是声明式编程的精髓,也是流程自动化的必要基础。
除此之外,由 Dynamic Provisioning 来分配存储还能获得更高的可管理性。如前面提到的回收策略,当希望 PersistentVolume 跟随 Pod 一同被销毁时,以前经常会配置回收策略为 Recycle 来回收空间,即让系统自动执行rm -rf /volume/*命令。
但是这种方式往往过于粗暴,要是遇到更精细的管理需求,如”删除到回收站”或者”敏感信息粉碎式彻底删除”这样的功能,实现起来就很麻烦。而 Dynamic Provisioning 中由于有 Provisioner 的存在,如何创建、如何回收都是由 Provisioner 的代码所管理的,这就带来了更高的灵活性。所以,现在 Kubernetes 官方已经明确建议废弃掉 Recycle 策略,如果有这类需求就改由 Dynamic Provisioning 去实现了。
另外,相较于 Dynamic Provisioning,Static Provisioning 的主要使用场景就局限于管理员能够手工管理存储的小型集群,它符合很多小型系统,尤其是私有化部署系统的现状,但并不符合当今运维自动化所提倡的思路。Static Provisioning 的存在,某种意义上也可以视为是对历史的一种兼容,在可见的将来,Kubernetes 肯定还是会把 Static Provisioning 作为用户分配存储的一种主要方案,来供用户选用。
小结
容器是镜像的运行时实例,为了保证镜像能够重复地产生出具备一致性的运行时实例,必须要求镜像本身是持久而稳定的,这就决定了在容器中发生的一切数据变动操作,都不能真正写入到镜像当中,否则必然会破坏镜像稳定不变的性质。
为此,容器中的数据修改操作,大多是基于 写入时复制 (Copy-on-Write)策略来实现的,容器会利用 叠加式文件系统 (OverlayFS)的特性,在用户意图对镜像进行修改时,自动将变更的内容写入到独立区域,再与原有数据叠加到一起,使其外观上看起来像是”覆盖”了原有内容。这种改动通常都是临时的,一旦容器终止运行,这些存储于独立区域中的变动信息也将被一并移除,不复存在。所以可见,如果不去进行额外的处理,容器默认是不具备持久化存储能力的。
而另一方面,容器作为信息系统的运行载体,必定会产生出有价值的、应该被持久保存的信息,比如扮演数据库角色的容器,大概没有什么系统能够接受数据库像缓存服务一样,重启之后会丢失全部数据;多个容器之间也经常需要通过共享存储来实现某些交互操作,比如我在 第 48 讲 中曾经举过的例子,Nginx 容器产生日志、Filebeat 容器收集日志,两者就需要共享同一块日志存储区域才能协同工作。
而正因为镜像的稳定性与生产数据持久性存在矛盾,所以我们才需要去重点了解这个问题:如何实现容器的持久化存储。
56 | Kubernetes存储扩展架构:一个真实的存储系统如何接入或移除新存储设备?
我们知道,容器存储具有很强的多样性,如何对接后端实际的存储系统,并且完全发挥出它所有的性能与功能,并不是 Kubernetes 团队所擅长的工作,这件事情只有存储提供商才能做到最好。所以,我们其实可以理解容器编排系统为什么会有很强烈的意愿,想把存储功能独立到外部去实现。
在 上节课 我已经反复提到过多次 In-Tree、Out-of-Tree 插件,那么今天这节课,我就会以存储插件的接口与实现为中心,带你去解析 Kubernetes 的容器存储生态。
Kubernetes 存储架构
在正式开始讲解 Kubernetes 的 In-Tree、Out-of-Tree 存储插件前,我们有必要先去了解一点 Kubernetes 存储架构的知识。了解一个真实的存储系统是如何接入到新创建的 Pod 中,成为可以读写访问的 Volume,以及当 Pod 被销毁时,Volume 如何被回收,回归到存储系统之中的。
那么,对于刚刚所说的这几点,Kubernetes 其实是参考了传统操作系统接入或移除新存储设备的做法,把接入或移除外部存储这件事情,分解为了以下三个操作:
- 决定应准备(Provision)何种存储 :Provision 可类比为给操作系统扩容而购买了新的存储设备。这步确定了接入存储的来源、容量、性能以及其他技术参数,它的逆操作是移除(Delete)存储。
- 将准备好的存储附加(Attach)到系统中 :Attach 可类比为将存储设备接入操作系统,此时尽管设备还不能使用,但你已经可以用操作系统的fdisk -l命令查看到设备。这步确定了存储的设备名称、驱动方式等面向系统侧的信息,它的逆操作是分离(Detach)存储设备。
- 将附加好的存储挂载(Mount)到系统中 :Mount 可类比为将设备挂载到系统的指定位置,也就是操作系统中mount命令的作用。这步确定了存储的访问目录、文件系统格式等面向应用侧的信息,它的逆操作是卸载(Unmount)存储设备。
实际上,前面步骤中提到的 Provision、Delete、Attach、Detach、Mount、Unmount 六种操作,并不是直接由 Kubernetes 来实现,而是在存储插件中完成的。它们会分别被 Kubernetes 通过两个控制器及一个管理器来进行调用,这些控制器、管理器的作用如下:
PV 控制器(PersistentVolume Controller)
“以容器构建系统”这个小章节中我介绍过,Kubernetes 里所有的控制器都遵循着相同的工作模式,即让实际状态尽可能接近期望状态。PV 控制器的期望状态有两个,分别是”所有未绑定的 PersistentVolume 都能处于可用状态”以及”所有处于等待状态的 PersistentVolumeClaim 都能配对到与之绑定的 PersistentVolume”。
它内部也有两个相对独立的核心逻辑(ClaimWorker 和 VolumeWorker)来分别跟踪这两种期望状态。可以简单地理解为 PV 控制器实现了 PersistentVolume 和 PersistentVolumeClaim 的生命周期管理职能。在这个过程中,它会根据需要调用存储驱动插件的 Provision/Delete 操作。
AD 控制器(Attach/Detach Controller)
AD 控制器的期望状态是”所有被调度到准备新创建 Pod 的节点,都附加好了要使用的存储;当 Pod 被销毁后,原本运行 Pod 的节点都分离了不再被使用的存储”。如果实际状态不符合该期望,会根据需要调用存储驱动插件的 Attach/Detach 操作。
Volume 管理器(Volume Manager)
Volume 管理器实际上是 kubelet 众多管理器的其中一个,它主要作用是支持本节点中 Volume 执行 Attach/Detach/Mount/Unmount 操作。你可能注意到这里不仅有 Mount/Unmount 操作,也出现了 Attach/Detach 操作。
这是历史原因导致的,因为最初版本的 Kubernetes 中并没有 AD 控制器,Attach/Detach 的职责也在 kubelet 中完成。而现在 kubelet 默认情况下已经不再会执行 Attach/Detach 了,但有少量旧程序已经依赖了由 kubelet 来实现 Attach/Detach 的内部逻辑,所以 kubelet 不得不设计一个—enable-controller-attach-detach参数,如果将其设置为false的话,就会重新回到旧的兼容模式上,由 kubelet 代替 AD 控制器来完成 Attach/Detach。
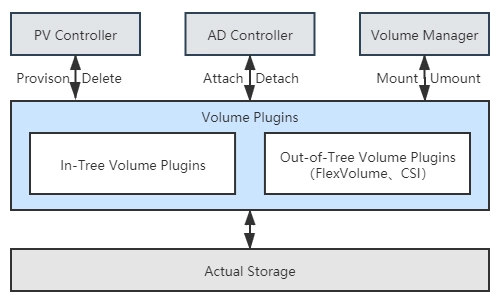
这样一来,后端的真实存储经过 Provision、Attach、Mount 操作之后,就形成了可以在容器中挂载的 Volume。当存储的生命周期完结,经过 Unmount、Detach、Delete 操作之后,Volume 便能够被存储系统回收。而对于某些存储来说,其中有一些操作可能是无效的,比如 NFS,实际使用并不需要 Attach,此时存储插件只需将 Attach 实现为空操作即可。
FlexVolume 与 CSI
Kubernetes 目前同时支持 FlexVolume 与 CSI (Container Storage Interface)两套独立的存储扩展机制。FlexVolume 是 Kubernetes 早期版本(1.2 版开始提供,1.8 版达到 GA 状态)就开始支持的扩展机制,它是只针对 Kubernetes 的私有的存储扩展,目前已经处于冻结状态,可以正常使用但不再发展新功能了。
CSI 则是从 Kubernetes 1.9 开始加入(1.13 版本达到 GA 状态)的扩展机制,如同之前我介绍过的 CRI 和 CNI 那样,CSI 是公开的技术规范。任何容器运行时、容器编排引擎只要愿意支持,都可以使用 CSI 规范去扩展自己的存储能力,这是目前 Kubernetes 重点发展的扩展机制。
由于是专门为 Kubernetes 量身订造的,所以 FlexVolume 的实现逻辑与上节课我介绍的 Kubernetes 存储架构高度一致。FlexVolume 驱动其实就是一个实现了 Attach、Detach、Mount、Unmount 操作的可执行文件(甚至可以仅仅是个 Shell 脚本)而已。该可执行文件应该存放在集群每个节点的/usr/libexec/kubernetes/kubelet-plugins/volume/exec目录里,其工作过程也就是,当 AD 控制器和 Volume 管理器需要进行 Attach、Detach、Mount、Unmount 操作时,自动调用它的对应方法接口,如下图所示。
如果仅仅考虑支持最基本的 Static Provisioning,那实现一个 FlexVolume Driver 确实是非常简单的。然而也是由于 FlexVolume 过于简单了,导致它应用起来会有诸多不便之处,比如说:
- FlexVolume 并不是全功能的驱动 :FlexVolume 不包含 Provision 和 Delete 操作,也就无法直接用于 Dynamic Provisioning,想要实现这个功能,除非你愿意再单独编写一个 External Provisioner。
- FlexVolume 部署维护都相对繁琐 :FlexVolume 是独立于 Kubernetes 的可执行文件,当集群节点增加时,需要由管理员在新节点上部署 FlexVolume Driver。为了避免耗费过多人力,有经验的系统管理员通常会专门编写一个 DaemonSet 来代替人工来完成这项任务。
- FlexVolume 实现复杂交互也相对繁琐 :FlexVolume 的每一次操作,都是对插件可执行文件的一次独立调用,这种插件实现方式在各种操作需要相互通讯时会很别扭。比如你希望在执行 Mount 操作的时候,生成一些额外的状态信息,并在后面执行 Unmount 操作时去使用这些信息时,却只能把信息记录在某个约定好的临时文件中,这样的做法对于一个面向生产的容器编排系统来说,实在是过于简陋了。
相比起 FlexVolume 的种种不足,CSI 可算是一个十分完善的存储扩展规范。这里”十分完善”可不是客套话,根据 GitHub 的自动代码行统计,FlexVolume 的规范文档仅有 155 行,而 CSI 则长达 2704 行。
那么从总体上看,CSI 规范可以分为需要容器系统去实现的组件,以及需要存储提供商去实现的组件两大部分。前者包括了存储整体架构、Volume 的生命周期模型、驱动注册、Volume 创建、挂载、扩容、快照、度量等内容,这些 Kubernetes 都已经完整地实现了,大体上包括以下几个组件:
- Driver Register :负责注册第三方插件,CSI 0.3 版本之后已经处于 Deprecated 状态,将会被 Node Driver Register 所取代。
- External Provisioner :调用第三方插件的接口来完成数据卷的创建与删除功能。
- External Attacher :调用第三方插件的接口来完成数据卷的挂载和操作。
- External Resizer :调用第三方插件的接口来完成数据卷的扩容操作。
- External Snapshotter :调用第三方插件的接口来完成快照的创建和删除。
- External Health Monitor :调用第三方插件的接口来提供度量监控数据。
但是,需要存储提供商去实现的组件才是 CSI 的主体部分,也就是我在前面多次提到的”第三方插件”。这部分着重定义了外部存储挂载到容器过程中所涉及操作的抽象接口和具体的通讯方式,主要包括以下三个 gRPC 接口:
- CSI Identity 接口 :用于描述插件的基本信息,比如插件版本号、插件所支持的 CSI 规范版本、插件是否支持存储卷创建、删除功能、是否支持存储卷挂载功能等等。此外 Identity 接口还用于检查插件的健康状态,开发者可以通过 Probe 接口对外提供存储的健康度量信息。
- CSI Controller 接口 :用于从存储系统的角度对存储资源进行管理,比如准备和移除存储(Provision、Delete 操作)、附加与分离存储(Attach、Detach 操作)、对存储进行快照等等。存储插件并不一定要实现这个接口的所有方法,对于存储本身就不支持的功能,可以在 CSI Identity 接口中声明为不提供。
- CSI Node 接口 :用于从集群节点的角度对存储资源进行操作,比如存储卷的分区和格式化、将存储卷挂载到指定目录上,或者将存储卷从指定目录上卸载,等等。
与 FlexVolume 以单独的可执行程序的存在形式不同,CSI 插件本身是由一组标准的 Kubernetes 资源所构成,CSI Controller 接口是一个以 StatefulSet 方式部署的 gRPC 服务,CSI Node 接口则是基于 DaemonSet 方式部署的 gRPC 服务。
这意味着虽然 CSI 实现起来要比 FlexVolume 复杂得多,但是却很容易安装——如同安装 CNI 插件及其它应用那样,直接载入 Manifest 文件即可,也不会遇到 FlexVolume 那样需要人工运维,或者自己编写 DaemonSet 来维护集群节点变更的问题。
此外,通过 gRPC 协议传递参数比通过命令行参数传递参数更加严谨,灵活和可靠,最起码不会出现多个接口之间协作只能写临时文件这样的尴尬状况。
从 In-Tree 到 Out-of-Tree
Kubernetes 原本曾内置了相当多的 In-Tree 的存储驱动,甚至还早于 Docker 宣布支持卷驱动功能,这种策略使得 Kubernetes 能够在云存储提供商发布官方驱动之前就将其纳入到支持范围中,同时也减轻了管理员维护的工作量,为它在诞生初期快速占领市场做出了一定的贡献。
但是,这种策略也让 Kubernetes 丧失了随时添加或修改存储驱动的灵活性,只能在更新大版本时才能加入或者修改驱动,导致云存储提供商被迫要与 Kubernetes 的发版节奏保持一致。此外,这个策略还涉及到第三方存储代码混杂在 Kubernetes 二进制文件中可能引起的可靠性及安全性问题。
因此,当 Kubernetes 成为市场主流以后——准确的时间点是从 1.14 版本开始,Kubernetes 启动了 In-Tree 存储驱动的 CSI 外置迁移工作,按照计划,在 1.21 到 1.22 版本(大约在 2021 年中期)时,Kubernetes 中主要的存储驱动,如 AWS EBS、GCE PD、vSphere 等都会迁移至符合 CSI 规范的 Out-of-Tree 实现,不再提供 In-Tree 的支持。
这种做法在设计上无疑是正确的,但是,这又会导致 Kubernetes 面临此前提过的该如何兼容旧功能的策略问题,我举个例子,下面 YAML 定义了一个 Pod:
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod-example
spec:
containers:
- name: nginx
image: nginx:latest
volumeMounts:
- name: html-pages-volume
mountPath: /usr/share/nginx/html
- name: config-volume
mountPath: /etc/nginx
volumes:
- name: html-pages-volume
hostPath: # 来自本地的存储
path: /srv/nginx/html
type: Directory
- name: config-volume
awsElasticBlockStore: # 来自AWS ESB的存储
volumeID: vol-0b39e0b08745caef4
fsType: ext4可以发现,其中用到了类型为 hostPath 的 Volume,这相当于 Docker 中驱动类型为 local 的 Volume,不需要专门的驱动;而类型为 awsElasticBlockStore 的 Volume,从名字上就能看出是指存储驱动为 AWS EBS 的 Volume,当 CSI 迁移完成,awsElasticBlockStore 从 In-Tree 卷驱动中移除掉之后,它就应该按照 CSI 的写法改写成如下形式:
- name: config-volume
csi:
driver: ebs.csi.aws.com
volumeAttributes:
- volumeID: vol-0b39e0b08745caef4
- fsType: ext4这样的要求有悖于”升级版本不应影响还在大范围使用的已有功能”这条原则,所以 Kubernetes 1.17 中又提出了称为 CSIMigration 的解决方案,让 Out-of-Tree 的驱动能够自动伪装成 In-Tree 的接口来提供服务。
这里我想说明的是,我之所以专门来给你介绍 Volume 的 CSI 迁移,倒不是由于它算是多么重要的特性,而是这种兼容性设计本身就是 Kubernetes 设计理念的一个缩影,在 Kubernetes 的代码与功能中随处可见。好的设计需要权衡多个方面的利益,很多时候都得顾及现实的影响,要求设计向现实妥协,而不能仅仅考虑理论最优的方案。
小结
这节课,我们学习了 Kubernetes 的存储扩展架构,知道了一个真实的存储系统是如何接入到新创建的 Pod 中,成为可以读写访问的 Volume,以及当 Pod 被销毁时,Volume 如何被回收,回归到存储系统之中的。
此外我们还要明确的是,目前的 Kubernetes 系统中存在两种存储扩展接口,分别是 FlexVolume 与 CSI,我们要知道这两种插件的相似与差异之处,以及这两种接口的大致的结构。
57 | Kubernetes存储生态系统:几种有代表性的CSI存储插件的实现
随着 Kubernetes 的 CSI 规范成为容器业界统一的存储接入标准,现在几乎所有的云计算厂商都支持自家的容器通过 CSI 规范去接入外部存储,能够应用于 CSI 与 FlexVolume 的存储插件更是多达数十上百款,下图就展示了部分容器存储提供商,可以说,容器存储已经算是形成了初步的生态环境。
不过在咱们的课程里,我并不会去展开讨论各种 CSI 存储插件的细节,我会采取跟 CNI 网络插件类似的讲述方式,以不同的存储类型为线索,介绍其中有代表性的实现。
实际上,目前出现过的存储系统和设备,我们都可以划分到块存储、文件存储和对象存储这三种存储类型之中,其划分的根本依据并不是各种存储是如何储存数据的,因为那完全是存储系统私有的事情。
我认为更合理的划分依据是,各种存储会提供什么形式的接口来供外部访问数据,而不同的外部访问接口会如何反过来影响存储的内部结构、性能与功能表现。虽然块存储、文件存储和对象存储可以彼此协同工作,但它们各自都有自己明确的擅长领域与优缺点。所以,只有理解它们的工作原理,因地制宜地选择最适合的存储,才能让系统达到最佳的工作状态。
那么接下来,我就按照它们出现的时间顺序来给你一一介绍下。
块存储
块存储是数据存储最古老的形式 ,它把数据都储存在一个或多个固定长度的 块) (Block)中,想要读写访问数据,就必须使用与存储相匹配的协议(SCSI、SATA、SAS、FCP、FCoE、iSCSI……)。
这里你可以类比一下前面 第 52 讲 提到的,网络通讯中网络栈的数据流动过程,你可以把存储设备中由块构成的信息流,与网络设备中由数据包构成的信息流进行对比。事实上,像 iSCSI 这种协议真的就是建设在 TCP/IP 网络之上,让上层以 SCSI 作为应用层协议对外提供服务的。
我们熟悉的硬盘就是最经典的块存储设备,以机械硬盘为例,一个块就是一个扇区,大小通常在 512 Bytes 至 4096 Bytes 之间。老式机械硬盘用 柱面 - 磁头 - 扇区号 (Cylinder-Head-Sector,CHS)组成的编号进行寻址,现代机械硬盘只用一个 逻辑块编号 (Logical Block Addressing,LBA)进行寻址。
为了便于管理,硬盘通常会以多个块(这些块甚至可以来自不同的物理设备,比如磁盘阵列的情况)来组成一个逻辑分区(Partition),将分区进行 高级格式化 之后就形成了卷(Volume),这就与 第 55 讲 中提到”Volume 是源于操作系统的概念”衔接了起来。
块存储由于贴近底层硬件,没有文件、目录、访问权限等的牵绊,所以性能通常都是最优秀的(吞吐量高,延迟低)。
另外,尽管人类作为信息系统的最终用户,并不会直接面对块来操作数据,多数应用程序也是基于文件而不是块来读写数据的,但是操作系统内核中,许多地方就是直接通过 块设备 (Block Device)接口来访问硬盘,一些追求 I/O 性能的软件,比如高性能的数据库也会支持直接读写块设备以提升磁盘 I/O。
而且因为块存储的特点是 具有排它性 ,一旦块设备被某个客户端挂载后,其他客户端就无法再访问上面的数据了。因此,Kubernetes 中挂载的块存储,大多的访问模式都要求必须是 RWO(ReadWriteOnce)的。
文件存储
好,下面我们接着来说说文件存储。
文件存储是最贴近人类用户的数据存储形式 ,数据存储在长度不固定的文件之中,用户可以针对文件进行新增、写入、追加、移动、复制、删除、重命名等各种操作,通常文件存储还会提供有文件查找、目录管理、权限控制等额外的高级功能。
文件存储的访问不像块存储那样有五花八门的协议,其 POSIX 接口(Portable Operating System Interface,POSIX)已经成为了事实标准,被各种商用的存储系统和操作系统共同支持。具体 POSIX 的文件操作接口我就不去举例罗列了,你可以类比 Linux 下的各种文件管理命令来自行想象一下。
绝大多数传统的文件存储都是基于块存储之上去实现的,”文件”这个概念的出现是因为”块”对人类用户来说实在是过于难以使用、难以管理了。我们可以近似地认为文件是由块所组成的更高级存储单位,对于固定不会发生变动的文件,直接让每个文件连续占用若干个块,在文件头尾加入标志区分即可,就比如像磁带、CD-ROM、DVD-ROM,就采用了由连续块来构成文件的存储方案。
不过,对于可能发生变动的场景,我们就必须考虑如何跨多个不连续的块来构成为文件。这种需求从数据结构的角度看,只需要在每个块中记录好下一个块的地址,形成链表结构就能满足。但是链表的缺点是只能依次顺序访问,这样访问文件中的任何内容都要从头读取多个块,这显然过于低效了。
事实上,真正被广泛运用的解决方案是把形成链表的指针整合起来统一存放,这就是 文件分配表 (File Allocation Table,FAT)。既然已经有了专门组织块结构来构成文件的分配表,那在表中再加入其他控制信息,就能很方便地扩展出更多的高级功能。
比如除了文件占用的块地址信息外,在表中再加上文件的逻辑位置就形成了目录,加上文件的访问标志就形成了权限,我们还可以再加上文件的名称、创建时间、所有者、修改者等一系列的元数据信息,来构成其他应用形式。
人们把定义文件分配表应该如何实现、储存哪些信息、提供什么功能的标准称为 文件系统 (File System),FAT32、NTFS、exFAT、ext2/3/4、XFS、BTRFS 等都是很常用的文件系统。而前面介绍存储插件接口时,我提到的对分区进行高级格式化操作,实际上就是在初始化一套空白的文件系统,供后续用户与应用程序访问。
文件存储相对于块存储来说是更高层次的存储类型,加入目录、权限等元素后形成的树状结构以及路径访问的方式,方便了人们对它的理解、记忆和访问;文件系统能够提供进程正在打开或正在读写某个文件的信息,这也有利于文件的共享处理。
但在另一方面,计算机需要把路径进行分解,然后逐级向下查找,最后才能查找到需要的文件。而要从文件分配表中确定具体数据存储的位置,就要判断文件的访问权限,并要记录每次修改文件的用户与时间,这些额外操作对于性能产生的负面影响也是无可避免的。因此,如果一个系统选择不采用文件存储的话,那磁盘 I/O 性能一般就是最主要的原因。
对象存储
对象存储 是相对较新的数据存储形式,它是一种随着云数据中心的兴起而发展起来的存储,是以非结构化数据为目标的存储方案。
这里的”对象”可以理解为一个元数据及与其配对的一个逻辑数据块的组合,元数据提供了对象所包含的上下文信息,比如数据的类型、大小、权限、创建人、创建时间,等等,数据块则存储了对象的具体内容。你也可以简单地理解为数据和元数据这两样东西共同构成了一个对象。
每个对象都有属于自己的全局唯一标识,这个标识会直接开放给最终用户使用,作为访问该对象的主要凭据,通常会是以 UUID 的形式呈现。对象存储的访问接口就是根据该唯一标识,对逻辑数据块进行的读写删除操作的,通常接口都会十分简单,甚至连修改操作权限都不会提供。
对象存储基本上只会在分布式存储系统之上去实现,由于对象存储天生就有明确的”元数据”概念,不必依靠文件系统来提供数据的描述信息,因此,完全可以将一大批对象的元数据集中存放在某一台(组)服务器上,再辅以多台 OSD(Object Storage Device)服务器来存储对象的数据块部分。
当外部要访问对象时,多台 OSD 能够同时对外发送数据,因此 对象存储不仅易于共享、拥有庞大的容量,还能提供非常高的吞吐量。 不过,由于需要先经过元数据查询确定 OSD 存放对象的确切位置,这个过程可能涉及多次网络传输,所以在延迟方面就会表现得相对较差。
由于对象的元数据仅描述对象本身的信息,与其他对象都没有关联,换而言之每个对象都是相互独立的,自然也就不存在目录的概念,可见对象存储天然就是扁平化的,与软件系统中很常见的 K/V 访问相类似。
不过许多对象存储会提供 Bucket 的概念,用户可以在逻辑上把它看作是”单层的目录”来使用。由于对象存储天生的分布式特性,以及极其低廉的扩展成本,使它很适合于 CDN 一类的应用,拿来存放图片、音视频等媒体内容,以及网页、脚本等静态资源。
选择合适的存储
那么,在理解了三种存储类型的基本原理后,接下来又到了治疗选择困难症的环节。主流的云计算厂商,比如国内的阿里云、腾讯云、华为云,都有自己专门的块存储、文件存储和对象存储服务,关于选择服务提供商的问题,我就不作建议了,你可以根据价格、合作关系、技术和品牌知名度等因素自行去处理。
而关于应该选择三种存储类型中哪一种的问题,这里我就以世界云计算市场占有率第一的亚马逊为例,给你简要对比介绍下它的不同存储类型产品的差异。
亚马逊的块存储服务是 Amazon Elastic Block Store (AWS EBS),你购买 EBS 之后,在 EC2(亚马逊的云计算主机)里看见的是一块原始的、未格式化的块设备。这点就决定了 EBS 并不能做为一个独立存储而存在,它总是和 EC2 同时被创建的,EC2 的操作系统也只能安装在 EBS 之上。
EBS 的大小理论上取决于建立的分区方案,也就是块大小乘以块数量。MBR 分区的块数量是 232,块大小通常是 512 Bytes,总容量为 2 TB;GPT 分区的块数量是 264,块大小通常是 4096 Bytes,总容量 64 ZB。当然这是理论值,64 ZB 已经超过了世界上所有信息的总和,不会有操作系统支持这种离谱的容量,AWS 也设置了上限是 16 TB,在此范围内的实际值就只取决于你的预算额度;EBS 的性能取决于你选择的存储介质类型(SSD、HDD),还有优化类型(通用性、预置型、吞吐量优化、冷存储优化等),这也会直接影响存储的费用成本。
EBS 适合作为系统引导卷,适合追求磁盘 I/O 的大型工作负载以及追求低时延的应用,比如 Oracle 等可以直接访问块设备的大型数据库。但 EBS 只允许被单个节点挂载,难以共享,这点在单机时代虽然是天经地义的,但在云计算和分布式时代就成为了很要命的缺陷。除了少数特殊的工作负载外(如前面说的 Oracle 数据库),我并不建议将它作为容器编排系统的主要外置存储来使用。
亚马逊的文件存储服务是 Amazon Elastic File System (AWS EFS),你购买 EFS 之后,只要在 EFS 控制台上创建好文件系统,并且管理好网络信息(如 IP 地址、子网)就可以直接使用,无需依附于任何 EC2 云主机。
EFS 的本质是完全托管在云端的 网络文件系统 (Network File System,NFS),你可以在任何兼容 POSIX 的操作系统中直接挂载它,而不会在/dev中看到新设备的存在。按照前面开头我提到的 Kubernetes 存储架构中的操作来说,就是你只需要考虑 Mount,无需考虑 Attach 了。
这样,得益于 NFS 的天然特性,EFS 的扩缩可以是完全自动、实时的,创建新文件时无需预置存储,删除已有文件时也不必手动缩容以节省费用。在高性能网络的支持下,EFS 的性能已经能够达到相当高的水平,尽管由于网络访问的限制,性能最高的 EFS 依然比不过最高水平的 EBS,但仍然能充分满足绝大多数应用运行的需要。
还有最重要的一点优势是由于脱离了块设备的束缚,EFS 能够轻易地被成百上千个 EC2 实例共享。 考虑到 EFS 的性能、动态弹性、可共享这些因素,我给出的明确建议是它可以作为大部分容器工作负载的首选存储。
亚马逊的对象存储服务是 Amazon Simple Storage Service (AWS S3),S3 通常是以 REST Endpoint 的形式对外部提供文件访问服务的,这种方式下你应该直接使用程序代码来访问 S3,而不是靠操作系统或者容器编排系统去挂载它。
如果你真的希望这样做,也可以通过存储网关(如 AWS Storage Gateway )将 S3 的存储能力转换为 NFS、SMB、iSCSI 等访问协议。经过转换后,操作系统或者容器就能够将其作为 Volume 来挂载了。
S3 也许是 AWS 最出名、使用面最广的存储服务,这个结果并不是由于它的性能优异,事实上 S3 的性能比起 EBS 和 EFS 来说是相对最差的,但它的优势在于它名字中”Simple”所标榜的 简单 。
我们挂载外部存储的目的,十有八九就是为了给程序提供存储服务,而使用 S3 就不必写一行代码,就能直接通过 HTTP Endpoint 进行读写访问,而且完全不需要考虑容量、维护和数据丢失的风险,这就是简单的价值。
除此之外,S3 的另一大优势就是它的价格相对于 EBS 和 EFS 来说,往往要低一至两个数量级,因此程序的备份还原、数据归档、灾难恢复、静态页面的托管、多媒体分发等功能,就非常适合使用 S3 来完成。
小结
这节课我们了解学习了块存储、文件存储和对象存储这三种存储类型的基本原理,而关于应该选择这三种存储类型中哪一种的问题,我以亚马逊为例,给你简要对比了下它的不同存储类型产品的差异。
最后我还想补充一点,你可以来看看下面的图例,这是截取自亚马逊销售材料中三种存储的对比。说实话,从目前的存储技术发展来看,其实不会有哪一种存储方案能够包打天下。你要知道,不同业务系统的场景需求不同,对存储的诉求就会不同,那么选择自然也会不同。
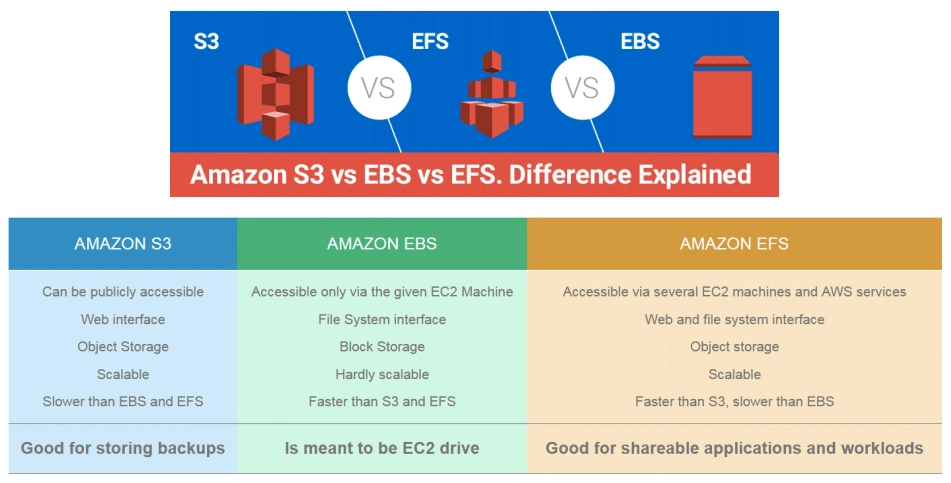
(图片来自 AWS 的 销售材料 )
58 | Kubernetes的资源模型与调度器设计
调度是容器编排系统最核心的功能之一 ,”编排”这个词本来也包含了”调度”的含义。调度是指为新创建出来的 Pod,寻找到一个最恰当的宿主机节点来运行它,而这个过程成功与否、结果恰当与否,关键就取决于容器编排系统是怎么管理和分配集群节点的资源的。
那么这样一来,我们就可以认为,调度必须要以容器编排系统的资源管控为前提。
因此这节课,我们就从 Kubernetes 的资源模型谈起,来学习下 Kubernetes 是如何为一个新创建出来的 Pod,寻找到一个最恰当的宿主机节点来运行的。
资源模型
在开始之前,我们先来理清一个概念: 资源是什么。
在 Kubernetes 中,资源是非常常用的术语, 从广义上来讲,Kubernetes 系统中所有你能接触的方方面面,都被抽象成了资源 ,比如表示工作负荷的资源(Pod、ReplicaSet、Service、……),表示存储的资源(Volume、PersistentVolume、Secret、……),表示策略的资源(SecurityContext、ResourceQuota、LimitRange、……),表示身份的资源(ServiceAccount、Role、ClusterRole、……),等等。
事实上,”一切皆为资源”的设计也是 Kubernetes 能够顺利施行声明式 API 的必要前提。Kubernetes 以资源为载体,建立了一套同时囊括了抽象元素(如策略、依赖、权限)和物理元素(如软件、硬件、网络)的 领域特定语言 。它通过不同层级间资源的使用关系,来描述上至整个集群甚至是集群联邦,下至某一块内存区域或者一小部分的处理器核心的状态,这些对资源状态的描述的集合,就共同构成了一幅信息系统工作运行的全景图。
在 第 48 讲 “以容器构建系统”里,我第一次提到了 Kubernetes 的资源模型,把它跟控制器模式一并列为了 Kubernetes 中最重要的两个设计思想。当然在这节课中,我们还会再次讨论资源模型,但是这里所说的主要是 狭义上的物理资源,即特指排除了广义的那些逻辑上的抽象资源,只包括能够与真实物理底层硬件对应起来的资源 ,比如处理器资源、内存资源、磁盘存储资源,等等。
另外需要说明的是,因为咱们今天讨论的话题是调度,而作为调度最基本单位的 Pod,只会与这些和物理硬件直接相关的资源产生供需关系,所以后面我提到的资源,如果没有额外说明的话,就都是特指狭义上的物理资源。
OK,现在我们说回到 Kubernetes 的资源模型上来。
首先,从编排系统的角度来看,Node 是资源的提供者,Pod 是资源的使用者,而调度是将两者进行恰当的撮合。
那么 Kubernetes 具体是如何撮合它们俩的呢?别着急,我们先从 Node 开始来了解。
Node 通常能够提供三方面的资源:计算资源(如处理器、图形处理器、内存)、存储资源(如磁盘容量、不同类型的介质)和网络资源(如带宽、网络地址)。其中与调度关系最密切的是处理器和内存,虽然它们都属于计算资源,但两者在调度时又有一些微妙的差别:
- 处理器这样的资源,被叫做是可压缩资源 (Compressible Resources),特点是当可压缩资源不足时,Pod 只会处于”饥饿状态”,运行变慢,但不会被系统杀死,也就是容器会被直接终止,或者是被要求限时退出。
- 而像内存这样的资源,则被叫做是不可压缩资源 (Incompressible Resources),特点是当不可压缩资源不足,或者超过了容器自己声明的最大限度时,Pod 就会因为内存溢出(Out-Of-Memory,OOM)而被系统直接杀掉。
Kubernetes 给处理器资源设定的默认计量单位是”逻辑处理器的个数” 。至于具体”一个逻辑处理器”应该如何理解,就要取决于节点的宿主机是如何解释的,它通常会是我们在/proc/cpuinfo中看到的处理器数量。比如,它有可能会是多路处理器系统上的一个处理器、多核处理器中的一个核心、云计算主机上的一个 虚拟化处理器 (Virtual CPU,vCPU),或者是处理器核心里的一条 超线程 (Hyper-Threading)。
总之,Kubernetes 只负责保证 Pod 能够使用到”一个处理器”的计算能力,而对不同硬件环境构成的 Kubernetes 集群,乃至同一个集群中不同硬件的宿主机节点来说,”一个处理器”所代表的真实算力完全有可能是不一样的。
另外在具体设置方面,Kubernetes 沿用了云计算中处理器限额设置的一贯做法。如果不明确标注单位,比如直接写 0.5,默认单位就是Core,即 0.5 个处理器;当然也可以明确使用Millcores为单位,比如写成 500 m,同样也代表 0.5 个处理器,因为 Kubernetes 规定了1 Core = 1000 Millcores。
而对于内存来说,它早已经有了广泛使用的计量单位,即 Bytes,如果设置中不明确标注单位,就会默认以 Bytes 计数。
为了实际设置的方便,Kubernetes 还支持以Ei、Pi、Ti、Gi、Mi、Ki,以及E、P、T、G、M、K为单位,这两者略微有一点儿差别。这里我就以Mi和M为例,它们分别是Mebibytes与Megabytes的缩写,前者表示 1024×1024 Bytes,后者表示 1000×1000 Bytes。
服务质量与优先级
那么到这里,我们要知道设定资源计量单位的目的,是为了管理员能够限制某个 Pod 对资源的过度占用,避免影响到其他 Pod 的正常运行。
Pod 是由一个到多个容器组成的,资源最终是交由 Pod 的各个容器去使用,所以资源的需求是设定在容器上的,具体的配置是 Pod 的spec.containers[].resource.limits/requests.cpu/memory字段。但是,对资源需求的配额则不是针对容器,而是针对 Pod 整体,Pod 的资源配额不需要手动设置,因为 Pod 的资源配额就是 Pod 包含的每个容器资源需求的累加值。
实际上,为容器设定最大的资源配额的做法,从 cgroups 诞生后就已经屡见不鲜了,但不知你有没有注意到,Kubernetes 给出的配置中有limits和requests两个设置项?
这两者的区别其实很简单:request是给调度器用的,Kubernetes 选择哪个节点运行 Pod,只会根据requests的值来进行决策;而limits才是给 cgroups 用的,Kubernetes 在向 cgroups 的传递资源配额时,会按照limits的值来进行设置。
Kubernetes 会采用这样的设计,完全是基于”心理学”的原因,因为 Google 根据 Borg 和 Omega 系统长期运行的实践经验,总结出了一条经验法则:用户提交工作负载时设置的资源配额,并不是容器调度一定必须严格遵守的值,因为根据实际经验,大多数的工作负载运行过程中,真正使用到的资源,其实都远小于它所请求的资源配额。
额外知识:Purchase Quota
Even though we encourage users to purchase no more quota than they need, many users overbuy because it insulates them against future shortages when their application’s user base grows.
即使我们已经努力建议用户不要过度申请资源配额,但仍难免有大量用户过度消费,他们总希望避免因用户增长而产生资源不足的现象。
—— Large-Scale Cluster Management at Google with Borg ,Google
当然,”多多益善”的想法完全符合人类的心理,大家提交的资源需求通常都是按照可能面临的最大压力去估计的,甚至考虑到了未来用户增长所导致的新需求。为了避免服务因资源不足而中断,都会往大了去申请,这点我们可以理解。
但是,如果直接按照申请的资源去分配限额,必然会导致服务器出现两方面的影响:一方面,在大多数时间里服务器都会有大量的硬件资源闲置;而另一方面,这些闲置资源又已经分配出去,有了明确的所有者,不能再被其他人利用,难以真正发挥价值。
不过我们也能想到,Kubernetes 不太可能因为把一个资源配额的设置,拆分成了limits和requests两个设置项 ,就能完全解决这个矛盾。所以为此,Kubernetes 还进行了许多额外的处理。
比如现在我们知道,一旦选择不按照最保守、最安全的方式去分配资源,就意味着容器编排系统必须要为有可能出现的极端情况买单。而如果允许节点给 Pod 分配的资源总和,超过了 Kubernetes 自己最大的可提供资源的话,假如某个时刻,这些 Pod 的总消耗真的超标了,就会不可避免地导致节点无法继续遵守调度时对 Pod 许下的资源承诺。
那么此时,Kubernetes 就迫不得已要杀掉一部分 Pod,以腾出资源来保证其余 Pod 能正常运行,这个操作就是我后面要给你介绍的 驱逐机制 (Eviction)。
而要想进行驱逐,首先 Kubernetes 就必须拿出当资源不足时,该先牺牲哪些 Pod、该保留哪些 Pod 的明确准则,所以由此就形成了 Kubernetes 的 服务质量等级(Quality of Service Level,QoS Level)和优先级(Priority)的概念。
我们先来了解下 Kubernetes 的服务质量等级的概念。
服务质量等级
质量等级是 Pod 的一个隐含属性,也是 Kubernetes 优先保障重要的服务,放弃一些没那么重要的服务的衡量准绳。
那到这里,不知道你有没有想到这样一个细节: 如果不去设置limits和requests会怎样?
答案是不设置处理器和内存的资源,就意味着没有上限,该 Pod 可以使用节点上所有可用的计算资源。不过你先别高兴得太早,这类 Pod 能以最灵活的方式去使用资源,但也正是这类 Pod 在扮演着最不稳定的风险来源的角色。
在论文《 Large-Scale Cluster Management at Google with Borg 》中,Google 明确地提出了针对这类 Pod 的一种近乎带着惩罚性质的处理建议:当节点硬件资源不足时,优先杀掉这类 Pod。说得文雅一点的话,就是给予这类 Pod 最低的服务质量等级。
Kubernetes 目前提供的服务质量等级一共分为三级,由高到低分别为 Guaranteed、Burstable 和 BestEffort:
- 如果 Pod 中所有的容器都设置了limits和requests,且两者的值相等,那此 Pod 的服务质量等级就是最高的 Guaranteed;
- 如果 Pod 中有部分容器的 requests 值小于limits值,或者只设置了requests而未设置limits,那此 Pod 的服务质量等级就是第二级 Burstable;
- 如果是前面说的那种情况,limits和requests两个都没设置,那就是最低的 BestEffort 了。
一般来说,我们会建议把数据库应用等有状态的应用,或者是一些重要的、要保证不能中断的业务的服务质量等级定为 Guaranteed。这样,除非是 Pod 使用超过了它们的limits所描述的不可压缩资源,或者节点的内存压力大到 Kubernetes 已经杀光所有等级更低的 Pod 了,否则它们都不会被系统自动杀死。
而相对地,我们也应该把一些临时的、不那么重要的任务设置为 BestEffort,这样有利于它们调度时能在更大的节点范围中寻找宿主机,也利于它们在宿主机中利用更多的资源,快速地完成任务,然后退出,尽量缩减影响范围;当然,遇到系统资源紧张时,它们也更容易被系统杀掉。
小说《动物庄园》:
All animals are equal, but some animals are more equal than others.
所有动物生来平等,但有些动物比其他动物更加平等。
—— Animal Farm: A Fairy Story , George Orwell , 1945
优先级
除了服务质量等级以外,Kubernetes 还允许系统管理员自行决定 Pod 的优先级,这是通过类型为 PriorityClass 的资源来实现的。优先级决定了 Pod 之间并不是平等的关系,而且这种不平等还不是谁会多占用一点儿的资源的问题,而是会直接影响 Pod 调度与生存的关键。
优先级会影响调度,这很容易理解,这就是说当多个 Pod 同时被调度的话,高优先级的 Pod 会优先被调度。而 Pod 越晚被调度,就越大概率地会因节点资源已被占用而不能成功。
但优先级影响更大的一方面,是指 Kubernetes 的 抢占机制 (Preemption),正常在没有设置优先级的情况下,如果 Pod 调度失败,就会暂时处于 Pending 状态被搁置起来,直到集群中有新节点加入或者旧 Pod 退出。
但是,如果有一个被设置了明确优先级的 Pod 调度失败,无法创建的话,Kubernetes 就会在系统中寻找出一批牺牲者(Victims),把它们杀掉以便给更高优先级的 Pod 让出资源。
而这个寻找的原则,就是在优先级低于待调度 Pod 的所有已调度的 Pod 里,按照优先级从低到高排序,从最低的杀起,直至腾出的资源可以满足待调度 Pod 的成功调度为止,或者已经找不到更低优先级的 Pod 为止。
驱逐机制
说实话,前面我动不动就提要杀掉某个 Pod,听起来实在是不够优雅,其实在 Kubernetes 中更专业的称呼是”驱逐”(Eviction,即资源回收),这也是我在前面提过要给你介绍的概念。
Pod 的驱逐机制是通过 kubelet 来执行的 ,kubelet 是部署在每个节点的集群管理程序,因为它本身就运行在节点中,所以最容易感知到节点的资源实时耗用情况。kubelet 一旦发现某种不可压缩资源将要耗尽,就会主动终止节点上服务质量等级比较低的 Pod,以保证其他更重要的 Pod 的安全。而被驱逐的 Pod 中,所有的容器都会被终止,Pod 的状态会被更改为 Failed。
现在,我们已经了解了内存这种最重要的不可压缩资源,那么在默认配置下,前面我所说的”资源即将耗尽”的”即将”,其具体阈值是可用内存小于 100 Mi。
而除了可用内存(memory.available)外,其他不可压缩资源还包括有:宿主机的可用磁盘空间(nodefs.available)、文件系统可用 inode 数量(nodefs.inodesFree),以及可用的容器运行时镜像存储空间(imagefs.available)。后面三个的阈值,都是按照实际容量的百分比来计算的,具体的默认值如下:
memory.available < 100Mi
nodefs.available < 10%
nodefs.inodesFree < 5%
imagefs.available < 15%管理员可以在 kubelet 启动时,通过命令行参数来修改这些默认值,比如说,如果是在可用内存只剩余 100 Mi 时才启动驱逐,那对大多数生产系统来说都过于危险了,所以我建议在生产环境中,可以考虑当内存剩余 10% 时就开始驱逐,具体的调整命令如下所示:
$ kubelet --eviction-hard=memory.available<10%如果你是一名 Java、C#、Golang 等习惯了自动内存管理机制的程序员,我还要提醒你一下, Kubernetes 的驱逐不能完全等同于编程语言中的垃圾收集器。
这里主要体现在两个方面。
一方面,我们要知道垃圾收集是安全的内存回收行为,而驱逐 Pod 是一种毁坏性的清理行为,它有可能会导致服务产生中断,因而必须更加谨慎。比如说,要同时兼顾到硬件资源可能只是短时间内,间歇性地超过了阈值的场景,以及资源正在被快速消耗,很快就会危及高服务质量的 Pod、甚至是整个节点稳定的场景。
如此一来,驱逐机制中就有了软驱逐(Soft Eviction)、硬驱逐(Hard Eviction)以及优雅退出期(Grace Period)的概念:
- 软驱逐 :通常会配置一个比较低的警戒线(比如可用内存仅剩 20%),当触及此线时,系统就会进入一段观察期。如果只是暂时的资源抖动,在观察期内能够恢复到正常水平的话,那就不会真正启动驱逐操作。否则,资源持续超过警戒线一段时间,就会触发 Pod 的优雅退出(Grace Shutdown),系统会通知 Pod 进行必要的清理工作(比如将缓存的数据落盘),然后自行结束。在优雅退出期结束后,系统会强制杀掉还没有自行了断的 Pod。
- 硬驱逐 :通常会配置一个比较高的终止线(比如可用内存仅剩 10%),一旦触及此线,系统就会立即强制杀掉 Pod,不理会优雅退出。
软驱逐是为了减少资源抖动对服务的影响,硬驱逐是为了保障核心系统的稳定,它们并不矛盾,一般会同时使用 ,如以下例子中所示:
$ kubelet --eviction-hard=memory.available<10% \
--eviction-soft=memory.available<20% \
--eviction-soft-grace-period=memory.available=1m30s \
--eviction-max-pod-grace-period=600另一方面,Kubernetes 的驱逐跟垃圾收集器的不同之处,还在于垃圾收集可以”应收尽收”,而驱逐显然不行,系统不能无缘无故地把整个节点中所有可驱逐的 Pod 都清空掉。但是,系统通常也不能只清理到刚刚低于警戒线就停止,必须要考虑到驱逐之后的新 Pod 调度与旧 Pod 运行的新增消耗。
比如,kubelet 驱逐了若干个 Pod,让资源使用率勉强低于阈值,那么很可能在极短的时间内,资源使用率又会因为某个 Pod 稍微占用了些许资源,而重新超过阈值,再产生新一次驱逐,如此往复。
为此,Kubernetes 提供了—eviction-minimum-reclaim参数,用于设置一旦驱逐发生之后,至少要清理出来多少资源才会终止。
不过,问题到这里还是没有全部解决。要知道,Kubernetes 中很少会单独创建 Pod,通常都是由 ReplicaSet、Deployment 等更高层资源来管理的。而这就意味着,当 Pod 被驱逐之后,它不会从此彻底消失,Kubernetes 会自动生成一个新的 Pod 来取代,并经过调度,选择一个节点继续运行。
这样也就是说,如果没有进行额外的处理,那很大概率这个新生成的 Pod,就会被调度到当前这个节点上重新创建,因为上一次调度就选择了这个节点,而且这个节点刚刚驱逐完一批 Pod,得到了空闲资源,那它显然应该符合此 Pod 的调度需求。
所以,为了避免被驱逐的 Pod 出现”阴魂不散”的问题,Kubernetes 还提供了另一个参数—eviction-pressure-transition-period来约束调度器,在驱逐发生之后多长时间内,不能往该节点调度 Pod。
另外,关于驱逐机制,你还应该意识到,既然这些措施被设计为以参数的形式开启,那就说明了它们一定不是放之四海皆准的通用准则。
举个例子,假设当前 Pod 是由 DaemonSet 控制的,一旦该 Pod 被驱逐,你又强行不允许节点在一段时间内接受调度,那显然就有违 DaemonSet 的语义了。
不过到目前,Kubernetes 其实并没有办法区分 Pod 是由 DaemonSet,还是别的高层次资源创建的,所以刚刚的这种假设情况确实有可能发生,而比较合理的解决方案,是让 DaemonSet 创建 Guaranteed 而不是 BestEffort 的 Pod。
总而言之,在 Kubernetes 还没有成熟到变为”傻瓜式”容器编排系统之前, 因地制宜地合理配置和运维 是都非常必要的。
最后我还想说明的是,关于服务质量、优先级、驱逐机制这些概念,都是 在 Pod 层面上限制资源,是仅针对单个 Pod 的低层次约束。 而在现实中,我们还经常会遇到面向更高层次去控制资源的需求,比如,想限制由多个 Pod 构成的微服务系统耗用的总资源,或者是由多名成员组成的团队耗用的总资源。
我举个具体例子,现在你想要在拥有 32 GiB 内存和 16 个处理器的集群里,允许 A 团队使用 20 GiB 内存和 10 个处理器的资源,再允许 B 团队使用 10 GiB 内存和 4 个处理器的资源,再预留 2 GiB 内存和 2 个处理器供将来分配。那么要满足这种资源限制的需求,Kubernetes 的解决方案是应该先为它们建立一个专用的名称空间,然后再在名称空间里建立 ResourceQuota 对象,来描述如何进行整体的资源约束。
但是这样,ResourceQuota 与调度就没有直接关系了,它针对的对象也不是 Pod,所以这里我所说的资源,可以是广义上的资源,系统不仅能够设置处理器、内存等物理资源的限额,还可以设置诸如 Pod 最大数量、ReplicaSet 最大数量、Service 最大数量、全部 PersistentVolumeClaim 的总存储容量等各种抽象资源的限额。
甚至,当 Kubernetes 预置的资源模型不能满足约束需要的时候,还能够根据实际情况去拓展,比如要控制 GPU 的使用数量,完全可以通过 Kubernetes 的设备插件(Device Plugin)机制,拓展出诸如nvidia.com/gpu: 4这样的配置来。
默认调度器
好,了解了 Kubernetes 的资源模型和服务质量、优先级、驱逐机制这些概念以后,我们再回过头来,探讨下前面开头我提出的问题: Kubernetes 是如何撮合 Pod 与 Node 的? 这其实也是最困难的一个问题。
现在我们知道,调度是为新创建出来的 Pod,寻找到一个最恰当的宿主机节点去运行它。而在这句话里,就包含有”运行”和”恰当”两个调度中的关键过程,它们具体是指:
运行 :从集群的所有节点中,找出一批剩余资源可以满足该 Pod 运行的节点。为此,Kubernetes 调度器设计了一组名为 Predicate 的筛选算法。
恰当 :从符合运行要求的节点中,找出一个最适合的节点完成调度。为此,Kubernetes 调度器设计了一组名为 Priority 的评价算法。
这两个算法的具体内容稍后我会详细给你解释,这里我要先说明白一点:在几个、十几个节点的集群里进行调度,调度器怎么实现都不会太困难,但是对于数千个、乃至更多节点的大规模集群,要实现高效的调度就绝不简单。
请你想象一下,现在有一个由数千节点组成的集群,每次 Pod 的创建,都必须依据各节点的实时资源状态来确定调度的目标节点,然而我们知道,各节点的资源是随着程序运行无时无刻都在变动的,资源状况只有它本身才清楚。
这样,如果每次调度都要发生数千次的远程访问来获取这些信息的话,那压力与耗时都很难降下来。所以结果不仅会让调度器成为集群管理的性能瓶颈,还会出现因耗时过长,某些节点上资源状况已发生变化,调度器的资源信息过时,而导致调度结果不准确等问题。
额外知识:Scheduler
Clusters and their workloads keep growing, and since the scheduler’s workload is roughly proportional to the cluster size, the scheduler is at risk of becoming a scalability bottleneck.
由于调度器的工作负载与集群规模大致成正比,随着集群和它们的工作负载不断增长,调度器很有可能会成为扩展性瓶颈所在。
—— Omega: Flexible, Scalable Schedulers for Large Compute Clusters ,Google
因此,针对前面所说的问题,Google 在论文《 Omega: Flexible, Scalable Schedulers for Large Compute Clusters 》里总结了自身的经验,并参考了当时 Apache Mesos 和 Hadoop on Demand (HOD)的实现,提出了一种共享状态(Shared State)的双循环调度机制。
这种调度机制后来不仅应用在 Google 的 Omega 系统(Borg 的下一代集群管理系统)中,也同样被 Kubernetes 继承了下来,它整体的工作流程如下图所示:
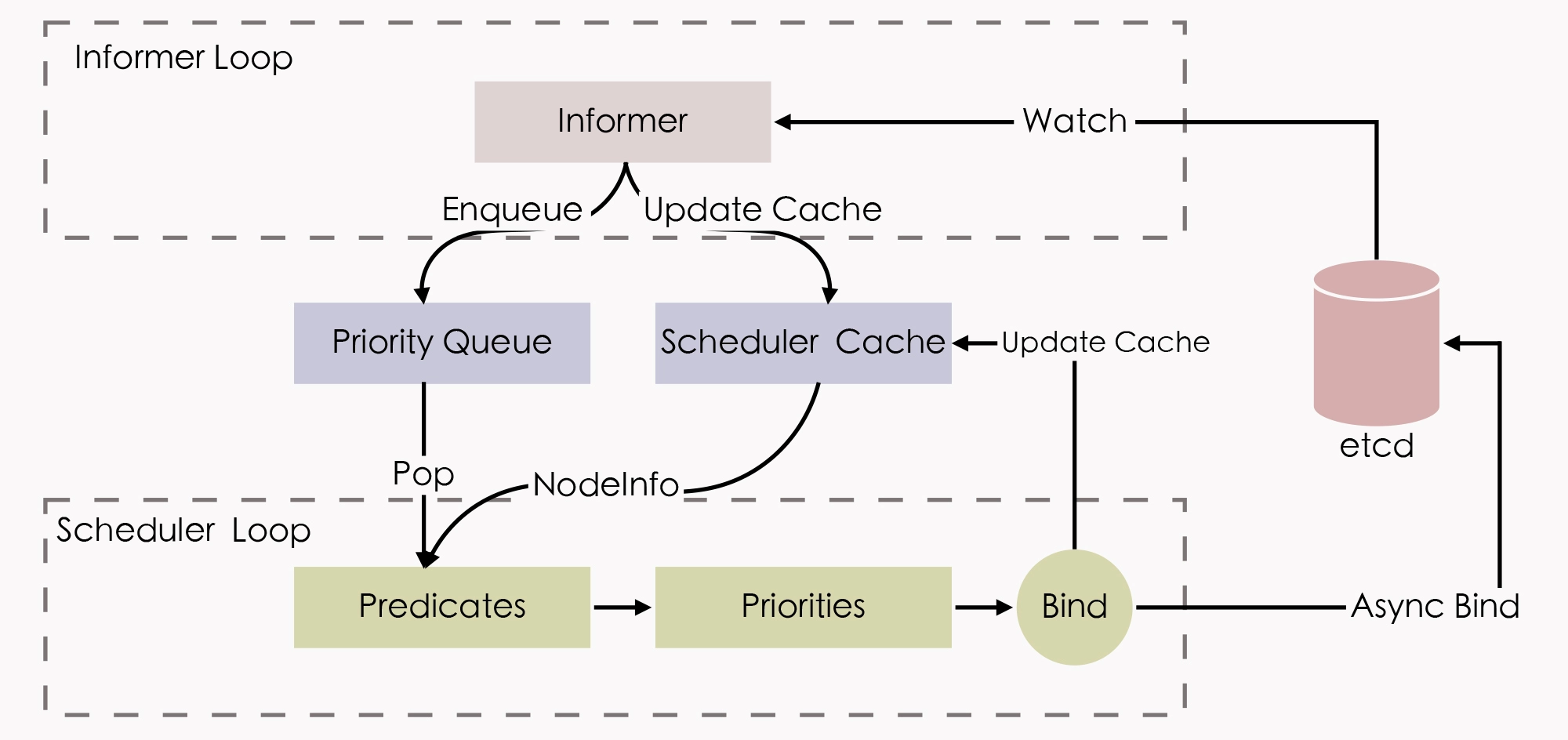
“状态共享的双循环”中,第一个控制循环可被称为”Informer Loop”,它是一系列 Informer 的集合,这些 Informer 会持续监视 etcd 中与调度相关资源(主要是 Pod 和 Node)的变化情况,一旦 Pod、Node 等资源出现变动,就会触发对应 Informer 的 Handler。
Informer Loop 的职责是根据 etcd 中的资源变化,去更新调度队列(Priority Queue)和调度缓存(Scheduler Cache)中的信息。
比如当有新 Pod 生成,就将其入队(Enqueue)到调度队列中,如有必要,还会根据优先级触发上节课我提到的插队和抢占操作。再比如,当有新的节点加入集群,或者已有的节点资源信息发生变动,Informer 也会把这些信息更新同步到调度缓存之中。
另一个控制循环可被称为”Scheduler Loop”,它的核心逻辑是不停地把调度队列中的 Pod 出队(Pop),然后使用 Predicate 算法进行节点选择。
Predicate 本质上是一组节点过滤器(Filter),它会根据预设的过滤策略来筛选节点。Kubernetes 中默认有三种过滤策略,分别是:
- 通用过滤策略 :最基础的调度过滤策略,用来检查节点是否能满足 Pod 声明中需要的资源。比如处理器、内存资源是否满足,主机端口与声明的 NodePort 是否存在冲突,Pod 的选择器或者 nodeAffinity 指定的节点是否与目标相匹配,等等。
- 卷过滤策略 :与存储相关的过滤策略,用来检查节点挂载的 Volume 是否存在冲突(比如将一个块设备挂载到两个节点上),或者 Volume 的 可用区域 是否与目标节点冲突,等等。在” Kubernetes 存储设计 “中提到的 Local PersistentVolume 的调度检查,就是在这里处理的。
- 节点过滤策略 :与宿主机相关的过滤策略,最典型的是 Kubernetes 的 污点与容忍度机制 (Taints and Tolerations),比如默认情况下,Kubernetes 会设置 Master 节点不允许被调度,这就是通过在 Master 中施加污点来避免的。前面我提到的控制节点处于驱逐状态,或者在驱逐后一段时间不允许调度,也是在这个策略里实现的。
此外,Predicate 算法所使用的一切数据,都来自于 调度缓存 ,它绝对不会去远程访问节点本身。这里你要知道,只有 Informer Loop 与 etcd 的监视操作才会涉及到远程调用,而 Scheduler Loop 中,除了最后的异步绑定要发起一次远程的 etcd 写入外,其余全部都是进程内访问,这一点正是调度器执行效率的重要保证。
所谓的调度缓存,就是两个控制循环的共享状态(Shared State) ,这样的设计避免了调度器每次调度时主动去轮询所有集群节点,保证了调度器的执行效率。
但是它也存在一定的局限,也就是调度缓存并不能完全避免因节点信息同步不及时,而导致调度过程中实际资源发生变化的情况,比如节点的某个端口在获取调度信息后、发生实际调度前被意外占用了。
为此,当调度结果出来以后,在 kubelet 真正创建 Pod 以前,还必须执行一次 Admit 操作,在该节点上重新做一遍 Predicate,来进行二次确认。 经过 Predicate 算法筛选出来符合要求的节点集,会交给 Priorities 算法来打分(0~10 分)排序,以便挑选出”最恰当”的一个。
这里的”恰当”其实是带有主观色彩的词语,Kubernetes 也提供了不同的打分规则来满足不同的主观需求,比如最常用的 LeastRequestedPriority 规则,它的计算公式是:
score = (cpu((capacity-sum(requested))×10/capacity) + memory((capacity-sum(requested))×10/capacity))/2从公式上,我们能很容易地看出,这就是在选择处理器和内存空闲资源最多的节点,因为这些资源剩余越多,得分就越高。经常与它一起工作的是 BalancedResourceAllocation 规则,它的公式是:
score = 10 - variance(cpuFraction,memoryFraction,volumeFraction)×10在这个公式中,三种 Fraction 的含义是 Pod 请求的资源除以节点上的可用资源,variance 函数的作用是计算各种资源之间的差距,差距越大,函数值越大。由此可知,BalancedResourceAllocation 规则的意图是希望调度完成后,所有节点里各种资源分配尽量均衡,避免节点上出现诸如处理器资源被大量分配、而内存大量剩余的尴尬状况。
Kubernetes 内置的其他的评分规则,还有 ImageLocalityPriority、NodeAffinityPriority、TaintTolerationPriority,等等,有兴趣的话你可以去阅读 Kubernetes 的源码,这里我就不再逐一解释了。
这样,经过 Predicate 的筛选、Priorities 的评分之后,调度器已经选出了调度的最终目标节点,最后一步就是通知目标节点的 kubelet 可以去创建 Pod 了。我们要知道,调度器并不会直接与 kubelet 通讯来创建 Pod,它只需要把待调度的 Pod 的nodeName字段更新为目标节点的名字即可,kubelet 本身会监视该值的变化来接手后续工作。
不过,从调度器在 etcd 中更新nodeName,到 kubelet 从 etcd 中检测到变化,再执行 Admit 操作二次确认调度可行性,最后到 Pod 开始实际创建,这个过程可能会持续一段不短的时间,如果一直等待这些工作都完成了,才宣告调度最终完成,那势必也会显著影响调度器的效率。
所以实际上,Kubernetes 调度器采用了 乐观绑定(Optimistic Binding) 的策略来解决这个问题,它会同步地更新调度缓存中 Pod 的nodeName字段,并异步地更新 etcd 中 Pod 的nodeName字段,这个操作被称为绑定(Binding)。如果最终调度成功了,那 etcd 与调度缓存中的信息最终必定会保持一致,否则如果调度失败了,那就会由 Informer 来根据 Pod 的变动,将调度成功却没有创建成功的 Pod 清空nodeName字段,重新同步回调度缓存中,以便促使另外一次调度的开始。
最后,你可能会注意到这个部分的小标题,我用的是”默认调度器”,这其实是在强调以上行为仅是 Kubernetes 默认的行为。对调度过程的大部分行为,你都可以通过 Scheduler Framework 暴露的接口来进行扩展和自定义,如下图所示:
可以看到,图中绿色的部分,就是 Scheduler Framework 暴露的扩展点。由于 Scheduler Framework 属于 Kubernetes 内部的扩展机制(通过 Golang 的 Plugin 机制来实现的,需静态编译),它的通用性跟我在前面课程中提到的其他扩展机制(比如 CRI、CNI、CSI 那些)无法相提并论,属于比较高级的 Kubernetes 管理技能了,这里我就简单地提一下,你稍作了解就行。
小结
调度可以分解为几个相对独立的子问题来研究,比如说,如何衡量工作任务的算力需求;如何区分工作任务的优先级,保障较重要的任务有较高的服务质量;如何在资源紧张时自动驱逐相对不重要的任务,等等。解决这一系列子问题的组件,就称为容器编排系统的调度器。
这节课,我带你学习了 Kubernetes 是如何为一个新创建出来的 Pod,寻找到一个最恰当的宿主机节点来运行的。由于 Kubernetes 基于”超卖”所设计的资源调度机制,在更合理充分利用物理服务器资源的同时,也让资源调度成为了一项具有风险和挑战性的工作,所以你只有正确理解了这节课介绍的服务质量、优先级、驱逐机制等概念,在生产实践中,才能在资源利用率最大化与服务稳定性之间取得良好平衡。
59 | 透明通讯的涅槃(上):通讯的成本
接下来这三节课,我们来学习目前最新的服务通讯方案:服务网格。
Kubernetes 为它管理的工作负载提供了工业级的韧性与弹性,也为每个处于运行状态的 Pod 维护其相互连通的虚拟化网络。不过,程序之间的通信不同于简单地在网络上拷贝数据,一个可连通的网络环境,仅仅是程序间能够可靠通信的必要但非充分的条件。
作为一名经历过 SOA、微服务、云原生洗礼的的分布式程序员,你必定已经深谙路由、容错、限流、加密、认证、授权、跟踪、度量等问题在分布式系统中的必要性。
在”远程服务调用”这个小章节里,我曾以” 通信的成本 “为主题,给你讲解了三十多年的计算机科学家们,对”远程服务调用是否可能实现为透明通信”的一场声势浩大的争论。 而今天,服务网格的诞生在某种意义上,就可以说就是当年透明通信的重生, 服务网格试图以容器、虚拟化网络、边车代理等技术所构筑的新一代通信基础设施为武器,重新对已经盖棺定论三十多年的程序间远程通信中,非透明的原则发起冲击。
今天,这场关于通信的变革仍然在酝酿发展当中。最后到底会是成功的逆袭,还是会成为另一场失败,我不敢妄言定论,但是作为程序通信发展历史的一名见证者,我会丝毫不吝啬对服务网格投去最高的期许与最深的祝愿。
通信的成本
程序间通信作为分布式架构的核心内容,我在第一个模块”演进中的架构”中,就已经从宏观角度讲述过它的演进过程。而在这节课里,我会从更微观、更聚焦的角度,分析不同时期应用程序该如何看待与实现通信方面的非功能性需求,以及它们是如何做到可靠通信的。
我会通过以下五个阶段的变化,帮助你理解分布式服务的通信是如何逐步演化成我们要探讨的主角”服务网格”的。
第一阶段
将通信的非功能性需求视作业务需求的一部分,由程序员来保障通信的可靠性。
这一阶段是软件企业刚刚开始尝试分布式时,选择的早期技术策略。这类系统原本所具有的通信能力不是作为系统功能的一部分被设计出来的,而是遇到问题后修补累积所形成的。
在刚开始时,系统往往只具备最基本的网络 API,比如集成 OKHTTP、gRPC 这些库来访问远程服务,如果远程访问接收到异常,就编写对应的重试或降级逻辑去应对处理。而在系统进入生产环境以后,遇到并解决的一个个通信问题,就逐渐在业务系统中留下了越来越多关于通信的代码逻辑。
这些通信的逻辑由业务系统的开发人员直接编写,与业务逻辑直接共处在一个进程空间之中,如下图所示(注:这里以及后面的一系列图片中,我会以”断路器”和”服务发现”这两个常见的功能来泛指所有的分布式通信所需的能力,但你要知道实际上并不局限于这两个功能)。
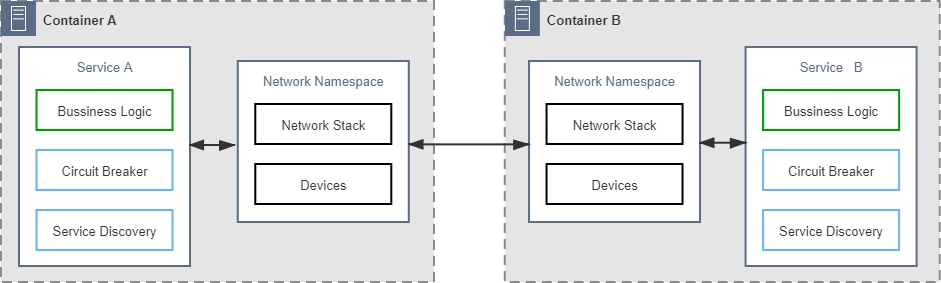
这一阶段的主要矛盾是绝大多数擅长业务逻辑的开发人员,其实都 并不擅长处理通信方面的问题。 要写出正确、高效、健壮的分布式通信代码,是一项极具专业性的工作。所以大多数的普通软件企业都很难在这个阶段支撑起一个靠谱的分布式系统来。
另一方面,把专业的通信功能强加于普通开发人员,这无疑为他们 带来了更多工作量 。尤其是这些”额外的工作”与原有的业务逻辑耦合在一起,让系统越来越复杂,也越来越容易出错。
第二阶段
将代码中的通信功能抽离重构成公共组件库,通信的可靠性由专业的平台程序员来保障。
开发人员解耦一贯依赖的有效办法是抽取分离代码与封装重构组件。实际上,微服务的普及也离不开一系列封装了分布式通信能力的公共组件库,其代表性产品有 Twitter 的 Finagle、Spring Cloud 中的许多组件等。
这些公共的通信组件由熟悉分布式的专业开发人员编写和维护,不仅效率更高、质量更好,还都提供了经过良好设计的 API 接口,让业务代码既可以使用它们的能力,又无需把处理通信的逻辑散布于业务代码当中。
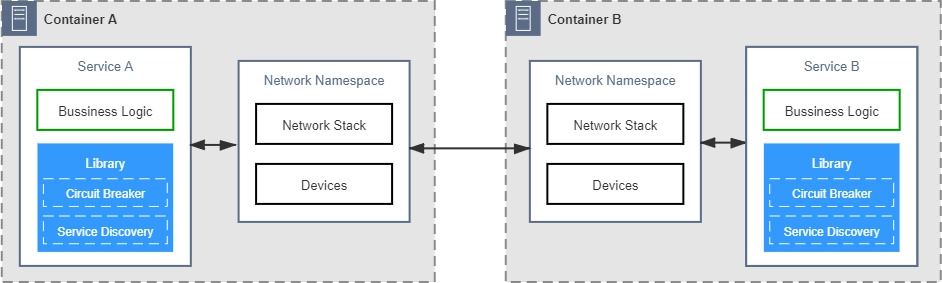
分布式通信组件让普通程序员开发出靠谱的微服务系统成为可能,这是无可争议的成绩。但普通程序员使用它们的成本依然很高,不仅要学习分布式的知识,还要学习这些公共组件的功能的使用规范,最麻烦的是,对于同一种问题往往还需学习多种不同的组件才能解决。
造成这些问题的主要原因 是因为通信组件是一段由特定编程语言开发出来的程序,是与语言绑定的,一个由 Python 编写的组件再优秀,对 Java 系统来说也没有太多的实用价值。目前,基于公共组件库开发微服务仍然是应用最为广泛的解决方案,但肯定不是一种完美的解决方案,这是微服务基础设施完全成熟之前必然会出现的应用形态,同时也一定是微服务进化过程中必然会被替代的过渡形态。
第三阶段
将负责通信的公共组件库分离到进程之外,程序间通过网络代理来交互,通信的可靠性由专门的网络代理提供商来保障。
为了能够让分布式通信组件与具体的编程语言脱钩,也为了避免程序员还要去专门学习这些组件的编程模型与 API 接口,这一阶段进化出了能专门负责可靠通信的 网络代理 。这些网络代理不再与业务逻辑部署于同一个进程空间,但仍然与业务系统处于同一个容器或者虚拟机当中,它们可以通过回环设备甚至是 UDS (Unix Domain Socket)进行交互,可以说具备相当高的网络性能。
也就是说,只要让网络代理接管掉程序七层或四层流量,就能够在代理上完成断路、容错等几乎所有的分布式通信功能,前面提到过的 Netflix Prana 就属于这类产品的典型代表。
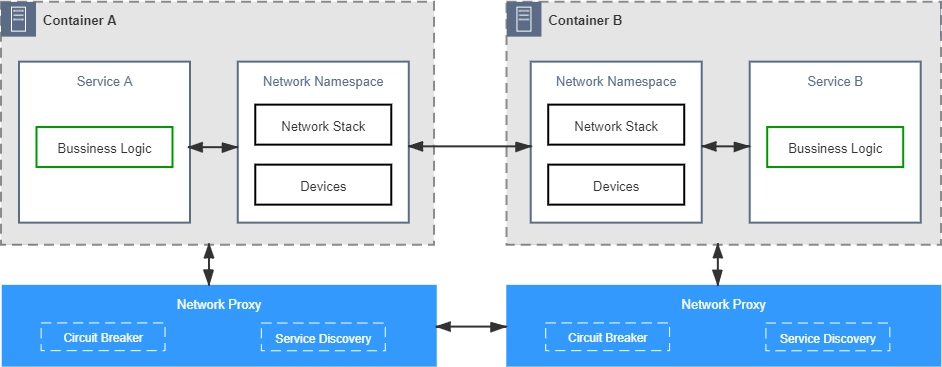
在通过网络代理来提升通信质量的思路提出以后,其本身的使用范围其实并不算特别广泛,但它的方向是正确的。这种思路后来演化出了 两种改进形态:
- 第一种形态,将网络代理从进程身边拉远,让它与进程分别处于不同的机器上,这样就可以同时给多个进程提供可靠通信的代理服务。这种形态逐渐演变成了今天我们常见的微服务网关。
- 第二种形态,如果将网络代理往进程方向推近,不仅能让它与进程处于同一个共享网络名称空间的容器组之中,还可以让它透明并强制地接管通讯,这便形成了下一阶段所说的边车代理。
第四阶段
将网络代理以边车的形式注入到应用容器,自动劫持应用的网络流量,让通信的可靠性由专门的通信基础设施来保障。
与前一阶段的独立代理相比,以边车模式运作的网络代理拥有两个无可比拟的优势:
它对流量的劫持是强制性的,通常是靠直接写容器的 iptables 转发表来实现。
此前,独立的网络代理只有程序首先去访问它,它才能被动地为程序提供可靠的通信服务,只要程序依然有选择不访问它的可能性,代理就永远只能充当服务者而不能成为管理者。上阶段的图中,保留的两个容器网络设备直接连接的箭头,就代表了这种可能性,而这一阶段的图例中,服务与网络名称空间的虚线箭头代表了被劫持后,应用程序以为存在,但实际并不存在的流量。
边车代理对应用是透明的,无需对已部署的应用程序代码进行任何改动,不需要引入任何的库(这点并不是绝对的,有部分边车代理也会要求有轻量级的 SDK),也不需要程序专门去访问某个特定的网络位置。
这意味着它对所有现存程序都具备开箱即用的适应性,无需修改旧程序就能直接享受到边车代理的服务,这样使得它的适用面就变得十分广泛。目前边车代理的代表性产品有 Linkerd、Envoy、MOSN 等。
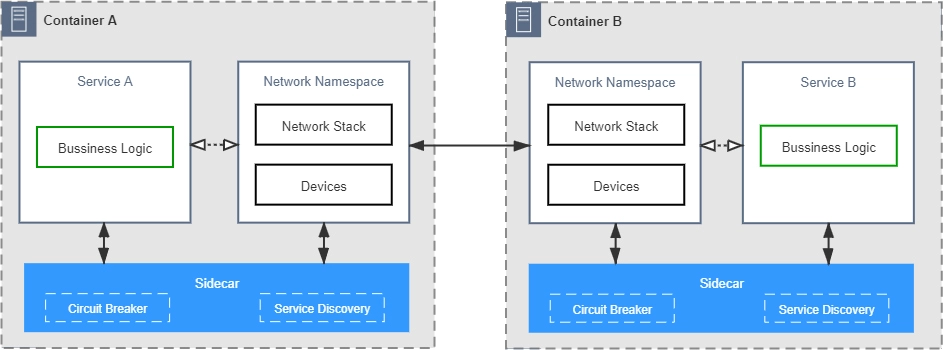
如果说边车代理还有什么不足之处的话,那大概就是来自于运维人员的不满了。边车代理能够透明且具有强制力地解决可靠通信的问题,但它本身也需要有足够的信息才能完成这项工作,比如获取可用服务的列表、得到每个服务名称对应的 IP 地址等等。
而这些信息不会从天上掉下来自动到边车里去,是需要由管理员主动去告知代理,或者代理主动从约定的好的位置获取的。可见, 管理代理本身也会产生额外的通信需求。 如果没有额外的支持,这些管理方面的通信都得由运维人员去埋单,由此而生的不满便可想而知。为了管理与协调边车代理,程序间通信进化到了最后一个阶段:服务网格。
第五阶段
将边车代理统一管控起来实现安全、可控、可观测的通信,将数据平面与控制平面分离开来,实现通用、透明的通信,这项工作就由专门的服务网格框架来保障。
从总体架构看,服务网格包括两大块内容,分别是由一系列与微服务共同部署的边车代理,以及用于控制这些代理的管理器所构成。代理与代理之间需要通信,用以转发程序间通信的数据包;代理与管理器之间也需要通信,用以传递路由管理、服务发现、数据遥测等控制信息。
服务网格使用 数据平面 (Data Plane)通信和 控制平面 (Control Plane)通信来形容这两类流量,下图中的实线就表示数据平面通信,虚线表示控制平面通信。
实际上,数据平面与控制平面并不是什么新鲜概念,它最初就是用在计算机网络之中的术语,通常是指网络层次的划分。在软件定义网络中,也把解耦数据平面与控制平面作为其最主要的特征之一。服务网格把计算机网络的经典概念引入到了程序通信之中,既可以说是对程序通信的一种变革创新,也可以说是对网络通信的一种发展传承。
小结
分离数据平面与控制平面的实质是将”程序”与”网络”进行解耦,把网络可能出现的问题(比如中断后重试、降级),与可能需要的功能(比如实现追踪度量)的处理过程从程序中拿出来,放到由控制平面指导的数据平面通信中去处理,这样来制造出一种”这些问题在程序间通信中根本不存在”的假象,仿佛网络和远程服务都是完美可靠的。
而这种完美的假象,就让应用之间可以非常简单地交互,而不必过多地考虑异常情况;而且也能够在不同的程序框架、不同的云服务提供商环境之间平稳地迁移。与此同时,还能让管理者能够不依赖程序支持就得到遥测所需的全部信息,能够根据角色、权限进行统一的访问控制,这些都是服务网格的价值所在。
61 | 服务网格与生态:聊聊服务网格的两项标准规范
这节课,我们来了解服务网格的主要规范与主流产品。
服务网格目前仍然处于技术浪潮的早期,不过现在业界早已普遍认可它的价值,基本上所有希望能影响云原生发展方向的企业都已经参与了进来。从最早 2016 年的 Linkerd 和 Envoy ,到 2017 年 Google、IBM 和 Lyft 共同发布的 Istio,再到后来 CNCF 把 Buoyant 的 Conduit 改名为 Linkerd2 ,再度参与 Istio 竞争。
而到了 2018 年后,服务网格的话语权争夺战已经全面升级到由云计算巨头直接主导,比如 Google 把 Istio 搬上 Google Cloud Platform,推出了 Istio 的公有云托管版本 Google Cloud Service Mesh;亚马逊推出了用于 AWS 的 App Mesh;微软推出了 Azure 完全托管版本的 Service Fabric Mesh,发布了自家的控制平面 Open Service Mesh ;国内的阿里巴巴也推出了基于 Istio 的修改版 SOFAMesh ,并开源了自己研发的 MOSN 代理。可以说,云计算的所有玩家都正在布局服务网格生态。
不过,市场繁荣的同时也带来了碎片化的问题。要知道,一个技术领域能够形成被业界普遍承认的规范标准,是这个领域从分头研究、各自开拓的萌芽状态,走向工业化生产应用的成熟状态的重要标志,标准的诞生可以说是每一项技术普及之路中都必须经历的”成人礼”。
在前面的课程中,我们接触过容器运行时领域的 CRI 规范 、容器网络领域的 CNI 规范 、容器存储领域的 CSI 规范 ,尽管服务网格诞生至今只有数年时间,但作为微服务、云原生的前沿热点,它也正在酝酿自己的标准规范,也就是这节课我们要讨论的主角: 服务网格接口 (Service Mesh Interface,SMI)与 通用数据平面 API (Universal Data Plane API,UDPA)。现在我们先来看下这两者之间的关系:
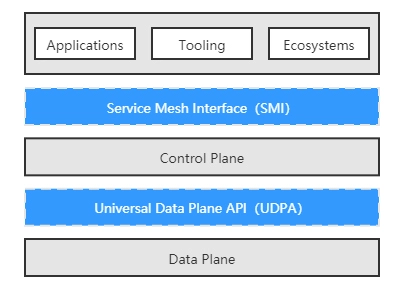
实际上, 服务网格是数据平面产品与控制平面产品的集合 ,所以在规范制订方面,很自然地也分成了两类:
- SMI 规范提供了外部环境(实际上就是 Kubernetes)与控制平面交互的标准,使得 Kubernetes 及在其之上的应用,能够无缝地切换各种服务网格产品;
- UDPA 规范则提供了控制平面与数据平面交互的标准,使得服务网格产品能够灵活地搭配不同的边车代理,针对不同场景的需求,发挥各款边车代理的功能或者性能优势。
可以发现,这两个规范并没有重叠,它们的关系与我在 容器运行时 中介绍到的 CRI 和 OCI 规范之间的关系很相似。下面我们就从这两个规范的起源和支持者的背景入手,了解一下它们要解决的问题及目前的发展状况。
服务网格接口
在 2019 年 5 月的 KubeCon 大会上,微软联合 Linkerd、HashiCorp、Solo、Kinvolk 和 Weaveworks 等一批云原生服务商,共同宣布了 Service Mesh Interface 规范,希望能在各家的服务网格产品之上建立一个抽象的 API 层,然后通过这个抽象来解耦和屏蔽底层服务网格实现,让上层的应用、工具、生态系统可以建立在同一个业界标准之上,从而实现应用程序在不同服务网格产品之间的无缝移植与互通。
如果你更熟悉 Istio 的话,那你可以把 SMI 的作用理解为是给服务网格提供了一套 Istio 中, VirtualService 、 DestinationRule 、 Gateway 等私有概念对等的行业标准版本,只要使用 SMI 中定义的标准资源,应用程序就可以在不同的控制平面上灵活迁移,唯一的要求是这些控制平面都支持了 SMI 规范。
SMI 与 Kubernetes 是彻底绑定的 ,规范的落地执行完全依靠在 Kubernetes 中部署 SMI 定义的 CRD 来实现,这一点在 SMI 的目标中被形容为” Kubernetes Native “,也就说明了微软等云服务厂商已经认定容器编排领域不会有 Kubernetes 之外的候选项了,这也是微软选择在 KubeCon 大会上公布 SMI 规范的原因。
但是在另外一端 , SMI 并不与包括行业第一的 Istio,或者是微软自家的 Open Service Mesh 在内的任何控制平面所绑定 ,这点在 SMI 的目标中被形容为”Provider Agnostic”,说明微软务实地看到了服务网格领域目前还处于群雄混战的现状。Provider Agnostic 对消费者有利,但对目前处于行业领先地位的 Istio 肯定是不利的,所以我们完全可以理解为什么 SMI 没有得到 Istio 及其背后的 Google、IBM 与 Lyft 的支持。
然而,在过去两年里,Istio 无论是发展策略上、还是设计上(过度设计)的风评都不算很好,业界一直在期待 Google 和 Istio 能做出改进,这种期待在持续两年的失望之后,已经有很多用户在考虑 Istio 以外的选择了。
所以,SMI 一经发布,就吸引了除 Istio 之外几乎所有的服务网格玩家的目光,大家全部参与了进来,这恐怕并不只是因为微软号召力巨大的缘故。而且为了对抗 Istio 的抵制,SMI 自己还提供了一个 Istio 的适配器 ,以便使用 Istio 的程序能平滑地迁移到 SMI 之上,所以遗留代码并不能为 Istio 构建出特别坚固的壁垒。
到了 2020 年 4 月,SMI 被托管到 CNCF,成为其中的一个 Sandbox 项目(Sandbox 是最低级别的项目,CNCF 只提供有限度的背书),如果能够经过孵化、毕业阶段的话,SMI 就有望成为公认的行业标准,这也是开源技术社区里民主管理的一点好处。

好了,到这里我们就了解了 SMI 的背景与价值,现在我们再来学习一下 SMI 的主要内容。目前( v0.5 版本 )的 SMI 规范包括四方面的 API 构成,下面我们就分别来看一下。
流量规范(Traffic Specs)
目标是定义流量的表示方式,比如 TCP 流量、HTTP/1 流量、HTTP/2 流量、gRPC 流量、WebSocket 流量等应该如何在配置中抽象和使用。目前 SMI 只提供了 TCP 和 HTTP 流量的直接支持,而且都比较简陋,比如 HTTP 流量的路由中,甚至连以 Header 作为判断条件都不支持。
当然,我们可以暂时自我安慰地解释为 SMI 在流量协议的扩展方面是完全开放的,没有功能也有可能自己扩充,哪怕不支持的或私有协议的流量,也有可能使用 SMI 来管理。而我们知道,流量表示是做路由和访问控制的必要基础,因为它必须要根据流量中的特征为条件,才能进行转发和控制,而流量规范中已经自带了路由能力,访问控制就被放到独立的规范中去实现了。
流量拆分(Traffic Split)
目标是定义不同版本服务之间的流量比例,提供流量治理的能力,比如限流、降级、容错,等等,以满足灰度发布、A/B 测试等场景。
SMI 的流量拆分是直接基于 Kubernetes 的 Service 资源来设置的,这样做的好处是使用者不需要去学习理解新的概念,而坏处是要拆分流量,就必须定义出具有层次结构的 Service,即 Service 后面不是 Pod,而是其他 Service。而 Istio 中则是设计了 VirtualService 这样的新概念来解决相同的问题,它是通过 Subset 来拆分流量。至于两者孰优孰劣,这就见仁见智了。
流量度量(Traffic Metrics)
目标是为资源提供通用集成点,度量工具可以通过访问这些集成点来抓取指标。这部分完全遵循了 Kubernetes 的 Metrics API 进行扩充。
流量访问控制(Traffic Access Control)
目标是根据客户端的身份配置,对特定的流量访问特定的服务提供简单的访问控制。SMI 绑定了 Kubernetes 的 ServiceAccount 来做服务身份访问控制,这里说的”简单”不是指它使用简单,而是说它只支持 ServiceAccount 一种身份机制,在正式使用中这恐怕是不足以应付所有场景的,日后应该还需要继续扩充。
以上这四种 API 目前暂时都是 Alpha 版本,也就是意味着它们还不够成熟,随时可能发生变动。从目前的版本来看,至少跟 Istio 的私有 API 相比,SMI 还没有看到明显的优势,不过考虑到 SMI 还处于项目早期阶段,不够强大也情有可原,希望未来 SMI 可以成长为一个足够坚实可用的技术规范,这也有助于避免数据平面出现一家独大的情况,有利于竞争与发展。
通用数据面 API
好,现在我们接着来了解一下通用数据面 API 的规范内容。同样是 2019 年 5 月,CNCF 创立了一个名为”通用数据平面 API 工作组”(Universal Data Plane API Working Group,UDPA-WG)的组织,其工作目标是制定类似于软件定义网络中,OpenFlow 协议的数据平面交互标准。可以说,工作组的名字被敲定的那一刻,就已经决定了它所产出的标准名字,必定是叫”通用数据平面 API”(Universal Data Plane API,UDPA)。
其实,如果不纠结于是否足够标准、是否是由足够权威的组织来制定的话,上节课我介绍数据平面时提到的 Envoy xDS 协议族,就已经完全满足了控制平面与数据平面交互的需要。
事实上,Envoy 正是 UDPA-WG 工作组的主要成员,在 2019 年 11 月的 EnvoyCon 大会上,Envoy 的核心开发者、UDPA 的负责人之一,来自 Google 公司的哈维 · 图奇(Harvey Tuch)做了一场以” The Universal Dataplane API:Envoy’s Next Generation APIs “为题的演讲,他详细而清晰地说明了 xDS 与 UDAP 之间的关系:UDAP 的研发就是基于 xDS 的经验为基础的,在未来 xDS 将逐渐向 UDPA 靠拢,最终将基于 UDPA 来实现。
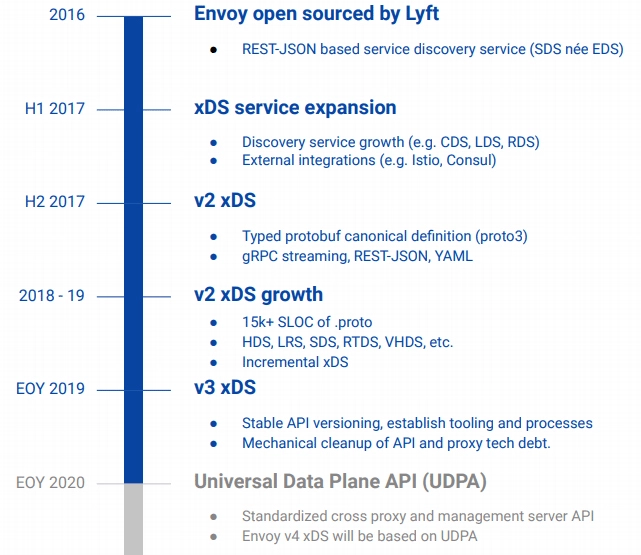
上图是我在哈维 · 图奇的演讲 PPT 中,截取的 UDPA 与 xDS 的融合时间表,在演讲中,哈维 · 图奇还提到了 xDS 协议的演进节奏会定为,每年推出一个大版本、每个版本从发布到淘汰起要经历 Alpha、Stable、Deprecated、Removed 四个阶段、每个阶段持续一年时间,简单地说就是每个大版本 xDS 在被淘汰前,会有三年的固定生命周期。
基于 UDPA 的 xDS v4 API,原本计划会在 2020 年发布,进入 Alpha 阶段,不过,我写下这段文字的时间是 2020 年的 10 月中旬,已经可以肯定地说前面所列的这些计划一定会破产,因为从目前公开的资料看来,UDPA 仍然处于早期设计阶段,距离完备都还有一段很长的路程,所以基于 UDPA 的 xDS v4 在 2020 年是铁定出不来了。
另外,在规范内容方面,由于 UDPA 连 Alpha 状态都还没能达到,目前公开的资料还很少。从 GitHub 和 Google 文档上能找到的部分设计原型文件来看,UDAP 的主要内容会分为 传输协议 (UDPA-TP,TransPort)和 数据模型 (UDPA-DM,Data Model)两部分,这两个部分是独立设计的,也就是说,以后完全有可能会出现不同的数据模型共用同一套传输协议的可能性。
服务网格生态
OK,到这里,我们就基本理清了服务网格的主要规范。其实,从 2016 年”Service Mesh”一词诞生至今,不过短短四年时间,服务网格就已经从研究理论变成了在工业界中广泛采用的技术,用户的态度也从观望走向落地生产。
那么到目前,服务网格市场已经形成了初步的生态格局,尽管还没有决出最终的胜利者,但我们已经能基本看清这个领域里几个有望染指圣杯的玩家。下面,我就按照数据平面和控制平面,给你分别介绍一下目前服务网格产品的主要竞争者。
首先我们来看看在数据平面的主流产品,主要有 5 种:
Linkerd
2016 年 1 月发布的 Linkerd 是服务网格的鼻祖,使用 Scala 语言开发的 Linkerd-proxy 也就成为了业界第一款正式的边车代理。一年后的 2017 年 1 月,Linkerd 成功进入 CNCF,成为云原生基金会的孵化项目,但此时的 Linkerd 其实已经显露出了明显的颓势:由于 Linkerd-proxy 运行需要 Java 虚拟机的支持,启动时间、预热、内存消耗等方面,相比起晚它半年发布的挑战者 Envoy,均处于全面劣势,因而 Linkerd 很快就被 Istio 和 Envoy 的组合所击败,结束了它短暂的统治期。
Envoy
2016 年 9 月开源的 Envoy 是目前边车代理产品中,市场占有率最高的一款,已经在很多个企业的生产环境里经受过大量检验。Envoy 最初由 Lyft 公司开发,后来 Lyft 与 Google 和 IBM 三方达成合作协议,Envoy 就成了 Istio 的默认数据平面。Envoy 使用 C++ 语言实现,比起 Linkerd 在资源消耗方面有了明显的改善。
此外,由于采用了公开的 xDS 协议进行控制,Envoy 并不只为 Istio 所私有,这个特性也让 Envoy 被很多其他的管理平面选用,为它夺得市场占有率桂冠做出了重要贡献。2017 年 9 月,Envoy 加入 CNCF,成为 CNCF 继 Linkerd 之后的第二个数据平面项目。
nginMesh
2017 年 9 月,在 NGINX Conf 2017 大会上,Nginx 官方公布了基于著名服务器产品 Nginx 实现的边车代理 nginMesh 。nginMesh 使用 C 语言开发(有部分模块用了 Golang 和 Rust),是 Nginx 从网络通信踏入程序通信的一次重要尝试。
而我们知道,Nginx 在网络通信和流量转发方面拥有其他厂商难以匹敌的成熟经验,因此本该成为数据平面的有力竞争者才对。然而结果却是 Nginix 在这方面投入资源有限,方向摇摆,让 nginMesh 的发展一直都不温不火,到了 2020 年,nginMesh 终于宣告失败,项目转入”非活跃”(No Longer Under Active)状态。
Conduit/Linkerd 2
2017 年 12 月,在 KubeCon 大会上,Buoyant 公司发布了 Conduit 的 0.1 版本,这是 Linkerd-proxy 被 Envoy 击败后,Buoyant 公司使用 Rust 语言重新开发的第二代的服务网格产品,最初是以 Conduit 命名,在 Conduit 加入 CNCF 后不久,Buoyant 公司宣布它与原有的 Linkerd 项目合并,被重新命名为 Linkerd 2 (这样就只算一个项目了)。
使用 Rust 重写后, Linkerd2-proxy 的性能与资源消耗方面,都已经不输 Envoy 了,但它的定位通常是作为 Linkerd 2 的专有数据平面,所以成功与否,在很大程度上还是要取决于 Linkerd 2 的发展如何。
MOSN
2018 年 6 月,来自蚂蚁金服的 MOSN 宣布开源,MOSN 是 SOFAStack 中的一部分,使用 Golang 语言实现,在阿里巴巴及蚂蚁金服中经受住了大规模的应用考验。由于 MOSN 是技术阿里生态的一部分,对于使用了 Dubbo 框架,或者 SOFABolt 这样的 RPC 协议的微服务应用,MOSN 往往能够提供些额外的便捷性。2019 年 12 月,MOSN 也加入了 CNCF Landscape 。
OK,前面我介绍的是知名度和使用率最高的一部分数据平面,我在选择时其实也考虑了不同程序语言实现的代表性,其他的没提及的数据平面还有 HAProxy Connect 、 Traefik 、 ServiceComb Mesher ,等等,我就不再逐一介绍了。
然后,除了数据平面,服务网格中另外一条争夺激烈的战线是控制平面产品,主要包括了以下几种:
Linkerd 2
这是 Buoyant 公司的服务网格产品,可以发现无论是数据平面还是控制平面,他们都采用了”Linkerd”和”Linkerd 2”的名字。
现在 Linkerd 2 的身份,已经从领跑者变成了 Istio 的挑战者。不过虽然代理的性能已经赶上了 Envoy,但功能上 Linkerd 2 还是不能跟 Istio 相媲美,在 mTLS、多集群支持、支持流量拆分条件的丰富程度等方面,Istio 都比 Linkerd 2 要更有优势,毕竟两者背后的研发资源并不对等,一方是创业公司 Buoyant,而另一方是 Google、IBM 等巨头。
然而,相比起 Linkerd 2,Istio 的缺点很大程度上也是由于其功能丰富带来的,每个用户真的都需要支持非 Kubernetes 环境、支持多集群单控制平面、支持切换不同的数据平面等这类特性吗? 其实我认为,在满足需要的前提下,更小的功能集合往往意味着更高的性能与易用性。
Istio
这是 Google、IBM 和 Lyft 公司联手打造的产品,它是以自己的 Envoy 为默认数据平面。Istio 是目前功能最强大的服务网格,如果你苦恼于这方面产品的选型,直接挑选 Istio 的话,不一定是最合适的,但起码能保证应该是不会有明显缺陷的选择;同时,Istio 也是市场占有率第一的控制平面,不少公司发布的服务网格产品都是在它的基础上派生增强而来的,比如蚂蚁金服的 SOFAMesh、Google Cloud Service Mesh 等。
不过,服务网格毕竟比容器运行时、容器编排要年轻,Istio 在服务网格领域尽管占有不小的优势,但统治力还远远不能与容器运行时领域的 Docker 和容器编排领域的 Kubernetes 相媲美。
Consul Connect
Consul Connect 是来自 HashiCorp 公司的服务网格,Consul Connect 的目标是把现有由 Consul 管理的集群,平滑升级为服务网格的解决方案。
就像 Connect 这个名字所预示的”链接”含义一样,Consul Connect 十分强调它整合集成的角色定位,它不跟具体的网络和运行平台绑定,可以切换多种数据平面(默认为 Envoy),支持多种运行平台,比如 Kubernetest、Nomad 或者标准的虚拟机环境。
OSM
Open Service Mesh(OSM)是微软公司在 2020 年 8 月开源的服务网格,它同样是以 Envoy 为数据平面。OSM 项目的其中一个主要目标,是作为 SMI 规范的参考实现。同时,为了跟强大却复杂的 Istio 进行差异化竞争,OSM 明确以”轻量简单”为卖点,通过减少边缘功能和对外暴露的 API 数量,降低服务网格的学习使用成本。
现在,服务网格正处于群雄争霸的战国时期,世界三大云计算厂商中,亚马逊的 AWS App Mesh 走的是专有闭源的发展路线,剩下就只有微软与 Google 具有相似的体量,能够对等地掰手腕了。
但是,它们又选择了截然不同的竞争策略:OSM 开源后,微软马上把它捐献给了 CNCF,成为开源社区的一部分;与此相对,尽管 CNCF 与 Istio 都有着 Google 的背景关系,但 Google 却不惜违反与 IBM、Lyft 之间的协议,拒绝将 Istio 托管至 CNCF,而是自建新组织转移了 Istio 的商标所有权。这种做法不出意外地遭到了开源界的抗议,让观众产生了一种微软与 Google 身份错位的感觉,在云计算的激烈竞争中,似乎已经再也分不清楚谁是恶龙、谁是屠龙少年了。
好,以上就是目前一些主流的控制平面的产品了,其他我没有提到的控制平面还有很多,比如 Traefik Mesh 、 Kuma ,等等,我就不再展开介绍了。如果你有兴趣的话,可以参考下我这里给出的链接。
小结
服务网格也许是未来的发展方向,但想要真正发展成熟并能大规模落地,还有很长的一段路要走。
一方面,相当多的程序员已经习惯了通过代码与组件库去进行微服务治理,并且已经积累了很多的经验,也能把产品做得足够成熟稳定,所以对服务网格的需求并不迫切;另一方面,目前服务网格产品的成熟度还有待提高,冒险迁移过于激进,也容易面临兼容性的问题。所以,也许我们要等到服务网格开始远离市场宣传的喧嚣,才会走向真正的落地。
结束语
程序员之路
到这里,我们的软件架构之旅就要到终点站了,首先感谢你与我一起学完了这门 70 多讲、30 多万字的课程。
这门课讲的是软件架构,不过这并不意味着你学完这门课程就要做架构师。我想,在座的同学在现在、将来或者至少过去曾经是一名程序员,所以在结束语中,我想来跟你聊一点儿与技术相关,但又不局限于具体技术的话题。
程序员的发展观
程序员通俗地说就是写程序代码的人,但在不少人的认知里,今天去写代码,却是为了日后可以不必再写代码。
从职业经理人的视角来看,不管是架构师、资深专家,还是研发部门管理者,这些程序员的”进阶职业”似乎都已经脱离了字面意义上的”写代码的人”,衡量他们工作目标的依据主要是治下的程序员是否有更高的工作效率、更好的投入产出。那么如此一来,不少程序员想成为”不必再写代码”的人,倒是也可以理解。
不过,从技术人员的视角来看,程序员这个群体天生就带有一种工匠式的图腾崇拜精神,大家都奉行达者为师,并不迷信管理自己的人,但尊重能够指导自己的人,爱讲逻辑、爱讲道理,讲不通至少还能”Talk is cheap, show me the code”。而如此一来,要脱离技术去管理好一群程序员,可是相当困难的。
其实,我之所以说这些,是 希望以后无论你的职业目标是永远做一名程序员,还是架构师,或者是成为一名研发管理者,都不要轻易地离开技术领域的一线。
离开技术、放弃编码的决定,很可能会像你高考之后放下的数学、生物、地理等知识那样,一旦放手,以后就很难有机会再重新捡起来。
久而久之,你对代码、技术、产品状态与团队研发状态的理解,就会渐渐和团队成员产生偏差错位,从而丧失在细节上给予指导的能力,丧失在专业问题上提出接地气解决方案的能力,只能在短期内无法验证对错的大战略方向上提意见,在会议、流程及团队管理措施上下功夫,在职业经理人式的宣讲与汇报上寻找存在感。
如果是这样,那么你就从团队的导师变成了管理者,最后你跟团队的关系,就会从携手并肩奋斗的伙伴,完全演变成了只能靠公司制度与管理职位的权力来维系的雇佣关系。
当然我也相信,假如能够轻松地做好技术,也没有人愿意随便放弃。我听过的离开技术一线最常见的原因,就是”年纪大了,时间不够用了”或者要”聚焦精力去做管理了”。对这种现象,我的看法是: 确实很难轻松地做好技术,但是在做好技术工作的前提下,却有可能比较轻松地做好架构和管理工作。
我自己也是一名架构师和管理者,在作自我介绍的场合,用的头衔却从来都是” 兼职一些管理工作的程序员 “,这是一种人设标签。如果你问我,为什么管理几十人、几百人的团队的同时,还能抽出时间去编码、去写作、去关注具体的细节与技术的潮流发展,我会理所当然地回答,”因为我是一名程序员”啊。
这句话的第一层意思是,我是程序员,去编码是天经地义的。另一层意思是,我是程序员,与一群最讲道理、最直来直往、最不需要琢磨小心思的程序员协同工作,管理才不需要耗费太多的精力,所以”兼职管理”才是可行的。
程序员的价值观
聊完编程与程序员的发展观,我们再来探讨两个关于程序员价值观方面的问题:
- 在工作中所需要的知识技能,自己并不感兴趣,该怎么办?
- 在工作中接触不到的知识技能,有没有必要专门去了解、学习,乃至刻意锻炼?
我们知道,工作的职责能跟自己感兴趣的方向一致、能跟自己知识体系的缺失形成互补,这样的机会是可遇不可求的。今天的软件业已经高度成熟了,分工日益细致,对于大多数人来说,聚焦在少数几个点上拧螺丝是常态,能够在广袤的舞台上造火箭才是特例。
所以,前面两个问题不一定是每位同学都认真思考过,但我相信它应该是每位程序员都实际遇到过的。比如,有位同学就在课程 开篇词 中提了一个问题,不知在你的职业生涯中的某个时刻,是不是也有过相似的感受:
周老师,想了解一下你之前是怎样从业务往架构转型的?我是工作两年的小白,一直都很想学习架构方面的课程,但是由于工作全是业务逻辑,而且是极其复杂繁琐的业务,每天都是对着协议研究业务实现,感觉自己都困在业务里面无法自拔。
人生苦短,光阴易逝,把有限的时间和精力投入到对自己最有价值的方向上显得尤为关键,大多数人都能接受”选择永远比努力更重要”的观点,但进一步问”什么才是好的选择”时,就只有少数人能对自己学习的知识技能、从事的工作方向做出定量的价值判断。
所以,这里我就以这位同学的问题为例,拿出自己的判断模型,供你参考:
价值 = (技能收益 + 知识收益) × 提升空间 / 投入成本
技能收益
刚刚的问题里提到的”每天都是对着协议研究业务实现”,就属于典型的技能,它往往代表着直接收益。
我认为,一项工作中每天都要用到的技能,不管你是否感兴趣,都值得花一些时间精力去掌握,因为它至少是对你短期的利益起到了明确的支撑作用;反之,永远都不会派上用场的屠龙术,再高大上也是水月镜花。
所以, 正视技能收益的意义就在于可以避免自己变得过度浮躁 ,而不是用”兴趣不合””发展不符”之类的借口去过度挑剔。
我也提倡兴趣驱动,提倡快乐工作,但不设前提条件的兴趣驱动就未免太过”凡尔赛”了。首先在社会中务实地生存,不涉及是否快乐,先把本分工作做对做好,再追求兴趣选择和机遇发展,这才是对多数人的最大的公平。
知识收益
问题中提到的”架构方面的课程”,有不少都属于知识。知识的收益往往是间接的,它最终会体现在缩减了模型中的”投入成本”因素,即降低 认知负荷 (Cognitive Load)上。世界上鲜有”烟囱式”的专业人才,专才的知识体系基本还是”金字塔式”的,这些人在领域里能够显著超过他人高度的前提条件,往往就是他们拥有超过他人的知识广度。
而具体到软件开发中,像 计算机体系结构、编译原理、操作系统 等原理性的知识,对于不写编译器、不开发操作系统的程序员来说,在实践中是几乎找不到直接的应用场景的。可是毫无疑问,这些知识就是程序员知识体系的基石,是许多实用技能和常见工具溯源的归宿。
我们花费一定的成本去学习这类知识,目的是要把自己的知识点筑成体系,把大量的、不同的、零散的知识点,通过内化、存储、整理、归档、输出等方式组合起来,以点成线、以线成面,最终形成系统的、有序的、清晰的脉络结构,这就是知识体系。
程序员是需要终身学习的群体 ,当有新的信息输入时,如果能在知识体系中快速找到它应该安放的位置,定位它的问题与解题空间,找到它与其他知识点的关联关系,那你接受新信息的认知负荷就降低了。通俗地讲,你就有了比别人更高的学习效率,更敏锐的技术触觉。
提升空间
如果一项工作对你来说是个全新的领域,甚至能称为是一项挑战,那风险的背后往往也蕴藏着更高的收益。但我把提升空间归入到价值判断的因素之中,更重要的目的是 规避舒适区的陷阱。
人性会在持续的颓废时发出示警,却也容易被无效的努力所欺骗。 我们去做一些已经完全得心应手的事情时,自然不会耗费什么精力,也不会觉得痛苦困难,如果把它当作打游戏看电影般的娱乐消遣,放松自己是合适的,但我们不应该再指望从中追求什么价值。
而没有价值,是因为提升空间已经下降到零了,可我们要注意,其中的投入成本根本不可能为零,因为成本中不仅包括精力,还包括时间。花时间重复去做已经完全熟练的事情,相当于计算分子为零的算式,结果自然是没有价值的。
投入成本
在这门架构课程中,我经常讲的一个词是”权衡”,经常说的一句话是”凡事不能只讲收益不谈成本”。在我的价值模型里,收益大小也是必须在确定的成本下,才有衡量比较的意义。这里的成本,既包括你花费的时间、金钱与机会,也包括你投入的知识、精神与毅力。
强调投入成本,是希望你 不要去钻牛角尖 。如果一项知识或技能,你学习起来非常吃力,花费大力气弄懂之后,过一段时间却又迅速地忘掉了,这很可能是因为你既没有实际应用它的场景,也没有在知识体系中建立好掌握它的稳固的前置基础。这种就属于你目前还拿不动的东西,不如趁早放手, 先做好减法,才能做好加法 ;你也不必觉得可惜,如果它对你来说是必要的,就一定还会再次出现,想躲也躲不掉。
好了,这就是我的价值判断模型,每个人都应该有属于自己的价值观,你可以参考,但不必非得跟谁的一致。我也并不是提倡凡事都要把价值判断当成公式一样去计算,而是希望你能养成一种类似的思维习惯。
将思考具象化
前面我谈论的是发展观、价值观这种大方向的话题,最后,我想以一个具体可操作的小话题来结束这篇结束语: 程序员应该如何构筑自己知识体系? 顺便我也跟你解释一下,为何这门课程会是一门公开课。
我践行的知识整理方法是”将思考具象化”。因为我们知道,思考这件事是外界不可知的,其过程如何、其结果如何只有自己心里才清楚。 如果不把自己思考的内容输出给他人,很容易就会被自己所欺骗,误以为自己已经理解得足够完备了。
在开篇词中,我提到过做这门课程的目的:做技术不仅要去看、去读、去想、去用,更要去写、去说。把自己”认为掌握了”的知识给叙述出来,能够说得条理清晰,讲得理直气壮;能够让别人听得明白,释去心中疑惑;能够把自己的观点交给别人的审视,乃至质疑。在这个过程中,就会挖掘出很多潜藏在”已知”背后的”未知”。
这个目的也是它成为免费公开课的原因:课程本身就是我对自己知识体系整理的成果,是我思考的具象化表现,在这件事情中,我自己是最大的受益者,而其后所做的极客时间课程,以及出版的纸质书籍,都可以算是额外的收获。这样看来,经济上的回报也就不那么重要了。
实际上,在这门架构课里,我不仅在探讨架构的知识与技术,也很希望能够把自己如何思考、整理、构筑知识体系的方法展示出来。之前的 用户故事 中,詹同学把它总结为”用输出来倒逼输入”,我看了心中觉得颇感知音。在此,一并感谢每位同学的支持与同行。

